CUDA Benchmarks
This page lists some micro benchmarks of the Accelerate CUDA backend. The test machine is a Mid 2012 MacBook Pro.
- 2.6 GHz Intel Core i7
- 16 GB 1600 MHz DDR3
- NVIDIA GeForce GT 650M 1024 MB (compute compatibility 3.0)
- Mac OS X 10.8.2
- CUDA release 5.0, driver version 5.0.37
Reported times include standard runtime overheads such as kernel loading, memory transfer, and so on. Implementations are made as similar as possible to each other, except where noted. Measurements are taken using criterion.
Note that the Accelerate CUDA memory manager caches arrays on the device, so times do not include the transfer of input arrays to the device, only the retrieval of results back to the host. The plain CUDA test programs have been made to match this behaviour.
The following benchmark computes the dot product of two vectors. The two input vectors are multiplied point wise and the resulting products summed, yielding a scalar result. Results are shown for Accelerate, the NVIDIA CUBLAS linear algebra library, and a sequential implementation using the vector package (unboxed).
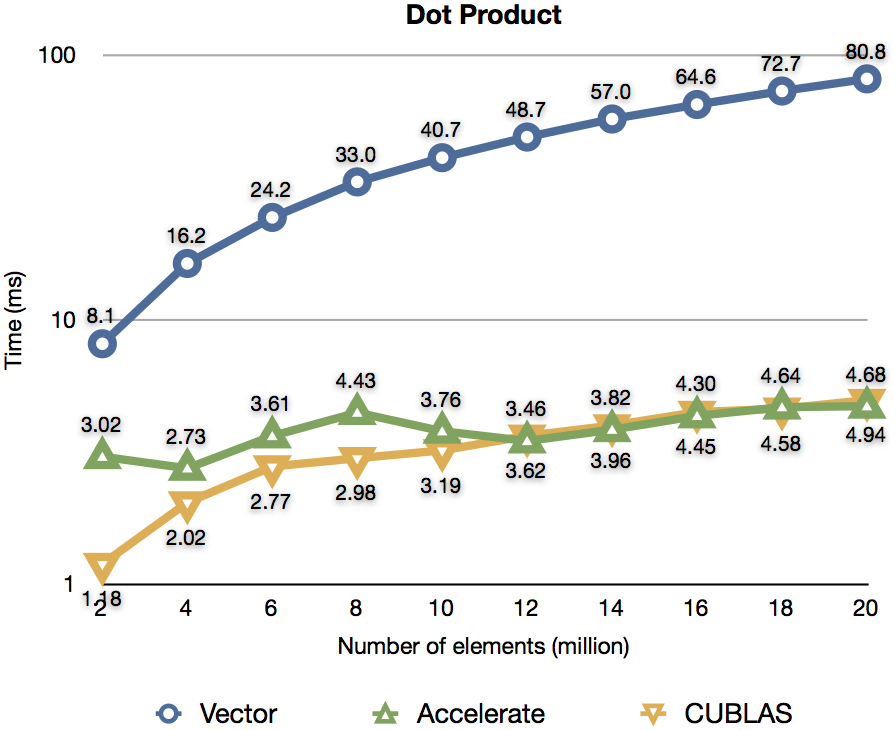
Last updated 2013-02-13. Code available here.
The Black-Scholes algorithm is a partial differential equation for modelling the evolution of a stock option price under certain assumptions. The following compares Accelerate to a reference implementation from NVIDIA's CUDA SDK.
Last updated 2013-02-13. Code available here.
The n-body simulation models the evolution of a system of n bodies in which each body continually interacts with each other body. A familiar example is an astrophysical simulation in which each body interacts via gravitational acceleration. The following reports for a naïve all-pairs approach to the simulation (complexity O(n2)) using Accelerate and the example simulation from NVIDIA's CUDA SDK.
NOTE: It appears that the simulations differ slightly: Accelerate takes into account the mass of each particle, whereas NVIDIA's solution does not. This has implications for bandwidth requirements, register pressure, thread occupancy, and so on.
Last updated 2013-02-13. Code available here.