Development
Development in NetCICD follows a pretty strict way of working:
- A developer creates some kind of change and tests it locally. For networks, this can be done using Cisco CML.
- When done, this change is saved to git. Git is a shared repository, a bit like a shared drive with some added benefits like versioning. Git comes from Liunux Kernel development and is geared towards controlled, shared development with large groups. Git follows a model based on releases and work is done on branches. A good explanation can be found in this post.
- Upon the change, the save gets a unique ID, the commit id. In addition, git triggers an orchestrator called Jenkins to start a testrun for this commit.
- Jenkins registers the requests and starts a lab in CML. This lab contains a jump host that isolates the lab from other labs and from where the lab can be controlled. The jump host connects back to Jenkins
- Jenkins instructs the host to retrieve an Ansible playbook from git (that is the NetCICD repo) and executes the playbook. When all is done and succesfully tested, Jenkins updates git with a green checkmark. When something fails, a red cross is added to the commit, so you can see how well it did.
- During the execution of the playbook, the ROBOT framework executes tests using Genie and PyATS, resulting in a directory with a HTML formatted test report. THe name of the directory is the commit-id. With a groovy script, this report is uploaded to Nexus, a write-once repository for artifacts. This implies that for every run not only the commit is preserved, but also the execution data of the Jenkins run and the resultign test report. This in turn implies that documentation of all tests executed during development is stored and easily accessible for later reference and to learn from. No more lost logging. Specifically this step will save a lot of time lateron.
- If the test fails, the committer is notified and can figure out what went wrong. If the tests were successfull, the committer is notified too
- Upon a successful test, a test run is scheduled for the physical test bed. Jenkins makes sure existing config is saved and no other work is interrupted.
- Again a test is run and the committer is notified of success or failure.
- When successful, a merge request/pull request is created to include the successful commit into the next release.
- Some other poor soul, often one or more of developers' colleagues, now vets the changes proposed, validates the tests executed and results and conclusions. If OK, a thumbs-up is given in git and if a sufficient number of thumbs-up are there, the change is merged with the code-to-be-released. Again the merged result is tested to make sure that the result does not contain hidden flaws from combined changes.
- When the time comes that the release is made available, the release branch is merged with the production branch (called master), and tested again. If that test fails, you have a production problem, but due to using git, you can revert the change.
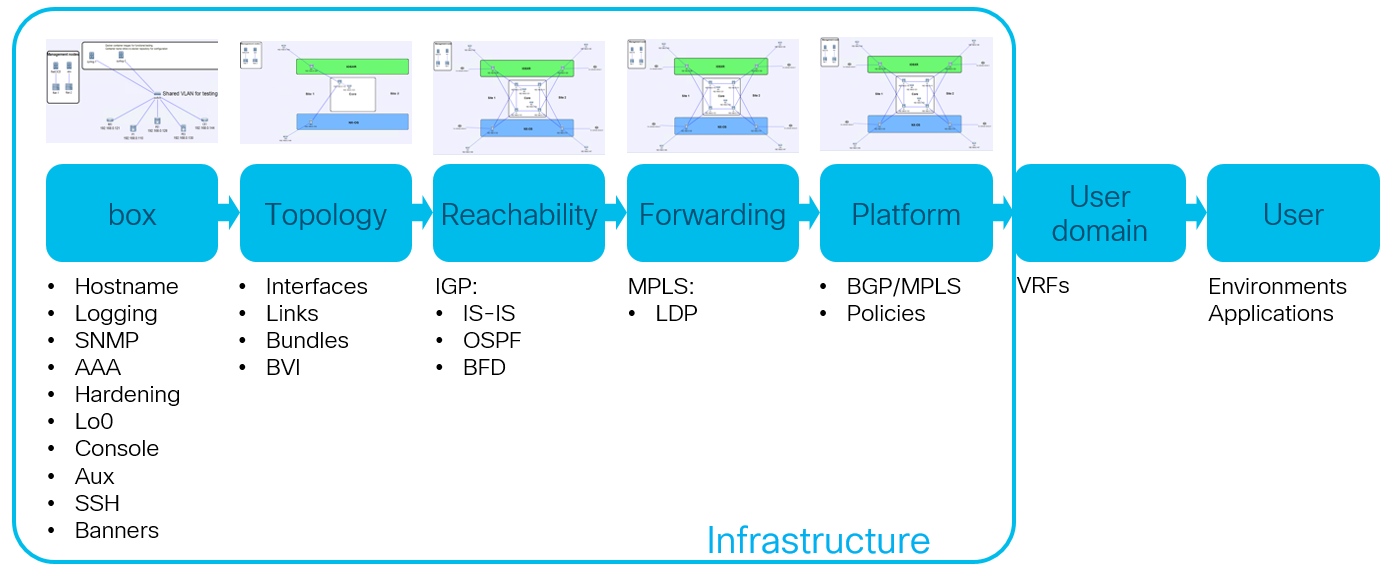
The flow above can take a very long time to report results. Following the "fail fast" paradigm, you want to perform as little work as possible when something is wrong. That is why NetCICD uses the structured setup of network configuration to create a set of stages that can fail as fast as possible. It starts with box specific configuration, then plain connectivity (i.e.interfaces), followed by reachability (i.e. igp routing protocols). So far, this can also work for any infrastructure device. The next steps are networking specific and create an MPLS forwarding plane, but you could also see SR here. On top of this, MPLS/VPN can be configured to provide a platform for user traffic.
Having a physical test bed is expensive and scheduling tests can be a real chore. Using Jenkins, this is less of a problem. When an environment is only given a single agent that is only allowed to run a single job at the same time, simulations queue and are executed sequentially. When the test bed is required for physical work, the agent can be taken off-line, causing Jenkins to wait until the agent becomes available again. The scheduled test then either times out or runs when the agent is brought back on-line. In order not to annoy too many of your colleagues, the config of the test bed must be saved before testing and restored afterwards.
For simulations in the virtual environment, multiple can be started in parallel. The only limit is the size of the license you get on the simulation platform, provided no IP confilcts arise.
In VIRL, this could be achieved using so-called private simulations using a private simulation network.
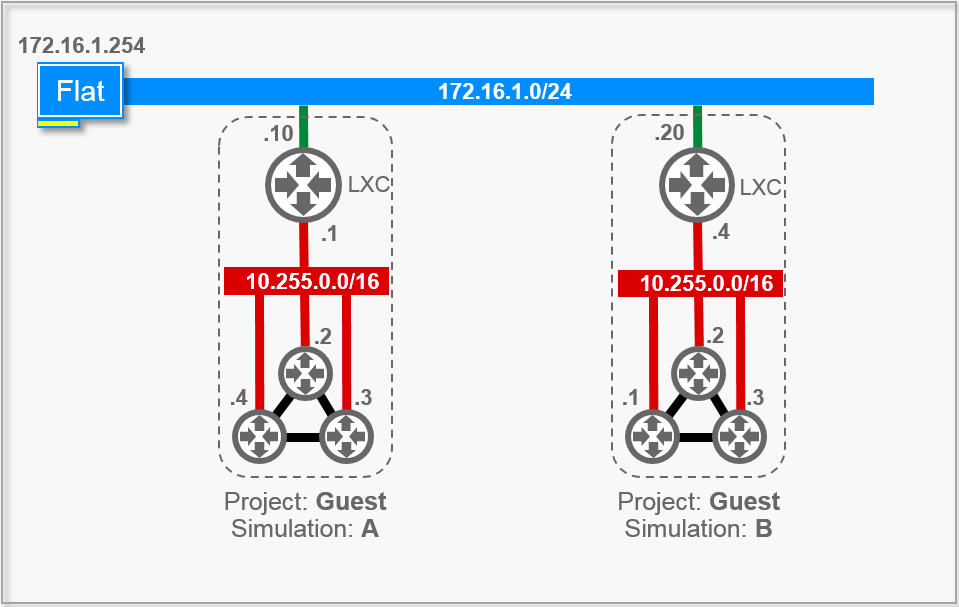
In CML-PE, you need to build such an environment yourself. In VMware Workstation, you add a second interface using a host-only network (vmnet1 in my case), just as was present in VIRL.
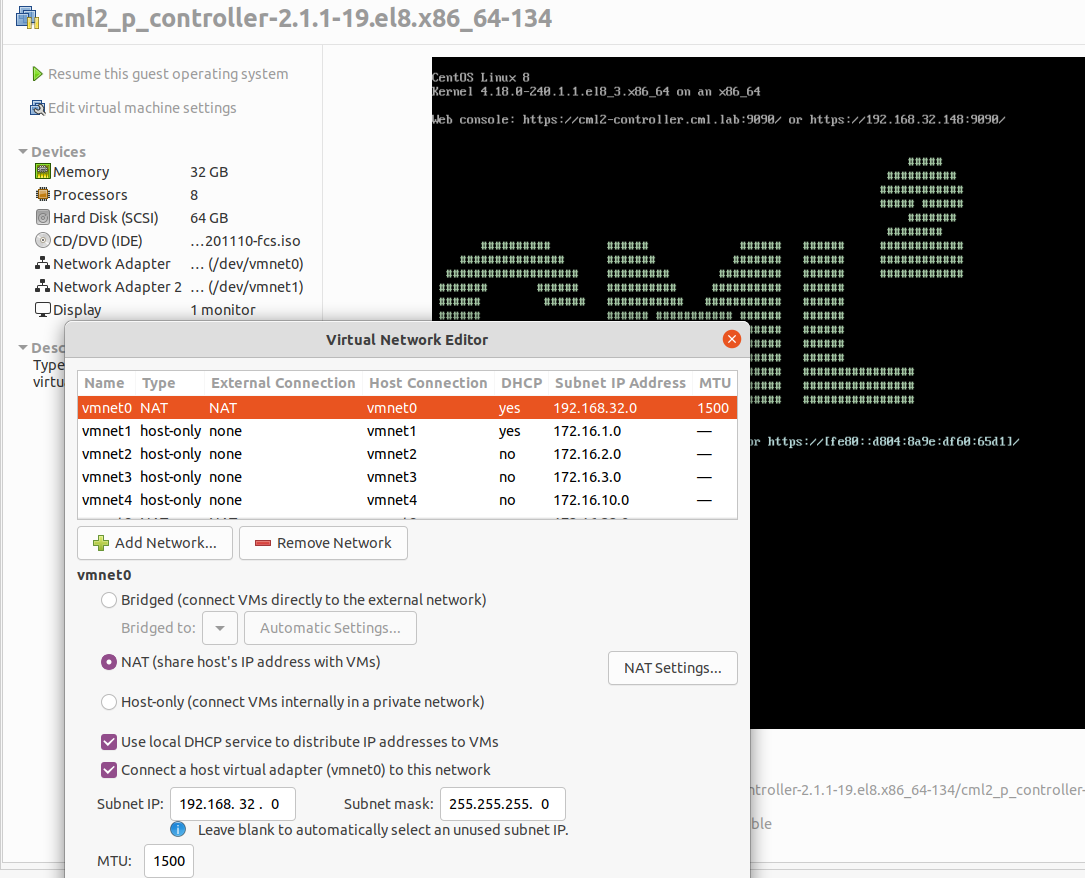
There it was called FLAT and in NetCICD with CML-PE, that network is repurposed. The IP range remains 172.16.1.0/24. In general, VMware assigns the host 172.16.1.1, which is the gateway for the Jenkins agent.
NetCICD uses a Jenkinsfile and Ansible playbooks with roles to deploy configurations to networking equipment. The definition and setup of the Jenkinsfile, those Ansible playbooks and the integration of the PyATS/ROBOT testing framework in the Ansible playbooks validates pages in itself.
In addition, minimal topologies are created for each test stage. These topologies are saved in the cml-pe directory of the git repository. The virl directory contains the topologies for version 1.5 of VIRL/CML.