PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds
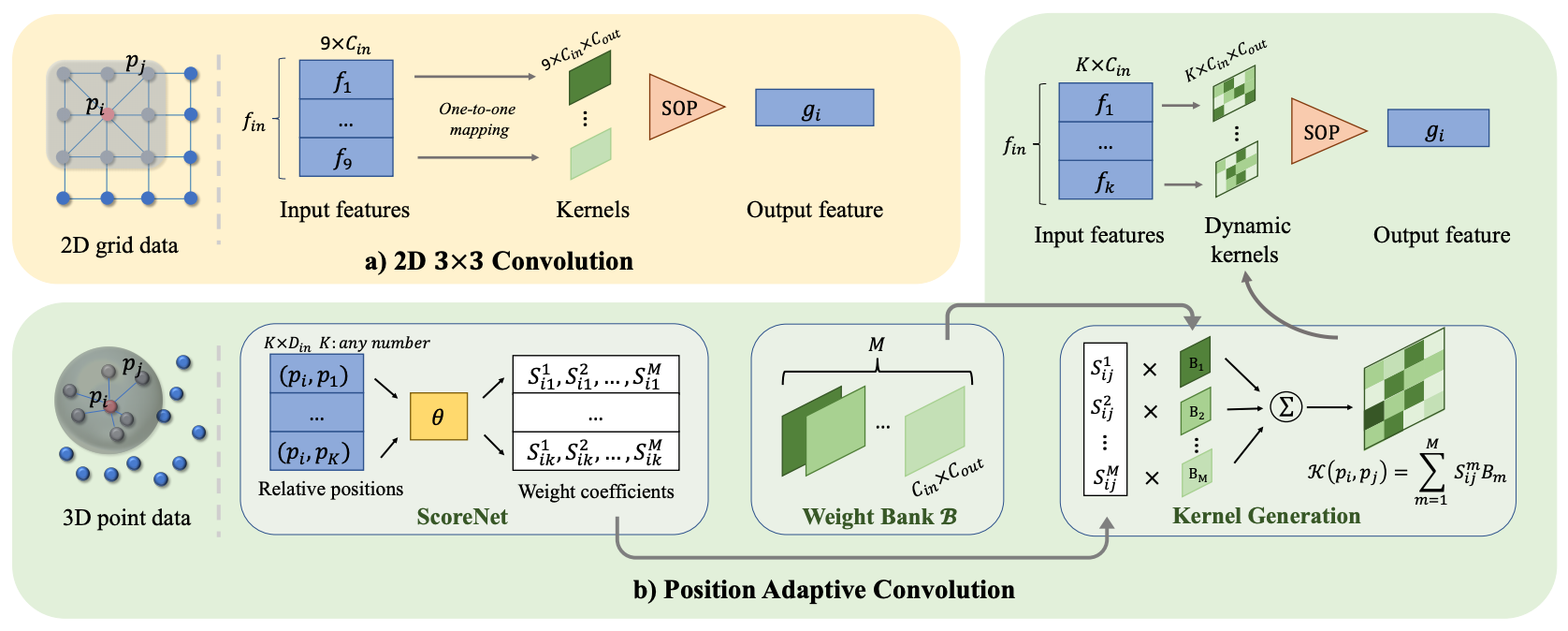
We introduce Position Adaptive Convolution (PAConv), a generic convolution operation for 3D point cloud processing. The key of PAConv is to construct the convolution kernel by dynamically assembling basic weight matrices stored in Weight Bank, where the coefficients of these weight matrices are self-adaptively learned from point positions through ScoreNet. In this way, the kernel is built in a data-driven manner, endowing PAConv with more flexibility than 2D convolutions to better handle the irregular and unordered point cloud data. Besides, the complexity of the learning process is reduced by combining weight matrices instead of brutally predicting kernels from point positions. Furthermore, different from the existing point convolution operators whose network architectures are often heavily engineered, we integrate our PAConv into classical MLP-based point cloud pipelines without changing network configurations. Even built on simple networks, our method still approaches or even surpasses the state-of-the-art models, and significantly improves baseline performance on both classification and segmentation tasks, yet with decent efficiency. Thorough ablation studies and visualizations are provided to understand PAConv.
We implement PAConv and provide the result and checkpoints on S3DIS dataset.
Notice: The original PAConv paper used step learning rate schedule. We discovered that cosine schedule achieves slightly better results and adopt it in our implementations.
| Method | Split | Lr schd | Mem (GB) | Inf time (fps) | mIoU (Val set) | Download |
|---|---|---|---|---|---|---|
| PAConv (SSG) | Area_5 | cosine 150e | 5.8 | 66.65 | model | log | |
| PAConv* (SSG) | Area_5 | cosine 200e | 3.8 | 65.33 | model | log |
Notes:
- We use XYZ+Color+Normalized_XYZ as input in all the experiments on S3DIS datasets.
Area_5Split means training the model on Area_1, 2, 3, 4, 6 and testing on Area_5.- PAConv* stands for the CUDA implementation of PAConv operations. See the paper appendix section D for more details. In our experiments, the training of PAConv* is found to be very unstable. We achieved slightly lower mIoU than the result in the paper, but is consistent with the result obtained by running their official code. Besides, although the GPU memory consumption of PAConv* is significantly lower than PAConv, its training and inference speed are actually slower (by ~10%).
Since PAConv testing adopts sliding patch inference which involves random point sampling, and the test script uses fixed random seeds while the random seeds of validation in training are not fixed, the test results may be slightly different from the results reported above.
@inproceedings{xu2021paconv,
title={PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds},
author={Xu, Mutian and Ding, Runyu and Zhao, Hengshuang and Qi, Xiaojuan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={3173--3182},
year={2021}
}