| theme | paginate |
|---|---|
default |
true |
Understand the current cloud networking basics. Have a hands-on experience with a learning tool focused on Networking aspects of Kubernetes (and multi-cluster networking using Skupper)
- ❗ a real Kubernetes setup
- ❗ a single-node k8s runner like minikube, kind
- Mininet based simulation
- Uses as many real components
- Models reality as close as possible
- Application executable packaged with its libraries and dependency
- No separate guest OS like virtual machines
- Light-weight and portable
- Isolation through namespace and cgroups
- Namespace: isolated view of resources like file system, network resources
- cgroups: Resource limit per process/container
- Docker: Single machine container deployment
- Kubernetes (k8s): Container Orchestration
- Across a cluster of machines
- Manage automated deployment, scaling


- Pods:Application specific logical host.
- group of containers with shared storage and network resources.


- Manage replicas and scaling of pods (for a desired state)
- Group of containers with shared storage and network resources.



- Containers in a pod can communicate over localhost
- Pods identified by a cluster IP.
- Service:
- Expose an application/pod
- Handle multiple replica with single end point
- Support dynamic up/down of pods

Get yourself a temporary k8s instance here: https://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-interactive/
Follow the instructions here: https://kubebyexample.com/concept/deployments
- Connect containers running on different workers
- Load balance multiple replicas as a single service
- Expose services by name
- App net features such as: rate limiting, health checks, blue-green testing
Now, do this across multiple clusters 😱

Most organization workloads are spanning multiple clusters now. This is still an unsolved problem!
- Introduce a Kubernetes networking concept
- Discuss how it works in reality
- Discuss how we run it in knetsim
- Hands on!
Either build the image:
docker build -t knetsim -f ./Dockerfile .
or pull the image:
docker pull ghcr.io/IBM/k8s-netsim:master
docker tag k8s-netsim:master knetsim
To run the container:
docker run -it --privileged --rm --entrypoint bash knetsim
- Workers and containers ⬅️
- Container-Container communication
- Service abstraction
- Ingress
- Multi-cluster communication

- Kubernetes clusters consist of workers, each running pods
- Control Plane: Manages workers and pods scheduling, fault-tolerance
kube-apiserver: REST based front end for k8s frontendetcd: highly-available key value store for backing k8s data
- Node Components:
kubelet: runs on every node to ensure containers are in running statekube-proxy: Maintains network rules on a node. Leverages system packet filtering layer if availablecontainer runtime: software for running containers. e.g.containerd,docker
- Each worker is setup with a
kubeletcomponent that manages containers - Containers are run using a runtime, like
containerdordocker
- We use mininet
hoststo represent each worker. - We run network namespaces to represent each container.
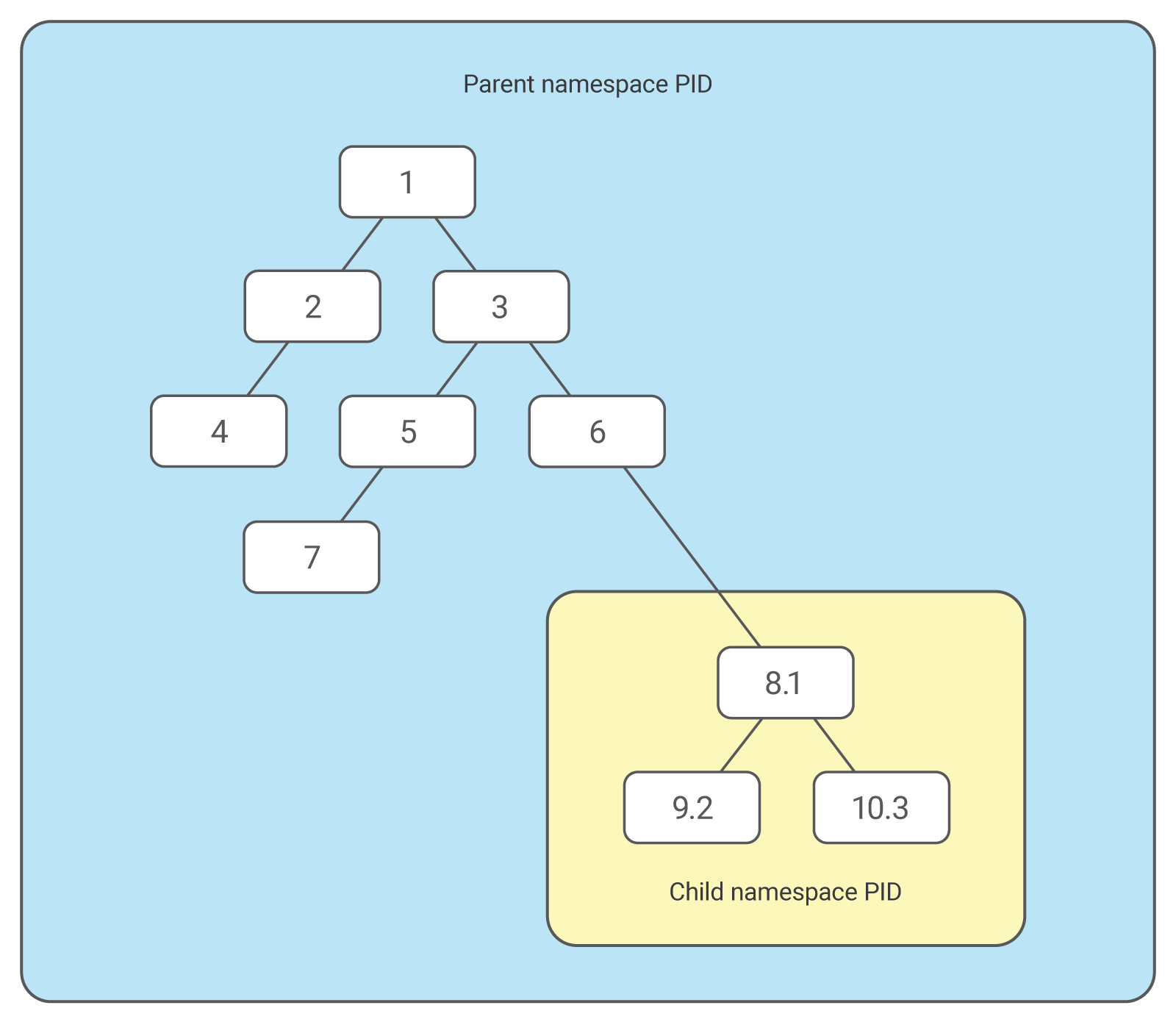
Kernel namespaces allow isolation of resources.
- user namespace: process can have
rootprivilege within its user namespace - process ID (PID) namespace: Have PIDs in namespace that are independent of other namespaces.
- network namespace: have an independent network stack (with routing rules, IP address)
- mount namespace: have moubt points without effecting host filesystem
- IPC namespace, UTS namespace

Can use the ip netns command to create network namespaces.
Create a new container to play with:
docker run -it --privileged --rm --entrypoint bash knetsim
Check the root namespace:
ifconfig
List namespace:
ip netns list
(should come up empty)
Create it:
ip netns add myns
It will currently be empty:
ip netns exec myns ifconfig
Create a new link:
ip netns exec myns ip link set lo up
Ping localhost both in the root namespace and the newly created net namespace.
Verify that the counters reported by ifconfig are independent.
Delete the ns:
ip netns del myns
(Delete the container too)
- Network Emulator
- Network of virtual hosts, switch, links on a machine

Run the simulator:
docker run -it --privileged --rm knetsim
*** Creating network
...
<ping commands>
*** Starting CLI:
mininet>
- We have 2 clusters with 3 workers each:
C0w1,C0w2andC0w3are workers => mininet hosts
Run commands on workers:
mininet> C0w1 ifconfig
- Ping the workers from each other.
- Each worker
w<i>has a containerc<i> - Exec into containers using this command:
mininet> py C0w1.exec_container("c1", "ifconfig")
- Run a few commands in the container. See that only the network namespace is different from the underlying worker.
- Create new containers:
mininet> py C0w1.create_container("c10")
(ignore the error it throws) 3. Delete the new container:
mininet> py C0w1.delete_container("c10")
- Workers and containers ✔️
- Container-Container communication ⬅️
- Service abstraction
- Ingress
- Multi-cluster communication
- For the moment, assume 2 services both have one replicas each
- 2 pods need to communicate
- Pod: group of containers with shared storage and network resources.
In brief:
- The network namespace of the container is assigned an interface (eg eth0)
- A pod is assigned an IP
- Packets from one pod needs to be routed to another pod
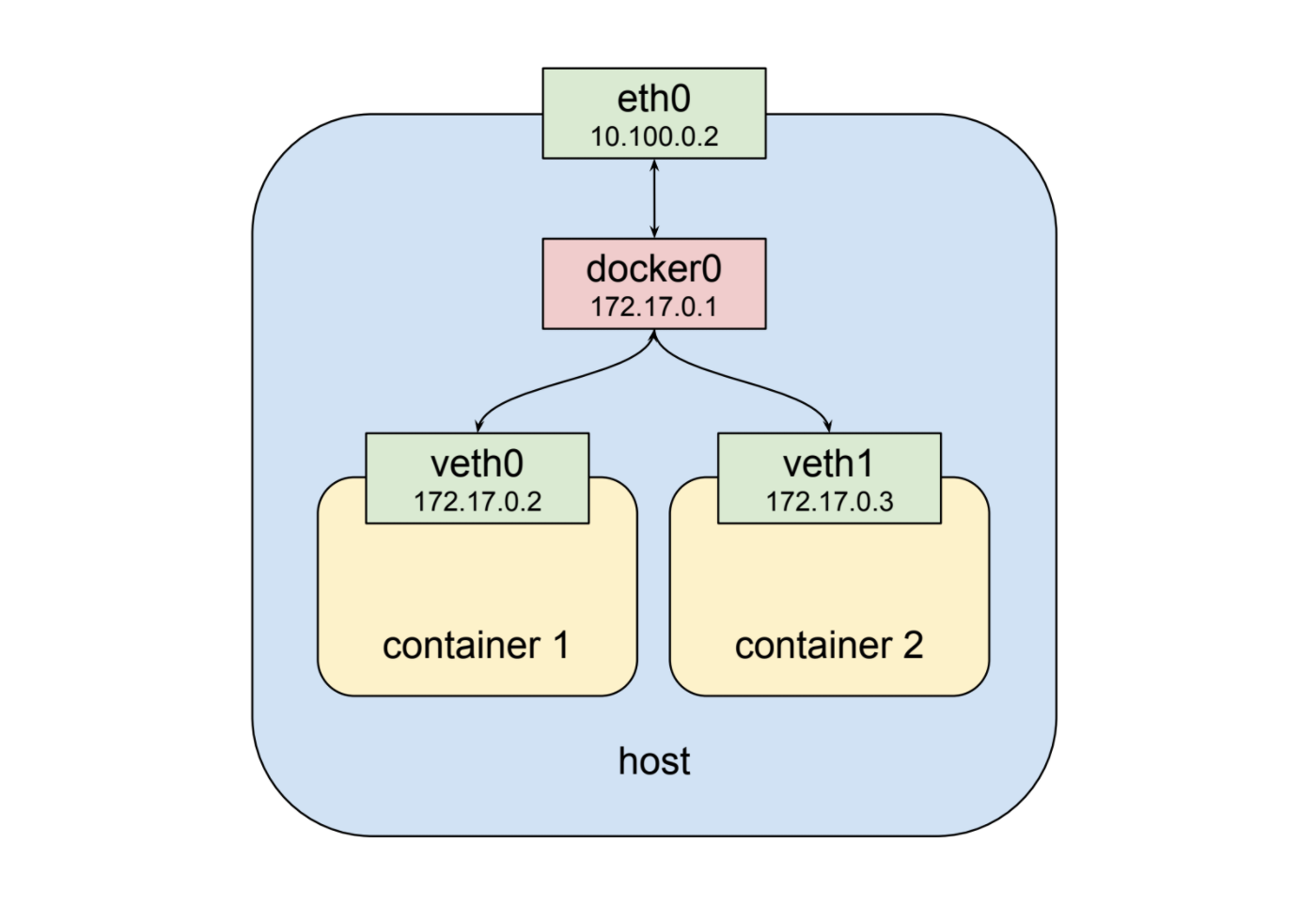
- Docker also needs the same setup
- Routing is much easier with a L2 bridge
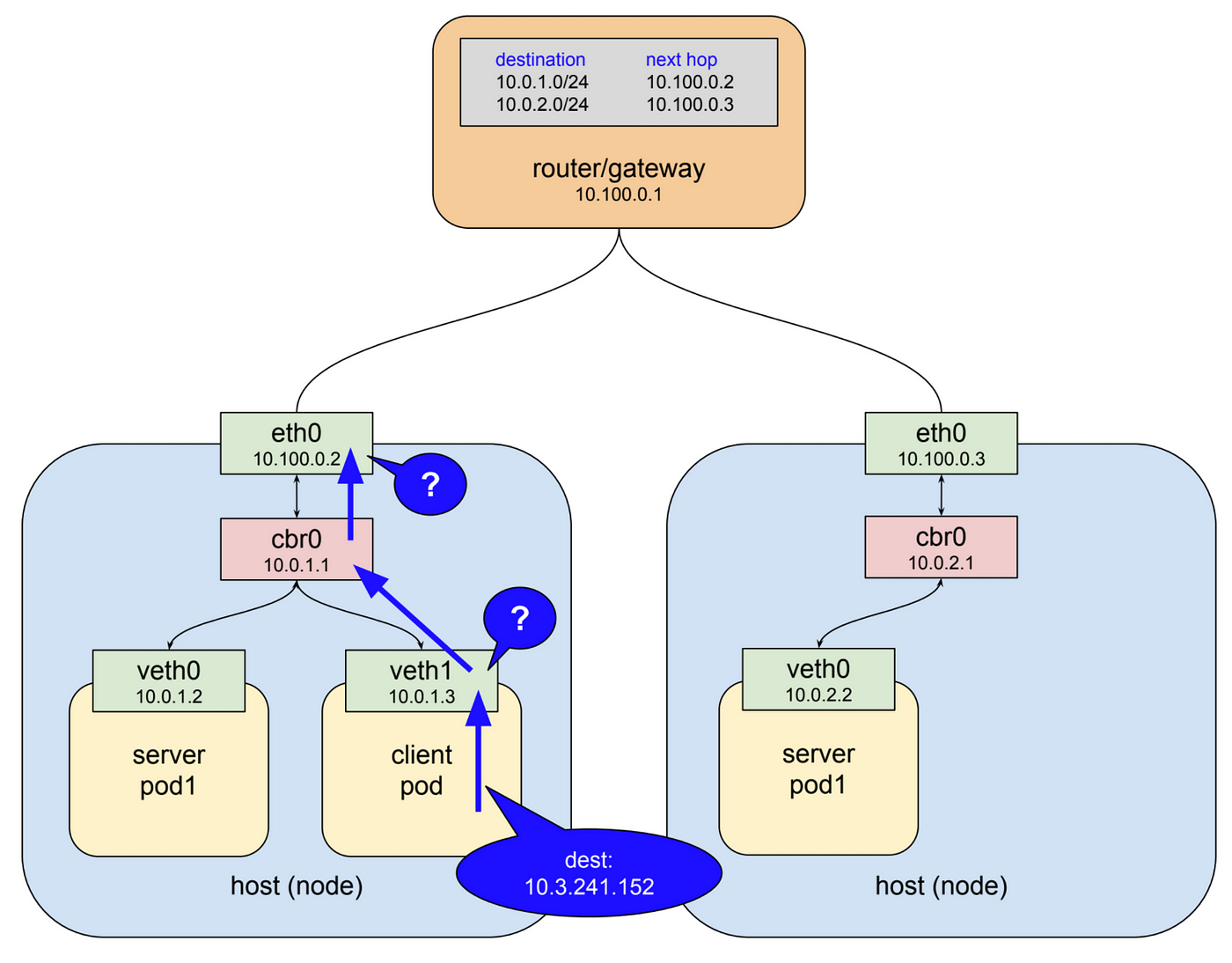
But what about pods across 2 workers?
-
Many different ways:
- Tunnel overlays like VXLAN (underlying network is unaware)
- Plain routing like BGP
-
Challenges:
- Different techniques for different clusters
- Pods keep changing

- Standard interface to manage container networking
- Different "plugins" that conform to the spec

Out of the box plugins: bridge, ipvlan, macvlan, dhcp
A lot of other plugins:
- Interface plugins: create interface for containers
- IP Address Management (IPAM) plugins: allocate IP address for a container
- Meta plugins: portmap, firewall etc
Can chain any number of plugins one after another.
Spec: https://www.cni.dev/docs/spec/
A plugin must be called with the following env variables:
- COMMAND: ADD, DEL, CHECK, VERSION
- CONTAINERID: id of the container
- NETNS: path to the net namespace of the container (eg. /run/netns/namespace1)
- IFNAME: name of intf to create inside the container
- ARGS: extra args
- PATH: where to search for the plugin
{
"cniVersion": "1.0.0",
"name": "dbnet",
"type": "bridge",
"bridge": "cni0",
"keyA": ["some more", "plugin specific", "configuration"],
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameservers": [ "10.1.0.1" ]
}
}
2 aspects to it:
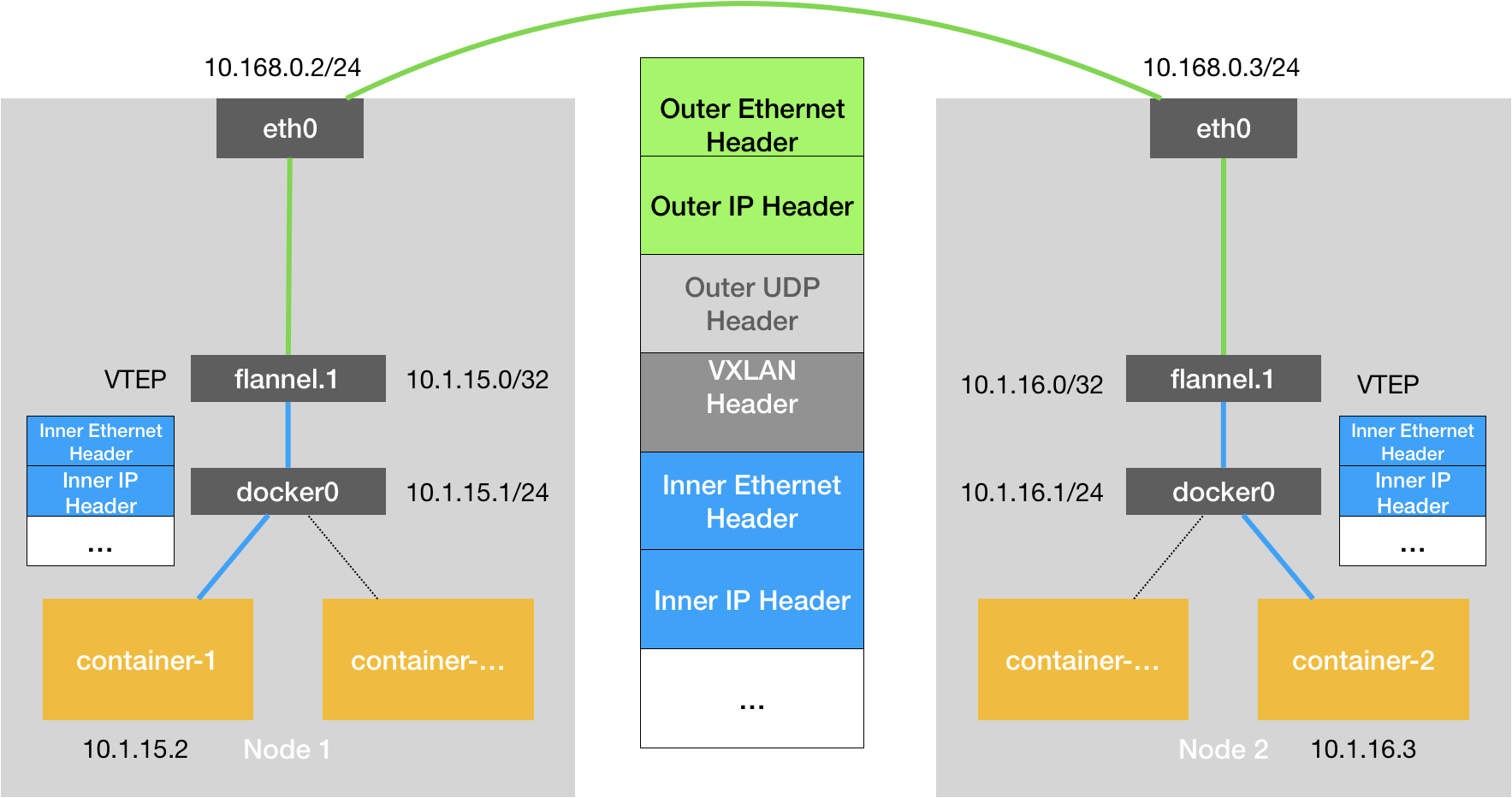
- The CNI plugin - flannel
- Who calls the CNI plugin? (since we dont have a real k8s runtime)
- Development tool that allows you to run cni plugins for a namespace
- See: https://www.cni.dev/docs/cnitool/
CNI_PATH=/opt/cni/bin
NETCONFPATH=/tmp/knetsim/<name>
cnitool add|del <name> /var/run/netns/<nsname>
How do we run it?
- A
flanneldbinary running per worker connected to an etcd cluster for the k8s cluster- etcd is a key-value store
- k8s comes with its own etcd setup
- The
flannelCNI plugin available on each worker to be called bycnitoolwhenever containers go up/down
- Cluster level configuration loaded into etcd first
- Bring up flannel daemons on each workers
- Setup CNI configuration to be used for container creation on all workers
- Create containers
Loaded into etcd from ./conf/flannel-network-config.json:
{
"Network": "11.0.0.0/8",
"SubnetLen": 20,
"SubnetMin": "11.10.0.0",
"SubnetMax": "11.99.0.0",
"Backend": {
"Type": "vxlan",
"VNI": 100,
"Port": 8472
}
}
Autogenerated by the flannel daemon on each worker:
FLANNEL_NETWORK=11.0.0.0/8
FLANNEL_SUBNET=11.10.128.1/20
FLANNEL_MTU=1450
FLANNEL_IPMASQ=false
{
"name": "C0w1",
"type": "flannel",
"subnetFile": "/tmp/knetsim/C0w1/flannel-subnet.env",
"dataDir": "/tmp/knetsim/C0w1/flannel",
"delegate": {"isDefaultGateway": true}
}
- Examine IPs of w1c1 and w2c2.
- Ping w2c2 from w1c1. Note: use the
ping <ip> -c 5command. - (Optional) Create a new container on one of the workers and see the IP assigned to it and check if you can connect to it.
The traffic flow here is: c1 > host bridge > vxlan tunnel > host bridge > c2 Let us trace the flow of the ping.
To obtain pid of worker processes:
ps aux | grep "mininet"
To run a command in a particular network namespace (using pid of worker nodes):
nsenter --net -t <pid> bash
To check for icmp packets on an intf:
tcpdump -i <intf> icmp
Check the bridge interfaces "flannel.100" on both hosts.
To check for packets on the vxlan port:
tcpdump port 8472
But, how to confirm if this is indeed VXLAN?
Use tshark protocol decoding:
tshark -V -d udp.port==8472,vxlan port 8472 |& less
- Examine the logs of flannel in the
/tmp/knetsimfolder. - Change the parameters of the flannel config in
conffolder and re-run and see the change in IPs.
- Workers and containers ✔️
- Container-Container communication ✔️
- Service abstraction ⬅️
- Ingress
- Multi-cluster communication
Users consume services, not pods We already know about pod ips, how do services work?



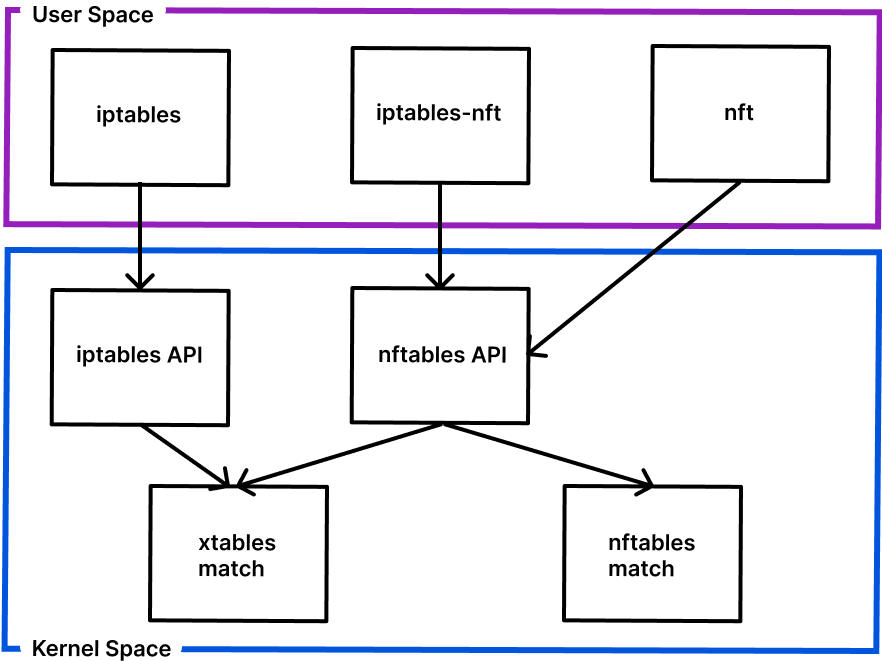
Using nftables to program static DNAT rules
- nftables is the replacement to iptables
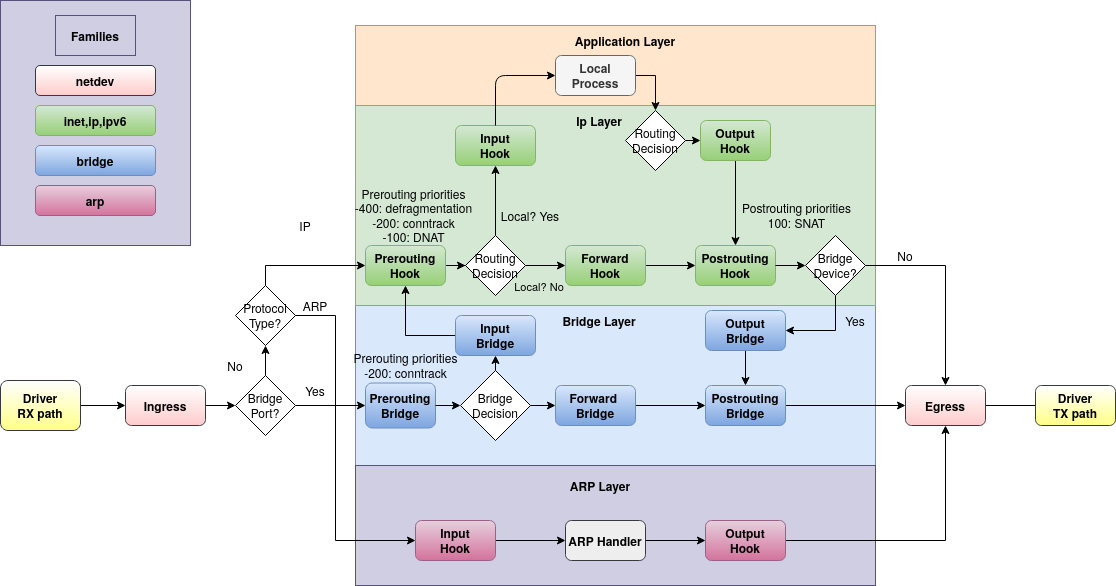
Let us run a new container for this experiment:
docker run -it --privileged --rm --entrypoint bash knetsim
Check the rules (will be empty):
nft list ruleset
Use this reference: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page (Go to the Basic Operations section)
nft add table ip table1
nft list ruleset # or
nft list table table1
Table family types: ip, arp, ip6, bridge, inet, netdev
nft add chain ip table1 chain1 { type filter hook output priority 0 \; policy accept \; }
nft list ruleset
-
ip refers to the table family (can be omitted)
-
table1 refers to the table we just created
-
chain1 is the name of the new chain
-
type is one of
filter,routeornat
nft add rule ip table1 chain1 ip daddr 8.8.8.8 counter
nft list ruleset
- You can match based on anything in the packet. Check: https://wiki.nftables.org/wiki-nftables/index.php/Quick_reference-nftables_in_10_minutes#Matches
counteris a statement
- Verdict statements:
accept,drop,queue(to userspace),continue,return,jump,goto counterlimit: rate limitingnat: dnat to or snat to
Refer to: https://wiki.nftables.org/wiki-nftables/index.php/Quick_reference-nftables_in_10_minutes#Statements
Counters should be empty:
nft list ruleset
Send a single packet:
ping -c 1 8.8.8.8
Counter should now be incremented:
nft list ruleset
Using handles to delete rules
nft -a list ruleset
nft delete rule ip table1 chain1 handle #handleno
nft list ruleset
nft delete chain ip table1 chain1
nft delete table ip table1
Exit the container.
- Intervals:
192.168.0.1-192.168.0.250,nft add rule filter input tcp ports 1-1024 drop - Concatenations (
.syntax) - Math operations: hashing, number series generators
- Sets and Maps (with Named variants)
- Quotas: a rule which will only match until a number of bytes have passed
- Flowtables: net stack bypass
- A better
iptables - tables -> chains -> rules
- Chains have to be created for a purpose:
filter,routeornat - Rules can have statements:
- Verdict statements:
accept,drop,jumpetc counter,limit,nat
- Verdict statements:
- A lot of other handy features
In the code, we have:
C0.kp_vip_add("100.64.10.1", ["c2", "c3"])
This means, we can access the containers c2 and c3 using this VIP.
- Ping this virtual ip from c1 and see that it works.
- Delete one of the 2 containers c2/c3 and see what happens. (Hint: repeat the ping a few times)
- Create a few containers and expose them using a new VIP.
- Examine the
nftrules added to the hosts.
- Workers and containers ✔️
- Container-Container communication ✔️
- Service abstraction ✔️
- Ingress ⬅️
- Multi-cluster communication
- Ingress: allows exposing of endpoints outside the cluster

- Allows to expose particular services at particular ports and paths
- Allows multiple services to be exposed at a single url - with path matches

- Ingress resource spec is not enough - we need a controller to actually implement this exposing
- Lot of available options:
- Each cloud provider has their own Ingress Controller implmentation
- HAProxy
- Nginx
- Traefik
- Istio
- Kong, Kush, Citrix, F5, Gloo.... the list goes on
-
We build our own ingress using Nginx
-
Use the same open-source standard nginx load balancer
-
Build our own configuration for it
-
Caveat: as before, this is not dynamic - manually built
# Setup containers for ingress
C0.get("w2").create_container("ic0")
C0.get("w2").exec_container_async("ic0", "./utils/ss.py S1-W2")
C0.get("w3").create_container("ic1")
C0.get("w3").exec_container_async("ic1", "./utils/ss.py S1-W3")
C0.kp_vip_add("100.64.11.1", ["ic0", "ic1"])
C0.get("w2").create_container("ic2")
C0.get("w2").exec_container_async("ic2", "./utils/ss.py S2-W2")
C0.get("w3").create_container("ic3")
C0.get("w3").exec_container_async("ic3", "./utils/ss.py S2-W3")
C0.kp_vip_add("100.64.11.2", ["ic2", "ic3"])
- A simple server script to serve static messages
- Two replicas (in name) to represent the first service 100.64.11.1
- Two replicas (in name) to represent the second service 100.64.11.2
C0.get("w1").run_ingress("grp1",
8001, [{"path": "/svc1", "endpoint": "100.64.11.1:8000"},
{"path": "/svc2", "endpoint": "100.64.11.2:8000"}])
to create an ingress at worker 1 that:
- serves the first service at the path /svc1
- serves the second service at the path /svc2
Note that the backing pods for both services are on workers 2 and 3, while the ingress is being exposed on worker 1.
Now, first access the service normally:
mininet> C0w1 curl 100.64.11.1:8000
S1-W2
If you run this a few times, the output fill alternate between S1-W2 and S1-W3. You can do a similar check with the other service: "100.64.11.2:8000".
Now, access it via the ingress:
mininet> C0w1 curl localhost:8001/svc1
S1-W2
If you call it a few times, you will see the output vary as before. Similarly call the "/svc2" path on the host.
First check the IP of the worker1 host:
mininet> C0w1 hostname -I
10.0.0.3 ...
Now, run the curl command above from another worker in the cluster. Let us use the etcd nodes for this purpose - they have nothing programmed on them - no services etc.
mininet> C0e1 curl 10.0.0.3:8001/svc1
Check that this access works for both paths. Think about the full stack of operations that are running right now to make this work.
- Workers and containers ✔️
- Container-Container communication ✔️
- Service abstraction ✔️
- Ingress ✔️
- Multi-cluster communication ⬅️
We have seen how containers and services within a cluster communicate.
What about services across clusters?
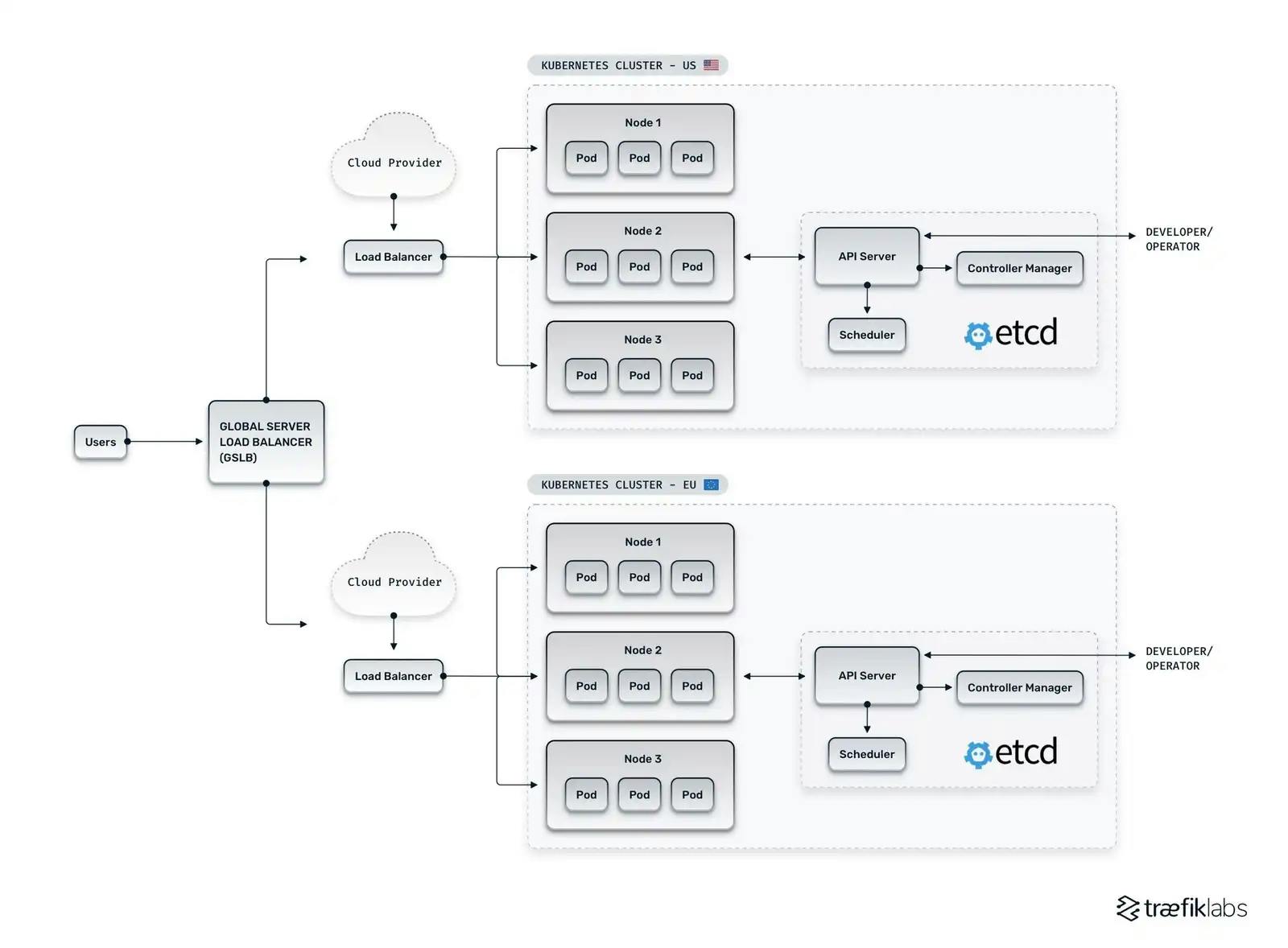
- Same provider: different zones, data centers
- Different providers: multi-cloud, hybrid-cloud, edge/telco clouds

- Connect public-cloud deployments with on-prem enterprise data centers
- Allows cloud transformation journey
- Allows mix and match of legacy applications with new apps
- Allows moving workloads from on-prem to clouds (and vice-versa) as situation changes

- Allow containers/services to talk across clusters
- Features:
- Routing: how to find the pathway from a container to another
- Management: adding/removing clusters, pods, services
- Security: encryption of cross-cluster traffic
- Policies: which apps can talk to which other apps
- These are features required for within cluster too - but a number of solutions exist for this
It doesn't yet!
- Active area of research - not solved yet
- Some existing solutions: Cilium Multi-cluster, Istio/Consul Multi-cluster, Submariner, Skupper
- Each solution trade-offs various aspects
We are also working in this space.
- Layer 7 service interconnect
- Open-source project: skupper.io
Let's go into some details.

Linking sites:
skupper init
# on one end
skupper token create site1.token
# on the other end
skupper link create site1.token
Exposing a service:
skupper expose deployment/backend --port 8080
- Any number of services communicate over the same skupper router

- Based on the AMQP Messaging queue system
- Skupper Routers are modified Qpid Dispatch Routers

A bit more complicated:
- Skupper Router to do the actual routing
- Site-Controller: to manage the links between various clusters
- Service-Controller: to manage services as they come up/down
We also use skupper-router, with manual configuration.
Let us look at how the config file looks like.
(Example is available in conf/ folder as solo0.json and solo1.json)
"router", {
"id": "c0",
"mode": "interior",
...
}
"listener", {
"name": "interior-listener",
"role": "inter-router",
"port": 55671,
"maxFrameSize": 16384,
"maxSessionFrames": 640
}
"router",
{
"id": "c1",
"mode": "interior",
...
}
"connector",
{
"name": "link1",
"role": "inter-router",
"host": "localhost",
"port": "55671",
"cost": 1,
"maxFrameSize": 16384,
"maxSessionFrames": 640
}
"tcpListener",
{
"name": "backend:8080",
"port": "1028",
"address": "backend:8080",
"siteId": "c0"
}
"tcpConnector",
{
"name": "backend",
"host": "localhost",
"port": "8090",
"address": "backend:8080",
"siteId": "c1"
}
- Generate conf json files based on user provided list of services to expose.
- Run one
skupper-routerin each cluster on worker0. - Containers in the cluster should connect to the skupper-router at a particular port for a given service.
Go read line number 79-94 in main.py.
Understand and reproduce it.
Examine the generated conf files in /tmp/knetsim/skupper folder.
Pros:
- Allow any number of services to talk across clusters with a single port exposed
- Provides encryption for cross-service links
Cons:
- Not efficient: in terms of performance overheads
- No provision for fine-grained policies
There are other solutions in the market that address a different set of tradeoffs
- Mesh of services
- Sidecars to manage service-service communication
- Handle:
- service discovery
- TLS certificate issuing
- metrics aggregation
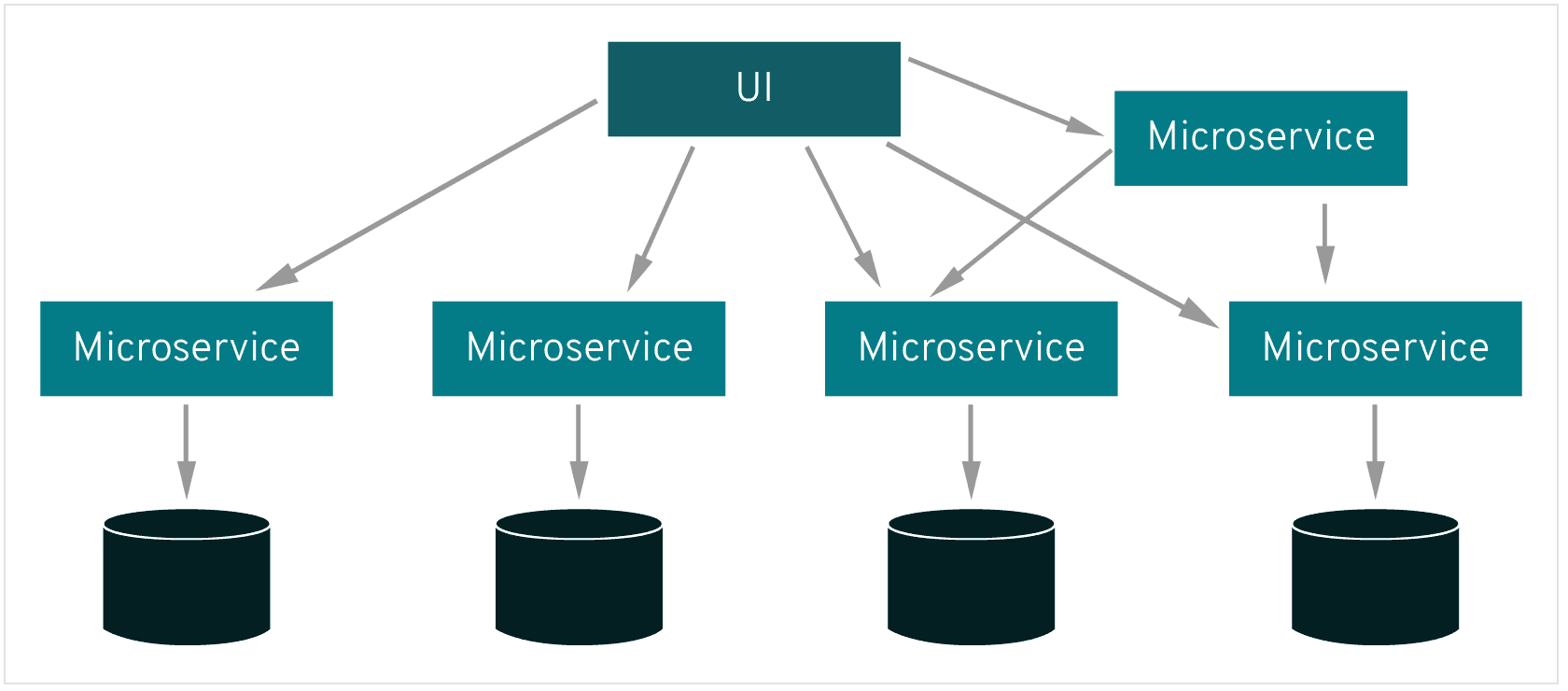
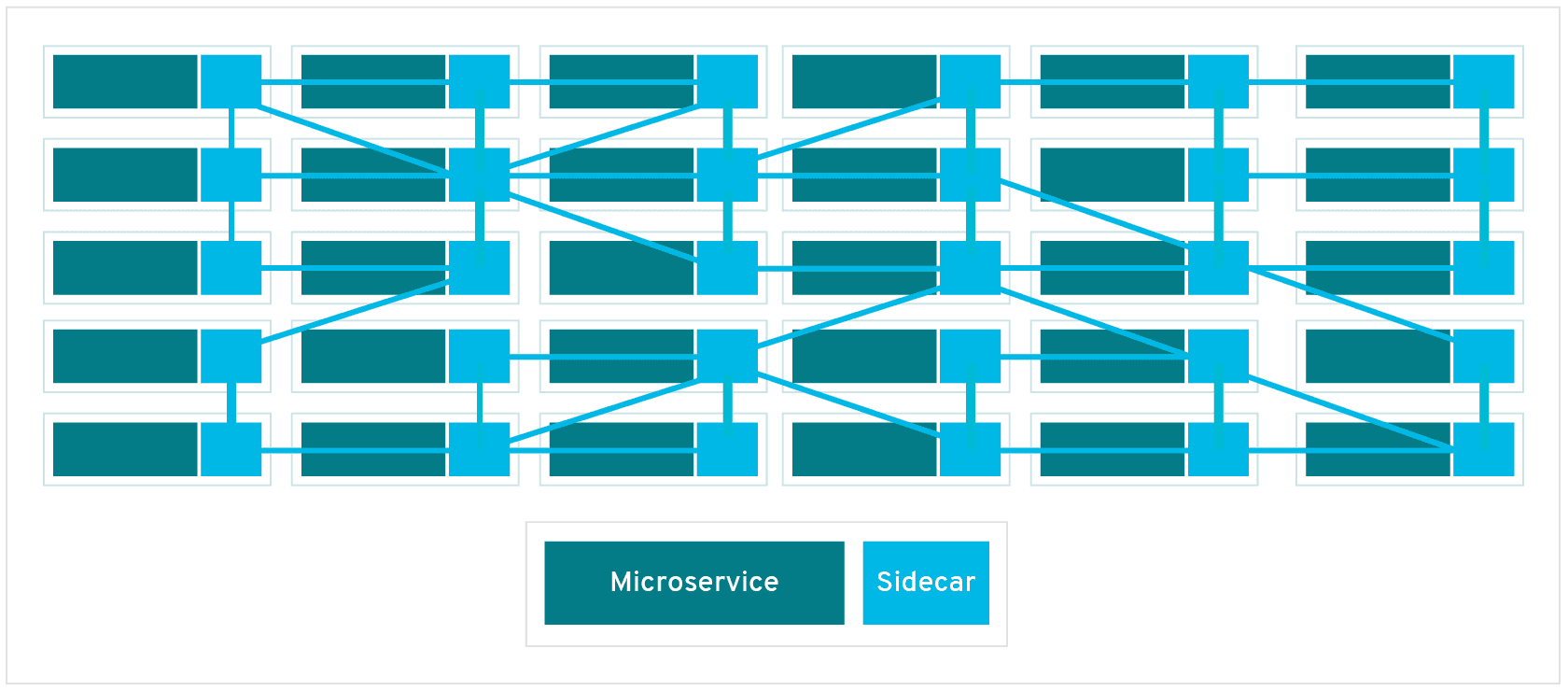
- load balancing, service-to-service authentication, and monitoring – with few or no service code changes

(https://istio.io/v1.2/docs/concepts/multicluster-deployments/) - Multiple control plane topology - Single-network shared control plane - Multi-network shared control plane: using istio gateways - Summary: tight coupling across clusters
What did we learn today?
- About the various layers in Kubernetes networking:
- Network namespaces
- Pod-pod communications: CNI spec and CNI plugins
- Service abstraction using
kube-proxy
- Intro to the world of multi-cluster networking
- Saw how Skupper works in connecting clusters
- Setup and configure your own kubernetes clusters more confidently
- Be able to compare and select CNI plugin solutions like Calico, Cilium
- Extend CNI functionalities
- Understand the CNCF networking landscape and how things fit with each other
- Plan multi-cluster/edge deployments
And of course, Conduct research in the exciting space of cloud-native networking