\\n  \\n
\\n
\\n\\nHere\'s how OpenBB solves this:\\n\\nFirst, we ensure complete data access:\\n\\n- Run everything on-premise or in your VPC\\n- Connect any data source: files, APIs, third-party feeds, anything\\n- Use a universal data layer that standardizes everything (whether it\'s CSV, Excel, Snowflake, or APIs)\\n\\nBut the real innovation?\\n\\nWe\'re building AI differently.\\n\\nInstead of forcing analysts to chat with a bot, we\'re embedding intelligence directly into their workspace.\\n\\nThink dashboards with widgets, not chat windows. Data visualization, not text conversations.\\n\\nThis is exactly what Kimberly Tan (partner @ a16z) predicted in [her analysis](https://a16z.com/big-ideas-in-tech-2025/):\\n\\n> _\\"Chat was the first experimental interface \u2014 now I expect there will be new, novel interaction mechanisms. In this phase, AI agents will be able to take direct action in the workflow, and the UI will be reimagined for humans to review work or do QA.\\"_\\n\\n
\\n\\nThe result?\\n\\n
\\n \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nUntil he did.\\n\\nWith our free tier - Matt was able to single-handedly create almost 50 different data widgets that he (and his team) will be able to access seamlessly on OpenBB.\\n\\nAs we shift to firms being more in control of their data, and with the clear gains from having an additional intelligence layer on top of that data - the need for OpenBB in the market has never been clearer.\\n\\nShifting the control back to financial firms.\\n\\nMore open. More adaptable.\\n\\nIf you want help on connecting your own backend (crypto or other) to OpenBB - reach out to myself and team."},{"id":"why-we-got-rid-of-pips-at-openbb","metadata":{"permalink":"/blog/why-we-got-rid-of-pips-at-openbb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.md","source":"@site/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.md","title":"Why we got rid of PIPs at OpenBB","description":"My thoughts on how removing PIPs can increase the company talent level","date":"2024-11-09T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"management","permalink":"/blog/tags/management"},{"inline":true,"label":"leadership","permalink":"/blog/tags/leadership"},{"inline":true,"label":"talent","permalink":"/blog/tags/talent"},{"inline":true,"label":"hiring","permalink":"/blog/tags/hiring"},{"inline":true,"label":"performance","permalink":"/blog/tags/performance"},{"inline":true,"label":"company-culture","permalink":"/blog/tags/company-culture"},{"inline":true,"label":"startups","permalink":"/blog/tags/startups"}],"readingTime":9.485,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-we-got-rid-of-pips-at-openbb","title":"Why we got rid of PIPs at OpenBB","date":"2024-11-09T00:00:00.000Z","image":"/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.png","tags":["openbb","management","leadership","talent","hiring","performance","company-culture","startups"],"description":"My thoughts on how removing PIPs can increase the company talent level","hideSidebar":true},"unlisted":false,"prevItem":{"title":"Today I saw a glimpse of the future","permalink":"/blog/today-i-saw-a-glimpse-of-the-future"},"nextItem":{"title":"Implement feedback loops EVERYWHERE you can","permalink":"/blog/implement-feedback-loops-everywhere-you-can"}},"content":"
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
 \\n
\\n  \\n
\\n\\n\\nThe problem with confident hallucinations is that, similar to why everyone dislikes liars, it leads to a lack of trust. So users begin to put everything that is output by an LLM under a microscope - even if what the model says is accurate.\\n\\n### How to avoid hallucinations\\n\\nThere are ways to address this and one of the key approaches we are extremely strong about at OpenBB is always tapping into information that is available.\\n\\nWhen a user asks a question that requires financial data, the OpenBB Copilot always searches for that data on OpenBB (either through data we make available or through private data that customers bring).\\n\\nThe Copilot will only answer the question if that data exists. This allows the model to cite the data used in its response, so the user can double-check.\\n\\nThis is how it looks.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nThis leads to less hallucination because the LLM isn\'t outputting tokens based on a prompt and its internal weights. Instead, it\'s using its internal weights, the prompt, and a function call.\\n\\nAssuming the function call succeeds - with correct widget retrieval and parameters - the data becomes available for the Copilot to use, which leads to higher accuracy.\\n\\nNote: This still means that Copilot needs to use the correct widget and the correct parameter, but there\'s a **higher likelihood of success** because if it isn\'t, the API call will fail, prompting the LLM to try again.\\n\\nHere\'s how it works behind the scenes, the OpenBB Copilot highlights its step-by-step reasoning so users can understand its thought process. Transparency is key.\\n\\n
\\n  \\n
\\n
\\n\\nThey get the \\"_Sentence Extracted From_\\" column, which they can copy and paste into a search field added at the top of the Earnings Transcript widget. This enable users to quickly validate the numbers that have been found.\\n\\nSee example below,\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
 \\n
\\n  \\n
\\n\\n\\nThis means that the model\'s output can be improved by doing extra work at the input level.\\n\\nData cleaning and pre-processing strikes again? \ud83d\ude03\\n\\nInterestingly, a few days ago, [OpenAI announced OpenAI o1](https://openai.com/o1/). Which is basically GPT-4o with Chain-of-Thought (COT). This means that this model is a \\"wannabe agent\\".\\n\\nIt takes in a prompt from the user and decomposes it in natural steps to solve it. Then at each step, it takes the output of the model from the previous step and predicts the next token. It turns out that this improves accuracy substantially.\\n\\nHowever, it still doesn\u2019t have access to external data. And that is why I call it a \\"wannabe agent\\".\\n\\nI love how Jeremiah put it in this [tweet](https://x.com/jlowin/status/1834722014839418962):\\n\\n> (...) Agents are also characterized by iterative behavior. But there\'s a key difference: while models like o1 iterate internally to refine their reasoning, agents engage in iterative interactions with the external world. They perceive the environment, take actions, observe the outcomes (or side effects) and adjust accordingly. This recursive process enables agents to handle tasks that require adaptability and responsiveness to real-world changes. (...)\\n\\n
\\n\\nSo, o1\'s model isn\'t an agent - but it can solve this problem. The reason is that it applies its own data cleaning/pre-processing step on its own, and doesn\'t rely on external factors.\\n\\n### Small Language Models\\n\\nOnce agents work, Small Language Models (SLM) will be much more viable for very specific use cases.\\n\\nIn logical terms, a Large Language Model is a model with weights.\\n\\nLarge means that it has a lot of them. But what tends to happen is LLMs need to be very big because they want these models to be really good at everything. The problem is that if you want the exact same model to be good at discussing soccer, programming, and speaking Portuguese, its weights are updated using these drastically different datasets. Now the premise is that the more weights there are, the less each weight will be affected by data from completely different domains.\\n\\nWhat a big LLM like GPT-4o is doing is trying to build a single Jarvis that knows about everything. Whereas we could have an SLM that does something extremely well and just focus on that, e.g. translating from English to Portuguese. The benefit of an SLM is that inference is likely faster, can be hosted on devices, and, in theory, it\'s better on a topic because it\'s been less \\"contaminated\\" during training by data that doesn\'t relate to the task at hand.\\n\\nImagine that a firm decides to use an SLM trained to retrieve data from SEC filings quickly and at scale. Or, we could train our own SLM to understand user intent and interact directly with the OpenBB Terminal interface.\\n\\n### Large Language Models as orchestrator\\n\\nIn my opinion, the best LLM in each category will win. And the second and third won\'t matter. It\'s a winner-takes-all kind of market. Unless in specific verticals such as inference time or open weights (e.g. for data security; more on this later).\\n\\nThe best example of this is OpenAI vs Anthropic.\\n\\nI had been using OpenAI\'s GPT-4 for coding for several months. After trying Anthropic\'s Sonnet 3.5 for coding, I never went back to OpenAI.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
 \\n
\\n  \\n
\\n\\n\\nWe believe in this idea so much, that we have open-source the architecture for firms to bring their own Copilot to OpenBB. More information is available [here](https://github.com/OpenBB-finance/copilot-for-terminal-pro/).\\n\\n### Turn off AI workflows\\n\\nWe have incorporated workflows that make users\' lives MUCH better. But they come at a cost: sharing data with an LLM provider.\\n\\nThese are the features:\\n\\n- **Widget title/description suggestion from Copilot**: This sends the content of the table or note output by Copilot to an LLM provider to receive suggestions of a title and description.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
Presenting at CIBC a few weeks ago at New York AI meetup
\\n\\n\\n## Next sparring sessions\\n\\nCurrently when I step in a ring I have mixed feelings, I\u2019m somewhat anxious but also excited about it.\\n\\nIt\u2019s weird.\\n\\nI mean, I know full well that I\u2019m going against folks who\u2019ve been in a ring since they were young - and I also know full well that I\u2019m going to get hit much more than I will hit.\\n\\n**However**, there\u2019s something exciting (poetic maybe?) about knowing that each time I step into the ring again, I will be able to land more punches, avoid more hits and be better mentally.\\n\\nLearning is the nature of the game.\\n\\nAnd the only failure is to not take any lessons from each fight.\\n\\nThis is the same for startups. I like what Bezos has to say on the topic, about [pushing Amazon to embrace failure](https://www.youtube.com/shorts/HmYj-UDT8jM).\\n\\n\\n  \\n
\\n
This picture was what convinced me to buy my own head gear
\\n\\n\\n## So, why do I love boxing?\\n\\nI think ultimately, the reason why I love boxing is the same as why I love startups.\\n\\nStartups push me everyday to be the best that I can be in so many different areas, there isn\u2019t a role that - for me - is as stimulating mentally as being a startup founder.\\n\\nThere are 100 different initiatives ongoing at all times, you have a team of composed of human beings (by nature, highly complex with different backgrounds and life experiences), you have startups trying to disrupt your business, you have well established incumbents, etc..\\n\\nBoxing is the same... but at the physical level.\\n\\nI step in the ring and need to be the best I can in multiple verticals - it isn\u2019t enough to be the best in one.\\n\\nI need to have a faster reaction to avoid punches, be light on my feet to surprise an opponent, land the combos where I put most of my energy in, trade-off balance between combos and stamina, and obviously all the mental side that comes from it too - which turns out is quite a lot.\\n\\nUltimately, as cheesy as it sounds, being a startup founder and doing boxing make me feel alive.\\n\\n\\n  \\n
\\n
Taking my father-in-law for a class
\\n"},{"id":"what-i-learned-in-3-years-at-openb","metadata":{"permalink":"/blog/what-i-learned-in-3-years-at-openb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-08-20-what-i-learned-in-3-years-at-openbb.md","source":"@site/blog/2024-08-20-what-i-learned-in-3-years-at-openbb.md","title":"What I Learned in 3 Years at OpenBB","description":"The OpenBB journey started officially 3 years ago. So I want to celebrate it by sharing 36 lessons I learned over the past 36 months as a founder and CEO of a fintech company.","date":"2024-08-20T00:00:00.000Z","tags":[{"inline":true,"label":"career development","permalink":"/blog/tags/career-development"},{"inline":true,"label":"technology","permalink":"/blog/tags/technology"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"leadership","permalink":"/blog/tags/leadership"}],"readingTime":2.91,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"what-i-learned-in-3-years-at-openb","title":"What I Learned in 3 Years at OpenBB","date":"2024-08-20T00:00:00.000Z","image":"/blog/2024-08-20-what-i-learned-in-3-years-at-openb.jpeg","tags":["career development","technology","OpenBB","learning","leadership"],"description":"The OpenBB journey started officially 3 years ago. So I want to celebrate it by sharing 36 lessons I learned over the past 36 months as a founder and CEO of a fintech company."},"unlisted":false,"prevItem":{"title":"Why I love boxing","permalink":"/blog/why-i-love-boxing"},"nextItem":{"title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","permalink":"/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare"}},"content":"\\n  \\n
\\n
\\n\\nIn the past 3 years, we have:\\n\\n- The [open source repo](https://github.com/OpenBB-finance/OpenBB) has been starred over 28,000 times and 220 contributors\\n- The OG OpenBB Terminal installer was downloaded over 150k times\\n- Refactored that application to a platform that could be pip installable\\n- Enabled users to fully [automate their research workflow in a script](https://youtu.be/cgeN3Ep2nEw?si=8e5en_xunWcBdKMM)\\n- Open-sourced an [LLM-powered financial analyst agent built on top of the OpenBB platform](https://github.com/OpenBB-finance/openbb-agents)\\n- Made an [OpenBB Bot](https://openbb.co/products/bot) that run over 4M commands in 20k+ servers with 50k+ users\\n- Developed an [Add-in for Excel](https://openbb.co/products/excel)\\n- Grew to a team of 16\\n- Built a community of over 100k people\\n- And finally, we built the foundation of the [first AI-powered financial terminal](https://openbb.co/products/pro) - more on this very very soon.\\n\\n
\\n\\nPersonally, during that timeline:\\n\\n- I got a second dog\\n- Visited US for the first time\\n- Got married on that first visit\\n- Left London to move to the Bay area a couple weeks after\\n- Moved to NYC\\n- Started boxing regularly\\n\\nWe are more locked in than ever before.\\n\\nCan\u2019t wait for the next 3 years. \ud83e\udd42"},{"id":"why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","metadata":{"permalink":"/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.md","source":"@site/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.md","title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","description":"As AI continues to advance, many jobs in finance are at risk. Learn why this shift is happening and how to prepare for the future.","date":"2024-08-06T00:00:00.000Z","tags":[{"inline":true,"label":"artificial intelligence","permalink":"/blog/tags/artificial-intelligence"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"career development","permalink":"/blog/tags/career-development"},{"inline":true,"label":"technology","permalink":"/blog/tags/technology"},{"inline":true,"label":"future of work","permalink":"/blog/tags/future-of-work"}],"readingTime":6.67,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","date":"2024-08-06T00:00:00.000Z","image":"/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.png","tags":["artificial intelligence","finance","career development","technology","future of work"],"description":"As AI continues to advance, many jobs in finance are at risk. Learn why this shift is happening and how to prepare for the future."},"unlisted":false,"prevItem":{"title":"What I Learned in 3 Years at OpenBB","permalink":"/blog/what-i-learned-in-3-years-at-openb"},"nextItem":{"title":"Inspired by Bia - How Her Fight Against Cancer Changed My Life","permalink":"/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life"}},"content":"
\\n  \\n
\\n
\\n  \\n
\\n
\\n \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\n\\nDidier
\\n
\\nIt was in the middle of laughter, in the middle of playfulness.
\\n
\\nIt was in the middle of tantrums and misunderstandings.
\\n
\\nIt was in the middle of sheets of paper fallen on the floor and of pieces of paper so efficiently utilized.
\\n
\\nIt was like this that our friendship grew!
\\n
\\nBeatriz \u2764\ufe0f
\\n
\\n\\nSaturday morning I got a call. A common friend let me know that she passed away unexpectedly.\\n\\nI was still in bed. I cried for hours. I didn\'t want to wake up. Maybe some part of me never did.\\n\\nShe had her entire life ahead of her.\\n\\nShe was kind, curious and loving. She would have accomplished so much.\\n\\nYet she was gone.\\n\\nNo one deserves to lose their best friend at 17. Not like that. It wasn\'t fair.\\n\\nBut that\'s cancer for you.\\n\\nCancer doesn\'t care.\\n\\nIt never did.\\n\\nFrom that moment onwards I changed my attitude towards life.\\n\\nI stopped doing things for the sake of doing them and always put 120%.\\n\\nI went from spending most of my time as a gamer and doing just enough to have good grades in high school to being the best student of my year in my BSc in Electrical and Computer Engineering, moving to London to have a distinction at Imperial College London (top 2 uni in the world) and now moving to NYC to increase chances of success for my startup.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n Donate here\\n
\\n\\nEvery donation matters. \u2764\ufe0f"},{"id":"my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","metadata":{"permalink":"/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.md","source":"@site/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.md","title":"My first-hand experience on AI impacting education through Perplexity, Cursor and ChatGPT","description":"AI will change education forever. Here\'s how I leveraged Perplexity, Cursor and ChatGPT to teach Supervised Learning and assess coursework.","date":"2024-06-30T00:00:00.000Z","tags":[{"inline":true,"label":"education","permalink":"/blog/tags/education"},{"inline":true,"label":"ai","permalink":"/blog/tags/ai"},{"inline":true,"label":"perplexity","permalink":"/blog/tags/perplexity"},{"inline":true,"label":"chatgpt","permalink":"/blog/tags/chatgpt"},{"inline":true,"label":"cursor","permalink":"/blog/tags/cursor"},{"inline":true,"label":"students","permalink":"/blog/tags/students"},{"inline":true,"label":"big data","permalink":"/blog/tags/big-data"},{"inline":true,"label":"analytics","permalink":"/blog/tags/analytics"},{"inline":true,"label":"supervised learning","permalink":"/blog/tags/supervised-learning"},{"inline":true,"label":"machine learning","permalink":"/blog/tags/machine-learning"}],"readingTime":11.45,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","title":"My first-hand experience on AI impacting education through Perplexity, Cursor and ChatGPT","date":"2024-06-30T00:00:00.000Z","image":"/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.png","tags":["education","ai","perplexity","chatgpt","cursor","students","big data","analytics","supervised learning","machine learning"],"description":"AI will change education forever. Here\'s how I leveraged Perplexity, Cursor and ChatGPT to teach Supervised Learning and assess coursework."},"unlisted":false,"prevItem":{"title":"Inspired by Bia - How Her Fight Against Cancer Changed My Life","permalink":"/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life"},"nextItem":{"title":"Why chat-only AI Financial Assistants are not the future","permalink":"/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future"}},"content":"\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nThis was not a trivial task, and definitely not a weekend job.\\n\\nExcept that **IT WAS**.\\n\\n### Perplexity enters the chat\\n\\nSince Perplexity\u2019s main value proposition is being better at Google than Google - I popped the following prompt into it.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\n> **PART II - Documentation and Quality**\\n> - **2.a. Code Quality and Readability:** Clarity and Structure: Is the code well-organized with clear and consistent formatting? Are comments used effectively to explain complex logic? Best Practices: Does the code follow standard coding practices (e.g., naming conventions, modularization)? Are functions and classes used appropriately?\\n>\\n> - **2.b. Documentation and Explanation in Comments or Notebook Markdown**: Clarity: Are the results and methodology clearly documented? Is there a detailed explanation of the steps taken and the reasons behind them? Visualization: Are visual aids (e.g., graphs, plots) used to illustrate key points and results? Are these visualizations clear and informative?\\n\\n
\\n\\n> **PART III - Code**\\n>\\n> - **3.a. Data Preprocessing and Cleaning**: Completeness: Are all necessary steps for data preprocessing included (e.g., handling missing values, encoding categorical variables, scaling features)? Justification: Are the preprocessing steps justified and explained? Is there a clear reason for the choices made?\\n>\\n> - **3.b. Data Exploration**: Initial Analysis: Is there an exploratory data analysis? Are descriptive statistics used to better understand the data? Visualization: Are visualizations (e.g., graphs, plots) used to illustrate data distribution, correlations, and important patterns? Are these visualizations clear and informative?\\n>\\n> - **3.c. Model Implementation and Training**: Correctness: Is the model implemented correctly according to the chosen algorithm? Are appropriate libraries and functions used? Parameter Tuning: Is there evidence of parameter tuning or optimization? Are the chosen parameters explained and justified?\\n>\\n> - **3.d. Evaluation and Validation**: Metrics: Are appropriate evaluation metrics chosen and calculated? Are these metrics relevant to the problem at hand? Validation Techniques: Are appropriate validation techniques used (e.g., cross-validation, train-test split)? Is there an analysis of the model\'s performance on both training and testing data?\\n\\n
\\n\\nThis was it.\\n\\nExactly what I was looking for.\\n\\nNow I could grade a student on each of these criteria, then select a final grade weight for each criteria (e.g. 5-15%), create a spreadsheet with such a table and call it a day.\\n\\nHowever, the most time-consuming task was coming - the grading itself.\\n\\nThere were 10 groups in total. So 10 notebooks that I had to look into, exploring completely different datasets with a different ML model being used, different ways to do exploratory data analysis, different ways to assess the model, different objectives, \u2026\\n\\n### Cursor helping with grading\\n\\nI opened [cursor](https://www.cursor.com/) (which is basically VSCode + ChatGPT) and probably the software I\u2019ve recommended the most to developers in 2024.\\n\\nAnd opened my first notebook.\\n\\nThen I thought, what if I had GPT-4o on my side - helping me to assess this coursework.\\n\\nIt didn\u2019t need to be perfect because I was doing it myself, but it could help me understand if there was any critical thing that I missed OR if it completely had a different grade than the one I was going to provide - which would enable me to spend more time on that criteria and iterate.\\n\\nIt gave me confidence that I was being fair to the students.\\n\\nAnd made me realize how hard it is for professors when they have 100s of students and have a subjective answer to grade. It\u2019s impossible to get it right. They try their best, but as soon as the answer is not binary (0 or 1), they are doomed to fail.\\n\\nSo how did I do it?\\n\\nGiven that I just wanted GPT-4o to quickly review each of the criterias based on the code, I created a prompt that I could use for all of notebooks that the students sent.\\n\\nThis is what my setup looked like\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
 \\n
\\n  \\n
\\n \\n
\\n  \\n
\\n\\n\\nAlso, related with the picture from the above. The battery is pretty weak, it needs to be charged often.\\n\\nThe rabbit r1 OS has a lot of room for improvement, a few things I\'ve experienced:\\n- Having a black screen that doesn\'t recover until I manually power off device;\\n- Not triggering the function I want - sometimes it looks for a specific wording, e.g. \\"start a recording session\\" works but \\"do a voice recording\\" does not. I would have expected for it to be able to understand intent;\\n- Sometimes I get a \\"The app is under maintenance. Please try again later\\" for functions that I know it is capable of doing;\\n- Every few minutes getting \\"unable to connect to Rabbit OS\\";\\n- Randomly losing the previous context - I assume this is because of the number of tokens that can fit in the context?;\\n- Spotify integration broken;\\n- Even though it knows my location (due to getting weather app location correct), the time is not correct and I can\'t update it through the settings.\\n\\nBut this is also the first product version and LLMs are by nature non-deterministic so these type of bugs are kind of expected.\\n\\nIt\'s a one-time $199 price tag. There\'s no recurring subscription. As a consumer, I like this a lot. A one-time purchase allows users to buy the product to experiment without any strong commitment (apart from that one-time fee of course). In terms of economics, I\'m not sure how Rabbit will handle a growing user base and better LLMs. During the event, they mentioned a partnership with both OpenAI and Anthropic. If they are using one of these models, someone needs to be paying for these tokens. For instance, for [OpenBB Terminal Pro](https://openbb.co/products/pro) we decided to allow usage similarly to how the ChatGPT free tier works, which basically rate limits based on usage and allows us to keep our costs controlled.\\n\\nMeta is attempting to commoditize LLMs, so if I were in rabbit\'s shoes I would consider hosting [Llama 3](https://llama.meta.com/llama3/) locally and providing inference from this directly. Maybe even do a partnership with [Groq](https://groq.com/) for users paying a small subscription - not so much because of the impressive 800 tokens/s inference (using Llama 3) since rabbit r1 uses voice and inference speed is less relevant, but for the cold start (i.e. the lag between user question and output). Meta\'s commercial license only applies to companies with over 700 Million active users, so I think Rabbit would be good for some time.\\n\\nPersonally, I wouldn\u2019t recommend rabbit r1 as a phone alternative. Not even close. If someone says that they stopped using their phone after having their rabbit r1, I can guarantee you that they weren\u2019t using their phone a lot anyway. I agree a lot with MKBHD in saying [Phones are OP](https://www.youtube.com/watch?v=TitZV6k8zfA).\\n\\nBut if you are reading this, you are probably wondering what are the use cases where I would recommend Rabbit r1. So let\'s do that.\\n\\n### This is a buy if\\n\\n- For kids that are curious and want to learn more about the world. Being able to have it before a phone, is very compelling. Imagine your kid being able to ask r1 what a word means and how to use it in a sentence, who person X is, how something works, to practice learning another language, as a complement when reading a book/studying. The advantage over the phone is that it doesn\'t have any other distractions. It would basically be Perplexity on the go, and thus the Perplexity tagline \\"Where knowledge begins\\" makes total sense.\\n\\n- As a device for two-way translation. The two-way is important, because if it\u2019s just one-way then using the phone is preferred. But being two-way allows for both people to interact with the device, which in my opinion is less personal than a phone and more like a gadget. We aren\'t there yet, but I\'m sure the model will keep improving and becoming better at this.\\n\\n- For content creators who want to \u201czone out\u201d and leave their phone at home and just use the record feature to record content, whether that is a blog post, a new lyrics or a podcast idea. \\n\\n- As a music device to be at the center of a table at a dinner, in the corner at a party selecting the tunes or on a roadtrip. People will enjoy interacting with it due to its unique nature, and that way you don\'t need to be blocked from using your phone.\\n\\n- As a virtual assistant. If the alarm feature was already implemented, I would\'ve likely already replace my Alexa, since rabbit r1 looks much nicer. Even more with the cool standing case.\\n\\n... and of course, the use case is worth $200 for you. There are likely devices that can achieve the same for a cheaper cost. I like the fact that is state-of-the-art and they are trying to innovate.\\n\\nAlso, the rabbit effect going up and down waiting to be prompted and the hears going up when listening is pretty sweet - see it [here](/blog/2024-04-28-rabbit-r1-there-is-hope_10.png).\\n\\nIn any case, there are two recurring topics in these use cases, so let\'s talk about each individually.\\n\\n### Main use cases\\n\\n1. **A very targeted use case** - The phone can be a double-edged sword. On the one hand, it\'s your door to the world and what\'s happening. On the other hand, it\'s your door to the world and what\'s happening. I say it this way because this can be extremely good or bad depending on the use case. Phones are optimized for users to spend time on them, apps are optimized to provide dopamine hits so users use them for longer. Notifications will interrupt you throughout the day so you remember to go back to the app, etc.. But sometimes you only want to do 1 thing, and don\'t want to be distracted from it. The best example are E-Books. You can read on your phone, iPad or laptop - yet people decide to buy a kindle so they can just do that. Read with no distractions. You are paying a premium for a product to remove the distractions. I believe that rabbit r1 can achieve this, particularly if they allow developers to build specific apps for specific use cases.\\n\\n2. **Gadget to be used by multiple people** (examples above: two-way translation or music device) - The phone has become a very personal device over the years. If someone gets access to your phone unlocked they have access to who you are (important emails, personal photos, chat conversations, the apps you use and how do you spend your time, the songs you listen or books you read, even confidential documents). So, there are certain scenarios where you don\'t want to borrow your phone to someone to do something, since that requires trust that they won\'t see anything that is confidential. I think Rabbit r1 can go after this category because its a shiny gadget that doesn\'t really hold any personal information from the user, and this way allows the user to keep their phone in their pocket while using rabbit r1 for some tasks that the phone could also do but would require for others to have access to it.\\n\\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nand\\n\\n> \u201cPerform a fundamentals financial analysis of AMZN using the most recently available data. What do you find that\u2019s interesting?\u201d\\n\\n
\\n\\nSince that was already working so well (watch the [presentation video here](https://www.youtube.com/watch?v=A-43EKK2PhE&embeds_referring_euri=https://openbb.co/blog/creating-an-ai-powered-financial-analyst&source_ve_path=MjM4NTE)), I wanted to bring these capabilities to Slack, show that this could be the future, and prove it would impact every analyst job.\\n\\nThat\u2019s when Goh Analyst was born.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nRecently, I wrote a blogpost about the [difference in culture between London and San Francisco](/blog/moving-from-london-to-the-bay-area-and-what-changed). I convinced my wife and dogs, packed our bags, and didn\'t look back. After all, I would live in the city with the highest density of builders per capita.\\n\\n**But why?**\\n\\nMost of my friends and family didn\'t understand why I would leave London. I liked the city, I enjoyed my lifestyle, I had friends, I played football with the same group every week, had dinner at the same restaurants, was close to family, and wouldn\'t be able to save money.\\n\\nLogically speaking, this move didn\'t make any sense. No one really told me that I was doing the right thing, but internally, I knew I had to.\\n\\nI believe this isn\'t so different from creating a startup. This blog post will explain what they have in common and why I did it.\\n\\n## Creating a startup / Deciding to leave your\xa0country\\n\\n[Elad Gil](http://eladgil.com/) wrote a really good [article](https://blog.eladgil.com/p/startups-are-an-act-of-desperation) on how creating a startup is an act of desperation. I believe that post could be equally applicable to moving countries, so I will list the same points used by Elad in the context of moving countries and provide examples. Most of the time, the person moving countries has a mix of the below bullet points.\\n\\n> **Career desperation.** Startups allow people early or stuck in their careers to jump a few steps ahead.\\n\\n
\\n\\nThis applies equally to moving, and is why I left Portugal to pursue an MSc at Imperial College London.\\n\\n> **Financial desperation.** If successful, a startup will also leapfrog you financially.\\n\\n
\\n\\nThis is the biggest motivation for people to move countries. This is why I was born in Switzerland, even though my parents are Portuguese. Having blue-collar jobs, they emigrated to a country with a better economy to provide my brother and me with a better life.\\n\\n> **Product or mission desperation.** The other reason startups often exist is that the founders are desperate for a product to exist in the world.\\n\\n
\\n\\nIn this case, it\'s the equivalent of hearing about Silicon Valley in documentaries or watching Steve Jobs presenting the iPhone in 2007. You cannot ignore that as an engineer, so you are desperate to move to be part of that tech scene.\\n\\n> **Desperation to do something big or important, and to avoid wasted time.** Some people want to \\"make a dent in the universe\\" and are motivated by doing something useful with their lives.\\n\\n
\\n\\nThis is what the \\"American dream\\" is all about. People moved to the US to do something bigger than themselves and achieve the promised dream.\\n\\n> **Revenge vs the Arena**\\n\\n
\\n\\nThe equivalent to this is when someone returns to their home country after several years outside with more wealth and/or experience.\\n\\n## Growing a startup / Living\xa0abroad\\n\\n### Mission and\xa0Vision\\n\\nWhen creating a company, you must have a clear mission and vision. This allows you to create a community/team that will be with you for the long run. Similarly, when moving countries, it\'s essential to have a well-defined goal. This doesn\'t mean that the goal cannot change; after all, companies pivot. However, you need to have a strategy that you follow until you don\'t.\\n\\n### Risk and Uncertainty\\n\\nStartups and moving to a new country both involve stepping into the unknown. Entrepreneurs often take financial and personal risks, while those moving countries leave behind familiar surroundings, support systems, and sometimes even their careers. Uncertainty becomes a constant companion, demanding adaptability, problem-solving skills, and the ability to embrace change with open arms.\\n\\n### Cultural Integration and Networking\\n\\nBuilding a successful startup requires networking, forming strategic partnerships, and understanding the market. Similarly, when moving countries, one must navigate cultural differences, learn new languages, and establish a network of contacts. Expanding social circles, building relationships, and immersing oneself in the local culture contribute to personal growth and enhance professional opportunities, just like in the startup world.\\n\\n### Resilience and Persistence\\n\\nBuilding a startup and moving countries demands unwavering resilience and persistence in facing challenges. Startups encounter setbacks, pivots, and failures, but successful entrepreneurs persist and learn from their experiences. Similarly, moving countries can bring unexpected hurdles, such as language barriers, difficulties making friends, challenges adapting to a new culture, or not finding a routine. Embracing these challenges with determination and adaptability paves the way for growth and achievement.\\n\\n### Learning and\xa0Growth\\n\\nStartups and moving countries are transformative experiences that offer immense personal and professional growth opportunities. Entrepreneurs continuously learn from their successes and failures in the startup world, refining their strategies and acquiring new skills. Likewise, moving countries provides a unique chance to learn about different cultures, broaden perspectives, and develop resilience, patience, and empathy. Both experiences foster personal development and shape individuals into more well-rounded and adaptable individuals.\\n\\n## Why did I do\xa0it?\\n\\nThe reason why I started OpenBB and also moved country is a combination of 2 factors:\\n\\n### Product or mission desperation.\\n\\nOn a startup level, I have experienced the need for an open-source investment research platform. That\'s why I wanted to create this platform, which was yet to exist. I think it wouldn\'t be possible if I didn\'t dedicate my time to it. This is why OpenBB\'s success is so important-it will enable millions of investors to have better access to data and better understand the financial market.\\n\\nGrowing up as an engineer fascinated by tech and innovation, the US has always been home to the biggest companies and hottest products. I\'ve always been attracted to Silicon Valley, but before OpenBB, I never had the chance to. The first job I applied to after finishing university was Waymo in CA, but they didn\'t sponsor VISAs for that role.\\n\\n### Desperation to do something big or important.\xa0\\n\\nOn a startup level, I want to work on something bigger than myself. I want to solve a problem that no one has solved before and build something useful for millions of people that can withstand time.\\n\\nI will do whatever it takes to build the first truly open-source investment research platform. Moving to SF increased my network opportunities with other entrepreneurs and builders from whom I can learn. I want to be fully immersed in this ecosystem and give it my all to do everything possible to help OpenBB succeed as a company, regardless of the outcome.\\n\\nNote: A few weeks ago, I moved to NYC because I truly believe living here would increase the chances of OpenBB\'s success compared to living in SF."},{"id":"moving-from-london-to-the-bay-area-and-what-changed","metadata":{"permalink":"/blog/moving-from-london-to-the-bay-area-and-what-changed","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.md","source":"@site/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.md","title":"Moving from London to the Bay Area and what changed","description":"Moving from London to the Bay Area and what changed","date":"2024-03-02T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"experience","permalink":"/blog/tags/experience"},{"inline":true,"label":"growth","permalink":"/blog/tags/growth"},{"inline":true,"label":"moving","permalink":"/blog/tags/moving"},{"inline":true,"label":"london","permalink":"/blog/tags/london"},{"inline":true,"label":"bay","permalink":"/blog/tags/bay"},{"inline":true,"label":"US","permalink":"/blog/tags/us"},{"inline":true,"label":"travel","permalink":"/blog/tags/travel"}],"readingTime":19.905,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"moving-from-london-to-the-bay-area-and-what-changed","title":"Moving from London to the Bay Area and what changed","date":"2024-03-02T00:00:00.000Z","image":"/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.png","tags":["learning","experience","growth","moving","london","bay","US","travel"],"description":"Moving from London to the Bay Area and what changed"},"unlisted":false,"prevItem":{"title":"Moving Countries and Starting a Company Ain\'t So Different","permalink":"/blog/moving-countries-and-starting-a-company-aint-so-different"},"nextItem":{"title":"OpenBB Copilot is now available to all Terminal Pro users","permalink":"/blog/openbb-copilot-now-available-to-all-terminal-pro-users"}},"content":"
\\n  \\n
\\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA few months ago, I wrote a blogpost about what was needed in order for my wife and our 2 dogs to move to the Bay Area from London. You can check that blog post [here](/blog/leaving-london-to-live-in-san-francisco/).\\n\\nSince then, I\u2019ve had some people asking me after living in the Bay for 1 year, what are the biggest differences I\u2019ve experienced in terms of lifestyle & culture.\\n\\nI will write a section below for each of the major topics I experienced. Note that this is based on my experience, and you may disagree/have different opinions than me on some of these - which are very welcome.\\n\\n## Living costs\\n\\nBack in 2016 when I was at university, in Portugal, I used to pay 200 euros/month to live in an apartment with a roommate. My university cost was 800 euros/year and my parents gave me a monthly allowance of 300 euros/month to pay for food and anything else. I didn\u2019t do many activities and would rarely go out, so I was able to live comfortably on that.\\n\\nOnce I moved to London (in 2017) to pursue a MSc. at Imperial College I was paying 1.6k \xa3/month for a studio in Earl\u2019s Court. This was walking distance from Imperial (didn\u2019t have to pay for transportation) and was cheaper than the accommodations that the university offered. The university was no longer 800 euros/year, it cost \xa311k for the entire MSc (1 year).\\n\\nSo there was a shock that I experienced in terms of living costs from Lisbon to London.\\n\\nOnce I decided to move to the Bay Area (2023) I knew that the living costs were going to be higher, but in my head \u201chow higher can these be?\u201d.\\n\\nOh boy.\\n\\nApparently, a lot.\\n\\n### Shopping\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
Elad Gil fireside with Satya Nadella at Stripe\'s HQ
\\n\\n\\n### Equity as part of compensation package\\n\\nMost European startups do not offer any equity. In the Bay Area, all startups offer equity. The earlier you join (higher risk) the more meaningful the options you get are. One of the reasons this works is because US employees are, in general, hard-working and will go the long way for their company. So this makes it so that incentives are aligned, and employees want to work harder because that equity can become much more meaningful than their base salary (potentially life-changing).\\n\\nOne of the reasons this works so well is that pretty much every US person knows someone in firsthand who made f-u money by selling their shares in secondaries, or has at least heard stories about this. While I was in the UK, before starting OpenBB, I didn\u2019t hear about this once. Also because companies have no interest in offering you equity if they don\u2019t have to.\\n\\nE.g. at my previous startup I used to stay working late into the night, because in my perspective this would increase the startup\'s chances of success. However, I had no equity. So this meant that if the startup was wildly successful, I would have no direct gains from it and the company would not owe me anything. Offering equity through a typical 4-year vesting schedule (with 1-year cliff) provides the perfect type of alignment.\\n\\n### Holidays\\n\\nThe amount of holidays is a good example that demonstrates the hard-working culture that so well characterizes the US. In the US they are used to having 2-weeks off in a full calendar year. In London, most companies offer at least 4-weeks, which is effectively 2x the number of holidays.\\n\\n## Driving culture\\n\\nThe London underground works impressively, I lived there for 5 years and never once even considered owning a car.\\n\\nI thought I could do the same in the US and people were being dramatic. That thought lasted maybe 2 days?\\n\\nOn the first day I had to go to Fedex which was a 15-20m walk, and when I told the apartment administrator that I was going to walk there she looked at me like I was crazy and said \u201cyou need to take your car\u201d. After walking there I understood what she meant and that unless you are in a city, the pedestrian sidewalks/roads just aren\u2019t prepared for pedestrians.\\n\\n### Differences\\n\\n- You drive on the right (x2) side of the road. Since I didn\u2019t drive in the UK, this was very easy for me as I\u2019m used to driving in Portugal where we also drive on the right side of the road.\\n- In the UK (or Europe, in general) having more than 3 lanes on the highway is atypical. In the US, having 6 lanes it\u2019s considered normal. Sometimes it\u2019s tricky and you can\u2019t be in the most right side because the 2 right lanes may both exit and thus you need to hop over 2 lanes to keep on the same route. This mistake can be costly.\\n- There are very very few roundabouts in the Bay. There are a LOT of intersections. I like it less (not because I think it\u2019s slower) but because it\u2019s more \u201cboring\u201d to wait for the green light and from my point of view, people are more likely to grab their phone during that time because they don\u2019t need to pay as much attention, at least compared to a roundabout where you are waiting for an opening to keep moving. (there are so few roundabouts that the first time I saw one I took a picture to share with my wife)\\n- There\u2019s a \u201cRight on Red\u201d policy. This means that if you are at an intersection and it\u2019s red for you to proceed if there\u2019s no incoming car from the left side you can turn right on the red. I like this because it allows for traffic to flow better. My wife doesn\u2019t like it because as a pedestrian sometimes cars start accelerating and don\u2019t respect pedestrian as much. Nonetheless, I love to make this joke when people from Europe visit, where I say that I\u2019m going to pass a red and they are shocked when they see me turning right on a red light.\\n- In the Bay they have FastTrack which allows people to pay to use the most-left lane and avoid traffic. Although this is capitalist I like it because if I\u2019m in a rush I can pay a few dollars to avoid the congestion - it\u2019s a type of SaaS - Speed as a Service \ud83d\ude04\\n\\n### Waymo\\n\\nWaymo, a self-driving car division that started off Google, was the first startup I applied to when I finished university. I have been bullish on self-driving cars since university - my dissertation was on that topic and I had to propose it myself, since there were no proposals for such. So seeing Waymo operating in SF was mind-blowing to me.\\n\\nAutonomous cars are a matter of time - and SF (and the Bay Area) being the city where Waymo starts operating, shows a lot about how progressive this city is. I recommend everyone to try one out.\\n\\nMy dad, someone who was born and raised in a small town in Portugal, and who understands very little about technology seeing this was something. Him seated in the passenger\u2019s seat for the full 16 min drive recording a wheel with no driver and ending the journey telling me \u201cI never thought I would see this in my life, thank you\u201d is something that no amount of money in this world could buy.\\n\\n\\n  \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe [OpenBB Copilo](https://openbb.co/use-cases/ai) is our latest addition to the [Terminal Pro](https://openbb.co/products/pro), and we could not be more excited to share it with you.\\n\\nIf you don\'t have access yet, join the [Terminal Pro waitlist](https://my.openbb.co/app/pro/early-access) and enjoy your 3-week free trial soon!\\n\\nNow, take a moment to meet your new **AI investment research partner**.\\n\\n\\n## What can the OpenBB Copilot do?\\n\\nOpenBB Copilot is multi-functional and can perform several tasks that are useful to analysts. We\u2019ll be exploring these below.\\n\\n\\n### Generic financial knowledge\\n\\nUsing OpenBB Copilot, you can ask any general financial question. For example:\\n\\n**What is the P/E ratio?**\\n\\n\\n\\nAs an additional bonus feature, OpenBB Copilot includes a LaTeX renderer to display mathematical formulas and equations.\\n\\n\\n### Conversation capability\\n\\nOpenBB Copilot is a conversational agent and is, therefore, aware of the chat history of the current conversation.\\n\\nAs a result, you can ask follow-up questions and steer OpenBB Copilot toward your line of inquiry while developing an investment thesis.\\n\\nTo clear the message history, for example, when investigating a new asset, you can click on the trashcan icon to start a new conversation.\\n\\n\\n\\n\\n### Terminal Pro as context\\n\\nIf you ask questions about the data on the dashboard, OpenBB Copilot will query the Terminal Pro for the data necessary to answer your query.\\n\\nThe Copilot has access to the dashboard metadata on the backend and can decide to retrieve data from any of the widgets currently on your dashboard.\\n\\nIn most cases, if you can see the data on your dashboard, you can assume OpenBB Copilot has access to it.\\n\\n\\n\\nThis is an application of what\u2019s known in the AI world as function calling, which allows LLMs to interact with external systems.\\n\\nThe OpenBB Copilot can choose to automatically retrieve the data from your dashboard if it needs it to answer your query.\\n\\nThe advantage of this approach is that, since you can retrieve data from any widget, you can also expand OpenBB Copilot\u2019s knowledge by adding custom widgets or by bringing your own data to the Terminal Pro.\\n\\n\\n### Query specific widgets\\n\\nSometimes, you may wish to focus your analysis and use OpenBB Copilot with only a specific subset of widgets.\\n\\nFor example, you may want to use OpenBB Copilot to assist you in a deep analysis of an earnings transcript in the \\"Earnings Transcript\\" widget without retrieving data from the rest of the dashboard.\\n\\nTo achieve this, you can chat with specifically selected widgets by clicking on the \\"Add widgets as context\\".\\n\\n\\n\\nSelecting a widget will make that widget\'s data available to OpenBB Copilot while excluding all the other widgets.\\n\\nYou can then use the Copilot as normal and the unselected widgets will be ignored by the Copilot.\\n\\n\\n### Query your own documents\\n\\nYou\u2019re also not limited by the data that is available in Terminal Pro.\\n\\nYou can upload your own documents for OpenBB Copilot to use as context while answering your queries.\\n\\nOpenBB Copilot currently supports txt, PDF, CSV and XLSX documents.\\n\\n\\n\\n### Citations\\n\\nWe understand that sometimes getting an answer from an AI chatbot with financial knowledge isn\u2019t satisfactory.\\n\\nYou often want to do further research or do your own fact-checking of the sources used to answer to your query.\\n\\nThat is why OpenBB Copilot provides citations as part of its answers.\\n\\nWhen using the Terminal Pro as context or chatting with your uploaded data files, the Copilot will cite which data sources it used to formulate the answers.\\n\\nSimply mouse over the citation to see which widget data was used, or which uploaded file was referenced. For PDF document specifically, the Copilot will also source the specific page that was used to answer your query.\\n\\n\\n\\n## What if you don\'t want to use our copilot?\\n\\nYou don\u2019t have to. That is the reason we came up with the Bring Your Own Copilot concept.\\n\\nIf you\u2019re an OpenBB Terminal Pro user, you\u2019re able to bring your own financial Copilot that has been fine-tuned and tweaked on your enterprise\u2019s private data.\\n\\nThis provides an edge to financial firms as they can access their own fine-tuned LLM with access to real-time data provided by the OpenBB Terminal Pro - making this the perfect combo to perform investment research.\\n\\nWe have an [open-source repository](https://github.com/OpenBB-finance/copilot-for-terminal-pro/tree/main) to help you make your own copilots accessible on the Terminal Pro.\\n\\nYou can also see the video below:\\n\\n\\n\\n
\\n\\nCheck out our [AI page](https://openbb.co/use-cases/ai) to learn more about these features and stay updated in the future."},{"id":"12-things-i-learned-in-2023","metadata":{"permalink":"/blog/12-things-i-learned-in-2023","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-22-12-things-i-learned-in-2023.md","source":"@site/blog/2024-01-22-12-things-i-learned-in-2023.md","title":"12 Things I Learned in 2023","description":"The 12 things I learned in 2023","date":"2024-01-22T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"experience","permalink":"/blog/tags/experience"},{"inline":true,"label":"growth","permalink":"/blog/tags/growth"}],"readingTime":4.17,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"12-things-i-learned-in-2023","title":"12 Things I Learned in 2023","date":"2024-01-22T00:00:00.000Z","image":"/blog/2024-01-22-12-things-i-learned-in-2023.png","tags":["learning","experience","growth"],"description":"The 12 things I learned in 2023"},"unlisted":false,"prevItem":{"title":"OpenBB Copilot is now available to all Terminal Pro users","permalink":"/blog/openbb-copilot-now-available-to-all-terminal-pro-users"},"nextItem":{"title":"Introducing the OpenBB Add-in for Excel","permalink":"/blog/introducing-the-openbb-add-in-for-excel"}},"content":"
\\n  \\n
\\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe 12 things I learned in 2023\\n\\n### 1. Don\'t delegate anything that you wouldn\'t do yourself.\\n\\nIt\'s extremely important to work on little things to show your team that nothing is too small to spend time on, and sets a precedent that you are willing to work on the ground next to them.\\n\\nE.g. Elon Musk sleeping at the gigafactory to show his team that he was there next to them.\\n\\n### 2. Be curious and humble enough to be willing to ask dumb questions.\\n\\nIf I don\'t know something, I never pretend understanding what the person is talking about.\\n\\nI would take the knowledge over a \\"smart\\" label, any day.\\n\\n### 3. Implement feedback loops on everything you do, otherwise you can\'t adapt.\\n\\nLast year I decided to work on [tracking our employee engagement](https://openbb.co/company/open/team), and this is one of the best and most valuable initiatives I have worked on.\\n\\nIt has provided us tons of feedback that we were able to act on, and improve what it\'s like to work for OpenBB. More information on this [here](https://openbb.co/blog/employee-engagement).\\n\\n### 4. UX is more important than UI.\\n\\nI keep seeing tweets about UI improvements on a website and/or product. I love that type of posts, and wish there was a similar trend going on for UX improvements.\\n\\nWhile UI is critical to attract users, UX is king to retain them.\\n\\nIt\u2019s like dating - the looks is in the UI and the personality is the UX.\\n\\nWhile they may be perceived as their own separate bubble, they are not. Someone with an amazing personality (UX) will appear as more beautiful (UI).\\n\\n### 5. If in presence of a 2-way door decision, you should decide fast.\\n\\nBeing fast to decide to do A instead of B in a 2-way door decision is ideal because even if that wasn\u2019t the correct decision, adapting after will still be better than being stuck at the decision stage.\\n\\nPlus, you\u2019ll be surprised by how many time you actually get it right given the level of context and knowledge you have in the space.\\n\\nKnowing what is a 1 and a 2-way door decision, separates great from poor leaders.\\n\\nI like [this video](https://tiktok.com/@evancarmichael/video/7317081673865235717) from Jeff Bezzos talking about this.\\n\\n### 6. There\u2019s a ton of data in intuition and common sense.\\n\\nAs a leader, most of the times you have to make decisions with no hard data evidence. And by hard data I mean a spreadsheet with numbers or a powerpoint with charts.\\n\\nHowever, you do have that data. It\u2019s just not in a clean format and lives on your head.\\n\\nThis data has been aggregating by spending more time thinking about the problem you are solving than anyone else, by talking with customers, by talking with partners, and everything in between.\\n\\nTrust your intuition, more often than not presentations are done to justify decisions that you knew were right all along. Skip that and you will be able to move faster.\\n\\n### 7. Hear feedback from everyone but only listen from a few.\\n\\nPeople paying for your product, will provide you 10x feedback compared to others. Use common sense for others.\\n\\n### 8. Be there for your team.\\n\\nMake sure to remind your team that you couldn\'t do it without them.\\n\\nA single off-line event per year is not enough.\\n\\nShow that you care by being there: asking about their family/pets/hobbies, messaging them when they perform above expectations, send them gifts when something negative happens, ... act like a friend but manage like a captain\\n\\n### 9. Fire B and C players early. \\n\\nKeeping a team of A players is hard but extremely rewarding, and necessary. \\n\\nIt sets the precedent that average work is not enough to work at your company, and high performers will want to work for you to be surrounded by people that push them everyday.\\n\\n### 10. Distribution is more important than product.\\n\\nTook me some time to understand this, but I have no doubts about this now.\\n\\nThis is why the sentence of \u201cA good product with great distribution will almost always beat a great product with poor distribution.\u201d\\n\\n### 11. Leave your comfort zone.\\n\\nI\'m really shy on stage and this year I\'ve presented a few times. And I\u2019ve impressed myself, while I\'m far from good I\'ve come a long way.\\n\\nWhen i started learning english my goal was to be able to make people laugh in english, that took a while.\\n\\nI\'ve now been able to make people laugh whilst on stage and I didn\'t expect that I\u2019d be able to do this anytime soon.\\n\\n### 12. Tell your loved ones how much they mean to you.\\n\\nMost of us have someone by our side that allow us to keep performing at highest level day in and day out.\\n\\nEnsure they know you couldn\'t be the person you are today without them."},{"id":"introducing-the-openbb-add-in-for-excel","metadata":{"permalink":"/blog/introducing-the-openbb-add-in-for-excel","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.md","source":"@site/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.md","title":"Introducing the OpenBB Add-in for Excel","description":"We acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry.","date":"2024-01-17T00:00:00.000Z","tags":[{"inline":true,"label":"excel","permalink":"/blog/tags/excel"},{"inline":true,"label":"launch","permalink":"/blog/tags/launch"},{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"announcement","permalink":"/blog/tags/announcement"}],"readingTime":3.665,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"introducing-the-openbb-add-in-for-excel","title":"Introducing the OpenBB Add-in for Excel","date":"2024-01-17T00:00:00.000Z","image":"/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.png","tags":["excel","launch","openbb","announcement"],"description":"We acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry."},"unlisted":false,"prevItem":{"title":"12 Things I Learned in 2023","permalink":"/blog/12-things-i-learned-in-2023"},"nextItem":{"title":"SlackGPT - Your Slack bot that summarizes unread messages","permalink":"/blog/slack-gpt-summarizing-messages"}},"content":"
\\n  \\n
\\n
\\n\\nWe acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nBuilding something people truly want requires direct engagement with them. After conducting over 100 interviews with analysts and quants, three key insights surfaced:\\n\\n1. The financial world runs on Excel.\\n\\n2. The primary value of the OpenBB Terminal Pro lies in its customization (bring your own data + widget/dashboard creation) and AI features.\\n\\n3. The financial world, **LITERALLY**, still runs on Excel.\\n\\nFor topic number 2, we were well underway towards building the [Terminal Pro](https://openbb.co/products/pro) as the most customizable and efficient financial terminal.\\n\\nBut for topics number 1 and 3, we weren\u2019t.\\n\\nSo we devised a small task force to tackle this effort and work with design partners towards building the [OpenBB Add-in for Excel](https://openbb.co/products/excel).\\n\\nThe goal was simple: **financial data available on the Terminal Pro should be accessible in Excel**.\\n\\nBut as we do for all our products, we wanted to understand where this product would sit in our ecosystem.\\n\\nSince the Terminal Pro offers a basic data tier (including historical price, fundamentals, analyst estimates, news, macro-economy, and forex) with redistribution rights, we decided to make those same datasets available in Excel.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nYou can find more tutorials in the [Documentation](https://docs.openbb.co/excel/getting-started/installation).\\n\\nFor more information, contact us at sales@openbb.finance or sign up for [our waitlist](https://my.openbb.co/app/pro/early-access)."},{"id":"slack-gpt-summarizing-messages","metadata":{"permalink":"/blog/slack-gpt-summarizing-messages","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-15-slack-gpt-summarizing-messages.md","source":"@site/blog/2024-01-15-slack-gpt-summarizing-messages.md","title":"SlackGPT - Your Slack bot that summarizes unread messages","description":"The SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel.","date":"2024-01-15T00:00:00.000Z","tags":[{"inline":true,"label":"slack","permalink":"/blog/tags/slack"},{"inline":true,"label":"slackgpt","permalink":"/blog/tags/slackgpt"},{"inline":true,"label":"llm","permalink":"/blog/tags/llm"},{"inline":true,"label":"summarization","permalink":"/blog/tags/summarization"},{"inline":true,"label":"open source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"bot","permalink":"/blog/tags/bot"}],"readingTime":3.825,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"slack-gpt-summarizing-messages","title":"SlackGPT - Your Slack bot that summarizes unread messages","date":"2024-01-15T00:00:00.000Z","image":"/blog/2024-01-15-slack-gpt-summarizing-messages.png","tags":["slack","slackgpt","llm","summarization","open source","bot"],"description":"The SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel."},"unlisted":false,"prevItem":{"title":"Introducing the OpenBB Add-in for Excel","permalink":"/blog/introducing-the-openbb-add-in-for-excel"},"nextItem":{"title":"Building my personal website in Docusaurus","permalink":"/blog/building-my-personal-website-in-docusaurus"}},"content":"
\\n  \\n
\\n
\\n\\nThe SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/slackGPT).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nSaw someone the other day tweeting that it would be great if there was a SlackGPT that could summarize all the Slack messages for when they wake up.\\n\\nAnd I immediately related to that. We are a team of 20, and I\'m the only one in SF. So when I wake up, most of the team is already half a day in or has just wrapped up.\\n\\nThat means that I always spend the first 30 minutes of the day reading messages to catch-up on everything.\\n\\nAnd tonight felt like hacking something quick.\\n\\nSo I created a script that:\\n\\n* Reads all Slack messages from the time I go to bed\\n* Summarizes the conversation of each channel\\n* The bot sends me a message with this summary\\n\\n## Getting Started\\n\\nClone the open source project [here](https://github.com/DidierRLopes/slackGPT).\\n\\n### Slack API\\n\\n1. Go to [Slack API page](https://api.slack.com/apps) and create a new app.\\n\\n2. Install the app in the workspace you are interested in summarizing Slack messages.\\n\\n3. Get the User OAuth Token which exists in the Install App settings. This will be needed to use Slack\'s SDK. Set this value as the `SLACK_TOKEN` on a `.env` file if you want to run the script locally or as a GitHub secret if you want to leverage the GitHub workflow.\\n\\n
\\n\\n
\\n  \\n
\\n
\\n\\n
\\n  \\n
\\n
\\n\\n
\\n  \\n
\\n
\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nHow I\'m using Docusaurus to build my own personal website.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOne of my goals for 2023 was to learn web development. Given that I knew 0 to nothing last year, I am extremely happy with my progress.\\n\\nI never had the time to fully dedicate to it in terms of doing a program/course \u2014 but as with anything in life, the best way to learn is by doing.\\n\\nAnd this year I worked on web development for:\\n\\n* OpenBB Hub \u2014 https://my.openbb.co\\n* OpenBB marketing website \u2014 https://openbb.co\\n* OpenBB docs \u2014 https://docs.openbb.co\\n* OpenBB Terminal Pro \u2014 https://pro.openbb.co\\n\\nThank you Jos\xe9 Donato for always helping me with anything!\\n\\nIn addition, I\u2019ve always wanted to have my own personal website. So I felt that this would be the perfect opportunity to do so as I could spend some time with it over weekends.\\n\\nAnd so I did, and open source here: https://github.com/DidierRLopes/personal-website\\n\\nHowever, this website was taking too much of my spare time, which I could use for more important work. And at the time I became very familiar with Docusaurus, which is what we use for OpenBB docs.\\n\\nSo I thought \u2014 why not just use Docusaurus to make my personal website? It\u2019s easy to edit, I\u2019m already very familiar with the architecture, and it\u2019s very easy to update when there\u2019s new information.\\n\\nSo that\u2019s what I did, and also made the entire code open source here: https://github.com/DidierRLopes/my-website\\n\\nYou can access the full website here \u2014 https://didierlopes.com/, and there you can find: my personal projects, books I\u2019ve read or want to read, interviews/webinars/podcasts, resume or even my blog.\\n\\nAny feedback is welcome."},{"id":"prediction-for-2024","metadata":{"permalink":"/blog/prediction-for-2024","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-01-prediction-for-2024.md","source":"@site/blog/2024-01-01-prediction-for-2024.md","title":"Prediction for 2024","description":"Companies will own multiple fine-tuned LLMs/SLMs for specific tasks.","date":"2024-01-01T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"ai","permalink":"/blog/tags/ai"},{"inline":true,"label":"agents","permalink":"/blog/tags/agents"},{"inline":true,"label":"copilot","permalink":"/blog/tags/copilot"},{"inline":true,"label":"llm","permalink":"/blog/tags/llm"},{"inline":true,"label":"pro","permalink":"/blog/tags/pro"},{"inline":true,"label":"fine-tune","permalink":"/blog/tags/fine-tune"}],"readingTime":1.73,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"prediction-for-2024","title":"Prediction for 2024","date":"2024-01-01T00:00:00.000Z","image":"/blog/2024-01-01-prediction-for-2024.png","tags":["openbb","finance","ai","agents","copilot","llm","pro","fine-tune"],"description":"Companies will own multiple fine-tuned LLMs/SLMs for specific tasks."},"unlisted":false,"prevItem":{"title":"Building my personal website in Docusaurus","permalink":"/blog/building-my-personal-website-in-docusaurus"},"nextItem":{"title":"Creating an AI-powered financial analyst","permalink":"/blog/creating-an-ai-powered-financial-analyst"}},"content":"
\\n  \\n
\\n
\\n\\nCompanies will own multiple fine-tuned LLMs/SLMs for specific tasks.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLLMs like ChatGPT are great for showing what these models are capable of doing in terms of breadth, but at the end of the day, you\u2019re going to look for depth. Instead of relying on one-size-fits-all solutions, companies will look towards the integration of multiple, fine-tuned language models tailored for specific actions.\\n\\nEnterprises are recognizing the importance of accuracy in their AI applications. General-purpose language models have been revolutionary, but the demand for specialized models is on the rise. From customer support interactions to complex data analysis, having dedicated language models for specific tasks enhances accuracy and efficiency. This is easy to understand since the weights that are being used for the LLM to have a big breadth of knowledge are repurposed for depth.\\n\\nPersonalization is no longer a luxury but a necessity. Specialized language models enable enterprises to deliver personalized experiences to their customers. We have to assume that everyone is utilizing the same models today, so offering ChatGPT in your product isn\u2019t good enough. You need to add alpha to it. And that is done through fine-tuning utilizing your private data.\\n\\nIn an era of increasing cyber threats and stringent regulations, the deployment of fine-tuned language models allows enterprises to enhance their security measures and ensure compliance with industry standards.\\n\\nAs for the financial industry, this is 100% going to happen. Firms will fine-tune language models locally utilizing their proprietary datasets and providing access to their Snowflake/Elastic/ClickHouse/.. instances. This collection of models will effectively enhance the productivity of the firm by 2/3x, even displacing jobs.\\n\\nWe are preparing for this shift at OpenBB and I spent the last few days working on a proof-of-concept with Jos\xe9 Donato that will allow users to bring their own copilots to the Terminal Pro. And even have these interact with each other.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nOur Platform aims to empower the OpenBB Copilot, an AI-powered financial analyst, to perform tasks ranging from knowledge retrieval to fully autonomous analysis. The architecture involves task decomposition, tool retrieval, and subtask agents, showcasing impressive results in both deterministic and non-deterministic workflows. Read on to explore its capabilities and don\'t forget to watch the demos.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/openbb-agents).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nAt OpenBB, we have been thinking deeply about how AI will impact the lives of analysts and quants. We recently [announced the OpenBB Platform](https://openbb.co/blog/goodbye-openbb-sdk-hello-openbb-platform) and have refactored it from the ground up to make it easier and simpler for quants/developers to access financial data. In addition, we hired a new head of AI to lead our AI efforts - you can read more about it [here](https://openbb.co/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig).\\n\\nI did a 20-minute presentation at the Open Core Summit on this topic that you can watch here:\\n\\n
\\n\\nOtherwise, the following post will summarize what we presented.\\n\\n## AI-Powered financial analyst roadmap\\n\\nWhen discussing what tasks we wanted our AI-powered Financial Analyst to be able to perform, we arrived at the following levels (in order of complexity):\\n\\n1. **Knowledge retrieval**: The agent can answer general financial queries without external resources. (eg. ChatGPT \\"as-is\\"). Here, the agent relies solely on its training data to answer questions.\\n\\n2. **Data retrieval**: The agent can answer queries using information inserted into the context (usually as part of a separate data retrieval process that isn\u2019t controlled by the model, such as using [similarity search](https://en.wikipedia.org/wiki/Similarity_search) across a knowledge database using the user\u2019s query).\\n\\n3. **Autonomous data retrieval**: The agent can answer queries by dynamically retrieving data not currently present in the context or the training data via function calling.\\n\\n4. **Complex workflow execution**: The agent can reason and answer queries that require a logical arrangement of knowledge retrieval, data retrieval, and autonomous data retrieval calling. It includes action planning and decision-making.\\n\\n5. **Fully autonomous analyst**: The agent can do all of the above but is self-directed. The agent can dynamically generate additional hypotheses, modify plans of action, and retrieve the necessary data, all while mid-workflow. The agent can make arguments for certain decisions, carry a discussion on the topic, and reason with you.\\n\\nOur goal is to enable OpenBB Copilot to perform all of the above. I presented a demo of how it would work in this video:\\n\\n
\\n\\n## Two types of prompts\\n\\nRather than first building an AI-powered financial analyst for the sake of it, we instead started from what we wanted to achieve. We came up with two distinct prompts and our goal was for the agent to be able to successfully perform both of these, but utilizing the same underlying \u201cagentic\u201d architecture.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nThis blog post delves into how our collaboration with MindsDB, Nixtla, LlamaIndex, and Langchain is revolutionizing the financial world. Read on to learn all about the event \\"The New FinAI Tech Stack\\" held last week in SF, California.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nIn early September, I attended a \u201cFuture of Finance\u201d event in NYC. Despite the presence of well-known financial professionals from top firms in the industry, I found the event lacked practical applications demonstrating how AI is impacting the financial sector.\\n\\nOnce I was back in the Bay Area, I had a barbecue with Jorge and Max from MindsDB and Nixtla, and I was commenting on that experience. To which Jorge promptly replied - why don\u2019t we do it ourselves? So following this discussion, we decided to put the AI in finance event in motion.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nSo at the event, Harrison presented this architecture which heavily relies on Langchain and OpenBB tools.\\n\\n
\\n  \\n
\\n
\\n\\nWe\'re considering organizing another event like this soon, possibly even in NYC.\\n\\nAnd if your firm is interested in early access to the OpenBB Terminal Pro, you can reach out to hello@openbb.finance, we\u2019d love to chat."},{"id":"goodbye-openbb-sdk-hello-openbb-platform","metadata":{"permalink":"/blog/goodbye-openbb-sdk-hello-openbb-platform","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.md","source":"@site/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.md","title":"Goodbye OpenBB SDK. Hello OpenBB Platform","description":"Today, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions.","date":"2023-11-29T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"platform","permalink":"/blog/tags/platform"},{"inline":true,"label":"sdk","permalink":"/blog/tags/sdk"},{"inline":true,"label":"core","permalink":"/blog/tags/core"},{"inline":true,"label":"extensions","permalink":"/blog/tags/extensions"}],"readingTime":4.08,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"goodbye-openbb-sdk-hello-openbb-platform","title":"Goodbye OpenBB SDK. Hello OpenBB Platform","date":"2023-11-29T00:00:00.000Z","image":"/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.png","tags":["openbb","platform","sdk","core","extensions"],"description":"Today, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions."},"unlisted":false,"prevItem":{"title":"The new FinAI Tech Stack","permalink":"/blog/the-new-finai-tech-stack"},"nextItem":{"title":"OpenBB Bot - our new addition to the OpenBB open source family","permalink":"/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family"}},"content":"
\\n  \\n
\\n
\\n\\nToday, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn the ever-evolving landscape of financial data integration and standardization, OpenBB has been revolutionizing the way individuals and organizations handle data from multiple data providers by utilizing our open-source products.\\n\\nWe have been talking about the OpenBB Platform v4 over the past few months. This is such a milestone for our team and for the financial world that we are renaming the OpenBB SDK into the OpenBB Platform.\\n\\nThe OpenBB Platform consists of the OpenBB Core and OpenBB Extensions.\\n\\nLet\u2019s dive into each of these, individually.\\n\\n## OpenBB Core\\n\\nThe OpenBB Core empowers quants and finance developers to create powerful data solutions, offering unparalleled simplicity, flexibility, and scalability. It follows the principle that \\"less is more.\\"\\n\\nThe core will consist of two main components:\\n\\n1. **Data Standardization Infrastructure:** This ensures that regardless of the type of data processed by the core, users can expect consistent conventions and naming. This facilitates a seamless experience, even when the data comes from completely different data providers.\\n\\n2. **Data Source Integration:** Developers will be able to effortlessly connect and integrate various data sources, including databases, APIs, and cloud storage systems.\\n\\n a) **Official partner integrations** will be available by having access to official endpoints from data vendors. This ensures the integrity of the data and provides a reference for what data is available to the end user. Our affiliate program will detail where commercial agreements are in place with OpenBB.\\n\\n b) Additionally, **community provider integrations** will be available, allowing the community to contribute their own integrations for specific use cases or share them with others through the open-source codebase.\\n\\n## OpenBB Extensions\\n\\nOpenBB extensions enhance the capabilities of the OpenBB Core, allowing developers to create custom functionalities and customize the overall Platform according to their specific needs. It is important to note that these extensions can be used as a standalone or integrated with the rest of the openBB ecosystem.\\n\\nThese extensions can be classified into two categories:\\n\\n
- \\n
- Official extensions developed and maintained by the OpenBB Team, such as the ML/AI Toolkit, Econometrics, and Reports; \\n
- Community extensions developed by the open-source community. These extensions focus on enabling intelligent data processing and custom workflows that assist users in their investing decision-making process. \\n
- \\n
- Enhanced Flexibility: The modular architecture of the Platform allows developers to choose and integrate only the components they need, avoiding unnecessary complexity. \\n\\n
- Scalability: The OpenBB Platform seamlessly scales with your data integration requirements, ensuring smooth performance even with large volumes of data. \\n\\n
- Extensibility: Developers can create their own extensions and contribute to the OpenBB ecosystem, fostering collaboration and innovation. \\n\\n
- Time and Cost Savings: With its intuitive interface and pre-built components, the OpenBB Platform accelerates development cycles, reducing time-to-market and costs associated with custom solutions. \\n
\\n\\nThe reimagined OpenBB SDK into OpenBB Platform (OpenBB Core and OpenBB Extensions), revolutionizes the data integration landscape.\\n\\nBy leveraging the power of OpenBB Core for data integration and standardization, and harnessing the capabilities of OpenBB Extensions for customization and advanced functionality, developers can unlock new possibilities and build cutting-edge data solutions.\\n\\nWhether you are working with diverse data sources or performing complex data transformations, the OpenBB Platform empowers you to conquer any data challenge and propel your organization towards data-driven success.\\n\\nWe invite users and enthusiasts to explore the OpenBB Platform v4, now available for download and installation from the [OpenBB Hub](https://docs.openbb.co/platform/installation), [Github](https://github.com/OpenBB-finance/OpenBBTerminal/tree/develop/openbb_platform), and [PyPI](https://pypi.org/project/openbb/).\\n\\n## Inside OpenBB: A peek into our team emails\\n\\nIn order to adhere to one of OpenBB\'s core values - Transparency - we want you to understand the journey we have undergone and the reason we have dedicated the past 9 months to this endeavor.\\n\\nSo, for the first time, we\'re sharing a confidential email thread that circulated among our entire team. This thread provides insight into our thought process when it comes to handling large projects at OpenBB.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nThe OpenBB Bot is now open source. Check out our Discord Bot architecture now on GitHub.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/openbb-bot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## What is the OpenBB Bot, and why did we build it?\\n\\nWhen the OpenBB Terminal first went viral, users were writing online that one of the things missing from our product was a chat feature like other investment platforms provide.\\n\\nHowever, we didn\u2019t understand why the chatting experience needed to be centralized in the application where users research their financial data. Plus, with the ever-growing userbase of apps like Discord, Telegram, Slack, and others, combined with their capabilities to build apps on top, we thought we could do more.\\n\\nWe believe in a future where you can query financial data right from where you are. Meaning you can chat with colleagues, from any of the apps you\u2019re already using.\\n\\nThis is when we partnered with OptionsFamBot (the biggest Discord financial bot that was present in 15k+ servers, reaching 1 M+ users) to build the OpenBB Bot.\\n\\nYou can read more about our launch in August 2022 [here](https://openbb.co/blog/openbb-bot-launch).\\n\\n## Failing to monetize. Failing to grow user base.\\n\\nTo provide OpenBB Bot users with access to 100+ financial commands (including expensive datasets such as the options and dark pool ones) we had to pay not just the data vendors but also for the display rights.\\n\\nThis was relatively expensive, but we considered it a marketing cost since we expected exponential user growth. We expected that since the Bot could be deployed in any server in a few seconds, more users would be exposed to the Bot, bringing the Bot to other servers, and so on...\\n\\n**However, that didn\u2019t happen.**\\n\\nIn September 2022, Discord changed its command syntax to force commands to start with \u201c/\u201d and the user drop was noticeable.\\n\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n  \\n
\\n
\\n\\nWith the launch of the OpenBB Terminal Pro approaching, we\'re excited to announce the hiring of Michael Struwig, a Ph.D. with expertise in AI and quantitative finance. Michael will help us to further our AI capabilities, reinforcing our commitment to innovation in the open-source finance space.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAI will be one of the technologies that will be looked back in hundreds of years as revolutionary, changing how humans live.\\n\\nWith the upcoming launch of the [OpenBB Terminal Pro](https://my.openbb.co/app/pro), we believe AI can push the limits of the way users do investment research.\\n\\nWe believe our ecosystem is positioned at the forefront of finance in terms of investment research. With the inception of the OpenBB Terminal Pro, we are standing at the cusp of a significant leap. Our journey began with [AskOBB](https://openbb.co/blog/breaking-barriers-with-openbb-and-llamaIndex), a tool that facilitated natural language interaction with financial data, but that was just the start.\\n\\nLast month, I wrote a [tweet](https://twitter.com/didier_lopes/status/1706731145776566399) explaining why we spent over $500,000 in revamping our core platform. We are committed to creating the best finance platform for quants/analysts to build with. Some key features are:\\n\\n
- \\n
- We are data vendor agnostic - we enable them \\n
- We are open source - everyone can contribute data \\n
- We standardize data across close to 100 different data providers \\n
- We put a lot of effort into our documentation \\n
\\n  \\n
\\n
- \\n
- Startups built around a particular feature - e.g. chatting with news. With LLMs becoming a commodity, over time it will be easy to understand that this is a feature and not a product itself. \\n
- Larger companies that put a small team together to explore generative AI to be seen as leaders in the space - but without an intention to bring such to market. Often because of outdated tech stack. \\n
\\n\\n
\\n  \\n
\\n
\\n\\n
\\n  \\n
\\n
\\n\\n\\n\\nMost of these generative AI features have been started as side projects by our team members, and once we validated the use case with financial professionals we incorporated it into the roadmap. However, we want to double down on this effort and therefore we\'re excited to welcome [Michael](https://twitter.com/MichaelNStruwig) to OpenBB.\\n\\n[Michael](https://twitter.com/MichaelNStruwig) has a PhD in Electrical and Electronic Engineering, has been doing AI for a few years, and prior to joining us was the CEO of Hudson & Thames Quantitative Research.\\n\\nI first heard him from his reading groups:\\n\\n
\\n\\n
\\n\\nIf you are excited about the field of open source, AI, and finance, and want to help - you can reach out to Michael on [Twitter](https://twitter.com/MichaelNStruwig)."},{"id":"writing-documentation-as-a-founder-is-underrated","metadata":{"permalink":"/blog/writing-documentation-as-a-founder-is-underrated","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.md","source":"@site/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.md","title":"Writing documentation, as a founder, is underrated.","description":"This blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall.","date":"2023-10-29T00:00:00.000Z","tags":[{"inline":true,"label":"documentation","permalink":"/blog/tags/documentation"},{"inline":true,"label":"founder","permalink":"/blog/tags/founder"},{"inline":true,"label":"startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"writing","permalink":"/blog/tags/writing"},{"inline":true,"label":"product","permalink":"/blog/tags/product"}],"readingTime":1.23,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"writing-documentation-as-a-founder-is-underrated","title":"Writing documentation, as a founder, is underrated.","date":"2023-10-29T00:00:00.000Z","image":"/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.png","tags":["documentation","founder","startup","writing","product"],"description":"This blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall."},"unlisted":false,"prevItem":{"title":"Revolutionizing AI at OpenBB with new leader, Michael Struwig","permalink":"/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig"},"nextItem":{"title":"Building the world\u2019s investment research infrastructure","permalink":"/blog/building-the-worlds-investment-research-infrastructure"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA founder spending time writing documentation is f*king underrated.\\n\\nWorking on your product documentation may not be the most rewarding task, but I strongly believe that it gives you an edge when pitching your product.\\n\\nGood documentation needs to strike the perfect balance between having enough context and being straight to the point.\\n\\nThis week someone asked us how many people worked on our documentation.\\n\\nThere have been less than 3 people working on it. Our North Star metric has been common sense and putting out documentation that we would enjoy reading/learning from ourselves.\\n\\nEarlier this year I also heard suggestions of hiring a dedicated technical writer.\\n\\nI think that\u2019s BS, at least at the early stages of your company.\\n\\nIt\u2019s the equivalent of saying that you should hire someone to tell your company vision or that the first sales shouldn\u2019t come from the founders.\\n\\nNo one knows your product better than yourself. And users (particularly devs) will notice the love put into documentation. + This will result in less customer support and a better user experience overall.\\n\\nHonestly, a very underrated task if you ask me."},{"id":"building-the-worlds-investment-research-infrastructure","metadata":{"permalink":"/blog/building-the-worlds-investment-research-infrastructure","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.md","source":"@site/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.md","title":"Building the world\u2019s investment research infrastructure","description":"This blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation.","date":"2023-10-19T00:00:00.000Z","tags":[{"inline":true,"label":"investment","permalink":"/blog/tags/investment"},{"inline":true,"label":"research","permalink":"/blog/tags/research"},{"inline":true,"label":"infrastructure","permalink":"/blog/tags/infrastructure"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":0.955,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"building-the-worlds-investment-research-infrastructure","title":"Building the world\u2019s investment research infrastructure","date":"2023-10-19T00:00:00.000Z","image":"/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.png","tags":["investment","research","infrastructure","OpenBB"],"description":"This blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation."},"unlisted":false,"prevItem":{"title":"Writing documentation, as a founder, is underrated.","permalink":"/blog/writing-documentation-as-a-founder-is-underrated"},"nextItem":{"title":"A $500k bet to build the best platform to do AI using financial data","permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n[OpenBB](http://openbb.co) team is comprised of 18 FTE.\\n\\nWe have 8 products: [OpenBB Platform](https://my.openbb.co/app/platform), [OpenBB Terminal](https://my.openbb.co/app/terminal), [OpenBB Bot](https://my.openbb.co/app/bot), [OpenBB Terminal Pro](https://my.openbb.co/app/pro), OpenBB Excel Add-In, [OpenBB Hub](https://my.openbb.co/app/hub), [OpenBB Docs](https://docs.openbb.co) and [Marketing website](https://openbb.co).\\n\\nThis means that on average we have around 2 people working on each product.\\n\\nThis is particularly wild when you look into the complexity associated with each of these products and being at the forefront of innovation.\\n\\nThat average includes not only engineers but design, product, and marketing.\\n\\nIn addition, our [Discord community](https://openbb.co/discord) has 14k+ people and we often get praised regarding how good our support is.\\n\\nRegardless of our future, I am proud of the team we put together and how efficiently we operate.\\n\\nIt would take a much larger company well over 5 years to build what we built in 2."},{"id":"a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","metadata":{"permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.md","source":"@site/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.md","title":"A $500k bet to build the best platform to do AI using financial data","description":"This blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024.","date":"2023-10-14T00:00:00.000Z","tags":[{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Data Access","permalink":"/blog/tags/data-access"},{"inline":true,"label":"Agents","permalink":"/blog/tags/agents"}],"readingTime":1.9,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","title":"A $500k bet to build the best platform to do AI using financial data","date":"2023-10-14T00:00:00.000Z","image":"/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.png","tags":["AI","Financial Data","OpenBB","Data Access","Agents"],"description":"This blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024."},"unlisted":false,"prevItem":{"title":"Building the world\u2019s investment research infrastructure","permalink":"/blog/building-the-worlds-investment-research-infrastructure"},"nextItem":{"title":"Work-life balance is bullsh*t","permalink":"/blog/work-life-balance-is-bullsh-t"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/openbb-agents/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEarlier this year we made a $500k bet.\\n\\nThe [OpenBB SDK](https://my.openbb.co/app/sdk) had access to over 500 data endpoints. But it was built as a second thought (after the Terminal) and it was extremely time-consuming to manage all dependencies.\\n\\nPlus, the SDK had more than just access to data and thus was bloated.\\n\\nSo we invested $500,000 to build it from the ground up and focus on data access.\\n\\nNow the OpenBB Platform (rebrand) is lean and scalable.\\n\\nIt can be used in Python (`pip install openbb==4.0.0a2`) but also for web development. More information [here](https://pypi.org/project/openbb/).\\n\\nAnd honestly, is the door to financial data.\\n\\n**Why am I saying all this?**\\n\\nBecause I predict that in 2024 this bet will have a massive payoff.\\n\\n**The reason?**\\n\\nAgents are going to be big.\\n\\nAnd when they are, financial firms that aren\u2019t leveraging them are going to have to spend a lot of resources to make up for the lack of efficiency.\\n\\n## Enter OpenBB Platform\\n\\n- We are data vendor agnostic (we enable them)\\n- We are open source (everyone can contribute data)\\n- We standardize data across close to 100 different data providers\\n- We put a lot of effort into our documentation\\n\\nThe last 3 points are key for agents, and why people will build agents on top of the OpenBB platform.\\n\\nIn a few hours, I was able to use the following prompt:\\n\\n```console\\n Check what are TSLA peers.\\n From those, check which one has the highest market cap. \\n Then, on the ticker that has the highest market cap get \\n the most recent rating from an analyst. And tell me who \\n was the analyst and what date was it that the rating was done\\n```\\n\\nTo have an agent execute this entire workflow in a 1/10th of the time that it would have taken an analyst to do.\\n\\nCheck for yourself the example below,\\n\\n"},{"id":"work-life-balance-is-bullsh-t","metadata":{"permalink":"/blog/work-life-balance-is-bullsh-t","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-09-16-work-life-balance-is-bullsh-t.md","source":"@site/blog/2023-09-16-work-life-balance-is-bullsh-t.md","title":"Work-life balance is bullsh*t","description":"This blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals.","date":"2023-09-16T00:00:00.000Z","tags":[{"inline":true,"label":"work-life balance","permalink":"/blog/tags/work-life-balance"},{"inline":true,"label":"success","permalink":"/blog/tags/success"},{"inline":true,"label":"career","permalink":"/blog/tags/career"},{"inline":true,"label":"hard work","permalink":"/blog/tags/hard-work"}],"readingTime":1.445,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"work-life-balance-is-bullsh-t","title":"Work-life balance is bullsh*t","date":"2023-09-16T00:00:00.000Z","image":"/blog/2023-09-16-work-life-balance-is-bullsh-t.png","tags":["work-life balance","success","career","hard work"],"description":"This blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals."},"unlisted":false,"prevItem":{"title":"A $500k bet to build the best platform to do AI using financial data","permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data"},"nextItem":{"title":"Target Market Analysis with the help of LLMs","permalink":"/blog/target-market-analysis-with-the-help-of-llms"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n\\nFor successful individuals, achieving a work-life balance is a luxury often associated with those born into wealth.\\n\\nLet me explain.\\n\\nThere must be a clear inverse correlation between success (let\u2019s say measured by wealth) and the size of your circle of friends.\\n\\n**If you want to be at the top of a field, you must work hard.**\\n\\nEnd.\\n\\nRegardless of what BS people say about work-life balance.\\n\\nYou may be lucky \u2014 right place right time kind of thing. But by default, you need to work hard to expand your luck\u2019s surface.\\n\\nAnd that means that you need to spend your personal time working harder, to be above average.\\n\\nSince time is limited you need to sacrifice time spent outside working hours, otherwise you will only be average.\\n\\nPeople will soon realize that in order to optimize for a successful career, cutting time spent with friends is a necessary evil.\\n\\nPlus, as you become older you\u2019ll prioritize physical health (which impacts your longevity + performance) and your relationship with your partner (which provides the most significant ROI in terms of happiness).\\n\\nSo, I suggest 2 things:\\n\\n- Work on a problem and in a space that you truly enjoy so you don\u2019t consider it work\\n- Build with people who share the same values as you so you consider them friends Once that happens, work-life balance means nothing.\\n\\nWhat\u2019s your take?"},{"id":"target-market-analysis-with-the-help-of-llms","metadata":{"permalink":"/blog/target-market-analysis-with-the-help-of-llms","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.md","source":"@site/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.md","title":"Target Market Analysis with the help of LLMs","description":"This blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage.","date":"2023-09-10T00:00:00.000Z","tags":[{"inline":true,"label":"Target Market Analysis","permalink":"/blog/tags/target-market-analysis"},{"inline":true,"label":"LLMs","permalink":"/blog/tags/ll-ms"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"BCG Matrix","permalink":"/blog/tags/bcg-matrix"},{"inline":true,"label":"GE McKinsey Matrix","permalink":"/blog/tags/ge-mc-kinsey-matrix"},{"inline":true,"label":"Market Attractiveness","permalink":"/blog/tags/market-attractiveness"},{"inline":true,"label":"Competitive Advantage","permalink":"/blog/tags/competitive-advantage"}],"readingTime":9.66,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"target-market-analysis-with-the-help-of-llms","title":"Target Market Analysis with the help of LLMs","date":"2023-09-10T00:00:00.000Z","image":"/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.png","tags":["Target Market Analysis","LLMs","OpenBB","BCG Matrix","GE McKinsey Matrix","Market Attractiveness","Competitive Advantage"],"description":"This blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage."},"unlisted":false,"prevItem":{"title":"Work-life balance is bullsh*t","permalink":"/blog/work-life-balance-is-bullsh-t"},"nextItem":{"title":"OpenBB 2 year anniversary","permalink":"/blog/openbb-2-year-anniversary"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/target-market-analysis/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAfter working on [OpenBB](https://openbb.co) for over 2 years, we learned which markets to go after and which markets to ignore. You may think that this is intuition, but it\u2019s actually the data that you gathered from talking with 100+ users and learning from others in the industry.\\n\\nHowever, people who don\u2019t know your business as well as you do (new joiners, advisors, or investors), don\u2019t understand why your target market is X and not Y. Hence, it\u2019s important to backtrace your \u201cexperience\u201d with data.\\n\\nThis blog post will focus on how you can perform target market analysis for your company. I will provide the framework and the code to leverage OpenAI to speed up that research process. All of this will be replicable, and you can do it for your own company.\\n\\n## Context\\n\\nThis framework is utilized for portfolio analysis in corporate strategy to analyze business units or product lines.\\n\\n### BCG Matrix\\n\\nInitially, BCG implemented its own framework, which you can read more about here. In a nutshell:\\n\\n_It uses two variables: relative market share and the market growth rate. By combining these two variables into a matrix, a corporation can plot their business units accordingly and determine where to allocate extra (financial) resources, where to cash out and where to divest._\\n\\n\\n\\n### GE McKinsey Matrix\\n\\nThen, the GE McKinsey Matrix was invented, which you can read more about here. To put it briefly:\\n\\n_It uses two variables: industry attractiveness and the competitive strength of a business unit. By combining these two variables into a matrix, a corporation can plot their business units accordingly and determine where to invest, where to hold their position, and where to harvest or divest._\\n\\n\\n\\nAs per the blog post, the main difference between these comes from the fact that the latter uses multiple factors that are combined to determine the measure of the two variables: industry attractiveness and competitive strength. Whereas the BCG Matrix only uses 1 variable per axis \u2014 relative market share and market growth rate.\\n\\nThe GE McKinsey Matrix (also known as the Nine-box matrix) has industry attractiveness on the y-axis and competitive strength on the x-axis.\\n\\nFor industry attractiveness, factors to consider can be: Industry size; Long-run growth rate; Industry structure; Industry life cycle; Macro environment; and Market segmentation.\\n\\nFor competitive strength, factors to consider can be: Profitability; Market share; Business growth; Brand equity; Level of differentiation; Firm resources; Efficiency and effectiveness of internal linkages; and Customer loyalty.\\n\\n## How do you build your Matrix?\\n\\nAll the data will be hypothetical. The goal is to share the process and framework. Each company and market will have its own.\\n\\n### 1. Define your factors\\n\\nWhen we talk about market attractiveness, from your company\u2019s perspective, what makes a market attractive? Consider all those factors and list them. Try to list all the factors that have a weight in that equation, but try to keep them under 10; otherwise, it\u2019s too many to have to assess, and at some point, their weight into the attractiveness is negligible.\\n\\nNow do the same for the factors that give your company a competitive advantage.\\n\\n### 2. Weigh each factor\\n \\nNot all factors are created equal. Some factors will influence whether a market is attractive or not. Similarly, for your competitive advantage, what factors give your company a bigger edge?\\n\\nThe goal is to select a weight for each factor so that the sum of the weights for all the factors adds up to 1. The outcome should look something like:\\n\\n\\n\\n### 3. Categorize each factor\\n\\nNow you need to decide how granular you want your assessment to be. Initially, at OpenBB, we started with a scale of 1\u20133 where 1 is low, 2 is medium, and 3 is high. However, soon we found this to not be good enough since there was not enough granularity. Thus, we increased the range from 1 to 5.\\n\\nOnce you decide on that range, you need to categorize it in a way that makes sense for each factor. This ensures that everyone on the team is on the same page when it comes to assessing a factor. For instance:\\n\\n\\n\\nThis Google / Excel spreadsheet should look like:\\n\\n\\n\\n### 4. Select a list of target markets you want to evaluate\\n\\nCreate a new Google spreadsheet / Excel page for each of them. This will allow you to contain all details for each target market on the same page.\\n\\nFor the purposes of this demonstration, we will use \u201cTargetMarket1,\u201d \u201cTargetMarket2,\u201d and \u201cTargetMarket3.\u201d\\n\\n### 5. Assess a target market based on selected factors\\n\\nNow that we have decided on all the factors associated with the target market attractiveness, as well as the competitive advantage, you need to assess each of these based on the target markets that you have selected.\\n\\nEach target market page should look something like this:\\n\\n\\n\\nThe factors and weights are automatically pulled from the \u201cFramework page\u201d built previously.\\n\\nHere you just need to set the rating from 1 to 5 (or according to the range you previously specified) based on the evaluation criteria defined. Each of these ratings is multiplied by the weight, and all of those values are summed up together. If your selected range is from 1 to 5, then it means that the minimum and maximum values are 1 and 5, since the weights add up to 1.\\n\\nNote that the last column allows you to add comments based on any additional information/criteria that you used to make a rating choice.\\n\\n### 6. Discover Total Addressable Market\\n\\nOn the spreadsheet above, you may have seen the total addressable market value. I will address how to find this value in a subsequent post.\\n\\nThis is extremely important because even if the market is really attractive, its size can dictate whether to pursue it or not. Most of the time, you don\u2019t want to be chasing a small market opportunity.\\n\\n### 7. Final matrix / chart\\n\\nOnce you have all this data, you can build the following for each of the target markets:\\n\\n\\n\\nNote that all you need from each target market is:\\n\\n**Competitive advantage** \u2014 the sum of all the factors and their levels multiplied by their weights gives the x-axis.\\n\\n**Target market attractiveness** \u2014 the sum of all the factors and their levels multiplied by their weights gives the y-axis.\\n\\n**Total Addressable Market (TAM)** \u2014 gives the bubble size on the chart.\\n\\nThen you are ready to make a decision on which market you wish to pursue, and you have data to back it up.\\n\\nNote: There are a lot of assumptions, and you\u2019ll never have it perfect. But with several iterations with your team, you\u2019ll gain more confidence in those assumptions over time, ensuring that you are on the right track and pursuing the right opportunity.\\n\\n## Using OpenAI to bounce ideas to assess a target market\\n\\nSometimes, it can be hard to provide a rating for each of the factors, or it would be better to bounce ideas off someone. This is where you can leverage OpenAI\u2019s GPT-4 to help you get started.\\n\\nI built a script that would read from an Excel spreadsheet all the information from the framework page that we have set. That basically means:\\n\\n- All the factors associated with target market attractiveness, and their levels of description\\n- All the factors associated with competitive advantage, and their levels of description\\n\\nThen I prompted GPT-4 to select a level for each of the factors of interest for both attractiveness and competitive advantage, based on what it knows about a specific target market.\\n\\nFor example, let\u2019s say we want to assess the competitive advantage for the target market \u201cHedge Funds\u201d \u2014 this is what the prompt looks like:\\n\\n We want to assess our competitive advantage based in relation \\n with factors where we are have an advantage. \\n \\n Can you classify those for the following target market: \'Hedge Funds\'\\n \\n The factors that we will access this market are presented below: \\n \\n When assessing Data Aggregation, these are the rules:\\n We attribute a value of 5 if We provide all data a market needs\\n We attribute a value of 4 if We provide most data a market needs\\n We attribute a value of 3 if We provide some data a market needs\\n We attribute a value of 2 if We provide very little data a market needs\\n We attribute a value of 1 if We provide no data a market needs\\n \\n When assessing Customization, these are the rules:\\n We attribute a value of 5 if Market will leverage our open source code\\n We attribute a value of 4 if Market will fully customize our platform to make it their own\\n We attribute a value of 3 if Market will customize a bit their platform\\n We attribute a value of 2 if Market will use platform as is and customize after some time\\n We attribute a value of 1 if Market will use platform as is\\n \\n When assessing Automation, these are the rules:\\n We attribute a value of 5 if Allows to save more than 70% of time\\n We attribute a value of 4 if Allows to save 50%-70% of time\\n We attribute a value of 3 if Allows to save 30%-50% of time\\n We attribute a value of 2 if Allows to save 15%-30% of time\\n We attribute a value of 1 if Doesn\'t save any time on automation\\n \\n When assessing Factor4, these are the rules:\\n We attribute a value of 5 if Very high\\n We attribute a value of 4 if High\\n We attribute a value of 3 if Medium\\n We attribute a value of 2 if Low\\n We attribute a value of 1 if Very low\\n \\n When assessing Factor5, these are the rules:\\n We attribute a value of 5 if Very high\\n We attribute a value of 4 if High\\n We attribute a value of 3 if Medium\\n We attribute a value of 2 if Low\\n We attribute a value of 1 if Very low\\n \\n Given this information, can you return a level for each of the factors \\n that is our competitive advantage from a viewpoint of Hedge Funds target market.\\n \\n Please return it in a json dictionary format with the factor and level only. \\n Do not add any other text apart from that. \\n Indent the json with 4 spaces.\\n\\nThen, using the following block of code, we can get OpenAI\u2019s GPT-4 to provide its input:\\n\\n```python\\n response = openai.ChatCompletion.create(\\n model=\\"gpt-4\\",\\n messages=[\\n {\\n \\"role\\": \\"system\\", \\n \\"content\\": \\n \\"\\"\\"\\n You are an outstanding financial analyst and were given the task \\n to perform market research on a possible market segment.\\n The company succces relies on your accuracy to categorize a \\n segment and classify according to the factors and levels specified.\\n \\"\\"\\"\\n },\\n {\\n \\"role\\": \\"user\\", \\n \\"content\\": prompt\\n },\\n ]\\n )\\n print(response.choices[0].message.content)\\n```\\n\\nThis is what the output looks like:\\n\\n```console\\n {\\n \\"Data Aggregation\\": 3,\\n \\"Customization\\": 4,\\n \\"Automation\\": 5,\\n \\"Factor4\\": 2,\\n \\"Factor5\\": 3\\n }\\n```\\n\\n**And that\u2019s it for today.**\\n\\nAll of this code is open source and available on my GitHub, here: https://github.com/DidierRLopes/target-market-analysis/tree/main\\n\\nI hope you find this insightful, I appreciate any feedback as always."},{"id":"openbb-2-year-anniversary","metadata":{"permalink":"/blog/openbb-2-year-anniversary","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-20-openbb-2-year-anniversary.md","source":"@site/blog/2023-08-20-openbb-2-year-anniversary.md","title":"OpenBB 2 year anniversary","description":"Two years of OpenBB. A look back at our achievements and growth in the world of open-source finance.","date":"2023-08-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Anniversary","permalink":"/blog/tags/anniversary"},{"inline":true,"label":"Achievements","permalink":"/blog/tags/achievements"},{"inline":true,"label":"Growth","permalink":"/blog/tags/growth"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"}],"readingTime":2.805,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"openbb-2-year-anniversary","title":"OpenBB 2 year anniversary","date":"2023-08-20T00:00:00.000Z","image":"/blog/2023-08-20-openbb-2-year-anniversary.png","tags":["OpenBB","Anniversary","Achievements","Growth","Finance"],"description":"Two years of OpenBB. A look back at our achievements and growth in the world of open-source finance."},"unlisted":false,"prevItem":{"title":"Target Market Analysis with the help of LLMs","permalink":"/blog/target-market-analysis-with-the-help-of-llms"},"nextItem":{"title":"How to handle equity top-ups at a seed stage startup","permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup"}},"content":"
\\n  \\n
\\n
\\n\\nTwo years of OpenBB: A look back at our achievements and growth in the world of open-source finance.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nToday is OpenBB 2 years anniversary of our incorporation. So it\u2019s important to look back and understand the magnitude of what we achieved in 24 months.\\n\\nIn that time we\u2019ve had:\\n\\n- 100k+ downloads of our installer since we started tracking it\\n- 2.5M bot commands have been run on Discord and Telegram from over 40k users\\n- GitHub project grew from 8k stars to 23k+, becoming #1 open source project in the topic of finance\\n- Our Discord group grew from 1k users to 13k+\\n- Our SDK has been pip installed over 25k times\\n- Our team grew from 3 to 19 around the globe\\n- For more, see http://openbb.co/open\\n\\nBut where were we 2 years ago?\\n\\n- Only Gamestonk Terminal, the name OpenBB only appeared when we came out of stealth mode in March 2022\\n- No OpenBB Hub (only launched in May 2023)\\n- No OpenBB SDK (only launched in Dec 2022)\\n- No OpenBB Bot (only launched in July 2022)\\n- No Terminal Pro or Excel Add-In early alpha (development started in 2023)\\n- No SDK v4 which allows community and data providers to build their own data connectors, easily (to be announced soon)\\n- No community routines \u2014 our first feature aimed at community with upvoting and sharing of routines\\n- No open source PyWry \u2014 A web-view rendering library in python we open source in Feb 2023\\n- No OpenBB Champions \u2014 Our way to highlight users that do impressive work on top of our ecosystem\\n- No partnerships with universities, financial societies or investment clubs\\n- No partnerships with data vendors \u2014 now we have close relationships with most vendors you would know\\n\\nIf we only focus on where Gamestonk Terminal was 2 years ago we had:\\n\\n- Static charts using matplotlib (Interactive ones using PyWry was launched in May 2023)\\n- No way for users to run routines from other users from the terminal directly (launched 3 days ago)\\n- No AskOBB feature with LlamaIndex (launched in June 2023)\\n- No way for users to customise the terminal, select default data sources and set their API keys \u2014 all from the Hub\\n- No way to double click an installer and get started in a few minutes \u2014 hassle free\\n- The documentation on markdown files across the repository, today people often praise our documentation in conversations\\n- No AI features, no reports menu, no dashboards menu, no fixed income, no futures, \u2026\\n- And the OpenBB Terminal charts looked like this\\n\\n\\n\\nBill Gates said the famous saying:\\n\\n> People overestimate what they can do in one year and underestimate what they can do in 10 years.\\n\\n
\\n\\nIn fast-paced startups, I think a better sentence would be, \u201cPeople overestimate what they can do in one week and underestimate what they can do in 1 year\u201d.\\n\\nLooking forward to continue building the future of investment research, we\u2019re just getting started.\\n\\nPS: On a personal level within those 2 years: I quit my full-time job to build OpenBB, got 2 dogs, got married and moved to the Bay Area. Life is great \u2764\ufe0f"},{"id":"how-to-handle-equity-top-ups-at-a-seed-stage-startup","metadata":{"permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.md","source":"@site/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.md","title":"How to handle equity top-ups at a seed stage startup","description":"In this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets.","date":"2023-08-09T00:00:00.000Z","tags":[{"inline":true,"label":"equity","permalink":"/blog/tags/equity"},{"inline":true,"label":"startups","permalink":"/blog/tags/startups"},{"inline":true,"label":"seed stage","permalink":"/blog/tags/seed-stage"},{"inline":true,"label":"equity top-ups","permalink":"/blog/tags/equity-top-ups"},{"inline":true,"label":"employee compensation","permalink":"/blog/tags/employee-compensation"}],"readingTime":7.935,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-handle-equity-top-ups-at-a-seed-stage-startup","title":"How to handle equity top-ups at a seed stage startup","date":"2023-08-09T00:00:00.000Z","image":"/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.png","tags":["equity","startups","seed stage","equity top-ups","employee compensation"],"description":"In this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets."},"unlisted":false,"prevItem":{"title":"OpenBB 2 year anniversary","permalink":"/blog/openbb-2-year-anniversary"},"nextItem":{"title":"How to handle equity at a seed-stage startup from Silicon Valley","permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley"}},"content":"
\\n  \\n
\\n
\\n\\nIn this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nPreviously, I shared how we handle equity at OpenBB in [this post](http://didierlopes.com/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley).\\n\\nThis blog post will continue that discussion and go over how we approach equity top-ups at OpenBB. It will provide a step-by-step guide on the implementation process and include links to relevant spreadsheets that you can use for your own startup.\\n\\nI will continue using the purely fictional example that I introduced in the previous blog post with John Doe.\\n\\nLet\u2019s imagine that John Doe was indeed the right candidate for OpenBB, and on **June 15, 2021**, he was hired and accepted an offer with **2000 options** vesting over the next 4 years with a 1-year cliff. For simplicity, let\u2019s assume that he will vest the 2000 shares by July 1, 2025 (ignoring the additional 2 weeks).\\n\\nThis means that by the end of June 2022, John will have vested 542 shares (13 x 2000 / 48), and for every following month, he will vest 42 shares per month. Note that we only start showing the shares from June 2022 because before that, he was in his cliff period.\\n\\n\\n\\nIf you do this calculation, you\u2019ll see that it adds up to 2022, whereas John was only granted 2000 shares. This is normal and is due to rounding, thus the shares associated with the last month are updated so that it matches the offer.\\n\\n\\n\\nIf any of the following situations arise:\\n\\n1. The initial assessment of the candidate was wrong, and they are not an IC but a Sr. IC.\\n2. The employee has exceeded expectations, and their equity no longer reflects the value they bring to the company.\\n3. The employee has other job offers, and you want to reinforce that they are an owner of the company and that their success is important.\\n4. The employee\u2019s vesting period is coming to an end, and they are considering leaving as they joined the company for the potential upside of an exit.\\n\\nOne option you have is to increase cash compensation. However, offering equity (ownership) is often a better option, especially for startups with limited cash resources.\\n\\nIn these situations, you need to consider an equity top-up. This means offering the employee a new equity grant on top of the shares they are currently vesting. There are multiple types of equity grants, but I will focus on the approach we use at [OpenBB](https://openbb.co) and explain how you can implement it as well.\\n\\nFirst, determine how many additional shares you want to grant to the individual and, more importantly, how many shares would be fair for them to vest each month. The former helps determine their stake in the company, while the latter helps assess their value compared to other team members.\\n\\nIn our case, let\u2019s assume it\u2019s February 2023, and John has been with the company for 20 months. We want to reward his contributions and bet on his future at the company, so we decide to grant him an additional 1,500 shares on top of his existing 2,000 shares.\\n\\nIn theory, some companies start a new 4-year vesting period with a 1-year cliff for the second grant. However, the issue with that approach is that the employee will start vesting two grants simultaneously: 2000/48 + 1500/48 shares per month. Once the first grant is fully vested, they will vest a lower amount of shares per month: 1500/48. This means the employee would have less incentive to stay when only the second grant is being executed.\\n\\nTo address this, we ensure that for the next 4 years from the vesting commencement date (VCD) of the second grant, the employee vests the same number of shares each month.\\n\\n## How can we do that?\\n\\n### Manual\\n\\nHere is the information we have:\\n\\n- 1st option grant VCD: **15 June 2021**\\n- 1st option grant shares: **2,000**\\n- 1st option grant schedule: **1/48 per month with 1 year cliff finishing on 30 June 2025**\\n\\nFrom here, we infer that in February 2023, John is vesting 42 shares per month and has already vested 542 shares (after the 1-year cliff) + 294 shares (7 x 42).\\n\\nNow, let\u2019s discuss the decisions we need to make for the second option grant:\\n\\n- 2nd option grant VCD: We want to start it ASAP, to retain employee \u2014 for instance **March 2023**\\n- 2nd option grant shares: **around 1,500**\\n- 2nd option grant schedule: **1/48 per month finishing on 30 March 2027**. Note that we removed the cliff since we know the value the employee brings and that \u201cprotection\u201d/\u201dretainer\u201d can be removed.\\n\\nBy utilizing maths, we can create the following equation:\\n\\n\\n\\nBy filling in the information that we know, we get:\\n\\n\\n\\nAnd thus we know that we can get the value that makes this happen.\\n\\n\\n\\nHowever, we don\u2019t want to give the employee fractional shares each month, so we select a round number around the one that makes him receive around 1,500 additional shares over the course of 4 years.\\n\\nIn this case, that number could be 55. This means that the top-up number would be 13 (55\u201342), except on the last month of vesting for the 1st grant where we need the adjustment.\\n\\nWhen we multiply 55 shares per month for the next 48 months starting in March 2023, that adds up to **2,640**.\\n\\nHowever, the employee was awarded **1,500 shares** (2nd grant) and still has 27 months (from March 2023 to May 2025) to vest 1st grant shares, which corresponds to a total of **1,122 shares** (42 * 26 + 30, remembering the adjustment done for the last month). This total would be **2,622**, which obviously is different from the expected 2,640.\\n\\nTherefore, we update the value of the number of shares given on the 2nd grant so that John receives 55 shares per month. In this case, for that to happen, the 2nd grant has to have a value of 1,573.\\n\\nBut obviously, you don\u2019t need to pick up your calculator every time you do this. I mean, what kind of engineer would I be if I didn\u2019t somehow automate this?\\n\\n### Automated\\n\\nThe spreadsheet below demonstrates what an employee vesting schedule looks like, and below I will write a step-by-step guide so you can fully customize it to your needs.\\n\\n\\n\\n- As a result, **E5** will be updated with 11 months afterward to represent the month before the cliff terminates, which consequently leads to the following months being displayed in **column E**.\\n\\n2. Fill in the 1st grant shares in **B5**\\n\\n- As a result, **G6** is updated with the total shares from the 1st grants vested after the 1st year. The following rows in **column G** are automatically updated until the vesting schedule terminates.\\n\\n3. Adjust **G41** so that the sum of shares in **column G** match the shares from the 1st grant in **B5**.\\n\\n4. Fill in the top up grant vesting commencement date (VCD) in **C6**\\n\\n- As a result, **column H** will automatically get populated based on the value that, when added with the cells in **column G**, returns the value in cell **B19**.\\n\\n- This will also allow us to compute the months that have already been vested from the initial shares in **B11** and consequently calculate the overlap between shares coming from the 1st and 2nd grant in **B12**.\\n\\n5. Fill in the top-up grant shares that you are thinking about offering to the employee in **B6**.\\n\\n- As a result, the same computations that were explained earlier in theory will occur. This will result in a recommendation for the top-up shares in **B15** and consequently the amount of shares that the employee will vest monthly in **B16** so that the amount of top-up grant shares is met.\\n\\n6. It is very likely that the number in **B16** will not be rounded. Hence, we fill **B19** with a rounded version of that number.\\n\\n- As a result, **column H** will be updated so that the total shares (from both grants) in **column F** matches the selected value in **B19**.\\n\\nWhen looking at the total top-up shares in **H67**, that value will no longer match the total top-up shares that we wanted to grant to the employee and that we decided at the beginning in **B6**. This is because we rounded the value and thus impacted the number of shares necessary to achieve that.\\n\\nThe amount of shares needed to update the recommendation in **B16** to the rounded version in **B19** is displayed as an \u201cerror\u201d in **B21**.\\n\\n7. In order to fix that, we simply need to update B6 with the sum of B6 and the error value from B21.\\n\\n- As a result of this, all the values should now match, and the combined total amount of shares given to the employee in **B8** should match the sum of the shares spread across dates in **F67**. Plus, the error should now be null in cell **B21**.\\n\\nAnd that\u2019s it.\\n\\nI hope you found this useful and are able to use it internally to share with your employees so they understand how the top-ups happen at your startup.\\n\\nIf you want access to this Excel template, feel free to reach out to me on Twitter or LinkedIn."},{"id":"how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","metadata":{"permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.md","source":"@site/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.md","title":"How to handle equity at a seed-stage startup from Silicon Valley","description":"A step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB.","date":"2023-08-03T00:00:00.000Z","tags":[{"inline":true,"label":"startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"equity","permalink":"/blog/tags/equity"},{"inline":true,"label":"Silicon Valley","permalink":"/blog/tags/silicon-valley"},{"inline":true,"label":"seed-stage","permalink":"/blog/tags/seed-stage"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":5.72,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","title":"How to handle equity at a seed-stage startup from Silicon Valley","date":"2023-08-03T00:00:00.000Z","image":"/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.png","tags":["startup","equity","Silicon Valley","seed-stage","OpenBB"],"description":"A step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB."},"unlisted":false,"prevItem":{"title":"How to handle equity top-ups at a seed stage startup","permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup"},"nextItem":{"title":"Keep track of your startup metrics using a custom iOS widget","permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget"}},"content":"
\\n  \\n
\\n
\\n\\nA step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAs a startup founder and CEO, you need to wear multiple hats, from engineering and product to design, marketing, and even finance.\\n\\nToday, I\u2019m going through the details of how we handle equity at OpenBB. This blog post provides a step-by-step guide on the implementation process, including links to relevant spreadsheets that you can reuse for your startup.\\n\\nTo make this post easier to follow, I will create a purely fictional example.\\n\\nJohn Doe, a software engineer from Portugal, has been contributing to the [open source OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) for a few consecutive weeks. He not only fixes bugs but also adds features that the community has requested through pull requests and on Discord. Additionally, he is a fast learner and gets along well with the current team. This sparks the interest of the OpenBB team because having this open-source contributor work with us full-time would be great, rather than being limited by his current full-time job.\\n\\nFrom here, we set up an initial exploratory call to better understand John Doe as an individual \u2014 what he is passionate about, why he has contributed to the project, and more. We follow up the call with an interview involving engineers to assess his skills and experience. Finally, he joins a call with me, where I sell the vision of the company and explain why what OpenBB is doing matters. At this point, we extend him an offer. Up until this stage, the recruiting process is standard, except for the fact that we have a \u201cfiltered\u201d candidate coming from the open-source community.\\n\\nHowever, as a startup, that offer cannot (or at least should not) consist solely of cash compensation. A startup [operates at a much faster pace](http://www.paulgraham.com/growth.html) and is riskier than a company. Therefore, in exchange for hard work and long hours, you should offer part of the company through equity, allowing the employee to benefit from the upside in case the company achieves a successful exit (IPO or sale).\\n\\nSo, how do we decide on the equity to offer the new hire?\\n\\nIt\u2019s easy. You follow your company Option Guidelines.\\n\\n## Option Guidelines\\n\\nThe Option Guidelines are an Excel spreadsheet approved by the board. In this document, you explicitly create **bands (minimum and maximum range options)** based on the role and stage of the company. Board approval is crucial as it allows you to extend the offer directly without needing permission from the board since the guidelines have already been approved.\\n\\nHere\u2019s what the document looks like:\\n\\n\\nThe total number of shares is random and not representative of OpenBB.\\n\\nFirst, you need to ask yourself what roles your company envisions needing. Within those roles, there are two things to consider:\\n\\n- **Departments:** You may differentiate between Engineering, Marketing, Operations, Sales, Finance, and HR/Admin. You can also add others such as Design, Product, etc. Note that having different departments does not necessarily mean you need different band structures.\\n\\n- **Titles:** You\u2019ll want to be able to \u201ccompare\u201d individuals based on their contributions. For instance, Vice President, Director, Manager, Senior Individual Contributor, and Individual Contributor. Note that if you have fewer titles, the bands should be wider to differentiate individuals with the same title. If you add five levels of Individual Contributors, you\u2019ll want narrower bands.\\n\\n I recommend starting with fewer titles, KISS: keep it simple stupid. Again, having different levels does not necessarily mean the bands need to be mutually exclusive. A Manager does not necessarily have a higher band than a Senior Individual Contributor; this depends on your own company culture.\\n\\nNext, you need to differentiate between **company stages**. This allows you to distinguish employees who join very early when the startup carries the most risk. We distinguish between three stages: Pre-production revenue, Pre-profit with production revenue, and Profitable.\\n\\nOnce all these categories are completed, you should have a similar table to the one shared above. Now, it\u2019s important to fill in the equity percentage. For privacy reasons, I will not provide the specific values for OpenBB but will create a random example.\\n\\nLet\u2019s imagine that OpenBB Charter has a total of 1 million shares (assuming only one class of stock for simplicity). If our priced round values the company at $10 million, this means that each share is valued at $10.\\n\\nOn the top left of the document, we will insert the number of shares, which is 1,000,000. Then, we adjust the % LOW and % HIGH columns, representing the range of company ownership we want to grant to this individual.\\n\\nLet\u2019s go through a fake example for the SW role:\\n\\n\\n\\nThe column \u201cLow Shrs\u201d is computed by multiplying the % LOW by the total number of shares. On the other hand, the column \u201cHigh Shrs\u201d is computed by multiplying the % HIGH by the total number of shares. This value is important as it represents the amount stipulated in the contract.\\n\\nLet\u2019s consider a scenario where the company is in the Pre-Profit stage with Production Revenue, and we want to hire an Engineering IC. Based on our assessment of their skillset and fairness in comparison to other team members, we would offer a contract that vests over time between 1000 and 2000 shares.\\n\\n\\n\\nNext, you need to decide on the vesting calendar that the company supports. The most common option is a 4-year vesting schedule with a 1-year cliff. This means that while you begin vesting during your first year, you need to stay with the company for the entire year to be able to exercise those options. The 1-year cliff protects the company from employees leaving early or underperforming.\\n\\nCarta provides a good explanation on how stock options work [here](https://carta.com/blog/equity-101-stock-option-basics/) \u2014 which I recommend to everyone.\\n\\nPlease note that in theory, while the value of these options is $10 per share, the startup will need to conduct a 409a valuation to determine the fair market value of each option, which is likely to be much lower than the initial price, such as $1 per share. And this is the strike price that employees will need to pay to exercise the shares.\\n\\nNote: when selecting the number of shares, use a number that is divisible by the number of months that the employee is vesting, e.g., for a 4-year vesting period that would be 48 (4 x 12), which ensures that employees get the same amount of shares each month, and there\u2019s no need to account for floating numbers.\\n\\nThis is it for today.\\n\\nIn Part II, I will talk about how you can handle equity top-ups.\\n\\nSo follow me if you want to learn more about what that process may look like."},{"id":"keep-track-of-your-startup-metrics-using-a-custom-ios-widget","metadata":{"permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.md","source":"@site/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.md","title":"Keep track of your startup metrics using a custom iOS widget","description":"Keep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills.","date":"2023-07-29T00:00:00.000Z","tags":[{"inline":true,"label":"iOS","permalink":"/blog/tags/i-os"},{"inline":true,"label":"Startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"Metrics","permalink":"/blog/tags/metrics"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Scriptable","permalink":"/blog/tags/scriptable"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.015,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"keep-track-of-your-startup-metrics-using-a-custom-ios-widget","title":"Keep track of your startup metrics using a custom iOS widget","date":"2023-07-29T00:00:00.000Z","image":"/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.png","tags":["iOS","Startup","Metrics","OpenBB","Scriptable","Open Source"],"description":"Keep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills."},"unlisted":false,"prevItem":{"title":"How to handle equity at a seed-stage startup from Silicon Valley","permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley"},"nextItem":{"title":"How to Use OpenAI to Extract Insights from Team Survey","permalink":"/blog/how-to-use-openai-to-extract-insights-from-team-survey"}},"content":"
\\n  \\n
\\n
\\n\\nKeep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/opensource-scriptable-widget/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you have a high level role in your organization, you are likely obsessed over a few metrics that act as the north star for your company. Whether that is MRR, number of customers, GitHub stars, AUM, .. depends on the type and stage of company, and what you are optimizing for.\\n\\nAt [OpenBB](https://openbb.co) we are currently optimizing for [OpenBB Hub](https://my.openbb.co) users, since this is the place where you have access to our entire suite of products. From [OpenBB Terminal](https://my.openbb.co/app/terminal), [OpenBB SDK](https://my.openbb.co/app/sdk), [OpenBB Bot](https://my.openbb.co/app/bot) and soon \u2014 the highly awaited [OpenBB Terminal Pro](https://my.openbb.co/app/pro).\\n\\nSo everyday I spent some time checking our startup [/open page](https://openbb.co/open). However, whenever I had to check these on mobile I had to open up the browser, type the link and then look for the metric of interest.\\n\\nHence, to save time, I built a custom iOS widget that displays these metrics of interest at all times. All I need to do is unlock my phone and *BAM*, they are right there.\\n\\nSo, today, I\u2019ll teach you how you can do the same with minimal coding skills required. I open source the entire code, so that you can get up to speed as fast as possible here: https://github.com/DidierRLopes/opensource-scriptable-widget\\n\\n## Track your open source metrics\\n\\nThis section will provide a plug-and-play example for your open source repository.\\n\\n\\n\\nThese are the steps necessary to have it working on your iOS device:\\n\\n1/ Download Scriptable app to your iOS device\\n\\n2/ Open Scriptable app and click on the \u201c+\u201d on the top right corner\\n\\n3/ Rename that script to whatever repo you would like to track\\n\\n4/ Copy the code from the file opensource.js on this repository\\n\\n5/ Paste it into that new script on your phone\\n\\n6/ Change the 4 initial parameters from the file:\\n\\n```python\\n const WIDGET_TITLE = \\"openbb.co/open\\"\\n const GITHUB_REPO = \\"OpenBB-finance/OpenBBTerminal\\"\\n const PIP_PACKAGE_NAME = \\"openbb\\"\\n const CACHED_DATA_HOURS = 1\\n```\\n\\n- If you only want to track GitHub stats, do `PIP_PACKAGE_NAME=\\"\\"`.\\n- If you only want to track PiPy stats, do `GITHUB_REPO=\\"\\"`.\\n- The `CACHED_DATA_HOURS` corresponds to the amount of hours where the data is not updated.\\n\\n7/ Run script to make sure that it works using the \u201cplay button\u201d on the bottom right corner\\n\\n8/ Leave the app\\n\\n9/ Leave your finger pressed on the iOS homepage\\n\\n10/ Click on the \u201c+\u201d on the left top corner\\n\\n11/ In the \u201cSearch Widgets\u201d tab look for \u201cScriptable\u201d\\n\\n12/ You will see \u201cRun Script\u201d and there are 3 pages. Select the type of widget size that you are interested in\\n\\n13/ Select \u201cAdd Widget\u201d\\n\\n14/ The widget will appear with the sentence \u201cLong press and edit widget to select the script to run\u201d\\n\\n15/ Do that and then you will have 3 options:\\n\\n- Script \u2014 Select script name that you renamed to earlier\\n- When Interacting \u2014 Select \u201cOpen URL\u201d \u2014 A new field will appear with \u201cURL\u201d then provide the link you want to open you cick on the widget (e.g. http://openbb.co)\\n- Parameter \u2014 If there\u2019s any parameter needed to the script\\n\\n16/ Click outside the window, and you should be all set!\\n\\nFeel free to contribute to the repository with other examples / templates!"},{"id":"how-to-use-openai-to-extract-insights-from-team-survey","metadata":{"permalink":"/blog/how-to-use-openai-to-extract-insights-from-team-survey","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.md","source":"@site/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.md","title":"How to Use OpenAI to Extract Insights from Team Survey","description":"This blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation.","date":"2023-07-21T00:00:00.000Z","tags":[{"inline":true,"label":"OpenAI","permalink":"/blog/tags/open-ai"},{"inline":true,"label":"Team Survey","permalink":"/blog/tags/team-survey"},{"inline":true,"label":"Insights","permalink":"/blog/tags/insights"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"},{"inline":true,"label":"Slack","permalink":"/blog/tags/slack"},{"inline":true,"label":"Airtable","permalink":"/blog/tags/airtable"}],"readingTime":8.01,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-use-openai-to-extract-insights-from-team-survey","title":"How to Use OpenAI to Extract Insights from Team Survey","date":"2023-07-21T00:00:00.000Z","image":"/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.png","tags":["OpenAI","Team Survey","Insights","Automation","Slack","Airtable"],"description":"This blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation."},"unlisted":false,"prevItem":{"title":"Keep track of your startup metrics using a custom iOS widget","permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget"},"nextItem":{"title":"Why the need for an open source investment research platform?","permalink":"/blog/why-the-need-for-an-open-source-investment-research-platform"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/insights-from-team-survey).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Motivation\\n\\nI\u2019ve been wanting to play with the OpenAI API for a while, but I\u2019ve had higher priority tasks. Yesterday, I thought that I could use the day to do this, but I didn\u2019t want to just try it in a notebook. Instead, I wanted to use it in a real project that could save me time.\\n\\nLast week, I posted about how at OpenBB we have developed a monthly team survey and automated the process of requesting information through Slack and Airtable. You can find more on that post [here](/blog/employees-are-leaving-be-proactive-about-employee-feedback).\\n\\n\\n\\nThis made me think that even though I have access to all this data, which OpenBB has made fully available [here](https://openbb.co/open), I still have to spend some time looking at the data to extract insights.\\n\\n
 \\n\\nWhat if I could automate that analysis using OpenAI? This is what I set out to build, and this post will focus on how I went from idea to implementation.\\n\\n## Requirements\\n\\nI already had a notebook that I used to analyze our Airtable data with our team survey in it. However, that analysis was quite \u201cheavy,\u201d and it was not straightforward to extract insights. Thus, one of the requirements was to use OpenAI to analyze the team survey feedback for the current month and highlight anything worth mentioning.\\n\\nAdditionally, I wanted to compare the team\u2019s experience to the prior month to understand if we were improving or not, and identify areas for further improvement. Finally, based on these insights, I wanted OpenAI to suggest what OpenBB, as a company, could do to improve our culture.\\n\\nTo achieve this using an OpenAI model, I could either export the team survey responses from Airtable in CSV and copy-paste them into ChatGPT, or I could automate the data retrieval using the Airtable API. Being an engineer, why would I do something in 5 minutes when I can spend 1 day automating it? \ud83e\udd23\\n\\nLastly, I didn\u2019t want to run this script and have to copy-paste the output into our Slack group so that everyone on the team could have access to the overall analysis and provide feedback/suggestions. Therefore, I would like to have a Slack integration that sends the output in a specific formatted way to our Slack channel.\\n\\nSo, the idea is as follows:\\n\\n
\\n\\nWhat if I could automate that analysis using OpenAI? This is what I set out to build, and this post will focus on how I went from idea to implementation.\\n\\n## Requirements\\n\\nI already had a notebook that I used to analyze our Airtable data with our team survey in it. However, that analysis was quite \u201cheavy,\u201d and it was not straightforward to extract insights. Thus, one of the requirements was to use OpenAI to analyze the team survey feedback for the current month and highlight anything worth mentioning.\\n\\nAdditionally, I wanted to compare the team\u2019s experience to the prior month to understand if we were improving or not, and identify areas for further improvement. Finally, based on these insights, I wanted OpenAI to suggest what OpenBB, as a company, could do to improve our culture.\\n\\nTo achieve this using an OpenAI model, I could either export the team survey responses from Airtable in CSV and copy-paste them into ChatGPT, or I could automate the data retrieval using the Airtable API. Being an engineer, why would I do something in 5 minutes when I can spend 1 day automating it? \ud83e\udd23\\n\\nLastly, I didn\u2019t want to run this script and have to copy-paste the output into our Slack group so that everyone on the team could have access to the overall analysis and provide feedback/suggestions. Therefore, I would like to have a Slack integration that sends the output in a specific formatted way to our Slack channel.\\n\\nSo, the idea is as follows:\\n\\n- \\n
- Retrieve team feedback responses from Airtable \\n
- Extract insights from the team survey data using OpenAI \\n
- Send the insights output to the OpenBB Slack channel \\n
\\n  \\n
\\n
\\n\\nOpenBB Terminal, an open-source investment research platform, is transforming the financial industry by addressing issues like data licensing, full-price bundle, lack of transparency and customization, and the need for a diverse community. This post explores why open source is crucial for us and the main problems in the space.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHaving a closed source OpenBB Terminal was never on the table.\\n\\nThe [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) is the platform it is today due to its open source nature. Launched almost 2.5 years ago, the interest on this platform was clear \u2014 aggregating an impressive 4000 stars on GitHub in under 24 hours from launch.\\n\\nThis number kept on growing along with the community (most of which gathers on [our Discord server](http://openbb.co/discord)) and allowed us to create the company OpenBB, see the story [here](http://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\n\\n\\nBut why is open source so important for us? To understand this, it\u2019s important for us go over the main problems in the space.\\n\\n
- \\n
- Data licensing \\n
- Full-price bundle \\n
- Transparency and customization \\n
- Community \\n
\\n  \\n
\\n
\\n\\nFrom Open Source to Open Startup: A journey of OpenBB towards transparency in the financial world.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nBeing open source isn\u2019t enough, at OpenBB we want to accelerate the transparency in the financial world.\\n\\nI want to start this blogpost by introducing the concept of an open startup. As this phrase can often be interpreted differently, here\u2019s the standard definition that ChatGPT gave me:\\n\\n> _\u201cAn open startup is a company that practices open innovation and transparent communication with its stakeholders, including customers, employees, and investors. This means that the company is willing to share information about its products, services, and business operations with the public and is open to input and feedback from all stakeholders._\\n\\n
\\n\\n> _Open startups typically have a strong focus on collaboration and community building, and they often use open source technology and principles in their operations. Some open startups may also be structured as cooperative or worker-owned enterprises, in which ownership and decision-making power are shared among employees.\u201d_\\n\\n## Why now?\\n\\nI\u2019ve been learning about the open startup movement for a while now and I always knew that I wanted OpenBB to follow this trend. At the end of the day, I want us to accelerate the openness and transparency in the financial world.\\n\\nBut until recently, this wasn\u2019t one of our top priorities. This all changed when the cryptocurrency exchange FTX collapsed. This was a house of cards and they stood for everything but transparency \u2014 not only with their users but also with their shareholders and team alike!\\n\\nJohn J. Ray III who has spent a career tackling large corporate failures involving allegations of criminal activity (like Enron), was appointed CEO of FTX to deal with the bankruptcy, and this is one of his quotes to the US congress:\\n\\n> _\u201cNever in my career have I seen such an utter failure of corporate controls at every level of an organization, from the lack of financial statements to a complete failure of any internal controls or governance whatsoever\u201d_\\n\\n
\\n\\nOpenBB wants to pave the way of transparency in the financial world.\\n\\n## Why open?\\n\\n### Transparency\\n\\nTransparency across team, shareholders, users and new hires is key. Everyone can see our growth in the same location; A single source of truth accessible to everyone at all times. We already have our code open source, which shows transparency in our engineering, so it only makes sense for us to behave in the same way with our business.\\n\\n### Accountability\\n\\nEveryone will know how we\u2019re doing, for better or worse. This will make us feel responsible to show accurate sustainable growth as this information becomes public. Since everyone has equity in the company, this will be our own skin in the game.\\n\\nWhen people ask, \u201cHow is OpenBB going?\u201d, this can be answered with a single link to our open page.\\n\\n### Community building\\n\\nEvery company is trying to build a community these days, but building a community is hard. By having all of our information publicly available, anyone from the community will know how we are doing at all times \u2014 similar to what the team, shareholders and investors know.\\n\\nThis helps to build trust in OpenBB and allow us to attract and retain talented employees who value transparency and an open culture.\\n\\n### Marketing\\n\\nUsers will be able to share our open page to share OpenBB metrics with other users, which will help to increase awareness for us.\\n\\nIn addition, we want to become leaders of open culture in the financial world, which is known for being a very closed industry. We want to influence companies in this sector and start a movement.\\n\\n### Fundraising\\n\\nSince starting OpenBB, I\u2019ve met well over 50 different investors, even without actively fundraising. Whilst this is a great way to start relationships, it\u2019s not sustainable as it takes valuable time away from talking with users/customers (and let\u2019s be honest, even developing :slight_smile:). So by having an open page, we will be able to discuss our growth async and more efficiently. And then, when we are actively fundraising, we can focus on the details.\\n\\n## How will it be done?\\n\\nWe are adding all our metrics and stats to [/open](https://openbb.co/open).\\n\\nOur open metrics will contain 4 main distinct sections to start with:\\n\\n#### Social Media metrics\\n\\nTwitter followers, Discord users, LinkedIn followers, YouTube views, Reddit followers. Allows to understand the strength of our community in the social media channels that we focus on.\\n\\n#### Team stats\\n\\nTeam distribution and employee engagement coming soon. Allows to understand where we are based and employee experience at OpenBB\\n\\n#### Product metrics\\n\\nOpenBB Hub users, OpenBB Bot, OpenBB SDK and OpenBB Terminal. Allows to hold us accountable for our user growth and the usage that our products have\\n\\n#### Developer metrics\\n\\nStars, forks, merged pull-requests, closed issues, contributors. Keep up-to-date with our development speed and how engaged the open source community is.\\n\\n\\n\\nFor all the metrics that are open source, there will be an \u24d8 in the top right to share information on why this chart was made open source and why it\u2019s important to us.\\n\\nOnce a metric is open, we do not intend to close it ever again, that is why all the metrics we are making public have gone through a thorough reasoning process and there\u2019s enough contextual information to understand its meaning.\\n\\nIf you can think of a metric that you would like to see on our open page, please feel free to DM me."},{"id":"employees-are-leaving-be-proactive-about-employee-feedback","metadata":{"permalink":"/blog/employees-are-leaving-be-proactive-about-employee-feedback","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.md","source":"@site/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.md","title":"Employees are leaving? Be proactive about employee feedback","description":"Employees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey.","date":"2023-06-29T00:00:00.000Z","tags":[{"inline":true,"label":"employee engagement","permalink":"/blog/tags/employee-engagement"},{"inline":true,"label":"feedback","permalink":"/blog/tags/feedback"},{"inline":true,"label":"work culture","permalink":"/blog/tags/work-culture"},{"inline":true,"label":"remote work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"team happiness","permalink":"/blog/tags/team-happiness"}],"readingTime":4.995,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"employees-are-leaving-be-proactive-about-employee-feedback","title":"Employees are leaving? Be proactive about employee feedback","date":"2023-06-29T00:00:00.000Z","image":"/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.png","tags":["employee engagement","feedback","work culture","remote work","team happiness"],"description":"Employees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey."},"unlisted":false,"prevItem":{"title":"From Open Source to Open Startup","permalink":"/blog/from-open-source-to-open-startup"},"nextItem":{"title":"Hybrid work sucks. It\u2019s worse than remote and office.","permalink":"/blog/hybrid-work-sucks-its-worse-than-remote-and-office"}},"content":"
\\n  \\n
\\n
\\n\\nEmployees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis blogpost shows the measures we are taking to ensure we have high employee engagement at OpenBB through a periodic feedback survey.\\n\\nWhen we started OpenBB, I was absolutely obsessed about our product. All my focus and time was dedicated to building our suite of products (OpenBB Terminal, OpenBB SDK or OpenBB Bot), or talking about these with our users. I care deeply about the OpenBB team, but I expected everyone to be as motivated as me, 24/7.\\n\\nBut things just don\u2019t work that way. Although we always have a fun quarterly event online, that isn\u2019t enough. Everyone knows that I\u2019m a big fan of remote work, but one clear down side of it is the lack of contact and face to face conversations which makes employee engagement more volatile. I say this, because I believe that when your team is together in the same space, it\u2019s easier to thrive off each others excitement and motivation.\\n\\nSoon enough, I realized that _\u201calone you can go faster, but with a team you can go far\u201d_. This is when I started putting time into understanding what we could be doing better to improve our work culture.\\n\\nSome things that we have now put into place include:\\n\\n- We updated the company values as a team, based on what we currently had that they were proud of and where they would like us to be in the future. In a startup, where the pace is incredibly fast and the team is constantly changing, I strongly believe that the values change over time too.\\n\\n- We had an [OpenBB rap](https://www.youtube.com/watch?time_continue=48&v=ThtSC8s0h6I&embeds_referring_euri=https%3A%2F%2Fopenbb.co%2Fblog&source_ve_path=MzY4NDIsMjg2NjMsMjg2NjY&ab_channel=OpenBB) made by a freestyler for our OpenBB Christmas event.\\n\\n- We started pushing for more transparency. We were already very transparent internally, but now we started to push this value externally too. Everyone in the company has skin in the game, this allows the team to feel as accountable for the metrics as I do. I wrote more about this in this blogpost: [From open source to open startup](/blog/from-open-source-to-open-startup), and I am currently working on the OpenBB Handbook too.\\n\\n- I started having office hours, where I can spend the time with the team chatting about anything (product, strategy, engineering, storytelling, even fundraising). The team knows that I\u2019m usually available, but having that 1 hour blocked gives them the confidence to know that that time booked in the day.\\n\\nHowever, there was something critical missing. I will explain what it is by using what I learned at university (that way I can say that my MSc in Control Systems was indeed useful for OpenBB \ud83d\ude43).\\n\\nWhat we had built is an open loop control system, and it looks something like this:\\n\\n\\n\\nThe problem? open loop systems can be inaccurate and unreliable. More importantly, because there is no feedback mechanism to correct inputs as the controller (leadership) never gets the information that comes out of the system (team engagement).\\n\\nThe key word here is feedback. An office hour session is great, but it\u2019s a poor \u201csensor device\u201d. The reason being that you are opening the door for the team to communicate with you, but that data isn\u2019t significant to extrapolate through the whole team.\\n\\nWe needed feedback. We needed to have a closed-loop system instead of an open one. By that I mean:\\n\\n\\n\\nThis allows us to constantly monitor our team happiness, and be able to react when the feedback doesn\u2019t match our desired culture.\\n\\nBut what is this feedback? What do we want to track? We didn\u2019t want to reinvent the wheel, so we looked up to how the best companies do it. In particular, we studied \u201cThe Psychology of Employee Engagement\u201d e-book from Workday written by Phillip Chambers.\\n\\nThis allowed us to come up with the following survey, where the team would reply anonymously to each of the questions with a rating from 1 to 10 where 1 corresponds to \u201cstrongly disagree\u201d and 10 corresponds to \u201cstrongly agree\u201d.\\n\\n- **Accomplishment:** I feel a regular sense of accomplishment\\n- **Autonomy:** I feel that I am given autonomy in the way I complete my tasks\\n- **Meetings:** I feel that I have a good amount of meetings every week. (this question was originally about environment, but due to our remote nature we felt that the amount of meetings was something more important to measure)\\n- **Freedom of Opinions:** I feel that I have a voice in the company and my opinion matters\\n- **Goal Setting:** I feel that both my goals and expectations are set clearly\\n- **Growth:** I feel that I have opportunities to grow professionally\\n- **Management Support:** I feel that my manager cares for me and empowers me\\n- **Meaningful Work:** I feel that my work matters\\n- **Organizational Fit:** I feel like the company values align with mine and we share the same goal\\n- **Peer relationships:** I feel connected with my colleagues and that I can be myself with them\\n- **Recognition:** I feel like I get recognized for my contributions\\n- **Reward:** I feel like I am rewarded fairly for my work\\n- **Strategy:** I feel like the company strategy is being communicated effectively\\n- **Workload:** I feel like I can manage my workload efficiently\\n\\nNow you may be wondering how we made this survey completely automated, the workflow is actually very straightforward and we were able to automate it. Here is what it looks like: Airtable + Slack \u2705\\n\\n\\n\\nEven though our salaries don\u2019t compete with the MAMAAs of this world, we believe that: our mission, our innovative products and unique culture are what makes us OpenBB. And why we can retain our talent.\\n\\nYou can find our employee engagement index at: https://openbb.co/company/open/team"},{"id":"hybrid-work-sucks-its-worse-than-remote-and-office","metadata":{"permalink":"/blog/hybrid-work-sucks-its-worse-than-remote-and-office","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.md","source":"@site/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.md","title":"Hybrid work sucks. It\u2019s worse than remote and office.","description":"Hybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution.","date":"2023-06-12T00:00:00.000Z","tags":[{"inline":true,"label":"remote work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"office work","permalink":"/blog/tags/office-work"},{"inline":true,"label":"hybrid work","permalink":"/blog/tags/hybrid-work"},{"inline":true,"label":"productivity","permalink":"/blog/tags/productivity"},{"inline":true,"label":"work culture","permalink":"/blog/tags/work-culture"}],"readingTime":11.715,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"hybrid-work-sucks-its-worse-than-remote-and-office","title":"Hybrid work sucks. It\u2019s worse than remote and office.","date":"2023-06-12T00:00:00.000Z","image":"/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.png","tags":["remote work","office work","hybrid work","productivity","work culture"],"description":"Hybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution."},"unlisted":false,"prevItem":{"title":"Employees are leaving? Be proactive about employee feedback","permalink":"/blog/employees-are-leaving-be-proactive-about-employee-feedback"},"nextItem":{"title":"Become an OpenBB Champion","permalink":"/blog/become-an-openbb-champion"}},"content":"
\\n  \\n
\\n
\\n\\nHybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis is my hot take for 2023, but bear with me.\\n\\n## Context\\n\\nEveryone on Twitter has been actively discussing that \u201cRemote work failed\u201d, e.g. [this tweet](https://twitter.com/DavidSacks/status/1663958149437743105?s=20) from David Sacks where he refers to [this blogpost](https://flocrivello.com/changing-my-mind-on-remote-about-being-in-san-francisco/), or [this tweet](https://twitter.com/paulg/status/1667580108247277570?s=20) from Paul Graham.\\n\\nWhile I\u2019m not going to pose as an expert on the topic, I feel like I\u2019ve experienced enough to have an opinion. My career so far has been:\\n\\n- 1 year of office work for a public company\\n- 1 year of remote work for a startup, plus a few months of hybrid work for the same startup\\n- 2 years of growing [OpenBB](https://openbb.co/) from 1 to 20 people, all fully remote.\\n\\nLet me first go over the advantages and disadvantages of remote and office work, so that I can focus this blog post on **why hybrid sucks**.\\n\\n## Remote work\\n\\nFirst of all, let\u2019s be pragmatic \u2014 remote works. (Before people comment, of course if you\u2019re a factory worker or similar, this doesn\u2019t apply).\\n\\n### Advantages\\n\\n
- \\n
- Increased employee retention and satisfaction: Remote work is seen as a desirable perk, improving job satisfaction and retention rates. You can check OpenBB team engagement here. \\n
- Expanded talent pool: It allows hiring from a global talent pool, resulting in a more diverse and skilled workforce, particularly in open source, where contributors come from all over the world. \\n
- Increased flexibility: Remote work offers employees more control over their schedules, leading to better work-life balance. \\n
- Improved productivity: There are fewer distractions and interruptions, which leads to increased productivity. \\n
- No commuting: Remote work eliminates the need to travel to the office, saving time, money, and energy. \\n
- Cost savings: It reduces expenses for both employees and employers, such as commuting and office-related costs. \\n
- \\n
- Limited face-to-face interaction: Remote work reduces in-person collaboration and social connections among colleagues. \\n
- Communication challenges: Reliance on digital tools may lead to misunderstandings or misinterpretations. There may also be technical issues or connectivity problems. \\n
- Blurred work-life boundaries: Clear separation between work and personal life becomes challenging. \\n
- Potential distractions: Remote work environments expose individuals to various distractions. \\n
- Challenges with collaboration: Coordinating tasks and scheduling can be more difficult remotely. \\n
- Reduced visibility and career advancement opportunities: Remote workers may have limited visibility and access to career growth. \\n
- \\n
- A strong leadership is necessary to keep the team aligned, motivated, and to create the company\u2019s culture. This helps mainly with the limited face-to-face interaction, challenges with collaboration, and reduced visibility and career advancement opportunities. \\n
- Do not track team members based on time but assess work based on output. Use meritocracy to reward the best team members and let go of low performers early. Remote work is not for everyone, and for those who cannot produce output/value to the company while working remotely, it means they weren\u2019t a good hire in the first place. In my personal opinion, the disadvantages of potential distractions and blurred work-life boundaries come down to the employee and their relationship with remote work, instead of the company. \\n
\\n\\nSometimes someone may not be producing as much value as expected, for one reason or another. _When you are working remotely, you accept that you will add value to the company, and time is no longer a measure. Thus, the emphasis on output/value becomes much stronger._\\n\\n## Office Work\\n\\nOffice also works.\\n\\n### Advantages\\n\\n
- \\n
- Enhanced company culture: Offices contribute to a shared sense of identity and mission. \\n
- Face-to-face collaboration: It allows for immediate interaction, fostering effective teamwork and problem-solving. \\n
- Social interaction: Offices provide opportunities for building relationships with coworkers, enhancing camaraderie. \\n
- Clear work-life boundaries: Physical office spaces establish separation between work and personal life. \\n
- Mentorship and learning: In-person environments facilitate mentorship and hands-on learning. \\n
- Improved supervision: Physical presence aids in monitoring performance and providing timely feedback. \\n
- \\n
- Commuting and transportation issues: Office work often involves commuting, which can lead to time-consuming and stressful travel, traffic congestion, and transportation expenses. \\n
- Lack of flexibility: Office work typically follows a fixed schedule, leaving less room for personal flexibility or adjustments to achieve work-life balance. \\n
- Office politics: Office environments can sometimes involve office politics, conflicts, or gossip that can affect productivity and job satisfaction. \\n
- High overhead costs: Maintaining physical office spaces can be costly for organizations, including expenses related to rent, utilities, and office supplies. \\n
- Limited geographic talent pool: Offices are often location-dependent, which may restrict access to a diverse and global talent pool, potentially limiting the variety of skills and perspectives within a workforce. \\n
- Distractions and interruptions: Open office layouts or noisy work environments can lead to frequent interruptions, reducing focus and productivity. \\n
- \\n
- Decreased productivity: When compared with remote or office, hybrid has lower productivity. This is due to the context switching associated with changing working environments. Personally, I have experienced this and found it frustrating to work until late at night, packing up and thinking about what I needed to carry for the next day, plus commuting. The next day, it took me much longer to get back into the flow of work compared to waking up and immediately continuing with the problem at hand. \\n
- Decreased flexibility: Hybrid work offers less flexibility than remote work but somewhat more than office work. However, this flexibility is often constrained by company policies, such as designated office and remote days or specific rules regarding remote work. When the company dictates the days employees can work remotely, the flexibility becomes somewhat artificial. \\n
- Communication challenges: As mentioned earlier, one of the reasons that office communication is a sword of 2 edges is because while in-person communication can be effective and fast, it often results in less documentation, which can impact new joiners. In a hybrid culture, this issue is so much worse, because it\u2019s hard to get the company aligned into the amount of level of documentation necessary. Plus, when WFH days rotate across divisions and teams, individuals working remotely may suffer from a lack of context that is shared among the team in the office, leading to silos and communication gaps.In addition to that in remote work employees can and expect to have to accommodate for different time zones but when you move people to hybrid the ones that need to go to the office will no longer adjust their times to match the ones WFH based on needs. \\n
- Blurred work-life boundaries: Hybrid work blurs the line between work and personal life. It no longer solely involves working from home and spending time with family but also includes being at work, interacting with co-workers, and commuting. This blurring can make it difficult to establish clear boundaries. \\n
- Limited geographic talent pool: Since you want employees to commute to the office a certain number of times per week or month, you can\u2019t hire them from anywhere. The geographic scope of talent acquisition becomes restricted, potentially limiting access to diverse skills and perspectives. \\n
- Many more distractions: Individuals face distractions both at home when working remotely and in the office from co-workers. PLUS, you get the distractions that come from your co-workers bringing you up to speed if something happened when you weren\u2019t in the office the day before (similar to the additional amount of chit chat that happens on Mondays due to weekend). \\n
- Costs and commuting: You may save some money with some WFH, but often the WFH days don\u2019t even justify going into a lower tier than a monthly subscription to public transports. So you end up spending the same, even if you travel less. This argument is less valid here in the Bay area where most people drive. Plus commuting those 3/4 days a week, is still a pain.When we talk about the employer costs then it\u2019s impossible to get it right. On the one hand you have too few people in the office which means you are overpaying for office space, on the other hand you cannot get everyone in. And this will always be impossible with a growing team + managing the WFH days of each team and division. \\n
- Decreased employee retention and satisfaction: In general, people tend to lean towards either remote work or office work. With hybrid work, those who prefer the office environment may work in the office most days, using WFH as an opportunity for personal tasks and potentially being less productive. On the other hand, those who prefer remote work will aim to WFH as much as possible and may feel dissatisfied with having to go to the office for the remaining days This can create a divide and decrease overall employee satisfaction. Additionally, this is even more pronounced when everyone in the leadership works in the office, since the company tends to follow culture from leaders and will have less incentives to accommodate team members that are not in the office. \\n
- Challenges with supervision: Physical presence in the office often aids in monitoring performance, but it becomes challenging to fairly evaluate the performance of team members in the office versus those working remotely in a hybrid setup. What is the basis that you use to evaluate them? Based on what you see when they are in the office? Do you still create ways to evaluate their output when WFH? Do you still check on them as often when the rest of your team is with you in the office? What about when you are WFH and have half of the team in the office and the other WFH? The amount of complexity that comes from managing this by itself, almost makes hybrid the worst choice. \\n
\\n  \\n
\\n
\\n\\nBecome an OpenBB Champion and join our passionate community. Share your experiences with our innovative products and help us democratize investment research through an open source approach.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDo you find yourself unable to live without one of OpenBB\u2019s innovative products? Have you pushed the boundaries of our tools and unlocked their full potential? If you answered yes, then this blog post is tailor-made for you!\\n\\nAt [OpenBB](https://openbb.co), we are actively seeking out [OpenBB Champions](https://my.openbb.co/app/hub/champions) \u2014 passionate community members who share our vision of democratizing investment research through an open source approach.\\n\\nWhether you utilize the [OpenBB Terminal](https://my.openbb.co/app/terminal) to streamline your investment research workflow, leverage the [OpenBB SDK](https://my.openbb.co/app/sdk) to create your own internal dashboards and notebooks, or employ the [OpenBB Bot](https://my.openbb.co/app/bot) to extract financial data within your finance community, we want to hear from you!\\n\\nTo qualify as an OpenBB Champion, you need to be an active user of one of our products and be willing to share your valuable experiences with our team. We\u2019re eager to learn more about your journey with OpenBB and how our products have transformed your workflow.\\n\\n
\\n  \\n
\\n
\\n\\n**Where\'s what we would like to know:**\\n\\n- Your background\\n- How you heard about OpenBB\\n- Workflow transformation since incorporating OpenBB into your toolkit\\n- Your favorite OpenBB product\\n- Your favorite feature within that product\\n- Future expectations from us\\n- Your end goal \u2014 ultimate objective or milestone\\n\\nAs an OpenBB Champion, your contribution will not go unnoticed. Here are the benefits you\u2019ll receive:\\n\\n### Exposure\\n\\nYour testimonial will be prominently featured on OpenBB\u2019s website, social media channels, and other marketing materials. This exposure will introduce your expertise to a wider audience, increasing your visibility within the investment research community.\\n\\n### Recognition\\n\\nYou will be officially recognized as an OpenBB Champion, highlighting your commitment to innovation and industry-leading practices. This recognition can bolster your credibility and authority in your field of expertise.\\n\\n### Networking\\n\\nAs part of the OpenBB Champion community, you will have exclusive access to networking opportunities with like-minded individuals who share your passion for OpenBB\u2019s products. Forge meaningful connections, exchange ideas, and collaborate with fellow champions to amplify your impact.\\n\\n### Merchandise\\n\\nTo show our appreciation for your support, the OpenBB team will send you exclusive OpenBB merchandise. Wear it proudly and let others know that you are part of our journey.\\n\\n\\n\\nIf you meet the requirements and are enthusiastic about becoming an [OpenBB Champion](https://openbb.co/blog?type=champions), we invite you to reach out to us at hello@openbb.finance. Our team will coordinate a podcast session with you.\\n\\nWe look forward to hearing from you."},{"id":"streamline-your-openbb-terminal-experience-with-openbb-hub","metadata":{"permalink":"/blog/streamline-your-openbb-terminal-experience-with-openbb-hub","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.md","source":"@site/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.md","title":"Streamline your OpenBB Terminal experience with OpenBB Hub","description":"Streamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management.","date":"2023-05-25T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OpenBB Hub","permalink":"/blog/tags/open-bb-hub"},{"inline":true,"label":"Terminal","permalink":"/blog/tags/terminal"},{"inline":true,"label":"API Key Management","permalink":"/blog/tags/api-key-management"},{"inline":true,"label":"Data Customization","permalink":"/blog/tags/data-customization"},{"inline":true,"label":"Personalization","permalink":"/blog/tags/personalization"},{"inline":true,"label":"Script Management","permalink":"/blog/tags/script-management"}],"readingTime":3.605,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"streamline-your-openbb-terminal-experience-with-openbb-hub","title":"Streamline your OpenBB Terminal experience with OpenBB Hub","date":"2023-05-25T00:00:00.000Z","image":"/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.png","tags":["OpenBB","OpenBB Hub","Terminal","API Key Management","Data Customization","Personalization","Script Management"],"description":"Streamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management."},"unlisted":false,"prevItem":{"title":"Become an OpenBB Champion","permalink":"/blog/become-an-openbb-champion"},"nextItem":{"title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data"}},"content":"
\\n  \\n
\\n
\\n\\nStreamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you\u2019re using the OpenBB Terminal, there\u2019s an essential component you shouldn\u2019t miss out on: the [OpenBB Hub](https://my.openbb.co/). In this blog post, we\u2019ll explore the significance of OpenBB Hub and why it truly matters for OpenBB users.\\n\\nBy delving into its key features, we\u2019ll uncover how OpenBB Hub elevates your experience with the OpenBB Terminal, providing you with enhanced capabilities and customization options. Let\u2019s dive in!\\n\\n## Login\\n\\nAs highlighted in our previous blog post [Introducing the OpenBB Hub](https://openbb.co/blog/introducing-the-openbb-hub), the OpenBB Hub is more than just a platform to access the OpenBB product ecosystem; it adds value to each individual product. Specifically, when it comes to the OpenBB Terminal, having an OpenBB Hub account offers tremendous advantages.\\n\\nNotably, the settings and features you configure within the hub persist across terminal updates and even when you log in from a new machine, allowing for a seamless and personalized experience.\\n\\n
\\n\\nWith the [OpenBB Hub](https://my.openbb.co/), you unlock a world of possibilities."},{"id":"openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","metadata":{"permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.md","source":"@site/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.md","title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","description":"A game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data.","date":"2023-05-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"Interactive Charts","permalink":"/blog/tags/interactive-charts"},{"inline":true,"label":"Interactive Tables","permalink":"/blog/tags/interactive-tables"},{"inline":true,"label":"Data Analysis","permalink":"/blog/tags/data-analysis"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.635,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","date":"2023-05-20T00:00:00.000Z","image":"/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.png","tags":["OpenBB","OpenBB Terminal","Interactive Charts","Interactive Tables","Data Analysis","Open Source"],"description":"A game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data."},"unlisted":false,"prevItem":{"title":"Streamline your OpenBB Terminal experience with OpenBB Hub","permalink":"/blog/streamline-your-openbb-terminal-experience-with-openbb-hub"},"nextItem":{"title":"Leaving London to live in San Francisco","permalink":"/blog/leaving-london-to-live-in-san-francisco"}},"content":"
\\n  \\n
\\n
\\n\\nA game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nNothing has changed, yet everything is different. A game-changing update empowering users with interactive charts and tables\\n\\nOur commitment to listening to user feedback and continuously improving our platform has led to a major update that will revolutionize the way you analyze data.\\n\\nOne of the main requests from our community has been regarding the interactivity of the charts and tables output by the [OpenBB Terminal](https://my.openbb.co/app/terminal). We are happy to say that we have delivered on this request with a complete overhaul of the terminal plotting library.\\n\\nNot only that, but our engineering team wasn\u2019t happy with the technical solutions available to bring interactivity to the terminal. So, in a true open-source fashion, the team built our own open-source library which will be announced soon.\\n\\n## Interactive charts\\n\\n
\\n\\nOne of the most significant additions in this update is the introduction of interactive charts. Gone are the days of static data representations.\\n\\nWith the OpenBB Terminal, you can now immerse yourself in a dynamic visual experience. Hover over specific data points to reveal detailed information, or effortlessly adjust the charts using intuitive pan and zoom capabilities. But that\u2019s not all \u2014 our drawing tools and annotations allow you to highlight crucial data points and ranges, giving you complete control over your analysis.\\n\\nThrough our user interviews, we discovered that many users faced challenges when overlaying financial time series. Taking this into account, we\u2019ve designed our new charting feature to make this process seamless. With the ability to easily overlay time series data and combine it with our powerful data exporting capabilities, OpenBB Terminal empowers you to perform in-depth analysis with unparalleled ease and precision.\\n\\n## Interactive tables\\n\\n
\\n\\nWe listened to our users\u2019 concerns about readability when dealing with large tables, and we have addressed these challenges head-on. The OpenBB Terminal now boasts interactive tables that are as aesthetically pleasing as they are functional.\\n\\nLeveraging our innovative open-source project, we have crafted a state-of-the-art table that is easy on the eyes and effortlessly responsive. Sorting, filtering, and manipulating table data has never been easier. This game-changing feature enables you to quickly and efficiently extract insights from vast amounts of data, enhancing your productivity and saving valuable time.\\n\\n## New fixed income menu\\n\\n
\\n\\nIn addition to the remarkable advancements in interactivity, we have squashed bugs and introduced a new Fixed Income menu. This means you now have access to an even wider range of data to fuel your analysis. OpenBB Terminal ensures that you are equipped with the right tools to gain a competitive edge in your investment research.\\n\\n## Wrap up - embrace the future of data analysis\\n\\nWe firmly believe that these new features will take your user experience to new heights and unlock a realm of possibilities for data analysis. Our dedicated team has poured countless hours into bringing these cutting-edge features to life, and we cannot wait to witness the impact they will have on your work.\\n\\nTo further amplify our commitment to open source, we will open source a powerful project that taps into web browser functionality from Python, opening up endless opportunities for developers and data enthusiasts.\\n\\nWe value your feedback and are eager to iterate on the OpenBB Terminal to ensure it meets your evolving needs. Reach out to us via email at hello@openbb.finance, Twitter, or Discord and let us know how we can enhance your experience further.\\n\\nIf you missed our exciting webinar unveiling these transformative features, fear not! We\u2019ve got you covered. Watch the video below to catch up and witness firsthand the incredible new capabilities our team has unleashed.\\n\\n
\\n\\nWelcome to a new era of data analysis with OpenBB Terminal. Get ready to explore, discover, and gain a competitive edge like never before."},{"id":"leaving-london-to-live-in-san-francisco","metadata":{"permalink":"/blog/leaving-london-to-live-in-san-francisco","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-13-leaving-london-to-live-in-san-francisco.md","source":"@site/blog/2023-05-13-leaving-london-to-live-in-san-francisco.md","title":"Leaving London to live in San Francisco","description":"Leaving London to live in San Francisco. A personal journey of relocating and starting a tech company in the heart of Silicon Valley.","date":"2023-05-13T00:00:00.000Z","tags":[{"inline":true,"label":"San Francisco","permalink":"/blog/tags/san-francisco"},{"inline":true,"label":"London","permalink":"/blog/tags/london"},{"inline":true,"label":"Relocation","permalink":"/blog/tags/relocation"},{"inline":true,"label":"Visa Process","permalink":"/blog/tags/visa-process"},{"inline":true,"label":"Startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":17.515,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"leaving-london-to-live-in-san-francisco","title":"Leaving London to live in San Francisco","date":"2023-05-13T00:00:00.000Z","image":"/blog/2023-05-13-leaving-london-to-live-in-san-francisco.png","tags":["San Francisco","London","Relocation","Visa Process","Startup","OpenBB"],"description":"Leaving London to live in San Francisco. A personal journey of relocating and starting a tech company in the heart of Silicon Valley."},"unlisted":false,"prevItem":{"title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data"},"nextItem":{"title":"Fully free financial chatbot","permalink":"/blog/fully-free-financial-chatbot"}},"content":"
\\n  \\n
\\n
\\n\\nLeaving London to live in San Francisco: A personal journey of relocating and starting a tech company in the heart of Silicon Valley.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Background\\n\\nI was born in Geneva, and when I was 8 years old, we moved back to Portugal, which is where my parents are originally from. After spending most of my teenage years in Portugal, I left sunny Lisbon \u2600\ufe0f to pursue a MSc. degree at Imperial College London \ud83d\udcbb. That\u2019s where I\u2019ve been living and working up until now. The main reasons behind my desire to move to San Francisco \u2600\ufe0f \ud83d\udcbb are the weather and the thriving tech ecosystem that surrounds it.\\n\\nDuring the Covid pandemic while in London, I took the opportunity to build my own [personal open source investment research platform](https://github.com/OpenBB-finance/OpenBBTerminal). This project allowed me to secure VC funding and establish a company called [OpenBB](https://openbb.co/). As the CEO of this company, I feel privileged to have the chance to make a lasting impact on the financial industry. Embracing this adventure and collaborating with individuals who are much smarter than I am is the least I can do for our team and for OpenBB.\\n\\nAs a first-time founder, I often find myself feeling slightly behind, which is why I\u2019m eager to absorb as much experience and knowledge as possible from other successful entrepreneurs. This is also why I managed to convince my wife and our dogs to join me in packing our bags and embarking on this journey into the unknown, much like my Portuguese ancestors did centuries ago \ud83d\udea2.\\n\\nNow, let\u2019s dive into what truly matters. This will be a lengthy ride, so make sure you\u2019re prepared for the journey ahead.\\n\\n## VISA\\n\\nFirst of all, you need to determine which visa you are eligible for in order to live and work in the US. You can find more information on this topic [here](https://travel.state.gov/content/travel/en/us-visas.html).\\n\\nIn my case, I decided to apply for an \u201cO-1 Visa: Individuals with Extraordinary Ability or Achievement\u201d and specifically highlighted my extraordinary ability in the field of Computer Science, specifically within the subfield of Automated Systems. It is crucial to specify a particular field to make the defense process smoother.\\n\\nI had the privilege of working with an exceptional immigration lawyer who assisted me in crafting my case, significantly increasing my chances of a successful approval. Here is a portion of the O-1 Petition that was submitted:\\n\\n\\n\\nAs you can see, there is quite a bit of paperwork required to support your case. In my situation, I needed the following documents: Curriculum Vitae, university grades, transcripts and diplomas, LinkedIn and GitHub profiles, posts that gained viral attention on platforms like Reddit and HackerNews, podcasts and conferences where I had spoken, projects that received online praise, any media coverage I had received, scholarly scientific publications, expert opinion letters, and even emails or direct messages from venture capitalists or professionals in the industry.\\n\\nEssentially, any relevant evidence is used to strengthen your case. For me, the most crucial elements were the expert opinion letters provided by our lead investor, former colleagues, or respected individuals in the field who were familiar with my work, as well as the research papers I had published and the media coverage I had received.\\n\\nOnce my O-1 visa was approved, I simply needed to take my passport to the US embassy in London to obtain the visa stamp. It\u2019s worth noting that if the wait time at the US embassy is lengthy, you have the option to visit another US embassy in another country where the process may be faster.\\n\\n## Arriving to the country\\n\\nI arrived in California on my own initially, with the plan for my wife and dogs to join me later. Thankfully, I had some contacts in California who provided me with their phone number and house address, which was helpful for getting settled. Since I didn\u2019t have a phone before finding an apartment, I had to rely on roaming data using my plan from the UK, which resulted in additional expenses.\\n\\nI would suggest either having a good deal for data roaming and international calls outside your country or obtaining a prepaid US phone. The latter is especially important if you\u2019re traveling alone because I often encountered registration forms that didn\u2019t accept foreign phone numbers.\\n\\nRegarding payments, I used my Revolut VISA card, which offers excellent foreign exchange rates for converting pounds to dollars. It\u2019s worth noting that I couldn\u2019t open a US bank account without a Social Security Number (SSN).\\n\\n### Social Security Number (SSN)\\n\\nIf you know someone in the US, it is advisable to apply for a Social Security Number (SSN) as soon as possible and provide their address and contact information if you don\u2019t have a US address of your own. An SSN is necessary for various purposes, and it may take up to two weeks for the card to arrive. When going to you nearest Social Security Administration (SSA) office, I would suggest arriving 30 minutes before opening hours to avoid long queues.\\n\\nTo apply for an SSN, you will need to bring the following documents to the SSA office: your passport, the I-797 form (O-1 visa approval notice), and the I-94 form (arrival record in the US).\\n\\n### Transportation\\n\\nI had the fortunate opportunity of having a friend lend me a car as soon as I arrived in California, and it made my life ten times easier. I highly recommend having something lined up in terms of transportation, as having a car enables you to get anywhere you need to go much more efficiently. To ensure I was covered, I simply needed to arrange car insurance. I opted for [Progressive](https://www.progressive.com/), and the process was quick and straightforward.\\n\\nWhile settling in, I occasionally relied on public transportation instead of driving, especially when traveling to the center of San Francisco. It took me some time to adjust to driving in the US, so public transport was a convenient alternative. If you plan on using public transportation services like BART or Caltrain, I suggest visiting [this website](https://www.iliveinthebayarea.com/knowledge-center/transit/) that provides information on available transportation options. It\u2019s also a good idea to purchase a [Clipper card](https://www.clippercard.com/), which allows you to load funds and easily tap it when boarding.\\n\\nAdditionally, if you anticipate passing through tolls, bridges, or utilizing the fast lane on the freeway, I recommend looking into acquiring a [Fastrack transponder](https://www.thetollroads.com/accounts/fastrak/transponder/) for a more seamless experience.\\n\\n## Finding an apartment\\n\\nApartment hunting proved to be quite stressful, considering that every day spent searching meant unnecessary expenses piling up while I still had my company to manage.\\n\\nUsing Uber for transportation was convenient and efficient, but the costs could add up quickly with multiple trips. To save money, I recommend scheduling house viewings on the same day in specific areas of interest and simply walking from one location to another.\\n\\nWhile dealing with lease agents, I encountered a mix of competence levels. Some were highly efficient, while others were less so. If you\u2019re genuinely interested in a particular apartment, it\u2019s important to exert some pressure to keep the process moving forward. Don\u2019t hesitate to call and inquire about updates.\\n\\nI was fond of the first house we saw, so I promptly paid $300, which covered certain fees. These fees were refundable if we decided not to proceed, but more importantly, they ensured that the house would be taken off the market. At this stage, both the agents and I wanted the process to move as quickly as possible. In our case, the target timeframe was three business days; if the process exceeded that, the house would be made available again.\\n\\nEven if you believe you\u2019ve found the perfect apartment, I still recommend continuing your search until the lease contract is signed. It\u2019s crucial to secure the apartment before assuming it\u2019s yours.\\n\\nBefore obtaining the keys, we had several tasks to complete: making the first payment, setting up utilities ([PG&E](https://www.pge.com/) for Gas and Electricity, and [Conservice](https://utilitiesinfo.conservice.com/) for water), providing proof of renter\u2019s liability insurance (I used [Assurant](https://assurantrenters.com/)\u2019s as it was conveniently associated with the community), and undergoing a pet screening (note that certain dog breeds are considered more dangerous and may not be accepted).\\n\\nMost importantly, my salary alone wasn\u2019t sufficient to guarantee that we could afford the rent. I needed a guarantor to vouch for me, as Europe does not have the concept of credit ratings.\\n\\nFortunately, our lead investor graciously agreed to be our guarantor when I asked him. Without someone fulfilling this role, I would have had to rely on a third-party service and pay several thousands of dollars, which would have been non-refundable and solely for the right to lease the house. This arrangement seemed rather illogical.\\n\\n## After the apartment\\n\\nI needed to notify [USCIS](https://www.uscis.gov/) of my new address since the last one on file was associated with the hotel where I was staying. I informed them that my new residence would be the updated address.\\n\\nFollowing that, my dogs flew from the UK using [Pets abroad UK](https://www.petsabroaduk.co.uk/). To save money, my wife didn\u2019t accompany them on the flight; instead, she arranged for them to be transported in the cargo hold of the airplane while I waited at the destination.\\n\\nHowever, I must admit that I didn\u2019t enjoy the experience, and in hindsight, I would have been willing to pay more for my dogs to have a better and safer flight. Although flying them from London, meant that unfortunately cargo was the option due to UK requirements. When I picked them up, they were visibly scared, and both my wife and I held our breath with worry throughout their entire journey. Our dogs\u2019 well-being was of utmost importance to us.\\n\\n\\n\\nThe house was mostly empty, so to save money, we acquired a lot of second-hand items for free. It was beneficial to know people in the area who were aware of others with unused items stored in their garages, which we were able to take. To retrieve this furniture and other objects, we either needed to rent a U-Haul (which wasn\u2019t possible without a California driver\u2019s license) or hire a moving company.\\n\\nOur next task was to search for second-hand items at significant discounts on websites such as [Craigslist](https://sfbay.craigslist.org/), [Nextdoor](https://nextdoor.com/) and [Facebook Marketplace](https://www.facebook.com/marketplace). However, we had to be cautious of scammers and remember that if a deal seemed too good to be true, it probably was.\\n\\nOnce we had gathered most of the second-hand items, we visited [Home Depot](https://www.homedepot.com/) to paint and improve the newly acquired furniture. For the items we couldn\u2019t find second-hand, we made purchases at [Costco](https://www.costco.com/).\\n\\nWe highly recommend getting an executive membership at Costco as it provides great value for money. Additionally, the gas prices at Costco are significantly cheaper compared to other places we\u2019ve seen.\\n\\n### Wi-Fi + Mobile plan\\n\\nAfter securing an apartment, I used my passport to visit an [AT&T](https://www.att.com/) store. Since I didn\u2019t have my SSN yet, they were accommodating and allowed me to use my passport for identification. However, if you choose a different service provider like Xfinity, you will need your SSN. Before selecting a plan, it\u2019s important to check the coverage in your area to ensure that 4G/5G works well.\\n\\nInitially, I set up Wi-Fi through Xfinity, but then I used that as leverage to negotiate a discount with AT&T. This worked because I was interested in a double play package, which included two phone plans and Wi-Fi. As a result, I obtained an e-sim with unlimited 5G data for both myself and my wife, along with Wi-Fi for our home, at a cost of approximately $150 per month.\\n\\n### Shopping\\n\\nThere\u2019s going to be a big shock in terms of prices; at least, we experienced one. Life in the Bay Area is over 2x more expensive than London.\\n\\n\\n\\nSo, we started learning how to buy things at a lower cost. Whole Foods is not a viable option as it\u2019s one of the most expensive stores. The 10 items above cost $69.34 on Whole Foods.\\n\\nInstead, we now tend to shop at Safeway and always try to time our visits to take advantage of discounts. Many shopping places offer coupons that can help you save a lot of money. Additionally, when you come across products on sale, it\u2019s better to buy them in larger quantities as it\u2019s usually worth it.\\n\\nMy wife is also a big fan of Trader Joe\u2019s with the prices there being quite reasonable too. They also have a great selection of cheeses which is a must being from Europe.\\n\\n## After obtaining an SSN\\n\\nAfter you obtain your SSN, there are a lot of new things that you are able to do since you are recognized as a \u201cperson.\u201d\\n\\n### Bank account\\n\\nCredit cards are recommended over debit cards, not just because of the security benefits, but also because of the credit rating associated with them. This is a concept that doesn\u2019t really exist in Europe but is significant in the US. Your credit score will determine whether you are approved for a loan and what interest rate you will be charged.\\n\\nThe agencies that handle your credit score are [Equifax.com](http://equifax.com/), [TransUnion.com](http://transunion.com/) and [Experian.com](http://experian.com/). It\u2019s free to register, and you should keep an eye on your credit files to ensure that your credit score doesn\u2019t decrease for any reason.\\n\\nWe ended up opening an account with [Bank of America](https://www.bankofamerica.com/). However, since we didn\u2019t have a credit score yet, we couldn\u2019t get a regular credit card. Instead, we had to apply for a secured credit card, where the maximum spending limit is determined by the amount of cash we use to back the credit card.\\n\\nWe also applied for an [AMEX card](https://www.americanexpress.com/us/credit-cards/card/blue-cash-everyday/?eep=26129&irgwc=1&veid=39E0XuRS3xyNT4BTy33WSUXYUkAwp0Tx32Qt0c0&affid=1193684&pid=IR&affname=NerdWallet%2C+Inc.&sid=14011830016&pmc=795&BUID=CCG&CRTV=controlaffcps&MPR=03) because [American Express](https://www.americanexpress.com/) has a partnership with the international credit-reporting startup Nova Credit. This allows immigrants to instantly translate credit reports from the UK to U.S.-equivalent credit reports when applying for AmEx consumer cards. However, it\u2019s important to note that AMEX cards are less widely accepted compared to VISA and MasterCard, so we were aware that they would only work in certain establishments.\\n\\nFor more information, these video were extremely helpful:\\n\\n- [Building credit and keeping yours healthy](https://bettermoneyhabits.bankofamerica.com/en/credit/building-credit)\\n- [How to build credit from scratch](https://bettermoneyhabits.bankofamerica.com/en/credit/start-building-credit)\\n- [Top 3 credit questions](https://bettermoneyhabits.bankofamerica.com/en/credit/top-credit-questions)\\n\\n### Car\\n\\nIt was now time for us to buy a car. We searched online for a few options. There are two things worth considering when buying a used car, as we did:\\n\\n- Firstly, you can use [https://www.kbb.com/car-values/](https://www.kbb.com/car-values/) to research the value of the car. This ensures that you don\u2019t get ripped off and provides an estimate of how much the car is worth based on the details you provide.\\n- Secondly, you can use [https://www.carfax.com/](https://www.carfax.com/) to research a car and its license plate. This helps you understand its accident history and any repairs it has undergone. It provides information about whether there have been major accidents in the car\u2019s history, frequent visits to the mechanic, and whether the repairs were done by authorized mechanics (e.g., BMW) or not.\\n\\nIf you prefer to play it safe, you can even bring a mechanic with you to the dealership to assess the car\u2019s condition.\\n\\nWe spoke with individuals, but ultimately decided to buy a car from a dealership because it offered fewer risks compared to buying from individuals. Moreover, the dealership took care of updating the vehicle records, ensuring that the vehicle would be registered under our name. This allowed us to update our car insurance with the Vehicle Identification Number (VIN) of the new vehicle.\\n\\nAfter a few months, we received the California Certificate of Title, which confirmed that I was the legal owner of the vehicle and included important vehicle identification information. Since this was my first car, I had to add an OpenBB reference to the front plate :)\\n\\n\\n\\nShoutouts to:\\n\\n- [Jiffy Lube](https://www.jiffylube.com/) for their car inspection services, tire inflation, oil changes, and more. They don\u2019t charge for the inspection and only charge for the services performed on the car. We had a great experience with them.\\n- [Costco gas station](https://www.costco.com/gasoline.html) for the cheapest gas we\u2019ve found so far.\\n\\n### Health Insurance\\n\\nCalifornia offers a portal called [Covered California](https://www.coveredca.com/), which provides state-approved health plans from various insurance companies. If your income is low, the state can subsidize your monthly premium. These plans fall into three categories, each with differences in costs and provider networks:\\n\\n
- \\n
- HMOs (Health Maintenance Organizations): Typically cheaper than PPOs, HMOs have smaller networks. You need to see your primary care physician before getting a referral to a specialist. \\n
- PPOs (Preferred Provider Organizations): Usually more expensive, PPOs offer a larger network and the ability to see providers outside of the network. You can also see specialists without a referral. \\n
- EPOS (Exclusive Provider Organizations): EPOS plans combine features of HMOs and PPOs. They have exclusive networks like HMOs, making them generally less expensive. However, you can make your own appointments with specialists, similar to PPOs. \\n
- \\n
- Monthly premium: The amount you pay each month for health plan coverage. It may be subsidized based on your income and household size. \\n
- Annual deductible: The amount you must pay before your plan starts covering services. \\n
- Annual maximum out-of-pocket: The total amount you pay in a calendar year (in addition to monthly premiums) for most services covered by your health care plan. \\n
\\n  \\n
\\n
\\n\\nThe OpenBB Bot is a financial chatbot that allows you to access financial data from Discord or Telegram along with other users. From equity data to crypto, options, darkpool, economy and much more! Now available for free to registered users.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWe know the market conditions haven\u2019t been great for anyone, particularly for investors. Instead of raising prices like trends, we have decided to offer our [OpenBB Bot](https://my.openbb.co/app/bot) individuals tier for free if you are a registered user.\\n\\n## What does this mean\\n\\nRegistered users for OpenBB Bot will see the following changes:\\n\\n- Users were limited to 100 options or dark pools commands per month. This limitation is completely removed.\\n- Users will no longer experience a 10s cooldown which means they can request investment research data sequentially and avoid breaking the conversation due to a delay imposed by the product\\n- Through our soon-to-be-announced new platform, you will be able to fully customize your charting style with up to 5 in chart technical indicators and 2 off charts. This is a big improvement over the 1 in chart and 1 off chart previously available.\\n- The number of custom alerts that the user can set for when certain threshold values are triggered has increased, from 3 to 10.\\n- Users can now set 10 watchlist tickers to pay close attention to and access data regarding them.\\n\\nBelow is a video of what the OpenBB Bot is capable of:\\n\\n\\n\\nThe interactive charts will open up within the [OpenBB Hub](https://my.openbb.co/) and in it you will be able to fully customize the technical analysis indicators that you see on the chart and even the candle chart color theme and type. A demo is shown below,\\n\\n
\\n\\nLike dozens of thousands of investors, join the OpenBB Hub so you can fully leverage the [OpenBB Bot](https://my.openbb.co/app/bot).\\n\\nYou can actually see how many users we have utilizing the bot on a daily basis on our [/open page](https://openbb.co/company/open/bot).\\n\\nWhile others zig, we zag. Here\u2019s the updated pricing:\\n\\n\\n\\nLooking forward to feedback!"},{"id":"free-investment-research-ecosystem-to-consistently-beat-the-market","metadata":{"permalink":"/blog/free-investment-research-ecosystem-to-consistently-beat-the-market","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.md","source":"@site/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.md","title":"Free investment research ecosystem to consistently beat the market","description":"The OpenBB Hub is a comprehensive platform for managing all products, data, subscriptions, and content for users, aiming to empower investors globally with tools previously exclusive to institutions.","date":"2023-05-05T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"OpenBB Bot","permalink":"/blog/tags/open-bb-bot"},{"inline":true,"label":"OpenBB SDK","permalink":"/blog/tags/open-bb-sdk"},{"inline":true,"label":"OpenBB Hub","permalink":"/blog/tags/open-bb-hub"}],"readingTime":5.945,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"free-investment-research-ecosystem-to-consistently-beat-the-market","title":"Free investment research ecosystem to consistently beat the market","date":"2023-05-05T00:00:00.000Z","image":"/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.png","tags":["OpenBB","Investment Research","OpenBB Terminal","OpenBB Bot","OpenBB SDK","OpenBB Hub"]},"unlisted":false,"prevItem":{"title":"Fully free financial chatbot","permalink":"/blog/fully-free-financial-chatbot"},"nextItem":{"title":"The role of AI and OpenBB in the future of investment research","permalink":"/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research"}},"content":"
\\n  \\n
\\n
\\n\\nThe OpenBB Hub is a comprehensive platform for managing all products, data, subscriptions, and content for users, aiming to empower investors globally with tools previously exclusive to institutions.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe OpenBB Hub is the new one-stop-shop for managing all products, data, subscriptions, and content for users!\\n\\n## Introduction\\n\\nWhen we started this journey, we always wanted to empower investors across the globe to have access to tools previously only available to institutions.\\n\\nWe started by building the [OpenBB Terminal](https://my.openbb.co/app/terminal) which is an open source investment research platform that users can customize as they see fit and build on top of.\\n\\nIf you haven\u2019t starred the repo, now is a good chance to do so [here](https://github.com/OpenBB-finance/OpenBBTerminal) \u2b50\ufe0f.\\n\\nThen, we wanted to address the social nature of investing. Instead of adding the chat functionality to OpenBB Terminal, we brought investment research data where these communities were already having fruitful discussions (Discord and Telegram). This makes much more sense from a user-convenience standpoint, and that\u2019s how the OpenBB Bot was born. More information [here](https://my.openbb.co/app/bot).\\n\\nAs much customization as the OpenBB Terminal allowed, we didn\u2019t give creators as much freedom as we could have since they would need to download the source code of the terminal in order to leverage our core.\\n\\n\\n\\nBut we we wanted to make this experience as seamless as possible so users could build on top of our foundation. Thus, we repurposed the core of the OpenBB Terminal into an OpenBB SDK that is \u201c_pip installable_\u201d from everywhere \u2014 [OpenBB](https://pypi.org/project/openbb/) . This means that all you need to have access to a universe of investment research data programmatically is python and running pip install openbb within a notebook.\\n\\nThis was a big win since the community reaction was very positive and we are now seeing it adopted by investors, educational courses, and even content creators. So much that we even created a tab to keep track of these on our [/open page](https://openbb.co/open).\\n\\nHowever, we focused too much on the products and didn\u2019t slow down to think about the user experience utilizing multiple OpenBB products. This is where OpenBB Hub comes into play. [OpenBB Hub](https://my.openbb.co/) is the platform we use to interact with our community, push OpenBB content, allow product management, and much more.\\n\\nTL;DR:\\n\\n- Allows to manage your OpenBB Terminal API keys, feature flags and settings. In addition, we allow users to save & share their openbb script routines\\n- Allows access to the OpenBB Terminal installer new versions\\n- Allows access to the OpenBB Bot dashboard \u2014 which allows fully customization from a user perspective. This improves your experience by 10x when using OpenBB Bot on Telegram or Discord.\\n- Allows to sign-up for early waitlist of OpenBB Terminal Pro\\n\\n## OpenBB Hub - OpenBB Terminal\\n\\nSince the beginning users have installed the OpenBB Terminal in multiple desktops due to its free nature. The issue? The API key management was a pain since there was not a way to sync these across different machines. Until now.\\n\\nWith [OpenBB Hub](https://my.openbb.co/) and using that account detail to log in the terminal, this problem gets fixed. Not only that, but users will benefit from default data sources, terminal color schema customization and even .openbb routines being manageable from Hub and more importantly accessible on a terminal instance as long as they login with their user details.\\n\\n\\n\\n## OpenBB Hub - OpenBB Bot\\n\\nToday we are also announcing the OpenBB Bot will be fully free for individuals. All you have to do is to register for the [OpenBB Hub](https://my.openbb.co/).\\n\\nFor users that were already users of our OpenBB Bot, the only change on the platform is pricing and an increase push towards better documentation and more tutorials. This is an initiative that we are taking company-wide to focus on better documentation and more content to fully leverage our suite of products.\\n\\nOpenBB bot is critical to us as we work hard towards making a full ecosystem for investment research. And now you can access this experience for free, and share investment research data with your friends / colleagues.\\n\\n\\n\\n## OpenBB Hub - OpenBB SDK\\n\\nAs the OpenBB SDK is in its core a pip installable package with its [own page on PiPy](https://pypi.org/project/openbb/) there aren\u2019t a lot of functionalities that we can make available in this page. We allow the user to set their API keys similarly to what we do in the Terminal, to improve UX when utilizing the SDK.\\n\\nIn addition, we are going to display open source projects built by the community that leverage our core so that they can serve as an inspiration to you. If you are working on something that uses OpenBB at its core, tag your GitHub repository with \u201copenbb\u201d and we\u2019ll add you to the list of projects that rely on our foundation.\\n\\n\\n\\n## OpenBB Hub - OpenBB Terminal Pro (waitlist)\\n\\nIf all these features weren\u2019t enough, we have decided to open the [OpenBB Terminal Pro WAITLIST](https://my.openbb.co/app/pro/early-access) for users who register on our OpenBB Hub.\\n\\nThe OpenBB Terminal Pro is something that has been months in the works and is yet our most exciting product to date. We have been holding back on it because we believe this will change the way investors think about investing. This time we worked with design partners and had dozens of user interviews from financial professionals to understand their pain points and what role we could fill. So even being able to start creating a waitlist around it is something that the team is very excited about.\\n\\nWe will gradually roll out the OpenBB Terminal Pro to a few users from the waitlist to get early feedback.\\n\\nIf you are one of these, I look forward to onboarding you personally \ud83e\udd1d\\n\\n\\n\\n## Final thoughts\\n\\nAlthough OpenBB Hub is not a product per se, the amount of work that the team put together to make this happen is something nothing short of extraordinary. This was the first project where the entire team (~20 people from engineering, product, design and marketing) had to work together as whole.\\n\\nThe OpenBB Terminal dashboard is completely new, the concept of login had to be invented and needed to function perfectly with the Hub. The SDK page is also new. The OpenBB Bot dashboard already existed, but we made the tier for individuals completely free, so we had to update it to reflect that big pricing change. And finally, we open the OpenBB Terminal Pro waitlist.\\n\\nThe [OpenBB Hub](https://my.openbb.co/) is completely free.\\n\\nAll you have to do is to register so we can know more information about yourself regarding your primary usage for our products (professional, academic, personal) \u2014 this allows us to understand what features to prioritize in the future and improve the quality of our products.\\n\\nIn case you missed the webinar, you can view it below so that you are up-to-date with all the exciting new features that the team has released.\\n\\n
"},{"id":"the-role-of-ai-and-openbb-in-the-future-of-investment-research","metadata":{"permalink":"/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.md","source":"@site/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.md","title":"The role of AI and OpenBB in the future of investment research","description":"How OpenBB can lead the future of finance using AI on top of an open source investment research platform.","date":"2023-04-03T00:00:00.000Z","tags":[{"inline":true,"label":"OpenAI","permalink":"/blog/tags/open-ai"},{"inline":true,"label":"future","permalink":"/blog/tags/future"},{"inline":true,"label":"ChatGPT","permalink":"/blog/tags/chat-gpt"},{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"}],"readingTime":3.655,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-role-of-ai-and-openbb-in-the-future-of-investment-research","title":"The role of AI and OpenBB in the future of investment research","date":"2023-04-03T00:00:00.000Z","image":"/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.png","tags":["OpenAI","future","ChatGPT","Discord"],"description":"How OpenBB can lead the future of finance using AI on top of an open source investment research platform."},"unlisted":false,"prevItem":{"title":"Free investment research ecosystem to consistently beat the market","permalink":"/blog/free-investment-research-ecosystem-to-consistently-beat-the-market"},"nextItem":{"title":"How I Used OpenAI API to improve our product documentation","permalink":"/blog/how-i-used-openai-api-to-improve-our-product-documentation"}},"content":"
\\n  \\n
\\n
\\n\\nHow OpenBB can lead the future of finance using AI on top of an open source investment research platform.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nThis blogpost won\'t speak about what the OpenBB Terminal can offer today. Instead, we are going to share where we think AI can play a role in the future of investment research, and how through an open source platform, we can lead that wave.\\n\\nA lot of this blog is based on the fact that the OpenBB Terminal is an open source investment research platform, and therefore it\'s very relevant to read [our blogpost about why we are open source](/blog/why-the-need-for-an-open-source-investment-research-platform).\\n\\nNote: This blogpost will share several proof-of-concepts that are still within R&D and are not yet ready for production. Also, this blogpost will assume that you are aware of LLMs such as ChatGPT and WhisperAI.\\n\\n## ChatGPT as the interface\\n\\nAn edge that incumbents have is the fact that they have been around for a very long time and spent a lot on educating users about their product. As a result, users are used to their platform. This makes it harder for users to switch to an unknown product, meaning they need to be 10x better than the competition for them to do so.\\n\\nHowever, what if there was no learning curve? What if you could use a product for the first time and know how to access all the information you wanted without spending any time reading the documentation? In essence, the educational incumbent advantage would become obsolete.\\n\\nWith the new LLM advancements, such as ChatGPT. We are not far from this reality. Below is a proof-of-concept of what this could look like:\\n\\n
\\n  \\n
\\n
\\n\\nIn this blog post, I share how I used the OpenAI API to improve our product documentation. I used ChatGPT to generate more detailed descriptions for our OpenBB Bot Discord commands, making them more understandable for new users.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/improve-documentation-using-openai).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe [documentation](https://docs.openbb.co/bot/reference/discord) of our free OpenBB Bot was pretty simplistic for most of the commands.\\n\\nFor instance, the description for the command `/dp alldp` was: \\"Last 15 Darkpool Trades\\", as seen below:\\n\\n\\n\\nFor more experienced traders, this may be enough. But for new users, these 4 words may not mean much.\\n\\nFor context, this is the output that a user would get if running `/dp alldp` on our [Discord server](https://openbb.co/discord).\\n\\n\\n\\nSo I talked with someone in our team about improving the documentation. Not only for the new users that wanted to utilize our free product but also so that we could train our own LLM on this better dataset.\\n\\nOver the weekend I had the idea: What if I provided ChatGPT with the current description and an example of how to use the command and asked it to provide a more detailed description?\\n\\nSo the next step was to try whether ChatGPT would indeed improve the current documentation.\\n\\nAfter a bit of prompt tweaking, I got a much better description than the one we currently had. See below:\\n\\n\\n\\nThe next step was rather straightforward. I created a script that iterated [through all our OpenBB Bot Discord documentation](https://github.com/OpenBB-finance/OpenBBTerminal) files and updated the old description with a more detailed one.\\n\\nThis is the template prompt that I used:\\n\\n> _Context: You are a developer writing a detailed documentation for a function that allows the user to retrieve desc utilizing the command example how would you explain what this command does in a single paragraph\u201d_\\n\\nWhere **desc** and **example** corresponds to the current description and example that each of our commands have, respectively.\\n\\nThe results can be seen below (done on [this PR](https://github.com/OpenBB-finance/OpenBBTerminal/pull/4657)),\\n\\n\\n\\nAs usual, I open source the script [here](https://github.com/DidierRLopes/improve-documentation-using-openai).\\n\\nThe funny thing is that I used an LLM output to improve our documentation. And we may use this data to train our own LLM.\\n\\nLLM-ception?"},{"id":"how-to-get-hired-by-an-exciting-tech-startup-in-2023","metadata":{"permalink":"/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.md","source":"@site/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.md","title":"How to get hired by an exciting tech startup in 2023","description":"The future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today.","date":"2023-01-22T00:00:00.000Z","tags":[{"inline":true,"label":"Career Advice","permalink":"/blog/tags/career-advice"},{"inline":true,"label":"Tech Startups","permalink":"/blog/tags/tech-startups"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Job Hunting","permalink":"/blog/tags/job-hunting"},{"inline":true,"label":"Software Engineering","permalink":"/blog/tags/software-engineering"}],"readingTime":5.425,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-get-hired-by-an-exciting-tech-startup-in-2023","title":"How to get hired by an exciting tech startup in 2023","date":"2023-01-22T00:00:00.000Z","image":"/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.png","tags":["Career Advice","Tech Startups","Open Source","Job Hunting","Software Engineering"],"description":"The future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today."},"unlisted":false,"prevItem":{"title":"How I Used OpenAI API to improve our product documentation","permalink":"/blog/how-i-used-openai-api-to-improve-our-product-documentation"},"nextItem":{"title":"Financial chat bots are underrated, and here\u2019s why.","permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why"}},"content":"
\\n  \\n
\\n
\\n\\nThe future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEveryone is doing the same hacker tests. Being good at interviews will no longer suffice to get a job in top tech company. Conventional CVs are too boring. Recruiters may like what they read, but this doesn\u2019t make them think any further about a person and think \u201cwow, we really need someone like them\u201d.\\n\\nUltimately, a CV cannot demonstrate creativity and in my opinion, to be a top engineer you need to be creative. Often there isn\u2019t an easy straightforward solution and being creative is what distinguishes top tier engineers from medium. I wrote a post about this [here](/blog/stop-doing-your-cv-in-word-or-latex).\\n\\nBelow I will let you know my views on what I would do to get a job at an exciting tech startup.\\n\\n## Work on open source projects\\n\\nOpen source is a great way to build your skills and get your name out there. It\u2019s also a great way to make connections with other developers, which can lead to referrals and job opportunities. If you want to show that you\u2019re a good engineer, open source is an excellent opportunity. This is because it allows you to demonstrate your problem-solving abilities, while also improving the codebase of a project that is potentially used by thousands of users \u2014 and because the project is open source, it never dies.\\n\\n**But which open source projects should you choose?**\\n\\nI\u2019d say that there are two routes that you can take here. You can select the project based on your **own use case** or you can **be strategic** about it.\\n\\n### Own use case\\n\\nDon\u2019t overthink it. The world of software is built on top of open source. If it weren\u2019t for open source, we would be living in the year 2000 or less. This means that your favorite apps are relying on open source projects, which you can be a part of!\\n\\nThis means that you can:\\n\\n- Contribute to an open source library that is used by a project that you like. E.g. someone from our team is a [cpython](https://github.com/python/cpython) contributor.\\n- Contribute to a product that you use that is Open Source. The advantage here is that you are able to literally customize the product that you are using.\\n\\nWith Red Hat in the 90s this open source movement is starting to be a very hot topic. [Joseph Jacks](https://twitter.com/JosephJacks_) from OSS Capital is one of the best investors (if not the best) in this space. The chart below that he put together illustrates well the growth of open source (shared in [this tweet](https://twitter.com/JosephJacks_/status/1494840009882361859?s=20))\\n\\n\\n\\n### Strategic\\n\\nIf you\u2019re reading this, there\u2019s a good chance that you want to make a positive impact on the future of technology. If so, it can be helpful to consider how your work will affect the lives of others. Take some time and think about what kind of role you would like to play in shaping those futures \u2014 are you someone who wants to improve people\u2019s physical well-being through health innovations? Or maybe achieve more efficient energy use through new technologies? This will help determine which companies or projects might be best suited for any given career path.\\n\\nOnce you figure out what motivates you, select an industry where you wish to find a job.\\n\\nThen there are multiple paths that you can take:\\n\\n- Look into the signals provided by top venture capital firms in that selected industry. I.e. see what open source companies are being backed in that space.\\n- Look into the developer engagement around the open source projects in that industry. You can not only use GitHub stars and forks, but you can use tools such as [https://analyzemyrepo.com](https://analyzemyrepo.com/analyze/OpenBB-finance/OpenBBTerminal) or [https://ossinsight.io/](https://ossinsight.io/)\\n- Cold email VCs to ask them about which open source products they are excited about. I say VCs because often their job is to find these startups early, so usually they have more recent information. But talking with devs or listening to people that you respect in the industry is equally valid.\\n\\nNote: By being an early contributor of a promising open source startup, you can become a core maintainer of a project and even make it to the founding team. This is how I met James, OpenBB\u2019s co-founder. He was an active developer in my own open source project, and I invited him to be part of the main maintainers of the project. When we built a company, he became a founding member.\\n\\n## Develop your own open source project\\n\\nI strongly believe that being able to successfully build your own open source project is severely underrated. There are so many components that you need to get right from so many departments that it shows a lot about your strengths as an individual and a preview of the value you could add to the team.\\n\\nYou may think that the only thing that you are demonstrating is your ability to write high-quality code since it will be open to the public. Well that\u2019s wrong. Here is a non-exhaustive list of skills that you show off\\n\\n- Solution to a real-world problem\\n- Design around the product\\n- User experience\\n- How you prioritize task and how fast you can ship high-quality code\\n- Interaction with others\\n- Marketing\\n- Listening to feedback from users\\n\\nThis is what I did with OpenBB Terminal: [https://github.com/OpenBB-finance/OpenBBTerminal](https://github.com/OpenBB-finance/OpenBBTerminal) and it has single handedly changed my life.\\n\\n## Conclusion\\n\\nIf you\u2019re looking for a job in 2023, the best thing you can do is to contribute to/develop open source projects.\\n\\nYou should be aware that you can also add value to an open source project by reporting bugs. You can even do more than just report a bug, but suggest a solution or workaround for the problem \u2014 this shows that not only are you paying attention to what\u2019s going on around you, but also that you have some ideas about how things could be improved \u2014 a combination that any hiring manager would love!\\n\\nI hope you found this post insightful.\\n\\nAny feedback is welcome."},{"id":"financial-chat-bots-are-underrated-and-heres-why","metadata":{"permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.md","source":"@site/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.md","title":"Financial chat bots are underrated, and here\u2019s why.","description":"In this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular.","date":"2023-01-05T00:00:00.000Z","tags":[{"inline":true,"label":"chatbots","permalink":"/blog/tags/chatbots"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OptionsFamBot","permalink":"/blog/tags/options-fam-bot"}],"readingTime":4.12,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"financial-chat-bots-are-underrated-and-heres-why","title":"Financial chat bots are underrated, and here\u2019s why.","date":"2023-01-05T00:00:00.000Z","image":"/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.png","tags":["chatbots","finance","AI","Discord","OpenBB","OptionsFamBot"],"description":"In this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular."},"unlisted":false,"prevItem":{"title":"How to get hired by an exciting tech startup in 2023","permalink":"/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023"},"nextItem":{"title":"Firing sucks. How to avoid doing so by hiring A players.","permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAt OpenBB, earlier this year we [joined forces with OptionsFamBot](https://openbb.co/products/bot). This was a bot that had a reach of over 1 Million users on Discord.\\n\\nToday, [OpenBB Bot](https://openbb.co/products/bot) is one of our more powerful products and I still think a lot of people are sleeping on it.\\n\\n### What is a chatting bot platform?\\n\\nAccording to [ChatGPT](https://chat.openai.com/chat):\\n\\n> _\u201cA chatbot platform is a software service or tool that enables the creation, management, and deployment of chatbots. These platforms typically provide a variety of tools and features for building, testing, and deploying chatbots, as well as options for integrating chatbots with other systems or services. Some chatbot platforms are designed to support the development of chatbots for specific industries or use cases, such as customer service, e-commerce, or marketing. Others are more general purpose, and can be used to build chatbots for a wide range of applications.\u201d_\\n\\n
\\n\\n### Why are chat bots not engaging?\\n\\nI believe that one of the reasons for this is because people usually associate chatbots with customer service or marketing. Not as a finalized product but as a feature.\\n\\nIf I ask ChatGPT about this, the main reasons are: Lack of personalized conversation, limited capabilities, poor design and high error rate.\\n\\n\\n\\nBut wait.. ChatGPT is **LITERALLY** a chat bot. Everything happens through a chat interface, which shows that you can build a successful product as a bot, as long as it adds enough value to the user.\\n\\nOne could argue that ChatGPT is not done in an established chatting platform, and that is **partially true**. The reason I say partially is because ChatGPT has an API, so developers can use it to develop their own chatting bots and deploy it in whatever chatting app they are interested in.\\n\\n## Examples of good chatting platforms\\n\\nI believe that Discord is in the forefront here due to: Free, easy to use, allows customizing servers with roles/channels/permissions, high-quality voice chat, strong communities.\\n\\nA testament to this is the fact that [midjourney](https://midjourney.com/) has built a successful chat bot that generates images from text prompts using AI, **SOLELY** relying on Discord. If you go into their website, the button \u201c**Join the Beta**\u201d takes you to their Discord server which has over **7 million users**!\\n\\nAs far as I know, this is the only example of a company that distributes their product solely through a chatting platform in a successful way.\\n\\n\\n\\n## Why are chat bots getting more popular?\\n\\nIn my opinion, there are a few factors why chat bots are becoming more popular:\\n\\n### Interactivity\\n\\nThe bots are becoming more interactive, almost working like an application within a chatting platform.\\n\\n\\n\\n### Speed\\n\\nThe speed of interaction is increasing over time, making the experience more seamless.\\n\\n\\n\\n### Customization\\n\\nThe level of customization allowed for these bots keeps on increasing.\\n\\n\\n\\n### Automation\\n\\nYou are starting to be able to create automated workflows. Not only for you, but for entire communities.\\n\\n\\n\\n### Notifications\\n\\nIt has notification features that can ping you similarly as if a friend sent you a message.\\n\\n\\n\\n### Monetization\\n\\nYou are going to start to be able to monetize products through it.\\n\\n\\n\\n### Community\\n\\nYou can use it within a server with friends/colleagues, and unlock a better user experience.\\n\\n\\n\\n### Standardization\\n\\nThe product can work similarly on multiple chatting platforms. By keeping the same method of interaction / commands, the user is allowed to pick their favourite chatting platform or even use it in more than 1.\\n\\n\\n\\n### Accessibility\\n\\nThese chatting platforms are developed for all devices and operating systems, making it a very powerful distribution system.\\n\\n\\n\\n## Why Finance?\\n\\nI\u2019ve spoke with over 100 people in the financial world in 2022. Over 50 are Bloomberg users. From those, 90% agree that their chatting feature is the most attractive feature \u2014 some of them going further and saying that that is the reason why they pay for it.\\n\\nBut what if you didn\u2019t need to pay $26 k / year for such feature. What if you could pay to have access to servers with big names in the industry? Or what if you could create your own servers? What if while you were talking with Cathie Wood about ARK performance, you could also access financial data from ARK to back up your arguments? All this while not leaving the chat.\\n\\nThis is the reason why I believe that financial chatting bots will become popular in 2023. And [OpenBB Bot](https://openbb.co/products/bot) will be leading that wave.\\n\\nTry it out for free on [OpenBB Discord server](https://openbb.co/discord) by using a command such as `/chart TSLA` and let me know what you think."},{"id":"firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","metadata":{"permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.md","source":"@site/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.md","title":"Firing sucks. How to avoid doing so by hiring A players.","description":"Firing is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment.","date":"2023-01-02T00:00:00.000Z","tags":[{"inline":true,"label":"Hiring","permalink":"/blog/tags/hiring"},{"inline":true,"label":"Management","permalink":"/blog/tags/management"},{"inline":true,"label":"A Players","permalink":"/blog/tags/a-players"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Career Advice","permalink":"/blog/tags/career-advice"}],"readingTime":18.91,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","title":"Firing sucks. How to avoid doing so by hiring A players.","date":"2023-01-02T00:00:00.000Z","image":"/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.png","tags":["Hiring","Management","A Players","OpenBB","Career Advice"],"description":"Firing is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment."},"unlisted":false,"prevItem":{"title":"Financial chat bots are underrated, and here\u2019s why.","permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why"},"nextItem":{"title":"How ChatGPT allowed me to leverage Twitter API 10x faster","permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster"}},"content":"
\\n  \\n
\\n
\\n\\nFiring is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn 2022, [OpenBB](http://openbb.co/) grew to 20 people. But amongst all of our hiring, we also had to let some people go.\\n\\nBefore 2022, I had never fired anyone in my life but in my new role, I had to learn how to do it. If you\u2019re a manager, you know that this is the hardest part of the job.\\n\\nHaving that said, I wanted to use my Christmas holidays to understand how we can avoid letting people go. For this, I needed to start from the beginning and improve our overall hiring process.\\n\\nThis blogpost will be highly based on the book **\u201cWho: The A Method for Hiring\u201d by Geoff Smart and Randy Street**, which I highly recommend.\\n\\n## A method for hiring\\n\\nWhat is an A player? _A candidate who has at least a 90 percent chance of achieving a set of outcomes that only the top 10 percent of possible candidates could achieve.\\n\\nIn this post, I will go over the steps to get an A team.\\n\\n\\n\\n## Scorecard\\n\\nThis is a document that describes the mission for the position, outcomes that must be accomplished, and competencies that fit with both the company culture and the role.\\n\\nThis is an example of what a scorecard should look like:\\n\\n\\n\\nLet\u2019s go through each of the sections in this document.\\n\\n### Mission\\n\\nThe mission is an executive summary of the job\u2019s core purpose. It boils the job down to its essence so everybody understands why you need to hire someone in this role.\\n\\nThe book talks about how you should avoid hiring a generalist. In my opinion, it depends on the stage of the company. At OpenBB, we are able to ship fast with a small team because we have a lot of generalists that are A players. However, finding a generalist A player is a much harder task than finding an A player specialist. Here, we benefit from having an open source project, since we get to build with candidates before we hire them.\\n\\n**How to:** _Develop a short statement of one to five sentences that describe why a role exists._\\n\\n### Outcomes\\n\\nDescribes what a person needs to accomplish in a role.\\n\\n> _\u201cWhile typical job descriptions break down because they focus on activities, or a list of things a person will be doing, scorecards succeed because they focus on outcomes, or what a person must get done.\u201d_\\n\\n
\\n\\n**How to:** _Develop 3 to 8 specific objective outcomes that a person must accomplish to achieve an A performance, ranked by order of importance._\\n\\n### Competencies\\n\\nDefine how you expect a new hire to operate in the fulfilment of the job and how they can achieve their objectives. What competencies really count?\\n\\n#### Ensure behavioural fit\\n\\nCritical competencies for A players are: Efficiency, honesty/integrity, organization, aggressiveness, follow-through, intelligence, analytical skills, attention to detail, persistence, proactivity.\\n\\nOthers may include: Ability to hire A players, ability to develop people, flexibility/adaptability, calm under pressure, strategic thinking/visioning, creativity/innovation, enthusiasm, work ethic, high standards, listening skills, openness. to criticism and ideas, communications, team work and persuasion.\\n\\n#### Ensure organizational fit\\n\\nEvaluating cultural fit begins with evaluating your company\u2019s values against the ones of the candidate.\\n\\nRecently, at OpenBB, I asked everyone to share with me a list of values that we currently had and they were proud of, and/or values that they would like to use instead. In a startup, where the pace is incredibly fast and the team is in constant change, I strongly believe values change over time. So I looked at everyone\u2019s inputs, and summarized them into the following OpenBB values: **Autonomy and Ownership, Innovation and Excellence, Transparent and Trustworthy, Diversity and Inclusion, Purpose and Passion, User Focused and Community Oriented.**\\n\\n**How to:** _Identify as many role-based competencies that you think are appropriate to describe the behaviors that someone must demonstrate to achieve the outcomes. Next, identify 5 to 8 competencies that describe your culture and place those on every scorecard._\\n\\n### From scorecard to strategy\\nThe beauty of a document like this is that they become the blueprint that links the theory of strategy to the reality of execution. They translate your business plans into role-by-role outcomes, create alignment among your team, unify your culture and ensure people understand your expectations.\\n\\nIn addition, they allow you to monitor employee progress over time in your annual review system and to rate your team as part of their talent review progress.\\n\\n**How to:** _Pressure-test your scorecard by comparing it with the business plan and scorecards of the people who will interface with the role. Ensure that there is consistency and alignment. Then share the scorecard with relevant parties, including peers and recruiters._\\n\\n## Source\\n\\nSystematic sourcing before you have slots to fill ensures you have high-quality candidates waiting when you need them.\\n\\n### Referrals from your professional and personal networks\\n\\nCreate a list of the ten most talented people you know and commit to speaking with at least one of them per week for the next ten weeks. At the end of each conversation ask \u201cWho are the most talented people you know?\u201d. Continue to build your list and continue to talk with at least one person per week. \u201c_Of all the ways to source candidates, the number one method is to ask for referrals from your personal and professional networks_\u201d.\\n\\n### Referrals from your employees\\n\\nAdd sourcing as an outcome on every scorecard for your team. Encourage employees to ask people in their networks. Offer a referral bonus. In-house referrals often provide better-targeted sourcing, this is because employees already know our needs and culture.\\n\\n### Deputizing friends of the firm\\n\\nConsider offering a referral bounty to select friends of the firm. It could be as inexpensive as merchandise or as expensive as a significant cash bonus. When talking with someone new at a party or a VC, always ask \u201c_who do you know who might be a good fit for my company?_\u201d\\n\\n### Sourcing system\\n\\nCreate a system that (1) captures the names and the contact information on everybody you source and (2) schedules weekly time on your calendar to follow up. Try to spend 30 minute every week sending messages or having calls with candidates from this database of A players.\\n\\n### Hiring external recruiters or hiring recruiting researchers\\n\\nThe book speaks about both, but from my experience of having an open company with an exciting mission that builds in public, these have not been relevant to us yet.\\n\\n## Select\\n\\nCreate a series of structured interviews which build on each other so you can rate your scorecard.\\n\\n### Screening Interview\\n\\nShort, phone-based interview designed to clear out B and C players from your roster of candidates.\\n\\n1. **What are your career goals?** If no goals echo your own website goals, screen them out. Ideally candidate will speak with passion and energy about their goals which are aligned with the role.\\n\\n2. **What are you really good at professionally?** Make sure that with the list of strengths, there are always examples to backup the claim. Ensure that those strengths are relevant to the competencies required in the scorecard, if not, screen them out.\\n\\n3. **What are you not good at or not interested in doing professionally?** Ignore strengths disguised as weakness. Ask again \u201cwhat are you really not good at or not interested in doing?\u201d, talented people will catch the hint. If you\u2019re still struggling to get a proper answer, put the fear of a reference check into the person \u2014 \u201cif you advance to the next step in our process, we will ask for your help in setting up some references. (\u2026) What would these references say are something things you are not good at or not interested in?\u201d\\n\\n4. **Who were your last five bosses, and what would they each rate your performance on a scale of 1\u201310 WHEN we talk to them?** The word \u2018when\u2019 is the key to unlock the truth. A rating of 7 is neutral, we are looking for 8 and above. After the rating answer always press for details.\\n\\n
\\n\\nIf you are happy with the interview so far, conclude the call by offering the candidate an opportunity to ask questions. Otherwise just thank them for their time.\\n\\n**Tips:**\\n\\n- Always compare the person\u2019s strengths with the ones on the scorecard.\\n- When in doubt, there\u2019s no doubt. You need to have the feeling that you have found the one.\\n- Get curious: What, How, Tell me more. Keep using this framework until you are clear about what the person is really saying.\\n- Hit the gong fast. If an answer automatically rules out a candidate, just end up the interview earlier and use your precious time to focus on A players.\\n\\n### Who to Interview\\n\\nChronological walk-through of a person\u2019s career.\\n\\nYou can begin by asking about the highs and lows of a person\u2019s educational experience to gain insight into their background. After this, ask them 5 simple questions for each job they had in the past.\\n\\n#### What were you hired to do?\\n\\nYou are trying to discover what their scorecard might have been if they had one for that role. Ask them \u201chow was your success measured in the role? What was the mission and key outcomes? What competencies mattered?\u201d.\\n\\n#### What accomplishments are you most proud of?\\n\\nIdeally, candidates will tell you about accomplishments that match the job outcomes they just described to you. Even better if they match the ones of the scorecard for the position you are trying to fill.\\n\\nNote: _A players tend to talk about outcomes linked to expectations, B and C players talk generally about events, people they met, or aspects of the job they liked without ever getting into results._\\n\\n#### What were some of the low points during that job?\\n\\nPeople can be hesitant to share their lows at first. Keep reframing the question over and over until the candidate gets the message. E.g. \u201c_What went really wrong? Biggest mistake? done differently? parts you didn\u2019t like? peers stronger than you?_\u201d\\n\\n#### Who were the people you worked with?\\n\\n- **What was your boss\u2019s name and how do you spell that?**\\n\\nForcing candidates to spell the name out no matter how common it might be sends a powerful message: you are going to call, so they should tell the truth. This is referred as the \u201cthreat of reference check (TORC)\u201d.\\n\\n- **What was it like working with them?**\\n\\nIdeally, you expect high praise for their bosses and how they received mentoring and coaching from them over the years. A neutral answer will sound somewhat more reserved \u2014 not positive nor negative.\\n\\n- **What WILL they tell me about your biggest strengths and areas to improve?**\\n\\nUse \u201cwill\u201d instead of \u201cwould\u201d so candidates know you mean business, and are therefore, more likely to tell you the truth since you will learn it from reference calls anyways. Dig in as much as you can.\\n\\n- **How would you rate the team you inherited on an A, B, C scale? What changes did you make? Did you hire anybody? Fire anybody? How would you rate the team when you left it on A,B,C scale.**\\n\\nThis is applicable to managers. And allows you to understand how they approach building a strong team. Do they accept the hand they have been dealt with or do they make changes to make a better hand? What changes do they make? How long does it take?\\n\\nApply TORC here too: _\u201cWhen we speak with team members of your team, what will they say were your biggest strengths and weaknesses as manager?\u201d_\\n\\n#### Why did you leave that job?\\n\\nWas the candidate promoted, recruited or fired from each job? How did they feel about it? How did their boss react to the news? E.g. A players are highly valued by their bosses.\\n\\nGet curious. Find out why and stick with it until you have a clear picture of what actually happened.\\n\\n**Conducting an effective who interview**\\n\\n- The hiring manager should conduct this interview. They own the hire, and are the ones who will suffer the consequences of making a mistake. Their career and job happiness depend on finding A players.\\n- Conduct an interview with a colleague (e.g. someone from HR, another manager or member of your team), this allows you to focus on questions and someone else to take notes.\\n- Kick off the interview by setting expectations, e.g. _\u201cWe are going to walk through each job you have held, for each job I am going to ask you five core questions. At the end we will discuss your career goals and aspirations and you will have a chance to ask me questions. If we mutually decide to continue, we will conduct reference calls to complete the process\u201d._\\n\\n**Master tactics**\\n\\n1. **Interrupting.** You have to interrupt the candidate, there is no avoiding it. At least once every 3/4 minutes. Smile broadly, match their enthusiasm level, and use reflective listening to get them to stop talking without demoralizing them.\\n2. **The three P\u2019s.** This helps you understand how valuable an accomplishment was in any context. (1) How did the performance compare to the previous year\u2019s performance; (2) How did your performance compare to the plan?; (3) How did your performance compare to that of peers?\\n3. **Push versus Pull.** People who perform are generally pulled to greater opportunities. People who perform poorly are often pushed out of their jobs.\\n4. **Painting a picture.** You\u2019ll only understand what a candidate is saying when you can literally see a picture of it in your mind. Always try to put yourself in their shoes.\\n5. **Stopping at the Stop signs.** Look for shifts in body language and other inconsistencies. \u201cWe did great in that role\u201d while shifting in their chair, looking down and covering their mouth may be a stop sign. When that happens, get curious and understand how \u201cgreat\u201d they actually did. What was actually their contribution?\\n\\n### Focused Interview\\n\\nGetting to know more. This is NOT another Who interview. It provides the chance to invite other team member to get their opinion, but the script should be followed. Think of this interview as the \u201codds enhancer\u201d to truly focus on the outcomes and/or competencies on the scorecard.\\n\\n1. The purpose of this interview is to talk about [specific outcome or competency]\\n2. What are your biggest accomplishments in this area during your career\\n3. What are your insights into your biggest mistakes and lessons learned in this area?\\n\\n
\\n\\nDon\u2019t be scared to use the \u201cWhat? How? Tell me more\u201d framework until you understand what the person did and how they did it.\\n\\nFeel free to have multiple shorter focused interviews to understand particular outcome/competencies.\\n\\n**Double-check the cultural fit.** Final gauge on the cultural fit \u2014 **critical!** Include competencies and outcomes that go beyond the specifics of the job to embrace the larger values of your company.\\n\\n### Reference Interview\\n\\nTesting what you learned. Don\u2019t skip the references!\\n\\n1. Pick the right references. Review your notes from the Who interview and pick the bosses, peers, and subordinates with whom you would like to speak. Don\u2019t just use the reference list the candidate gives you.\\n2. Ask the candidate to contact the references to set up the calls. Some companies have a policy that prevents employees from serving as references, so you can increase your chances of talking with a reference if the candidate sets this up.\\n3. Conduct the right number of reference interviews. The book recommends 3 past bosses, 2 peers/customers and 2 subordinates.\\n\\n
\\n\\n**Reference interview guide:**\\n\\n1. **In what context did you work with the person?** Conversation starter and memory jogger.\\n2. **What were the person\u2019s biggest strengths?** Ask for multiple examples to put strengths and development areas into context. Don\u2019t forget to get curious by using \u201cWhat? How? Tell me more\u201d framework to clarify responses.\\n3. **What were the person\u2019s biggest areas for improvement back then?** The wording \u2018back then\u2019 liberates the reference to talk about weaknesses that existed in the past. \u201cIn truth, we believe, people don\u2019t change that much. People aren\u2019t mutual funds. Past performance really is an indicator of future performance.\u201d\\n4. **How would you rate their overall performance in that job on a 1\u201310 scale?** What about their performance causes you to give that rating? Remember that 6 is really a 2. How does this rating compare with what the candidate said in advance? Wide discrepancy is alarming.\\n5. **The person mentioned that they struggled with ____ on that job. Can you talk more about that?** Test something the candidate told you by framing it as a question for the reference. E.g. \u201cthe person mentioned that you MIGHT SAY he was disorganized. Can you tell me more about that?\u201d the wording is again very important as \u2018might say\u2019 suggests to the reference that they have permission to talk about the subject because the candidate raised it.\\n\\n
\\n\\nThese questions follow the same pattern as the other interviews. This makes it very easy to merge what you hear with what you have already learned about a candidate.\\n\\n**Tips:**\\n\\n- **Avoid accepting a candidate\u2019s reference list at face value.** E.g. either use your own network for gathering objective unbiased data or try to reach out to subordinates or people two levels below who interacted with the candidate to get a more honest answer.\\n- **Hearing or understanding the code for risky candidates.** Be able to read between lines. People don\u2019t like to give negative reference, so your best defense is to pay close attention to what people say and how they say it. Examples of bad signs: If they just confirm dates of employment, um\u2019s and er\u2019s is hesitation, absence of enthusiasm (faint praise).\\n\\n### Decide who to hire\\n\\n**Skill-Will Bull\u2019s Eye**\\n\\nDoes somebody\u2019s skill (what they can do) and will (what they want to do) match your scorecard? This is a person\u2019s skill-will profile.\\n\\n\\n\\nYou should have plenty of data at this stage to make this assessment.\\n\\n- **Skill has to do with a candidate\u2019s ability to achieve the individual outcomes on your scorecard.** If you believe a candidate has a 90% or better chance to achieve a certain outcome based on the data gathered, rate them an A, otherwise a B or a C. Repeat for each outcome.\\n- **Will has to do with the motivations and competencies a candidate brings to the table.** For each competency, does the data suggest there is a 90% or better chance that the candidate will display that competency? If so rate them an A, otherwise a B or C. Repeat for each competency.\\n\\nAn A player is someone whose skill and will match your scorecard. Anything less is a B or C, no matter the experience or seeming talent level.\\n\\n**Red Flags: When to dive beneath the surface**\\n\\nThese flags may not be deal killers, but they are likely to signal that there is something worth exploring beneath the surface:\\n\\n- Does not mention past failures\\n- Exaggerates their answers\\n- Takes credit for the work of others\\n- Speaks poorly of past bosses\\n- Cannot explain job moves\\n- People most important to the candidate are unsupportive of a change\\n- For managerial hires, never had to hire or fire anybody\\n- Seems more interested in compensation and benefits than in the job itself\\n- Tries too hard to look like an expert\\n- Self-absorbed\\n\\nMore behavioral warning signs:\\n\\n- Winning too much\\n- Adding too much value\\n- Starting a sentence with \u2018no\u2019, \u2018but\u2019, or \u2018however\u2019\\n- Telling the world how smart we are\\n- Making destructive comments about previous colleagues\\n- Blaming others\\n- Making excuses\\n- The excessive need to \u2018be me\u2019\\n\\n**How to decide:**\\n\\n1. Take out your scorecards that you have completed on each candidate\\n2. Make sure you have rated all of the candidates on the scorecard. If you have not given each candidate an overall A, B or C grade, do so now. Make any updates you need to based on the reference interviews. Look at the data, consider the opinions and observations of the interview team, and give a final grade.\\n3. If you have no A\u2019s, then restart your process and the second step: source.\\n4. If you have one A, decide to hire that person.\\n5. If you have multiple A\u2019s, then rank them and decide to hire the best A among them.\\n\\n## Sell\\n\\nOnce candidates pass the selection, persuade them to join. The key to successfully selling your candidate to your company is putting yourself in their shoes.\\n\\n### Five F\u2019s of selling\\n\\nThere are 5 areas that candidates tend to care about, make sure to address each of these 5 areas until you get the person onboard.\\n\\n1. **Selling Fit:** This ties together the company\u2019s vision, needs and culture with the candidate\u2019s goals, strengths and values.\\n2. **Selling Family:** Takes into account the broader trauma of changing jobs.\\n3. **Selling Freedom:** The autonomy the candidate will have to make their own decisions.\\n4. **Selling Fortune:** Reflects the stability of your company and the overall financial upside.\\n5. **Selling Fun:** Describes the work environment and personal relationships the candidate will make.\\n\\n### Five waves of selling\\n\\nSelling should be something that happens throughout the entire hiring process. In particular, there are five distinct phases that merit increased selling effort:\\n\\n1. When you source\\n2. When you interview\\n3. The time between your offer and the candidate acceptance\\n4. The time between the candidate\u2019s acceptance and their first day\\n5. The new hire\u2019s first one hundred days on the job\\n\\n### Persistent pays off\\n\\nOnce you have identified the right candidate, you must be persistent and do whatever you can to sign the deal.\\n\\n### How to: sell A Players\\n\\n1. Identify which of the five F\u2019s really matter to the candidate.\\n2. Create and execute a plan to address the relevant F\u2019s during the five waves of selling.\\n3. Be persistent. Don\u2019t give up until you have your A player on board.\\n\\n## Conclusion\\n\\nIn a more simplistic image, this is what the A method boils down too.\\n\\n\\n\\nI really enjoyed reading this book and I am taking a lot of these learnings to improve the hiring processes at OpenBB."},{"id":"how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","metadata":{"permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.md","source":"@site/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.md","title":"How ChatGPT allowed me to leverage Twitter API 10x faster","description":"Leveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates.","date":"2022-12-11T00:00:00.000Z","tags":[{"inline":true,"label":"ChatGPT","permalink":"/blog/tags/chat-gpt"},{"inline":true,"label":"Twitter API","permalink":"/blog/tags/twitter-api"},{"inline":true,"label":"Tweepy","permalink":"/blog/tags/tweepy"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"}],"readingTime":2.4,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","title":"How ChatGPT allowed me to leverage Twitter API 10x faster","date":"2022-12-11T00:00:00.000Z","image":"/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.png","tags":["ChatGPT","Twitter API","Tweepy","Python","Programming"],"description":"Leveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates."},"unlisted":false,"prevItem":{"title":"Firing sucks. How to avoid doing so by hiring A players.","permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players"},"nextItem":{"title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla"}},"content":"
\\n  \\n
\\n
\\n\\nLeveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nFor a while now, users have been asking for adding real-time financial news on [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\nSince OpenBB Terminal is a command line interface for the world\u2019s financial data, and there is no threading going on \u2014 there was never a very straightforward way to do this.\\n\\n**Until today.**\\n\\nAfter recalling [this tweet](https://twitter.com/elonmusk/status/1591121142961799168?s=20&t=j-cjTu-XA9SNcY8PBrbUnQ) from Elon earlier in November, I realized that I\u2019ve been using Twitter for news substantially more than MSM.\\n\\n\\n\\nSo, my next train of thought was; What if I was able to somehow display the latest tweets from Twitter accounts that I trust. In particular, accounts that have up-to-date information and usually mention the words \u201cJUST IN\u201d or \u201cBREAKING\u201d. E.g. [@WatcherGuru](https://twitter.com/WatcherGuru) or [@unusual_whales](https://twitter.com/unusual_whales).\\n\\nBy doing this, I could then use the bottom of the OpenBB Terminal to highlight the news. An example of this is below:\\n\\n\\n\\n## Coding and ChatGPT\\n\\nThe next step for me was to implement the code!\\n\\nFirst, I needed to understand how I could have access to the last tweet of a specific user account. I already had a Twitter API account created, which meant I already had the key, token and secrets, therefore, I just needed to read documentation to understand how to use the Twitter API. Hence, I started reading [Twitter\u2019s developer documentation](https://developer.twitter.com/en/docs/twitter-api/tweets/search/api-reference/get-tweets-search-recent).\\n\\nThe day before I had been playing around with ChatGPT. And like everyone else, I was very impressed. One of the things that surprised me the most was how good it was at outputting working code with an explanation along the lines.\\n\\nSo, while I was reading the documentation, I was thinking \u201cI wish there was a way for me to just be able to get the last N tweets of an account without needing to dig in the developer documentation\u201d. Could ChatGPT be the answer?\\n\\nSo I tried\u2026\\n\\n\\n\\nThis was already amazing. But I\u2019m lazy and didn\u2019t want to copy all the cells individually to put it into a Jupyter notebook, so asked ChatGPT to provide the code output as a single block. I wasn\u2019t convinced it was going to work. **But it did**.\\n\\n\\n\\n\u2026 it just worked. \ud83e\udd2f\\n\\nAfter that, I needed the timestamp associated with the tweet, to see how old it was. As usual, I started looking into [Tweepy documentation](https://docs.tweepy.org/en/latest/authentication.html#twitter-api-v2).\\n\\n**Ups, what was I doing again?**\\n\\nAfter a couple of seconds, I went onto ChatGPT and asked how I could get the timestamp of a tweet using Tweepy library.\\n\\n**And \ud83e\ude84, it worked again!!!**\\n\\n\\n\\nOne thing that is for sure: ChatGPT is going to truly disrupt many industries. And I will be here for it.\\n\\nPS: The PR with this addition is in development [here](https://github.com/OpenBB-finance/OpenBBTerminal/pull/3757)."},{"id":"how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","metadata":{"permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.md","source":"@site/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.md","title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","description":"How I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal.","date":"2022-12-07T00:00:00.000Z","tags":[{"inline":true,"label":"Machine Learning","permalink":"/blog/tags/machine-learning"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Academia","permalink":"/blog/tags/academia"},{"inline":true,"label":"ICMLA","permalink":"/blog/tags/icmla"},{"inline":true,"label":"NURVV Run","permalink":"/blog/tags/nurvv-run"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":10.895,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","date":"2022-12-07T00:00:00.000Z","image":"/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.png","tags":["Machine Learning","Data Science","Academia","ICMLA","NURVV Run","Open Source"],"description":"How I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal."},"unlisted":false,"prevItem":{"title":"How ChatGPT allowed me to leverage Twitter API 10x faster","permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster"},"nextItem":{"title":"The future of finance with open source and AI","permalink":"/blog/the-future-of-finance-with-open-source-and-ai"}},"content":"
\\n  \\n
\\n
\\n\\nHow I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/step-detection-ML).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOne year ago, I raised $ 8.8 millions to build [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) full time. But since I was working at a startup in the UK, I had a 3 month notice period.\\n\\nDuring that time I worked on documenting pretty much everything I had been working on, BUT that felt short. I felt like the data that came out of our [NURVV Run](http://www.nurvv.com/) product could be used with a machine learning algorithm in order to detect a foot strike quite efficiently.\\n\\n\\n\\nSo I asked my company:\\n\\n> _If I use my spare time to work on this paper will you sponsor me if I get accepted?_\\n\\n
\\n\\n**My goal was to increase the visibility of our product in academia.** And given I spent some time reading papers in the area, I knew that what I had in mind had a shot at working.\\n\\n**My background is not data science, and this was my first time \u201cofficially\u201d working on machine learning.** I wasn\u2019t 100% sure that my idea would work, but after spending more than 1 year at the company, I knew how the data behaved. I thought I could build an algorithm robust enough to be able to detect a foot strike more efficiently than what others had.\\n\\nAfter some time, the company accepted my proposal, and between the time to decide to apply to [International Conference on Machine Learning and Applications (ICMLA)](https://www.icmla-conference.org/icmla21/) and getting ready to start working on the paper, there was 1 week left.\\n\\nI thought that this window was rather tight given that I had to clean the data, work on the entire code behind the paper from idea to implementation, and write the damn paper. **I knew this was gonna be tight, but oh boy.** I had one of the harshest weeks of my life. I barely slept for 7 straight days, and skipped the company team event in order to make it through the deadline.\\n\\nBecause of that, I will go into what happened at each step along the way with images. I will skip the cleaning data and boring parts, don\u2019t worry. If you just want to read the final paper, you can find it here: [\u201dStep Detection using SVM on NURVV Trackers\u201d](https://ieeexplore.ieee.org/abstract/document/9680024).\\n\\nAlso, if you\u2019ve been following me, you know how much I love open source. Owing to that I open source the code behind the project [here](https://github.com/DidierRLopes/step-detection-ML).\\n\\n## Exploratory Data Analysis\\n\\nThe Nurvv trackers have an **Inertial Measurement Unit (IMU) tracks linear acceleration (accelerometer) and rotational rate (gyroscope)**. Sometimes it also contains a magnetometer. And Nurvv gave me access to 6 runs from 6 different runners.\\n\\nMy first step was to look into how this data looked. On the left you can see the acceleration (m/s\xb2) and the angular velocity (rad/s).\\n\\n\\n\\nI knew that our **IMU had a sampling rate of 1125 Hz** (which means that each data point gets sampled at approximately every 888.89\u03bcs) and **this was critical in order to detect the oscillations that occur when a foot strike occurs** (i.e. impact of the foot on the floor makes the IMU oscillate). Thus I zoomed in the zone of impact and used a scatter plot to understand if we were \u201cmissing\u201d information.\\n\\n\\n\\nI found it interesting that **the distance between the samples were larger at the time of the impact**. So I plotted the IMU accelerometer data and the IMU gyroscope data in a 3D plot interactively as a function of time (below you can see a snapshot).\\n\\n\\n\\nFrom here it was interesting to note that when the foot is in the air, the samples are somehow concentrated (darker blue), whereas when a step occurs (more sparse) they behave erratically. The plot above was snapshotted with 3 steps that occurred.\\n\\nFrom that 3D plot I had the intuition that by utilizing a **principal component analysis (PCA**)**, I could reduce the dimensionality without losing much information. The result is shown below,\\n\\n\\n\\nThis made me think that I could use a **support vector machine (SVM)** in order to detect whether a foot strike has occurred or not. And what I was most excited about it was:\\n\\n- **This model isn\u2019t time-dependant.** Meaning that it would be fascinating to be able to predict whether a step occurred or not without the notion of time, but the current IMU data.\\n- We can develop an SVM model for each runner style. Then create an **ensemble model with hard voting** which allowed for the model that has seen more similar data, to be more confident in the classification of foot strike vs not foot strike.\\n\\nBut this was all a theory, I needed to prove it.\\n\\nThe first issue I had was: **SVM is a supervised learning model**. This meant that for the sampling data I was providing the model, I would have to classify whether those samples corresponded to a foot strike or not.\\n\\n**The issue?** Although the product had **force sensitive resistors (FSR)** in the insoles, I didn\u2019t have access to the samples that corresponded with these IMU samples.\\n\\nSo I knew that I would have to classify the data myself. Manually would have been a nightmare and not reliable enough, so I needed to build an algorithm that could classify the data quite reliably. **Signal processing theory, here I go.**\\n\\n### Labelling data for a supervised learning problem\\n\\n1. Get the raw IMU samples (accelerometer and gyroscope)\\n2. Do the difference in magnitude between the accelerometers samples and then the gyroscope samples\\n3. Apply root sum squared to the magnitude difference of accelerometer data, and then similarly to gyroscope data\\n4. Standardize the accelerometer data and the gyroscope data. This is so the data can be somehow compared with each other since the magnitude varies as one represents linear acceleration and the other angular rate.\\n5. Do the average between these 2 signals. This makes the data more robust.\\n6. Finally, apply a convolution to the resulting signal with a rectangular pulse. This allows to remove \u201cdrops\u201d from the signal and ensures a smoother signal.\\n\\n
\\n\\nBelow you can see the formulas and signal changes that were made in order to obtain the final result:\\n\\n\\n\\n\\n\\nAfter this, I selected a sensible value of 0.3 to be used as a threshold on the resulting signal to classify step vs no-step.\\n\\n\\n\\nI applied the difference between each first foot strike detected in order to make sure that there was no missed step. As you can see above the stride time is around 700ms which is what is expected of a runner jogging.\\n\\nSomeone might be wondering; If this gives such a great result, why did I need machine learning in the first place? **The reason is because standardization and convolution (steps 4 and steps 6) are a post-processing signal technique.** Therefore, it cannot be deployed in running time, and relies on data that happens in the future.\\n\\nFor illustration purposes, here is how the initial raw IMU data behaves against the labelling from signal processing approach (red background means no step, while green background means step).\\n\\n\\n\\n## Support Vector Machine for classification\\n\\nFor the model, SVM was selected because:\\n\\n- It works well with high dimensional data (6 IMU samples) because it only uses a few of these points (called support vectors) to create this hyperplane (decision boundary) between classes.\\n- SVM is ideal for binary classification problems.\\n- RBF kernel allows to handle non-linear data.\\n\\nThis is the type of classification that SVM is capable of (this is the raw acceleration data with a PCA applied, and the SVM classification on the background for a model that was trained using that same data).\\n\\n\\n\\n### C and gamma hyperparameters\\n\\n- Given each dataset is rather large to perform **grid search optimization** on C and gamma, a subset of each of the datasets is used to extract these parameters.\\n- Each dataset subset is now split: 80% for training data and 20% for validation.\\n- Thus, 80% of the data subset is used to apply SVM with different combinations of C and gamma over a 2D grid. The remaining 20% is used to test the logistic loss and assess optimal hyperparameters.\\n\\n### Training and testing\\n\\n- 80% of data is used for training and 20% is used for testing.\\n- Although the testing is done **out-of-sample**, given the nature of the data (where it comes from the same distribution) it is almost as if it was an **in-sample**.\\n- In our case this is ideal as we want each model to perform very well on its own dataset. We want each model to generalize well for that very specific type of data (runner style, speed and terrain).\\n- A 5-sample moving average is applied before assessing the classification of our model, this is to remove spurious samples. A small window needs to be selected to not introduce a delay in the recognition of a step.\\n- Since our data set is imbalanced (i.e. there are more samples being no-step than step samples) we\u2019ll use **Geometric Mean (G-Mean) evaluation score**, since this measure tries to maximize the accuracy on each of the classes while keeping their accuracies balanced.\\n\\n### Result\\n\\nIn the same dataset where we trained our SVM, we were able to achieve a G-Mean of 0.9645. This is rather expected since this is a powerful model and it was trained on that same data.\\n\\n\\n\\nFrom the graph above this result is very positive given that the mislabelling always occurs at the boundary of a step / no-step detection. And since the sampling occurs very fast, we have some margin of error.\\n\\n## Ensemble SVM model architecture\\n\\nThis model as expected had a poor performance in an unseen dataset. This is normal as the data came from a different runner, running at a different speed in a different terrain. Thus, in order to create a more robust model, we built this ensemble SVM model architecture.\\n\\n\\n\\nEach dataset has the signal processing technique applied in order to obtain the labelling. With this labels, an SVM model can be trained.\\n\\nThen, an **unseen dataset** (not used for training) will be used as input for all the trained SVM models. I.e. each input (3 accelerometer samples and 3 gyroscope samples) will be given to each SVM model which will output 0 or 1 to denote no-step or step, respectively.\\n\\nMy rationale there was: _I could do a major voting approach, BUT because of how I trained the data. It could happen that one of the models had the sample being very inside the boundary, whereas 2 others had it just outside, and the later would win. This is not what I was looking for._\\n\\nBecause of this boundary approach associated with SVMs, I knew that although SVM doesn\u2019t provide probability estimates directly, these could be calculated. So I took advantage of that. And used that probability estimate to select whether the input was considered a stop or not. My rationale was: the model that has seen more similar IMU samples is likely to have a higher confidence in their output and as output they will have what I provided as a label in advance.\\n\\nFinally, I applied a **5-sample moving average** to the step (1) / no-step (0) output and round the value to be classified as step and no-step. This allowed to remove spurious samples.\\n\\n### Results\\n\\nThe prediction for a single SVM was extremely accurate because the model was trained on data samples from that same run (i.e. distribution). On the other hand, the ensemble prediction didn\u2019t run on data from that distribution, hence, making this problem much more complex. However, even with that constraint, a G-Mean of 0.8756 was still achieved.\\n\\n\\n\\n## Future work\\n\\n- Employ the data coming from the \u201dsmart\u201d insoles as an alternative ground-truth for determining step versus no-step conditions.\\n- The diversity of the data set can also be expanded to account for more surfaces, running speeds and styles.\\n- Explore whether the characteristics of the PCA plot of IMU data can be used to categorize different running styles.\\n- The exploration of different classification algorithms for the step detection problem, e.g. applying a long-short term memory (LTSM) neural network algorithm to exploit the time-dependency between samples.\\n- Implement this proof-of-concept code on the production NURVV Run system, to test the prediction technique in a real-life scenario and consider computational time.\\n\\n## Final remarks\\n\\nThis was my first most technical blogpost where I went into details in how I wrote a ML paper that was accepted in a major conference in 1 week. Would love to know your thoughts on it.\\n\\nFeel free to check the full paper version here: https://ieeexplore.ieee.org/abstract/document/9680024"},{"id":"the-future-of-finance-with-open-source-and-ai","metadata":{"permalink":"/blog/the-future-of-finance-with-open-source-and-ai","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.md","source":"@site/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.md","title":"The future of finance with open source and AI","description":"The future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface.","date":"2022-12-04T00:00:00.000Z","tags":[{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Future","permalink":"/blog/tags/future"}],"readingTime":5.57,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-future-of-finance-with-open-source-and-ai","title":"The future of finance with open source and AI","date":"2022-12-04T00:00:00.000Z","image":"/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.png","tags":["Open Source","AI","Finance","Future"],"description":"The future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface."},"unlisted":false,"prevItem":{"title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla"},"nextItem":{"title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released"}},"content":"
\\n  \\n
\\n
\\n\\nThe future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis post will talk about my (very) u\u0336n\u0336biased opinion about the future of finance built on top of open source and AI.\\n\\n## Open Source platform\\n\\n\\n\\n### Data licensing vs Marketplace\\n\\nCurrent monopolies spend an enormous amount of cash on financial data licensing. There are dozens of different asset classes (stocks, options, crypto, NFTs, currencies, bonds, ETFs, mutual funds, \u2026) and these often vary based on geography. **That makes the overall investment research industry a very tough market to compete.** Startups cannot disrupt the space without a massive capital injection. This is also why startups usually focus on a certain asset class in a certain geography.\\n\\n**In my opinion, the only shot we have to disrupt incumbents is by not owning the data but becoming the infra layer between data sources and users.** _This is no different than Uber not owning cars, Airbnb not owning apartments or Deliveroo not owning restaurants._\\n\\n**This also has a great advantage which is being able to integrate new data sources very fast and easily.** Plus, owing to open source, anyone can add it. On the other hand, it\u2019s very unlikely that an incumbent will add data that you require. Plus, if they do, they will need to license the data and therefore decrease their margins \u2014 unless they increase the price to users.\\n\\n### Full-price bundle\\n\\nCurrent incumbents pricing is usually a complete bundled offering. **This means that regardless of what you are utilizing in terms of both breadth and depth, you pay the full price tag.** A good analogy is like a restaurant ONLY having a buffet when all you want is a bottle of water, or some chips. What happens is that a user ends up paying for data that they are not using.\\n\\nIn 2022, this is a very outdated take. Companies are looking to get leaner, and it doesn\u2019t make sense to pay for data that you aren\u2019t going to leverage. **Being the infrastructure between users and data sources allows you to create value to both**; Since users will have access to all the data they want and pay for the ones they use, and data sources will have access to a big pool of users and may not need to create a dashboard product to monetize their offerings.\\n\\n### Transparency & Customization\\n\\nCurrent incumbents have built several in-house financial models. **Although these are often customizable, their customization is typically limited.** That is because what is usually customizable are the values/weights, but not necessarily the formulas \u2014 that is kept hidden in their source code. This is an issue because that code cannot be validated and users cannot modify it.\\n\\nWith open source, the story is completely different. **Users can see every single line of code, and therefore not only audit the code quality but adapt the models/formulas to their own needs.** At the end of the day, there is no point in re-inventing the wheel for financial theory that has been around for decades.\\n\\nBy having the code open source, users can rely on the fact that these formulas have been validated/tested by thousands or millions of users and, therefore, there\u2019s a very low chance that these are wrong. **In addition, users are more secure because they can investigate the code and check/fix any vulnerabilities.**\\n\\n### Community\\n\\nOne of the best parts of open source is the integrated community that it creates. This attracts people from every background, gender or ethnicity. Such a pool of diversity tends to allow for better ideas and pushes a project further. With people from the community being able to contribute, this also drives innovation.\\n\\n[OpenBB](http://my.openbb.co/app/terminal/community-routines) has been driven a lot by the community so far. What started as a terminal mostly focused on stocks, soon evolved into including a broad range of datasets and considering several geographies. E.g. A contributor from Sweeden integrated Avanza API to the mutual funds menu that would only appear if users were looking into mutual funds from Sweden. This shows the power of community.\\n\\nHaving the platform be _open source_ is key.\\n\\n## GPT as the interface\\n\\n**One of the hedges that incumbents have is the fact that they have been around for a very long time and spent a lot on educating users about their product.** As a result, users are used to their platform. This makes them harder to switch to an unknown product. This is also why a product needs to be 10x better than competition for users to switch.\\n\\n**However, what if there was no learning curve?** What if you could use a product for the first time and knew how to access all the data without spending any time reading the documentation. **In essence, the educational incumbent advantage would become obsolete.**\\n\\nWith the new LLM advancements, such as [ChatGPT](https://chat.openai.com/chat). We are not far from this reality.\\n\\n\\n\\nPlus, if this is built on top of an open source project it means that the **community can help in improving the model** by providing more training data (e.g. provide a text as input and the corresponding command as output) or even confirm whether or not the chart that pops up was accurate. In addition, along with data sources you can imagine that the community could start contributing with new languages for the GPT model.\\n\\nYou can easily imagine that such interface would work well with a speech recognition model (something like [whisper](https://github.com/openai/whisper) but that allowed real-time).\\n\\n**This makes using a new investment research platform easy, but more importantly makes retrieving information much faster and efficient.**\\n\\n## GPT to build investment research reports\\n\\nOne of the new features that were announced with [OpenBB Terminal 2.0](https://openbb.co/blog/openbb-terminal-2-acai) was the automated reports generation that utilizes [papermill](https://github.com/nteract/papermill) to leverage jupyter notebook templates.\\n\\n\\n\\nAs it stands creating one of these notebook templates requires some coding skills and reading [OpenBB documentation](https://docs.openbb.co/) to understand how to retrieve the data of interest providing the correct function and necessary arguments.\\n\\n**But, for a second, imagine if you could build these notebook templates with almost no-code?**\\n\\nThe proof-of-concept below in combination with the automated report generation should allow you to further understand the breakthrough that we may accomplish in the following few months.\\n\\n\\n\\n**My prediction is that open source + AI will disrupt the financial sector in the upcoming years.**\\n\\n[OpenBB](https://openbb.co/) will be leading that wave.\\n\\nThanks for reading!"},{"id":"bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","metadata":{"permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.md","source":"@site/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.md","title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","description":"OpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform.","date":"2022-11-29T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB Terminal 2.0","permalink":"/blog/tags/open-bb-terminal-2-0"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"ML","permalink":"/blog/tags/ml"},{"inline":true,"label":"SDK","permalink":"/blog/tags/sdk"}],"readingTime":1.725,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","date":"2022-11-29T00:00:00.000Z","image":"/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.png","tags":["OpenBB Terminal 2.0","Investment Research","Financial Data","AI","ML","SDK"],"description":"OpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform."},"unlisted":false,"prevItem":{"title":"The future of finance with open source and AI","permalink":"/blog/the-future-of-finance-with-open-source-and-ai"},"nextItem":{"title":"Sweepstake World Cup 2022 for your startup team","permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team"}},"content":"
\\n  \\n
\\n
\\n\\nOpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAlmost 2 years ago, I started building my own investment research platform. 2 months later I named it Gamestonk Terminal, made it open source and shared it on Reddit. The rest is history.\\n\\nSince then, we surpassed [17,800 stars on Github](https://github.com/OpenBB-finance/OpenBBTerminal). Raised $ 8.8 million in our seed round. Build a very competitive team and our OpenBB brand is now recognized by most in the financial space. You can read more about our story [here](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\n**Our mission to democratize investment research has not changed.** Over the past few months we have been heads down and building and today I\u2019m excited to share with you the announcement of OpenBB Terminal 2.0.\\n\\nThe headline is:\\n\\n> _OpenBB Terminal 2.0 is more than an application, it\u2019s a platform._\\n\\n
\\n\\nA summary:\\n- We are releasing OpenBB SDK which allows developers to use a single API to access the world\u2019s raw financial data in order to build their own products / dashboards.\\n\\nThe SDK will allow users to create report templates in a matter of minutes and run them for custom tickers at any time in a matter of seconds; Instead of spending hours and starting a report from scratch every single time. We envision a world where the community can share these and help each other at becoming better investors.\\n\\n\\n\\n- We are also bringing a state-of-the-art AI / ML toolkit to the financial industry, to be used alongside all the data sources our platform has access to (stocks, crypto, NFTs, options, forex, ETFs, mutual funds, macro economic data and even alternative data).\\n\\n\\n\\nFor more information, you can read our announcement here: https://openbb.co/blog/openbb-terminal-2-acai\\n\\nOr even better, watch the announcement [here](https://openbb.co/blog/openbb-terminal-2-event)!"},{"id":"sweepstake-world-cup-2022-for-your-startup-team","metadata":{"permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.md","source":"@site/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.md","title":"Sweepstake World Cup 2022 for your startup team","description":"In this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event.","date":"2022-11-26T00:00:00.000Z","tags":[{"inline":true,"label":"World Cup 2022","permalink":"/blog/tags/world-cup-2022"},{"inline":true,"label":"Startup Team","permalink":"/blog/tags/startup-team"},{"inline":true,"label":"Sweepstake","permalink":"/blog/tags/sweepstake"},{"inline":true,"label":"Team Building","permalink":"/blog/tags/team-building"},{"inline":true,"label":"Slack Bot","permalink":"/blog/tags/slack-bot"}],"readingTime":2.07,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"sweepstake-world-cup-2022-for-your-startup-team","title":"Sweepstake World Cup 2022 for your startup team","date":"2022-11-26T00:00:00.000Z","image":"/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.png","tags":["World Cup 2022","Startup Team","Sweepstake","Team Building","Slack Bot"],"description":"In this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event."},"unlisted":false,"prevItem":{"title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released"},"nextItem":{"title":"5 steps I used to change my job title in less than 1 year","permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAt [OpenBB](https://openbb.co/), the team puts in so much hard work for [our product](https://github.com/OpenBB-finance/OpenBBTerminal) that doing a team event is like a breath of fresh air. With the World Cup 2022 now taking place and more than half of the team being from Europe (where football is the main sport), we thought that it would be nice to run an OpenBB sweepstake.\\n\\nWe decided to offer a prize to the teams that end up on the podium. 1st place gets X, 2nd place gets Y and 3rd place gets Z - with $ X > $ Y > $Z.\\n\\nThe next step was to assign teams to each employee, so at the end of our all hands meeting we did just that. For that we used this free website: https://spinnerwheel.com/fifa-world-cup-sweepstake-generator.\\n\\nThis allowed us to spin the wheel of team members and then spin wheel of countries, and get a 1:1 match \u2014 it was quite funny to have everyone involved and see the reactions as the wheel was slowing down.\\n\\n\\n\\n**Most companies stop here.**\\n\\n...\\n\\nThe best part about the sweepstake for me, is that the team members that don\u2019t usually interact with each other on a day to day basis have the opportunity to talk amongst themselves for this.\\n\\nSo, to encourage these team interactions, the first step was to create a slack channel #worldcup-2022 that we could use to discuss each game.\\n\\n**But that isn\u2019t enough**, because sometimes you require a trigger to start a discussion about the results and the next fixtures.\\n\\nI looked for a slack bot that achieved this, but **I didn\u2019t find one**.\\n\\nSo I built one using Python which you can find [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\nThis is the notification that the #worldcup-2022 receives everyday after all the matches have been played.\\n\\n\\n\\nThe outcome has been great so far! Our team engagement is even higher than usual and we see team members that don\u2019t work directly with each other having the opportunity to get to know others better.\\n\\nIf you want to do the same for your team, follow the instructions highlighted [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\nAny feedback is appreciated!"},{"id":"5-steps-i-used-to-change-my-job-title-in-less-than-1-year","metadata":{"permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.md","source":"@site/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.md","title":"5 steps I used to change my job title in less than 1 year","description":"This blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition.","date":"2022-11-14T00:00:00.000Z","tags":[{"inline":true,"label":"career","permalink":"/blog/tags/career"},{"inline":true,"label":"job change","permalink":"/blog/tags/job-change"},{"inline":true,"label":"sensor fusion engineer","permalink":"/blog/tags/sensor-fusion-engineer"},{"inline":true,"label":"roadmap","permalink":"/blog/tags/roadmap"},{"inline":true,"label":"hard work","permalink":"/blog/tags/hard-work"}],"readingTime":5.61,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"5-steps-i-used-to-change-my-job-title-in-less-than-1-year","title":"5 steps I used to change my job title in less than 1 year","date":"2022-11-14T00:00:00.000Z","image":"/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.png","tags":["career","job change","sensor fusion engineer","roadmap","hard work"],"description":"This blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition."},"unlisted":false,"prevItem":{"title":"Sweepstake World Cup 2022 for your startup team","permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team"},"nextItem":{"title":"How to grow your open source community from scratch","permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn March 2020, I joined a startup as an Embedded Firmware Engineer. The startup\u2019s product focuses on smart running insoles with lightweight trackers that fit any running shoes.\\n\\nThe company was small, and the firmware team was myself and 2 Senior Embedded Firmware Engineers.\\n\\nWhat I liked the most about this team was that our interests complemented each other very well. One of the Senior Embedded Firmware Engineers was very strong at wireless communications (BLE, ANT) while the other was great at communication protocols (SPI, I2C). On my end, my strength was from my MSc in Control Systems and my past experience with GNSS. In addition, I had a very high interest in learning about Inertial Navigation System (INS). My goal was to become a Sensor Fusion Engineer.\\n\\nSo what did I do to become a Sensor Fusion Engineer?\\n\\n## Declare your intent\\n\\nSince day 1 in the company, my team lead knew that my goal was to become a Sensor Fusion Engineer.\\n\\nThis is very important, as your manager can keep this in the back of their mind when assigning tasks to you. For instance, my team lead was giving me a lot of material around the way our product processed external samples as this was critical to the INS.\\n\\n## Define a roadmap\\n\\nI asked my manager: \u201c_What do I need to do to be recognized as a Sensor Fusion Engineer_\u201d.\\n\\nKnowing about the matter is not enough, you want to have the credentials so that you can jump faster in your career.\\n\\nMy team lead was not aware of the capabilities I would need to have to become a Sensor Fusion Engineer, so he spent quite some time doing due diligence on this. Good managers will go out of their way to help you grow.\\n\\nAfter some time, we discussed what I would need to do at the company to be recognized as Sensor Fusion Engineer and built a roadmap in order to get there.\\n\\n## Work hard\\n\\nWork extremely hard towards that roadmap.\\n\\nI was not only working towards that roadmap, but I was also working towards it at 2.5x the average speed. I was working 80h \u2014 100h / weeks during that time.\\n\\nI was being pulled into all meetings that discussed sensor fusion, I was reading old documentation to understand the decisions that I made, I was reading codebase and questioning all code (which allowed me to find some issues) and I was taking online courses on top of this.\\n\\nMore importantly, I was experimenting with the product. Theory will only help you so much, you need to get your hands dirty or you will never be able to fully master a skill.\\n\\n## Frequently revise your roadmap\\n\\nThroughout all my 1:1 with my manager, we always revisited the roadmap \u2014 even if briefly. This made sure that he knew how serious I was about this topic, and allowed me to demonstrate my progress.\\n\\nThis also allowed myself to look back and realize my own progress. I would spend time educating him on what I had learned and how we could apply that in our product, including some simulations I had done in Python.\\n\\n## Prove yourself\\n\\nDon\u2019t miss an opportunity to prove yourself.\\n\\nThis is the most critical point, you need to prove that you are capable of delivering by actually demonstrating a real example.\\n\\nThis is the egg or chicken first problem. When you don\u2019t have the initial experience, your company won\u2019t trust you to apply your knowledge. But if your company doesn\u2019t give you the chance you will never get the experience.\\n\\nIn our case, users started getting weird jumps in altitude reported by the trackers. And we needed to figure out the issue fast as this was increasing the churn. I immediately knew I was able to solve this, and knew I had to grab this opportunity.\\n\\nOur trackers were not taking the GPS location in the estimation of user altitude, and I knew that considering that would substantially improve the estimation as the altitude has less chances to change drastically over a small distance.\\n\\nFinally, my degree and hundreds of hours of work were paying off. That day, I wrote our C/C++ altitude estimation algorithm in Python and provided with an input that had a spurious jump in pressure readings \u2014 i.e. I recreated how the issue was happening.\\n\\nI proceeded to implement a Kalman Filter solution to consider GPS readings as well, and the result was a massive improvement. The jump in altitude was non-existant now.\\n\\nIn the daily standup the next day, I had accomplished most of my tasks for the sprint and asked the product owner if I could take a shot at fixing the altitude issue. He was a bit hesitant, but I had a notebook ready to show the problem recreated and my proposed solution in Python.\\n\\nHe accepted and gave me the next 3 days to work on it and to present results on Monday. I didn\u2019t sleep until that Monday. Implementing from Python to C++ was the easy part. The hard part was debugging + optimizing the weights of the Kalman Filter.\\n\\nI was touching the code. Performing an over the air upgrade. Going outside for a run in a track with a bridge where I knew the altitude. Analyzing results at home. Iterate.\\n\\nMonday arrived and I presented results, and they looked so much better. The proposed solution was accepted. Our INS algorithm hadn\u2019t changed in a long time, so a lot of testing was needed.\\n\\nAfter that, the company accepted to offer me the title of Sensor Fusion engineer. Without a pay rise, but that was fine as for me it was about speeding up my career.\\n\\n## Conclusion\\n\\n- Declare intent\\n- Define roadmap\\n- Work towards that roadmap\\n- Frequently revise roadmap\\n- Don\u2019t miss an opportunity to prove yourself\\n\\n**Note:** If the company doesn\u2019t give you a chance to prove yourself, you should interview for that position with other companies. And if another company offers you that job, you will have the leverage that another company perceives you as that.\\n\\nI like [this video](https://youtube.com/shorts/x71Rm0MWVHY?si=BvtmjrE31d6U1bpV) about understanding your market value. And I think it can be extended in terms of your skillset if you want to change your role.\\n\\nFeedback as always is welcome :)"},{"id":"how-to-grow-your-open-source-community-from-scratch.md","metadata":{"permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.md","source":"@site/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.md","title":"How to grow your open source community from scratch","description":"Growing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project.","date":"2022-11-10T00:00:00.000Z","tags":[{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"},{"inline":true,"label":"Project Management","permalink":"/blog/tags/project-management"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"}],"readingTime":3.92,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-grow-your-open-source-community-from-scratch.md","title":"How to grow your open source community from scratch","date":"2022-11-10T00:00:00.000Z","image":"/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.png","tags":["Open Source","Community Building","Project Management","OpenBB Terminal"],"description":"Growing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project."},"unlisted":false,"prevItem":{"title":"5 steps I used to change my job title in less than 1 year","permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year"},"nextItem":{"title":"How to learn 10x faster than average","permalink":"/blog/how-to-learn-10x-faster-than-average"}},"content":"
\\n  \\n
\\n
\\n\\nGrowing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n### Project naming\\n\\nThe name should be short, memorable, unique and related with the project.\\n\\nWhen I started what we call OpenBB Terminal today, the name of the project was \u201cStock Market Bot\u201d or something silly like that. I knew that wouldn\u2019t be the last name, but I didn\u2019t have any inspiration and in the meantime I was focused on building the platform.\\n\\nI am an Elon Musk fan, and was a GameStop investor. This meant that once I saw [this tweet](https://twitter.com/elonmusk/status/1354174279894642703) \u2014 I didn\u2019t blink twice and knew this was the name I was waiting for.\\n\\n\\n\\nThat\u2019s when Gamestonk Terminal (now OpenBB Terminal) was born.\\n\\n### Keep the project private until MVP\\n\\n- There will be less pressure than building in public, and you will be able to iterate much faster.\\n- No users asking for features or reporting bugs when MVP is still under development.\\n- Most importantly, this guarantees that when the users see the MVP they know where you are heading with the project.\\n\\nI worked on Gamestonk Terminal for 2 months on my own. The code architecture changed several times as I was in this experimental phase. And if you look into the source code I even committed API keys accidentally. But I had no pressure, so I was able to ship extremely fast.\\n\\n### Prepare to onboard the community\\n\\n- Make the documentation standout (not only \u201cgetting started\u201d but also \u201ccontributing\u201d).\\n- Create \u201cquick win\u201d tickets that the community can address quickly.\\n- Start a group channel on Discord or Slack, which allows you to interact with contributors and discuss features / roadmap and keep them engaged.\\n- Mention \u201cstarring\u201d the project. As simple as this sounds, this helps with growth as its easy to forget to star the project, even though you were interested in what you saw.\\n\\nSome people from our current team told me recently that they fell in love with the README of the project the first time they saw it. In particular with this quote:\\n\\n> _\u201cGamestonk Terminal is an awesome stock and crypto market terminal that has been developed for fun, while I saw my GME shares tanking. But hey, I like the stock.\u201d_\\n\\n
\\n\\nThis allowed me to gain not only contributors, but maintainers. And nowadays, team members.\\n\\n### Change the project visibility to public\\n\\n- This allows everyone to have a first look into the project, it\u2019s the \u201cHello World\u201d moment.\\n- When sharing the project, describe the problem you are trying to solve and make sure your audience relates with that problem.\\n- Share your project on relevant channels (e.g. Reddit, HackerNews, ProductHunt) \u2014 where your audience is.\\n\\nI have been building in open source for a while, without much success. Until Gamestonk Terminal.\\n\\nThe difference? I shared Gamestonk Terminal on:\\n\\n- Reddit r/SuperStonk \u2014 where the retail traders with the same issue as me were gathered\\n- Reddit r/python \u2014 where the community shares projects built in python\\n- HackerNews \u2014 where I leveraged the name of a known brand in the same industry and insinuated that my tool was similar but affordable. The title was: \u201c[Can\u2019t afford Bloomberg Terminal? No prob, I built the next best thing](https://news.ycombinator.com/item?id=26258773)\u201d.\\n\\n### Keep developing in public\\n\\n- Keep the community updated on the roadmap and progress. You can do this by doing demos of what you have accomplished as you add new features (e.g. [on YouTube](https://www.youtube.com/watch?v=fqGPK8OVHLk) or [on Twitter](https://twitter.com/didier_lopes/status/1567117888590340098)) which allows the community to understand what sort of tasks you are working on, and what they would learn if they were to contribute. It basically gives the community a hindsight into what a contributor will be able to work on / achieve.\\n- Get early feedback and prioritise accordingly.\\n- Occasionally go back to the same channels (e.g. Reddit, Hackernews) to report progress. This guarantees that they know the project is not dead and helps your project staying relevant and on their minds.\\n- Develop in public through livestreams (e.g. [live Coding](https://www.youtube.com/watch?v=9BMI9cleTTg)) or by sharing what you are working on through social media (e.g. [adding a futures menu](https://twitter.com/didier_lopes/status/1579414220256387072)).\\n\\n\\n\\nTL;DR: On how to grow your open source project:\\n\\n- Project naming\\n- Keep project private until MVP\\n- Prepare to onboard the community\\n- Change the project visibility to public\\n- Keep developing in public"},{"id":"how-to-learn-10x-faster-than-average","metadata":{"permalink":"/blog/how-to-learn-10x-faster-than-average","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-27-how-to-learn-10x-faster-than-average.md","source":"@site/blog/2022-10-27-how-to-learn-10x-faster-than-average.md","title":"How to learn 10x faster than average","description":"Learn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively.","date":"2022-10-27T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"self-improvement","permalink":"/blog/tags/self-improvement"},{"inline":true,"label":"skills","permalink":"/blog/tags/skills"},{"inline":true,"label":"education","permalink":"/blog/tags/education"}],"readingTime":2.98,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-learn-10x-faster-than-average","title":"How to learn 10x faster than average","date":"2022-10-27T00:00:00.000Z","image":"/blog/2022-10-27-how-to-learn-10x-faster-than-average.png","tags":["learning","self-improvement","skills","education"],"description":"Learn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively."},"unlisted":false,"prevItem":{"title":"How to grow your open source community from scratch","permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md"},"nextItem":{"title":"Twitter thread to LinkedIn carousel in python","permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds"}},"content":"
\\n  \\n
\\n
\\n\\nLearn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEveryone is a self learner. But people\u2019s rhythm of self learning can be vastly different.\\n\\n### Have a good reason to learn this new skill\\n\\nWhat is the main fundamental reason why you want to learn this skill? If you don\u2019t have a one sentence answer, you probably don\u2019t need to learn it.\\n\\nUniversity teaches you hundreds of topics that you end up not being good at because you have no interest in it.\\n\\nAvoid spending your precious time on developing a skill that you have no interest or purpose in. Avoid trends too for this reason.\\n\\n### Research and read about the best way to learn the basics\\n\\nThis should take no longer than one afternoon. Avoid promoted content.\\n\\nUsually, you\u2019re able to find a course/book/video that is acclaimed by the community to be the best to get started with.\\n\\nSo we are looking for the equivalent of \u201cMachine Learning from Andrew Ng\u201d for the skill you want to master.\\n\\n### Consume the basics like your life depends on it\\n\\nThis will be the foundation of all your subsequent learning in this new area. Put your phone away, and take notes.\\n\\nRevisit those notes, and if necessary go back in time to understand the basics.\\n\\nIt took me above average time to finish Machine Learning from Andrew Ng.\\n\\nHowever, since this, whenever I learn or even think about AI problems this is now easier because of that laid out work.\\n\\n### Test your knowledge with a real problem (aka get your hands dirty)\\n\\nAnd no, I don\u2019t mean do an exercise that you find online.\\n\\nDefine a problem that you can solve with the skills you acquired and work on it.\\n\\nDon\u2019t ask for the answer. Don\u2019t Google for the solution, but Google for something that is a current impediment on your solution.\\n\\nIf you are struggling on formulating the Google prompt, revisit your first notes on the skill.\\n\\n### Keep learning about the topic\\n\\nThe getting started foundation will only get you so far. It\u2019s likely that soon you will grow out of that and need to expand your knowledge.\\n\\nDon\u2019t jump on this step too early. Make sure your basics are covered before you move on.\\n\\nGo back to the real problem you worked on, and see how the new learned skills could be applied for that same problem.\\n\\nIf those skills aren\u2019t necessarily in that first problem, it\u2019s also a good sign. It\u2019s a sign that you learned not only the skill but when it is and it isn\u2019t used.\\n\\n### Iterate\\n\\nKeep iterating between using this new skill to solve a real problem and learning from courses/videos/books.\\n\\nThere isn\u2019t a \u201cyou made it\u201d badge. But you know you did, once you\u2019re able to look for a specific piece of information on a video/book to fill in the gap for something you needed for your real problem.\\n\\n\\n\\nTL;DR on how to learn 10x faster than average\\n\\n1. Have a good reason to learn this new skill.\\n2. Research and read about the best way to learn the basics.\\n3. Consume the basics like your life depended on it.\\n4. Test your knowledge with a real problem.\\n5. Keep learning about the topic.\\n6. Iterate."},{"id":"how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","metadata":{"permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.md","source":"@site/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.md","title":"Twitter thread to LinkedIn carousel in python","description":"In this blog post, I share how I built a Python tool that converts a Twitter thread into a LinkedIn carousel in seconds. This tool is open source and contributions for improvements are welcome.","date":"2022-10-23T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"LinkedIn","permalink":"/blog/tags/linked-in"},{"inline":true,"label":"Twitter","permalink":"/blog/tags/twitter"},{"inline":true,"label":"Carousel","permalink":"/blog/tags/carousel"},{"inline":true,"label":"Content Creation","permalink":"/blog/tags/content-creation"}],"readingTime":1.775,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","title":"Twitter thread to LinkedIn carousel in python","date":"2022-10-23T00:00:00.000Z","image":"/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.png","tags":["Python","LinkedIn","Twitter","Carousel","Content Creation"]},"unlisted":false,"prevItem":{"title":"How to learn 10x faster than average","permalink":"/blog/how-to-learn-10x-faster-than-average"},"nextItem":{"title":"How I would do due diligence on $AMT using OpenBB Terminal","permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blog post, I share how I built a Python tool that converts a Twitter thread into a LinkedIn carousel in seconds. This tool is open source and contributions for improvements are welcome.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/thread-to-carousel/tree/master).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAs content creators, it would be good if the same content could be utilised across every platform easily. Sometimes you need some tweaks based on audience, but often the same content is used across all platforms.\\n\\nI noticed recently that LinkedIn carousels have been picking a lot of traction, and given I have some nice Twitter threads ([example](https://twitter.com/didier_lopes/status/1570731358204600323?s=20&t=SAO9fD7FR7jeTE-6kem6Mg)) I thought that it would be great if I could convert them into a LinkedIn carousel.\\n\\nSo, I looked for free tools and didn\u2019t find anything good enough. I ended up using [canvas](https://canvas.apps.chrome/) to re-create the thread \u2014 which you can find [here](https://www.linkedin.com/posts/didier-lopes_due-diligence-on-amt-using-openbb-terminal-activity-6977569279395176448-TFMn?utm_source=share&utm_medium=member_desktop). It worked well, but it was time consuming and for most cases, I don\u2019t want to be messing around with the design side of things.\\n\\n\\n\\nAs a true software engineer and pythonist, I obtained the Twitter API keys and built a tool that would convert a Twitter thread into a LinkedIn carousel in a matter of seconds.\\n\\nAnd as usual, I open sourced it: https://github.com/DidierRLopes/thread-to-carousel.\\n\\nThis tool is far from perfect, and a lot can be improved on the design side of things to: Recognize emojis; Highlight mentions; Change the size of the box based on the text; Better text placement when images attached; Better URL link display.\\n\\nThe goal for me wasn\u2019t to build a perfect tool, but something easy enough that did the job. And, as the project is open source, I expect to have users contributing to the script so that it can be improved over time.\\n\\nToday I run it using:\\n\\n```console\\npython convert2carousel.py https://twitter.com/didier_lopes/status/1581247044228100096\\n```\\n\\nAnd the result can be found [here](https://www.linkedin.com/posts/didier-lopes_football-momentum-indicator-carousel-activity-6989972573782482944-nM9s?utm_source=share&utm_medium=member_desktop).\\n\\n\\n\\nFeel free to check the project here and I look forward to having contributors helping me improve it!\\n\\nAs always, any feedback welcome \ud83d\ude4f\ud83c\udffd"},{"id":"how-i-would-do-due-diligence-on-amt-using-openbb-terminal","metadata":{"permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.md","source":"@site/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.md","title":"How I would do due diligence on $AMT using OpenBB Terminal","description":"This blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis.","date":"2022-10-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Stocks","permalink":"/blog/tags/stocks"},{"inline":true,"label":"Due Diligence","permalink":"/blog/tags/due-diligence"}],"readingTime":1.785,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-would-do-due-diligence-on-amt-using-openbb-terminal","title":"How I would do due diligence on $AMT using OpenBB Terminal","date":"2022-10-20T00:00:00.000Z","image":"/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.png","tags":["OpenBB Terminal","Investment Research","Stocks","Due Diligence"],"description":"This blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis."},"unlisted":false,"prevItem":{"title":"Twitter thread to LinkedIn carousel in python","permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds"},"nextItem":{"title":"Stop doing your CV in Word or LaTeX","permalink":"/blog/stop-doing-your-cv-in-word-or-latex"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLast month someone on Twitter asked me to do a thread on how I would do due diligence on $AMT using the free and open source [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\nBelow I demonstrate what you can expect from using that platform.\\n\\nWe could go much deeper, but this shows examples of output that you can expect. With over 800 commands and over 100 data sources, this is a very small subset of what you can achieve through this platform.\\n\\nIn addition, this will only be in relation with stocks data, but the terminal also has access to options, crypto, ETFs, mutual funds, NFTs, macro economy, futures and even alternative data!\\n\\nMore information on the platform and how to install it [here](https://my.openbb.co/app/terminal/download).\\n\\nStrap in.\\n\\n```console\\n$ /stocks/load AMT/candle\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/mktcap\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/mgmt\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/income/balance/cash\\n```\\n\\n\\n\\n\\n\\n\\n\\n```console\\n$ /stocks/fa/shrs\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/sust\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/divs\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/dcf\\n```\\n\\n\\n\\n```console\\n$ /stocks/ins/stats\\n```\\n\\n\\n\\n```console\\n$ /stocks/dps/psi\\n```\\n\\n\\n\\n```console\\n$ /stocks/gov/histcont\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/rating\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/pt\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/est\\n```\\n\\n\\n\\n```console\\n$ /stocks/ta/sma\\n```\\n\\n\\n\\n```console\\n$ /stocks/ta/recom/summary\\n```\\n\\n\\n\\n```console\\n$ /stocks/ba/sentiment\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/metric tc\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/metric fcf\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/vis oi\\n```\\n\\n\\n\\n```console\\n$ /stocks/ca/historical/hcorr\\n```\\n\\n\\n\\n\\n\\n```console\\n$ /stocks/ca/cashflow/income/balance\\n```\\n\\n\\n\\n\\n\\n\\n\\nI know this can be overwhelming information and it takes some time to run all these commands.\\n\\nHence I created a [script](https://github.com/OpenBB-finance/OpenBBTerminal/blob/main/openbb_terminal/miscellaneous/routines/due_diligence_stock.openbb). So now you can run all of these commands in one go, with:\\n\\n```console\\n$ /exe due_diligence_stock.openbb -i AMT\\n```\\n\\nAny feedback is welcome!\\n\\nAnd if you want to ask questions about the product before installing it, feel free to join us on Discord here: https://openbb.co/discord"},{"id":"stop-doing-your-cv-in-word-or-latex","metadata":{"permalink":"/blog/stop-doing-your-cv-in-word-or-latex","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.md","source":"@site/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.md","title":"Stop doing your CV in Word or LaTeX","description":"The future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions.","date":"2022-10-15T00:00:00.000Z","tags":[{"inline":true,"label":"GitHub","permalink":"/blog/tags/git-hub"},{"inline":true,"label":"CV","permalink":"/blog/tags/cv"},{"inline":true,"label":"Career","permalink":"/blog/tags/career"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Developer","permalink":"/blog/tags/developer"}],"readingTime":2.695,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"stop-doing-your-cv-in-word-or-latex","title":"Stop doing your CV in Word or LaTeX","date":"2022-10-15T00:00:00.000Z","image":"/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.png","tags":["GitHub","CV","Career","Open Source","Developer"],"description":"The future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions."},"unlisted":false,"prevItem":{"title":"How I would do due diligence on $AMT using OpenBB Terminal","permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal"},"nextItem":{"title":"Why you should drop yfinance API and adopt OpenBB SDK","permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk"}},"content":"
\\n  \\n
\\n
\\n\\nThe future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe purpose of a CV is to summarize someone\u2019s career, qualifications and education. **As an engineer or developer, I strongly believe that the future of CVs lies within GitHub.**\\n\\nIn fact, GitHub has realized this and they now allow you to create your own \u201c_profile page_\u201d by creating a repository with the same name as your GitHub username. E.g. https://github.com/DidierRLopes\\n\\nIn my humble opinion, this isn\u2019t being talked enough. Previously, you needed a CV document to talk about your background, education, previous jobs and could rely on your GitHub profile to show your projects. With this update, CVs have become obsolete. When hiring for [OpenBB](https://openbb.co/), I put a lot of weight into the public GitHub of each engineer.\\n\\nThis is my current [GitHub profile page](https://github.com/DidierRLopes).\\n\\n\\n\\nMy profile page is now much simpler since I\u2019ve worked on my [own personal website](https://didierrlopes.github.io/personal-website/), but you can see [here](https://github.com/DidierRLopes/DidierRLopes/tree/98c27cfb087fc8ce6986f4ea8136e76ca14f145b) what my GitHub profile page looked like before. Creating your own personalized website for me is the next step after GitHub, as you can be as creative as you want while showing off your coding skills.\\n\\nMy repository is my way of showing the world what I can do on my own. From a blank sheet to a finalized project. **Sometimes useful, sometimes for fun, but always with the intention to learn more and challenge myself.**\\n\\nThe reason I think that GitHub profile\u2019s are the CVs of the future for engineers/developers, is not only because you can now both talk about yourself in it and display your portfolio, but because of its open source nature.\\n\\nWith products like: https://ossinsight.io/analyze/DidierRLopes, you will be able to dive deeper on engineering skills than ever before.\\n\\n\\n\\nCompanies will be able to assess a candidate based on their open source work:\\n\\n- How do they interact with the community? What are their communication skills?\\n- Do they practice teamwork? And mentor more junior developers?\\n- Are they leaving comments in the code? Is their code readable in the first place?\\n- What about testing? Are they following good practices?\\n- What\u2019s their time to reply to issues? Or to review PRs from peers?\\n- Activity? What are their working hour patterns like?\\n- \u2026\\n\\nImagine a world where everyone develops in the wild. You can see everything and be part of any project. You have your own profile, you talk with others through issues or PRs, you build together. There is no gender, no race, no nationality,.. people are conneced through projects they believe in. **In essence, this is the developer metaverse, and I\u2019m all here for it.**\\n\\n\\n\\n**EDIT:** The reader should be aware that nowadays a properly formatted resume is still critical when added to a job board. This is because automated resume readers expect a certain format in order to recommend candidates to companies and vice-versa.\\n\\nHope you enjoyed this post. As always, any feedback welcome! \ud83d\ude4f"},{"id":"why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","metadata":{"permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.md","source":"@site/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.md","title":"Why you should drop yfinance API and adopt OpenBB SDK","description":"Why you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners.","date":"2022-10-01T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB SDK","permalink":"/blog/tags/open-bb-sdk"},{"inline":true,"label":"yfinance API","permalink":"/blog/tags/yfinance-api"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"APIs","permalink":"/blog/tags/ap-is"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":2.11,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","title":"Why you should drop yfinance API and adopt OpenBB SDK","date":"2022-10-01T00:00:00.000Z","image":"/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.png","tags":["OpenBB SDK","yfinance API","Financial Data","APIs","Open Source"],"description":"Why you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners."},"unlisted":false,"prevItem":{"title":"Stop doing your CV in Word or LaTeX","permalink":"/blog/stop-doing-your-cv-in-word-or-latex"},"nextItem":{"title":"How I became CEO of OpenBB","permalink":"/blog/how-i-became-ceo-of-openbb"}},"content":"
\\n  \\n
\\n
\\n\\nWhy you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOpenBB SDK will be released later this month \ud83d\udc40.\\n\\n[yfinance API](https://github.com/ranaroussi/yfinance) is an unofficial (not affiliated) API around [Yahoo Finance website](https://finance.yahoo.com/).\\n\\nAlthough it is used in over 12,600 projects on GitHub and is downloaded on average 90,000 per week. This is still an unofficial wrapper. As you can see from Yahoo Finance website, it uses an ad revenue business model. This means that Yahoo Finance doesn\u2019t has any incentive from having users utilizing it through Yfinance API.\\n\\nIf one day Yahoo Finance website adds a paywall through an API key, then Yahoo Finance would:\\n\\n1. Either become obsolete\\n2. Or adopt the same architecture of OpenBB where an API key from a data source is necessary\\n\\n
\\n\\nRegardless, Yfinance API retrieves data that exists on a third-party website: Yahoo Finance website. This means that this API is limited by the data Yahoo Finance is currently paying for redistribution. And thus, users get only what data is supported through the website.\\n\\nOn the other hand, OpenBB SDK allows you to retrieve data from over 50 different APIs (and growing). With yfinance being one of these APIs.\\n\\nSince OpenBB SDK requires API keys from most of the data sources, these have incentives to partner with OpenBB. Because:\\n\\n1. Marketing opportunity due to significant larger pool of users\\n2. New revenue stream\\n\\n
\\n\\nIn essence, Yfinance API:\\n\\n- Not officially supported by Yahoo Finance\\n- No incentive for Yahoo Finance\\n- Limited data by what Yahoo Finance displays\\n- May become obsolete\\n\\nOn the other hand, OpenBB SDK:\\n\\n- Marketing for new data sources\\n- New revenue stream for partners through premium API keys\\n- (Almost) unlimited data - open source project that keeps on adding new data sources\\n- Multiple data sources for same data (user has choices)\\n\\nAs counter-intuitive as it sounds:\\n\\nThe shutting down of yfinance API (which is one of the data sources that OpenBB SDK has access to) would be beneficial to OpenBB adoption. This is because users would need to migrate to OpenBB SDK as that\u2019s the most mature and maintained open source financial API.\\n\\nIf you have any questions, feel free to drop me a message!"},{"id":"how-i-became-ceo-of-openbb","metadata":{"permalink":"/blog/how-i-became-ceo-of-openbb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-08-14-how-i-became-ceo-of-openbb.md","source":"@site/blog/2022-08-14-how-i-became-ceo-of-openbb.md","title":"How I became CEO of OpenBB","description":"This post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance.","date":"2022-08-14T00:00:00.000Z","tags":[{"inline":true,"label":"python","permalink":"/blog/tags/python"},{"inline":true,"label":"publishing","permalink":"/blog/tags/publishing"},{"inline":true,"label":"package","permalink":"/blog/tags/package"},{"inline":true,"label":"pypi","permalink":"/blog/tags/pypi"}],"readingTime":3.655,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-became-ceo-of-openbb","title":"How I became CEO of OpenBB","date":"2022-08-14T00:00:00.000Z","image":"/blog/2022-08-14-how-i-became-ceo-of-openbb.png","tags":["python","publishing","package","pypi"],"description":"This post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance."},"unlisted":false,"prevItem":{"title":"Why you should drop yfinance API and adopt OpenBB SDK","permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk"},"nextItem":{"title":"Web3, symbols and community","permalink":"/blog/web3-symbols-and-community"}},"content":"
\\n  \\n
\\n
\\n\\nThis post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nBoth my parents are Portuguese and emigrated to Switzerland for better conditions. This is where my brother and I were born. We moved back to our small hometown in Portugal when I was 8 years old.\\n\\nWhen I was 21 years old I moved to London to pursue my MSc in control systems at the Imperial College. I also joined a semiconductor company as a Software Design Engineer.\\n\\n\\n\\nIn my spare time I learned Python so I could become more proficient in machine learning and artificial intelligence. When my mathematics professor learned of my interest in Python he challenged me to write the [code behind his PhD thesis](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast) on \\"_Data Science in the Modeling and Forecasting of Financial Time Series: from Classic methodologies to Deep Learning_\\" which combined open source, ML/AI and finance. This was when I first started to realize my passion for financial data.\\n\\n\\n\\nI was inspired by books like \\"_Rich dad Poor dad_\\" which allowed me to understand that the only way to build true generational wealth is through investing. Now that I started to accumulate more savings through my professional pursuits, and with my finance interest increasing from my thesis work, I wanted to invest my own capital.\\n\\nWhat I learned was that investing was a highly cumbersome process. Unlike coding where the tooling (e.g. VSCode) is optimized for efficiency and allows us to automate a lot of processes, investing was highly inefficient and impossible to automate.\\n\\nI was spending hours doing my own investment research (multiple tabs open researching several different sources on a ticker, screenshot the data to put on a document or share with friends, write my thoughts, and repeat), and this had to be done for every single ticker at different instances of time otherwise the data would become irrelevant.\\n\\nI learned from Reddit users how they gained insights and performed due diligence. I quickly realized their \\"workflow\\" was just as inefficient as mine. I concluded that the only aspect of research that should require user input is the interpretation. As far as I was concerned, all data gathering should be automated.\\n\\nI began investigating potential investment research tools that allowed automation and couldn\'t find any, not even the mythical $24k/year Bloomberg terminal. I looked for platforms on GitHub where I could build on top of with no success.\\n\\nDuring Covid Christmas break, the flight to visit my parents was cancelled, so I ended up staying at home and sketching/building what would become my own investment research platform. I noticed that there were hundreds of data providers offering free data tiers where the data provided didn\'t correlate with each other. If I wanted access to paid datasets or more requests per minute it would be as simple as to upgrade my API key to a paid plan.\\n\\n\\n\\nOver the next two months I built a python based command line interface in my spare time for and released the first lines of code as Open Source under the name \\"Gamestonk Terminal\\" since I was an investor in Gamestop and Elon Musk had recently tweeted his now infamous [\\"Gamestonk\\" tweet](https://twitter.com/elonmusk/status/1354174279894642703?s=20).\\n\\nThe project went viral in a couple of minutes on [Reddit](https://www.reddit.com/r/Python/comments/m515yk/gamestonk_terminal_the_equivalent_to_an/) and [HackerNews](https://news.ycombinator.com/item?id=26258773). In under 24h we had over 4,000 stars on [GitHub](https://github.com/OpenBB-finance/OpenBBTerminal), and hundreds of messages requesting features, thanking me for the tool, or reporting bugs.\\n\\nThe number of issues and feature requests was overwhelming for a single person working part-time, so I created a [Discord group](https://openbb.co/discord) and started building a community of users. Many of those same first users went on to become core maintainers of the project. The community started adding new data sources, new features and even new asset classes to the project\u200a-\u200asoon after we were supporting crypto, ETFs, options, forex, and macro economy.\\n\\nMy goal was never to build a business/company with this product. My motivation was to create a better investment research platform that was unavailable until then. When we got approached by JJ (from OSS Capital), it was a no-brainer to create OpenBB, as this would allow me to accelerate the product vision and build the world\'s leading investment research platform."},{"id":"web3-symbols-and-community","metadata":{"permalink":"/blog/web3-symbols-and-community","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-06-28-web3-symbols-and-community.md","source":"@site/blog/2022-06-28-web3-symbols-and-community.md","title":"Web3, symbols and community","description":"This blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users.","date":"2022-06-28T00:00:00.000Z","tags":[{"inline":true,"label":"Web3","permalink":"/blog/tags/web-3"},{"inline":true,"label":"Community","permalink":"/blog/tags/community"},{"inline":true,"label":"Decentralization","permalink":"/blog/tags/decentralization"},{"inline":true,"label":"Blockchain","permalink":"/blog/tags/blockchain"},{"inline":true,"label":"Smart Contracts","permalink":"/blog/tags/smart-contracts"}],"readingTime":5.48,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"web3-symbols-and-community","title":"Web3, symbols and community","date":"2022-06-28T00:00:00.000Z","image":"/blog/2022-06-28-web3-symbols-and-community.png","tags":["Web3","Community","Decentralization","Blockchain","Smart Contracts"],"description":"This blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users."},"unlisted":false,"prevItem":{"title":"How I became CEO of OpenBB","permalink":"/blog/how-i-became-ceo-of-openbb"},"nextItem":{"title":"Remote + Flexible work >> Salary","permalink":"/blog/remote-flexible-work-salary"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you have been paying attention to the Web 3.0 space, you should have realized that most of the projects in the space rely on strong communities.\\n\\n### Why on Web 3.0?\\n\\nOn a centralized concept (Web 2), there is usually a regulatory entity that decides whether something is True or False on a project/product. This means that there\u2019s a single centralized company responsible for making a decision and users must trust that this entity is acting on their best interests.\\n\\nFurthermore, the users do not stand to win anything whether the decision is True or False. They may identify more with one of the outcomes, but there is no personal incentive to the user. Even if a user can relate with the outcomes they never feel a sense of belonging, as deep down they are aware that their opinion is not being taken into account.\\n\\nOn a decentralized concept (Web 3), the story is the very different. A decentralized community is responsible for deciding the True or False, based on a voting framework defined a-priori. This means that the group of users, based on smart contracts executed on the blockchain, can vote on a particular decision. **This is where the importance of a strong community kicks in.**\\n\\nOn Web 2 the users must trust that such entity is acting on user\u2019s best interests. That trust, on Web 3, occurs in form of a strong community. The best way for a user to trust the decisions of a group of people is to know that a group shares the same values and has incentives towards the success of the same project/product.\\n\\n**In fact, I believe that in general when these votes occur, the more unanimous the decisions are, the stronger the community is.**\\n\\n> **NOTE:** Although Web 3 communities are stronger than Web 2 ones, I believe that when something goes wrong the Web 3 communities break faster as they don\u2019t have a common enemy due to the decentralized concept (e.g. LUNA debacle). On the other hand, Web 2 communities can \u201chold\u201d onto the fact that their common enemy is now the entity that they trusted to act on their best interests (e.g. Robinhood vs wallstreetbets).\\n\\n### Why build strong communities?\\n\\n_The Web 3.0 concept doesn\u2019t only benefit from strong communities but is built on top of it._ For worldwide adoption in products/projects/companies the space need strong communities.\\n\\nWhy does money have value? Because people believe that they will be able to exchange it for goods/services in the future. Why do people believe that? Because they trust the entity that is managing such currency.\\n\\nAnalogously, for a digital asset to have value, people need to believe that they will be able to exchange it for goods/services in the future. Since there is no entity to trust, people need to believe that the community will believe that a certain digital asset has value. This belief exists because there are incentives (usually financial or status) for its members.\\n\\nOnce this happens we enter into the law of supply and demand where the value of digital asset goes up as there is either less supply or more demand.\\n\\nThese communities can easily be found on CT or Discord/Telegram servers.\\n\\n\\n\\n### How are strong communities created?\\n\\nIf we learn from history, we see that the most loyal and bigger communities **always recurred at symbology** to achieve such, some examples: sports clubs, religion, countries, clans, societies, \u2026\\n\\nThe truth is that we humans constantly seek this sense of belonging (or are afraid of being alone). When we see multiple people on social media utilizing the same symbols to represent their beliefs, we want to be part of that group, of that community.\\n\\nThis can be seen over and over again on Web3, particularly in CT:\\n\\n- Changing the eyes\u2019 color of your twitter\u2019s pfp which represents being bullish on crypto (usually red for BTC and blue for ETH)\\n- Emojis after the username\\n- Utilizing the NFT you acquired from a collection that you believe in\\n- Adding a \u201c.eth\u201d at the end of the username\\n\\n\\n\\n### Why does this matter?\\n\\nCompanies outside of the Web 3.0 space will start picking up on this to build stronger communities and have a stronger identity (e.g. Notion and their employees pfp on social media). This is even more relevant for open source companies (Web 2.5 if you will), which rely on their communities to build a successful company (e.g. Hugging Face \ud83e\udd17 ).\\n\\n> _I believe that companies will start thinking about the emojis that their community can use while coming up with the name of the brand and logo._\\n\\n
\\n\\nAs for OpenBB, we are a fintech open source company that focuses on providing better investment research for everyone, anywhere. The finance sector we are in is composed of multiple players that have been on the top of the industry for decades. We come in with a radical different approach, bottom-up.\\n\\n> _Being open source for us is not a choice but a need if we are to disrupt traditional investment research platforms with years of head start._\\n\\n
\\n\\nOnce we knew that we wanted the logo to be extracted from the \u201cBB\u201d, it was immediate that the butterfly emoji (\ud83e\udd8b) would be used. Furthermore, a butterfly is a metaphor for transformation, which in our context, represents OpenBB Terminal allowing each investor to evolve and finally fly (i.e. achieve financial freedom).\\n\\nIn order for our users to start relating to the butterfly emoji (\ud83e\udd8b) with our brand we have several cues:\\n\\n- On the landing page\\n\\n\\n\\n- Official social media channels\\n- Our team members use it in their socials\\n\\n\\n\\n- On the OpenBB Terminal as the default flair,\\n\\n\\n\\nAnd even to replace the asterisk (*) when inserting the password to enter our OpenBB Bot platform, **because details matter.**\\n\\n\\n\\nAnd that is what we are doing at OpenBB to build a stronger community? Do you have any other tips/tricks? Feel free to share them!\\n\\nHope you enjoyed this post and as always, am looking to hear feedback!\\n\\n_PS: I\u2019d like to take this chance to say that our OpenBB Bot launch will occur in the coming weeks, you won\u2019t have to wait much longer \ud83e\udd8b_"},{"id":"remote-flexible-work-salary","metadata":{"permalink":"/blog/remote-flexible-work-salary","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-05-03-remote-flexible-work-salary.md","source":"@site/blog/2022-05-03-remote-flexible-work-salary.md","title":"Remote + Flexible work >> Salary","description":"This blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity.","date":"2022-05-03T00:00:00.000Z","tags":[{"inline":true,"label":"Remote Work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"Flexible Hours","permalink":"/blog/tags/flexible-hours"},{"inline":true,"label":"Work Life Balance","permalink":"/blog/tags/work-life-balance"},{"inline":true,"label":"Productivity","permalink":"/blog/tags/productivity"}],"readingTime":4.785,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"remote-flexible-work-salary","title":"Remote + Flexible work >> Salary","date":"2022-05-03T00:00:00.000Z","image":"/blog/2022-05-03-remote-flexible-work-salary.png","tags":["Remote Work","Flexible Hours","Work Life Balance","Productivity"],"description":"This blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity."},"unlisted":false,"prevItem":{"title":"Web3, symbols and community","permalink":"/blog/web3-symbols-and-community"},"nextItem":{"title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nI was thinking about remote + flexible hours, and I don\u2019t think I would ever work for a company without these. At least by choice \ud83d\ude43\\n\\nI mean, who would tell Morty and Sum Sum that I wouldn\u2019t be at home to play?\\n\\n**I\u2019m a strong believer that work should wrap around your lifestyle and not vice-versa.**\\n\\nOn average, a person works 40 hours a week and sleeps 8 hours a day. This means that out of 168h per week you have 72h for personal time. In terms of percentage we have: 24% for work, 33% for sleep, and 43% for personal time.\\n\\nSo how come most people have almost 2x as much personal time compared to work time and they still feel like they are in this 9\u20135 rat race and their life revolves around work?\\n\\nWell, here\u2019s the 4 scenarios as I see it\u2026\\n\\n**1. The work is not remote (and not flexible).**\\n\\n - If we account for the commute and stress associated with, personal time gets directly transferred into work time.\\n - E.g. with a daily 2 hour commute Mon-Fri, which is very typical, this means that your personal time is divided into 30% for work and 37% for personal. This isn\u2019t event including the part where you have to prepare to leave the house, and the tiredness resultant from the commute.\\n\\n**2. The work is remote but not flexible.**\\n\\n - This is much better than the previous. But it\u2019s still not good enough. The argument here is not due to absolute time but performance and state of mind.\\n - Life is not straightforward. We, as individuals, are very different between ourselves. Our bodies, mind, brain, relationships, \u2026 work very differently. By not being flexible on the working hours you are basically ignoring all of that diversity and grouping everyone into a single 9\u20135 + Mon-Fri category.\\n - _The \u201cironic\u201d part is that most companies promote diversity and don\u2019t think about this. Which just shows that the diversity topic has become very much a marketing vehicle._\\n - In my case, I\u2019m a night owl, I don\u2019t usually wake up too early, because I am much more productive when I stay awake until 3/4 am. If I have to wake up early because someone decided that 8:30am was the time that everyone needed to \u201ccheck in\u201d you are basically not getting the most out of me.\\n - One may wonder, well, this is a company problem because they are paying for an employee that is not performing as much as they could. Unfortunately, that\u2019s not true, it\u2019s a much bigger problem to the employee. This is because when an employee excels at a job they tend to have a much happier life which in turn increases performance, which increases happiness, and so on and so forth.\\n\\n**3. There is no mention for not remote but flexible because, in my opinion, that makes very little sense.**\\n\\n**4. Now, let\u2019s imagine the scenario where the work is remote and flexible.**\\n\\n - This is where it gets interesting. When we fall on this scenario your job perspective changes drastically. This is because at this point you put yourself first and can define your own priorities while having a pool of time to get a job done at your own time.\\n - E.g. you can plan activities with friends, do exercise, meditate, \u2026 whatever suits your lifestyle. Which will give you a boost of energy to perform even better at your job. On top of this, you don\u2019t need to squash the work within Mon-Fri, once you are in this flexible regime you may use the weekend to your advantage. Flights at 20 Euros on Tuesday to come back Thursday? Fine, I\u2019ll work during weekend to make up for this time\\n - There are people that love a 9\u20135 Mon-Fri schedule and that is fine. For those it means that the 9\u20135 Mon-Fri system implemented got it right. In fact, I would argue, that they are still wrapping work around lifestyle, it\u2019s just that their lifestyle is working 9\u20135 Mon-Fri and enjoying time outside these hours.\\n\\nThe downsides of this fully flexible work are:\\n\\n- Interaction with coworkers and communication. But with us going global due to remote work, it doesn\u2019t really matter, since the 9\u20135 hours of different countries would already lead to this problem\\n- Tracking employee timesheet. I think that a company shouldn\u2019t track an employee timesheet because results are far more important than working hours, and can be just as measurable.\\n\\n\\n\\nAll of this to say that at OpenBB we have:\\n\\n- **REMOTE WORK:** As long as you are in a location with internet access, we are not worried. This allows us to build a strong diverse team with different backgrounds and ideas.\\n- **FLEXIBLE HOURS:** We believe that your work should wrap around your lifestyle and not vice-versa. As long as you excel, you will not be asked why you woke up at noon.\\n- **UNLIMITED HOLIDAYS:** Who has time to track holidays when building such an exciting project? We trust in our people to manage their own PTO and keep performing at the highest level.\\n\\nAND this is how I sleep at night having no idea at what time John logged in and out:\\n\\n\\n\\nOhhh, and we\u2019re hiring!\\n\\nIf you provide a referral to someone that ends up joining OpenBB, I will transfer you $100 as a token of appreciation \ud83e\udd8b"},{"id":"looking-for-a-new-tattoo-openbb-has-you-covered-literally","metadata":{"permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.md","source":"@site/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.md","title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","description":"Exploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy.","date":"2022-04-21T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Marketing","permalink":"/blog/tags/marketing"},{"inline":true,"label":"Tattoo","permalink":"/blog/tags/tattoo"},{"inline":true,"label":"Brand Awareness","permalink":"/blog/tags/brand-awareness"}],"readingTime":3.125,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"looking-for-a-new-tattoo-openbb-has-you-covered-literally","title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","date":"2022-04-21T00:00:00.000Z","image":"/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.png","tags":["OpenBB","Marketing","Tattoo","Brand Awareness"],"description":"Exploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy."},"unlisted":false,"prevItem":{"title":"Remote + Flexible work >> Salary","permalink":"/blog/remote-flexible-work-salary"},"nextItem":{"title":"How I created the best discord meme bot","permalink":"/blog/how-i-created-the-best-discord-meme-bot"}},"content":"
\\n  \\n
\\n
\\n\\nExploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWhen [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) started last year, I went from having your typical career as a Software Engineer to becoming a co-founder & CEO of a C-Corporation overnight. One thing that I\u2019ve really learnt from this change, is I can no longer code for 12\u201316 hours a day straight as my role now involves so much more than this\u2026 and most interestingly, one of those things is marketing.\\n\\nDuring Easter in Lisbon, I was thinking about how to increase the visability of [OpenBB](https://openbb.co/). _An investment research platform for everyone, anywhere_. Seems self-explanatory and something most of us would relate to, but the problem is reaching a bigger audience.\\n\\nDue to [our $8.5M funding](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did) we have money in the bank, which means we can afford to do some ads campaigns. However, I very much dislike the traditional type of ads, whether that is with Google, Instagram, Twitter or YouTube. Particularly YouTube ones, when I see an ad there I immediately think less of the product being advertised due to how intrusive these are.\\n\\nThat\u2019s why I started thinking of ways to share our OpenBB brand in a non-intrusive way. In fact, I went one step further and started thinking when I personally would welcome ads.\\n\\nFunnily enough, the first thing that came to my mind was when I go to the bathroom without my phone. Although there\u2019s no ads on the back of shampoos/shower gel/soap/spray, I would very much welcome them.\\n\\n\\n\\nIt\u2019s not like knowing the %s of ingredients that makes up cleaning products has a lot of use cases\u2026\\n\\nThis brought me to the conclusion that I would only welcome ads if I was bored and didn\u2019t have anything keeping me \u201ctoo busy\u201d. This immediately made me think of London underground ads (the most effective type of DOOH imho). I always read those ads. The main reason being that I don\u2019t have WiFi underground and the noise is too loud to listen to a podcast. Hence, I imagined the underground looking like:\\n\\n\\n\\nWhen I checked for the prices, I was looking at a marketing campaign for a couple of days in a couple of stations costing over 5 digits, which is quite expensive for the short time-span.\\n\\nTherefore, I started to think of cheaper alternatives that yielded a better ROI. The next thing that passed through my mind was wearing OpenBB swag (yet to be revealed, [subscribe to our newsletter](https://openbb.co/newsletter) to know more). However, I feel like nowadays everyone has a t-shirt with a different logo and these aren\u2019t as noticeable as before \u2014 at least that\u2019s my perspective.\\n\\nThis lead me to think: **What about a tattoo?** It\u2019s a similar concept than OpenBB clothes but more powerful. In addition, when wearing OpenBB clothes with a visible tattoo, this will create a \u201ccuriosity\u201d effect since the symbol is repeated (clothes and tattoo). In addition, I\u2019ve not come across anyone using their body to express their brand.\\n\\nLater that day I booked a tattoo slot, paid 100 euros, and got the OpenBB logo on the back of my arm as shown below,\\n\\n\\n\\nI will let you know on my socials how many people ask about this tattoo over the course of my life.\\n\\nAnd if you like [our logo](https://www.openbb.design/9242dc28c/p/809a44-logo) and [our values](https://www.openbb.design/9242dc28c/p/91bbcc-our-values), OpenBB will pay you for the tattoo.\\n\\n**One things for sure, now I can definitely put the gym membership as a company expense since I\u2019m a walking billboard \ud83d\ude04**\\n\\nThe first walking/running/coding/eating/drinking OpenBB billboard."},{"id":"how-i-created-the-best-discord-meme-bot","metadata":{"permalink":"/blog/how-i-created-the-best-discord-meme-bot","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.md","source":"@site/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.md","title":"How I created the best discord meme bot","description":"In this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot.","date":"2022-04-09T00:00:00.000Z","tags":[{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"},{"inline":true,"label":"Meme Bot","permalink":"/blog/tags/meme-bot"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"}],"readingTime":3.89,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-created-the-best-discord-meme-bot","title":"How I created the best discord meme bot","date":"2022-04-09T00:00:00.000Z","image":"/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.png","tags":["Discord","Meme Bot","Open Source","Community Building"],"description":"In this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot."},"unlisted":false,"prevItem":{"title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally"},"nextItem":{"title":"Meet the most advanced investment research platform","permalink":"/blog/meet-the-most-advanced-investment-research-platform"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/discord-memes).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Background\\n\\nOver the past few weeks, life has been very chaotic on my end, mostly due to the announcement of [OpenBB](http://www.openbb.co/) last week which you can read the full story on [here](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\nWhen I started [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal), all my focus was on building, building and building. Once I made the project open source and contributors started to appear, I slowly saw my time shifting **from building a product to building a community**. This community ultimately would end up building the product, but from my end, I need to be able to pass on my passion to the project and vision.\\n\\nDeveloping features for the terminal only took me a couple of minutes, whereas the connection with the community is a long-time game. You don\u2019t become close with someone you\u2019ve never met within couple of minutes. Instead you need to put effort into the relationship and **consistency is key**.\\n\\nThe community on our Discord was growing day by day. And so was my relationship with the people in it. The truth is, we were not only sharing insights about the platform, but were laughing and bonding together whilst building it. **And memes/gifs are a big part of these interactions.**\\n\\nFor people who know me, they know how much I love memes and how I can always create memes for every situation (honestly, all the time I spent on Instagram is finally paying off).\\n\\nAlthough I believe that we have one of the most exciting open source projects going on, I also strongly believe that our fun culture (i.e. memes) is what makes contributors want to work in this particualr environment. **Building the future of investment research can be fun and this is what we\u2019re proving.**\\n\\nAt this stage, I think I\u2019ve spent more time interacting with people than I have working on the platform. The funny thing is that **the platform is 10x better than what it would be if I was working on my own**. Creating a strong community pays off and this is why since the start I was having calls with literally everyone to help them install our platform. Today, most of the team at OpenBB was met on Discord whilst working on the platform. **I didn\u2019t need any interviews, they weren\u2019t candidates anymore but people that I enjoyed to work with** and wanted on the team.\\n\\nSorry for the background story, but it was important to me to explain why I worked on this. **The interesting part of the article starts now.**\\n\\n## Development\\n\\n**The idea of Discord Memes is to avoid to open [imgflip](https://imgflip.com/) everytime I wanted to add text to a meme.** Personally, I love the gifs available through Discord but I think a meme with text is much more powerful (and funny).\\n\\nWhen I started coding this here and there, I wanted the code to be super straightforward so it was very simple and fast to add a new meme to the pool. And so I did.\\n\\nThe process to add new memes is incredibly easy. Go to the [project](https://github.com/DidierRLopes/discord-memes) and star it for starters (also [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) since you\u2019re at it). Then,\\n\\n1. Add the meme you want to the `memes/` folder, e.g. `spongebob.jpg`\\n\\n2. Then create a function with the same name of the image (e.g. `spongebob`) with the following format\\n\\n
\\n\\n```python\\n@create_and_send_meme()\\ndef spongebob(inter, text: str = None, _=None):\\n if text:\\n _.text(\\n 0.5,\\n 0.2,\\n \\"\\\\n\\".join(wrap(\'\'.join(choice((str.upper, str.lower))(c) for c in text), 40)),\\n fontsize=20,\\n color=\\"white\\",\\n alpha=0.9,\\n horizontalalignment=\\"center\\",\\n path_effects=[pe.withStroke(linewidth=4, foreground=\\"black\\")]\\n )\\n return _\\n```\\n\\n3. That\u2019s it.\\n\\n
\\n\\n**Note:** I created a python decorator `@create_and_send_meme()` that basically abstracts all the memes created and picks up the image on memes with the same name of the function. This way, the person adding a meme just needs to focus on the text on the image, i.e. it\'s location, size, where it wraps, colours and alignment.\\n\\nI used a playground.ipynb notebook, which is also on the repo, to increase the speed of the text placement on each of the memes I added.\\n\\nThis is how it looks,\\n\\n\\n\\nOR\\n\\n\\n\\nAs you can see, our Discord server just stepped up. [Join us](https://openbb.co/discord) to try out the meme bot, build the future of investment research or just to say hi.\\n\\nWe\u2019ll be waiting for you. \ud83e\udd8b"},{"id":"meet-the-most-advanced-investment-research-platform","metadata":{"permalink":"/blog/meet-the-most-advanced-investment-research-platform","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.md","source":"@site/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.md","title":"Meet the most advanced investment research platform","description":"Meet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities.","date":"2022-03-21T00:00:00.000Z","tags":[{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"},{"inline":true,"label":"Routines","permalink":"/blog/tags/routines"}],"readingTime":1.42,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"meet-the-most-advanced-investment-research-platform","title":"Meet the most advanced investment research platform","date":"2022-03-21T00:00:00.000Z","image":"/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.png","tags":["Investment Research","Gamestonk Terminal","Automation","Routines"],"description":"Meet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities."},"unlisted":false,"prevItem":{"title":"How I created the best discord meme bot","permalink":"/blog/how-i-created-the-best-discord-meme-bot"},"nextItem":{"title":"UX/UI is better than features","permalink":"/blog/gamestonk-terminal-ux-features"}},"content":"
\\n  \\n
\\n
\\n\\nMeet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nSeveral people have asked me why [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) doesn\u2019t have release versions, and the main reason is because at the pace the team codes and the rate that new features / bug fixes appear it doesn\u2019t yet makes sense to do so.\\n\\nTo give you an example, recently I shared the first **DEMO of what the terminal can do**, and I mention about our \u201croutines\u201d automation concept.\\n\\n
\\n\\nOne week later, using the latest version of the terminal, on top of that simplistic routine type you are able to:\\n\\n1. Provide variable input variables when calling the routine using $ARGV[i] (I used Perl convention here eheh)\\n2. Execute routines from within the terminal directly\\n3. Add comments to the routines so the process is more clear\\n4. Exporting data to a folder of choice is now possible\\n5. Exporting a file with a pre-defined name is now possible\\n6. Allow for the first line of the routines to be selecting a folder to export ALL the data\\n\\n
\\n\\nSee below a 1 minute video of what these routine automated scripts look like!\\n\\n
\\n\\nReach out if you have any question to the team, there\u2019s very little we can\u2019t do!\\n\\nThis is the way!"},{"id":"gamestonk-terminal-ux-features","metadata":{"permalink":"/blog/gamestonk-terminal-ux-features","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-01-06-gamestonk-terminal-ux-features.md","source":"@site/blog/2022-01-06-gamestonk-terminal-ux-features.md","title":"UX/UI is better than features","description":"Gamestonk Terminal\'s UX/UI features and the teamwork behind their implementation.","date":"2022-01-06T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"UX/UI","permalink":"/blog/tags/ux-ui"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"},{"inline":true,"label":"Teamwork","permalink":"/blog/tags/teamwork"}],"readingTime":4.19,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-ux-features","title":"UX/UI is better than features","date":"2022-01-06T00:00:00.000Z","image":"/blog/2022-01-06-gamestonk-terminal-ux-features.png","tags":["Gamestonk Terminal","UX/UI","Software Development","Teamwork"],"description":"Gamestonk Terminal\'s UX/UI features and the teamwork behind their implementation."},"unlisted":false,"prevItem":{"title":"Meet the most advanced investment research platform","permalink":"/blog/meet-the-most-advanced-investment-research-platform"},"nextItem":{"title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal"}},"content":"
\\n  \\n
\\n
\\n\\nGamestonk Terminal\'s UX/UI features and the teamwork behind their implementation.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n**Features attract users, UX/UI conquers them \u2694\ufe0f**\\n\\nThroughout month of December, me and 3 of the most active maintainers of [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) had a meeting where we discussed shifting our focus from adding features, to improving the terminal UX/UI to make it even more attractive. The main outcomes of these meeting were:\\n\\n1. Relative and Absolute menu jumping, e.g. if i\u2019m in crypto/ta and want to go to stocks/ta I can do:\\n\\n a. Absolute: `/stocks/load tsla/ta`\\n\\n b. Relative: `../../stocks/load tsla/ta`\\n\\n3. Scripting feature. You can now interact with the terminal through a sequence of commands, e.g.: `stocks/disc/ugs -l 3/gtech/active`.\\n\\n4. `reset` command everywhere to allow for faster development as it exits from the terminal and comes to the same menu running new terminal code and its API keys.\\n\\n5. Auto-completion in commands with choices.\\n\\n6. When misspelling a command name, if it\u2019s similar enough that the terminal recognises the right command, it will replace it, to speed up interaction.\\n\\n
\\n\\n\\n\\n6. Running a `.gst` job, like `python terminal.py scripts/test_stocks_disc.gst` which allows to run a sequence of commands of the terminal. In the future we can take advantage of this for integration tests. The user can build their own daily routines to speed up the investment process.\\n\\n
\\n\\n\\n\\nNow, I know what you\u2019re thinking. This is a massive improvement over the terminal usage up until now, and that\u2019s a **LOT** of code changes. Which is very much true, to be specific, this engineering effort resulted in:\\n\\n> **370 files changed with 44,875 additions and 18,463 deletions**\\n\\n
\\n\\nAnd you may be wondering how long did this take us to do. Nope, it wasn\u2019t months but\u2026\\n\\n\\n\\n**1 week. Yup, a single f*king week.** You can see that it was finalised with these PRs ([#1049](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1049), [#1041](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1041), [#1048](https://medium.com/@dro-lopes/gamestonk-terminal-ux-features-f9754b484919#1048)).\\n\\nIn that week we split work, did pair programming, we called each other to discuss better implementation practices, we changed the architecture 2/3 more times\u2026 On top of that, I was feeling overwhelmed with the stocks menu, I clearly underestimated how many features we have (how naive\u2026), so the 3 other maintainers jumped on it and helped me out. In 3 or so years of software engineering, this was** teamwork like I\u2019ve not felt before**.\\n\\nThat weekend I was so happy as we accomplished this task that I think I didn\u2019t even work on the terminal that Sunday! Doesn\u2019t happen often these days!\\n\\nHowever, as a good friend of mine told me:\\n\\n> _**\u201cThe entertainment industry hasn\u2019t found yet something more appealing than developing code towards a product I believe in and with people I like\u201d**_\\n\\n
\\n\\nI still think about this often, and this is what I tell my girlfriend, to explain why I\u2019m coding and not playing Mario Kart 8 Deluxe with her. (the fact she always beats me at it also may be considered as a factor \ud83e\udd23).\\n\\nYou may be thinking this is a one off, the reality is that **it isn\u2019t**. Another example can be seen in [this blog post](https://dev.to/northern64bit/aspiring-16-year-old-quant-developer-contributing-to-open-source-application-16k4). This goes over the story of the development of our discord bot where it all started from a message from a **16yo contributor that wants to become a quant**. He wanted to not only improve his python skills with us but also bring the terminal features to a bigger audience. Working with us in an open-source project is helping him towards achieving his life-goal dream.\\n\\nWhile I write this post another contributor, finishing his CPA, is working on [improving the code resulting from that UX effort by creating a base class](https://github.com/OpenBB-finance/OpenBBTerminal/pull/1141) so that new developers can add controllers much easily (he estimates a reduction of 11% of codebase size based on \u201cnapkin maths\u201d as he puts it).\\n\\n\\n\\nWhile user experience is critical, so is user interface. And that is why our next engineering effort will be around it. We already have something in the works in [this PR](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1140), where we can draw lines and write text! Almost like TradingView (almost\u2026 \ud83d\ude2c).\\n\\n\\n\\nSo, keep on the lookout because 2022 is gonna be a big year for us!! \ud83e\udd8b \ud83d\ude80\\n\\nOhh, before I say thanks for the read and all that, it\u2019s also worth mentioning that there\u2019s a PR in the queue for a new context called \u201c**alternative data**\u201d, which already has a **COVID menu** to factor that data into account on your investments.\\n\\n\\n\\n_PS: The blue text is because we are transitioning towards [rich package](https://github.com/Textualize/rich) which gives a lot more freedom when it comes to improving our user interface._\\n\\n
\\n\\nThanks for your read, and if you enjoy Gamestonk Terminal, please reach out to [our discord](https://discord.gg/ptYabd8w) to say thank you, or ideally: for **@terp340** to change date format to dd/MM/YYYY \u2014 **the only correct one**!\\n\\nHappy 2022 with lots of love \u2764\ufe0f"},{"id":"sector-and-industry-analysis-gamestonk-terminal","metadata":{"permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.md","source":"@site/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.md","title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","description":"The development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package.","date":"2021-12-02T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Sector Analysis","permalink":"/blog/tags/sector-analysis"},{"inline":true,"label":"Industry Analysis","permalink":"/blog/tags/industry-analysis"},{"inline":true,"label":"FinanceDatabase","permalink":"/blog/tags/finance-database"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":4.01,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"sector-and-industry-analysis-gamestonk-terminal","title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","date":"2021-12-02T00:00:00.000Z","image":"/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.png","tags":["Gamestonk Terminal","Sector Analysis","Industry Analysis","FinanceDatabase","Open Source"],"description":"The development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package."},"unlisted":false,"prevItem":{"title":"UX/UI is better than features","permalink":"/blog/gamestonk-terminal-ux-features"},"nextItem":{"title":"Handing your twitter account to your most avid community member","permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member"}},"content":"
\\n  \\n
\\n
\\n\\nThe development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe end-to-end story of developing a new **Sector and Industry Analysis** for [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) from scratch.\\n\\nOn the 13th of October, [Jeroen Bouma](https://github.com/JerBouma) (a ALM advisor and python enthusiast) reached out in order to integrate his [FinanceDatabase package](https://github.com/JerBouma/FinanceDatabase) into [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal).\\n\\n\\n\\nAfter having a call with Jeroen to bounce ideas, it was clear that our terminal needed such capability to be even more powerful (as if **over 500 features** already and counting didn\u2019t already do the trick eheh). However, at the time I was too busy to work on the concept so I asked Jeroen if he could sketch something up on a jupyter notebook.\\n\\nWithin the following week, Jeroen sent a Jupyter notebook explaining the FinanceDatabase module and what we could have in a Sector and Industry analysis.\\n\\n\\n\\nIn addition, he also mentioned his [PassiveInvestor package](https://github.com/JerBouma/ThePassiveInvestor), and ended up [implementing it on his own in Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/857)! This was a great addition, as it strengthened our **ETF context** and provided a slick Excel report for the Excel fans out there! See his [LinkedIn post](https://www.linkedin.com/feed/update/urn:li:activity:6859887432532291584/) on the experience.\\n\\n\\n\\n...\\n\\nForward to last weekend (1.5 months later), I had a free Sunday afternoon so started working on the development of this menu. I started by thinking about what would make this menu more flexible and powerful.\\n\\n\\n\\nThese were my thoughts about what it needs:\\n\\n- **Several filtering parameters** as the number of companies in the database is pretty huge with 155.705 tickers, 16 sectors, 242 industries, 111 countries and 82 exchanges. These were the filters selected: Country, Sector, Industry, Market Cap and Flag to include/exclude international exchanges.\\n- **To be able to do some statistics on the sector**, industries and countries (e.g. companies per sector/industry with a specified country and market cap) which allows users to better understand companies landscape of a sector and industry.\\n- **To get the financials of the companies that fall under that filter subset** (e.g. return on assets, quick ratio, debt to equity), and then compare these in order to get the best performers.\\n- Since one of the previous financials isn\u2019t enough to understand which company would be best to invest in, I wanted the filtered companies to have the capability to jump onto the comparison analysis menu so you could get all the capabilities of comparing historical price data, volume data, income/balance/cash flow, sentiment, or even technical indicators.\\n- If in the stocks context I had Tesla loaded, I wanted to go into this sia menu and get all the filtering parameters to be ready to filter for companies similar to Tesla in terms of (Sector, Industry, Country and Market Cap).\\n\\nBy Sunday night, I created the [pull request for this](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/995). Due to the due diligent reviews performed by the main contributors of the project, the menu got a lot of improvements. Some of them were:\\n- Do not display companies that account for under a certain threshold (1%) and therefore sum them in an \u201cOthers\u201d slice.\\n- Allow to export all the data as a table.\\n- After filtering and getting financials, save the data for faster data retrieval if the same filters are used.\\n- Minor bug fixes.\\n\\nAfter a lot of comments and feedback from the main maintainers, and everyone being happy with this first iteration, the PR got merged. In fact, one of the main maintainers found a hidden gem while testing it.\\n\\n\\n\\nIn the meantime, I\u2019ve been in contact with Jeroen about adding some more capabilities to his FinanceDatabase package so that everyone could benefit from them. Some examples are:\\n- When an industry is selected, the corresponding sector should be automatically filled.\\n- If I select a country and a market cap for filtering, my sector choices should be bounded by what exists within those.\\n- I should be able to query about companies landscape in terms of a country. E.g. I want to understand what countries have the most large cap companies within the Financial Services sector.\\n\\nThis would not only make the FinanceDatabase a more powerful Package, which would in turn benefit Gamestonk Terminal sia menu, and ultimately our thousands of users!\\n\\n\\n\\nThis is an example of how the Sector and Industry Analysis menu looks (as a bonus I show how you can go into the Comparison Analysis menu):\\n\\n\\n\\nNext time you know, it all starts with an e-mail. At Gamestonk Terminal we are on a role to have the best investment research terminal, and hope this story reflects it.\\n\\nTry it now, it\u2019s free. \u2764\ufe0f"},{"id":"handing-your-twitter-account-to-your-most-avid-community-member","metadata":{"permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.md","source":"@site/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.md","title":"Handing your twitter account to your most avid community member","description":"Handing over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement.","date":"2021-11-17T00:00:00.000Z","tags":[{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"},{"inline":true,"label":"Twitter","permalink":"/blog/tags/twitter"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"}],"readingTime":4.305,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"handing-your-twitter-account-to-your-most-avid-community-member","title":"Handing your twitter account to your most avid community member","date":"2021-11-17T00:00:00.000Z","image":"/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.png","tags":["Community Building","Twitter","Open Source","Gamestonk Terminal"],"description":"Handing over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement."},"unlisted":false,"prevItem":{"title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal"},"nextItem":{"title":"The Start of my Machine Learning journey","permalink":"/blog/the-start-of-my-machine-learning-journey"}},"content":"
\\n  \\n
\\n
\\n\\nHanding over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWhen I started [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) I had no idea of the reach and impact it would have. From getting **over 3.5k stars on GitHub on the first single day alone**, to trending [on Reddit](https://www.reddit.com/r/algotrading/comments/lrndzi/cant_afford_the_bloomberg_terminal_no_worries_i/) and receiving overwhelming feedback, to receiving a message from an ex-colleague based in Switzerland about my name being [top 1 on Hackernews](https://news.ycombinator.com/item?id=26258773). As if this wasn\u2019t enough, a couple of days later the project got featured by [VICE Magazine](https://www.vice.com/en/article/qjp9vp/gamestonk-terminal-is-a-diy-meme-stock-version-of-bloomberg-terminal) and [Daily Fintech](https://dailyfintech.com/2021/02/25/never-underestimate-bloomberg-but-here-are-5-reasons-why-the-gamestonk-terminal-is-a-contender/).\\n\\nAs a result, my social life was impacted and had little time to even cuddle my puppy, due to the amount of feature requests, issues\u2026 the usual somehow ungrateful life of an open-source maintainer\u2026 I\u2019m not complaining though, as I live for this.\\n\\n\\n\\nMoving forward a couple of weeks, it became clear to myself that I was building a strong community around what can/will/should be a leading product in the emerging fintech industry and Internet 3.0. Therefore, I knew that github issues and discussions wouldn\u2019t be enough to interact with all members of the community, so Discord turned out to be the best option going forward (let\u2019s be honest: mostly because of the convenience that Discord offers to share memes, feel free to check my creations on [our Discord](https://discord.gg/2KnVnkDTxM), you can thank me later).\\n\\nMy next rookie mistake was thinking I could use Discord announcements and @ everyone, as a means for updating the community on new features. Being the #1 investment research free and open-source project on github gets you several PRs a day being merged, so in all the fairness the announcements were recurrent with constant several new features. You can check my [one hour live programming stream](https://www.youtube.com/watch?v=9BMI9cleTTg) of adding a feature to the terminal.\\n\\n\\n\\nThis is when I realized that Discord wasn\u2019t the best place for this type of communication. I needed a platform where I could share these features ad-hoc and that only alerted users who wanted to be up-to-date with our latest features. And this is when I created our [Twitter account](https://twitter.com/gamestonkt), @gamestonkt.\\n\\nReviewing the history of our Twitter feed, you can see that this is exclusively what our handle was used for. It just shared new features every day. It felt like I was always playing catchup to the growing number of features piling up in the queue waiting to be announced on Twitter. With the project already having **over 500 features** in less 1 year, this inevitable outcome would be a surprise to no one. (**yup, I repeat, over 500**).\\n\\n\\n\\nHowever, I felt like **it missed personality**... With time being a limiting factor \u2014 time was more efficiently used improving the terminal \u2014 the public facing demonstrations were a lower priority. When you believe this much in a product, the product ends up speaking for itself.\\n\\n> _\u201cIf you build it, they will come\u201d \u2014 Field of Dreams_\\n\\n
\\n\\nIt then occurred to me, why am I handling our Twitter? Why not leave this up to one of our most avid and vocal users that has been with project since beginning?\\n\\nAs Jim from \u201cThe Office\u201d would do, let\u2019s do a PROS & CONS table.\\n\\n### Pros\\n\\n- The user represents the community that the twitter content is targeted at.\\n- The user is an active daily user and will help to demonstrate features in the terminal.\\n- The user is keen on learning the ins and outs of the product.\\n- This user is not only a user anymore but a friend given his interaction with the maintainers.\\n- Lastly, I get to spend time doing what I enjoy: coding and meme content on our Discord.\\n\\n### Cons\\n\\n- The user finds out my mother\u2019s maiden name and the name of my first pet.\\n\\nThis is really a no brainer the more you think about it. I think it depends a lot on the type of people you have in your community and how confident you are on this individual .\\n\\nWe were lucky, because we had the **perfect fit**: an active Discord user **@Danglewood**, who had built an engaged audience, generating over 130K+ in Reddit karma over Q2 2021. It was clear that **@Danglewood** was having an impact on driving traffic and user engagement by posting data and his personal research with screenshots of Gamestonk Terminal.\\n\\nIn the future, **our report feature will allow easy sharing of this information**, I already can\u2019t wait for this. Through a combination of humour and truths, he was engaging the audience\u2019s curiosity by providing them with ways to filter out the ever-present noise within stock market information.\\n\\nIt made sense to bring this approach to [our Twitter](https://twitter.com/gamestonkt) feed which has since transformed and now offers insights, educational nuggets, and data as well as presenting new features. The end result speaks for itself!\\n\\n\\n\\nOn your end, what is your opinion? And why do you 100% agree that this was the best decision?"},{"id":"the-start-of-my-machine-learning-journey","metadata":{"permalink":"/blog/the-start-of-my-machine-learning-journey","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-11-07-the-start-of-my-machine-learning-journey.md","source":"@site/blog/2021-11-07-the-start-of-my-machine-learning-journey.md","title":"The Start of my Machine Learning journey","description":"The start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms.","date":"2021-11-07T00:00:00.000Z","tags":[{"inline":true,"label":"Machine Learning","permalink":"/blog/tags/machine-learning"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Education","permalink":"/blog/tags/education"},{"inline":true,"label":"Self-Learning","permalink":"/blog/tags/self-learning"}],"readingTime":4.62,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-start-of-my-machine-learning-journey","title":"The Start of my Machine Learning journey","date":"2021-11-07T00:00:00.000Z","image":"/blog/2021-11-07-the-start-of-my-machine-learning-journey.png","tags":["Machine Learning","Python","Data Science","Education","Self-Learning"],"description":"The start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms."},"unlisted":false,"prevItem":{"title":"Handing your twitter account to your most avid community member","permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member"},"nextItem":{"title":"An unusual journey learning about NNs for a PhD thesis","permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis"}},"content":"
\\n  \\n
\\n
\\n\\nThe start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDuring my studies at [Imperial College London](https://www.imperial.ac.uk/) - 3ish years ago - I was introduced to the topic of Machine Learning, an area that I had always been interested about.\\n\\nAt that time, not only I didn\'t know python, as `from sklearn.decomposition import PCA` wasn\u2019t allowed. Therefore, we had to write the PCA (and other) algorithms in Matlab from scratch, which was great because it exposed us to the maths behind each algorithm.\\n\\n\\n\\nThe gif above is from my graduation at Royal Albert Hall with a MSc. in Control Systems with Distinction.\\n\\nAfter concluding my thesis (and paper): \\"[Energy savings from an Ecological Cooperative Adaptive Cruise Control: a Battery Electric Vehicle platoon investigation](https://ieeexplore.ieee.org/abstract/document/8796226)\\", which was presented at the 2019 European Control Conference in Napoli, I had finally time to focus on Machine Learning topics during my spare time through late hours and into weekends.\\n\\nI started by doing the famous MOOC **\u201cMachine Learning - Andrew Ng\u201d**. Saying that the course was good is an understatement. I ended up spending a long time on the course as I was taking notes and revising daily; I was still behaving like a university student even without the exam at the end! Not only the theory is really detailed, but the coursework in Matlab allowed me to understand what\u2019s going on under the hood. Given that I was already a heavy Matlab user, due to its usage throughout my entire academic journey, I could focus on the ML section.\\n\\nAfter this course, I knew that I had learnt a lot, but I also knew that if I wanted to use ML for real-applications, I\u2019d have to learn Python. Given that I knew Matlab, I choose to start reading a python book that had Data Science application in mind. Hence, I started reading **\u201cPython Data Science Handbook\u201d**. This, along with several hours of practicing on available datasets, has taught me pretty much all I know about Numpy, Pandas and Matplotlib. Although this book also contains a last chapter with ML algorithms, these are rather brief.\\n\\n> _In my previous job at Nurvv, where I worked as Sensor Fusion Engineer, I developed a python analysis tool that parsed all the raw data from a running session and conveyed that information into meaningful plots. This allowed us to analyse whether a run was successful from the Firmware side of things, and this was critical for our development. This tool was created mainly from the knowledged gathered from the book mentioned above._\\n\\n
\\n\\nFollowing this, I was rather confident with my Python skills. Therefore, I wanted to crack-on learning how to use ML algorithms with Python through the beauty of imports. It comes without saying that I had to start from the best-seller **\u201cHands-on Machine Learning with Scikit-Learn, Keras and TensorFlow\u201d**. This book was what I was expecting and more. From time to time, when I\u2019m working on personal projects, I still flick through it. This book also allowed me to develop many more personal projects (most of them public in [my GitHub](https://github.com/DidierRLopes), as I\u2019m a big Open-Source fan \u2014 you should know that as I made [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) repository public).\\n\\n\\n\\nThe project that has been my biggest challenge was working with a friend on his PhD thesis entitled _\u201cModelling and Forecasting of Time-Series: A data science approach that compares classic methodologies with deep learning methodologies\u201d_. Not only interpreting and discussing results but writing the code behind it. S/O to the resources: **\u201cForecasting: Principles and Practice\u201d** and **\u201chttps://machinelearningmastery.com\u201d**. Without these, this work would have been much harder.\\n\\nThroughout my short journey, I followed many people related with DS. People that I thought that in some shape or form added value through their posts. One of these, was Andriy Burkov. I remember when he started talking about creating the **\u201cThe Hundred-Page Machine Learning Book\u201d** and specifically, I remember his Linkedin\'s poll to select the colour of one of the bubbles for his books\' cover. I voted purple; the result was yellow. So, I took the freedom to fix the cover of his book, as you can see below.\\n\\n\\n\\nMy gecko Reidid on \u201cThe Hundred-Page Machine Learning Book\u201d\u200b, in order to keep industry standards of ML books with reptiles.\\n\\nI really enjoyed his book since it can explain everything, while keeping it simple and short. As I learned at University, _Keep It Simple, Stupid_. Also, his book is distributed in a \u201cread first, buy later\u201d principle. This meant that I was able to flick through the content of the book before buying it. Personally, I think this should be adopted more often, at least for technical books.\\n\\nFinally, last summer, while on holiday in Portugal, I read **\u201cApproaching (almost) any machine learning\u201d**, which I found to be great for people that have read about the theory but were wondering where/how to apply it.\\n\\nThe next ML books in my list are:\\n- **Deep Learning** \u2014 Aaron Courville, Ian Goodfellow, and Yoshua Bengio\\n- **The Elements of Statistical Learning** \u2014 Jerome H. Friedman, Robert Tibshirani e Trevor Hastie\\n- **Pattern Recognition and Machine Learning** \u2014 Christopher Bishop\\n- **Understanding Machine Learning: From Theory to Algorithms** \u2014 Shai Ben-David and Shai Shalev-Shwartz\\n\\nLet me know if you think these are good books, or if there are others that you\u2019d recommend."},{"id":"an-unusual-journey-learning-about-nns-for-a-phd-thesis","metadata":{"permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.md","source":"@site/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.md","title":"An unusual journey learning about NNs for a PhD thesis","description":"An unusual journey of learning about Neural Networks for a PhD thesis. This blog post details the author\'s experience of assisting in the programming aspect of a PhD thesis, focusing on the study of various models and their forecasting performance.","date":"2021-10-22T00:00:00.000Z","tags":[{"inline":true,"label":"PhD Thesis","permalink":"/blog/tags/ph-d-thesis"},{"inline":true,"label":"Neural Networks","permalink":"/blog/tags/neural-networks"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Time Series Forecasting","permalink":"/blog/tags/time-series-forecasting"}],"readingTime":3.625,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"an-unusual-journey-learning-about-nns-for-a-phd-thesis","title":"An unusual journey learning about NNs for a PhD thesis","date":"2021-10-22T00:00:00.000Z","image":"/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.png","tags":["PhD Thesis","Neural Networks","Python","Time Series Forecasting"]},"unlisted":false,"prevItem":{"title":"The Start of my Machine Learning journey","permalink":"/blog/the-start-of-my-machine-learning-journey"},"nextItem":{"title":"How I created a bot in python to participate in NFT giveaways","permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways"}},"content":"
\\n  \\n
\\n
\\n\\nAn unusual journey of learning about Neural Networks for a PhD thesis. This blog post details the author\'s experience of assisting in the programming aspect of a PhD thesis, focusing on the study of various models and their forecasting performance.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOn 14th February of 2019, my previous Maths and Statistics teacher \u2014 [Filipe](https://www.linkedin.com/in/filipe-r-ramos-a66242143/) - sent me a messaged because of a Linkedin post I shared about work I was doing in python.\\n\\nIt turns out that Filipe was looking for someone to help him with his PhD thesis, in specific, with the programming side of it. The challenge was to study diverse models (from classical to neural networks) and assess their forecasting performance. Since time series prediction was always a topic that I found fascinating and hadn\u2019t had time to study, I thought this would be the perfect timing to do so.\\n\\nSo from February 2019 onwards, this exciting journey started. I was working full-time so in order to be able to take part in this, I was only sleeping 4/5h a day. I started reading a lot of books and practicing my python coding skills in order to be more helpful. Then around June, we started working together on the code. We had around 2\u20133h discussions a couple times a week where we would discuss the point of the situation code-wise and where we wanted to be, we kept in touch about this every day.\\n\\nFrom the repo, which is open source [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast), you can see that we explored: Exploratory Data Analysis; ARIMA and SARIMA; Exponential Smoothing; Deep Neural Network. The final part of this work consisted in an innovative approach to tackle an univariate time series, which you can find [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast/blob/master/DNN_ourApproach.ipynb). On top of that, a library of cross-validation for Neural Networks was developed, which is now being used in real data science applications, see [here](https://github.com/DidierRLopes/timeseries-cv).\\n\\nThe work, which took around 1 year to complete, can be divided into 3 distinct phases:\\n\\n- The **coding** phase lasted around 3 months. I would write the code, test the code and then touch base with Filipe to ensure we were going in the right direction.\\n- The **tweaking and analysis phase** took around another 3 months. Here, Filipe took the code I had completed and analysed multiple time series with different trends and seasonalities; tweaked different models; trained and validated these; and started interpreting results. In this phase, me and Filipe would discuss the code from a pragmatic point of view, and improve it based on what Filipe wanted to see/analyse. This phase was so intense that Filipe flew out to London twice to meet me, almost over a period of 1 month.\\n- The **writing of the thesis phase** took an additional 6 months. Here Filipe basically translated the results and analysis seen on the notebook of the thesis, wrote a full theoretical background on the models used and interpreted the applicability of these.\\n\\nThe full work, _\u201cData Science in the Modeling and Forecasting of Financial timeseries: from Classic methodologies to Deep Learning\u201d_, can be found in [here](https://ciencia.iscte-iul.pt/publications/data-science-na-modelacao-e-previsao-de-series-economico-financeiras-das-metodologias-classicas-ao/82703) or stored in [here](https://repositorio.iscte-iul.pt/handle/10071/22964).\\n\\nDuring this time, Filipe was also working full-time as he was a teaching assistant in three different universities. In spite of the adversities, Filipe achieved an impressive approved with \u201c_unanimous distinction_\u201d (maximum classification) from ISCTE Business School, Lisbon, Portugal.\\n\\nMy character waiting for people to join my chatroom to discuss our poster.\\n\\n\\n\\nLast week, at XXV Congress of the Portuguese Statistical Society (SPE 2021), we presented:\\n\\n- A poster that you can find [here](https://www.researchgate.net/publication/355360806_Forecasting_models_for_time-series_a_comparative_study_between_classical_methodologies_and_Deep_Learning), titled: _\u201cForecasting models for time-series: a comparative study between classical methodologies and Deep Learning\u201d_\\n- A presentation that you can find [here](https://www.researchgate.net/publication/355360897_Explorando_o_poder_da_memoria_das_redes_neuronais_LSTM_na_modelacao_e_previsao_do_PSI_20), titled: _\u201cExplorando o poder da mem\xf3ria das redes neuronais LSTM na modela\xe7\xe3o e previs\xe3o do PSI 20\u201d_\\n\\n\\n\\nThe poster above was presented at XXV Congress of the Portuguese Statistical Society (SPE 2021).\\n\\nI started this journey with my previous maths teacher and ended it with a close friend! Excited to see what other articles/publications we\u2019ll be working on together in the future.\\n\\nPS: The ARIMA/ETS/MLP/RNN/LSTM models learned from this work, consisted the basis of the prediction menu on [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal).\\n\\nAs always, feel free to provide feedback!"},{"id":"how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","metadata":{"permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.md","source":"@site/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.md","title":"How I created a bot in python to participate in NFT giveaways","description":"In this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork.","date":"2021-09-30T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Bot","permalink":"/blog/tags/bot"},{"inline":true,"label":"NFT","permalink":"/blog/tags/nft"},{"inline":true,"label":"Giveaways","permalink":"/blog/tags/giveaways"},{"inline":true,"label":"Reddit","permalink":"/blog/tags/reddit"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"}],"readingTime":2.82,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","title":"How I created a bot in python to participate in NFT giveaways","date":"2021-09-30T00:00:00.000Z","image":"/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.png","tags":["Python","Bot","NFT","Giveaways","Reddit","Automation"],"description":"In this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork."},"unlisted":false,"prevItem":{"title":"An unusual journey learning about NNs for a PhD thesis","permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis"},"nextItem":{"title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GiveawayNFTbot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLately I\u2019ve been looking into NFTs. I\u2019ve observed that more and more people are trying to innovate and create their own pieces of art. Some of them are impressive, some of them aren\u2019t. But,\\n\\n> _Beauty is in the eye of the beholder \u2014 Margaret Wolfe Hungerford_\\n\\n
\\n\\nHowever, in my humble opinion, what distinguishes some art from others, is most of the time not the art itself but the community around it. For example, when everyone starts talking about the \u2018new best thing\u2019 you feel more pressure to get involved.\\n\\nBecause of this dynamic, creators are investing in ways to increase their collectibles popularity by building their community. A great example is [ParallelNFT](https://parallel.life/) and the dystopic story that is being created around their cards \u2014 in their case, it\u2019s fairly easy to understand that once a big community is formed around such cards, video games, movies and even series are on the table. For the first time ever, we would go from selling collectibles to creating some form of entertainment. A whole new industry in the making.\\n\\nHowever, not every digital creator has the resources to create a full concept around their cards. Does this mean that they can\u2019t create a community around it? No. But they must find other ways. One of the most popular ways I\u2019ve seen is through giveaways. Similar to what small clothing brands do to increase their popularity. This is a great tactic in my opinion, since giveaway not only give you a bigger audience (people that participate and re-share content) but it makes the cards have multiple owners. This, as a result, makes the collection more attractive for NFT collectors.\\n\\n_When demand exceeds supply_, **prices tend to rise.**\\n\\nAnd these creators are using Reddit as the platform of their giveaways.\\n\\n\\n\\nWhen scrolling through reddit you will notice that all these posts have certain things in common:\\n- They ask for an up-vote on the post\\n- A comment with your wallet address\\n- To favourite their artwork\\n- They may also ask to you to join their Discord\\n- For a follow on their Twitter or Instagram\\n- If you can retweet or share a story\\n\\nThese are things that take time, and a bot can perfectly do this. Therefore, I wrote a [giveaway NFT bot](https://github.com/DidierRLopes/GiveawayNFTbot) to simplify my work. Now I just sit down and read robot vacuum reviews while the bot: upvotes, comments and opens their Opensea link for me to favourite their artwork.\\n\\nI\u2019ve already won multiple NFTs with this, which is exciting\u2014 you never know where the next [CryptoPunks](https://twitter.com/cryptopunksbot) are at.\\n\\nThere\u2019s actually 1 collection that I particularly like and believe has a lot of potential, it\u2019s called [CryptoCartoonEaters](https://opensea.io/collection/crypto-cartooneaters) and due to the uniqueness of each collectible (only 100 made), I really think it has a great potential. I acquired my favourite cartoon as a kid: Goku Eating a Burger.\\n\\n\\n\\nLet me know if you find this article interesting, and if you used the bot as well!"},{"id":"gamestonk-terminal-cant-stop-won-t-stop","metadata":{"permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.md","source":"@site/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.md","title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","description":"Gamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool.","date":"2021-09-16T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Docker","permalink":"/blog/tags/docker"},{"inline":true,"label":"Jupyter Lab","permalink":"/blog/tags/jupyter-lab"},{"inline":true,"label":"Hugo Website","permalink":"/blog/tags/hugo-website"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Trading","permalink":"/blog/tags/trading"}],"readingTime":3.175,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-cant-stop-won-t-stop","title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","date":"2021-09-16T00:00:00.000Z","image":"/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.png","tags":["Gamestonk Terminal","Open Source","Docker","Jupyter Lab","Hugo Website","Python","Finance","Trading"],"description":"Gamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool."},"unlisted":false,"prevItem":{"title":"How I created a bot in python to participate in NFT giveaways","permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways"},"nextItem":{"title":"Time-Series CrossValidation for NN","permalink":"/blog/time-series-crossvalidation-for-nn"}},"content":"
\\n  \\n
\\n
\\n\\nGamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHey all,\\n\\nDo any of you know what **Docker, Jupyter Lab integration, features website and new features** have in common? Well this is what has been happening in [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) world since last month, and **MORE**!\\n\\n### Docker\\n\\n- This has been a highly requested feature from our more experienced dev users, as it allows you to run our code in a container, pull the image and then get going with a smooth installation process. You will also be able to run Jupyer Lab from our Docker container.\\n\\n### Jupyter Lab Integration\\n\\n- Jupyter is on course to take over the world (see [here](https://netflixtechblog.com/notebook-innovation-591ee3221233)).\\n- Big investment banks like JP Morgan use Jupyter too, see [this](https://github.com/jpmorganchase/jupyterlab_templates).\\n- Professionals in the industry such as Data Scientists, Data Analysts and Machine Learning engineers are familiar with the combo dockers+notebooks. Therefore, it makes our terminal an attractive Open-Source project to devote time to.\\n- Academia students and universities will be able to use terminal data through a notebook for their projects and coursework. We\u2019re on track to be able to achieve something on this soon!\\n\\n### Hugo Website\\n\\n- Link [here](https://gamestonkterminal.github.io/GamestonkTerminal/).\\n- This will not only simplify a contributor\u2019s documentation process, but it will also let non-Gamestonkers now see the vast number of features we offer and yes, when you read \u201coffer\u201d this is actually an offer since the tool is **completely free** to use.\\n\\n### Main New features\\n\\n- New Dark Pool Shorts menu\\n- Refactored and improved Crypto menu!!!\\n- Dark Pool and Crypto report generation\\n- Excel Discounted Cash Flow created by a MBA student\\n- Big code refactoring to allow for contributors to easily get started with our codebase\\n- Contributing document (click here).\\n\\n### Tier 2 features\\n- [Sentiment Investor](https://sentimentinvestor.com/) data features implemented by the SI team themselves\\n- Feature/fraud indicators implemented by a MBA student\\n- Multiple plotting for economy data for more insight extraction\\n- Screener presets to not miss out on promising tickers\\n- Several new Technical Analysis indicators, e.g. Fibonacci, Fisher transform, Centre of gravity, zlma, Donchian channels\u2026\\n- Unusual options activity\\n- Hot penny stocks in discovery menu\\n- A contributor implementation of a realtime earnings expected move, from [The Geek of Wallstreet](https://thegeekofwallstreet.com/2021/08/03/realtime-earnings-data/)\\n- Several new YahooFinance commands to discover promising tickers\\n- Refactor Exploratory Data Analysis and Residual Analysis menus into a Quantitative Analysis one\\n\\nAs if this wasn\u2019t enough, we\u2019re also working towards a [Discord bot](https://github.com/GamestonkTerminal/DiscordBot) so you can make best use of our terminal when discussing trading strategies with your friends. This was an initiative from a contributor, which just goes to show how much **we rely on our community to drive our project**.\\n\\nIf you appreciate what we\u2019re doing and want a better free and Open-Source financial tool, you should definitely star the project on our github [here](https://github.com/GamestonkTerminal/GamestonkTerminal), join [our Discord channel](https://discord.gg/Up2QGbMKHY), and follow our [twitter account](https://twitter.com/gamestonkt?lang=en). Not necessarily in that order! :)\\n\\nHave you been following our project and want to join our growing community? Here are a few tips on how to get started:\\n- Join our Discord and tell us about your experience so far\\n- Let us know what else you would like to see in the terminal\\n- You can help to improve our crypto terminal, which is 99% taken care of from our contributors!\\n- Help us add any features! You don\u2019t know python? This may be your cue to learn with our team!\\n\\nMuch love!\\nGST Team & Community"},{"id":"time-series-crossvalidation-for-nn","metadata":{"permalink":"/blog/time-series-crossvalidation-for-nn","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-04-time-series-crossvalidation-for-nn.md","source":"@site/blog/2021-09-04-time-series-crossvalidation-for-nn.md","title":"Time-Series CrossValidation for NN","description":"This blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN).","date":"2021-09-04T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Deep Learning","permalink":"/blog/tags/deep-learning"},{"inline":true,"label":"Time Series","permalink":"/blog/tags/time-series"},{"inline":true,"label":"Cross Validation","permalink":"/blog/tags/cross-validation"},{"inline":true,"label":"Neural Networks","permalink":"/blog/tags/neural-networks"}],"readingTime":2.66,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"time-series-crossvalidation-for-nn","title":"Time-Series CrossValidation for NN","date":"2021-09-04T00:00:00.000Z","image":"/blog/2021-09-04-time-series-crossvalidation-for-nn.png","tags":["Python","Data Science","Deep Learning","Time Series","Cross Validation","Neural Networks"],"description":"This blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN)."},"unlisted":false,"prevItem":{"title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop"},"nextItem":{"title":"Ranking 99 Mind f*ck movies","permalink":"/blog/ranking-99-mind-f-ck-movies"}},"content":"
\\n  \\n
\\n
\\n\\nThis blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN).\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/timeseries-cv).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n2 years ago, [Filipe Ramos](https://www.linkedin.com/in/ACoAACK9n24BrpxWf0HMa9bL7MSHleu2YVXpI5E) my previous maths and probability teacher, knowing that I had a special interest in Data Science, challenged me to help him in his PhD thesis \u201c_Data Science na Modela\xe7\xe3o e Previs\xe3o de S\xe9ries Econ\xf3mico-financeiras: das Metodologias Cl\xe1ssicas ao Deep Learning_\u201d.\\n\\nAlthough we have been discussing theory, analysis and results, my main contribution was to write the Python code behind the thesis.\\n\\nAs a result, I have written a python module that splits a given univariate time-series based on cross-validation techniques so that these can be fed to a Deep Neural Network (DNN) to extract training/validation/test errors.\\n\\nI know that there are examples of these online, but this was made from scratch so that we could personalise it according to the thesis\u2019 needs, and grasp better what was at stake when performing different cross-validation techniques.\\n\\n**The idea is given a training dataset, the package will split it into Train, Validation and Test sets, by means of either Forward Chaining, K-Fold or Group K-Fold.**\\n\\nAs parameters the user can not only select the number of inputs (`n_steps_input`) and outputs (`n_steps_forecast`), but also the number of samples (`n_steps_jump`) to jump in the data to train.\\n\\nThe best way to install the package is as follows: `pip install timeseries-cv` and then use it with `import tsxv`. See the module developed [here](https://pypi.org/project/timeseries-cv/).\\n\\nThis can be seen more intuitively using the jupyter notebook: \u201c_example.ipynb_\u201d Below you can find an example of the usage of each function for the following Time-Series:\\n\\n```python\\ntimeSeries = array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26])\\n```\\n\\n## Split Train\\n\\n```python\\nfrom tsxv.splitTrain import \\nsplit_train, \\nsplit_train_variableInput\\nX, y = split_train(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y = split_train_variableInput(timeSeries, minSamplesTrain=10, n_steps_forecast=3, n_steps_jump=3)\\n```\\n\\n
 \\n
\\n  \\n
\\n \\n
\\n  \\n
\\n\\n\\n\\n\\n## Split Train Val Test\\n\\n```python\\nfrom tsxv.splitTrainValTest import split_train_val_test_forwardChaining, \\nsplit_train_val_test_kFold,\\nsplit_train_val_test_groupKFold\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_forwardChaining(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_kFold(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_groupKFold(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\n```\\n\\n
 \\n
\\n  \\n
\\n\\n\\n\\n\\nThis module has not only been used for my friends\u2019 thesis but also for a Data Science company and [Gamestonk Terminal](/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal), that I know of :)\\n\\nYou can check the stats of the module [here](https://pypistats.org/packages/timeseries-cv)."},{"id":"ranking-99-mind-f-ck-movies","metadata":{"permalink":"/blog/ranking-99-mind-f-ck-movies","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-08-15-ranking-99-mind-f-ck-movies.md","source":"@site/blog/2021-08-15-ranking-99-mind-f-ck-movies.md","title":"Ranking 99 Mind f*ck movies","description":"Ranking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python.","date":"2021-08-15T00:00:00.000Z","tags":[{"inline":true,"label":"Movies","permalink":"/blog/tags/movies"},{"inline":true,"label":"Thrillers","permalink":"/blog/tags/thrillers"},{"inline":true,"label":"IMDbPy","permalink":"/blog/tags/im-db-py"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Sorting Algorithm","permalink":"/blog/tags/sorting-algorithm"}],"readingTime":2.135,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"ranking-99-mind-f-ck-movies","title":"Ranking 99 Mind f*ck movies","date":"2021-08-15T00:00:00.000Z","image":"/blog/2021-08-15-ranking-99-mind-f-ck-movies.png","tags":["Movies","Thrillers","IMDbPy","Python","Sorting Algorithm"],"description":"Ranking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python."},"unlisted":false,"prevItem":{"title":"Time-Series CrossValidation for NN","permalink":"/blog/time-series-crossvalidation-for-nn"},"nextItem":{"title":"K-means algorithm to visit a new city","permalink":"/blog/k-means-clustering-to-visit-a-new-city"}},"content":"
\\n  \\n
\\n
\\n\\nRanking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/SortMoviesPerRating).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDuring the Christmas holidays, me and my girlfriend, after watching The Office [US] twice in a row, and knowing most of Dwight\u2019s pranks off by heart, decided that it was time to find something worth watching.\\n\\nAlthough there\u2019s lots of tempting series out there, we didn\u2019t want to follow that path as we don\u2019t like the \u201caddiction\u201d effect that a series has. Also, we have the same taste regarding movies, where **we both enjoy complex thriller plots**, that leave your mind to resonate about them long after being done with it. Personally, I consider a movie great when it still crosses my mind when trying to sleep or the day after. So, thriller movies it was.\\n\\nAfter doing a little research work I came across this list of movies on Reddit: [99 mind f*ck movies](https://www.reddit.com/r/coolguides/comments/geipee/99_mindfck_movies/). I knew this list was good because most of my favourite movies were there, e.g. _The Prestige, Inception, The Usual Suspects, Primal Fear_, and _Ex Machina_.\\n\\nSo, the movie list was decided, and with that, also our new year\u2019s resolution.\\n\\nHowever, this list had 2 issues:\\n\\n**1. The list didn\u2019t have any particular order.** We would like to have the list ranked from best to worst, so that watching the best ones first will keep our motivation levels up to finish the list.\\n\\n**2. The movie title didn\u2019t have the released year.** Although we don\u2019t particularly mind old movies, sometimes we\u2019re just not in the mood to watch a B&W screen, or poor image resolution.\\n\\nTherefore, while Meg was busy, I was on a role to hack something that would both sort the list based on IMDB ranking, and add the release years to the titles.\\n\\nIn a couple of minutes, I was already playing with [IMDbPy API](https://imdbpy.github.io/). This allowed me to have the sorting algorithm running in the background pretty quick. Within the hour, we already had our sorted movie list. Which I have attached below for future reference.\\n\\n\\n\\nThe first movie of the list that none of us had already watched was the movie [Incendies](https://www.imdb.com/title/tt1255953/). After having watched this movie, I can already tell you that sorting out this list was worth it. Definitely mind blowing, and a great watch.\\n\\nAs usual, you can find the source code on my github: [SortMoviesPerRating](https://github.com/DidierRLopes/SortMoviesPerRating).\\n\\nHope you enjoyed this read!"},{"id":"k-means-clustering-to-visit-a-new-city","metadata":{"permalink":"/blog/k-means-clustering-to-visit-a-new-city","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.md","source":"@site/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.md","title":"K-means algorithm to visit a new city","description":"In this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions.","date":"2021-08-01T00:00:00.000Z","tags":[{"inline":true,"label":"K-means","permalink":"/blog/tags/k-means"},{"inline":true,"label":"Algorithm","permalink":"/blog/tags/algorithm"},{"inline":true,"label":"Travel","permalink":"/blog/tags/travel"},{"inline":true,"label":"Efficiency","permalink":"/blog/tags/efficiency"},{"inline":true,"label":"London","permalink":"/blog/tags/london"},{"inline":true,"label":"GPS","permalink":"/blog/tags/gps"},{"inline":true,"label":"Clustering","permalink":"/blog/tags/clustering"}],"readingTime":2.69,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"k-means-clustering-to-visit-a-new-city","title":"K-means algorithm to visit a new city","date":"2021-08-01T00:00:00.000Z","image":"/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.png","tags":["K-means","Algorithm","Travel","Efficiency","London","GPS","Clustering"],"description":"In this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions."},"unlisted":false,"prevItem":{"title":"Ranking 99 Mind f*ck movies","permalink":"/blog/ranking-99-mind-f-ck-movies"},"nextItem":{"title":"Minion Recipes Program","permalink":"/blog/minion-recipes-program"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/LondonVisit).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nUsually when I book a weekend getaway, I spend quite some time doing 2 things:\\n\\n- Writing down the main attractions I want to see\\n- Depicting the travel path to maximise efficiency and see the most in less time (I\u2019m a bit of an efficiency freak myself, sorry)\\n\\n**This repository aims to decide which attractions to visit in London as a function of the number of days that you will be visiting, by applying K-means algorithm.**\\n\\nAs input you need to give the GPS coordinates of the main attractions you want to visit during your stay, and the number of days you are planning to visit. Notice that attractions that are not within the map screenshot boundaries will be discarded. See disclaimer below.\\n\\nThe K-means algorithm will interpret: List of GPS coordinates of the main attractions that you want to visit as 2D samples, after converting to UTM. Number of days of the visit as Number of clusters.\\n\\nOf course, this is rather unrealistic because of several reasons, such as:\\n\\n- Not taking into account if they want to just pass by the London Eye, or have a ride on it;\\n- Assumes that we are in a no man\u2019s land since it completely bypasses the existence of other buildings, roads, \u2026;\\n- Does not consider altitude, even though London is rather plane;\\n- Does not consider the number of attractions that one can possibly do per day;\\n- Plus, if there was to be an attraction really far from the centre, it may happen that the algorithm considers an entire day for it (this would depend upon kernel initialisation)\\n\\nNonetheless, I think this is a funny exercise, and if I were to select the areas to visit by myself, **it would most likely be a similar choice to the one taken by K-means**.\\n\\n**Disclaimer**: I did not know how to use Google API (neither wanted to pay for a key to be fair) hence I just took a screenshot of google maps and wrote down the coordinate of the lower left corner, so that I could use it as my origin. I also took the right top corner coordinate so that I could give the map with an \u201caccurate\u201d scaling.\\n\\n**Note**: GPS coordinates (latitude, longitude) have degrees has units, thus, explaining why the conversion to UTM coordinates, which uses meters.\\n\\nImmediately below you can see the result of a visit to London for 2, 3 and 4 days.\\n\\n\\n\\n
 \\n
\\n  \\n
\\n\\n\\nThis project was done for fun. However, I believe that by creating a tuple per location with coordinates and estimate of time taken on each attraction, something nice could come out of this.\\n\\nHope you find this interesting. Let me know your thoughts."},{"id":"minion-recipes-program","metadata":{"permalink":"/blog/minion-recipes-program","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-07-23-minion-recipes-program.md","source":"@site/blog/2021-07-23-minion-recipes-program.md","title":"Minion Recipes Program","description":"In this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons.","date":"2021-07-23T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Recipes","permalink":"/blog/tags/recipes"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"}],"readingTime":2.535,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"minion-recipes-program","title":"Minion Recipes Program","date":"2021-07-23T00:00:00.000Z","image":"/blog/2021-07-23-minion-recipes-program.png","tags":["Python","Programming","Recipes","Software Development"],"description":"In this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons."},"unlisted":false,"prevItem":{"title":"K-means algorithm to visit a new city","permalink":"/blog/k-means-clustering-to-visit-a-new-city"},"nextItem":{"title":"Household bills Program","permalink":"/blog/household-bills-program"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/RecipesProgram).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOnce I developed the [Housebills program](/blog/household-bills-program), I really enjoyed the feeling of being able to create usable software from scratch. Therefore, that year during Christmas, I wanted to challenge myself to see if I could find any interesting project to do in only 1 week.\\n\\nI started by nagging my dad and brother for them to tell me something that would be useful to them in their daily lives. Sadly, none of them had any idea. Then, I went to the kitchen to ask my mum the same. She was busy searching recipes for xmas on her messy notebook, so she also said no.\\n\\nI sat there next to her thinking about what I could do, while she kept on going back and forth in her notebook searching. I don\u2019t know if she had been reading about the binary search algorithm, or if she was just opening pages randomly. What I know is that 1 week later I did a program for her to keep her recipes. Safe to say that I saved Christmas, I guess.\\n\\nNote: Before the end of that year, I still upgraded the software for its version 2.0, which included more than 20 minion icons. To this day, I think she opens the program to see the minion icons more than the recipes themselves.\\n\\nBelow it displays the interfaces used, and these correspond to: Red-Visualize; Add; Blue-Add; Green-Edit; and Yellow-Remove recipes.\\n\\n\\n\\nPS: Any resemblance with the Microsoft colour scheme is pure coincidence eheh.\\n\\nWhen adding a recipe, the following window will be displayed.\\n\\n\\n\\nThis allows you to add both a recipe, and a category (i.e. the \u201cTiramisu\u201d recipe would be within \u201cDesserts\u201d category).\\n\\nThe recipe content would include:\\n\\n- Name of the recipe\\n- Ingredients\\n- Preparation\\n- Comment\\n\\nWhen visualising a recipe, the following window will be displayed.\\n\\n\\n\\nWhere the recipe dialog box would prompt the recipes based on the category chosen on its left. Then, after selecting a recipe, the ingredients, preparation and comment would be filled out.\\n\\nWhen editing a recipe, the following window will be displayed. This is similar to the visualisation window, with the difference that the text boxes are editable, and therefore, the recipe can be improved.\\n\\n\\n\\nNote: throughout the program there are Message Dialog boxes (as shown above) that tell the user whether the recipe has been successfully (or not) edited, added or removed.\\n\\nFinally, in order to remove a recipe, the following window would be displayed. Where you can either delete a single recipe, or the entire category.\\n\\n\\n\\nThe recipe database is handled in the most robust way: **with plain text files**, obviously.\\n\\nAs always, hope you had a nice read."},{"id":"household-bills-program","metadata":{"permalink":"/blog/household-bills-program","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-07-17-household-bills-program.md","source":"@site/blog/2021-07-17-household-bills-program.md","title":"Household bills Program","description":"In this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application.","date":"2021-07-17T00:00:00.000Z","tags":[{"inline":true,"label":"Java","permalink":"/blog/tags/java"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"GUI","permalink":"/blog/tags/gui"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"},{"inline":true,"label":"Side Project","permalink":"/blog/tags/side-project"}],"readingTime":4.56,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"household-bills-program","title":"Household bills Program","date":"2021-07-17T00:00:00.000Z","image":"/blog/2021-07-17-household-bills-program.png","tags":["Java","Programming","GUI","Software Development","Side Project"],"description":"In this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application."},"unlisted":false,"prevItem":{"title":"Minion Recipes Program","permalink":"/blog/minion-recipes-program"},"nextItem":{"title":"My journey of memorising a deck of 52 shuffled cards","permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/HouseholdBills).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n**My first side project.**\\n\\nBefore University, I spent most of my spare time playing counter-strike (my steam account had **more than 1000 hours played**, that\u2019s more than 41 entire days playing in a row). I was a decent player I\u2019d say, you can see a compilation of \u201calmosts\u201d I\u2019ve done [here](https://www.youtube.com/watch?v=ocsJzNJJB50).\\n\\nHowever, I knew this wasn\u2019t the way. I realised that if I used the amount of time I was spending on online games for learning, I would have a much bigger satisfaction return. And, in the long term, my life would be better.\\n\\n**So I started studying hard.** I started valuing my time more, and declined most of the parties I was invited to because I was busy working late hours. Don\u2019t get me wrong, I\u2019m an easy person. I like to think I make friends easily. However, I just had different priorities, and partying just wasn\u2019t one of them. As my parents say: _\u201cEverything has its own time\u201d_.\\n\\nIn my 2nd year of University, I was getting really good grades, which means that I started having discussions with the other best students in the course. **That\u2019s how I met one of the smartest people I know to this day**. This guy was a proper hands-on person, he didn\u2019t study half the time I did, but he was always busy with something.\\n\\nHe had a band, developed his own personalised guitar pedals and amplifiers, and developed some apps for fun. He did this all while having excellent results at University, which is insane. That\u2019s when I realised that he was not only giving more priority to these hobbies in relation to partying or meeting people, **BUT also in relation to doing courseworks or studying for exams**. He\u2019d never fail a coursework/exam, but that further study could have bumped a grade from 17 to a 19 out of 20.\\n\\nOne day, we were meant to meet at his place to work on a coursework together, and he shown me an app that he had developed for him and his girlfriend. The app was a simple command line interface that was able to split their usual household bills (rent, water bill, food shop, cat food, etc). **I found that fascinating.**\\n\\nI told him I would create one for myself. Since I had read about how to use Java to make a pretty GUI, I thought why not give this a go (although I had no idea about OOP). In addition, I didn\u2019t want my program to look the same as his, so I thought my version could be as if it was an upgrade.\\n\\n...\\n\\nAfter that, I was on a mission. Little did I know that after this, I never really stopped having an interest in working on new side projects.\\n\\nThe planning steps were:\\n\\n**1. Decide main features.**\\n Add new household bills to split, Give money, and See bills.\\n\\n**2.Sketch what the GUI should look like**\\n\\n**3. Devise data structure associated with a new Household bill split.**\\n This was important for both coding, and also database management.\\n\\n**4. Work out the math associated with the splitting and giving**\\n\\nThe development process was to **\u201cdivide to conquer\u201d**. I split the tasks into several sub-tasks, and after every new little code change I was testing the code to make sure that nothing was broken. I re-iterate through design and code several times, until I was happy with my solution. Then I did some clean-up/improvements, such as: Adding pictures of the users, Login password, Frenchies as icons.\\n\\n**On a funny side note:** As I didn\u2019t know how to work with DBs at that time, I used text files to save and load all the information. Meaning that if my brother ever opened one of those text files (which weren\u2019t properly hidden\u2026), I could have passed from him owing me 100 euros to me owing him 10 million. The software was on his laptop, and I had an hardcoded password, so in theory he couldn\u2019t manually add any bill without my presence \u2014 I guess that was enough for him to think that the product was bullet-proof.\\n\\nSee images below of the program:\\n\\n
 \\n
\\n  \\n
\\n\\n\\n
 \\n
\\n  \\n
\\n\\n\\nYou can find more information about this on my GitHub, [here](https://github.com/DidierRLopes/HouseholdBills).\\n\\n**The program ended up being used for more than 3 years.** Since I lived with other people other than my brother, I had to update the name/image on the program to represent that. Since I was new to coding, I didn\u2019t think about the future. Therefore, when that time came, I had to manually replace the names one by one in the code. I also had friends requesting to use the program, which lead to me adapting this to their names/figures.\\n\\nIt was a fun project and I definitely learned loads from it. The most important thing was that I was able to do whatever **I wanted software-wise as long as I dedicated enough time for it.**\\n\\nHope you had a fun read. Thanks!"},{"id":"my-journey-of-memorising-a-deck-of-52-shuffled-cards","metadata":{"permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.md","source":"@site/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.md","title":"My journey of memorising a deck of 52 shuffled cards","description":"In this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique.","date":"2021-06-26T00:00:00.000Z","tags":[{"inline":true,"label":"Memory Training","permalink":"/blog/tags/memory-training"},{"inline":true,"label":"PAO System","permalink":"/blog/tags/pao-system"},{"inline":true,"label":"Memory Palace","permalink":"/blog/tags/memory-palace"},{"inline":true,"label":"Card Memorisation","permalink":"/blog/tags/card-memorisation"}],"readingTime":9.175,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"my-journey-of-memorising-a-deck-of-52-shuffled-cards","title":"My journey of memorising a deck of 52 shuffled cards","date":"2021-06-26T00:00:00.000Z","image":"/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.png","tags":["Memory Training","PAO System","Memory Palace","Card Memorisation"],"description":"In this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique."},"unlisted":false,"prevItem":{"title":"Household bills Program","permalink":"/blog/household-bills-program"},"nextItem":{"title":"Customizable Meme Filter","permalink":"/blog/customizable-meme-filter"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA few years back, I wanted to read a book about memory and found the best-selling book **\u201cMoonwalking with Einstein: The Art and Science of Remembering Everything\u201d** an ideal choice. I won\u2019t go into too much detail about the book which is a great read, if you don\u2019t trust me, trust Bill Gates, who called the book \u201c_absolutely phenomenal_\u201d. But let me give you a brief sequence of events from the author and journalist of the book, Joshua Foer:\\n\\n- It starts by observing the extraordinary accomplishments of mental athletes at a memory championship.\\n- Foer meets Tony Buzan, the trim 67-year-old English self-help guru who founded the [World Memory Championships](http://www.worldmemorychampionships.com/) in 1991 and who insists the brain is \u201clike a muscle\u201d: exercise it and it gets stronger.\\n- Foer learns the art of memory training.\\n- He practices his memory muscles for 1 year with help of a shambling 24-year-old from Oxford who becomes his mentor.\\n- He then finds himself in the finals of the US Memory Championships, alongside \u2018mental athletes\u2019 who could memorise the precise order of ten shuffled decks of cards in under an hour.\\n\\nIf you\u2019re interested, here\u2019s a [nice review](https://www.theguardian.com/science/2012/nov/21/moonwalking-einstein-joshua-foer-review) on the book.\\n\\n## My thoughts after reading book\\n\\nAfter finishing this book, more than anything I was curious. Unlike Joshua Foer, I didn\u2019t want to dedicate a full year to the cause, but I still wanted to give it a go so I could look back and think: \u201cHere\u2019s something pretty useless for the day-to-day. Yet, how cool is that I can memorise 52 random cards?\u201d.\\n\\n\\n\\nFor people who know me, they know how much I hate to leave things unfinished. Whether that\u2019s a task that I set myself, or \u2018just\u2019 not leaving any pizza leftover. Therefore, I knew that if I really wanted to do this, I\u2019d have to set aside time for it, and so I did. The text under is my journey to memorise a shuffled deck of 52 cards.\\n\\n## Technique (PAO + Memory Palace)\\n\\nThe mnemonic \u201c**Memory Palace**\u201d technique that I was about to use was referred to on the aforementioned book. The ancient mnemonic technique was first practiced by Simonides of Ceos over 2,500 years ago. When googling the term, the definition is:\\n\\n_A Memory Palace is an imaginary location in your mind where you can store mnemonic images. The most common type of memory palace involves making a journey through a place you know well, like a building or town. Along that journey there are specific locations that you always visit in the same order._\\n\\nThe mnemonic images would be conceived using the famous PAO system. This term means:\\n\\n_The Person-Action-Object System (or \u201cPAO\u201d System) is a popular method for memorising long random numbers and decks of playing cards. \u2026 Some people assign arbitrary images to the numbers without any phonetic conversion. The digits are usually chunked in 2 or 3 digits and then placed into loci in a Memory Palace._\\n\\nThe idea is to take advantage of what we humans are best at, photographic memory.\\n\\n## The journey of memorising a shuffled deck of 52 cards\\n\\n### 1. Create your own personal PAO system.\\n\\nFor each card of the deck you have to have an associated _Person_, _Action_ and _Object_. It\u2019s useful to have the least possible rules, and have these intersecting simultaneous cards, so that there\u2019s less to memorise. Here\u2019s how I did it:\\n\\n- Define a **category** for each **suit** (e.g. Hearts represents friends)\\n- Define **something** for each **type**.\\n - From 1 to 10 I\u2019ve defined the starting letter of the person (e.g. Card 7 represents a person with name starting with letter K or C).\\n - For the court (Queen, Jack, King) I\u2019ve defined them as a powerful male/female. (e.g. King is the GOAT of the category).\\n\\nBelow you can see what the table looks like:\\n\\n\\n\\n**Note:** The Person is the main existing link, hence it needs to be something that you think of immediately when the category and the type of the card is known.\\n\\nI had to change my cards several times as some of the PAO\u2019s I had weren\u2019t memorable enough, either because the name was too common, or because I didn\u2019t relate that much to this person.\\n\\n### 2. Memorise each card with it\u2019s PAO system\\n\\nOnce the table above is filled in, the next step is to associate each card with it\u2019s **Person-Action-Object**. I find that as long as you can remember the person name of the card by doing the cross between category and type, the action-object comes easily.\\n\\nFor instance:\\n\\n\\n\\n**Jack \u2666: Einstein \u2014 Writing Equations \u2014 Blackboard**\\n\\n- When I see a **Diamond**, I know we are in the **Celebrities** category. Since this is a **Jack** I know it\u2019s an **important person**. I\u2019ve selected Musk to be my GOAT, so this has to be **Einstein**. The **writing equations** and **blackboard** comes trivially when thinking about Einstein.\\n\\n**8 \u2663: Floyd Mayweather \u2014 Skipping \u2014 Rope**\\n\\n- When a **Club** appears, I know we are in the **Athletes** category. Since this is an **8** I know the name starts with an **F or V**. This promptly reminds me of **Floyd**. The **skipping** and **rope** come immediately, due to my own personal experiences from improving my skipping skills and looking at videos of Mayweather. I find that the more the personal and creative you get with this, the easier it is to remember.\\n\\n**King \u2660: Goku \u2014 Powering up \u2014 Blonde Hair**\\n\\n- If I see a **Spade**, I know we are in the **Cartoon** category. Since this is a King I know that this character is the **GOAT**. Which immediately triggers my brain to Goku, since it used to be my favourite cartoon as a kid. Trivially, comes the powering up as action, and the blonde hair as object.\\n\\nIn order to remember all the cards, my trick was to have a deck of cards where on the back of each card I wrote its own PAO. So that if I didn\u2019t remember, instead of looking at the table, I could look at the back of the card. However, I find it important to sometimes not quit trying to remember immediately, as when you initially struggle to remember a card, when you eventually do, your brain retains this information so much better.\\n\\n**Note: At this step you may realise that you keep forgetting the same PAO card. I recommend you going back to step 1 and re-defining it.** Once I did this to the cards I kept forgetting, I was in a much better position.\\n\\n### 3. Create your own memory palace\\n\\nThis is the easiest step. I used the house I grew up in in Portugal, and decided to place 4 PAO instruments (i.e. 12 cards) per house division. Meaning that by the time I was in the first room upstairs, I was already 36 cards down the deck.\\n\\nSince I\u2019m not living in Portugal, let me show you what I mean by using a picture of my current living room in London. The spots I would select in here would have been: 1. Top of table with candles; 2. Top of side table; 3. Inside my gecko\u2019s vivarium; 4. As a program on the TV.\\n\\n\\n\\n**Note: Make sure you always remember your memory palace spots, otherwise you may overlook them once looking for the next 3 set of cards.** The way I think about this is imagining that I lost my keys, and mentally going back in time to try to understand where they could be.\\n\\n### 4. Practice memorising each set of 3 cards PAO\\n\\nThis is where the creativity comes in. **When picking 3 cards from the deck, you picture the Person of the 1st card, the Action of the 2nd one, and the Object of the 3rd one.**\\n\\nLet\u2019s imagine we\u2019ve got the cards aforementioned.\\n\\n**- Card 1: Jack \u2666**\\n * Einstein \u2014 Writing Equations \u2014 Blackboard\\n\\n**- Card 2: 8 \u2663**\\n * Floyd Mayweather \u2014 Skipping \u2014 Rope\\n\\n**- Card 3: King \u2660**\\n * Goku \u2014 Powering up \u2014 Blonde Hair\\n\\nIn my brain, this would lead to\\n\\n\\n\\n**Note: At this point you may realise that some combos of cards don\u2019t work well together. **If this is bad enough to not make you remember the 3 card PAO, I recommend updating your PAO system to something that\u2019s easier to generalise.\\n\\n### 5. Place each 3 cards PAO onto the memory palace\\n\\nFor instance, if I were to place the **Einstein Skipping with Blonde Hair** on the **3rd spot of my living room (my gecko\u2019s vivarium)**, in my head, I would picture something like this:\\n\\n\\n\\n**Note: I recommend trying to have the 3 card PAO interacting with the environment to improve memory.** In this case, I would have thought about the Blonde Skipping Einstein having to do skipping so fast that the gecko coudn\u2019t come close because the rope was going too fast. The more original/different, the more chances you have to remember this scenario.\\n\\n### 6. Re-iterate the memory palace with new 3 card PAO every time\\n\\nInstead of memorising a new 3 card PAO in a memory palace location and then moving on, I always go back to the start and think about all the previous 3 card PAO\u2019s from start. This will ensure you don\u2019t forget the oldest 3 card PAO. In fact, it will make it so that the oldest 3 card PAO are repeated more times than the newer ones, so it\u2019s all balanced out.\\n\\n### 7. Practice and Practice\\n\\nI found out that after memorising my PAO system (which took a long time) and the memory palace, it was fairly easy to memorise the shuffled 52 deck of cards. However, it was taking me way too long to memorise it AND say it out loud.\\n\\nOnce I started practicing more and more time started decreasing. The last time I tried, I managed to do it under 10 minutes, which is not great but I\u2019ll take it. As I mentioned, I just wanted to be able to do it, I didn\u2019t care much about the time.\\n\\nAlso, I still needed to think about the category + type of the card every-time, I think the time to memorise the deck of cards decreases exponentially once you actually associate each card image to it\u2019s PAO. But for that you need to practice more, which for me was getting boring.\\n\\n...\\n\\nThis is a different post than the ones I usually do, but I find it extremely interesting. Hence why I was keen on sharing it.\\n\\nLet me know if you\u2019ve heard about it, or want to give this a go.\\n\\nThanks for reading!"},{"id":"customizable-meme-filter","metadata":{"permalink":"/blog/customizable-meme-filter","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-06-12-customizable-meme-filter.md","source":"@site/blog/2021-06-12-customizable-meme-filter.md","title":"Customizable Meme Filter","description":"In this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme.","date":"2021-06-12T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Meme Filter","permalink":"/blog/tags/meme-filter"},{"inline":true,"label":"Image Processing","permalink":"/blog/tags/image-processing"},{"inline":true,"label":"Face Recognition","permalink":"/blog/tags/face-recognition"}],"readingTime":2.54,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"customizable-meme-filter","title":"Customizable Meme Filter","date":"2021-06-12T00:00:00.000Z","image":"/blog/2021-06-12-customizable-meme-filter.png","tags":["Python","Meme Filter","Image Processing","Face Recognition"],"description":"In this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme."},"unlisted":false,"prevItem":{"title":"My journey of memorising a deck of 52 shuffled cards","permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards"},"nextItem":{"title":"NeistPoint Project","permalink":"/blog/neistpoint-project"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/meme-filter).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nFor the people who know me, they know how much I enjoy memes. I\u2019ve got to admit, whenever I go to museums I have a lot of fun captioning artwork as memes. **As I like to say, I go for the art, and I stay for the memes.**\\n\\nOne day while commuting to work (you can still see the [first commit](https://github.com/DidierRLopes/meme-filter/commit/59be427571c96350d9652922b3ab2ba52ddf18af) which dates back to 10 February of 2020 and has only notes of the sketch of this idea in Portuguese) I thought:\\n\\n> \u201cIt would be funny if there was a snapchat kind of filter where given the number of people on the screen, a random meme was selected and each person would be one of its characters\u201d.\\n\\n
\\n\\nSince I was still improving my Python skills, I thought why not do it in Python. After 1 month, I already had the working code, however, since I was switching jobs at the time my commute time reduced drastically and so did my time to work on this. It took around 1 more month to finish the cleaning up of the script (324 lines) to be more readable, and at the same time Covid happened. **The latter explains why my hair is blonde on the demo below** :)\\n\\nUsage:\\n\\n```console\\n./didifilter.py \u2014 location=memes \u2014 caption=\u2019Which meme am I?\u2019 \u2014 initial=30 \u2014 final=50 -b \u2014 max=3\\n```\\n\\n\\n\\n**To sum up:** This program is meant to be an advanced version of the known snapchat filter where there are random images spinning on top of people\u2019s heads. The main improvement is that you can not only select the images you want to choose from and the caption, but you can also play it with friends (recognizing more than 1 face at the same time).\\n\\nThe best part of the script is that it is meant to be easily customizable. Any person is able to create their own filter by creating a folder with the images they want within a folder with 1, 2, \u2026 based on the number of people they are meant to be used (apart from when backwardCompatible flag is enabled), and select/specify different types of flags/parameters, e.g.:\\n\\n```console\\n./didifilter.py \u2014 locationFolder=celebrities \u2014 caption=\u2019What celeb am I?\u2019 \u2014 max=2 -v \u2014 video=\u201dexampleVideo\u201d\\n```\\n\\n```console\\n./didifilter.py --locationFolder=pokemons --caption=\\"Who\'s this pokemon?\\" --width=250 --height=150 --max=1 -p\\n```\\n\\n**AND**, you can also quickly tweak the code to adapt it to do something else. Here\u2019s me **pranking** my girlfriend with a psyduck when the query was: \u201c_Who do I look like?_\u201d\\n\\n\\n\\nHope you have a nice read and enjoy the filter. You can find the code [here](https://github.com/DidierRLopes/meme-filter).\\n\\nFeel free to provide feedback, as always!"},{"id":"neistpoint-project","metadata":{"permalink":"/blog/neistpoint-project","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-05-23-neistpoint-project.md","source":"@site/blog/2021-05-23-neistpoint-project.md","title":"NeistPoint Project","description":"In this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++.","date":"2021-05-23T00:00:00.000Z","tags":[{"inline":true,"label":"NeistPoint","permalink":"/blog/tags/neist-point"},{"inline":true,"label":"Clothing Brand","permalink":"/blog/tags/clothing-brand"},{"inline":true,"label":"Sustainability","permalink":"/blog/tags/sustainability"},{"inline":true,"label":"Project Management","permalink":"/blog/tags/project-management"},{"inline":true,"label":"C++","permalink":"/blog/tags/c"},{"inline":true,"label":"Stock Management","permalink":"/blog/tags/stock-management"}],"readingTime":3.025,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"neistpoint-project","title":"NeistPoint Project","date":"2021-05-23T00:00:00.000Z","image":"/blog/2021-05-23-neistpoint-project.png","tags":["NeistPoint","Clothing Brand","Sustainability","Project Management","C++","Stock Management"],"description":"In this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++."},"unlisted":false,"prevItem":{"title":"Customizable Meme Filter","permalink":"/blog/customizable-meme-filter"},"nextItem":{"title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/NeistpointCLI).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nMore than 2 years ago, me and some friends started a clothing brand - **NeistPoint**. The logo and name is inspired by the Neist Point Lighthouse in the Isle of Skye. The motto was \u201c**For a greener future and a bluer ocean**\u201d, and the goal was to raise awareness to contribute for a sustainable environment.\\n\\nAt **Neist**, we tried to not be yet another clothing brand, but actually to fill the current gap in the retail industry by producing high-quality, eco-friendly clothes at affordable prices. And we achieved that. For instance, our t-shirts are made of 100% organic ring-spun combed cotton, and they last longer than my Lacoste t-shirts \u2014 seriously.\\n\\nThe problem is that to be profitable, you need to either increase the prices of your products, or decrease the quality, which were not things we wanted to do since they didn\u2019t represent the value of our brand. Due to that, and the fact that the team behind our brand no longer has time/resources, we\u2019re dropping our **last ever** season now.\\n\\nAnyway, no regrets from my side, it has been a great learning experience to understand what is involved around the creation of a brand, being a project manager internally, and doing something other than coding in my spare time. _Also, most importantly, ending up with a full new wardrobe of pieces that I love and that will probably last for my kids._\\n\\nSorry for this rambling, just wanted to share this context with everyone.\\n\\n## Implementation\\n\\nGiven that our team had no experience in clothing whatsoever, and based on our needs, our steps to make this a high-quality product were:\\n\\n1. Get the best (environmentaly friendly) clothing material\\n2. Send it to the best embroidery store in Portugal\\n3. Package it and forward it onto the customer\\n\\n
\\n\\n\\n\\nThis process was **far from being optimised**. In fact, pretty much everything was manual. Apart from the creation of the clothes. Therefore, we needed a Software to keep track of the products at each of it\u2019s stages: _material to request, material shipping, material in stock, product to create, product creating, product in stock, and product sent_.\\n\\nSince I didn\u2019t find anything that I liked online, and I knew how to code, I thought the best solution was to develop something myself. This way it could be adapted to perfectly fit my own requirements (advantages of being your own product owner eheh). In addition, I wanted to improve my C++ skills, so I thought, **why not?**\\n\\n\\n\\nFor 1 week or so, during my commute I worked on the [NeistPoint Stock Managemen](https://github.com/DidierRLopes/NeistpointCLI) tool. To be honest, I think it took longer to devise the architecture behind it than to actually write the code, as there were lots of things that I wanted to be taken into account. Also, the fact that the \u201cdatabase\u201d is a .csv file, was intentional. This way, we could share this file between the team members.\\n\\nHope someone finds this tool interesting, and gets inspired to develop their own software to meet their own project requirements. In the meantime, feel free to check us one last time on [our website](https://neistclothing.com/) or [instagram](https://www.instagram.com/neistclothing/). You may even spot me in some of the pictures!\\n\\nThe repository for the code can be found here: https://github.com/DidierRLopes/NeistpointCLI\\n\\nThanks for reading, as always!"},{"id":"move-over-bloomberg-terminal-here-comes-gamestonk-terminal","metadata":{"permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.md","source":"@site/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.md","title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","description":"In this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.","date":"2021-04-23T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Stock Market","permalink":"/blog/tags/stock-market"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":2.375,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"move-over-bloomberg-terminal-here-comes-gamestonk-terminal","title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","date":"2021-04-23T00:00:00.000Z","image":"/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.png","tags":["Gamestonk Terminal","Finance","Stock Market","Programming","Open Source"],"description":"In this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more."},"unlisted":false,"prevItem":{"title":"NeistPoint Project","permalink":"/blog/neistpoint-project"},"nextItem":{"title":"Momentum Football Bets","permalink":"/blog/momentum-football-bets"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHey all,\\n\\n2 months ago I made a terminal that I had been working on my spare time, to help me on my stock research, open-source. See [here](/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal).\\n\\n## The motto\\n\\nGamestonk Terminal provides a modern Python-based integrated environment for investment research, that allows the average joe retail trader to leverage state-of-the-art Data Science and Machine Learning technologies.\\n\\nAs a modern Python-based environment, Gamestonk Terminal opens access to numerous Python data libraries in Data Science (Pandas, Numpy, Scipy, Jupyter), Machine Learning (Pytorch, Tensorflow, Sklearn, Flair), and Data Acquisition (Beautiful Soup, and numerous third-party APIs).\\n\\nAs of today, and thanks to all your help and the traction created around it, the terminal is looking better than ever. Now it\u2019s no longer only me taking care of the repo, but also 2 other experienced devs, who are adding features on a daily basis and increasing the robustness of the codebase. Feel free to wander through the FEATURES page to see what you would get out of this tool!\\n\\nIf some of you thought it was amazing 2 months ago, you won\u2019t believe what it looks like now. You can check out the ROADMAP for all the features that have been added since, but let me list some of them:\\n\\n- **New** Screener for stocks, which allows users to save their presets and share them\\n- **New** Options menu\\n- **New** Comparison Analysis to compare several tickers in their historical price, sentiment, or fundamental analysis\\n- **New** Portfolio Optimisation that assigns stocks weights based on risk level specified by the user\\n- **New** Exploratory Data Analysis menu that looks at historical data from a statistic point of view\\n- **New** Residual Analysis after using a statistical model for prediction\\n- **New** menu to provide access to your portfolio (supports Robinhood, Ally invest, Alpaca, and Degiro)\\n- **New** Cryptocurrency, Forex, and FRED menus\\n- Prediction with backtesting\\n- Technical analysis that includes a score and a summary\\n- Due Diligence menu with data from Dark Pools, and also Failure to Deliver\\n- Sentiment analysis from news provided from collaboration with a company that provides this feature paid. Free for us!\\n\\nAs always feedback is appreciated, and contributions even more so!\\n\\nLet\u2019s try to reduce the gap between the amount of information that the Hedge Funds have access to in comparison with the usual retail trader.\\n\\nBloomberg Terminal, we\u2019re coming for you.\\n\\nFeel free to join our discord at https://discord.gg/Up2QGbMKHY."},{"id":"momentum-football-bets","metadata":{"permalink":"/blog/momentum-football-bets","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-04-07-momentum-football-bets.md","source":"@site/blog/2021-04-07-momentum-football-bets.md","title":"Momentum Football Bets","description":"In this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python.","date":"2021-04-07T00:00:00.000Z","tags":[{"inline":true,"label":"Football","permalink":"/blog/tags/football"},{"inline":true,"label":"Betting","permalink":"/blog/tags/betting"},{"inline":true,"label":"Momentum","permalink":"/blog/tags/momentum"},{"inline":true,"label":"Web Scraping","permalink":"/blog/tags/web-scraping"},{"inline":true,"label":"Beautiful Soup","permalink":"/blog/tags/beautiful-soup"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"}],"readingTime":3.275,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"momentum-football-bets","title":"Momentum Football Bets","date":"2021-04-07T00:00:00.000Z","image":"/blog/2021-04-07-momentum-football-bets.png","tags":["Football","Betting","Momentum","Web Scraping","Beautiful Soup","Python"],"description":"In this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python."},"unlisted":false,"prevItem":{"title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal"},"nextItem":{"title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","permalink":"/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/momentum-football-bets).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis Easter, I spoke with my girlfriend\u2019s father and there were several football matches happening that weekend, he started talking about betting on some of those matches.\\n\\nHe carried on to explain me his betting routine, which consisted of:\\n\\n1. Checking the next fixtures for a specific competition: https://www.skysports.com/premier-league-fixtures\\n2. Checking the last results of each of the team and \u201cestimate\u201d their momentum (e.g. https://www.skysports.com/football/wolverhampton-wanderers-vs-liverpool/stats/429116)\\n\\n
\\n\\nThen, iterate these 2 steps for all the fixtures happening, from Premier League, Championship, League One, and League Two.\\n\\nSince I recently learned how to use Beautiful Soup to scrap data from web pages (see [GamestonkTerminal](https://dro-lopes.medium.com/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal-a263c001a61f)), I thought that I could create an automated task that would do all of these steps with a simple double click executable. After checking that I could extract such data from SkySports, I let him know that by the next day I would have something working.\\n\\nAfter dinner, I started working on the project, and before I went to sleep I had the first prototype working, which you can see in [here](https://github.com/DidierRLopes/momentum-football-bets).\\n\\nOn top of \u201chis\u201d automated task, I created a \u201cmomentum score\u201d which tries to estimate the momentum score based on what my girlfriend\u2019s father told me that he does. He looks into the last games of the team and see if they have a positive momentum by looking to see if they come from a winning series.\\n\\nSo, I thought it would be good to attribute a weight to each of the last matches where the most recent match would have the biggest weight, and last one from the 6 provided from SkySports stats would have the lowest weight. Together with this weight, I thought we could use the sum of the weight to the score in case of a win, subtract in case of loss, and don\u2019t do anything in case of a draw.\\n\\nSo, in simple terms, if score is positive the team is likely to have been winning their last matches, if score is negative the team is likely to have loss their last matches.\\n\\nBut then, I thought:\\n\\n_\u201cOk, this is nice. But when you bet, you don\u2019t bet on a single team, but on the result between the 2 teams that are playing each other.\u201d_ I.e. if team A has an amazing momentum, and so has team B, the bet will \u2014 in theory \u2014 be risky.\\n\\nHence, the next step was to address this concern. This was done by checking the momentum score difference between the teams, the bigger the momentum score, the less risky \u2014 in theory \u2014 a bet would be. What we want to see is a team that has been doing amazing for the past 6 games, and one that has been performing consistently bad.\\n\\nLastly, I added a confidence filter so that the terminal would only output the games that shown at least a certain X confidence. And also, an argument that would select the number of days in the future that we could look for fixtures.\\n\\nAfter having this implemented, the day after was about polishing the code, adding some colouring and emojis, creating a repository for it, a README, discussing the binning of the momentum score and bet confidence terms, creating a logo for it, and creating an executable + adding the logo which my girlfriend did.\\n\\n\\n\\nAfter this, we were quite excited to backtest the app. We filtered the next features with a big confidence bet score (to have less risk), and put 20 pounds on 3 different accumulators. [And it\u2019s gone.](https://www.youtube.com/watch?v=-DT7bX-B1Mg)\\n\\nHope you had a good read. Feedback is always appreciated."},{"id":"gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","metadata":{"permalink":"/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.md","source":"@site/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.md","title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","description":"In this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.","date":"2021-03-14T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Stock Market","permalink":"/blog/tags/stock-market"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.2,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","date":"2021-03-14T00:00:00.000Z","image":"/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.png","tags":["Gamestonk Terminal","Finance","Stock Market","Programming","Open Source"],"description":"In this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more."},"unlisted":false,"prevItem":{"title":"Momentum Football Bets","permalink":"/blog/momentum-football-bets"}},"content":"
\\n  \\n
\\n
\\n\\nIn this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you like stocks and are careful with the way you spend your money, (me saying it seems counter-intuitive given that I bought GME at the peak, I know) you know how much time goes into buying shares of a stock.\\n\\nYou need to: Find stocks that are somehow undervalued; Research on the company, and its competitors; Check that the financials are healthy; Look into different technical indicators; Investigate SEC fillings and Insider activity; Look up for next earnings date and analysts estimates; Estimate market\u2019s sentiment through Reddit, Twitter, Stocktwits; Read news;. \u2026 the list goes on.\\n\\nIt\u2019s tedious and I don\u2019t have 24k for a Bloomberg terminal. Which led me to the idea during xmas break to spend the time creating my own terminal. I introduce you to \u201cGamestonk Terminal\u201d (probably should\u2019ve sent 1 tweet everyday to Elon Musk for copyrights permission eheh).\\n\\nAs someone mentioned, this is meant to be like a swiss army knife for finance.\\n\\nIt contains the following functionalities:\\n\\n- **Discover Stocks**: Some features are: Top gainers; Sectors performance; upcoming earnings releases; top high shorted interest stocks; top stocks with low float; top orders on fidelity; and some SPAC websites with news/calendars.\\n\\n- **Market Sentiment**: Main features are: Scrolling through Reddit main posts, and most tickers mentions; Extracting trending symbols on stocktwits, or even stocktwit sentiment based on bull/bear flags; Twitter in-depth sentiment prediction using AI; Google mentions over time.\\n\\n- **Research Web pages**: List of good pages to do research on a stock, e.g. macroaxis, zacks, macrotrends, ..\\n\\n- **Fundamental Analysis**: Read financials from a company from Market Watch, Yahoo Finance, Alpha Vantage, and Financial Modeling Prep API. Since I only rely on free data, I added the information from all of these, so that the user can get it from the source it trusts the most. Also exports management team behind stock, along with their pages on Google, to speed up research process.\\n\\n- **Technical Analysis**: The usual technical indicators: sma, rsi, macd, adx, bbands, and more.\\n\\n- **Due Diligence**: It has several features that I found to be really useful. Some of them are: Latest news of the company; Analyst prices and ratings; Price target from several analysts plot over time vs stock price; Insider activity, and these timestamps marked on the stock price historical data; Latest SEC fillings; Short interest over time; A check for financial warnings based on Sean Seah book.\\n\\n- **Prediction Techniques**: The one I had more fun with. It tries to predict the stock price, from simple models like sma and arima to complex neural network models, like LSTM. The additional capability here is that all of these are easy to configure. Either through command line arguments, or even in form of a configuration file to define your NN. It also allows backtesting.\\n\\n- **Reports**: Allows you to run several jobs functionalities and write daily notes on a stock, so that you can assess what you thought about the stock in the past, to perform better decisions.\\n\\n- **Comparison Analysis**: Allows to compare different stocks.\\n\\n- **On the ROADMAP**: Cryptocurrencies, Portfolio Analysis, Credit Analysis. Feel free to add the features you\u2019d like and we would happily work on it.\\n\\nThis project will always remain open-source, and the idea is that it can grow substantially over-time so that more and more people start taking advantage of it.\\n\\nFeel free to contribute towards the project.\\n\\nFeedback is extremely welcome!"}]}}')}}]); \ No newline at end of file diff --git a/assets/js/f81c1134.f3b9cd9d.js b/assets/js/f81c1134.f3b9cd9d.js deleted file mode 100644 index ae470979d..000000000 --- a/assets/js/f81c1134.f3b9cd9d.js +++ /dev/null @@ -1 +0,0 @@ -"use strict";(self.webpackChunkmy_website=self.webpackChunkmy_website||[]).push([[44031],{4108:e=>{e.exports=JSON.parse('{"archive":{"blogPosts":[{"id":"ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will","metadata":{"permalink":"/blog/ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-12-27-ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will.md","source":"@site/blog/2024-12-27-ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will.md","title":"AI Chatbots Won\'t Revolutionize Finance, But Intelligent Workspaces Will","description":"Beyond the AI hype - why the future of financial analysis isn\'t about chatbots, but about intelligent workspaces that combine your data, tools, and AI exactly when you need them.","date":"2024-12-27T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"artificial intelligence","permalink":"/blog/tags/artificial-intelligence"},{"inline":true,"label":"chatgpt","permalink":"/blog/tags/chatgpt"},{"inline":true,"label":"financial analytics","permalink":"/blog/tags/financial-analytics"},{"inline":true,"label":"future of finance","permalink":"/blog/tags/future-of-finance"}],"readingTime":2.355,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will","title":"AI Chatbots Won\'t Revolutionize Finance, But Intelligent Workspaces Will","date":"2024-12-27T00:00:00.000Z","image":"/blog/2024-12-27-ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will","tags":["openbb","artificial intelligence","chatgpt","financial analytics","future of finance"],"description":"Beyond the AI hype - why the future of financial analysis isn\'t about chatbots, but about intelligent workspaces that combine your data, tools, and AI exactly when you need them.","hideSidebar":true},"unlisted":false,"nextItem":{"title":"OpenBB and our global reach since leaving beta","permalink":"/blog/openbb-and-our-global-reach-since-leaving-beta"}},"content":"
\\n \\n
\\n\\nHere\'s how OpenBB solves this:\\n\\nFirst, we ensure complete data access:\\n\\n- Run everything on-premise or in your VPC\\n- Connect any data source: files, APIs, third-party feeds, anything\\n- Use a universal data layer that standardizes everything (whether it\'s CSV, Excel, Snowflake, or APIs)\\n\\nBut the real innovation?\\n\\nWe\'re building AI differently.\\n\\nInstead of forcing analysts to chat with a bot, we\'re embedding intelligence directly into their workspace.\\n\\nThink dashboards with widgets, not chat windows. Data visualization, not text conversations.\\n\\nThis is exactly what Kimberly Tan (partner @ a16z) predicted in [her analysis](https://a16z.com/big-ideas-in-tech-2025/):\\n\\n> _\\"Chat was the first experimental interface \u2014 now I expect there will be new, novel interaction mechanisms. In this phase, AI agents will be able to take direct action in the workflow, and the UI will be reimagined for humans to review work or do QA.\\"_\\n\\n
\\n\\nThe result?\\n\\n
\\n  \\n
\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nUntil he did.\\n\\nWith our free tier - Matt was able to single-handedly create almost 50 different data widgets that he (and his team) will be able to access seamlessly on OpenBB.\\n\\nAs we shift to firms being more in control of their data, and with the clear gains from having an additional intelligence layer on top of that data - the need for OpenBB in the market has never been clearer.\\n\\nShifting the control back to financial firms.\\n\\nMore open. More adaptable.\\n\\nIf you want help on connecting your own backend (crypto or other) to OpenBB - reach out to myself and team."},{"id":"why-we-got-rid-of-pips-at-openbb","metadata":{"permalink":"/blog/why-we-got-rid-of-pips-at-openbb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.md","source":"@site/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.md","title":"Why we got rid of PIPs at OpenBB","description":"My thoughts on how removing PIPs can increase the company talent level","date":"2024-11-09T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"management","permalink":"/blog/tags/management"},{"inline":true,"label":"leadership","permalink":"/blog/tags/leadership"},{"inline":true,"label":"talent","permalink":"/blog/tags/talent"},{"inline":true,"label":"hiring","permalink":"/blog/tags/hiring"},{"inline":true,"label":"performance","permalink":"/blog/tags/performance"},{"inline":true,"label":"company-culture","permalink":"/blog/tags/company-culture"},{"inline":true,"label":"startups","permalink":"/blog/tags/startups"}],"readingTime":9.485,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-we-got-rid-of-pips-at-openbb","title":"Why we got rid of PIPs at OpenBB","date":"2024-11-09T00:00:00.000Z","image":"/blog/2024-11-09-why-we-got-rid-of-pips-at-openbb.png","tags":["openbb","management","leadership","talent","hiring","performance","company-culture","startups"],"description":"My thoughts on how removing PIPs can increase the company talent level","hideSidebar":true},"unlisted":false,"prevItem":{"title":"Today I saw a glimpse of the future","permalink":"/blog/today-i-saw-a-glimpse-of-the-future"},"nextItem":{"title":"Implement feedback loops EVERYWHERE you can","permalink":"/blog/implement-feedback-loops-everywhere-you-can"}},"content":"
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n\\n\\nThe problem with confident hallucinations is that, similar to why everyone dislikes liars, it leads to a lack of trust. So users begin to put everything that is output by an LLM under a microscope - even if what the model says is accurate.\\n\\n### How to avoid hallucinations\\n\\nThere are ways to address this and one of the key approaches we are extremely strong about at OpenBB is always tapping into information that is available.\\n\\nWhen a user asks a question that requires financial data, the OpenBB Copilot always searches for that data on OpenBB (either through data we make available or through private data that customers bring).\\n\\nThe Copilot will only answer the question if that data exists. This allows the model to cite the data used in its response, so the user can double-check.\\n\\nThis is how it looks.\\n\\n
\\n \\n
\\n \\n
\\n\\nThis leads to less hallucination because the LLM isn\'t outputting tokens based on a prompt and its internal weights. Instead, it\'s using its internal weights, the prompt, and a function call.\\n\\nAssuming the function call succeeds - with correct widget retrieval and parameters - the data becomes available for the Copilot to use, which leads to higher accuracy.\\n\\nNote: This still means that Copilot needs to use the correct widget and the correct parameter, but there\'s a **higher likelihood of success** because if it isn\'t, the API call will fail, prompting the LLM to try again.\\n\\nHere\'s how it works behind the scenes, the OpenBB Copilot highlights its step-by-step reasoning so users can understand its thought process. Transparency is key.\\n\\n
\\n \\n
\\n\\nThey get the \\"_Sentence Extracted From_\\" column, which they can copy and paste into a search field added at the top of the Earnings Transcript widget. This enable users to quickly validate the numbers that have been found.\\n\\nSee example below,\\n\\n
\\n \\n
\\n \\n
\\n \\n\\n\\nThis means that the model\'s output can be improved by doing extra work at the input level.\\n\\nData cleaning and pre-processing strikes again? \ud83d\ude03\\n\\nInterestingly, a few days ago, [OpenAI announced OpenAI o1](https://openai.com/o1/). Which is basically GPT-4o with Chain-of-Thought (COT). This means that this model is a \\"wannabe agent\\".\\n\\nIt takes in a prompt from the user and decomposes it in natural steps to solve it. Then at each step, it takes the output of the model from the previous step and predicts the next token. It turns out that this improves accuracy substantially.\\n\\nHowever, it still doesn\u2019t have access to external data. And that is why I call it a \\"wannabe agent\\".\\n\\nI love how Jeremiah put it in this [tweet](https://x.com/jlowin/status/1834722014839418962):\\n\\n> (...) Agents are also characterized by iterative behavior. But there\'s a key difference: while models like o1 iterate internally to refine their reasoning, agents engage in iterative interactions with the external world. They perceive the environment, take actions, observe the outcomes (or side effects) and adjust accordingly. This recursive process enables agents to handle tasks that require adaptability and responsiveness to real-world changes. (...)\\n\\n
\\n\\nSo, o1\'s model isn\'t an agent - but it can solve this problem. The reason is that it applies its own data cleaning/pre-processing step on its own, and doesn\'t rely on external factors.\\n\\n### Small Language Models\\n\\nOnce agents work, Small Language Models (SLM) will be much more viable for very specific use cases.\\n\\nIn logical terms, a Large Language Model is a model with weights.\\n\\nLarge means that it has a lot of them. But what tends to happen is LLMs need to be very big because they want these models to be really good at everything. The problem is that if you want the exact same model to be good at discussing soccer, programming, and speaking Portuguese, its weights are updated using these drastically different datasets. Now the premise is that the more weights there are, the less each weight will be affected by data from completely different domains.\\n\\nWhat a big LLM like GPT-4o is doing is trying to build a single Jarvis that knows about everything. Whereas we could have an SLM that does something extremely well and just focus on that, e.g. translating from English to Portuguese. The benefit of an SLM is that inference is likely faster, can be hosted on devices, and, in theory, it\'s better on a topic because it\'s been less \\"contaminated\\" during training by data that doesn\'t relate to the task at hand.\\n\\nImagine that a firm decides to use an SLM trained to retrieve data from SEC filings quickly and at scale. Or, we could train our own SLM to understand user intent and interact directly with the OpenBB Terminal interface.\\n\\n### Large Language Models as orchestrator\\n\\nIn my opinion, the best LLM in each category will win. And the second and third won\'t matter. It\'s a winner-takes-all kind of market. Unless in specific verticals such as inference time or open weights (e.g. for data security; more on this later).\\n\\nThe best example of this is OpenAI vs Anthropic.\\n\\nI had been using OpenAI\'s GPT-4 for coding for several months. After trying Anthropic\'s Sonnet 3.5 for coding, I never went back to OpenAI.\\n\\n
\\n \\n
\\n \\n
\\n \\n\\n\\nWe believe in this idea so much, that we have open-source the architecture for firms to bring their own Copilot to OpenBB. More information is available [here](https://github.com/OpenBB-finance/copilot-for-terminal-pro/).\\n\\n### Turn off AI workflows\\n\\nWe have incorporated workflows that make users\' lives MUCH better. But they come at a cost: sharing data with an LLM provider.\\n\\nThese are the features:\\n\\n- **Widget title/description suggestion from Copilot**: This sends the content of the table or note output by Copilot to an LLM provider to receive suggestions of a title and description.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
Presenting at CIBC a few weeks ago at New York AI meetup
\\n\\n\\n## Next sparring sessions\\n\\nCurrently when I step in a ring I have mixed feelings, I\u2019m somewhat anxious but also excited about it.\\n\\nIt\u2019s weird.\\n\\nI mean, I know full well that I\u2019m going against folks who\u2019ve been in a ring since they were young - and I also know full well that I\u2019m going to get hit much more than I will hit.\\n\\n**However**, there\u2019s something exciting (poetic maybe?) about knowing that each time I step into the ring again, I will be able to land more punches, avoid more hits and be better mentally.\\n\\nLearning is the nature of the game.\\n\\nAnd the only failure is to not take any lessons from each fight.\\n\\nThis is the same for startups. I like what Bezos has to say on the topic, about [pushing Amazon to embrace failure](https://www.youtube.com/shorts/HmYj-UDT8jM).\\n\\n\\n \\n
This picture was what convinced me to buy my own head gear
\\n\\n\\n## So, why do I love boxing?\\n\\nI think ultimately, the reason why I love boxing is the same as why I love startups.\\n\\nStartups push me everyday to be the best that I can be in so many different areas, there isn\u2019t a role that - for me - is as stimulating mentally as being a startup founder.\\n\\nThere are 100 different initiatives ongoing at all times, you have a team of composed of human beings (by nature, highly complex with different backgrounds and life experiences), you have startups trying to disrupt your business, you have well established incumbents, etc..\\n\\nBoxing is the same... but at the physical level.\\n\\nI step in the ring and need to be the best I can in multiple verticals - it isn\u2019t enough to be the best in one.\\n\\nI need to have a faster reaction to avoid punches, be light on my feet to surprise an opponent, land the combos where I put most of my energy in, trade-off balance between combos and stamina, and obviously all the mental side that comes from it too - which turns out is quite a lot.\\n\\nUltimately, as cheesy as it sounds, being a startup founder and doing boxing make me feel alive.\\n\\n\\n \\n
Taking my father-in-law for a class
\\n"},{"id":"what-i-learned-in-3-years-at-openb","metadata":{"permalink":"/blog/what-i-learned-in-3-years-at-openb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-08-20-what-i-learned-in-3-years-at-openbb.md","source":"@site/blog/2024-08-20-what-i-learned-in-3-years-at-openbb.md","title":"What I Learned in 3 Years at OpenBB","description":"The OpenBB journey started officially 3 years ago. So I want to celebrate it by sharing 36 lessons I learned over the past 36 months as a founder and CEO of a fintech company.","date":"2024-08-20T00:00:00.000Z","tags":[{"inline":true,"label":"career development","permalink":"/blog/tags/career-development"},{"inline":true,"label":"technology","permalink":"/blog/tags/technology"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"leadership","permalink":"/blog/tags/leadership"}],"readingTime":2.91,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"what-i-learned-in-3-years-at-openb","title":"What I Learned in 3 Years at OpenBB","date":"2024-08-20T00:00:00.000Z","image":"/blog/2024-08-20-what-i-learned-in-3-years-at-openb.jpeg","tags":["career development","technology","OpenBB","learning","leadership"],"description":"The OpenBB journey started officially 3 years ago. So I want to celebrate it by sharing 36 lessons I learned over the past 36 months as a founder and CEO of a fintech company."},"unlisted":false,"prevItem":{"title":"Why I love boxing","permalink":"/blog/why-i-love-boxing"},"nextItem":{"title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","permalink":"/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare"}},"content":"\\n \\n
\\n\\nIn the past 3 years, we have:\\n\\n- The [open source repo](https://github.com/OpenBB-finance/OpenBB) has been starred over 28,000 times and 220 contributors\\n- The OG OpenBB Terminal installer was downloaded over 150k times\\n- Refactored that application to a platform that could be pip installable\\n- Enabled users to fully [automate their research workflow in a script](https://youtu.be/cgeN3Ep2nEw?si=8e5en_xunWcBdKMM)\\n- Open-sourced an [LLM-powered financial analyst agent built on top of the OpenBB platform](https://github.com/OpenBB-finance/openbb-agents)\\n- Made an [OpenBB Bot](https://openbb.co/products/bot) that run over 4M commands in 20k+ servers with 50k+ users\\n- Developed an [Add-in for Excel](https://openbb.co/products/excel)\\n- Grew to a team of 16\\n- Built a community of over 100k people\\n- And finally, we built the foundation of the [first AI-powered financial terminal](https://openbb.co/products/pro) - more on this very very soon.\\n\\n
\\n\\nPersonally, during that timeline:\\n\\n- I got a second dog\\n- Visited US for the first time\\n- Got married on that first visit\\n- Left London to move to the Bay area a couple weeks after\\n- Moved to NYC\\n- Started boxing regularly\\n\\nWe are more locked in than ever before.\\n\\nCan\u2019t wait for the next 3 years. \ud83e\udd42"},{"id":"why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","metadata":{"permalink":"/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.md","source":"@site/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.md","title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","description":"As AI continues to advance, many jobs in finance are at risk. Learn why this shift is happening and how to prepare for the future.","date":"2024-08-06T00:00:00.000Z","tags":[{"inline":true,"label":"artificial intelligence","permalink":"/blog/tags/artificial-intelligence"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"career development","permalink":"/blog/tags/career-development"},{"inline":true,"label":"technology","permalink":"/blog/tags/technology"},{"inline":true,"label":"future of work","permalink":"/blog/tags/future-of-work"}],"readingTime":6.67,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare","title":"Why AI Will Replace Jobs in Finance and How You Should Prepare","date":"2024-08-06T00:00:00.000Z","image":"/blog/2024-08-06-why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare.png","tags":["artificial intelligence","finance","career development","technology","future of work"],"description":"As AI continues to advance, many jobs in finance are at risk. Learn why this shift is happening and how to prepare for the future."},"unlisted":false,"prevItem":{"title":"What I Learned in 3 Years at OpenBB","permalink":"/blog/what-i-learned-in-3-years-at-openb"},"nextItem":{"title":"Inspired by Bia - How Her Fight Against Cancer Changed My Life","permalink":"/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life"}},"content":"
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\n\\nDidier
\\n
\\nIt was in the middle of laughter, in the middle of playfulness.
\\n
\\nIt was in the middle of tantrums and misunderstandings.
\\n
\\nIt was in the middle of sheets of paper fallen on the floor and of pieces of paper so efficiently utilized.
\\n
\\nIt was like this that our friendship grew!
\\n
\\nBeatriz \u2764\ufe0f
\\n
\\n\\nSaturday morning I got a call. A common friend let me know that she passed away unexpectedly.\\n\\nI was still in bed. I cried for hours. I didn\'t want to wake up. Maybe some part of me never did.\\n\\nShe had her entire life ahead of her.\\n\\nShe was kind, curious and loving. She would have accomplished so much.\\n\\nYet she was gone.\\n\\nNo one deserves to lose their best friend at 17. Not like that. It wasn\'t fair.\\n\\nBut that\'s cancer for you.\\n\\nCancer doesn\'t care.\\n\\nIt never did.\\n\\nFrom that moment onwards I changed my attitude towards life.\\n\\nI stopped doing things for the sake of doing them and always put 120%.\\n\\nI went from spending most of my time as a gamer and doing just enough to have good grades in high school to being the best student of my year in my BSc in Electrical and Computer Engineering, moving to London to have a distinction at Imperial College London (top 2 uni in the world) and now moving to NYC to increase chances of success for my startup.\\n\\n
\\n \\n
\\n \\n
\\n Donate here\\n
\\n\\nEvery donation matters. \u2764\ufe0f"},{"id":"my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","metadata":{"permalink":"/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.md","source":"@site/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.md","title":"My first-hand experience on AI impacting education through Perplexity, Cursor and ChatGPT","description":"AI will change education forever. Here\'s how I leveraged Perplexity, Cursor and ChatGPT to teach Supervised Learning and assess coursework.","date":"2024-06-30T00:00:00.000Z","tags":[{"inline":true,"label":"education","permalink":"/blog/tags/education"},{"inline":true,"label":"ai","permalink":"/blog/tags/ai"},{"inline":true,"label":"perplexity","permalink":"/blog/tags/perplexity"},{"inline":true,"label":"chatgpt","permalink":"/blog/tags/chatgpt"},{"inline":true,"label":"cursor","permalink":"/blog/tags/cursor"},{"inline":true,"label":"students","permalink":"/blog/tags/students"},{"inline":true,"label":"big data","permalink":"/blog/tags/big-data"},{"inline":true,"label":"analytics","permalink":"/blog/tags/analytics"},{"inline":true,"label":"supervised learning","permalink":"/blog/tags/supervised-learning"},{"inline":true,"label":"machine learning","permalink":"/blog/tags/machine-learning"}],"readingTime":11.45,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt","title":"My first-hand experience on AI impacting education through Perplexity, Cursor and ChatGPT","date":"2024-06-30T00:00:00.000Z","image":"/blog/2024-06-30-my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt.png","tags":["education","ai","perplexity","chatgpt","cursor","students","big data","analytics","supervised learning","machine learning"],"description":"AI will change education forever. Here\'s how I leveraged Perplexity, Cursor and ChatGPT to teach Supervised Learning and assess coursework."},"unlisted":false,"prevItem":{"title":"Inspired by Bia - How Her Fight Against Cancer Changed My Life","permalink":"/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life"},"nextItem":{"title":"Why chat-only AI Financial Assistants are not the future","permalink":"/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future"}},"content":"\\n \\n
\\n \\n
\\n\\nThis was not a trivial task, and definitely not a weekend job.\\n\\nExcept that **IT WAS**.\\n\\n### Perplexity enters the chat\\n\\nSince Perplexity\u2019s main value proposition is being better at Google than Google - I popped the following prompt into it.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\n> **PART II - Documentation and Quality**\\n> - **2.a. Code Quality and Readability:** Clarity and Structure: Is the code well-organized with clear and consistent formatting? Are comments used effectively to explain complex logic? Best Practices: Does the code follow standard coding practices (e.g., naming conventions, modularization)? Are functions and classes used appropriately?\\n>\\n> - **2.b. Documentation and Explanation in Comments or Notebook Markdown**: Clarity: Are the results and methodology clearly documented? Is there a detailed explanation of the steps taken and the reasons behind them? Visualization: Are visual aids (e.g., graphs, plots) used to illustrate key points and results? Are these visualizations clear and informative?\\n\\n
\\n\\n> **PART III - Code**\\n>\\n> - **3.a. Data Preprocessing and Cleaning**: Completeness: Are all necessary steps for data preprocessing included (e.g., handling missing values, encoding categorical variables, scaling features)? Justification: Are the preprocessing steps justified and explained? Is there a clear reason for the choices made?\\n>\\n> - **3.b. Data Exploration**: Initial Analysis: Is there an exploratory data analysis? Are descriptive statistics used to better understand the data? Visualization: Are visualizations (e.g., graphs, plots) used to illustrate data distribution, correlations, and important patterns? Are these visualizations clear and informative?\\n>\\n> - **3.c. Model Implementation and Training**: Correctness: Is the model implemented correctly according to the chosen algorithm? Are appropriate libraries and functions used? Parameter Tuning: Is there evidence of parameter tuning or optimization? Are the chosen parameters explained and justified?\\n>\\n> - **3.d. Evaluation and Validation**: Metrics: Are appropriate evaluation metrics chosen and calculated? Are these metrics relevant to the problem at hand? Validation Techniques: Are appropriate validation techniques used (e.g., cross-validation, train-test split)? Is there an analysis of the model\'s performance on both training and testing data?\\n\\n
\\n\\nThis was it.\\n\\nExactly what I was looking for.\\n\\nNow I could grade a student on each of these criteria, then select a final grade weight for each criteria (e.g. 5-15%), create a spreadsheet with such a table and call it a day.\\n\\nHowever, the most time-consuming task was coming - the grading itself.\\n\\nThere were 10 groups in total. So 10 notebooks that I had to look into, exploring completely different datasets with a different ML model being used, different ways to do exploratory data analysis, different ways to assess the model, different objectives, \u2026\\n\\n### Cursor helping with grading\\n\\nI opened [cursor](https://www.cursor.com/) (which is basically VSCode + ChatGPT) and probably the software I\u2019ve recommended the most to developers in 2024.\\n\\nAnd opened my first notebook.\\n\\nThen I thought, what if I had GPT-4o on my side - helping me to assess this coursework.\\n\\nIt didn\u2019t need to be perfect because I was doing it myself, but it could help me understand if there was any critical thing that I missed OR if it completely had a different grade than the one I was going to provide - which would enable me to spend more time on that criteria and iterate.\\n\\nIt gave me confidence that I was being fair to the students.\\n\\nAnd made me realize how hard it is for professors when they have 100s of students and have a subjective answer to grade. It\u2019s impossible to get it right. They try their best, but as soon as the answer is not binary (0 or 1), they are doomed to fail.\\n\\nSo how did I do it?\\n\\nGiven that I just wanted GPT-4o to quickly review each of the criterias based on the code, I created a prompt that I could use for all of notebooks that the students sent.\\n\\nThis is what my setup looked like\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n \\n \\n\\n\\nAlso, related with the picture from the above. The battery is pretty weak, it needs to be charged often.\\n\\nThe rabbit r1 OS has a lot of room for improvement, a few things I\'ve experienced:\\n- Having a black screen that doesn\'t recover until I manually power off device;\\n- Not triggering the function I want - sometimes it looks for a specific wording, e.g. \\"start a recording session\\" works but \\"do a voice recording\\" does not. I would have expected for it to be able to understand intent;\\n- Sometimes I get a \\"The app is under maintenance. Please try again later\\" for functions that I know it is capable of doing;\\n- Every few minutes getting \\"unable to connect to Rabbit OS\\";\\n- Randomly losing the previous context - I assume this is because of the number of tokens that can fit in the context?;\\n- Spotify integration broken;\\n- Even though it knows my location (due to getting weather app location correct), the time is not correct and I can\'t update it through the settings.\\n\\nBut this is also the first product version and LLMs are by nature non-deterministic so these type of bugs are kind of expected.\\n\\nIt\'s a one-time $199 price tag. There\'s no recurring subscription. As a consumer, I like this a lot. A one-time purchase allows users to buy the product to experiment without any strong commitment (apart from that one-time fee of course). In terms of economics, I\'m not sure how Rabbit will handle a growing user base and better LLMs. During the event, they mentioned a partnership with both OpenAI and Anthropic. If they are using one of these models, someone needs to be paying for these tokens. For instance, for [OpenBB Terminal Pro](https://openbb.co/products/pro) we decided to allow usage similarly to how the ChatGPT free tier works, which basically rate limits based on usage and allows us to keep our costs controlled.\\n\\nMeta is attempting to commoditize LLMs, so if I were in rabbit\'s shoes I would consider hosting [Llama 3](https://llama.meta.com/llama3/) locally and providing inference from this directly. Maybe even do a partnership with [Groq](https://groq.com/) for users paying a small subscription - not so much because of the impressive 800 tokens/s inference (using Llama 3) since rabbit r1 uses voice and inference speed is less relevant, but for the cold start (i.e. the lag between user question and output). Meta\'s commercial license only applies to companies with over 700 Million active users, so I think Rabbit would be good for some time.\\n\\nPersonally, I wouldn\u2019t recommend rabbit r1 as a phone alternative. Not even close. If someone says that they stopped using their phone after having their rabbit r1, I can guarantee you that they weren\u2019t using their phone a lot anyway. I agree a lot with MKBHD in saying [Phones are OP](https://www.youtube.com/watch?v=TitZV6k8zfA).\\n\\nBut if you are reading this, you are probably wondering what are the use cases where I would recommend Rabbit r1. So let\'s do that.\\n\\n### This is a buy if\\n\\n- For kids that are curious and want to learn more about the world. Being able to have it before a phone, is very compelling. Imagine your kid being able to ask r1 what a word means and how to use it in a sentence, who person X is, how something works, to practice learning another language, as a complement when reading a book/studying. The advantage over the phone is that it doesn\'t have any other distractions. It would basically be Perplexity on the go, and thus the Perplexity tagline \\"Where knowledge begins\\" makes total sense.\\n\\n- As a device for two-way translation. The two-way is important, because if it\u2019s just one-way then using the phone is preferred. But being two-way allows for both people to interact with the device, which in my opinion is less personal than a phone and more like a gadget. We aren\'t there yet, but I\'m sure the model will keep improving and becoming better at this.\\n\\n- For content creators who want to \u201czone out\u201d and leave their phone at home and just use the record feature to record content, whether that is a blog post, a new lyrics or a podcast idea. \\n\\n- As a music device to be at the center of a table at a dinner, in the corner at a party selecting the tunes or on a roadtrip. People will enjoy interacting with it due to its unique nature, and that way you don\'t need to be blocked from using your phone.\\n\\n- As a virtual assistant. If the alarm feature was already implemented, I would\'ve likely already replace my Alexa, since rabbit r1 looks much nicer. Even more with the cool standing case.\\n\\n... and of course, the use case is worth $200 for you. There are likely devices that can achieve the same for a cheaper cost. I like the fact that is state-of-the-art and they are trying to innovate.\\n\\nAlso, the rabbit effect going up and down waiting to be prompted and the hears going up when listening is pretty sweet - see it [here](/blog/2024-04-28-rabbit-r1-there-is-hope_10.png).\\n\\nIn any case, there are two recurring topics in these use cases, so let\'s talk about each individually.\\n\\n### Main use cases\\n\\n1. **A very targeted use case** - The phone can be a double-edged sword. On the one hand, it\'s your door to the world and what\'s happening. On the other hand, it\'s your door to the world and what\'s happening. I say it this way because this can be extremely good or bad depending on the use case. Phones are optimized for users to spend time on them, apps are optimized to provide dopamine hits so users use them for longer. Notifications will interrupt you throughout the day so you remember to go back to the app, etc.. But sometimes you only want to do 1 thing, and don\'t want to be distracted from it. The best example are E-Books. You can read on your phone, iPad or laptop - yet people decide to buy a kindle so they can just do that. Read with no distractions. You are paying a premium for a product to remove the distractions. I believe that rabbit r1 can achieve this, particularly if they allow developers to build specific apps for specific use cases.\\n\\n2. **Gadget to be used by multiple people** (examples above: two-way translation or music device) - The phone has become a very personal device over the years. If someone gets access to your phone unlocked they have access to who you are (important emails, personal photos, chat conversations, the apps you use and how do you spend your time, the songs you listen or books you read, even confidential documents). So, there are certain scenarios where you don\'t want to borrow your phone to someone to do something, since that requires trust that they won\'t see anything that is confidential. I think Rabbit r1 can go after this category because its a shiny gadget that doesn\'t really hold any personal information from the user, and this way allows the user to keep their phone in their pocket while using rabbit r1 for some tasks that the phone could also do but would require for others to have access to it.\\n\\n
\\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nand\\n\\n> \u201cPerform a fundamentals financial analysis of AMZN using the most recently available data. What do you find that\u2019s interesting?\u201d\\n\\n
\\n\\nSince that was already working so well (watch the [presentation video here](https://www.youtube.com/watch?v=A-43EKK2PhE&embeds_referring_euri=https://openbb.co/blog/creating-an-ai-powered-financial-analyst&source_ve_path=MjM4NTE)), I wanted to bring these capabilities to Slack, show that this could be the future, and prove it would impact every analyst job.\\n\\nThat\u2019s when Goh Analyst was born.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nRecently, I wrote a blogpost about the [difference in culture between London and San Francisco](/blog/moving-from-london-to-the-bay-area-and-what-changed). I convinced my wife and dogs, packed our bags, and didn\'t look back. After all, I would live in the city with the highest density of builders per capita.\\n\\n**But why?**\\n\\nMost of my friends and family didn\'t understand why I would leave London. I liked the city, I enjoyed my lifestyle, I had friends, I played football with the same group every week, had dinner at the same restaurants, was close to family, and wouldn\'t be able to save money.\\n\\nLogically speaking, this move didn\'t make any sense. No one really told me that I was doing the right thing, but internally, I knew I had to.\\n\\nI believe this isn\'t so different from creating a startup. This blog post will explain what they have in common and why I did it.\\n\\n## Creating a startup / Deciding to leave your\xa0country\\n\\n[Elad Gil](http://eladgil.com/) wrote a really good [article](https://blog.eladgil.com/p/startups-are-an-act-of-desperation) on how creating a startup is an act of desperation. I believe that post could be equally applicable to moving countries, so I will list the same points used by Elad in the context of moving countries and provide examples. Most of the time, the person moving countries has a mix of the below bullet points.\\n\\n> **Career desperation.** Startups allow people early or stuck in their careers to jump a few steps ahead.\\n\\n
\\n\\nThis applies equally to moving, and is why I left Portugal to pursue an MSc at Imperial College London.\\n\\n> **Financial desperation.** If successful, a startup will also leapfrog you financially.\\n\\n
\\n\\nThis is the biggest motivation for people to move countries. This is why I was born in Switzerland, even though my parents are Portuguese. Having blue-collar jobs, they emigrated to a country with a better economy to provide my brother and me with a better life.\\n\\n> **Product or mission desperation.** The other reason startups often exist is that the founders are desperate for a product to exist in the world.\\n\\n
\\n\\nIn this case, it\'s the equivalent of hearing about Silicon Valley in documentaries or watching Steve Jobs presenting the iPhone in 2007. You cannot ignore that as an engineer, so you are desperate to move to be part of that tech scene.\\n\\n> **Desperation to do something big or important, and to avoid wasted time.** Some people want to \\"make a dent in the universe\\" and are motivated by doing something useful with their lives.\\n\\n
\\n\\nThis is what the \\"American dream\\" is all about. People moved to the US to do something bigger than themselves and achieve the promised dream.\\n\\n> **Revenge vs the Arena**\\n\\n
\\n\\nThe equivalent to this is when someone returns to their home country after several years outside with more wealth and/or experience.\\n\\n## Growing a startup / Living\xa0abroad\\n\\n### Mission and\xa0Vision\\n\\nWhen creating a company, you must have a clear mission and vision. This allows you to create a community/team that will be with you for the long run. Similarly, when moving countries, it\'s essential to have a well-defined goal. This doesn\'t mean that the goal cannot change; after all, companies pivot. However, you need to have a strategy that you follow until you don\'t.\\n\\n### Risk and Uncertainty\\n\\nStartups and moving to a new country both involve stepping into the unknown. Entrepreneurs often take financial and personal risks, while those moving countries leave behind familiar surroundings, support systems, and sometimes even their careers. Uncertainty becomes a constant companion, demanding adaptability, problem-solving skills, and the ability to embrace change with open arms.\\n\\n### Cultural Integration and Networking\\n\\nBuilding a successful startup requires networking, forming strategic partnerships, and understanding the market. Similarly, when moving countries, one must navigate cultural differences, learn new languages, and establish a network of contacts. Expanding social circles, building relationships, and immersing oneself in the local culture contribute to personal growth and enhance professional opportunities, just like in the startup world.\\n\\n### Resilience and Persistence\\n\\nBuilding a startup and moving countries demands unwavering resilience and persistence in facing challenges. Startups encounter setbacks, pivots, and failures, but successful entrepreneurs persist and learn from their experiences. Similarly, moving countries can bring unexpected hurdles, such as language barriers, difficulties making friends, challenges adapting to a new culture, or not finding a routine. Embracing these challenges with determination and adaptability paves the way for growth and achievement.\\n\\n### Learning and\xa0Growth\\n\\nStartups and moving countries are transformative experiences that offer immense personal and professional growth opportunities. Entrepreneurs continuously learn from their successes and failures in the startup world, refining their strategies and acquiring new skills. Likewise, moving countries provides a unique chance to learn about different cultures, broaden perspectives, and develop resilience, patience, and empathy. Both experiences foster personal development and shape individuals into more well-rounded and adaptable individuals.\\n\\n## Why did I do\xa0it?\\n\\nThe reason why I started OpenBB and also moved country is a combination of 2 factors:\\n\\n### Product or mission desperation.\\n\\nOn a startup level, I have experienced the need for an open-source investment research platform. That\'s why I wanted to create this platform, which was yet to exist. I think it wouldn\'t be possible if I didn\'t dedicate my time to it. This is why OpenBB\'s success is so important-it will enable millions of investors to have better access to data and better understand the financial market.\\n\\nGrowing up as an engineer fascinated by tech and innovation, the US has always been home to the biggest companies and hottest products. I\'ve always been attracted to Silicon Valley, but before OpenBB, I never had the chance to. The first job I applied to after finishing university was Waymo in CA, but they didn\'t sponsor VISAs for that role.\\n\\n### Desperation to do something big or important.\xa0\\n\\nOn a startup level, I want to work on something bigger than myself. I want to solve a problem that no one has solved before and build something useful for millions of people that can withstand time.\\n\\nI will do whatever it takes to build the first truly open-source investment research platform. Moving to SF increased my network opportunities with other entrepreneurs and builders from whom I can learn. I want to be fully immersed in this ecosystem and give it my all to do everything possible to help OpenBB succeed as a company, regardless of the outcome.\\n\\nNote: A few weeks ago, I moved to NYC because I truly believe living here would increase the chances of OpenBB\'s success compared to living in SF."},{"id":"moving-from-london-to-the-bay-area-and-what-changed","metadata":{"permalink":"/blog/moving-from-london-to-the-bay-area-and-what-changed","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.md","source":"@site/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.md","title":"Moving from London to the Bay Area and what changed","description":"Moving from London to the Bay Area and what changed","date":"2024-03-02T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"experience","permalink":"/blog/tags/experience"},{"inline":true,"label":"growth","permalink":"/blog/tags/growth"},{"inline":true,"label":"moving","permalink":"/blog/tags/moving"},{"inline":true,"label":"london","permalink":"/blog/tags/london"},{"inline":true,"label":"bay","permalink":"/blog/tags/bay"},{"inline":true,"label":"US","permalink":"/blog/tags/us"},{"inline":true,"label":"travel","permalink":"/blog/tags/travel"}],"readingTime":19.905,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"moving-from-london-to-the-bay-area-and-what-changed","title":"Moving from London to the Bay Area and what changed","date":"2024-03-02T00:00:00.000Z","image":"/blog/2024-03-02-moving-from-london-to-the-bay-area-and-what-changed.png","tags":["learning","experience","growth","moving","london","bay","US","travel"],"description":"Moving from London to the Bay Area and what changed"},"unlisted":false,"prevItem":{"title":"Moving Countries and Starting a Company Ain\'t So Different","permalink":"/blog/moving-countries-and-starting-a-company-aint-so-different"},"nextItem":{"title":"OpenBB Copilot is now available to all Terminal Pro users","permalink":"/blog/openbb-copilot-now-available-to-all-terminal-pro-users"}},"content":"
\\n \\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA few months ago, I wrote a blogpost about what was needed in order for my wife and our 2 dogs to move to the Bay Area from London. You can check that blog post [here](/blog/leaving-london-to-live-in-san-francisco/).\\n\\nSince then, I\u2019ve had some people asking me after living in the Bay for 1 year, what are the biggest differences I\u2019ve experienced in terms of lifestyle & culture.\\n\\nI will write a section below for each of the major topics I experienced. Note that this is based on my experience, and you may disagree/have different opinions than me on some of these - which are very welcome.\\n\\n## Living costs\\n\\nBack in 2016 when I was at university, in Portugal, I used to pay 200 euros/month to live in an apartment with a roommate. My university cost was 800 euros/year and my parents gave me a monthly allowance of 300 euros/month to pay for food and anything else. I didn\u2019t do many activities and would rarely go out, so I was able to live comfortably on that.\\n\\nOnce I moved to London (in 2017) to pursue a MSc. at Imperial College I was paying 1.6k \xa3/month for a studio in Earl\u2019s Court. This was walking distance from Imperial (didn\u2019t have to pay for transportation) and was cheaper than the accommodations that the university offered. The university was no longer 800 euros/year, it cost \xa311k for the entire MSc (1 year).\\n\\nSo there was a shock that I experienced in terms of living costs from Lisbon to London.\\n\\nOnce I decided to move to the Bay Area (2023) I knew that the living costs were going to be higher, but in my head \u201chow higher can these be?\u201d.\\n\\nOh boy.\\n\\nApparently, a lot.\\n\\n### Shopping\\n\\n
\\n \\n
\\n \\n \\n
\\n \\n
\\n \\n
\\n \\n \\n
\\n \\n
\\n \\n
\\n \\n
Elad Gil fireside with Satya Nadella at Stripe\'s HQ
\\n\\n\\n### Equity as part of compensation package\\n\\nMost European startups do not offer any equity. In the Bay Area, all startups offer equity. The earlier you join (higher risk) the more meaningful the options you get are. One of the reasons this works is because US employees are, in general, hard-working and will go the long way for their company. So this makes it so that incentives are aligned, and employees want to work harder because that equity can become much more meaningful than their base salary (potentially life-changing).\\n\\nOne of the reasons this works so well is that pretty much every US person knows someone in firsthand who made f-u money by selling their shares in secondaries, or has at least heard stories about this. While I was in the UK, before starting OpenBB, I didn\u2019t hear about this once. Also because companies have no interest in offering you equity if they don\u2019t have to.\\n\\nE.g. at my previous startup I used to stay working late into the night, because in my perspective this would increase the startup\'s chances of success. However, I had no equity. So this meant that if the startup was wildly successful, I would have no direct gains from it and the company would not owe me anything. Offering equity through a typical 4-year vesting schedule (with 1-year cliff) provides the perfect type of alignment.\\n\\n### Holidays\\n\\nThe amount of holidays is a good example that demonstrates the hard-working culture that so well characterizes the US. In the US they are used to having 2-weeks off in a full calendar year. In London, most companies offer at least 4-weeks, which is effectively 2x the number of holidays.\\n\\n## Driving culture\\n\\nThe London underground works impressively, I lived there for 5 years and never once even considered owning a car.\\n\\nI thought I could do the same in the US and people were being dramatic. That thought lasted maybe 2 days?\\n\\nOn the first day I had to go to Fedex which was a 15-20m walk, and when I told the apartment administrator that I was going to walk there she looked at me like I was crazy and said \u201cyou need to take your car\u201d. After walking there I understood what she meant and that unless you are in a city, the pedestrian sidewalks/roads just aren\u2019t prepared for pedestrians.\\n\\n### Differences\\n\\n- You drive on the right (x2) side of the road. Since I didn\u2019t drive in the UK, this was very easy for me as I\u2019m used to driving in Portugal where we also drive on the right side of the road.\\n- In the UK (or Europe, in general) having more than 3 lanes on the highway is atypical. In the US, having 6 lanes it\u2019s considered normal. Sometimes it\u2019s tricky and you can\u2019t be in the most right side because the 2 right lanes may both exit and thus you need to hop over 2 lanes to keep on the same route. This mistake can be costly.\\n- There are very very few roundabouts in the Bay. There are a LOT of intersections. I like it less (not because I think it\u2019s slower) but because it\u2019s more \u201cboring\u201d to wait for the green light and from my point of view, people are more likely to grab their phone during that time because they don\u2019t need to pay as much attention, at least compared to a roundabout where you are waiting for an opening to keep moving. (there are so few roundabouts that the first time I saw one I took a picture to share with my wife)\\n- There\u2019s a \u201cRight on Red\u201d policy. This means that if you are at an intersection and it\u2019s red for you to proceed if there\u2019s no incoming car from the left side you can turn right on the red. I like this because it allows for traffic to flow better. My wife doesn\u2019t like it because as a pedestrian sometimes cars start accelerating and don\u2019t respect pedestrian as much. Nonetheless, I love to make this joke when people from Europe visit, where I say that I\u2019m going to pass a red and they are shocked when they see me turning right on a red light.\\n- In the Bay they have FastTrack which allows people to pay to use the most-left lane and avoid traffic. Although this is capitalist I like it because if I\u2019m in a rush I can pay a few dollars to avoid the congestion - it\u2019s a type of SaaS - Speed as a Service \ud83d\ude04\\n\\n### Waymo\\n\\nWaymo, a self-driving car division that started off Google, was the first startup I applied to when I finished university. I have been bullish on self-driving cars since university - my dissertation was on that topic and I had to propose it myself, since there were no proposals for such. So seeing Waymo operating in SF was mind-blowing to me.\\n\\nAutonomous cars are a matter of time - and SF (and the Bay Area) being the city where Waymo starts operating, shows a lot about how progressive this city is. I recommend everyone to try one out.\\n\\nMy dad, someone who was born and raised in a small town in Portugal, and who understands very little about technology seeing this was something. Him seated in the passenger\u2019s seat for the full 16 min drive recording a wheel with no driver and ending the journey telling me \u201cI never thought I would see this in my life, thank you\u201d is something that no amount of money in this world could buy.\\n\\n\\n \\n \\n
\\n \\n
\\n \\n \\n
\\n \\n
\\n \\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe [OpenBB Copilo](https://openbb.co/use-cases/ai) is our latest addition to the [Terminal Pro](https://openbb.co/products/pro), and we could not be more excited to share it with you.\\n\\nIf you don\'t have access yet, join the [Terminal Pro waitlist](https://my.openbb.co/app/pro/early-access) and enjoy your 3-week free trial soon!\\n\\nNow, take a moment to meet your new **AI investment research partner**.\\n\\n\\n## What can the OpenBB Copilot do?\\n\\nOpenBB Copilot is multi-functional and can perform several tasks that are useful to analysts. We\u2019ll be exploring these below.\\n\\n\\n### Generic financial knowledge\\n\\nUsing OpenBB Copilot, you can ask any general financial question. For example:\\n\\n**What is the P/E ratio?**\\n\\n\\n\\nAs an additional bonus feature, OpenBB Copilot includes a LaTeX renderer to display mathematical formulas and equations.\\n\\n\\n### Conversation capability\\n\\nOpenBB Copilot is a conversational agent and is, therefore, aware of the chat history of the current conversation.\\n\\nAs a result, you can ask follow-up questions and steer OpenBB Copilot toward your line of inquiry while developing an investment thesis.\\n\\nTo clear the message history, for example, when investigating a new asset, you can click on the trashcan icon to start a new conversation.\\n\\n\\n\\n\\n### Terminal Pro as context\\n\\nIf you ask questions about the data on the dashboard, OpenBB Copilot will query the Terminal Pro for the data necessary to answer your query.\\n\\nThe Copilot has access to the dashboard metadata on the backend and can decide to retrieve data from any of the widgets currently on your dashboard.\\n\\nIn most cases, if you can see the data on your dashboard, you can assume OpenBB Copilot has access to it.\\n\\n\\n\\nThis is an application of what\u2019s known in the AI world as function calling, which allows LLMs to interact with external systems.\\n\\nThe OpenBB Copilot can choose to automatically retrieve the data from your dashboard if it needs it to answer your query.\\n\\nThe advantage of this approach is that, since you can retrieve data from any widget, you can also expand OpenBB Copilot\u2019s knowledge by adding custom widgets or by bringing your own data to the Terminal Pro.\\n\\n\\n### Query specific widgets\\n\\nSometimes, you may wish to focus your analysis and use OpenBB Copilot with only a specific subset of widgets.\\n\\nFor example, you may want to use OpenBB Copilot to assist you in a deep analysis of an earnings transcript in the \\"Earnings Transcript\\" widget without retrieving data from the rest of the dashboard.\\n\\nTo achieve this, you can chat with specifically selected widgets by clicking on the \\"Add widgets as context\\".\\n\\n\\n\\nSelecting a widget will make that widget\'s data available to OpenBB Copilot while excluding all the other widgets.\\n\\nYou can then use the Copilot as normal and the unselected widgets will be ignored by the Copilot.\\n\\n\\n### Query your own documents\\n\\nYou\u2019re also not limited by the data that is available in Terminal Pro.\\n\\nYou can upload your own documents for OpenBB Copilot to use as context while answering your queries.\\n\\nOpenBB Copilot currently supports txt, PDF, CSV and XLSX documents.\\n\\n\\n\\n### Citations\\n\\nWe understand that sometimes getting an answer from an AI chatbot with financial knowledge isn\u2019t satisfactory.\\n\\nYou often want to do further research or do your own fact-checking of the sources used to answer to your query.\\n\\nThat is why OpenBB Copilot provides citations as part of its answers.\\n\\nWhen using the Terminal Pro as context or chatting with your uploaded data files, the Copilot will cite which data sources it used to formulate the answers.\\n\\nSimply mouse over the citation to see which widget data was used, or which uploaded file was referenced. For PDF document specifically, the Copilot will also source the specific page that was used to answer your query.\\n\\n\\n\\n## What if you don\'t want to use our copilot?\\n\\nYou don\u2019t have to. That is the reason we came up with the Bring Your Own Copilot concept.\\n\\nIf you\u2019re an OpenBB Terminal Pro user, you\u2019re able to bring your own financial Copilot that has been fine-tuned and tweaked on your enterprise\u2019s private data.\\n\\nThis provides an edge to financial firms as they can access their own fine-tuned LLM with access to real-time data provided by the OpenBB Terminal Pro - making this the perfect combo to perform investment research.\\n\\nWe have an [open-source repository](https://github.com/OpenBB-finance/copilot-for-terminal-pro/tree/main) to help you make your own copilots accessible on the Terminal Pro.\\n\\nYou can also see the video below:\\n\\n\\n\\n
\\n\\nCheck out our [AI page](https://openbb.co/use-cases/ai) to learn more about these features and stay updated in the future."},{"id":"12-things-i-learned-in-2023","metadata":{"permalink":"/blog/12-things-i-learned-in-2023","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-22-12-things-i-learned-in-2023.md","source":"@site/blog/2024-01-22-12-things-i-learned-in-2023.md","title":"12 Things I Learned in 2023","description":"The 12 things I learned in 2023","date":"2024-01-22T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"experience","permalink":"/blog/tags/experience"},{"inline":true,"label":"growth","permalink":"/blog/tags/growth"}],"readingTime":4.17,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"12-things-i-learned-in-2023","title":"12 Things I Learned in 2023","date":"2024-01-22T00:00:00.000Z","image":"/blog/2024-01-22-12-things-i-learned-in-2023.png","tags":["learning","experience","growth"],"description":"The 12 things I learned in 2023"},"unlisted":false,"prevItem":{"title":"OpenBB Copilot is now available to all Terminal Pro users","permalink":"/blog/openbb-copilot-now-available-to-all-terminal-pro-users"},"nextItem":{"title":"Introducing the OpenBB Add-in for Excel","permalink":"/blog/introducing-the-openbb-add-in-for-excel"}},"content":"
\\n \\n
\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe 12 things I learned in 2023\\n\\n### 1. Don\'t delegate anything that you wouldn\'t do yourself.\\n\\nIt\'s extremely important to work on little things to show your team that nothing is too small to spend time on, and sets a precedent that you are willing to work on the ground next to them.\\n\\nE.g. Elon Musk sleeping at the gigafactory to show his team that he was there next to them.\\n\\n### 2. Be curious and humble enough to be willing to ask dumb questions.\\n\\nIf I don\'t know something, I never pretend understanding what the person is talking about.\\n\\nI would take the knowledge over a \\"smart\\" label, any day.\\n\\n### 3. Implement feedback loops on everything you do, otherwise you can\'t adapt.\\n\\nLast year I decided to work on [tracking our employee engagement](https://openbb.co/company/open/team), and this is one of the best and most valuable initiatives I have worked on.\\n\\nIt has provided us tons of feedback that we were able to act on, and improve what it\'s like to work for OpenBB. More information on this [here](https://openbb.co/blog/employee-engagement).\\n\\n### 4. UX is more important than UI.\\n\\nI keep seeing tweets about UI improvements on a website and/or product. I love that type of posts, and wish there was a similar trend going on for UX improvements.\\n\\nWhile UI is critical to attract users, UX is king to retain them.\\n\\nIt\u2019s like dating - the looks is in the UI and the personality is the UX.\\n\\nWhile they may be perceived as their own separate bubble, they are not. Someone with an amazing personality (UX) will appear as more beautiful (UI).\\n\\n### 5. If in presence of a 2-way door decision, you should decide fast.\\n\\nBeing fast to decide to do A instead of B in a 2-way door decision is ideal because even if that wasn\u2019t the correct decision, adapting after will still be better than being stuck at the decision stage.\\n\\nPlus, you\u2019ll be surprised by how many time you actually get it right given the level of context and knowledge you have in the space.\\n\\nKnowing what is a 1 and a 2-way door decision, separates great from poor leaders.\\n\\nI like [this video](https://tiktok.com/@evancarmichael/video/7317081673865235717) from Jeff Bezzos talking about this.\\n\\n### 6. There\u2019s a ton of data in intuition and common sense.\\n\\nAs a leader, most of the times you have to make decisions with no hard data evidence. And by hard data I mean a spreadsheet with numbers or a powerpoint with charts.\\n\\nHowever, you do have that data. It\u2019s just not in a clean format and lives on your head.\\n\\nThis data has been aggregating by spending more time thinking about the problem you are solving than anyone else, by talking with customers, by talking with partners, and everything in between.\\n\\nTrust your intuition, more often than not presentations are done to justify decisions that you knew were right all along. Skip that and you will be able to move faster.\\n\\n### 7. Hear feedback from everyone but only listen from a few.\\n\\nPeople paying for your product, will provide you 10x feedback compared to others. Use common sense for others.\\n\\n### 8. Be there for your team.\\n\\nMake sure to remind your team that you couldn\'t do it without them.\\n\\nA single off-line event per year is not enough.\\n\\nShow that you care by being there: asking about their family/pets/hobbies, messaging them when they perform above expectations, send them gifts when something negative happens, ... act like a friend but manage like a captain\\n\\n### 9. Fire B and C players early. \\n\\nKeeping a team of A players is hard but extremely rewarding, and necessary. \\n\\nIt sets the precedent that average work is not enough to work at your company, and high performers will want to work for you to be surrounded by people that push them everyday.\\n\\n### 10. Distribution is more important than product.\\n\\nTook me some time to understand this, but I have no doubts about this now.\\n\\nThis is why the sentence of \u201cA good product with great distribution will almost always beat a great product with poor distribution.\u201d\\n\\n### 11. Leave your comfort zone.\\n\\nI\'m really shy on stage and this year I\'ve presented a few times. And I\u2019ve impressed myself, while I\'m far from good I\'ve come a long way.\\n\\nWhen i started learning english my goal was to be able to make people laugh in english, that took a while.\\n\\nI\'ve now been able to make people laugh whilst on stage and I didn\'t expect that I\u2019d be able to do this anytime soon.\\n\\n### 12. Tell your loved ones how much they mean to you.\\n\\nMost of us have someone by our side that allow us to keep performing at highest level day in and day out.\\n\\nEnsure they know you couldn\'t be the person you are today without them."},{"id":"introducing-the-openbb-add-in-for-excel","metadata":{"permalink":"/blog/introducing-the-openbb-add-in-for-excel","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.md","source":"@site/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.md","title":"Introducing the OpenBB Add-in for Excel","description":"We acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry.","date":"2024-01-17T00:00:00.000Z","tags":[{"inline":true,"label":"excel","permalink":"/blog/tags/excel"},{"inline":true,"label":"launch","permalink":"/blog/tags/launch"},{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"announcement","permalink":"/blog/tags/announcement"}],"readingTime":3.665,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"introducing-the-openbb-add-in-for-excel","title":"Introducing the OpenBB Add-in for Excel","date":"2024-01-17T00:00:00.000Z","image":"/blog/2024-01-17-introducing-the-openbb-add-in-for-excel.png","tags":["excel","launch","openbb","announcement"],"description":"We acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry."},"unlisted":false,"prevItem":{"title":"12 Things I Learned in 2023","permalink":"/blog/12-things-i-learned-in-2023"},"nextItem":{"title":"SlackGPT - Your Slack bot that summarizes unread messages","permalink":"/blog/slack-gpt-summarizing-messages"}},"content":"
\\n \\n
\\n\\nWe acknowledged the enduring centrality of Excel in the financial sector, so we\'re now making data from the Terminal Pro readily available in Excel. We\'re also excitedly working to integrate the \\"Bring Your Own Data\\" feature into our Excel Add-in, a move we foresee as a transformative step in the financial data industry.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nBuilding something people truly want requires direct engagement with them. After conducting over 100 interviews with analysts and quants, three key insights surfaced:\\n\\n1. The financial world runs on Excel.\\n\\n2. The primary value of the OpenBB Terminal Pro lies in its customization (bring your own data + widget/dashboard creation) and AI features.\\n\\n3. The financial world, **LITERALLY**, still runs on Excel.\\n\\nFor topic number 2, we were well underway towards building the [Terminal Pro](https://openbb.co/products/pro) as the most customizable and efficient financial terminal.\\n\\nBut for topics number 1 and 3, we weren\u2019t.\\n\\nSo we devised a small task force to tackle this effort and work with design partners towards building the [OpenBB Add-in for Excel](https://openbb.co/products/excel).\\n\\nThe goal was simple: **financial data available on the Terminal Pro should be accessible in Excel**.\\n\\nBut as we do for all our products, we wanted to understand where this product would sit in our ecosystem.\\n\\nSince the Terminal Pro offers a basic data tier (including historical price, fundamentals, analyst estimates, news, macro-economy, and forex) with redistribution rights, we decided to make those same datasets available in Excel.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nYou can find more tutorials in the [Documentation](https://docs.openbb.co/excel/getting-started/installation).\\n\\nFor more information, contact us at sales@openbb.finance or sign up for [our waitlist](https://my.openbb.co/app/pro/early-access)."},{"id":"slack-gpt-summarizing-messages","metadata":{"permalink":"/blog/slack-gpt-summarizing-messages","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-15-slack-gpt-summarizing-messages.md","source":"@site/blog/2024-01-15-slack-gpt-summarizing-messages.md","title":"SlackGPT - Your Slack bot that summarizes unread messages","description":"The SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel.","date":"2024-01-15T00:00:00.000Z","tags":[{"inline":true,"label":"slack","permalink":"/blog/tags/slack"},{"inline":true,"label":"slackgpt","permalink":"/blog/tags/slackgpt"},{"inline":true,"label":"llm","permalink":"/blog/tags/llm"},{"inline":true,"label":"summarization","permalink":"/blog/tags/summarization"},{"inline":true,"label":"open source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"bot","permalink":"/blog/tags/bot"}],"readingTime":3.825,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"slack-gpt-summarizing-messages","title":"SlackGPT - Your Slack bot that summarizes unread messages","date":"2024-01-15T00:00:00.000Z","image":"/blog/2024-01-15-slack-gpt-summarizing-messages.png","tags":["slack","slackgpt","llm","summarization","open source","bot"],"description":"The SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel."},"unlisted":false,"prevItem":{"title":"Introducing the OpenBB Add-in for Excel","permalink":"/blog/introducing-the-openbb-add-in-for-excel"},"nextItem":{"title":"Building my personal website in Docusaurus","permalink":"/blog/building-my-personal-website-in-docusaurus"}},"content":"
\\n \\n
\\n\\nThe SlackGPT is a Slack bot that summarizes conversations and sends you a summary per channel.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/slackGPT).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nSaw someone the other day tweeting that it would be great if there was a SlackGPT that could summarize all the Slack messages for when they wake up.\\n\\nAnd I immediately related to that. We are a team of 20, and I\'m the only one in SF. So when I wake up, most of the team is already half a day in or has just wrapped up.\\n\\nThat means that I always spend the first 30 minutes of the day reading messages to catch-up on everything.\\n\\nAnd tonight felt like hacking something quick.\\n\\nSo I created a script that:\\n\\n* Reads all Slack messages from the time I go to bed\\n* Summarizes the conversation of each channel\\n* The bot sends me a message with this summary\\n\\n## Getting Started\\n\\nClone the open source project [here](https://github.com/DidierRLopes/slackGPT).\\n\\n### Slack API\\n\\n1. Go to [Slack API page](https://api.slack.com/apps) and create a new app.\\n\\n2. Install the app in the workspace you are interested in summarizing Slack messages.\\n\\n3. Get the User OAuth Token which exists in the Install App settings. This will be needed to use Slack\'s SDK. Set this value as the `SLACK_TOKEN` on a `.env` file if you want to run the script locally or as a GitHub secret if you want to leverage the GitHub workflow.\\n\\n
\\n\\n
\\n \\n
\\n\\n
\\n \\n
\\n\\n
\\n \\n
\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nHow I\'m using Docusaurus to build my own personal website.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOne of my goals for 2023 was to learn web development. Given that I knew 0 to nothing last year, I am extremely happy with my progress.\\n\\nI never had the time to fully dedicate to it in terms of doing a program/course \u2014 but as with anything in life, the best way to learn is by doing.\\n\\nAnd this year I worked on web development for:\\n\\n* OpenBB Hub \u2014 https://my.openbb.co\\n* OpenBB marketing website \u2014 https://openbb.co\\n* OpenBB docs \u2014 https://docs.openbb.co\\n* OpenBB Terminal Pro \u2014 https://pro.openbb.co\\n\\nThank you Jos\xe9 Donato for always helping me with anything!\\n\\nIn addition, I\u2019ve always wanted to have my own personal website. So I felt that this would be the perfect opportunity to do so as I could spend some time with it over weekends.\\n\\nAnd so I did, and open source here: https://github.com/DidierRLopes/personal-website\\n\\nHowever, this website was taking too much of my spare time, which I could use for more important work. And at the time I became very familiar with Docusaurus, which is what we use for OpenBB docs.\\n\\nSo I thought \u2014 why not just use Docusaurus to make my personal website? It\u2019s easy to edit, I\u2019m already very familiar with the architecture, and it\u2019s very easy to update when there\u2019s new information.\\n\\nSo that\u2019s what I did, and also made the entire code open source here: https://github.com/DidierRLopes/my-website\\n\\nYou can access the full website here \u2014 https://didierlopes.com/, and there you can find: my personal projects, books I\u2019ve read or want to read, interviews/webinars/podcasts, resume or even my blog.\\n\\nAny feedback is welcome."},{"id":"prediction-for-2024","metadata":{"permalink":"/blog/prediction-for-2024","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2024-01-01-prediction-for-2024.md","source":"@site/blog/2024-01-01-prediction-for-2024.md","title":"Prediction for 2024","description":"Companies will own multiple fine-tuned LLMs/SLMs for specific tasks.","date":"2024-01-01T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"ai","permalink":"/blog/tags/ai"},{"inline":true,"label":"agents","permalink":"/blog/tags/agents"},{"inline":true,"label":"copilot","permalink":"/blog/tags/copilot"},{"inline":true,"label":"llm","permalink":"/blog/tags/llm"},{"inline":true,"label":"pro","permalink":"/blog/tags/pro"},{"inline":true,"label":"fine-tune","permalink":"/blog/tags/fine-tune"}],"readingTime":1.73,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"prediction-for-2024","title":"Prediction for 2024","date":"2024-01-01T00:00:00.000Z","image":"/blog/2024-01-01-prediction-for-2024.png","tags":["openbb","finance","ai","agents","copilot","llm","pro","fine-tune"],"description":"Companies will own multiple fine-tuned LLMs/SLMs for specific tasks."},"unlisted":false,"prevItem":{"title":"Building my personal website in Docusaurus","permalink":"/blog/building-my-personal-website-in-docusaurus"},"nextItem":{"title":"Creating an AI-powered financial analyst","permalink":"/blog/creating-an-ai-powered-financial-analyst"}},"content":"
\\n \\n
\\n\\nCompanies will own multiple fine-tuned LLMs/SLMs for specific tasks.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLLMs like ChatGPT are great for showing what these models are capable of doing in terms of breadth, but at the end of the day, you\u2019re going to look for depth. Instead of relying on one-size-fits-all solutions, companies will look towards the integration of multiple, fine-tuned language models tailored for specific actions.\\n\\nEnterprises are recognizing the importance of accuracy in their AI applications. General-purpose language models have been revolutionary, but the demand for specialized models is on the rise. From customer support interactions to complex data analysis, having dedicated language models for specific tasks enhances accuracy and efficiency. This is easy to understand since the weights that are being used for the LLM to have a big breadth of knowledge are repurposed for depth.\\n\\nPersonalization is no longer a luxury but a necessity. Specialized language models enable enterprises to deliver personalized experiences to their customers. We have to assume that everyone is utilizing the same models today, so offering ChatGPT in your product isn\u2019t good enough. You need to add alpha to it. And that is done through fine-tuning utilizing your private data.\\n\\nIn an era of increasing cyber threats and stringent regulations, the deployment of fine-tuned language models allows enterprises to enhance their security measures and ensure compliance with industry standards.\\n\\nAs for the financial industry, this is 100% going to happen. Firms will fine-tune language models locally utilizing their proprietary datasets and providing access to their Snowflake/Elastic/ClickHouse/.. instances. This collection of models will effectively enhance the productivity of the firm by 2/3x, even displacing jobs.\\n\\nWe are preparing for this shift at OpenBB and I spent the last few days working on a proof-of-concept with Jos\xe9 Donato that will allow users to bring their own copilots to the Terminal Pro. And even have these interact with each other.\\n\\n
\\n \\n
\\n \\n
\\n\\nOur Platform aims to empower the OpenBB Copilot, an AI-powered financial analyst, to perform tasks ranging from knowledge retrieval to fully autonomous analysis. The architecture involves task decomposition, tool retrieval, and subtask agents, showcasing impressive results in both deterministic and non-deterministic workflows. Read on to explore its capabilities and don\'t forget to watch the demos.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/openbb-agents).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nAt OpenBB, we have been thinking deeply about how AI will impact the lives of analysts and quants. We recently [announced the OpenBB Platform](https://openbb.co/blog/goodbye-openbb-sdk-hello-openbb-platform) and have refactored it from the ground up to make it easier and simpler for quants/developers to access financial data. In addition, we hired a new head of AI to lead our AI efforts - you can read more about it [here](https://openbb.co/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig).\\n\\nI did a 20-minute presentation at the Open Core Summit on this topic that you can watch here:\\n\\n
\\n\\nOtherwise, the following post will summarize what we presented.\\n\\n## AI-Powered financial analyst roadmap\\n\\nWhen discussing what tasks we wanted our AI-powered Financial Analyst to be able to perform, we arrived at the following levels (in order of complexity):\\n\\n1. **Knowledge retrieval**: The agent can answer general financial queries without external resources. (eg. ChatGPT \\"as-is\\"). Here, the agent relies solely on its training data to answer questions.\\n\\n2. **Data retrieval**: The agent can answer queries using information inserted into the context (usually as part of a separate data retrieval process that isn\u2019t controlled by the model, such as using [similarity search](https://en.wikipedia.org/wiki/Similarity_search) across a knowledge database using the user\u2019s query).\\n\\n3. **Autonomous data retrieval**: The agent can answer queries by dynamically retrieving data not currently present in the context or the training data via function calling.\\n\\n4. **Complex workflow execution**: The agent can reason and answer queries that require a logical arrangement of knowledge retrieval, data retrieval, and autonomous data retrieval calling. It includes action planning and decision-making.\\n\\n5. **Fully autonomous analyst**: The agent can do all of the above but is self-directed. The agent can dynamically generate additional hypotheses, modify plans of action, and retrieve the necessary data, all while mid-workflow. The agent can make arguments for certain decisions, carry a discussion on the topic, and reason with you.\\n\\nOur goal is to enable OpenBB Copilot to perform all of the above. I presented a demo of how it would work in this video:\\n\\n
\\n\\n## Two types of prompts\\n\\nRather than first building an AI-powered financial analyst for the sake of it, we instead started from what we wanted to achieve. We came up with two distinct prompts and our goal was for the agent to be able to successfully perform both of these, but utilizing the same underlying \u201cagentic\u201d architecture.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nThis blog post delves into how our collaboration with MindsDB, Nixtla, LlamaIndex, and Langchain is revolutionizing the financial world. Read on to learn all about the event \\"The New FinAI Tech Stack\\" held last week in SF, California.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nIn early September, I attended a \u201cFuture of Finance\u201d event in NYC. Despite the presence of well-known financial professionals from top firms in the industry, I found the event lacked practical applications demonstrating how AI is impacting the financial sector.\\n\\nOnce I was back in the Bay Area, I had a barbecue with Jorge and Max from MindsDB and Nixtla, and I was commenting on that experience. To which Jorge promptly replied - why don\u2019t we do it ourselves? So following this discussion, we decided to put the AI in finance event in motion.\\n\\n
\\n \\n
\\n \\n
\\n\\nSo at the event, Harrison presented this architecture which heavily relies on Langchain and OpenBB tools.\\n\\n
\\n \\n
\\n\\nWe\'re considering organizing another event like this soon, possibly even in NYC.\\n\\nAnd if your firm is interested in early access to the OpenBB Terminal Pro, you can reach out to hello@openbb.finance, we\u2019d love to chat."},{"id":"goodbye-openbb-sdk-hello-openbb-platform","metadata":{"permalink":"/blog/goodbye-openbb-sdk-hello-openbb-platform","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.md","source":"@site/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.md","title":"Goodbye OpenBB SDK. Hello OpenBB Platform","description":"Today, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions.","date":"2023-11-29T00:00:00.000Z","tags":[{"inline":true,"label":"openbb","permalink":"/blog/tags/openbb"},{"inline":true,"label":"platform","permalink":"/blog/tags/platform"},{"inline":true,"label":"sdk","permalink":"/blog/tags/sdk"},{"inline":true,"label":"core","permalink":"/blog/tags/core"},{"inline":true,"label":"extensions","permalink":"/blog/tags/extensions"}],"readingTime":4.08,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"goodbye-openbb-sdk-hello-openbb-platform","title":"Goodbye OpenBB SDK. Hello OpenBB Platform","date":"2023-11-29T00:00:00.000Z","image":"/blog/2023-11-29-goodbye-openbb-sdk-hello-openbb-platform.png","tags":["openbb","platform","sdk","core","extensions"],"description":"Today, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions."},"unlisted":false,"prevItem":{"title":"The new FinAI Tech Stack","permalink":"/blog/the-new-finai-tech-stack"},"nextItem":{"title":"OpenBB Bot - our new addition to the OpenBB open source family","permalink":"/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family"}},"content":"
\\n \\n
\\n\\nToday, we are thrilled to announce the new OpenBB SDK, a game-changing platform that is now divided into the robustness of OpenBB Core and the limitless potential of OpenBB extensions.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn the ever-evolving landscape of financial data integration and standardization, OpenBB has been revolutionizing the way individuals and organizations handle data from multiple data providers by utilizing our open-source products.\\n\\nWe have been talking about the OpenBB Platform v4 over the past few months. This is such a milestone for our team and for the financial world that we are renaming the OpenBB SDK into the OpenBB Platform.\\n\\nThe OpenBB Platform consists of the OpenBB Core and OpenBB Extensions.\\n\\nLet\u2019s dive into each of these, individually.\\n\\n## OpenBB Core\\n\\nThe OpenBB Core empowers quants and finance developers to create powerful data solutions, offering unparalleled simplicity, flexibility, and scalability. It follows the principle that \\"less is more.\\"\\n\\nThe core will consist of two main components:\\n\\n1. **Data Standardization Infrastructure:** This ensures that regardless of the type of data processed by the core, users can expect consistent conventions and naming. This facilitates a seamless experience, even when the data comes from completely different data providers.\\n\\n2. **Data Source Integration:** Developers will be able to effortlessly connect and integrate various data sources, including databases, APIs, and cloud storage systems.\\n\\n a) **Official partner integrations** will be available by having access to official endpoints from data vendors. This ensures the integrity of the data and provides a reference for what data is available to the end user. Our affiliate program will detail where commercial agreements are in place with OpenBB.\\n\\n b) Additionally, **community provider integrations** will be available, allowing the community to contribute their own integrations for specific use cases or share them with others through the open-source codebase.\\n\\n## OpenBB Extensions\\n\\nOpenBB extensions enhance the capabilities of the OpenBB Core, allowing developers to create custom functionalities and customize the overall Platform according to their specific needs. It is important to note that these extensions can be used as a standalone or integrated with the rest of the openBB ecosystem.\\n\\nThese extensions can be classified into two categories:\\n\\n
- \\n
- Official extensions developed and maintained by the OpenBB Team, such as the ML/AI Toolkit, Econometrics, and Reports; \\n
- Community extensions developed by the open-source community. These extensions focus on enabling intelligent data processing and custom workflows that assist users in their investing decision-making process. \\n
- \\n
- Enhanced Flexibility: The modular architecture of the Platform allows developers to choose and integrate only the components they need, avoiding unnecessary complexity. \\n\\n
- Scalability: The OpenBB Platform seamlessly scales with your data integration requirements, ensuring smooth performance even with large volumes of data. \\n\\n
- Extensibility: Developers can create their own extensions and contribute to the OpenBB ecosystem, fostering collaboration and innovation. \\n\\n
- Time and Cost Savings: With its intuitive interface and pre-built components, the OpenBB Platform accelerates development cycles, reducing time-to-market and costs associated with custom solutions. \\n
\\n\\nThe reimagined OpenBB SDK into OpenBB Platform (OpenBB Core and OpenBB Extensions), revolutionizes the data integration landscape.\\n\\nBy leveraging the power of OpenBB Core for data integration and standardization, and harnessing the capabilities of OpenBB Extensions for customization and advanced functionality, developers can unlock new possibilities and build cutting-edge data solutions.\\n\\nWhether you are working with diverse data sources or performing complex data transformations, the OpenBB Platform empowers you to conquer any data challenge and propel your organization towards data-driven success.\\n\\nWe invite users and enthusiasts to explore the OpenBB Platform v4, now available for download and installation from the [OpenBB Hub](https://docs.openbb.co/platform/installation), [Github](https://github.com/OpenBB-finance/OpenBBTerminal/tree/develop/openbb_platform), and [PyPI](https://pypi.org/project/openbb/).\\n\\n## Inside OpenBB: A peek into our team emails\\n\\nIn order to adhere to one of OpenBB\'s core values - Transparency - we want you to understand the journey we have undergone and the reason we have dedicated the past 9 months to this endeavor.\\n\\nSo, for the first time, we\'re sharing a confidential email thread that circulated among our entire team. This thread provides insight into our thought process when it comes to handling large projects at OpenBB.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nThe OpenBB Bot is now open source. Check out our Discord Bot architecture now on GitHub.\\n\\nThe open source code is available [here](https://github.com/OpenBB-finance/openbb-bot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## What is the OpenBB Bot, and why did we build it?\\n\\nWhen the OpenBB Terminal first went viral, users were writing online that one of the things missing from our product was a chat feature like other investment platforms provide.\\n\\nHowever, we didn\u2019t understand why the chatting experience needed to be centralized in the application where users research their financial data. Plus, with the ever-growing userbase of apps like Discord, Telegram, Slack, and others, combined with their capabilities to build apps on top, we thought we could do more.\\n\\nWe believe in a future where you can query financial data right from where you are. Meaning you can chat with colleagues, from any of the apps you\u2019re already using.\\n\\nThis is when we partnered with OptionsFamBot (the biggest Discord financial bot that was present in 15k+ servers, reaching 1 M+ users) to build the OpenBB Bot.\\n\\nYou can read more about our launch in August 2022 [here](https://openbb.co/blog/openbb-bot-launch).\\n\\n## Failing to monetize. Failing to grow user base.\\n\\nTo provide OpenBB Bot users with access to 100+ financial commands (including expensive datasets such as the options and dark pool ones) we had to pay not just the data vendors but also for the display rights.\\n\\nThis was relatively expensive, but we considered it a marketing cost since we expected exponential user growth. We expected that since the Bot could be deployed in any server in a few seconds, more users would be exposed to the Bot, bringing the Bot to other servers, and so on...\\n\\n**However, that didn\u2019t happen.**\\n\\nIn September 2022, Discord changed its command syntax to force commands to start with \u201c/\u201d and the user drop was noticeable.\\n\\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n \\n
\\n\\nWith the launch of the OpenBB Terminal Pro approaching, we\'re excited to announce the hiring of Michael Struwig, a Ph.D. with expertise in AI and quantitative finance. Michael will help us to further our AI capabilities, reinforcing our commitment to innovation in the open-source finance space.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAI will be one of the technologies that will be looked back in hundreds of years as revolutionary, changing how humans live.\\n\\nWith the upcoming launch of the [OpenBB Terminal Pro](https://my.openbb.co/app/pro), we believe AI can push the limits of the way users do investment research.\\n\\nWe believe our ecosystem is positioned at the forefront of finance in terms of investment research. With the inception of the OpenBB Terminal Pro, we are standing at the cusp of a significant leap. Our journey began with [AskOBB](https://openbb.co/blog/breaking-barriers-with-openbb-and-llamaIndex), a tool that facilitated natural language interaction with financial data, but that was just the start.\\n\\nLast month, I wrote a [tweet](https://twitter.com/didier_lopes/status/1706731145776566399) explaining why we spent over $500,000 in revamping our core platform. We are committed to creating the best finance platform for quants/analysts to build with. Some key features are:\\n\\n
- \\n
- We are data vendor agnostic - we enable them \\n
- We are open source - everyone can contribute data \\n
- We standardize data across close to 100 different data providers \\n
- We put a lot of effort into our documentation \\n
\\n \\n
- \\n
- Startups built around a particular feature - e.g. chatting with news. With LLMs becoming a commodity, over time it will be easy to understand that this is a feature and not a product itself. \\n
- Larger companies that put a small team together to explore generative AI to be seen as leaders in the space - but without an intention to bring such to market. Often because of outdated tech stack. \\n
\\n\\n
\\n \\n
\\n\\n
\\n \\n
\\n\\n\\n\\nMost of these generative AI features have been started as side projects by our team members, and once we validated the use case with financial professionals we incorporated it into the roadmap. However, we want to double down on this effort and therefore we\'re excited to welcome [Michael](https://twitter.com/MichaelNStruwig) to OpenBB.\\n\\n[Michael](https://twitter.com/MichaelNStruwig) has a PhD in Electrical and Electronic Engineering, has been doing AI for a few years, and prior to joining us was the CEO of Hudson & Thames Quantitative Research.\\n\\nI first heard him from his reading groups:\\n\\n
\\n\\n
\\n\\nIf you are excited about the field of open source, AI, and finance, and want to help - you can reach out to Michael on [Twitter](https://twitter.com/MichaelNStruwig)."},{"id":"writing-documentation-as-a-founder-is-underrated","metadata":{"permalink":"/blog/writing-documentation-as-a-founder-is-underrated","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.md","source":"@site/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.md","title":"Writing documentation, as a founder, is underrated.","description":"This blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall.","date":"2023-10-29T00:00:00.000Z","tags":[{"inline":true,"label":"documentation","permalink":"/blog/tags/documentation"},{"inline":true,"label":"founder","permalink":"/blog/tags/founder"},{"inline":true,"label":"startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"writing","permalink":"/blog/tags/writing"},{"inline":true,"label":"product","permalink":"/blog/tags/product"}],"readingTime":1.23,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"writing-documentation-as-a-founder-is-underrated","title":"Writing documentation, as a founder, is underrated.","date":"2023-10-29T00:00:00.000Z","image":"/blog/2023-10-29-writing-documentation-as-a-founder-is-underrated.png","tags":["documentation","founder","startup","writing","product"],"description":"This blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall."},"unlisted":false,"prevItem":{"title":"Revolutionizing AI at OpenBB with new leader, Michael Struwig","permalink":"/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig"},"nextItem":{"title":"Building the world\u2019s investment research infrastructure","permalink":"/blog/building-the-worlds-investment-research-infrastructure"}},"content":"
\\n \\n
\\n\\nThis blog post emphasizes the importance of writing documentation as a founder. It discusses how it can give an edge when pitching your product and how it can result in less customer support and a better user experience overall.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA founder spending time writing documentation is f*king underrated.\\n\\nWorking on your product documentation may not be the most rewarding task, but I strongly believe that it gives you an edge when pitching your product.\\n\\nGood documentation needs to strike the perfect balance between having enough context and being straight to the point.\\n\\nThis week someone asked us how many people worked on our documentation.\\n\\nThere have been less than 3 people working on it. Our North Star metric has been common sense and putting out documentation that we would enjoy reading/learning from ourselves.\\n\\nEarlier this year I also heard suggestions of hiring a dedicated technical writer.\\n\\nI think that\u2019s BS, at least at the early stages of your company.\\n\\nIt\u2019s the equivalent of saying that you should hire someone to tell your company vision or that the first sales shouldn\u2019t come from the founders.\\n\\nNo one knows your product better than yourself. And users (particularly devs) will notice the love put into documentation. + This will result in less customer support and a better user experience overall.\\n\\nHonestly, a very underrated task if you ask me."},{"id":"building-the-worlds-investment-research-infrastructure","metadata":{"permalink":"/blog/building-the-worlds-investment-research-infrastructure","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.md","source":"@site/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.md","title":"Building the world\u2019s investment research infrastructure","description":"This blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation.","date":"2023-10-19T00:00:00.000Z","tags":[{"inline":true,"label":"investment","permalink":"/blog/tags/investment"},{"inline":true,"label":"research","permalink":"/blog/tags/research"},{"inline":true,"label":"infrastructure","permalink":"/blog/tags/infrastructure"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":0.955,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"building-the-worlds-investment-research-infrastructure","title":"Building the world\u2019s investment research infrastructure","date":"2023-10-19T00:00:00.000Z","image":"/blog/2023-10-19-building-the-worlds-investment-research-infrastructure.png","tags":["investment","research","infrastructure","OpenBB"],"description":"This blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation."},"unlisted":false,"prevItem":{"title":"Writing documentation, as a founder, is underrated.","permalink":"/blog/writing-documentation-as-a-founder-is-underrated"},"nextItem":{"title":"A $500k bet to build the best platform to do AI using financial data","permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data"}},"content":"
\\n \\n
\\n\\nThis blog post discusses the process and challenges of building the world\'s investment research infrastructure. It provides an insight into the products developed by the OpenBB team and their efficient operation.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n[OpenBB](http://openbb.co) team is comprised of 18 FTE.\\n\\nWe have 8 products: [OpenBB Platform](https://my.openbb.co/app/platform), [OpenBB Terminal](https://my.openbb.co/app/terminal), [OpenBB Bot](https://my.openbb.co/app/bot), [OpenBB Terminal Pro](https://my.openbb.co/app/pro), OpenBB Excel Add-In, [OpenBB Hub](https://my.openbb.co/app/hub), [OpenBB Docs](https://docs.openbb.co) and [Marketing website](https://openbb.co).\\n\\nThis means that on average we have around 2 people working on each product.\\n\\nThis is particularly wild when you look into the complexity associated with each of these products and being at the forefront of innovation.\\n\\nThat average includes not only engineers but design, product, and marketing.\\n\\nIn addition, our [Discord community](https://openbb.co/discord) has 14k+ people and we often get praised regarding how good our support is.\\n\\nRegardless of our future, I am proud of the team we put together and how efficiently we operate.\\n\\nIt would take a much larger company well over 5 years to build what we built in 2."},{"id":"a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","metadata":{"permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.md","source":"@site/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.md","title":"A $500k bet to build the best platform to do AI using financial data","description":"This blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024.","date":"2023-10-14T00:00:00.000Z","tags":[{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Data Access","permalink":"/blog/tags/data-access"},{"inline":true,"label":"Agents","permalink":"/blog/tags/agents"}],"readingTime":1.9,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data","title":"A $500k bet to build the best platform to do AI using financial data","date":"2023-10-14T00:00:00.000Z","image":"/blog/2023-10-14-a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data.png","tags":["AI","Financial Data","OpenBB","Data Access","Agents"],"description":"This blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024."},"unlisted":false,"prevItem":{"title":"Building the world\u2019s investment research infrastructure","permalink":"/blog/building-the-worlds-investment-research-infrastructure"},"nextItem":{"title":"Work-life balance is bullsh*t","permalink":"/blog/work-life-balance-is-bullsh-t"}},"content":"
\\n \\n
\\n\\nThis blog post discusses our $500k investment in building the best platform for AI using financial data. We focus on the rebranding of OpenBB SDK to OpenBB Platform, its features, and the potential payoff of this bet in 2024.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/openbb-agents/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEarlier this year we made a $500k bet.\\n\\nThe [OpenBB SDK](https://my.openbb.co/app/sdk) had access to over 500 data endpoints. But it was built as a second thought (after the Terminal) and it was extremely time-consuming to manage all dependencies.\\n\\nPlus, the SDK had more than just access to data and thus was bloated.\\n\\nSo we invested $500,000 to build it from the ground up and focus on data access.\\n\\nNow the OpenBB Platform (rebrand) is lean and scalable.\\n\\nIt can be used in Python (`pip install openbb==4.0.0a2`) but also for web development. More information [here](https://pypi.org/project/openbb/).\\n\\nAnd honestly, is the door to financial data.\\n\\n**Why am I saying all this?**\\n\\nBecause I predict that in 2024 this bet will have a massive payoff.\\n\\n**The reason?**\\n\\nAgents are going to be big.\\n\\nAnd when they are, financial firms that aren\u2019t leveraging them are going to have to spend a lot of resources to make up for the lack of efficiency.\\n\\n## Enter OpenBB Platform\\n\\n- We are data vendor agnostic (we enable them)\\n- We are open source (everyone can contribute data)\\n- We standardize data across close to 100 different data providers\\n- We put a lot of effort into our documentation\\n\\nThe last 3 points are key for agents, and why people will build agents on top of the OpenBB platform.\\n\\nIn a few hours, I was able to use the following prompt:\\n\\n```console\\n Check what are TSLA peers.\\n From those, check which one has the highest market cap. \\n Then, on the ticker that has the highest market cap get \\n the most recent rating from an analyst. And tell me who \\n was the analyst and what date was it that the rating was done\\n```\\n\\nTo have an agent execute this entire workflow in a 1/10th of the time that it would have taken an analyst to do.\\n\\nCheck for yourself the example below,\\n\\n"},{"id":"work-life-balance-is-bullsh-t","metadata":{"permalink":"/blog/work-life-balance-is-bullsh-t","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-09-16-work-life-balance-is-bullsh-t.md","source":"@site/blog/2023-09-16-work-life-balance-is-bullsh-t.md","title":"Work-life balance is bullsh*t","description":"This blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals.","date":"2023-09-16T00:00:00.000Z","tags":[{"inline":true,"label":"work-life balance","permalink":"/blog/tags/work-life-balance"},{"inline":true,"label":"success","permalink":"/blog/tags/success"},{"inline":true,"label":"career","permalink":"/blog/tags/career"},{"inline":true,"label":"hard work","permalink":"/blog/tags/hard-work"}],"readingTime":1.445,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"work-life-balance-is-bullsh-t","title":"Work-life balance is bullsh*t","date":"2023-09-16T00:00:00.000Z","image":"/blog/2023-09-16-work-life-balance-is-bullsh-t.png","tags":["work-life balance","success","career","hard work"],"description":"This blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals."},"unlisted":false,"prevItem":{"title":"A $500k bet to build the best platform to do AI using financial data","permalink":"/blog/a-500k-bet-to-build-the-best-platform-to-do-ai-using-financial-data"},"nextItem":{"title":"Target Market Analysis with the help of LLMs","permalink":"/blog/target-market-analysis-with-the-help-of-llms"}},"content":"
\\n \\n
\\n\\nThis blog post challenges the concept of work-life balance, arguing that success often requires sacrifices in personal time and relationships. It suggests that true balance comes from finding joy in your work and surrounding yourself with like-minded individuals.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n\\nFor successful individuals, achieving a work-life balance is a luxury often associated with those born into wealth.\\n\\nLet me explain.\\n\\nThere must be a clear inverse correlation between success (let\u2019s say measured by wealth) and the size of your circle of friends.\\n\\n**If you want to be at the top of a field, you must work hard.**\\n\\nEnd.\\n\\nRegardless of what BS people say about work-life balance.\\n\\nYou may be lucky \u2014 right place right time kind of thing. But by default, you need to work hard to expand your luck\u2019s surface.\\n\\nAnd that means that you need to spend your personal time working harder, to be above average.\\n\\nSince time is limited you need to sacrifice time spent outside working hours, otherwise you will only be average.\\n\\nPeople will soon realize that in order to optimize for a successful career, cutting time spent with friends is a necessary evil.\\n\\nPlus, as you become older you\u2019ll prioritize physical health (which impacts your longevity + performance) and your relationship with your partner (which provides the most significant ROI in terms of happiness).\\n\\nSo, I suggest 2 things:\\n\\n- Work on a problem and in a space that you truly enjoy so you don\u2019t consider it work\\n- Build with people who share the same values as you so you consider them friends Once that happens, work-life balance means nothing.\\n\\nWhat\u2019s your take?"},{"id":"target-market-analysis-with-the-help-of-llms","metadata":{"permalink":"/blog/target-market-analysis-with-the-help-of-llms","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.md","source":"@site/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.md","title":"Target Market Analysis with the help of LLMs","description":"This blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage.","date":"2023-09-10T00:00:00.000Z","tags":[{"inline":true,"label":"Target Market Analysis","permalink":"/blog/tags/target-market-analysis"},{"inline":true,"label":"LLMs","permalink":"/blog/tags/ll-ms"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"BCG Matrix","permalink":"/blog/tags/bcg-matrix"},{"inline":true,"label":"GE McKinsey Matrix","permalink":"/blog/tags/ge-mc-kinsey-matrix"},{"inline":true,"label":"Market Attractiveness","permalink":"/blog/tags/market-attractiveness"},{"inline":true,"label":"Competitive Advantage","permalink":"/blog/tags/competitive-advantage"}],"readingTime":9.66,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"target-market-analysis-with-the-help-of-llms","title":"Target Market Analysis with the help of LLMs","date":"2023-09-10T00:00:00.000Z","image":"/blog/2023-09-10-target-market-analysis-with-the-help-of-llms.png","tags":["Target Market Analysis","LLMs","OpenBB","BCG Matrix","GE McKinsey Matrix","Market Attractiveness","Competitive Advantage"],"description":"This blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage."},"unlisted":false,"prevItem":{"title":"Work-life balance is bullsh*t","permalink":"/blog/work-life-balance-is-bullsh-t"},"nextItem":{"title":"OpenBB 2 year anniversary","permalink":"/blog/openbb-2-year-anniversary"}},"content":"
\\n \\n
\\n\\nThis blog post provides a comprehensive guide on how to perform target market analysis for your company using LLMs. It includes a detailed explanation of the BCG Matrix and the GE McKinsey Matrix, and how these frameworks can be used to determine market attractiveness and competitive advantage.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/target-market-analysis/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAfter working on [OpenBB](https://openbb.co) for over 2 years, we learned which markets to go after and which markets to ignore. You may think that this is intuition, but it\u2019s actually the data that you gathered from talking with 100+ users and learning from others in the industry.\\n\\nHowever, people who don\u2019t know your business as well as you do (new joiners, advisors, or investors), don\u2019t understand why your target market is X and not Y. Hence, it\u2019s important to backtrace your \u201cexperience\u201d with data.\\n\\nThis blog post will focus on how you can perform target market analysis for your company. I will provide the framework and the code to leverage OpenAI to speed up that research process. All of this will be replicable, and you can do it for your own company.\\n\\n## Context\\n\\nThis framework is utilized for portfolio analysis in corporate strategy to analyze business units or product lines.\\n\\n### BCG Matrix\\n\\nInitially, BCG implemented its own framework, which you can read more about here. In a nutshell:\\n\\n_It uses two variables: relative market share and the market growth rate. By combining these two variables into a matrix, a corporation can plot their business units accordingly and determine where to allocate extra (financial) resources, where to cash out and where to divest._\\n\\n\\n\\n### GE McKinsey Matrix\\n\\nThen, the GE McKinsey Matrix was invented, which you can read more about here. To put it briefly:\\n\\n_It uses two variables: industry attractiveness and the competitive strength of a business unit. By combining these two variables into a matrix, a corporation can plot their business units accordingly and determine where to invest, where to hold their position, and where to harvest or divest._\\n\\n\\n\\nAs per the blog post, the main difference between these comes from the fact that the latter uses multiple factors that are combined to determine the measure of the two variables: industry attractiveness and competitive strength. Whereas the BCG Matrix only uses 1 variable per axis \u2014 relative market share and market growth rate.\\n\\nThe GE McKinsey Matrix (also known as the Nine-box matrix) has industry attractiveness on the y-axis and competitive strength on the x-axis.\\n\\nFor industry attractiveness, factors to consider can be: Industry size; Long-run growth rate; Industry structure; Industry life cycle; Macro environment; and Market segmentation.\\n\\nFor competitive strength, factors to consider can be: Profitability; Market share; Business growth; Brand equity; Level of differentiation; Firm resources; Efficiency and effectiveness of internal linkages; and Customer loyalty.\\n\\n## How do you build your Matrix?\\n\\nAll the data will be hypothetical. The goal is to share the process and framework. Each company and market will have its own.\\n\\n### 1. Define your factors\\n\\nWhen we talk about market attractiveness, from your company\u2019s perspective, what makes a market attractive? Consider all those factors and list them. Try to list all the factors that have a weight in that equation, but try to keep them under 10; otherwise, it\u2019s too many to have to assess, and at some point, their weight into the attractiveness is negligible.\\n\\nNow do the same for the factors that give your company a competitive advantage.\\n\\n### 2. Weigh each factor\\n \\nNot all factors are created equal. Some factors will influence whether a market is attractive or not. Similarly, for your competitive advantage, what factors give your company a bigger edge?\\n\\nThe goal is to select a weight for each factor so that the sum of the weights for all the factors adds up to 1. The outcome should look something like:\\n\\n\\n\\n### 3. Categorize each factor\\n\\nNow you need to decide how granular you want your assessment to be. Initially, at OpenBB, we started with a scale of 1\u20133 where 1 is low, 2 is medium, and 3 is high. However, soon we found this to not be good enough since there was not enough granularity. Thus, we increased the range from 1 to 5.\\n\\nOnce you decide on that range, you need to categorize it in a way that makes sense for each factor. This ensures that everyone on the team is on the same page when it comes to assessing a factor. For instance:\\n\\n\\n\\nThis Google / Excel spreadsheet should look like:\\n\\n\\n\\n### 4. Select a list of target markets you want to evaluate\\n\\nCreate a new Google spreadsheet / Excel page for each of them. This will allow you to contain all details for each target market on the same page.\\n\\nFor the purposes of this demonstration, we will use \u201cTargetMarket1,\u201d \u201cTargetMarket2,\u201d and \u201cTargetMarket3.\u201d\\n\\n### 5. Assess a target market based on selected factors\\n\\nNow that we have decided on all the factors associated with the target market attractiveness, as well as the competitive advantage, you need to assess each of these based on the target markets that you have selected.\\n\\nEach target market page should look something like this:\\n\\n\\n\\nThe factors and weights are automatically pulled from the \u201cFramework page\u201d built previously.\\n\\nHere you just need to set the rating from 1 to 5 (or according to the range you previously specified) based on the evaluation criteria defined. Each of these ratings is multiplied by the weight, and all of those values are summed up together. If your selected range is from 1 to 5, then it means that the minimum and maximum values are 1 and 5, since the weights add up to 1.\\n\\nNote that the last column allows you to add comments based on any additional information/criteria that you used to make a rating choice.\\n\\n### 6. Discover Total Addressable Market\\n\\nOn the spreadsheet above, you may have seen the total addressable market value. I will address how to find this value in a subsequent post.\\n\\nThis is extremely important because even if the market is really attractive, its size can dictate whether to pursue it or not. Most of the time, you don\u2019t want to be chasing a small market opportunity.\\n\\n### 7. Final matrix / chart\\n\\nOnce you have all this data, you can build the following for each of the target markets:\\n\\n\\n\\nNote that all you need from each target market is:\\n\\n**Competitive advantage** \u2014 the sum of all the factors and their levels multiplied by their weights gives the x-axis.\\n\\n**Target market attractiveness** \u2014 the sum of all the factors and their levels multiplied by their weights gives the y-axis.\\n\\n**Total Addressable Market (TAM)** \u2014 gives the bubble size on the chart.\\n\\nThen you are ready to make a decision on which market you wish to pursue, and you have data to back it up.\\n\\nNote: There are a lot of assumptions, and you\u2019ll never have it perfect. But with several iterations with your team, you\u2019ll gain more confidence in those assumptions over time, ensuring that you are on the right track and pursuing the right opportunity.\\n\\n## Using OpenAI to bounce ideas to assess a target market\\n\\nSometimes, it can be hard to provide a rating for each of the factors, or it would be better to bounce ideas off someone. This is where you can leverage OpenAI\u2019s GPT-4 to help you get started.\\n\\nI built a script that would read from an Excel spreadsheet all the information from the framework page that we have set. That basically means:\\n\\n- All the factors associated with target market attractiveness, and their levels of description\\n- All the factors associated with competitive advantage, and their levels of description\\n\\nThen I prompted GPT-4 to select a level for each of the factors of interest for both attractiveness and competitive advantage, based on what it knows about a specific target market.\\n\\nFor example, let\u2019s say we want to assess the competitive advantage for the target market \u201cHedge Funds\u201d \u2014 this is what the prompt looks like:\\n\\n We want to assess our competitive advantage based in relation \\n with factors where we are have an advantage. \\n \\n Can you classify those for the following target market: \'Hedge Funds\'\\n \\n The factors that we will access this market are presented below: \\n \\n When assessing Data Aggregation, these are the rules:\\n We attribute a value of 5 if We provide all data a market needs\\n We attribute a value of 4 if We provide most data a market needs\\n We attribute a value of 3 if We provide some data a market needs\\n We attribute a value of 2 if We provide very little data a market needs\\n We attribute a value of 1 if We provide no data a market needs\\n \\n When assessing Customization, these are the rules:\\n We attribute a value of 5 if Market will leverage our open source code\\n We attribute a value of 4 if Market will fully customize our platform to make it their own\\n We attribute a value of 3 if Market will customize a bit their platform\\n We attribute a value of 2 if Market will use platform as is and customize after some time\\n We attribute a value of 1 if Market will use platform as is\\n \\n When assessing Automation, these are the rules:\\n We attribute a value of 5 if Allows to save more than 70% of time\\n We attribute a value of 4 if Allows to save 50%-70% of time\\n We attribute a value of 3 if Allows to save 30%-50% of time\\n We attribute a value of 2 if Allows to save 15%-30% of time\\n We attribute a value of 1 if Doesn\'t save any time on automation\\n \\n When assessing Factor4, these are the rules:\\n We attribute a value of 5 if Very high\\n We attribute a value of 4 if High\\n We attribute a value of 3 if Medium\\n We attribute a value of 2 if Low\\n We attribute a value of 1 if Very low\\n \\n When assessing Factor5, these are the rules:\\n We attribute a value of 5 if Very high\\n We attribute a value of 4 if High\\n We attribute a value of 3 if Medium\\n We attribute a value of 2 if Low\\n We attribute a value of 1 if Very low\\n \\n Given this information, can you return a level for each of the factors \\n that is our competitive advantage from a viewpoint of Hedge Funds target market.\\n \\n Please return it in a json dictionary format with the factor and level only. \\n Do not add any other text apart from that. \\n Indent the json with 4 spaces.\\n\\nThen, using the following block of code, we can get OpenAI\u2019s GPT-4 to provide its input:\\n\\n```python\\n response = openai.ChatCompletion.create(\\n model=\\"gpt-4\\",\\n messages=[\\n {\\n \\"role\\": \\"system\\", \\n \\"content\\": \\n \\"\\"\\"\\n You are an outstanding financial analyst and were given the task \\n to perform market research on a possible market segment.\\n The company succces relies on your accuracy to categorize a \\n segment and classify according to the factors and levels specified.\\n \\"\\"\\"\\n },\\n {\\n \\"role\\": \\"user\\", \\n \\"content\\": prompt\\n },\\n ]\\n )\\n print(response.choices[0].message.content)\\n```\\n\\nThis is what the output looks like:\\n\\n```console\\n {\\n \\"Data Aggregation\\": 3,\\n \\"Customization\\": 4,\\n \\"Automation\\": 5,\\n \\"Factor4\\": 2,\\n \\"Factor5\\": 3\\n }\\n```\\n\\n**And that\u2019s it for today.**\\n\\nAll of this code is open source and available on my GitHub, here: https://github.com/DidierRLopes/target-market-analysis/tree/main\\n\\nI hope you find this insightful, I appreciate any feedback as always."},{"id":"openbb-2-year-anniversary","metadata":{"permalink":"/blog/openbb-2-year-anniversary","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-20-openbb-2-year-anniversary.md","source":"@site/blog/2023-08-20-openbb-2-year-anniversary.md","title":"OpenBB 2 year anniversary","description":"Two years of OpenBB. A look back at our achievements and growth in the world of open-source finance.","date":"2023-08-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Anniversary","permalink":"/blog/tags/anniversary"},{"inline":true,"label":"Achievements","permalink":"/blog/tags/achievements"},{"inline":true,"label":"Growth","permalink":"/blog/tags/growth"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"}],"readingTime":2.805,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"openbb-2-year-anniversary","title":"OpenBB 2 year anniversary","date":"2023-08-20T00:00:00.000Z","image":"/blog/2023-08-20-openbb-2-year-anniversary.png","tags":["OpenBB","Anniversary","Achievements","Growth","Finance"],"description":"Two years of OpenBB. A look back at our achievements and growth in the world of open-source finance."},"unlisted":false,"prevItem":{"title":"Target Market Analysis with the help of LLMs","permalink":"/blog/target-market-analysis-with-the-help-of-llms"},"nextItem":{"title":"How to handle equity top-ups at a seed stage startup","permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup"}},"content":"
\\n \\n
\\n\\nTwo years of OpenBB: A look back at our achievements and growth in the world of open-source finance.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nToday is OpenBB 2 years anniversary of our incorporation. So it\u2019s important to look back and understand the magnitude of what we achieved in 24 months.\\n\\nIn that time we\u2019ve had:\\n\\n- 100k+ downloads of our installer since we started tracking it\\n- 2.5M bot commands have been run on Discord and Telegram from over 40k users\\n- GitHub project grew from 8k stars to 23k+, becoming #1 open source project in the topic of finance\\n- Our Discord group grew from 1k users to 13k+\\n- Our SDK has been pip installed over 25k times\\n- Our team grew from 3 to 19 around the globe\\n- For more, see http://openbb.co/open\\n\\nBut where were we 2 years ago?\\n\\n- Only Gamestonk Terminal, the name OpenBB only appeared when we came out of stealth mode in March 2022\\n- No OpenBB Hub (only launched in May 2023)\\n- No OpenBB SDK (only launched in Dec 2022)\\n- No OpenBB Bot (only launched in July 2022)\\n- No Terminal Pro or Excel Add-In early alpha (development started in 2023)\\n- No SDK v4 which allows community and data providers to build their own data connectors, easily (to be announced soon)\\n- No community routines \u2014 our first feature aimed at community with upvoting and sharing of routines\\n- No open source PyWry \u2014 A web-view rendering library in python we open source in Feb 2023\\n- No OpenBB Champions \u2014 Our way to highlight users that do impressive work on top of our ecosystem\\n- No partnerships with universities, financial societies or investment clubs\\n- No partnerships with data vendors \u2014 now we have close relationships with most vendors you would know\\n\\nIf we only focus on where Gamestonk Terminal was 2 years ago we had:\\n\\n- Static charts using matplotlib (Interactive ones using PyWry was launched in May 2023)\\n- No way for users to run routines from other users from the terminal directly (launched 3 days ago)\\n- No AskOBB feature with LlamaIndex (launched in June 2023)\\n- No way for users to customise the terminal, select default data sources and set their API keys \u2014 all from the Hub\\n- No way to double click an installer and get started in a few minutes \u2014 hassle free\\n- The documentation on markdown files across the repository, today people often praise our documentation in conversations\\n- No AI features, no reports menu, no dashboards menu, no fixed income, no futures, \u2026\\n- And the OpenBB Terminal charts looked like this\\n\\n\\n\\nBill Gates said the famous saying:\\n\\n> People overestimate what they can do in one year and underestimate what they can do in 10 years.\\n\\n
\\n\\nIn fast-paced startups, I think a better sentence would be, \u201cPeople overestimate what they can do in one week and underestimate what they can do in 1 year\u201d.\\n\\nLooking forward to continue building the future of investment research, we\u2019re just getting started.\\n\\nPS: On a personal level within those 2 years: I quit my full-time job to build OpenBB, got 2 dogs, got married and moved to the Bay Area. Life is great \u2764\ufe0f"},{"id":"how-to-handle-equity-top-ups-at-a-seed-stage-startup","metadata":{"permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.md","source":"@site/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.md","title":"How to handle equity top-ups at a seed stage startup","description":"In this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets.","date":"2023-08-09T00:00:00.000Z","tags":[{"inline":true,"label":"equity","permalink":"/blog/tags/equity"},{"inline":true,"label":"startups","permalink":"/blog/tags/startups"},{"inline":true,"label":"seed stage","permalink":"/blog/tags/seed-stage"},{"inline":true,"label":"equity top-ups","permalink":"/blog/tags/equity-top-ups"},{"inline":true,"label":"employee compensation","permalink":"/blog/tags/employee-compensation"}],"readingTime":7.935,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-handle-equity-top-ups-at-a-seed-stage-startup","title":"How to handle equity top-ups at a seed stage startup","date":"2023-08-09T00:00:00.000Z","image":"/blog/2023-08-09-how-to-handle-equity-top-ups-at-a-seed-stage-startup.png","tags":["equity","startups","seed stage","equity top-ups","employee compensation"],"description":"In this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets."},"unlisted":false,"prevItem":{"title":"OpenBB 2 year anniversary","permalink":"/blog/openbb-2-year-anniversary"},"nextItem":{"title":"How to handle equity at a seed-stage startup from Silicon Valley","permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley"}},"content":"
\\n \\n
\\n\\nIn this post, we discuss how to handle equity top-ups at a seed stage startup, providing a step-by-step guide on the implementation process and including links to relevant spreadsheets.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nPreviously, I shared how we handle equity at OpenBB in [this post](http://didierlopes.com/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley).\\n\\nThis blog post will continue that discussion and go over how we approach equity top-ups at OpenBB. It will provide a step-by-step guide on the implementation process and include links to relevant spreadsheets that you can use for your own startup.\\n\\nI will continue using the purely fictional example that I introduced in the previous blog post with John Doe.\\n\\nLet\u2019s imagine that John Doe was indeed the right candidate for OpenBB, and on **June 15, 2021**, he was hired and accepted an offer with **2000 options** vesting over the next 4 years with a 1-year cliff. For simplicity, let\u2019s assume that he will vest the 2000 shares by July 1, 2025 (ignoring the additional 2 weeks).\\n\\nThis means that by the end of June 2022, John will have vested 542 shares (13 x 2000 / 48), and for every following month, he will vest 42 shares per month. Note that we only start showing the shares from June 2022 because before that, he was in his cliff period.\\n\\n\\n\\nIf you do this calculation, you\u2019ll see that it adds up to 2022, whereas John was only granted 2000 shares. This is normal and is due to rounding, thus the shares associated with the last month are updated so that it matches the offer.\\n\\n\\n\\nIf any of the following situations arise:\\n\\n1. The initial assessment of the candidate was wrong, and they are not an IC but a Sr. IC.\\n2. The employee has exceeded expectations, and their equity no longer reflects the value they bring to the company.\\n3. The employee has other job offers, and you want to reinforce that they are an owner of the company and that their success is important.\\n4. The employee\u2019s vesting period is coming to an end, and they are considering leaving as they joined the company for the potential upside of an exit.\\n\\nOne option you have is to increase cash compensation. However, offering equity (ownership) is often a better option, especially for startups with limited cash resources.\\n\\nIn these situations, you need to consider an equity top-up. This means offering the employee a new equity grant on top of the shares they are currently vesting. There are multiple types of equity grants, but I will focus on the approach we use at [OpenBB](https://openbb.co) and explain how you can implement it as well.\\n\\nFirst, determine how many additional shares you want to grant to the individual and, more importantly, how many shares would be fair for them to vest each month. The former helps determine their stake in the company, while the latter helps assess their value compared to other team members.\\n\\nIn our case, let\u2019s assume it\u2019s February 2023, and John has been with the company for 20 months. We want to reward his contributions and bet on his future at the company, so we decide to grant him an additional 1,500 shares on top of his existing 2,000 shares.\\n\\nIn theory, some companies start a new 4-year vesting period with a 1-year cliff for the second grant. However, the issue with that approach is that the employee will start vesting two grants simultaneously: 2000/48 + 1500/48 shares per month. Once the first grant is fully vested, they will vest a lower amount of shares per month: 1500/48. This means the employee would have less incentive to stay when only the second grant is being executed.\\n\\nTo address this, we ensure that for the next 4 years from the vesting commencement date (VCD) of the second grant, the employee vests the same number of shares each month.\\n\\n## How can we do that?\\n\\n### Manual\\n\\nHere is the information we have:\\n\\n- 1st option grant VCD: **15 June 2021**\\n- 1st option grant shares: **2,000**\\n- 1st option grant schedule: **1/48 per month with 1 year cliff finishing on 30 June 2025**\\n\\nFrom here, we infer that in February 2023, John is vesting 42 shares per month and has already vested 542 shares (after the 1-year cliff) + 294 shares (7 x 42).\\n\\nNow, let\u2019s discuss the decisions we need to make for the second option grant:\\n\\n- 2nd option grant VCD: We want to start it ASAP, to retain employee \u2014 for instance **March 2023**\\n- 2nd option grant shares: **around 1,500**\\n- 2nd option grant schedule: **1/48 per month finishing on 30 March 2027**. Note that we removed the cliff since we know the value the employee brings and that \u201cprotection\u201d/\u201dretainer\u201d can be removed.\\n\\nBy utilizing maths, we can create the following equation:\\n\\n\\n\\nBy filling in the information that we know, we get:\\n\\n\\n\\nAnd thus we know that we can get the value that makes this happen.\\n\\n\\n\\nHowever, we don\u2019t want to give the employee fractional shares each month, so we select a round number around the one that makes him receive around 1,500 additional shares over the course of 4 years.\\n\\nIn this case, that number could be 55. This means that the top-up number would be 13 (55\u201342), except on the last month of vesting for the 1st grant where we need the adjustment.\\n\\nWhen we multiply 55 shares per month for the next 48 months starting in March 2023, that adds up to **2,640**.\\n\\nHowever, the employee was awarded **1,500 shares** (2nd grant) and still has 27 months (from March 2023 to May 2025) to vest 1st grant shares, which corresponds to a total of **1,122 shares** (42 * 26 + 30, remembering the adjustment done for the last month). This total would be **2,622**, which obviously is different from the expected 2,640.\\n\\nTherefore, we update the value of the number of shares given on the 2nd grant so that John receives 55 shares per month. In this case, for that to happen, the 2nd grant has to have a value of 1,573.\\n\\nBut obviously, you don\u2019t need to pick up your calculator every time you do this. I mean, what kind of engineer would I be if I didn\u2019t somehow automate this?\\n\\n### Automated\\n\\nThe spreadsheet below demonstrates what an employee vesting schedule looks like, and below I will write a step-by-step guide so you can fully customize it to your needs.\\n\\n\\n\\n- As a result, **E5** will be updated with 11 months afterward to represent the month before the cliff terminates, which consequently leads to the following months being displayed in **column E**.\\n\\n2. Fill in the 1st grant shares in **B5**\\n\\n- As a result, **G6** is updated with the total shares from the 1st grants vested after the 1st year. The following rows in **column G** are automatically updated until the vesting schedule terminates.\\n\\n3. Adjust **G41** so that the sum of shares in **column G** match the shares from the 1st grant in **B5**.\\n\\n4. Fill in the top up grant vesting commencement date (VCD) in **C6**\\n\\n- As a result, **column H** will automatically get populated based on the value that, when added with the cells in **column G**, returns the value in cell **B19**.\\n\\n- This will also allow us to compute the months that have already been vested from the initial shares in **B11** and consequently calculate the overlap between shares coming from the 1st and 2nd grant in **B12**.\\n\\n5. Fill in the top-up grant shares that you are thinking about offering to the employee in **B6**.\\n\\n- As a result, the same computations that were explained earlier in theory will occur. This will result in a recommendation for the top-up shares in **B15** and consequently the amount of shares that the employee will vest monthly in **B16** so that the amount of top-up grant shares is met.\\n\\n6. It is very likely that the number in **B16** will not be rounded. Hence, we fill **B19** with a rounded version of that number.\\n\\n- As a result, **column H** will be updated so that the total shares (from both grants) in **column F** matches the selected value in **B19**.\\n\\nWhen looking at the total top-up shares in **H67**, that value will no longer match the total top-up shares that we wanted to grant to the employee and that we decided at the beginning in **B6**. This is because we rounded the value and thus impacted the number of shares necessary to achieve that.\\n\\nThe amount of shares needed to update the recommendation in **B16** to the rounded version in **B19** is displayed as an \u201cerror\u201d in **B21**.\\n\\n7. In order to fix that, we simply need to update B6 with the sum of B6 and the error value from B21.\\n\\n- As a result of this, all the values should now match, and the combined total amount of shares given to the employee in **B8** should match the sum of the shares spread across dates in **F67**. Plus, the error should now be null in cell **B21**.\\n\\nAnd that\u2019s it.\\n\\nI hope you found this useful and are able to use it internally to share with your employees so they understand how the top-ups happen at your startup.\\n\\nIf you want access to this Excel template, feel free to reach out to me on Twitter or LinkedIn."},{"id":"how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","metadata":{"permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.md","source":"@site/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.md","title":"How to handle equity at a seed-stage startup from Silicon Valley","description":"A step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB.","date":"2023-08-03T00:00:00.000Z","tags":[{"inline":true,"label":"startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"equity","permalink":"/blog/tags/equity"},{"inline":true,"label":"Silicon Valley","permalink":"/blog/tags/silicon-valley"},{"inline":true,"label":"seed-stage","permalink":"/blog/tags/seed-stage"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":5.72,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley","title":"How to handle equity at a seed-stage startup from Silicon Valley","date":"2023-08-03T00:00:00.000Z","image":"/blog/2023-08-03-how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley.png","tags":["startup","equity","Silicon Valley","seed-stage","OpenBB"],"description":"A step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB."},"unlisted":false,"prevItem":{"title":"How to handle equity top-ups at a seed stage startup","permalink":"/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup"},"nextItem":{"title":"Keep track of your startup metrics using a custom iOS widget","permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget"}},"content":"
\\n \\n
\\n\\nA step-by-step guide on how to handle equity at a seed-stage startup, using a fictional example from OpenBB.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAs a startup founder and CEO, you need to wear multiple hats, from engineering and product to design, marketing, and even finance.\\n\\nToday, I\u2019m going through the details of how we handle equity at OpenBB. This blog post provides a step-by-step guide on the implementation process, including links to relevant spreadsheets that you can reuse for your startup.\\n\\nTo make this post easier to follow, I will create a purely fictional example.\\n\\nJohn Doe, a software engineer from Portugal, has been contributing to the [open source OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) for a few consecutive weeks. He not only fixes bugs but also adds features that the community has requested through pull requests and on Discord. Additionally, he is a fast learner and gets along well with the current team. This sparks the interest of the OpenBB team because having this open-source contributor work with us full-time would be great, rather than being limited by his current full-time job.\\n\\nFrom here, we set up an initial exploratory call to better understand John Doe as an individual \u2014 what he is passionate about, why he has contributed to the project, and more. We follow up the call with an interview involving engineers to assess his skills and experience. Finally, he joins a call with me, where I sell the vision of the company and explain why what OpenBB is doing matters. At this point, we extend him an offer. Up until this stage, the recruiting process is standard, except for the fact that we have a \u201cfiltered\u201d candidate coming from the open-source community.\\n\\nHowever, as a startup, that offer cannot (or at least should not) consist solely of cash compensation. A startup [operates at a much faster pace](http://www.paulgraham.com/growth.html) and is riskier than a company. Therefore, in exchange for hard work and long hours, you should offer part of the company through equity, allowing the employee to benefit from the upside in case the company achieves a successful exit (IPO or sale).\\n\\nSo, how do we decide on the equity to offer the new hire?\\n\\nIt\u2019s easy. You follow your company Option Guidelines.\\n\\n## Option Guidelines\\n\\nThe Option Guidelines are an Excel spreadsheet approved by the board. In this document, you explicitly create **bands (minimum and maximum range options)** based on the role and stage of the company. Board approval is crucial as it allows you to extend the offer directly without needing permission from the board since the guidelines have already been approved.\\n\\nHere\u2019s what the document looks like:\\n\\n\\nThe total number of shares is random and not representative of OpenBB.\\n\\nFirst, you need to ask yourself what roles your company envisions needing. Within those roles, there are two things to consider:\\n\\n- **Departments:** You may differentiate between Engineering, Marketing, Operations, Sales, Finance, and HR/Admin. You can also add others such as Design, Product, etc. Note that having different departments does not necessarily mean you need different band structures.\\n\\n- **Titles:** You\u2019ll want to be able to \u201ccompare\u201d individuals based on their contributions. For instance, Vice President, Director, Manager, Senior Individual Contributor, and Individual Contributor. Note that if you have fewer titles, the bands should be wider to differentiate individuals with the same title. If you add five levels of Individual Contributors, you\u2019ll want narrower bands.\\n\\n I recommend starting with fewer titles, KISS: keep it simple stupid. Again, having different levels does not necessarily mean the bands need to be mutually exclusive. A Manager does not necessarily have a higher band than a Senior Individual Contributor; this depends on your own company culture.\\n\\nNext, you need to differentiate between **company stages**. This allows you to distinguish employees who join very early when the startup carries the most risk. We distinguish between three stages: Pre-production revenue, Pre-profit with production revenue, and Profitable.\\n\\nOnce all these categories are completed, you should have a similar table to the one shared above. Now, it\u2019s important to fill in the equity percentage. For privacy reasons, I will not provide the specific values for OpenBB but will create a random example.\\n\\nLet\u2019s imagine that OpenBB Charter has a total of 1 million shares (assuming only one class of stock for simplicity). If our priced round values the company at $10 million, this means that each share is valued at $10.\\n\\nOn the top left of the document, we will insert the number of shares, which is 1,000,000. Then, we adjust the % LOW and % HIGH columns, representing the range of company ownership we want to grant to this individual.\\n\\nLet\u2019s go through a fake example for the SW role:\\n\\n\\n\\nThe column \u201cLow Shrs\u201d is computed by multiplying the % LOW by the total number of shares. On the other hand, the column \u201cHigh Shrs\u201d is computed by multiplying the % HIGH by the total number of shares. This value is important as it represents the amount stipulated in the contract.\\n\\nLet\u2019s consider a scenario where the company is in the Pre-Profit stage with Production Revenue, and we want to hire an Engineering IC. Based on our assessment of their skillset and fairness in comparison to other team members, we would offer a contract that vests over time between 1000 and 2000 shares.\\n\\n\\n\\nNext, you need to decide on the vesting calendar that the company supports. The most common option is a 4-year vesting schedule with a 1-year cliff. This means that while you begin vesting during your first year, you need to stay with the company for the entire year to be able to exercise those options. The 1-year cliff protects the company from employees leaving early or underperforming.\\n\\nCarta provides a good explanation on how stock options work [here](https://carta.com/blog/equity-101-stock-option-basics/) \u2014 which I recommend to everyone.\\n\\nPlease note that in theory, while the value of these options is $10 per share, the startup will need to conduct a 409a valuation to determine the fair market value of each option, which is likely to be much lower than the initial price, such as $1 per share. And this is the strike price that employees will need to pay to exercise the shares.\\n\\nNote: when selecting the number of shares, use a number that is divisible by the number of months that the employee is vesting, e.g., for a 4-year vesting period that would be 48 (4 x 12), which ensures that employees get the same amount of shares each month, and there\u2019s no need to account for floating numbers.\\n\\nThis is it for today.\\n\\nIn Part II, I will talk about how you can handle equity top-ups.\\n\\nSo follow me if you want to learn more about what that process may look like."},{"id":"keep-track-of-your-startup-metrics-using-a-custom-ios-widget","metadata":{"permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.md","source":"@site/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.md","title":"Keep track of your startup metrics using a custom iOS widget","description":"Keep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills.","date":"2023-07-29T00:00:00.000Z","tags":[{"inline":true,"label":"iOS","permalink":"/blog/tags/i-os"},{"inline":true,"label":"Startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"Metrics","permalink":"/blog/tags/metrics"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Scriptable","permalink":"/blog/tags/scriptable"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.015,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"keep-track-of-your-startup-metrics-using-a-custom-ios-widget","title":"Keep track of your startup metrics using a custom iOS widget","date":"2023-07-29T00:00:00.000Z","image":"/blog/2023-07-29-keep-track-of-your-startup-metrics-using-a-custom-ios-widget.png","tags":["iOS","Startup","Metrics","OpenBB","Scriptable","Open Source"],"description":"Keep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills."},"unlisted":false,"prevItem":{"title":"How to handle equity at a seed-stage startup from Silicon Valley","permalink":"/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley"},"nextItem":{"title":"How to Use OpenAI to Extract Insights from Team Survey","permalink":"/blog/how-to-use-openai-to-extract-insights-from-team-survey"}},"content":"
\\n \\n
\\n\\nKeep track of your startup metrics using a custom iOS widget. This blog post will guide you on how to build a custom iOS widget that displays your startup metrics at all times. The entire code is open source and requires minimal coding skills.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/opensource-scriptable-widget/tree/main).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you have a high level role in your organization, you are likely obsessed over a few metrics that act as the north star for your company. Whether that is MRR, number of customers, GitHub stars, AUM, .. depends on the type and stage of company, and what you are optimizing for.\\n\\nAt [OpenBB](https://openbb.co) we are currently optimizing for [OpenBB Hub](https://my.openbb.co) users, since this is the place where you have access to our entire suite of products. From [OpenBB Terminal](https://my.openbb.co/app/terminal), [OpenBB SDK](https://my.openbb.co/app/sdk), [OpenBB Bot](https://my.openbb.co/app/bot) and soon \u2014 the highly awaited [OpenBB Terminal Pro](https://my.openbb.co/app/pro).\\n\\nSo everyday I spent some time checking our startup [/open page](https://openbb.co/open). However, whenever I had to check these on mobile I had to open up the browser, type the link and then look for the metric of interest.\\n\\nHence, to save time, I built a custom iOS widget that displays these metrics of interest at all times. All I need to do is unlock my phone and *BAM*, they are right there.\\n\\nSo, today, I\u2019ll teach you how you can do the same with minimal coding skills required. I open source the entire code, so that you can get up to speed as fast as possible here: https://github.com/DidierRLopes/opensource-scriptable-widget\\n\\n## Track your open source metrics\\n\\nThis section will provide a plug-and-play example for your open source repository.\\n\\n\\n\\nThese are the steps necessary to have it working on your iOS device:\\n\\n1/ Download Scriptable app to your iOS device\\n\\n2/ Open Scriptable app and click on the \u201c+\u201d on the top right corner\\n\\n3/ Rename that script to whatever repo you would like to track\\n\\n4/ Copy the code from the file opensource.js on this repository\\n\\n5/ Paste it into that new script on your phone\\n\\n6/ Change the 4 initial parameters from the file:\\n\\n```python\\n const WIDGET_TITLE = \\"openbb.co/open\\"\\n const GITHUB_REPO = \\"OpenBB-finance/OpenBBTerminal\\"\\n const PIP_PACKAGE_NAME = \\"openbb\\"\\n const CACHED_DATA_HOURS = 1\\n```\\n\\n- If you only want to track GitHub stats, do `PIP_PACKAGE_NAME=\\"\\"`.\\n- If you only want to track PiPy stats, do `GITHUB_REPO=\\"\\"`.\\n- The `CACHED_DATA_HOURS` corresponds to the amount of hours where the data is not updated.\\n\\n7/ Run script to make sure that it works using the \u201cplay button\u201d on the bottom right corner\\n\\n8/ Leave the app\\n\\n9/ Leave your finger pressed on the iOS homepage\\n\\n10/ Click on the \u201c+\u201d on the left top corner\\n\\n11/ In the \u201cSearch Widgets\u201d tab look for \u201cScriptable\u201d\\n\\n12/ You will see \u201cRun Script\u201d and there are 3 pages. Select the type of widget size that you are interested in\\n\\n13/ Select \u201cAdd Widget\u201d\\n\\n14/ The widget will appear with the sentence \u201cLong press and edit widget to select the script to run\u201d\\n\\n15/ Do that and then you will have 3 options:\\n\\n- Script \u2014 Select script name that you renamed to earlier\\n- When Interacting \u2014 Select \u201cOpen URL\u201d \u2014 A new field will appear with \u201cURL\u201d then provide the link you want to open you cick on the widget (e.g. http://openbb.co)\\n- Parameter \u2014 If there\u2019s any parameter needed to the script\\n\\n16/ Click outside the window, and you should be all set!\\n\\nFeel free to contribute to the repository with other examples / templates!"},{"id":"how-to-use-openai-to-extract-insights-from-team-survey","metadata":{"permalink":"/blog/how-to-use-openai-to-extract-insights-from-team-survey","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.md","source":"@site/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.md","title":"How to Use OpenAI to Extract Insights from Team Survey","description":"This blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation.","date":"2023-07-21T00:00:00.000Z","tags":[{"inline":true,"label":"OpenAI","permalink":"/blog/tags/open-ai"},{"inline":true,"label":"Team Survey","permalink":"/blog/tags/team-survey"},{"inline":true,"label":"Insights","permalink":"/blog/tags/insights"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"},{"inline":true,"label":"Slack","permalink":"/blog/tags/slack"},{"inline":true,"label":"Airtable","permalink":"/blog/tags/airtable"}],"readingTime":8.01,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-use-openai-to-extract-insights-from-team-survey","title":"How to Use OpenAI to Extract Insights from Team Survey","date":"2023-07-21T00:00:00.000Z","image":"/blog/2023-07-21-how-to-use-openai-to-extract-insights-from-team-survey.png","tags":["OpenAI","Team Survey","Insights","Automation","Slack","Airtable"],"description":"This blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation."},"unlisted":false,"prevItem":{"title":"Keep track of your startup metrics using a custom iOS widget","permalink":"/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget"},"nextItem":{"title":"Why the need for an open source investment research platform?","permalink":"/blog/why-the-need-for-an-open-source-investment-research-platform"}},"content":"
\\n \\n
\\n\\nThis blog post discusses how to use OpenAI to extract insights from team survey data. It covers the motivation behind the project, the requirements, and the implementation process, including the use of the Slack API and Airtable API for automation.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/insights-from-team-survey).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Motivation\\n\\nI\u2019ve been wanting to play with the OpenAI API for a while, but I\u2019ve had higher priority tasks. Yesterday, I thought that I could use the day to do this, but I didn\u2019t want to just try it in a notebook. Instead, I wanted to use it in a real project that could save me time.\\n\\nLast week, I posted about how at OpenBB we have developed a monthly team survey and automated the process of requesting information through Slack and Airtable. You can find more on that post [here](/blog/employees-are-leaving-be-proactive-about-employee-feedback).\\n\\n\\n\\nThis made me think that even though I have access to all this data, which OpenBB has made fully available [here](https://openbb.co/open), I still have to spend some time looking at the data to extract insights.\\n\\n
\\n\\nWhat if I could automate that analysis using OpenAI? This is what I set out to build, and this post will focus on how I went from idea to implementation.\\n\\n## Requirements\\n\\nI already had a notebook that I used to analyze our Airtable data with our team survey in it. However, that analysis was quite \u201cheavy,\u201d and it was not straightforward to extract insights. Thus, one of the requirements was to use OpenAI to analyze the team survey feedback for the current month and highlight anything worth mentioning.\\n\\nAdditionally, I wanted to compare the team\u2019s experience to the prior month to understand if we were improving or not, and identify areas for further improvement. Finally, based on these insights, I wanted OpenAI to suggest what OpenBB, as a company, could do to improve our culture.\\n\\nTo achieve this using an OpenAI model, I could either export the team survey responses from Airtable in CSV and copy-paste them into ChatGPT, or I could automate the data retrieval using the Airtable API. Being an engineer, why would I do something in 5 minutes when I can spend 1 day automating it? \ud83e\udd23\\n\\nLastly, I didn\u2019t want to run this script and have to copy-paste the output into our Slack group so that everyone on the team could have access to the overall analysis and provide feedback/suggestions. Therefore, I would like to have a Slack integration that sends the output in a specific formatted way to our Slack channel.\\n\\nSo, the idea is as follows:\\n\\n- \\n
- Retrieve team feedback responses from Airtable \\n
- Extract insights from the team survey data using OpenAI \\n
- Send the insights output to the OpenBB Slack channel \\n
\\n \\n
\\n\\nOpenBB Terminal, an open-source investment research platform, is transforming the financial industry by addressing issues like data licensing, full-price bundle, lack of transparency and customization, and the need for a diverse community. This post explores why open source is crucial for us and the main problems in the space.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHaving a closed source OpenBB Terminal was never on the table.\\n\\nThe [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) is the platform it is today due to its open source nature. Launched almost 2.5 years ago, the interest on this platform was clear \u2014 aggregating an impressive 4000 stars on GitHub in under 24 hours from launch.\\n\\nThis number kept on growing along with the community (most of which gathers on [our Discord server](http://openbb.co/discord)) and allowed us to create the company OpenBB, see the story [here](http://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\n\\n\\nBut why is open source so important for us? To understand this, it\u2019s important for us go over the main problems in the space.\\n\\n
- \\n
- Data licensing \\n
- Full-price bundle \\n
- Transparency and customization \\n
- Community \\n
\\n \\n
\\n\\nFrom Open Source to Open Startup: A journey of OpenBB towards transparency in the financial world.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nBeing open source isn\u2019t enough, at OpenBB we want to accelerate the transparency in the financial world.\\n\\nI want to start this blogpost by introducing the concept of an open startup. As this phrase can often be interpreted differently, here\u2019s the standard definition that ChatGPT gave me:\\n\\n> _\u201cAn open startup is a company that practices open innovation and transparent communication with its stakeholders, including customers, employees, and investors. This means that the company is willing to share information about its products, services, and business operations with the public and is open to input and feedback from all stakeholders._\\n\\n
\\n\\n> _Open startups typically have a strong focus on collaboration and community building, and they often use open source technology and principles in their operations. Some open startups may also be structured as cooperative or worker-owned enterprises, in which ownership and decision-making power are shared among employees.\u201d_\\n\\n## Why now?\\n\\nI\u2019ve been learning about the open startup movement for a while now and I always knew that I wanted OpenBB to follow this trend. At the end of the day, I want us to accelerate the openness and transparency in the financial world.\\n\\nBut until recently, this wasn\u2019t one of our top priorities. This all changed when the cryptocurrency exchange FTX collapsed. This was a house of cards and they stood for everything but transparency \u2014 not only with their users but also with their shareholders and team alike!\\n\\nJohn J. Ray III who has spent a career tackling large corporate failures involving allegations of criminal activity (like Enron), was appointed CEO of FTX to deal with the bankruptcy, and this is one of his quotes to the US congress:\\n\\n> _\u201cNever in my career have I seen such an utter failure of corporate controls at every level of an organization, from the lack of financial statements to a complete failure of any internal controls or governance whatsoever\u201d_\\n\\n
\\n\\nOpenBB wants to pave the way of transparency in the financial world.\\n\\n## Why open?\\n\\n### Transparency\\n\\nTransparency across team, shareholders, users and new hires is key. Everyone can see our growth in the same location; A single source of truth accessible to everyone at all times. We already have our code open source, which shows transparency in our engineering, so it only makes sense for us to behave in the same way with our business.\\n\\n### Accountability\\n\\nEveryone will know how we\u2019re doing, for better or worse. This will make us feel responsible to show accurate sustainable growth as this information becomes public. Since everyone has equity in the company, this will be our own skin in the game.\\n\\nWhen people ask, \u201cHow is OpenBB going?\u201d, this can be answered with a single link to our open page.\\n\\n### Community building\\n\\nEvery company is trying to build a community these days, but building a community is hard. By having all of our information publicly available, anyone from the community will know how we are doing at all times \u2014 similar to what the team, shareholders and investors know.\\n\\nThis helps to build trust in OpenBB and allow us to attract and retain talented employees who value transparency and an open culture.\\n\\n### Marketing\\n\\nUsers will be able to share our open page to share OpenBB metrics with other users, which will help to increase awareness for us.\\n\\nIn addition, we want to become leaders of open culture in the financial world, which is known for being a very closed industry. We want to influence companies in this sector and start a movement.\\n\\n### Fundraising\\n\\nSince starting OpenBB, I\u2019ve met well over 50 different investors, even without actively fundraising. Whilst this is a great way to start relationships, it\u2019s not sustainable as it takes valuable time away from talking with users/customers (and let\u2019s be honest, even developing :slight_smile:). So by having an open page, we will be able to discuss our growth async and more efficiently. And then, when we are actively fundraising, we can focus on the details.\\n\\n## How will it be done?\\n\\nWe are adding all our metrics and stats to [/open](https://openbb.co/open).\\n\\nOur open metrics will contain 4 main distinct sections to start with:\\n\\n#### Social Media metrics\\n\\nTwitter followers, Discord users, LinkedIn followers, YouTube views, Reddit followers. Allows to understand the strength of our community in the social media channels that we focus on.\\n\\n#### Team stats\\n\\nTeam distribution and employee engagement coming soon. Allows to understand where we are based and employee experience at OpenBB\\n\\n#### Product metrics\\n\\nOpenBB Hub users, OpenBB Bot, OpenBB SDK and OpenBB Terminal. Allows to hold us accountable for our user growth and the usage that our products have\\n\\n#### Developer metrics\\n\\nStars, forks, merged pull-requests, closed issues, contributors. Keep up-to-date with our development speed and how engaged the open source community is.\\n\\n\\n\\nFor all the metrics that are open source, there will be an \u24d8 in the top right to share information on why this chart was made open source and why it\u2019s important to us.\\n\\nOnce a metric is open, we do not intend to close it ever again, that is why all the metrics we are making public have gone through a thorough reasoning process and there\u2019s enough contextual information to understand its meaning.\\n\\nIf you can think of a metric that you would like to see on our open page, please feel free to DM me."},{"id":"employees-are-leaving-be-proactive-about-employee-feedback","metadata":{"permalink":"/blog/employees-are-leaving-be-proactive-about-employee-feedback","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.md","source":"@site/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.md","title":"Employees are leaving? Be proactive about employee feedback","description":"Employees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey.","date":"2023-06-29T00:00:00.000Z","tags":[{"inline":true,"label":"employee engagement","permalink":"/blog/tags/employee-engagement"},{"inline":true,"label":"feedback","permalink":"/blog/tags/feedback"},{"inline":true,"label":"work culture","permalink":"/blog/tags/work-culture"},{"inline":true,"label":"remote work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"team happiness","permalink":"/blog/tags/team-happiness"}],"readingTime":4.995,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"employees-are-leaving-be-proactive-about-employee-feedback","title":"Employees are leaving? Be proactive about employee feedback","date":"2023-06-29T00:00:00.000Z","image":"/blog/2023-06-29-employees-are-leaving-be-proactive-about-employee-feedback.png","tags":["employee engagement","feedback","work culture","remote work","team happiness"],"description":"Employees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey."},"unlisted":false,"prevItem":{"title":"From Open Source to Open Startup","permalink":"/blog/from-open-source-to-open-startup"},"nextItem":{"title":"Hybrid work sucks. It\u2019s worse than remote and office.","permalink":"/blog/hybrid-work-sucks-its-worse-than-remote-and-office"}},"content":"
\\n \\n
\\n\\nEmployees are leaving? Be proactive about employee feedback. This blogpost discusses the importance of employee feedback and how we at OpenBB are ensuring high employee engagement through a periodic feedback survey.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis blogpost shows the measures we are taking to ensure we have high employee engagement at OpenBB through a periodic feedback survey.\\n\\nWhen we started OpenBB, I was absolutely obsessed about our product. All my focus and time was dedicated to building our suite of products (OpenBB Terminal, OpenBB SDK or OpenBB Bot), or talking about these with our users. I care deeply about the OpenBB team, but I expected everyone to be as motivated as me, 24/7.\\n\\nBut things just don\u2019t work that way. Although we always have a fun quarterly event online, that isn\u2019t enough. Everyone knows that I\u2019m a big fan of remote work, but one clear down side of it is the lack of contact and face to face conversations which makes employee engagement more volatile. I say this, because I believe that when your team is together in the same space, it\u2019s easier to thrive off each others excitement and motivation.\\n\\nSoon enough, I realized that _\u201calone you can go faster, but with a team you can go far\u201d_. This is when I started putting time into understanding what we could be doing better to improve our work culture.\\n\\nSome things that we have now put into place include:\\n\\n- We updated the company values as a team, based on what we currently had that they were proud of and where they would like us to be in the future. In a startup, where the pace is incredibly fast and the team is constantly changing, I strongly believe that the values change over time too.\\n\\n- We had an [OpenBB rap](https://www.youtube.com/watch?time_continue=48&v=ThtSC8s0h6I&embeds_referring_euri=https%3A%2F%2Fopenbb.co%2Fblog&source_ve_path=MzY4NDIsMjg2NjMsMjg2NjY&ab_channel=OpenBB) made by a freestyler for our OpenBB Christmas event.\\n\\n- We started pushing for more transparency. We were already very transparent internally, but now we started to push this value externally too. Everyone in the company has skin in the game, this allows the team to feel as accountable for the metrics as I do. I wrote more about this in this blogpost: [From open source to open startup](/blog/from-open-source-to-open-startup), and I am currently working on the OpenBB Handbook too.\\n\\n- I started having office hours, where I can spend the time with the team chatting about anything (product, strategy, engineering, storytelling, even fundraising). The team knows that I\u2019m usually available, but having that 1 hour blocked gives them the confidence to know that that time booked in the day.\\n\\nHowever, there was something critical missing. I will explain what it is by using what I learned at university (that way I can say that my MSc in Control Systems was indeed useful for OpenBB \ud83d\ude43).\\n\\nWhat we had built is an open loop control system, and it looks something like this:\\n\\n\\n\\nThe problem? open loop systems can be inaccurate and unreliable. More importantly, because there is no feedback mechanism to correct inputs as the controller (leadership) never gets the information that comes out of the system (team engagement).\\n\\nThe key word here is feedback. An office hour session is great, but it\u2019s a poor \u201csensor device\u201d. The reason being that you are opening the door for the team to communicate with you, but that data isn\u2019t significant to extrapolate through the whole team.\\n\\nWe needed feedback. We needed to have a closed-loop system instead of an open one. By that I mean:\\n\\n\\n\\nThis allows us to constantly monitor our team happiness, and be able to react when the feedback doesn\u2019t match our desired culture.\\n\\nBut what is this feedback? What do we want to track? We didn\u2019t want to reinvent the wheel, so we looked up to how the best companies do it. In particular, we studied \u201cThe Psychology of Employee Engagement\u201d e-book from Workday written by Phillip Chambers.\\n\\nThis allowed us to come up with the following survey, where the team would reply anonymously to each of the questions with a rating from 1 to 10 where 1 corresponds to \u201cstrongly disagree\u201d and 10 corresponds to \u201cstrongly agree\u201d.\\n\\n- **Accomplishment:** I feel a regular sense of accomplishment\\n- **Autonomy:** I feel that I am given autonomy in the way I complete my tasks\\n- **Meetings:** I feel that I have a good amount of meetings every week. (this question was originally about environment, but due to our remote nature we felt that the amount of meetings was something more important to measure)\\n- **Freedom of Opinions:** I feel that I have a voice in the company and my opinion matters\\n- **Goal Setting:** I feel that both my goals and expectations are set clearly\\n- **Growth:** I feel that I have opportunities to grow professionally\\n- **Management Support:** I feel that my manager cares for me and empowers me\\n- **Meaningful Work:** I feel that my work matters\\n- **Organizational Fit:** I feel like the company values align with mine and we share the same goal\\n- **Peer relationships:** I feel connected with my colleagues and that I can be myself with them\\n- **Recognition:** I feel like I get recognized for my contributions\\n- **Reward:** I feel like I am rewarded fairly for my work\\n- **Strategy:** I feel like the company strategy is being communicated effectively\\n- **Workload:** I feel like I can manage my workload efficiently\\n\\nNow you may be wondering how we made this survey completely automated, the workflow is actually very straightforward and we were able to automate it. Here is what it looks like: Airtable + Slack \u2705\\n\\n\\n\\nEven though our salaries don\u2019t compete with the MAMAAs of this world, we believe that: our mission, our innovative products and unique culture are what makes us OpenBB. And why we can retain our talent.\\n\\nYou can find our employee engagement index at: https://openbb.co/company/open/team"},{"id":"hybrid-work-sucks-its-worse-than-remote-and-office","metadata":{"permalink":"/blog/hybrid-work-sucks-its-worse-than-remote-and-office","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.md","source":"@site/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.md","title":"Hybrid work sucks. It\u2019s worse than remote and office.","description":"Hybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution.","date":"2023-06-12T00:00:00.000Z","tags":[{"inline":true,"label":"remote work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"office work","permalink":"/blog/tags/office-work"},{"inline":true,"label":"hybrid work","permalink":"/blog/tags/hybrid-work"},{"inline":true,"label":"productivity","permalink":"/blog/tags/productivity"},{"inline":true,"label":"work culture","permalink":"/blog/tags/work-culture"}],"readingTime":11.715,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"hybrid-work-sucks-its-worse-than-remote-and-office","title":"Hybrid work sucks. It\u2019s worse than remote and office.","date":"2023-06-12T00:00:00.000Z","image":"/blog/2023-06-12-hybrid-work-sucks-its-worse-than-remote-and-office.png","tags":["remote work","office work","hybrid work","productivity","work culture"],"description":"Hybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution."},"unlisted":false,"prevItem":{"title":"Employees are leaving? Be proactive about employee feedback","permalink":"/blog/employees-are-leaving-be-proactive-about-employee-feedback"},"nextItem":{"title":"Become an OpenBB Champion","permalink":"/blog/become-an-openbb-champion"}},"content":"
\\n \\n
\\n\\nHybrid work, a combination of remote and office work, is not as beneficial as it seems. This blog post discusses the pros and cons of remote and office work, and why hybrid work might not be the best solution.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis is my hot take for 2023, but bear with me.\\n\\n## Context\\n\\nEveryone on Twitter has been actively discussing that \u201cRemote work failed\u201d, e.g. [this tweet](https://twitter.com/DavidSacks/status/1663958149437743105?s=20) from David Sacks where he refers to [this blogpost](https://flocrivello.com/changing-my-mind-on-remote-about-being-in-san-francisco/), or [this tweet](https://twitter.com/paulg/status/1667580108247277570?s=20) from Paul Graham.\\n\\nWhile I\u2019m not going to pose as an expert on the topic, I feel like I\u2019ve experienced enough to have an opinion. My career so far has been:\\n\\n- 1 year of office work for a public company\\n- 1 year of remote work for a startup, plus a few months of hybrid work for the same startup\\n- 2 years of growing [OpenBB](https://openbb.co/) from 1 to 20 people, all fully remote.\\n\\nLet me first go over the advantages and disadvantages of remote and office work, so that I can focus this blog post on **why hybrid sucks**.\\n\\n## Remote work\\n\\nFirst of all, let\u2019s be pragmatic \u2014 remote works. (Before people comment, of course if you\u2019re a factory worker or similar, this doesn\u2019t apply).\\n\\n### Advantages\\n\\n
- \\n
- Increased employee retention and satisfaction: Remote work is seen as a desirable perk, improving job satisfaction and retention rates. You can check OpenBB team engagement here. \\n
- Expanded talent pool: It allows hiring from a global talent pool, resulting in a more diverse and skilled workforce, particularly in open source, where contributors come from all over the world. \\n
- Increased flexibility: Remote work offers employees more control over their schedules, leading to better work-life balance. \\n
- Improved productivity: There are fewer distractions and interruptions, which leads to increased productivity. \\n
- No commuting: Remote work eliminates the need to travel to the office, saving time, money, and energy. \\n
- Cost savings: It reduces expenses for both employees and employers, such as commuting and office-related costs. \\n
- \\n
- Limited face-to-face interaction: Remote work reduces in-person collaboration and social connections among colleagues. \\n
- Communication challenges: Reliance on digital tools may lead to misunderstandings or misinterpretations. There may also be technical issues or connectivity problems. \\n
- Blurred work-life boundaries: Clear separation between work and personal life becomes challenging. \\n
- Potential distractions: Remote work environments expose individuals to various distractions. \\n
- Challenges with collaboration: Coordinating tasks and scheduling can be more difficult remotely. \\n
- Reduced visibility and career advancement opportunities: Remote workers may have limited visibility and access to career growth. \\n
- \\n
- A strong leadership is necessary to keep the team aligned, motivated, and to create the company\u2019s culture. This helps mainly with the limited face-to-face interaction, challenges with collaboration, and reduced visibility and career advancement opportunities. \\n
- Do not track team members based on time but assess work based on output. Use meritocracy to reward the best team members and let go of low performers early. Remote work is not for everyone, and for those who cannot produce output/value to the company while working remotely, it means they weren\u2019t a good hire in the first place. In my personal opinion, the disadvantages of potential distractions and blurred work-life boundaries come down to the employee and their relationship with remote work, instead of the company. \\n
\\n\\nSometimes someone may not be producing as much value as expected, for one reason or another. _When you are working remotely, you accept that you will add value to the company, and time is no longer a measure. Thus, the emphasis on output/value becomes much stronger._\\n\\n## Office Work\\n\\nOffice also works.\\n\\n### Advantages\\n\\n
- \\n
- Enhanced company culture: Offices contribute to a shared sense of identity and mission. \\n
- Face-to-face collaboration: It allows for immediate interaction, fostering effective teamwork and problem-solving. \\n
- Social interaction: Offices provide opportunities for building relationships with coworkers, enhancing camaraderie. \\n
- Clear work-life boundaries: Physical office spaces establish separation between work and personal life. \\n
- Mentorship and learning: In-person environments facilitate mentorship and hands-on learning. \\n
- Improved supervision: Physical presence aids in monitoring performance and providing timely feedback. \\n
- \\n
- Commuting and transportation issues: Office work often involves commuting, which can lead to time-consuming and stressful travel, traffic congestion, and transportation expenses. \\n
- Lack of flexibility: Office work typically follows a fixed schedule, leaving less room for personal flexibility or adjustments to achieve work-life balance. \\n
- Office politics: Office environments can sometimes involve office politics, conflicts, or gossip that can affect productivity and job satisfaction. \\n
- High overhead costs: Maintaining physical office spaces can be costly for organizations, including expenses related to rent, utilities, and office supplies. \\n
- Limited geographic talent pool: Offices are often location-dependent, which may restrict access to a diverse and global talent pool, potentially limiting the variety of skills and perspectives within a workforce. \\n
- Distractions and interruptions: Open office layouts or noisy work environments can lead to frequent interruptions, reducing focus and productivity. \\n
- \\n
- Decreased productivity: When compared with remote or office, hybrid has lower productivity. This is due to the context switching associated with changing working environments. Personally, I have experienced this and found it frustrating to work until late at night, packing up and thinking about what I needed to carry for the next day, plus commuting. The next day, it took me much longer to get back into the flow of work compared to waking up and immediately continuing with the problem at hand. \\n
- Decreased flexibility: Hybrid work offers less flexibility than remote work but somewhat more than office work. However, this flexibility is often constrained by company policies, such as designated office and remote days or specific rules regarding remote work. When the company dictates the days employees can work remotely, the flexibility becomes somewhat artificial. \\n
- Communication challenges: As mentioned earlier, one of the reasons that office communication is a sword of 2 edges is because while in-person communication can be effective and fast, it often results in less documentation, which can impact new joiners. In a hybrid culture, this issue is so much worse, because it\u2019s hard to get the company aligned into the amount of level of documentation necessary. Plus, when WFH days rotate across divisions and teams, individuals working remotely may suffer from a lack of context that is shared among the team in the office, leading to silos and communication gaps.In addition to that in remote work employees can and expect to have to accommodate for different time zones but when you move people to hybrid the ones that need to go to the office will no longer adjust their times to match the ones WFH based on needs. \\n
- Blurred work-life boundaries: Hybrid work blurs the line between work and personal life. It no longer solely involves working from home and spending time with family but also includes being at work, interacting with co-workers, and commuting. This blurring can make it difficult to establish clear boundaries. \\n
- Limited geographic talent pool: Since you want employees to commute to the office a certain number of times per week or month, you can\u2019t hire them from anywhere. The geographic scope of talent acquisition becomes restricted, potentially limiting access to diverse skills and perspectives. \\n
- Many more distractions: Individuals face distractions both at home when working remotely and in the office from co-workers. PLUS, you get the distractions that come from your co-workers bringing you up to speed if something happened when you weren\u2019t in the office the day before (similar to the additional amount of chit chat that happens on Mondays due to weekend). \\n
- Costs and commuting: You may save some money with some WFH, but often the WFH days don\u2019t even justify going into a lower tier than a monthly subscription to public transports. So you end up spending the same, even if you travel less. This argument is less valid here in the Bay area where most people drive. Plus commuting those 3/4 days a week, is still a pain.When we talk about the employer costs then it\u2019s impossible to get it right. On the one hand you have too few people in the office which means you are overpaying for office space, on the other hand you cannot get everyone in. And this will always be impossible with a growing team + managing the WFH days of each team and division. \\n
- Decreased employee retention and satisfaction: In general, people tend to lean towards either remote work or office work. With hybrid work, those who prefer the office environment may work in the office most days, using WFH as an opportunity for personal tasks and potentially being less productive. On the other hand, those who prefer remote work will aim to WFH as much as possible and may feel dissatisfied with having to go to the office for the remaining days This can create a divide and decrease overall employee satisfaction. Additionally, this is even more pronounced when everyone in the leadership works in the office, since the company tends to follow culture from leaders and will have less incentives to accommodate team members that are not in the office. \\n
- Challenges with supervision: Physical presence in the office often aids in monitoring performance, but it becomes challenging to fairly evaluate the performance of team members in the office versus those working remotely in a hybrid setup. What is the basis that you use to evaluate them? Based on what you see when they are in the office? Do you still create ways to evaluate their output when WFH? Do you still check on them as often when the rest of your team is with you in the office? What about when you are WFH and have half of the team in the office and the other WFH? The amount of complexity that comes from managing this by itself, almost makes hybrid the worst choice. \\n
\\n \\n
\\n\\nBecome an OpenBB Champion and join our passionate community. Share your experiences with our innovative products and help us democratize investment research through an open source approach.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDo you find yourself unable to live without one of OpenBB\u2019s innovative products? Have you pushed the boundaries of our tools and unlocked their full potential? If you answered yes, then this blog post is tailor-made for you!\\n\\nAt [OpenBB](https://openbb.co), we are actively seeking out [OpenBB Champions](https://my.openbb.co/app/hub/champions) \u2014 passionate community members who share our vision of democratizing investment research through an open source approach.\\n\\nWhether you utilize the [OpenBB Terminal](https://my.openbb.co/app/terminal) to streamline your investment research workflow, leverage the [OpenBB SDK](https://my.openbb.co/app/sdk) to create your own internal dashboards and notebooks, or employ the [OpenBB Bot](https://my.openbb.co/app/bot) to extract financial data within your finance community, we want to hear from you!\\n\\nTo qualify as an OpenBB Champion, you need to be an active user of one of our products and be willing to share your valuable experiences with our team. We\u2019re eager to learn more about your journey with OpenBB and how our products have transformed your workflow.\\n\\n
\\n \\n
\\n\\n**Where\'s what we would like to know:**\\n\\n- Your background\\n- How you heard about OpenBB\\n- Workflow transformation since incorporating OpenBB into your toolkit\\n- Your favorite OpenBB product\\n- Your favorite feature within that product\\n- Future expectations from us\\n- Your end goal \u2014 ultimate objective or milestone\\n\\nAs an OpenBB Champion, your contribution will not go unnoticed. Here are the benefits you\u2019ll receive:\\n\\n### Exposure\\n\\nYour testimonial will be prominently featured on OpenBB\u2019s website, social media channels, and other marketing materials. This exposure will introduce your expertise to a wider audience, increasing your visibility within the investment research community.\\n\\n### Recognition\\n\\nYou will be officially recognized as an OpenBB Champion, highlighting your commitment to innovation and industry-leading practices. This recognition can bolster your credibility and authority in your field of expertise.\\n\\n### Networking\\n\\nAs part of the OpenBB Champion community, you will have exclusive access to networking opportunities with like-minded individuals who share your passion for OpenBB\u2019s products. Forge meaningful connections, exchange ideas, and collaborate with fellow champions to amplify your impact.\\n\\n### Merchandise\\n\\nTo show our appreciation for your support, the OpenBB team will send you exclusive OpenBB merchandise. Wear it proudly and let others know that you are part of our journey.\\n\\n\\n\\nIf you meet the requirements and are enthusiastic about becoming an [OpenBB Champion](https://openbb.co/blog?type=champions), we invite you to reach out to us at hello@openbb.finance. Our team will coordinate a podcast session with you.\\n\\nWe look forward to hearing from you."},{"id":"streamline-your-openbb-terminal-experience-with-openbb-hub","metadata":{"permalink":"/blog/streamline-your-openbb-terminal-experience-with-openbb-hub","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.md","source":"@site/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.md","title":"Streamline your OpenBB Terminal experience with OpenBB Hub","description":"Streamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management.","date":"2023-05-25T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OpenBB Hub","permalink":"/blog/tags/open-bb-hub"},{"inline":true,"label":"Terminal","permalink":"/blog/tags/terminal"},{"inline":true,"label":"API Key Management","permalink":"/blog/tags/api-key-management"},{"inline":true,"label":"Data Customization","permalink":"/blog/tags/data-customization"},{"inline":true,"label":"Personalization","permalink":"/blog/tags/personalization"},{"inline":true,"label":"Script Management","permalink":"/blog/tags/script-management"}],"readingTime":3.605,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"streamline-your-openbb-terminal-experience-with-openbb-hub","title":"Streamline your OpenBB Terminal experience with OpenBB Hub","date":"2023-05-25T00:00:00.000Z","image":"/blog/2023-05-25-streamline-your-openbb-terminal-experience-with-openbb-hub.png","tags":["OpenBB","OpenBB Hub","Terminal","API Key Management","Data Customization","Personalization","Script Management"],"description":"Streamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management."},"unlisted":false,"prevItem":{"title":"Become an OpenBB Champion","permalink":"/blog/become-an-openbb-champion"},"nextItem":{"title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data"}},"content":"
\\n \\n
\\n\\nStreamline your OpenBB Terminal experience with OpenBB Hub. Learn about its key features, including API key management, data customization, personalization, and script management.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you\u2019re using the OpenBB Terminal, there\u2019s an essential component you shouldn\u2019t miss out on: the [OpenBB Hub](https://my.openbb.co/). In this blog post, we\u2019ll explore the significance of OpenBB Hub and why it truly matters for OpenBB users.\\n\\nBy delving into its key features, we\u2019ll uncover how OpenBB Hub elevates your experience with the OpenBB Terminal, providing you with enhanced capabilities and customization options. Let\u2019s dive in!\\n\\n## Login\\n\\nAs highlighted in our previous blog post [Introducing the OpenBB Hub](https://openbb.co/blog/introducing-the-openbb-hub), the OpenBB Hub is more than just a platform to access the OpenBB product ecosystem; it adds value to each individual product. Specifically, when it comes to the OpenBB Terminal, having an OpenBB Hub account offers tremendous advantages.\\n\\nNotably, the settings and features you configure within the hub persist across terminal updates and even when you log in from a new machine, allowing for a seamless and personalized experience.\\n\\n
\\n\\nWith the [OpenBB Hub](https://my.openbb.co/), you unlock a world of possibilities."},{"id":"openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","metadata":{"permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.md","source":"@site/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.md","title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","description":"A game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data.","date":"2023-05-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"Interactive Charts","permalink":"/blog/tags/interactive-charts"},{"inline":true,"label":"Interactive Tables","permalink":"/blog/tags/interactive-tables"},{"inline":true,"label":"Data Analysis","permalink":"/blog/tags/data-analysis"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.635,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"openbb-terminal-3-0-a-new-interactive-way-to-analyze-data","title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","date":"2023-05-20T00:00:00.000Z","image":"/blog/2023-05-20-openbb-terminal-3-0-a-new-interactive-way-to-analyze-data.png","tags":["OpenBB","OpenBB Terminal","Interactive Charts","Interactive Tables","Data Analysis","Open Source"],"description":"A game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data."},"unlisted":false,"prevItem":{"title":"Streamline your OpenBB Terminal experience with OpenBB Hub","permalink":"/blog/streamline-your-openbb-terminal-experience-with-openbb-hub"},"nextItem":{"title":"Leaving London to live in San Francisco","permalink":"/blog/leaving-london-to-live-in-san-francisco"}},"content":"
\\n \\n
\\n\\nA game-changing update to OpenBB Terminal, introducing interactive charts and tables, empowering users with a new way to analyze data.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nNothing has changed, yet everything is different. A game-changing update empowering users with interactive charts and tables\\n\\nOur commitment to listening to user feedback and continuously improving our platform has led to a major update that will revolutionize the way you analyze data.\\n\\nOne of the main requests from our community has been regarding the interactivity of the charts and tables output by the [OpenBB Terminal](https://my.openbb.co/app/terminal). We are happy to say that we have delivered on this request with a complete overhaul of the terminal plotting library.\\n\\nNot only that, but our engineering team wasn\u2019t happy with the technical solutions available to bring interactivity to the terminal. So, in a true open-source fashion, the team built our own open-source library which will be announced soon.\\n\\n## Interactive charts\\n\\n
\\n\\nOne of the most significant additions in this update is the introduction of interactive charts. Gone are the days of static data representations.\\n\\nWith the OpenBB Terminal, you can now immerse yourself in a dynamic visual experience. Hover over specific data points to reveal detailed information, or effortlessly adjust the charts using intuitive pan and zoom capabilities. But that\u2019s not all \u2014 our drawing tools and annotations allow you to highlight crucial data points and ranges, giving you complete control over your analysis.\\n\\nThrough our user interviews, we discovered that many users faced challenges when overlaying financial time series. Taking this into account, we\u2019ve designed our new charting feature to make this process seamless. With the ability to easily overlay time series data and combine it with our powerful data exporting capabilities, OpenBB Terminal empowers you to perform in-depth analysis with unparalleled ease and precision.\\n\\n## Interactive tables\\n\\n
\\n\\nWe listened to our users\u2019 concerns about readability when dealing with large tables, and we have addressed these challenges head-on. The OpenBB Terminal now boasts interactive tables that are as aesthetically pleasing as they are functional.\\n\\nLeveraging our innovative open-source project, we have crafted a state-of-the-art table that is easy on the eyes and effortlessly responsive. Sorting, filtering, and manipulating table data has never been easier. This game-changing feature enables you to quickly and efficiently extract insights from vast amounts of data, enhancing your productivity and saving valuable time.\\n\\n## New fixed income menu\\n\\n
\\n\\nIn addition to the remarkable advancements in interactivity, we have squashed bugs and introduced a new Fixed Income menu. This means you now have access to an even wider range of data to fuel your analysis. OpenBB Terminal ensures that you are equipped with the right tools to gain a competitive edge in your investment research.\\n\\n## Wrap up - embrace the future of data analysis\\n\\nWe firmly believe that these new features will take your user experience to new heights and unlock a realm of possibilities for data analysis. Our dedicated team has poured countless hours into bringing these cutting-edge features to life, and we cannot wait to witness the impact they will have on your work.\\n\\nTo further amplify our commitment to open source, we will open source a powerful project that taps into web browser functionality from Python, opening up endless opportunities for developers and data enthusiasts.\\n\\nWe value your feedback and are eager to iterate on the OpenBB Terminal to ensure it meets your evolving needs. Reach out to us via email at hello@openbb.finance, Twitter, or Discord and let us know how we can enhance your experience further.\\n\\nIf you missed our exciting webinar unveiling these transformative features, fear not! We\u2019ve got you covered. Watch the video below to catch up and witness firsthand the incredible new capabilities our team has unleashed.\\n\\n
\\n\\nWelcome to a new era of data analysis with OpenBB Terminal. Get ready to explore, discover, and gain a competitive edge like never before."},{"id":"leaving-london-to-live-in-san-francisco","metadata":{"permalink":"/blog/leaving-london-to-live-in-san-francisco","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-13-leaving-london-to-live-in-san-francisco.md","source":"@site/blog/2023-05-13-leaving-london-to-live-in-san-francisco.md","title":"Leaving London to live in San Francisco","description":"Leaving London to live in San Francisco. A personal journey of relocating and starting a tech company in the heart of Silicon Valley.","date":"2023-05-13T00:00:00.000Z","tags":[{"inline":true,"label":"San Francisco","permalink":"/blog/tags/san-francisco"},{"inline":true,"label":"London","permalink":"/blog/tags/london"},{"inline":true,"label":"Relocation","permalink":"/blog/tags/relocation"},{"inline":true,"label":"Visa Process","permalink":"/blog/tags/visa-process"},{"inline":true,"label":"Startup","permalink":"/blog/tags/startup"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"}],"readingTime":17.515,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"leaving-london-to-live-in-san-francisco","title":"Leaving London to live in San Francisco","date":"2023-05-13T00:00:00.000Z","image":"/blog/2023-05-13-leaving-london-to-live-in-san-francisco.png","tags":["San Francisco","London","Relocation","Visa Process","Startup","OpenBB"],"description":"Leaving London to live in San Francisco. A personal journey of relocating and starting a tech company in the heart of Silicon Valley."},"unlisted":false,"prevItem":{"title":"OpenBB Terminal 3.0 - a new interactive way to analyze data","permalink":"/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data"},"nextItem":{"title":"Fully free financial chatbot","permalink":"/blog/fully-free-financial-chatbot"}},"content":"
\\n \\n
\\n\\nLeaving London to live in San Francisco: A personal journey of relocating and starting a tech company in the heart of Silicon Valley.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Background\\n\\nI was born in Geneva, and when I was 8 years old, we moved back to Portugal, which is where my parents are originally from. After spending most of my teenage years in Portugal, I left sunny Lisbon \u2600\ufe0f to pursue a MSc. degree at Imperial College London \ud83d\udcbb. That\u2019s where I\u2019ve been living and working up until now. The main reasons behind my desire to move to San Francisco \u2600\ufe0f \ud83d\udcbb are the weather and the thriving tech ecosystem that surrounds it.\\n\\nDuring the Covid pandemic while in London, I took the opportunity to build my own [personal open source investment research platform](https://github.com/OpenBB-finance/OpenBBTerminal). This project allowed me to secure VC funding and establish a company called [OpenBB](https://openbb.co/). As the CEO of this company, I feel privileged to have the chance to make a lasting impact on the financial industry. Embracing this adventure and collaborating with individuals who are much smarter than I am is the least I can do for our team and for OpenBB.\\n\\nAs a first-time founder, I often find myself feeling slightly behind, which is why I\u2019m eager to absorb as much experience and knowledge as possible from other successful entrepreneurs. This is also why I managed to convince my wife and our dogs to join me in packing our bags and embarking on this journey into the unknown, much like my Portuguese ancestors did centuries ago \ud83d\udea2.\\n\\nNow, let\u2019s dive into what truly matters. This will be a lengthy ride, so make sure you\u2019re prepared for the journey ahead.\\n\\n## VISA\\n\\nFirst of all, you need to determine which visa you are eligible for in order to live and work in the US. You can find more information on this topic [here](https://travel.state.gov/content/travel/en/us-visas.html).\\n\\nIn my case, I decided to apply for an \u201cO-1 Visa: Individuals with Extraordinary Ability or Achievement\u201d and specifically highlighted my extraordinary ability in the field of Computer Science, specifically within the subfield of Automated Systems. It is crucial to specify a particular field to make the defense process smoother.\\n\\nI had the privilege of working with an exceptional immigration lawyer who assisted me in crafting my case, significantly increasing my chances of a successful approval. Here is a portion of the O-1 Petition that was submitted:\\n\\n\\n\\nAs you can see, there is quite a bit of paperwork required to support your case. In my situation, I needed the following documents: Curriculum Vitae, university grades, transcripts and diplomas, LinkedIn and GitHub profiles, posts that gained viral attention on platforms like Reddit and HackerNews, podcasts and conferences where I had spoken, projects that received online praise, any media coverage I had received, scholarly scientific publications, expert opinion letters, and even emails or direct messages from venture capitalists or professionals in the industry.\\n\\nEssentially, any relevant evidence is used to strengthen your case. For me, the most crucial elements were the expert opinion letters provided by our lead investor, former colleagues, or respected individuals in the field who were familiar with my work, as well as the research papers I had published and the media coverage I had received.\\n\\nOnce my O-1 visa was approved, I simply needed to take my passport to the US embassy in London to obtain the visa stamp. It\u2019s worth noting that if the wait time at the US embassy is lengthy, you have the option to visit another US embassy in another country where the process may be faster.\\n\\n## Arriving to the country\\n\\nI arrived in California on my own initially, with the plan for my wife and dogs to join me later. Thankfully, I had some contacts in California who provided me with their phone number and house address, which was helpful for getting settled. Since I didn\u2019t have a phone before finding an apartment, I had to rely on roaming data using my plan from the UK, which resulted in additional expenses.\\n\\nI would suggest either having a good deal for data roaming and international calls outside your country or obtaining a prepaid US phone. The latter is especially important if you\u2019re traveling alone because I often encountered registration forms that didn\u2019t accept foreign phone numbers.\\n\\nRegarding payments, I used my Revolut VISA card, which offers excellent foreign exchange rates for converting pounds to dollars. It\u2019s worth noting that I couldn\u2019t open a US bank account without a Social Security Number (SSN).\\n\\n### Social Security Number (SSN)\\n\\nIf you know someone in the US, it is advisable to apply for a Social Security Number (SSN) as soon as possible and provide their address and contact information if you don\u2019t have a US address of your own. An SSN is necessary for various purposes, and it may take up to two weeks for the card to arrive. When going to you nearest Social Security Administration (SSA) office, I would suggest arriving 30 minutes before opening hours to avoid long queues.\\n\\nTo apply for an SSN, you will need to bring the following documents to the SSA office: your passport, the I-797 form (O-1 visa approval notice), and the I-94 form (arrival record in the US).\\n\\n### Transportation\\n\\nI had the fortunate opportunity of having a friend lend me a car as soon as I arrived in California, and it made my life ten times easier. I highly recommend having something lined up in terms of transportation, as having a car enables you to get anywhere you need to go much more efficiently. To ensure I was covered, I simply needed to arrange car insurance. I opted for [Progressive](https://www.progressive.com/), and the process was quick and straightforward.\\n\\nWhile settling in, I occasionally relied on public transportation instead of driving, especially when traveling to the center of San Francisco. It took me some time to adjust to driving in the US, so public transport was a convenient alternative. If you plan on using public transportation services like BART or Caltrain, I suggest visiting [this website](https://www.iliveinthebayarea.com/knowledge-center/transit/) that provides information on available transportation options. It\u2019s also a good idea to purchase a [Clipper card](https://www.clippercard.com/), which allows you to load funds and easily tap it when boarding.\\n\\nAdditionally, if you anticipate passing through tolls, bridges, or utilizing the fast lane on the freeway, I recommend looking into acquiring a [Fastrack transponder](https://www.thetollroads.com/accounts/fastrak/transponder/) for a more seamless experience.\\n\\n## Finding an apartment\\n\\nApartment hunting proved to be quite stressful, considering that every day spent searching meant unnecessary expenses piling up while I still had my company to manage.\\n\\nUsing Uber for transportation was convenient and efficient, but the costs could add up quickly with multiple trips. To save money, I recommend scheduling house viewings on the same day in specific areas of interest and simply walking from one location to another.\\n\\nWhile dealing with lease agents, I encountered a mix of competence levels. Some were highly efficient, while others were less so. If you\u2019re genuinely interested in a particular apartment, it\u2019s important to exert some pressure to keep the process moving forward. Don\u2019t hesitate to call and inquire about updates.\\n\\nI was fond of the first house we saw, so I promptly paid $300, which covered certain fees. These fees were refundable if we decided not to proceed, but more importantly, they ensured that the house would be taken off the market. At this stage, both the agents and I wanted the process to move as quickly as possible. In our case, the target timeframe was three business days; if the process exceeded that, the house would be made available again.\\n\\nEven if you believe you\u2019ve found the perfect apartment, I still recommend continuing your search until the lease contract is signed. It\u2019s crucial to secure the apartment before assuming it\u2019s yours.\\n\\nBefore obtaining the keys, we had several tasks to complete: making the first payment, setting up utilities ([PG&E](https://www.pge.com/) for Gas and Electricity, and [Conservice](https://utilitiesinfo.conservice.com/) for water), providing proof of renter\u2019s liability insurance (I used [Assurant](https://assurantrenters.com/)\u2019s as it was conveniently associated with the community), and undergoing a pet screening (note that certain dog breeds are considered more dangerous and may not be accepted).\\n\\nMost importantly, my salary alone wasn\u2019t sufficient to guarantee that we could afford the rent. I needed a guarantor to vouch for me, as Europe does not have the concept of credit ratings.\\n\\nFortunately, our lead investor graciously agreed to be our guarantor when I asked him. Without someone fulfilling this role, I would have had to rely on a third-party service and pay several thousands of dollars, which would have been non-refundable and solely for the right to lease the house. This arrangement seemed rather illogical.\\n\\n## After the apartment\\n\\nI needed to notify [USCIS](https://www.uscis.gov/) of my new address since the last one on file was associated with the hotel where I was staying. I informed them that my new residence would be the updated address.\\n\\nFollowing that, my dogs flew from the UK using [Pets abroad UK](https://www.petsabroaduk.co.uk/). To save money, my wife didn\u2019t accompany them on the flight; instead, she arranged for them to be transported in the cargo hold of the airplane while I waited at the destination.\\n\\nHowever, I must admit that I didn\u2019t enjoy the experience, and in hindsight, I would have been willing to pay more for my dogs to have a better and safer flight. Although flying them from London, meant that unfortunately cargo was the option due to UK requirements. When I picked them up, they were visibly scared, and both my wife and I held our breath with worry throughout their entire journey. Our dogs\u2019 well-being was of utmost importance to us.\\n\\n\\n\\nThe house was mostly empty, so to save money, we acquired a lot of second-hand items for free. It was beneficial to know people in the area who were aware of others with unused items stored in their garages, which we were able to take. To retrieve this furniture and other objects, we either needed to rent a U-Haul (which wasn\u2019t possible without a California driver\u2019s license) or hire a moving company.\\n\\nOur next task was to search for second-hand items at significant discounts on websites such as [Craigslist](https://sfbay.craigslist.org/), [Nextdoor](https://nextdoor.com/) and [Facebook Marketplace](https://www.facebook.com/marketplace). However, we had to be cautious of scammers and remember that if a deal seemed too good to be true, it probably was.\\n\\nOnce we had gathered most of the second-hand items, we visited [Home Depot](https://www.homedepot.com/) to paint and improve the newly acquired furniture. For the items we couldn\u2019t find second-hand, we made purchases at [Costco](https://www.costco.com/).\\n\\nWe highly recommend getting an executive membership at Costco as it provides great value for money. Additionally, the gas prices at Costco are significantly cheaper compared to other places we\u2019ve seen.\\n\\n### Wi-Fi + Mobile plan\\n\\nAfter securing an apartment, I used my passport to visit an [AT&T](https://www.att.com/) store. Since I didn\u2019t have my SSN yet, they were accommodating and allowed me to use my passport for identification. However, if you choose a different service provider like Xfinity, you will need your SSN. Before selecting a plan, it\u2019s important to check the coverage in your area to ensure that 4G/5G works well.\\n\\nInitially, I set up Wi-Fi through Xfinity, but then I used that as leverage to negotiate a discount with AT&T. This worked because I was interested in a double play package, which included two phone plans and Wi-Fi. As a result, I obtained an e-sim with unlimited 5G data for both myself and my wife, along with Wi-Fi for our home, at a cost of approximately $150 per month.\\n\\n### Shopping\\n\\nThere\u2019s going to be a big shock in terms of prices; at least, we experienced one. Life in the Bay Area is over 2x more expensive than London.\\n\\n\\n\\nSo, we started learning how to buy things at a lower cost. Whole Foods is not a viable option as it\u2019s one of the most expensive stores. The 10 items above cost $69.34 on Whole Foods.\\n\\nInstead, we now tend to shop at Safeway and always try to time our visits to take advantage of discounts. Many shopping places offer coupons that can help you save a lot of money. Additionally, when you come across products on sale, it\u2019s better to buy them in larger quantities as it\u2019s usually worth it.\\n\\nMy wife is also a big fan of Trader Joe\u2019s with the prices there being quite reasonable too. They also have a great selection of cheeses which is a must being from Europe.\\n\\n## After obtaining an SSN\\n\\nAfter you obtain your SSN, there are a lot of new things that you are able to do since you are recognized as a \u201cperson.\u201d\\n\\n### Bank account\\n\\nCredit cards are recommended over debit cards, not just because of the security benefits, but also because of the credit rating associated with them. This is a concept that doesn\u2019t really exist in Europe but is significant in the US. Your credit score will determine whether you are approved for a loan and what interest rate you will be charged.\\n\\nThe agencies that handle your credit score are [Equifax.com](http://equifax.com/), [TransUnion.com](http://transunion.com/) and [Experian.com](http://experian.com/). It\u2019s free to register, and you should keep an eye on your credit files to ensure that your credit score doesn\u2019t decrease for any reason.\\n\\nWe ended up opening an account with [Bank of America](https://www.bankofamerica.com/). However, since we didn\u2019t have a credit score yet, we couldn\u2019t get a regular credit card. Instead, we had to apply for a secured credit card, where the maximum spending limit is determined by the amount of cash we use to back the credit card.\\n\\nWe also applied for an [AMEX card](https://www.americanexpress.com/us/credit-cards/card/blue-cash-everyday/?eep=26129&irgwc=1&veid=39E0XuRS3xyNT4BTy33WSUXYUkAwp0Tx32Qt0c0&affid=1193684&pid=IR&affname=NerdWallet%2C+Inc.&sid=14011830016&pmc=795&BUID=CCG&CRTV=controlaffcps&MPR=03) because [American Express](https://www.americanexpress.com/) has a partnership with the international credit-reporting startup Nova Credit. This allows immigrants to instantly translate credit reports from the UK to U.S.-equivalent credit reports when applying for AmEx consumer cards. However, it\u2019s important to note that AMEX cards are less widely accepted compared to VISA and MasterCard, so we were aware that they would only work in certain establishments.\\n\\nFor more information, these video were extremely helpful:\\n\\n- [Building credit and keeping yours healthy](https://bettermoneyhabits.bankofamerica.com/en/credit/building-credit)\\n- [How to build credit from scratch](https://bettermoneyhabits.bankofamerica.com/en/credit/start-building-credit)\\n- [Top 3 credit questions](https://bettermoneyhabits.bankofamerica.com/en/credit/top-credit-questions)\\n\\n### Car\\n\\nIt was now time for us to buy a car. We searched online for a few options. There are two things worth considering when buying a used car, as we did:\\n\\n- Firstly, you can use [https://www.kbb.com/car-values/](https://www.kbb.com/car-values/) to research the value of the car. This ensures that you don\u2019t get ripped off and provides an estimate of how much the car is worth based on the details you provide.\\n- Secondly, you can use [https://www.carfax.com/](https://www.carfax.com/) to research a car and its license plate. This helps you understand its accident history and any repairs it has undergone. It provides information about whether there have been major accidents in the car\u2019s history, frequent visits to the mechanic, and whether the repairs were done by authorized mechanics (e.g., BMW) or not.\\n\\nIf you prefer to play it safe, you can even bring a mechanic with you to the dealership to assess the car\u2019s condition.\\n\\nWe spoke with individuals, but ultimately decided to buy a car from a dealership because it offered fewer risks compared to buying from individuals. Moreover, the dealership took care of updating the vehicle records, ensuring that the vehicle would be registered under our name. This allowed us to update our car insurance with the Vehicle Identification Number (VIN) of the new vehicle.\\n\\nAfter a few months, we received the California Certificate of Title, which confirmed that I was the legal owner of the vehicle and included important vehicle identification information. Since this was my first car, I had to add an OpenBB reference to the front plate :)\\n\\n\\n\\nShoutouts to:\\n\\n- [Jiffy Lube](https://www.jiffylube.com/) for their car inspection services, tire inflation, oil changes, and more. They don\u2019t charge for the inspection and only charge for the services performed on the car. We had a great experience with them.\\n- [Costco gas station](https://www.costco.com/gasoline.html) for the cheapest gas we\u2019ve found so far.\\n\\n### Health Insurance\\n\\nCalifornia offers a portal called [Covered California](https://www.coveredca.com/), which provides state-approved health plans from various insurance companies. If your income is low, the state can subsidize your monthly premium. These plans fall into three categories, each with differences in costs and provider networks:\\n\\n
- \\n
- HMOs (Health Maintenance Organizations): Typically cheaper than PPOs, HMOs have smaller networks. You need to see your primary care physician before getting a referral to a specialist. \\n
- PPOs (Preferred Provider Organizations): Usually more expensive, PPOs offer a larger network and the ability to see providers outside of the network. You can also see specialists without a referral. \\n
- EPOS (Exclusive Provider Organizations): EPOS plans combine features of HMOs and PPOs. They have exclusive networks like HMOs, making them generally less expensive. However, you can make your own appointments with specialists, similar to PPOs. \\n
- \\n
- Monthly premium: The amount you pay each month for health plan coverage. It may be subsidized based on your income and household size. \\n
- Annual deductible: The amount you must pay before your plan starts covering services. \\n
- Annual maximum out-of-pocket: The total amount you pay in a calendar year (in addition to monthly premiums) for most services covered by your health care plan. \\n
\\n \\n
\\n\\nThe OpenBB Bot is a financial chatbot that allows you to access financial data from Discord or Telegram along with other users. From equity data to crypto, options, darkpool, economy and much more! Now available for free to registered users.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWe know the market conditions haven\u2019t been great for anyone, particularly for investors. Instead of raising prices like trends, we have decided to offer our [OpenBB Bot](https://my.openbb.co/app/bot) individuals tier for free if you are a registered user.\\n\\n## What does this mean\\n\\nRegistered users for OpenBB Bot will see the following changes:\\n\\n- Users were limited to 100 options or dark pools commands per month. This limitation is completely removed.\\n- Users will no longer experience a 10s cooldown which means they can request investment research data sequentially and avoid breaking the conversation due to a delay imposed by the product\\n- Through our soon-to-be-announced new platform, you will be able to fully customize your charting style with up to 5 in chart technical indicators and 2 off charts. This is a big improvement over the 1 in chart and 1 off chart previously available.\\n- The number of custom alerts that the user can set for when certain threshold values are triggered has increased, from 3 to 10.\\n- Users can now set 10 watchlist tickers to pay close attention to and access data regarding them.\\n\\nBelow is a video of what the OpenBB Bot is capable of:\\n\\n\\n\\nThe interactive charts will open up within the [OpenBB Hub](https://my.openbb.co/) and in it you will be able to fully customize the technical analysis indicators that you see on the chart and even the candle chart color theme and type. A demo is shown below,\\n\\n
\\n\\nLike dozens of thousands of investors, join the OpenBB Hub so you can fully leverage the [OpenBB Bot](https://my.openbb.co/app/bot).\\n\\nYou can actually see how many users we have utilizing the bot on a daily basis on our [/open page](https://openbb.co/company/open/bot).\\n\\nWhile others zig, we zag. Here\u2019s the updated pricing:\\n\\n\\n\\nLooking forward to feedback!"},{"id":"free-investment-research-ecosystem-to-consistently-beat-the-market","metadata":{"permalink":"/blog/free-investment-research-ecosystem-to-consistently-beat-the-market","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.md","source":"@site/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.md","title":"Free investment research ecosystem to consistently beat the market","description":"The OpenBB Hub is a comprehensive platform for managing all products, data, subscriptions, and content for users, aiming to empower investors globally with tools previously exclusive to institutions.","date":"2023-05-05T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"OpenBB Bot","permalink":"/blog/tags/open-bb-bot"},{"inline":true,"label":"OpenBB SDK","permalink":"/blog/tags/open-bb-sdk"},{"inline":true,"label":"OpenBB Hub","permalink":"/blog/tags/open-bb-hub"}],"readingTime":5.945,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"free-investment-research-ecosystem-to-consistently-beat-the-market","title":"Free investment research ecosystem to consistently beat the market","date":"2023-05-05T00:00:00.000Z","image":"/blog/2023-05-05-free-investment-research-ecosystem-to-consistently-beat-the-market.png","tags":["OpenBB","Investment Research","OpenBB Terminal","OpenBB Bot","OpenBB SDK","OpenBB Hub"]},"unlisted":false,"prevItem":{"title":"Fully free financial chatbot","permalink":"/blog/fully-free-financial-chatbot"},"nextItem":{"title":"The role of AI and OpenBB in the future of investment research","permalink":"/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research"}},"content":"
\\n \\n
\\n\\nThe OpenBB Hub is a comprehensive platform for managing all products, data, subscriptions, and content for users, aiming to empower investors globally with tools previously exclusive to institutions.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe OpenBB Hub is the new one-stop-shop for managing all products, data, subscriptions, and content for users!\\n\\n## Introduction\\n\\nWhen we started this journey, we always wanted to empower investors across the globe to have access to tools previously only available to institutions.\\n\\nWe started by building the [OpenBB Terminal](https://my.openbb.co/app/terminal) which is an open source investment research platform that users can customize as they see fit and build on top of.\\n\\nIf you haven\u2019t starred the repo, now is a good chance to do so [here](https://github.com/OpenBB-finance/OpenBBTerminal) \u2b50\ufe0f.\\n\\nThen, we wanted to address the social nature of investing. Instead of adding the chat functionality to OpenBB Terminal, we brought investment research data where these communities were already having fruitful discussions (Discord and Telegram). This makes much more sense from a user-convenience standpoint, and that\u2019s how the OpenBB Bot was born. More information [here](https://my.openbb.co/app/bot).\\n\\nAs much customization as the OpenBB Terminal allowed, we didn\u2019t give creators as much freedom as we could have since they would need to download the source code of the terminal in order to leverage our core.\\n\\n\\n\\nBut we we wanted to make this experience as seamless as possible so users could build on top of our foundation. Thus, we repurposed the core of the OpenBB Terminal into an OpenBB SDK that is \u201c_pip installable_\u201d from everywhere \u2014 [OpenBB](https://pypi.org/project/openbb/) . This means that all you need to have access to a universe of investment research data programmatically is python and running pip install openbb within a notebook.\\n\\nThis was a big win since the community reaction was very positive and we are now seeing it adopted by investors, educational courses, and even content creators. So much that we even created a tab to keep track of these on our [/open page](https://openbb.co/open).\\n\\nHowever, we focused too much on the products and didn\u2019t slow down to think about the user experience utilizing multiple OpenBB products. This is where OpenBB Hub comes into play. [OpenBB Hub](https://my.openbb.co/) is the platform we use to interact with our community, push OpenBB content, allow product management, and much more.\\n\\nTL;DR:\\n\\n- Allows to manage your OpenBB Terminal API keys, feature flags and settings. In addition, we allow users to save & share their openbb script routines\\n- Allows access to the OpenBB Terminal installer new versions\\n- Allows access to the OpenBB Bot dashboard \u2014 which allows fully customization from a user perspective. This improves your experience by 10x when using OpenBB Bot on Telegram or Discord.\\n- Allows to sign-up for early waitlist of OpenBB Terminal Pro\\n\\n## OpenBB Hub - OpenBB Terminal\\n\\nSince the beginning users have installed the OpenBB Terminal in multiple desktops due to its free nature. The issue? The API key management was a pain since there was not a way to sync these across different machines. Until now.\\n\\nWith [OpenBB Hub](https://my.openbb.co/) and using that account detail to log in the terminal, this problem gets fixed. Not only that, but users will benefit from default data sources, terminal color schema customization and even .openbb routines being manageable from Hub and more importantly accessible on a terminal instance as long as they login with their user details.\\n\\n\\n\\n## OpenBB Hub - OpenBB Bot\\n\\nToday we are also announcing the OpenBB Bot will be fully free for individuals. All you have to do is to register for the [OpenBB Hub](https://my.openbb.co/).\\n\\nFor users that were already users of our OpenBB Bot, the only change on the platform is pricing and an increase push towards better documentation and more tutorials. This is an initiative that we are taking company-wide to focus on better documentation and more content to fully leverage our suite of products.\\n\\nOpenBB bot is critical to us as we work hard towards making a full ecosystem for investment research. And now you can access this experience for free, and share investment research data with your friends / colleagues.\\n\\n\\n\\n## OpenBB Hub - OpenBB SDK\\n\\nAs the OpenBB SDK is in its core a pip installable package with its [own page on PiPy](https://pypi.org/project/openbb/) there aren\u2019t a lot of functionalities that we can make available in this page. We allow the user to set their API keys similarly to what we do in the Terminal, to improve UX when utilizing the SDK.\\n\\nIn addition, we are going to display open source projects built by the community that leverage our core so that they can serve as an inspiration to you. If you are working on something that uses OpenBB at its core, tag your GitHub repository with \u201copenbb\u201d and we\u2019ll add you to the list of projects that rely on our foundation.\\n\\n\\n\\n## OpenBB Hub - OpenBB Terminal Pro (waitlist)\\n\\nIf all these features weren\u2019t enough, we have decided to open the [OpenBB Terminal Pro WAITLIST](https://my.openbb.co/app/pro/early-access) for users who register on our OpenBB Hub.\\n\\nThe OpenBB Terminal Pro is something that has been months in the works and is yet our most exciting product to date. We have been holding back on it because we believe this will change the way investors think about investing. This time we worked with design partners and had dozens of user interviews from financial professionals to understand their pain points and what role we could fill. So even being able to start creating a waitlist around it is something that the team is very excited about.\\n\\nWe will gradually roll out the OpenBB Terminal Pro to a few users from the waitlist to get early feedback.\\n\\nIf you are one of these, I look forward to onboarding you personally \ud83e\udd1d\\n\\n\\n\\n## Final thoughts\\n\\nAlthough OpenBB Hub is not a product per se, the amount of work that the team put together to make this happen is something nothing short of extraordinary. This was the first project where the entire team (~20 people from engineering, product, design and marketing) had to work together as whole.\\n\\nThe OpenBB Terminal dashboard is completely new, the concept of login had to be invented and needed to function perfectly with the Hub. The SDK page is also new. The OpenBB Bot dashboard already existed, but we made the tier for individuals completely free, so we had to update it to reflect that big pricing change. And finally, we open the OpenBB Terminal Pro waitlist.\\n\\nThe [OpenBB Hub](https://my.openbb.co/) is completely free.\\n\\nAll you have to do is to register so we can know more information about yourself regarding your primary usage for our products (professional, academic, personal) \u2014 this allows us to understand what features to prioritize in the future and improve the quality of our products.\\n\\nIn case you missed the webinar, you can view it below so that you are up-to-date with all the exciting new features that the team has released.\\n\\n
"},{"id":"the-role-of-ai-and-openbb-in-the-future-of-investment-research","metadata":{"permalink":"/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.md","source":"@site/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.md","title":"The role of AI and OpenBB in the future of investment research","description":"How OpenBB can lead the future of finance using AI on top of an open source investment research platform.","date":"2023-04-03T00:00:00.000Z","tags":[{"inline":true,"label":"OpenAI","permalink":"/blog/tags/open-ai"},{"inline":true,"label":"future","permalink":"/blog/tags/future"},{"inline":true,"label":"ChatGPT","permalink":"/blog/tags/chat-gpt"},{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"}],"readingTime":3.655,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-role-of-ai-and-openbb-in-the-future-of-investment-research","title":"The role of AI and OpenBB in the future of investment research","date":"2023-04-03T00:00:00.000Z","image":"/blog/2023-04-03-the-role-of-ai-and-openbb-in-the-future-of-investment-research.png","tags":["OpenAI","future","ChatGPT","Discord"],"description":"How OpenBB can lead the future of finance using AI on top of an open source investment research platform."},"unlisted":false,"prevItem":{"title":"Free investment research ecosystem to consistently beat the market","permalink":"/blog/free-investment-research-ecosystem-to-consistently-beat-the-market"},"nextItem":{"title":"How I Used OpenAI API to improve our product documentation","permalink":"/blog/how-i-used-openai-api-to-improve-our-product-documentation"}},"content":"
\\n \\n
\\n\\nHow OpenBB can lead the future of finance using AI on top of an open source investment research platform.\\n\\nThe open source code is available [here](https://github.com/openbb-finance/OpenBBTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Introduction\\n\\nThis blogpost won\'t speak about what the OpenBB Terminal can offer today. Instead, we are going to share where we think AI can play a role in the future of investment research, and how through an open source platform, we can lead that wave.\\n\\nA lot of this blog is based on the fact that the OpenBB Terminal is an open source investment research platform, and therefore it\'s very relevant to read [our blogpost about why we are open source](/blog/why-the-need-for-an-open-source-investment-research-platform).\\n\\nNote: This blogpost will share several proof-of-concepts that are still within R&D and are not yet ready for production. Also, this blogpost will assume that you are aware of LLMs such as ChatGPT and WhisperAI.\\n\\n## ChatGPT as the interface\\n\\nAn edge that incumbents have is the fact that they have been around for a very long time and spent a lot on educating users about their product. As a result, users are used to their platform. This makes it harder for users to switch to an unknown product, meaning they need to be 10x better than the competition for them to do so.\\n\\nHowever, what if there was no learning curve? What if you could use a product for the first time and know how to access all the information you wanted without spending any time reading the documentation? In essence, the educational incumbent advantage would become obsolete.\\n\\nWith the new LLM advancements, such as ChatGPT. We are not far from this reality. Below is a proof-of-concept of what this could look like:\\n\\n
\\n \\n
\\n\\nIn this blog post, I share how I used the OpenAI API to improve our product documentation. I used ChatGPT to generate more detailed descriptions for our OpenBB Bot Discord commands, making them more understandable for new users.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/improve-documentation-using-openai).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe [documentation](https://docs.openbb.co/bot/reference/discord) of our free OpenBB Bot was pretty simplistic for most of the commands.\\n\\nFor instance, the description for the command `/dp alldp` was: \\"Last 15 Darkpool Trades\\", as seen below:\\n\\n\\n\\nFor more experienced traders, this may be enough. But for new users, these 4 words may not mean much.\\n\\nFor context, this is the output that a user would get if running `/dp alldp` on our [Discord server](https://openbb.co/discord).\\n\\n\\n\\nSo I talked with someone in our team about improving the documentation. Not only for the new users that wanted to utilize our free product but also so that we could train our own LLM on this better dataset.\\n\\nOver the weekend I had the idea: What if I provided ChatGPT with the current description and an example of how to use the command and asked it to provide a more detailed description?\\n\\nSo the next step was to try whether ChatGPT would indeed improve the current documentation.\\n\\nAfter a bit of prompt tweaking, I got a much better description than the one we currently had. See below:\\n\\n\\n\\nThe next step was rather straightforward. I created a script that iterated [through all our OpenBB Bot Discord documentation](https://github.com/OpenBB-finance/OpenBBTerminal) files and updated the old description with a more detailed one.\\n\\nThis is the template prompt that I used:\\n\\n> _Context: You are a developer writing a detailed documentation for a function that allows the user to retrieve desc utilizing the command example how would you explain what this command does in a single paragraph\u201d_\\n\\nWhere **desc** and **example** corresponds to the current description and example that each of our commands have, respectively.\\n\\nThe results can be seen below (done on [this PR](https://github.com/OpenBB-finance/OpenBBTerminal/pull/4657)),\\n\\n\\n\\nAs usual, I open source the script [here](https://github.com/DidierRLopes/improve-documentation-using-openai).\\n\\nThe funny thing is that I used an LLM output to improve our documentation. And we may use this data to train our own LLM.\\n\\nLLM-ception?"},{"id":"how-to-get-hired-by-an-exciting-tech-startup-in-2023","metadata":{"permalink":"/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.md","source":"@site/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.md","title":"How to get hired by an exciting tech startup in 2023","description":"The future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today.","date":"2023-01-22T00:00:00.000Z","tags":[{"inline":true,"label":"Career Advice","permalink":"/blog/tags/career-advice"},{"inline":true,"label":"Tech Startups","permalink":"/blog/tags/tech-startups"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Job Hunting","permalink":"/blog/tags/job-hunting"},{"inline":true,"label":"Software Engineering","permalink":"/blog/tags/software-engineering"}],"readingTime":5.425,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-get-hired-by-an-exciting-tech-startup-in-2023","title":"How to get hired by an exciting tech startup in 2023","date":"2023-01-22T00:00:00.000Z","image":"/blog/2023-01-22-how-to-get-hired-by-an-exciting-tech-startup-in-2023.png","tags":["Career Advice","Tech Startups","Open Source","Job Hunting","Software Engineering"],"description":"The future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today."},"unlisted":false,"prevItem":{"title":"How I Used OpenAI API to improve our product documentation","permalink":"/blog/how-i-used-openai-api-to-improve-our-product-documentation"},"nextItem":{"title":"Financial chat bots are underrated, and here\u2019s why.","permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why"}},"content":"
\\n \\n
\\n\\nThe future is a strange place. We\u2019re not entirely sure what it will look like, but we do know that it will be shaped by the choices we make today. And while I can\u2019t tell you exactly how to get a job in 2023, I can help you set yourself up for success by showing you some of the best ways to build your career today.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEveryone is doing the same hacker tests. Being good at interviews will no longer suffice to get a job in top tech company. Conventional CVs are too boring. Recruiters may like what they read, but this doesn\u2019t make them think any further about a person and think \u201cwow, we really need someone like them\u201d.\\n\\nUltimately, a CV cannot demonstrate creativity and in my opinion, to be a top engineer you need to be creative. Often there isn\u2019t an easy straightforward solution and being creative is what distinguishes top tier engineers from medium. I wrote a post about this [here](/blog/stop-doing-your-cv-in-word-or-latex).\\n\\nBelow I will let you know my views on what I would do to get a job at an exciting tech startup.\\n\\n## Work on open source projects\\n\\nOpen source is a great way to build your skills and get your name out there. It\u2019s also a great way to make connections with other developers, which can lead to referrals and job opportunities. If you want to show that you\u2019re a good engineer, open source is an excellent opportunity. This is because it allows you to demonstrate your problem-solving abilities, while also improving the codebase of a project that is potentially used by thousands of users \u2014 and because the project is open source, it never dies.\\n\\n**But which open source projects should you choose?**\\n\\nI\u2019d say that there are two routes that you can take here. You can select the project based on your **own use case** or you can **be strategic** about it.\\n\\n### Own use case\\n\\nDon\u2019t overthink it. The world of software is built on top of open source. If it weren\u2019t for open source, we would be living in the year 2000 or less. This means that your favorite apps are relying on open source projects, which you can be a part of!\\n\\nThis means that you can:\\n\\n- Contribute to an open source library that is used by a project that you like. E.g. someone from our team is a [cpython](https://github.com/python/cpython) contributor.\\n- Contribute to a product that you use that is Open Source. The advantage here is that you are able to literally customize the product that you are using.\\n\\nWith Red Hat in the 90s this open source movement is starting to be a very hot topic. [Joseph Jacks](https://twitter.com/JosephJacks_) from OSS Capital is one of the best investors (if not the best) in this space. The chart below that he put together illustrates well the growth of open source (shared in [this tweet](https://twitter.com/JosephJacks_/status/1494840009882361859?s=20))\\n\\n\\n\\n### Strategic\\n\\nIf you\u2019re reading this, there\u2019s a good chance that you want to make a positive impact on the future of technology. If so, it can be helpful to consider how your work will affect the lives of others. Take some time and think about what kind of role you would like to play in shaping those futures \u2014 are you someone who wants to improve people\u2019s physical well-being through health innovations? Or maybe achieve more efficient energy use through new technologies? This will help determine which companies or projects might be best suited for any given career path.\\n\\nOnce you figure out what motivates you, select an industry where you wish to find a job.\\n\\nThen there are multiple paths that you can take:\\n\\n- Look into the signals provided by top venture capital firms in that selected industry. I.e. see what open source companies are being backed in that space.\\n- Look into the developer engagement around the open source projects in that industry. You can not only use GitHub stars and forks, but you can use tools such as [https://analyzemyrepo.com](https://analyzemyrepo.com/analyze/OpenBB-finance/OpenBBTerminal) or [https://ossinsight.io/](https://ossinsight.io/)\\n- Cold email VCs to ask them about which open source products they are excited about. I say VCs because often their job is to find these startups early, so usually they have more recent information. But talking with devs or listening to people that you respect in the industry is equally valid.\\n\\nNote: By being an early contributor of a promising open source startup, you can become a core maintainer of a project and even make it to the founding team. This is how I met James, OpenBB\u2019s co-founder. He was an active developer in my own open source project, and I invited him to be part of the main maintainers of the project. When we built a company, he became a founding member.\\n\\n## Develop your own open source project\\n\\nI strongly believe that being able to successfully build your own open source project is severely underrated. There are so many components that you need to get right from so many departments that it shows a lot about your strengths as an individual and a preview of the value you could add to the team.\\n\\nYou may think that the only thing that you are demonstrating is your ability to write high-quality code since it will be open to the public. Well that\u2019s wrong. Here is a non-exhaustive list of skills that you show off\\n\\n- Solution to a real-world problem\\n- Design around the product\\n- User experience\\n- How you prioritize task and how fast you can ship high-quality code\\n- Interaction with others\\n- Marketing\\n- Listening to feedback from users\\n\\nThis is what I did with OpenBB Terminal: [https://github.com/OpenBB-finance/OpenBBTerminal](https://github.com/OpenBB-finance/OpenBBTerminal) and it has single handedly changed my life.\\n\\n## Conclusion\\n\\nIf you\u2019re looking for a job in 2023, the best thing you can do is to contribute to/develop open source projects.\\n\\nYou should be aware that you can also add value to an open source project by reporting bugs. You can even do more than just report a bug, but suggest a solution or workaround for the problem \u2014 this shows that not only are you paying attention to what\u2019s going on around you, but also that you have some ideas about how things could be improved \u2014 a combination that any hiring manager would love!\\n\\nI hope you found this post insightful.\\n\\nAny feedback is welcome."},{"id":"financial-chat-bots-are-underrated-and-heres-why","metadata":{"permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.md","source":"@site/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.md","title":"Financial chat bots are underrated, and here\u2019s why.","description":"In this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular.","date":"2023-01-05T00:00:00.000Z","tags":[{"inline":true,"label":"chatbots","permalink":"/blog/tags/chatbots"},{"inline":true,"label":"finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"OptionsFamBot","permalink":"/blog/tags/options-fam-bot"}],"readingTime":4.12,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"financial-chat-bots-are-underrated-and-heres-why","title":"Financial chat bots are underrated, and here\u2019s why.","date":"2023-01-05T00:00:00.000Z","image":"/blog/2023-01-05-financial-chat-bots-are-underrated-and-heres-why.png","tags":["chatbots","finance","AI","Discord","OpenBB","OptionsFamBot"],"description":"In this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular."},"unlisted":false,"prevItem":{"title":"How to get hired by an exciting tech startup in 2023","permalink":"/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023"},"nextItem":{"title":"Firing sucks. How to avoid doing so by hiring A players.","permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players"}},"content":"
\\n \\n
\\n\\nIn this blog post, we discuss the underrated potential of financial chat bots, our collaboration with OptionsFamBot, and why chat bots are becoming increasingly popular.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAt OpenBB, earlier this year we [joined forces with OptionsFamBot](https://openbb.co/products/bot). This was a bot that had a reach of over 1 Million users on Discord.\\n\\nToday, [OpenBB Bot](https://openbb.co/products/bot) is one of our more powerful products and I still think a lot of people are sleeping on it.\\n\\n### What is a chatting bot platform?\\n\\nAccording to [ChatGPT](https://chat.openai.com/chat):\\n\\n> _\u201cA chatbot platform is a software service or tool that enables the creation, management, and deployment of chatbots. These platforms typically provide a variety of tools and features for building, testing, and deploying chatbots, as well as options for integrating chatbots with other systems or services. Some chatbot platforms are designed to support the development of chatbots for specific industries or use cases, such as customer service, e-commerce, or marketing. Others are more general purpose, and can be used to build chatbots for a wide range of applications.\u201d_\\n\\n
\\n\\n### Why are chat bots not engaging?\\n\\nI believe that one of the reasons for this is because people usually associate chatbots with customer service or marketing. Not as a finalized product but as a feature.\\n\\nIf I ask ChatGPT about this, the main reasons are: Lack of personalized conversation, limited capabilities, poor design and high error rate.\\n\\n\\n\\nBut wait.. ChatGPT is **LITERALLY** a chat bot. Everything happens through a chat interface, which shows that you can build a successful product as a bot, as long as it adds enough value to the user.\\n\\nOne could argue that ChatGPT is not done in an established chatting platform, and that is **partially true**. The reason I say partially is because ChatGPT has an API, so developers can use it to develop their own chatting bots and deploy it in whatever chatting app they are interested in.\\n\\n## Examples of good chatting platforms\\n\\nI believe that Discord is in the forefront here due to: Free, easy to use, allows customizing servers with roles/channels/permissions, high-quality voice chat, strong communities.\\n\\nA testament to this is the fact that [midjourney](https://midjourney.com/) has built a successful chat bot that generates images from text prompts using AI, **SOLELY** relying on Discord. If you go into their website, the button \u201c**Join the Beta**\u201d takes you to their Discord server which has over **7 million users**!\\n\\nAs far as I know, this is the only example of a company that distributes their product solely through a chatting platform in a successful way.\\n\\n\\n\\n## Why are chat bots getting more popular?\\n\\nIn my opinion, there are a few factors why chat bots are becoming more popular:\\n\\n### Interactivity\\n\\nThe bots are becoming more interactive, almost working like an application within a chatting platform.\\n\\n\\n\\n### Speed\\n\\nThe speed of interaction is increasing over time, making the experience more seamless.\\n\\n\\n\\n### Customization\\n\\nThe level of customization allowed for these bots keeps on increasing.\\n\\n\\n\\n### Automation\\n\\nYou are starting to be able to create automated workflows. Not only for you, but for entire communities.\\n\\n\\n\\n### Notifications\\n\\nIt has notification features that can ping you similarly as if a friend sent you a message.\\n\\n\\n\\n### Monetization\\n\\nYou are going to start to be able to monetize products through it.\\n\\n\\n\\n### Community\\n\\nYou can use it within a server with friends/colleagues, and unlock a better user experience.\\n\\n\\n\\n### Standardization\\n\\nThe product can work similarly on multiple chatting platforms. By keeping the same method of interaction / commands, the user is allowed to pick their favourite chatting platform or even use it in more than 1.\\n\\n\\n\\n### Accessibility\\n\\nThese chatting platforms are developed for all devices and operating systems, making it a very powerful distribution system.\\n\\n\\n\\n## Why Finance?\\n\\nI\u2019ve spoke with over 100 people in the financial world in 2022. Over 50 are Bloomberg users. From those, 90% agree that their chatting feature is the most attractive feature \u2014 some of them going further and saying that that is the reason why they pay for it.\\n\\nBut what if you didn\u2019t need to pay $26 k / year for such feature. What if you could pay to have access to servers with big names in the industry? Or what if you could create your own servers? What if while you were talking with Cathie Wood about ARK performance, you could also access financial data from ARK to back up your arguments? All this while not leaving the chat.\\n\\nThis is the reason why I believe that financial chatting bots will become popular in 2023. And [OpenBB Bot](https://openbb.co/products/bot) will be leading that wave.\\n\\nTry it out for free on [OpenBB Discord server](https://openbb.co/discord) by using a command such as `/chart TSLA` and let me know what you think."},{"id":"firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","metadata":{"permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.md","source":"@site/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.md","title":"Firing sucks. How to avoid doing so by hiring A players.","description":"Firing is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment.","date":"2023-01-02T00:00:00.000Z","tags":[{"inline":true,"label":"Hiring","permalink":"/blog/tags/hiring"},{"inline":true,"label":"Management","permalink":"/blog/tags/management"},{"inline":true,"label":"A Players","permalink":"/blog/tags/a-players"},{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Career Advice","permalink":"/blog/tags/career-advice"}],"readingTime":18.91,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"firing-sucks-how-to-avoid-doing-so-by-hiring-a-players","title":"Firing sucks. How to avoid doing so by hiring A players.","date":"2023-01-02T00:00:00.000Z","image":"/blog/2023-01-02-firing-sucks-how-to-avoid-doing-so-by-hiring-a-players.png","tags":["Hiring","Management","A Players","OpenBB","Career Advice"],"description":"Firing is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment."},"unlisted":false,"prevItem":{"title":"Financial chat bots are underrated, and here\u2019s why.","permalink":"/blog/financial-chat-bots-are-underrated-and-heres-why"},"nextItem":{"title":"How ChatGPT allowed me to leverage Twitter API 10x faster","permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster"}},"content":"
\\n \\n
\\n\\nFiring is tough. This blogpost discusses how to avoid it by hiring A players, improving the hiring process, and understanding the importance of a scorecard in recruitment.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn 2022, [OpenBB](http://openbb.co/) grew to 20 people. But amongst all of our hiring, we also had to let some people go.\\n\\nBefore 2022, I had never fired anyone in my life but in my new role, I had to learn how to do it. If you\u2019re a manager, you know that this is the hardest part of the job.\\n\\nHaving that said, I wanted to use my Christmas holidays to understand how we can avoid letting people go. For this, I needed to start from the beginning and improve our overall hiring process.\\n\\nThis blogpost will be highly based on the book **\u201cWho: The A Method for Hiring\u201d by Geoff Smart and Randy Street**, which I highly recommend.\\n\\n## A method for hiring\\n\\nWhat is an A player? _A candidate who has at least a 90 percent chance of achieving a set of outcomes that only the top 10 percent of possible candidates could achieve.\\n\\nIn this post, I will go over the steps to get an A team.\\n\\n\\n\\n## Scorecard\\n\\nThis is a document that describes the mission for the position, outcomes that must be accomplished, and competencies that fit with both the company culture and the role.\\n\\nThis is an example of what a scorecard should look like:\\n\\n\\n\\nLet\u2019s go through each of the sections in this document.\\n\\n### Mission\\n\\nThe mission is an executive summary of the job\u2019s core purpose. It boils the job down to its essence so everybody understands why you need to hire someone in this role.\\n\\nThe book talks about how you should avoid hiring a generalist. In my opinion, it depends on the stage of the company. At OpenBB, we are able to ship fast with a small team because we have a lot of generalists that are A players. However, finding a generalist A player is a much harder task than finding an A player specialist. Here, we benefit from having an open source project, since we get to build with candidates before we hire them.\\n\\n**How to:** _Develop a short statement of one to five sentences that describe why a role exists._\\n\\n### Outcomes\\n\\nDescribes what a person needs to accomplish in a role.\\n\\n> _\u201cWhile typical job descriptions break down because they focus on activities, or a list of things a person will be doing, scorecards succeed because they focus on outcomes, or what a person must get done.\u201d_\\n\\n
\\n\\n**How to:** _Develop 3 to 8 specific objective outcomes that a person must accomplish to achieve an A performance, ranked by order of importance._\\n\\n### Competencies\\n\\nDefine how you expect a new hire to operate in the fulfilment of the job and how they can achieve their objectives. What competencies really count?\\n\\n#### Ensure behavioural fit\\n\\nCritical competencies for A players are: Efficiency, honesty/integrity, organization, aggressiveness, follow-through, intelligence, analytical skills, attention to detail, persistence, proactivity.\\n\\nOthers may include: Ability to hire A players, ability to develop people, flexibility/adaptability, calm under pressure, strategic thinking/visioning, creativity/innovation, enthusiasm, work ethic, high standards, listening skills, openness. to criticism and ideas, communications, team work and persuasion.\\n\\n#### Ensure organizational fit\\n\\nEvaluating cultural fit begins with evaluating your company\u2019s values against the ones of the candidate.\\n\\nRecently, at OpenBB, I asked everyone to share with me a list of values that we currently had and they were proud of, and/or values that they would like to use instead. In a startup, where the pace is incredibly fast and the team is in constant change, I strongly believe values change over time. So I looked at everyone\u2019s inputs, and summarized them into the following OpenBB values: **Autonomy and Ownership, Innovation and Excellence, Transparent and Trustworthy, Diversity and Inclusion, Purpose and Passion, User Focused and Community Oriented.**\\n\\n**How to:** _Identify as many role-based competencies that you think are appropriate to describe the behaviors that someone must demonstrate to achieve the outcomes. Next, identify 5 to 8 competencies that describe your culture and place those on every scorecard._\\n\\n### From scorecard to strategy\\nThe beauty of a document like this is that they become the blueprint that links the theory of strategy to the reality of execution. They translate your business plans into role-by-role outcomes, create alignment among your team, unify your culture and ensure people understand your expectations.\\n\\nIn addition, they allow you to monitor employee progress over time in your annual review system and to rate your team as part of their talent review progress.\\n\\n**How to:** _Pressure-test your scorecard by comparing it with the business plan and scorecards of the people who will interface with the role. Ensure that there is consistency and alignment. Then share the scorecard with relevant parties, including peers and recruiters._\\n\\n## Source\\n\\nSystematic sourcing before you have slots to fill ensures you have high-quality candidates waiting when you need them.\\n\\n### Referrals from your professional and personal networks\\n\\nCreate a list of the ten most talented people you know and commit to speaking with at least one of them per week for the next ten weeks. At the end of each conversation ask \u201cWho are the most talented people you know?\u201d. Continue to build your list and continue to talk with at least one person per week. \u201c_Of all the ways to source candidates, the number one method is to ask for referrals from your personal and professional networks_\u201d.\\n\\n### Referrals from your employees\\n\\nAdd sourcing as an outcome on every scorecard for your team. Encourage employees to ask people in their networks. Offer a referral bonus. In-house referrals often provide better-targeted sourcing, this is because employees already know our needs and culture.\\n\\n### Deputizing friends of the firm\\n\\nConsider offering a referral bounty to select friends of the firm. It could be as inexpensive as merchandise or as expensive as a significant cash bonus. When talking with someone new at a party or a VC, always ask \u201c_who do you know who might be a good fit for my company?_\u201d\\n\\n### Sourcing system\\n\\nCreate a system that (1) captures the names and the contact information on everybody you source and (2) schedules weekly time on your calendar to follow up. Try to spend 30 minute every week sending messages or having calls with candidates from this database of A players.\\n\\n### Hiring external recruiters or hiring recruiting researchers\\n\\nThe book speaks about both, but from my experience of having an open company with an exciting mission that builds in public, these have not been relevant to us yet.\\n\\n## Select\\n\\nCreate a series of structured interviews which build on each other so you can rate your scorecard.\\n\\n### Screening Interview\\n\\nShort, phone-based interview designed to clear out B and C players from your roster of candidates.\\n\\n1. **What are your career goals?** If no goals echo your own website goals, screen them out. Ideally candidate will speak with passion and energy about their goals which are aligned with the role.\\n\\n2. **What are you really good at professionally?** Make sure that with the list of strengths, there are always examples to backup the claim. Ensure that those strengths are relevant to the competencies required in the scorecard, if not, screen them out.\\n\\n3. **What are you not good at or not interested in doing professionally?** Ignore strengths disguised as weakness. Ask again \u201cwhat are you really not good at or not interested in doing?\u201d, talented people will catch the hint. If you\u2019re still struggling to get a proper answer, put the fear of a reference check into the person \u2014 \u201cif you advance to the next step in our process, we will ask for your help in setting up some references. (\u2026) What would these references say are something things you are not good at or not interested in?\u201d\\n\\n4. **Who were your last five bosses, and what would they each rate your performance on a scale of 1\u201310 WHEN we talk to them?** The word \u2018when\u2019 is the key to unlock the truth. A rating of 7 is neutral, we are looking for 8 and above. After the rating answer always press for details.\\n\\n
\\n\\nIf you are happy with the interview so far, conclude the call by offering the candidate an opportunity to ask questions. Otherwise just thank them for their time.\\n\\n**Tips:**\\n\\n- Always compare the person\u2019s strengths with the ones on the scorecard.\\n- When in doubt, there\u2019s no doubt. You need to have the feeling that you have found the one.\\n- Get curious: What, How, Tell me more. Keep using this framework until you are clear about what the person is really saying.\\n- Hit the gong fast. If an answer automatically rules out a candidate, just end up the interview earlier and use your precious time to focus on A players.\\n\\n### Who to Interview\\n\\nChronological walk-through of a person\u2019s career.\\n\\nYou can begin by asking about the highs and lows of a person\u2019s educational experience to gain insight into their background. After this, ask them 5 simple questions for each job they had in the past.\\n\\n#### What were you hired to do?\\n\\nYou are trying to discover what their scorecard might have been if they had one for that role. Ask them \u201chow was your success measured in the role? What was the mission and key outcomes? What competencies mattered?\u201d.\\n\\n#### What accomplishments are you most proud of?\\n\\nIdeally, candidates will tell you about accomplishments that match the job outcomes they just described to you. Even better if they match the ones of the scorecard for the position you are trying to fill.\\n\\nNote: _A players tend to talk about outcomes linked to expectations, B and C players talk generally about events, people they met, or aspects of the job they liked without ever getting into results._\\n\\n#### What were some of the low points during that job?\\n\\nPeople can be hesitant to share their lows at first. Keep reframing the question over and over until the candidate gets the message. E.g. \u201c_What went really wrong? Biggest mistake? done differently? parts you didn\u2019t like? peers stronger than you?_\u201d\\n\\n#### Who were the people you worked with?\\n\\n- **What was your boss\u2019s name and how do you spell that?**\\n\\nForcing candidates to spell the name out no matter how common it might be sends a powerful message: you are going to call, so they should tell the truth. This is referred as the \u201cthreat of reference check (TORC)\u201d.\\n\\n- **What was it like working with them?**\\n\\nIdeally, you expect high praise for their bosses and how they received mentoring and coaching from them over the years. A neutral answer will sound somewhat more reserved \u2014 not positive nor negative.\\n\\n- **What WILL they tell me about your biggest strengths and areas to improve?**\\n\\nUse \u201cwill\u201d instead of \u201cwould\u201d so candidates know you mean business, and are therefore, more likely to tell you the truth since you will learn it from reference calls anyways. Dig in as much as you can.\\n\\n- **How would you rate the team you inherited on an A, B, C scale? What changes did you make? Did you hire anybody? Fire anybody? How would you rate the team when you left it on A,B,C scale.**\\n\\nThis is applicable to managers. And allows you to understand how they approach building a strong team. Do they accept the hand they have been dealt with or do they make changes to make a better hand? What changes do they make? How long does it take?\\n\\nApply TORC here too: _\u201cWhen we speak with team members of your team, what will they say were your biggest strengths and weaknesses as manager?\u201d_\\n\\n#### Why did you leave that job?\\n\\nWas the candidate promoted, recruited or fired from each job? How did they feel about it? How did their boss react to the news? E.g. A players are highly valued by their bosses.\\n\\nGet curious. Find out why and stick with it until you have a clear picture of what actually happened.\\n\\n**Conducting an effective who interview**\\n\\n- The hiring manager should conduct this interview. They own the hire, and are the ones who will suffer the consequences of making a mistake. Their career and job happiness depend on finding A players.\\n- Conduct an interview with a colleague (e.g. someone from HR, another manager or member of your team), this allows you to focus on questions and someone else to take notes.\\n- Kick off the interview by setting expectations, e.g. _\u201cWe are going to walk through each job you have held, for each job I am going to ask you five core questions. At the end we will discuss your career goals and aspirations and you will have a chance to ask me questions. If we mutually decide to continue, we will conduct reference calls to complete the process\u201d._\\n\\n**Master tactics**\\n\\n1. **Interrupting.** You have to interrupt the candidate, there is no avoiding it. At least once every 3/4 minutes. Smile broadly, match their enthusiasm level, and use reflective listening to get them to stop talking without demoralizing them.\\n2. **The three P\u2019s.** This helps you understand how valuable an accomplishment was in any context. (1) How did the performance compare to the previous year\u2019s performance; (2) How did your performance compare to the plan?; (3) How did your performance compare to that of peers?\\n3. **Push versus Pull.** People who perform are generally pulled to greater opportunities. People who perform poorly are often pushed out of their jobs.\\n4. **Painting a picture.** You\u2019ll only understand what a candidate is saying when you can literally see a picture of it in your mind. Always try to put yourself in their shoes.\\n5. **Stopping at the Stop signs.** Look for shifts in body language and other inconsistencies. \u201cWe did great in that role\u201d while shifting in their chair, looking down and covering their mouth may be a stop sign. When that happens, get curious and understand how \u201cgreat\u201d they actually did. What was actually their contribution?\\n\\n### Focused Interview\\n\\nGetting to know more. This is NOT another Who interview. It provides the chance to invite other team member to get their opinion, but the script should be followed. Think of this interview as the \u201codds enhancer\u201d to truly focus on the outcomes and/or competencies on the scorecard.\\n\\n1. The purpose of this interview is to talk about [specific outcome or competency]\\n2. What are your biggest accomplishments in this area during your career\\n3. What are your insights into your biggest mistakes and lessons learned in this area?\\n\\n
\\n\\nDon\u2019t be scared to use the \u201cWhat? How? Tell me more\u201d framework until you understand what the person did and how they did it.\\n\\nFeel free to have multiple shorter focused interviews to understand particular outcome/competencies.\\n\\n**Double-check the cultural fit.** Final gauge on the cultural fit \u2014 **critical!** Include competencies and outcomes that go beyond the specifics of the job to embrace the larger values of your company.\\n\\n### Reference Interview\\n\\nTesting what you learned. Don\u2019t skip the references!\\n\\n1. Pick the right references. Review your notes from the Who interview and pick the bosses, peers, and subordinates with whom you would like to speak. Don\u2019t just use the reference list the candidate gives you.\\n2. Ask the candidate to contact the references to set up the calls. Some companies have a policy that prevents employees from serving as references, so you can increase your chances of talking with a reference if the candidate sets this up.\\n3. Conduct the right number of reference interviews. The book recommends 3 past bosses, 2 peers/customers and 2 subordinates.\\n\\n
\\n\\n**Reference interview guide:**\\n\\n1. **In what context did you work with the person?** Conversation starter and memory jogger.\\n2. **What were the person\u2019s biggest strengths?** Ask for multiple examples to put strengths and development areas into context. Don\u2019t forget to get curious by using \u201cWhat? How? Tell me more\u201d framework to clarify responses.\\n3. **What were the person\u2019s biggest areas for improvement back then?** The wording \u2018back then\u2019 liberates the reference to talk about weaknesses that existed in the past. \u201cIn truth, we believe, people don\u2019t change that much. People aren\u2019t mutual funds. Past performance really is an indicator of future performance.\u201d\\n4. **How would you rate their overall performance in that job on a 1\u201310 scale?** What about their performance causes you to give that rating? Remember that 6 is really a 2. How does this rating compare with what the candidate said in advance? Wide discrepancy is alarming.\\n5. **The person mentioned that they struggled with ____ on that job. Can you talk more about that?** Test something the candidate told you by framing it as a question for the reference. E.g. \u201cthe person mentioned that you MIGHT SAY he was disorganized. Can you tell me more about that?\u201d the wording is again very important as \u2018might say\u2019 suggests to the reference that they have permission to talk about the subject because the candidate raised it.\\n\\n
\\n\\nThese questions follow the same pattern as the other interviews. This makes it very easy to merge what you hear with what you have already learned about a candidate.\\n\\n**Tips:**\\n\\n- **Avoid accepting a candidate\u2019s reference list at face value.** E.g. either use your own network for gathering objective unbiased data or try to reach out to subordinates or people two levels below who interacted with the candidate to get a more honest answer.\\n- **Hearing or understanding the code for risky candidates.** Be able to read between lines. People don\u2019t like to give negative reference, so your best defense is to pay close attention to what people say and how they say it. Examples of bad signs: If they just confirm dates of employment, um\u2019s and er\u2019s is hesitation, absence of enthusiasm (faint praise).\\n\\n### Decide who to hire\\n\\n**Skill-Will Bull\u2019s Eye**\\n\\nDoes somebody\u2019s skill (what they can do) and will (what they want to do) match your scorecard? This is a person\u2019s skill-will profile.\\n\\n\\n\\nYou should have plenty of data at this stage to make this assessment.\\n\\n- **Skill has to do with a candidate\u2019s ability to achieve the individual outcomes on your scorecard.** If you believe a candidate has a 90% or better chance to achieve a certain outcome based on the data gathered, rate them an A, otherwise a B or a C. Repeat for each outcome.\\n- **Will has to do with the motivations and competencies a candidate brings to the table.** For each competency, does the data suggest there is a 90% or better chance that the candidate will display that competency? If so rate them an A, otherwise a B or C. Repeat for each competency.\\n\\nAn A player is someone whose skill and will match your scorecard. Anything less is a B or C, no matter the experience or seeming talent level.\\n\\n**Red Flags: When to dive beneath the surface**\\n\\nThese flags may not be deal killers, but they are likely to signal that there is something worth exploring beneath the surface:\\n\\n- Does not mention past failures\\n- Exaggerates their answers\\n- Takes credit for the work of others\\n- Speaks poorly of past bosses\\n- Cannot explain job moves\\n- People most important to the candidate are unsupportive of a change\\n- For managerial hires, never had to hire or fire anybody\\n- Seems more interested in compensation and benefits than in the job itself\\n- Tries too hard to look like an expert\\n- Self-absorbed\\n\\nMore behavioral warning signs:\\n\\n- Winning too much\\n- Adding too much value\\n- Starting a sentence with \u2018no\u2019, \u2018but\u2019, or \u2018however\u2019\\n- Telling the world how smart we are\\n- Making destructive comments about previous colleagues\\n- Blaming others\\n- Making excuses\\n- The excessive need to \u2018be me\u2019\\n\\n**How to decide:**\\n\\n1. Take out your scorecards that you have completed on each candidate\\n2. Make sure you have rated all of the candidates on the scorecard. If you have not given each candidate an overall A, B or C grade, do so now. Make any updates you need to based on the reference interviews. Look at the data, consider the opinions and observations of the interview team, and give a final grade.\\n3. If you have no A\u2019s, then restart your process and the second step: source.\\n4. If you have one A, decide to hire that person.\\n5. If you have multiple A\u2019s, then rank them and decide to hire the best A among them.\\n\\n## Sell\\n\\nOnce candidates pass the selection, persuade them to join. The key to successfully selling your candidate to your company is putting yourself in their shoes.\\n\\n### Five F\u2019s of selling\\n\\nThere are 5 areas that candidates tend to care about, make sure to address each of these 5 areas until you get the person onboard.\\n\\n1. **Selling Fit:** This ties together the company\u2019s vision, needs and culture with the candidate\u2019s goals, strengths and values.\\n2. **Selling Family:** Takes into account the broader trauma of changing jobs.\\n3. **Selling Freedom:** The autonomy the candidate will have to make their own decisions.\\n4. **Selling Fortune:** Reflects the stability of your company and the overall financial upside.\\n5. **Selling Fun:** Describes the work environment and personal relationships the candidate will make.\\n\\n### Five waves of selling\\n\\nSelling should be something that happens throughout the entire hiring process. In particular, there are five distinct phases that merit increased selling effort:\\n\\n1. When you source\\n2. When you interview\\n3. The time between your offer and the candidate acceptance\\n4. The time between the candidate\u2019s acceptance and their first day\\n5. The new hire\u2019s first one hundred days on the job\\n\\n### Persistent pays off\\n\\nOnce you have identified the right candidate, you must be persistent and do whatever you can to sign the deal.\\n\\n### How to: sell A Players\\n\\n1. Identify which of the five F\u2019s really matter to the candidate.\\n2. Create and execute a plan to address the relevant F\u2019s during the five waves of selling.\\n3. Be persistent. Don\u2019t give up until you have your A player on board.\\n\\n## Conclusion\\n\\nIn a more simplistic image, this is what the A method boils down too.\\n\\n\\n\\nI really enjoyed reading this book and I am taking a lot of these learnings to improve the hiring processes at OpenBB."},{"id":"how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","metadata":{"permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.md","source":"@site/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.md","title":"How ChatGPT allowed me to leverage Twitter API 10x faster","description":"Leveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates.","date":"2022-12-11T00:00:00.000Z","tags":[{"inline":true,"label":"ChatGPT","permalink":"/blog/tags/chat-gpt"},{"inline":true,"label":"Twitter API","permalink":"/blog/tags/twitter-api"},{"inline":true,"label":"Tweepy","permalink":"/blog/tags/tweepy"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"}],"readingTime":2.4,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster","title":"How ChatGPT allowed me to leverage Twitter API 10x faster","date":"2022-12-11T00:00:00.000Z","image":"/blog/2022-12-11-how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster.png","tags":["ChatGPT","Twitter API","Tweepy","Python","Programming"],"description":"Leveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates."},"unlisted":false,"prevItem":{"title":"Firing sucks. How to avoid doing so by hiring A players.","permalink":"/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players"},"nextItem":{"title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla"}},"content":"
\\n \\n
\\n\\nLeveraging the power of ChatGPT to interact with Twitter API for real-time financial news updates.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nFor a while now, users have been asking for adding real-time financial news on [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\nSince OpenBB Terminal is a command line interface for the world\u2019s financial data, and there is no threading going on \u2014 there was never a very straightforward way to do this.\\n\\n**Until today.**\\n\\nAfter recalling [this tweet](https://twitter.com/elonmusk/status/1591121142961799168?s=20&t=j-cjTu-XA9SNcY8PBrbUnQ) from Elon earlier in November, I realized that I\u2019ve been using Twitter for news substantially more than MSM.\\n\\n\\n\\nSo, my next train of thought was; What if I was able to somehow display the latest tweets from Twitter accounts that I trust. In particular, accounts that have up-to-date information and usually mention the words \u201cJUST IN\u201d or \u201cBREAKING\u201d. E.g. [@WatcherGuru](https://twitter.com/WatcherGuru) or [@unusual_whales](https://twitter.com/unusual_whales).\\n\\nBy doing this, I could then use the bottom of the OpenBB Terminal to highlight the news. An example of this is below:\\n\\n\\n\\n## Coding and ChatGPT\\n\\nThe next step for me was to implement the code!\\n\\nFirst, I needed to understand how I could have access to the last tweet of a specific user account. I already had a Twitter API account created, which meant I already had the key, token and secrets, therefore, I just needed to read documentation to understand how to use the Twitter API. Hence, I started reading [Twitter\u2019s developer documentation](https://developer.twitter.com/en/docs/twitter-api/tweets/search/api-reference/get-tweets-search-recent).\\n\\nThe day before I had been playing around with ChatGPT. And like everyone else, I was very impressed. One of the things that surprised me the most was how good it was at outputting working code with an explanation along the lines.\\n\\nSo, while I was reading the documentation, I was thinking \u201cI wish there was a way for me to just be able to get the last N tweets of an account without needing to dig in the developer documentation\u201d. Could ChatGPT be the answer?\\n\\nSo I tried\u2026\\n\\n\\n\\nThis was already amazing. But I\u2019m lazy and didn\u2019t want to copy all the cells individually to put it into a Jupyter notebook, so asked ChatGPT to provide the code output as a single block. I wasn\u2019t convinced it was going to work. **But it did**.\\n\\n\\n\\n\u2026 it just worked. \ud83e\udd2f\\n\\nAfter that, I needed the timestamp associated with the tweet, to see how old it was. As usual, I started looking into [Tweepy documentation](https://docs.tweepy.org/en/latest/authentication.html#twitter-api-v2).\\n\\n**Ups, what was I doing again?**\\n\\nAfter a couple of seconds, I went onto ChatGPT and asked how I could get the timestamp of a tweet using Tweepy library.\\n\\n**And \ud83e\ude84, it worked again!!!**\\n\\n\\n\\nOne thing that is for sure: ChatGPT is going to truly disrupt many industries. And I will be here for it.\\n\\nPS: The PR with this addition is in development [here](https://github.com/OpenBB-finance/OpenBBTerminal/pull/3757)."},{"id":"how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","metadata":{"permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.md","source":"@site/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.md","title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","description":"How I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal.","date":"2022-12-07T00:00:00.000Z","tags":[{"inline":true,"label":"Machine Learning","permalink":"/blog/tags/machine-learning"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Academia","permalink":"/blog/tags/academia"},{"inline":true,"label":"ICMLA","permalink":"/blog/tags/icmla"},{"inline":true,"label":"NURVV Run","permalink":"/blog/tags/nurvv-run"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":10.895,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla","title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","date":"2022-12-07T00:00:00.000Z","image":"/blog/2022-12-07-how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla.png","tags":["Machine Learning","Data Science","Academia","ICMLA","NURVV Run","Open Source"],"description":"How I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal."},"unlisted":false,"prevItem":{"title":"How ChatGPT allowed me to leverage Twitter API 10x faster","permalink":"/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster"},"nextItem":{"title":"The future of finance with open source and AI","permalink":"/blog/the-future-of-finance-with-open-source-and-ai"}},"content":"
\\n \\n
\\n\\nHow I wrote a machine learning paper in 1 week that got accepted to ICMLA while working full time and raised $8.8 million for OpenBB Terminal.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/step-detection-ML).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOne year ago, I raised $ 8.8 millions to build [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) full time. But since I was working at a startup in the UK, I had a 3 month notice period.\\n\\nDuring that time I worked on documenting pretty much everything I had been working on, BUT that felt short. I felt like the data that came out of our [NURVV Run](http://www.nurvv.com/) product could be used with a machine learning algorithm in order to detect a foot strike quite efficiently.\\n\\n\\n\\nSo I asked my company:\\n\\n> _If I use my spare time to work on this paper will you sponsor me if I get accepted?_\\n\\n
\\n\\n**My goal was to increase the visibility of our product in academia.** And given I spent some time reading papers in the area, I knew that what I had in mind had a shot at working.\\n\\n**My background is not data science, and this was my first time \u201cofficially\u201d working on machine learning.** I wasn\u2019t 100% sure that my idea would work, but after spending more than 1 year at the company, I knew how the data behaved. I thought I could build an algorithm robust enough to be able to detect a foot strike more efficiently than what others had.\\n\\nAfter some time, the company accepted my proposal, and between the time to decide to apply to [International Conference on Machine Learning and Applications (ICMLA)](https://www.icmla-conference.org/icmla21/) and getting ready to start working on the paper, there was 1 week left.\\n\\nI thought that this window was rather tight given that I had to clean the data, work on the entire code behind the paper from idea to implementation, and write the damn paper. **I knew this was gonna be tight, but oh boy.** I had one of the harshest weeks of my life. I barely slept for 7 straight days, and skipped the company team event in order to make it through the deadline.\\n\\nBecause of that, I will go into what happened at each step along the way with images. I will skip the cleaning data and boring parts, don\u2019t worry. If you just want to read the final paper, you can find it here: [\u201dStep Detection using SVM on NURVV Trackers\u201d](https://ieeexplore.ieee.org/abstract/document/9680024).\\n\\nAlso, if you\u2019ve been following me, you know how much I love open source. Owing to that I open source the code behind the project [here](https://github.com/DidierRLopes/step-detection-ML).\\n\\n## Exploratory Data Analysis\\n\\nThe Nurvv trackers have an **Inertial Measurement Unit (IMU) tracks linear acceleration (accelerometer) and rotational rate (gyroscope)**. Sometimes it also contains a magnetometer. And Nurvv gave me access to 6 runs from 6 different runners.\\n\\nMy first step was to look into how this data looked. On the left you can see the acceleration (m/s\xb2) and the angular velocity (rad/s).\\n\\n\\n\\nI knew that our **IMU had a sampling rate of 1125 Hz** (which means that each data point gets sampled at approximately every 888.89\u03bcs) and **this was critical in order to detect the oscillations that occur when a foot strike occurs** (i.e. impact of the foot on the floor makes the IMU oscillate). Thus I zoomed in the zone of impact and used a scatter plot to understand if we were \u201cmissing\u201d information.\\n\\n\\n\\nI found it interesting that **the distance between the samples were larger at the time of the impact**. So I plotted the IMU accelerometer data and the IMU gyroscope data in a 3D plot interactively as a function of time (below you can see a snapshot).\\n\\n\\n\\nFrom here it was interesting to note that when the foot is in the air, the samples are somehow concentrated (darker blue), whereas when a step occurs (more sparse) they behave erratically. The plot above was snapshotted with 3 steps that occurred.\\n\\nFrom that 3D plot I had the intuition that by utilizing a **principal component analysis (PCA**)**, I could reduce the dimensionality without losing much information. The result is shown below,\\n\\n\\n\\nThis made me think that I could use a **support vector machine (SVM)** in order to detect whether a foot strike has occurred or not. And what I was most excited about it was:\\n\\n- **This model isn\u2019t time-dependant.** Meaning that it would be fascinating to be able to predict whether a step occurred or not without the notion of time, but the current IMU data.\\n- We can develop an SVM model for each runner style. Then create an **ensemble model with hard voting** which allowed for the model that has seen more similar data, to be more confident in the classification of foot strike vs not foot strike.\\n\\nBut this was all a theory, I needed to prove it.\\n\\nThe first issue I had was: **SVM is a supervised learning model**. This meant that for the sampling data I was providing the model, I would have to classify whether those samples corresponded to a foot strike or not.\\n\\n**The issue?** Although the product had **force sensitive resistors (FSR)** in the insoles, I didn\u2019t have access to the samples that corresponded with these IMU samples.\\n\\nSo I knew that I would have to classify the data myself. Manually would have been a nightmare and not reliable enough, so I needed to build an algorithm that could classify the data quite reliably. **Signal processing theory, here I go.**\\n\\n### Labelling data for a supervised learning problem\\n\\n1. Get the raw IMU samples (accelerometer and gyroscope)\\n2. Do the difference in magnitude between the accelerometers samples and then the gyroscope samples\\n3. Apply root sum squared to the magnitude difference of accelerometer data, and then similarly to gyroscope data\\n4. Standardize the accelerometer data and the gyroscope data. This is so the data can be somehow compared with each other since the magnitude varies as one represents linear acceleration and the other angular rate.\\n5. Do the average between these 2 signals. This makes the data more robust.\\n6. Finally, apply a convolution to the resulting signal with a rectangular pulse. This allows to remove \u201cdrops\u201d from the signal and ensures a smoother signal.\\n\\n
\\n\\nBelow you can see the formulas and signal changes that were made in order to obtain the final result:\\n\\n\\n\\n\\n\\nAfter this, I selected a sensible value of 0.3 to be used as a threshold on the resulting signal to classify step vs no-step.\\n\\n\\n\\nI applied the difference between each first foot strike detected in order to make sure that there was no missed step. As you can see above the stride time is around 700ms which is what is expected of a runner jogging.\\n\\nSomeone might be wondering; If this gives such a great result, why did I need machine learning in the first place? **The reason is because standardization and convolution (steps 4 and steps 6) are a post-processing signal technique.** Therefore, it cannot be deployed in running time, and relies on data that happens in the future.\\n\\nFor illustration purposes, here is how the initial raw IMU data behaves against the labelling from signal processing approach (red background means no step, while green background means step).\\n\\n\\n\\n## Support Vector Machine for classification\\n\\nFor the model, SVM was selected because:\\n\\n- It works well with high dimensional data (6 IMU samples) because it only uses a few of these points (called support vectors) to create this hyperplane (decision boundary) between classes.\\n- SVM is ideal for binary classification problems.\\n- RBF kernel allows to handle non-linear data.\\n\\nThis is the type of classification that SVM is capable of (this is the raw acceleration data with a PCA applied, and the SVM classification on the background for a model that was trained using that same data).\\n\\n\\n\\n### C and gamma hyperparameters\\n\\n- Given each dataset is rather large to perform **grid search optimization** on C and gamma, a subset of each of the datasets is used to extract these parameters.\\n- Each dataset subset is now split: 80% for training data and 20% for validation.\\n- Thus, 80% of the data subset is used to apply SVM with different combinations of C and gamma over a 2D grid. The remaining 20% is used to test the logistic loss and assess optimal hyperparameters.\\n\\n### Training and testing\\n\\n- 80% of data is used for training and 20% is used for testing.\\n- Although the testing is done **out-of-sample**, given the nature of the data (where it comes from the same distribution) it is almost as if it was an **in-sample**.\\n- In our case this is ideal as we want each model to perform very well on its own dataset. We want each model to generalize well for that very specific type of data (runner style, speed and terrain).\\n- A 5-sample moving average is applied before assessing the classification of our model, this is to remove spurious samples. A small window needs to be selected to not introduce a delay in the recognition of a step.\\n- Since our data set is imbalanced (i.e. there are more samples being no-step than step samples) we\u2019ll use **Geometric Mean (G-Mean) evaluation score**, since this measure tries to maximize the accuracy on each of the classes while keeping their accuracies balanced.\\n\\n### Result\\n\\nIn the same dataset where we trained our SVM, we were able to achieve a G-Mean of 0.9645. This is rather expected since this is a powerful model and it was trained on that same data.\\n\\n\\n\\nFrom the graph above this result is very positive given that the mislabelling always occurs at the boundary of a step / no-step detection. And since the sampling occurs very fast, we have some margin of error.\\n\\n## Ensemble SVM model architecture\\n\\nThis model as expected had a poor performance in an unseen dataset. This is normal as the data came from a different runner, running at a different speed in a different terrain. Thus, in order to create a more robust model, we built this ensemble SVM model architecture.\\n\\n\\n\\nEach dataset has the signal processing technique applied in order to obtain the labelling. With this labels, an SVM model can be trained.\\n\\nThen, an **unseen dataset** (not used for training) will be used as input for all the trained SVM models. I.e. each input (3 accelerometer samples and 3 gyroscope samples) will be given to each SVM model which will output 0 or 1 to denote no-step or step, respectively.\\n\\nMy rationale there was: _I could do a major voting approach, BUT because of how I trained the data. It could happen that one of the models had the sample being very inside the boundary, whereas 2 others had it just outside, and the later would win. This is not what I was looking for._\\n\\nBecause of this boundary approach associated with SVMs, I knew that although SVM doesn\u2019t provide probability estimates directly, these could be calculated. So I took advantage of that. And used that probability estimate to select whether the input was considered a stop or not. My rationale was: the model that has seen more similar IMU samples is likely to have a higher confidence in their output and as output they will have what I provided as a label in advance.\\n\\nFinally, I applied a **5-sample moving average** to the step (1) / no-step (0) output and round the value to be classified as step and no-step. This allowed to remove spurious samples.\\n\\n### Results\\n\\nThe prediction for a single SVM was extremely accurate because the model was trained on data samples from that same run (i.e. distribution). On the other hand, the ensemble prediction didn\u2019t run on data from that distribution, hence, making this problem much more complex. However, even with that constraint, a G-Mean of 0.8756 was still achieved.\\n\\n\\n\\n## Future work\\n\\n- Employ the data coming from the \u201dsmart\u201d insoles as an alternative ground-truth for determining step versus no-step conditions.\\n- The diversity of the data set can also be expanded to account for more surfaces, running speeds and styles.\\n- Explore whether the characteristics of the PCA plot of IMU data can be used to categorize different running styles.\\n- The exploration of different classification algorithms for the step detection problem, e.g. applying a long-short term memory (LTSM) neural network algorithm to exploit the time-dependency between samples.\\n- Implement this proof-of-concept code on the production NURVV Run system, to test the prediction technique in a real-life scenario and consider computational time.\\n\\n## Final remarks\\n\\nThis was my first most technical blogpost where I went into details in how I wrote a ML paper that was accepted in a major conference in 1 week. Would love to know your thoughts on it.\\n\\nFeel free to check the full paper version here: https://ieeexplore.ieee.org/abstract/document/9680024"},{"id":"the-future-of-finance-with-open-source-and-ai","metadata":{"permalink":"/blog/the-future-of-finance-with-open-source-and-ai","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.md","source":"@site/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.md","title":"The future of finance with open source and AI","description":"The future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface.","date":"2022-12-04T00:00:00.000Z","tags":[{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Future","permalink":"/blog/tags/future"}],"readingTime":5.57,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-future-of-finance-with-open-source-and-ai","title":"The future of finance with open source and AI","date":"2022-12-04T00:00:00.000Z","image":"/blog/2022-12-04-the-future-of-finance-with-open-source-and-ai.png","tags":["Open Source","AI","Finance","Future"],"description":"The future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface."},"unlisted":false,"prevItem":{"title":"How I wrote a machine learning paper in 1 week that got accepted to International Conference in Machine Learning Applications","permalink":"/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla"},"nextItem":{"title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released"}},"content":"
\\n \\n
\\n\\nThe future of finance is being reshaped by open source and AI. This post discusses the potential of these technologies in disrupting the financial industry, the advantages of open source, and the role of AI in user interface.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis post will talk about my (very) u\u0336n\u0336biased opinion about the future of finance built on top of open source and AI.\\n\\n## Open Source platform\\n\\n\\n\\n### Data licensing vs Marketplace\\n\\nCurrent monopolies spend an enormous amount of cash on financial data licensing. There are dozens of different asset classes (stocks, options, crypto, NFTs, currencies, bonds, ETFs, mutual funds, \u2026) and these often vary based on geography. **That makes the overall investment research industry a very tough market to compete.** Startups cannot disrupt the space without a massive capital injection. This is also why startups usually focus on a certain asset class in a certain geography.\\n\\n**In my opinion, the only shot we have to disrupt incumbents is by not owning the data but becoming the infra layer between data sources and users.** _This is no different than Uber not owning cars, Airbnb not owning apartments or Deliveroo not owning restaurants._\\n\\n**This also has a great advantage which is being able to integrate new data sources very fast and easily.** Plus, owing to open source, anyone can add it. On the other hand, it\u2019s very unlikely that an incumbent will add data that you require. Plus, if they do, they will need to license the data and therefore decrease their margins \u2014 unless they increase the price to users.\\n\\n### Full-price bundle\\n\\nCurrent incumbents pricing is usually a complete bundled offering. **This means that regardless of what you are utilizing in terms of both breadth and depth, you pay the full price tag.** A good analogy is like a restaurant ONLY having a buffet when all you want is a bottle of water, or some chips. What happens is that a user ends up paying for data that they are not using.\\n\\nIn 2022, this is a very outdated take. Companies are looking to get leaner, and it doesn\u2019t make sense to pay for data that you aren\u2019t going to leverage. **Being the infrastructure between users and data sources allows you to create value to both**; Since users will have access to all the data they want and pay for the ones they use, and data sources will have access to a big pool of users and may not need to create a dashboard product to monetize their offerings.\\n\\n### Transparency & Customization\\n\\nCurrent incumbents have built several in-house financial models. **Although these are often customizable, their customization is typically limited.** That is because what is usually customizable are the values/weights, but not necessarily the formulas \u2014 that is kept hidden in their source code. This is an issue because that code cannot be validated and users cannot modify it.\\n\\nWith open source, the story is completely different. **Users can see every single line of code, and therefore not only audit the code quality but adapt the models/formulas to their own needs.** At the end of the day, there is no point in re-inventing the wheel for financial theory that has been around for decades.\\n\\nBy having the code open source, users can rely on the fact that these formulas have been validated/tested by thousands or millions of users and, therefore, there\u2019s a very low chance that these are wrong. **In addition, users are more secure because they can investigate the code and check/fix any vulnerabilities.**\\n\\n### Community\\n\\nOne of the best parts of open source is the integrated community that it creates. This attracts people from every background, gender or ethnicity. Such a pool of diversity tends to allow for better ideas and pushes a project further. With people from the community being able to contribute, this also drives innovation.\\n\\n[OpenBB](http://my.openbb.co/app/terminal/community-routines) has been driven a lot by the community so far. What started as a terminal mostly focused on stocks, soon evolved into including a broad range of datasets and considering several geographies. E.g. A contributor from Sweeden integrated Avanza API to the mutual funds menu that would only appear if users were looking into mutual funds from Sweden. This shows the power of community.\\n\\nHaving the platform be _open source_ is key.\\n\\n## GPT as the interface\\n\\n**One of the hedges that incumbents have is the fact that they have been around for a very long time and spent a lot on educating users about their product.** As a result, users are used to their platform. This makes them harder to switch to an unknown product. This is also why a product needs to be 10x better than competition for users to switch.\\n\\n**However, what if there was no learning curve?** What if you could use a product for the first time and knew how to access all the data without spending any time reading the documentation. **In essence, the educational incumbent advantage would become obsolete.**\\n\\nWith the new LLM advancements, such as [ChatGPT](https://chat.openai.com/chat). We are not far from this reality.\\n\\n\\n\\nPlus, if this is built on top of an open source project it means that the **community can help in improving the model** by providing more training data (e.g. provide a text as input and the corresponding command as output) or even confirm whether or not the chart that pops up was accurate. In addition, along with data sources you can imagine that the community could start contributing with new languages for the GPT model.\\n\\nYou can easily imagine that such interface would work well with a speech recognition model (something like [whisper](https://github.com/openai/whisper) but that allowed real-time).\\n\\n**This makes using a new investment research platform easy, but more importantly makes retrieving information much faster and efficient.**\\n\\n## GPT to build investment research reports\\n\\nOne of the new features that were announced with [OpenBB Terminal 2.0](https://openbb.co/blog/openbb-terminal-2-acai) was the automated reports generation that utilizes [papermill](https://github.com/nteract/papermill) to leverage jupyter notebook templates.\\n\\n\\n\\nAs it stands creating one of these notebook templates requires some coding skills and reading [OpenBB documentation](https://docs.openbb.co/) to understand how to retrieve the data of interest providing the correct function and necessary arguments.\\n\\n**But, for a second, imagine if you could build these notebook templates with almost no-code?**\\n\\nThe proof-of-concept below in combination with the automated report generation should allow you to further understand the breakthrough that we may accomplish in the following few months.\\n\\n\\n\\n**My prediction is that open source + AI will disrupt the financial sector in the upcoming years.**\\n\\n[OpenBB](https://openbb.co/) will be leading that wave.\\n\\nThanks for reading!"},{"id":"bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","metadata":{"permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.md","source":"@site/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.md","title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","description":"OpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform.","date":"2022-11-29T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB Terminal 2.0","permalink":"/blog/tags/open-bb-terminal-2-0"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"AI","permalink":"/blog/tags/ai"},{"inline":true,"label":"ML","permalink":"/blog/tags/ml"},{"inline":true,"label":"SDK","permalink":"/blog/tags/sdk"}],"readingTime":1.725,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released","title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","date":"2022-11-29T00:00:00.000Z","image":"/blog/2022-11-29-bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released.png","tags":["OpenBB Terminal 2.0","Investment Research","Financial Data","AI","ML","SDK"],"description":"OpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform."},"unlisted":false,"prevItem":{"title":"The future of finance with open source and AI","permalink":"/blog/the-future-of-finance-with-open-source-and-ai"},"nextItem":{"title":"Sweepstake World Cup 2022 for your startup team","permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team"}},"content":"
\\n \\n
\\n\\nOpenBB Terminal 2.0 has been released. This blog post discusses the new features and improvements, including the release of OpenBB SDK, a state-of-the-art AI/ML toolkit for the financial industry, and the vision for a community-driven investment research platform.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAlmost 2 years ago, I started building my own investment research platform. 2 months later I named it Gamestonk Terminal, made it open source and shared it on Reddit. The rest is history.\\n\\nSince then, we surpassed [17,800 stars on Github](https://github.com/OpenBB-finance/OpenBBTerminal). Raised $ 8.8 million in our seed round. Build a very competitive team and our OpenBB brand is now recognized by most in the financial space. You can read more about our story [here](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\n**Our mission to democratize investment research has not changed.** Over the past few months we have been heads down and building and today I\u2019m excited to share with you the announcement of OpenBB Terminal 2.0.\\n\\nThe headline is:\\n\\n> _OpenBB Terminal 2.0 is more than an application, it\u2019s a platform._\\n\\n
\\n\\nA summary:\\n- We are releasing OpenBB SDK which allows developers to use a single API to access the world\u2019s raw financial data in order to build their own products / dashboards.\\n\\nThe SDK will allow users to create report templates in a matter of minutes and run them for custom tickers at any time in a matter of seconds; Instead of spending hours and starting a report from scratch every single time. We envision a world where the community can share these and help each other at becoming better investors.\\n\\n\\n\\n- We are also bringing a state-of-the-art AI / ML toolkit to the financial industry, to be used alongside all the data sources our platform has access to (stocks, crypto, NFTs, options, forex, ETFs, mutual funds, macro economic data and even alternative data).\\n\\n\\n\\nFor more information, you can read our announcement here: https://openbb.co/blog/openbb-terminal-2-acai\\n\\nOr even better, watch the announcement [here](https://openbb.co/blog/openbb-terminal-2-event)!"},{"id":"sweepstake-world-cup-2022-for-your-startup-team","metadata":{"permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.md","source":"@site/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.md","title":"Sweepstake World Cup 2022 for your startup team","description":"In this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event.","date":"2022-11-26T00:00:00.000Z","tags":[{"inline":true,"label":"World Cup 2022","permalink":"/blog/tags/world-cup-2022"},{"inline":true,"label":"Startup Team","permalink":"/blog/tags/startup-team"},{"inline":true,"label":"Sweepstake","permalink":"/blog/tags/sweepstake"},{"inline":true,"label":"Team Building","permalink":"/blog/tags/team-building"},{"inline":true,"label":"Slack Bot","permalink":"/blog/tags/slack-bot"}],"readingTime":2.07,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"sweepstake-world-cup-2022-for-your-startup-team","title":"Sweepstake World Cup 2022 for your startup team","date":"2022-11-26T00:00:00.000Z","image":"/blog/2022-11-26-sweepstake-world-cup-2022-for-your-startup-team.png","tags":["World Cup 2022","Startup Team","Sweepstake","Team Building","Slack Bot"],"description":"In this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event."},"unlisted":false,"prevItem":{"title":"Bloomberg Terminal is no more. OpenBB Terminal 2.0 has just been released.","permalink":"/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released"},"nextItem":{"title":"5 steps I used to change my job title in less than 1 year","permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year"}},"content":"
\\n \\n
\\n\\nIn this blogpost, we share how we organized a World Cup 2022 sweepstake for our startup team as a team building activity, and how we built a slack bot to facilitate discussions around the event.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAt [OpenBB](https://openbb.co/), the team puts in so much hard work for [our product](https://github.com/OpenBB-finance/OpenBBTerminal) that doing a team event is like a breath of fresh air. With the World Cup 2022 now taking place and more than half of the team being from Europe (where football is the main sport), we thought that it would be nice to run an OpenBB sweepstake.\\n\\nWe decided to offer a prize to the teams that end up on the podium. 1st place gets X, 2nd place gets Y and 3rd place gets Z - with $ X > $ Y > $Z.\\n\\nThe next step was to assign teams to each employee, so at the end of our all hands meeting we did just that. For that we used this free website: https://spinnerwheel.com/fifa-world-cup-sweepstake-generator.\\n\\nThis allowed us to spin the wheel of team members and then spin wheel of countries, and get a 1:1 match \u2014 it was quite funny to have everyone involved and see the reactions as the wheel was slowing down.\\n\\n\\n\\n**Most companies stop here.**\\n\\n...\\n\\nThe best part about the sweepstake for me, is that the team members that don\u2019t usually interact with each other on a day to day basis have the opportunity to talk amongst themselves for this.\\n\\nSo, to encourage these team interactions, the first step was to create a slack channel #worldcup-2022 that we could use to discuss each game.\\n\\n**But that isn\u2019t enough**, because sometimes you require a trigger to start a discussion about the results and the next fixtures.\\n\\nI looked for a slack bot that achieved this, but **I didn\u2019t find one**.\\n\\nSo I built one using Python which you can find [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\nThis is the notification that the #worldcup-2022 receives everyday after all the matches have been played.\\n\\n\\n\\nThe outcome has been great so far! Our team engagement is even higher than usual and we see team members that don\u2019t work directly with each other having the opportunity to get to know others better.\\n\\nIf you want to do the same for your team, follow the instructions highlighted [here](https://github.com/DidierRLopes/worldcup2022-sweepstake-slackbot).\\n\\nAny feedback is appreciated!"},{"id":"5-steps-i-used-to-change-my-job-title-in-less-than-1-year","metadata":{"permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.md","source":"@site/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.md","title":"5 steps I used to change my job title in less than 1 year","description":"This blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition.","date":"2022-11-14T00:00:00.000Z","tags":[{"inline":true,"label":"career","permalink":"/blog/tags/career"},{"inline":true,"label":"job change","permalink":"/blog/tags/job-change"},{"inline":true,"label":"sensor fusion engineer","permalink":"/blog/tags/sensor-fusion-engineer"},{"inline":true,"label":"roadmap","permalink":"/blog/tags/roadmap"},{"inline":true,"label":"hard work","permalink":"/blog/tags/hard-work"}],"readingTime":5.61,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"5-steps-i-used-to-change-my-job-title-in-less-than-1-year","title":"5 steps I used to change my job title in less than 1 year","date":"2022-11-14T00:00:00.000Z","image":"/blog/2022-11-14-5-steps-i-used-to-change-my-job-title-in-less-than-1-year.png","tags":["career","job change","sensor fusion engineer","roadmap","hard work"],"description":"This blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition."},"unlisted":false,"prevItem":{"title":"Sweepstake World Cup 2022 for your startup team","permalink":"/blog/sweepstake-world-cup-2022-for-your-startup-team"},"nextItem":{"title":"How to grow your open source community from scratch","permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md"}},"content":"
\\n \\n
\\n\\nThis blog post outlines the five steps I took to change my job title from an Embedded Firmware Engineer to a Sensor Fusion Engineer in less than a year. It provides a roadmap for others who may be looking to make a similar career transition.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIn March 2020, I joined a startup as an Embedded Firmware Engineer. The startup\u2019s product focuses on smart running insoles with lightweight trackers that fit any running shoes.\\n\\nThe company was small, and the firmware team was myself and 2 Senior Embedded Firmware Engineers.\\n\\nWhat I liked the most about this team was that our interests complemented each other very well. One of the Senior Embedded Firmware Engineers was very strong at wireless communications (BLE, ANT) while the other was great at communication protocols (SPI, I2C). On my end, my strength was from my MSc in Control Systems and my past experience with GNSS. In addition, I had a very high interest in learning about Inertial Navigation System (INS). My goal was to become a Sensor Fusion Engineer.\\n\\nSo what did I do to become a Sensor Fusion Engineer?\\n\\n## Declare your intent\\n\\nSince day 1 in the company, my team lead knew that my goal was to become a Sensor Fusion Engineer.\\n\\nThis is very important, as your manager can keep this in the back of their mind when assigning tasks to you. For instance, my team lead was giving me a lot of material around the way our product processed external samples as this was critical to the INS.\\n\\n## Define a roadmap\\n\\nI asked my manager: \u201c_What do I need to do to be recognized as a Sensor Fusion Engineer_\u201d.\\n\\nKnowing about the matter is not enough, you want to have the credentials so that you can jump faster in your career.\\n\\nMy team lead was not aware of the capabilities I would need to have to become a Sensor Fusion Engineer, so he spent quite some time doing due diligence on this. Good managers will go out of their way to help you grow.\\n\\nAfter some time, we discussed what I would need to do at the company to be recognized as Sensor Fusion Engineer and built a roadmap in order to get there.\\n\\n## Work hard\\n\\nWork extremely hard towards that roadmap.\\n\\nI was not only working towards that roadmap, but I was also working towards it at 2.5x the average speed. I was working 80h \u2014 100h / weeks during that time.\\n\\nI was being pulled into all meetings that discussed sensor fusion, I was reading old documentation to understand the decisions that I made, I was reading codebase and questioning all code (which allowed me to find some issues) and I was taking online courses on top of this.\\n\\nMore importantly, I was experimenting with the product. Theory will only help you so much, you need to get your hands dirty or you will never be able to fully master a skill.\\n\\n## Frequently revise your roadmap\\n\\nThroughout all my 1:1 with my manager, we always revisited the roadmap \u2014 even if briefly. This made sure that he knew how serious I was about this topic, and allowed me to demonstrate my progress.\\n\\nThis also allowed myself to look back and realize my own progress. I would spend time educating him on what I had learned and how we could apply that in our product, including some simulations I had done in Python.\\n\\n## Prove yourself\\n\\nDon\u2019t miss an opportunity to prove yourself.\\n\\nThis is the most critical point, you need to prove that you are capable of delivering by actually demonstrating a real example.\\n\\nThis is the egg or chicken first problem. When you don\u2019t have the initial experience, your company won\u2019t trust you to apply your knowledge. But if your company doesn\u2019t give you the chance you will never get the experience.\\n\\nIn our case, users started getting weird jumps in altitude reported by the trackers. And we needed to figure out the issue fast as this was increasing the churn. I immediately knew I was able to solve this, and knew I had to grab this opportunity.\\n\\nOur trackers were not taking the GPS location in the estimation of user altitude, and I knew that considering that would substantially improve the estimation as the altitude has less chances to change drastically over a small distance.\\n\\nFinally, my degree and hundreds of hours of work were paying off. That day, I wrote our C/C++ altitude estimation algorithm in Python and provided with an input that had a spurious jump in pressure readings \u2014 i.e. I recreated how the issue was happening.\\n\\nI proceeded to implement a Kalman Filter solution to consider GPS readings as well, and the result was a massive improvement. The jump in altitude was non-existant now.\\n\\nIn the daily standup the next day, I had accomplished most of my tasks for the sprint and asked the product owner if I could take a shot at fixing the altitude issue. He was a bit hesitant, but I had a notebook ready to show the problem recreated and my proposed solution in Python.\\n\\nHe accepted and gave me the next 3 days to work on it and to present results on Monday. I didn\u2019t sleep until that Monday. Implementing from Python to C++ was the easy part. The hard part was debugging + optimizing the weights of the Kalman Filter.\\n\\nI was touching the code. Performing an over the air upgrade. Going outside for a run in a track with a bridge where I knew the altitude. Analyzing results at home. Iterate.\\n\\nMonday arrived and I presented results, and they looked so much better. The proposed solution was accepted. Our INS algorithm hadn\u2019t changed in a long time, so a lot of testing was needed.\\n\\nAfter that, the company accepted to offer me the title of Sensor Fusion engineer. Without a pay rise, but that was fine as for me it was about speeding up my career.\\n\\n## Conclusion\\n\\n- Declare intent\\n- Define roadmap\\n- Work towards that roadmap\\n- Frequently revise roadmap\\n- Don\u2019t miss an opportunity to prove yourself\\n\\n**Note:** If the company doesn\u2019t give you a chance to prove yourself, you should interview for that position with other companies. And if another company offers you that job, you will have the leverage that another company perceives you as that.\\n\\nI like [this video](https://youtube.com/shorts/x71Rm0MWVHY?si=BvtmjrE31d6U1bpV) about understanding your market value. And I think it can be extended in terms of your skillset if you want to change your role.\\n\\nFeedback as always is welcome :)"},{"id":"how-to-grow-your-open-source-community-from-scratch.md","metadata":{"permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.md","source":"@site/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.md","title":"How to grow your open source community from scratch","description":"Growing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project.","date":"2022-11-10T00:00:00.000Z","tags":[{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"},{"inline":true,"label":"Project Management","permalink":"/blog/tags/project-management"},{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"}],"readingTime":3.92,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-grow-your-open-source-community-from-scratch.md","title":"How to grow your open source community from scratch","date":"2022-11-10T00:00:00.000Z","image":"/blog/2022-11-10-how-to-grow-your-open-source-community-from-scratch.png","tags":["Open Source","Community Building","Project Management","OpenBB Terminal"],"description":"Growing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project."},"unlisted":false,"prevItem":{"title":"5 steps I used to change my job title in less than 1 year","permalink":"/blog/5-steps-i-used-to-change-my-job-title-in-less-than-1-year"},"nextItem":{"title":"How to learn 10x faster than average","permalink":"/blog/how-to-learn-10x-faster-than-average"}},"content":"
\\n \\n
\\n\\nGrowing an open source community from scratch is a challenging task. This blogpost shares insights and strategies on how to effectively build and manage an open source community, using the example of the OpenBB Terminal project.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n### Project naming\\n\\nThe name should be short, memorable, unique and related with the project.\\n\\nWhen I started what we call OpenBB Terminal today, the name of the project was \u201cStock Market Bot\u201d or something silly like that. I knew that wouldn\u2019t be the last name, but I didn\u2019t have any inspiration and in the meantime I was focused on building the platform.\\n\\nI am an Elon Musk fan, and was a GameStop investor. This meant that once I saw [this tweet](https://twitter.com/elonmusk/status/1354174279894642703) \u2014 I didn\u2019t blink twice and knew this was the name I was waiting for.\\n\\n\\n\\nThat\u2019s when Gamestonk Terminal (now OpenBB Terminal) was born.\\n\\n### Keep the project private until MVP\\n\\n- There will be less pressure than building in public, and you will be able to iterate much faster.\\n- No users asking for features or reporting bugs when MVP is still under development.\\n- Most importantly, this guarantees that when the users see the MVP they know where you are heading with the project.\\n\\nI worked on Gamestonk Terminal for 2 months on my own. The code architecture changed several times as I was in this experimental phase. And if you look into the source code I even committed API keys accidentally. But I had no pressure, so I was able to ship extremely fast.\\n\\n### Prepare to onboard the community\\n\\n- Make the documentation standout (not only \u201cgetting started\u201d but also \u201ccontributing\u201d).\\n- Create \u201cquick win\u201d tickets that the community can address quickly.\\n- Start a group channel on Discord or Slack, which allows you to interact with contributors and discuss features / roadmap and keep them engaged.\\n- Mention \u201cstarring\u201d the project. As simple as this sounds, this helps with growth as its easy to forget to star the project, even though you were interested in what you saw.\\n\\nSome people from our current team told me recently that they fell in love with the README of the project the first time they saw it. In particular with this quote:\\n\\n> _\u201cGamestonk Terminal is an awesome stock and crypto market terminal that has been developed for fun, while I saw my GME shares tanking. But hey, I like the stock.\u201d_\\n\\n
\\n\\nThis allowed me to gain not only contributors, but maintainers. And nowadays, team members.\\n\\n### Change the project visibility to public\\n\\n- This allows everyone to have a first look into the project, it\u2019s the \u201cHello World\u201d moment.\\n- When sharing the project, describe the problem you are trying to solve and make sure your audience relates with that problem.\\n- Share your project on relevant channels (e.g. Reddit, HackerNews, ProductHunt) \u2014 where your audience is.\\n\\nI have been building in open source for a while, without much success. Until Gamestonk Terminal.\\n\\nThe difference? I shared Gamestonk Terminal on:\\n\\n- Reddit r/SuperStonk \u2014 where the retail traders with the same issue as me were gathered\\n- Reddit r/python \u2014 where the community shares projects built in python\\n- HackerNews \u2014 where I leveraged the name of a known brand in the same industry and insinuated that my tool was similar but affordable. The title was: \u201c[Can\u2019t afford Bloomberg Terminal? No prob, I built the next best thing](https://news.ycombinator.com/item?id=26258773)\u201d.\\n\\n### Keep developing in public\\n\\n- Keep the community updated on the roadmap and progress. You can do this by doing demos of what you have accomplished as you add new features (e.g. [on YouTube](https://www.youtube.com/watch?v=fqGPK8OVHLk) or [on Twitter](https://twitter.com/didier_lopes/status/1567117888590340098)) which allows the community to understand what sort of tasks you are working on, and what they would learn if they were to contribute. It basically gives the community a hindsight into what a contributor will be able to work on / achieve.\\n- Get early feedback and prioritise accordingly.\\n- Occasionally go back to the same channels (e.g. Reddit, Hackernews) to report progress. This guarantees that they know the project is not dead and helps your project staying relevant and on their minds.\\n- Develop in public through livestreams (e.g. [live Coding](https://www.youtube.com/watch?v=9BMI9cleTTg)) or by sharing what you are working on through social media (e.g. [adding a futures menu](https://twitter.com/didier_lopes/status/1579414220256387072)).\\n\\n\\n\\nTL;DR: On how to grow your open source project:\\n\\n- Project naming\\n- Keep project private until MVP\\n- Prepare to onboard the community\\n- Change the project visibility to public\\n- Keep developing in public"},{"id":"how-to-learn-10x-faster-than-average","metadata":{"permalink":"/blog/how-to-learn-10x-faster-than-average","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-27-how-to-learn-10x-faster-than-average.md","source":"@site/blog/2022-10-27-how-to-learn-10x-faster-than-average.md","title":"How to learn 10x faster than average","description":"Learn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively.","date":"2022-10-27T00:00:00.000Z","tags":[{"inline":true,"label":"learning","permalink":"/blog/tags/learning"},{"inline":true,"label":"self-improvement","permalink":"/blog/tags/self-improvement"},{"inline":true,"label":"skills","permalink":"/blog/tags/skills"},{"inline":true,"label":"education","permalink":"/blog/tags/education"}],"readingTime":2.98,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-learn-10x-faster-than-average","title":"How to learn 10x faster than average","date":"2022-10-27T00:00:00.000Z","image":"/blog/2022-10-27-how-to-learn-10x-faster-than-average.png","tags":["learning","self-improvement","skills","education"],"description":"Learn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively."},"unlisted":false,"prevItem":{"title":"How to grow your open source community from scratch","permalink":"/blog/how-to-grow-your-open-source-community-from-scratch.md"},"nextItem":{"title":"Twitter thread to LinkedIn carousel in python","permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds"}},"content":"
\\n \\n
\\n\\nLearn how to accelerate your learning process and become 10x faster than average. This blog post provides practical steps to enhance your self-learning abilities and master new skills effectively.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nEveryone is a self learner. But people\u2019s rhythm of self learning can be vastly different.\\n\\n### Have a good reason to learn this new skill\\n\\nWhat is the main fundamental reason why you want to learn this skill? If you don\u2019t have a one sentence answer, you probably don\u2019t need to learn it.\\n\\nUniversity teaches you hundreds of topics that you end up not being good at because you have no interest in it.\\n\\nAvoid spending your precious time on developing a skill that you have no interest or purpose in. Avoid trends too for this reason.\\n\\n### Research and read about the best way to learn the basics\\n\\nThis should take no longer than one afternoon. Avoid promoted content.\\n\\nUsually, you\u2019re able to find a course/book/video that is acclaimed by the community to be the best to get started with.\\n\\nSo we are looking for the equivalent of \u201cMachine Learning from Andrew Ng\u201d for the skill you want to master.\\n\\n### Consume the basics like your life depends on it\\n\\nThis will be the foundation of all your subsequent learning in this new area. Put your phone away, and take notes.\\n\\nRevisit those notes, and if necessary go back in time to understand the basics.\\n\\nIt took me above average time to finish Machine Learning from Andrew Ng.\\n\\nHowever, since this, whenever I learn or even think about AI problems this is now easier because of that laid out work.\\n\\n### Test your knowledge with a real problem (aka get your hands dirty)\\n\\nAnd no, I don\u2019t mean do an exercise that you find online.\\n\\nDefine a problem that you can solve with the skills you acquired and work on it.\\n\\nDon\u2019t ask for the answer. Don\u2019t Google for the solution, but Google for something that is a current impediment on your solution.\\n\\nIf you are struggling on formulating the Google prompt, revisit your first notes on the skill.\\n\\n### Keep learning about the topic\\n\\nThe getting started foundation will only get you so far. It\u2019s likely that soon you will grow out of that and need to expand your knowledge.\\n\\nDon\u2019t jump on this step too early. Make sure your basics are covered before you move on.\\n\\nGo back to the real problem you worked on, and see how the new learned skills could be applied for that same problem.\\n\\nIf those skills aren\u2019t necessarily in that first problem, it\u2019s also a good sign. It\u2019s a sign that you learned not only the skill but when it is and it isn\u2019t used.\\n\\n### Iterate\\n\\nKeep iterating between using this new skill to solve a real problem and learning from courses/videos/books.\\n\\nThere isn\u2019t a \u201cyou made it\u201d badge. But you know you did, once you\u2019re able to look for a specific piece of information on a video/book to fill in the gap for something you needed for your real problem.\\n\\n\\n\\nTL;DR on how to learn 10x faster than average\\n\\n1. Have a good reason to learn this new skill.\\n2. Research and read about the best way to learn the basics.\\n3. Consume the basics like your life depended on it.\\n4. Test your knowledge with a real problem.\\n5. Keep learning about the topic.\\n6. Iterate."},{"id":"how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","metadata":{"permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.md","source":"@site/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.md","title":"Twitter thread to LinkedIn carousel in python","description":"In this blog post, I share how I built a Python tool that converts a Twitter thread into a LinkedIn carousel in seconds. This tool is open source and contributions for improvements are welcome.","date":"2022-10-23T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"LinkedIn","permalink":"/blog/tags/linked-in"},{"inline":true,"label":"Twitter","permalink":"/blog/tags/twitter"},{"inline":true,"label":"Carousel","permalink":"/blog/tags/carousel"},{"inline":true,"label":"Content Creation","permalink":"/blog/tags/content-creation"}],"readingTime":1.775,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds","title":"Twitter thread to LinkedIn carousel in python","date":"2022-10-23T00:00:00.000Z","image":"/blog/2022-10-23-how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds.png","tags":["Python","LinkedIn","Twitter","Carousel","Content Creation"]},"unlisted":false,"prevItem":{"title":"How to learn 10x faster than average","permalink":"/blog/how-to-learn-10x-faster-than-average"},"nextItem":{"title":"How I would do due diligence on $AMT using OpenBB Terminal","permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal"}},"content":"
\\n \\n
\\n\\nIn this blog post, I share how I built a Python tool that converts a Twitter thread into a LinkedIn carousel in seconds. This tool is open source and contributions for improvements are welcome.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/thread-to-carousel/tree/master).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nAs content creators, it would be good if the same content could be utilised across every platform easily. Sometimes you need some tweaks based on audience, but often the same content is used across all platforms.\\n\\nI noticed recently that LinkedIn carousels have been picking a lot of traction, and given I have some nice Twitter threads ([example](https://twitter.com/didier_lopes/status/1570731358204600323?s=20&t=SAO9fD7FR7jeTE-6kem6Mg)) I thought that it would be great if I could convert them into a LinkedIn carousel.\\n\\nSo, I looked for free tools and didn\u2019t find anything good enough. I ended up using [canvas](https://canvas.apps.chrome/) to re-create the thread \u2014 which you can find [here](https://www.linkedin.com/posts/didier-lopes_due-diligence-on-amt-using-openbb-terminal-activity-6977569279395176448-TFMn?utm_source=share&utm_medium=member_desktop). It worked well, but it was time consuming and for most cases, I don\u2019t want to be messing around with the design side of things.\\n\\n\\n\\nAs a true software engineer and pythonist, I obtained the Twitter API keys and built a tool that would convert a Twitter thread into a LinkedIn carousel in a matter of seconds.\\n\\nAnd as usual, I open sourced it: https://github.com/DidierRLopes/thread-to-carousel.\\n\\nThis tool is far from perfect, and a lot can be improved on the design side of things to: Recognize emojis; Highlight mentions; Change the size of the box based on the text; Better text placement when images attached; Better URL link display.\\n\\nThe goal for me wasn\u2019t to build a perfect tool, but something easy enough that did the job. And, as the project is open source, I expect to have users contributing to the script so that it can be improved over time.\\n\\nToday I run it using:\\n\\n```console\\npython convert2carousel.py https://twitter.com/didier_lopes/status/1581247044228100096\\n```\\n\\nAnd the result can be found [here](https://www.linkedin.com/posts/didier-lopes_football-momentum-indicator-carousel-activity-6989972573782482944-nM9s?utm_source=share&utm_medium=member_desktop).\\n\\n\\n\\nFeel free to check the project here and I look forward to having contributors helping me improve it!\\n\\nAs always, any feedback welcome \ud83d\ude4f\ud83c\udffd"},{"id":"how-i-would-do-due-diligence-on-amt-using-openbb-terminal","metadata":{"permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.md","source":"@site/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.md","title":"How I would do due diligence on $AMT using OpenBB Terminal","description":"This blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis.","date":"2022-10-20T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB Terminal","permalink":"/blog/tags/open-bb-terminal"},{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Stocks","permalink":"/blog/tags/stocks"},{"inline":true,"label":"Due Diligence","permalink":"/blog/tags/due-diligence"}],"readingTime":1.785,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-would-do-due-diligence-on-amt-using-openbb-terminal","title":"How I would do due diligence on $AMT using OpenBB Terminal","date":"2022-10-20T00:00:00.000Z","image":"/blog/2022-10-20-how-i-would-do-due-diligence-on-amt-using-openbb-terminal.png","tags":["OpenBB Terminal","Investment Research","Stocks","Due Diligence"],"description":"This blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis."},"unlisted":false,"prevItem":{"title":"Twitter thread to LinkedIn carousel in python","permalink":"/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds"},"nextItem":{"title":"Stop doing your CV in Word or LaTeX","permalink":"/blog/stop-doing-your-cv-in-word-or-latex"}},"content":"
\\n \\n
\\n\\nThis blog post provides a detailed walkthrough on how to conduct due diligence on $AMT using the OpenBB Terminal, a free and open source platform for financial data analysis.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLast month someone on Twitter asked me to do a thread on how I would do due diligence on $AMT using the free and open source [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal).\\n\\nBelow I demonstrate what you can expect from using that platform.\\n\\nWe could go much deeper, but this shows examples of output that you can expect. With over 800 commands and over 100 data sources, this is a very small subset of what you can achieve through this platform.\\n\\nIn addition, this will only be in relation with stocks data, but the terminal also has access to options, crypto, ETFs, mutual funds, NFTs, macro economy, futures and even alternative data!\\n\\nMore information on the platform and how to install it [here](https://my.openbb.co/app/terminal/download).\\n\\nStrap in.\\n\\n```console\\n$ /stocks/load AMT/candle\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/mktcap\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/mgmt\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/income/balance/cash\\n```\\n\\n\\n\\n\\n\\n\\n\\n```console\\n$ /stocks/fa/shrs\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/sust\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/divs\\n```\\n\\n\\n\\n```console\\n$ /stocks/fa/dcf\\n```\\n\\n\\n\\n```console\\n$ /stocks/ins/stats\\n```\\n\\n\\n\\n```console\\n$ /stocks/dps/psi\\n```\\n\\n\\n\\n```console\\n$ /stocks/gov/histcont\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/rating\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/pt\\n```\\n\\n\\n\\n```console\\n$ /stocks/dd/est\\n```\\n\\n\\n\\n```console\\n$ /stocks/ta/sma\\n```\\n\\n\\n\\n```console\\n$ /stocks/ta/recom/summary\\n```\\n\\n\\n\\n```console\\n$ /stocks/ba/sentiment\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/metric tc\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/metric fcf\\n```\\n\\n\\n\\n```console\\n$ /stocks/sia/vis oi\\n```\\n\\n\\n\\n```console\\n$ /stocks/ca/historical/hcorr\\n```\\n\\n\\n\\n\\n\\n```console\\n$ /stocks/ca/cashflow/income/balance\\n```\\n\\n\\n\\n\\n\\n\\n\\nI know this can be overwhelming information and it takes some time to run all these commands.\\n\\nHence I created a [script](https://github.com/OpenBB-finance/OpenBBTerminal/blob/main/openbb_terminal/miscellaneous/routines/due_diligence_stock.openbb). So now you can run all of these commands in one go, with:\\n\\n```console\\n$ /exe due_diligence_stock.openbb -i AMT\\n```\\n\\nAny feedback is welcome!\\n\\nAnd if you want to ask questions about the product before installing it, feel free to join us on Discord here: https://openbb.co/discord"},{"id":"stop-doing-your-cv-in-word-or-latex","metadata":{"permalink":"/blog/stop-doing-your-cv-in-word-or-latex","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.md","source":"@site/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.md","title":"Stop doing your CV in Word or LaTeX","description":"The future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions.","date":"2022-10-15T00:00:00.000Z","tags":[{"inline":true,"label":"GitHub","permalink":"/blog/tags/git-hub"},{"inline":true,"label":"CV","permalink":"/blog/tags/cv"},{"inline":true,"label":"Career","permalink":"/blog/tags/career"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Developer","permalink":"/blog/tags/developer"}],"readingTime":2.695,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"stop-doing-your-cv-in-word-or-latex","title":"Stop doing your CV in Word or LaTeX","date":"2022-10-15T00:00:00.000Z","image":"/blog/2022-10-15-stop-doing-your-cv-in-word-or-latex.png","tags":["GitHub","CV","Career","Open Source","Developer"],"description":"The future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions."},"unlisted":false,"prevItem":{"title":"How I would do due diligence on $AMT using OpenBB Terminal","permalink":"/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal"},"nextItem":{"title":"Why you should drop yfinance API and adopt OpenBB SDK","permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk"}},"content":"
\\n \\n
\\n\\nThe future of CVs for engineers and developers lies within GitHub. This post discusses why GitHub profiles are becoming the new CVs and how they can provide a more comprehensive view of a candidate\'s skills and contributions.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe purpose of a CV is to summarize someone\u2019s career, qualifications and education. **As an engineer or developer, I strongly believe that the future of CVs lies within GitHub.**\\n\\nIn fact, GitHub has realized this and they now allow you to create your own \u201c_profile page_\u201d by creating a repository with the same name as your GitHub username. E.g. https://github.com/DidierRLopes\\n\\nIn my humble opinion, this isn\u2019t being talked enough. Previously, you needed a CV document to talk about your background, education, previous jobs and could rely on your GitHub profile to show your projects. With this update, CVs have become obsolete. When hiring for [OpenBB](https://openbb.co/), I put a lot of weight into the public GitHub of each engineer.\\n\\nThis is my current [GitHub profile page](https://github.com/DidierRLopes).\\n\\n\\n\\nMy profile page is now much simpler since I\u2019ve worked on my [own personal website](https://didierrlopes.github.io/personal-website/), but you can see [here](https://github.com/DidierRLopes/DidierRLopes/tree/98c27cfb087fc8ce6986f4ea8136e76ca14f145b) what my GitHub profile page looked like before. Creating your own personalized website for me is the next step after GitHub, as you can be as creative as you want while showing off your coding skills.\\n\\nMy repository is my way of showing the world what I can do on my own. From a blank sheet to a finalized project. **Sometimes useful, sometimes for fun, but always with the intention to learn more and challenge myself.**\\n\\nThe reason I think that GitHub profile\u2019s are the CVs of the future for engineers/developers, is not only because you can now both talk about yourself in it and display your portfolio, but because of its open source nature.\\n\\nWith products like: https://ossinsight.io/analyze/DidierRLopes, you will be able to dive deeper on engineering skills than ever before.\\n\\n\\n\\nCompanies will be able to assess a candidate based on their open source work:\\n\\n- How do they interact with the community? What are their communication skills?\\n- Do they practice teamwork? And mentor more junior developers?\\n- Are they leaving comments in the code? Is their code readable in the first place?\\n- What about testing? Are they following good practices?\\n- What\u2019s their time to reply to issues? Or to review PRs from peers?\\n- Activity? What are their working hour patterns like?\\n- \u2026\\n\\nImagine a world where everyone develops in the wild. You can see everything and be part of any project. You have your own profile, you talk with others through issues or PRs, you build together. There is no gender, no race, no nationality,.. people are conneced through projects they believe in. **In essence, this is the developer metaverse, and I\u2019m all here for it.**\\n\\n\\n\\n**EDIT:** The reader should be aware that nowadays a properly formatted resume is still critical when added to a job board. This is because automated resume readers expect a certain format in order to recommend candidates to companies and vice-versa.\\n\\nHope you enjoyed this post. As always, any feedback welcome! \ud83d\ude4f"},{"id":"why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","metadata":{"permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.md","source":"@site/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.md","title":"Why you should drop yfinance API and adopt OpenBB SDK","description":"Why you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners.","date":"2022-10-01T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB SDK","permalink":"/blog/tags/open-bb-sdk"},{"inline":true,"label":"yfinance API","permalink":"/blog/tags/yfinance-api"},{"inline":true,"label":"Financial Data","permalink":"/blog/tags/financial-data"},{"inline":true,"label":"APIs","permalink":"/blog/tags/ap-is"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":2.11,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"why-you-should-drop-yfinance-api-and-adopt-openbb-sdk","title":"Why you should drop yfinance API and adopt OpenBB SDK","date":"2022-10-01T00:00:00.000Z","image":"/blog/2022-10-01-why-you-should-drop-yfinance-api-and-adopt-openbb-sdk.png","tags":["OpenBB SDK","yfinance API","Financial Data","APIs","Open Source"],"description":"Why you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners."},"unlisted":false,"prevItem":{"title":"Stop doing your CV in Word or LaTeX","permalink":"/blog/stop-doing-your-cv-in-word-or-latex"},"nextItem":{"title":"How I became CEO of OpenBB","permalink":"/blog/how-i-became-ceo-of-openbb"}},"content":"
\\n \\n
\\n\\nWhy you should consider switching from yfinance API to OpenBB SDK for financial data retrieval. OpenBB SDK offers access to multiple data sources, potential for unlimited data, and incentives for data source partners.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOpenBB SDK will be released later this month \ud83d\udc40.\\n\\n[yfinance API](https://github.com/ranaroussi/yfinance) is an unofficial (not affiliated) API around [Yahoo Finance website](https://finance.yahoo.com/).\\n\\nAlthough it is used in over 12,600 projects on GitHub and is downloaded on average 90,000 per week. This is still an unofficial wrapper. As you can see from Yahoo Finance website, it uses an ad revenue business model. This means that Yahoo Finance doesn\u2019t has any incentive from having users utilizing it through Yfinance API.\\n\\nIf one day Yahoo Finance website adds a paywall through an API key, then Yahoo Finance would:\\n\\n1. Either become obsolete\\n2. Or adopt the same architecture of OpenBB where an API key from a data source is necessary\\n\\n
\\n\\nRegardless, Yfinance API retrieves data that exists on a third-party website: Yahoo Finance website. This means that this API is limited by the data Yahoo Finance is currently paying for redistribution. And thus, users get only what data is supported through the website.\\n\\nOn the other hand, OpenBB SDK allows you to retrieve data from over 50 different APIs (and growing). With yfinance being one of these APIs.\\n\\nSince OpenBB SDK requires API keys from most of the data sources, these have incentives to partner with OpenBB. Because:\\n\\n1. Marketing opportunity due to significant larger pool of users\\n2. New revenue stream\\n\\n
\\n\\nIn essence, Yfinance API:\\n\\n- Not officially supported by Yahoo Finance\\n- No incentive for Yahoo Finance\\n- Limited data by what Yahoo Finance displays\\n- May become obsolete\\n\\nOn the other hand, OpenBB SDK:\\n\\n- Marketing for new data sources\\n- New revenue stream for partners through premium API keys\\n- (Almost) unlimited data - open source project that keeps on adding new data sources\\n- Multiple data sources for same data (user has choices)\\n\\nAs counter-intuitive as it sounds:\\n\\nThe shutting down of yfinance API (which is one of the data sources that OpenBB SDK has access to) would be beneficial to OpenBB adoption. This is because users would need to migrate to OpenBB SDK as that\u2019s the most mature and maintained open source financial API.\\n\\nIf you have any questions, feel free to drop me a message!"},{"id":"how-i-became-ceo-of-openbb","metadata":{"permalink":"/blog/how-i-became-ceo-of-openbb","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-08-14-how-i-became-ceo-of-openbb.md","source":"@site/blog/2022-08-14-how-i-became-ceo-of-openbb.md","title":"How I became CEO of OpenBB","description":"This post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance.","date":"2022-08-14T00:00:00.000Z","tags":[{"inline":true,"label":"python","permalink":"/blog/tags/python"},{"inline":true,"label":"publishing","permalink":"/blog/tags/publishing"},{"inline":true,"label":"package","permalink":"/blog/tags/package"},{"inline":true,"label":"pypi","permalink":"/blog/tags/pypi"}],"readingTime":3.655,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-became-ceo-of-openbb","title":"How I became CEO of OpenBB","date":"2022-08-14T00:00:00.000Z","image":"/blog/2022-08-14-how-i-became-ceo-of-openbb.png","tags":["python","publishing","package","pypi"],"description":"This post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance."},"unlisted":false,"prevItem":{"title":"Why you should drop yfinance API and adopt OpenBB SDK","permalink":"/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk"},"nextItem":{"title":"Web3, symbols and community","permalink":"/blog/web3-symbols-and-community"}},"content":"
\\n \\n
\\n\\nThis post talks about my story of becoming the CEO of OpenBB, the company behind the fastest growing open source project in\xa0finance.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nBoth my parents are Portuguese and emigrated to Switzerland for better conditions. This is where my brother and I were born. We moved back to our small hometown in Portugal when I was 8 years old.\\n\\nWhen I was 21 years old I moved to London to pursue my MSc in control systems at the Imperial College. I also joined a semiconductor company as a Software Design Engineer.\\n\\n\\n\\nIn my spare time I learned Python so I could become more proficient in machine learning and artificial intelligence. When my mathematics professor learned of my interest in Python he challenged me to write the [code behind his PhD thesis](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast) on \\"_Data Science in the Modeling and Forecasting of Financial Time Series: from Classic methodologies to Deep Learning_\\" which combined open source, ML/AI and finance. This was when I first started to realize my passion for financial data.\\n\\n\\n\\nI was inspired by books like \\"_Rich dad Poor dad_\\" which allowed me to understand that the only way to build true generational wealth is through investing. Now that I started to accumulate more savings through my professional pursuits, and with my finance interest increasing from my thesis work, I wanted to invest my own capital.\\n\\nWhat I learned was that investing was a highly cumbersome process. Unlike coding where the tooling (e.g. VSCode) is optimized for efficiency and allows us to automate a lot of processes, investing was highly inefficient and impossible to automate.\\n\\nI was spending hours doing my own investment research (multiple tabs open researching several different sources on a ticker, screenshot the data to put on a document or share with friends, write my thoughts, and repeat), and this had to be done for every single ticker at different instances of time otherwise the data would become irrelevant.\\n\\nI learned from Reddit users how they gained insights and performed due diligence. I quickly realized their \\"workflow\\" was just as inefficient as mine. I concluded that the only aspect of research that should require user input is the interpretation. As far as I was concerned, all data gathering should be automated.\\n\\nI began investigating potential investment research tools that allowed automation and couldn\'t find any, not even the mythical $24k/year Bloomberg terminal. I looked for platforms on GitHub where I could build on top of with no success.\\n\\nDuring Covid Christmas break, the flight to visit my parents was cancelled, so I ended up staying at home and sketching/building what would become my own investment research platform. I noticed that there were hundreds of data providers offering free data tiers where the data provided didn\'t correlate with each other. If I wanted access to paid datasets or more requests per minute it would be as simple as to upgrade my API key to a paid plan.\\n\\n\\n\\nOver the next two months I built a python based command line interface in my spare time for and released the first lines of code as Open Source under the name \\"Gamestonk Terminal\\" since I was an investor in Gamestop and Elon Musk had recently tweeted his now infamous [\\"Gamestonk\\" tweet](https://twitter.com/elonmusk/status/1354174279894642703?s=20).\\n\\nThe project went viral in a couple of minutes on [Reddit](https://www.reddit.com/r/Python/comments/m515yk/gamestonk_terminal_the_equivalent_to_an/) and [HackerNews](https://news.ycombinator.com/item?id=26258773). In under 24h we had over 4,000 stars on [GitHub](https://github.com/OpenBB-finance/OpenBBTerminal), and hundreds of messages requesting features, thanking me for the tool, or reporting bugs.\\n\\nThe number of issues and feature requests was overwhelming for a single person working part-time, so I created a [Discord group](https://openbb.co/discord) and started building a community of users. Many of those same first users went on to become core maintainers of the project. The community started adding new data sources, new features and even new asset classes to the project\u200a-\u200asoon after we were supporting crypto, ETFs, options, forex, and macro economy.\\n\\nMy goal was never to build a business/company with this product. My motivation was to create a better investment research platform that was unavailable until then. When we got approached by JJ (from OSS Capital), it was a no-brainer to create OpenBB, as this would allow me to accelerate the product vision and build the world\'s leading investment research platform."},{"id":"web3-symbols-and-community","metadata":{"permalink":"/blog/web3-symbols-and-community","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-06-28-web3-symbols-and-community.md","source":"@site/blog/2022-06-28-web3-symbols-and-community.md","title":"Web3, symbols and community","description":"This blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users.","date":"2022-06-28T00:00:00.000Z","tags":[{"inline":true,"label":"Web3","permalink":"/blog/tags/web-3"},{"inline":true,"label":"Community","permalink":"/blog/tags/community"},{"inline":true,"label":"Decentralization","permalink":"/blog/tags/decentralization"},{"inline":true,"label":"Blockchain","permalink":"/blog/tags/blockchain"},{"inline":true,"label":"Smart Contracts","permalink":"/blog/tags/smart-contracts"}],"readingTime":5.48,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"web3-symbols-and-community","title":"Web3, symbols and community","date":"2022-06-28T00:00:00.000Z","image":"/blog/2022-06-28-web3-symbols-and-community.png","tags":["Web3","Community","Decentralization","Blockchain","Smart Contracts"],"description":"This blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users."},"unlisted":false,"prevItem":{"title":"How I became CEO of OpenBB","permalink":"/blog/how-i-became-ceo-of-openbb"},"nextItem":{"title":"Remote + Flexible work >> Salary","permalink":"/blog/remote-flexible-work-salary"}},"content":"
\\n \\n
\\n\\nThis blog post discusses the importance of strong communities in the Web 3.0 space, the role of decentralization, and how voting frameworks based on smart contracts can empower users.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you have been paying attention to the Web 3.0 space, you should have realized that most of the projects in the space rely on strong communities.\\n\\n### Why on Web 3.0?\\n\\nOn a centralized concept (Web 2), there is usually a regulatory entity that decides whether something is True or False on a project/product. This means that there\u2019s a single centralized company responsible for making a decision and users must trust that this entity is acting on their best interests.\\n\\nFurthermore, the users do not stand to win anything whether the decision is True or False. They may identify more with one of the outcomes, but there is no personal incentive to the user. Even if a user can relate with the outcomes they never feel a sense of belonging, as deep down they are aware that their opinion is not being taken into account.\\n\\nOn a decentralized concept (Web 3), the story is the very different. A decentralized community is responsible for deciding the True or False, based on a voting framework defined a-priori. This means that the group of users, based on smart contracts executed on the blockchain, can vote on a particular decision. **This is where the importance of a strong community kicks in.**\\n\\nOn Web 2 the users must trust that such entity is acting on user\u2019s best interests. That trust, on Web 3, occurs in form of a strong community. The best way for a user to trust the decisions of a group of people is to know that a group shares the same values and has incentives towards the success of the same project/product.\\n\\n**In fact, I believe that in general when these votes occur, the more unanimous the decisions are, the stronger the community is.**\\n\\n> **NOTE:** Although Web 3 communities are stronger than Web 2 ones, I believe that when something goes wrong the Web 3 communities break faster as they don\u2019t have a common enemy due to the decentralized concept (e.g. LUNA debacle). On the other hand, Web 2 communities can \u201chold\u201d onto the fact that their common enemy is now the entity that they trusted to act on their best interests (e.g. Robinhood vs wallstreetbets).\\n\\n### Why build strong communities?\\n\\n_The Web 3.0 concept doesn\u2019t only benefit from strong communities but is built on top of it._ For worldwide adoption in products/projects/companies the space need strong communities.\\n\\nWhy does money have value? Because people believe that they will be able to exchange it for goods/services in the future. Why do people believe that? Because they trust the entity that is managing such currency.\\n\\nAnalogously, for a digital asset to have value, people need to believe that they will be able to exchange it for goods/services in the future. Since there is no entity to trust, people need to believe that the community will believe that a certain digital asset has value. This belief exists because there are incentives (usually financial or status) for its members.\\n\\nOnce this happens we enter into the law of supply and demand where the value of digital asset goes up as there is either less supply or more demand.\\n\\nThese communities can easily be found on CT or Discord/Telegram servers.\\n\\n\\n\\n### How are strong communities created?\\n\\nIf we learn from history, we see that the most loyal and bigger communities **always recurred at symbology** to achieve such, some examples: sports clubs, religion, countries, clans, societies, \u2026\\n\\nThe truth is that we humans constantly seek this sense of belonging (or are afraid of being alone). When we see multiple people on social media utilizing the same symbols to represent their beliefs, we want to be part of that group, of that community.\\n\\nThis can be seen over and over again on Web3, particularly in CT:\\n\\n- Changing the eyes\u2019 color of your twitter\u2019s pfp which represents being bullish on crypto (usually red for BTC and blue for ETH)\\n- Emojis after the username\\n- Utilizing the NFT you acquired from a collection that you believe in\\n- Adding a \u201c.eth\u201d at the end of the username\\n\\n\\n\\n### Why does this matter?\\n\\nCompanies outside of the Web 3.0 space will start picking up on this to build stronger communities and have a stronger identity (e.g. Notion and their employees pfp on social media). This is even more relevant for open source companies (Web 2.5 if you will), which rely on their communities to build a successful company (e.g. Hugging Face \ud83e\udd17 ).\\n\\n> _I believe that companies will start thinking about the emojis that their community can use while coming up with the name of the brand and logo._\\n\\n
\\n\\nAs for OpenBB, we are a fintech open source company that focuses on providing better investment research for everyone, anywhere. The finance sector we are in is composed of multiple players that have been on the top of the industry for decades. We come in with a radical different approach, bottom-up.\\n\\n> _Being open source for us is not a choice but a need if we are to disrupt traditional investment research platforms with years of head start._\\n\\n
\\n\\nOnce we knew that we wanted the logo to be extracted from the \u201cBB\u201d, it was immediate that the butterfly emoji (\ud83e\udd8b) would be used. Furthermore, a butterfly is a metaphor for transformation, which in our context, represents OpenBB Terminal allowing each investor to evolve and finally fly (i.e. achieve financial freedom).\\n\\nIn order for our users to start relating to the butterfly emoji (\ud83e\udd8b) with our brand we have several cues:\\n\\n- On the landing page\\n\\n\\n\\n- Official social media channels\\n- Our team members use it in their socials\\n\\n\\n\\n- On the OpenBB Terminal as the default flair,\\n\\n\\n\\nAnd even to replace the asterisk (*) when inserting the password to enter our OpenBB Bot platform, **because details matter.**\\n\\n\\n\\nAnd that is what we are doing at OpenBB to build a stronger community? Do you have any other tips/tricks? Feel free to share them!\\n\\nHope you enjoyed this post and as always, am looking to hear feedback!\\n\\n_PS: I\u2019d like to take this chance to say that our OpenBB Bot launch will occur in the coming weeks, you won\u2019t have to wait much longer \ud83e\udd8b_"},{"id":"remote-flexible-work-salary","metadata":{"permalink":"/blog/remote-flexible-work-salary","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-05-03-remote-flexible-work-salary.md","source":"@site/blog/2022-05-03-remote-flexible-work-salary.md","title":"Remote + Flexible work >> Salary","description":"This blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity.","date":"2022-05-03T00:00:00.000Z","tags":[{"inline":true,"label":"Remote Work","permalink":"/blog/tags/remote-work"},{"inline":true,"label":"Flexible Hours","permalink":"/blog/tags/flexible-hours"},{"inline":true,"label":"Work Life Balance","permalink":"/blog/tags/work-life-balance"},{"inline":true,"label":"Productivity","permalink":"/blog/tags/productivity"}],"readingTime":4.785,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"remote-flexible-work-salary","title":"Remote + Flexible work >> Salary","date":"2022-05-03T00:00:00.000Z","image":"/blog/2022-05-03-remote-flexible-work-salary.png","tags":["Remote Work","Flexible Hours","Work Life Balance","Productivity"],"description":"This blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity."},"unlisted":false,"prevItem":{"title":"Web3, symbols and community","permalink":"/blog/web3-symbols-and-community"},"nextItem":{"title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally"}},"content":"
\\n \\n
\\n\\nThis blog post discusses the importance of remote and flexible work hours, and how it can significantly improve work-life balance and productivity.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nI was thinking about remote + flexible hours, and I don\u2019t think I would ever work for a company without these. At least by choice \ud83d\ude43\\n\\nI mean, who would tell Morty and Sum Sum that I wouldn\u2019t be at home to play?\\n\\n**I\u2019m a strong believer that work should wrap around your lifestyle and not vice-versa.**\\n\\nOn average, a person works 40 hours a week and sleeps 8 hours a day. This means that out of 168h per week you have 72h for personal time. In terms of percentage we have: 24% for work, 33% for sleep, and 43% for personal time.\\n\\nSo how come most people have almost 2x as much personal time compared to work time and they still feel like they are in this 9\u20135 rat race and their life revolves around work?\\n\\nWell, here\u2019s the 4 scenarios as I see it\u2026\\n\\n**1. The work is not remote (and not flexible).**\\n\\n - If we account for the commute and stress associated with, personal time gets directly transferred into work time.\\n - E.g. with a daily 2 hour commute Mon-Fri, which is very typical, this means that your personal time is divided into 30% for work and 37% for personal. This isn\u2019t event including the part where you have to prepare to leave the house, and the tiredness resultant from the commute.\\n\\n**2. The work is remote but not flexible.**\\n\\n - This is much better than the previous. But it\u2019s still not good enough. The argument here is not due to absolute time but performance and state of mind.\\n - Life is not straightforward. We, as individuals, are very different between ourselves. Our bodies, mind, brain, relationships, \u2026 work very differently. By not being flexible on the working hours you are basically ignoring all of that diversity and grouping everyone into a single 9\u20135 + Mon-Fri category.\\n - _The \u201cironic\u201d part is that most companies promote diversity and don\u2019t think about this. Which just shows that the diversity topic has become very much a marketing vehicle._\\n - In my case, I\u2019m a night owl, I don\u2019t usually wake up too early, because I am much more productive when I stay awake until 3/4 am. If I have to wake up early because someone decided that 8:30am was the time that everyone needed to \u201ccheck in\u201d you are basically not getting the most out of me.\\n - One may wonder, well, this is a company problem because they are paying for an employee that is not performing as much as they could. Unfortunately, that\u2019s not true, it\u2019s a much bigger problem to the employee. This is because when an employee excels at a job they tend to have a much happier life which in turn increases performance, which increases happiness, and so on and so forth.\\n\\n**3. There is no mention for not remote but flexible because, in my opinion, that makes very little sense.**\\n\\n**4. Now, let\u2019s imagine the scenario where the work is remote and flexible.**\\n\\n - This is where it gets interesting. When we fall on this scenario your job perspective changes drastically. This is because at this point you put yourself first and can define your own priorities while having a pool of time to get a job done at your own time.\\n - E.g. you can plan activities with friends, do exercise, meditate, \u2026 whatever suits your lifestyle. Which will give you a boost of energy to perform even better at your job. On top of this, you don\u2019t need to squash the work within Mon-Fri, once you are in this flexible regime you may use the weekend to your advantage. Flights at 20 Euros on Tuesday to come back Thursday? Fine, I\u2019ll work during weekend to make up for this time\\n - There are people that love a 9\u20135 Mon-Fri schedule and that is fine. For those it means that the 9\u20135 Mon-Fri system implemented got it right. In fact, I would argue, that they are still wrapping work around lifestyle, it\u2019s just that their lifestyle is working 9\u20135 Mon-Fri and enjoying time outside these hours.\\n\\nThe downsides of this fully flexible work are:\\n\\n- Interaction with coworkers and communication. But with us going global due to remote work, it doesn\u2019t really matter, since the 9\u20135 hours of different countries would already lead to this problem\\n- Tracking employee timesheet. I think that a company shouldn\u2019t track an employee timesheet because results are far more important than working hours, and can be just as measurable.\\n\\n\\n\\nAll of this to say that at OpenBB we have:\\n\\n- **REMOTE WORK:** As long as you are in a location with internet access, we are not worried. This allows us to build a strong diverse team with different backgrounds and ideas.\\n- **FLEXIBLE HOURS:** We believe that your work should wrap around your lifestyle and not vice-versa. As long as you excel, you will not be asked why you woke up at noon.\\n- **UNLIMITED HOLIDAYS:** Who has time to track holidays when building such an exciting project? We trust in our people to manage their own PTO and keep performing at the highest level.\\n\\nAND this is how I sleep at night having no idea at what time John logged in and out:\\n\\n\\n\\nOhhh, and we\u2019re hiring!\\n\\nIf you provide a referral to someone that ends up joining OpenBB, I will transfer you $100 as a token of appreciation \ud83e\udd8b"},{"id":"looking-for-a-new-tattoo-openbb-has-you-covered-literally","metadata":{"permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.md","source":"@site/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.md","title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","description":"Exploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy.","date":"2022-04-21T00:00:00.000Z","tags":[{"inline":true,"label":"OpenBB","permalink":"/blog/tags/open-bb"},{"inline":true,"label":"Marketing","permalink":"/blog/tags/marketing"},{"inline":true,"label":"Tattoo","permalink":"/blog/tags/tattoo"},{"inline":true,"label":"Brand Awareness","permalink":"/blog/tags/brand-awareness"}],"readingTime":3.125,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"looking-for-a-new-tattoo-openbb-has-you-covered-literally","title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","date":"2022-04-21T00:00:00.000Z","image":"/blog/2022-04-21-looking-for-a-new-tattoo-openbb-has-you-covered-literally.png","tags":["OpenBB","Marketing","Tattoo","Brand Awareness"],"description":"Exploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy."},"unlisted":false,"prevItem":{"title":"Remote + Flexible work >> Salary","permalink":"/blog/remote-flexible-work-salary"},"nextItem":{"title":"How I created the best discord meme bot","permalink":"/blog/how-i-created-the-best-discord-meme-bot"}},"content":"
\\n \\n
\\n\\nExploring unconventional ways to increase brand visibility, OpenBB\'s co-founder gets a tattoo of the company logo. This blog post discusses the thought process behind this unique marketing strategy.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWhen [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) started last year, I went from having your typical career as a Software Engineer to becoming a co-founder & CEO of a C-Corporation overnight. One thing that I\u2019ve really learnt from this change, is I can no longer code for 12\u201316 hours a day straight as my role now involves so much more than this\u2026 and most interestingly, one of those things is marketing.\\n\\nDuring Easter in Lisbon, I was thinking about how to increase the visability of [OpenBB](https://openbb.co/). _An investment research platform for everyone, anywhere_. Seems self-explanatory and something most of us would relate to, but the problem is reaching a bigger audience.\\n\\nDue to [our $8.5M funding](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did) we have money in the bank, which means we can afford to do some ads campaigns. However, I very much dislike the traditional type of ads, whether that is with Google, Instagram, Twitter or YouTube. Particularly YouTube ones, when I see an ad there I immediately think less of the product being advertised due to how intrusive these are.\\n\\nThat\u2019s why I started thinking of ways to share our OpenBB brand in a non-intrusive way. In fact, I went one step further and started thinking when I personally would welcome ads.\\n\\nFunnily enough, the first thing that came to my mind was when I go to the bathroom without my phone. Although there\u2019s no ads on the back of shampoos/shower gel/soap/spray, I would very much welcome them.\\n\\n\\n\\nIt\u2019s not like knowing the %s of ingredients that makes up cleaning products has a lot of use cases\u2026\\n\\nThis brought me to the conclusion that I would only welcome ads if I was bored and didn\u2019t have anything keeping me \u201ctoo busy\u201d. This immediately made me think of London underground ads (the most effective type of DOOH imho). I always read those ads. The main reason being that I don\u2019t have WiFi underground and the noise is too loud to listen to a podcast. Hence, I imagined the underground looking like:\\n\\n\\n\\nWhen I checked for the prices, I was looking at a marketing campaign for a couple of days in a couple of stations costing over 5 digits, which is quite expensive for the short time-span.\\n\\nTherefore, I started to think of cheaper alternatives that yielded a better ROI. The next thing that passed through my mind was wearing OpenBB swag (yet to be revealed, [subscribe to our newsletter](https://openbb.co/newsletter) to know more). However, I feel like nowadays everyone has a t-shirt with a different logo and these aren\u2019t as noticeable as before \u2014 at least that\u2019s my perspective.\\n\\nThis lead me to think: **What about a tattoo?** It\u2019s a similar concept than OpenBB clothes but more powerful. In addition, when wearing OpenBB clothes with a visible tattoo, this will create a \u201ccuriosity\u201d effect since the symbol is repeated (clothes and tattoo). In addition, I\u2019ve not come across anyone using their body to express their brand.\\n\\nLater that day I booked a tattoo slot, paid 100 euros, and got the OpenBB logo on the back of my arm as shown below,\\n\\n\\n\\nI will let you know on my socials how many people ask about this tattoo over the course of my life.\\n\\nAnd if you like [our logo](https://www.openbb.design/9242dc28c/p/809a44-logo) and [our values](https://www.openbb.design/9242dc28c/p/91bbcc-our-values), OpenBB will pay you for the tattoo.\\n\\n**One things for sure, now I can definitely put the gym membership as a company expense since I\u2019m a walking billboard \ud83d\ude04**\\n\\nThe first walking/running/coding/eating/drinking OpenBB billboard."},{"id":"how-i-created-the-best-discord-meme-bot","metadata":{"permalink":"/blog/how-i-created-the-best-discord-meme-bot","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.md","source":"@site/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.md","title":"How I created the best discord meme bot","description":"In this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot.","date":"2022-04-09T00:00:00.000Z","tags":[{"inline":true,"label":"Discord","permalink":"/blog/tags/discord"},{"inline":true,"label":"Meme Bot","permalink":"/blog/tags/meme-bot"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"}],"readingTime":3.89,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-created-the-best-discord-meme-bot","title":"How I created the best discord meme bot","date":"2022-04-09T00:00:00.000Z","image":"/blog/2022-04-09-how-i-created-the-best-discord-meme-bot.png","tags":["Discord","Meme Bot","Open Source","Community Building"],"description":"In this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot."},"unlisted":false,"prevItem":{"title":"Looking for a new tattoo? OpenBB has you covered\u2026 literally.","permalink":"/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally"},"nextItem":{"title":"Meet the most advanced investment research platform","permalink":"/blog/meet-the-most-advanced-investment-research-platform"}},"content":"
\\n \\n
\\n\\nIn this blog post, I share my journey of creating a Discord meme bot, the role it played in building a vibrant community around our open source project, and how you can add your own memes to the bot.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/discord-memes).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Background\\n\\nOver the past few weeks, life has been very chaotic on my end, mostly due to the announcement of [OpenBB](http://www.openbb.co/) last week which you can read the full story on [here](https://openbb.co/blog/gme-didnt-take-me-to-the-moon-but-gamestonk-terminal-did).\\n\\nWhen I started [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal), all my focus was on building, building and building. Once I made the project open source and contributors started to appear, I slowly saw my time shifting **from building a product to building a community**. This community ultimately would end up building the product, but from my end, I need to be able to pass on my passion to the project and vision.\\n\\nDeveloping features for the terminal only took me a couple of minutes, whereas the connection with the community is a long-time game. You don\u2019t become close with someone you\u2019ve never met within couple of minutes. Instead you need to put effort into the relationship and **consistency is key**.\\n\\nThe community on our Discord was growing day by day. And so was my relationship with the people in it. The truth is, we were not only sharing insights about the platform, but were laughing and bonding together whilst building it. **And memes/gifs are a big part of these interactions.**\\n\\nFor people who know me, they know how much I love memes and how I can always create memes for every situation (honestly, all the time I spent on Instagram is finally paying off).\\n\\nAlthough I believe that we have one of the most exciting open source projects going on, I also strongly believe that our fun culture (i.e. memes) is what makes contributors want to work in this particualr environment. **Building the future of investment research can be fun and this is what we\u2019re proving.**\\n\\nAt this stage, I think I\u2019ve spent more time interacting with people than I have working on the platform. The funny thing is that **the platform is 10x better than what it would be if I was working on my own**. Creating a strong community pays off and this is why since the start I was having calls with literally everyone to help them install our platform. Today, most of the team at OpenBB was met on Discord whilst working on the platform. **I didn\u2019t need any interviews, they weren\u2019t candidates anymore but people that I enjoyed to work with** and wanted on the team.\\n\\nSorry for the background story, but it was important to me to explain why I worked on this. **The interesting part of the article starts now.**\\n\\n## Development\\n\\n**The idea of Discord Memes is to avoid to open [imgflip](https://imgflip.com/) everytime I wanted to add text to a meme.** Personally, I love the gifs available through Discord but I think a meme with text is much more powerful (and funny).\\n\\nWhen I started coding this here and there, I wanted the code to be super straightforward so it was very simple and fast to add a new meme to the pool. And so I did.\\n\\nThe process to add new memes is incredibly easy. Go to the [project](https://github.com/DidierRLopes/discord-memes) and star it for starters (also [OpenBB Terminal](https://github.com/OpenBB-finance/OpenBBTerminal) since you\u2019re at it). Then,\\n\\n1. Add the meme you want to the `memes/` folder, e.g. `spongebob.jpg`\\n\\n2. Then create a function with the same name of the image (e.g. `spongebob`) with the following format\\n\\n
\\n\\n```python\\n@create_and_send_meme()\\ndef spongebob(inter, text: str = None, _=None):\\n if text:\\n _.text(\\n 0.5,\\n 0.2,\\n \\"\\\\n\\".join(wrap(\'\'.join(choice((str.upper, str.lower))(c) for c in text), 40)),\\n fontsize=20,\\n color=\\"white\\",\\n alpha=0.9,\\n horizontalalignment=\\"center\\",\\n path_effects=[pe.withStroke(linewidth=4, foreground=\\"black\\")]\\n )\\n return _\\n```\\n\\n3. That\u2019s it.\\n\\n
\\n\\n**Note:** I created a python decorator `@create_and_send_meme()` that basically abstracts all the memes created and picks up the image on memes with the same name of the function. This way, the person adding a meme just needs to focus on the text on the image, i.e. it\'s location, size, where it wraps, colours and alignment.\\n\\nI used a playground.ipynb notebook, which is also on the repo, to increase the speed of the text placement on each of the memes I added.\\n\\nThis is how it looks,\\n\\n\\n\\nOR\\n\\n\\n\\nAs you can see, our Discord server just stepped up. [Join us](https://openbb.co/discord) to try out the meme bot, build the future of investment research or just to say hi.\\n\\nWe\u2019ll be waiting for you. \ud83e\udd8b"},{"id":"meet-the-most-advanced-investment-research-platform","metadata":{"permalink":"/blog/meet-the-most-advanced-investment-research-platform","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.md","source":"@site/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.md","title":"Meet the most advanced investment research platform","description":"Meet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities.","date":"2022-03-21T00:00:00.000Z","tags":[{"inline":true,"label":"Investment Research","permalink":"/blog/tags/investment-research"},{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"},{"inline":true,"label":"Routines","permalink":"/blog/tags/routines"}],"readingTime":1.42,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"meet-the-most-advanced-investment-research-platform","title":"Meet the most advanced investment research platform","date":"2022-03-21T00:00:00.000Z","image":"/blog/2022-03-21-meet-the-most-advanced-investment-research-platform.png","tags":["Investment Research","Gamestonk Terminal","Automation","Routines"],"description":"Meet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities."},"unlisted":false,"prevItem":{"title":"How I created the best discord meme bot","permalink":"/blog/how-i-created-the-best-discord-meme-bot"},"nextItem":{"title":"UX/UI is better than features","permalink":"/blog/gamestonk-terminal-ux-features"}},"content":"
\\n \\n
\\n\\nMeet the most advanced investment research platform. This blog post introduces Gamestonk Terminal, an advanced investment research platform, and discusses its features and automation capabilities.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nSeveral people have asked me why [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) doesn\u2019t have release versions, and the main reason is because at the pace the team codes and the rate that new features / bug fixes appear it doesn\u2019t yet makes sense to do so.\\n\\nTo give you an example, recently I shared the first **DEMO of what the terminal can do**, and I mention about our \u201croutines\u201d automation concept.\\n\\n
\\n\\nOne week later, using the latest version of the terminal, on top of that simplistic routine type you are able to:\\n\\n1. Provide variable input variables when calling the routine using $ARGV[i] (I used Perl convention here eheh)\\n2. Execute routines from within the terminal directly\\n3. Add comments to the routines so the process is more clear\\n4. Exporting data to a folder of choice is now possible\\n5. Exporting a file with a pre-defined name is now possible\\n6. Allow for the first line of the routines to be selecting a folder to export ALL the data\\n\\n
\\n\\nSee below a 1 minute video of what these routine automated scripts look like!\\n\\n
\\n\\nReach out if you have any question to the team, there\u2019s very little we can\u2019t do!\\n\\nThis is the way!"},{"id":"gamestonk-terminal-ux-features","metadata":{"permalink":"/blog/gamestonk-terminal-ux-features","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2022-01-06-gamestonk-terminal-ux-features.md","source":"@site/blog/2022-01-06-gamestonk-terminal-ux-features.md","title":"UX/UI is better than features","description":"Gamestonk Terminal\'s UX/UI features and the teamwork behind their implementation.","date":"2022-01-06T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"UX/UI","permalink":"/blog/tags/ux-ui"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"},{"inline":true,"label":"Teamwork","permalink":"/blog/tags/teamwork"}],"readingTime":4.19,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-ux-features","title":"UX/UI is better than features","date":"2022-01-06T00:00:00.000Z","image":"/blog/2022-01-06-gamestonk-terminal-ux-features.png","tags":["Gamestonk Terminal","UX/UI","Software Development","Teamwork"],"description":"Gamestonk Terminal\'s UX/UI features and the teamwork behind their implementation."},"unlisted":false,"prevItem":{"title":"Meet the most advanced investment research platform","permalink":"/blog/meet-the-most-advanced-investment-research-platform"},"nextItem":{"title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal"}},"content":"
\\n \\n
\\n\\nGamestonk Terminal\'s UX/UI features and the teamwork behind their implementation.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n**Features attract users, UX/UI conquers them \u2694\ufe0f**\\n\\nThroughout month of December, me and 3 of the most active maintainers of [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) had a meeting where we discussed shifting our focus from adding features, to improving the terminal UX/UI to make it even more attractive. The main outcomes of these meeting were:\\n\\n1. Relative and Absolute menu jumping, e.g. if i\u2019m in crypto/ta and want to go to stocks/ta I can do:\\n\\n a. Absolute: `/stocks/load tsla/ta`\\n\\n b. Relative: `../../stocks/load tsla/ta`\\n\\n3. Scripting feature. You can now interact with the terminal through a sequence of commands, e.g.: `stocks/disc/ugs -l 3/gtech/active`.\\n\\n4. `reset` command everywhere to allow for faster development as it exits from the terminal and comes to the same menu running new terminal code and its API keys.\\n\\n5. Auto-completion in commands with choices.\\n\\n6. When misspelling a command name, if it\u2019s similar enough that the terminal recognises the right command, it will replace it, to speed up interaction.\\n\\n
\\n\\n\\n\\n6. Running a `.gst` job, like `python terminal.py scripts/test_stocks_disc.gst` which allows to run a sequence of commands of the terminal. In the future we can take advantage of this for integration tests. The user can build their own daily routines to speed up the investment process.\\n\\n
\\n\\n\\n\\nNow, I know what you\u2019re thinking. This is a massive improvement over the terminal usage up until now, and that\u2019s a **LOT** of code changes. Which is very much true, to be specific, this engineering effort resulted in:\\n\\n> **370 files changed with 44,875 additions and 18,463 deletions**\\n\\n
\\n\\nAnd you may be wondering how long did this take us to do. Nope, it wasn\u2019t months but\u2026\\n\\n\\n\\n**1 week. Yup, a single f*king week.** You can see that it was finalised with these PRs ([#1049](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1049), [#1041](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1041), [#1048](https://medium.com/@dro-lopes/gamestonk-terminal-ux-features-f9754b484919#1048)).\\n\\nIn that week we split work, did pair programming, we called each other to discuss better implementation practices, we changed the architecture 2/3 more times\u2026 On top of that, I was feeling overwhelmed with the stocks menu, I clearly underestimated how many features we have (how naive\u2026), so the 3 other maintainers jumped on it and helped me out. In 3 or so years of software engineering, this was** teamwork like I\u2019ve not felt before**.\\n\\nThat weekend I was so happy as we accomplished this task that I think I didn\u2019t even work on the terminal that Sunday! Doesn\u2019t happen often these days!\\n\\nHowever, as a good friend of mine told me:\\n\\n> _**\u201cThe entertainment industry hasn\u2019t found yet something more appealing than developing code towards a product I believe in and with people I like\u201d**_\\n\\n
\\n\\nI still think about this often, and this is what I tell my girlfriend, to explain why I\u2019m coding and not playing Mario Kart 8 Deluxe with her. (the fact she always beats me at it also may be considered as a factor \ud83e\udd23).\\n\\nYou may be thinking this is a one off, the reality is that **it isn\u2019t**. Another example can be seen in [this blog post](https://dev.to/northern64bit/aspiring-16-year-old-quant-developer-contributing-to-open-source-application-16k4). This goes over the story of the development of our discord bot where it all started from a message from a **16yo contributor that wants to become a quant**. He wanted to not only improve his python skills with us but also bring the terminal features to a bigger audience. Working with us in an open-source project is helping him towards achieving his life-goal dream.\\n\\nWhile I write this post another contributor, finishing his CPA, is working on [improving the code resulting from that UX effort by creating a base class](https://github.com/OpenBB-finance/OpenBBTerminal/pull/1141) so that new developers can add controllers much easily (he estimates a reduction of 11% of codebase size based on \u201cnapkin maths\u201d as he puts it).\\n\\n\\n\\nWhile user experience is critical, so is user interface. And that is why our next engineering effort will be around it. We already have something in the works in [this PR](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/1140), where we can draw lines and write text! Almost like TradingView (almost\u2026 \ud83d\ude2c).\\n\\n\\n\\nSo, keep on the lookout because 2022 is gonna be a big year for us!! \ud83e\udd8b \ud83d\ude80\\n\\nOhh, before I say thanks for the read and all that, it\u2019s also worth mentioning that there\u2019s a PR in the queue for a new context called \u201c**alternative data**\u201d, which already has a **COVID menu** to factor that data into account on your investments.\\n\\n\\n\\n_PS: The blue text is because we are transitioning towards [rich package](https://github.com/Textualize/rich) which gives a lot more freedom when it comes to improving our user interface._\\n\\n
\\n\\nThanks for your read, and if you enjoy Gamestonk Terminal, please reach out to [our discord](https://discord.gg/ptYabd8w) to say thank you, or ideally: for **@terp340** to change date format to dd/MM/YYYY \u2014 **the only correct one**!\\n\\nHappy 2022 with lots of love \u2764\ufe0f"},{"id":"sector-and-industry-analysis-gamestonk-terminal","metadata":{"permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.md","source":"@site/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.md","title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","description":"The development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package.","date":"2021-12-02T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Sector Analysis","permalink":"/blog/tags/sector-analysis"},{"inline":true,"label":"Industry Analysis","permalink":"/blog/tags/industry-analysis"},{"inline":true,"label":"FinanceDatabase","permalink":"/blog/tags/finance-database"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":4.01,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"sector-and-industry-analysis-gamestonk-terminal","title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","date":"2021-12-02T00:00:00.000Z","image":"/blog/2021-12-02-sector-and-industry-analysis-gamestonk-terminal.png","tags":["Gamestonk Terminal","Sector Analysis","Industry Analysis","FinanceDatabase","Open Source"],"description":"The development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package."},"unlisted":false,"prevItem":{"title":"UX/UI is better than features","permalink":"/blog/gamestonk-terminal-ux-features"},"nextItem":{"title":"Handing your twitter account to your most avid community member","permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member"}},"content":"
\\n \\n
\\n\\nThe development journey of a new Sector and Industry Analysis feature for Gamestonk Terminal, integrating the FinanceDatabase package.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThe end-to-end story of developing a new **Sector and Industry Analysis** for [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) from scratch.\\n\\nOn the 13th of October, [Jeroen Bouma](https://github.com/JerBouma) (a ALM advisor and python enthusiast) reached out in order to integrate his [FinanceDatabase package](https://github.com/JerBouma/FinanceDatabase) into [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal).\\n\\n\\n\\nAfter having a call with Jeroen to bounce ideas, it was clear that our terminal needed such capability to be even more powerful (as if **over 500 features** already and counting didn\u2019t already do the trick eheh). However, at the time I was too busy to work on the concept so I asked Jeroen if he could sketch something up on a jupyter notebook.\\n\\nWithin the following week, Jeroen sent a Jupyter notebook explaining the FinanceDatabase module and what we could have in a Sector and Industry analysis.\\n\\n\\n\\nIn addition, he also mentioned his [PassiveInvestor package](https://github.com/JerBouma/ThePassiveInvestor), and ended up [implementing it on his own in Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/857)! This was a great addition, as it strengthened our **ETF context** and provided a slick Excel report for the Excel fans out there! See his [LinkedIn post](https://www.linkedin.com/feed/update/urn:li:activity:6859887432532291584/) on the experience.\\n\\n\\n\\n...\\n\\nForward to last weekend (1.5 months later), I had a free Sunday afternoon so started working on the development of this menu. I started by thinking about what would make this menu more flexible and powerful.\\n\\n\\n\\nThese were my thoughts about what it needs:\\n\\n- **Several filtering parameters** as the number of companies in the database is pretty huge with 155.705 tickers, 16 sectors, 242 industries, 111 countries and 82 exchanges. These were the filters selected: Country, Sector, Industry, Market Cap and Flag to include/exclude international exchanges.\\n- **To be able to do some statistics on the sector**, industries and countries (e.g. companies per sector/industry with a specified country and market cap) which allows users to better understand companies landscape of a sector and industry.\\n- **To get the financials of the companies that fall under that filter subset** (e.g. return on assets, quick ratio, debt to equity), and then compare these in order to get the best performers.\\n- Since one of the previous financials isn\u2019t enough to understand which company would be best to invest in, I wanted the filtered companies to have the capability to jump onto the comparison analysis menu so you could get all the capabilities of comparing historical price data, volume data, income/balance/cash flow, sentiment, or even technical indicators.\\n- If in the stocks context I had Tesla loaded, I wanted to go into this sia menu and get all the filtering parameters to be ready to filter for companies similar to Tesla in terms of (Sector, Industry, Country and Market Cap).\\n\\nBy Sunday night, I created the [pull request for this](https://github.com/GamestonkTerminal/GamestonkTerminal/pull/995). Due to the due diligent reviews performed by the main contributors of the project, the menu got a lot of improvements. Some of them were:\\n- Do not display companies that account for under a certain threshold (1%) and therefore sum them in an \u201cOthers\u201d slice.\\n- Allow to export all the data as a table.\\n- After filtering and getting financials, save the data for faster data retrieval if the same filters are used.\\n- Minor bug fixes.\\n\\nAfter a lot of comments and feedback from the main maintainers, and everyone being happy with this first iteration, the PR got merged. In fact, one of the main maintainers found a hidden gem while testing it.\\n\\n\\n\\nIn the meantime, I\u2019ve been in contact with Jeroen about adding some more capabilities to his FinanceDatabase package so that everyone could benefit from them. Some examples are:\\n- When an industry is selected, the corresponding sector should be automatically filled.\\n- If I select a country and a market cap for filtering, my sector choices should be bounded by what exists within those.\\n- I should be able to query about companies landscape in terms of a country. E.g. I want to understand what countries have the most large cap companies within the Financial Services sector.\\n\\nThis would not only make the FinanceDatabase a more powerful Package, which would in turn benefit Gamestonk Terminal sia menu, and ultimately our thousands of users!\\n\\n\\n\\nThis is an example of how the Sector and Industry Analysis menu looks (as a bonus I show how you can go into the Comparison Analysis menu):\\n\\n\\n\\nNext time you know, it all starts with an e-mail. At Gamestonk Terminal we are on a role to have the best investment research terminal, and hope this story reflects it.\\n\\nTry it now, it\u2019s free. \u2764\ufe0f"},{"id":"handing-your-twitter-account-to-your-most-avid-community-member","metadata":{"permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.md","source":"@site/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.md","title":"Handing your twitter account to your most avid community member","description":"Handing over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement.","date":"2021-11-17T00:00:00.000Z","tags":[{"inline":true,"label":"Community Building","permalink":"/blog/tags/community-building"},{"inline":true,"label":"Twitter","permalink":"/blog/tags/twitter"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"}],"readingTime":4.305,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"handing-your-twitter-account-to-your-most-avid-community-member","title":"Handing your twitter account to your most avid community member","date":"2021-11-17T00:00:00.000Z","image":"/blog/2021-11-17-handing-your-twitter-account-to-your-most-avid-community-member.png","tags":["Community Building","Twitter","Open Source","Gamestonk Terminal"],"description":"Handing over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement."},"unlisted":false,"prevItem":{"title":"Sector and Industry Analysis \u2014 Gamestonk Terminal","permalink":"/blog/sector-and-industry-analysis-gamestonk-terminal"},"nextItem":{"title":"The Start of my Machine Learning journey","permalink":"/blog/the-start-of-my-machine-learning-journey"}},"content":"
\\n \\n
\\n\\nHanding over the Twitter account of Gamestonk Terminal to an active community member and the impact it had on the project\'s growth and engagement.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nWhen I started [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) I had no idea of the reach and impact it would have. From getting **over 3.5k stars on GitHub on the first single day alone**, to trending [on Reddit](https://www.reddit.com/r/algotrading/comments/lrndzi/cant_afford_the_bloomberg_terminal_no_worries_i/) and receiving overwhelming feedback, to receiving a message from an ex-colleague based in Switzerland about my name being [top 1 on Hackernews](https://news.ycombinator.com/item?id=26258773). As if this wasn\u2019t enough, a couple of days later the project got featured by [VICE Magazine](https://www.vice.com/en/article/qjp9vp/gamestonk-terminal-is-a-diy-meme-stock-version-of-bloomberg-terminal) and [Daily Fintech](https://dailyfintech.com/2021/02/25/never-underestimate-bloomberg-but-here-are-5-reasons-why-the-gamestonk-terminal-is-a-contender/).\\n\\nAs a result, my social life was impacted and had little time to even cuddle my puppy, due to the amount of feature requests, issues\u2026 the usual somehow ungrateful life of an open-source maintainer\u2026 I\u2019m not complaining though, as I live for this.\\n\\n\\n\\nMoving forward a couple of weeks, it became clear to myself that I was building a strong community around what can/will/should be a leading product in the emerging fintech industry and Internet 3.0. Therefore, I knew that github issues and discussions wouldn\u2019t be enough to interact with all members of the community, so Discord turned out to be the best option going forward (let\u2019s be honest: mostly because of the convenience that Discord offers to share memes, feel free to check my creations on [our Discord](https://discord.gg/2KnVnkDTxM), you can thank me later).\\n\\nMy next rookie mistake was thinking I could use Discord announcements and @ everyone, as a means for updating the community on new features. Being the #1 investment research free and open-source project on github gets you several PRs a day being merged, so in all the fairness the announcements were recurrent with constant several new features. You can check my [one hour live programming stream](https://www.youtube.com/watch?v=9BMI9cleTTg) of adding a feature to the terminal.\\n\\n\\n\\nThis is when I realized that Discord wasn\u2019t the best place for this type of communication. I needed a platform where I could share these features ad-hoc and that only alerted users who wanted to be up-to-date with our latest features. And this is when I created our [Twitter account](https://twitter.com/gamestonkt), @gamestonkt.\\n\\nReviewing the history of our Twitter feed, you can see that this is exclusively what our handle was used for. It just shared new features every day. It felt like I was always playing catchup to the growing number of features piling up in the queue waiting to be announced on Twitter. With the project already having **over 500 features** in less 1 year, this inevitable outcome would be a surprise to no one. (**yup, I repeat, over 500**).\\n\\n\\n\\nHowever, I felt like **it missed personality**... With time being a limiting factor \u2014 time was more efficiently used improving the terminal \u2014 the public facing demonstrations were a lower priority. When you believe this much in a product, the product ends up speaking for itself.\\n\\n> _\u201cIf you build it, they will come\u201d \u2014 Field of Dreams_\\n\\n
\\n\\nIt then occurred to me, why am I handling our Twitter? Why not leave this up to one of our most avid and vocal users that has been with project since beginning?\\n\\nAs Jim from \u201cThe Office\u201d would do, let\u2019s do a PROS & CONS table.\\n\\n### Pros\\n\\n- The user represents the community that the twitter content is targeted at.\\n- The user is an active daily user and will help to demonstrate features in the terminal.\\n- The user is keen on learning the ins and outs of the product.\\n- This user is not only a user anymore but a friend given his interaction with the maintainers.\\n- Lastly, I get to spend time doing what I enjoy: coding and meme content on our Discord.\\n\\n### Cons\\n\\n- The user finds out my mother\u2019s maiden name and the name of my first pet.\\n\\nThis is really a no brainer the more you think about it. I think it depends a lot on the type of people you have in your community and how confident you are on this individual .\\n\\nWe were lucky, because we had the **perfect fit**: an active Discord user **@Danglewood**, who had built an engaged audience, generating over 130K+ in Reddit karma over Q2 2021. It was clear that **@Danglewood** was having an impact on driving traffic and user engagement by posting data and his personal research with screenshots of Gamestonk Terminal.\\n\\nIn the future, **our report feature will allow easy sharing of this information**, I already can\u2019t wait for this. Through a combination of humour and truths, he was engaging the audience\u2019s curiosity by providing them with ways to filter out the ever-present noise within stock market information.\\n\\nIt made sense to bring this approach to [our Twitter](https://twitter.com/gamestonkt) feed which has since transformed and now offers insights, educational nuggets, and data as well as presenting new features. The end result speaks for itself!\\n\\n\\n\\nOn your end, what is your opinion? And why do you 100% agree that this was the best decision?"},{"id":"the-start-of-my-machine-learning-journey","metadata":{"permalink":"/blog/the-start-of-my-machine-learning-journey","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-11-07-the-start-of-my-machine-learning-journey.md","source":"@site/blog/2021-11-07-the-start-of-my-machine-learning-journey.md","title":"The Start of my Machine Learning journey","description":"The start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms.","date":"2021-11-07T00:00:00.000Z","tags":[{"inline":true,"label":"Machine Learning","permalink":"/blog/tags/machine-learning"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Education","permalink":"/blog/tags/education"},{"inline":true,"label":"Self-Learning","permalink":"/blog/tags/self-learning"}],"readingTime":4.62,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"the-start-of-my-machine-learning-journey","title":"The Start of my Machine Learning journey","date":"2021-11-07T00:00:00.000Z","image":"/blog/2021-11-07-the-start-of-my-machine-learning-journey.png","tags":["Machine Learning","Python","Data Science","Education","Self-Learning"],"description":"The start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms."},"unlisted":false,"prevItem":{"title":"Handing your twitter account to your most avid community member","permalink":"/blog/handing-your-twitter-account-to-your-most-avid-community-member"},"nextItem":{"title":"An unusual journey learning about NNs for a PhD thesis","permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis"}},"content":"
\\n \\n
\\n\\nThe start of my journey into the world of Machine Learning, from learning Python to understanding the underlying mathematics of ML algorithms.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDuring my studies at [Imperial College London](https://www.imperial.ac.uk/) - 3ish years ago - I was introduced to the topic of Machine Learning, an area that I had always been interested about.\\n\\nAt that time, not only I didn\'t know python, as `from sklearn.decomposition import PCA` wasn\u2019t allowed. Therefore, we had to write the PCA (and other) algorithms in Matlab from scratch, which was great because it exposed us to the maths behind each algorithm.\\n\\n\\n\\nThe gif above is from my graduation at Royal Albert Hall with a MSc. in Control Systems with Distinction.\\n\\nAfter concluding my thesis (and paper): \\"[Energy savings from an Ecological Cooperative Adaptive Cruise Control: a Battery Electric Vehicle platoon investigation](https://ieeexplore.ieee.org/abstract/document/8796226)\\", which was presented at the 2019 European Control Conference in Napoli, I had finally time to focus on Machine Learning topics during my spare time through late hours and into weekends.\\n\\nI started by doing the famous MOOC **\u201cMachine Learning - Andrew Ng\u201d**. Saying that the course was good is an understatement. I ended up spending a long time on the course as I was taking notes and revising daily; I was still behaving like a university student even without the exam at the end! Not only the theory is really detailed, but the coursework in Matlab allowed me to understand what\u2019s going on under the hood. Given that I was already a heavy Matlab user, due to its usage throughout my entire academic journey, I could focus on the ML section.\\n\\nAfter this course, I knew that I had learnt a lot, but I also knew that if I wanted to use ML for real-applications, I\u2019d have to learn Python. Given that I knew Matlab, I choose to start reading a python book that had Data Science application in mind. Hence, I started reading **\u201cPython Data Science Handbook\u201d**. This, along with several hours of practicing on available datasets, has taught me pretty much all I know about Numpy, Pandas and Matplotlib. Although this book also contains a last chapter with ML algorithms, these are rather brief.\\n\\n> _In my previous job at Nurvv, where I worked as Sensor Fusion Engineer, I developed a python analysis tool that parsed all the raw data from a running session and conveyed that information into meaningful plots. This allowed us to analyse whether a run was successful from the Firmware side of things, and this was critical for our development. This tool was created mainly from the knowledged gathered from the book mentioned above._\\n\\n
\\n\\nFollowing this, I was rather confident with my Python skills. Therefore, I wanted to crack-on learning how to use ML algorithms with Python through the beauty of imports. It comes without saying that I had to start from the best-seller **\u201cHands-on Machine Learning with Scikit-Learn, Keras and TensorFlow\u201d**. This book was what I was expecting and more. From time to time, when I\u2019m working on personal projects, I still flick through it. This book also allowed me to develop many more personal projects (most of them public in [my GitHub](https://github.com/DidierRLopes), as I\u2019m a big Open-Source fan \u2014 you should know that as I made [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) repository public).\\n\\n\\n\\nThe project that has been my biggest challenge was working with a friend on his PhD thesis entitled _\u201cModelling and Forecasting of Time-Series: A data science approach that compares classic methodologies with deep learning methodologies\u201d_. Not only interpreting and discussing results but writing the code behind it. S/O to the resources: **\u201cForecasting: Principles and Practice\u201d** and **\u201chttps://machinelearningmastery.com\u201d**. Without these, this work would have been much harder.\\n\\nThroughout my short journey, I followed many people related with DS. People that I thought that in some shape or form added value through their posts. One of these, was Andriy Burkov. I remember when he started talking about creating the **\u201cThe Hundred-Page Machine Learning Book\u201d** and specifically, I remember his Linkedin\'s poll to select the colour of one of the bubbles for his books\' cover. I voted purple; the result was yellow. So, I took the freedom to fix the cover of his book, as you can see below.\\n\\n\\n\\nMy gecko Reidid on \u201cThe Hundred-Page Machine Learning Book\u201d\u200b, in order to keep industry standards of ML books with reptiles.\\n\\nI really enjoyed his book since it can explain everything, while keeping it simple and short. As I learned at University, _Keep It Simple, Stupid_. Also, his book is distributed in a \u201cread first, buy later\u201d principle. This meant that I was able to flick through the content of the book before buying it. Personally, I think this should be adopted more often, at least for technical books.\\n\\nFinally, last summer, while on holiday in Portugal, I read **\u201cApproaching (almost) any machine learning\u201d**, which I found to be great for people that have read about the theory but were wondering where/how to apply it.\\n\\nThe next ML books in my list are:\\n- **Deep Learning** \u2014 Aaron Courville, Ian Goodfellow, and Yoshua Bengio\\n- **The Elements of Statistical Learning** \u2014 Jerome H. Friedman, Robert Tibshirani e Trevor Hastie\\n- **Pattern Recognition and Machine Learning** \u2014 Christopher Bishop\\n- **Understanding Machine Learning: From Theory to Algorithms** \u2014 Shai Ben-David and Shai Shalev-Shwartz\\n\\nLet me know if you think these are good books, or if there are others that you\u2019d recommend."},{"id":"an-unusual-journey-learning-about-nns-for-a-phd-thesis","metadata":{"permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.md","source":"@site/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.md","title":"An unusual journey learning about NNs for a PhD thesis","description":"An unusual journey of learning about Neural Networks for a PhD thesis. This blog post details the author\'s experience of assisting in the programming aspect of a PhD thesis, focusing on the study of various models and their forecasting performance.","date":"2021-10-22T00:00:00.000Z","tags":[{"inline":true,"label":"PhD Thesis","permalink":"/blog/tags/ph-d-thesis"},{"inline":true,"label":"Neural Networks","permalink":"/blog/tags/neural-networks"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Time Series Forecasting","permalink":"/blog/tags/time-series-forecasting"}],"readingTime":3.625,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"an-unusual-journey-learning-about-nns-for-a-phd-thesis","title":"An unusual journey learning about NNs for a PhD thesis","date":"2021-10-22T00:00:00.000Z","image":"/blog/2021-10-22-an-unusual-journey-learning-about-nns-for-a-phd-thesis.png","tags":["PhD Thesis","Neural Networks","Python","Time Series Forecasting"]},"unlisted":false,"prevItem":{"title":"The Start of my Machine Learning journey","permalink":"/blog/the-start-of-my-machine-learning-journey"},"nextItem":{"title":"How I created a bot in python to participate in NFT giveaways","permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways"}},"content":"
\\n \\n
\\n\\nAn unusual journey of learning about Neural Networks for a PhD thesis. This blog post details the author\'s experience of assisting in the programming aspect of a PhD thesis, focusing on the study of various models and their forecasting performance.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOn 14th February of 2019, my previous Maths and Statistics teacher \u2014 [Filipe](https://www.linkedin.com/in/filipe-r-ramos-a66242143/) - sent me a messaged because of a Linkedin post I shared about work I was doing in python.\\n\\nIt turns out that Filipe was looking for someone to help him with his PhD thesis, in specific, with the programming side of it. The challenge was to study diverse models (from classical to neural networks) and assess their forecasting performance. Since time series prediction was always a topic that I found fascinating and hadn\u2019t had time to study, I thought this would be the perfect timing to do so.\\n\\nSo from February 2019 onwards, this exciting journey started. I was working full-time so in order to be able to take part in this, I was only sleeping 4/5h a day. I started reading a lot of books and practicing my python coding skills in order to be more helpful. Then around June, we started working together on the code. We had around 2\u20133h discussions a couple times a week where we would discuss the point of the situation code-wise and where we wanted to be, we kept in touch about this every day.\\n\\nFrom the repo, which is open source [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast), you can see that we explored: Exploratory Data Analysis; ARIMA and SARIMA; Exponential Smoothing; Deep Neural Network. The final part of this work consisted in an innovative approach to tackle an univariate time series, which you can find [here](https://github.com/DidierRLopes/UnivariateTimeSeriesForecast/blob/master/DNN_ourApproach.ipynb). On top of that, a library of cross-validation for Neural Networks was developed, which is now being used in real data science applications, see [here](https://github.com/DidierRLopes/timeseries-cv).\\n\\nThe work, which took around 1 year to complete, can be divided into 3 distinct phases:\\n\\n- The **coding** phase lasted around 3 months. I would write the code, test the code and then touch base with Filipe to ensure we were going in the right direction.\\n- The **tweaking and analysis phase** took around another 3 months. Here, Filipe took the code I had completed and analysed multiple time series with different trends and seasonalities; tweaked different models; trained and validated these; and started interpreting results. In this phase, me and Filipe would discuss the code from a pragmatic point of view, and improve it based on what Filipe wanted to see/analyse. This phase was so intense that Filipe flew out to London twice to meet me, almost over a period of 1 month.\\n- The **writing of the thesis phase** took an additional 6 months. Here Filipe basically translated the results and analysis seen on the notebook of the thesis, wrote a full theoretical background on the models used and interpreted the applicability of these.\\n\\nThe full work, _\u201cData Science in the Modeling and Forecasting of Financial timeseries: from Classic methodologies to Deep Learning\u201d_, can be found in [here](https://ciencia.iscte-iul.pt/publications/data-science-na-modelacao-e-previsao-de-series-economico-financeiras-das-metodologias-classicas-ao/82703) or stored in [here](https://repositorio.iscte-iul.pt/handle/10071/22964).\\n\\nDuring this time, Filipe was also working full-time as he was a teaching assistant in three different universities. In spite of the adversities, Filipe achieved an impressive approved with \u201c_unanimous distinction_\u201d (maximum classification) from ISCTE Business School, Lisbon, Portugal.\\n\\nMy character waiting for people to join my chatroom to discuss our poster.\\n\\n\\n\\nLast week, at XXV Congress of the Portuguese Statistical Society (SPE 2021), we presented:\\n\\n- A poster that you can find [here](https://www.researchgate.net/publication/355360806_Forecasting_models_for_time-series_a_comparative_study_between_classical_methodologies_and_Deep_Learning), titled: _\u201cForecasting models for time-series: a comparative study between classical methodologies and Deep Learning\u201d_\\n- A presentation that you can find [here](https://www.researchgate.net/publication/355360897_Explorando_o_poder_da_memoria_das_redes_neuronais_LSTM_na_modelacao_e_previsao_do_PSI_20), titled: _\u201cExplorando o poder da mem\xf3ria das redes neuronais LSTM na modela\xe7\xe3o e previs\xe3o do PSI 20\u201d_\\n\\n\\n\\nThe poster above was presented at XXV Congress of the Portuguese Statistical Society (SPE 2021).\\n\\nI started this journey with my previous maths teacher and ended it with a close friend! Excited to see what other articles/publications we\u2019ll be working on together in the future.\\n\\nPS: The ARIMA/ETS/MLP/RNN/LSTM models learned from this work, consisted the basis of the prediction menu on [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal).\\n\\nAs always, feel free to provide feedback!"},{"id":"how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","metadata":{"permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.md","source":"@site/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.md","title":"How I created a bot in python to participate in NFT giveaways","description":"In this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork.","date":"2021-09-30T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Bot","permalink":"/blog/tags/bot"},{"inline":true,"label":"NFT","permalink":"/blog/tags/nft"},{"inline":true,"label":"Giveaways","permalink":"/blog/tags/giveaways"},{"inline":true,"label":"Reddit","permalink":"/blog/tags/reddit"},{"inline":true,"label":"Automation","permalink":"/blog/tags/automation"}],"readingTime":2.82,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"how-i-created-a-bot-in-python-to-participate-in-nft-giveaways","title":"How I created a bot in python to participate in NFT giveaways","date":"2021-09-30T00:00:00.000Z","image":"/blog/2021-09-30-how-i-created-a-bot-in-python-to-participate-in-nft-giveaways.png","tags":["Python","Bot","NFT","Giveaways","Reddit","Automation"],"description":"In this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork."},"unlisted":false,"prevItem":{"title":"An unusual journey learning about NNs for a PhD thesis","permalink":"/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis"},"nextItem":{"title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share how I created a bot in Python to automate participation in NFT giveaways on Reddit. The bot simplifies tasks such as upvoting posts, commenting, and opening Opensea links to favourite artwork.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GiveawayNFTbot).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nLately I\u2019ve been looking into NFTs. I\u2019ve observed that more and more people are trying to innovate and create their own pieces of art. Some of them are impressive, some of them aren\u2019t. But,\\n\\n> _Beauty is in the eye of the beholder \u2014 Margaret Wolfe Hungerford_\\n\\n
\\n\\nHowever, in my humble opinion, what distinguishes some art from others, is most of the time not the art itself but the community around it. For example, when everyone starts talking about the \u2018new best thing\u2019 you feel more pressure to get involved.\\n\\nBecause of this dynamic, creators are investing in ways to increase their collectibles popularity by building their community. A great example is [ParallelNFT](https://parallel.life/) and the dystopic story that is being created around their cards \u2014 in their case, it\u2019s fairly easy to understand that once a big community is formed around such cards, video games, movies and even series are on the table. For the first time ever, we would go from selling collectibles to creating some form of entertainment. A whole new industry in the making.\\n\\nHowever, not every digital creator has the resources to create a full concept around their cards. Does this mean that they can\u2019t create a community around it? No. But they must find other ways. One of the most popular ways I\u2019ve seen is through giveaways. Similar to what small clothing brands do to increase their popularity. This is a great tactic in my opinion, since giveaway not only give you a bigger audience (people that participate and re-share content) but it makes the cards have multiple owners. This, as a result, makes the collection more attractive for NFT collectors.\\n\\n_When demand exceeds supply_, **prices tend to rise.**\\n\\nAnd these creators are using Reddit as the platform of their giveaways.\\n\\n\\n\\nWhen scrolling through reddit you will notice that all these posts have certain things in common:\\n- They ask for an up-vote on the post\\n- A comment with your wallet address\\n- To favourite their artwork\\n- They may also ask to you to join their Discord\\n- For a follow on their Twitter or Instagram\\n- If you can retweet or share a story\\n\\nThese are things that take time, and a bot can perfectly do this. Therefore, I wrote a [giveaway NFT bot](https://github.com/DidierRLopes/GiveawayNFTbot) to simplify my work. Now I just sit down and read robot vacuum reviews while the bot: upvotes, comments and opens their Opensea link for me to favourite their artwork.\\n\\nI\u2019ve already won multiple NFTs with this, which is exciting\u2014 you never know where the next [CryptoPunks](https://twitter.com/cryptopunksbot) are at.\\n\\nThere\u2019s actually 1 collection that I particularly like and believe has a lot of potential, it\u2019s called [CryptoCartoonEaters](https://opensea.io/collection/crypto-cartooneaters) and due to the uniqueness of each collectible (only 100 made), I really think it has a great potential. I acquired my favourite cartoon as a kid: Goku Eating a Burger.\\n\\n\\n\\nLet me know if you find this article interesting, and if you used the bot as well!"},{"id":"gamestonk-terminal-cant-stop-won-t-stop","metadata":{"permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.md","source":"@site/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.md","title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","description":"Gamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool.","date":"2021-09-16T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"},{"inline":true,"label":"Docker","permalink":"/blog/tags/docker"},{"inline":true,"label":"Jupyter Lab","permalink":"/blog/tags/jupyter-lab"},{"inline":true,"label":"Hugo Website","permalink":"/blog/tags/hugo-website"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Trading","permalink":"/blog/tags/trading"}],"readingTime":3.175,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-cant-stop-won-t-stop","title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","date":"2021-09-16T00:00:00.000Z","image":"/blog/2021-09-16-gamestonk-terminal-cant-stop-won-t-stop.png","tags":["Gamestonk Terminal","Open Source","Docker","Jupyter Lab","Hugo Website","Python","Finance","Trading"],"description":"Gamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool."},"unlisted":false,"prevItem":{"title":"How I created a bot in python to participate in NFT giveaways","permalink":"/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways"},"nextItem":{"title":"Time-Series CrossValidation for NN","permalink":"/blog/time-series-crossvalidation-for-nn"}},"content":"
\\n \\n
\\n\\nGamestonk Terminal\'s latest updates including Docker integration, Jupyter Lab integration, a new Hugo website, and new features. A summary of the recent developments and future plans for the open-source financial tool.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHey all,\\n\\nDo any of you know what **Docker, Jupyter Lab integration, features website and new features** have in common? Well this is what has been happening in [Gamestonk Terminal](https://github.com/GamestonkTerminal/GamestonkTerminal) world since last month, and **MORE**!\\n\\n### Docker\\n\\n- This has been a highly requested feature from our more experienced dev users, as it allows you to run our code in a container, pull the image and then get going with a smooth installation process. You will also be able to run Jupyer Lab from our Docker container.\\n\\n### Jupyter Lab Integration\\n\\n- Jupyter is on course to take over the world (see [here](https://netflixtechblog.com/notebook-innovation-591ee3221233)).\\n- Big investment banks like JP Morgan use Jupyter too, see [this](https://github.com/jpmorganchase/jupyterlab_templates).\\n- Professionals in the industry such as Data Scientists, Data Analysts and Machine Learning engineers are familiar with the combo dockers+notebooks. Therefore, it makes our terminal an attractive Open-Source project to devote time to.\\n- Academia students and universities will be able to use terminal data through a notebook for their projects and coursework. We\u2019re on track to be able to achieve something on this soon!\\n\\n### Hugo Website\\n\\n- Link [here](https://gamestonkterminal.github.io/GamestonkTerminal/).\\n- This will not only simplify a contributor\u2019s documentation process, but it will also let non-Gamestonkers now see the vast number of features we offer and yes, when you read \u201coffer\u201d this is actually an offer since the tool is **completely free** to use.\\n\\n### Main New features\\n\\n- New Dark Pool Shorts menu\\n- Refactored and improved Crypto menu!!!\\n- Dark Pool and Crypto report generation\\n- Excel Discounted Cash Flow created by a MBA student\\n- Big code refactoring to allow for contributors to easily get started with our codebase\\n- Contributing document (click here).\\n\\n### Tier 2 features\\n- [Sentiment Investor](https://sentimentinvestor.com/) data features implemented by the SI team themselves\\n- Feature/fraud indicators implemented by a MBA student\\n- Multiple plotting for economy data for more insight extraction\\n- Screener presets to not miss out on promising tickers\\n- Several new Technical Analysis indicators, e.g. Fibonacci, Fisher transform, Centre of gravity, zlma, Donchian channels\u2026\\n- Unusual options activity\\n- Hot penny stocks in discovery menu\\n- A contributor implementation of a realtime earnings expected move, from [The Geek of Wallstreet](https://thegeekofwallstreet.com/2021/08/03/realtime-earnings-data/)\\n- Several new YahooFinance commands to discover promising tickers\\n- Refactor Exploratory Data Analysis and Residual Analysis menus into a Quantitative Analysis one\\n\\nAs if this wasn\u2019t enough, we\u2019re also working towards a [Discord bot](https://github.com/GamestonkTerminal/DiscordBot) so you can make best use of our terminal when discussing trading strategies with your friends. This was an initiative from a contributor, which just goes to show how much **we rely on our community to drive our project**.\\n\\nIf you appreciate what we\u2019re doing and want a better free and Open-Source financial tool, you should definitely star the project on our github [here](https://github.com/GamestonkTerminal/GamestonkTerminal), join [our Discord channel](https://discord.gg/Up2QGbMKHY), and follow our [twitter account](https://twitter.com/gamestonkt?lang=en). Not necessarily in that order! :)\\n\\nHave you been following our project and want to join our growing community? Here are a few tips on how to get started:\\n- Join our Discord and tell us about your experience so far\\n- Let us know what else you would like to see in the terminal\\n- You can help to improve our crypto terminal, which is 99% taken care of from our contributors!\\n- Help us add any features! You don\u2019t know python? This may be your cue to learn with our team!\\n\\nMuch love!\\nGST Team & Community"},{"id":"time-series-crossvalidation-for-nn","metadata":{"permalink":"/blog/time-series-crossvalidation-for-nn","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-09-04-time-series-crossvalidation-for-nn.md","source":"@site/blog/2021-09-04-time-series-crossvalidation-for-nn.md","title":"Time-Series CrossValidation for NN","description":"This blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN).","date":"2021-09-04T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Data Science","permalink":"/blog/tags/data-science"},{"inline":true,"label":"Deep Learning","permalink":"/blog/tags/deep-learning"},{"inline":true,"label":"Time Series","permalink":"/blog/tags/time-series"},{"inline":true,"label":"Cross Validation","permalink":"/blog/tags/cross-validation"},{"inline":true,"label":"Neural Networks","permalink":"/blog/tags/neural-networks"}],"readingTime":2.66,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"time-series-crossvalidation-for-nn","title":"Time-Series CrossValidation for NN","date":"2021-09-04T00:00:00.000Z","image":"/blog/2021-09-04-time-series-crossvalidation-for-nn.png","tags":["Python","Data Science","Deep Learning","Time Series","Cross Validation","Neural Networks"],"description":"This blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN)."},"unlisted":false,"prevItem":{"title":"Gamestonk Terminal \u2014 Can\u2019t Stop, Won\u2019t Stop","permalink":"/blog/gamestonk-terminal-cant-stop-won-t-stop"},"nextItem":{"title":"Ranking 99 Mind f*ck movies","permalink":"/blog/ranking-99-mind-f-ck-movies"}},"content":"
\\n \\n
\\n\\nThis blog post discusses the creation of a Python module for splitting univariate time-series data using cross-validation techniques. The module is designed to prepare data for training, validation, and testing in a Deep Neural Network (DNN).\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/timeseries-cv).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n2 years ago, [Filipe Ramos](https://www.linkedin.com/in/ACoAACK9n24BrpxWf0HMa9bL7MSHleu2YVXpI5E) my previous maths and probability teacher, knowing that I had a special interest in Data Science, challenged me to help him in his PhD thesis \u201c_Data Science na Modela\xe7\xe3o e Previs\xe3o de S\xe9ries Econ\xf3mico-financeiras: das Metodologias Cl\xe1ssicas ao Deep Learning_\u201d.\\n\\nAlthough we have been discussing theory, analysis and results, my main contribution was to write the Python code behind the thesis.\\n\\nAs a result, I have written a python module that splits a given univariate time-series based on cross-validation techniques so that these can be fed to a Deep Neural Network (DNN) to extract training/validation/test errors.\\n\\nI know that there are examples of these online, but this was made from scratch so that we could personalise it according to the thesis\u2019 needs, and grasp better what was at stake when performing different cross-validation techniques.\\n\\n**The idea is given a training dataset, the package will split it into Train, Validation and Test sets, by means of either Forward Chaining, K-Fold or Group K-Fold.**\\n\\nAs parameters the user can not only select the number of inputs (`n_steps_input`) and outputs (`n_steps_forecast`), but also the number of samples (`n_steps_jump`) to jump in the data to train.\\n\\nThe best way to install the package is as follows: `pip install timeseries-cv` and then use it with `import tsxv`. See the module developed [here](https://pypi.org/project/timeseries-cv/).\\n\\nThis can be seen more intuitively using the jupyter notebook: \u201c_example.ipynb_\u201d Below you can find an example of the usage of each function for the following Time-Series:\\n\\n```python\\ntimeSeries = array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26])\\n```\\n\\n## Split Train\\n\\n```python\\nfrom tsxv.splitTrain import \\nsplit_train, \\nsplit_train_variableInput\\nX, y = split_train(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y = split_train_variableInput(timeSeries, minSamplesTrain=10, n_steps_forecast=3, n_steps_jump=3)\\n```\\n\\n
\\n \\n\\n \\n\\n\\n\\n\\n## Split Train Val Test\\n\\n```python\\nfrom tsxv.splitTrainValTest import split_train_val_test_forwardChaining, \\nsplit_train_val_test_kFold,\\nsplit_train_val_test_groupKFold\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_forwardChaining(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_kFold(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\nX, y, Xcv, ycv, Xtest, ytest = split_train_val_test_groupKFold(timeSeries, n_steps_input=4, n_steps_forecast=3, n_steps_jump=2)\\n```\\n\\n
\\n \\n\\n\\n\\n\\nThis module has not only been used for my friends\u2019 thesis but also for a Data Science company and [Gamestonk Terminal](/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal), that I know of :)\\n\\nYou can check the stats of the module [here](https://pypistats.org/packages/timeseries-cv)."},{"id":"ranking-99-mind-f-ck-movies","metadata":{"permalink":"/blog/ranking-99-mind-f-ck-movies","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-08-15-ranking-99-mind-f-ck-movies.md","source":"@site/blog/2021-08-15-ranking-99-mind-f-ck-movies.md","title":"Ranking 99 Mind f*ck movies","description":"Ranking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python.","date":"2021-08-15T00:00:00.000Z","tags":[{"inline":true,"label":"Movies","permalink":"/blog/tags/movies"},{"inline":true,"label":"Thrillers","permalink":"/blog/tags/thrillers"},{"inline":true,"label":"IMDbPy","permalink":"/blog/tags/im-db-py"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Sorting Algorithm","permalink":"/blog/tags/sorting-algorithm"}],"readingTime":2.135,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"ranking-99-mind-f-ck-movies","title":"Ranking 99 Mind f*ck movies","date":"2021-08-15T00:00:00.000Z","image":"/blog/2021-08-15-ranking-99-mind-f-ck-movies.png","tags":["Movies","Thrillers","IMDbPy","Python","Sorting Algorithm"],"description":"Ranking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python."},"unlisted":false,"prevItem":{"title":"Time-Series CrossValidation for NN","permalink":"/blog/time-series-crossvalidation-for-nn"},"nextItem":{"title":"K-means algorithm to visit a new city","permalink":"/blog/k-means-clustering-to-visit-a-new-city"}},"content":"
\\n \\n
\\n\\nRanking and sorting a list of 99 mind-bending thriller movies using IMDbPy API in Python.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/SortMoviesPerRating).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nDuring the Christmas holidays, me and my girlfriend, after watching The Office [US] twice in a row, and knowing most of Dwight\u2019s pranks off by heart, decided that it was time to find something worth watching.\\n\\nAlthough there\u2019s lots of tempting series out there, we didn\u2019t want to follow that path as we don\u2019t like the \u201caddiction\u201d effect that a series has. Also, we have the same taste regarding movies, where **we both enjoy complex thriller plots**, that leave your mind to resonate about them long after being done with it. Personally, I consider a movie great when it still crosses my mind when trying to sleep or the day after. So, thriller movies it was.\\n\\nAfter doing a little research work I came across this list of movies on Reddit: [99 mind f*ck movies](https://www.reddit.com/r/coolguides/comments/geipee/99_mindfck_movies/). I knew this list was good because most of my favourite movies were there, e.g. _The Prestige, Inception, The Usual Suspects, Primal Fear_, and _Ex Machina_.\\n\\nSo, the movie list was decided, and with that, also our new year\u2019s resolution.\\n\\nHowever, this list had 2 issues:\\n\\n**1. The list didn\u2019t have any particular order.** We would like to have the list ranked from best to worst, so that watching the best ones first will keep our motivation levels up to finish the list.\\n\\n**2. The movie title didn\u2019t have the released year.** Although we don\u2019t particularly mind old movies, sometimes we\u2019re just not in the mood to watch a B&W screen, or poor image resolution.\\n\\nTherefore, while Meg was busy, I was on a role to hack something that would both sort the list based on IMDB ranking, and add the release years to the titles.\\n\\nIn a couple of minutes, I was already playing with [IMDbPy API](https://imdbpy.github.io/). This allowed me to have the sorting algorithm running in the background pretty quick. Within the hour, we already had our sorted movie list. Which I have attached below for future reference.\\n\\n\\n\\nThe first movie of the list that none of us had already watched was the movie [Incendies](https://www.imdb.com/title/tt1255953/). After having watched this movie, I can already tell you that sorting out this list was worth it. Definitely mind blowing, and a great watch.\\n\\nAs usual, you can find the source code on my github: [SortMoviesPerRating](https://github.com/DidierRLopes/SortMoviesPerRating).\\n\\nHope you enjoyed this read!"},{"id":"k-means-clustering-to-visit-a-new-city","metadata":{"permalink":"/blog/k-means-clustering-to-visit-a-new-city","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.md","source":"@site/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.md","title":"K-means algorithm to visit a new city","description":"In this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions.","date":"2021-08-01T00:00:00.000Z","tags":[{"inline":true,"label":"K-means","permalink":"/blog/tags/k-means"},{"inline":true,"label":"Algorithm","permalink":"/blog/tags/algorithm"},{"inline":true,"label":"Travel","permalink":"/blog/tags/travel"},{"inline":true,"label":"Efficiency","permalink":"/blog/tags/efficiency"},{"inline":true,"label":"London","permalink":"/blog/tags/london"},{"inline":true,"label":"GPS","permalink":"/blog/tags/gps"},{"inline":true,"label":"Clustering","permalink":"/blog/tags/clustering"}],"readingTime":2.69,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"k-means-clustering-to-visit-a-new-city","title":"K-means algorithm to visit a new city","date":"2021-08-01T00:00:00.000Z","image":"/blog/2021-08-01-k-means-clustering-to-visit-a-new-city.png","tags":["K-means","Algorithm","Travel","Efficiency","London","GPS","Clustering"],"description":"In this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions."},"unlisted":false,"prevItem":{"title":"Ranking 99 Mind f*ck movies","permalink":"/blog/ranking-99-mind-f-ck-movies"},"nextItem":{"title":"Minion Recipes Program","permalink":"/blog/minion-recipes-program"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share how I used the K-means algorithm to plan a visit to London. The algorithm helps to decide which attractions to visit based on the number of days of the visit and the GPS coordinates of the attractions.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/LondonVisit).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nUsually when I book a weekend getaway, I spend quite some time doing 2 things:\\n\\n- Writing down the main attractions I want to see\\n- Depicting the travel path to maximise efficiency and see the most in less time (I\u2019m a bit of an efficiency freak myself, sorry)\\n\\n**This repository aims to decide which attractions to visit in London as a function of the number of days that you will be visiting, by applying K-means algorithm.**\\n\\nAs input you need to give the GPS coordinates of the main attractions you want to visit during your stay, and the number of days you are planning to visit. Notice that attractions that are not within the map screenshot boundaries will be discarded. See disclaimer below.\\n\\nThe K-means algorithm will interpret: List of GPS coordinates of the main attractions that you want to visit as 2D samples, after converting to UTM. Number of days of the visit as Number of clusters.\\n\\nOf course, this is rather unrealistic because of several reasons, such as:\\n\\n- Not taking into account if they want to just pass by the London Eye, or have a ride on it;\\n- Assumes that we are in a no man\u2019s land since it completely bypasses the existence of other buildings, roads, \u2026;\\n- Does not consider altitude, even though London is rather plane;\\n- Does not consider the number of attractions that one can possibly do per day;\\n- Plus, if there was to be an attraction really far from the centre, it may happen that the algorithm considers an entire day for it (this would depend upon kernel initialisation)\\n\\nNonetheless, I think this is a funny exercise, and if I were to select the areas to visit by myself, **it would most likely be a similar choice to the one taken by K-means**.\\n\\n**Disclaimer**: I did not know how to use Google API (neither wanted to pay for a key to be fair) hence I just took a screenshot of google maps and wrote down the coordinate of the lower left corner, so that I could use it as my origin. I also took the right top corner coordinate so that I could give the map with an \u201caccurate\u201d scaling.\\n\\n**Note**: GPS coordinates (latitude, longitude) have degrees has units, thus, explaining why the conversion to UTM coordinates, which uses meters.\\n\\nImmediately below you can see the result of a visit to London for 2, 3 and 4 days.\\n\\n\\n\\n
\\n \\n\\n\\nThis project was done for fun. However, I believe that by creating a tuple per location with coordinates and estimate of time taken on each attraction, something nice could come out of this.\\n\\nHope you find this interesting. Let me know your thoughts."},{"id":"minion-recipes-program","metadata":{"permalink":"/blog/minion-recipes-program","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-07-23-minion-recipes-program.md","source":"@site/blog/2021-07-23-minion-recipes-program.md","title":"Minion Recipes Program","description":"In this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons.","date":"2021-07-23T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Recipes","permalink":"/blog/tags/recipes"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"}],"readingTime":2.535,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"minion-recipes-program","title":"Minion Recipes Program","date":"2021-07-23T00:00:00.000Z","image":"/blog/2021-07-23-minion-recipes-program.png","tags":["Python","Programming","Recipes","Software Development"],"description":"In this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons."},"unlisted":false,"prevItem":{"title":"K-means algorithm to visit a new city","permalink":"/blog/k-means-clustering-to-visit-a-new-city"},"nextItem":{"title":"Household bills Program","permalink":"/blog/household-bills-program"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share how I developed a program to help my mum manage her recipes. The program allows for adding, editing, and removing recipes, and even includes fun minion icons.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/RecipesProgram).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nOnce I developed the [Housebills program](/blog/household-bills-program), I really enjoyed the feeling of being able to create usable software from scratch. Therefore, that year during Christmas, I wanted to challenge myself to see if I could find any interesting project to do in only 1 week.\\n\\nI started by nagging my dad and brother for them to tell me something that would be useful to them in their daily lives. Sadly, none of them had any idea. Then, I went to the kitchen to ask my mum the same. She was busy searching recipes for xmas on her messy notebook, so she also said no.\\n\\nI sat there next to her thinking about what I could do, while she kept on going back and forth in her notebook searching. I don\u2019t know if she had been reading about the binary search algorithm, or if she was just opening pages randomly. What I know is that 1 week later I did a program for her to keep her recipes. Safe to say that I saved Christmas, I guess.\\n\\nNote: Before the end of that year, I still upgraded the software for its version 2.0, which included more than 20 minion icons. To this day, I think she opens the program to see the minion icons more than the recipes themselves.\\n\\nBelow it displays the interfaces used, and these correspond to: Red-Visualize; Add; Blue-Add; Green-Edit; and Yellow-Remove recipes.\\n\\n\\n\\nPS: Any resemblance with the Microsoft colour scheme is pure coincidence eheh.\\n\\nWhen adding a recipe, the following window will be displayed.\\n\\n\\n\\nThis allows you to add both a recipe, and a category (i.e. the \u201cTiramisu\u201d recipe would be within \u201cDesserts\u201d category).\\n\\nThe recipe content would include:\\n\\n- Name of the recipe\\n- Ingredients\\n- Preparation\\n- Comment\\n\\nWhen visualising a recipe, the following window will be displayed.\\n\\n\\n\\nWhere the recipe dialog box would prompt the recipes based on the category chosen on its left. Then, after selecting a recipe, the ingredients, preparation and comment would be filled out.\\n\\nWhen editing a recipe, the following window will be displayed. This is similar to the visualisation window, with the difference that the text boxes are editable, and therefore, the recipe can be improved.\\n\\n\\n\\nNote: throughout the program there are Message Dialog boxes (as shown above) that tell the user whether the recipe has been successfully (or not) edited, added or removed.\\n\\nFinally, in order to remove a recipe, the following window would be displayed. Where you can either delete a single recipe, or the entire category.\\n\\n\\n\\nThe recipe database is handled in the most robust way: **with plain text files**, obviously.\\n\\nAs always, hope you had a nice read."},{"id":"household-bills-program","metadata":{"permalink":"/blog/household-bills-program","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-07-17-household-bills-program.md","source":"@site/blog/2021-07-17-household-bills-program.md","title":"Household bills Program","description":"In this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application.","date":"2021-07-17T00:00:00.000Z","tags":[{"inline":true,"label":"Java","permalink":"/blog/tags/java"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"GUI","permalink":"/blog/tags/gui"},{"inline":true,"label":"Software Development","permalink":"/blog/tags/software-development"},{"inline":true,"label":"Side Project","permalink":"/blog/tags/side-project"}],"readingTime":4.56,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"household-bills-program","title":"Household bills Program","date":"2021-07-17T00:00:00.000Z","image":"/blog/2021-07-17-household-bills-program.png","tags":["Java","Programming","GUI","Software Development","Side Project"],"description":"In this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application."},"unlisted":false,"prevItem":{"title":"Minion Recipes Program","permalink":"/blog/minion-recipes-program"},"nextItem":{"title":"My journey of memorising a deck of 52 shuffled cards","permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share my journey of creating a program to split household bills. This was my first side project where I used Java to create a GUI application.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/HouseholdBills).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n**My first side project.**\\n\\nBefore University, I spent most of my spare time playing counter-strike (my steam account had **more than 1000 hours played**, that\u2019s more than 41 entire days playing in a row). I was a decent player I\u2019d say, you can see a compilation of \u201calmosts\u201d I\u2019ve done [here](https://www.youtube.com/watch?v=ocsJzNJJB50).\\n\\nHowever, I knew this wasn\u2019t the way. I realised that if I used the amount of time I was spending on online games for learning, I would have a much bigger satisfaction return. And, in the long term, my life would be better.\\n\\n**So I started studying hard.** I started valuing my time more, and declined most of the parties I was invited to because I was busy working late hours. Don\u2019t get me wrong, I\u2019m an easy person. I like to think I make friends easily. However, I just had different priorities, and partying just wasn\u2019t one of them. As my parents say: _\u201cEverything has its own time\u201d_.\\n\\nIn my 2nd year of University, I was getting really good grades, which means that I started having discussions with the other best students in the course. **That\u2019s how I met one of the smartest people I know to this day**. This guy was a proper hands-on person, he didn\u2019t study half the time I did, but he was always busy with something.\\n\\nHe had a band, developed his own personalised guitar pedals and amplifiers, and developed some apps for fun. He did this all while having excellent results at University, which is insane. That\u2019s when I realised that he was not only giving more priority to these hobbies in relation to partying or meeting people, **BUT also in relation to doing courseworks or studying for exams**. He\u2019d never fail a coursework/exam, but that further study could have bumped a grade from 17 to a 19 out of 20.\\n\\nOne day, we were meant to meet at his place to work on a coursework together, and he shown me an app that he had developed for him and his girlfriend. The app was a simple command line interface that was able to split their usual household bills (rent, water bill, food shop, cat food, etc). **I found that fascinating.**\\n\\nI told him I would create one for myself. Since I had read about how to use Java to make a pretty GUI, I thought why not give this a go (although I had no idea about OOP). In addition, I didn\u2019t want my program to look the same as his, so I thought my version could be as if it was an upgrade.\\n\\n...\\n\\nAfter that, I was on a mission. Little did I know that after this, I never really stopped having an interest in working on new side projects.\\n\\nThe planning steps were:\\n\\n**1. Decide main features.**\\n Add new household bills to split, Give money, and See bills.\\n\\n**2.Sketch what the GUI should look like**\\n\\n**3. Devise data structure associated with a new Household bill split.**\\n This was important for both coding, and also database management.\\n\\n**4. Work out the math associated with the splitting and giving**\\n\\nThe development process was to **\u201cdivide to conquer\u201d**. I split the tasks into several sub-tasks, and after every new little code change I was testing the code to make sure that nothing was broken. I re-iterate through design and code several times, until I was happy with my solution. Then I did some clean-up/improvements, such as: Adding pictures of the users, Login password, Frenchies as icons.\\n\\n**On a funny side note:** As I didn\u2019t know how to work with DBs at that time, I used text files to save and load all the information. Meaning that if my brother ever opened one of those text files (which weren\u2019t properly hidden\u2026), I could have passed from him owing me 100 euros to me owing him 10 million. The software was on his laptop, and I had an hardcoded password, so in theory he couldn\u2019t manually add any bill without my presence \u2014 I guess that was enough for him to think that the product was bullet-proof.\\n\\nSee images below of the program:\\n\\n
\\n \\n\\n\\n
\\n \\n\\n\\nYou can find more information about this on my GitHub, [here](https://github.com/DidierRLopes/HouseholdBills).\\n\\n**The program ended up being used for more than 3 years.** Since I lived with other people other than my brother, I had to update the name/image on the program to represent that. Since I was new to coding, I didn\u2019t think about the future. Therefore, when that time came, I had to manually replace the names one by one in the code. I also had friends requesting to use the program, which lead to me adapting this to their names/figures.\\n\\nIt was a fun project and I definitely learned loads from it. The most important thing was that I was able to do whatever **I wanted software-wise as long as I dedicated enough time for it.**\\n\\nHope you had a fun read. Thanks!"},{"id":"my-journey-of-memorising-a-deck-of-52-shuffled-cards","metadata":{"permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.md","source":"@site/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.md","title":"My journey of memorising a deck of 52 shuffled cards","description":"In this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique.","date":"2021-06-26T00:00:00.000Z","tags":[{"inline":true,"label":"Memory Training","permalink":"/blog/tags/memory-training"},{"inline":true,"label":"PAO System","permalink":"/blog/tags/pao-system"},{"inline":true,"label":"Memory Palace","permalink":"/blog/tags/memory-palace"},{"inline":true,"label":"Card Memorisation","permalink":"/blog/tags/card-memorisation"}],"readingTime":9.175,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"my-journey-of-memorising-a-deck-of-52-shuffled-cards","title":"My journey of memorising a deck of 52 shuffled cards","date":"2021-06-26T00:00:00.000Z","image":"/blog/2021-06-26-my-journey-of-memorising-a-deck-of-52-shuffled-cards.png","tags":["Memory Training","PAO System","Memory Palace","Card Memorisation"],"description":"In this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique."},"unlisted":false,"prevItem":{"title":"Household bills Program","permalink":"/blog/household-bills-program"},"nextItem":{"title":"Customizable Meme Filter","permalink":"/blog/customizable-meme-filter"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share my journey of memorising a deck of 52 shuffled cards using the PAO system and Memory Palace technique.\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nA few years back, I wanted to read a book about memory and found the best-selling book **\u201cMoonwalking with Einstein: The Art and Science of Remembering Everything\u201d** an ideal choice. I won\u2019t go into too much detail about the book which is a great read, if you don\u2019t trust me, trust Bill Gates, who called the book \u201c_absolutely phenomenal_\u201d. But let me give you a brief sequence of events from the author and journalist of the book, Joshua Foer:\\n\\n- It starts by observing the extraordinary accomplishments of mental athletes at a memory championship.\\n- Foer meets Tony Buzan, the trim 67-year-old English self-help guru who founded the [World Memory Championships](http://www.worldmemorychampionships.com/) in 1991 and who insists the brain is \u201clike a muscle\u201d: exercise it and it gets stronger.\\n- Foer learns the art of memory training.\\n- He practices his memory muscles for 1 year with help of a shambling 24-year-old from Oxford who becomes his mentor.\\n- He then finds himself in the finals of the US Memory Championships, alongside \u2018mental athletes\u2019 who could memorise the precise order of ten shuffled decks of cards in under an hour.\\n\\nIf you\u2019re interested, here\u2019s a [nice review](https://www.theguardian.com/science/2012/nov/21/moonwalking-einstein-joshua-foer-review) on the book.\\n\\n## My thoughts after reading book\\n\\nAfter finishing this book, more than anything I was curious. Unlike Joshua Foer, I didn\u2019t want to dedicate a full year to the cause, but I still wanted to give it a go so I could look back and think: \u201cHere\u2019s something pretty useless for the day-to-day. Yet, how cool is that I can memorise 52 random cards?\u201d.\\n\\n\\n\\nFor people who know me, they know how much I hate to leave things unfinished. Whether that\u2019s a task that I set myself, or \u2018just\u2019 not leaving any pizza leftover. Therefore, I knew that if I really wanted to do this, I\u2019d have to set aside time for it, and so I did. The text under is my journey to memorise a shuffled deck of 52 cards.\\n\\n## Technique (PAO + Memory Palace)\\n\\nThe mnemonic \u201c**Memory Palace**\u201d technique that I was about to use was referred to on the aforementioned book. The ancient mnemonic technique was first practiced by Simonides of Ceos over 2,500 years ago. When googling the term, the definition is:\\n\\n_A Memory Palace is an imaginary location in your mind where you can store mnemonic images. The most common type of memory palace involves making a journey through a place you know well, like a building or town. Along that journey there are specific locations that you always visit in the same order._\\n\\nThe mnemonic images would be conceived using the famous PAO system. This term means:\\n\\n_The Person-Action-Object System (or \u201cPAO\u201d System) is a popular method for memorising long random numbers and decks of playing cards. \u2026 Some people assign arbitrary images to the numbers without any phonetic conversion. The digits are usually chunked in 2 or 3 digits and then placed into loci in a Memory Palace._\\n\\nThe idea is to take advantage of what we humans are best at, photographic memory.\\n\\n## The journey of memorising a shuffled deck of 52 cards\\n\\n### 1. Create your own personal PAO system.\\n\\nFor each card of the deck you have to have an associated _Person_, _Action_ and _Object_. It\u2019s useful to have the least possible rules, and have these intersecting simultaneous cards, so that there\u2019s less to memorise. Here\u2019s how I did it:\\n\\n- Define a **category** for each **suit** (e.g. Hearts represents friends)\\n- Define **something** for each **type**.\\n - From 1 to 10 I\u2019ve defined the starting letter of the person (e.g. Card 7 represents a person with name starting with letter K or C).\\n - For the court (Queen, Jack, King) I\u2019ve defined them as a powerful male/female. (e.g. King is the GOAT of the category).\\n\\nBelow you can see what the table looks like:\\n\\n\\n\\n**Note:** The Person is the main existing link, hence it needs to be something that you think of immediately when the category and the type of the card is known.\\n\\nI had to change my cards several times as some of the PAO\u2019s I had weren\u2019t memorable enough, either because the name was too common, or because I didn\u2019t relate that much to this person.\\n\\n### 2. Memorise each card with it\u2019s PAO system\\n\\nOnce the table above is filled in, the next step is to associate each card with it\u2019s **Person-Action-Object**. I find that as long as you can remember the person name of the card by doing the cross between category and type, the action-object comes easily.\\n\\nFor instance:\\n\\n\\n\\n**Jack \u2666: Einstein \u2014 Writing Equations \u2014 Blackboard**\\n\\n- When I see a **Diamond**, I know we are in the **Celebrities** category. Since this is a **Jack** I know it\u2019s an **important person**. I\u2019ve selected Musk to be my GOAT, so this has to be **Einstein**. The **writing equations** and **blackboard** comes trivially when thinking about Einstein.\\n\\n**8 \u2663: Floyd Mayweather \u2014 Skipping \u2014 Rope**\\n\\n- When a **Club** appears, I know we are in the **Athletes** category. Since this is an **8** I know the name starts with an **F or V**. This promptly reminds me of **Floyd**. The **skipping** and **rope** come immediately, due to my own personal experiences from improving my skipping skills and looking at videos of Mayweather. I find that the more the personal and creative you get with this, the easier it is to remember.\\n\\n**King \u2660: Goku \u2014 Powering up \u2014 Blonde Hair**\\n\\n- If I see a **Spade**, I know we are in the **Cartoon** category. Since this is a King I know that this character is the **GOAT**. Which immediately triggers my brain to Goku, since it used to be my favourite cartoon as a kid. Trivially, comes the powering up as action, and the blonde hair as object.\\n\\nIn order to remember all the cards, my trick was to have a deck of cards where on the back of each card I wrote its own PAO. So that if I didn\u2019t remember, instead of looking at the table, I could look at the back of the card. However, I find it important to sometimes not quit trying to remember immediately, as when you initially struggle to remember a card, when you eventually do, your brain retains this information so much better.\\n\\n**Note: At this step you may realise that you keep forgetting the same PAO card. I recommend you going back to step 1 and re-defining it.** Once I did this to the cards I kept forgetting, I was in a much better position.\\n\\n### 3. Create your own memory palace\\n\\nThis is the easiest step. I used the house I grew up in in Portugal, and decided to place 4 PAO instruments (i.e. 12 cards) per house division. Meaning that by the time I was in the first room upstairs, I was already 36 cards down the deck.\\n\\nSince I\u2019m not living in Portugal, let me show you what I mean by using a picture of my current living room in London. The spots I would select in here would have been: 1. Top of table with candles; 2. Top of side table; 3. Inside my gecko\u2019s vivarium; 4. As a program on the TV.\\n\\n\\n\\n**Note: Make sure you always remember your memory palace spots, otherwise you may overlook them once looking for the next 3 set of cards.** The way I think about this is imagining that I lost my keys, and mentally going back in time to try to understand where they could be.\\n\\n### 4. Practice memorising each set of 3 cards PAO\\n\\nThis is where the creativity comes in. **When picking 3 cards from the deck, you picture the Person of the 1st card, the Action of the 2nd one, and the Object of the 3rd one.**\\n\\nLet\u2019s imagine we\u2019ve got the cards aforementioned.\\n\\n**- Card 1: Jack \u2666**\\n * Einstein \u2014 Writing Equations \u2014 Blackboard\\n\\n**- Card 2: 8 \u2663**\\n * Floyd Mayweather \u2014 Skipping \u2014 Rope\\n\\n**- Card 3: King \u2660**\\n * Goku \u2014 Powering up \u2014 Blonde Hair\\n\\nIn my brain, this would lead to\\n\\n\\n\\n**Note: At this point you may realise that some combos of cards don\u2019t work well together. **If this is bad enough to not make you remember the 3 card PAO, I recommend updating your PAO system to something that\u2019s easier to generalise.\\n\\n### 5. Place each 3 cards PAO onto the memory palace\\n\\nFor instance, if I were to place the **Einstein Skipping with Blonde Hair** on the **3rd spot of my living room (my gecko\u2019s vivarium)**, in my head, I would picture something like this:\\n\\n\\n\\n**Note: I recommend trying to have the 3 card PAO interacting with the environment to improve memory.** In this case, I would have thought about the Blonde Skipping Einstein having to do skipping so fast that the gecko coudn\u2019t come close because the rope was going too fast. The more original/different, the more chances you have to remember this scenario.\\n\\n### 6. Re-iterate the memory palace with new 3 card PAO every time\\n\\nInstead of memorising a new 3 card PAO in a memory palace location and then moving on, I always go back to the start and think about all the previous 3 card PAO\u2019s from start. This will ensure you don\u2019t forget the oldest 3 card PAO. In fact, it will make it so that the oldest 3 card PAO are repeated more times than the newer ones, so it\u2019s all balanced out.\\n\\n### 7. Practice and Practice\\n\\nI found out that after memorising my PAO system (which took a long time) and the memory palace, it was fairly easy to memorise the shuffled 52 deck of cards. However, it was taking me way too long to memorise it AND say it out loud.\\n\\nOnce I started practicing more and more time started decreasing. The last time I tried, I managed to do it under 10 minutes, which is not great but I\u2019ll take it. As I mentioned, I just wanted to be able to do it, I didn\u2019t care much about the time.\\n\\nAlso, I still needed to think about the category + type of the card every-time, I think the time to memorise the deck of cards decreases exponentially once you actually associate each card image to it\u2019s PAO. But for that you need to practice more, which for me was getting boring.\\n\\n...\\n\\nThis is a different post than the ones I usually do, but I find it extremely interesting. Hence why I was keen on sharing it.\\n\\nLet me know if you\u2019ve heard about it, or want to give this a go.\\n\\nThanks for reading!"},{"id":"customizable-meme-filter","metadata":{"permalink":"/blog/customizable-meme-filter","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-06-12-customizable-meme-filter.md","source":"@site/blog/2021-06-12-customizable-meme-filter.md","title":"Customizable Meme Filter","description":"In this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme.","date":"2021-06-12T00:00:00.000Z","tags":[{"inline":true,"label":"Python","permalink":"/blog/tags/python"},{"inline":true,"label":"Meme Filter","permalink":"/blog/tags/meme-filter"},{"inline":true,"label":"Image Processing","permalink":"/blog/tags/image-processing"},{"inline":true,"label":"Face Recognition","permalink":"/blog/tags/face-recognition"}],"readingTime":2.54,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"customizable-meme-filter","title":"Customizable Meme Filter","date":"2021-06-12T00:00:00.000Z","image":"/blog/2021-06-12-customizable-meme-filter.png","tags":["Python","Meme Filter","Image Processing","Face Recognition"],"description":"In this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme."},"unlisted":false,"prevItem":{"title":"My journey of memorising a deck of 52 shuffled cards","permalink":"/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards"},"nextItem":{"title":"NeistPoint Project","permalink":"/blog/neistpoint-project"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share my journey of creating a customizable meme filter using Python. This filter selects a random meme based on the number of people on the screen and assigns each person to a character in the meme.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/meme-filter).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nFor the people who know me, they know how much I enjoy memes. I\u2019ve got to admit, whenever I go to museums I have a lot of fun captioning artwork as memes. **As I like to say, I go for the art, and I stay for the memes.**\\n\\nOne day while commuting to work (you can still see the [first commit](https://github.com/DidierRLopes/meme-filter/commit/59be427571c96350d9652922b3ab2ba52ddf18af) which dates back to 10 February of 2020 and has only notes of the sketch of this idea in Portuguese) I thought:\\n\\n> \u201cIt would be funny if there was a snapchat kind of filter where given the number of people on the screen, a random meme was selected and each person would be one of its characters\u201d.\\n\\n
\\n\\nSince I was still improving my Python skills, I thought why not do it in Python. After 1 month, I already had the working code, however, since I was switching jobs at the time my commute time reduced drastically and so did my time to work on this. It took around 1 more month to finish the cleaning up of the script (324 lines) to be more readable, and at the same time Covid happened. **The latter explains why my hair is blonde on the demo below** :)\\n\\nUsage:\\n\\n```console\\n./didifilter.py \u2014 location=memes \u2014 caption=\u2019Which meme am I?\u2019 \u2014 initial=30 \u2014 final=50 -b \u2014 max=3\\n```\\n\\n\\n\\n**To sum up:** This program is meant to be an advanced version of the known snapchat filter where there are random images spinning on top of people\u2019s heads. The main improvement is that you can not only select the images you want to choose from and the caption, but you can also play it with friends (recognizing more than 1 face at the same time).\\n\\nThe best part of the script is that it is meant to be easily customizable. Any person is able to create their own filter by creating a folder with the images they want within a folder with 1, 2, \u2026 based on the number of people they are meant to be used (apart from when backwardCompatible flag is enabled), and select/specify different types of flags/parameters, e.g.:\\n\\n```console\\n./didifilter.py \u2014 locationFolder=celebrities \u2014 caption=\u2019What celeb am I?\u2019 \u2014 max=2 -v \u2014 video=\u201dexampleVideo\u201d\\n```\\n\\n```console\\n./didifilter.py --locationFolder=pokemons --caption=\\"Who\'s this pokemon?\\" --width=250 --height=150 --max=1 -p\\n```\\n\\n**AND**, you can also quickly tweak the code to adapt it to do something else. Here\u2019s me **pranking** my girlfriend with a psyduck when the query was: \u201c_Who do I look like?_\u201d\\n\\n\\n\\nHope you have a nice read and enjoy the filter. You can find the code [here](https://github.com/DidierRLopes/meme-filter).\\n\\nFeel free to provide feedback, as always!"},{"id":"neistpoint-project","metadata":{"permalink":"/blog/neistpoint-project","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-05-23-neistpoint-project.md","source":"@site/blog/2021-05-23-neistpoint-project.md","title":"NeistPoint Project","description":"In this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++.","date":"2021-05-23T00:00:00.000Z","tags":[{"inline":true,"label":"NeistPoint","permalink":"/blog/tags/neist-point"},{"inline":true,"label":"Clothing Brand","permalink":"/blog/tags/clothing-brand"},{"inline":true,"label":"Sustainability","permalink":"/blog/tags/sustainability"},{"inline":true,"label":"Project Management","permalink":"/blog/tags/project-management"},{"inline":true,"label":"C++","permalink":"/blog/tags/c"},{"inline":true,"label":"Stock Management","permalink":"/blog/tags/stock-management"}],"readingTime":3.025,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"neistpoint-project","title":"NeistPoint Project","date":"2021-05-23T00:00:00.000Z","image":"/blog/2021-05-23-neistpoint-project.png","tags":["NeistPoint","Clothing Brand","Sustainability","Project Management","C++","Stock Management"],"description":"In this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++."},"unlisted":false,"prevItem":{"title":"Customizable Meme Filter","permalink":"/blog/customizable-meme-filter"},"nextItem":{"title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share my journey of starting a sustainable clothing brand, managing the project, and developing a stock management tool in C++.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/NeistpointCLI).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\n## Context\\n\\nMore than 2 years ago, me and some friends started a clothing brand - **NeistPoint**. The logo and name is inspired by the Neist Point Lighthouse in the Isle of Skye. The motto was \u201c**For a greener future and a bluer ocean**\u201d, and the goal was to raise awareness to contribute for a sustainable environment.\\n\\nAt **Neist**, we tried to not be yet another clothing brand, but actually to fill the current gap in the retail industry by producing high-quality, eco-friendly clothes at affordable prices. And we achieved that. For instance, our t-shirts are made of 100% organic ring-spun combed cotton, and they last longer than my Lacoste t-shirts \u2014 seriously.\\n\\nThe problem is that to be profitable, you need to either increase the prices of your products, or decrease the quality, which were not things we wanted to do since they didn\u2019t represent the value of our brand. Due to that, and the fact that the team behind our brand no longer has time/resources, we\u2019re dropping our **last ever** season now.\\n\\nAnyway, no regrets from my side, it has been a great learning experience to understand what is involved around the creation of a brand, being a project manager internally, and doing something other than coding in my spare time. _Also, most importantly, ending up with a full new wardrobe of pieces that I love and that will probably last for my kids._\\n\\nSorry for this rambling, just wanted to share this context with everyone.\\n\\n## Implementation\\n\\nGiven that our team had no experience in clothing whatsoever, and based on our needs, our steps to make this a high-quality product were:\\n\\n1. Get the best (environmentaly friendly) clothing material\\n2. Send it to the best embroidery store in Portugal\\n3. Package it and forward it onto the customer\\n\\n
\\n\\n\\n\\nThis process was **far from being optimised**. In fact, pretty much everything was manual. Apart from the creation of the clothes. Therefore, we needed a Software to keep track of the products at each of it\u2019s stages: _material to request, material shipping, material in stock, product to create, product creating, product in stock, and product sent_.\\n\\nSince I didn\u2019t find anything that I liked online, and I knew how to code, I thought the best solution was to develop something myself. This way it could be adapted to perfectly fit my own requirements (advantages of being your own product owner eheh). In addition, I wanted to improve my C++ skills, so I thought, **why not?**\\n\\n\\n\\nFor 1 week or so, during my commute I worked on the [NeistPoint Stock Managemen](https://github.com/DidierRLopes/NeistpointCLI) tool. To be honest, I think it took longer to devise the architecture behind it than to actually write the code, as there were lots of things that I wanted to be taken into account. Also, the fact that the \u201cdatabase\u201d is a .csv file, was intentional. This way, we could share this file between the team members.\\n\\nHope someone finds this tool interesting, and gets inspired to develop their own software to meet their own project requirements. In the meantime, feel free to check us one last time on [our website](https://neistclothing.com/) or [instagram](https://www.instagram.com/neistclothing/). You may even spot me in some of the pictures!\\n\\nThe repository for the code can be found here: https://github.com/DidierRLopes/NeistpointCLI\\n\\nThanks for reading, as always!"},{"id":"move-over-bloomberg-terminal-here-comes-gamestonk-terminal","metadata":{"permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.md","source":"@site/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.md","title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","description":"In this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.","date":"2021-04-23T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Stock Market","permalink":"/blog/tags/stock-market"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":2.375,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"move-over-bloomberg-terminal-here-comes-gamestonk-terminal","title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","date":"2021-04-23T00:00:00.000Z","image":"/blog/2021-04-23-move-over-bloomberg-terminal-here-comes-gamestonk-terminal.png","tags":["Gamestonk Terminal","Finance","Stock Market","Programming","Open Source"],"description":"In this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more."},"unlisted":false,"prevItem":{"title":"NeistPoint Project","permalink":"/blog/neistpoint-project"},"nextItem":{"title":"Momentum Football Bets","permalink":"/blog/momentum-football-bets"}},"content":"
\\n \\n
\\n\\nIn this blogpost, we introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nHey all,\\n\\n2 months ago I made a terminal that I had been working on my spare time, to help me on my stock research, open-source. See [here](/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal).\\n\\n## The motto\\n\\nGamestonk Terminal provides a modern Python-based integrated environment for investment research, that allows the average joe retail trader to leverage state-of-the-art Data Science and Machine Learning technologies.\\n\\nAs a modern Python-based environment, Gamestonk Terminal opens access to numerous Python data libraries in Data Science (Pandas, Numpy, Scipy, Jupyter), Machine Learning (Pytorch, Tensorflow, Sklearn, Flair), and Data Acquisition (Beautiful Soup, and numerous third-party APIs).\\n\\nAs of today, and thanks to all your help and the traction created around it, the terminal is looking better than ever. Now it\u2019s no longer only me taking care of the repo, but also 2 other experienced devs, who are adding features on a daily basis and increasing the robustness of the codebase. Feel free to wander through the FEATURES page to see what you would get out of this tool!\\n\\nIf some of you thought it was amazing 2 months ago, you won\u2019t believe what it looks like now. You can check out the ROADMAP for all the features that have been added since, but let me list some of them:\\n\\n- **New** Screener for stocks, which allows users to save their presets and share them\\n- **New** Options menu\\n- **New** Comparison Analysis to compare several tickers in their historical price, sentiment, or fundamental analysis\\n- **New** Portfolio Optimisation that assigns stocks weights based on risk level specified by the user\\n- **New** Exploratory Data Analysis menu that looks at historical data from a statistic point of view\\n- **New** Residual Analysis after using a statistical model for prediction\\n- **New** menu to provide access to your portfolio (supports Robinhood, Ally invest, Alpaca, and Degiro)\\n- **New** Cryptocurrency, Forex, and FRED menus\\n- Prediction with backtesting\\n- Technical analysis that includes a score and a summary\\n- Due Diligence menu with data from Dark Pools, and also Failure to Deliver\\n- Sentiment analysis from news provided from collaboration with a company that provides this feature paid. Free for us!\\n\\nAs always feedback is appreciated, and contributions even more so!\\n\\nLet\u2019s try to reduce the gap between the amount of information that the Hedge Funds have access to in comparison with the usual retail trader.\\n\\nBloomberg Terminal, we\u2019re coming for you.\\n\\nFeel free to join our discord at https://discord.gg/Up2QGbMKHY."},{"id":"momentum-football-bets","metadata":{"permalink":"/blog/momentum-football-bets","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-04-07-momentum-football-bets.md","source":"@site/blog/2021-04-07-momentum-football-bets.md","title":"Momentum Football Bets","description":"In this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python.","date":"2021-04-07T00:00:00.000Z","tags":[{"inline":true,"label":"Football","permalink":"/blog/tags/football"},{"inline":true,"label":"Betting","permalink":"/blog/tags/betting"},{"inline":true,"label":"Momentum","permalink":"/blog/tags/momentum"},{"inline":true,"label":"Web Scraping","permalink":"/blog/tags/web-scraping"},{"inline":true,"label":"Beautiful Soup","permalink":"/blog/tags/beautiful-soup"},{"inline":true,"label":"Python","permalink":"/blog/tags/python"}],"readingTime":3.275,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"momentum-football-bets","title":"Momentum Football Bets","date":"2021-04-07T00:00:00.000Z","image":"/blog/2021-04-07-momentum-football-bets.png","tags":["Football","Betting","Momentum","Web Scraping","Beautiful Soup","Python"],"description":"In this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python."},"unlisted":false,"prevItem":{"title":"Move over Bloomberg Terminal, here comes Gamestonk Terminal","permalink":"/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal"},"nextItem":{"title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","permalink":"/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I share how I developed an automated task to estimate the momentum of football teams for betting purposes using Beautiful Soup and Python.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/momentum-football-bets).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nThis Easter, I spoke with my girlfriend\u2019s father and there were several football matches happening that weekend, he started talking about betting on some of those matches.\\n\\nHe carried on to explain me his betting routine, which consisted of:\\n\\n1. Checking the next fixtures for a specific competition: https://www.skysports.com/premier-league-fixtures\\n2. Checking the last results of each of the team and \u201cestimate\u201d their momentum (e.g. https://www.skysports.com/football/wolverhampton-wanderers-vs-liverpool/stats/429116)\\n\\n
\\n\\nThen, iterate these 2 steps for all the fixtures happening, from Premier League, Championship, League One, and League Two.\\n\\nSince I recently learned how to use Beautiful Soup to scrap data from web pages (see [GamestonkTerminal](https://dro-lopes.medium.com/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal-a263c001a61f)), I thought that I could create an automated task that would do all of these steps with a simple double click executable. After checking that I could extract such data from SkySports, I let him know that by the next day I would have something working.\\n\\nAfter dinner, I started working on the project, and before I went to sleep I had the first prototype working, which you can see in [here](https://github.com/DidierRLopes/momentum-football-bets).\\n\\nOn top of \u201chis\u201d automated task, I created a \u201cmomentum score\u201d which tries to estimate the momentum score based on what my girlfriend\u2019s father told me that he does. He looks into the last games of the team and see if they have a positive momentum by looking to see if they come from a winning series.\\n\\nSo, I thought it would be good to attribute a weight to each of the last matches where the most recent match would have the biggest weight, and last one from the 6 provided from SkySports stats would have the lowest weight. Together with this weight, I thought we could use the sum of the weight to the score in case of a win, subtract in case of loss, and don\u2019t do anything in case of a draw.\\n\\nSo, in simple terms, if score is positive the team is likely to have been winning their last matches, if score is negative the team is likely to have loss their last matches.\\n\\nBut then, I thought:\\n\\n_\u201cOk, this is nice. But when you bet, you don\u2019t bet on a single team, but on the result between the 2 teams that are playing each other.\u201d_ I.e. if team A has an amazing momentum, and so has team B, the bet will \u2014 in theory \u2014 be risky.\\n\\nHence, the next step was to address this concern. This was done by checking the momentum score difference between the teams, the bigger the momentum score, the less risky \u2014 in theory \u2014 a bet would be. What we want to see is a team that has been doing amazing for the past 6 games, and one that has been performing consistently bad.\\n\\nLastly, I added a confidence filter so that the terminal would only output the games that shown at least a certain X confidence. And also, an argument that would select the number of days in the future that we could look for fixtures.\\n\\nAfter having this implemented, the day after was about polishing the code, adding some colouring and emojis, creating a repository for it, a README, discussing the binning of the momentum score and bet confidence terms, creating a logo for it, and creating an executable + adding the logo which my girlfriend did.\\n\\n\\n\\nAfter this, we were quite excited to backtest the app. We filtered the next features with a big confidence bet score (to have less risk), and put 20 pounds on 3 different accumulators. [And it\u2019s gone.](https://www.youtube.com/watch?v=-DT7bX-B1Mg)\\n\\nHope you had a good read. Feedback is always appreciated."},{"id":"gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","metadata":{"permalink":"/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","editUrl":"https://github.com/DidierRLopes/my-website/tree/main/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.md","source":"@site/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.md","title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","description":"In this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.","date":"2021-03-14T00:00:00.000Z","tags":[{"inline":true,"label":"Gamestonk Terminal","permalink":"/blog/tags/gamestonk-terminal"},{"inline":true,"label":"Finance","permalink":"/blog/tags/finance"},{"inline":true,"label":"Stock Market","permalink":"/blog/tags/stock-market"},{"inline":true,"label":"Programming","permalink":"/blog/tags/programming"},{"inline":true,"label":"Open Source","permalink":"/blog/tags/open-source"}],"readingTime":3.2,"hasTruncateMarker":true,"authors":[],"frontMatter":{"slug":"gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal","title":"Gamestonk Terminal - The next best thing after Bloomberg Terminal","date":"2021-03-14T00:00:00.000Z","image":"/blog/2021-03-14-gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal.png","tags":["Gamestonk Terminal","Finance","Stock Market","Programming","Open Source"],"description":"In this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more."},"unlisted":false,"prevItem":{"title":"Momentum Football Bets","permalink":"/blog/momentum-football-bets"}},"content":"
\\n \\n
\\n\\nIn this blogpost, I introduce Gamestonk Terminal, an open-source project that aims to be a comprehensive tool for financial analysis and stock market research. It includes functionalities for discovering stocks, market sentiment analysis, fundamental and technical analysis, due diligence, prediction techniques, and more.\\n\\nThe open source code is available [here](https://github.com/DidierRLopes/GamestonkTerminal).\\n\\n\x3c!-- truncate --\x3e\\n\\n\\n\\nIf you like stocks and are careful with the way you spend your money, (me saying it seems counter-intuitive given that I bought GME at the peak, I know) you know how much time goes into buying shares of a stock.\\n\\nYou need to: Find stocks that are somehow undervalued; Research on the company, and its competitors; Check that the financials are healthy; Look into different technical indicators; Investigate SEC fillings and Insider activity; Look up for next earnings date and analysts estimates; Estimate market\u2019s sentiment through Reddit, Twitter, Stocktwits; Read news;. \u2026 the list goes on.\\n\\nIt\u2019s tedious and I don\u2019t have 24k for a Bloomberg terminal. Which led me to the idea during xmas break to spend the time creating my own terminal. I introduce you to \u201cGamestonk Terminal\u201d (probably should\u2019ve sent 1 tweet everyday to Elon Musk for copyrights permission eheh).\\n\\nAs someone mentioned, this is meant to be like a swiss army knife for finance.\\n\\nIt contains the following functionalities:\\n\\n- **Discover Stocks**: Some features are: Top gainers; Sectors performance; upcoming earnings releases; top high shorted interest stocks; top stocks with low float; top orders on fidelity; and some SPAC websites with news/calendars.\\n\\n- **Market Sentiment**: Main features are: Scrolling through Reddit main posts, and most tickers mentions; Extracting trending symbols on stocktwits, or even stocktwit sentiment based on bull/bear flags; Twitter in-depth sentiment prediction using AI; Google mentions over time.\\n\\n- **Research Web pages**: List of good pages to do research on a stock, e.g. macroaxis, zacks, macrotrends, ..\\n\\n- **Fundamental Analysis**: Read financials from a company from Market Watch, Yahoo Finance, Alpha Vantage, and Financial Modeling Prep API. Since I only rely on free data, I added the information from all of these, so that the user can get it from the source it trusts the most. Also exports management team behind stock, along with their pages on Google, to speed up research process.\\n\\n- **Technical Analysis**: The usual technical indicators: sma, rsi, macd, adx, bbands, and more.\\n\\n- **Due Diligence**: It has several features that I found to be really useful. Some of them are: Latest news of the company; Analyst prices and ratings; Price target from several analysts plot over time vs stock price; Insider activity, and these timestamps marked on the stock price historical data; Latest SEC fillings; Short interest over time; A check for financial warnings based on Sean Seah book.\\n\\n- **Prediction Techniques**: The one I had more fun with. It tries to predict the stock price, from simple models like sma and arima to complex neural network models, like LSTM. The additional capability here is that all of these are easy to configure. Either through command line arguments, or even in form of a configuration file to define your NN. It also allows backtesting.\\n\\n- **Reports**: Allows you to run several jobs functionalities and write daily notes on a stock, so that you can assess what you thought about the stock in the past, to perform better decisions.\\n\\n- **Comparison Analysis**: Allows to compare different stocks.\\n\\n- **On the ROADMAP**: Cryptocurrencies, Portfolio Analysis, Credit Analysis. Feel free to add the features you\u2019d like and we would happily work on it.\\n\\nThis project will always remain open-source, and the idea is that it can grow substantially over-time so that more and more people start taking advantage of it.\\n\\nFeel free to contribute towards the project.\\n\\nFeedback is extremely welcome!"}]}}')}}]); \ No newline at end of file diff --git a/assets/js/runtime~main.8bc1b8dc.js b/assets/js/runtime~main.17d060b2.js similarity index 99% rename from assets/js/runtime~main.8bc1b8dc.js rename to assets/js/runtime~main.17d060b2.js index b0680868c..b87fc0405 100644 --- a/assets/js/runtime~main.8bc1b8dc.js +++ b/assets/js/runtime~main.17d060b2.js @@ -1 +1 @@ -(()=>{"use strict";var e,a,b,c,d,f={},t={};function r(e){var a=t[e];if(void 0!==a)return a.exports;var b=t[e]={id:e,loaded:!1,exports:{}};return f[e].call(b.exports,b,b.exports,r),b.loaded=!0,b.exports}r.m=f,r.c=t,e=[],r.O=(a,b,c,d)=>{if(!b){var f=1/0;for(i=0;i
The result?
-

A workspace where:
- AI appears only when needed (for insights, summaries, or generating visualizations) diff --git a/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis/index.html b/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis/index.html index f1efac24c..b7bc4c7cd 100644 --- a/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis/index.html +++ b/blog/an-unusual-journey-learning-about-nns-for-a-phd-thesis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/archive/index.html b/blog/archive/index.html index cfc8067ab..1f276717f 100644 --- a/blog/archive/index.html +++ b/blog/archive/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/atom.xml b/blog/atom.xml index 3bcd5cda6..9434d0817 100644 --- a/blog/atom.xml +++ b/blog/atom.xml @@ -46,7 +46,7 @@
- AI appears only when needed (for insights, summaries, or generating visualizations) diff --git a/blog/become-an-openbb-champion/index.html b/blog/become-an-openbb-champion/index.html index b64ee4cdc..70c444aab 100644 --- a/blog/become-an-openbb-champion/index.html +++ b/blog/become-an-openbb-champion/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released/index.html b/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released/index.html index df31f47ab..8836a01d5 100644 --- a/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released/index.html +++ b/blog/bloomberg-terminal-is-no-more-openbb-terminal-2-0-has-just-been-released/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/building-my-personal-website-in-docusaurus/index.html b/blog/building-my-personal-website-in-docusaurus/index.html index 9bf5f79f1..0a6b1813c 100644 --- a/blog/building-my-personal-website-in-docusaurus/index.html +++ b/blog/building-my-personal-website-in-docusaurus/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/building-the-worlds-investment-research-infrastructure/index.html b/blog/building-the-worlds-investment-research-infrastructure/index.html index dca241149..33a8913cf 100644 --- a/blog/building-the-worlds-investment-research-infrastructure/index.html +++ b/blog/building-the-worlds-investment-research-infrastructure/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/chatgpt-and-the-future-of-ai-in-finance/index.html b/blog/chatgpt-and-the-future-of-ai-in-finance/index.html index cdc9c55fa..891b4158b 100644 --- a/blog/chatgpt-and-the-future-of-ai-in-finance/index.html +++ b/blog/chatgpt-and-the-future-of-ai-in-finance/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/creating-an-ai-powered-financial-analyst/index.html b/blog/creating-an-ai-powered-financial-analyst/index.html index 0b1093791..b1b99bee5 100644 --- a/blog/creating-an-ai-powered-financial-analyst/index.html +++ b/blog/creating-an-ai-powered-financial-analyst/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/customizable-meme-filter/index.html b/blog/customizable-meme-filter/index.html index f46bdb3b3..8444b7f9e 100644 --- a/blog/customizable-meme-filter/index.html +++ b/blog/customizable-meme-filter/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/employees-are-leaving-be-proactive-about-employee-feedback/index.html b/blog/employees-are-leaving-be-proactive-about-employee-feedback/index.html index 33647ab38..f2cd35b6f 100644 --- a/blog/employees-are-leaving-be-proactive-about-employee-feedback/index.html +++ b/blog/employees-are-leaving-be-proactive-about-employee-feedback/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/feed.json b/blog/feed.json index 251ad60de..83350d032 100644 --- a/blog/feed.json +++ b/blog/feed.json @@ -6,7 +6,7 @@ "items": [ { "id": "https://didierlopes.com/blog/ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will", - "content_html": "
- The best AI model is useless without access to your data. \n
- Access to data isn't enough - AI needs to handle complete workflows, not just conversations. \n
- They can't access your proprietary data \n
- They can't handle complex financial workflows \n
- They force analysts to work in an unnatural chat interface \n
- Run everything on-premise or in your VPC \n
- Connect any data source: files, APIs, third-party feeds, anything \n
- Use a universal data layer that standardizes everything (whether it's CSV, Excel, Snowflake, or APIs) \n
- AI appears only when needed (for insights, summaries, or generating visualizations) \n
- Firms can adopt AI at their own pace \n
- Analysts keep their familiar workflows while gaining AI superpowers \n
- The best AI model is useless without access to your data. \n
- Access to data isn't enough - AI needs to handle complete workflows, not just conversations. \n
- They can't access your proprietary data \n
- They can't handle complex financial workflows \n
- They force analysts to work in an unnatural chat interface \n
- Run everything on-premise or in your VPC \n
- Connect any data source: files, APIs, third-party feeds, anything \n
- Use a universal data layer that standardizes everything (whether it's CSV, Excel, Snowflake, or APIs) \n
- AI appears only when needed (for insights, summaries, or generating visualizations) \n
- Firms can adopt AI at their own pace \n
- Analysts keep their familiar workflows while gaining AI superpowers \n
- AI appears only when needed (for insights, summaries, or generating visualizations) diff --git a/blog/sector-and-industry-analysis-gamestonk-terminal/index.html b/blog/sector-and-industry-analysis-gamestonk-terminal/index.html index 8f4865520..e0198ab30 100644 --- a/blog/sector-and-industry-analysis-gamestonk-terminal/index.html +++ b/blog/sector-and-industry-analysis-gamestonk-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/slack-gpt-summarizing-messages/index.html b/blog/slack-gpt-summarizing-messages/index.html index 550f383ca..8ab32f8e4 100644 --- a/blog/slack-gpt-summarizing-messages/index.html +++ b/blog/slack-gpt-summarizing-messages/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/stop-doing-your-cv-in-word-or-latex/index.html b/blog/stop-doing-your-cv-in-word-or-latex/index.html index a2b7f9b3b..50cf743f9 100644 --- a/blog/stop-doing-your-cv-in-word-or-latex/index.html +++ b/blog/stop-doing-your-cv-in-word-or-latex/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/streamline-your-openbb-terminal-experience-with-openbb-hub/index.html b/blog/streamline-your-openbb-terminal-experience-with-openbb-hub/index.html index c7afa1233..b805089c6 100644 --- a/blog/streamline-your-openbb-terminal-experience-with-openbb-hub/index.html +++ b/blog/streamline-your-openbb-terminal-experience-with-openbb-hub/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/sweepstake-world-cup-2022-for-your-startup-team/index.html b/blog/sweepstake-world-cup-2022-for-your-startup-team/index.html index 6aef27b3e..fa7d227e6 100644 --- a/blog/sweepstake-world-cup-2022-for-your-startup-team/index.html +++ b/blog/sweepstake-world-cup-2022-for-your-startup-team/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/a-players/index.html b/blog/tags/a-players/index.html index ba8cb19e4..325dfc999 100644 --- a/blog/tags/a-players/index.html +++ b/blog/tags/a-players/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/academia/index.html b/blog/tags/academia/index.html index 8d2539a5c..a92fd8e2a 100644 --- a/blog/tags/academia/index.html +++ b/blog/tags/academia/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/achievements/index.html b/blog/tags/achievements/index.html index e9289f5b7..6f868ea64 100644 --- a/blog/tags/achievements/index.html +++ b/blog/tags/achievements/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/agent/index.html b/blog/tags/agent/index.html index 7247166d5..297196022 100644 --- a/blog/tags/agent/index.html +++ b/blog/tags/agent/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/agents/index.html b/blog/tags/agents/index.html index b76e2c038..0809b2404 100644 --- a/blog/tags/agents/index.html +++ b/blog/tags/agents/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ai/index.html b/blog/tags/ai/index.html index b50dfd4de..42dfbab87 100644 --- a/blog/tags/ai/index.html +++ b/blog/tags/ai/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/airtable/index.html b/blog/tags/airtable/index.html index 61a27d65b..b010fc517 100644 --- a/blog/tags/airtable/index.html +++ b/blog/tags/airtable/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/algorithm/index.html b/blog/tags/algorithm/index.html index 54a7ee2c6..8186076b4 100644 --- a/blog/tags/algorithm/index.html +++ b/blog/tags/algorithm/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/analyst/index.html b/blog/tags/analyst/index.html index 40c43921f..424e30ff6 100644 --- a/blog/tags/analyst/index.html +++ b/blog/tags/analyst/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/analytics/index.html b/blog/tags/analytics/index.html index 7c95628ad..21f3ba96b 100644 --- a/blog/tags/analytics/index.html +++ b/blog/tags/analytics/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/anniversary/index.html b/blog/tags/anniversary/index.html index 6af5e7d21..c3c9a3b9e 100644 --- a/blog/tags/anniversary/index.html +++ b/blog/tags/anniversary/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/announcement/index.html b/blog/tags/announcement/index.html index dcc97339d..0b20558d7 100644 --- a/blog/tags/announcement/index.html +++ b/blog/tags/announcement/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ap-is/index.html b/blog/tags/ap-is/index.html index ddeb2ca86..d04570752 100644 --- a/blog/tags/ap-is/index.html +++ b/blog/tags/ap-is/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/api-key-management/index.html b/blog/tags/api-key-management/index.html index 1a5e967b9..55f3b81ec 100644 --- a/blog/tags/api-key-management/index.html +++ b/blog/tags/api-key-management/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/api/index.html b/blog/tags/api/index.html index 4b4676592..64f82653d 100644 --- a/blog/tags/api/index.html +++ b/blog/tags/api/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/artificial-intelligence/index.html b/blog/tags/artificial-intelligence/index.html index 09abcec28..064acb276 100644 --- a/blog/tags/artificial-intelligence/index.html +++ b/blog/tags/artificial-intelligence/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/automation/index.html b/blog/tags/automation/index.html index a0ebbaf3e..0846d92c5 100644 --- a/blog/tags/automation/index.html +++ b/blog/tags/automation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/bay/index.html b/blog/tags/bay/index.html index b8609548e..81c27ae4f 100644 --- a/blog/tags/bay/index.html +++ b/blog/tags/bay/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/bcg-matrix/index.html b/blog/tags/bcg-matrix/index.html index 5f03b4e3d..72f29a92c 100644 --- a/blog/tags/bcg-matrix/index.html +++ b/blog/tags/bcg-matrix/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/beautiful-soup/index.html b/blog/tags/beautiful-soup/index.html index f1d5c6e19..56362cd26 100644 --- a/blog/tags/beautiful-soup/index.html +++ b/blog/tags/beautiful-soup/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/betting/index.html b/blog/tags/betting/index.html index 4d3e72bd0..96db46084 100644 --- a/blog/tags/betting/index.html +++ b/blog/tags/betting/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/big-data/index.html b/blog/tags/big-data/index.html index 2be33045a..292596339 100644 --- a/blog/tags/big-data/index.html +++ b/blog/tags/big-data/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/birthday/index.html b/blog/tags/birthday/index.html index 780e471a7..71afda5c8 100644 --- a/blog/tags/birthday/index.html +++ b/blog/tags/birthday/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/blackrock/index.html b/blog/tags/blackrock/index.html index 219a17c57..2fb18a17a 100644 --- a/blog/tags/blackrock/index.html +++ b/blog/tags/blackrock/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/blockchain/index.html b/blog/tags/blockchain/index.html index f4bfbc95b..4d4cacacc 100644 --- a/blog/tags/blockchain/index.html +++ b/blog/tags/blockchain/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/blog/index.html b/blog/tags/blog/index.html index df2d9cd8d..cf80c7a28 100644 --- a/blog/tags/blog/index.html +++ b/blog/tags/blog/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/bot/index.html b/blog/tags/bot/index.html index 332e316bf..25d5f5f5a 100644 --- a/blog/tags/bot/index.html +++ b/blog/tags/bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/boxing/index.html b/blog/tags/boxing/index.html index e44522239..d49214930 100644 --- a/blog/tags/boxing/index.html +++ b/blog/tags/boxing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/brand-awareness/index.html b/blog/tags/brand-awareness/index.html index 8d720b10a..7665fd2d4 100644 --- a/blog/tags/brand-awareness/index.html +++ b/blog/tags/brand-awareness/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/c/index.html b/blog/tags/c/index.html index 657460bf8..7f7653826 100644 --- a/blog/tags/c/index.html +++ b/blog/tags/c/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/cancer/index.html b/blog/tags/cancer/index.html index f7e1befac..a66737151 100644 --- a/blog/tags/cancer/index.html +++ b/blog/tags/cancer/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/card-memorisation/index.html b/blog/tags/card-memorisation/index.html index 5f46befbe..89ceef011 100644 --- a/blog/tags/card-memorisation/index.html +++ b/blog/tags/card-memorisation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/career-advice/index.html b/blog/tags/career-advice/index.html index f031766dd..590574f98 100644 --- a/blog/tags/career-advice/index.html +++ b/blog/tags/career-advice/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/career-development/index.html b/blog/tags/career-development/index.html index db4f95c0d..fa4912e0a 100644 --- a/blog/tags/career-development/index.html +++ b/blog/tags/career-development/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/career/index.html b/blog/tags/career/index.html index 9248f8cd0..0c180e7b7 100644 --- a/blog/tags/career/index.html +++ b/blog/tags/career/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/carousel/index.html b/blog/tags/carousel/index.html index bb6c54b30..cc77febfb 100644 --- a/blog/tags/carousel/index.html +++ b/blog/tags/carousel/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/charity/index.html b/blog/tags/charity/index.html index e08ccb472..1026ce5fd 100644 --- a/blog/tags/charity/index.html +++ b/blog/tags/charity/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/chat-gpt/index.html b/blog/tags/chat-gpt/index.html index 1a1eccdc1..519b11df2 100644 --- a/blog/tags/chat-gpt/index.html +++ b/blog/tags/chat-gpt/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/chat/index.html b/blog/tags/chat/index.html index 86f08e47f..a66edcf4e 100644 --- a/blog/tags/chat/index.html +++ b/blog/tags/chat/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/chatbots/index.html b/blog/tags/chatbots/index.html index b19d6966b..5a6fc9e19 100644 --- a/blog/tags/chatbots/index.html +++ b/blog/tags/chatbots/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/chatgpt/index.html b/blog/tags/chatgpt/index.html index bef357686..0a59f374e 100644 --- a/blog/tags/chatgpt/index.html +++ b/blog/tags/chatgpt/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/citadel/index.html b/blog/tags/citadel/index.html index ba0cc787e..e070851f7 100644 --- a/blog/tags/citadel/index.html +++ b/blog/tags/citadel/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/clothing-brand/index.html b/blog/tags/clothing-brand/index.html index 8bc541934..e69acbbe6 100644 --- a/blog/tags/clothing-brand/index.html +++ b/blog/tags/clothing-brand/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/clustering/index.html b/blog/tags/clustering/index.html index 21f4a0508..38c8f5068 100644 --- a/blog/tags/clustering/index.html +++ b/blog/tags/clustering/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/community-building/index.html b/blog/tags/community-building/index.html index 105dac59a..644c18a4c 100644 --- a/blog/tags/community-building/index.html +++ b/blog/tags/community-building/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/community/index.html b/blog/tags/community/index.html index 1a4d2ba74..2f80621ad 100644 --- a/blog/tags/community/index.html +++ b/blog/tags/community/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/company-culture/index.html b/blog/tags/company-culture/index.html index 08c05506b..ee9391876 100644 --- a/blog/tags/company-culture/index.html +++ b/blog/tags/company-culture/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/competitive-advantage/index.html b/blog/tags/competitive-advantage/index.html index a4ba67dbb..8521b7944 100644 --- a/blog/tags/competitive-advantage/index.html +++ b/blog/tags/competitive-advantage/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/content-creation/index.html b/blog/tags/content-creation/index.html index e4c8f9789..a7b3ebd66 100644 --- a/blog/tags/content-creation/index.html +++ b/blog/tags/content-creation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/copilot/index.html b/blog/tags/copilot/index.html index 7588898c3..470cbb199 100644 --- a/blog/tags/copilot/index.html +++ b/blog/tags/copilot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/core/index.html b/blog/tags/core/index.html index 612e9338b..7fc9fca23 100644 --- a/blog/tags/core/index.html +++ b/blog/tags/core/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/cornell/index.html b/blog/tags/cornell/index.html index 8cdb3a066..a01e62c8d 100644 --- a/blog/tags/cornell/index.html +++ b/blog/tags/cornell/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/cross-validation/index.html b/blog/tags/cross-validation/index.html index f403cf2f1..a2cdfb11f 100644 --- a/blog/tags/cross-validation/index.html +++ b/blog/tags/cross-validation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/crypto/index.html b/blog/tags/crypto/index.html index 6d1761816..f7e41ad83 100644 --- a/blog/tags/crypto/index.html +++ b/blog/tags/crypto/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/culture/index.html b/blog/tags/culture/index.html index ba421671a..48efcdbf8 100644 --- a/blog/tags/culture/index.html +++ b/blog/tags/culture/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/cursor/index.html b/blog/tags/cursor/index.html index 913209bb4..95fd13277 100644 --- a/blog/tags/cursor/index.html +++ b/blog/tags/cursor/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/customization/index.html b/blog/tags/customization/index.html index de8e39d0d..adcae370d 100644 --- a/blog/tags/customization/index.html +++ b/blog/tags/customization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/cv/index.html b/blog/tags/cv/index.html index 666bf6ecb..beaec2c21 100644 --- a/blog/tags/cv/index.html +++ b/blog/tags/cv/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/dad/index.html b/blog/tags/dad/index.html index ca92c7e74..27e7f413d 100644 --- a/blog/tags/dad/index.html +++ b/blog/tags/dad/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/darkpool/index.html b/blog/tags/darkpool/index.html index 6faf4b9d4..2340cd03d 100644 --- a/blog/tags/darkpool/index.html +++ b/blog/tags/darkpool/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/data-access/index.html b/blog/tags/data-access/index.html index 30143b7be..29b4c851c 100644 --- a/blog/tags/data-access/index.html +++ b/blog/tags/data-access/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/data-analysis/index.html b/blog/tags/data-analysis/index.html index 146009c3c..5c665aff4 100644 --- a/blog/tags/data-analysis/index.html +++ b/blog/tags/data-analysis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/data-customization/index.html b/blog/tags/data-customization/index.html index d71e5046d..96c8f90d3 100644 --- a/blog/tags/data-customization/index.html +++ b/blog/tags/data-customization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/data-licensing/index.html b/blog/tags/data-licensing/index.html index 5708f8222..7aa530023 100644 --- a/blog/tags/data-licensing/index.html +++ b/blog/tags/data-licensing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/data-science/index.html b/blog/tags/data-science/index.html index 1f93d15b0..2c98d2262 100644 --- a/blog/tags/data-science/index.html +++ b/blog/tags/data-science/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/decentralization/index.html b/blog/tags/decentralization/index.html index f2e3c2961..4105fa09e 100644 --- a/blog/tags/decentralization/index.html +++ b/blog/tags/decentralization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/deep-learning/index.html b/blog/tags/deep-learning/index.html index 256de83c7..75ea6ffc4 100644 --- a/blog/tags/deep-learning/index.html +++ b/blog/tags/deep-learning/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/developer/index.html b/blog/tags/developer/index.html index 9673518ba..cbc8062ee 100644 --- a/blog/tags/developer/index.html +++ b/blog/tags/developer/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/development/index.html b/blog/tags/development/index.html index 44f5e46bd..923da6443 100644 --- a/blog/tags/development/index.html +++ b/blog/tags/development/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/discord/index.html b/blog/tags/discord/index.html index b91854499..a9ee645fc 100644 --- a/blog/tags/discord/index.html +++ b/blog/tags/discord/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/disease/index.html b/blog/tags/disease/index.html index 4dc39edb0..c8f3a49e9 100644 --- a/blog/tags/disease/index.html +++ b/blog/tags/disease/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/docker/index.html b/blog/tags/docker/index.html index bd9acb174..b8b5843f1 100644 --- a/blog/tags/docker/index.html +++ b/blog/tags/docker/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/documentation/index.html b/blog/tags/documentation/index.html index 7c0916d15..18c9c1c7d 100644 --- a/blog/tags/documentation/index.html +++ b/blog/tags/documentation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/docusaurus/index.html b/blog/tags/docusaurus/index.html index a552bdced..60fb0e243 100644 --- a/blog/tags/docusaurus/index.html +++ b/blog/tags/docusaurus/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/due-diligence/index.html b/blog/tags/due-diligence/index.html index 671d52f97..af26a7b62 100644 --- a/blog/tags/due-diligence/index.html +++ b/blog/tags/due-diligence/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/economy/index.html b/blog/tags/economy/index.html index b6ac807a5..e29a40da4 100644 --- a/blog/tags/economy/index.html +++ b/blog/tags/economy/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/education/index.html b/blog/tags/education/index.html index e022c85df..4378e59d0 100644 --- a/blog/tags/education/index.html +++ b/blog/tags/education/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/efficiency/index.html b/blog/tags/efficiency/index.html index 0d893dcf0..02e6adc5d 100644 --- a/blog/tags/efficiency/index.html +++ b/blog/tags/efficiency/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/employee-compensation/index.html b/blog/tags/employee-compensation/index.html index 42dc49587..4d1e88fe6 100644 --- a/blog/tags/employee-compensation/index.html +++ b/blog/tags/employee-compensation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/employee-engagement/index.html b/blog/tags/employee-engagement/index.html index f5ec5c38d..9277b5cc8 100644 --- a/blog/tags/employee-engagement/index.html +++ b/blog/tags/employee-engagement/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/engineering/index.html b/blog/tags/engineering/index.html index b49a5fd7d..40ea3b354 100644 --- a/blog/tags/engineering/index.html +++ b/blog/tags/engineering/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/equity-top-ups/index.html b/blog/tags/equity-top-ups/index.html index a3b2c3efb..db5ae2cbf 100644 --- a/blog/tags/equity-top-ups/index.html +++ b/blog/tags/equity-top-ups/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/equity/index.html b/blog/tags/equity/index.html index ec3acd29e..92229d88e 100644 --- a/blog/tags/equity/index.html +++ b/blog/tags/equity/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/excel/index.html b/blog/tags/excel/index.html index 7a30840c0..a2cf43d41 100644 --- a/blog/tags/excel/index.html +++ b/blog/tags/excel/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/experience/index.html b/blog/tags/experience/index.html index 8f9b3dec3..ca45922db 100644 --- a/blog/tags/experience/index.html +++ b/blog/tags/experience/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/extensions/index.html b/blog/tags/extensions/index.html index 20b233666..52fcf84b9 100644 --- a/blog/tags/extensions/index.html +++ b/blog/tags/extensions/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/face-recognition/index.html b/blog/tags/face-recognition/index.html index d45ea998a..d4f339e62 100644 --- a/blog/tags/face-recognition/index.html +++ b/blog/tags/face-recognition/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/family/index.html b/blog/tags/family/index.html index 353900159..409277303 100644 --- a/blog/tags/family/index.html +++ b/blog/tags/family/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/feedback/index.html b/blog/tags/feedback/index.html index 2ee85fd90..718638979 100644 --- a/blog/tags/feedback/index.html +++ b/blog/tags/feedback/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/finance-assistant/index.html b/blog/tags/finance-assistant/index.html index 1f6e56378..8a1b31cbe 100644 --- a/blog/tags/finance-assistant/index.html +++ b/blog/tags/finance-assistant/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/finance-database/index.html b/blog/tags/finance-database/index.html index 612dc9779..d84e1bbcf 100644 --- a/blog/tags/finance-database/index.html +++ b/blog/tags/finance-database/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/finance/index.html b/blog/tags/finance/index.html index f463c4f04..c2b83fb99 100644 --- a/blog/tags/finance/index.html +++ b/blog/tags/finance/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/financial-analytics/index.html b/blog/tags/financial-analytics/index.html index 3c4277d07..e2ca6727a 100644 --- a/blog/tags/financial-analytics/index.html +++ b/blog/tags/financial-analytics/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/financial-chatbot/index.html b/blog/tags/financial-chatbot/index.html index 16d09f2ed..0ddb6bc1a 100644 --- a/blog/tags/financial-chatbot/index.html +++ b/blog/tags/financial-chatbot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/financial-data/index.html b/blog/tags/financial-data/index.html index 8e5943775..76abc9d57 100644 --- a/blog/tags/financial-data/index.html +++ b/blog/tags/financial-data/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/financial-world/index.html b/blog/tags/financial-world/index.html index b678536dc..c4baeb9d5 100644 --- a/blog/tags/financial-world/index.html +++ b/blog/tags/financial-world/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/fine-tune/index.html b/blog/tags/fine-tune/index.html index e57d1dd4a..9b17218b7 100644 --- a/blog/tags/fine-tune/index.html +++ b/blog/tags/fine-tune/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/flexible-hours/index.html b/blog/tags/flexible-hours/index.html index 9f82d0cad..37363549a 100644 --- a/blog/tags/flexible-hours/index.html +++ b/blog/tags/flexible-hours/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/football/index.html b/blog/tags/football/index.html index 5c43e1754..aed11709f 100644 --- a/blog/tags/football/index.html +++ b/blog/tags/football/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/founder/index.html b/blog/tags/founder/index.html index 0e954be43..e964e3961 100644 --- a/blog/tags/founder/index.html +++ b/blog/tags/founder/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/free/index.html b/blog/tags/free/index.html index 11f00cb6e..44d4cea13 100644 --- a/blog/tags/free/index.html +++ b/blog/tags/free/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/function-calling/index.html b/blog/tags/function-calling/index.html index aeb447a1a..85fa5ae63 100644 --- a/blog/tags/function-calling/index.html +++ b/blog/tags/function-calling/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/future-of-finance/index.html b/blog/tags/future-of-finance/index.html index fdde54fce..328ae568e 100644 --- a/blog/tags/future-of-finance/index.html +++ b/blog/tags/future-of-finance/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/future-of-work/index.html b/blog/tags/future-of-work/index.html index 4ab19ddf5..2e0da6e9a 100644 --- a/blog/tags/future-of-work/index.html +++ b/blog/tags/future-of-work/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/future/index.html b/blog/tags/future/index.html index c7aca1510..636f527c4 100644 --- a/blog/tags/future/index.html +++ b/blog/tags/future/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/gadget/index.html b/blog/tags/gadget/index.html index 1f83959bd..75ae618f7 100644 --- a/blog/tags/gadget/index.html +++ b/blog/tags/gadget/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/gamestonk-terminal/index.html b/blog/tags/gamestonk-terminal/index.html index 7424faf85..93eb38828 100644 --- a/blog/tags/gamestonk-terminal/index.html +++ b/blog/tags/gamestonk-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ge-mc-kinsey-matrix/index.html b/blog/tags/ge-mc-kinsey-matrix/index.html index a6b13a2de..122255d31 100644 --- a/blog/tags/ge-mc-kinsey-matrix/index.html +++ b/blog/tags/ge-mc-kinsey-matrix/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/generative-ai/index.html b/blog/tags/generative-ai/index.html index bb5a897bd..d9c53ec4c 100644 --- a/blog/tags/generative-ai/index.html +++ b/blog/tags/generative-ai/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/git-hub/index.html b/blog/tags/git-hub/index.html index 6f878c343..5e8175168 100644 --- a/blog/tags/git-hub/index.html +++ b/blog/tags/git-hub/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/giveaways/index.html b/blog/tags/giveaways/index.html index 11e7a2176..74d7effa6 100644 --- a/blog/tags/giveaways/index.html +++ b/blog/tags/giveaways/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/global-audience/index.html b/blog/tags/global-audience/index.html index 0607adf25..28bb438e7 100644 --- a/blog/tags/global-audience/index.html +++ b/blog/tags/global-audience/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/gps/index.html b/blog/tags/gps/index.html index b4843cef6..46b51977d 100644 --- a/blog/tags/gps/index.html +++ b/blog/tags/gps/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/growth/index.html b/blog/tags/growth/index.html index 8a56acc19..37f4edca7 100644 --- a/blog/tags/growth/index.html +++ b/blog/tags/growth/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/gui/index.html b/blog/tags/gui/index.html index c3a8bbcc1..9e608c9b2 100644 --- a/blog/tags/gui/index.html +++ b/blog/tags/gui/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/hard-work/index.html b/blog/tags/hard-work/index.html index c8528e06b..f823fe722 100644 --- a/blog/tags/hard-work/index.html +++ b/blog/tags/hard-work/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/hiring/index.html b/blog/tags/hiring/index.html index a8c706178..4f2078ae9 100644 --- a/blog/tags/hiring/index.html +++ b/blog/tags/hiring/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/hugo-website/index.html b/blog/tags/hugo-website/index.html index 2d014504a..225192d7e 100644 --- a/blog/tags/hugo-website/index.html +++ b/blog/tags/hugo-website/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/hybrid-work/index.html b/blog/tags/hybrid-work/index.html index 28d0d46b0..1bf6f9d5a 100644 --- a/blog/tags/hybrid-work/index.html +++ b/blog/tags/hybrid-work/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/i-os/index.html b/blog/tags/i-os/index.html index aa3aa0541..3afc559e4 100644 --- a/blog/tags/i-os/index.html +++ b/blog/tags/i-os/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/icmla/index.html b/blog/tags/icmla/index.html index ed27d1a31..c3ff18a28 100644 --- a/blog/tags/icmla/index.html +++ b/blog/tags/icmla/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/im-db-py/index.html b/blog/tags/im-db-py/index.html index d8d42e441..2847f5cbf 100644 --- a/blog/tags/im-db-py/index.html +++ b/blog/tags/im-db-py/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/image-processing/index.html b/blog/tags/image-processing/index.html index e222fbef4..6533e423a 100644 --- a/blog/tags/image-processing/index.html +++ b/blog/tags/image-processing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/index.html b/blog/tags/index.html index 67b66886a..7d5d7d565 100644 --- a/blog/tags/index.html +++ b/blog/tags/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/industry-analysis/index.html b/blog/tags/industry-analysis/index.html index 8bc179e16..4e7299a11 100644 --- a/blog/tags/industry-analysis/index.html +++ b/blog/tags/industry-analysis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/infrastructure/index.html b/blog/tags/infrastructure/index.html index df2586124..60bea9a68 100644 --- a/blog/tags/infrastructure/index.html +++ b/blog/tags/infrastructure/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/insights/index.html b/blog/tags/insights/index.html index b505ef2f2..b628b296d 100644 --- a/blog/tags/insights/index.html +++ b/blog/tags/insights/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/interactive-charts/index.html b/blog/tags/interactive-charts/index.html index 8501a5e13..c88c2cfae 100644 --- a/blog/tags/interactive-charts/index.html +++ b/blog/tags/interactive-charts/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/interactive-tables/index.html b/blog/tags/interactive-tables/index.html index 46f5b20fb..88d04c5f1 100644 --- a/blog/tags/interactive-tables/index.html +++ b/blog/tags/interactive-tables/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/interface/index.html b/blog/tags/interface/index.html index d50e444fe..8846b4c6f 100644 --- a/blog/tags/interface/index.html +++ b/blog/tags/interface/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/internationalization/index.html b/blog/tags/internationalization/index.html index ea6dfc34d..8b41d74fc 100644 --- a/blog/tags/internationalization/index.html +++ b/blog/tags/internationalization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/investment-research/index.html b/blog/tags/investment-research/index.html index 76ce3c89e..faae5874b 100644 --- a/blog/tags/investment-research/index.html +++ b/blog/tags/investment-research/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/investment/index.html b/blog/tags/investment/index.html index c6574acfc..c9ec8bb40 100644 --- a/blog/tags/investment/index.html +++ b/blog/tags/investment/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/java/index.html b/blog/tags/java/index.html index 270f5a025..862dda22a 100644 --- a/blog/tags/java/index.html +++ b/blog/tags/java/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/job-change/index.html b/blog/tags/job-change/index.html index 9707e0f0b..1e3013a5d 100644 --- a/blog/tags/job-change/index.html +++ b/blog/tags/job-change/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/job-hunting/index.html b/blog/tags/job-hunting/index.html index 3819690e3..6b372dabf 100644 --- a/blog/tags/job-hunting/index.html +++ b/blog/tags/job-hunting/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/jupyter-lab/index.html b/blog/tags/jupyter-lab/index.html index f2deaef8d..76f8065f4 100644 --- a/blog/tags/jupyter-lab/index.html +++ b/blog/tags/jupyter-lab/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/k-means/index.html b/blog/tags/k-means/index.html index f9f385167..eed43385d 100644 --- a/blog/tags/k-means/index.html +++ b/blog/tags/k-means/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/langchain/index.html b/blog/tags/langchain/index.html index 85586e3a5..ed1e6fdf6 100644 --- a/blog/tags/langchain/index.html +++ b/blog/tags/langchain/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/languages/index.html b/blog/tags/languages/index.html index 0550abf8b..82a7337db 100644 --- a/blog/tags/languages/index.html +++ b/blog/tags/languages/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/launch/index.html b/blog/tags/launch/index.html index b00fba9d4..dbae27e86 100644 --- a/blog/tags/launch/index.html +++ b/blog/tags/launch/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/leadership/index.html b/blog/tags/leadership/index.html index 7103b790d..1eca6da2d 100644 --- a/blog/tags/leadership/index.html +++ b/blog/tags/leadership/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/learning/index.html b/blog/tags/learning/index.html index 6224b548c..2aa96a4ef 100644 --- a/blog/tags/learning/index.html +++ b/blog/tags/learning/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/linked-in/index.html b/blog/tags/linked-in/index.html index 579775041..4961956b3 100644 --- a/blog/tags/linked-in/index.html +++ b/blog/tags/linked-in/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ll-ms/index.html b/blog/tags/ll-ms/index.html index 26023eed8..ecdf50656 100644 --- a/blog/tags/ll-ms/index.html +++ b/blog/tags/ll-ms/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/llamaindex/index.html b/blog/tags/llamaindex/index.html index 2522b6d37..d999d3128 100644 --- a/blog/tags/llamaindex/index.html +++ b/blog/tags/llamaindex/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/llm/index.html b/blog/tags/llm/index.html index 0efae23a1..ef8d50f59 100644 --- a/blog/tags/llm/index.html +++ b/blog/tags/llm/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/london/index.html b/blog/tags/london/index.html index b57fb66cf..ee9f4f432 100644 --- a/blog/tags/london/index.html +++ b/blog/tags/london/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/machine-learning/index.html b/blog/tags/machine-learning/index.html index bd921dbe6..7b5a8d575 100644 --- a/blog/tags/machine-learning/index.html +++ b/blog/tags/machine-learning/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/management/index.html b/blog/tags/management/index.html index bde09bdaf..d63e3e4c0 100644 --- a/blog/tags/management/index.html +++ b/blog/tags/management/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/market-attractiveness/index.html b/blog/tags/market-attractiveness/index.html index 8da0eea6d..b61eb3d85 100644 --- a/blog/tags/market-attractiveness/index.html +++ b/blog/tags/market-attractiveness/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/marketing/index.html b/blog/tags/marketing/index.html index c06af3a31..e18535363 100644 --- a/blog/tags/marketing/index.html +++ b/blog/tags/marketing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/meme-bot/index.html b/blog/tags/meme-bot/index.html index d4878c87d..9971ffc64 100644 --- a/blog/tags/meme-bot/index.html +++ b/blog/tags/meme-bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/meme-filter/index.html b/blog/tags/meme-filter/index.html index 64f3a310a..b5cf9eb7f 100644 --- a/blog/tags/meme-filter/index.html +++ b/blog/tags/meme-filter/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/memory-palace/index.html b/blog/tags/memory-palace/index.html index 54ff05172..b0504a7a1 100644 --- a/blog/tags/memory-palace/index.html +++ b/blog/tags/memory-palace/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/memory-training/index.html b/blog/tags/memory-training/index.html index c64c917f4..503e14616 100644 --- a/blog/tags/memory-training/index.html +++ b/blog/tags/memory-training/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/metrics/index.html b/blog/tags/metrics/index.html index 28e06bc51..fb35c3c90 100644 --- a/blog/tags/metrics/index.html +++ b/blog/tags/metrics/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/mindsdb/index.html b/blog/tags/mindsdb/index.html index bfff15288..ff4902723 100644 --- a/blog/tags/mindsdb/index.html +++ b/blog/tags/mindsdb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ml/index.html b/blog/tags/ml/index.html index 113c2648b..94741d0c9 100644 --- a/blog/tags/ml/index.html +++ b/blog/tags/ml/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/mobile/index.html b/blog/tags/mobile/index.html index 5b4a2c270..912ee1003 100644 --- a/blog/tags/mobile/index.html +++ b/blog/tags/mobile/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/momentum/index.html b/blog/tags/momentum/index.html index d5bdd2ea0..d64407f87 100644 --- a/blog/tags/momentum/index.html +++ b/blog/tags/momentum/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/monetization/index.html b/blog/tags/monetization/index.html index 004105948..4ffe985da 100644 --- a/blog/tags/monetization/index.html +++ b/blog/tags/monetization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/movies/index.html b/blog/tags/movies/index.html index e5a33b4ed..523ace9e9 100644 --- a/blog/tags/movies/index.html +++ b/blog/tags/movies/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/moving/index.html b/blog/tags/moving/index.html index f0a4c9c73..5be00cec1 100644 --- a/blog/tags/moving/index.html +++ b/blog/tags/moving/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/neist-point/index.html b/blog/tags/neist-point/index.html index 8c5f1493d..7c7be4098 100644 --- a/blog/tags/neist-point/index.html +++ b/blog/tags/neist-point/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/neural-networks/index.html b/blog/tags/neural-networks/index.html index b6d4291a9..8329fc7bb 100644 --- a/blog/tags/neural-networks/index.html +++ b/blog/tags/neural-networks/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/nft/index.html b/blog/tags/nft/index.html index a86776d21..09617274c 100644 --- a/blog/tags/nft/index.html +++ b/blog/tags/nft/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/nixtla/index.html b/blog/tags/nixtla/index.html index 7afe58b68..9a15ef7ba 100644 --- a/blog/tags/nixtla/index.html +++ b/blog/tags/nixtla/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/nurvv-run/index.html b/blog/tags/nurvv-run/index.html index f97253503..40f9c4658 100644 --- a/blog/tags/nurvv-run/index.html +++ b/blog/tags/nurvv-run/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/nyc/index.html b/blog/tags/nyc/index.html index a8263f029..54f8f749f 100644 --- a/blog/tags/nyc/index.html +++ b/blog/tags/nyc/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/office-work/index.html b/blog/tags/office-work/index.html index 8dbafe7e1..e49b2fa5d 100644 --- a/blog/tags/office-work/index.html +++ b/blog/tags/office-work/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-ai/index.html b/blog/tags/open-ai/index.html index fe4a16541..2e1b4d9e2 100644 --- a/blog/tags/open-ai/index.html +++ b/blog/tags/open-ai/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-bot/index.html b/blog/tags/open-bb-bot/index.html index 9cd46caec..76947e368 100644 --- a/blog/tags/open-bb-bot/index.html +++ b/blog/tags/open-bb-bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-champion/index.html b/blog/tags/open-bb-champion/index.html index a9c2aee58..a2b68cab2 100644 --- a/blog/tags/open-bb-champion/index.html +++ b/blog/tags/open-bb-champion/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-hub/index.html b/blog/tags/open-bb-hub/index.html index 38387db01..cae125683 100644 --- a/blog/tags/open-bb-hub/index.html +++ b/blog/tags/open-bb-hub/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-sdk/index.html b/blog/tags/open-bb-sdk/index.html index 3a06d6844..a6ba96eca 100644 --- a/blog/tags/open-bb-sdk/index.html +++ b/blog/tags/open-bb-sdk/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-terminal-2-0/index.html b/blog/tags/open-bb-terminal-2-0/index.html index ab6b0dd14..3797e18ea 100644 --- a/blog/tags/open-bb-terminal-2-0/index.html +++ b/blog/tags/open-bb-terminal-2-0/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb-terminal/index.html b/blog/tags/open-bb-terminal/index.html index 0a441a203..192077fd8 100644 --- a/blog/tags/open-bb-terminal/index.html +++ b/blog/tags/open-bb-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-bb/index.html b/blog/tags/open-bb/index.html index ee28880e9..24595e224 100644 --- a/blog/tags/open-bb/index.html +++ b/blog/tags/open-bb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-source/index.html b/blog/tags/open-source/index.html index 3e3106725..09ad747a2 100644 --- a/blog/tags/open-source/index.html +++ b/blog/tags/open-source/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/open-startup/index.html b/blog/tags/open-startup/index.html index 13760ea91..66aa4e78e 100644 --- a/blog/tags/open-startup/index.html +++ b/blog/tags/open-startup/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/openbb/index.html b/blog/tags/openbb/index.html index 5e9029c6d..2347f26a6 100644 --- a/blog/tags/openbb/index.html +++ b/blog/tags/openbb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/options-fam-bot/index.html b/blog/tags/options-fam-bot/index.html index 7775a5430..a5dd18562 100644 --- a/blog/tags/options-fam-bot/index.html +++ b/blog/tags/options-fam-bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/options/index.html b/blog/tags/options/index.html index 812795c0b..f38076f08 100644 --- a/blog/tags/options/index.html +++ b/blog/tags/options/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/package/index.html b/blog/tags/package/index.html index ffe7d648b..48da0fbe8 100644 --- a/blog/tags/package/index.html +++ b/blog/tags/package/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/pao-system/index.html b/blog/tags/pao-system/index.html index 82940513a..0712f082b 100644 --- a/blog/tags/pao-system/index.html +++ b/blog/tags/pao-system/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/performance/index.html b/blog/tags/performance/index.html index f9c38e3f7..ddb1a85e8 100644 --- a/blog/tags/performance/index.html +++ b/blog/tags/performance/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/perplexity/index.html b/blog/tags/perplexity/index.html index 6c800c1e6..6af6bbf0c 100644 --- a/blog/tags/perplexity/index.html +++ b/blog/tags/perplexity/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/personal/index.html b/blog/tags/personal/index.html index 282cba43c..933c5b56c 100644 --- a/blog/tags/personal/index.html +++ b/blog/tags/personal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/personalization/index.html b/blog/tags/personalization/index.html index b58b971ab..46ca9798d 100644 --- a/blog/tags/personalization/index.html +++ b/blog/tags/personalization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ph-d-thesis/index.html b/blog/tags/ph-d-thesis/index.html index 94a6b68a4..fe9863af3 100644 --- a/blog/tags/ph-d-thesis/index.html +++ b/blog/tags/ph-d-thesis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/platform/index.html b/blog/tags/platform/index.html index ff27ae8bc..8b2b561e4 100644 --- a/blog/tags/platform/index.html +++ b/blog/tags/platform/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/pro/index.html b/blog/tags/pro/index.html index 5605bac9c..a28432ddb 100644 --- a/blog/tags/pro/index.html +++ b/blog/tags/pro/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/product-documentation/index.html b/blog/tags/product-documentation/index.html index 2e31257c2..29b232a08 100644 --- a/blog/tags/product-documentation/index.html +++ b/blog/tags/product-documentation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/product/index.html b/blog/tags/product/index.html index 69f26cbfd..b7618a139 100644 --- a/blog/tags/product/index.html +++ b/blog/tags/product/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/productivity/index.html b/blog/tags/productivity/index.html index 8ed23977c..292fb169a 100644 --- a/blog/tags/productivity/index.html +++ b/blog/tags/productivity/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/programming/index.html b/blog/tags/programming/index.html index bf0ea112e..9533ccc03 100644 --- a/blog/tags/programming/index.html +++ b/blog/tags/programming/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/project-management/index.html b/blog/tags/project-management/index.html index 4a518182b..6b5a69630 100644 --- a/blog/tags/project-management/index.html +++ b/blog/tags/project-management/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/publishing/index.html b/blog/tags/publishing/index.html index 04391bf30..8708b8768 100644 --- a/blog/tags/publishing/index.html +++ b/blog/tags/publishing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/pwa/index.html b/blog/tags/pwa/index.html index 51879e23d..756b3255b 100644 --- a/blog/tags/pwa/index.html +++ b/blog/tags/pwa/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/pypi/index.html b/blog/tags/pypi/index.html index 7cdb20d29..2af82e6a5 100644 --- a/blog/tags/pypi/index.html +++ b/blog/tags/pypi/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/python/index.html b/blog/tags/python/index.html index 649646c1b..fdf1afbcb 100644 --- a/blog/tags/python/index.html +++ b/blog/tags/python/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/quant/index.html b/blog/tags/quant/index.html index ab10f910e..7c646c041 100644 --- a/blog/tags/quant/index.html +++ b/blog/tags/quant/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/rabbit-r-1/index.html b/blog/tags/rabbit-r-1/index.html index 1d9057775..4dca8d8ed 100644 --- a/blog/tags/rabbit-r-1/index.html +++ b/blog/tags/rabbit-r-1/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/reach/index.html b/blog/tags/reach/index.html index bba11157d..35601c4d8 100644 --- a/blog/tags/reach/index.html +++ b/blog/tags/reach/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/recipes/index.html b/blog/tags/recipes/index.html index 74cc98da6..6e57efad0 100644 --- a/blog/tags/recipes/index.html +++ b/blog/tags/recipes/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/reddit/index.html b/blog/tags/reddit/index.html index 97c4d2e41..da1c6b9d4 100644 --- a/blog/tags/reddit/index.html +++ b/blog/tags/reddit/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/relocation/index.html b/blog/tags/relocation/index.html index e1d81dd55..5844324ef 100644 --- a/blog/tags/relocation/index.html +++ b/blog/tags/relocation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/remote-work/index.html b/blog/tags/remote-work/index.html index dfe535fb3..a779b48fb 100644 --- a/blog/tags/remote-work/index.html +++ b/blog/tags/remote-work/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/research/index.html b/blog/tags/research/index.html index 155203935..e44ecd2d1 100644 --- a/blog/tags/research/index.html +++ b/blog/tags/research/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/review/index.html b/blog/tags/review/index.html index 66929c923..1baf71238 100644 --- a/blog/tags/review/index.html +++ b/blog/tags/review/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/roadmap/index.html b/blog/tags/roadmap/index.html index f9ee59fc2..317b945d7 100644 --- a/blog/tags/roadmap/index.html +++ b/blog/tags/roadmap/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/routines/index.html b/blog/tags/routines/index.html index bd7eaf463..6aa5bb005 100644 --- a/blog/tags/routines/index.html +++ b/blog/tags/routines/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/san-francisco/index.html b/blog/tags/san-francisco/index.html index d9b04913a..fb769fa9f 100644 --- a/blog/tags/san-francisco/index.html +++ b/blog/tags/san-francisco/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/script-management/index.html b/blog/tags/script-management/index.html index ca0e8844b..eb03b9fff 100644 --- a/blog/tags/script-management/index.html +++ b/blog/tags/script-management/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/scriptable/index.html b/blog/tags/scriptable/index.html index c7c9cfee9..837947394 100644 --- a/blog/tags/scriptable/index.html +++ b/blog/tags/scriptable/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sdk/index.html b/blog/tags/sdk/index.html index b63bf27f1..82b3ae21e 100644 --- a/blog/tags/sdk/index.html +++ b/blog/tags/sdk/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sector-analysis/index.html b/blog/tags/sector-analysis/index.html index ad6f7a75c..72676d350 100644 --- a/blog/tags/sector-analysis/index.html +++ b/blog/tags/sector-analysis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/seed-stage/index.html b/blog/tags/seed-stage/index.html index be4992a82..a01f07b7b 100644 --- a/blog/tags/seed-stage/index.html +++ b/blog/tags/seed-stage/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/self-improvement/index.html b/blog/tags/self-improvement/index.html index b57dd62f0..a14d55b9c 100644 --- a/blog/tags/self-improvement/index.html +++ b/blog/tags/self-improvement/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/self-learning/index.html b/blog/tags/self-learning/index.html index 4f8c61cfd..03a587ccf 100644 --- a/blog/tags/self-learning/index.html +++ b/blog/tags/self-learning/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sensor-fusion-engineer/index.html b/blog/tags/sensor-fusion-engineer/index.html index 38cd60bd4..bc69522c7 100644 --- a/blog/tags/sensor-fusion-engineer/index.html +++ b/blog/tags/sensor-fusion-engineer/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/side-project/index.html b/blog/tags/side-project/index.html index b9afe79b7..26cd53f9e 100644 --- a/blog/tags/side-project/index.html +++ b/blog/tags/side-project/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/silicon-valley/index.html b/blog/tags/silicon-valley/index.html index 1d7dd5d3e..17929fe26 100644 --- a/blog/tags/silicon-valley/index.html +++ b/blog/tags/silicon-valley/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/skills/index.html b/blog/tags/skills/index.html index 1c9066e3f..93ca7ea82 100644 --- a/blog/tags/skills/index.html +++ b/blog/tags/skills/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/slack-bot/index.html b/blog/tags/slack-bot/index.html index 8ed155791..1f46c3440 100644 --- a/blog/tags/slack-bot/index.html +++ b/blog/tags/slack-bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/slack/index.html b/blog/tags/slack/index.html index dc34fa5a9..5c6039abf 100644 --- a/blog/tags/slack/index.html +++ b/blog/tags/slack/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/slackgpt/index.html b/blog/tags/slackgpt/index.html index 723ac04f7..d318da0cc 100644 --- a/blog/tags/slackgpt/index.html +++ b/blog/tags/slackgpt/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/smart-contracts/index.html b/blog/tags/smart-contracts/index.html index 8616d8bcf..ace600893 100644 --- a/blog/tags/smart-contracts/index.html +++ b/blog/tags/smart-contracts/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/software-development/index.html b/blog/tags/software-development/index.html index 50716d2eb..896acca27 100644 --- a/blog/tags/software-development/index.html +++ b/blog/tags/software-development/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/software-engineering/index.html b/blog/tags/software-engineering/index.html index d3e11c992..28e35ac54 100644 --- a/blog/tags/software-engineering/index.html +++ b/blog/tags/software-engineering/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sorting-algorithm/index.html b/blog/tags/sorting-algorithm/index.html index de934dda2..458c344f9 100644 --- a/blog/tags/sorting-algorithm/index.html +++ b/blog/tags/sorting-algorithm/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/startup-team/index.html b/blog/tags/startup-team/index.html index 3a457402e..209dff770 100644 --- a/blog/tags/startup-team/index.html +++ b/blog/tags/startup-team/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/startup/index.html b/blog/tags/startup/index.html index f3201b900..4d6d57e4a 100644 --- a/blog/tags/startup/index.html +++ b/blog/tags/startup/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/startups/index.html b/blog/tags/startups/index.html index 6467ad6fa..64377b50d 100644 --- a/blog/tags/startups/index.html +++ b/blog/tags/startups/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/stock-management/index.html b/blog/tags/stock-management/index.html index b3fec59e4..03fc6b14f 100644 --- a/blog/tags/stock-management/index.html +++ b/blog/tags/stock-management/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/stock-market/index.html b/blog/tags/stock-market/index.html index 4995dd454..8f1cffe7b 100644 --- a/blog/tags/stock-market/index.html +++ b/blog/tags/stock-market/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/stocks/index.html b/blog/tags/stocks/index.html index 13c574ed1..ac6b92683 100644 --- a/blog/tags/stocks/index.html +++ b/blog/tags/stocks/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/students/index.html b/blog/tags/students/index.html index 38a859bcb..09b520ec9 100644 --- a/blog/tags/students/index.html +++ b/blog/tags/students/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/success/index.html b/blog/tags/success/index.html index 08832434a..c1edd167d 100644 --- a/blog/tags/success/index.html +++ b/blog/tags/success/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/summarization/index.html b/blog/tags/summarization/index.html index f2279d802..f96604283 100644 --- a/blog/tags/summarization/index.html +++ b/blog/tags/summarization/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/supervised-learning/index.html b/blog/tags/supervised-learning/index.html index 77be5a5f1..cd2c15019 100644 --- a/blog/tags/supervised-learning/index.html +++ b/blog/tags/supervised-learning/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sustainability/index.html b/blog/tags/sustainability/index.html index 146f0d29b..cde8b752f 100644 --- a/blog/tags/sustainability/index.html +++ b/blog/tags/sustainability/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/sweepstake/index.html b/blog/tags/sweepstake/index.html index 0d6fd143f..2e1f37126 100644 --- a/blog/tags/sweepstake/index.html +++ b/blog/tags/sweepstake/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/talent/index.html b/blog/tags/talent/index.html index 0c9ddd0d8..7a28db9a2 100644 --- a/blog/tags/talent/index.html +++ b/blog/tags/talent/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/target-market-analysis/index.html b/blog/tags/target-market-analysis/index.html index 6abfc61f1..334e961f7 100644 --- a/blog/tags/target-market-analysis/index.html +++ b/blog/tags/target-market-analysis/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/tattoo/index.html b/blog/tags/tattoo/index.html index 6218d74cc..b8250fb63 100644 --- a/blog/tags/tattoo/index.html +++ b/blog/tags/tattoo/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/team-building/index.html b/blog/tags/team-building/index.html index d0ae1e69e..ef8274113 100644 --- a/blog/tags/team-building/index.html +++ b/blog/tags/team-building/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/team-happiness/index.html b/blog/tags/team-happiness/index.html index f06b55de8..7e221dd11 100644 --- a/blog/tags/team-happiness/index.html +++ b/blog/tags/team-happiness/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/team-survey/index.html b/blog/tags/team-survey/index.html index 7b3c08429..cdf5193e4 100644 --- a/blog/tags/team-survey/index.html +++ b/blog/tags/team-survey/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/teamwork/index.html b/blog/tags/teamwork/index.html index 8f81a1ecb..481c2a3d8 100644 --- a/blog/tags/teamwork/index.html +++ b/blog/tags/teamwork/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/tech-startups/index.html b/blog/tags/tech-startups/index.html index 662bbec8f..065240534 100644 --- a/blog/tags/tech-startups/index.html +++ b/blog/tags/tech-startups/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/tech/index.html b/blog/tags/tech/index.html index 57400b540..4f622716f 100644 --- a/blog/tags/tech/index.html +++ b/blog/tags/tech/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/technology/index.html b/blog/tags/technology/index.html index e4a0526ad..63effc34e 100644 --- a/blog/tags/technology/index.html +++ b/blog/tags/technology/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/telegram/index.html b/blog/tags/telegram/index.html index 8ce932728..fc8580847 100644 --- a/blog/tags/telegram/index.html +++ b/blog/tags/telegram/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/terminal/index.html b/blog/tags/terminal/index.html index 12afbe853..1d1e4fb33 100644 --- a/blog/tags/terminal/index.html +++ b/blog/tags/terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/thrillers/index.html b/blog/tags/thrillers/index.html index 0e8f00b88..f199a241c 100644 --- a/blog/tags/thrillers/index.html +++ b/blog/tags/thrillers/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/time-series-forecasting/index.html b/blog/tags/time-series-forecasting/index.html index 0363f0d0e..c1001bba8 100644 --- a/blog/tags/time-series-forecasting/index.html +++ b/blog/tags/time-series-forecasting/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/time-series/index.html b/blog/tags/time-series/index.html index 5f86d6c06..c281f9e0e 100644 --- a/blog/tags/time-series/index.html +++ b/blog/tags/time-series/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/tools/index.html b/blog/tags/tools/index.html index a30691421..955d6e271 100644 --- a/blog/tags/tools/index.html +++ b/blog/tags/tools/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/trading/index.html b/blog/tags/trading/index.html index 80a3b70f3..21e5b9e57 100644 --- a/blog/tags/trading/index.html +++ b/blog/tags/trading/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/transparency/index.html b/blog/tags/transparency/index.html index 4301c30f9..3bc9f93c9 100644 --- a/blog/tags/transparency/index.html +++ b/blog/tags/transparency/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/travel/index.html b/blog/tags/travel/index.html index d07706e6e..2ef684018 100644 --- a/blog/tags/travel/index.html +++ b/blog/tags/travel/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/tweepy/index.html b/blog/tags/tweepy/index.html index af08a9069..08a78ec3e 100644 --- a/blog/tags/tweepy/index.html +++ b/blog/tags/tweepy/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/twitter-api/index.html b/blog/tags/twitter-api/index.html index 4f040af41..b13124425 100644 --- a/blog/tags/twitter-api/index.html +++ b/blog/tags/twitter-api/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/twitter/index.html b/blog/tags/twitter/index.html index 3b162a8a8..56ac5d05f 100644 --- a/blog/tags/twitter/index.html +++ b/blog/tags/twitter/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/twosigma/index.html b/blog/tags/twosigma/index.html index 892d394cc..ed6c7a858 100644 --- a/blog/tags/twosigma/index.html +++ b/blog/tags/twosigma/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/us/index.html b/blog/tags/us/index.html index 564587d6f..bf8f95ad6 100644 --- a/blog/tags/us/index.html +++ b/blog/tags/us/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ux-ui/index.html b/blog/tags/ux-ui/index.html index 64fa083ee..b7ca6d728 100644 --- a/blog/tags/ux-ui/index.html +++ b/blog/tags/ux-ui/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/ux/index.html b/blog/tags/ux/index.html index b2b3348c4..f61c58a39 100644 --- a/blog/tags/ux/index.html +++ b/blog/tags/ux/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/visa-process/index.html b/blog/tags/visa-process/index.html index 9b2b7e784..c9d3ecb8d 100644 --- a/blog/tags/visa-process/index.html +++ b/blog/tags/visa-process/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/vision/index.html b/blog/tags/vision/index.html index 53b9a4d10..29c79fd69 100644 --- a/blog/tags/vision/index.html +++ b/blog/tags/vision/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/web-3/index.html b/blog/tags/web-3/index.html index 94c16f11c..4dad5f5aa 100644 --- a/blog/tags/web-3/index.html +++ b/blog/tags/web-3/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/web-development/index.html b/blog/tags/web-development/index.html index 6b329657c..2ea21746a 100644 --- a/blog/tags/web-development/index.html +++ b/blog/tags/web-development/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/web-scraping/index.html b/blog/tags/web-scraping/index.html index 32e41c6bf..3851175f5 100644 --- a/blog/tags/web-scraping/index.html +++ b/blog/tags/web-scraping/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/website/index.html b/blog/tags/website/index.html index 8beb5a0e0..337668722 100644 --- a/blog/tags/website/index.html +++ b/blog/tags/website/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/work-culture/index.html b/blog/tags/work-culture/index.html index e1fb19dca..b40ed7b75 100644 --- a/blog/tags/work-culture/index.html +++ b/blog/tags/work-culture/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/work-life-balance/index.html b/blog/tags/work-life-balance/index.html index 11f9d1bce..00219d9df 100644 --- a/blog/tags/work-life-balance/index.html +++ b/blog/tags/work-life-balance/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/workspace/index.html b/blog/tags/workspace/index.html index d0ba4a33a..5c7fc83eb 100644 --- a/blog/tags/workspace/index.html +++ b/blog/tags/workspace/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/world-cup-2022/index.html b/blog/tags/world-cup-2022/index.html index 5cd05f8d7..958788340 100644 --- a/blog/tags/world-cup-2022/index.html +++ b/blog/tags/world-cup-2022/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/writing/index.html b/blog/tags/writing/index.html index ee5efbbc3..dfef67d85 100644 --- a/blog/tags/writing/index.html +++ b/blog/tags/writing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/tags/yfinance-api/index.html b/blog/tags/yfinance-api/index.html index a35313674..0dfdc10a9 100644 --- a/blog/tags/yfinance-api/index.html +++ b/blog/tags/yfinance-api/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/target-market-analysis-with-the-help-of-llms/index.html b/blog/target-market-analysis-with-the-help-of-llms/index.html index f82a82d69..cd1b8352b 100644 --- a/blog/target-market-analysis-with-the-help-of-llms/index.html +++ b/blog/target-market-analysis-with-the-help-of-llms/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/the-future-of-finance-with-open-source-and-ai/index.html b/blog/the-future-of-finance-with-open-source-and-ai/index.html index d4c1b91c9..e3006a099 100644 --- a/blog/the-future-of-finance-with-open-source-and-ai/index.html +++ b/blog/the-future-of-finance-with-open-source-and-ai/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/the-new-finai-tech-stack/index.html b/blog/the-new-finai-tech-stack/index.html index 42e4ae8f8..a9135c26f 100644 --- a/blog/the-new-finai-tech-stack/index.html +++ b/blog/the-new-finai-tech-stack/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research/index.html b/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research/index.html index ad03cd585..82c99fc81 100644 --- a/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research/index.html +++ b/blog/the-role-of-ai-and-openbb-in-the-future-of-investment-research/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/the-start-of-my-machine-learning-journey/index.html b/blog/the-start-of-my-machine-learning-journey/index.html index 0864c7b2a..f6dbdad5a 100644 --- a/blog/the-start-of-my-machine-learning-journey/index.html +++ b/blog/the-start-of-my-machine-learning-journey/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/time-series-crossvalidation-for-nn/index.html b/blog/time-series-crossvalidation-for-nn/index.html index 24a94151d..d67012a6f 100644 --- a/blog/time-series-crossvalidation-for-nn/index.html +++ b/blog/time-series-crossvalidation-for-nn/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/today-i-saw-a-glimpse-of-the-future/index.html b/blog/today-i-saw-a-glimpse-of-the-future/index.html index 9377dcfdd..ddc34e8bc 100644 --- a/blog/today-i-saw-a-glimpse-of-the-future/index.html +++ b/blog/today-i-saw-a-glimpse-of-the-future/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/web3-symbols-and-community/index.html b/blog/web3-symbols-and-community/index.html index 93ec80f75..cf2df74ab 100644 --- a/blog/web3-symbols-and-community/index.html +++ b/blog/web3-symbols-and-community/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/what-i-learned-in-3-years-at-openb/index.html b/blog/what-i-learned-in-3-years-at-openb/index.html index 26454161c..b1bc6802a 100644 --- a/blog/what-i-learned-in-3-years-at-openb/index.html +++ b/blog/what-i-learned-in-3-years-at-openb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-ai-analysts-need-human-like-workspaces-not-just-chat-interfaces/index.html b/blog/why-ai-analysts-need-human-like-workspaces-not-just-chat-interfaces/index.html index ef11689f8..3f17e411b 100644 --- a/blog/why-ai-analysts-need-human-like-workspaces-not-just-chat-interfaces/index.html +++ b/blog/why-ai-analysts-need-human-like-workspaces-not-just-chat-interfaces/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare/index.html b/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare/index.html index fca4cd6aa..dbfee7820 100644 --- a/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare/index.html +++ b/blog/why-ai-will-replace-jobs-in-finance-and-how-you-should-prepare/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future/index.html b/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future/index.html index c3827ce2c..2eff10eaf 100644 --- a/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future/index.html +++ b/blog/why-chat-only-AI-Financial-Assistants-are-not-the-future/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-i-love-boxing/index.html b/blog/why-i-love-boxing/index.html index 3c62aa852..cb8bb66d8 100644 --- a/blog/why-i-love-boxing/index.html +++ b/blog/why-i-love-boxing/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-the-need-for-an-open-source-investment-research-platform/index.html b/blog/why-the-need-for-an-open-source-investment-research-platform/index.html index c58103785..1ec7fa478 100644 --- a/blog/why-the-need-for-an-open-source-investment-research-platform/index.html +++ b/blog/why-the-need-for-an-open-source-investment-research-platform/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-we-got-rid-of-pips-at-openbb/index.html b/blog/why-we-got-rid-of-pips-at-openbb/index.html index 71ac0669b..cb2779183 100644 --- a/blog/why-we-got-rid-of-pips-at-openbb/index.html +++ b/blog/why-we-got-rid-of-pips-at-openbb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk/index.html b/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk/index.html index 464bc212b..24422e3d5 100644 --- a/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk/index.html +++ b/blog/why-you-should-drop-yfinance-api-and-adopt-openbb-sdk/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/work-life-balance-is-bullsh-t/index.html b/blog/work-life-balance-is-bullsh-t/index.html index d4394dd1b..b67d16684 100644 --- a/blog/work-life-balance-is-bullsh-t/index.html +++ b/blog/work-life-balance-is-bullsh-t/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/writing-documentation-as-a-founder-is-underrated/index.html b/blog/writing-documentation-as-a-founder-is-underrated/index.html index c97e19c8f..53eeadc90 100644 --- a/blog/writing-documentation-as-a-founder-is-underrated/index.html +++ b/blog/writing-documentation-as-a-founder-is-underrated/index.html @@ -16,7 +16,7 @@ - + diff --git a/books/already-read/index.html b/books/already-read/index.html index fb13cf951..0e0f858d4 100644 --- a/books/already-read/index.html +++ b/books/already-read/index.html @@ -16,7 +16,7 @@ - + diff --git a/books/to-read/index.html b/books/to-read/index.html index e7fcb79c0..636c7165b 100644 --- a/books/to-read/index.html +++ b/books/to-read/index.html @@ -16,7 +16,7 @@ - + diff --git a/index.html b/index.html index 27e2a97c1..96850c8e2 100644 --- a/index.html +++ b/index.html @@ -16,7 +16,7 @@ - + diff --git a/markdown-page/index.html b/markdown-page/index.html index ec5e7767d..dcc8067de 100644 --- a/markdown-page/index.html +++ b/markdown-page/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/interviews/index.html b/media/interviews/index.html index 60b0f3126..86d05c608 100644 --- a/media/interviews/index.html +++ b/media/interviews/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/news-mentions/index.html b/media/news-mentions/index.html index 6e1fa70e5..9aed07902 100644 --- a/media/news-mentions/index.html +++ b/media/news-mentions/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/on-stage/index.html b/media/on-stage/index.html index 46380231d..9430e579d 100644 --- a/media/on-stage/index.html +++ b/media/on-stage/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/podcasts/index.html b/media/podcasts/index.html index 65e64b970..cb3659762 100644 --- a/media/podcasts/index.html +++ b/media/podcasts/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/product-videos/index.html b/media/product-videos/index.html index 34ef7fe84..9a506ec99 100644 --- a/media/product-videos/index.html +++ b/media/product-videos/index.html @@ -16,7 +16,7 @@ - + diff --git a/media/webinars/index.html b/media/webinars/index.html index e1fa812ad..39f8e2dc2 100644 --- a/media/webinars/index.html +++ b/media/webinars/index.html @@ -16,7 +16,7 @@ - + diff --git a/projects/index.html b/projects/index.html index 4885a234b..fce7ad2fa 100644 --- a/projects/index.html +++ b/projects/index.html @@ -16,7 +16,7 @@ - + diff --git a/resume/articles/index.html b/resume/articles/index.html index 330caf3a0..87cb8b6ed 100644 --- a/resume/articles/index.html +++ b/resume/articles/index.html @@ -16,7 +16,7 @@ - + diff --git a/resume/courses/index.html b/resume/courses/index.html index 9ab6c43bc..833d6e281 100644 --- a/resume/courses/index.html +++ b/resume/courses/index.html @@ -16,7 +16,7 @@ - + diff --git a/resume/education/index.html b/resume/education/index.html index 5cf953206..d66137278 100644 --- a/resume/education/index.html +++ b/resume/education/index.html @@ -16,7 +16,7 @@ - + diff --git a/resume/experience/index.html b/resume/experience/index.html index b6e5b1b70..258d33c78 100644 --- a/resume/experience/index.html +++ b/resume/experience/index.html @@ -16,7 +16,7 @@ - + diff --git a/search/index.html b/search/index.html index 7b9afedd4..2e1897abb 100644 --- a/search/index.html +++ b/search/index.html @@ -16,7 +16,7 @@ - +
The result?
-
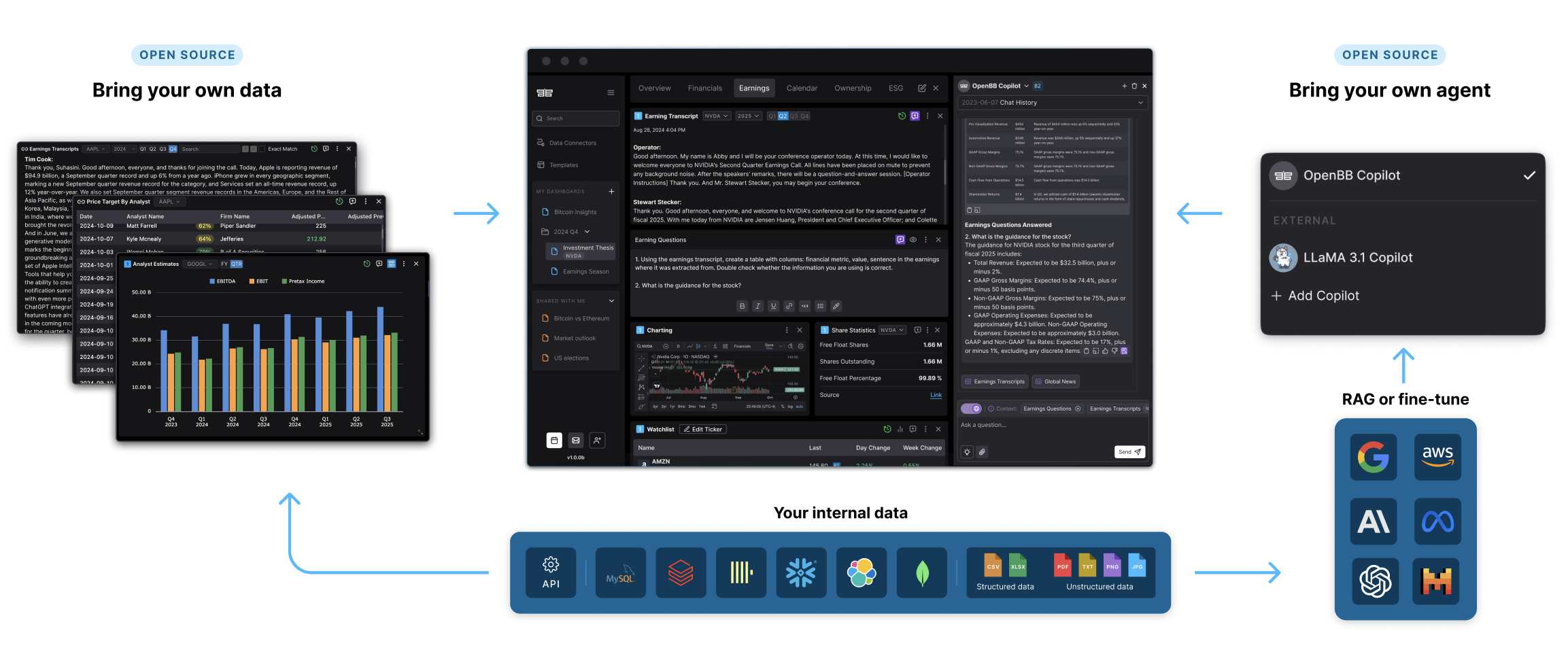
A workspace where:

Why the future of financial analysis isn't about chatbots, but about intelligent workspaces that combine your data, tools, and AI exactly when you need them.
\n\nWhen ChatGPT launched, everyone rushed to build financial chatbots. But they missed two fundamental truths:
\n- \n
The problem with financial chatbots:
\n- \n
\n
Here's how OpenBB solves this:
\nFirst, we ensure complete data access:
\n- \n
But the real innovation?
\nWe're building AI differently.
\nInstead of forcing analysts to chat with a bot, we're embedding intelligence directly into their workspace.
\nThink dashboards with widgets, not chat windows. Data visualization, not text conversations.
\nThis is exactly what Kimberly Tan (partner @ a16z) predicted in her analysis:
\n\n\n\"Chat was the first experimental interface — now I expect there will be new, novel interaction mechanisms. In this phase, AI agents will be able to take direct action in the workflow, and the UI will be reimagined for humans to review work or do QA.\"
\n
\n
The result?
\n
A workspace where:
\n- \n
Let me show you this in action.
\nLast week, I shared how Matt from VanEck built a powerful dashboard integrating multiple distinct data sources on OpenBB. Post with comments can be found here.
\nI only showed a screenshot of this dashboard with data.
\nThere was no sign of AI in it.
\nHowever, if I had simply pressed shortcut \"Ctrl+L\", the copilot window would have opened and I would have been able to natively interact with the data - and generate new data from it.
\n
This demonstrates that the future of financial AI isn't about chatbots - it's about intelligent workspaces.
\nAs Jason from PyQuantNews astutely observes: \"OpenBB solves the data aggregation and centralization challenge without relying on AI, creating a ton of value from it. And then, you allow users to utilize AI in their workflows as they see fit.\"
\nThis isn't just another AI product.
\nIt's the future of financial analysis - where AI enhances your workspace instead of replacing it.
", + "content_html": "
Why the future of financial analysis isn't about chatbots, but about intelligent workspaces that combine your data, tools, and AI exactly when you need them.
\n\nWhen ChatGPT launched, everyone rushed to build financial chatbots. But they missed two fundamental truths:
\n- \n
The problem with financial chatbots:
\n- \n
\n
Here's how OpenBB solves this:
\nFirst, we ensure complete data access:
\n- \n
But the real innovation?
\nWe're building AI differently.
\nInstead of forcing analysts to chat with a bot, we're embedding intelligence directly into their workspace.
\nThink dashboards with widgets, not chat windows. Data visualization, not text conversations.
\nThis is exactly what Kimberly Tan (partner @ a16z) predicted in her analysis:
\n\n\n\"Chat was the first experimental interface — now I expect there will be new, novel interaction mechanisms. In this phase, AI agents will be able to take direct action in the workflow, and the UI will be reimagined for humans to review work or do QA.\"
\n
\n
The result?
\n
A workspace where:
\n- \n
Let me show you this in action.
\nLast week, I shared how Matt from VanEck built a powerful dashboard integrating multiple distinct data sources on OpenBB. Post with comments can be found here.
\nI only showed a screenshot of this dashboard with data.
\nThere was no sign of AI in it.
\nHowever, if I had simply pressed shortcut \"Ctrl+L\", the copilot window would have opened and I would have been able to natively interact with the data - and generate new data from it.
\n
This demonstrates that the future of financial AI isn't about chatbots - it's about intelligent workspaces.
\nAs Jason from PyQuantNews astutely observes: \"OpenBB solves the data aggregation and centralization challenge without relying on AI, creating a ton of value from it. And then, you allow users to utilize AI in their workflows as they see fit.\"
\nThis isn't just another AI product.
\nIt's the future of financial analysis - where AI enhances your workspace instead of replacing it.
", "url": "https://didierlopes.com/blog/ai-chatbots-wont-revolutionize-finance-but-intelligent-workspaces-will", "title": "AI Chatbots Won't Revolutionize Finance, But Intelligent Workspaces Will", "summary": "Beyond the AI hype - why the future of financial analysis isn't about chatbots, but about intelligent workspaces that combine your data, tools, and AI exactly when you need them.", diff --git a/blog/financial-chat-bots-are-underrated-and-heres-why/index.html b/blog/financial-chat-bots-are-underrated-and-heres-why/index.html index 241164266..1875b230d 100644 --- a/blog/financial-chat-bots-are-underrated-and-heres-why/index.html +++ b/blog/financial-chat-bots-are-underrated-and-heres-why/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players/index.html b/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players/index.html index d0ad1e910..c549d9109 100644 --- a/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players/index.html +++ b/blog/firing-sucks-how-to-avoid-doing-so-by-hiring-a-players/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/free-investment-research-ecosystem-to-consistently-beat-the-market/index.html b/blog/free-investment-research-ecosystem-to-consistently-beat-the-market/index.html index 2dea91769..6d3ab87f6 100644 --- a/blog/free-investment-research-ecosystem-to-consistently-beat-the-market/index.html +++ b/blog/free-investment-research-ecosystem-to-consistently-beat-the-market/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/from-open-source-to-open-startup/index.html b/blog/from-open-source-to-open-startup/index.html index eaeb4f7df..b705106c8 100644 --- a/blog/from-open-source-to-open-startup/index.html +++ b/blog/from-open-source-to-open-startup/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/fully-free-financial-chatbot/index.html b/blog/fully-free-financial-chatbot/index.html index 7ec080145..1001fc830 100644 --- a/blog/fully-free-financial-chatbot/index.html +++ b/blog/fully-free-financial-chatbot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/gamestonk-terminal-cant-stop-won-t-stop/index.html b/blog/gamestonk-terminal-cant-stop-won-t-stop/index.html index 5bc021bb5..90da6a9c2 100644 --- a/blog/gamestonk-terminal-cant-stop-won-t-stop/index.html +++ b/blog/gamestonk-terminal-cant-stop-won-t-stop/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal/index.html b/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal/index.html index 3bda8a742..de424bdea 100644 --- a/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal/index.html +++ b/blog/gamestonk-terminal-the-next-best-thing-after-bloomberg-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/gamestonk-terminal-ux-features/index.html b/blog/gamestonk-terminal-ux-features/index.html index 6722f49cd..0fae081ef 100644 --- a/blog/gamestonk-terminal-ux-features/index.html +++ b/blog/gamestonk-terminal-ux-features/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/goh-analyst-the-ai-powered-financial-analyst-who-lives-on-slack/index.html b/blog/goh-analyst-the-ai-powered-financial-analyst-who-lives-on-slack/index.html index b21b7d2bf..0e00987c7 100644 --- a/blog/goh-analyst-the-ai-powered-financial-analyst-who-lives-on-slack/index.html +++ b/blog/goh-analyst-the-ai-powered-financial-analyst-who-lives-on-slack/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/goodbye-openbb-sdk-hello-openbb-platform/index.html b/blog/goodbye-openbb-sdk-hello-openbb-platform/index.html index c04c3ab4c..33262d2d8 100644 --- a/blog/goodbye-openbb-sdk-hello-openbb-platform/index.html +++ b/blog/goodbye-openbb-sdk-hello-openbb-platform/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/handing-your-twitter-account-to-your-most-avid-community-member/index.html b/blog/handing-your-twitter-account-to-your-most-avid-community-member/index.html index e8c170141..b1e33eef5 100644 --- a/blog/handing-your-twitter-account-to-your-most-avid-community-member/index.html +++ b/blog/handing-your-twitter-account-to-your-most-avid-community-member/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/household-bills-program/index.html b/blog/household-bills-program/index.html index c86b292be..16bd6267e 100644 --- a/blog/household-bills-program/index.html +++ b/blog/household-bills-program/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster/index.html b/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster/index.html index dce15be87..6c94a73fc 100644 --- a/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster/index.html +++ b/blog/how-chatgpt-allowed-me-to-leverage-twitter-api-10x-faster/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-became-ceo-of-openbb/index.html b/blog/how-i-became-ceo-of-openbb/index.html index c14730cf8..13261caf3 100644 --- a/blog/how-i-became-ceo-of-openbb/index.html +++ b/blog/how-i-became-ceo-of-openbb/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways/index.html b/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways/index.html index 62624d98d..be84b3661 100644 --- a/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways/index.html +++ b/blog/how-i-created-a-bot-in-python-to-participate-in-nft-giveaways/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-created-the-best-discord-meme-bot/index.html b/blog/how-i-created-the-best-discord-meme-bot/index.html index bfc0f1103..faedaeaa6 100644 --- a/blog/how-i-created-the-best-discord-meme-bot/index.html +++ b/blog/how-i-created-the-best-discord-meme-bot/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-used-openai-api-to-improve-our-product-documentation/index.html b/blog/how-i-used-openai-api-to-improve-our-product-documentation/index.html index d3ff6b896..076fef2eb 100644 --- a/blog/how-i-used-openai-api-to-improve-our-product-documentation/index.html +++ b/blog/how-i-used-openai-api-to-improve-our-product-documentation/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal/index.html b/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal/index.html index 401581dee..bd2f1dbf0 100644 --- a/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal/index.html +++ b/blog/how-i-would-do-due-diligence-on-amt-using-openbb-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla/index.html b/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla/index.html index eaa436e76..14ec62009 100644 --- a/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla/index.html +++ b/blog/how-i-wrote-a-machine-learning-paper-in-1-week-that-got-accepted-to-icmla/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds/index.html b/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds/index.html index 6a51506c4..26f1ee2bd 100644 --- a/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds/index.html +++ b/blog/how-to-convert-a-twitter-thread-into-a-linkedin-carousel-in-seconds/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023/index.html b/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023/index.html index f3698153f..d5595cbf9 100644 --- a/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023/index.html +++ b/blog/how-to-get-hired-by-an-exciting-tech-startup-in-2023/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-grow-your-open-source-community-from-scratch.md/index.html b/blog/how-to-grow-your-open-source-community-from-scratch.md/index.html index a5ad4ece3..88ed62a5c 100644 --- a/blog/how-to-grow-your-open-source-community-from-scratch.md/index.html +++ b/blog/how-to-grow-your-open-source-community-from-scratch.md/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley/index.html b/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley/index.html index 4e9a856ce..8e79e2b1a 100644 --- a/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley/index.html +++ b/blog/how-to-handle-equity-at-a-seed-stage-startup-from-silicon-valley/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup/index.html b/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup/index.html index 6002bb174..d2536c137 100644 --- a/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup/index.html +++ b/blog/how-to-handle-equity-top-ups-at-a-seed-stage-startup/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-learn-10x-faster-than-average/index.html b/blog/how-to-learn-10x-faster-than-average/index.html index 182d990f4..28a50c377 100644 --- a/blog/how-to-learn-10x-faster-than-average/index.html +++ b/blog/how-to-learn-10x-faster-than-average/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/how-to-use-openai-to-extract-insights-from-team-survey/index.html b/blog/how-to-use-openai-to-extract-insights-from-team-survey/index.html index 7a922060b..54836cbb3 100644 --- a/blog/how-to-use-openai-to-extract-insights-from-team-survey/index.html +++ b/blog/how-to-use-openai-to-extract-insights-from-team-survey/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/hybrid-work-sucks-its-worse-than-remote-and-office/index.html b/blog/hybrid-work-sucks-its-worse-than-remote-and-office/index.html index 514a73d12..5ae1ab2dd 100644 --- a/blog/hybrid-work-sucks-its-worse-than-remote-and-office/index.html +++ b/blog/hybrid-work-sucks-its-worse-than-remote-and-office/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/implement-feedback-loops-everywhere-you-can/index.html b/blog/implement-feedback-loops-everywhere-you-can/index.html index 557abd052..4b7e3d681 100644 --- a/blog/implement-feedback-loops-everywhere-you-can/index.html +++ b/blog/implement-feedback-loops-everywhere-you-can/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/index.html b/blog/index.html index bc66298d3..bf4b58e20 100644 --- a/blog/index.html +++ b/blog/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life/index.html b/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life/index.html index 968ad9235..efa037e4a 100644 --- a/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life/index.html +++ b/blog/inspired-by-bia-how-her-fight-against-cancer-changed-my-life/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/introducing-the-openbb-add-in-for-excel/index.html b/blog/introducing-the-openbb-add-in-for-excel/index.html index 187f17417..73bac46fe 100644 --- a/blog/introducing-the-openbb-add-in-for-excel/index.html +++ b/blog/introducing-the-openbb-add-in-for-excel/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/k-means-clustering-to-visit-a-new-city/index.html b/blog/k-means-clustering-to-visit-a-new-city/index.html index 31d54e98d..b6e9949c7 100644 --- a/blog/k-means-clustering-to-visit-a-new-city/index.html +++ b/blog/k-means-clustering-to-visit-a-new-city/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget/index.html b/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget/index.html index c6dc7523d..af7e281d0 100644 --- a/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget/index.html +++ b/blog/keep-track-of-your-startup-metrics-using-a-custom-ios-widget/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/leaving-london-to-live-in-san-francisco/index.html b/blog/leaving-london-to-live-in-san-francisco/index.html index da612bf25..528d5ce58 100644 --- a/blog/leaving-london-to-live-in-san-francisco/index.html +++ b/blog/leaving-london-to-live-in-san-francisco/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally/index.html b/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally/index.html index 5f8dce3c2..937d479be 100644 --- a/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally/index.html +++ b/blog/looking-for-a-new-tattoo-openbb-has-you-covered-literally/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/meet-the-most-advanced-investment-research-platform/index.html b/blog/meet-the-most-advanced-investment-research-platform/index.html index c43106911..ab2faf64a 100644 --- a/blog/meet-the-most-advanced-investment-research-platform/index.html +++ b/blog/meet-the-most-advanced-investment-research-platform/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/minion-recipes-program/index.html b/blog/minion-recipes-program/index.html index e4450a2c2..4c5d09c66 100644 --- a/blog/minion-recipes-program/index.html +++ b/blog/minion-recipes-program/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/momentum-football-bets/index.html b/blog/momentum-football-bets/index.html index 2685e82c2..d4c0bf486 100644 --- a/blog/momentum-football-bets/index.html +++ b/blog/momentum-football-bets/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal/index.html b/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal/index.html index 9f61906d1..663414b22 100644 --- a/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal/index.html +++ b/blog/move-over-bloomberg-terminal-here-comes-gamestonk-terminal/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/moving-countries-and-starting-a-company-aint-so-different/index.html b/blog/moving-countries-and-starting-a-company-aint-so-different/index.html index 352fea9fb..a229228c0 100644 --- a/blog/moving-countries-and-starting-a-company-aint-so-different/index.html +++ b/blog/moving-countries-and-starting-a-company-aint-so-different/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/moving-from-london-to-the-bay-area-and-what-changed/index.html b/blog/moving-from-london-to-the-bay-area-and-what-changed/index.html index 542788fba..1f9a6ed4f 100644 --- a/blog/moving-from-london-to-the-bay-area-and-what-changed/index.html +++ b/blog/moving-from-london-to-the-bay-area-and-what-changed/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt/index.html b/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt/index.html index e915d6abd..9d78c12fb 100644 --- a/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt/index.html +++ b/blog/my-first-hand-experience-on-ai-impacting-education-through-perplexity-cursor-and-chatgpt/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards/index.html b/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards/index.html index 4fefc7037..bd64038f5 100644 --- a/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards/index.html +++ b/blog/my-journey-of-memorising-a-deck-of-52-shuffled-cards/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/neistpoint-project/index.html b/blog/neistpoint-project/index.html index 9995c9d80..ab6139adc 100644 --- a/blog/neistpoint-project/index.html +++ b/blog/neistpoint-project/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-2-year-anniversary/index.html b/blog/openbb-2-year-anniversary/index.html index 9c0f0906e..9cf4ce4e9 100644 --- a/blog/openbb-2-year-anniversary/index.html +++ b/blog/openbb-2-year-anniversary/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-and-our-global-reach-since-leaving-beta/index.html b/blog/openbb-and-our-global-reach-since-leaving-beta/index.html index ccb5e083f..056c8c898 100644 --- a/blog/openbb-and-our-global-reach-since-leaving-beta/index.html +++ b/blog/openbb-and-our-global-reach-since-leaving-beta/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family/index.html b/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family/index.html index 1dca9d888..c23d3ffe0 100644 --- a/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family/index.html +++ b/blog/openbb-bot-our-new-addition-to-the-openbb-open-source-family/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-copilot-now-available-to-all-terminal-pro-users/index.html b/blog/openbb-copilot-now-available-to-all-terminal-pro-users/index.html index ef6256e2b..56c8ebbbc 100644 --- a/blog/openbb-copilot-now-available-to-all-terminal-pro-users/index.html +++ b/blog/openbb-copilot-now-available-to-all-terminal-pro-users/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-mobile-app-coming-soon/index.html b/blog/openbb-mobile-app-coming-soon/index.html index b08d77734..7f3498f51 100644 --- a/blog/openbb-mobile-app-coming-soon/index.html +++ b/blog/openbb-mobile-app-coming-soon/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data/index.html b/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data/index.html index 397254f87..74c9a2dee 100644 --- a/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data/index.html +++ b/blog/openbb-terminal-3-0-a-new-interactive-way-to-analyze-data/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/prediction-for-2024/index.html b/blog/prediction-for-2024/index.html index a909d4b6c..78b0277f7 100644 --- a/blog/prediction-for-2024/index.html +++ b/blog/prediction-for-2024/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/rabbit-r1-there-is-hope/index.html b/blog/rabbit-r1-there-is-hope/index.html index c329775e1..50bfb0bb7 100644 --- a/blog/rabbit-r1-there-is-hope/index.html +++ b/blog/rabbit-r1-there-is-hope/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/ranking-99-mind-f-ck-movies/index.html b/blog/ranking-99-mind-f-ck-movies/index.html index 4cb88e894..ffac7b4bd 100644 --- a/blog/ranking-99-mind-f-ck-movies/index.html +++ b/blog/ranking-99-mind-f-ck-movies/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/remote-flexible-work-salary/index.html b/blog/remote-flexible-work-salary/index.html index 5f6d64b38..4feef2973 100644 --- a/blog/remote-flexible-work-salary/index.html +++ b/blog/remote-flexible-work-salary/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig/index.html b/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig/index.html index 6fe9e1ef0..48cd62248 100644 --- a/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig/index.html +++ b/blog/revolutionizing-ai-at-openbb-with-new-leader-michael-struwig/index.html @@ -16,7 +16,7 @@ - + diff --git a/blog/rss.xml b/blog/rss.xml index 529edb7b7..c23de77e8 100644 --- a/blog/rss.xml +++ b/blog/rss.xml @@ -47,7 +47,7 @@The result?
-
A workspace where: