 (1).png)
 (1) (1).png)
 (1) (1) (1).png)
 (1).png)
 (1) (1).png)
 (1).png)
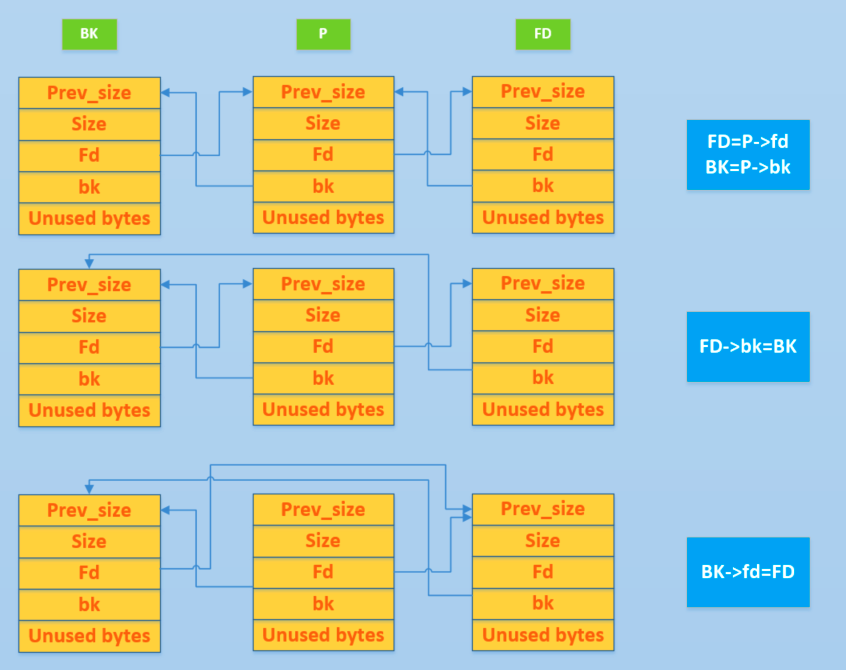
https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png
 (1) (1).png)
https://ctf-wiki.mahaloz.re/pwn/linux/glibc-heap/implementation/figure/unlink_smallbin_intro.png
 (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1).png)
 (1) (1) (1).png)
 (1) (1) (1) (1).png)
 {% endhint %}
-
{% endhint %}
- (1) (1) (1) (1) (1) (1).png)
 {% endhint %}
-
{% endhint %}
- (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1) (1).png)

 (1) (1) (1) (1) (1) (1).png)
 (1) (1) (1) (1) (1).png) {% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
- (1).png)
 (1) (1).png)
 (1) (1) (1).png)
 (1) (1) (1) (1).png)
 (1) (1).png)
 (1) (1) (1).png)
 (1) (1) (1).png)
 (1) (1) (1).png) {% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
{% endhint %}
-
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
 (1).png)
 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
{kind=link}