Day 2 - Wednesday 12/06/2024 DAY 1 - Tuesday 11/06/2024 09:00 CEST 10:00 EEST Welcome and Introduction Presenters: J\u00f8rn Dietze (LUST) and Harvey Richardson (HPE) 09:15 CEST 10:15 EEST LUMI Architecture, Programming and Runtime Environment Presenters: Harvey Richardson (HPE) 09:45 CEST 10:45 EEST Exercises (session 1) Presenter: Alfio Lazzaro (HPE) 10:15 CEST 11:15 EEST Break (15 minutes) 10:30 CEST 11:30 EEST Introduction to Performance Analysis with Perftools Presenters Thierry Braconnier (HPE) 11:10 CEST 12:10 EEST Performance Optimization: Improving Single-Core Efficiency Presenter: Jean-Yves Vet (HPE) 11:40 CEST 12:40 EEST Application Placement Presenters: Jean-Yves Vet (HPE) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 14:00 EEST Optimization/performance analysis demo and exercise Presenters: Alfio Lazzaro (HPE) 14:30 CEST 15:30 EEST Break (30 minutes) 15:00 CEST 16:00 EEST Optimization/performance analysis demo and exercise Presenters: Alfio Lazzaro (HPE) 16:30 CEST 17:30 EEST End of the workshop day DAY 2 - Wednesday 12/06/2024 09:00 CEST 10:00 EEST AMD Profiling Tools Overview & Omnitrace Presenter: Samuel A\u00f1tao (AMD) 10:00 CEST 11:00 EEST Exercises (session 2) Presenter: Samuel A\u00f1tao (AMD) 10:30 CEST 11:30 EEST Break (15 minutes) 10:45 CEST 11:45 EEST Introduction to Omniperf Presenters: Samuel A\u00f1tao (AMD) 11:30 CEST 12:#0 EEST Exercises (session 3) Presenter: Samuel A\u00f1tao (AMD) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 14:00 EEST MPI Optimizations Presenters: Harvey Richardson (HPE) 13:30 CEST 14:30 EEST Exercises (session 4) Presenter: Harvey Richardson (HPE) 14:00 CEST 15:00 EEST IO Optimizations Presenters: Harvey Richardson (HPE) 14:35 CEST 15:35 EEST Exercises (session 5) Presenter: Harvey Richardson (HPE) 15:05 CEST 16:05 EEST Break (15 minutes) 15:20 CEST 16:20 EEST Open session and Q&A Option to work on your own code 16:30 CEST 17:30 EEST End of the workshop"}]}
\ No newline at end of file
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Overview of LUMI trainings","text":""},{"location":"#organised-by-lust-in-cooperation-with-partners","title":"Organised by LUST in cooperation with partners","text":""},{"location":"#regular-trainings","title":"Regular trainings","text":"Upcoming or currently running events with materials already partly available:
- Advanced LUMI course (October 28-31, 2024)
Most recently completed main training events:
-
Introductory LUMI training aimed at regular users: LUMI 2-day training (May 2-3, 2023)
Short URL to the most recently completed introductory training for regular users: lumi-supercomputer.github.io/intro-latest
-
4-day comprehensive LUMI training aimed at developers and advanced users, mostly focusing on traditional HPC users: Comprehensive general LUMI course (April 23-26, 2024)
Short URL to the most recently completed comprehensive LUMI training aimed at developers and advanced users: lumi-supercomputer.github.io/comprehensive-latest
-
Comprehensive training specifically for AI users: Moving your AI training jobs to LUMI: A Hands-On Workshop. A 2-day AI workshop (May 29-30, 2024)
Short URL to the most recently completed training for AI users: lumi-supercomputer.github.io/AI-latest
-
Performance Analysis and Optimization Workshop, Oslo, 12-12 June 2024
Other recent LUST-organised trainings for which the material is still very up-to-date and relevant:
- HPE and AMD profiling tools (October 9, 2024)
"},{"location":"#lumi-user-coffee-break-talks","title":"LUMI User Coffee Break Talks","text":"Archive of recordings and questions
-
LUMI Update Webinar (October 2, 2024)
-
HyperQueue (January 31, 2024)
-
Open OnDemand: A web interface for LUMI (November 29, 2023)
-
Cotainr on LUMI (September 27, 2023)
-
Spack on LUMI (August 30, 2023)
-
Current state of running AI workloads on LUMI (June 28, 2023)
"},{"location":"#recent-courses-made-available-by-lumi-consortium-partners-and-coes","title":"Recent courses made available by LUMI consortium partners and CoEs","text":" - Workshop: How to run GROMACS efficiently on LUMI (January 24-25, 2024, BioExcel/CSC Finland/KTH Sweden)
- Interactive Slurm tutorial developed by DeiC (Denmark)
"},{"location":"#course-archive","title":"Course archive","text":""},{"location":"#lust-provided-regular-trainings","title":"LUST-provided regular trainings","text":"By theme in reverse chronological order:
- Short introductory trainings to LUMI
- Supercomputing with LUMI (May, 2024 in Amsterdam)
- LUMI 1-day training (February, 2024)
- LUMI 1-day training (September, 2023)
- LUMI 1-day training (May 9 and 16, 2023)
- Comprehensive general LUMI trainings aimed at at developers and advanced users, mostly focusing on traditional HPC users
- Advanced LUMI course (October 28-31, 2024)
- Comprehensive general LUMI course (April 23-26, 2024)
- Comprehensive general LUMI course (October 3-6, 2023)
- Comprehensive general LUMI course (May 30 - June 2, 2023)
- Comprehensive general LUMI course (February 14-17, 2023)
- LUMI-G Training (January 11, 2023)
- Detailed introduction to the LUMI-C environment and architecture (November 23/24, 2022)
- LUMI-G Pilot Training (August 23, 2022)
- Detailed introduction to the LUMI-C environment and architecture (April 27/28, 2022)
- Comprehensive AI trainings for LUMI:
- Moving your AI training jobs to LUMI: A Hands-On Workshop. A 2-day AI workshop (May 29-30, 2024)
- Performance analysis tools and/or program optimization
- HPE and AMD profiling tools (October 9, 2024)
- Performance Analysis and Optimization Workshop, Oslo, 12-12 June 2024
- HPE and AMD profiling tools (November 22, 2023)
- HPE and AMD profiling tools (April 13, 2023)
- Materials from Hackathons
- LUMI-G hackathon (October 14-18, 2024)
- LUMI-G hackathon (April 17-21, 2023)
- EasyBuild on LUMI
- EasyBuild course for CSC and local organisations (May 9/11, 2022)
"},{"location":"#courses-made-available-by-lumi-consortium-partners-and-coes","title":"Courses made available by LUMI consortium partners and CoEs","text":" - Workshop: How to run GROMACS efficiently on LUMI (January 24-25, 2024, BioExcel/CSC Finland/KTH Sweden)
- Interactive Slurm tutorial developed by DeiC (Denmark)
"},{"location":"#information-for-local-organisations","title":"Information for local organisations","text":"The materials in the GitHub repository Lumi-supercomputer/LUMI-training-materials and all materials linked in this web site and served from 462000265.lumidata.eu that are presented by a member of LUST are licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. This includes all of the material of the LUMI 1-day trainings series.
Presentations given by AMD of which some material can be downloaded from this web site and from 462000265.lumidata.eu are copyrighted by AMD, or in cases where AMD is using material available in the public domain (e.g., for exercises), licensed under the source license for that material. Using AMD copyrighted materials should be discussed with AMD.
All presentation material presented by HPE is copyrighted by HPE and can only be shared with people who have an account on LUMI. Therefore that material is not available via this web site and can only be accessed on LUMI itself.
"},{"location":"1day-20230509/","title":"LUMI 1-day training May 2023","text":""},{"location":"1day-20230509/#organisation","title":"Organisation","text":""},{"location":"1day-20230509/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":" -
Create a directory in the scratch of the training project, or if you want to keep the exercises around for a while after the session and have already another project on LUMI, in a subdirectory or your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of the project:
mkdir -p /scratch/project_465000523/$USER/exercises\ncd /scratch/project_465000523/$USER/exercises\n
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/1day-20230509/files/exercises-20230509.tar.gz\ntar -xf exercises-20230509.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"1day-20230509/#downloads","title":"Downloads","text":"Presentation Slides Notes recording Introduction / / recording LUMI Architecture slides notes recording HPE Cray Programming Environment slides notes recording Modules on LUMI slides notes recording LUMI Software Stacks slides notes recording Exercises 1 / notes / Running Jobs on LUMI slides / recording Exercises 2 / notes / Introduction to Lustre and Best Practices slides / recording LUMI User Support slides / recording"},{"location":"1day-20230509/01_Architecture/","title":"The LUMI Architecture","text":"In this presentation, we will build up LUMI part by part, stressing those aspects that are important to know to run on LUMI efficiently and define jobs that can scale.
"},{"location":"1day-20230509/01_Architecture/#lumi-is","title":"LUMI is ...","text":"LUMI is a pre-exascale supercomputer, and not a superfast PC nor a compute cloud architecture.
Each of these architectures have their own strengths and weaknesses and offer different compromises and it is key to chose the right infrastructure for the job and use the right tools for each infrastructure.
Just some examples of using the wrong tools or infrastructure:
-
We've had users who were disappointed about the speed of a single core and were expecting that this would be much faster than their PCs. Supercomputers however are optimised for performance per Watt and get their performance from using lots of cores through well-designed software. If you want the fastest core possible, you'll need a gaming PC.
-
Even the GPU may not be that much faster for some tasks than GPUs in gaming PCs, especially since an MI250x should be treated as two GPUs for most practical purposes. The better double precision floating point operations and matrix operations, also at full precision, requires transistors also that on some other GPUs are used for rendering hardware or for single precision compute units.
-
A user complained that they did not succeed in getting their nice remote development environment to work on LUMI. The original author of these notes took a test license and downloaded a trial version. It was a very nice environment but really made for local development and remote development in a cloud environment with virtual machines individually protected by personal firewalls and was not only hard to get working on a supercomputer but also insecure.
-
CERN came telling on a EuroHPC Summit Week before the COVID pandemic that they would start using more HPC and less cloud and that they expected a 40% cost reduction that way. A few years later they published a paper with their experiences and it was mostly disappointment. The HPC infrastructure didn't fit their model for software distribution and performance was poor. Basically their solution was designed around the strengths of a typical cloud infrastructure and relied precisely on those things that did make their cloud infrastructure more expensive than the HPC infrastructure they tested. It relied on fast local disks that require a proper management layer in the software, (ab)using the file system as a database for unstructured data, a software distribution mechanism that requires an additional daemon running permanently on the compute nodes (and local storage on those nodes), ...
True supercomputers, and LUMI in particular, are built for scalable parallel applications and features that are found on smaller clusters or on workstations that pose a threat to scalability are removed from the system. It is also a shred infrastructure but with a much more lightweight management layer than a cloud infrastructure and far less isolation between users, meaning that abuse by one user can have more of a negative impact on other users than in a cloud infrastructure. Supercomputers since the mid to late '80s are also build according to the principle of trying to reduce the hardware cost by using cleverly designed software both at the system and application level. They perform best when streaming data through the machine at all levels of the memory hierarchy and are not built at all for random access to small bits of data (where the definition of \"small\" depends on the level in the memory hierarchy).
At several points in this course you will see how this impacts what you can do with a supercomputer and how you work with a supercomputer.
"},{"location":"1day-20230509/01_Architecture/#lumi-spec-sheet-a-modular-system","title":"LUMI spec sheet: A modular system","text":"So we've already seen that LUMI is in the first place a EuroHPC pre-exascale machine. LUMI is built to prepare for the exascale era and to fit in the EuroHPC ecosystem. But it does not even mean that it has to cater to all pre-exascale compute needs. The EuroHPC JU tries to build systems that have some flexibility, but also does not try to cover all needs with a single machine. They are building 3 pre-exascale systems with different architecture to explore multiple architectures and to cater to a more diverse audience.
LUMI is also a very modular machine designed according to the principles explored in a series of European projects, and in particular DEEP and its successors) that explored the cluster-booster concept.
LUMI is in the first place a huge GPGPU supercomputer. The GPU partition of LUMI, called LUMI-G, contains 2560 nodes with a single 64-core AMD EPYC 7A53 CPU and 4 AMD MI250x GPUs. Each node has 512 GB of RAM attached to the CPU (the maximum the CPU can handle without compromising bandwidth) and 128 GB of HBM2e memory per GPU. Each GPU node has a theoretical peak performance of 200 TFlops in single (FP32) or double (FP64) precision vector arithmetic (and twice that with the packed FP32 format, but that is not well supported so this number is not often quoted). The matrix units are capable of about 400 TFlops in FP32 or FP64. However, compared to the NVIDIA GPUs, the performance for lower precision formats used in some AI applications is not that stellar.
LUMI also has a large CPU-only partition, called LUMI-C, for jobs that do not run well on GPUs, but also integrated enough with the GPU partition that it is possible to have applications that combine both node types. LUMI-C consists of 1536 nodes with 2 64-core AMD EPYC 7763 CPUs. 32 of those nodes have 1TB of RAM (with some of these nodes actually reserved for special purposes such as connecting to a Quantum computer), 128 have 512 GB and 1376 have 256 GB of RAM.
LUMI also has a 7 PB flash based file system running the Lustre parallel file system. This system is often denoted as LUMI-F. The bandwidth of that system is 1740 GB/s. Note however that this is still a remote file system with a parallel file system on it, so do not expect that it will behave as the local SSD in your laptop. But that is also the topic of another session in this course.
The main work storage is provided by 4 20 PB hard disk based Lustre file systems with a bandwidth of 240 GB/s each. That section of the machine is often denoted as LUMI-P.
Big parallel file systems need to be used in the proper way to be able to offer the performance that one would expect from their specifications. This is important enough that we have a separate session about that in this course.
Currently LUMI has 4 login nodes, called user access nodes in the HPE Cray world. They each have 2 64-core AMD EPYC 7742 processors and 1 TB of RAM. Note that whereas the GPU and CPU compute nodes have the Zen3 architecture code-named \"Milan\", the processors on the login nodes are Zen2 processors, code-named \"Rome\". Zen3 adds some new instructions so if a compiler generates them, that code would not run on the login nodes. These instructions are basically used in cryptography though. However, many instructions have very different latency, so a compiler that optimises specifically for Zen3 may chose another ordering of instructions then when optimising for Zen2 so it may still make sense to compile specifically for the compute nodes on LuMI.
All compute nodes, login nodes and storage are linked together through a high-performance interconnect. LUMI uses the Slingshot 11 interconnect which is developed by HPE Cray, so not the Mellanox/NVIDIA InfiniBand that you may be familiar with from many smaller clusters, and as we shall discuss later this also influences how you work on LUMI.
Some services for LUMI are still in the planning.
LUMI also has nodes for interactive data analytics. 8 of those have two 64-core Zen2/Rome CPUs with 4 TB of RAM per node, while 8 others have dual 64-core Zen2/Rome CPUs and 8 NVIDIA A40 GPUs for visualisation. Currently we are working on an Open OnDemand based service to make some fo those facilities available. Note though that these nodes are meant for a very specific use, so it is not that we will also be offering, e.g., GPU compute facilities on NVIDIA hardware, and that these are shared resources that should not be monopolised by a single user (so no hope to run an MPI job on 8 4TB nodes).
An object based file system similar to the Allas service of CSC that some of the Finnish users may be familiar with is also being worked on.
Early on a small partition for containerised micro-services managed with Kubernetes was also planned, but that may never materialize due to lack of people to set it up and manage it.
In this section of the course we will now build up LUMI step by step.
"},{"location":"1day-20230509/01_Architecture/#building-lumi-the-cpu-amd-7xx3-milanzen3-cpu","title":"Building LUMI: The CPU AMD 7xx3 (Milan/Zen3) CPU","text":"The LUMI-C and LUMI-G compute nodes use third generation AMD EPYC CPUs. Whereas Intel CPUs launched in the same period were built out of a single large monolithic piece of silicon (that only changed recently with some variants of the Sapphire Rapids CPU launched in early 2023), AMD CPUs are build out of multiple so-called chiplets.
The basic building block of Zen3 CPUs is the Core Complex Die (CCD). Each CCD contains 8 cores, and each core has 32 kB of L1 instruction and 32 kB of L1 data cache, and 512 kB of L2 cache. The L3 cache is shared across all cores on a chiplet and has a total size of 32 MB on LUMI (there are some variants of the processor where this is 96MB). At the user level, the instruction set is basically equivalent to that of the Intel Broadwell generation. AVX2 vector instructions and the FMA instruction are fully supported, but there is no support for any of the AVX-512 versions that can be found on Intel Skylake server processors and later generations. Hence the number of floating point operations that a core can in theory do each clock cycle is 16 (in double precision) rather than the 32 some Intel processors are capable of.
The full processor package for the AMD EPYC processors used in LUMI have 8 such Core Complex Dies for a total of 64 cores. The caches are not shared between different CCDs, so it also implies that the processor has 8 so-called L3 cache regions. (Some cheaper variants have only 4 CCDs, and some have CCDs with only 6 or fewer cores enabled but the same 32 MB of L3 cache per CCD).
Each CCD connects to the memory/IO die through an Infinity Fabric link. The memory/IO die contains the memory controllers, connections to connect two CPU packages together, PCIe lanes to connect to external hardware, and some additional hardware, e.g., for managing the processor. The memory/IO die supports 4 dual channel DDR4 memory controllers providing a total of 8 64-bit wide memory channels. From a logical point of view the memory/IO-die is split in 4 quadrants, with each quadrant having a dual channel memory controller and 2 CCDs. They basically act as 4 NUMA domains. For a core it is slightly faster to access memory in its own quadrant than memory attached to another quadrant, though for the 4 quadrants within the same socket the difference is small. (In fact, the BIOS can be set to show only two or one NUMA domain which is advantageous in some cases, like the typical load pattern of login nodes where it is impossible to nicely spread processes and their memory across the 4 NUMA domains).
The theoretical memory bandwidth of a complete package is around 200 GB/s. However, that bandwidth is not available to a single core but can only be used if enough cores spread over all CCDs are used.
"},{"location":"1day-20230509/01_Architecture/#building-lumi-a-lumi-c-node","title":"Building LUMI: a LUMI-C node","text":"A compute node is then built out of two such processor packages, connected though 4 16-bit wide Infinity Fabric connections with a total theoretical bandwidth of 144 GB/s in each direction. So note that the bandwidth in each direction is less than the memory bandwidth of a socket. Again, it is not really possible to use the full memory bandwidth of a node using just cores on a single socket. Only one of the two sockets has a direct connection to the high performance Slingshot interconnect though.
"},{"location":"1day-20230509/01_Architecture/#a-strong-hierarchy-in-the-node","title":"A strong hierarchy in the node","text":"As can be seen from the node architecture in the previous slide, the CPU compute nodes have a very hierarchical architecture. When mapping an application onto one or more compute nodes, it is key for performance to take that hierarchy into account. This is also the reason why we will pay so much attention to thread and process pinning in this tutorial course.
At the coarsest level, each core supports two hardware threads (what Intel calls hyperthreads). Those hardware threads share all the resources of a core, including the L1 data and instruction caches and the L2 cache. At the next level, a Core Complex Die contains (up to) 8 cores. These cores share the L3 cache and the link to the memory/IO die. Next, as configured on the LUMI compute nodes, there are 2 Core Complex Dies in a NUMA node. These two CCDs share the DRAM channels of that NUMA node. At the fourth level in our hierarchy 4 NUMA nodes are grouped in a socket. Those 4 nodes share an inter-socket link. At the fifth and last level in our shared memory hierarchy there are two sockets in a node. On LUMI, they share a single Slingshot inter-node link.
The finer the level (the lower the number), the shorter the distance and hence the data delay is between threads that need to communicate with each other through the memory hierarchy, and the higher the bandwidth.
This table tells us a lot about how one should map jobs, processes and threads onto a node. E.g., if a process has fewer then 8 processing threads running concurrently, these should be mapped to cores on a single CCD so that they can share the L3 cache, unless they are sufficiently independent of one another, but even in the latter case the additional cores on those CCDs should not be used by other processes as they may push your data out of the cache or saturate the link to the memory/IO die and hence slow down some threads of your process. Similarly, on a 256 GB compute node each NUMA node has 32 GB of RAM (or actually a bit less as the OS also needs memory, etc.), so if you have a job that uses 50 GB of memory but only, say, 12 threads, you should really have two NuMA nodes reserved for that job as otherwise other threads or processes running on cores in those NUMA nodes could saturate some resources needed by your job. It might also be preferential to spread those 12 threads over the 4 CCDs in those 2 NUMA domains unless communication through the L3 threads would be the bottleneck in your application.
"},{"location":"1day-20230509/01_Architecture/#hierarchy-delays-in-numbers","title":"Hierarchy: delays in numbers","text":"This slide shows the ACPI System Locality distance Information Table (SLIT) as returned by, e.g., numactl -H which gives relative distances to memory from a core. E.g., a value of 32 means that access takes 3.2x times the time it would take to access memory attached to the same NUMA node. We can see from this table that the penalty for accessing memory in another NUMA domain in the same socket is still relatively minor (20% extra time), but accessing memory attached to the other socket is a lot more expensive. If a process running on one socket would only access memory attached to the other socket, it would run a lot slower which is why Linux has mechanisms to try to avoid that, but this cannot be done in all scenarios which is why on some clusters you will be allocated cores in proportion to the amount of memory you require, even if that is more cores than you really need (and you will be billed for them).
"},{"location":"1day-20230509/01_Architecture/#building-lumi-concept-lumi-g-node","title":"Building LUMI: Concept LUMI-G node","text":"This slide shows a conceptual view of a LUMI-G compute node. This node is unlike any Intel-architecture-CPU-with-NVIDIA-GPU compute node you may have seen before, and rather mimics the architecture of the USA pre-exascale machines Summit and Sierra which have IBM POWER9 CPUs paired with NVIDIA V100 GPUs.
Each GPU node consists of one 64-core AMD EPYC CPU and 4 AMD MI250x GPUs. So far nothing special. However, two elements make this compute node very special. The GPUs are not connected to the CPU though a PCIe bus. Instead they are connected through the same links that AMD uses to link the GPUs together, or to link the two sockets in the LUMI-C compute nodes, known as xGMI or Infinity Fabric. This enables CPU and GPU to access each others memory rather seamlessly and to implement coherent caches across the whole system. The second remarkable element is that the Slingshot interface cards connect directly to the GPUs (through a PCIe interface on the GPU) rather than two the CPU. The CPUs have a shorter path to the communication network than the CPU in this design.
This makes the LUMI-G compute node really a \"GPU first\" system. The architecture looks more like a GPU system with a CPU as the accelerator for tasks that a GPU is not good at such as some scalar processing or running an OS, rather than a CPU node with GPU accelerator.
It is also a good fit with the cluster-booster design explored in the DEEP project series. In that design, parts of your application that cannot be properly accelerated would run on CPU nodes, while booster GPU nodes would be used for those parts that can (at least if those two could execute concurrently with each other). Different node types are mixed and matched as needed for each specific application, rather than building clusters with massive and expensive nodes that few applications can fully exploit. As the cost per transistor does not decrease anymore, one has to look for ways to use each transistor as efficiently as possible...
It is also important to realise that even though we call the partition \"LUMI-G\", the MI250x is not a GPU in the true sense of the word. It is not a rendering GPU, which for AMD is currently the RDNA architecture with version 3 just out, but a compute accelerator with an architecture that evolved from a GPU architecture, in this case the VEGA architecture from AMD. The architecture of the MI200 series is also known as CDNA2, with the MI100 series being just CDNA, the first version. Much of the hardware that does not serve compute purposes has been removed from the design to have more transistors available for compute. Rendering is possible, but it will be software-based rendering with some GPU acceleration for certain parts of the pipeline, but not full hardware rendering.
This is not an evolution at AMD only. The same is happening with NVIDIA GPUs and there is a reason why the latest generation is called \"Hopper\" for compute and \"Ada Lovelace\" for rendering GPUs. Several of the functional blocks in the Ada Lovelace architecture are missing in the Hopper architecture to make room for more compute power and double precision compute units. E.g., Hopper does not contain the ray tracing units of Ada Lovelace.
Graphics on one hand and HPC and AI on the other hand are becoming separate workloads for which manufacturers make different, specialised cards, and if you have applications that need both, you'll have to rework them to work in two phases, or to use two types of nodes and communicate between them over the interconnect, and look for supercomputers that support both workloads.
But so far for the sales presentation, let's get back to reality...
"},{"location":"1day-20230509/01_Architecture/#building-lumi-what-a-lumi-g-node-really-looks-like","title":"Building LUMI: What a LUMI-G node really looks like","text":"Or the full picture with the bandwidths added to it:
The LUMI-G node uses the 64-core AMD 7A53 EPYC processor, known under the code name \"Trento\". This is basically a Zen3 processor but with a customised memory/IO die, designed specifically for HPE Cray (and in fact Cray itself, before the merger) for the USA Coral-project to build the Frontier supercomputer, the fastest system in the world at the end of 2022 according to at least the Top500 list. Just as the CPUs in the LUMI-C nodes, it is a design with 8 CCDs and a memory/IO die.
The MI250x GPU is also not a single massive die, but contains two compute dies besides the 8 stacks of HBM2e memory, 4 stacks or 64 GB per compute die. The two compute dies in a package are linked together through 4 16-bit Infinity Fabric links. These links run at a higher speed than the links between two CPU sockets in a LUMI-C node, but per link the bandwidth is still only 50 GB/s per direction, creating a total bandwidth of 200 GB/s per direction between the two compute dies in an MI250x GPU. That amount of bandwidth is very low compared to even the memory bandwidth, which is roughly 1.6 TB/s peak per die, let alone compared to whatever bandwidth caches on the compute dies would have or the bandwidth of the internal structures that connect all compute engines on the compute die. Hence the two dies in a single package cannot function efficiently as as single GPU which is one reason why each MI250x GPU on LUMI is actually seen as two GPUs.
Each compute die uses a further 2 or 3 of those Infinity Fabric (or xGNI) links to connect to some compute dies in other MI250x packages. In total, each MI250x package is connected through 5 such links to other MI250x packages. These links run at the same 25 GT/s speed as the links between two compute dies in a package, but even then the bandwidth is only a meager 250 GB/s per direction, less than an NVIDIA A100 GPU which offers 300 GB/s per direction or the NVIDIA H100 GPU which offers 450 GB/s per direction. Each Infinity Fabric link may be twice as fast as each NVLINK 3 or 4 link (NVIDIA Ampere and Hopper respectively), offering 50 GB/s per direction rather than 25 GB/s per direction for NVLINK, but each Ampere GPU has 12 such links and each Hopper GPU 18 (and in fact a further 18 similar ones to link to a Grace CPU), while each MI250x package has only 5 such links available to link to other GPUs (and the three that we still need to discuss).
Note also that even though the connection between MI250x packages is all-to-all, the connection between GPU dies is all but all-to-all. as each GPU die connects to only 3 other GPU dies. There are basically two rings that don't need to share links in the topology, and then some extra connections. The rings are:
- 1 - 0 - 6 - 7 - 5 - 4 - 2 - 3 - 1
- 1 - 5 - 4 - 2 - 3 - 7 - 6 - 0 - 1
Each compute die is also connected to one CPU Core Complex Die (or as documentation of the node sometimes says, L3 cache region). This connection only runs at the same speed as the links between CPUs on the LUMI-C CPU nodes, i.e., 36 GB/s per direction (which is still enough for all 8 GPU compute dies together to saturate the memory bandwidth of the CPU). This implies that each of the 8 GPU dies has a preferred CPU die to work with, and this should definitely be taken into account when mapping processes and threads on a LUMI-G node.
The figure also shows another problem with the LUMI-G node: The mapping between CPU cores/dies and GPU dies is all but logical:
GPU die CCD hardware threads NUMA node 0 6 48-55, 112-119 3 1 7 56-63, 120-127 3 2 2 16-23, 80-87 1 3 3 24-31, 88-95 1 4 0 0-7, 64-71 0 5 1 8-15, 72-79 0 6 4 32-39, 96-103 2 7 5 40-47, 104, 11 2 and as we shall see later in the course, exploiting this is a bit tricky at the moment.
"},{"location":"1day-20230509/01_Architecture/#what-the-future-looks-like","title":"What the future looks like...","text":"Some users may be annoyed by the \"small\" amount of memory on each node. Others may be annoyed by the limited CPU capacity on a node compared to some systems with NVIDIA GPUs. It is however very much in line with the cluster-booster philosophy already mentioned a few times, and it does seem to be the future according to both AMD and Intel. In fact, it looks like with respect to memory capacity things may even get worse.
We saw the first little steps of bringing GPU and CPU closer together and integrating both memory spaces in the USA pre-exascale systems Summit and Sierra. The LUMI-G node which was really designed for the first USA exascale systems continues on this philosophy, albeit with a CPU and GPU from a different manufacturer. Given that manufacturing large dies becomes prohibitively expensive in newer semiconductor processes and that the transistor density on a die is also not increasing at the same rate anymore with process shrinks, manufacturers are starting to look at other ways of increasing the number of transistors per \"chip\" or should we say package. So multi-die designs are here to stay, and as is already the case in the AMD CPUs, different dies may be manufactured with different processes for economical reasons.
Moreover, a closer integration of CPU and GPU would not only make programming easier as memory management becomes easier, it would also enable some code to run on GPU accelerators that is currently bottlenecked by memory transfers between GPU and CPU.
AMD at its 2022 Investor day and at CES 2023 in early January, and Intel at an Investor day in 2022 gave a glimpse of how they see the future. The future is one where one or more CPU dies, GPU dies and memory controllers are combined in a single package and - contrary to the Grace Hopper design of NVIDIA - where CPU and GPU share memory controllers. At CES 2023, AMD already showed a MI300 package that will be used in El Capitan, one of the next USA exascale systems (the third one if Aurora gets built in time). It employs 13 chiplets in two layers, linked to (still only) 8 memory stacks (albeit of a slightly faster type than on the MI250x). The 4 dies on the bottom layer are likely the controllers for memory and inter-GPU links as they produce the least heat, while it was announced that the GPU would feature 24 Zen4 cores, so the top layer consists likely of 3 CPU and 6 GPU chiplets. It looks like the AMD design may have no further memory beyond the 8 HBM stacks, likely providing 128 GB of RAM.
Intel has shown only very conceptual drawings of its Falcon Shores chip which it calls an XPU, but those drawings suggest that that chip will also support some low-bandwidth but higher capacity external memory, similar to the approach taken in some Sapphire Rapids Xeon processors that combine HBM memory on-package with DDR5 memory outside the package. Falcon Shores will be the next generation of Intel GPUs for HPC, after Ponte Vecchio which will be used in the Aurora supercomputer. It is currently not clear though if Intel will already use the integrated CPU+GPU model for the Falcon Shores generation or if this is getting postponed.
However, a CPU closely integrated with accelerators is nothing new as Apple Silicon is rumoured to do exactly that in its latest generations, including the M-family chips.
"},{"location":"1day-20230509/01_Architecture/#building-lumi-the-slingshot-interconnect","title":"Building LUMI: The Slingshot interconnect","text":"All nodes of LUMI, including the login, management and storage nodes, are linked together using the Slingshot interconnect (and almost all use Slingshot 11, the full implementation with 200 Gb/s bandwidth per direction).
Slingshot is an interconnect developed by HPE Cray and based on Ethernet, but with proprietary extensions for better HPC performance. It adapts to the regular Ethernet protocols when talking to a node that only supports Ethernet, so one of the attractive features is that regular servers with Ethernet can be directly connected to the Slingshot network switches. HPE Cray has a tradition of developing their own interconnect for very large systems. As in previous generations, a lot of attention went to adaptive routing and congestion control. There are basically two versions of it. The early version was named Slingshot 10, ran at 100 Gb/s per direction and did not yet have all features. It was used on the initial deployment of LUMI-C compute nodes but has since been upgraded to the full version. The full version with all features is called Slingshot 11. It supports a bandwidth of 200 Gb/s per direction, comparable to HDR InfiniBand with 4x links.
Slingshot is a different interconnect from your typical Mellanox/NVIDIA InfiniBand implementation and hence also has a different software stack. This implies that there are no UCX libraries on the system as the Slingshot 11 adapters do not support that. Instead, the software stack is based on libfabric (as is the stack for many other Ethernet-derived solutions and even Omni-Path has switched to libfabric under its new owner).
LUMI uses the dragonfly topology. This topology is designed to scale to a very large number of connections while still minimizing the amount of long cables that have to be used. However, with its complicated set of connections it does rely on adaptive routing and congestion control for optimal performance more than the fat tree topology used in many smaller clusters. It also needs so-called high-radix switches. The Slingshot switch, code-named Rosetta, has 64 ports. 16 of those ports connect directly to compute nodes (and the next slide will show you how). Switches are then combined in groups. Within a group there is an all-to-all connection between switches: Each switch is connected to each other switch. So traffic between two nodes of a group passes only via two switches if it takes the shortest route. However, as there is typically only one 200 Gb/s direct connection between two switches in a group, if all 16 nodes on two switches in a group would be communicating heavily with each other, it is clear that some traffic will have to take a different route. In fact, it may be statistically better if the 32 involved nodes would be spread more evenly over the group, so topology based scheduling of jobs and getting the processes of a job on as few switches as possible may not be that important on a dragonfly Slingshot network. The groups in a slingshot network are then also connected in an all-to-all fashion, but the number of direct links between two groups is again limited so traffic again may not always want to take the shortest path. The shortest path between two nodes in a dragonfly topology never involves more than 3 hops between switches (so 4 switches): One from the switch the node is connected to the switch in its group that connects to the other group, a second hop to the other group, and then a third hop in the destination group to the switch the destination node is attached to.
"},{"location":"1day-20230509/01_Architecture/#assembling-lumi","title":"Assembling LUMI","text":"Let's now have a look at how everything connects together to the supercomputer LUMI. LUMI does use a custom rack design for the compute nodes that is also fully water cooled. It is build out of units that can contain up to 4 custom cabinets, and a cooling distribution unit (CDU). The size of the complex as depicted in the slide is approximately 12 m2. Each cabinet contains 8 compute chassis in 2 columns of 4 rows. In between the two columns is all the power circuitry. Each compute chassis can contain 8 compute blades that are mounted vertically. Each compute blade can contain multiple nodes, depending on the type of compute blades. HPE Cray have multiple types of compute nodes, also with different types of GPUs. In fact, the Aurora supercomputer which uses Intel CPUs and GPUs and El Capitan, which uses the MI300 series of APU (integrated CPU and GPU) will use the same design with a different compute blade. Each LUMI-C compute blade contains 4 compute nodes and two network interface cards, with each network interface card implementing two Slingshot interfaces and connecting to two nodes. A LUMI-G compute blade contains two nodes and 4 network interface cards, where each interface card now connects to two GPUs in the same node. All connections for power, management network and high performance interconnect of the compute node are at the back of the compute blade. At the front of the compute blades one can find the connections to the cooling manifolds that distribute cooling water to the blades. One compute blade of LUMI-G can consume up to 5kW, so the power density of this setup is incredible, with 40 kW for a single compute chassis.
The back of each cabinet is equally genius. At the back each cabinet has 8 switch chassis, each matching the position of a compute chassis. The switch chassis contains the connection to the power delivery system and a switch for the management network and has 8 positions for switch blades. These are mounted horizontally and connect directly to the compute blades. Each slingshot switch has 8x2 ports on the inner side for that purpose, two for each compute blade. Hence for LUMI-C two switch blades are needed in each switch chassis as each blade has 4 network interfaces, and for LUMI-G 4 switch blades are needed for each compute chassis as those nodes have 8 network interfaces. Note that this also implies that the nodes on the same compute blade of LUMI-C will be on two different switches even though in the node numbering they are numbered consecutively. For LUMI-G both nodes on a blade will be on a different pair of switches and each node is connected to two switches. Thw switch blades are also water cooled (each one can consume up to 250W). No currently possible configuration of the Cray EX system needs that all switch positions in the switch chassis.
This does not mean that the extra positions cannot be useful in the future. If not for an interconnect, one could, e.g., export PCIe ports to the back and attach, e.g., PCIe-based storage via blades as the switch blade environment is certainly less hostile to such storage than the very dense and very hot compute blades.
"},{"location":"1day-20230509/01_Architecture/#lumi-assembled","title":"LUMI assembled","text":"This slide shows LUMI fully assembled (as least as it was at the end of 2022).
At the front there are 5 rows of cabinets similar to the ones in the exploded Cray EX picture on the previous slide. Each row has 2 CDUs and 6 cabinets with compute nodes. The first row, the one with the wolf, contains all nodes of LUMI-C, while the other four rows, with the letters of LUMI, contain the GPU accelerator nodes. At the back of the room there are more regular server racks that house the storage, management nodes, some special compute nodes , etc. The total size is roughly the size of a tennis court.
Remark
The water temperature that a system like the Cray EX can handle is so high that in fact the water can be cooled again with so-called \"free cooling\", by just radiating the heat to the environment rather than using systems with compressors similar to air conditioning systems, especially in regions with a colder climate. The LUMI supercomputer is housed in Kajaani in Finland, with moderate temperature almost year round, and the heat produced by the supercomputer is fed into the central heating system of the city, making it one of the greenest supercomputers in the world as it is also fed with renewable energy.
"},{"location":"1day-20230509/02_CPE/","title":"The HPE Cray Programming Environment","text":"Every user needs to know the basics about the programming environment as after all most software is installed through the programming environment, and to some extent it also determines how programs should be run.
"},{"location":"1day-20230509/02_CPE/#why-do-i-need-to-know-this","title":"Why do I need to know this?","text":"The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is \"I only want to run some programs, why do I need to know about programming environments?\"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Even when installing software from prebuild binaries some modules might still be needed, e.g., as you may want to inject an optimised MPI library as we shall see in the container section of this course.
"},{"location":"1day-20230509/02_CPE/#the-operating-system-on-lumi","title":"The operating system on LUMI","text":"The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes.
This also implies that some software that works perfectly fine on the login nodes may not work on the compute nodes. E.g., there is no /run/user/$UID directory and we have experienced that D-Bus (which stands for Desktop-Bus) also does not work as one should expect.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer. Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
"},{"location":"1day-20230509/02_CPE/#programming-models","title":"Programming models","text":"On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP, which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org. The AMD GPUs are not yet fully supported by Julia.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. LUMI will in the future have some nodes with NVIDIA GPUs but these nodes are meant for visualisation and not for compute.
"},{"location":"1day-20230509/02_CPE/#the-development-environment-on-lumi","title":"The development environment on LUMI","text":"Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects, and as they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise three times a year with HPE for more material.
"},{"location":"1day-20230509/02_CPE/#the-cray-compiling-environment","title":"The Cray Compiling Environment","text":"The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions use are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend developed by HPE Cray, but an LLVM-based backend. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. They claim full OpenMP 4.5 support with partial (and growing) support for OpenMP 5.0 and 5.1. More information about the OpenMP support is found by checking a manual page:
man intro_openmp\n
which does require that the cce module is loaded. The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x. Information is available via man intro_openacc\n
AMD and HPE Cray still recommend moving to OpenMP which is a much broader supported standard. There are no plans to also support OpenACC in the C/C++ compiler. The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
"},{"location":"1day-20230509/02_CPE/#scientific-and-math-libraries","title":"Scientific and math libraries","text":"Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSCi_ACC, which contains a subset of the routines of LibSci. We don't have much experience in the support team with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions.
"},{"location":"1day-20230509/02_CPE/#cray-mpi","title":"Cray MPI","text":"HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully support the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is allo fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact allowed by the standard which only requires a process starter and suggest mpirun or mpiexec depending on the version of the standard. Instead the Slurm srun command is used as the process starter. This actually makes a lot of sense as the MPI application should be mapped correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
"},{"location":"1day-20230509/02_CPE/#lmod","title":"Lmod","text":"Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on\\ a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded. module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to a module unload followed by a module load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
"},{"location":"1day-20230509/02_CPE/#compiler-wrappers","title":"Compiler wrappers","text":"The HPE Cray PE compilers are usually used through compiler wrappers. The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn. The wrapper then calls the selected compiler. Which compiler will be called is determined by which compiler module is loaded. As shown on the slide \"Development environment on LUMI\", on LUMI the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc), the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers (module amd) are available. On other HPE Cray systems, you may also find the Intel compilers or on systems with NVIDIA GPUS, the NVIDIA HPC compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc, mpiCC, mpif90, etc. on LUMI. The regular compiler wrappers do the job as soon as the cray-mpich module is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libsci module is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the --craype-verbose flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
"},{"location":"1day-20230509/02_CPE/#selecting-the-version-of-the-cpe","title":"Selecting the version of the CPE","text":"The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 22.08 for the version released in August 2022. There are usually 10 releases per year (basically every month except July and January), though not all versions are ever offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming environment. It is possible to change the default version for loading further modules by loading one of the versions of the cpe module. E.g., assuming the 22.08 version would be present on the system, it can be loaded through
module load cpe/22.08\n
Loading this module will also try to switch the already loaded PE modules to the versions from that release. This does not always work correctly, due to some bugs in most versions of this module and a limitation of Lmod. Executing the module load twice will fix this: module load cpe/22.08\nmodule load cpe/22.08\n
The module will also produce a warning when it is unloaded (which is also the case when you do a module load of cpe when one is already loaded, as it then first unloads the already loaded cpe module). The warning can be ignored, but keep in mind that what it says is true, it cannot restore the environment you found on LUMI at login. The cpe module is also not needed when using the LUMI software stacks, but more about that later.
"},{"location":"1day-20230509/02_CPE/#the-target-modules","title":"The target modules","text":"The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-rome selects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milan is the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trento is the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofi selects the libfabric communication layer which is needed for Slingshot 11.craype-network-none omits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these settings: -target-cpu, -target-accel and -target-network.
"},{"location":"1day-20230509/02_CPE/#prgenv-and-compiler-modules","title":"PrgEnv and compiler modules","text":"In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the programming environment. These modules will load the compiler wrapper (craype), compiler, MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they activate:
PrgEnv Description Compiler module Compilers PrgEnv-cray Cray Compiling Environment cce craycc, crayCC, crayftn PrgEnv-gnu GNU Compiler Collection gcc gcc, g++, gfortran PrgEnv-aocc AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang PrgEnv-amd AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang There is also a second module that offers the AMD ROCm environment, rocm. That module has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU, hipcc with the GNU compilers or GPU support with the Cray compilers.
"},{"location":"1day-20230509/02_CPE/#getting-help","title":"Getting help","text":"Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers and compiler wrappers, the following man pages are relevant:
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers, the switch -help should be used instead as the double dash version is passed to the compiler.
The wrappers also support the -dumpversion flag to show the version of the underlying compiler. Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn\nftn-2107 ftn: ERROR in command line\n No valid filenames are specified on the command line.\n$ explain ftn-2107\n\nError : No valid filenames are specified on the command line.\n\nAt least one file name must appear on the command line, with any command-line\noptions. Verify that a file name was specified, and also check for an\nerroneous command-line option which may cause the file name to appear to be\nan argument to that option.\n
On older Cray systems this used to be a very useful command with more compilers but as HPE Cray is using more and more open source components instead there are fewer commands that give additional documentation via the explain command.
Lastly, there is also a lot of information in the \"Developing\" section of the LUMI documentation.
"},{"location":"1day-20230509/02_CPE/#google-chatgpt-and-lumi","title":"Google, ChatGPT and LUMI","text":"When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command that searches for a term in the manual pages. It is often useful to better understand some error messages. E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem. You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and, e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE\n
"},{"location":"1day-20230509/02_CPE/#other-modules","title":"Other modules","text":"Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
"},{"location":"1day-20230509/02_CPE/#warning-1-you-do-not-always-get-what-you-expect","title":"Warning 1: You do not always get what you expect...","text":"The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system) which correspond to the version of the programming environment that is set as the default when installed. This is very much the behaviour of Linux applications also that pick standard libraries in a few standard directories and it enables many programs build with the HPE Cray PE to run without reconstructing the environment and in some cases to mix programs compiled with different compilers with ease (with the emphasis on some as there may still be library conflicts between other libraries when not using the so-called rpath linking). This does have an annoying side effect though: If the default PE on the system changes, all applications will use different libraries and hence the behaviour of your application may change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic linking where the search path for the libraries is stored in each executable separately. On Linux, the search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules that have their libraries also in the default location, add the directories that contain the actual version of the libraries corresponding to the version of the module to the PATH-style environment variable CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
Small demo of adapting LD_LIBRARY_PATH: An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08\n$ module load lumi-CPEtools/1.0-cpeGNU-22.08\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007f420cd55000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)\n ...\n$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007fb38c1e0000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)\n ...\n
The ldd command shows which libraries are used by an executable. Only a part of the very long output is shown in the above example. But we can already see that in the first case, the library libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/ which clearly is for a specific version of cray-mpich. We do provide an experimental module lumi-CrayPath that tries to fix LD_LIBRARY_PATH in a way that unloading the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting the CRAY_ADD_RPATHenvironment variable:
export CRAY_ADD_RPATH=yes\n
"},{"location":"1day-20230509/02_CPE/#warning-2-order-matters","title":"Warning 2: Order matters","text":"Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftw only becomes available when a processor target module is loadedcray-mpich requires both the network target module craype-network-ofi and a compiler module to be loadedcray-hdf5 requires a compiler module to be loaded and cray-netcdf in turn requires cray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found with module spider. That command can also tell which other modules should be loaded before a module can be loaded, but unfortunately due to the sometimes non-standard way the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also why we didn't demonstrate it here.
"},{"location":"1day-20230509/03_Modules/","title":"Modules on LUMI","text":"Intended audience
As this course is designed for people already familiar with HPC systems and as virtually any cluster nowadays uses some form of module environment, this section assumes that the reader is already familiar with a module environment but not necessarily the one used on LUMI.
"},{"location":"1day-20230509/03_Modules/#module-environments","title":"Module environments","text":"Modules are commonly used on HPC systems to enable users to create custom environments and select between multiple versions of applications. Note that this also implies that applications on HPC systems are often not installed in the regular directories one would expect from the documentation of some packages, as that location may not even always support proper multi-version installations and as one prefers to have a software stack which is as isolated as possible from the system installation to keep the image that has to be loaded on the compute nodes small.
Another use of modules not mentioned on the slide is to configure the programs that is being activated. E.g., some packages expect certain additional environment variables to be set and modules can often take care of that also.
There are 3 systems in use for module management. The oldest is a C implementation of the commands using module files written in Tcl. The development of that system stopped around 2012, with version 3.2.10. This system is supported by the HPE Cray Programming Environment. A second system builds upon the C implementation but now uses Tcl also for the module command and not only for the module files. It is developed in France at the C\u00c9A compute centre. The version numbering was continued from the C implementation, starting with version 4.0.0. The third system and currently probably the most popular one is Lmod, a version written in Lua with module files also written in Lua. Lmod also supports most Tcl module files. It is also supported by HPE Cray, though they tend to be a bit slow in following versions.
On LUMI we have chosen to use Lmod. As it is very popular, many users may already be familiar with it, though it does make sense to revisit some of the commands that are specific for Lmod and differ from those in the two other implementations.
It is important to realise that each module that you see in the overview corresponds to a module file that contains the actual instructions that should be executed when loading or unloading a module, but also other information such as some properties of the module, information for search and help information.
Links - Old-style environment modules on SourceForge
- TCL Environment Modules home page on SourceForge and the development on GitHub
- Lmod documentation and Lmod development on GitHub
I know Lmod, should I continue?
Lmod is a very flexible tool. Not all sides using Lmod use all features, and Lmod can be configured in different ways to the extent that it may even look like a very different module system for people coming from another cluster. So yes, it makes sense to continue reading as Lmod on LUMI may have some tricks that are not available on your home cluster.
"},{"location":"1day-20230509/03_Modules/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"1day-20230509/03_Modules/#benefits-of-a-hierarchy","title":"Benefits of a hierarchy","text":"When the hierarchy is well designed, you get some protection from loading modules that do not work together well. E.g., in the HPE Cray PE it is not possible to load the MPI library built for another compiler than your current main compiler. This is currently not exploited as much as we could on LUMI, mainly because we realised at the start that too many users are not familiar enough with hierarchies and would get confused more than the hierarchy helps them.
Another benefit is that when \"swapping\" a module that makes other modules available with a different one, Lmod will try to look for equivalent modules in the list of modules made available by the newly loaded module.
An easy example (though a tricky one as there are other mechanisms at play also) it to load a different programming environment in the default login environment right after login:
$ module load PrgEnv-aocc\n
which results in
The first two lines of output are due to to other mechanisms that are at work here, and the order of the lines may seem strange but that has to do with the way Lmod works internally. Each of the PrgEnv modules hard loads a compiler module which is why Lmod tells you that it is loading aocc/3.2.0. However, there is also another mechanism at work that causes cce/15.0.0 and PrgEnv-cray/8.3.3 to be unloaded, but more about that in the next subsection (next slide).
The important line for the hierarchy in the output are the lines starting with \"Due to MODULEPATH changes...\". Remember that we said that each module has a corresponding module file. Just as binaries on a system, these are organised in a directory structure, and there is a path, in this case MODULEPATH, that determines where Lmod will look for module files. The hierarchy is implemented with a directory structure and the environment variable MODULEPATH, and when the cce/15.0.0 module was unloaded and aocc/3.2.0 module was loaded, that MODULEPATH was changed. As a result, the version of the cray-mpich module for the cce/15.0.0 compiler became unavailable, but one with the same module name for the aocc/3.2.0 compiler became available and hence Lmod unloaded the version for the cce/15.0.0 compiler as it is no longer available but loaded the matching one for the aocc/3.2.0 compiler.
"},{"location":"1day-20230509/03_Modules/#about-module-names-and-families","title":"About module names and families","text":"In Lmod you cannot have two modules with the same name loaded at the same time. On LUMI, when you load a module with the same name as an already loaded module, that other module will be unloaded automatically before loading the new one. There is even no need to use the module swap command for that (which in Lmod corresponds to a module unload of the first module and a module load of the second). This gives you an automatic protection against some conflicts if the names of the modules are properly chosen.
Note
Some clusters do not allow the automatic unloading of a module with the same name as the one you're trying to load, but on LUMI we felt that this is a necessary feature to fully exploit a hierarchy.
Lmod goes further also. It also has a family concept: A module can belong to a family (and at most 1) and no two modules of the same family can be loaded together. The family property is something that is defined in the module file. It is commonly used on systems with multiple compilers and multiple MPI implementations to ensure that each compiler and each MPI implementation can have a logical name without encoding that name in the version string (like needing to have compiler/gcc-11.2.0 rather than gcc/11.2.0), while still having an easy way to avoid having two compilers or MPI implementations loaded at the same time. On LUMI, the conflicting module of the same family will be unloaded automatically when loading another module of that particular family.
This is shown in the example in the previous subsection (the module load PrgEnv-gnu in a fresh long shell) in two places. It is the mechanism that unloaded PrgEnv-cray when loading PrgEnv-gnu and that then unloaded cce/14.0.1 when the PrgEnv-gnu module loaded the gcc/11.2.0 module.
Note
Some clusters do not allow the automatic unloading of a module of the same family as the one you're trying to load and produce an error message instead. On LUMI, we felt that this is a necessary feature to fully exploit the hierarchy and the HPE Cray Programming Environment also relies very much on this feature being enabled to make live easier for users.
"},{"location":"1day-20230509/03_Modules/#extensions","title":"Extensions","text":"It would not make sense to have a separate module for each of the hundreds of R packages or tens of Python packages that a software stack may contain. In fact, as the software for each module is installed in a separate directory it would also create a performance problem due to excess directory accesses simply to find out where a command is located, and very long search path environment variables such as PATH or the various variables packages such as Python, R or Julia use to find extension packages. On LUMI related packages are often bundled in a single module.
Now you may wonder: If a module cannot be simply named after the package it contains as it contains several ones, how can I then find the appropriate module to load? Lmod has a solution for that through the so-called extension mechanism. An Lmod module can define extensions, and some of the search commands for modules will also search in the extensions of a module. Unfortunately, the HP{E Cray PE cray-python and cray-R modules do not provide that information at the moment as they too contain several packages that may benefit from linking to optimised math libraries.
"},{"location":"1day-20230509/03_Modules/#searching-for-modules-the-module-spider-command","title":"Searching for modules: the module spider command","text":"There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. The spider command will not only search in module names for the package, but also in extensions of the modules and so will be able to tell you that a package is delivered by another module. See Example 4 below where we will search for the CMake tools.
-
The third use of module spider is with the full name of a module. This shows two kinds of information. First it shows which combinations of other modules one might have to load to get access to the package. That works for both modules and extensions of modules. In the latter case it will show both the module, and other modules that you might have to load first to make the module available. Second it will also show help information for the module if the module file provides such information.
"},{"location":"1day-20230509/03_Modules/#example-1-running-module-spider-on-lumi","title":"Example 1: Running module spider on LUMI","text":"Let's first run the module spider command. The output varies over time, but at the time of writing, and leaving out a lot of the output, one would have gotten:
On the second screen we see, e.g., the ARMForge module which was available in just a single version at that time, and then Autoconf where the version is in blue and followed by (E). This denotes that the Autoconf package is actually provided as an extension of another module, and one of the next examples will tell us how to figure out which one.
The third screen shows the last few lines of the output, which actually also shows some help information for the command.
"},{"location":"1day-20230509/03_Modules/#example-2-searching-for-the-fftw-module-which-happens-to-be-provided-by-the-pe","title":"Example 2: Searching for the FFTW module which happens to be provided by the PE","text":"Next let us search for the popular FFTW library on LUMI:
$ module spider FFTW\n
produces
This shows that the FFTW library is actually provided by the cray-fftw module and was at the time that this was tested available in 3 versions. Note that (a) it is not case sensitive as FFTW is not in capitals in the module name and (b) it also finds modules where the argument of module spider is only part of the name.
The output also suggests us to dig a bit deeper and check for a specific version, so let's run
$ module spider cray-fftw/3.3.10.3\n
This produces:
We now get a long list of possible combinations of modules that would enable us to load this module. What these modules are will be explained in the next session of this course. However, it does show a weakness when module spider is used with the HPE Cray PE. In some cases, not all possible combinations are shown (and this is the case here as the module is actually available directly after login and also via some other combinations of modules that are not shown). This is because the HPE Cray Programming Environment is system-installed and sits next to the application software stacks that are managed differently, but in some cases also because the HPE Cray PE sometimes fails to give the complete combination of modules that is needed. The command does work well with the software managed by the LUMI User Support Team as the next two examples will show.
"},{"location":"1day-20230509/03_Modules/#example-3-searching-for-gnuplot","title":"Example 3: Searching for GNUplot","text":"To see if GNUplot is available, we'd first search for the name of the package:
$ module spider GNUplot\n
This produces:
The output again shows that the search is not case sensitive which is fortunate as uppercase and lowercase letters are not always used in the same way on different clusters. Some management tools for scientific software stacks will only use lowercase letters, while the package we use on LUMI often uses both.
We see that there are a lot of versions installed on the system and that the version actually contains more information (e.g., -cpeGNU-22.12) that we will explain in the next part of this course. But you might of course guess that it has to do with the compilers that were used. It may look strange to you to have the same software built with different compilers. However, mixing compilers is sometimes risky as a library compiled with one compiler may not work in an executable compiled with another one, so to enable workflows that use multiple tools we try to offer many tools compiled with multiple compilers (as for most software we don't use rpath linking which could help to solve that problem). So you want to chose the appropriate line in terms of the other software that you will be using.
The output again suggests to dig a bit further for more information, so let's try
$ module spider gnuplot/5.4.6-cpeGNU-22.12\n
This produces:
In this case, this module is provided by 3 different combinations of modules that also will be explained in the next part of this course. Furthermore, the output of the command now also shows some help information about the module, with some links to further documentation available on the system or on the web. The format of the output is generated automatically by the software installation tool that we use and we sometimes have to do some effort to fit all information in there.
For some packages we also have additional information in our LUMI Software Library web site so it is often worth looking there also.
"},{"location":"1day-20230509/03_Modules/#example-4-searching-for-an-extension-of-a-module-cmake","title":"Example 4: Searching for an extension of a module: CMake.","text":"The cmake command on LUMI is available in the operating system image, but as is often the case with such tools distributed with the OS, it is a rather old version and you may want to use a newer one.
If you would just look through the list of available modules, even after loading some other modules to activate a larger software stack, you will not find any module called CMake though. But let's use the powers of module spider and try
$ module spider cmake\n
which produces
The output above shows us that there are actually four other versions of CMake on the system, but their version is followed by (E) which says that they are extensions of other modules. There is no module called CMake on the system. But Lmod already tells us how to find out which module actually provides the CMake tools. So let's try
$ module spider CMake/3.25.2\n
which produces
This shows us that the version is provided by a number of buildtools modules, and for each of those modules also shows us which other modules should be loaded to get access to the commands. E.g., the first line tells us that there is a module buildtools/22.08 that provides that version of CMake, but that we first need to load some other modules, with LUMI/22.08 and partition/L (in that order) one such combination.
So in this case, after
$ module load LUMI/22.12 partition/L buildtools/22.12\n
the cmake command would be available.
And you could of course also use
$ module spider buildtools/22.12\n
to get even more information about the buildtools module, including any help included in the module.
"},{"location":"1day-20230509/03_Modules/#alternative-search-the-module-keyword-command","title":"Alternative search: the module keyword command","text":"Lmod has a second way of searching for modules: module keyword, but unfortunately it does not yet work very well on LUMI as the version of Lmod is rather old and still has some bugs in the processing of the command.
The module keyword command searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Let us look for packages that allow us to download software via the https protocol. One could try
$ module keyword https\n
which produces a lot of output:
The bug in the Lmod 8.3 version on LUMI is that all extensions are shown in the output while they are irrelevant. On the second screen though we see cURL and on the fourth screen wget which are two tools that can be used to fetch files from the internet.
LUMI Software Library
The LUMI Software Library also has a search box in the upper right. We will see in the next section of this course that much of the software of LUMI is managed through a tool called EasyBuild, and each module file corresponds to an EasyBuild recipe which is a file with the .eb extension. Hence the keywords can also be found in the EasyBuild recipes which are included in this web site, and from a page with an EasyBuild recipe (which may not mean much for you) it is easy to go back to the software package page itself for more information. Hence you can use the search box to search for packages that may not be installed on the system.
The example given above though, searching for `https, would not work via that box as most EasyBuild recipes include https web links to refer to, e.g., documentation and would be shown in the result.
The LUMI Software Library site includes both software installed in our central software stack and software for which we make customisable build recipes available for user installation, but more about that in the tutorial section on LUMI software stacks.
"},{"location":"1day-20230509/03_Modules/#sticky-modules-and-the-module-purge-command","title":"Sticky modules and the module purge command","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that help to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Let us look at the output of the module avail command, taken just after login on the system at the time of writing of these notes (the exact list of modules shown is a bit fluid):
Next to the names of modules you sometimes see one or more letters. The (D) means that that is currently the default version of the module, the one that will be loaded if you do not specify a version. Note that the default version may depend on other modules that are already loaded as we have seen in the discussion of the programming environment.
The (L) means that a module is currently loaded.
The (S) means that the module is a sticky module.
Next to the rocm module you see (D:5.0.2:5.2.0). The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
At the end of the overview the extensions are also shown. If this would be fully implemented on LUMI, the list might become very long. There is a way in Lmod to hide that output but unfortunately it does not work on LUMI yet due to another bug in the already old version of Lmod.
"},{"location":"1day-20230509/03_Modules/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed in the above example that we don't show directories of module files in the overview (as is the case on most clusters) but descriptive texts about the module group. This is just one view on the module tree though, and it can be changed easily by loading a version of the ModuleLabel module.
ModuleLabel/label produces the default view of the previous exampleModuleLabel/PEhierarchy still uses descriptive texts but will show the whole module hierarchy of the HPE Cray Programming Environment.ModuleLabel/system does not use the descriptive texts but shows module directories instead.
When using any kind of descriptive labels, Lmod can actually bundle module files from different directories in a single category and this is used heavily when ModuleLabel/label is loaded and to some extent also when ModuleLabel/PEhierarchy is loaded.
It is rather hard to provide multiple colour schemes in Lmod, and as we do not know how your terminal is configured it is also impossible to find a colour scheme that works for all users. Hence we made it possible to turn on and off the use of colours by Lmod through the ModuleColour/on and ModuleColour/off modules.
In the future, as soon as we have a version of Lmod where module extensions function properly, we will also provide a module to turn on and off the display of extension in the output of module avail .
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. You can still load them if you know they exist and specify the full version but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work if you use modules that are hidden in the context you're in or if you try to use any module that was designed for us to maintain the system and is therefore hidden from regular users.
Example
An example that will only become clear in the next session: When working with the software stack called LUMI/22.08, which is built upon the HPE Cray Programming Environment version 22.08, all (well, most) of the modules corresponding to other version of the Cray PE are hidden.
"},{"location":"1day-20230509/03_Modules/#getting-help-with-the-module-help-command","title":"Getting help with the module help command","text":"Lmod has the module help command to get help on modules
$ module help\n
without further arguments will show some help on the module command.
With the name of a module specified, it will show the help information for the default version of that module, and with a full name and version specified it will show this information specifically for that version of the module. But note that module help can only show help for currently available modules.
Try, e.g., the following commands:
$ module help cray-mpich\n$ module help cray-python/3.9.13.1\n$ module help buildtools/22.12\n
Lmod also has another command that produces more limited information (and is currently not fully exploited on LUMI): module whatis. It is more a way to tag a module with different kinds of information, some of which has a special meaning for Lmod and is used at some places, e.g., in the output of module spider without arguments.
Try, e.g.,:
$ module whatis Subversion\n$ module whatis Subversion/1.14.2\n
"},{"location":"1day-20230509/03_Modules/#a-note-on-caching","title":"A note on caching","text":"Modules are stored as (small) files in the file system. Having a large module system with much software preinstalled for everybody means a lot of small files which will make our Lustre file system very unhappy. Fortunately Lmod does use caches by default. On LUMI we currently have no system cache and only a user cache. That cache can be found in $HOME/.lmod.d.
That cache is also refreshed automatically every 24 hours. You'll notice when this happens as, e.g., the module spider and module available commands will be slow during the rebuild. you may need to clean the cache after installing new software as on LUMI Lmod does not always detect changes to the installed software,
Sometimes you may have to clear the cache also if you get very strange answers from module spider. It looks like the non-standard way in which the HPE Cray Programming Environment does certain things in Lmod can cause inconsistencies in the cache. This is also one of the reasons whey we do not yet have a central cache for that software that is installed in the central stacks as we are not sure when that cache is in good shape.
"},{"location":"1day-20230509/03_Modules/#a-note-on-other-commands","title":"A note on other commands","text":"As this tutorial assumes some experience with using modules on other clusters, we haven't paid much attention to some of the basic commands that are mostly the same across all three module environments implementations. The module load, module unload and module list commands work largely as you would expect, though the output style of module list may be a little different from what you expect. The latter may show some inactive modules. These are modules that were loaded at some point, got unloaded when a module closer to the root of the hierarchy of the module system got unloaded, and they will be reloaded automatically when that module or an equivalent (family or name) module is loaded that makes this one or an equivalent module available again.
Example
To demonstrate this, try in a fresh login shell (with the lines starting with a $ the commands that you should enter at the command prompt):
$ module unload craype-network-ofi\n\nInactive Modules:\n 1) cray-mpich\n\n$ module load craype-network-ofi\n\nActivating Modules:\n 1) cray-mpich/8.1.23\n
The cray-mpich module needs both a valid network architecture target module to be loaded (not craype-network-none) and a compiler module. Here we remove the network target module which inactivates the cray-mpich module, but the module gets reactivated again as soon as the network target module is reloaded.
The module swap command is basically equivalent to a module unload followed by a module load. With one argument it will look for a module with the same name that is loaded and unload that one before loading the given module. With two modules, it will unload the first one and then load the second one. The module swap command is not really needed on LUMI as loading a conflicting module (name or family) will automatically unload the previously loaded one. However, in case of replacing a module of the same family with a different name, module swap can be a little faster than just a module load as that command will need additional operations as in the first step it will discover the family conflict and then try to resolve that in the following steps (but explaining that in detail would take us too far in the internals of Lmod).
"},{"location":"1day-20230509/03_Modules/#links","title":"Links","text":"These links were OK at the time of the course. This tutorial will age over time though and is not maintained but may be replaced with evolved versions when the course is organised again, so links may break over time.
- Lmod documentation and more specifically the User Guide for Lmod which is the part specifically for regular users who do not want to design their own modules.
- Information on the module environment in the LUMI documentation
"},{"location":"1day-20230509/04_Software_stacks/","title":"LUMI Software Stacks","text":"In this section we discuss
- Several of the ways in which we offer software on LUMI
- Managing software in our primary software stack which is based on EasyBuild
"},{"location":"1day-20230509/04_Software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"1day-20230509/04_Software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a coherent unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"1day-20230509/04_Software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place. We do offer some help so set up Spack also but it is mostly offered \"as is\" an we will not do bug-fixing or development in Spack package files.
"},{"location":"1day-20230509/04_Software_stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire send out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model build on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky.
"},{"location":"1day-20230509/04_Software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
"},{"location":"1day-20230509/04_Software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"1day-20230509/04_Software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"1day-20230509/04_Software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It ia also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"1day-20230509/04_Software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12 and LUMI/23.03 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. We may have a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which we install software that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"1day-20230509/04_Software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"1day-20230509/04_Software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. We expect this to happen especially with packages that require specific MPI versions. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And we need a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"1day-20230509/04_Software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is our primary software installation tool. We selected this as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the build-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain we would have problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the Intel compiler will simply optimize for a two decades old CPU.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"1day-20230509/04_Software_stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"1day-20230509/04_Software_stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with teh system toolchain, but we do avoid mixing those when linking as that may cause problems. The reason is that we try to use as much as possible static linking in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"1day-20230509/04_Software_stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2021.4, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeCray-22.08 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/22.08.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.8.0-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2021.4-cpeCray-22.08-PLUMED-2.8.0-CPE.
"},{"location":"1day-20230509/04_Software_stacks/#installing","title":"Installing","text":""},{"location":"1day-20230509/04_Software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"1day-20230509/04_Software_stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"1day-20230509/04_Software_stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS we already have support. At the moment we have to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
We now also have the LUMI Software Library which lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Output of the search commands:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"1day-20230509/04_Software_stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"There is a little problem though that you may run into. Sometimes the module does not show up immediately. This is because Lmod keeps a cache when it feels that Lmod searches become too slow and often fails to detect that the cache is outdated. The easy solution is then to simply remove the cache which is in $HOME/.lmod.d/.cache, which you can do with
rm -rf $HOME/.lmod.d/.cache\n
And we have seen some very rare cases where even that did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment. Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
"},{"location":"1day-20230509/04_Software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.0-cpeGNU-22.08.eb \u2013r . \n
"},{"location":"1day-20230509/04_Software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/easybuild/easyconfigs.
"},{"location":"1day-20230509/04_Software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory, and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"1day-20230509/04_Software_stacks/#easybuild-tips-and-tricks","title":"EasyBuild tips and tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"1day-20230509/04_Software_stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"1day-20230509/05_Exercises_1/","title":"Exercises 1: Modules, the HPE Cray PE and EasyBuild","text":"See the instructions to set up for the exercises.
"},{"location":"1day-20230509/05_Exercises_1/#exercises-on-the-use-of-modules","title":"Exercises on the use of modules","text":" -
The Bison program installed in the OS image is pretty old (version 3.0.4) and we want to use a newer one. Is there one available on LUMI?
Click to see the solution. module spider Bison\n
tells us that there are indeed newer versions available on the system.
The versions that have a compiler name (usually gcc) in their name followed by some seemingly random characters are installed with Spack and not in the CrayEnv or LUMI environments.
To get more information about Bison/3.8.2:
module spider Bison/3.8.2\n
tells us that Bison 3.8.2 is provided by a couple of buildtools modules and available in all partitions in several versions of the LUMI software stack and in CrayEnv.
Alternatively, in this case
module keyword Bison\n
would also have shown that Bison is part of several versions of the buildtools module.
The module spider command is often the better command if you use names that with a high likelihood could be the name of a package, while module keyword is often the better choice for words that are more a keyword. But if one does not return the solution it is a good idea to try the other one also.
-
The htop command is a nice alternative for the top command with a more powerful user interface. However, typing htop on the command line produces an error message. Can you find and run htop?
Click to see the solution. We can use either module spider htop or module keyword htop to find out that htop is indeed available on the system. With module keyword htop we'll find out immediately that it is in the systools modules and some of those seem to be numbered after editions of the LUMI stack suggesting that they may be linked to a stack, with module spider you'll first see that it is an extension of a module and see the versions. You may again see some versions installed with Spack.
Let's check further for htop/3.2.1 that should exist according to module spider htop:
module spider htop/3.2.1\n
tells us that this version of htop is available in all partitions of LUMI/22.08 and LUMI/22.06, and in CrayEnv. Let us just run it in the CrayEnv environment:
module load CrayEnv\nmodule load systools/22.08\nhtop\n
(You can quit htop by pressing q on the keyboard.)
-
In the future LUMI will offer Open OnDemand as a browser-based interface to LUMI that will also enable running some graphical programs. At the moment the way to do this is through a so-called VNC server. Do we have such a tool on LUMI, and if so, how can we use it?
Click to see the solution. module spider VNC and module keyword VNC can again both be used to check if there is software available to use VNC. Both will show that there is a module lumi-vnc in several versions. If you try loading the older ones of these (the version number points at the date of some scripts) you will notice that some produce a warning as they are deprecated. However, when installing a new version we cannot remove older ones in one sweep, and users may have hardcoded full module names in scripts they use to set their environment, so we chose to not immediate delete these older versions.
One thing you can always try to get more information about how to run a program, is to ask for the help information of the module. For this to work the module must first be available, or you have to use module spider with the full name of the module. We see that version 20230110 is the newest version of the module, so let's try that one:
module spider lumi-vnc/20230110\n
The output may look a little strange as it mentions init-lumi as one of the modules that you can load. That is because this tool is available even outside CrayEnv or the LUMI stacks. But this command also shows a long help test telling you how to use this module (though it does assume some familiarity with how X11 graphics work on Linux).
Note that if there is only a single version on the system, as is the case for the course in May 2023, the module spider VNC command without specific version or correct module name will already display the help information.
-
Search for the bzip2 tool (and not just the bunzip2 command as we also need the bzip2 command) and make sure that you can use software compiled with the Cray compilers in the LUMI stacks in the same session.
Click to see the solution. module spider bzip2\n
shows that there are versions of bzip2 for several of the cpe* toolchains and in several versions of the LUMI software stack.
Of course we prefer to use a recent software stack, the 22.08 or 22.12 (but as of early May 2023, there is a lot more software ready-to-install for 22.08). And since we want to use other software compiled with the Cray compilers also, we really want a cpeCray version to avoid conflicts between different toolchains. So the module we want to load is bzip2/1.0.8-cpeCray-22.08.
To figure out how to load it, use
module spider bzip2/1.0.8-cpeCray-22.08\n
and see that (as expected from the name) we need to load LUMI/22.08 and can then use it in any of the partitions.
"},{"location":"1day-20230509/05_Exercises_1/#exercises-on-compiling-software-by-hand","title":"Exercises on compiling software by hand","text":"These exercises are optional during the session, but useful if you expect to be compiling software yourself. The source files mentioned can be found in the subdirectory CPE of the download.
"},{"location":"1day-20230509/05_Exercises_1/#compilation-of-a-program-1-a-simple-hello-world-program","title":"Compilation of a program 1: A simple \"Hello, world\" program","text":"Four different implementations of a simple \"Hello, World!\" program are provided in the CPE subdirectory:
hello_world.c is an implementation in C,hello_world.cc is an implementation in C++,hello_world.f is an implementation in Fortran using the fixed format source form,hello_world.f90 is an implementation in Fortran using the more modern free format source form.
Try to compile these programs using the programming environment of your choice.
Click to see the solution. We'll use the default version of the programming environment (22.12 at the moment of the course in May 2023), but in case you want to use a particular version, e.g., the 22.08 version, and want to be very sure that all modules are loaded correctly from the start you could consider using
module load cpe/22.08\nmodule load cpe/22.08\n
So note that we do twice the same command as the first iteration does not always succeed to reload all modules in the correct version. Do not combine both lines into a single module load statement as that would again trigger the bug that prevents all modules to be reloaded in the first iteration.
The sample programs that we asked you to compile do not use the GPU. So there are three programming environments that we can use: PrgEnv-gnu, PrgEnv-cray and PrgEnv-aocc. All three will work, and they work almost the same.
Let's start with an easy case, compiling the C version of the program with the GNU C compiler. For this all we need to do is
module load PrgEnv-gnu\ncc hello_world.c\n
which will generate an executable named a.out. If you are not comfortable using the default version of gcc (which produces the warning message when loading the PrgEnv-gnu module) you can always load the gcc/11.2.0 module instead after loading PrgEnv-gnu.
Of course it is better to give the executable a proper name which can be done with the -o compiler option:
module load PrgEnv-gnu\ncc hello_world.c -o hello_world.x\n
Try running this program:
./hello_world.x\n
to see that it indeed works. We did forget another important compiler option, but we'll discover that in the next exercise.
The other programs are equally easy to compile using the compiler wrappers:
CC hello_world.cc -o hello_world.x\nftn hello_world.f -o hello_world.x\nftn hello_world.f90 -o hello_world.x\n
"},{"location":"1day-20230509/05_Exercises_1/#compilation-of-a-program-2-a-program-with-blas","title":"Compilation of a program 2: A program with BLAS","text":"In the CPE subdirectory you'll find the C program matrix_mult_C.c and the Fortran program matrix_mult_F.f90. Both do the same thing: a matrix-matrix multiplication using the 6 different orders of the three nested loops involved in doing a matrix-matrix multiplication, and a call to the BLAS routine DGEMM that does the same for comparison.
Compile either of these programs using the Cray LibSci library for the BLAS routine. Do not use OpenMP shared memory parallelisation. The code does not use MPI.
The resulting executable takes one command line argument, the size of the square matrix. Run the script using 1000 for the matrix size and see what happens.
Note that the time results may be very unreliable as we are currently doing this on the login nodes. In the session of Slurm you'll learn how to request compute nodes and it might be interesting to redo this on a compute node with a larger matrix size as the with a matrix size of 1000 all data may stay in the third level cache and you will not notice the differences that you should note. Also, because these nodes are shared with a lot of people any benchmarking is completely unreliable.
If this program takes more than half a minute or so before the first result line in the table, starting with ijk-variant, is printed, you've very likely done something wrong (unless the load on the system is extreme). In fact, if you've done things well the time reported for the ijk-variant should be well under 3 seconds for both the C and Fortran versions...
Click to see the solution. Just as in the previous exercise, this is a pure CPU program so we can chose between the same three programming environments.
The one additional \"difficulty\" is that we need to link with the BLAS library. This is very easy however in the HPE Cray PE if you use the compiler wrappers rather than calling the compilers yourself: you only need to make sure that the cray-libsci module is loaded and the wrappers will take care of the rest. And on most systems (including LUMI) this module will be loaded automatically when you load the PrgEnv-* module.
To compile with the GNU C compiler, all you need to do is
module load PrgEnv-gnu\ncc -O3 matrix_mult_C.c -o matrix_mult_C_gnu.x\n
will generate the executable matrix_mult_C_gnu.x.
Note that we add the -O3 option and it is very important to add either -O2 or -O3 as by default the GNU compiler will generate code without any optimization for debugging purposes, and that code is in this case easily five times or more slower. So if you got much longer run times than indicated this is likely the mistake that you made.
To use the Cray C compiler instead only one small change is needed: Loading a different programming environment module:
module load PrgEnv-cray\ncc -O3 matrix_mult_C.c -o matrix_mult_C_cray.x\n
will generate the executable matrix_mult_C_cray.x.
Likewise for the AMD AOCC compiler we can try with loading yet another PrgEnv-* module:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -o matrix_mult_C_aocc.x\n
but it turns out that this fails with linker error messages about not being able to find the sin and cos functions. When using the AOCC compiler the libm library with basic math functions is not linked automatically, but this is easily done by adding the -lm flag:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -lm -o matrix_mult_C_aocc.x\n
For the Fortran version of the program we have to use the ftn compiler wrapper instead, and the issue with the math libraries in the AOCC compiler does not occur. So we get
module load PrgEnv-gnu\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_gnu.x\n
for the GNU Fortran compiler,
module load PrgEnv-cray\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_cray.x\n
for the Cray Fortran compiler and
module load PrgEnv-aocc\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_aocc.x\n
for the AMD Fortran compiler.
When running the program you will see that even though the 6 different loop orderings produce the same result, the time needed to compile the matrix-matrix product is very different and those differences would be even more pronounced with bigger matrices (which you can do after the session on using Slurm).
The exercise also shows that not all codes are equal even if they produce a result of the same quality. The six different loop orderings run at very different speed, and none of our simple implementations can beat a good library, in this case the BLAS library included in LibSci.
The results with the Cray Fortran compiler are particularly interesting. The result for the BLAS library is slower which we do not yet understand, but it also turns out that for four of the six loop orderings we get the same result as with the BLAS library DGEMM routine. It looks like the compiler simply recognized that this was code for a matrix-matrix multiplication and replaced it with a call to the BLAS library. The Fortran 90 matrix multiplication is also replaced by a call of the DGEMM routine. To confirm all this, unload the cray-libsci module and try to compile again and you will see five error messages about not being able to find DGEMM.
"},{"location":"1day-20230509/05_Exercises_1/#compilation-of-a-program-3-a-hybrid-mpiopenmp-program","title":"Compilation of a program 3: A hybrid MPI/OpenMP program","text":"The file mpi_omp_hello.c is a hybrid MPI and OpenMP C program that sends a message from each thread in each MPI rank. It is basically a simplified version of the programs found in the lumi-CPEtools modules that can be used to quickly check the core assignment in a hybrid MPI and OpenMP job (see later in this tutorial). It is again just a CPU-based program.
Compile the program with your favourite C compiler on LUMI.
We have not yet seen how to start an MPI program. However, you can run the executable on the login nodes and it will then contain just a single MPI rank.
Click to see the solution. In the HPE Cray PE environment, you don't use mpicc to compile a C MPI program, but you just use the cc wrapper as for any other C program. To enable MPI you have to make sure that the cray-mpich module is loaded. This module will usually be loaded by loading one of the PrgEnv-* modules, but only if the right network target module, which is craype-network-ofi, is also already loaded.
Compiling the program is very simple:
module load PrgEnv-gnu\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_gnu.x\n
to compile with the GNU C compiler,
module load PrgEnv-cray\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_cray.x\n
to compile with the Cray C compiler, and
module load PrgEnv-aocc\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_aocc.x\n
to compile with the AMD AOCC compiler.
To run the executables it is not even needed to have the respective PrgEnv-* module loaded since the binaries will use a copy of the libraries stored in a default directory, though there have been bugs in the past preventing this to work with PrgEnv-aocc.
"},{"location":"1day-20230509/05_Exercises_1/#information-in-the-lumi-software-library","title":"Information in the LUMI Software Library","text":"Explore the LUMI Software Library.
- Search for information for the package ParaView and quickly read through the page
Click to see the solution. Link to the ParaView documentation
It is an example of a package for which we have both user-level and some technical information. The page will first show some license information, then the actual user information which in case of this package is very detailed and long. But it is also a somewhat complicated package to use. It will become easier when LUMI evolves a bit further, but there will always be some pain. Next comes the more technical part: Links to the EasyBuild recipe and some information about how we build the package.
We currently only provide ParaView in the cpeGNU toolchain. This is because it has a lot of dependencies that are not trivial to compile and to port to the other compilers on the system, and EasyBuild is strict about mixing compilers basically because it can cause a lot of problems, e.g., due to conflicts between OpenMP runtimes.
"},{"location":"1day-20230509/05_Exercises_1/#installing-software-with-easybuild","title":"Installing software with EasyBuild","text":"These exercises are based on material from the EasyBuild tutorials (and we have a special version for LUMI also).
Note: If you want to be able to uninstall all software installed through the exercises easily, we suggest you make a separate EasyBuild installation for the course, e.g., in /scratch/project_465000523/$USER/eb-course if you make the exercises during the course:
- Start from a clean login shell with only the standard modules loaded.
-
Set EBU_USER_PREFIX:
export EBU_USER_PREFIX=/scratch/project_465000523/$USER/eb-course\n
You'll need to do that in every shell session where you want to install or use that software.
-
From now on you can again safely load the necessary LUMI and partition modules for the exercise.
-
At the end, when you don't need the software installation anymore, you can simply remove the directory that you just created.
rm -rf /scratch/project_465000523/$USER/eb-course\n
"},{"location":"1day-20230509/05_Exercises_1/#installing-a-simple-program-without-dependencies-with-easybuild","title":"Installing a simple program without dependencies with EasyBuild","text":"The LUMI Software Library contains the package eb-tutorial. Install the version of the package for the cpeCray toolchain in the 22.08 version of the software stack.
At the time of this course, in early May 2023, we're still working on EasyBuild build recipes for the 22.12 version of the software stack.
Click to see the solution. -
We can check the eb-tutorial page in the LUMI Software Library if we want to see more information about the package.
You'll notice that there are versions of the EasyConfigs for cpeGNU and cpeCray. As we want to install software with the cpeCray toolchain for LUMI/22.08, we'll need the cpeCray-22.08 version which is the EasyConfig eb-tutorial-1.0.1-cpeCray-22.08.eb.
-
Obviously we need to load the LUMI/22.08 module. If we would like to install software for the CPU compute nodes, you need to also load partition/C. To be able to use EasyBuild, we also need the EasyBuild-user module.
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now all we need to do is run the eb command from EasyBuild to install the software.
Let's however take the slow approach and first check if what dependencies the package needs:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb -D\n
We can do this from any directory as the EasyConfig file is already in the LUMI Software Library and will be located automatically by EasyBuild. You'll see that all dependencies are already on the system so we can proceed with the installation:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb \n
-
After this you should have a module eb-tutorial/1.0.1-cpeCray-22.08 but it may not show up yet due to the caching of Lmod. Try
module av eb-tutorial/1.0.1-cpeCray-22.08\n
If this produces an error message complaining that the module cannot be found, it is time to clear the Lmod cache:
rm -rf $HOME/.lmod.d/.cache\n
-
Now that we have the module, we can check what it actually does:
module help eb-tutorial/1.0.1-cpeCray-22.08\n
and we see that it provides the eb-tutorial command.
-
So let's now try to run this command:
module load eb-tutorial/1.0.1-cpeCray-22.08\neb-tutorial\n
Note that if you now want to install one of the other versions of this module, EasyBuild will complain that some modules are loaded that it doesn't like to see, including the eb-tutorial module and the cpeCray modules so it is better to unload those first:
module unload cpeCray eb-tutorial\n
"},{"location":"1day-20230509/05_Exercises_1/#installing-an-easyconfig-given-to-you-by-lumi-user-support","title":"Installing an EasyConfig given to you by LUMI User Support","text":"Sometimes we have no solution ready in the LUMI Software Library, but we prepare one or more custom EasyBuild recipes for you. Let's mimic this case. In practice we would likely send those as attachments to a mail from the ticketing system and you would be asked to put them in a separate directory (basically since putting them at the top of your home directory would in some cases let EasyBuild search your whole home directory for dependencies which would be a very slow process).
You've been given two EasyConfig files to install a tool called py-eb-tutorial which is in fact a Python package that uses the eb-tutorial package installed in the previous exercise. These EasyConfig files are in the EasyBuild subdirectory of the exercises for this course. In the first exercise you are asked to install the version of py-eb-tutorial for the cpeCray/22.08 toolchain.
Click to see the solution. -
Go to the EasyBuild subdirectory of the exercises and check that it indeed contains the py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb and py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb files. It is the first one that we need for this exercise.
You can see that we have used a very long name as we are also using a version suffix to make clear which version of Python we'll be using.
-
Let's first check for the dependencies (out of curiosity):
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb -D\n
and you'll see that all dependencies are found (at least if you made the previous exercise successfully). You may find it strange that it shows no Python module but that is because we are using the cray-python module which is not installed through EasyBuild and only known to EasyBuild as an external module.
-
And now we can install the package:
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb\n
-
To use the package all we need to do is to load the module and to run the command that it defines:
module load py-eb-tutorial/1.0.0-cpeCray-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
with the same remark as in the previous exercise if Lmod fails to find the module.
You may want to do this step in a separate terminal session set up the same way, or you will get an error message in the next exercise with EasyBuild complaining that there are some modules loaded that should not be loaded.
"},{"location":"1day-20230509/05_Exercises_1/#installing-software-with-uninstalled-dependencies","title":"Installing software with uninstalled dependencies","text":"Now you're asked to also install the version of py-eb-tutorial for the cpeGNU toolchain in LUMI/22.08 (and the solution given below assumes you haven'ty accidentally installed the wrong EasyBuild recipe in one of the previous two exercises).
Click to see the solution. -
We again work in the same environment as in the previous two exercises. Nothing has changed here. Hence if not done yet we need
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now go to the EasyBuild subdirectory of the exercises (if not there yet from the previous exercise) and check what the py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb needs:
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -D\n
We'll now see that there are two missing modules. Not only is the py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 that we try to install missing, but also the eb-tutorial/1.0.1-cpeGNU-22.08. EasyBuild does however manage to find a recipe from which this module can be built in the pre-installed build recipes.
-
We can install both packages separately, but it is perfectly possible to install both packages in a single eb command by using the -r option to tell EasyBuild to also install all dependencies.
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -r\n
-
At the end you'll now notice (with module avail) that both the module eb-tutorial/1.0.1-cpeGNU-22.08 and py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 are now present.
To run you can use
module load py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
"},{"location":"1day-20230509/06_Running_jobs/","title":"Running jobs","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230509/07_Exercises_2/","title":"Exercises 2: Running jobs with Slurm","text":""},{"location":"1day-20230509/07_Exercises_2/#exercises-on-the-slurm-allocation-modes","title":"Exercises on the Slurm allocation modes","text":" -
Run single task on the CPU partition with srun using multiple cpu cores. Inspect default task allocation with taskset command (taskset -cp $$ will show you cpu numbers allocated to a current process).
Click to see the solution. srun --partition=small --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --partition=small --account=<project_id> bash -c 'taskset -cp $$' \n
Note you need to replace <project_id> with actual project account ID in a form of project_ plus 9 digits number.
The command runs single process (bash shell with a native Linux taskset tool showing process's CPU affinity) on a compute node. You can use man taskset command to see how the tool works.
-
Try Slurm allocations with hybrid_check tool program from the LUMI Software Stack. The program is preinstalled on the system.
Use the simple job script to run parallel program with multiple tasks (MPI ranks) and threads (OpenMP). Test task/threads affinity with sbatch submission on the CPU partition.
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/22.12\nmodule load lumi-CPEtools\n\nsrun hybrid_check -n -r\n
Be careful with copy/paste of script body while it may brake some specific characters.
Click to see the solution. Save script contents into job.sh file (you can use nano console text editor for instance), remember to use valid project account name.
Submit job script using sbatch command.
sbatch job.sh\n
The job output is saved in the slurm-<job_id>.out file. You can view it's contents with either less or more shell commands.
Actual task/threads affinity may depend on the specific OpenMP runtime but you should see \"block\" thread affinity as a default behaviour.
-
Improve threads affinity with OpenMP runtime variables. Alter your script and add MPI runtime variable to see another cpu mask summary.
Click to see the solution. Export SRUN_CPUS_PER_TASK environment variable to follow convention from recent Slurm's versions in your script. Add this line before the hybrid_check call:
export SRUN_CPUS_PER_TASK=16 \n
Add OpenMP environment variables definition to your script:
export OMP_NUM_THREADS=${SRUN_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n
You can also add MPI runtime variable to see another cpu mask summary:
export MPICH_CPUMASK_DISPLAY=1\n
Note hybrid_check and MPICH cpu mask may not be consistent. It is found to be confusing.
-
Build hello_jobstep program tool using interactive shell on a GPU node. You can pull the source code for the program from git repository https://code.ornl.gov/olcf/hello_jobstep.git. It uses Makefile for building. Try to run the program interactively.
Click to see the solution. Clone the code using git command:
git clone https://code.ornl.gov/olcf/hello_jobstep.git\n
It will create hello_jobstep directory consisting source code and Makefile.
Allocate resources for a single task with a single GPU with salloc:
salloc --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=1 --gpus-per-node=1 --time=10 --account=<project_id>\n
Note that, after allocation being granted, you receive new shell but still on the compute node. You need to use srun to execute on the allocated node.
Start interactive session on a GPU node:
srun --pty bash -i\n
Note now you are on the compute node. --pty option for srun is required to interact with the remote shell.
Enter the hello_jobstep directory and issue make command. It will fail without additional options and modules.
module load rocm\n
Note compiler (and entire programming environment) is the one you have set (or not) in the origin shell on the login node.
Nevertheless rocm module is required to build code for GPU.
make LMOD_SYSTEM_NAME=\"frontier\"\n
You need to add LMOD_SYSTEM_NAME=\"frontier\" variable for make while the code originates from the Frontier system.
You can exercise to fix Makefile and enable it for LUMI :)
Eventually you can just execute ./hello_jobstep binary program to see how it behaves:
./hello_jobstep\n
Note executing the program with srun in the srun interactive session will result in a hang. You need to work with --overlap option for srun to mitigate it.
Still remember to terminate your interactive session with exit command.
exit\n
"},{"location":"1day-20230509/07_Exercises_2/#slurm-custom-binding-on-gpu-nodes","title":"Slurm custom binding on GPU nodes","text":" -
Allocate one GPU node with one task per GPU and bind tasks to each CCD (8-core group sharing L3 cache) leaving first (#0) and last (#7) cores unused. Run a program with 6 threads per task and inspect actual task/threads affinity.
Click to see the solution. Begin with the example from the slides with 7 cores per task:
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu:0xfe000000000000,0xfe00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe0000,0xfe000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe,0xfe00,\"\nCPU_BIND=\"${CPU_BIND}0xfe00000000,0xfe0000000000\"\n\nexport OMP_NUM_THREADS=7\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nexport MPICH_CPUMASK_DISPLAY=1\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu ./hello_jobstep/hello_jobstep\n
If you save the script in the job_step.sh then simply submit it with sbatch. Inspect the job output.
Now you would need to alter masks to disable 7th core of each of the group (CCD). Base mask is then 01111110 which is 0x7e in hexadecimal notation.
Try to apply new bitmask, change the corresponding variable to spawn 6 threads per task and check how new binding works.
"},{"location":"1day-20230509/08_Lustre_intro/","title":"I/O and file systems","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230509/09_LUMI_support/","title":"How to get support and documentation","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230509/notes_20230509/","title":"Questions session 9 May 2023","text":""},{"location":"1day-20230509/notes_20230509/#lumi-hardware","title":"LUMI Hardware","text":" -
\"Real LUMI-G node\" slide presented the CPU with two threads per core. I assume it is just to give full insight, what the CPU allows, but you are not using hyper-threading, right?
Answer: SMT is activated but not used by default excepted if you ask for it in your job script with --hint=multithread. The same applies to LUMI-C nodes.
"},{"location":"1day-20230509/notes_20230509/#programming-environment-module-system","title":"Programming Environment & Module System","text":" -
Is there a way to reload all sticky modules (with one command), if you first have unloaded all sticky modules.
Answer: If you have \"force purged\" all modules, you can get the default environment with module restore but it will not reload non-default sticky modules you may have loaded previously.
"},{"location":"1day-20230509/notes_20230509/#using-and-installing-software","title":"Using and Installing Software","text":" -
Is \"lumi-container-wrapper\" related to https://cotainr.readthedocs.io/en/latest/ by DeiC from Denmark?
Answer:
-
No. It is a different tool. It's the LUMI version of the tykky tool available on the CSC Puhti and Mahti clusters.
-
The cotainr tool from DeiC is also available though (see the LUMI Software Library page) but we're waiting for them to test it on newer versions of the Cray PE.
-
What does RPM stand for?
Answer: RPM stands for Redhat Package Manager. It is a popular tool for distributing Linux software as binaries for direct installation in the OS image.
-
If I installed a software and prepared a module file by myself, is there a place I can contribute my module to the LUMI user community? Maybe it can save time when a new LUMI user is struggling installing the same exact software.
Answer: Yes, of course. We have a GitHub repository for that. https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib/ Just create a pull request there and we will have a look and merge it
-
What options --try-toolchain-version=22.08 --robot help us with?
Answer: These options should work as in the regular EasyBuild. (and the -r I used is the abbreviation of --robot)
In fact, because I want a reproducible build environment most EasyConfigs that we offer also use the buildtools module, but as the version I use the toolchain_version variable so that that dependency is automatically adapted also. We bundle several build tools not only to have less modules, but also to have to adapt fewer dependency versions...
-
Which changes were made in lumi-container-wrapper compared to tykky?
Answer: It uses a different base container better suited for LUMI and for Python it is configure to build upon cray-python.
-
For how long will this project (project_465000522) be available?
Answer: It will stay active for the next two days (terminates on May, 11th).
-
I have installed cp2k with easybuil, but I'm not able to run any programs, because it stops running in between and error file shows Segmentation fault - invalid memory reference? This is a problem I am not figuring out how to solve. Any help regarding this.
Answer: Too few details to say a lot. You may have made errors during installation though most of those errors would lead to different errors. However, you may have hit a bug in CP2K also, or a bug in the PRogramming Environment. We have several users who have successfully used our recipes, but they may have been trying different things with CP2K. Our configuration for CP2K (at least the CPU version) is also based on the configuration used on a similar Cray system at CSCS which is one of the machines used by the CP2K developers...
This is also more the type of problem that is better handled through a ticket though it is unclear from the description if we can do a lot about it.
"},{"location":"1day-20230509/notes_20230509/#exercise-session-1","title":"Exercise session 1","text":" -
Lmod shows \"LUMI/23.03 partition/D\" as the only available pre-requisite with LUMI/23.03 for the VNC module. Yet, despite this I am able to:
module load LUMI/23.03 partition/L\nmodule load lumi-vnc\n
Does this mean that Lmod is just not able to show all of the possible pre-requisite combinations? Or will lumi-vnc turn out not to work correctly with partition/L?
Answer: partition/D should not even be shown, that is a bug in the software installation that I need to correct.
But a nice find. The output is confusing because LMOD gets confused by some hidden software stacks and partitions. It actually also shows a line init-lumi/0.2 which is a module that you have loaded automatically at login. And this in turns means that having this module is enough to use lumi-vnc, i.e., it works everywhere even without any LUMI stack or CrayEnv.
-
In general, if I set export EBU_USER_PREFIX for project directory, do I also need to set another one for the scratch?
Answer: No, it points to the root of the software installation which is one clear place. The reason to install in .project and not in /scratch is that you want the software installation to be available for your whole project. If you check the disk use policies in the storage section of the docs you'd see that data on /scratch is not meant to be there for the whole project but can be erased after 90 days which is not what you want with your software installation.
"},{"location":"1day-20230509/notes_20230509/#running-jobs","title":"Running jobs","text":" -
Is it possible to get an exemption from the the maximum 2 day allocation?
Answer: No. No exceptions are made at all. We don't want nodes to be monopolized by a user and it makes maintenance more difficult. Moreover, given the intrinsic instability of large clusters it is essential that jobs use codes that store intermediate states from which can be restarted.
Users have been using dependent jobs with success to automatically start the follow-on job after the previous one ends.\n
-
Is it not possible to use the singularity build command?
Answer: Not all options of singularity build work. Any build requiring fakeroot will fail as that is disabled due to security concerns.
-
Does this (binding tasks to resrouces) mean that it will be necessary to use custom bindings to align tasks with specific NUMA domains on each CPU? (Since NUMA domains seem to be a level in-between cores and sockets)
Answer: If you are using all cores on an exclusive node the standard ways in which Slurm distributes processes and threads may do just what you want.
Even if, e.g., it would turn out that it is better to use only 75% of the cores and you would be using 16 MPI processes with 6 threads per process, then a creative solution is to ask Slurm for 8 cores per task and then set OMP_NUM_THREADS=6 to only start 6 threads. There are often creative solutions.
Some clusters will redefine the socket to coincide with the NUMA domain but it looks like this is not done on LUMI.
-
Where do we look up the specific NUMA domain / GPU correspondence? In the LUMI documentation? Or perhaps by a command in LUMI?
Answer:
-
If we enable hardware threads for a job/allocation, does \"--cpus-per-task\" become HW threads?
Answer: Yes:
# 2 HWT per core, all cores allocated \n$ srun -pstandard --cpus-per-task=256 --hint=multithread --pty bash -c 'taskset -c -p $$'\npid 161159's current affinity list: 0-255\n\n# 2 HWT per core but only the first 64 cores allocated \n$ srun -pstandard --cpus-per-task=128 --hint=multithread --pty bash -c 'taskset -c -p $$'\npid 161411's current affinity list: 0-63,128-191\n
-
Is it possible to make sure a job requesting 16 cores is allocated all cores in one NUMA domain?
Answer:
-
Is your question for sub-node allocations (small and small-g partitions)?
- Yes, the question is not relevant for production runs, it was only out of interest. It is something to be aware of during scaling tests for example.
- Our advise to users in our local compute centre who have to do scaling tests to submit a proposal for time on LUMI (or our Tier-1 systems) is to use exclusive nodes to avoid surprises and reduce randomness. The most objective way is probably if you want to do a test on 16 nodes to run 8 such tests next to one another to fill up the node. Because there is another issue also. I haven't tried if the options to fix the clock speed from Slurm work on LUMI, but depending on the other work that is going on in a socket the clock speed of the cores may vary.
-
I doubt there is a way to do that for the sub-node allocation partitions. I can't find one that works at the moment. Binding really only works well on job-exclusive nodes. For me this is a shortcomming of Slurm as it doesn't have enough levels in its hierarchy for modern clusters.
-
For a sub-node allocation, you will get random cores depending on which cores are available:
$ srun -psmall --cpus-per-task=16 --pty bash -c 'taskset -c -p $$'\npid 46818's current affinity list: 44-46,50,52-63\n\n$ srun -pstandard --cpus-per-task=16 --pty bash -c 'taskset -c -p $$'\npid 220496's current affinity list: 0-15\n
"},{"location":"1day-20230509/notes_20230509/#storage","title":"Storage","text":" -
To access /scratch/ from a container, we have to mount it. However, we need the full path and not just the symlink. Where do we find the full path?
Answer: You can use file /scratch/project_465000522 for example. Don't try to mount the whole scratch. That will not work. The project_* subdirectories in /scratch are distributed across the 4 file systems of LUMI-P. ls -l /scratch/project_465000522 will actually show you which file system is serving that project's scratch directory.
-
The documentation page states that \"Automatic cleaning of project scratch and fast storage is not active at the moment\". Is this still true, and will the users be informed if this changes?
Answer:
-
This is still true today and usually users are informed about changes but with short notice. Quota were also disabled for a while due to problems after an upgrade last July but solving those problems became a higher priority when abuse was noticed, and there was only 14 days notice. So abusing scratch and flash for long-term storage is asking for increasing the priority of that part of the LUMI setup working... I'd say, don't count on it as the message may arrive as well when you are on a holiday.
-
For slightly longer time storage but still limited to the lifetime of your project there is also the object storage. However, at the moment only rather basic tools to use that storage are already available.
-
What is the preferred way for transferring data between LUMI and some external server or other supercomputer e.g. CSC Mahti?
Answer:
-
Mahti is so close to LUMI (as far as I know even in the same data centre but a different hall) that connection latency should not limit bandwidth so that you can just use sftp.
I believe the CSC documentation also contains information on how to access the allas object storage from LUMI. Using allas as intermediate system is also an option. Or the LUMI-O storage but at the moment allas is both more developed and better documented. (For readers: allas is a CSC object system only available to users that are CSC clients and not to other users of LUMI.)
-
For supercomputers that are \"farther away\" from LUMI where bandwidth is a problem when using sftp, it looks like the LUMI-O object storage is a solution as the tools that read from the object storage use so-called \"multi-stream transport\" so that they can better deal with connections with a high latency. The documentation on how to access the LUMI object storage from elsewhere needs work though.
"},{"location":"1day-20230509/notes_20230516/","title":"Questions session 16 May 2023","text":""},{"location":"1day-20230509/notes_20230516/#lumi-architecture","title":"LUMI Architecture","text":" -
The slides say the GPUs have 128 GB mem, but when I queried the information with the HIP-framework it only returned 64 GB mem. Does it differ on different partitions or something?
- Kurt will go into more detail soon. But each GPU has 128GB but each GPU conists of 2 dies (basically independent GPUs). Each of those has 64GB. Basically each LUMI-G node has in practise 8 GPUs on 4 cards.
-
This is maybe a better question for when you will discuss software, but seeing the AMD hardware, my question is how compatible the GPU partitions/software are with DL frameworks such as Tensorflow and PyTorch. Are the systems fully ROCm compatible? Are there downsides compared to CUDA implementations?
- Let's discuss that later in detail. But short answer: ROCm is not as mature as CUDA yet but most DL frameworks work already quite well.
-
I believe the GPU nodes have 64 cores. But from the slides I understood that the nodes have 1 CPU with 8 cores. Just as a note: this is output from hip:
Device 0:\n Total Global Memory: 63.9844 GB\n Compute Capability: 9.0\n Max Threads per Block: 1024\n Multiprocessor Count: 110\n Max Threads per Multiprocessor: 2048\n Clock Rate: 1700 MHz\n Memory Clock Rate: 1600 MHz\n Memory Bus Width: 4096 bits\n L2 Cache Size: 8 MB\n Total Constant Memory: 2048 MB\n Warp Size: 64\n Concurrent Kernels: Yes\n ECC Enabled: No\n Unified Memory: No\n
- The slide was about the CPUs in the node. The basic element of the GPU is the \"Compute Unit\" (CU) (the \"multiprocessor count\" in the above output). And one CU has 4 16-wide SIMD units and 4 matrix core units. AMD doesn't use the word core very often in the context of GPU as what NVIDIA calls a core is actually called an Arithmetic and Logical Unit in a CPU and is only a part of a core.
"},{"location":"1day-20230509/notes_20230516/#cray-programming-environment","title":"Cray Programming Environment","text":" -
what is called underneath with compiling with hipcc? rocm compiler I assume? - @bcsj
-
Actually it is AMD's branch of Clang.
-
@bcsj: sidenote, I've had trouble with compiling GPU code with the CC compiler, which I assume calls something else underneath. The code would run, but in a profiler it showed that a lot of memory was being allocated when it shouldn't. hipcc compiling fixed this issue.
-
I believe CC is using different Clang frontend being Cray's branch of Clang with a slightly different codebase. At the end it should use the same ROCm backend. It may require more debugging to understand the problem.
-
@bcsj: possibly ... it was some very simple kernels though, so I'm pretty confident it was not a kernel-issue. The profiling was done using APEX and rocmprofiler. Kevin Huck helped me, during the TAU/APEX course.
-
The frontend that CC is using depends on which modules you have loaded. IF the cce compiler module is loaded, it will use the Cray clang frontend while if the amd compiler module is loaded it will use the AMD ROCm C++ compiler.
-
@mszpindler Could you please post a support ticket than we can investigate memory issues, thanks.
-
@bcsj: It's been a while and I restructured my environment to avoid the issue, but I'll see if I can find the setup I used before.
-
What is the policy on changes to these centrally installed and supported modules? Are versions guaranteed to be available for a certain period of time?
- Unfortunately not at the moment. WE hope to be able to provide LTS (Long term support) versions in the future but they are not yet vendor supported. But we will always inform you about changes to the SW stack.
"},{"location":"1day-20230509/notes_20230516/#module-system","title":"Module System","text":" -
Are open source simulation software such as quantum espresso centrally installed on LUMI?
-
Please use the Software Library https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/q/QuantumESPRESSO/ to understand what the policy is.
-
Short answer: No, almost no softare (except debugger, profilers) is installed globally. But you will see soon, that it is very easy to install SW yourself with Easybuild using our easyconfigs (basically building recipes).
-
The program I am using and developing requires certain dependencies such as paralution, PETSc, Boost... Is it possible to manually install these dependencies if not available among the modules listed?
-
Yes, it is actually very easy and will be the topic of the next session (and we have some configurations on Boost on the system, try module spider Boost...)
-
We have an installation recipe for one configuration of PETSc also. And PETSc is one of those libraries that does strange things behind the scenes that can cause it to stop working after a system update... We have not tried paralution. But basically there are an estimated 40,000 scientific software packages not counting the 300,000+ packages on PyPi, R packages, etc., so there is no way any system can support them all.
-
@mszpindler Please try PETSc with recipes from https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/p/PETSc/ If you see wrong behaviour then please open support ticket.
-
Can I use modules that are available on CSC supercomputers?
- Basically we use different set of modules and even a different primary system to manage the modules. The machines are different, the team managing the machine is different, and the licenses for software on puhti or mahti do not always allow use on LUMI, and certainly not for all users on LUMI, while we have no way to control who has access and who has not.
-
If i find out that my application is able to work in different programming environments (different compilers), which should I prefer? Cray?
-
No answer that is always right, you have to benchmark to know.
And even for packages for which we offer build recipes we cannot do that benchmarking as it requires domain knowledge to develop proper benchmarks. And the answer may even differe on the test case.
- Ok, test with Cray first..
-
Again, if you look at the Software Library https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/q/QuantumESPRESSO/ then you can see recipe (easyconfigs) versions for specific programmming environments. Those listed there, are supported.
"},{"location":"1day-20230509/notes_20230516/#using-and-installing-software","title":"Using and installing software","text":" -
In our own tier-1 I've always used virtual envs successfully. The reason that I do not rely on containers is that I often work on editable installs that I pull from git. Looking at the documentation (https://docs.lumi-supercomputer.eu/software/installing/container-wrapper/#plain-pip-installations) it seems that this is not supported. In other words: I would like to be able to create an environment, install an editable Python git repo, and when an updated comes to the remote repo, just pull it and keep using the env. If I understand correctly I would need to rebuild the container after every git pull on LUMI?
-
I t is actually CSC's development called Tykky https://docs.csc.fi/computing/containers/tykky/ and I believe you can try with pip-containerize update ... to update existing image but you need to try if it works with your specific environment.
-
Something really difficult: You can spread a Python installation over multiple directories. So you could put all dependencies of your software in a container and mount a directory from outside in which you install the software you're developing. That would already reduce the load of small packages on the file system.
The speed difference can be dramatic. On the installation side I've worked on 5 or 6 big clusters on Europe. On the slowest it took me 2 hours to install a bunch of Python packages that installed in under 30 seconds on the SSD of my laptop... Measuring the speed difference while running is more difficult as I couldn't run the benchmarks on my PC and as there are other factors in play also. But CSC reports that a 30% speedup is not that uncommon from using Tykky.
-
I have successfully installed Python repos as editable, by setting PYTHONUSERBASE to point to the project directory and then using both --user and --editable flags with pip.
-
There is some information on containers also in the \"Additional Softwre on LUMI\" talks in our 4-day course. The latest for which notes and a recording are available is the presentation during the February 2023 course.
-
Sorry, probably you are going to speak about containers later. I'm just interested in the opportunity to use one particular commercial software from within, say, Singularity container on LUMI. So, if I sort out the license server issues, is it possible for virtually any kind of software or there are limitations? If yes, is it, overall, a good idea? Does it make the performance of the software run deteriorate?
-
Unless there is MPI involved you can try to run any, say DockerHub, container image on LUMI. For the MPI parallel software packages it may still work on a single node but do not expect them to run on multiple computing nodes.
-
There is some information on containers also in the \"Additional Softwre on LUMI\" talks in our 4-day course. The latest for which notes and a recording are available is the presentation during the February 2023 course.
"},{"location":"1day-20230509/notes_20230516/#exercises","title":"Exercises","text":" -
Looking at the Exercise 1.1 solution, I don't really see any difference between the outputs from module spider Bison and module spider Bison/3.8.2, but from how the solution reads, it seems like they shouldn't be the same?
-
That's because there were two different versions on the system when I prepared the exercise. It found a version generated with Spack also and it looks like the person managing that stack disabled that module again. If module spider finds only a single version it produces the output it would produce when called with the full version as the argument.
I wanted to use it as an example to show you how you can quickly see from the module spider output if a program comes from the LUMI stacks or from Spack...
-
You can see the different behaviours with for example module spider buildtools
-
is there a module similar to cray-libsci for loading/linking hipBlas? So far I've been doing that manually. I tried to module spider hipblas but that returns nothing.
-
No, there is not. AMD doesn't polish its environment as much HPE Cray.
Also, all of ROCm is in a single module and as several of those modules are provided by HPE and AMD they don't contain the necessary information to search for components with module spider.
-
Is there a similar tool to csc-projects for checking info on your projects?
- Yes, please try
lumi-allocations command-line tool.
-
Perhaps I missed this earlier, but what is LUMI-D?
- It is the name that was used for the \"Data Analytics and Visualisation partition\" which basically turns out to be two partitions that need a different setup. It consists of 8 nodes with 4 TB of memory that really have the same architecture as the login nodes hence can use software of what we will later in the course call
partition/L, and 8 nodes with 8 NVIDIA A30 GPUs for visualisation each.
"},{"location":"1day-20230509/notes_20230516/#running-jobs-with-slurm","title":"Running jobs with Slurm","text":" -
Would it be possible to show an example of how to run R interactively on a compute node?
-
If you don't need X11, one way is
srun -n 1 -c 1 -t 1:00:00 -p small -A project_465000XXX --pty bash\nmodule load cray-R\nR\n
which would ask for 1 core for 1 hour. For some shared memory parallel processing you'd use a larger value for c but you may have to set environment variables to tell R to use more threads.
-
Is Rstudio server exist as a module on LUMI? Is it planned to be added at some point? Is it possible for normal user to install it?
- We expect to be able to offer Rstudio with Open OnDemand, but no time set for now. But as any batch system, LUMI is not that well suited for interactive work as there is no guarantee that your interactive session will start immediately. Some resources will be set aside for Open OnDemand and I assume it will be possible to oversubscribe some resources. But LUST is not currently involved with the setup so there is not much we can say.
-
May be a beginner question.. When to work with GPU nodes and when it is less efficient to use it? Does it depend on the structure of the data or the software used? Is it possible to use GPU nodes with R scripts?
-
GPU comute requires software that explicitly supports compute on GPU. GPUs are never used automatically. Base R does not use GPU compute. Some R packages may as in principle some large linear algebra operations that are used in statistics may benefit from GPU acceleration. However, they will have to support AMD GPUs and not NVIDIA GPUs.
There is no simple answer when GPU compute offers benefits and when it does not as it depends a lot on the software that is being used also.
-
How to monitor the progress / resources use (e.g. how much RAM / # cores are actually used) of currently running and finished batch jobs?
-
Slurm sstat command can give information on running jobs. Once the job has finished, sacct can be used. Both commands have very customizable output but they will not tell you core per core how that core was used. Then you need to do active profiling.
-
You can also attach an interactive job step to a running job (as shown on slide 9). I'm not sure rocm-smi works reliably in that case (it didn't always in the past), but commands like top and htop (the latter provided by the systools module) should work to monitor the CPU use.
-
Do job-arrays open program the number of processes which we specified with --ntasks=1? or it will open 16 independent jobs with 1 processes for each job?
- A job array with 16 elements in the job array is 16 jobs for the scheduler if that is what you mean. If you want multiple processes in one job you'd submit a single job for the combined resources of all 16 jobs and then use srun to start 16 processes in that job.
What happens if we choose job-array=1-16 and --ntasks=2? It will use 16 jobs and each jobs has 2 tasks, right?
- Yes. After all some people may want to use a job array for management where each element of the job array is an MPI program.
-
Is the limit \"total jobs in the queue\" or \"total concurrntly running\"?
-
There are two different limits that are both shown in the LUMI documentation. There is a limit on the number of jobs running concurrently and a limit on the number of jobs in the queue (which includes running jobs). That limit is also very low. LUMI is a very large cluster and the total number of jobs that a scheduler can handle of all users together is limited. Schedulers don't scale well. Which is why the limit on the number of jobs is considerably lower than it typically is on small clusters.
The right way to deal with parallelism on big systems is using a hierarchy, and this holds for job management also: The scheduler to allocate bigger chunks of the machine and then run another tool to create parallelism in the job.
-
Out of curiousity, how did the GPU-id and NUMA-id misalignment occur? It somehow makes me surprised that/(if?) it is consistently wired in this same \"weird\" manner all over the nodes.
-
Luckily it is consistent. I'm pretty sure it is basically a result of the motherboard design. The connections between the GPUs determine which GPU considers itself GPU 0 during the boot procedure, while the connections between the GPU socket and CPU socket determine the mapping between CCDs and GPU dies.
- Interesting, thanks for the answer!
-
Regarding the containers and MPI... If I want to run my software on multiple nodes from within a Singularity container with decent scalability, should I use host (LUMI's) MPI, right? Then, which MPI should I make this software work with? Open MPI, Intel MPI - don't work on LUMI, right? What should I aim at then?
-
Open MPI doesn't work very well at the moment. Some people got enough performance from it though for CPU codes and I worked on a recent ticket where it worked well for a user within a node.
HPE Cray is also working on a translation layer from Open MPI 4.1 to Cray MPICH.
-
We know that Intel internally must have an MPI that is compatible with LUMI as they are building the software environment for the USA Aurora supercomputer that uses the same interconnect as LUMI. But so far experiments with the versions distributed with oneAPI etc. have been a disappointment. It might be possible to try to force the application compiled with Intel MPI to use Cray MPICH as they should have the same binary interface.
-
But the MPI on LUMI is basically compatible with the ABI from MPICH 3.4.
-
The main advise it though to avoid containers and software that comes as binaries when you want to use MPI. It is often a pain to get the software to work properly. Containers are good for some level of portability between sufficiently similar machines with a close enough OS kernel, same hardware and same kernel modules, and were never meant to be portable in all cases. They work very well in, e.g., a cluster management environment (And they are used on the LUMI management nodes) but then you know that the containers will be moving between identical hardware (or very similar hardware if the vendor provides them ready-to-run).
-
Is it possible to list all nodes with their resource occupation? I want to see how many GPUs / memory is available on different nodes.
-
All GPU nodes are identical. There is only one node type. And the majority of the GPU nodes is job exclusive so another job could not even start on them.
- So if my application utilizes only 1 GPU, it will still hold the whole node with all GPUs?
-
It depends on what partition you use. If you use standard-g, yes and you will pay for the full node. On small-g you are billed based on a combination of memory use, core use and GPU use (as if, e.g., you ask for half the CPU memory of a node you basically make it impossible for others to efficiently use half of the GPUs and half of the CPU cores, so you would be billed for half a node).
But it makes no sense to try to be cleverer than the scheduler and think that \"look, there are two GPUs free on that node so if I now submit a job that requires only 2 GPUs it will run immediately\" as the scheduler may already have reserved those resources for another job for which it is gathering enough GPUs or nodes to run.
-
Is it possible for us as users to see the current status of LUMI nodes (e.g. using dashboard or a command line)? I mean how many nodes are used or available to work? How many jobs are currently queuing (including other users). I just need to know what would be the expected waiting time for running my jobs.
sinfo gives some information but that tells nothing about the queueing time for a job. Any command that gives such information is basically a random number generator. Other jobs can end sooner making resources available earlier, or other users with higher priority jobs may enter the queue and push your job further back.
-
Are nodes assigned exclusively for projects? I mean, If I am submitting a job for a particular project, would I have access to most of the resources or for specific nodes? Is there a quota per project and how to know how much of this quotaa is used?
-
Nodes are either shared among jobs or exclusively assigned to jobs depending on the partition.
-
Each job is also attached to a project for billing purposes. Your resource allocator should have given information about that and billing is documented well in the LUMI documentation. Maciej showed the command to check how much you have consumed (lumi-allocations).
-
And each job also runs as a user which determines what you can access on the system.
-
How priority is determined? Does submitting more jobs or jobs that consume time or memory results in lower priority? Does priority is determined per user or project?
- We don't have precise details and it would make no sense either as it is a complicated formula that can be adjusted if the need arises to ensure fair use of LUMI. Priority is a property of a job, not of a project or of a user, but it can be influenced by factors that are user- or project-dependent, like fair use which is actually difficult on LUMI due to the different size of allocations, some projects have a 100 times more compute time than some others so the scheduler should also make sure that those users with huge projects can run jobs often enough.
-
Is it possible to submit a job that may take more than 3 days?
-
No, and we make no exceptions at all. This is on one hand to prevent monopolisation of a partition by a single user, and on the other hand because it creates a maintenance nightmare as a rolling update of the system can take as long as the longest running job.
Moreover, it is also a protection against yourself as large systems are inherently less stable than smaller systems so there is a much higher chance that your long running job may fail an hour before it would have finished.
-
If I allocate only a single GPU, will I automatically get assigned a GPU and a CPU which are \"close\" in the setup? (Assuming such an allocation is available)
-
Not sure about that and I even doubt it at the moment. It was definitely not the case before the upgrade, but it looks like the scheduler is still not doing a proper job. The only way to properly control binding is on exclusive nodes.
You could try to run 8 subjobs in a job each using their own GPU, but then at the moment you may be hit with another scheduler bug for which we are still waiting for a fix from HPE.
-
Maybe I'm missing a point, but re slide #32: why do we want to skip core 8, 16, 24, 32, ...?
- For reasons of symmetry as core 0 cannot be used as it is reserved. It's a bit strange to use 7 threads on CCD 0 and then 8 threads on each of the other one.
Okay, so it is becuase you don't want other tasks to behave differently from the first which only got 7 cores. Am I understanding that right?
- If these would be 8 fully independent programs it makes sense to use a different set of resources for each. But in an MPI program it is often easier if each rank has the same amount of resources. And after all the speed of your parallel process is determined by the slowest of the processes anyway.
Okay, I think that makes sense to me.
- On Frontier they actually block each 8th core by default and we have asked AMD if this may have an advantage as driver threads for each GPU could then run on a different core which may be advantageous if you cannot really use these cores for applications anyway.
-
Follow-up in Question 31.: If I reserve 2 GPUs, can I expect them to be the two GCDs on 1 device?
- No unfortunately, just as Slurm can also not guarantee on the CPU partition that all your cores would be on a single CCD (or within a single cache domain). With machines as LUMI we really need new scheduling technology that is more aware of the hierarchy in resources for sub-node scheduling.
Okay, so I'd need to reserve the whole node to gain that kind of control.
"},{"location":"1day-20230509/notes_20230516/#exercises_1","title":"Exercises","text":" -
Rather general question: Does there exist a wiki or open document that would provide suggestions and hints for best practices when using different scientific software on LUMI? The guidelines provided in this course show that LUMI can support a wide range of programming environments and compilers, as well as specific optimization tools and methods. From my understanding, these considerations can vary greatly for each application or software. Therefore, any experience with specific programs could prove invaluable in saving a significant amount of resources.
-
No. There are basically too many different packages in use to even be feasible to put an effort in it, and for some packages it really depends a lot on the actual problem you are solving. Sometimes completely different settings are needed depending on which parts of the packages that are being used (some packages support different algorithms that may be parallelised completely differently) and what problem you are trying to solve.
That experience should come from user communities of a package as the same experience may be useful on several systems. And much of it may even transfer to systems that are not identical. I have seen manuals of software packages that do try to provide those insights. But, e.g., if your application is not too much restricted by the communication network than there is really no difference between running on LUMI or any other cluster with 64-core Milan CPUs of which there are more and more out these days, and it may even carry over to the newer Genoa CPU.
For the GPUs it may be a bit different as HPE Cray is the only company that can sell this particular version (the MI250X) and others can only sell the regular MI250 which connects through PCIe. But even then in most cases that experience will be the same. There aren't that many MI200-faily GPUs out in the field though, most companies seem to be waiting for its successor.
Thanks. Alright, I take that the best practice should be seeked from the community of specific software.
"},{"location":"1day-20230509/notes_20230516/#lustre-io","title":"Lustre I/O","text":" -
Just a note: I've been on the receiving end of file-system downtime. First my project was down, then it went up and my user folder went down. That felt rather annoying... D: Wish both was on the same partition.
-
We know but the maintenance was urgent. It was a bug that corrupts files. One system was hit with corruption issues and it turned out that there were more serious problems on a second one also. It would have been better though if they had taken the whole system down, and maybe they could have done the work in the time it took now to do two of the four file systems...
-
It is impossible to get the home directory and project space guaranteed on the same partition. Users can have multiple projects and projects have multiple users so there is no way we can organise that. In fact, several users come in via the course project before they even have a \"real\" project on LUMI...
My colleague got lucky in this regard, since we only have one project :p
- Most of us in user support have two userids, one with CSC for our LUST work and then we got another one, either from our local organisation or because we needed to have one in Puhuri also for other work (before it was possible to have a single ID for the two systems that are used for user management). One of us was blocked on both accounts simultaneously, then tried to get a third account via an appointment at another university and was unlucky to get that one also on the same file system...
poor guy ...
- Moreover there is a simple formala that connects your userid and project id to the respective storage system it is on...
-
What is the difference between these folders at higher hierarchy? For example, my user folder is located at /pfs/lustrep4/users. Each of these folders contain folders for users and projects.
- They are all on the same file systems but with different quota policies and different retention policies.
Then may be my personal files and project files are located in different parent folder, isn't it?
- Project and scratch will always be on the same file system but is assigned independently from the user home directory, basically because what I explained above. There is a many-to-many mapping between users and projects.
-
Are files removed from LUMI after certain days of no activity?
-
The policies are an evolving thing but accounts that are not used for too long are blocked even if they have an active project because an unattended account is a security risk.
-
Files on scratch and flash will be cleaned in the future after 90 or 30 days respectively (likely access date though and not creation date). This is rather common on big clusters actually.
-
All files of your project are removed 90 days after the end of the project and not recoverable.
-
Not sure how long a userid can exist without a project attached to it, but we already have closed accounts on LUMI with all files removed.
-
And note that LUMI is not meant for data archiving. There is no backup, not even of the home directory. You are responsible for transfering all data to an external storage service, likely your home institute.
"},{"location":"1day-20230509/notes_20230516/#lumi-user-support","title":"LUMI User Support","text":" -
Re the Tallinn course: will it be recorded too, like this one? And where will this course recording be available?
-
The problem with the 4-day courses that there is lot of copyrighted material in there that we can only make available to users of LUMI. So far this has been done with a project that was only accessible to those who took the course but we are looking to put them in a place were all users can access the data on LUMI. The HPE lectures will never go on the web though. There is a chance that we will be allowed to put the AMD presentations on the web.
There is actually material from previous courses already on the course archive web site that J\u00f8rn referred to in his introduction, on lumi-supercomputer.github.io/LUMI-training-materials.
I'm mostly interested in the GPU-profiling, but I can't attend due to other events.
- Part of that is HPE material for which we are looking for a better solution, part of it is AMD material and so far we have been allowed to put their slides on the web, but we have to ask for the recordings. We only got a access to a system capable of serving the recordings last week so we are still working on that.
-
Can we cancel our tickets ourselves, if the problem \"magically\" solves meanwhile :)?
"},{"location":"1day-20230509/schedule/","title":"Schedule (tentative)","text":"09:00 CEST\u00a0\u00a0 10:00 EEST Welcome and introduction Presenter: J\u00f8rn Dietze (LUST) Recording: 09:10 CEST 10:10 EEST LUMI Architecture Presenter: Kurt Lust Notes and slides (PDF) Recording: 09:40 CEST 10:40 EEST HPE Cray Programming Environment Presenter: Kurt Lust Notes and slides (PDF) Recording: 10:10 CEST 11:10 EEST Modules on LUMI Presenter: Kurt Lust Notes and slides (PDF) Recording: 10:45 CEST 11:45 EEST Break 11:00 CEST 12:00 EEST LUMI Software Stacks Presenter: Kurt Lust Notes and slides (PDF) Recording: 11:45 CEST 12:45 EEST Hands-on Exercise assignments and solutions 12:15 CEST 13:15 EEST Lunch break 13:15 CEST 14:15 EEST Running jobs on LUMI Presenter: Maciej Szpindler slides (PDF) Recording: 15:15 CEST 16:15 EEST Hands-on Exercise assignments and solutions 15:30 CEST 16:39 EEST Break 15:40 CEST 16:40 EEST Introduction to Lustre and Best Practices Presenter: J\u00f8rn Dietze slides (PDF) Recording: 15:50 CEST 16:50 EEST LUMI User Support Presenter: J\u00f8rn Dietze slides (PDF) Recording: 16:15 CEST 17:15 EEST General Q&A 16:30 CEST 17:30 EEST Course end"},{"location":"1day-20230509/video_00_Introduction/","title":"Welcome and introduction","text":"Presenter: J\u00f8rn Dietze (LUST)
"},{"location":"1day-20230509/video_01_LUMI_Architecture/","title":"LUMI Architecture","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230509/video_02_HPE_Cray_Programming_Environment/","title":"HPE Cray Programming Environment","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230509/video_03_Modules_on_LUMI/","title":"Modules on LUMI","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230509/video_04_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230509/video_06_Running_Jobs_on_LUMI/","title":"Running Jobs on LUMI","text":"Presenter: Maciej Szpindler (LUST)
Additional materials
"},{"location":"1day-20230509/video_08_Introduction_to_Lustre_and_Best_Practices/","title":"Introduction to Lustre and Best Practices","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"1day-20230509/video_09_LUMI_User_Support/","title":"LUMI User Support","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"1day-20230921/","title":"LUMI 1-day training 21 September 2023","text":""},{"location":"1day-20230921/#organisation","title":"Organisation","text":""},{"location":"1day-20230921/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":" -
Create a directory in the scratch of the training project, or if you want to keep the exercises around for a while after the session and have already another project on LUMI, in a subdirectory or your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of the project:
mkdir -p /scratch/project_465000688/$USER/exercises\ncd /scratch/project_465000688/$USER/exercises\n
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/1day-20230921/files/exercises-20230921.tar.gz\ntar -xf exercises-20230921.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"1day-20230921/#downloads","title":"Downloads","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes recording Introduction / / recording LUMI Architecture slides notes recording HPE Cray Programming Environment slides notes recording Modules on LUMI slides notes recording LUMI Software Stacks slides notes recording Exercises 1 / notes / Running Jobs on LUMI slides / recording Exercises 2 / notes / Introduction to Lustre and Best Practices slides / recording LUMI User Support slides / recording Appendix: Additional documentation / documentation /"},{"location":"1day-20230921/01_Architecture/","title":"The LUMI Architecture","text":"In this presentation, we will build up LUMI part by part, stressing those aspects that are important to know to run on LUMI efficiently and define jobs that can scale.
"},{"location":"1day-20230921/01_Architecture/#why-do-i-kneed-to-know-this","title":"Why do I kneed to know this?","text":"You may wonder why you need to know about system architecture if all you want to do is to run some programs.
A supercomputer is not simply a scaled-ups smartphone or PC that will offer good performance automatically. But it is a very expensive infrastructure, with an investment of 160M EURO for LUMI and an estimated total cost (including operations) of 250M EURO. So it is important to use the computer efficiently.
And that efficiency comes not for free. Instead in most cases it is important to properly map an application on the available resources to run efficiently. The way an application is developed is important for this, but it is not the only factor. Every application needs some user help to run in the most efficient way, and that requires an understanding of
-
The hardware architecture of the supercomputer, which is something that we discuss in this section.
-
The middleware: the layers of software that sit between the application on one hand and the hardware and operating system on the other hand. This is a topic of discussion in several sessions of this course.
-
The application. This is very domain-specific and application-specific and hence cannot be the topic of a general course like this one. In fact, there are so many different applications and often considerable domain knowledge is required so that a small support team like the one of LUMI cannot provide that information. It is up to scientific communities to organise such trainings, and then up to users to combine the knowledge of an application obtained from such a course with the knowledge about the computer you want to use and its middleware obtained from courses such as this one or our 4-day more advanced course.
"},{"location":"1day-20230921/01_Architecture/#lumi-is","title":"LUMI is ...","text":"LUMI is a pre-exascale supercomputer, and not a superfast PC nor a compute cloud architecture.
Each of these architectures have their own strengths and weaknesses and offer different compromises and it is key to chose the right infrastructure for the job and use the right tools for each infrastructure.
Just some examples of using the wrong tools or infrastructure:
-
The single thread performance of the CPU is lower than on a high-end PC. We've had users who were disappointed about the speed of a single core and were expecting that this would be much faster than their PCs. Supercomputers however are optimised for performance per Watt and get their performance from using lots of cores through well-designed software. If you want the fastest core possible, you'll need a gaming PC.
E.g., the AMD 5800X is a popular CPU for high end gaming PCs using the same core architecture as the CPUs in LUMI. It runs at a base clock of 3.8 GHz and a boost clock of 4.7 GHz if only one core is used and the system has proper cooling. The 7763 used in the compute nodes of LUMI-C runs at a base clock of 2.45 GHz and a boost clock of 3.5 GHz. If you have only one single core job to run on your PC, you'll be able to reach that boost clock while on LUMI you'd probably need to have a large part of the node for yourself, and even then the performance for jobs that are not memory bandwidth limited will be lower than that of the gaming PC.
-
For some data formats the GPU performance may be slower also than on a high end gaming PC. This is even more so because an MI250x should be treated as two GPUs for most practical purposes. The better double precision floating point operations and matrix operations, also at full precision, require transistors also that on some other GPUs are used for rendering hardware or for single precision compute units.
E.g., a single GPU die of the MI250X (half a GPU) has a peak FP32 performance at the boost clock of almost 24 TFlops or 48 TFlops in the packed format which is actually hard for a compiler to exploit, while the high-end AMD graphics GPU RX 7900 XTX claims 61 TFlops at the boost clock. But the FP64 performance of one MI250X die is also close to 24 TFlops in vector math, while the RX 7900 XTX does less than 2 TFlops in that data format which is important for a lot of scientific computing applications.
-
Compute GPUs and rendering GPUs are different beasts these days. We had a user who wanted to use the ray tracing units to do rendering. The MI250X does not have texture units or ray tracing units though. It is not a real graphics processor anymore.
-
The environment is different also. It is not that because it runs some Linux it handles are your Linux software. A user complained that they did not succeed in getting their nice remote development environment to work on LUMI. The original author of these notes took a test license and downloaded a trial version. It was a very nice environment but really made for local development and remote development in a cloud environment with virtual machines individually protected by personal firewalls and was not only hard to get working on a supercomputer but also insecure.
-
And supercomputer need proper software that exploits the strengths and works around the weaknesses of their architecture. CERN came telling on a EuroHPC Summit Week before the COVID pandemic that they would start using more HPC and less cloud and that they expected a 40% cost reduction that way. A few years later they published a paper with their experiences and it was mostly disappointment. The HPC infrastructure didn't fit their model for software distribution and performance was poor. Basically their solution was designed around the strengths of a typical cloud infrastructure and relied precisely on those things that did make their cloud infrastructure more expensive than the HPC infrastructure they tested. It relied on fast local disks that require a proper management layer in the software, (ab)using the file system as a database for unstructured data, a software distribution mechanism that requires an additional daemon running permanently on the compute nodes (and local storage on those nodes), ...
True supercomputers, and LUMI in particular, are built for scalable parallel applications and features that are found on smaller clusters or on workstations that pose a threat to scalability are removed from the system. It is also a shared infrastructure but with a much more lightweight management layer than a cloud infrastructure and far less isolation between users, meaning that abuse by one user can have more of a negative impact on other users than in a cloud infrastructure. Supercomputers since the mid to late '80s are also built according to the principle of trying to reduce the hardware cost by using cleverly designed software both at the system and application level. They perform best when streaming data through the machine at all levels of the memory hierarchy and are not built at all for random access to small bits of data (where the definition of \"small\" depends on the level in the memory hierarchy).
At several points in this course you will see how this impacts what you can do with a supercomputer and how you work with a supercomputer.
"},{"location":"1day-20230921/01_Architecture/#lumi-spec-sheet-a-modular-system","title":"LUMI spec sheet: A modular system","text":"So we've already seen that LUMI is in the first place a EuroHPC pre-exascale machine. LUMI is built to prepare for the exascale era and to fit in the EuroHPC ecosystem. But it does not even mean that it has to cater to all pre-exascale compute needs. The EuroHPC JU tries to build systems that have some flexibility, but also does not try to cover all needs with a single machine. They are building 3 pre-exascale systems with different architecture to explore multiple architectures and to cater to a more diverse audience.
LUMI is also a very modular machine designed according to the principles explored in a series of European projects, and in particular DEEP and its successors) that explored the cluster-booster concept. E.g., in a complicated multiphysics simulation you could be using regular CPU nodes for the physics that cannot be GPU-accelerated communicating with compute GPU nodes for the physics that can be GPU-accelerated, then add a number of CPU nodes to do the I/O and a specialised render GPU node for in-situ visualisation.
LUMI is in the first place a huge GPGPU supercomputer. The GPU partition of LUMI, called LUMI-G, contains 2928 (2978?) nodes with a single 64-core AMD EPYC 7A53 CPU and 4 AMD MI250x GPUs. Each node has 512 GB of RAM attached to the CPU (the maximum the CPU can handle without compromising bandwidth) and 128 GB of HBM2e memory per GPU. Each GPU node has a theoretical peak performance of nearly 200 TFlops in single (FP32) or double (FP64) precision vector arithmetic (and twice that with the packed FP32 format, but that is not well supported so this number is not often quoted). The matrix units are capable of about 400 TFlops in FP32 or FP64. However, compared to the NVIDIA GPUs, the performance for lower precision formats used in some AI applications is not that stellar.
LUMI also has a large CPU-only partition, called LUMI-C, for jobs that do not run well on GPUs, but also integrated enough with the GPU partition that it is possible to have applications that combine both node types. LUMI-C consists of 1536 nodes with 2 64-core AMD EPYC 7763 CPUs. 32 of those nodes have 1TB of RAM (with some of these nodes actually reserved for special purposes such as connecting to a Quantum computer), 128 have 512 GB and 1376 have 256 GB of RAM.
LUMI also has two smaller groups of nodes for interactive data analytics. 8 of those nodes have two 64-core Zen2/Rome CPUs with 4 TB of RAM per node, while 8 others have dual 64-core Zen2/Rome CPUs and 8 NVIDIA A40 GPUs for visualisation. Currently we are working on an Open OnDemand based service to make some fo those facilities available. Note though that these nodes are meant for a very specific use, so it is not that we will also be offering, e.g., GPU compute facilities on NVIDIA hardware, and that these are shared resources that should not be monopolised by a single user (so no hope to run an MPI job on 8 4TB nodes).
LUMI also has a 8 PB flash based file system running the Lustre parallel file system. This system is often denoted as LUMI-F. The bandwidth of that system is 1740 GB/s. Note however that this is still a remote file system with a parallel file system on it, so do not expect that it will behave as the local SSD in your laptop. But that is also the topic of another session in this course.
The main work storage is provided by 4 20 PB hard disk based Lustre file systems with a bandwidth of 240 GB/s each. That section of the machine is often denoted as LUMI-P.
Big parallel file systems need to be used in the proper way to be able to offer the performance that one would expect from their specifications. This is important enough that we have a separate session about that in this course.
An object based file system similar to the Allas service of CSC that some of the Finnish users may be familiar with is also being worked on. At the moment the interface to that system is still rather primitive.
Currently LUMI has 4 login nodes, called user access nodes in the HPE Cray world. They each have 2 64-core AMD EPYC 7742 processors and 1 TB of RAM. Note that whereas the GPU and CPU compute nodes have the Zen3 architecture code-named \"Milan\", the processors on the login nodes are Zen2 processors, code-named \"Rome\". Zen3 adds some new instructions so if a compiler generates them, that code would not run on the login nodes. These instructions are basically used in cryptography though. However, many instructions have very different latency, so a compiler that optimises specifically for Zen3 may chose another ordering of instructions then when optimising for Zen2 so it may still make sense to compile specifically for the compute nodes on LUMI.
All compute nodes, login nodes and storage are linked together through a high-performance interconnect. LUMI uses the Slingshot 11 interconnect which is developed by HPE Cray, so not the Mellanox/NVIDIA InfiniBand that you may be familiar with from many smaller clusters, and as we shall discuss later this also influences how you work on LUMI.
Early on a small partition for containerised micro-services managed with Kubernetes was also planned, but that may never materialize due to lack of people to set it up and manage it.
In this section of the course we will now build up LUMI step by step.
"},{"location":"1day-20230921/01_Architecture/#building-lumi-the-cpu-amd-7xx3-milanzen3-cpu","title":"Building LUMI: The CPU AMD 7xx3 (Milan/Zen3) CPU","text":"The LUMI-C and LUMI-G compute nodes use third generation AMD EPYC CPUs. Whereas Intel CPUs launched in the same period were built out of a single large monolithic piece of silicon (that only changed recently with some variants of the Sapphire Rapids CPU launched in early 2023), AMD CPUs are build out of multiple so-called chiplets.
The basic building block of Zen3 CPUs is the Core Complex Die (CCD). Each CCD contains 8 cores, and each core has 32 kB of L1 instruction and 32 kB of L1 data cache, and 512 kB of L2 cache. The L3 cache is shared across all cores on a chiplet and has a total size of 32 MB on LUMI (there are some variants of the processor where this is 96MB). At the user level, the instruction set is basically equivalent to that of the Intel Broadwell generation. AVX2 vector instructions and the FMA instruction are fully supported, but there is no support for any of the AVX-512 versions that can be found on Intel Skylake server processors and later generations. Hence the number of floating point operations that a core can in theory do each clock cycle is 16 (in double precision) rather than the 32 some Intel processors are capable of.
The full processor package for the AMD EPYC processors used in LUMI have 8 such Core Complex Dies for a total of 64 cores. The caches are not shared between different CCDs, so it also implies that the processor has 8 so-called L3 cache regions. (Some cheaper variants have only 4 CCDs, and some have CCDs with only 6 or fewer cores enabled but the same 32 MB of L3 cache per CCD).
Each CCD connects to the memory/IO die through an Infinity Fabric link. The memory/IO die contains the memory controllers, connections to connect two CPU packages together, PCIe lanes to connect to external hardware, and some additional hardware, e.g., for managing the processor. The memory/IO die supports 4 dual channel DDR4 memory controllers providing a total of 8 64-bit wide memory channels. From a logical point of view the memory/IO-die is split in 4 quadrants, with each quadrant having a dual channel memory controller and 2 CCDs. They basically act as 4 NUMA domains. For a core it is slightly faster to access memory in its own quadrant than memory attached to another quadrant, though for the 4 quadrants within the same socket the difference is small. (In fact, the BIOS can be set to show only two or one NUMA domain which is advantageous in some cases, like the typical load pattern of login nodes where it is impossible to nicely spread processes and their memory across the 4 NUMA domains).
The theoretical memory bandwidth of a complete package is around 200 GB/s. However, that bandwidth is not available to a single core but can only be used if enough cores spread over all CCDs are used.
"},{"location":"1day-20230921/01_Architecture/#building-lumi-a-lumi-c-node","title":"Building LUMI: A LUMI-C node","text":"A compute node is then built out of two such processor packages, connected through 4 16-bit wide Infinity Fabric connections with a total theoretical bandwidth of 144 GB/s in each direction. So note that the bandwidth in each direction is less than the memory bandwidth of a socket. Again, it is not really possible to use the full memory bandwidth of a node using just cores on a single socket. Only one of the two sockets has a direct connection to the high performance Slingshot interconnect though.
"},{"location":"1day-20230921/01_Architecture/#a-strong-hierarchy-in-the-node","title":"A strong hierarchy in the node","text":"As can be seen from the node architecture in the previous slide, the CPU compute nodes have a very hierarchical architecture. When mapping an application onto one or more compute nodes, it is key for performance to take that hierarchy into account. This is also the reason why we will pay so much attention to thread and process pinning in this tutorial course.
At the coarsest level, each core supports two hardware threads (what Intel calls hyperthreads). Those hardware threads share all the resources of a core, including the L1 data and instruction caches and the L2 cache, execution units and space for register renaming. At the next level, a Core Complex Die contains (up to) 8 cores. These cores share the L3 cache and the link to the memory/IO die. Next, as configured on the LUMI compute nodes, there are 2 Core Complex Dies in a NUMA node. These two CCDs share the DRAM channels of that NUMA node. At the fourth level in our hierarchy 4 NUMA nodes are grouped in a socket. Those 4 NUMA nodes share an inter-socket link. At the fifth and last level in our shared memory hierarchy there are two sockets in a node. On LUMI, they share a single Slingshot inter-node link.
The finer the level (the lower the number), the shorter the distance and hence the data delay is between threads that need to communicate with each other through the memory hierarchy, and the higher the bandwidth.
This table tells us a lot about how one should map jobs, processes and threads onto a node. E.g., if a process has fewer then 8 processing threads running concurrently, these should be mapped to cores on a single CCD so that they can share the L3 cache, unless they are sufficiently independent of one another, but even in the latter case the additional cores on those CCDs should not be used by other processes as they may push your data out of the cache or saturate the link to the memory/IO die and hence slow down some threads of your process. Similarly, on a 256 GB compute node each NUMA node has 32 GB of RAM (or actually a bit less as the OS also needs memory, etc.), so if you have a job that uses 50 GB of memory but only, say, 12 threads, you should really have two NUMA nodes reserved for that job as otherwise other threads or processes running on cores in those NUMA nodes could saturate some resources needed by your job. It might also be preferential to spread those 12 threads over the 4 CCDs in those 2 NUMA domains unless communication through the L3 threads would be the bottleneck in your application.
"},{"location":"1day-20230921/01_Architecture/#hierarchy-delays-in-numbers","title":"Hierarchy: delays in numbers","text":"This slide shows the ACPI System Locality distance Information Table (SLIT) as returned by, e.g., numactl -H which gives relative distances to memory from a core. E.g., a value of 32 means that access takes 3.2x times the time it would take to access memory attached to the same NUMA node. We can see from this table that the penalty for accessing memory in another NUMA domain in the same socket is still relatively minor (20% extra time), but accessing memory attached to the other socket is a lot more expensive. If a process running on one socket would only access memory attached to the other socket, it would run a lot slower which is why Linux has mechanisms to try to avoid that, but this cannot be done in all scenarios which is why on some clusters you will be allocated cores in proportion to the amount of memory you require, even if that is more cores than you really need (and you will be billed for them).
"},{"location":"1day-20230921/01_Architecture/#building-lumi-concept-lumi-g-node","title":"Building LUMI: Concept LUMI-G node","text":"This slide shows a conceptual view of a LUMI-G compute node. This node is unlike any Intel-architecture-CPU-with-NVIDIA-GPU compute node you may have seen before, and rather mimics the architecture of the USA pre-exascale machines Summit and Sierra which have IBM POWER9 CPUs paired with NVIDIA V100 GPUs.
Each GPU node consists of one 64-core AMD EPYC CPU and 4 AMD MI250x GPUs. So far nothing special. However, two elements make this compute node very special. First, the GPUs are not connected to the CPU though a PCIe bus. Instead they are connected through the same links that AMD uses to link the GPUs together, or to link the two sockets in the LUMI-C compute nodes, known as xGMI or Infinity Fabric. This enables unified memory across CPU and GPUs and provides partial cache coherency across the system. The CPUs coherently cache the CPU DDR and GPU HBM memory, but each GPU only coherently caches its own local memory. The second remarkable element is that the Slingshot interface cards connect directly to the GPUs (through a PCIe interface on the GPU) rather than two the CPU. The GPUs have a shorter path to the communication network than the CPU in this design.
This makes the LUMI-G compute node really a \"GPU first\" system. The architecture looks more like a GPU system with a CPU as the accelerator for tasks that a GPU is not good at such as some scalar processing or running an OS, rather than a CPU node with GPU accelerator.
It is also a good fit with the cluster-booster design explored in the DEEP project series. In that design, parts of your application that cannot be properly accelerated would run on CPU nodes, while booster GPU nodes would be used for those parts that can (at least if those two could execute concurrently with each other). Different node types are mixed and matched as needed for each specific application, rather than building clusters with massive and expensive nodes that few applications can fully exploit. As the cost per transistor does not decrease anymore, one has to look for ways to use each transistor as efficiently as possible...
It is also important to realise that even though we call the partition \"LUMI-G\", the MI250x is not a GPU in the true sense of the word. It is not a rendering GPU, which for AMD is currently the RDNA architecture with version 3 just out, but a compute accelerator with an architecture that evolved from a GPU architecture, in this case the VEGA architecture from AMD. The architecture of the MI200 series is also known as CDNA2, with the MI100 series being just CDNA, the first version. Much of the hardware that does not serve compute purposes has been removed from the design to have more transistors available for compute. Rendering is possible, but it will be software-based rendering with some GPU acceleration for certain parts of the pipeline, but not full hardware rendering.
This is not an evolution at AMD only. The same is happening with NVIDIA GPUs and there is a reason why the latest generation is called \"Hopper\" for compute and \"Ada Lovelace\" for rendering GPUs. Several of the functional blocks in the Ada Lovelace architecture are missing in the Hopper architecture to make room for more compute power and double precision compute units. E.g., Hopper does not contain the ray tracing units of Ada Lovelace. The Intel Data Center GPU Max code named \"Ponte Vecchio\" is the only current GPU for HPC that still offers full hardware rendering support (and even ray tracing).
Graphics on one hand and HPC and AI on the other hand are becoming separate workloads for which manufacturers make different, specialised cards, and if you have applications that need both, you'll have to rework them to work in two phases, or to use two types of nodes and communicate between them over the interconnect, and look for supercomputers that support both workloads.
But so far for the sales presentation, let's get back to reality...
"},{"location":"1day-20230921/01_Architecture/#building-lumi-what-a-lumi-g-node-really-looks-like","title":"Building LUMI: What a LUMI-G node really looks like","text":"Or the full picture with the bandwidths added to it:
The LUMI-G node uses the 64-core AMD 7A53 EPYC processor, known under the code name \"Trento\". This is basically a Zen3 processor but with a customised memory/IO die, designed specifically for HPE Cray (and in fact Cray itself, before the merger) for the USA Coral-project to build the Frontier supercomputer, the fastest system in the world at the end of 2022 according to at least the Top500 list. Just as the CPUs in the LUMI-C nodes, it is a design with 8 CCDs and a memory/IO die.
The MI250x GPU is also not a single massive die, but contains two compute dies besides the 8 stacks of HBM2e memory, 4 stacks or 64 GB per compute die. The two compute dies in a package are linked together through 4 16-bit Infinity Fabric links. These links run at a higher speed than the links between two CPU sockets in a LUMI-C node, but per link the bandwidth is still only 50 GB/s per direction, creating a total bandwidth of 200 GB/s per direction between the two compute dies in an MI250x GPU. That amount of bandwidth is very low compared to even the memory bandwidth, which is roughly 1.6 TB/s peak per die, let alone compared to whatever bandwidth caches on the compute dies would have or the bandwidth of the internal structures that connect all compute engines on the compute die. Hence the two dies in a single package cannot function efficiently as as single GPU which is one reason why each MI250x GPU on LUMI is actually seen as two GPUs.
Each compute die uses a further 2 or 3 of those Infinity Fabric (or xGNI) links to connect to some compute dies in other MI250x packages. In total, each MI250x package is connected through 5 such links to other MI250x packages. These links run at the same 25 GT/s speed as the links between two compute dies in a package, but even then the bandwidth is only a meager 250 GB/s per direction, less than an NVIDIA A100 GPU which offers 300 GB/s per direction or the NVIDIA H100 GPU which offers 450 GB/s per direction. Each Infinity Fabric link may be twice as fast as each NVLINK 3 or 4 link (NVIDIA Ampere and Hopper respectively), offering 50 GB/s per direction rather than 25 GB/s per direction for NVLINK, but each Ampere GPU has 12 such links and each Hopper GPU 18 (and in fact a further 18 similar ones to link to a Grace CPU), while each MI250x package has only 5 such links available to link to other GPUs (and the three that we still need to discuss).
Note also that even though the connection between MI250x packages is all-to-all, the connection between GPU dies is all but all-to-all. as each GPU die connects to only 3 other GPU dies. There are basically two bidirectional rings that don't need to share links in the topology, and then some extra connections. The rings are:
- Green ring: 1 - 0 - 6 - 7 - 5 - 4 - 2 - 3 - 1
- Red ring: 1 - 0 - 2 - 3 - 7 - 6 - 4 - 5 - 1
These rings play a role in the inter-GPU communication in AI applications using RCCL.
Each compute die is also connected to one CPU Core Complex Die (or as documentation of the node sometimes says, L3 cache region). This connection only runs at the same speed as the links between CPUs on the LUMI-C CPU nodes, i.e., 36 GB/s per direction (which is still enough for all 8 GPU compute dies together to saturate the memory bandwidth of the CPU). This implies that each of the 8 GPU dies has a preferred CPU die to work with, and this should definitely be taken into account when mapping processes and threads on a LUMI-G node.
The figure also shows another problem with the LUMI-G node: The mapping between CPU cores/dies and GPU dies is all but logical:
GPU die CCD hardware threads NUMA node 0 6 48-55, 112-119 3 1 7 56-63, 120-127 3 2 2 16-23, 80-87 1 3 3 24-31, 88-95 1 4 0 0-7, 64-71 0 5 1 8-15, 72-79 0 6 4 32-39, 96-103 2 7 5 40-47, 104, 11 2 and as we shall see later in the course, exploiting this is a bit tricky at the moment.
"},{"location":"1day-20230921/01_Architecture/#what-the-future-looks-like","title":"What the future looks like...","text":"Some users may be annoyed by the \"small\" amount of memory on each node. Others may be annoyed by the limited CPU capacity on a node compared to some systems with NVIDIA GPUs. It is however very much in line with the cluster-booster philosophy already mentioned a few times, and it does seem to be the future according to AMD (with Intel also working into that direction). In fact, it looks like with respect to memory capacity things may even get worse.
We saw the first little steps of bringing GPU and CPU closer together and integrating both memory spaces in the USA pre-exascale systems Summit and Sierra. The LUMI-G node which was really designed for one of the first USA exascale systems continues on this philosophy, albeit with a CPU and GPU from a different manufacturer. Given that manufacturing large dies becomes prohibitively expensive in newer semiconductor processes and that the transistor density on a die is also not increasing at the same rate anymore with process shrinks, manufacturers are starting to look at other ways of increasing the number of transistors per \"chip\" or should we say package. So multi-die designs are here to stay, and as is already the case in the AMD CPUs, different dies may be manufactured with different processes for economical reasons.
Moreover, a closer integration of CPU and GPU would not only make programming easier as memory management becomes easier, it would also enable some codes to run on GPU accelerators that are currently bottlenecked by memory transfers between GPU and CPU.
AMD at its 2022 Investor day and at CES 2023 in early January, and Intel at an Investor day in 2022 gave a glimpse of how they see the future. The future is one where one or more CPU dies, GPU dies and memory controllers are combined in a single package and - contrary to the Grace Hopper design of NVIDIA - where CPU and GPU share memory controllers. At CES 2023, AMD already showed a MI300A package that will be used in El Capitan, one of the next USA exascale systems (the third one if Aurora gets built in time). It employs 13 chiplets in two layers, linked to (still only) 8 memory stacks (albeit of a slightly faster type than on the MI250x). The 4 chiplets on the bottom layer are the memory controllers and inter-GPU links (an they can be at the bottom as they produce less heat). Furthermore each package features 6 GPU dies and 3 Zen4 \"Genoa\" CPU dies. The MI300A still uses only 8 HBM stacks and is also limited to 16 GB stacks, providing a total of 128 GB of RAM.
Intel at some point has shown only very conceptual drawings of its Falcon Shores chip which it calls an XPU, but those drawings suggest that that chip will also support some low-bandwidth but higher capacity external memory, similar to the approach taken in some Sapphire Rapids Xeon processors that combine HBM memory on-package with DDR5 memory outside the package. Falcon Shores will be the next generation of Intel GPUs for HPC, after Ponte Vecchio which will be used in the Aurora supercomputer. It is currently very likely though that Intel will revert to a traditional design for Falcon Shores and push out the integrated CPU+GPU model to a later generation.
However, a CPU closely integrated with accelerators is nothing new as Apple Silicon is rumoured to do exactly that in its latest generations, including the M-family chips.
"},{"location":"1day-20230921/01_Architecture/#building-lumi-the-slingshot-interconnect","title":"Building LUMI: The Slingshot interconnect","text":"All nodes of LUMI, including the login, management and storage nodes, are linked together using the Slingshot interconnect (and almost all use Slingshot 11, the full implementation with 200 Gb/s bandwidth per direction).
Slingshot is an interconnect developed by HPE Cray and based on Ethernet, but with proprietary extensions for better HPC performance. It adapts to the regular Ethernet protocols when talking to a node that only supports Ethernet, so one of the attractive features is that regular servers with Ethernet can be directly connected to the Slingshot network switches. HPE Cray has a tradition of developing their own interconnect for very large systems. As in previous generations, a lot of attention went to adaptive routing and congestion control. There are basically two versions of it. The early version was named Slingshot 10, ran at 100 Gb/s per direction and did not yet have all features. It was used on the initial deployment of LUMI-C compute nodes but has since been upgraded to the full version. The full version with all features is called Slingshot 11. It supports a bandwidth of 200 Gb/s per direction, comparable to HDR InfiniBand with 4x links.
Slingshot is a different interconnect from your typical Mellanox/NVIDIA InfiniBand implementation and hence also has a different software stack. This implies that there are no UCX libraries on the system as the Slingshot 11 adapters do not support that. Instead, the software stack is based on libfabric (as is the stack for many other Ethernet-derived solutions and even Omni-Path has switched to libfabric under its new owner).
LUMI uses the dragonfly topology. This topology is designed to scale to a very large number of connections while still minimizing the amount of long cables that have to be used. However, with its complicated set of connections it does rely on adaptive routing and congestion control for optimal performance more than the fat tree topology used in many smaller clusters. It also needs so-called high-radix switches. The Slingshot switch, code-named Rosetta, has 64 ports. 16 of those ports connect directly to compute nodes (and the next slide will show you how). Switches are then combined in groups. Within a group there is an all-to-all connection between switches: Each switch is connected to each other switch. So traffic between two nodes of a group passes only via two switches if it takes the shortest route. However, as there is typically only one 200 Gb/s direct connection between two switches in a group, if all 16 nodes on two switches in a group would be communicating heavily with each other, it is clear that some traffic will have to take a different route. In fact, it may be statistically better if the 32 involved nodes would be spread more evenly over the group, so topology based scheduling of jobs and getting the processes of a job on as few switches as possible may not be that important on a dragonfly Slingshot network. The groups in a slingshot network are then also connected in an all-to-all fashion, but the number of direct links between two groups is again limited so traffic again may not always want to take the shortest path. The shortest path between two nodes in a dragonfly topology never involves more than 3 hops between switches (so 4 switches): One from the switch the node is connected to the switch in its group that connects to the other group, a second hop to the other group, and then a third hop in the destination group to the switch the destination node is attached to.
"},{"location":"1day-20230921/01_Architecture/#assembling-lumi","title":"Assembling LUMI","text":"Let's now have a look at how everything connects together to the supercomputer LUMI. It does show that LUMI is not your standard cluster build out of standard servers.
LUMI is built very compactly to minimise physical distance between nodes and to reduce the cabling mess typical for many clusters. LUMI does use a custom rack design for the compute nodes that is also fully water cooled. It is build out of units that can contain up to 4 custom cabinets, and a cooling distribution unit (CDU). The size of the complex as depicted in the slide is approximately 12 m2. Each cabinet contains 8 compute chassis in 2 columns of 4 rows. In between the two columns is all the power circuitry. Each compute chassis can contain 8 compute blades that are mounted vertically. Each compute blade can contain multiple nodes, depending on the type of compute blades. HPE Cray have multiple types of compute nodes, also with different types of GPUs. In fact, the Aurora supercomputer which uses Intel CPUs and GPUs and El Capitan, which uses the MI300A APUs (integrated CPU and GPU) will use the same design with a different compute blade. Each LUMI-C compute blade contains 4 compute nodes and two network interface cards, with each network interface card implementing two Slingshot interfaces and connecting to two nodes. A LUMI-G compute blade contains two nodes and 4 network interface cards, where each interface card now connects to two GPUs in the same node. All connections for power, management network and high performance interconnect of the compute node are at the back of the compute blade. At the front of the compute blades one can find the connections to the cooling manifolds that distribute cooling water to the blades. One compute blade of LUMI-G can consume up to 5kW, so the power density of this setup is incredible, with 40 kW for a single compute chassis.
The back of each cabinet is equally genius. At the back each cabinet has 8 switch chassis, each matching the position of a compute chassis. The switch chassis contains the connection to the power delivery system and a switch for the management network and has 8 positions for switch blades. These are mounted horizontally and connect directly to the compute blades. Each slingshot switch has 8x2 ports on the inner side for that purpose, two for each compute blade. Hence for LUMI-C two switch blades are needed in each switch chassis as each blade has 4 network interfaces, and for LUMI-G 4 switch blades are needed for each compute chassis as those nodes have 8 network interfaces. Note that this also implies that the nodes on the same compute blade of LUMI-C will be on two different switches even though in the node numbering they are numbered consecutively. For LUMI-G both nodes on a blade will be on a different pair of switches and each node is connected to two switches. So when you get a few sequentially numbered nodes, they will not be on a single switch (LUMI-C) or switch pair (LUMI-G). The switch blades are also water cooled (each one can consume up to 250W). No currently possible configuration of the Cray EX system needs that all switch positions in the switch chassis.
This does not mean that the extra positions cannot be useful in the future. If not for an interconnect, one could, e.g., export PCIe ports to the back and attach, e.g., PCIe-based storage via blades as the switch blade environment is certainly less hostile to such storage than the very dense and very hot compute blades.
"},{"location":"1day-20230921/01_Architecture/#lumi-assembled","title":"LUMI assembled","text":"This slide shows LUMI fully assembled (as least as it was at the end of 2022).
At the front there are 5 rows of cabinets similar to the ones in the exploded Cray EX picture on the previous slide. Each row has 2 CDUs and 6 cabinets with compute nodes. The first row, the one with the wolf, contains all nodes of LUMI-C, while the other four rows, with the letters of LUMI, contain the GPU accelerator nodes. At the back of the room there are more regular server racks that house the storage, management nodes, some special compute nodes , etc. The total size is roughly the size of a tennis court.
Remark
The water temperature that a system like the Cray EX can handle is so high that in fact the water can be cooled again with so-called \"free cooling\", by just radiating the heat to the environment rather than using systems with compressors similar to air conditioning systems, especially in regions with a colder climate. The LUMI supercomputer is housed in Kajaani in Finland, with moderate temperature almost year round, and the heat produced by the supercomputer is fed into the central heating system of the city, making it one of the greenest supercomputers in the world as it is also fed with renewable energy.
"},{"location":"1day-20230921/02_CPE/","title":"The HPE Cray Programming Environment","text":"In this session we discuss some of the basics of the operating system and programming environment on LUMI. Whether you like it or not, every user of a supercomputer like LUMI gets confronted with these elements at some point.
"},{"location":"1day-20230921/02_CPE/#why-do-i-need-to-know-this","title":"Why do I need to know this?","text":"The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is \"I only want to run some programs, why do I need to know about programming environments?\"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished. And some of the essential middleware that turns the hardware with some variant of Linux into a parallel supercomputers is part of the programming environment. The binary interfaces to those libraries are also not as standardised as for the more common Linux system libraries.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Compiling on the system is also the easiest way to guarantee compatibility of the binaries with the system.
Even when installing software from prebuilt binaries some modules might still be needed. Prebuilt binaries will typically include the essential runtime libraries for the parallel technologies they use, but these may not be compatible with LUMI. In some cases this can be solved by injecting a library from LUMI, e.g., you may want to inject an optimised MPI library as we shall see in the container section of this course. But sometimes a binary is simply incompatible with LUMI and there is no other solution than to build the software from sources.
"},{"location":"1day-20230921/02_CPE/#the-operating-system-on-lumi","title":"The operating system on LUMI","text":"The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes. This in turn led to an asymmetry in the setup so now 8 cores are reserved, one per CCD, so that all CCDs are equal again.
This also implies that some software that works perfectly fine on the login nodes may not work on the compute nodes. E.g., there is no /run/user/$UID directory and we have experienced that D-Bus (which stands for Desktop-Bus) also does not work as one should expect.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer. Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
"},{"location":"1day-20230921/02_CPE/#programming-models","title":"Programming models","text":"On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP, which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. The visualisation nodes in LUMI have NVIDIA rendering GPUs but these nodes are meant for visualisation and not for compute.
"},{"location":"1day-20230921/02_CPE/#the-development-environment-on-lumi","title":"The development environment on LUMI","text":"Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects. As they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
Specifically not on LUMI are the Intel and NVIDIA programming environments, nor is the regular Intel oneAPI HPC Toolkit. The classic Intel compilers pose problems on AMD CPUs as -xHost cannot be relied on, but it appears that the new compilers that are based on Clang and an LLVM backend behave better. Various MKL versions are also troublesome, with different workarounds for different versions, though here also it seems that Intel now has code that works well on AMD for many MKL routines. We have experienced problems with Intel MPI when testing it on LUMI though in principle it should be possible to use Cray MPICH as they are derived from the same version of MPICH. The NVIDIA programming environment doesn't make sense on an AMD GPU system, but it could have been usefull for some visualisation software on the visualisation nodes.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise three times a year with HPE for more material.
Python and R
Big Python and R installations can consist of lots of small files. Parallel file systems such as Lustre used on LUMI cannot work efficiently with such files. Therefore such installations should be containerised.
We offer two tools for that on LUMI with different strengths and weaknesses:
-
lumi-container-wrapper can build upon Cray Python when installing packages with pip or can do independent Conda installations from an environments file. The tool also create wrapper scripts for all commands in the bin subdirectory of the container installation so that the user does not always need to be aware that they are working in a container.
It is the LUMI-equivalent of the tykky module on the Finnish national systems operated by CSC.
-
cotainr is a tool developed by the Danish LUMI-partner DeIC to build some types of containers in user space and is also a good tool to containerise a Conda installation.
"},{"location":"1day-20230921/02_CPE/#the-cray-compiling-environment","title":"The Cray Compiling Environment","text":"The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend and optimiser developed by HPE Cray, but an LLVM-based code generator. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. They claim full OpenMP 4.5 support with partial (and growing) support for OpenMP 5.0 and 5.1. More information about the OpenMP support is found by checking a manual page:
man intro_openmp\n
which does require that the cce module is loaded. The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x. Information is available via man intro_openacc\n
AMD and HPE Cray still recommend moving to OpenMP which is a much broader supported standard. There are no plans to also support OpenACC in the Cray C/C++ compiler, nor are there any plans for support by AMD in the ROCm stack. The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
"},{"location":"1day-20230921/02_CPE/#scientific-and-math-libraries","title":"Scientific and math libraries","text":"Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSci_ACC, which contains a subset of the routines of LibSci. We don't have much experience in the support team with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions. These are included because it is essential that they interface properly with MPI parallel I/O and the Lustre file system to offer the best bandwidth to and from storage.
Cray used to offer more pre-installed third party libraries for which the only added value was that they compiled the binaries. Instead they now offer build scripts in a GitHub repository.
"},{"location":"1day-20230921/02_CPE/#cray-mpi","title":"Cray MPI","text":"HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully supports the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is allo fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact allowed by the standard which only requires a process starter and suggest mpirun or mpiexec depending on the version of the standard. Instead the Slurm srun command is used as the process starter. This actually makes a lot of sense as the MPI application should be mapped correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
"},{"location":"1day-20230921/02_CPE/#lmod","title":"Lmod","text":"Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded. module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to a module unload followed by a module load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
"},{"location":"1day-20230921/02_CPE/#compiler-wrappers","title":"Compiler wrappers","text":"The HPE Cray PE compilers are usually used through compiler wrappers. The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn. The wrapper then calls the selected compiler. Which compiler will be called is determined by which compiler module is loaded. As shown on the slide \"Development environment on LUMI\", on LUMI the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc), the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers (module amd) are available. On other HPE Cray systems, you may also find the Intel compilers or on systems with NVIDIA GPUs, the NVIDIA HPC compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc, mpiCC, mpif90, etc. on LUMI. The regular compiler wrappers do the job as soon as the cray-mpich module is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libsci module is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the --craype-verbose flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
The compiler wrappers are provided by the craype module (but you don't have to load that module by hand).
"},{"location":"1day-20230921/02_CPE/#selecting-the-version-of-the-cpe","title":"Selecting the version of the CPE","text":"The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 22.08 for the version released in August 2022. There are usually 10 releases per year (basically every month except July and January), though not all versions are ever offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming environment. It is possible to change the default version for loading further modules by loading one of the versions of the cpe module. E.g., assuming the 22.08 version would be present on the system, it can be loaded through
module load cpe/22.08\n
Loading this module will also try to switch the already loaded PE modules to the versions from that release. This does not always work correctly, due to some bugs in most versions of this module and a limitation of Lmod. Executing the module load twice will fix this: module load cpe/22.08\nmodule load cpe/22.08\n
The module will also produce a warning when it is unloaded (which is also the case when you do a module load of cpe when one is already loaded, as it then first unloads the already loaded cpe module). The warning can be ignored, but keep in mind that what it says is true, it cannot restore the environment you found on LUMI at login. The cpe module is also not needed when using the LUMI software stacks, but more about that later.
"},{"location":"1day-20230921/02_CPE/#the-target-modules","title":"The target modules","text":"The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-rome selects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milan is the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trento is the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofi selects the libfabric communication layer which is needed for Slingshot 11.craype-network-none omits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these settings: -target-cpu, -target-accel and -target-network.
"},{"location":"1day-20230921/02_CPE/#prgenv-and-compiler-modules","title":"PrgEnv and compiler modules","text":"In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the programming environment. These modules will load the compiler wrapper (craype), compiler, MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they activate:
PrgEnv Description Compiler module Compilers PrgEnv-cray Cray Compiling Environment cce craycc, crayCC, crayftn PrgEnv-gnu GNU Compiler Collection gcc gcc, g++, gfortran PrgEnv-aocc AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang PrgEnv-amd AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang There is also a second module that offers the AMD ROCm environment, rocm. That module has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU, hipcc with the GNU compilers or GPU support with the Cray compilers.
The HPE Cray PE now also contains some mixed programming environments that combine the C/C++ compiler from one environment with the Fortran compiler from another. Currently on LUMI there is PrgEnv-cray-amd using the Cray Fortran compiler with the AMD ROCm C/C++ compiler and PrgEnv-gnu-amd using the GNU Fortran compiler with the AMD ROCm C/C++ compiler.
"},{"location":"1day-20230921/02_CPE/#getting-help","title":"Getting help","text":"Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers and compiler wrappers, the following man pages are relevant:
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers, the switch -help should be used instead as the double dash version is passed to the compiler.
The wrappers also support the -dumpversion flag to show the version of the underlying compiler. Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn\nftn-2107 ftn: ERROR in command line\n No valid filenames are specified on the command line.\n$ explain ftn-2107\n\nError : No valid filenames are specified on the command line.\n\nAt least one file name must appear on the command line, with any command-line\noptions. Verify that a file name was specified, and also check for an\nerroneous command-line option which may cause the file name to appear to be\nan argument to that option.\n
On older Cray systems this used to be a very useful command with more compilers but as HPE Cray is using more and more open source components instead there are fewer commands that give additional documentation via the explain command.
Lastly, there is also a lot of information in the \"Developing\" section of the LUMI documentation.
"},{"location":"1day-20230921/02_CPE/#google-chatgpt-and-lumi","title":"Google, ChatGPT and LUMI","text":"When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command that searches for a term in the manual pages. It is often useful to better understand some error messages. E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem. You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and, e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE\n
The new online documentation is now also complete enough that it makes sense trying the search box on that page instead.
"},{"location":"1day-20230921/02_CPE/#other-modules","title":"Other modules","text":"Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
"},{"location":"1day-20230921/02_CPE/#warning-1-you-do-not-always-get-what-you-expect","title":"Warning 1: You do not always get what you expect...","text":"The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system) which correspond to the version of the programming environment that is set as the default when installed. This is very much the behaviour of Linux applications also that pick standard libraries in a few standard directories and it enables many programs build with the HPE Cray PE to run without reconstructing the environment and in some cases to mix programs compiled with different compilers with ease (with the emphasis on some as there may still be library conflicts between other libraries when not using the so-called rpath linking). This does have an annoying side effect though: If the default PE on the system changes, all applications will use different libraries and hence the behaviour of your application may change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic linking where the search path for the libraries is stored in each executable separately. On Linux, the search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules that have their libraries also in the default location, add the directories that contain the actual version of the libraries corresponding to the version of the module to the PATH-style environment variable CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
Small demo of adapting LD_LIBRARY_PATH: An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08\n$ module load lumi-CPEtools/1.0-cpeGNU-22.08\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007f420cd55000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)\n ...\n$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007fb38c1e0000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)\n ...\n
The ldd command shows which libraries are used by an executable. Only a part of the very long output is shown in the above example. But we can already see that in the first case, the library libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/ which clearly is for a specific version of cray-mpich. We do provide an experimental module lumi-CrayPath that tries to fix LD_LIBRARY_PATH in a way that unloading the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting the CRAY_ADD_RPATHenvironment variable:
export CRAY_ADD_RPATH=yes\n
However, there is also a good side to the standard Cray PE behaviour. Updates of the underlying operating system or network software stack may break older versions of the MPI library. By letting the applications use the default libraries and updating the defaults to a newer version, most applications will still run while they would fail if any of the two tricks to force the use of the intended library version are used. This has actually happened after a big LUMI update in March 2023, when all software that used rpath-linking had to be rebuild as the MPICH library that was present before the update did not longer work.
"},{"location":"1day-20230921/02_CPE/#warning-2-order-matters","title":"Warning 2: Order matters","text":"Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftw only becomes available when a processor target module is loadedcray-mpich requires both the network target module craype-network-ofi and a compiler module to be loadedcray-hdf5 requires a compiler module to be loaded and cray-netcdf in turn requires cray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found with module spider. That command can also tell which other modules should be loaded before a module can be loaded, but unfortunately due to the sometimes non-standard way the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also why we didn't demonstrate it here.
"},{"location":"1day-20230921/03_Modules/","title":"Modules on LUMI","text":"Intended audience
As this course is designed for people already familiar with HPC systems. As virtually any cluster nowadays uses some form of module environment, this section assumes that the reader is already familiar with a module environment but not necessarily the one used on LUMI.
"},{"location":"1day-20230921/03_Modules/#module-environments","title":"Module environments","text":"An HPC cluster is a multi-user machine. Different users may need different versions of the same application, and each user has their own preferences for the environment. Hence there is no \"one size fits all\" for HPC and mechanisms are needed to support the diverse requirements of multiple users on a single machine. This is where modules play an important role. They are commonly used on HPC systems to enable users to create custom environments and select between multiple versions of applications. Note that this also implies that applications on HPC systems are often not installed in the regular directories one would expect from the documentation of some packages, as that location may not even always support proper multi-version installations and as one prefers to have a software stack which is as isolated as possible from the system installation to keep the image that has to be loaded on the compute nodes small.
Another use of modules not mentioned on the slide is to configure the programs that are being activated. E.g., some packages expect certain additional environment variables to be set and modules can often take care of that also.
There are 3 systems in use for module management. The oldest is a C implementation of the commands using module files written in Tcl. The development of that system stopped around 2012, with version 3.2.10. This system is supported by the HPE Cray Programming Environment. A second system builds upon the C implementation but now uses Tcl also for the module command and not only for the module files. It is developed in France at the C\u00c9A compute centre. The version numbering was continued from the C implementation, starting with version 4.0.0. The third system and currently probably the most popular one is Lmod, a version written in Lua with module files also written in Lua. Lmod also supports most Tcl module files. It is also supported by HPE Cray, though they tend to be a bit slow in following versions. The original developer of Lmod, Robert McLay, retired at the end of August 2023, but TACC, the centre where he worked, is committed to at least maintain Lmod though it may not see much new development anymore.
On LUMI we have chosen to use Lmod. As it is very popular, many users may already be familiar with it, though it does make sense to revisit some of the commands that are specific for Lmod and differ from those in the two other implementations.
It is important to realise that each module that you see in the overview corresponds to a module file that contains the actual instructions that should be executed when loading or unloading a module, but also other information such as some properties of the module, information for search and help information.
Links - Old-style environment modules on SourceForge
- TCL Environment Modules home page on SourceForge and the development on GitHub
- Lmod documentation and Lmod development on GitHub
I know Lmod, should I continue?
Lmod is a very flexible tool. Not all sides using Lmod use all features, and Lmod can be configured in different ways to the extent that it may even look like a very different module system for people coming from another cluster. So yes, it makes sense to continue reading as Lmod on LUMI may have some tricks that are not available on your home cluster.
"},{"location":"1day-20230921/03_Modules/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"1day-20230921/03_Modules/#benefits-of-a-hierarchy","title":"Benefits of a hierarchy","text":"When the hierarchy is well designed, you get some protection from loading modules that do not work together well. E.g., in the HPE Cray PE it is not possible to load the MPI library built for another compiler than your current main compiler. This is currently not exploited as much as we could on LUMI, mainly because we realised at the start that too many users are not familiar enough with hierarchies and would get confused more than the hierarchy helps them.
Another benefit is that when \"swapping\" a module that makes other modules available with a different one, Lmod will try to look for equivalent modules in the list of modules made available by the newly loaded module.
An easy example (though a tricky one as there are other mechanisms at play also) it to load a different programming environment in the default login environment right after login:
$ module load PrgEnv-aocc\n
which results in
The first two lines of output are due to to other mechanisms that are at work here, and the order of the lines may seem strange but that has to do with the way Lmod works internally. Each of the PrgEnv modules hard loads a compiler module which is why Lmod tells you that it is loading aocc/3.2.0. However, there is also another mechanism at work that causes cce/15.0.0 and PrgEnv-cray/8.3.3 to be unloaded, but more about that in the next subsection (next slide).
The important line for the hierarchy in the output are the lines starting with \"Due to MODULEPATH changes...\". Remember that we said that each module has a corresponding module file. Just as binaries on a system, these are organised in a directory structure, and there is a path, in this case MODULEPATH, that determines where Lmod will look for module files. The hierarchy is implemented with a directory structure and the environment variable MODULEPATH, and when the cce/15.0.0 module was unloaded and aocc/3.2.0 module was loaded, that MODULEPATH was changed. As a result, the version of the cray-mpich module for the cce/15.0.0 compiler became unavailable, but one with the same module name for the aocc/3.2.0 compiler became available and hence Lmod unloaded the version for the cce/15.0.0 compiler as it is no longer available but loaded the matching one for the aocc/3.2.0 compiler.
"},{"location":"1day-20230921/03_Modules/#about-module-names-and-families","title":"About module names and families","text":"In Lmod you cannot have two modules with the same name loaded at the same time. On LUMI, when you load a module with the same name as an already loaded module, that other module will be unloaded automatically before loading the new one. There is even no need to use the module swap command for that (which in Lmod corresponds to a module unload of the first module and a module load of the second). This gives you an automatic protection against some conflicts if the names of the modules are properly chosen.
Note
Some clusters do not allow the automatic unloading of a module with the same name as the one you're trying to load, but on LUMI we felt that this is a necessary feature to fully exploit a hierarchy.
Lmod goes further also. It also has a family concept: A module can belong to a family (and at most 1) and no two modules of the same family can be loaded together. The family property is something that is defined in the module file. It is commonly used on systems with multiple compilers and multiple MPI implementations to ensure that each compiler and each MPI implementation can have a logical name without encoding that name in the version string (like needing to have compiler/gcc-11.2.0 or compiler/gcc/11.2.0 rather than gcc/11.2.0), while still having an easy way to avoid having two compilers or MPI implementations loaded at the same time. On LUMI, the conflicting module of the same family will be unloaded automatically when loading another module of that particular family.
This is shown in the example in the previous subsection (the module load PrgEnv-aocc in a fresh long shell) in two places. It is the mechanism that unloaded PrgEnv-cray when loading PrgEnv-aocc and that then unloaded cce/14.0.1 when the PrgEnv-aocc module loaded the aocc/3.2.0 module.
Note
Some clusters do not allow the automatic unloading of a module of the same family as the one you're trying to load and produce an error message instead. On LUMI, we felt that this is a necessary feature to fully exploit the hierarchy and the HPE Cray Programming Environment also relies very much on this feature being enabled to make live easier for users.
"},{"location":"1day-20230921/03_Modules/#extensions","title":"Extensions","text":"It would not make sense to have a separate module for each of the hundreds of R packages or tens of Python packages that a software stack may contain. In fact, as the software for each module is installed in a separate directory it would also create a performance problem due to excess directory accesses simply to find out where a command is located, and very long search path environment variables such as PATH or the various variables packages such as Python, R or Julia use to find extension packages. On LUMI related packages are often bundled in a single module.
Now you may wonder: If a module cannot be simply named after the package it contains as it contains several ones, how can I then find the appropriate module to load? Lmod has a solution for that through the so-called extension mechanism. An Lmod module can define extensions, and some of the search commands for modules will also search in the extensions of a module. Unfortunately, the HPE Cray PE cray-python and cray-R modules do not provide that information at the moment as they too contain several packages that may benefit from linking to optimised math libraries.
"},{"location":"1day-20230921/03_Modules/#searching-for-modules-the-module-spider-command","title":"Searching for modules: the module spider command","text":"There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. The spider command will not only search in module names for the package, but also in extensions of the modules and so will be able to tell you that a package is delivered by another module. See Example 4 below where we will search for the CMake tools.
-
The third use of module spider is with the full name of a module. This shows two kinds of information. First it shows which combinations of other modules one might have to load to get access to the package. That works for both modules and extensions of modules. In the latter case it will show both the module, and other modules that you might have to load first to make the module available. Second it will also show help information for the module if the module file provides such information.
"},{"location":"1day-20230921/03_Modules/#example-1-running-module-spider-on-lumi","title":"Example 1: Running module spider on LUMI","text":"Let's first run the module spider command. The output varies over time, but at the time of writing, and leaving out a lot of the output, one would have gotten:
On the second screen we see, e.g., the ARMForge module which was available in just a single version at that time, and then Autoconf where the version is in blue and followed by (E). This denotes that the Autoconf package is actually provided as an extension of another module, and one of the next examples will tell us how to figure out which one.
The third screen shows the last few lines of the output, which actually also shows some help information for the command.
"},{"location":"1day-20230921/03_Modules/#example-2-searching-for-the-fftw-module-which-happens-to-be-provided-by-the-pe","title":"Example 2: Searching for the FFTW module which happens to be provided by the PE","text":"Next let us search for the popular FFTW library on LUMI:
$ module spider FFTW\n
produces
This shows that the FFTW library is actually provided by the cray-fftw module and was at the time that this was tested available in 3 versions. Note that (a) it is not case sensitive as FFTW is not in capitals in the module name and (b) it also finds modules where the argument of module spider is only part of the name.
The output also suggests us to dig a bit deeper and check for a specific version, so let's run
$ module spider cray-fftw/3.3.10.3\n
This produces:
We now get a long list of possible combinations of modules that would enable us to load this module. What these modules are will be explained in the next session of this course. However, it does show a weakness when module spider is used with the HPE Cray PE. In some cases, not all possible combinations are shown (and this is the case here as the module is actually available directly after login and also via some other combinations of modules that are not shown). This is because the HPE Cray Programming Environment is system-installed and sits next to the application software stacks that are managed differently, but in some cases also because the HPE Cray PE sometimes fails to give the complete combination of modules that is needed. The command does work well with the software managed by the LUMI User Support Team as the next two examples will show.
"},{"location":"1day-20230921/03_Modules/#example-3-searching-for-gnuplot","title":"Example 3: Searching for GNUplot","text":"To see if GNUplot is available, we'd first search for the name of the package:
$ module spider GNUplot\n
This produces:
The output again shows that the search is not case sensitive which is fortunate as uppercase and lowercase letters are not always used in the same way on different clusters. Some management tools for scientific software stacks will only use lowercase letters, while the package we use for the LUMI software stacks often uses both.
We see that there are a lot of versions installed on the system and that the version actually contains more information (e.g., -cpeGNU-22.12) that we will explain in the next part of this course. But you might of course guess that it has to do with the compilers that were used. It may look strange to you to have the same software built with different compilers. However, mixing compilers is sometimes risky as a library compiled with one compiler may not work in an executable compiled with another one, so to enable workflows that use multiple tools we try to offer many tools compiled with multiple compilers (as for most software we don't use rpath linking which could help to solve that problem). So you want to chose the appropriate line in terms of the other software that you will be using.
The output again suggests to dig a bit further for more information, so let's try
$ module spider gnuplot/5.4.6-cpeGNU-22.12\n
This produces:
In this case, this module is provided by 3 different combinations of modules that also will be explained in the next part of this course. Furthermore, the output of the command now also shows some help information about the module, with some links to further documentation available on the system or on the web. The format of the output is generated automatically by the software installation tool that we use and we sometimes have to do some effort to fit all information in there.
For some packages we also have additional information in our LUMI Software Library web site so it is often worth looking there also.
"},{"location":"1day-20230921/03_Modules/#example-4-searching-for-an-extension-of-a-module-cmake","title":"Example 4: Searching for an extension of a module: CMake.","text":"The cmake command on LUMI is available in the operating system image, but as is often the case with such tools distributed with the OS, it is a rather old version and you may want to use a newer one.
If you would just look through the list of available modules, even after loading some other modules to activate a larger software stack, you will not find any module called CMake though. But let's use the powers of module spider and try
$ module spider CMake\n
which produces
The output above shows us that there are actually four other versions of CMake on the system, but their version is followed by (E) which says that they are extensions of other modules. There is no module called CMake on the system. But Lmod already tells us how to find out which module actually provides the CMake tools. So let's try
$ module spider CMake/3.25.2\n
which produces
This shows us that the version is provided by a number of buildtools modules, and for each of those modules also shows us which other modules should be loaded to get access to the commands. E.g., the first line tells us that there is a module buildtools/23.03 that provides that version of CMake, but that we first need to load some other modules, with LUMI/23.03 and partition/L (in that order) one such combination.
So in this case, after
$ module load LUMI/23.03 partition/L buildtools/23.03\n
the cmake command would be available.
And you could of course also use
$ module spider buildtools/23.03\n
to get even more information about the buildtools module, including any help included in the module.
"},{"location":"1day-20230921/03_Modules/#alternative-search-the-module-keyword-command","title":"Alternative search: the module keyword command","text":"Lmod has a second way of searching for modules: module keyword, but unfortunately it does not yet work very well on LUMI as the version of Lmod is rather old and still has some bugs in the processing of the command.
The module keyword command searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Let us look for packages that allow us to download software via the https protocol. One could try
$ module keyword https\n
which produces a lot of output:
The bug in the Lmod 8.3 version on LUMI is that all extensions are shown in the output while they are irrelevant. On the second screen though we see cURL and on the fourth screen wget which are two tools that can be used to fetch files from the internet.
LUMI Software Library
The LUMI Software Library also has a search box in the upper right. We will see in the next section of this course that much of the software of LUMI is managed through a tool called EasyBuild, and each module file corresponds to an EasyBuild recipe which is a file with the .eb extension. Hence the keywords can also be found in the EasyBuild recipes which are included in this web site, and from a page with an EasyBuild recipe (which may not mean much for you) it is easy to go back to the software package page itself for more information. Hence you can use the search box to search for packages that may not be installed on the system.
The example given above though, searching for https, would not work via that box as most EasyBuild recipes include https web links to refer to, e.g., documentation and would be shown in the result.
The LUMI Software Library site includes both software installed in our central software stack and software for which we make customisable build recipes available for user installation, but more about that in the tutorial section on LUMI software stacks.
"},{"location":"1day-20230921/03_Modules/#sticky-modules-and-the-module-purge-command","title":"Sticky modules and the module purge command","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Let us look at the output of the module avail command, taken just after login on the system at the time of writing of these notes (the exact list of modules shown is a bit fluid):
Next to the names of modules you sometimes see one or more letters. The (D) means that that is currently the default version of the module, the one that will be loaded if you do not specify a version. Note that the default version may depend on other modules that are already loaded as we have seen in the discussion of the programming environment.
The (L) means that a module is currently loaded.
The (S) means that the module is a sticky module.
Next to the rocm module you see (D:5.0.2:5.2.0). The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
At the end of the overview the extensions are also shown. If this would be fully implemented on LUMI, the list might become very long. There is a way in Lmod to hide that output but unfortunately it does not work on LUMI yet due to another bug in the already old version of Lmod.
"},{"location":"1day-20230921/03_Modules/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed in the above example that we don't show directories of module files in the overview (as is the case on most clusters) but descriptive texts about the module group. This is just one view on the module tree though, and it can be changed easily by loading a version of the ModuleLabel module.
ModuleLabel/label produces the default view of the previous exampleModuleLabel/PEhierarchy still uses descriptive texts but will show the whole module hierarchy of the HPE Cray Programming Environment.ModuleLabel/system does not use the descriptive texts but shows module directories instead.
When using any kind of descriptive labels, Lmod can actually bundle module files from different directories in a single category and this is used heavily when ModuleLabel/label is loaded and to some extent also when ModuleLabel/PEhierarchy is loaded.
It is rather hard to provide multiple colour schemes in Lmod, and as we do not know how your terminal is configured it is also impossible to find a colour scheme that works for all users. Hence we made it possible to turn on and off the use of colours by Lmod through the ModuleColour/on and ModuleColour/off modules.
In the future, as soon as we have a version of Lmod where module extensions function properly, we will also provide a module to turn on and off the display of extension in the output of module avail .
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. You can still load them if you know they exist and specify the full version but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work if you use modules that are hidden in the context you're in or if you try to use any module that was designed for us to maintain the system and is therefore hidden from regular users.
Example
An example that will only become clear in the next session: When working with the software stack called LUMI/22.08, which is built upon the HPE Cray Programming Environment version 22.08, all (well, most) of the modules corresponding to other version of the Cray PE are hidden.
"},{"location":"1day-20230921/03_Modules/#getting-help-with-the-module-help-command","title":"Getting help with the module help command","text":"Lmod has the module help command to get help on modules
$ module help\n
without further arguments will show some help on the module command.
With the name of a module specified, it will show the help information for the default version of that module, and with a full name and version specified it will show this information specifically for that version of the module. But note that module help can only show help for currently available modules.
Try, e.g., the following commands:
$ module help cray-mpich\n$ module help cray-python/3.9.13.1\n$ module help buildtools/22.12\n
Lmod also has another command that produces more limited information (and is currently not fully exploited on LUMI): module whatis. It is more a way to tag a module with different kinds of information, some of which has a special meaning for Lmod and is used at some places, e.g., in the output of module spider without arguments.
Try, e.g.,:
$ module whatis Subversion\n$ module whatis Subversion/1.14.2\n
"},{"location":"1day-20230921/03_Modules/#a-note-on-caching","title":"A note on caching","text":"Modules are stored as (small) files in the file system. Having a large module system with much software preinstalled for everybody means a lot of small files which will make our Lustre file system very unhappy. Fortunately Lmod does use caches by default. On LUMI we currently have no system cache and only a user cache. That cache can be found in $HOME/.lmod.d/.cache.
That cache is also refreshed automatically every 24 hours. You'll notice when this happens as, e.g., the module spider and module available commands will be slow during the rebuild. you may need to clean the cache after installing new software as on LUMI Lmod does not always detect changes to the installed software,
Sometimes you may have to clear the cache also if you get very strange answers from module spider. It looks like the non-standard way in which the HPE Cray Programming Environment does certain things in Lmod can cause inconsistencies in the cache. This is also one of the reasons whey we do not yet have a central cache for that software that is installed in the central stacks as we are not sure when that cache is in good shape.
"},{"location":"1day-20230921/03_Modules/#a-note-on-other-commands","title":"A note on other commands","text":"As this tutorial assumes some experience with using modules on other clusters, we haven't paid much attention to some of the basic commands that are mostly the same across all three module environments implementations. The module load, module unload and module list commands work largely as you would expect, though the output style of module list may be a little different from what you expect. The latter may show some inactive modules. These are modules that were loaded at some point, got unloaded when a module closer to the root of the hierarchy of the module system got unloaded, and they will be reloaded automatically when that module or an equivalent (family or name) module is loaded that makes this one or an equivalent module available again.
Example
To demonstrate this, try in a fresh login shell (with the lines starting with a $ the commands that you should enter at the command prompt):
$ module unload craype-network-ofi\n\nInactive Modules:\n 1) cray-mpich\n\n$ module load craype-network-ofi\n\nActivating Modules:\n 1) cray-mpich/8.1.23\n
The cray-mpich module needs both a valid network architecture target module to be loaded (not craype-network-none) and a compiler module. Here we remove the network target module which inactivates the cray-mpich module, but the module gets reactivated again as soon as the network target module is reloaded.
The module swap command is basically equivalent to a module unload followed by a module load. With one argument it will look for a module with the same name that is loaded and unload that one before loading the given module. With two modules, it will unload the first one and then load the second one. The module swap command is not really needed on LUMI as loading a conflicting module (name or family) will automatically unload the previously loaded one. However, in case of replacing a module of the same family with a different name, module swap can be a little faster than just a module load as that command will need additional operations as in the first step it will discover the family conflict and then try to resolve that in the following steps (but explaining that in detail would take us too far in the internals of Lmod).
"},{"location":"1day-20230921/03_Modules/#links","title":"Links","text":"These links were OK at the time of the course. This tutorial will age over time though and is not maintained but may be replaced with evolved versions when the course is organised again, so links may break over time.
- Lmod documentation and more specifically the User Guide for Lmod which is the part specifically for regular users who do not want to design their own modules.
- Information on the module environment in the LUMI documentation
"},{"location":"1day-20230921/04_Software_stacks/","title":"LUMI Software Stacks","text":"In this section we discuss
- Several of the ways in which we offer software on LUMI
- Managing software in our primary software stack which is based on EasyBuild
"},{"location":"1day-20230921/04_Software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"1day-20230921/04_Software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"1day-20230921/04_Software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We do offer some help to set up Spack also but it is mostly offered \"as is\" and we will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"1day-20230921/04_Software_stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky. As an alternative we also offer cotainr, a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space and can be used to containerise a conda-installation.
"},{"location":"1day-20230921/04_Software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"1day-20230921/04_Software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"1day-20230921/04_Software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"1day-20230921/04_Software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"1day-20230921/04_Software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12 and LUMI/23.03 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"1day-20230921/04_Software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"1day-20230921/04_Software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"1day-20230921/04_Software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the build-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"1day-20230921/04_Software_stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"1day-20230921/04_Software_stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"1day-20230921/04_Software_stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2021.4, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeCray-22.08 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/22.08.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.8.0-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2021.4-cpeCray-22.08-PLUMED-2.8.0-CPE.
"},{"location":"1day-20230921/04_Software_stacks/#installing","title":"Installing","text":""},{"location":"1day-20230921/04_Software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"1day-20230921/04_Software_stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"1day-20230921/04_Software_stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS there is already support on LUMI. An easy way to do that is to simply check the LUMI Software Library. This web site lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Alternatively one can use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Output of the search commands:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb -r\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"1day-20230921/04_Software_stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.lmod.d/.cache. You can do this with
rm -rf $HOME/.lmod.d/.cache\n
"},{"location":"1day-20230921/04_Software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.0-cpeGNU-22.08.eb \u2013r . \n
"},{"location":"1day-20230921/04_Software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"1day-20230921/04_Software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elsewhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"1day-20230921/04_Software_stacks/#easybuild-tips-and-tricks","title":"EasyBuild tips and tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"1day-20230921/04_Software_stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"1day-20230921/05_Exercises_1/","title":"Exercises 1: Modules, the HPE Cray PE and EasyBuild","text":"See the instructions to set up for the exercises.
"},{"location":"1day-20230921/05_Exercises_1/#exercises-on-the-use-of-modules","title":"Exercises on the use of modules","text":" -
The Bison program installed in the OS image is pretty old (version 3.0.4) and we want to use a newer one. Is there one available on LUMI?
Click to see the solution. module spider Bison\n
tells us that there are indeed newer versions available on the system.
The versions that have a compiler name (usually gcc) in their name followed by some seemingly random characters are installed with Spack and not in the CrayEnv or LUMI environments.
If there would be more than one version of Bison reported, you could get more information about a specific version, e.g., Bison/3.8.2 with:
module spider Bison/3.8.2\n
tells us that Bison 3.8.2 is provided by a couple of buildtools modules and available in all partitions in several versions of the LUMI software stack and in CrayEnv.
Alternatively, in this case
module keyword Bison\n
would also have shown that Bison is part of several versions of the buildtools module.
The module spider command is often the better command if you use names that with a high likelihood could be the name of a package, while module keyword is often the better choice for words that are more a keyword. But if one does not return the solution it is a good idea to try the other one also.
-
The htop command is a nice alternative for the top command with a more powerful user interface. However, typing htop on the command line produces an error message. Can you find and run htop?
Click to see the solution. We can use either module spider htop or module keyword htop to find out that htop is indeed available on the system. With module keyword htop we'll find out immediately that it is in the systools modules and some of those seem to be numbered after editions of the LUMI stack suggesting that they may be linked to a stack, with module spider you'll first see that it is an extension of a module and see the versions. You may again see some versions installed with Spack.
Let's check further for htop/3.2.1 that should exist according to module spider htop:
module spider htop/3.2.1\n
tells us that this version of htop is available in all partitions of LUMI/23.03, LUMI/22.12, LUMI/22.08 and LUMI/22.06, and in CrayEnv. Let us just run it in the CrayEnv environment:
module load CrayEnv\nmodule load systools/22.08\nhtop\n
(You can quit htop by pressing q on the keyboard.)
-
In the future LUMI will offer Open OnDemand as a browser-based interface to LUMI that will also enable running some graphical programs. At the moment the way to do this is through a so-called VNC server. Do we have such a tool on LUMI, and if so, how can we use it?
Click to see the solution. module spider VNC and module keyword VNC can again both be used to check if there is software available to use VNC. There is currently only one available version of the module, but at times there may be more. In those cases loading the older ones (the version number points at the date of some scripts in that module) you will notice that they may produce a warning about being deprecated. You may wonder why they were not uninstalled right away. This is because we cannot remove older versions when installing a newer one right away as it may be in use by users, and for non-interactive job scripts, there may also be job scripts in the queue that have the older version hard-coded in the script.
As there is currently only one version on the system, you get the help information right away. If there were more versions you could still get the help information of the newest version by simply using module spider with the full module name and version. E.g., if the module spider VNC would have shown that lumi-vnc/20230110 exists, you could get the help information using
module spider lumi-vnc/20230110\n
The output may look a little strange as it mentions init-lumi as one of the modules that you can load. That is because this tool is available even outside CrayEnv or the LUMI stacks. But this command also shows a long help text telling you how to use this module (though it does assume some familiarity with how X11 graphics work on Linux).
Note that if there is only a single version on the system, as is the case for the course in September 2023, the module spider VNC command without specific version or correct module name will already display the help information.
-
Search for the bzip2 tool (and not just the bunzip2 command as we also need the bzip2 command) and make sure that you can use software compiled with the Cray compilers in the LUMI stacks in the same session.
Click to see the solution. module spider bzip2\n
shows that there are versions of bzip2 for several of the cpe* toolchains and in several versions of the LUMI software stack.
Of course we prefer to use a recent software stack, the 22.08 or 22.12 (but as of September 2023, there is still more software ready-to-install for 22.08). And since we want to use other software compiled with the Cray compilers also, we really want a cpeCray version to avoid conflicts between different toolchains. So the module we want to load is bzip2/1.0.8-cpeCray-22.08.
To figure out how to load it, use
module spider bzip2/1.0.8-cpeCray-22.08\n
and see that (as expected from the name) we need to load LUMI/22.08 and can then use it in any of the partitions.
"},{"location":"1day-20230921/05_Exercises_1/#exercises-on-compiling-software-by-hand","title":"Exercises on compiling software by hand","text":"These exercises are optional during the session, but useful if you expect to be compiling software yourself. The source files mentioned can be found in the subdirectory CPE of the download.
"},{"location":"1day-20230921/05_Exercises_1/#compilation-of-a-program-1-a-simple-hello-world-program","title":"Compilation of a program 1: A simple \"Hello, world\" program","text":"Four different implementations of a simple \"Hello, World!\" program are provided in the CPE subdirectory:
hello_world.c is an implementation in C,hello_world.cc is an implementation in C++,hello_world.f is an implementation in Fortran using the fixed format source form,hello_world.f90 is an implementation in Fortran using the more modern free format source form.
Try to compile these programs using the programming environment of your choice.
Click to see the solution. We'll use the default version of the programming environment (22.12 at the moment of the course in May 2023), but in case you want to use a particular version, e.g., the 22.08 version, and want to be very sure that all modules are loaded correctly from the start you could consider using
module load cpe/22.08\nmodule load cpe/22.08\n
So note that we do twice the same command as the first iteration does not always succeed to reload all modules in the correct version. Do not combine both lines into a single module load statement as that would again trigger the bug that prevents all modules to be reloaded in the first iteration.
The sample programs that we asked you to compile do not use the GPU. So there are three programming environments that we can use: PrgEnv-gnu, PrgEnv-cray and PrgEnv-aocc. All three will work, and they work almost the same.
Let's start with an easy case, compiling the C version of the program with the GNU C compiler. For this all we need to do is
module load PrgEnv-gnu\ncc hello_world.c\n
which will generate an executable named a.out. If you are not comfortable using the default version of gcc (which produces the warning message when loading the PrgEnv-gnu module) you can always load the gcc/11.2.0 module instead after loading PrgEnv-gnu.
Of course it is better to give the executable a proper name which can be done with the -o compiler option:
module load PrgEnv-gnu\ncc hello_world.c -o hello_world.x\n
Try running this program:
./hello_world.x\n
to see that it indeed works. We did forget another important compiler option, but we'll discover that in the next exercise.
The other programs are equally easy to compile using the compiler wrappers:
CC hello_world.cc -o hello_world.x\nftn hello_world.f -o hello_world.x\nftn hello_world.f90 -o hello_world.x\n
"},{"location":"1day-20230921/05_Exercises_1/#compilation-of-a-program-2-a-program-with-blas","title":"Compilation of a program 2: A program with BLAS","text":"In the CPE subdirectory you'll find the C program matrix_mult_C.c and the Fortran program matrix_mult_F.f90. Both do the same thing: a matrix-matrix multiplication using the 6 different orders of the three nested loops involved in doing a matrix-matrix multiplication, and a call to the BLAS routine DGEMM that does the same for comparison.
Compile either of these programs using the Cray LibSci library for the BLAS routine. Do not use OpenMP shared memory parallelisation. The code does not use MPI.
The resulting executable takes one command line argument, the size of the square matrix. Run the script using 1000 for the matrix size and see what happens.
Note that the time results may be very unreliable as we are currently doing this on the login nodes. In the session of Slurm you'll learn how to request compute nodes and it might be interesting to redo this on a compute node with a larger matrix size as the with a matrix size of 1000 all data may stay in the third level cache and you will not notice the differences that you should note. Also, because these nodes are shared with a lot of people any benchmarking is completely unreliable.
If this program takes more than half a minute or so before the first result line in the table, starting with ijk-variant, is printed, you've very likely done something wrong (unless the load on the system is extreme). In fact, if you've done things well the time reported for the ijk-variant should be well under 3 seconds for both the C and Fortran versions...
Click to see the solution. Just as in the previous exercise, this is a pure CPU program so we can chose between the same three programming environments.
The one additional \"difficulty\" is that we need to link with the BLAS library. This is very easy however in the HPE Cray PE if you use the compiler wrappers rather than calling the compilers yourself: you only need to make sure that the cray-libsci module is loaded and the wrappers will take care of the rest. And on most systems (including LUMI) this module will be loaded automatically when you load the PrgEnv-* module.
To compile with the GNU C compiler, all you need to do is
module load PrgEnv-gnu\ncc -O3 matrix_mult_C.c -o matrix_mult_C_gnu.x\n
will generate the executable matrix_mult_C_gnu.x.
Note that we add the -O3 option and it is very important to add either -O2 or -O3 as by default the GNU compiler will generate code without any optimization for debugging purposes, and that code is in this case easily five times or more slower. So if you got much longer run times than indicated this is likely the mistake that you made.
To use the Cray C compiler instead only one small change is needed: Loading a different programming environment module:
module load PrgEnv-cray\ncc -O3 matrix_mult_C.c -o matrix_mult_C_cray.x\n
will generate the executable matrix_mult_C_cray.x.
Likewise for the AMD AOCC compiler we can try with loading yet another PrgEnv-* module:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -o matrix_mult_C_aocc.x\n
but it turns out that this fails with linker error messages about not being able to find the sin and cos functions. When using the AOCC compiler the libm library with basic math functions is not linked automatically, but this is easily done by adding the -lm flag:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -lm -o matrix_mult_C_aocc.x\n
For the Fortran version of the program we have to use the ftn compiler wrapper instead, and the issue with the math libraries in the AOCC compiler does not occur. So we get
module load PrgEnv-gnu\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_gnu.x\n
for the GNU Fortran compiler,
module load PrgEnv-cray\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_cray.x\n
for the Cray Fortran compiler and
module load PrgEnv-aocc\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_aocc.x\n
for the AMD Fortran compiler.
When running the program you will see that even though the 6 different loop orderings produce the same result, the time needed to compile the matrix-matrix product is very different and those differences would be even more pronounced with bigger matrices (which you can do after the session on using Slurm).
The exercise also shows that not all codes are equal even if they produce a result of the same quality. The six different loop orderings run at very different speed, and none of our simple implementations can beat a good library, in this case the BLAS library included in LibSci.
The results with the Cray Fortran compiler are particularly interesting. The result for the BLAS library is slower which we do not yet understand, but it also turns out that for four of the six loop orderings we get the same result as with the BLAS library DGEMM routine. It looks like the compiler simply recognized that this was code for a matrix-matrix multiplication and replaced it with a call to the BLAS library. The Fortran 90 matrix multiplication is also replaced by a call of the DGEMM routine. To confirm all this, unload the cray-libsci module and try to compile again and you will see five error messages about not being able to find DGEMM.
"},{"location":"1day-20230921/05_Exercises_1/#compilation-of-a-program-3-a-hybrid-mpiopenmp-program","title":"Compilation of a program 3: A hybrid MPI/OpenMP program","text":"The file mpi_omp_hello.c is a hybrid MPI and OpenMP C program that sends a message from each thread in each MPI rank. It is basically a simplified version of the programs found in the lumi-CPEtools modules that can be used to quickly check the core assignment in a hybrid MPI and OpenMP job (see later in this tutorial). It is again just a CPU-based program.
Compile the program with your favourite C compiler on LUMI.
We have not yet seen how to start an MPI program. However, you can run the executable on the login nodes and it will then contain just a single MPI rank.
Click to see the solution. In the HPE Cray PE environment, you don't use mpicc to compile a C MPI program, but you just use the cc wrapper as for any other C program. To enable MPI you have to make sure that the cray-mpich module is loaded. This module will usually be loaded by loading one of the PrgEnv-* modules, but only if the right network target module, which is craype-network-ofi, is also already loaded.
Compiling the program is very simple:
module load PrgEnv-gnu\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_gnu.x\n
to compile with the GNU C compiler,
module load PrgEnv-cray\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_cray.x\n
to compile with the Cray C compiler, and
module load PrgEnv-aocc\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_aocc.x\n
to compile with the AMD AOCC compiler.
To run the executables it is not even needed to have the respective PrgEnv-* module loaded since the binaries will use a copy of the libraries stored in a default directory, though there have been bugs in the past preventing this to work with PrgEnv-aocc.
"},{"location":"1day-20230921/05_Exercises_1/#information-in-the-lumi-software-library","title":"Information in the LUMI Software Library","text":"Explore the LUMI Software Library.
- Search for information for the package ParaView and quickly read through the page
Click to see the solution. Link to the ParaView documentation
It is an example of a package for which we have both user-level and some technical information. The page will first show some license information, then the actual user information which in case of this package is very detailed and long. But it is also a somewhat complicated package to use. It will become easier when LUMI evolves a bit further, but there will always be some pain. Next comes the more technical part: Links to the EasyBuild recipe and some information about how we build the package.
We currently only provide ParaView in the cpeGNU toolchain. This is because it has a lot of dependencies that are not trivial to compile and to port to the other compilers on the system, and EasyBuild is strict about mixing compilers basically because it can cause a lot of problems, e.g., due to conflicts between OpenMP runtimes.
"},{"location":"1day-20230921/05_Exercises_1/#installing-software-with-easybuild","title":"Installing software with EasyBuild","text":"These exercises are based on material from the EasyBuild tutorials (and we have a special version for LUMI also).
Note: If you want to be able to uninstall all software installed through the exercises easily, we suggest you make a separate EasyBuild installation for the course, e.g., in /scratch/project_465000688/$USER/eb-course if you make the exercises during the course:
- Start from a clean login shell with only the standard modules loaded.
-
Create the directory for the EasyBuild installation (if you haven't done this yet):
mkdir -p /scratch/project_465000688/$USER/eb-course\n
-
Set EBU_USER_PREFIX:
export EBU_USER_PREFIX=/scratch/project_465000688/$USER/eb-course\n
You'll need to do that in every shell session where you want to install or use that software.
-
From now on you can again safely load the necessary LUMI and partition modules for the exercise.
-
At the end, when you don't need the software installation anymore, you can simply remove the directory that you just created.
rm -rf /scratch/project_465000688/$USER/eb-course\n
"},{"location":"1day-20230921/05_Exercises_1/#installing-a-simple-program-without-dependencies-with-easybuild","title":"Installing a simple program without dependencies with EasyBuild","text":"The LUMI Software Library contains the package eb-tutorial. Install the version of the package for the cpeCray toolchain in the 22.12 version of the software stack.
Click to see the solution. -
We can check the eb-tutorial page in the LUMI Software Library if we want to see more information about the package.
You'll notice that there are versions of the EasyConfigs for cpeGNU and cpeCray. As we want to install software with the cpeCray toolchain for LUMI/22.12, we'll need the cpeCray-22.12 version which is the EasyConfig eb-tutorial-1.0.1-cpeCray-22.12.eb.
-
Obviously we need to load the LUMI/22.08 module. If we would like to install software for the CPU compute nodes, you need to also load partition/C. To be able to use EasyBuild, we also need the EasyBuild-user module.
module load LUMI/22.12 partition/C\nmodule load EasyBuild-user\n
-
Now all we need to do is run the eb command from EasyBuild to install the software.
Let's however take the slow approach and first check if what dependencies the package needs:
eb eb-tutorial-1.0.1-cpeCray-22.12.eb -D\n
We can do this from any directory as the EasyConfig file is already in the LUMI Software Library and will be located automatically by EasyBuild. You'll see that all dependencies are already on the system so we can proceed with the installation:
eb eb-tutorial-1.0.1-cpeCray-22.12.eb \n
-
After this you should have a module eb-tutorial/1.0.1-cpeCray-22.12 but it may not show up yet due to the caching of Lmod. Try
module av eb-tutorial/1.0.1-cpeCray-22.12\n
If this produces an error message complaining that the module cannot be found, it is time to clear the Lmod cache:
rm -rf $HOME/.lmod.d/.cache\n
-
Now that we have the module, we can check what it actually does:
module help eb-tutorial/1.0.1-cpeCray-22.12\n
and we see that it provides the eb-tutorial command.
-
So let's now try to run this command:
module load eb-tutorial/1.0.1-cpeCray-22.12\neb-tutorial\n
Note that if you now want to install one of the other versions of this module, EasyBuild will complain that some modules are loaded that it doesn't like to see, including the eb-tutorial module and the cpeCray modules so it is better to unload those first:
module unload cpeCray eb-tutorial\n
Clean before proceeding After this exercise you'll have to clean your environment before being able to make the next exercise:
- Unload the
eb-tutorial modules - The
cpeCray module would also produce a warning
module unload eb-tutorial cpeCray\n
"},{"location":"1day-20230921/05_Exercises_1/#installing-an-easyconfig-given-to-you-by-lumi-user-support","title":"Installing an EasyConfig given to you by LUMI User Support","text":"Sometimes we have no solution ready in the LUMI Software Library, but we prepare one or more custom EasyBuild recipes for you. Let's mimic this case. In practice we would likely send those as attachments to a mail from the ticketing system and you would be asked to put them in a separate directory (basically since putting them at the top of your home directory would in some cases let EasyBuild search your whole home directory for dependencies which would be a very slow process).
You've been given two EasyConfig files to install a tool called py-eb-tutorial which is in fact a Python package that uses the eb-tutorial package installed in the previous exercise. These EasyConfig files are in the EasyBuild subdirectory of the exercises for this course. In the first exercise you are asked to install the version of py-eb-tutorial for the cpeCray/22.12 toolchain.
Click to see the solution. -
Go to the EasyBuild subdirectory of the exercises and check that it indeed contains the py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb and py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb files. It is the first one that we need for this exercise.
You can see that we have used a very long name as we are also using a version suffix to make clear which version of Python we'll be using.
-
Let's first check for the dependencies (out of curiosity):
eb py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb -D\n
and you'll see that all dependencies are found (at least if you made the previous exercise successfully). You may find it strange that it shows no Python module but that is because we are using the cray-python module which is not installed through EasyBuild and only known to EasyBuild as an external module.
-
And now we can install the package:
eb py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb\n
-
To use the package all we need to do is to load the module and to run the command that it defines:
module load py-eb-tutorial/1.0.0-cpeCray-22.12-cray-python-3.9.13.1\npy-eb-tutorial\n
with the same remark as in the previous exercise if Lmod fails to find the module.
You may want to do this step in a separate terminal session set up the same way, or you will get an error message in the next exercise with EasyBuild complaining that there are some modules loaded that should not be loaded.
Clean before proceeding After this exercise you'll have to clean your environment before being able to make the next exercise:
- Unload the
py-eb-tutorial and eb-tutorial modules - The
cpeCray module would also produce a warning - And the
py-eb-tutorial also loaded the cray-python module which causes EasyBuild to produce a nasty error messages if it is loaded when the eb command is called
module unload py-eb-tutorial eb-tutorial cpeCray cray-python\n
"},{"location":"1day-20230921/05_Exercises_1/#installing-software-with-uninstalled-dependencies","title":"Installing software with uninstalled dependencies","text":"Now you're asked to also install the version of py-eb-tutorial for the cpeGNU toolchain in LUMI/22.12 (and the solution given below assumes you haven't accidentally installed the wrong EasyBuild recipe in one of the previous two exercises).
Click to see the solution. -
We again work in the same environment as in the previous two exercises. Nothing has changed here. Hence if not done yet we need
module load LUMI/22.12 partition/C\nmodule load EasyBuild-user\n
-
Now go to the EasyBuild subdirectory of the exercises (if not there yet from the previous exercise) and check what the py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb needs:
eb py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb -D\n
We'll now see that there are two missing modules. Not only is the py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1 that we try to install missing, but also the eb-tutorial/1.0.1-cpeGNU-22.12. EasyBuild does however manage to find a recipe from which this module can be built in the pre-installed build recipes.
-
We can install both packages separately, but it is perfectly possible to install both packages in a single eb command by using the -r option to tell EasyBuild to also install all dependencies.
eb py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb -r\n
-
At the end you'll now notice (with module avail) that both the module eb-tutorial/1.0.1-cpeGNU-22.12 and py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1 are now present.
To run you can use
module load py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1\npy-eb-tutorial\n
"},{"location":"1day-20230921/06_Running_jobs/","title":"Running jobs","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230921/07_Exercises_2/","title":"Exercises 2: Running jobs with Slurm","text":""},{"location":"1day-20230921/07_Exercises_2/#exercises-on-the-slurm-allocation-modes","title":"Exercises on the Slurm allocation modes","text":" -
Run single task with a job step of srun using multiple cpu cores. Inspect default task allocation with taskset command (taskset -cp $$ will show you cpu numbers allocated to a current process). Try with standard-g and small-g partitions. Are there any diffences? You may need to use specific reservation for standard-g partition to avoid long waiting.
Click to see the solution. srun --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> bash -c 'taskset -cp $$' \n
Note you need to replace <project_id> with actual project account ID in a form of project_ plus 9 digits number.
srun --partition=standard-g --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> --reservation=<res_id> bash -c 'taskset -cp $$' \n
The command runs single process (bash shell with a native Linux taskset tool showing process's CPU affinity) on a compute node. You can use man taskset command to see how the tool works.
-
Try Slurm allocations with hybrid_check tool program from the LUMI Software Stack. The program is preinstalled on the system.
Use the simple job script to run parallel program with multiple tasks (MPI ranks) and threads (OpenMP). Test task/threads affinity with sbatch submission on the CPU partition.
#!/bin/bash -l\n#SBATCH --partition=small-g # Partition name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=6 # 6 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/22.12\nmodule load lumi-CPEtools\n\nsrun hybrid_check -n -r\n
Be careful with copy/paste of script body while it may brake some specific characters.
Click to see the solution. Save script contents into job.sh file (you can use nano console text editor for instance), remember to use valid project account name.
Submit job script using sbatch command.
sbatch job.sh\n
The job output is saved in the slurm-<job_id>.out file. You can view it's contents with either less or more shell commands.
Actual task/threads affinity may depend on the specific OpenMP runtime but you should see \"block\" thread affinity as a default behaviour.
-
Improve threads affinity with OpenMP runtime variables. Alter your script and add MPI runtime variable to see another cpu mask summary.
Click to see the solution. Export SRUN_CPUS_PER_TASK environment variable to follow convention from recent Slurm's versions in your script. Add this line before the hybrid_check call:
export SRUN_CPUS_PER_TASK=16 \n
Add OpenMP environment variables definition to your script:
export OMP_NUM_THREADS=${SRUN_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n
You can also add MPI runtime variable to see another cpu mask summary:
export MPICH_CPUMASK_DISPLAY=1\n
Note hybrid_check and MPICH cpu mask may not be consistent. It is found to be confusing.
-
Use gpu_check program tool using interactive shell on a GPU node to inspect device binding. Check on which CCD task's CPU core and GPU device are allocated (this is shown with -l option of the tool program).
Click to see the solution. Allocate resources for a single task with a single GPU with salloc:
salloc --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=1 --gpus-per-node=1 --time=10 --account=<project_id>\n
Note that, after allocation being granted, you receive new shell but still on the compute node. You need to use srun to execute on the allocated node.
You need to load specific modules to access tools with GPU support.
module load LUMI/22.12 partition/G\n
module load lumi-CPEtools\n
Run `gpu_check` interactively on a compute node:\n\n ```\n srun gpu_check -l\n ```\n
Still remember to terminate your interactive session with exit command.
exit\n
"},{"location":"1day-20230921/07_Exercises_2/#slurm-custom-binding-on-gpu-nodes","title":"Slurm custom binding on GPU nodes","text":" -
Allocate one GPU node with one task per GPU and bind tasks to each CCD (8-core group sharing L3 cache). Use 7 threads per task having low noise mode of the GPU nodes in mind. Use select_gpu wrapper to map exactly one GPU per task.
Click to see the solution. Begin with the example from the slides with 7 cores per task:
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\n module load LUMI/22.12\n module load partition/G\n module load lumi-CPEtools\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nexport OMP_NUM_THREADS=7\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpus-per-task=${OMP_NUM_THREADS} ./select_gpu gpu_check -l\n
You need to add explicit --cpus-per-task option for srun to get correct GPU mapping. If you save the script in the job_step.sh then simply submit it with sbatch. Inspect the job output.
-
Change your CPU binding leaving first (#0) and last (#7) cores unused. Run a program with 6 threads per task and inspect actual task/threads affinity.
Click to see the solution. Now you would need to alter masks to disable 7th core of each of the group (CCD). Base mask is then 01111110 which is 0x7e in hexadecimal notation.
Try to apply new bitmask, change the corresponding variable to spawn 6 threads per task and check how new binding works.
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\n module load LUMI/22.12\n module load partition/G\n module load lumi-CPEtools\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu:0x7e000000000000,0x7e00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0x7e0000,0x7e000000,\"\nCPU_BIND=\"${CPU_BIND}0x7e,0x7e00,\"\nCPU_BIND=\"${CPU_BIND}0x7e00000000,0x7e0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu gpu_check -l\n
"},{"location":"1day-20230921/08_Lustre_intro/","title":"I/O and file systems","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230921/09_LUMI_support/","title":"How to get support and documentation","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20230921/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"1day-20230921/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.8, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
"},{"location":"1day-20230921/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"1day-20230921/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"1day-20230921/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --help crayCC --help crayftn --help craycc --craype-help crayCC --craype-help crayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --help CC --help ftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"1day-20230921/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"1day-20230921/notes_20230921/","title":"Questions session 21 September 2023","text":""},{"location":"1day-20230921/notes_20230921/#lumi-hardware","title":"LUMI Hardware","text":" -
When we run sbatch with --cpus-per-node=X are we allocating X cores or X CCDs or X NUMA nodes ...?
-
You allocate cores (not threads). But admittedly the slurm nomenclature is really confusing.
-
Slurm had threads (hardware threads), cores (physical cores) and CPUs. A CPU is the smallest individually allocatable unit which on LUMI is configured to be the core. Unfortunately Slurm does not fully understand the full hierarchy of a modern cluster which makes it different to request all cores in a single CCD or single NUMA domain.
-
I have been experiencing very long queueing times recently and have been warned that i am out of storage hours although i have more or less cleaned my output (|I am aware disk space and storage hours are not the same thing) but i am wondering if these long times are related to storage hours
- It's not related. Removing files when running out of storage allocation (in TB/hours) does make the TB/hours as each file stored on LUMI will consumes these TB/hours from your allocation as long as it's present on the system. When you delete a file, it will stop being billed but the TB/hours consumed will still be definitively gone.
Thanks, then what is the way to go forward as i have yet only spent 30% of my CPU hours :)
- Is your allocation granted by a consortium country or EuroHPC JU?
Consortium country
- Contact the resource allocator of your country to request additional TB/hours
Will do so, thanks a lot :)
-
Out of curiosity, if LUMI is a GPU-first system, why offer (what remains a quite large amount of) CPU-only nodes?
-
I think there are many answers to that question. I guess that some are political, but they idea is also to support heterogenous jobs with some parts of a workflow to run on CPU nodes with others running on GPUs.
-
Additionally, LUMI performance is 2% LUMI-C and 98% LUMI-G.
-
Same question as 1. What about when we run sbatch with --gpus-per-node=X, what are we allocating?
- One GCD, so you can ask for a maximum of 8 per LUMI-G node.
-
I've been communicated that GPUs process batches of 32 items in 1 cycle on Nvidia (ie. using batch size of 33 first does 32 items in one cycle and 1 item in a separate cycle). Is this the same on AMD? And is this a hardware feature, as one could assume?
-
AMD compute GPUs use 64-wide wavefronts but there is a catch. In practice, the wavefront will be divided in 4x16 workitems which match the compute units (CUs) architecture that feature 4x16-wide SIMD units. Each of these units are assigned a wavefront. The wavefront once assigned to one SIMD unit will be processed in 4 cycles (16 workitems/cycle). As there is 4 SIMD units per CU, 4 wavefronts can be active at the same time in a CU and the total throughput of a CU can be seen as 1x 64-wide wavefront/cycle/CU.
-
See the documentation for more details about the MI250x GPUs.
-
How are GPU hours billed on standard-g and on small-g? Is it the number of GPU hours that you request for a job, using the argument #SBATCH --time, or is it the actual GPU usage per job, which is usually less than the requested hours?
-
For GPU compute, your project is allocated GPU-core-hours that are consumed when running jobs on the GPU nodes https://docs.lumi-supercomputer.eu/runjobs/lumi_env/billing/#gpu-billing
-
For the standard-g partition, where full nodes are allocated, the 4 GPUs modules are billed. For the small-g and dev-g Slurm partitions, where allocation can be done at the level of Graphics Compute Dies (GCD), you will be billed at a 0.5 rate per GCD allocated.
Thanks! I understand this, but if e.g. I request #SBATCH --time=24h and my job fails after 2 hours, am I billed for 24h or for 2h?
- You should be billed for 2 hours if your job is killed. Beware that there is a possibility that your job hangs when your job fails and you'd be billed for the time it hangs as well.
"},{"location":"1day-20230921/notes_20230921/#programming-environment-modules","title":"Programming Environment & modules","text":" -
The slide mentioned the cray-*-ofi for OFI. Do we still need to use the AWS OFI mentioned in some compiling instructions?
-
Do you mean the AWS OFI plugin for RCCL? That's different for the cray-*-ofi module. The craype-network-ofi is meant to select the Cray MPI network backend. With the Slingshot-11 network only libfabric/OFI is supported. In the past we had Slingshiot-10 interconnects and the craype-network-ucx module can be use to select the UCX backend. It's no longer supported. However, the craype-network-* modules are still useful as it's basically a way to switch MPI on and off in the compiler wrapper:
module load craype-network-none: disable MPImodule load craype-network-ofi: enable MPI
-
The AWS OFI plugin is a plugin for RCCL (AMD GPU collective communication library, replacement for NVIDIA NCCL). This plugin is used so that RCCL can use the Slingshot-11 interconnect as it does not support it out of the box.
-
If we need to compile a library with gcc to generate our executables with support for MPI, do we have to load all the corresponding Cray modules or one of the PrgEnvs and the cray MPI module?
- Most of the time only loading
PrgEnv-gnu is sufficient as the MPI module is loaded by default. The Cray compiler wrapper will automatically link to the correct MPI library for the Programming Environment you selected by loading a PrgEnv-* module.
-
What does it mean that a module is hidden?, it seems that it would be silently skipped, how we can change that state?
- It means that the is not listed in any searches by default because it might have problems or incompatibilities. you can display all modules including the hidden ones by loading the
ModulePowerUser/LUMI module.
-
Do we have a PyTorch module?
- Yes, as user installable with EasyBuild (https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/p/PyTorch/) or in CSC software collecion (https://docs.lumi-supercomputer.eu/software/local/csc/)
-
I just want to point out that the slides of today seem to be inaccessible, as are the ones from previous training days. E.g. https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/ and clicking on any \"slides\" link fails.
-
Same issue as above. Can the slides be hosted somewhere else so that they are accessible to everyone?
- You could download it from LUMI with
wget and then move to your computer from there.
This worked for me, but accessing it with three different browsers did not work.
-
I also guess that is something firewall related but weird that you can access lumi via ssh but not LUMI-O.
-
I read that some browser extensions and some proxies can also cause this problem. Most of these connection problems are actually not caused by the server (LUMI-O for the slides and recordings) but somewhere else between the server and your browser or the browser itself. It's a bit weird, we've been using LUMI-O as the source for big files for a while now and never got complaints or tickets.
Sysadmins did note some random problems with LUMI-O recently and are investigating, it may or may not be related to that also. But I (KL) have been pushing lots of data to and pulling lots of data from LUMI-O in the past days from different computers and browsers while preparing this course and the upcoming 4-day course without issues.
"},{"location":"1day-20230921/notes_20230921/#lumi-software-stacks","title":"LUMI Software Stacks","text":" -
What is the difference between lumi-container-wrapper/cotainr and Singularity containers?
- Both our tools use singularity in the background but help you with creating the containers, so you don't have to build the container yourself.
-
Let's say I want to build PyTorch (with GPU support of course). Am I understanding correctly that I should load PrgEnv-amd?
-
Both PrgEnv-amd, -cray and -gnu work with rocm which GPU enabled codes rely on. Basically first two environmnents give you Clang/LLVM based compilers. I doubt PyTorch requires Clang as a host compiler to be compiled for AMD GPUs.
-
For PyTorch the way to go is to use GNU for the host (CPU) compilation in conjunction with the rocm module to have access to hipcc for GPU code compilation. Compiling PyTorch with PrgEnv-cray or PrgEnv-amd is likely to fail due to some packages using intel flavoured inline assembly that is not supported by Clang based compilers.
- Okay. Got it. But the latest rocm module available is 5.3.3 that is very old (current that is VERY new is 5.7.0). Do I need to compile my own rocm also?
-
ROCm version is related to AMD GPU driver version. With current SLES kernel version Cray OS is based on, ROCm versions > 5.4 are not supported, unfortunately. A major system update with new AMD GPU driver will be at the end of the year at the earliest.
-
You can try other ROCm versions in containers. It does turn out that some newer versions work for some users even with the current driver. E.g., one of our AMD support people has used PyTorch with ROCm 5.5 in a container. The problem with newer ROCm versions is that (a) they are based around gcc 12 and the gcc 12 on the system is broken so we cannot fully support it and (b) ROCm libraries are also used by, e.g., GPU-aware MPICH and newer versions cause problems with cray-mpich.
Recent ROCm versions show improvements in particular in the support libraries for AI so I can understand why as a user of PyTorch or Tensorflow you'd like a newer version.
We realise many users are frustrated by this. The problem is that installing ROCm on a supercomputer is not as simple as it is on a workstation. On LUMI, it triggers a chain of events. We need a newer GPU driver. That in turn needs a newer OS kernel. However, software on a supercomputer is managed through a management environment and that management environment needs an update also to support that newer kernel. So at the end updating ROCm requires updating the full software stack on LUMI and likely a week or more of downtime, and extensive testing before starting the process. There are only a few systems like LUMI in the world which also implies that the installation procedures are not thoroughly tested and that whenever a big update of LUMI is done, problems show up. Nowadays we have a test system to detect most of the problems before they are actually rolled out on the big systems, but in the early days we didn't and the first big update which was scheduled to take 3 weeks took 7 weeks in the end due to problems... So I hope you can understand why a big machine as LUMI is not the best environment if you want the very latest... It is only a pity that there is no second smaller development machine on which we could take more risks as it wouldn't matter as much if that one would be down for a few weeks.
-
Our AMD support person has also been building a properly set up container for PyTorch. I'd have to check in the LUMI documentation where to find it but that may be a more easy way. Compiling PyTorch can be tricky.
-
Regarding the long queue times i ve asked in question 2, would using the small nodes instead of the standard nodes help as some of the runs are literally taking only 2 minutes to run, which prepare the model for the actual production run that should be run in standard nodes?
- It may or may not and the answer is time-dependent. They are scheduled fairly independently. There was actually a mail after the last downtime to users to ask to use small/small-g more for jobs that can run in that partition. I'd have to check what the partition sizes are today, but the sysadmins at some point also moved some nodes from small to standard to try to balance the waiting times more. If those 2-minute jobs are also very small in node count (which I assume as you want to run them in small) and if the time you request is then also very low (like 10 minutes or so to be sure), they are ideal as backfill though and may start quickly on standard/standard-g actually and actually only use time that would otherwise been wasted. I've been rather successful with that strategy when preparing this and another course I am teaching about LUMI ;-) Sometimes my waiting times on standard/standard-g also became longer, and I assume an overloaded scheduler was partly to blame.
So instead of asking standard with 48 hours request, asking small with say 1 hour (or smaller?) does not really change? another reason i use standard is because the model runs hardcored with 88 CPUs whether or not it is a preperation run or a production run.
-
The element that really matters if you want your job to start quickly, is to be realistic with the time your request. If you know that it is something that finishes quickly, don't request the maximum allowed time. On standard and standard-g there is usually quite some room to run programs as backfill. The scheduler will schedule lower priority jobs on idle nodes that it is saving for a big job if it knows that that job will have finished before it expects to have collected enough nodes for that big highest priority job. If you always request the maximum wall time even if you know that it will not be needed, the job will never be used as backfill. But if you know a job will end in 5 minutes and then only request like, say, 10 minutes to have some safety margin, there is a high chance that the scheduler will select it to fill up holes in the machine. Nothing worse for a scheduler than all users just requesting the default maximum wall time rather than a realistic walltime as then it has no room to play with to fill up gaps in the machine.
-
And there is even another element to be realistic with wall times. There are ways in which a job can crash where the scheduler fails to detect that the job has terminated and so keeps the allocation. It looks like in particular on LUMI some MPI crashes can remain undetected, probably because MPI fails to kill all processes involved. You will then be billed for the whole time that the job keeps the allocation, not for the time before it crashed.
"},{"location":"1day-20230921/notes_20230921/#exercise-session-1","title":"Exercise session 1","text":"/
"},{"location":"1day-20230921/notes_20230921/#running-jobs","title":"Running jobs","text":" -
Why does the small partition allow to allocate 256G memory per node while debug allows only 224G?
- It's because the high-memory nodes (512GB and 1TB) are in the
small partition. Standard nodes in both small and debug have the same amount of memory available (224GB). If you go above that in the small partition, you will get an allocation on one of the high-memory nodes instead of a a standard one. Note that if you go above 2GB/cores you will be billed for this extra memory usage. See here for details of the billing policy.
I see, thanks. So from this I understand that when I request --partition=small; --mem=256G;, the job will not be assigned to a standard node. Only high-memory nodes will be available. It is not made clear on CPU nodes - LUMI-C that not all of the memory can be allocated. I assumed that I can request all 256G from a standard node.
- It's explained here but you are right it's not stated in the hardware section. The reason is that in reality, the node actually have 256GB of memory but part of it is reserved for the operating system. LUMI nodes are diskless, so we have to reserve quite a big chunk of the memory to make sure the OS has enough space.
How much memory can be allocated on 512G and 1TB nodes?
- On all nodes of LUMI it is the physcial amount of RAM minus 32 GB (480 GB and 992 GB). For the LUMI-G nodes: 512 GB installed, 480 GB available.
-
Is the --mail-user functionality already working for LUMI slurm jobs? It is working on our national clusters, but so far hasn't worked for me on LUMI (with --mail-type=all)
- Unfortunately, it's not active. The LUMI User Support Team has raised the issue multiple times (since the start of the LUMI-C pilot actually) but sysadmins never made the necessary configuration. I understand it can be frustrating for users as it's a very basic feature that should be working.
-
Does --ntasks=X signify the number of srun calls, i.e. number of steps in a job?
-
No. It is used inside srun. srun creates one job step with multiple tasks, each task basically being a copy of a process that is started. It is possible though to ask sbatch for, e.g, 5 tasks with 4 cores each, and then use multiple srun commands with each srun asking to create 1 task with 4 cores. Unfortunately we do see problems with network configurations when trying to run multiple job steps with multple srun commands simultaneously (by starting them in the background with an & and then waiting untill all have ended).
You would use --ntasks=X, e.g., to start an MPI job with X ranks.
I am confused when you could define, say --ntasks=8 and --cpus-per-task=2. Are we then allocating 16 cores or 8 cores?
- 16 cores. Each task can then use 2 cores which would be the case for a hybrid MPI/OpenMP job. It would also guarantee that these cores are in groups of 2, because on
small you would have no guarantee that all cores are on a single node. It may instead use cores from several nodes.
-
I just want to comment on the question on --mail-user. In Norway, on the Saga HPC cluster it was used until a user directed the emails from a large array to the helpdesk of Saga, that filled the helpdesk server. Then it was decided to stop the functionality.
-
Even without users redirecting them to the help desk there are potential problems. Not that much on LUMI as we have a very low limit on the number of jobs, but no mail administrators would be happy with a user running a large array job on the cluster as each job in the array is a separate job and would send a mail. Imagine a user doing throughput computing and starting a few 1000s of jobs in a short time.... It might actually lead to mail systems thinking they're being spammed.
Another problem is failures of the receiver etc.
And another problem on LUMI is what to do if no mail user is given in the job script. Due to the way user accounts are created on LUMI (there are several channels) it is not as easy as on some university systems to link a mail address to a userID.
-
There was a comment that using --gpus-per-task was tricky. Perhaps I missed it, what was the pitfall of using it?
-
The problem is the way in which Slurm does GPU binding which is not compatible with GPU-aware MPI. I'm not sure how technical you are and hence if you can understand my answer, but let's try.
For CPUs Linux has two mechanisms to limit access to cores by a process or threads. One is so-called control groups and another one is affinity masks. Control groups really limit what a process can see and Slurm uses it at the job step level with one control group shared by all tasks in a job step on a node. That means that the tasks (processes) on a node can, e.g., share memory, which is used to communicate through memory. At the task/process level affinity masks are used which do not block sharing memory etc.
For GPU binding there are also two mechanisms. One is a Linux mechanism, again the control groups. The other one is via the ROCm runtime via the ROCR_VISIBLE_DEVICES mentioned during the presentation. You can compare this a little bit with affinity masks except that it is not OS-controlled and hence can be overwritten. The problem with --gpus-per-task is that Slurm uses both mechanisms and uses them both at the task level. The consequence is that two tasks cannot see each others memory and that hence communication via shared GPU memory is no longer possible. The funny thing is that Slurm will actually still set ROCR_VISIBLE_DEVICES also in some cases. So it is basically a bug or feature in the way Slurm works with AMD GPUs. It should use control groups only at the job step level, not at the task level, and then things could work.
I don't use MPI, I only have ML applications in Python. Is this still a relevant problem?
- Yes, if you have multiple tasks. I gave MPI as the example but it holds for all communication mechanisms that go via shared memory for efficiency. RCCL for instance will also be affected. If you have something with
--ntasks=1 it should not matter though.
-
I am using torch.distributed.run() for starting my multi-GPU computation. I provide --ntasks=1 (I use only single node). Then as a parameter to torch.distributed.run, I give --nproc_per_node=#NUM_GPUS. AFAIK, the torch.distributed.run then starts #NUM_GPUS processes. Does this cause binding problems? If so, can I somehow provide a custom mapping for this setup?
-
Torch will have to do the binding itself if it starts the processes. Our PyTorch expert is not in the call though, I'm not sure about the right answer.
Does it start #NUM_GPUS processes because it has that many GPUs or because it has that many cores? If it is the former I would actually consider to give Torch access to all CPU cores.
I suspect Torch could benefit from a proper mapping, not only a proper mapping of CPU-to-GPU but also even a correct ordering of the GPUs. I understand that RCCL often communicates in a ring fashion so it would be usefull to exploit the fact that there are rings hidden in the topology of the node. But I don't think that anybody in our team has ever experimented with that.
One process per GPU. Thanks! Something that I will have to look into..
-
What does the numbers in srun --cpu-bind option represent fe00 etc?
- These are hexadecimal numbers where each bit represents a core (actually hardware thread to be precise) with the lowest order bit representing core 0. So for
fe00: do not use core 0-7 (the last two 0's, so 8 zero bits), then the e corresponds to the bit pattern 1110 so do not use core 8 but use core 9, 10 and 11, and f corresponds to the bit pattern 1111 which is then use cores 12, 13, 14 and 15. So effectively: this concrete example means use CCD 1 (they are numbered from 0) except for the first core of that CCD which cannot be used because it is set aside for the OS and not available to Slurm.
-
Adding to the previous question: would this specific example cpu binding scheme also work for jobs on the small-g partition?
- Only if you request the whole node with
--exclusive. Manual binding is only possible if you have access to the full node as otherwise you cannot know which subset of cores is assigned to your application, and as currently Slurm is not capable to make sure that you get a reasonable set of cores and matching GPUs on the small-g partition. Which is one of the reasons why the small-g partition is so small: It is not a very good way to work with the GPUs.
-
To which Numa domain I should bind which GCD? I remember it was not Numa domain 0 to GCD 0, etc.
- Good question. There are examples of valid masks in the GPU examples in the LUMI documentation but that is not the clearest way to present things. There is a graphical view on the GPU nodes page in the LUMI documentation. I've put the information in tabular form in the notes I made for my presentations.
"},{"location":"1day-20230921/notes_20230921/#exercises-2","title":"Exercises 2","text":" -
Will we get some information today on how to (in practice) profile (and afterwards, improve) existing code for use on LUMI?
-
No. Profiling is a big topic on our 4-day courses that we have two or three times a year. However, if you have a userid on LUMI you have access to recordings of previous presentations. Check material from the course in Tallinn in June 2023 and we'll soon have new material after the course in Warsaw in two weeks. That course is on October 3-6 but I'm not sure if it is still possible to join. On-site is full I believe and online is also pretty full.
There is also some material from a profiling course in April 2023 but especially the HPE part there was a bit more \"phylosophical\" discussing how to intepret data from profiles and how to use that to improve your application.
Thank you very much, that material will be very useful!
- If you are interested in GPU profiling there are also some examples on Rocprof and Omnitrace here https://hackmd.io/@gmarkoma/lumi_training_ee#Rocprof (it is a part of materials from course in Tallin).
"},{"location":"1day-20230921/notes_20230921/#introduction-to-lustre","title":"Introduction to Lustre","text":" -
What is the default striping behaviour if we write a file without calling lfs setstripe?
-
By default only a single OST will be used. This is to avoid problems with users who don't understand LUSTRE and create lots of small files. The more OSTs a file is spread over, the more servers the metadata server has to talk to when opening and closing a file, and if these are not used anyway this is a waste of resources. It may not seem logical though on a system that is built for large applications and large files...
However, I'm sure there are plenty of people in the course who in practice dump a dataset on LUMI as thousands of 100 kB files and refuse to do the effort to use a structured file format to host the whole dataset in a single file. And then there are those Conda installations with 100k small files.
-
Does striping matter only if I/O is the bottleneck?
- Mostly. But then we have users who write files that are literally 100s of GB and then it really matters. One user has reported 50 GB/s on LUMI P after optimising the striping for the file...
-
I just checked. My python venv seems to contain ~6k files. Did not know about the possibility to containerize it before today. Is it worth doing in this case, or if not, how many files should I have before containerizing?
-
It's hard to put a hard number on it as it also depends on how the files are used. We tend to consider 6k as still acceptable though it is a lot. It also depends on how you use them. If you run jobs that would start that Python process on 100's of cores simultaneously it is of course a bigger problem than if you have only one instance of Python running at a time.
But as a reference: HPE Cray during the course mentions that one LUMI-P file system is capable of probably 200k metadata operations per second which is not much and surprising little if you compare that to what you can do on a local SSD in a laptop. IOPS don't scale well when you try to build larger storage systems.
If your venv works well with lumi-container-wrapper it may not be much work though to test if it is worth trying.
-
It is also not just a LUMI thing but a problem on all large supercomputers. When I worked on a PRACE project on a cluster at BSC, I had a Python installation that took 30 minutes to install on the parallel file system but installed in 10s or so on my laptop...
"},{"location":"1day-20230921/notes_20230921/#lumi-support","title":"LUMI support","text":" -
Does LUMI support Jupyter notebooks or has a Jupyter hub? As one of the task of my project is to create catalogs / jupyter notebooks for the data generated in the project.
-
No official support but we know that users have gotten notebooks to work. Something will come with Open OnDemand but not date set yet for availability of that. After all, LUMI is in the first place a system to process large batch jobs and not a system for interactive work or workstation replacement, so it does not have a high priority for us.
-
Since the data cannot stay on LUMI after your project - LUMI is not a data archive solution - I wonder if LUMI is even the ideal machine to develop those notebooks or if that should be done with the machine where the data will ultimately land on?
-
And if the data is really important to you: Please be aware that there are no backups on LUMI!
-
Does LUMI has interactive nodes through VNC (as in the exercise) to use the visualization nodes interactively?
-
VNC is available through the lumi-vnc module which contains help about how it works. But otherwise the visualisation nodes are still pretty broken, not sure if vgl-run actually works. As for the previous question, it is not a very high priority at the moment, not for LUST and not for CSC who has to do much of the basic setup. Support should improve when Open OnDemand becomes available which is being worked on by CSC.
Light VNC sessions can run on the login nodes, but you can always start an interactive job on a compute node, start VNC there and the start-vnc script will actually tell you how you can connect to the VNC server from outside using either a VNC client (the server is TurboVNC) or via a web browser (less efficient though for heavy graphics).
-
Are the tickets publicly viewable? Is there any plan to add some public issue tracker system? We have something like this on our local cluster, and it's quite nice for seeing what the current problems are and what is being done about them.
- There are no such plans at the moment. Security and privacy are big issues. And since LUMI accounts come onto the system via so many ways organising login is also not easy as we have to interface with multiple IdM systems. We do have a status page at https://www.lumi-supercomputer.eu/lumi-service-status/ but that one is also limited.
"},{"location":"1day-20230921/notes_20230921/#general-qa","title":"General Q&A","text":" -
One question regarding SLURM job scripts: on our clusters, I am using the command seff $SLURM_JOBID at the end of the file to get output on the consumed resources. But I think seff is not available on LUMI?
-
It is not on LUMI. It is actually an optional command and not part of core Slurm. We've tested seff and it turns out that the numbers that it produces on LUMI are wrong because it doesn't deal correctly with the way we do hyperthreading and report about that in the Slurm database.
If you really want to try: seff in the LUMI Software Library but don't send us tickets about the wrong output. We know the output is wrong in most cases.
"},{"location":"1day-20230921/schedule/","title":"Schedule (tentative)","text":"09:00 CEST\u00a0\u00a0 10:00 EEST Welcome and introduction Presenter: J\u00f8rn Dietze (LUST) 09:10 CEST 10:10 EEST LUMI Architecture Presenter: Kurt Lust 09:40 CEST 10:40 EEST HPE Cray Programming Environment Presenter: Kurt Lust 10:10 CEST 11:10 EEST Modules on LUMI Presenter: Kurt Lust 10:45 CEST 11:45 EEST Break 11:00 CEST 12:00 EEST LUMI Software Stacks Presenter: Kurt Lust 11:45 CEST 12:45 EEST Hands-on Exercise assignments and solutions 12:15 CEST 13:15 EEST Lunch break 13:15 CEST 14:15 EEST Running jobs on LUMI Presenter: Maciej Szpindler 14:45 CEST 15:4 EEST Hands-on Exercise assignments and solutions 15:15 CEST 16:15 EEST Break 15:30 CEST 16:30 EEST Introduction to Lustre and Best Practices Presenter: J\u00f8rn Dietze 15:50 CEST 16:50 EEST LUMI User Support Presenter: J\u00f8rn Dietze 16:15 CEST 17:15 EEST General Q&A 16:30 CEST 17:30 EEST Course end"},{"location":"1day-20230921/video_00_Introduction/","title":"Welcome and introduction","text":"Presenter: J\u00f8rn Dietze (LUST)
"},{"location":"1day-20230921/video_01_LUMI_Architecture/","title":"LUMI Architecture","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230921/video_02_HPE_Cray_Programming_Environment/","title":"HPE Cray Programming Environment","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230921/video_03_Modules_on_LUMI/","title":"Modules on LUMI","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230921/video_04_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20230921/video_06_Running_Jobs_on_LUMI/","title":"Running Jobs on LUMI","text":"Presenter: Maciej Szpindler (LUST)
Additional materials
"},{"location":"1day-20230921/video_08_Introduction_to_Lustre_and_Best_Practices/","title":"Introduction to Lustre and Best Practices","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"1day-20230921/video_09_LUMI_User_Support/","title":"LUMI User Support","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"1day-20240208/","title":"LUMI 1-day training 8 February 2024","text":""},{"location":"1day-20240208/#organisation","title":"Organisation","text":""},{"location":"1day-20240208/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":" -
Create a directory in the scratch of the training project, or if you want to keep the exercises around for a while after the session and have already another project on LUMI, in a subdirectory or your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of the project:
mkdir -p /scratch/project_465000961/$USER/exercises\ncd /scratch/project_465000961/$USER/exercises\n
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/1day-20240208/files/exercises-20240208.tar.gz\ntar -xf exercises-20240208.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"1day-20240208/#downloads","title":"Downloads","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes recording Introduction / / recording LUMI Architecture slides notes recording HPE Cray Programming Environment slides notes recording Modules on LUMI slides notes recording LUMI Software Stacks slides notes recording Exercises 1 / notes / Running Jobs on LUMI slides / recording Exercises 2 / notes / Introduction to Lustre and Best Practices slides / recording LUMI User Support slides / recording Appendix: Additional documentation / documentation /"},{"location":"1day-20240208/01_Architecture/","title":"The LUMI Architecture","text":"In this presentation, we will build up LUMI part by part, stressing those aspects that are important to know to run on LUMI efficiently and define jobs that can scale.
"},{"location":"1day-20240208/01_Architecture/#why-do-i-kneed-to-know-this","title":"Why do I kneed to know this?","text":"You may wonder why you need to know about system architecture if all you want to do is to run some programs.
A supercomputer is not simply a scaled-up smartphone or PC that will offer good performance automatically. It is a shared infrastructure and you don't get the whole machine to yourself. Instead you have to request a suitable fraction of the computer for the work you want to do. But it is also a very expensive infrastructure, with an investment of 160M EURO for LUMI and an estimated total cost (including operations) of 250M EURO. So it is important to use the computer efficiently.
And that efficiency comes not for free. Instead in most cases it is important to properly map an application on the available resources to run efficiently. The way an application is developed is important for this, but it is not the only factor. Every application needs some user help to run in the most efficient way, and that requires an understanding of
-
The hardware architecture of the supercomputer, which is something that we discuss in this section.
-
The middleware: the layers of software that sit between the application on one hand and the hardware and operating system on the other hand. LUMI runs a sligthly modified version of Linux. But Linux is not a supercomputer operating system. Missing functionality in Linux is offered by other software layers instead that on supercomputers often come as part of the programming environment. This is a topic of discussion in several sessions of this course.
-
The application. This is very domain-specific and application-specific and hence cannot be the topic of a general course like this one. In fact, there are so many different applications and often considerable domain knowledge is required so that a small support team like the one of LUMI cannot provide that information.
-
Moreover, the way an application should be used may even depend on the particular problem that you are trying to solve. Bigger problems, bigger computers, and different settings may be needed in the application.
It is up to scientific communities to organise trainings that teach you individual applications and how to use them for different problem types, and then up to users to combine the knowledge of an application obtained from such a course with the knowledge about the computer you want to use and its middleware obtained from courses such as this one or our 4-day more advanced course.
Some users expect that a support team can give answers to all those questions, even to the third and fourth bullet of the above list. If a support team could do that, it would basically imply that they could simply do all the research that users do and much faster as they are assumed to have the answer ready in hours...
"},{"location":"1day-20240208/01_Architecture/#lumi-is","title":"LUMI is ...","text":"LUMI is a pre-exascale supercomputer, and not a superfast PC nor a compute cloud architecture.
Each of these architectures have their own strengths and weaknesses and offer different compromises and it is key to chose the right infrastructure for the job and use the right tools for each infrastructure.
Just some examples of using the wrong tools or infrastructure:
-
The single thread performance of the CPU is lower than on a high-end PC. We've had users who were disappointed about the speed of a single core and were expecting that this would be much faster than their PCs. Supercomputers however are optimised for performance per Watt and get their performance from using lots of cores through well-designed software. If you want the fastest core possible, you'll need a gaming PC.
E.g., the AMD 5800X is a popular CPU for high end gaming PCs using the same core architecture as the CPUs in LUMI. It runs at a base clock of 3.8 GHz and a boost clock of 4.7 GHz if only one core is used and the system has proper cooling. The 7763 used in the compute nodes of LUMI-C runs at a base clock of 2.45 GHz and a boost clock of 3.5 GHz. If you have only one single core job to run on your PC, you'll be able to reach that boost clock while on LUMI you'd probably need to have a large part of the node for yourself, and even then the performance for jobs that are not memory bandwidth limited will be lower than that of the gaming PC.
-
For some data formats the GPU performance may be slower also than on a high end gaming PC. This is even more so because an MI250x should be treated as two GPUs for most practical purposes. The better double precision floating point operations and matrix operations, also at full precision, require transistors also that on some other GPUs are used for rendering hardware or for single precision compute units.
E.g., a single GPU die of the MI250X (half a GPU) has a peak FP32 performance at the boost clock of almost 24 TFlops or 48 TFlops in the packed format which is actually hard for a compiler to exploit, while the high-end AMD graphics GPU RX 7900 XTX claims 61 TFlops at the boost clock. But the FP64 performance of one MI250X die is also close to 24 TFlops in vector math, while the RX 7900 XTX does less than 2 TFlops in that data format which is important for a lot of scientific computing applications.
-
Compute GPUs and rendering GPUs are different beasts these days. We had a user who wanted to use the ray tracing units to do rendering. The MI250X does not have texture units or ray tracing units though. It is not a real graphics processor anymore.
-
The environment is different also. It is not that because it runs some Linux it handles are your Linux software. A user complained that they did not succeed in getting their nice remote development environment to work on LUMI. The original author of these notes took a test license and downloaded a trial version. It was a very nice environment but really made for local development and remote development in a cloud environment with virtual machines individually protected by personal firewalls and was not only hard to get working on a supercomputer but also insecure.
-
And supercomputer need proper software that exploits the strengths and works around the weaknesses of their architecture. CERN came telling on a EuroHPC Summit Week before the COVID pandemic that they would start using more HPC and less cloud and that they expected a 40% cost reduction that way. A few years later they published a paper with their experiences and it was mostly disappointment. The HPC infrastructure didn't fit their model for software distribution and performance was poor. Basically their solution was designed around the strengths of a typical cloud infrastructure and relied precisely on those things that did make their cloud infrastructure more expensive than the HPC infrastructure they tested. It relied on fast local disks that require a proper management layer in the software, (ab)using the file system as a database for unstructured data, a software distribution mechanism that requires an additional daemon running permanently on the compute nodes (and local storage on those nodes), ...
True supercomputers, and LUMI in particular, are built for scalable parallel applications and features that are found on smaller clusters or on workstations that pose a threat to scalability are removed from the system. It is also a shared infrastructure but with a much more lightweight management layer than a cloud infrastructure and far less isolation between users, meaning that abuse by one user can have more of a negative impact on other users than in a cloud infrastructure. Supercomputers since the mid to late '80s are also built according to the principle of trying to reduce the hardware cost by using cleverly designed software both at the system and application level. They perform best when streaming data through the machine at all levels of the memory hierarchy and are not built at all for random access to small bits of data (where the definition of \"small\" depends on the level in the memory hierarchy).
At several points in this course you will see how this impacts what you can do with a supercomputer and how you work with a supercomputer.
"},{"location":"1day-20240208/01_Architecture/#lumi-spec-sheet-a-modular-system","title":"LUMI spec sheet: A modular system","text":"So we've already seen that LUMI is in the first place a EuroHPC pre-exascale machine. LUMI is built to prepare for the exascale era and to fit in the EuroHPC ecosystem. But it does not even mean that it has to cater to all pre-exascale compute needs. The EuroHPC JU tries to build systems that have some flexibility, but also does not try to cover all needs with a single machine. They are building 3 pre-exascale systems with different architecture to explore multiple architectures and to cater to a more diverse audience. LUMI is an AMD GPU-based supercomputer, Leonardo uses NVIDIA H100 GPUS and also has a CPU section with nodes with some high-bandwidth memory, and MareNostrum5 has a very large CPU section besides an NVIDIA GPU section.
LUMI is also a very modular machine designed according to the principles explored in a series of European projects, and in particular DEEP and its successors) that explored the cluster-booster concept. E.g., in a complicated multiphysics simulation you could be using regular CPU nodes for the physics that cannot be GPU-accelerated communicating with compute GPU nodes for the physics that can be GPU-accelerated, then add a number of CPU nodes to do the I/O and a specialised render GPU node for in-situ visualisation.
LUMI is in the first place a huge GPGPU supercomputer. The GPU partition of LUMI, called LUMI-G, contains 2978 nodes with a single 64-core AMD EPYC 7A53 CPU and 4 AMD MI250x GPUs. Each node has 512 GB of RAM attached to the CPU (the maximum the CPU can handle without compromising bandwidth) and 128 GB of HBM2e memory per GPU. Each GPU node has a theoretical peak performance of nearly 200 TFlops in single (FP32) or double (FP64) precision vector arithmetic (and twice that with the packed FP32 format, but that is not well supported so this number is not often quoted). The matrix units are capable of about 400 TFlops in FP32 or FP64. However, compared to the NVIDIA GPUs, the performance for lower precision formats used in some AI applications is not that stellar.
LUMI also has a large CPU-only partition, called LUMI-C, for jobs that do not run well on GPUs, but also integrated enough with the GPU partition that it is possible to have applications that combine both node types. LUMI-C consists of 2048 nodes with 2 64-core AMD EPYC 7763 CPUs. 32 of those nodes have 1TB of RAM (with some of these nodes actually reserved for special purposes such as connecting to a Quantum computer), 128 have 512 GB and 1888 have 256 GB of RAM.
LUMI also has two smaller groups of nodes for interactive data analytics. 8 of those nodes have two 64-core Zen2/Rome CPUs with 4 TB of RAM per node, while 8 others have dual 64-core Zen2/Rome CPUs and 8 NVIDIA A40 GPUs for visualisation. There is also an Open OnDemand based service (web interface) to make some fo those facilities available. Note though that these nodes are meant for a very specific use, so it is not that we will also be offering, e.g., GPU compute facilities on NVIDIA hardware, and that these are shared resources that should not be monopolised by a single user (so no hope to run an MPI job on 8 4TB nodes).
LUMI also has a 8 PB flash based file system running the Lustre parallel file system. This system is often denoted as LUMI-F. The bandwidth of that system is over 2 TB/s. Note however that this is still a remote file system with a parallel file system on it, so do not expect that it will behave as the local SSD in your laptop. But that is also the topic of another session in this course.
The main work storage is provided by 4 20 PB hard disk based Lustre file systems with a bandwidth of 240 GB/s each. That section of the machine is often denoted as LUMI-P.
Big parallel file systems need to be used in the proper way to be able to offer the performance that one would expect from their specifications. This is important enough that we have a separate session about that in this course.
An object based file system similar to the Allas service of CSC that some of the Finnish users may be familiar with is also being worked on. At the moment the interface to that system is still rather primitive.
Currently LUMI has 4 login nodes for ssh access, called user access nodes in the HPE Cray world. They each have 2 64-core AMD EPYC 7742 processors and 1 TB of RAM. Note that whereas the GPU and CPU compute nodes have the Zen3 architecture code-named \"Milan\", the processors on the login nodes are Zen2 processors, code-named \"Rome\". Zen3 adds some new instructions so if a compiler generates them, that code would not run on the login nodes. These instructions are basically used in cryptography though. However, many instructions have very different latency, so a compiler that optimises specifically for Zen3 may chose another ordering of instructions then when optimising for Zen2 so it may still make sense to compile specifically for the compute nodes on LUMI.
There are also some additional login nodes for access via the web-based Open OnDemand interface.
All compute nodes, login nodes and storage are linked together through a high-performance interconnect. LUMI uses the Slingshot 11 interconnect which is developed by HPE Cray, so not the Mellanox/NVIDIA InfiniBand that you may be familiar with from many smaller clusters, and as we shall discuss later this also influences how you work on LUMI.
Early on a small partition for containerised micro-services managed with Kubernetes was also planned, but that may never materialize due to lack of people to set it up and manage it.
In this section of the course we will now build up LUMI step by step.
"},{"location":"1day-20240208/01_Architecture/#building-lumi-the-cpu-amd-7xx3-milanzen3-cpu","title":"Building LUMI: The CPU AMD 7xx3 (Milan/Zen3) CPU","text":"The LUMI-C and LUMI-G compute nodes use third generation AMD EPYC CPUs. Whereas Intel CPUs launched in the same period were built out of a single large monolithic piece of silicon (that only changed recently with some variants of the Sapphire Rapids CPU launched in early 2023), AMD CPUs are made up of multiple so-called chiplets.
The basic building block of Zen3 CPUs is the Core Complex Die (CCD). Each CCD contains 8 cores, and each core has 32 kB of L1 instruction and 32 kB of L1 data cache, and 512 kB of L2 cache. The L3 cache is shared across all cores on a chiplet and has a total size of 32 MB on LUMI (there are some variants of the processor where this is 96MB). At the user level, the instruction set is basically equivalent to that of the Intel Broadwell generation. AVX2 vector instructions and the FMA instruction are fully supported, but there is no support for any of the AVX-512 versions that can be found on Intel Skylake server processors and later generations. Hence the number of floating point operations that a core can in theory do each clock cycle is 16 (in double precision) rather than the 32 some Intel processors are capable of.
The full processor package for the AMD EPYC processors used in LUMI have 8 such Core Complex Dies for a total of 64 cores. The caches are not shared between different CCDs, so it also implies that the processor has 8 so-called L3 cache regions. (Some cheaper variants have only 4 CCDs, and some have CCDs with only 6 or fewer cores enabled but the same 32 MB of L3 cache per CCD).
Each CCD connects to the memory/IO die through an Infinity Fabric link. The memory/IO die contains the memory controllers, connections to connect two CPU packages together, PCIe lanes to connect to external hardware, and some additional hardware, e.g., for managing the processor. The memory/IO die supports 4 dual channel DDR4 memory controllers providing a total of 8 64-bit wide memory. From a logical point of view the memory/IO-die is split in 4 quadrants, with each quadrant having a dual channel memory controller and 2 CCDs. They basically act as 4 NUMA domains. For a core it is slightly faster to access memory in its own quadrant than memory attached to another quadrant, though for the 4 quadrants within the same socket the difference is small. (In fact, the BIOS can be set to show only two or one NUMA domain which is advantageous in some cases, like the typical load pattern of login nodes where it is impossible to nicely spread processes and their memory across the 4 NUMA domains).
The theoretical memory bandwidth of a complete package is around 200 GB/s. However, that bandwidth is not available to a single core but can only be used if enough cores spread over all CCDs are used.
"},{"location":"1day-20240208/01_Architecture/#building-lumi-a-lumi-c-node","title":"Building LUMI: A LUMI-C node","text":"A compute node is then built out of two such processor packages, connected through 4 16-bit wide Infinity Fabric connections with a total theoretical bandwidth of 144 GB/s in each direction. So note that the bandwidth in each direction is less than the memory bandwidth of a socket. Again, it is not really possible to use the full memory bandwidth of a node using just cores on a single socket. Only one of the two sockets has a direct connection to the high performance Slingshot interconnect though.
"},{"location":"1day-20240208/01_Architecture/#a-strong-hierarchy-in-the-node","title":"A strong hierarchy in the node","text":"As can be seen from the node architecture in the previous slide, the CPU compute nodes have a very hierarchical architecture. When mapping an application onto one or more compute nodes, it is key for performance to take that hierarchy into account. This is also the reason why we will pay so much attention to thread and process pinning in this tutorial course.
At the coarsest level, each core supports two hardware threads (what Intel calls hyperthreads). Those hardware threads share all the resources of a core, including the L1 data and instruction caches and the L2 cache, execution units and space for register renaming. At the next level, a Core Complex Die contains (up to) 8 cores. These cores share the L3 cache and the link to the memory/IO die. Next, as configured on the LUMI compute nodes, there are 2 Core Complex Dies in a NUMA node. These two CCDs share the DRAM channels of that NUMA node. At the fourth level in our hierarchy 4 NUMA nodes are grouped in a socket. Those 4 NUMA nodes share an inter-socket link. At the fifth and last level in our shared memory hierarchy there are two sockets in a node. On LUMI, they share a single Slingshot inter-node link.
The finer the level (the lower the number), the shorter the distance and hence the data delay is between threads that need to communicate with each other through the memory hierarchy, and the higher the bandwidth.
This table tells us a lot about how one should map jobs, processes and threads onto a node. E.g., if a process has fewer then 8 processing threads running concurrently, these should be mapped to cores on a single CCD so that they can share the L3 cache, unless they are sufficiently independent of one another, but even in the latter case the additional cores on those CCDs should not be used by other processes as they may push your data out of the cache or saturate the link to the memory/IO die and hence slow down some threads of your process. Similarly, on a 256 GB compute node each NUMA node has 32 GB of RAM (or actually a bit less as the OS also needs memory, etc.), so if you have a job that uses 50 GB of memory but only, say, 12 threads, you should really have two NUMA nodes reserved for that job as otherwise other threads or processes running on cores in those NUMA nodes could saturate some resources needed by your job. It might also be preferential to spread those 12 threads over the 4 CCDs in those 2 NUMA domains unless communication through the L3 threads would be the bottleneck in your application.
"},{"location":"1day-20240208/01_Architecture/#hierarchy-delays-in-numbers","title":"Hierarchy: delays in numbers","text":"This slide shows the ACPI System Locality distance Information Table (SLIT) as returned by, e.g., numactl -H which gives relative distances to memory from a core. E.g., a value of 32 means that access takes 3.2x times the time it would take to access memory attached to the same NUMA node. We can see from this table that the penalty for accessing memory in another NUMA domain in the same socket is still relatively minor (20% extra time), but accessing memory attached to the other socket is a lot more expensive. If a process running on one socket would only access memory attached to the other socket, it would run a lot slower which is why Linux has mechanisms to try to avoid that, but this cannot be done in all scenarios which is why on some clusters you will be allocated cores in proportion to the amount of memory you require, even if that is more cores than you really need (and you will be billed for them).
"},{"location":"1day-20240208/01_Architecture/#building-lumi-concept-lumi-g-node","title":"Building LUMI: Concept LUMI-G node","text":"This slide shows a conceptual view of a LUMI-G compute node. This node is unlike any Intel-architecture-CPU-with-NVIDIA-GPU compute node you may have seen before, and rather mimics the architecture of the USA pre-exascale machines Summit and Sierra which have IBM POWER9 CPUs paired with NVIDIA V100 GPUs.
Each GPU node consists of one 64-core AMD EPYC CPU and 4 AMD MI250x GPUs. So far nothing special. However, two elements make this compute node very special. First, the GPUs are not connected to the CPU though a PCIe bus. Instead they are connected through the same links that AMD uses to link the GPUs together, or to link the two sockets in the LUMI-C compute nodes, known as xGMI or Infinity Fabric. This enables unified memory across CPU and GPUs and provides partial cache coherency across the system. The CPUs coherently cache the CPU DDR and GPU HBM memory, but each GPU only coherently caches its own local memory. The second remarkable element is that the Slingshot interface cards connect directly to the GPUs (through a PCIe interface on the GPU) rather than two the CPU. The GPUs have a shorter path to the communication network than the CPU in this design.
This makes the LUMI-G compute node really a \"GPU first\" system. The architecture looks more like a GPU system with a CPU as the accelerator for tasks that a GPU is not good at such as some scalar processing or running an OS, rather than a CPU node with GPU accelerator.
It is also a good fit with the cluster-booster design explored in the DEEP project series. In that design, parts of your application that cannot be properly accelerated would run on CPU nodes, while booster GPU nodes would be used for those parts that can (at least if those two could execute concurrently with each other). Different node types are mixed and matched as needed for each specific application, rather than building clusters with massive and expensive nodes that few applications can fully exploit. As the cost per transistor does not decrease anymore, one has to look for ways to use each transistor as efficiently as possible...
It is also important to realise that even though we call the partition \"LUMI-G\", the MI250x is not a GPU in the true sense of the word. It is not a rendering GPU, which for AMD is currently the RDNA architecture with version 3 just out, but a compute accelerator with an architecture that evolved from a GPU architecture, in this case the VEGA architecture from AMD. The architecture of the MI200 series is also known as CDNA2, with the MI100 series being just CDNA, the first version. Much of the hardware that does not serve compute purposes has been removed from the design to have more transistors available for compute. Rendering is possible, but it will be software-based rendering with some GPU acceleration for certain parts of the pipeline, but not full hardware rendering.
This is not an evolution at AMD only. The same is happening with NVIDIA GPUs and there is a reason why the latest generation is called \"Hopper\" for compute and \"Ada Lovelace\" for rendering GPUs. Several of the functional blocks in the Ada Lovelace architecture are missing in the Hopper architecture to make room for more compute power and double precision compute units. E.g., Hopper does not contain the ray tracing units of Ada Lovelace. The Intel Data Center GPU Max code named \"Ponte Vecchio\" is the only current GPU for HPC that still offers full hardware rendering support (and even ray tracing).
Graphics on one hand and HPC and AI on the other hand are becoming separate workloads for which manufacturers make different, specialised cards, and if you have applications that need both, you'll have to rework them to work in two phases, or to use two types of nodes and communicate between them over the interconnect, and look for supercomputers that support both workloads.
But so far for the sales presentation, let's get back to reality...
"},{"location":"1day-20240208/01_Architecture/#building-lumi-what-a-lumi-g-node-really-looks-like","title":"Building LUMI: What a LUMI-G node really looks like","text":"Or the full picture with the bandwidths added to it:
The LUMI-G node uses the 64-core AMD 7A53 EPYC processor, known under the code name \"Trento\". This is basically a Zen3 processor but with a customised memory/IO die, designed specifically for HPE Cray (and in fact Cray itself, before the merger) for the USA Coral-project to build the Frontier supercomputer, the fastest system in the world at the end of 2022 according to at least the Top500 list. Just as the CPUs in the LUMI-C nodes, it is a design with 8 CCDs and a memory/IO die.
The MI250x GPU is also not a single massive die, but contains two compute dies besides the 8 stacks of HBM2e memory, 4 stacks or 64 GB per compute die. The two compute dies in a package are linked together through 4 16-bit Infinity Fabric links. These links run at a higher speed than the links between two CPU sockets in a LUMI-C node, but per link the bandwidth is still only 50 GB/s per direction, creating a total bandwidth of 200 GB/s per direction between the two compute dies in an MI250x GPU. That amount of bandwidth is very low compared to even the memory bandwidth, which is roughly 1.6 TB/s peak per die, let alone compared to whatever bandwidth caches on the compute dies would have or the bandwidth of the internal structures that connect all compute engines on the compute die. Hence the two dies in a single package cannot function efficiently as as single GPU which is one reason why each MI250x GPU on LUMI is actually seen as two GPUs.
Each compute die uses a further 2 or 3 of those Infinity Fabric (or xGNI) links to connect to some compute dies in other MI250x packages. In total, each MI250x package is connected through 5 such links to other MI250x packages. These links run at the same 25 GT/s speed as the links between two compute dies in a package, but even then the bandwidth is only a meager 250 GB/s per direction, less than an NVIDIA A100 GPU which offers 300 GB/s per direction or the NVIDIA H100 GPU which offers 450 GB/s per direction. Each Infinity Fabric link may be twice as fast as each NVLINK 3 or 4 link (NVIDIA Ampere and Hopper respectively), offering 50 GB/s per direction rather than 25 GB/s per direction for NVLINK, but each Ampere GPU has 12 such links and each Hopper GPU 18 (and in fact a further 18 similar ones to link to a Grace CPU), while each MI250x package has only 5 such links available to link to other GPUs (and the three that we still need to discuss).
Note also that even though the connection between MI250x packages is all-to-all, the connection between GPU dies is all but all-to-all. as each GPU die connects to only 3 other GPU dies. There are basically two bidirectional rings that don't need to share links in the topology, and then some extra connections. The rings are:
- Green ring: 1 - 0 - 6 - 7 - 5 - 4 - 2 - 3 - 1
- Red ring: 1 - 0 - 2 - 3 - 7 - 6 - 4 - 5 - 1
These rings play a role in the inter-GPU communication in AI applications using RCCL.
Each compute die is also connected to one CPU Core Complex Die (or as documentation of the node sometimes says, L3 cache region). This connection only runs at the same speed as the links between CPUs on the LUMI-C CPU nodes, i.e., 36 GB/s per direction (which is still enough for all 8 GPU compute dies together to saturate the memory bandwidth of the CPU). This implies that each of the 8 GPU dies has a preferred CPU die to work with, and this should definitely be taken into account when mapping processes and threads on a LUMI-G node.
The figure also shows another problem with the LUMI-G node: The mapping between CPU cores/dies and GPU dies is all but logical:
GPU die CCD hardware threads NUMA node 0 6 48-55, 112-119 3 1 7 56-63, 120-127 3 2 2 16-23, 80-87 1 3 3 24-31, 88-95 1 4 0 0-7, 64-71 0 5 1 8-15, 72-79 0 6 4 32-39, 96-103 2 7 5 40-47, 104, 11 2 and as we shall see later in the course, exploiting this is a bit tricky at the moment.
"},{"location":"1day-20240208/01_Architecture/#what-the-future-looks-like","title":"What the future looks like...","text":"Some users may be annoyed by the \"small\" amount of memory on each node. Others may be annoyed by the limited CPU capacity on a node compared to some systems with NVIDIA GPUs. It is however very much in line with the cluster-booster philosophy already mentioned a few times, and it does seem to be the future according to AMD (with Intel also working into that direction). In fact, it looks like with respect to memory capacity things may even get worse.
We saw the first little steps of bringing GPU and CPU closer together and integrating both memory spaces in the USA pre-exascale systems Summit and Sierra. The LUMI-G node which was really designed for one of the first USA exascale systems continues on this philosophy, albeit with a CPU and GPU from a different manufacturer. Given that manufacturing large dies becomes prohibitively expensive in newer semiconductor processes and that the transistor density on a die is also not increasing at the same rate anymore with process shrinks, manufacturers are starting to look at other ways of increasing the number of transistors per \"chip\" or should we say package. So multi-die designs are here to stay, and as is already the case in the AMD CPUs, different dies may be manufactured with different processes for economical reasons.
Moreover, a closer integration of CPU and GPU would not only make programming easier as memory management becomes easier, it would also enable some codes to run on GPU accelerators that are currently bottlenecked by memory transfers between GPU and CPU.
Such a chip is exactly what AMD launched in December 2023 with the MI300A version of the MI300 series. It employs 13 chiplets in two layers, linked to (still only) 8 memory stacks (albeit of a much faster type than on the MI250x). The 4 chiplets on the bottom layer are the memory controllers and inter-GPU links (an they can be at the bottom as they produce less heat). Furthermore each package features 6 GPU dies (now called XCD or Accelerated Compute Die as they really can't do graphics) and 3 Zen4 \"Genoa\" CPU dies. In the MI300A the memory is still limited to 8 16 GB stacks, providing a total of 128 GB of RAM. The MI300X, which is the regular version without built-in CPU, already uses 24 GB stacks for a total of 192 GB of memory, but presumably those were not yet available when the design of MI300A was tested for the launch customer, the El Capitan supercomputer. HLRS is building the Hunter cluster based on AMD MI300A as a transitional system to their first exascale-class system Herder that will become operational by 2027.
Intel at some point has shown only very conceptual drawings of its Falcon Shores chip which it calls an XPU, but those drawings suggest that that chip will also support some low-bandwidth but higher capacity external memory, similar to the approach taken in some Sapphire Rapids Xeon processors that combine HBM memory on-package with DDR5 memory outside the package. Falcon Shores will be the next generation of Intel GPUs for HPC, after Ponte Vecchio which will be used in the Aurora supercomputer. It is currently very likely though that Intel will revert to a traditional design for Falcon Shores and push out the integrated CPU+GPU model to a later generation.
However, a CPU closely integrated with accelerators is nothing new as Apple Silicon is rumoured to do exactly that in its latest generations, including the M-family chips.
"},{"location":"1day-20240208/01_Architecture/#building-lumi-the-slingshot-interconnect","title":"Building LUMI: The Slingshot interconnect","text":"All nodes of LUMI, including the login, management and storage nodes, are linked together using the Slingshot interconnect (and almost all use Slingshot 11, the full implementation with 200 Gb/s bandwidth per direction).
Slingshot is an interconnect developed by HPE Cray and based on Ethernet, but with proprietary extensions for better HPC performance. It adapts to the regular Ethernet protocols when talking to a node that only supports Ethernet, so one of the attractive features is that regular servers with Ethernet can be directly connected to the Slingshot network switches. HPE Cray has a tradition of developing their own interconnect for very large systems. As in previous generations, a lot of attention went to adaptive routing and congestion control. There are basically two versions of it. The early version was named Slingshot 10, ran at 100 Gb/s per direction and did not yet have all features. It was used on the initial deployment of LUMI-C compute nodes but has since been upgraded to the full version. The full version with all features is called Slingshot 11. It supports a bandwidth of 200 Gb/s per direction, comparable to HDR InfiniBand with 4x links.
Slingshot is a different interconnect from your typical Mellanox/NVIDIA InfiniBand implementation and hence also has a different software stack. This implies that there are no UCX libraries on the system as the Slingshot 11 adapters do not support that. Instead, the software stack is based on libfabric (as is the stack for many other Ethernet-derived solutions and even Omni-Path has switched to libfabric under its new owner).
LUMI uses the dragonfly topology. This topology is designed to scale to a very large number of connections while still minimizing the amount of long cables that have to be used. However, with its complicated set of connections it does rely on adaptive routing and congestion control for optimal performance more than the fat tree topology used in many smaller clusters. It also needs so-called high-radix switches. The Slingshot switch, code-named Rosetta, has 64 ports. 16 of those ports connect directly to compute nodes (and the next slide will show you how). Switches are then combined in groups. Within a group there is an all-to-all connection between switches: Each switch is connected to each other switch. So traffic between two nodes of a group passes only via two switches if it takes the shortest route. However, as there is typically only one 200 Gb/s direct connection between two switches in a group, if all 16 nodes on two switches in a group would be communicating heavily with each other, it is clear that some traffic will have to take a different route. In fact, it may be statistically better if the 32 involved nodes would be spread more evenly over the group, so topology based scheduling of jobs and getting the processes of a job on as few switches as possible may not be that important on a dragonfly Slingshot network. The groups in a slingshot network are then also connected in an all-to-all fashion, but the number of direct links between two groups is again limited so traffic again may not always want to take the shortest path. The shortest path between two nodes in a dragonfly topology never involves more than 3 hops between switches (so 4 switches): One from the switch the node is connected to the switch in its group that connects to the other group, a second hop to the other group, and then a third hop in the destination group to the switch the destination node is attached to.
"},{"location":"1day-20240208/01_Architecture/#assembling-lumi","title":"Assembling LUMI","text":"Let's now have a look at how everything connects together to the supercomputer LUMI. It does show that LUMI is not your standard cluster build out of standard servers.
LUMI is built very compactly to minimise physical distance between nodes and to reduce the cabling mess typical for many clusters. LUMI does use a custom rack design for the compute nodes that is also fully water cooled. It is build out of units that can contain up to 4 custom cabinets, and a cooling distribution unit (CDU). The size of the complex as depicted in the slide is approximately 12 m2. Each cabinet contains 8 compute chassis in 2 columns of 4 rows. In between the two columns is all the power circuitry. Each compute chassis can contain 8 compute blades that are mounted vertically. Each compute blade can contain multiple nodes, depending on the type of compute blades. HPE Cray have multiple types of compute nodes, also with different types of GPUs. In fact, the Aurora supercomputer which uses Intel CPUs and GPUs and El Capitan, which uses the MI300A APUs (integrated CPU and GPU) will use the same design with a different compute blade. Each LUMI-C compute blade contains 4 compute nodes and two network interface cards, with each network interface card implementing two Slingshot interfaces and connecting to two nodes. A LUMI-G compute blade contains two nodes and 4 network interface cards, where each interface card now connects to two GPUs in the same node. All connections for power, management network and high performance interconnect of the compute node are at the back of the compute blade. At the front of the compute blades one can find the connections to the cooling manifolds that distribute cooling water to the blades. One compute blade of LUMI-G can consume up to 5kW, so the power density of this setup is incredible, with 40 kW for a single compute chassis.
The back of each cabinet is equally genius. At the back each cabinet has 8 switch chassis, each matching the position of a compute chassis. The switch chassis contains the connection to the power delivery system and a switch for the management network and has 8 positions for switch blades. These are mounted horizontally and connect directly to the compute blades. Each slingshot switch has 8x2 ports on the inner side for that purpose, two for each compute blade. Hence for LUMI-C two switch blades are needed in each switch chassis as each blade has 4 network interfaces, and for LUMI-G 4 switch blades are needed for each compute chassis as those nodes have 8 network interfaces. Note that this also implies that the nodes on the same compute blade of LUMI-C will be on two different switches even though in the node numbering they are numbered consecutively. For LUMI-G both nodes on a blade will be on a different pair of switches and each node is connected to two switches. So when you get a few sequentially numbered nodes, they will not be on a single switch (LUMI-C) or switch pair (LUMI-G). The switch blades are also water cooled (each one can consume up to 250W). No currently possible configuration of the Cray EX system needs all switch positions in the switch chassis.
This does not mean that the extra positions cannot be useful in the future. If not for an interconnect, one could, e.g., export PCIe ports to the back and attach, e.g., PCIe-based storage via blades as the switch blade environment is certainly less hostile to such storage than the very dense and very hot compute blades.
"},{"location":"1day-20240208/01_Architecture/#lumi-assembled","title":"LUMI assembled","text":"This slide shows LUMI fully assembled (as least as it was at the end of 2022).
At the front there are 5 rows of cabinets similar to the ones in the exploded Cray EX picture on the previous slide. Each row has 2 CDUs and 6 cabinets with compute nodes. The first row, the one with the wolf, contains all nodes of LUMI-C, while the other four rows, with the letters of LUMI, contain the GPU accelerator nodes. At the back of the room there are more regular server racks that house the storage, management nodes, some special compute nodes , etc. The total size is roughly the size of a tennis court.
Remark
The water temperature that a system like the Cray EX can handle is so high that in fact the water can be cooled again with so-called \"free cooling\", by just radiating the heat to the environment rather than using systems with compressors similar to air conditioning systems, especially in regions with a colder climate. The LUMI supercomputer is housed in Kajaani in Finland, with moderate temperature almost year round, and the heat produced by the supercomputer is fed into the central heating system of the city, making it one of the greenest supercomputers in the world as it is also fed with renewable energy.
"},{"location":"1day-20240208/02_CPE/","title":"The HPE Cray Programming Environment","text":"In this session we discuss some of the basics of the operating system and programming environment on LUMI. Whether you like it or not, every user of a supercomputer like LUMI gets confronted with these elements at some point.
"},{"location":"1day-20240208/02_CPE/#why-do-i-need-to-know-this","title":"Why do I need to know this?","text":"The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is \"I only want to run some programs, why do I need to know about programming environments?\"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished. And some of the essential middleware that turns the hardware with some variant of Linux into a parallel supercomputers is part of the programming environment. The binary interfaces to those libraries are also not as standardised as for the more common Linux system libraries.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Compiling on the system is also the easiest way to guarantee compatibility of the binaries with the system.
Even when installing software from prebuilt binaries some modules might still be needed. Prebuilt binaries will typically include the essential runtime libraries for the parallel technologies they use, but these may not be compatible with LUMI. In some cases this can be solved by injecting a library from LUMI, e.g., you may want to inject an optimised MPI library as we shall see in the container section of this course. But sometimes a binary is simply incompatible with LUMI and there is no other solution than to build the software from sources.
"},{"location":"1day-20240208/02_CPE/#the-operating-system-on-lumi","title":"The operating system on LUMI","text":"The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes. This in turn led to an asymmetry in the setup so now 8 cores are reserved, one per CCD, so that all CCDs are equal again.
This also implies that some software that works perfectly fine on the login nodes may not work on the compute nodes. E.g., there is no /run/user/$UID directory and we have experienced that D-Bus (which stands for Desktop-Bus) also does not work as one should expect.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer (and certainly not in the same way as they would be on a workstation). Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
"},{"location":"1day-20240208/02_CPE/#programming-models","title":"Programming models","text":"On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP, which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. The visualisation nodes in LUMI have NVIDIA rendering GPUs but these nodes are meant for visualisation and not for compute.
"},{"location":"1day-20240208/02_CPE/#the-development-environment-on-lumi","title":"The development environment on LUMI","text":"Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects. As they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
Specifically not on LUMI are the Intel and NVIDIA programming environments, nor is the regular Intel oneAPI HPC Toolkit. The classic Intel compilers pose problems on AMD CPUs as -xHost cannot be relied on, but it appears that the new compilers that are based on Clang and an LLVM backend behave better. Various MKL versions are also troublesome, with different workarounds for different versions, though here also it seems that Intel now has code that works well on AMD for many MKL routines. We have experienced problems with Intel MPI when testing it on LUMI though in principle it should be possible to use Cray MPICH as they are derived from the same version of MPICH. The NVIDIA programming environment doesn't make sense on an AMD GPU system, but it could be useful for some visualisation software on the visualisation nodes so it is currently installed on those nodes.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise several times a year with HPE for more material.
Python and R
Big Python and R installations can consist of lots of small files. Parallel file systems such as Lustre used on LUMI cannot work efficiently with such files. Therefore such installations should be containerised.
We offer two tools for that on LUMI with different strengths and weaknesses:
-
lumi-container-wrapper can build upon Cray Python when installing packages with pip or can do independent Conda installations from an environments file. The tool also create wrapper scripts for all commands in the bin subdirectory of the container installation so that the user does not always need to be aware that they are working in a container.
It is the LUMI-equivalent of the tykky module on the Finnish national systems operated by CSC.
-
cotainr is a tool developed by the Danish LUMI-partner DeIC to build some types of containers in user space and is also a good tool to containerise a Conda installation.
"},{"location":"1day-20240208/02_CPE/#the-cray-compiling-environment","title":"The Cray Compiling Environment","text":"The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend and optimiser developed by HPE Cray, but an LLVM-based code generator. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. They claim full OpenMP 4.5 support with partial (and growing) support for OpenMP 5.0 and 5.1. More information about the OpenMP support is found by checking a manual page:
man intro_openmp\n
which does require that the cce module is loaded. The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x. Information is available via man intro_openacc\n
AMD and HPE Cray still recommend moving to OpenMP which is a much broader supported standard. There are no plans to also support OpenACC in the Cray C/C++ compiler, nor are there any plans for support by AMD in the ROCm stack. The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
"},{"location":"1day-20240208/02_CPE/#scientific-and-math-libraries","title":"Scientific and math libraries","text":"Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSci_ACC, which contains a subset of the routines of LibSci. We don't have much experience in the support team with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions. These are included because it is essential that they interface properly with MPI parallel I/O and the Lustre file system to offer the best bandwidth to and from storage.
Cray used to offer more pre-installed third party libraries for which the only added value was that they compiled the binaries. Instead they now offer build scripts in a GitHub repository.
"},{"location":"1day-20240208/02_CPE/#cray-mpi","title":"Cray MPI","text":"HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully supports the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is allo fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact allowed by the standard which only requires a process starter and suggest mpirun or mpiexec depending on the version of the standard. Instead the Slurm srun command is used as the process starter. This actually makes a lot of sense as the MPI application should be mapped correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
"},{"location":"1day-20240208/02_CPE/#lmod","title":"Lmod","text":"Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded. module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to a module unload followed by a module load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
"},{"location":"1day-20240208/02_CPE/#compiler-wrappers","title":"Compiler wrappers","text":"The HPE Cray PE compilers are usually used through compiler wrappers. The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn. The wrapper then calls the selected compiler. Which compiler will be called is determined by which compiler module is loaded. As shown on the slide \"Development environment on LUMI\", on LUMI the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc), the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers (module amd) are available. On the visualisation nodes, the NVIDIA HPC compiler is currently also installed (module nvhpc). On other HPE Cray systems, you may also find the Intel compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc, mpiCC, mpif90, etc. on LUMI (well, there is nowadays, but their use is discouraged). The regular compiler wrappers do the job as soon as the cray-mpich module is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libsci module is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the -craype-verbose flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
The compiler wrappers are provided by the craype module (but you don't have to load that module by hand).
"},{"location":"1day-20240208/02_CPE/#selecting-the-version-of-the-cpe","title":"Selecting the version of the CPE","text":"The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 23.09 for the version released in September 2023. There are several releases each year (at least 4), but not all of them are offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming environment. It is possible to change the default version for loading further modules by loading one of the versions of the cpe module. E.g., assuming the 23.09 version would be present on the system, it can be loaded through
module load cpe/23.09\n
Loading this module will also try to switch the already loaded PE modules to the versions from that release. This does not always work correctly, due to some bugs in most versions of this module and a limitation of Lmod. Executing the module load twice will fix this: module load cpe/23.09\nmodule load cpe/23.09\n
The module will also produce a warning when it is unloaded (which is also the case when you do a module load of cpe when one is already loaded, as it then first unloads the already loaded cpe module). The warning can be ignored, but keep in mind that what it says is true, it cannot restore the environment you found on LUMI at login. The cpe module is also not needed when using the LUMI software stacks, but more about that later.
"},{"location":"1day-20240208/02_CPE/#the-target-modules","title":"The target modules","text":"The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-rome selects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milan is the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trento is the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofi selects the libfabric communication layer which is needed for Slingshot 11.craype-network-none omits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these settings: -target-cpu, -target-accel and -target-network.
"},{"location":"1day-20240208/02_CPE/#prgenv-and-compiler-modules","title":"PrgEnv and compiler modules","text":"In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the programming environment. These modules will load the compiler wrapper (craype), compiler, MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they activate:
PrgEnv Description Compiler module Compilers PrgEnv-cray Cray Compiling Environment cce craycc, crayCC, crayftn PrgEnv-gnu GNU Compiler Collection gcc gcc, g++, gfortran PrgEnv-aocc AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang PrgEnv-amd AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang There is also a second module that offers the AMD ROCm environment, rocm. That module has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU, hipcc with the GNU compilers or GPU support with the Cray compilers.
The HPE Cray PE now also contains some mixed programming environments that combine the C/C++ compiler from one environment with the Fortran compiler from another. Currently on LUMI there is PrgEnv-cray-amd using the Cray Fortran compiler with the AMD ROCm C/C++ compiler and PrgEnv-gnu-amd using the GNU Fortran compiler with the AMD ROCm C/C++ compiler.
Changes to the GNU compilers in 23.12 The HPE Cray PE will change the way it offers the GNU compilers in releases starting from 23.12. Rather than packaging the GNU compilers, HPE Cray will use the default development compiler version of SUSE Linux, which for SP4 is currently GCC 12.3 (not to be confused with the system default which is still 7.5, the compiler that was offered with the initial release of SUSE Enterprise Linux 15).
In releases up to the 23.09 which we currently have on Linux, the GNU compilers are offered through the gcc compiler module. When loaded, it adds newer versions of the gcc, g++ and gfortran compilers to the path, calling the version indicated by the version of the gcc module.
In releases from 23.12 on, that compiler module is now called gcc-native, and the compilers are - at least in the version for SUSE 15 SP4 - called gcc-12, g++-12 and gfortran-12, while gcc, g++ and gfortran will compile with version 7.5, the default version for SUSE 15.
"},{"location":"1day-20240208/02_CPE/#getting-help","title":"Getting help","text":"Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers, the following man pages are relevant:
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - There used to be manual pages for the wrappers also but they are currently hijacked by the GNU manual pages.
Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers, the switch -help should be used instead as the double dash version is passed to the compiler.
The wrappers have a number of options specific to them. Information about them can be obtained by using the --craype-help flag with the wrappers. The wrappers also support the -dumpversion flag to show the version of the underlying compiler. Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn\nftn-2107 ftn: ERROR in command line\n No valid filenames are specified on the command line.\n$ explain ftn-2107\n\nError : No valid filenames are specified on the command line.\n\nAt least one file name must appear on the command line, with any command-line\noptions. Verify that a file name was specified, and also check for an\nerroneous command-line option which may cause the file name to appear to be\nan argument to that option.\n
On older Cray systems this used to be a very useful command with more compilers but as HPE Cray is using more and more open source components instead there are fewer commands that give additional documentation via the explain command.
Lastly, there is also a lot of information in the \"Developing\" section of the LUMI documentation.
"},{"location":"1day-20240208/02_CPE/#google-chatgpt-and-lumi","title":"Google, ChatGPT and LUMI","text":"When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command that searches for a term in the manual pages. It is often useful to better understand some error messages. E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem. You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and, e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE\n
The new online documentation is now also complete enough that it makes sense trying the search box on that page instead.
"},{"location":"1day-20240208/02_CPE/#other-modules","title":"Other modules","text":"Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
"},{"location":"1day-20240208/02_CPE/#warning-1-you-do-not-always-get-what-you-expect","title":"Warning 1: You do not always get what you expect...","text":"The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system) which correspond to the version of the programming environment that is set as the system default when installed. This is very much the behaviour of Linux applications also that pick standard libraries in a few standard directories and it enables many programs build with the HPE Cray PE to run without reconstructing the environment and in some cases to mix programs compiled with different compilers with ease (with the emphasis on some as there may still be library conflicts between other libraries when not using the so-called rpath linking). This does have an annoying side effect though: If the default PE on the system changes, all applications will use different libraries and hence the behaviour of your application may change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic linking where the search path for the libraries is stored in each executable separately. On Linux, the search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules that have their libraries also in the default location, add the directories that contain the actual version of the libraries corresponding to the version of the module to the PATH-style environment variable CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
Small demo of adapting LD_LIBRARY_PATH: An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08\n$ module load lumi-CPEtools/1.0-cpeGNU-22.08\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007f420cd55000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)\n ...\n$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007fb38c1e0000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)\n ...\n
The ldd command shows which libraries are used by an executable. Only a part of the very long output is shown in the above example. But we can already see that in the first case, the library libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/ which clearly is for a specific version of cray-mpich. We do provide an experimental module lumi-CrayPath that tries to fix LD_LIBRARY_PATH in a way that unloading the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting the CRAY_ADD_RPATHenvironment variable:
export CRAY_ADD_RPATH=yes\n
However, there is also a good side to the standard Cray PE behaviour. Updates of the underlying operating system or network software stack may break older versions of the MPI library. By letting the applications use the default libraries and updating the defaults to a newer version, most applications will still run while they would fail if any of the two tricks to force the use of the intended library version are used. This has actually happened after a big LUMI update in March 2023, when all software that used rpath-linking had to be rebuild as the MPICH library that was present before the update did not longer work.
"},{"location":"1day-20240208/02_CPE/#warning-2-order-matters","title":"Warning 2: Order matters","text":"Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftw only becomes available when a processor target module is loadedcray-mpich requires both the network target module craype-network-ofi and a compiler module to be loadedcray-hdf5 requires a compiler module to be loaded and cray-netcdf in turn requires cray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found with module spider. That command can also tell which other modules should be loaded before a module can be loaded, but unfortunately due to the sometimes non-standard way the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also why we didn't demonstrate it here.
"},{"location":"1day-20240208/02_CPE/#note-compiling-without-the-hpe-cray-pe-wrappers","title":"Note: Compiling without the HPE Cray PE wrappers","text":"It is now possible to work without the HPE Cray PE compiler wrappers and to use the compilers in a way you may be more familiar with from other HPC systems.
In that case, you would likely want to load a compiler module without loading the PrgEnv-* module and craype module (which would be loaded automatically by the PrgEnv-* module). The compiler module and compiler driver names are then given by the following table:
Description Compiler module Compilers Cray Compiling Environment cce craycc, crayCC, crayftn GNU Compiler Collection gccgcc-native gcc, g++, gfortrangcc-12, g++-12, gfortran-12 AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang Recent versions of the cray-mpich module now also provide the traditional MPI compiler wrappers such as mpicc, mpicxx or mpifort. Note that you will still need to ensure that the network target module craype-network-ofi is loaded to be able to load the cray-mpich module! The cray-mpich module also defines the environment variable MPICH_DIR that points to the MPI installation for the selected compiler.
To manually use the BLAS and LAPACK libraries, you'll still have to load the cray-libsci module. This module defines the CRAY_LIBSCI_PREFIX_DIR environment variable that points to the directory with the library and include file subdirectories for the selected compiler. (This environment variable will be renamed to CRAY_PE_LIBSCI_PREFIX_DIR in release 23.12 of the programming environment.) See the intro_libsci manual page for information about the different libraries.
To be able to use the cray-fftw FFTW libraries, you still need to load the right CPU target module, even though you need to specify the target architecture yourself now when calling the compilers. This is because the HPE Cray PE does not come with a multi-cpu version of the FFTW libraries, but specific versions for each CPU (or sometimes group of similar CPUs). Here again some environment variables may be useful to point the compiler and linker to the installation: FFTW_ROOT for the root of the installation for the specific CPU (the library is otherwise compiler-independent), FFTW_INC for the subdirectory with the include files and FFTW_DIR for the directory with the libraries.
Other modules that you may want to use also typically define some useful environment variables.
"},{"location":"1day-20240208/03_Modules/","title":"Modules on LUMI","text":"Intended audience
As this course is designed for people already familiar with HPC systems and as virtually any cluster nowadays uses some form of module environment, this section assumes that the reader is already familiar with a module environment but not necessarily the one used on LUMI.
"},{"location":"1day-20240208/03_Modules/#module-environments","title":"Module environments","text":"An HPC cluster is a multi-user machine. Different users may need different versions of the same application, and each user has their own preferences for the environment. Hence there is no \"one size fits all\" for HPC and mechanisms are needed to support the diverse requirements of multiple users on a single machine. This is where modules play an important role. They are commonly used on HPC systems to enable users to create custom environments and select between multiple versions of applications. Note that this also implies that applications on HPC systems are often not installed in the regular directories one would expect from the documentation of some packages, as that location may not even always support proper multi-version installations and as one prefers to have a software stack which is as isolated as possible from the system installation to keep the image that has to be loaded on the compute nodes small.
Another use of modules not mentioned on the slide is to configure the programs that are being activated. E.g., some packages expect certain additional environment variables to be set and modules can often take care of that also.
There are 3 systems in use for module management. The oldest is a C implementation of the commands using module files written in Tcl. The development of that system stopped around 2012, with version 3.2.10. This system is supported by the HPE Cray Programming Environment. A second system builds upon the C implementation but now uses Tcl also for the module command and not only for the module files. It is developed in France at the C\u00c9A compute centre. The version numbering was continued from the C implementation, starting with version 4.0.0. The third system and currently probably the most popular one is Lmod, a version written in Lua with module files also written in Lua. Lmod also supports most Tcl module files. It is also supported by HPE Cray, though they tend to be a bit slow in following versions. The original developer of Lmod, Robert McLay, retired at the end of August 2023, but TACC, the centre where he worked, is committed to at least maintain Lmod though it may not see much new development anymore.
On LUMI we have chosen to use Lmod. As it is very popular, many users may already be familiar with it, though it does make sense to revisit some of the commands that are specific for Lmod and differ from those in the two other implementations.
It is important to realise that each module that you see in the overview corresponds to a module file that contains the actual instructions that should be executed when loading or unloading a module, but also other information such as some properties of the module, information for search and help information.
Links - Old-style environment modules on SourceForge
- TCL Environment Modules home page on SourceForge and the development on GitHub
- Lmod documentation and Lmod development on GitHub
I know Lmod, should I continue?
Lmod is a very flexible tool. Not all sites using Lmod use all features, and Lmod can be configured in different ways to the extent that it may even look like a very different module system for people coming from another cluster. So yes, it makes sense to continue reading as Lmod on LUMI may have some tricks that are not available on your home cluster.
Standard OS software
Most large HPC systems use enterprise-level Linux distributions: derivatives of the stable Red Hat or SUSE distributions. Those distributions typically have a life span of 5 years or even more during which they receive security updates and ports of some newer features, but some of the core elements of such a distribution stay at the same version to break as little as possible between minor version updates. Python and the system compiler are typical examples of those. Red Hat 8 and SUSE Enterprise Linux 15 both came with Python 3.6 in their first version, and keep using this version as the base version of Python even though official support from the Python Software Foundation has long ended. Similarly, the default GNU compiler version offered on those system also remains the same. The compiler may not even fully support some of the newer CPUs the code is running on. E.g., the system compiler of SUSE Enterprise Linux 15, GCC 7.5, does not support the zen2 \"Rome\" or zen3 \"Milan\" CPUs on LUMI.
HPC systems will usually offer newer versions of those system packages through modules and users should always use those. The OS-included tools are really only for system management and system related tasks and serve a different purpose which actually requires a version that remains stable across a number of updates to not break things at the core of the OS. Users however will typically have a choice between several newer versions through modules, which also enables them to track the evolution and transition to a new version at the best suited moment.
"},{"location":"1day-20240208/03_Modules/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"1day-20240208/03_Modules/#benefits-of-a-hierarchy","title":"Benefits of a hierarchy","text":"When the hierarchy is well designed, you get some protection from loading modules that do not work together well. E.g., in the HPE Cray PE it is not possible to load the MPI library built for another compiler than your current main compiler. This is currently not exploited as much as we could on LUMI, mainly because we realised at the start that too many users are not familiar enough with hierarchies and would get confused more than the hierarchy helps them.
Another benefit is that when \"swapping\" a module that makes other modules available with a different one, Lmod will try to look for equivalent modules in the list of modules made available by the newly loaded module.
An easy example (though a tricky one as there are other mechanisms at play also) it to load a different programming environment in the default login environment right after login:
$ module load PrgEnv-aocc\n
which results in the output in the next slide:
The first two lines of output are due to to other mechanisms that are at work here, and the order of the lines may seem strange but that has to do with the way Lmod works internally. Each of the PrgEnv modules hard loads a compiler module which is why Lmod tells you that it is loading aocc/3.2.0. However, there is also another mechanism at work that causes cce/16.0.0 and PrgEnv-cray/8.4.0 to be unloaded, but more about that in the next subsection (next slide).
The important line for the hierarchy in the output are the lines starting with \"Due to MODULEPATH changes...\". Remember that we said that each module has a corresponding module file. Just as binaries on a system, these are organised in a directory structure, and there is a path, in this case MODULEPATH, that determines where Lmod will look for module files. The hierarchy is implemented with a directory structure and the environment variable MODULEPATH, and when the cce/16.0.0 module was unloaded and aocc/3.2.0 module was loaded, that MODULEPATH was changed. As a result, the version of the cray-mpich module for the cce/16.0.0 compiler became unavailable, but one with the same module name for the aocc/3.2.0 compiler became available and hence Lmod unloaded the version for the cce/16.0.0 compiler as it is no longer available but loaded the matching one for the aocc/3.2.0 compiler.
"},{"location":"1day-20240208/03_Modules/#about-module-names-and-families","title":"About module names and families","text":"In Lmod you cannot have two modules with the same name loaded at the same time. On LUMI, when you load a module with the same name as an already loaded module, that other module will be unloaded automatically before loading the new one. There is even no need to use the module swap command for that (which in Lmod corresponds to a module unload of the first module and a module load of the second). This gives you an automatic protection against some conflicts if the names of the modules are properly chosen.
Note
Some clusters do not allow the automatic unloading of a module with the same name as the one you're trying to load, but on LUMI we felt that this is a necessary feature to fully exploit a hierarchy.
Lmod goes further also. It also has a family concept: A module can belong to a family (and at most 1) and no two modules of the same family can be loaded together. The family property is something that is defined in the module file. It is commonly used on systems with multiple compilers and multiple MPI implementations to ensure that each compiler and each MPI implementation can have a logical name without encoding that name in the version string (like needing to have compiler/gcc-11.2.0 or compiler/gcc/11.2.0 rather than gcc/11.2.0), while still having an easy way to avoid having two compilers or MPI implementations loaded at the same time. On LUMI, the conflicting module of the same family will be unloaded automatically when loading another module of that particular family.
This is shown in the example in the previous subsection (the module load PrgEnv-aocc in a fresh long shell) in two places. It is the mechanism that unloaded PrgEnv-cray when loading PrgEnv-aocc and that then unloaded cce/16.0.1 when the PrgEnv-aocc module loaded the aocc/3.2.0 module.
Note
Some clusters do not allow the automatic unloading of a module of the same family as the one you're trying to load and produce an error message instead. On LUMI, we felt that this is a necessary feature to fully exploit the hierarchy and the HPE Cray Programming Environment also relies very much on this feature being enabled to make live easier for users.
"},{"location":"1day-20240208/03_Modules/#extensions","title":"Extensions","text":"It would not make sense to have a separate module for each of the hundreds of R packages or tens of Python packages that a software stack may contain. In fact, as the software for each module is installed in a separate directory it would also create a performance problem due to excess directory accesses simply to find out where a command is located, and very long search path environment variables such as PATH or the various variables packages such as Python, R or Julia use to find extension packages. On LUMI related packages are often bundled in a single module.
Now you may wonder: If a module cannot be simply named after the package it contains as it contains several ones, how can I then find the appropriate module to load? Lmod has a solution for that through the so-called extension mechanism. An Lmod module can define extensions, and some of the search commands for modules will also search in the extensions of a module. Unfortunately, the HPE Cray PE cray-python and cray-R modules do not provide that information at the moment as they too contain several packages that may benefit from linking to optimised math libraries.
"},{"location":"1day-20240208/03_Modules/#searching-for-modules-the-module-spider-command","title":"Searching for modules: The module spider command","text":"There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. The spider command will not only search in module names for the package, but also in extensions of the modules and so will be able to tell you that a package is delivered by another module. See Example 4 below where we will search for the CMake tools.
-
The third use of module spider is with the full name of a module. This shows two kinds of information. First it shows which combinations of other modules one might have to load to get access to the package. That works for both modules and extensions of modules. In the latter case it will show both the module, and other modules that you might have to load first to make the module available. Second it will also show help information for the module if the module file provides such information.
"},{"location":"1day-20240208/03_Modules/#example-1-running-module-spider-on-lumi","title":"Example 1: Running module spider on LUMI","text":"Let's first run the module spider command. The output varies over time, but at the time of writing, and leaving out a lot of the output, one would have gotten:
On the second screen we see, e.g., the ARMForge module which was available in just a single version at that time, and then Autoconf where the version is in blue and followed by (E). This denotes that the Autoconf package is actually provided as an extension of another module, and one of the next examples will tell us how to figure out which one.
The third screen shows the last few lines of the output, which actually also shows some help information for the command.
"},{"location":"1day-20240208/03_Modules/#example-2-searching-for-the-fftw-module-which-happens-to-be-provided-by-the-pe","title":"Example 2: Searching for the FFTW module which happens to be provided by the PE","text":"Next let us search for the popular FFTW library on LUMI:
$ module spider FFTW\n
produces
This shows that the FFTW library is actually provided by the cray-fftw module and was at the time that this was tested available in 3 versions. Note that (a) it is not case sensitive as FFTW is not in capitals in the module name and (b) it also finds modules where the argument of module spider is only part of the name.
The output also suggests us to dig a bit deeper and check for a specific version, so let's run
$ module spider cray-fftw/3.3.10.5\n
This produces:
We now get a long list of possible combinations of modules that would enable us to load this module. What these modules are will be explained in the next session of this course. However, it does show a weakness when module spider is used with the HPE Cray PE. In some cases, not all possible combinations are shown (and this is the case here as the module is actually available directly after login and also via some other combinations of modules that are not shown). This is because the HPE Cray Programming Environment is system-installed and sits next to the application software stacks that are managed differently, but in some cases also because the HPE Cray PE sometimes fails to give the complete combination of modules that is needed. The command does work well with the software managed by the LUMI User Support Team as the next two examples will show.
"},{"location":"1day-20240208/03_Modules/#example-3-searching-for-gnuplot","title":"Example 3: Searching for GNUplot","text":"To see if GNUplot is available, we'd first search for the name of the package:
$ module spider GNUplot\n
This produces:
The output again shows that the search is not case sensitive which is fortunate as uppercase and lowercase letters are not always used in the same way on different clusters. Some management tools for scientific software stacks will only use lowercase letters, while the package we use for the LUMI software stacks often uses both.
We see that there are a lot of versions installed on the system and that the version actually contains more information (e.g., -cpeGNU-23.09) that we will explain in the next part of this course. But you might of course guess that it has to do with the compilers that were used. It may look strange to you to have the same software built with different compilers. However, mixing compilers is sometimes risky as a library compiled with one compiler may not work in an executable compiled with another one, so to enable workflows that use multiple tools we try to offer many tools compiled with multiple compilers (as for most software we don't use rpath linking which could help to solve that problem). So you want to chose the appropriate line in terms of the other software that you will be using.
The output again suggests to dig a bit further for more information, so let's try
$ module spider gnuplot/5.4.8-cpeGNU-23.09\n
This produces:
In this case, this module is provided by 3 different combinations of modules that also will be explained in the next part of this course. Furthermore, the output of the command now also shows some help information about the module, with some links to further documentation available on the system or on the web. The format of the output is generated automatically by the software installation tool that we use and we sometimes have to do some effort to fit all information in there.
For some packages we also have additional information in our LUMI Software Library web site so it is often worth looking there also.
"},{"location":"1day-20240208/03_Modules/#example-4-searching-for-an-extension-of-a-module-cmake","title":"Example 4: Searching for an extension of a module: CMake.","text":"The cmake command on LUMI is available in the operating system image, but as is often the case with such tools distributed with the OS, it is a rather old version and you may want to use a newer one.
If you would just look through the list of available modules, even after loading some other modules to activate a larger software stack, you will not find any module called CMake though. But let's use the powers of module spider and try
$ module spider CMake\n
which produces
The output above shows us that there are actually four other versions of CMake on the system, but their version is followed by (E) which says that they are extensions of other modules. There is no module called CMake on the system. But Lmod already tells us how to find out which module actually provides the CMake tools. So let's try
$ module spider CMake/3.27.7\n
which produces
This shows us that the version is provided by a number of buildtools modules, and for each of those modules also shows us which other modules should be loaded to get access to the commands. E.g., the first line tells us that there is a module buildtools/23.09 that provides that version of CMake, but that we first need to load some other modules, with LUMI/23.09 and partition/L (in that order) one such combination.
So in this case, after
$ module load LUMI/23.09 partition/L buildtools/23.09\n
the cmake command would be available.
And you could of course also use
$ module spider buildtools/23.09\n
to get even more information about the buildtools module, including any help included in the module.
"},{"location":"1day-20240208/03_Modules/#alternative-search-the-module-keyword-command","title":"Alternative search: the module keyword command","text":"Lmod has a second way of searching for modules: module keyword. It searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Let us look for packages that allow us to download software via the https protocol. One could try
$ module keyword https\n
which produces a the following output:
cURL and wget are indeed two tools that can be used to fetch files from the internet.
LUMI Software Library
The LUMI Software Library also has a search box in the upper right. We will see in the next section of this course that much of the software of LUMI is managed through a tool called EasyBuild, and each module file corresponds to an EasyBuild recipe which is a file with the .eb extension. Hence the keywords can also be found in the EasyBuild recipes which are included in this web site, and from a page with an EasyBuild recipe (which may not mean much for you) it is easy to go back to the software package page itself for more information. Hence you can use the search box to search for packages that may not be installed on the system.
The example given above though, searching for https, would not work via that box as most EasyBuild recipes include https web links to refer to, e.g., documentation and would be shown in the result.
The LUMI Software Library site includes both software installed in our central software stack and software for which we make customisable build recipes available for user installation, but more about that in the tutorial section on LUMI software stacks.
"},{"location":"1day-20240208/03_Modules/#sticky-modules-and-the-module-purge-command","title":"Sticky modules and the module purge command","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Let us look at the output of the module avail command, taken just after login on the system at the time of writing of these notes (the exact list of modules shown is a bit fluid):
Next to the names of modules you sometimes see one or more letters. The (D) means that that is currently the default version of the module, the one that will be loaded if you do not specify a version. Note that the default version may depend on other modules that are already loaded as we have seen in the discussion of the programming environment.
The (L) means that a module is currently loaded.
The (S) means that the module is a sticky module.
Next to the rocm module (on the fourth screen) you see (D:5.0.2:5.2.0). The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
At the end of the overview the extensions are also shown. If this would be fully implemented on LUMI, the list might become very long. However, as we shall see next, there is an easy way to hide those from view.
"},{"location":"1day-20240208/03_Modules/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed in the above example that we don't show directories of module files in the overview (as is the case on most clusters) but descriptive texts about the module group. This is just one view on the module tree though, and it can be changed easily by loading a version of the ModuleLabel module.
ModuleLabel/label produces the default view of the previous example.ModuleLabel/PEhierarchy still uses descriptive texts but will show the whole module hierarchy of the HPE Cray Programming Environment.ModuleLabel/system does not use the descriptive texts but shows module directories instead.
When using any kind of descriptive labels, Lmod can actually bundle module files from different directories in a single category and this is used heavily when ModuleLabel/label is loaded and to some extent also when ModuleLabel/PEhierarchy is loaded.
It is rather hard to provide multiple colour schemes in Lmod, and as we do not know how your terminal is configured it is also impossible to find a colour scheme that works for all users. Hence we made it possible to turn on and off the use of colours by Lmod through the ModuleColour/on and ModuleColour/off modules.
As the module extensions list in the output of module avail could potentially become very long over time (certainly if there would be Python or R modules installed with EasyBuild that show all included Python or R packages in that list) you may want to hide those. You can do this by loading the ModuleExtensions/hide module and undo this again by loading ModuleExtensions/show.
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. You can still load them if you know they exist and specify the full version but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work if you use modules that are hidden in the context you're in or if you try to use any module that was designed for us to maintain the system and is therefore hidden from regular users.
Example
An example that will only become clear in the next session: When working with the software stack called LUMI/23.09, which is built upon the HPE Cray Programming Environment version 23.09, all (well, most) of the modules corresponding to other version of the Cray PE are hidden.
"},{"location":"1day-20240208/03_Modules/#getting-help-with-the-module-help-command","title":"Getting help with the module help command","text":"Lmod has the module help command to get help on modules
$ module help\n
without further arguments will show some help on the module command.
With the name of a module specified, it will show the help information for the default version of that module, and with a full name and version specified it will show this information specifically for that version of the module. But note that module help can only show help for currently available modules.
Try, e.g., the following commands:
$ module help cray-mpich\n$ module help cray-python/3.10.10\n$ module help buildtools/23.09\n
Lmod also has another command that produces more limited information (and is currently not fully exploited on LUMI): module whatis. It is more a way to tag a module with different kinds of information, some of which has a special meaning for Lmod and is used at some places, e.g., in the output of module spider without arguments.
Try, e.g.,:
$ module whatis Subversion\n$ module whatis Subversion/1.14.2\n
"},{"location":"1day-20240208/03_Modules/#a-note-on-caching","title":"A note on caching","text":"Modules are stored as (small) files in the file system. Having a large module system with much software preinstalled for everybody means a lot of small files which will make our Lustre file system very unhappy. Fortunately Lmod does use caches by default. On LUMI we currently have no system cache and only a user cache. That cache can be found in $HOME/.cache/lmod (and in some versions of LMOD in $HOME/.lmod.d/.cache).
That cache is also refreshed automatically every 24 hours. You'll notice when this happens as, e.g., the module spider and module available commands will be slow during the rebuild. you may need to clean the cache after installing new software as on LUMI Lmod does not always detect changes to the installed software,
Sometimes you may have to clear the cache also if you get very strange answers from module spider. It looks like the non-standard way in which the HPE Cray Programming Environment does certain things in Lmod can cause inconsistencies in the cache. This is also one of the reasons whey we do not yet have a central cache for that software that is installed in the central stacks as we are not sure when that cache is in good shape.
"},{"location":"1day-20240208/03_Modules/#a-note-on-other-commands","title":"A note on other commands","text":"As this tutorial assumes some experience with using modules on other clusters, we haven't paid much attention to some of the basic commands that are mostly the same across all three module environments implementations. The module load, module unload and module list commands work largely as you would expect, though the output style of module list may be a little different from what you expect. The latter may show some inactive modules. These are modules that were loaded at some point, got unloaded when a module closer to the root of the hierarchy of the module system got unloaded, and they will be reloaded automatically when that module or an equivalent (family or name) module is loaded that makes this one or an equivalent module available again.
Example
To demonstrate this, try in a fresh login shell (with the lines starting with a $ the commands that you should enter at the command prompt):
$ module unload craype-network-ofi\n\nInactive Modules:\n 1) cray-mpich\n\n$ module load craype-network-ofi\n\nActivating Modules:\n 1) cray-mpich/8.1.27\n
The cray-mpich module needs both a valid network architecture target module to be loaded (not craype-network-none) and a compiler module. Here we remove the network target module which inactivates the cray-mpich module, but the module gets reactivated again as soon as the network target module is reloaded.
The module swap command is basically equivalent to a module unload followed by a module load. With one argument it will look for a module with the same name that is loaded and unload that one before loading the given module. With two modules, it will unload the first one and then load the second one. The module swap command is not really needed on LUMI as loading a conflicting module (name or family) will automatically unload the previously loaded one. However, in case of replacing a module of the same family with a different name, module swap can be a little faster than just a module load as that command will need additional operations as in the first step it will discover the family conflict and then try to resolve that in the following steps (but explaining that in detail would take us too far in the internals of Lmod).
"},{"location":"1day-20240208/03_Modules/#links","title":"Links","text":"These links were OK at the time of the course. This tutorial will age over time though and is not maintained but may be replaced with evolved versions when the course is organised again, so links may break over time.
- Lmod documentation and more specifically the User Guide for Lmod which is the part specifically for regular users who do not want to design their own modules.
- Information on the module environment in the LUMI documentation
"},{"location":"1day-20240208/04_Software_stacks/","title":"LUMI Software Stacks","text":"In this section we discuss
- Several of the ways in which we offer software on LUMI
- Managing software in our primary software stack which is based on EasyBuild
"},{"location":"1day-20240208/04_Software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"1day-20240208/04_Software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack than your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 12 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 10 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised environments. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"1day-20240208/04_Software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer a growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We do offer some help to set up Spack also but it is mostly offered \"as is\" and we will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"1day-20240208/04_Software_stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric, the Open Fabrics Interface (OFI) library, using a specific provider for the NIC used on LUMI, the so-called Cassini provider (CXI), so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky. As an alternative we also offer cotainr, a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space and can be used to containerise a conda-installation.
"},{"location":"1day-20240208/04_Software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"1day-20240208/04_Software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"1day-20240208/04_Software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"1day-20240208/04_Software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"1day-20240208/04_Software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12, LUMI/23.03 and LUMI/23.09 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"1day-20240208/04_Software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"1day-20240208/04_Software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"1day-20240208/04_Software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"1day-20240208/04_Software_stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"1day-20240208/04_Software_stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"1day-20240208/04_Software_stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2022.5, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeGNU-23.09 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/23.09.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.9.0-noPython-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.
"},{"location":"1day-20240208/04_Software_stacks/#installing","title":"Installing","text":""},{"location":"1day-20240208/04_Software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants of the project to solve a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"1day-20240208/04_Software_stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module. It works correctly for a lot of CPU-only software, but fails more frequently for GPU software as the installation scripts will try to run scripts that detect which GPU is present, or try to run tests on the GPU, even if you tell which GPU type to use, which does not work on the login nodes.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"1day-20240208/04_Software_stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS there is already support on LUMI. An easy way to do that is to simply check the LUMI Software Library. This web site lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Alternatively one can use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Output of the search commands:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb. This is GROMACS 2022.5 with the PLUMED 2.9.0 plugin, built with the GNU compilers from LUMI/23.09, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb -r\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"1day-20240208/04_Software_stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.cache/lmod. You can do this with
rm -rf $HOME/.cache/lmod\n
(With older versions of Lmod the cache directory is $HOME/.lmod.d/cache.)"},{"location":"1day-20240208/04_Software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.4.1-cpeGNU-22.12-build01.eb \u2013r . \n
"},{"location":"1day-20240208/04_Software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"1day-20240208/04_Software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elsewhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"1day-20240208/04_Software_stacks/#easybuild-tips-and-tricks","title":"EasyBuild tips and tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"1day-20240208/04_Software_stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on tutorial.easybuild.io. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"1day-20240208/05_Exercises_1/","title":"Exercises 1: Modules, the HPE Cray PE and EasyBuild","text":"See the instructions to set up for the exercises.
"},{"location":"1day-20240208/05_Exercises_1/#exercises-on-the-use-of-modules","title":"Exercises on the use of modules","text":" -
The Bison program installed in the OS image is pretty old (version 3.0.4) and we want to use a newer one. Is there one available on LUMI?
Click to see the solution. module spider Bison\n
tells us that there are indeed newer versions available on the system.
The versions that have a compiler name (usually gcc) in their name followed by some seemingly random characters are installed with Spack and not in the CrayEnv or LUMI environments.
If there would be more than one version of Bison reported, you could get more information about a specific version, e.g., Bison/3.8.2 with:
module spider Bison/3.8.2\n
tells us that Bison 3.8.2 is provided by a couple of buildtools modules and available in all partitions in several versions of the LUMI software stack and in CrayEnv.
Alternatively, in this case
module keyword Bison\n
would also have shown that Bison is part of several versions of the buildtools module.
The module spider command is often the better command if you use names that with a high likelihood could be the name of a package, while module keyword is often the better choice for words that are more a keyword. But if one does not return the solution it is a good idea to try the other one also.
-
The htop command is a nice alternative for the top command with a more powerful user interface. However, typing htop on the command line produces an error message. Can you find and run htop?
Click to see the solution. We can use either module spider htop or module keyword htop to find out that htop is indeed available on the system. With module keyword htop we'll find out immediately that it is in the systools modules and some of those seem to be numbered after editions of the LUMI stack suggesting that they may be linked to a stack, with module spider you'll first see that it is an extension of a module and see the versions. You may again see some versions installed with Spack.
Let's check further for htop/3.2.1 that should exist according to module spider htop:
module spider htop/3.2.1\n
tells us that this version of htop is available in all partitions of LUMI/23.03, LUMI/22.12, LUMI/22.08 and LUMI/22.06, and in CrayEnv. Let us just run it in the CrayEnv environment:
module load CrayEnv\nmodule load systools/22.08\nhtop\n
(You can quit htop by pressing q on the keyboard.)
-
LUMI now offers Open OnDemand as a browser-based interface to LUMI that will also enable running some graphical programs. Another way to do this is through a so-called VNC server (and that is actually what Open OnDemand is using under the hood also, but through its own internal installation). Do we have such a tool on LUMI, and if so, how can we use it?
Click to see the solution. module spider VNC and module keyword VNC can again both be used to check if there is software available to use VNC. There is currently only one available version of the module, but at times there may be more. In those cases loading the older ones (the version number points at the date of some scripts in that module) you will notice that they may produce a warning about being deprecated. You may wonder why they were not uninstalled right away. This is because we cannot remove older versions when installing a newer one right away as it may be in use by users, and for non-interactive job scripts, there may also be job scripts in the queue that have the older version hard-coded in the script.
As there is currently only one version on the system, you get the help information right away. If there were more versions you could still get the help information of the newest version by simply using module spider with the full module name and version. E.g., if the module spider VNC would have shown that lumi-vnc/20230110 exists, you could get the help information using
module spider lumi-vnc/20230110\n
The output may look a little strange as it mentions init-lumi as one of the modules that you can load. That is because this tool is available even outside CrayEnv or the LUMI stacks. But this command also shows a long help text telling you how to use this module (though it does assume some familiarity with how X11 graphics work on Linux).
Note that if there is only a single version on the system, as is the case for the course in February 2024, the module spider VNC command without specific version or correct module name will already display the help information.
-
Search for the bzip2 tool (and not just the bunzip2 command as we also need the bzip2 command) and make sure that you can use software compiled with the Cray compilers in the LUMI stacks in the same session.
Click to see the solution. module spider bzip2\n
shows that there are versions of bzip2 for several of the cpe* toolchains and in several versions of the LUMI software stack.
Of course we prefer to use a recent software stack, the 22.12 or 23.09 (but as of February 2024, there is still more software ready-to-install for 22.12 and maybe even '22.08'). And since we want to use other software compiled with the Cray compilers also, we really want a cpeCray version to avoid conflicts between different toolchains. So the module we want to load is bzip2/1.0.8-cpeCray-23.09.
To figure out how to load it, use
module spider bzip2/1.0.8-cpeCray-23.09\n
and see that (as expected from the name) we need to load LUMI/23.09 and can then use it in any of the partitions.
"},{"location":"1day-20240208/05_Exercises_1/#exercises-on-compiling-software-by-hand","title":"Exercises on compiling software by hand","text":"These exercises are optional during the session, but useful if you expect to be compiling software yourself. The source files mentioned can be found in the subdirectory CPE of the download.
"},{"location":"1day-20240208/05_Exercises_1/#compilation-of-a-program-1-a-simple-hello-world-program","title":"Compilation of a program 1: A simple \"Hello, world\" program","text":"Four different implementations of a simple \"Hello, World!\" program are provided in the CPE subdirectory:
hello_world.c is an implementation in C,hello_world.cc is an implementation in C++,hello_world.f is an implementation in Fortran using the fixed format source form,hello_world.f90 is an implementation in Fortran using the more modern free format source form.
Try to compile these programs using the programming environment of your choice.
Click to see the solution. We'll use the default version of the programming environment (23.09 at the moment of the course in February 2024), but in case you want to use a particular version, e.g., the 22.12 version, and want to be very sure that all modules are loaded correctly from the start you could consider using
module load cpe/22.12\nmodule load cpe/22.12\n
So note that we do twice the same command as the first iteration does not always succeed to reload all modules in the correct version. Do not combine both lines into a single module load statement as that would again trigger the bug that prevents all modules to be reloaded in the first iteration.
The sample programs that we asked you to compile do not use the GPU. So there are three programming environments that we can use: PrgEnv-gnu, PrgEnv-cray and PrgEnv-aocc. All three will work, and they work almost the same.
Let's start with an easy case, compiling the C version of the program with the GNU C compiler. For this all we need to do is
module load PrgEnv-gnu\ncc hello_world.c\n
which will generate an executable named a.out. If you are not comfortable using the default version of gcc (which produces the warning message when loading the PrgEnv-gnu module) you can always load the gcc/11.2.0 module instead after loading PrgEnv-gnu.
Of course it is better to give the executable a proper name which can be done with the -o compiler option:
module load PrgEnv-gnu\ncc hello_world.c -o hello_world.x\n
Try running this program:
./hello_world.x\n
to see that it indeed works. We did forget another important compiler option, but we'll discover that in the next exercise.
The other programs are equally easy to compile using the compiler wrappers:
CC hello_world.cc -o hello_world.x\nftn hello_world.f -o hello_world.x\nftn hello_world.f90 -o hello_world.x\n
"},{"location":"1day-20240208/05_Exercises_1/#compilation-of-a-program-2-a-program-with-blas","title":"Compilation of a program 2: A program with BLAS","text":"In the CPE subdirectory you'll find the C program matrix_mult_C.c and the Fortran program matrix_mult_F.f90. Both do the same thing: a matrix-matrix multiplication using the 6 different orders of the three nested loops involved in doing a matrix-matrix multiplication, and a call to the BLAS routine DGEMM that does the same for comparison.
Compile either of these programs using the Cray LibSci library for the BLAS routine. Do not use OpenMP shared memory parallelisation. The code does not use MPI.
The resulting executable takes one command line argument, the size of the square matrix. Run the script using 1000 for the matrix size and see what happens.
Note that the time results may be very unreliable as we are currently doing this on the login nodes. In the session of Slurm you'll learn how to request compute nodes and it might be interesting to redo this on a compute node with a larger matrix size as the with a matrix size of 1000 all data may stay in the third level cache and you will not notice the differences that you should note. Also, because these nodes are shared with a lot of people any benchmarking is completely unreliable.
If this program takes more than half a minute or so before the first result line in the table, starting with ijk-variant, is printed, you've very likely done something wrong (unless the load on the system is extreme). In fact, if you've done things well the time reported for the ijk-variant should be well under 3 seconds for both the C and Fortran versions...
Click to see the solution. Just as in the previous exercise, this is a pure CPU program so we can chose between the same three programming environments.
The one additional \"difficulty\" is that we need to link with the BLAS library. This is very easy however in the HPE Cray PE if you use the compiler wrappers rather than calling the compilers yourself: you only need to make sure that the cray-libsci module is loaded and the wrappers will take care of the rest. And on most systems (including LUMI) this module will be loaded automatically when you load the PrgEnv-* module.
To compile with the GNU C compiler, all you need to do is
module load PrgEnv-gnu\ncc -O3 matrix_mult_C.c -o matrix_mult_C_gnu.x\n
will generate the executable matrix_mult_C_gnu.x.
Note that we add the -O3 option and it is very important to add either -O2 or -O3 as by default the GNU compiler will generate code without any optimization for debugging purposes, and that code is in this case easily five times or more slower. So if you got much longer run times than indicated this is likely the mistake that you made.
To use the Cray C compiler instead only one small change is needed: Loading a different programming environment module:
module load PrgEnv-cray\ncc -O3 matrix_mult_C.c -o matrix_mult_C_cray.x\n
will generate the executable matrix_mult_C_cray.x.
Likewise for the AMD AOCC compiler we can try with loading yet another PrgEnv-* module:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -o matrix_mult_C_aocc.x\n
but it turns out that this fails with linker error messages about not being able to find the sin and cos functions. When using the AOCC compiler the libm library with basic math functions is not linked automatically, but this is easily done by adding the -lm flag:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -lm -o matrix_mult_C_aocc.x\n
For the Fortran version of the program we have to use the ftn compiler wrapper instead, and the issue with the math libraries in the AOCC compiler does not occur. So we get
module load PrgEnv-gnu\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_gnu.x\n
for the GNU Fortran compiler,
module load PrgEnv-cray\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_cray.x\n
for the Cray Fortran compiler and
module load PrgEnv-aocc\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_aocc.x\n
for the AMD Fortran compiler.
When running the program you will see that even though the 6 different loop orderings produce the same result, the time needed to compile the matrix-matrix product is very different and those differences would be even more pronounced with bigger matrices (which you can do after the session on using Slurm).
The exercise also shows that not all codes are equal even if they produce a result of the same quality. The six different loop orderings run at very different speed, and none of our simple implementations can beat a good library, in this case the BLAS library included in LibSci.
The results with the Cray Fortran compiler are particularly interesting. The result for the BLAS library is slower which we do not yet understand, but it also turns out that for four of the six loop orderings we get the same result as with the BLAS library DGEMM routine. It looks like the compiler simply recognized that this was code for a matrix-matrix multiplication and replaced it with a call to the BLAS library. The Fortran 90 matrix multiplication is also replaced by a call of the DGEMM routine. To confirm all this, unload the cray-libsci module and try to compile again and you will see five error messages about not being able to find DGEMM.
"},{"location":"1day-20240208/05_Exercises_1/#compilation-of-a-program-3-a-hybrid-mpiopenmp-program","title":"Compilation of a program 3: A hybrid MPI/OpenMP program","text":"The file mpi_omp_hello.c is a hybrid MPI and OpenMP C program that sends a message from each thread in each MPI rank. It is basically a simplified version of the programs found in the lumi-CPEtools modules that can be used to quickly check the core assignment in a hybrid MPI and OpenMP job (see later in this tutorial). It is again just a CPU-based program.
Compile the program with your favourite C compiler on LUMI.
We have not yet seen how to start an MPI program. However, you can run the executable on the login nodes and it will then contain just a single MPI rank.
Click to see the solution. In the HPE Cray PE environment, you don't use mpicc to compile a C MPI program, but you just use the cc wrapper as for any other C program. To enable MPI you have to make sure that the cray-mpich module is loaded. This module will usually be loaded by loading one of the PrgEnv-* modules, but only if the right network target module, which is craype-network-ofi, is also already loaded.
Compiling the program is very simple:
module load PrgEnv-gnu\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_gnu.x\n
to compile with the GNU C compiler,
module load PrgEnv-cray\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_cray.x\n
to compile with the Cray C compiler, and
module load PrgEnv-aocc\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_aocc.x\n
to compile with the AMD AOCC compiler.
To run the executables it is not even needed to have the respective PrgEnv-* module loaded since the binaries will use a copy of the libraries stored in a default directory, though there have been bugs in the past preventing this to work with PrgEnv-aocc.
"},{"location":"1day-20240208/05_Exercises_1/#information-in-the-lumi-software-library","title":"Information in the LUMI Software Library","text":"Explore the LUMI Software Library.
- Search for information for the package ParaView and quickly read through the page
Click to see the solution. Link to the ParaView documentation
It is an example of a package for which we have both user-level and some technical information. The page will first show some license information, then the actual user information which in case of this package is very detailed and long. But it is also a somewhat complicated package to use. It will become easier when LUMI evolves a bit further, but there will always be some pain. Next comes the more technical part: Links to the EasyBuild recipe and some information about how we build the package.
We currently only provide ParaView in the cpeGNU toolchain. This is because it has a lot of dependencies that are not trivial to compile and to port to the other compilers on the system, and EasyBuild is strict about mixing compilers basically because it can cause a lot of problems, e.g., due to conflicts between OpenMP runtimes.
"},{"location":"1day-20240208/05_Exercises_1/#installing-software-with-easybuild","title":"Installing software with EasyBuild","text":"These exercises are based on material from the EasyBuild tutorials (and we have a special version for LUMI also).
Note: If you want to be able to uninstall all software installed through the exercises easily, we suggest you make a separate EasyBuild installation for the course, e.g., in /scratch/project_465000961/$USER/eb-course if you make the exercises during the course:
- Start from a clean login shell with only the standard modules loaded.
-
Create the directory for the EasyBuild installation (if you haven't done this yet):
mkdir -p /scratch/project_465000961/$USER/eb-course\n
-
Set EBU_USER_PREFIX:
export EBU_USER_PREFIX=/scratch/project_465000961/$USER/eb-course\n
You'll need to do that in every shell session where you want to install or use that software.
-
From now on you can again safely load the necessary LUMI and partition modules for the exercise.
-
At the end, when you don't need the software installation anymore, you can simply remove the directory that you just created.
rm -rf /scratch/project_465000961/$USER/eb-course\n
"},{"location":"1day-20240208/05_Exercises_1/#installing-a-simple-program-without-dependencies-with-easybuild","title":"Installing a simple program without dependencies with EasyBuild","text":"The LUMI Software Library contains the package eb-tutorial. Install the version of the package for the cpeCray toolchain in the 22.12 version of the software stack.
Click to see the solution. -
We can check the eb-tutorial page in the LUMI Software Library if we want to see more information about the package.
You'll notice that there are versions of the EasyConfigs for cpeGNU and cpeCray. As we want to install software with the cpeCray toolchain for LUMI/22.12, we'll need the cpeCray-22.12 version which is the EasyConfig eb-tutorial-1.0.1-cpeCray-22.12.eb.
-
Obviously we need to load the LUMI/22.12 module. If we would like to install software for the CPU compute nodes, you need to also load partition/C. To be able to use EasyBuild, we also need the EasyBuild-user module.
module load LUMI/22.12 partition/C\nmodule load EasyBuild-user\n
-
Now all we need to do is run the eb command from EasyBuild to install the software.
Let's however take the slow approach and first check if what dependencies the package needs:
eb eb-tutorial-1.0.1-cpeCray-22.12.eb -D\n
We can do this from any directory as the EasyConfig file is already in the LUMI Software Library and will be located automatically by EasyBuild. You'll see that all dependencies are already on the system so we can proceed with the installation:
eb eb-tutorial-1.0.1-cpeCray-22.12.eb \n
-
After this you should have a module eb-tutorial/1.0.1-cpeCray-22.12 but it may not show up yet due to the caching of Lmod. Try
module av eb-tutorial/1.0.1-cpeCray-22.12\n
If this produces an error message complaining that the module cannot be found, it is time to clear the Lmod cache:
rm -rf $HOME/.cache/lmod\n
-
Now that we have the module, we can check what it actually does:
module help eb-tutorial/1.0.1-cpeCray-22.12\n
and we see that it provides the eb-tutorial command.
-
So let's now try to run this command:
module load eb-tutorial/1.0.1-cpeCray-22.12\neb-tutorial\n
Note that if you now want to install one of the other versions of this module, EasyBuild will complain that some modules are loaded that it doesn't like to see, including the eb-tutorial module and the cpeCray modules so it is better to unload those first:
module unload cpeCray eb-tutorial\n
Clean before proceeding After this exercise you'll have to clean your environment before being able to make the next exercise:
- Unload the
eb-tutorial modules - The
cpeCray module would also produce a warning
module unload eb-tutorial cpeCray\n
"},{"location":"1day-20240208/05_Exercises_1/#installing-an-easyconfig-given-to-you-by-lumi-user-support","title":"Installing an EasyConfig given to you by LUMI User Support","text":"Sometimes we have no solution ready in the LUMI Software Library, but we prepare one or more custom EasyBuild recipes for you. Let's mimic this case. In practice we would likely send those as attachments to a mail from the ticketing system and you would be asked to put them in a separate directory (basically since putting them at the top of your home directory would in some cases let EasyBuild search your whole home directory for dependencies which would be a very slow process).
You've been given two EasyConfig files to install a tool called py-eb-tutorial which is in fact a Python package that uses the eb-tutorial package installed in the previous exercise. These EasyConfig files are in the EasyBuild subdirectory of the exercises for this course. In the first exercise you are asked to install the version of py-eb-tutorial for the cpeCray/22.12 toolchain.
Click to see the solution. -
Go to the EasyBuild subdirectory of the exercises and check that it indeed contains the py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb and py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb files. It is the first one that we need for this exercise.
You can see that we have used a very long name as we are also using a version suffix to make clear which version of Python we'll be using.
-
Let's first check for the dependencies (out of curiosity):
eb py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb -D\n
and you'll see that all dependencies are found (at least if you made the previous exercise successfully). You may find it strange that it shows no Python module but that is because we are using the cray-python module which is not installed through EasyBuild and only known to EasyBuild as an external module.
-
And now we can install the package:
eb py-eb-tutorial-1.0.0-cpeCray-22.12-cray-python-3.9.13.1.eb\n
-
To use the package all we need to do is to load the module and to run the command that it defines:
module load py-eb-tutorial/1.0.0-cpeCray-22.12-cray-python-3.9.13.1\npy-eb-tutorial\n
with the same remark as in the previous exercise if Lmod fails to find the module.
You may want to do this step in a separate terminal session set up the same way, or you will get an error message in the next exercise with EasyBuild complaining that there are some modules loaded that should not be loaded.
Clean before proceeding After this exercise you'll have to clean your environment before being able to make the next exercise:
- Unload the
py-eb-tutorial and eb-tutorial modules - The
cpeCray module would also produce a warning - And the
py-eb-tutorial also loaded the cray-python module which causes EasyBuild to produce a nasty error messages if it is loaded when the eb command is called
module unload py-eb-tutorial eb-tutorial cpeCray cray-python\n
"},{"location":"1day-20240208/05_Exercises_1/#installing-software-with-uninstalled-dependencies","title":"Installing software with uninstalled dependencies","text":"Now you're asked to also install the version of py-eb-tutorial for the cpeGNU toolchain in LUMI/22.12 (and the solution given below assumes you haven't accidentally installed the wrong EasyBuild recipe in one of the previous two exercises).
Click to see the solution. -
We again work in the same environment as in the previous two exercises. Nothing has changed here. Hence if not done yet we need
module load LUMI/22.12 partition/C\nmodule load EasyBuild-user\n
-
Now go to the EasyBuild subdirectory of the exercises (if not there yet from the previous exercise) and check what the py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb needs:
eb py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb -D\n
We'll now see that there are two missing modules. Not only is the py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1 that we try to install missing, but also the eb-tutorial/1.0.1-cpeGNU-22.12. EasyBuild does however manage to find a recipe from which this module can be built in the pre-installed build recipes.
-
We can install both packages separately, but it is perfectly possible to install both packages in a single eb command by using the -r option to tell EasyBuild to also install all dependencies.
eb py-eb-tutorial-1.0.0-cpeGNU-22.12-cray-python-3.9.13.1.eb -r\n
-
At the end you'll now notice (with module avail) that both the module eb-tutorial/1.0.1-cpeGNU-22.12 and py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1 are now present.
To run you can use
module load py-eb-tutorial/1.0.0-cpeGNU-22.12-cray-python-3.9.13.1\npy-eb-tutorial\n
"},{"location":"1day-20240208/06_Running_jobs/","title":"Running jobs","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20240208/07_Exercises_2/","title":"Exercises 2: Running jobs with Slurm","text":""},{"location":"1day-20240208/07_Exercises_2/#exercises-on-the-slurm-allocation-modes","title":"Exercises on the Slurm allocation modes","text":" -
Run single task with a job step of srun using multiple cpu cores. Inspect default task allocation with taskset command (taskset -cp $$ will show you cpu numbers allocated to a current process). Try with standard-g and small-g partitions. Are there any diffences? You may need to use specific reservation for standard-g partition to avoid long waiting.
Click to see the solution. srun --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> bash -c 'taskset -cp $$' \n
Note you need to replace <project_id> with actual project account ID in a form of project_ plus 9 digits number.
srun --partition=standard-g --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> --reservation=<res_id> bash -c 'taskset -cp $$' \n
The command runs single process (bash shell with a native Linux taskset tool showing process's CPU affinity) on a compute node. You can use man taskset command to see how the tool works.
-
Try Slurm allocations with hybrid_check tool program from the LUMI Software Stack. The program is preinstalled on the system.
Use the simple job script to run parallel program with multiple tasks (MPI ranks) and threads (OpenMP). Test task/threads affinity with sbatch submission on the CPU partition.
#!/bin/bash -l\n#SBATCH --partition=small-g # Partition name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=6 # 6 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools\n\nsrun hybrid_check -n -r\n
Be careful with copy/paste of script body while it may brake some specific characters.
Click to see the solution. Save script contents into job.sh file (you can use nano console text editor for instance), remember to use valid project account name.
Submit job script using sbatch command.
sbatch job.sh\n
The job output is saved in the slurm-<job_id>.out file. You can view it's contents with either less or more shell commands.
Actual task/threads affinity may depend on the specific OpenMP runtime but you should see \"block\" thread affinity as a default behaviour.
-
Improve threads affinity with OpenMP runtime variables. Alter your script and add MPI runtime variable to see another cpu mask summary.
Click to see the solution. Export SRUN_CPUS_PER_TASK environment variable to follow convention from recent Slurm's versions in your script. Add this line before the hybrid_check call:
export SRUN_CPUS_PER_TASK=16 \n
Add OpenMP environment variables definition to your script:
export OMP_NUM_THREADS=${SRUN_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n
You can also add MPI runtime variable to see another cpu mask summary:
export MPICH_CPUMASK_DISPLAY=1\n
Note hybrid_check and MPICH cpu mask may not be consistent. It is found to be confusing.
-
Use gpu_check program tool using interactive shell on a GPU node to inspect device binding. Check on which CCD task's CPU core and GPU device are allocated (this is shown with -l option of the tool program).
Click to see the solution. Allocate resources for a single task with a single GPU with salloc:
salloc --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=1 --gpus-per-node=1 --time=10 --account=<project_id>\n
Note that, after allocation being granted, you receive new shell but still on the compute node. You need to use srun to execute on the allocated node.
You need to load specific modules to access tools with GPU support.
module load LUMI/23.09 partition/G\n
module load lumi-CPEtools\n
Run `gpu_check` interactively on a compute node:\n\n ```\n srun gpu_check -l\n ```\n
Still remember to terminate your interactive session with exit command.
exit\n
"},{"location":"1day-20240208/07_Exercises_2/#slurm-custom-binding-on-gpu-nodes","title":"Slurm custom binding on GPU nodes","text":" -
Allocate one GPU node with one task per GPU and bind tasks to each CCD (8-core group sharing L3 cache). Use 7 threads per task having low noise mode of the GPU nodes in mind. Use select_gpu wrapper to map exactly one GPU per task.
Click to see the solution. Begin with the example from the slides with 7 cores per task:
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\nmodule load LUMI/23.09\nmodule load partition/G\nmodule load lumi-CPEtools\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nexport OMP_NUM_THREADS=7\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpus-per-task=${OMP_NUM_THREADS} ./select_gpu gpu_check -l\n
You need to add explicit --cpus-per-task option for srun to get correct GPU mapping. If you save the script in the job_step.sh then simply submit it with sbatch. Inspect the job output.
-
Change your CPU binding leaving first (#0) and last (#7) cores unused. Run a program with 6 threads per task and inspect actual task/threads affinity.
Click to see the solution. Now you would need to alter masks to disable 7th core of each of the group (CCD). Base mask is then 01111110 which is 0x7e in hexadecimal notation.
Try to apply new bitmask, change the corresponding variable to spawn 6 threads per task and check how new binding works.
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\nmodule load LUMI/23.09\nmodule load partition/G\nmodule load lumi-CPEtools\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu:0x7e000000000000,0x7e00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0x7e0000,0x7e000000,\"\nCPU_BIND=\"${CPU_BIND}0x7e,0x7e00,\"\nCPU_BIND=\"${CPU_BIND}0x7e00000000,0x7e0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu gpu_check -l\n
"},{"location":"1day-20240208/08_Lustre_intro/","title":"I/O and file systems","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20240208/09_LUMI_support/","title":"How to get support and documentation","text":"No notes for now.
See the slides (PDF).
"},{"location":"1day-20240208/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"1day-20240208/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.10, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
Mentioned in the Lustre presentation: The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"1day-20240208/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version. The web version is not completely equivalent with the version provided by the man command on LUMI as the latter also contain additional information specific to the Slingshot 11 interconnect of LUMI.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"1day-20240208/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"1day-20240208/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"1day-20240208/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"1day-20240208/A01_Documentation/#web-tutorials","title":"Web tutorials","text":" - Interactive Slurm tutorial developed by DeiC (Denmark)
"},{"location":"1day-20240208/notes_20240208/","title":"Questions session 8 February 2024","text":"The questions of the hedgedoc document have been reordered according to topics, and some questions that are not relevant after the course have been omitted.
"},{"location":"1day-20240208/notes_20240208/#icebreaker-question-what-kind-of-software-dowill-you-run-on-lumi","title":"Icebreaker question: What kind of software do/will you run on LUMI?","text":" - Hope to run pytorch(pyro) or tensorflow probability
- NequIP and Allegro (pytorch based) and run LAMMPS with pair_allegro (MPI + pytorch)
- AI/ML Stuff, PyTorch 1
- Pytorch + huggingface and stuff (deepspeed etc) +1
- PyTorch, other NMT stuff_
- Pytorch , JAX and DL Megatron-DeepSpeed in AMD-Rocm GPU and using containers and SLURM to run distributed GPU training
- Tensorflow, pytorch, cpu and gpu jobs with high I/O
- Spark
- Conda environments for Python
- OpenFoam
- CPU jobs with high I/O
- MPI/OpenMPI
- MPI - OpenACC
- Fortran + OpenMP offloading to GPUs
"},{"location":"1day-20240208/notes_20240208/#lumi-hardware","title":"LUMI Hardware","text":" -
What does CCD stand for?
- Core complex dies. There are 8 CCDs per processor with 8 cores each. LUMI-C has 2 processors (CPUs) per node while LUMI-G nodes have one.
-
What is the use of NUMA
-
It is a way of designing CPUs. It means that not all cores have the same memory access time with regards to L3 cache. So data stored in one L3 cache (shared by 8 cores) can be accessed very efficiently by those 8 cores but takes longer to be access by the other 56 cores in that CPU.
WikiPedia article on NUMA
-
Can you say something about storage to GPU data path...
- Can you elaborate a bit what you want to know?
To get data to GPU, should that be read to RAM first or is there any majic like the slingshot GPU connection
- Is your question: \"is there an AMD equivalent of NVIDIA's GPU direct storage?\"
yes
Is there any benchmarking results on, reading data to GPU from HDD Vs sending data in one GPU to another GPU in another machine via slingshot, i.e. what is the best way to distribute 128Gb across GPUs.
- I don't think we did any benchmark of data loading from the file system to the GPU memory but GPU-to-GPU communication will always be faster than File system-to-GPU data loading.
-
What is the reasoning behind choosing AMD GPUs vs NVIDIA GPUs? Are we going to get AMD's MI300 GPUs at LUMI as well? Is it because of cheaper and environmental reasons?
-
The AMD offer was better compared to the NVIDIA offer during the procurement of LUMI. NVIDIA knows they are in a quasi-monopoly position with their proprietary CUDA stack and tries to exploit this to raise prices...
-
MI300: Not at the moment but it can't be excluded if an extension of LUMI occurs at some point
-
Is it possible to visit LUMI supercomputer in Kajaani?
- Rather not but it of course depends on what is the reason and context. Send us a ticket with some more info and we will come back to you. https://lumi-supercomputer.eu/user-support/need-help/
"},{"location":"1day-20240208/notes_20240208/#programming-environment-modules","title":"Programming Environment & modules","text":" -
The GNU compilers do not have OpenMP offload to GPUs, ok. But can we use them with HIP?
-
Not to compile HIP code but we have build applications mixing HIP and Fortran using the Cray/AMD compilers for HIP and GNU gfortran for the fortran part. HIP code can only be compiled using a LLVM/clang based compiler like the AMD ROCm compilers or the Cray C/C++ compilers.
But this is precisely why you have to load the rocm module when using the GNU or Cray compilers to compile for the GPUs...
-
Are the modules LUMI/22.08 (S,D) LUMI/22.12 (S) LUMI/23.03... tool chains ?
- They are software stacks. Kurt will discuss them in the software stacks session.
-
What are differences between GNU GCC compiler and Cray compilers?
-
For general differences between the compilers there are many sources in internet. On LUMI, there are pages in our docs for Cray and GNU compilers:
-
They are totally different code bases to do the same thing. They are as different as Chrome and Firefox are: Just as these are two browsers that can browse the same web pages, the Cray and GNU compilers are two sets of compilers that can compile the same code but have nothing in common otherwise.
The Cray compilers are based on Clang and LLVM technology. Most vendors are actually moving to that code base for commercial compilers also. All GPU compilers are currently based on LLVM technology, also for GPUs from NVIDIA and Intel. The new Intel compilers are also based on Clang and LLVM (and just as Cray they use their own frontend due to lack of an open source one of sufficient quality).
-
Are these craype-... modules loaded automatically when you loadthe software stack?
-
By default, when you log in, PrgEnv-cray is loaded. It includes the Cray compilers, cray-mpich and cray-libsci (BLAS, LAPACK, ...)
-
I'll come back to that in the software stack presentation.
-
How do software stacks, Programming Env, tool-chains are related to each other conceptually?
-
Basically Programming Env is compiler (C,C++,Fortran), it's runtime libraries and entire set of libraries built against the compiler (AMD environment lacks Fortran compiler); Software Stack is entire application collection built with possibly all Programming Environments in a given release version (toolchains); Toolchain is technical concept for a specific Programming Env version and fixed set of related libraries.
-
Software Stack could be CrayEnv (native Cray Programming Environment), LUMI or Spack
-
In practice you can select Programming Env with either PrgEnv- (gnu, cray, amd) modules (Cray's native) or cpeGNU, cpeCray, cpeAMD; these are equivalent but latter ones are used in LUMI toolchains
-
Toolchain is a concept used with LUMI Software Stack and they are cpeGNU/x.y or cpeCray/x.y or cpeAMD/x.y where x.y stands for specific LUMI/x.y release which in turn follows x.y release of the Cray Programming Environment.
-
What kind of support is there for Julia-based software development? Do I need to install julia and Julia ML libraries like Flux.jl locally?
-
We have some info in our docs here: https://docs.lumi-supercomputer.eu/runjobs/scheduled-jobs/julia/
-
Alternatively, you can use a julia module provided by CSC: https://docs.lumi-supercomputer.eu/software/local/csc/
-
Setting up proper Julia development environment might be quite complex on LUMI. One of the possible ways is to use Spack (which is available as an alternative LUMI Software Stack).
-
Basically the Julia developers themselves advise to not try to compile Julia yourself and give very little information on how to do it properly. They advise to use their binaries...
"},{"location":"1day-20240208/notes_20240208/#modules","title":"Modules","text":" -
module av seems to be quite slow, am I missing something?
- It happend to me as well first time, but subsequent calls are faster, may be some caching ? (let me try... yes that's right)
- The Lmod cache is purged every day. The first
module av of the day will always be slow but subsequent commands should be way faster.
-
Is there any guide to help to quickly find a desired module (e.g. LAMMPS)? It seems that module av | grep -i lammps or module spider LAMMPS cannot help.
-
There is the Software Library page from which you can at least easily see what modules are available
-
We have very few modules preinstalled but as Kurt will explain soon. It is very easy to install them yourself using EasyBuild based on the recipes listed on the above mentioned software library.
"},{"location":"1day-20240208/notes_20240208/#lumi-software-stacks","title":"LUMI Software Stacks","text":" -
Are you going to install more scientific packages in future, or it's on users to install them via the EasyBuild?
- You can see from the LUMI software library what is pre-installed or installable with EasyBuild. More EasyBuild recipes are constantly developed by the user support team. Does this answer to your question?
I think so, from the link I see that it is mostly on users to install their own packages if possible.
- Yes, the collection of pre-installed software is kept small for a reason. The current presentation enlightens this.
-
Do you encourge users to use conda even for installing non-python packages due to (large) storage space they probably take on user home directory (e.g. ~/.conda)?
- You can use Conda but not natively as you are used to from your laptop and maybe other clusters. We do not encourage native conda installations (just using
conda create) as this creates many tens to hundreds of thousands of files and puts quite some pressure on the filesystem. Instead we offer two tools to create a conda environment inside a container. One of them is cotainr
Do mean like using Singularity container?
I'm not quite sure that using Singularity env works well for all cases. For example, what if a user develops code on ondemand/jupyter and wants to use his/her own Singularity-based conda env as a custom kernel?
-
Open OnDemand is actually heavily based on containerised software itself...
-
We really encourage users to use software installed properly for the system via EasyBuild or Spack, but that is not always possible because sometimes the dependency chains of especially bioinformatics software are too long. For PyTorch and TensorFlow we advise to try to build on top of containers provided by AMD and discusses in the LUMI Software Library.
The size of a software installation in terms of number of gigabytes is not a problem for a computer as LUMI. What is a problem is the number of files, and in particular the number of files that is being read while starting/using the package, and that determines if it is better to put it in a container.
-
How does EasyBuild manage versions of our custom software?
- Do you mean EB recipes that you install from LUMI software stack, or EB recipes that you have developed/modified yourself?
The ones that I develop myself
- The ones you have developed yourself are managed the same way as the ones from LUMI software stack, if you just locate your own recipes in a correct place. This is documented shortly in the lumi documentation EasyBuild page.
Thanks
- I'm not sure what to write about this without just repeating the documentation, but please ask if something is unclear
I understand it now, I'm not very used to use EB.
-
I will need Netcdf-c and netcdf-fortran compiled with the GNU toolchain (my application only works with that, not with other compilers) is that available as modules already or will I have to install them myself with Easybuild?
cray-netcdf modules (part of the Cray Programming Environment) are recommended to use unless other specific version is required. They combine the C and Fortran interfaces in a single module, not in 3 different modules like some default EasyBuild installations do.
OK so I found a combination of module which seems \"compatible\": module load LUMI/22.08 partition/C gcc/12.2.0 craype cray-mpich/8.1.27 cray-hdf5-parallel/1.12.1.5 cray-netcdf-hdf5parallel/4.8.1.5 but it does not have pnetcdf,
- Parallel netCDF is served by another module called
cray-parallel-netcdf
There is this combination: module load LUMI/22.08 partition/C gcc/12.2.0 cray-mpich/8.1.25 cray-parallel-netcdf/1.12.2.5 but it still has not got pnetcdf: --has-pnetcdf -> no Parallel netcdf and pnetcdf are two different things
cray-parallel-netcdf/1.12.2.5 does not have the nc-config command so you likely have some other module loaded that provides that command. All I can find in that module is pnetcdf-config that declares it is \"PNetCDF 1.12.2\".
That would be great if there was a netcdf-c/netcdf-fortran that was built with it, is there? All I need is a set netcdf-c/netcdf-fortran built with pnetcdf in the gcc \"familly\", so maybe
It is netcdf-c and netcdf-fortran I need, my application does not use pnetcdf directly but the netcdf has to be build with pnetcdf, otherwise the performance is very bad
module keyword netcdf pnetcdf finds 3 matches:
cray-netcdf: cray-netcdf/4.8.1.5\ncray-netcdf-hdf5parallel: cray-netcdf-hdf5parallel/4.8.1.5\ncray-parallel-netcdf: cray-parallel-netcdf/1.12.2.5\n
and none of the has both netcdf and pnetcdf, strange, no?
- Not so strange I think. Isn't PNetCDF a rather old backend?
No, it is maintained, and still used a lot (all the latest releases of netcdf use it)
-
The other two netCDF modules provided by Cray use HDF5 in different configurations (one of them parallel) as the backend. That should also give very good parallel I/O performance when used in the proper way.
But it shows the point Kurt made in the talk: A central software stack is not practical anymore as too many users want specialised configurations that are different from others... You'll probably have to compile your own versions if the C and Fortran interface provided by cray-parallel-netcdf is different.
Maybe should I build it myself, if there is an Easybuild recipe available?
-
There is none at the moment as so far the 3 Cray-provided configurations have been enough for everybody. There is also none with the common EasyBuild toolchains. It is just as the Cray modules: Either netCDF-C etc. with HDF5 backend, or PnetCDF as a separate package comparable in configuration to cray-parallel-netcdf.
Spack seems to support building netCDF-C/-Fortran with PnetCDF but it is also not the default configuration.
OK, to start with I will try with load LUMI/22.08 partition/C gcc/12.2.0 craype cray-mpich/8.1.27 cray-hdf5-parallel/1.12.1.5 cray-netcdf-hdf5parallel/4.8.1.5 (that is without pnetcdf)
-
I wanted to install some modules in EasyBuild. I did this:
module load LUMI/23.09 partition/C\nmodule load EasyBuild-user\neb ncview-2.1.9-cpeCray-23.09.eb -r\neb CDO-2.3.0-cpeCray-23.09.eb -r\neb NCO-5.1.8-cpeCray-23.09.eb -r\n
and then I loaded everything and worked, but when I try it in a new tab it does not work. Does anyone know why?
jelealro@uan01:~> module load ncview/2.1.9-cpeCray-23.09\n\nLmod has detected the following error: The following module(s) are unknown:\n\"ncview/2.1.9-cpeCray-23.09\"\n\nPlease check the spelling or version number. Also try \"module spider ...\"\nIt is also possible your cache file is out-of-date; it may help to try:\n $ module --ignore_cache load \"ncview/2.1.9-cpeCray-23.09\"\n
- You have to load the same version of the software stack that you used to compile. I.e.
module load LUMI/23.09 partition/C then you can find the modules with module avail. Alternatively, module spider NCO will still list the package and show you how to load it.
I opened a new tab and did this:
module purge\nmodule load LUMI/23.09 partition/C\nmodule load ncview/2.1.9-cpeCray-23.09\nmodule load CDO/2.3.0-cpeCray-23.09 \nmodule load NCO/5.1.8-cpeCray-23.09\n
but the error still remained
- Did you add
export EBU_USER_PREFIX=... to your bashr? Otherwise lmod doesn't know where your modules are.
When I built the Easybuld I did it at my home just for testing, here. export EBU_USER_PREFIX=/users/jelealro/my_easybuild. And no, I don't have it in my bashrc.
-
Try logging in again, then do
export EBU_USER_PREFIX=/users/jelealro/my_easybuild\nmodule load LUMI/23.09 partition/C\nmodule av NCO\n
It worked! thanks you. I was missing the first line EBU_USER_PREFIX:...
- As discussed it is best to have Easybuild install into your project (but if you only have the training project now, your home is also okay for testing). Put the line in your .bashrc then it will always find your installed modules.
Noted it, I will just re do it in the project folder. Thank you!
"},{"location":"1day-20240208/notes_20240208/#exercise-session-1","title":"Exercise session 1","text":"/
"},{"location":"1day-20240208/notes_20240208/#running-jobs","title":"Running jobs","text":" -
I am a bioinformatician and don't really understand all of the computer science behind LUMI. I have used PBS job submission at Oak Ridge National Lab, so I have some background to begin (not entirely lost), however I have no idea where to start with LUMI to download my program and submit jobs. Is this covered at a beginner level in this section about slurm submission?
-
I hope you will find it helpful to start. But you may need a more elementary course like the ones that the local organisation should give to train beginners. This course is too fast-paced for beginners.
-
And what system at ORNL still uses PBS, or do you mean Slurm?
-
If you are familiar with Slurm, I'd suggest to see some of the [LUMI specific examples from the documentation. If you are not familiar with Slurm, a basic Slurm tutorial at first could be helpful. E.g. DeiC (Denmark) has developed this Slurm learning tutorial. About what to do on LUMI to get your software in use, it depends what software you are using. If you can't find your software in the LUMI software library or from local stack by CSC or otherwise have any questions of how to proceed in practice, you can also [open a ticket]https://www.lumi-supercomputer.eu/user-support/need-help/).
-
Should we reserve 8 GPUs per node when submitting a SLURM job, considering that 4 GPUs act like 8?
- Yes, Slurm thinks of one GCD (Graphics Compute Die) (each MI250X consists of two GCDs) as one GPU. So ask for 8 gpus if you want to book the whole node.
Does this apply for LUMI C, LUMI G, and so on?
- Only LUMI-G nodes have GPUs, so it only applies to slurm partitions on LUMI-G (
standard-g, dev-g, small-g)
-
Follow up to the previous question. I got following error when book 8 gpus per node: `Node 0: Incorrect process allocation input. Do I miss something?
- Can you show me what slurm parameters you use? Which partition?
Sure:
#SBATCH --partition=standard-g\n#SBATCH --nodes=1\n#SBATCH --ntasks-per-node=8\n#SBATCH --gpus-per-node=8\n
- Strange, but it also doesn't look like a slurm error. Probably best to open a ticket. https://lumi-supercomputer.eu/user-support/need-help/
Aha, OK - just wanted to ensure if I am doing some wrong when booking.
- You may need to limit GPU visibility to each task if your application expects one GPU per task (MPI rank)
Thanks for the suggesstion. I am doing it by setting the ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID at runtime.
- So it is likely not the case.
I guess if the error is not related to Slurm, then I must look into application configuration parameters. Thanks.
-
Is it possible to run and debug a GPU dependent code without submitting it as a batch job, during development and small testing phase.
-
Why use salloc instead of just providing all the options to srun?
- About what usage scenario are you thinking? Interactive runs or job scripts?
Interactive runs. im not used to run salloc first and then use srun to reach a compute resource. Usually I provide everything as options to srun. nodes, cores, memory, time, partitions, projects, etc..
-
You can do both ways, and somewhat this is a matter of preference, I think. I've understood that salloc would be more useful in some more complex cases, though.
-
salloc is a command to create an allocation. The srun command is meant to create a job step in an allocation. It has a side effect though: If it is run outside an allocation it will create an allocation. However, some options for creating an allocation and for a job step have a different meaning for both tasks. And this can lead to unexpected side effects when you use srun to create the allocation and start a job step with a single command.
srun is particularly troublesome if you want an interactive session in which you can then start a distributed memory application.
-
If we submit a slurm script with --partition=standard-g but without requesting any GPUs, which resources are billed? The CPU or GPU hours ?
- You will be billed GPU hours, and in the case of
standard-g you effectively get the whole node, whether you use it or not, so you will be billed 4 GPU hours for every hour you use the node. It is only normal: On LUMI you are billed for resources that others cannot use because of your request, whether you use them or not. Likewise, if you would ask for resources on small-g you will be billed based on the amount of cores, amount of GPUs and amount of memory you request. If you request a disproportional amount of one resource, you'll be billed for a similar amount of the other resources. So if you would ask for half of the cores or half of the memory, you'd still be billed for 4 GCDs (so 2 GPU hours per hour use) as you effectively make 4 GCDs unusable for others.
The output of lumi-allocations command is:
Project | CPU (used/allocated)| GPU (used/allocated)| Storage (used/allocated)\n--------------------------------------------------------------------------------------------------------------------------------------\nproject_465000961 | 12/10000000 (0.0%) core/hours| 0/1000 (0.0%) gpu/hours| 0/10 (0.0%) TB/hours\n
which means so far we only used CPU-resources (?)
-
Maybe you've not done what you think, but also, lumi-allocations is not immediate. The data of a job has to be processed first offline and the tables that lumi-allocations shows are updated only a few times per day because of this.
-
According to the billing pagesin the documeentation this will be billed in GPU hours, even if you only use CPU hours.
-
Can you run a CPU-GPU hybrid code on GPU partition?
- Sure. You have 56 cores available on each G node. You could also do heterogenous slurm jobs with some part (some MPI ranks) run on C nodes and some on G nodes. But this is a bit more advanced.
-
Do we need to have \"module load\" things in the job file?
-
That's a matter of preference if you want to load necessary modules before sending your job script to queue, or in the job script
-
I would recommend putting all module loads into the job script to make it more obvious what is happening and more reproducible. We get enough tickets from users claiming that they ran exactly the same job as before and that it used to work but now doesn't work, and often it is because the job was launched from a different environment and does not build the complete environment it needs in the job script.
-
So, if I'm running a job on 100 nodes, with --exclusive and I want to use all the memory on the nodes, with --mem=0 it can lead to strange behaviour?
- There have been some problems in the past with nodes that had less memory available than expected due to memory leaks in the OS. By asking explicitly for nodes with 224G (LUMI-C) or 480G (LUMI-G) you ensure that you don't get nodes where less is available due to a memory leak.
-
How do I run gpu_check? I loaded
module load LUMI/23.09\nmodule load lumi-CPEtools\n
and allocated resources with salloc and when I do srun gpu_check -l (as shown in the slides) I get slurmstepd: error: execve(): gpu_check: No such file or directory
- At least you seem to be missing loading the
partition/G ?
Indeed, I was missing partition/G. thanks!
- As
gpu_check can only work on LUMI-G nodes, I did not include it in the other versions for lumi-CPEtools.
-
Can I get different thread count for different tasks in the same job with one binary ?
- Heterogeneous jobs can do that. Or you take the largest number that you want for each task and use, e.g., OpenMP functions in your code to limit threads depending on the process, but that may be hard. Is there a good use case for that? A single binary that takes an input argument to behave differently depending on the value of that input argument?
-
What's the difference between ROCR_VISBLE_DEVICES and HIP_VISBLE_DEVICES?
-
I found this discussion about the differences or this doc page.
-
HIP_VISBLE_DEVICES seems to only affect device indices exposed to HIP applications while ROCR_VISBLE_DEVICES applies to all applications using the user mode ROCm software stack.
So, in principle, can one use them interchangeably for HIP application?
- I wouldn't do so because Slurm already uses
ROCR_VISIBLE_DEVICES. If they get conflicting values you may be in for some painful debugging...
-
To be safe is it better to not bind to closest and do it explicitly? I'm not sure if, e.g., for PyTorch, there's direct communication between GPUs.
- It is safer indeed. PyTorch uses RCCL as far as I know so yes, it will do direct communication between GPUs and given that many GPU configurations used for AI have much slower communication via the CPU than direct communication between GPUs (NVIDIA links between GPUs are really fast compared to PCIe, and the external bandwidth between LUMI GPU packages is also 250 GB/s compared to 72 GB/s to the CPU) having good direct communication may be essential for performance.
-
If I submit a 256 cores job on 2 nodes without hyperthreading, and if I use the multi_prog option of srun, what should my program configuration file look like ? I want to be sure that my tasks are on both nodes, and I am confused by the numbering (does it change depending on the hyperthreading option?).
0 ./prog_1.exe\n...\n127 ./prog_2.exe\n128 ./prog_2.exe\n...\n255 ./prog_2.exe\n
or
0 ./prog_1.exe\n...\n127 ./prog_2.exe <--- Sure? Shouldn't it be prog_1? No. Well, the distribution of the programs among the tasks is another question, but for starter I just want to be sure that I use the 2 nodes\n256 ./prog_2.exe\n...\n383 ./prog_2.exe\n
- If you want to be sure, I recommend using the tools in the
lumi-CPEtools module to check how tasks and threads are allocated... That's what we also do before we give answers to such questions as we are not a dictionary either that know all ins and outs of Slurm without checking things.
-
When I bind the CPU using these hex values, do I always use the same mask? This assumes allocation to a full node? In case I'm not using the full node, should I use bindings?
-
All binding parameters only work with the --exclusive flag set (which is done implicitely on standard-g). You can't affect the binding on small-g (except if you set --exclusive.
-
The mask uses 7 cores and one GPU per task and 8 tasks, if you want to use less cores or less GPUs you have to adapt it.
But if your program uses OpenMP threads on the CPU side, you can still use the \"large\" mask and further restrict with the OpenMP environment variables (OMP_NUM_THREADS).
-
Refering to slide 36 here, is there a reason why NUMA and GPU numbering are completely independent ? Wouldn't it make more sense, for simpler usability, to have similar numbering, or if the default binding was the optimal one ?
-
Yes, that is quite annoying but there seems to be some HW reason for that. I don't know why it is not possible to map it, so that you don't see it as a user.
-
CCDs get their numbering from the position in the CPU package. GCDs in a package get their numbering from their position in the GPU packages, and between GPUs I think some order in communication links will determine a numbering when booting the node.
Now the problem is really to lay all the connections on the circuit board. I'm sure there would be an ordering so that they number in the same way, but that may not be physically possible or would require a much more expensive circuit board with more layers to make all connections between GCDs and between GCDs and CCDs.
-
Probably this depends on the application, but roughly, how much worse is the performance if one does not do the correct CPU \u2192 GPU binding ?
-
I believe most spectacular difference we have seen is almost double. It is probably more important for HIP codes and GPU to GPU communication.
-
The heavier traffic between CPU and GPU, the larger the difference will be...
-
What if I want to modify one of these provided containers to add some application. How should we do it?
- One possible approach is with singularity overlays https://docs.sylabs.io/guides/3.11/user-guide/persistent_overlays.html
-
Is there anyway to measure the energy/power consumed by the application? +1
-
No. In theory it should be possible at the node level, but even that is not implemented at the moment. On a shared node it is simply impossible.
-
ROCm tools can report some numbers but they are known to be unreliable.
Are node-level measurements also not possible on --exclusive booked node?
-
We simply don't have the software that could be called with user rights to gather the data from the counters in the node and service modules. And even then the data is very coarse and hard to reproduce as on modern computers there is a lot of variability between nodes.
To get as good a result as possible on the Linpack benchmark for the Top500 they actually needed to play with individual power caps for nodes and GPUs to make all of them about as fast as it is the slowest GPU that determines progress of the parallel benchmark, while they also had to stay within a certain power consumption limit per rack to avoid overheating.
If you could measure, don't be surprised that when your application runs on a different node, power consumption could differ by 20% or more...
-
Is there a way (example, a script) to get the cpu and memory performance of a finished job?
- There is some very coarse information stored in the Slurm accounting database that you can request via
sacct. But this is only overal use of memory and overall consumed CPU time.
When I use `sacct --account=, it is basically printing the headings but no information related to the job. May I know what I am missing?
- If you want to give a jobID the option is
-j or --jobs and not --account. Moreover, you'll have to specify the output that you want with -o or --format. There is a long field of possible output fields and some examples in the sacct manual page. Often sacct only searches in a specific time window for information so depending on the options that you use you may have to specify a start and end time for the search.
-
We are supposed to use Cray MPI, but when working with containers we need the singularity-bindings, correct? I have an open ticket regarding these bindings, and apparently they are not working. Do we have an ETA for when they'll be available again?
- This should be an easy fix. Can you provide the ticket number?
Sure: LUMI #3552
- Oh, OK, your ticket was in the hand of a member of the team who quit recently so it was not progressing. I will take it.
"},{"location":"1day-20240208/notes_20240208/#exercises-2","title":"Exercises 2","text":""},{"location":"1day-20240208/notes_20240208/#introduction-to-lustre","title":"Introduction to Lustre","text":" -
How do you deal with hierarchical file formats such as zarr (which have many subfolders and small files) on LUMI?
-
I don't know for sure for zarr specifically and how it works with the file system, so the answer may not be entirely accurate.
If those subfolders are INSIDE a big file Lustre only has to deal with the big file and it should work well. If it is one of those things that thinks that it should simply dump those files and folders as regular files and folders, then it is not a technology that is suitable for HPC clusters with parallel file systems. If my quick googling returned the right information then it is doing the latter and simply not made for HPC systems. It compares itself with netCDF and HDF5 but these are proper technologies for HPC that do the work themselves INSIDE a big file rather than letting the regular file system deal with it.
From all the information I have at the moment, zarr is the perfect example of something mentioned in the architecture presentation of the course: Not all technologies developed for workstations or for cloud infrastructures, work well on HPC systems (and vice-versa). Zarr is an example of a technology built for a totally different storage model than that used on the LUMI supercomputer. It may be perfect for a typical cloud use case, where you would be using a fat node as a big workstation or a small virtual cluster with its own local file system, but at first it looks terrible for a parallel file system shared across a large HPC cluster like LUMI.
On systems the size of LUMI you have no other solution than to work with hierarchies. It is the case for the job system: Slurm cannot deal with hundreds of thousands of minute-sized jobs but you need to use a hierarchical scheduling system for that. And it is the case for data formats. Lustre cannot deal with hundreds of thousands of small files, but you need a hierarchical approach with a file system inside a big file. You'd need file system that costs several times more per PB to deal with those things at the scale of LUMI.
-
What Block Size do you have on the LUSTRE Filesysten? i want to generate one billion 2 byte files
-
You're simply not allowed to generate one billion 2 byte files and will never get the file quota for that. On the contrary, this will be considered as a denial-of-service attack on the file system and abuse of LUMI with all consequences that come with that.
2 billion 2 byte numbers belong in a single file on an HPC cluster, and you read that file as a whole in memory before using the data.
If the reason to use 1B files is that you want to also run 1B small processes that generate those files and that therefore you cannot use a single file: That is also a very, very bad idea, even if you use a subscheduler such as HyperQueue as just starting those 1B small processes may stretch the metadata service a lot.
Scaling software is not starting more copies of it, and just starting more copies of a program is not what a supercomputer like LUMI is built for. You need a different and way more expensive type of infrastructure for that. Scaling would be turning that program into a subroutine that you can call in a loop to generate a lot of those 2-byte numbers in a single run and store those intelligently in a single file.
-
How can we specify the location such as scracth to store the experiment results (>20GB) generated during the execution?
-
The output is usually automatically located at the same directory location from where you submit the job.
-
Hopefully you're not pumping 20GB of output via printf to stdout? That is not a good strategy to get a good I/O bandwidth. You should write such files properly with proper C/Fortran library calls. And then it is your program or probably the start directory of your program that will determine where the files will end up.
They are HDF5 files. Could you please specify which #SBATCH option you mentioned above to redirect them?
-
No we can't, because it is your specific application that determines where the files will land, not Slurm. Maybe they will land in the directory where the application is started (so go to that directory with cd will do the job), maybe your application does something different. You cannot redirect arbitrary files in Slurm, you can only redirect the stdout and stderr devices of Linux.
-
About redirecting stdout and stderr, please see the sbatch manual page (e.g. #SBATCH -o /your/chosen/location/output.%a.out) but indeed this doesn't actually redirect the output created by the application
-
Let\u2019s assume I have one HDF5 file (~300GB), which stores my entire dataset, consisting of videos (~80k). I store each video as a single HDF5 dataset, where each element consists of the bytes of the corresponding video frame. I spawn multiple threads (pinned to each processor core), which randomly access the videos. What would be some rules of thumb to optimise the Lustre stripping for better performance?
- I think we need to ask HPE for advice on that and even they may not know.
Besides going for sequential access (e.g., webdataset), is there anything a user can do to limit the I/O bottleneck involving random access (i.e., typical machine learning workflow)?
-
Random I/O in HDF5 will already be less of a bottleneck for the system than random access to data in lots of individual files on the file system. I'd also expect the flash filesystem to perform better than the hard disk based file systems. They are charged at 10 times the rate of the hard disk based ones, but there is a good reason for that: they were also 10 times as expensive per PB...
-
I think general rule is to use high stripe-count value for such a large dataset files. For instance -1 will use all OSTs. There are 12 OSTs.
"},{"location":"1day-20240208/notes_20240208/#lumi-support","title":"LUMI support","text":""},{"location":"1day-20240208/notes_20240208/#general-qa","title":"General Q&A","text":""},{"location":"1day-20240208/schedule/","title":"Schedule (tentative)","text":"09:00 CEST\u00a0\u00a0 10:00 EEST Welcome and introduction Presenter: J\u00f8rn Dietze (LUST) 09:10 CEST 10:10 EEST LUMI Architecture Presenter: Kurt Lust 09:40 CEST 10:40 EEST HPE Cray Programming Environment Presenter: Kurt Lust 10:15 CEST 11:15 EEST Modules on LUMI Presenter: Kurt Lust 10:45 CEST 11:45 EEST Break 11:00 CEST 12:00 EEST LUMI Software Stacks Presenter: Kurt Lust 11:45 CEST 12:45 EEST Hands-on Exercise assignments and solutions 12:15 CEST 13:15 EEST Lunch break 13:15 CEST 14:15 EEST Running jobs on LUMI Presenter: Maciej Szpindler 14:45 CEST 15:4 EEST Hands-on Exercise assignments and solutions 15:15 CEST 16:15 EEST Break 15:30 CEST 16:30 EEST Introduction to Lustre and Best Practices Presenter: J\u00f8rn Dietze 15:50 CEST 16:50 EEST LUMI User Support Presenter: J\u00f8rn Dietze 16:15 CEST 17:15 EEST General Q&A 16:30 CEST 17:30 EEST Course end"},{"location":"1day-20240208/video_00_Introduction/","title":"Welcome and introduction","text":"Presenter: J\u00f8rn Dietze (LUST)
"},{"location":"1day-20240208/video_01_LUMI_Architecture/","title":"LUMI Architecture","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20240208/video_02_HPE_Cray_Programming_Environment/","title":"HPE Cray Programming Environment","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20240208/video_03_Modules_on_LUMI/","title":"Modules on LUMI","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20240208/video_04_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"1day-20240208/video_06_Running_Jobs_on_LUMI/","title":"Running Jobs on LUMI","text":"Presenter: Maciej Szpindler (LUST)
Additional materials
"},{"location":"1day-20240208/video_08_Introduction_to_Lustre_and_Best_Practices/","title":"Introduction to Lustre and Best Practices","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"1day-20240208/video_09_LUMI_User_Support/","title":"LUMI User Support","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"2day-20240502/","title":"Supercomputing with LUMI - Amsterdam, May 2-3, 2024","text":""},{"location":"2day-20240502/#course-organisation","title":"Course organisation","text":" -
Location: SURF, Science Park 140, 1098 XG, Amsterdam, The Netherlands
-
Schedule
"},{"location":"2day-20240502/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":"If you have an active project on LUMI, you should be able to make the exercises in that project. You will only need an very minimum of CPU and GPU billing units for this.
-
Create a directory in the scratch of your project, or if you want to keep the exercises around for a while, in a subdirectory of your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of your project:
mkdir -p /scratch/project_465001102/$USER/exercises\ncd /scratch/project_465001102/$USER/exercises\n
where you have to replace project_465001102 using the number of your own project.
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/2day-20240502/files/exercises-20240502.tar.gz\ntar -xf exercises-20240502.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"2day-20240502/#course-materials","title":"Course materials","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes recording Welcome and Introduction slides notes video LUMI Architecture slides notes video HPE Cray Programming Environment slides notes video Getting Access to LUMI slides notes video Exercises 1 / notes / Modules on LUMI slides notes video Exercises 2 / notes / LUMI Software Stacks slides notes video Exercises 3 / notes / Wrap-Up Day 1 slides / video Introduction Day 2 slides / video Slurm on LUMI slides notes video Process and Thread Distribution and Binding slides notes video Exercises 4 / notes / I/O and File Systems on LUMI slides notes video Containers on LUMI-C and LUMI-G slides notes video Demo 1 (optional) / notes video Demo 2 (optional) / notes video LUMI Support and Documentation slides notes video LUMI in The Netherlands slides / video What Else? slides / video A1 Additional documentation / notes /"},{"location":"2day-20240502/#web-links","title":"Web links","text":""},{"location":"2day-20240502/#acknowledgement","title":"Acknowledgement","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities. The VSC is funded by FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders).
"},{"location":"2day-20240502/00_Introduction/","title":"Introduction to the notes","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities with funding from FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders) which we hereby acknowledge.
Various training materials and the documentation from the Belgian Walloon HPC project C\u00c9CI were also a great source of inspiration.
"},{"location":"2day-20240502/00_Introduction/#about-the-structure-of-the-notes","title":"About the structure of the notes","text":"Colour coding and boxes in the material:
Remark
This is a remark: Some additional information that may be nice to read. or some additional information that you may want to have a look at.
Note
Just a quick note on the side, but do have a look at it.
Audience
A box telling you who this part of the notes is written for, or why it would be good to read it even if you think you don't need it.
Example
An example to make the material clearer or to try something out.
Exercise
An exercise
Solution
The solution to the exercise. You will have to click on the box to see the solution.
Bug
This is a discussion about a bug.
Nice-to-know
This is a little fact which is nice-to-know but not necessary to understand the material.
Intermediate
Information that may not be useful to every LUMI user, but if you are the kind of person who likes to explore manuals and try out things that we did not discuss in the course, you may want to read this...
Advanced
Similar to the intermediate material, but it requires even more technical skills to understand this stuff.
Technical
Material specific to readers with very technical interests.
"},{"location":"2day-20240502/01_Architecture/","title":"The LUMI Architecture","text":"In this presentation, we will build up LUMI part by part, stressing those aspects that are important to know to run on LUMI efficiently and define jobs that can scale.
"},{"location":"2day-20240502/01_Architecture/#why-do-i-kneed-to-know-this","title":"Why do I kneed to know this?","text":"You may wonder why you need to know about system architecture if all you want to do is to run some programs.
A supercomputer is not simply a scaled-up smartphone or PC that will offer good performance automatically. It is a shared infrastructure and you don't get the whole machine to yourself. Instead you have to request a suitable fraction of the computer for the work you want to do. But it is also a very expensive infrastructure, with an investment of 160M EURO for LUMI and an estimated total cost (including operations) of 250M EURO. So it is important to use the computer efficiently.
And that efficiency comes not for free. Instead in most cases it is important to properly map an application on the available resources to run efficiently. The way an application is developed is important for this, but it is not the only factor. Every application needs some user help to run in the most efficient way, and that requires an understanding of
-
The hardware architecture of the supercomputer, which is something that we discuss in this section.
-
The middleware: the layers of software that sit between the application on one hand and the hardware and operating system on the other hand. LUMI runs a sligthly modified version of Linux. But Linux is not a supercomputer operating system. Missing functionality in Linux is offered by other software layers instead that on supercomputers often come as part of the programming environment. This is a topic of discussion in several sessions of this course.
-
The application. This is very domain-specific and application-specific and hence cannot be the topic of a general course like this one. In fact, there are so many different applications and often considerable domain knowledge is required so that a small support team like the one of LUMI cannot provide that information.
-
Moreover, the way an application should be used may even depend on the particular problem that you are trying to solve. Bigger problems, bigger computers, and different settings may be needed in the application.
It is up to scientific communities to organise trainings that teach you individual applications and how to use them for different problem types, and then up to users to combine the knowledge of an application obtained from such a course with the knowledge about the computer you want to use and its middleware obtained from courses such as this one or our 4-day more advanced course.
Some users expect that a support team can give answers to all those questions, even to the third and fourth bullet of the above list. If a support team could do that, it would basically imply that they could simply do all the research that users do and much faster as they are assumed to have the answer ready in hours...
"},{"location":"2day-20240502/01_Architecture/#lumi-is","title":"LUMI is ...","text":"LUMI is a pre-exascale supercomputer, and not a superfast PC nor a compute cloud architecture.
Each of these architectures have their own strengths and weaknesses and offer different compromises and it is key to chose the right infrastructure for the job and use the right tools for each infrastructure.
Just some examples of using the wrong tools or infrastructure:
-
The single thread performance of the CPU is lower than on a high-end PC. We've had users who were disappointed about the speed of a single core and were expecting that this would be much faster than their PCs. Supercomputers however are optimised for performance per Watt and get their performance from using lots of cores through well-designed software. If you want the fastest core possible, you'll need a gaming PC.
E.g., the AMD 5800X is a popular CPU for high end gaming PCs using the same core architecture as the CPUs in LUMI. It runs at a base clock of 3.8 GHz and a boost clock of 4.7 GHz if only one core is used and the system has proper cooling. The 7763 used in the compute nodes of LUMI-C runs at a base clock of 2.45 GHz and a boost clock of 3.5 GHz. If you have only one single core job to run on your PC, you'll be able to reach that boost clock while on LUMI you'd probably need to have a large part of the node for yourself, and even then the performance for jobs that are not memory bandwidth limited will be lower than that of the gaming PC.
-
For some data formats the GPU performance may be slower also than on a high end gaming PC. This is even more so because an MI250X should be treated as two GPUs for most practical purposes. The better double precision floating point operations and matrix operations, also at full precision, require transistors also that on some other GPUs are used for rendering hardware or for single precision compute units.
E.g., a single GPU die of the MI250X (half a GPU) has a peak FP32 performance at the boost clock of almost 24 TFlops or 48 TFlops in the packed format which is actually hard for a compiler to exploit, while the high-end AMD graphics GPU RX 7900 XTX claims 61 TFlops at the boost clock. But the FP64 performance of one MI250X die is also close to 24 TFlops in vector math, while the RX 7900 XTX does less than 2 TFlops in that data format which is important for a lot of scientific computing applications.
-
Compute GPUs and rendering GPUs are different beasts these days. We had a user who wanted to use the ray tracing units to do rendering. The MI250X does not have texture units or ray tracing units though. It is not a real graphics processor anymore.
-
The environment is different also. It is not that because it runs some Linux it handles are your Linux software. A user complained that they did not succeed in getting their nice remote development environment to work on LUMI. The original author of these notes took a test license and downloaded a trial version. It was a very nice environment but really made for local development and remote development in a cloud environment with virtual machines individually protected by personal firewalls and was not only hard to get working on a supercomputer but also insecure.
-
And supercomputers need proper software that exploits the strengths and works around the weaknesses of their architecture. CERN came telling on a EuroHPC Summit Week before the COVID pandemic that they would start using more HPC and less cloud and that they expected a 40% cost reduction that way. A few years later they published a paper with their experiences and it was mostly disappointment. The HPC infrastructure didn't fit their model for software distribution and performance was poor. Basically their solution was designed around the strengths of a typical cloud infrastructure and relied precisely on those things that did make their cloud infrastructure more expensive than the HPC infrastructure they tested. It relied on fast local disks that require a proper management layer in the software, (ab)using the file system as a database for unstructured data, a software distribution mechanism that requires an additional daemon running permanently on the compute nodes (and local storage on those nodes), ...
True supercomputers, and LUMI in particular, are built for scalable parallel applications and features that are found on smaller clusters or on workstations that pose a threat to scalability are removed from the system. It is also a shared infrastructure but with a much more lightweight management layer than a cloud infrastructure and far less isolation between users, meaning that abuse by one user can have more of a negative impact on other users than in a cloud infrastructure. Supercomputers since the mid to late '80s are also built according to the principle of trying to reduce the hardware cost by using cleverly designed software both at the system and application level. They perform best when streaming data through the machine at all levels of the memory hierarchy and are not built at all for random access to small bits of data (where the definition of \"small\" depends on the level in the memory hierarchy).
At several points in this course you will see how this impacts what you can do with a supercomputer and how you work with a supercomputer.
And LUMI is not just a supercomputer, it is a pre-exascale supercomputer. This implies that it is using new and leading edge technology and pushing the limits of current technology. But this also means that it will have some features that many observe as problems that smaller clusters using more conventional technology will not have. Stability is definitely less, bigger networks definitely come with more problems (and are an important cause of those stability problems), not everything scales as you would hope (think of the scheduler and file system IOPS discussed later in this course), ...
"},{"location":"2day-20240502/01_Architecture/#lumi-spec-sheet-a-modular-system","title":"LUMI spec sheet: A modular system","text":"So we've already seen that LUMI is in the first place a EuroHPC pre-exascale machine. LUMI is built to prepare for the exascale era and to fit in the EuroHPC ecosystem. But it does not even mean that it has to cater to all pre-exascale compute needs. The EuroHPC JU tries to build systems that have some flexibility, but also does not try to cover all needs with a single machine. They are building 3 pre-exascale systems with different architecture to explore multiple architectures and to cater to a more diverse audience. LUMI is an AMD GPU-based supercomputer, Leonardo uses NVIDIA A100 GPUS, and MareNostrum5 has a very large CPU section besides an NVIDIA Hopper GPU section.
LUMI is also a very modular machine designed according to the principles explored in a series of European projects, and in particular DEEP and its successors) that explored the cluster-booster concept. E.g., in a complicated multiphysics simulation you could be using regular CPU nodes for the physics that cannot be GPU-accelerated communicating with compute GPU nodes for the physics that can be GPU-accelerated, then add a number of CPU nodes to do the I/O and a specialised render GPU node for in-situ visualisation.
LUMI is in the first place a huge GPGPU supercomputer. The GPU partition of LUMI, called LUMI-G, contains 2978 nodes with a single 64-core AMD EPYC 7A53 CPU and 4 AMD MI250X GPUs. Each node has 512 GB of RAM attached to the CPU (the maximum the CPU can handle without compromising bandwidth) and 128 GB of HBM2e memory per GPU. Each GPU node has a theoretical peak performance of nearly 200 TFlops in single (FP32) or double (FP64) precision vector arithmetic (and twice that with the packed FP32 format, but that is not well supported so this number is not often quoted). The matrix units are capable of about 400 TFlops in FP32 or FP64. However, compared to the NVIDIA GPUs, the performance for lower precision formats used in some AI applications is not that stellar.
LUMI also has a large CPU-only partition, called LUMI-C, for jobs that do not run well on GPUs, but also integrated enough with the GPU partition that it is possible to have applications that combine both node types. LUMI-C consists of 2048 nodes with 2 64-core AMD EPYC 7763 CPUs. 32 of those nodes have 1TB of RAM (with some of these nodes actually reserved for special purposes such as connecting to a Quantum computer), 128 have 512 GB and 1888 have 256 GB of RAM.
LUMI also has two smaller groups of nodes for interactive data analytics. 8 of those nodes have two 64-core Zen2/Rome CPUs with 4 TB of RAM per node, while 8 others have dual 64-core Zen2/Rome CPUs and 8 NVIDIA A40 GPUs for visualisation. There is also an Open OnDemand based service (web interface) to make some fo those facilities available. Note though that these nodes are meant for a very specific use, so it is not that we will also be offering, e.g., GPU compute facilities on NVIDIA hardware, and that these are shared resources that should not be monopolised by a single user (so no hope to run an MPI job on 8 4TB nodes).
LUMI also has a 8 PB flash based file system running the Lustre parallel file system. This system is often denoted as LUMI-F. The bandwidth of that system is over 2 TB/s. Note however that this is still a remote file system with a parallel file system on it, so do not expect that it will behave as the local SSD in your laptop. But that is also the topic of another session in this course.
The main work storage is provided by 4 20 PB hard disk based Lustre file systems with a bandwidth of 240 GB/s each. That section of the machine is often denoted as LUMI-P.
Big parallel file systems need to be used in the proper way to be able to offer the performance that one would expect from their specifications. This is important enough that we have a separate session about that in this course.
There is also a 30 PB object based file system similar to the Allas service of CSC that some of the Finnish users may be familiar with is also being worked on. At the moment the interface to that system is still rather primitive.
Currently LUMI has 4 login nodes for ssh access, called user access nodes in the HPE Cray world. They each have 2 64-core AMD EPYC 7742 processors and 1 TB of RAM. Note that whereas the GPU and CPU compute nodes have the Zen3 architecture code-named \"Milan\", the processors on the login nodes are Zen2 processors, code-named \"Rome\". Zen3 adds some new instructions so if a compiler generates them, that code would not run on the login nodes. These instructions are basically used in cryptography though. However, many instructions have very different latency, so a compiler that optimises specifically for Zen3 may chose another ordering of instructions then when optimising for Zen2 so it may still make sense to compile specifically for the compute nodes on LUMI.
There are also some additional login nodes for access via the web-based Open OnDemand interface.
All compute nodes, login nodes and storage are linked together through a high-performance interconnect. LUMI uses the Slingshot 11 interconnect which is developed by HPE Cray, so not the Mellanox/NVIDIA InfiniBand that you may be familiar with from many smaller clusters, and as we shall discuss later this also influences how you work on LUMI.
Early on a small partition for containerised micro-services managed with Kubernetes was also planned, but that may never materialize due to lack of people to set it up and manage it.
In this section of the course we will now build up LUMI step by step.
"},{"location":"2day-20240502/01_Architecture/#building-lumi-the-cpu-amd-7xx3-milanzen3-cpu","title":"Building LUMI: The CPU AMD 7xx3 (Milan/Zen3) CPU","text":"The LUMI-C and LUMI-G compute nodes use third generation AMD EPYC CPUs. Whereas Intel CPUs launched in the same period were built out of a single large monolithic piece of silicon (that only changed recently with some variants of the Sapphire Rapids CPU launched in early 2023), AMD CPUs are made up of multiple so-called chiplets.
The basic building block of Zen3 CPUs is the Core Complex Die (CCD). Each CCD contains 8 cores, and each core has 32 kB of L1 instruction and 32 kB of L1 data cache, and 512 kB of L2 cache. The L3 cache is shared across all cores on a chiplet and has a total size of 32 MB on LUMI (there are some variants of the processor where this is 96MB). At the user level, the instruction set is basically equivalent to that of the Intel Broadwell generation. AVX2 vector instructions and the FMA instruction are fully supported, but there is no support for any of the AVX-512 versions that can be found on Intel Skylake server processors and later generations. Hence the number of floating point operations that a core can in theory do each clock cycle is 16 (in double precision) rather than the 32 some Intel processors are capable of.
The full processor package for the AMD EPYC processors used in LUMI have 8 such Core Complex Dies for a total of 64 cores. The caches are not shared between different CCDs, so it also implies that the processor has 8 so-called L3 cache regions or domains. (Some cheaper variants have only 4 CCDs, and some have CCDs with only 6 or fewer cores enabled but the same 32 MB of L3 cache per CCD).
Each CCD connects to the memory/IO die through an Infinity Fabric link. The memory/IO die contains the memory controllers, connections to connect two CPU packages together, PCIe lanes to connect to external hardware, and some additional hardware, e.g., for managing the processor. The memory/IO die supports 4 dual channel DDR4 memory controllers providing a total of 8 64-bit wide memory channels. From a logical point of view the memory/IO-die is split in 4 quadrants, with each quadrant having a dual channel memory controller and 2 CCDs. They basically act as 4 NUMA domains. For a core it is slightly faster to access memory in its own quadrant than memory attached to another quadrant, though for the 4 quadrants within the same socket the difference is small. (In fact, the BIOS can be set to show only two or one NUMA domain which is advantageous in some cases, like the typical load pattern of login nodes where it is impossible to nicely spread processes and their memory across the 4 NUMA domains).
The theoretical memory bandwidth of a complete package is around 200 GB/s. However, that bandwidth is not available to a single core but can only be used if enough cores spread over all CCDs are used.
"},{"location":"2day-20240502/01_Architecture/#building-lumi-a-lumi-c-node","title":"Building LUMI: a LUMI-C node","text":"A compute node is then built out of two such processor packages, connected through 4 16-bit wide Infinity Fabric connections with a total theoretical bandwidth of 144 GB/s in each direction. So note that the bandwidth in each direction is less than the memory bandwidth of a socket. Again, it is not really possible to use the full memory bandwidth of a node using just cores on a single socket. Only one of the two sockets has a direct connection to the high performance Slingshot interconnect though.
"},{"location":"2day-20240502/01_Architecture/#a-strong-hierarchy-in-the-node","title":"A strong hierarchy in the node","text":"As can be seen from the node architecture in the previous slide, the CPU compute nodes have a very hierarchical architecture. When mapping an application onto one or more compute nodes, it is key for performance to take that hierarchy into account. This is also the reason why we will pay so much attention to thread and process pinning in this tutorial course.
At the coarsest level, each core supports two hardware threads (what Intel calls hyperthreads). Those hardware threads share all the resources of a core, including the L1 data and instruction caches and the L2 cache, execution units and space for register renaming. At the next level, a Core Complex Die contains (up to) 8 cores. These cores share the L3 cache and the link to the memory/IO die. Next, as configured on the LUMI compute nodes, there are 2 Core Complex Dies in a NUMA node. These two CCDs share the DRAM channels of that NUMA node. At the fourth level in our hierarchy 4 NUMA nodes are grouped in a socket. Those 4 nodes share an inter-socket link. At the fifth and last level in our shared memory hierarchy there are two sockets in a node. On LUMI, they share a single Slingshot inter-node link.
The finer the level (the lower the number), the shorter the distance and hence the data delay is between threads that need to communicate with each other through the memory hierarchy, and the higher the bandwidth.
This table tells us a lot about how one should map jobs, processes and threads onto a node. E.g., if a process has fewer then 8 processing threads running concurrently, these should be mapped to cores on a single CCD so that they can share the L3 cache, unless they are sufficiently independent of one another, but even in the latter case the additional cores on those CCDs should not be used by other processes as they may push your data out of the cache or saturate the link to the memory/IO die and hence slow down some threads of your process. Similarly, on a 256 GB compute node each NUMA node has 32 GB of RAM (or actually a bit less as the OS also needs memory, etc.), so if you have a job that uses 50 GB of memory but only, say, 12 threads, you should really have two NUMA nodes reserved for that job as otherwise other threads or processes running on cores in those NUMA nodes could saturate some resources needed by your job. It might also be preferential to spread those 12 threads over the 4 CCDs in those 2 NUMA domains unless communication through the L3 threads would be the bottleneck in your application.
"},{"location":"2day-20240502/01_Architecture/#hierarchy-delays-in-numbers","title":"Hierarchy: delays in numbers","text":"This slide shows the Advanced Configuration and Power Interface System Locality distance Information Table (ACPI SLIT) as returned by, e.g., numactl -H which gives relative distances to memory from a core. E.g., a value of 32 means that access takes 3.2x times the time it would take to access memory attached to the same NUMA node. We can see from this table that the penalty for accessing memory in another NUMA domain in the same socket is still relatively minor (20% extra time), but accessing memory attached to the other socket is a lot more expensive. If a process running on one socket would only access memory attached to the other socket, it would run a lot slower which is why Linux has mechanisms to try to avoid that, but this cannot be done in all scenarios which is why on some clusters you will be allocated cores in proportion to the amount of memory you require, even if that is more cores than you really need (and you will be billed for them).
"},{"location":"2day-20240502/01_Architecture/#building-lumi-concept-lumi-g-node","title":"Building LUMI: Concept LUMI-G node","text":"This slide shows a conceptual view of a LUMI-G compute node. This node is unlike any Intel-architecture-CPU-with-NVIDIA-GPU compute node you may have seen before, and rather mimics the architecture of the USA pre-exascale machines Summit and Sierra which have IBM POWER9 CPUs paired with NVIDIA V100 GPUs.
Each GPU node consists of one 64-core AMD EPYC CPU and 4 AMD MI250X GPUs. So far nothing special. However, two elements make this compute node very special. First, the GPUs are not connected to the CPU though a PCIe bus. Instead they are connected through the same links that AMD uses to link the GPUs together, or to link the two sockets in the LUMI-C compute nodes, known as xGMI or Infinity Fabric. This enables unified memory across CPU and GPUS and provides partial cache coherency across the system. The CPUs coherently cache the CPU DDR and GPU HBM memory, but each GPU only coherently caches its own local memory. The second remarkable element is that the Slingshot interface cards connect directly to the GPUs (through a PCIe interface on the GPU) rather than to the CPU. The GPUs have a shorter path to the communication network than the CPU in this design.
This makes the LUMI-G compute node really a \"GPU first\" system. The architecture looks more like a GPU system with a CPU as the accelerator for tasks that a GPU is not good at such as some scalar processing or running an OS, rather than a CPU node with GPU accelerator.
It is also a good fit with the cluster-booster design explored in the DEEP project series. In that design, parts of your application that cannot be properly accelerated would run on CPU nodes, while booster GPU nodes would be used for those parts that can (at least if those two could execute concurrently with each other). Different node types are mixed and matched as needed for each specific application, rather than building clusters with massive and expensive nodes that few applications can fully exploit. As the cost per transistor does not decrease anymore, one has to look for ways to use each transistor as efficiently as possible...
It is also important to realise that even though we call the partition \"LUMI-G\", the MI250X is not a GPU in the true sense of the word. It is not a rendering GPU, which for AMD is currently the RDNA architecture with version 3 out and version 4 coming, but a compute accelerator with an architecture that evolved from a GPU architecture, in this case the VEGA architecture from AMD. The architecture of the MI200 series is also known as CDNA2, with the MI100 series being just CDNA, the first version. Much of the hardware that does not serve compute purposes has been removed from the design to have more transistors available for compute. Rendering is possible, but it will be software-based rendering with some GPU acceleration for certain parts of the pipeline, but not full hardware rendering.
This is not an evolution at AMD only. The same is happening with NVIDIA GPUs and there is a reason why the latest generation is called \"Hopper\" for compute and \"Ada Lovelace\" for rendering GPUs. Several of the functional blocks in the Ada Lovelace architecture are missing in the Hopper architecture to make room for more compute power and double precision compute units. E.g., Hopper does not contain the ray tracing units of Ada Lovelace. The Intel Data Center GPU Max code named \"Ponte Vecchio\" is the only current GPU for HPC that still offers full hardware rendering support (and even ray tracing).
Graphics on one hand and HPC and AI on the other hand are becoming separate workloads for which manufacturers make different, specialised cards, and if you have applications that need both, you'll have to rework them to work in two phases, or to use two types of nodes and communicate between them over the interconnect, and look for supercomputers that support both workloads. And nowadays we're even starting to see a split between chips that really target AI and chips that target a more traditional HPC workload, with the latter threatened as there is currently much more money to make in the AI market. And within AI we're starting to see specialised accelerators for inference.
But so far for the sales presentation, let's get back to reality...
"},{"location":"2day-20240502/01_Architecture/#building-lumi-what-a-lumi-g-node-really-looks-like","title":"Building LUMI: What a LUMI-G node really looks like","text":"Or the full picture with the bandwidths added to it:
The LUMI-G node uses the 64-core AMD 7A53 EPYC processor, known under the code name \"Trento\". This is basically a Zen3 processor but with a customised memory/IO die, designed specifically for HPE Cray (and in fact Cray itself, before the merger) for the USA Coral-project to build the Frontier supercomputer, the fastest system in the world at the end of 2022 according to at least the Top500 list. Just as the CPUs in the LUMI-C nodes, it is a design with 8 CCDs and a memory/IO die.
The MI250X GPU is also not a single massive die, but contains two compute dies besides the 8 stacks of HBM2e memory, 4 stacks or 64 GB per compute die. The two compute dies in a package are linked together through 4 16-bit Infinity Fabric links. These links run at a higher speed than the links between two CPU sockets in a LUMI-C node, but per link the bandwidth is still only 50 GB/s per direction, creating a total bandwidth of 200 GB/s per direction between the two compute dies in an MI250X GPU. That amount of bandwidth is very low compared to even the memory bandwidth, which is roughly 1.6 TB/s peak per die, let alone compared to whatever bandwidth caches on the compute dies would have or the bandwidth of the internal structures that connect all compute engines on the compute die. Hence the two dies in a single package cannot function efficiently as as single GPU which is one reason why each MI250X GPU on LUMI is actually seen as two GPUs.
Each compute die uses a further 2 or 3 of those Infinity Fabric (or xGNI) links to connect to some compute dies in other MI250X packages. In total, each MI250X package is connected through 5 such links to other MI250X packages. These links run at the same 25 GT/s speed as the links between two compute dies in a package, but even then the bandwidth is only a meager 250 GB/s per direction, less than an NVIDIA A100 GPU which offers 300 GB/s per direction or the NVIDIA H100 GPU which offers 450 GB/s per direction. Each Infinity Fabric link may be twice as fast as each NVLINK 3 or 4 link (NVIDIA Ampere and Hopper respectively), offering 50 GB/s per direction rather than 25 GB/s per direction for NVLINK, but each Ampere GPU has 12 such links and each Hopper GPU 18 (and in fact a further 18 similar ones to link to a Grace CPU), while each MI250X package has only 5 such links available to link to other GPUs (and the three that we still need to discuss).
Note also that even though the connection between MI250X packages is all-to-all, the connection between GPU dies is all but all-to-all. as each GPU die connects to only 3 other GPU dies. There are basically two bidirectional rings that don't need to share links in the topology, and then some extra connections. The rings are:
- Green ring: 1 - 0 - 6 - 7 - 5 - 4 - 2 - 3 - 1
- Red ring: 1 - 0 - 2 - 3 - 7 - 6 - 4 - 5 - 1
These rings play a role in the inter-GPU communication in AI applications using RCCL.
Each compute die is also connected to one CPU Core Complex Die (or as documentation of the node sometimes says, L3 cache region). This connection only runs at the same speed as the links between CPUs on the LUMI-C CPU nodes, i.e., 36 GB/s per direction (which is still enough for all 8 GPU compute dies together to saturate the memory bandwidth of the CPU). This implies that each of the 8 GPU dies has a preferred CPU die to work with, and this should definitely be taken into account when mapping processes and threads on a LUMI-G node.
The figure also shows another problem with the LUMI-G node: The mapping between CPU cores/dies and GPU dies is all but logical:
GPU die CCD hardware threads NUMA node 0 6 48-55, 112-119 3 1 7 56-63, 120-127 3 2 2 16-23, 80-87 1 3 3 24-31, 88-95 1 4 0 0-7, 64-71 0 5 1 8-15, 72-79 0 6 4 32-39, 96-103 2 7 5 40-47, 104, 11 2 and as we shall see later in the course, exploiting this is a bit tricky at the moment.
"},{"location":"2day-20240502/01_Architecture/#what-the-future-looks-like","title":"What the future looks like...","text":"Some users may be annoyed by the \"small\" amount of memory on each node. Others may be annoyed by the limited CPU capacity on a node compared to some systems with NVIDIA GPUs. It is however very much in line with the cluster-booster philosophy already mentioned a few times, and it does seem to be the future according to AMD (with Intel also working into that direction). In fact, it looks like with respect to memory capacity things may even get worse.
We saw the first little steps of bringing GPU and CPU closer together and integrating both memory spaces in the USA pre-exascale systems Summit and Sierra. The LUMI-G node which was really designed for one of the first USA exascale systems continues on this philosophy, albeit with a CPU and GPU from a different manufacturer. Given that manufacturing large dies becomes prohibitively expensive in newer semiconductor processes and that the transistor density on a die is also not increasing at the same rate anymore with process shrinks, manufacturers are starting to look at other ways of increasing the number of transistors per \"chip\" or should we say package. So multi-die designs are here to stay, and as is already the case in the AMD CPUs, different dies may be manufactured with different processes for economical reasons.
Moreover, a closer integration of CPU and GPU would not only make programming easier as memory management becomes easier, it would also enable some codes to run on GPU accelerators that are currently bottlenecked by memory transfers between GPU and CPU.
Such a chip is exactly what AMD launched in December 2023 with the MI300A version of the MI300 series. It employs 13 chiplets in two layers, linked to (still only) 8 memory stacks (albeit of a much faster type than on the MI250X). The 4 chiplets on the bottom layer are the memory controllers and inter-GPU links (an they can be at the bottom as they produce less heat). Furthermore each package features 6 GPU dies (now called XCD or Accelerated Compute Die as they really can't do graphics) and 3 Zen4 \"Genoa\" CPU dies. In the MI300A the memory is still limited to 8 16 GB stacks, providing a total of 128 GB of RAM. The MI300X, which is the regular version without built-in CPU, already uses 24 GB stacks for a total of 192 GB of memory, but presumably those were not yet available when the design of MI300A was tested for the launch customer, the El Capitan supercomputer. HLRS is building the Hunter cluster based on AMD MI300A as a transitional system to their first exascale-class system Herder that will become operational by 2027.
Intel at some point has shown only very conceptual drawings of its Falcon Shores chip which it calls an XPU, but those drawings suggest that that chip will also support some low-bandwidth but higher capacity external memory, similar to the approach taken in some Sapphire Rapids Xeon processors that combine HBM memory on-package with DDR5 memory outside the package. Falcon Shores will be the next generation of Intel GPUs for HPC, after Ponte Vecchio which will be used in the Aurora supercomputer. It is currently very likely though that Intel will revert to a traditional design for Falcon Shores and push out the integrated CPU+GPU model to a later generation.
However, a CPU closely integrated with accelerators is nothing new as Apple Silicon is rumoured to do exactly that in its latest generations, including the M-family chips.
"},{"location":"2day-20240502/01_Architecture/#building-lumi-the-slingshot-interconnect","title":"Building LUMI: The Slingshot interconnect","text":"All nodes of LUMI, including the login, management and storage nodes, are linked together using the Slingshot interconnect (and almost all use Slingshot 11, the full implementation with 200 Gb/s bandwidth per direction).
Slingshot is an interconnect developed by HPE Cray and based on Ethernet, but with proprietary extensions for better HPC performance. It adapts to the regular Ethernet protocols when talking to a node that only supports Ethernet, so one of the attractive features is that regular servers with Ethernet can be directly connected to the Slingshot network switches. HPE Cray has a tradition of developing their own interconnect for very large systems. As in previous generations, a lot of attention went to adaptive routing and congestion control. There are basically two versions of it. The early version was named Slingshot 10, ran at 100 Gb/s per direction and did not yet have all features. It was used on the initial deployment of LUMI-C compute nodes but has since been upgraded to the full version. The full version with all features is called Slingshot 11. It supports a bandwidth of 200 Gb/s per direction, comparable to HDR InfiniBand with 4x links.
Slingshot is a different interconnect from your typical Mellanox/NVIDIA InfiniBand implementation and hence also has a different software stack. This implies that there are no UCX libraries on the system as the Slingshot 11 adapters do not support that. Instead, the software stack is based on libfabric (as is the stack for many other Ethernet-derived solutions and even Omni-Path has switched to libfabric under its new owner).
LUMI uses the dragonfly topology. This topology is designed to scale to a very large number of connections while still minimizing the amount of long cables that have to be used. However, with its complicated set of connections it does rely heavily on adaptive routing and congestion control for optimal performance more than the fat tree topology used in many smaller clusters. It also needs so-called high-radix switches. The Slingshot switch, code-named Rosetta, has 64 ports. 16 of those ports connect directly to compute nodes (and the next slide will show you how). Switches are then combined in groups. Within a group there is an all-to-all connection between switches: Each switch is connected to each other switch. So traffic between two nodes of a group passes only via two switches if it takes the shortest route. However, as there is typically only one 200 Gb/s direct connection between two switches in a group, if all 16 nodes on two switches in a group would be communicating heavily with each other, it is clear that some traffic will have to take a different route. In fact, it may be statistically better if the 32 involved nodes would be spread more evenly over the group, so topology based scheduling of jobs and getting the processes of a job on as few switches as possible may not be that important on a dragonfly Slingshot network. The groups in a slingshot network are then also connected in an all-to-all fashion, but the number of direct links between two groups is again limited so traffic again may not always want to take the shortest path. The shortest path between two nodes in a dragonfly topology never involves more than 3 hops between switches (so 4 switches): One from the switch the node is connected to the switch in its group that connects to the other group, a second hop to the other group, and then a third hop in the destination group to the switch the destination node is attached to.
"},{"location":"2day-20240502/01_Architecture/#assembling-lumi","title":"Assembling LUMI","text":"Let's now have a look at how everything connects together to the supercomputer LUMI. It does show that LUMI is not your standard cluster build out of standard servers.
LUMI is built very compactly to minimise physical distance between nodes and to reduce the cabling mess typical for many clusters and the costs of cabling. High-speed copper cables are expensive, but optical cables and the transceivers that are needed are even more expensive and actually also consume a significant amount of power compared to the switch power. The design of LUMI is compact enough that within a rack, switches can be connected with copper cables in the current network technology and optical cabling is only needed between racks.
LUMI does use a custom rack design for the compute nodes that is also fully water cooled. It is build out of units that can contain up to 4 custom cabinets, and a cooling distribution unit (CDU). The size of the complex as depicted in the slide is approximately 12 m2. Each cabinet contains 8 compute chassis in 2 columns of 4 rows. In between the two columns is all the power circuitry. Each compute chassis can contain 8 compute blades that are mounted vertically. Each compute blade can contain multiple nodes, depending on the type of compute blades. HPE Cray have multiple types of compute nodes, also with different types of GPUs. In fact, the Aurora supercomputer which uses Intel CPUs and GPUs and El Capitan, which uses the MI300A APUs (integrated CPU and GPU) will use the same design with a different compute blade. Each LUMI-C compute blade contains 4 compute nodes and two network interface cards, with each network interface card implementing two Slingshot interfaces and connecting to two nodes. A LUMI-G compute blade contains two nodes and 4 network interface cards, where each interface card now connects to two GPUs in the same node. All connections for power, management network and high performance interconnect of the compute node are at the back of the compute blade. At the front of the compute blades one can find the connections to the cooling manifolds that distribute cooling water to the blades. One compute blade of LUMI-G can consume up to 5kW, so the power density of this setup is incredible, with 40 kW for a single compute chassis.
The back of each cabinet is equally genius. At the back each cabinet has 8 switch chassis, each matching the position of a compute chassis. The switch chassis contains the connection to the power delivery system and a switch for the management network and has 8 positions for switch blades. These are mounted horizontally and connect directly to the compute blades. Each slingshot switch has 8x2 ports on the inner side for that purpose, two for each compute blade. Hence for LUMI-C two switch blades are needed in each switch chassis as each blade has 4 network interfaces, and for LUMI-G 4 switch blades are needed for each compute chassis as those nodes have 8 network interfaces. Note that this also implies that the nodes on the same compute blade of LUMI-C will be on two different switches even though in the node numbering they are numbered consecutively. For LUMI-G both nodes on a blade will be on a different pair of switches and each node is connected to two switches. So when you get a few sequentially numbered nodes, they will not be on a single switch (LUMI-C) or switch pair (LUMI-G). The switch blades are also water cooled (each one can consume up to 250W). No currently possible configuration of the Cray EX system needs all switch positions in the switch chassis.
This does not mean that the extra positions cannot be useful in the future. If not for an interconnect, one could, e.g., export PCIe ports to the back and attach, e.g., PCIe-based storage via blades as the switch blade environment is certainly less hostile to such storage than the very dense and very hot compute blades.
"},{"location":"2day-20240502/01_Architecture/#lumi-assembled","title":"LUMI assembled","text":"This slide shows LUMI fully assembled (as least as it was at the end of 2022).
At the front there are 5 rows of cabinets similar to the ones in the exploded Cray EX picture on the previous slide. Each row has 2 CDUs and 6 cabinets with compute nodes. The first row, the one with the wolf, contains all nodes of LUMI-C, while the other four rows, with the letters of LUMI, contain the GPU accelerator nodes. At the back of the room there are more regular server racks that house the storage, management nodes, some special compute nodes , etc. The total size is roughly the size of a tennis court.
Remark
The water temperature that a system like the Cray EX can handle is so high that in fact the water can be cooled again with so-called \"free cooling\", by just radiating the heat to the environment rather than using systems with compressors similar to air conditioning systems, especially in regions with a colder climate. The LUMI supercomputer is housed in Kajaani in Finland, with moderate temperature almost year round, and the heat produced by the supercomputer is fed into the central heating system of the city, making it one of the greenest supercomputers in the world as it is also fed with renewable energy.
"},{"location":"2day-20240502/02_CPE/","title":"HPE Cray Programming Environment","text":"In this session we discuss some of the basics of the operating system and programming environment on LUMI. Whether you like it or not, every user of a supercomputer like LUMI gets confronted with these elements at some point.
"},{"location":"2day-20240502/02_CPE/#why-do-i-need-to-know-this","title":"Why do I need to know this?","text":"The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is \"I only want to run some programs, why do I need to know about programming environments?\"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished. And some of the essential middleware that turns the hardware with some variant of Linux into a parallel supercomputers is part of the programming environment. The binary interfaces to those libraries are also not as standardised as for the more common Linux system libraries.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Compiling on the system is also the easiest way to guarantee compatibility of the binaries with the system.
Even when installing software from prebuilt binaries some modules might still be needed. Prebuilt binaries will typically include the essential runtime libraries for the parallel technologies they use, but these may not be compatible with LUMI. In some cases this can be solved by injecting a library from LUMI, e.g., you may want to inject an optimised MPI library as we shall see in the container section of this course. But sometimes a binary is simply incompatible with LUMI and there is no other solution than to build the software from sources.
"},{"location":"2day-20240502/02_CPE/#the-operating-system-on-lumi","title":"The operating system on LUMI","text":"The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes. This in turn led to an asymmetry in the setup so now 8 cores are reserved, one per CCD, so that all CCDs are equal again.
This also implies that some software that works perfectly fine on the login nodes may not work on the compute nodes. E.g., you will see that there is no /run/user/$UID directory.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer (and certainly not in the same way as they would be on a workstation). Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
Some missing pieces Compute nodes don't run a per-user dbus daemon, so some if not all DBUS functionality is missing. And D-Bus may sometimes show up in places where you don't expect it... It may come from freedesktop.org but is is not only used for desktop software.
Compute nodes on a Cray system have Lustre as the main file system. They do not import any networked file system like NFS, GPFS or CernVM-FS (the latter used by, e.g., Cern for distributing software for the Large Haedron Collider and the EESSI project). Instead these file systems are mounted on external servers in the admin section of the cluster and the Cray Data Virtualisation Service (DVS) is then used to access those file systems from the compute nodes over the high-speed interconnect.
"},{"location":"2day-20240502/02_CPE/#low-noise-mode","title":"Low-noise mode","text":"Low-noise mode has meant different things throughout the history of Cray systems. Sometimes the mode described above, using only a selection of the regular Linux daemons on the compute nodes, was already called low-noise mode while some Cray systems provided another mode in which those daemons were activated. Depending on the cluster this was then called \"emulation mode\" or \"Cluster Compatibility Mode\". The latter is not implemented on LUMI, and even if it would, compatibility would still be limited by the special requirements to use the Slingshot interconnect and to have GPU-aware communication over Slingshot.
However, it turned out that even the noise reduction described above was not yet sufficient to pass some large-scale scalability tests, and therefore another form of \"low-noise\" mode is implemented on the GPU nodes of LUMI where OS processes are restricted to a reserved core, actually core 0. This leaves us with an asymmetric structure of the node, where the first CCD has 7 available cores while the other ones have 8, but as that created a headache for users to get a proper distribution of tasks and threads over the CPU (see the \"Process and thread distribution and binding\" chapter), the choice was made to also disable the first core on each of the other CCDs so that users now effectively see a 56-core node with 8 CCDs with 7 cores each.
This is actually an idea Cray has been experimenting with in the past already, ever since we've had nodes with 20 or more cores with the AMD Magny-Cours processors in 2010.
"},{"location":"2day-20240502/02_CPE/#programming-models","title":"Programming models","text":"On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP (Heterogeneous-Compute Interface for Portability), which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org. The AMD GPUs are not yet fully supported by Julia.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. The visualisation nodes in LUMI have NVIDIA rendering GPUs but these nodes are meant for visualisation and not for compute.
"},{"location":"2day-20240502/02_CPE/#the-development-environment-on-lumi","title":"The development environment on LUMI","text":"Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects. As they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
Specifically not on LUMI is the Intel programming environment, nor is the regular Intel oneAPI HPC Toolkit. The classic Intel compilers pose problems on AMD CPUs as -xHost cannot be relied on, but it appears that the new compilers that are based on Clang and an LLVM backend behave better. Various MKL versions are also troublesome, with different workarounds for different versions, though here also it seems that Intel now has code that works well on AMD for many MKL routines. We have experienced problems with Intel MPI when testing it on LUMI though in principle it should be possible to use Cray MPICH as they are derived from the same version of MPICH. The NVIDIA programming environment doesn't make sense on an AMD GPU system, but it could be useful for some visualisation software on the visualisation nodes so it is currently installed on those nodes.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise several times a year with HPE for more material.
"},{"location":"2day-20240502/02_CPE/#the-cray-compiling-environment","title":"The Cray Compiling Environment","text":"The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend and optimiser developed by HPE Cray, but an LLVM-based code generator. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. In their most recent versions, they claim full OpenMP 5.0 support with partial (and growing) support for OpenMP 5.1 and 5.2. More information about the OpenMP support is found by checking a manual page:
man intro_openmp\n
which does require that the cce module is loaded, or the web version of that page which may be for a more recent version of the programming environment than available on LUMI. The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x. Information is available via man intro_openacc\n
or the corresponding web version of that page which again may be for a more recent version of the programming environment than available on LUMI. AMD and HPE Cray still recommend moving to OpenMP which is a much broader supported standard. There are no plans to also support OpenACC in the Cray C/C++ compiler, nor are there any plans for support by AMD in the ROCm stack. The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
"},{"location":"2day-20240502/02_CPE/#scientific-and-math-libraries","title":"Scientific and math libraries","text":"Cray Scientific and Math Libraries overview web page
Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSci_ACC, which contains a subset of the routines of LibSci. We or the LUMI USer Support Team don't have much experience with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions. These are included because it is essential that they interface properly with MPI parallel I/O and the Lustre file system to offer the best bandwidth to and from storage.
Cray used to offer more pre-installed third party libraries for which the only added value was that they compiled the binaries. Instead they now offer build scripts in a GitHub repository.
"},{"location":"2day-20240502/02_CPE/#cray-mpi","title":"Cray MPI","text":"HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully supports the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is also fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact allowed by the standard which only requires a process starter and suggest mpirun or mpiexec depending on the version of the standard. Instead the Slurm srun command is used as the process starter. This actually makes a lot of sense as the MPI application should be mapped correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
"},{"location":"2day-20240502/02_CPE/#gpu-aware-mpi","title":"GPU-aware MPI","text":"Cray MPICH does support GPU-aware MPI, so it is possible to directly use GPU-attached communication buffers using device pointers. The implementation supports (a) GPU-NIC RDMA for efficient inter-node MPI transfers and (b) GPU Peer2Peer IPC for efficient intra-node transfers. The latter mechanism comes with some restrictions though that we will discuss in the chapter \"Process and thread distribution and binding\".
GPU-aware MPI needs to be enabled explicitly, which you can do by setting an environment variable:
export MPICH_GPU_SUPPORT_ENABLED=1\n
In addition to this, if the GPU code does use MPI operations that access GPU-attached memory regions it is best to also set
export MPICH_OFI_NIC_POLICY=GPU\n
to tell MPICH to always use the NIC closest to the GPU.
If only CPU communication buffers are used, then it may be better to set
export MPICH_OFI_NIC_POLICY=NUMA\n
which tells MPICH to use the NIC closest to the CPU NUMA domain.
Depending on how Slurm is used, Peer2Peer IPC may not work and in those cases you may want to turn it off using
export MPICH_GPU_IPC_ENABLED=0\n
or alternatively export MPICH_SMP_SINGLE_COPY_MODE=NONE\n
Both options entail a serious loss of performance. The underlying problem is that the way in which Slurm does GPU binding using control groups makes other GPUS from other tasks in the node invisible to a task. More information about Cray MPICH and the many environment variables to fine-tune performance can be found in the manual page
man intro_mpi\n
or its web-based version which may be for a newer version than available on LUMI.
"},{"location":"2day-20240502/02_CPE/#lmod","title":"Lmod","text":"Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded. module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to a module unload followed by a module load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
"},{"location":"2day-20240502/02_CPE/#compiler-wrappers","title":"Compiler wrappers","text":"The HPE Cray PE compilers are usually used through compiler wrappers. The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn. The wrapper then calls the selected compiler. Which compiler will be called is determined by which compiler module is loaded. As shown on the slide \"Development environment on LUMI\", on LUMI the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc), the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers (module amd) are available. On the visualisation nodes, the NVIDIA HPC compiler is currently also installed (module nvhpc). On other HPE Cray systems, you may also find the Intel compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc, mpiCC, mpif90, etc. on LUMI (well, there is nowadays, but their use is discouraged). The regular compiler wrappers do the job as soon as the cray-mpich module is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libsci module is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the -craype-verbose flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
The compiler wrappers are provided by the craype module (but you don't have to load that module by hand).
"},{"location":"2day-20240502/02_CPE/#selecting-the-version-of-the-cpe","title":"Selecting the version of the CPE","text":"The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 23.09 for the version released in September 2023. There are several releases each year (at least 4), but not all of them are offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming environment. It is possible to change the default version for loading further modules by loading one of the versions of the cpe module. E.g., assuming the 23.09 version would be present on the system, it can be loaded through
module load cpe/23.09\n
Loading this module will also try to switch the already loaded PE modules to the versions from that release. This does not always work correctly, due to some bugs in most versions of this module and a limitation of Lmod. Executing the module load twice will fix this: module load cpe/23.09\nmodule load cpe/23.09\n
The module will also produce a warning when it is unloaded (which is also the case when you do a module load of cpe when one is already loaded, as it then first unloads the already loaded cpe module). The warning can be ignored, but keep in mind that what it says is true, it cannot restore the environment you found on LUMI at login. The cpe module is also not needed when using the LUMI software stacks, but more about that later.
"},{"location":"2day-20240502/02_CPE/#the-target-modules","title":"The target modules","text":"The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-rome selects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milan is the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trento is the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofi selects the libfabric communication layer which is needed for Slingshot 11.craype-network-none omits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these settings: -target-cpu, -target-accel and -target-network.
"},{"location":"2day-20240502/02_CPE/#prgenv-and-compiler-modules","title":"PrgEnv and compiler modules","text":"In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the programming environment. These modules will load the compiler wrapper (craype), compiler, MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they activate:
PrgEnv Description Compiler module Compilers PrgEnv-cray Cray Compiling Environment cce craycc, crayCC, crayftn PrgEnv-gnu GNU Compiler Collection gccgcc-native(*) gcc, g++, gfortrangcc-12, g++-12, gfortran-12 PrgEnv-aocc AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang PrgEnv-amd AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang (*) See the note \"Changes to the GNU compilers in 23.12\".
There is also a second module that offers the AMD ROCm environment, rocm. That module has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU, hipcc with the GNU compilers or GPU support with the Cray compilers.
Changes to the GNU compilers in 23.12 The HPE Cray PE will change the way it offers the GNU compilers in releases starting from 23.12. Rather than packaging the GNU compilers, HPE Cray will use the default development compiler version of SUSE Linux, which for SP4 is currently GCC 12.3 (not to be confused with the system default which is still 7.5, the compiler that was offered with the initial release of SUSE Enterprise Linux 15).
In releases up to the 23.09 which we currently have on Linux, the GNU compilers are offered through the gcc compiler module. When loaded, it adds newer versions of the gcc, g++ and gfortran compilers to the path, calling the version indicated by the version of the gcc module.
In releases from 23.12 on, that compiler module is now called gcc-native, and the compilers are - at least in the version for SUSE 15 SP4 - called gcc-12, g++-12 and gfortran-12, while gcc, g++ and gfortran will compile with version 7.5, the default version for SUSE 15.
"},{"location":"2day-20240502/02_CPE/#getting-help","title":"Getting help","text":"Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers, the following man pages are relevant:
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - There used to be manual pages for the wrappers also but they are currently hijacked by the GNU manual pages.
Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers, the switch -help should be used instead as the double dash version is passed to the compiler.
The wrappers have a number of options specific to them. Information about them can be obtained by using the --craype-help flag with the wrappers. The wrappers also support the -dumpversion flag to show the version of the underlying compiler. Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn\nftn-2107 ftn: ERROR in command line\n No valid filenames are specified on the command line.\n$ explain ftn-2107\n\nError : No valid filenames are specified on the command line.\n\nAt least one file name must appear on the command line, with any command-line\noptions. Verify that a file name was specified, and also check for an\nerroneous command-line option which may cause the file name to appear to be\nan argument to that option.\n
On older Cray systems this used to be a very useful command with more compilers but as HPE Cray is using more and more open source components instead there are fewer commands that give additional documentation via the explain command.
Lastly, there is also a lot of information in the \"Developing\" section of the LUMI documentation.
"},{"location":"2day-20240502/02_CPE/#google-chatgpt-and-lumi","title":"Google, ChatGPT and LUMI","text":"When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command that searches for a term in the manual pages. It is often useful to better understand some error messages. E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem. You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and, e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE\n
The online documentation is now also complete enough that it makes sense trying the search box on that page instead.
"},{"location":"2day-20240502/02_CPE/#other-modules","title":"Other modules","text":"Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
"},{"location":"2day-20240502/02_CPE/#warning-1-you-do-not-always-get-what-you-expect","title":"Warning 1: You do not always get what you expect...","text":"The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system) which correspond to the version of the programming environment that is set as the system default when installed. This is very much the behaviour of Linux applications also that pick standard libraries in a few standard directories and it enables many programs build with the HPE Cray PE to run without reconstructing the environment and in some cases to mix programs compiled with different compilers with ease (with the emphasis on some as there may still be library conflicts between other libraries when not using the so-called rpath linking). This does have an annoying side effect though: If the default PE on the system changes, all applications will use different libraries and hence the behaviour of your application may change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic linking where the search path for the libraries is stored in each executable separately. On Linux, the search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules that have their libraries also in the default location, add the directories that contain the actual version of the libraries corresponding to the version of the module to the PATH-style environment variable CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
Small demo of adapting LD_LIBRARY_PATH: An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08\n$ module load lumi-CPEtools/1.0-cpeGNU-22.08\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007f420cd55000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)\n ...\n$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007fb38c1e0000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)\n ...\n
The ldd command shows which libraries are used by an executable. Only a part of the very long output is shown in the above example. But we can already see that in the first case, the library libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/ which clearly is for a specific version of cray-mpich. We do provide the module lumi-CrayPath that tries to fix LD_LIBRARY_PATH in a way that unloading the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting the CRAY_ADD_RPATH environment variable:
export CRAY_ADD_RPATH=yes\n
However, there is also a good side to the standard Cray PE behaviour. Updates of the underlying operating system or network software stack may break older versions of the MPI library. By letting the applications use the default libraries and updating the defaults to a newer version, most applications will still run while they would fail if any of the two tricks to force the use of the intended library version are used. This has actually happened after a big LUMI update in March 2023, when all software that used rpath-linking had to be rebuild as the MPICH library that was present before the update did not longer work.
"},{"location":"2day-20240502/02_CPE/#warning-2-order-matters","title":"Warning 2: Order matters","text":"Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftw only becomes available when a processor target module is loadedcray-mpich requires both the network target module craype-network-ofi and a compiler module to be loadedcray-hdf5 requires a compiler module to be loaded and cray-netcdf in turn requires cray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found with module spider. That command can also tell which other modules should be loaded before a module can be loaded, but unfortunately due to the sometimes non-standard way the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also why we didn't demonstrate it here.
"},{"location":"2day-20240502/02_CPE/#note-compiling-without-the-hpe-cray-pe-wrappers","title":"Note: Compiling without the HPE Cray PE wrappers","text":"It is now possible to work without the HPE Cray PE compiler wrappers and to use the compilers in a way you may be more familiar with from other HPC systems.
In that case, you would likely want to load a compiler module without loading the PrgEnv-* module and craype module (which would be loaded automatically by the PrgEnv-* module). The compiler module and compiler driver names are then given by the following table:
Description Compiler module Compilers Cray Compiling Environment cce craycc, crayCC, crayftn GNU Compiler Collection gccgcc-native gcc, g++, gfortrangcc-12, g++-12, gfortran-12 AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang Recent versions of the cray-mpich module now also provide the traditional MPI compiler wrappers such as mpicc, mpicxx or mpifort. Note that you will still need to ensure that the network target module craype-network-ofi is loaded to be able to load the cray-mpich module! The cray-mpich module also defines the environment variable MPICH_DIR that points to the MPI installation for the selected compiler.
To manually use the BLAS and LAPACK libraries, you'll still have to load the cray-libsci module. This module defines the CRAY_LIBSCI_PREFIX_DIR environment variable that points to the directory with the library and include file subdirectories for the selected compiler. (This environment variable will be renamed to CRAY_PE_LIBSCI_PREFIX_DIR in release 23.12 of the programming environment.) See the intro_libsci manual page for information about the different libraries.
To be able to use the cray-fftw FFTW libraries, you still need to load the right CPU target module, even though you need to specify the target architecture yourself now when calling the compilers. This is because the HPE Cray PE does not come with a multi-cpu version of the FFTW libraries, but specific versions for each CPU (or sometimes group of similar CPUs). Here again some environment variables may be useful to point the compiler and linker to the installation: FFTW_ROOT for the root of the installation for the specific CPU (the library is otherwise compiler-independent), FFTW_INC for the subdirectory with the include files and FFTW_DIR for the directory with the libraries.
Other modules that you may want to use also typically define some useful environment variables.
"},{"location":"2day-20240502/03_LUMI_access/","title":"Getting Access to LUMI","text":""},{"location":"2day-20240502/03_LUMI_access/#who-pays-the-bills","title":"Who pays the bills?","text":"LUMI is one of the larger EuroHPC supercomputers. EuroHPC currently funds supercomputers in three different classes:
-
There are a number of so-called petascale supercomputers. The first ones of those are Meluxina (in Luxembourg), VEGA (in Slovenia), Karolina (in the Czech Republic), Discoverer (in Bulgaria) and Deucalion (in Portugal).
-
A number of pre-exascale supercomputers, LUMI being one of them. The other two are Leonardo (in Italy) and MareNostrum 5 (in Spain)
-
A decision has already been taken on two exascale supercomputers: Jupiter (in Germany) and Jules Verne (consortium name) (in France).
Depending on the machine, EuroHPC pays one third up to half of the bill, while the remainder of the budget comes from the hosting country, usually with the help of a consortium of countries. For LUMI, EuroHPC paid half of the bill and is the actual owner of the machine.
LUMI is hosted in Finland but operated by a consortium of 11 countries. Each LUMI consortium country can set its own policies for a national access program, within the limits of what the supercomputer can technically sustain. There is a \"Get Started\" page on the main LUMI website with links to the various access programs.
Web links:
- EuroHPC JU supercomputers
- LUMI website \"Get Started\" page with links to relevant web pages for EuroHPC access and access via consortium countries.
"},{"location":"2day-20240502/03_LUMI_access/#users-and-projects","title":"Users and projects","text":"LUMI works like most European large supercomputers: Users are members of projects.
A project corresponds to a coherent amount of work that is being done by a single person or a collaboration of a group of people. It typically corresponds to a research project, though there are other project types also, e.g., to give people access in the context of a course, or for organisational issues, e.g., a project for a local support organisation. Most projects are short-lived, with a typical duration of 4 to 6 months for benchmarking projects or one year for a regular project (which is the maximum duration agreed upon in the consortium).
Projects are also the basis for most research allocations on LUMI. In LUMI there are three types of resource allocations, and each project needs at least two of them:
- A compute budget for the CPU nodes of LUMI (LUMI-C and the CPU-only large memory nodes), expressed in core-hours.
- A compute budget for the GPU nodes of LUMI (LUMI-G and the visualisation nodes), expressed in GPU-hours. As the mechanism was already fixed before it became publicly known that for all practical purposes one AMD MI250X GPU should really be treated as 2 GPUs, one GPU-hour is one hour on a full MI250X, so computing for one hour on a full LUMI-G GPU node costs 4 GPU-hours.
- A storage budget which is expressed in TB-hours. Only storage that is actually being used is charged on LUMI, to encourage users to clean up temporary storage. The rate at which storage is charged depends on the file system, but more about that later when we discuss the available file spaces.
These budgets are assigned and managed by the resource allocators, not by the LUMI User Support Team. The LUMI User Support Team also cannot add additional billing units to your project.
LUMI projects will typically have multiple project numbers which may be a bit confusing:
- Each RA may have its own numbering system, often based on the numbering used for the project requests. Note that the LUMI User Support Team is not aware of that numbering as it is purely internal to the RA.
-
Each project on LUMI also gets a LUMI project ID which also corresponds to a Linux group to manage access to the project resources. These project IDs are of the form project_465XXXXXX for most projects but project_462XXXXXX for projects that are managed by the internal system of CSC Finland.
This is also the project number that you should mention when contacting the central LUMI User Support.
Besides projects there are also user accounts. Each user account on LUMI corresponds to a physical person, and user accounts should not be shared. Some physical persons have more than one user account but this is an unfortunate consequence of decisions made very early in the LUMI project about how projects on LUMI would be managed. Users themselves cannot do a lot without a project as all a user has on LUMI is a small personal disk space which is simply a Linux requirement. To do anything useful on LUMI users need to be member of a project. There are also \"robot accounts\" for special purposes that would not correspond to a physical person but have a specific goal (like organising data ingestion from an external source) and few projects are granted such an account.
There ia a many-to-many mapping between projects and user accounts. Projects can of course have multiple users who collaborate in the project, but a user account can also be part of multiple projects. The latter is more common than you may think, as. e.g., you may become member of a training project when you take a LUMI training.
Most resources are attached to projects. The one resource that is attached to a user account is a small home directory to store user-specific configuration files. That home directory is not billed but can also not be extended. For some purposes you may have to store things that would usually automatically be placed in the home directory in a separate directory, e.g., in the project scratch space, and link to it. This may be the case when you try to convert big docker containers into singularity containers as the singularity cache can eat a lot of disk space. (Or sometimes setting an environment variable is enough to redirect to a different directory.)
"},{"location":"2day-20240502/03_LUMI_access/#project-management","title":"Project management","text":"A large system like LUMI with many entities giving independent access to the system to users needs an automated system to manage those projects and users. There are two such systems for LUMI. CSC, the hosting institution from Finland, uses its own internal system to manage projects allocated on the Finnish national share. This system manages the \"642\"-projects. The other system is called Puhuri and is developed in a collaboration between the Nordic countries to manage more than just LUMI projects. It can be used to manage multiple supercomputers but also to manage access to other resources such as experimental equipment. Puhuri projects can span multiple resources (e.g., multiple supercomputers so that you can create a workflow involving Tier-2, Tier-1 and Tier-0 resources).
There are multiple frontends in use for Puhuri. Some countries use their own frontend that links to the Puhuri backend to give their users a familiar feeling, while other countries use a Puhuri frontend that they either host and manage themselves, or run on the Puhuri infrastructure. Due to this diversity, we cannot really demo project management in the course but need to leave this to the local organisations.
The login to Puhuri is in general via MyAccessID, which is a G\u00c9ANT service. G\u00c9ANT is the international organisation that manages the research network in Europe. MyAccessID then in turn connects to your institute identity provider and a number of alternatives. It is important that you always use the same credentials to log in via MyAccessID, otherwise you create another user in MyAccessID that is unknown to Puhuri and get all kinds of strange error messages. MyAccessID is also used for ssh key management, so that in the future, when MyAccessID might serve more machines, you'd have a single set of ssh keys for all infrastructures.
Puhuri can be used to check your remaining project resources, but once your user account on LUMI is created, it is very easy to do this on the command line with the lumi-workspaces command.
Web links
-
Puhuri documentation, look for the \"User Guides\".
-
The lumi-workspaces command is provided through the lumi-tools module which is loaded by default. The command will usually give the output you need when used without any argument.
"},{"location":"2day-20240502/03_LUMI_access/#file-spaces","title":"File spaces","text":"LUMI has file spaces that are linked to a user account and file spaces that are linked to projects.
The only permanent file space linked to a user account is the home directory which is of the form /users/<my_uid>. It is limited in both size and number of files it can contain, and neither limit can be expanded. It should only be used for things that are not project-related and first and foremost for those things that Linux and software automatically stores in a home directory like user-specific software configuration files. It is not billed as users can exist temporarily without an active project but therefore is also very limited in size.
Each project also has 4 permanent or semi-permanent file spaces that are all billed against the storage budget of the project.
-
Permanent (for the duration of the project) storage on a hard disk based Lustre filesystem accessed via /project/project_46YXXXXXX. This is the place to perform the software installation for the project (as it is assumed that a project is a coherent amount of work it is only natural to assume that everybody in the project needs the same software), or to store input data etc. that will be needed for the duration of the project.
Storing one TB for one hour on the disk based Lustre file systems costs 1 TB-hour.
-
Semi-permanent scratch storage on a hard disk based Lustre filesystem accessed via /scratch/project_46YXXXXXX. Files in this storage space can in principle be erased automatically after 90 days. This is not happening yet on LUMI, but will be activated if the storage space starts to fill up.
Storing one TB for one hour on the disk based Lustre file systems costs 1 TB-hour.
-
Semi-permanent scratch storage on an SSD based Lustre filesystem accessed via /flash/project_46YXXXXXX. Files in this storage space can in principle be erased automatically after 30 days. This is not happening yet on LUMI, but will be activated if the scratch storage space starts to fill up.
Storing one TB for one hour on the flash based Lustre file system costs 10 TB-hour, also reflecting the purchase cost difference of the systems.
-
Permanent (for the duration of the project) storage on the hard disk based object filesystem.
Storing one TB for one hour on the object based file system costs 0.5 TB-hour.
The use of space in each file space is limited by block and file quota. Block quota limit the capacity you can use, while file quota limit the number of so-called inodes you can use. Each file, each subdirectory and each link use an inode. As we shall see later in this course or as you may have seen in other HPC courses already, parallel file systems are not built to deal with hundreds of thousands of small files and are very inefficient at that. Therefore block quota on LUMI tend to be rather flexible (except for the home directory) but file quota are rather strict and will not easily get extended. Software installations that require tens of thousands of small files should be done in containers (e.g., conda installations or any big Python installation) while data should also be organised in proper file formats rather than being dumped on the file system abusing the file system as a database. Quota extensions are currently handled by the central LUMI User Support Team.
So storage billing units come from the RA, block and file quota come from the LUMI User Support Team!
LUMI has four disk based Lustre file systems that house /users, /project and /scratch. The /project and /scratch directories of your project will always be on the same parallel file system, but your home directory may be on a different one. Both are assigned automatically during project and account creation and these assignments cannot be changed by the LUMI User Support Team. As there is a many-to-many mapping between user accounts and projects it is not possible to ensure that user accounts are on the same file system as their main project. In fact, many users enter LUMI for the first time through a course project and not through one of their main compute projects...
It is important to note that even though /flash is SSD based storage, it is still a parallel file system and will not behave the way an SSD in your PC does. The cost of opening and closing a file is still very high due to it being both a networked and a parallel file system rather than a local drive. In fact, the cost for metadata operations is not always that much lower as on the hard disk based parallel file systems as both use SSDs to store the metadata (but some metadata operations on Lustre involve both the metadata and object servers and the latter are faster on /flash). Once a file is opened and with a proper data access pattern (big accesses, properly striped files which we will discuss later in this course) the flash file system can give a lot more bandwidth than the disk based ones.
It is important to note that LUMI is not a data archiving service or a data publishing service. \"Permanent\" in the above discussion only means \"for the duration of the project\". There is no backup, not even of the home directory. And 90 days after the end of the project all data from the project is irrevocably deleted from the system. User accounts without project will also be closed, as will user accounts that remain inactive for several months, even if an active project is still attached to them.
If you run out of storage billing units, access to the job queues or even to the storage can be blocked and you should contact your resource allocator for extra billing units. It is important that you clean up after a run as LUMI is not meant for long-term data archiving. But at the same time it is completely normal that you cannot do so right after a run, or as a job may not launch immediately, that you need to put input data on the system long before a run starts. So data needed for or resulting from a run has to stay on the system for a few days or weeks, and you need to budget for that in your project request.
Web links:
- Overview of storage systems on LUMI
- Billing policies (includes those for storage)
"},{"location":"2day-20240502/03_LUMI_access/#access","title":"Access","text":"LUMI currently has 4 login nodes through which users can enter the system via key-based ssh. The generic name of those login nodes is lumi.csc.fi. Using the generic names will put you onto one of the available nodes more or less at random and will avoid contacting a login node that is down for maintenance. However, in some cases one needs to enter a specific login node. E.g., tools for remote editing or remote file synchronisation such as Visual Studio Code or Eclipse usually don't like it if they get a different node every time they try to connect, e.g., because they may start a remote server and try to create multiple connections to that server. In that case you have to use a specific login node, which you can do through the names lumi-uan01.csc.fi up to lumi-uan04.csc.fi. (UAN is the abbreviation for User Access Node, the term Cray uses for login nodes.)
Key management is for most users done via MyAccessID: mms.myaccessid.org. This is the case for all user accounts who got their first project on LUMI via Puhuri. User accounts that were created via the My CSC service have to use the my.csc.fi portal to manage their keys. It recently became possible to link your account in My CSC to MyAccessID so that you do not get a second account on LUMI ones you join a Puhuri-managed project, and in this case your keys are still managed through the My CSC service.
LUMI now also provides a web interface via Open OnDemand. The URL is https://www.lumi.csc.fi/. It also offers a number of tools that can be useful for visualisation via a web browser, but it is still work-in-progress.
There is currently moderate support for technologies for GUI applications on LUMI. Running X11 over ssh (via ssh -X) is unbearably slow for most users as X11 is not meant to be used over long-distance networks and is very latency-sensitive. The alternative is VNC, which we currently offer in two different ways:
- Via the \"Desktop\" app in Open OnDemand, which will give you a VNC session with the rather lightweight Xfce desktop environment,
- and through the
lumi-vnc module which was our primary method when Open OnDemand for LUMI was not ready yet.
You can connect through a web browser or a VNC client. Don't expect more advanced desktop environments: LUMI is not meant to be your remote graphics workstation and we cannot afford to spend tens of compute nodes on offering this service.
Web links:
- LUMI documentation on logging in to LUMI and creating suitable SSH keys
- CSC documentation on linking My CSC to MyAccessID
A walk through the Open OnDemand interface
To enter the LUMI OpenOndemand interface, point your browser to www.lumi.csc.fi. You will get the screen:
Most likely you just want to log on, so click on \"Go to login\" and the \"Select authentication provider\" screen should appear, with a link to give you more information about which authentication method to use:
Basically, if you are a CSC user (and definitely when you're on a CSC 462* project) you'll want to use the \"CSC\" or \"Haka\" choice, while other users will need MyAccessID.
The whole login process is not shown, but after successful authentication, you end up at the main screen (that you can also go back to by clicking the LUMI-logo in the upper left corner):
The list of pinned apps may change over time, and more apps are available via the menu at the top. Most apps will run in the context of a job, so you will need billing units, and those apps will also present you with a form to chose the resources you want to use, but that will only be discussed in the session on Slurm.
Two apps don't run in the context of a job: The \"Login node shell\" and \"Home Directory\" apps, and we'll first have a look at those.
The \"Login node shell\" does just what you expect from it\": It opens a tab in the browser with a shell on one of the login nodes. Open OnDemand uses its own set of login nodes, as you can see from the name of the node, but these nodes are otherwise identical to the login nodes that you access via an ssh client on your laptop, and the same policies apply. They should not be used for running applications and only be used for small work or not too heavy compilations.
Let's now select the \"Home Directory\" app. We get:
The \"Home Directory\" app presents you with an interface through which you cannot only browse your home directory, but also the project, scratch and flash directories of all your projects. It can be used for some elementary file access and also to upload and download files.
It is not suitable though to upload or download very big files, or download large subdirectories (multiple files will be packed in a ZIP archive) as browsers may not be reliable enough and as there are also restrictions on how big an archive Open OnDemand can create.
For transferring lots of data, transfer via LUMI-O is certainly the better option at the moment.
Finally, let's have a look at the \"Desktop\" app.
The \"Desktop\" app will present you with a simple GUI desktop based on the Xfce desktop environment. This app needs to run in the context of a job and although it can run on several partitions on LUMI, its main use is to be able to use some visualisation applications, so your best choice is likely to use the partition with visualisation GPUs (see the session on Slurm). As we have not discussed jobs yet, we will skip how to fill in the form that is presented to you.
The desktop is basically run in a VNC session, a popular protocol for remote desktop support in Linux. It can be used through a web browser, which is what you get if you click the \"Launch Desktop\" button, but there are other choices also.
After launching/connecting to the desktop you get:
There is a small settings menu hidden at the left (expanded in the picture) to do some settings of the web interface that we are using here. Right-clicking with the mouse on the desktop gives you a menu with a number of applications.
This is in no means meant to be a replacement of your own workstation, so the software choice is limited and will remain limited. It should never be your main environment for all your work. LUMI is not meant to simply provide small workstations to all of Europe. And it will also react a lot slower than what you are used to from a workstation in front of you. This is 100% normal and simply the result of using a computer which is far away so there is a high network latency.
"},{"location":"2day-20240502/03_LUMI_access/#data-transfer","title":"Data transfer","text":"There are currently two main options to transfer data to and from LUMI.
The first one is to use sftp to the login nodes, authenticating via your ssh key. There is a lot of software available for all major operating systems, both command line based and GUI based. The sftp protocol can be very slow over high latency connections. This is because it is a protocol that opens only a single stream for communication with the remote host, and the bandwidth one can reach via a single stream in the TCP network protocol used for such connections, is limited not only by the bandwidth of all links involved but also by the latency. After sending a certain amount of data, the sender will wait for a confirmation that the data has arrived, and if the latency is high, that confirmation takes more time to reach the sender, limiting the effective bandwidth that can be reached over the connection. LUMI is not to blame for that; the whole path from the system from which you initiate the connection to LUMI is responsible and every step adds to the latency. We've seen many cases where the biggest contributor to the latency was actually the campus network of the user.
The second important option is to transfer data via the object storage system LUMI-O. To transfer data to LUMI, you'd first push the data to LUMI-O and then on LUMI pull it from LUMI-O. When transferring data to your home institute, you'd first push it onto LUMI-O from LUMI and then pull the data from LUMI-O to your work machine. LUMI offers some support for various tools, including rclone and S3cmd. There also exist many GUI clients to access object storage. Even though in principle any tool that can connect via the S3 protocol can work, the LUMI User Support Team cannot give you instructions for every possible tool. Those tools for accessing object storage tend to set up multiple data streams and hence will offer a much higher effective bandwidth, even on high latency connections.
Alternatively, you can also chose to access external servers from LUMI if you have client software that runs on LUMI (or if that software is already installed on LUMI, e.g., rclone and S3cmd), but the LUMI User Support Team cannot tell you how to configure tools to use an external service that we have no access to.
Unfortunately there is no support yet for Globus or other forms of gridFTP.
"},{"location":"2day-20240502/03_LUMI_access/#what-is-lumi-o","title":"What is LUMI-O?","text":"LUMI-O is an object storage system (based on Ceph). Users from Finland may be familiar with Allas, which is similar to the LUMI object storage system, though LUMI doesn't provide all the functionality of Allas.
Object file systems need specific tools to access data. They are usually not mounted as a regular filesystem (though some tools can make them appear as a regular file system) and accessing them needs authentication via temporary keys that are different from your ssh keys and are not only bound to you, but also to the project for which you want to access LUMI-O. So if you want to use LUMI-O for multiple projects simultaneously, you'll need keys for each project.
Object storage is not organised in files and directories. A much flatter structure is used with buckets that contain objects:
-
Buckets: Containers used to store one or more objects. Object storage uses a flat structure with only one level which means that buckets cannot contain other buckets.
-
Objects: Any type of data. An object is stored in a bucket.
-
Metadata: Both buckets and objects have metadata specific to them. The metadata of a bucket specifies, e.g., the access rights to the bucket. While traditional file systems have fixed metadata (filename, creation date, type, etc.), an object storage allows you to add custom metadata.
Objects can be served on the web also. This is in fact how recordings of some of the LUST courses are served currently. However, LUMI-O is not meant to be used as a data publishing service and is not an alternative to services provided by, e.g., EUDAT or several local academic service providers.
"},{"location":"2day-20240502/03_LUMI_access/#accessing-lumi-o","title":"Accessing LUMI-O","text":"Access to LUMI-O is based on temporary keys that need to be generated via a web interface (though there may be alternatives in the future).
There are currently three command-line tools pre-installed on LUMI: rclone (which is the easiest tool if you want public and private data), s3cmd and restic.
But you can also access LUMI-O with similar tools from outside LUMI. Configuring them may be a bit tricky and the LUMI User Support Team cannot help you with each and every client tool on your personal machine. However, the web interface that is used to generate the keys, can also generate code snippets or configuration file snippets for various tools, and that will make configuring them a lot easier.
In the future access via Open OnDemand should also become possible.
"},{"location":"2day-20240502/03_LUMI_access/#key-generation","title":"Key generation","text":"Keys are generated via a web interface that can be found at auth.lumidata.eu. In the future it should become possible to do so directly in the Open OnDemand interface, and may even from the command line.
Let's walk through the interface:
A walk through the credentials management web interface of LUMI-O
After entering the URL auth.lumidata.eu, you're presented with a welcome screen on which you have to click the \"Go to login\" button.
This will present you with the already familiar (from Open OnDemand) screen to select your authentication provider:
Proceed with login in through your relevant authentication provider (not shown here) and you will be presented with a screen that show your active projects:
Click the project for which you want to generate a key, and the column to the right will appear. Chose how long the key should be valid (1 week or 168 hours is the maximum currently, but the life can be extended) and a description for the key. The latter is useful if you generate multiple keys for different use. E.g., for security reasons you may want to use different keys from different machines so that one machine can be disabled quickly if the machine would be compromised or stolen.
Next click on the \"Generate key\" button, and a new key will appear in the \"Available keys\" section:
Now click on the key to get more information about the key:
At the top of the screen you see three elements that will be important if you use the LUMI command line tool lumio-conf to generate configuration files for rclone and s3cmd: the project number (but you knew that one), the \"Access key\" and \"Secret key\".
Scrolling down a bit more:
The \"Extend key\" field can be used to extend the life of the key, to a maximum of 168 hours past the current time.
The \"Configuration templates\" is the way to generate code snippets or configuration file snippets for various tools (see the list on the slide). After selecting \"rclone\" and clicking the \"Generate\" button, a new screen opens:
This screen shows us the snippet for the rclone configuration file (on Linux it is ~/.config/rclone/rclone.conf). Notice that it creates to so-called endpoints. In the slide this is lumi-465001102-private and lumi-465001102-public, for storing buckets and objects which are private or public (i.e., also web-accessible).
"},{"location":"2day-20240502/03_LUMI_access/#configuring-lumi-o-tools","title":"Configuring LUMI-O tools","text":"On LUMI, you can use the lumnio-conf tool to configure rclone and s3cmd. To access the tool, you need to load the lumio module first, which is always available. The same module will also load a module that makes rclone, s3cmd and restic available.
Whe starting lumio-conf, it will present with a couple of questions: The project number associated with the key, the access key and the secret key. We have shown above where in the web interface that information can be found. A future version may or may not be more automatic. As we shall see in the next slide, currently the rclone configuration generated by this tool is (unfortunately) different from the one generated by the web interface.
Another way to configure tools for object storage access is simply via the code snippets and configuration files snippets as has already been discussed before. The same snippets should also work when you run the tools on a different computer.
"},{"location":"2day-20240502/03_LUMI_access/#rclone-on-lumi-o","title":"rclone on LUMI-O","text":"The rclone configuration file for LUMI-O contains two end points, and unfortunately at the moment both ways discussed on the previous slide, produce different end points.
- When using
lumio-conf, you'll get: lumi-o as the end point for buckets and object that should be private, i.e., not publicly accessible via the web interface, andlumi-pub for buckets and objects that should be publicly accessible. It does appear to be possible to have both types in a single bucket though.
- When using the web generator you get specific end points for each project, so it is possible to access data from multiple projects simultaneously from a single configuration file:
lumi-46YXXXXXX-private is the end point to be used for buckets and objects that should be private, andlumi-46YXXXXXX-public is the end point for data that should be publicly accessible.
A description of the main rclone commands is outside the scope of this tutorial, but some options are discussed in the LUMI documentation, and the same page also contains some documentation for s3cmd and restic. See the links below for even more documentation.
"},{"location":"2day-20240502/03_LUMI_access/#further-lumi-o-documentation","title":"Further LUMI-O documentation","text":""},{"location":"2day-20240502/04_Modules/","title":"Modules on LUMI","text":"Intended audience
As this course is designed for people already familiar with HPC systems and as virtually any cluster nowadays uses some form of module environment, this section assumes that the reader is already familiar with a module environment but not necessarily the one used on LUMI.
However, even if you are very familiar with Lmod it makes sense to go through these notes as not every Lmod configuration is the same.
"},{"location":"2day-20240502/04_Modules/#module-environments","title":"Module environments","text":"An HPC cluster is a multi-user machine. Different users may need different versions of the same application, and each user has their own preferences for the environment. Hence there is no \"one size fits all\" for HPC and mechanisms are needed to support the diverse requirements of multiple users on a single machine. This is where modules play an important role. They are commonly used on HPC systems to enable users to create custom environments and select between multiple versions of applications. Note that this also implies that applications on HPC systems are often not installed in the regular directories one would expect from the documentation of some packages, as that location may not even always support proper multi-version installations and as system administrators prefer to have a software stack which is as isolated as possible from the system installation to keep the image that has to be loaded on the compute nodes small.
Another use of modules not mentioned on the slide is to configure the programs that are being activated. E.g., some packages expect certain additional environment variables to be set and modules can often take care of that also.
There are 3 systems in use for module management. The oldest is a C implementation of the commands using module files written in Tcl. The development of that system stopped around 2012, with version 3.2.10. This system is supported by the HPE Cray Programming Environment. A second system builds upon the C implementation but now uses Tcl also for the module command and not only for the module files. It is developed in France at the C\u00c9A compute centre. The version numbering was continued from the C implementation, starting with version 4.0.0. The third system and currently probably the most popular one is Lmod, a version written in Lua with module files also written in Lua. Lmod also supports most Tcl module files. It is also supported by HPE Cray, though they tend to be a bit slow in following versions. The original developer of Lmod, Robert McLay, retired at the end of August 2023, but TACC, the centre where he worked, is committed to at least maintain Lmod though it may not see much new development anymore.
On LUMI we have chosen to use Lmod. As it is very popular, many users may already be familiar with it, though it does make sense to revisit some of the commands that are specific for Lmod and differ from those in the two other implementations.
It is important to realise that each module that you see in the overview corresponds to a module file that contains the actual instructions that should be executed when loading or unloading a module, but also other information such as some properties of the module, information for search and help information.
Links - Old-style environment modules on SourceForge
- TCL Environment Modules home page on SourceForge and the development on GitHub
- Lmod documentation and Lmod development on GitHub
I know Lmod, should I continue?
Lmod is a very flexible tool. Not all sites using Lmod use all features, and Lmod can be configured in different ways to the extent that it may even look like a very different module system for people coming from another cluster. So yes, it makes sense to continue reading as Lmod on LUMI may have some tricks that are not available on your home cluster. E.g., several of the features that we rely upon on LUMI may be disabled on clusters where admins try to mimic the old behaviour of the C/Tcl module implementation after switching to Lmod.
Standard OS software
Most large HPC systems use enterprise-level Linux distributions: derivatives of the stable Red Hat or SUSE distributions. Those distributions typically have a life span of 5 years or even more during which they receive security updates and ports of some newer features, but some of the core elements of such a distribution stay at the same version to break as little as possible between minor version updates. Python and the system compiler are typical examples of those. Red Hat 8 and SUSE Enterprise Linux 15 both came with Python 3.6 in their first version, and keep using this version as the base version of Python even though official support from the Python Software Foundation has long ended. Similarly, the default GNU compiler version offered on those system also remains the same. The compiler may not even fully support some of the newer CPUs the code is running on. E.g., the system compiler of SUSE Enterprise Linux 15, GCC 7.5, does not support the zen2 \"Rome\" or zen3 \"Milan\" CPUs on LUMI.
HPC systems will usually offer newer versions of those system packages through modules and users should always use those. The OS-included tools are really only for system management and system related tasks and serve a different purpose which actually requires a version that remains stable across a number of updates to not break things at the core of the OS. Users however will typically have a choice between several newer versions through modules, which also enables them to track the evolution and transition to a new version at the best suited moment.
"},{"location":"2day-20240502/04_Modules/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"2day-20240502/04_Modules/#benefits-of-a-hierarchy","title":"Benefits of a hierarchy","text":"When the hierarchy is well designed, you get some protection from loading modules that do not work together well. E.g., in the HPE Cray PE it is not possible to load the MPI library built for another compiler than your current main compiler. This is currently not exploited as much as we could on LUMI, mainly because we realised at the start that too many users are not familiar enough with hierarchies and would get confused more than the hierarchy helps them.
Another benefit is that when \"swapping\" a module that makes other modules available with a different one, Lmod will try to look for equivalent modules in the list of modules made available by the newly loaded module.
An easy example (though a tricky one as there are other mechanisms at play also) it to load a different programming environment in the default login environment right after login:
$ module load PrgEnv-aocc\n
which results in the next slide:
The first two lines of output are due to to other mechanisms that are at work here, and the order of the lines may seem strange but that has to do with the way Lmod works internally. Each of the PrgEnv modules hard loads a compiler module which is why Lmod tells you that it is loading aocc/3.2.0. However, there is also another mechanism at work that causes cce/16.0.0 and PrgEnv-cray/8.4.0 to be unloaded, but more about that in the next subsection (next slide).
The important line for the hierarchy in the output are the lines starting with \"Due to MODULEPATH changes...\". Remember that we said that each module has a corresponding module file. Just as binaries on a system, these are organised in a directory structure, and there is a path, in this case MODULEPATH, that determines where Lmod will look for module files. The hierarchy is implemented with a directory structure and the environment variable MODULEPATH, and when the cce/16.0.0 module was unloaded and aocc/3.2.0 module was loaded, that MODULEPATH was changed. As a result, the version of the cray-mpich module for the cce/16.0.0 compiler became unavailable, but one with the same module name for the aocc/3.2.0 compiler became available and hence Lmod unloaded the version for the cce/16.0.0 compiler as it is no longer available but loaded the matching one for the aocc/3.2.0 compiler.
"},{"location":"2day-20240502/04_Modules/#about-module-names-and-families","title":"About module names and families","text":"In Lmod you cannot have two modules with the same name loaded at the same time. On LUMI, when you load a module with the same name as an already loaded module, that other module will be unloaded automatically before loading the new one. There is even no need to use the module swap command for that (which in Lmod corresponds to a module unload of the first module and a module load of the second). This gives you an automatic protection against some conflicts if the names of the modules are properly chosen.
Note
Some clusters do not allow the automatic unloading of a module with the same name as the one you're trying to load, but on LUMI we felt that this is a necessary feature to fully exploit a hierarchy.
Lmod goes further also. It also has a family concept: A module can belong to a family (and at most 1) and no two modules of the same family can be loaded together. The family property is something that is defined in the module file. It is commonly used on systems with multiple compilers and multiple MPI implementations to ensure that each compiler and each MPI implementation can have a logical name without encoding that name in the version string (like needing to have compiler/gcc-11.2.0 or compiler/gcc/11.2.0 rather than gcc/11.2.0), while still having an easy way to avoid having two compilers or MPI implementations loaded at the same time. On LUMI, the conflicting module of the same family will be unloaded automatically when loading another module of that particular family.
This is shown in the example in the previous subsection (the module load PrgEnv-gnu in a fresh long shell) in two places. It is the mechanism that unloaded PrgEnv-cray when loading PrgEnv-gnu and that then unloaded cce/16.0.1 when the PrgEnv-gnu module loaded the gcc/11.2.0 module.
Note
Some clusters do not allow the automatic unloading of a module of the same family as the one you're trying to load and produce an error message instead. On LUMI, we felt that this is a necessary feature to fully exploit the hierarchy and the HPE Cray Programming Environment also relies very much on this feature being enabled to make live easier for users.
"},{"location":"2day-20240502/04_Modules/#extensions","title":"Extensions","text":"It would not make sense to have a separate module for each of the hundreds of R packages or tens of Python packages that a software stack may contain. In fact, as the software for each module is installed in a separate directory it would also create a performance problem due to excess directory accesses simply to find out where a command is located, and very long search path environment variables such as PATH or the various variables packages such as Python, R or Julia use to find extension packages. On LUMI related packages are often bundled in a single module.
Now you may wonder: If a module cannot be simply named after the package it contains as it contains several ones, how can I then find the appropriate module to load? Lmod has a solution for that through the so-called extension mechanism. An Lmod module can define extensions, and some of the search commands for modules will also search in the extensions of a module. Unfortunately, the HPE Cray PE cray-python and cray-R modules do not provide that information at the moment as they too contain several packages that may benefit from linking to optimised math libraries.
"},{"location":"2day-20240502/04_Modules/#searching-for-modules-the-module-spider-command","title":"Searching for modules: The module spider command","text":"There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. The spider command will not only search in module names for the package, but also in extensions of the modules and so will be able to tell you that a package is delivered by another module. See Example 4 below where we will search for the CMake tools.
-
The third use of module spider is with the full name of a module. This shows two kinds of information. First it shows which combinations of other modules one might have to load to get access to the package. That works for both modules and extensions of modules. In the latter case it will show both the module, and other modules that you might have to load first to make the module available. Second it will also show help information for the module if the module file provides such information.
"},{"location":"2day-20240502/04_Modules/#example-1-running-module-spider-on-lumi","title":"Example 1: Running module spider on LUMI","text":"Let's first run the module spider command. The output varies over time, but at the time of writing, and leaving out a lot of the output, one would have gotten:
On the second screen we see, e.g., the ARMForge module which was available in just a single version at that time, and then Autoconf where the version is in blue and followed by (E). This denotes that the Autoconf package is actually provided as an extension of another module, and one of the next examples will tell us how to figure out which one.
The third screen shows the last few lines of the output, which actually also shows some help information for the command.
"},{"location":"2day-20240502/04_Modules/#example-2-searching-for-the-fftw-module-which-happens-to-be-provided-by-the-pe","title":"Example 2: Searching for the FFTW module which happens to be provided by the PE","text":"Next let us search for the popular FFTW library on LUMI:
$ module spider FFTW\n
produces
This shows that the FFTW library is actually provided by the cray-fftw module and was at the time that this was tested available in 4 versions. Note that (a) it is not case sensitive as FFTW is not in capitals in the module name and (b) it also finds modules where the argument of module spider is only part of the name.
The output also suggests us to dig a bit deeper and check for a specific version, so let's run
$ module spider cray-fftw/3.3.10.3\n
This produces:
We now get a long list of possible combinations of modules that would enable us to load this module. What these modules are will be explained in the next session of this course. However, it does show a weakness when module spider is used with the HPE Cray PE. In some cases, not all possible combinations are shown (and this is the case here as the module is actually available directly after login and also via some other combinations of modules that are not shown). This is because the HPE Cray Programming Environment is system-installed and sits next to the application software stacks that are managed differently, but in some cases also because the HPE Cray PE sometimes fails to give the complete combination of modules that is needed. The command does work well with the software managed by the LUMI User Support Team as the next two examples will show.
"},{"location":"2day-20240502/04_Modules/#example-3-searching-for-gnuplot","title":"Example 3: Searching for GNUplot","text":"To see if GNUplot is available, we'd first search for the name of the package:
$ module spider GNUplot\n
This produces:
The output again shows that the search is not case sensitive which is fortunate as uppercase and lowercase letters are not always used in the same way on different clusters. Some management tools for scientific software stacks will only use lowercase letters, while the package we use for the LUMI software stacks often uses both.
We see that there are a lot of versions installed on the system and that the version actually contains more information (e.g., -cpeGNU-23.09) that we will explain in the next part of this course. But you might of course guess that it has to do with the compilers that were used. It may look strange to you to have the same software built with different compilers. However, mixing compilers is sometimes risky as a library compiled with one compiler may not work in an executable compiled with another one, so to enable workflows that use multiple tools we try to offer many tools compiled with multiple compilers (as for most software we don't use rpath linking which could help to solve that problem). So you want to chose the appropriate line in terms of the other software that you will be using.
The output again suggests to dig a bit further for more information, so let's try
$ module spider gnuplot/5.4.8-cpeGNU-23.09\n
This produces:
In this case, this module is provided by 3 different combinations of modules that also will be explained in the next part of this course. Furthermore, the output of the command now also shows some help information about the module, with some links to further documentation available on the system or on the web. The format of the output is generated automatically by the software installation tool that we use and we sometimes have to do some effort to fit all information in there.
For some packages we also have additional information in our LUMI Software Library web site so it is often worth looking there also.
"},{"location":"2day-20240502/04_Modules/#example-4-searching-for-an-extension-of-a-module-cmake","title":"Example 4: Searching for an extension of a module: CMake.","text":"The cmake command on LUMI is available in the operating system image, but as is often the case with such tools distributed with the OS, it is a rather old version and you may want to use a newer one.
If you would just look through the list of available modules, even after loading some other modules to activate a larger software stack, you will not find any module called CMake though. But let's use the powers of module spider and try
$ module spider CMake\n
which produces
The output above shows us that there are actually 5 other versions of CMake on the system, but their version is followed by (E) which says that they are extensions of other modules. There is no module called CMake on the system. But Lmod already tells us how to find out which module actually provides the CMake tools. So let's try
$ module spider CMake/3.27.7\n
which produces
This shows us that the version is provided by a number of buildtools modules, and for each of those modules also shows us which other modules should be loaded to get access to the commands. E.g., the first line tells us that there is a module buildtools/23.09 that provides that version of CMake, but that we first need to load some other modules, with LUMI/23.09 and partition/L (in that order) one such combination.
So in this case, after
$ module load LUMI/23.09 partition/L buildtools/23.09\n
the cmake command would be available.
And you could of course also use
$ module spider buildtools/23.09\n
to get even more information about the buildtools module, including any help included in the module.
"},{"location":"2day-20240502/04_Modules/#alternative-search-the-module-keyword-command","title":"Alternative search: the module keyword command","text":"Lmod has a second way of searching for modules: module keyword. It searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found. We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Let us look for packages that allow us to download software via the https protocol. One could try
$ module keyword https\n
which produces the following output:
cURL and wget are indeed two tools that can be used to fetch files from the internet.
LUMI Software Library
The LUMI Software Library also has a search box in the upper right. We will see in the next section of this course that much of the software of LUMI is managed through a tool called EasyBuild, and each module file corresponds to an EasyBuild recipe which is a file with the .eb extension. Hence the keywords can also be found in the EasyBuild recipes which are included in this web site, and from a page with an EasyBuild recipe (which may not mean much for you) it is easy to go back to the software package page itself for more information. Hence you can use the search box to search for packages that may not be installed on the system.
The example given above though, searching for https, would not work via that box as most EasyBuild recipes include https web links to refer to, e.g., documentation and would be shown in the result.
The LUMI Software Library site includes both software installed in our central software stack and software for which we make customisable build recipes available for user installation, but more about that in the tutorial section on LUMI software stacks.
"},{"location":"2day-20240502/04_Modules/#sticky-modules-and-the-module-purge-command","title":"Sticky modules and the module purge command","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have unexpected side effects. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Let us look at the output of the module avail command, taken just after login on the system at the time of writing of these notes (the exact list of modules shown is a bit fluid):
Next to the names of modules you sometimes see one or more letters. The (D) means that that is currently the default version of the module, the one that will be loaded if you do not specify a version. Note that the default version may depend on other modules that are already loaded as we have seen in the discussion of the programming environment.
The (L) means that a module is currently loaded.
The (S) means that the module is a sticky module.
Next to the rocm module (on the fourth screen) you see (D:5.0.2:5.2.0). The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
At the end of the overview the extensions are also shown. If this would be fully implemented on LUMI, the list could become very long. However, as we shall see next, there is an easy way to hide those from view. We haven't used them very intensely so far as there was a bug in older versions of Lmod so that turning off the view didn't work and so that extensions that were not in available modules, were also shown. But that is fixed in current versions.
"},{"location":"2day-20240502/04_Modules/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed in the above example that we don't show directories of module files in the overview (as is the case on most clusters) but descriptive texts about the module group. This is just one view on the module tree though, and it can be changed easily by loading a version of the ModuleLabel module.
ModuleLabel/label produces the default view of the previous example. ModuleLabel/PEhierarchy still uses descriptive texts but will show the whole module hierarchy of the HPE Cray Programming Environment.ModuleLabel/system does not use the descriptive texts but shows module directories instead.
When using any kind of descriptive labels, Lmod can actually bundle module files from different directories in a single category and this is used heavily when ModuleLabel/label is loaded and to some extent also when ModuleLabel/PEhierarchy is loaded.
It is rather hard to provide multiple colour schemes in Lmod, and as we do not know how your terminal is configured it is also impossible to find a colour scheme that works for all users. Hence we made it possible to turn on and off the use of colours by Lmod through the ModuleColour/on and ModuleColour/off modules.
As the module extensions list in the output of module avail could potentially become very long over time (certainly if there would be Python or R modules installed with EasyBuild that show all included Python or R packages in that list) you may want to hide those. You can do this by loading the ModuleExtensions/hide module and undo this again by loading ModuleExtensions/show.
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. You can still load them if you know they exist and specify the full version but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work if you use modules that are hidden in the context you're in or if you try to use any module that was designed for us to maintain the system and is therefore hidden from regular users.
Example
An example that will only become clear in the next session: When working with the software stack called LUMI/23.09, which is built upon the HPE Cray Programming Environment version 23.09, all (well, most) of the modules corresponding to other versions of the Cray PE are hidden.
"},{"location":"2day-20240502/04_Modules/#getting-help-with-the-module-help-command","title":"Getting help with the module help command","text":"Lmod has the module help command to get help on modules
$ module help\n
without further arguments will show some help on the module command.
With the name of a module specified, it will show the help information for the default version of that module, and with a full name and version specified it will show this information specifically for that version of the module. But note that module help can only show help for currently available modules.
Try, e.g., the following commands:
$ module help cray-mpich\n$ module help cray-python/3.10.10\n$ module help buildtools/23.09\n
Lmod also has another command that produces more limited information (and is currently not fully exploited on LUMI): module whatis. It is more a way to tag a module with different kinds of information, some of which has a special meaning for Lmod and is used at some places, e.g., in the output of module spider without arguments.
Try, e.g.,:
$ module whatis Subversion\n$ module whatis Subversion/1.14.2\n
"},{"location":"2day-20240502/04_Modules/#a-note-on-caching","title":"A note on caching","text":"Modules are stored as (small) files in the file system. Having a large module system with much software preinstalled for everybody means a lot of small files which will make our Lustre file system very unhappy. Fortunately Lmod does use caches by default. On LUMI we currently have no system cache and only a user cache. That cache can be found in $HOME/.cache/lmod (and in some versions of LMOD in $HOME/.lmod.d/.cache).
That cache is also refreshed automatically every 24 hours. You'll notice when this happens as, e.g., the module spider and module available commands will be slow during the rebuild. you may need to clean the cache after installing new software as on LUMI Lmod does not always detect changes to the installed software,
Sometimes you may have to clear the cache also if you get very strange answers from module spider. It looks like the non-standard way in which the HPE Cray Programming Environment does certain things in Lmod can cause inconsistencies in the cache. This is also one of the reasons whey we do not yet have a central cache for that software that is installed in the central stacks as we are not sure when that cache is in good shape.
"},{"location":"2day-20240502/04_Modules/#a-note-on-other-commands","title":"A note on other commands","text":"As this tutorial assumes some experience with using modules on other clusters, we haven't paid much attention to some of the basic commands that are mostly the same across all three module environments implementations. The module load, module unload and module list commands work largely as you would expect, though the output style of module list may be a little different from what you expect. The latter may show some inactive modules. These are modules that were loaded at some point, got unloaded when a module closer to the root of the hierarchy of the module system got unloaded, and they will be reloaded automatically when that module or an equivalent (family or name) module is loaded that makes this one or an equivalent module available again.
Example
To demonstrate this, try in a fresh login shell (with the lines starting with a $ the commands that you should enter at the command prompt):
$ module unload craype-network-ofi\n\nInactive Modules:\n 1) cray-mpich\n\n$ module load craype-network-ofi\n\nActivating Modules:\n 1) cray-mpich/8.1.27\n
The cray-mpich module needs both a valid network architecture target module to be loaded (not craype-network-none) and a compiler module. Here we remove the network target module which inactivates the cray-mpich module, but the module gets reactivated again as soon as the network target module is reloaded.
The module swap command is basically equivalent to a module unload followed by a module load. With one argument it will look for a module with the same name that is loaded and unload that one before loading the given module. With two modules, it will unload the first one and then load the second one. The module swap command is not really needed on LUMI as loading a conflicting module (name or family) will automatically unload the previously loaded one. However, in case of replacing a module of the same family with a different name, module swap can be a little faster than just a module load as that command will need additional operations as in the first step it will discover the family conflict and then try to resolve that in the following steps (but explaining that in detail would take us too far in the internals of Lmod).
"},{"location":"2day-20240502/04_Modules/#links","title":"Links","text":"These links were OK at the time of the course. This tutorial will age over time though and is not maintained but may be replaced with evolved versions when the course is organised again, so links may break over time.
- Lmod documentation and more specifically the User Guide for Lmod which is the part specifically for regular users who do not want to design their own modules.
- Information on the module environment in the LUMI documentation
"},{"location":"2day-20240502/05_Software_stacks/","title":"LUMI Software Stacks","text":"In this section we discuss
- Several of the ways in which we offer software on LUMI
- Managing software in our primary software stack which is based on EasyBuild
"},{"location":"2day-20240502/05_Software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"2day-20240502/05_Software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack than your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in supercomputers in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems.
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 12 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For the major LUMI stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 10 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
There is an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"2day-20240502/05_Software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"The LUMI User Support Team (LUST) tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but LUST decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. The stack is also made very easy to extend. So LUMI has many base libraries and some packages already pre-installed but also provides an easy and very transparent way to install additional packages in your project space in exactly the same way as is done for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system a choice had to be made between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. LUMI chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations there was a choice between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. LUMI chose to go with EasyBuild as the primary tool for which the LUST also does some development. However, as we shall see, the EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. LUMI does offer a growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as LUMI cannot automatically determine a suitable place.
The LUST does offer some help to set up Spack also but it is mostly offered \"as is\" and LUST will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"2day-20240502/05_Software_stacks/#software-policies","title":"Software policies","text":"As any site, LUMI also has a number of policies about software installation, and these policies are further developed as the LUMI team gains experience in what they can do with the amount of people in LUST and what they cannot do.
LUMI uses a bring-your-own-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as the LUST does not even have the necessary information to determine if a particular user can use a particular license, so that responsibility must be shifted to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push LUMI onto the industrial rather than academic pricing as they have no guarantee that LUMI operations will obey to the academic license restrictions.
- And lastly, the LUMI project doesn't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume the whole LUMI software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So LUMI has to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that LUMI invests in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not their task. Some consortium countries may also have a local support team that can help. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric, the Open Fabrics Interface (OFI) library, using a specific provider for the NIC used on LUMI, the so-called Cassini provider (CXI), so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why LUMI currently states in its policy that a LUMI user should be capable of installing their software themselves or have another support channel. The LUST cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code. Again some help is possible at the Belgian level but our resources are also limited.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason LUMI also requires to containerize conda and Python installations. On LUMI two tools are offered for this.
- cotainr is a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space. Its current version focusses on containerising a conda-installation.
- The second tool is a container-based wrapper generator that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the
cray-python module. On LUMI the tool is called lumi-container-wrapper but users of the CSC national systems will know it as Tykky.
Both tools are pre-installed on the system and ready-to-use.
"},{"location":"2day-20240502/05_Software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"LUMI offers several software stacks:
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which the LUST installs software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. There are tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. If the need would arrise, a fourth partition could be created for the visualisation nodes with zen2 CPUs and NVIDIA GPUs.
LUMI also offers an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but support is limited and no bug-fixing in Spack is done.
In the far future the LUST will also look at a stack based on the common EasyBuild toolchains as-is, but problems are expected with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so no promises whatsoever are made about a time frame for this development.
"},{"location":"2day-20240502/05_Software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"2day-20240502/05_Software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course or the 4-day comprehensive courses that LUST organises.
"},{"location":"2day-20240502/05_Software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And they are sometimes used to work around problems in Cray-provided modules that cannot changed easily due to the way system administration on a Cray system is done.
This is also the environment in which the LUST installs most software, and from the name of the modules you can see which compilers we used.
"},{"location":"2day-20240502/05_Software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12, LUMI/23.03 and LUMI/23.09 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"2day-20240502/05_Software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"2day-20240502/05_Software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the Slingshot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"2day-20240502/05_Software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead LUMI has its own EasyBuild build recipes that are also made available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before it is even deployed on the system.
LUMI also offers the LUMI Software Library which documents all software for which there are LUMI-specific EasyBuild recipes available. This includes both the pre-installed software and the software for which recipes are provided in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"2day-20240502/05_Software_stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"2day-20240502/05_Software_stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
LUMI doesn't use the standard EasyBuild toolchains but its own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but on LUMI it is used for a bit more as it offers a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (LUMI doesn't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as LUMI does not use hierarchy in the Lmod implementation of the software stack at the toolchain level, the module system will not protect you from these mistakes. When the LUST set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"2day-20240502/05_Software_stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2022.5, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeGNU-23.09 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/23.09.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.9.0-noPython-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.
"},{"location":"2day-20240502/05_Software_stacks/#installing","title":"Installing","text":""},{"location":"2day-20240502/05_Software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants of the project to solve a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"2day-20240502/05_Software_stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module. It works correctly for a lot of CPU-only software, but fails more frequently for GPU software as the installation scripts will try to run scripts that detect which GPU is present, or try to run tests on the GPU, even if you tell which GPU type to use, which does not work on the login nodes.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"2day-20240502/05_Software_stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS there is already support on LUMI. An easy way to do that is to simply check the LUMI Software Library. This web site lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Alternatively one can use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Results of the searches:
In the LUMI Software Library, after some scrolling through the page for GROMACS, the list of EasyBuild recipes is found in the \"User-installable modules (and EasyConfigs)\" section:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb. This is GROMACS 2022.5 with the PLUMED 2.9.0 plugin, built with the GNU compilers from LUMI/23.09, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb -r\n
Running EasyBuild to install GROMACS and dependency
The command
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb -r\n
results in:
EasyBuild detects PLUMED is a dependency and because of the -r option, it first installs the required version of PLUMED.
When the installation of PLUMED finishes, EasyBuild starts the installation of GROMACS. It mentions something we haven't seen when installing PLUMED:
== starting iteration #0\n
GROMACS can be installed in many configurations, and they generate executables with different names. Our EasyConfig combines 4 popular installations in one: Single and double precision and with and without MPI, so it will do 4 iterations. As EasyBuild is developed by geeks, counting starts from 0.
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"2day-20240502/05_Software_stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.cache/lmod. You can do this with
rm -rf $HOME/.cache/lmod\n
(With older versions of Lmod the cache directory is $HOME/.lmod.d/cache.)"},{"location":"2day-20240502/05_Software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. LUMI would likely be in violation of the license if it would offer the download somewhere where EasyBuild can find it, and it is also a way to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP LUMI provides EasyBuild recipes, but you will still have to download the source file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.4.1-cpeGNU-22.12-build01.eb \u2013r . \n
"},{"location":"2day-20240502/05_Software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"2day-20240502/05_Software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elswhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"2day-20240502/05_Software_stacks/#easybuild-tips-and-tricks","title":"EasyBuild tips and tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When a toolchain is updated on the system, the versions of all installed libraries are often also bumped to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
LUMI provides documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why things are done in a particular way.
"},{"location":"2day-20240502/05_Software_stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on tutorial.easybuild.io. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"2day-20240502/06_Slurm/","title":"Slurm on LUMI","text":"Who is this for?
We assume some familiarity with job scheduling in this section. The notes will cover some of the more basic aspects of Slurm also, though it may be rather brief on some aspects of Slurm as we assume the majority of users is already rather familiar with Slurm.
Even if you have a lot of experience with Slurm, it may still be useful to have a quick look at this section as Slurm is not always configured in the same way.
Links to Slurm material
Links to Slurm material on this web page are all for the version on LUMI at the time of the course. Some of the links in the PDF of the slides however are to the newest version.
"},{"location":"2day-20240502/06_Slurm/#what-is-slurm","title":"What is Slurm","text":"Slurm is both a resource manager and job scheduler for supercomputers in a single package.
A resource manager manages all user-exposed resources on a supercomputer: cores, GPUs or other accelerators, nodes, ... It sets up the resources to run a job and cleans up after the job, and may also give additional facilities to start applications in a job. Slurm does all this.
But Slurm is also a job scheduler. It will assign jobs to resources, following policies set by sysadmins to ensure a good use of the machine and a fair distribution of resources among projects.
Slurm is the most popular resource manager and job scheduler at the moment and is used on more than 50% of all big supercomputers. It is an open source package with commercial support. Slurm is a very flexible and configurable tool with the help of tens or even hundreds of plugins. This also implies that Slurm installations on different machines can also differ a lot and that not all features available on one computer are also available on another. So do not expect that Slurm will behave the same on LUMI as on that other computer you're familiar with, even if that other computer may have hardware that is very similar to LUMI.
Slurm is starting to show its age and has trouble dealing in an elegant and proper way with the deep hierarcy of resources in modern supercomputers. So Slurm will not always be as straightforward to use as we would like it, and some tricks will be needed on LUMI. Yet there is no better option at this moment that is sufficiently mature.
Nice to know...
Lawrence Livermore National Laboratory, the USA national laboratory that originally developed Slurm is now working on the development of another resource and job management framework called flux. It will be used on the third USA exascale supercomputer El Capitan which is currently being assembled.
"},{"location":"2day-20240502/06_Slurm/#slurm-concepts-physical-resources","title":"Slurm concepts: Physical resources","text":"The machine model of Slurm is bit more limited than what we would like for LUMI.
On the CPU side it knows:
-
A node: The hardware that runs a single operating system image
-
A socket: On LUMI a Slurm socket corresponds to a physical socket, so there are two sockets on the CPU nodes and a single socket on a GPU node.
Alternatively a cluster could be configured to let a Slurm socket correspond to a NUMA nore or L3 cache region, but this is something that sysadmins need to do so even if this would be useful for your job, you cannot do so.
-
A core is a physical core in the system
-
A thread is a hardware thread in the system (virtual core)
-
A CPU is a \"consumable resource\" and the unit at which CPU processing capacity is allocated to a job. On LUMI a Slurm CPU corresponds to a physical core, but Slurm could also be configured to let it correspond to a hardware thread.
The first three bullets already show the problem we have with Slurm on LUMI: For three levels in the hierarchy of CPU resources on a node: the socket, the NUMA domain and the L3 cache domain, there is only one concept in Slurm, so we are not able to fully specify the hierarchy in resources that we want when sharing nodes with other jobs.
A GPU in Slurm is an accelerator and on LUMI corresponds to one GCD of an MI250X, so one half of an MI250X.
"},{"location":"2day-20240502/06_Slurm/#slurm-concepts-logical-resources","title":"Slurm concepts: Logical resources","text":" -
A partition: is a job queue with limits and access control. Limits include maximum wall time for a job, the maximum number of nodes a single job can use, or the maximum number of jobs a user can run simultaneously in the partition. The access control mechanism determines who can run jobs in the partition.
It is different from what we call LUMI-C and LUMI-G, or the partition/C and partition/G modules in the LUMI software stacks.
Each partition covers a number of nodes, but partitions can overlap. This is not the case for the partitions that are visible to users on LUMI. Each partition covers a disjunct set of nodes. There are hidden partitions though that overlap with other partitions, but they are not accessible to regular users.
-
A job in Slurm is basically only a resource allocation request.
-
A job step is a set of (possibly parallel) tasks within a job
-
Each batch job always has a special job step called the batch job step which runs the job script on the first node of a job allocation.
-
An MPI application will typically run in its own job step.
-
Serial or shared memory applications are often run in the batch job step but there can be good reasons to create a separate job step for those applications.
-
A task executes in a job step and corresponds to a Linux process (and possibly subprocesses)
Of course a task cannot use more CPUs than available in a single node as a process can only run within a single operating system image.
"},{"location":"2day-20240502/06_Slurm/#slurm-is-first-and-foremost-a-batch-scheduler","title":"Slurm is first and foremost a batch scheduler","text":"And LUMI is in the first place a batch processing supercomputer.
A supercomputer like LUMI is a very large and very expensive machine. This implies that it also has to be used as efficiently as possible which in turn implies that we don't want to wast time waiting for input as is the case in an interactive program.
On top of that, very few programs can use the whole capacity of the supercomputer, so in practice a supercomputer is a shared resource and each simultaneous user gets a fraction on the machine depending on the requirements that they specify. Yet, as parallel applications work best when performance is predictable, it is also important to isolate users enough from each other.
Research supercomputers are also typically very busy with lots of users so one often has to wait a little before resources are available. This may be different on some commercial supercomputers and is also different on commercial cloud infrastructures, but the \"price per unit of work done on the cluster\" is also very different from an academic supercomputer and few or no funding agencies are willing to carry that cost.
Due to all this the preferred execution model on supercomputer is via batch jobs as they don't have to wait for input from the user, specified via batch scripts with resource specification where the user asks precisely the amount of resources needed for the job, submitted to a queueing system with a scheduler to select the next job in a fair way based on available resources and scheduling policies set by the compute centre.
LUMI does have some facilities for interactive jobs, and with the introduction of Open On Demand some more may be available. But it is far from ideal, and you will also be billed for the idle time of the resources you request. In fact, if you only need some interactive resources for a quick 10-minute experiment and don't need too many resources, the wait may be minimal thanks to a scheduler mechanism called backfill where the scheduler looks for small and short jobs to fill up the gaps left while the scheduler is collecting resources for a big job.
"},{"location":"2day-20240502/06_Slurm/#a-slurm-batch-script","title":"A Slurm batch script","text":"Slurm batch scripts (also called job scripts) are conceptually not that different from batch scripts for other HPC schedulers. A typical batch script will have 4 parts:
-
The shebang line with the shell to use. We advise to use the bash shell (/bin/bash or /usr/bin/bash) If omitted, a very restricted shell will be used and some commands (e.g., related to modules) may fail. In principle any shell language that uses a hashtag to denote comments can be used, but we would advise against experimenting and the LUMI User Support Team will only support bash.
-
Specification of resources and some other instructions for the scheduler and resource manager. This part is also optional as one can also pass the instructions via the command line of sbatch, the command to submit a batch job. But again, we would advise against omitting this block as specifying all options on the command line can be very tedious.
-
Building a suitable environment for the job. This part is also optional as on LUMI, Slurm will copy the environment from the node from which the job was submitted. This may not be the ideal envrionment for your job, and if you later resubmit the job you may do so accidentally from a different environment so it is a good practice to specify the environment.
-
The commands you want to execute.
Blocks 3 and 4 can of course be mixed as you may want to execute a second command in a different environment.
On the following slides we will explore in particular the second block and to some extent how to start programs (the fourth block).
lumi-CPEtools module
The lumi-CPEtools module will be used a lot in this session of the course and in the next one on binding. It contains among other things a number of programs to quickly visualise how a serial, OpenMP, MPI or hybrid OpenMP/MPI application would run on LUMI and which cores and GPUs would be used. It is a very useful tool to discover how Slurm options work without using a lot of billing units and we would advise you to use it whenever you suspect Slurm isn't doing what you meant to do.
It has its documentation page in the LUMI Software Library.
"},{"location":"2day-20240502/06_Slurm/#partitions","title":"Partitions","text":"Remark
Jobs run in partitions so the first thing we should wonder when setting up a job is which partition to use for a job (or sometimes partitions in case of a heterogeneous job which will be discussed later).
Slurm partitions are possibly overlapping groups of nodes with similar resources or associated limits. Each partition typically targets a particular job profile. E.g., LUMI has partitions for large multi-node jobs, for smaller jobs that often cannot fill a node, for some quick debug work and for some special resources that are very limited (the nodes with 4TB of memory and the nodes with GPUs for visualisation). The number of jobs a user can have running simultaneously in each partition or have in the queue, the maximum wall time for a job, the number of nodes a job can use are all different for different partitions.
There are two types of partitions on LUMI:
-
Exclusive node use by a single job. This ensures that parallel jobs can have a clean environment with no jitter caused by other users running on the node and with full control of how tasks and threads are mapped onto the available resources. This may be essential for the performance of a lot of codes.
-
Allocatable by resources (CPU and GPU). In these partitions nodes are shared by multiple users and multiple jobs, though in principle it is possible to ask for exclusive use which will however increase your waiting time in the queue. The cores you get are not always continuously numbered, nor do you always get the minimum number of nodes needed for the number of tasks requested. A proper mapping of cores onto GPUs is also not ensured at all. The fragmentation of resources is a real problem on these nodes and this may be an issue for the performance of your code.
It is also important to realise that the default settings for certain Slurm parameters may differ between partitions and hence a node in a partition allocatable by resource but for which exclusive access was requested may still react differently to a node in the exclusive partitions.
In general it is important to use some common sense when requesting resources and to have some understanding of what each Slurm parameter really means. Overspecifying resources (using more parameters than needed for the desired effect) may result in unexpected conflicts between parameters and error messages.
For the overview of Slurm partitions, see the LUMI documentation, \"Slurm partitions\" page. In the overview on the slides we did not mention partitions that are hidden to regular users.
The policies for partitions and the available partitions may change over time to fine tune the operation of LUMI and depending on needs observed by the system administrators and LUMI User Support Team, so don't take the above tables in the slide for granted.
Some useful commands with respect to Slurm partitions:
-
To request information about the available partitions, use sinfo -s:
$ sinfo -s\nPARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST\ndebug up 30:00 1/7/0/8 nid[002500-002501,002504-002506,002595-002597]\ninteractive up 8:00:00 2/2/0/4 nid[002502,002507,002594,002599]\nq_fiqci up 15:00 0/1/0/1 nid002598\nq_industry up 15:00 0/1/0/1 nid002598\nq_nordiq up 15:00 0/1/0/1 nid002503\nsmall up 3-00:00:00 281/8/17/306 nid[002280-002499,002508-002593]\nstandard up 2-00:00:00 1612/1/115/1728 nid[001000-002279,002600-003047]\ndev-g up 3:00:00 44/2/2/48 nid[005002-005025,007954-007977]\nsmall-g up 3-00:00:00 191/2/5/198 nid[005026-005123,007852-007951]\nstandard-g up 2-00:00:00 1641/749/338/272 nid[005124-007851]\nlargemem up 1-00:00:00 0/5/1/6 nid[000101-000106]\nlumid up 4:00:00 1/6/1/8 nid[000016-000023]\n
The fourth column shows 4 numbers: The number of nodes that are currently fully or partially allocated to jobs, the number of idle nodes, the number of nodes in one of the other possible states (and not user-accessible) and the total number of nodes in the partition. Sometimes a large number of nodes can be in the \"O\"column, e.g., when mechanical maintenance is needed (like problem with the cooling). Also note that the width of the NODES field is not enough as the total number of nodes for standard-g doesn't make sense, but this is easyly solved, e.g., using
sinfo -o \"%11P %.5a %.10l %.20F %N\"\n
Note that this overview may show partitions that are not hidden but also not accessible to everyone. E.g., the q_nordic and q_fiqci partitions are used to access experimental quantum computers that are only available to some users of those countries that paid for those machines.
It is not clear to the LUMI Support Team what the interactive partition, that uses dome GPU nodes, is meant for as it was introduced without informing the support. The resources in that partition are very limited so it is not meant for widespread use.
-
For technically-oriented people, some more details about a partition can be obtained with scontrol show partition <partition-name>.
Additional example with sinfo Try
$ sinfo --format \"%4D %10P %25f %.4c %.8m %25G %N\"\nNODE PARTITION AVAIL_FEATURES CPUS MEMORY GRES NODELIST\n5 debug AMD_EPYC_7763,x1005 256 229376 (null) nid[002500-002501,002504-002506]\n3 debug AMD_EPYC_7763,x1006 256 229376 (null) nid[002595-002597]\n2 interactiv AMD_EPYC_7763,x1005 256 229376 (null) nid[002502,002507]\n2 interactiv AMD_EPYC_7763,x1006 256 229376 (null) nid[002594,002599]\n256 ju-standar AMD_EPYC_7763,x1001 256 229376 (null) nid[001256-001511]\n256 ju-standar AMD_EPYC_7763,x1004 256 229376 (null) nid[002024-002279]\n96 ju-standar AMD_EPYC_7763,x1006 256 229376 (null) nid[002600-002695]\n256 ju-strateg AMD_EPYC_7763,x1000 256 229376 (null) nid[001000-001255]\n1 q_fiqci AMD_EPYC_7763,x1006 256 229376 (null) nid002598\n1 q_industry AMD_EPYC_7763,x1006 256 229376 (null) nid002598\n1 q_nordiq AMD_EPYC_7763,x1005 256 229376 (null) nid002503\n248 small AMD_EPYC_7763,x1005 256 229376+ (null) nid[002280-002499,002508-002535]\n58 small AMD_EPYC_7763,x1006 256 229376 (null) nid[002536-002593]\n256 standard AMD_EPYC_7763,x1003 256 229376 (null) nid[001768-002023]\n256 standard AMD_EPYC_7763,x1002 256 229376 (null) nid[001512-001767]\n256 standard AMD_EPYC_7763,x1007 256 229376 (null) nid[002792-003047]\n96 standard AMD_EPYC_7763,x1006 256 229376 (null) nid[002696-002791]\n2 dev-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8 nid[007974-007975]\n22 dev-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8(S:0) nid[007954-007973,007976-007977]\n24 dev-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8(S:0) nid[005002-005025]\n2 ju-standar AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8 nid[005356-005357]\n7 ju-standar AMD_EPYC_7A53,x1103 128 491520 gpu:mi250:8 nid[005472-005473,005478-005479,005486-005487,005493]\n8 ju-standar AMD_EPYC_7A53,x1105 128 491520 gpu:mi250:8 nid[005648-005649,005679,005682-005683,005735,005738-005739]\n2 ju-standar AMD_EPYC_7A53,x1200 128 491520 gpu:mi250:8 nid[005810-005811]\n3 ju-standar AMD_EPYC_7A53,x1204 128 491520 gpu:mi250:8 nid[006301,006312-006313]\n1 ju-standar AMD_EPYC_7A53,x1205 128 491520 gpu:mi250:8 nid006367\n2 ju-standar AMD_EPYC_7A53,x1404 128 491520 gpu:mi250:8 nid[007760-007761]\n9 ju-standar AMD_EPYC_7A53,x1201 128 491520 gpu:mi250:8 nid[005881,005886-005887,005897,005917,005919,005939,005969,005991]\n90 ju-standar AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8(S:0) nid[005280-005355,005358-005371]\n117 ju-standar AMD_EPYC_7A53,x1103 128 491520 gpu:mi250:8(S:0) nid[005372-005471,005474-005477,005480-005485,005488-005492,005494-005495]\n116 ju-standar AMD_EPYC_7A53,x1105 128 491520 gpu:mi250:8(S:0) nid[005620-005647,005650-005678,005680-005681,005684-005734,005736-005737,005740-005743]\n122 ju-standar AMD_EPYC_7A53,x1200 128 491520 gpu:mi250:8(S:0) nid[005744-005809,005812-005867]\n115 ju-standar AMD_EPYC_7A53,x1201 128 491520 gpu:mi250:8(S:0) nid[005868-005880,005882-005885,005888-005896,005898-005916,005918,005920-005938,005940-005968,005970-005990]\n121 ju-standar AMD_EPYC_7A53,x1204 128 491520 gpu:mi250:8(S:0) nid[006240-006300,006302-006311,006314-006363]\n123 ju-standar AMD_EPYC_7A53,x1205 128 491520 gpu:mi250:8(S:0) nid[006364-006366,006368-006487]\n122 ju-standar AMD_EPYC_7A53,x1404 128 491520 gpu:mi250:8(S:0) nid[007728-007759,007762-007851]\n3 ju-strateg AMD_EPYC_7A53,x1101 128 491520 gpu:mi250:8 nid[005224,005242-005243]\n8 ju-strateg AMD_EPYC_7A53,x1203 128 491520 gpu:mi250:8 nid[006136-006137,006153,006201,006214-006215,006236-006237]\n5 ju-strateg AMD_EPYC_7A53,x1202 128 491520 gpu:mi250:8 nid[006035,006041,006047,006080-006081]\n121 ju-strateg AMD_EPYC_7A53,x1101 128 491520 gpu:mi250:8(S:0) nid[005124-005223,005225-005241,005244-005247]\n32 ju-strateg AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8(S:0) nid[005248-005279]\n116 ju-strateg AMD_EPYC_7A53,x1203 128 491520 gpu:mi250:8(S:0) nid[006116-006135,006138-006152,006154-006200,006202-006213,006216-006235,006238-006239]\n119 ju-strateg AMD_EPYC_7A53,x1202 128 491520 gpu:mi250:8(S:0) nid[005992-006034,006036-006040,006042-006046,006048-006079,006082-006115]\n1 small-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8 nid005059\n97 small-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8(S:0) nid[005026-005058,005060-005123]\n100 small-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8(S:0) nid[007852-007951]\n2 standard-g AMD_EPYC_7A53,x1104 128 491520 gpu:mi250:8 nid[005554-005555]\n117 standard-g AMD_EPYC_7A53,x1300 128 491520 gpu:mi250:8(S:0) nid[006488-006505,006510-006521,006524-006550,006552-006611]\n7 standard-g AMD_EPYC_7A53,x1300 128 491520 gpu:mi250:8 nid[006506-006509,006522-006523,006551]\n121 standard-g AMD_EPYC_7A53,x1301 128 491520 gpu:mi250:8(S:0) nid[006612-006657,006660-006703,006705-006735]\n3 standard-g AMD_EPYC_7A53,x1301 128 491520 gpu:mi250:8 nid[006658-006659,006704]\n117 standard-g AMD_EPYC_7A53,x1302 128 491520 gpu:mi250:8(S:0) nid[006736-006740,006744-006765,006768-006849,006852-006859]\n7 standard-g AMD_EPYC_7A53,x1302 128 491520 gpu:mi250:8 nid[006741-006743,006766-006767,006850-006851]\n8 standard-g AMD_EPYC_7A53,x1304 128 491520 gpu:mi250:8 nid[007000-007001,007044-007045,007076-007077,007092-007093]\n5 standard-g AMD_EPYC_7A53,x1305 128 491520 gpu:mi250:8 nid[007130-007131,007172-007173,007211]\n2 standard-g AMD_EPYC_7A53,x1400 128 491520 gpu:mi250:8 nid[007294-007295]\n1 standard-g AMD_EPYC_7A53,x1401 128 491520 gpu:mi250:8 nid007398\n1 standard-g AMD_EPYC_7A53,x1403 128 491520 gpu:mi250:8 nid007655\n122 standard-g AMD_EPYC_7A53,x1104 128 491520 gpu:mi250:8(S:0) nid[005496-005553,005556-005619]\n124 standard-g AMD_EPYC_7A53,x1303 128 491520 gpu:mi250:8(S:0) nid[006860-006983]\n116 standard-g AMD_EPYC_7A53,x1304 128 491520 gpu:mi250:8(S:0) nid[006984-006999,007002-007043,007046-007075,007078-007091,007094-007107]\n119 standard-g AMD_EPYC_7A53,x1305 128 491520 gpu:mi250:8(S:0) nid[007108-007129,007132-007171,007174-007210,007212-007231]\n122 standard-g AMD_EPYC_7A53,x1400 128 491520 gpu:mi250:8(S:0) nid[007232-007293,007296-007355]\n123 standard-g AMD_EPYC_7A53,x1401 128 491520 gpu:mi250:8(S:0) nid[007356-007397,007399-007479]\n124 standard-g AMD_EPYC_7A53,x1402 128 491520 gpu:mi250:8(S:0) nid[007480-007603]\n123 standard-g AMD_EPYC_7A53,x1403 128 491520 gpu:mi250:8(S:0) nid[007604-007654,007656-007727]\n6 largemem AMD_EPYC_7742 256 4096000+ (null) nid[000101-000106]\n8 lumid AMD_EPYC_7742 256 2048000 gpu:a40:8,nvme:40000 nid[000016-000023]\n
(Output may vary over time) This shows more information about the system. The xNNNN feature corresponds to groups in the Slingshot interconnect and may be useful if you want to try to get a job running in a single group (which is too advanced for this course).
The memory size is given in megabyte (MiB, multiples of 1024). The \"+\" in the second group of the small partition is because that partition also contains the 512 GB and 1 TB regular compute nodes. The memory reported is always 32 GB less than you would expect from the node specifications. This is because 32 GB on each node is reserved for the OS and the RAM disk it needs.
"},{"location":"2day-20240502/06_Slurm/#accounting-of-jobs","title":"Accounting of jobs","text":"The use of resources by a job is billed to projects, not users. All management is also done at the project level, not at the \"user-in-a-project\" level. As users can have multiple projects, the system cannot know to which project a job should be billed, so it is mandatory to specify a project account (of the form project_46YXXXXXX) with every command that creates an allocation.
Billing on LUMI is not based on which resources you effectively use, but on the amount of resources that others cannot use well because of your allocation. This assumes that you make proportional use of CPU cores, CPU memory and GPUs (actually GCDs). If you job makes a disproportionally high use of one of those resources, you will be billed based on that use. For the CPU nodes, the billing is based on both the number of cores you request in your allocation and the amount of memory compared to the amount of memory per core in a regular node, and the highest of the two numbers is used. For the GPU nodes, the formula looks at the number of cores compared to he number of cores per GPU, the amount of CPU memory compared to the amount of memory per GCD (so 64 GB), and the amount of GPUs and the highest amount determines for how many GCDs you will be billed (with a cost of 0.5 GPU-hour per hour per GCD). For jobs in job-exclusive partitions you are automatically billed for the full node as no other job can use that node, so 128 core-hours per hour for the standard partition or 4 GPU-hours per hour for the standard-g partition.
E.g., if you would ask for only one core but 128 GB of memory, half of what a regular LUMI-C node has, you'd be billed for the use of 64 cores. Or assume you want to use only one GCD but want to use 16 cores and 256 GB of system RAM with it, then you would be billed for 4 GPUs/GCDs: 256 GB of memory makes it impossible for other users to use 4 GPUs/GCDs in the system, and 16 cores make it impossible to use 2 GPUs/GCDs, so the highest number of those is 4, which means that you will pay 2 GPU-hours per hour that you use the allocation (as GPU-hours are based on a full MI250x and not on a GCD which is the GPU for Slurm).
This billing policy is unreasonable!
Users who have no experience with performance optimisation may think this way of billing is unfair. After all, there may be users who need far less than 2 GB of memory per core so they could still use the other cores on a node where I am using only one core but 128 GB of memory, right? Well, no, and this has everything to do with the very hierarchical nature of a modern compute node, with on LUMI-C 2 sockets, 4 NUMA domains per socket, and 2 L3 cache domains per NUMA domain. Assuming your job would get the first core on the first socket (called core 0 and socket 0 as computers tend to number from 0). Linux will then allocate the memory of the job as close as possible to that core, so it will fill up the 4 NUMA domains of that socket. It can migrate unused memory to the other socket, but let's assume your code does not only need 128 GB but also accesses bits and pieces from it everywhere all the time. Another application running on socket 0 may then get part or all of its memory on socket 1, and the latency to access that memory is more than 3 times higher, so performance of that application will suffer. In other words, the other cores in socket 0 cannot be used with full efficiency.
This is not a hypothetical scenario. The author of this text has seem benchmarks run on one of the largest systems in Flanders that didn't scale at all and for some core configuration ran at only 10% of the speed they should have been running at...
Still, even with this billing policy Slurm on LUMI is a far from perfect scheduler and core, GPU and memory allocation on the non-exclusive partitions are far from optimal. Which is why we spend a section of the course on binding applications to resources.
The billing is done in a postprocessing step in the system based on data from the Slurm job database, but the Slurm accounting features do not produce the correct numbers. E.g., Slurm counts the core hours based on the virtual cores so the numbers are double of what they should be. There are two ways to check the state of an allocation, though both work with some delay.
-
The lumi-workspaces and lumi-allocations commands show the total amount of billing units consumed. In regular operation of the system these numbers are updated approximately once an hour.
lumi-workspaces is the all-in command that intends to show all information that is useful to a regular user, while lumi-allocations is a specialised tool that only shows billing units, but he numbers shown by both tools come from the same database and are identical.
-
For projects managed via Puhuri, Puhuri can show billing unit use per month, but the delay is larger than with the lumi-workspaces command.
Billing unit use per user in a project
The current project management system in LUMI cannot show the use of billing units per person within a project.
For storage quota this would be very expensive to organise as quota are managed by Lustre on a group basis.
For CPU and GPU billing units it would in principle be possible as the Slurm database contains the necessary information, but there are no plans to implement such a feature. It is assumed that every PI makes sure that members of their projects use LUMI in a responsible way and ensures that they have sufficient experience to realise what they are doing.
"},{"location":"2day-20240502/06_Slurm/#queueing-and-fairness","title":"Queueing and fairness","text":"Remark
Jobs are queued until they can run so we should wonder how that system works.
LUMI is a pre-exascale machine meant to foster research into exascale applications. As a result the scheduler setup of LUMI favours large jobs (though some users with large jobs will claim that it doesn't do so enough yet). Most nodes are reserved for larger jobs (in the standard and standard-g partitions), and the priority computation also favours larger jobs (in terms of number of nodes).
When you submit a job, it will be queued until suitable resources are available for the requested time window. Each job has a priority attached to it which the scheduler computes based on a number of factors, such as size of the job, how much you have been running in the past days, and how long the job has been waiting already. LUMI is not a first come, first served system. Keep in mind that you may see a lot of free nodes on LUMI yet your small job may not yet start immediately as the scheduler may be gathering nodes for a big job with a higher priority.
The sprio command will list the different elements that determine the priority of your job but is basically a command for system administrators as users cannot influence those numbers nor do they say a lot unless you understand all intricacies of the job policies chosen by the site, and those policies may be fine-tuned over time to optimise the operation of the cluster. The fairshare parameter influences the priority of jobs depending on how much users or projects (this is not clear to us at the moment) have been running jobs in the past few days and is a very dangerous parameter on a supercomputer where the largest project is over 1000 times the size of the smallest projects, as treating all projects equally for the fair share would make it impossible for big projects to consume all their CPU time.
Another concept of the scheduler on LUMI is backfill. On a system supporting very large jobs as LUMI, the scheduler will often be collecting nodes to run those large jobs, and this may take a while, particularly since the maximal wall time for a job in the standard partitions is rather large for such a system. If you need one quarter of the nodes for a big job on a partition on which most users would launch jobs that use the full two days of walltime, one can expect that it takes half a day to gather those nodes. However, the LUMI scheduler will schedule short jobs even though they have a lower priority on the nodes already collected if it expects that those jobs will be finisehd before it expects to have all nodes for the big job. This mechanism is called backfill and is the reason why short experiments of half an hour or so often start quickly on LUMI even though the queue is very long.
"},{"location":"2day-20240502/06_Slurm/#managing-slurm-jobs","title":"Managing Slurm jobs","text":"Before experimenting with jobs on LUMI, it is good to discuss how to manage those jobs. We will not discuss the commands in detail and instead refer to the pretty decent manual pages that in fact can also be found on the web.
-
The command to check the status of the queue is squeue. It is also a good command to find out the job IDs of your jobs if you didn't write them down after submitting the job.
Two command line flags are useful:
-
--me will restrict the output to your jobs only
-
--start will give an estimated start time for each job. Note that this really doesn't say much as the scheduler cannot predict the future. On one hand, other jobs that are running already or scheduled to run before your job, may have overestimated the time they need and end early. But on the other hand, the scheduler does not use a \"first come, first serve\" policy so another user may submit a job that gets a higher priority than yours, pushing back the start time of your job. So it is basically a random number generator.
-
To delete a job, use scancel <jobID>
-
An important command to manage jobs while they are running is sstat -j <jobID>. This command display real-time information directly gathered from the resource manager component of Slurm and can also be used to show information about individual job steps using the job step identifier (which is in most case <jobID>.0 for the first regular job step and so on). We will cover this command in more detail further in the notes of this session.
-
The sacct -j <jobID> command can be used both while the job is running and when the job has finished. It is the main command to get information about a job after the job has finished. All information comes from a database, also while the job is running, so the information is available with some delay compared to the information obtained with sstat for a running job. It will also produce information about individual job steps. We will cover this command in more detail further in the notes of this session.
The sacct command will also be used in various examples in this section of the tutorial to investigate the behaviour of Slurm.
"},{"location":"2day-20240502/06_Slurm/#creating-a-slurm-job","title":"Creating a Slurm job","text":"Slurm has three main commands to create jobs and job steps. Remember that a job is just a request for an allocation. Your applications always have to run inside a job step.
The salloc command only creates an allocation but does not create a job step. The behaviour of salloc differs between clusters! On LUMI, salloc will put you in a new shell on the node from which you issued the salloc command, typically the login node. Your allocation will exist until you exit that shell with the exit command or with the CONTROL-D key combination. Creating an allocation with salloc is good for interactive work.
Differences in salloc behaviour.
On some systems salloc does not only create a job allocation but will also create a job step, the so-called \"interactive job step\" on a node of the allocation, similar to the way that the sbatch command discussed later will create a so-called \"batch job step\".
The main purpose of the srun command is to create a job step in an allocation. When run outside of a job (outside an allocation) it will also create a job allocation. However, be careful when using this command to also create the job in which the job step will run as some options work differently as for the commands meant to create an allocation. When creating a job with salloc you will have to use srun to start anything on the node(s) in the allocation as it is not possible to, e.g., reach the nodes with ssh.
The sbatch command both creates a job and then starts a job step, the so-called batch job step, to run the job script on the first node of the job allocation. In principle it is possible to start both sequential and shared memory processes directly in the batch job step without creating a new job step with srun, but keep in mind that the resources may be different from what you expect to see in some cases as some of the options given with the sbatch command will only be enforced when starting another job step from the batch job step. To run any multi-process job (e.g., MPI) you will have to use srun or a process starter that internally calls srun to start the job. When using Cray MPICH as the MPI implementation (and it is the only one that is fully supported on LUMI) you will have to use srun as the process starter.
"},{"location":"2day-20240502/06_Slurm/#passing-options-to-srun-salloc-and-sbatch","title":"Passing options to srun, salloc and sbatch","text":"There are several ways to pass options and flags to the srun, salloc and sbatch command.
The lowest priority way and only for the sbatch command is specifying the options (mostly resource-related) in the batch script itself on #SBATCH lines. These lines should not be interrupted by commands, and it is not possible to use environment variables to specify values of options.
Higher in priority is specifying options and flags through environment variables. For the sbatch command this are the SBATCH_* environment variables, for salloc the SALLOC_* environment variables and for srun the SLURM_* and some SRUN_* environment variables. For the sbatch command this will overwrite values on the #SBATCH lines. You can find lists in the manual pages of the sbatch, salloc and srun command. Specifying command line options via environment variables that are hidden in your .profile or .bashrc file or any script that you run before starting your work, is not free of risks. Users often forget that they set those environment variables and are then surprised that the Slurm commands act differently then expected. E.g., it is very tempting to set the project account to use in environment variables but if you then get a second project you may be running inadvertently in the wrong project.
The highest priority is for flags and options given on the command line. The position of those options is important though. With the sbatch command they have to be specified before the batch script as otherwise they will be passed to the batch script as command line options for that script. Likewise, with srun they have to be specified before the command you want to execute as otherwise they would be passed to that command as flags and options.
Several options specified to sbatch or salloc are also forwarded to srun via SLURM_* environment variables set in the job by these commands.
"},{"location":"2day-20240502/06_Slurm/#specifying-options","title":"Specifying options","text":"Slurm commands have way more options and flags than we can discuss in this course or even the 4-day comprehensive course organised by the LUMI User Support Team. Moreover, if and how they work may depend on the specific configuration of Slurm. Slurm has so many options that no two clusters are the same.
Slurm command can exist in two variants:
-
The long variant, with a double dash, is of the form --long-option=<value> or --long-option <value>
-
But many popular commands also have a single letter variant, with a single dash: -S <value> or -S<value>
This is no different from many popular Linux commands.
Slurm commands for creating allocations and job steps have many different flags for specifying the allocation and the organisation of tasks in that allocation. Not all combinations are valid, and it is not possible to sum up all possible configurations for all possible scenarios. Use common sense and if something does not work, check the manual page and try something different. Overspecifying options is not a good idea as you may very well create conflicts, and we will see some examples in this section and the next section on binding. However, underspecifying is not a good idea either as some defaults may be used you didn't think of. Some combinations also just don't make sense, and we will warn for some on the following slides and try to bring some structure in the wealth of options.
"},{"location":"2day-20240502/06_Slurm/#some-common-options-to-all-partitions","title":"Some common options to all partitions","text":"For CPU and GPU requests, a different strategy should be used for \"allocatable by node\" and \"allocatable by resource\" partitions, and this will be discussed later. A number of options however are common to both strategies and will be discussed first. All are typically used on #SBATCH lines in job scripts, but can also be used on the command line and the first three are certainly needed with salloc also.
-
Specify the account to which the job should be billed with --account=project_46YXXXXXX or -A project_46YXXXXXX. This is mandatory; without this your job will not run.
-
Specify the partition: --partition=<partition> or -p <partition>. This option is also necessary on LUMI as there is currently no default partition.
-
Specify the wall time for the job: --time=<timespec> or -t <timespec>. There are multiple formats for the time specifications, but the most common ones are minutes (one number), minutes:seconds (two numbers separated by a colon) and hours:minutes:seconds (three numbers separated by a column). If not specified, the partition-dependent default time is used.
It does make sense to make a reasonable estimate for the wall time needed. It does protect you a bit in case your application hangs for some reason, and short jobs that also don't need too many nodes have a high chance of running quicker as they can be used as backfill while the scheduler is gathering nodes for a big job.
-
Completely optional: Specify a name for the job with --job-name=<name> or -J <name>. Short but clear job names help to make the output of squeue easier to interpret, and the name can be used to generate a name for the output file that captures output to stdout and stderr also.
-
For courses or other special opportunities such as the \"hero runs\" (a system for projects that want to test extreme scalability beyond the limits of the regular partitions), reservations are used. You can specify the reservation (or even multiple reservations as a comma-separated list) with --reservation=<name>.
In principle no reservations are given to regular users for regular work as this is unfair to other users. It would not be possible to do all work in reservations and bypass the scheduler as the scheduling would be extremely complicated and the administration enormous. And empty reservations do not lead to efficient machine use. Schedulers have been developed for a reason.
-
Slurm also has options to send mail to a given address when a job starts or ends or some other job-related events occur, but this is currently not configured on LUMI.
"},{"location":"2day-20240502/06_Slurm/#redirecting-output","title":"Redirecting output","text":"Slurm has two options to redirect stdout and stderr respectively: --output=<template> or -o <template> for stdout and --error=<template> or -e <template> for stderr. They work together in the following way:
-
If neither --output not --error is specified, then stdout and stderr are merged and redirected to the file slurm-<jobid>.out.
-
If --output is specified but --error is not, then stdout and stderr are merged and redirected to the file given with --output.
-
If --output is not specified but --error, then stdout will still be redirected to slurm-<jobid>.out, but stderr will be redirected to the file indicated by the --error option.
-
If both --output and --error are specified, then stdout is redirected to the file given by --output and stderr is redirected to the file given by --error.
It is possible to insert codes in the filename that will be replaced at runtime with the corresponding Slurm information. Examples are %x which will be replaced with the name of the job (that you can then best set with --job-name) and %j which will be replaced with the job ID (job number). It is recommended to always include the latter in the template for the filename as this ensures unique names if the same job script would be run a few times with different input files. Discussing all patterns that can be used for the filename is outside the scope of this tutorial, but you can find them all in the sbatch manual page in the \"filename pattern\" section.
"},{"location":"2day-20240502/06_Slurm/#requesting-resources-cpus-and-gpus","title":"Requesting resources: CPUs and GPUs","text":"Slurm is very flexible in the way resources can be requested. Covering every scenario and every possible way to request CPUs and GPUs is impossible, so we will present a scheme that works for most users and jobs.
First, you have to distinguish between two strategies for requesting resources, each with their own pros and cons. We'll call them \"per-node allocations\" and \"per-core allocations\":
-
\"Per-node allocations\": Request suitable nodes (number of nodes and partition) with sbatch or salloc but postpone specifying the full structure of the job step (i.e., tasks, cpus per task, gpus per task, ...) until you actually start the job step with srun.
This strategy relies on job-exclusive nodes, so works on the standard and standard-g partitions that are \"allocatable-by-node\" partitions, but can be used on the \"allocatable-by-resource\" partitions also it the --exclusive flag is used with sbatch or salloc (on the command line or with and #SBATCH --exclusive line for sbatch).
This strategy gives you the ultimate flexibility in the job as you can run multiple job steps with a different structure in the same job rather than having to submit multiple jobs with job dependencies to ensure that they are started in the proper order. E.g., you could first have an initialisation step that generates input files in a multi-threaded shared memory program and then run a pure MPI job with a single-threaded process per rank.
This strategy also gives you full control over how the application is mapped onto the available hardware: mapping of MPI ranks across nodes and within nodes, binding of threads to cores, and binding of GPUs to MPI ranks. This will be the topic of the next section of the course and is for some applications very important to get optimal performance on modern supercomputer nodes that have a strongly hierarchical architecture (which in fact is not only the case for AMD processors, but will likely be an issue on some Intel Sapphire Rapids processors also).
The downside is that allocations and hence billing is always per full node, so if you need only half a node you waste a lot of billing units. It shows that to exploit the full power of a supercomputer you really need to have problems and applications that can at least exploit a full node.
-
\"Per-core allocations\": Specify the full job step structure when creating the job allocation and optionally limit the choice fo Slurm for the resource allocation by specifying a number of nodes that should be used.
The problem is that Slurm cannot create a correct allocation on an \"allocatable by resource\" partition if it would only know the total number of CPUs and total number of GPUs that you need. Slurm does not automatically allocate the resources on the minimal number of nodes (and even then there could be problems) and cannot know how you intend to use the resources to ensure that the resources are actually useful for you job. E.g., if you ask for 16 cores and Slurm would spread them over two or more nodes, then they would not be useful to run a shared memory program as such a program cannot span nodes. Or if you really want to run an MPI application that needs 4 ranks and 4 cores per rank, then those cores must be assigned in groups of 4 within nodes as an MPI rank cannot span nodes. The same holds for GPUs. If you would ask for 16 cores and 4 GPUs you may still be using them in different ways. Most users will probably intend to start an MPI program with 4 ranks that each use 4 cores and one GPU, and in that case the allocation should be done in groups that each contain 4 cores and 1 GPU but can be spread over up to 4 nodes, but you may as well intend to run a 16-thread shared memory application that also needs 4 GPUs.
The upside of this is that with this strategy you will only get what you really need when used in an \"allocatable-by-resources\" partition, so if you don't need a full node, you won't be billed for a full node (assuming of course that you don't request that much memory that you basically need a full node's memory).
One downside is that you are now somewhat bound to the job structure. You can run job steps with a different structure, but they may produce a warning or may not run at all if the job step cannot be mapped on the resources allocated to the job.
More importantly, most options to do binding (see the next chapter) cannot be used or don't make sense anyway as there is no guarantee your cores will be allocated in a dense configuration.
However, if you can live with those restrictions and if your job size falls within the limits of the \"allocatable per resource\" partitions, and cannot fill up the minimal number of nodes that would be used, then this strategy ensures you're only billed for the minimal amount of resources that are made unavailable by your job.
This choice is something you need to think about in advance and there are no easy guidelines. Simply say \"use the first strategy if your job fills whole nodes anyway and the second one otherwise\" doesn't make sense as your job may be so sensitive to its mapping to resources that it could perform very badly in the second case. The real problem is that there is no good way in Slurm to ask for a number of L3 cache regions (CPU chiplets), a number of NUMA node or a number of sockets and also no easy way to always do the proper binding if you would get resources that way (but that is something that can only be understood after the next session). If a single job needs only a half node and if all jobs take about the same time anyway, it might be better to bundle them by hand in jobs and do a proper mapping of each subjob on the available resources (e.g., in case of two jobs on a CPU node, map each on a socket).
"},{"location":"2day-20240502/06_Slurm/#resources-for-per-node-allocations","title":"Resources for per-node allocations","text":"In a per-node allocation, all you need to specify is the partition and the number of nodes needed, and in some cases, the amount of memory. In this scenario, one should use those Slurm options that specify resources per node also.
The partition is specified using --partition=<partition or -p <partition>.
The number of nodes is specified with --nodes=<number_of_nodes> or its short form -N <number_of_nodes>.
If you want to use a per-node allocation on a partition which is allocatable-by-resources such as small and small-g, you also need to specify the --exclusive flag. On LUMI this flag does not have the same effect as running on a partition that is allocatable-by-node. The --exclusive flag does allocate all cores and GPUs on the node to your job, but the memory use is still limited by other parameters in the Slurm configuration. In fact, this can also be the case for allocatable-by-node partitions, but there the limit is set to allow the use of all available memory. Currently the interplay between various parameters in the Slurm configuration results in a limit of 112 GB of memory on the small partition and 64 GB on the standard partition when running in --exclusive mode. It is possible to change this with the --mem option.
You can request all memory on a node by using --mem=0. This is currently the default behaviour on nodes in the standard and standard-g partition so not really needed there. It is needed on all of the partitions that are allocatable-by-resource.
We've experienced that it may be a better option to actually specify the maximum amount of useable memory on a node which is the memory capacity of the node you want minus 32 GB, so you can use --mem=224G for a regular CPU node or --mem=480G for a GPU node. In the past we have had memory leaks on compute nodes that were not detected by the node health checks, resulting in users getting nodes with less available memory than expected, but specifying these amounts protected them against getting such nodes. (And similarly you could use --mem=480G and --mem=992G for the 512 GB and 1 TB compute nodes in the small partition, but note that running on these nodes is expensive!)
Example jobscript (click to expand) The following job script runs a shared memory program in the batch job step, which shows that it has access to all hardware threads and all GPUs in a node at that moment:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-minimal-small-g\n#SBATCH --partition=small-g\n#SBATCH --exclusive\n#SBATCH --nodes=1\n#SBATCH --mem=480G\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ngpu_check\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
As we are using small-g here instead of standard-g, we added the #SBATCH --exclusive and #SBATCH --mem=480G lines.
A similar job script for a CPU-node in LUMI-C and now in the standard partition would look like:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-minimal-standard\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\nomp_check\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
gpu_check and omp_check are two programs provided by the lumi-CPEtools modules to check the allocations. Try man lumi-CPEtools after loading the module. The programs will be used extensively in the next section on binding also, and are written to check how your program would behave in the allocation without burning through tons of billing units.
By default you will get all the CPUs in each node that is allocated in a per-node allocation. The Slurm options to request CPUs on a per-node basis are not really useful on LUMI, but might be on clusters with multiple node types in a single partition as they enable you to specify the minimum number of sockets, cores and hardware threads a node should have.
We advise against using the options to request CPUs on LUMI because it is more likely to cause problems due to user error than to solve problems. Some of these options also conflict with options that will be used later in the course.
There is no direct way to specify the number of cores per node. Instead one has to specify the number sockets and then the number of cores per socket and one can specify even the number of hardware threads per core, though we will favour another mechanism later in these course notes.
The two options are:
-
Specify --sockets-per-node=<sockets and --cores-per-socket=<cores> and maybe even --threads-per-core=<threads>. For LUMI-C the maximal specification is
--sockets-per-node=2 --cores-per-socket-64\n
and for LUMI-G
--sockets-per-node=1 --cores-per-socket=56\n
Note that on LUMI-G, nodes have 64 cores but one core is reserved for the operating system and drivers to reduce OS jitter that limits the scalability of large jobs. Requesting 64 cores will lead to error messages or jobs getting stuck.
-
There is a shorthand for those parameters: --extra-node-info=<sockets>[:cores] or -B --extra-node-info=<sockets>[:cores] where the second and third number are optional. The full maximal specification for LUMI-C would be --extra-node-info=2:64 and for LUMI-G --extra-node-info=1:56.
What about --threads-per-core? Slurm also has a --threads-per-core (or a third number with --extra-node-info) which is a somewhat misleading name. On LUMI, as hardware threads are turned on, you would expect that you can use --threads-per-core=2 but if you try, you will see that your job is not accepted. This because on LUMI, the smallest allocatable processor resource (called the CPU in Slurm) is a core and not a hardware thread (or virtual core as they are also called). There is another mechanism to enable or disable hyperthreading in regular job steps that we will discuss later.
By default you will get all the GPUs in each node that is allocated in a per-node allocation. The Slurm options to request GPUs on a per-node basis are not really useful on LUMI, but might be on clusters with multiple types of GPUs in a single partition as they enable you to specify which type of node you want. If you insist, slurm has several options to specify the number of GPUs for this scenario:
-
The most logical one to use for a per-node allocation is --gpus-per-node=8 to request 8 GPUs per node. You can use a lower value, but this doesn't make much sense as you will be billed for the full node anyway.
It also has an option to also specify the type of the GPU but that doesn't really make sense on LUMI. On LUMI, you could in principle use --gpus-per-node=mi250:8.
-
--gpus=<number> or -G <number> specifies the total number of GPUs needed for the job. In our opinion this is a dangerous option to use as when you change the number of nodes, you likely also want to change the number of GPUs for the job and you may overlook this. Here again it is possible to specify the type of the GPU also. Moreover, if you ask for fewer GPUs than are present in the total number of nodes you request, you may get a very strange distribution of the available GPUs across the nodes.
Example of an unexpected allocation Assuming SLURM_ACCOUNT is set to a valid project with access to the partition used:
module load LUMI/23.09 partition/G lumi-CPEtools\nsrun --partition standard-g --time 5:00 --nodes 2 --tasks-per-node 1 --gpus 8 gpu_check\n
returns
MPI 000 - OMP 000 - HWT 001 - Node nid007264 - RT_GPU_ID 0,1,2,3,4,5,6 - GPU_ID 0,1,2,3,4,5,6 - Bus_ID c1,c9,ce,d1,d6,d9,dc\nMPI 001 - OMP 000 - HWT 001 - Node nid007265 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\n
So 7 GPUs were allocated on the first node and 1 on the second.
-
A GPU belongs to the family of \"generic consumable resources\" (or GRES) in Slurm and there is an option to request any type of GRES that can also be used. Now you also need to specify the type of the GRES. The number you have to specify if on a per-node basis, so on LUMI you can use --gres=gpu:8 or --gres=gpu:mi250:8.
As these options are also forwarded to srun, it will save you from specifying them there.
"},{"location":"2day-20240502/06_Slurm/#per-node-allocations-starting-a-job-step","title":"Per-node allocations: Starting a job step","text":"Serial or shared-memory multithreaded programs in a batch script can in principle be run in the batch job step. As we shall see though the effect may be different from what you expect. However, if you are working interactively via salloc, you are in a shell on the node on which you called salloc, typically a login node, and to run anything on the compute nodes you will have to start a job step.
The command to start a new job step is srun. But it needs a number of arguments in most cases. After all, a job step consists of a number of equal-sized tasks (considering only homogeneous job steps at the moment, the typical case for most users) that each need a number of cores or hardware threads and, in case of GPU compute, access to a number of GPUs.
There are several ways telling Slurm how many tasks should be created and what the resources are for each individual task, but this scheme is an easy scheme:
-
Specifying the number of tasks: You can specify per node or the total number:
-
Specifying the total number of tasks: --ntasks=<ntasks or -n ntasks. There is a risk associated to this approach which is the same as when specifying the total number of GPUs for a job: If you change the number of nodes, then you should change the total number of tasks also. However, it is also very useful in certain cases. Sometimes the number of tasks cannot be easily adapted and does not fit perfectly into your allocation (cannot be divided by the number of nodes). In that case, specifying the total number of nodes makes perfect sense.
-
Specifying on a per node basis: --ntasks-per-node=<ntasks> is possible in combination with --nodes according to the Slurm manual. In fact, this would be a logical thing to do in a per node allocation. However, we see it fail on LUMI when it is used as an option for srun and not with sbatch, even though it should work according to the documentation.
The reason for the failure is that Slurm when starting a batch job defines a large number of SLURM_* and SRUN_* variables. Some only give information about the allocation, but others are picked up by srun as options and some of those options have a higher priority than --ntasks-per-node. So the trick is to unset both SLURM_NTASKS and SLURM_NPROCS. The --ntasks option triggered by SLURM_NTASKS has a higher priority than --ntasks-per-node. SLURM_NPROCS was used in older versions of Slurm as with the same function as the current environment variable SLURM_NTASKS and therefore also implicitly specifies --ntasks if SLURM_NTASKS is removed from the environment.
The option is safe to use with sbatch though.
Lesson: If you want to play it safe and not bother with modifying the environment that Slurm creates, use the total number of tasks --ntasks if you want to specify the number of tasks with srun.
-
Specifying the number of CPUs (cores on LUMI) for each task. The easiest way to do this is by using --cpus-per-task=<number_CPUs> or -c <number_CPUs>.
-
Specifying the number of GPUs per task. Following the Slurm manuals, the following seems the easiest way:
-
Use --gpus-per-task=<number_GPUs> to bind one or more GPUs to each task. This is probably the most used option in this scheme.
-
If however you want multiple tasks to share a GPU, then you should use --ntasks-per-gpu=<number_of_tasks>. There are use cases where this makes sense.
This however does not always work...
The job steps created in this simple scheme do not always run the programs at optimal efficiency. Slurm has various strategies to assign tasks to nodes, and there is an option which we will discuss in the next session of the course (binding) to change that. Moreover, not all clusters use the same default setting for this strategy. Cores and GPUs are assigned in order and this is not always the best order.
It is also possible to specify these options already on #SBATCH lines. Slurm will transform those options into SLURM_* environment variables that will then be picked up by srun. However, this behaviour has changed in more recent versions of Slurm. E.g., --cpus-per-task is no longer automatically picked up by srun as there were side effects with some MPI implementations on some clusters. CSC has modified the configuration to again forward that option (now via an SRUN_* environment variable) but certain use cases beyond the basic one described above are not covered. And take into account that not all cluster operators will do that as there are also good reasons not to do so. Otherwise the developers of Slurm wouldn't have changed that behaviour in the first place.
Demonstrator for the problems with --tasks-per-node (click to expand) Try the batch script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-jobstart-standard-demo1\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\necho \"Submitted from $SLURM_SUBMIT_HOST\"\necho \"Running on $SLURM_JOB_NODELIST\"\necho\necho -e \"Job script:\\n$(cat $0)\\n\"\necho \"SLURM_* and SRUN_* environment variables:\"\nenv | egrep ^SLURM\nenv | egrep ^SRUN\n\nset -x\n# This works\nsrun --ntasks=32 --cpus-per-task=8 hybrid_check -r\n\n# This does not work\nsrun --ntasks-per-node=16 --cpus-per-task=8 hybrid_check -r\n\n# But this works again\nunset SLURM_NTASKS\nunset SLURM_NPROCS\nsrun --ntasks-per-node=16 --cpus-per-task=8 hybrid_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
"},{"location":"2day-20240502/06_Slurm/#a-warning-for-gpu-applications","title":"A warning for GPU applications","text":"Allocating GPUs with --gpus-per-task or --tasks-per-gpu may seem the most logical thing to do when reading the Slurm manual pages. It does come with a problem though resulting of how Slurm currently manages the AMD GPUs, and now the discussion becomes more technical.
Slurm currently uses a separate control group per task for the GPUs. Now control groups are a mechanism in Linux for restricting resources available to a process and its childdren. Putting the GPUs in a separate control group per task limits the ways in intra-node communication can be done between GPUs, and this in turn is incompatible with some software.
The solution is to ensure that all tasks within a node see all GPUs in the node and then to manually perform the binding of each task to the GPUs it needs using a different mechanism more like affinity masks for CPUs. It can be tricky to do though as many options for srun do a mapping under the hood.
As we need a mechanisms that are not yet discussed yet in this chapter, we refer to the chapter \"Process and thread distribution and binding\" for a more ellaborate discussion and a solution.
Unfortunately using AMD GPUs in Slurm is more complicated then it should be (and we will see even more problems).
"},{"location":"2day-20240502/06_Slurm/#turning-simultaneous-multithreading-on-or-off","title":"Turning simultaneous multithreading on or off","text":"Hardware threads are enabled by default at the operating system level. In Slurm however, regular job steps start by default with hardware threads disabled. This is not true though for the batch job step as the example below will show.
Hardware threading for a regular job step can be turned on explicitly with --hint=multhithread and turned off explicitly with --hint=nomultithread, with the latter the default on LUMI. The hint should be given as an option to sbatch(e.g., as a line #SBATCH --hint=multithread) and not as an option of srun.
The way it works is a bit confusing though. We've always told, and that is also what the Slurm manual tells, that a CPU is the smallest allocatable unit and that on LUMI, Slurm is set to use the core as the smallest allocatable unit. So you would expect that srun --cpus-per-task=4 combined with #SBATCH --hint=multithread would give you 4 cores with in total 8 threads, but instead you will get 2 cores with 4 hardware threads. In other words, it looks like (at least with the settings on LUMI) #SBATCH --hint=multithread changes the meaning of CPU in the context of an srun command to a hardware thread instead of a core. This is illustrated with the example below.
Use of --hint=(no)multithread (click to expand) We consider the job script
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-multithread\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=multithread\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\necho -e \"Job script:\\n$(cat $0)\\n\"\n\nset -x\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
We consider three variants of this script:
-
Without the #SBATCH --hint=multithread line to see the default behaviour of Slurm on LUMI. The relevant lines of the output are:
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001847 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238727 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238727.bat+ batch project_4+ 256 RUNNING 0:0 \n4238727.0 omp_check project_4+ 8 RUNNING 0:0 \n
The omp_check program detects that it should run 4 threads (we didn't even need to help by setting OMP_NUM_THREADS) and uses cores 0 till 3 which are the first 4 physical cores on the processor.
The output of the sacct command claims that the job (which is the first line of the table) got allocated 256 CPUs. This is a confusing feature of sacct: it shows the number of hardware threads even though the Slurm CPU on LUMI is defined as a core. The next line shows the batch job step which actually does see all hardware threads of all cores (and in general, all hardware threads of all allocated cores of the first node of the job). The final line, with the '.0' job step, shows that that core was using 8 hardware threads, even though omp_check only saw 4. This is because the default behaviour (as the next test will confirm) is --hint=nomultithread.
Note that sacct shows the last job step as running even though it has finished. This is because sacct gets the information not from the compute node but from a database, and it looks like the full information has not yet derived in the database. A short sleep before the sacct call would cure this problem.
-
Now replace the #SBATCH --hint=multithread with #SBATCH --hint=nomultithread. The relevant lines of the output are now
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001847 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238730 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238730.bat+ batch project_4+ 256 RUNNING 0:0 \n4238730.0 omp_check project_4+ 8 RUNNING 0:0 \n
The output is no different from the previous case which confirms that this is the default behaviour.
-
Lastly, we run the above script unmodified, i.e., with #SBATCH --hint=multithread Now the relevant lines of the output are:
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001847 mask 0-1, 128-129\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238728 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238728.bat+ batch project_4+ 256 RUNNING 0:0 \n4238728.0 omp_check project_4+ 4 COMPLETED 0:0 \n
The omp_check program again detects only 4 threads but now runs them on the first two physical cores and the corresponding second hardware thread for these cores. The output of sacct now shows 4 in the \"AllocCPUS\" command for the .0 job step, which confirms that indeed only 2 cores with both hardware threads were allocated instead of 4 cores.
Buggy behaviour when used with srun Consider the following job script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-bug2\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --hint=multithread\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeGNU-22.12\n\nset -x\nsrun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nsrun -n 1 -c 4 --hint=multithread omp_check -r\n\nOMP_NUM_THREADS=8 srun -n 1 -c 4 --hint=multithread omp_check -r\n\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n\nset -x\nsrun -n 1 -c 256 --hint=multithread omp_check -r\n
The relevant lines of the output are:
+ srun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001246 mask 0-3\n\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001246 mask 0-1, 128-129\n\n+ OMP_NUM_THREADS=8\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 8 threads in a single process\n\n++ omp_check: OpenMP thread 0/8 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/8 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/8 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/8 on cpu 1/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 4/8 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 5/8 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 6/8 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 7/8 on cpu 1/256 of nid001246 mask 0-1, 128-129\n\n+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001246 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238801 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238801.bat+ batch project_4+ 256 RUNNING 0:0 \n4238801.0 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.1 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.2 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.3 omp_check project_4+ 8 COMPLETED 0:0 \n\n+ srun -n 1 -c 256 --hint=multithread omp_check -r\nsrun: error: Unable to create step for job 4238919: More processors requested than permitted\n
The first omp_check runs as expected. The seocnd one uses only 2 cores but all 4 hyperthreads on those cores. This is also not unexpected. In the third case we force the use of 8 threads, and they all land on the 4 hardware threads of 2 cores. Again, this is not unexpected. And neither is the output of the last run of omp_cehck which is again with multithreading disabled as requested in the #SBATCH lines. What is surprising though is the output of sacct: It claims there were 8 hardware threads, so 4 cores, allocated to the second (the .1) and third (the .2) job step while whatever we tried, omp_check could only see 2 cores and 4 hardware threads. Indeed, if we would try to run with -c 256 then srun will fail.
But now try the reverse: we turn multithreading on in the #SBATCH lines and try to turn it off again with srun:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-bug2\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --hint=multithread\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeGNU-22.12\n\nset -x\nsrun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nsrun -n 1 -c 4 --hint=multithread omp_check -r\n\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
The relevant part of the output is now
+ srun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 1/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 2/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 3/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 0/256 of nid001460 mask 0-3\n\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001460 mask 0-1, 128-129\n\n++ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001460 mask 0-1, 128-129\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238802 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238802.bat+ batch project_4+ 256 RUNNING 0:0 \n4238802.0 omp_check project_4+ 8 COMPLETED 0:0 \n4238802.1 omp_check project_4+ 4 COMPLETED 0:0 \n4238802.2 omp_check project_4+ 4 COMPLETED 0:0 \n
And this is fully as expected. The first srun does not use hardware threads as requested by srun, the second run does use hardware threads and only 2 cores which is also what we requested with the srun command, and the last one also uses hardware threads. The output of sacct (and in particular the AllocCPUS comumn) not fully confirms that indeed there were only 2 cores allocated to the second and third run.
So turning hardware threads on in the #SBATCH lines and then off again with srun works as expected, but the opposite, explicitly turning it off in the #SBATCH lines (or relying on the default which is off) and then trying to turn it on again, does not work.
"},{"location":"2day-20240502/06_Slurm/#per-core-allocations","title":"Per-core allocations","text":""},{"location":"2day-20240502/06_Slurm/#when-to-use","title":"When to use?","text":"Not all jobs can use entire nodes efficiently, and therefore the LUMI setup does provide some partitions that enable users to define jobs that use only a part of a node. This scheme enables the user to only request the resources that are really needed for the job (and only get billed for those at least if they are proportional to the resources that a node provides), but also comes with the disadvantage that it is not possible to control how cores and GPUs are allocated within a node. Codes that depend on proper mapping of threads and processes on L3 cache regions, NUMA nodes or sockets, or on shortest paths between cores in a task and the associated GPU(s) may see an unpredictable performance loss as the mapping (a) will rarely be optimal unless you are very lucky (and always be suboptimal for GPUs in the current LUMI setup) and (b) will also depend on other jobs already running on the set of nodes assigned to your job.
Unfortunately,
-
Slurm does not seem to fully understand the GPU topology on LUMI and cannot take that properly into account when assigning resources to a job or task in a job, and
-
Slurm does not support the hierarchy in the compute nodes of LUMI. There is no way to specifically request all cores in a socket, NUMA node or L3 cache region. It is only possible on a per-node level which is the case that we already discussed.
Instead, you have to specify the task structure in the #SBATCH lines of a job script or as the command line arguments of sbatch and salloc that you will need to run the job.
"},{"location":"2day-20240502/06_Slurm/#resource-request","title":"Resource request","text":"To request an allocation, you have to specify the task structure of the job step you want to run using mostly the same options that we have discussed on the slides \"Per-node allocations: Starting a job step\":
-
Now you should specify just the total amount of tasks needed using --ntasks=<number> or -n <number>. As the number of nodes is not fixed in this allocation type, --ntasks-per-node=<ntasks> does not make much sense.
It is possible to request a number of nodes using --nodes, and it can even take two arguments: --nodes=<min>-<max> to specify the minimum and maximum number of nodes that Slurm should use rather than the exact number (and there are even more options), but really the only case where it makes sense to use --nodes with --ntasks-per-node in this case, is if all tasks would fit on a single node and you also want to force them on a single node so that all MPI communications are done through shared memory rather than via the Slingshot interconnect.
Restricting the choice of resources for the scheduler may increase your waiting time in the queue though.
-
Specifying the number of CPUs (cores on LUMI) for each task. The easiest way to do this is by using --cpus-per-task=<number> or -c <number.
Note that as has been discussed before, the standard behaviour of recent versions of Slurm is to no longer forward --cpus-per-task from the sbatch or salloc level to the srun level though CSC has made a configuration change in Slurm that will still try to do this though with some limitations.
-
Specifying the number of GPUs per task. The easiest way here is:
-
Use --gpus-per-task=<number_GPUs> to bind one or more GPUs to each task. This is probably the most used option in this scheme.
-
If however you want multiple tasks to share a GPU, then you should use --ntasks-per-gpu=<number_of_tasks>. There are use cases where this makes sense. However, at the time of writing this does not work properly.
While this does ensure a proper distribution of GPUs across nodes compatible with the distributions of cores to run the requested tasks, we will again run into binding issues when these options are propagated to srun to create the actual job steps, and hre this is even more tricky to solve.
We will again discuss a solution in the Chapter \"Process and thread distribution and binding\"
-
CPU memory. By default you get less than the memory per core on the node type. To change:
-
Against the logic there is no --mem-per-task=<number>, instead memory needs to be specified in function of the other allocated resources.
-
Use --mem-per-cpu=<number> to request memory per CPU (use k, m, g to specify kilobytes, megabytes or gigabytes)
-
Alternatively on a GPU allocation --mem-per-gpu=<number>. This is still CPU memory and not GPU memory!
-
Specifying memory per node with --mem doesn't make much sense unless the number of nodes is fixed.
--ntasks-per-gpu=<number> does not work
At the time of writing there were several problems when using --ntasks-per-gpu=<number> in combination with --ntasks=<number>. While according to the Slurm documentation this is a valid request and Slurm should automatically determine the right number of GPUs to allocate, it turns out that instead you need to specify the number of GPUs with --gpus=<number> together with --ntasks-per-gpu=<number> and let Slurm compute the number of tasks.
Moreover, we've seen cases where the final allocation was completely wrong, with tasks ending up with the wrong number of GPUs or on the wrong node (like too many tasks on one and too little on another compared to the number of GPUs set aside in each of these nodes).
--sockets-per-node and --ntasks-per-socket
If you don't read the manual pages of Slurm carefully enough you may have the impression that you can use parameters like --sockets-per-node and --ntasks-per-socket to force all tasks on a single socket (and get a single socket), but these options will not work as you expect.
The --sockets-per-node option is not used to request an exact resource, but to specify a type of node by specifying the minimal number of sockets a node should have.It is an irrelevant option on LUMI as each partition does have only a single node type.
If you read the manual carefully, you will also see that there is a subtle difference between --ntasks-per-node and --ntasks-per-socket: With --ntasks-per-node you specify the exact number of tasks for each node while with --tasks-per-socket you specify the maximum number of tasks for each socket. So all hope that something like
--ntasks=8 --ntasks-per-socket=8 --cpus-per-task=8\n
would always ensure that you get a socket for yourself with each task nicely assigned to a single L3 cache domain, is futile.
"},{"location":"2day-20240502/06_Slurm/#different-job-steps-in-a-single-job","title":"Different job steps in a single job","text":"It is possible to have an srun command with a different task structure in your job script. This will work if no task requires more CPUs or GPUs than in the original request, and if there are either not more tasks either or if an entire number of tasks in the new structure fits in a task in the structure from the allocation and the total number of tasks does not exceed the original number multiplied with that entire number. Other cases may work randomly, depending on how Slurm did the actual allocation. In fact, this may even be abused to ensure that all tasks are allocated to a single node, though this is done more elegantly by just specifying --nodes=1.
With GPUs though it can become very complicated to avoid binding problems if the Slurm way of implementing GPU binding does not work for you.
Some examples that work and don't work (click to expand) Consider the job script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-small-multiple-srun\n#SBATCH --partition=small\n#SBATCH --ntasks=4\n#SBATCH --cpus-per-task=4\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --acount=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\necho \"Running on $SLURM_JOB_NODELIST\"\n\nset -x\n\nomp_check\n\nsrun --ntasks=1 --cpus-per-task=3 omp_check\n\nsrun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nsrun --ntasks=4 --cpus-per-task=1 mpi_check\n\nsrun --ntasks=16 --cpus-per-task=1 mpi_check\n\nsrun --ntasks=1 --cpus-per-task=16 omp_check\n\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
In the first output example (with lots of output deleted) we got the full allocation of 16 cores on a single node, and in fact, even 16 consecutive cores though spread across 3 L3 cache domains. We'll go over the output in steps:
Running on nid002154\n\n+ omp_check\n\nRunning 32 threads in a single process\n\n++ omp_check: OpenMP thread 0/32 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/32 on cpu 148/256 of nid002154\n...\n
The first omp_check command was started without using srun and hence ran on all hardware cores allocated to the job. This is why hardware threading is enabled and why the executable sees 32 cores.
+ srun --ntasks=1 --cpus-per-task=3 omp_check\n\nRunning 3 threads in a single process\n\n++ omp_check: OpenMP thread 0/3 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/3 on cpu 21/256 of nid002154\n++ omp_check: OpenMP thread 2/3 on cpu 22/256 of nid002154\n
Next omp_check was started via srun --ntasks=1 --cpus-per-task=3. One task instead of 4, and the task is also smaller in terms of number of nodes as the tasks requested in SBATCH lines, and Slurm starts the executable without problems. It runs on three cores, correctly detects that number, and also correctly does not use hardware threading.
+ srun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nRunning 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 23/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 24/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 25/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 26/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 27/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 28/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 29/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 30/256 of nid002154\n
Next we tried to start 2 instead of 4 MPI processes with 4 cores each which also works without problems. The allocation now starts on core 23 but that is because Slurm was still finishing the job step on cores 20 till 22 from the previous srun command. This may or may not happen and is also related to a remark we made before about using sacct at the end of the job where the last job step may still be shown as running instead of completed.
+ srun --ntasks=4 --cpus-per-task=1 mpi_check\n\nRunning 4 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/4 on cpu 20/256 of nid002154\n++ mpi_check: MPI rank 1/4 on cpu 21/256 of nid002154\n++ mpi_check: MPI rank 2/4 on cpu 22/256 of nid002154\n++ mpi_check: MPI rank 3/4 on cpu 23/256 of nid002154\n
Now we tried to start 4 tasks with 1 core each. This time we were lucky and the system considered the previous srun completely finished and gave us the first 4 cores of the allocation.
+ srun --ntasks=16 --cpus-per-task=1 mpi_check\nsrun: Job 4268529 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268529\n\nRunning 16 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/16 on cpu 20/256 of nid002154\n++ mpi_check: MPI rank 1/16 on cpu 21/256 of nid002154\n++ mpi_check: MPI rank 2/16 on cpu 22/256 of nid002154\n++ mpi_check: MPI rank 3/16 on cpu 23/256 of nid002154\n++ mpi_check: MPI rank 4/16 on cpu 24/256 of nid002154\n++ mpi_check: MPI rank 5/16 on cpu 25/256 of nid002154\n...\n
With the above srun command we try to start 16 single-threaded MPI processes. This fits perfectly in the allocation as it simply needs to put 4 of these tasks in the space reserved for one task in the #SBATCH request. The warning at the start may or may not happen. Basically Slurm was still freeing up the cores from the previous run and therefore the new srun dind't have enough resources the first time it tried to, but it automatically tried a second time.
+ srun --ntasks=1 --cpus-per-task=16 omp_check\nsrun: Job step's --cpus-per-task value exceeds that of job (16 > 4). Job step may never run.\nsrun: Job 4268529 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268529\n\nRunning 16 threads in a single process\n\n++ omp_check: OpenMP thread 0/16 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/16 on cpu 21/256 of nid002154\n++ omp_check: OpenMP thread 2/16 on cpu 22/256 of nid002154\n...\n
In the final srun command we try to run a single 16-core OpenMP run. This time Slurm produces a warning as it would be impossible to fit a 16-cpre shared memory run in the space of 4 4-core tasks if the resources for those tasks would have been spread across multiple nodes. The next warning is again for the same reason as in the previous case, but ultimately the command does run on all 16 cores allocated and without using hardware threading.
+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4268529 slurm-sma+ small project_4+ 32 RUNNING 0:0 \n4268529.bat+ batch project_4+ 32 RUNNING 0:0 \n4268529.0 omp_check project_4+ 6 COMPLETED 0:0 \n4268529.1 hybrid_ch+ project_4+ 16 COMPLETED 0:0 \n4268529.2 mpi_check project_4+ 8 COMPLETED 0:0 \n4268529.3 mpi_check project_4+ 32 COMPLETED 0:0 \n4268529.4 omp_check project_4+ 32 RUNNING 0:0 \n
The output of sacct confirms what we have been seeing. The first omp_check was run without srun and ran in the original batch step which had all hardware threads of all 16 allocated cores available. The next omp_check ran on 3 cores but 6 is shwon in this scheme which is normal as the \"other\" hardware thread on each core is implicitly also reserved. And the same holds for all other numbers in that column.
At another time I was less lucky and got the tasks spread out across 4 nodes, each running a single 4-core task. Let's go through the output again:
Running on nid[002154,002195,002206,002476]\n\n+ omp_check\n\nRunning 8 threads in a single process\n\n++ omp_check: OpenMP thread 0/8 on cpu 36/256 of nid002154\n++ omp_check: OpenMP thread 1/8 on cpu 164/256 of nid002154\n++ omp_check: OpenMP thread 2/8 on cpu 37/256 of nid002154\n++ omp_check: OpenMP thread 3/8 on cpu 165/256 of nid002154\n++ omp_check: OpenMP thread 4/8 on cpu 38/256 of nid002154\n++ omp_check: OpenMP thread 5/8 on cpu 166/256 of nid002154\n++ omp_check: OpenMP thread 6/8 on cpu 39/256 of nid002154\n++ omp_check: OpenMP thread 7/8 on cpu 167/256 of nid002154\n
The first omp_check now uses all hardware threads of the 4 cores allocated in the first node of the job (while using 16 cores/32 threads in the configuration where all cores were allocated on a single node).
+ srun --ntasks=1 --cpus-per-task=3 omp_check\n\nRunning 3 threads in a single process\n\n++ omp_check: OpenMP thread 0/3 on cpu 36/256 of nid002154\n++ omp_check: OpenMP thread 1/3 on cpu 37/256 of nid002154\n++ omp_check: OpenMP thread 2/3 on cpu 38/256 of nid002154\n
Running a three core OpenMP job goes without problems as it nicely fits within the space of a single task of the #SBATCH allocation.
+ srun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nRunning 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 36/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 37/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 38/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 39/256 of nid002195\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 46/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 47/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 48/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 49/256 of nid002206\n
Running 2 4-thread MPI processes also goes without problems. In this case we got the second and third task from the original allocation, likely because Slurm was still freeing up the first node after the previous srun command.
+ srun --ntasks=4 --cpus-per-task=1 mpi_check\nsrun: Job 4268614 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268614\n\nRunning 4 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/4 on cpu 36/256 of nid002154\n++ mpi_check: MPI rank 1/4 on cpu 36/256 of nid002195\n++ mpi_check: MPI rank 2/4 on cpu 46/256 of nid002206\n++ mpi_check: MPI rank 3/4 on cpu 0/256 of nid002476\n
Running 4 single threaded processes also goes without problems (but the fact that they are scheduled on 4 different nodes here is likely an artifact of the way we had to force to get more than one node as the small partition on LUMI was not very busy at that time).
+ srun --ntasks=16 --cpus-per-task=1 mpi_check\n\nRunning 16 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/16 on cpu 36/256 of nid002154\n++ mpi_check: MPI rank 1/16 on cpu 37/256 of nid002154\n++ mpi_check: MPI rank 2/16 on cpu 38/256 of nid002154\n++ mpi_check: MPI rank 3/16 on cpu 39/256 of nid002154\n++ mpi_check: MPI rank 4/16 on cpu 36/256 of nid002195\n++ mpi_check: MPI rank 5/16 on cpu 37/256 of nid002195\n++ mpi_check: MPI rank 6/16 on cpu 38/256 of nid002195\n++ mpi_check: MPI rank 7/16 on cpu 39/256 of nid002195\n++ mpi_check: MPI rank 8/16 on cpu 46/256 of nid002206\n++ mpi_check: MPI rank 9/16 on cpu 47/256 of nid002206\n++ mpi_check: MPI rank 10/16 on cpu 48/256 of nid002206\n++ mpi_check: MPI rank 11/16 on cpu 49/256 of nid002206\n++ mpi_check: MPI rank 12/16 on cpu 0/256 of nid002476\n++ mpi_check: MPI rank 13/16 on cpu 1/256 of nid002476\n++ mpi_check: MPI rank 14/16 on cpu 2/256 of nid002476\n++ mpi_check: MPI rank 15/16 on cpu 3/256 of nid002476\n
16 single threaded MPI processes also works without problems.
+ srun --ntasks=1 --cpus-per-task=16 omp_check\nsrun: Job step's --cpus-per-task value exceeds that of job (16 > 4). Job step may never run.\nsrun: Warning: can't run 1 processes on 4 nodes, setting nnodes to 1\nsrun: error: Unable to create step for job 4268614: More processors requested than permitted\n...\n
However, trying to run a single 16-thread process now fails. Slurm first warns us that it might fail, then tries and lets it fail.
"},{"location":"2day-20240502/06_Slurm/#the-job-environment","title":"The job environment","text":"On LUMI, sbatch, salloc and srun will all by default copy the environment in which they run to the job step they start (the batch job step for sbatch, an interactive job step for salloc and a regular job step for srun). For salloc this is normal behaviour as it also starts an interactive shell on the login nodes (and it cannot be changed with a command line parameter). For srun, any other behaviour would be a pain as each job step would need to set up an environment. But for sbatch this may be surprising to some as the environment on the login nodes may not be the best environment for the compute nodes. Indeed, we do recommend to reload, e.g., the LUMI modules to use software optimised specifically for the compute nodes or to have full support of ROCm.
It is possible to change this behaviour or to define extra environment variables with sbatch and srun using the command line option --export:
-
--export=NONE will start the job (step) in a clean environment. The environment will not be inherited, but Slurm will attempt to re-create the user environment even if no login shell is called or used in the batch script. (--export=NIL would give you a truly empty environment.)
-
To define extra environment variables, use --export=ALL,VAR1=VALUE1 which would pass all existing environment variables and define a new one, VAR1, with the value VALUE1. It is of course also possible to define more environment variables using a comma-separated list (without spaces). With sbatch, specifying --export on the command line that way is a way to parameterise a batch script. With srun it can be very useful with heterogeneous jobs if different parts of the job need a different setting for an environment variable (e.g., OMP_NUM_THREADS).
Note however that ALL in the above --export option is essential as otherwise only the environment variable VAR1 would be defined.
It is in fact possible to pass only select environment variables by listing them without assigning a new value and omitting the ALL but we see no practical use of that on LUMI as the list of environment variables that is needed to have a job script in which you can work more or less normally is rather long.
Passing argumetns to a batch script
With the Slurm sbatch command, any argument passed after the name of the job script is passed to the job script as an argument, so you can use regular bash shell argument processing to pass arguments to the bash script and do not necessarily need to use --export. Consider the following job script to demonstrate both options:
! /usr/bin/bash\n#SBATCH --job-name=slurm-small-parameters\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\necho \"Batch script parameter 0: $0\"\necho \"Batch script parameter 1: $1\"\necho \"Environment variable PAR1: $PAR1\"\n
Now start this with (assuming the job script is saved as slurm-small-parameters.slurm)
$ sbatch --export=ALL,PAR1=\"Hello\" slurm-small-parameters.slurm 'Wow, this works!'\n
and check the output file when the job is completed:
Batch script parameter 0: /var/spool/slurmd/job4278998/slurm_script\nBatch script parameter 1: Wow, this works!\nEnvironment variable PAR1: Hello\n
You see that you do not get the path to the job script as it was submitted (which you may expect to be the value of $0). Instead the job script is buffered when you execute sbatch and started from a different directory. $1 works as expected, and PAR1 is also defined.
In fact, passing arguments through command line arguments of the bash script is a more robust mechanism than using --export as can be seen from the bug discussed below...
Fragile behaviour of --export
One of the problems with --export is that you cannot really assign any variable to a new environment variable the way you would do it on the bash command line. It is not clear what internal processing is going on, but the value is not always what you would expect. In particular, problems can be expected when the value of the variable contains a semicolon.
E.g., try the command from the previous example with --export=ALL,PAR1='Hello, world' and it turns out that only Hello is passed as the value of the variable.
"},{"location":"2day-20240502/06_Slurm/#automatic-requeueing","title":"Automatic requeueing","text":"LUMI has the Slurm automatic requeueing of jobs upon node failure enabled. So jobs will be automatically resubmitted when one of the allocated nodes fails. For this an identical job ID is used and by default the prefious output will be truncated when the requeueed job starts.
There are some options to influence this behaviour:
-
Automatic requeueing can be disabled at job submission with the --no-requeue option of the sbatch command.
-
Truncating of the output files can be avoided by specifying --open-mode=append.
-
It is also possible to detect in a job script if a job has been restarted or not. For this Slurm sets the environment variable SLURM_RESTART_COUNT which is 0 the first time a job script runs and augmented by one at every restart.
"},{"location":"2day-20240502/06_Slurm/#job-dependencies","title":"Job dependencies","text":"The maximum wall time that a job can run on LUMI is fairly long for a Tier-0 system. Many other big systems in Europe will only allow a maximum wall time of 24 hours. Despite this, this is not yet enough for some users. One way to deal with this is ensure that programs end in time and write the necessary restart information in a file, then start a new job that continues from that file.
You don't have to wait to submit that second job. Instead, it is possible to tell Slurm that the second job should not start before the first one has ended (and ended successfully). This is done through job dependencies. It would take us too far to discuss all possible cases in this tutorial.
One example is
$ sbatch --dependency=afterok:<jobID> jobdepend.slurm \n
With this statement, the job defined by the job script jobdpend.slurm will not start until the job with the given jobID has ended successfully (and you may have to clean up the queue if it never ends successfully). But there are other possibilities also, e.g., start another job after a list of jobs has ended, or after a job has failed. We refer to the sbatch manual page where you should look for --dependency on the page.
It is also possible to automate the process of submitting a chain of dependent jobs. For this the sbatch flag --parsable can be used which on LUMI will only print the job number of the job being submitted. So to let the job defined by jobdepend.slurm run after the job defined by jobfirst.slurm while submitting both at the same time, you can use something like
first=$(sbatch --parsable jobfirst.slurm)\nsbatch --dependency=afterok:$first jobdepend.slurm\n
"},{"location":"2day-20240502/06_Slurm/#interactive-jobs","title":"Interactive jobs","text":"Interactive jobs can have several goals, e.g.,
-
Simply testing a code or steps to take to get a code to run while developing a job script. In this case you will likely want an allocation in which you can also easily run parallel MPI jobs.
-
Compiling a code usually works better interactively, but here you only need an allocation for a single task supporting multiple cores if your code supports a parallel build process. Building on the compute nodes is needed if architecture-specific optimisations are desired while the code building process does not support cross-compiling (e.g., because the build process adds -march=native or a similar compiler switch even if it is told not to do so) or ie you want to compile software for the GPUs that during the configure or build process needs a GPU to be present in the node to detect its features.
-
Attaching to a running job to inspect how it is doing.
"},{"location":"2day-20240502/06_Slurm/#interactive-jobs-with-salloc","title":"Interactive jobs with salloc","text":"This is a very good way of working for the first scenario described above.
Using salloc will create a pool of resources reserved for interactive execution, and will start a new shell on the node where you called salloc(usually a login node). As such it does not take resources away from other job steps that you will create so the shell is a good environment to test most stuff that you would execute in the batch job step of a job script.
To execute any code on one of the allocated compute nodes, be it a large sequential program, a shared memory program, distributed memory program or hybrid code, you can use srun in the same way as we have discussed for job scripts.
It is possible to obtain an interactive shell on the first allocated compute node with
srun --pty $SHELL\n
(which if nothing more is specified would give you a single core for the shell), but keep in mind that this takes away resources from other job steps so if you try to start further job steps from that interactive shell you will note that you have fewer resources available, and will have to force overlap (with --overlap), so it is not very practical to work that way.
To terminate the allocation, simply exit the shell that was created by salloc with exit or the CTRL-D key combination (and the same holds for the interactive shell in the previous paragraph).
Example with salloc and a GPU code (click to expand) $ salloc --account=project_46YXXXXXX --partition=standard-g --nodes=2 --time=15\nsalloc: Pending job allocation 4292946\nsalloc: job 4292946 queued and waiting for resources\nsalloc: job 4292946 has been allocated resources\nsalloc: Granted job allocation 4292946\n$ module load LUMI/22.12 partition/G lumi-CPEtools/1.1-cpeCray-22.12\n\n...\n\n$ srun -n 16 -c 2 --gpus-per-task 1 gpu_check\nMPI 000 - OMP 000 - HWT 001 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 000 - OMP 001 - HWT 002 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 001 - OMP 000 - HWT 003 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 001 - OMP 001 - HWT 004 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 002 - OMP 000 - HWT 005 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 002 - OMP 001 - HWT 006 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 003 - OMP 000 - HWT 007 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 003 - OMP 001 - HWT 008 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 004 - OMP 000 - HWT 009 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 004 - OMP 001 - HWT 010 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 005 - OMP 000 - HWT 011 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 005 - OMP 001 - HWT 012 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 006 - OMP 000 - HWT 013 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 006 - OMP 001 - HWT 014 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 007 - OMP 000 - HWT 015 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 007 - OMP 001 - HWT 016 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 008 - OMP 000 - HWT 001 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 008 - OMP 001 - HWT 002 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 009 - OMP 000 - HWT 003 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 009 - OMP 001 - HWT 004 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 010 - OMP 000 - HWT 005 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 010 - OMP 001 - HWT 006 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 011 - OMP 000 - HWT 007 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 011 - OMP 001 - HWT 008 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 012 - OMP 000 - HWT 009 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 012 - OMP 001 - HWT 010 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 013 - OMP 000 - HWT 011 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 013 - OMP 001 - HWT 012 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 014 - OMP 000 - HWT 013 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 014 - OMP 001 - HWT 014 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 015 - OMP 000 - HWT 015 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 015 - OMP 001 - HWT 016 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\n
"},{"location":"2day-20240502/06_Slurm/#interactive-jobs-with-srun","title":"Interactive jobs with srun","text":"Starting an interactive job with srun is good to get an interactive shell in which you want to do some work without starting further job steps, e.g., for compilation on the compute nodes or to run an interactive shared memory program such as R. It is not ideal if you want to spawn further job steps with srun within the same allocation as the interactive shell already fills a task slot, so you'd have to overlap if you want to use all resources of the job in the next job step.
For this kind of work you'll rarely need a whole node so small, small-g, debug or dev-g will likely be your partitions of choice.
To start such a job, you'd use
srun --account=project_46YXXXXXX --partition=<partition> --ntasks=1 --cpus-per-task=<number> --time=<time> --pty=$SHELL\n
or with the short options
srun -A project_46YXXXXXX -p <partition> -n 1 -c <number> -t <time> --pty $SHELL\n
For the GPU nodes you'd also add a --gpus-per-task=<number> to request a number of GPUs.
To end the interactive job, all you need to do is to leave the shell with exit or the CTRL-D key combination.
"},{"location":"2day-20240502/06_Slurm/#inspecting-a-running-job","title":"Inspecting a running job","text":"On LUMI it is not possible to use ssh to log on to a compute node in use by one of your jobs. Instead you need to use Slurm to attach a shell to an already running job. This can be done with srun, but there are two differences with the previous scenario. First, you do not need a new allocation but need to tell srun to use an existing allocation. As there is already an allocation, srun does not need your project account in this case. Second, usually the job will be using all its resources so there is no room in the allocation to create another job step with the interactive shell. This is solved by telling srun that the resources should overlap with those already in use.
To start an interactive shell on the first allocated node of a specific job/allocation, use
srun --jobid=<jobID> --overlap --pty $SHELL\n
and to start an interactive shell on another node of the jobm simply add a -w or --nodelist argument:
srun --jobid=<jobID> --nodelist=nid00XXXX --overlap --pty $SHELL\nsrun --jobid=<jobID> -w nid00XXXX --overlap --pty $SHELL\n
Instead of starting a shell, you could also just run a command, e.g., top, to inspect what the nodes are doing.
Note that you can find out the nodes allocated to your job using squeue (probably the easiest as the nodes are shown by default), sstat or salloc.
"},{"location":"2day-20240502/06_Slurm/#job-arrays","title":"Job arrays","text":"Job arrays is a mechanism to submit a large number of related jobs with the same batch script in a single sbatch operation.
As an example, consider the job script job_array.slurm
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=1\n#SBATCH --mem-per-cpu=1G\n#SBATCH --time=15:00\n\nINPUT_FILE=\"input_${SLURM_ARRAY_TASK_ID}.dat\"\nOUTPUT_FILE=\"output_${SLURM_ARRAY_TASK_ID}.dat\"\n\n./test_set -input ${INPUT_FILE} -output ${OUTPUT_FILE}\n
Note that Slurm defines the environment variable SLURM_ARRAY_TASK_ID which will have a unique value for each job of the job array, varying in the range given at job submission. This enables to distinguish between the different runs and can be used to generate names of input and output files.
Submitting this job script and running it for values of SLURM_ARRAY_TASK_ID going from 1 to 50 could be done with
$ sbatch --array 1-50 job_array.slurm\n
Note that this will count for 50 Slurm jobs so the size of your array jobs on LUMI is limited by the rather strict limit on job size. LUMI is made as a system for big jobs, and is a system with a lot of users, and there are only that many simultaneous jobs that a scheduler can deal with. Users doing throughput computing should do some kind of hierarchical scheduling, running a subscheduler in the job that then further start subjobs.
"},{"location":"2day-20240502/06_Slurm/#heterogeneous-jobs","title":"Heterogeneous jobs","text":"A heterogeneous job is one in which multiple executables run in a single MPI_COMM_WORLD, or a single executable runs in different combinations (e.g., some multithreaded and some single-threaded MPI ranks where the latter take a different code path from the former and do a different task). One example is large simulation codes that use separate I/O servers to take care of the parallel I/O ot the file system.
There are two ways to start such a job:
-
Create groups in the SBATCH lines, separated by #SBATCH hetjob lines, and then recall these groups with srun. This is the most powerful mechanism as in principle one could use nodes in different partitions for different parts of the heterogeneous job.
-
Request the total number of nodes needed with the #SBATCH lines and then do the rest entirely with srun, when starting the heterogeneous job step. The different blocks in srun are separated by a colon. In this case we can only use a single partition.
The Slurm support for heterogeneous jobs is not very good and problems to often occur, or new bugs are being introduced.
-
The different parts of heterogeneous jobs in the first way of specifying them, are treated as different jobs which may give problems with the scheduling.
-
When using the srun method, these are still separate job steps and it looks like a second job is created internally to run these, and on a separate set of nodes.
Let's show with an example (worked out more in the text than in the slides) Consider the following case of a 2-component job:
We will simulate this case with the hybrid_check program from the lumi-CPEtools module that we have used in earlier examples also.
The job script for the first method would look like:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-sbatch\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --ntasks-per-node=32\n#SBATCH --cpus-per-task=4\n#SBATCH hetjob\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --ntasks-per-node=4\n#SBATCH --cpus-per-task=32\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --het-group=0 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_0 --export=ALL,OMP_NUM_THREADS=4 hybrid_check -l app_A : \\\n --het-group=1 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_1 --export=ALL,OMP_NUM_THREADS=32 hybrid_check -l app_B\n\nsrun --het-group=0 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_0 hybrid_check -l hybrid_check -l app_A : \\\n --het-group=1 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_1 hybrid_check -l hybrid_check -l app_B\n\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
There is a single srun command. --het-group=0 tells srun to pick up the settings for the first heterogeneous group (before the #SBATCH hetjob line), and use that to start the hybrid_check program with the command line arguments -l app_A. Next we have the column to tell srun that we start with the second group, which is done in the same way. Note that since recent versions of Slurm do no longer propagate the value for --cpus-per-task, we need to specify the value here explicitly which we can do via an environment variable. This is one of the cases where the patch to work around this new behaviour on LUMI does not work.
This job script shows also demonstrates how a different value of a variable can be passed to each component using --export, even though this was not needed as the second case would show.
The output of this job script would look lik (with a lot omitted):
srun: Job step's --cpus-per-task value exceeds that of job (32 > 4). Job step may never run.\n\nRunning 40 MPI ranks with between 4 and 32 threads each (total number of threads: 384).\n\n++ app_A: MPI rank 0/40 OpenMP thread 0/4 on cpu 0/256 of nid001083\n++ app_A: MPI rank 0/40 OpenMP thread 1/4 on cpu 1/256 of nid001083\n...\n++ app_A: MPI rank 31/40 OpenMP thread 2/4 on cpu 126/256 of nid001083\n++ app_A: MPI rank 31/40 OpenMP thread 3/4 on cpu 127/256 of nid001083\n++ app_B: MPI rank 32/40 OpenMP thread 0/32 on cpu 0/256 of nid001544\n++ app_B: MPI rank 32/40 OpenMP thread 1/32 on cpu 1/256 of nid001544\n...\n++ app_B: MPI rank 35/40 OpenMP thread 30/32 on cpu 126/256 of nid001544\n++ app_B: MPI rank 35/40 OpenMP thread 31/32 on cpu 127/256 of nid001544\n++ app_B: MPI rank 36/40 OpenMP thread 0/32 on cpu 0/256 of nid001545\n++ app_B: MPI rank 36/40 OpenMP thread 1/32 on cpu 1/256 of nid001545\n...\n++ app_B: MPI rank 39/40 OpenMP thread 30/32 on cpu 126/256 of nid001545\n++ app_B: MPI rank 39/40 OpenMP thread 31/32 on cpu 127/256 of nid001545\n... (second run produces identical output)\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4285795+0 slurm-her+ standard project_4+ 256 RUNNING 0:0 \n4285795+0.b+ batch project_4+ 256 RUNNING 0:0 \n4285795+0.0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4285795+0.1 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4285795+1 slurm-her+ standard project_4+ 512 RUNNING 0:0 \n4285795+1.0 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n4285795+1.1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n
The warning at the start can be safely ignored. It just shows how heterogeneous job were an afterthought in Slurm and likely implemented in a very dirty way. We see that we get what we expected: 32 MPI ranks on the first node of the allocation, then 4 on each of the other two nodes.
The output of sacct is somewhat surprising. Slurm has essnetially started two jobs, with jobIDs that end with +0 and +1, and it first shows all job steps for the first job, which is the batch job step and the first group of both srun commands, and then shows the second job and its job steps, again indicating that heterogeneous jobs are not really treated as a single job.
The same example can also be done by just allocating 3 nodes and then using more arguments with srun to start the application:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-srun\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=3\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --ntasks=32 --cpus-per-task=4 --export=ALL,OMP_NUM_THREADS=4 hybrid_check -l app_A : \\\n --ntasks=8 --cpus-per-task=32 --export=ALL,OMP_NUM_THREADS=32 hybrid_check -l app_B\n\nsrun --ntasks=32 --cpus-per-task=4 hybrid_check -l app_A : \\\n --ntasks=8 --cpus-per-task=32 hybrid_check -l app_B\n\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
The output of the two srun commands is essentially the same as before, but the output of sacct is different:
sacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4284021 slurm-her+ standard project_4+ 768 RUNNING 0:0 \n4284021.bat+ batch project_4+ 256 RUNNING 0:0 \n4284021.0+0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4284021.0+1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n4284021.1+0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4284021.1+1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n
We now get a single job ID but the job step for each of the srun commands is split in two separate job steps, a +0 and a +1.
Erratic behaviour of --nnodes=<X> --ntasks-per-node=<Y>
One can wonder if in the second case we could still specify resources on a per-node basis in the srun command:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-srun\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=3\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --nodes=1 --ntasks-per-node=32 --cpus-per-task=4 hybrid_check -l hybrid_check -l app_A : \\\n --nodes=2 --ntasks-per-node=4 --cpus-per-task=32 hybrid_check -l hybrid_check -l app_B\n
It turns out that this does not work at all. Both components get the wrong number of tasks. For some reason only 3 copies were started of the first application on the first node of the allocation, the 2 32-thread processes on the second node and one 32-thread process on the third node, also with an unexpected thread distribution.
This shows that before starting a big application it may make sense to check with the tools from the lumi-CPEtools module if the allocation would be what you expect as Slurm is definitely not free of problems when it comes to hetereogeneous jobs.
"},{"location":"2day-20240502/06_Slurm/#simultaneous-job-steps","title":"Simultaneous job steps","text":"It is possible to run multiple job steps in parallel on LUMI. The core of your job script would look something like:
#! /usr/bin/bash\n...\n#SBATCH partition=standard\n...\nsrun -n4 -c16 exe1 &\nsleep 2\nsrun -n8 -c8 exe2 &\nwait\n
The first srun statement will start a hybrid job of 4 tasks with 16 cores each on the first 64 cores of the node, the second srun statement would start a hybrid job of 8 tasks with 8 cores each on the remaining 64 cores. The sleep 2 statement is used because we have experienced that from time to time even though the second srun statement cannot be executed immediately as the resource manager is busy with the first one. The wait command at the end is essential, as otherwise the batch job step would end without waiting for the two srun commands to finish the work they started, and the whole job would be killed.
Running multiple job steps in parallel in a single job can be useful if you want to ensure a proper binding and hence do not want to use the \"allocate by resources\" partition, while a single job step is not enough to fill an exclusive node. It does turn out to be tricky though, especially when GPU nodes are being used, and with proper binding of the resources. In some cases the --overlap parameter of srun may help a bit. (And some have reported that in some cases --exact is needed instead, but this parameter is already implied if --cpus-per-task can be used.)
A longer example Consider the bash job script for an exclusive CPU node:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-simultaneous-CPU-1\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=2:00\n#SBATCH --output %x-%j.txt\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\necho \"Submitted from $SLURM_SUBMIT_HOST\"\necho \"Running on $SLURM_JOB_NODELIST\"\necho\necho -e \"Job script:\\n$(cat $0)\\n\"\necho \"SLURM_* environment variables:\"\nenv | egrep ^SLURM\n\nfor i in $(seq 0 7)\ndo \n srun --ntasks=1 --cpus-per-task=16 --output=\"slurm-simultaneous-CPU-1-$SLURM_JOB_ID-$i.txt\" \\\n bash -c \"export ROCR_VISIBLE_DEVICES=${GPU_BIND[$i]} && omp_check -w 30\" &\n\n sleep 2\ndone\n\nwait\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID --format JobID%-13,Start,End,AllocCPUS,NCPUS,TotalCPU,MaxRSS --units=M )\\n\"\n
It will start 8 parallel job steps and in total create 9 files: One file with the output of the job script itself, and then one file for each job step with the output specific to that job step. the sacct command at the end shows that the 8 job parallel job steps indeed overlap, as can be seen from the start and end time of each, with the TotalCPU column confirming that they are also consuming CPU time during that time. The last bit of the output of the main batch file looks like:
sacct for the job:\nJobID Start End AllocCPUS NCPUS TotalCPU MaxRSS \n------------- ------------------- ------------------- ---------- ---------- ---------- ---------- \n6849913 2024-04-09T16:15:45 Unknown 256 256 01:04:07 \n6849913.batch 2024-04-09T16:15:45 Unknown 256 256 00:00:00 \n6849913.0 2024-04-09T16:15:54 2024-04-09T16:16:25 32 32 08:00.834 6.92M \n6849913.1 2024-04-09T16:15:56 2024-04-09T16:16:26 32 32 08:00.854 6.98M \n6849913.2 2024-04-09T16:15:58 2024-04-09T16:16:29 32 32 08:00.859 6.76M \n6849913.3 2024-04-09T16:16:00 2024-04-09T16:16:30 32 32 08:00.793 6.76M \n6849913.4 2024-04-09T16:16:02 2024-04-09T16:16:33 32 32 08:00.870 6.59M \n6849913.5 2024-04-09T16:16:04 2024-04-09T16:16:34 32 32 08:01.046 8.57M \n6849913.6 2024-04-09T16:16:06 2024-04-09T16:16:36 32 32 08:01.133 6.76M \n6849913.7 2024-04-09T16:16:08 2024-04-09T16:16:39 32 32 08:00.793 6.57M \n
Obviously as we execute the sacct command in the job the end time of the batch job step and hence the job as a whole are still unknown. We ask omp_check to do some computations during 30 seconds on each thread, and so we see that the CPU time consumed by each 16-core job is indeed around 8 minutes, while start and end time of each job step showed that they executed for roughly 30s each and nicely overlapped.
"},{"location":"2day-20240502/06_Slurm/#slurm-job-monitoring-commands","title":"Slurm job monitoring commands","text":"Slurm has two useful commands to monitor jobs that we want to discuss a bit further:
-
sstat is a command to monitor jobs that are currently running. It gets its information directly from the resource manager component of Slurm.
-
sacct is a command to get information about terminated jobs. It gets its information from the Slurm accounting database. As that database is not continuously updated, information about running jobs may already be present but is far from real-time.
Some users may also be familiar with the sreport command, but it is of limited use on LUMI.
"},{"location":"2day-20240502/06_Slurm/#the-sstat-command","title":"The sstat command","text":"The sstat command is a command to get real-time information about a running job. That information is obtained from the resource manager components in Slurm and not from the accounting database. The command can only produce information about job steps that are currently being executed and cannot be used to get information about jobs tha thave already been terminated, or job steps that have terminated from jobs that are still running.
In its most simple form, you'd likely use the -j (or --jobs) flag to specify the job for which you want information:
sstat -j 1234567\n
and you may like to add the -a flag to get information about all job steps for which information is available. You can also restrict to a single job step, e.g.,
sstat -j 1234567.0\n
The command produces a lot of output though and it is nearly impossible to interpret the output, even on a very wide monitor.
To restrict that output to something that can actually be handled, you can use the -o or --format flag to specify the columns that you want to see.
E.g., the following variant would show for each job step the minimum amount of CPU time that a task has consumed, and the average across all tasks. These numbers should be fairly close if the job has a good load balance.
$ sstat -a -j 1234567 -o JobID,MinCPU,AveCPU\nJobID MinCPU AveCPU\n------------ ---------- ----------\n1234567.bat+ 00:00:00 00:00:00\n1234567.1 00:23:44 00:26:02\n
The above output is from an MPI job that has two job steps in it. The first step was a quick initialisation step and that one has terminated already, so we get no information about that step. The 1234567.1 step is the currently executing one, and we do note a slight load inbalance in this case. No measurable amount of time has been consumed running the batch script itself outside the srun commands in this case.
It can also be used to monitor memory use of the application. E.g.,
$ sstat -a -j 1234567 -o JobID,MaxRSS,MaxRSSTask,MaxRSSNode\nJobID MaxRSS MaxRSSTask MaxRSSNode\n------------ ---------- ---------- ----------\n1234567.bat+ 25500K 0 nid001522\n1234567.1 153556K 0 nid001522\n
will show the maximum amount of resident memory used by any of the tasks, and also tell you which task that is and on which node it is running.
You can get a list of output fields using sstat -e or sstat --helpformat. Or check the \"Job Status Fields\" section in the sstat manual page. That page also contains further examples.
"},{"location":"2day-20240502/06_Slurm/#the-sacct-command","title":"The sacct command","text":"The sacct command shows information kept in the Slurm job accounting database. Its main use is to extract information about jobs or job steps that have already terminated. It will however also provide information about running jobs and job steps, but that information if not real-time and only pushed periodically to the accounting database.
If you know the job ID of the job you want to investigate, you can specify it directly using the -j or --jobs flag. E.g.,
$ sacct -j 1234567\nJobID JobName Partition Account AllocCPUS State ExitCode\n------------ ---------- ---------- ---------- ---------- ---------- --------\n1234567 healthy_u+ standard project_4+ 512 COMPLETED 0:0\n1234567.bat+ batch project_4+ 256 COMPLETED 0:0\n1234567.0 gmx_mpi_d project_4+ 2 COMPLETED 0:0\n1234567.1 gmx_mpi_d project_4+ 512 COMPLETED 0:0\n
This report is for a GROMACS job that ran on two nodes. The first line gives the data for the overall job. The second line is for the batch job step that ran the batch script. That job got access to all resources on the first node of the job which is why 256 is shown in the AllocCPUS column (as that data is reported using the number of virtual cores). Job step .0 was really an initialisation step that ran as a single task on a single physical core of the node, while the .1 step was running on both nodes (as 256 tasks each on a physical core but that again cannot be directly derived from the output shown here).
You can also change the amount of output that is shown using either --brief (which will show a lot less) or --long (which shows an unwieldly amount of information similar to sstat), and just as with sstat, the information can be fully customised using -o or --format, but as there is a lot more information in the accounting database, the format options are different.
As an example, let's check the CPU time and memory used by a job:
$ sacct -j 1234567 --format JobID%-13,AllocCPUS,MinCPU%15,AveCPU%15,MaxRSS,AveRSS --units=M\nJobID AllocCPUS MinCPU AveCPU MaxRSS AveRSS\n------------- ---------- --------------- --------------- ---------- ----------\n1234567 512\n1234567.batch 256 00:00:00 00:00:00 25.88M 25.88M\n1234567.0 2 00:00:00 00:00:00 5.05M 5.05M\n1234567.1 512 01:20:02 01:26:19 173.08M 135.27M\n
This is again the two node MPI job that we've used in the previous example. We used --units=M to get the memory use per task in megabytes, which is the proper option here as tasks are relatively small (but not uncommonly small for an HPC system when a properly scaling code is used). The %15 is used to specify the width of the field as otherwise some of that information could be truncated (and the width of 15 would have been needed if this were a shared memory program or a program that ran for longer than a day). By default, specifying the field width will right justify the information in the columns. The %-13 tells to use a field width of 13 and to left-justify the data in that column.
You can get a list of output fields using sacct -e or sacct --helpformat. Or check the \"Job Accounting Fields\" section in the sacct manual page. That page also contains further examples.
Using sacct is a bit harder if you don't have the job ID of the job for which you want information. You can run sacct without any arguments, and in that case it will produce output for your jobs that have run since midnight. It is also possible to define the start time (with -S or --starttime) and the end time (with -E or --endtime) of the time window for which job data should be shown, and there are even more features to filter jobs, though some of them are really more useful for administrators.
This is only a very brief introduction to sacct, basically so that you know that it exists and what its main purpose is. But you can find more information in the sacct manual page
"},{"location":"2day-20240502/06_Slurm/#the-sreport-command","title":"The sreport command","text":"The sreport command is a command to create summary reports from data in the Slurm accounting database. Its main use is to track consumed resources in a project.
On LUMI it is of little use as as the billing is not done by Slurm but by a script that runs outside of Slurm that uses data from the Slurm accounting database. That data is gathered in a different database though with no direct user access, and only some summary reports are brought back to the system (and used by the lumi-workspaces command and some other tools for user and project monitoring). So the correct billing information is not available in the Slurm accounting database, nor can it be easily derived from data in the summary reports as the billing is more complicated than some billing for individual elements such as core use, memory use and accelerator use. E.g., one can get summary reports mentioning the amount of core hours used per user for a project, but that is reported for all partitions together and hence irrelevant to get an idea of how the CPU billing units were consumed.
This section is mostly to discourage you to use sreport as its information is often misleading and certainly it it is used to follow up your use of billing units on LUMI, but should you insist, there is more information in the sreport manual page.
"},{"location":"2day-20240502/06_Slurm/#other-trainings-and-materials","title":"Other trainings and materials","text":" - DeiC, the Danish organisation in the LUMI consortium, has develop an online Slurm tutorial
"},{"location":"2day-20240502/07_Binding/","title":"Process and Thread Distribution and Binding","text":""},{"location":"2day-20240502/07_Binding/#what-are-we-talking-about-in-this-session","title":"What are we talking about in this session?","text":"Distribution is the process of distributing processes and threads across the available resources of the job (nodes, sockets, NUMA nodes, cores, ...), and binding is the process of ensuring they stay there as naturally processes and threads are only bound to a node (OS image) but will migrate between cores. Binding can also ensure that processes cannot use resources they shouldn't use.
When running a distributed memory program, the process starter - mpirun or mpiexec on many clusters, or srun on LUMI - will distribute the processes over the available nodes. Within a node, it is possible to pin or attach processes or even individual threads in processes to one or more cores (actually hardware threads) and other resources, which is called process binding.
The system software (Linux, ROCmTM and Slurm) has several mechanisms for that. Slurm uses Linux cgroups or control groups to limit the resources that a job can use within a node and thus to isolate jobs from one another on a node so that one job cannot deplete the resources of another job, and sometimes even uses control groups at the task level to restrict some resources for a task (currently when doing task-level GPU binding via Slurm). The second mechanism is processor affinity which works at the process and thread level and is used by Slurm at the task level and can be used by the OpenMP runtime to further limit thread migration. It works through affinity masks which indicate the hardware threads that a thread or process can use. There is also a third mechanism provided by the ROCmTM runtime to control which GPUs can be used.
Some of the tools in the lumi-CPEtools module can show the affinity mask for each thread (or effectively the process for single-threaded processes) so you can use these tools to study the affinity masks and check the distribution and binding of processes and threads. The serial_check, omp_check, mpi_check and hybrid_check programs can be used to study thread binding. In fact, hybrid_check can be used in all cases, but the other three show more compact output for serial, shared memory OpenMP and single-threaded MPI processes respectively. The gpu_check command can be used to study the steps in GPU binding.
Credits for these programs The hybrid_check program and its derivatives serial_check, omp_check and mpi_check are similar to the xthi program used in the 4-day comprehensive LUMI course organised by the LUST in collaboration with HPE Cray and AMD. Its main source of inspiration is a very similar program, acheck, written by Harvey Richardson of HPE Cray and used in an earlier course, but it is a complete rewrite of that application.
One of the advantages of hybrid_check and its derivatives is that the output is sorted internally already and hence is more readable. The tool also has various extensions, e.g., putting some load on the CPU cores so that you can in some cases demonstrate thread migration as the Linux scheduler tries to distribute the load in a good way.
The gpu_check program builds upon the hello_jobstep program from ORNL with several extensions implemented by the LUST.
(ORNL is the national lab that operates Frontier, an exascale supercomputer based on the same node type as LUMI-G.)
In this section we will consider process and thread distribution and binding at several levels:
-
When creating an allocation, Slurm will already reserve resources at the node level, but this has been discussed already in the Slurm session of the course.
It will also already employ control groups to restrict the access to those reaources on a per-node per-job basis.
-
When creating a job step, Slurm will distribute the tasks over the available resources, bind them to CPUs and depending on how the job step was started, bind them to a subset of the GPUs available to the task on the node it is running on.
-
With Cray MPICH, you can change the binding between MPI ranks and Slurm tasks. Normally MPI rank i would be assigned to task i in the job step, but sometimes there are reasons to change this. The mapping options offered by Cray MPICH are more powerful than what can be obtained with the options to change the task distribution in Slurm.
-
The OpenMP runtime also uses library calls and environment variables to redistribute and pin threads within the subset of hardware threads available to the process. Note that different compilers use different OpenMP runtimes so the default behaviour will not be the same for all compilers, and on LUMI is different for the Cray compiler compared to the GNU and AMD compilers.
-
Finally, the ROCm runtime also can limit the use of GPUs by a process to a subset of the ones that are available to the process through the use of the ROCR_VISIBLE_DEVICES environment variable.
Binding almost only makes sense on job-exclusive nodes as only then you have full control over all available resources. On \"allocatable by resources\" partitions you usually do not know which resources are available. The advanced Slurm binding options that we will discuss do not work in those cases, and the options offered by the MPICH, OpenMP and ROCm runtimes may work very unpredictable, though OpenMP thread binding may still help a bit with performance in some cases.
Warning
Note also that some srun options that we have seen (sometimes already given at the sbatch or salloc level but picket up by srun) already do a simple binding, so those options cannot be combined with the options that we will discuss in this session. This is the case for --cpus-per-task, --gpus-per-task and --ntasks-per-gpu. In fact, the latter two options will also change the numbering of the GPUs visible to the ROCm runtime, so using ROCR_VISIBLE_DEVICES may also lead to surprises!
"},{"location":"2day-20240502/07_Binding/#why-do-i-need-this","title":"Why do I need this?","text":"As we have somewhat in the \"LUMI Architecture\" session of this course and as you may know from other courses, modern supercomputer nodes have increasingly a very hierarchical architecture. This hierarchical architecture is extremely pronounced on the AMD EPYC architecture used in LUMI but is also increasingly showing up with Intel processors and the ARM server processors, and is also relevant but often ignored in GPU clusters.
A proper binding of resources to the application is becoming more and more essential for good performance and scalability on supercomputers.
-
Memory locality is very important, and even if an application would be written to take the NUMA character properly into account at the thread level, a bad mapping of these threads to the cores may result into threads having to access memory that is far away (with the worst case on a different socket) extensively.
Memory locality at the process level is easy as usually processes share little or no memory. So if you would have an MPI application where each rank needs 14 GB of memory and so only 16 ranks can run on a regular node, then it is essential to ensure that these ranks are spread out nicely over the whole node, with one rank per CCD. The default of Slurm when allocating 16 single-thread tasks on a node would be to put them all on the first two CCDs, so the first NUMA-domain, which would give very poor performance as a lot of memory accesses would have to go across sockets.
-
If threads in a process don't have sufficient memory locality it may be very important to run all threads in as few L3 cache domains as possible, ideally just one, as otherwise you risk having a lot of conflicts between the different L3 caches that require resolution and can slow down the process a lot.
This already shows that there is no single works-for-all solution, because if those threads would use all memory on a node and each have good memory locality then it would be better to spread them out as much possible. You really need to understand your application to do proper resource mapping, and the fact that it can be so application-dependent is also why Slurm and the various runtimes cannot take care of it automatically.
-
In some cases it is important on the GPU nodes to ensure that tasks are nicely spread out over CCDs with each task using the GPU (GCD) that is closest to the CCD the task is running on. This is certainly the case if the application would rely on cache-coherent access to GPU memory from the CPU.
-
With careful mapping of MPI ranks on nodes you can often reduce the amount of inter-node data transfer in favour of the faster intra-node transfers. This requires some understanding of the communication pattern of your MPI application.
-
For GPU-aware MPI: Check if the intra-node communication pattern can map onto the links between the GCDs.
"},{"location":"2day-20240502/07_Binding/#core-numbering","title":"Core numbering","text":"Linux core numbering is not hierarchical and may look a bit strange. This is because Linux core numbering was fixed before hardware threads were added, and later on hardware threads were simply added to the numbering scheme.
As is usual with computers, numbering starts from 0. Core 0 is the first hardware thread (or we could say the actual core) of the first core of the first CCD (CCD 0) of the first NUMA domain (NUMA domain 0) of the first socket (socket 0). Core 1 is then the first hardware thread of the second core of the same CCD, and so on, going over all cores in a CCD, then NUMA domain and then socket. So on LUMI-C, core 0 till 63 are on the first socket and core 64 till 127 on the second one. The numbering of the second hardware thread of each core - we could say the virtual core - then starts where the numbering of the actual cores ends, so 64 for LUMI-G (which has only one socket per node) or 128 for LUMI-C. This has the advantage that if hardware threading is turned off at the BIOS/UEFI level, the numbering of the actual cores does not change.
On LUMI G, core 0 and its second hardware thread 64 are reserved by the low noise mode and cannot be used by Slurm or applications. This is done to help reduce OS jitter which can kill scalability of large parallel applications. However, it also creates an assymetry that is hard to deal with. (For this reason they chose to disable the first core of every CCD on Frontier, so core 0, 8, 16, ... and corresponding hardware threads 64, 72, ..., but on LUMI this is not yet the case). Don't be surprised if when running a GPU code you see a lot of activity on core 0. It is caused by the ROCmTM driver and is precisely the reason why that core is reserved, as that activity would break scalability of applications that expect to have the same amount of available compute power on each core.
Note that even with --hint=nomultithread the hardware threads will still be turned on at the hardware level and be visible in the OS (e.g., in /proc/cpuinfo). In fact, the batch job step will use them, but they will not be used by applications in job steps started with subsequent srun commands.
Slurm under-the-hoods example We will use the Linux lstopo and taskset commands to study how a job step sees the system and how task affinity is used to manage the CPUs for a task. Consider the job script:
#!/bin/bash\n#SBATCH --job-name=cpu-numbering-demo1\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=16\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Output of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Taskset of current shell: \\$(taskset -p \\$\\$)\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\n\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\necho -e \"\\nFull lstopo output in the job:\\n$(lstopo -p)\\n\\n\"\necho -e \"Taskset of the current shell: $(taskset -p $$)\\n\"\n\necho \"Running two tasks on 4 cores each, extracting parts from lstopo output in each:\"\nsrun -n 2 -c 4 ./task_lstopo_$SLURM_JOB_ID\necho\ncat output-$SLURM_JOB_ID-0\necho\ncat output-$SLURM_JOB_ID-1\n\necho -e \"\\nRunning hybrid_check in the same configuration::\"\nsrun -n 2 -c 4 hybrid_check -r\n\n/bin/rm task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-0 output-$SLURM_JOB_ID-1\n
It creates a small test program that we will use to run lstopo and gather its output on two tasks with 4 cores each. All this is done in a job allocation with 16 cores on the small partition.
The results of this script will differ strongly between runs as Slurm can give different valid configurations for this request. Below is one possible output we got.
Let's first look at the output of the lstopo and taskset commands run in the batch job step:
Full lstopo output in the job:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n L2 P#108 (512KB) + L1d P#108 (32KB) + L1i P#108 (32KB) + Core P#44\n PU P#108\n PU P#236\n L2 P#109 (512KB) + L1d P#109 (32KB) + L1i P#109 (32KB) + Core P#45\n PU P#109\n PU P#237\n L2 P#110 (512KB) + L1d P#110 (32KB) + L1i P#110 (32KB) + Core P#46\n PU P#110\n PU P#238\n L2 P#111 (512KB) + L1d P#111 (32KB) + L1i P#111 (32KB) + Core P#47\n PU P#111\n PU P#239\n Group0\n NUMANode P#7 (31GB)\n L3 P#14 (32MB)\n L2 P#112 (512KB) + L1d P#112 (32KB) + L1i P#112 (32KB) + Core P#48\n PU P#112\n PU P#240\n L2 P#113 (512KB) + L1d P#113 (32KB) + L1i P#113 (32KB) + Core P#49\n PU P#113\n PU P#241\n L2 P#114 (512KB) + L1d P#114 (32KB) + L1i P#114 (32KB) + Core P#50\n PU P#114\n PU P#242\n L2 P#115 (512KB) + L1d P#115 (32KB) + L1i P#115 (32KB) + Core P#51\n PU P#115\n PU P#243\n\nTaskset of the current shell: pid 81788's current affinity mask: ffff0000000000000000000000000000ffff0000000000000000000000000\n
Note the way the cores are represented. There are 16 lines the lines L2 ... + L1d ... + L1i ... + Core ... that represent the 16 cores requested. We have used the -p option of lstopo to ensure that lstopo would show us the physical number as seen by the bare OS. The numbers indicated after each core are within the socket but the number indicated right after L2 is the global core numbering within the node as seen by the bare OS. The two PU lines (Processing Unit) after each core are correspond to the hardware threads and are also the numbers as seen by the bare OS.
We see that in this allocation the cores are not spread over the minimal number of L3 cache domains that would be possible, but across three domains. In this particular allocation the cores are still consecutive cores, but even that is not guaranteed in an \"Allocatable by resources\" partition. Despite --hint=nomultithread being the default behaviour, at this level we still see both hardware threads for each physical core in the taskset.
Next look at the output printed by lines 29 and 31:
Task 0\nOutput of lstopo:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n Group0\n NUMANode P#7 (31GB)\nTaskset of current shell: pid 82340's current affinity mask: f0000000000000000000000000\n\nTask 1\nOutput of lstopo:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n Group0\n NUMANode P#7 (31GB)\nTaskset of current shell: pid 82341's current affinity mask: f00000000000000000000000000\n
The output of lstopo -p is the same for both: we get the same 8 cores. This is because all cores for all tasks on a node are gathered in a single control group. Instead, affinity masks are used to ensure that both tasks of 4 threads are scheduled on different cores. If we have a look at booth taskset lines:
Taskset of current shell: pid 82340's current affinity mask: 0f0000000000000000000000000\nTaskset of current shell: pid 82341's current affinity mask: f00000000000000000000000000\n
we see that they are indeed different (a zero was added to the front of the first to make the difference clearer). The first task got cores 100 till 103 and the second task got cores 104 till 107. This also shows an important property: Tasksets are defined based on the bare OS numbering of the cores, not based on a numbering relative to the control group, with cores numbered from 0 to 15 in this example. It also implies that it is not possible to set a taskset manually without knowing which physical cores can be used!
The output of the srun command on line 34 confirms this:
Running 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 101/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 102/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 103/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 100/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 106/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 107/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 104/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 105/256 of nid002040 mask 104-107\n
Note however that this output will depend on the compiler used to compile hybrid_check. The Cray compiler will produce different output as it has a different default strategy for OpenMP threads and will by default pin each thread to a different hardware thread if possible.
"},{"location":"2day-20240502/07_Binding/#gpu-numbering","title":"GPU numbering","text":"The numbering of the GPUs is a very tricky thing on LUMI.
The only way to reliably identify the physical GPU is through the PCIe bus ID. This does not change over time or in an allocation where access to some resources is limited through cgroups. It is the same on all nodes.
Based on these PICe bus IDs, the OS will assign numbers to the GPU. It are those numbers that are shown in the figure in the Architecture chapter - \"Building LUMI: What a LUMI-G node really looks like\". We will call this the bare OS numbering or global numbering in these notes.
Slurm manages GPUs for jobs through the control group mechanism. Now if a job requesting 4 GPUs would get the GPUs that are numbered 4 to 7 in bare OS numbering, it would still see them as GPUs 0 to 3, and this is the numbering that one would have to use for the ROCR_VISIBLE_DEVICES environment variable that is used to further limit the GPUs that the ROCm runtime will use in an application. We will call this the job-local numbering.
Inside task of a regular job step, Slurm can further restrict the GPUs that are visible through control groups at the task level, leading to yet another numbering that starts from 0 which we will call the task-local numbering.
Note also that Slurm does take care of setting the ROCR_VISIBLE_DEVICES environment variable. It will be set at the start of a batch job step giving access to all GPUs that are available in the allocation, and will also be set by srun for each task. But you don't need to know in your application which numbers these are as, e.g., the HIP runtime will number the GPUs that are available from 0 on.
A more technical example demonstrating what Slurm does (click to expand) We will use the Linux lstopocommand and the ROCR_VISIBLE_DEVICES environment variable to study how a job step sees the system and how task affinity is used to manage the CPUs for a task. Consider the job script:
#!/bin/bash\n#SBATCH --job-name=gpu-numbering-demo1\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=standard-g\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=15:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Relevant lines of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p | awk '/ PCI.*Display/ || /GPU/ || / Core / || /PU L/ {print \\$0}' >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"ROCR_VISIBLE_DEVICES: \\$ROCR_VISIBLE_DEVICES\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\necho -e \"\\nFull lstopo output in the job:\\n$(lstopo -p)\\n\\n\"\necho -e \"Extract GPU info:\\n$(lstopo -p | awk '/ PCI.*Display/ || /GPU/ {print $0}')\\n\" \necho \"ROCR_VISIBLE_DEVICES at the start of the job script: $ROCR_VISIBLE_DEVICES\"\n\necho \"Running two tasks with 4 GPUs each, extracting parts from lstopo output in each:\"\nsrun -n 2 -c 1 --gpus-per-task=4 ./task_lstopo_$SLURM_JOB_ID\necho\ncat output-$SLURM_JOB_ID-0\necho\ncat output-$SLURM_JOB_ID-1\n\necho -e \"\\nRunning gpu_check in the same configuration::\"\nsrun -n 2 -c 1 --gpus-per-task=4 gpu_check -l\n\n/bin/rm task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-0 output-$SLURM_JOB_ID-1\n
It creates a small test program that is run on two tasks and records some information on the system. The output is not sent to the screen directly as it could end up mixed between the tasks which is far from ideal.
Let's first have a look at the first lines of the lstopo -p output:
Full lstopo output in the job:\nMachine (503GB total) + Package P#0\n Group0\n NUMANode P#0 (125GB)\n L3 P#0 (32MB)\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n PU P#1\n PU P#65\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PU P#2\n PU P#66\n L2 P#3 (512KB) + L1d P#3 (32KB) + L1i P#3 (32KB) + Core P#3\n PU P#3\n PU P#67\n L2 P#4 (512KB) + L1d P#4 (32KB) + L1i P#4 (32KB) + Core P#4\n PU P#4\n PU P#68\n L2 P#5 (512KB) + L1d P#5 (32KB) + L1i P#5 (32KB) + Core P#5\n PU P#5\n PU P#69\n L2 P#6 (512KB) + L1d P#6 (32KB) + L1i P#6 (32KB) + Core P#6\n PU P#6\n PU P#70\n L2 P#7 (512KB) + L1d P#7 (32KB) + L1i P#7 (32KB) + Core P#7\n PU P#7\n PU P#71\n HostBridge\n PCIBridge\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi4\"\n L3 P#1 (32MB)\n L2 P#9 (512KB) + L1d P#9 (32KB) + L1i P#9 (32KB) + Core P#9\n PU P#9\n PU P#73\n L2 P#10 (512KB) + L1d P#10 (32KB) + L1i P#10 (32KB) + Core P#10\n PU P#10\n PU P#74\n L2 P#11 (512KB) + L1d P#11 (32KB) + L1i P#11 (32KB) + Core P#11\n PU P#11\n PU P#75\n L2 P#12 (512KB) + L1d P#12 (32KB) + L1i P#12 (32KB) + Core P#12\n PU P#12\n PU P#76\n L2 P#13 (512KB) + L1d P#13 (32KB) + L1i P#13 (32KB) + Core P#13\n PU P#13\n PU P#77\n L2 P#14 (512KB) + L1d P#14 (32KB) + L1i P#14 (32KB) + Core P#14\n PU P#14\n PU P#78\n L2 P#15 (512KB) + L1d P#15 (32KB) + L1i P#15 (32KB) + Core P#15\n PU P#15\n PU P#79\n HostBridge\n PCIBridge\n PCI d5:00.0 (Ethernet)\n Net \"hsn2\"\n PCIBridge\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi5\"\n HostBridge\n PCIBridge\n PCI 91:00.0 (Ethernet)\n Net \"nmn0\"\n...\n
We see only 7 cores in the each block (the lines L2 ... + L1d ... + L1i ... + Core ...) because the first physical core on each CCD is reserved for the OS.
The lstopo -p output also clearly suggests that each GCD has a special link to a particular CCD
Next check the output generated by lines 22 and 23 where we select the lines that show information about the GPUs and print some more information:
Extract GPU info:\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi4\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi5\"\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI d9:00.0 (Display)\n GPU(RSMI) \"rsmi6\"\n PCI de:00.0 (Display)\n GPU(RSMI) \"rsmi7\"\n PCI c1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI c6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n\nROCR_VISIBLE_DEVICES at the start of the job script: 0,1,2,3,4,5,6,7\n
All 8 GPUs are visible and note the numbering on each line below the line with the PCIe bus ID. We also notice that ROCR_VISIBLE_DEVICES was set by Slurm and includes all 8 GPUs.
Next we run two tasks requesting 4 GPUs and a single core without hardware threading each. The output of those two tasks is gathered in files that are then sent to the standard output in lines 28 and 30:
Task 0\nRelevant lines of lstopo:\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PCI d1:00.0 (Display)\n PCI d6:00.0 (Display)\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI d9:00.0 (Display)\n PCI de:00.0 (Display)\n PCI c1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI c6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\nROCR_VISIBLE_DEVICES: 0,1,2,3\n\nTask 1\nRelevant lines of lstopo:\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n PCI c9:00.0 (Display)\n PCI ce:00.0 (Display)\n PCI d9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI de:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI c1:00.0 (Display)\n PCI c6:00.0 (Display)\nROCR_VISIBLE_DEVICES: 0,1,2,3\n
Each task sees GPUs named 'rsmi0' till 'rsmi3', but look better and you see that these are not the same. If you compare with the first output of lstopo which we ran in the batch job step, we notice that task 0 gets the first 4 GPUs in the node while task 1 gets the next 4, that were named rsmi4 till rsmi7 before. The other 4 GPUs are invisible in each of the tasks. Note also that in both tasks ROCR_VISIBLE_DEVICES has the same value 0,1,2,3 as the numbers detected by lstopo in that task are used.
The lstopo command does see two cores though for each task (but they are the same) because the cores are not isolated by cgroups on a per-task level, but on a per-job level.
Finally we have the output of the gpu_check command run in the same configuration. The -l option that was used prints some extra information that makes it easier to check the mapping: For the hardware threads it shows the CCD and for each GPU it shows the GCD number based on the physical order of the GPUs and the corresponding CCD that should be used for best performance:
MPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid005163 - RT_GPU_ID 0,1,2,3 - GPU_ID 0,1,2,3 - Bus_ID c1(GCD0/CCD6),c6(GCD1/CCD7),c9(GCD2/CCD2),cc(GCD3/CCD3)\nMPI 001 - OMP 000 - HWT 002 (CCD0) - Node nid005163 - RT_GPU_ID 0,1,2,3 - GPU_ID 0,1,2,3 - Bus_ID d1(GCD4/CCD0),d6(GCD5/CCD1),d9(GCD6/CCD4),dc(GCD7/CCD5)\n
RT_GPU_ID is the numbering of devices used in the program itself, GPU_ID is essentially the value of ROCR_VISIBLE_DEVICES, the logical numbers of the GPUs in the control group and Bus_ID shows the relevant part of the PCIe bus ID.
The above example is very technical and not suited for every reader. One important conclusion though that is of use when running on LUMI is that Slurm works differently with CPUs and GPUs on LUMI. Cores and GPUs are treated differently. Cores access is controlled by control groups at the job step level on each node and at the task level by affinity masks. The equivalent for GPUs would be to also use control groups at the job step level and then ROCR_VISIBLE_DEVICES to further set access to GPUs for each task, but this is not what is currently happening in Slurm on LUMI. Instead it is using control groups at the task level.
Playing with control group and ROCR_VISIBLE_DEVICES (click to expand) Consider the following (tricky and maybe not very realistic) job script.
#!/bin/bash\n#SBATCH --job-name=gpu-numbering-demo2\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_1gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_1gpu_$SLURM_JOB_ID\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\nsleep \\$((SLURM_LOCALID * 5))\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Relevant lines of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p | awk '/ PCI.*Display/ || /GPU/ || / Core / || /PU L/ {print \\$0}' >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"ROCR_VISIBLE_DEVICES: \\$ROCR_VISIBLE_DEVICES\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\n# Start a background task to pick GPUs with global numbers 0 and 1\nsrun -n 1 -c 1 --gpus=2 sleep 60 &\nsleep 5\n\nset -x\nsrun -n 4 -c 1 --gpus=4 ./task_lstopo_$SLURM_JOB_ID\nset +x\n\ncat output-$SLURM_JOB_ID-0\n\nset -x\nsrun -n 4 -c 1 --gpus=4 ./select_1gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\nwait\n\n/bin/rm select_1gpu_$SLURM_JOB_ID task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-*\n
We create two small programs that we will use in here. The first one is used to set ROCR_VISIBLE_DEVICES to the value of SLURM_LOCALID which is the local task number within a node of a Slurm task (so always numbered starting from 0 per node). We will use this to tell the gpu_check program that we will run which GPU should be used by which task. The second program is one we have seen before already and just shows some relevant output of lstopo to see which GPUs are in principle available to the task and then also prints the value of ROCR_VISIBLE_DEVICES. We did have to put in some task-dependent delay as it turns out that running multiple lstopo commands on a node together can cause problems.
The tricky bit is line 29. Here we start an srun command on the background that steals two GPUs. In this way, we ensure that the next srun command will not be able to get the GCDs 0 and 1 from the regular full-node numbering. The delay is again to ensure that the next srun works without conflicts as internally Slurm is still finishing steps from the first srun.
On line 33 we run our command that extracts info from lstopo. As we already know from the more technical example above the output will be the same for each task so in line 36 we only look at the output of the first task:
Relevant lines of lstopo:\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n L2 P#3 (512KB) + L1d P#3 (32KB) + L1i P#3 (32KB) + Core P#3\n L2 P#4 (512KB) + L1d P#4 (32KB) + L1i P#4 (32KB) + Core P#4\n L2 P#5 (512KB) + L1d P#5 (32KB) + L1i P#5 (32KB) + Core P#5\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n PCI d9:00.0 (Display)\n PCI de:00.0 (Display)\n PCI c1:00.0 (Display)\n PCI c6:00.0 (Display)\nROCR_VISIBLE_DEVICES: 0,1,2,3\n
If you'd compare with output from a full-node lstopo -p shown in the previous example, you'd see that we actually got the GPUs with regular full node numbering 2 till 5, but they have been renumbered from 0 to 3. And notice that ROCR_VISIBLE_DEVICES now also refers to this numbering and not the regular full node numbering when setting which GPUs can be used.
The srun command on line 40 will now run gpu_check through the select_1gpu_$SLURM_JOB_ID wrapper that gives task 0 access to GPU 0 in the \"local\" numbering, which should be GPU2/CCD2 in the regular full node numbering, etc. Its output is
MPI 000 - OMP 000 - HWT 002 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID cc(GCD3/CCD3)\nMPI 002 - OMP 000 - HWT 004 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID d1(GCD4/CCD0)\nMPI 003 - OMP 000 - HWT 005 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID d6(GCD5/CCD1)\n
which confirms that out strategy worked. So in this example we have 4 tasks running in a control group that in principle gives each task access to all 4 GPUs, but with actual access further restricted to a different GPU per task via ROCR_VISIBLE_DEVICES.
This again rather technical example demonstrates another difference between the way one works with CPUs and with GPUs. Affinity masks for CPUs refer to the \"bare OS\" numbering of hardware threads, while the numbering used for ROCR_VISIBLE_DEVICES which determines which GPUs the ROCm runtime can use, uses the numbering within the current control group.
Running GPUs in a different control group per task has consequences for the way inter-GPU communication within a node can be organised so the above examples are important. It is essential to run MPI applications with optimal efficiency.
"},{"location":"2day-20240502/07_Binding/#task-distribution-with-slurm","title":"Task distribution with Slurm","text":"The Slurm srun command offers the --distribution option to influence the distribution of tasks across nodes (level 1), sockets or NUMA domains (level 2 and sockets or NUMA) or even across cores in the socket or NUMA domain (third level). The first level is the most useful level, the second level is sometimes used but the third level is very tricky and both the second and third level are often better replaced with other mechanisms that will also be discussed in this chapter on distribution and binding.
The general form of the --distribution option is
--distribution={*|block|cyclic|arbitrary|plane=<size>}[:{*|block|cyclic|fcyclic}[:{*|block|cyclic|fcyclic}]][,{Pack|NoPack}]\n
-
Level 1: Distribution across nodes. There are three useful options for LUMI:
-
block which is the default: A number of consecutive tasks is allocated on the first node, then another number of consecutive tasks on the second node, and so on till the last node of the allocation. Not all nodes may have the same number of tasks and this is determined by the optional pack or nopack parameter at the end.
-
With pack the first node in the allocation is first filled up as much as possible, then the second node, etc.
-
With nopack a more balanced approach is taken filling up all nodes as equally as possible. In fact, the number of tasks on each node will correspond to that of the cyclic distribution, but the task numbers will be different.
-
cyclic assigns the tasks in a round-robin fashion to the nodes of the allocation. The first task is allocated to the first node, then the second one to the second node, and so on, and when all nodes of the allocation have received one task, the next one will be allocated again on the first node.
-
plane=<size> is a combination of both of the former methods: Blocks of <size> consecutive tasks are allocated in a cyclic way.
-
Level 2: Here we are distributing and pinning the tasks assigned to a node at level 1 across the sockets and cores of that node.
As this option already does a form of binding, it may conflict with other options that we will discuss later that also perform binding. In practice, this second level is less useful as often other mechanisms will be preferred for doing a proper binding, or the default behaviour is OK for simple distribution problems.
-
block will assign whole tasks to consecutive sets of cores on the node. On LUMI-C, it will first fill up the first socket before moving on to the second socket.
-
cyclic assigns the first task of a node to a set of consecutive cores on the first socket, then the second task to a set of cores on the second socket, etc., in a round-robin way. It will do its best to not allocate tasks across sockets.
-
fcyclic is a very strange distribution, where tasks requesting more than 1 CPU per task will see those spread out across sockets.
We cannot see how this is useful on an AMD CPU except for cases where we have only one task per node which accesses a lot of memory (more than offered by a single socket) but does so in a very NUMA-aware way.
-
Level 3 is beyond the scope of an introductory course and rarely used.
The default behaviour of Slurm depends on LUMI seems to be block:block,nopack if --distribution is not specified, though it is best to always verify as it can change over time and as the manual indicates that the default differs according to the number of tasks compared to the number of nodes. The defaults are also very tricky if a binding option at level 2 (or 3) is replaced with a * to mark the default behaviour, e.g., --distribution=\"block:*\" gives the result of --distribution=block:cyclic while --distribution=block has the same effect as --distribution=block:block.
This option only makes sense on job-exclusive nodes.
"},{"location":"2day-20240502/07_Binding/#task-to-cpu-binding-with-slurm","title":"Task-to-CPU binding with Slurm","text":"The level 2 and 3 options from the previous section already do some binding. But we will now discuss a different option that enables very precise binding of tasks to hardware threads in Slurm.
The mechanism does conflict with some Slurm options that implicitly already do some binding, e.g., it will not always work together with --cpus-per-task and --hint=[no]multithread may also not act as expected depending on how the options are used. Level \u2154 control via --distribution sometimes also make no sense when this option is used (and will be ignored).
Task-to-CPU binding is controlled through the Slurm option
--cpu-bind=[{quiet|verbose},]<type>\n
We'll describe a few of the possibilities for the <type> parameter but for a more concrete overview we refer to the Slurm srun manual page
-
--cpu-bind=threads is the default behaviour on LUMI.
-
--cpu-bind=map_cpu:<cpu_id_for_task_0>,<cpu_id_for_task_1>, ... is used when tasks are bound to single cores. The first number is the number of the hardware thread for the task with local task ID 0, etc. In other words, this option at the same time also defines the slots that can be used by the --distribution option above and replaces level 2 and level 3 of that option.
E.g.,
salloc --nodes=1 --partition=standard-g\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeGNU-23.09\nsrun --ntasks=8 --cpu-bind=map_cpu:49,57,17,25,1,9,33,41 mpi_check -r\n
will run the first task on hardware threads 49, the second task on 57, third on 17, fourth on 25, fifth on 1, sixth on 9, seventh on 33 and eight on 41.
This may look like a very strange numbering, but we will see an application for it further in this chapter.
-
--cpu-bind=mask_cpu:<mask_for_task_0>,<mask_for_task_1>,... is similar to map_cpu, but now multiple hardware threads can be specified per task through a mask. The mask is a hexadecimal number and leading zeros can be omitted. The least significant bit in the mask corresponds to HWT 0, etc.
Masks can become very long, but we shall see that this option is very useful on the nodes of the standard-g partition. Just as with map_cpu, this option replaces level 2 and 3 of the --distribution option.
E.g.,
salloc --nodes=1 --partition=standard-g\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeGNU-23.09\nsrun --ntasks=8 --cpu-bind=mask_cpu:7e000000000000,7e00000000000000,7e0000,7e000000,7e,7e00,7e00000000,7e0000000000 hybrid_check -r\n
will run the first task on hardware threads 49-54, the second task on 57-62, third on 17-22, fourth on 25-30, fifth on 1-6, sixth on 9-14, seventh on 33-38 and eight on 41-46.
The --cpu-bind=map_cpu and --cpu-bind=mask_gpu options also do not go together with -c / --cpus-per-task. Both commands define a binding (the latter in combination with the default --gpu-bind=threads) and these will usually conflict.
There are more options, but these are currently most relevant ones on LUMI. That may change in the future as LUMI User Support is investigating whether it isn't better to change the concept of \"socket\" in Slurm given how important it sometimes is to carefully map onto L3 cache domains for performance.
"},{"location":"2day-20240502/07_Binding/#task-to-gpu-binding-with-slurm","title":"Task-to-GPU binding with Slurm","text":"Doing the task-to-GPU binding fully via Slurm is currently not recommended on LUMI. The problem is that Slurm uses control groups at the task level rather than just ROCR_VISIBLE_DEVICES with the latter being more or less the equivalent of affinity masks. When using control groups this way, the other GPUs in a job step on a node become completely invisible to a task, and the Peer2Peer IPC mechanism for communication cannot be used anymore.
We present the options for completeness, and as it may still help users if the control group setup is not a problem for the application.
Task-to-GPU binding is done with
--gpu-bind=[verbose,]<type>\n
(see the Slurm manual) which is somewhat similar to --cpu-binding (to the extent that that makes sense).
Some options for the <type> parameter that are worth considering:
-
--gpu-bind=closest: This currently does not work well on LUMI. The problem is being investigated so the situation may have changed by the time you read this.
-
--gpu-bind=none: Turns off the GPU binding of Slurm. This can actually be useful on shared node jobs where doing a proper allocation of GPUs is difficult. You can then first use Slurm options such as --gpus-per-task to get a working allocation of GPUs and CPUs, then un-bind and rebind using a different mechanism that we will discuss later.
-
--gpu-bind=map_gpu:<list> is the equivalent of --cpu-bind=map_cpu:<list>. This option only makes sense on a job-exclusive node and is for jobs that need a single GPU per task. It defines the list of GPUs that should be used, with the task with local ID 0 using the first one in the list, etc. The numbering and topology was already discussed in the \"LUMI ARchitecture\" chapter, section \"Building LUMI: What a LUMI-G really looks like.
-
--gpu-bind=mask_gpu:<list> is the equivalent of --cpu-bind=mask_cpu:<list>. Now the bits in the mask correspond to individual GPUs, with GPU 0 the least significant bit. This option again only makes sense on a job-exclusive node.
Though map_gpu and mask_gpu could be very useful to get a proper mapping taking the topology of the node into account, due to the current limitation of creating a control group per task it can not often be used as it breaks some efficient communication mechanisms between tasks, including the GPU Peer2Peer IPC used by Cray MPICH for intro-node MPI transfers if GPU aware MPI support is enabled.
What do the HPE Cray manuals say about this? (Click to expand) From the HPE Cray CoE: \"Slurm may choose to use cgroups to implement the required affinity settings. Typically, the use of cgroups has the downside of preventing the use of GPU Peer2Peer IPC mechanisms. By default Cray MPI uses IPC for implementing intra-node, inter-process MPI data movement operations that involve GPU-attached user buffers. When Slurm\u2019s cgroups settings are in effect, users are advised to set MPICH_SMP_SINGLE_COPY_MODE=NONE or MPICH_GPU_IPC_ENABLED=0 to disable the use of IPC-based implementations. Disabling IPC also has a noticeable impact on intra-node MPI performance when GPU-attached memory regions are involved.\"
This is exactly what Slurm does on LUMI.
"},{"location":"2day-20240502/07_Binding/#mpi-rank-redistribution-with-cray-mpich","title":"MPI rank redistribution with Cray MPICH","text":"By default MPI rank i will use Slurm task i in a parallel job step. With Cray MPICH this can be changed via the environment variable MPICH_RANK_REORDER_METHOD. It provides an even more powerful way of reordering MPI ranks than the Slurm --distribution option as one can define fully custom orderings.
Rank reordering is an advanced topic that is discussed in more detail in the 4-day LUMI comprehensive courses organised by the LUMI User Support Team. The material of the latest one can be found via the course archive web page and is discussed in the \"MPI Topics on the HPE Cray EX Supercomputer\" which is often given on day 3.
Rank reordering can be used to reduce the number of inter-node messages or to spread those ranks that do parallel I/O over more nodes to increase the I/O bandwidth that can be obtained in the application.
Possible values for MPICH_RANK_REORDER_METHOD are:
-
export MPICH_RANK_REORDER_METHOD=0: Round-robin placement of the MPI ranks. This is the equivalent of the cyclic ordering in Slurm.
-
export MPICH_RANK_REORDER_METHOD=1: This is the default and it preserves the ordering of Slurm, and the only one that makes sense with other L1 Slurm distributions than block.
The Cray MPICH manual confusingly calls this \"SMP-style ordering\".
-
export MPICH_RANK_REORDER_METHOD=2: Folded rank placement. This is somewhat similar to round-robin, but when the last node is reached, the node list is transferred in the opposite direction.
-
export MPICH_RANK_REORDER_METHOD=3: Use a custom ordering, given by the MPICH_RANK_ORDER file which gives a comma-separated list of the MPI ranks in the order they should be assigned to slots on the nodes. The default filename MPICH_RANK_ORDER can be overwritten through the environment variable MPICH_RANK_REORDER_FILE.
Rank reordering does not always work well if Slurm is not using the (default) block ordering. As the lumi-CPEtools mpi_check, hybrid_check and gpu_check commands use Cray MPICH they can be used to test the Cray MPICH rank reordering also. The MPI ranks that are displayed are the MPI ranks as seen through MPI calls and not the value of SLURM_PROCID which is the Slurm task number.
The HPE Cray Programming Environment actually has profiling tools that help you determine the optimal rank ordering for a particular run, which is useful if you do a lot of runs with the same problem size (and hence same number of nodes and tasks).
Try the following job script (click to expand)
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=renumber-demo\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\nset -x\necho -e \"\\nSMP-style distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=1\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nSMP-style distribution on top of cyclic.\"\nexport MPICH_RANK_REORDER_METHOD=1\nsrun -n 8 -c 32 -m cyclic mpi_check -r\necho -e \"\\nRound-robin distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=0\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nFolded distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=2\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nCustom distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=3\ncat >MPICH_RANK_ORDER <<EOF\n0,1,4,5,2,3,6,7\nEOF\ncat MPICH_RANK_ORDER\nsrun -n 8 -c 32 -m block mpi_check -r\n/bin/rm MPICH_RANK_ORDER\nset +x\n
Ths script starts 8 tasks that each take a quarter node.
-
The first srun command (on line 15) is just the block distribution. The first 4 MPI ranks are on the first node, the next 4 on the second node.
+ export MPICH_RANK_REORDER_METHOD=1\n+ MPICH_RANK_REORDER_METHOD=1\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 17/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 2/8 on cpu 65/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 3/8 on cpu 111/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 4/8 on cpu 0/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 5/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 6/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 7/8 on cpu 120/256 of nid001805 mask 96-127\n
-
The second srun command, on line 18, is an example where the Slurm cyclic distribution is preserved. MPI rank 0 now lands on the first 32 cores of node 0 of the allocation, MPI rank 1 on the first 32 cores of node 1 of the allocation, then task 2 on the second 32 cores of node 0, and so on:
+ export MPICH_RANK_REORDER_METHOD=1\n+ MPICH_RANK_REORDER_METHOD=1\n+ srun -n 8 -c 32 -m cyclic mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 33/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 79/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
-
The third srun command, on line 21, uses Cray MPICH rank reordering instead to get a round-robin ordering rather than using the Slurm --distribution=cyclic option. The result is the same as in the previous case:
+ export MPICH_RANK_REORDER_METHOD=0\n+ MPICH_RANK_REORDER_METHOD=0\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 47/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
-
The fourth srun command, on line 24, demonstrates the folded ordering: Rank 0 runs on the first 32 cores of node 0 of the allocation, rank 1 on the first 32 of node 1, then rank 2 runs on the second set of 32 cores again on node 1, with rank 3 then running on the second 32 cores of node 0, rank 4 on the third group of 32 cores of node 0, rank 5 on the third group of 32 cores on rank 1, and so on. So the nodes are filled in the order 0, 1, 1, 0, 0, 1, 1, 0.
+ export MPICH_RANK_REORDER_METHOD=2\n+ MPICH_RANK_REORDER_METHOD=2\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 17/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001805 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001804 mask 96-127\n
-
The fifth example ('srun' on line 31) demonstrate a custom reordering. Here we face a 4x2-grid which we want to split in 2 2x2 groups. So where the ranks in our grid are numbered as
0 1 2 3\n4 5 6 7\n
we really want the left half of the grid on the first node of the allocation and the right half on the second node as this gives us less inter-node communication than when we would put the first line on the first node and the second line on the second. So basically we want ranks 0, 1, 4 and 5 on the first node and ranks 2, 3, 6 and 7 on the second node, which is done by creating the reorder file with content
0,1,4,5,2,3,6,7\n
The resulting output is
+ export MPICH_RANK_REORDER_METHOD=3\n+ MPICH_RANK_REORDER_METHOD=3\n+ cat\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 2/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 3/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 6/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
"},{"location":"2day-20240502/07_Binding/#refining-core-binding-in-openmp-applications","title":"Refining core binding in OpenMP applications","text":"In a Slurm batch job step, threads of a shared memory process will be contained to all hardware threads of all available cores on the first node of your allocation. To contain a shared memory program to the hardware threads asked for in the allocation (i.e., to ensure that --hint=[no]multithread has effect) you'd have to start the shared memory program with srun in a regular job step.
Any multithreaded executable run as a shared memory job or ranks in a hybrid MPI/multithread job, will - when started properly via srun - get access to a group of cores via an affinity mask. In some cases you will want to manually refine the way individual threads of each process are mapped onto the available hardware threads.
In OpenMP, this is usually done through environment variables (it can also be done partially in the program through library calls). A number of environment variables is standardised in the OpenMP standard, but some implementations offer some additional non-standard ones, or non-standard values for the standard environment variables. Below we discuss the more important of the standard ones:
-
OMP_NUM_THREADS is used to set the number of CPU threads OpenMP will use. In its most basic form this is a single number (but you can give multiple comma-separated numbers for nested parallelism).
OpenMP programs on LUMI will usually correctly detect how many hardware threads are available to the task and use one OpenMP thread per hardware thread. There are cases where you may want to ask for a certain number of hardware threads when allocating resources, e.g., to easily get a good mapping of tasks on cores, but do not want to use them all, e.g., because your application is too memory bandwidth or cache constrained and using fewer threads actually gives better overall performance on a per-node basis.
-
OMP_PLACES is used to restrict each OpenMP thread to a group of hardware threads. Possible values include:
OMP_PLACES=threads to restrict OpenMP threads to a single hardware threadOMP_PLACES=cores to restrict each OpenMP threads to a single core (but all hardware threads associated with that core)OMP_PLACES=sockets to restrict each OpenMP thread to the hardware threads of a single socket-
And it is possible to give a list with explicit values, e.g.,
export OMP_PLACES=\"{0:4}:3:8\"\n
which is also equivalent to
export OMP_PLACES=\"{0,1,2,3},{8,9,10,11},{16,17,18,19}\"\n
so each OpenMP thread is restricted to a different group of 4 hardware threads. The numbers in the list are not the physical Linux hardware thread numbers, but are relative to the hardware threads available in the affinity mask of the task.
More general, {a:b}:c:d means b numbers starting from a (so a, a+1, ..., a+b-1), repeated c times, at every repeat shifted by d. There are more variants to generate lists of places and we show another one in the example below. But in all the syntax may look strange and there are manuals that give the wrong information (including some versions of the manual for the GNU OpenMP runtime).
Note that this is different from the core numbers that would be used in --cpu-bind=map_cpu or --gpu-bind=mask_cpu which sets the CPUs or groups of CPUs available to each thread and which always use the physical numbering and not a numbering that is local to the job allocation.
-
OMP_PROC_BIND: Sets how threads are distributed over the places. Possible values are:
-
OMP_PROC_BIND=false: Turn off OpenMP thread binding. Each thread will get access to all hardware threads available in to the task (and defined by a Linux affinity mask in Slurm).
-
OMP_PROC_BIND=close: If more places are available than there are OpenMP threads, then try to put the OpenMP threads in different places as close as possible to the master thread. In general, bind as close as possible to the master thread while still distributing for load balancing.
-
OMP_PROC_BIND=spread: Spread threads out as evenly as possible over the places available to the task.
-
OMP_PROC_BIND=master: Bind threads to the same place as the master thread. The place is determined by the OMP_PLACES environment variable and it is clear this makes no sense if that place is just a single hardware thread or single core as all threads would then be competing for the resources of a single core.
Multiple values of close, spread and master in a comma-separated list are possible to organise nested OpenMP parallelism, but this is outside of the scope of this tutorial.
The Cray Compilation Environment also has an additional non-standard option auto which is actually the default and tries to do a reasonable job for most cases. On the other compilers on LUMI, the default behaviour is false unless the next environment variable, OMP_PLACES, is specified.
-
OMP_DISPLAY_AFFINITY: When set tot TRUE information about the affinity binding of each thread will be shown which is good for debugging purposes.
For single-level OpenMP parallelism, the omp_check and hybrid_check programs from the lumi-CPEtools modules can also be used to check the OpenMP thread binding.
Some examples (click to expand) Consider the following job script:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=omp-demo\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=multithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\nset -x\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=false\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nunset OMP_PROC_BIND\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=spread\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=threads\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nexport OMP_PLACES=cores\nsrun -n 1 -c 32 --hint=multithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=\"{0:8}:4:8\"\nsrun -n 1 -c 32 --hint=multithread omp_check -r\n\nexport OMP_PLACES=\"{0:4,16:4}:4:4\"\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nset +x\n
Let's check the output step by step:
In the first block we run 2 srun commands that actually both use 16 cores, but first with hardware threading enabled in Slurm and then with multithread mode off in Slurm:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=false\n+ OMP_PROC_BIND=false\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 1/4 on cpu 137/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 2/4 on cpu 129/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 3/4 on cpu 143/256 of nid001077 mask 0-15, 128-143\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 1/4 on cpu 15/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 3/4 on cpu 14/256 of nid001077 mask 0-15\n
OMP_PROC_BIND was explicitly set to false to disable the Cray Compilation Environment default behaviour. The masks reported by omp_check cover all hardware threads available to the task in Slurm: Both hardware threads for the 16 first cores in the multithread case and just the primary hardware thread on the first 16 cores in the second case. So each OpenMP thread can in principle migrate over all available hardware threads.
In the second block we unset the PROC_BIND environment variable to demonstrate the behaviour of the Cray Compilation Environment. The output would be different had we used the cpeGNU or cpeAOCC version.
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ unset OMP_PROC_BIND\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 1/256 of nid001077 mask 0-3, 128-131\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4-7, 132-135\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8-11, 136-139\n++ omp_check: OpenMP thread 3/4 on cpu 142/256 of nid001077 mask 12-15, 140-143\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4-7\n++ omp_check: OpenMP thread 2/4 on cpu 9/256 of nid001077 mask 8-11\n++ omp_check: OpenMP thread 3/4 on cpu 15/256 of nid001077 mask 12-15\n
The default behaviour of the CCE is very nice: Threads are nicely spread out over the available cores and then all get access to their own group of hardware threads that in this case with 4 threads for 16 cores spans 4 cores for each thread. In fact, also in other cases the default behaviour of CCE will be a binding that works well for many cases.
In the next experiment we demonstrate the close binding:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 128/256 of nid001077 mask 128\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001077 mask 129\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001077 mask 2\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001077 mask 3\n
In the first case, with Slurm multithreading mode on, we see that the 4 threads are now concentrated on only 2 cores but each gets pinned to its own hardware thread. In general this behaviour is not what one wants if more cores are available as on each core two threads will now be competing for available resources. In the second case, with Slurm multithreading disabled, the threads are bound to the first 4 cores, with one core for each thread.
Next we demonstrate the spread binding:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=spread\n+ OMP_PROC_BIND=spread\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8\n++ omp_check: OpenMP thread 3/4 on cpu 12/256 of nid001077 mask 12\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8\n++ omp_check: OpenMP thread 3/4 on cpu 12/256 of nid001077 mask 12\n
The result is now the same in both cases as we have fewer threads than physical cores. Each OpenMP thread is bound to a single core, but these cores are spread out over the first 16 cores of the node.
Next we return to the close binding but try both threads and cores as places with Slurm multithreading turned on for both cases:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ export OMP_PLACES=threads\n+ OMP_PLACES=threads\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 128/256 of nid001077 mask 128\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001077 mask 129\n\n+ export OMP_PLACES=cores\n+ OMP_PLACES=cores\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0, 128\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001077 mask 1, 129\n++ omp_check: OpenMP thread 2/4 on cpu 130/256 of nid001077 mask 2, 130\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001077 mask 3, 131\n
With threads as places we get again the distribution with two OpenMP threads on each physical core, each with their own hardware thread. With cores as places, we get only one thread per physical core, but each thread has access to both hardware threads of that physical core.
And lastly we play a bit with custom placements:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ export 'OMP_PLACES={0:8}:4:8'\n+ OMP_PLACES='{0:8}:4:8'\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-7\n++ omp_check: OpenMP thread 1/4 on cpu 8/256 of nid001077 mask 8-15\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001077 mask 128-135\n++ omp_check: OpenMP thread 3/4 on cpu 136/256 of nid001077 mask 136-143\n
OMP_PLACES='{0:8}:4:8 means: Take starting from core with logical number 0 8 cores and repeat this 4 times, shifting by 8 each time, so effectively
OMP_PLACES=\"{ 0,1,2,3,4,5,6,7},{8,9,10,11,12,13,14,15},{16,17,18,19,20,21,22,23},{24,25,26,27,27,28,30,31}\"\n
omp_check however shows the OS numbering for the hardware threads so we can see what this places variable means: the first thread can get scheduled on the first hardware thread of the first 8 cores, the second thread on the first hardware thread of the next 8 cores, the third OpenMP thread on the second thread of the first 8 cores, and the fourth OpenMP thread on the second hardware thread of the next 8 cores. In other words, the logical numbering of the threads follows the same ordering as at the OS level: First the first hardware thread of each core, then the second hardware thread.
When trying another variant with
OMP_PACES={0:4,16:4}:4:4\n
which is equivalent to
OMP_PLACES={0,1,2,3,16,17,18,19},{4,5,6,7,20,21,22,23},{8,9,10,11,24,25,26,27},{12,13,14,15,28,29,30,31}\"\n
we get a much nicer distribution:
+ export 'OMP_PLACES={0:4,16:4}:4:4'\n+ OMP_PLACES='{0:4,16:4}:4:4'\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-3, 128-131\n++ omp_check: OpenMP thread 1/4 on cpu 132/256 of nid001077 mask 4-7, 132-135\n++ omp_check: OpenMP thread 2/4 on cpu 136/256 of nid001077 mask 8-11, 136-139\n++ omp_check: OpenMP thread 3/4 on cpu 140/256 of nid001077 mask 12-15, 140-143\n
We only discussed a subset of the environment variables defined in the OpenMP standard. Several implementations also offer additional environment variables, e.g., a number of GOMP_* environment variables in the GNU Compiler Collection implementation or KMP_* variables in the Intel compiler (not available on LUMI).
Some further documentation:
-
The OMP_* environment variables and a number of environment variables specific for the runtime libraries of the Cray Compiling Environment are discussed in the intro_openmp manual page, section \"Environment variables\".
-
A list of OMP_ environment variables in the OpenMP 5.1 standard (as the current list in the HTML version of the 5.2 standard has some problems).
"},{"location":"2day-20240502/07_Binding/#gpu-binding-with-rocr_visible_devices","title":"GPU binding with ROCR_VISIBLE_DEVICES","text":"The ROCR_VISIBLE_DEVICES environment variable restricts access to GPUs at the ROCm platform runtime level. Contrary to control groups however this mechanism is compatible with the Peer2Peer IPC used by GPU-aware Cray MPI for intra-node communication.
The value of the ROCR_VISIBLE_DEVICES environment variable is a list of device indices that will be exposed to the applications. The device indices do depend on the control group. Visible devices in a control group are always numbered from 0.
So though ROCR_VISIBLE_DEVICES has the same function as affinity masks for CPUs, it is different in many respects.
-
Affinity masks are part of the Linux kernel and fully OS-controlled, while ROCR_VISIBLE_DEVICES is interpreted in the ROCmTM stack.
-
Affinity masks are set through an OS call and that call can enforce that the new mask cannot be less restrictive than the parent mask. ROCR_VISIBLE_DEVICES is just an environment variable, so at the time that you try to set it to a value that you shouldn't use, there is no check.
-
Affinity masks always use the global numbering of hardware threads while ROCR_VISIBLE_DEVICES uses the local numbering in the currently active control group. So the GPU that corresponds to 0 in ROCR_VISIBLE_DEVICES is not always the same GPU.
Alternative values for ROCR_VISIBLE_DEVICES Instead of device indices, ROCR_VISIBLE_DEVICES also accepts GPU UUIDs that are unique to each GPU. This is less practical then it seems as the UUIDs of GPUs are different on each node so one would need to discover them first before they can be used.
"},{"location":"2day-20240502/07_Binding/#combining-slurm-task-binding-with-rocr_visible_devices","title":"Combining Slurm task binding with ROCR_VISIBLE_DEVICES","text":"In the chapter on the architecture of LUMI we discussed what a LUMI-G really looks like.
The full topology of a LUMI-G compute node is shown in the figure:
Note that the numbering of GCDs does not correspond to the numbering of CCDs/cores. However, for optimal memory transfers (and certainly if cache-coherent memory access from CPU to GPU would be used) it is better to ensure that each GCD collaborates with the matched CCD in an MPI rank. So we have the mapping:
CCD HWTs Available HWTs GCD 0 0-7, 64-71 1-7, 65-71 4 1 8-15, 72-79 9-15, 73-79 5 2 16-23, 80-87 17-23, 81-87 2 3 24-32, 88-95 25-32, 89-95 3 4 32-39, 96-103 33-39, 97-103 6 5 40-47, 104-111 41-47, 105-111 7 6 48-55, 112-119 49-55, 113-119 0 7 56-63, 120-127 57-63, 121-127 1 or the reverse mapping
GCD CCD HWTs Available HWTs 0 6 48-55, 112-119 49-55, 113-119 1 7 56-63, 120-127 57-63, 121-127 2 2 16-23, 80-87 17-23, 81-87 3 3 24-32, 88-95 25-32, 89-95 4 0 0-7, 64-71 1-7, 65-71 5 1 8-15, 72-79 9-15, 73-79 6 4 32-39, 96-103 33-39, 97-103 7 5 40-47, 104-111 41-47, 105-111 Moreover, if you look more carefully at the topology, you can see that the connections between the GCDs contain a number of rings:
-
Green ring: 0 - 1 - 3 - 2 - 4 - 5 - 7 - 6 - 0
-
Red ring: 0 - 1 - 5 - 4 - 6 - 7 - 3 - 2 - 0
-
Sharing some connections with the previous ones, but can be combined with the green ring: 0 - 1 - 5 - 4 - 2 - 3 - 7 - 6 - 0
So if your application would use a ring mapping for communication and use communication from GPU buffers for that, than it may be advantageous to map the MPI ranks on one of those rings which would mean that neither the order of the CCDs nor the order of the GCDs is trivial.
Some other topologies can also be mapped on these connections (but unfortunately not a 3D cube).
Note: The red ring and green ring correspond to the red and green rings on page 6 of the \"Introducing AMD CDNATM 2 Architecture\" whitepaper.
To implement a proper CCD-to-GCD mapping we will use two mechanisms:
-
On the CPU side we'll use Slurm --cpu-bind. Sometimes we can also simply use -c or --cpus-per-task (in particular in the case below with linear ordering of the CCDs and 7 cores per task)
-
On the GPU side we will manually assign GPUs via a different value of ROCR_VISIBLE_DEVICES for each thread. To accomplish this we will have to write a wrapper script which we will generate in the job script.
Let us start with the simplest case:
"},{"location":"2day-20240502/07_Binding/#linear-assignment-of-gcd-then-match-the-cores","title":"Linear assignment of GCD, then match the cores","text":"One possible job script to accomplish this is:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-linear-GCD\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:49,57,17,25,1,9,33,41\"\n\nCPU_BIND2=\"mask_cpu:0xfe000000000000,0xfe00000000000000\"\nCPU_BIND2=\"$CPU_BIND2,0xfe0000,0xfe000000\"\nCPU_BIND2=\"$CPU_BIND2,0xfe,0xfe00\"\nCPU_BIND2=\"$CPU_BIND2,0xfe00000000,0xfe0000000000\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
To select the GPUs we either use a map with numbers of cores (ideal for pure MPI programs) or masks (the only option for hybrid programs). The mask that we give in the example uses 7 cores per CCD and always skips the first core, as is required on LUMI as the first core of each chiplet is reserved and not available to Slurm jobs. To select the right GPU for ROCR_VISIBLE_DEVICES we can use the Slurm local task ID which is also what the MPI rank will be. We use a so-called \"bash here document\" to generate the script. Note that in the bash here document we needed to protect the $ with a backslash (so use \\$) as otherwise the variables would already be expanded when generating the script file.
Instead of the somewhat complicated --ntasks with srun we could have specified --ntasks-per-node=8 on a #SBATCH line which would have fixed the structure for all srun commands. Even though we want to use all GPUs in the node, --gpus-per-node or an equivalent option has to be specified either as an #SBATCH line or with each srun command or no GPUs will be made available to the tasks started by the srun command.
Note the output of the second srun command:
MPI 000 - OMP 000 - HWT 049 (CCD6) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 057 (CCD7) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 017 (CCD2) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 025 (CCD3) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 001 (CCD0) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 009 (CCD1) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 033 (CCD4) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 041 (CCD5) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\n
With the -l option we also print some information about the CCD that a core belongs to and the GCD and corresponding optimal CCD for each PCIe bus ID, which makes it very easy to check if the mapping is as intended. Note that the GCDs are indeed in the linear order starting with GCD0.
"},{"location":"2day-20240502/07_Binding/#linear-assignment-of-the-ccds-then-match-the-gcd","title":"Linear assignment of the CCDs, then match the GCD","text":"To modify the order of the GPUs, we now use an array with the desired order in the select_gpu script. With the current setup of LUMI, with one core reserved on each chiplet, there are now two options to get the proper CPUs:
-
We can use masks to define the cores for each slot, but they will now look more regular, or
-
we can simply use --cpus-per-task=7 and then further restrict the number of threads per task with OMP_NUM_THREADS.
The job script (for option 1) now becomes:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-linear-CCD\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/22.12 partition/G lumi-CPEtools/1.1-cpeCray-22.12\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGPU_ORDER=(4 5 2 3 6 7 0 1)\nexport ROCR_VISIBLE_DEVICES=\\${GPU_ORDER[\\$SLURM_LOCALID]}\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:1,9,17,25,33,41,49,57\"\n\nCPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:0x00000000000000fe,0x000000000000fe00\"\nCPU_BIND2=\"$CPU_BIND2,0x0000000000fe0000,0x00000000fe000000\"\nCPU_BIND2=\"$CPU_BIND2,0x000000fe00000000,0x0000fe0000000000\"\nCPU_BIND2=\"$CPU_BIND2,0x00fe000000000000,0xfe00000000000000\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
The leading zeros in the masks in the CPU_BIND2 environment variable are not needed but we added them as it makes it easier to see which chiplet is used in what position.
"},{"location":"2day-20240502/07_Binding/#the-green-ring","title":"The green ring","text":"As a final example for whole node allocations, lets bind tasks such that the MPI ranks are mapped upon the green ring which is GCD 0 - 1 - 3 - 2 - 4 - 5 - 7 - 6 - 0. In other words, we want to create the mapping
Task GCD CCD Available cores 0 0 6 49-55, 113-119 1 1 7 57-63, 121-127 2 3 3 25-32, 89-95 3 2 2 17-23, 81-87 4 4 0 1-7, 65-71 5 5 1 9-15, 73-79 6 7 5 41-47, 105-111 7 6 4 33-39, 97-103 This mapping would be useful when using GPU-to-GPU communication in a scenario where task i only communicates with tasks i-1 and i+1 (module 8), so the communication pattern is a ring.
Now we need to reorder both the cores and the GCDs, so we basically combine the approach taken in the two scripts above:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-ring-green\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\n# Mapping:\n# | Task | GCD | CCD | Available cores |\n# |-----:|----:|----:|:----------------|\n# | 0 | 0 | 6 | 49-55, 113-119 |\n# | 1 | 1 | 7 | 57-63, 121-127 |\n# | 2 | 3 | 3 | 25-32, 89-95 |\n# | 3 | 2 | 2 | 17-23, 81-87 |\n# | 4 | 4 | 0 | 1-7, 65-71 |\n# | 5 | 5 | 1 | 9-15, 73-79 |\n# | 6 | 7 | 5 | 41-47, 105-111 |\n# | 7 | 6 | 4 | 33-39, 97-103 |\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGPU_ORDER=(0 1 3 2 4 5 7 6)\nexport ROCR_VISIBLE_DEVICES=\\${GPU_ORDER[\\$SLURM_LOCALID]}\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:49,57,25,17,1,9,41,33\"\n\nCCD_MASK=( 0x00000000000000fe \\\n 0x000000000000fe00 \\\n 0x0000000000fe0000 \\\n 0x00000000fe000000 \\\n 0x000000fe00000000 \\\n 0x0000fe0000000000 \\\n 0x00fe000000000000 \\\n 0xfe00000000000000 )\nCPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:${CCD_MASK[6]},${CCD_MASK[7]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[3]},${CCD_MASK[2]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[0]},${CCD_MASK[1]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[5]},${CCD_MASK[4]}\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
The values for GPU_ORDER are easily read from the second column of the table with the mapping that we prepared. The cores to use for the pure MPI run are also easily read from the table: simply take the first core of each line. Finally, to build the mask, we used some bash trickery. We first define the bash array CCD_MASK with the mask for each chiplet. As this has a regular structure, this is easy to build. Then we compose the mask list for the CPUs by indexing in that array, where the indices are easily read from the third column in the mapping.
The alternative code to build CPU_BIND2 is
CPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:0x00fe000000000000,0xfe00000000000000\"\nCPU_BIND2=\"$CPU_BIND2,0x00000000fe000000,0x0000000000fe0000\"\nCPU_BIND2=\"$CPU_BIND2,0x00000000000000fe,0x000000000000fe00\"\nCPU_BIND2=\"$CPU_BIND2,0x0000fe0000000000,0x000000fe00000000\"\n
which may be shorter, but requires some puzzling to build and hence is more prone to error.
The output of the second srun command is now
MPI 000 - OMP 000 - HWT 049 (CCD6) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 057 (CCD7) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 025 (CCD3) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 000 - HWT 017 (CCD2) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 004 - OMP 000 - HWT 001 (CCD0) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 009 (CCD1) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 041 (CCD5) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 000 - HWT 033 (CCD4) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\n
Checking the last column, we see that the GCDs are indeed in the desired order for the green ring, and is is also easy to check that each task is also mapped on the optimal CCD for the GCD.
Job script with some more advanced bash
#!/bin/bash\n#SBATCH --job-name=map-advanced-multiple\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\n#\n# Define the order of the GPUs and the core mask for CCD0\n# It is important that the order of the GPUs is a string with the numbers separated by spaces.\n#\nGCD_ORDER=\"0 1 5 4 6 7 3 2\"\ncoremask='2#00000010' # Can use the binary representation, hexadecimal with 0x, or decimal\n\n#\n# run_gpu script, takes the string with GCDs as the first argument.\n#\ncat << EOF > run_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGCD_ORDER=( \\$1 )\nshift\nexport ROCR_VISIBLE_DEVICES=\\${GCD_ORDER[\\$SLURM_LOCALID]}\nexec \"\\$@\"\nEOF\nchmod +x run_gpu_$SLURM_JOB_ID\n\n#\n# Build the CPU binding\n# Argument one is mask, all other arguments are treated as an array of GCD numbers.\n#\n\nfunction generate_mask {\n\n # First argument is the mask for CCD0\n mask=$1\n\n # Other arguments are either a string already with the GCDs, or just one GCD per argument.\n shift\n GCDs=( \"$@\" )\n # Fully expand (doesn't matter as the loop can deal with it, but good if we want to check the number)\n GCDs=( ${GCDs[@]} )\n\n # For each GCD, the corresponding CCD number in the optimal mapping.\n MAP_to_CCD=( 6 7 2 3 0 1 4 5 )\n\n CPU_BIND=\"\"\n\n # Loop over the GCDs in the order of the list to compute the corresponding\n # CPU mask.\n for GCD in ${GCDs[@]}\n do\n # Get the matching CCD for this GCD\n CCD=${MAP_to_CCD[$GCD]}\n\n # Shift the mask for CCD0 to the position for CCD $CCD\n printf -v tmpvar \"0x%016x\" $((mask << $((CCD*8))))\n\n # Add to CPU_BIND. We'll remove the leading , this creates later.\n CPU_BIND=\"$CPU_BIND,$tmpvar\"\n done\n\n # Strip the leading ,\n CPU_BIND=\"${CPU_BIND#,}\"\n\n # Return the result by printing to stdout\n printf \"$CPU_BIND\"\n\n}\n\n#\n# Running the check programs\n#\n\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\n# Some mappings:\nlinear_CCD=\"4 5 2 3 6 7 0 1\"\nlinear_GCD=\"0 1 2 3 4 5 6 7\" \nring_green=\"0 1 3 2 4 5 7 6\"\nring_red=\"0 1 5 4 6 7 3 2\"\n\necho -e \"\\nTest runs:\\n\"\n\necho -e \"\\nConsecutive CCDs:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $linear_CCD) \\\n ./run_gpu_$SLURM_JOB_ID \"$linear_CCD\" gpu_check -l\n\necho -e \"\\nConsecutive GCDs:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $linear_GCD) \\\n ./run_gpu_$SLURM_JOB_ID \"$linear_GCD\" gpu_check -l\n\necho -e \"\\nGreen ring:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $ring_green) \\\n ./run_gpu_$SLURM_JOB_ID \"$ring_green\" gpu_check -l\n\necho -e \"\\nRed ring:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $ring_red) \\\n ./run_gpu_$SLURM_JOB_ID \"$ring_red\" gpu_check -l\n\necho -e \"\\nFirst two CPU NUMA domains (assuming one node in the allocation):\"\nhalf=\"4 5 2 3\"\nsrun --ntasks=4 \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $half) \\\n ./run_gpu_$SLURM_JOB_ID \"$half\" gpu_check -l\n\n/bin/rm -f run_gpu_$SLURM_JOB_ID\n
In this script, we have modified the and renamed the usual select_gpu script (renamed to run_cpu) to take as the first argument a string with a space-separated list of the GCDs to use. This has been combined with the bash function generate_mask (which could have been transformed in a script as well) that computes the CPU mask starting from the mask for CCD0 and shifting that mask as needed. The input is the mask to use and then the GCDs to use, either as a single string or as a series of arguments (e.g., resulting from an array expansion).
Both commands are then combined in the srun command. The generate_mask function is used to generate the mask for --gpu-bind while the run_gpu script is used to set ROCR_VISIBLE_DEVICES for each task. The examples also show how easy it is to experiment with different mappings. The one limitation of the script and function is that there can be only 1 GPU per task and one task per GPU, and the CPU mask is also limited to a single CCD (which makes sense with the GPU restriction). Generating masks that also include the second hardware thread is not supported yet. (We use bash arithmetic internally which is limited to 64-bit integers).
"},{"location":"2day-20240502/07_Binding/#what-about-allocate-by-resources-partitions","title":"What about \"allocate by resources\" partitions?","text":"On partitions that are \"allocatable by resource\", e.g., small-g, you are never guaranteed that tasks will be spread in a reasonable way over the CCDs and that the matching GPUs will be available to your job. Creating an optimal mapping or taking the topology into account is hence impossible.
What is possible though is work around the fact that with the usual options for such resource allocations, Slurm will lock up the GPUs for individual tasks in control groups so that the Peer2Peer IPC intra-node communication mechanism has to be turned off. We can do this for job steps that follow the pattern of resources allocated via the sbatch arguments (usually #SBATCH lines), and rely on three elements for that:
-
We can turn off the Slurm GPU binding mechanism with --gpu-bind=none.
-
Even then, the GPUs will still be locked up in a control group on each node for the job and hence on each node be numbered starting from zero.
-
And each task also has a local ID that can be used to map the appropriate number of GPUs to each task.
This can be demonstrated with the following job script:
#! /bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-smallg-1gpt\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=small-g\n#SBATCH --ntasks=12\n#SBATCH --cpus-per-task=2\n#SBATCH --gpus-per-task=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\ncat << EOF > echo_dev_$SLURM_JOB_ID\n#!/bin/bash\nprintf -v task \"%02d\" \\$SLURM_PROCID\necho \"Task \\$task or node.local_id \\$SLURM_NODEID.\\$SLURM_LOCALID sees ROCR_VISIBLE_DEVICES=\\$ROCR_VISIBLE_DEVICES\"\nEOF\nchmod +x ./echo_dev_$SLURM_JOB_ID\n\nset -x\nsrun gpu_check -l\nsrun ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID echo_dev_$SLURM_JOB_ID\n
To run this job successfully, we need 12 GPUs so obviously the tasks will be spread over more than one node. The echo_dev command in this script only shows us the value of ROCR_VISIBLE_DEVICES for the task at that point, something that gpu_check in fact also reports as GPU_ID, but this is just in case you don't believe...
The output of the first srun command is:
+ srun gpu_check -l\nMPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 000 - OMP 001 - HWT 002 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 001 - OMP 001 - HWT 004 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 005 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 002 - OMP 001 - HWT 006 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 007 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 001 - HWT 008 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 009 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1(GCD4/CCD0)\nMPI 004 - OMP 001 - HWT 010 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 011 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6(GCD5/CCD1)\nMPI 005 - OMP 001 - HWT 012 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 013 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9(GCD6/CCD4)\nMPI 006 - OMP 001 - HWT 014 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 015 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 001 - HWT 016 (CCD2) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc(GCD7/CCD5)\nMPI 008 - OMP 000 - HWT 001 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 008 - OMP 001 - HWT 002 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 009 - OMP 000 - HWT 003 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 009 - OMP 001 - HWT 004 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 010 - OMP 000 - HWT 005 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 010 - OMP 001 - HWT 006 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 011 - OMP 000 - HWT 007 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 011 - OMP 001 - HWT 008 (CCD1) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\n
In other words, we see that we did get cores on two nodes that obviously are not well aligned with the GCDs, and 8 GPUS on the first and 4 on the second node.
The output of the second srun is:
+ srun ./echo_dev_4359428\n+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=0\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=0\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=0\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=0\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=0\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=0\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=0\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=0\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=0\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=0\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=0\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=0\n
It is normal that each task sees ROCR_VISIBLE_DEVICES=0 even though we have seen that they all use a different GPU. This is because each task is locked up in a control group with only one GPU, which then gets number 0.
The output of the third srun command is:
+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=\n
Slurm in fact did not set ROCR_VISIBLE_DEVICES because we turned binding off.
In the next srun command we set ROCR_VISIBLE_DEVICES based on the local task ID and get:
+ srun --gpu-bind=none ./select_gpu_4359428 ./echo_dev_4359428\n+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=0\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=1\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=2\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=3\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=4\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=5\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=6\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=7\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=0\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=1\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=2\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=3\n
Finally, we run gpu_check again and see the same assignment of physical GPUs again as when we started, but now with different logical device numbers passed by ROCR_VISIBLE_DEVICES. The device number for the hip runtime is always 0 though which is normal as ROCR_VISIBLE_DEVICES restricts the access of the hip runtime to one GPU.
+ srun --gpu-bind=none ./select_gpu_4359428 gpu_check -l\nMPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 000 - OMP 001 - HWT 002 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 001 - OMP 001 - HWT 004 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 005 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 002 - OMP 001 - HWT 006 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 007 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 001 - HWT 008 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 009 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 004 - OMP 001 - HWT 010 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 011 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 005 - OMP 001 - HWT 012 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 013 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 006 - OMP 001 - HWT 014 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 015 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 001 - HWT 016 (CCD2) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 008 - OMP 000 - HWT 001 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 008 - OMP 001 - HWT 002 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 009 - OMP 000 - HWT 003 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 009 - OMP 001 - HWT 004 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 010 - OMP 000 - HWT 005 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 010 - OMP 001 - HWT 006 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 011 - OMP 000 - HWT 007 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 011 - OMP 001 - HWT 008 (CCD1) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\n
Example job script when using 2 GPUs per task.
#! /bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-smallg-2gpt\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=small-g\n#SBATCH --ntasks=6\n#SBATCH --cpus-per-task=2\n#SBATCH --gpus-per-task=2\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$((SLURM_LOCALID*2)),\\$((SLURM_LOCALID*2+1))\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\ncat << EOF > echo_dev_$SLURM_JOB_ID\n#!/bin/bash\nprintf -v task \"%02d\" \\$SLURM_PROCID\necho \"Task \\$task or node.local_id \\$SLURM_NODEID.\\$SLURM_LOCALID sees ROCR_VISIBLE_DEVICES=\\$ROCR_VISIBLE_DEVICES\"\nEOF\nchmod +x ./echo_dev_$SLURM_JOB_ID\n\nset -x\nsrun gpu_check -l\nsrun ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID echo_dev_$SLURM_JOB_ID\n
The changes that were required are only minimal. We now assign 2 GPUs to ROCR_VISIBLE_DEVICES which is easily done with some bash arithmetic.
"},{"location":"2day-20240502/07_Binding/#further-material","title":"Further material","text":" -
Distribution and binding is discussed in more detail in our 4-day comprehensive LUMI courses. Check for the lecture on \"Advanced Placement\" which is usually given on day 2 of the course.
Material of this presentation is available to all LUMI users on the system. Check the course website for the names of the files.
-
Rank reordering in Cray MPICH is discussed is also discussed in more detail in our 4-day comprehensive LUMI courses, but in the lecture on \"MPI Topics on the HPE Cray EX Supercomputer\" (often on day 3 of the course) that discusses more advanced MPI on LUMI, including loads of environment variables that can be used to improve the performance.
"},{"location":"2day-20240502/08_Lustre/","title":"I/O and File Systems on LUMI","text":""},{"location":"2day-20240502/08_Lustre/#file-systems-on-lumi","title":"File systems on LUMI","text":"Supercomputing since the second half of the 1980s has almost always been about trying to build a very fast system from relatively cheap volume components or technologies (as low as you can go without loosing too much reliability) and very cleverly written software both at the system level (to make the system look like a true single system as much as possible) and at the application level (to deal with the restrictions that inevitably come with such a setup).
The Lustre parallel file system that we use on LUMI (and that is its main file system serving user files) fits in that way of thinking. A large file system is built by linking many fairly regular file servers through a fast network to the compute resources to build a single system with a lot of storage capacity and a lot of bandwidth. It has its restrictions also though: not all types of IOPs (number of I/O operations per second) scale as well or as easily as bandwidth and capacity so this comes with usage restrictions on large clusters that may a lot more severe than you are used to from small systems. And yes, it is completely normal that some file operations are slower than on the SSD of a good PC.
HPE Cray EX systems go even one step further. Lustre is the only network file system directly served to the compute nodes. Other network file system come via a piece of software called Data Virtualisation Service (abbreviated DVS) that basically forwards I/O requests to servers in the management section of the cluster where the actual file system runs. This is part of the measures that Cray takes in Cray Operating System to minimise OS jitter on the compute nodes to improve scalability of applications, and to reduce the memory footprint of the OS on the compute nodes.
"},{"location":"2day-20240502/08_Lustre/#lustre-building-blocks","title":"Lustre building blocks","text":"A key element of Lustre - but also of other parallel file systems for large parallel computers such as BeeGFS, Spectrum Scale (formerly GPFS) or PanFS - is the separation of metadata and the actual file data, as the way both are accessed and used is very different.
A Lustre system consists of the following blocks:
-
Metadata servers (MDSes) with one or more metadata targets (MDTs) each store namespace metadata such as filenames, directories and access permissions, and the file layout.
Each MDT is a filesystem, usually with some level of RAID or similar technologies for increased reliability. Usually there is also more than one MDS and they are put in a high availability setup for increased availability (and this is the case in LUMI).
Metadata is accessed in small bits and it does not need much capacity. However, metadata accesses are hard to parallelise so it makes sense to go for the fastest storage possible even if that storage is very expensive per terabyte. On LUMI all metadata servers use SSDs.
-
Object storage servers (OSSes) with one or more object storage targets (OSTs) each store the actual data. Data from a single file can be distributed across multiple OSTs and even multiple OSSes. As we shall see, this is also the key to getting very high bandwidth access to the data.
Each OST is a filesystem, again usually with some level of RAID or similar technologies to survive disk failures. One OSS typically has between 1 and 8 OSTs, and in a big setup a high availability setup will be used again (as is the case in LUMI).
The total capacity of a Lustre file system is the sum of the capacity of all OSTs in the Lustre file system. Lustre file systems are often many petabytes large.
Now you may think differently based upon prices that you see in the PC market for hard drives and SSDs, but SSDs of data centre quality are still up to 10 times as expensive as hard drives of data centre quality. Building a file system of several tens of petabytes out of SSDs is still extremely expensive and rarely done, certainly in an environment with a high write pressure on the file system as that requires the highest quality SSDs. Hence it is not uncommon that supercomputers will use mostly hard drives for their large storage systems.
On LUMI there is roughly 80 PB spread across 4 large hard disk based Lustre file systems, and 8.5 PB in an SSD-based Lustre file system. However, all MDSes use SSD storage.
-
Lustre clients access and use the data. They make the whole Lustre file system look like a single file system.
Lustre is transparent in functionality. You can use a Lustre file system just as any other regular file system, with all your regular applications. However, it is not transparent when it comes to performance: How you use Lustre can have a huge impact on performance. Lustre is optimised very much for high bandwidth access to large chunks of data at a time from multiple nodes in the application simultaneously, and is not very good at handling access to a large pool of small files instead.
So you have to store your data (but also your applications as the are a kind of data also) in an appropriate way, in fewer but larger files instead of more smaller files. Some centres with large supercomputers will advise you to containerise software for optimal performance. On LUMI we do advise Python users or users who install software through Conda to do so.
-
All these components are linked together through a high performance interconnect. On HPE Cray EX systems - but on more an more other systems also - there is no separate network anymore for storage access and the same high performance interconnect that is also used for internode communication by applications (through, e.g., MPI) is used for that purpose.
-
There is also a management server which is not mentioned on the slides, but that component is not essential to understand the behaviour of Lustre for the purpose of this lecture.
Links
See also the \"Lustre Components\" in \"Understanding Lustre Internals\" on the Lustre Wiki
"},{"location":"2day-20240502/08_Lustre/#striping-large-files-are-spread-across-osts","title":"Striping: Large files are spread across OSTs","text":"On Lustre, large files are typically broken into blocks called stripes or chunks that are then cyclically spread across a number of chunk files called objects in LUSTRE, each on a separate OST. In the figure in the slide above, the file is spread across the OSTs 0, 2, 4 and 6.
This process is completely transparent to the user with respect to correctness. The Lustre client takes care of the process and presents a traditional file to the application program. It is however not transparent with respect to performance. The performance of reading and writing a file depends a lot on how the file is spread across the OSTs of a file system.
Basically, there are two parameters that have to be chosen: The size of the stripes (all stripes have the same size in this example, except for the last one which may be smaller) and the number of OSTs that should be used for a file. Lustre itself takes care of choosing the OSTs in general.
There are variants of Lustre where one has multiple layouts per file which can come in handy if one doesn't know the size of the file in advance. The first part of the file will then typically be written with fewer OSTs and/or smaller chunks, but this is outside the scope of this course. The feature is known as Progressive File Layout.
The stripe size and number of OSTs used can be chosen on a file-by-file basis. The default on LUMI is to use only one OST for a file. This is done because that is the most reasonable choice for the many small files that many unsuspecting users have, and as we shall see, it is sometimes even the best choice for users working with large files. But it is not always the best choice. And unfortunately there is no single set of parameters that is good for all users.
Objects
The term \"object\" nowadays has different meanings, even in the storage world. The Object Storage Servers in Lustre should not be confused with the object storage used in cloud solutions such as Amazon Web Services (AWS) with the S3 storage service or the LUMI-O object storage. In fact, the Object Storage Servers use a regular file system such as ZFS or ldiskfs to store the \"objects\".
"},{"location":"2day-20240502/08_Lustre/#accessing-a-file","title":"Accessing a file","text":"Let's now study how Lustre will access a file for reading or writing. Let's assume that the second client in the above picture wants to write something to the file.
-
The first step is opening the file.
For that, the Lustre client has to talk to the metadata server (MDS) and query some information about the file.
The MDS in turn will return information about the file, including the layout of the file: chunksize and the OSSes/OSTs that keep the chunks of the file.
-
From that point on, the client doesn't need to talk to the MDS anymore and can talk directly to the OSSes to write data to the OSTs or read data from the OSTs.
"},{"location":"2day-20240502/08_Lustre/#parallelism-is-key","title":"Parallelism is key!","text":"The metadata servers can be the bottleneck in a Lustre setup. It is not easy to spread metadata across multiple MDSes efficiently. Moreover, the amount of metadata for any given file is small, so any metadata operation will translate into small disk accesses on the MDTs and hence not fully exploit the speed that some RAID setups can give you.
However, when reading and writing data, there are up to four levels of parallelism:
-
The read and write operations can engage multiple OSSes.
-
Since a single modern OSS can handle more bandwidth than a some OSTs can deliver, OSSes may have multiple OSTs.
How many OSTs are engaged is something that a user has control over.
-
An OST will contain many disks or SSDs, typically with some kind of RAID, but hence each read or write operation to an OST can engage multiple disks.
An OST will only be used optimally when doing large enough file accesses. But the file system client may help you here with caching.
-
Internally, SSDs are also parallel devices. The high bandwidth of modern high-end SSDs is the result of engaging multiple channels to the actual storage \"chips\" internally.
So to fully benefit from a Lustre file system, it is best to work with relatively few files (to not overload the MDS) but very large disk accesses. Very small I/O operations wouldn't even benefit from the RAID acceleration, and this is especially true for very small files as they cannot even benefit from caching provided by the file system client (otherwise a file system client may read in more data than requested, as file access is often sequential anyway so it would be prepared for the next access). To make efficient use of the OSTs it is important to have a relatively large chunk size and relatively large I/O operations, even more so for hard disk based file systems as if the OST file system manages to organise the data well on disk, it is a good way to reduce the impact on effective bandwidth of the inherent latency of disk access. And to engage multiple OSTs simultaneously (and thus reach a bandwidth which is much higher than a single OST can provide), even larger disk accesses will be needed so that multiple chunks are read or written simultaneously. Usually you will have to do the I/O in a distributed memory application from multiple nodes simultaneously as otherwise the bandwidth to the interconnect and processing capacity of the client software of a single node might become the limiting factor.
Not all codes are using Lustre optimally though, even with the best care of their users.
-
Some codes use files in scientific data formats like HDF5 and netCDF, and when written properly they can have very scalable performance.
A good code will write data to large files, from multiple nodes simultaneously, but will avoid doing I/O from too many ranks simultaneously to avoid bombarding the OSSes/OSTs with I/O requests. But that is a topic for a more advanced course...
One user has reported reading data from the hard disk based parallel file systems at about 25% of the maximal bandwidth, which is very good given that other users where also using that file system at the same time and not always in an optimal way.
Surprisingly many of these codes may be rather old. But their authors grew up with noisy floppy drives (do you still know what that is) and slow hard drives so learned how to program efficiently.
-
But some codes open one or more files per MPI rank. Those codes may have difficulties scaling to a large number of ranks, as they will put a heavy burden on the MDS when those files are created, but also may bombard each OSS/OST with too many I/O requests.
Some of these codes are rather old also, but were never designed to scale to thousands of MPI ranks. However, nowadays some users are trying to solve such big problems that the computations do scale reasonably well. But the I/O of those codes becomes a problem...
-
But some users simply abuse the file system as an unstructured database and simply drop their data as tens of thousands or even millions of small files with each one data element, rather than structuring that data in suitable file formats. This is especially common in science fields that became popular relatively recently - bio-informatics and AI - as those users typically started their work on modern PCs with fast SSDs.
The problem there is that metadata access and small I/O operations don't scale well to large systems. Even copying such a data set to a local SSD would be a problem should a compute node have a local SSD, but local SSDs suitable for supercomputers are also very expensive as they have to deal with lots of write operations. Your gene data or training data set may be relatively static, but on a supercomputer you cannot keep the same node for weeks so you'd need to rewrite your data to local disks very often. And there are shared file systems with better small file performance than Lustre, but those that scale to the size of even a fraction of Lustre, are also very expensive. And remember that supercomputing works exactly the opposite way: Try to reduce costs by using relatively cheap hardware but cleverly written software at all levels (system and application) as at a very large scale, this is ultimately cheaper than investing more in hardware and less in software.
Lustre was originally designed to achieve very high bandwidth to/from a small number of files, and that is in fact a good match for well organised scientific data sets and/or checkpoint data, but was not designed to handle large numbers of small files. Nowadays of course optimisations to deal better with small files are being made, but they may come at a high hardware cost.
"},{"location":"2day-20240502/08_Lustre/#how-to-determine-the-striping-values","title":"How to determine the striping values?","text":"If you only access relatively small files (up to a few hundreds of kilobytes) and access them sequentially, then you are out of luck. There is not much you can do. Engaging multiple OSTs for a single file is not useful at all in this case, and you will also have no parallelism from accessing multiple files that may be stored on different OSTs. The metadata operations may also be rather expensive compared to the cost of reading the file once opened.
As a rule of thumb, if you access a lot of data with a data access pattern that can exploit parallelism, try to use all OSTs of the Lustre file system without unnecessary overloading them:
-
If the number of files that will be accessed simultaneously is larger than the number of OSTs, it is best to not spread a single file across OSTs and hence use a stripe count of 1.
It will also reduce Lustre contention and OST file locking and as such gain performance for everybody.
-
At the opposite end, if you access only one very large file and use large or parallel disk accesses, set the stripe count to the number of OSTs (or a smaller number if you notice in benchmarking that the I/O performance plateaus). On a system the size of LUMI with storage as powerful as on LUMI, this will only work if you have more than on I/O client.
-
When using multiple similar sized files simultaneously but less files than there are OSTs, you should probably chose the stripe count such that the product of the number of files and the stripe count is approximately the number of OSTs. E.g., with 32 OSTs and 8 files, set the stripe count to 4.
It is better not to force the system to use specific OSTs but to let it chose OSTs at random.
The typical stripe size (size of the chunks) to use can be a bit harder to determine. Typically this will be 1MB or more, and it can be up to 4 GB, but that only makes sense for very large files. The ideal stripe size will also depend on the characteristics of the I/O in the file. If the application never writes more than 1 GB of data in a single sequential or parallel I/O operation before continuing with more computations, obviously with a stripe size of 1 GB you'd be engaging only a single OST for each write operation.
"},{"location":"2day-20240502/08_Lustre/#managing-the-striping-parameters","title":"Managing the striping parameters","text":"The basic Lustre command for regular users to do special operations on Lustre is the lfs command, which has various subcommands.
The first interesting subcommand is df which has a similar purpose as the regular Linux df command: Return information about the filesystem. In particular,
lfs df -h\n
will return information about all available Lustre filesystems. The -h flag tells the command to use \"human-readable\" number formats: return sizes in gigabytes and terabytes rather than blocks. On LUMI, the output starts with:
$ lfs df -h\nUUID bytes Used Available Use% Mounted on\nlustref1-MDT0000_UUID 11.8T 16.8G 11.6T 1% /pfs/lustref1[MDT:0]\nlustref1-MDT0001_UUID 11.8T 4.1G 11.6T 1% /pfs/lustref1[MDT:1]\nlustref1-MDT0002_UUID 11.8T 2.8G 11.7T 1% /pfs/lustref1[MDT:2]\nlustref1-MDT0003_UUID 11.8T 2.7G 11.7T 1% /pfs/lustref1[MDT:3]\nlustref1-OST0000_UUID 121.3T 21.5T 98.5T 18% /pfs/lustref1[OST:0]\nlustref1-OST0001_UUID 121.3T 21.6T 98.4T 18% /pfs/lustref1[OST:1]\nlustref1-OST0002_UUID 121.3T 21.4T 98.6T 18% /pfs/lustref1[OST:2]\nlustref1-OST0003_UUID 121.3T 21.4T 98.6T 18% /pfs/lustref1[OST:3]\n
so the command can also be used to see the number of MDTs and OSTs available in each filesystem, with the capacity.
Striping in Lustre is set at a filesystem level by the sysadmins, but users can adjust the settings at the directory level (which then sets the default for files created in that directory) and file level. Once a file is created, the striping configuration cannot be changed anymore on-the-fly.
To inspect the striping configuration, one can use the getstripe subcommand of lfs.
Let us first use it at the directory level:
$ lfs getstripe -d /appl/lumi/SW\nstripe_count: 1 stripe_size: 1048576 pattern: 0 stripe_offset: -1\n\n$ lfs getstripe -d --raw /appl/lumi/SW\nstripe_count: 0 stripe_size: 0 pattern: 0 stripe_offset: -1\n
The -d flag tells that we only want information about the directory itself and not about everything in that directory. The first lfs getstripe command tells us that files created in this directory will use only a single OST and have a stripe size of 1 MiB. By adding the --raw we actually see the settings that have been made specifically for this directory. The 0 for stripe_count and stripe_size means that the default value is being used, and the stripe_offset of -1 also indicates the default value.
We can also use lfs getstripe for individual files:
$ lfs getstripe /appl/lumi/LUMI-SoftwareStack/etc/motd.txt\n/appl/lumi/LUMI-SoftwareStack/etc/motd.txt\nlmm_stripe_count: 1\nlmm_stripe_size: 1048576\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 10\n obdidx objid objid group\n 10 56614379 0x35fddeb 0\n
Now lfs getstripe does not only return the stripe size and number of OSTs used, but it will also show the OSTs that are actually used (in the column obdidx of the output). The lmm_stripe_offset is also the number of the OST with the first object of the file.
The final subcommand that we will discuss is the setstripe subcommand to set the striping policy for a file or directory.
Let us first look at setting a striping policy at the directory level:
$ module use /appl/local/training/modules/2day-20240502\n$ module load lumi-training-tools\n$ mkdir testdir\n$ lfs setstripe -S 2m -c 4 testdir\n$ cd testdir\n$ mkfile 2g testfile1\n$ lfs getstripe testfile1\ntestfile1\nlmm_stripe_count: 4\nlmm_stripe_size: 2097152\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 28\n obdidx objid objid group\n 28 66250987 0x3f2e8eb 0\n 30 66282908 0x3f3659c 0\n 1 71789920 0x4476d60 0\n 5 71781120 0x4474b00 0\n
The lumi-training-tools module provides the mkfile command that we use in this example.
We first create a directory and then set the striping parameters to a stripe size of 2 MiB (the -S flag) and a so-called stripe count, the number of OSTs used for the file, of 4 (the -c flag).
Next we go into the subdirectory and use the mkfile command to generate a file of 2 GiB.
When we now check the file layout of the file that we just created with lfs getstripe, we see that the file now indeed uses 4 OSTs with a stripe size of 2 MiB, and has object on in this case OSTs 28, 30, 1 and 5.
However, we can even control striping at the level of an individual file. The condition is that the layout of the file is set as soon as it is created. We can do this also with lfs setstripe:
$ lfs setstripe -S 16m -c 2 testfile2\n$ ls -lh\ntotal 0\n-rw-rw---- 1 XXXXXXXX project_462000000 2.0G Jan 15 16:17 testfile1\n-rw-rw---- 1 XXXXXXXX project_462000000 0 Jan 15 16:23 testfile2\n$ lfs getstripe testfile2\ntestfile2\nlmm_stripe_count: 2\nlmm_stripe_size: 16777216\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 10\n obdidx objid objid group\n 10 71752411 0x446dadb 0\n 14 71812909 0x447c72d 0\n
In this example, the lfs setstripe command will create an empty file but with the required layout. In this case we have set the stripe size to 16 MiB and use only 2 OSTs, and the lfs getstripe command confirms that information. We can now open the file to write data into it with the regular file operations of the Linux glibc library or your favourite programming language (though of course you need to take into account that the file already exists so you should use routines that do not return an error if the file already exists).
Lustre API
Lustre also offers a C API to directly set file layout properties, etc., from your package. Few scientific packages seem to support it though.
"},{"location":"2day-20240502/08_Lustre/#the-metadata-servers","title":"The metadata servers","text":"Parallelising metadata access is very difficult. Even large Lustre filesystems have very few metadata servers. They are a finite and shared resource, and overloading the metadata server slows down the file system for all users.
The metadata servers are involved in many operations. The play a role in creating, opening and also closing files. The provide some of the attributes of a file. And they also play a role in file locking.
Yet the metadata servers have a very finite capacity. The Lustre documentation claims that in theory a single metadata server should be capable of up to 200,000 operations per second, depending on the type of request. However, 75,000 operations per second may be more realistic.
As a user, many operations that you think are harmless from using your PC, are in fact expensive operations on a supercomputer with a large parallel file system and you will find \"Lustre best practices\" pages on web sites of many large supercomputer centres. Some tips for regular users:
-
Any command that requests attributes is fairly expensive and should not be used in large directories. This holds even for something as trivial as ls -l. But it is even more so for commands as du that run recursively through attributes of lots of files.
-
Opening a file is also rather expensive as it involves a metadata server and one or more object servers. It is not a good idea to frequently open and close the same file while processing data.
-
Therefore access to many small files from many processes is not a good idea. One example of this is using Python, and even more so if you do distributed memory parallel computing with Python. This is why on LUMI we ask to do big Python installations in containers. Another alternative is to run such programs from /tmp (and get them on /tmp from an archive file).
For data, it is not a good idea to dump a big dataset as lots of small files on the filesystem. Data should be properly organised, preferably using file formats that support parallel access from many processes simultaneously. Technologies popular in supercomputing are HDF5, netCDF and ADIOS2. Sometimes libraries that read tar-files or other archive file formats without first fully uncompressing, may even be enough for read-only data. Or if your software runs in a container, you may be able to put your read-only dataset into a SquashFS file and mount into a container.
-
Likewise, shuffling data in a distributed memory program should not be done via the filesystem (put data on a shared filesystem and then read it again in a different order) but by direct communication between the processes over the interconnect.
-
It is also obvious that directories with thousands of files should be avoided as even an ls -l command on that directory generates a high load on the metadata servers. But the same holds for commands such as du or find.
Note that the lfs command also has a subcommand find (see man lfs-find), but it cannot do everything that the regular Linux find command can do. E.g., the --exec functionality is missing. But to simply list files it will put less strain on the filesystem as running the regular Linux find command.
There are many more tips more specifically for programmers. As good use of the filesystems on a supercomputer is important and wrong use has consequences for all other users, it is an important topic in the 4-day comprehensive LUMI course that the LUMI User Support Team organises a few times per year, and you'll find many more tips about proper use of Lustre in that lecture (which is only available to actual users on LUMI unfortunately).
"},{"location":"2day-20240502/08_Lustre/#lustre-on-lumi","title":"Lustre on LUMI","text":"LUMI has 5 Lustre filesystems:
The file storage sometimes denoted as LUMI-P consists of 4 disk based Lustre filesystems, each with a capacity of roughly 18 PB and 240 GB/s aggregated bandwidth in the optimal case (which of course is shared by all users, no single user will ever observe that bandwidth unless they have the machine for themselves). Each of the 4 systems has 2 MDTs, one per MDS (but in a high availability setup), and 32 OSTs spread across 16 OSSes, so 2 OSTs per OSS. All 4 systems are used to serve the home directories, persistent project space and regular scratch space, but also, e.g., most of the software pre-installed on LUMI. Some of that pre-installed software is copied on all 4 systems to distribute the load.
The fifth Lustre filesystem of LUMI is also known as LUMI-F, where the \"F\" stands for flash as it is entirely based on SSDs. It currently has a capacity of approximately 8.5 PB and a total of over 2 TB/s aggregated bandwidth. The system has 4 MDTs spread across 4 MDSes, and 72 OSTs and 72 OSSes, os 1 OST per OSS (as a single OST already offers a lot more bandwidth and hence needs more server capacity than a hard disk based OST).
"},{"location":"2day-20240502/08_Lustre/#storage-areas","title":"Storage areas","text":"The table on the slide above summarises the available file areas on the Lustre filesystems. That information is also available in the LUMI docs.
-
The home directory your personal area and mostly meant for configuration files and caches of Linux commands, etc., and not meant for project-related work. It is fixed in size and number of files. No extension of those limits is ever granted.
-
The persistent project directory is meant to be the main work place for your project. A LUMI project is also meant to be a close collaboration between people, and not something simply provided to a research group for all their work.
By default users get 50 GB of storage and 100,000 inodes (files and directories). The storage volume can be increased to 500 GB on request to the central LUMI help desk, but the number of inodes is fixed (though some small extensions have been granted if the user has a very good reason) as we want to avoid that the filesystems get overloaded by users working with lots of small files directly on the Lustre filesystem.
The data is persistent for the project lifetime, but removed 90 days after the end of the project.
-
The project scratch space on LUMI-P is by default 50 TB but can on request be extended up to 500 TB. The number of files is limited to 2M, again to discourage using many small files.
Data is only guaranteed to stay on the file system for 90 days. After 90 days, an automatic cleaning procedure may remove data (but it has not yet been necessary so far as other policies work well to keep the storage reasonably clean).
-
Finally, each project also gets some fast scratch space on LUMI-F. The default amount of storage is 2 TB, but can be extended to up to 100 TB. The number of inodes is limited to 1M, and data can be removed automatically after 30 days (but again this has not happened yet).
It is important to note that LUMI is not meant to be used as a safe data archive. There is no backup of any of the filesystems, and there is no archiving of data of expired projects or user accounts. Users are responsible for moving their data to systems suitable for archival.
Storage use on LUMI is limited in two independent ways:
-
Traditional Linux block and file quota limit the maximum capacity you can use (in volume and number of inodes, roughly the number of files and directories combined).
-
But actual storage use is also \"billed\" on a use-per-hour basis. The idea behind this is that a user may run a program that generates a lot of data, but after some post-processing much of the data can be deleted so that other users can use that capacity again, and to encourage that behaviour you are billed based not on peak use, but based on the combination of the volume that you use and the time you use it for.
E.g., if you would have 10 GB on the LUMI-P storage for 100 hours, you'd be billed 1 TB hour for that. If subsequently you reduce your usage to 2 GB, then it would take 500 hours before you have consumed another TB hour. Storage use is monitored hourly for this billing process, and if you run out of storage billing units you will not be able to run jobs anymore.
The billing rate also depends on the file system used. As the flash storage system was roughly 10 times as expensive in purchase as the hard disk based file systems, storage on /flash is also billed at 10 times the rate, so with 1 TB hour you can only store 100 GB for 1 hour on that system.
Storage in your home directory is not billed but that should not mean that you should abuse your home directory for other purposes then a home directory is meant to be used, and an extension of the home directory will never be granted.
"},{"location":"2day-20240502/08_Lustre/#object-storage-lumi-o","title":"Object storage: LUMI-O","text":"LUMI has yet another storage system: An object storage system based on CEPH with a capacity of 30 PB. It can be used for storing, sharing and staging data. It is not mounted on the compute nodes in a traditional way (as it is also structured differently) but can be accessed with tools such as rclone and s3cmd.
It can also be reached easily from outside LUMI and is a proper intermediate stage to get data to and from LUMI, also because several object storage tools perform much better on high latency long-distance connections than tools as sftp.
The downside is that to access LUMI-O, temporary authentication credentials have to be generated, which currently can only be done via a web interface, after which information about those credentials needs to be copied to configuration files or to fields in a GUI for GUI tools.
Data on LUMI-O is persistent for the duration of the project. It is also billed, but as object storage is fairly cheap, is is billed at half the rate of LUMI-P. The quota are currently fixed at 150 TB per project, with a maximum of 1k buckets and 500k objects per bucket.
This short course does not offer enough time to fully discuss working with the object storage of LUMI. However, it was discussed to some extent already in the \"Getting Access to LUMI\" chapter and there is also some info in the LUMI documentation.
"},{"location":"2day-20240502/08_Lustre/#links","title":"Links","text":" -
The lfs command itself is documented through a manual page that can be accessed at the LUMI command line with man lfs. The various subcommands each come with their own man page, e.g., lfs-df, lfs-getstripe, lfs-setstripe and lfs-find.
-
Understanding Lustre Internals on the Lustre Wiki.
-
Lustre Basics and Lustre Best Practices in the knowledge base of the NASA supercomputers.
-
Introduction to DVS in an administration guide
"},{"location":"2day-20240502/09_Containers/","title":"Containers on LUMI-C and LUMI-G","text":""},{"location":"2day-20240502/09_Containers/#what-are-we-talking-about-in-this-chapter","title":"What are we talking about in this chapter?","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers,
-
and pay some attention to the use of some of our pre-built AI containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"2day-20240502/09_Containers/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers built on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software. Containers may offer more reproducibility than recompiling software for a different platform, but all you're trying to do is reproducing the same wrong result as in particular floating point operations are only an approximation for real numbers. When talking about reproducibility, you should think the way experimentalists do: You have a result and an error margin, and it is important to have an idea of that error margin too.
But full portability is as much a myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the Slingshot interconnect, may fail (or if you're lucky just fall back to TCP sockets in MPI, completely killing scalability, but technically speaking still working so portable). Containers that expect a certain version range of a particular driver on the system may fail if a different, out-of-range version of that driver is on the system instead (think the ROCm driver).
Even if a container is portable to LUMI, it may not yet be performance-portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At UAntwerpen we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"2day-20240502/09_Containers/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
Software installations that would otherwise be impossible. E.g., some software may not even be suited for installation in a multi-user HPC system as it uses fixed paths that are not compatible with installation in module-controlled software stacks. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system software region. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
They are also of interest if compiling the software takes too much work while any processor-specific optimisation that could be obtained by compiling oneself, isn't really important. E.g., if a full stack of GUI libraries is needed, as they are rarely the speed-limiting factor in an application.
-
As an example, Conda installations are not appreciated on the main Lustre file system.
On one hand, Conda installations tend to generate lots of small files (and then even more due to a linking strategy that does not work on Lustre). So they need to be containerised just for storage manageability.
They also re-install lots of libraries that may already be on the system in a different version. The isolation offered by a container environment may be a good idea to ensure that all software picks up the right versions.
-
An example of software that is usually very hard to install is a GUI application, as they tend to have tons of dependencies and recompiling can be tricky. Yet rather often the binary packages that you can download cannot be installed wherever you want, so a container can come to the rescue.
-
Another example where containers have proven to be useful on LUMI is to experiment with newer versions of ROCm than we can offer on the system.
This often comes with limitations though, as (a) that ROCm version is still limited by the drivers on the system and (b) we've seen incompatibilities between newer ROCm versions and the Cray MPICH libraries.
-
And a combination of both: LUST with the help of AMD have prepared some containers with popular AI applications. These containers use some software from Conda, a newer ROCm version installed through RPMs, and some performance-critical code that is compiled specifically for LUMI.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"2day-20240502/09_Containers/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS. Currently we offer Singularity Community Edition 3.11.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container either by creating a tarball from a docker container on the remote system and then converting that to the singularity .sif format on LUMI, or by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory. This can lead to exhaustion of your disk quota for your home directory. So you may want to use the environment variable SINGULARITY_CACHEDIR to put the cache in, e.g,, your scratch space (but even then you want to clean up after the pull operation so save on your storage billing units).
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require user namespaces, cannot be supported for security reasons (as user namespaces in Linux are riddled with security issues). Enabling features that are known to have had several serious security vulnerabilities in the recent past, or that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container using what the SingularityCE user guide calls \"unprivileged proot builds\". This requires loading the proot command which is provided by the systools/23.09 module or later versions provided in CrayEnv or LUMI/23.09 or later. The SingularityCE user guide mentions several restrictions of this process. The general guideline from the manual is: \"Generally, if your definition file starts from an existing SIF/OCI container image, and adds software using system package managers, an unprivileged proot build is appropriate. If your definition file compiles and installs large complex software from source, you may wish to investigate --remote or --fakeroot builds instead.\" But on LUMI we cannot yet provide --fakeroot builds due to security constraints (as that process also requires user namespaces).
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI (and some for ROCm are already there).
"},{"location":"2day-20240502/09_Containers/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and /dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables. E.g.,
export SINGULARITY_BIND='/pfs,/scratch,/projappl,/project,/flash'\n
will ensure that you have access to the scratch, project and flash directories of your project.
For some containers that are provided by the LUMI User Support Team, modules are also available that set SINGULARITY_BINDPATH so that all necessary system libraries are available in the container and users can access all their files using the same paths as outside the container.
"},{"location":"2day-20240502/09_Containers/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI Slingshot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and until version 5 full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the Slingshot 11 interconnect, so work is going on for better support for OFI in general and Cray Slingshot in particular and for full GPU support.
"},{"location":"2day-20240502/09_Containers/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
"},{"location":"2day-20240502/09_Containers/#bindings-for-singularity","title":"Bindings for singularity","text":"The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY_PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the singularity-bindings in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
"},{"location":"2day-20240502/09_Containers/#vnc-container","title":"VNC container","text":"The second tool is a container that we provide with some bash functions to start a VNC server as one way to run GUI programs and as an alternative to the (currently more sophisticated) VNC-based GUI desktop setup offered in Open OnDemand (see the \"Getting Access to LUMI notes\"). It can be used in CrayEnv or in the LUMI stacks through the lumi-vnc module. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
For most users, the Open OnDemand web interface and tools offered in that interface will be a better alternative.
"},{"location":"2day-20240502/09_Containers/#cotainr-build-conda-containers-on-lumi","title":"cotainr: Build Conda containers on LUMI","text":"The third tool is cotainr, a tool developed by DeIC, the Danish partner in the LUMI consortium. It is a tool to pack a Conda installation into a container. It runs entirely in user space and doesn't need any special rights. (For the container specialists: It is based on the container sandbox idea to build containers in user space.)
Containers build with cotainr are used just as other containers, so through the singularity commands discussed before.
AI course
The cotainr tool is also used extensively in our AI training/workshop to build containers with AI software on top of some ROCmTM containers that we provide. A link to the course material of that training was not yet available at the time of this course.
"},{"location":"2day-20240502/09_Containers/#container-wrapper-for-python-packages-and-conda","title":"Container wrapper for Python packages and conda","text":"The fourth tool is a container wrapper tool that users from Finland may also know as Tykky (the name on their national systems). It is a tool to wrap Python and conda installations in a container and then create wrapper scripts for the commands in the bin subdirectory so that for most practical use cases the commands can be used without directly using singularity commands. Whereas cotainr fully exposes the container to users and its software is accessed through the regular singularity commands, Tykky tries to hide this complexity with wrapper scripts that take care of all bindings and calling singularity. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run the tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation. So strictly speaking it does not create a container, but a SquashFS file that is then mounted in a small existing base container. However, the wrappers created for all commands in the bin subdirectory of the conda or Python installation take care of doing the proper bindings. If you want to use the container through singularity commands however, you'll have to do that mounting by hand.
We do strongly recommend to use cotainr or the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a tempororary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"2day-20240502/09_Containers/#pre-built-ai-containers","title":"Pre-built AI containers","text":"LUST with the help of AMD is also building some containers with popular AI software. These containers contain a ROCm version that is appropriate for the software, use Conda for some components, but have several of the performance critical components built specifically for LUMI for near-optimal performance. Depending on the software they also contain a RCCL library with the appropriate plugin to work well on the Slingshot 11 interconnect, or a horovod compiled to use Cray MPICH.
The containers can be provided through a module that is user-installable with EasyBuild. That module sets the SINGULARITY_BIND environment variable to ensure proper bindings (as they need, e.g., the libfabric library from the system and the proper \"CXI provider\" for libfabric to connect to the Slingshot interconnect). The module will also provide an environment variable to refer to the container (name with full path) to make it easy to refer to the container in job scripts. Some of the modules also provide some scripts that may make using the containers easier in some standard scenarios. Alternatively, the user support team is also working on some modules for users who want to run the containers as manually as possible yet want an easy way to deal with the necessary bindings of user file systems and HPE Cray PE components needed from the system (see also course notes for the AI training/workshop, still \"future\" at the time of this course so we cannot link to them).
These containers can be found through the LUMI Software Library and are marked with a container label. At the time of the course, there are containers for
- PyTorch, which is the best tested and most developed one,
- TensorFlow,
- JAX,
- AlphaFold,
- ROCm and
- mpi4py.
"},{"location":"2day-20240502/09_Containers/#running-the-ai-containers-complicated-way-without-modules","title":"Running the AI containers - complicated way without modules","text":"The containers that we provide have everything they need to use RCCL and/or MPI on LUMI. It is not needed to use the singularity-bindings/system module described earlier as that module tries to bind too much external software to the container.
Yet to be able to properly use the containers, users do need to take care of some bindings
-
Some system directories and libraries have to be bound to the container:
-B /var/spool/slurmd,/opt/cray,/usr/lib64/libcxi.so.1,/usr/lib64/libjansson.so.4\n
The first one is needed to work together with Slurm. The second one contains the MPI and libfabric library. The third one is the actual component that binds libfabric to the Slingshot network adapter and is called the CXI provider, and the last one is a library that is needed by some LUMI system libraries but not in the container.
-
By default your home directory will be available in the container, but as your home directory is not your main workspace, you may want to bind your subdirectory in /project, /scratch and/or /flash also.
There are also a number of components that may need further initialisation:
-
The MIOpen library has problems with file/record locking on Lustre so some environment variables are needed to move some work directories.
-
RCCL needs to be told the right network interfaces to use as otherwise it tends to take the interface to the management network of the cluster instead and gets stuck.
-
GPU-aware MPI also needs to be set up (see earlier in the course)
-
Your AI package may need some environment variables too (e.g., MASTER_ADDR and MASTER_PORT for distributed learning with PyTorch)
Moreover, most (if not all at the moment) containers that we provide with Python packages, are built using Conda to install Python. When entering those containers, conda needs to be activated. The containers are built in such a way that the environment variable WITH_CONDA provides the necessary command, so in most cases you only need to run
$WITH_CONDA\n
as a command in the script that is executed in the container or on the command line.
"},{"location":"2day-20240502/09_Containers/#running-the-containers-through-easybuild-generated-modules","title":"Running the containers through EasyBuild-generated modules","text":"Doing all those initialisations, is a burden. Therefore we provide EasyBuild recipes to \"install\" the containers and to provide a module that helps setting environment variables in the initialisation.
For packages for which we know generic usage patterns, we provide some scripts that do most settings. When using the module, those scripts will be available in the /runscripts directory in the container, but are also in a subdirectory on the Lustre file system. So in principle you can even edit them or add your own scripts, though they would be erased if you reinstall the module with EasyBuild.
They also define a number of environment variables that make life easier. E.g., the SINGULARITY_BINDPATH environment variable is already set to bind the necessary files and directories from the system and to make sure that your project, scratch and flash spaces are available at the same location as on LUMI so that even symbolic links in those directories should still work.
We recently started adding a pre-configured virtual environment to the containers to add your own packages. The virtual environment can be found in the container in a subdirectory of /user-software/venv. To install packages from within the container, this directory needs to be writeable which is done by binding /user-software to the $CONTAINERROOT/user-software subdirectory outside the container. If you add a lot of packages that way, you re-create the filesystem issues that the container is supposed to solve, but we have a solution for that also. These containers provide the make-squashfs command to generate a SquashFS file from the installation that will be used by the container instead next time the module for the container is reloaded. And in case you prefer to fully delete the user-software subdirectory afterwards from $CONTAINERROOT, it can be re-created using unmake-squashfs so that you can add further packages. You can also use /user-software to install software in other ways from within the container and can basically create whatever subdirectory you want into it.
These containers with pre-configured virtual environment offer another advantage also: The module injects a number of environment variables into the container so that it is no longer needed to activate the conda environment and Python virtual environment by sourcing scripts.
In fact, someone with EasyBuild experience may even help you to further extend the recipe that we provide to already install extra packages, and we provide an example of how to do that with our PyTorch containers.
Installing the EasyBuild recipes for those containers is also done via the EasyBuild-user module, but it is best to use a special trick. There is a special partition called partition/container that is only used to install those containers and when using that partition for the installation, the container will be available in all versions of the LUMI stack and in the CrayEnv stack.
Installation is as simple as, e.g.,
module load LUMI partition/container EasyBuild-user\neb PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb\n
Before running it is best to clean up (module purge) or take a new shell to avoid conflicts with environment variables provided by other modules.
The installation with EasyBuild will make a copy from the .sif Singularity container image file that we provide somewhere in /appl/local/containers to the software installation subdirectory of your $EBU_USER_PREFIX EasyBuild installation directory. These files are big and you may wish to delete that file which is easily done: After loading the container module, the environment variable SIF contains the name with full path of the container file. After removing the container file from your personal software directory, you need to reload the container module and from then on, SIF will point to the corresponding container in /appl/local/containers/easybuild-sif-images. We don't really recommend removing the container image though and certainly not if you are interested in reproducibility. We may remove the image in /appl/local/containers/easybuild-sif-images without prior notice if we notice that the container has too many problems, e.g., after a system update. But that same container that doesn't work well for others, may work well enough for you that you don't want to rebuild whatever environment you built with the container.
"},{"location":"2day-20240502/09_Containers/#example-distributed-learning-without-using-easybuild","title":"Example: Distributed learning without using EasyBuild","text":"To really run this example, some additional program files and data files are needed that are not explained in this text. You can find more information on the PyTorch page in the LUMI Software Library.
We'll need to create a number of scripts before we can even run the container.
The first script is a Python program to extract the name of the master node from a Slurm environment variable. Store it in get-master.py:
import argparse\ndef get_parser():\n parser = argparse.ArgumentParser(description=\"Extract master node name from Slurm node list\",\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"nodelist\", help=\"Slurm nodelist\")\n return parser\n\n\nif __name__ == '__main__':\n parser = get_parser()\n args = parser.parse_args()\n\n first_nodelist = args.nodelist.split(',')[0]\n\n if '[' in first_nodelist:\n a = first_nodelist.split('[')\n first_node = a[0] + a[1].split('-')[0]\n\n else:\n first_node = first_nodelist\n\n print(first_node)\n
Second, we need a script that we will run in the container. Store the script as run-pytorch.sh:
#!/bin/bash -e\n\n# Make sure GPUs are up\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n\n# !Remove this if using an image extended with cotainr or a container from elsewhere.!\n# Start conda environment inside the container\n$WITH_CONDA\n\n# MIOPEN needs some initialisation for the cache as the default location\n# does not work on LUMI as Lustre does not provide the necessary features.\nexport MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\nsleep 2\n\n# Optional! Set NCCL debug output to check correct use of aws-ofi-rccl (these are very verbose)\nexport NCCL_DEBUG=INFO\nexport NCCL_DEBUG_SUBSYS=INIT,COLL\n\n# Set interfaces to be used by RCCL.\n# This is needed as otherwise RCCL tries to use a network interface it has\n# no access to on LUMI.\nexport NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n\n# Set ROCR_VISIBLE_DEVICES so that each task uses the proper GPU\nexport ROCR_VISIBLE_DEVICES=$SLURM_LOCALID\n\n# Report affinity to check\necho \"Rank $SLURM_PROCID --> $(taskset -p $$); GPU $ROCR_VISIBLE_DEVICES\"\n\n# The usual PyTorch initialisations (also needed on NVIDIA)\n# Note that since we fix the port ID it is not possible to run, e.g., two\n# instances via this script using half a node each.\nexport MASTER_ADDR=$(python get-master.py \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\nexport WORLD_SIZE=$SLURM_NPROCS\nexport RANK=$SLURM_PROCID\n\n# Run app\ncd /workdir/mnist\npython -u mnist_DDP.py --gpu --modelpath model\n
The script needs to be executable.
The script sets a number of environment variables. Some are fairly standard when using PyTorch on an HPC cluster while others are specific for the LUMI interconnect and architecture or the AMD ROCm environment. We notice a number of things:
-
At the start we just print some information about the GPU. We do this only ones on each node on the process which is why we test on $SLURM_LOCALID, which is a numbering starting from 0 on each node of the job:
if [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n
-
The container uses a Conda environment internally. So to make the right version of Python and its packages availabe, we need to activate the environment. The precise command to activate the environment is stored in $WITH_CONDA and we can just call it by specifying the variable as a bash command.
-
The MIOPEN_ environment variables are needed to make MIOpen create its caches on /tmp as doing this on Lustre fails because of file locking issues:
export MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\n
These caches are used to store compiled kernels.
-
It is also essential to tell RCCL, the communication library, which network adapters to use. These environment variables start with NCCL_ because ROCm tries to keep things as similar as possible to NCCL in the NVIDIA ecosystem:
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n
Without this RCCL may try to use a network adapter meant for system management rather than inter-node communications!
-
We also set ROCR_VISIBLE_DEVICES to ensure that each task uses the proper GPU. This is again based on the local task ID of each Slurm task.
-
Furthermore some environment variables are needed by PyTorch itself that are also needed on NVIDIA systems.
PyTorch needs to find the master for communication which is done through the get-master.py script that we created before:
export MASTER_ADDR=$(python get-master.py \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\n
As we fix the port number here, the conda-python-distributed script that we provide, has to run on exclusive nodes. Running, e.g., 2 4-GPU jobs on the same node with this command will not work as there will be a conflict for the TCP port for communication on the master as MASTER_PORT is hard-coded in this version of the script.
And finally you need a job script that you can then submit with sbatch. Lets call it my-job.sh:
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --tasks-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=00:10:00\n#SBATCH --account=project_<your_project_id>\n\nCONTAINER=your-container-image.sif\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\nsrun --cpu-bind=mask_cpu:$MYMASKS \\\nsingularity exec \\\n -B /var/spool/slurmd \\\n -B /opt/cray \\\n -B /usr/lib64/libcxi.so.1 \\\n -B /usr/lib64/libjansson.so.4 \\\n -B $PWD:/workdir \\\n $CONTAINER /workdir/run-pytorch.sh\n
The important parts here are:
-
We start PyTorch via srun and this is recommended. The torchrun command is not supported on LUMI, as is any other process starter that can be found in AI software that uses ssh to start processes on other nodes rather than going via the resource manager (with, e.g., srun).
-
We also use a particular CPU mapping so that each rank can use the corresponding GPU number (which is taken care of in the run-pytorch.sh script). We use the \"Linear assignment of GCD, then match the cores\" strategy.
-
Note the bindings. In this case we do not even bind the full /project, /scratch and /flash subdirectories, but simply make the current subdirectory that we are using outside the container available as /workdir in the container. This also implies that any non-relative symbolic link or any relative symbolic link that takes you out of the current directory and its subdirectories, will not work, which is awkward as you may want several libraries to run from to have simultaneous jobs, but, e.g., don't want to copy your dataset to each of those directories.
"},{"location":"2day-20240502/09_Containers/#example-distributed-learning-with-the-easybuild-generated-module","title":"Example: Distributed learning with the EasyBuild-generated module","text":"To really run this example, some additional program files and data files are needed that are not explained in this text. You can find more information on the PyTorch page in the LUMI Software Library.
It turns out that the first two above scripts in the example above, are fairly generic. Therefore the module provides a slight variant of the second script, now called conda-python-distributed, that at the end calls python, passing it all arguments it got and hence can be used to start other Python code also. It is in $CONTAINERROOT/runscripts or in the container as /runscripts.
As the module also takes care of bindings, the job script is simplified to
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --tasks-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=00:10:00\n#SBATCH --account=project_<your_project_id>\n\nmodule load LUMI # Which version doesn't matter, it is only to get the container.\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\ncd mnist\nsrun --cpu-bind=mask_cpu:$MYMASKS \\\n singularity exec $SIFPYTORCH \\\n conda-python-distributed -u mnist_DDP.py --gpu --modelpath model\n
So basically you only need to take care of the proper CPU bindings where we again use the \"Linear assignment of GCD, then match the cores\" strategy.
"},{"location":"2day-20240502/09_Containers/#extending-the-containers","title":"Extending the containers","text":"We can never provide all software that is needed for every user in our containers. But there are several mechanisms that can be used to extend the containers that we provide:
"},{"location":"2day-20240502/09_Containers/#extending-the-container-with-cotainr","title":"Extending the container with cotainr","text":"The LUMI Software Library offers some container images for ROCmTM. Though these images can be used simply to experiment with different versions of ROCm, an important use of those images is as base images for the cotainr tool that supports Conda to install software in the container.
Some care is needed though when you want to build your own AI containers. You need to ensure that binaries for AMD GPUs are used, as by default you may get served NVIDIA-only binaries. MPI can also be a problem, as the base image does not yet provide, e.g., a properly configures mpi4py (which would likely be installed in a way that conflicts with cotainr).
The container images that we provide can be found in the following directories on LUMI:
-
/appl/local/containers/sif-images: Symbolic link to the latest version of the container for each ROCm version provided. Those links can change without notice!
-
/appl/local/containers/tested-containers: Tested containers provided as a Singularity .sif file and a docker-generated tarball. Containers in this directory are removed quickly when a new version becomes available.
-
/appl/local/containers/easybuild-sif-images : Singularity .sif images used with the EasyConfigs that we provide. They tend to be available for a longer time than in the other two subdirectories.
First you need to create a yaml file to tell Conda which is called by cotainr which packages need to be installed. An example is given in the \"Using the images as base image for cotainr\" section of the LUMI Software Library rocm page. Next we need to run cotainr with the right base image to generate the container:
module load LUMI/22.12 cotainr\ncotainr build my-new-image.sif \\\n --base-image=/appl/local/containers/sif-images/lumi-rocm-rocm-5.4.6.sif \\\n --conda-env=py311_rocm542_pytorch.yml\n
The cotainr command takes three arguments in this example:
-
my-new-image.sif is the name of the container image that it will generate.
-
--base-image=/appl/local/containers/sif-images/lumi-rocm-rocm-5.4.6.sif points to the base image that we will use, in this case the latest version of the ROCm 5.4.6 container provided on LUMI.
This version was chosen for this case as ROCm 5.4 is the most recent version for which the driver on LUMI at the time of writing (early May 2024) offers guaranteed support.
-
--conda-env=py311_rocm542_pytorch.yml
The result is a container for which you will still need to provide the proper bindings to some libraries on the system (to interface properly with Slurm and so that RCCL with the OFI plugin can work) and to your spaces in the file system that you want to use. Or you can adapt an EasyBuild-generated module for the ROCm container that you used to use your container instead (which will require the EasyBuild eb command flag --sourcepath to specify where it can find the container that you generated, and you cannot delete it from the installation afterwards). In the future, we may provide some other installable module(s) with generic bindings to use instead.
"},{"location":"2day-20240502/09_Containers/#extending-the-container-with-the-singularity-unprivileged-proot-build","title":"Extending the container with the singularity unprivileged proot build","text":"Singularity specialists can also build upon an existing container using singularity build. The options for build processes are limited though because we have no support for user namespaces or the fakeroot feature. The \"Unprivileged proot builds\" feature from recent SingularityCE versions is supported though.
To use this feature, you first need to write a singularity-compatible container definition file, e.g.,
Bootstrap: localimage\n\nFrom: /appl/local/containers/easybuild-sif-images/lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-dockerhash-f72ddd8ef883.sif\n\n%post\n\nzypper -n install -y Mesa libglvnd libgthread-2_0-0 hostname\n
which is a definition file that will use the SUSE zypper software installation tool to add a number of packages to one of the LUMI PyTorch containers to provide support for software OpenGL rendering (the CDNA GPUs do not support OpenGL acceleration) and the hostname command.
To use the singularity build command, we first need to make the proot command available. This is currently not installed in the LUMI system image, but is provided by the systools/23.09 and later modules that can be found in the corresponding LUMI stack and in the CrayEnv environment.
To update the container, run:
module load LUMI/23.09 systools\nsingularity build my-new-container.sif my-container-definition.def\n
Note:
-
In this example, as we use the LUMI/23.09 module, there is no need to specify the version of systools as there is only one in this stack. An alternative would have been to use
module load CrayEnv systools/23.09\n
-
The singularity build command takes two options: The first one is the name of the new container image that it generates and the second one is the container definition file.
When starting from a base image installed with one of our EasyBuild recipes, it is possible to overwrite the image file and in fact, the module that was generated with EasyBuild might just work...
"},{"location":"2day-20240502/09_Containers/#extending-the-container-through-a-python-virtual-environment","title":"Extending the container through a Python virtual environment","text":"Some newer containers installed with EasyBuild already include a pre-initialised virtual environment (created with venv). The location in the filesystem of that virtual environment is:
-
/user-software/venv/MyVEnv in the container, where MyVEnv is actually different in different containers. We used the same name as for the Conda environment.
-
$CONTAINERROOT/user-software/venv/MyVEnv outside the container (unless that directory structure is replaced with the $CONTAINERROOT/user-software.squashfs file).
That directory struture was chosen to (a) make it possible to install a second virtual environment in /user-software/venv while (b) also leaving space to install software by hand in /user-software and hence create a bin and lib subdirectory in those (though they currently are not automatically added to the search paths for executables and shared libraries in the container).
The whole process is very simple with those containers that already have a pre-initialised virtual environment as the module already intialises several environment variables in the container that have the combined effect of activating both the Conda installation and then on top of it, the default Python virtual environment.
Outside the container, we need to load the container module, and then we can easily go into the container using the SIF environment variable to point to its name:
module load LUMI\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\nsingularity shell $SIF\n
and in the container, at the Singularity> prompt, we can use pip install without extra options, e.g.,
pip install pytorch-lightning\n
As already discussed before in this session of the tutorial, such a Python virtual environment has the potential to create a lot of small files in the Lustre $CONTAINERROOT/user-software subdirectory, which can wipe out all benefits we got from using a container for the Python installation. But our modules with virtual environment support offer a solution for this also: the make-squashfs command (which should be run outside the container) will convert the user-software subdirectory in $CONTAINERROOT into the SquashFS file user-software.squashfs which, after reloading the module, will be used to provide the /user-software subdirectory in the container. The downside is that now /user-software is read-only as it comes from the SquashFS file. To install further packages, you'd have to remove the user-software.squashfs file again and reload the container module.
Currently the make-squashfs file will not remove the $CONTAINERROOT/user-software subdirectory, but once you have verified that the SquashFS file is OK and useable in the container, you can safely delete it yourself. We also provide the unmake-squasfs script to re-generate the $CONTAINERROOT/user-software subdirectory (though attribues such as file time, etc., will not be the same as before).
It is of course possible to use this technique with all Python containers, but you may have to do a lot more steps by hand, such as adding the binding for a directory for the virtual environment, creating and activating the environment, and replacing the directory with a SquashFS file to improve file system performance.
"},{"location":"2day-20240502/09_Containers/#conclusion-container-limitations-on-lumi","title":"Conclusion: Container limitations on LUMI","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance. Also, containers do not abstract the hardware unlike some virtual machine solutions.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the Slingshot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
Likewise, for containers for distributed AI, one may need to inject an appropriate RCCL plugin to fully use the Slingshot 11 interconnect.
-
As containers rely on drivers in the kernel of the host OS, the AMD driver may also cause problems. AMD only guarantees compatibility of the driver with two minor versions before and after the ROCm release for which the driver was meant. Hence containers using a very old version of ROCm or a very new version compared to what is available on LUMI, may not always work as expected.
-
The support for building containers on LUMI is currently very limited due to security concerns. Any build process that requires elevated privileges, fakeroot or user namespaces will not work.
"},{"location":"2day-20240502/10_Support/","title":"LUMI Support and Documentation","text":""},{"location":"2day-20240502/10_Support/#distributed-nature-of-lumi-support","title":"Distributed nature of LUMI support","text":"User support for LUMI comes from several parties. Unfortunately, as every participating consortium countries has some responsibilities also and solves things differently, there is no central point where you can go with all questions.
Resource allocators work independently from each other and the central LUMI User Support Team. This also implies that they are the only ones who can help you with questions regarding your allocation: How to apply for compute time on LUMI, add users to your project, running out of resources (billing units) for your project, failure to even get access to the portal managing the allocations given by your resource allocator (e.g., because you let expire an invite), ... For granted EuroHPC projects, support is available via lumi-customer-accounts@csc.fi, but you will have to contact EuroHPC directly at access@eurohpc-ju.europa.eu if, e.g., you need more resources or an extension to your project.
The central LUMI User Support Team (LUST) offers L1 and basic L2 support. Given that the LUST team is very small compared to the number of project granted annually on LUMI (roughly 10 FTE for on the order of 700 projects per year, and support is not their only task), it is clear that the amount of support they can give is limited. E.g., don't expect them to install all software you request for them. There is simply too much software and too much software with badly written install code to do that with that number of people. Nor should you expect domain expertise from them. Though several members of the LUST have been scientist before, it does not mean that they can understand all scientific problems thrown at them or all codes used by users. Also, the team cannot fix bugs for you in the codes that you use, and usually not in the system code either. For fixing bugs in HPE or AMD-provided software, they are backed by a team of experts from those companies. However, fixing bugs in compilers or libraries and implementing those changes on the system takes time. The system software on a big shared machine cannot be upgraded as easily as on a personal workstation. Usually you will have to look for workarounds, or if they show up in a preparatory project, postpone applying for an allocation until all problems are fixed.
EuroHPC has also granted the EPICURE project that started in February 2024 to set up a network for advanced L2 and L3 support across EuroHPC centres. At the time of the course, the project is still in its startup phase. Moreover, this project is also so small that it will have to select the problems they tackle.
In principle the EuroHPC Centres of Excellence should also play a role in porting some applications in their field of expertise and offer some support and training, but so far especially the support and training are not yet what one would like to have.
Basically given the growing complexity of scientific computing and diversity in the software field, what one needs is the equivalent of the \"lab technician\" that many experimental groups have who can then work with various support instances, a so-called Research Software Engineer...
"},{"location":"2day-20240502/10_Support/#support-level-0-help-yourself","title":"Support level 0: Help yourself!","text":"Support starts with taking responsibility yourself and use the available sources of information before contacting support. Support is not meant to be a search assistant for already available information.
The LUMI User Support Team has prepared trainings and a lot of documentation about LUMI. Good software packages also come with documentation, and usually it is possible to find trainings for major packages. And a support team is also not there to solve communication problems in the team in which you collaborate on a project!
"},{"location":"2day-20240502/10_Support/#take-a-training","title":"Take a training!","text":"There exist system-specific and application-specific trainings. Ideally of course a user would want a one-step solution, having a specific training for a specific application on a specific system (and preferably with the workflow tools they will be using, if any), but that is simply not possible. The group that would be interested in such a training is for most packages too small, and it is nearly impossible to find suitable teachers for such course given the amount of expertise that is needed in both the specific application and the specific system. It would also be hard to repeat such a training with a high enough frequency to deal with the continuous inflow of new users.
The LUMI User Support Team organises 2 system-specific trainings:
-
There is a 1- or 2-day introductory course entirely given by members of the LUST. The training does assume familiarity with HPC systems, and each local organisation should offer such courses for their local systems already.
-
And there is a 4-day comprehensive training with more attention on how to run efficiently, and on the development and profiling tools. Even if you are not a developer, you may benefit from more knowledge about these tools as especially a profiler can give you insight in why your application does not run as expected.
Application-specific trainings should come from other instances though that have the necessary domain knowledge: Groups that develop the applications, user groups, the EuroHPC Centres of Excellence, ...
Currently the training landscape in Europe is not too well organised. EuroHPC is starting some new training initiatives to succeed the excellent PRACE trainings. Moreover, CASTIEL, the centre coordinating the National Competence Centres and EuroHPC Centres of Excellence also tries to maintain an overview of available trainings (and several National Competence Centres organise trainings open to others also).
"},{"location":"2day-20240502/10_Support/#readsearch-the-documentation","title":"Read/search the documentation","text":"The LUST has developed extensive documentation for LUMI. That documentation is split in two parts:
-
The main documentation at docs.lumi-supercomputer.eu covers the LUMI system itself and includes topics such as how to get on the system, where to place your files, how to start jobs, how to use the programming environment, how to install software, etc.
-
The LUMI Software Library contains an overview of software pre-installed on LUMI or for which we have install recipes to start from. For some software packages, it also contains additional information on how to use the software on LUMI.
That part of the documentation is generated automatically from information in the various repositories that are used to manage those installation recipes. It is kept deliberately separate, partly to have a more focused search in both documentation systems and partly because it is managed and updated very differently.
Both documentation systems contain a search box which may help you find pages if you cannot find them easily navigating the documentation structure. E.g., you may use the search box in the LUMI Software Library to search for a specific package as it may be bundled with other packages in a single module with a different name.
Some examples:
-
Search in the main documentation at docs.lumi-supercomputer.eu for \"quota\" and it will take you to pages that among other things explain how much quota you have in what partition.
-
Users of the Finnish national systems have been told to use a tool called \"Tykky\" to pack conda and Python installations to reduce the stress on the filesystems and wonder if that tool is also on LUMI. So let's search in the LUMI Software Library:
It is, but with a different name as foreigners can't pronounce those Finnish names anyway and as something more descriptive was needed.
-
Try searching for the htop command in the LUMI Software Library
So yes, htop is on LUMI, but if you read the page you'll see it is in a module together with some other small tools.
"},{"location":"2day-20240502/10_Support/#talk-to-your-colleagues","title":"Talk to your colleagues","text":"A LUMI project is meant to correspond to a coherent research project in which usually multiple people collaborate.
This implies that your colleagues may have run in the same problem and may already have a solution, or they didn't even experience it as a problem and know how to do it. So talk to your colleagues first.
Support teams are not meant to deal with your team's communication problems. There is nothing worse than having the same question asked multiple times from different people in the same project. As a project does not have a dedicated support engineer, the second time a question is asked it may land at a different person in the support team so that it is not recognized that the question has been asked already and the answer is readily available, resulting in a loss of time for the support team and other, maybe more important questions, remaining unanswered. Similarly bad is contacting multiple help desks with the same question without telling them, as that will also duplicate efforts to solve a question. We've seen it often that users contact both a local help desk and the LUST help desk without telling.
Resources on LUMI are managed on a project basis, not on a user-in-project basis, so if you want to know what other users in the same project are doing with the resources, you have to talk to them and not to the LUST. We do not have systems in place to monitor use on a per-user, per-project basis, only on a per-project basis, and also have no plans to develop such tools as a project is meant to be a close collaboration of all involved users.
LUMI events and on-site courses are also an excellent opportunity to network with more remote colleagues and learn from them! Which is why we favour on-site participation for courses. No video conferencing system can give you the same experience as being physically present at a course or event.
"},{"location":"2day-20240502/10_Support/#l1-and-basic-l2-support-lust","title":"L1 and basic L2 support: LUST","text":"The LUMI User Support Team is responsible for providing L1 and basic L2 support to users of the system. Their work starts from the moment that you have userid on LUMI (the local RA is responsible for ensuring that you get a userid when a project has been assigned).
The LUST is a distributed team roughly 10 FTE strong, with people in all LUMI consortium countries, but they work as a team, coordinated by CSC. 10 of the LUMI consortium countries each have one or more members in LUST. However, you will not necessarily be helped by one of the team members from your own country, even when you are in a consortium country, when you contact LUST, but by the team member who is most familiar with your problem.
There are some problems that we need to pass on to HPE or AMD, particularly if it may be caused by bugs in system software, but also because they have more experts with in-depth knowledge of very specific tools.
The LUMI help desk is staffed from Monday till Friday between 8am and 6pm Amsterdam time (CE(S)T) except on public holidays in Finland. You can expect a same day first response if your support query is well formulated and submitted long enough before closing time, but a full solution of your problem may of course take longer, depending on how busy the help desk is and the complexity of the problem.
Data security on LUMI is very important. Some LUMI projects may host confidential data, and especially industrial LUMI users may have big concerns about who can access their data. Therefore only very, very few people on LUMI have the necessary rights to access user data on the system, and those people even went through a background check. The LUST members do not have that level of access, so we cannot see your data and you will have to pass all relevant information to the LUST through other means!
The LUST help desk should be contacted through web forms in the \"User Support - Contact Us\" section of the main LUMI web site. The page is also linked from the \"Help Desk\" page in the LUMI documentation. These forms help you to provide more information that we need to deal with your support request. Please do not email directly to the support web address (that you will know as soon as we answer at ticket as that is done through e-mail). Also, separate issues should go in separate tickets so that separate people in the LUST can deal with them, and you should not reopen an old ticket for a new question, also because then only the person who dealt with the previous ticket gets notified, and they may be on vacation or even not work for LUMI anymore, so your new request may remain unnoticed for a long time.
"},{"location":"2day-20240502/10_Support/#tips-for-writing-good-tickets-that-we-can-answer-promptly","title":"Tips for writing good tickets that we can answer promptly","text":""},{"location":"2day-20240502/10_Support/#how-not-to-write-a-ticket","title":"How not to write a ticket","text":" -
Use a meaningful subject line. All we see in the ticket overview is a number and the subject line, so we need to find back a ticket we're working on based on that information alone.
Yes, we have a user on LUMI who managed to send 8 tickets in a short time with the subject line \"Geoscience\" but 8 rather different problems...
Hints:
- For common problems, including your name in the subject may be a good idea.
- For software problems, including the name of the package helps a lot. So not \"Missing software\" but \"Need help installing QuTiP 4.3.1 on CPU\". Or not \"Program crashes\" but \"UppASD returns an MPI error when using more than 1000 ranks\".
-
Be accurate when describing the problem. Support staff members are not clairvoyants with mysterious superpowers who can read your mind across the internet.
We'll discuss this a bit more further in this lecture.
-
If you have no time to work with us on the problem yourself, then tell so.
Note: The priorities added to the ticket are currently rather confusing. You have three choices in the forms: \"It affects severely my work\", \"It is annoying, but I can work\", and \"I can continue to work normally\", which map to \"high\", \"medium\" and \"low\". So tickets are very easily marked as high priority because you cannot work on LUMI, even though you have so much other work to do that it is really not that urgent or that you don't even have time to answer quickly.
The improved version could be something like this:
"},{"location":"2day-20240502/10_Support/#how-to-write-tickets","title":"How to write tickets","text":""},{"location":"2day-20240502/10_Support/#1-ticket-1-issue-1-ticket","title":"1 ticket = 1 issue = 1 ticket","text":" -
If you have multiple unrelated issues, submit them as multiple tickets. In a support team, each member has their own specialisation so different issues may end up with different people. Tickets need to be assigned to people who will deal with the problem, and it becomes very inefficient if multiple people have to work on different parts of the ticket simultaneously.
Moreover, the communication in a ticket will also become very confusing if multiple issues are discussed simultaneously.
-
Conversely, don't submit multiple tickets for a single issue just because you are too lazy to look for the previous e-mail if you haven't been able to do your part of the work for some days. If you've really lost the email, at least tell us that it is related to a previous ticket so that we can try to find it back.
So keep the emails you get from the help desk to reply!
-
Avoid reusing exactly the same subject line. Surely there must be something different for the new problem?
-
Avoid reopening old tickets that have been closed long ago.
If you get a message that a ticket has been closed (basically because there has been no reply for several weeks so we assume the issue is not relevant anymore) and you feel it should not have been closed, reply immediately.
When you reply to a closed ticket and the person who did the ticket is not around (e.g., on vacation or left the help desk team), your reply may get unnoticed for weeks. Closed tickets are not passed to a colleague when we go on a holiday or leave.
-
Certainly do not reopen old tickets with new issues. Apart from the fact that the person who did the ticket before may not be around, they may also have no time to deal with the ticket quickly or may not even be the right person to deal with it.
"},{"location":"2day-20240502/10_Support/#the-subject-line-is-important","title":"The subject line is important!","text":" -
The support team has two identifiers in your ticket: Your mail address and the subject that you specified in the form (LUST help desk) or email (LUMI-BE help desk). So:
-
Use consistently the same mail address for tickets. This helps us locate previous requests from you and hence can give us more background about what you are trying to do.
The help desk is a professional service, and you use LUMI for professional work, so use your company or university mail address and not some private one.
-
Make sure your subject line is already descriptive and likely unique in our system.
We use the subject line to distinguish between tickets we're dealing with so make sure that it can easily be distinguished from others and is easy to find back.
-
So include relevant keywords in your subject, e.g.,
Some proper examples are
-
User abcdefgh cannot log in via web interface
So we know we may have to pass this to our Open OnDemand experts, and your userid makes the message likely unique. Moreover, after looking into account databases etc., we can immediately find back the ticket as the userid is in the subject.
-
ICON installation needs libxml2
-
VASP produces MPI error message when using more than 1024 ranks
"},{"location":"2day-20240502/10_Support/#think-with-us","title":"Think with us","text":" -
Provide enough information for us to understand who you are:
-
Name: and the name as we would see it on the system, not some nickname.
-
Userid: Important especially for login problems.
-
Project number:
- When talking to the LUST: they don't know EuroHPC or your local organisation's project numbers, only the 462xxxxxx and 465xxxxxx numbers, and that is what they need.
- If you have a local support organisation though, the local project number may be useful for them, as it may then land with someone who does not have access to the LUMI project numbers of all projects they manage.
-
For login and data transfer problems, your client environment is often also important to diagnose the problem.
-
What software are you using, and how was it installed or where did you find it?
We know that certain installation procedures (e.g., simply downloading a binary) may cause certain problems on LUMI. Also, there are some software installations on LUMI for which neither LUST nor the local help desk is responsible, so we need to direct to to their support instances when problems occur that are likely related to that software.
-
Describe your environment (though experience learns that some errors are caused by users not even remembering they've changed things while those changes can cause problems)
-
Which modules are you using?
-
Do you have special stuff in .bashrc or .profile?
-
For problems with running jobs, the batch script that you are using can be very useful.
-
Describe what worked so far, and if it ever worked: when? E.g., was this before a system update?
The LUST has had tickets were a user told that something worked before but as we questioned further it was long ago before a system update that we know broke some things that affects some programs...
-
What did you change since then? Think carefully about that. When something worked some time ago but doesn't work know the cause is very often something you changed as a user and not something going on on the system.
-
What did you already try to solve the problem?
-
How can we reproduce the problem? A simple and quick reproducer speeds up the time to answer your ticket. Conversely, if it takes a 24-hour run on 256 nodes to see the problem it is very, very likely that the support team cannot help you.
Moreover, if you are using licensed software with a license that does not cover the support team members, usually we cannot do much for you. LUST will knowingly violate software licenses only to solve your problems (and neither will your local support team)!
-
The LUST help desk members know a lot about LUMI but they are (usually) not researchers in your field so cannot help you with problems that require domain knowledge in your field. We can impossibly know all software packages and tell you how to use them (and, e.g., correct errors in your input files). And the same likely holds for your local support organisation.
You as a user should be the domain expert, and since you are doing computational science, somewhat multidisciplinary and know something about both the \"computational\" and the \"science\".
We as the support team should be the expert in the \"computational\". Some of us where researchers in the past so have some domain knowledge about a the specific subfield we were working in, but there are simply too many scientific domains and subdomains to have full coverage of that in a central support team for a generic infrastructure.
We do see that lots of crashes and performance problems with software are in fact caused by wrong use of the package!
However, some users expect that we understand the science they are doing, find the errors in their model and run that on LUMI, preferably by the evening they submitted the ticket. If we could do that, then we could basically make a Ph.D that usually takes 4 years in 4 weeks and wouldn't need users anymore as it would be more fun to produce the science that our funding agencies expect ourselves.
-
The LUST help desk members know a lot about LUMI but cannot know or solve everything and may need to pass your problem to other instances, and in particular HPE or AMD.
Debugging system software is not the task of the of the LUST. Issues with compilers or libraries can only be solved by those instances that produce those compilers or libraries, and this takes time.
We have a way of working that enables us to quickly let users test changes to software in the user software stack by making user installations relatively easy and reproducible using EasyBuild, but changing the software installed in the system images - which includes the Cray programming environment - where changes have an effect on how the system runs and can affect all users, are non-trivial and many of those changes can only be made during maintenance breaks.
"},{"location":"2day-20240502/10_Support/#beware-of-the-xy-problem","title":"Beware of the XY-problem!","text":"Partly quoting from xyproblem.info: Users are often tempted to ask questions about the solution they have in mind and where they got stuck, while it may actually be the wrong solution to the actual problem. As a result one can waste a lot of time attempting to get the solution they have in mind to work, while at the end it turns out that that solution does not work. It goes as follows:
- The user wants to do X.
- The user doesn't really know how to do X. However, they think that doing Y first would be a good step towards solving X.
- But the user doesn't really know how to do Y either and gets stuck there too.
- So the user contacts the help desk to help with solving problem Y.
- The help desk tries to help with solving Y, but is confused because Y seems a very strange and unusual problem to solve.
- Once Y is solved with the help of the help desk, the user is still stuck and cannot solve X yet.
- User contacts the help desk again for further help and it turns out that Y wasn't needed in the first place as it is not part of a suitable solution for X.
Or as one of the colleagues of the author of these notes says: \"Often the help desk knows the solution, but doesn't know the problem so cannot give the solution.\"
To prevent this, you as a user has to be complete in your description:
-
Give the broader problem and intent (so X), not just the small problem (Y) on which you got stuck.
-
Promptly provide information when the help desk asks you, even if you think that information is irrelevant. The help desk team member may have a very different look on the problem and come up with a solution that you couldn't think of, and you may be too focused on the solution that you have in mind to see a better solution.
-
Being complete also means that if you ruled out some solutions, share with the help desk why you ruled them out as it can help the help desk team member to understand what you really want.
After all, if your analysis of your problem was fully correct, you wouldn't need to ask for help, don't you?
"},{"location":"2day-20240502/10_Support/#what-support-can-we-offer","title":"What support can we offer?","text":""},{"location":"2day-20240502/10_Support/#restrictions","title":"Restrictions","text":"Contrary to what you may be familiar with from your local Tier-2 system and support staff, team members of the LUMI help desks have no elevated privileges. This holds for both the LUST and LUMI-BE help desk.
As a result,
-
We cannot access user files. A specific person of the LUMI-BE help desk can access your project, scratch and flash folders if you make them part of the project. This requires a few steps and therefore is only done for a longer collaboration between a LUMI project and that help desk member. The LUST members don't do that.
-
Help desk team members cannot install or modify system packages or settings.
A good sysadmin usually wouldn't do so either. You are working on a multi-user system and you have to take into account that any change that is beneficial for you, may have adverse effects for other users or for the system as a whole.
E.g., installing additional software in the images takes away from the available memory on each node, slows down the system boot slightly, and can conflict with software that is installed through other ways.
-
The help desk cannot extend the walltime of jobs.
Requests are never granted, even not if the extended wall time would still be within the limits of the partition.
-
The LUST is in close contact with the sysadmins, but as the sysadmins are very busy people they will not promptly deal with any problem. Any problem though endangering the stability of the system gets a high priority.
-
The help desk does not monitor running jobs. Sysadmins monitor the general health of the system, but will not try to pick out inefficient jobs unless the job does something that has a very negative effect on the system.
"},{"location":"2day-20240502/10_Support/#what-support-can-and-cannot-do","title":"What support can and cannot do","text":" -
The LUST help desk does not replace a good introductory HPC course nor is it a search engine for the documentation. L0 support is the responsibility of every user.
-
Resource allocators are responsible for the first steps in getting a project and userid on LUMI. EuroHPC projects the support is offered through CSC, the operator of LUMI, at lumi-customer-accounts@csc.fi, or by EuroHPC itself at access@eurohpc-ju.europa.eu if you have not yet been granted a project by them.
Once your project is created and accepted (and the resource allocator can confirm that you properly accepted the invitation), support for account problems (in particular login problems) moves to the LUST.
-
If you run out of block or file quota, the LUST can increase your quota within the limits specified in the LUMI documentation.
If you run out of billing units for compute or storage, only the instance that granted your project can help you, your resource allocator for local projects and access@eurohpc-ju.europa.eu for EuroHPC projects (CSC EuroHPC support at lumi-customer-accounts@csc.fi cannot help you directly for project extensions and increase of billing units).
Projects cannot be extended past one year unless the granting instance is willing to take a charge on the annual budget for the remaining billing units.
-
The LUST cannot do much complete software installations but often can give useful advice and do some of the work.
Note however that the LUST may not even be allowed to help you due to software license restrictions. Moreover, LUST has technically speaking a zone where they can install software on the system, but this is only done for software that the LUST can properly support across system updates and that is of interest to a wide enough audience. It is also not done for software where many users may want a specifically customised installation. Neither is it done for software that LUST cannot sufficiently test themselves.
-
The LUST can help with questions regarding compute and storage use. LUST provides L1 and basic L2 support. These are basically problems that can solved in hours rather than days or weeks. More advanced support has to come from other channels though, including support efforts from your local organisation, EuroHPC Centres of Excellence, EPICURE, ...
-
The LUST can help with analysing the source of crashes or poor performance, with the emphasis on help as they rarely have all the application knowledge required to dig deep. And it will still require a significant effort from your side also.
-
However, LUST is not a debugging service (though of course we do take responsibility for code that we developed).
-
The LUST has some resources for work on porting and optimising codes to/for AMD GPUs via porting calls and hackathons respectively. But we are not a general code porting and optimisation service. And even in the porting call projects, you are responsible for doing the majority of the work, LUST only supports.
-
The LUST cannot do your science or solve your science problems though.
Remember:
\"Supercomputer support is there to support you in the computational aspects of your work related to the supercomputer but not to take over your work.\"
Any support will always be a collaboration where you may have to do most of the work. Supercomputer support services are not a free replacement of a research software engineer (the equivalent of the lab assistant that many experimental groups have).
"},{"location":"2day-20240502/10_Support/#links","title":"Links","text":""},{"location":"2day-20240502/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"2day-20240502/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.10, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCD 3.11 User Guide
"},{"location":"2day-20240502/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc (no online manual page, load cray-libsci_acc to see the manual page on the system)
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3 (with cray-fftw loaded)
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"2day-20240502/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"2day-20240502/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"2day-20240502/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
GENCI Adastra documentation. Adastra is another system similar to LUMI. Its GPU nodes are the same as on LUMI (but it also has a small partition with the newer MI300A APUs) while the CPU partition uses the newer zen4/Genoa generation AMD EPYC CPUs.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"2day-20240502/Demo1/","title":"Demo 1: Fooocus","text":""},{"location":"2day-20240502/Demo1/#description-of-the-demo","title":"Description of the demo","text":"Fooocus is an AI-based image generating package that is available under the GNU General Public License V3.
The version on which we first prepared this demo, insists on writing in the directories with some of the Fooocus files, so we cannot put Fooocus in a container at the moment.
It is based on PyTorch. However, we cannot use the containers provided on LUMI as-is as additional system level libraries are needed for the graphics.
This demo shows:
-
Installing one of the containers provided on LUMI with EasyBuild,
-
Installing additional software in the container with the SingularityCE \"unprivileged proot builds\" process and the SUSE Linux zypper install tool,
-
Further adding packages in a virtual environment and putting them in a SquashFS file for better file system performance, and
-
Using that setup with Fooocus.
"},{"location":"2day-20240502/Demo1/#video-of-the-demo","title":"Video of the demo","text":""},{"location":"2day-20240502/Demo1/#notes","title":"Notes","text":""},{"location":"2day-20240502/Demo1/#step-1-checking-fooocus","title":"Step 1: Checking Fooocus","text":"Let's create an installation directory for the demo. Set the environment variable installdir to a proper value for the directories on LUMI that you have access to.
installdir=/project/project_465001102/kurtlust/DEMO1\nmkdir -p \"$installdir\" ; cd \"$installdir\"\n
We are now in the installation directory of which we also ensured its existence first. Let's now download and unpack Fooocus release 2.3.1 (the one we tested for this demo)
fooocusversion=2.3.1\nwget https://github.com/lllyasviel/Fooocus/archive/refs/tags/$fooocusversion.zip\nunzip $fooocusversion.zip\nrm -f $fooocusversion.zip\n
If we check what's in the Fooocus directory:
ls Fooocus-$fooocusversion\n
we see a rather messy bunch of mostly Python files missing the traditional setup scripts that you expect with a Python package. So installing this could become a messy thing...
It also contains a Dockerfile (to build a base Docker container), a requirements_docker.txt and a requirements_versions.txt file that give hints about what exactly is needed. The Dockerfile suggests close to the top that some OpenGL libraries will be needed. And the fact that it can be fully installed in a docker container also indicates that there must in fact be ways to run it in readonly directories, but in this demo we'll put Fooocus in a place were it can write. The requirements_docker.txt file also suggests to use Pytorch 2.0, but we'll take some risks though and use a newer version of PyTorch than suggested as for AMD GPUs it is often important to use recently enough versions (and because that version has a more sophisticated module better suited for what we want to demonstrate).
"},{"location":"2day-20240502/Demo1/#step-2-install-the-pytorch-container","title":"Step 2: Install the PyTorch container","text":"We can find an overview of the available PyTorch containers on the PyTorch page in the LUMI Software Library. We'll use a version that already has support for Python virtual environments built in as that will make it a lot easier to install extra Python packages. Moreover, as we have also seen that we will need to change the container, we'll follow a somewhat atypical build process.
Rather than installing directly from the available EasyBuild recipes, we'll edit an EasyConfig to change the name to reflect that we have made changes and installed Fooocus with it. First we must prepare a temporary directory to do this work and also set up EasyBuild:
mkdir -p \"$installdir/tmp\" ; cd \"$installdir/tmp\"\nmodule purge\nmodule load LUMI/23.09 partition/container EasyBuild-user\n
We'll now use a function of EasyBuild to copy an existing EasyConfig file to a new location, and rename it in one move to reflect the module version that we want:
eb --copy-ec PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
This is not enough to generate a module PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315, we also need to edit the versionsuffix line in the EasyBuild recipe. Of course you can do this easily with your favourite editor, but to avoid errors we'll use a command for the demo that you only need to copy:
sed -e \"s|^\\(versionsuffix.*\\)-singularity-20240315|\\1-Fooocus-singularity-20240315|\" -i PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
Let's check:
grep versionsuffix PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
which returns
versionsuffix = f'-rocm-{local_c_rocm_version}-python-{local_c_python_mm}-Fooocus-singularity-20240315'\n
so we see that the versionsuffix line looks rather strange but we do see that the -Fooocus- part is injected in the name so we assume everything is OK.
We're now ready to install the container with EasyBuild:
eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
The documentation in the PyTorch page in the LUMI Software Library suggests that we can now delete the container file in the installation directory, but this is a bad idea in this case as we want to build our own container and hence will not use one of the containers provided on the system while running.
We're now finished with EasyBuild so don't need the modules related to EasyBuild anymore. So lets's clean the environment an load the PyTorch container module that we just built with EasyBuild:
module purge\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Notice that we don't need to load partition/container anymore. Any partition would do, and in fact, we can even use CrayEnv instead of LUMI/23.09.
Notice that the container module provides the environment variables SIF and SIFPYTORCH, both of which point to the .sif file of the container:
echo $SIF\necho $SIFPYTORCH\n
We'll make use of that when we add SUSE packages to the container.
"},{"location":"2day-20240502/Demo1/#step-3-adding-some-suse-packages","title":"Step 3: Adding some SUSE packages","text":"To update the singularity container, we need three things.
First, the PyTorch module cannot be loaded as it sets a number of singularity-related environment variables. Yet we want to use the value of SIF, so we will simply save it in a different environment variable before unloading the module:
export CONTAINERFILE=\"$SIF\"\nmodule unload PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Second, the proot command is not available by default on LUMI, but it can be enabled by loading the systools module in LUMI/23.09 or newer stacks, or systools/23.09 or newer in CrayEnv:
module load systools\n
Third, we need a file defining the build process for singularity. This is a bit technical and outside the scope of this tutorial to explain what goes into this file. It can be created with the following shell command:
cat > lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def <<EOF\n\nBootstrap: localimage\n\nFrom: $CONTAINERFILE\n\n%post\n\nzypper -n install -y Mesa libglvnd libgthread-2_0-0 hostname\n\nEOF\n
You can check the file with
cat lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def\n
We basically install an OpenGL library that emulates on the CPU and some missing tools. Note that the AMD MI250X GPUs are not rendering GPUs, so we cannot run hardware accelerated rendering on them.
An annoying element of the singularity build procedure is that it is not very friendly for a Lustre filesystem. We'll do the build process on a login node, where we have access to a personal RAM disk area that will also be cleaned automatically when we log out, which is always useful for a demo. Therefore we need to set two environment variables for Singularity, and create two directories, which is done with the following commands:
export SINGULARITY_CACHEDIR=$XDG_RUNTIME_DIR/singularity/cache\nexport SINGULARITY_TMPDIR=$XDG_RUNTIME_DIR/singularity/tmp\n\nmkdir -p $SINGULARITY_CACHEDIR\nmkdir -p $SINGULARITY_TMPDIR\n
Now we're ready to do the actual magic and rebuild the container with additional packages installed in it:
singularity build $CONTAINERFILE lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def\n
The build process will ask you if you want to continue as it will overwrite the container file, so confirm with y. The whole build process may take a couple of minutes.
We'll be kind to our fellow LUMI users and already clean up the directories that we just created:
rm -rf $XDG_RUNTIME_DIR/singularity\n
Let's reload the container:
module load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
and do some checks:
singularity shell $SIF\n
brings us into the container (note that the command prompt has changed).
The command
which python\n
returns
/user-software/venv/pytorch/bin/python\n
which shows that the virtual environment pre-installed in the container is indeed active.
We do have the hostname command in the container (one of the packages mentioned in the container .def file that we created) as is easily tested:
hostname\n
and
ls /usr/lib64/*mesa*\n
shows that indeed a number of MESA libraries are installed (the OpenGL installation that we did).
We can now leave the container with the
exit\n
command (or CTRL-D key combination).
So it looks we are ready to start installing Python packages...
"},{"location":"2day-20240502/Demo1/#step-4-adding-python-packages","title":"Step 4: Adding Python packages","text":"To install the packages, we'll use the requirements_versions.txt file which we found in the Fooocus directories. The installation has to happen from within the container though. So let's got to the Fooocus directory and go into the container again:
cd \"$installdir/Fooocus-$fooocusversion\"\nsingularity shell $SIF\n
We'll install the extra packages simply with the pip tool:
pip install -r requirements_versions.txt\n
This process may again take a few minutes.
After finishing,
ls /user-software/venv/pytorch/lib/python3.10/site-packages/\n
shows that indeed a lot of packages have been installed. Though accessible from the container, they are not in the container .sif file as that file cannot be written.
Let's leave the container again:
exit\n
Now try:
ls $CONTAINERROOT/user-software/venv/pytorch/lib/python3.10/site-packages/\n
and notice that we see the same long list of packages. In fact, a trick to see the number of files and directories is
lfs find $CONTAINERROOT/user-software/venv/pytorch/lib/python3.10/site-packages | wc -l\n
which prints the name of all files and directories and then counts the number of lines, and we see that this is a considerable number. Lustre isn't really that fond of it. However, the module also provides an easy solution: We can convert the $EBROOTPYTORCH/user-software subdirectory into a SquashFS file that can be mounted as a filesystem in the container, and the module provides all the tools to make this easy to do. All we need to do is to run
make-squashfs\n
This will also take some time as the script limits the resources the make-squashfs can use to keep the load on the login nodes low. Now we can then safely remove the user-software subdirectory:
rm -rf $CONTAINERROOT/user-software\n
Before continuing, we do need to reload the module so that the bindings between the container and files and directories on LUMI are reset:
module load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Just check
singularity exec $SIF ls /user-software/venv/pytorch/lib/python3.10/site-packages\n
and see that our package installation is still there!
However, we can no longer write in that directory. E.g., try
touch /user-software/test\n
to create an empty file test in /user-software and note that we get an error message.
So now we are ready-to-run.
"},{"location":"2day-20240502/Demo1/#the-reward-running-fooocus","title":"The reward: Running Fooocus","text":"First confirm we'll in the directory containing the Fooocus package (which should be the case if you followed these instructions):
cd \"$installdir/Fooocus-$fooocusversion\"\n
We'll start an interactive job with a single GPU:
srun -psmall-g -n1 -c7 --time=30:00 --gpus=1 --mem=60G -A project_465001102 --pty bash\n
The necessary modules will still be available, but if you are running from a new shell, you can load them again:
module load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Also check the hostname if it is not part of your prompt as you will need it later:
hostname\n
We can now go into the container:
singularity shell $SIF\n
and launch Fooocus:
python launch.py --listen --disable-xformers\n
Fooocus provides a web interface. If you're the only one on the node using Fooocus, it should run on port 7865. To access it from our laptop, we need to create an SSH tunnel to LUMI. The precise statement needed for this will depend on your ssh implementation. Assuming you've define a lumi rule in the ssh config file to make life easy and use an OpenSSH-style ssh client, you can use:
ssh -N -L 7865:nid00XXXX:7865 lumi\n
replacing with the node name that we got from the hostname command`.
Next, simply open a web browser on your laptop and point to
http://localhost:7865\n
"},{"location":"2day-20240502/Demo1/#alternative-way-of-running","title":"Alternative way of running","text":"We can also launch Fooocus directly from the srun command, e.g., from the directory containing the Fooocus code,
module load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\nsrun -psmall-g -n1 -c7 --time=30:00 --gpus=1 --mem=60G -A project_465001102 --pty \\\n bash -c 'echo -e \"Running on $(hostname)\\n\" ; singularity exec $SIF python launch.py --listen --disable-xformers'\n
It will also print the host name on which the Fooocus is running, so you can connect to Fooocus using the same procedure as above.
"},{"location":"2day-20240502/Demo1/#further-discovery","title":"Further discovery","text":" - YouTube channel \"Jump Into AI\" has a Fooocus playlist
"},{"location":"2day-20240502/Demo2/","title":"Demo option 2: A short walk-through for distributed learning","text":""},{"location":"2day-20240502/Demo2/#description-of-the-demo","title":"Description of the demo","text":"In this demo, we will install one of the PyTorch containers provided on LUMI and run a simple distributed learning example that the LUMI User Support Team also uses for internal testing.
The demo follows largely the instructions for distributed learning from the PyTorch page in the LUMI Software Library.
This demo shows:
"},{"location":"2day-20240502/Demo2/#video-of-the-demo","title":"Video of the demo","text":""},{"location":"2day-20240502/Demo2/#notes","title":"Notes","text":""},{"location":"2day-20240502/Demo2/#step-1-getting-some-files-that-we-will-use","title":"Step 1: Getting some files that we will use","text":"Let's create an installation directory for the demo. Set the environment variable installdir to a proper value for the directories on LUMI that you have access to.
installdir=/project/project_465001102/kurtlust/DEMO2\nmkdir -p \"$installdir\" ; cd \"$installdir\"\n
We are now in the installation directory of which we also ensured its existence first. Let's now download some files that we will use:
wget https://raw.githubusercontent.com/Lumi-supercomputer/lumi-reframe-tests/main/checks/containers/ML_containers/src/pytorch/mnist/mnist_DDP.py\nmkdir -p model ; cd model\nwget https://github.com/Lumi-supercomputer/lumi-reframe-tests/raw/main/checks/containers/ML_containers/src/pytorch/mnist/model/model_gpu.dat\ncd ..\n
The first two files are actually files that were developed for testing some PyTorch containers on LUMI after system upgrades.
The demo also uses a popular dataset (one of the MNIST datasets) from Yann LeCun, a data scientist at Meta. The pointers to the dataset are actually included in the torchvision package which is why it is not easy to track where the data comes from. The script that we use will download the data if it is not present, but does so on each process, leading to a high load on the web server providing the data and throttling after a few tries, so we will prepare the data instead in the $installdir subdirectory:
mkdir -p data/MNIST/raw\nwget --recursive --level=1 --cut-dirs=3 --no-host-directories \\\n --directory-prefix=data/MNIST/raw --accept '*.gz' http://yann.lecun.com/exdb/mnist/\ngunzip data/MNIST/raw/*.gz\nfor i in $(seq 0 31); do ln -s data \"data$i\"; done\n
"},{"location":"2day-20240502/Demo2/#step-2-installing-the-container","title":"Step 2: Installing the container","text":"We can find an overview of the available PyTorch containers on the PyTorch page in the LUMI Software Library. We'll use a version that already has support for Python virtual environments built in as that will make it a lot easier to install extra Python packages.
First we need to load and configure EasyBuild and make sure that EasyBuild can run in a clean environment:
module purge\nmodule load LUMI/23.09 partition/container EasyBuild-user\n
The partition/container is a \"special\" partition whose main purpose is to tell EasyBuild-user (and other modules that we use to install software on the system) to configure EasyBuild to install container modules. Afterwards, these containers are available in any partition of the LUMI stacks and in the CrayEnv stack. The EasyBuild-user module here is responsible of configuring EasyBuild and also ensures that a proper version of EasyBuild is loaded.
After loading EasyBuild-user, installing the container from the EasyBuild recipe is very easy:
eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb\n
We're now finished with EasyBuild so don't need the modules related to EasyBuild anymore. So lets's clean the environment an load the PyTorch container module that we just built with EasyBuild:
module purge\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n
Note that the module defines two environment variables that point to the .sif file of the container:
echo $SIF\necho $SIFPYTORCH\n
All our container modules provide the SIF environment variable, but the name of the second one depends on the name of the package, and it may be safer to use should you load multiple container modules of different packages to quickly switch between them.
If you're really concerned about disk space...
... you may chose to delete the version of the container that we have installed. To continue, you then need to reload the PyTorch module:
rm -f $SIF\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n
Now check again the SIF and SIFPYTORCH environment variables and note that they now point to files in /appl/local/containers:
echo $SIF\necho $SIFPYTORCH\n
We do not recommend you remove the container file as your module will stop working if the image is removed from /appl/local/containers which we do when we deem the file not useful anymore as it causes trouble for too many users. But it may still work fine for what you do with it...
All containers with module files also define the environment variable CONTAINERROOT, pointing to the directory in which EasyBuild installs the .sif file (and not pointing to /appl/local/containers if you've removed the container .sif file). The standard EasyBuild variable EBROOTPYTORCH is also defined and serves the same purpose, but of course has a different name for other packages.
Let's do some checks:
singularity shell $SIF\n
brings us into the container (note that the command prompt has changed).
The command
which python\n
returns
/user-software/venv/pytorch/bin/python\n
which shows that the virtual environment pre-installed in the container is indeed active.
Let's leave the container again:
exit\n
and check the $CONTAINERROOT directory:
module load systools\ntree $CONTAINERROOT\n
There is a lot of stuff in there. If we scroll up enough, we see:
-
A subdirectory easybuild which among other things turns out to contain copies of the EasyBuild recipe that we used. This directory basically contains all important files to reproduce the installation, except for the container it used itself.
-
The user-software subdirectory contains all the files that can be found in the container also in /user-software. (It is simply bound to that directory in the container through an environmet variable that the module sets.)
-
There is a bin subdirectory with some scripts. The start-shell script is only there for historical reasons and compatibility with some other containers, but the make-squashfs and unmake-squashfs files are useful and can be used to make the Python virtual environment more filesystem-friendly by converting the user-software subdirectory into a SquashFS file which is then mounted in the container.
-
The runscripts subdirectory contains some scripts that we will use to simplify running the container. The scripts by no means cover all use cases, but they are nice examples about how scripts for your specific tasks could be written. This directory is also mounted in the container as /runscripts so that it is easy to access.
"},{"location":"2day-20240502/Demo2/#step-3-running-a-distributed-learning-example","title":"Step 3: Running a distributed learning example.","text":"The conda-python-distributed script is written to ease distributed learning with PyTorch. Distributed learning requires some initialisation of environment variables that are used by PyTorch or by libraries from the ROCmTM stack. It passes its arguments to the Python command. It is mostly meant to be used on full nodes with one task per GPU, as in other cases not all initialisations make sense or are even valid.
Let's check the script:
cat $CONTAINERROOT/runscripts/conda-python-distributed\n
The first block,
if [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n
has mostly a debugging purpose. One task per node will run rocm-smi on that node and its output can be used to check if all GPUs are available as expected. The sleep command is there because we have experienced that sometimes there is still stuff going on in the background that may prevent later commands to fail.
The next block does some very needed initialisations for the MIOpen cache, an important library for neural networks, as the default location causes problems on LUMI as Lustre locking is not compatible with MIOpen:
export MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\n# Set MIOpen cache to a temporary folder.\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\nsleep 2\n
These commands basically move the cache to a subdirectory of /tmp.
Next we need to tell RCCL, the communication library, which interfaces it should use as otherwise it may try to communicate over the management network of LUMI which does not work. This is done through some NCCL_* environment variables which may be counterintuitive, but RCCL is basically the equivalent of NVIDIA NCCL.
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n
Fourth, we need to ensure that each task uses the proper GPU. This is one point where we assume that one GPU (GCD) per task is used. The script also assumes that the \"Linear assignment of GCD, then match the cores\" idea is used, so we will need some more complicated CPU mapping in the job script.
PyTorch also needs some initialisation that are basically the same on NVIDIA and AMD hardware. This includes setting a master for the communication (the first node of a job) and a port for the communication. That port is hard-coded, so a second instance of the script on the same node would fail. So we basically assume that we use full nodes. To determine that master, another script from the runscripts subdirectory is used.
export MASTER_ADDR=$(/runscripts/get-master \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\nexport WORLD_SIZE=$SLURM_NPROCS\nexport RANK=$SLURM_PROCID\n
Now we can turn our attention to the job script. Create a script mnist.slurm in the demo directory $installdir by copying the code below:
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=5:00\n#SBATCH --account=project_<your_project_id>\n\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=mask_cpu:$MYMASKS \\\n singularity exec $SIFPYTORCH \\\n conda-python-distributed -u mnist_DDP.py --gpu --modelpath model\n
Launch the script by setting some environment variables to use the course account and reservation:
export SBATCH_ACCOUNT=project_465001102\nexport SBATCH_RESERVATION=TODO\n
and then launching the job script:
sbatch mnist.slurm\n
(After the course, use any valid project with GPU billing units and omit the SBATCH_RESERVATION environment variable)
When the job script ends (which is usually fast once it gets the resources to run), the output can be found in output_mnist.slurm_1234567.txt where you need to replace 1234567 with the actual job id.
"},{"location":"2day-20240502/E03_Exercises_1/","title":"Exercises 1: Elementary access and the HPE Cray PE","text":"See the instructions to set up for the exercises.
"},{"location":"2day-20240502/E03_Exercises_1/#accessing-lumi","title":"Accessing LUMI","text":" -
Log on to an arbitrary login node of LUMI.
Can you find how to check your quota and status of your allocation?
Click to see the solution. How to check your quota and status of your allocation, is explained in the message-of-the-day at the bottom of the \"Announcements\" section: you can use the lumi-workspaces command.
-
How can you log on to a specific login node of LUMI, e.g., the login node \"uan01\"?
Click to see the solution. To log in to the login node \"uan01\", use the hostname lumi-uan01.csc.fi instead of lumi.csc.fi.
This may be useful if you use software on your desktop that tries to connect repeatedly to LUMI and then tries to find, e.g., a running server that it created before.
-
Create a shell on a login node using the Open OnDemand web interface?
Click to see the solution. - Point your web browser to
https://www.lumi.csc.fi. With some browsers it is sufficient to type lumi.csc.fi in the address bar while others require www.lumi.csc.fi. - Click the \"Go to login\" button. What you need to do here, depends on how you got your account. For the course you will have to proceed with the \"MyAccessID\" option \"Login Puhuri\" in most cases.
- Once you're in the web interface, click on \"Login node shell\" (likely the third choice on the first line). It will open a new tab in the browser with a login shell on LUMI. Note that Open OnDemand uses a different set of login nodes.
-
Try to transfer a file from your desktop/laptop to your home directory via the Open OnDemand web interface.
Click to see the solution. - Go back into Open OnDemand if you have left it after the previous exercise.
- On the main screen of the web interface, choose \"Home directory\".
- Depending on the browser and your system you may be able to just drag-and-drop files into the frame that shows your files, or you can click the blue \"Upload\" button towards the top of the screen.
"},{"location":"2day-20240502/E03_Exercises_1/#exercises-on-compiling-software-by-hand","title":"Exercises on compiling software by hand","text":"These exercises are optional during the session, but useful if you expect to be compiling software yourself. The source files mentioned can be found in the subdirectory CPE of the download.
"},{"location":"2day-20240502/E03_Exercises_1/#compilation-of-a-program-1-a-simple-hello-world-program","title":"Compilation of a program 1: A simple \"Hello, world\" program","text":"Four different implementations of a simple \"Hello, World!\" program are provided in the CPE subdirectory:
hello_world.c is an implementation in C,hello_world.cc is an implementation in C++,hello_world.f is an implementation in Fortran using the fixed format source form,hello_world.f90 is an implementation in Fortran using the more modern free format source form.
Try to compile these programs using the programming environment of your choice.
Click to see the solution. We'll use the default version of the programming environment (23.09 at the moment of the course in May 2024), but in case you want to use a particular version, e.g., the 22.12 version, and want to be very sure that all modules are loaded correctly from the start you could consider using
module load cpe/22.12\nmodule load cpe/22.12\n
So note that we do twice the same command as the first iteration does not always succeed to reload all modules in the correct version. Do not combine both lines into a single module load statement as that would again trigger the bug that prevents all modules to be reloaded in the first iteration.
The sample programs that we asked you to compile do not use the GPU. So there are three programming environments that we can use: PrgEnv-gnu, PrgEnv-cray and PrgEnv-aocc. All three will work, and they work almost the same.
Let's start with an easy case, compiling the C version of the program with the GNU C compiler. For this all we need to do is
module load PrgEnv-gnu\ncc hello_world.c\n
which will generate an executable named a.out. If you are not comfortable using the default version of gcc (which produces the warning message when loading the PrgEnv-gnu module) you can always load the gcc/11.2.0 module instead after loading PrgEnv-gnu.
Of course it is better to give the executable a proper name which can be done with the -o compiler option:
module load PrgEnv-gnu\ncc hello_world.c -o hello_world.x\n
Try running this program:
./hello_world.x\n
to see that it indeed works. We did forget another important compiler option, but we'll discover that in the next exercise.
The other programs are equally easy to compile using the compiler wrappers:
CC hello_world.cc -o hello_world.x\nftn hello_world.f -o hello_world.x\nftn hello_world.f90 -o hello_world.x\n
"},{"location":"2day-20240502/E03_Exercises_1/#compilation-of-a-program-2-a-program-with-blas","title":"Compilation of a program 2: A program with BLAS","text":"In the CPE subdirectory you'll find the C program matrix_mult_C.c and the Fortran program matrix_mult_F.f90. Both do the same thing: a matrix-matrix multiplication using the 6 different orders of the three nested loops involved in doing a matrix-matrix multiplication, and a call to the BLAS routine DGEMM that does the same for comparison.
Compile either of these programs using the Cray LibSci library for the BLAS routine. Do not use OpenMP shared memory parallelisation. The code does not use MPI.
The resulting executable takes one command line argument, the size of the square matrix. Run the script using 1000 for the matrix size and see what happens.
Note that the time results may be very unreliable as we are currently doing this on the login nodes. In the session of Slurm you'll learn how to request compute nodes and it might be interesting to redo this on a compute node with a larger matrix size as the with a matrix size of 1000 all data may stay in the third level cache and you will not notice the differences that you should note. Also, because these nodes are shared with a lot of people any benchmarking is completely unreliable.
If this program takes more than half a minute or so before the first result line in the table, starting with ijk-variant, is printed, you've very likely done something wrong (unless the load on the system is extreme). In fact, if you've done things well the time reported for the ijk-variant should be well under 3 seconds for both the C and Fortran versions...
Click to see the solution. Just as in the previous exercise, this is a pure CPU program so we can chose between the same three programming environments.
The one additional \"difficulty\" is that we need to link with the BLAS library. This is very easy however in the HPE Cray PE if you use the compiler wrappers rather than calling the compilers yourself: you only need to make sure that the cray-libsci module is loaded and the wrappers will take care of the rest. And on most systems (including LUMI) this module will be loaded automatically when you load the PrgEnv-* module.
To compile with the GNU C compiler, all you need to do is
module load PrgEnv-gnu\ncc -O3 matrix_mult_C.c -o matrix_mult_C_gnu.x\n
will generate the executable matrix_mult_C_gnu.x.
Note that we add the -O3 option and it is very important to add either -O2 or -O3 as by default the GNU compiler will generate code without any optimization for debugging purposes, and that code is in this case easily five times or more slower. So if you got much longer run times than indicated this is likely the mistake that you made.
To use the Cray C compiler instead only one small change is needed: Loading a different programming environment module:
module load PrgEnv-cray\ncc -O3 matrix_mult_C.c -o matrix_mult_C_cray.x\n
will generate the executable matrix_mult_C_cray.x.
Likewise for the AMD AOCC compiler we can try with loading yet another PrgEnv-* module:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -o matrix_mult_C_aocc.x\n
but it turns out that this fails with linker error messages about not being able to find the sin and cos functions. When using the AOCC compiler the libm library with basic math functions is not linked automatically, but this is easily done by adding the -lm flag:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -lm -o matrix_mult_C_aocc.x\n
For the Fortran version of the program we have to use the ftn compiler wrapper instead, and the issue with the math libraries in the AOCC compiler does not occur. So we get
module load PrgEnv-gnu\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_gnu.x\n
for the GNU Fortran compiler,
module load PrgEnv-cray\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_cray.x\n
for the Cray Fortran compiler and
module load PrgEnv-aocc\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_aocc.x\n
for the AMD Fortran compiler.
When running the program you will see that even though the 6 different loop orderings produce the same result, the time needed to compile the matrix-matrix product is very different and those differences would be even more pronounced with bigger matrices (which you can do after the session on using Slurm).
The exercise also shows that not all codes are equal even if they produce a result of the same quality. The six different loop orderings run at very different speed, and none of our simple implementations can beat a good library, in this case the BLAS library included in LibSci.
The results with the Cray Fortran compiler are particularly interesting. The result for the BLAS library is slower which we do not yet understand, but it also turns out that for four of the six loop orderings we get the same result as with the BLAS library DGEMM routine. It looks like the compiler simply recognized that this was code for a matrix-matrix multiplication and replaced it with a call to the BLAS library. The Fortran 90 matrix multiplication is also replaced by a call of the DGEMM routine. To confirm all this, unload the cray-libsci module and try to compile again and you will see five error messages about not being able to find DGEMM.
"},{"location":"2day-20240502/E03_Exercises_1/#compilation-of-a-program-3-a-hybrid-mpiopenmp-program","title":"Compilation of a program 3: A hybrid MPI/OpenMP program","text":"The file mpi_omp_hello.c is a hybrid MPI and OpenMP C program that sends a message from each thread in each MPI rank. It is basically a simplified version of the programs found in the lumi-CPEtools modules that can be used to quickly check the core assignment in a hybrid MPI and OpenMP job (see later in this tutorial). It is again just a CPU-based program.
Compile the program with your favourite C compiler on LUMI.
We have not yet seen how to start an MPI program. However, you can run the executable on the login nodes and it will then contain just a single MPI rank.
Click to see the solution. In the HPE Cray PE environment, you don't use mpicc to compile a C MPI program, but you just use the cc wrapper as for any other C program. To enable MPI you have to make sure that the cray-mpich module is loaded. This module will usually be loaded by loading one of the PrgEnv-* modules, but only if the right network target module, which is craype-network-ofi, is also already loaded.
Compiling the program is very simple:
module load PrgEnv-gnu\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_gnu.x\n
to compile with the GNU C compiler,
module load PrgEnv-cray\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_cray.x\n
to compile with the Cray C compiler, and
module load PrgEnv-aocc\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_aocc.x\n
to compile with the AMD AOCC compiler.
To run the executables it is not even needed to have the respective PrgEnv-* module loaded since the binaries will use a copy of the libraries stored in a default directory, though there have been bugs in the past preventing this to work with PrgEnv-aocc.
"},{"location":"2day-20240502/E04_Exercises_2/","title":"Exercises 2: Modules on LUMI","text":"See the instructions to set up for the exercises.
"},{"location":"2day-20240502/E04_Exercises_2/#exercises-on-the-use-of-modules","title":"Exercises on the use of modules","text":" -
The Cray CPE comes with a number of differently configured HDF5 libraries.
a. Which ones can you find?
b. Can you find more documentation about those libraries?
Click to see the solution module spider HDF5\n
or
module spider hdf5\n
can produce a lot of output on the system. It will show you three modules though (but this might be under \"Other possible matches\") that have cray- in their name: cray-hdf5, cray-hdf5-parallel and cray-netcdf-hdf5parallel. The first two of these really provide HDF5 configured in two different ways. The third one is another library using HDF5 as a backend. The other hdf5 modules that you might see are modules generated by Spack (see a little bit in the next session).
If you want more information about the cray-hdf5 module, you can try
module spider cray-hdf5\n
and then for a specific version
module spider cray-hdf5/1.12.2.7\n
and see that there is not much information. Even worse, the help of this particular version refers to the release info but mentions the wrong filename. The path is correct, but the file where the info is, is
/opt/cray/pe/hdf5/1.12.2.7/release_info.md\n
(and the same holds true for cray-hdf5-parallel)
-
The Bison program installed in the OS image is pretty old (version 3.0.4) and we want to use a newer one. Is there one available on LUMI?
Click to see the solution. module spider Bison\n
tells us that there are indeed newer versions available on the system.
The versions that have a compiler name (usually gcc) in their name followed by some seemingly random characters are installed with Spack and not in the CrayEnv or LUMI environments.
To get more information about Bison/3.8.2 if you didn't get it already with the previous command:
module spider Bison/3.8.2\n
tells us that Bison 3.8.2 is provided by a couple of buildtools modules and available in all partitions in several versions of the LUMI software stack and in CrayEnv.
Alternatively, in this case
module keyword Bison\n
would also have shown that Bison is part of several versions of the buildtools module.
The module spider command is often the better command if you use names that with a high likelihood could be the name of a package, while module keyword is often the better choice for words that are more a keyword. But if one does not return the solution it is a good idea to try the other one also.
A problem with too much different versions of software on the system...
If you tried
module spider bison\n
to look for Bison, you wouldn't have found the version in buildtools which is the main version of Bison on LUMI in the main supported software stack (see the next presentation), but only versions that are currently on the system and installed through Spack.
-
The htop command is a nice alternative for the top command with a more powerful user interface. However, typing htop on the command line produces an error message. Can you find and run htop?
Click to see the solution. We can use either module spider htop or module keyword htop to find out that htop is indeed available on the system. With module keyword htop we'll find out immediately that it is in the systools modules and some of those seem to be numbered after editions of the LUMI stack suggesting that they may be linked to a stack, with module spider you'll first see that it is an extension of a module and see the versions. You may again see some versions installed with Spack.
Let's check further for htop/3.2.1 that should exist according to module spider htop:
module spider htop/3.2.1\n
tells us that this version of htop is available in all partitions of LUMI/22.08 and LUMI/22.06, and in CrayEnv. Let us just run it in the CrayEnv environment:
module load CrayEnv\nmodule load systools/22.08\nhtop\n
(You can quit htop by pressing q on the keyboard.)
-
LUMI now offers Open OnDemand as a browser-based interface to LUMI that enables running some graphical programs through a VNC server. But for users who do not want to use Open OnDemand apps, there is currently another way to start a VNC server (and that was the way to use graphical programs before the Open OnDemand interface was ready and may still be relevant if Open OnDemand would fail after a system update). Can you find the tool on LUMI, and if so, how can we use it?
Click to see the solution. module spider VNC and module keyword VNC can again both be used to check if there is software available to use VNC. Both will show that there is a module lumi-vnc in several versions. If you try loading the older ones of these (the version number points at the date of some scripts) you will notice that some produce a warning as they are deprecated. However, when installing a new version we cannot remove older ones in one sweep, and users may have hardcoded full module names in scripts they use to set their environment, so we chose to not immediate delete these older versions.
One thing you can always try to get more information about how to run a program, is to ask for the help information of the module. For this to work the module must first be available, or you have to use module spider with the full name of the module. We see that version 20230110 is the newest version of the module, so let's try that one:
module spider lumi-vnc/20230110\n
The output may look a little strange as it mentions init-lumi as one of the modules that you can load. That is because this tool is available even outside CrayEnv or the LUMI stacks. But this command also shows a long help test telling you how to use this module (though it does assume some familiarity with how X11 graphics work on Linux).
Note that if there is only a single version on the system, as is the case for the course in May 2023, the module spider VNC command without specific version or correct module name will already display the help information.
"},{"location":"2day-20240502/E05_Exercises_3/","title":"Exercises 3: LUMI Software Stacks and EasyBuild","text":"See the instructions to set up for the exercises.
"},{"location":"2day-20240502/E05_Exercises_3/#information-in-the-lumi-software-library","title":"Information in the LUMI Software Library","text":"Explore the LUMI Software Library.
- Search for information for the package ParaView and quickly read through the page
Click to see the solution. Link to the ParaView documentation
It is an example of a package for which we have both user-level and some technical information. The page will first show some license information, then the actual user information which in case of this package is very detailed and long. But it is also a somewhat complicated package to use. It will become easier when LUMI evolves a bit further, but there will always be some pain. Next comes the more technical part: Links to the EasyBuild recipe and some information about how we build the package.
We currently only provide ParaView in the cpeGNU toolchain. This is because it has a lot of dependencies that are not trivial to compile and to port to the other compilers on the system, and EasyBuild is strict about mixing compilers basically because it can cause a lot of problems, e.g., due to conflicts between OpenMP runtimes.
"},{"location":"2day-20240502/E05_Exercises_3/#using-modules-in-the-lumi-software-stack","title":"Using modules in the LUMI software stack","text":" -
Search for the bzip2 tool (and not just the bunzip2 command as we also need the bzip2 command) and make sure that you can use software compiled with the Cray compilers in the LUMI stacks in the same session.
Click to see the solution. module spider bzip2\n
shows that there are versions of bzip2 for several of the cpe* toolchains and in several versions of the LUMI software stack.
Of course we prefer to use a recent software stack, the 22.08 or 22.12 (but as of early May 2023, there is a lot more software ready-to-install for 22.08). And since we want to use other software compiled with the Cray compilers also, we really want a cpeCray version to avoid conflicts between different toolchains. So the module we want to load is bzip2/1.0.8-cpeCray-22.08.
To figure out how to load it, use
module spider bzip2/1.0.8-cpeCray-22.08\n
and see that (as expected from the name) we need to load LUMI/22.08 and can then use it in any of the partitions.
"},{"location":"2day-20240502/E05_Exercises_3/#installing-software-with-easybuild","title":"Installing software with EasyBuild","text":"These exercises are based on material from the EasyBuild tutorials (and we have a special version for LUMI also).
Note: If you want to be able to uninstall all software installed through the exercises easily, we suggest you make a separate EasyBuild installation for the course, e.g., in /scratch/project_465000523/$USER/eb-course if you make the exercises during the course:
- Start from a clean login shell with only the standard modules loaded.
-
Set EBU_USER_PREFIX:
export EBU_USER_PREFIX=/scratch/project_465000523/$USER/eb-course\n
You'll need to do that in every shell session where you want to install or use that software.
-
From now on you can again safely load the necessary LUMI and partition modules for the exercise.
-
At the end, when you don't need the software installation anymore, you can simply remove the directory that you just created.
rm -rf /scratch/project_465000523/$USER/eb-course\n
"},{"location":"2day-20240502/E05_Exercises_3/#installing-a-simple-program-without-dependencies-with-easybuild","title":"Installing a simple program without dependencies with EasyBuild","text":"The LUMI Software Library contains the package eb-tutorial. Install the version of the package for the cpeCray toolchain in the 22.08 version of the software stack.
At the time of this course, in early May 2023, we're still working on EasyBuild build recipes for the 22.12 version of the software stack.
Click to see the solution. -
We can check the eb-tutorial page in the LUMI Software Library if we want to see more information about the package.
You'll notice that there are versions of the EasyConfigs for cpeGNU and cpeCray. As we want to install software with the cpeCray toolchain for LUMI/22.08, we'll need the cpeCray-22.08 version which is the EasyConfig eb-tutorial-1.0.1-cpeCray-22.08.eb.
-
Obviously we need to load the LUMI/22.08 module. If we would like to install software for the CPU compute nodes, you need to also load partition/C. To be able to use EasyBuild, we also need the EasyBuild-user module.
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now all we need to do is run the eb command from EasyBuild to install the software.
Let's however take the slow approach and first check if what dependencies the package needs:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb -D\n
We can do this from any directory as the EasyConfig file is already in the LUMI Software Library and will be located automatically by EasyBuild. You'll see that all dependencies are already on the system so we can proceed with the installation:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb \n
-
After this you should have a module eb-tutorial/1.0.1-cpeCray-22.08 but it may not show up yet due to the caching of Lmod. Try
module av eb-tutorial/1.0.1-cpeCray-22.08\n
If this produces an error message complaining that the module cannot be found, it is time to clear the Lmod cache:
rm -rf $HOME/.lmod.d/.cache\n
-
Now that we have the module, we can check what it actually does:
module help eb-tutorial/1.0.1-cpeCray-22.08\n
and we see that it provides the eb-tutorial command.
-
So let's now try to run this command:
module load eb-tutorial/1.0.1-cpeCray-22.08\neb-tutorial\n
Note that if you now want to install one of the other versions of this module, EasyBuild will complain that some modules are loaded that it doesn't like to see, including the eb-tutorial module and the cpeCray modules so it is better to unload those first:
module unload cpeCray eb-tutorial\n
"},{"location":"2day-20240502/E05_Exercises_3/#installing-an-easyconfig-given-to-you-by-lumi-user-support","title":"Installing an EasyConfig given to you by LUMI User Support","text":"Sometimes we have no solution ready in the LUMI Software Library, but we prepare one or more custom EasyBuild recipes for you. Let's mimic this case. In practice we would likely send those as attachments to a mail from the ticketing system and you would be asked to put them in a separate directory (basically since putting them at the top of your home directory would in some cases let EasyBuild search your whole home directory for dependencies which would be a very slow process).
You've been given two EasyConfig files to install a tool called py-eb-tutorial which is in fact a Python package that uses the eb-tutorial package installed in the previous exercise. These EasyConfig files are in the EasyBuild subdirectory of the exercises for this course. In the first exercise you are asked to install the version of py-eb-tutorial for the cpeCray/22.08 toolchain.
Click to see the solution. -
Go to the EasyBuild subdirectory of the exercises and check that it indeed contains the py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb and py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb files. It is the first one that we need for this exercise.
You can see that we have used a very long name as we are also using a version suffix to make clear which version of Python we'll be using.
-
Let's first check for the dependencies (out of curiosity):
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb -D\n
and you'll see that all dependencies are found (at least if you made the previous exercise successfully). You may find it strange that it shows no Python module but that is because we are using the cray-python module which is not installed through EasyBuild and only known to EasyBuild as an external module.
-
And now we can install the package:
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb\n
-
To use the package all we need to do is to load the module and to run the command that it defines:
module load py-eb-tutorial/1.0.0-cpeCray-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
with the same remark as in the previous exercise if Lmod fails to find the module.
You may want to do this step in a separate terminal session set up the same way, or you will get an error message in the next exercise with EasyBuild complaining that there are some modules loaded that should not be loaded.
"},{"location":"2day-20240502/E05_Exercises_3/#installing-software-with-uninstalled-dependencies","title":"Installing software with uninstalled dependencies","text":"Now you're asked to also install the version of py-eb-tutorial for the cpeGNU toolchain in LUMI/22.08 (and the solution given below assumes you haven'ty accidentally installed the wrong EasyBuild recipe in one of the previous two exercises).
Click to see the solution. -
We again work in the same environment as in the previous two exercises. Nothing has changed here. Hence if not done yet we need
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now go to the EasyBuild subdirectory of the exercises (if not there yet from the previous exercise) and check what the py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb needs:
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -D\n
We'll now see that there are two missing modules. Not only is the py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 that we try to install missing, but also the eb-tutorial/1.0.1-cpeGNU-22.08. EasyBuild does however manage to find a recipe from which this module can be built in the pre-installed build recipes.
-
We can install both packages separately, but it is perfectly possible to install both packages in a single eb command by using the -r option to tell EasyBuild to also install all dependencies.
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -r\n
-
At the end you'll now notice (with module avail) that both the module eb-tutorial/1.0.1-cpeGNU-22.08 and py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 are now present.
To run you can use
module load py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
"},{"location":"2day-20240502/E07_Exercises_4/","title":"Exercises 4: Running jobs with Slurm","text":"For these exercises, you'll need to take care of some settings:
-
For the CPU exercises we advise to use the small partition and for the exercises on GPU the standard-g partition.
-
During the course you can use the course training project project_465001102 for these exercises. A few days after the course you will need to use a different project on LUMI.
-
On May 3 we have a reservation that you can use (through #SBATCH --reservation=...):
-
For the small partition, the reservation name is LUMI_Intro_SURF_small
-
For the standard-g partition, the reservation name is LUMI_Intro_SURF_standardg
An alternative (during the course only) for manually specifying these parameters, is to set them through modules. For this, first add an additional directory to the module search path:
module use /appl/local/training/modules/2day-20240502\n
and then you can load either the module exercises/small or exercises/standard-g.
Check what these modules do...
Try, e.g.,
module show exercises/small\n
to get an idea of what these modules do. Can you see which environment variables they set?
"},{"location":"2day-20240502/E07_Exercises_4/#exercises-on-the-slurm-allocation-modes","title":"Exercises on the Slurm allocation modes","text":" -
In this exercise we check how cores would be assigned to a shared memory program. Run a single task on the CPU partition with srun using 16 cpu cores. Inspect the default task allocation with the taskset command (taskset -cp $$ will show you the cpu numbers allocated to the current process).
Click to see the solution. srun --partition=small --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> bash -c 'taskset -cp $$' \n
Note that you need to replace <project_id> with the actual project account ID of the form project_ plus a 9 digits number.
The command runs a single process (bash shell with the native Linux taskset tool showing process's CPU affinity) on a compute node. You can use the man taskset command to see how the tool works.
-
Next we'll try a hybrid MPI/OpenMP program. For this we will use the hybrid_check tool from the lumi-CPEtools module of the LUMI Software Stack. This module is preinstalled on the system and has versions for all versions of the LUMI software stack and all toolchains and partitions in those stacks.
Use the simple job script below to run a parallel program with multiple tasks (MPI ranks) and threads (OpenMP). Submit with sbatch on the CPU partition and check task and thread affinity.
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\nsrun --cpus-per-task=$SLURM_CPUS_PER_TASK hybrid_check -n -r\n
Be careful with copy/paste of the script body as copy problems with special characters or a double dash may occur, depending on the editor you use.
Click to see the solution. Save the script contents into the file job.sh (you can use the nano console text editor for instance). Remember to use valid project account name.
Submit the job script using the sbatch command:
sbatch job.sh\n
The job output is saved in the slurm-<job_id>.out file. You can view its content with either the less or more shell commands.
The actual task/threads affinity may depend on the specific OpenMP runtime (if you literally use this job script it will be the GNU OpenMP runtime).
-
Improve the thread affinity with OpenMP runtime variables. Alter the script from the previous exercise and ensure that each thread is bound to a specific core.
Click to see the solution. Add the following OpenMP environment variables definition to your script:
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n
You can also use an MPI runtime variable to have MPI itself report a cpu mask summary for each MPI rank:
export MPICH_CPUMASK_DISPLAY=1\n
Note hybrid_check and MPICH cpu mask may not be consistent. It is found to be confusing.
To avoid having to use the --cpus-per-task flag, you can also set the environment variable SRUN_CPUS_PER_TASK instead:
export SRUN_CPUS_PER_TASK=16 \n
On LUMI this is not strictly necessary as the Slurm SBATCH processing has been modified to set this environment variable, but that was a clunky patch to reconstruct some old behaviour of Slurm and we have already seen cases where the patch did not work (but that were more complex cases that required different environment variables for a similar function).
The list of environment variables that the srun command can use as input, is actually confusing, as some start with SLURM_ but a few start with SRUN_ while the SLURM_ equivalent is ignored.
So we end up with the following script:
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\nexport SRUN_CPUS_PER_TASK=$SLURM_CPUS_PER_TASK\n\nexport OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nexport MPICH_CPUMASK_DISPLAY=1\n\nsrun hybrid_check -n -r\n
Note that MPI returns the CPU mask per process in binary form (a long string of zeros and ones) where the last number is for core 0. Also, you'll see that with the OpenMP environment variables set, it will look like only one core can be used by each MPI task, but that is because it only shows the mask for the main process which becomes OpenMP thread 0. Remove the OpenMP environment variables and you'll see that each task now gets 16 possible cores to run on, and the same is true for each OpenMP thread (at least when using the GNU compilers, the Cray compilers have different default behaviour for OpenMP which actually makes more sense for most scientific computing codes).
-
Build the hello_jobstep program tool using interactive shell on a GPU node. You can pull the source code for the program from git repository https://code.ornl.gov/olcf/hello_jobstep.git. It uses a Makefile for building and requires Clang and HIP. The hello_jobstep program is actually the main source of inspiration for the gpu_check program in the lumi-CPEtools modules for partition/G. Try to run the program interactively.
Click to see the solution. Clone the code using git command:
git clone https://code.ornl.gov/olcf/hello_jobstep.git\n
It will create hello_jobstep directory consisting source code and Makefile.
Allocate resources for a single task with a single GPU with salloc:
salloc --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=1 --gpus-per-node=1 --time=10 --account=<project_id>\n
Note that, after allocation is granted, you receive new shell but are still on the compute node. You need to use the srun command to run on the allocated node.
Start interactive session on a GPU node:
srun --pty bash -i\n
Note now you are on the compute node. --pty option for srun is required to interact with the remote shell.
Enter the hello_jobstep directory and issue make command.
As an example we will built with the system default programming environment, PrgEnv-cray in CrayEnv. Just to be sure we'll load even the programming environment module explicitly.
The build will fail if the rocm module is not loaded when using PrgEnv-cray.
module load CrayEnv\nmodule load PrgEnv-cray\nmodule load rocm\n
To build the code, use
make LMOD_SYSTEM_NAME=\"frontier\"\n
You need to add LMOD_SYSTEM_NAME=\"frontier\" variable for make as the code originates from the Frontier system and doesn't know LUMI.
(As an exercise you can try to fix the Makefile and enable it for LUMI :))
Finally you can just execute ./hello_jobstep binary program to see how it behaves:
./hello_jobstep\n
Note that executing the program with srun in the srun interactive session will result in a hang. You need to work with --overlap option for srun to mitigate this.
Remember to terminate your interactive session with exit command.
exit\n
and then do the same for the shell created by salloc also.
"},{"location":"2day-20240502/E07_Exercises_4/#slurm-custom-binding-on-gpu-nodes","title":"Slurm custom binding on GPU nodes","text":" -
Allocate one GPU node with one task per GPU and bind tasks to each CCD (8-core group sharing L3 cache) leaving the first (#0) and last (#7) cores unused. Run a program with 6 threads per task and inspect the actual task/threads affinity using either the hello_jobstep executable generated in the previous exercise, or the gpu_check command from tne lumi-CPEtools module.
Click to see the solution. We can chose between different approaches. In the example below, we follow the \"GPU binding: Linear GCD, match cores\" slides and we only need to adapt the CPU mask:
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\nCPU_BIND=\"mask_cpu:0xfe000000000000,0xfe00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe0000,0xfe000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe,0xfe00,\"\nCPU_BIND=\"${CPU_BIND}0xfe00000000,0xfe0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu_$SLURM_JOB_ID ./hello_jobstep\n
The base mask we need for this exercise, with each first and last core of a chiplet disabled, is 01111110 which is 0x7e in hexadecimal notation.
Save the job script as job_step.sh then simply submit it with sbatch from the directory that contains the hello_jobstep executable. Inspect the job output.
Note that in fact as this program was compiled with the Cray compiler in the previous exercise, you don't even need to use the OMP_* environment variables above as the threads are automatically pinned to a single core and as the correct number of threads is derived from the affinity mask for each task.
Or using gpu_check instead (and we'll use the cpeGNU version again):
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\nCPU_BIND=\"mask_cpu:0xfe000000000000,0xfe00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe0000,0xfe000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe,0xfe00,\"\nCPU_BIND=\"${CPU_BIND}0xfe00000000,0xfe0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu_$SLURM_JOB_ID gpu_check -l\n
"},{"location":"2day-20240502/extra_00_Introduction/","title":"Introduction","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_01_Architecture/","title":"LUMI Architecture","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_02_CPE/","title":"The HPE Cray Programming Environment","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_02_CPE/#qa","title":"Q&A","text":" -
Are there plans to bump the available rocm version in the near future ?
-
It is planned in summer
-
But LUMI will never be on the bleeding edge. It is a small effort to do so on a workstation because it has to work only for you so you upgrade whenever you are ready. It is a big upgrade on a supercomputer as it has to work with all other software also. E.g., users relying on GPU-aware MPI would not like that feature to be broken just because some AI people want the latest ROCm to use the latest nightly PyTorch build. GPU software stacks consist of lots of libraries running on top of a driver, and you can have only one driver on the system and each driver support only a limited range of library versions. So you can see that it is hard to keep everybody happy... Basically we have to wait until it is supported in all components that are important in LUMI for all users.
"},{"location":"2day-20240502/extra_03_LUMI_access/","title":"Getting Access to LUMI","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_03_LUMI_access/#qa","title":"Q&A","text":" -
Are there plans to have LUMI as a Globus end point ?
- We don't have it at the moment and unfortunately, we don't have the man power to add it.
-
Do you you other tools e.g., iRODS for data transfer/storage management? I am curious to know if projects use some automation to move data from/to LUMI, or users do it themselves (irrespective of the size oftheir data)
- We currently don't have the iRODS tools on LUMI. There was a request from my home country (Flanders/Belgium) so their local support team is looking into it. As we shall also discuss in the support talk, we are open to help from local support teams for such things so I hope they will do the installation in a way that we can then offer the recipe to other users also. What we as the LUMI support team cannot do is tell users how it should be configured to access, e.g., the VSC or Surf iRODS infrastructures as we are not managing those infrastructures.
"},{"location":"2day-20240502/extra_04_Modules/","title":"Modules on LUMI","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_05_Software_stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_05_Software_stacks/#qa","title":"Q&A","text":" -
Can we submit EasyBuild config files to the GitHub official repo for package we want to share with other users ?
- Sure. We work with pull requests
"},{"location":"2day-20240502/extra_06_Slurm/","title":"Slurm on LUMI","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_06_Slurm/#qa","title":"Q&A","text":" -
Can we get energy consumption from sacct on LUMI ?
-
No, but you can read them from /sys/cray/pm_counters/. You need to read those counters before and after the job (meaning before and after the srun command), then do the math and you can have the energy consumption. There are several of them, cpu, gpu and memory. They are only available on compute nodes.
Note though that it only makes sense when using whole nodes for the job, and that there are also shared elements in a cluster whose power consumption cannot be measured or assigned to individual jobs, e.g., storage and the interconnect.
"},{"location":"2day-20240502/extra_07_Binding/","title":"Process and Thread Distribution and Binding","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_08_Lustre/","title":"I/O and File Systems on LUMI","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_09_Containers/","title":"Containers on LUMI-C and LUMI-G","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_10_Support/","title":"LUMI Support and Documentation","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_11_Netherlands/","title":"LUMI in The Netherlands","text":"Presenter: Henk Dreuning (LUST & SURF)
Extra materials
"},{"location":"2day-20240502/extra_12_What_else/","title":"What Else?","text":"A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it.
Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_13_WrapUpDay1/","title":"Wrap-Up Day 1","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/extra_14_IntroductionDay2/","title":"Introduction Day 2","text":"Presenter: Kurt Lust (LUST)
Extra materials
"},{"location":"2day-20240502/index.links.noGit/","title":"Supercomputing with LUMI - Amsterdam, May 2-3, 2024","text":""},{"location":"2day-20240502/index.links.noGit/#course-organisation","title":"Course organisation","text":" -
Location: SURF, Science Park 140, 1098 XG, Amsterdam, The Netherlands
-
Schedule
-
HedgeDoc for questions
"},{"location":"2day-20240502/index.links.noGit/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":"If you have an active project on LUMI, you should be able to make the exercises in that project. You will only need an very minimum of CPU and GPU billing units for this.
-
Create a directory in the scratch of your project, or if you want to keep the exercises around for a while, in a subdirectory of your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of your project:
mkdir -p /scratch/project_465001102/$USER/exercises\ncd /scratch/project_465001102/$USER/exercises\n
where you have to replace project_465001102 using the number of your own project.
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/2day-20240502/files/exercises-20240502.tar.gz\ntar -xf exercises-20240502.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"2day-20240502/index.links.noGit/#course-materials","title":"Course materials","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes recording Welcome and Introduction slides notes video LUMI Architecture slides notes video HPE Cray Programming Environment slides notes video Getting Access to LUMI slides notes video Exercises 1 / notes / Modules on LUMI slides notes video Exercises 2 / notes / LUMI Software Stacks slides notes video Exercises 3 / notes / Slurm on LUMI slides notes video Process and Thread Distribution and Binding slides notes video Exercises 4 / notes / I/O and File Systems on LUMI slides notes video Containers on LUMI-C and LUMI-G slides notes video Demo 1 (optional) / notes video Demo 2 (optional) / notes video LUMI Support and Documentation slides notes video LUMI in The Netherlands / / / What Else? slides / / A1 Additional documentation / notes /"},{"location":"2day-20240502/index.links.noGit/#web-links","title":"Web links","text":""},{"location":"2day-20240502/index.links.noGit/#acknowledgement","title":"Acknowledgement","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities. The VSC is funded by FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders).
"},{"location":"2day-20240502/index.noLinks.noGit/","title":"Supercomputing with LUMI - Amsterdam, May 2-3, 2024","text":""},{"location":"2day-20240502/index.noLinks.noGit/#course-organisation","title":"Course organisation","text":" -
Location: SURF, Science Park 140, 1098 XG, Amsterdam, The Netherlands
-
Schedule
-
HedgeDoc for questions
"},{"location":"2day-20240502/index.noLinks.noGit/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":"If you have an active project on LUMI, you should be able to make the exercises in that project. You will only need an very minimum of CPU and GPU billing units for this.
-
Create a directory in the scratch of your project, or if you want to keep the exercises around for a while, in a subdirectory of your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of your project:
mkdir -p /scratch/project_465001102/$USER/exercises\ncd /scratch/project_465001102/$USER/exercises\n
where you have to replace project_465001102 using the number of your own project.
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/2day-20240502/files/exercises-20240502.tar.gz\ntar -xf exercises-20240502.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"2day-20240502/index.noLinks.noGit/#course-materials","title":"Course materials","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes recording A1 Additional documentation / notes /"},{"location":"2day-20240502/index.noLinks.noGit/#web-links","title":"Web links","text":""},{"location":"2day-20240502/index.noLinks.noGit/#acknowledgement","title":"Acknowledgement","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities. The VSC is funded by FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders).
"},{"location":"2day-20240502/schedule.links.noGit/","title":"Schedule","text":" - Day 1
- Day 2 DAY 1 - Thursday 02/05 09:45 CEST 10:45 EEST Welcome and Introduction 10:00 CEST 11:00 EEST LUMI Architecture 10:40 CEST 11:40 EEST HPE Cray Programming Environment 11:25 CEST 12:25 EEST Break and networking (30 minutes) 11:55 CEST 12:55 EEST Getting Access to LUMI 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #1) 14:00 CEST 15:00 EEST Modules on LUMI 14:35 CEST 15:35 EEST Exercises (session #2) 14:50 CEST 15:50 EEST Break and networking (30 minutes) 15:20 CEST 16:20 EEST LUMI Software Stacks 16:15 CEST 17:15 EEST Exercises (session #3) 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A DAY 2 - Friday 03/05 09:45 CEST 10:45 EEST Short welcome, recap and plan for the day 10:00 CEST 11:00 EEST Slurm on LUMI 11:15 CEST 12:15 EEST Break and networking (30 minutes) 11:55 CEST 12:55 EEST Process and Thread Distribution and Binding 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #4) 14:00 CEST 15:00 EEST I/O and File Systems on LUMI 14:30 CEST 15:30 EEST Containers on LUMI-C and LUMI-G 15:30 CEST 16:30 EEST Break and networking (30 minutes) 16:00 CEST 17:00 EEST LUMI Support and Documentation 16:20 CEST 17:20 EEST LUMI in The Netherlands 16:35 CEST 17:35 EEST What Else? A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it. 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A"},{"location":"2day-20240502/schedule/","title":"Schedule","text":"
- Day 1
- Day 2 DAY 1 - Thursday 02/05 09:45 CEST 10:45 EEST Welcome and Introduction 10:00 CEST 11:00 EEST LUMI Architecture 10:40 CEST 11:40 EEST HPE Cray Programming Environment 11:25 CEST 12:25 EEST Break and networking (30 minutes) 11:55 CEST 12:55 EEST Getting Access to LUMI 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #1) 14:00 CEST 15:00 EEST Modules on LUMI 14:35 CEST 15:35 EEST Exercises (session #2) 14:50 CEST 15:50 EEST Break and networking (30 minutes) 15:20 CEST 16:20 EEST LUMI Software Stacks 16:15 CEST 17:15 EEST Exercises (session #3) 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A DAY 2 - Friday 03/05 09:45 CEST 10:45 EEST Short welcome, recap and plan for the day 10:00 CEST 11:00 EEST Slurm on LUMI 11:15 CEST 12:15 EEST Break and networking (30 minutes) 11:45 CEST 12:45 EEST Process and Thread Distribution and Binding 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #4) 14:00 CEST 15:00 EEST I/O and File Systems on LUMI 14:30 CEST 15:30 EEST Containers on LUMI-C and LUMI-G 15:30 CEST 16:30 EEST Break and networking (30 minutes) 16:00 CEST 17:00 EEST LUMI Support and Documentation 16:20 CEST 17:20 EEST LUMI in The Netherlands 16:35 CEST 17:35 EEST What Else? A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it. 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A"},{"location":"2day-20240502/schedule.noLinks.noGit/","title":"Schedule","text":"
- Day 1
- Day 2 DAY 1 - Thursday 02/05 09:45 CEST 10:45 EEST Welcome and Introduction 10:00 CEST 11:00 EEST LUMI Architecture 10:40 CEST 11:40 EEST HPE Cray Programming Environment 11:25 CEST 12:25 EEST Break and networking (30 minutes) 11:55 CEST 12:55 EEST Getting Access to LUMI 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #1) 14:00 CEST 15:00 EEST Modules on LUMI 14:35 CEST 15:35 EEST Exercises (session #2) 14:50 CEST 15:50 EEST Break and networking (30 minutes) 15:20 CEST 16:20 EEST LUMI Software Stacks 16:15 CEST 17:15 EEST Exercises (session #3) 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A DAY 2 - Friday 03/05 09:45 CEST 10:45 EEST Short welcome, recap and plan for the day 10:00 CEST 11:00 EEST Slurm on LUMI 11:15 CEST 12:15 EEST Break and networking (30 minutes) 11:55 CEST 12:55 EEST Process and Thread Distribution and Binding 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #4) 14:00 CEST 15:00 EEST I/O and File Systems on LUMI 14:30 CEST 15:30 EEST Containers on LUMI-C and LUMI-G 15:30 CEST 16:30 EEST Break and networking (30 minutes) 16:00 CEST 17:00 EEST LUMI Support and Documentation 16:20 CEST 17:20 EEST LUMI in The Netherlands 16:35 CEST 17:35 EEST What Else? A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it. 16:45 CEST 17:45 EEST Wrap-up of the day and free Q&A"},{"location":"2day-next/","title":"Supercomputing with LUMI - Next version","text":""},{"location":"2day-next/#course-organisation","title":"Course organisation","text":""},{"location":"2day-next/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":"
If you have an active project on LUMI, you should be able to make the exercises in that project. You will only need an very minimum of CPU and GPU billing units for this.
-
Create a directory in the scratch of your project, or if you want to keep the exercises around for a while, in a subdirectory of your project directory or in your home directory (though we don't recommend the latter). Then go into that directory.
E.g., in the scratch directory of your project:
mkdir -p /scratch/project_465001102/$USER/exercises\ncd /scratch/project_465001102/$USER/exercises\n
where you have to replace project_465001102 using the number of your own project.
-
Now download the exercises and un-tar:
wget https://462000265.lumidata.eu/2day-next/files/exercises-20240502.tar.gz\ntar -xf exercises-20240502.tar.gz\n
Link to the tar-file with the exercises
-
You're all set to go!
"},{"location":"2day-next/#course-materials","title":"Course materials","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides Notes Exercises Recording Welcome and Introduction S / / V Introduction to the course notes / N / / LUMI Architecture S N / V HPE Cray Programming Environment S N E V Getting Access to LUMI S N E V Exercises 1 / / / / Modules on LUMI S N E V Exercises 2 / / / / LUMI Software Stacks S N E V Exercises 3 / / / / Wrap-Up Day 1 S / / V Introduction Day 2 S / / V Slurm on LUMI S N E V Process and Thread Distribution and Binding S N E V Exercises 4 / / / / Using Lustre S N / V Containers on LUMI-C and LUMI-G S N / V Demo 1 (optional) / N / V Demo 2 (optional) / N / V LUMI Support and Documentation S N / V What Else? S / / V A1 Additional documentation / N / /"},{"location":"2day-next/#web-links","title":"Web links","text":""},{"location":"2day-next/#acknowledgement","title":"Acknowledgement","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities. The VSC is funded by FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders).
"},{"location":"2day-next/00-Introduction/","title":"Introduction to the notes","text":"Though a LUST course, the course borrows a lot of material from a similar course prepared by the Belgian local organisation, which in turn was prepared in the framework of the VSC Tier-0 support activities with funding from FWO - Fonds Wetenschappelijk Onderzoek - Vlaanderen (or Research Foundation \u2013 Flanders) which we hereby acknowledge.
Various training materials and the documentation from the Belgian Walloon HPC project C\u00c9CI were also a great source of inspiration.
"},{"location":"2day-next/00-Introduction/#about-the-structure-of-the-notes","title":"About the structure of the notes","text":"Colour coding and boxes in the material:
Remark
This is a remark: Some additional information that may be nice to read. or some additional information that you may want to have a look at.
Note
Just a quick note on the side, but do have a look at it.
Audience
A box telling you who this part of the notes is written for, or why it would be good to read it even if you think you don't need it.
Example
An example to make the material clearer or to try something out.
Exercise
An exercise
Solution
The solution to the exercise. You will have to click on the box to see the solution.
Bug
This is a discussion about a bug.
Nice-to-know
This is a little fact which is nice-to-know but not necessary to understand the material.
Intermediate
Information that may not be useful to every LUMI user, but if you are the kind of person who likes to explore manuals and try out things that we did not discuss in the course, you may want to read this...
Advanced
Similar to the intermediate material, but it requires even more technical skills to understand this stuff.
Technical
Material specific to readers with very technical interests.
"},{"location":"2day-next/01-Architecture/","title":"The LUMI Architecture","text":"In this presentation, we will build up LUMI part by part, stressing those aspects that are important to know to run on LUMI efficiently and define jobs that can scale.
"},{"location":"2day-next/01-Architecture/#why-do-i-kneed-to-know-this","title":"Why do I kneed to know this?","text":"You may wonder why you need to know about system architecture if all you want to do is to run some programs.
A supercomputer is not simply a scaled-up smartphone or PC that will offer good performance automatically. It is a shared infrastructure and you don't get the whole machine to yourself. Instead you have to request a suitable fraction of the computer for the work you want to do. But it is also a very expensive infrastructure, with an investment of 160M EURO for LUMI and an estimated total cost (including operations) of 250M EURO. So it is important to use the computer efficiently.
And that efficiency comes not for free. Instead in most cases it is important to properly map an application on the available resources to run efficiently. The way an application is developed is important for this, but it is not the only factor. Every application needs some user help to run in the most efficient way, and that requires an understanding of
-
The hardware architecture of the supercomputer, which is something that we discuss in this section.
-
The middleware: the layers of software that sit between the application on one hand and the hardware and operating system on the other hand. LUMI runs a sligthly modified version of Linux. But Linux is not a supercomputer operating system. Missing functionality in Linux is offered by other software layers instead that on supercomputers often come as part of the programming environment. This is a topic of discussion in several sessions of this course.
-
The application. This is very domain-specific and application-specific and hence cannot be the topic of a general course like this one. In fact, there are so many different applications and often considerable domain knowledge is required so that a small support team like the one of LUMI cannot provide that information.
-
Moreover, the way an application should be used may even depend on the particular problem that you are trying to solve. Bigger problems, bigger computers, and different settings may be needed in the application.
It is up to scientific communities to organise trainings that teach you individual applications and how to use them for different problem types, and then up to users to combine the knowledge of an application obtained from such a course with the knowledge about the computer you want to use and its middleware obtained from courses such as this one or our 4-day more advanced course.
Some users expect that a support team can give answers to all those questions, even to the third and fourth bullet of the above list. If a support team could do that, it would basically imply that they could simply do all the research that users do and much faster as they are assumed to have the answer ready in hours...
"},{"location":"2day-next/01-Architecture/#lumi-is","title":"LUMI is ...","text":"LUMI is a pre-exascale supercomputer, and not a superfast PC nor a compute cloud architecture.
Each of these architectures have their own strengths and weaknesses and offer different compromises and it is key to chose the right infrastructure for the job and use the right tools for each infrastructure.
Just some examples of using the wrong tools or infrastructure:
-
The single thread performance of the CPU is lower than on a high-end PC. We've had users who were disappointed about the speed of a single core and were expecting that this would be much faster than their PCs. Supercomputers however are optimised for performance per Watt and get their performance from using lots of cores through well-designed software. If you want the fastest core possible, you'll need a gaming PC.
E.g., the AMD 5800X is a popular CPU for high end gaming PCs using the same core architecture as the CPUs in LUMI. It runs at a base clock of 3.8 GHz and a boost clock of 4.7 GHz if only one core is used and the system has proper cooling. The 7763 used in the compute nodes of LUMI-C runs at a base clock of 2.45 GHz and a boost clock of 3.5 GHz. If you have only one single core job to run on your PC, you'll be able to reach that boost clock while on LUMI you'd probably need to have a large part of the node for yourself, and even then the performance for jobs that are not memory bandwidth limited will be lower than that of the gaming PC.
-
For some data formats the GPU performance may be slower also than on a high end gaming PC. This is even more so because an MI250X should be treated as two GPUs for most practical purposes. The better double precision floating point operations and matrix operations, also at full precision, require transistors also that on some other GPUs are used for rendering hardware or for single precision compute units.
E.g., a single GPU die of the MI250X (half a GPU) has a peak FP32 performance at the boost clock of almost 24 TFlops or 48 TFlops in the packed format which is actually hard for a compiler to exploit, while the high-end AMD graphics GPU RX 7900 XTX claims 61 TFlops at the boost clock. But the FP64 performance of one MI250X die is also close to 24 TFlops in vector math, while the RX 7900 XTX does less than 2 TFlops in that data format which is important for a lot of scientific computing applications.
-
Compute GPUs and rendering GPUs are different beasts these days. We had a user who wanted to use the ray tracing units to do rendering. The MI250X does not have texture units or ray tracing units though. It is not a real graphics processor anymore.
-
The environment is different also. It is not that because it runs some Linux it handles are your Linux software. A user complained that they did not succeed in getting their nice remote development environment to work on LUMI. The original author of these notes took a test license and downloaded a trial version. It was a very nice environment but really made for local development and remote development in a cloud environment with virtual machines individually protected by personal firewalls and was not only hard to get working on a supercomputer but also insecure.
-
And supercomputers need proper software that exploits the strengths and works around the weaknesses of their architecture. CERN came telling on a EuroHPC Summit Week before the COVID pandemic that they would start using more HPC and less cloud and that they expected a 40% cost reduction that way. A few years later they published a paper with their experiences and it was mostly disappointment. The HPC infrastructure didn't fit their model for software distribution and performance was poor. Basically their solution was designed around the strengths of a typical cloud infrastructure and relied precisely on those things that did make their cloud infrastructure more expensive than the HPC infrastructure they tested. It relied on fast local disks that require a proper management layer in the software, (ab)using the file system as a database for unstructured data, a software distribution mechanism that requires an additional daemon running permanently on the compute nodes (and local storage on those nodes), ...
True supercomputers, and LUMI in particular, are built for scalable parallel applications and features that are found on smaller clusters or on workstations that pose a threat to scalability are removed from the system. It is also a shared infrastructure but with a much more lightweight management layer than a cloud infrastructure and far less isolation between users, meaning that abuse by one user can have more of a negative impact on other users than in a cloud infrastructure. Supercomputers since the mid to late '80s are also built according to the principle of trying to reduce the hardware cost by using cleverly designed software both at the system and application level. They perform best when streaming data through the machine at all levels of the memory hierarchy and are not built at all for random access to small bits of data (where the definition of \"small\" depends on the level in the memory hierarchy).
At several points in this course you will see how this impacts what you can do with a supercomputer and how you work with a supercomputer.
And LUMI is not just a supercomputer, it is a pre-exascale supercomputer. This implies that it is using new and leading edge technology and pushing the limits of current technology. But this also means that it will have some features that many observe as problems that smaller clusters using more conventional technology will not have. Stability is definitely less, bigger networks definitely come with more problems (and are an important cause of those stability problems), not everything scales as you would hope (think of the scheduler and file system IOPS discussed later in this course), ...
"},{"location":"2day-next/01-Architecture/#lumi-spec-sheet-a-modular-system","title":"LUMI spec sheet: A modular system","text":"So we've already seen that LUMI is in the first place a EuroHPC pre-exascale machine. LUMI is built to prepare for the exascale era and to fit in the EuroHPC ecosystem. But it does not even mean that it has to cater to all pre-exascale compute needs. The EuroHPC JU tries to build systems that have some flexibility, but also does not try to cover all needs with a single machine. They are building 3 pre-exascale systems with different architecture to explore multiple architectures and to cater to a more diverse audience. LUMI is an AMD GPU-based supercomputer, Leonardo uses NVIDIA A100 GPUS, and MareNostrum5 has a very large CPU section besides an NVIDIA Hopper GPU section.
LUMI is also a very modular machine designed according to the principles explored in a series of European projects, and in particular DEEP and its successors) that explored the cluster-booster concept. E.g., in a complicated multiphysics simulation you could be using regular CPU nodes for the physics that cannot be GPU-accelerated communicating with compute GPU nodes for the physics that can be GPU-accelerated, then add a number of CPU nodes to do the I/O and a specialised render GPU node for in-situ visualisation.
LUMI is in the first place a huge GPGPU supercomputer. The GPU partition of LUMI, called LUMI-G, contains 2978 nodes with a single 64-core AMD EPYC 7A53 CPU and 4 AMD MI250X GPUs. Each node has 512 GB of RAM attached to the CPU (the maximum the CPU can handle without compromising bandwidth) and 128 GB of HBM2e memory per GPU. Each GPU node has a theoretical peak performance of nearly 200 TFlops in single (FP32) or double (FP64) precision vector arithmetic (and twice that with the packed FP32 format, but that is not well supported so this number is not often quoted). The matrix units are capable of about 400 TFlops in FP32 or FP64. However, compared to the NVIDIA GPUs, the performance for lower precision formats used in some AI applications is not that stellar.
LUMI also has a large CPU-only partition, called LUMI-C, for jobs that do not run well on GPUs, but also integrated enough with the GPU partition that it is possible to have applications that combine both node types. LUMI-C consists of 2048 nodes with 2 64-core AMD EPYC 7763 CPUs. 32 of those nodes have 1TB of RAM (with some of these nodes actually reserved for special purposes such as connecting to a Quantum computer), 128 have 512 GB and 1888 have 256 GB of RAM.
LUMI also has two smaller groups of nodes for interactive data analytics. 8 of those nodes have two 64-core Zen2/Rome CPUs with 4 TB of RAM per node, while 8 others have dual 64-core Zen2/Rome CPUs and 8 NVIDIA A40 GPUs for visualisation. There is also an Open OnDemand based service (web interface) to make some fo those facilities available. Note though that these nodes are meant for a very specific use, so it is not that we will also be offering, e.g., GPU compute facilities on NVIDIA hardware, and that these are shared resources that should not be monopolised by a single user (so no hope to run an MPI job on 8 4TB nodes).
LUMI also has a 8 PB flash based file system running the Lustre parallel file system. This system is often denoted as LUMI-F. The bandwidth of that system is over 2 TB/s. Note however that this is still a remote file system with a parallel file system on it, so do not expect that it will behave as the local SSD in your laptop. But that is also the topic of another session in this course.
The main work storage is provided by 4 20 PB hard disk based Lustre file systems with a bandwidth of 240 GB/s each. That section of the machine is often denoted as LUMI-P.
Big parallel file systems need to be used in the proper way to be able to offer the performance that one would expect from their specifications. This is important enough that we have a separate session about that in this course.
There is also a 30 PB object based file system similar to the Allas service of CSC that some of the Finnish users may be familiar with is also being worked on. At the moment the interface to that system is still rather primitive.
Currently LUMI has 4 login nodes for ssh access, called user access nodes in the HPE Cray world. They each have 2 64-core AMD EPYC 7742 processors and 1 TB of RAM. Note that whereas the GPU and CPU compute nodes have the Zen3 architecture code-named \"Milan\", the processors on the login nodes are Zen2 processors, code-named \"Rome\". Zen3 adds some new instructions so if a compiler generates them, that code would not run on the login nodes. These instructions are basically used in cryptography though. However, many instructions have very different latency, so a compiler that optimises specifically for Zen3 may chose another ordering of instructions then when optimising for Zen2 so it may still make sense to compile specifically for the compute nodes on LUMI.
There are also some additional login nodes for access via the web-based Open OnDemand interface.
All compute nodes, login nodes and storage are linked together through a high-performance interconnect. LUMI uses the Slingshot 11 interconnect which is developed by HPE Cray, so not the Mellanox/NVIDIA InfiniBand that you may be familiar with from many smaller clusters, and as we shall discuss later this also influences how you work on LUMI.
Early on a small partition for containerised micro-services managed with Kubernetes was also planned, but that may never materialize due to lack of people to set it up and manage it.
In this section of the course we will now build up LUMI step by step.
"},{"location":"2day-next/01-Architecture/#building-lumi-the-cpu-amd-7xx3-milanzen3-cpu","title":"Building LUMI: The CPU AMD 7xx3 (Milan/Zen3) CPU","text":"The LUMI-C and LUMI-G compute nodes use third generation AMD EPYC CPUs. Whereas Intel CPUs launched in the same period were built out of a single large monolithic piece of silicon (that only changed recently with some variants of the Sapphire Rapids CPU launched in early 2023), AMD CPUs are made up of multiple so-called chiplets.
The basic building block of Zen3 CPUs is the Core Complex Die (CCD). Each CCD contains 8 cores, and each core has 32 kB of L1 instruction and 32 kB of L1 data cache, and 512 kB of L2 cache. The L3 cache is shared across all cores on a chiplet and has a total size of 32 MB on LUMI (there are some variants of the processor where this is 96MB). At the user level, the instruction set is basically equivalent to that of the Intel Broadwell generation. AVX2 vector instructions and the FMA instruction are fully supported, but there is no support for any of the AVX-512 versions that can be found on Intel Skylake server processors and later generations. Hence the number of floating point operations that a core can in theory do each clock cycle is 16 (in double precision) rather than the 32 some Intel processors are capable of.
The full processor package for the AMD EPYC processors used in LUMI have 8 such Core Complex Dies for a total of 64 cores. The caches are not shared between different CCDs, so it also implies that the processor has 8 so-called L3 cache regions or domains. (Some cheaper variants have only 4 CCDs, and some have CCDs with only 6 or fewer cores enabled but the same 32 MB of L3 cache per CCD).
Each CCD connects to the memory/IO die through an Infinity Fabric link. The memory/IO die contains the memory controllers, connections to connect two CPU packages together, PCIe lanes to connect to external hardware, and some additional hardware, e.g., for managing the processor. The memory/IO die supports 4 dual channel DDR4 memory controllers providing a total of 8 64-bit wide memory channels. From a logical point of view the memory/IO-die is split in 4 quadrants, with each quadrant having a dual channel memory controller and 2 CCDs. They basically act as 4 NUMA domains. For a core it is slightly faster to access memory in its own quadrant than memory attached to another quadrant, though for the 4 quadrants within the same socket the difference is small. (In fact, the BIOS can be set to show only two or one NUMA domain which is advantageous in some cases, like the typical load pattern of login nodes where it is impossible to nicely spread processes and their memory across the 4 NUMA domains).
The theoretical memory bandwidth of a complete package is around 200 GB/s. However, that bandwidth is not available to a single core but can only be used if enough cores spread over all CCDs are used.
"},{"location":"2day-next/01-Architecture/#building-lumi-a-lumi-c-node","title":"Building LUMI: a LUMI-C node","text":"A compute node is then built out of two such processor packages, connected through 4 16-bit wide Infinity Fabric connections with a total theoretical bandwidth of 144 GB/s in each direction. So note that the bandwidth in each direction is less than the memory bandwidth of a socket. Again, it is not really possible to use the full memory bandwidth of a node using just cores on a single socket. Only one of the two sockets has a direct connection to the high performance Slingshot interconnect though.
"},{"location":"2day-next/01-Architecture/#a-strong-hierarchy-in-the-node","title":"A strong hierarchy in the node","text":"As can be seen from the node architecture in the previous slide, the CPU compute nodes have a very hierarchical architecture. When mapping an application onto one or more compute nodes, it is key for performance to take that hierarchy into account. This is also the reason why we will pay so much attention to thread and process pinning in this tutorial course.
At the coarsest level, each core supports two hardware threads (what Intel calls hyperthreads). Those hardware threads share all the resources of a core, including the L1 data and instruction caches and the L2 cache, execution units and space for register renaming. At the next level, a Core Complex Die contains (up to) 8 cores. These cores share the L3 cache and the link to the memory/IO die. Next, as configured on the LUMI compute nodes, there are 2 Core Complex Dies in a NUMA node. These two CCDs share the DRAM channels of that NUMA node. At the fourth level in our hierarchy 4 NUMA nodes are grouped in a socket. Those 4 nodes share an inter-socket link. At the fifth and last level in our shared memory hierarchy there are two sockets in a node. On LUMI, they share a single Slingshot inter-node link.
The finer the level (the lower the number), the shorter the distance and hence the data delay is between threads that need to communicate with each other through the memory hierarchy, and the higher the bandwidth.
This table tells us a lot about how one should map jobs, processes and threads onto a node. E.g., if a process has fewer then 8 processing threads running concurrently, these should be mapped to cores on a single CCD so that they can share the L3 cache, unless they are sufficiently independent of one another, but even in the latter case the additional cores on those CCDs should not be used by other processes as they may push your data out of the cache or saturate the link to the memory/IO die and hence slow down some threads of your process. Similarly, on a 256 GB compute node each NUMA node has 32 GB of RAM (or actually a bit less as the OS also needs memory, etc.), so if you have a job that uses 50 GB of memory but only, say, 12 threads, you should really have two NUMA nodes reserved for that job as otherwise other threads or processes running on cores in those NUMA nodes could saturate some resources needed by your job. It might also be preferential to spread those 12 threads over the 4 CCDs in those 2 NUMA domains unless communication through the L3 threads would be the bottleneck in your application.
"},{"location":"2day-next/01-Architecture/#hierarchy-delays-in-numbers","title":"Hierarchy: delays in numbers","text":"This slide shows the Advanced Configuration and Power Interface System Locality distance Information Table (ACPI SLIT) as returned by, e.g., numactl -H which gives relative distances to memory from a core. E.g., a value of 32 means that access takes 3.2x times the time it would take to access memory attached to the same NUMA node. We can see from this table that the penalty for accessing memory in another NUMA domain in the same socket is still relatively minor (20% extra time), but accessing memory attached to the other socket is a lot more expensive. If a process running on one socket would only access memory attached to the other socket, it would run a lot slower which is why Linux has mechanisms to try to avoid that, but this cannot be done in all scenarios which is why on some clusters you will be allocated cores in proportion to the amount of memory you require, even if that is more cores than you really need (and you will be billed for them).
"},{"location":"2day-next/01-Architecture/#building-lumi-concept-lumi-g-node","title":"Building LUMI: Concept LUMI-G node","text":"This slide shows a conceptual view of a LUMI-G compute node. This node is unlike any Intel-architecture-CPU-with-NVIDIA-GPU compute node you may have seen before, and rather mimics the architecture of the USA pre-exascale machines Summit and Sierra which have IBM POWER9 CPUs paired with NVIDIA V100 GPUs.
Each GPU node consists of one 64-core AMD EPYC CPU and 4 AMD MI250X GPUs. So far nothing special. However, two elements make this compute node very special. First, the GPUs are not connected to the CPU though a PCIe bus. Instead they are connected through the same links that AMD uses to link the GPUs together, or to link the two sockets in the LUMI-C compute nodes, known as xGMI or Infinity Fabric. This enables unified memory across CPU and GPUS and provides partial cache coherency across the system. The CPUs coherently cache the CPU DDR and GPU HBM memory, but each GPU only coherently caches its own local memory. The second remarkable element is that the Slingshot interface cards connect directly to the GPUs (through a PCIe interface on the GPU) rather than to the CPU. The GPUs have a shorter path to the communication network than the CPU in this design.
This makes the LUMI-G compute node really a \"GPU first\" system. The architecture looks more like a GPU system with a CPU as the accelerator for tasks that a GPU is not good at such as some scalar processing or running an OS, rather than a CPU node with GPU accelerator.
It is also a good fit with the cluster-booster design explored in the DEEP project series. In that design, parts of your application that cannot be properly accelerated would run on CPU nodes, while booster GPU nodes would be used for those parts that can (at least if those two could execute concurrently with each other). Different node types are mixed and matched as needed for each specific application, rather than building clusters with massive and expensive nodes that few applications can fully exploit. As the cost per transistor does not decrease anymore, one has to look for ways to use each transistor as efficiently as possible...
It is also important to realise that even though we call the partition \"LUMI-G\", the MI250X is not a GPU in the true sense of the word. It is not a rendering GPU, which for AMD is currently the RDNA architecture with version 3 out and version 4 coming, but a compute accelerator with an architecture that evolved from a GPU architecture, in this case the VEGA architecture from AMD. The architecture of the MI200 series is also known as CDNA2, with the MI100 series being just CDNA, the first version. Much of the hardware that does not serve compute purposes has been removed from the design to have more transistors available for compute. Rendering is possible, but it will be software-based rendering with some GPU acceleration for certain parts of the pipeline, but not full hardware rendering.
This is not an evolution at AMD only. The same is happening with NVIDIA GPUs and there is a reason why the latest generation is called \"Hopper\" for compute and \"Ada Lovelace\" for rendering GPUs. Several of the functional blocks in the Ada Lovelace architecture are missing in the Hopper architecture to make room for more compute power and double precision compute units. E.g., Hopper does not contain the ray tracing units of Ada Lovelace. The Intel Data Center GPU Max code named \"Ponte Vecchio\" is the only current GPU for HPC that still offers full hardware rendering support (and even ray tracing).
Graphics on one hand and HPC and AI on the other hand are becoming separate workloads for which manufacturers make different, specialised cards, and if you have applications that need both, you'll have to rework them to work in two phases, or to use two types of nodes and communicate between them over the interconnect, and look for supercomputers that support both workloads. And nowadays we're even starting to see a split between chips that really target AI and chips that target a more traditional HPC workload, with the latter threatened as there is currently much more money to make in the AI market. And within AI we're starting to see specialised accelerators for inference.
But so far for the sales presentation, let's get back to reality...
"},{"location":"2day-next/01-Architecture/#building-lumi-what-a-lumi-g-node-really-looks-like","title":"Building LUMI: What a LUMI-G node really looks like","text":"Or the full picture with the bandwidths added to it:
The LUMI-G node uses the 64-core AMD 7A53 EPYC processor, known under the code name \"Trento\". This is basically a Zen3 processor but with a customised memory/IO die, designed specifically for HPE Cray (and in fact Cray itself, before the merger) for the USA Coral-project to build the Frontier supercomputer, the fastest system in the world at the end of 2022 according to at least the Top500 list. Just as the CPUs in the LUMI-C nodes, it is a design with 8 CCDs and a memory/IO die.
The MI250X GPU is also not a single massive die, but contains two compute dies besides the 8 stacks of HBM2e memory, 4 stacks or 64 GB per compute die. The two compute dies in a package are linked together through 4 16-bit Infinity Fabric links. These links run at a higher speed than the links between two CPU sockets in a LUMI-C node, but per link the bandwidth is still only 50 GB/s per direction, creating a total bandwidth of 200 GB/s per direction between the two compute dies in an MI250X GPU. That amount of bandwidth is very low compared to even the memory bandwidth, which is roughly 1.6 TB/s peak per die, let alone compared to whatever bandwidth caches on the compute dies would have or the bandwidth of the internal structures that connect all compute engines on the compute die. Hence the two dies in a single package cannot function efficiently as as single GPU which is one reason why each MI250X GPU on LUMI is actually seen as two GPUs.
Each compute die uses a further 2 or 3 of those Infinity Fabric (or xGNI) links to connect to some compute dies in other MI250X packages. In total, each MI250X package is connected through 5 such links to other MI250X packages. These links run at the same 25 GT/s speed as the links between two compute dies in a package, but even then the bandwidth is only a meager 250 GB/s per direction, less than an NVIDIA A100 GPU which offers 300 GB/s per direction or the NVIDIA H100 GPU which offers 450 GB/s per direction. Each Infinity Fabric link may be twice as fast as each NVLINK 3 or 4 link (NVIDIA Ampere and Hopper respectively), offering 50 GB/s per direction rather than 25 GB/s per direction for NVLINK, but each Ampere GPU has 12 such links and each Hopper GPU 18 (and in fact a further 18 similar ones to link to a Grace CPU), while each MI250X package has only 5 such links available to link to other GPUs (and the three that we still need to discuss).
Note also that even though the connection between MI250X packages is all-to-all, the connection between GPU dies is all but all-to-all. as each GPU die connects to only 3 other GPU dies. There are basically two bidirectional rings that don't need to share links in the topology, and then some extra connections. The rings are:
- Green ring: 1 - 0 - 6 - 7 - 5 - 4 - 2 - 3 - 1
- Red ring: 1 - 0 - 2 - 3 - 7 - 6 - 4 - 5 - 1
These rings play a role in the inter-GPU communication in AI applications using RCCL.
Each compute die is also connected to one CPU Core Complex Die (or as documentation of the node sometimes says, L3 cache region). This connection only runs at the same speed as the links between CPUs on the LUMI-C CPU nodes, i.e., 36 GB/s per direction (which is still enough for all 8 GPU compute dies together to saturate the memory bandwidth of the CPU). This implies that each of the 8 GPU dies has a preferred CPU die to work with, and this should definitely be taken into account when mapping processes and threads on a LUMI-G node.
The figure also shows another problem with the LUMI-G node: The mapping between CPU cores/dies and GPU dies is all but logical:
GPU die CCD hardware threads NUMA node 0 6 48-55, 112-119 3 1 7 56-63, 120-127 3 2 2 16-23, 80-87 1 3 3 24-31, 88-95 1 4 0 0-7, 64-71 0 5 1 8-15, 72-79 0 6 4 32-39, 96-103 2 7 5 40-47, 104, 11 2 and as we shall see later in the course, exploiting this is a bit tricky at the moment.
"},{"location":"2day-next/01-Architecture/#what-the-future-looks-like","title":"What the future looks like...","text":"Some users may be annoyed by the \"small\" amount of memory on each node. Others may be annoyed by the limited CPU capacity on a node compared to some systems with NVIDIA GPUs. It is however very much in line with the cluster-booster philosophy already mentioned a few times, and it does seem to be the future according to AMD (with Intel also working into that direction). In fact, it looks like with respect to memory capacity things may even get worse.
We saw the first little steps of bringing GPU and CPU closer together and integrating both memory spaces in the USA pre-exascale systems Summit and Sierra. The LUMI-G node which was really designed for one of the first USA exascale systems continues on this philosophy, albeit with a CPU and GPU from a different manufacturer. Given that manufacturing large dies becomes prohibitively expensive in newer semiconductor processes and that the transistor density on a die is also not increasing at the same rate anymore with process shrinks, manufacturers are starting to look at other ways of increasing the number of transistors per \"chip\" or should we say package. So multi-die designs are here to stay, and as is already the case in the AMD CPUs, different dies may be manufactured with different processes for economical reasons.
Moreover, a closer integration of CPU and GPU would not only make programming easier as memory management becomes easier, it would also enable some codes to run on GPU accelerators that are currently bottlenecked by memory transfers between GPU and CPU.
Such a chip is exactly what AMD launched in December 2023 with the MI300A version of the MI300 series. It employs 13 chiplets in two layers, linked to (still only) 8 memory stacks (albeit of a much faster type than on the MI250X). The 4 chiplets on the bottom layer are the memory controllers and inter-GPU links (an they can be at the bottom as they produce less heat). Furthermore each package features 6 GPU dies (now called XCD or Accelerated Compute Die as they really can't do graphics) and 3 Zen4 \"Genoa\" CPU dies. In the MI300A the memory is still limited to 8 16 GB stacks, providing a total of 128 GB of RAM. The MI300X, which is the regular version without built-in CPU, already uses 24 GB stacks for a total of 192 GB of memory, but presumably those were not yet available when the design of MI300A was tested for the launch customer, the El Capitan supercomputer. HLRS is building the Hunter cluster based on AMD MI300A as a transitional system to their first exascale-class system Herder that will become operational by 2027. The fact that the chip has recently been selected for the Hunter development system also indicates that even if no successor using the same techniques to combine GPU and CPU compute dies and memory would be made, there should at least be a successor that towards software behaves very similarly.
Intel at some point has shown only very conceptual drawings of its Falcon Shores chip which it calls an XPU, but those drawings suggest that that chip will also support some low-bandwidth but higher capacity external memory, similar to the approach taken in some Sapphire Rapids Xeon processors that combine HBM memory on-package with DDR5 memory outside the package. Falcon Shores will be the next generation of Intel GPUs for HPC, after Ponte Vecchio which will be used in the Aurora supercomputer. It is currently very likely though that Intel will revert to a traditional design for Falcon Shores and push out the integrated CPU+GPU model to a later generation.
"},{"location":"2day-next/01-Architecture/#building-lumi-the-slingshot-interconnect","title":"Building LUMI: The Slingshot interconnect","text":"All nodes of LUMI, including the login, management and storage nodes, are linked together using the Slingshot interconnect (and almost all use Slingshot 11, the full implementation with 200 Gb/s bandwidth per direction).
Slingshot is an interconnect developed by HPE Cray and based on Ethernet, but with proprietary extensions for better HPC performance. It adapts to the regular Ethernet protocols when talking to a node that only supports Ethernet, so one of the attractive features is that regular servers with Ethernet can be directly connected to the Slingshot network switches. HPE Cray has a tradition of developing their own interconnect for very large systems. As in previous generations, a lot of attention went to adaptive routing and congestion control. There are basically two versions of it. The early version was named Slingshot 10, ran at 100 Gb/s per direction and did not yet have all features. It was used on the initial deployment of LUMI-C compute nodes but has since been upgraded to the full version. The full version with all features is called Slingshot 11. It supports a bandwidth of 200 Gb/s per direction, comparable to HDR InfiniBand with 4x links.
Slingshot is a different interconnect from your typical Mellanox/NVIDIA InfiniBand implementation and hence also has a different software stack. This implies that there are no UCX libraries on the system as the Slingshot 11 adapters do not support that. Instead, the software stack is based on libfabric (as is the stack for many other Ethernet-derived solutions and even Omni-Path has switched to libfabric under its new owner).
LUMI uses the dragonfly topology. This topology is designed to scale to a very large number of connections while still minimizing the amount of long cables that have to be used. However, with its complicated set of connections it does rely heavily on adaptive routing and congestion control for optimal performance more than the fat tree topology used in many smaller clusters. It also needs so-called high-radix switches. The Slingshot switch, code-named Rosetta, has 64 ports. 16 of those ports connect directly to compute nodes (and the next slide will show you how). Switches are then combined in groups. Within a group there is an all-to-all connection between switches: Each switch is connected to each other switch. So traffic between two nodes of a group passes only via two switches if it takes the shortest route. However, as there is typically only one 200 Gb/s direct connection between two switches in a group, if all 16 nodes on two switches in a group would be communicating heavily with each other, it is clear that some traffic will have to take a different route. In fact, it may be statistically better if the 32 involved nodes would be spread more evenly over the group, so topology based scheduling of jobs and getting the processes of a job on as few switches as possible may not be that important on a dragonfly Slingshot network. The groups in a slingshot network are then also connected in an all-to-all fashion, but the number of direct links between two groups is again limited so traffic again may not always want to take the shortest path. The shortest path between two nodes in a dragonfly topology never involves more than 3 hops between switches (so 4 switches): One from the switch the node is connected to the switch in its group that connects to the other group, a second hop to the other group, and then a third hop in the destination group to the switch the destination node is attached to.
"},{"location":"2day-next/01-Architecture/#assembling-lumi","title":"Assembling LUMI","text":"Let's now have a look at how everything connects together to the supercomputer LUMI. It does show that LUMI is not your standard cluster build out of standard servers.
LUMI is built very compactly to minimise physical distance between nodes and to reduce the cabling mess typical for many clusters and the costs of cabling. High-speed copper cables are expensive, but optical cables and the transceivers that are needed are even more expensive and actually also consume a significant amount of power compared to the switch power. The design of LUMI is compact enough that within a rack, switches can be connected with copper cables in the current network technology and optical cabling is only needed between racks.
LUMI does use a custom rack design for the compute nodes that is also fully water cooled. It is build out of units that can contain up to 4 custom cabinets, and a cooling distribution unit (CDU). The size of the complex as depicted in the slide is approximately 12 m2. Each cabinet contains 8 compute chassis in 2 columns of 4 rows. In between the two columns is all the power circuitry. Each compute chassis can contain 8 compute blades that are mounted vertically. Each compute blade can contain multiple nodes, depending on the type of compute blades. HPE Cray have multiple types of compute nodes, also with different types of GPUs. In fact, the Aurora supercomputer which uses Intel CPUs and GPUs and El Capitan, which uses the MI300A APUs (integrated CPU and GPU) will use the same design with a different compute blade. Each LUMI-C compute blade contains 4 compute nodes and two network interface cards, with each network interface card implementing two Slingshot interfaces and connecting to two nodes. A LUMI-G compute blade contains two nodes and 4 network interface cards, where each interface card now connects to two GPUs in the same node. All connections for power, management network and high performance interconnect of the compute node are at the back of the compute blade. At the front of the compute blades one can find the connections to the cooling manifolds that distribute cooling water to the blades. One compute blade of LUMI-G can consume up to 5kW, so the power density of this setup is incredible, with 40 kW for a single compute chassis.
The back of each cabinet is equally genius. At the back each cabinet has 8 switch chassis, each matching the position of a compute chassis. The switch chassis contains the connection to the power delivery system and a switch for the management network and has 8 positions for switch blades. These are mounted horizontally and connect directly to the compute blades. Each slingshot switch has 8x2 ports on the inner side for that purpose, two for each compute blade. Hence for LUMI-C two switch blades are needed in each switch chassis as each blade has 4 network interfaces, and for LUMI-G 4 switch blades are needed for each compute chassis as those nodes have 8 network interfaces. Note that this also implies that the nodes on the same compute blade of LUMI-C will be on two different switches even though in the node numbering they are numbered consecutively. For LUMI-G both nodes on a blade will be on a different pair of switches and each node is connected to two switches. So when you get a few sequentially numbered nodes, they will not be on a single switch (LUMI-C) or switch pair (LUMI-G). The switch blades are also water cooled (each one can consume up to 250W). No currently possible configuration of the Cray EX system needs all switch positions in the switch chassis.
This does not mean that the extra positions cannot be useful in the future. If not for an interconnect, one could, e.g., export PCIe ports to the back and attach, e.g., PCIe-based storage via blades as the switch blade environment is certainly less hostile to such storage than the very dense and very hot compute blades.
"},{"location":"2day-next/01-Architecture/#lumi-assembled","title":"LUMI assembled","text":"This slide shows LUMI fully assembled (as least as it was at the end of 2022).
At the front there are 5 rows of cabinets similar to the ones in the exploded Cray EX picture on the previous slide. Each row has 2 CDUs and 6 cabinets with compute nodes. The first row, the one with the wolf, contains all nodes of LUMI-C, while the other four rows, with the letters of LUMI, contain the GPU accelerator nodes. At the back of the room there are more regular server racks that house the storage, management nodes, some special compute nodes , etc. The total size is roughly the size of a tennis court.
Remark
The water temperature that a system like the Cray EX can handle is so high that in fact the water can be cooled again with so-called \"free cooling\", by just radiating the heat to the environment rather than using systems with compressors similar to air conditioning systems, especially in regions with a colder climate. The LUMI supercomputer is housed in Kajaani in Finland, with moderate temperature almost year round, and the heat produced by the supercomputer is fed into the central heating system of the city, making it one of the greenest supercomputers in the world as it is also fed with renewable energy.
"},{"location":"2day-next/02-CPE/","title":"HPE Cray Programming Environment","text":"In this session we discuss some of the basics of the operating system and programming environment on LUMI. Whether you like it or not, every user of a supercomputer like LUMI gets confronted with these elements at some point.
"},{"location":"2day-next/02-CPE/#why-do-i-need-to-know-this","title":"Why do I need to know this?","text":"The typical reaction of someone who only wants to run software on an HPC system when confronted with a talk about development tools is \"I only want to run some programs, why do I need to know about programming environments?\"
The answer is that development environments are an intrinsic part of an HPC system. No HPC system is as polished as a personal computer and the software users want to use is typically very unpolished. And some of the essential middleware that turns the hardware with some variant of Linux into a parallel supercomputers is part of the programming environment. The binary interfaces to those libraries are also not as standardised as for the more common Linux system libraries.
Programs on an HPC cluster are preferably installed from sources to generate binaries optimised for the system. CPUs have gotten new instructions over time that can sometimes speed-up execution of a program a lot, and compiler optimisations that take specific strengths and weaknesses of particular CPUs into account can also gain some performance. Even just a 10% performance gain on an investment of 160 million EURO such as LUMI means a lot of money. When running, the build environment on most systems needs to be at least partially recreated. This is somewhat less relevant on Cray systems as we will see at the end of this part of the course, but if you want reproducibility it becomes important again.
Compiling on the system is also the easiest way to guarantee compatibility of the binaries with the system.
Even when installing software from prebuilt binaries some modules might still be needed. Prebuilt binaries will typically include the essential runtime libraries for the parallel technologies they use, but these may not be compatible with LUMI. In some cases this can be solved by injecting a library from LUMI, e.g., you may want to inject an optimised MPI library as we shall see in the container section of this course. But sometimes a binary is simply incompatible with LUMI and there is no other solution than to build the software from sources.
"},{"location":"2day-next/02-CPE/#the-operating-system-on-lumi","title":"The operating system on LUMI","text":"The login nodes of LUMI run a regular SUSE Linux Enterprise Server 15 SP4 distribution. The compute nodes however run Cray OS, a restricted version of the SUSE Linux that runs on the login nodes. Some daemons are inactive or configured differently and Cray also does not support all regular file systems. The goal of this is to minimize OS jitter, interrupts that the OS handles and slow down random cores at random moments, that can limit scalability of programs. Yet on the GPU nodes there was still the need to reserve one core for the OS and driver processes. This in turn led to an asymmetry in the setup so now 8 cores are reserved, one per CCD, so that all CCDs are equal again.
This also implies that some software that works perfectly fine on the login nodes may not work on the compute nodes. E.g., you will see that there is no /run/user/$UID directory.
Large HPC clusters also have a small system image, so don't expect all the bells-and-whistles from a Linux workstation to be present on a large supercomputer (and certainly not in the same way as they would be on a workstation). Since LUMI compute nodes are diskless, the system image actually occupies RAM which is another reason to keep it small.
Some missing pieces Compute nodes don't run a per-user dbus daemon, so some if not all DBUS functionality is missing. And D-Bus may sometimes show up in places where you don't expect it... It may come from freedesktop.org but is is not only used for desktop software.
Compute nodes on a Cray system have Lustre as the main file system. They do not import any networked file system like NFS, GPFS or CernVM-FS (the latter used by, e.g., Cern for distributing software for the Large Haedron Collider and the EESSI project). Instead these file systems are mounted on external servers in the admin section of the cluster and the Cray Data Virtualisation Service (DVS) is then used to access those file systems from the compute nodes over the high-speed interconnect.
"},{"location":"2day-next/02-CPE/#low-noise-mode","title":"Low-noise mode","text":"Low-noise mode has meant different things throughout the history of Cray systems. Sometimes the mode described above, using only a selection of the regular Linux daemons on the compute nodes, was already called low-noise mode while some Cray systems provided another mode in which those daemons were activated. Depending on the cluster this was then called \"emulation mode\" or \"Cluster Compatibility Mode\". The latter is not implemented on LUMI, and even if it would, compatibility would still be limited by the special requirements to use the Slingshot interconnect and to have GPU-aware communication over Slingshot.
However, it turned out that even the noise reduction described above was not yet sufficient to pass some large-scale scalability tests, and therefore another form of \"low-noise\" mode is implemented on the GPU nodes of LUMI where OS processes are restricted to a reserved core, actually core 0. This leaves us with an asymmetric structure of the node, where the first CCD has 7 available cores while the other ones have 8, but as that created a headache for users to get a proper distribution of tasks and threads over the CPU (see the \"Process and thread distribution and binding\" chapter), the choice was made to also disable the first core on each of the other CCDs so that users now effectively see a 56-core node with 8 CCDs with 7 cores each.
This is actually an idea Cray has been experimenting with in the past already, ever since we've had nodes with 20 or more cores with the AMD Magny-Cours processors in 2010.
"},{"location":"2day-next/02-CPE/#programming-models","title":"Programming models","text":"On LUMI we have several C/C++ and Fortran compilers. These will be discussed more in this session.
There is also support for MPI and SHMEM for distributed applications. And we also support RCCL, the ROCm-equivalent of the CUDA NCCL library that is popular in machine learning packages.
All compilers have some level of OpenMP support, and two compilers support OpenMP offload to the AMD GPUs, but again more about that later.
OpenACC, the other directive-based model for GPU offloading, is only supported in the Cray Fortran compiler. There is no commitment of neither HPE Cray or AMD to extend that support to C/C++ or other compilers, even though there is work going on in the LLVM community and several compilers on the system are based on LLVM.
The other important programming model for AMD GPUs is HIP (Heterogeneous-Compute Interface for Portability), which is their alternative for the proprietary CUDA model. It does not support all CUDA features though (basically it is more CUDA 7 or 8 level) and there is also no equivalent to CUDA Fortran.
The commitment to OpenCL is very unclear, and this actually holds for other GPU vendors also.
We also try to provide SYCL as it is a programming language/model that works on all three GPU families currently used in HPC.
Python is of course pre-installed on the system but we do ask to use big Python installations in a special way as Python puts a tremendous load on the file system. More about that later in this course.
Some users also report some success in running Julia. We don't have full support though and have to depend on binaries as provided by julialang.org. The AMD GPUs are not yet fully supported by Julia.
It is important to realise that there is no CUDA on AMD GPUs and there will never be as this is a proprietary technology that other vendors cannot implement. The visualisation nodes in LUMI have NVIDIA rendering GPUs but these nodes are meant for visualisation and not for compute.
"},{"location":"2day-next/02-CPE/#the-development-environment-on-lumi","title":"The development environment on LUMI","text":"Long ago, Cray designed its own processors and hence had to develop their own compilers. They kept doing so, also when they moved to using more standard components, and had a lot of expertise in that field, especially when it comes to the needs of scientific codes, programming models that are almost only used in scientific computing or stem from such projects. As they develop their own interconnects, it does make sense to also develop an MPI implementation that can use the interconnect in an optimal way. They also have a long tradition in developing performance measurement and analysis tools and debugging tools that work in the context of HPC.
The first important component of the HPE Cray Programming Environment is the compilers. Cray still builds its own compilers for C/C++ and Fortran, called the Cray Compiling Environment (CCE). Furthermore, the GNU compilers are also supported on every Cray system, though at the moment AMD GPU support is not enabled. Depending on the hardware of the system other compilers will also be provided and integrated in the environment. On LUMI two other compilers are available: the AMD AOCC compiler for CPU-only code and the AMD ROCm compilers for GPU programming. Both contain a C/C++ compiler based on Clang and LLVM and a Fortran compiler which is currently based on the former PGI frontend with LLVM backend. The ROCm compilers also contain the support for HIP, AMD's CUDA clone.
The second component is the Cray Scientific and Math libraries, containing the usual suspects as BLAS, LAPACK and ScaLAPACK, and FFTW, but also some data libraries and Cray-only libraries.
The third component is the Cray Message Passing Toolkit. It provides an MPI implementation optimized for Cray systems, but also the Cray SHMEM libraries, an implementation of OpenSHMEM 1.5.
The fourth component is some Cray-unique sauce to integrate all these components, and support for hugepages to make memory access more efficient for some programs that allocate huge chunks of memory at once.
Other components include the Cray Performance Measurement and Analysis Tools and the Cray Debugging Support Tools that will not be discussed in this one-day course, and Python and R modules that both also provide some packages compiled with support for the Cray Scientific Libraries.
Besides the tools provided by HPE Cray, several of the development tools from the ROCm stack are also available on the system while some others can be user-installed (and one of those, Omniperf, is not available due to security concerns). Furthermore there are some third party tools available on LUMI, including Linaro Forge (previously ARM Forge) and Vampir and some open source profiling tools.
Specifically not on LUMI is the Intel programming environment, nor is the regular Intel oneAPI HPC Toolkit. The classic Intel compilers pose problems on AMD CPUs as -xHost cannot be relied on, but it appears that the new compilers that are based on Clang and an LLVM backend behave better. Various MKL versions are also troublesome, with different workarounds for different versions, though here also it seems that Intel now has code that works well on AMD for many MKL routines. We have experienced problems with Intel MPI when testing it on LUMI though in principle it should be possible to use Cray MPICH as they are derived from the same version of MPICH. The NVIDIA programming environment doesn't make sense on an AMD GPU system, but it could be useful for some visualisation software on the visualisation nodes so it is currently installed on those nodes.
We will now discuss some of these components in a little bit more detail, but refer to the 4-day trainings that we organise several times a year with HPE for more material.
"},{"location":"2day-next/02-CPE/#the-cray-compiling-environment","title":"The Cray Compiling Environment","text":"The Cray Compiling Environment are the default compilers on many Cray systems and on LUMI. These compilers are designed specifically for scientific software in an HPC environment. The current versions are LLVM-based with extensions by HPE Cray for automatic vectorization and shared memory parallelization, technology that they have experience with since the late '70s or '80s.
The compiler offers extensive standards support. The C and C++ compiler is essentially their own build of Clang with LLVM with some of their optimisation plugins and OpenMP run-time. The version numbering of the CCE currently follows the major versions of the Clang compiler used. The support for C and C++ language standards corresponds to that of Clang. The Fortran compiler uses a frontend and optimiser developed by HPE Cray, but an LLVM-based code generator. The compiler supports most of Fortran 2018 (ISO/IEC 1539:2018). The CCE Fortran compiler is known to be very strict with language standards. Programs that use GNU or Intel extensions will usually fail to compile, and unfortunately since many developers only test with these compilers, much Fortran code is not fully standards compliant and will fail.
All CCE compilers support OpenMP, with offload for AMD and NVIDIA GPUs. In their most recent versions, they claim full OpenMP 5.0 support with partial (and growing) support for OpenMP 5.1 and 5.2. More information about the OpenMP support is found by checking a manual page:
man intro_openmp\n
which does require that the cce module is loaded, or the web version of that page which may be for a more recent version of the programming environment than available on LUMI. The Fortran compiler also supports OpenACC for AMD and NVIDIA GPUs. That implementation claims to be fully OpenACC 2.0 compliant, and offers partial support for OpenACC 2.x/3.x. Information is available via man intro_openacc\n
or the corresponding web version of that page which again may be for a more recent version of the programming environment than available on LUMI. AMD and HPE Cray still recommend moving to OpenMP which is a much broader supported standard. There are no plans to also support OpenACC in the Cray C/C++ compiler, nor are there any plans for support by AMD in the ROCm stack. The CCE compilers also offer support for some PGAS (Partitioned Global Address Space) languages. UPC 1.2 is supported, as is Fortran 2008 coarray support. These implementations do not require a preprocessor that first translates the code to regular C or Fortran. There is also support for debugging with Linaro Forge.
Lastly, there are also bindings for MPI.
"},{"location":"2day-next/02-CPE/#scientific-and-math-libraries","title":"Scientific and math libraries","text":"Cray Scientific and Math Libraries overview web page
Some mathematical libraries have become so popular that they basically define an API for which several implementations exist, and CPU manufacturers and some open source groups spend a significant amount of resources to make optimal implementations for each CPU architecture.
The most notorious library of that type is BLAS, a set of basic linear algebra subroutines for vector-vector, matrix-vector and matrix-matrix implementations. It is the basis for many other libraries that need those linear algebra operations, including Lapack, a library with solvers for linear systems and eigenvalue problems.
The HPE Cray LibSci library contains BLAS and its C-interface CBLAS, and LAPACK and its C interface LAPACKE. It also adds ScaLAPACK, a distributed memory version of LAPACK, and BLACS, the Basic Linear Algebra Communication Subprograms, which is the communication layer used by ScaLAPACK. The BLAS library combines implementations from different sources, to try to offer the most optimal one for several architectures and a range of matrix and vector sizes.
LibSci also contains one component which is HPE Cray-only: IRT, the Iterative Refinement Toolkit, which allows to do mixed precision computations for LAPACK operations that can speed up the generation of a double precision result with nearly a factor of two for those problems that are suited for iterative refinement. If you are familiar with numerical analysis, you probably know that the matrix should not be too ill-conditioned for that.
There is also a GPU-optimized version of LibSci, called LibSci_ACC, which contains a subset of the routines of LibSci. We or the LUMI USer Support Team don't have much experience with this library though. It can be compared with what Intel is doing with oneAPI MKL which also offers GPU versions of some of the traditional MKL routines.
Another separate component of the scientific and mathematical libraries is FFTW3, Fastest Fourier Transforms in the West, which comes with optimized versions for all CPU architectures supported by recent HPE Cray machines.
Finally, the scientific and math libraries also contain HDF5 and netCDF libraries in sequential and parallel versions. These are included because it is essential that they interface properly with MPI parallel I/O and the Lustre file system to offer the best bandwidth to and from storage.
Cray used to offer more pre-installed third party libraries for which the only added value was that they compiled the binaries. Instead they now offer build scripts in a GitHub repository.
"},{"location":"2day-next/02-CPE/#cray-mpi","title":"Cray MPI","text":"HPE Cray build their own MPI library with optimisations for their own interconnects. The Cray MPI library is derived from the ANL MPICH 3.4 code base and fully supports the ABI (Application Binary Interface) of that application which implies that in principle it should be possible to swap the MPI library of applications build with that ABI with the Cray MPICH library. Or in other words, if you can only get a binary distribution of an application and that application was build against an MPI library compatible with the MPICH 3.4 ABI (which includes Intel MPI) it should be possible to exchange that library for the Cray one to have optimised communication on the Cray Slingshot interconnect.
Cray MPI contains many tweaks specifically for Cray systems. HPE Cray claim improved algorithms for many collectives, an asynchronous progress engine to improve overlap of communications and computations, customizable collective buffering when using MPI-IO, and optimized remote memory access (MPI one-sided communication) which also supports passive remote memory access.
When used in the correct way (some attention is needed when linking applications) it is also fully GPU aware with currently support for AMD and NVIDIA GPUs.
The MPI library also supports bindings for Fortran 2008.
MPI 3.1 is almost completely supported, with two exceptions. Dynamic process management is not supported (and a problem anyway on systems with batch schedulers), and when using CCE MPI_LONG_DOUBLE and MPI_C_LONG_DOUBLE_COMPLEX are also not supported.
The Cray MPI library does not support the mpirun or mpiexec commands, which is in fact allowed by the standard which only requires a process starter and suggest mpirun or mpiexec depending on the version of the standard. Instead the Slurm srun command is used as the process starter. This actually makes a lot of sense as the MPI application should be mapped correctly on the allocated resources, and the resource manager is better suited to do so.
Cray MPI on LUMI is layered on top of libfabric, which in turn uses the so-called Cassini provider to interface with the hardware. UCX is not supported on LUMI (but Cray MPI can support it when used on InfiniBand clusters). It also uses a GPU Transfer Library (GTL) for GPU-aware MPI.
"},{"location":"2day-next/02-CPE/#gpu-aware-mpi","title":"GPU-aware MPI","text":"Cray MPICH does support GPU-aware MPI, so it is possible to directly use GPU-attached communication buffers using device pointers. The implementation supports (a) GPU-NIC RDMA for efficient inter-node MPI transfers and (b) GPU Peer2Peer IPC for efficient intra-node transfers. The latter mechanism comes with some restrictions though that we will discuss in the chapter \"Process and thread distribution and binding\".
GPU-aware MPI needs to be enabled explicitly, which you can do by setting an environment variable:
export MPICH_GPU_SUPPORT_ENABLED=1\n
In addition to this, if the GPU code does use MPI operations that access GPU-attached memory regions it is best to also set
export MPICH_OFI_NIC_POLICY=GPU\n
to tell MPICH to always use the NIC closest to the GPU.
If only CPU communication buffers are used, then it may be better to set
export MPICH_OFI_NIC_POLICY=NUMA\n
which tells MPICH to use the NIC closest to the CPU NUMA domain.
Depending on how Slurm is used, Peer2Peer IPC may not work and in those cases you may want to turn it off using
export MPICH_GPU_IPC_ENABLED=0\n
or alternatively export MPICH_SMP_SINGLE_COPY_MODE=NONE\n
Both options entail a serious loss of performance. The underlying problem is that the way in which Slurm does GPU binding using control groups makes other GPUS from other tasks in the node invisible to a task. More information about Cray MPICH and the many environment variables to fine-tune performance can be found in the manual page
man intro_mpi\n
or its web-based version which may be for a newer version than available on LUMI.
"},{"location":"2day-next/02-CPE/#lmod","title":"Lmod","text":"Virtually all clusters use modules to enable the users to configure the environment and select the versions of software they want. There are three different module systems around. One is an old implementation that is hardly evolving anymore but that can still be found on a number of clusters. HPE Cray still offers it as an option. Modulefiles are written in TCL, but the tool itself is in C. The more popular tool at the moment is probably Lmod. It is largely compatible with modulefiles for the old tool, but prefers modulefiles written in LUA. It is also supported by the HPE Cray PE and is our choice on LUMI. The final implementation is a full TCL implementation developed in France and also in use on some large systems in Europe.
Fortunately the basic commands are largely similar in those implementations, but what differs is the way to search for modules. We will now only discuss the basic commands, the more advanced ones will be discussed in the next session of this tutorial course.
Modules also play an important role in configuring the HPE Cray PE, but before touching that topic we present the basic commands:
module avail: Lists all modules that can currently be loaded. module list: Lists all modules that are currently loadedmodule load: Command used to load a module. Add the name and version of the module.module unload: Unload a module. Using the name is enough as there can only one version be loaded of a module.module swap: Unload the first module given and then load the second one. In Lmod this is really equivalent to a module unload followed by a module load.
Lmod supports a hierarchical module system. Such a module setup distinguishes between installed modules and available modules. The installed modules are all modules that can be loaded in one way or another by the module systems, but loading some of those may require loading other modules first. The available modules are the modules that can be loaded directly without loading any other module. The list of available modules changes all the time based on modules that are already loaded, and if you unload a module that makes other loaded modules unavailable, those will also be deactivated by Lmod. The advantage of a hierarchical module system is that one can support multiple configurations of a module while all configurations can have the same name and version. This is not fully exploited on LUMI, but it is used a lot in the HPE Cray PE. E.g., the MPI libraries for the various compilers on the system all have the same name and version yet make different binaries available depending on the compiler that is being used.
"},{"location":"2day-next/02-CPE/#compiler-wrappers","title":"Compiler wrappers","text":"The HPE Cray PE compilers are usually used through compiler wrappers. The wrapper for C is cc, the one for C++ is CC and the one for Fortran is ftn. The wrapper then calls the selected compiler. Which compiler will be called is determined by which compiler module is loaded. As shown on the slide \"Development environment on LUMI\", on LUMI the Cray Compiling Environment (module cce), GNU Compiler Collection (module gcc), the AMD Optimizing Compiler for CPUs (module aocc) and the ROCm LLVM-based compilers (module amd) are available. On the visualisation nodes, the NVIDIA HPC compiler is currently also installed (module nvhpc). On other HPE Cray systems, you may also find the Intel compilers.
The target architectures for CPU and GPU are also selected through modules, so it is better to not use compiler options such as -march=native. This makes cross compiling also easier.
The wrappers will also automatically link in certain libraries, and make the include files available, depending on which other modules are loaded. In some cases it tries to do so cleverly, like selecting an MPI, OpenMP, hybrid or sequential option depending on whether the MPI module is loaded and/or OpenMP compiler flag is used. This is the case for:
- The MPI libraries. There is no
mpicc, mpiCC, mpif90, etc. on LUMI (well, there is nowadays, but their use is discouraged). The regular compiler wrappers do the job as soon as the cray-mpich module is loaded. - LibSci and FFTW are linked automatically if the corresponding modules are loaded. So no need to look, e.g., for the BLAS or LAPACK libraries: They will be offered to the linker if the
cray-libsci module is loaded (and it is an example of where the wrappers try to take the right version based not only on compiler, but also on whether MPI is loaded or not and the OpenMP compiler flag). - netCDF and HDF5
It is possible to see which compiler and linker flags the wrappers add through the -craype-verbose flag.
The wrappers do have some flags of their own, but also accept all flags of the selected compiler and simply pass those to those compilers.
The compiler wrappers are provided by the craype module (but you don't have to load that module by hand).
"},{"location":"2day-next/02-CPE/#selecting-the-version-of-the-cpe","title":"Selecting the version of the CPE","text":"The version numbers of the HPE Cray PE are of the form yy.dd, e.g., 23.09 for the version released in September 2023. There are several releases each year (at least 4), but not all of them are offered on LUMI.
There is always a default version assigned by the sysadmins when installing the programming environment. It is possible to change the default version for loading further modules by loading one of the versions of the cpe module. E.g., assuming the 23.09 version would be present on the system, it can be loaded through
module load cpe/23.09\n
Loading this module will also try to switch the already loaded PE modules to the versions from that release. This does not always work correctly, due to some bugs in most versions of this module and a limitation of Lmod. Executing the module load twice will fix this: module load cpe/23.09\nmodule load cpe/23.09\n
The module will also produce a warning when it is unloaded (which is also the case when you do a module load of cpe when one is already loaded, as it then first unloads the already loaded cpe module). The warning can be ignored, but keep in mind that what it says is true, it cannot restore the environment you found on LUMI at login. The cpe module is also not needed when using the LUMI software stacks, but more about that later.
"},{"location":"2day-next/02-CPE/#the-target-modules","title":"The target modules","text":"The target modules are used to select the CPU and GPU optimization targets and to select the network communication layer.
On LUMI there are three CPU target modules that are relevant:
craype-x86-rome selects the Zen2 CPU family code named Rome. These CPUs are used on the login nodes and the nodes of the data analytics and visualisation partition of LUMI. However, as Zen3 is a superset of Zen2, software compiled to this target should run everywhere, but may not exploit the full potential of the LUMI-C and LUMI-G nodes (though the performance loss is likely minor).craype-x86-milan is the target module for the Zen3 CPUs code named Milan that are used on the CPU-only compute nodes of LUMI (the LUMI-C partition).craype-x86-trento is the target module for the Zen3 CPUs code named Trento that are used on the GPU compute nodes of LUMI (the LUMI-G partition).
Two GPU target modules are relevant for LUMI:
craype-accel-host: Will tell some compilers to compile offload code for the host instead.craype-accel-gfx90a: Compile offload code for the MI200 series GPUs that are used on LUMI-G.
Two network target modules are relevant for LUMI:
craype-network-ofi selects the libfabric communication layer which is needed for Slingshot 11.craype-network-none omits all network specific libraries.
The compiler wrappers also have corresponding compiler flags that can be used to overwrite these settings: -target-cpu, -target-accel and -target-network.
"},{"location":"2day-next/02-CPE/#prgenv-and-compiler-modules","title":"PrgEnv and compiler modules","text":"In the HPE Cray PE, the PrgEnv-* modules are usually used to load a specific variant of the programming environment. These modules will load the compiler wrapper (craype), compiler, MPI and LibSci module and may load some other modules also.
The following table gives an overview of the available PrgEnv-* modules and the compilers they activate:
PrgEnv Description Compiler module Compilers PrgEnv-cray Cray Compiling Environment cce craycc, crayCC, crayftn PrgEnv-gnu GNU Compiler Collection gccgcc-native(*) gcc, g++, gfortrangcc-12, g++-12, gfortran-12 PrgEnv-aocc AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang PrgEnv-amd AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang (*) See the note \"Changes to the GNU compilers in 23.12\".
There is also a second module that offers the AMD ROCm environment, rocm. That module has to be used with PrgEnv-cray and PrgEnv-gnu to enable MPI-aware GPU, hipcc with the GNU compilers or GPU support with the Cray compilers.
Changes to the GNU compilers in 23.12 The HPE Cray PE will change the way it offers the GNU compilers in releases starting from 23.12. Rather than packaging the GNU compilers, HPE Cray will use the default development compiler version of SUSE Linux, which for SP4 is currently GCC 12.3 (not to be confused with the system default which is still 7.5, the compiler that was offered with the initial release of SUSE Enterprise Linux 15).
In releases up to the 23.09 which we currently have on Linux, the GNU compilers are offered through the gcc compiler module. When loaded, it adds newer versions of the gcc, g++ and gfortran compilers to the path, calling the version indicated by the version of the gcc module.
In releases from 23.12 on, that compiler module is now called gcc-native, and the compilers are - at least in the version for SUSE 15 SP4 - called gcc-12, g++-12 and gfortran-12, while gcc, g++ and gfortran will compile with version 7.5, the default version for SUSE 15.
"},{"location":"2day-next/02-CPE/#getting-help","title":"Getting help","text":"Help on the HPE Cray Programming Environment is offered mostly through manual pages and compiler flags. Online help is limited and difficult to locate.
For the compilers, the following man pages are relevant:
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - There used to be manual pages for the wrappers also but they are currently hijacked by the GNU manual pages.
Recently, HPE Cray have also created a web version of some of the CPE documentation.
Some compilers also support the --help flag, e.g., amdclang --help. For the wrappers, the switch -help should be used instead as the double dash version is passed to the compiler.
The wrappers have a number of options specific to them. Information about them can be obtained by using the --craype-help flag with the wrappers. The wrappers also support the -dumpversion flag to show the version of the underlying compiler. Many other commands, including the actual compilers, use --version to show the version.
For Cray Fortran compiler error messages, the explain command is also helpful. E.g.,
$ ftn\nftn-2107 ftn: ERROR in command line\n No valid filenames are specified on the command line.\n$ explain ftn-2107\n\nError : No valid filenames are specified on the command line.\n\nAt least one file name must appear on the command line, with any command-line\noptions. Verify that a file name was specified, and also check for an\nerroneous command-line option which may cause the file name to appear to be\nan argument to that option.\n
On older Cray systems this used to be a very useful command with more compilers but as HPE Cray is using more and more open source components instead there are fewer commands that give additional documentation via the explain command.
Lastly, there is also a lot of information in the \"Developing\" section of the LUMI documentation.
"},{"location":"2day-next/02-CPE/#google-chatgpt-and-lumi","title":"Google, ChatGPT and LUMI","text":"When looking for information on the HPE Cray Programming Environment using search engines such as Google, you'll be disappointed how few results show up. HPE doesn't put much information on the internet, and the environment so far was mostly used on Cray systems of which there are not that many.
The same holds for ChatGPT. In fact, much of the training of the current version of ChatGPT was done with data of two or so years ago and there is not that much suitable training data available on the internet either.
The HPE Cray environment has a command line alternative to search engines though: the man -K command that searches for a term in the manual pages. It is often useful to better understand some error messages. E.g., sometimes Cray MPICH will suggest you to set some environment variable to work around some problem. You may remember that man intro_mpi gives a lot of information about Cray MPICH, but if you don't and, e.g., the error message suggests you to set FI_CXI_RX_MATCH_MODE to either software or hybrid, one way to find out where you can get more information about this environment variable is
man -K FI_CXI_RX_MATCH_MODE\n
The online documentation is now also complete enough that it makes sense trying the search box on that page instead.
"},{"location":"2day-next/02-CPE/#other-modules","title":"Other modules","text":"Other modules that are relevant even to users who do not do development:
- MPI:
cray-mpich. - LibSci:
cray-libsci - Cray FFTW3 library:
cray-fftw - HDF5:
cray-hdf5: Serial HDF5 I/O librarycray-hdf5-parallel: Parallel HDF5 I/O library
- NetCDF:
cray-netcdfcray-netcdf-hdf5parallelcray-parallel-netcdf
- Python:
cray-python, already contains a selection of packages that interface with other libraries of the HPE Cray PE, including mpi4py, NumPy, SciPy and pandas. - R:
cray-R
The HPE Cray PE also offers other modules for debugging, profiling, performance analysis, etc. that are not covered in this short version of the LUMI course. Many more are covered in the 4-day courses for developers that we organise several times per year with the help of HPE and AMD.
"},{"location":"2day-next/02-CPE/#warning-1-you-do-not-always-get-what-you-expect","title":"Warning 1: You do not always get what you expect...","text":"The HPE Cray PE packs a surprise in terms of the libraries it uses, certainly for users who come from an environment where the software is managed through EasyBuild, but also for most other users.
The PE does not use the versions of many libraries determined by the loaded modules at runtime but instead uses default versions of libraries (which are actually in /opt/cray/pe/lib64 on the system) which correspond to the version of the programming environment that is set as the system default when installed. This is very much the behaviour of Linux applications also that pick standard libraries in a few standard directories and it enables many programs build with the HPE Cray PE to run without reconstructing the environment and in some cases to mix programs compiled with different compilers with ease (with the emphasis on some as there may still be library conflicts between other libraries when not using the so-called rpath linking). This does have an annoying side effect though: If the default PE on the system changes, all applications will use different libraries and hence the behaviour of your application may change.
Luckily there are some solutions to this problem.
By default the Cray PE uses dynamic linking, and does not use rpath linking, which is a form of dynamic linking where the search path for the libraries is stored in each executable separately. On Linux, the search path for libraries is set through the environment variable LD_LIBRARY_PATH. Those Cray PE modules that have their libraries also in the default location, add the directories that contain the actual version of the libraries corresponding to the version of the module to the PATH-style environment variable CRAY_LD_LIBRARY_PATH. Hence all one needs to do is to ensure that those directories are put in LD_LIBRARY_PATH which is searched before the default location:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
Small demo of adapting LD_LIBRARY_PATH: An example that can only be fully understood after the section on the LUMI software stacks:
$ module load LUMI/22.08\n$ module load lumi-CPEtools/1.0-cpeGNU-22.08\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007f420cd55000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007f420c929000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/lib64/libmpi_gnu_91.so.12 (0x00007f4209da4000)\n ...\n$ export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n$ ldd $EBROOTLUMIMINCPETOOLS/bin/mpi_check\n linux-vdso.so.1 (0x00007fb38c1e0000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fb38bdb4000)\n libmpi_gnu_91.so.12 => /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/libmpi_gnu_91.so.12 (0x00007fb389198000)\n ...\n
The ldd command shows which libraries are used by an executable. Only a part of the very long output is shown in the above example. But we can already see that in the first case, the library libmpi_gnu_91.so.12 is taken from opt/cray/pe/lib64 which is the directory with the default versions, while in the second case it is taken from /opt/cray/pe/mpich/8.1.18/ofi/gnu/9.1/lib/ which clearly is for a specific version of cray-mpich. We do provide the module lumi-CrayPath that tries to fix LD_LIBRARY_PATH in a way that unloading the module fixes LD_LIBRARY_PATH again to the state before adding CRAY_LD_LIBRARY_PATH and that reloading the module adapts LD_LIBRARY_PATH to the current value of CRAY_LD_LIBRARY_PATH. Loading that module after loading all other modules should fix this issue for most if not all software.
The second solution would be to use rpath-linking for the Cray PE libraries, which can be done by setting the CRAY_ADD_RPATH environment variable:
export CRAY_ADD_RPATH=yes\n
However, there is also a good side to the standard Cray PE behaviour. Updates of the underlying operating system or network software stack may break older versions of the MPI library. By letting the applications use the default libraries and updating the defaults to a newer version, most applications will still run while they would fail if any of the two tricks to force the use of the intended library version are used. This has actually happened after a big LUMI update in March 2023, when all software that used rpath-linking had to be rebuild as the MPICH library that was present before the update did not longer work.
"},{"location":"2day-next/02-CPE/#warning-2-order-matters","title":"Warning 2: Order matters","text":"Lmod is a hierarchical module scheme and this is exploited by the HPE Cray PE. Not all modules are available right away and some only become available after loading other modules. E.g.,
cray-fftw only becomes available when a processor target module is loadedcray-mpich requires both the network target module craype-network-ofi and a compiler module to be loadedcray-hdf5 requires a compiler module to be loaded and cray-netcdf in turn requires cray-hdf5
but there are many more examples in the programming environment.
In the next section of the course we will see how unavailable modules can still be found with module spider. That command can also tell which other modules should be loaded before a module can be loaded, but unfortunately due to the sometimes non-standard way the HPE Cray PE uses Lmod that information is not always complete for the PE, which is also why we didn't demonstrate it here.
"},{"location":"2day-next/02-CPE/#note-compiling-without-the-hpe-cray-pe-wrappers","title":"Note: Compiling without the HPE Cray PE wrappers","text":"It is now possible to work without the HPE Cray PE compiler wrappers and to use the compilers in a way you may be more familiar with from other HPC systems.
In that case, you would likely want to load a compiler module without loading the PrgEnv-* module and craype module (which would be loaded automatically by the PrgEnv-* module). The compiler module and compiler driver names are then given by the following table:
Description Compiler module Compilers Cray Compiling Environment cce craycc, crayCC, crayftn GNU Compiler Collection gccgcc-native gcc, g++, gfortrangcc-12, g++-12, gfortran-12 AMD Optimizing Compilers(CPU only) aocc clang, clang++, flang AMD ROCm LLVM compilers (GPU support) amd amdclang, amdclang++, amdflang Recent versions of the cray-mpich module now also provide the traditional MPI compiler wrappers such as mpicc, mpicxx or mpifort. Note that you will still need to ensure that the network target module craype-network-ofi is loaded to be able to load the cray-mpich module! The cray-mpich module also defines the environment variable MPICH_DIR that points to the MPI installation for the selected compiler.
To manually use the BLAS and LAPACK libraries, you'll still have to load the cray-libsci module. This module defines the CRAY_LIBSCI_PREFIX_DIR environment variable that points to the directory with the library and include file subdirectories for the selected compiler. (This environment variable will be renamed to CRAY_PE_LIBSCI_PREFIX_DIR in release 23.12 of the programming environment.) See the intro_libsci manual page for information about the different libraries.
To be able to use the cray-fftw FFTW libraries, you still need to load the right CPU target module, even though you need to specify the target architecture yourself now when calling the compilers. This is because the HPE Cray PE does not come with a multi-cpu version of the FFTW libraries, but specific versions for each CPU (or sometimes group of similar CPUs). Here again some environment variables may be useful to point the compiler and linker to the installation: FFTW_ROOT for the root of the installation for the specific CPU (the library is otherwise compiler-independent), FFTW_INC for the subdirectory with the include files and FFTW_DIR for the directory with the libraries.
Other modules that you may want to use also typically define some useful environment variables.
"},{"location":"2day-next/03-Access/","title":"Getting Access to LUMI","text":""},{"location":"2day-next/03-Access/#who-pays-the-bills","title":"Who pays the bills?","text":"LUMI is one of the larger EuroHPC supercomputers. EuroHPC currently funds supercomputers in three different classes:
-
There are a number of so-called petascale supercomputers. The first ones of those are Meluxina (in Luxembourg), VEGA (in Slovenia), Karolina (in the Czech Republic), Discoverer (in Bulgaria) and Deucalion (in Portugal).
-
A number of pre-exascale supercomputers, LUMI being one of them. The other two are Leonardo (in Italy) and MareNostrum 5 (in Spain)
-
A decision has already been taken on two exascale supercomputers: Jupiter (in Germany) and Jules Verne (consortium name) (in France).
Depending on the machine, EuroHPC pays one third up to half of the bill, while the remainder of the budget comes from the hosting country, usually with the help of a consortium of countries. For LUMI, EuroHPC paid half of the bill and is the actual owner of the machine.
LUMI is hosted in Finland but operated by a consortium of 11 countries. Each LUMI consortium country can set its own policies for a national access program, within the limits of what the supercomputer can technically sustain. There is a \"Get Started\" page on the main LUMI website with links to the various access programs.
Web links:
- EuroHPC JU supercomputers
- LUMI website \"Get Started\" page with links to relevant web pages for EuroHPC access and access via consortium countries.
"},{"location":"2day-next/03-Access/#users-and-projects","title":"Users and projects","text":"LUMI works like most European large supercomputers: Users are members of projects.
A project corresponds to a coherent amount of work that is being done by a single person or a collaboration of a group of people. It typically corresponds to a research project, though there are other project types also, e.g., to give people access in the context of a course, or for organisational issues, e.g., a project for a local support organisation. Most projects are short-lived, with a typical duration of 4 to 6 months for benchmarking projects or one year for a regular project (which is the maximum duration agreed upon in the consortium).
Projects are also the basis for most research allocations on LUMI. In LUMI there are three types of resource allocations, and each project needs at least two of them:
- A compute budget for the CPU nodes of LUMI (LUMI-C and the CPU-only large memory nodes), expressed in core-hours.
- A compute budget for the GPU nodes of LUMI (LUMI-G and the visualisation nodes), expressed in GPU-hours. As the mechanism was already fixed before it became publicly known that for all practical purposes one AMD MI250X GPU should really be treated as 2 GPUs, one GPU-hour is one hour on a full MI250X, so computing for one hour on a full LUMI-G GPU node costs 4 GPU-hours.
- A storage budget which is expressed in TB-hours. Only storage that is actually being used is charged on LUMI, to encourage users to clean up temporary storage. The rate at which storage is charged depends on the file system, but more about that later when we discuss the available file spaces.
These budgets are assigned and managed by the resource allocators, not by the LUMI User Support Team. The LUMI User Support Team also cannot add additional billing units to your project.
LUMI projects will typically have multiple project numbers which may be a bit confusing:
- Each RA may have its own numbering system, often based on the numbering used for the project requests. Note that the LUMI User Support Team is not aware of that numbering as it is purely internal to the RA.
-
Each project on LUMI also gets a LUMI project ID which also corresponds to a Linux group to manage access to the project resources. These project IDs are of the form project_465XXXXXX for most projects but project_462XXXXXX for projects that are managed by the internal system of CSC Finland.
This is also the project number that you should mention when contacting the central LUMI User Support.
Besides projects there are also user accounts. Each user account on LUMI corresponds to a physical person, and user accounts should not be shared. Some physical persons have more than one user account but this is an unfortunate consequence of decisions made very early in the LUMI project about how projects on LUMI would be managed. Users themselves cannot do a lot without a project as all a user has on LUMI is a small personal disk space which is simply a Linux requirement. To do anything useful on LUMI users need to be member of a project. There are also \"robot accounts\" for special purposes that would not correspond to a physical person but have a specific goal (like organising data ingestion from an external source) and few projects are granted such an account.
There ia a many-to-many mapping between projects and user accounts. Projects can of course have multiple users who collaborate in the project, but a user account can also be part of multiple projects. The latter is more common than you may think, as. e.g., you may become member of a training project when you take a LUMI training.
Most resources are attached to projects. The one resource that is attached to a user account is a small home directory to store user-specific configuration files. That home directory is not billed but can also not be extended. For some purposes you may have to store things that would usually automatically be placed in the home directory in a separate directory, e.g., in the project scratch space, and link to it. This may be the case when you try to convert big docker containers into singularity containers as the singularity cache can eat a lot of disk space. (Or sometimes setting an environment variable is enough to redirect to a different directory.)
"},{"location":"2day-next/03-Access/#project-management","title":"Project management","text":"A large system like LUMI with many entities giving independent access to the system to users needs an automated system to manage those projects and users. There are two such systems for LUMI. CSC, the hosting institution from Finland, uses its own internal system to manage projects allocated on the Finnish national share. This system manages the \"642\"-projects. The other system is called Puhuri and is developed in a collaboration between the Nordic countries to manage more than just LUMI projects. It can be used to manage multiple supercomputers but also to manage access to other resources such as experimental equipment. Puhuri projects can span multiple resources (e.g., multiple supercomputers so that you can create a workflow involving Tier-2, Tier-1 and Tier-0 resources).
There are multiple frontends in use for Puhuri. Some countries use their own frontend that links to the Puhuri backend to give their users a familiar feeling, while other countries use a Puhuri frontend that they either host and manage themselves, or run on the Puhuri infrastructure. Due to this diversity, we cannot really demo project management in the course but need to leave this to the local organisations.
The login to Puhuri is in general via MyAccessID, which is a G\u00c9ANT service. G\u00c9ANT is the international organisation that manages the research network in Europe. MyAccessID then in turn connects to your institute identity provider and a number of alternatives. It is important that you always use the same credentials to log in via MyAccessID, otherwise you create another user in MyAccessID that is unknown to Puhuri and get all kinds of strange error messages. MyAccessID is also used for ssh key management, so that in the future, when MyAccessID might serve more machines, you'd have a single set of ssh keys for all infrastructures.
Puhuri can be used to check your remaining project resources, but once your user account on LUMI is created, it is very easy to do this on the command line with the lumi-workspaces command.
Web links
-
Puhuri documentation, look for the \"User Guides\".
-
The lumi-workspaces command is provided through the lumi-tools module which is loaded by default. The command will usually give the output you need when used without any argument.
"},{"location":"2day-next/03-Access/#file-spaces","title":"File spaces","text":"LUMI has file spaces that are linked to a user account and file spaces that are linked to projects.
"},{"location":"2day-next/03-Access/#per-user-file-spaces","title":"Per-user file spaces","text":"The only permanent file space linked to a user account is the home directory which is of the form /users/<my_uid>. It is limited in both size and number of files it can contain, and neither limit can be expanded. It should only be used for things that are not project-related and first and foremost for those things that Linux and software automatically stores in a home directory like user-specific software configuration files. It is not billed as users can exist temporarily without an active project but therefore is also very limited in size.
"},{"location":"2day-next/03-Access/#per-project-file-spaces","title":"Per-project file spaces","text":"Each project also has 4 permanent or semi-permanent file spaces that are all billed against the storage budget of the project.
-
Permanent (for the duration of the project) storage on a hard disk based Lustre filesystem accessed via /project/project_46YXXXXXX. This is the place to perform the software installation for the project (as it is assumed that a project is a coherent amount of work it is only natural to assume that everybody in the project needs the same software), or to store input data etc. that will be needed for the duration of the project.
Storing one TB for one hour on the disk based Lustre file systems costs 1 TB-hour. As would storing 10 GB for 100 hours.
-
Semi-permanent scratch storage on a hard disk based Lustre filesystem accessed via /scratch/project_46YXXXXXX. Files in this storage space can in principle be erased automatically after 90 days. This is not happening yet on LUMI, but will be activated if the storage space starts to fill up.
Storing one TB for one hour on the disk based Lustre file systems costs 1 TB-hour.
-
Semi-permanent scratch storage on an SSD based Lustre filesystem accessed via /flash/project_46YXXXXXX. Files in this storage space can in principle be erased automatically after 30 days. This is not happening yet on LUMI, but will be activated if the scratch storage space starts to fill up.
Storing one TB for one hour on the flash based Lustre file system costs 10 TB-hour, also reflecting the purchase cost difference of the systems.
-
Permanent (for the duration of the project) storage on the hard disk based object filesystem.
Storing one TB for one hour on the object based file system costs 0.5 TB-hour.
"},{"location":"2day-next/03-Access/#quota","title":"Quota","text":"The slide above also shows the quota on each volume. This information is also available in the LUMI docs.
The use of space in each file space is limited by block and file quota. Block quota limit the capacity you can use, while file quota limit the number of so-called inodes you can use. Each file, each subdirectory and each link use an inode. As we shall see later in this course (in the section on Lustre) or as you may have seen in other HPC courses already, parallel file systems are not built to deal with hundreds of thousands of small files and are very inefficient at that. Therefore block quota on LUMI tend to be rather flexible (except for the home directory) but file quota are rather strict and will not easily get extended. Software installations that require tens of thousands of small files should be done in containers (e.g., conda installations or any big Python installation) while data should also be organised in proper file formats rather than being dumped on the file system abusing the file system as a database.
In the above slide, the \"Capacity\" column shows the block quota and the \"Files\" column show the total number of so-called inodes available in the file space.
The project file spaces can be expanded in capacity within the limits specified. However, as big parallel file systems are very bad at handling lots of small files (see also the session on Lustre), the files quota (or more accurately inode quota) are rather strict and not easily raised (and if raised, not by an order of magnitude).
So storage use on LUMI is limited in two independent ways:
-
Traditional Linux block and file quota limit the maximum capacity you can use (in volume and number of inodes, roughly the number of files and directories combined).
-
But actual storage use is also \"billed\" on a use-per-hour basis. The idea behind this is that a user may run a program that generates a lot of data, but after some post-processing much of the data can be deleted so that other users can use that capacity again, and to encourage that behaviour you are billed based not on peak use, but based on the combination of the volume that you use and the time you use it for.
Storage use is monitored hourly for the billing process. If you run out of storage billing units, you will not be able to run jobs anymore.
Storage in your home directory is not billed but that should not mean that you should abuse your home directory for other purposes then a home directory is meant to be used, and an extension of the home directory will never be granted. If you run out of space for, e.g., caches, you should relocate them to, e.g., your scratch space, which can sometimes be done by setting an environment variable and in other cases by just using symbolic links to preserve the structure of the caching subdirectories in your home directory while storing data elsewhere.
Quota extensions are currently handled by the central LUMI User Support Team. But storage billing units, just as any billing unit, comes from your resource allocator, and the LUMI User Support Team cannot give you any storage billing units.
"},{"location":"2day-next/03-Access/#some-additional-information","title":"Some additional information","text":"LUMI has four disk based Lustre file systems that house /users, /project and /scratch. The /project and /scratch directories of your project will always be on the same parallel file system, but your home directory may be on a different one. Both are assigned automatically during project and account creation and these assignments cannot be changed by the LUMI User Support Team. As there is a many-to-many mapping between user accounts and projects it is not possible to ensure that user accounts are on the same file system as their main project. In fact, many users enter LUMI for the first time through a course project and not through one of their main compute projects...
It is important to note that even though /flash is SSD based storage, it is still a parallel file system and will not behave the way an SSD in your PC does. The cost of opening and closing a file is still very high due to it being both a networked and a parallel file system rather than a local drive. In fact, the cost for metadata operations is not always that much lower as on the hard disk based parallel file systems as both use SSDs to store the metadata (but some metadata operations on Lustre involve both the metadata and object servers and the latter are faster on /flash). Once a file is opened and with a proper data access pattern (big accesses, properly striped files which we will discuss later in this course) the flash file system can give a lot more bandwidth than the disk based ones.
It is important to note that LUMI is not a data archiving service or a data publishing service. \"Permanent\" in the above discussion only means \"for the duration of the project\". There is no backup, not even of the home directory. And 90 days after the end of the project all data from the project is irrevocably deleted from the system. User accounts without project will also be closed, as will user accounts that remain inactive for several months, even if an active project is still attached to them.
If you run out of storage billing units, access to the job queues or even to the storage can be blocked and you should contact your resource allocator for extra billing units. It is important that you clean up after a run as LUMI is not meant for long-term data archiving. But at the same time it is completely normal that you cannot do so right after a run, or as a job may not launch immediately, that you need to put input data on the system long before a run starts. So data needed for or resulting from a run has to stay on the system for a few days or weeks, and you need to budget for that in your project request.
Web links:
- Overview of storage systems on LUMI
- Billing policies (includes those for storage)
"},{"location":"2day-next/03-Access/#access","title":"Access","text":"LUMI currently has 4 login nodes through which users can enter the system via key-based ssh. The generic name of those login nodes is lumi.csc.fi. Using the generic names will put you onto one of the available nodes more or less at random and will avoid contacting a login node that is down for maintenance. However, in some cases one needs to enter a specific login node. E.g., tools for remote editing or remote file synchronisation such as Visual Studio Code or Eclipse usually don't like it if they get a different node every time they try to connect, e.g., because they may start a remote server and try to create multiple connections to that server. In that case you have to use a specific login node, which you can do through the names lumi-uan01.csc.fi up to lumi-uan04.csc.fi. (UAN is the abbreviation for User Access Node, the term Cray uses for login nodes.)
Key management is for most users done via MyAccessID: mms.myaccessid.org. This is the case for all user accounts who got their first project on LUMI via Puhuri. User accounts that were created via the My CSC service have to use the my.csc.fi portal to manage their keys. It recently became possible to link your account in My CSC to MyAccessID so that you do not get a second account on LUMI ones you join a Puhuri-managed project, and in this case your keys are still managed through the My CSC service.
LUMI now also provides a web interface via Open OnDemand. The URL is https://www.lumi.csc.fi/. It also offers a number of tools that can be useful for visualisation via a web browser, but it is still work-in-progress.
There is currently moderate support for technologies for GUI applications on LUMI. Running X11 over ssh (via ssh -X) is unbearably slow for most users as X11 is not meant to be used over long-distance networks and is very latency-sensitive. The alternative is VNC, which we currently offer in two different ways:
- Via the \"Desktop\" app in Open OnDemand, which will give you a VNC session with the rather lightweight Xfce desktop environment,
- and through the
lumi-vnc module which was our primary method when Open OnDemand for LUMI was not ready yet.
You can connect through a web browser or a VNC client. Don't expect more advanced desktop environments: LUMI is not meant to be your remote graphics workstation and we cannot afford to spend tens of compute nodes on offering this service.
Web links:
- LUMI documentation on logging in to LUMI and creating suitable SSH keys
- CSC documentation on linking My CSC to MyAccessID
A walk through the Open OnDemand interface
To enter the LUMI OpenOndemand interface, point your browser to www.lumi.csc.fi. You will get the screen:
Most likely you just want to log on, so click on \"Go to login\" and the \"Select authentication provider\" screen should appear, with a link to give you more information about which authentication method to use:
Basically, if you are a CSC user (and definitely when you're on a CSC 462* project) you'll want to use the \"CSC\" or \"Haka\" choice, while other users will need MyAccessID.
The whole login process is not shown, but after successful authentication, you end up at the main screen (that you can also go back to by clicking the LUMI-logo in the upper left corner):
The list of pinned apps may change over time, and more apps are available via the menu at the top. Most apps will run in the context of a job, so you will need billing units, and those apps will also present you with a form to chose the resources you want to use, but that will only be discussed in the session on Slurm.
Two apps don't run in the context of a job: The \"Login node shell\" and \"Home Directory\" apps, and we'll first have a look at those.
The \"Login node shell\" does just what you expect from it\": It opens a tab in the browser with a shell on one of the login nodes. Open OnDemand uses its own set of login nodes, as you can see from the name of the node, but these nodes are otherwise identical to the login nodes that you access via an ssh client on your laptop, and the same policies apply. They should not be used for running applications and only be used for small work or not too heavy compilations.
Let's now select the \"Home Directory\" app. We get:
The \"Home Directory\" app presents you with an interface through which you cannot only browse your home directory, but also the project, scratch and flash directories of all your projects. It can be used for some elementary file access and also to upload and download files.
It is not suitable though to upload or download very big files, or download large subdirectories (multiple files will be packed in a ZIP archive) as browsers may not be reliable enough and as there are also restrictions on how big an archive Open OnDemand can create.
For transferring lots of data, transfer via LUMI-O is certainly the better option at the moment.
Finally, let's have a look at the \"Desktop\" app.
The \"Desktop\" app will present you with a simple GUI desktop based on the Xfce desktop environment. This app needs to run in the context of a job and although it can run on several partitions on LUMI, its main use is to be able to use some visualisation applications, so your best choice is likely to use the partition with visualisation GPUs (see the session on Slurm). As we have not discussed jobs yet, we will skip how to fill in the form that is presented to you.
The desktop is basically run in a VNC session, a popular protocol for remote desktop support in Linux. It can be used through a web browser, which is what you get if you click the \"Launch Desktop\" button, but there are other choices also.
After launching/connecting to the desktop you get:
There is a small settings menu hidden at the left (expanded in the picture) to do some settings of the web interface that we are using here. Right-clicking with the mouse on the desktop gives you a menu with a number of applications.
This is in no means meant to be a replacement of your own workstation, so the software choice is limited and will remain limited. It should never be your main environment for all your work. LUMI is not meant to simply provide small workstations to all of Europe. And it will also react a lot slower than what you are used to from a workstation in front of you. This is 100% normal and simply the result of using a computer which is far away so there is a high network latency.
"},{"location":"2day-next/03-Access/#data-transfer","title":"Data transfer","text":"There are currently two main options to transfer data to and from LUMI.
The first one is to use sftp to the login nodes, authenticating via your ssh key. There is a lot of software available for all major operating systems, both command line based and GUI based. The sftp protocol can be very slow over high latency connections. This is because it is a protocol that opens only a single stream for communication with the remote host, and the bandwidth one can reach via a single stream in the TCP network protocol used for such connections, is limited not only by the bandwidth of all links involved but also by the latency. After sending a certain amount of data, the sender will wait for a confirmation that the data has arrived, and if the latency is high, that confirmation takes more time to reach the sender, limiting the effective bandwidth that can be reached over the connection. LUMI is not to blame for that; the whole path from the system from which you initiate the connection to LUMI is responsible and every step adds to the latency. We've seen many cases where the biggest contributor to the latency was actually the campus network of the user.
The second important option is to transfer data via the object storage system LUMI-O. To transfer data to LUMI, you'd first push the data to LUMI-O and then on LUMI pull it from LUMI-O. When transferring data to your home institute, you'd first push it onto LUMI-O from LUMI and then pull the data from LUMI-O to your work machine. LUMI offers some support for various tools, including rclone and S3cmd. There also exist many GUI clients to access object storage. Even though in principle any tool that can connect via the S3 protocol can work, the LUMI User Support Team cannot give you instructions for every possible tool. Those tools for accessing object storage tend to set up multiple data streams and hence will offer a much higher effective bandwidth, even on high latency connections.
Alternatively, you can also chose to access external servers from LUMI if you have client software that runs on LUMI (or if that software is already installed on LUMI, e.g., rclone and S3cmd), but the LUMI User Support Team cannot tell you how to configure tools to use an external service that we have no access to.
Unfortunately there is no support yet for Globus or other forms of gridFTP.
"},{"location":"2day-next/03-Access/#what-is-lumi-o","title":"What is LUMI-O?","text":"LUMI-O is an object storage system (based on Ceph). Users from Finland may be familiar with Allas, which is similar to the LUMI object storage system, though LUMI doesn't provide all the functionality of Allas.
Object file systems need specific tools to access data. They are usually not mounted as a regular filesystem (though some tools can make them appear as a regular file system) and accessing them needs authentication via temporary keys that are different from your ssh keys and are not only bound to you, but also to the project for which you want to access LUMI-O. So if you want to use LUMI-O for multiple projects simultaneously, you'll need keys for each project.
Object storage is not organised in files and directories. A much flatter structure is used with buckets that contain objects:
-
Buckets: Containers used to store one or more objects. Object storage uses a flat structure with only one level which means that buckets cannot contain other buckets.
-
Objects: Any type of data. An object is stored in a bucket.
-
Metadata: Both buckets and objects have metadata specific to them. The metadata of a bucket specifies, e.g., the access rights to the bucket. While traditional file systems have fixed metadata (filename, creation date, type, etc.), an object storage allows you to add custom metadata.
Objects can be served on the web also. This is in fact how recordings of some of the LUST courses are served currently. However, LUMI-O is not meant to be used as a data publishing service and is not an alternative to services provided by, e.g., EUDAT or several local academic service providers.
The object storage can be easily reached from outside LUMI also. In fact, during downtimes, LUMI-O is often still operational as its software stack is managed completely independently from LUMI. It is therefore also very well suited as a mechanism for data transfer to and from LUMI. Moreover, tools for object storage often perform much better on high latency long-distance connections than tools as sftp.
LUMI-O is based on the Ceph object file system. It has a total capacity of 30 PB. Storage is persistent for the duration of a project. Projects get a quota of 150 TB and can create up to 1K buckets and 500K objects per bucket. These quota are currently fixed and cannot be modified. Storage on LUMI-O is billed at 0.5 TB\u00b7hour per TB per hour, half that of /scratch or /project. It can be a good alternative to store data from your project that still needs to be transferred but is not immediately needed by jobs, or to maintain backups on LUMI yourself.
"},{"location":"2day-next/03-Access/#accessing-lumi-o","title":"Accessing LUMI-O","text":"Access to LUMI-O is based on temporary keys that need to be generated via a web interface (though there may be alternatives in the future).
There are currently three command-line tools pre-installed on LUMI: rclone (which is the easiest tool if you want public and private data), s3cmd and restic.
But you can also access LUMI-O with similar tools from outside LUMI. Configuring them may be a bit tricky and the LUMI User Support Team cannot help you with each and every client tool on your personal machine. However, the web interface that is used to generate the keys, can also generate code snippets or configuration file snippets for various tools, and that will make configuring them a lot easier.
In the future access via Open OnDemand should also become possible.
"},{"location":"2day-next/03-Access/#key-generation","title":"Key generation","text":"Keys are generated via a web interface that can be found at auth.lumidata.eu. In the future it should become possible to do so directly in the Open OnDemand interface, and may even from the command line.
Let's walk through the interface:
A walk through the credentials management web interface of LUMI-O
After entering the URL auth.lumidata.eu, you're presented with a welcome screen on which you have to click the \"Go to login\" button.
This will present you with the already familiar (from Open OnDemand) screen to select your authentication provider:
Proceed with login in through your relevant authentication provider (not shown here) and you will be presented with a screen that show your active projects:
Click the project for which you want to generate a key, and the column to the right will appear. Chose how long the key should be valid (1 week or 168 hours is the maximum currently, but the life can be extended) and a description for the key. The latter is useful if you generate multiple keys for different use. E.g., for security reasons you may want to use different keys from different machines so that one machine can be disabled quickly if the machine would be compromised or stolen.
Next click on the \"Generate key\" button, and a new key will appear in the \"Available keys\" section:
Now click on the key to get more information about the key:
At the top of the screen you see three elements that will be important if you use the LUMI command line tool lumio-conf to generate configuration files for rclone and s3cmd: the project number (but you knew that one), the \"Access key\" and \"Secret key\".
Scrolling down a bit more:
The \"Extend key\" field can be used to extend the life of the key, to a maximum of 168 hours past the current time.
The \"Configuration templates\" is the way to generate code snippets or configuration file snippets for various tools (see the list on the slide). After selecting \"rclone\" and clicking the \"Generate\" button, a new screen opens:
This screen shows us the snippet for the rclone configuration file (on Linux it is ~/.config/rclone/rclone.conf). Notice that it creates to so-called endpoints. In the slide this is lumi-465001102-private and lumi-465001102-public, for storing buckets and objects which are private or public (i.e., also web-accessible).
"},{"location":"2day-next/03-Access/#configuring-lumi-o-tools","title":"Configuring LUMI-O tools","text":"On LUMI, you can use the lumnio-conf tool to configure rclone and s3cmd. To access the tool, you need to load the lumio module first, which is always available. The same module will also load a module that makes rclone, s3cmd and restic available.
Whe starting lumio-conf, it will present with a couple of questions: The project number associated with the key, the access key and the secret key. We have shown above where in the web interface that information can be found. A future version may or may not be more automatic. As we shall see in the next slide, currently the rclone configuration generated by this tool is (unfortunately) different from the one generated by the web interface.
Another way to configure tools for object storage access is simply via the code snippets and configuration files snippets as has already been discussed before. The same snippets should also work when you run the tools on a different computer.
"},{"location":"2day-next/03-Access/#rclone-on-lumi-o","title":"rclone on LUMI-O","text":"The rclone configuration file for LUMI-O contains two end points, and unfortunately at the moment both ways discussed on the previous slide, produce different end points.
- When using
lumio-conf, you'll get: lumi-o as the end point for buckets and object that should be private, i.e., not publicly accessible via the web interface, andlumi-pub for buckets and objects that should be publicly accessible. It does appear to be possible to have both types in a single bucket though.
- When using the web generator you get specific end points for each project, so it is possible to access data from multiple projects simultaneously from a single configuration file:
lumi-46YXXXXXX-private is the end point to be used for buckets and objects that should be private, andlumi-46YXXXXXX-public is the end point for data that should be publicly accessible.
A description of the main rclone commands is outside the scope of this tutorial, but some options are discussed in the LUMI documentation, and the same page also contains some documentation for s3cmd and restic. See the links below for even more documentation.
"},{"location":"2day-next/03-Access/#further-lumi-o-documentation","title":"Further LUMI-O documentation","text":""},{"location":"2day-next/04-Modules/","title":"Modules on LUMI","text":"Intended audience
As this course is designed for people already familiar with HPC systems and as virtually any cluster nowadays uses some form of module environment, this section assumes that the reader is already familiar with a module environment but not necessarily the one used on LUMI.
However, even if you are very familiar with Lmod it makes sense to go through these notes as not every Lmod configuration is the same.
"},{"location":"2day-next/04-Modules/#module-environments","title":"Module environments","text":"An HPC cluster is a multi-user machine. Different users may need different versions of the same application, and each user has their own preferences for the environment. Hence there is no \"one size fits all\" for HPC and mechanisms are needed to support the diverse requirements of multiple users on a single machine. This is where modules play an important role. They are commonly used on HPC systems to enable users to create custom environments and select between multiple versions of applications. Note that this also implies that applications on HPC systems are often not installed in the regular directories one would expect from the documentation of some packages, as that location may not even always support proper multi-version installations and as system administrators prefer to have a software stack which is as isolated as possible from the system installation to keep the image that has to be loaded on the compute nodes small.
Another use of modules is to configure the programs that are being activated. E.g., some packages expect certain additional environment variables to be set and modules can often take care of that also.
There are 3 systems in use for module management. The oldest is a C implementation of the commands using module files written in Tcl. The development of that system stopped around 2012, with version 3.2.10. This system is supported by the HPE Cray Programming Environment. A second system builds upon the C implementation but now uses Tcl also for the module command and not only for the module files. It is developed in France at the C\u00c9A compute centre. The version numbering was continued from the C implementation, starting with version 4.0.0. The third system and currently probably the most popular one is Lmod, a version written in Lua with module files also written in Lua. Lmod also supports most Tcl module files. It is also supported by HPE Cray, though they tend to be a bit slow in following versions. The original developer of Lmod, Robert McLay, retired at the end of August 2023, but TACC, the centre where he worked, is committed to at least maintain Lmod though it may not see much new development anymore.
On LUMI we have chosen to use Lmod. As it is very popular, many users may already be familiar with it, though it does make sense to revisit some of the commands that are specific for Lmod and differ from those in the two other implementations.
It is important to realise that each module that you see in the overview corresponds to a module file that contains the actual instructions that should be executed when loading or unloading a module, but also other information such as some properties of the module, information for search and help information.
Links - Old-style environment modules on SourceForge
- TCL Environment Modules home page on SourceForge and the development on GitHub
- Lmod documentation and Lmod development on GitHub
I know Lmod, should I continue?
Lmod is a very flexible tool. Not all sites using Lmod use all features, and Lmod can be configured in different ways to the extent that it may even look like a very different module system for people coming from another cluster. So yes, it makes sense to continue reading as Lmod on LUMI may have some tricks that are not available on your home cluster. E.g., several of the features that we rely upon on LUMI may be disabled on clusters where admins try to mimic the old behaviour of the C/Tcl module implementation after switching to Lmod.
Standard OS software
Most large HPC systems use enterprise-level Linux distributions: derivatives of the stable Red Hat or SUSE distributions. Those distributions typically have a life span of 5 years or even more during which they receive security updates and ports of some newer features, but some of the core elements of such a distribution stay at the same version to break as little as possible between minor version updates. Python and the system compiler are typical examples of those. Red Hat 8 and SUSE Enterprise Linux 15 both came with Python 3.6 in their first version, and keep using this version as the base version of Python even though official support from the Python Software Foundation has long ended. Similarly, the default GNU compiler version offered on those system also remains the same. The compiler may not even fully support some of the newer CPUs the code is running on. E.g., the system compiler of SUSE Enterprise Linux 15, GCC 7.5, does not support the zen2 \"Rome\" or zen3 \"Milan\" CPUs on LUMI.
HPC systems will usually offer newer versions of those system packages through modules and users should always use those. The OS-included tools are really only for system management and system related tasks and serve a different purpose which actually requires a version that remains stable across a number of updates to not break things at the core of the OS. Users however will typically have a choice between several newer versions through modules, which also enables them to track the evolution and transition to a new version at the best suited moment.
"},{"location":"2day-next/04-Modules/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. -
But Lmod also has other commands, module spider and module keyword, to search in the list of installed modules.
On LUMI, we had to restrict the search space of module spider. By default, module spider will only search in the Cray PE modules, the CrayEnv stack and the LUMI stacks. This is done for performance reasons. However, as we shall discuss later, you can load a module or set an environment variable to enable searching all installed modules. The behaviour is also not fully consistent. Lmod uses a cache which it refreshes once every 24 hours, or after manually clearing the cache. If a rebuild happens while modules from another software stack are available, that stack will also be indexed and results for that stack shown in the results of module spider. It is a price we had to pay though as due to the large number of modules and the many organisations managing modules, the user cache rebuild time became too long and system caches are hard to manage also.
"},{"location":"2day-next/04-Modules/#benefits-of-a-hierarchy","title":"Benefits of a hierarchy","text":"When the hierarchy is well designed, you get some protection from loading modules that do not work together well. E.g., in the HPE Cray PE it is not possible to load the MPI library built for another compiler than your current main compiler. This is currently not exploited as much as we could on LUMI, mainly because we realised at the start that too many users are not familiar enough with hierarchies and would get confused more than the hierarchy helps them.
Another benefit is that when \"swapping\" a module that makes other modules available with a different one, Lmod will try to look for equivalent modules in the list of modules made available by the newly loaded module.
An easy example (though a tricky one as there are other mechanisms at play also) it to load a different programming environment in the default login environment right after login:
$ module load PrgEnv-gnu\n
which results in the next slide:
The first two lines of output are due to to other mechanisms that are at work here, and the order of the lines may seem strange but that has to do with the way Lmod works internally. Each of the PrgEnv modules hard loads a compiler module which is why Lmod tells you that it is loading gcc-native/13.2. However, there is also another mechanism at work that causes cce/17.0.1 and PrgEnv-cray/8.5.0 to be unloaded, but more about that in the next subsection (next slide).
The important line for the hierarchy in the output are the lines starting with \"Due to MODULEPATH changes...\". Remember that we said that each module has a corresponding module file. Just as binaries on a system, these are organised in a directory structure, and there is a path, in this case MODULEPATH, that determines where Lmod will look for module files. The hierarchy is implemented with a directory structure and the environment variable MODULEPATH, and when the cce/17.0.1 module was unloaded and gcc-native/13.2 module was loaded, that MODULEPATH was changed. As a result, the version of the cray-mpich module for the cce/17.0.1 compiler became unavailable, but one with the same module name for the gcc-native/13.2 compiler became available and hence Lmod unloaded the version for the cce/17.0.1 compiler as it is no longer available but loaded the matching one for the gcc-native/13.2 compiler.
"},{"location":"2day-next/04-Modules/#about-module-names-and-families","title":"About module names and families","text":"In Lmod you cannot have two modules with the same name loaded at the same time. On LUMI, when you load a module with the same name as an already loaded module, that other module will be unloaded automatically before loading the new one. There is even no need to use the module swap command for that (which in Lmod corresponds to a module unload of the first module and a module load of the second). This gives you an automatic protection against some conflicts if the names of the modules are properly chosen.
Remark
Some clusters do not allow the automatic unloading of a module with the same name as the one you're trying to load, but on LUMI we felt that this is a necessary feature to fully exploit a hierarchy.
Lmod goes further also. It also has a family concept: A module can belong to a family (and at most 1) and no two modules of the same family can be loaded together. The family property is something that is defined in the module file. It is commonly used on systems with multiple compilers and multiple MPI implementations to ensure that each compiler and each MPI implementation can have a logical name without encoding that name in the version string (like needing to have compiler/gcc-13.2 or compiler/gcc/13.2 rather than gcc-native/13.2), while still having an easy way to avoid having two compilers or MPI implementations loaded at the same time. On LUMI, the conflicting module of the same family will be unloaded automatically when loading another module of that particular family.
This is shown in the example in the previous subsection (the module load PrgEnv-gnu in a fresh long shell) in two places. It is the mechanism that unloaded PrgEnv-cray when loading PrgEnv-gnu and that then unloaded cce/17.0.1 when the PrgEnv-gnu module loaded the gcc-native/13.2 module.
Remark
Some clusters do not allow the automatic unloading of a module of the same family as the one you're trying to load and produce an error message instead. On LUMI, we felt that this is a necessary feature to fully exploit the hierarchy and the HPE Cray Programming Environment also relies very much on this feature being enabled to make live easier for users.
"},{"location":"2day-next/04-Modules/#extensions","title":"Extensions","text":"It would not make sense to have a separate module for each of the hundreds of R packages or tens of Python packages that a software stack may contain. In fact, as the software for each module is installed in a separate directory it would also create a performance problem due to excess directory accesses simply to find out where a command is located, and very long search path environment variables such as PATH or the various variables packages such as Python, R or Julia use to find extension packages. On LUMI related packages are often bundled in a single module.
Now you may wonder: If a module cannot be simply named after the package it contains as it contains several ones, how can I then find the appropriate module to load? Lmod has a solution for that through the so-called extension mechanism. An Lmod module can define extensions, and some of the search commands for modules will also search in the extensions of a module. Unfortunately, the HPE Cray PE cray-python and cray-R modules do not provide that information at the moment as they too contain several packages that may benefit from linking to optimised math libraries.
"},{"location":"2day-next/04-Modules/#searching-for-modules-the-module-spider-command","title":"Searching for modules: The module spider command","text":"There are three ways to use module spider, discovering software in more and more detail. All variants however will by default only check the Cray PE, the CrayEnv stack and the LUMI stacks, unless another software stack is loaded through a module or module use statement and the cache is regenerated during that period.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. The spider command will not only search in module names for the package, but also in extensions of the modules and so will be able to tell you that a package is delivered by another module. See Example 4 below where we will search for the CMake tools.
-
The third use of module spider is with the full name of a module. This shows two kinds of information. First it shows which combinations of other modules one might have to load to get access to the package. That works for both modules and extensions of modules. In the latter case it will show both the module, and other modules that you might have to load first to make the module available. Second it will also show help information for the module if the module file provides such information.
"},{"location":"2day-next/04-Modules/#example-1-running-module-spider-on-lumi","title":"Example 1: Running module spider on LUMI","text":"Let's first run the module spider command. The output varies over time, but at the time of writing, and leaving out a lot of the output, one would have gotten:
On the second screen we see, e.g., the ARMForge module which was available in just a single version at that time, and then Autoconf where the version is in blue and followed by (E). This denotes that the Autoconf package is actually provided as an extension of another module, and one of the next examples will tell us how to figure out which one.
The third screen shows the last few lines of the output, which actually also shows some help information for the command.
"},{"location":"2day-next/04-Modules/#example-2-searching-for-the-fftw-module-which-happens-to-be-provided-by-the-pe","title":"Example 2: Searching for the FFTW module which happens to be provided by the PE","text":"Next let us search for the popular FFTW library on LUMI:
$ module spider FFTW\n
produces
This shows that the FFTW library is actually provided by the cray-fftw module and was at the time that this was tested available in 4 versions. Note that (a) it is not case sensitive as FFTW is not in capitals in the module name and (b) it also finds modules where the argument of module spider is only part of the name.
The output also suggests us to dig a bit deeper and check for a specific version, so let's run
$ module spider cray-fftw/3.3.10.7\n
This produces:
We now get a long list of possible combinations of modules that would enable us to load this module. What these modules are will be explained in the next session of this course. However, it does show a weakness when module spider is used with the HPE Cray PE. In some cases, not all possible combinations are shown (and this is the case here as the module is actually available directly after login and also via some other combinations of modules that are not shown). This is because the HPE Cray Programming Environment is system-installed and sits next to the application software stacks that are managed differently, but in some cases also because the HPE Cray PE uses Lmod in a different way than intended by the Lmod developers, causing the spider command to not find some combinations that would actually work. The command does work well with the software managed by the LUMI User Support Team as the next two examples will show.
"},{"location":"2day-next/04-Modules/#example-3-searching-for-gnuplot","title":"Example 3: Searching for GNUplot","text":"To see if GNUplot is available, we'd first search for the name of the package:
$ module spider gnuplot\n
This produces:
We see that there are a lot of versions installed on the system and that the version actually contains more information (e.g., -cpeGNU-24.03) that we will explain in the next part of this course. But you might of course guess that it has to do with the compilers that were used. It may look strange to you to have the same software built with different compilers. However, mixing compilers is sometimes risky as a library compiled with one compiler may not work in an executable compiled with another one, so to enable workflows that use multiple tools we try to offer many tools compiled with multiple compilers (as for most software we don't use rpath linking which could help to solve that problem). So you want to chose the appropriate line in terms of the other software that you will be using.
The output again suggests to dig a bit further for more information, so let's try
$ module spider gnuplot/5.4.10-cpeGNU-24.03\n
This produces:
In this case, this module is provided by 3 different combinations of modules that also will be explained in the next part of this course. Furthermore, the output of the command now also shows some help information about the module, with some links to further documentation available on the system or on the web. The format of the output is generated automatically by the software installation tool that we use and we sometimes have to do some effort to fit all information in there.
For some packages we also have additional information in our LUMI Software Library web site so it is often worth looking there also.
"},{"location":"2day-next/04-Modules/#example-4-searching-for-an-extension-of-a-module-cmake","title":"Example 4: Searching for an extension of a module: CMake.","text":"The cmake command on LUMI is available in the operating system image, but as is often the case with such tools distributed with the OS, it is a rather old version and you may want to use a newer one.
If you would just look through the list of available modules, even after loading some other modules to activate a larger software stack, you will not find any module called CMake though. But let's use the powers of module spider and try
$ module spider CMake\n
which produces
The output above shows us that there are actually 3 other versions of CMake on the system, but their version is followed by (E) which says that they are extensions of other modules. There is no module called CMake on the system. But Lmod already tells us how to find out which module actually provides the CMake tools. So let's try
$ module spider CMake/3.29.3\n
which produces
This shows us that the version is provided by a number of buildtools modules, and for each of those modules also shows us which other modules should be loaded to get access to the commands. E.g., the first line tells us that there is a module buildtools/24.03 that provides that version of CMake, but that we first need to load some other modules, with LUMI/24.03 and partition/L (in that order) one such combination.
So in this case, after
$ module load LUMI/24.03 partition/L buildtools/24.03\n
the cmake command would be available.
And you could of course also use
$ module spider buildtools/24.03\n
to get even more information about the buildtools module, including any help included in the module.
"},{"location":"2day-next/04-Modules/#alternative-search-the-module-keyword-command","title":"Alternative search: the module keyword command","text":"Lmod has a second way of searching for modules: module keyword. It searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found. We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Let us look for packages that allow us to download software via the https protocol. One could try
$ module keyword https\n
which produces the following output:
cURL and wget are indeed two tools that can be used to fetch files from the internet.
LUMI Software Library
The LUMI Software Library also has a search box in the upper right. We will see in the next section of this course that much of the software of LUMI is managed through a tool called EasyBuild, and each module file corresponds to an EasyBuild recipe which is a file with the .eb extension. Hence the keywords can also be found in the EasyBuild recipes which are included in this web site, and from a page with an EasyBuild recipe (which may not mean much for you) it is easy to go back to the software package page itself for more information. Hence you can use the search box to search for packages that may not be installed on the system.
The example given above though, searching for https, would not work via that box as most EasyBuild recipes include https web links to refer to, e.g., documentation and would be shown in the result.
The LUMI Software Library site includes both software installed in our central software stack and software for which we make customisable build recipes available for user installation, but more about that in the tutorial section on LUMI software stacks.
"},{"location":"2day-next/04-Modules/#sticky-modules-and-the-module-purge-command","title":"Sticky modules and the module purge command","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have unexpected side effects. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Let us look at the output of the module avail command, taken just after login on the system at the time of writing of these notes (the exact list of modules shown is a bit fluid):
Next to the names of modules you sometimes see one or more letters. The (D) means that that is currently the default version of the module, the one that will be loaded if you do not specify a version. Note that the default version may depend on other modules that are already loaded as we have seen in the discussion of the programming environment.
The (L) means that a module is currently loaded.
The (S) means that the module is a sticky module.
Next to the rocm module (on the fourth screen) you see (5.0.2:5.1.0:5.2.0:5.2.3:5.5.1:5.7.0:6.0.0). This shows that the rocm/6.0.3 module can also be loaded as rocm/5.0.2 or any of the other versions in that list. Some of them were old versions that have been removed from the system in later updates, and others are versions that are hard-coded some of the Cray PE modules and other files but have never been on the system as we had an already patched version. (E.g., the 24.03 version of the Cray PE will sometimes try to load rocm/6.0.0 while we have immediate had rocm/6.0.3 on the system which corrects some bugs).
At the end of the overview the extensions are also shown. If this would be fully implemented on LUMI, the list could become very long. However, as we shall see next, there is an easy way to hide those from view. We haven't used extensions very intensely so far as there was a bug in older versions of Lmod so that turning off the view didn't work and so that extensions that were not in available modules, were also shown. But that is fixed in current versions.
"},{"location":"2day-next/04-Modules/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed in the above example that we don't show directories of module files in the overview (as is the case on most clusters) but descriptive texts about the module group. This is just one view on the module tree though, and it can be changed easily by loading a version of the ModuleLabel module.
ModuleLabel/label produces the default view of the previous example. ModuleLabel/PEhierarchy still uses descriptive texts but will show the whole module hierarchy of the HPE Cray Programming Environment.ModuleLabel/system does not use the descriptive texts but shows module directories instead.
When using any kind of descriptive labels, Lmod can actually bundle module files from different directories in a single category and this is used heavily when ModuleLabel/label is loaded and to some extent also when ModuleLabel/PEhierarchy is loaded.
It is rather hard to provide multiple colour schemes in Lmod, and as we do not know how your terminal is configured it is also impossible to find a colour scheme that works for all users. Hence we made it possible to turn on and off the use of colours by Lmod through the ModuleColour/on and ModuleColour/off modules.
As the module extensions list in the output of module avail could potentially become very long over time (certainly if there would be Python or R modules installed with EasyBuild that show all included Python or R packages in that list) you may want to hide those. You can do this by loading the ModuleExtensions/hide module and undo this again by loading ModuleExtensions/show.
There are two ways to tell module spider to search in all installed modules. One is more meant as a temporary solution: Load
module load ModuleFullSpider/on\n
and this is turned off again by force-unloading this module or loading
module load ModuleFullSpider/off\n
The second and permanent way is to set add the line
export LUMI_FULL_SPIDER=1\n
to your .profile file and from then on, module spider will index all modules on the system. Note that this can have a large impact on the performance of the module spider and module avail commands that can easily \"hang\" for a minute or more if a cache rebuild is needed, which is the case after installing software with EasyBuild or once every 24 hours.
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. You can still load them if you know they exist and specify the full version but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work if you use modules that are hidden in the context you're in or if you try to use any module that was designed for us to maintain the system and is therefore hidden from regular users.
Another way to show hidden modules also, is to use the --show_hidden flag of the module command with the avail subcommand: module --show_hidden avail.
With ModulePowerUser, all modules will be displayed as if they are regular modules, while module --show_hidden avail will still grey the hidden modules and add an (H) to them so that they are easily recognised.
Example
An example that will only become clear in the next session: When working with the software stack called LUMI/24.03, which is built upon the HPE Cray Programming Environment version 24.03, all (well, most) of the modules corresponding to other versions of the Cray PE are hidden.
Just try
$ module load LUMI/24.03\n$ module avail\n
and you'll see a lot of new packages that have become available, but will also see less Cray PE modules.
"},{"location":"2day-next/04-Modules/#getting-help-with-the-module-help-command","title":"Getting help with the module help command","text":"Lmod has the module help command to get help on modules
$ module help\n
without further arguments will show some help on the module command.
With the name of a module specified, it will show the help information for the default version of that module, and with a full name and version specified it will show this information specifically for that version of the module. But note that module help can only show help for currently available modules.
Try, e.g., the following commands:
$ module help cray-mpich\n$ module help cray-python/3.11.7\n$ module help buildtools/24.03\n
Lmod also has another command that produces more limited information (and is currently not fully exploited on LUMI): module whatis. It is more a way to tag a module with different kinds of information, some of which has a special meaning for Lmod and is used at some places, e.g., in the output of module spider without arguments.
Try, e.g.,:
$ module whatis Subversion\n$ module whatis Subversion/1.14.3\n
"},{"location":"2day-next/04-Modules/#a-note-on-caching","title":"A note on caching","text":"Modules are stored as (small) files in the file system. Having a large module system with much software preinstalled for everybody means a lot of small files which will make our Lustre file system very unhappy. Fortunately Lmod does use caches by default. On LUMI we currently have no system cache and only a user cache. That cache can be found in $HOME/.cache/lmod (and in some versions of LMOD in $HOME/.lmod.d/.cache).
That cache is also refreshed automatically every 24 hours. You'll notice when this happens as, e.g., the module spider and module available commands will be slow during the rebuild. you may need to clean the cache after installing new software as on LUMI Lmod does not always detect changes to the installed software,
Sometimes you may have to clear the cache also if you get very strange answers from module spider. It looks like the non-standard way in which the HPE Cray Programming Environment does certain things in Lmod can cause inconsistencies in the cache. This is also one of the reasons whey we do not yet have a central cache for that software that is installed in the central stacks as we are not sure when that cache is in good shape.
"},{"location":"2day-next/04-Modules/#a-note-on-other-commands","title":"A note on other commands","text":"As this tutorial assumes some experience with using modules on other clusters, we haven't paid much attention to some of the basic commands that are mostly the same across all three module environments implementations. The module load, module unload and module list commands work largely as you would expect, though the output style of module list may be a little different from what you expect. The latter may show some inactive modules. These are modules that were loaded at some point, got unloaded when a module closer to the root of the hierarchy of the module system got unloaded, and they will be reloaded automatically when that module or an equivalent (family or name) module is loaded that makes this one or an equivalent module available again.
Example
To demonstrate this, try in a fresh login shell (with the lines starting with a $ the commands that you should enter at the command prompt):
$ module unload craype-network-ofi\n\nInactive Modules:\n 1) cray-mpich\n\n$ module load craype-network-ofi\n\nActivating Modules:\n 1) cray-mpich/8.1.29\n
The cray-mpich module needs both a valid network architecture target module to be loaded (not craype-network-none) and a compiler module. Here we remove the network target module which inactivates the cray-mpich module, but the module gets reactivated again as soon as the network target module is reloaded.
The module swap command is basically equivalent to a module unload followed by a module load. With one argument it will look for a module with the same name that is loaded and unload that one before loading the given module. With two modules, it will unload the first one and then load the second one. The module swap command is not really needed on LUMI as loading a conflicting module (name or family) will automatically unload the previously loaded one. However, in case of replacing a module of the same family with a different name, module swap can be a little faster than just a module load as that command will need additional operations as in the first step it will discover the family conflict and then try to resolve that in the following steps (but explaining that in detail would take us too far in the internals of Lmod).
"},{"location":"2day-next/04-Modules/#links","title":"Links","text":"These links were OK at the time of the course. This tutorial will age over time though and is not maintained but may be replaced with evolved versions when the course is organised again, so links may break over time.
- Lmod documentation and more specifically the User Guide for Lmod which is the part specifically for regular users who do not want to design their own modules.
- Information on the module environment in the LUMI documentation
"},{"location":"2day-next/05-SoftwareStacks/","title":"LUMI Software Stacks","text":"In this section we discuss
- Several of the ways in which we offer software on LUMI
- Managing software in our primary software stack which is based on EasyBuild
"},{"location":"2day-next/05-SoftwareStacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"2day-next/05-SoftwareStacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack than your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in supercomputers in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems.
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 12 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For the major LUMI stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 10 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
There is an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"2day-next/05-SoftwareStacks/#the-lumi-solution","title":"The LUMI solution","text":"The LUMI User Support Team (LUST) tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but LUST decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. The stack is also made very easy to extend. So LUMI has many base libraries and some packages already pre-installed but also provides an easy and very transparent way to install additional packages in your project space in exactly the same way as is done for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system a choice had to be made between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. LUMI chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations there was a choice between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. LUMI chose to go with EasyBuild as the primary tool for which the LUST also does some development. However, as we shall see, the EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. LUMI does offer a growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as LUMI cannot automatically determine a suitable place.
The LUST does offer some help to set up Spack also but it is mostly offered \"as is\" and LUST will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"2day-next/05-SoftwareStacks/#software-policies","title":"Software policies","text":"As any site, LUMI also has a number of policies about software installation, and these policies are further developed as the LUMI team gains experience in what they can do with the amount of people in LUST and what they cannot do.
LUMI uses a bring-your-own-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as the LUST does not even have the necessary information to determine if a particular user can use a particular license, so that responsibility must be shifted to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push LUMI onto the industrial rather than academic pricing as they have no guarantee that LUMI operations will obey to the academic license restrictions.
- And lastly, the LUMI project doesn't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume the whole LUMI software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So LUMI has to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that LUMI invests in packages that are developed by European companies or at least have large development teams in Europe.
Some restrictions coming from software licenses
-
Anaconda cannot be used legally on LUMI, neither can you use Miniconda to pull packages from the Anaconda Public Repository. You have to use alternatives such as conda-forge.
See point 2.1 of the \"Anaconda Terms of Service\".
-
The LUMI support team cannot really help much with VASP as most people in the support team are not covered by a valid VASP license. VASP licenses typically even contain a list of people who are allowed to touch the source code, and one person per license who can download the source code.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not their task. Some consortium countries may also have a local support team that can help. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric, the Open Fabrics Interface (OFI) library, using a specific provider for the NIC used on LUMI, the so-called Cassini provider (CXI), so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why LUMI currently states in its policy that a LUMI user should be capable of installing their software themselves or have another support channel. The LUST cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code. Again some help is possible at the Belgian level but our resources are also limited.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason LUMI also requires to containerize conda and Python installations. On LUMI two tools are offered for this.
- cotainr is a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space. Its current version focusses on containerising a conda-installation.
- The second tool is a container-based wrapper generator that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the
cray-python module. On LUMI the tool is called lumi-container-wrapper but users of the CSC national systems will know it as Tykky.
Both tools are pre-installed on the system and ready-to-use.
"},{"location":"2day-next/05-SoftwareStacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"LUMI offers several software stacks:
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which the LUST installs software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. There are tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. If the need would arrise, a fourth partition could be created for the visualisation nodes with zen2 CPUs and NVIDIA GPUs.
LUMI also offers an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but support is limited and no bug-fixing in Spack is done.
Some partner organisations in the LUMI consortium also provide pre-installed software on LUMI. This software is not manages by the LUMI User Support Team and as a consequence of this, support is only provided through those organisations that manage the software. Though they did promise to offer some basic support for everybody, the level of support may be different depending on how your project ended up on LUMI as they receive no EuroHPC funding for this. There is also no guarantee that software in those stacks is compatible with anything else on LUMI. The stacks are provided by modules whose name starts with Local-. Currently there are two such stacks on LUMI:
-
Local-CSC: Enables software installed and maintained by CSC. Most of that software is available to all users, though some packages are restricted or only useful to users of other CSC services (e.g., the allas module).
Some of that software builds on software in the LUMI stacks, some is based on containers with wrapper scripts, and some is compiled outside of any software management environment on LUMI.
The names of the modules don't follow the conventions of the LUMI stacks, but those used on the Finnish national systems.
-
Local-quantum contains some packages of general use, but also some packages that are only relevant to Finnish researchers with an account on the Helmi quantum computer. Helmi is not a EuroHPC-JU computer so being eligible for an account on LUMI does not mean that you are also eligible for an account on Helmi.
In the far future the LUST will also look at a stack based on the common EasyBuild toolchains as-is, but problems are expected with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so no promises whatsoever are made about a time frame for this development.
"},{"location":"2day-next/05-SoftwareStacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"2day-next/05-SoftwareStacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course or the 4-day comprehensive courses that LUST organises.
"},{"location":"2day-next/05-SoftwareStacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And they are sometimes used to work around problems in Cray-provided modules that cannot changed easily due to the way system administration on a Cray system is done.
This is also the environment in which the LUST installs most software, and from the name of the modules you can see which compilers we used.
"},{"location":"2day-next/05-SoftwareStacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/24.03, LUMI/23.12, LUMI/23.09, LUMI/23.03, LUMI/22.12 and LUMI/22.08 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"2day-next/05-SoftwareStacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"2day-next/05-SoftwareStacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the Slingshot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"2day-next/05-SoftwareStacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead LUMI has its own EasyBuild build recipes that are also made available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before it is even deployed on the system.
LUMI also offers the LUMI Software Library which documents all software for which there are LUMI-specific EasyBuild recipes available. This includes both the pre-installed software and the software for which recipes are provided in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"2day-next/05-SoftwareStacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"2day-next/05-SoftwareStacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
LUMI doesn't use the standard EasyBuild toolchains but its own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but on LUMI it is used for a bit more as it offers a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (LUMI doesn't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as LUMI does not use hierarchy in the Lmod implementation of the software stack at the toolchain level, the module system will not protect you from these mistakes. When the LUST set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"2day-next/05-SoftwareStacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2024.3, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeGNU-24.03 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/24.03.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.9.2-noPython-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.
"},{"location":"2day-next/05-SoftwareStacks/#installing","title":"Installing","text":""},{"location":"2day-next/05-SoftwareStacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants of the project to solve a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"2day-next/05-SoftwareStacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module. It works correctly for a lot of CPU-only software, but fails more frequently for GPU software as the installation scripts will try to run scripts that detect which GPU is present, or try to run tests on the GPU, even if you tell which GPU type to use, which does not work on the login nodes.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"2day-next/05-SoftwareStacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS there is already support on LUMI. An easy way to do that is to simply check the LUMI Software Library. This web site lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Alternatively one can use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Results of the searches:
In the LUMI Software Library, after some scrolling through the page for GROMACS, the list of EasyBuild recipes is found in the \"User-installable modules (and EasyConfigs)\" section:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb. This is GROMACS 2024.3 with the PLUMED 2.9.2 plugin, built with the GNU compilers from LUMI/24.03, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb -r\n
Running EasyBuild to install GROMACS and dependency
The command
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb -r\n
results in:
EasyBuild detects PLUMED is a dependency and because of the -r option, it first installs the required version of PLUMED.
When the installation of PLUMED finishes, EasyBuild starts the installation of GROMACS. It mentions something we haven't seen when installing PLUMED:
== starting iteration #0\n
GROMACS can be installed in many configurations, and they generate executables with different names. Our EasyConfig combines 4 popular installations in one: Single and double precision and with and without MPI, so it will do 4 iterations. As EasyBuild is developed by geeks, counting starts from 0.
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"2day-next/05-SoftwareStacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.cache/lmod. You can do this with
rm -rf $HOME/.cache/lmod\n
(With older versions of Lmod the cache directory is $HOME/.lmod.d/cache.)"},{"location":"2day-next/05-SoftwareStacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. LUMI would likely be in violation of the license if it would offer the download somewhere where EasyBuild can find it, and it is also a way to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP LUMI provides EasyBuild recipes, but you will still have to download the source file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.4.2 with the GNU compilers: eb VASP-6.4.2-cpeGNU-23.09-build02.eb \u2013r . \n
"},{"location":"2day-next/05-SoftwareStacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"2day-next/05-SoftwareStacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elswhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"2day-next/05-SoftwareStacks/#easybuild-tips-and-tricks","title":"EasyBuild tips and tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When a toolchain is updated on the system, the versions of all installed libraries are often also bumped to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
LUMI provides documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why things are done in a particular way.
"},{"location":"2day-next/05-SoftwareStacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on tutorial.easybuild.io. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"2day-next/06-Slurm/","title":"Slurm on LUMI","text":"Who is this for?
We assume some familiarity with job scheduling in this section. The notes will cover some of the more basic aspects of Slurm also, though it may be rather brief on some aspects of Slurm as we assume the majority of users is already rather familiar with Slurm.
Even if you have a lot of experience with Slurm, it may still be useful to have a quick look at this section as Slurm is not always configured in the same way.
Links to Slurm material
Links to Slurm material on this web page are all for the version on LUMI at the time of the course. Some of the links in the PDF of the slides however are to the newest version.
"},{"location":"2day-next/06-Slurm/#what-is-slurm","title":"What is Slurm","text":"Slurm is both a resource manager and job scheduler for supercomputers in a single package.
A resource manager manages all user-exposed resources on a supercomputer: cores, GPUs or other accelerators, nodes, ... It sets up the resources to run a job and cleans up after the job, and may also give additional facilities to start applications in a job. Slurm does all this.
But Slurm is also a job scheduler. It will assign jobs to resources, following policies set by sysadmins to ensure a good use of the machine and a fair distribution of resources among projects.
Slurm is the most popular resource manager and job scheduler at the moment and is used on more than 50% of all big supercomputers. It is an open source package with commercial support. Slurm is a very flexible and configurable tool with the help of tens or even hundreds of plugins. This also implies that Slurm installations on different machines can also differ a lot and that not all features available on one computer are also available on another. So do not expect that Slurm will behave the same on LUMI as on that other computer you're familiar with, even if that other computer may have hardware that is very similar to LUMI.
Slurm is starting to show its age and has trouble dealing in an elegant and proper way with the deep hierarcy of resources in modern supercomputers. So Slurm will not always be as straightforward to use as we would like it, and some tricks will be needed on LUMI. Yet there is no better option at this moment that is sufficiently mature.
Nice to know...
Lawrence Livermore National Laboratory, the USA national laboratory that originally developed Slurm is now working on the development of another resource and job management framework called flux. It will be used on the third USA exascale supercomputer El Capitan which is currently being assembled.
"},{"location":"2day-next/06-Slurm/#slurm-concepts-physical-resources","title":"Slurm concepts: Physical resources","text":"The machine model of Slurm is bit more limited than what we would like for LUMI.
On the CPU side it knows:
-
A node: The hardware that runs a single operating system image
-
A socket: On LUMI a Slurm socket corresponds to a physical socket, so there are two sockets on the CPU nodes and a single socket on a GPU node.
Alternatively a cluster could be configured to let a Slurm socket correspond to a NUMA nore or L3 cache region, but this is something that sysadmins need to do so even if this would be useful for your job, you cannot do so.
-
A core is a physical core in the system
-
A thread is a hardware thread in the system (virtual core)
-
A CPU is a \"consumable resource\" and the unit at which CPU processing capacity is allocated to a job. On LUMI a Slurm CPU corresponds to a physical core, but Slurm could also be configured to let it correspond to a hardware thread.
The first three bullets already show the problem we have with Slurm on LUMI: For three levels in the hierarchy of CPU resources on a node: the socket, the NUMA domain and the L3 cache domain, there is only one concept in Slurm, so we are not able to fully specify the hierarchy in resources that we want when sharing nodes with other jobs.
A GPU in Slurm is an accelerator and on LUMI corresponds to one GCD of an MI250X, so one half of an MI250X.
"},{"location":"2day-next/06-Slurm/#slurm-concepts-logical-resources","title":"Slurm concepts: Logical resources","text":" -
A partition: is a job queue with limits and access control. Limits include maximum wall time for a job, the maximum number of nodes a single job can use, or the maximum number of jobs a user can run simultaneously in the partition. The access control mechanism determines who can run jobs in the partition.
It is different from what we call LUMI-C and LUMI-G, or the partition/C and partition/G modules in the LUMI software stacks.
Each partition covers a number of nodes, but partitions can overlap. This is not the case for the partitions that are visible to users on LUMI. Each partition covers a disjunct set of nodes. There are hidden partitions though that overlap with other partitions, but they are not accessible to regular users.
-
A job in Slurm is basically only a resource allocation request.
-
A job step is a set of (possibly parallel) tasks within a job
-
Each batch job always has a special job step called the batch job step which runs the job script on the first node of a job allocation.
-
An MPI application will typically run in its own job step.
-
Serial or shared memory applications are often run in the batch job step but there can be good reasons to create a separate job step for those applications.
-
A task executes in a job step and corresponds to a Linux process (and possibly subprocesses)
Of course a task cannot use more CPUs than available in a single node as a process can only run within a single operating system image.
"},{"location":"2day-next/06-Slurm/#slurm-is-first-and-foremost-a-batch-scheduler","title":"Slurm is first and foremost a batch scheduler","text":"And LUMI is in the first place a batch processing supercomputer.
A supercomputer like LUMI is a very large and very expensive machine. This implies that it also has to be used as efficiently as possible which in turn implies that we don't want to wast time waiting for input as is the case in an interactive program.
On top of that, very few programs can use the whole capacity of the supercomputer, so in practice a supercomputer is a shared resource and each simultaneous user gets a fraction on the machine depending on the requirements that they specify. Yet, as parallel applications work best when performance is predictable, it is also important to isolate users enough from each other.
Research supercomputers are also typically very busy with lots of users so one often has to wait a little before resources are available. This may be different on some commercial supercomputers and is also different on commercial cloud infrastructures, but the \"price per unit of work done on the cluster\" is also very different from an academic supercomputer and few or no funding agencies are willing to carry that cost.
Due to all this the preferred execution model on supercomputer is via batch jobs as they don't have to wait for input from the user, specified via batch scripts with resource specification where the user asks precisely the amount of resources needed for the job, submitted to a queueing system with a scheduler to select the next job in a fair way based on available resources and scheduling policies set by the compute centre.
LUMI does have some facilities for interactive jobs, and with the introduction of Open On Demand some more may be available. But it is far from ideal, and you will also be billed for the idle time of the resources you request. In fact, if you only need some interactive resources for a quick 10-minute experiment and don't need too many resources, the wait may be minimal thanks to a scheduler mechanism called backfill where the scheduler looks for small and short jobs to fill up the gaps left while the scheduler is collecting resources for a big job.
"},{"location":"2day-next/06-Slurm/#a-slurm-batch-script","title":"A Slurm batch script","text":"Slurm batch scripts (also called job scripts) are conceptually not that different from batch scripts for other HPC schedulers. A typical batch script will have 4 parts:
-
The shebang line with the shell to use. We advise to use the bash shell (/bin/bash or /usr/bin/bash) If omitted, a very restricted shell will be used and some commands (e.g., related to modules) may fail. In principle any shell language that uses a hashtag to denote comments can be used, but we would advise against experimenting and the LUMI User Support Team will only support bash.
-
Specification of resources and some other instructions for the scheduler and resource manager. This part is also optional as one can also pass the instructions via the command line of sbatch, the command to submit a batch job. But again, we would advise against omitting this block as specifying all options on the command line can be very tedious.
-
Building a suitable environment for the job. This part is also optional as on LUMI, Slurm will copy the environment from the node from which the job was submitted. This may not be the ideal envrionment for your job, and if you later resubmit the job you may do so accidentally from a different environment so it is a good practice to specify the environment.
-
The commands you want to execute.
Blocks 3 and 4 can of course be mixed as you may want to execute a second command in a different environment.
On the following slides we will explore in particular the second block and to some extent how to start programs (the fourth block).
lumi-CPEtools module
The lumi-CPEtools module will be used a lot in this session of the course and in the next one on binding. It contains among other things a number of programs to quickly visualise how a serial, OpenMP, MPI or hybrid OpenMP/MPI application would run on LUMI and which cores and GPUs would be used. It is a very useful tool to discover how Slurm options work without using a lot of billing units and we would advise you to use it whenever you suspect Slurm isn't doing what you meant to do.
It has its documentation page in the LUMI Software Library.
"},{"location":"2day-next/06-Slurm/#partitions","title":"Partitions","text":"Remark
Jobs run in partitions so the first thing we should wonder when setting up a job is which partition to use for a job (or sometimes partitions in case of a heterogeneous job which will be discussed later).
Slurm partitions are possibly overlapping groups of nodes with similar resources or associated limits. Each partition typically targets a particular job profile. E.g., LUMI has partitions for large multi-node jobs, for smaller jobs that often cannot fill a node, for some quick debug work and for some special resources that are very limited (the nodes with 4TB of memory and the nodes with GPUs for visualisation). The number of jobs a user can have running simultaneously in each partition or have in the queue, the maximum wall time for a job, the number of nodes a job can use are all different for different partitions.
There are two types of partitions on LUMI:
-
Exclusive node use by a single job. This ensures that parallel jobs can have a clean environment with no jitter caused by other users running on the node and with full control of how tasks and threads are mapped onto the available resources. This may be essential for the performance of a lot of codes.
-
Allocatable by resources (CPU and GPU). In these partitions nodes are shared by multiple users and multiple jobs, though in principle it is possible to ask for exclusive use which will however increase your waiting time in the queue. The cores you get are not always continuously numbered, nor do you always get the minimum number of nodes needed for the number of tasks requested. A proper mapping of cores onto GPUs is also not ensured at all. The fragmentation of resources is a real problem on these nodes and this may be an issue for the performance of your code.
It is also important to realise that the default settings for certain Slurm parameters may differ between partitions and hence a node in a partition allocatable by resource but for which exclusive access was requested may still react differently to a node in the exclusive partitions.
In general it is important to use some common sense when requesting resources and to have some understanding of what each Slurm parameter really means. Overspecifying resources (using more parameters than needed for the desired effect) may result in unexpected conflicts between parameters and error messages.
For the overview of Slurm partitions, see the LUMI documentation, \"Slurm partitions\" page. In the overview on the slides we did not mention partitions that are hidden to regular users.
The policies for partitions and the available partitions may change over time to fine tune the operation of LUMI and depending on needs observed by the system administrators and LUMI User Support Team, so don't take the above tables in the slide for granted.
Some useful commands with respect to Slurm partitions:
-
To request information about the available partitions, use sinfo -s:
$ sinfo -s\nPARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST\ndebug up 30:00 1/7/0/8 nid[002500-002501,002504-002506,002595-002597]\ninteractive up 8:00:00 2/2/0/4 nid[002502,002507,002594,002599]\nq_fiqci up 15:00 0/1/0/1 nid002598\nq_industry up 15:00 0/1/0/1 nid002598\nq_nordiq up 15:00 0/1/0/1 nid002503\nsmall up 3-00:00:00 281/8/17/306 nid[002280-002499,002508-002593]\nstandard up 2-00:00:00 1612/1/115/1728 nid[001000-002279,002600-003047]\ndev-g up 3:00:00 44/2/2/48 nid[005002-005025,007954-007977]\nsmall-g up 3-00:00:00 191/2/5/198 nid[005026-005123,007852-007951]\nstandard-g up 2-00:00:00 1641/749/338/272 nid[005124-007851]\nlargemem up 1-00:00:00 0/5/1/6 nid[000101-000106]\nlumid up 4:00:00 1/6/1/8 nid[000016-000023]\n
The fourth column shows 4 numbers: The number of nodes that are currently fully or partially allocated to jobs, the number of idle nodes, the number of nodes in one of the other possible states (and not user-accessible) and the total number of nodes in the partition. Sometimes a large number of nodes can be in the \"O\" column, e.g., when mechanical maintenance is needed (like problem with the cooling). Also note that the width of the NODES field is not enough as the total number of nodes for standard-g doesn't make sense, but this is easyly solved, e.g., using
sinfo -o \"%11P %.5a %.10l %.20F %N\"\n
Note that this overview may show partitions that are not hidden but also not accessible to everyone. E.g., the q_nordic and q_fiqci partitions are used to access experimental quantum computers that are only available to some users of those countries that paid for those machines.
It is not clear to the LUMI Support Team what the interactive partition, that uses dome GPU nodes, is meant for as it was introduced without informing the support. The resources in that partition are very limited so it is not meant for widespread use.
-
For technically-oriented people, some more details about a partition can be obtained with scontrol show partition <partition-name>.
Additional example with sinfo Try
$ sinfo --format \"%4D %10P %25f %.4c %.8m %25G %N\"\nNODE PARTITION AVAIL_FEATURES CPUS MEMORY GRES NODELIST\n5 debug AMD_EPYC_7763,x1005 256 229376 (null) nid[002500-002501,002504-002506]\n3 debug AMD_EPYC_7763,x1006 256 229376 (null) nid[002595-002597]\n2 interactiv AMD_EPYC_7763,x1005 256 229376 (null) nid[002502,002507]\n2 interactiv AMD_EPYC_7763,x1006 256 229376 (null) nid[002594,002599]\n256 ju-standar AMD_EPYC_7763,x1001 256 229376 (null) nid[001256-001511]\n256 ju-standar AMD_EPYC_7763,x1004 256 229376 (null) nid[002024-002279]\n96 ju-standar AMD_EPYC_7763,x1006 256 229376 (null) nid[002600-002695]\n256 ju-strateg AMD_EPYC_7763,x1000 256 229376 (null) nid[001000-001255]\n1 q_fiqci AMD_EPYC_7763,x1006 256 229376 (null) nid002598\n1 q_industry AMD_EPYC_7763,x1006 256 229376 (null) nid002598\n1 q_nordiq AMD_EPYC_7763,x1005 256 229376 (null) nid002503\n248 small AMD_EPYC_7763,x1005 256 229376+ (null) nid[002280-002499,002508-002535]\n58 small AMD_EPYC_7763,x1006 256 229376 (null) nid[002536-002593]\n256 standard AMD_EPYC_7763,x1003 256 229376 (null) nid[001768-002023]\n256 standard AMD_EPYC_7763,x1002 256 229376 (null) nid[001512-001767]\n256 standard AMD_EPYC_7763,x1007 256 229376 (null) nid[002792-003047]\n96 standard AMD_EPYC_7763,x1006 256 229376 (null) nid[002696-002791]\n2 dev-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8 nid[007974-007975]\n22 dev-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8(S:0) nid[007954-007973,007976-007977]\n24 dev-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8(S:0) nid[005002-005025]\n2 ju-standar AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8 nid[005356-005357]\n7 ju-standar AMD_EPYC_7A53,x1103 128 491520 gpu:mi250:8 nid[005472-005473,005478-005479,005486-005487,005493]\n8 ju-standar AMD_EPYC_7A53,x1105 128 491520 gpu:mi250:8 nid[005648-005649,005679,005682-005683,005735,005738-005739]\n2 ju-standar AMD_EPYC_7A53,x1200 128 491520 gpu:mi250:8 nid[005810-005811]\n3 ju-standar AMD_EPYC_7A53,x1204 128 491520 gpu:mi250:8 nid[006301,006312-006313]\n1 ju-standar AMD_EPYC_7A53,x1205 128 491520 gpu:mi250:8 nid006367\n2 ju-standar AMD_EPYC_7A53,x1404 128 491520 gpu:mi250:8 nid[007760-007761]\n9 ju-standar AMD_EPYC_7A53,x1201 128 491520 gpu:mi250:8 nid[005881,005886-005887,005897,005917,005919,005939,005969,005991]\n90 ju-standar AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8(S:0) nid[005280-005355,005358-005371]\n117 ju-standar AMD_EPYC_7A53,x1103 128 491520 gpu:mi250:8(S:0) nid[005372-005471,005474-005477,005480-005485,005488-005492,005494-005495]\n116 ju-standar AMD_EPYC_7A53,x1105 128 491520 gpu:mi250:8(S:0) nid[005620-005647,005650-005678,005680-005681,005684-005734,005736-005737,005740-005743]\n122 ju-standar AMD_EPYC_7A53,x1200 128 491520 gpu:mi250:8(S:0) nid[005744-005809,005812-005867]\n115 ju-standar AMD_EPYC_7A53,x1201 128 491520 gpu:mi250:8(S:0) nid[005868-005880,005882-005885,005888-005896,005898-005916,005918,005920-005938,005940-005968,005970-005990]\n121 ju-standar AMD_EPYC_7A53,x1204 128 491520 gpu:mi250:8(S:0) nid[006240-006300,006302-006311,006314-006363]\n123 ju-standar AMD_EPYC_7A53,x1205 128 491520 gpu:mi250:8(S:0) nid[006364-006366,006368-006487]\n122 ju-standar AMD_EPYC_7A53,x1404 128 491520 gpu:mi250:8(S:0) nid[007728-007759,007762-007851]\n3 ju-strateg AMD_EPYC_7A53,x1101 128 491520 gpu:mi250:8 nid[005224,005242-005243]\n8 ju-strateg AMD_EPYC_7A53,x1203 128 491520 gpu:mi250:8 nid[006136-006137,006153,006201,006214-006215,006236-006237]\n5 ju-strateg AMD_EPYC_7A53,x1202 128 491520 gpu:mi250:8 nid[006035,006041,006047,006080-006081]\n121 ju-strateg AMD_EPYC_7A53,x1101 128 491520 gpu:mi250:8(S:0) nid[005124-005223,005225-005241,005244-005247]\n32 ju-strateg AMD_EPYC_7A53,x1102 128 491520 gpu:mi250:8(S:0) nid[005248-005279]\n116 ju-strateg AMD_EPYC_7A53,x1203 128 491520 gpu:mi250:8(S:0) nid[006116-006135,006138-006152,006154-006200,006202-006213,006216-006235,006238-006239]\n119 ju-strateg AMD_EPYC_7A53,x1202 128 491520 gpu:mi250:8(S:0) nid[005992-006034,006036-006040,006042-006046,006048-006079,006082-006115]\n1 small-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8 nid005059\n97 small-g AMD_EPYC_7A53,x1100 128 491520 gpu:mi250:8(S:0) nid[005026-005058,005060-005123]\n100 small-g AMD_EPYC_7A53,x1405 128 491520 gpu:mi250:8(S:0) nid[007852-007951]\n2 standard-g AMD_EPYC_7A53,x1104 128 491520 gpu:mi250:8 nid[005554-005555]\n117 standard-g AMD_EPYC_7A53,x1300 128 491520 gpu:mi250:8(S:0) nid[006488-006505,006510-006521,006524-006550,006552-006611]\n7 standard-g AMD_EPYC_7A53,x1300 128 491520 gpu:mi250:8 nid[006506-006509,006522-006523,006551]\n121 standard-g AMD_EPYC_7A53,x1301 128 491520 gpu:mi250:8(S:0) nid[006612-006657,006660-006703,006705-006735]\n3 standard-g AMD_EPYC_7A53,x1301 128 491520 gpu:mi250:8 nid[006658-006659,006704]\n117 standard-g AMD_EPYC_7A53,x1302 128 491520 gpu:mi250:8(S:0) nid[006736-006740,006744-006765,006768-006849,006852-006859]\n7 standard-g AMD_EPYC_7A53,x1302 128 491520 gpu:mi250:8 nid[006741-006743,006766-006767,006850-006851]\n8 standard-g AMD_EPYC_7A53,x1304 128 491520 gpu:mi250:8 nid[007000-007001,007044-007045,007076-007077,007092-007093]\n5 standard-g AMD_EPYC_7A53,x1305 128 491520 gpu:mi250:8 nid[007130-007131,007172-007173,007211]\n2 standard-g AMD_EPYC_7A53,x1400 128 491520 gpu:mi250:8 nid[007294-007295]\n1 standard-g AMD_EPYC_7A53,x1401 128 491520 gpu:mi250:8 nid007398\n1 standard-g AMD_EPYC_7A53,x1403 128 491520 gpu:mi250:8 nid007655\n122 standard-g AMD_EPYC_7A53,x1104 128 491520 gpu:mi250:8(S:0) nid[005496-005553,005556-005619]\n124 standard-g AMD_EPYC_7A53,x1303 128 491520 gpu:mi250:8(S:0) nid[006860-006983]\n116 standard-g AMD_EPYC_7A53,x1304 128 491520 gpu:mi250:8(S:0) nid[006984-006999,007002-007043,007046-007075,007078-007091,007094-007107]\n119 standard-g AMD_EPYC_7A53,x1305 128 491520 gpu:mi250:8(S:0) nid[007108-007129,007132-007171,007174-007210,007212-007231]\n122 standard-g AMD_EPYC_7A53,x1400 128 491520 gpu:mi250:8(S:0) nid[007232-007293,007296-007355]\n123 standard-g AMD_EPYC_7A53,x1401 128 491520 gpu:mi250:8(S:0) nid[007356-007397,007399-007479]\n124 standard-g AMD_EPYC_7A53,x1402 128 491520 gpu:mi250:8(S:0) nid[007480-007603]\n123 standard-g AMD_EPYC_7A53,x1403 128 491520 gpu:mi250:8(S:0) nid[007604-007654,007656-007727]\n6 largemem AMD_EPYC_7742 256 4096000+ (null) nid[000101-000106]\n8 lumid AMD_EPYC_7742 256 2048000 gpu:a40:8,nvme:40000 nid[000016-000023]\n
(Output may vary over time) This shows more information about the system. The xNNNN feature corresponds to groups in the Slingshot interconnect and may be useful if you want to try to get a job running in a single group (which is too advanced for this course).
The memory size is given in megabyte (MiB, multiples of 1024). The \"+\" in the second group of the small partition is because that partition also contains the 512 GB and 1 TB regular compute nodes. The memory reported is always 32 GB less than you would expect from the node specifications. This is because 32 GB on each node is reserved for the OS and the RAM disk it needs.
"},{"location":"2day-next/06-Slurm/#accounting-of-jobs","title":"Accounting of jobs","text":"The use of resources by a job is billed to projects, not users. All management is also done at the project level, not at the \"user-in-a-project\" level. As users can have multiple projects, the system cannot know to which project a job should be billed, so it is mandatory to specify a project account (of the form project_46YXXXXXX) with every command that creates an allocation.
Billing on LUMI is not based on which resources you effectively use, but on the amount of resources that others cannot use well because of your allocation. This assumes that you make proportional use of CPU cores, CPU memory and GPUs (actually GCDs). If you job makes a disproportionally high use of one of those resources, you will be billed based on that use. For the CPU nodes, the billing is based on both the number of cores you request in your allocation and the amount of memory compared to the amount of memory per core in a regular node, and the highest of the two numbers is used. For the GPU nodes, the formula looks at the number of cores compared to he number of cores per GPU, the amount of CPU memory compared to the amount of memory per GCD (so 64 GB), and the amount of GPUs and the highest amount determines for how many GCDs you will be billed (with a cost of 0.5 GPU-hour per hour per GCD). For jobs in job-exclusive partitions you are automatically billed for the full node as no other job can use that node, so 128 core-hours per hour for the standard partition or 4 GPU-hours per hour for the standard-g partition.
E.g., if you would ask for only one core but 128 GB of memory, half of what a regular LUMI-C node has, you'd be billed for the use of 64 cores. Or assume you want to use only one GCD but want to use 16 cores and 256 GB of system RAM with it, then you would be billed for 4 GPUs/GCDs: 256 GB of memory makes it impossible for other users to use 4 GPUs/GCDs in the system, and 16 cores make it impossible to use 2 GPUs/GCDs, so the highest number of those is 4, which means that you will pay 2 GPU-hours per hour that you use the allocation (as GPU-hours are based on a full MI250x and not on a GCD which is the GPU for Slurm).
This billing policy is unreasonable!
Users who have no experience with performance optimisation may think this way of billing is unfair. After all, there may be users who need far less than 2 GB of memory per core so they could still use the other cores on a node where I am using only one core but 128 GB of memory, right? Well, no, and this has everything to do with the very hierarchical nature of a modern compute node, with on LUMI-C 2 sockets, 4 NUMA domains per socket, and 2 L3 cache domains per NUMA domain. Assuming your job would get the first core on the first socket (called core 0 and socket 0 as computers tend to number from 0). Linux will then allocate the memory of the job as close as possible to that core, so it will fill up the 4 NUMA domains of that socket. It can migrate unused memory to the other socket, but let's assume your code does not only need 128 GB but also accesses bits and pieces from it everywhere all the time. Another application running on socket 0 may then get part or all of its memory on socket 1, and the latency to access that memory is more than 3 times higher, so performance of that application will suffer. In other words, the other cores in socket 0 cannot be used with full efficiency.
This is not a hypothetical scenario. The author of this text has seem benchmarks run on one of the largest systems in Flanders that didn't scale at all and for some core configuration ran at only 10% of the speed they should have been running at...
Still, even with this billing policy Slurm on LUMI is a far from perfect scheduler and core, GPU and memory allocation on the non-exclusive partitions are far from optimal. Which is why we spend a section of the course on binding applications to resources.
The billing is done in a postprocessing step in the system based on data from the Slurm job database, but the Slurm accounting features do not produce the correct numbers. E.g., Slurm counts the core hours based on the virtual cores so the numbers are double of what they should be. There are two ways to check the state of an allocation, though both work with some delay.
-
The lumi-workspaces and lumi-allocations commands show the total amount of billing units consumed. In regular operation of the system these numbers are updated approximately once an hour.
lumi-workspaces is the all-in command that intends to show all information that is useful to a regular user, while lumi-allocations is a specialised tool that only shows billing units, but he numbers shown by both tools come from the same database and are identical.
-
For projects managed via Puhuri, Puhuri can show billing unit use per month, but the delay is larger than with the lumi-workspaces command.
Billing unit use per user in a project
The current project management system in LUMI cannot show the use of billing units per person within a project.
For storage quota this would be very expensive to organise as quota are managed by Lustre on a group basis.
For CPU and GPU billing units it would in principle be possible as the Slurm database contains the necessary information, but there are no plans to implement such a feature. It is assumed that every PI makes sure that members of their projects use LUMI in a responsible way and ensures that they have sufficient experience to realise what they are doing.
"},{"location":"2day-next/06-Slurm/#queueing-and-fairness","title":"Queueing and fairness","text":"Remark
Jobs are queued until they can run so we should wonder how that system works.
LUMI is a pre-exascale machine meant to foster research into exascale applications. As a result the scheduler setup of LUMI favours large jobs (though some users with large jobs will claim that it doesn't do so enough yet). Most nodes are reserved for larger jobs (in the standard and standard-g partitions), and the priority computation also favours larger jobs (in terms of number of nodes).
When you submit a job, it will be queued until suitable resources are available for the requested time window. Each job has a priority attached to it which the scheduler computes based on a number of factors, such as size of the job, how much you have been running in the past days, and how long the job has been waiting already. LUMI is not a first come, first served system. Keep in mind that you may see a lot of free nodes on LUMI yet your small job may not yet start immediately as the scheduler may be gathering nodes for a big job with a higher priority.
The sprio command will list the different elements that determine the priority of your job but is basically a command for system administrators as users cannot influence those numbers nor do they say a lot unless you understand all intricacies of the job policies chosen by the site, and those policies may be fine-tuned over time to optimise the operation of the cluster. The fairshare parameter influences the priority of jobs depending on how much users or projects (this is not clear to us at the moment) have been running jobs in the past few days and is a very dangerous parameter on a supercomputer where the largest project is over 1000 times the size of the smallest projects, as treating all projects equally for the fair share would make it impossible for big projects to consume all their CPU time.
Another concept of the scheduler on LUMI is backfill. On a system supporting very large jobs as LUMI, the scheduler will often be collecting nodes to run those large jobs, and this may take a while, particularly since the maximal wall time for a job in the standard partitions is rather large for such a system. If you need one quarter of the nodes for a big job on a partition on which most users would launch jobs that use the full two days of walltime, one can expect that it takes half a day to gather those nodes. However, the LUMI scheduler will schedule short jobs even though they have a lower priority on the nodes already collected if it expects that those jobs will be finisehd before it expects to have all nodes for the big job. This mechanism is called backfill and is the reason why short experiments of half an hour or so often start quickly on LUMI even though the queue is very long.
"},{"location":"2day-next/06-Slurm/#managing-slurm-jobs","title":"Managing Slurm jobs","text":"Before experimenting with jobs on LUMI, it is good to discuss how to manage those jobs. We will not discuss the commands in detail and instead refer to the pretty decent manual pages that in fact can also be found on the web.
-
The command to check the status of the queue is squeue. It is also a good command to find out the job IDs of your jobs if you didn't write them down after submitting the job.
Two command line flags are useful:
-
--me will restrict the output to your jobs only
-
--start will give an estimated start time for each job. Note that this really doesn't say much as the scheduler cannot predict the future. On one hand, other jobs that are running already or scheduled to run before your job, may have overestimated the time they need and end early. But on the other hand, the scheduler does not use a \"first come, first serve\" policy so another user may submit a job that gets a higher priority than yours, pushing back the start time of your job. So it is basically a random number generator.
-
To delete a job, use scancel <jobID>
-
An important command to manage jobs while they are running is sstat -j <jobID>. This command display real-time information directly gathered from the resource manager component of Slurm and can also be used to show information about individual job steps using the job step identifier (which is in most case <jobID>.0 for the first regular job step and so on). We will cover this command in more detail further in the notes of this session.
-
The sacct -j <jobID> command can be used both while the job is running and when the job has finished. It is the main command to get information about a job after the job has finished. All information comes from a database, also while the job is running, so the information is available with some delay compared to the information obtained with sstat for a running job. It will also produce information about individual job steps. We will cover this command in more detail further in the notes of this session.
The sacct command will also be used in various examples in this section of the tutorial to investigate the behaviour of Slurm.
"},{"location":"2day-next/06-Slurm/#creating-a-slurm-job","title":"Creating a Slurm job","text":"Slurm has three main commands to create jobs and job steps. Remember that a job is just a request for an allocation. Your applications always have to run inside a job step.
The salloc command only creates an allocation but does not create a job step. The behaviour of salloc differs between clusters! On LUMI, salloc will put you in a new shell on the node from which you issued the salloc command, typically the login node. Your allocation will exist until you exit that shell with the exit command or with the CONTROL-D key combination. Creating an allocation with salloc is good for interactive work.
Differences in salloc behaviour.
On some systems salloc does not only create a job allocation but will also create a job step, the so-called \"interactive job step\" on a node of the allocation, similar to the way that the sbatch command discussed later will create a so-called \"batch job step\".
The main purpose of the srun command is to create a job step in an allocation. When run outside of a job (outside an allocation) it will also create a job allocation. However, be careful when using this command to also create the job in which the job step will run as some options work differently as for the commands meant to create an allocation. When creating a job with salloc you will have to use srun to start anything on the node(s) in the allocation as it is not possible to, e.g., reach the nodes with ssh.
The sbatch command both creates a job and then starts a job step, the so-called batch job step, to run the job script on the first node of the job allocation. In principle it is possible to start both sequential and shared memory processes directly in the batch job step without creating a new job step with srun, but keep in mind that the resources may be different from what you expect to see in some cases as some of the options given with the sbatch command will only be enforced when starting another job step from the batch job step. To run any multi-process job (e.g., MPI) you will have to use srun or a process starter that internally calls srun to start the job. When using Cray MPICH as the MPI implementation (and it is the only one that is fully supported on LUMI) you will have to use srun as the process starter.
"},{"location":"2day-next/06-Slurm/#passing-options-to-srun-salloc-and-sbatch","title":"Passing options to srun, salloc and sbatch","text":"There are several ways to pass options and flags to the srun, salloc and sbatch command.
The lowest priority way and only for the sbatch command is specifying the options (mostly resource-related) in the batch script itself on #SBATCH lines. These lines should not be interrupted by commands, and it is not possible to use environment variables to specify values of options.
Higher in priority is specifying options and flags through environment variables. For the sbatch command this are the SBATCH_* environment variables, for salloc the SALLOC_* environment variables and for srun the SLURM_* and some SRUN_* environment variables. For the sbatch command this will overwrite values on the #SBATCH lines. You can find lists in the manual pages of the sbatch, salloc and srun command. Specifying command line options via environment variables that are hidden in your .profile or .bashrc file or any script that you run before starting your work, is not free of risks. Users often forget that they set those environment variables and are then surprised that the Slurm commands act differently then expected. E.g., it is very tempting to set the project account to use in environment variables but if you then get a second project you may be running inadvertently in the wrong project.
The highest priority is for flags and options given on the command line. The position of those options is important though. With the sbatch command they have to be specified before the batch script as otherwise they will be passed to the batch script as command line options for that script. Likewise, with srun they have to be specified before the command you want to execute as otherwise they would be passed to that command as flags and options.
Several options specified to sbatch or salloc are also forwarded to srun via SLURM_* environment variables set in the job by these commands. These may interfere with options specified on the srun command line and lead to unexpected behaviour.
Example: Conflict between --ntasks and --ntasks-per-node We'll meet this example later on in these notes,when we discuss starting a job step in per-node allocations. You'll need some Slurm experience to understand this example at this point, but keep it in mind when you read further in these notes.
Two different options to specify the number of tasks in a job step are --ntasks and --ntasks-per-node. The --ntasks command line options specifies the total number of tasks for the job step, and these will be distributed across nodes according to rules we will discuss later. The --ntasks-per-node command line option on the other hand requests that that number of tasks is launched on each node of the job (which really only makes sense if you have entire nodes, e.g., in node-exclusive allocations) and is attractive as it is easy to scale your allocation by just changing the number of nodes.
Checking the srun manual page for the --ntasks-per-node option, you read that the --ntasks option takes precedence and if present, --ntasks-per-node will be interpreted as the maximum number of tasks per node.
Now depending on how the allocation was made, Slurm may set the environment variables SLURM_NTASKS and SLURM_NPROCS (the latter for historical reasons) that have the same effect as specifying --ntasks. So if these environment variables are present in the environment of your job script, they have effectively the effect of specifying --ntasks even though you did not specify it explicitly on the srun command line and --ntasks-per-node will no longer be the exact number of tasks. And this may happen even if you have never specified any --ntasks flag anywhere simply because Slurm fills in some defaults for certain parameters when creating an allocation...
"},{"location":"2day-next/06-Slurm/#specifying-options","title":"Specifying options","text":"Slurm commands have way more options and flags than we can discuss in this course or even the 4-day comprehensive course organised by the LUMI User Support Team. Moreover, if and how they work may depend on the specific configuration of Slurm. Slurm has so many options that no two clusters are the same.
Slurm command can exist in two variants:
-
The long variant, with a double dash, is of the form --long-option=<value> or --long-option <value>
-
But many popular commands also have a single letter variant, with a single dash: -S <value> or -S<value>
This is no different from many popular Linux commands.
Slurm commands for creating allocations and job steps have many different flags for specifying the allocation and the organisation of tasks in that allocation. Not all combinations are valid, and it is not possible to sum up all possible configurations for all possible scenarios. Use common sense and if something does not work, check the manual page and try something different. Overspecifying options is not a good idea as you may very well create conflicts, and we will see some examples in this section and the next section on binding. However, underspecifying is not a good idea either as some defaults may be used you didn't think of. Some combinations also just don't make sense, and we will warn for some on the following slides and try to bring some structure in the wealth of options.
"},{"location":"2day-next/06-Slurm/#some-common-options-to-all-partitions","title":"Some common options to all partitions","text":"For CPU and GPU requests, a different strategy should be used for \"allocatable by node\" and \"allocatable by resource\" partitions, and this will be discussed later. A number of options however are common to both strategies and will be discussed first. All are typically used on #SBATCH lines in job scripts, but can also be used on the command line and the first three are certainly needed with salloc also.
-
Specify the account to which the job should be billed with --account=project_46YXXXXXX or -A project_46YXXXXXX. This is mandatory; without this your job will not run.
-
Specify the partition: --partition=<partition> or -p <partition>. This option is also necessary on LUMI as there is currently no default partition.
-
Specify the wall time for the job: --time=<timespec> or -t <timespec>. There are multiple formats for the time specifications, but the most common ones are minutes (one number), minutes:seconds (two numbers separated by a colon) and hours:minutes:seconds (three numbers separated by a column). If not specified, the partition-dependent default time is used.
It does make sense to make a reasonable estimate for the wall time needed. It does protect you a bit in case your application hangs for some reason, and short jobs that also don't need too many nodes have a high chance of running quicker as they can be used as backfill while the scheduler is gathering nodes for a big job.
-
Completely optional: Specify a name for the job with --job-name=<name> or -J <name>. Short but clear job names help to make the output of squeue easier to interpret, and the name can be used to generate a name for the output file that captures output to stdout and stderr also.
-
For courses or other special opportunities such as the \"hero runs\" (a system for projects that want to test extreme scalability beyond the limits of the regular partitions), reservations are used. You can specify the reservation (or even multiple reservations as a comma-separated list) with --reservation=<name>.
In principle no reservations are given to regular users for regular work as this is unfair to other users. It would not be possible to do all work in reservations and bypass the scheduler as the scheduling would be extremely complicated and the administration enormous. And empty reservations do not lead to efficient machine use. Schedulers have been developed for a reason.
-
Slurm also has options to send mail to a given address when a job starts or ends or some other job-related events occur, but this is currently not configured on LUMI.
"},{"location":"2day-next/06-Slurm/#redirecting-output","title":"Redirecting output","text":"Slurm has two options to redirect stdout and stderr respectively: --output=<template> or -o <template> for stdout and --error=<template> or -e <template> for stderr. They work together in the following way:
-
If neither --output not --error is specified, then stdout and stderr are merged and redirected to the file slurm-<jobid>.out.
-
If --output is specified but --error is not, then stdout and stderr are merged and redirected to the file given with --output.
-
If --output is not specified but --error, then stdout will still be redirected to slurm-<jobid>.out, but stderr will be redirected to the file indicated by the --error option.
-
If both --output and --error are specified, then stdout is redirected to the file given by --output and stderr is redirected to the file given by --error.
It is possible to insert codes in the filename that will be replaced at runtime with the corresponding Slurm information. Examples are %x which will be replaced with the name of the job (that you can then best set with --job-name) and %j which will be replaced with the job ID (job number). It is recommended to always include the latter in the template for the filename as this ensures unique names if the same job script would be run a few times with different input files. Discussing all patterns that can be used for the filename is outside the scope of this tutorial, but you can find them all in the sbatch manual page in the \"filename pattern\" section.
"},{"location":"2day-next/06-Slurm/#requesting-resources-cpus-and-gpus","title":"Requesting resources: CPUs and GPUs","text":"Slurm is very flexible in the way resources can be requested. Covering every scenario and every possible way to request CPUs and GPUs is impossible, so we will present a scheme that works for most users and jobs.
First, you have to distinguish between two strategies for requesting resources, each with their own pros and cons. We'll call them \"per-node allocations\" and \"per-core allocations\":
-
\"Per-node allocations\": Request suitable nodes (number of nodes and partition) with sbatch or salloc but postpone specifying the full structure of the job step (i.e., tasks, cpus per task, gpus per task, ...) until you actually start the job step with srun.
This strategy relies on job-exclusive nodes, so works on the standard and standard-g partitions that are \"allocatable-by-node\" partitions, but can be used on the \"allocatable-by-resource\" partitions also it the --exclusive flag is used with sbatch or salloc (on the command line or with and #SBATCH --exclusive line for sbatch).
This strategy gives you the ultimate flexibility in the job as you can run multiple job steps with a different structure in the same job rather than having to submit multiple jobs with job dependencies to ensure that they are started in the proper order. E.g., you could first have an initialisation step that generates input files in a multi-threaded shared memory program and then run a pure MPI job with a single-threaded process per rank.
This strategy also gives you full control over how the application is mapped onto the available hardware: mapping of MPI ranks across nodes and within nodes, binding of threads to cores, and binding of GPUs to MPI ranks. This will be the topic of the next section of the course and is for some applications very important to get optimal performance on modern supercomputer nodes that have a strongly hierarchical architecture (which in fact is not only the case for AMD processors, but will likely be an issue on some Intel Sapphire Rapids processors also).
The downside is that allocations and hence billing is always per full node, so if you need only half a node you waste a lot of billing units. It shows that to exploit the full power of a supercomputer you really need to have problems and applications that can at least exploit a full node.
-
\"Per-core allocations\": Specify the full job step structure when creating the job allocation and optionally limit the choice fo Slurm for the resource allocation by specifying a number of nodes that should be used.
The problem is that Slurm cannot create a correct allocation on an \"allocatable by resource\" partition if it would only know the total number of CPUs and total number of GPUs that you need. Slurm does not automatically allocate the resources on the minimal number of nodes (and even then there could be problems) and cannot know how you intend to use the resources to ensure that the resources are actually useful for you job. E.g., if you ask for 16 cores and Slurm would spread them over two or more nodes, then they would not be useful to run a shared memory program as such a program cannot span nodes. Or if you really want to run an MPI application that needs 4 ranks and 4 cores per rank, then those cores must be assigned in groups of 4 within nodes as an MPI rank cannot span nodes. The same holds for GPUs. If you would ask for 16 cores and 4 GPUs you may still be using them in different ways. Most users will probably intend to start an MPI program with 4 ranks that each use 4 cores and one GPU, and in that case the allocation should be done in groups that each contain 4 cores and 1 GPU but can be spread over up to 4 nodes, but you may as well intend to run a 16-thread shared memory application that also needs 4 GPUs.
The upside of this is that with this strategy you will only get what you really need when used in an \"allocatable-by-resources\" partition, so if you don't need a full node, you won't be billed for a full node (assuming of course that you don't request that much memory that you basically need a full node's memory).
One downside is that you are now somewhat bound to the job structure. You can run job steps with a different structure, but they may produce a warning or may not run at all if the job step cannot be mapped on the resources allocated to the job.
More importantly, most options to do binding (see the next chapter) cannot be used or don't make sense anyway as there is no guarantee your cores will be allocated in a dense configuration.
However, if you can live with those restrictions and if your job size falls within the limits of the \"allocatable per resource\" partitions, and cannot fill up the minimal number of nodes that would be used, then this strategy ensures you're only billed for the minimal amount of resources that are made unavailable by your job.
This choice is something you need to think about in advance and there are no easy guidelines. Simply say \"use the first strategy if your job fills whole nodes anyway and the second one otherwise\" doesn't make sense as your job may be so sensitive to its mapping to resources that it could perform very badly in the second case. The real problem is that there is no good way in Slurm to ask for a number of L3 cache regions (CPU chiplets), a number of NUMA node or a number of sockets and also no easy way to always do the proper binding if you would get resources that way (but that is something that can only be understood after the next session). If a single job needs only a half node and if all jobs take about the same time anyway, it might be better to bundle them by hand in jobs and do a proper mapping of each subjob on the available resources (e.g., in case of two jobs on a CPU node, map each on a socket).
"},{"location":"2day-next/06-Slurm/#resources-for-per-node-allocations","title":"Resources for per-node allocations","text":"In a per-node allocation, all you need to specify is the partition and the number of nodes needed, and in some cases, the amount of memory. In this scenario, one should use those Slurm options that specify resources per node also.
The partition is specified using --partition=<partition or -p <partition>.
The number of nodes is specified with --nodes=<number_of_nodes> or its short form -N <number_of_nodes>.
If you want to use a per-node allocation on a partition which is allocatable-by-resources such as small and small-g, you also need to specify the --exclusive flag. On LUMI this flag does not have the same effect as running on a partition that is allocatable-by-node. The --exclusive flag does allocate all cores and GPUs on the node to your job, but the memory use is still limited by other parameters in the Slurm configuration. In fact, this can also be the case for allocatable-by-node partitions, but there the limit is set to allow the use of all available memory. Currently the interplay between various parameters in the Slurm configuration results in a limit of 112 GB of memory on the small partition and 64 GB on the standard partition when running in --exclusive mode. It is possible to change this with the --mem option.
You can request all memory on a node by using --mem=0. This is currently the default behaviour on nodes in the standard and standard-g partition so not really needed there. It is needed on all of the partitions that are allocatable-by-resource.
We've experienced that it may be a better option to actually specify the maximum amount of useable memory on a node which is the memory capacity of the node you want minus 32 GB, so you can use --mem=224G for a regular CPU node or --mem=480G for a GPU node. In the past we have had memory leaks on compute nodes that were not detected by the node health checks, resulting in users getting nodes with less available memory than expected, but specifying these amounts protected them against getting such nodes. (And similarly you could use --mem=480G and --mem=992G for the 512 GB and 1 TB compute nodes in the small partition, but note that running on these nodes is expensive!)
Example jobscript (click to expand) The following job script runs a shared memory program in the batch job step, which shows that it has access to all hardware threads and all GPUs in a node at that moment:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-minimal-small-g\n#SBATCH --partition=small-g\n#SBATCH --exclusive\n#SBATCH --nodes=1\n#SBATCH --mem=480G\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ngpu_check\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
As we are using small-g here instead of standard-g, we added the #SBATCH --exclusive and #SBATCH --mem=480G lines.
A similar job script for a CPU-node in LUMI-C and now in the standard partition would look like:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-minimal-standard\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\nomp_check\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
gpu_check and omp_check are two programs provided by the lumi-CPEtools modules to check the allocations. Try man lumi-CPEtools after loading the module. The programs will be used extensively in the next section on binding also, and are written to check how your program would behave in the allocation without burning through tons of billing units.
By default you will get all the CPUs in each node that is allocated in a per-node allocation. The Slurm options to request CPUs on a per-node basis are not really useful on LUMI, but might be on clusters with multiple node types in a single partition as they enable you to specify the minimum number of sockets, cores and hardware threads a node should have.
We advise against using the options to request CPUs on LUMI because it is more likely to cause problems due to user error than to solve problems. Some of these options also conflict with options that will be used later in the course.
There is no direct way to specify the number of cores per node. Instead one has to specify the number sockets and then the number of cores per socket and one can specify even the number of hardware threads per core, though we will favour another mechanism later in these course notes.
The two options are:
-
Specify --sockets-per-node=<sockets and --cores-per-socket=<cores> and maybe even --threads-per-core=<threads>. For LUMI-C the maximal specification is
--sockets-per-node=2 --cores-per-socket-64\n
and for LUMI-G
--sockets-per-node=1 --cores-per-socket=56\n
Note that on LUMI-G, nodes have 64 cores but one core is reserved for the operating system and drivers to reduce OS jitter that limits the scalability of large jobs. Requesting 64 cores will lead to error messages or jobs getting stuck.
-
There is a shorthand for those parameters: --extra-node-info=<sockets>[:cores] or -B --extra-node-info=<sockets>[:cores] where the second and third number are optional. The full maximal specification for LUMI-C would be --extra-node-info=2:64 and for LUMI-G --extra-node-info=1:56.
What about --threads-per-core? Slurm also has a --threads-per-core (or a third number with --extra-node-info) which is a somewhat misleading name. On LUMI, as hardware threads are turned on, you would expect that you can use --threads-per-core=2 but if you try, you will see that your job is not accepted. This because on LUMI, the smallest allocatable processor resource (called the CPU in Slurm) is a core and not a hardware thread (or virtual core as they are also called). There is another mechanism to enable or disable hyperthreading in regular job steps that we will discuss later.
By default you will get all the GPUs in each node that is allocated in a per-node allocation. The Slurm options to request GPUs on a per-node basis are not really useful on LUMI, but might be on clusters with multiple types of GPUs in a single partition as they enable you to specify which type of node you want. If you insist, slurm has several options to specify the number of GPUs for this scenario:
-
The most logical one to use for a per-node allocation is --gpus-per-node=8 to request 8 GPUs per node. You can use a lower value, but this doesn't make much sense as you will be billed for the full node anyway.
It also has an option to also specify the type of the GPU but that doesn't really make sense on LUMI. On LUMI, you could in principle use --gpus-per-node=mi250:8.
-
--gpus=<number> or -G <number> specifies the total number of GPUs needed for the job. In our opinion this is a dangerous option to use as when you change the number of nodes, you likely also want to change the number of GPUs for the job and you may overlook this. Here again it is possible to specify the type of the GPU also. Moreover, if you ask for fewer GPUs than are present in the total number of nodes you request, you may get a very strange distribution of the available GPUs across the nodes.
Example of an unexpected allocation Assuming SLURM_ACCOUNT is set to a valid project with access to the partition used:
module load LUMI/23.09 partition/G lumi-CPEtools\nsrun --partition standard-g --time 5:00 --nodes 2 --tasks-per-node 1 --gpus 8 gpu_check\n
returns
MPI 000 - OMP 000 - HWT 001 - Node nid007264 - RT_GPU_ID 0,1,2,3,4,5,6 - GPU_ID 0,1,2,3,4,5,6 - Bus_ID c1,c9,ce,d1,d6,d9,dc\nMPI 001 - OMP 000 - HWT 001 - Node nid007265 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\n
So 7 GPUs were allocated on the first node and 1 on the second.
-
A GPU belongs to the family of \"generic consumable resources\" (or GRES) in Slurm and there is an option to request any type of GRES that can also be used. Now you also need to specify the type of the GRES. The number you have to specify if on a per-node basis, so on LUMI you can use --gres=gpu:8 or --gres=gpu:mi250:8.
As these options are also forwarded to srun, it will save you from specifying them there.
"},{"location":"2day-next/06-Slurm/#per-node-allocations-starting-a-job-step","title":"Per-node allocations: Starting a job step","text":"Serial or shared-memory multithreaded programs in a batch script can in principle be run in the batch job step. As we shall see though the effect may be different from what you expect. However, if you are working interactively via salloc, you are in a shell on the node on which you called salloc, typically a login node, and to run anything on the compute nodes you will have to start a job step.
The command to start a new job step is srun. But it needs a number of arguments in most cases. After all, a job step consists of a number of equal-sized tasks (considering only homogeneous job steps at the moment, the typical case for most users) that each need a number of cores or hardware threads and, in case of GPU compute, access to a number of GPUs.
There are several ways telling Slurm how many tasks should be created and what the resources are for each individual task, but this scheme is an easy scheme:
-
Specifying the number of tasks: You can specify per node or the total number:
-
Specifying the total number of tasks: --ntasks=<ntasks or -n ntasks. There is a risk associated to this approach which is the same as when specifying the total number of GPUs for a job: If you change the number of nodes, then you should change the total number of tasks also. However, it is also very useful in certain cases. Sometimes the number of tasks cannot be easily adapted and does not fit perfectly into your allocation (cannot be divided by the number of nodes). In that case, specifying the total number of nodes makes perfect sense.
-
Specifying on a per node basis: --ntasks-per-node=<ntasks> is possible in combination with --nodes according to the Slurm manual. In fact, this would be a logical thing to do in a per node allocation. However, we see it fail on LUMI when it is used as an option for srun and not with sbatch, even though it should work according to the documentation.
The reason for the failure is that Slurm when starting a batch job defines a large number of SLURM_* and SRUN_* variables. Some only give information about the allocation, but others are picked up by srun as options and some of those options have a higher priority than --ntasks-per-node. So the trick is to unset both SLURM_NTASKS and SLURM_NPROCS. The --ntasks option triggered by SLURM_NTASKS has a higher priority than --ntasks-per-node. SLURM_NPROCS was used in older versions of Slurm as with the same function as the current environment variable SLURM_NTASKS and therefore also implicitly specifies --ntasks if SLURM_NTASKS is removed from the environment.
The option is safe to use with sbatch though.
Lesson: If you want to play it safe and not bother with modifying the environment that Slurm creates, use the total number of tasks --ntasks if you want to specify the number of tasks with srun.
-
Specifying the number of CPUs (cores on LUMI) for each task. The easiest way to do this is by using --cpus-per-task=<number_CPUs> or -c <number_CPUs>.
-
Specifying the number of GPUs per task. Following the Slurm manuals, the following seems the easiest way:
-
Use --gpus-per-task=<number_GPUs> to bind one or more GPUs to each task. This is probably the most used option in this scheme.
-
If however you want multiple tasks to share a GPU, then you should use --ntasks-per-gpu=<number_of_tasks>. There are use cases where this makes sense.
This however does not always work...
The job steps created in this simple scheme do not always run the programs at optimal efficiency. Slurm has various strategies to assign tasks to nodes, and there is an option which we will discuss in the next session of the course (binding) to change that. Moreover, not all clusters use the same default setting for this strategy. Cores and GPUs are assigned in order and this is not always the best order.
It is also possible to specify these options already on #SBATCH lines. Slurm will transform those options into SLURM_* environment variables that will then be picked up by srun. However, this behaviour has changed in more recent versions of Slurm. E.g., --cpus-per-task is no longer automatically picked up by srun as there were side effects with some MPI implementations on some clusters. CSC has modified the configuration to again forward that option (now via an SRUN_* environment variable) but certain use cases beyond the basic one described above are not covered. And take into account that not all cluster operators will do that as there are also good reasons not to do so. Otherwise the developers of Slurm wouldn't have changed that behaviour in the first place.
Demonstrator for the problems with --tasks-per-node (click to expand) Try the batch script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-perNode-jobstart-standard-demo1\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\necho \"Submitted from $SLURM_SUBMIT_HOST\"\necho \"Running on $SLURM_JOB_NODELIST\"\necho\necho -e \"Job script:\\n$(cat $0)\\n\"\necho \"SLURM_* and SRUN_* environment variables:\"\nenv | egrep ^SLURM\nenv | egrep ^SRUN\n\nset -x\n# This works\nsrun --ntasks=32 --cpus-per-task=8 hybrid_check -r\n\n# This does not work\nsrun --ntasks-per-node=16 --cpus-per-task=8 hybrid_check -r\n\n# But this works again\nunset SLURM_NTASKS\nunset SLURM_NPROCS\nsrun --ntasks-per-node=16 --cpus-per-task=8 hybrid_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
"},{"location":"2day-next/06-Slurm/#a-warning-for-gpu-applications","title":"A warning for GPU applications","text":"Allocating GPUs with --gpus-per-task or --tasks-per-gpu may seem the most logical thing to do when reading the Slurm manual pages. It does come with a problem though resulting of how Slurm currently manages the AMD GPUs, and now the discussion becomes more technical.
Slurm currently uses a separate control group per task for the GPUs. Now control groups are a mechanism in Linux for restricting resources available to a process and its childdren. Putting the GPUs in a separate control group per task limits the ways in intra-node communication can be done between GPUs, and this in turn is incompatible with some software.
The solution is to ensure that all tasks within a node see all GPUs in the node and then to manually perform the binding of each task to the GPUs it needs using a different mechanism more like affinity masks for CPUs. It can be tricky to do though as many options for srun do a mapping under the hood.
As we need a mechanisms that are not yet discussed yet in this chapter, we refer to the chapter \"Process and thread distribution and binding\" for a more ellaborate discussion and a solution.
Unfortunately using AMD GPUs in Slurm is more complicated then it should be (and we will see even more problems).
"},{"location":"2day-next/06-Slurm/#turning-simultaneous-multithreading-on-or-off","title":"Turning simultaneous multithreading on or off","text":"Hardware threads are enabled by default at the operating system level. In Slurm however, regular job steps start by default with hardware threads disabled. This is not true though for the batch job step as the example below will show.
Hardware threading for a regular job step can be turned on explicitly with --hint=multhithread and turned off explicitly with --hint=nomultithread, with the latter the default on LUMI. The hint should be given as an option to sbatch(e.g., as a line #SBATCH --hint=multithread) and not as an option of srun.
The way it works is a bit confusing though. We've always told, and that is also what the Slurm manual tells, that a CPU is the smallest allocatable unit and that on LUMI, Slurm is set to use the core as the smallest allocatable unit. So you would expect that srun --cpus-per-task=4 combined with #SBATCH --hint=multithread would give you 4 cores with in total 8 threads, but instead you will get 2 cores with 4 hardware threads. In other words, it looks like (at least with the settings on LUMI) #SBATCH --hint=multithread changes the meaning of CPU in the context of an srun command to a hardware thread instead of a core. This is illustrated with the example below.
Use of --hint=(no)multithread (click to expand) We consider the job script
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-multithread\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=multithread\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\necho -e \"Job script:\\n$(cat $0)\\n\"\n\nset -x\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
We consider three variants of this script:
-
Without the #SBATCH --hint=multithread line to see the default behaviour of Slurm on LUMI. The relevant lines of the output are:
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001847 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238727 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238727.bat+ batch project_4+ 256 RUNNING 0:0 \n4238727.0 omp_check project_4+ 8 RUNNING 0:0 \n
The omp_check program detects that it should run 4 threads (we didn't even need to help by setting OMP_NUM_THREADS) and uses cores 0 till 3 which are the first 4 physical cores on the processor.
The output of the sacct command claims that the job (which is the first line of the table) got allocated 256 CPUs. This is a confusing feature of sacct: it shows the number of hardware threads even though the Slurm CPU on LUMI is defined as a core. The next line shows the batch job step which actually does see all hardware threads of all cores (and in general, all hardware threads of all allocated cores of the first node of the job). The final line, with the '.0' job step, shows that that core was using 8 hardware threads, even though omp_check only saw 4. This is because the default behaviour (as the next test will confirm) is --hint=nomultithread.
Note that sacct shows the last job step as running even though it has finished. This is because sacct gets the information not from the compute node but from a database, and it looks like the full information has not yet derived in the database. A short sleep before the sacct call would cure this problem.
-
Now replace the #SBATCH --hint=multithread with #SBATCH --hint=nomultithread. The relevant lines of the output are now
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001847 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001847 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238730 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238730.bat+ batch project_4+ 256 RUNNING 0:0 \n4238730.0 omp_check project_4+ 8 RUNNING 0:0 \n
The output is no different from the previous case which confirms that this is the default behaviour.
-
Lastly, we run the above script unmodified, i.e., with #SBATCH --hint=multithread Now the relevant lines of the output are:
+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001847 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001847 mask 0-1, 128-129\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238728 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238728.bat+ batch project_4+ 256 RUNNING 0:0 \n4238728.0 omp_check project_4+ 4 COMPLETED 0:0 \n
The omp_check program again detects only 4 threads but now runs them on the first two physical cores and the corresponding second hardware thread for these cores. The output of sacct now shows 4 in the \"AllocCPUS\" command for the .0 job step, which confirms that indeed only 2 cores with both hardware threads were allocated instead of 4 cores.
Buggy behaviour when used with srun Consider the following job script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-bug2\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --hint=multithread\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeGNU-22.12\n\nset -x\nsrun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nsrun -n 1 -c 4 --hint=multithread omp_check -r\n\nOMP_NUM_THREADS=8 srun -n 1 -c 4 --hint=multithread omp_check -r\n\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n\nset -x\nsrun -n 1 -c 256 --hint=multithread omp_check -r\n
The relevant lines of the output are:
+ srun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001246 mask 0-3\n\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001246 mask 0-1, 128-129\n\n+ OMP_NUM_THREADS=8\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 8 threads in a single process\n\n++ omp_check: OpenMP thread 0/8 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/8 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/8 on cpu 0/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/8 on cpu 1/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 4/8 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 5/8 on cpu 128/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 6/8 on cpu 129/256 of nid001246 mask 0-1, 128-129\n++ omp_check: OpenMP thread 7/8 on cpu 1/256 of nid001246 mask 0-1, 128-129\n\n+ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001246 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001246 mask 0-3\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238801 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238801.bat+ batch project_4+ 256 RUNNING 0:0 \n4238801.0 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.1 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.2 omp_check project_4+ 8 COMPLETED 0:0 \n4238801.3 omp_check project_4+ 8 COMPLETED 0:0 \n\n+ srun -n 1 -c 256 --hint=multithread omp_check -r\nsrun: error: Unable to create step for job 4238919: More processors requested than permitted\n
The first omp_check runs as expected. The seocnd one uses only 2 cores but all 4 hyperthreads on those cores. This is also not unexpected. In the third case we force the use of 8 threads, and they all land on the 4 hardware threads of 2 cores. Again, this is not unexpected. And neither is the output of the last run of omp_cehck which is again with multithreading disabled as requested in the #SBATCH lines. What is surprising though is the output of sacct: It claims there were 8 hardware threads, so 4 cores, allocated to the second (the .1) and third (the .2) job step while whatever we tried, omp_check could only see 2 cores and 4 hardware threads. Indeed, if we would try to run with -c 256 then srun will fail.
But now try the reverse: we turn multithreading on in the #SBATCH lines and try to turn it off again with srun:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-HWT-standard-bug2\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --time=2:00\n#SBATCH --output=%x-%j.txt\n#SBATCH --hint=multithread\n#SBATCH --account=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeGNU-22.12\n\nset -x\nsrun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nsrun -n 1 -c 4 --hint=multithread omp_check -r\n\nsrun -n 1 -c 4 omp_check -r\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
The relevant part of the output is now
+ srun -n 1 -c 4 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 1/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 2/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 2/4 on cpu 3/256 of nid001460 mask 0-3\n++ omp_check: OpenMP thread 3/4 on cpu 0/256 of nid001460 mask 0-3\n\n+ srun -n 1 -c 4 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001460 mask 0-1, 128-129\n\n++ srun -n 1 -c 4 omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 1/4 on cpu 129/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001460 mask 0-1, 128-129\n++ omp_check: OpenMP thread 3/4 on cpu 1/256 of nid001460 mask 0-1, 128-129\n\n+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4238802 slurm-HWT+ standard project_4+ 256 RUNNING 0:0 \n4238802.bat+ batch project_4+ 256 RUNNING 0:0 \n4238802.0 omp_check project_4+ 8 COMPLETED 0:0 \n4238802.1 omp_check project_4+ 4 COMPLETED 0:0 \n4238802.2 omp_check project_4+ 4 COMPLETED 0:0 \n
And this is fully as expected. The first srun does not use hardware threads as requested by srun, the second run does use hardware threads and only 2 cores which is also what we requested with the srun command, and the last one also uses hardware threads. The output of sacct (and in particular the AllocCPUS comumn) not fully confirms that indeed there were only 2 cores allocated to the second and third run.
So turning hardware threads on in the #SBATCH lines and then off again with srun works as expected, but the opposite, explicitly turning it off in the #SBATCH lines (or relying on the default which is off) and then trying to turn it on again, does not work.
"},{"location":"2day-next/06-Slurm/#per-core-allocations","title":"Per-core allocations","text":""},{"location":"2day-next/06-Slurm/#when-to-use","title":"When to use?","text":"Not all jobs can use entire nodes efficiently, and therefore the LUMI setup does provide some partitions that enable users to define jobs that use only a part of a node. This scheme enables the user to only request the resources that are really needed for the job (and only get billed for those at least if they are proportional to the resources that a node provides), but also comes with the disadvantage that it is not possible to control how cores and GPUs are allocated within a node. Codes that depend on proper mapping of threads and processes on L3 cache regions, NUMA nodes or sockets, or on shortest paths between cores in a task and the associated GPU(s) may see an unpredictable performance loss as the mapping (a) will rarely be optimal unless you are very lucky (and always be suboptimal for GPUs in the current LUMI setup) and (b) will also depend on other jobs already running on the set of nodes assigned to your job.
Unfortunately,
-
Slurm does not seem to fully understand the GPU topology on LUMI and cannot take that properly into account when assigning resources to a job or task in a job, and
-
Slurm does not support the hierarchy in the compute nodes of LUMI. There is no way to specifically request all cores in a socket, NUMA node or L3 cache region. It is only possible on a per-node level which is the case that we already discussed.
Instead, you have to specify the task structure in the #SBATCH lines of a job script or as the command line arguments of sbatch and salloc that you will need to run the job.
"},{"location":"2day-next/06-Slurm/#resource-request","title":"Resource request","text":"To request an allocation, you have to specify the task structure of the job step you want to run using mostly the same options that we have discussed on the slides \"Per-node allocations: Starting a job step\":
-
Now you should specify just the total amount of tasks needed using --ntasks=<number> or -n <number>. As the number of nodes is not fixed in this allocation type, --ntasks-per-node=<ntasks> does not make much sense.
It is possible to request a number of nodes using --nodes, and it can even take two arguments: --nodes=<min>-<max> to specify the minimum and maximum number of nodes that Slurm should use rather than the exact number (and there are even more options), but really the only case where it makes sense to use --nodes with --ntasks-per-node in this case, is if all tasks would fit on a single node and you also want to force them on a single node so that all MPI communications are done through shared memory rather than via the Slingshot interconnect.
Restricting the choice of resources for the scheduler may increase your waiting time in the queue though.
-
Specifying the number of CPUs (cores on LUMI) for each task. The easiest way to do this is by using --cpus-per-task=<number> or -c <number.
Note that as has been discussed before, the standard behaviour of recent versions of Slurm is to no longer forward --cpus-per-task from the sbatch or salloc level to the srun level though CSC has made a configuration change in Slurm that will still try to do this though with some limitations.
-
Specifying the number of GPUs per task. The easiest way here is:
-
Use --gpus-per-task=<number_GPUs> to bind one or more GPUs to each task. This is probably the most used option in this scheme.
-
If however you want multiple tasks to share a GPU, then you should use --ntasks-per-gpu=<number_of_tasks>. There are use cases where this makes sense. However, at the time of writing this does not work properly.
While this does ensure a proper distribution of GPUs across nodes compatible with the distributions of cores to run the requested tasks, we will again run into binding issues when these options are propagated to srun to create the actual job steps, and hre this is even more tricky to solve.
We will again discuss a solution in the Chapter \"Process and thread distribution and binding\"
-
CPU memory. By default you get less than the memory per core on the node type. To change:
-
Against the logic there is no --mem-per-task=<number>, instead memory needs to be specified in function of the other allocated resources.
-
Use --mem-per-cpu=<number> to request memory per CPU (use k, m, g to specify kilobytes, megabytes or gigabytes)
-
Alternatively on a GPU allocation --mem-per-gpu=<number>. This is still CPU memory and not GPU memory!
-
Specifying memory per node with --mem doesn't make much sense unless the number of nodes is fixed.
--ntasks-per-gpu=<number> does not work
At the time of writing there were several problems when using --ntasks-per-gpu=<number> in combination with --ntasks=<number>. While according to the Slurm documentation this is a valid request and Slurm should automatically determine the right number of GPUs to allocate, it turns out that instead you need to specify the number of GPUs with --gpus=<number> together with --ntasks-per-gpu=<number> and let Slurm compute the number of tasks.
Moreover, we've seen cases where the final allocation was completely wrong, with tasks ending up with the wrong number of GPUs or on the wrong node (like too many tasks on one and too little on another compared to the number of GPUs set aside in each of these nodes).
--sockets-per-node and --ntasks-per-socket
If you don't read the manual pages of Slurm carefully enough you may have the impression that you can use parameters like --sockets-per-node and --ntasks-per-socket to force all tasks on a single socket (and get a single socket), but these options will not work as you expect.
The --sockets-per-node option is not used to request an exact resource, but to specify a type of node by specifying the minimal number of sockets a node should have.It is an irrelevant option on LUMI as each partition does have only a single node type.
If you read the manual carefully, you will also see that there is a subtle difference between --ntasks-per-node and --ntasks-per-socket: With --ntasks-per-node you specify the exact number of tasks for each node while with --tasks-per-socket you specify the maximum number of tasks for each socket. So all hope that something like
--ntasks=8 --ntasks-per-socket=8 --cpus-per-task=8\n
would always ensure that you get a socket for yourself with each task nicely assigned to a single L3 cache domain, is futile.
"},{"location":"2day-next/06-Slurm/#different-job-steps-in-a-single-job","title":"Different job steps in a single job","text":"It is possible to have an srun command with a different task structure in your job script. This will work if no task requires more CPUs or GPUs than in the original request, and if there are either not more tasks either or if an entire number of tasks in the new structure fits in a task in the structure from the allocation and the total number of tasks does not exceed the original number multiplied with that entire number. Other cases may work randomly, depending on how Slurm did the actual allocation. In fact, this may even be abused to ensure that all tasks are allocated to a single node, though this is done more elegantly by just specifying --nodes=1.
With GPUs though it can become very complicated to avoid binding problems if the Slurm way of implementing GPU binding does not work for you.
Some examples that work and don't work (click to expand) Consider the job script:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-small-multiple-srun\n#SBATCH --partition=small\n#SBATCH --ntasks=4\n#SBATCH --cpus-per-task=4\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --acount=project_46YXXXXXX\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\necho \"Running on $SLURM_JOB_NODELIST\"\n\nset -x\n\nomp_check\n\nsrun --ntasks=1 --cpus-per-task=3 omp_check\n\nsrun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nsrun --ntasks=4 --cpus-per-task=1 mpi_check\n\nsrun --ntasks=16 --cpus-per-task=1 mpi_check\n\nsrun --ntasks=1 --cpus-per-task=16 omp_check\n\nset +x\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
In the first output example (with lots of output deleted) we got the full allocation of 16 cores on a single node, and in fact, even 16 consecutive cores though spread across 3 L3 cache domains. We'll go over the output in steps:
Running on nid002154\n\n+ omp_check\n\nRunning 32 threads in a single process\n\n++ omp_check: OpenMP thread 0/32 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/32 on cpu 148/256 of nid002154\n...\n
The first omp_check command was started without using srun and hence ran on all hardware cores allocated to the job. This is why hardware threading is enabled and why the executable sees 32 cores.
+ srun --ntasks=1 --cpus-per-task=3 omp_check\n\nRunning 3 threads in a single process\n\n++ omp_check: OpenMP thread 0/3 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/3 on cpu 21/256 of nid002154\n++ omp_check: OpenMP thread 2/3 on cpu 22/256 of nid002154\n
Next omp_check was started via srun --ntasks=1 --cpus-per-task=3. One task instead of 4, and the task is also smaller in terms of number of nodes as the tasks requested in SBATCH lines, and Slurm starts the executable without problems. It runs on three cores, correctly detects that number, and also correctly does not use hardware threading.
+ srun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nRunning 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 23/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 24/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 25/256 of nid002154\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 26/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 27/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 28/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 29/256 of nid002154\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 30/256 of nid002154\n
Next we tried to start 2 instead of 4 MPI processes with 4 cores each which also works without problems. The allocation now starts on core 23 but that is because Slurm was still finishing the job step on cores 20 till 22 from the previous srun command. This may or may not happen and is also related to a remark we made before about using sacct at the end of the job where the last job step may still be shown as running instead of completed.
+ srun --ntasks=4 --cpus-per-task=1 mpi_check\n\nRunning 4 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/4 on cpu 20/256 of nid002154\n++ mpi_check: MPI rank 1/4 on cpu 21/256 of nid002154\n++ mpi_check: MPI rank 2/4 on cpu 22/256 of nid002154\n++ mpi_check: MPI rank 3/4 on cpu 23/256 of nid002154\n
Now we tried to start 4 tasks with 1 core each. This time we were lucky and the system considered the previous srun completely finished and gave us the first 4 cores of the allocation.
+ srun --ntasks=16 --cpus-per-task=1 mpi_check\nsrun: Job 4268529 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268529\n\nRunning 16 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/16 on cpu 20/256 of nid002154\n++ mpi_check: MPI rank 1/16 on cpu 21/256 of nid002154\n++ mpi_check: MPI rank 2/16 on cpu 22/256 of nid002154\n++ mpi_check: MPI rank 3/16 on cpu 23/256 of nid002154\n++ mpi_check: MPI rank 4/16 on cpu 24/256 of nid002154\n++ mpi_check: MPI rank 5/16 on cpu 25/256 of nid002154\n...\n
With the above srun command we try to start 16 single-threaded MPI processes. This fits perfectly in the allocation as it simply needs to put 4 of these tasks in the space reserved for one task in the #SBATCH request. The warning at the start may or may not happen. Basically Slurm was still freeing up the cores from the previous run and therefore the new srun dind't have enough resources the first time it tried to, but it automatically tried a second time.
+ srun --ntasks=1 --cpus-per-task=16 omp_check\nsrun: Job step's --cpus-per-task value exceeds that of job (16 > 4). Job step may never run.\nsrun: Job 4268529 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268529\n\nRunning 16 threads in a single process\n\n++ omp_check: OpenMP thread 0/16 on cpu 20/256 of nid002154\n++ omp_check: OpenMP thread 1/16 on cpu 21/256 of nid002154\n++ omp_check: OpenMP thread 2/16 on cpu 22/256 of nid002154\n...\n
In the final srun command we try to run a single 16-core OpenMP run. This time Slurm produces a warning as it would be impossible to fit a 16-cpre shared memory run in the space of 4 4-core tasks if the resources for those tasks would have been spread across multiple nodes. The next warning is again for the same reason as in the previous case, but ultimately the command does run on all 16 cores allocated and without using hardware threading.
+ set +x\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4268529 slurm-sma+ small project_4+ 32 RUNNING 0:0 \n4268529.bat+ batch project_4+ 32 RUNNING 0:0 \n4268529.0 omp_check project_4+ 6 COMPLETED 0:0 \n4268529.1 hybrid_ch+ project_4+ 16 COMPLETED 0:0 \n4268529.2 mpi_check project_4+ 8 COMPLETED 0:0 \n4268529.3 mpi_check project_4+ 32 COMPLETED 0:0 \n4268529.4 omp_check project_4+ 32 RUNNING 0:0 \n
The output of sacct confirms what we have been seeing. The first omp_check was run without srun and ran in the original batch step which had all hardware threads of all 16 allocated cores available. The next omp_check ran on 3 cores but 6 is shwon in this scheme which is normal as the \"other\" hardware thread on each core is implicitly also reserved. And the same holds for all other numbers in that column.
At another time I was less lucky and got the tasks spread out across 4 nodes, each running a single 4-core task. Let's go through the output again:
Running on nid[002154,002195,002206,002476]\n\n+ omp_check\n\nRunning 8 threads in a single process\n\n++ omp_check: OpenMP thread 0/8 on cpu 36/256 of nid002154\n++ omp_check: OpenMP thread 1/8 on cpu 164/256 of nid002154\n++ omp_check: OpenMP thread 2/8 on cpu 37/256 of nid002154\n++ omp_check: OpenMP thread 3/8 on cpu 165/256 of nid002154\n++ omp_check: OpenMP thread 4/8 on cpu 38/256 of nid002154\n++ omp_check: OpenMP thread 5/8 on cpu 166/256 of nid002154\n++ omp_check: OpenMP thread 6/8 on cpu 39/256 of nid002154\n++ omp_check: OpenMP thread 7/8 on cpu 167/256 of nid002154\n
The first omp_check now uses all hardware threads of the 4 cores allocated in the first node of the job (while using 16 cores/32 threads in the configuration where all cores were allocated on a single node).
+ srun --ntasks=1 --cpus-per-task=3 omp_check\n\nRunning 3 threads in a single process\n\n++ omp_check: OpenMP thread 0/3 on cpu 36/256 of nid002154\n++ omp_check: OpenMP thread 1/3 on cpu 37/256 of nid002154\n++ omp_check: OpenMP thread 2/3 on cpu 38/256 of nid002154\n
Running a three core OpenMP job goes without problems as it nicely fits within the space of a single task of the #SBATCH allocation.
+ srun --ntasks=2 --cpus-per-task=4 hybrid_check\n\nRunning 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 36/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 37/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 38/256 of nid002195\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 39/256 of nid002195\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 46/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 47/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 48/256 of nid002206\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 49/256 of nid002206\n
Running 2 4-thread MPI processes also goes without problems. In this case we got the second and third task from the original allocation, likely because Slurm was still freeing up the first node after the previous srun command.
+ srun --ntasks=4 --cpus-per-task=1 mpi_check\nsrun: Job 4268614 step creation temporarily disabled, retrying (Requested nodes are busy)\nsrun: Step created for job 4268614\n\nRunning 4 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/4 on cpu 36/256 of nid002154\n++ mpi_check: MPI rank 1/4 on cpu 36/256 of nid002195\n++ mpi_check: MPI rank 2/4 on cpu 46/256 of nid002206\n++ mpi_check: MPI rank 3/4 on cpu 0/256 of nid002476\n
Running 4 single threaded processes also goes without problems (but the fact that they are scheduled on 4 different nodes here is likely an artifact of the way we had to force to get more than one node as the small partition on LUMI was not very busy at that time).
+ srun --ntasks=16 --cpus-per-task=1 mpi_check\n\nRunning 16 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/16 on cpu 36/256 of nid002154\n++ mpi_check: MPI rank 1/16 on cpu 37/256 of nid002154\n++ mpi_check: MPI rank 2/16 on cpu 38/256 of nid002154\n++ mpi_check: MPI rank 3/16 on cpu 39/256 of nid002154\n++ mpi_check: MPI rank 4/16 on cpu 36/256 of nid002195\n++ mpi_check: MPI rank 5/16 on cpu 37/256 of nid002195\n++ mpi_check: MPI rank 6/16 on cpu 38/256 of nid002195\n++ mpi_check: MPI rank 7/16 on cpu 39/256 of nid002195\n++ mpi_check: MPI rank 8/16 on cpu 46/256 of nid002206\n++ mpi_check: MPI rank 9/16 on cpu 47/256 of nid002206\n++ mpi_check: MPI rank 10/16 on cpu 48/256 of nid002206\n++ mpi_check: MPI rank 11/16 on cpu 49/256 of nid002206\n++ mpi_check: MPI rank 12/16 on cpu 0/256 of nid002476\n++ mpi_check: MPI rank 13/16 on cpu 1/256 of nid002476\n++ mpi_check: MPI rank 14/16 on cpu 2/256 of nid002476\n++ mpi_check: MPI rank 15/16 on cpu 3/256 of nid002476\n
16 single threaded MPI processes also works without problems.
+ srun --ntasks=1 --cpus-per-task=16 omp_check\nsrun: Job step's --cpus-per-task value exceeds that of job (16 > 4). Job step may never run.\nsrun: Warning: can't run 1 processes on 4 nodes, setting nnodes to 1\nsrun: error: Unable to create step for job 4268614: More processors requested than permitted\n...\n
However, trying to run a single 16-thread process now fails. Slurm first warns us that it might fail, then tries and lets it fail.
"},{"location":"2day-next/06-Slurm/#the-job-environment","title":"The job environment","text":"On LUMI, sbatch, salloc and srun will all by default copy the environment in which they run to the job step they start (the batch job step for sbatch, an interactive job step for salloc and a regular job step for srun). For salloc this is normal behaviour as it also starts an interactive shell on the login nodes (and it cannot be changed with a command line parameter). For srun, any other behaviour would be a pain as each job step would need to set up an environment. But for sbatch this may be surprising to some as the environment on the login nodes may not be the best environment for the compute nodes. Indeed, we do recommend to reload, e.g., the LUMI modules to use software optimised specifically for the compute nodes or to have full support of ROCm.
It is possible to change this behaviour or to define extra environment variables with sbatch and srun using the command line option --export:
-
--export=NONE will start the job (step) in a clean environment. The environment will not be inherited, but Slurm will attempt to re-create the user environment even if no login shell is called or used in the batch script. (--export=NIL would give you a truly empty environment.)
-
To define extra environment variables, use --export=ALL,VAR1=VALUE1 which would pass all existing environment variables and define a new one, VAR1, with the value VALUE1. It is of course also possible to define more environment variables using a comma-separated list (without spaces). With sbatch, specifying --export on the command line that way is a way to parameterise a batch script. With srun it can be very useful with heterogeneous jobs if different parts of the job need a different setting for an environment variable (e.g., OMP_NUM_THREADS).
Note however that ALL in the above --export option is essential as otherwise only the environment variable VAR1 would be defined.
It is in fact possible to pass only select environment variables by listing them without assigning a new value and omitting the ALL but we see no practical use of that on LUMI as the list of environment variables that is needed to have a job script in which you can work more or less normally is rather long.
Passing argumetns to a batch script
With the Slurm sbatch command, any argument passed after the name of the job script is passed to the job script as an argument, so you can use regular bash shell argument processing to pass arguments to the bash script and do not necessarily need to use --export. Consider the following job script to demonstrate both options:
! /usr/bin/bash\n#SBATCH --job-name=slurm-small-parameters\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n\necho \"Batch script parameter 0: $0\"\necho \"Batch script parameter 1: $1\"\necho \"Environment variable PAR1: $PAR1\"\n
Now start this with (assuming the job script is saved as slurm-small-parameters.slurm)
$ sbatch --export=ALL,PAR1=\"Hello\" slurm-small-parameters.slurm 'Wow, this works!'\n
and check the output file when the job is completed:
Batch script parameter 0: /var/spool/slurmd/job4278998/slurm_script\nBatch script parameter 1: Wow, this works!\nEnvironment variable PAR1: Hello\n
You see that you do not get the path to the job script as it was submitted (which you may expect to be the value of $0). Instead the job script is buffered when you execute sbatch and started from a different directory. $1 works as expected, and PAR1 is also defined.
In fact, passing arguments through command line arguments of the bash script is a more robust mechanism than using --export as can be seen from the bug discussed below...
Fragile behaviour of --export
One of the problems with --export is that you cannot really assign any variable to a new environment variable the way you would do it on the bash command line. It is not clear what internal processing is going on, but the value is not always what you would expect. In particular, problems can be expected when the value of the variable contains a semicolon.
E.g., try the command from the previous example with --export=ALL,PAR1='Hello, world' and it turns out that only Hello is passed as the value of the variable.
"},{"location":"2day-next/06-Slurm/#automatic-requeueing","title":"Automatic requeueing","text":"LUMI has the Slurm automatic requeueing of jobs upon node failure enabled. So jobs will be automatically resubmitted when one of the allocated nodes fails. For this an identical job ID is used and by default the prefious output will be truncated when the requeueed job starts.
There are some options to influence this behaviour:
-
Automatic requeueing can be disabled at job submission with the --no-requeue option of the sbatch command.
-
Truncating of the output files can be avoided by specifying --open-mode=append.
-
It is also possible to detect in a job script if a job has been restarted or not. For this Slurm sets the environment variable SLURM_RESTART_COUNT which is 0 the first time a job script runs and augmented by one at every restart.
"},{"location":"2day-next/06-Slurm/#job-dependencies","title":"Job dependencies","text":"The maximum wall time that a job can run on LUMI is fairly long for a Tier-0 system. Many other big systems in Europe will only allow a maximum wall time of 24 hours. Despite this, this is not yet enough for some users. One way to deal with this is ensure that programs end in time and write the necessary restart information in a file, then start a new job that continues from that file.
You don't have to wait to submit that second job. Instead, it is possible to tell Slurm that the second job should not start before the first one has ended (and ended successfully). This is done through job dependencies. It would take us too far to discuss all possible cases in this tutorial.
One example is
$ sbatch --dependency=afterok:<jobID> jobdepend.slurm \n
With this statement, the job defined by the job script jobdpend.slurm will not start until the job with the given jobID has ended successfully (and you may have to clean up the queue if it never ends successfully). But there are other possibilities also, e.g., start another job after a list of jobs has ended, or after a job has failed. We refer to the sbatch manual page where you should look for --dependency on the page.
It is also possible to automate the process of submitting a chain of dependent jobs. For this the sbatch flag --parsable can be used which on LUMI will only print the job number of the job being submitted. So to let the job defined by jobdepend.slurm run after the job defined by jobfirst.slurm while submitting both at the same time, you can use something like
first=$(sbatch --parsable jobfirst.slurm)\nsbatch --dependency=afterok:$first jobdepend.slurm\n
"},{"location":"2day-next/06-Slurm/#interactive-jobs","title":"Interactive jobs","text":"Interactive jobs can have several goals, e.g.,
-
Simply testing a code or steps to take to get a code to run while developing a job script. In this case you will likely want an allocation in which you can also easily run parallel MPI jobs.
-
Compiling a code usually works better interactively, but here you only need an allocation for a single task supporting multiple cores if your code supports a parallel build process. Building on the compute nodes is needed if architecture-specific optimisations are desired while the code building process does not support cross-compiling (e.g., because the build process adds -march=native or a similar compiler switch even if it is told not to do so) or ie you want to compile software for the GPUs that during the configure or build process needs a GPU to be present in the node to detect its features.
-
Attaching to a running job to inspect how it is doing.
"},{"location":"2day-next/06-Slurm/#interactive-jobs-with-salloc","title":"Interactive jobs with salloc","text":"This is a very good way of working for the first scenario described above.
Using salloc will create a pool of resources reserved for interactive execution, and will start a new shell on the node where you called salloc(usually a login node). As such it does not take resources away from other job steps that you will create so the shell is a good environment to test most stuff that you would execute in the batch job step of a job script.
To execute any code on one of the allocated compute nodes, be it a large sequential program, a shared memory program, distributed memory program or hybrid code, you can use srun in the same way as we have discussed for job scripts.
It is possible to obtain an interactive shell on the first allocated compute node with
srun --pty $SHELL\n
(which if nothing more is specified would give you a single core for the shell), but keep in mind that this takes away resources from other job steps so if you try to start further job steps from that interactive shell you will note that you have fewer resources available, and will have to force overlap (with --overlap), so it is not very practical to work that way.
To terminate the allocation, simply exit the shell that was created by salloc with exit or the CTRL-D key combination (and the same holds for the interactive shell in the previous paragraph).
Example with salloc and a GPU code (click to expand) $ salloc --account=project_46YXXXXXX --partition=standard-g --nodes=2 --time=15\nsalloc: Pending job allocation 4292946\nsalloc: job 4292946 queued and waiting for resources\nsalloc: job 4292946 has been allocated resources\nsalloc: Granted job allocation 4292946\n$ module load LUMI/22.12 partition/G lumi-CPEtools/1.1-cpeCray-22.12\n\n...\n\n$ srun -n 16 -c 2 --gpus-per-task 1 gpu_check\nMPI 000 - OMP 000 - HWT 001 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 000 - OMP 001 - HWT 002 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 001 - OMP 000 - HWT 003 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 001 - OMP 001 - HWT 004 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 002 - OMP 000 - HWT 005 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 002 - OMP 001 - HWT 006 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 003 - OMP 000 - HWT 007 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 003 - OMP 001 - HWT 008 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 004 - OMP 000 - HWT 009 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 004 - OMP 001 - HWT 010 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 005 - OMP 000 - HWT 011 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 005 - OMP 001 - HWT 012 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 006 - OMP 000 - HWT 013 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 006 - OMP 001 - HWT 014 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 007 - OMP 000 - HWT 015 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 007 - OMP 001 - HWT 016 - Node nid005191 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 008 - OMP 000 - HWT 001 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 008 - OMP 001 - HWT 002 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 009 - OMP 000 - HWT 003 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 009 - OMP 001 - HWT 004 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 010 - OMP 000 - HWT 005 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 010 - OMP 001 - HWT 006 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 011 - OMP 000 - HWT 007 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 011 - OMP 001 - HWT 008 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\nMPI 012 - OMP 000 - HWT 009 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 012 - OMP 001 - HWT 010 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1\nMPI 013 - OMP 000 - HWT 011 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 013 - OMP 001 - HWT 012 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6\nMPI 014 - OMP 000 - HWT 013 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 014 - OMP 001 - HWT 014 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9\nMPI 015 - OMP 000 - HWT 015 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\nMPI 015 - OMP 001 - HWT 016 - Node nid005192 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc\n
"},{"location":"2day-next/06-Slurm/#interactive-jobs-with-srun","title":"Interactive jobs with srun","text":"Starting an interactive job with srun is good to get an interactive shell in which you want to do some work without starting further job steps, e.g., for compilation on the compute nodes or to run an interactive shared memory program such as R. It is not ideal if you want to spawn further job steps with srun within the same allocation as the interactive shell already fills a task slot, so you'd have to overlap if you want to use all resources of the job in the next job step.
For this kind of work you'll rarely need a whole node so small, small-g, debug or dev-g will likely be your partitions of choice.
To start such a job, you'd use
srun --account=project_46YXXXXXX --partition=<partition> --ntasks=1 --cpus-per-task=<number> --time=<time> --pty=$SHELL\n
or with the short options
srun -A project_46YXXXXXX -p <partition> -n 1 -c <number> -t <time> --pty $SHELL\n
For the GPU nodes you'd also add a --gpus-per-task=<number> to request a number of GPUs.
To end the interactive job, all you need to do is to leave the shell with exit or the CTRL-D key combination.
"},{"location":"2day-next/06-Slurm/#inspecting-a-running-job","title":"Inspecting a running job","text":"On LUMI it is not possible to use ssh to log on to a compute node in use by one of your jobs. Instead you need to use Slurm to attach a shell to an already running job. This can be done with srun, but there are two differences with the previous scenario. First, you do not need a new allocation but need to tell srun to use an existing allocation. As there is already an allocation, srun does not need your project account in this case. Second, usually the job will be using all its resources so there is no room in the allocation to create another job step with the interactive shell. This is solved by telling srun that the resources should overlap with those already in use.
To start an interactive shell on the first allocated node of a specific job/allocation, use
srun --jobid=<jobID> --overlap --pty $SHELL\n
and to start an interactive shell on another node of the jobm simply add a -w or --nodelist argument:
srun --jobid=<jobID> --nodelist=nid00XXXX --overlap --pty $SHELL\nsrun --jobid=<jobID> -w nid00XXXX --overlap --pty $SHELL\n
Instead of starting a shell, you could also just run a command, e.g., top, to inspect what the nodes are doing.
Note that you can find out the nodes allocated to your job using squeue (probably the easiest as the nodes are shown by default), sstat or salloc.
"},{"location":"2day-next/06-Slurm/#job-arrays","title":"Job arrays","text":"Job arrays is a mechanism to submit a large number of related jobs with the same batch script in a single sbatch operation.
As an example, consider the job script job_array.slurm
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=1\n#SBATCH --mem-per-cpu=1G\n#SBATCH --time=15:00\n\nINPUT_FILE=\"input_${SLURM_ARRAY_TASK_ID}.dat\"\nOUTPUT_FILE=\"output_${SLURM_ARRAY_TASK_ID}.dat\"\n\n./test_set -input ${INPUT_FILE} -output ${OUTPUT_FILE}\n
Note that Slurm defines the environment variable SLURM_ARRAY_TASK_ID which will have a unique value for each job of the job array, varying in the range given at job submission. This enables to distinguish between the different runs and can be used to generate names of input and output files.
Submitting this job script and running it for values of SLURM_ARRAY_TASK_ID going from 1 to 50 could be done with
$ sbatch --array 1-50 job_array.slurm\n
Note that this will count for 50 Slurm jobs so the size of your array jobs on LUMI is limited by the rather strict limit on job size. LUMI is made as a system for big jobs, and is a system with a lot of users, and there are only that many simultaneous jobs that a scheduler can deal with. Users doing throughput computing should do some kind of hierarchical scheduling, running a subscheduler in the job that then further start subjobs.
"},{"location":"2day-next/06-Slurm/#heterogeneous-jobs","title":"Heterogeneous jobs","text":"A heterogeneous job is one in which multiple executables run in a single MPI_COMM_WORLD, or a single executable runs in different combinations (e.g., some multithreaded and some single-threaded MPI ranks where the latter take a different code path from the former and do a different task). One example is large simulation codes that use separate I/O servers to take care of the parallel I/O ot the file system.
There are two ways to start such a job:
-
Create groups in the SBATCH lines, separated by #SBATCH hetjob lines, and then recall these groups with srun. This is the most powerful mechanism as in principle one could use nodes in different partitions for different parts of the heterogeneous job.
-
Request the total number of nodes needed with the #SBATCH lines and then do the rest entirely with srun, when starting the heterogeneous job step. The different blocks in srun are separated by a colon. In this case we can only use a single partition.
The Slurm support for heterogeneous jobs is not very good and problems to often occur, or new bugs are being introduced.
-
The different parts of heterogeneous jobs in the first way of specifying them, are treated as different jobs which may give problems with the scheduling.
-
When using the srun method, these are still separate job steps and it looks like a second job is created internally to run these, and on a separate set of nodes.
Let's show with an example (worked out more in the text than in the slides) Consider the following case of a 2-component job:
We will simulate this case with the hybrid_check program from the lumi-CPEtools module that we have used in earlier examples also.
The job script for the first method would look like:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-sbatch\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --ntasks-per-node=32\n#SBATCH --cpus-per-task=4\n#SBATCH hetjob\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --ntasks-per-node=4\n#SBATCH --cpus-per-task=32\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --het-group=0 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_0 --export=ALL,OMP_NUM_THREADS=4 hybrid_check -l app_A : \\\n --het-group=1 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_1 --export=ALL,OMP_NUM_THREADS=32 hybrid_check -l app_B\n\nsrun --het-group=0 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_0 hybrid_check -l hybrid_check -l app_A : \\\n --het-group=1 --cpus-per-task=$SLURM_CPUS_PER_TASK_HET_GROUP_1 hybrid_check -l hybrid_check -l app_B\n\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
There is a single srun command. --het-group=0 tells srun to pick up the settings for the first heterogeneous group (before the #SBATCH hetjob line), and use that to start the hybrid_check program with the command line arguments -l app_A. Next we have the column to tell srun that we start with the second group, which is done in the same way. Note that since recent versions of Slurm do no longer propagate the value for --cpus-per-task, we need to specify the value here explicitly which we can do via an environment variable. This is one of the cases where the patch to work around this new behaviour on LUMI does not work.
This job script shows also demonstrates how a different value of a variable can be passed to each component using --export, even though this was not needed as the second case would show.
The output of this job script would look lik (with a lot omitted):
srun: Job step's --cpus-per-task value exceeds that of job (32 > 4). Job step may never run.\n\nRunning 40 MPI ranks with between 4 and 32 threads each (total number of threads: 384).\n\n++ app_A: MPI rank 0/40 OpenMP thread 0/4 on cpu 0/256 of nid001083\n++ app_A: MPI rank 0/40 OpenMP thread 1/4 on cpu 1/256 of nid001083\n...\n++ app_A: MPI rank 31/40 OpenMP thread 2/4 on cpu 126/256 of nid001083\n++ app_A: MPI rank 31/40 OpenMP thread 3/4 on cpu 127/256 of nid001083\n++ app_B: MPI rank 32/40 OpenMP thread 0/32 on cpu 0/256 of nid001544\n++ app_B: MPI rank 32/40 OpenMP thread 1/32 on cpu 1/256 of nid001544\n...\n++ app_B: MPI rank 35/40 OpenMP thread 30/32 on cpu 126/256 of nid001544\n++ app_B: MPI rank 35/40 OpenMP thread 31/32 on cpu 127/256 of nid001544\n++ app_B: MPI rank 36/40 OpenMP thread 0/32 on cpu 0/256 of nid001545\n++ app_B: MPI rank 36/40 OpenMP thread 1/32 on cpu 1/256 of nid001545\n...\n++ app_B: MPI rank 39/40 OpenMP thread 30/32 on cpu 126/256 of nid001545\n++ app_B: MPI rank 39/40 OpenMP thread 31/32 on cpu 127/256 of nid001545\n... (second run produces identical output)\n\nsacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4285795+0 slurm-her+ standard project_4+ 256 RUNNING 0:0 \n4285795+0.b+ batch project_4+ 256 RUNNING 0:0 \n4285795+0.0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4285795+0.1 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4285795+1 slurm-her+ standard project_4+ 512 RUNNING 0:0 \n4285795+1.0 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n4285795+1.1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n
The warning at the start can be safely ignored. It just shows how heterogeneous job were an afterthought in Slurm and likely implemented in a very dirty way. We see that we get what we expected: 32 MPI ranks on the first node of the allocation, then 4 on each of the other two nodes.
The output of sacct is somewhat surprising. Slurm has essnetially started two jobs, with jobIDs that end with +0 and +1, and it first shows all job steps for the first job, which is the batch job step and the first group of both srun commands, and then shows the second job and its job steps, again indicating that heterogeneous jobs are not really treated as a single job.
The same example can also be done by just allocating 3 nodes and then using more arguments with srun to start the application:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-srun\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=3\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --ntasks=32 --cpus-per-task=4 --export=ALL,OMP_NUM_THREADS=4 hybrid_check -l app_A : \\\n --ntasks=8 --cpus-per-task=32 --export=ALL,OMP_NUM_THREADS=32 hybrid_check -l app_B\n\nsrun --ntasks=32 --cpus-per-task=4 hybrid_check -l app_A : \\\n --ntasks=8 --cpus-per-task=32 hybrid_check -l app_B\n\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID)\\n\"\n
The output of the two srun commands is essentially the same as before, but the output of sacct is different:
sacct for the job:\nJobID JobName Partition Account AllocCPUS State ExitCode \n------------ ---------- ---------- ---------- ---------- ---------- -------- \n4284021 slurm-her+ standard project_4+ 768 RUNNING 0:0 \n4284021.bat+ batch project_4+ 256 RUNNING 0:0 \n4284021.0+0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4284021.0+1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n4284021.1+0 hybrid_ch+ project_4+ 256 COMPLETED 0:0 \n4284021.1+1 hybrid_ch+ project_4+ 512 COMPLETED 0:0 \n
We now get a single job ID but the job step for each of the srun commands is split in two separate job steps, a +0 and a +1.
Erratic behaviour of --nnodes=<X> --ntasks-per-node=<Y>
One can wonder if in the second case we could still specify resources on a per-node basis in the srun command:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-herterogeneous-srun\n#SBATCH --time=5:00\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=3\n\nmodule load LUMI/22.12 partition/C lumi-CPEtools/1.1-cpeCray-22.12\n\nsrun --nodes=1 --ntasks-per-node=32 --cpus-per-task=4 hybrid_check -l hybrid_check -l app_A : \\\n --nodes=2 --ntasks-per-node=4 --cpus-per-task=32 hybrid_check -l hybrid_check -l app_B\n
It turns out that this does not work at all. Both components get the wrong number of tasks. For some reason only 3 copies were started of the first application on the first node of the allocation, the 2 32-thread processes on the second node and one 32-thread process on the third node, also with an unexpected thread distribution.
This shows that before starting a big application it may make sense to check with the tools from the lumi-CPEtools module if the allocation would be what you expect as Slurm is definitely not free of problems when it comes to hetereogeneous jobs.
"},{"location":"2day-next/06-Slurm/#simultaneous-job-steps","title":"Simultaneous job steps","text":"It is possible to run multiple job steps in parallel on LUMI. The core of your job script would look something like:
#! /usr/bin/bash\n...\n#SBATCH partition=standard\n...\nsrun -n4 -c16 exe1 &\nsleep 2\nsrun -n8 -c8 exe2 &\nwait\n
The first srun statement will start a hybrid job of 4 tasks with 16 cores each on the first 64 cores of the node, the second srun statement would start a hybrid job of 8 tasks with 8 cores each on the remaining 64 cores. The sleep 2 statement is used because we have experienced that from time to time even though the second srun statement cannot be executed immediately as the resource manager is busy with the first one. The wait command at the end is essential, as otherwise the batch job step would end without waiting for the two srun commands to finish the work they started, and the whole job would be killed.
Running multiple job steps in parallel in a single job can be useful if you want to ensure a proper binding and hence do not want to use the \"allocate by resources\" partition, while a single job step is not enough to fill an exclusive node. It does turn out to be tricky though, especially when GPU nodes are being used, and with proper binding of the resources. In some cases the --overlap parameter of srun may help a bit. (And some have reported that in some cases --exact is needed instead, but this parameter is already implied if --cpus-per-task can be used.)
Note that we have observed unexpected behaviour when using this on nodes that were not job-exclusive, likely caused by Slurm bugs. It also doesn't make much sense to use this feature in that case. The main reason to use it, is to be able to do proper mapping/binding of resources even when a single job step cannot fill a whole node. In other cases it may simply be easier to have multiple jobs, one for each job step that you would run simultaneously.
A longer example Consider the bash job script for an exclusive CPU node:
#! /usr/bin/bash\n#SBATCH --job-name=slurm-simultaneous-CPU-1\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=2:00\n#SBATCH --output %x-%j.txt\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\necho \"Submitted from $SLURM_SUBMIT_HOST\"\necho \"Running on $SLURM_JOB_NODELIST\"\necho\necho -e \"Job script:\\n$(cat $0)\\n\"\necho \"SLURM_* environment variables:\"\nenv | egrep ^SLURM\n\nfor i in $(seq 0 7)\ndo \n srun --ntasks=1 --cpus-per-task=16 --output=\"slurm-simultaneous-CPU-1-$SLURM_JOB_ID-$i.txt\" \\\n bash -c \"export ROCR_VISIBLE_DEVICES=${GPU_BIND[$i]} && omp_check -w 30\" &\n\n sleep 2\ndone\n\nwait\n\nsleep 2\necho -e \"\\nsacct for the job:\\n$(sacct -j $SLURM_JOB_ID --format JobID%-13,Start,End,AllocCPUS,NCPUS,TotalCPU,MaxRSS --units=M )\\n\"\n
It will start 8 parallel job steps and in total create 9 files: One file with the output of the job script itself, and then one file for each job step with the output specific to that job step. the sacct command at the end shows that the 8 job parallel job steps indeed overlap, as can be seen from the start and end time of each, with the TotalCPU column confirming that they are also consuming CPU time during that time. The last bit of the output of the main batch file looks like:
sacct for the job:\nJobID Start End AllocCPUS NCPUS TotalCPU MaxRSS \n------------- ------------------- ------------------- ---------- ---------- ---------- ---------- \n6849913 2024-04-09T16:15:45 Unknown 256 256 01:04:07 \n6849913.batch 2024-04-09T16:15:45 Unknown 256 256 00:00:00 \n6849913.0 2024-04-09T16:15:54 2024-04-09T16:16:25 32 32 08:00.834 6.92M \n6849913.1 2024-04-09T16:15:56 2024-04-09T16:16:26 32 32 08:00.854 6.98M \n6849913.2 2024-04-09T16:15:58 2024-04-09T16:16:29 32 32 08:00.859 6.76M \n6849913.3 2024-04-09T16:16:00 2024-04-09T16:16:30 32 32 08:00.793 6.76M \n6849913.4 2024-04-09T16:16:02 2024-04-09T16:16:33 32 32 08:00.870 6.59M \n6849913.5 2024-04-09T16:16:04 2024-04-09T16:16:34 32 32 08:01.046 8.57M \n6849913.6 2024-04-09T16:16:06 2024-04-09T16:16:36 32 32 08:01.133 6.76M \n6849913.7 2024-04-09T16:16:08 2024-04-09T16:16:39 32 32 08:00.793 6.57M \n
Obviously as we execute the sacct command in the job the end time of the batch job step and hence the job as a whole are still unknown. We ask omp_check to do some computations during 30 seconds on each thread, and so we see that the CPU time consumed by each 16-core job is indeed around 8 minutes, while start and end time of each job step showed that they executed for roughly 30s each and nicely overlapped.
"},{"location":"2day-next/06-Slurm/#slurm-job-monitoring-commands","title":"Slurm job monitoring commands","text":"Slurm has two useful commands to monitor jobs that we want to discuss a bit further:
-
sstat is a command to monitor jobs that are currently running. It gets its information directly from the resource manager component of Slurm.
-
sacct is a command to get information about terminated jobs. It gets its information from the Slurm accounting database. As that database is not continuously updated, information about running jobs may already be present but is far from real-time.
Some users may also be familiar with the sreport command, but it is of limited use on LUMI.
"},{"location":"2day-next/06-Slurm/#the-sstat-command","title":"The sstat command","text":"The sstat command is a command to get real-time information about a running job. That information is obtained from the resource manager components in Slurm and not from the accounting database. The command can only produce information about job steps that are currently being executed and cannot be used to get information about jobs tha thave already been terminated, or job steps that have terminated from jobs that are still running.
In its most simple form, you'd likely use the -j (or --jobs) flag to specify the job for which you want information:
sstat -j 1234567\n
and you may like to add the -a flag to get information about all job steps for which information is available. You can also restrict to a single job step, e.g.,
sstat -j 1234567.0\n
The command produces a lot of output though and it is nearly impossible to interpret the output, even on a very wide monitor.
To restrict that output to something that can actually be handled, you can use the -o or --format flag to specify the columns that you want to see.
E.g., the following variant would show for each job step the minimum amount of CPU time that a task has consumed, and the average across all tasks. These numbers should be fairly close if the job has a good load balance.
$ sstat -a -j 1234567 -o JobID,MinCPU,AveCPU\nJobID MinCPU AveCPU\n------------ ---------- ----------\n1234567.bat+ 00:00:00 00:00:00\n1234567.1 00:23:44 00:26:02\n
The above output is from an MPI job that has two job steps in it. The first step was a quick initialisation step and that one has terminated already, so we get no information about that step. The 1234567.1 step is the currently executing one, and we do note a slight load inbalance in this case. No measurable amount of time has been consumed running the batch script itself outside the srun commands in this case.
It can also be used to monitor memory use of the application. E.g.,
$ sstat -a -j 1234567 -o JobID,MaxRSS,MaxRSSTask,MaxRSSNode\nJobID MaxRSS MaxRSSTask MaxRSSNode\n------------ ---------- ---------- ----------\n1234567.bat+ 25500K 0 nid001522\n1234567.1 153556K 0 nid001522\n
will show the maximum amount of resident memory used by any of the tasks, and also tell you which task that is and on which node it is running.
You can get a list of output fields using sstat -e or sstat --helpformat. Or check the \"Job Status Fields\" section in the sstat manual page. That page also contains further examples.
"},{"location":"2day-next/06-Slurm/#the-sacct-command","title":"The sacct command","text":"The sacct command shows information kept in the Slurm job accounting database. Its main use is to extract information about jobs or job steps that have already terminated. It will however also provide information about running jobs and job steps, but that information if not real-time and only pushed periodically to the accounting database.
If you know the job ID of the job you want to investigate, you can specify it directly using the -j or --jobs flag. E.g.,
$ sacct -j 1234567\nJobID JobName Partition Account AllocCPUS State ExitCode\n------------ ---------- ---------- ---------- ---------- ---------- --------\n1234567 healthy_u+ standard project_4+ 512 COMPLETED 0:0\n1234567.bat+ batch project_4+ 256 COMPLETED 0:0\n1234567.0 gmx_mpi_d project_4+ 2 COMPLETED 0:0\n1234567.1 gmx_mpi_d project_4+ 512 COMPLETED 0:0\n
This report is for a GROMACS job that ran on two nodes. The first line gives the data for the overall job. The second line is for the batch job step that ran the batch script. That job got access to all resources on the first node of the job which is why 256 is shown in the AllocCPUS column (as that data is reported using the number of virtual cores). Job step .0 was really an initialisation step that ran as a single task on a single physical core of the node, while the .1 step was running on both nodes (as 256 tasks each on a physical core but that again cannot be directly derived from the output shown here).
You can also change the amount of output that is shown using either --brief (which will show a lot less) or --long (which shows an unwieldly amount of information similar to sstat), and just as with sstat, the information can be fully customised using -o or --format, but as there is a lot more information in the accounting database, the format options are different.
As an example, let's check the CPU time and memory used by a job:
$ sacct -j 1234567 --format JobID%-13,AllocCPUS,MinCPU%15,AveCPU%15,MaxRSS,AveRSS --units=M\nJobID AllocCPUS MinCPU AveCPU MaxRSS AveRSS\n------------- ---------- --------------- --------------- ---------- ----------\n1234567 512\n1234567.batch 256 00:00:00 00:00:00 25.88M 25.88M\n1234567.0 2 00:00:00 00:00:00 5.05M 5.05M\n1234567.1 512 01:20:02 01:26:19 173.08M 135.27M\n
This is again the two node MPI job that we've used in the previous example. We used --units=M to get the memory use per task in megabytes, which is the proper option here as tasks are relatively small (but not uncommonly small for an HPC system when a properly scaling code is used). The %15 is used to specify the width of the field as otherwise some of that information could be truncated (and the width of 15 would have been needed if this were a shared memory program or a program that ran for longer than a day). By default, specifying the field width will right justify the information in the columns. The %-13 tells to use a field width of 13 and to left-justify the data in that column.
You can get a list of output fields using sacct -e or sacct --helpformat. Or check the \"Job Accounting Fields\" section in the sacct manual page. That page also contains further examples.
Using sacct is a bit harder if you don't have the job ID of the job for which you want information. You can run sacct without any arguments, and in that case it will produce output for your jobs that have run since midnight. It is also possible to define the start time (with -S or --starttime) and the end time (with -E or --endtime) of the time window for which job data should be shown, and there are even more features to filter jobs, though some of them are really more useful for administrators.
This is only a very brief introduction to sacct, basically so that you know that it exists and what its main purpose is. But you can find more information in the sacct manual page
"},{"location":"2day-next/06-Slurm/#the-sreport-command","title":"The sreport command","text":"The sreport command is a command to create summary reports from data in the Slurm accounting database. Its main use is to track consumed resources in a project.
On LUMI it is of little use as as the billing is not done by Slurm but by a script that runs outside of Slurm that uses data from the Slurm accounting database. That data is gathered in a different database though with no direct user access, and only some summary reports are brought back to the system (and used by the lumi-workspaces command and some other tools for user and project monitoring). So the correct billing information is not available in the Slurm accounting database, nor can it be easily derived from data in the summary reports as the billing is more complicated than some billing for individual elements such as core use, memory use and accelerator use. E.g., one can get summary reports mentioning the amount of core hours used per user for a project, but that is reported for all partitions together and hence irrelevant to get an idea of how the CPU billing units were consumed.
This section is mostly to discourage you to use sreport as its information is often misleading and certainly it it is used to follow up your use of billing units on LUMI, but should you insist, there is more information in the sreport manual page.
"},{"location":"2day-next/06-Slurm/#other-trainings-and-materials","title":"Other trainings and materials","text":" - DeiC, the Danish organisation in the LUMI consortium, has develop an online Slurm tutorial
"},{"location":"2day-next/07-Binding/","title":"Process and Thread Distribution and Binding","text":""},{"location":"2day-next/07-Binding/#what-are-we-talking-about-in-this-session","title":"What are we talking about in this session?","text":"Distribution is the process of distributing processes and threads across the available resources of the job (nodes, sockets, NUMA nodes, cores, ...), and binding is the process of ensuring they stay there as naturally processes and threads are only bound to a node (OS image) but will migrate between cores. Binding can also ensure that processes cannot use resources they shouldn't use.
When running a distributed memory program, the process starter - mpirun or mpiexec on many clusters, or srun on LUMI - will distribute the processes over the available nodes. Within a node, it is possible to pin or attach processes or even individual threads in processes to one or more cores (actually hardware threads) and other resources, which is called process binding.
The system software (Linux, ROCmTM and Slurm) has several mechanisms for that. Slurm uses Linux cgroups or control groups to limit the resources that a job can use within a node and thus to isolate jobs from one another on a node so that one job cannot deplete the resources of another job, and sometimes even uses control groups at the task level to restrict some resources for a task (currently when doing task-level GPU binding via Slurm). The second mechanism is processor affinity which works at the process and thread level and is used by Slurm at the task level and can be used by the OpenMP runtime to further limit thread migration. It works through affinity masks which indicate the hardware threads that a thread or process can use. There is also a third mechanism provided by the ROCmTM runtime to control which GPUs can be used.
Some of the tools in the lumi-CPEtools module can show the affinity mask for each thread (or effectively the process for single-threaded processes) so you can use these tools to study the affinity masks and check the distribution and binding of processes and threads. The serial_check, omp_check, mpi_check and hybrid_check programs can be used to study thread binding. In fact, hybrid_check can be used in all cases, but the other three show more compact output for serial, shared memory OpenMP and single-threaded MPI processes respectively. The gpu_check command can be used to study the steps in GPU binding.
Credits for these programs The hybrid_check program and its derivatives serial_check, omp_check and mpi_check are similar to the xthi program used in the 4-day comprehensive LUMI course organised by the LUST in collaboration with HPE Cray and AMD. Its main source of inspiration is a very similar program, acheck, written by Harvey Richardson of HPE Cray and used in an earlier course, but it is a complete rewrite of that application.
One of the advantages of hybrid_check and its derivatives is that the output is sorted internally already and hence is more readable. The tool also has various extensions, e.g., putting some load on the CPU cores so that you can in some cases demonstrate thread migration as the Linux scheduler tries to distribute the load in a good way.
The gpu_check program builds upon the hello_jobstep program from ORNL with several extensions implemented by the LUST.
(ORNL is the national lab that operates Frontier, an exascale supercomputer based on the same node type as LUMI-G.)
In this section we will consider process and thread distribution and binding at several levels:
-
When creating an allocation, Slurm will already reserve resources at the node level, but this has been discussed already in the Slurm session of the course.
It will also already employ control groups to restrict the access to those reaources on a per-node per-job basis.
-
When creating a job step, Slurm will distribute the tasks over the available resources, bind them to CPUs and depending on how the job step was started, bind them to a subset of the GPUs available to the task on the node it is running on.
-
With Cray MPICH, you can change the binding between MPI ranks and Slurm tasks. Normally MPI rank i would be assigned to task i in the job step, but sometimes there are reasons to change this. The mapping options offered by Cray MPICH are more powerful than what can be obtained with the options to change the task distribution in Slurm.
-
The OpenMP runtime also uses library calls and environment variables to redistribute and pin threads within the subset of hardware threads available to the process. Note that different compilers use different OpenMP runtimes so the default behaviour will not be the same for all compilers, and on LUMI is different for the Cray compiler compared to the GNU and AMD compilers.
-
Finally, the ROCm runtime also can limit the use of GPUs by a process to a subset of the ones that are available to the process through the use of the ROCR_VISIBLE_DEVICES environment variable.
Binding almost only makes sense on job-exclusive nodes as only then you have full control over all available resources. On \"allocatable by resources\" partitions you usually do not know which resources are available. The advanced Slurm binding options that we will discuss do not work in those cases, and the options offered by the MPICH, OpenMP and ROCm runtimes may work very unpredictable, though OpenMP thread binding may still help a bit with performance in some cases.
Warning
Note also that some srun options that we have seen (sometimes already given at the sbatch or salloc level but picket up by srun) already do a simple binding, so those options cannot be combined with the options that we will discuss in this session. This is the case for --cpus-per-task, --gpus-per-task and --ntasks-per-gpu. In fact, the latter two options will also change the numbering of the GPUs visible to the ROCm runtime, so using ROCR_VISIBLE_DEVICES may also lead to surprises!
"},{"location":"2day-next/07-Binding/#why-do-i-need-this","title":"Why do I need this?","text":"As we have seen in the \"LUMI Architecture\" session of this course and as you may know from other courses, modern supercomputer nodes have increasingly a very hierarchical architecture. This hierarchical architecture is extremely pronounced on the AMD EPYC architecture used in LUMI but is also increasingly showing up with Intel processors and the ARM server processors, and is also relevant but often ignored in GPU clusters.
A proper binding of resources to the application is becoming more and more essential for good performance and scalability on supercomputers.
-
Memory locality is very important, and even if an application would be written to take the NUMA character properly into account at the thread level, a bad mapping of these threads to the cores may result into threads having to access memory that is far away (with the worst case on a different socket) extensively.
Memory locality at the process level is easy as usually processes share little or no memory. So if you would have an MPI application where each rank needs 14 GB of memory and so only 16 ranks can run on a regular node, then it is essential to ensure that these ranks are spread out nicely over the whole node, with one rank per CCD. The default of Slurm when allocating 16 single-thread tasks on a node would be to put them all on the first two CCDs, so the first NUMA-domain, which would give very poor performance as a lot of memory accesses would have to go across sockets.
-
If threads in a process don't have sufficient memory locality it may be very important to run all threads in as few L3 cache domains as possible, ideally just one, as otherwise you risk having a lot of conflicts between the different L3 caches that require resolution and can slow down the process a lot.
This already shows that there is no single works-for-all solution, because if those threads would use all memory on a node and each have good memory locality then it would be better to spread them out as much possible. You really need to understand your application to do proper resource mapping, and the fact that it can be so application-dependent is also why Slurm and the various runtimes cannot take care of it automatically.
-
In some cases it is important on the GPU nodes to ensure that tasks are nicely spread out over CCDs with each task using the GPU (GCD) that is closest to the CCD the task is running on. This is certainly the case if the application would rely on cache-coherent access to GPU memory from the CPU.
-
With careful mapping of MPI ranks on nodes you can often reduce the amount of inter-node data transfer in favour of the faster intra-node transfers. This requires some understanding of the communication pattern of your MPI application.
-
For GPU-aware MPI: Check if the intra-node communication pattern can map onto the links between the GCDs.
"},{"location":"2day-next/07-Binding/#core-numbering","title":"Core numbering","text":"Linux core numbering is not hierarchical and may look a bit strange. This is because Linux core numbering was fixed before hardware threads were added, and later on hardware threads were simply added to the numbering scheme.
As is usual with computers, numbering starts from 0. Core 0 is the first hardware thread (or we could say the actual core) of the first core of the first CCD (CCD 0) of the first NUMA domain (NUMA domain 0) of the first socket (socket 0). Core 1 is then the first hardware thread of the second core of the same CCD, and so on, going over all cores in a CCD, then NUMA domain and then socket. So on LUMI-C, core 0 till 63 are on the first socket and core 64 till 127 on the second one. The numbering of the second hardware thread of each core - we could say the virtual core - then starts where the numbering of the actual cores ends, so 64 for LUMI-G (which has only one socket per node) or 128 for LUMI-C. This has the advantage that if hardware threading is turned off at the BIOS/UEFI level, the numbering of the actual cores does not change.
On LUMI G, core 0 and its second hardware thread 64 are reserved by the low noise mode and cannot be used by Slurm or applications. This is done to help reduce OS jitter which can kill scalability of large parallel applications. However, it also creates an assymetry that is hard to deal with. (For this reason they chose to disable the first core of every CCD on Frontier, so core 0, 8, 16, ... and corresponding hardware threads 64, 72, ..., but on LUMI this is not yet the case). Don't be surprised if when running a GPU code you see a lot of activity on core 0. It is caused by the ROCmTM driver and is precisely the reason why that core is reserved, as that activity would break scalability of applications that expect to have the same amount of available compute power on each core.
Note that even with --hint=nomultithread the hardware threads will still be turned on at the hardware level and be visible in the OS (e.g., in /proc/cpuinfo). In fact, the batch job step will use them, but they will not be used by applications in job steps started with subsequent srun commands.
Slurm under-the-hoods example We will use the Linux lstopo and taskset commands to study how a job step sees the system and how task affinity is used to manage the CPUs for a task. Consider the job script:
#!/bin/bash\n#SBATCH --job-name=cpu-numbering-demo1\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=small\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=16\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Output of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Taskset of current shell: \\$(taskset -p \\$\\$)\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\n\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\necho -e \"\\nFull lstopo output in the job:\\n$(lstopo -p)\\n\\n\"\necho -e \"Taskset of the current shell: $(taskset -p $$)\\n\"\n\necho \"Running two tasks on 4 cores each, extracting parts from lstopo output in each:\"\nsrun -n 2 -c 4 ./task_lstopo_$SLURM_JOB_ID\necho\ncat output-$SLURM_JOB_ID-0\necho\ncat output-$SLURM_JOB_ID-1\n\necho -e \"\\nRunning hybrid_check in the same configuration::\"\nsrun -n 2 -c 4 hybrid_check -r\n\n/bin/rm task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-0 output-$SLURM_JOB_ID-1\n
It creates a small test program that we will use to run lstopo and gather its output on two tasks with 4 cores each. All this is done in a job allocation with 16 cores on the small partition.
The results of this script will differ strongly between runs as Slurm can give different valid configurations for this request. Below is one possible output we got.
Let's first look at the output of the lstopo and taskset commands run in the batch job step:
Full lstopo output in the job:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n L2 P#108 (512KB) + L1d P#108 (32KB) + L1i P#108 (32KB) + Core P#44\n PU P#108\n PU P#236\n L2 P#109 (512KB) + L1d P#109 (32KB) + L1i P#109 (32KB) + Core P#45\n PU P#109\n PU P#237\n L2 P#110 (512KB) + L1d P#110 (32KB) + L1i P#110 (32KB) + Core P#46\n PU P#110\n PU P#238\n L2 P#111 (512KB) + L1d P#111 (32KB) + L1i P#111 (32KB) + Core P#47\n PU P#111\n PU P#239\n Group0\n NUMANode P#7 (31GB)\n L3 P#14 (32MB)\n L2 P#112 (512KB) + L1d P#112 (32KB) + L1i P#112 (32KB) + Core P#48\n PU P#112\n PU P#240\n L2 P#113 (512KB) + L1d P#113 (32KB) + L1i P#113 (32KB) + Core P#49\n PU P#113\n PU P#241\n L2 P#114 (512KB) + L1d P#114 (32KB) + L1i P#114 (32KB) + Core P#50\n PU P#114\n PU P#242\n L2 P#115 (512KB) + L1d P#115 (32KB) + L1i P#115 (32KB) + Core P#51\n PU P#115\n PU P#243\n\nTaskset of the current shell: pid 81788's current affinity mask: ffff0000000000000000000000000000ffff0000000000000000000000000\n
Note the way the cores are represented. There are 16 lines the lines L2 ... + L1d ... + L1i ... + Core ... that represent the 16 cores requested. We have used the -p option of lstopo to ensure that lstopo would show us the physical number as seen by the bare OS. The numbers indicated after each core are within the socket but the number indicated right after L2 is the global core numbering within the node as seen by the bare OS. The two PU lines (Processing Unit) after each core are correspond to the hardware threads and are also the numbers as seen by the bare OS.
We see that in this allocation the cores are not spread over the minimal number of L3 cache domains that would be possible, but across three domains. In this particular allocation the cores are still consecutive cores, but even that is not guaranteed in an \"Allocatable by resources\" partition. Despite --hint=nomultithread being the default behaviour, at this level we still see both hardware threads for each physical core in the taskset.
Next look at the output printed by lines 29 and 31:
Task 0\nOutput of lstopo:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n Group0\n NUMANode P#7 (31GB)\nTaskset of current shell: pid 82340's current affinity mask: f0000000000000000000000000\n\nTask 1\nOutput of lstopo:\nMachine (251GB total)\n Package P#0\n Group0\n NUMANode P#0 (31GB)\n Group0\n NUMANode P#1 (31GB)\n HostBridge\n PCIBridge\n PCI 41:00.0 (Ethernet)\n Net \"nmn0\"\n Group0\n NUMANode P#2 (31GB)\n HostBridge\n PCIBridge\n PCI 21:00.0 (Ethernet)\n Net \"hsn0\"\n Group0\n NUMANode P#3 (31GB)\n Package P#1\n Group0\n NUMANode P#4 (31GB)\n Group0\n NUMANode P#5 (31GB)\n Group0\n NUMANode P#6 (31GB)\n L3 P#12 (32MB)\n L2 P#100 (512KB) + L1d P#100 (32KB) + L1i P#100 (32KB) + Core P#36\n PU P#100\n PU P#228\n L2 P#101 (512KB) + L1d P#101 (32KB) + L1i P#101 (32KB) + Core P#37\n PU P#101\n PU P#229\n L2 P#102 (512KB) + L1d P#102 (32KB) + L1i P#102 (32KB) + Core P#38\n PU P#102\n PU P#230\n L2 P#103 (512KB) + L1d P#103 (32KB) + L1i P#103 (32KB) + Core P#39\n PU P#103\n PU P#231\n L3 P#13 (32MB)\n L2 P#104 (512KB) + L1d P#104 (32KB) + L1i P#104 (32KB) + Core P#40\n PU P#104\n PU P#232\n L2 P#105 (512KB) + L1d P#105 (32KB) + L1i P#105 (32KB) + Core P#41\n PU P#105\n PU P#233\n L2 P#106 (512KB) + L1d P#106 (32KB) + L1i P#106 (32KB) + Core P#42\n PU P#106\n PU P#234\n L2 P#107 (512KB) + L1d P#107 (32KB) + L1i P#107 (32KB) + Core P#43\n PU P#107\n PU P#235\n Group0\n NUMANode P#7 (31GB)\nTaskset of current shell: pid 82341's current affinity mask: f00000000000000000000000000\n
The output of lstopo -p is the same for both: we get the same 8 cores. This is because all cores for all tasks on a node are gathered in a single control group. Instead, affinity masks are used to ensure that both tasks of 4 threads are scheduled on different cores. If we have a look at booth taskset lines:
Taskset of current shell: pid 82340's current affinity mask: 0f0000000000000000000000000\nTaskset of current shell: pid 82341's current affinity mask: f00000000000000000000000000\n
we see that they are indeed different (a zero was added to the front of the first to make the difference clearer). The first task got cores 100 till 103 and the second task got cores 104 till 107. This also shows an important property: Tasksets are defined based on the bare OS numbering of the cores, not based on a numbering relative to the control group, with cores numbered from 0 to 15 in this example. It also implies that it is not possible to set a taskset manually without knowing which physical cores can be used!
The output of the srun command on line 34 confirms this:
Running 2 MPI ranks with 4 threads each (total number of threads: 8).\n\n++ hybrid_check: MPI rank 0/2 OpenMP thread 0/4 on cpu 101/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 1/4 on cpu 102/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 2/4 on cpu 103/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 0/2 OpenMP thread 3/4 on cpu 100/256 of nid002040 mask 100-103\n++ hybrid_check: MPI rank 1/2 OpenMP thread 0/4 on cpu 106/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 1/4 on cpu 107/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 2/4 on cpu 104/256 of nid002040 mask 104-107\n++ hybrid_check: MPI rank 1/2 OpenMP thread 3/4 on cpu 105/256 of nid002040 mask 104-107\n
Note however that this output will depend on the compiler used to compile hybrid_check. The Cray compiler will produce different output as it has a different default strategy for OpenMP threads and will by default pin each thread to a different hardware thread if possible.
"},{"location":"2day-next/07-Binding/#gpu-numbering","title":"GPU numbering","text":"The numbering of the GPUs is a very tricky thing on LUMI.
The only way to reliably identify the physical GPU is through the PCIe bus ID. This does not change over time or in an allocation where access to some resources is limited through cgroups. It is the same on all nodes.
Based on these PICe bus IDs, the OS will assign numbers to the GPU. It are those numbers that are shown in the figure in the Architecture chapter - \"Building LUMI: What a LUMI-G node really looks like\". We will call this the bare OS numbering or global numbering in these notes.
Slurm manages GPUs for jobs through the control group mechanism. Now if a job requesting 4 GPUs would get the GPUs that are numbered 4 to 7 in bare OS numbering, it would still see them as GPUs 0 to 3, and this is the numbering that one would have to use for the ROCR_VISIBLE_DEVICES environment variable that is used to further limit the GPUs that the ROCm runtime will use in an application. We will call this the job-local numbering.
Inside task of a regular job step, Slurm can further restrict the GPUs that are visible through control groups at the task level, leading to yet another numbering that starts from 0 which we will call the task-local numbering.
Note also that Slurm does take care of setting the ROCR_VISIBLE_DEVICES environment variable. It will be set at the start of a batch job step giving access to all GPUs that are available in the allocation, and will also be set by srun for each task. But you don't need to know in your application which numbers these are as, e.g., the HIP runtime will number the GPUs that are available from 0 on.
A more technical example demonstrating what Slurm does (click to expand) We will use the Linux lstopocommand and the ROCR_VISIBLE_DEVICES environment variable to study how a job step sees the system and how task affinity is used to manage the CPUs for a task. Consider the job script:
#!/bin/bash\n#SBATCH --job-name=gpu-numbering-demo1\n#SBATCH --output %x-%j.txt\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --partition=standard-g\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=15:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Relevant lines of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p | awk '/ PCI.*Display/ || /GPU/ || / Core / || /PU L/ {print \\$0}' >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"ROCR_VISIBLE_DEVICES: \\$ROCR_VISIBLE_DEVICES\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\necho -e \"\\nFull lstopo output in the job:\\n$(lstopo -p)\\n\\n\"\necho -e \"Extract GPU info:\\n$(lstopo -p | awk '/ PCI.*Display/ || /GPU/ {print $0}')\\n\" \necho \"ROCR_VISIBLE_DEVICES at the start of the job script: $ROCR_VISIBLE_DEVICES\"\n\necho \"Running two tasks with 4 GPUs each, extracting parts from lstopo output in each:\"\nsrun -n 2 -c 1 --gpus-per-task=4 ./task_lstopo_$SLURM_JOB_ID\necho\ncat output-$SLURM_JOB_ID-0\necho\ncat output-$SLURM_JOB_ID-1\n\necho -e \"\\nRunning gpu_check in the same configuration::\"\nsrun -n 2 -c 1 --gpus-per-task=4 gpu_check -l\n\n/bin/rm task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-0 output-$SLURM_JOB_ID-1\n
It creates a small test program that is run on two tasks and records some information on the system. The output is not sent to the screen directly as it could end up mixed between the tasks which is far from ideal.
Let's first have a look at the first lines of the lstopo -p output:
Full lstopo output in the job:\nMachine (503GB total) + Package P#0\n Group0\n NUMANode P#0 (125GB)\n L3 P#0 (32MB)\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n PU P#1\n PU P#65\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PU P#2\n PU P#66\n L2 P#3 (512KB) + L1d P#3 (32KB) + L1i P#3 (32KB) + Core P#3\n PU P#3\n PU P#67\n L2 P#4 (512KB) + L1d P#4 (32KB) + L1i P#4 (32KB) + Core P#4\n PU P#4\n PU P#68\n L2 P#5 (512KB) + L1d P#5 (32KB) + L1i P#5 (32KB) + Core P#5\n PU P#5\n PU P#69\n L2 P#6 (512KB) + L1d P#6 (32KB) + L1i P#6 (32KB) + Core P#6\n PU P#6\n PU P#70\n L2 P#7 (512KB) + L1d P#7 (32KB) + L1i P#7 (32KB) + Core P#7\n PU P#7\n PU P#71\n HostBridge\n PCIBridge\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi4\"\n L3 P#1 (32MB)\n L2 P#9 (512KB) + L1d P#9 (32KB) + L1i P#9 (32KB) + Core P#9\n PU P#9\n PU P#73\n L2 P#10 (512KB) + L1d P#10 (32KB) + L1i P#10 (32KB) + Core P#10\n PU P#10\n PU P#74\n L2 P#11 (512KB) + L1d P#11 (32KB) + L1i P#11 (32KB) + Core P#11\n PU P#11\n PU P#75\n L2 P#12 (512KB) + L1d P#12 (32KB) + L1i P#12 (32KB) + Core P#12\n PU P#12\n PU P#76\n L2 P#13 (512KB) + L1d P#13 (32KB) + L1i P#13 (32KB) + Core P#13\n PU P#13\n PU P#77\n L2 P#14 (512KB) + L1d P#14 (32KB) + L1i P#14 (32KB) + Core P#14\n PU P#14\n PU P#78\n L2 P#15 (512KB) + L1d P#15 (32KB) + L1i P#15 (32KB) + Core P#15\n PU P#15\n PU P#79\n HostBridge\n PCIBridge\n PCI d5:00.0 (Ethernet)\n Net \"hsn2\"\n PCIBridge\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi5\"\n HostBridge\n PCIBridge\n PCI 91:00.0 (Ethernet)\n Net \"nmn0\"\n...\n
We see only 7 cores in the each block (the lines L2 ... + L1d ... + L1i ... + Core ...) because the first physical core on each CCD is reserved for the OS.
The lstopo -p output also clearly suggests that each GCD has a special link to a particular CCD
Next check the output generated by lines 22 and 23 where we select the lines that show information about the GPUs and print some more information:
Extract GPU info:\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi4\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi5\"\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI d9:00.0 (Display)\n GPU(RSMI) \"rsmi6\"\n PCI de:00.0 (Display)\n GPU(RSMI) \"rsmi7\"\n PCI c1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI c6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n\nROCR_VISIBLE_DEVICES at the start of the job script: 0,1,2,3,4,5,6,7\n
All 8 GPUs are visible and note the numbering on each line below the line with the PCIe bus ID. We also notice that ROCR_VISIBLE_DEVICES was set by Slurm and includes all 8 GPUs.
Next we run two tasks requesting 4 GPUs and a single core without hardware threading each. The output of those two tasks is gathered in files that are then sent to the standard output in lines 28 and 30:
Task 0\nRelevant lines of lstopo:\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PCI d1:00.0 (Display)\n PCI d6:00.0 (Display)\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI d9:00.0 (Display)\n PCI de:00.0 (Display)\n PCI c1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI c6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\nROCR_VISIBLE_DEVICES: 0,1,2,3\n\nTask 1\nRelevant lines of lstopo:\n L2 P#1 (512KB) + L1d P#1 (32KB) + L1i P#1 (32KB) + Core P#1\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n PCI c9:00.0 (Display)\n PCI ce:00.0 (Display)\n PCI d9:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI de:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI c1:00.0 (Display)\n PCI c6:00.0 (Display)\nROCR_VISIBLE_DEVICES: 0,1,2,3\n
Each task sees GPUs named 'rsmi0' till 'rsmi3', but look better and you see that these are not the same. If you compare with the first output of lstopo which we ran in the batch job step, we notice that task 0 gets the first 4 GPUs in the node while task 1 gets the next 4, that were named rsmi4 till rsmi7 before. The other 4 GPUs are invisible in each of the tasks. Note also that in both tasks ROCR_VISIBLE_DEVICES has the same value 0,1,2,3 as the numbers detected by lstopo in that task are used.
The lstopo command does see two cores though for each task (but they are the same) because the cores are not isolated by cgroups on a per-task level, but on a per-job level.
Finally we have the output of the gpu_check command run in the same configuration. The -l option that was used prints some extra information that makes it easier to check the mapping: For the hardware threads it shows the CCD and for each GPU it shows the GCD number based on the physical order of the GPUs and the corresponding CCD that should be used for best performance:
MPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid005163 - RT_GPU_ID 0,1,2,3 - GPU_ID 0,1,2,3 - Bus_ID c1(GCD0/CCD6),c6(GCD1/CCD7),c9(GCD2/CCD2),cc(GCD3/CCD3)\nMPI 001 - OMP 000 - HWT 002 (CCD0) - Node nid005163 - RT_GPU_ID 0,1,2,3 - GPU_ID 0,1,2,3 - Bus_ID d1(GCD4/CCD0),d6(GCD5/CCD1),d9(GCD6/CCD4),dc(GCD7/CCD5)\n
RT_GPU_ID is the numbering of devices used in the program itself, GPU_ID is essentially the value of ROCR_VISIBLE_DEVICES, the logical numbers of the GPUs in the control group and Bus_ID shows the relevant part of the PCIe bus ID.
The above example is very technical and not suited for every reader. One important conclusion though that is of use when running on LUMI is that Slurm works differently with CPUs and GPUs on LUMI. Cores and GPUs are treated differently. Cores access is controlled by control groups at the job step level on each node and at the task level by affinity masks. The equivalent for GPUs would be to also use control groups at the job step level and then ROCR_VISIBLE_DEVICES to further set access to GPUs for each task, but this is not what is currently happening in Slurm on LUMI. Instead it is using control groups at the task level.
Playing with control group and ROCR_VISIBLE_DEVICES (click to expand) Consider the following (tricky and maybe not very realistic) job script.
#!/bin/bash\n#SBATCH --job-name=gpu-numbering-demo2\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --nodes=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_1gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_1gpu_$SLURM_JOB_ID\n\ncat << EOF > task_lstopo_$SLURM_JOB_ID\n#!/bin/bash\nsleep \\$((SLURM_LOCALID * 5))\necho \"Task \\$SLURM_LOCALID\" > output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"Relevant lines of lstopo:\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nlstopo -p | awk '/ PCI.*Display/ || /GPU/ || / Core / || /PU L/ {print \\$0}' >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\necho \"ROCR_VISIBLE_DEVICES: \\$ROCR_VISIBLE_DEVICES\" >> output-\\$SLURM_JOB_ID-\\$SLURM_LOCALID\nEOF\nchmod +x ./task_lstopo_$SLURM_JOB_ID\n\n# Start a background task to pick GPUs with global numbers 0 and 1\nsrun -n 1 -c 1 --gpus=2 sleep 60 &\nsleep 5\n\nset -x\nsrun -n 4 -c 1 --gpus=4 ./task_lstopo_$SLURM_JOB_ID\nset +x\n\ncat output-$SLURM_JOB_ID-0\n\nset -x\nsrun -n 4 -c 1 --gpus=4 ./select_1gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\nwait\n\n/bin/rm select_1gpu_$SLURM_JOB_ID task_lstopo_$SLURM_JOB_ID output-$SLURM_JOB_ID-*\n
We create two small programs that we will use in here. The first one is used to set ROCR_VISIBLE_DEVICES to the value of SLURM_LOCALID which is the local task number within a node of a Slurm task (so always numbered starting from 0 per node). We will use this to tell the gpu_check program that we will run which GPU should be used by which task. The second program is one we have seen before already and just shows some relevant output of lstopo to see which GPUs are in principle available to the task and then also prints the value of ROCR_VISIBLE_DEVICES. We did have to put in some task-dependent delay as it turns out that running multiple lstopo commands on a node together can cause problems.
The tricky bit is line 29. Here we start an srun command on the background that steals two GPUs. In this way, we ensure that the next srun command will not be able to get the GCDs 0 and 1 from the regular full-node numbering. The delay is again to ensure that the next srun works without conflicts as internally Slurm is still finishing steps from the first srun.
On line 33 we run our command that extracts info from lstopo. As we already know from the more technical example above the output will be the same for each task so in line 36 we only look at the output of the first task:
Relevant lines of lstopo:\n L2 P#2 (512KB) + L1d P#2 (32KB) + L1i P#2 (32KB) + Core P#2\n L2 P#3 (512KB) + L1d P#3 (32KB) + L1i P#3 (32KB) + Core P#3\n L2 P#4 (512KB) + L1d P#4 (32KB) + L1i P#4 (32KB) + Core P#4\n L2 P#5 (512KB) + L1d P#5 (32KB) + L1i P#5 (32KB) + Core P#5\n PCI d1:00.0 (Display)\n GPU(RSMI) \"rsmi2\"\n PCI d6:00.0 (Display)\n GPU(RSMI) \"rsmi3\"\n PCI c9:00.0 (Display)\n GPU(RSMI) \"rsmi0\"\n PCI ce:00.0 (Display)\n GPU(RSMI) \"rsmi1\"\n PCI d9:00.0 (Display)\n PCI de:00.0 (Display)\n PCI c1:00.0 (Display)\n PCI c6:00.0 (Display)\nROCR_VISIBLE_DEVICES: 0,1,2,3\n
If you'd compare with output from a full-node lstopo -p shown in the previous example, you'd see that we actually got the GPUs with regular full node numbering 2 till 5, but they have been renumbered from 0 to 3. And notice that ROCR_VISIBLE_DEVICES now also refers to this numbering and not the regular full node numbering when setting which GPUs can be used.
The srun command on line 40 will now run gpu_check through the select_1gpu_$SLURM_JOB_ID wrapper that gives task 0 access to GPU 0 in the \"local\" numbering, which should be GPU2/CCD2 in the regular full node numbering, etc. Its output is
MPI 000 - OMP 000 - HWT 002 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID cc(GCD3/CCD3)\nMPI 002 - OMP 000 - HWT 004 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID d1(GCD4/CCD0)\nMPI 003 - OMP 000 - HWT 005 (CCD0) - Node nid005350 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID d6(GCD5/CCD1)\n
which confirms that out strategy worked. So in this example we have 4 tasks running in a control group that in principle gives each task access to all 4 GPUs, but with actual access further restricted to a different GPU per task via ROCR_VISIBLE_DEVICES.
This again rather technical example demonstrates another difference between the way one works with CPUs and with GPUs. Affinity masks for CPUs refer to the \"bare OS\" numbering of hardware threads, while the numbering used for ROCR_VISIBLE_DEVICES which determines which GPUs the ROCm runtime can use, uses the numbering within the current control group.
Running GPUs in a different control group per task has consequences for the way inter-GPU communication within a node can be organised so the above examples are important. It is essential to run MPI applications with optimal efficiency.
"},{"location":"2day-next/07-Binding/#task-distribution-with-slurm","title":"Task distribution with Slurm","text":"The Slurm srun command offers the --distribution option to influence the distribution of tasks across nodes (level 1), sockets or NUMA domains (level 2 and sockets or NUMA) or even across cores in the socket or NUMA domain (third level). The first level is the most useful level, the second level is sometimes used but the third level is very tricky and both the second and third level are often better replaced with other mechanisms that will also be discussed in this chapter on distribution and binding.
The general form of the --distribution option is
--distribution={*|block|cyclic|arbitrary|plane=<size>}[:{*|block|cyclic|fcyclic}[:{*|block|cyclic|fcyclic}]][,{Pack|NoPack}]\n
-
Level 1: Distribution across nodes. There are three useful options for LUMI:
-
block which is the default: A number of consecutive tasks is allocated on the first node, then another number of consecutive tasks on the second node, and so on till the last node of the allocation. Not all nodes may have the same number of tasks and this is determined by the optional pack or nopack parameter at the end.
-
With pack the first node in the allocation is first filled up as much as possible, then the second node, etc.
-
With nopack a more balanced approach is taken filling up all nodes as equally as possible. In fact, the number of tasks on each node will correspond to that of the cyclic distribution, but the task numbers will be different.
-
cyclic assigns the tasks in a round-robin fashion to the nodes of the allocation. The first task is allocated to the first node, then the second one to the second node, and so on, and when all nodes of the allocation have received one task, the next one will be allocated again on the first node.
-
plane=<size> is a combination of both of the former methods: Blocks of <size> consecutive tasks are allocated in a cyclic way.
-
Level 2: Here we are distributing and pinning the tasks assigned to a node at level 1 across the sockets and cores of that node.
As this option already does a form of binding, it may conflict with other options that we will discuss later that also perform binding. In practice, this second level is less useful as often other mechanisms will be preferred for doing a proper binding, or the default behaviour is OK for simple distribution problems.
-
block will assign whole tasks to consecutive sets of cores on the node. On LUMI-C, it will first fill up the first socket before moving on to the second socket.
-
cyclic assigns the first task of a node to a set of consecutive cores on the first socket, then the second task to a set of cores on the second socket, etc., in a round-robin way. It will do its best to not allocate tasks across sockets.
-
fcyclic is a very strange distribution, where tasks requesting more than 1 CPU per task will see those spread out across sockets.
We cannot see how this is useful on an AMD CPU except for cases where we have only one task per node which accesses a lot of memory (more than offered by a single socket) but does so in a very NUMA-aware way.
-
Level 3 is beyond the scope of an introductory course and rarely used.
The default behaviour of Slurm depends on LUMI seems to be block:block,nopack if --distribution is not specified, though it is best to always verify as it can change over time and as the manual indicates that the default differs according to the number of tasks compared to the number of nodes. The defaults are also very tricky if a binding option at level 2 (or 3) is replaced with a * to mark the default behaviour, e.g., --distribution=\"block:*\" gives the result of --distribution=block:cyclic while --distribution=block has the same effect as --distribution=block:block.
This option only makes sense on job-exclusive nodes.
"},{"location":"2day-next/07-Binding/#task-to-cpu-binding-with-slurm","title":"Task-to-CPU binding with Slurm","text":"The level 2 and 3 options from the previous section already do some binding. But we will now discuss a different option that enables very precise binding of tasks to hardware threads in Slurm.
The mechanism does conflict with some Slurm options that implicitly already do some binding, e.g., it will not always work together with --cpus-per-task and --hint=[no]multithread may also not act as expected depending on how the options are used. Level \u2154 control via --distribution sometimes also make no sense when this option is used (and will be ignored).
Task-to-CPU binding is controlled through the Slurm option
--cpu-bind=[{quiet|verbose},]<type>\n
We'll describe a few of the possibilities for the <type> parameter but for a more concrete overview we refer to the Slurm srun manual page
-
--cpu-bind=threads is the default behaviour on LUMI.
-
--cpu-bind=map_cpu:<cpu_id_for_task_0>,<cpu_id_for_task_1>, ... is used when tasks are bound to single cores. The first number is the number of the hardware thread for the task with local task ID 0, etc. In other words, this option at the same time also defines the slots that can be used by the --distribution option above and replaces level 2 and level 3 of that option.
E.g.,
salloc --nodes=1 --partition=standard-g\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeGNU-23.09\nsrun --ntasks=8 --cpu-bind=map_cpu:49,57,17,25,1,9,33,41 mpi_check -r\n
will run the first task on hardware threads 49, the second task on 57, third on 17, fourth on 25, fifth on 1, sixth on 9, seventh on 33 and eight on 41.
This may look like a very strange numbering, but we will see an application for it further in this chapter.
-
--cpu-bind=mask_cpu:<mask_for_task_0>,<mask_for_task_1>,... is similar to map_cpu, but now multiple hardware threads can be specified per task through a mask. The mask is a hexadecimal number and leading zeros can be omitted. The least significant bit in the mask corresponds to HWT 0, etc.
Masks can become very long, but we shall see that this option is very useful on the nodes of the standard-g partition. Just as with map_cpu, this option replaces level 2 and 3 of the --distribution option.
E.g.,
salloc --nodes=1 --partition=standard-g\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeGNU-23.09\nsrun --ntasks=8 --cpu-bind=mask_cpu:7e000000000000,7e00000000000000,7e0000,7e000000,7e,7e00,7e00000000,7e0000000000 hybrid_check -r\n
will run the first task on hardware threads 49-54, the second task on 57-62, third on 17-22, fourth on 25-30, fifth on 1-6, sixth on 9-14, seventh on 33-38 and eight on 41-46.
The --cpu-bind=map_cpu and --cpu-bind=mask_gpu options also do not go together with -c / --cpus-per-task. Both commands define a binding (the latter in combination with the default --gpu-bind=threads) and these will usually conflict.
There are more options, but these are currently most relevant ones on LUMI. That may change in the future as LUMI User Support is investigating whether it isn't better to change the concept of \"socket\" in Slurm given how important it sometimes is to carefully map onto L3 cache domains for performance.
"},{"location":"2day-next/07-Binding/#task-to-gpu-binding-with-slurm","title":"Task-to-GPU binding with Slurm","text":"Doing the task-to-GPU binding fully via Slurm is currently not recommended on LUMI. The problem is that Slurm uses control groups at the task level rather than just ROCR_VISIBLE_DEVICES with the latter being more or less the equivalent of affinity masks. When using control groups this way, the other GPUs in a job step on a node become completely invisible to a task, and the Peer2Peer IPC mechanism for communication cannot be used anymore.
We present the options for completeness, and as it may still help users if the control group setup is not a problem for the application.
Task-to-GPU binding is done with
--gpu-bind=[verbose,]<type>\n
(see the Slurm manual) which is somewhat similar to --cpu-binding (to the extent that that makes sense).
Some options for the <type> parameter that are worth considering:
-
--gpu-bind=closest: This currently does not work well on LUMI. The problem is being investigated so the situation may have changed by the time you read this.
-
--gpu-bind=none: Turns off the GPU binding of Slurm. This can actually be useful on shared node jobs where doing a proper allocation of GPUs is difficult. You can then first use Slurm options such as --gpus-per-task to get a working allocation of GPUs and CPUs, then un-bind and rebind using a different mechanism that we will discuss later.
-
--gpu-bind=map_gpu:<list> is the equivalent of --cpu-bind=map_cpu:<list>. This option only makes sense on a job-exclusive node and is for jobs that need a single GPU per task. It defines the list of GPUs that should be used, with the task with local ID 0 using the first one in the list, etc. The numbering and topology was already discussed in the \"LUMI ARchitecture\" chapter, section \"Building LUMI: What a LUMI-G really looks like.
-
--gpu-bind=mask_gpu:<list> is the equivalent of --cpu-bind=mask_cpu:<list>. Now the bits in the mask correspond to individual GPUs, with GPU 0 the least significant bit. This option again only makes sense on a job-exclusive node.
Though map_gpu and mask_gpu could be very useful to get a proper mapping taking the topology of the node into account, due to the current limitation of creating a control group per task it can not often be used as it breaks some efficient communication mechanisms between tasks, including the GPU Peer2Peer IPC used by Cray MPICH for intro-node MPI transfers if GPU aware MPI support is enabled.
What do the HPE Cray manuals say about this? (Click to expand) From the HPE Cray CoE: \"Slurm may choose to use cgroups to implement the required affinity settings. Typically, the use of cgroups has the downside of preventing the use of GPU Peer2Peer IPC mechanisms. By default Cray MPI uses IPC for implementing intra-node, inter-process MPI data movement operations that involve GPU-attached user buffers. When Slurm\u2019s cgroups settings are in effect, users are advised to set MPICH_SMP_SINGLE_COPY_MODE=NONE or MPICH_GPU_IPC_ENABLED=0 to disable the use of IPC-based implementations. Disabling IPC also has a noticeable impact on intra-node MPI performance when GPU-attached memory regions are involved.\"
This is exactly what Slurm does on LUMI.
"},{"location":"2day-next/07-Binding/#mpi-rank-redistribution-with-cray-mpich","title":"MPI rank redistribution with Cray MPICH","text":"By default MPI rank i will use Slurm task i in a parallel job step. With Cray MPICH this can be changed via the environment variable MPICH_RANK_REORDER_METHOD. It provides an even more powerful way of reordering MPI ranks than the Slurm --distribution option as one can define fully custom orderings.
Rank reordering is an advanced topic that is discussed in more detail in the 4-day LUMI comprehensive courses organised by the LUMI User Support Team. The material of the latest one can be found via the course archive web page and is discussed in the \"MPI Topics on the HPE Cray EX Supercomputer\" which is often given on day 3.
Rank reordering can be used to reduce the number of inter-node messages or to spread those ranks that do parallel I/O over more nodes to increase the I/O bandwidth that can be obtained in the application.
Possible values for MPICH_RANK_REORDER_METHOD are:
-
export MPICH_RANK_REORDER_METHOD=0: Round-robin placement of the MPI ranks. This is the equivalent of the cyclic ordering in Slurm.
-
export MPICH_RANK_REORDER_METHOD=1: This is the default and it preserves the ordering of Slurm, and the only one that makes sense with other L1 Slurm distributions than block.
The Cray MPICH manual confusingly calls this \"SMP-style ordering\".
-
export MPICH_RANK_REORDER_METHOD=2: Folded rank placement. This is somewhat similar to round-robin, but when the last node is reached, the node list is transferred in the opposite direction.
-
export MPICH_RANK_REORDER_METHOD=3: Use a custom ordering, given by the MPICH_RANK_ORDER file which gives a comma-separated list of the MPI ranks in the order they should be assigned to slots on the nodes. The default filename MPICH_RANK_ORDER can be overwritten through the environment variable MPICH_RANK_REORDER_FILE.
Rank reordering does not always work well if Slurm is not using the (default) block ordering. As the lumi-CPEtools mpi_check, hybrid_check and gpu_check commands use Cray MPICH they can be used to test the Cray MPICH rank reordering also. The MPI ranks that are displayed are the MPI ranks as seen through MPI calls and not the value of SLURM_PROCID which is the Slurm task number.
The HPE Cray Programming Environment actually has profiling tools that help you determine the optimal rank ordering for a particular run, which is useful if you do a lot of runs with the same problem size (and hence same number of nodes and tasks).
Try the following job script (click to expand)
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=renumber-demo\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=2\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeGNU-23.09\n\nset -x\necho -e \"\\nSMP-style distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=1\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nSMP-style distribution on top of cyclic.\"\nexport MPICH_RANK_REORDER_METHOD=1\nsrun -n 8 -c 32 -m cyclic mpi_check -r\necho -e \"\\nRound-robin distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=0\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nFolded distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=2\nsrun -n 8 -c 32 -m block mpi_check -r\necho -e \"\\nCustom distribution on top of block.\"\nexport MPICH_RANK_REORDER_METHOD=3\ncat >MPICH_RANK_ORDER <<EOF\n0,1,4,5,2,3,6,7\nEOF\ncat MPICH_RANK_ORDER\nsrun -n 8 -c 32 -m block mpi_check -r\n/bin/rm MPICH_RANK_ORDER\nset +x\n
Ths script starts 8 tasks that each take a quarter node.
-
The first srun command (on line 15) is just the block distribution. The first 4 MPI ranks are on the first node, the next 4 on the second node.
+ export MPICH_RANK_REORDER_METHOD=1\n+ MPICH_RANK_REORDER_METHOD=1\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 17/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 2/8 on cpu 65/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 3/8 on cpu 111/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 4/8 on cpu 0/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 5/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 6/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 7/8 on cpu 120/256 of nid001805 mask 96-127\n
-
The second srun command, on line 18, is an example where the Slurm cyclic distribution is preserved. MPI rank 0 now lands on the first 32 cores of node 0 of the allocation, MPI rank 1 on the first 32 cores of node 1 of the allocation, then task 2 on the second 32 cores of node 0, and so on:
+ export MPICH_RANK_REORDER_METHOD=1\n+ MPICH_RANK_REORDER_METHOD=1\n+ srun -n 8 -c 32 -m cyclic mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 33/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 79/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
-
The third srun command, on line 21, uses Cray MPICH rank reordering instead to get a round-robin ordering rather than using the Slurm --distribution=cyclic option. The result is the same as in the previous case:
+ export MPICH_RANK_REORDER_METHOD=0\n+ MPICH_RANK_REORDER_METHOD=0\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 47/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
-
The fourth srun command, on line 24, demonstrates the folded ordering: Rank 0 runs on the first 32 cores of node 0 of the allocation, rank 1 on the first 32 of node 1, then rank 2 runs on the second set of 32 cores again on node 1, with rank 3 then running on the second 32 cores of node 0, rank 4 on the third group of 32 cores of node 0, rank 5 on the third group of 32 cores on rank 1, and so on. So the nodes are filled in the order 0, 1, 1, 0, 0, 1, 1, 0.
+ export MPICH_RANK_REORDER_METHOD=2\n+ MPICH_RANK_REORDER_METHOD=2\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 17/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 2/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 3/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 6/8 on cpu 112/256 of nid001805 mask 96-127\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001804 mask 96-127\n
-
The fifth example ('srun' on line 31) demonstrate a custom reordering. Here we face a 4x2-grid which we want to split in 2 2x2 groups. So where the ranks in our grid are numbered as
0 1 2 3\n4 5 6 7\n
we really want the left half of the grid on the first node of the allocation and the right half on the second node as this gives us less inter-node communication than when we would put the first line on the first node and the second line on the second. So basically we want ranks 0, 1, 4 and 5 on the first node and ranks 2, 3, 6 and 7 on the second node, which is done by creating the reorder file with content
0,1,4,5,2,3,6,7\n
The resulting output is
+ export MPICH_RANK_REORDER_METHOD=3\n+ MPICH_RANK_REORDER_METHOD=3\n+ cat\n+ srun -n 8 -c 32 -m block mpi_check -r\n\nRunning 8 single-threaded MPI ranks.\n\n++ mpi_check: MPI rank 0/8 on cpu 0/256 of nid001804 mask 0-31\n++ mpi_check: MPI rank 1/8 on cpu 32/256 of nid001804 mask 32-63\n++ mpi_check: MPI rank 2/8 on cpu 1/256 of nid001805 mask 0-31\n++ mpi_check: MPI rank 3/8 on cpu 32/256 of nid001805 mask 32-63\n++ mpi_check: MPI rank 4/8 on cpu 64/256 of nid001804 mask 64-95\n++ mpi_check: MPI rank 5/8 on cpu 112/256 of nid001804 mask 96-127\n++ mpi_check: MPI rank 6/8 on cpu 64/256 of nid001805 mask 64-95\n++ mpi_check: MPI rank 7/8 on cpu 112/256 of nid001805 mask 96-127\n
"},{"location":"2day-next/07-Binding/#refining-core-binding-in-openmp-applications","title":"Refining core binding in OpenMP applications","text":"In a Slurm batch job step, threads of a shared memory process will be contained to all hardware threads of all available cores on the first node of your allocation. To contain a shared memory program to the hardware threads asked for in the allocation (i.e., to ensure that --hint=[no]multithread has effect) you'd have to start the shared memory program with srun in a regular job step.
Any multithreaded executable run as a shared memory job or ranks in a hybrid MPI/multithread job, will - when started properly via srun - get access to a group of cores via an affinity mask. In some cases you will want to manually refine the way individual threads of each process are mapped onto the available hardware threads.
In OpenMP, this is usually done through environment variables (it can also be done partially in the program through library calls). A number of environment variables is standardised in the OpenMP standard, but some implementations offer some additional non-standard ones, or non-standard values for the standard environment variables. Below we discuss the more important of the standard ones:
-
OMP_NUM_THREADS is used to set the number of CPU threads OpenMP will use. In its most basic form this is a single number (but you can give multiple comma-separated numbers for nested parallelism).
OpenMP programs on LUMI will usually correctly detect how many hardware threads are available to the task and use one OpenMP thread per hardware thread. There are cases where you may want to ask for a certain number of hardware threads when allocating resources, e.g., to easily get a good mapping of tasks on cores, but do not want to use them all, e.g., because your application is too memory bandwidth or cache constrained and using fewer threads actually gives better overall performance on a per-node basis.
-
OMP_PLACES is used to restrict each OpenMP thread to a group of hardware threads. Possible values include:
OMP_PLACES=threads to restrict OpenMP threads to a single hardware threadOMP_PLACES=cores to restrict each OpenMP threads to a single core (but all hardware threads associated with that core)OMP_PLACES=sockets to restrict each OpenMP thread to the hardware threads of a single socket-
And it is possible to give a list with explicit values, e.g.,
export OMP_PLACES=\"{0:4}:3:8\"\n
which is also equivalent to
export OMP_PLACES=\"{0,1,2,3},{8,9,10,11},{16,17,18,19}\"\n
so each OpenMP thread is restricted to a different group of 4 hardware threads. The numbers in the list are not the physical Linux hardware thread numbers, but are relative to the hardware threads available in the affinity mask of the task.
More general, {a:b}:c:d means b numbers starting from a (so a, a+1, ..., a+b-1), repeated c times, at every repeat shifted by d. There are more variants to generate lists of places and we show another one in the example below. But in all the syntax may look strange and there are manuals that give the wrong information (including some versions of the manual for the GNU OpenMP runtime).
Note that this is different from the core numbers that would be used in --cpu-bind=map_cpu or --gpu-bind=mask_cpu which sets the CPUs or groups of CPUs available to each thread and which always use the physical numbering and not a numbering that is local to the job allocation.
-
OMP_PROC_BIND: Sets how threads are distributed over the places. Possible values are:
-
OMP_PROC_BIND=false: Turn off OpenMP thread binding. Each thread will get access to all hardware threads available in to the task (and defined by a Linux affinity mask in Slurm).
-
OMP_PROC_BIND=close: If more places are available than there are OpenMP threads, then try to put the OpenMP threads in different places as close as possible to the master thread. In general, bind as close as possible to the master thread while still distributing for load balancing.
-
OMP_PROC_BIND=spread: Spread threads out as evenly as possible over the places available to the task.
-
OMP_PROC_BIND=master: Bind threads to the same place as the master thread. The place is determined by the OMP_PLACES environment variable and it is clear this makes no sense if that place is just a single hardware thread or single core as all threads would then be competing for the resources of a single core.
Multiple values of close, spread and master in a comma-separated list are possible to organise nested OpenMP parallelism, but this is outside of the scope of this tutorial.
The Cray Compilation Environment also has an additional non-standard option auto which is actually the default and tries to do a reasonable job for most cases. On the other compilers on LUMI, the default behaviour is false unless the next environment variable, OMP_PLACES, is specified.
-
OMP_DISPLAY_AFFINITY: When set tot TRUE information about the affinity binding of each thread will be shown which is good for debugging purposes.
For single-level OpenMP parallelism, the omp_check and hybrid_check programs from the lumi-CPEtools modules can also be used to check the OpenMP thread binding.
Some examples (click to expand) Consider the following job script:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=omp-demo\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard\n#SBATCH --nodes=1\n#SBATCH --hint=multithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/C lumi-CPEtools/1.1-cpeCray-23.09\n\nset -x\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=false\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nunset OMP_PROC_BIND\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=spread\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nsrun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=threads\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nexport OMP_PLACES=cores\nsrun -n 1 -c 32 --hint=multithread omp_check -r\n\nexport OMP_NUM_THREADS=4\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=\"{0:8}:4:8\"\nsrun -n 1 -c 32 --hint=multithread omp_check -r\n\nexport OMP_PLACES=\"{0:4,16:4}:4:4\"\nsrun -n 1 -c 32 --hint=multithread omp_check -r\nset +x\n
Let's check the output step by step:
In the first block we run 2 srun commands that actually both use 16 cores, but first with hardware threading enabled in Slurm and then with multithread mode off in Slurm:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=false\n+ OMP_PROC_BIND=false\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 1/4 on cpu 137/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 2/4 on cpu 129/256 of nid001077 mask 0-15, 128-143\n++ omp_check: OpenMP thread 3/4 on cpu 143/256 of nid001077 mask 0-15, 128-143\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 1/4 on cpu 15/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 0-15\n++ omp_check: OpenMP thread 3/4 on cpu 14/256 of nid001077 mask 0-15\n
OMP_PROC_BIND was explicitly set to false to disable the Cray Compilation Environment default behaviour. The masks reported by omp_check cover all hardware threads available to the task in Slurm: Both hardware threads for the 16 first cores in the multithread case and just the primary hardware thread on the first 16 cores in the second case. So each OpenMP thread can in principle migrate over all available hardware threads.
In the second block we unset the PROC_BIND environment variable to demonstrate the behaviour of the Cray Compilation Environment. The output would be different had we used the cpeGNU or cpeAOCC version.
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ unset OMP_PROC_BIND\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 1/256 of nid001077 mask 0-3, 128-131\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4-7, 132-135\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8-11, 136-139\n++ omp_check: OpenMP thread 3/4 on cpu 142/256 of nid001077 mask 12-15, 140-143\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-3\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4-7\n++ omp_check: OpenMP thread 2/4 on cpu 9/256 of nid001077 mask 8-11\n++ omp_check: OpenMP thread 3/4 on cpu 15/256 of nid001077 mask 12-15\n
The default behaviour of the CCE is very nice: Threads are nicely spread out over the available cores and then all get access to their own group of hardware threads that in this case with 4 threads for 16 cores spans 4 cores for each thread. In fact, also in other cases the default behaviour of CCE will be a binding that works well for many cases.
In the next experiment we demonstrate the close binding:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 128/256 of nid001077 mask 128\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001077 mask 129\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 2/4 on cpu 2/256 of nid001077 mask 2\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001077 mask 3\n
In the first case, with Slurm multithreading mode on, we see that the 4 threads are now concentrated on only 2 cores but each gets pinned to its own hardware thread. In general this behaviour is not what one wants if more cores are available as on each core two threads will now be competing for available resources. In the second case, with Slurm multithreading disabled, the threads are bound to the first 4 cores, with one core for each thread.
Next we demonstrate the spread binding:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=spread\n+ OMP_PROC_BIND=spread\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8\n++ omp_check: OpenMP thread 3/4 on cpu 12/256 of nid001077 mask 12\n\n+ srun -n 1 -c 16 --hint=nomultithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 4/256 of nid001077 mask 4\n++ omp_check: OpenMP thread 2/4 on cpu 8/256 of nid001077 mask 8\n++ omp_check: OpenMP thread 3/4 on cpu 12/256 of nid001077 mask 12\n
The result is now the same in both cases as we have fewer threads than physical cores. Each OpenMP thread is bound to a single core, but these cores are spread out over the first 16 cores of the node.
Next we return to the close binding but try both threads and cores as places with Slurm multithreading turned on for both cases:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ export OMP_PLACES=threads\n+ OMP_PLACES=threads\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0\n++ omp_check: OpenMP thread 1/4 on cpu 128/256 of nid001077 mask 128\n++ omp_check: OpenMP thread 2/4 on cpu 1/256 of nid001077 mask 1\n++ omp_check: OpenMP thread 3/4 on cpu 129/256 of nid001077 mask 129\n\n+ export OMP_PLACES=cores\n+ OMP_PLACES=cores\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0, 128\n++ omp_check: OpenMP thread 1/4 on cpu 1/256 of nid001077 mask 1, 129\n++ omp_check: OpenMP thread 2/4 on cpu 130/256 of nid001077 mask 2, 130\n++ omp_check: OpenMP thread 3/4 on cpu 3/256 of nid001077 mask 3, 131\n
With threads as places we get again the distribution with two OpenMP threads on each physical core, each with their own hardware thread. With cores as places, we get only one thread per physical core, but each thread has access to both hardware threads of that physical core.
And lastly we play a bit with custom placements:
+ export OMP_NUM_THREADS=4\n+ OMP_NUM_THREADS=4\n+ export OMP_PROC_BIND=close\n+ OMP_PROC_BIND=close\n+ export 'OMP_PLACES={0:8}:4:8'\n+ OMP_PLACES='{0:8}:4:8'\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-7\n++ omp_check: OpenMP thread 1/4 on cpu 8/256 of nid001077 mask 8-15\n++ omp_check: OpenMP thread 2/4 on cpu 128/256 of nid001077 mask 128-135\n++ omp_check: OpenMP thread 3/4 on cpu 136/256 of nid001077 mask 136-143\n
OMP_PLACES='{0:8}:4:8 means: Take starting from core with logical number 0 8 cores and repeat this 4 times, shifting by 8 each time, so effectively
OMP_PLACES=\"{ 0,1,2,3,4,5,6,7},{8,9,10,11,12,13,14,15},{16,17,18,19,20,21,22,23},{24,25,26,27,27,28,30,31}\"\n
omp_check however shows the OS numbering for the hardware threads so we can see what this places variable means: the first thread can get scheduled on the first hardware thread of the first 8 cores, the second thread on the first hardware thread of the next 8 cores, the third OpenMP thread on the second thread of the first 8 cores, and the fourth OpenMP thread on the second hardware thread of the next 8 cores. In other words, the logical numbering of the threads follows the same ordering as at the OS level: First the first hardware thread of each core, then the second hardware thread.
When trying another variant with
OMP_PACES={0:4,16:4}:4:4\n
which is equivalent to
OMP_PLACES={0,1,2,3,16,17,18,19},{4,5,6,7,20,21,22,23},{8,9,10,11,24,25,26,27},{12,13,14,15,28,29,30,31}\"\n
we get a much nicer distribution:
+ export 'OMP_PLACES={0:4,16:4}:4:4'\n+ OMP_PLACES='{0:4,16:4}:4:4'\n+ srun -n 1 -c 32 --hint=multithread omp_check -r\n\nRunning 4 threads in a single process\n\n++ omp_check: OpenMP thread 0/4 on cpu 0/256 of nid001077 mask 0-3, 128-131\n++ omp_check: OpenMP thread 1/4 on cpu 132/256 of nid001077 mask 4-7, 132-135\n++ omp_check: OpenMP thread 2/4 on cpu 136/256 of nid001077 mask 8-11, 136-139\n++ omp_check: OpenMP thread 3/4 on cpu 140/256 of nid001077 mask 12-15, 140-143\n
We only discussed a subset of the environment variables defined in the OpenMP standard. Several implementations also offer additional environment variables, e.g., a number of GOMP_* environment variables in the GNU Compiler Collection implementation or KMP_* variables in the Intel compiler (not available on LUMI).
Some further documentation:
-
The OMP_* environment variables and a number of environment variables specific for the runtime libraries of the Cray Compiling Environment are discussed in the intro_openmp manual page, section \"Environment variables\".
-
A list of OMP_ environment variables in the OpenMP 5.1 standard (as the current list in the HTML version of the 5.2 standard has some problems).
"},{"location":"2day-next/07-Binding/#gpu-binding-with-rocr_visible_devices","title":"GPU binding with ROCR_VISIBLE_DEVICES","text":"The ROCR_VISIBLE_DEVICES environment variable restricts access to GPUs at the ROCm platform runtime level. Contrary to control groups however this mechanism is compatible with the Peer2Peer IPC used by GPU-aware Cray MPI for intra-node communication.
The value of the ROCR_VISIBLE_DEVICES environment variable is a list of device indices that will be exposed to the applications. The device indices do depend on the control group. Visible devices in a control group are always numbered from 0.
So though ROCR_VISIBLE_DEVICES has the same function as affinity masks for CPUs, it is different in many respects.
-
Affinity masks are part of the Linux kernel and fully OS-controlled, while ROCR_VISIBLE_DEVICES is interpreted in the ROCmTM stack.
-
Affinity masks are set through an OS call and that call can enforce that the new mask cannot be less restrictive than the parent mask. ROCR_VISIBLE_DEVICES is just an environment variable, so at the time that you try to set it to a value that you shouldn't use, there is no check.
-
Affinity masks always use the global numbering of hardware threads while ROCR_VISIBLE_DEVICES uses the local numbering in the currently active control group. So the GPU that corresponds to 0 in ROCR_VISIBLE_DEVICES is not always the same GPU.
Alternative values for ROCR_VISIBLE_DEVICES Instead of device indices, ROCR_VISIBLE_DEVICES also accepts GPU UUIDs that are unique to each GPU. This is less practical then it seems as the UUIDs of GPUs are different on each node so one would need to discover them first before they can be used.
"},{"location":"2day-next/07-Binding/#combining-slurm-task-binding-with-rocr_visible_devices","title":"Combining Slurm task binding with ROCR_VISIBLE_DEVICES","text":"In the chapter on the architecture of LUMI we discussed what a LUMI-G really looks like.
The full topology of a LUMI-G compute node is shown in the figure:
Note that the numbering of GCDs does not correspond to the numbering of CCDs/cores. However, for optimal memory transfers (and certainly if cache-coherent memory access from CPU to GPU would be used) it is better to ensure that each GCD collaborates with the matched CCD in an MPI rank. So we have the mapping:
CCD HWTs Available HWTs GCD 0 0-7, 64-71 1-7, 65-71 4 1 8-15, 72-79 9-15, 73-79 5 2 16-23, 80-87 17-23, 81-87 2 3 24-32, 88-95 25-32, 89-95 3 4 32-39, 96-103 33-39, 97-103 6 5 40-47, 104-111 41-47, 105-111 7 6 48-55, 112-119 49-55, 113-119 0 7 56-63, 120-127 57-63, 121-127 1 or the reverse mapping
GCD CCD HWTs Available HWTs 0 6 48-55, 112-119 49-55, 113-119 1 7 56-63, 120-127 57-63, 121-127 2 2 16-23, 80-87 17-23, 81-87 3 3 24-32, 88-95 25-32, 89-95 4 0 0-7, 64-71 1-7, 65-71 5 1 8-15, 72-79 9-15, 73-79 6 4 32-39, 96-103 33-39, 97-103 7 5 40-47, 104-111 41-47, 105-111 Moreover, if you look more carefully at the topology, you can see that the connections between the GCDs contain a number of rings:
-
Green ring: 0 - 1 - 3 - 2 - 4 - 5 - 7 - 6 - 0
-
Red ring: 0 - 1 - 5 - 4 - 6 - 7 - 3 - 2 - 0
-
Sharing some connections with the previous ones, but can be combined with the green ring: 0 - 1 - 5 - 4 - 2 - 3 - 7 - 6 - 0
So if your application would use a ring mapping for communication and use communication from GPU buffers for that, than it may be advantageous to map the MPI ranks on one of those rings which would mean that neither the order of the CCDs nor the order of the GCDs is trivial.
Some other topologies can also be mapped on these connections (but unfortunately not a 3D cube).
Note: The red ring and green ring correspond to the red and green rings on page 6 of the \"Introducing AMD CDNATM 2 Architecture\" whitepaper.
To implement a proper CCD-to-GCD mapping we will use two mechanisms:
-
On the CPU side we'll use Slurm --cpu-bind. Sometimes we can also simply use -c or --cpus-per-task (in particular in the case below with linear ordering of the CCDs and 7 cores per task)
-
On the GPU side we will manually assign GPUs via a different value of ROCR_VISIBLE_DEVICES for each thread. To accomplish this we will have to write a wrapper script which we will generate in the job script.
Let us start with the simplest case:
"},{"location":"2day-next/07-Binding/#linear-assignment-of-gcd-then-match-the-cores","title":"Linear assignment of GCD, then match the cores","text":"One possible job script to accomplish this is:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-linear-GCD\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:49,57,17,25,1,9,33,41\"\n\nCPU_BIND2=\"mask_cpu:0xfe000000000000,0xfe00000000000000\"\nCPU_BIND2=\"$CPU_BIND2,0xfe0000,0xfe000000\"\nCPU_BIND2=\"$CPU_BIND2,0xfe,0xfe00\"\nCPU_BIND2=\"$CPU_BIND2,0xfe00000000,0xfe0000000000\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
To select the GPUs we either use a map with numbers of cores (ideal for pure MPI programs) or masks (the only option for hybrid programs). The mask that we give in the example uses 7 cores per CCD and always skips the first core, as is required on LUMI as the first core of each chiplet is reserved and not available to Slurm jobs. To select the right GPU for ROCR_VISIBLE_DEVICES we can use the Slurm local task ID which is also what the MPI rank will be. We use a so-called \"bash here document\" to generate the script. Note that in the bash here document we needed to protect the $ with a backslash (so use \\$) as otherwise the variables would already be expanded when generating the script file.
Instead of the somewhat complicated --ntasks with srun we could have specified --ntasks-per-node=8 on a #SBATCH line which would have fixed the structure for all srun commands. Even though we want to use all GPUs in the node, --gpus-per-node or an equivalent option has to be specified either as an #SBATCH line or with each srun command or no GPUs will be made available to the tasks started by the srun command.
Note the output of the second srun command:
MPI 000 - OMP 000 - HWT 049 (CCD6) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 057 (CCD7) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 017 (CCD2) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 025 (CCD3) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 001 (CCD0) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 009 (CCD1) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 033 (CCD4) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 041 (CCD5) - Node nid006872 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\n
With the -l option we also print some information about the CCD that a core belongs to and the GCD and corresponding optimal CCD for each PCIe bus ID, which makes it very easy to check if the mapping is as intended. Note that the GCDs are indeed in the linear order starting with GCD0.
"},{"location":"2day-next/07-Binding/#linear-assignment-of-the-ccds-then-match-the-gcd","title":"Linear assignment of the CCDs, then match the GCD","text":"To modify the order of the GPUs, we now use an array with the desired order in the select_gpu script. With the current setup of LUMI, with one core reserved on each chiplet, there are now two options to get the proper CPUs:
-
We can use masks to define the cores for each slot, but they will now look more regular, or
-
we can simply use --cpus-per-task=7 and then further restrict the number of threads per task with OMP_NUM_THREADS.
The job script (for option 1) now becomes:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-linear-CCD\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/22.12 partition/G lumi-CPEtools/1.1-cpeCray-22.12\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGPU_ORDER=(4 5 2 3 6 7 0 1)\nexport ROCR_VISIBLE_DEVICES=\\${GPU_ORDER[\\$SLURM_LOCALID]}\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:1,9,17,25,33,41,49,57\"\n\nCPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:0x00000000000000fe,0x000000000000fe00\"\nCPU_BIND2=\"$CPU_BIND2,0x0000000000fe0000,0x00000000fe000000\"\nCPU_BIND2=\"$CPU_BIND2,0x000000fe00000000,0x0000fe0000000000\"\nCPU_BIND2=\"$CPU_BIND2,0x00fe000000000000,0xfe00000000000000\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
The leading zeros in the masks in the CPU_BIND2 environment variable are not needed but we added them as it makes it easier to see which chiplet is used in what position.
"},{"location":"2day-next/07-Binding/#the-green-ring","title":"The green ring","text":"As a final example for whole node allocations, lets bind tasks such that the MPI ranks are mapped upon the green ring which is GCD 0 - 1 - 3 - 2 - 4 - 5 - 7 - 6 - 0. In other words, we want to create the mapping
Task GCD CCD Available cores 0 0 6 49-55, 113-119 1 1 7 57-63, 121-127 2 3 3 25-32, 89-95 3 2 2 17-23, 81-87 4 4 0 1-7, 65-71 5 5 1 9-15, 73-79 6 7 5 41-47, 105-111 7 6 4 33-39, 97-103 This mapping would be useful when using GPU-to-GPU communication in a scenario where task i only communicates with tasks i-1 and i+1 (module 8), so the communication pattern is a ring.
Now we need to reorder both the cores and the GCDs, so we basically combine the approach taken in the two scripts above:
#!/bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-ring-green\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\n# Mapping:\n# | Task | GCD | CCD | Available cores |\n# |-----:|----:|----:|:----------------|\n# | 0 | 0 | 6 | 49-55, 113-119 |\n# | 1 | 1 | 7 | 57-63, 121-127 |\n# | 2 | 3 | 3 | 25-32, 89-95 |\n# | 3 | 2 | 2 | 17-23, 81-87 |\n# | 4 | 4 | 0 | 1-7, 65-71 |\n# | 5 | 5 | 1 | 9-15, 73-79 |\n# | 6 | 7 | 5 | 41-47, 105-111 |\n# | 7 | 6 | 4 | 33-39, 97-103 |\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGPU_ORDER=(0 1 3 2 4 5 7 6)\nexport ROCR_VISIBLE_DEVICES=\\${GPU_ORDER[\\$SLURM_LOCALID]}\nexec \\$*\nEOF\nchmod +x select_gpu_$SLURM_JOB_ID\n\nCPU_BIND1=\"map_cpu:49,57,25,17,1,9,41,33\"\n\nCCD_MASK=( 0x00000000000000fe \\\n 0x000000000000fe00 \\\n 0x0000000000fe0000 \\\n 0x00000000fe000000 \\\n 0x000000fe00000000 \\\n 0x0000fe0000000000 \\\n 0x00fe000000000000 \\\n 0xfe00000000000000 )\nCPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:${CCD_MASK[6]},${CCD_MASK[7]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[3]},${CCD_MASK[2]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[0]},${CCD_MASK[1]}\"\nCPU_BIND2=\"$CPU_BIND2,${CCD_MASK[5]},${CCD_MASK[4]}\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=0\n\necho -e \"\\nPure MPI:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID mpi_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND1 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\necho -e \"\\nHybrid:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID hybrid_check -r\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=$CPU_BIND2 ./select_gpu_$SLURM_JOB_ID gpu_check -l\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID\n
The values for GPU_ORDER are easily read from the second column of the table with the mapping that we prepared. The cores to use for the pure MPI run are also easily read from the table: simply take the first core of each line. Finally, to build the mask, we used some bash trickery. We first define the bash array CCD_MASK with the mask for each chiplet. As this has a regular structure, this is easy to build. Then we compose the mask list for the CPUs by indexing in that array, where the indices are easily read from the third column in the mapping.
The alternative code to build CPU_BIND2 is
CPU_BIND2=\"mask_cpu\"\nCPU_BIND2=\"$CPU_BIND2:0x00fe000000000000,0xfe00000000000000\"\nCPU_BIND2=\"$CPU_BIND2,0x00000000fe000000,0x0000000000fe0000\"\nCPU_BIND2=\"$CPU_BIND2,0x00000000000000fe,0x000000000000fe00\"\nCPU_BIND2=\"$CPU_BIND2,0x0000fe0000000000,0x000000fe00000000\"\n
which may be shorter, but requires some puzzling to build and hence is more prone to error.
The output of the second srun command is now
MPI 000 - OMP 000 - HWT 049 (CCD6) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 057 (CCD7) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 025 (CCD3) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 000 - HWT 017 (CCD2) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 004 - OMP 000 - HWT 001 (CCD0) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 009 (CCD1) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 041 (CCD5) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 000 - HWT 033 (CCD4) - Node nid005083 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\n
Checking the last column, we see that the GCDs are indeed in the desired order for the green ring, and is is also easy to check that each task is also mapped on the optimal CCD for the GCD.
Job script with some more advanced bash
#!/bin/bash\n#SBATCH --job-name=map-advanced-multiple\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=standard-g\n#SBATCH --gpus-per-node=8\n#SBATCH --nodes=1\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\n#\n# Define the order of the GPUs and the core mask for CCD0\n# It is important that the order of the GPUs is a string with the numbers separated by spaces.\n#\nGCD_ORDER=\"0 1 5 4 6 7 3 2\"\ncoremask='2#00000010' # Can use the binary representation, hexadecimal with 0x, or decimal\n\n#\n# run_gpu script, takes the string with GCDs as the first argument.\n#\ncat << EOF > run_gpu_$SLURM_JOB_ID\n#!/bin/bash\nGCD_ORDER=( \\$1 )\nshift\nexport ROCR_VISIBLE_DEVICES=\\${GCD_ORDER[\\$SLURM_LOCALID]}\nexec \"\\$@\"\nEOF\nchmod +x run_gpu_$SLURM_JOB_ID\n\n#\n# Build the CPU binding\n# Argument one is mask, all other arguments are treated as an array of GCD numbers.\n#\n\nfunction generate_mask {\n\n # First argument is the mask for CCD0\n mask=$1\n\n # Other arguments are either a string already with the GCDs, or just one GCD per argument.\n shift\n GCDs=( \"$@\" )\n # Fully expand (doesn't matter as the loop can deal with it, but good if we want to check the number)\n GCDs=( ${GCDs[@]} )\n\n # For each GCD, the corresponding CCD number in the optimal mapping.\n MAP_to_CCD=( 6 7 2 3 0 1 4 5 )\n\n CPU_BIND=\"\"\n\n # Loop over the GCDs in the order of the list to compute the corresponding\n # CPU mask.\n for GCD in ${GCDs[@]}\n do\n # Get the matching CCD for this GCD\n CCD=${MAP_to_CCD[$GCD]}\n\n # Shift the mask for CCD0 to the position for CCD $CCD\n printf -v tmpvar \"0x%016x\" $((mask << $((CCD*8))))\n\n # Add to CPU_BIND. We'll remove the leading , this creates later.\n CPU_BIND=\"$CPU_BIND,$tmpvar\"\n done\n\n # Strip the leading ,\n CPU_BIND=\"${CPU_BIND#,}\"\n\n # Return the result by printing to stdout\n printf \"$CPU_BIND\"\n\n}\n\n#\n# Running the check programs\n#\n\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\n# Some mappings:\nlinear_CCD=\"4 5 2 3 6 7 0 1\"\nlinear_GCD=\"0 1 2 3 4 5 6 7\" \nring_green=\"0 1 3 2 4 5 7 6\"\nring_red=\"0 1 5 4 6 7 3 2\"\n\necho -e \"\\nTest runs:\\n\"\n\necho -e \"\\nConsecutive CCDs:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $linear_CCD) \\\n ./run_gpu_$SLURM_JOB_ID \"$linear_CCD\" gpu_check -l\n\necho -e \"\\nConsecutive GCDs:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $linear_GCD) \\\n ./run_gpu_$SLURM_JOB_ID \"$linear_GCD\" gpu_check -l\n\necho -e \"\\nGreen ring:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $ring_green) \\\n ./run_gpu_$SLURM_JOB_ID \"$ring_green\" gpu_check -l\n\necho -e \"\\nRed ring:\\n\"\nsrun --ntasks=$((SLURM_NNODES*8)) \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $ring_red) \\\n ./run_gpu_$SLURM_JOB_ID \"$ring_red\" gpu_check -l\n\necho -e \"\\nFirst two CPU NUMA domains (assuming one node in the allocation):\"\nhalf=\"4 5 2 3\"\nsrun --ntasks=4 \\\n --cpu-bind=mask_cpu:$(generate_mask $coremask $half) \\\n ./run_gpu_$SLURM_JOB_ID \"$half\" gpu_check -l\n\n/bin/rm -f run_gpu_$SLURM_JOB_ID\n
In this script, we have modified the and renamed the usual select_gpu script (renamed to run_cpu) to take as the first argument a string with a space-separated list of the GCDs to use. This has been combined with the bash function generate_mask (which could have been transformed in a script as well) that computes the CPU mask starting from the mask for CCD0 and shifting that mask as needed. The input is the mask to use and then the GCDs to use, either as a single string or as a series of arguments (e.g., resulting from an array expansion).
Both commands are then combined in the srun command. The generate_mask function is used to generate the mask for --gpu-bind while the run_gpu script is used to set ROCR_VISIBLE_DEVICES for each task. The examples also show how easy it is to experiment with different mappings. The one limitation of the script and function is that there can be only 1 GPU per task and one task per GPU, and the CPU mask is also limited to a single CCD (which makes sense with the GPU restriction). Generating masks that also include the second hardware thread is not supported yet. (We use bash arithmetic internally which is limited to 64-bit integers).
"},{"location":"2day-next/07-Binding/#what-about-allocate-by-resources-partitions","title":"What about \"allocate by resources\" partitions?","text":"On partitions that are \"allocatable by resource\", e.g., small-g, you are never guaranteed that tasks will be spread in a reasonable way over the CCDs and that the matching GPUs will be available to your job. Creating an optimal mapping or taking the topology into account is hence impossible.
What is possible though is work around the fact that with the usual options for such resource allocations, Slurm will lock up the GPUs for individual tasks in control groups so that the Peer2Peer IPC intra-node communication mechanism has to be turned off. We can do this for job steps that follow the pattern of resources allocated via the sbatch arguments (usually #SBATCH lines), and rely on three elements for that:
-
We can turn off the Slurm GPU binding mechanism with --gpu-bind=none.
-
Even then, the GPUs will still be locked up in a control group on each node for the job and hence on each node be numbered starting from zero.
-
And each task also has a local ID that can be used to map the appropriate number of GPUs to each task.
This can be demonstrated with the following job script:
#! /bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-smallg-1gpt\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=small-g\n#SBATCH --ntasks=12\n#SBATCH --cpus-per-task=2\n#SBATCH --gpus-per-task=1\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\ncat << EOF > echo_dev_$SLURM_JOB_ID\n#!/bin/bash\nprintf -v task \"%02d\" \\$SLURM_PROCID\necho \"Task \\$task or node.local_id \\$SLURM_NODEID.\\$SLURM_LOCALID sees ROCR_VISIBLE_DEVICES=\\$ROCR_VISIBLE_DEVICES\"\nEOF\nchmod +x ./echo_dev_$SLURM_JOB_ID\n\nset -x\nsrun gpu_check -l\nsrun ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID echo_dev_$SLURM_JOB_ID\n
To run this job successfully, we need 12 GPUs so obviously the tasks will be spread over more than one node. The echo_dev command in this script only shows us the value of ROCR_VISIBLE_DEVICES for the task at that point, something that gpu_check in fact also reports as GPU_ID, but this is just in case you don't believe...
The output of the first srun command is:
+ srun gpu_check -l\nMPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 000 - OMP 001 - HWT 002 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 001 - OMP 001 - HWT 004 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 005 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 002 - OMP 001 - HWT 006 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 007 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 001 - HWT 008 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 009 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1(GCD4/CCD0)\nMPI 004 - OMP 001 - HWT 010 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 011 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6(GCD5/CCD1)\nMPI 005 - OMP 001 - HWT 012 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 013 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9(GCD6/CCD4)\nMPI 006 - OMP 001 - HWT 014 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 015 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 001 - HWT 016 (CCD2) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID dc(GCD7/CCD5)\nMPI 008 - OMP 000 - HWT 001 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 008 - OMP 001 - HWT 002 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 009 - OMP 000 - HWT 003 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 009 - OMP 001 - HWT 004 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6(GCD1/CCD7)\nMPI 010 - OMP 000 - HWT 005 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 010 - OMP 001 - HWT 006 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9(GCD2/CCD2)\nMPI 011 - OMP 000 - HWT 007 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\nMPI 011 - OMP 001 - HWT 008 (CCD1) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID cc(GCD3/CCD3)\n
In other words, we see that we did get cores on two nodes that obviously are not well aligned with the GCDs, and 8 GPUS on the first and 4 on the second node.
The output of the second srun is:
+ srun ./echo_dev_4359428\n+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=0\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=0\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=0\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=0\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=0\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=0\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=0\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=0\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=0\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=0\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=0\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=0\n
It is normal that each task sees ROCR_VISIBLE_DEVICES=0 even though we have seen that they all use a different GPU. This is because each task is locked up in a control group with only one GPU, which then gets number 0.
The output of the third srun command is:
+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=\n
Slurm in fact did not set ROCR_VISIBLE_DEVICES because we turned binding off.
In the next srun command we set ROCR_VISIBLE_DEVICES based on the local task ID and get:
+ srun --gpu-bind=none ./select_gpu_4359428 ./echo_dev_4359428\n+ sort\nTask 00 or node.local_id 0.0 sees ROCR_VISIBLE_DEVICES=0\nTask 01 or node.local_id 0.1 sees ROCR_VISIBLE_DEVICES=1\nTask 02 or node.local_id 0.2 sees ROCR_VISIBLE_DEVICES=2\nTask 03 or node.local_id 0.3 sees ROCR_VISIBLE_DEVICES=3\nTask 04 or node.local_id 0.4 sees ROCR_VISIBLE_DEVICES=4\nTask 05 or node.local_id 0.5 sees ROCR_VISIBLE_DEVICES=5\nTask 06 or node.local_id 0.6 sees ROCR_VISIBLE_DEVICES=6\nTask 07 or node.local_id 0.7 sees ROCR_VISIBLE_DEVICES=7\nTask 08 or node.local_id 1.0 sees ROCR_VISIBLE_DEVICES=0\nTask 09 or node.local_id 1.1 sees ROCR_VISIBLE_DEVICES=1\nTask 10 or node.local_id 1.2 sees ROCR_VISIBLE_DEVICES=2\nTask 11 or node.local_id 1.3 sees ROCR_VISIBLE_DEVICES=3\n
Finally, we run gpu_check again and see the same assignment of physical GPUs again as when we started, but now with different logical device numbers passed by ROCR_VISIBLE_DEVICES. The device number for the hip runtime is always 0 though which is normal as ROCR_VISIBLE_DEVICES restricts the access of the hip runtime to one GPU.
+ srun --gpu-bind=none ./select_gpu_4359428 gpu_check -l\nMPI 000 - OMP 000 - HWT 001 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 000 - OMP 001 - HWT 002 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 001 - OMP 000 - HWT 003 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 001 - OMP 001 - HWT 004 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 002 - OMP 000 - HWT 005 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 002 - OMP 001 - HWT 006 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 003 - OMP 000 - HWT 007 (CCD0) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 003 - OMP 001 - HWT 008 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 004 - OMP 000 - HWT 009 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 004 - OMP 001 - HWT 010 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 4 - Bus_ID d1(GCD4/CCD0)\nMPI 005 - OMP 000 - HWT 011 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 005 - OMP 001 - HWT 012 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 5 - Bus_ID d6(GCD5/CCD1)\nMPI 006 - OMP 000 - HWT 013 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 006 - OMP 001 - HWT 014 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 6 - Bus_ID d9(GCD6/CCD4)\nMPI 007 - OMP 000 - HWT 015 (CCD1) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 007 - OMP 001 - HWT 016 (CCD2) - Node nid007379 - RT_GPU_ID 0 - GPU_ID 7 - Bus_ID dc(GCD7/CCD5)\nMPI 008 - OMP 000 - HWT 001 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 008 - OMP 001 - HWT 002 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1(GCD0/CCD6)\nMPI 009 - OMP 000 - HWT 003 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 009 - OMP 001 - HWT 004 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID c6(GCD1/CCD7)\nMPI 010 - OMP 000 - HWT 005 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 010 - OMP 001 - HWT 006 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID c9(GCD2/CCD2)\nMPI 011 - OMP 000 - HWT 007 (CCD0) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\nMPI 011 - OMP 001 - HWT 008 (CCD1) - Node nid007380 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID cc(GCD3/CCD3)\n
Example job script when using 2 GPUs per task.
#! /bin/bash\n#SBATCH --account=project_46YXXXXXX\n#SBATCH --job-name=map-smallg-2gpt\n#SBATCH --output %x-%j.txt\n#SBATCH --partition=small-g\n#SBATCH --ntasks=6\n#SBATCH --cpus-per-task=2\n#SBATCH --gpus-per-task=2\n#SBATCH --hint=nomultithread\n#SBATCH --time=5:00\n\nmodule load LUMI/23.09 partition/G lumi-CPEtools/1.1-cpeCray-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$((SLURM_LOCALID*2)),\\$((SLURM_LOCALID*2+1))\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\ncat << EOF > echo_dev_$SLURM_JOB_ID\n#!/bin/bash\nprintf -v task \"%02d\" \\$SLURM_PROCID\necho \"Task \\$task or node.local_id \\$SLURM_NODEID.\\$SLURM_LOCALID sees ROCR_VISIBLE_DEVICES=\\$ROCR_VISIBLE_DEVICES\"\nEOF\nchmod +x ./echo_dev_$SLURM_JOB_ID\n\nset -x\nsrun gpu_check -l\nsrun ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID ./echo_dev_$SLURM_JOB_ID | sort\nsrun --gpu-bind=none ./select_gpu_$SLURM_JOB_ID gpu_check -l\nset +x\n\n/bin/rm -f select_gpu_$SLURM_JOB_ID echo_dev_$SLURM_JOB_ID\n
The changes that were required are only minimal. We now assign 2 GPUs to ROCR_VISIBLE_DEVICES which is easily done with some bash arithmetic.
"},{"location":"2day-next/07-Binding/#further-material","title":"Further material","text":" -
Distribution and binding is discussed in more detail in our 4-day comprehensive LUMI courses. Check for the lecture on \"Advanced Placement\" which is usually given on day 2 of the course.
Material of this presentation is available to all LUMI users on the system. Check the course website for the names of the files.
-
Rank reordering in Cray MPICH is discussed is also discussed in more detail in our 4-day comprehensive LUMI courses, but in the lecture on \"MPI Topics on the HPE Cray EX Supercomputer\" (often on day 3 of the course) that discusses more advanced MPI on LUMI, including loads of environment variables that can be used to improve the performance.
"},{"location":"2day-next/08-Lustre/","title":"Using Lustre","text":""},{"location":"2day-next/08-Lustre/#file-systems-on-lumi","title":"File systems on LUMI","text":"Supercomputing since the second half of the 1980s has almost always been about trying to build a very fast system from relatively cheap volume components or technologies (as low as you can go without loosing too much reliability) and very cleverly written software both at the system level (to make the system look like a true single system as much as possible) and at the application level (to deal with the restrictions that inevitably come with such a setup).
The Lustre parallel file system that we use on LUMI (and that is its main file system serving user files) fits in that way of thinking. A large file system is built by linking many fairly regular file servers through a fast network to the compute resources to build a single system with a lot of storage capacity and a lot of bandwidth. It has its restrictions also though: not all types of IOPs (number of I/O operations per second) scale as well or as easily as bandwidth and capacity so this comes with usage restrictions on large clusters that may a lot more severe than you are used to from small systems. And yes, it is completely normal that some file operations are slower than on the SSD of a good PC.
HPE Cray EX systems go even one step further. Lustre is the only network file system directly served to the compute nodes. Other network file system come via a piece of software called Data Virtualisation Service (abbreviated DVS) that basically forwards I/O requests to servers in the management section of the cluster where the actual file system runs. This is part of the measures that Cray takes in Cray Operating System to minimise OS jitter on the compute nodes to improve scalability of applications, and to reduce the memory footprint of the OS on the compute nodes.
"},{"location":"2day-next/08-Lustre/#lustre-building-blocks","title":"Lustre building blocks","text":"A key element of Lustre - but also of other parallel file systems for large parallel computers such as BeeGFS, Spectrum Scale (formerly GPFS) or PanFS - is the separation of metadata and the actual file data, as the way both are accessed and used is very different.
A Lustre system consists of the following blocks:
-
Metadata servers (MDSes) with one or more metadata targets (MDTs) each store namespace metadata such as filenames, directories and access permissions, and the file layout.
Each MDT is a filesystem, usually with some level of RAID or similar technologies for increased reliability. Usually there is also more than one MDS and they are put in a high availability setup for increased availability (and this is the case in LUMI).
Metadata is accessed in small bits and it does not need much capacity. However, metadata accesses are hard to parallelise so it makes sense to go for the fastest storage possible even if that storage is very expensive per terabyte. On LUMI all metadata servers use SSDs.
-
Object storage servers (OSSes) with one or more object storage targets (OSTs) each store the actual data. Data from a single file can be distributed across multiple OSTs and even multiple OSSes. As we shall see, this is also the key to getting very high bandwidth access to the data.
Each OST is a filesystem, again usually with some level of RAID or similar technologies to survive disk failures. One OSS typically has between 1 and 8 OSTs, and in a big setup a high availability setup will be used again (as is the case in LUMI).
The total capacity of a Lustre file system is the sum of the capacity of all OSTs in the Lustre file system. Lustre file systems are often many petabytes large.
Now you may think differently based upon prices that you see in the PC market for hard drives and SSDs, but SSDs of data centre quality are still up to 10 times as expensive as hard drives of data centre quality. Building a file system of several tens of petabytes out of SSDs is still extremely expensive and rarely done, certainly in an environment with a high write pressure on the file system as that requires the highest quality SSDs. Hence it is not uncommon that supercomputers will use mostly hard drives for their large storage systems.
On LUMI there is roughly 80 PB spread across 4 large hard disk based Lustre file systems, and 8.5 PB in an SSD-based Lustre file system. However, all MDSes use SSD storage.
-
Lustre clients access and use the data. They make the whole Lustre file system look like a single file system.
Lustre is transparent in functionality. You can use a Lustre file system just as any other regular file system, with all your regular applications. However, it is not transparent when it comes to performance: How you use Lustre can have a huge impact on performance. Lustre is optimised very much for high bandwidth access to large chunks of data at a time from multiple nodes in the application simultaneously, and is not very good at handling access to a large pool of small files instead.
So you have to store your data (but also your applications as the are a kind of data also) in an appropriate way, in fewer but larger files instead of more smaller files. Some centres with large supercomputers will advise you to containerise software for optimal performance. On LUMI we do advise Python users or users who install software through Conda to do so.
-
All these components are linked together through a high performance interconnect. On HPE Cray EX systems - but on more an more other systems also - there is no separate network anymore for storage access and the same high performance interconnect that is also used for internode communication by applications (through, e.g., MPI) is used for that purpose.
-
There is also a management server which is not mentioned on the slides, but that component is not essential to understand the behaviour of Lustre for the purpose of this lecture.
Links
See also the \"Lustre Components\" in \"Understanding Lustre Internals\" on the Lustre Wiki
"},{"location":"2day-next/08-Lustre/#striping-large-files-are-spread-across-osts","title":"Striping: Large files are spread across OSTs","text":"On Lustre, large files are typically broken into blocks called stripes or chunks that are then cyclically spread across a number of chunk files called objects in LUSTRE, each on a separate OST. In the figure in the slide above, the file is spread across the OSTs 0, 2, 4 and 6.
This process is completely transparent to the user with respect to correctness. The Lustre client takes care of the process and presents a traditional file to the application program. It is however not transparent with respect to performance. The performance of reading and writing a file depends a lot on how the file is spread across the OSTs of a file system.
Basically, there are two parameters that have to be chosen: The size of the stripes (all stripes have the same size in this example, except for the last one which may be smaller) and the number of OSTs that should be used for a file. Lustre itself takes care of choosing the OSTs in general.
There are variants of Lustre where one has multiple layouts per file which can come in handy if one doesn't know the size of the file in advance. The first part of the file will then typically be written with fewer OSTs and/or smaller chunks, but this is outside the scope of this course. The feature is known as Progressive File Layout.
The stripe size and number of OSTs used can be chosen on a file-by-file basis. The default on LUMI is to use only one OST for a file. This is done because that is the most reasonable choice for the many small files that many unsuspecting users have, and as we shall see, it is sometimes even the best choice for users working with large files. But it is not always the best choice. And unfortunately there is no single set of parameters that is good for all users.
Objects
The term \"object\" nowadays has different meanings, even in the storage world. The Object Storage Servers in Lustre should not be confused with the object storage used in cloud solutions such as Amazon Web Services (AWS) with the S3 storage service or the LUMI-O object storage. In fact, the Object Storage Servers use a regular file system such as ZFS or ldiskfs to store the \"objects\".
"},{"location":"2day-next/08-Lustre/#accessing-a-file","title":"Accessing a file","text":"Let's now study how Lustre will access a file for reading or writing. Let's assume that the second client in the above picture wants to write something to the file.
-
The first step is opening the file.
For that, the Lustre client has to talk to the metadata server (MDS) and query some information about the file.
The MDS in turn will return information about the file, including the layout of the file: chunksize and the OSSes/OSTs that keep the chunks of the file.
-
From that point on, the client doesn't need to talk to the MDS anymore and can talk directly to the OSSes to write data to the OSTs or read data from the OSTs.
"},{"location":"2day-next/08-Lustre/#parallelism-is-key","title":"Parallelism is key!","text":"The metadata servers can be the bottleneck in a Lustre setup. It is not easy to spread metadata across multiple MDSes efficiently. Moreover, the amount of metadata for any given file is small, so any metadata operation will translate into small disk accesses on the MDTs and hence not fully exploit the speed that some RAID setups can give you.
However, when reading and writing data, there are up to four levels of parallelism:
-
The read and write operations can engage multiple OSSes.
-
Since a single modern OSS can handle more bandwidth than a some OSTs can deliver, OSSes may have multiple OSTs.
How many OSTs are engaged is something that a user has control over.
-
An OST will contain many disks or SSDs, typically with some kind of RAID, but hence each read or write operation to an OST can engage multiple disks.
An OST will only be used optimally when doing large enough file accesses. But the file system client may help you here with caching.
-
Internally, SSDs are also parallel devices. The high bandwidth of modern high-end SSDs is the result of engaging multiple channels to the actual storage \"chips\" internally.
So to fully benefit from a Lustre file system, it is best to work with relatively few files (to not overload the MDS) but very large disk accesses. Very small I/O operations wouldn't even benefit from the RAID acceleration, and this is especially true for very small files as they cannot even benefit from caching provided by the file system client (otherwise a file system client may read in more data than requested, as file access is often sequential anyway so it would be prepared for the next access). To make efficient use of the OSTs it is important to have a relatively large chunk size and relatively large I/O operations, even more so for hard disk based file systems as if the OST file system manages to organise the data well on disk, it is a good way to reduce the impact on effective bandwidth of the inherent latency of disk access. And to engage multiple OSTs simultaneously (and thus reach a bandwidth which is much higher than a single OST can provide), even larger disk accesses will be needed so that multiple chunks are read or written simultaneously. Usually you will have to do the I/O in a distributed memory application from multiple nodes simultaneously as otherwise the bandwidth to the interconnect and processing capacity of the client software of a single node might become the limiting factor.
Not all codes are using Lustre optimally though, even with the best care of their users.
-
Some codes use files in scientific data formats like HDF5 and netCDF, and when written properly they can have very scalable performance.
A good code will write data to large files, from multiple nodes simultaneously, but will avoid doing I/O from too many ranks simultaneously to avoid bombarding the OSSes/OSTs with I/O requests. But that is a topic for a more advanced course...
One user has reported reading data from the hard disk based parallel file systems at about 25% of the maximal bandwidth, which is very good given that other users where also using that file system at the same time and not always in an optimal way.
Surprisingly many of these codes may be rather old. But their authors grew up with noisy floppy drives (do you still know what that is) and slow hard drives so learned how to program efficiently.
-
But some codes open one or more files per MPI rank. Those codes may have difficulties scaling to a large number of ranks, as they will put a heavy burden on the MDS when those files are created, but also may bombard each OSS/OST with too many I/O requests.
Some of these codes are rather old also, but were never designed to scale to thousands of MPI ranks. However, nowadays some users are trying to solve such big problems that the computations do scale reasonably well. But the I/O of those codes becomes a problem...
-
But some users simply abuse the file system as an unstructured database and simply drop their data as tens of thousands or even millions of small files with each one data element, rather than structuring that data in suitable file formats. This is especially common in science fields that became popular relatively recently - bio-informatics and AI - as those users typically started their work on modern PCs with fast SSDs.
The problem there is that metadata access and small I/O operations don't scale well to large systems. Even copying such a data set to a local SSD would be a problem should a compute node have a local SSD, but local SSDs suitable for supercomputers are also very expensive as they have to deal with lots of write operations. Your gene data or training data set may be relatively static, but on a supercomputer you cannot keep the same node for weeks so you'd need to rewrite your data to local disks very often. And there are shared file systems with better small file performance than Lustre, but those that scale to the size of even a fraction of Lustre, are also very expensive. And remember that supercomputing works exactly the opposite way: Try to reduce costs by using relatively cheap hardware but cleverly written software at all levels (system and application) as at a very large scale, this is ultimately cheaper than investing more in hardware and less in software.
Lustre was originally designed to achieve very high bandwidth to/from a small number of files, and that is in fact a good match for well organised scientific data sets and/or checkpoint data, but was not designed to handle large numbers of small files. Nowadays of course optimisations to deal better with small files are being made, but they may come at a high hardware cost.
"},{"location":"2day-next/08-Lustre/#how-to-determine-the-striping-values","title":"How to determine the striping values?","text":"If you only access relatively small files (up to a few hundreds of kilobytes) and access them sequentially, then you are out of luck. There is not much you can do. Engaging multiple OSTs for a single file is not useful at all in this case, and you will also have no parallelism from accessing multiple files that may be stored on different OSTs. The metadata operations may also be rather expensive compared to the cost of reading the file once opened.
As a rule of thumb, if you access a lot of data with a data access pattern that can exploit parallelism, try to use all OSTs of the Lustre file system without unnecessary overloading them:
-
If the number of files that will be accessed simultaneously is larger than the number of OSTs, it is best to not spread a single file across OSTs and hence use a stripe count of 1.
It will also reduce Lustre contention and OST file locking and as such gain performance for everybody.
-
At the opposite end, if you access only one very large file and use large or parallel disk accesses, set the stripe count to the number of OSTs (or a smaller number if you notice in benchmarking that the I/O performance plateaus). On a system the size of LUMI with storage as powerful as on LUMI, this will only work if you have more than on I/O client.
-
When using multiple similar sized files simultaneously but less files than there are OSTs, you should probably chose the stripe count such that the product of the number of files and the stripe count is approximately the number of OSTs. E.g., with 32 OSTs and 8 files, set the stripe count to 4.
It is better not to force the system to use specific OSTs but to let it chose OSTs at random.
The typical stripe size (size of the chunks) to use can be a bit harder to determine. Typically this will be 1MB or more, and it can be up to 4 GB, but that only makes sense for very large files. The ideal stripe size will also depend on the characteristics of the I/O in the file. If the application never writes more than 1 GB of data in a single sequential or parallel I/O operation before continuing with more computations, obviously with a stripe size of 1 GB you'd be engaging only a single OST for each write operation.
"},{"location":"2day-next/08-Lustre/#managing-the-striping-parameters","title":"Managing the striping parameters","text":"The basic Lustre command for regular users to do special operations on Lustre is the lfs command, which has various subcommands.
The first interesting subcommand is df which has a similar purpose as the regular Linux df command: Return information about the filesystem. In particular,
lfs df -h\n
will return information about all available Lustre filesystems. The -h flag tells the command to use \"human-readable\" number formats: return sizes in gigabytes and terabytes rather than blocks. On LUMI, the output starts with:
$ lfs df -h\nUUID bytes Used Available Use% Mounted on\nlustref1-MDT0000_UUID 11.8T 16.8G 11.6T 1% /pfs/lustref1[MDT:0]\nlustref1-MDT0001_UUID 11.8T 4.1G 11.6T 1% /pfs/lustref1[MDT:1]\nlustref1-MDT0002_UUID 11.8T 2.8G 11.7T 1% /pfs/lustref1[MDT:2]\nlustref1-MDT0003_UUID 11.8T 2.7G 11.7T 1% /pfs/lustref1[MDT:3]\nlustref1-OST0000_UUID 121.3T 21.5T 98.5T 18% /pfs/lustref1[OST:0]\nlustref1-OST0001_UUID 121.3T 21.6T 98.4T 18% /pfs/lustref1[OST:1]\nlustref1-OST0002_UUID 121.3T 21.4T 98.6T 18% /pfs/lustref1[OST:2]\nlustref1-OST0003_UUID 121.3T 21.4T 98.6T 18% /pfs/lustref1[OST:3]\n
so the command can also be used to see the number of MDTs and OSTs available in each filesystem, with the capacity.
Striping in Lustre is set at a filesystem level by the sysadmins, but users can adjust the settings at the directory level (which then sets the default for files created in that directory) and file level. Once a file is created, the striping configuration cannot be changed anymore on-the-fly.
To inspect the striping configuration, one can use the getstripe subcommand of lfs.
Let us first use it at the directory level:
$ lfs getstripe -d /appl/lumi/SW\nstripe_count: 1 stripe_size: 1048576 pattern: 0 stripe_offset: -1\n\n$ lfs getstripe -d --raw /appl/lumi/SW\nstripe_count: 0 stripe_size: 0 pattern: 0 stripe_offset: -1\n
The -d flag tells that we only want information about the directory itself and not about everything in that directory. The first lfs getstripe command tells us that files created in this directory will use only a single OST and have a stripe size of 1 MiB. By adding the --raw we actually see the settings that have been made specifically for this directory. The 0 for stripe_count and stripe_size means that the default value is being used, and the stripe_offset of -1 also indicates the default value.
We can also use lfs getstripe for individual files:
$ lfs getstripe /appl/lumi/LUMI-SoftwareStack/etc/motd.txt\n/appl/lumi/LUMI-SoftwareStack/etc/motd.txt\nlmm_stripe_count: 1\nlmm_stripe_size: 1048576\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 10\n obdidx objid objid group\n 10 56614379 0x35fddeb 0\n
Now lfs getstripe does not only return the stripe size and number of OSTs used, but it will also show the OSTs that are actually used (in the column obdidx of the output). The lmm_stripe_offset is also the number of the OST with the first object of the file.
The final subcommand that we will discuss is the setstripe subcommand to set the striping policy for a file or directory.
Let us first look at setting a striping policy at the directory level:
$ module use /appl/local/training/modules/2day-20240502\n$ module load lumi-training-tools\n$ mkdir testdir\n$ lfs setstripe -S 2m -c 4 testdir\n$ cd testdir\n$ mkfile 2g testfile1\n$ lfs getstripe testfile1\ntestfile1\nlmm_stripe_count: 4\nlmm_stripe_size: 2097152\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 28\n obdidx objid objid group\n 28 66250987 0x3f2e8eb 0\n 30 66282908 0x3f3659c 0\n 1 71789920 0x4476d60 0\n 5 71781120 0x4474b00 0\n
The lumi-training-tools module provides the mkfile command that we use in this example.
We first create a directory and then set the striping parameters to a stripe size of 2 MiB (the -S flag) and a so-called stripe count, the number of OSTs used for the file, of 4 (the -c flag).
Next we go into the subdirectory and use the mkfile command to generate a file of 2 GiB.
When we now check the file layout of the file that we just created with lfs getstripe, we see that the file now indeed uses 4 OSTs with a stripe size of 2 MiB, and has object on in this case OSTs 28, 30, 1 and 5.
However, we can even control striping at the level of an individual file. The condition is that the layout of the file is set as soon as it is created. We can do this also with lfs setstripe:
$ lfs setstripe -S 16m -c 2 testfile2\n$ ls -lh\ntotal 0\n-rw-rw---- 1 XXXXXXXX project_462000000 2.0G Jan 15 16:17 testfile1\n-rw-rw---- 1 XXXXXXXX project_462000000 0 Jan 15 16:23 testfile2\n$ lfs getstripe testfile2\ntestfile2\nlmm_stripe_count: 2\nlmm_stripe_size: 16777216\nlmm_pattern: raid0\nlmm_layout_gen: 0\nlmm_stripe_offset: 10\n obdidx objid objid group\n 10 71752411 0x446dadb 0\n 14 71812909 0x447c72d 0\n
In this example, the lfs setstripe command will create an empty file but with the required layout. In this case we have set the stripe size to 16 MiB and use only 2 OSTs, and the lfs getstripe command confirms that information. We can now open the file to write data into it with the regular file operations of the Linux glibc library or your favourite programming language (though of course you need to take into account that the file already exists so you should use routines that do not return an error if the file already exists).
Lustre API
Lustre also offers a C API to directly set file layout properties, etc., from your package. Few scientific packages seem to support it though.
"},{"location":"2day-next/08-Lustre/#the-metadata-servers","title":"The metadata servers","text":"Parallelising metadata access is very difficult. Even large Lustre filesystems have very few metadata servers. They are a finite and shared resource, and overloading the metadata server slows down the file system for all users.
The metadata servers are involved in many operations. The play a role in creating, opening and also closing files. The provide some of the attributes of a file. And they also play a role in file locking.
Yet the metadata servers have a very finite capacity. The Lustre documentation claims that in theory a single metadata server should be capable of up to 200,000 operations per second, depending on the type of request. However, 75,000 operations per second may be more realistic.
As a user, many operations that you think are harmless from using your PC, are in fact expensive operations on a supercomputer with a large parallel file system and you will find \"Lustre best practices\" pages on web sites of many large supercomputer centres. Some tips for regular users:
-
Any command that requests attributes is fairly expensive and should not be used in large directories. This holds even for something as trivial as ls -l. But it is even more so for commands as du that run recursively through attributes of lots of files.
-
Opening a file is also rather expensive as it involves a metadata server and one or more object servers. It is not a good idea to frequently open and close the same file while processing data.
-
Therefore access to many small files from many processes is not a good idea. One example of this is using Python, and even more so if you do distributed memory parallel computing with Python. This is why on LUMI we ask to do big Python installations in containers. Another alternative is to run such programs from /tmp (and get them on /tmp from an archive file).
For data, it is not a good idea to dump a big dataset as lots of small files on the filesystem. Data should be properly organised, preferably using file formats that support parallel access from many processes simultaneously. Technologies popular in supercomputing are HDF5, netCDF and ADIOS2. Sometimes libraries that read tar-files or other archive file formats without first fully uncompressing, may even be enough for read-only data. Or if your software runs in a container, you may be able to put your read-only dataset into a SquashFS file and mount into a container.
-
Likewise, shuffling data in a distributed memory program should not be done via the filesystem (put data on a shared filesystem and then read it again in a different order) but by direct communication between the processes over the interconnect.
-
It is also obvious that directories with thousands of files should be avoided as even an ls -l command on that directory generates a high load on the metadata servers. But the same holds for commands such as du or find.
Note that the lfs command also has a subcommand find (see man lfs-find), but it cannot do everything that the regular Linux find command can do. E.g., the --exec functionality is missing. But to simply list files it will put less strain on the filesystem as running the regular Linux find command.
There are many more tips more specifically for programmers. As good use of the filesystems on a supercomputer is important and wrong use has consequences for all other users, it is an important topic in the 4-day comprehensive LUMI course that the LUMI User Support Team organises a few times per year, and you'll find many more tips about proper use of Lustre in that lecture (which is only available to actual users on LUMI unfortunately).
"},{"location":"2day-next/08-Lustre/#lustre-on-lumi","title":"Lustre on LUMI","text":"LUMI has 5 Lustre filesystems:
The file storage sometimes denoted as LUMI-P consists of 4 disk based Lustre filesystems, each with a capacity of roughly 18 PB and 240 GB/s aggregated bandwidth in the optimal case (which of course is shared by all users, no single user will ever observe that bandwidth unless they have the machine for themselves). Each of the 4 systems has 2 MDTs, one per MDS (but in a high availability setup), and 32 OSTs spread across 16 OSSes, so 2 OSTs per OSS. All 4 systems are used to serve the home directories, persistent project space and regular scratch space, but also, e.g., most of the software pre-installed on LUMI. Some of that pre-installed software is copied on all 4 systems to distribute the load.
The fifth Lustre filesystem of LUMI is also known as LUMI-F, where the \"F\" stands for flash as it is entirely based on SSDs. It currently has a capacity of approximately 8.5 PB and a total of over 2 TB/s aggregated bandwidth. The system has 4 MDTs spread across 4 MDSes, and 72 OSTs and 72 OSSes, os 1 OST per OSS (as a single OST already offers a lot more bandwidth and hence needs more server capacity than a hard disk based OST).
"},{"location":"2day-next/08-Lustre/#links","title":"Links","text":" -
The lfs command itself is documented through a manual page that can be accessed at the LUMI command line with man lfs. The various subcommands each come with their own man page, e.g., lfs-df, lfs-getstripe, lfs-setstripe and lfs-find.
-
Understanding Lustre Internals on the Lustre Wiki.
-
Lustre Basics and Lustre Best Practices in the knowledge base of the NASA supercomputers.
-
Introduction to DVS in an administration guide
"},{"location":"2day-next/09-Containers/","title":"Containers on LUMI-C and LUMI-G","text":""},{"location":"2day-next/09-Containers/#what-are-we-talking-about-in-this-chapter","title":"What are we talking about in this chapter?","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers,
-
and pay some attention to the use of some of our pre-built AI containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"2day-next/09-Containers/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers built on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software. Containers may offer more reproducibility than recompiling software for a different platform, but all you're trying to do is reproducing the same wrong result as in particular floating point operations are only an approximation for real numbers. When talking about reproducibility, you should think the way experimentalists do: You have a result and an error margin, and it is important to have an idea of that error margin too.
But full portability is as much a myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the Slingshot interconnect, may fail (or if you're lucky just fall back to TCP sockets in MPI, completely killing scalability, but technically speaking still working so portable). Containers that expect a certain version range of a particular driver on the system may fail if a different, out-of-range version of that driver is on the system instead (think the ROCm driver).
Even if a container is portable to LUMI, it may not yet be performance-portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At UAntwerpen we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"2day-next/09-Containers/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
Software installations that would otherwise be impossible. E.g., some software may not even be suited for installation in a multi-user HPC system as it uses fixed paths that are not compatible with installation in module-controlled software stacks. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system software region. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
They are also of interest if compiling the software takes too much work while any processor-specific optimisation that could be obtained by compiling oneself, isn't really important. E.g., if a full stack of GUI libraries is needed, as they are rarely the speed-limiting factor in an application.
-
As an example, Conda installations are not appreciated on the main Lustre file system.
On one hand, Conda installations tend to generate lots of small files (and then even more due to a linking strategy that does not work on Lustre). So they need to be containerised just for storage manageability.
They also re-install lots of libraries that may already be on the system in a different version. The isolation offered by a container environment may be a good idea to ensure that all software picks up the right versions.
-
An example of software that is usually very hard to install is a GUI application, as they tend to have tons of dependencies and recompiling can be tricky. Yet rather often the binary packages that you can download cannot be installed wherever you want, so a container can come to the rescue.
-
Another example where containers have proven to be useful on LUMI is to experiment with newer versions of ROCm than we can offer on the system.
This often comes with limitations though, as (a) that ROCm version is still limited by the drivers on the system and (b) we've seen incompatibilities between newer ROCm versions and the Cray MPICH libraries.
-
And a combination of both: LUST with the help of AMD have prepared some containers with popular AI applications. These containers use some software from Conda, a newer ROCm version installed through RPMs, and some performance-critical code that is compiled specifically for LUMI.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"2day-next/09-Containers/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS. Currently we offer Singularity Community Edition 4.1.3.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container either by creating a tarball from a docker container on the remote system and then converting that to the singularity .sif format on LUMI, or by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory. This can lead to exhaustion of your disk quota for your home directory. So you may want to use the environment variable SINGULARITY_CACHEDIR to put the cache in, e.g,, your scratch space (but even then you want to clean up after the pull operation so save on your storage billing units).
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require user namespaces, cannot be supported for security reasons (as user namespaces in Linux are riddled with security issues). Enabling features that are known to have had several serious security vulnerabilities in the recent past, or that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container using what the SingularityCE user guide calls \"unprivileged proot builds\". This requires loading the proot command which is provided by the systools/23.09 module or later versions provided in CrayEnv or LUMI/23.09 or later. The SingularityCE user guide mentions several restrictions of this process. The general guideline from the manual is: \"Generally, if your definition file starts from an existing SIF/OCI container image, and adds software using system package managers, an unprivileged proot build is appropriate. If your definition file compiles and installs large complex software from source, you may wish to investigate --remote or --fakeroot builds instead.\" But on LUMI we cannot yet provide --fakeroot builds due to security constraints (as that process also requires user namespaces).
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI (and some for ROCm are already there).
"},{"location":"2day-next/09-Containers/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and /dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables. E.g.,
export SINGULARITY_BIND='/pfs,/scratch,/projappl,/project,/flash'\n
will ensure that you have access to the scratch, project and flash directories of your project.
For some containers that are provided by the LUMI User Support Team, modules are also available that set SINGULARITY_BINDPATH so that all necessary system libraries are available in the container and users can access all their files using the same paths as outside the container.
"},{"location":"2day-next/09-Containers/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI Slingshot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and until version 5 full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the Slingshot 11 interconnect, so work is going on for better support for OFI in general and Cray Slingshot in particular and for full GPU support.
"},{"location":"2day-next/09-Containers/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
"},{"location":"2day-next/09-Containers/#bindings-for-singularity","title":"Bindings for singularity","text":"The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY_PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the singularity-bindings in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
"},{"location":"2day-next/09-Containers/#vnc-container","title":"VNC container","text":"The second tool is a container that we provide with some bash functions to start a VNC server as one way to run GUI programs and as an alternative to the (currently more sophisticated) VNC-based GUI desktop setup offered in Open OnDemand (see the \"Getting Access to LUMI notes\"). It can be used in CrayEnv or in the LUMI stacks through the lumi-vnc module. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
For most users, the Open OnDemand web interface and tools offered in that interface will be a better alternative.
"},{"location":"2day-next/09-Containers/#cotainr-build-conda-containers-on-lumi","title":"cotainr: Build Conda containers on LUMI","text":"The third tool is cotainr, a tool developed by DeIC, the Danish partner in the LUMI consortium. It is a tool to pack a Conda installation into a container. It runs entirely in user space and doesn't need any special rights. (For the container specialists: It is based on the container sandbox idea to build containers in user space.)
Containers build with cotainr are used just as other containers, so through the singularity commands discussed before.
AI course
The cotainr tool is also used extensively in our AI training/workshop to build containers with AI software on top of some ROCmTM containers that we provide.
"},{"location":"2day-next/09-Containers/#container-wrapper-for-python-packages-and-conda","title":"Container wrapper for Python packages and conda","text":"The fourth tool is a container wrapper tool that users from Finland may also know as Tykky (the name on their national systems). It is a tool to wrap Python and conda installations in a container and then create wrapper scripts for the commands in the bin subdirectory so that for most practical use cases the commands can be used without directly using singularity commands. Whereas cotainr fully exposes the container to users and its software is accessed through the regular singularity commands, Tykky tries to hide this complexity with wrapper scripts that take care of all bindings and calling singularity. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks.
The tool can work in four modes:
-
It can create a conda environment based on a Conda environment file and create wrapper scripts for that installation.
-
It can install a number of Python packages via pip and create wrapper scripts. On LUMI, this is done on top of one of the cray-python modules that already contain optimised versions of NumPy, SciPy and pandas. Python packages are specified in a requirements.txt file used by pip.
-
It can do a combination of both of the above: Install a Conda-based Python environment and in one go also install a number of additional Python packages via pip.
-
The fourth option is to use the container wrapper to create wrapper scripts for commands in an existing container.
For the first three options, the container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation. So strictly speaking it does not create a container, but a SquashFS file that is then mounted in a small existing base container. However, the wrappers created for all commands in the bin subdirectory of the conda or Python installation take care of doing the proper bindings. If you want to use the container through singularity commands however, you'll have to do that mounting by hand, including mounting the SquashFS file on the right directory in the container.
Note that the wrapper scripts may seem transparent, but running a script that contains the wrapper commands outside the container may have different results from running the same script inside the container. The reason is that each of the wrapper commands internally still call singularity to run the command in the container, and singularity does not pass the whole environment to the container, but only environment variables that are explicitly defined to be passed to the container by prepending their name with SINGULARITYENV_. E.g., when running AI application such as PyTorch, several environment variables need to be set in advance and doing so with the regular names would not work with the wrapper scripts.
We do strongly recommend to use cotainr or the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper for a Conda installation Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a tempororary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
Relevant documentation for lumi-container-wrapper
- Page in the main LUMI documentation
lumi-container-wrapper in the LUMI Software Library- Tykky page in the CSC documentation
"},{"location":"2day-next/09-Containers/#pre-built-ai-containers","title":"Pre-built AI containers","text":"LUST with the help of AMD is also building some containers with popular AI software. These containers contain a ROCm version that is appropriate for the software, use Conda for some components, but have several of the performance critical components built specifically for LUMI for near-optimal performance. Depending on the software they also contain a RCCL library with the appropriate plugin to work well on the Slingshot 11 interconnect, or a horovod compiled to use Cray MPICH.
The containers can be provided through a module that is user-installable with EasyBuild. That module sets the SINGULARITY_BIND environment variable to ensure proper bindings (as they need, e.g., the libfabric library from the system and the proper \"CXI provider\" for libfabric to connect to the Slingshot interconnect). The module will also provide an environment variable to refer to the container (name with full path) to make it easy to refer to the container in job scripts. Some of the modules also provide some scripts that may make using the containers easier in some standard scenarios. Alternatively, the user support team is also working on some modules for users who want to run the containers as manually as possible yet want an easy way to deal with the necessary bindings of user file systems and HPE Cray PE components needed from the system (see also course notes for the AI training/workshop, still \"future\" at the time of this course so we cannot link to them).
These containers can be found through the LUMI Software Library and are marked with a container label. At the time of the course, there are containers for
- PyTorch, which is the best tested and most developed one,
- TensorFlow,
- JAX,
- AlphaFold,
- ROCm and
- mpi4py.
"},{"location":"2day-next/09-Containers/#running-the-ai-containers-complicated-way-without-modules","title":"Running the AI containers - complicated way without modules","text":"The containers that we provide have everything they need to use RCCL and/or MPI on LUMI. It is not needed to use the singularity-bindings/system module described earlier as that module tries to bind too much external software to the container.
Yet to be able to properly use the containers, users do need to take care of some bindings
-
Some system directories and libraries have to be bound to the container:
-B /var/spool/slurmd,/opt/cray,/usr/lib64/libcxi.so.1,/usr/lib64/libjansson.so.4\n
The first one is needed to work together with Slurm. The second one contains the MPI and libfabric library. The third one is the actual component that binds libfabric to the Slingshot network adapter and is called the CXI provider, and the last one is a library that is needed by some LUMI system libraries but not in the container.
-
By default your home directory will be available in the container, but as your home directory is not your main workspace, you may want to bind your subdirectory in /project, /scratch and/or /flash also.
There are also a number of components that may need further initialisation:
-
The MIOpen library has problems with file/record locking on Lustre so some environment variables are needed to move some work directories.
-
RCCL needs to be told the right network interfaces to use as otherwise it tends to take the interface to the management network of the cluster instead and gets stuck.
-
GPU-aware MPI also needs to be set up (see earlier in the course)
-
Your AI package may need some environment variables too (e.g., MASTER_ADDR and MASTER_PORT for distributed learning with PyTorch)
Moreover, most (if not all at the moment) containers that we provide with Python packages, are built using Conda to install Python. When entering those containers, conda needs to be activated. The containers are built in such a way that the environment variable WITH_CONDA provides the necessary command, so in most cases you only need to run
$WITH_CONDA\n
as a command in the script that is executed in the container or on the command line.
"},{"location":"2day-next/09-Containers/#running-the-containers-through-easybuild-generated-modules","title":"Running the containers through EasyBuild-generated modules","text":"Doing all those initialisations, is a burden. Therefore we provide EasyBuild recipes to \"install\" the containers and to provide a module that helps setting environment variables in the initialisation.
For packages for which we know generic usage patterns, we provide some scripts that do most settings. When using the module, those scripts will be available in the /runscripts directory in the container, but are also in a subdirectory on the Lustre file system. So in principle you can even edit them or add your own scripts, though they would be erased if you reinstall the module with EasyBuild.
They also define a number of environment variables that make life easier. E.g., the SINGULARITY_BINDPATH environment variable is already set to bind the necessary files and directories from the system and to make sure that your project, scratch and flash spaces are available at the same location as on LUMI so that even symbolic links in those directories should still work.
We recently started adding a pre-configured virtual environment to the containers to add your own packages. The virtual environment can be found in the container in a subdirectory of /user-software/venv. To install packages from within the container, this directory needs to be writeable which is done by binding /user-software to the $CONTAINERROOT/user-software subdirectory outside the container. If you add a lot of packages that way, you re-create the filesystem issues that the container is supposed to solve, but we have a solution for that also. These containers provide the make-squashfs command to generate a SquashFS file from the installation that will be used by the container instead next time the module for the container is reloaded. And in case you prefer to fully delete the user-software subdirectory afterwards from $CONTAINERROOT, it can be re-created using unmake-squashfs so that you can add further packages. You can also use /user-software to install software in other ways from within the container and can basically create whatever subdirectory you want into it.
These containers with pre-configured virtual environment offer another advantage also: The module injects a number of environment variables into the container so that it is no longer needed to activate the conda environment and Python virtual environment by sourcing scripts.
In fact, someone with EasyBuild experience may even help you to further extend the recipe that we provide to already install extra packages, and we provide an example of how to do that with our PyTorch containers.
Installing the EasyBuild recipes for those containers is also done via the EasyBuild-user module, but it is best to use a special trick. There is a special partition called partition/container that is only used to install those containers and when using that partition for the installation, the container will be available in all versions of the LUMI stack and in the CrayEnv stack.
Installation is as simple as, e.g.,
module load LUMI partition/container EasyBuild-user\neb PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb\n
Before running it is best to clean up (module purge) or take a new shell to avoid conflicts with environment variables provided by other modules.
The installation with EasyBuild will make a copy from the .sif Singularity container image file that we provide somewhere in /appl/local/containers to the software installation subdirectory of your $EBU_USER_PREFIX EasyBuild installation directory. These files are big and you may wish to delete that file which is easily done: After loading the container module, the environment variable SIF contains the name with full path of the container file. After removing the container file from your personal software directory, you need to reload the container module and from then on, SIF will point to the corresponding container in /appl/local/containers/easybuild-sif-images. We don't really recommend removing the container image though and certainly not if you are interested in reproducibility. We may remove the image in /appl/local/containers/easybuild-sif-images without prior notice if we notice that the container has too many problems, e.g., after a system update. But that same container that doesn't work well for others, may work well enough for you that you don't want to rebuild whatever environment you built with the container.
"},{"location":"2day-next/09-Containers/#example-distributed-learning-without-using-easybuild","title":"Example: Distributed learning without using EasyBuild","text":"To really run this example, some additional program files and data files are needed that are not explained in this text. You can find more information on the PyTorch page in the LUMI Software Library.
We'll need to create a number of scripts before we can even run the container.
The first script is a Python program to extract the name of the master node from a Slurm environment variable. Store it in get-master.py:
import argparse\ndef get_parser():\n parser = argparse.ArgumentParser(description=\"Extract master node name from Slurm node list\",\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"nodelist\", help=\"Slurm nodelist\")\n return parser\n\n\nif __name__ == '__main__':\n parser = get_parser()\n args = parser.parse_args()\n\n first_nodelist = args.nodelist.split(',')[0]\n\n if '[' in first_nodelist:\n a = first_nodelist.split('[')\n first_node = a[0] + a[1].split('-')[0]\n\n else:\n first_node = first_nodelist\n\n print(first_node)\n
Second, we need a script that we will run in the container. Store the script as run-pytorch.sh:
#!/bin/bash -e\n\n# Make sure GPUs are up\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n\n# !Remove this if using an image extended with cotainr or a container from elsewhere.!\n# Start conda environment inside the container\n$WITH_CONDA\n\n# MIOPEN needs some initialisation for the cache as the default location\n# does not work on LUMI as Lustre does not provide the necessary features.\nexport MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\nsleep 2\n\n# Optional! Set NCCL debug output to check correct use of aws-ofi-rccl (these are very verbose)\nexport NCCL_DEBUG=INFO\nexport NCCL_DEBUG_SUBSYS=INIT,COLL\n\n# Set interfaces to be used by RCCL.\n# This is needed as otherwise RCCL tries to use a network interface it has\n# no access to on LUMI.\nexport NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n\n# Set ROCR_VISIBLE_DEVICES so that each task uses the proper GPU\nexport ROCR_VISIBLE_DEVICES=$SLURM_LOCALID\n\n# Report affinity to check\necho \"Rank $SLURM_PROCID --> $(taskset -p $$); GPU $ROCR_VISIBLE_DEVICES\"\n\n# The usual PyTorch initialisations (also needed on NVIDIA)\n# Note that since we fix the port ID it is not possible to run, e.g., two\n# instances via this script using half a node each.\nexport MASTER_ADDR=$(python get-master.py \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\nexport WORLD_SIZE=$SLURM_NPROCS\nexport RANK=$SLURM_PROCID\n\n# Run app\ncd /workdir/mnist\npython -u mnist_DDP.py --gpu --modelpath model\n
The script needs to be executable.
The script sets a number of environment variables. Some are fairly standard when using PyTorch on an HPC cluster while others are specific for the LUMI interconnect and architecture or the AMD ROCm environment. We notice a number of things:
-
At the start we just print some information about the GPU. We do this only ones on each node on the process which is why we test on $SLURM_LOCALID, which is a numbering starting from 0 on each node of the job:
if [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n
-
The container uses a Conda environment internally. So to make the right version of Python and its packages availabe, we need to activate the environment. The precise command to activate the environment is stored in $WITH_CONDA and we can just call it by specifying the variable as a bash command.
-
The MIOPEN_ environment variables are needed to make MIOpen create its caches on /tmp as doing this on Lustre fails because of file locking issues:
export MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\n
These caches are used to store compiled kernels.
-
It is also essential to tell RCCL, the communication library, which network adapters to use. These environment variables start with NCCL_ because ROCm tries to keep things as similar as possible to NCCL in the NVIDIA ecosystem:
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n
Without this RCCL may try to use a network adapter meant for system management rather than inter-node communications!
-
We also set ROCR_VISIBLE_DEVICES to ensure that each task uses the proper GPU. This is again based on the local task ID of each Slurm task.
-
Furthermore some environment variables are needed by PyTorch itself that are also needed on NVIDIA systems.
PyTorch needs to find the master for communication which is done through the get-master.py script that we created before:
export MASTER_ADDR=$(python get-master.py \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\n
As we fix the port number here, the conda-python-distributed script that we provide, has to run on exclusive nodes. Running, e.g., 2 4-GPU jobs on the same node with this command will not work as there will be a conflict for the TCP port for communication on the master as MASTER_PORT is hard-coded in this version of the script.
And finally you need a job script that you can then submit with sbatch. Lets call it my-job.sh:
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --tasks-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=00:10:00\n#SBATCH --account=project_<your_project_id>\n\nCONTAINER=your-container-image.sif\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\nsrun --cpu-bind=mask_cpu:$MYMASKS \\\nsingularity exec \\\n -B /var/spool/slurmd \\\n -B /opt/cray \\\n -B /usr/lib64/libcxi.so.1 \\\n -B /usr/lib64/libjansson.so.4 \\\n -B $PWD:/workdir \\\n $CONTAINER /workdir/run-pytorch.sh\n
The important parts here are:
-
We start PyTorch via srun and this is recommended. The torchrun command is not supported on LUMI, as is any other process starter that can be found in AI software that uses ssh to start processes on other nodes rather than going via the resource manager (with, e.g., srun).
-
We also use a particular CPU mapping so that each rank can use the corresponding GPU number (which is taken care of in the run-pytorch.sh script). We use the \"Linear assignment of GCD, then match the cores\" strategy.
-
Note the bindings. In this case we do not even bind the full /project, /scratch and /flash subdirectories, but simply make the current subdirectory that we are using outside the container available as /workdir in the container. This also implies that any non-relative symbolic link or any relative symbolic link that takes you out of the current directory and its subdirectories, will not work, which is awkward as you may want several libraries to run from to have simultaneous jobs, but, e.g., don't want to copy your dataset to each of those directories.
"},{"location":"2day-next/09-Containers/#example-distributed-learning-with-the-easybuild-generated-module","title":"Example: Distributed learning with the EasyBuild-generated module","text":"To really run this example, some additional program files and data files are needed that are not explained in this text. You can find more information on the PyTorch page in the LUMI Software Library.
It turns out that the first two above scripts in the example above, are fairly generic. Therefore the module provides a slight variant of the second script, now called conda-python-distributed, that at the end calls python, passing it all arguments it got and hence can be used to start other Python code also. It is in $CONTAINERROOT/runscripts or in the container as /runscripts.
As the module also takes care of bindings, the job script is simplified to
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --tasks-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=00:10:00\n#SBATCH --account=project_<your_project_id>\n\nmodule load LUMI # Which version doesn't matter, it is only to get the container.\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\ncd mnist\nsrun --cpu-bind=mask_cpu:$MYMASKS \\\n singularity exec $SIFPYTORCH \\\n conda-python-distributed -u mnist_DDP.py --gpu --modelpath model\n
So basically you only need to take care of the proper CPU bindings where we again use the \"Linear assignment of GCD, then match the cores\" strategy.
"},{"location":"2day-next/09-Containers/#extending-the-containers","title":"Extending the containers","text":"We can never provide all software that is needed for every user in our containers. But there are several mechanisms that can be used to extend the containers that we provide:
"},{"location":"2day-next/09-Containers/#extending-the-container-with-cotainr","title":"Extending the container with cotainr","text":"The LUMI Software Library offers some container images for ROCmTM. Though these images can be used simply to experiment with different versions of ROCm, an important use of those images is as base images for the cotainr tool that supports Conda to install software in the container.
Some care is needed though when you want to build your own AI containers. You need to ensure that binaries for AMD GPUs are used, as by default you may get served NVIDIA-only binaries. MPI can also be a problem, as the base image does not yet provide, e.g., a properly configures mpi4py (which would likely be installed in a way that conflicts with cotainr).
The container images that we provide can be found in the following directories on LUMI:
-
/appl/local/containers/sif-images: Symbolic link to the latest version of the container for each ROCm version provided. Those links can change without notice!
-
/appl/local/containers/tested-containers: Tested containers provided as a Singularity .sif file and a docker-generated tarball. Containers in this directory are removed quickly when a new version becomes available.
-
/appl/local/containers/easybuild-sif-images : Singularity .sif images used with the EasyConfigs that we provide. They tend to be available for a longer time than in the other two subdirectories.
First you need to create a yaml file to tell Conda which is called by cotainr which packages need to be installed. An example is given in the \"Using the images as base image for cotainr\" section of the LUMI Software Library rocm page. Next we need to run cotainr with the right base image to generate the container:
module load LUMI/22.12 cotainr\ncotainr build my-new-image.sif \\\n --base-image=/appl/local/containers/sif-images/lumi-rocm-rocm-5.4.6.sif \\\n --conda-env=py311_rocm542_pytorch.yml\n
The cotainr command takes three arguments in this example:
-
my-new-image.sif is the name of the container image that it will generate.
-
--base-image=/appl/local/containers/sif-images/lumi-rocm-rocm-5.4.6.sif points to the base image that we will use, in this case the latest version of the ROCm 5.4.6 container provided on LUMI.
This version was chosen for this case as ROCm 5.4 is the most recent version for which the driver on LUMI at the time of writing (early May 2024) offers guaranteed support.
-
--conda-env=py311_rocm542_pytorch.yml
The result is a container for which you will still need to provide the proper bindings to some libraries on the system (to interface properly with Slurm and so that RCCL with the OFI plugin can work) and to your spaces in the file system that you want to use. Or you can adapt an EasyBuild-generated module for the ROCm container that you used to use your container instead (which will require the EasyBuild eb command flag --sourcepath to specify where it can find the container that you generated, and you cannot delete it from the installation afterwards). In the future, we may provide some other installable module(s) with generic bindings to use instead.
"},{"location":"2day-next/09-Containers/#extending-the-container-with-the-singularity-unprivileged-proot-build","title":"Extending the container with the singularity unprivileged proot build","text":"Singularity specialists can also build upon an existing container using singularity build. The options for build processes are limited though because we have no support for user namespaces or the fakeroot feature. The \"Unprivileged proot builds\" feature from recent SingularityCE versions is supported though.
To use this feature, you first need to write a singularity-compatible container definition file, e.g.,
Bootstrap: localimage\n\nFrom: /appl/local/containers/easybuild-sif-images/lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-dockerhash-f72ddd8ef883.sif\n\n%post\n\nzypper -n install -y Mesa libglvnd libgthread-2_0-0 hostname\n
which is a definition file that will use the SUSE zypper software installation tool to add a number of packages to one of the LUMI PyTorch containers to provide support for software OpenGL rendering (the CDNA GPUs do not support OpenGL acceleration) and the hostname command.
To use the singularity build command, we first need to make the proot command available. This is currently not installed in the LUMI system image, but is provided by the systools/23.09 and later modules that can be found in the corresponding LUMI stack and in the CrayEnv environment.
To update the container, run:
module load LUMI/23.09 systools\nsingularity build my-new-container.sif my-container-definition.def\n
Note:
-
In this example, as we use the LUMI/23.09 module, there is no need to specify the version of systools as there is only one in this stack. An alternative would have been to use
module load CrayEnv systools/23.09\n
-
The singularity build command takes two options: The first one is the name of the new container image that it generates and the second one is the container definition file.
When starting from a base image installed with one of our EasyBuild recipes, it is possible to overwrite the image file and in fact, the module that was generated with EasyBuild might just work...
"},{"location":"2day-next/09-Containers/#extending-the-container-through-a-python-virtual-environment","title":"Extending the container through a Python virtual environment","text":"Some newer containers installed with EasyBuild already include a pre-initialised virtual environment (created with venv). The location in the filesystem of that virtual environment is:
-
/user-software/venv/MyVEnv in the container, where MyVEnv is actually different in different containers. We used the same name as for the Conda environment.
-
$CONTAINERROOT/user-software/venv/MyVEnv outside the container (unless that directory structure is replaced with the $CONTAINERROOT/user-software.squashfs file).
That directory struture was chosen to (a) make it possible to install a second virtual environment in /user-software/venv while (b) also leaving space to install software by hand in /user-software and hence create a bin and lib subdirectory in those (though they currently are not automatically added to the search paths for executables and shared libraries in the container).
The whole process is very simple with those containers that already have a pre-initialised virtual environment as the module already intialises several environment variables in the container that have the combined effect of activating both the Conda installation and then on top of it, the default Python virtual environment.
Outside the container, we need to load the container module, and then we can easily go into the container using the SIF environment variable to point to its name:
module load LUMI\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\nsingularity shell $SIF\n
and in the container, at the Singularity> prompt, we can use pip install without extra options, e.g.,
pip install pytorch-lightning\n
As already discussed before in this session of the tutorial, such a Python virtual environment has the potential to create a lot of small files in the Lustre $CONTAINERROOT/user-software subdirectory, which can wipe out all benefits we got from using a container for the Python installation. But our modules with virtual environment support offer a solution for this also: the make-squashfs command (which should be run outside the container) will convert the user-software subdirectory in $CONTAINERROOT into the SquashFS file user-software.squashfs which, after reloading the module, will be used to provide the /user-software subdirectory in the container. The downside is that now /user-software is read-only as it comes from the SquashFS file. To install further packages, you'd have to remove the user-software.squashfs file again and reload the container module.
Currently the make-squashfs file will not remove the $CONTAINERROOT/user-software subdirectory, but once you have verified that the SquashFS file is OK and useable in the container, you can safely delete it yourself. We also provide the unmake-squasfs script to re-generate the $CONTAINERROOT/user-software subdirectory (though attribues such as file time, etc., will not be the same as before).
It is of course possible to use this technique with all Python containers, but you may have to do a lot more steps by hand, such as adding the binding for a directory for the virtual environment, creating and activating the environment, and replacing the directory with a SquashFS file to improve file system performance.
"},{"location":"2day-next/09-Containers/#conclusion-container-limitations-on-lumi","title":"Conclusion: Container limitations on LUMI","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance. Also, containers do not abstract the hardware unlike some virtual machine solutions.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the Slingshot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
Likewise, for containers for distributed AI, one may need to inject an appropriate RCCL plugin to fully use the Slingshot 11 interconnect.
-
As containers rely on drivers in the kernel of the host OS, the AMD driver may also cause problems. AMD only guarantees compatibility of the driver with two minor versions before and after the ROCm release for which the driver was meant. Hence containers using a very old version of ROCm or a very new version compared to what is available on LUMI, may not always work as expected.
-
The support for building containers on LUMI is currently very limited due to security concerns. Any build process that requires elevated privileges, fakeroot or user namespaces will not work.
"},{"location":"2day-next/10-Support/","title":"LUMI Support and Documentation","text":""},{"location":"2day-next/10-Support/#distributed-nature-of-lumi-support","title":"Distributed nature of LUMI support","text":"User support for LUMI comes from several parties. Unfortunately, as every participating consortium countries has some responsibilities also and solves things differently, there is no central point where you can go with all questions.
Resource allocators work independently from each other and the central LUMI User Support Team. This also implies that they are the only ones who can help you with questions regarding your allocation: How to apply for compute time on LUMI, add users to your project, running out of resources (billing units) for your project, failure to even get access to the portal managing the allocations given by your resource allocator (e.g., because you let expire an invite), ... For granted EuroHPC projects, support is available via lumi-customer-accounts@csc.fi, but you will have to contact EuroHPC directly at access@eurohpc-ju.europa.eu if, e.g., you need more resources or an extension to your project.
The central LUMI User Support Team (LUST) offers L1 and basic L2 support. Given that the LUST team is very small compared to the number of project granted annually on LUMI (roughly 10 FTE for on the order of 700 projects per year, and support is not their only task), it is clear that the amount of support they can give is limited. E.g., don't expect them to install all software you request for them. There is simply too much software and too much software with badly written install code to do that with that number of people. Nor should you expect domain expertise from them. Though several members of the LUST have been scientist before, it does not mean that they can understand all scientific problems thrown at them or all codes used by users. Also, the team cannot fix bugs for you in the codes that you use, and usually not in the system code either. For fixing bugs in HPE or AMD-provided software, they are backed by a team of experts from those companies. However, fixing bugs in compilers or libraries and implementing those changes on the system takes time. The system software on a big shared machine cannot be upgraded as easily as on a personal workstation. Usually you will have to look for workarounds, or if they show up in a preparatory project, postpone applying for an allocation until all problems are fixed.
EuroHPC has also granted the EPICURE project that started in February 2024 to set up a network for advanced L2 and L3 support across EuroHPC centres. At the time of the course, the project is still in its startup phase. Moreover, this project is also so small that it will have to select the problems they tackle.
In principle the EuroHPC Centres of Excellence should also play a role in porting some applications in their field of expertise and offer some support and training, but so far especially the support and training are not yet what one would like to have.
Basically given the growing complexity of scientific computing and diversity in the software field, what one needs is the equivalent of the \"lab technician\" that many experimental groups have who can then work with various support instances, a so-called Research Software Engineer...
"},{"location":"2day-next/10-Support/#support-level-0-help-yourself","title":"Support level 0: Help yourself!","text":"Support starts with taking responsibility yourself and use the available sources of information before contacting support. Support is not meant to be a search assistant for already available information.
The LUMI User Support Team has prepared trainings and a lot of documentation about LUMI. Good software packages also come with documentation, and usually it is possible to find trainings for major packages. And a support team is also not there to solve communication problems in the team in which you collaborate on a project!
"},{"location":"2day-next/10-Support/#take-a-training","title":"Take a training!","text":"There exist system-specific and application-specific trainings. Ideally of course a user would want a one-step solution, having a specific training for a specific application on a specific system (and preferably with the workflow tools they will be using, if any), but that is simply not possible. The group that would be interested in such a training is for most packages too small, and it is nearly impossible to find suitable teachers for such course given the amount of expertise that is needed in both the specific application and the specific system. It would also be hard to repeat such a training with a high enough frequency to deal with the continuous inflow of new users.
The LUMI User Support Team organises 2 system-specific trainings:
-
There is a 1- or 2-day introductory course entirely given by members of the LUST. The training does assume familiarity with HPC systems, and each local organisation should offer such courses for their local systems already.
-
And there is a 4-day comprehensive training with more attention on how to run efficiently, and on the development and profiling tools. Even if you are not a developer, you may benefit from more knowledge about these tools as especially a profiler can give you insight in why your application does not run as expected.
Application-specific trainings should come from other instances though that have the necessary domain knowledge: Groups that develop the applications, user groups, the EuroHPC Centres of Excellence, ...
Currently the training landscape in Europe is not too well organised. EuroHPC is starting some new training initiatives to succeed the excellent PRACE trainings. Moreover, CASTIEL, the centre coordinating the National Competence Centres and EuroHPC Centres of Excellence also tries to maintain an overview of available trainings (and several National Competence Centres organise trainings open to others also).
"},{"location":"2day-next/10-Support/#readsearch-the-documentation","title":"Read/search the documentation","text":"The LUST has developed extensive documentation for LUMI. That documentation is split in two parts:
-
The main documentation at docs.lumi-supercomputer.eu covers the LUMI system itself and includes topics such as how to get on the system, where to place your files, how to start jobs, how to use the programming environment, how to install software, etc.
-
The LUMI Software Library contains an overview of software pre-installed on LUMI or for which we have install recipes to start from. For some software packages, it also contains additional information on how to use the software on LUMI.
That part of the documentation is generated automatically from information in the various repositories that are used to manage those installation recipes. It is kept deliberately separate, partly to have a more focused search in both documentation systems and partly because it is managed and updated very differently.
Both documentation systems contain a search box which may help you find pages if you cannot find them easily navigating the documentation structure. E.g., you may use the search box in the LUMI Software Library to search for a specific package as it may be bundled with other packages in a single module with a different name.
Some examples:
-
Search in the main documentation at docs.lumi-supercomputer.eu for \"quota\" and it will take you to pages that among other things explain how much quota you have in what partition.
-
Users of the Finnish national systems have been told to use a tool called \"Tykky\" to pack conda and Python installations to reduce the stress on the filesystems and wonder if that tool is also on LUMI. So let's search in the LUMI Software Library:
It is, but with a different name as foreigners can't pronounce those Finnish names anyway and as something more descriptive was needed.
-
Try searching for the htop command in the LUMI Software Library
So yes, htop is on LUMI, but if you read the page you'll see it is in a module together with some other small tools.
"},{"location":"2day-next/10-Support/#talk-to-your-colleagues","title":"Talk to your colleagues","text":"A LUMI project is meant to correspond to a coherent research project in which usually multiple people collaborate.
This implies that your colleagues may have run in the same problem and may already have a solution, or they didn't even experience it as a problem and know how to do it. So talk to your colleagues first.
Support teams are not meant to deal with your team's communication problems. There is nothing worse than having the same question asked multiple times from different people in the same project. As a project does not have a dedicated support engineer, the second time a question is asked it may land at a different person in the support team so that it is not recognized that the question has been asked already and the answer is readily available, resulting in a loss of time for the support team and other, maybe more important questions, remaining unanswered. Similarly bad is contacting multiple help desks with the same question without telling them, as that will also duplicate efforts to solve a question. We've seen it often that users contact both a local help desk and the LUST help desk without telling.
Resources on LUMI are managed on a project basis, not on a user-in-project basis, so if you want to know what other users in the same project are doing with the resources, you have to talk to them and not to the LUST. We do not have systems in place to monitor use on a per-user, per-project basis, only on a per-project basis, and also have no plans to develop such tools as a project is meant to be a close collaboration of all involved users.
LUMI events and on-site courses are also an excellent opportunity to network with more remote colleagues and learn from them! Which is why we favour on-site participation for courses. No video conferencing system can give you the same experience as being physically present at a course or event.
"},{"location":"2day-next/10-Support/#l1-and-basic-l2-support-lust","title":"L1 and basic L2 support: LUST","text":"The LUMI User Support Team is responsible for providing L1 and basic L2 support to users of the system. Their work starts from the moment that you have userid on LUMI (the local RA is responsible for ensuring that you get a userid when a project has been assigned).
The LUST is a distributed team roughly 10 FTE strong, with people in all LUMI consortium countries, but they work as a team, coordinated by CSC. 10 of the LUMI consortium countries each have one or more members in LUST. However, you will not necessarily be helped by one of the team members from your own country, even when you are in a consortium country, when you contact LUST, but by the team member who is most familiar with your problem.
There are some problems that we need to pass on to HPE or AMD, particularly if it may be caused by bugs in system software, but also because they have more experts with in-depth knowledge of very specific tools.
The LUMI help desk is staffed from Monday till Friday between 8am and 6pm Amsterdam time (CE(S)T) except on public holidays in Finland. You can expect a same day first response if your support query is well formulated and submitted long enough before closing time, but a full solution of your problem may of course take longer, depending on how busy the help desk is and the complexity of the problem.
Data security on LUMI is very important. Some LUMI projects may host confidential data, and especially industrial LUMI users may have big concerns about who can access their data. Therefore only very, very few people on LUMI have the necessary rights to access user data on the system, and those people even went through a background check. The LUST members do not have that level of access, so we cannot see your data and you will have to pass all relevant information to the LUST through other means!
The LUST help desk should be contacted through web forms in the \"User Support - Contact Us\" section of the main LUMI web site. The page is also linked from the \"Help Desk\" page in the LUMI documentation. These forms help you to provide more information that we need to deal with your support request. Please do not email directly to the support web address (that you will know as soon as we answer at ticket as that is done through e-mail). Also, separate issues should go in separate tickets so that separate people in the LUST can deal with them, and you should not reopen an old ticket for a new question, also because then only the person who dealt with the previous ticket gets notified, and they may be on vacation or even not work for LUMI anymore, so your new request may remain unnoticed for a long time.
"},{"location":"2day-next/10-Support/#tips-for-writing-good-tickets-that-we-can-answer-promptly","title":"Tips for writing good tickets that we can answer promptly","text":""},{"location":"2day-next/10-Support/#how-not-to-write-a-ticket","title":"How not to write a ticket","text":" -
Use a meaningful subject line. All we see in the ticket overview is a number and the subject line, so we need to find back a ticket we're working on based on that information alone.
Yes, we have a user on LUMI who managed to send 8 tickets in a short time with the subject line \"Geoscience\" but 8 rather different problems...
Hints:
- For common problems, including your name in the subject may be a good idea.
- For software problems, including the name of the package helps a lot. So not \"Missing software\" but \"Need help installing QuTiP 4.3.1 on CPU\". Or not \"Program crashes\" but \"UppASD returns an MPI error when using more than 1000 ranks\".
-
Be accurate when describing the problem. Support staff members are not clairvoyants with mysterious superpowers who can read your mind across the internet.
We'll discuss this a bit more further in this lecture.
-
If you have no time to work with us on the problem yourself, then tell so.
Note: The priorities added to the ticket are currently rather confusing. You have three choices in the forms: \"It affects severely my work\", \"It is annoying, but I can work\", and \"I can continue to work normally\", which map to \"high\", \"medium\" and \"low\". So tickets are very easily marked as high priority because you cannot work on LUMI, even though you have so much other work to do that it is really not that urgent or that you don't even have time to answer quickly.
The improved version could be something like this:
"},{"location":"2day-next/10-Support/#how-to-write-tickets","title":"How to write tickets","text":""},{"location":"2day-next/10-Support/#1-ticket-1-issue-1-ticket","title":"1 ticket = 1 issue = 1 ticket","text":" -
If you have multiple unrelated issues, submit them as multiple tickets. In a support team, each member has their own specialisation so different issues may end up with different people. Tickets need to be assigned to people who will deal with the problem, and it becomes very inefficient if multiple people have to work on different parts of the ticket simultaneously.
Moreover, the communication in a ticket will also become very confusing if multiple issues are discussed simultaneously.
-
Conversely, don't submit multiple tickets for a single issue just because you are too lazy to look for the previous e-mail if you haven't been able to do your part of the work for some days. If you've really lost the email, at least tell us that it is related to a previous ticket so that we can try to find it back.
So keep the emails you get from the help desk to reply!
-
Avoid reusing exactly the same subject line. Surely there must be something different for the new problem?
-
Avoid reopening old tickets that have been closed long ago.
If you get a message that a ticket has been closed (basically because there has been no reply for several weeks so we assume the issue is not relevant anymore) and you feel it should not have been closed, reply immediately.
When you reply to a closed ticket and the person who did the ticket is not around (e.g., on vacation or left the help desk team), your reply may get unnoticed for weeks. Closed tickets are not passed to a colleague when we go on a holiday or leave.
-
Certainly do not reopen old tickets with new issues. Apart from the fact that the person who did the ticket before may not be around, they may also have no time to deal with the ticket quickly or may not even be the right person to deal with it.
"},{"location":"2day-next/10-Support/#the-subject-line-is-important","title":"The subject line is important!","text":" -
The support team has two identifiers in your ticket: Your mail address and the subject that you specified in the form (LUST help desk) or email (LUMI-BE help desk). So:
-
Use consistently the same mail address for tickets. This helps us locate previous requests from you and hence can give us more background about what you are trying to do.
The help desk is a professional service, and you use LUMI for professional work, so use your company or university mail address and not some private one.
-
Make sure your subject line is already descriptive and likely unique in our system.
We use the subject line to distinguish between tickets we're dealing with so make sure that it can easily be distinguished from others and is easy to find back.
-
So include relevant keywords in your subject, e.g.,
Some proper examples are
-
User abcdefgh cannot log in via web interface
So we know we may have to pass this to our Open OnDemand experts, and your userid makes the message likely unique. Moreover, after looking into account databases etc., we can immediately find back the ticket as the userid is in the subject.
-
ICON installation needs libxml2
-
VASP produces MPI error message when using more than 1024 ranks
"},{"location":"2day-next/10-Support/#think-with-us","title":"Think with us","text":" -
Provide enough information for us to understand who you are:
-
Name: and the name as we would see it on the system, not some nickname.
-
Userid: Important especially for login problems.
-
Project number:
- When talking to the LUST: they don't know EuroHPC or your local organisation's project numbers, only the 462xxxxxx and 465xxxxxx numbers, and that is what they need.
- If you have a local support organisation though, the local project number may be useful for them, as it may then land with someone who does not have access to the LUMI project numbers of all projects they manage.
-
For login and data transfer problems, your client environment is often also important to diagnose the problem.
-
What software are you using, and how was it installed or where did you find it?
We know that certain installation procedures (e.g., simply downloading a binary) may cause certain problems on LUMI. Also, there are some software installations on LUMI for which neither LUST nor the local help desk is responsible, so we need to direct to to their support instances when problems occur that are likely related to that software.
-
Describe your environment (though experience learns that some errors are caused by users not even remembering they've changed things while those changes can cause problems)
-
Which modules are you using?
-
Do you have special stuff in .bashrc or .profile?
-
For problems with running jobs, the batch script that you are using can be very useful.
-
Describe what worked so far, and if it ever worked: when? E.g., was this before a system update?
The LUST has had tickets were a user told that something worked before but as we questioned further it was long ago before a system update that we know broke some things that affects some programs...
-
What did you change since then? Think carefully about that. When something worked some time ago but doesn't work know the cause is very often something you changed as a user and not something going on on the system.
-
What did you already try to solve the problem?
-
How can we reproduce the problem? A simple and quick reproducer speeds up the time to answer your ticket. Conversely, if it takes a 24-hour run on 256 nodes to see the problem it is very, very likely that the support team cannot help you.
Moreover, if you are using licensed software with a license that does not cover the support team members, usually we cannot do much for you. LUST will knowingly violate software licenses only to solve your problems (and neither will your local support team)!
-
The LUST help desk members know a lot about LUMI but they are (usually) not researchers in your field so cannot help you with problems that require domain knowledge in your field. We can impossibly know all software packages and tell you how to use them (and, e.g., correct errors in your input files). And the same likely holds for your local support organisation.
You as a user should be the domain expert, and since you are doing computational science, somewhat multidisciplinary and know something about both the \"computational\" and the \"science\".
We as the support team should be the expert in the \"computational\". Some of us where researchers in the past so have some domain knowledge about a the specific subfield we were working in, but there are simply too many scientific domains and subdomains to have full coverage of that in a central support team for a generic infrastructure.
We do see that lots of crashes and performance problems with software are in fact caused by wrong use of the package!
However, some users expect that we understand the science they are doing, find the errors in their model and run that on LUMI, preferably by the evening they submitted the ticket. If we could do that, then we could basically make a Ph.D that usually takes 4 years in 4 weeks and wouldn't need users anymore as it would be more fun to produce the science that our funding agencies expect ourselves.
-
The LUST help desk members know a lot about LUMI but cannot know or solve everything and may need to pass your problem to other instances, and in particular HPE or AMD.
Debugging system software is not the task of the of the LUST. Issues with compilers or libraries can only be solved by those instances that produce those compilers or libraries, and this takes time.
We have a way of working that enables us to quickly let users test changes to software in the user software stack by making user installations relatively easy and reproducible using EasyBuild, but changing the software installed in the system images - which includes the Cray programming environment - where changes have an effect on how the system runs and can affect all users, are non-trivial and many of those changes can only be made during maintenance breaks.
"},{"location":"2day-next/10-Support/#beware-of-the-xy-problem","title":"Beware of the XY-problem!","text":"Partly quoting from xyproblem.info: Users are often tempted to ask questions about the solution they have in mind and where they got stuck, while it may actually be the wrong solution to the actual problem. As a result one can waste a lot of time attempting to get the solution they have in mind to work, while at the end it turns out that that solution does not work. It goes as follows:
- The user wants to do X.
- The user doesn't really know how to do X. However, they think that doing Y first would be a good step towards solving X.
- But the user doesn't really know how to do Y either and gets stuck there too.
- So the user contacts the help desk to help with solving problem Y.
- The help desk tries to help with solving Y, but is confused because Y seems a very strange and unusual problem to solve.
- Once Y is solved with the help of the help desk, the user is still stuck and cannot solve X yet.
- User contacts the help desk again for further help and it turns out that Y wasn't needed in the first place as it is not part of a suitable solution for X.
Or as one of the colleagues of the author of these notes says: \"Often the help desk knows the solution, but doesn't know the problem so cannot give the solution.\"
To prevent this, you as a user has to be complete in your description:
-
Give the broader problem and intent (so X), not just the small problem (Y) on which you got stuck.
-
Promptly provide information when the help desk asks you, even if you think that information is irrelevant. The help desk team member may have a very different look on the problem and come up with a solution that you couldn't think of, and you may be too focused on the solution that you have in mind to see a better solution.
-
Being complete also means that if you ruled out some solutions, share with the help desk why you ruled them out as it can help the help desk team member to understand what you really want.
After all, if your analysis of your problem was fully correct, you wouldn't need to ask for help, don't you?
"},{"location":"2day-next/10-Support/#what-support-can-we-offer","title":"What support can we offer?","text":""},{"location":"2day-next/10-Support/#restrictions","title":"Restrictions","text":"Contrary to what you may be familiar with from your local Tier-2 system and support staff, team members of the LUMI help desks have no elevated privileges. This holds for both the LUST and LUMI-BE help desk.
As a result,
-
We cannot access user files. A specific person of the LUMI-BE help desk can access your project, scratch and flash folders if you make them part of the project. This requires a few steps and therefore is only done for a longer collaboration between a LUMI project and that help desk member. The LUST members don't do that.
-
Help desk team members cannot install or modify system packages or settings.
A good sysadmin usually wouldn't do so either. You are working on a multi-user system and you have to take into account that any change that is beneficial for you, may have adverse effects for other users or for the system as a whole.
E.g., installing additional software in the images takes away from the available memory on each node, slows down the system boot slightly, and can conflict with software that is installed through other ways.
-
The help desk cannot extend the walltime of jobs.
Requests are never granted, even not if the extended wall time would still be within the limits of the partition.
-
The LUST is in close contact with the sysadmins, but as the sysadmins are very busy people they will not promptly deal with any problem. Any problem though endangering the stability of the system gets a high priority.
-
The help desk does not monitor running jobs. Sysadmins monitor the general health of the system, but will not try to pick out inefficient jobs unless the job does something that has a very negative effect on the system.
"},{"location":"2day-next/10-Support/#what-support-can-and-cannot-do","title":"What support can and cannot do","text":" -
The LUST help desk does not replace a good introductory HPC course nor is it a search engine for the documentation. L0 support is the responsibility of every user.
-
Resource allocators are responsible for the first steps in getting a project and userid on LUMI. EuroHPC projects the support is offered through CSC, the operator of LUMI, at lumi-customer-accounts@csc.fi, or by EuroHPC itself at access@eurohpc-ju.europa.eu if you have not yet been granted a project by them.
Once your project is created and accepted (and the resource allocator can confirm that you properly accepted the invitation), support for account problems (in particular login problems) moves to the LUST.
-
If you run out of block or file quota, the LUST can increase your quota within the limits specified in the LUMI documentation.
If you run out of billing units for compute or storage, only the instance that granted your project can help you, your resource allocator for local projects and access@eurohpc-ju.europa.eu for EuroHPC projects (CSC EuroHPC support at lumi-customer-accounts@csc.fi cannot help you directly for project extensions and increase of billing units).
Projects cannot be extended past one year unless the granting instance is willing to take a charge on the annual budget for the remaining billing units.
-
The LUST cannot do much complete software installations but often can give useful advice and do some of the work.
Note however that the LUST may not even be allowed to help you due to software license restrictions. Moreover, LUST has technically speaking a zone where they can install software on the system, but this is only done for software that the LUST can properly support across system updates and that is of interest to a wide enough audience. It is also not done for software where many users may want a specifically customised installation. Neither is it done for software that LUST cannot sufficiently test themselves.
-
The LUST can help with questions regarding compute and storage use. LUST provides L1 and basic L2 support. These are basically problems that can solved in hours rather than days or weeks. More advanced support has to come from other channels though, including support efforts from your local organisation, EuroHPC Centres of Excellence, EPICURE, ...
-
The LUST can help with analysing the source of crashes or poor performance, with the emphasis on help as they rarely have all the application knowledge required to dig deep. And it will still require a significant effort from your side also.
-
However, LUST is not a debugging service (though of course we do take responsibility for code that we developed).
-
The LUST has some resources for work on porting and optimising codes to/for AMD GPUs via porting calls and hackathons respectively. But we are not a general code porting and optimisation service. And even in the porting call projects, you are responsible for doing the majority of the work, LUST only supports.
-
The LUST cannot do your science or solve your science problems though.
Remember:
\"Supercomputer support is there to support you in the computational aspects of your work related to the supercomputer but not to take over your work.\"
Any support will always be a collaboration where you may have to do most of the work. Supercomputer support services are not a free replacement of a research software engineer (the equivalent of the lab assistant that many experimental groups have).
"},{"location":"2day-next/10-Support/#links","title":"Links","text":""},{"location":"2day-next/A01-Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"2day-next/A01-Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 23.02.7, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCD 3.11 User Guide
"},{"location":"2day-next/A01-Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"2day-next/A01-Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"2day-next/A01-Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"2day-next/A01-Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"2day-next/Demo1/","title":"Demo 1: Fooocus","text":"Fooocus is an AI-based image generating package that is available under the GNU General Public License V3.
The version on which we first prepared this demo, insists on writing in the directories with some of the Fooocus files, so we cannot put Fooocus in a container at the moment.
It is based on PyTorch. However, we cannot use the containers provided on LUMI as-is as additional system level libraries are needed for the graphics.
This demo shows:
-
Installing one of the containers provided on LUMI with EasyBuild,
-
Installing additional software in the container with the SingularityCE \"unprivileged proot builds\" process and the SUSE Linux zypper install tool,
-
Further adding packages in a virtual environment and putting them in a SquashFS file for better file system performance, and
-
Using that setup with Fooocus.
"},{"location":"2day-next/Demo1/#video-of-the-demo","title":"Video of the demo","text":""},{"location":"2day-next/Demo1/#step-1-checking-fooocus","title":"Step 1: Checking Fooocus","text":"Let's create an installation directory for the demo. Set the environment variable installdir to a proper value for the directories on LUMI that you have access to.
installdir=/project/project_465001102/kurtlust/DEMO1\nmkdir -p \"$installdir\" ; cd \"$installdir\"\n
We are now in the installation directory of which we also ensured its existence first. Let's now download and unpack Fooocus release 2.3.1 (the one we tested for this demo)
fooocusversion=2.3.1\nwget https://github.com/lllyasviel/Fooocus/archive/refs/tags/$fooocusversion.zip\nunzip $fooocusversion.zip\nrm -f $fooocusversion.zip\n
If we check what's in the Fooocus directory:
ls Fooocus-$fooocusversion\n
we see a rather messy bunch of mostly Python files missing the traditional setup scripts that you expect with a Python package. So installing this could become a messy thing...
It also contains a Dockerfile (to build a base Docker container), a requirements_docker.txt and a requirements_versions.txt file that give hints about what exactly is needed. The Dockerfile suggests close to the top that some OpenGL libraries will be needed. And the fact that it can be fully installed in a docker container also indicates that there must in fact be ways to run it in readonly directories, but in this demo we'll put Fooocus in a place were it can write. The requirements_docker.txt file also suggests to use Pytorch 2.0, but we'll take some risks though and use a newer version of PyTorch than suggested as for AMD GPUs it is often important to use recently enough versions (and because that version has a more sophisticated module better suited for what we want to demonstrate).
"},{"location":"2day-next/Demo1/#step-2-install-the-pytorch-container","title":"Step 2: Install the PyTorch container","text":"We can find an overview of the available PyTorch containers on the PyTorch page in the LUMI Software Library. We'll use a version that already has support for Python virtual environments built in as that will make it a lot easier to install extra Python packages. Moreover, as we have also seen that we will need to change the container, we'll follow a somewhat atypical build process.
Rather than installing directly from the available EasyBuild recipes, we'll edit an EasyConfig to change the name to reflect that we have made changes and installed Fooocus with it. First we must prepare a temporary directory to do this work and also set up EasyBuild:
mkdir -p \"$installdir/tmp\" ; cd \"$installdir/tmp\"\nmodule purge\nmodule load LUMI/23.09 partition/container EasyBuild-user\n
We'll now use a function of EasyBuild to copy an existing EasyConfig file to a new location, and rename it in one move to reflect the module version that we want:
eb --copy-ec PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
This is not enough to generate a module PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315, we also need to edit the versionsuffix line in the EasyBuild recipe. Of course you can do this easily with your favourite editor, but to avoid errors we'll use a command for the demo that you only need to copy:
sed -e \"s|^\\(versionsuffix.*\\)-singularity-20240315|\\1-Fooocus-singularity-20240315|\" -i PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
Let's check:
grep versionsuffix PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
which returns
versionsuffix = f'-rocm-{local_c_rocm_version}-python-{local_c_python_mm}-Fooocus-singularity-20240315'\n
so we see that the versionsuffix line looks rather strange but we do see that the -Fooocus- part is injected in the name so we assume everything is OK.
We're now ready to install the container with EasyBuild:
eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315.eb\n
The documentation in the PyTorch page in the LUMI Software Library suggests that we can now delete the container file in the installation directory, but this is a bad idea in this case as we want to build our own container and hence will not use one of the containers provided on the system while running.
We're now finished with EasyBuild so don't need the modules related to EasyBuild anymore. So lets's clean the environment an load the PyTorch container module that we just built with EasyBuild:
module purge\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Notice that we don't need to load partition/container anymore. Any partition would do, and in fact, we can even use CrayEnv instead of LUMI/23.09.
Notice that the container module provides the environment variables SIF and SIFPYTORCH, both of which point to the .sif file of the container:
echo $SIF\necho $SIFPYTORCH\n
We'll make use of that when we add SUSE packages to the container.
"},{"location":"2day-next/Demo1/#step-3-adding-some-suse-packages","title":"Step 3: Adding some SUSE packages","text":"To update the singularity container, we need three things.
First, the PyTorch module cannot be loaded as it sets a number of singularity-related environment variables. Yet we want to use the value of SIF, so we will simply save it in a different environment variable before unloading the module:
export CONTAINERFILE=\"$SIF\"\nmodule unload PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Second, the proot command is not available by default on LUMI, but it can be enabled by loading the systools module in LUMI/23.09 or newer stacks, or systools/23.09 or newer in CrayEnv:
module load systools\n
Third, we need a file defining the build process for singularity. This is a bit technical and outside the scope of this tutorial to explain what goes into this file. It can be created with the following shell command:
cat > lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def <<EOF\n\nBootstrap: localimage\n\nFrom: $CONTAINERFILE\n\n%post\n\nzypper -n install -y Mesa libglvnd libgthread-2_0-0 hostname\n\nEOF\n
You can check the file with
cat lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def\n
We basically install an OpenGL library that emulates on the CPU and some missing tools. Note that the AMD MI250X GPUs are not rendering GPUs, so we cannot run hardware accelerated rendering on them.
An annoying element of the singularity build procedure is that it is not very friendly for a Lustre filesystem. We'll do the build process on a login node, where we have access to a personal RAM disk area that will also be cleaned automatically when we log out, which is always useful for a demo. Therefore we need to set two environment variables for Singularity, and create two directories, which is done with the following commands:
export SINGULARITY_CACHEDIR=$XDG_RUNTIME_DIR/singularity/cache\nexport SINGULARITY_TMPDIR=$XDG_RUNTIME_DIR/singularity/tmp\n\nmkdir -p $SINGULARITY_CACHEDIR\nmkdir -p $SINGULARITY_TMPDIR\n
Now we're ready to do the actual magic and rebuild the container with additional packages installed in it:
singularity build $CONTAINERFILE lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.2.0-Fooocus.def\n
The build process will ask you if you want to continue as it will overwrite the container file, so confirm with y. The whole build process may take a couple of minutes.
We'll be kind to our fellow LUMI users and already clean up the directories that we just created:
rm -rf $XDG_RUNTIME_DIR/singularity\n
Let's reload the container:
module load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
and do some checks:
singularity shell $SIF\n
brings us into the container (note that the command prompt has changed).
The command
which python\n
returns
/user-software/venv/pytorch/bin/python\n
which shows that the virtual environment pre-installed in the container is indeed active.
We do have the hostname command in the container (one of the packages mentioned in the container .def file that we created) as is easily tested:
hostname\n
and
ls /usr/lib64/*mesa*\n
shows that indeed a number of MESA libraries are installed (the OpenGL installation that we did).
We can now leave the container with the
exit\n
command (or CTRL-D key combination).
So it looks we are ready to start installing Python packages...
"},{"location":"2day-next/Demo1/#step-4-adding-python-packages","title":"Step 4: Adding Python packages","text":"To install the packages, we'll use the requirements_versions.txt file which we found in the Fooocus directories. The installation has to happen from within the container though. So let's got to the Fooocus directory and go into the container again:
cd \"$installdir/Fooocus-$fooocusversion\"\nsingularity shell $SIF\n
We'll install the extra packages simply with the pip tool:
pip install -r requirements_versions.txt\n
This process may again take a few minutes.
After finishing,
ls /user-software/venv/pytorch/lib/python3.10/site-packages/\n
shows that indeed a lot of packages have been installed. Though accessible from the container, they are not in the container .sif file as that file cannot be written.
Let's leave the container again:
exit\n
Now try:
ls $CONTAINERROOT/user-software/venv/pytorch/lib/python3.10/site-packages/\n
and notice that we see the same long list of packages. In fact, a trick to see the number of files and directories is
lfs find $CONTAINERROOT/user-software/venv/pytorch/lib/python3.10/site-packages | wc -l\n
which prints the name of all files and directories and then counts the number of lines, and we see that this is a considerable number. Lustre isn't really that fond of it. However, the module also provides an easy solution: We can convert the $EBROOTPYTORCH/user-software subdirectory into a SquashFS file that can be mounted as a filesystem in the container, and the module provides all the tools to make this easy to do. All we need to do is to run
make-squashfs\n
This will also take some time as the script limits the resources the make-squashfs can use to keep the load on the login nodes low. Now we can then safely remove the user-software subdirectory:
rm -rf $CONTAINERROOT/user-software\n
Before continuing, we do need to reload the module so that the bindings between the container and files and directories on LUMI are reset:
module load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Just check
singularity exec $SIF ls /user-software/venv/pytorch/lib/python3.10/site-packages\n
and see that our package installation is still there!
However, we can no longer write in that directory. E.g., try
touch /user-software/test\n
to create an empty file test in /user-software and note that we get an error message.
So now we are ready-to-run.
"},{"location":"2day-next/Demo1/#the-reward-running-fooocus","title":"The reward: Running Fooocus","text":"First confirm we'll in the directory containing the Fooocus package (which should be the case if you followed these instructions):
cd \"$installdir/Fooocus-$fooocusversion\"\n
We'll start an interactive job with a single GPU:
srun -psmall-g -n1 -c7 --time=30:00 --gpus=1 --mem=60G -A project_465001102 --pty bash\n
The necessary modules will still be available, but if you are running from a new shell, you can load them again:
module load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\n
Also check the hostname if it is not part of your prompt as you will need it later:
hostname\n
We can now go into the container:
singularity shell $SIF\n
and launch Fooocus:
python launch.py --listen --disable-xformers\n
Fooocus provides a web interface. If you're the only one on the node using Fooocus, it should run on port 7865. To access it from our laptop, we need to create an SSH tunnel to LUMI. The precise statement needed for this will depend on your ssh implementation. Assuming you've define a lumi rule in the ssh config file to make life easy and use an OpenSSH-style ssh client, you can use:
ssh -N -L 7865:nid00XXXX:7865 lumi\n
replacing with the node name that we got from the hostname command`.
Next, simply open a web browser on your laptop and point to
http://localhost:7865\n
"},{"location":"2day-next/Demo1/#alternative-way-of-running","title":"Alternative way of running","text":"We can also launch Fooocus directly from the srun command, e.g., from the directory containing the Fooocus code,
module load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-Fooocus-singularity-20240315\nsrun -psmall-g -n1 -c7 --time=30:00 --gpus=1 --mem=60G -A project_465001102 --pty \\\n bash -c 'echo -e \"Running on $(hostname)\\n\" ; singularity exec $SIF python launch.py --listen --disable-xformers'\n
It will also print the host name on which the Fooocus is running, so you can connect to Fooocus using the same procedure as above.
"},{"location":"2day-next/Demo1/#further-discovery","title":"Further discovery","text":" - YouTube channel \"Jump Into AI\" has a Fooocus playlist
"},{"location":"2day-next/Demo2/","title":"Demo option 2: A short walk-through for distributed learning","text":"In this demo, we will install one of the PyTorch containers provided on LUMI and run a simple distributed learning example that the LUMI User Support Team also uses for internal testing.
The demo follows largely the instructions for distributed learning from the PyTorch page in the LUMI Software Library.
This demo shows:
"},{"location":"2day-next/Demo2/#video-of-the-demo","title":"Video of the demo","text":""},{"location":"2day-next/Demo2/#step-1-getting-some-files-that-we-will-use","title":"Step 1: Getting some files that we will use","text":"Let's create an installation directory for the demo. Set the environment variable installdir to a proper value for the directories on LUMI that you have access to.
installdir=/project/project_465001102/kurtlust/DEMO2\nmkdir -p \"$installdir\" ; cd \"$installdir\"\n
We are now in the installation directory of which we also ensured its existence first. Let's now download some files that we will use:
wget https://raw.githubusercontent.com/Lumi-supercomputer/lumi-reframe-tests/main/checks/containers/ML_containers/src/pytorch/mnist/mnist_DDP.py\nmkdir -p model ; cd model\nwget https://github.com/Lumi-supercomputer/lumi-reframe-tests/raw/main/checks/containers/ML_containers/src/pytorch/mnist/model/model_gpu.dat\ncd ..\n
The first two files are actually files that were developed for testing some PyTorch containers on LUMI after system upgrades.
The demo also uses a popular dataset (one of the MNIST datasets) from Yann LeCun, a data scientist at Meta. The pointers to the dataset are actually included in the torchvision package which is why it is not easy to track where the data comes from. The script that we use will download the data if it is not present, but does so on each process, leading to a high load on the web server providing the data and throttling after a few tries, so we will prepare the data instead in the $installdir subdirectory:
mkdir -p data/MNIST/raw\nwget --recursive --level=1 --cut-dirs=3 --no-host-directories \\\n --directory-prefix=data/MNIST/raw --accept '*.gz' http://yann.lecun.com/exdb/mnist/\ngunzip data/MNIST/raw/*.gz\nfor i in $(seq 0 31); do ln -s data \"data$i\"; done\n
"},{"location":"2day-next/Demo2/#step-2-installing-the-container","title":"Step 2: Installing the container","text":"We can find an overview of the available PyTorch containers on the PyTorch page in the LUMI Software Library. We'll use a version that already has support for Python virtual environments built in as that will make it a lot easier to install extra Python packages.
First we need to load and configure EasyBuild and make sure that EasyBuild can run in a clean environment:
module purge\nmodule load LUMI/23.09 partition/container EasyBuild-user\n
The partition/container is a \"special\" partition whose main purpose is to tell EasyBuild-user (and other modules that we use to install software on the system) to configure EasyBuild to install container modules. Afterwards, these containers are available in any partition of the LUMI stacks and in the CrayEnv stack. The EasyBuild-user module here is responsible of configuring EasyBuild and also ensures that a proper version of EasyBuild is loaded.
After loading EasyBuild-user, installing the container from the EasyBuild recipe is very easy:
eb PyTorch-2.2.0-rocm-5.6.1-python-3.10-singularity-20240315.eb\n
We're now finished with EasyBuild so don't need the modules related to EasyBuild anymore. So lets's clean the environment an load the PyTorch container module that we just built with EasyBuild:
module purge\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n
Note that the module defines two environment variables that point to the .sif file of the container:
echo $SIF\necho $SIFPYTORCH\n
All our container modules provide the SIF environment variable, but the name of the second one depends on the name of the package, and it may be safer to use should you load multiple container modules of different packages to quickly switch between them.
If you're really concerned about disk space...
... you may chose to delete the version of the container that we have installed. To continue, you then need to reload the PyTorch module:
rm -f $SIF\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n
Now check again the SIF and SIFPYTORCH environment variables and note that they now point to files in /appl/local/containers:
echo $SIF\necho $SIFPYTORCH\n
We do not recommend you remove the container file as your module will stop working if the image is removed from /appl/local/containers which we do when we deem the file not useful anymore as it causes trouble for too many users. But it may still work fine for what you do with it...
All containers with module files also define the environment variable CONTAINERROOT, pointing to the directory in which EasyBuild installs the .sif file (and not pointing to /appl/local/containers if you've removed the container .sif file). The standard EasyBuild variable EBROOTPYTORCH is also defined and serves the same purpose, but of course has a different name for other packages.
Let's do some checks:
singularity shell $SIF\n
brings us into the container (note that the command prompt has changed).
The command
which python\n
returns
/user-software/venv/pytorch/bin/python\n
which shows that the virtual environment pre-installed in the container is indeed active.
Let's leave the container again:
exit\n
and check the $CONTAINERROOT directory:
module load systools\ntree $CONTAINERROOT\n
There is a lot of stuff in there. If we scroll up enough, we see:
-
A subdirectory easybuild which among other things turns out to contain copies of the EasyBuild recipe that we used. This directory basically contains all important files to reproduce the installation, except for the container it used itself.
-
The user-software subdirectory contains all the files that can be found in the container also in /user-software. (It is simply bound to that directory in the container through an environmet variable that the module sets.)
-
There is a bin subdirectory with some scripts. The start-shell script is only there for historical reasons and compatibility with some other containers, but the make-squashfs and unmake-squashfs files are useful and can be used to make the Python virtual environment more filesystem-friendly by converting the user-software subdirectory into a SquashFS file which is then mounted in the container.
-
The runscripts subdirectory contains some scripts that we will use to simplify running the container. The scripts by no means cover all use cases, but they are nice examples about how scripts for your specific tasks could be written. This directory is also mounted in the container as /runscripts so that it is easy to access.
"},{"location":"2day-next/Demo2/#step-3-running-a-distributed-learning-example","title":"Step 3: Running a distributed learning example.","text":"The conda-python-distributed script is written to ease distributed learning with PyTorch. Distributed learning requires some initialisation of environment variables that are used by PyTorch or by libraries from the ROCmTM stack. It passes its arguments to the Python command. It is mostly meant to be used on full nodes with one task per GPU, as in other cases not all initialisations make sense or are even valid.
Let's check the script:
cat $CONTAINERROOT/runscripts/conda-python-distributed\n
The first block,
if [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n
has mostly a debugging purpose. One task per node will run rocm-smi on that node and its output can be used to check if all GPUs are available as expected. The sleep command is there because we have experienced that sometimes there is still stuff going on in the background that may prevent later commands to fail.
The next block does some very needed initialisations for the MIOpen cache, an important library for neural networks, as the default location causes problems on LUMI as Lustre locking is not compatible with MIOpen:
export MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\n# Set MIOpen cache to a temporary folder.\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rm -rf $MIOPEN_USER_DB_PATH\n mkdir -p $MIOPEN_USER_DB_PATH\nfi\nsleep 2\n
These commands basically move the cache to a subdirectory of /tmp.
Next we need to tell RCCL, the communication library, which interfaces it should use as otherwise it may try to communicate over the management network of LUMI which does not work. This is done through some NCCL_* environment variables which may be counterintuitive, but RCCL is basically the equivalent of NVIDIA NCCL.
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\nexport NCCL_NET_GDR_LEVEL=3\n
Fourth, we need to ensure that each task uses the proper GPU. This is one point where we assume that one GPU (GCD) per task is used. The script also assumes that the \"Linear assignment of GCD, then match the cores\" idea is used, so we will need some more complicated CPU mapping in the job script.
PyTorch also needs some initialisation that are basically the same on NVIDIA and AMD hardware. This includes setting a master for the communication (the first node of a job) and a port for the communication. That port is hard-coded, so a second instance of the script on the same node would fail. So we basically assume that we use full nodes. To determine that master, another script from the runscripts subdirectory is used.
export MASTER_ADDR=$(/runscripts/get-master \"$SLURM_NODELIST\")\nexport MASTER_PORT=29500\nexport WORLD_SIZE=$SLURM_NPROCS\nexport RANK=$SLURM_PROCID\n
Now we can turn our attention to the job script. Create a script mnist.slurm in the demo directory $installdir by copying the code below:
#!/bin/bash -e\n#SBATCH --nodes=4\n#SBATCH --gpus-per-node=8\n#SBATCH --output=\"output_%x_%j.txt\"\n#SBATCH --partition=standard-g\n#SBATCH --mem=480G\n#SBATCH --time=5:00\n#SBATCH --account=project_<your_project_id>\n\nmodule load LUMI/23.09\nmodule load PyTorch/2.2.0-rocm-5.6.1-python-3.10-singularity-20240315\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\nsrun --ntasks=$((SLURM_NNODES*8)) --cpu-bind=mask_cpu:$MYMASKS \\\n singularity exec $SIFPYTORCH \\\n conda-python-distributed -u mnist_DDP.py --gpu --modelpath model\n
Launch the script by setting some environment variables to use the course account and reservation:
export SBATCH_ACCOUNT=project_465001102\nexport SBATCH_RESERVATION=TODO\n
and then launching the job script:
sbatch mnist.slurm\n
(After the course, use any valid project with GPU billing units and omit the SBATCH_RESERVATION environment variable)
When the job script ends (which is usually fast once it gets the resources to run), the output can be found in output_mnist.slurm_1234567.txt where you need to replace 1234567 with the actual job id.
"},{"location":"2day-next/E02-CPE/","title":"Exercises: HPE Cray Programming Environment","text":"See the instructions to set up for the exercises.
These exercises are optional during the session, but useful if you expect to be compiling software yourself. The source files mentioned can be found in the subdirectory CPE of the download.
"},{"location":"2day-next/E02-CPE/#compilation-of-a-program-1-a-simple-hello-world-program","title":"Compilation of a program 1: A simple \"Hello, world\" program","text":"Four different implementations of a simple \"Hello, World!\" program are provided in the CPE subdirectory:
hello_world.c is an implementation in C,hello_world.cc is an implementation in C++,hello_world.f is an implementation in Fortran using the fixed format source form,hello_world.f90 is an implementation in Fortran using the more modern free format source form.
Try to compile these programs using the programming environment of your choice.
Click to see the solution. We'll use the default version of the programming environment (23.09 at the moment of the course in May 2024), but in case you want to use a particular version, e.g., the 22.12 version, and want to be very sure that all modules are loaded correctly from the start you could consider using
module load cpe/22.12\nmodule load cpe/22.12\n
So note that we do twice the same command as the first iteration does not always succeed to reload all modules in the correct version. Do not combine both lines into a single module load statement as that would again trigger the bug that prevents all modules to be reloaded in the first iteration.
The sample programs that we asked you to compile do not use the GPU. So there are three programming environments that we can use: PrgEnv-gnu, PrgEnv-cray and PrgEnv-aocc. All three will work, and they work almost the same.
Let's start with an easy case, compiling the C version of the program with the GNU C compiler. For this all we need to do is
module load PrgEnv-gnu\ncc hello_world.c\n
which will generate an executable named a.out. If you are not comfortable using the default version of gcc (which produces the warning message when loading the PrgEnv-gnu module) you can always load the gcc/11.2.0 module instead after loading PrgEnv-gnu.
Of course it is better to give the executable a proper name which can be done with the -o compiler option:
module load PrgEnv-gnu\ncc hello_world.c -o hello_world.x\n
Try running this program:
./hello_world.x\n
to see that it indeed works. We did forget another important compiler option, but we'll discover that in the next exercise.
The other programs are equally easy to compile using the compiler wrappers:
CC hello_world.cc -o hello_world.x\nftn hello_world.f -o hello_world.x\nftn hello_world.f90 -o hello_world.x\n
"},{"location":"2day-next/E02-CPE/#compilation-of-a-program-2-a-program-with-blas","title":"Compilation of a program 2: A program with BLAS","text":"In the CPE subdirectory you'll find the C program matrix_mult_C.c and the Fortran program matrix_mult_F.f90. Both do the same thing: a matrix-matrix multiplication using the 6 different orders of the three nested loops involved in doing a matrix-matrix multiplication, and a call to the BLAS routine DGEMM that does the same for comparison.
Compile either of these programs using the Cray LibSci library for the BLAS routine. Do not use OpenMP shared memory parallelisation. The code does not use MPI.
The resulting executable takes one command line argument, the size of the square matrix. Run the script using 1000 for the matrix size and see what happens.
Note that the time results may be very unreliable as we are currently doing this on the login nodes. In the session of Slurm you'll learn how to request compute nodes and it might be interesting to redo this on a compute node with a larger matrix size as the with a matrix size of 1000 all data may stay in the third level cache and you will not notice the differences that you should note. Also, because these nodes are shared with a lot of people any benchmarking is completely unreliable.
If this program takes more than half a minute or so before the first result line in the table, starting with ijk-variant, is printed, you've very likely done something wrong (unless the load on the system is extreme). In fact, if you've done things well the time reported for the ijk-variant should be well under 3 seconds for both the C and Fortran versions...
Click to see the solution. Just as in the previous exercise, this is a pure CPU program so we can chose between the same three programming environments.
The one additional \"difficulty\" is that we need to link with the BLAS library. This is very easy however in the HPE Cray PE if you use the compiler wrappers rather than calling the compilers yourself: you only need to make sure that the cray-libsci module is loaded and the wrappers will take care of the rest. And on most systems (including LUMI) this module will be loaded automatically when you load the PrgEnv-* module.
To compile with the GNU C compiler, all you need to do is
module load PrgEnv-gnu\ncc -O3 matrix_mult_C.c -o matrix_mult_C_gnu.x\n
will generate the executable matrix_mult_C_gnu.x.
Note that we add the -O3 option and it is very important to add either -O2 or -O3 as by default the GNU compiler will generate code without any optimization for debugging purposes, and that code is in this case easily five times or more slower. So if you got much longer run times than indicated this is likely the mistake that you made.
To use the Cray C compiler instead only one small change is needed: Loading a different programming environment module:
module load PrgEnv-cray\ncc -O3 matrix_mult_C.c -o matrix_mult_C_cray.x\n
will generate the executable matrix_mult_C_cray.x.
Likewise for the AMD AOCC compiler we can try with loading yet another PrgEnv-* module:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -o matrix_mult_C_aocc.x\n
but it turns out that this fails with linker error messages about not being able to find the sin and cos functions. When using the AOCC compiler the libm library with basic math functions is not linked automatically, but this is easily done by adding the -lm flag:
module load PrgEnv-aocc\ncc -O3 matrix_mult_C.c -lm -o matrix_mult_C_aocc.x\n
For the Fortran version of the program we have to use the ftn compiler wrapper instead, and the issue with the math libraries in the AOCC compiler does not occur. So we get
module load PrgEnv-gnu\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_gnu.x\n
for the GNU Fortran compiler,
module load PrgEnv-cray\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_cray.x\n
for the Cray Fortran compiler and
module load PrgEnv-aocc\nftn -O3 matrix_mult_F.f90 -o matrix_mult_F_aocc.x\n
for the AMD Fortran compiler.
When running the program you will see that even though the 6 different loop orderings produce the same result, the time needed to compile the matrix-matrix product is very different and those differences would be even more pronounced with bigger matrices (which you can do after the session on using Slurm).
The exercise also shows that not all codes are equal even if they produce a result of the same quality. The six different loop orderings run at very different speed, and none of our simple implementations can beat a good library, in this case the BLAS library included in LibSci.
The results with the Cray Fortran compiler are particularly interesting. The result for the BLAS library is slower which we do not yet understand, but it also turns out that for four of the six loop orderings we get the same result as with the BLAS library DGEMM routine. It looks like the compiler simply recognized that this was code for a matrix-matrix multiplication and replaced it with a call to the BLAS library. The Fortran 90 matrix multiplication is also replaced by a call of the DGEMM routine. To confirm all this, unload the cray-libsci module and try to compile again and you will see five error messages about not being able to find DGEMM.
"},{"location":"2day-next/E02-CPE/#compilation-of-a-program-3-a-hybrid-mpiopenmp-program","title":"Compilation of a program 3: A hybrid MPI/OpenMP program","text":"The file mpi_omp_hello.c is a hybrid MPI and OpenMP C program that sends a message from each thread in each MPI rank. It is basically a simplified version of the programs found in the lumi-CPEtools modules that can be used to quickly check the core assignment in a hybrid MPI and OpenMP job (see later in this tutorial). It is again just a CPU-based program.
Compile the program with your favourite C compiler on LUMI.
We have not yet seen how to start an MPI program. However, you can run the executable on the login nodes and it will then contain just a single MPI rank.
Click to see the solution. In the HPE Cray PE environment, you don't use mpicc to compile a C MPI program, but you just use the cc wrapper as for any other C program. To enable MPI you have to make sure that the cray-mpich module is loaded. This module will usually be loaded by loading one of the PrgEnv-* modules, but only if the right network target module, which is craype-network-ofi, is also already loaded.
Compiling the program is very simple:
module load PrgEnv-gnu\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_gnu.x\n
to compile with the GNU C compiler,
module load PrgEnv-cray\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_cray.x\n
to compile with the Cray C compiler, and
module load PrgEnv-aocc\ncc -O3 -fopenmp mpi_omp_hello.c -o mpi_omp_hello_aocc.x\n
to compile with the AMD AOCC compiler.
To run the executables it is not even needed to have the respective PrgEnv-* module loaded since the binaries will use a copy of the libraries stored in a default directory, though there have been bugs in the past preventing this to work with PrgEnv-aocc.
"},{"location":"2day-next/E03-Access/","title":"Exercises: Accessing LUMI","text":"See the instructions to set up for the exercises.
-
Log on to an arbitrary login node of LUMI.
Can you find how to check your quota and status of your allocation?
Click to see the solution. How to check your quota and status of your allocation, is explained in the message-of-the-day at the bottom of the \"Announcements\" section: you can use the lumi-workspaces command.
-
How can you log on to a specific login node of LUMI, e.g., the login node \"uan01\"?
Click to see the solution. To log in to the login node \"uan01\", use the hostname lumi-uan01.csc.fi instead of lumi.csc.fi.
This may be useful if you use software on your desktop that tries to connect repeatedly to LUMI and then tries to find, e.g., a running server that it created before.
-
Create a shell on a login node using the Open OnDemand web interface?
Click to see the solution. - Point your web browser to
https://www.lumi.csc.fi. With some browsers it is sufficient to type lumi.csc.fi in the address bar while others require www.lumi.csc.fi. - Click the \"Go to login\" button. What you need to do here, depends on how you got your account. For the course you will have to proceed with the \"MyAccessID\" option \"Login Puhuri\" in most cases.
- Once you're in the web interface, click on \"Login node shell\" (likely the third choice on the first line). It will open a new tab in the browser with a login shell on LUMI. Note that Open OnDemand uses a different set of login nodes.
-
Try to transfer a file from your desktop/laptop to your home directory via the Open OnDemand web interface.
Click to see the solution. - Go back into Open OnDemand if you have left it after the previous exercise.
- On the main screen of the web interface, choose \"Home directory\".
- Depending on the browser and your system you may be able to just drag-and-drop files into the frame that shows your files, or you can click the blue \"Upload\" button towards the top of the screen.
"},{"location":"2day-next/E04-Modules/","title":"Exercises: Modules on LUMI","text":"See the instructions to set up for the exercises.
-
The Cray CPE comes with a number of differently configured HDF5 libraries.
a. Which ones can you find?
b. Can you find more documentation about those libraries?
Click to see the solution module spider HDF5\n
or
module spider hdf5\n
can produce a lot of output on the system. It will show you three modules though (but this might be under \"Other possible matches\") that have cray- in their name: cray-hdf5, cray-hdf5-parallel and cray-netcdf-hdf5parallel. The first two of these really provide HDF5 configured in two different ways. The third one is another library using HDF5 as a backend. The other hdf5 modules that you might see are modules generated by Spack (see a little bit in the next session).
If you want more information about the cray-hdf5 module, you can try
module spider cray-hdf5\n
and then for a specific version
module spider cray-hdf5/1.12.2.7\n
and see that there is not much information. Even worse, the help of this particular version refers to the release info but mentions the wrong filename. The path is correct, but the file where the info is, is
/opt/cray/pe/hdf5/1.12.2.7/release_info.md\n
(and the same holds true for cray-hdf5-parallel)
-
The Bison program installed in the OS image is pretty old (version 3.0.4) and we want to use a newer one. Is there one available on LUMI?
Click to see the solution. module spider Bison\n
tells us that there are indeed newer versions available on the system.
The versions that have a compiler name (usually gcc) in their name followed by some seemingly random characters are installed with Spack and not in the CrayEnv or LUMI environments.
To get more information about Bison/3.8.2 if you didn't get it already with the previous command:
module spider Bison/3.8.2\n
tells us that Bison 3.8.2 is provided by a couple of buildtools modules and available in all partitions in several versions of the LUMI software stack and in CrayEnv.
Alternatively, in this case
module keyword Bison\n
would also have shown that Bison is part of several versions of the buildtools module.
The module spider command is often the better command if you use names that with a high likelihood could be the name of a package, while module keyword is often the better choice for words that are more a keyword. But if one does not return the solution it is a good idea to try the other one also.
A problem with too much different versions of software on the system...
If you tried
module spider bison\n
to look for Bison, you wouldn't have found the version in buildtools which is the main version of Bison on LUMI in the main supported software stack (see the next presentation), but only versions that are currently on the system and installed through Spack.
-
The htop command is a nice alternative for the top command with a more powerful user interface. However, typing htop on the command line produces an error message. Can you find and run htop?
Click to see the solution. We can use either module spider htop or module keyword htop to find out that htop is indeed available on the system. With module keyword htop we'll find out immediately that it is in the systools modules and some of those seem to be numbered after editions of the LUMI stack suggesting that they may be linked to a stack, with module spider you'll first see that it is an extension of a module and see the versions. You may again see some versions installed with Spack.
Let's check further for htop/3.2.1 that should exist according to module spider htop:
module spider htop/3.2.1\n
tells us that this version of htop is available in all partitions of LUMI/22.08 and LUMI/22.06, and in CrayEnv. Let us just run it in the CrayEnv environment:
module load CrayEnv\nmodule load systools/22.08\nhtop\n
(You can quit htop by pressing q on the keyboard.)
-
LUMI now offers Open OnDemand as a browser-based interface to LUMI that enables running some graphical programs through a VNC server. But for users who do not want to use Open OnDemand apps, there is currently another way to start a VNC server (and that was the way to use graphical programs before the Open OnDemand interface was ready and may still be relevant if Open OnDemand would fail after a system update). Can you find the tool on LUMI, and if so, how can we use it?
Click to see the solution. module spider VNC and module keyword VNC can again both be used to check if there is software available to use VNC. Both will show that there is a module lumi-vnc in several versions. If you try loading the older ones of these (the version number points at the date of some scripts) you will notice that some produce a warning as they are deprecated. However, when installing a new version we cannot remove older ones in one sweep, and users may have hardcoded full module names in scripts they use to set their environment, so we chose to not immediate delete these older versions.
One thing you can always try to get more information about how to run a program, is to ask for the help information of the module. For this to work the module must first be available, or you have to use module spider with the full name of the module. We see that version 20230110 is the newest version of the module, so let's try that one:
module spider lumi-vnc/20230110\n
The output may look a little strange as it mentions init-lumi as one of the modules that you can load. That is because this tool is available even outside CrayEnv or the LUMI stacks. But this command also shows a long help test telling you how to use this module (though it does assume some familiarity with how X11 graphics work on Linux).
Note that if there is only a single version on the system, as is the case for the course in May 2023, the module spider VNC command without specific version or correct module name will already display the help information.
"},{"location":"2day-next/E05-SoftwareStacks/","title":"Exercises: LUMI Software Stacks","text":"See the instructions to set up for the exercises.
"},{"location":"2day-next/E05-SoftwareStacks/#information-in-the-lumi-software-library","title":"Information in the LUMI Software Library","text":"Explore the LUMI Software Library.
- Search for information for the package ParaView and quickly read through the page
Click to see the solution. Link to the ParaView documentation
It is an example of a package for which we have both user-level and some technical information. The page will first show some license information, then the actual user information which in case of this package is very detailed and long. But it is also a somewhat complicated package to use. It will become easier when LUMI evolves a bit further, but there will always be some pain. Next comes the more technical part: Links to the EasyBuild recipe and some information about how we build the package.
We currently only provide ParaView in the cpeGNU toolchain. This is because it has a lot of dependencies that are not trivial to compile and to port to the other compilers on the system, and EasyBuild is strict about mixing compilers basically because it can cause a lot of problems, e.g., due to conflicts between OpenMP runtimes.
"},{"location":"2day-next/E05-SoftwareStacks/#using-modules-in-the-lumi-software-stack","title":"Using modules in the LUMI software stack","text":" -
Search for the bzip2 tool (and not just the bunzip2 command as we also need the bzip2 command) and make sure that you can use software compiled with the Cray compilers in the LUMI stacks in the same session.
Click to see the solution. module spider bzip2\n
shows that there are versions of bzip2 for several of the cpe* toolchains and in several versions of the LUMI software stack.
Of course we prefer to use a recent software stack, the 22.08 or 22.12 (but as of early May 2023, there is a lot more software ready-to-install for 22.08). And since we want to use other software compiled with the Cray compilers also, we really want a cpeCray version to avoid conflicts between different toolchains. So the module we want to load is bzip2/1.0.8-cpeCray-22.08.
To figure out how to load it, use
module spider bzip2/1.0.8-cpeCray-22.08\n
and see that (as expected from the name) we need to load LUMI/22.08 and can then use it in any of the partitions.
"},{"location":"2day-next/E05-SoftwareStacks/#installing-software-with-easybuild","title":"Installing software with EasyBuild","text":"These exercises are based on material from the EasyBuild tutorials (and we have a special version for LUMI also).
Note: If you want to be able to uninstall all software installed through the exercises easily, we suggest you make a separate EasyBuild installation for the course, e.g., in /scratch/project_465000523/$USER/eb-course if you make the exercises during the course:
- Start from a clean login shell with only the standard modules loaded.
-
Set EBU_USER_PREFIX:
export EBU_USER_PREFIX=/scratch/project_465000523/$USER/eb-course\n
You'll need to do that in every shell session where you want to install or use that software.
-
From now on you can again safely load the necessary LUMI and partition modules for the exercise.
-
At the end, when you don't need the software installation anymore, you can simply remove the directory that you just created.
rm -rf /scratch/project_465000523/$USER/eb-course\n
"},{"location":"2day-next/E05-SoftwareStacks/#installing-a-simple-program-without-dependencies-with-easybuild","title":"Installing a simple program without dependencies with EasyBuild","text":"The LUMI Software Library contains the package eb-tutorial. Install the version of the package for the cpeCray toolchain in the 22.08 version of the software stack.
At the time of this course, in early May 2023, we're still working on EasyBuild build recipes for the 22.12 version of the software stack.
Click to see the solution. -
We can check the eb-tutorial page in the LUMI Software Library if we want to see more information about the package.
You'll notice that there are versions of the EasyConfigs for cpeGNU and cpeCray. As we want to install software with the cpeCray toolchain for LUMI/22.08, we'll need the cpeCray-22.08 version which is the EasyConfig eb-tutorial-1.0.1-cpeCray-22.08.eb.
-
Obviously we need to load the LUMI/22.08 module. If we would like to install software for the CPU compute nodes, you need to also load partition/C. To be able to use EasyBuild, we also need the EasyBuild-user module.
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now all we need to do is run the eb command from EasyBuild to install the software.
Let's however take the slow approach and first check if what dependencies the package needs:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb -D\n
We can do this from any directory as the EasyConfig file is already in the LUMI Software Library and will be located automatically by EasyBuild. You'll see that all dependencies are already on the system so we can proceed with the installation:
eb eb-tutorial-1.0.1-cpeCray-22.08.eb \n
-
After this you should have a module eb-tutorial/1.0.1-cpeCray-22.08 but it may not show up yet due to the caching of Lmod. Try
module av eb-tutorial/1.0.1-cpeCray-22.08\n
If this produces an error message complaining that the module cannot be found, it is time to clear the Lmod cache:
rm -rf $HOME/.lmod.d/.cache\n
-
Now that we have the module, we can check what it actually does:
module help eb-tutorial/1.0.1-cpeCray-22.08\n
and we see that it provides the eb-tutorial command.
-
So let's now try to run this command:
module load eb-tutorial/1.0.1-cpeCray-22.08\neb-tutorial\n
Note that if you now want to install one of the other versions of this module, EasyBuild will complain that some modules are loaded that it doesn't like to see, including the eb-tutorial module and the cpeCray modules so it is better to unload those first:
module unload cpeCray eb-tutorial\n
"},{"location":"2day-next/E05-SoftwareStacks/#installing-an-easyconfig-given-to-you-by-lumi-user-support","title":"Installing an EasyConfig given to you by LUMI User Support","text":"Sometimes we have no solution ready in the LUMI Software Library, but we prepare one or more custom EasyBuild recipes for you. Let's mimic this case. In practice we would likely send those as attachments to a mail from the ticketing system and you would be asked to put them in a separate directory (basically since putting them at the top of your home directory would in some cases let EasyBuild search your whole home directory for dependencies which would be a very slow process).
You've been given two EasyConfig files to install a tool called py-eb-tutorial which is in fact a Python package that uses the eb-tutorial package installed in the previous exercise. These EasyConfig files are in the EasyBuild subdirectory of the exercises for this course. In the first exercise you are asked to install the version of py-eb-tutorial for the cpeCray/22.08 toolchain.
Click to see the solution. -
Go to the EasyBuild subdirectory of the exercises and check that it indeed contains the py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb and py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb files. It is the first one that we need for this exercise.
You can see that we have used a very long name as we are also using a version suffix to make clear which version of Python we'll be using.
-
Let's first check for the dependencies (out of curiosity):
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb -D\n
and you'll see that all dependencies are found (at least if you made the previous exercise successfully). You may find it strange that it shows no Python module but that is because we are using the cray-python module which is not installed through EasyBuild and only known to EasyBuild as an external module.
-
And now we can install the package:
eb py-eb-tutorial-1.0.0-cpeCray-22.08-cray-python-3.9.12.1.eb\n
-
To use the package all we need to do is to load the module and to run the command that it defines:
module load py-eb-tutorial/1.0.0-cpeCray-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
with the same remark as in the previous exercise if Lmod fails to find the module.
You may want to do this step in a separate terminal session set up the same way, or you will get an error message in the next exercise with EasyBuild complaining that there are some modules loaded that should not be loaded.
"},{"location":"2day-next/E05-SoftwareStacks/#installing-software-with-uninstalled-dependencies","title":"Installing software with uninstalled dependencies","text":"Now you're asked to also install the version of py-eb-tutorial for the cpeGNU toolchain in LUMI/22.08 (and the solution given below assumes you haven'ty accidentally installed the wrong EasyBuild recipe in one of the previous two exercises).
Click to see the solution. -
We again work in the same environment as in the previous two exercises. Nothing has changed here. Hence if not done yet we need
module load LUMI/22.08 partition/C\nmodule load EasyBuild-user\n
-
Now go to the EasyBuild subdirectory of the exercises (if not there yet from the previous exercise) and check what the py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb needs:
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -D\n
We'll now see that there are two missing modules. Not only is the py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 that we try to install missing, but also the eb-tutorial/1.0.1-cpeGNU-22.08. EasyBuild does however manage to find a recipe from which this module can be built in the pre-installed build recipes.
-
We can install both packages separately, but it is perfectly possible to install both packages in a single eb command by using the -r option to tell EasyBuild to also install all dependencies.
eb py-eb-tutorial-1.0.0-cpeGNU-22.08-cray-python-3.9.12.1.eb -r\n
-
At the end you'll now notice (with module avail) that both the module eb-tutorial/1.0.1-cpeGNU-22.08 and py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1 are now present.
To run you can use
module load py-eb-tutorial/1.0.0-cpeGNU-22.08-cray-python-3.9.12.1\npy-eb-tutorial\n
"},{"location":"2day-next/E06-Slurm/","title":"Exercises: Slurm on LUMI","text":""},{"location":"2day-next/E06-Slurm/#basic-exercises","title":"Basic exercises","text":" -
In this exercise we check how cores would be assigned to a shared memory program. Run a single task on the CPU partition with srun using 16 cpu cores. Inspect the default task allocation with the taskset command (taskset -cp $$ will show you the cpu numbers allocated to the current process).
Click to see the solution. srun --partition=small --nodes=1 --tasks=1 --cpus-per-task=16 --time=5 --account=<project_id> bash -c 'taskset -cp $$' \n
Note that you need to replace <project_id> with the actual project account ID of the form project_ plus a 9 digits number.
The command runs a single process (bash shell with the native Linux taskset tool showing process's CPU affinity) on a compute node. You can use the man taskset command to see how the tool works.
-
Next we'll try a hybrid MPI/OpenMP program. For this we will use the hybrid_check tool from the lumi-CPEtools module of the LUMI Software Stack. This module is preinstalled on the system and has versions for all versions of the LUMI software stack and all toolchains and partitions in those stacks.
Use the simple job script below to run a parallel program with multiple tasks (MPI ranks) and threads (OpenMP). Submit with sbatch on the CPU partition and check task and thread affinity.
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\nsrun --cpus-per-task=$SLURM_CPUS_PER_TASK hybrid_check -n -r\n
Be careful with copy/paste of the script body as copy problems with special characters or a double dash may occur, depending on the editor you use.
Click to see the solution. Save the script contents into the file job.sh (you can use the nano console text editor for instance). Remember to use valid project account name.
Submit the job script using the sbatch command:
sbatch job.sh\n
The job output is saved in the slurm-<job_id>.out file. You can view its content with either the less or more shell commands.
The actual task/threads affinity may depend on the specific OpenMP runtime (if you literally use this job script it will be the GNU OpenMP runtime).
"},{"location":"2day-next/E06-Slurm/#advanced-exercises","title":"Advanced exercises","text":"These exercises combine material from several chapters of the tutorial.
-
Build the hello_jobstep program tool using interactive shell on a GPU node. You can pull the source code for the program from git repository https://code.ornl.gov/olcf/hello_jobstep.git. It uses a Makefile for building and requires Clang and HIP. The hello_jobstep program is actually the main source of inspiration for the gpu_check program in the lumi-CPEtools modules for partition/G. Try to run the program interactively.
Click to see the solution. Clone the code using git command:
git clone https://code.ornl.gov/olcf/hello_jobstep.git\n
It will create hello_jobstep directory consisting source code and Makefile.
Allocate resources for a single task with a single GPU with salloc:
salloc --partition=small-g --nodes=1 --tasks=1 --cpus-per-task=1 --gpus-per-node=1 --time=10 --account=<project_id>\n
Note that, after allocation is granted, you receive new shell but are still on the compute node. You need to use the srun command to run on the allocated node.
Start interactive session on a GPU node:
srun --pty bash -i\n
Note now you are on the compute node. --pty option for srun is required to interact with the remote shell.
Enter the hello_jobstep directory and issue make command.
As an example we will built with the system default programming environment, PrgEnv-cray in CrayEnv. Just to be sure we'll load even the programming environment module explicitly.
The build will fail if the rocm module is not loaded when using PrgEnv-cray.
module load CrayEnv\nmodule load PrgEnv-cray\nmodule load rocm\n
To build the code, use
make LMOD_SYSTEM_NAME=\"frontier\"\n
You need to add LMOD_SYSTEM_NAME=\"frontier\" variable for make as the code originates from the Frontier system and doesn't know LUMI.
(As an exercise you can try to fix the Makefile and enable it for LUMI :))
Finally you can just execute ./hello_jobstep binary program to see how it behaves:
./hello_jobstep\n
Note that executing the program with srun in the srun interactive session will result in a hang. You need to work with --overlap option for srun to mitigate this.
Remember to terminate your interactive session with exit command.
exit\n
and then do the same for the shell created by salloc also.
"},{"location":"2day-next/E07-Binding/","title":"Exercises: Process and Thread Distribution and Binding","text":""},{"location":"2day-next/E07-Binding/#exercises-on-the-slurm-allocation-modes","title":"Exercises on the Slurm allocation modes","text":" -
We return to the hybrid MPI/OpenMP example from the Slurm exercises.
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\nsrun --cpus-per-task=$SLURM_CPS_PER_TASK hybrid_check -n -r\n
Improve the thread affinity with OpenMP runtime variables. Alter the script from the previous exercise and ensure that each thread is bound to a specific core.
Click to see the solution. Add the following OpenMP environment variables definition to your script:
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n
You can also use an MPI runtime variable to have MPI itself report a cpu mask summary for each MPI rank:
export MPICH_CPUMASK_DISPLAY=1\n
Note hybrid_check and MPICH cpu mask may not be consistent. It is found to be confusing.
To avoid having to use the --cpus-per-task flag, you can also set the environment variable SRUN_CPUS_PER_TASK instead:
export SRUN_CPUS_PER_TASK=16 \n
On LUMI this is not strictly necessary as the Slurm SBATCH processing has been modified to set this environment variable, but that was a clunky patch to reconstruct some old behaviour of Slurm and we have already seen cases where the patch did not work (but that were more complex cases that required different environment variables for a similar function).
The list of environment variables that the srun command can use as input, is actually confusing, as some start with SLURM_ but a few start with SRUN_ while the SLURM_ equivalent is ignored.
So we end up with the following script:
#!/bin/bash -l\n#SBATCH --partition=small # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --cpus-per-task=16 # 16 threads per task\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\nexport SRUN_CPUS_PER_TASK=$SLURM_CPUS_PER_TASK\n\nexport OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nexport MPICH_CPUMASK_DISPLAY=1\n\nsrun hybrid_check -n -r\n
Note that MPI returns the CPU mask per process in binary form (a long string of zeros and ones) where the last number is for core 0. Also, you'll see that with the OpenMP environment variables set, it will look like only one core can be used by each MPI task, but that is because it only shows the mask for the main process which becomes OpenMP thread 0. Remove the OpenMP environment variables and you'll see that each task now gets 16 possible cores to run on, and the same is true for each OpenMP thread (at least when using the GNU compilers, the Cray compilers have different default behaviour for OpenMP which actually makes more sense for most scientific computing codes).
-
Binding on GPU nodes: Allocate one GPU node with one task per GPU and bind tasks to each CCD (8-core group sharing L3 cache) leaving the first (#0) and last (#7) cores unused. Run a program with 6 threads per task and inspect the actual task/threads affinity using either the hello_jobstep executable generated in the previous exercise, or the gpu_check command from tne lumi-CPEtools module.
Click to see the solution. We can chose between different approaches. In the example below, we follow the \"GPU binding: Linear GCD, match cores\" slides and we only need to adapt the CPU mask:
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\nCPU_BIND=\"mask_cpu:0xfe000000000000,0xfe00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe0000,0xfe000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe,0xfe00,\"\nCPU_BIND=\"${CPU_BIND}0xfe00000000,0xfe0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu_$SLURM_JOB_ID ./hello_jobstep\n
The base mask we need for this exercise, with each first and last core of a chiplet disabled, is 01111110 which is 0x7e in hexadecimal notation.
Save the job script as job_step.sh then simply submit it with sbatch from the directory that contains the hello_jobstep executable. Inspect the job output.
Note that in fact as this program was compiled with the Cray compiler in the previous exercise, you don't even need to use the OMP_* environment variables above as the threads are automatically pinned to a single core and as the correct number of threads is derived from the affinity mask for each task.
Or using gpu_check instead (and we'll use the cpeGNU version again):
#!/bin/bash -l\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=1 # Total number of nodes\n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=5 # Run time (minutes)\n#SBATCH --account=<project_id> # Project for billing\n#SBATCH --hint=nomultithread\n\nmodule load LUMI/23.09\nmodule load lumi-CPEtools/1.1-cpeGNU-23.09\n\ncat << EOF > select_gpu_$SLURM_JOB_ID\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu_$SLURM_JOB_ID\n\nCPU_BIND=\"mask_cpu:0xfe000000000000,0xfe00000000000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe0000,0xfe000000,\"\nCPU_BIND=\"${CPU_BIND}0xfe,0xfe00,\"\nCPU_BIND=\"${CPU_BIND}0xfe00000000,0xfe0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport OMP_PROC_BIND=close\nexport OMP_PLACES=cores\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu_$SLURM_JOB_ID gpu_check -l\n
"},{"location":"2day-next/M01-Architecture/","title":"LUMI Architecture","text":"Presenter: Kurt Lust (LUST)
Some insight in the hardware of LUMI is necessary to understand what LUMI can do and what it cannot do, and to understand how an application can be mapped upon the machine for optimal performance.
"},{"location":"2day-next/M01-Architecture/#materials","title":"Materials","text":""},{"location":"2day-next/M01-Architecture/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M02-CPE/","title":"The HPE Cray Programming Environment","text":"Presenter: Kurt Lust (LUST)
As Linux itself is not a complete supercomputer operating system, many components that are essential for the proper functioning of a supercomputer are separate packages (such as the Slurm scheduler discussed later in this course) or part of programming environments. It is important to understand the consequences of this, even if all you want is to simply run a program.
"},{"location":"2day-next/M02-CPE/#materials","title":"Materials","text":""},{"location":"2day-next/M02-CPE/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M03-Access/","title":"Getting Access to LUMI","text":"Presenter: Kurt Lust (LUST)
We discuss the options to log on to LUMI and to transfer data.
"},{"location":"2day-next/M03-Access/#materials","title":"Materials","text":""},{"location":"2day-next/M03-Access/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M04-Modules/","title":"Modules on LUMI","text":"Presenter: Kurt Lust (LUST)
LUMI uses Lmod, but as Lmod can be configured in different ways, even an experienced Lmod user can learn from this presentation how we use modules on LUMI and how modules can be found.
"},{"location":"2day-next/M04-Modules/#materials","title":"Materials","text":""},{"location":"2day-next/M04-Modules/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M05-SoftwareStacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
In this presentation we discuss how application software is made available to users of LUMI. For users of smaller Tier-2 clusters with large support teams compared to the user base of the machine, the approach taken on LUMI may be a bit unusual...
"},{"location":"2day-next/M05-SoftwareStacks/#materials","title":"Materials","text":""},{"location":"2day-next/M05-SoftwareStacks/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M06-Slurm/","title":"Slurm on LUMI","text":"Presenter: Kurt Lust (LUST)
Slurm is the batch job scheduler used on LUMI. As no two Slurm configurations are identical, even an experienced Slurm user should have a quick look at the notes of this talk to understand the particular configuration on LUMI.
"},{"location":"2day-next/M06-Slurm/#materials","title":"Materials","text":""},{"location":"2day-next/M06-Slurm/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M07-Binding/","title":"Process and Thread Distribution and Binding","text":"Presenter: Kurt Lust (LUST)
To get good performance on hardware with a strong hierarchy as AMD EPYC processors and GPUs, it is important to map processes and threads properly on the hardware. This talk discusses the various mechanisms available on LUMI for this.
"},{"location":"2day-next/M07-Binding/#materials","title":"Materials","text":""},{"location":"2day-next/M07-Binding/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M08-Lustre/","title":"Using Lustre","text":"Presenter: Kurt Lust (LUST)
Lustre is a parallel file system and the main file system on LUMI. It is important to realise what the strengths and weaknesses of Lustre at the scale of a machine as LUMI are and how to use it properly and not disturb the work of other users.
"},{"location":"2day-next/M08-Lustre/#materials","title":"Materials","text":""},{"location":"2day-next/M09-Containers/","title":"Containers on LUMI-C and LUMI-G","text":"Presenter: Kurt Lust (LUST)
Containers are a way on LUMI to deal with the too-many-small-files software installations on LUMI, e.g., large Python or Conda installations. They are also a way to install software that is hard to compile, e.g., because no source code is available or because there are simply too many dependencies.
"},{"location":"2day-next/M09-Containers/#materials","title":"Materials","text":""},{"location":"2day-next/M09-Containers/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/M10-Support/","title":"LUMI Support and Documentation","text":"Presenter: Kurt Lust (LUST)
Where can I find documentation or get training, and which support services are available for what problems? And how can I formulate a support ticket so that I can get a quick answer without much back-and-forth mailing?
"},{"location":"2day-next/M10-Support/#materials","title":"Materials","text":""},{"location":"2day-next/M10-Support/#qa","title":"Q&A","text":"/
"},{"location":"2day-next/ME03-Exercises-1/","title":"Exercises 1: Elementary access and the HPE Cray PE","text":" - Start with the exercises on \"Getting Access to LUMI\"
- Continue with the exercises on the \"HPE Cray Programming environment\"
"},{"location":"2day-next/ME04-Exercises-2/","title":"Exercises 2: Modules on LUMI","text":" - Exercises on \"Modules on LUMI\"
"},{"location":"2day-next/ME05-Exercises-3/","title":"Exercises 3: LUMI Software Stacks and EasyBuild","text":" - Exercises on \"LUMI Software Stacks\"
"},{"location":"2day-next/ME07-Exercises-4/","title":"Exercises 4: Running jobs with Slurm","text":""},{"location":"2day-next/ME07-Exercises-4/#intro","title":"Intro","text":"For these exercises, you'll need to take care of some settings:
-
For the CPU exercises we advise to use the small partition and for the exercises on GPU the standard-g partition.
-
During the course you can use the course training project project_465001102 for these exercises. A few days after the course you will need to use a different project on LUMI.
-
On May 3 we have a reservation that you can use (through #SBATCH --reservation=...):
-
For the small partition, the reservation name is LUMI_Intro_SURF_small
-
For the standard-g partition, the reservation name is LUMI_Intro_SURF_standardg
An alternative (during the course only) for manually specifying these parameters, is to set them through modules. For this, first add an additional directory to the module search path:
module use /appl/local/training/modules/2day-20240502\n
and then you can load either the module exercises/small or exercises/standard-g.
Check what these modules do...
Try, e.g.,
module show exercises/small\n
to get an idea of what these modules do. Can you see which environment variables they set?
"},{"location":"2day-next/ME07-Exercises-4/#exercises","title":"Exercises","text":" - Start with the exercises on \"Slurm on LUMI\"
- Proceed with the exercises on \"Process and Thread Distribution and Binding\"
"},{"location":"2day-next/MI01-IntroductionCourse/","title":"Introduction","text":"Presenter: Kurt Lust (LUST)
"},{"location":"2day-next/MI01-IntroductionCourse/#materials","title":"Materials","text":""},{"location":"2day-next/MI02-WrapUpDay1/","title":"Wrap-Up Day 1","text":"Presenter: Kurt Lust (LUST)
"},{"location":"2day-next/MI02-WrapUpDay1/#materials","title":"Materials","text":""},{"location":"2day-next/MI03-IntroductionDay2/","title":"Introduction Day 2","text":"Presenter: Kurt Lust (LUST)
"},{"location":"2day-next/MI03-IntroductionDay2/#materials","title":"Materials","text":""},{"location":"2day-next/MI04-WhatElse/","title":"What Else?","text":"Presenter: Kurt Lust (LUST)
A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it.
"},{"location":"2day-next/MI04-WhatElse/#materials","title":"Materials","text":""},{"location":"2day-next/schedule/","title":"Schedule","text":" - Day 1
- Day 2 DAY 1 - ADD DATE 09:15 CEST 10:15 EEST Welcome and Introduction 09:30 CEST 10:30 EEST LUMI Architecture Some insight in the hardware of LUMI is necessary to understand what LUMI can do and what it cannot do, and to understand how an application can be mapped upon the machine for optimal performance. 10:15 CEST 11:15 EEST HPE Cray Programming Environment As Linux itself is not a complete supercomputer operating system, many components that are essential for the proper functioning of a supercomputer are separate packages (such as the Slurm scheduler discussed on day 2) or part of programming environments. It is important to understand the consequences of this, even if all you want is to simply run a program. 11:15 CEST 12:15 EEST Break and networking (30 minutes) 11:45 CEST 12:45 EEST Getting Access to LUMI We discuss the options to log on to LUMI and to transfer data. 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #1) 14:00 CEST 15:00 EEST Modules on LUMI LUMI uses Lmod, but as Lmod can be configured in different ways, even an experienced Lmod user can learn from this presentation how we use modules on LUMI and how modules can be found. 14:40 CEST 15:40 EEST Exercises (session #2) 15:00 CEST 16:00 EEST Break and networking (20 minutes) 15:20 CEST 16:20 EEST LUMI Software Stacks In this presentation we discuss how application software is made available to users of LUMI. For users of smaller Tier-2 clusters with large support teams compared to the user base of the machine, the approach taken on LUMI may be a bit unusual... 16:20 CEST 17:20 EEST Exercises (session #3) 16:50 CEST 17:50 EEST Wrap-up of the day 17:00 CEST 18:00 EEST Free Q&A 17:30 CEST 18:30 EEST End of day 1 DAY 2 - ADD DATE 09:15 CEST 10:15 EEST Short welcome, recap and plan for the day 09:30 CEST 10:30 EEST Slurm on LUMI Slurm is the batch job scheduler used on LUMI. As no two Slurm configurations are identical, even an experienced Slurm user should have a quick look at the notes of this talk to understand the particular configuration on LUMI. 11:00 CEST 12:00 EEST Break and networking (30 minutes) 11:30 CEST 12:30 EEST Process and Thread Distribution and Binding To get good performance on hardware with a strong hierarchy as AMD EPYC processors and GPUs, it is important to map processes and threads properly on the hardware. This talk discusses the various mechanisms available on LUMI for this. 12:30 CEST 13:30 EEST Lunch break (60 minutes) 13:30 CEST 14:30 EEST Exercises (session #4) 14:00 CEST 15:00 EEST Using Lustre Lustre is a parallel file system and the main file system on LUMI. It is important to realise what the strengths and weaknesses of Lustre at the scale of a machine as LUMI are and how to use it properly and not disturb the work of other users. 14:30 CEST 15:30 EEST Containers on LUMI-C and LUMI-G Containers are a way on LUMI to deal with the too-many-small-files software installations on LUMI, e.g., large Python or Conda installations. They are also a way to install software that is hard to compile, e.g., because no source code is available or because there are simply too many dependencies. 15:30 CEST 16:30 EEST Break and networking (30 minutes) 16:00 CEST 17:00 EEST LUMI Support and Documentation Where can I find documentation or get training, and which support services are available for what problems? And how can I formulate a support ticket so that I can get a quick answer without much back-and-forth mailing? 16:30 CEST 17:30 EEST SPACE FOR A LOCAL TALK 16:45 CEST 17:45 EEST What Else? A brief discussion about what else LUST offers, what is not covered in this course, and how you can learn about it. 17:00 CEST 18:00 EEST Free Q&A 17:30 CEST 18:30 EEST End of day 2"},{"location":"4day-20230214/","title":"Comprehensive General LUMI Training, February 14-17, 2023","text":""},{"location":"4day-20230214/#course-organisation","title":"Course organisation","text":""},{"location":"4day-20230214/#downloads","title":"Downloads","text":"
- Slides presentation \"LUMI Software Stacks\" (but you may prefer reading the notes)
- Slides AMD:
- Introduction to the AMD ROCmTM Ecosystem
- AMD Debugger: ROCgdb
- Introduction to Rocporf Profiling Tool
- Introduction to OmniTools
- Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"4day-20230214/#videos","title":"Videos","text":" - Welcome and introduction
- Additional software on LUMI
- LUMI support and LUMI documentation
"},{"location":"4day-20230214/#other-material-only-available-on-lumi","title":"Other material only available on LUMI","text":"The following materials are available to members of the project_465000388 project only:
- Slides of presentations given by HPE people are in
/project/project_465000388/slides/HPE on LUMI - Exercises from the HPE sessions are in
/project/project_465000388/exercises/HPE on LUMI
"},{"location":"4day-20230214/#notes","title":"Notes","text":" -
Notes from the HedgeDOC pages:
Published with delay.
-
Notes on the presentation \"LUMI Software Stacks\"
-
Additional notes and exercises from the AMD session (External link!)
"},{"location":"4day-20230214/#exercises","title":"Exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"4day-20230214/hedgedoc_notes_day1/","title":"Notes from the HedgeDoc page - day 1","text":"These are the notes from the LUMI training, 1114-17.02.2023, 9:00--17:30 (CET) on Zoom.
- Day 1: This page
- Day 2
- Day 3
- Day 4
"},{"location":"4day-20230214/hedgedoc_notes_day1/#other-questions-regarding-organisation-or-lumi-in-general","title":"Other questions regarding organisation or LUMI in general","text":" -
I managed to log onto Lumi, but after a few minutes everything \"freezes\" and I have to use a different terminal to log in again: is it normal? That already happened several times since this morning, even using different login nodes).
- It depends. If it freezes forever than it may be your terminal application or unstable connection. Shorter freezes that can still last 30 seconds or more are currently unfortunately a common problem on LUMI and caused by file system issues for which the technicians still haven't found a proper solution. There's only two of the four login nodes operating at the moment I think (one down for repair and one crashed yesterday evening and is not up again yet, at least not when I checked half an hour ago) the load on the login nodes is also a bit higher than usual.
- uan02 seems to work a bit better
-
Will we find material in the /scratch/project_465000388 folder?
- The location of the files will be posted on here and later appear in https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/schedule/
-
Is LUMI up? I am not able to connect at all.
- One of the login nodes has crashed but is unfortunately still in lumi.csc.fi. Try lumi-uan01.csc.fi or lumi-uan02.csc.fi.
-
Is LUMI planning to introduce MFA at some point in the near future?
- No such plans for ssh so far, it is already complicated enough and we already have enough \"connot log on tickets\"... But identity providers may require it independently of LUMI when you log in to MyAccessID.
-
I read about a Lumi partition for \"visualization\", with Nvidia GPUs, is that meant for instance to use Jupyter notebooks?
- That service will be offered later via Open OnDemand. No date set yet, but hopefully before the summer. The nodes have only just become available and still need to be set up. Be aware though that you have to use Jupyter in a proper way or other people can break into your account via Jupyter, and that it is not meant for large amounts of interactive work, but to offer an interface to prepare batch jobs that you can then launch to the cluster. LUMI-G is the most important part of the LUMI investment so it is only normal that getting that partition working properly has the highest priority.
- That makes perfect sense
- Looking forward to it
"},{"location":"4day-20230214/hedgedoc_notes_day1/#introduction-to-hpe-cray-hardware-and-programming-environment","title":"Introduction to HPE Cray Hardware and Programming Environment","text":" -
Once a job starts on a particular node, can we get direct access to this node (I mean while the job is running, can we interact with it, for monitoring purposes for example)?
- https://docs.lumi-supercomputer.eu/runjobs/scheduled-jobs/interactive/
- See the sessions on Slurm. Currently only with
srun, not with ssh, as srun is the only command that can guarantee your session would end up in the CPU sets of your job.
-
Why was LUSTRE chosen as the FileSystem? What others were considered?
- Almost all really big clusters run Lustre. Spectrum Scale is very expensive and BeeGFS probably doesn't have the maturity for such a cluster. And it is actually not a choice of CSC but a choice made by vendors when answering the tender. HPE Cray only offers Lustre on clusters the size of LUMI, with their own storage system which is actually a beautiful design.
- There is an ongoing discussion in the supercomputing community whether the whole concept of a global parallel file system will work in the future. There might be a scale, when it simply does not work any longer.
- I agree. And it is part of the reason why the main parallel file system is split in four. But there is currently no other affordable and sufficiently scalable technology that can also run on affordable hardware. I know a flash based technology that claims to scale better, but just the hardware cost would be 10 times the hardware cost of the current main storage. There is a reason why we bill storage on the flash file system at ten times the rate of the disk based storage, as that is also the price difference of the system. And HPE is working on local buffers that are rumoured to be used in El Capitan, but even that is still a system that integrates with Lustre. Google for \"Rabbit storage HPE\" or something like that.
-
Can you use MPI MPMD to run one program on LUMI-C and another on LUMI-G including communication between the two programs?
- Yes, it is possible, but not so well tested yet. We are interested in your experiences if you try this! There is a known problem with the scheduler if you do this across partitions though. In trying to make life easier for \"basic\" users a decision was taken that makes MPMD more difficult. So the LUMI-C + LUMI-G scenario is currently difficult basically because those jobs have difficulties getting scheduled.
- That's too bad. Are there plans to improve it?
- If you can convince the sysadmins and technical responsible of the project... It would mean that every user has to change the way they work with LUMI so I'm afraid it is rather unlikely and will require a lot of discussion. I'm in favour though as this is also the model EuroHPC promotes via the DEEP series of projects.
- Indeed and it is one of the advantages of having two or more separate partitions.
- If you look at the EuroHPC supercomputers, they are all designed with different specialised partitions. The problem is probably that a select group of researchers and compute centres directly involved in the projects that explored this design are very aware of this but many other centres or in the case of LUMI also other groups involved in the decision process on scheduler policies are not enough aware of this way of designing applications. We do see it used by climate scientists already with codes where simulation, I/O and in-situ visualisation are collaborating but different programs, but I'm only aware of one project which asked this for LUMI-C and LUMI-G so my answer is based on what the technical responsible of the LUMI project answered about the problems that can be expected.
- Ok. Thanks alot for the answers. I will try it in the near future so perhaps you will see another request soon :) In my case it is for multiscale molecular dynamics simulations (computational chemistry).
- I've added the request to the items to be discussed with sysadmins and technical responsibles of the project.
-
Is there any difference between Trento and Milan that the user should care about?
- The only difference I know is the link to the GPUs. From the ISA point-of-view they are the same.
- The main difference seems to be in the I/O die as now all 128 lanes coming out of the chip support xGNI/Infinity Fabric rather than only 64 of them while the other 64 only supported PCIe. I wouldn't expect much more changes as this is a really low production part, only used in HPE Cray systems with MI250x.
-
Is it possible to use RStudio Server (for interactive programming with R) on LUMI (probably as a singularity container)?
- Singularity is installed, so if you have a container, it should run.
- It might also come in Open OnDemand, a service that is still under development, but in that case it might be more to simply prepare data for a job that would then be launched or to postprocess data.
-
When will be the recordings available?
- Some days after the course. We don't have a pipeline yet to upload them immediately after the training.
- It takes some postprocessing and this requires time. We are all busy with the course so this is basically evening work and work for after the course. The place where they are stored will be announced in https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/schedule/
-
It seems that the On Demand service will provide things like Rstudio, Jupyter, etc. but most users do not need the \"basic\" Rstudio or Jupyter but a lot of various packages with them: how will that be managed?
- Not clear as we don't have the personpower to install everything for everybody so we focus on the main components that have a lot of users. I guess local support teams will have to develop containers that we can then fit in the setup.
- Will this On Demand service allow users to run their own containers with all they need inside? (because nobody really uses bare Jupyter or Rstudio, do they?)
- We cannot answer these questions yet as the service is not being set up by us but offered by one of the LUMI partners (in this case CSC) who will do the main setup.
-
What is the typical daily KWh of LUMI?
- It has rarely run at full load I think but from what I remember its design power is around 6 MW.
-
Is there a way for users to get accurate figures about the actual electrical power consumption of particular jobs, on CPUs
- Not at the moment and I doubt this will appear soon. It is also largely impossible as measurements are on the node level so it doesn't make sense for shared nodes. And on exclusive nodes you only get data for the node as a whole, so if you use only one core you'd likely still see 80W or 100W basically because of all the power consumed by the I/O die and network interface, even wehn idle.
- even at that level electrical consumption information would be useful, to compare several simulations, etc.
- I don't know what your experiences are with it, but I have used it on one PRACE cluster and the results were totally worthless as a comparison as there was too much background power consumption. So I don't think this has a high level of priority for LUMI. Profiling an application and getting an idea of how well it uses the cache hierarhcy and how much bandwidth it requires to memory would be a much better comparison. But unfortunately even that is limited on LUMI at the moment I believe. Hardware counter monitoring by users had to be turned off due to security problems in the Linux kernel.
- I was thinking about comparisons between a single run on Lumi using thousands of CPUs vs. a similar run on a smaller machine with less CPUs during a longer time
- I hope you realise how much power is consumed by, e.g., the network? Every switch blade in LUMI actually has a power consumption of up to 250W (and is therefore also water cooled), about as much as a processor socket, so any measurement would still have a very large error margin. And in fact, the answer is obvious. The run wil less CPUs on a smaller cluster will always consume less assuming the cluster has a similar design with respect to efficiency, as with more CPUs for the same problem you always loose parallel efficiency and as the bigger the network becomes the more power you consume. The latter is also nicely shown in the Green500 list, You'll see there bunches of similar machines together with the smaller one always on top since the network power is less. Which is whey the Frontier TDS (which is not Frontier but just its test system) is in that list ahead of Adastra, Frontier itself and LUMI even though these are all systems with the same design. I guess the reason why Frontier is above LUMI in that list is probably because they seemed to have access to a different version of some software for their Top500 run as they also get better scalability than LUMI despite using the same node and network design.
-
Is see that there are plans for a Container Orchestration Platform - LUMI-K. What will be the purpose of this partition?
- It will likely never appear due to lack of personpower to implement the service. The idea was to have a platform for microservices (the Galaxy's etc. of this world)
-
What is the average waiting time until a SLURM job get submitted to LUMI [I understand this may vary depeding on the requested RAM/time/etc, but I mean is it a matter of hours or days...]? How the priority of jobs is determined?
- Generally speaking, LUMI, like many HPC clusters, is optimized for throughput and not short waiting times. It is not really meant for \"interactive\" use like this. That being said, there are special queues for short interactive jobs and debugging, where the waiting time is short, but you cannot run large jobs there.
- We don't know ourselves what goes in the priority system. Currently the waiting time is often very low but that will change when LUMI becomes used a lot more.
- The maximum walltime in the standard queue is 2 days, meaning that if your job has top priority (for example, if you have run very little in your project), it will start within 2 days. It will often be a lot faster than that.
- Is it possible to have walltime more than 2 days for specific jobs expected to need more time?
- Unfortunately not. You have to use so-called \"checkpointing\", i.e. saving intermediate results to disk, so that your job can be restarted. Even if you have a lot of data in RAM, this should be possible to do using e.g. flash file system. Also given the general instability seen on LUMI now, it is not advisble to try to run very long jobs, hardware may break... This is not necessarily a \"fault\" in the LUMI design, as clusters grow larger, with many components, some nodes in your jobs will eventually fail if you run e.g. a 1000-node job.
- LUMI is meant for scalable applications. Also on big clusters you can expect a lot of failures so it is not wise to have long running jobs that you cannot restart. Longer jobs also make maintenance difficult. And they lead to monopolisation of resources by a single user.
- is it possible to request an extension for already running job, if it is expected to be finished in longer time?
-
Is it possible to provide some hints on the role of containers and its possible role in LUMI ?
- We will discuss containers tomorrow. But we expect more and more workloads to use containers. But be aware that containers need to be optimized/adapted to run efficiently (or at all) on LUMI. Usually, MPI is the problem.
-
When will GCC 12 become available on LUMI?
- In a future version of the Cray programming environment. We do not know the exact date yet. Which special feature of GCC 12 do you need?
- We need it just because it makes the installation of our software dependencies, especially ExaTensor, much easier. We have recently HIPified this but it's not easy to tune for the new supercomputer https://github.com/ORNL-QCI/ExaTENSOR (distributed tensor library)
- There is a chance that the CPE 23.02 will be installed during the next maintenance period as it contains some patches that we really need in other compilers also, and that one contains 12.2. The next maintenance period is currently expected in March but may need to shift if the software contained in it turns out to be too immature.
-
Which visualization software will be available on the nvidia-visualization nodes? ParaView? VisIT? COVISE? VISTLE?
- Partly based on user demand and partly based on what other support organisations also contribute as we are too small a team to do everything for everybody. The whole LUMI project is set up with the idea that all individual countries also contribute to support. More info about that in a presentation tomorrow afternoon. Just remember the visualisation team at HLRS is as big as the whole LUMI User Support Team so we cannot do miracles. We already have a ParaVeiwe server build recipe with software rendering so I guess you can expect that one to be adapted.
-
Looking at the software list, is distributed computing/ shared computing supported/ have been tested? https://en.wikipedia.org/wiki/Folding%40home
- It would normally not make sense to use LUMI for workloads which could run in a distributed setup, like e.g. Folding at Home. The whole point with a supercomputer system like LUMI is to have a very fast network that connects the different servers in the system.
- LUMI is in the first place a capability computing system, build to run jobs that require lots of compute power with very low latency and very high bandwidth between the processing elements to be able to scale applications. Using it for stuff that could run on simple servers like Folding@Home that can do with much cheaper hardware is a waste of money.
-
Regarding Python: What do I have to consider to run Python code in an optimised way? We have heard about cray-python before.
- See tomorrow, and some other presentations that may mention cray-python which is really mostly a normal Python with some pre-installed packages carefully linked to optimised math libraries from Cray. The bigger problem is the way Python uses the file system but that will be discussed tomorrow afternoon.
- Please note that we hope to include more content related to Python in future (HPE) presentations.
-
On Lumi-G is there Tensorflow and Pytorch available?
- Not preinstalled as there are really too many combinations with other Python packages that users may want and as due to the setup of LUMI there is currently even only some GPU software that we can install properly but you can use containers or download wheels yourself and there is actually info on how to run it in the docs.
- Again, available software is discussed in its own presentation tomorrow afternoon.
- TF and PyTorch are available in the CSC local software collection https://docs.lumi-supercomputer.eu/software/local/csc/ (not maintained/supported by LUST)
-
Which ROCm version is the \"most\" compatible with what is on Lumi-G?
- The only ones that we can truly support are the ones that come with the Cray PE (so not the 5.2.5 and 5.3.3). HPE Cray tested the version of the software that is on LUMI with ROCm 5.0, 5.1 and 5.2. The driver should be recent enough to run 5.3.x but no guarantee that it will work together with, e.g., Cray MPICH (though it seems to work in the testing we have done so far but that can never be exhaustive)
-
Why for some modules (e.g. python) there are several options with the same version number (3.9.12-gcc-n7, 3.9.12-gcc-v4, etc.). Are there any differences? How could we tell?
- The modules with the \"funny names\" in the end \"-n7\", \"-v4\" are generated by Spack. These are shortened hash codes identifying the version. You will normally not see them unless you load the Spack module. You will have to check the complete Spack \"spec\" of the module to determine exactly how they were built. You can use the command
spack find -lv python, for example. - And for those installed through EasyBuild (which have things like cpeGNU-22.08 etc. in their name): see tomorrow afternoon.
- I checked and they are exactly the same :/.
-
Nob question: I'm confused on what is PrgEnv and modules such as PerfTools. What is the difference between them?
- PrgEnv sets modules for a given env (i.e. compiler base: gnu, amd, aocc, cray). This is the entry point of the Programming Environment (PE). Given that, all other modules will be set to that PE. Therefore, you can have PrgEnv-cray and then perftools module will be set for the cray environment. We discuss more on the next lectures (and hands-on).
- There are separate presentations on all that is in perftools coming over the next days.
-
Follow up question: I'm interested in working with AMD developement tools. How do I set my PrgEnv to use the AMD compilers and compatible libs?
- We will discuss that in the Compiler session. But yes, you can use PrgEnv-amd for that (if you want GPU support) or PrgEnv-aocc (CPU support only). Just do
module swap PrgEnv-cray PrgEnv-amd. More on the next lectures. - KL: No need for
module swap on LUMI as Lmod is configured with auto-swap. So module load PrgEnv-amd would also do.
-
What is the minimal environment I have to load to run a singularity container on Lumi-G (with GPUs mainly)?
- https://docs.lumi-supercomputer.eu/runjobs/scheduled-jobs/container-jobs/
- Depends on what part of the environment is already in the container...
- Assuming it is an \"official\" rocm-tensorflow image (so with the drivers, python, etc), which Lumi modules do I need to load?
- We only have a longer description for PyTorch, right now: https://docs.lumi-supercomputer.eu/software/packages/pytorch/
- Very likely none at all as you then only need singularity which is installed in the OS. Unless you need the RCCL plugin for better communication. It should not be that different for Tensorflow as it is for PyTorch.
-
Is the environment firewall set as DENY for all outgoing (internet) TCP. i guess reverse proxy is not recommended
ping google.com\nPING google.com (142.250.179.174) 56(84) bytes of data \n
..hangs - Internet access from the compute nodes should be enabled soon if not enabled yet. Some nodes might still need a reboot for that.
- Ping is never a good test as that is blocked on many systems nowadays.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#first-steps-for-running-on-cray-ex-hardware","title":"First steps for running on Cray EX Hardware","text":" -
Is that possible to change cpu numbers per task in one slurm script to optimize the CPU utilization?
- You mean different number of CPUs for each task, e.g. first task 2 cores, second task 8 cpus?
- Yes, exactly, and these tasks are running in order
- You can request the total number of tasks and then start the individual programs with
srun -n N
-
When I execute sinfo, I get almost 40 lines of output. For example, I see 20 lines that start with standard-g. What is the meaning of that?
- use
sinfo -s or pipe it through less or head sinfo reports a line for each status of the nodes, e.g. standard-g for drained nodes, idle, resv... (check the 5th column). man sinfo for more details.
-
Is it possible to pass arguments to #SBATCH parameters in the jobscript?(not possible with PBS e.g.)
- I am not sure that I understand what you mean, but if it is what I think the answer is no. But instead of using #SBATCH lines you can also pass those settings via environment variables or via command line parameters. Typing
man sbatch may bring you quickly to the manual page of sbatch if you need more information (for me it is the first hit but that is probably because I've used it soo often). - environment variables would work fine I guess, thanks
-
Sometimes srun knows what you asked for (#SBATCH) and then it is enough to just run srun without, e.g., the -n option. Is that not the case on LUMI?
- It is the case on LUMI also.
- There are some defaults but it is always better to be explicit in your job script.
-
Sometimes I need to download large satellite images (~200 GB), it only use one CPU in login node, however, considering the I/O issues recently, should I move downloading in compute node or can I continue in login node?
- The I/O problem to the outside world was a defective cable and has been repaired.
- It might be better to chose for a push strategy to move data onto LUMI rather than a pull strategy from LUMI. Soon there will be the object file system also which will likely be the prefered way to use as an intermediate for large files.
- Given the slow speeds of single stream downloads/uploads from and to LUMI doing this in a compute job seems like a waste of billing units and it won't help with the reliability problem.
-
is --gres per node or total number of GPUs?
-
I think it was mentioned but I didn't catch if all jobs get exclusive node access, i.e., --exclusive? Ok, it was just answered. Since it is not exclusive by default, I guess one should also specify memory?
- It depends on the partition, see https://docs.lumi-supercomputer.eu/runjobs/scheduled-jobs/partitions/
-
Is it possible to see the std/err output of the running batch job?
- each job will dump a file for stdout and a file for stderr. Just answered in the presentation.
- But I mean when job is still running
- Yes. There is some buffering so output is not always immediate but it is not stored elsewhere first and only copied to your account at the end of the job as on some other systems.
- perfect, thanks
- Is it possible to define the size of that buffer, to minimise the time it takes for the contents of the stdout/stderr files to be updated?
- Yes, there is an option to activate unbuffered output with srun.
srun --unbuffered ... But this in not adviced as it increases the load on the file system if your program does lots of small writes.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#exercise-setup","title":"Exercise setup","text":"Exercise
Copy the exercises to your home or project folder cp /project/project_465000388/exercises/HPE/ProgrammingModels.tar $HOME Unpack it with tar xf ProgrammingModels.tar and read the README file or better transfer the pdf to your local machine with scp (run it from your local machine). To set the necessary environment variables, source lumi_c.sh with source /project/project_465000388/exercises/HPE/lumi_c.sh (or lumi_g.sh equivalent for GPU nodes)
-
Should we copy the exercise to the scratch directory?
- I'd suggest copying to your home directory, and if you would use the scratch of project_465000388 then keep in mind that there are many people in that project so create a directory with your login name. But doing this in you home directory will give you more privacy.
-
Is there a scratch area ? Or should run in home ? (bit slow at times)
- scratch, project and home are really on the same four file systems so there is no speed difference between them, What differs is the policy: Number of files allowed, maximum capacity allowed, how long does data remain before it is cleaned automatically, ... Yes, we know we have file system problems and that sometimes the file systems are slow and we do not yet know to which extent this is caused by hardware problems that are not yet discovered, by software problems (for example with VASP or simply in the file system software) or simply by users abusing the file systems and causing a slowdown for everybody. It is very likely that there is more than one factor that plays a role.
-
I still failed to get my account of my new csc account (I had an old csc account). When I applied it via MyAccessID, it prompted that \"The level of assurance provided by your home organization for you does not meet the required level when logging in to the service. From March 1, 2023, you will not be able to access the service.\"
- Just ignore that. It is just a warning about future changes in the background.
- So what I need is just to fill in the registration? It needs the project number 465000388 and project manager email, what should I fill in for the project manager email?
- I link MyAccessID with my csc account now, but the project 4659000388 is not shown on the list of projects.
-
sbatch: error: Batch job submission failed: Requested node configuration is not available from sbatch pi.slurm
- Have you run
source lumi_c.sh? - no, sorry, did lumi_g
- Is there a job script for lumi_g trial ?
- In the next lectures, but yes, you can use one of the GPU examples or adjust the existing job launcher (this is pi_acc.slurm)
- okay, but for now lumi_c is intended for ALL scripts ( without adjusting anything) ? Then I do that.
- but also with source lumi_c.sh + make clean + make and sbatch pi.slurm same error for me
- yes, standard works; thanks
- I have got the same error, although I sourced lumi_c. Do I need to fill something into the job account area within the script?
- Could you check you have the right partition in the file? I've changed the scripts, so you maybe using an old version?
- May I ask you, what you entered for these options? For SBATCH -p I am not sure what to fill in.
standard or standard-g. Please check the lumi_g.sh and lumi_c.sh for the updated version.
- Thank you! That helped me! I am new in this area, so it is still a bit confusing, but now I get a clue.
-
How to compile pi_hip (in C)? Tried make clean & source lumi_g.sh & make but that fails
-
I managed to Unpack it with tar xf ProgrammingModels.tar, but where are lumi_g.sh and lumi_c.sh?
- It is in the main directory (
/projappl/project_465000388/exercises/HPE/) since it is common to all exercises. - So, the instructions to do the excercises are in the PDF file?
- yes and README too
-
pi_hip with 8 GPUs takes about 2.3s whereas it is faster with only 8 MPI ranks (and marginally slower with 2 MPIs), is it normal? I expected the GPU version to be much faster than the CPU...
- the example is not really using multiple gpus... BTW, it is not using MPI...
- First, yes it is using one GPU, secondly some of these examples are really just there so you can see what that example looks like in the programming model chosen. The HIP example in a way is an outlier because it needs a reduction ( add up all the counts) and I want the example to do everything on the GPU, it is doing this by a simple method (atomic addition). If we cared about performance we would do that in another way but it would really complicate the example. If you run the HIP example on 8 tasks it will run the single-GPU example eight times. I have not yet created an MPI/HIP version.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#overview-of-compilers-and-parallel-programming-models","title":"Overview of compilers and Parallel Programming Models","text":" -
Are there any SYCL implementation available on LUMI? For example hipSYCL with HIP backend.
- Not installed by default and without any guarantee that they work in all cases, but we do have a build recipe for hipSYCL (which actually renamed to Open SYCL a couple of days ago) and someone has also succeeded in building the open-sourced version of DPC++. No guarantee though that it works for all cases or always plays nice with Cray MPICH. See tomorrow afternoon about how to expand the LUMI software stack. https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib/tree/main/easybuild/easyconfigs/h/hipSYCL or even better https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/h/hipSYCL/
- I'd wish though that HPE Cray and AMD would offer proper support as this is a good model to be able to target all three main HPC GPU families and even more exotic hardware.
- (Harvey) We have built SYCL at another site but I'm not sure of the status. As for officially supporting it, I don't know of any plans but you could equally argue that Raja or Kokkos could be supported as an alternative higher-level framework.
-
Apologies if this was explained while I was away, are there any plans / roadmap for moving the Cray Fortran compiler to be LLVM-based, or is it expected it will remain based on Cray's proprietary backend?
- No. The Fortran compiler has always been extremely good, The C++ compiler specifically was not keeping up with standards and had very long compilation times and these were some of the drivers to make the change there. I think open source Fortran is also a moving target, the new Flang (f18) seems a work in progres.
- (user comment) OK, thank you (Intel also moved their C compiler backend to LLVM and they seem to be now following the same path with their Fortran compiler, so we were wondering if Cray's strategy would be the same; really happy to hear it's not, since this gives us access to a wider range of implementations).
- (Harvey) Best I don't comment on Intel. I'm interested to see how the classic Intel compilers and the OneAPI ones develop, particularly for Fortran.
- (Kurt) I keep wondering what Intel is actually doing with Fortran. Are they indeed fully moving to a new flang (and contributing to it) or did they really just port their frontend to an LLVM backend?
- I think they re-built their frontend on top of an LLVM backend (sorry for the off-topic)
-
Is (or will) HIP also be compatible with Intel Habana GPUs?
- I have no idea, but I assume hipSYCL can work for that...
-
(Kurt) Habana is not a GPU but an AI accelerator with a different architecture. Or do you mean the XE line (Ponte Vecchio, Rialto Bridge, Falcon Shores)?
But even there the answer is no. AMD will not do it. The way they also can support CUDA is because it is only an API translation. And Intel will not do it either, their preferred programming models for XE are Data Parallel C++ which is their SYCL implementation and OpenMP offload.
- (User comment) Project to enable HIP applications to run on Intel hardware exists. See here as well as this presentation. No idea if it will run on a specialized hardware like the Habana AI processors.
-
(Kurt) I really doubt HIP can do anything on Habana when I check their web site. I suspect it is more of a matrix processor and not a vector processing and they even say very little about programming on their web site. It doesn't really look like hardware that fits the CUDA/HIP programming model. I hadn't heard about the ANL project to port HIP yet. The only one I had seen already was a project that did something similar as HIP but was basically a one person effort that had died already.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#exercise","title":"Exercise","text":"Exercise
- Copy the exercises to your home or project folder
cp /project/project_465000388/exercises/HPE/ProgrammingModels.tar $HOME - Unpack it with
tar xf ProgrammingModels.tar and read the README file or the pdf at doc/ProgrammingModelExamples.pdf. - To set the necessary environment variables, source
lumi_c.sh with source /project/project_465000388/exercises/HPE/lumi_c.sh (or lumi_g.sh equivalent for GPU nodes) - Try out different compilers (by switching compiler environments, e.g.
module swap PrgEnv-gnu) either manually e.g. cc C/pi_mpi.c or use make Makefile.allcompilers
- is there a simple command to restore the default module configuration?
-
How does the compilation of the acceleration example work? I have been trying some modules, but it did not work.
- See pi/setup_modules, there is a script setup_LUMI-G.sh that you can source to load the modules that Alfio talked about. You need to load the new environment variables from lumi_g.sh or put the right options in the batch script to select partition and request gpus. The standard Makefile has a target acc that should build those examples with CCE.
- For non-pi examples you would need to check any relevant instructions
source /project/project_465000388/exercises/HPE/lumi_g.sh- Please share error messages or explain more if you are still stuck.
- Thanks for your help! I will try to implement.
-
I tried to use the pi_acc.slurm script, but sbatch says the requested node configuration is not available. The changes I did was add -A project_465000388
- could you update your
lumi_g_sh script? We udpated it with the new partition. - I copied lumi_g just now, but looks like it's the same as lumi_c.sh
-
It runs through, but there is a complaint in the out file that /var/spool/slurmd/job2843827/slurm_script: line 33: ../../setup_acc.sh: No such file or directory
-
You need to point it to a script that sets up the gpu modules, so the file in the setup_modules, I should have fixed that so it did not need editing.
- yes
- I'd already done the setup manually, so it still worked
- Finally works for me
- Sorry for the incovenient...
-
I still try to run exercise one, but not success? \"No partition specified or system default partition\"
- please, source lumi_c.sh or lumi_g.sh first.
- is there a way to check if the sourcing process worked?
echo $SLURM_ACCOUNT should report project_465000388 - still got error should I remove some arguments?
- pi.slurm?
- Also please copy those two files again as they were updated (lumi_c.sh, lumi_g.sh)
- I did, my I have the content of pi.slurm to be excuted?
- I still can't excute pi.slurm!!!
- via
sbatch pi.slurm? - I just change the content
- SBATCH -A project_465000388
- is this correct or #SBATCH -A y11?
- this the error \".........../ProgrammingModels/jobscripts/../C/pi_serial: No such file or directory\"
- should i set the directory?
-
I'm trying to run my own application with MPI+gpus following the explaination in the slides, but I either get the errorMPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked if I set MPICH_GPU_SUPPORT_ENABLED=1 or
MPICH ERROR [Rank 0] [job id 2843791.3] [Tue Feb 14 16:11:55 2023] [nid007564] - Abort(1616271) (rank 0 in comm 0): Fatal error in PMPI_Init: Other MPI error, error stack:\nMPIR_Init_thread(171).......: \nMPID_Init(506)..............: \nMPIDI_OFI_mpi_init_hook(837): \ncreate_endpoint(1382).......: OFI EP enable failed (ofi_init.c:1382:create_endpoint:Address already in use)\n
if I set MPICH_GPU_SUPPORT_ENABLED=0 - Is the GPU target module loaded? You need the GPU target (and recompile) to tell MPI to use the GPU. It will discussed tomorrow.
- ok, thanks! And I believe so, I do
module load craype-accel-amd-gfx90a
- Then you have to recompile. Did you?
- Yes, everything was compiled with that line already loaded
- can you show the
module list output? - OK, what's the
ldd <exe> output? We just need to check if the gtl library (used by MPI) is linked in. Just grep for gtl. - OK, it is there... Can you run within the jobscript?
- Put ldd command in the job script just before the srun of your executable. It would be better to have ldd of your executable. Somehow the gtl library is not present when you run, so I can assume you have to load the module in the jobscript.
- It's a python package, so I don't have an executable
- OK, then, can you do
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH? Please note that the wrappers does the magic for you, but here you have python... (actually it is export LD_LIBRARY_PATH=/opt/cray/pe/lib64/:$LD_LIBRARY_PATH) - I still get the same two outcomes, depending on
MPICH_GPU_SUPPORT_ENABLED (everything being recompiled on a fresh environment)
-
Are the timings correct? In the previous exercise, it claimed the serial code took 6 seconds, but it was done almost instantly
-
You wrote in hints for the 2nd exercise: \"Try out different compilers (by switching compiler environments, e.g. module swap PrgEnv-gnu) either manually e.g. cc C/pi_mpi.c or use make Makefile.allcompilers\", but the variant - make Makefile.allcompilers, does not work properly make: Nothing to be done for 'Makefile.allcompilers'
make cleanmake -f Makefile.allcompilers- It won't build binaries that are already there.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#cray-scientific-libraries","title":"Cray Scientific Libraries","text":"No questions during the session.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#exercises","title":"Exercises","text":"Exercise
- Copy the exercises to your home or project folder
cp /project/project_465000388/exercises/HPE/ProgrammingModels.tar $HOME - Unpack it with
tar xf ProgrammingModels.tar and read the README file or the pdf at doc/ProgrammingModelExamples.pdf. -
To set the necessary environment variables, source lumi_c.sh with source /project/project_465000388/exercises/HPE/lumi_c.sh (or lumi_g.sh equivalent for GPU nodes)
-
Directory libsci_acc: Test with LibSci_ACC, check the different interfaces and environment variables
-
Just to clarify? for the 3rd exercise, to copy from /project/project_465000388/exercises/HPE/libsci_acc ? The file called \"ProgrammingModels.tar\" does not contain dir \"libsci_acc\"
- Yes, this is another example. Need to copy it.
- The slide being shared at the moment is tying to convey that these are different directories.
-
This is rather a compilers/packages question. I compile the software using cmake on the login node using ftn (Cray Fortran : Version 14.0.2). In the submission script I do \"module load CrayEnv\" and the following is printed on the *.e file: Lmod is automatically replacing \"craype-x86-rome\" with \"craype-x86-milan\". My question is if the milan architecture was indeed taken into account during compilation, since this was done on the login node
- If you didn't load the
craype-x86-milan module on the login node before compilation, then your binary is optimized for Rome. See the slides of the morning session about cross-compilation for more information. - We'll discuss
CrayEnv tomorrow. It always loads the most suitable target module for the node on which you execute the load (or the module purge which causes an automatic reload), though there is currently a bug that manifests on the dev-g partition (basically because there were some nodes added to the system that I did not know about so did not adapt the code). So to compile with zen3 optimizations on the login nodes you'd still have to make sure craype-x86-milan is loaded as that is not what CrayEnv will do for you. - Also note that cross-compilation does not always work as some programs come with configuration scripts that think it is wise to add a
-march=native(or -xHost for Intel) to the command line which may overwrite options that the Cray wrapper passes to cross-compile. - I see, thanks. So would it make sense to compile on a compute nodes to make sure everything is setup correctly without me having to load the appropriate modules?
- Yes, it is always safer to do so. Though so far for our software stack we do compile on a login node. For most programs so far this seems OK. It is most often \"research code quality\" applications that I have trouble with.
"},{"location":"4day-20230214/hedgedoc_notes_day1/#qa-day-1","title":"Q&A day 1","text":" -
I have a program writting with cuda module, for optimization purpose and getting it run on AMD GPU on LUMI. Based on what I learned today, first, I need to convert my code with hip (or something else?), then compile it with proper enviroment, am I right?
- AMD presentations will cover the hipification tools that can be used for this.
-
Not a question but I am working on Python and so far using Pytorch Lightning works, not sure if optimized though, so it's nice to see that we have some abstraction without fiddling too much with the code.
- https://docs.amd.com/bundle/ROCm-Deep-Learning-Guide-v5.3/page/Frameworks_Installation.html. The relevant bit is how to instruct pip to get the right wheels:
--extra-index-url https://download.pytorch.org/whl/nightly/rocm5.2/ - Yup, it is also important to do some
export to use more than 1 GPU. CSC has a modules for pytorch that sets it right. https://docs.lumi-supercomputer.eu/software/local/csc/
-
Are the python libraries global or are libraries supposed to be local venv
- Users should manage their libraries but can ellect a given python instalation to use it directly or to create virtual environments. Special care should be given to not have many files in the virtual environments. More details on what users can do will be explained tomorrow.
-
Are tools to synchronize between local and remote supported and advisable to use? (e.g. Synchting) Can a user continously run a single-core job to keep alive the server?
- No. That is a waste of your billing units and you should also not do it on the login nodes. Use a more clever way of synching that doesn't need to be running all the time.
- Any suggestions for a cleverer way?
- It depends what it is for. E.g., my development directories are synchronised but for that I simply use Eclipse as the IDE.
- check VS code remote plugin
- (Kurt) That one is for remote editing, you still have to synch via another plugin or in another way. I did notice the visual studio remote can be a bit unreliable on a high latency connection so take that into account.
- And of course I just use rsync from time to time but start it only when I need it.
-
Is there a list of essential modules that we should have to run jobs both for CPU and GPU particions? I accidentaly purged a lot of them and now is too difficult to add them 1-1.
- It depends on the PrgEnv. You can use a script to put your modules so that you can source it. CPU is out-of-the-box. For GPU you need:
module load craype-accel-amd-gfx90a rocm - We'll talk about another solution also that is implemented on LUMI.
-
If you require a specific name for mpi compilation (e.g. mpifort), do you recommend using alias or update-alternatives to change the name?
- If you can set an alias it implies you can change the command I think? If this was hardcoded I would write a wrapper script in your path.
- (Kurt) The wrapper script might be the better alternative as you need to do something in a bash script to be able to use aliases. By default they are not available in shell scripts.
-
About VS Code, are you aware of any way that allows it to run on compute nodes and not on the login node?
- We have not tested this yet.
- There should be a way to just start vscoded server and use it via a web browser. But I've never tried it, and you'd still need to create an ssh tunnel from the machine on which you run the browser to a login node which then forwards all data to the compute node (the way one would also use the
lumi-vnc module to contact a VNC server)
-
Will SSHing into allocated compute nodes be allowed?
- Not clear if they will ever allow it. It does make it more difficult to clean up a node. So far the only solution is to go to the node with an interactive srun, which sometimes needs an option to overlap with tasks that are already on the node.
- Precisely, rocm-smi or some other monitoring tool (e.g. htop).
"},{"location":"4day-20230214/hedgedoc_notes_day2/","title":"Notes from the HedgeDoc page","text":"These are the notes from the LUMI training, 1114-17.02.2023, 9:00--17:30 (CET) on Zoom.
- Day 1
- Day 2: This page
- Day 3
- Day 4
"},{"location":"4day-20230214/hedgedoc_notes_day2/#openacc-and-openmp-offload-with-cray-compilation-environment","title":"OpenACC and OpenMP offload with Cray Compilation Environment","text":" -
Can you have both OpenMP and OpenACC directives in a code (assuming you only activate one of them)?
- Yes. This is quite common to mix OpenMP for multithreading on the host and OpenACC for the device. For OpenMP and OpenACC, both on the device, yes you can selectively select one of the other using macros. Note that OpenACC is enabled by default for the Cray Fortran compiler so if you don't want to use OpenACC you have to explicitly disable it. OpenMP need to be enabled explicitly.
-
Are there features in OpenACC that are not available (and not planned) in OpenMP?
- I will raise this at the end of the talk.
- Thanks for the answer. Very useful.
- In practice, we have seen that people only stay with OpenACC if they already have in their (Fortran) code (i.e. from previous work with enabling Nvidia GPU support), new porting projects tend to choose OpenMP offloading.
- Follow-up question: How is the support of OpenACC vs OpenMP in compilers. I would maybe expect that OpenMP would be more widely supported, now and especially in the future?
- The assumption is correct, OpenMP is the target for most compilers. As far I know, GNU will target Mi250 in GCC 13. I'm not aware of a real OpenACC in GNU. NVIDIA is supporting OpenACC for their compilers.
-
What gives better performance on LUMI-G OpenMP offloading or OpenACC offloading? (C/C++)
- There is no OpenACC support for C/C++.
- Hypothetically speaking, there is no big performance difference between OpenACC and OpenMP offload in theory, sometimes they even share the same back-end. In practice, OpenMP offers somewhat more control at the programmer level for optimizations, whereas in OpenACC, they compiler has more freedom in optimizing.
-
T his is not related to the presented topic, but every time I login to Lumi I get this message: \"/usr/bin/manpath: can't set the locale; make sure $LC_* and $LANG are correct\", how can I fix it?
- I think I saw that on Mac ssh consoles
- I am using a Mac, so that is probably related
- I have had the same problem before and fixed it by adding
SendEnv LANG LC_* in my SSH config file. - Will try that - No difference
- Did you simply add a line in the .ssh/config with
SendEnv LANG LC_*?
- The other problem that I have also had on a Mac was that it had sent a locale that was not recognized by the system I was logging on to.
- Nothing seems to fix it, I will leave it like that for now since it does not affect anything else
-
Working on a Fortran+OpenACC+hipBlas/hipFFT code which has currently a CPU and a GPU version. The two versions have become very different: CPU version has lots of function calls inside the OpenMP loop. GPU version has all the parallelism at the lowest level. Looking for ways to get back to one code base. Any chance to use craype-accel-host to get good performance on CPU and GPU targets?!
- the host is not meant to be for performance, for instance it will likely use a single thread. Check the man page intro_openmp for more details.
- How to (best) organize the code to support multiple GPU architectures is still an open question. Before, you could \"get away\" with only having support for 1 type of GPUs, and have that as a special branch of compilation, but with several types of GPUs and/or accelerators in the future (at least Nvidia, Intel, AMD...) it will become more difficult to do it like that. I have seen a few projects with successful support of several kinds of accelerators, what they typically do is to abstract it to a common matrix/vector library in the application (a \"matrix class\" or similar) and then have this module support different GPU/accelerator backends (including pure CPU execution).
- Yes, this a common issue. Moreover, it you have multiple libraries accessing to the GPU, they don't talk each other (even worse for a multi-gpu case), so memory pooling is quite difficult.
-
Can we print out some of the slides from yesterday, for personal use? \"Programming Environment and Modules\"
- Sure, but please do not redistribute the digital form.
- The HPE slides and exercises can be copied for personal use by people attending the course. Some of the exercise examples are open source and were downloaded from the relevant repositories.
"},{"location":"4day-20230214/hedgedoc_notes_day2/#exercises","title":"Exercises","text":"Exercise
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directories for this exercise:
openmp-target, openacc-mpi-demos, BabelStream - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file.
- T o run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_g.sh (GPU) or source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Try different parallel offload programming models (openACC, OpenMP, HIP) and examples.
-
Has anything changed in the exercise files since yesterday, i.e., should we update our copy?
- Probably no changes to these folders but better copy again. Some other files for later changed.
-
Are there job scripts available for today's exercise or I make them myself ?
- they are available (follow the readme)
- readme says Execute ... srun -n1 ...
- yes, correct. If you would like to submit (they are quite short runs), you can use one of the yesterday batch script.
- sorry, in my build/ there is no file ctest; nto sure I understand what to submit +1
- ctest is a command, it will run the tests produced by cmake. If you are interested in the single binaries, then they are in the directories
build/tests/bin. Otherwise ctest will execute all.
- test all worked; thanks
- Might be an easy one, sorry: I got the return that No partition was specified. Has anyone experience with that?
- Need to source the lumi_g.sh file to get SLURM configurtion.
- is there a useful sequence in which to study the tests/*/.cpp s ? Seem many of those
- So, check the original code at https://github.com/ye-luo/openmp-target. The idea is to check OpenMP offload functionalities and check if they are supported by Compilers. If the tests are OK, then the assumption is that the compile is working.
- The exercise is not to understand the workings of the source files ? but to apply this comprehensive test then ? (tests were all passed according to job output)
- It depends if you want to understand how OpenMP works, then you are welcome to check the code, sure. Otherwise the exercises is to give examples on how to use the Offload OpenMP with CCE.
- okay, got it, thanks.
-
In openmp-target exercise I got the following error after the last make command \"An accelerator module must be loaded for the compiler to support \"target\" related directive !$OMP TARGET\"
- Have you loaded the GPU module? (
source setup_modules/setup_LUMI-G.sh) - I use the command \"source /project/project_465000388/exercises/HPE/lumi_g.sh\"
- This one is to set SLURM, you need to set the modules for the GPU (a different file)
-
Modules were loaded, but make couldn't find the compiler - BabelStream
- Which example are you trying to run?
- What's the error? could check the modules too?
Currently Loaded Modules:1) libfabric/1.15.0.0 3) xpmem/2.4.4-2.3_9.1__gff0e1d9.shasta 5) LUMI/22.08 (S) 7) craype-accel-amd-gfx90a 2) craype-network-ofi 4) partition/L- You are missing PrgEnv-cray...
-
Inside the makefile of /exercises/HPE/openacc-mpi-demos/src/, there are some comments after FC and FFLAGS. Are they meant as a guide for something?
- Those examples are taken from https://github.com/RonRahaman/openacc-mpi-demos which uses the NVIDIA compiler as baseline. I agree that I can remove the comments... Sorry for the confusion.
- Thanks, actually I find those comments useful, I might try in a machine with NVIDIA. Some comment that these are for NVIDIA would clarify things.
- Then you are welcome to use the original code. Note, it requires the nvidia compiler (previously PGI).
-
In BabelStream example, the OpenMP compilation (with make) gives an error:
CC -fopenmp -O3 -DOMP src/main.cpp src/omp/OMPStream.cpp -I src/ -I src/omp -DOMP_TARGET_GPU -o omp.x\nwarning: src/omp/OMPStream.cpp:108:3: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Wpass-failed=transform-warning]\n
The HIP compilation works fine. - this is a warning. It says that it cannot vectorize the loop (O3 enables vectorization), but this is fine since we are running on the GPU anyway. BTW, if you want to inspect more, I suggest to add the listing flag (-fsave-loopmark) to get more info.
- I added the flag in Makefile (CC -fopenmp -O3 -fsave-loopmark -DOMP src/main.cpp src/omp/OMPStream.cpp -I src/ -I src/omp -DOMP_TARGET_GPU -o omp.x) but the output is the same as before
- It will generate a file .lst that you can inspect and get more info.
-
In BabelStream, the OpenMP code OMPStream.cpp, there is #pragma omp target enter data map... I assume this defines mapping of data onto devices. Where is the device list for OMP further defined in the code? or is this all?
- This is an OpenMP question, actually. With the call
pragma omp target enter data map(alloc: a[0:array_size], b[0:array_size], c[0:array_size]) (line 31) you map those data to the GPUs (it does allocate them). Then there will be an #pragma omp target exit data map(release: a[0:array_size], b[0:array_size], c[0:array_size]) (line 46) to release the data. Then, the way OpenMP offload works is that if you do another map for the same data, OpenMP will check that data exists already on the device and it will reuse those allocations. - Thanks! Could you please clarify where is the device list itself defined in the code, so that OMP knows which devices it should map the data to?
- This the default device, i.e. device_id 0.
- Ahh, ok, thanks. I saw this device_id 0, but I thought it can't be so easy :)
- Yeah, it is done via
omp_set_default_device(device); (line 26). You can also use the clause device (this is for multi-gpus, actually). - the id 0 means graphic card 0 on a multi-card node?
- It is part of the current talk. It is GPU 0, but then you can set
HIP_VISIBLE_DEVICES=2 and OpenMP will have GPU_ID=0 for the device 2 (maybe I'm confusing you). The point is that OpenMP uses at runtime the available GPUs, provided by ROCM. But then you can change the GPU order via HIP_VISIBLE_DEVICES=1,0. Wait for this afternoon exercises...
"},{"location":"4day-20230214/hedgedoc_notes_day2/#advanced-application-placement","title":"Advanced Application Placement","text":" -
I was a bit confused by this definition of CPU. Can it be repeated and expanded?
- I have uploaded the talk
- We will try to use cpu in this talk to mean what Linux calls a cpu which is a hardware thread in a core - so 2 per core.
-
Could it be the case that when a thread needs to access data in a remote cache (different core), OS rather migrates the thread instead of accessing (or even copying) the data? I'm suspecting such a behavior since sometimes pinning threads is slower than allowing OS to migrate them inside a NUMA domain. Any suggestions what to check?
- Well, this is definitely the case. Within the same NUMA can be a good trade-off. This is a bit experimental, you have to try which affinity is best for you.
-
Any possibility to identify who did a binding (the different SW components)?
- You can get various components to report what they did (Slurm/MPI/OpenMP) but in general anything can override the binding or at least further constrain it. This is why it is good to run an application (as a proxy for your own) from your job script to double check this.
- It is not obvious when it comes to frameworks and applications that do their own thing to set the binding. We are covering MPI, MPI/OpenMP as they are the most common. We can at least use Slurm to set the binding of any process it starts and as long as that keeps within the binding it was given that at least gives us some control.
- In general, there is no trace on what is setting the binding...
"},{"location":"4day-20230214/hedgedoc_notes_day2/#exercises_1","title":"Exercises","text":"Exercise
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directories for this exercise:
XTHI (try out application) and ACHECK (pdf doc & application similar to xthi but nicer output) - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file. Check that you don't have unnecessary (GPU) modules loaded.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Try different parallel different binding options for CPU execution (look at slides and use envars to change and display the order
-
Is it common to use different bindings depending on the size of the computations?
- No sure I understand the question on what you mean by \"different\". Usually you have to check the best match for your application. For example, if you are memory bound, then you may decide to spread your threads such that they will use multiple memory channels.
- The most common situation at scale is just to fill up multiple nodes using cores in sequence and if you use threads then choose OMP_NUM_THREADS so tasks fit nicely in NUMA regions and don't span them. It is when you want to do something special where other options come into play.
-
While compiling xthi.c I got the following error
ld.lld: error: undefined symbol: omp_get_thread_num\n>>> referenced by xthi.c\n>>> /tmp/xthi-c56fa1.o:(main)\nclang-14: error: linker command failed with exit code 1 (use -v to see invocation)\n
- Sorry, the readme is missing
-fopenmp. - I'm a bit confused, the Cray cc wasn't supposed to have openmp ON by default?
- Only OpenACC is the default.
- Not anymore, but it was before yes !
-
I'm trying the example ACHECK and I get ./acheck-cray: error while loading shared libraries: libamdhip64.so.5: cannot open shared object file: No such file or directory. I have done source /project/project_465000388/exercises/HPE/lumi_c.sh. What am I missing here ?
- I think you will need to
source /project/project_465000388/exercises/HPE/lumi_g.sh instead to get the relevant modules for the GPUs. - Those modules are setting the SLURM environment. I assume you have the GPU modules loaded. Please, unload them, recompile and run.
- I suggest you do the exercise on LUMI-C for this session. Perhaps you built it with gpu modules and are running on LUMI-C. (it would work on LUMI-G if you have LUMI-G Slurm and modules setup but there is no need to)
-
Why? -> slurmstepd: error: execve(): xthi.c: Permission denied!!!
- are you using the provided job.slurm?
- I have the following there:
#!/bin/bash\n\n#SBATCH -t 1\n\nexport OMP_NUM_THREADS=1\n\necho srun a.out\nsrun a.out | sort\n
then ou have to run via sbatch job.slurm. Is it what you are doing? - a.out I have change it to xthi.c as the above script cause an error \"execve(): xthi: No such file or directory\"
- Put it back to a.out...
- Error: execve(): xthi: No such file or directory
-
OK, you compile and it will produce a.out, do you have it? Then, sbatch job.slurm will submit it. The job.slurm above doesn't mention any xthi, so I don't know where you error is coming from...
#!/bin/bash\n\n#SBATCH -t 1\n\nexport OMP_NUM_THREADS=1\n\necho srun a.out\nsrun a.out | sort\n
-
Then you have to compile first...
- when i try to compile i got
- ld.lld: error: undefined symbol: omp_get_thread_num
- Need to add -fopenmp flag. I've update the Readme.
- I cant see the update letme try copy it again
- Done, thank you
-
I tried \"cc -fopenmp xthi.c \" but got many errors like \"xthi.c:65:27: error: use of undeclared identifier 'hnbuf' rank, thread, hnbuf, clbuf); \"
- Need to set for LUMI_C. Unload the GPU modules and recompile.
- Yes.. I use \"source /project/project_465000388/exercises/HPE/lumi_c.sh\"..still the same error.
- This is for setting SLURM stuff. Do you hav ethe modules
rocm and craype-accel-amd-gfx90a? If so, please unload them and recompile. - Now I got the error \"fatal error: mpi.h: No such file or directory\"..
- Which modules do you have? I suggest to open a new and fresh terminal connection...
-
Run make on openmp-target and it went well. Next ran
srun -v -n1 --gres=gpu:8 ctest\nsrun: error: Unable to allocate resources: Requested node configuration is not available\n
What node configuration was it looking for or is there a way to see what is required there. should we swap back to rome for that use case : swap craype-x86-rome craype-x86-trento - openmp-target example is usig GPU. Are you setting SLURM for the GPU nodes (script lumi_g.sh)?
-
Is the Lumi-D partition mentionned yesterday accessible now to try, or should we make a new application for that?
- There is a session this afternoon describing the LUMI environment in detail, suggest you ask again if this is not covered there.
- LUMI-D is two things:
- The large memory nodes that are available and have the same architecture as the login nodes
- The visualisation nodes. They were releases again on February 13 but have hardly any software installed at the moment. Given the relative investment in LUMI-G, LUMI-C and the visualisation nodes it is clear that they won't get too much attention anytime soon.
-
Bit Mask: Slurm Script -> sbatch: error: Batch job submission failed: Requested node configuration is not available, why?
- is the SLURM setting done? (script lumi_c.sh)
- Could post the job.slum script?
- I just copy and paste from slides, am I correct? page 50
- let me try... Works for me.
- There are other problems that I'm investigating. but at least I can submit it. Check at
/pfs/lustrep1/projappl/project_465000388/alfiolaz/training_exercises/XTHI/mask.slurm
"},{"location":"4day-20230214/hedgedoc_notes_day2/#understanding-cray-mpi-on-slingshot-rank-reordering-and-mpmd-launch","title":"Understanding Cray MPI on Slingshot, rank reordering and MPMD launch","text":" -
Is the overlap really happens in practice? Or only when there is extra core available with openmp?
- Threads have little to do with cores. One core can run multiple threads, but in case of computational threads this is not a good idea as they will fight for the cache. But having a background thread on top of a computational thread is sometimes a good idea. And actually a good use of hyperthreading also (using the Intel term, AMD calls them SMT I believe)
- And sometimes part of the background work is also done by the network adapter, which should be the case for SlingShot 11.
- Is there a way to check that the communications really happen while the computation is done and not just at the mpi_Wait?
- Some answers were given at slides 21-24.
-
Could one for example use a hyperthread for a MPI async thread even if the application doesn't use hyperthreading?
- Yes, but likely it would not help that much
-
In terms of overlapping computation/communication, what happens when one uses neighbourhood collectives? They have the non-blocking alternative and all processes involved know who they are sending to and receiving from. eg: MPI_Ineighbor_alltoall
- I'm not sure that we provide special optimizations for those collectives. I assume it is just like all others... It is worth to try!
- MPI expert reply: We do support non-blocking neighborhood collectives. They are functional but not super optimized. If there are specific use cases then we suggest to open a ticket and we can investigate more.
- I understand that the nonblocking collectives can be progressed by the progress thread, the neighbourhood collectives are much newer to I'm not sure of the status of that.
-
With NVIDIA gpu-aware MPI, MPI calls perform a whole-device barrier call before/after the communications, rendering async calls ... not async. Does LUMI's implementation do the same?
- I'm not sure if we do the same blocking, but the LUMI design is different and NIC are attached to the GPUs memory directly. As far I can see, we use streams for the communications, so it should not be blocking.
- MPI expert reply: Cray MPI does not do a device-level barrier before/after sync. More specifically, we do not do a hipStreamSynchronize before/after MPI. But, an application still needs to do a device-level sync on their own to make sure specific compute kernels have completed and the buffers used for MPI ops are correctly updated before MPI ops can be issued. They need to do MPI_Waitall to make sure MPI non-blocking ops have completed. They do not have to do a cuda(hip)StreamSynchronize/cuda(hip)DeviceSynchronize before starting the next round of kernels.
- Is there a way for the user to interact with the stream used by MPI, or to direct MPI to a specific stream?
- I don't think so, at least the man page doesn't report any hint for that.
-
How many times does rank re-ordering really helped in performance according to your experience?
- Answered by the speaker: HPE Cray's internal benchmarking team has found it useful on many occasions.
-
I asked this yesterday and understand that is \"difficult\" to use MPMD on LUMI-C and LUMI-G at the same time which I hope will change. Can you comment on that?
- I've basically said everything I can say about that yesterday. It is not an MPI issue but an issue with the way the scheduler works when different parts of the job run in different partitions.
- Does difficult effectively mean impossible? If not, are there any tricks to make it work better?
- It is just not well-tested. Remember that LUMI-G is very new, so there has simple not been enough time and/or people trying it out to establish \"best practice\" yet. We need brave users (like you!) to try it out and bring some feedback.
- (Kurt) I don't think the previous remark is right. From the technical staff of LUMI I heard that the problem is that if a job uses 2 (or more) partitions, it does not follow the regular route through the scheduler but uses backfill slots.
-
Related to question 30, what is the recommended way on LUMI to perform async communications between GPUs, ideally with control of the GPU stream, sot that the synchronisation is done in the background and we avoid the latency of StreamSynchronise. GPU-aware MPI? RCCL? One-sided MPI?
- RCCL is not really MPI. Then, GPU-aware uses a special library (called GTL = GPU Transfer library), so MPI P2P and one-sided follows the same route. I don't think you have controls on streams used in the MPI.
- RCCL allows asynchronous control of the streams and also computes the collective on the GPU.
- The problem of RCCL is that you have to use the Slingshot plugin to use the network, otherwise it would not work (and it is only collectives, btw). I would stick with MPI, unless yo have an application which already uses RCCL...
- Is the Slingshot plugin bad? at the moment, I can choose between RCCL (I cannot use collectives, so I use ncclGroupStart), CPU-based MPI and GPU-aware MPI in my app, but all of these options are kind of unsatisfactory at the moment. (CPU-based MPI is the fastest...)
- Then, I suggest to open a ticket and ask help for your particular case... without knowing the details is hard to reply.
- ok, thank you, I'll do that.
- There are good reasons to use RCCL over MPI - you can have collectives queued in the device while previous compute are being done. This is important for latency bound codes. The plugin should work well. I'm only aware of a bug that can be exposed with heavy threading - but that is a libfabric bug not really a plugin bug. RCCL also allows point to point.
- This is a good question and in fact is the low-level layer I alluded to in the presentation without naming it. At the moment I'm inclined to say we have to look at this on a case by case basis.
-
What benchmarks for async MPI (comp./comm overlap) are you exactly referring?
- Who are you asking? I did not mention a benchmark in the talk other than the osu on or off device bandwidth test.
- I was asking Harvey. Sorry, I thought you said some people are doing benchmarking on MPI communication and computation overlapping. I'm quite interested in enabling that. Do you know any materials or examples how exactly this should be implemented (e.g. the use of buffers that you mentioned), configured, and checked?
- (Alfio) A lot of work in this context was done in CP2K code. Unfortunately, there are no special tricks. For large message MPI will wait... It depends on your case.
- my usecase is grid based algorithm (LBM) with a process sending rather small messages only to neigbours (stencil) but in very short timesteps, meaning the MPI latency is significant for large scales. My feeling is it is suitable for the overlapping, but not sure how to enable that.
- And follow-up question: why the expected improvement is only 10-15% (as mentioned)? I would expect theoretically near to 100% overlap in case of sufficient computation portion (similar to GPU computation/data transfer overlaping)
- (Peter): I interpreted what Harvey said as 10-15% application performance improvment. So even if the MPI communication is improved a lot, there is still compute to do...
- thanks, then that really depends on application, not sure about the numbers. Any suggestions about the material requested?
- (Harvey) I'm just reporting examples people have mentioned to me, that does not mean that you can't do better, as with all optimizations it all depends on the specific situation.
"},{"location":"4day-20230214/hedgedoc_notes_day2/#exercises_2","title":"Exercises","text":"Exercise
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directories for this exercise:
ProgrammingModels or any other you want to try. - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file. Check that you don't have unnecessary (GPU) modules loaded.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU) or
Suggestions:
- Test the Pi Example with MPI or MPI/openMP on 4 nodes and 4 tasks
- Show where the ranks/threads are running by using the appropriate MPICH-environment variable
- Use environment variables to change this order (rank-reordering)
Alternatively: Try different different binding options for GPU execution. Files are in gpu_perf_binding, see Exercise_day1-2.pdf (/project/project_465000388/slides/HPE/)
:::
-
I did not understand how to generate the report for gpu binding, sorry. Is there a script or are we still using xthi?
- This is the hello_jobstep tool, xthi does not report anything about GPUs
- You can also find it here https://code.ornl.gov/olcf/hello_jobstep/-/tree/master
-
went through the exercise pdf steps; but get HIP Error - hello_jobstep.cpp:54: 'hipErrorNoDevice'; submitted to standard-g
- did you use --gres to request gpus?
- Have you updated the exercice's folder since yesterday ? I think the 'gres' part has been added this morning.
- did not for this directory; will do
- Ok great !
-
When I try to run job.slurm in hello_jobstep, an error arise \"sbatch: error: Batch job submission failed: Requested node configuration is not available\"!!!
- Have you source the ../lumi_g.sh script ?
- yes source /project/project_465000388/exercises/HPE/lumi_c.sh, is it?
- so, why the error arise, have tried for the second folder, but the same error!!!
- Use lumi_g.sh, this is gpu_perf_binding
- In which order?
-
I am trying to run the gpu_perf_binding test, but in the slurm output I get: HIP Error - hello_jobstep.cpp:54: 'hipErrorNoDevice'
- you are missing the \"#SBATCH --gres=gpu:8\" option in the batch file, so you don't reserve any GPU.
-
In fact, this has been corrected this morning, if you download the exercices folder again, it should work fine now
-
ok ! let me know. Don't forget to source both lumi_g.sh and gpu_env.sh
- It works now, the problem seems to have been an interactive run that didn't shut down properly.
-
What do you mean by \"Launch himeno from the root directory\"? the job.slurm is located in the dir gpu_perf_binding/himeno
- sorry this is not up to date, you can launch it from the himeno directory directly.
- you can launch the job.slurm directly from /himeno directory
- but the file \"select_gpu.sh\" is located in another dir & the error mesage is generated: \"slurmstepd: error: execve(): select_gpu.sh\"
- could you update the entire directory? We did update it before lunch, sorry for the incovenience.
- OK, understood. -- still does not work as the file \"select_gpu.sh\" is located in another dir (one level above, i.e. in gpu_perf_binding/ dir), not in the gpu_perf_binding/himeno/ dir it works only in case if in file job.job.slurm the shown below lines are both kept commented : ## UNCOMMENT to add proper binding #gpu_bind=select_gpu.sh cpu_bind=\"--cpu-bind=map_cpu:50,58,18,26,2,10,34,42\" what for is used the \"## UNCOMMENT to add proper binding\"
-
Not related to this tutorial's material. I have a problem with one of my applications which does domain decomposition and uses MPI. I could run 4 tasks on 4 nodes (1 task/node) without issues. Or run 128 tasks in a single node. However, MPI crashes start when running more tasks per node (>=4). MPI appears to crash with MPIDI_OFI_handle_cq_error(1062): OFI poll failed (ofi_events.c:1064:MPIDI_OFI_handle_cq_error:Input/output error - PTLTE_NOT_FOUND). This software was run on another cray machine (ARCHER2 to be precise) on ~ 200 nodes and no issues were observed. So at least, there is some confidence that the communication/MPI part was implemented correctly. Any quick advice/hints, or if anyone has experienced something similar? (sorry for the off-topic)
- Open a ticket...
- (Harvey) That error signature can be a secondary effect, some other node/rank may have failed before you got that message, for example running out of memory. But I agree if you submit a ticket we can investigate.
- A colleague of mine had open a ticket on December and we tried all suggestions but unfortunately did not solve our problem. Even after the update, this issue still occurs. Thanks anyway!
"},{"location":"4day-20230214/hedgedoc_notes_day2/#additional-software-on-lumi","title":"Additional software on LUMI","text":" -
Do we have a strategy/recommended practice for storing parameterised 'passwords', hashes, etc. Or is there a vault ala Terraform/Azure?
- We do not have any such service running on LUMI.
-
Typical workflow is to compile on a login node and run on LUMI-C or LUMI-G. For compilation, what module should we use: partition/L (because we are on a longin node) or partition/C or /G (to match the one optimised for the partition where we will be running the compiled binaries)?
- Yes, when compiling on the login nodes, you need to load the partition module for the hardware you want to target/run. It means replacing partition/L by partition/C for LUMI-C and partition/G for LUMI-G.
- It is often possible to compile software for GPU nodes on the login nodes, using the
rocm module, but it is better to compile GPU software on a GPU node, because the login nodes do not have any GPUs installed, which sometimes confuses installations scripts. - So partition/L module should only be used to run directly on the login nodes stuff that will not be used later on LUMI-C/LUMI-G? (e.g., post-processing)?
- Yes, or if you plan to use the \"largemem\" or LUMI-D nodes that have Zen 2 CPUs. It will work, you may gain some efficiency from using partition/C or partition/G, and it will not support compilation of GPU software properly
-
How do you get the paths that are set by a module if you need to give them explicitely (include/lib folders)?
module show modulename shows what the module is really doing- Easybuild installed packages define a
EBROOT<UPPERCASENAME> environment variable. For example the zlib module will define the EBROOTZLIB environment variable. This variable can be used to provide installroot to autotools and cmake. Use env | grep EBROOT to list such variables
-
Is lumi-workspaces still deprecated? I got once or twice this message while loading it.
lumi-workspaces is not deprecated but the module is. The command is available by default now. It has been extended to also show the compute and storage billing units consumption/allocation.- As I said in the presentation, it is replaced by
lumi-tools which is loaded by default. Try module help lumi-tools for more info on the commands that are in the current version as this will evolve over time.
-
I think he just mentioned it but I missed it. Is it possible for anyone to add LUMI EasyBuild recipes?
- Yes, we accept pull requests on GitHub into the LUMI-EasyBuild-Contrib repository, which is available by default on LUMI for everyone. But you do not need to have your recipe accepted there, you just write own and use it with our toolchains.
- Sounds good. In case one would like it to be generally available to other users.
- Then it should be on Github.
- And of course you can also use your own repository if it is only for your own project. See also the notes for the presentation
-
What's the recommended way of building new packages with easybuild for LUMI-G? Launching an interactive job?
- This is definitely the safest thing to do. Hint: For now if you have CPU billing units and if the process does not take too long you could use the partition
eap which is still free, but that might not be for long anymore.
-
I wrapped my conda env uisng lumi container wrapper, and usually I need to export some specific PATH and PYTHONPATH from Conda env to excute some programs directly from command line, how can I do the similar thing with lumi container wrapper?
-
I'm not sure I understand the question sufficiently to take it to the developer. Is there a small example that we could try without having to install too much stuff?
- for example, under conda environment, i need to export the following paths
ISCE_HOME=/project/project_465000359/EasyBuild/SW/LUMI-22.08/C/Anaconda3/2021.04/envs/isce_test/lib/python3.8/site-packages/isce, export PATH=\"$PATH:$ISCE_HOME/bin:$ISCE_HOME/applications:$ISCE_HOME/components/contrib/stack/topsStack\" to run applications under topsStack from command line.
-
if you export SINGULARITYENV_ISCE_HOME=<value>, then ISCE_HOME will be set in the container
"},{"location":"4day-20230214/hedgedoc_notes_day2/#general-qa-day-2","title":"General Q&A day 2","text":" -
How long will we have access to this project for?
- 3 months as for all expired LUMI project.
-
Will the number of files quota (100K) be a hard quota? As in it would be impossible to create more than 100K files.
- For the project and home directories, yes. Exception may be possible but it really need to have a very good motivation. You can have up to 2M files in your
/scratch but the files there will be removed after 3 months.
-
How do you verify that frameworks like pytorch or other complex program packages use the resources efficiently?
- We have started planning some course material tackling that question. But early stage.
-
I am running the hello_jobstep example and for each rank RT_GPU_ID is zero, while GPU_ID is the one expected. Probably it is not so clear to me the meaning of RT_GPU_ID, but why is it zero? Thank you! PS: I found this https://github.com/olcf-tutorials/jsrun_quick_start_guide/blob/master/README.md ; is this number always zero because this is the only GPU seen by the rank?
"},{"location":"4day-20230214/hedgedoc_notes_day3/","title":"Notes from the HedgeDoc page - day 3","text":"These are the notes from the LUMI training, 1114-17.02.2023, 9:00--17:30 (CET) on Zoom.
- Day 1
- Day 2
- Day 3: This page
- Day 4
"},{"location":"4day-20230214/hedgedoc_notes_day3/#performance-optimization-improving-single-core-efficiency","title":"Performance Optimization: Improving single-core efficiency","text":" -
Sorry, I have a question from yesterday. I run the hello_jobstep example, and for each rank RT_GPU_ID is zero, while GPU_ID is the one expected. Probably it is not so clear to me the meaning of RT_GPU_ID, but why is it zero? Thank you! PS: I found this https://github.com/olcf-tutorials/jsrun_quick_start_guide/blob/master/README.md ; is this number zero for all GPU_IDs because this is the only GPU seen by the rank?
- So, RT is the runtime value taken from the get
hipGetDevice. Now, you run by forcing ROCR_VISIBLE_DEVICES to a given GPU per each rank (via the select_gpu scripts). Let's assume we do ROCR_VISIBLE_DEVICES=2, then at runtime you will access a single GPU whose id is 0. If you set ROCR_VISIBLE_DEVICES=2,3, then runtime ID will be 0, 1. I'm not sure if I'm confusing you... You can find more examples at https://docs.olcf.ornl.gov/systems/crusher_quick_start_guide.html#mapping-1-task-per-gpu. - I think I understood! Thank you very much!
- This is why that code can print the busid of the GPU, so that you can tell which physical GPU was being used.
-
I might have missed it, but what is the motivation for padding arrays? Don't we destroy the locality of our original arrays if there is something in-between ?
- (Alfio) this is for memory access, you access the data in cache lines (64 bytes), so you want to align your data for that size. Note that also MI250x can require data alignemnt. I think AMD will discuss that. A CPU example: https://stackoverflow.com/questions/3994035/what-is-aligned-memory-allocation
- (Harvey) The point (as noted below) is that often you index into both arrays by the same offset and both of those accesses might collide on cache resources. The point of the presentation is to really give you a feel for the transformations the compilers can and might do so that if you start to delve into optimizing an important part of your code then this is useful to understand, even if you just look at compiler commentry and optimization options and don't want to consider restructuring the code. The compilers (and hardware) get better and better all the time.
- (Kurt) A data element at a particular address cannot end up everywhere in cache, but only in a limited set of cache elements (for L1/L2 cache often only 4 or 8 locations). Now with the original declarations, assume that array A starts at address addr_a, then array B will start at address addr_b = addr_a + 64648 (number of elements in the array times 8 bytes per data element). Alignment of B will still be OK if that for A is OK (and actually for modern CPUs doesn't matter too much according to two experts of Erlangen I recnetly talked to). But as addr_b = addr_A + 2^15, so shifted by a power of two, it is rather likely that B(1,1) ends up in the same small set of cache lines as A(1,1), and the same for C(1,1). So doing operations in the same index region in A, B and C simultaneously may have the effect that they kick each other out of the cache. This is most easily seen if we would have cache associativity 1 (imaginary case), where each data element can be in only one cache location, and with a cache size of 2^15 bytes. Then B(1,1) and C(1,1) would map to the same cache location as A(1,1) and even doing something simple as C(i,j) = sin(A(i,j)) + cos(B(i,j)) would cause cache conflicts. By shifting with 128 bytes as in the example this is avoided.
-
How do you know what loop unroll level and strip mining size to use? Trial and error? Or is there some information to look for?
- (Alfio) Most of the compilers are doing a good job already. It really depends on the instructions of the loop (number of loads/store and computation intensity). You can check the listings to check what the compiler is doing for you and then you can add some directives to try to force more unrolling. Unrolling by hand is quite unsual nowadays...
- (Kurt) But it is one of those points were selecting the right architecture in the compiler can make a difference, and something that will definitely matter with Zen4 (which we do not have on LUMI). But the AVX-512 instruction set supported by Zen4 (code named Genoa) has features that enable the compiler to generate more elegant loop unrolling code. Some users may think that there cannot be a difference since the vector units still process in 256-bit chunks in that version of the CPU, but it is one of those cases where using new instructions can improve performance, which is why I stressed so much yesterday that it is important to optimize for the architecture. For zen2 and zen3, even though the core design is different and latencies for instructions have changed, I don't know if the differences are large enough that the compiler would chose for different unrolling strategies. In a course on program optimization I recently took we got an example where it turned out that AVX-512 even when restricted to 256 bit registers had a big advantage over AVX-2 even though with both instruction sets you get the same theoretical peak performance on the processor we were using for the training (which was in Intel Skylake, it was not on LUMI).
"},{"location":"4day-20230214/hedgedoc_notes_day3/#debugging-at-scale-gdb4hpc-valgrind4hpc-atp-stat","title":"Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat","text":" - Is STAT and ATP for cray compiler only?
- They are not restricted to just the Cray compiler
- Are all the tools in this morning lecture for cray compiler only? I anticipate the question :)
- No, you can use with any compilers (PrgEnv's)
- Please be aware that there are some known issues with the current software on LUMI so some of these tools are not operating properly. Until the software can be updated we recommend using gdb4hpc.
"},{"location":"4day-20230214/hedgedoc_notes_day3/#exercise","title":"Exercise","text":"Exercise
General remarks: - Exercise notes and files including pdf and Readme with instructions on LUMI at project/project_465000388/exercies/HPE - Directory for this exercise: debugging - Copy the files to your home or project folder before working on the exercises. - In some exercises you have source additional files to load the right modules necessary, check the README file.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_g.sh (GPU) or source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Exercise:
- deadlock subfolder: gdb4hpc for CPU example Don't forget to
source /project/project_465000388/exercises/HPE/lumi_c.sh - subfolder: environment variables for GPU example Don't forget to
source /project/project_465000388/exercises/HPE/lumi_g.sh & load GPU modules
-
launcher-args -N2 is the one identical to srun argument list ? (in valgrind4hpc call)
- yes: it sets the number of nodes used for the underlying srun command used by valgrind4hpc
- but -n1 is given by valgrid arg
- yes -n is the number of processes used by valgrind4hpc (and also the number of processes for the underlying srun command used by valgrind4hpc)
- valgrind4hpc \u2013n1 --launcher-args... gives me cannot find exec n1
- when I post the code line I cannot edit anymore; trying to modify pi_threads.slurm; added module load; put the srun args into --launcher-args; but -n1 seems to be a problem
- The launcher-args are for you to specify extra arguments about the distribution of the tasks (you don't put -n though)
-
With gdb4hpc in an interactive job, how to check I'm on the allocated compute node and not the login node? (hostname doesn't work there)
- the launch command in gdb4hpc uses an underlying srun command and thus, used the ressources of the salloc command
- ok thanks, and theoretically in case of multiple allocated jobs, how to select which to use?
- focus p{0}, check the slides (page 24). The man page is also giving some good examples
- Sorry, I don't understand how to use the focus comand to select a job (not process). On page 24 I can see only how to select set of processes.
- Ah, you want to attach to an existing job?
- yes, I mean if I allocate multiple interactive jobs and then I want to launch gdb4hpc on one of them
- You have to run gdb4hpc in the same salloc. You start salloc and then run the app under gdb4hpc.
- ok, probably I have to check how really salloc works, I'm PBS user, thanks
- So, salloc gives you a set of reserved nodes and it will return with a shell on the login node. Then you can run
srun to submit to the reserved nodes. The equivalent on batch processing is sbatch. - oh I see, I was confused with the login shell - so even its a login, it is already linked with the particular interactive job (allocated nodes), right?
- correct, everyting you run after salloc with
srun (gdb4hpc or valgrind4hpc use srun under the hood) will run on the reserved nodes. You can check that with salloc you get a lot of SLURM_ environment variables set by SLURM, for example echo $SLURM_NODELIST - ok, understand, cool tip, thank you
- the corresponding PBS is
qsub -I, if recall correctly... - yes, but it returns directly the first node shell
- ah, this can be configured on SLURM too (sysadmin SLURM conf). However, on LUMI you will still remain on the login node.
-
When in an gdb4hpc session, I can switch to one process with focus $p{0}. But how do I get a listing of that process to see the source of where it is stuck or breaked?
- this is the standard gdb command then, for instance
where - use the list (short 1) gdb command. Since you \"have\" a focus on 0, gdb will list source file for process 0
-
For the valgrind4hpc exercise, I did it a first time and got the expected output, then I fixed the code, recompiled and ran the ./hello directly to make sure it worked. However when running valgring4hpc again I still get the same output as the first time (whereas this time obviously there was no more bug): is there something I should have reset to get the correct output instead of:
HEAP SUMMARY:\n in use at exit: 16 bytes in 1 blocks\n\nLEAK SUMMARY:\n definitely lost: 16 bytes in 1 blocks\n indirectly lost: 0 bytes in 0 blocks\n possibly lost: 0 bytes in 0 blocks\n still reachable: 0 bytes in 0 blocks\n\nERROR SUMMARY: 31 errors from 109 contexts (suppressed 1259\n
- you have the same error on the 16 bytes lost because you do not free(test) in both cases. But the invalid write of size 4 are removed if you change test[6]= and test[10]= by for example test[2]= and test[3]=
- these are in the libraries, no related to users. You can expect masking of those errors in the future.
- yes the library where the errors occur in the outputs is /usr/lib64/libcxi.so.1 and you can see the errors are in cxil_* functions from this library
"},{"location":"4day-20230214/hedgedoc_notes_day3/#io-optimisation-parallel-io","title":"I/O Optimisation - Parallel I/O","text":" -
How does Lustre work with HDF5?
- HDF5 is built on top of MPI-IO, which means that HDF5 will make good use of all the underlying infrastructure provided for Lustre by MPI-IO.
"},{"location":"4day-20230214/hedgedoc_notes_day3/#exercise_1","title":"Exercise","text":"Exercise
Remarks:
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directory for this exercise:
io_lustre - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_g.sh (GPU) or source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Exercise
- Try out different Lustre striping parameters and use relevant MPI environment variables
- Do the environmental variables (like MPICH_MPIIO_HINTS) always prevail over what could be explicitely set in the code/script?
- Do the environmental variables (like MPICH_MPIIO_HINTS) always prevail over what could be explicitely set in the code/script?
- If you set striping on a file by lfs setstripe then that is fixed. For a directory then I expect an API or the envar to override the default policy when files are created.
- I'm not sure if the envar will override something set explicity in an API, for example hints passed to an Open function, I would doubt it.
"},{"location":"4day-20230214/hedgedoc_notes_day3/#introduction-to-the-amd-rocmtm-ecosystem","title":"Introduction to the AMD ROCmTM ecosystem","text":" -
When we use gres=gpu:2 are we guaranteed that the two dies will be on the same card?
- I doubt. The scheduler is not very good at assigning only a part of a GPU node. And the same actually holds for the CPU where you are not guaranteed to have all cores in, e.g., the same socket even if your allocations can fit into a single socket. If you are performance concerned you should really allocate nodes exclusively and then organise multiple jobs within the node yourself if you want to make good use of your GPU billing units.
-
Is there some slurm option gpus per node?
- I'm not sure how you would like to use it, as we only have one type of GPU node and as you would be billed the full node anyway even if you would use only two GPUs on a node as noone else can use them?
- It actually exists in Slurm and you will see it in some examples in the documentation but it is one of those options that should be used with care as you may get more than you want.
-
hipcc calls nvcc on nvidia platforms. What is it calling on amd platforms? Is it hip-clang?
- It is calling clang - HIP support has been upstreamed to the clang compiler.
- Basic idea is that
hipcc calls clang++ -xhip. In practice it adds more flags. If you are really curious about what hipcc is doing, you can have a look at the source code.
-
On CUDA we can set --gpu-architecture=all, to compile for all supported architectures by this CUDA Toolkit version, this way our code is more portable. Is there a HIP equivalent to compile for all supported AMD architectures by this HIP version? I know we can set multiple architectures (using multiple uses of -offload-arch=), but is there also a way not to have to list them one by one (this would also make it future proof, so that we would not need to add new GPU architectures)?
- AMD can confirm but I don't think there is an equivalent to
--gpu-architecture=all for the AMD GPUs compilation. - No, there is not, as there is no promise of backward compatibility between ISAs for the different GPUs. Typically the relevant/tested targets are listed in the build system of an application. If not set explicitly, the tools will try to determine the GPUs available on the machine where the compile job is running. The GPUs are detected by the ROCm tools
rocminfo and rocm_agent_enumerate. This means that the right automatic GPU identification happens if you compile in the compute nodes. I'd say, is always a good practice to list explicitly the targets. - On the login nodes you can \"trick\" the
rocm_agent_enumerator by setting an environment variable (ROCM_TARGET_LST) that points to a file with a list of targets. These targets will then be used by hipcc.
-
4 SIMD per CU. Does this mean that 4 wavefronts are needed to utilize the CU 100%?
- No. You have 4 x 16-wide SIMD units. The wavefront is 64 wide. Each SIMD unit takes 4 cycles to process an instruction, as you have 4 of them you can imagine that, throughput wise, you have one wavefront being computed in each cycle.
- So the wavefront execution is splitted among the 4 SIMD units?
- Correct, having said that, most likely you want several wavefronts running to enable them to hide latencies from each other.
-
What about the support for C++17 stdpar (GPU offloading) on LUMI. Is it possible?
- Need to get back to you on that and check if the current version of clang enables that. I can say however that the thrust paradigm is supported and very much where the std::par inspiration comes from.
"},{"location":"4day-20230214/hedgedoc_notes_day3/#exercises","title":"Exercises","text":"Exercise
Find the instructions here
-
I'm just compiled the exercise vectoradd.cpp, but I'm getting the following output:
$ make vectoradd_hip.exe \n/opt/rocm/hip/bin/hipcc --offload-arch=gfx90a -g -c -o vectoradd_hip.o vectoradd_hip.cpp\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\n/opt/rocm/hip/bin/hipcc --offload-arch=gfx90a vectoradd_hip.o -o vectoradd_hip.exe\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\n
But to my surprise I was able to submit and run the example: $ srun -n 1 ./vectoradd_hip.exe \n System minor 0\n System major 9\n agent prop name \nhip Device prop succeeded \nPASSED!\n
The questions are: - Is this normal?
- am I forgetting something?
Just for reference, I have loaded my PrgEnv as follows:
$ salloc -N 1 -p small-g --gpus=1 -t 10:00 -A project_465000388\nsalloc: Pending job allocation 2907604\nsalloc: job 2907604 queued and waiting for resources\nsalloc: job 2907604 has been allocated resources\nsalloc: Granted job allocation 2907604\n$ module load rocm\n$ module load craype-accel-amd-gfx90a\n$ module load PrgEnv-amd\n
-
These are error messages coming from Perl which I assume is used in the hipcc wrapper. This error message has little to do with our system and likely more to do with information that your client PC passes to LUMI. When I log on to LUMI I have LANG set to en_US.UTF-8 but I remember having problems one one system (don't remember if it was LUMI) when logging in from my Mac as it tried to pass a locale that was not supported on the system I was logging on into. It is not something you will correct with loading modules.
-
The LOCAL warnings are harmless when it comes to the code generation. I have in my SSH configuration:
Host lumi*\nSetEnv LC_CTYPE=\"C\"\n
- You could also try
export LC_ALL=en_US.utf8 or some other language.
-
I get the following output when I request hipcc --version:
$ module load PrgEnv-amd\n$ module load craype-accel-amd-gfx90a\n$ module load rocm\n$ hipcc --version\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\nHIP version: 5.0.13601-ded05588\nAMD clang version 14.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-5.0.2 22065 030a405a181176f1a7749819092f4ef8ea5f0758)\nTarget: x86_64-unknown-linux-gnu\nThread model: posix\nInstalledDir: /opt/rocm-5.0.2/llvm/bin\n
- See the previous question, it is the same issue.
-
I'm getting annoying output from the hipify-perl.sh script
$ROCM_PATH/hip/bin/hipify-perl -inplace -print-stats nbody-orig.cu \nperl: warning: Setting locale failed.\nperl: warning: Please check that your locale settings:\n LANGUAGE = (unset),\n LC_ALL = (unset),\n LC_CTYPE = \"UTF-8\",\n LANG = (unset)\n are supported and installed on your system.\nperl: warning: Falling back to the standard locale (\"C\").\n info: converted 10 CUDA->HIP refs ( error:0 init:0 version:0 device:0 context:0 module:0 memory:4 virtual_memory:0 stream_ordered_memory:0 addressing:0 stream:0 event:0 external_resource_interop:0 stream_memory:0 execution:0 graph:0 occupancy:0 texture:0 surface:0 peer:0 graphics:0 interactions:0 profiler:0 openGL:0 D3D9:0 D3D10:0 D3D11:0 VDPAU:0 EGL:0 thread:0 complex:0 library:0 device_library:0 device_function:3 include:0 include_cuda_main_header:0 type:0 literal:0 numeric_literal:2 define:0 extern_shared:0 kernel_launch:1 )\n warning:0 LOC:91 in 'nbody-orig.cu'\n hipMemcpy 2\n hipLaunchKernelGGL 1\n hipFree 1\n hipMemcpyDeviceToHost 1\n hipMalloc 1\n hipMemcpyHostToDevice 1\n
but I can see that the script produced the expected modifications. Is there a way to correct this so I can obtain the expected output?
- See the two previous questions
- did you login from a Mac?
- setting LANGUAGE=C or something like that should fix the problem. This is a Linux issue that your LANGUAGE is not set. It was also an issue mentioned in previous days. I'd have to look up the exact syntax and variables to set. I think there was a solution posted a day or two ago that if you are on a Mac you can set something in the terminal program to set these variables.
-
make gives error; does it need additional modules ? I sourced the setup_LUMI-G.sh
- You can use the ROCm stack directly without using the CPE modules if you want if you don't need integration with MPI etc.. There are a set of module commands at the top of the document.
- See below, the order of modules at the top of the docuement are not correct.
- but where should the vectoradd example be made ?
- Ah, sorry, make was trying to execute vectoradd; which failed; so the build must be done one a gpu node ?
- where to do need to salloc here ?
- I made and salloc -n1 --gres=gpu:1 now; module swapped to PrgEnv-amd; make clean & make vector... ; then srun -n 1 ./vector...exe; error message ierror while loading shared libraries: libamdhip64.so.5
- execute module load rocm
-
I get the error: Lmod has detected the following error: Cannot load module \"amd/5.0.2\" because these module(s) are loaded: rocm
- unload rocm. I suggest to load
PrgEnv-amd - The rocm module of the Cray PE is for use with the GNU and Cray compilers. The
amd module is the compiler module for PrgEnv-amd and provides these tools already. - When I try 'module load PrgEnv-amd', I got the same error
- Then use the universal trick in case of errors: Log out and log in again to have a proper clean shell as you've probably screwed up something in your modules. Just after login,
PrgEnv-amd should load properly unless you screwed up something your .profile or .bashrc file. - Another solution is to modify the LD_LIBRARY_PATH
- export LD_LIBRARY_PATH=/opt/rocm/llvm/lib:$LD_LIBRARY_PATH
- The error is because the front-end has rocm 5.0.2 and the compute node has rocm 5.1.0. Going to /opt/rocm avoids the problem. You can also compile on the compute node (srun make) and it will avoid the problem.
-
Module swap PrgEnv-cray PrgEnv-amd causes this error ?
Lmod has detected the following error: Cannot load module \"amd/5.0.2\" because these module(s) are loaded:\nrocm\n\nWhile processing the following module(s):\nModule fullname Module Filename\n--------------- ---------------\namd/5.0.2 /opt/cray/pe/lmod/modulefiles/core/amd/5.0.2.lua\nPrgEnv-amd/8.3.3 /opt/cray/pe/lmod/modulefiles/core/PrgEnv-amd/8.3.3.lua'\n
- same as the previous question, unload rocm. Note that PrgEnv-amd is using rocm under the hood
- When I try 'module load PrgEnv-amd', I got the same error
- Did you run
module unload rocm first?
-
When the command is applied salloc -N 1 -p small-g --gpus=1 -t 10:00 -A project_465000388, I am getting the following error message salloc: error: Job submit/allocate failed: Requested node configuration is not available
- This works for me. Try to reset your environment see if it helps.
- logout & login again to lumi, it works fine now, thank you!
-
Can somone confirm the correct order of the module commands listed at the top of the training page. https://hackmd.io/rhopZnwTSm2xIYM3OUhwUA
-
Yes, indeed, the order is incorrect. Please use:
module rm rocm\nmodule load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\nmodule load rocm\n
(I have confirmed that is the right order)
- what about ? source /project/project_465000388/exercises/HPE/lumi_g.sh
-
This file is to set SLURM, no relation with modules. And it was for the HPE exercises
-
Nob question: where are located the perl scripts to test hipify the examples?
- /opt/rocm/bin/hipify-perl They are inside ROCm bin directory
-
I am getting errors when I try to run for instance ./stream:
srun: Job xxx step creation still disabled, retrying (Requested nodes are busy)\n
What does it mean (I did the salloc, etc.)? - try
srun -n 1 ./stream - was the salloc success? or maybe you wait for a free node? run: srun -n 1 hostname
- I had the impression that I was allocated a node, but srun -n 1 hostname is stalled
- ok run salloc again and wait to be sure
-
Once I login to LUMI, I got the following modules:
Currently Loaded Modules:\n 1) craype-x86-rome 3) craype-network-ofi 5) xpmem/2.4.4-2.3_9.1__gff0e1d9.shasta 7) craype/2.7.17 9) cray-mpich/8.1.18 11) PrgEnv-cray/8.3.3 13) lumi-tools/23.01 (S)\n 2) libfabric/1.15.0.0 4) perftools-base/22.06.0 6) cce/14.0.2 8) cray-dsmml/0.2.2 10) cray-libsci/22.08.1.1 12) ModuleLabel/label (S) 14) init-lumi/0.1 (S)\n\n Where:\n S: Module is Sticky, requires --force to unload or purge\n
Supposing that now I want to run on the GPU partition, what's the recommend modules I should load or swap? I've seen a few ways of loading the modules, but I wonder if there's one recommended way of doing that. Specifically I'd like to run a code with HIP and GPU-aware MPI. Also, what should I do if I'm to install a new library using the interactive node. - You have a few different options. You can run with the Cray and AMD and I think the GNU Programming Environments. The modules need to loaded in the proper order or a fix used for the path to work around the different rocm paths on the front-end and the compute node. Your choice between these three options is usually driven by what your code is usually compiled with. All of them have rocm support for the HIP code. The only question is if there is an issue with GPU-aware MPI, but I think it works with all of them.
- You can enable GPU-aware MPI via
export MPICH_GPU_SUPPORT_ENABLED=1. Check HPE slides on MPI (day 2) for more details.
-
For Exercise 2: Code conversion from CUDA to HIP using HIPify tools (10 min) it says that hipify-perl.sh is in $ROCM_PATH/hip/bin however I cannot see it in /opt/rocm/hip/bin: is it hipify-perl (without .sh) that we should use?
- yes sorry use
hipify-perl - I think this changed with ROCm versions. This version is hipify-perl and later ones use hipify-perl.sh
"},{"location":"4day-20230214/hedgedoc_notes_day3/#amd-debugging-rocgdb","title":"AMD Debugging: ROCgdb","text":" - (How) does ROCgdb with multiple nodes/GPUS? or what are the differences to gdb4hpc in the end?
- (Alfio) gdb4hpc enables debugging of MPI applications, then you can use it to debug GPU kernels too. For GPU, gdb4hpc uses rocgdb
- note that we do need a software update to enable GPU kernel debugging (breaking inside the kernel) with gdb4hpc at the moment
"},{"location":"4day-20230214/hedgedoc_notes_day3/#exercise_2","title":"Exercise","text":"Exercise
Find the instructions here Try the debugging section.
To get the saxpy.cpp file:
- Get the exercise:
git clone https://github.com/AMD/HPCTrainingExamples.git - Go to
HPCTrainingExamples/HIP/saxpy
Also try the TUI (graphical interface) with rocgdb -tui interface Hint: Get an interactive session on the compute node to use the TUI interface with:
srun --interactive --pty [--jobid=<jobid>] bash\n
which assumes that you already have an allocation with salloc. The slides of the presentation are available on LUMI at /projappl/project_465000388/slides/AMD/02_Rocgdb_Tutorial.pdf
- Where exactly \"saxpy\" (Go to HPCTrainingExamples/HIP/saxpy) is located? in /project/project_465000388/exercises/AMD/HIP-Examples/ ?
"},{"location":"4day-20230214/hedgedoc_notes_day3/#introduction-to-rocprof-profiling-tool","title":"Introduction to Rocprof Profiling Tool","text":" -
It is a more general question, rather than practical. Some of us participate in EU projects and utilise AMDs technology, can you suggest how we can effectively implement Digital Twin Objects $applications, using this monitoring interface? Just suggetions => We can discuss it tomorrow during the Q&A!
- (Harvey) For anyone interested in CSC/LUMI connection here have a look at https://stories.ecmwf.int/finlands-csc-leads-international-partnership-to-deliver-destination-earths-climate-change-adaptation-digital-twin/index.html
"},{"location":"4day-20230214/hedgedoc_notes_day3/#exercises_1","title":"Exercises","text":"Exercise
Find the instructions here. Try the rocprof section.
The slides of the presentation are available on LUMI at /projappl/project_465000388/slides/AMD/03_intro_rocprof.pdf
-
Can you refer where/when the \"manual\" from your colleague will be published?
- What do you mean by manual?
- The presenter mentioned, that some of his colleagues is preparing some kind of manual about rocm profiling (probably metrics, counters, etc.). I would be interested in that, so I'm basically just asking where to look.
-
I am getting an error message that the module called \"rocminfo\" is not loaded (when \"rocprof --stats nbody-orig 65536\" is executed)
- rocminfo should be in the path, not a module. Could this be a path or environment problem?
- rocprof --stats nbody-orig 65536
RPL: on '230216_180254' from '/opt/rocm-5.0.2/rocprofiler' in '/...path.../HPCTrainingExamples/HIPIFY/mini-nbody/hip'\nRPL: profiling '\"nbody-orig\" \"65536\"'\nRPL: input file ''\nRPL: output dir '/tmp/rpl_data_230216_180254_38827'\nRPL: result dir '/tmp/rpl_data_230216_180254_38827/input_results_230216_180254'\n65536, 6227.599\nTraceback (most recent call last):\nFile \"/opt/rocm-5.0.2/rocprofiler/bin/tblextr.py\", line 777, in <module>\n metadata_gen(sysinfo_file, 'rocminfo')\nFile \"/opt/rocm-5.0.2/rocprofiler/bin/tblextr.py\", line 107, in metadata_gen\n raise Exception('Could not run command: \"' + sysinfo_cmd + '\"')\nException: Could not run command: \"rocminfo\"\nProfiling data corrupted: ' /tmp/rpl_data_230216_180254_38827/input_results_230216_180254/results.txt'\n
-
Definitely a path problem due to the mismatch in ROCm versions. Try
export LD_LIBRARY_PATH=/opt/rocm/llvm/lib:$LD_LIBRARY_PATH\n
You can see that it is trying to load rocm 5.0.2. Loading the modules in the right order will also fix the problem. You can see this by doing a srun ls -l /opt and you will see that compute nodes have /opt/rocm-5.1.0. - But there is only rocm/5.0.2 available, it is loaded by default (checked with module list) Which order is correct??
-
Try
module rm rocm\nmodule load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\nmodule load rocm\n
- login nodes have rocm/5.0.2, while compute nodes have rocm/5.1.0. Try
export PATH=/opt/rocm:$PATH (same for LD_LIBRARY_PATH). Check question 19.
"},{"location":"4day-20230214/hedgedoc_notes_day4/","title":"Notes from the HedgeDoc page - day 4","text":"These are the notes from the LUMI training, 1114-17.02.2023, 9:00--17:30 (CET) on Zoom.
- Day 1
- Day 2
- Day 3
- Day 4: This page
"},{"location":"4day-20230214/hedgedoc_notes_day4/#introduction-to-perftools","title":"Introduction to Perftools","text":" -
A question from the first day, sorry :-) My Fortran code with OpenMP offload does not compile with -O2 (cray compiler) due to inlining issues; is it possible to quench inlining for a specific routine only?
- (Harvey)
man inline it might apply to whole file though so need to check, manpage might indicate this. - The ipa compiler option (man crayftn) also affects inlining.
- yes, I discovered it does not compile due to inling, ao I reduced to level 1, 2 gives errors as well..
- Thank you!
- (Peter) Setting
__attribute__((noinline)) before the subroutine can be done in standard Clang, at least. CrayCC seems to accept it when I compile a simple program. - It might also be worth to compile with -O2 but just turn of inlining with the appropriate compiler option (-hipa0 I believe for Fortran).
-
Would it be possible to use a pointer / annotate / ??? to visually guide the narration through complex slides ? not sure whether technically possible
- (Harvey) It looks like Zoom does now have this capability but it has to be enabled before sharing a presentation and is embedded in menus, I really don't want to interrupt Alfio to try this live but we will look into this. Thanks for the suggestion.
- (not Harvey) It is certainly possible but depending on the software that is used for the presentation and the way of sharing (just a window or the whole screen) it requires additional software that the speaker may not have installed.
- It's a remark to take with us should there once again be a fully virtual course but it looks like the next two will be in-person with broadcast and then the technique that works for the room will determine how slides are broadcast.
- thank you
- I second the suggestion/request for future courses, it was especially difficult to follow through Alfio's slides. Maybe consider a different meeting software (one more targeted at teaching like BigBlueButton which supports the pointer) in the future? At least for me on Linux it is hit-and-miss if Zoom finds my audio (no problems with BBB or jitsi or even Teams, though)
-
Is there a maximum duration of the measurement session supported, more or less?
- Not in time terms but you can use a lot of disk space with a very large number of ranks and specifically if you turn off the statistics aggregation in time. There are controls to help here, for example only tracing a subset of the ranks or turning on and off collection at certain points.
-
Where can I find the apprentice downloads?
- On LUMI, in
$CRAYPAT_ROOT/share/desktop_installers/ (with perftools-base loaded, which is loaded in the login environment) - See also
module help perftools-base. - (Note that on LUMI the perftools default is the latest version installed. If you were using a system somewhere else with a newer perftools available than the default you can download the desktop installer of the latest version.)
- (Kurt) Actually the above about the default is only true at login and at the moment as currently it is indeed the latest version of the PE which is the default at login. If you load a
cpe module of an older environmont (cpe/21.12 for example) the default version of perftools-base will be the one that came with that release of the PE, and the same holds if you use the an older version of the LUMI software stacks.
"},{"location":"4day-20230214/hedgedoc_notes_day4/#exercises","title":"Exercises","text":"Exercise
General remarks
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directories for this exercise:
perftools-lite, perftools-lite-gpu - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_g.sh (GPU) or source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Exercise:
- Follow the readme and get familiar with the perftools-lite commands and outputs
-
Can we connect jupyternotebook on Lumi? How to set the environments?
-
what exactly is \"exclusive time\" mentioned in report ?
- you have inclusive and exclusive time per each function: the latter is the amount of time spent purely in that function, excluding time spent in child functions (inclusive is the opposite).
-
What tool is suitable for tracing memory allocations/free?
- you can use the perftools and analyse the memory traffic. Check the man page for pat_build, option -g memory (and wait for next talk on pat_build description).
- If you are more interested in debugging memory allocations then valgrind/valgrind4hpc might be more relevant
- I would be interested to detect where the allocations and frees happen (for analysing different applications, without knowing the details from source codes)
- wrapping them would it be an option? https://stackoverflow.com/questions/262439/create-a-wrapper-function-for-malloc-and-free-in-c I think jemalloc has something similar too (no sure though), see https://github.com/jemalloc/jemalloc/wiki/Use-Case%3A-Heap-Profiling
- I'm not aware of that, I'll check it, thank you
-
Are the perftools available also outside LUMI, e.g. outside Cray environment?
- No they are not. They are designed for analysis of large scale applications in the HPE Cray EX environment, there are a lot of dependencies and assumptions (fast file system for example), I'm not sure it would be that easy to do this.
- You can get the HPE Cray PE for certain HPE servers also but it is a commercial product and I don't know the pricing. I know a non-Cray HPE cluster that has them though.
- yes, I'm thinking about non-Cray HPE cluster. Can you reveal what is the name of that non-Cray HPE cluster with perftools installed? I think I've heard about HLRS, but not sure.
- HLRS doesn't have them from what I remember (I worked on that machine two years ago). That is a cluster that was ordered before the HPE-Cray merger I believe. It has some older modules from HPE, like aan HPE MPI implementation. Unless things have changed recently. But Lucia, a very recent cluster in Belgium (and not a EuroHPC cluster), came with the HPE Cray PE so likely also perftools (I don't have an account on that machine so I cannot verify). Not sure if Karolina, one of the EuroHPC petascale systems and also an HPE system has them.
- Karolina unfortunately doesn't have them
-
pat[WARNING][0]: performance counters are disabled because PAPI initialization failed ; perftool-lite-gpu can not measure gpu performance and hardware counters with papi together?
- This is OK, it will explained in the next presentation. LUMI doesn't allow hardware counters at the moment due to a security issue, but the rest of tracing information is fine. It is not a problem of the perftools, it is OS setup defined by LUMI system administration that does not allow performance counters (PAPI events are not available).
- understood, thank you! papi_avail is quite martinet here.. is this so on all partitions?
- LUST people can confirm, but I see that the put the kernel in paranoid mode on all compute nodes, so I would say yes...
- Indeed yes at the moment. They were disabled after some security issues were discovered.
-
why \"pat_report expfile.lite-samples\" has no more information?
- could you elaborate more?
- based on readme \"More information can be retrieved with pat_report expfile.lite-samples.*/\"\", but it is empty file?
- OK, you are running
pat_report expfile.lite-samples.*/ and don't see the output?
-
my_output.lite-loops.* is empty!, I cant see any output after run?
- is it still running maybe?
-
Can I see how many GPUs per rank from the summary and their ID?
- summary of craypat? Well, I would suggest to use the tools we presented for the affinity checking...
- Yes and it worked perfectly thank you! But I would like to check with other tools if possible, and I guess that the kernel performances are summarized over GPUs here, maybe there is an option to resolve this information?
- No sure, really. Check the man pages. If it is something we can get from rocprof, then I would say yes (assuming that craypat can do over MPI ranks). I have to check... Update: it seems it not possible, at least I cannot find anything useful for multigpus..
-
There is an issue with OpenMP offload region?
Warnings:\nOpenMP regions included 2 regions with no end address, and\n2 regions with an invalid address range, and they were ignored.\n\nAn exit() call or a STOP statement can cause missing end addresses.\nInvalid address ranges indicate a problem with data collection.\n
- This is a warning that it says you are using a STOP within the parallel region. Is it one of our example?
- yes, I am in perftools-lite-gpu/ directory
- This warning means that somehow the loop completed and the end address could not be recorded. If the reason is not clear by inspection of the loop (and it is hard to work out where it is) I'm afraid it needs knowledge of the perftools internals to investigate this further.
- OK, we will look into it. What matters is that you get the info you need in the profile of course.
-
Related to the previous question on hardware counters. - if HW counters are disabled, how to identify the node-level performance efficiency (w.r.t. HW capabilities)? And follow-up: is it planned to enable the HW counters access (what timeframe if yes)?
- There is no time frame as we don't know when the security concerns that triggered disabling them will be resolved.
- Can you please elaborate more on the security issue?
- We have representatives from the LUMI Support Team here but policies around the system are set by the CSC staff managing the system and they are not represented in this training, and even then might not want to comment. If you want to make your voice heard that this capability should be enabled then you could put in a ticket.
- (Kurt) I cannot really say much as this is decided and followed up by the sysadmins, not by us. It is well known however that hardware counters can often be abused to get information about other processes running on the CPU which can be abused. But as that should have been known already when LUMI was set up and the counters were enabled initially, it appears that there has been more than that, or active exploits, that may have driven that decision. I'd hope a solution could be that some nodes are set aside with exclusive use, but maintining different settings on different nodes of the same type is always risky by itself, and it may have been decided that you could still gain crucial information about the OS... LUMI is a shared machine so we also have to take the right for privacy and the fact that we also have to cater to industrial research into account and hence that safety of data of other users is important. A shared machine always comes with compromises...
-
Sorry, this question is still related to the CPU-GPU affinity check that I would like to run with an alternative approach than hello_jobstep. My concern is motivated by this result that I get when I check the affinity, by using a batch job and environmnet we are using for some tests on LUMI
Lmod is automatically replacing \"gcc/11.2.0\" with \"cce/14.0.2\".\n\nROCR_VISIBLE_DEVICES: 0,1,2,3,4,5,6,7\nMPI 000 - OMP 000 - HWT 001 - Node nid005031 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c1\nMPI 001 - OMP 000 - HWT 002 - Node nid005031 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c6\nMPI 002 - OMP 000 - HWT 003 - Node nid005031 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9\nMPI 003 - OMP 000 - HWT 004 - Node nid005031 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID ce\n
Am I initializing something wrong in the environment? Do the MPI ranks see the same GPU? I see different BUS_ID
"},{"location":"4day-20230214/hedgedoc_notes_day4/#advanced-performance-analysis","title":"Advanced performance analysis","text":" - Is there any user guide or tutorials for the advanced perftools (except the man/help pages of commands)?
- These slides are the best material
- (Alfio) https://support.hpe.com/hpesc/public/docDisplay?docId=a00114942en_us&page=About_the_Performance_Analysis_Tools_User_Guide.html
- There is more documentation on that site but it is a very hard one to find things on. There are, e.g., also PDF manuals.
"},{"location":"4day-20230214/hedgedoc_notes_day4/#exercise","title":"Exercise","text":"Exercise
General remarks:
- Exercise notes and files including pdf and Readme with instructions on LUMI at
project/project_465000388/exercies/HPE - Directory for this exercise:
perftools - Copy the files to your home or project folder before working on the exercises.
- In some exercises you have source additional files to load the right modules necessary, check the README file.
- To run slurm jobs, set the necessary variables for this course by
source /project/project_465000388/exercises/HPE/lumi_g.sh (GPU) or source /project/project_465000388/exercises/HPE/lumi_c.sh (CPU)
Exercise:
- Follow the Readme.md files in each subfolder of
perftools and get familiar with the perftools commands and outputs
"},{"location":"4day-20230214/hedgedoc_notes_day4/#introduction-to-amd-omnitrace","title":"Introduction to AMD Omnitrace","text":" -
Related again to the hardware counter issues: Is there a workaround to get at least some basic metrics, e.g. IPC or bandwidth, with the disabled counters?
- Not that I know. Sampling-based tracing cannot generate these. I'm not sure if the kernel setting has also disabled all hardware counters on the GPUs though, worth testing.
- Omnitrace does have a variety of data collection methods including hardware counters and sampling. Some of these capabilities are still available even if hardware counters are blocked.
-
Is ommitrace installed on LUMI as a module?
- Not yet. It is installed in a project directory for the exercises following the talk.
"},{"location":"4day-20230214/hedgedoc_notes_day4/#exercise_1","title":"Exercise","text":"Exercise
Find the instructions here. Try the Omnitrace section.
The slides of the presentation are available on LUMI at /projappl/project_465000388/slides/AMD/
-
When can the users expect Omnitrace to become available? Okey, there is the easyconfig available in a branch omnitrace.
- We have two levels in the stack depending on how stable a package is, how many configurations are needed to cover all uses, and to what extent we can offer support for it. The reality is that we get requests for so many different tools that we can no longer follow it all with the central support team, let alone update it every time a new version of the PE is installed, and users would already want this to also happen more frequently.
- The answer in the Zoom session went far from the question. Simply was asking, if you will provide the eb file. But I found it. https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib/blob/omnitrace/easybuild/easyconfigs/o/omnitrace/omnitrace-1.7.3.eb
- Yes, we are looking into it. No committed date yet, when it will be ready. The version you refer to above is not supported and in a branch where development happens.
- You can try to install it with the
spack module also, but when I tried right now (spack install omnitrace) the installation failed (\"missing boost\"), likely some problem with the upstream package.py.
-
I am having an issue trying to allocate resources salloc: error: Job submit/allocate failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits) even trying for 10 mins allocation.
-
The lumi_g.sh file in the HPE exercises directory will setup Slurm for the LUMI-G nodes using the course project etc. If you have not loaded that can you share the Slurm options you used?
-
Did you have a previous salloc active? Yes and I cancelled it with scancel <jobid>.
-
I am trying \"srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace\", but an error message is generated \"/project/project_465000388/software/omnitrace/1.7.3/bin/omnitrace-avail: error while loading shared libraries: libamdhip64.so.5: cannot open shared object file: No such file or directory\" +3
- some hip module missing?
module load rocm seemed to fix it
- yes, should be mentioned in the instructions..
-
Is this output expected?
srun -n 1 omnitrace-avail -G omnitrace_all.cfg --all\n/project/project_465000388/software/omnitrace/1.7.3/bin/omnitrace-avail: /project/project_465000388/software/omnitrace/1.7.3/lib/libroctracer64.so.4: no version information available (required by /project/project_465000388/software/omnitrace/1.7.3/bin/omnitrace-avail)\n/project/project_465000388/software/omnitrace/1.7.3/bin/omnitrace-avail: /project/project_465000388/software/omnitrace/1.7.3/lib/libroctracer64.so.4: no version information available (required by /project/project_465000388/software/omnitrace/1.7.3/bin/omnitrace-avail)\n[omnitrace] /proc/sys/kernel/perf_event_paranoid has a value of 3. Disabling PAPI (requires a value <= 2)...\n[omnitrace] In order to enable PAPI support, run 'echo N | sudo tee /proc/sys/kernel/perf_event_paranoid' where N is <= 2\n[omnitrace][avail] No HIP devices found. GPU HW counters will not be available\n
- I'm afraid you may not have loaded ROCm properly into your environment.
- I loaded rocm/5.0.2 module and exported the PATH and LD_LIBRARY_PATH environments as mentioned in instructions in an interactive job (salloc)
- What was your salloc command?
- just sourced lumi_g.sh with longer walltime
- (Alfio) see previous questions on hardware counters, PAPI events are not available on LUMI. Have you added
--gres option to allocate GPUs? - I'm aware of that, but not sure if related to e.g.
no version information available or No HIP devices found - with
srun -n 1 --gres=gpu:8 omnitrace-avail -G omnitrace_all.cfg --all the command hangs after the \"PAPI not supported\" lines
"},{"location":"4day-20230214/hedgedoc_notes_day4/#introduction-to-amd-omniperf","title":"Introduction to AMD Omniperf","text":" -
What is the issue with the GUI of OmniPerf?
-
It is browser based and starts a web server. The port on which the server runs is very easy to guess as the software uses a deterministic rule to try out ports, and access to the port is not protected by a password or better mechanism, so it is very easy to hack into an OmniPerf session of another user. As a support team, we do not want to take any responsibility for that so will not support it until better security in the package is in place.
If you run the GUI on your laptop it might be best to ensure that access to your laptop is also restricted by a firewall or other people on the network you're on might be able to break into your session.
-
I find this tool very interesting, is there any HPC site supporting it? (centralized support)
- I don't know, I also cannot find the tool in the Frontier documentation so we are likely not the only one with concerns...
- ORNL has the tool they used it to many hackathons
- https://www.olcf.ornl.gov/wp-content/uploads/AMD_Hierarchical_Roofline_ORNL_10-12-22.pdf they had also an event just for roofline
-
When I am executing \"srun -n 1 --gpus 1 omniperf profile -n vcopy_all -- ./vcopy 1048576 256\", an error is generated \"ROOFLINE ERROR: Unable to locate expected binary (/pfs/lustrep1/projappl/project_465000388/software/omniperf/bin/utils/rooflines/roofline-sle15sp3-mi200-rocm5)).\" It looks like : \"ls: cannot access '/pfs/lustrep1/projappl/project_465000388/software/omniperf/bin/utils/rooflines/roofline-sle15sp3-mi200-rocm5': Permission denied\"
- Permissions on the file are indeed wrong, I've messaged the owner of the files to change them.
- Try again please
"},{"location":"4day-20230214/hedgedoc_notes_day4/#tools-in-action-an-example-with-pytorch","title":"Tools in Action - An Example with Pytorch","text":" -
Can we get ROCm 5.3.3 on the system?
- It is there but we cannot guarantee it will always play nicely with the HPE Cray PE nor that it will always work correctly as in the past there have been problems with hard-coded paths in some libraries etc. We cannot actively support it.
-
It is available in the CrayEnv or LUMI/22.08 + partition/G environments.
module load CrayEnv\nmodule load rocm/5.3.3\n
or module load LUMI/22.08\nmodule load partition/G\nmodule load rocm/5.3.3\n
Note that, with MIOpen and this module, you will use the rocm installed in /opt/rocm for kernels JIT compilation due to some hardcoded paths in the MIOpen library.
-
This looks really interesting, can the presentation be uploaded?
- As with all presentations the video will be uploaded some time after the session. Slides should come also but they have some problems with slow upload speed from the machine from which they were trying.
-
(Harvey) Loved the srun command which flew by too fast to catch fully, I adapted it a little to avoid the hex map...
> srun -c 7 -N 1 -n 4 bash -c 'echo \"Task $SLURM_PROCID RVD $ROCR_VISIBLE_DEVICES `taskset -c -p $$`\"' | sed 's/pid.*current //'\nTask 0 RVD 0,1,2,3,4,5,6,7 affinity list: 1-7\nTask 2 RVD 0,1,2,3,4,5,6,7 affinity list: 15-21\nTask 3 RVD 0,1,2,3,4,5,6,7 affinity list: 22-28\nTask 1 RVD 0,1,2,3,4,5,6,7 affinity list: 8-14\n
-
A late question on Perftools... should I use a particular approach if I compile my app with autotools? Or loading the module is enough?
- If you pass the compiler wrappers to configure script, i.e.,
CC=cc CXX=CC FC=ftn F90=ftn it should be enough to load the module. - One small caveat: some autotools (and the same for CMake etc.) installation \"scripts\" do not follow all the conventions of those tools and in that case there can be difficulties. I have seen tools that had the compiler name or compiler options hardcoded instead of using the environment variables...
- I confess I raised this question because I was trying measuring the application with perftools-lite, but without instrumenting and I get no report. Compiling with the module loaded fails but I did not reconfigure
- Then it is rather likely you were using the system gcc, or if you were using PrgEnv-gnu it may have found that gcc. That is usually first in the search list when autotools tries to locate the compiler itselves. Which is kind of strange as the original name of the C compiler on UNIX was actually
cc (but there was no C++ in those days, when dinosaurs like \"Mainframus Rex\" and \"Digitalus PDP\" still roamed the earth). - I am afraid is something nastier.. is parallel compilation discouraged with instrumentation?
- For C or C++ code it would surprise me, but for fortran code parallel compilation (if you mean things like
make -j 16) does not always work, independent from the fact that you are using instrumentation. - It is Fortran.. hope sequential compilations solves, thank you for the help!
- sequential worked, at least to compile.. Can I understand somehow that the binary is instrumented? From ldd *.exe I don't know what to look for.
- In a very simple Fortran test program that I tried, I see that among others
libpapi.so.6.0 is now shown in the output of ldd which is definitely a library that has to do with instrumentation.
-
When we are pip installing a package that requires some compilation step using PyTorch as dependency (e.g. https://github.com/rusty1s/pytorch_scatter), what is the preferred approach to make sure that we are using the right compiler and flags for LUMI?
- There is unfortunately no fixed rule for Python. There are compilers hard-coded in a Python configuration file, but not all install scripts for
pip look at these. Others will honour the environment variables given in the previous question. As a software installer, I despise Python as installing packages has become a complete mess with like 10 different official ways of installing packages in as many different styles of installation and yet packages that find something else to try. So it is sometimes really a case-by-case answer. And given that AI applications have a tradition of coming up with strange installation procedures... - Please send us a ticket if you want us to have a closer look. We need more time than what such a QA provide to give you a proper answer regarding this particular package.
- Thanks, will do! I completely agree with the broken packaging and distribution system of Python, but it seems that they are trying to amend with some recent PEPs (don't remember the numbers though).
"},{"location":"4day-20230214/hedgedoc_notes_day4/#general-qa","title":"General Q&A","text":" -
For how long the access to this course account at lumi (project_465000388) and materials (in particular, to go through all exercises) will be available after the last day of the course? Do we expect to have updated instructions/ guidelines (cleaned from \"bugs\" & more clearly written text) for exercises? or still to follow the older versions (and trying to find on what was/is missing and to fix somehow)?
- The data: I think for three months at least. But access to the compute time allocated to the project ends automatically at the end of the day.
- It would be really valuable if we could run the exercises for 1-2 more days
- Agree (Thanasis) - keep it running for the weekend (+1)
-
Is this example Samuel is showing available somewhere?
- not the large example which was used to show a real application
- He promised a smaller example (easier managable) applicable to LUMI. Looking forward for that.
-
Can we get examples from Samuel's presentation?
- I can share scripts and slides - the application would need to go with something more simple with no license issues.
- Look in
/project/project_465000388/slides/AMD/pytorch-based-examples
-
When compiling for LUMI AMD GPU, what is the difference between the flags --offload-arch=gfx90a and --amdgpu-target=gfx90a? (sorry for the mistake)
- Answer from AMD in the session:
--amdgpu-target is the older one that is deprecated. - I saw it when compiling pip packages (see above) as output when
--debug --verbose and on the frontier docs.
-
Are there BLAS / LAPACK besides Cray LibSci available?
- Both OpenBLAS and BLIS tend to work well by themselves on LUMI (for CPU calculations), but watch out if you mix e.g. OpenBLAS and LibSci because they can contain identical symbols. Intel MKL works, in some cases, with some \"hacks\", but it can be difficult, hit and miss...
- In which module are they included?
- You can install some of them in your own home/project directory with Spack if you want, e.g.
spack install openblas. - And there are EasyBuild recipes for some of them also, check the LUMI Software Libary mentioned a few times over the course, but these will almost certainly cause problems when linked with other modules build with EasyBuild that employ BLAS or Lapack (but then the same would hold if you would start mixing spack generated libraries that are generated with a different BLAS and/or LAPACK library). We do not install software that so clearly can conflict with other software that we installed in the central stack.
-
It would be cool to have a GH repo for the docs where we can send pull requests to.
- Our docs are hosted on GH and you can find the link in the bottom right (click on the little GH logo). https://github.com/Lumi-supercomputer/lumi-userguide/
- Pull request are of course the best but we are also grateful for issues about improvements or topics missing.
- Very cool thanks! p.s. are typos fixes also accepted?
- Sure. We will carefully review all PR and if we can support the changes, we will definitely merge it.
-
We are porting an C++ MPI app to LUMI and getting MPI errors like: (Cray MPI)
Assertion failed in file ../src/mpid/ch4/netmod/include/../ofi/ofi_events.c at line 379: dtp_ != NULL\nMPICH ERROR [Rank 1800] [job id 2932607.0] [Fri Feb 17 14:38:57 2023] [nid001179] - Abort(1): Internal error\n
or (AOCC) MPICH ERROR [Rank 6088] [job id 2618312.0] [Sun Jan 22 20:58:44 2023] [nid001271] - Abort(404369807) (rank 6088 in comm 0): Fatal error in PMPI_Waitany: Other MPI error, error stack:\nPMPI_Waitany(277)..............: MPI_Waitany(count=13, req_array=0x2b7b970, index=0x7ffcc40da984, status=0x7ffcc40da988) failed\nPMPI_Waitany(245)..............: \nMPIDI_Progress_test(80)........: \nMPIDI_OFI_handle_cq_error(1062): OFI poll failed (ofi_events.c:1064:MPIDI_OFI_handle_cq_error:Input/output error - PTLTE_NOT_FOUND)\n
- Please submit a ticket.
- We've had the same issue and opened a ticket but as you say the team is small and could not really dive deep because any suggestion the LUST team offered did not work. Would be interested it this problem is resolved.
- Can you write the ticket number here, will review next week (or as per comment below)
- \"LUMI #1059 MPICH errors\". Send by my colleague at UCL
-
This is an issue that probably requires a software upgrade that is outside the control of LUST. Sending a ticket is still useful as it help us detect recurring issues. The issue is with HPE already and discussed with the HPE person that assists the sysadmins as the OFI poll errors are very low level. They also often result from a failure on another node of your job.
These errors are also not related to any specific compiler but come from errors that occur in layers underneath the MPI libraries.
"},{"location":"4day-20230214/schedule/","title":"Course schedule","text":"All times CET.
- Day 1
- Day 2
- Day 3
- Day 4 DAY 1 09:00\u00a0\u00a0 Welcome and introduction Presenters: Emmanuel Ory (LUST), J\u00f8rn Dietze (LUST), Harvey Richardson (HPE) Recording 09:10 HPE Cray EX architecture Presenter: Harvey Richardson (HPE) Slide files:
/project/project_465000388/slides/HPE/01_EX_Architecture.pdf on LUMI only. Recording: /project/project_465000388/recordings/01_Cray_EX_Architecture.mp4 on LUMI only. 10:10 Programming Environment and Modules Presenter: Harvey Richardson (HPE) Slide files: /project/project_465000388/slides/HPE/02_PE_and_Modules.pdf on LUMI only. Recording: /project/project_465000388/recordings/02_Programming_Environment_and_Modules.mp4 on LUMI only. 10:40 break (15 minutes) 10:55 Running Applications - Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
Presenter: Harvey Richardson (HPE) Slide file: /project/project_465000388/slides/HPE/03_Running_Applications_Slurm.pdf on LUMI only. Recording: /project/project_465000388/recordings/03_Running_Applications.mp4 on LUMI only. 11:15 Exercises Exercises are in /project/project_465000388/exercises/HPE on LUMI only. 12:00 lunch break (90 minutes) 13:30 Compilers and Parallel Programming Models - An introduction to the compiler suites available, including examples of how to get additional information about the compilation process.
- Cray Compilation Environment (CCE) and options relevant to porting and performance. CCE classic to Clang transition.
- Description of the Parallel Programming models.
Presenter: Alfio Lazzaro (HPE) Slide files: /project/project_465000388/slides/HPE/04_Compilers_and_Programming_Models.pdf on LUMI only. Recording: /project/project_465000388/recordings/04_Compilers_and_Programming_Models.mp4 on LUMI only. 14:30 Exercises 15:00 break (30 minutes) - Exercises on programming models: Try swapping compilers and some GPU programs.
15:30 Cray Scientific Libraries - The Cray Scientific Libraries for CPU and GPU execution.
Presenter: Alfio Lazzaro (HPE) Slide files: /project/project_465000388/slides/HPE/05_Libraries.pdf on LUMI only. Recording: /project/project_465000388/recordings/05_Libraries.mp4 on LUMI only. 16:00 Exercises 16:45 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions) 17:30 End of the course day DAY 2 09:00 CCE Offloading Models - Directive-based approach for GPU offloading execution with the Cray Compilation Environment.
Presenter: Alfio Lazzaro (HPE) Slide file: /project/project_465000388/slides/HPE/06_Directives_Programming.pdf on LUMI only. Recording: /project/project_465000388/recordings/06_Directives_programming.mp4 on LUMI only. 09:45 Exercises See also: /project/project_465000388/slides/HPE/Exercises_alldays.pdf on LUMI only. 10:15 break (30 minutes) 10:45 Advanced Placement - More detailed treatment of Slurm binding technology and OpenMP controls.
Presenter: Jean Pourroy (HPE) Slide file: /project/project_465000388/slides/HPE/07_Advanced_Placement.pdf on LUMI only. Recording: /project/project_465000388/recordings/07_Advanced_Placement.mp4 on LUMI only. 11:40 Exercises 12:10 lunch break (65 minutes) 13:15 Understanding Cray MPI on Slingshot, rank reordering and MPMD launch - High level overview of Cray MPI on Slingshot
- Useful environment variable controls
- Rank reordering and MPMD application launch
Presenter: Harvey Richardson (HPE) Slide file: /project/project_465000388/slides/HPE/08_cray_mpi_MPMD_medium.pdf on LUMI only. Recording: /project/project_465000388/recordings/08_MPI_Topics.mp4 on LUMI only. 14.15 Exercises 14:45 break (15 minutes) 15:00 Additional software on LUMI - Software policy.
- Software environment on LUMI.
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LUST) Slides for download (PDF) Notes available Recording 16:30 LUMI support and LUMI documentation. - What can we help you with and what not? How to get help, how to write good support requests.
- Some typical/frequent support questions of users on LUMI?
Presenter: J\u00f8rn Dietze (LUST) Recording 17:00 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions) 17:30 End of the course day DAY 3 09:00 Performance Optimization: Improving Single-core Efficiency Presenter: Jean Pourroy (HPE) Slide file: /project/project_465000388/slides/HPE/09_cpu_performance_optimization.pdf on LUMI only. Recording: /project/project_465000388/recordings/11_CPU_Performance_Optimization.mp4 on LUMI only. 09:45 Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat Presenter: Thierry Braconnier (HPE) Slide file: /project/project_465000388/slides/HPE/10_debugging_at_scale.pdf on LUMI only. Recording: /project/project_465000388/recordings/12_Debugging_at_Scale.mp4 on LUMI only. 10:10 Exercises 10:30 break 10:50 I/O Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system.
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes.
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations
- Further considerations of parallel I/O and other APIs.
- Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson (HPE) Slide file: /project/project_465000388/slides/HPE/11_IO_medium_LUMI.pdf on LUMI only. Recording: /project/project_465000388/recordings/13_IO_Optimization.mp4 on LUMI only. 11:40 Exercises 12:10 lunch break 13:30 Introduction to AMD ROCmTM ecosystem Presenter: George Markomanolis (AMD) Slides for download (PDF) Recording: /project/project_465000388/recordings/14_Introduction_AMD_ROCm.mp4 on LUMI only. 14:30 Exercises Notes and exercises AMD 15:00 break 15:30 AMD Debugger: ROCgdb Presenter: Bob Robey (AMD) Slides for download (PDF) Recording: /project/project_465000388/recordings/15_AMD_Rocgdb_Tutorial.mp4 on LUMI only. 16:05 Exercises Notes and exercises AMD 16:25 Introduction to Rocprof Profiling Tool Presenter: George Markomanolis (AMD) Slides for download (PDF) Recording: /project/project_465000388/recordings/16_Introduction_Rocprof.mp4 on LUMI only. 16:45 Exercises Notes and exercises AMD 17:10 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions) 17:30 End of the course day DAY 4 09:00 Introduction to Perftools - Overview of the Cray Performance and Analysis toolkit for profiling applications.
- Demo: Visualization of performance data with Apprentice2 Presenter: Alfio Lazzaro (HPE) Slide file:
/project/project_465000388/slides/HPE/12_introduction_to_perftools.pdf on LUMI only. Recording: /project/project_465000388/recordings/17_Introduction_to_Perftools.mp4 on LUMI only. 09:40 Exercises Info about the exercises in /project/project_465000388/slides/HPE/Exercises_alldays.pdf on LUMI only. 10:10 break 10:30 Advanced Performance Analysis - Automatic performance analysis and loop work estimated with perftools
- Communication Imbalance, Hardware Counters, Perftools API, OpenMP
- Compiler feedback and variable scoping with Reveal
Presenter: Thierry Braconnier (HPE) Slide file: /project/project_465000388/slides/HPE/13_advanced_performance_analysis_merged.pdf on LUMI only. Recording: /project/project_465000388/recordings/18_Advanced_Performance_Analysis.mp4 on LUMI only. 11:25 Exercises Info about the exercises in /project/project_465000388/slides/HPE/Exercises_alldays.pdf on LUMI only. 12:00 lunch break (90 minutes) 13:34 Introduction to OmniTools (late start due to technical problems) Presenter: Suyash Tandon (AMD) Slides for download (PDF) Recording: /project/project_465000388/recordings/19_Introduction_to_OmniTools.mp4 on LUMI only. 14:20 Exercises 14:45 Introduction do AMD Omniperf Presenter: George Markomanolis (AMD) Recording: /project/project_465000388/recordings/20_Introduction_to_Omniperf.mp4 on LUMI only. 15:20 break 15:40 Tools in Action - An Example with Pytorch Presenter: Samuel Antao (AMD) 17:00 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions) Some examples from the presentation: /pfs/lustrep1/projappl/project_465000388/slides/AMD/pytorch-based-examples on LUMI only. Recording: /project/project_465000388/recordings/21_Tools_in_Action_Pytorch_Demo.mp4 on LUMI only. 17:30 End of the course"},{"location":"4day-20230214/software_stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
- Some remarks about using containers on LUMI.
"},{"location":"4day-20230214/software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"4day-20230214/software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a coherent unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character.
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"4day-20230214/software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparant way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be acustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We have a pre-configured Spack installation also but do not do any package development in Spack ourselves. The setup is meant for users familiar with Spack who can also solve problems that occur on the road, but we already did the work of ensuring that Spack is correctly configured for the HPE Cray compilers.
"},{"location":"4day-20230214/software_stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionaire send out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model build on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intro-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions, driver versions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-bus comes to mind.
Also, the LUNI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that has not yet been mentioned is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky.
"},{"location":"4day-20230214/software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using the that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also provide the spack modules which provide some support to install software with Spack. This stack is meant for users who are very familiar with Spack and can deal with the problems Spack may throw at you. We have no intent to debug or modify Spack package files ourselves, but did an effort to configure Spack to use the compilers provided by the HPE Cray PE.
In the distant future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"4day-20230214/software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"4day-20230214/software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"4day-20230214/software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It ia also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change. E.g., the PrgEnv-aocc/21.12 module can successfully use the aocc/3.1.0 compilers.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"4day-20230214/software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/21.12 and LUMI/22.08 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes, partition/G for the GPU nodes and in the future we may have partition/D for the visualisation nodes.
There is also a hidden partition/common module in which we install software that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"4day-20230214/software_stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"4day-20230214/software_stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the small number of modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"4day-20230214/software_stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1 (when infrastructure for a demo is available)
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 10 versions of GNUplot. There are two installations of GNUplot 5.4.2 and eight of 5.4.3. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there are four versions, 3.21.2, 3.22.2, 3.23.2 and 3.24.0, but now they are shown in blue with an \"E\" behind the name. That is because there is no module called CMake on LUMI. Instead the tool is provided by another module that in this case contains a collection of popular build tools and that we will discover shortly.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.3-cpeGNU-22.08. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are two ways to load the module: By loading LUMI/22.08 combined with partition/C or by loading LUMI/22.08 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/22.08 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.24.0. This will now show us that this tool is in the buildtools/22.08 module (among others) and give us 6 different options to load that module as it is provided in the CrayEnv and the LUMI/22.08 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider cmake\nmodule spider gnuplot/5.4.3-cpeGNU-22.08\nmodule spider CMake/3.24.0\n
"},{"location":"4day-20230214/software_stacks/#module-keyword-command","title":"Module keyword command","text":"module keyword will search for a module using a keyword but it is currently not very useful on LUMI because of a bug in the current version of Cray Lmod which is solved in the more recent versions. Currently the output contains a lot of irrelevant modules, basically all extensions of modules on the system.
What module keyword really does is search in the module description and help for the word that you give as an argument. Try for instance module keyword quota and you'll see two relevant modules, lumi-workspaces (which would actually show a depracation warning when you load the module) and lumi-tools.
On LUMI we do try to put enough information in the module files to make this a suitable additional way to discover software that is already installed on the system, more so than in regular EasyBuild installations.
Demo module keyword Try the following command:
module keyword quota\n
"},{"location":"4day-20230214/software_stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"You may have been taught that module purge is a command that unloads all modules and on some systems they might tell you in trainings not to use it because it may also remove some basic modules that you need to use the system. On LUMI for instance there is an init-lumi module that does some of the setup of the module system and should be reloaded after a normal module purge. On Cray systems module purge will also unload the target modules while those are typically not loaded by the PrgEnv modules so you'd need to reload them by hand before the PrgEnv modules would work.
Lmod however does have the concept of \"sticky modules\". These are not unloaded by module purge but are re-loaded, so unloaded and almost immediately loaded again, though you can always force-unload them with module --force purge or module --force unload for individual modules.
Demo Try the following command:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded, but we'll come back to that later also.
(Skipping a screen in the output as ther eis nothing special)
Note the two categories for the PE modules. The target modules get their own block.
Here we see the modules for the software stack that we have just discussed.
And this screen shows the extensions of modules (like the CMake tool we've tried to locate before)
At the end of the output we also get some information about the meaning of the letters used in the display.
Try the following commands and carefully observe the output:
module load LUMI/22.08 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similarly in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"4day-20230214/software_stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/22.08 stack we prefer that users use the Cray programming environment modules that come with release 22.08 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Demo Try the following commands:
module load LUMI/22.08\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"4day-20230214/software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"4day-20230214/software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and as including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. We expect this to happen especially with packages that require specific MPI versions. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And we need a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"4day-20230214/software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is our primary software installation tool. We selected this as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain we would have problems with MPI. EasyBuild there uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost with the classic compilers or the Intel compiler will simply optimize for a two decades old CPU.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system. We also maintain a list of all EasyBuild recipes installed in the central stack maintained by LUST or available in the main EasyConfig repository LUMI-EasyBuild-contrib in the LUMI Software Library.
"},{"location":"4day-20230214/software_stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs are are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"4day-20230214/software_stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with teh system toolchain, but we do avoid mixing those when linking as that may cause problems. The reason is that we try to use as much as possible static linking in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"4day-20230214/software_stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2021.4, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeCray-22.08 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is and easyconfig for installation in LUMI/22.08.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.8.0-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2021.4-cpeCray-22.08-PLUMED-2.8.0-CPE.
"},{"location":"4day-20230214/software_stacks/#installing-software","title":"Installing software","text":""},{"location":"4day-20230214/software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .bash_profile or .bashrc. This variable is not only used by the module that will load and configure EasyBuild (the EasyBuild-user module) to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"4day-20230214/software_stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"Once that environment variable is set, all you need to do to activate EasyBuild is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition. Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
It is currently problematic for the GPU nodes as due to a misconfiguration of the system the ROCm version is not the same on the login and GPU compute nodes, but that will hopefully be solved in the next update of the system.
"},{"location":"4day-20230214/software_stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Demo moment 2
Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS we already have support. At the moment we have to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
We now also have the LUMI Software Library which lists all software that we manage via EasyBuild and make available either preinstalled on the system or as an EasyBuild recipe for user installation. Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS we do expect that GPU builds for LUMI will become available early on in the deployment of LUMI-G so we've already added a so-called version suffix to distinguish between CPU and GPU versions. To install it, we first run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb -r\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
Demo of the EasyBuild installation of GROMACS
End of demo moment 2
"},{"location":"4day-20230214/software_stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"There is a little problem though that you may run into. Sometimes the module does not show up immediately. This is because Lmod keeps a cache when it feels that Lmod searches become too slow and often fails to detect that the cache is outdated. The easy solution is then to simply remove the cache which is in $HOME/.lmod.d/.cache, which you can do with
rm -rf $HOME/.lmod.d/.cache\n
And we have seen some very rare cases where even that did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment. Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work. Often you also don't need to be an EasyBuild expert to adapt the build recipe to install, e.g., a slightly different version of the package that better suits your needs.
"},{"location":"4day-20230214/software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r .\n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.2-cpeGNU-22.08.eb -r .\n
"},{"location":"4day-20230214/software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greates before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/easybuild/easyconfigs.
"},{"location":"4day-20230214/software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory, and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software. Also, there are rare cases in which EasyBuild cannot save the sources because they are automatically downloaded during the installation procedure outside the control of EasyBuild with no way to teach EasyBuild where to download those files and place them to avoid them to be downloaded automatically. This is, e.g., often te case for software written in Rust.
Moreover, EasyBuild also keeps copies of all installed easconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"4day-20230214/software_stacks/#easybuild-tips-tricks","title":"EasyBuild tips & tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"4day-20230214/software_stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"I also want to give some pointers to more information in case you want to learn a lot more about, e.g., developing support for your code in EasyBuild, or for support people who want to adapt our EasyConfigs for users requesting a specific configuration of a package.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
In the past we also organised a training for CSC staff and staff from other local support organisations. The latest version of the training materials is currently available on klust.github.io/easybuild-tutorial.
"},{"location":"4day-20230214/software_stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of manpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"4day-20230214/software_stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software.
But full portability is a much greater myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually build for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the SlingShot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
Even if a container is portable to LUMI, it may not yet be performance portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"4day-20230214/software_stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
When setting up very large software environments, e.g., some Python and R environments, they can still be very helpful, even if you may have to change some elements in your build recipes from your regular cluster or workstation. Some software may also be simply too hard to install from sources in the typical HPC way of working.
-
And related to the previous point is also that some software may not even be suited for installation in a multi-user HPC system. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and doesn't allowed to be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"4day-20230214/software_stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory or in $XDG_RUNTIME_DIR (works only on the login nodes). The former can lead to exhaustion of your storage quota, so check and clean up from time to time. You may also want to clean up $XDG_RUNTIME_DIR, but this directory is also automatically cleaned when you log out from your last running session on that (login) node.
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently no support for building containers on LUMI and I do not expect that to change quickly. It would require enabling some features in the Linux kernel that have seen some very serious security vulnerabilities in recent years.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI.
"},{"location":"4day-20230214/software_stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the contianer indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables.
"},{"location":"4day-20230214/software_stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, ie.e, use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI SlingShot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We have no good solutions at the moment to run them with good performance. We only have a partial solution for the CPU nodes, and on the GPU nodes Open MPI is very problematic at the moment. This is both due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE does not yet support on Cray EX systems. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and currently full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the SlingShot 11 interconnect so work is going on for better support for OFI and for full GPU support on systems that rely on OFI and do not support UCX.
"},{"location":"4day-20230214/software_stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY__PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the module in the LUMI Software Library.
The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
The final tool is a container wrapper tool that users from Finland may also know as Tykky. It is a tool to wrap Python and conda installations in a limited number of files in a transparent way. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run a tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation.
We do strongly recommend to use the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
|Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a temprorary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"4day-20230214/software_stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
-
Building containers is currently not supported on LUMI due to security concerns.
"},{"location":"4day-20230214/video_00_Introduction/","title":"Welcome and introduction","text":"Presenters: Emmanuel Ory (LUST), J\u00f8rn Dietze (LUST), Harvey Richardson (HPE)
"},{"location":"4day-20230214/video_09_LUMI_Software_Stack/","title":"Additional software on LUMI","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"4day-20230214/video_10_LUMI_User_Support/","title":"LUMI support and LUMI documentation","text":"Presenter: J\u00f8rn Dietze (LUST)
"},{"location":"4day-20230530/","title":"Comprehensive General LUMI Training, May 30 - June 2, 2023","text":""},{"location":"4day-20230530/#course-organisation","title":"Course organisation","text":" -
Location: TalTech IT Kolled\u017e, Raja 4c, Tallinn, Estonia, room ICO-221
Public transportation in Tallinn
-
Original schedule (PDF)
Dynamic schedule (adapted as the course progresses)
The dynamic schedule also contains links to pages with information about the course materials, but those links are also available below on this page.
-
HedgeDoc for questions
-
There are two Slurm reservations for the course:
- CPU nodes:
training_cpu - GPU nodes:
training-gpu
"},{"location":"4day-20230530/#course-materials","title":"Course materials","text":"Course materials include the Q&A of each session, slides when available and notes when available.
Due to copyright issues some of the materials are only available to current LUMI users and have to be downloaded from LUMI.
Presentation slides notes recording Introduction / / web HPE Cray EX Architecture lumi / lumi Programming Environment and Modules lumi / lumi Running Applications lumi / lumi Exercises #1 / / / Compilers and Parallel Programming Models lumi / lumi Exercises #2 / / / Cray Scientific Libraries lumi / lumi Exercises #3 / / / CCE Offloading Models lumi / lumi Debugging at Scale lumi / lumi Exercises #4 / / / Advanced Placement lumi / lumi Exercises #5 / / / LUMI Software Stacks web web web Introduction to HIP Programming web / web Exercises #6 / / / Introduction to Perftools lumi / lumi Exercises #7 / / / Advanced Performance Analysis lumi / lumi Exercises #8 / / / MPI Topics on the HPE Cray EX Supercomputer lumi / lumi Exercises #9 / / / AMD Debugger: ROCgdb web / web Exercises #10 / / / Introduction to ROC-Profiler (rocprof) web / web Exercises #11 / / / Performance Optimization: Improving single-core Efficiency lumi / lumi Python and Frameworks lumi / lumi Exercises #12 / / / Optimizing Large Scale I/O lumi / lumi Exercises #13 / / / Introduction to OmniTrace web (until p. 61) / web Exercises #14 / / / Introduction to Omniperf web (from p. 62) / web Exercises #15 / / / Tools in Action - An Example with Pytorch web / web LUMI User Support web / web"},{"location":"4day-20230530/#making-the-exercises-after-the-course","title":"Making the exercises after the course","text":""},{"location":"4day-20230530/#hpe","title":"HPE","text":"The exercise material remains available in the course archive on LUMI:
-
The PDF notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
The other files for the exercises in either a bzip2-compressed tar file /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2\n
in the directory where you want to work on the exercises. This will create the exercises/HPE subdirectory from the training project.
However, instead of running the lumi_c.sh or liumi_g.sh scripts that only work for the course as they set the course project as the active project for Slurm and also set a reservation, use the lumi_c_after.sh and lumi_g_after.sh scripts instead, but first edit them to use one of your projects.
"},{"location":"4day-20230530/#amd","title":"AMD","text":"There are online notes about the AMD exercises. A PDF print-out with less navigation features is also available and is particularly usefull should the online notes become unavailable.
The other files for the exercises are available in either a bzip2-compressed tar file /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_AMD_.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_AMD.tar and can also be downloaded. ( bzip2-compressed tar download or uncompressed tar download)
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_AMD.tar.bz2\n
in the directory where you want to work on the exercises. This will create the exercises/AMD subdirectory from the training project. You can do so in the same directory where you installed the HPE exercises.
The software that was installed in the training project is also available as a bzip2-compressed tar archive on LUMI as /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Software_AMD.tar.bz2. You can install it in the same directory where you installed the files but beware when interpreting instructions as the path to the software installation is different now.
Warning
The software and exercises were tested thoroughly at the time of the course. LUMI however is in continuous evolution and changes to the system may break exercises and software
"},{"location":"4day-20230530/#links-to-documentation","title":"Links to documentation","text":"The links to all documentation mentioned during the talks is on a separate page.
"},{"location":"4day-20230530/#external-material-for-exercises","title":"External material for exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"4day-20230530/documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"4day-20230530/documentation/#web-documentation","title":"Web documentation","text":" -
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
Mentioned in the Lustre presentation: The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20230530/documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"4day-20230530/documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"4day-20230530/documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --help crayCC --help crayftn --help craycc --craype-help crayCC --craype-help crayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --help CC --help ftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"4day-20230530/documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"4day-20230530/extra_1_00_Introduction/","title":"Introduction","text":"Presenters: Emmanuel Ory (LUST), Harvey Richardson (HPE)
"},{"location":"4day-20230530/extra_1_01_HPE_Cray_EX_Architecture/","title":"HPE Cray EX Architecture","text":"Presenter: Harvey Richardson (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_01_HPE_Cray_EX_Architecuture.pdf/project/project_465000524/slides/HPE/01_EX_Architecture.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_01_HPE_Cray_EX_Architecture.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_1_01_HPE_Cray_EX_Architecture/#qa","title":"Q&A","text":" -
Could you elaborate what memory coherency between GPUs and CPUs means?
Answer [Kurt] I'll ask the AMD people to comment a bit more on it during their presentation as it is something that is even unclear to the support team at the moment. There is a difference between what the hardware can do and what can be done with good performance. As the GPUs are connected through xGMI/InfinityFabric to the CPU full cache coherency is in theory possible but in practice there is a bandwidth problem so I don't think any user of LUMI has fully exploited this.
Answer [Sam AMD] Coherency means there are some guarantees provided by the hardware and runtimes when it comes to make memory activity visible to the different resources in the system: CPUs and GPUs, as well as within the resources in each CPU and GPU. It is fair to think as memory being fully coherent accross CPU threads. When it comes to CPU and GPU memory that is still the case, though there are cases when that is true only at the synchroization points between the two devices. It is important to distinguish between the so called coarse-grain memory and fine-grain memory. Coarse-grain memory is provided by default by the HIP runtime through its hipMalloc API whereas fine-grain memory is provided by default by the other memory allocators available on the system. For instance, it is only valid to do a system-wide atomic in fine-grained memory as course-grain memory coherency outside synchronization points is only guaranteed within a GCD (Graphics Compute Die).
Followup [Juhan Taltech]: When thinking from the user point of view, e.g. using PyTorch, would there be some additional convenience or is this currently not yet available at 3rd party library level? There are separate instructions for moving tensors from/to differet memories.
Answer [Sam AMD] There is no real difference in the memories - virtual address space is the same - is just in the allocators which provide different coherency semantics. E.g. if Pytorch allocates a piece of memory it has to work with its semantics. This is not different than what Pytorch has been doing for other GPU vendors. If someone uses the high-level Pytorch interface to control the placement of tensors, he/she can trust the implementation to do the right thing, e.g. if there is coarse-grained memory being used makes sure a synchroniation or some mechanism of assuring dependencies (stream) is in place. If an implementation is making assumptions on some coherency semantic it has to make sure the allocators are correct. E.g. OpenMP requires the user to indicate unified shared memory to prevent the runtime from creating coarse-grain memory transfers.
For completeness, the coherency mechanism between CPU-GPUs is fueled by the xGMI link hability to force the retry of a memory access in the presence of a page-fault. This is enabled by default and can be disabled per-process by doing export HSA_XNACK=0. Doing so will result in a seg-fault if the program tries to access physical memory on a GPU that belongs to the CPU or vice-versa.
"},{"location":"4day-20230530/extra_1_02_Programming_Environment_and_Modules/","title":"Programming Environment and Modules","text":"Presenter: Harvey Richardson (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_02_Programming_Environment_and_Modules.pdf/project/project_465000524/slides/HPE/02_PE_and_Modules.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_02_Programming_Environment_and_Modules.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_1_02_Programming_Environment_and_Modules/#qa","title":"Q&A","text":" -
What are the differences between module and spack? When should we install software using module and spack?
Answer By default we install software using EasyBuild which is done via the LUMI modules. Spack is provided as an alternative without much support for those who know Spack. It is configured to use the compilers on the system, but we will not do any debugging or package development in Spack. A bit more about this in the presentation on LUMI software stacks on Wednesday afternoon (day 2). Spack can also generate module files, if you want, but it is not mandatory, and other options might be better (Spack environments or spack load).
-
Regarding module load. Are CDO command, NCO command, and ncview modules available? If so, how can one correctly load them? Any documentation available? seems that they are available via easy build https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/
Answer See the presentation on the afternoon of day 2 about how to find software on LUMI and how we deal with software and all possible configurations, and how to install with EasyBuild.
-
What is the difference between PrgEnv-xxx and CCE?
Answer PrgEnv-... set up the whole environment: Compiler, MPI and LibSci and the compiler wrappers. CCE is just the compiler module corresponding to PrgEnv-cray, but does not yet offer MPI, LibSci or the compiler wrappers.
"},{"location":"4day-20230530/extra_1_03_Running_Applications/","title":"Running Applications","text":"Presenter: Harvey Richardson (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_03_Running_Applications.pdf/project/project_465000524/slides/HPE/03_Running_Applications_Slurm.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_03_Running_Applications.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_1_03_Running_Applications/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_1_04_Exercises_1/","title":"Exercise session 1","text":" -
Exercise materials in /project/project_465000524/exercises/HPE/day1/ProgrammingModels for the lifetime of the project and only for project members.
See /project/project_465000524/exercises/HPE/day1/ProgrammingModelExamples_SLURM.pdf
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_1_04_Exercises_1/#qa","title":"Q&A","text":" -
sprun command in the very end of the exercise pdf, is that a typo ?
**Answer** Yes\n
-
I have following modules loaded on a GPU node:
Currently Loaded Modules:\n 1) init-lumi/0.2 (S) 4) cce/15.0.0 7) libfabric/1.15.2.0 10) cray-libsci/22.12.1.1 13) rocm/5.2.3\n 2) lumi-tools/23.04 (S) 5) craype/2.7.19 8) craype-network-ofi 11) PrgEnv-cray/8.3.3\n 3) ModuleLabel/label (S) 6) cray-dsmml/0.2.2 9) cray-mpich/8.1.23 12) craype-accel-amd-gfx90a\n
When I compile the pi_hip target, I get a warning:
No supported cpu target is set, CRAY_CPU_TARGET=x86-64 will be used.\n
Is this ok, am I missing a module to set this variable, or should it be set manually? Answer Can you try with a fresh shell? I've just tried and it works:
> module load craype-accel-amd-gfx90a rocm\n> make acc\ncc -o pi_openmp_device pi_openmp_device.c -fopenmp\nCC -xhip -o pi_hip pi_hip.cpp\nIn file included from pi_hip.cpp:9:\n
Ignore the warnings... -
With lumi_c.sh, PrgEnv-cray, craype-x86-milan, craype-accel-host: C_timers/pi_mpi compiles, but running it results in:
MPICH ERROR [Rank 0] [job id 3605521.0] [Tue May 30 12:41:09 2023] [nid002042] - Abort(-1) (rank 0 in comm 0): MPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked\n(Other MPI error)\n\naborting job:\nMPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked\n
(serial and openmpi tests worked fine) Answer Could you list your modules? You should not use craype-accel-host if you are running a CPU code on LUMI_c.
-
With PrgEnv-amd, craype-x86-milan, rocm/5.2.3: compilation fails because CC --cray-print-opts=libs returns a string which includes, among others, -lsci_amd -lsci_amd,-lflangrti,-lflang,-lpgmath -ldl (note the commas and missing spacs between flags) and this is seen in the error ld.lld: error: unable to find library -lsci_amd,-lflangrti,-lflang,-lpgmath. A workaround is to set HIPCC_LINK_FLAGS_APPEND manually and call hipcc directly, but the CC call should be fixed for this combo.
Answer [Alfio HPE] I cannot reproduce this problem, could you provide the list of modules? This is what I get:
> CC --cray-print-opts=libs\n-L/opt/cray/pe/mpich/8.1.23/ofi/amd/5.0/lib -L/opt/cray/pe/mpich/8.1.23/gtl/lib \n-L/opt/cray/pe/libsci/22.12.1.1/AMD/4.0/x86_64/lib -L/opt/rocm/lib64 -L/opt/rocm/lib -L/opt/rocm/rocprofiler/lib \n-L/opt/rocm/rocprofiler/tool -L/opt/rocm/roctracer/lib -L/opt/rocm/roctracer/tool -L/opt/rocm/hip/lib \n-L/opt/cray/xpmem/2.5.2-2.4_3.20__gd0f7936.shasta/lib64 -L/opt/cray/pe/dsmml/0.2.2/dsmml//lib -lamdhip64 \n-Wl,--as-needed,-lsci_amd_mpi,--no-as-needed -Wl,--as-needed,-lsci_amd,--no-as-needed -ldl -Wl,\n--as-needed,-lmpi_amd,--no-as-needed -lmpi_gtl_hsa -Wl,--as-needed,-ldsmml,--no-as-needed -lxpmem\n
Reply After quite a bit of testing, I found that repeated loading of modules LUMI/22.08, PrgEnv-amd, partition/G sometimes ended up loading also the module cray-libsci/22.08.1.1 which results in the broken link flags. Switching to cray-libsci/22.12.1.1 gives the correct flags again. But indeed, it's not deterministic which combo of modules you get unless you do a force purge first.
[Kurt] As we shall also see tomorrow this is the wrong way of using the LUMI modules. You should not use the PrgEnv-* modules with the LUMI modules unlwss you understand what is happening and you should load the partition module immediately after the LUMI module.
Due to the way Lmod works loading modules that change the defaults such as the cpe modules and the LUMI modules should not be used in a single module statement with modules for which you want the default version without specifying any version. What you see in different behaviour is likely the result of sometimes loading in a single module call and sometimes not. It may be better to switch to using the full CPE 22.12 set though. There are a few broken links in the LibSci installation for AMD in 22.08.
"},{"location":"4day-20230530/extra_1_05_Compilers_and_Parallel_Programming_Models/","title":"Compilers and Parallel Programming Models","text":"Presenter: Alfio Lazzaro (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_05_Compilers_and_Parallel_Programming_Models.pdf/project/project_465000524/slides/HPE/04_Compilers_and_Programming_Models.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_05_Compilers_and_Parallel_Programming_Models.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_1_05_Compilers_and_Parallel_Programming_Models/#qa","title":"Q&A","text":" -
Rocm has two backends, HIP and OpenCL that cannot be made available at the same time, i.e. the packages conflict. Could you give some background why is that and why OpenCL and HIP in Rocm cannot coexist?
Answer [Sam AMD] I believe OpenCL and HIP supporting libraries can coexist in the system. Having the two models coexist in the same application I'll have to investigate as I didn't try that before.
-
So what approach should one use to compile code which uses MPI, OpenMP threads (but no OpenMP offload), and HIP all in one code and in the same source code files as well?
Answer [Sam AMD] If you are building HIP code in the source file you need to rule out GNU. I'd try with the Cray wrappers (CC) with -x hip to point out you want that to be interpreted as an HIP source code. Because you care about OpenMP you need to enable it with -fopenmp. You could always use the ROCm clang and link MPI in if you feel confortable with it. Order matters: -fopenmp needs to come prior to -x hip.
Reply Currently Loaded Modules:
``` 1) craype-accel-amd-gfx90a 3) craype/2.7.19 5) libfabric/1.15.2.0 7) cray-mpich/8.1.23 9) PrgEnv-cray/8.3.3 11) craype-x86-trento 2) cce/15.0.0 4) cray-dsmml/0.2.2 6) craype-network-ofi 8) cray-libsci/22.12.1.1 10) rocm/5.2.3 ````
I compile with: CC -g -O3 -fopenmp -x hip Trying to link with: CC -fopenmp --hip-link -o executable sourceobjects.o libraries I get Warning: Ignoring device section hip-amdgcn-amd-amdhsa-gfx90a
"},{"location":"4day-20230530/extra_1_06_Exercises_2/","title":"Exercise session 2","text":""},{"location":"4day-20230530/extra_1_06_Exercises_2/#qa","title":"Q&A","text":" -
I changed my environment to PrgEnv-gnu, and trying to run the Makefile, but it gave me this message Makefile:7: *** Currently PrgEnv-gnu is not supported, switch to PrgEnv-cray or use Makefile.allcompilers. Stop.. Could you please guide me how to run make for the gnu?
Answer make -f Makefile.allcompilers
Follow up it gave me this: make: Nothing to be done for 'all'.
Answer You need to get rid of the previous compilation with make -f Makefile.allcompilers clean
"},{"location":"4day-20230530/extra_1_07_Cray_Scientific_Libraries/","title":"Cray Scientific Libraries","text":"Presenter: Alfio Lazzaro (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_07_Cray_Scientific_Libraries.pdf/project/project_465000524/slides/HPE/05_Libraries.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_07_Cray_Scientific_Libraries.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_1_07_Cray_Scientific_Libraries/#qa","title":"Q&A","text":" -
Is it a good practice to run converted CUDA library by HIP in AMD GPUs? if no, any other better solution?
Answer Usually it is a good starting point, especially if you know the code. But there are differences that you should take into account to optimise the code. E.g., the \"warp size\" is 64 instead of 32.
"},{"location":"4day-20230530/extra_1_08_Exercises_3/","title":"Exercise session 3","text":" -
See /project/project_465000524/slides/HPE/Exercises.pdf. The files for the exercises are in /project/project_465000524/exercises/HPE/day1/libsci_acc.
Test with LibSci_ACC, check the different interfaces and environment variables.
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_1_08_Exercises_3/#qa","title":"Q&A","text":" -
Do we still need to modify the job script? I logged in (to get a fresh shell), did source lumi_g.sh and submitted the script. The LibSci_ACC automatic interface runs terminates with:
srun: error: nid007242: task 3: Bus error\nsrun: launch/slurm: _step_signal: Terminating StepId=3606826.1\nslurmstepd: error: *** STEP 3606826.1 ON nid007242 CANCELLED AT 2023-05-30T15:48:22 ***\nsrun: error: nid007242: tasks 0,2: Terminated\nsrun: error: nid007242: task 1: Bus error (core dumped)\n
Similar problem for the third run (Adding avoiding heuristics on input data). The run titled \"Adding MPI G2G enabled\" runs fine again, and with 8s seems faster than what was shown in the presentation.
Update
The job.slurm file for this exercise has been updated compared to this morning, after making the following changes
25,26c25\n< module load cray-libsci_acc/22.08.1.1\n< export LD_LIBRARY_PATH=${CRAY_LD_LIBRARY_PATH}:${LD_LIBRARY_PATH}\n---\n> module load cray-libsci_acc\n
the problem that was mentiond above goes away.
"},{"location":"4day-20230530/extra_1_09_Offload_CCE/","title":"CCE Offloading Models","text":"Presenter: Alfio Lazzaro (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-1_09_Offload_CCE.pdf/project/project_465000524/slides/HPE/06_Directives_Programming.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/1_09_Offload_CCE.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_2_01_Debugging_at_Scale/","title":"Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat","text":"Presenter: Thierry Braconnier (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-2_01_Debugging_at_Scale.pdf/project/project_465000524/slides/HPE/08_debugging_at_scale.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/2_01_Debugging_at_Scale.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_2_01_Debugging_at_Scale/#qa","title":"Q&A","text":" -
Which tool should I use /study to get an output of specific parameters or a N-dimensional field for further debugging?
Answer [Alfio] gdb4hpc is your friend. You can print values.
"},{"location":"4day-20230530/extra_2_02_Exercises_4/","title":"Exercise session 4","text":" -
Files for the exercises are in /project/project_465000524/exercises/HPE/day2/debugging for the lifetime of the project and only for project members.
There are Readme.md files in every directory.
-
There are also more information in /project/project_465000524/slides/HPE/Exercises.pdf.
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_2_02_Exercises_4/#qa","title":"Q&A","text":" -
I am looking at the ATP exercise. The tool looks interesting, but even for the trivial program of the exercise, I get a stack trace with > 30 levels containing calls I can't make sense of (crayTrInitBytesOn, do_lookup_x, __GI__IO_file_doallocate). Is there a way to suppress calls to some specific libraries? Do you just ignore that output? Or do they start making sense as you get more experience with stack traces?
Answer Asked the Cray people and there is really no way. You should just train your brain to neglect anything below MPI. It is not the most popular tool.
-
How can i fix this error?
/training/day2/debugging/ATP> stat-view atpMergedBT.dot\nTraceback (most recent call last):\n File \"/opt/cray/pe/stat/4.11.13/lib/python3.6/site-packages/STATmain.py\", line 73, in <module>\n raise import_exception\n File \"/opt/cray/pe/stat/4.11.13/lib/python3.6/site-packages/STATmain.py\", line 40, in <module>\n from STATGUI import STATGUI_main\n File \"/opt/cray/pe/stat/4.11.13/lib/python3.6/site-packages/STATGUI.py\", line 40, in <module>\n import STATview\n File \"/opt/cray/pe/stat/4.11.13/lib/python3.6/site-packages/STATview.py\", line 55, in <module>\n raise Exception('$DISPLAY is not set. Ensure that X11 forwarding is enabled.\\n')\nException: $DISPLAY is not set. Ensure that X11 forwarding is enabled.\n
Answer It's an X11 program so either you need an X11 server on your local PC or whatever you are using and then connect with ssh -X, but that only works well on a fast enough connection (low latency). Or you use the VNC server pRovided by the lumi-vnc module. Run
module spider lumi-vnc\nmodule spider lumi-vnc/20230110\n
for more information.
"},{"location":"4day-20230530/extra_2_03_Advanced_Application_Placement/","title":"Advanced Placement","text":"Presenter: Jean Pourroy (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-2_03_Advanced_Application_Placement.pdf/project/project_465000524/slides/HPE/07_Advanced_Placement.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/2_03_Advanced_Application_Placement.mp4
These materials can only be distributed to actual users of LUMI (active user account).
Remark
The lumi-CPEtools module (in the LUMI software stacks, see this afternoon) contains an alternative for xthi but not yet for the hello_jobstep tool.
"},{"location":"4day-20230530/extra_2_03_Advanced_Application_Placement/#qa","title":"Q&A","text":" -
Why is it not possible to hardcode binding on system level? Are there usecases where no binding or non-standard bindings are preffered?
Answer We want to give the freedom to users as there are non-standard use cases. Sometimes it is better to have all threads in the same NUMA domain, sometimes you want to spread that.
And for the GPU mapping: you'd need to ask the Slurm developers... Even getting good defaults in Slurm is hard. We'd really have to be able to always allocate in multiples of chiplets each with the matching GPU.
"},{"location":"4day-20230530/extra_2_04_Exercises_5/","title":"Exercise session 5","text":" -
Files for the exercises are in /project/project_465000524/exercises/HPE/day2/Binding and /project/project_465000524/exercises/HPE/day2/gpu_perf_binding
There are Readme.md files or PDF files with more information in the directories..
-
There are also more information in /project/project_465000524/slides/HPE/Exercises.pdf.
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_2_04_Exercises_5/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_2_05_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Archive on LUMI:
The information in this talk is also covered by the following talks from the 1-day courses:
- Modules on LUMI
- LUMI Software Stacks
"},{"location":"4day-20230530/extra_2_05_LUMI_Software_Stacks/#qa","title":"Q&A","text":" -
How to install a specific version of Python, e.g., 3.10, in the userspace? Is there a shortcut allowing to use EasyBuild or other wrapper?
- Kurt will talk about this later in this talk
- I see a ticket were such install has been requested. Are you the user who requested it? Not on LUMI
- OK, so, it means we have mutliple users interested in a Python 3.10 install. Can you send a ticket? I will have a look. sure, thanks!
- Take a look at cotainr which allows you to easily create a Singularity/Apptainer container containing a Conda/pip environment. On LUMI you can
module load LUMI, module load cotainr to get access to cotainr.
-
Would it be more preferable to install with EasyBuild than Spack in LUMI? or maybe both are the same without any differences?
- (Peter) This is a bit like the Emacs vs Vim debate, it depends on what you are used to, and if the software that you want is available as a package/recipe. One important difference is that the install recipes for optimized and tested software by the LUMI support team and collaborators are for EasyBuild in the
LUMI-Easybuild-contrib repository, but on the other hand, some popular software packages like Lammps, Trilinos etc from the US exascale program (for Frontier) have good Spack packages. Generally speaking, Spack tends to be popular with people who develop their own code, whereas it is easier to \"just install\" something with Easybuild as a user, if you only want to run the software, not develop it. - Thanks!
-
Some easybuild packages may be quite heavy regarding ammount of files. i.e CDO has ~21k after building with eb. Thats nearly quarter of file quota of a user (100k) or ~1% project file quota (2M). In a home system only final binary is needed to do the job. Can the final EasyBuild/ directory be cleaned up after installation, to get only minimum ammount of files to run the aplication? Or are there any hints how to deal the file quota issue after eb installation.
- (Peter) Do you mean that the final installation 21k files? Or just that 21k files are needed during the build? The build files (in
/tmp) are automatically cleaned by EasyBuild. In general, many files is problem with the parallel file systems. In some cases, you may have to use containers to work around this. We can, in some cases, increase the quotas, but there needs to be good reasons. I do not think that there is some automatic way to \"strip out\" files in EasyBuild, you would probably have to do it by hand. Also, when I check the Spack package for CDO, it seems to install only the binary files, so it might be possible to modify the EB install script for CDO. - EasyBuild creates 20k new files, which are counted. If clean up is automatically done, then, yes, they are there.
- It's not CDO itself, but ecCodes that is included as a dependency. (and other 2-3 aditional softs)
- spacks seems to be the proper solution for it if it stores only few binaries after install.
- (Peter) the CDO module is already installed on the system, but you have to load the
spack module to see it. If that is the only thing you need, it might be enough. - (Kurt) If EasyBuild installs that many file than it is usually because the default
make install does so, so it is also a problem with the installation procedure of that software.
-
What way should I go, if I want to use PyOpenCL and mpi4py? Is there a way to install it threough EasyBuild?
- (Peter) We do not have much experience with OpenCL+MPI through Python. Generally speaking, OpenCL is not well-supported on LUMI, it sort-of works, but is not so popular. My spontaneous thought is that this is something that I would try to install by hand, at first. The
cray-mpich module on the system has a nice MPI4Py, it is probably a good start. Then I would try to build PyOpenCL myself using the OpenCL runtime and headers in /opt/rocm. - (Kurt) mpi4py was discussed yesterday as a component that is included in the cray-python modules because it needs to be compiled specifically for cray-mpich. We had the OpenCL discussion yesterday also: Support is unclear and it is basically a deprecated technology...
-
Could the documentation on https://docs.lumi-supercomputer.eu/development/compiling/prgenv/ please be clarified? It's not exactly straightforward which combos of modules one should use. It would prevent a lot of lost effort due to trying to get unsupported combinations to work...
- (Peter) It is difficult for us, and not so meaningful, to try to reproduce or recreate the full documentation for the Cray Programming Environment.
- (Alfio) Cray PE documentation is available at https://cpe.ext.hpe.com/docs/
- The comment about \"every user wants software configured the way they want\" also applies to documentation. Users wish the documentation is written is such a way it describes exactly what they need. Unfortunately, it is impossible for us to describe every use cases. As a consequence, we can only provide an overview of the available PrgEnv and target modules. However, if you have any suggestion regarding the documentation please create an issue.
"},{"location":"4day-20230530/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/","title":"Introduction to HIP Programming","text":"Presenter: Samuel Ant\u00e3o (AMD)
Note
ROCm 5.5 for the brave:
module purge\nmodule load CrayEnv\nmodule load PrgEnv-cray/8.3.3\nmodule load craype-accel-amd-gfx90a\nmodule load gcc/11.2.0 \n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load suse-repo-deps\nmodule load rocm/5.5.0.lua\n
(Not provided by LUST and as it says, for the brave, problems can be expected...)
"},{"location":"4day-20230530/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/#qa","title":"Q&A","text":" -
Are CUDA applications using tensor cores (through cuBLAS or similar libraries) expected to translate well to HIP/ROCm code using matrix cores (AMD\u2019s equivalent to NVIDIA tensor cores)? What is the current status regarding support for matrix cores on HIP/ROCm libraries?
- Yes, the libraries support matrix cores, for example hipBLAS will use cuBLAS if you run on NVIDIA and rocBLAS if you run on AMD GPUS. Matrix cores are supported through the libraries.
- (Peter) I know that at least rocBLAS and rocWMMA have matrix core support.
-
What are the expected numbers for hip-stream? For instance for the Copy I get 1280GiB/s, while peak memory bandwidth is advertised to be above 3000GiB/s (https://www.amd.com/en/products/server-accelerators/instinct-mi250x)?
- This number sounds good, peak memory is theoretical 1.6 TB/s but achievable 1.3 TB/s per GCD, if you use both GCDs, then you get double close to 2.6 TB/s. This hip-stream works for one GCD only. It is improtant to know when we compare data to be familiar with the GCDs, if you use 1 GCD, you use actually half the GPU. See this: https://www.servethehome.com/wp-content/uploads/2022/08/AMD-MI250X-MVM-at-HC34-Floorplan.jpg in the middle there is the connection between the GCDs.
"},{"location":"4day-20230530/extra_2_07_Exercises_6/","title":"Exercise session 6","text":" -
On-line exercise notes.
PDF backup
-
Exercises can be copied from /project/project_465000524/exercises/AMD/HPCTrainingExamples during the lifetime of the project, only by members of the project.
-
Exercises are archived as compressed and uncompressed tar files:
"},{"location":"4day-20230530/extra_2_07_Exercises_6/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_01_Introduction_to_Perftools/","title":"Introduction to Perftools","text":"Presenter: Alfio Lazzaro (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-3_01_Introduction_to_Perftools.pdf/project/project_465000524/slides/HPE/09_introduction_to_perftools.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/3_01_Introduction_to_Perftools.mp4
These materials can only be distributed to actual users of LUMI (active user account).
Info
You can find the downloads of Apprentice2 and Reveal on LUMI in $CRAYPAT_ROOT/share/desktop_installers/. This only works when the perftools-base module is loaded, but this is the case at login.
"},{"location":"4day-20230530/extra_3_01_Introduction_to_Perftools/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_02_Exercises_7/","title":"Exercise session 7","text":" -
See /project/project_465000524/slides/HPE/Exercises.pdf for the exercises.
-
Files are in /project/project_465000524/exercises/HPE/day3
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_3_02_Exercises_7/#qa","title":"Q&A","text":" -
I tried perfools-lite on another example and got the following message from pat-report:
Observation: MPI Grid Detection\n\n There appears to be point-to-point MPI communication in a 4 X 128\n grid pattern. The 24.6% of the total execution time spent in MPI\n functions might be reduced with a rank order that maximizes\n communication between ranks on the same node. The effect of several\n rank orders is estimated below.\n\n No custom rank order was found that is better than the RoundRobin\n order.\n\n Rank Order On-Node On-Node MPICH_RANK_REORDER_METHOD\n Bytes/PE Bytes/PE%\n of Total\n Bytes/PE\n\n RoundRobin 1.517e+11 100.00% 0\n Fold 1.517e+11 100.00% 2\n SMP 0.000e+00 0.00% 1\n
Normally for this code, SMP rank ordering should make sure that collective communication is all intra-node and inter-node communication is limited to point-to-point MPI calls. So I don't really get why the recommendation is to switch to RoundRobin (if I understand this remark correctly)? Is this recommendation only based on analysing point-to-point communication?
Answer: Yes, you understood the remark correctly. This warning means that Cray PAT detected a suboptimal communication topology and according to the tool estimate, a round-robin rank ordering should maximize intra-node communications. There is a session about that at the beginning of the afternoon.
Reply: I would be very surprised if round-robin rank ordering would be beneficial in this case. I tried to run a job with it, but this failed with:
srun: error: task 256 launch failed: Error configuring interconnect\n
and similar lines for each task. The job script looks as follows: module load LUMI/22.12 partition/C\nmodule load cpeCray/22.12\nmodule load cray-hdf5-parallel/1.12.2.1\nmodule load cray-fftw/3.3.10.3\n\nexport MPICH_RANK_REORDER_METHOD=0\nsrun ${executable}\n
"},{"location":"4day-20230530/extra_3_03_Advanced_Performance_Analysis/","title":"Advanced Performance Analysis","text":"Presenter: Thierry Braconnier (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-3_03_Advanced_Performace_analysis.pdf/project/project_465000524/slides/HPE/10_advanced_performance_analysis_merged.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/3_03_Advanced_Performance_Analysis.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_3_03_Advanced_Performance_Analysis/#qa","title":"Q&A","text":" -
Do I get it right that perftool can actually point/suggest me the code which will improve /benefit from GPUs?
Answer: Not quite. Performance analysis is a pre-requisite for any optimization work. If the code spends a lot of time in MPI or I/O then concentrate on that. If you can identify areas of the code where computation is significant then think about taking those to the GPU.
"},{"location":"4day-20230530/extra_3_04_Exercises_8/","title":"Exercise session 8","text":" -
See /project/project_465000524/slides/HPE/Exercises.pdf for the exercises.
-
Files are in /project/project_465000524/exercises/HPE/day3
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_3_04_Exercises_8/#qa","title":"Q&A","text":" -
Do I get it right that perftool can actually point/suggest me the code which will improve /benefit from GPUs?
- Not quite. Performance analysis is a pre-requisite for any optimization work. If the code spends a lot of time in MPI or I/O then concentrate on that. If you can identify areas of the code where computation is significant then think about taking those to the GPU. /thansk, got the discussion/
-
MPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked while running the python example (perftools-python)
- Are you compiling without the compiler wrappers, there is an extra library that needs to be linked otherwise.
- No compilation is involved as I run a Python script. It is odd that there is something \"compiler\"-related jumps out.
- Are you using mpi4py from cray-python?
time srun -n 4 pat_run `which python` heat-p2p.py, ah, yes, in the imports. from mpi4py import MPI- Are you online (remote) or in the room? online
- For GPU applications built without the wrappers you need libraries from here ${PE_MPICH_GTL_DIR_amd_gfx90a} ${PE_MPICH_GTL_LIBS_amd_gfx90a} I need to get that gtl library, I need to get Alfio to look. (Alfio is looking but has network issue at the moment)
- (Alfio) By any chance, do you have the MPICH_GPU_SUPPORT_ENABLED set? no idea, will check ... yes. Should I unset it? yes, this is for G2G MPI. There is a way to preload the library in python, if needed.
- Works, thanks!
- The issue here is that this envar tells the MPI you want to do GPU to GPU communication avoiding the cpu and to do that it needs this extra library. As Alfo notes this needs special setup in python to get this library. Glad this fixed it. We will talk a little
- more about python in a later session.
Comment: Hei! I would like to emphasize that Python is a rapidly developing language, which warrants fast version changes. As the language evolves, it introduces new features that users may want to use for their benefit. It also introduces backward incompatibility, as always. I see it as important that users have a choice of versions already as modules (userspace Python is a possibility, but a rather ugly one). The idea applies not only to the training but to LUMI in general.
Answer to the comment: As long as Python does not have decent version management and decent package management what you ask is simply impossible. The Python community turned Python into a complete mess. Breaking compatibility with older code every 18 months is just a crazy idea. It turns Python in an unstable platform. So users using it should be prepared to deal with an unstable platform that cannot be properly supported. Or just look at the extremely poor code management in crucial projects such as NumPy. If you're looking for an example for a computer science course about how to make something that is unsupportable, NumPy is your perfect example. You don't realise how much time people who work on software installation tools lose with each version trying to get that package to work properly on new platforms. In that light it is not surprising the the version that HPE Cray can provide to us is a bit behind the leading edge. Maybe the Python community should learn how to manage a project in an enterprise quality way if they want enterprise quality support for their tools.
By the way, I don't know if we mean the same thing with \"user space software installation\", but as on an HPC cluster the amount of software that can be installed in the system image is very limited almost all software is installed in \"user space\", so an application that cannot be properly installed in \"user space\" is not suited for an HPC cluster. E.g., potential compatibility problems with new system software is not the only reason why we don't keep old versions of the PE on the system.
Pure Python is also extremely inefficient and all efforts to make a proper JIT platform for Python so far have failed. All work only in a few cases. Now that we are in a era where transistors don't become cheaper anymore so it is no longer possible to get more performance in the next machine by using more transistors without raising budgets considerably, it is actually becoming important to look at better languages that can actually run efficiently.
(Harvey) I think is is more a discussion for the pub
(Philipp) I agree. I am old enough to witness 2.95 to 3.x transition in GCC, which makes me softer in these matters. Nevertheless, there is no right answer, indeed.
"},{"location":"4day-20230530/extra_3_05_Cray_MPI_on_Slingshot/","title":"MPI Topics on the HPE Cray EX Supercomputer","text":"Presenter: Harvey Richardson (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-3_05_Cray_MPI_on_Slingshot.pdf/project/project_465000524/slides/HPE/11_cray_mpi_MPMD_medium.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/3_05_Cray_MPI_on_Slingshot.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_3_05_Cray_MPI_on_Slingshot/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_06_Exercises_9/","title":"Exercise session 9","text":" -
Continue with the previous exercises or go back to any of the former examples (e.g., the ProgrammingModels one) and try out the material of the talk.
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_3_06_Exercises_9/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_07_AMD_ROCgdb_Debugger/","title":"AMD ROCgdb debugger","text":"Presenter: Samuel Ant\u00e3o (AMD)
"},{"location":"4day-20230530/extra_3_07_AMD_ROCgdb_Debugger/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_08_Exercises_10/","title":"Exercise session 10","text":""},{"location":"4day-20230530/extra_3_08_Exercises_10/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/","title":"Introduction to ROC-Profiler (rocprof)","text":"Presenter: Samuel Ant\u00e3o (AMD)
Note
Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"4day-20230530/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/#qa","title":"Q&A","text":""},{"location":"4day-20230530/extra_3_10_Exercises_11/","title":"Exercise session 11","text":""},{"location":"4day-20230530/extra_3_10_Exercises_11/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_01_Performance_Optimization_Improving_Single_Core/","title":"Performance Optimization: Improving Single-core Efficiency","text":"Presenter: Jean Pourroy (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_01_Performance_Optimization_Improving_Single_Core.pdf/project/project_465000524/slides/HPE/12_cpu_performance_optimization.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/4_01_Performance_Optimization_Improving_Single_Core.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_4_01_Performance_Optimization_Improving_Single_Core/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_02_Introduction_to_Python_on_Cray_EX/","title":"Introduction to Python on Cray EX","text":"Presenter: Alfio Lazzaro (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_02_Introduction_to_Python_on_Cray_EX.pdf/project/project_465000524/slides/HPE/13_Python_Frameworks.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/4_02_Introduction_to_Python_on_Cray_EX.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_4_02_Introduction_to_Python_on_Cray_EX/#qa","title":"Q&A","text":" -
Are Pytorch and Tensorflow installed on LUMI, or users shall install those themselves? I couldn't find any related modules with \"module spider pytorch\" or \"module keyword pytorch\".
- https://docs.lumi-supercomputer.eu/software/packages/pytorch/
- Most users want PyTorch with additional packages anyway so need a customised installation.
- (Christian) I would highly recommend to use a Singularity/Apptainer container. Take a look at the ROCm dockerhub containers to see if they fit your needs. If you need a more customized container and are used to conda/pip environments, have a look at cotainr which makes it very easy to build a container based on your conda/pip environment (just remember that you have make your conda/pip environment compatible with LUMI, e.g. installing a ROCm-enabled PyTorch wheel). On LUMI cotainr is available via
module load LUMI, module load cotainr. - (Christian) You may also use the container based modules from the local CSC software stack. Just be aware that these are primarily intended for the CSC users. Support for this local software stack is provided by CSC - the LUMI User Support Team can only provide very limited support.
"},{"location":"4day-20230530/extra_4_03_Exercises_12/","title":"Exercise session 12","text":" -
See /project/project_465000524/slides/HPE/Exercises.pdf for the exercises.
-
Files are in /project/project_465000524/exercises/HPE/day3
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_4_03_Exercises_12/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_04_IO_Optimization_Parallel_IO/","title":"I/O Optimization - Parallel I/O","text":"Presenter: Harvey Richardson (HPE)
- Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_04_IO_Optimization_Parallel_IO.pdf/project/project_465000524/slides/HPE/14_IO_medium_LUMI.pdf (temporary, for the lifetime of the project)
- Recording available on LUMI as:
/appl/local/training/4day-20230530/recordings/4_04_IO_Optimization_Parallel_IO.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20230530/extra_4_04_IO_Optimization_Parallel_IO/#links","title":"Links","text":" - The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20230530/extra_4_04_IO_Optimization_Parallel_IO/#qa","title":"Q&A","text":" -
Could you please elaborate on using HDF5. What are pros and cons compared to using raw FS? Can it improve performance on LUMI?
- Passed to the speaker in the talk, will be in the recording.
-
I have a dataset of 5 million files ranging from several KB to tens of GB, 50 TB in total. I am looking into optimilly merging files. What is a reasonable number of files and reasonable file sizes to aim at? Would it be ok if those files will range from several KB to several TB, or shall I try to balance them by size?
- Passed to the speaker in the talk, will be in the recording.
-
I see that my previous question was too specific. But could you please give some general advice what is a reasonable range of file sizes on LUSTRE? And may it cause problems to work with files of several TB and of several KB at the same time in parallel (and independent) processes?
Answer: The previous question was not too specific but not specific enough as the right answer depends on a lot of factors. Whether working with files of multiple TBs and files of multiple Kb's simultaneously is problematic or not also depends on how you use them and how many small files there are. I'd say that in general it may be better to organise them in a directory structure where small and big files are in different directories so that you can set optimal striping parameters for both. But then again this matters less if you use the Lustre API or the MPI I/O hints discussed in the talk when creating the large files. Then you could set the directory striping parameters to something that corresponds with the small files (there was a slide giving some hints depending on the number of files) and use the API to set a proper striping for the large files. Getting good performance from large files requires a different way of working with the files then getting good performance from small files. E.g., when I read sub-megabyte files I read them in a single operation (which may not be that important anymore with better buffering in the OS) and then process the files in-memory (for text files in C this would mean using sscanf instead of fscanf, etc.)
The correct answer really depends on more details.
-
There are modules called cray-hdf5-parallel on LUMI. Does that imply the cray-hdf5 modules do not support parallel I/O?
- for HPD5 to get the parallel support you need the parallel version
"},{"location":"4day-20230530/extra_4_05_Exercises_13/","title":"Exercise session 13","text":" -
See /project/project_465000524/slides/HPE/Exercises.pdf for the exercises.
-
Material for the IO exercises is in /project/project_465000524/exercises/HPE/day4/VH1-io.
And of course you can continue on previous exercises.
-
Permanent archive on LUMI:
-
Exercise notes in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Exercises_HPE.tar
"},{"location":"4day-20230530/extra_4_05_Exercises_13/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_06_AMD_Ominitrace/","title":"Introduction to OmniTrace","text":"Presenter: Samuel Ant\u00e3o (AMD)
-
Slides on the web (up to slide 61)
-
Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_06_AMD_Omnitrace.pdf/project/project_465000524/slides/AMD/session-3-tutorial_omnitools.pdf (temporary, for the lifetime of the project)
-
Video also available on LUMI as /appl/local/training/4day-20230530/recordings/4_06_AMD_Ominitrace.mp4
"},{"location":"4day-20230530/extra_4_06_AMD_Ominitrace/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_07_Exercises_14/","title":"Exercise session 14","text":" -
On-line exercise notes.
PDF backup
-
Exercises can be copied from /project/project_465000524/exercises/AMD/HPCTrainingExamples
-
Exercises are archived as compressed and uncompressed tar files:
-
The necessary version of OmniTrace is installed in the software installation in /project/project_465000524/software.
The installation can be recovered from the archive (bzip2-compressed tar file) on LUMI: /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Software_AMD.tar.bz2
This installation was tested for the course but will fail at some point due to changes to the system.
"},{"location":"4day-20230530/extra_4_07_Exercises_14/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_08_AMD_Ominiperf/","title":"AMD Omniperf","text":"Presenter: Samuel Ant\u00e3o (AMD)
Slides in the same stack as the OmniTrace ones, starting from slide 62:
"},{"location":"4day-20230530/extra_4_08_AMD_Ominiperf/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_09_Exercises_15/","title":"Exercise session 15","text":" -
On-line exercise notes.
PDF backup
-
Exercises can be copied from /project/project_465000524/exercises/AMD/HPCTrainingExamples
-
Exercises are archived as compressed and uncompressed tar files:
-
The necessary version of Omniperf is installed in the software installation in /project/project_465000524/software.
The installation can be recovered from the archive (bzip2-compressed tar file) on LUMI: /appl/local/training/4day-20230530/files/LUMI-4day-20230530-Software_AMD.tar.bz2
This installation was tested for the course but will fail at some point due to changes to the system.
Note that Omniperf poses security risks as it is based on an unprotected web server running on a predicable port number.
"},{"location":"4day-20230530/extra_4_09_Exercises_15/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_10_Best_Practices_GPU_Optimization/","title":"Tools in Action - An Example with Pytorch","text":"Presenter: Samuel Ant\u00e3o (AMD)
-
Slides on the web
-
Downloadable scripts as bzip2-compressed tar archive and uncompressed tar archive
-
Slides available on LUMI as:
/appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_10_Best_Practices_GPU_Optimization.pdf/project/project_465000524/slides/AMD/session-4-ToolsInActionPytorchExample-LUMI.pdf (temporary, for the lifetime of the project)
-
Scripts archived on lumi as bzip2-compressed tar archive in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_10_scripts.tar.bz2 and uncompressed tar archive in /appl/local/training/4day-20230530/files/LUMI-4day-20230530-4_10_scripts.tar.
-
Video also available on LUMI as /appl/local/training/4day-20230530/recordings/4_10_Best_Practices_GPU_Optimization.mp4
"},{"location":"4day-20230530/extra_4_10_Best_Practices_GPU_Optimization/#qa","title":"Q&A","text":"/
"},{"location":"4day-20230530/extra_4_11_LUMI_Support_and_Documentation/","title":"LUMI User Support","text":"Presenter: Anne Vomm
The information in this talk is also covered by the following talk from the 1-day courses:
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
- Some remarks about using containers on LUMI.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a coherent unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users, but one that is followed by more and more big centres.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. This did turn out to be a good decision after the system update of March 2023 as some packages were incapable of picking up new libraries. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place. We do offer some help so set up Spack also but it is mostly offered \"as is\" an we will not do bug-fixing or development in Spack package files.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire send out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model build on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It ia also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12 and LUMI/23.03 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. We may have a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which we install software that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1 (when infrastructure for a demo is available)
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 17 versions of GNUplot. There are 12 installations of GNUplot 5.4.3 (of which 3 with Spack, their name has a different structure) and five of 5.4.6. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there are four versions,3.22.2, 3.23.2, 3.24.0 and 3.25.2, that are shown in blue with an \"E\" behind the name. That is because these are not provided by a module called CMake on LUMI, but by another module that in this case contains a collection of popular build tools and that we will discover shortly.
There are also a couple of regular modules called cmake that come from software installed differently.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.6-cpeGNU-22.12. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are three ways to load the module: By loading LUMI/22.12 combined with partition/C, by loading LUMI/22.12 combined with partition/G or by loading LUMI/22.12 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/22.12 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.25.2. This will now show us that this tool is in the buildtools/22.12 module (among others) and give us 4 different options to load that module as it is provided in the CrayEnv and the LUMI/22.12 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider cmake\nmodule spider gnuplot/5.4.6-cpeGNU-22.12\nmodule spider CMake/3.25.2\n
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#module-keyword-command","title":"Module keyword command","text":"Lmod has a second way of searching for modules: module keyword, but unfortunately it does not yet work very well on LUMI as the version of Lmod is rather old and still has some bugs in the processing of the command.
The module keyword command searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Demo module keyword Try the following command:
module keyword https\n
The bug in the Lmod 8.3 version on LUMI is that all extensions are shown in the output while they are irrelevant.
On the second screen though we see cURL which is a tool to download files over, among others, https.
And the fourth screen wget which is also a tool to download files from the internet over an https connection.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that help to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Demo Try the following command:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded, but we'll come back to that later also.
Note the two categories for the PE modules. The target modules get their own block. The screen below also shows (D:5.0.2:5.2.0) next to the rocm module. The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
In the next screen we see the modules for the software stack that we have just discussed.
And the screen below shows the extensions of modules (like the CMake tool we've tried to locate before)
At the end of the output we also get some information about the meaning of the letters used in the display.
Try the following commands and carefully observe the output:
module load LUMI/22.08 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similarly in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/22.12 stack we prefer that users use the Cray programming environment modules that come with release 22.12 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Demo Try the following commands:
module load LUMI/22.12\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. We expect this to happen especially with packages that require specific MPI versions. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And we need a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is our primary software installation tool. We selected this as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the build-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain we would have problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the Intel compiler will simply optimize for a two decades old CPU.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with teh system toolchain, but we do avoid mixing those when linking as that may cause problems. The reason is that we try to use as much as possible static linking in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2021.4, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeCray-22.08 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/22.08.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.8.0-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2021.4-cpeCray-22.08-PLUMED-2.8.0-CPE.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#installing-software","title":"Installing software","text":""},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Demo moment 2
Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS we already have support. At the moment we have to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
We now also have the LUMI Software Library which lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
Demo of the EasyBuild installation of GROMACS
End of demo moment 2
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"There is a little problem though that you may run into. Sometimes the module does not show up immediately. This is because Lmod keeps a cache when it feels that Lmod searches become too slow and often fails to detect that the cache is outdated. The easy solution is then to simply remove the cache which is in $HOME/.lmod.d/.cache, which you can do with
rm -rf $HOME/.lmod.d/.cache\n
And we have seen some very rare cases where even that did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment. Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.0-cpeGNU-22.08.eb \u2013r . \n
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/easybuild/easyconfigs.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory, and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#easybuild-tips-tricks","title":"EasyBuild tips & tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"I also want to give some pointers to more information in case you want to learn a lot more about, e.g., developing support for your code in EasyBuild, or for support people who want to adapt our EasyConfigs for users requesting a specific configuration of a package.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software.
But full portability is a much greater myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the SlingShot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
Even if a container is portable to LUMI, it may not yet be performance portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
When setting up very large software environments, e.g., some Python and R environments, they can still be very helpful, even if you may have to change some elements in your build recipes from your regular cluster or workstation. Some software may also be simply too hard to install from sources in the typical HPC way of working.
-
And related to the previous point is also that some software may not even be suited for installation in a multi-user HPC system. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory or in $XDG_RUNTIME_DIR (works only on the login nodes). The former can lead to exhaustion of your storage quota, so check and clean up from time to time. You may also want to clean up $XDG_RUNTIME_DIR, but this directory is also automatically cleaned when you log out from your last running session on that (login) node.
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require fakeroot, cannot be supported for security reasons. Enabling features that are known to have had several serious security vulnerabilities in the recent past, ot that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container. We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI SlingShot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and currently full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the SlingShot 11 interconnect so work is going on for better support for OFI and for full GPU support on systems that rely on OFI and do not support UCX.
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY__PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the module in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
The final tool is a container wrapper tool that users from Finland may also know as Tykky. It is a tool to wrap Python and conda installations in a limited number of files in a transparent way. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run a tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation.
We do strongly recommend to use the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
|Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a temprorary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"4day-20230530/notes_2_05_LUMI_Software_Stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
-
Building containers is currently not supported on LUMI due to security concerns.
"},{"location":"4day-20230530/schedule/","title":"Course schedule","text":" - Day 1
- Day 2
- Day 3
- Day 4 DAY 1 - Tuesday 30/05 09:00 EEST 08:00 CEST Welcome and introduction Presenters: Emmanuel Ory (LUST), Harvey Richardson (HPE)( 09:15 EEST 08:15 CEST HPE Cray EX architecture Presenter: Harvey Richardson (HPE) 10:00 EEST 09:00 CEST Programming Environment and Modules Presenter: Harvey Richardson (HPE) 10:30 EEST 09:30 CEST Break (20 minutes) 10:50 EEST 09:40 CEST Running Applications
- Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
Presenter: Harvey Richardson (HPE) 11:15 EEST 10:15 CEST Exercises (session #1) 12:00 EEST 11:00 CEST Lunch break (90 minutes) 13:30 EEST 12:30 CEST Compilers and Parallel Programming Models - An introduction to the compiler suites available, including examples of how to get additional information about the compilation process.
- Cray Compilation Environment (CCE) and options relevant to porting and performance. CCE classic to Clang transition.
- Description of the Parallel Programming models.
Presenter: Alfio Lazzaro (HPE) 14:40 EEST 13:40 CEST Exercises (session #2) 15:00 EEST 14:00 CEST Break (15 minutes) 15:15 EEST 14:15 CEST Cray Scientific Libraries - The Cray Scientific Libraries for CPU and GPU execution.
Presenter: Alfio Lazzaro (HPE) 15:45 EEST 14:45 CEST Exercises (session #3) 16:10 EEST 15:10 CEST CCE Offloading Models - Directive-based approach for GPU offloading execution with the Cray Compilation Environment. Presenter: Alfio Lazzaro (HPE) 16:45 EEST 15:45 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 2 - Wednesday 31/05 09:00 EEST 08:00 CEST Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat Presenter: Thierry Braconnier (HPE) 09:45 EEST 08:45 CEST Exercises (session #4) 10:15 EEST 09:15 CEST Break (15 minutes) 10:30 EEST 09:30 CEST Advanced Placement
- More detailed treatment of Slurm binding technology and OpenMP controls.
Presenter: Jean Pourroy (HPE) 11:30 EEST 10:30 CEST Exercises (session #5) 12:00 EEST 11:00 CEST Lunch break (90 minutes) 13:30 EEST 12:30 CEST LUMI Software Stacks - Software policy.
- Software environment on LUMI.
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LUST) 15:00 EEST 14:00 CEST Break (30 minutes) 15:30 EEST 14:30 CEST Introduction to HIP Programming The AMD ROCmTM ecosystem HIP programming
Presenter: Samuel Ant\u00e3o (AMD) 16:30 EEST 15:30 CEST Exercises (session #6) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 3 - Thursday 01/06 09:00 EEST 08:00 CEST Introduction to Perftools - Overview of the Cray Performance and Analysis toolkit for profiling applications.
- Demo: Visualization of performance data with Apprentice2 Presenter: Alfio Lazzaro (HPE) 09:40 EEST 08:40 CEST Exercises (session #7) 10:10 EEST 09:10 CEST Break 10:30 EEST 09:30 CEST Advanced Performance Analysis
- Automatic performance analysis and loop work estimated with perftools
- Communication Imbalance, Hardware Counters, Perftools API, OpenMP
- Compiler feedback and variable scoping with Reveal
Presenter: Thierry Braconnier (HPE) 11:30 EEST 10:30 CEST Exercises (session #8) 12:00 EEST 11:00 CEST Lunch break 13:15 EEST 12:15 CEST MPI Topics on the HPE Cray EX Supercomputer - High level overview of Cray MPI on Slingshot
- Useful environment variable controls
- Rank reordering and MPMD application launch
Presenter: Harvey Richardson (HPE) 14:15 EEST 13:15 CEST Exercises (session #9) 14:45 EEST 13:45 CEST Break 15:00 EEST 14:00 CEST AMD Debugger: ROCgdb Presenter: Samuel Ant\u00e3o (AMD) 15:30 EEST 14:30 CEST Exercises (session #10) 15:45 EEST 14:45 CEST Introduction to ROC-Profiler (rocprof) Presenter: Samuel Ant\u00e3o (AMD) 16:25 EEST 15:25 CEST Exercises (session #11) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 4 - Friday June 2 09:00 EEST 08:00 CEST Performance Optimization: Improving Single-core Efficiency Presenter: Jean Pourroy (HPE) 09:50 EEST 08:50 CEST Python and Frameworks Cray Python for the Cray EX
Presenter: Alfio Lazzaro (HPE) 10:00 EEST 09:00 CEST Exercises (session #12) 10:15 EEST 09:15 CEST Break 10:30 EEST 09:30 CEST Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system.
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes.
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations
- Further considerations of parallel I/O and other APIs.
- Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson (HPE) 11:20 EEST 10:20 CEST Exercises (session #13) 12:00 EEST 11:00 CEST Lunch break (75 minutes) 13:15 EEST 12:15 CEST Introduction to OmniTrace Presenter: Samuel Ant\u00e3o (AMD) 13:45 EEST 12:45 CEST Exercises (session #14) 14:00 EEST 13:00 CEST Introduction to Omniperf Presenter: Samuel Ant\u00e3o (AMD) 14:30 EEST 13:30 CEST Exercises (session #15) 14:45 EEST 13:45 CEST Break 15:00 EEST 14:00 CEST Tools in Action - An Example with Pytorch Presenter: Samuel Ant\u00e3o (AMD) 16:30 EEST 15:30 CEST LUMI User Support - What can we help you with and what not? How to get help, how to write good support requests.
- Some typical/frequent support questions of users on LUMI?
Presenter: Anne Vomm (LUST) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course"},{"location":"4day-20231003/","title":"Comprehensive General LUMI Training, October 3-6, 2023","text":""},{"location":"4day-20231003/#course-organisation","title":"Course organisation","text":" -
Location: Centrum Konferencyjne IBIB PAN, Ks. Trojdena 4, 02-109 Warsaw, Poland (Institute of Biocybernetics and Biomedical Engineering Polish Academy of Sciences).
Public transportation in Warsaw
-
Original schedule (PDF)
Dynamic schedule (adapted as the course progresses)
The dynamic schedule also contains links to pages with information about the course materials, but those links are also available below on this page.
"},{"location":"4day-20231003/#course-materials","title":"Course materials","text":"Course materials include the Q&A of each session, slides when available and notes when available.
Due to copyright issues some of the materials are only available to current LUMI users and have to be downloaded from LUMI.
Note: Some links in the table below are dead and will remain so until after the end of the course.
Presentation slides notes recording Introduction / / web HPE Cray EX Architecture lumi / lumi Programming Environment and Modules lumi / lumi Exercises #1a / / / Running Applications lumi / lumi Exercises #1b / / / Compilers and Parallel Programming Models lumi / lumi Exercises #2 / / / Cray Scientific Libraries lumi / lumi CCE Offloading Models lumi / lumi Exercises #3 / / / Advanced Placement lumi / lumi Exercises #4 / / / Debugging at Scale lumi / lumi Exercises #5 / / / LUMI Software Stacks web web web Introduction to the AMD ROCm Ecosystem web / web Exercises #6 / / / Introduction to Perftools lumi / lumi Exercises #7 / / / Advanced Performance Analysis lumi / lumi Exercises #8 / / / MPI Topics on the HPE Cray EX Supercomputer lumi / lumi Exercises #9 / / / AMD Debugger: ROCgdb web / web Exercises #10 / / / Introduction to ROC-Profiler (rocprof) web / web Exercises #11 / / / Python and Frameworks lumi / lumi Performance Optimization: Improving single-core Efficiency lumi / lumi Exercises #12 / / / Optimizing Large Scale I/O lumi / lumi Exercises #13 / / / Introduction to OmniTrace web / web Introduction to Omniperf web / web Exercises #14 / / / Exercises #15 / / / Tools in Action - An Example with Pytorch web / web LUMI User Support web / web Appendix: Additional documentation / documentation /"},{"location":"4day-20231003/#making-the-exercises-after-the-course","title":"Making the exercises after the course","text":""},{"location":"4day-20231003/#hpe","title":"HPE","text":"The exercise material remains available in the course archive on LUMI:
-
The PDF notes in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
The other files for the exercises in either a bzip2-compressed tar file /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2\n
in the directory where you want to work on the exercises. This will create the exercises/HPE subdirectory from the training project.
However, instead of running the lumi_c.sh or lumi_g.sh scripts that only work for the course as they set the course project as the active project for Slurm and also set a reservation, use the lumi_c_after.sh and lumi_g_after.sh scripts instead, but first edit them to use one of your projects.
"},{"location":"4day-20231003/#amd","title":"AMD","text":"There are online notes about the AMD exercises. A PDF print-out with less navigation features is also available and is particularly useful should the online notes become unavailable. A web backup is also available, but corrections to the original made after the course are not included.
The other files for the exercises are available in either a bzip2-compressed tar file /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD_.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar and can also be downloaded. ( bzip2-compressed tar download or uncompressed tar download)
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2\n
in the directory where you want to work on the exercises. This will create the exercises/AMD subdirectory from the training project. You can do so in the same directory where you installed the HPE exercises.
Warning
The software and exercises were tested thoroughly at the time of the course. LUMI however is in continuous evolution and changes to the system may break exercises and software
"},{"location":"4day-20231003/#links-to-documentation","title":"Links to documentation","text":"The links to all documentation mentioned during the talks is on a separate page.
"},{"location":"4day-20231003/#external-material-for-exercises","title":"External material for exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"4day-20231003/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"4day-20231003/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.8, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
Mentioned in the Lustre presentation: The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20231003/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"4day-20231003/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"4day-20231003/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --help crayCC --help crayftn --help craycc --craype-help crayCC --craype-help crayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --help CC --help ftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"4day-20231003/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"4day-20231003/exercises_AMD_hackmd/","title":"LUMI Training Warsaw","text":""},{"location":"4day-20231003/exercises_AMD_hackmd/#login-to-lumi","title":"Login to Lumi","text":"ssh USERNAME@lumi.csc.fi\n
To simplify the login to LUMI, you can add the following to your .ssh/config file. # LUMI\nHost lumi\nUser <USERNAME>\n Hostname lumi.csc.fi\n IdentityFile <HOME_DIRECTORY>/.ssh/id_rsa \n ServerAliveInterval 600\n ServerAliveCountMax 30\n
The ServerAlive* lines in the config file may be added to avoid timeouts when idle.
Now you can shorten your login command to the following.
ssh lumi\n
If you are able to log in with the ssh command, you should be able to use the secure copy command to transfer files. For example, you can copy the presentation slides from lumi to view them.
scp lumi:/project/project_465000644/Slides/AMD/<file_name> <local_filename>\n
You can also copy all the slides with the . From your local system:
mkdir slides\nscp -r lumi:/project/project_465000644/Slides/AMD/* slides\n
If you don't have the additions to the config file, you would need a longer command:
mkdir slides\nscp -r -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465000644/slides/AMD/ slides\n
or for a single file
scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465000644/slides/AMD/<file_name> <local_filename>\n
"},{"location":"4day-20231003/exercises_AMD_hackmd/#hip-exercises","title":"HIP Exercises","text":"We assume that you have already allocated resources with salloc
cp -r /project/project_465000644/Exercises/AMD/HPCTrainingExamples/ .
salloc -N 1 -p small-g --gpus=1 -t 10:00 -A project_465000644
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\nmodule load rocm\n
The examples are also available on github: git clone https://github.com/amd/HPCTrainingExamples\n
However, we recommend using the version in /project/project_465000644/Exercises/AMD/HPCTrainingExamples as it has been tuned to the current LUMI environment."},{"location":"4day-20231003/exercises_AMD_hackmd/#basic-examples","title":"Basic examples","text":"cd HPCTrainingExamples/HIP/vectorAdd
Examine files here \u2013 README, Makefile and vectoradd_hip.cpp Notice that Makefile requires HIP_PATH to be set. Check with module show rocm or echo $HIP_PATH Also, the Makefile builds and runs the code. We\u2019ll do the steps separately. Check also the HIPFLAGS in the Makefile.
make vectoradd_hip.exe\nsrun -n 1 ./vectoradd_hip.exe\n
We can use SLURM submission script, let's call it hip_batch.sh:
#!/bin/bash\n#SBATCH -p small-g\n#SBATCH -N 1\n#SBATCH --gpus=1\n#SBATCH -t 10:00\n#SBATCH -A project_465000644\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\ncd $PWD/HPCTrainingExamples/HIP/vectorAdd \n\nexport HCC_AMDGPU_TARGET=gfx90a\nmake vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Submit the script sbatch hip_batch.sh
Check for output in slurm-<job-id>.out or error in slurm-<job-id>.err
Compile and run with Cray compiler
CC -x hip vectoradd.hip -o vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Now let\u2019s try the cuda-stream example from https://github.com/ROCm-Developer-Tools/HIP-Examples. This example is from the original McCalpin code as ported to CUDA by Nvidia. This version has been ported to use HIP. See add4 for another similar stream example.
export HCC_AMDGPU_TARGET=gfx90a\ncd HIP-Examples/cuda-stream\nmake\nsrun -n 1 ./stream\n
Note that it builds with the hipcc compiler. You should get a report of the Copy, Scale, Add, and Triad cases. The variable export HCC_AMDGPU_TARGET=gfx90a is not needed in case one sets the target GPU for MI250x as part of the compiler flags as --offload-arch=gfx90a. Now check the other examples in HPCTrainingExamples/HIP like jacobi etc.
"},{"location":"4day-20231003/exercises_AMD_hackmd/#hipify","title":"Hipify","text":"We\u2019ll use the same HPCTrainingExamples that were downloaded for the first exercise.
Get a node allocation.
salloc -N 1 --ntasks=1 --gpus=1 -p small-g -A project_465000644 \u2013-t 00:10:00`\n
A batch version of the example is also shown.
"},{"location":"4day-20231003/exercises_AMD_hackmd/#hipify-examples","title":"Hipify Examples","text":""},{"location":"4day-20231003/exercises_AMD_hackmd/#exercise-1-manual-code-conversion-from-cuda-to-hip-10-min","title":"Exercise 1: Manual code conversion from CUDA to HIP (10 min)","text":"Choose one or more of the CUDA samples in HPCTrainingExamples/HIPIFY/mini-nbody/cuda directory. Manually convert it to HIP. Tip: for example, the cudaMalloc will be called hipMalloc. Some code suggestions include nbody-block.cu, nbody-orig.cu, nbody-soa.cu
You\u2019ll want to compile on the node you\u2019ve been allocated so that hipcc will choose the correct GPU architecture.
"},{"location":"4day-20231003/exercises_AMD_hackmd/#exercise-2-code-conversion-from-cuda-to-hip-using-hipify-tools-10-min","title":"Exercise 2: Code conversion from CUDA to HIP using HIPify tools (10 min)","text":"Use the hipify-perl script to \u201chipify\u201d the CUDA samples you used to manually convert to HIP in Exercise 1. hipify-perl is in $ROCM_PATH/bin directory and should be in your path.
First test the conversion to see what will be converted
hipify-perl -no-output -print-stats nbody-orig.cu\n
You'll see the statistics of HIP APIs that will be generated.
[HIPIFY] info: file 'nbody-orig.cu' statisitics:\n CONVERTED refs count: 10\n TOTAL lines of code: 91\n WARNINGS: 0\n[HIPIFY] info: CONVERTED refs by names:\n cudaFree => hipFree: 1\n cudaMalloc => hipMalloc: 1\n cudaMemcpy => hipMemcpy: 2\n cudaMemcpyDeviceToHost => hipMemcpyDeviceToHost: 1\n cudaMemcpyHostToDevice => hipMemcpyHostToDevice: 1\n
hipify-perl is in $ROCM_PATH/bin directory and should be in your path. In some versions of ROCm, the script is called hipify-perl.
Now let's actually do the conversion.
hipify-perl nbody-orig.cu > nbody-orig.cpp\n
Compile the HIP programs.
hipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig`\n
The #define SHMOO fixes some timer printouts. Add --offload-arch=<gpu_type> if not set by the environment to specify the GPU type and avoid the autodetection issues when running on a single GPU on a node.
- Fix any compiler issues, for example, if there was something that didn\u2019t hipify correctly.
- Be on the lookout for hard-coded Nvidia specific things like warp sizes and PTX.
Run the program
srun ./nbody-orig\n
A batch version of Exercise 2 is:
#!/bin/bash\n#SBATCH -N 1\n#SBATCH --ntasks=1\n#SBATCH --gpus=1\n#SBATCH -p small-g\n#SBATCH -A project_465000644\n#SBATCH -t 00:10:00\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n\ncd HPCTrainingExamples/mini-nbody/cuda\nhipify-perl -print-stats nbody-orig.cu > nbody-orig.cpp\nhipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig\nsrun ./nbody-orig\ncd ../../..\n
Notes:
- Hipify tools do not check correctness
hipconvertinplace-perl is a convenience script that does hipify-perl -inplace -print-stats command
"},{"location":"4day-20231003/exercises_AMD_hackmd/#debugging","title":"Debugging","text":"The first exercise will be the same as the one covered in the presentation so that we can focus on the mechanics. Then there will be additional exercises to explore further or you can start debugging your own applications.
Get the exercise: git clone https://github.com/AMD/HPCTrainingExamples.git
Go to HPCTrainingExamples/HIP/saxpy
Edit the saxpy.hip file and comment out the two hipMalloc lines.
71 //hipMalloc(&d_x, size);\n72 //hipMalloc(&d_y, size);\n
Now let's try using rocgdb to find the error.
Compile the code with
hipcc --offload-arch=gfx90a -o saxpy saxpy.hip
- Allocate a compute node.
- Run the code
srun ./saxpy
Output
Memory access fault by GPU node-4 (Agent handle: 0x32f330) on address (nil). Reason: Unknown.\n
How do we find the error? Let's start up the debugger. First, we\u2019ll recompile the code to help the debugging process. We also set the number of CPU OpenMP threads to reduce the number of threads seen by the debugger. hipcc -ggdb -O0 --offload-arch=gfx90a -o saxpy saxpy.hip\nexport OMP_NUM_THREADS=1\n
We have two options for running the debugger. We can use an interactive session, or we can just simply use a regular srun command.
srun rocgdb saxpy
The interactive approach uses:
srun --interactive --pty [--jobid=<jobid>] bash \nrocgdb ./saxpy \n
We need to supply the jobid if we have more than one job so that it knows which to use. We can also choose to use one of the Text User Interfaces (TUI) or Graphics User Interfaces (GUI). We look to see what is available.
which cgdb\n -- not found\n -- run with cgdb -d rocgdb <executable>\nwhich ddd\n -- not found\n -- run with ddd --debugger rocgdb\nwhich gdbgui\n -- not found\n -- run with gdbgui --gdb-cmd /opt/rocm/bin/rocgdb\nrocgdb \u2013tui\n -- found\n
We have the TUI interface for rocgdb. We need an interactive session on the compute node to run with this interface. We do this by using the following command.
srun --interactive --pty [-jobid=<jobid>] bash \nrocgdb -tui ./saxpy\n
The following is based on using the standard gdb interface. Using the TUI or GUI interfaces should be similar. You should see some output like the following once the debugger starts.
[output]\nGNU gdb (rocm-rel-5.1-36) 11.2\nCopyright (C) 2022 Free Software Foundation, Inc. \nLicense GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>\nThis is free software: you are free to change and redistribute it.\nThere is NO WARRANTY, to the extent permitted by law.\nType \"show copying\" and \"show warranty\" for details.\nThis GDB was configured as \"x86_64-pc-linux-gnu\".\nType \"show configuration\" for configuration details.\nFor bug reporting instructions, please see:\n<https://github.com/ROCm-Developer-Tools/ROCgdb/issues>.\nFind the GDB manual and other documentation resources online at:\n <http://www.gnu.org/software/gdb/documentation/>. \nFor help, type \"help\".\nType \"apropos word\" to search for commands related to \"word\"...\nReading symbols from ./saxpy...\n
Now it is waiting for us to tell it what to do. We'll go for broke and just type run
(gdb) run\n\n[output] \nThread 3 \"saxpy\" received signal SIGSEGV, Segmentation fault.[Switching to thread 3, lane 0 (AMDGPU Lane 1:2:1:1/0 (0,0,0)[0,0,0])]\n0x000015554a001094 in saxpy (n=<optimized out>, x=<optimized out>, incx=<optimized out>, y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n31 y[i] += a*x[i];\n
The line number 57 is a clue. Now let\u2019s dive a little deeper by getting the GPU thread trace
(gdb) info threads [ shorthand - i th ]\n\n [output]\n Id Target Id Frame\n 1 Thread 0x15555552d300 (LWP 40477) \"saxpy\" 0x000015554b67ebc9 in ?? ()\n from /opt/rocm/lib/libhsa-runtime64.so.1\n 2 Thread 0x15554a9ac700 (LWP 40485) \"saxpy\" 0x00001555533e1c47 in ioctl () \n from /lib64/libc.so.6\n* 3 AMDGPU Wave 1:2:1:1 (0,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 4 AMDGPU Wave 1:2:1:2 (0,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57 \n 5 AMDGPU Wave 1:2:1:3 (1,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy (\n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 6 AMDGPU Wave 1:2:1:4 (1,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n
Note that the GPU threads are also shown! Switch to thread 1 (CPU)
(gdb) thread 1 [ shorthand - t 1]\n[output] \n[Switching to thread 1 (Thread 0x15555552d300 (LWP 47136))]\n#0 0x000015554b67ebc9 in ?? () from /opt/rocm/lib/libhsa-runtime64.so.1\n
where
...
#12 0x0000155553b5b419 in hipDeviceSynchronize ()\n from /opt/rocm/lib/libamdhip64.so.5\n#13 0x000000000020d6fd in main () at saxpy.hip:79\n\n(gdb) break saxpy.hip:78 [ shorthand \u2013 b saxpy.hip:78]\n\n[output] \nBreakpoint 2 at 0x21a830: file saxpy.hip, line 78\n\n(gdb) run [ shorthand \u2013 r ]\n\nBreakpoint 1, main () at saxpy.hip:78\n48 saxpy<<<num_groups, group_size>>>(n, d_x, 1, d_y, 1);\n
From here we can investigate the input to the kernel and see that the memory has not been allocated. Restart the program in the debugger.
srun --interactive --pty [-jobid=<jobid>] rocgdb ./saxpy\n(gdb) list 55,74\n\n(gdb) b 60\n\n[output] \n\nBreakpoint 1 at 0x219ea2: file saxpy.cpp, line 62.\n
Alternativelly, one can specify we want to stop at the start of the routine before the allocations.
(gdb) b main\nBreakpoint 2 at 0x219ea2: file saxpy.cpp, line 62.\n
We can now run our application again! (gdb) run\n[output] \nStarting program ...\n...\nBreakpoint 2, main() at saxpy.cpp:62\n62 int n=256;\n\n(gdb) p d_y\n[output] \n$1 = (float *) 0x13 <_start>\n
Should have intialized the pointer to NULL! It makes it easier to debug faulty alocations. In anycase, this is a very unlikely address - usually dynamic allocation live in a high address range, e.g. 0x123456789000.
(gdb) n\n[output] \n63 std::size_t size = sizeof(float)*n;\n\n(gdb) n\n[output] \nBreakpoint 1, main () at saxpy.cpp:67\n67 init(n, h_x, d_x);\n\n(gdb) p h_x\n[output] \n$2 = (float *) 0x219cd0 <_start>\n(gdb) p *x@5\n
Prints out the next 5 values pointed to by h_x
[output] \n$3 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n
Random values printed out \u2013 not initialized!
(gdb) b 56\n\n(gdb) c\n\n[output] \nThread 5 \u201csaxpy\u201d hit Breakpoint 3 \u2026.\n56 if (i < n)\n\n(gdb) info threads\n\nShows both CPU and GPU threads\n(gdb) p x\n\n[output] \n$4 = (const float *) 0x219cd0 <_start>\n\n(gdb) p *x@5\n
This can either yeild unintialized results or just complain that the address can't be accessed: [output] \n$5 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n\nor \n\nCannot access memory at address 0x13\n
Let's move to the next statement:
(gdb) n\n\n(gdb) n\n\n(gdb) n\n
Until reach line 57. We can now inspect the indexing and the array contents should the memory be accesible. (gdb) p i\n\n[output] \n$6 = 0\n\n(gdb) p y[0]\n\n[output] \n$7 = -2.12e14\n\n(gdb) p x[0]\n\n[output] \n$8 = -2.43e-33\n\n(gdb) p a\n[output] \n$9 = 1\n
We can see that there are multiple problems with this kernel. X and Y are not initialized. Each value of X is multiplied by 1.0 and then added to the existing value of Y.
"},{"location":"4day-20231003/exercises_AMD_hackmd/#rocprof","title":"Rocprof","text":"Setup environment
salloc -N 1 --gpus=8 -p small-g --exclusive -A project_465000644 -t 20:00\n\nmodule load PrgEnv-cray\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n
Download examples repo and navigate to the HIPIFY exercises cd ~/HPCTrainingExamples/HIPIFY/mini-nbody/hip/\n
Compile and run one case. We are on the front-end node, so we have two ways to compile for the GPU that we want to run on.
- The first is to explicitly set the GPU archicture when compiling (We are effectively cross-compiling for a GPU that is present where we are compiling).
hipcc -I../ -DSHMOO --offload-arch=gfx90a nbody-orig.hip -o nbody-orig\n
- The other option is to compile on the compute node where the compiler will auto-detect which GPU is present. Note that the autodetection may fail if you do not have all the GPUs (depending on the ROCm version). If that occurs, you will need to set
export ROCM_GPU=gfx90a.
srun hipcc -I../ -DSHMOO nbody-orig.cpp -o nbody-orig\n
Now Run rocprof on nbody-orig to obtain hotspots list
srun rocprof --stats nbody-orig 65536\n
Check Results cat results.csv\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Using --basenames on will show only kernel names without their parameters. srun rocprof --stats --basenames on nbody-orig 65536\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Trace HIP calls with --hip-trace srun rocprof --stats --hip-trace nbody-orig 65536\n
Check the new file results.hip_stats.csv cat results.hip_stats.csv\n
Profile also the HSA API with the --hsa-trace srun rocprof --stats --hip-trace --hsa-trace nbody-orig 65536\n
Check the new file results.hsa_stats.csv cat results.hsa_stats.csv\n
On your laptop, download results.json scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:<path_to_file>/results.json results.json\n
Open a browser and go to https://ui.perfetto.dev/. Click on Open trace file in the top left corner. Navigate to the results.json you just downloaded. Use the keys WASD to zoom in and move right and left in the GUI Navigation\nw/s Zoom in/out\na/d Pan left/right\n
Read about hardware counters available for the GPU on this system (look for gfx90a section)
less $ROCM_PATH/lib/rocprofiler/gfx_metrics.xml\n
Create a rocprof_counters.txt file with the counters you would like to collect vi rocprof_counters.txt\n
Content for rocprof_counters.txt: pmc : Wavefronts VALUInsts\npmc : SALUInsts SFetchInsts GDSInsts\npmc : MemUnitBusy ALUStalledByLDS\n
Execute with the counters we just added: srun rocprof --timestamp on -i rocprof_counters.txt nbody-orig 65536\n
You'll notice that rocprof runs 3 passes, one for each set of counters we have in that file. Contents of rocprof_counters.csv
cat rocprof_counters.csv\n
"},{"location":"4day-20231003/exercises_AMD_hackmd/#omnitrace","title":"Omnitrace","text":" Omnitrace is known to work better with ROCm versions more recent than 5.2.3. So we use a ROCm 5.4.3 installation for this.
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omnitrace/1.10.3-rocm-5.4.x\n
- Allocate resources with
salloc
salloc -N 1 --ntasks=1 --partition=small-g --gpus=1 -A project_465000644 --time=00:15:00
- Check the various options and their values and also a second command for description
srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace --brief --description
- Create an Omnitrace configuration file with description per option
srun -n 1 omnitrace-avail -G omnitrace.cfg --all
- Declare to use this configuration file:
export OMNITRACE_CONFIG_FILE=/path/omnitrace.cfg
- Get the training examples:
cp -r /project/project_465000644/Exercises/AMD/HPCTrainingExamples/ .
-
Now build the code
maketime srun -n 1 --gpus 1 Jacobi_hip -g 1 1
-
Check the duration
"},{"location":"4day-20231003/exercises_AMD_hackmd/#dynamic-instrumentation","title":"Dynamic instrumentation","text":" - Execute dynamic instrumentation:
time srun -n 1 --gpus 1 omnitrace-instrument -- ./saxpy and check the duration
- About Jacobi example, as the dynamic instrumentation wuld take long time, check what the binary calls and gets instrumented:
nm --demangle Jacobi_hip | egrep -i ' (t|u) ' - Available functions to instrument:
srun -n 1 --gpus 1 omnitrace-instrument -v 1 --simulate --print-available functions -- ./Jacobi_hip -g 1 1 - the simulate option means that it will not execute the binary
"},{"location":"4day-20231003/exercises_AMD_hackmd/#binary-rewriting-to-be-used-with-mpi-codes-and-decreases-overhead","title":"Binary rewriting (to be used with MPI codes and decreases overhead)","text":" -
Binary rewriting: srun -n 1 --gpus 1 omnitrace-instrument -v -1 --print-available functions -o jacobi.inst -- ./Jacobi_hip
- We created a new instrumented binary called jacobi.inst
-
Executing the new instrumented binary: time srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and check the duration
- See the list of the instrumented GPU calls:
cat omnitrace-jacobi.inst-output/TIMESTAMP/roctracer.txt
"},{"location":"4day-20231003/exercises_AMD_hackmd/#visualization","title":"Visualization","text":" - Copy the
perfetto-trace.proto to your laptop, open the web page https://ui.perfetto.dev/ click to open the trace and select the file
"},{"location":"4day-20231003/exercises_AMD_hackmd/#hardware-counters","title":"Hardware counters","text":" - See a list of all the counters:
srun -n 1 --gpus 1 omnitrace-avail --all - Declare in your configuration file:
OMNITRACE_ROCM_EVENTS = GPUBusy,Wavefronts,VALUBusy,L2CacheHit,MemUnitBusy - Execute:
srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and copy the perfetto file and visualize
"},{"location":"4day-20231003/exercises_AMD_hackmd/#sampling","title":"Sampling","text":"Activate in your configuration file OMNITRACE_USE_SAMPLING = true and OMNITRACE_SAMPLING_FREQ = 100, execute and visualize
"},{"location":"4day-20231003/exercises_AMD_hackmd/#kernel-timings","title":"Kernel timings","text":" - Open the file
omnitrace-binary-output/timestamp/wall_clock.txt (replace binary and timestamp with your information) - In order to see the kernels gathered in your configuration file, make sure that
OMNITRACE_USE_TIMEMORY = true and OMNITRACE_FLAT_PROFILE = true, execute the code and open again the file omnitrace-binary-output/timestamp/wall_clock.txt
"},{"location":"4day-20231003/exercises_AMD_hackmd/#call-stack","title":"Call-stack","text":"Edit your omnitrace.cfg:
OMNITRACE_USE_SAMPLING = true;\u00a0\nOMNITRACE_SAMPLING_FREQ = 100\n
Execute again the instrumented binary and now you can see the call-stack when you visualize with perfetto.
"},{"location":"4day-20231003/exercises_AMD_hackmd/#omniperf","title":"Omniperf","text":" Omniperf is using a virtual environemtn to keep its python dependencies.
module load cray-python\nmodule load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omniperf/1.0.10-rocm-5.4.x\n\nsource /pfs/lustrep2/projappl/project_462000125/samantao-public/omnitools/venv/bin/activate\n
- Reserve a GPU, compile the exercise and execute Omniperf, observe how many times the code is executed
salloc -N 1 --ntasks=1 --partition=small-g --gpus=1 -A project_465000644 --time=00:30:00\ncp -r /project/project_465000644/Exercises/AMD/HPCTrainingExamples/ .\ncd HPCTrainingExamples/HIP/dgemm/\nmkdir build\ncd build\ncmake ..\nmake\ncd bin\nsrun -n 1 omniperf profile -n dgemm -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv\n
-
Run srun -n 1 --gpus 1 omniperf profile -h to see all the options
-
Now is created a workload in the directory workloads with the name dgemm (the argument of the -n). So, we can analyze it
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ &> dgemm_analyze.txt\n
- If you want to only roofline analysis, then execute:
srun -n 1 omniperf profile -n dgemm --roof-only -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv
There is no need for srun to analyze but we want to avoid everybody to use the login node. Explore the file dgemm_analyze.txt
- We can select specific IP Blocks, like:
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ -b 7.1.2\n
But you need to know the code of the IP Block
- If you have installed Omniperf on your laptop (no ROCm required for analysis) then you can download the data and execute:
omniperf analyze -p workloads/dgemm/mi200/ --gui\n
- Open the web page: http://IP:8050/ The IP will be displayed in the output
"},{"location":"4day-20231003/exercises_AMD_hackmd/#mnist-example","title":"MNIST example","text":"This example is supported by the files in /project/project_465000644/Exercises/AMD/Pytorch. These script experiment with different tools with a more realistic application. They cover PyTorch, how to install it, run it and then profile and debug a MNIST based training. We selected the one in https://github.com/kubeflow/examples/blob/master/pytorch_mnist/training/ddp/mnist/mnist_DDP.py but the concept would be similar for any PyTorch-based distributed training.
This is mostly based on a two node allocation.
-
Installing PyTorch directly on the filesystem using the system python installation. ./01-install-direct.sh
-
Installing PyTorch in a virtual environment based on the system python installation. ./02-install-venv.sh
-
Installing PyTorch in a condo environment based on the condo package python version. ./03-install-conda.sh
-
Installing PyTorch from source on top of a base condo environment. It builds with debug symbols which can be useful to facilitate debugging. ./04-install-source.sh
-
Testing a container prepared for LUMI that comprises PyTorch. ./05-test-container.sh
-
Test the right affinity settings. ./06-afinity-testing.sh
-
Complete example with MNIST training with all the trimmings to run it properly on LUMI. ./07-mnist-example.sh
-
Examples using rocprof, Omnitrace and Omniperf. ./08-mnist-rocprof.sh ./09-mnist-omnitrace.sh ./10-mnist-omnitrace-python.sh ./11-mnist-omniperf.sh
-
Example that debugs an hang in the application leveraging rocgdb. ./12-mnist-debug.sh
"},{"location":"4day-20231003/extra_1_00_Introduction/","title":"Introduction","text":"Presenters: Emmanuel Ory (LUST), Harvey Richardson (HPE)
Archived materials on LUMI:
- Recording:
/appl/local/training/4day-20231003/recordings/1_00_Introduction.mp4
"},{"location":"4day-20231003/extra_1_01_HPE_Cray_EX_Architecture/","title":"HPE Cray EX Architecture","text":"Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_1_01_HPE_Cray_EX_Architecture/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_1_02_Programming_Environment_and_Modules/","title":"Programming Environment and Modules","text":"Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-1_02_Programming_Environment_and_Modules.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/1_02_Programming_Environment_and_Modules.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_1_02_Programming_Environment_and_Modules/#qa","title":"Q&A","text":" -
Is Open MPI fully supported on CRAY?
-
No, the only really supported MPI implementation is Cray MPICH. Using OpenMPI on LUMI can be quite challeging at the moment.
-
On the CPU side: OpenMPI can work with libfabric but we still have problems to interface OpenMPI properly with the Slurm resource manager which is needed for correctly starting multinode jobs.
-
On the GPU side: AMD support in OpenMPI is based on UCX which is not supported on Slingshot. Since Slingshot is used on the three first USA exascale systems, the OpenMPI team is looking for solutions, but they are not yet there.
-
HPE also has a compatility library to interface OpenMPI programs with Cray MPICH but the version we have on LUMI is still too buggy, and I don't know (I doubt actually) that it supports GPU-aware MPI.
-
But blame the OpenMPI guys for focussing too much on a library which is too much controlled by NVIDIA (UCX). It is not only HPE Cray that has problems with this, but basically every other network vendor. It's one of those examples where focussing too much on a technology that is not really open but overly controlled by the at that moment biggest player in the field, causes problems on other architectures.
-
If we have multiple C compilers, how to figure out which one to use?
-
You can use wrappers such as cc, CC, ftn. This will be covered in the next presentation and it makes it easy to switch compilers.
-
And do benchmarking.... It is not possible to say \"if your application does this or that, then this compiler is best....\"
-
Which compilers do you suggest? CRAY ones?
-
I know of one project that has done benchmarking and they came to the conclusion that the Cray compiler was the best for them.
-
But its Fortran compiler is very strict when it comes to standard compliance. I've seen their optimizer do very nice things though...
-
The reality is that most users are probably using the GNU compilers because that is what they are used to. It is important to note thought that GPU compilers for NVIDIA, AMD and Intel GPUs are all derived from a Clang/LLVM code base and that most vendor compilers are also derived from that code base. In, e.g., embedded systems, Clang/LLVM based compilers are already the gold standard. Scientific computing will have to move into that direction also because that is where support for new CPUs and GPUs will appear first.
-
Is there possibility to generate module tree which can show any loadable modules in hierarchy?
- No, and part of the problem is that on a Cray system it is not a tree. Cray abuses LMOD hierarchies and does it in a non-intended way so sometimes you need to load 2 modules to make another one available, and they have done it so that you can load those two in any order. E.g., to see the MPI modules you need to load a compiler and a network target module (
craype-network-ofi).
-
What was the difference between Rome, Trento, etc?
-
Rome is the zen2 architecture. It has its core organised in groups of 4 sharing the L3 cache.
-
Milan is the zen3 architecture. It is a complete core update with some new instructions though most if not all of those are for kernel and library use and will not be generated by a compiler. It has its cores organised in groups of 8 sharing L3 cache.
-
Trento is a zen3 variant with different I/O. It has 128 InfinityFabric links to the outside world rather than 64 InfinityFabric + 64 PCIe-only links. These are used to connect to the GCDs (16 links per GCD). InfinityFabric is the interconnect used to link two CPU sockets but also used in the socket to link the dies that make a single CPU. It offers a level of cache coherence that cannot be offered by PCIe. And now also used to link the GCDs to each other. Though as those connections are too slow for the fast GPUs there is no full cache coherency on the GPU nodes. For compilers, there is no difference as the compute dies are the same.
-
Which is the most generic compiler-and-tools module - PrgEnv-*? Is loading this module provide me a full set: compiler + MPI + BLAS/LAPACK/ScaLAPACK libraries?
- Yes. The basically do a module load of various other modules: Compiler wrappers, compiler, MPICH and LibSci.
-
What was the difference between programming environments (PrgEnv) and compiler modules?
-
PrgEnv modules load multiple modules: compiler wrappers, a compiler module, a cray-mpich module that fits with the compiler, and a LibSci library that is compatible with the compiler.
-
The compiler modules only load the actual compiler.
"},{"location":"4day-20231003/extra_1_03_Running_Applications/","title":"Running Applications","text":"Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_1_03_Running_Applications/#qa","title":"Q&A","text":" -
Are other launchers except srun (mpiexec, mpirun) supported?
What about software precompiled and delivered with own mpiexec - we need to wrapper it?
- This is usually anyway a problem of precompiled software as these are usually build with OpenMPI which is currently not supported on LUMI (only MPICH and ABI compatible ones)
Have you tried some wrappers for Open MPI, eg wi4mpi?
-
No, we haven't and are too small a team to do that. We only support such software for which we can get support elsewhere ourselves.
-
Software that hardcodes the name of the MPI process starter is badly written software. That software should be corrected. The MPI standard only tells that there should be a process starter but does not enforce that it should be called mpirun or mpiexec.
-
If I run a serial exec via sbatch without srun, where is the process running? on the login (UAN) node?
- It will run on a compute node
-
So if 'Idle' in the output of sinfo -s does not mean available nodes, how can we see the amount of available nodes?
- Not sure, if I understand correctly. Why should it notshow the avialable nodes under \"idle\"?
- I guess the question here is how to see nodes that are immediately allocatable, which as far as I know is not possible. \"Idle\" here would just stand for
not doing anything right now, not free to do anything. - It's quite difficult to know. Because there may be a job in the queue that's going to use the idle nodes. But for the moment, it's still in the queue, waiting its turn. That's why it's difficult/impossible to know which node is immediately available.
- You cannot see the truly available nodes because nodes may be available to some jobs but not to others. E.g., if the scheduler expects that it will take another hour to gather enough nodes for the large job that is highest in priority, it may still decide that it is safe to start a smaller half hour job using the nodes that it is reserving for the big job. That process is called \"backfill\". It is not a good idea to try to manipulate the scheduler and it doesn't make sense either since you are not the only user. By the time you would have read the information about available nodes, they may not be available anymore.
-
In my experience, I never observed a speed-up when using multi-thread (tasks-per-node between 128 and 256) for well-coded MPI applications. Can you make an example of when this would be an advantage? Is it really possible? Does it maybe depend on the PEs?
-
As the performance of most HPC applications is limited by the performance of the memory bus, it is rare to see an improvement in performance by enabling or disabling hyperthreading. The best thing to do is try it, and hope for a pleasant surprise, but I agree with you that this rarely happens.
-
Hyperthreading seems to work best with bad code that has lots of unpredictable branches on which a processor can get stuck. It works very well, e.g., on server systems used to run databases.
-
Is there a difference in using srun or salloc to run jobs directly on computing nodes?
-
Yes. I would advise you not to use srun by default to start jobs directly but always use either sbatch for batch jobs or salloc if you want to run interactively, unless you are aware that using srun outside an salloc or sbatch environment has some options that will work in a different way and can live with that.
-
salloc does not start a job. It only creates an allocation and will give you a shell on the node where you executed salloc (typically a login node), and only when you use srun to create a so-called job step you will get onto the compute node.
-
sbatch creates an allocation and then executes a script on the first node of that allocation.
-
The primary function of srun is to create a job step inside an existing allocation. However, if it is not run into an allocation, it will also create an allocation. Some options have sligthly diffent meaning when creating a job step and when creating an allocation and this is why srun may act differently when run outside an allocation.
"},{"location":"4day-20231003/extra_1_04_Exercises_1/","title":"Exercise session 1: Running applications","text":"Exercises are in Exercises/HPE/day1/ProgrammingModels.`
See Exercises/HPE/day1/ProgrammingModels/ProgrammingModelExamples_SLURM.pdf Run on the system and get familiar with Slurm commands.
"},{"location":"4day-20231003/extra_1_04_Exercises_1/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_1_04_Exercises_1/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_1_05_Compilers_and_Parallel_Programming_Models/","title":"Compilers and Parallel Programming Models","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-1_05_Compilers_and_Parallel_Programming_Models.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/1_05_Compilers_and_Parallel_Programming_Models.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_1_05_Compilers_and_Parallel_Programming_Models/#qa","title":"Q&A","text":" -
What are your experiences with magnitude of performance increase that can be achieved using larger pagesizes?
- No actual experience myself but it will be very program-dependent and it is not orders of magnitude. This is about getting the last 5% or 10% of performance out of a code. It is only useful if the program also allocates its memory in sufficiently large blocks.
-
Was the -hfpN floating point optimization for Fortran only?
- The floating point optimization control options for C/C++ are indeed different. Options starting with
-h are probably all Fortran-only. Clang options can be found, e.g., on this page. That page lists a lot of very fine-grained options, but also, e.g., -ffp-model which combines many of these options.
-
I am not sure I understand what the Default option for dynamic linking does. As far as I understand, this is supposed to link to the default Linux library. Does it mean that it does not matter what library I did load via the modules? For example, if I link to lapack, will my module loaded be replaced by some default?
-
This is only for libraries that come with the Cray PE, not for your own libraries. Dynamic linking can be used for OS libraries, Cray PE libraries, and your own libraries. When starting an application, the loader will look for those libraries in a number of standard places, some places that may be encoded in the executable (via rpath and/or runpath), and in places pointed to by the environment variable LD_LIBRARY_PATH. The Cray PE modules are special in that (a) the path to the shared libraries is not always added to LD_LIBRARY_PATH but to CRAY_LD_LIBRARY_PATH and (b) the wrappers inject the directory with the default versions of the libraries in the executables. So by default, since many of the Cray PE libraries are not in LD_LIBRARY_PATH and since the path to default versions is in the executable, the loader will use the default version.
There are two ways to avoid that. One is to add CRAY_LD_LIBRARY_PATH to the front of LD_LIBRARY_PATH as was explained in I think an earlier talk. We also have the lumi-CrayPath which can help you manage that. The other option is the environment variable CRAY_ADD_RPATH or corresponding command line argument to tell the wrappers to include the paths in the executable.
You have more reproducibility when including the specific library versions explicitly, but also a higher chance that your application stops working after a system update. We had several applications that rpathed the MPI library fail after a system update in March of this year.
-
But are the intel compilers supported by LUMI or are they shown only as a term of comparison?
- As Alfio said at the beginning, they are only shown for comparison. We cannot support them as we get no support upstream for the compilers and we know there are problems with Intel MPI on LUMI and some MKL routines.
-
If I want a newer rocm is is possible to build my own?
- Yes and no. Some things will work, others won't. First, ROCm has a driver part also that is installed in the OS kernel, and each ROCm version only works with certain versions of the driver. ROCm 5.3 and 5.4 are guaranteed to work with the driver we currently have on LUMI, newer versions are not guaranteed though one of the AMD support people has used ROCm 5.5.1 successfully on LUMI for some applications. But second, some other libraries on the system also depend on LUMI and may not be compatible with the newer version. E.g., we know that GPU aware MPI in the current Cray MPICH versions fails with ROCm 5.5. Also, the wrappers will not work with a ROCm that you install yourself so you'll have to do some more manual adding of compiler flags. Let's say there are reasons why LUST decided to provide a 5.3 version but not the newer versions as they all have some problems on LUMI which may or may not hit you.
-
Did the PrgEnv-cray-amd load all the required modules for GPU compiling, such as craype-accel-amd-gfx90a?
- The target modules (like
craype-accel-amd-gfx90a) are never loaded by the PrgEnv modules but always need to be loaded by hand. This is because a system can have multiple different models of GPU so the PrgEnv module cannot know which one to load.
-
Sometimes it may be complicated to have mixed C/fortran linking. Among the different PEs, is there a suggested choice for this type of mixed compilation?
- I believe what mixed compilation is primarly considered for is AMD GPU compilers (without Fortran support) and GNU Fortran.
-
Was the recommendation to use 32MB Hugepages?
- 2MB but it is easy to experiment. You don't need to relink to change the size of the hugepages, just load another module at runtime.
"},{"location":"4day-20231003/extra_1_06_Exercises_2/","title":"Exercise session 2: Compilers","text":"The exercises are basically the same as in session #1. You can now play with different programming models and optimisation options.
"},{"location":"4day-20231003/extra_1_06_Exercises_2/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_1_06_Exercises_2/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_1_07_Cray_Scientific_Libraries/","title":"Cray Scientific Libraries","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_1_07_Cray_Scientific_Libraries/#qa","title":"Q&A","text":" -
When should we link libsci when compiling GPU applications?
- Many GPU codes will use other linear algebra libraries on the GPU but may still want to do some small computations on the CPU, and for those computations libsci may be useful. The problem with LibSci_acc is that it is HPE Cray proprietary. Nice on LUMI or to get some code using some GPU acceleration that otherwise wouldn't, but not a good starting point if you want to develop a code that you also want to use on non-HPE Cray systems.
-
When should we link libsci_acc when compiling GPU applications? (ie. Doesn't HIP handle it all?)
- If you don't want to use HIP or ROCm-specific libraries with their function names but want to use the routines that you can easily swap out for the CPU versions.
"},{"location":"4day-20231003/extra_1_08_Exercises_3/","title":"Exercise session 3: Cray Scientific Libraries","text":"The files for the exercises are in Exercises/HPE/day1/libsci_acc.
Test with LibSci_ACC, check the different interfaces and environment variables.
"},{"location":"4day-20231003/extra_1_08_Exercises_3/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_1_08_Exercises_3/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_1_09_Offload_CCE/","title":"CCE Offloading Models","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_2_01_Advanced_Application_Placement/","title":"Advanced Placement","text":"Presenter: Jean Pourroy (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-2_01_Advanced_Application_Placement.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/2_01_Advanced_Application_Placement.mp4
These materials can only be distributed to actual users of LUMI (active user account).
Remark
The lumi-CPEtools module (in the LUMI software stacks, see this afternoon) contains alternatives for xthi and the hello_jobstep tool.
This module also contains the gpu_check command which was mentioned in the presentation.
"},{"location":"4day-20231003/extra_2_01_Advanced_Application_Placement/#qa","title":"Q&A","text":" -
Can you explain NUMA domain shortly?
- NUMA stands for Non-Uniform Memory Access, at a high level it means that when you do a memory operation some memory is \"closer\" to a processor than other menory.
- It was in the first presentation yesterday, so you can check back the recordings once they are available. Basically some memory is closer to some chiplets of the AMD processor than to others. On any machine, each socket is a NUMA domain as the communication between two sockets is bandwidth limited and adds a lot of latency to the memory access (x3.2). But on AMD internally one socket can also be subdivided in 4 NUMA domains, but there the latency difference is only 20%.
-
How do I see from command line in which NUMA domain my GPUs are?
- Future slides will cover this
lstopo is a command that can give such information. But it may be easier to work with the tables in the documentation, and once you start running we have a program in the the lumi-CPEtools module that shows you information about the binding of each MPI task. It is a very similar program to one that will be mentioned later in this lecture. You really have to look at the PCIe address as both the ROCm runtime and so-called Linux control groups can cause renumbering of the GPUs.rocm-smi command also has option (--showtopo) to show which NUMA domain GPU is attached to.
-
Where is the gpu_check tool? In perftools?
-
So, if we check SLURM_LOCALID in our application and assign the GPU based on that (using the given mapping), we should have good binding?
- Yes. But only if you use exclusive nodes (so nodes in
standard-g or full nodes in small-g with --exclusive) as doing binding requires full control over all resources in the node. So if your application is very sensitive to communication between CPU and GPU you have to use full nodes and if your application cannot use all GPUS, try to start with srun multiple copies of your application with different input on the same node.
-
So, just to confirm: was using --gpu-bind ok or not?
- Not OK if you want the tasks that
srun starts to communicate with each other. It causes GPU-aware MPI to fail as it can no longer do GPU memory to GPU memory copy for intra-node communication between tasks.
-
Can we take advantage of GPU binding if using one GPU only?
- Only if you allocate a whole node and then start 8 of those tasks by playing a bit with
srun and some scripts to start your application (e.g., use one srun to start 8 of those tasks via a script that does not only set ROCR_VISIBLE_DEVICES but also directs the copy of the application to the right input files). It is also possible to play with multiple srun commands running in the background but at several times in the past we have had problems with that on LUMI. We cannot always guarantee a good mapping on small-g between the cores that you get allocated and the GPU that you get allocated. So if you have a lot of CPU-to-GPU communication going on you may notice large variations in performance between jobs on small-g.
"},{"location":"4day-20231003/extra_2_02_Exercises_4/","title":"Exercise session 4: Placement","text":"The files for the exercises can be found in Exercises/HPE/day2/Binding and Exercises/HPE/day2/gpu_perf_binding.
Try different binding options for CPU execution (look at slides and use envars to change order and display the order) and for GPU execution (gpu_perf_binding). See also the PDF or README.md files in those directories.
Check slide 6 and 7 of the exercise assignments for more information.
"},{"location":"4day-20231003/extra_2_02_Exercises_4/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_2_02_Exercises_4/#qa","title":"Q&A","text":" -
What is MPICH_GPU_SUPPORT_ENABLED (in gpu_env.sh)? I don't think we covered that in slides.
- No. That comes tomorrow afternoon in the advanced Cray MPICH presentation. It is to enable GPU-aware MPI.
-
I'm not able to load lumi-CPEtools...
- Did you load a
LUMI module before trying to load CPE tools? - Thanks! That was it.
- We will discuss this afternoon how to use the software stack.
"},{"location":"4day-20231003/extra_2_03_Debugging_at_Scale/","title":"Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat","text":"Presenter: Thierry Braconnier (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_2_03_Debugging_at_Scale/#qa","title":"Q&A","text":" -
Sometimes my jobs hang for a long time at start before anything apparently happens. Is cray-stat the right tool to debug this?
-
How to properly load a coredump from a Singularity container using rocgdb?
- no sure how to answer to this question... I assume you have the debugging symbols of the applications, so could you open a shell and mount rocgdb in the container to open the core file?
-
What is the difference between the sanitizer tools and the standard debugging tools offered by the CCE that we discussed yesterday (e.g. options like -h bounds , etc etc)?
-
OK, those checks at runtime are related to some special cases (like bound checking). The asan (address sanitezer) offers more checks (check the corresponding webpages, e.g. https://clang.llvm.org/docs/AddressSanitizer.html )
-
The sanizers are in all compilers nowadays, sanizers4hpc is just an aggregator of the outputs for multiple ranks.
-
Was CRAY_ACC_DEBUG only for OpenMP applications?
- correct, only CCE and OpenACC and OpenMP
"},{"location":"4day-20231003/extra_2_04_Exercises_5/","title":"Exercise session 5: Cray PE Debugging Tools","text":"Exercises are in Exercises/HPE/day2/debugging.
Try the debugging tools in this subdirectory. There are Readme.md files in every directory with more information.
"},{"location":"4day-20231003/extra_2_04_Exercises_5/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_2_04_Exercises_5/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_2_05_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Materials available on the web:
Archived materials on LUMI:
"},{"location":"4day-20231003/extra_2_05_LUMI_Software_Stacks/#additional-materials","title":"Additional materials","text":" -
The information in this talk is also partly covered by the following talks from the 1-day courses:
-
Modules on LUMI
-
LUMI Software Stacks
-
The cotainr package was presented during the September 27, 2003 user coffee break
"},{"location":"4day-20231003/extra_2_05_LUMI_Software_Stacks/#qa","title":"Q&A","text":" -
module keyword was said not to be very practical on LUMI at the moment. In what way its functionality is limited at the moment and are there plans to expand it?
-
A bug in the Lmod 8.3 version on LUMI is that all extensions are shown in the output of a module keyword command while they are irrelevant. The version of Lmod installed on LUMI is something that is outside of LUST responsability. We need to wait an update by Cray.
-
KL That update actually exists and is part of newer distributions of the PE, but it has not yet been installed on LUMI.
-
The speaker mentioned LUMI freezing for a few minutes from time to time. What is the cause?
- The two minute freezes are related to a Lustre process getting stuck and the sysadmins suspect that it is related to crashes on nodes. The load on the metadata servers cause severe performance degradation of Lustre, but not complete freezes.
-
Compilation and some post-processing tools are available on the login node, but it's not really clear which jobs can be run on the login node and which should be moved to compute nodes. Are there any guidelines about this?
- Login nodes are really meant for compilation and modification to the code and analysis, but not actually running the code. Do you have a concrete example? Using the login nodes to run long scripts consuming a lot of resources, to avoid having to pay for billing units would not be something that is allowed.
- Sometimes I process my computed data to extract some results. Scripts are serial and can take around 10 minutes. I would like to run them on login node to get the numbers as soon as I can.
- That sounds okay. If you could build this into the script that would be good too, but it doesn't sound like a problem. Installing some software probably puts a bigger strain on the system.
-
Do you take requests for easyconfigs for new software and how long does it typically take to make a new config?
- Easyconfigs are usually created upon user requests. How long it take us to create a new recipe depends on the complexity of the installation. Most of the time, if we don't have too much on our plate at the time of the request, we provide a recipe in less than 2 days. You might have to wait for a longer period of time for packages that have a lot of dependencies or for packages that do not compile nicely in a Cray environment. It also depend if the softwarte is for CPU or GPU. For CPU softwares, we usually can start from the standard EasyBuild recipes and convert it to cpeGNU, which can be quite fast. For GPU softwares however, we have to start from scratch.
-
I have encountered troubles in OpenMP thread placement of MPI/OpenMP program on cluster with Intel CPUs. It has EasyBuild system for building. What system can you advice for recompiling everything by myself including compiler, MPI, BLAS, FFT, GSL? Spack, EB? Something else? I have written bash scripts for compilation, but it is not especially nice way if I try many versions with different compile options. I tried to learn EB, Spack. I miss real simplicity of buildroot like configuring many things in menu. Which of build automation systems should I choose?
-
That is most likely not a problem with the compilers, EasyBuild or Spack but it may be a problem with the MPI library and is more likely a problem with the resource manager on that cluster. There are subtle differences in the OpeMP environment variables between different compilers (some are standard but every implementation offers some additional ones). It may be that the sysadmins are not aware enough of the importance of binding and have the resource manager configured in a way that it makes it impossible to fully control it.
Basically the task binding with MPI has to be done by the process starter. One of the reasons to use srun on LUMI and not some mpirun is that srun fully understands the allocation and hence can do a better job of process binding. mpirun/mpiexec will sometimes internally recognise that srun is available and use it, but this may require setting enviornment variables.
OpenMP binding really only works within the limits set by the CPU affinity mask, and the latter is also set by the resource manager/process starter. So that may also explain problems.
The source code of the tools that we include in lumi-CPEtools is publicly available and in fact we use some of those tools also on my home cluster in Antwerp which is mixed AMD and Intel with CentOS instead of SUSE. See the links in the lumi-CPEtools page in the LUMI Software Library for the GitHub repository.
Thank you very much for providing useful hints. Actually I and admins started with OpenMPI through mpiexec .... Now I understand that OpenMPI is the first thing to try to change, as despite good binding maps something screws up with thread binding.
-
You have touched the issue that Lustre reacts too slow on lots of small files. What do you think about filesystem images on lustre like ext4 image or squashfs image?
-
Some of the tools we provide, like lumi-container-wrapper uses squashfs images to bundle pip and conda installations. This squashfs image is subsequently used, by mounting it with singularity. This improves the situation but is still not optimal. The file is opened and closed only once, so that is as good for the Lustre metadata server as it can be. But those file systems often work with a block size of 4kB so every file access to data in the container will translate into 4kB accesses of the Lustre file system. No problem there, but it will not give you the performance you expect from Lustre. What is not clear to me is how it works with caching mechanisms that all file systems have.
-
Regarding the Lustre freeze issue, I'm suprised by the response of my colleague as there is, as far as I know, no proven link between these freezes and a lot of small file operations. I have experienced these freezes during maintenace breaks when the system was completely idle and with no user connected.
-
The complete freezes are very likely not related to the use of lots of small files. They occur when a Lustre process freezes and seem to be related to nodes crashing. However, if you notice slow performance but no freezing, then that seems to be caused by a too high load on the metadata server which would typically be caused by users working in directories with thousands of files (and then it doesn't always matter if they are small or big) or indeed by users working with lots of small files.
- Thank you very much for the answer. I experienced such freezes on other cluster - Ares in Cracow. Now I am kinda surprized that it may not be connected with I/O or directory traversing.
-
Yes, it might be or I/O but also network related. It has been way worst in the past and a network stack upgrade improved the situation
-
In case of Ares is related with I/O not the network. Some users overburden the Lustre FS there and Lustre unfortunaltely does not have reliable QoS.
- Ok, thanks a lot for the clarification.
-
Note that if a Lustre client crashes or becomes uncommunicative while holding locks it can cause all processes on other clients(nodes) accessing the same resouce (directory) to hang for a significant time until those locks get released.
-
What are the pros and cons of using EasyBuild instead of containers such as lumi-container-wrapper and singularity?
- EasBuild will compile most software so that it is exploits the system as much as possible, at least if the compiler options are chosen well (and EasyBuild tries to enforce good ones).
- EasBuild software installs directly on the system so you can use all debugger tools etc., that often don't work with containers due to the isolation that containers provide.
- But containers on LUMI can solve the problem of software that uses lots of small files and puts such a strain on the metadata servers that other users also suffer.
- And Python installations with lots of dependencies can be so complex that even if we could allow it for the metadata, it may still be a problem to develop the EasyBuild recipes. That is also why I would like to be able to use the standard EasyBuild recipes at least for non-GPU software as they have put a lot of effort into recipes for Python packages.
-
How are the PrgEnv-cray and cpeCray (for example) different?
- PrgEnv-cray works slightly differently internally in the way it loads particular versions of software. Basically there are
cpe modules to set the version but that module is extremely buggy. cpeCray is a module installed by EasyBuild that EasyBuild can fully understand and that works around the problems of the cpe + PrgEnv-* modules.
"},{"location":"4day-20231003/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/","title":"Introduction to the AMD ROCmTM Ecosystem","text":"Presenter: Jakub Kurzak (AMD)
Materials available on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-2_06_Introduction_to_AMD_ROCm_Ecosystem.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/2_06_Introduction_to_AMD_ROCm_Ecosystem.mp4
Note
ROCm 5.5 for the brave:
module purge\nmodule load CrayEnv\nmodule load PrgEnv-cray/8.3.3\nmodule load craype-accel-amd-gfx90a\nmodule load gcc/11.2.0 \n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load suse-repo-deps\nmodule load rocm/5.5.0.lua\n
(Not provided by LUST and as it says, for the brave, problems can be expected...)
"},{"location":"4day-20231003/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/#qa","title":"Q&A","text":" -
Me too doing CUDA. But is it a way to write code able to run both on AMD and CUDA?
- CUDA is code meant to run on NVIDIA GPUs, it won't run on AMD. HIP, on the other hand, can run on both NVIDIA and AMD GPUs. There are also some porting codes(hipify-clang, hipify-perl) to help in translating your code from CUDA to HIP.
-
If I have a code that runs with Pytorch for CUDA , in principle it would work on LUMI too by only installing the PyTorch version for ROCm, right? (particularly torchscatter)
- Yes, it should without change if you only use PyTorch. If you use other packages that depend on CUDA it might not. I have to check for torchscatter. Pytorch comes with a builtin \"hipify\" tools that can convert CUDA code of plugins automatically, but it needs to be enabled by the developper of the plugin. Sometimes, it's really simple. I had a ticket in the past where I \"ported\" a pytorch plugin to HIP by changing 2 lines of code :)
I will try then! Thanks
- I had a look and I see references to ROCm in the setup.py, so I think it should work on LUMI. If you need help building this plugin, please submit a ticket.
-
What is a \"warp\" (or a \"wave\")?
- Warp is NVIDIA terminology and Wavefront is AMD terminology. For both they correspond to the same level structure. Warp is a structure of 32 threads that run at the same time and execute the same instructions, basically a vector thread. For AMD it is the same, but with 64 threads.
-
How are LUMI and Frontier different with regards to the user guides?
-
Slurm setup is different
-
The whole software stack is different. There are differences at the HPE level as they have a different management stack which translates into other differences, and different versions of the PE installed, and there are differences in the software they installed on top of that.
"},{"location":"4day-20231003/extra_2_07_Exercises_6/","title":"Exercise session 6: HIP tools","text":"Exercise assignments can be found in the AMD exercise notes, sections on HIP Exercises and Hipify.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20231003/extra_2_07_Exercises_6/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar
"},{"location":"4day-20231003/extra_2_07_Exercises_6/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_3_01_Introduction_to_Perftools/","title":"Introduction to Perftools","text":"Presenters: Thierry Braconnier (HPE) and Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
Info
You can find the downloads of Apprentice2 and Reveal on LUMI in $CRAYPAT_ROOT/share/desktop_installers/. This only works when the perftools-base module is loaded, but this is the case at login.
"},{"location":"4day-20231003/extra_3_01_Introduction_to_Perftools/#qa","title":"Q&A","text":" -
Can I use perftools with an application that I build using Easybuilds?
-
It is tricky. In principle when you do performance analysis you want complete control over how the application is build and that is rather the opposite of what you want when using EasyBuild. But there are tricks to inject additional compiler options in EasyBuild or to make sure that certain environment variables are set when compiling. But that requires changing the EasyConfig itself, there is no way to inject those things via command line options of EasyBuild.
There will also be problems with the sanity checks as the executables get a modified name. So whenever EasyBuild implements a test to check if the executable is present, or tries to run the executable, that test will fail.
-
In general though the -lite modules should just work. For the more advanced use of perftools you will need to inject an extra step into the build to get the instrumented executable.
-
Is it possible to use multiple perftools-lite-* modules at the same time?
- No, the modules are exclusive and LMOD will present to load two modules (you get an unload of the current loaded module and load of the new one). For complex analysis, you have to use
pat_build and decide which analysis to do (next presentation).
"},{"location":"4day-20231003/extra_3_02_Exercises_7/","title":"Exercise session 7: perftools-lite","text":"The files for the exercises can be found in Exercises/HPE/day3/perftools-lite and Exercises/HPE/day3/perftools-lite-gpu. Follow the Readme.md description and get familiar with the perftools-lite commands and outputs.
- Subdirectory perftools-lite needs
lumi_c.sh (or lumi_c_after.sh) to be sourced. - Subdirectory perftools-lite-gpu needs
lumi_g.sh (or lumi_g_after.sh) to be sourced.
"},{"location":"4day-20231003/extra_3_02_Exercises_7/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_3_02_Exercises_7/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_3_03_Advanced_Performance_Analysis/","title":"Advanced Performance Analysis","text":"Presenter: Thierry Braconnier (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-3_03_Advanced_Performace_analysis.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/3_03_Advanced_Performance_Analysis.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_3_03_Advanced_Performance_Analysis/#qa","title":"Q&A","text":" -
In general, is the reliability of the profiling times (flops, percentages) equally good for directly compiled routines, cray libraries, external libraries? Are the perftools sufficient to get a reliable overview or is it always better to accompany this analysis with a direct output of the system times?
-
The goal of any profiler tool is to provide reliable analysis of the execution. Of course it can affect the overall performance with overhead (or it can apply serialization in some parts). It really depends on the application, I don't think there is a final answer for that. For this reason perftools is always providing the non-instrumented version so that you can compare the overall execution.
-
But any other debug or profiling code you put in the application may also influence the application, especially if you also do immediate I/O of the numbers rather than storing them somewhere and doing all I/O outside of code that you want to time.
-
The biggest danger is with tracing if you trace very small fast functions, perftools tries not to do this.
"},{"location":"4day-20231003/extra_3_04_Exercises_8/","title":"Exercise session 8: perftools","text":"The files for the exercises can be found in Exercises/HPE/day3/perftools and its subdirectories. Follow the Readme.md description (per each directory) and get familiar with the perftools commands and outputs.
- Subdirectories perftools, perftools-api, perftools-hwpc, perftools-python, and perftools-apa need lumi_c.sh (or
lumi_c_after.sh) to be sourced. - Subdirectories perftools-for-hip and perftools-for-omp-offload need lumi_g.sh (or
lumi_g_after.sh) to be sourced
"},{"location":"4day-20231003/extra_3_04_Exercises_8/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_3_04_Exercises_8/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_3_05_Cray_MPI_on_Slingshot/","title":"MPI Topics on the HPE Cray EX Supercomputer","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_3_05_Cray_MPI_on_Slingshot/#qa","title":"Q&A","text":" -
If you use GPU-aware MPI with larger eager messages, is there no risk of running out of memory even quicker? (Well, this would also be the case for CPU, but somehow on LUMI memory errors on the GPU for big MPI jobs are more common)
- There is a limit to how much you can increase the maximum size for eager messages. But yes, we do think that it also increases the amount of memory that MPI will use for buffering.
-
How does the aws-ofi-rccl fit together with all this?
- RCCL is not MPI, it is a different distributed memory communication protocol. And the
aws-ofi-rccl plugin is a plugin for RCCL that enables it to communicate via the OFI communication library on LUMI which then uses the Cassini provider to work with SlingShot 11. Otherwise it would use a standard Linux protocol that is much slower.
"},{"location":"4day-20231003/extra_3_06_Exercises_9/","title":"Exercise session 9: Cray MPICH","text":"The files for the exercises can be found in Exercises/HPE/day3/PRogrammingModels. Test the Pi example with MPI or MPI/OpenMP on 4 nodes and 4 tasks. Show where the ranks/threads are running by using the appropriate MPICH environment variable. Use environment variables to change this order (rank-reordering).
Alternatively, continue with the previous exercises if these are more relevant for your work.
"},{"location":"4day-20231003/extra_3_06_Exercises_9/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_3_06_Exercises_9/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_3_07_AMD_ROCgdb_Debugger/","title":"AMD ROCgdb debugger","text":"Presenter: Jakub Kurzak (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20231003/extra_3_07_AMD_ROCgdb_Debugger/#qa","title":"Q&A","text":" -
What is FMA?
-
Fused Multiply Add: Computes x*y+z (if it where scalar) or multiplying equivalent elements if x, y and z are vectors (so x[i]*y[i]+z[i] for all elements).
This instruction has some advantages. It is a common operation in numeric codes and it does 2 flops per vector element in a single operation (and can do so faster than a separate multiple and add instruction). Moreover, it is usually done with a smaller roundoff error than using two separate instructions.
It has been popular on CPUs from certain vendors since the nineties, and was added to the x86 instruction set with the haswell generation around 2014. It is also a popular operation on GPUs.
-
About the slide 26. Do I understand correctly that there are 16 units that each is like and ALU more than a core? The difference would be that ALUs can run different instructions, while these units have to run the same one. Do I understand correctly? You called the 10 threads running like the hyperthreading and I wondered if it works like this. ...
-
There are 4 vector units which are 16 lanes wide and process 64-element vectors in 4 passes. These units have to be compared to, e.g., the AVX/AVX2/AVX-512 vector units on an Intel processor.
Thanks to NVIDIA, core, thread, etc., are all confusing names in the GPU world as they are all redefined in a completely different meaning as for CPUs.
-
I have a bit off-topic question. Can the ROCm be run also on Radeon cards, like 7900 XTX? Thank you!
-
The very latest version of ROCm (5.7) has support for some Radeon cards. We and other sites have been pushing AMD for a long time as we feel users need a cheaper way to write software for AMD GPUs. You should be aware though that the RDNA architecture is rather different vrom the CDNA architecture. It is based on vectors of length 32 instead of 64 (though it still supports the latter I believe for compatibility with the older GCN architecture).
I am not sure which features are supported and which are not, and AMD person would need to answer that.
-
The 7900 XTX is supported on windows but not on Linux, where the only supported Radeon card in the Radeon VII. Note that, some ROCm libraries are Linux exclusive. At the moment, you do not have the full ROCm experience with a Radeon card.
"},{"location":"4day-20231003/extra_3_08_Exercises_10/","title":"Exercise session 10: Debugging with ROCgdb","text":"Exercise assignments can be found in the AMD exercise notes, section on Debugging.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20231003/extra_3_08_Exercises_10/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar
"},{"location":"4day-20231003/extra_3_08_Exercises_10/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/","title":"Introduction to ROC-Profiler (rocprof)","text":"Presenter: Samuel Ant\u00e3o (AMD)
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-3_09_Introduction_to_Rocprof_Profiling_Tool.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/3_09_Introduction_to_Rocprof_Profiling_Tool.mp4
Note
Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"4day-20231003/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/#qa","title":"Q&A","text":" -
According to the schedule this was going to be rocprof session. Is it tomorrow then?
- Not sure which agenda you're looking at, but the rocprof session is after this exercise round at 16:00
- My bad, sorry! :)
-
Let's say my GPU bindings are bad. How would I detect this using the profiler?
-
See the recording for the answer.
-
Difficult to detect via a profiler. You may see some low bandwidth but you are never sure that it is caused by a wrong biding.
-
We have the gpu_check command in lumi-CPEtools to check the binding but that does not work for applications that do the binding themselves.
-
Can we see the GPU memory usage in the profiler output? Or is there some other signal in the profiler to detect if we are not using the GPU memory efficiently?
-
See the recording. You can see the allocations that you did.
-
AMD needs to doublecheck, but Omnitrace (discussed tomorrow) may give more information.
-
Whether memory is used well is more difficult for a profiler to tell. You can see bandwidths and number of read and write operations, but that does not necessarily imply that memory is used well or badly.
-
Nvtop could help figuring out general memory allocation. https://github.com/Syllo/nvtop GPU agnostic
"},{"location":"4day-20231003/extra_3_10_Exercises_11/","title":"Exercise session 11: Rocprof","text":"Exercise assignments can be found in the AMD exercise notes, section on Rocprof.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20231003/extra_3_10_Exercises_11/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar
"},{"location":"4day-20231003/extra_3_10_Exercises_11/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_4_01_Introduction_to_Python_on_Cray_EX/","title":"Introduction to Python on Cray EX","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_01_Introduction_to_Python_on_Cray_EX.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/4_01_Introduction_to_Python_on_Cray_EX.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_4_01_Introduction_to_Python_on_Cray_EX/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_4_02_Performance_Optimization_Improving_Single_Core/","title":"Performance Optimization: Improving Single-core Efficiency","text":"Presenter: Jean Pourroy (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_02_Performance_Optimization_Improving_Single_Core.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/4_02_Performance_Optimization_Improving_Single_Core.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_4_02_Performance_Optimization_Improving_Single_Core/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_4_03_Exercises_12/","title":"Exercise session 12: Node-level performance","text":"The files for the exercises can be found in Exercises/HPE/day4/node_performance. Try different compiler optimizations and see the impact on performance.
"},{"location":"4day-20231003/extra_4_03_Exercises_12/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_4_03_Exercises_12/#qa","title":"Q&A","text":" -
What is the expexcted difference between -O1 and -O3 in day4/node_performance test? Suprisingly I got longer total time for -O3 (37.668011) than for -O1 (37.296712) and I wondering is this is completely outside expected range or the optimizations produce similar results in this case? Thanks!
- Is optimization level in Makefile overwritten by command-line-set value?
- Are you sure? It looks like both are using the same optimization level, the difference is well within noise and differences between nodes.
Is there a way to verify which optimization was used in each run?
- The goal of the exercise is not to compare runtimes though but compare the output of the profiler which may point to different problems in some part of the code. I do indeed also get very similar performance otherwise.
Ohh, thanks for explanation, I supposed there will be also a noticeble performance boost so I was wondering whether I am doing something wrong...
- I just tried the exercise myself and the results are strange. I'll try to figure out who made that exercise but he's not here at the moment. It might be that it was tested with a different or older compiler that gave other results or had worse optimisation at
-O1. With -O0 you do see significant differences and one particular loop operation that takes a lot more time.
I tried -O0 and got also a significant slowdown (75.074496) so probably in this case -O1 and -O3 just led to similar compute times and there was no error...
- This is indeed what I suspect, the exercise needs an update...
"},{"location":"4day-20231003/extra_4_04_IO_Optimization_Parallel_IO/","title":"I/O Optimization - Parallel I/O","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20231003/extra_4_04_IO_Optimization_Parallel_IO/#links","title":"Links","text":" - The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20231003/extra_4_04_IO_Optimization_Parallel_IO/#qa","title":"Q&A","text":" -
Rules of thumb for setting the stripe size?
-
See slide 23
-
HPE sometimes says 1 MB but it turns out to depend on how your program does I/O. I remember a ticket of a project reporting that they had to set it much, much higher for optimal bandwidth but then they got close to one quarter of the quoted peak bandwidth of the file system for reads which was very, very good considering that many users where also using the file system at that moment.
-
If you can write large chunks of data or are using a library that buffers (fortran I/O, C file I/O operations) then experiment with larger stripe sizes.
-
Let's say I have gigabytes of training data (in 1 or 2 files). I put them on /flash/PROJECT. Does the striping apply there also?
-
Yes, sometimes, depending on how you do I/O in your code. If the I/O operations are of a type that scales (large parallel I/O from multiple nodes), it will help. And on LUMI-G maybe even from one node if the I/O would be properly using all NICs. With a single NIC, the bandwidth that NIC can deliver may already close to what you can get from one OST if that one has a low load at that time. And with small I/O operations, striping will not give you anything, neither on disk nor on flash, and you'll be limited by latency of a network file system.
But the whole idea is also that having optimal I/O enables you to use cheaper storage and get the same results as on expensive faster storage. The flash file system is billed at ten times the rage as the hard disk file system for a reason. It was also that much more expensive when purchased.
-
Thank you very much for very interesting topic - MPI-IO. I'm totaly new to it. Which resources can you advice me? You mentioned The ExaIO project, as a development over HDF5. I intend to start from much more primitive things and then if necessary to go upper level. I have found an article https://phillipmdickens.github.io/pubs/paper1.pdf but it is 13 years old. This question, as for me, deserves the whole day. Which resources can you advice me to learn about MPI-IO/or non-mpi hacks like asynchronous I/O?
-
I have no time to check now, I have too much processing of the course materials to do at the moment, but maybe some of the following links can put you on the way:
-
Slides from an Archer course which was for an older Cray machine. The may have an update somewhere for Archer2 which is even closer to LUMI.
-
Slides from CSCS, also a Cray site
-
A video from PRACE. It may be worth to go their training materials of their past trainings. It may contain interesting stuff.
-
Material from a training from Argonne National Lab. That group created MPICH, the basis for Cray MPICH, and their MPI I/O code is actually used by other MPI implementatons also.
Basically, googling for \"MPI I/O training materials\" does seem to return a lot of useable materials.
-
A question a bit close to I/O. I intend to write MPI/OpenMP program. Let's assume that we have several compute nodes, consisting of 4 NUMA nodes, with NIC(s) connected to single NUMA node. I need processing messages like a pipeline, namely receive message, process it then send it keeping their order. I suppose using 4 MPI processes running many OpenMP threads each because I am not sure that I can divide tasks more. How should I organize this avoiding nonnecessary memory copying and keeping memory locality for each OpenMP thread? Can you advice any literature how to write something similar in C/C++ or where to look about it? Are there any articles or books about such \"pipeline pattern\"?
- I don't think we can answer this today, if you could summarise your exact scenario further and submit a LUMI ticket asking it be sent to the CoE then we can have a look and hopefully come back with some advice.
Ok thank you. I am at very early stage. I think I need to rethink it and possibly write some primitive prototype in order to ask more detailed questions.
- It may be worth to search for PRACE training archives. They used to have good courses about intra-node optimization which is what matters here. E.g., there used to be excellent courses given by Georg Hager and Gerhard Wellein of FAU Erlangen. Some of that material might be online in the PRACE archives.
"},{"location":"4day-20231003/extra_4_05_Exercises_13/","title":"Exercise session 13: Lustre I/O","text":"The files for the exercises can be found in Exercises/HPE/day4/VH1-io. Untar the file and you'll find a full I/O experiment with striping.
Alternatively, look again at the MPI exercises with Apprentice If you did not do this before, set PAT_RT_SUMMARY=0. You get trace data per rank when you do this (huge file). Set only 2 cycles in the input file (indat). Use app2 on the .ap2 file to see new displays (see help).
"},{"location":"4day-20231003/extra_4_05_Exercises_13/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_HPE.tar
"},{"location":"4day-20231003/extra_4_05_Exercises_13/#qa","title":"Q&A","text":" -
Is there a typo in the README? For the lfs setstripe -c ${STRIPE_COUNT} -s ${STRIPE_SIZE} ${RUNDIR}/output should the capital -S be used instead of -s?
- Indeed. I wonder how this was never noted, the error is in the slide also which has been used for 2 years... It turns out to be wrong on the slide (corrected version is now available), wrong in the README (in the project directory, archived version corrected), but correct in the script where
-S is used.
"},{"location":"4day-20231003/extra_4_06_AMD_Omnitrace/","title":"Introduction to OmniTrace","text":"Presenter: Samuel Ant\u00e3o (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20231003/extra_4_06_AMD_Omnitrace/#qa","title":"Q&A","text":" -
Where do we get rocm 5.4.3? I thought that the latest on LUMI is 5.3.3 (and even that is not supported).
-
LUST does not support anything newer than 5.3.3 because newer versions are not 100% compatible with the PE we have. However, the exercises for this talk point to an unofficial one. But don't complain if it does not work for what you want to do (e.g., problems with gcc or MPI hangs may occur, and the installation plays not nice with the Cray PE wrappers).
There is hope that after the next system update later this fall ROCM 5.5 will be available, but sysadmins are still testing everything involved with that update so it is not yet 100% certain it will be ready for the next maintenance window.
-
5.3.3 is not supported in the sense that if there turn out to be problem with it in combination with the PE, we cannot upstream problems to get a solution from the vendor, and also it is not compatible with the way PrgEnv-amd works. However, it has been successfully used on LUMI by several users.
"},{"location":"4day-20231003/extra_4_07_Exercises_14/","title":"Exercise session 14: Omnitrace","text":"Exercise assignments can be found in the AMD exercise notes, section on Omnitrace.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20231003/extra_4_07_Exercises_14/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar
"},{"location":"4day-20231003/extra_4_07_Exercises_14/#qa","title":"Q&A","text":"/
"},{"location":"4day-20231003/extra_4_08_AMD_Omniperf/","title":"AMD Omniperf","text":"Presenter: Jakub Kurzak (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20231003/extra_4_08_AMD_Omniperf/#qa","title":"Q&A","text":" -
What is HBM?
- High-Bandwidth Memory. It is the memory technology used on most compute GPUs. Both the AMD MI100/200 series as the main compute GPUs of NVIDIA (P100, V100, A100, H100) and Intel (Ponte Vecchio) use it.
"},{"location":"4day-20231003/extra_4_09_Exercises_15/","title":"Exercise session 15: Omniperf","text":"Exercise assignments can be found in the AMD exercise notes, section on Omniperf.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20231003/extra_4_09_Exercises_15/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20231003/files/LUMI-4day-20231003-Exercises_AMD.tar
"},{"location":"4day-20231003/extra_4_09_Exercises_15/#qa","title":"Q&A","text":" -
When I try executing commands from the first hackmd.io link, this is what I get:
salloc -N 1 --ntasks=1 --partition=small-g --gpus=1 -A project_465000644 --time=00:15:00 salloc: error: Job submit/allocate failed: Requested node configuration is not available salloc: Job allocation 4701325 has been revoked.
- could you
source /project/project_465000644/Exercises/HPE/lumi_g.sh . It could be that you run the lumi_c.sh script which sets some variables that could clash with the salloc.
Yes, I did source the lumi_g.sh
- OK. I checked the
lumi_g.sh script and even the environment variables that it sets influence salloc in a way that creates conflicts with your command line. So the trick is to log in again and not source any of those scripts and then the salloc line will work, but you will not be working in the reservation, or to not add the -A and --partition argument as they are set by environment variables. What is actually happening is that because of the enviornment variables the reservation is activated but you're asking for nodes outside the reservation.
Yes, it works when not sourcing anything. Is the salloc in the linked document really needed and it wouldn't be better to forgo it and just use the reservation?
"},{"location":"4day-20231003/extra_4_10_Best_Practices_GPU_Optimization/","title":"Tools in Action - An Example with Pytorch","text":"Presenter: Samuel Ant\u00e3o (AMD)
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_10_Best_Practices_GPU_Optimization.pdf
-
Scripts as bzip2-compressed tar archive in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_10_scripts.tar.bz2 and uncompressed tar archive in /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_10_scripts.tar.
-
Recording: /appl/local/training/4day-20231003/recordings/4_10_Best_Practices_GPU_Optimization.mp4
"},{"location":"4day-20231003/extra_4_10_Best_Practices_GPU_Optimization/#qa","title":"Q&A","text":" -
If PyTorch does not use MPI, what does it use?
- RCCL, the ROCm version of the NVIDIA NCCL library. It needs a plugin to communicate across nodes but I guess that will also be shown in the talk.
-
Why we don't need libsci for BLAS, LAPACK, etc?
- He is using a different one here because it doesn't really matter if you may a Pytorch for GPU. BLAS operations will run on the GPU with ROCm libraries.
Why not EasyBuild then?
- The build process is not very compatible with EasyBuild. It is possible but adapting the EasyConfigs that exist for Pytorch to LUMI is too time-consuming for us at the moment. And in the end we want to end up in a container which comes later in the talk...
-
I thought conda and python packages should be installed in containers?
-
Preferably, especially if they become large in number of files. It is also comming up in the talk... Running outside a container can be useful though if you need to go in the code with debuggers and profilers.
An in between solution, especially if you work on exclusive nodes, could be to install in /tmp which would be very good for performance also. You could then store a tar archive and uncompress that in the job to do the installation, and still be able to use debuggers etc. easily.
-
How does Singularity enable more recent ROCm versions?
-
Because you can put dependencies in there also that are not on the system. E.g., recent ROCm versions are build with a newer version of gcc than is the default on LUMI, and with a container you can put the right compiler runtime libraries where ROCm can also find them.
One of the major reasons to use containers is to provide libraries that are not on the system or that are required in a different version than on the system without creating conflicts.
-
What does MIOpen do?
- It is the ROCm equivalent of cuDNN and is the BLAS of machine learning applications: It contains optimised implementations of common operations in machine learning applications. Each vendor tries to make its optimised implementation of those routines. Intel also has an mklDNN for its CPUs and now GPU also. Pytorch and Tensorflow both use it.
-
Do we have access to these scripts?
- They are in the
Exercises/AMD/Pytorch subdirectory, and archived via this page.
-
Meta question: Are we allowed to share/show
-
AMD and LUST slides and recordings: Yes, they can be shared at will, just acknowleding they come from a LUMI course. However, for LUST material, if you want to use the material in your own trainings or more formal presentations, you should make it very clear that LUST did not check modifications or if they are still up-to-date and hence cannot be responsible for errors. To re-use AMD material in more formal events it is best to contact them. (Notice, e.g., that AMD people presenting have to show a disclaimer at the end so they will likely require something similar if you copy from their slides.)
-
HPE slides and recordings: Only to people with a userid on LUMI.
-
Basically if we make them directly available via web links they can be shared informally, just mentioning where they come from, and if they are only available on the system in the training project or /appl/local/training but not via a direct web link, then access is restricted to people with a userid.
-
You can always share this link to our training material webpage
-
Is there offline version of perfetto.dev? Because one should have local version if looking in long time perspective. Remote things tend to make changes which break everything or make it for payment.
-
According to AMD, no, perfetto is only available in online version.
The code is available in a GitHub repository though so it should be possible to set up a web server yourself running perfetto.
I do notice there are downloads in that repository also but I do not know if they contain a complete web server etc., or need to be installed on top of one already existing. I cannot check as my Mac detects the files as suspicious and refuses to download.
Thank you very much. Well, just cloning that repo may fix it.
"},{"location":"4day-20231003/extra_4_11_LUMI_Support_and_Documentation/","title":"LUMI User Support","text":"Presenter: J\u00f8rn Dietze (LUST)
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20231003/files/LUMI-4day-20231003-4_11_LUMI_Support_and_Documentation.pdf
-
Recording: /appl/local/training/4day-20231003/recordings/4_11_LUMI_Support_and_Documentation.mp4
The information in this talk is also covered by the following talk from the 1-day courses:
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
- Some remarks about using containers on LUMI.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We do offer some help to set up Spack also but it is mostly offered \"as is\" and we will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. On LUMI the tool is called lumi-container-wrapper but it may by some from CSC also be known as Tykky. As an alternative we also offer cotainr, a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space and can be used to containerise a conda-installation.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12 and LUMI/23.03 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1 (when infrastructure for a demo is available)
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 17 versions of GNUplot. There are 12 installations of GNUplot 5.4.3 (of which 3 with Spack, their name has a different structure) and five of 5.4.6. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there are four versions,3.22.2, 3.23.2, 3.24.0 and 3.25.2, that are shown in blue with an \"E\" behind the name. That is because these are not provided by a module called CMake on LUMI, but by another module that in this case contains a collection of popular build tools and that we will discover shortly.
There are also a couple of regular modules called cmake that come from software installed differently.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.6-cpeGNU-22.12. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are three ways to load the module: By loading LUMI/22.12 combined with partition/C, by loading LUMI/22.12 combined with partition/G or by loading LUMI/22.12 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/22.12 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.25.2. This will now show us that this tool is in the buildtools/22.12 module (among others) and give us 4 different options to load that module as it is provided in the CrayEnv and the LUMI/22.12 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider cmake\nmodule spider gnuplot/5.4.6-cpeGNU-22.12\nmodule spider CMake/3.25.2\n
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#module-keyword-command","title":"Module keyword command","text":"Lmod has a second way of searching for modules: module keyword, but unfortunately it does not yet work very well on LUMI as the version of Lmod is rather old and still has some bugs in the processing of the command.
The module keyword command searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Demo module keyword Try the following command:
module keyword https\n
The bug in the Lmod 8.3 version on LUMI is that all extensions are shown in the output while they are irrelevant.
On the second screen though we see cURL which is a tool to download files over, among others, https.
And the fourth screen wget which is also a tool to download files from the internet over an https connection.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Demo Try the following command:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded, but we'll come back to that later also.
Note the two categories for the PE modules. The target modules get their own block. The screen below also shows (D:5.0.2:5.2.0) next to the rocm module. The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
In the next screen we see the modules for the software stack that we have just discussed.
And the screen below shows the extensions of modules (like the CMake tool we've tried to locate before)
At the end of the output we also get some information about the meaning of the letters used in the display.
Try the following commands and carefully observe the output:
module load LUMI/22.08 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similarly in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/22.12 stack we prefer that users use the Cray programming environment modules that come with release 22.12 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Demo Try the following commands:
module load LUMI/22.12\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the build-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2021.4, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeCray-22.08 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/22.08.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.8.0-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2021.4-cpeCray-22.08-PLUMED-2.8.0-CPE.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#installing-software","title":"Installing software","text":""},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Demo moment 2
Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS we already have support. The easy way is to check the LUMI Software Library which lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. A command-line alternative is to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb \u2013r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
Demo of the EasyBuild installation of GROMACS
End of demo moment 2
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.lmod.d/.cache. You can do this with
rm -rf $HOME/.lmod.d/.cache\n
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.0-cpeGNU-22.08.eb \u2013r . \n
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elsewhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#easybuild-tips-tricks","title":"EasyBuild tips & tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"I also want to give some pointers to more information in case you want to learn a lot more about, e.g., developing support for your code in EasyBuild, or for support people who want to adapt our EasyConfigs for users requesting a specific configuration of a package.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software.
But full portability is a much greater myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the SlingShot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
Even if a container is portable to LUMI, it may not yet be performance portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
Software installations that would otherwise be impossible. E.g., some software may not even be suited for installation in a multi-user HPC system as it uses fixed paths that are not compatible with installation in module-controlled software stacks. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
-
As an example, Conda installations are not appreciated on the main Lustre file system.
On one hand, Conda installations tend to generate lots of small files (and then even more due to a linking strategy that does not work on Lustre). So they need to be containerised just for storage manageability.
They also re-install lots of libraries that may already be on the system in a different version. The isolation offered by a container environment may be a good idea to ensure that all software picks up the right versions.
-
Another example where containers have proven to be useful on LUMI is to experiment with newer versions of ROCm than we can offer on the system.
This often comes with limitations though, as (a) that ROCm version is still limited by the drivers on the system and (b) we've seen incompatibilities between newer ROCm versions and the Cray MPICH libraries.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory. This can lead to exhaustion of your disk quota for your home directory. So you may want to use the environment variable SINGULARITY_CACHEDIR to put the cache in, e.g,, your scratch space (but even then you want to clean up after the pull operation so save on your storage billing units).
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require fakeroot or user namespaces, cannot be supported for security reasons (with user namespaces in particular a huge security concern as the Linux implementation is riddled with security issues). Enabling features that are known to have had several serious security vulnerabilities in the recent past, or that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container. We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI SlingShot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and currently full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the SlingShot 11 interconnect so work is going on for better support for OFI and for full GPU support on systems that rely on OFI and do not support UCX.
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY_PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the singularity-bindings in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks through the lumi-vnc module. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
The third tool is a container wrapper tool that users from Finland may also know as Tykky. It is a tool to wrap Python and conda installations in a container and then create wrapper scripts for the commands in the bin subdirectory so that for most practical use cases the commands can be used without directly using singularity commands. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run the tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation.
We do strongly recommend to use the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a tempororary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
The final tool is cotainr, a tool developed by DeIC, the Danish partner in the LUMI consortium. It is another tool to pack a Conda installation into a container, but it does so in a more container-like way (so no wrapper scripts). Just as lumi-container-wrapper, it runs entirely in user space and doesn't need any special rights. (For the container specialists: It is based on the container sandbox idea to build containers in user space.)
"},{"location":"4day-20231003/notes_2_05_LUMI_Software_Stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance. Also, containers do not abstract the hardware unlike some virtual machine solutions.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
Likewise, for containers for distributed AI, one may need to inject an appropriate RCCL plugin to fully use the SlingShot 11 interconnect.
-
The support for building containers on LUMI is currently very limited due to security concerns. Any build process that requires elevated privileges, fakeroot or user namespaces will not work.
"},{"location":"4day-20231003/schedule/","title":"Course schedule","text":" - Day 1
- Day 2
- Day 3
- Day 4 DAY 1 - Tuesday 03/10 09:00 CEST 10:00 EEST Welcome and introduction Presenters: Emmanuel Ory (LUST), Harvey Richardson (HPE) 09:15 CEST 10:15 EEST HPE Cray EX architecture
- Focus on the HPE Cray EX hardware architecture
Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE) Part on the interconnect postponed as the original speaker got stuck at an airport on the way to Warsaw. 09:35CEST 10:35 EEST Programming Environment and Modules - Focus on the HPE Cray EX software stack
- Tutorial on the Cray module environment and compiler wrapper scripts
Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE) 10:20 CEST 11:20 EEST Exercises (session #1a) You can now make the programming model exercises. Exercises are in /project/project_465000644/exercises/HPE on LUMI only. 10:45 CEST 11:45 EEST Break (15 minutes) 11:00 CEST 12:00 EEST Running Applications - Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
Presenter: Alfio Lazzaro (HPE), replacing Harvey Richardson (HPE) 11:20 CEST 12:20 EEST Exercises (session #1b) 12:00 CEST 13:00 EEST Lunch break (90 minutes) 13:30 CEST 14:30 EEST Compilers and Parallel Programming Models - An introduction to the compiler suites available, including examples of how to get additional information about the compilation process.
- Cray Compilation Environment (CCE) and options relevant to porting and performance. CCE classic to Clang transition.
- Description of the Parallel Programming models.
Presenter: Alfio Lazzaro (HPE) 14:30 CEST 15:30 EEST Exercises (session #2) 15:00 CEST 16:00 EEST Break (15 minutes) 15:15 CEST 16:15 EEST HPE Cray EX architecture: Part 2: The interconnect - Focus on the HPE Cray EX hardware architecture
Presenter: Harvey Richardson (HPE) 15:45 CEST 16:45 EEST Cray Scientific Libraries - The Cray Scientific Libraries for CPU and GPU execution.
Presenter: Alfio Lazzaro (HPE) 15:45 CEST 16:45 EEST Exercises (session #3) 16:10 EEST 17:10 EEST CCE Offloading Models - Directive-based approach for GPU offloading execution with the Cray Compilation Environment. Presenter: Alfio Lazzaro (HPE) 16:40 CEST 17:40 EEST Exercises (session #3) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course day DAY 2 - Wednesday 04/10 09:00 CEST 10:00 EEST Advanced Placement
- More detailed treatment of Slurm binding technology and OpenMP controls.
Presenter: Jean Pourroy (HPE) 10:00 CEST 11:00 EEST Exercises (session #4) 10:30 CEST 11:30 EEST Break (15 minutes) 10:45 CEST 11:45 EEST Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat Presenter: Thierry Braconnier (HPE) 11:30 CEST 12:30 EEST Exercises (session #5) 12:00 CEST 13:00 EEST Lunch break (90 minutes) 13:30 CEST 14:30 EEST LUMI Software Stacks - Software policy.
- Software environment on LUMI.
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LUST) 15:00 CEST 16:00 EEST Break (30 minutes) 15:30 CEST 16:30 EEST Introduction to the AMD ROCmTM Ecosystem The AMD ROCmTM ecosystem HIP programming
Presenter: Jakub Kurzak (AMD) 16:30 CEST 17:30 EEST Exercises (session #6) 17:00 CEST 16:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 18:30 EEST End of the course day DAY 3 - Thursday 05/10 09:00 CEST 10:00 EEST Introduction to Perftools - Overview of the Cray Performance and Analysis toolkit for profiling applications.
- Demo: Visualization of performance data with Apprentice2 Presenter: Thierry Braconnier (HPE) and Alfio Lazzaro (HPE) 09:40 CEST 10:40 EEST Exercises (session #7) 10:10 CEST 11:10 EEST Break 10:30 CEST 11:30 EEST Advanced Performance Analysis
- Automatic performance analysis and loop work estimated with perftools
- Communication Imbalance, Hardware Counters, Perftools API, OpenMP
- Compiler feedback and variable scoping with Reveal
Presenter: Thierry Braconnier (HPE) 11:15 CEST 12:15 EEST Exercises (session #8) 12:00 EEST 13:00 EEST Lunch break 13:15 CEST 14:15 EEST MPI Topics on the HPE Cray EX Supercomputer - High level overview of Cray MPI on Slingshot
- Useful environment variable controls
- Rank reordering and MPMD application launch
Presenter: Harvey Richardson (HPE) 14:15 CEST 15:15 EEST Exercises (session #9) 14:45 CEST 15:45 EEST Break 15:00 CEST 16:00 EEST AMD Debugger: ROCgdb Presenter: Jakub Kurzak (AMD) 15:30 CEST 16:30 EEST Exercises (session #10) 16:00 CEST 17:00 EEST Introduction to ROC-Profiler (rocprof) Presenter: Samuel Ant\u00e3o (AMD) 16:30 CEST 17:30 EEST Exercises (session #11) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course day DAY 4 - Friday 06/10 9:00 CEST 10:00 EEST Python and Frameworks Presenter: Alfio Lazzaro (HPE) 09:15 CEST 10:15 EEST Performance Optimization: Improving Single-core Efficiency Presenter: Jean Pourroy (HPE) 10:00 CEST 11:00 EEST Exercises (session #12) 10:15 CEST 11:15 EEST Break 10:30 CEST 11:30 EEST Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system.
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes.
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations: Further considerations of parallel I/O and other APIs.
- Being nice to Lustre: Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson (HPE) 11:30 CEST 12:30 EEST Exercises (session #13) 12:00 CEST 13:00 EEST Lunch break (75 minutes) 13:15 CEST 14:15 EEST Introduction to OmniTrace Presenter: Samuel Ant\u00e3o (AMD) 13:50 CEST 14:50 EEST Introduction to Omniperf Presenter: Jakub Kurzak (AMD) 14:30 CEST 15:30 EEST Exercises (session #14) and Exercises (session #15) combined 14:45 CEST 15:45 EEST Break 15:00 CEST 16:00 EEST Tools in Action - An Example with Pytorch Presenter: Samuel Ant\u00e3o (AMD) 16:40 CEST 17:40 EEST LUMI User Support - What can we help you with and what not? How to get help, how to write good support requests.
- Some typical/frequent support questions of users on LUMI?
Presenter: J\u00f8rn Dietze (LUST) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course"},{"location":"4day-20240423/","title":"Comprehensive General LUMI Training, April 23-26, 2024","text":""},{"location":"4day-20240423/#course-organisation","title":"Course organisation","text":" -
Location: CSC, Keilaranta 14, 02150 Espoo, Finland
Room: Dogmi.
Upon arrival at CSC, please register in the lobby at the entrance of the C building, Life Sciences Center, Keilaranta 14 (round doors). It is likely you will receive a QR-code to scan at the entrance the day before, and that greatly speeds up the registration process.
Public transportation in Helsinki. A very easy way to buy tickets is via the HSL app, but it is best to set it up before you travel so that payment goes quickly.
The venue is close to the \"Keilaniemi - K\u00e4geludden\" metro station, providing an excellent connection with the hotels downtown.
-
Original schedule (PDF)
Dynamic schedule (adapted as the course progresses)
The dynamic schedule also contains links to pages with information about the course materials, but those links are also available below on this page.
"},{"location":"4day-20240423/#course-materials","title":"Course materials","text":"Course materials include the Q&A of each session, slides when available and notes when available.
Due to copyright issues some of the materials are only available to current LUMI users and have to be downloaded from LUMI.
Note: Some links in the table below are dead and will remain so until after the end of the course.
Presentation slides notes recording Introduction / / web HPE Cray EX Architecture lumi / lumi Programming Environment and Modules lumi / lumi Running Applications lumi / lumi Exercises #1 / / / Compilers and Parallel Programming Models lumi / lumi Exercises #2 / / / Cray Scientific Libraries lumi / lumi Exercises #3 / / / CCE Offloading Models lumi / lumi Introduction to the AMD ROCm Ecosystem web / web Exercises #4 / / / Debugging at Scale lumi / lumi Exercises #5 / / / Advanced Placement lumi / lumi Exercises #6 / / / LUMI Software Stacks web web web Introduction to Perftools lumi / lumi Exercises #7 / / / Advanced Performance Analysis lumi / lumi Exercises #8 / / / MPI Topics on the HPE Cray EX Supercomputer lumi / lumi Exercises #9 / / / AMD Debugger: ROCgdb web / web Exercises #10 / / / Introduction to ROC-Profiler (rocprof) web / web Exercises #11 / / / Introduction to Python on Cray EX lumi / lumi Frameworks for porting applications to GPUs lumi / lumi Performance Optimization: Improving single-core Efficiency lumi / lumi Exercises #12 / / / Optimizing Large Scale I/O lumi / lumi Exercises #13 / / / Introduction to OmniTrace web / web Exercises #14 / / / Introduction to Omniperf web / web Exercises #15 / / / Tools in Action - An Example with Pytorch web / web LUMI User Support web web web Appendix: Additional documentation / documentation / Appendix: Miscellaneous questions / questions /"},{"location":"4day-20240423/#making-the-exercises-after-the-course","title":"Making the exercises after the course","text":""},{"location":"4day-20240423/#hpe","title":"HPE","text":"The exercise material remains available in the course archive on LUMI:
-
The PDF notes in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
The other files for the exercises in either a bzip2-compressed tar file /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2\n
in the directory where you want to work on the exercises. This will create the Exercises/HPE subdirectory from the training project.
However, instead of running the lumi_c.sh or lumi_g.sh scripts that only work for the course as they set the course project as the active project for Slurm and also set a reservation, use the lumi_c_after.sh and lumi_g_after.sh scripts instead, but first edit them to use one of your projects.
"},{"location":"4day-20240423/#amd","title":"AMD","text":"There are online notes about the AMD exercises. A PDF print-out with less navigation features is also available and is particularly useful should the online notes become unavailable. A web backup is also available, but corrections to the original made after the course are not included.
The other files for the exercises are available in either a bzip2-compressed tar file /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD_.tar.bz2 or an uncompressed tar file /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar and can also be downloaded. ( bzip2-compressed tar download or uncompressed tar download)
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2\n
in the directory where you want to work on the exercises. This will create the exercises/AMD subdirectory from the training project. You can do so in the same directory where you installed the HPE exercises.
Warning
The software and exercises were tested thoroughly at the time of the course. LUMI however is in continuous evolution and changes to the system may break exercises and software
"},{"location":"4day-20240423/#links-to-documentation","title":"Links to documentation","text":"The links to all documentation mentioned during the talks is on a separate page.
"},{"location":"4day-20240423/#external-material-for-exercises","title":"External material for exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"4day-20240423/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"4day-20240423/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.10, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 but is fairly complete by now. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCD 3.11 User Guide
"},{"location":"4day-20240423/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"4day-20240423/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"4day-20240423/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"4day-20240423/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"4day-20240423/A02_Misc_Questions/","title":"Miscellaneous questions","text":" -
Do we have to have some Conda Venv in our LUMI profile to be able to execute my python script? Because now, it returns:
$ python -V\n-bash: python: command not found\n
ok, it seems to return the standard python, in my LUMI profile:
$ python3 -V\nPython 3.6.15\n
-
That is the topic of a different talk. If you are not using any module, then you are working the wrong way as you only get the (old) system Python. On a modern HPC system, if software does not come from a module or a container, you're doing the wrong thing. The system Python is python3 by the way. The cray-python modules provide newer versions of Python.
$ module load cray-python\n$ python -V \nPython 3.10.10\n
In our CSC Puhti HPC, we get Tykki module which is a container to activate all virtual machine pip install capabilities, I thought we had a same setup in LUMI, too!
- Again, see day 2, the software stacks presentation, for the LUMI equivalent. LUMI is a multinational machine so cannot exactly mirror any national cluster.
-
Is there currently any deep learning pre-installed modules in LUMI? $ module avail does not seem to return any familiar platforms nor libraries!
- See day 2, the software stacks presentation, for our software policies and how we manage software and how to find out where to find software. AI software will be on the second last slide as it is the culmination of all material in that talk given the complexity of that software.
-
If you want to have your own virtual environment, for example with anaconda, how do you create this?
- See day 2, the software stacks presentation, also. Preferably in a container, and we have an equivalent of the Tykky tool on Puhti/Mahti (if you know this as a Finnish user) and
cotainr, another tool to build containers with a conda installation.
-
In terms of Moving data to/from LUMI, do we have a capability to connect it to CSC ALLAS for efficient data storage, or should I traditionally use $ rsync command to transfer from my local machine to /scratch/proj_XXXXX directory?
- Yes, but you should check the CSC documentation, not the LUMI documentation. The LUMI User Support Team has no access to Allas and cannot help you with that, CSC set that one up. See this page.
"},{"location":"4day-20240423/exercises_AMD_hackmd/","title":"AMD Exercises","text":""},{"location":"4day-20240423/exercises_AMD_hackmd/#login-to-lumi","title":"Login to Lumi","text":"ssh USERNAME@lumi.csc.fi\n
To simplify the login to LUMI, you can add the following to your .ssh/config file. # LUMI\nHost lumi\nUser <USERNAME>\n Hostname lumi.csc.fi\n IdentityFile <HOME_DIRECTORY>/.ssh/id_rsa \n ServerAliveInterval 600\n ServerAliveCountMax 30\n
The ServerAlive* lines in the config file may be added to avoid timeouts when idle.
Now you can shorten your login command to the following.
ssh lumi\n
If you are able to log in with the ssh command, you should be able to use the secure copy command to transfer files. For example, you can copy the presentation slides from lumi to view them.
scp lumi:/project/project_465001098/Slides/AMD/<file_name> <local_filename>\n
You can also copy all the slides with the . From your local system:
mkdir slides\nscp -r lumi:/project/project_465001098/Slides/AMD/* slides\n
If you don't have the additions to the config file, you would need a longer command:
mkdir slides\nscp -r -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465001098/slides/AMD/ slides\n
or for a single file
scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465001098/slides/AMD/<file_name> <local_filename>\n
"},{"location":"4day-20240423/exercises_AMD_hackmd/#hip-exercises","title":"HIP Exercises","text":"We assume that you have already allocated resources with salloc
cp -r /project/project_465001098/Exercises/AMD/HPCTrainingExamples/ .
salloc -N 1 -p standard-g --gpus=1 -t 10:00 -A project_465001098 --reservation LUMItraining_G
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\nmodule load rocm\n
The examples are also available on github: git clone https://github.com/amd/HPCTrainingExamples\n
However, we recommend using the version in /project/project_465001098/Exercises/AMD/HPCTrainingExamples as it has been tuned to the current LUMI environment."},{"location":"4day-20240423/exercises_AMD_hackmd/#basic-examples","title":"Basic examples","text":"cd HPCTrainingExamples/HIP/vectorAdd
Examine files here \u2013 README, Makefile and vectoradd_hip.cpp Notice that Makefile requires HIP_PATH to be set. Check with module show rocm or echo $HIP_PATH Also, the Makefile builds and runs the code. We\u2019ll do the steps separately. Check also the HIPFLAGS in the Makefile.
make\nsrun -n 1 ./vectoradd\n
We can use SLURM submission script, let's call it hip_batch.sh:
#!/bin/bash\n#SBATCH -p standard-g\n#SBATCH -N 1\n#SBATCH --gpus=1\n#SBATCH -t 10:00\n#SBATCH --reservation LUMItraining_G\n#SBATCH -A project_465001098\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\ncd $PWD/HPCTrainingExamples/HIP/vectorAdd \n\nexport HCC_AMDGPU_TARGET=gfx90a\nmake vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Submit the script sbatch hip_batch.sh
Check for output in slurm-<job-id>.out or error in slurm-<job-id>.err
Compile and run with Cray compiler
CC -x hip vectoradd.hip -o vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Now let\u2019s try the cuda-stream example from https://github.com/ROCm-Developer-Tools/HIP-Examples. This example is from the original McCalpin code as ported to CUDA by Nvidia. This version has been ported to use HIP. See add4 for another similar stream example.
git clone https://github.com/ROCm-Developer-Tools/HIP-Examples\nexport HCC_AMDGPU_TARGET=gfx90a\ncd HIP-Examples/cuda-stream\nmake\nsrun -n 1 ./stream\n
Note that it builds with the hipcc compiler. You should get a report of the Copy, Scale, Add, and Triad cases. The variable export HCC_AMDGPU_TARGET=gfx90a is not needed in case one sets the target GPU for MI250x as part of the compiler flags as --offload-arch=gfx90a. Now check the other examples in HPCTrainingExamples/HIP like jacobi etc.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#hipify","title":"Hipify","text":"We\u2019ll use the same HPCTrainingExamples that were downloaded for the first exercise.
Get a node allocation.
salloc -N 1 --ntasks=1 --gpus=1 -p standard-g -A project_465001098 \u2013-t 00:10:00`--reservation LUMItraining_G\n
A batch version of the example is also shown.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#hipify-examples","title":"Hipify Examples","text":""},{"location":"4day-20240423/exercises_AMD_hackmd/#exercise-1-manual-code-conversion-from-cuda-to-hip-10-min","title":"Exercise 1: Manual code conversion from CUDA to HIP (10 min)","text":"Choose one or more of the CUDA samples in HPCTrainingExamples/HIPIFY/mini-nbody/cuda directory. Manually convert it to HIP. Tip: for example, the cudaMalloc will be called hipMalloc. Some code suggestions include nbody-block.cu, nbody-orig.cu, nbody-soa.cu
You\u2019ll want to compile on the node you\u2019ve been allocated so that hipcc will choose the correct GPU architecture.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#exercise-2-code-conversion-from-cuda-to-hip-using-hipify-tools-10-min","title":"Exercise 2: Code conversion from CUDA to HIP using HIPify tools (10 min)","text":"Use the hipify-perl script to \u201chipify\u201d the CUDA samples you used to manually convert to HIP in Exercise 1. hipify-perl is in $ROCM_PATH/bin directory and should be in your path.
First test the conversion to see what will be converted
hipify-perl -no-output -print-stats nbody-orig.cu\n
You'll see the statistics of HIP APIs that will be generated.
[HIPIFY] info: file 'nbody-orig.cu' statisitics:\n CONVERTED refs count: 10\n TOTAL lines of code: 91\n WARNINGS: 0\n[HIPIFY] info: CONVERTED refs by names:\n cudaFree => hipFree: 1\n cudaMalloc => hipMalloc: 1\n cudaMemcpy => hipMemcpy: 2\n cudaMemcpyDeviceToHost => hipMemcpyDeviceToHost: 1\n cudaMemcpyHostToDevice => hipMemcpyHostToDevice: 1\n
hipify-perl is in $ROCM_PATH/bin directory and should be in your path. In some versions of ROCm, the script is called hipify-perl.
Now let's actually do the conversion.
hipify-perl nbody-orig.cu > nbody-orig.cpp\n
Compile the HIP programs.
hipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig
The `#define SHMOO` fixes some timer printouts. \nAdd `--offload-arch=<gpu_type>` if not set by the environment to specify \nthe GPU type and avoid the autodetection issues when running on a single \nGPU on a node.\n
- Fix any compiler issues, for example, if there was something that didn\u2019t hipify correctly.
- Be on the lookout for hard-coded Nvidia specific things like warp sizes and PTX.
Run the program
srun ./nbody-orig\n
A batch version of Exercise 2 is:
#!/bin/bash\n#SBATCH -N 1\n#SBATCH --ntasks=1\n#SBATCH --gpus=1\n#SBATCH -p standard-g\n#SBATCH -A project_465001098\n#SBATCH -t 00:10:00\n#SBATCH --reservation LUMItraining_G\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n\nexport HCC_AMDGPU_TARGET=gfx90a\n\ncd HPCTrainingExamples/mini-nbody/cuda\nhipify-perl -print-stats nbody-orig.cu > nbody-orig.cpp\nhipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig\nsrun ./nbody-orig\ncd ../../..\n
Notes:
- Hipify tools do not check correctness
hipconvertinplace-perl is a convenience script that does hipify-perl -inplace -print-stats command
"},{"location":"4day-20240423/exercises_AMD_hackmd/#debugging","title":"Debugging","text":"The first exercise will be the same as the one covered in the presentation so that we can focus on the mechanics. Then there will be additional exercises to explore further or you can start debugging your own applications.
If required, copy the exercises:
cp -r /project/project_465001098/Exercises/AMD/HPCTrainingExamples/ .
Go to HPCTrainingExamples/HIP/saxpy
Edit the saxpy.hip file and comment out the two hipMalloc lines.
71 //hipMalloc(&d_x, size);\n72 //hipMalloc(&d_y, size);\n
Allocate resources: salloc -N 1 -p standard-g --gpus=1 -t 30:00 -A project_465001098 --reservation LUMItraining_G
Now let's try using rocgdb to find the error.
Compile the code with
hipcc --offload-arch=gfx90a -o saxpy saxpy.hip
- Allocate a compute node.
- Run the code
srun -n 1 --gpus 1 ./saxpy
Output
Memory access fault by GPU node-4 (Agent handle: 0x32f330) on address (nil). Reason: Unknown.\n
How do we find the error? Let's start up the debugger. First, we\u2019ll recompile the code to help the debugging process. We also set the number of CPU OpenMP threads to reduce the number of threads seen by the debugger. hipcc -ggdb -O0 --offload-arch=gfx90a -o saxpy saxpy.hip\nexport OMP_NUM_THREADS=1\n
We have two options for running the debugger. We can use an interactive session, or we can just simply use a regular srun command.
srun rocgdb saxpy
The interactive approach uses:
srun --interactive --pty [--jobid=<jobid>] bash \nrocgdb ./saxpy \n
We need to supply the jobid if we have more than one job so that it knows which to use. We can also choose to use one of the Text User Interfaces (TUI) or Graphics User Interfaces (GUI). We look to see what is available.
which cgdb\n -- not found\n -- run with cgdb -d rocgdb <executable>\nwhich ddd\n -- not found\n -- run with ddd --debugger rocgdb\nwhich gdbgui\n -- not found\n -- run with gdbgui --gdb-cmd /opt/rocm/bin/rocgdb\nrocgdb \u2013tui\n -- found\n
We have the TUI interface for rocgdb. We need an interactive session on the compute node to run with this interface. We do this by using the following command.
srun --interactive --pty [-jobid=<jobid>] bash \nrocgdb -tui ./saxpy\n
The following is based on using the standard gdb interface. Using the TUI or GUI interfaces should be similar. You should see some output like the following once the debugger starts.
[output]\nGNU gdb (rocm-rel-5.1-36) 11.2\nCopyright (C) 2022 Free Software Foundation, Inc. \nLicense GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>\nThis is free software: you are free to change and redistribute it.\nThere is NO WARRANTY, to the extent permitted by law.\nType \"show copying\" and \"show warranty\" for details.\nThis GDB was configured as \"x86_64-pc-linux-gnu\".\nType \"show configuration\" for configuration details.\nFor bug reporting instructions, please see:\n<https://github.com/ROCm-Developer-Tools/ROCgdb/issues>.\nFind the GDB manual and other documentation resources online at:\n <http://www.gnu.org/software/gdb/documentation/>. \nFor help, type \"help\".\nType \"apropos word\" to search for commands related to \"word\"...\nReading symbols from ./saxpy...\n
Now it is waiting for us to tell it what to do. We'll go for broke and just type run
(gdb) run\n\n[output] \nThread 3 \"saxpy\" received signal SIGSEGV, Segmentation fault.[Switching to thread 3, lane 0 (AMDGPU Lane 1:2:1:1/0 (0,0,0)[0,0,0])]\n0x000015554a001094 in saxpy (n=<optimized out>, x=<optimized out>, incx=<optimized out>, y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n31 y[i] += a*x[i];\n
The line number 57 is a clue. Now let\u2019s dive a little deeper by getting the GPU thread trace
(gdb) info threads [ shorthand - i th ]\n\n [output]\n Id Target Id Frame\n 1 Thread 0x15555552d300 (LWP 40477) \"saxpy\" 0x000015554b67ebc9 in ?? ()\n from /opt/rocm/lib/libhsa-runtime64.so.1\n 2 Thread 0x15554a9ac700 (LWP 40485) \"saxpy\" 0x00001555533e1c47 in ioctl () \n from /lib64/libc.so.6\n* 3 AMDGPU Wave 1:2:1:1 (0,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 4 AMDGPU Wave 1:2:1:2 (0,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57 \n 5 AMDGPU Wave 1:2:1:3 (1,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy (\n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 6 AMDGPU Wave 1:2:1:4 (1,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n
Note that the GPU threads are also shown! Switch to thread 1 (CPU)
(gdb) thread 1 [ shorthand - t 1]\n[output] \n[Switching to thread 1 (Thread 0x15555552d300 (LWP 47136))]\n#0 0x000015554b67ebc9 in ?? () from /opt/rocm/lib/libhsa-runtime64.so.1\n
where
...
#12 0x0000155553b5b419 in hipDeviceSynchronize ()\n from /opt/rocm/lib/libamdhip64.so.5\n#13 0x000000000020d6fd in main () at saxpy.hip:79\n\n(gdb) break saxpy.hip:78 [ shorthand \u2013 b saxpy.hip:78]\n\n[output] \nBreakpoint 2 at 0x21a830: file saxpy.hip, line 78\n\n(gdb) run [ shorthand \u2013 r ]\n\nBreakpoint 1, main () at saxpy.hip:78\n48 saxpy<<<num_groups, group_size>>>(n, d_x, 1, d_y, 1);\n
From here we can investigate the input to the kernel and see that the memory has not been allocated. Restart the program in the debugger.
srun --interactive --pty [-jobid=<jobid>] rocgdb ./saxpy\n(gdb) list 55,74\n\n(gdb) b 60\n\n[output] \n\nBreakpoint 1 at 0x219ea2: file saxpy.cpp, line 62.\n
Alternativelly, one can specify we want to stop at the start of the routine before the allocations.
(gdb) b main\nBreakpoint 2 at 0x219ea2: file saxpy.cpp, line 62.\n
We can now run our application again! (gdb) run\n[output] \nStarting program ...\n...\nBreakpoint 2, main() at saxpy.cpp:62\n62 int n=256;\n\n(gdb) p d_y\n[output] \n$1 = (float *) 0x13 <_start>\n
Should have intialized the pointer to NULL! It makes it easier to debug faulty alocations. In anycase, this is a very unlikely address - usually dynamic allocation live in a high address range, e.g. 0x123456789000.
(gdb) n\n[output] \n63 std::size_t size = sizeof(float)*n;\n\n(gdb) n\n[output] \nBreakpoint 1, main () at saxpy.cpp:67\n67 init(n, h_x, d_x);\n\n(gdb) p h_x\n[output] \n$2 = (float *) 0x219cd0 <_start>\n(gdb) p *h_x@5\n
Prints out the next 5 values pointed to by h_x
[output] \n$3 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n
Random values printed out \u2013 not initialized!
(gdb) b 56\n\n(gdb) c\n\n[output] \nThread 5 \u201csaxpy\u201d hit Breakpoint 3 \u2026.\n56 if (i < n)\n\n(gdb) info threads\n\nShows both CPU and GPU threads\n(gdb) p x\n\n[output] \n$4 = (const float *) 0x219cd0 <_start>\n\n(gdb) p *x@5\n
This can either yeild unintialized results or just complain that the address can't be accessed: [output] \n$5 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n\nor \n\nCannot access memory at address 0x13\n
Let's move to the next statement:
(gdb) n\n\n(gdb) n\n\n(gdb) n\n
Until reach line 57. We can now inspect the indexing and the array contents should the memory be accesible. (gdb) p i\n\n[output] \n$6 = 0\n\n(gdb) p y[0]\n\n[output] \n$7 = -2.12e14\n\n(gdb) p x[0]\n\n[output] \n$8 = -2.43e-33\n\n(gdb) p a\n[output] \n$9 = 1\n
We can see that there are multiple problems with this kernel. X and Y are not initialized. Each value of X is multiplied by 1.0 and then added to the existing value of Y.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#rocprof","title":"Rocprof","text":"Setup environment
salloc -N 1 --gpus=8 -p standard-g --exclusive -A project_465001098 -t 20:00 --reservation LUMItraining_G\n\nmodule load PrgEnv-cray\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n
Download examples repo and navigate to the HIPIFY exercises cd ~/HPCTrainingExamples/HIPIFY/mini-nbody/hip/\n
Compile and run one case. We are on the front-end node, so we have two ways to compile for the GPU that we want to run on.
- The first is to explicitly set the GPU archicture when compiling (We are effectively cross-compiling for a GPU that is present where we are compiling).
hipcc -I../ -DSHMOO --offload-arch=gfx90a nbody-orig.hip -o nbody-orig\n
- The other option is to compile on the compute node where the compiler will auto-detect which GPU is present. Note that the autodetection may fail if you do not have all the GPUs (depending on the ROCm version). If that occurs, you will need to set
export ROCM_GPU=gfx90a.
srun hipcc -I../ -DSHMOO nbody-orig.cpp -o nbody-orig\n
Now Run rocprof on nbody-orig to obtain hotspots list
srun rocprof --stats nbody-orig 65536\n
Check Results cat results.csv\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Using --basenames on will show only kernel names without their parameters. srun rocprof --stats --basenames on nbody-orig 65536\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Trace HIP calls with --hip-trace srun rocprof --stats --hip-trace nbody-orig 65536\n
Check the new file results.hip_stats.csv cat results.hip_stats.csv\n
Profile also the HSA API with the --hsa-trace srun rocprof --stats --hip-trace --hsa-trace nbody-orig 65536\n
Check the new file results.hsa_stats.csv cat results.hsa_stats.csv\n
On your laptop, download results.json scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:<path_to_file>/results.json results.json\n
Open a browser and go to https://ui.perfetto.dev/. Click on Open trace file in the top left corner. Navigate to the results.json you just downloaded. Use the keystrokes W,A,S,D to zoom in and move right and left in the GUI Navigation\nw/s Zoom in/out\na/d Pan left/right\n
"},{"location":"4day-20240423/exercises_AMD_hackmd/#perfetto-issue","title":"Perfetto issue","text":"Perfetto seems to introduced a bug, Sam created a container with a perfetto version that works with the rocprof traces. If you want to use that one you need to run docker on your laptop.
From your laptop:
sudo dockerd\n
and in another terminal sudo docker run -it --rm -p 10000:10000 --name myperfetto sfantao/perfetto4rocm\n
The open your web browser to: http://localhost:10000/ and open the trace.
Read about hardware counters available for the GPU on this system (look for gfx90a section)
less $ROCM_PATH/lib/rocprofiler/gfx_metrics.xml\n
Create a rocprof_counters.txt file with the counters you would like to collect vi rocprof_counters.txt\n
Content for rocprof_counters.txt: pmc : Wavefronts VALUInsts\npmc : SALUInsts SFetchInsts GDSInsts\npmc : MemUnitBusy ALUStalledByLDS\n
Execute with the counters we just added: srun rocprof --timestamp on -i rocprof_counters.txt nbody-orig 65536\n
You'll notice that rocprof runs 3 passes, one for each set of counters we have in that file. Contents of rocprof_counters.csv
cat rocprof_counters.csv\n
"},{"location":"4day-20240423/exercises_AMD_hackmd/#omnitrace","title":"Omnitrace","text":" Omnitrace is known to work better with ROCm versions more recent than 5.2.3. So we use a ROCm 5.4.3 installation for this.
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omnitrace/1.10.3-rocm-5.4.x\n
- Allocate resources with
salloc
salloc -N 1 --ntasks=1 --partition=standard-g --gpus=1 -A project_465001098 --time=00:15:00 --reservation LUMItraining_G
- Check the various options and their values and also a second command for description
srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace --brief --description
- Create an Omnitrace configuration file with description per option
srun -n 1 omnitrace-avail -G omnitrace.cfg --all
- Declare to use this configuration file:
export OMNITRACE_CONFIG_FILE=/path/omnitrace.cfg
- Get the training examples:
cp -r /project/project_465001098/Exercises/AMD/HPCTrainingExamples/ .
-
Now build the code
make -f Makefile.craytime srun -n 1 --gpus 1 Jacobi_hip -g 1 1
-
Check the duration
"},{"location":"4day-20240423/exercises_AMD_hackmd/#dynamic-instrumentation","title":"Dynamic instrumentation","text":" - Execute dynamic instrumentation:
time srun -n 1 --gpus 1 omnitrace-instrument -- ./saxpy and check the duration
- About Jacobi example, as the dynamic instrumentation wuld take long time, check what the binary calls and gets instrumented:
nm --demangle Jacobi_hip | egrep -i ' (t|u) ' - Available functions to instrument:
srun -n 1 --gpus 1 omnitrace-instrument -v 1 --simulate --print-available functions -- ./Jacobi_hip -g 1 1 - the simulate option means that it will not execute the binary
"},{"location":"4day-20240423/exercises_AMD_hackmd/#binary-rewriting-to-be-used-with-mpi-codes-and-decreases-overhead","title":"Binary rewriting (to be used with MPI codes and decreases overhead)","text":" -
Binary rewriting: srun -n 1 --gpus 1 omnitrace-instrument -v -1 --print-available functions -o jacobi.inst -- ./Jacobi_hip
- We created a new instrumented binary called jacobi.inst
-
Executing the new instrumented binary: time srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and check the duration
- See the list of the instrumented GPU calls:
cat omnitrace-jacobi.inst-output/TIMESTAMP/roctracer.txt
"},{"location":"4day-20240423/exercises_AMD_hackmd/#visualization","title":"Visualization","text":" - Copy the
perfetto-trace.proto to your laptop, open the web page https://ui.perfetto.dev/ click to open the trace and select the file
"},{"location":"4day-20240423/exercises_AMD_hackmd/#hardware-counters","title":"Hardware counters","text":" - See a list of all the counters:
srun -n 1 --gpus 1 omnitrace-avail --all - Declare in your configuration file:
OMNITRACE_ROCM_EVENTS = GPUBusy,Wavefronts,VALUBusy,L2CacheHit,MemUnitBusy - Execute:
srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and copy the perfetto file and visualize
"},{"location":"4day-20240423/exercises_AMD_hackmd/#sampling","title":"Sampling","text":"Activate in your configuration file OMNITRACE_USE_SAMPLING = true and OMNITRACE_SAMPLING_FREQ = 100, execute and visualize
"},{"location":"4day-20240423/exercises_AMD_hackmd/#kernel-timings","title":"Kernel timings","text":" - Open the file
omnitrace-binary-output/timestamp/wall_clock.txt (replace binary and timestamp with your information) - In order to see the kernels gathered in your configuration file, make sure that
OMNITRACE_USE_TIMEMORY = true and OMNITRACE_FLAT_PROFILE = true, execute the code and open again the file omnitrace-binary-output/timestamp/wall_clock.txt
"},{"location":"4day-20240423/exercises_AMD_hackmd/#call-stack","title":"Call-stack","text":"Edit your omnitrace.cfg:
OMNITRACE_USE_SAMPLING = true;\u00a0\nOMNITRACE_SAMPLING_FREQ = 100\n
Execute again the instrumented binary and now you can see the call-stack when you visualize with perfetto.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#omniperf","title":"Omniperf","text":" Omniperf is using a virtual environemtn to keep its python dependencies.
module load cray-python\nmodule load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omniperf/1.0.10-rocm-5.4.x\n\nsource /pfs/lustrep2/projappl/project_462000125/samantao-public/omnitools/venv/bin/activate\n
- Reserve a GPU, compile the exercise and execute Omniperf, observe how many times the code is executed
salloc -N 1 --ntasks=1 --partition=small-g --gpus=1 -A project_465001098 --time=00:30:00\ncp -r /project/project_465001098/Exercises/AMD/HPCTrainingExamples/ .\ncd HPCTrainingExamples/HIP/dgemm/\nmkdir build\ncd build\ncmake ..\nmake\ncd bin\nsrun -n 1 omniperf profile -n dgemm -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv\n
-
Run srun -n 1 --gpus 1 omniperf profile -h to see all the options
-
Now is created a workload in the directory workloads with the name dgemm (the argument of the -n). So, we can analyze it
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ &> dgemm_analyze.txt\n
- If you want to only roofline analysis, then execute:
srun -n 1 omniperf profile -n dgemm --roof-only -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv
There is no need for srun to analyze but we want to avoid everybody to use the login node. Explore the file dgemm_analyze.txt
- We can select specific IP Blocks, like:
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ -b 7.1.2\n
But you need to know the code of the IP Block
- If you have installed Omniperf on your laptop (no ROCm required for analysis) then you can download the data and execute:
omniperf analyze -p workloads/dgemm/mi200/ --gui\n
- Open the web page: http://IP:8050/ The IP will be displayed in the output
For more exercises, visit here: https://github.com/amd/HPCTrainingExamples/tree/main/OmniperfExamples or locally HPCTrainingExamples/OmniperfExamples, there are 5 exercises, in each directory there is a readme file with instructions.
"},{"location":"4day-20240423/exercises_AMD_hackmd/#mnist-example","title":"MNIST example","text":"This example is supported by the files in /project/project_465000644/Exercises/AMD/Pytorch. These script experiment with different tools with a more realistic application. They cover PyTorch, how to install it, run it and then profile and debug a MNIST based training. We selected the one in https://github.com/kubeflow/examples/blob/master/pytorch_mnist/training/ddp/mnist/mnist_DDP.py but the concept would be similar for any PyTorch-based distributed training.
This is mostly based on a two node allocation.
-
Installing PyTorch directly on the filesystem using the system python installation. ./01-install-direct.sh
-
Installing PyTorch in a virtual environment based on the system python installation. ./02-install-venv.sh
-
Installing PyTorch in a condo environment based on the condo package python version. ./03-install-conda.sh
-
Installing PyTorch from source on top of a base condo environment. It builds with debug symbols which can be useful to facilitate debugging. ./04-install-source.sh
-
Testing a container prepared for LUMI that comprises PyTorch. ./05-test-container.sh
-
Test the right affinity settings. ./06-afinity-testing.sh
-
Complete example with MNIST training with all the trimmings to run it properly on LUMI. ./07-mnist-example.sh
-
Examples using rocprof, Omnitrace and Omniperf. ./08-mnist-rocprof.sh ./09-mnist-omnitrace.sh ./10-mnist-omnitrace-python.sh ./11-mnist-omniperf.sh
-
Example that debugs an hang in the application leveraging rocgdb. ./12-mnist-debug.sh
"},{"location":"4day-20240423/extra_1_00_Introduction/","title":"Introduction","text":"Presenters: Heidi Reiman (LUST), Harvey Richardson (HPE)
Archived materials on LUMI:
- Recording:
/appl/local/training/4day-20240423/recordings/1_00_Introduction.mp4
"},{"location":"4day-20240423/extra_1_01_HPE_Cray_EX_Architecture/","title":"HPE Cray EX Architecture","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_1_01_HPE_Cray_EX_Architecture/#qa","title":"Q&A","text":" -
Can an AMD GPU in LUMI be used to run typical Nvidia GPU platforms, such as pytorch or tensorflow? If I run my python script, do I have to import specific libraries to enable AMD gpus? Or it's pretty much quite similar to Nvidia?
-
It cannot run binaries for NVIDIA GPUs, but much software has been ported, including PyTorch and Tensorflow. It is like with CPUs: an ARM CPU cannot run x86 binaries and vice-versa. As we will see in the HIP talk tomorrow, many libraries for NVIDIA have an equivalent for AMD. But NVIDIA is proprietary technology (to protect their own market and be able to charge more), so it is not always really one-to-one as even function names in the NVIDIA ecosystem are sometimes protected. But, e.g., when you install Python packages you may have to tell pip to use the right binaries for the AMD ecosystem.
-
See also tomorrow afternoon in the software stack talk to learn how you can find out what we have.
-
For most AI frameworks, if you install them correctly then you don't need to change anything in your code to make it work.
-
Is speculative execution on epyc enable by default?
- Yes, it would be very slow without. It is not something you can enable or disable on a CPU, it sits too deep in the architecture.
"},{"location":"4day-20240423/extra_1_02_Programming_Environment_and_Modules/","title":"Programming Environment and Modules","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-1_02_Programming_Environment_and_Modules.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/1_02_Programming_Environment_and_Modules.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_1_02_Programming_Environment_and_Modules/#qa","title":"Q&A","text":" -
Because you talked about FFTW3, is there something I can do to use a distributed FFT on GPUs? I checked and there is only the intra-node hipFFTXt.
-
We can support 3rd party libraries also if we know which ones users want.
In one of the talks tomorrow you will see that supporting distributed libraries is not trivial for a vendor, as they need to be compiled specifically for the right MPI library, which is why it is hard to do for AMD.
-
There is work in progress from AMD but I can not say for any timeline. You can check this one: https://icl.utk.edu/fft/ but I htink I heard that the performance is not great.
"},{"location":"4day-20240423/extra_1_03_Running_Applications/","title":"Running Applications","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_1_03_Running_Applications/#qa","title":"Q&A","text":" -
Can you clarify the differences between: ntasks-per-core vs ntasks-per-node and ntasks in SLURM terminology?
-ntasks is the total number of MPI ranks, -ntasks-per-node is the number of MPI ranks per each node, e.g. I want to run 128 MPI ranks with 4 ranks per each node (i.e. 32 nodes), so I can use: --ntasks=128 --ntasks-per-node=4. The -ntasks-per-core is only relevant if you want to use hyperthreads. You can find more info with man srun.
-
What does $SBATCH --exclusive do? is it quite mandatory to include it in my bash script when executing sbatch job?
exclusive is set for some queues, so you will get the entire node even if you are asking for less resources (you can use scontrol show partition standard, where standard is the queue, and check for the \"EXCLUSIVE\"). And you can use it in the other partitions (e.g., small and small-g) to get exclusive access to that node (and of course be billed for exclusive acces). But a node in small or small-g will still not be fully equivalent to a node in standard or standard-g, as some defaults, e.g., for memory, are set differently.
"},{"location":"4day-20240423/extra_1_04_Exercises_1/","title":"Exercise session 1: Running applications","text":"Exercises are in Exercises/HPE/day1/ProgrammingModels.`
See Exercises/HPE/day1/ProgrammingModels/ProgrammingModelExamples_SLURM.pdf Run on the system and get familiar with Slurm commands.
"},{"location":"4day-20240423/extra_1_04_Exercises_1/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_1_04_Exercises_1/#qa","title":"Q&A","text":" -
Instead of slurm I would be interested in using myqueue to submit my scripts. Do you know if this is possible? https://myqueue.readthedocs.io/en/latest/
- We do not recommend it but you can try it yourself. It may be tricky to configure properly and we do not offer support fot the tool. Remember you will be charged for automatically (re)submitted jobs which can run out of your control if the myqueue instance is not properly configured.
-
I'm trying to compile the pi_hip.cpp CC -xhip -o test.hip pi_hip.cpp, BUT I am getting 26 warnings. e.g.
In file included from /opt/rocm/hip/include/hip/amd_detail/texture_fetch_functions.h:26:\nIn file included from /opt/rocm/hip/include/hip/amd_detail/../../../../include/hip/amd_detail/texture_fetch_functions.h:28:\n/opt/rocm/hip/include/hip/hip_texture_types.h:25:9: warning: This file is deprecated. Use file from include path /opt/rocm-ver/include/ and prefix with hip [-W#pragma-messages]\n#pragma message(\"This file is deprecated. Use file from include path /opt/rocm-ver/include/ and prefix with hip\u201d)\n
How to get rid of those warnings ?
- This is the Cray compiler wrapper including the old (deprecated) path. This is harmless and can be ignored. If it really bother you, you can use the
-Wno-#pragma-messages compiler flag to silence the warning.
-
How to launch one simple command with srun, which partition and command to use?
-
You need to specify partition with -p option, standard-g for GPU nodes and standard for CPU only
-
Project account is also mandatory with -A option, project_465001098 is for the training purpose
-
You can also use reservation to use extra reserved resources, --reservation=LUMItraining_G or LUMItraining_G; this is only valid for this training
-
To get actual GPU devices allocated, use --gpus= from 1 to 8 for per node allocation
-
Use --exclusive to get the node(s) allocated for your job exclusively, if you submit to small(-g) or dev-g partitions
-
What if I get this error when trying to utilize GPU resources?
salloc -p dev-g -A project_465001098 -n 1 --gpus=8\nsalloc: Pending job allocation 6925988\nsalloc: job 6925988 queued and waiting for resources\nsalloc: job 6925988 has been allocated resources\nsalloc: Granted job allocation 6925988\npiangate@uan01:~/prova1> rocm-smi \ncat: /sys/module/amdgpu/initstate: No such file or directory\nERROR:root:Driver not initialized (amdgpu not found in modules)\n
"},{"location":"4day-20240423/extra_1_05_Compilers_and_Parallel_Programming_Models/","title":"Compilers and Parallel Programming Models","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-1_05_Compilers_and_Parallel_Programming_Models.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/1_05_Compilers_and_Parallel_Programming_Models.mp4
These materials can only be distributed to actual users of LUMI (active user account).
Alternative for modifying LD_LIBRARY_PATH
Instead of using LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH, you can also use the module lumi-CrayPath. Loading it essentially does that setting for LD_LIBRARY_PATH, unloading tries to restore the old situation, and reloading while the module is already loaded, will adapt to a possibly modified $CRAY_LD_LIBRARY_PATH. (So basically use it after loading all other modules that you need.)
"},{"location":"4day-20240423/extra_1_05_Compilers_and_Parallel_Programming_Models/#qa","title":"Q&A","text":" -
Should we compile something on access node?
-
It is usually fine. Cray Programming environment (PrgEnv- modules) does cross-compilation but you need to understand what is your target architecture (craype- modules are responsible for that). For clarity LUMI Software Environment provides partition modules /L (for login nodes architecture) and /C, /G for CPU and AMD GPU nodes accordingly.
-
Very big compiles should be done in a job.
-
The last talk on day 2 will also give some more information about environments we offer that make configuring the target modules easier.
-
Can I write a code in which offloading is performed with HIP and CPU parallelization is with OpenMP in the same source code?
- Yes, you can. In this case you have to add
-fopenmp -xhip in this order.
-
Does LibSci have a sparse solver like pardiso solver in MKL? If no, does LUMI have a sparse solver of any kind in the modules?
-
From AMD point of view check https://github.com/ROCm/hipSPARSE, HPE can answer for the LibSci.
-
No in libsci, only dense
-
If any particular libraries are of interest then we would be able to suggest the best way to build them.
"},{"location":"4day-20240423/extra_1_06_Exercises_2/","title":"Exercise session 2: Compilers","text":"The exercises are basically the same as in session #1. You can now play with different programming models and optimisation options.
"},{"location":"4day-20240423/extra_1_06_Exercises_2/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_1_06_Exercises_2/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_1_07_Cray_Scientific_Libraries/","title":"Cray Scientific Libraries","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_1_07_Cray_Scientific_Libraries/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_1_08_Exercises_3/","title":"Exercise session 3: Cray Scientific Libraries","text":"The files for the exercises are in Exercises/HPE/day1/libsci_acc.
Test with LibSci_ACC, check the different interfaces and environment variables.
"},{"location":"4day-20240423/extra_1_08_Exercises_3/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_1_08_Exercises_3/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_1_09_Offload_CCE/","title":"CCE Offloading Models","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_1_09_Offload_CCE/#qa","title":"Q&A","text":" -
Going back to compiling codes with HIP, could you just clarify how it would be best to do this with cmake in either the GNU or Cray environments? I have attempted it with a code I use (FHI-aims) since the talk on this this morning, but I am still struggling with it. Obviously this is quite specific to my own use case. I am also happy to talk about this on the zoom call if it's easier. -
- You can use
-DCMAKE_CXX_COMPILER=CC and add the flag -DCMAKE_CXX_FLAGS=\"-xhip\", but it really depends on the cmake. I suggest to check rocm.docs.amd.com/en/latest/conceptual/cmake-packages.html.
"},{"location":"4day-20240423/extra_2_01_Introduction_to_AMD_ROCm_Ecosystem/","title":"Introduction to the AMD ROCmTM Ecosystem","text":"Presenter: George Markomanolis (AMD)
Materials available on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-2_01_Introduction_to_AMD_ROCm_Ecosystem.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/2_01_Introduction_to_AMD_ROCm_Ecosystem.mp4
"},{"location":"4day-20240423/extra_2_01_Introduction_to_AMD_ROCm_Ecosystem/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_2_02_Exercises_4/","title":"Exercise session 4: HIP tools","text":"Exercise assignments can be found in the AMD exercise notes, sections on HIP Exercises and Hipify.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20240423/extra_2_02_Exercises_4/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar
"},{"location":"4day-20240423/extra_2_02_Exercises_4/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_2_03_Debugging_at_Scale/","title":"Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat","text":"Presenter: Thierry Braconnier (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_2_03_Debugging_at_Scale/#qa","title":"Q&A","text":" -
Can all these tools be used with GPU offloading?
- Sanitizers are not available for the GPUs with rocm 5.2, AMD is working on that with ROCm 5.7.
"},{"location":"4day-20240423/extra_2_04_Exercises_5/","title":"Exercise session 5: Cray PE Debugging Tools","text":"Exercises are in Exercises/HPE/day2/debugging.
Try the debugging tools in this subdirectory. There are Readme.md files in every directory with more information.
"},{"location":"4day-20240423/extra_2_04_Exercises_5/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_2_04_Exercises_5/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_2_05_Advanced_Application_Placement/","title":"Advanced Placement","text":"Presenter: Jean-Yves Vet (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-2_05_Advanced_Application_Placement.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/2_05_Advanced_Application_Placement.mp4
These materials can only be distributed to actual users of LUMI (active user account).
Remark
The lumi-CPEtools module contains several tools mentioned in the presentation.
Note that these commands also have various command line options that were not mentioned and show more information about the actual binding.
"},{"location":"4day-20240423/extra_2_05_Advanced_Application_Placement/#qa","title":"Q&A","text":" -
Is the gpu direct RDMA supported on LUMI-G? And how to enable it?
-
MPICH_GPU_SUPPORT_ENABLED=1
-
It is also different than on NVIDIA platforms. On LUMI there is no equivalent to NVIDIA GPUdirect needed as the GPUs are connected to the CPUs via InfinityFabric/xGMI, which is much more powerful than PCIe.
-
What is the difference between MPICH_GPU_SUPPORT_ENABLED and MPICH_GPU_SUPPORT?
- This is a typo on the slide, both should mention
MPICH_GPU_SUPPORT_ENABLED, this will be fixed.
-
Is it possible to see that GPU-aware MPI is enabled from profiling?
- Yes, but note that LUMI design by default implies copies from GPU memory to the network.
"},{"location":"4day-20240423/extra_2_06_Exercises_6/","title":"Exercise session 4: Placement","text":"The files for the exercises can be found in Exercises/HPE/day2/Binding and Exercises/HPE/day2/gpu_perf_binding.
Try different binding options for CPU execution (look at slides and use envars to change order and display the order) and for GPU execution (gpu_perf_binding). See also the PDF or README.md files in those directories.
"},{"location":"4day-20240423/extra_2_06_Exercises_6/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_2_06_Exercises_6/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_2_07_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Materials available on the web:
Archived materials on LUMI:
"},{"location":"4day-20240423/extra_2_07_LUMI_Software_Stacks/#additional-materials","title":"Additional materials","text":" -
The information in this talk is also partly covered by the following talks from the 1-day courses:
-
Modules on LUMI
-
LUMI Software Stacks
-
The cotainr package was presented during the September 27, 2023 user coffee break
"},{"location":"4day-20240423/extra_2_07_LUMI_Software_Stacks/#qa","title":"Q&A","text":" -
If you have a licensed software, such as VASP, how do I use that licensed software in lumi?
- LUMI uses a bring your own license model. It differs per software package how this would work. For VASP we have documented the installation procedure in the LUMI Software Library VASP page.
-
Question on EasyBuilder. Any reason to support Ansible (better logging, yaml support, etc..) Seems there is an Ansible module for EasyBuilder: GitHub link and YouTube presentation Ansible with EasyBuild from an EasyBuild user meeting.
- The repo you point to is the work of one of my colleague and is not meant to be used by users, only by system administrators. The goal was basically to have a way to (re)-deploy an EasyBuild managed software stack on multiple architectures. This project is unmaintained.
-
Why EasyBuild and not spack as a package manager? I mean what is it better between them?
-
EuroHPC politics was a consideration as other sites in Europe were already using EasyBuild. There was a lot of experience in Switzerland.
-
EasyBuild is rigid and can be well tested. Spack is more versatile and now quite powerful if you want to create environments for multiple packages. Although Spack is very attractive, there is some concern on what is going to fund future developments.
-
I am trying to create a conda environment in a container, however t seems that it keeps disconnecting my interaction VS code and login shell. Are containers only limited to a few python packages?
-
LUMI supports specific tools to build containers for conda environments so I expect this will be covered later in this talk. I am not aware of any limits.
-
It sounds like you have connection problems, or maybe have a configuration issue in your interactive session. If you are disconnected this is not caused by the process of extending/building containers.
-
Can you take existing containers (Pytorch container for example) and install additional python packages on that container?
-
I'm told by Alfio that the proot functionality gives you a nice way to do this.
-
And for the containers that we provide, it can also be done in a virtual environment. For one of the containers we already have an automated way to make it more file system friendly, but see the documentation of Pytorch in the LUMI Software Library where this question is answered, or after next week, check the materials of the Amsterdam course (day 2 afternoon).
-
Basically, you can do the following:
# Start a shell in your singularity container\nsingularity exec -B ./workdir /path-to-singularity-image/myimage.sif bash\n\n#\n# Now we are running inside the container\n#\n\n# activate container conda\n$WITH_CONDA\n\n# create virtual environment to extent conda (read-only one)\npython -m venv --system-site-packages /workdir/venvsource \n/workdir/venv/bin/activate\npython -m pip install my-extra-package\nexit\n\n# Now we are running outside the container\n# We can now invoke singularity as this to leverage the combination of conda and virtual env.\nsingularity exec -B ./workdir /path-to-singularity-image/myimage.sif \\\n bash -c '$WITH_CONDA ; PYTHONPATH=/workdir/vnv/lib/pythonx.y/site-packages python3 ./myapp'\n
-
Will does PyTorch examples he just mentioned be available here? In this workshop?
-
They are available on LUMI, I'm not sure if using hem is going to be covered here, but the AMD talk on the last day may show examples of running these.
-
Check at https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/p/PyTorch/ (which links to the path at /appl/local/containers)
-
There will be some examples on building pytorch and using it on Friday.
"},{"location":"4day-20240423/extra_3_01_Introduction_to_Perftools/","title":"Introduction to Perftools","text":"Presenters: Thierry Braconnier (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
Info
You can find the downloads of Apprentice2 and Reveal on LUMI in $CRAYPAT_ROOT/share/desktop_installers/. This only works when the perftools-base module is loaded, but this is the case at login.
"},{"location":"4day-20240423/extra_3_01_Introduction_to_Perftools/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_02_Exercises_7/","title":"Exercise session 7: perftools-lite","text":"The files for the exercises can be found in Exercises/HPE/day3/perftools-lite and Exercises/HPE/day3/perftools-lite-gpu. Follow the Readme.md description and get familiar with the perftools-lite commands and outputs.
"},{"location":"4day-20240423/extra_3_02_Exercises_7/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_3_02_Exercises_7/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_03_Advanced_Performance_Analysis/","title":"Advanced Performance Analysis","text":"Presenter: Thierry Braconnier (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-3_03_Advanced_Performance_analysis.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/3_03_Advanced_Performance_Analysis.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_3_03_Advanced_Performance_Analysis/#qa","title":"Q&A","text":" -
Does the tool enable profiling MPI-OpenACC Fortran ?
- Yes,
-g mpi,openacc (MPI is default). I suggest to use perftools-lite-gpu as a start
-
Reveal only suggests the code for openMP?
- Yes It works best for Fortran codes, for C/C++ is still able to generate directives, but likely it will not able to scope all variables. This is due to the aliasing that is common in C.
-
Is perftools supported on Intel and NVIDIA GPUs ?
- The programming environment supports multiple hardware platforms, so yes. But of course you need a license and cannot simply copy it from LUMI, that would be abuse. (see slide 58)
"},{"location":"4day-20240423/extra_3_04_Exercises_8/","title":"Exercise session 8: perftools","text":"The files for the exercises can be found in Exercises/HPE/day3/perftools and its subdirectories. Follow the Readme.md description (per each directory) and get familiar with the perftools commands and outputs.
-
Subdirectories perftools, perftools-api, perftools-hwpc, perftools-python, and perftools-apa need lumi_c.sh (or lumi_c_after.sh) to be sourced.
-
Subdirectories perftools-for-hip and perftools-for-omp-offload need lumi_g.sh (or lumi_g_after.sh) to be sourced
"},{"location":"4day-20240423/extra_3_04_Exercises_8/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_3_04_Exercises_8/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_05_Cray_MPI_on_Slingshot/","title":"MPI Topics on the HPE Cray EX Supercomputer","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_3_05_Cray_MPI_on_Slingshot/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_06_Exercises_9/","title":"Exercise session 9: Cray MPICH","text":"The files for the exercises can be found in Exercises/HPE/day3/ProgrammingModels. Test the Pi example with MPI or MPI/OpenMP on 4 nodes and 4 tasks. Show where the ranks/threads are running by using the appropriate MPICH environment variable. Use environment variables to change this order (rank-reordering).
Alternatively, continue with the previous exercises if these are more relevant for your work.
"},{"location":"4day-20240423/extra_3_06_Exercises_9/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_3_06_Exercises_9/#qa","title":"Q&A","text":" -
If I set --hint=nomultithread, can my task use the second thread of the cpu core, isn't it still the same core? If not, am I missing some performance here? I don't know how the hyperthread/SMT works behind the scene
- If you set
--hint=nomultithread, you'll get an affinity mask that doesn't include the second hardware thread and there is no way this can be undone later. Affinity masks are the Linux mechanism that Slurm uses at the task level in job steps.
I have checked the cgroup hierarchy of the task and also the cpu affinity in /proc/status, in cgroup it will show the CPU id of the second thread but in the cpu affinity, it only shows the first CPU id of the first thread of the core, which is quite confusing.
- Slurm only uses cgroups to limit access at the full job step level and job level, not at the task level, as otherwise you'd have problems with shared memory computation for the same reasons that it was explained you should not use, e.g.,
--gpus-per-task for the GPUs. You probably checked for a task in an srun that --hint=nomultithread (which is actually the default) and one core per task?
Yes, it's a task in an srun. o expl, I request 2 tasks and --cpu-per-tasks=2, cgroup ill show that step_0.task_0 and step_0.task_1 has access to cpus 23-26, 87-90, cpu affinity will be 23-24 for task_0 and 25-26 for task_1, which is a bit confusing because psutil which shows the logical core will detect that thread 23,24,87,88 are working even if I don't request access to the thread 87,88.
- I am not exactly sure what
psutil is doing, but what you see is normal Slurm behaviour. As LUMI always allocates full cores and as the cgroup is set for the whole job step, your job step which uses 4 cores gets a cgroup containing virtual cores 23-26 and 87-90 (assuming LUMI-G), but for each task level the affinity mask will restrict you to two hardware threads, on different physical cores due to the --hint=nomultithread . I'd have to dig into what psutil does exactly to understand what it reports. I've never experimented with it on LUMI.
psutil query the data from /proc but thank you for explaining, I have an application where I want to monitor cpu/gpu utilization so just want to make sure that our metric is correct. I just thought that the cpu affinity for a task is will also use the logical core like the cgroup.
-
I am trying to run the MPI-OpenMP (CPU) example with binding option. Can you provide guidance on how to do the correct binding such that one MPI-process should correspond to one NUMA node and that OMP threads spread across cpu-cores within that NUMA node with correct binding. (LUMI-C)
-
You can use:
#!/bin/bash\n#SBATCH -p standard\n#SBATCH --nodes=2\n#SBATCH --exclusive\n#SBATCH --ntasks-per-node=8\n#SBATCH --hint=nomultithread\n\nexport OMP_PLACES=cores\nexport OMP_PROC_BIND=true\nexport OMP_NUM_THREADS=6\n\nmodule load LUMI/2309\nmodule load partition/C\nmodule load lumi-CPEtools\nsrun -c ${OMP_NUM_THREADS} hybrid_check\n
The output will be:
Running 16 MPI ranks with 16 threads each (total number of threads: 256).\n\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 0/16 on cpu 0/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 1/16 on cpu 1/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 2/16 on cpu 2/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 3/16 on cpu 3/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 4/16 on cpu 4/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 5/16 on cpu 5/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 6/16 on cpu 6/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 7/16 on cpu 7/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 8/16 on cpu 8/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 9/16 on cpu 9/256 of nid001001\n ++ hybrid_check: MPI rank 0/16 OpenMP thread 10/16 on cpu 10/256 of nid001001\n
Now, the problem is that there are 4 NUMAs per socket, so 16 cores per each NUMA, but L3 cache is shared across 8 cores only. So the suggestion is to double the ranks-per-node a nd have 8 threads instead. But you can try and see in terms of performance.
"},{"location":"4day-20240423/extra_3_07_AMD_ROCgdb_Debugger/","title":"AMD ROCgdb debugger","text":"Presenter: George Markomanolis (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20240423/extra_3_07_AMD_ROCgdb_Debugger/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_08_Exercises_10/","title":"Exercise session 10: Debugging with ROCgdb","text":"Exercise assignments can be found in the AMD exercise notes, section on Debugging.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20240423/extra_3_08_Exercises_10/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar
"},{"location":"4day-20240423/extra_3_08_Exercises_10/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/","title":"Introduction to ROC-Profiler (rocprof)","text":"Presenter: George Markomanolis (AMD)
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-3_09_Introduction_to_Rocprof_Profiling_Tool.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/3_09_Introduction_to_Rocprof_Profiling_Tool.mp4
Note
Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"4day-20240423/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_3_10_Exercises_11/","title":"Exercise session 11: Profiling with AMD Rocprof","text":"Exercise assignments can be found in the AMD exercise notes, section on Rocprof.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20240423/extra_3_10_Exercises_11/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar
"},{"location":"4day-20240423/extra_3_10_Exercises_11/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_01_Introduction_to_Python_on_Cray_EX/","title":"Introduction to Python on Cray EX","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_01_Introduction_to_Python_on_Cray_EX.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/4_01_Introduction_to_Python_on_Cray_EX.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_4_01_Introduction_to_Python_on_Cray_EX/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_02_Porting_to_GPU/","title":"Porting Applications to GPU","text":"Presenter: Alfio Lazzaro (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_4_02_Porting_to_GPU/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_03_Performance_Optimization_Improving_Single_Core/","title":"Performance Optimization: Improving Single-core Efficiency","text":"Presenter: Jean-Yves Vet (HPE)
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_03_Performance_Optimization_Improving_Single_Core.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/4_03_Performance_Optimization_Improving_Single_Core.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_4_03_Performance_Optimization_Improving_Single_Core/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_04_Exercises_12/","title":"Exercise session 12: Node-level performance","text":"The files for the exercises can be found in Exercises/HPE/day4/node_performance. Try different compiler optimizations and see the impact on performance.
"},{"location":"4day-20240423/extra_4_04_Exercises_12/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_4_04_Exercises_12/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_05_IO_Optimization_Parallel_IO/","title":"I/O Optimization - Parallel I/O","text":"Presenter: Harvey Richardson (HPE)
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"4day-20240423/extra_4_05_IO_Optimization_Parallel_IO/#links","title":"Links","text":" - The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20240423/extra_4_05_IO_Optimization_Parallel_IO/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_06_Exercises_13/","title":"Exercise session 13: Lustre I/O","text":"The files for the exercises can be found in Exercises/HPE/day4/VH1-io. Untar the file and you'll find a full I/O experiment with striping.
Alternatively, look again at the MPI exercises with Apprentice If you did not do this before, set PAT_RT_SUMMARY=0. You get trace data per rank when you do this (huge file). Set only 2 cycles in the input file (indat). Use app2 on the .ap2 file to see new displays (see help).
"},{"location":"4day-20240423/extra_4_06_Exercises_13/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_HPE.tar
"},{"location":"4day-20240423/extra_4_06_Exercises_13/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_07_AMD_Omnitrace/","title":"Introduction to OmniTrace","text":"Presenter: George Markomanoulis (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20240423/extra_4_07_AMD_Omnitrace/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_08_Exercises_14/","title":"Exercise session 14: Omnitrace","text":"Exercise assignments can be found in the AMD exercise notes, section on Omnitrace.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20240423/extra_4_08_Exercises_14/#materials","title":"Materials","text":"Temporary location of materials (for the lifetime of the training project):
- Exercises can be copied from
/project/project_465001098/exercises/AMD/HPCTrainingExamples
Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar
"},{"location":"4day-20240423/extra_4_08_Exercises_14/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_09_AMD_Omniperf/","title":"AMD Omniperf","text":"Presenter: George Markomanolis (AMD)
Materials on the web:
Archived materials on LUMI:
"},{"location":"4day-20240423/extra_4_09_AMD_Omniperf/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_10_Exercises_15/","title":"Exercise session 15: Omniperf","text":"Exercise assignments can be found in the AMD exercise notes, section on Omniperf.
Exercise files can be copied from Exercises/AMD/HPCTrainingExamples.
"},{"location":"4day-20240423/extra_4_10_Exercises_15/#materials","title":"Materials","text":"Materials on the web:
-
AMD exercise assignments and notes
PDF backup and local web backup.
-
Exercise files: Download as .tar.bz2 or download as .tar
Archived materials on LUMI:
-
Exercise assignments PDF: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.pdf
-
Exercise files: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar.bz2 or /appl/local/training/4day-20240423/files/LUMI-4day-20240423-Exercises_AMD.tar
"},{"location":"4day-20240423/extra_4_10_Exercises_15/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_11_Best_Practices_GPU_Optimization/","title":"Best practices: GPU Optimization, tips & tricks / demo","text":"Presenter: George Markomanolis (AMD) and Samuel Antao (AMD)
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_11_Best_Practices_GPU_Optimization.pdf
-
Scripts as bzip2-compressed tar archive in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_11_scripts.tar.bz2 and uncompressed tar archive in /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_11_scripts.tar.
-
Recording: /appl/local/training/4day-20240423/recordings/4_11_Best_Practices_GPU_Optimization.mp4
PyTorch in the LUMI Software Library
The example in this demo is also used as the example in our Pytorch page in the LUMI Software Library.
"},{"location":"4day-20240423/extra_4_11_Best_Practices_GPU_Optimization/#qa","title":"Q&A","text":"/
"},{"location":"4day-20240423/extra_4_12_LUMI_Support_and_Documentation/","title":"LUMI User Support","text":"Presenter: Kurt Lust (LUST)
Note that there were some technical glitches during the demo. These have been edited out of the video.
Materials on the web:
Archived materials on LUMI:
-
Slides: /appl/local/training/4day-20240423/files/LUMI-4day-20240423-4_12_LUMI_Support_and_Documentation.pdf
-
Recording: /appl/local/training/4day-20240423/recordings/4_12_LUMI_Support_and_Documentation.mp4
The information in this talk is also covered by the following talk from the 1-day courses:
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
- Some remarks about using containers on LUMI.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems (though LUMI is by now rather stable) and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack than your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 12 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 10 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised environments. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer a growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We do offer some help to set up Spack also but it is mostly offered \"as is\" and we will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-own-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- Commercial software often doesn't run properly on LUMI. E.g., we've had lots of trouble already with packages that use an MPI library that does not recognise our scheduler properly, or does not recognise the Slingshot network, yet is not sufficiently ABI-compatible with Cray MPICH or the libfabric library on LUMI so that we cannot substitute with our own libraries. Vendors also aren't always that interested to help us out as many software vendors offer their software-as-a-service in the cloud, so a big machine as LUMI that also works with industry, is not only a potential customer but mostly a potential competitor.
- And lastly, we don't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason LUMI also requires to containerize conda and Python installations. On LUMI two tools are offered for this.
- cotainr is a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space. Its current version focusses on containerising a conda-installation.
- The second tool is a container-based wrapper generator that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the
cray-python module. On LUMI the tool is called lumi-container-wrapper but users of the CSC national systems will know it as Tykky.
Both tools are pre-installed on the system and ready-to-use.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/22.08, LUMI/22.12, LUMI/23.03 and LUMI/23.09 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#module-spider-command","title":"Module spider command","text":"(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 17 versions of GNUplot. There were 9 installations of GNUplot 5.4.3, five of 5.4.6 and 3 of 5.4.8 at the moment the slide was made (see further down these notes for the output). The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there were five versions at the moment the slides were made, 3.22.2, 3.23.2, 3.24.0, 3.25.2 and 3.27.7, that are shown in blue with an \"E\" behind the name. That is because these are not provided by a module called CMake on LUMI, but by another module that in this case contains a collection of popular build tools and that we will discover shortly.
You may also see a couple of regular modules called cmake that come from software installed differently.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.8-cpeGNU-23.09. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are three ways to load the module: By loading LUMI/23.09 combined with partition/C, by loading LUMI/23.09 combined with partition/G or by loading LUMI/23.09 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/23.09 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.27.7. This will now show us that this tool is in the buildtools/23.09 module (among others) and give us 4 different options to load that module as it is provided in the CrayEnv and the LUMI/23.09 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider cmake\nmodule spider gnuplot/5.4.8-cpeGNU-23.09\nmodule spider CMake/3.27.7\n
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#module-keyword-command","title":"Module keyword command","text":"Lmod has a second way of searching for modules: module keyword. It searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Demo module keyword Try the following command:
module keyword https\n
cURL and wget are indeed two tools that can be used to fetch files from the internet.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Demo Try the following command immediately after login:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded, but we'll come back to that later also. The letter \"S\" denotes a sticky module.
The screen above also shows (D:5.0.2:5.2.0) next to the rocm module. The D means that this version of the module, 5.2.3, is currently the default on the system. The two version numbers next to this module show that the module can also be loaded as rocm/5.0.2 and rocm/5.2.0. These are two modules that were removed from the system during the last update of the system, but version 5.2.3 can be loaded as a replacement of these modules so that software that used the removed modules may still work without recompiling.
The first screen started category \"HPE-Cray PE modules\". We now see that there is a second set of modules associated with the programming environment, the \"HPE-Cray PE target modules\".
In the above screen we also see the modules for the software stack that we have discussed earlier in this text.
And the screen above shows some extensions of modules (but the list is short at this point as most modules containing extensions only become available after loading one of the software stacks).
At the end of the output we also get some information about the meaning of the letters used in the display.
Try the following commands and carefully observe the output:
module load LUMI/23.09 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\nmodule av\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. -
Similarly in the LUMI stacks, as the LUMI module itself is reloaded, it will also reload a partition module that would be the one for the node it is on. You may see messages from that process.
However, the partition module that was loaded also gets reloaded in the process. Now some versions of LMOD did so in the wrong order, and that caused problems. With the current version though the partition module is reloaded after the LUMI module so the state you had before the module purge is correctly restored.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
As the module extensions list in the output of module avail could potentially become very long over time (certainly if there would be Python or R modules installed with EasyBuild that show all included Python or R packages in that list) you may want to hide those. You can do this by loading the ModuleExtensions/hide module and undo this again by loading ModuleExtensions/show.
Demo Try the following commands:
module avail\nmodule load ModuleExtensions/hide\nmodule avail\nmodule load ModuleExtensions/show\nmodule avail\n
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/23.09 stack we prefer that users use the Cray programming environment modules that come with release 23.09 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Demo Try the following commands:
module load LUMI/23.09\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the Slingshot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2022.5, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeGNU-23.09 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/23.09.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.9.0-noPython-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#installing-software","title":"Installing software","text":""},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants of the project to solve a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module. It works correctly for a lot of CPU-only software, but fails more frequently for GPU software as the installation scripts will try to run scripts that detect which GPU is present, or try to run tests on the GPU, even if you tell which GPU type to use, which does not work on the login nodes.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS we already have support. The easy way is to check the LUMI Software Library which lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. A command-line alternative is to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Results of the searches:
In the LUMI Software Library, after some scrolling through the page for GROMACS, the list of EasyBuild recipes is found in the \"User-installable modules (and EasyConfigs)\" section:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb. This is GROMACS 2022.5 with the PLUMED 2.9.0 plugin, built with the GNU compilers from LUMI/23.09, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2022.5-cpeGNU-23.09-PLUMED-2.9.0-noPython-CPU.eb -r\n
Demo of the EasyBuild installation of GROMACS
EasyBuild detects PLUMED is a dependency and because of the -r option, it first installs the required version of PLUMED.
When the installation of PLUMED finishes, EasyBuild starts the installation of GROMACS. It mentions something we haven't seen when installing PLUMED:
== starting iteration #0\n
GROMACS can be installed in many configurations, and they generate executables with different names. Our EasyConfig combines 4 popular installations in one: Single and double precision and with and without MPI, so it will do 4 iterations. As EasyBuild is developed by geeks, counting starts from 0.
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.cache/lmod. You can do this with
rm -rf $HOME/.cache/lmod\n
(With older versions of Lmod the cache directory is $HOME/.lmod.d/cache.)"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.4.1 with the GNU compilers: eb VASP-6.4.1-cpeGNU-22.12-build01.eb \u2013r . \n
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elsewhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#easybuild-tips-tricks","title":"EasyBuild tips & tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"I also want to give some pointers to more information in case you want to learn a lot more about, e.g., developing support for your code in EasyBuild, or for support people who want to adapt our EasyConfigs for users requesting a specific configuration of a package.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on tutorial.easybuild.io. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software.
But full portability is as much a myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the Slingshot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
Even if a container is portable to LUMI, it may not yet be performance portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
Software installations that would otherwise be impossible. E.g., some software may not even be suited for installation in a multi-user HPC system as it uses fixed paths that are not compatible with installation in module-controlled software stacks. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
-
As an example, Conda installations are not appreciated on the main Lustre file system.
On one hand, Conda installations tend to generate lots of small files (and then even more due to a linking strategy that does not work on Lustre). So they need to be containerised just for storage manageability.
They also re-install lots of libraries that may already be on the system in a different version. The isolation offered by a container environment may be a good idea to ensure that all software picks up the right versions.
-
An example of software that is usually very hard to installed is a GUI application, as they tend to have tons of dependencies and recompiling can be tricky. Yet rather often the binary packages that you can download cannot be installed wherever you want, so a container can come to the rescue.
-
Another example where containers have proven to be useful on LUMI is to experiment with newer versions of ROCm than we can offer on the system.
This often comes with limitations though, as (a) that ROCm version is still limited by the drivers on the system and (b) we've seen incompatibilities between newer ROCm versions and the Cray MPICH libraries.
-
And a combination of both: LUST with the help of AMD have prepared some containers with popular AI applications. These containers use some software from Conda, a newer ROCm version installed through RPMs, and some performance-critical code that is compiled specifically for LUMI.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS. Currently we offer Singularity Community Edition 3.11.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory. This can lead to exhaustion of your disk quota for your home directory. So you may want to use the environment variable SINGULARITY_CACHEDIR to put the cache in, e.g,, your scratch space (but even then you want to clean up after the pull operation so save on your storage billing units).
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require user namespaces, cannot be supported for security reasons (as user namespaces in Linux are riddled with security issues). Enabling features that are known to have had several serious security vulnerabilities in the recent past, or that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container using what the SingularityCE user guide calls \"unprivileged proot builds\". This requires loading the proot command which is provided by the systools/23.09 module or later versions provided in CrayEnv or LUMI/23.09 or later. The SingularityCE user guide mentions several restrictions of this process. The general guideline from the manual is: \"Generally, if your definition file starts from an existing SIF/OCI container image, and adds software using system package managers, an unprivileged proot build is appropriate. If your definition file compiles and installs large complex software from source, you may wish to investigate --remote or --fakeroot builds instead.\" But on LUMI we cannot yet provide --fakeroot builds due to security constraints.
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI (and some for ROCm are already there).
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and /dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables. And it is more tricky than it appears as some of those directories themselves are links to other directories that also need to be mounted. Currently to use your project, scratch and flash directory in the container you need to use the bindings
--bind /pfs,/scratch,/projappl,/project,/flash\n
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI Slingshot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and until version 5 full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the Slingshot 11 interconnect, so work is going on for better support for OFI in general and Cray Slingshot in particular and for full GPU support.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#bindings-for-singularity","title":"Bindings for singularity","text":"The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY_PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the singularity-bindings in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#vnc-container","title":"VNC container","text":"The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks through the lumi-vnc module. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
For most users, the Open OnDemand web interface and tools offered in that interface will be a better alternative.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#cotainr-build-conda-containers-on-lumi","title":"cotainr: Build Conda containers on LUMI","text":"The third tool is cotainr, a tool developed by DeIC, the Danish partner in the LUMI consortium. It is a tool to pack a Conda installation into a container. It runs entirely in user space and doesn't need any special rights. (For the container specialists: It is based on the container sandbox idea to build containers in user space.)
Containers build with cotainr are used just as other containers, so through the singularity commands discussed before.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#container-wrapper-for-python-packages-and-conda","title":"Container wrapper for Python packages and conda","text":"The fourth tool is a container wrapper tool that users from Finland may also know as Tykky (the name on their national systems). It is a tool to wrap Python and conda installations in a container and then create wrapper scripts for the commands in the bin subdirectory so that for most practical use cases the commands can be used without directly using singularity commands. Whereas cotainr fully exposes the container to users and its software is accessed through the regular singularity commands, Tykky tries to hide this complexity with wrapper scripts that take care of all bindings and calling singularity. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run the tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation. So strictly speaking it does not create a container, but a SquashFS file that is then mounted in a small existing base container. However, the wrappers created for all commands in the bin subdirectory of the conda or Python installation take care of doing the proper bindings. If you want to use the container through singularity commands however, you'll have to do that mounting by hand.
We do strongly recommend to use the container wrapper tool or cotainr for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a tempororary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#pre-built-ai-containers","title":"Pre-built AI containers","text":"LUST with the help of AMD is also building some containers with popular AI software. These containers contain a ROCm version that is appropriate for the software, use Conda for some components, but have several of the performance critical components built specifically for LUMI for near-optimal performance. Depending on the software they also contain a RCCL library with the appropriate plugin to work well on the Slingshot 11 interconnect, or a horovod compiled to use Cray MPICH.
The containers are provided through a module which sets the SINGULARITY_BIND environment variable to ensure proper bindings (as they need, e.g., the libfabric library from the system and the proper \"CXI provider\" for libfabric to connect to the Slingshot interconnect). The module will also provide an environment variable to refer to the container (name with full path) to make it easy to refer to the container in job scripts.
These containers can be found through the LUMI Software Library and are marked with a container label. At the time of the course, there are containers for
- PyTorch, which is the best tested and most developed one,
- TensorFlow,
- JAX,
- AlphaFold,
- ROCm and
- mpi4py.
"},{"location":"4day-20240423/notes_2_07_LUMI_Software_Stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance. Also, containers do not abstract the hardware unlike some virtual machine solutions.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
Likewise, for containers for distributed AI, one may need to inject an appropriate RCCL plugin to fully use the SlingShot 11 interconnect.
-
As containers rely on drivers in the kernel of the host OS, the AMD driver may also cause problems. AMD only guarantees compatibility of the driver with two minor versions before and after the ROCm release for which the driver was meant. Hence containers using a very old version of ROCm or a very new version compared to what is available on LUMI, may not always work as expected.
-
The support for building containers on LUMI is currently very limited due to security concerns. Any build process that requires elevated privileges, fakeroot or user namespaces will not work.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/","title":"LUMI Support and Documentation","text":""},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#distributed-nature-of-lumi-support","title":"Distributed nature of LUMI support","text":"User support for LUMI comes from several parties. Unfortunately, as every participating consortium countries has some responsibilities also and solves things differently, there is no central point where you can go with all questions.
Resource allocators work independently from each other and the central LUMI User Support Team. This also implies that they are the only ones who can help you with questions regarding your allocation: How to apply for compute time on LUMI, add users to your project, running out of resources (billing units) for your project, failure to even get access to the portal managing the allocations given by your resource allocator (e.g., because you let expire an invite), ... For granted EuroHPC projects, support is available via lumi-customer-accounts@csc.fi, but you will have to contact EuroHPC directly at access@eurohpc-ju.europa.eu if, e.g., you need more resources or an extension to your project.
The central LUMI User Support Team (LUST) offers L1 and basic L2 support. Given that the LUST team is very small compared to the number of project granted annually on LUMI (roughly 10 FTE for on the order of 700 projects per year, and support is not their only task), it is clear that the amount of support they can give is limited. E.g., don't expect them to install all software you request for them. There is simply too much software and too much software with badly written install code to do that with that number of people. Nor should you expect domain expertise from them. Though several members of the LUST have been scientist before, it does not mean that they can understand all scientific problems thrown at them or all codes used by users. Also, the team cannot fix bugs for you in the codes that you use, and usually not in the system code either. For fixing bugs in HPE or AMD-provided software, they are backed by a team of experts from those companies. However, fixing bugs in compilers or libraries and implementing those changes on the system takes time. The system software on a big shared machine cannot be upgraded as easily as on a personal workstation. Usually you will have to look for workarounds, or if they show up in a preparatory project, postpone applying for an allocation until all problems are fixed.
EuroHPC has also granted the EPICURE project that started in February 2024 to set up a network for advanced L2 and L3 support across EuroHPC centres. At the time of the course, the project is still in its startup phase. Moreover, this project is also so small that it will have to select the problems they tackle.
In principle the EuroHPC Centres of Excellence should also play a role in porting some applications in their field of expertise and offer some support and training, but so far especially the support and training are not yet what one would like to have.
Basically given the growing complexity of scientific computing and diversity in the software field, what one needs is the equivalent of the \"lab technician\" that many experimental groups have who can then work with various support instances, a so-called Research Software Engineer...
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#support-level-0-help-yourself","title":"Support level 0: Help yourself!","text":"Support starts with taking responsibility yourself and use the available sources of information before contacting support. Support is not meant to be a search assistant for already available information.
The LUMI User Support Team has prepared trainings and a lot of documentation about LUMI. Good software packages also come with documentation, and usually it is possible to find trainings for major packages. And a support team is also not there to solve communication problems in the team in which you collaborate on a project!
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#take-a-training","title":"Take a training!","text":"There exist system-specific and application-specific trainings. Ideally of course a user would want a one-step solution, having a specific training for a specific application on a specific system (and preferably with the workflow tools they will be using, if any), but that is simply not possible. The group that would be interested in such a training is for most packages too small, and it is nearly impossible to find suitable teachers for such course given the amount of expertise that is needed in both the specific application and the specific system. It would also be hard to repeat such a training with a high enough frequency to deal with the continuous inflow of new users.
The LUMI User Support Team organises 2 system-specific trainings:
-
There is a 1- or 2-day introductory course entirely given by members of the LUST. The training does assume familiarity with HPC systems, and each local organisation should offer such courses for their local systems already.
-
And there is a 4-day comprehensive training with more attention on how to run efficiently, and on the development and profiling tools. Even if you are not a developer, you may benefit from more knowledge about these tools as especially a profiler can give you insight in why your application does not run as expected.
Application-specific trainings should come from other instances though that have the necessary domain knowledge: Groups that develop the applications, user groups, the EuroHPC Centres of Excellence, ...
Currently the training landscape in Europe is not too well organised. EuroHPC is starting some new training initiatives to succeed the excellent PRACE trainings. Moreover, CASTIEL, the centre coordinating the National Competence Centres and EuroHPC Centres of Excellence also tries to maintain an overview of available trainings (and several National Competence Centres organise trainings open to others also).
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#readsearch-the-documentation","title":"Read/search the documentation","text":"The LUST has developed extensive documentation for LUMI. That documentation is split in two parts:
-
The main documentation at docs.lumi-supercomputer.eu covers the LUMI system itself and includes topics such as how to get on the system, where to place your files, how to start jobs, how to use the programming environment, how to install software, etc.
-
The LUMI Software Library contains an overview of software pre-installed on LUMI or for which we have install recipes to start from. For some software packages, it also contains additional information on how to use the software on LUMI.
That part of the documentation is generated automatically from information in the various repositories that are used to manage those installation recipes. It is kept deliberately separate, partly to have a more focused search in both documentation systems and partly because it is managed and updated very differently.
Both documentation systems contain a search box which may help you find pages if you cannot find them easily navigating the documentation structure. E.g., you may use the search box in the LUMI Software Library to search for a specific package as it may be bundled with other packages in a single module with a different name.
Some examples:
-
Search in the main documentation at docs.lumi-supercomputer.eu for \"quota\" and it will take you to pages that among other things explain how much quota you have in what partition.
-
Users of the Finnish national systems have been told to use a tool called \"Tykky\" to pack conda and Python installations to reduce the stress on the filesystems and wonder if that tool is also on LUMI. So let's search in the LUMI Software Library:
It is, but with a different name as foreigners can't pronounce those Finnish names anyway and as something more descriptive was needed.
-
Try searching for the htop command in the LUMI Software Library
So yes, htop is on LUMI, but if you read the page you'll see it is in a module together with some other small tools.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#keep-track-of-the-lumi-status","title":"Keep track of the LUMI status","text":" -
Downtimes on LUMI and major issues are announced on the user mailing list, so read our mails, and it might be a good idea to keep track of the announced downtimes in a calendar.
-
Moreover, there is also the LUMI Service Status page where we repeat those announcements, and even some more issues and keep track of them. So consult this page before asking support. The problem may already be known or you may simply have overlooked one of our announcements.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#talk-to-your-colleagues","title":"Talk to your colleagues","text":"A LUMI project is meant to correspond to a coherent research project in which usually multiple people collaborate.
This implies that your colleagues may have run in the same problem and may already have a solution, or they didn't even experience it as a problem and know how to do it. So talk to your colleagues first.
Support teams are not meant to deal with your team's communication problems. There is nothing worse than having the same question asked multiple times from different people in the same project. As a project does not have a dedicated support engineer, the second time a question is asked it may land at a different person in the support team so that it is not recognized that the question has been asked already and the answer is readily available, resulting in a loss of time for the support team and other, maybe more important questions, remaining unanswered. Similarly bad is contacting multiple help desks with the same question without telling them, as that will also duplicate efforts to solve a question. We've seen it often that users contact both a local help desk and the LUST help desk without telling.
Resources on LUMI are managed on a project basis, not on a user-in-project basis, so if you want to know what other users in the same project are doing with the resources, you have to talk to them and not to the LUST. We do not have systems in place to monitor use on a per-user, per-project basis, only on a per-project basis, and also have no plans to develop such tools as a project is meant to be a close collaboration of all involved users.
LUMI events and on-site courses are also an excellent opportunity to network with more remote colleagues and learn from them! Which is why we favour on-site participation for courses. No video conferencing system can give you the same experience as being physically present at a course or event.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#l1-and-basic-l2-support-lust","title":"L1 and basic L2 support: LUST","text":"The LUMI User Support Team is responsible for providing L1 and basic L2 support to users of the system. Their work starts from the moment that you have userid on LUMI (the local RA is responsible for ensuring that you get a userid when a project has been assigned).
The LUST is a distributed team roughly 10 FTE strong, with people in all LUMI consortium countries, but they work as a team, coordinated by CSC. 10 of the LUMI consortium countries each have one or more members in LUST. However, you will not necessarily be helped by one of the team members from your own country, even when you are in a consortium country, when you contact LUST, but by the team member who is most familiar with your problem.
There are some problems that we need to pass on to HPE or AMD, particularly if it may be caused by bugs in system software, but also because they have more experts with in-depth knowledge of very specific tools.
The LUMI help desk is staffed from Monday till Friday between 9am and 7pm Helsinki time (EE(S)T) except on public holidays in Finland. You can expect a same day first response if your support query is well formulated and submitted long enough before closing time, but a full solution of your problem may of course take longer, depending on how busy the help desk is and the complexity of the problem.
Data security on LUMI is very important. Some LUMI projects may host confidential data, and especially industrial LUMI users may have big concerns about who can access their data. Therefore only very, very few people on LUMI have the necessary rights to access user data on the system, and those people even went through a background check. The LUST members do not have that level of access, so we cannot see your data and you will have to pass all relevant information to the LUST through other means!
The LUST help desk should be contacted through web forms in the \"User Support - Contact Us\" section of the main LUMI web site. The page is also linked from the \"Help Desk\" page in the LUMI documentation. These forms help you to provide more information that we need to deal with your support request. Please do not email directly to the support web address (that you will know as soon as we answer at ticket as that is done through e-mail). Also, separate issues should go in separate tickets so that separate people in the LUST can deal with them, and you should not reopen an old ticket for a new question, also because then only the person who dealt with the previous ticket gets notified, and they may be on vacation or even not work for LUMI anymore, so your new request may remain unnoticed for a long time.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#tips-for-writing-good-tickets-that-we-can-answer-promptly","title":"Tips for writing good tickets that we can answer promptly","text":""},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#how-not-to-write-a-ticket","title":"How not to write a ticket","text":" -
Use a meaningful subject line. All we see in the ticket overview is a number and the subject line, so we need to find back a ticket we're working on based on that information alone.
Yes, we have a user on LUMI who managed to send 8 tickets in a short time with the subject line \"Geoscience\" but 8 rather different problems...
Hints:
- For common problems, including your name in the subject may be a good idea.
- For software problems, including the name of the package helps a lot. So not \"Missing software\" but \"Need help installing QuTiP 4.3.1 on CPU\". Or not \"Program crashes\" but \"UppASD returns an MPI error when using more than 1000 ranks\".
-
Be accurate when describing the problem. Support staff members are not clairvoyants with mysterious superpowers who can read your mind across the internet.
We'll discuss this a bit more further in this lecture.
-
If you have no time to work with us on the problem yourself, then tell so.
Note: The priorities added to the ticket are currently rather confusing. You have three choices in the forms: \"It affects severely my work\", \"It is annoying, but I can work\", and \"I can continue to work normally\", which map to \"high\", \"medium\" and \"low\". So tickets are very easily marked as high priority because you cannot work on LUMI, even though you have so much other work to do that it is really not that urgent or that you don't even have time to answer quickly.
The improved version could be something like this:
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#how-to-write-tickets","title":"How to write tickets","text":""},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#1-ticket-1-issue-1-ticket","title":"1 ticket = 1 issue = 1 ticket","text":" -
If you have multiple unrelated issues, submit them as multiple tickets. In a support team, each member has their own specialisation so different issues may end up with different people. Tickets need to be assigned to people who will deal with the problem, and it becomes very inefficient if multiple people have to work on different parts of the ticket simultaneously.
Moreover, the communication in a ticket will also become very confusing if multiple issues are discussed simultaneously.
-
Conversely, don't submit multiple tickets for a single issue just because you are too lazy to look for the previous e-mail if you haven't been able to do your part of the work for some days. If you've really lost the email, at least tell us that it is related to a previous ticket so that we can try to find it back.
So keep the emails you get from the help desk to reply!
-
Avoid reusing exactly the same subject line. Surely there must be something different for the new problem?
-
Avoid reopening old tickets that have been closed long ago.
If you get a message that a ticket has been closed (basically because there has been no reply for several weeks so we assume the issue is not relevant anymore) and you feel it should not have been closed, reply immediately.
When you reply to a closed ticket and the person who did the ticket is not around (e.g., on vacation or left the help desk team), your reply may get unnoticed for weeks. Closed tickets are not passed to a colleague when we go on a holiday or leave.
-
Certainly do not reopen old tickets with new issues. Apart from the fact that the person who did the ticket before may not be around, they may also have no time to deal with the ticket quickly or may not even be the right person to deal with it.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#the-subject-line-is-important","title":"The subject line is important!","text":" -
The support team has two identifiers in your ticket: Your mail address and the subject that you specified in the form (LUST help desk) or email (LUMI-BE help desk). So:
-
Use consistently the same mail address for tickets. This helps us locate previous requests from you and hence can give us more background about what you are trying to do.
The help desk is a professional service, and you use LUMI for professional work, so use your company or university mail address and not some private one.
-
Make sure your subject line is already descriptive and likely unique in our system.
We use the subject line to distinguish between tickets we're dealing with so make sure that it can easily be distinguished from others and is easy to find back.
-
So include relevant keywords in your subject, e.g.,
Some proper examples are
-
User abcdefgh cannot log in via web interface
So we know we may have to pass this to our Open OnDemand experts, and your userid makes the message likely unique. Moreover, after looking into account databases etc., we can immediately find back the ticket as the userid is in the subject.
-
ICON installation needs libxml2
-
VASP produces MPI error message when using more than 1024 ranks
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#think-with-us","title":"Think with us","text":" -
Provide enough information for us to understand who you are:
-
Name: and the name as we would see it on the system, not some nickname.
-
Userid: Important especially for login problems.
-
Project number:
- When talking to the LUST: they don't know EuroHPC or your local organisation's project numbers, only the 462xxxxxx and 465xxxxxx numbers, and that is what they need.
- If you have a local support organisation though, the local project number may be useful for them, as it may then land with someone who does not have access to the LUMI project numbers of all projects they manage.
-
For login and data transfer problems, your client environment is often also important to diagnose the problem.
-
What software are you using, and how was it installed or where did you find it?
We know that certain installation procedures (e.g., simply downloading a binary) may cause certain problems on LUMI. Also, there are some software installations on LUMI for which neither LUST nor the local help desk is responsible, so we need to direct to to their support instances when problems occur that are likely related to that software.
-
Describe your environment (though experience learns that some errors are caused by users not even remembering they've changed things while those changes can cause problems)
-
Which modules are you using?
-
Do you have special stuff in .bashrc or .profile?
-
For problems with running jobs, the batch script that you are using can be very useful.
-
Describe what worked so far, and if it ever worked: when? E.g., was this before a system update?
The LUST has had tickets were a user told that something worked before but as we questioned further it was long ago before a system update that we know broke some things that affects some programs...
-
What did you change since then? Think carefully about that. When something worked some time ago but doesn't work know the cause is very often something you changed as a user and not something going on on the system.
-
What did you already try to solve the problem?
-
How can we reproduce the problem? A simple and quick reproducer speeds up the time to answer your ticket. Conversely, if it takes a 24-hour run on 256 nodes to see the problem it is very, very likely that the support team cannot help you.
Moreover, if you are using licensed software with a license that does not cover the support team members, usually we cannot do much for you. LUST will knowingly violate software licenses only to solve your problems (and neither will your local support team)!
-
The LUST help desk members know a lot about LUMI but they are (usually) not researchers in your field so cannot help you with problems that require domain knowledge in your field. We can impossibly know all software packages and tell you how to use them (and, e.g., correct errors in your input files). And the same likely holds for your local support organisation.
You as a user should be the domain expert, and since you are doing computational science, somewhat multidisciplinary and know something about both the \"computational\" and the \"science\".
We as the support team should be the expert in the \"computational\". Some of us where researchers in the past so have some domain knowledge about a the specific subfield we were working in, but there are simply too many scientific domains and subdomains to have full coverage of that in a central support team for a generic infrastructure.
We do see that lots of crashes and performance problems with software are in fact caused by wrong use of the package!
However, some users expect that we understand the science they are doing, find the errors in their model and run that on LUMI, preferably by the evening they submitted the ticket. If we could do that, then we could basically make a Ph.D that usually takes 4 years in 4 weeks and wouldn't need users anymore as it would be more fun to produce the science that our funding agencies expect ourselves.
-
The LUST help desk members know a lot about LUMI but cannot know or solve everything and may need to pass your problem to other instances, and in particular HPE or AMD.
Debugging system software is not the task of the of the LUST. Issues with compilers or libraries can only be solved by those instances that produce those compilers or libraries, and this takes time.
We have a way of working that enables us to quickly let users test changes to software in the user software stack by making user installations relatively easy and reproducible using EasyBuild, but changing the software installed in the system images - which includes the Cray programming environment - where changes have an effect on how the system runs and can affect all users, are non-trivial and many of those changes can only be made during maintenance breaks.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#beware-of-the-xy-problem","title":"Beware of the XY-problem!","text":"Partly quoting from xyproblem.info: Users are often tempted to ask questions about the solution they have in mind and where they got stuck, while it may actually be the wrong solution to the actual problem. As a result one can waste a lot of time attempting to get the solution they have in mind to work, while at the end it turns out that that solution does not work. It goes as follows:
- The user wants to do X.
- The user doesn't really know how to do X. However, they think that doing Y first would be a good step towards solving X.
- But the user doesn't really know how to do Y either and gets stuck there too.
- So the user contacts the help desk to help with solving problem Y.
- The help desk tries to help with solving Y, but is confused because Y seems a very strange and unusual problem to solve.
- Once Y is solved with the help of the help desk, the user is still stuck and cannot solve X yet.
- User contacts the help desk again for further help and it turns out that Y wasn't needed in the first place as it is not part of a suitable solution for X.
Or as one of the colleagues of the author of these notes says: \"Often the help desk knows the solution, but doesn't know the problem so cannot give the solution.\"
To prevent this, you as a user has to be complete in your description:
-
Give the broader problem and intent (so X), not just the small problem (Y) on which you got stuck.
-
Promptly provide information when the help desk asks you, even if you think that information is irrelevant. The help desk team member may have a very different look on the problem and come up with a solution that you couldn't think of, and you may be too focused on the solution that you have in mind to see a better solution.
-
Being complete also means that if you ruled out some solutions, share with the help desk why you ruled them out as it can help the help desk team member to understand what you really want.
After all, if your analysis of your problem was fully correct, you wouldn't need to ask for help, don't you?
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#what-support-can-we-offer","title":"What support can we offer?","text":""},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#restrictions","title":"Restrictions","text":"Contrary to what you may be familiar with from your local Tier-2 system and support staff, team members of the LUMI help desks have no elevated privileges. This holds for both the LUST and LUMI-BE help desk.
As a result,
-
We cannot access user files. A specific person of the LUMI-BE help desk can access your project, scratch and flash folders if you make them part of the project. This requires a few steps and therefore is only done for a longer collaboration between a LUMI project and that help desk member. The LUST members don't do that.
-
Help desk team members cannot install or modify system packages or settings.
A good sysadmin usually wouldn't do so either. You are working on a multi-user system and you have to take into account that any change that is beneficial for you, may have adverse effects for other users or for the system as a whole.
E.g., installing additional software in the images takes away from the available memory on each node, slows down the system boot slightly, and can conflict with software that is installed through other ways.
-
The help desk cannot extend the walltime of jobs.
Requests are never granted, even not if the extended wall time would still be within the limits of the partition.
-
The LUST is in close contact with the sysadmins, but as the sysadmins are very busy people they will not promptly deal with any problem. Any problem though endangering the stability of the system gets a high priority.
-
The help desk does not monitor running jobs. Sysadmins monitor the general health of the system, but will not try to pick out inefficient jobs unless the job does something that has a very negative effect on the system.
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#what-support-can-and-cannot-do","title":"What support can and cannot do","text":" -
The LUST help desk does not replace a good introductory HPC course nor is it a search engine for the documentation. L0 support is the responsibility of every user.
-
Resource allocators are responsible for the first steps in getting a project and userid on LUMI. EuroHPC projects the support is offered through CSC, the operator of LUMI, at lumi-customer-accounts@csc.fi, or by EuroHPC itself at access@eurohpc-ju.europa.eu if you have not yet been granted a project by them.
Once your project is created and accepted (and the resource allocator can confirm that you properly accepted the invitation), support for account problems (in particular login problems) moves to the LUST.
-
If you run out of block or file quota, the LUST can increase your quota within the limits specified in the LUMI documentation.
If you run out of billing units for compute or storage, only the instance that granted your project can help you, your resource allocator for local projects and access@eurohpc-ju.europa.eu for EuroHPC projects (CSC EuroHPC support at lumi-customer-accounts@csc.fi cannot help you directly for project extensions and increase of billing units).
Projects cannot be extended past one year unless the granting instance is willing to take a charge on the annual budget for the remaining billing units.
-
The LUST cannot do much complete software installations but often can give useful advice and do some of the work.
Note however that the LUST may not even be allowed to help you due to software license restrictions. Moreover, LUST has technically speaking a zone where they can install software on the system, but this is only done for software that the LUST can properly support across system updates and that is of interest to a wide enough audience. It is also not done for software where many users may want a specifically customised installation. Neither is it done for software that LUST cannot sufficiently test themselves.
-
The LUST can help with questions regarding compute and storage use. LUST provides L1 and basic L2 support. These are basically problems that can solved in hours rather than days or weeks. More advanced support has to come from other channels though, including support efforts from your local organisation, EuroHPC Centres of Excellence, EPICURE, ...
-
The LUST can help with analysing the source of crashes or poor performance, with the emphasis on help as they rarely have all the application knowledge required to dig deep. And it will still require a significant effort from your side also.
-
However, LUST is not a debugging service (though of course we do take responsibility for code that we developed).
-
The LUST has some resources for work on porting and optimising codes to/for AMD GPUs via porting calls and hackathons respectively. But we are not a general code porting and optimisation service. And even in the porting call projects, you are responsible for doing the majority of the work, LUST only supports.
-
The LUST cannot do your science or solve your science problems though.
Remember:
\"Supercomputer support is there to support you in the computational aspects of your work related to the supercomputer but not to take over your work.\"
Any support will always be a collaboration where you may have to do most of the work. Supercomputer support services are not a free replacement of a research software engineer (the equivalent of the lab assistant that many experimental groups have).
"},{"location":"4day-20240423/notes_4_12_LUMI_Support_and_Documentation/#links","title":"Links","text":""},{"location":"4day-20240423/schedule/","title":"Course schedule","text":" - Day 1
- Day 2
- Day 3
- Day 4 DAY 1 - Tuesday 23/04 09:00 EEST 08:00 CEST Welcome and introduction Presenters: Heidi Reiman (LUST), Harvey Richardson (HPE) 09:15 EEST 08:15 CEST HPE Cray EX architecture Presenter: Harvey Richardson (HPE) 10:15 EEST 09:15 CEST Programming Environment and Modules Presenter: Harvey Richardson (HPE) 10:45 EEST 09:15 CEST Break (15 minutes) 11:00 EEST 10:00 CEST Running Applications
- Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
Presenter: Harvey Richardson (HPE) 11:20 EEST 10:20 CEST Exercises (session #1) 12:00 EEST 11:00 CEST Lunch break (90 minutes) 13:30 EEST 12:30 CEST Compilers and Parallel Programming Models - An introduction to the compiler suites available, including examples of how to get additional information about the compilation process.
- Cray Compilation Environment (CCE) and options relevant to porting and performance. CCE classic to Clang transition.
- Description of the Parallel Programming models.
Presenter: Alfio Lazzaro (HPE) 14:30 EEST 13:30 CEST Exercises (session #2) 15:00 EEST 14:00 CEST Break (15 minutes) 15:15 EEST 14:15 CEST Cray Scientific Libraries - The Cray Scientific Libraries for CPU and GPU execution.
Presenter: Alfio Lazzaro (HPE) 15:45 EEST 14:45 CEST Exercises (session #3) 16:15 EEST 15:15 CEST CCE Offloading Models - Directive-based approach for GPU offloading execution with the Cray Compilation Environment. Presenter: Alfio Lazzaro (HPE) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 2 - Wednesday 24/04 09:00 EEST 08:00 CEST Introduction to HIP Programming
The AMD ROCmTM ecosystem HIP programming
Presenter: George Markomanolis (AMD) 10:00 EEST 9:00 CEST Exercises (session #4) 10:30 EEST 09:30 CEST Break (15 minutes) 10:45 EEST 09:45 CEST Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat Presenter: Thierry Braconnier (HPE) 11:30 EEST 10:30 CEST Exercises (session #4) 12:00 EEST 11:00 CEST Lunch break (80 minutes) 13:20 EEST 12:20 CEST Advanced Placement - More detailed treatment of Slurm binding technology and OpenMP controls.
Presenter: Jean-Yves Vet (HPE) 14:20 EEST 13:20 CEST Exercises (session #5) 14:50 EEST 13:50 CEST Break (20 minutes) 15:10 EEST 14:10 CEST LUMI Software Stacks - Software policy.
- Software environment on LUMI.
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LUST) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 3 - Thursday 25/04 09:00 EEST 08:00 CEST Introduction to Perftools - Overview of the Cray Performance and Analysis toolkit for profiling applications.
- Demo: Visualization of performance data with Apprentice2 Presenter: Thierry Braconnier (HPE) 09:40 EEST 08:40 CEST Exercises (session #7) 10:10 EEST 09:10 CEST Break (20 minutes) 10:30 EEST 09:30 CEST Advanced Performance Analysis
- Automatic performance analysis and loop work estimated with perftools
- Communication Imbalance, Hardware Counters, Perftools API, OpenMP
- Compiler feedback and variable scoping with Reveal
Presenter: Thierry Braconnier (HPE) 11:30 EEST 10:30 CEST Exercises (session #8) 12:00 EEST 11:00 CEST Lunch break 13:15 EEST 12:15 CEST MPI Topics on the HPE Cray EX Supercomputer - High level overview of Cray MPI on Slingshot
- Useful environment variable controls
- Rank reordering and MPMD application launch
Presenter: Harvey Richardson (HPE) 14:15 EEST 13:15 CEST Exercises (session #9) 14:45 EEST 13:45 CEST Break 15:00 EEST 14:00 CEST AMD Debugger: ROCgdb Presenter: George Markomanolis (AMD) 15:30 EEST 14:30 CEST Exercises (session #10) 15:45 EEST 14:45 CEST Introduction to ROC-Profiler (rocprof) Presenter: George Markomanolis (AMD) 16:25 EEST 15:25 CEST Exercises (session #11) 17:00 EEST 16:00 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 EEST 16:30 CEST End of the course day DAY 4 - Friday 26/04 09:00 EEST 08:00 CEST Introduction to Python on Cray EX Cray Python for the Cray EX
Presenter: Alfio Lazzaro (HPE) 09:10 EEST 08:10 CEST Porting Applications to GPU Presenter: Alfio Lazzaro (HPE) 09:35 EEST 08:35 CEST Performance Optimization: Improving Single-core Efficiency Presenter: Jean-Yves Vet (HPE) 10:00 EEST 09:00 CEST Exercises (session #12) 10:15 EEST 09:15 CEST Break 10:30 EEST 09:30 CEST Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system.
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes.
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations
- Further considerations of parallel I/O and other APIs.
- Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson (HPE) 11:30 EEST 10:30 CEST Exercises (session #13) 12:00 EEST 11:00 CEST Lunch break (60 minutes) 13:00 EEST 12:00 CEST Introduction to OmniTrace Presenter: George Markomanolis (AMD) 13:25 EEST 12:25 CEST Exercises (session #14) 13:45 EEST 12:45 CEST Introduction to Omniperf Presenter: George Markomanolis (AMD) 14:10 EEST 13:10 CEST Exercises (session #15) 14:30 EEST 13:30 CEST Break 14:45 EEST 13:45 CEST Best practices: GPU Optimization, tips & tricks / demo Presenter: George Markomanolis (AMD) and Samuel Antao (AMD) 16:15 EEST 15:15 CEST LUMI User Support - What can we help you with and what not? How to get help, how to write good support requests.
- Some typical/frequent support questions of users on LUMI?
Presenter: Kurt Lust (LUST) 16:45 EEST 15:45 CEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:15 EEST 16:15 CEST End of the course"},{"location":"4day-20241028/","title":"Advanced LUMI Training, October 28-31, 2024","text":""},{"location":"4day-20241028/#course-organisation","title":"Course organisation","text":" -
Location: SURF, Science Park 140, 1098 XG Amsterdam, The Netherlands
-
The public transportation is run by GVB.
-
Whatever type of ticket you have, you always need to check in and check out.
It is now perfectly possible to do so with your bank card, but of course you should use the same one to check in and check out.
If you use your bank card, you can use their app Gappie to follow up your use. The app also provides routing, and you can by regular single or multi-day tickets in it that will then work with a QR code.
-
Gappie app for iOS and Gappie app for Android
-
Multi-day tickets are interesting if you take public transportation a lot. You can buy them in the Gappie app, but opening the app and scanning the QR code is a slow process compared to tapping a credit card on the reader. If all travel you need is from a hotel in the centre to the venue and back, it isn't worth it.
-
Amsterdam is more than canals and the red light district
-
Original schedule (PDF)
Dynamic schedule (adapted as the course progresses)
The dynamic schedule also contains links to pages with information about the course materials, but those links are also available below on this page.
-
During the course, there are two Slurm reservations available:
- CPU nodes:
lumic_ams - GPU nodes:
lumig_ams
They can be used in conjunction with the training project project_465001362.
Note that the reservations and course project should only be used for making the exercises during the course and not for running your own jobs. The resources allocated to the course are very limited.
"},{"location":"4day-20241028/#course-materials","title":"Course materials","text":"Course materials include the Q&A of each session, slides when available and notes when available.
Due to copyright issues some of the materials are only available to current LUMI users and have to be downloaded from LUMI.
Note: Some links in the table below are dead and will remain so until after the end of the course.
Presentation slides notes recording Appendix: Additional documentation / documentation /"},{"location":"4day-20241028/#links-to-documentation","title":"Links to documentation","text":"The links to all documentation mentioned during the talks is on a separate page.
"},{"location":"4day-20241028/#external-material-for-exercises","title":"External material for exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"4day-20241028/A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"4day-20241028/A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 23.02.7, on the system at the time of the course
-
HPE Cray Programming Environment web documentation contains a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09 and aocc/4.1.0 in 23.12/24.03)
-
Clang 17.0.1 version (cce/17.0.0 in 23.12 and cce/17.0.1 in 24.03)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCE 4.1 User Guide
"},{"location":"4day-20241028/A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
man cc (or latest version)
-
man CC (or latest version)
-
man ftn (or latest version)
-
OpenMP in CCE
man intro_openmp (or latest version)
-
OpenACC in CCE
man intro_openacc (or latest version)
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version. The links on this page are for the version on LUMI at the time of the course.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"4day-20241028/A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"4day-20241028/A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"4day-20241028/A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"4day-20241028/A02_Misc_Questions/","title":"Miscellaneous questions","text":"/
"},{"location":"4day-20241028/exercises_AMD_hackmd/","title":"AMD Exercises","text":""},{"location":"4day-20241028/exercises_AMD_hackmd/#login-to-lumi","title":"Login to Lumi","text":"ssh USERNAME@lumi.csc.fi\n
To simplify the login to LUMI, you can add the following to your .ssh/config file. # LUMI\nHost lumi\nUser <USERNAME>\n Hostname lumi.csc.fi\n IdentityFile <HOME_DIRECTORY>/.ssh/id_rsa \n ServerAliveInterval 600\n ServerAliveCountMax 30\n
The ServerAlive* lines in the config file may be added to avoid timeouts when idle.
Now you can shorten your login command to the following.
ssh lumi\n
If you are able to log in with the ssh command, you should be able to use the secure copy command to transfer files. For example, you can copy the presentation slides from lumi to view them.
scp lumi:/project/project_465001362/Slides/AMD/<file_name> <local_filename>\n
You can also copy all the slides with the . From your local system:
mkdir slides\nscp -r lumi:/project/project_465001362/Slides/AMD/* slides\n
If you don't have the additions to the config file, you would need a longer command:
mkdir slides\nscp -r -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465001362/slides/AMD/ slides\n
or for a single file
scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:/project/project_465001362/slides/AMD/<file_name> <local_filename>\n
"},{"location":"4day-20241028/exercises_AMD_hackmd/#hip-exercises","title":"HIP Exercises","text":"We assume that you have already allocated resources with salloc
cp -r /project/project_465001362/Exercises/AMD/HPCTrainingExamples/ .
salloc -N 1 -p standard-g --gpus=1 -t 10:00 -A project_465001362 --reservation LUMItraining_G
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\nmodule load rocm\n
The examples are also available on github: git clone https://github.com/amd/HPCTrainingExamples\n
However, we recommend using the version in /project/project_465001362/Exercises/AMD/HPCTrainingExamples as it has been tuned to the current LUMI environment."},{"location":"4day-20241028/exercises_AMD_hackmd/#basic-examples","title":"Basic examples","text":"cd HPCTrainingExamples/HIP/vectorAdd
Examine files here \u2013 README, Makefile and vectoradd_hip.cpp Notice that Makefile requires HIP_PATH to be set. Check with module show rocm or echo $HIP_PATH Also, the Makefile builds and runs the code. We\u2019ll do the steps separately. Check also the HIPFLAGS in the Makefile.
make\nsrun -n 1 ./vectoradd\n
We can use SLURM submission script, let's call it hip_batch.sh:
#!/bin/bash\n#SBATCH -p standard-g\n#SBATCH -N 1\n#SBATCH --gpus=1\n#SBATCH -t 10:00\n#SBATCH --reservation LUMItraining_G\n#SBATCH -A project_465001362\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\ncd $PWD/HPCTrainingExamples/HIP/vectorAdd \n\nexport HCC_AMDGPU_TARGET=gfx90a\nmake vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Submit the script sbatch hip_batch.sh
Check for output in slurm-<job-id>.out or error in slurm-<job-id>.err
Compile and run with Cray compiler
CC -x hip vectoradd.hip -o vectoradd\nsrun -n 1 --gpus 1 ./vectoradd\n
Now let\u2019s try the cuda-stream example from https://github.com/ROCm-Developer-Tools/HIP-Examples. This example is from the original McCalpin code as ported to CUDA by Nvidia. This version has been ported to use HIP. See add4 for another similar stream example.
git clone https://github.com/ROCm-Developer-Tools/HIP-Examples\nexport HCC_AMDGPU_TARGET=gfx90a\ncd HIP-Examples/cuda-stream\nmake\nsrun -n 1 ./stream\n
Note that it builds with the hipcc compiler. You should get a report of the Copy, Scale, Add, and Triad cases. The variable export HCC_AMDGPU_TARGET=gfx90a is not needed in case one sets the target GPU for MI250x as part of the compiler flags as --offload-arch=gfx90a. Now check the other examples in HPCTrainingExamples/HIP like jacobi etc.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#hipify","title":"Hipify","text":"We\u2019ll use the same HPCTrainingExamples that were downloaded for the first exercise.
Get a node allocation.
salloc -N 1 --ntasks=1 --gpus=1 -p standard-g -A project_465001362 \u2013-t 00:10:00`--reservation LUMItraining_G\n
A batch version of the example is also shown.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#hipify-examples","title":"Hipify Examples","text":""},{"location":"4day-20241028/exercises_AMD_hackmd/#exercise-1-manual-code-conversion-from-cuda-to-hip-10-min","title":"Exercise 1: Manual code conversion from CUDA to HIP (10 min)","text":"Choose one or more of the CUDA samples in HPCTrainingExamples/HIPIFY/mini-nbody/cuda directory. Manually convert it to HIP. Tip: for example, the cudaMalloc will be called hipMalloc. Some code suggestions include nbody-block.cu, nbody-orig.cu, nbody-soa.cu
You\u2019ll want to compile on the node you\u2019ve been allocated so that hipcc will choose the correct GPU architecture.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#exercise-2-code-conversion-from-cuda-to-hip-using-hipify-tools-10-min","title":"Exercise 2: Code conversion from CUDA to HIP using HIPify tools (10 min)","text":"Use the hipify-perl script to \u201chipify\u201d the CUDA samples you used to manually convert to HIP in Exercise 1. hipify-perl is in $ROCM_PATH/bin directory and should be in your path.
First test the conversion to see what will be converted
hipify-perl -no-output -print-stats nbody-orig.cu\n
You'll see the statistics of HIP APIs that will be generated.
[HIPIFY] info: file 'nbody-orig.cu' statisitics:\n CONVERTED refs count: 10\n TOTAL lines of code: 91\n WARNINGS: 0\n[HIPIFY] info: CONVERTED refs by names:\n cudaFree => hipFree: 1\n cudaMalloc => hipMalloc: 1\n cudaMemcpy => hipMemcpy: 2\n cudaMemcpyDeviceToHost => hipMemcpyDeviceToHost: 1\n cudaMemcpyHostToDevice => hipMemcpyHostToDevice: 1\n
hipify-perl is in $ROCM_PATH/bin directory and should be in your path. In some versions of ROCm, the script is called hipify-perl.
Now let's actually do the conversion.
hipify-perl nbody-orig.cu > nbody-orig.cpp\n
Compile the HIP programs.
hipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig
The `#define SHMOO` fixes some timer printouts. \nAdd `--offload-arch=<gpu_type>` if not set by the environment to specify \nthe GPU type and avoid the autodetection issues when running on a single \nGPU on a node.\n
- Fix any compiler issues, for example, if there was something that didn\u2019t hipify correctly.
- Be on the lookout for hard-coded Nvidia specific things like warp sizes and PTX.
Run the program
srun ./nbody-orig\n
A batch version of Exercise 2 is:
#!/bin/bash\n#SBATCH -N 1\n#SBATCH --ntasks=1\n#SBATCH --gpus=1\n#SBATCH -p standard-g\n#SBATCH -A project_465001362\n#SBATCH -t 00:10:00\n#SBATCH --reservation LUMItraining_G\n\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n\nexport HCC_AMDGPU_TARGET=gfx90a\n\ncd HPCTrainingExamples/mini-nbody/cuda\nhipify-perl -print-stats nbody-orig.cu > nbody-orig.cpp\nhipcc -DSHMOO -I ../ nbody-orig.cpp -o nbody-orig\nsrun ./nbody-orig\ncd ../../..\n
Notes:
- Hipify tools do not check correctness
hipconvertinplace-perl is a convenience script that does hipify-perl -inplace -print-stats command
"},{"location":"4day-20241028/exercises_AMD_hackmd/#debugging","title":"Debugging","text":"The first exercise will be the same as the one covered in the presentation so that we can focus on the mechanics. Then there will be additional exercises to explore further or you can start debugging your own applications.
If required, copy the exercises:
cp -r /project/project_465001362/Exercises/AMD/HPCTrainingExamples/ .
Go to HPCTrainingExamples/HIP/saxpy
Edit the saxpy.hip file and comment out the two hipMalloc lines.
71 //hipMalloc(&d_x, size);\n72 //hipMalloc(&d_y, size);\n
Allocate resources: salloc -N 1 -p standard-g --gpus=1 -t 30:00 -A project_465001362 --reservation LUMItraining_G
Now let's try using rocgdb to find the error.
Compile the code with
hipcc --offload-arch=gfx90a -o saxpy saxpy.hip
- Allocate a compute node.
- Run the code
srun -n 1 --gpus 1 ./saxpy
Output
Memory access fault by GPU node-4 (Agent handle: 0x32f330) on address (nil). Reason: Unknown.\n
How do we find the error? Let's start up the debugger. First, we\u2019ll recompile the code to help the debugging process. We also set the number of CPU OpenMP threads to reduce the number of threads seen by the debugger. hipcc -ggdb -O0 --offload-arch=gfx90a -o saxpy saxpy.hip\nexport OMP_NUM_THREADS=1\n
We have two options for running the debugger. We can use an interactive session, or we can just simply use a regular srun command.
srun rocgdb saxpy
The interactive approach uses:
srun --interactive --pty [--jobid=<jobid>] bash \nrocgdb ./saxpy \n
We need to supply the jobid if we have more than one job so that it knows which to use. We can also choose to use one of the Text User Interfaces (TUI) or Graphics User Interfaces (GUI). We look to see what is available.
which cgdb\n -- not found\n -- run with cgdb -d rocgdb <executable>\nwhich ddd\n -- not found\n -- run with ddd --debugger rocgdb\nwhich gdbgui\n -- not found\n -- run with gdbgui --gdb-cmd /opt/rocm/bin/rocgdb\nrocgdb \u2013tui\n -- found\n
We have the TUI interface for rocgdb. We need an interactive session on the compute node to run with this interface. We do this by using the following command.
srun --interactive --pty [-jobid=<jobid>] bash \nrocgdb -tui ./saxpy\n
The following is based on using the standard gdb interface. Using the TUI or GUI interfaces should be similar. You should see some output like the following once the debugger starts.
[output]\nGNU gdb (rocm-rel-5.1-36) 11.2\nCopyright (C) 2022 Free Software Foundation, Inc. \nLicense GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>\nThis is free software: you are free to change and redistribute it.\nThere is NO WARRANTY, to the extent permitted by law.\nType \"show copying\" and \"show warranty\" for details.\nThis GDB was configured as \"x86_64-pc-linux-gnu\".\nType \"show configuration\" for configuration details.\nFor bug reporting instructions, please see:\n<https://github.com/ROCm-Developer-Tools/ROCgdb/issues>.\nFind the GDB manual and other documentation resources online at:\n <http://www.gnu.org/software/gdb/documentation/>. \nFor help, type \"help\".\nType \"apropos word\" to search for commands related to \"word\"...\nReading symbols from ./saxpy...\n
Now it is waiting for us to tell it what to do. We'll go for broke and just type run
(gdb) run\n\n[output] \nThread 3 \"saxpy\" received signal SIGSEGV, Segmentation fault.[Switching to thread 3, lane 0 (AMDGPU Lane 1:2:1:1/0 (0,0,0)[0,0,0])]\n0x000015554a001094 in saxpy (n=<optimized out>, x=<optimized out>, incx=<optimized out>, y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n31 y[i] += a*x[i];\n
The line number 57 is a clue. Now let\u2019s dive a little deeper by getting the GPU thread trace
(gdb) info threads [ shorthand - i th ]\n\n [output]\n Id Target Id Frame\n 1 Thread 0x15555552d300 (LWP 40477) \"saxpy\" 0x000015554b67ebc9 in ?? ()\n from /opt/rocm/lib/libhsa-runtime64.so.1\n 2 Thread 0x15554a9ac700 (LWP 40485) \"saxpy\" 0x00001555533e1c47 in ioctl () \n from /lib64/libc.so.6\n* 3 AMDGPU Wave 1:2:1:1 (0,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 4 AMDGPU Wave 1:2:1:2 (0,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57 \n 5 AMDGPU Wave 1:2:1:3 (1,0,0)/0 \"saxpy\" 0x000015554a001094 in saxpy (\n n=<optimized out>, x=<optimized out>, incx=<optimized out>, \n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n 6 AMDGPU Wave 1:2:1:4 (1,0,0)/1 \"saxpy\" 0x000015554a001094 in saxpy ( \n n=<optimized out>, x=<optimized out>, incx=<optimized out>,\n y=<optimized out>, incy=<optimized out>) at saxpy.hip:57\n
Note that the GPU threads are also shown! Switch to thread 1 (CPU)
(gdb) thread 1 [ shorthand - t 1]\n[output] \n[Switching to thread 1 (Thread 0x15555552d300 (LWP 47136))]\n#0 0x000015554b67ebc9 in ?? () from /opt/rocm/lib/libhsa-runtime64.so.1\n
where
...
#12 0x0000155553b5b419 in hipDeviceSynchronize ()\n from /opt/rocm/lib/libamdhip64.so.5\n#13 0x000000000020d6fd in main () at saxpy.hip:79\n\n(gdb) break saxpy.hip:78 [ shorthand \u2013 b saxpy.hip:78]\n\n[output] \nBreakpoint 2 at 0x21a830: file saxpy.hip, line 78\n\n(gdb) run [ shorthand \u2013 r ]\n\nBreakpoint 1, main () at saxpy.hip:78\n48 saxpy<<<num_groups, group_size>>>(n, d_x, 1, d_y, 1);\n
From here we can investigate the input to the kernel and see that the memory has not been allocated. Restart the program in the debugger.
srun --interactive --pty [-jobid=<jobid>] rocgdb ./saxpy\n(gdb) list 55,74\n\n(gdb) b 60\n\n[output] \n\nBreakpoint 1 at 0x219ea2: file saxpy.cpp, line 62.\n
Alternativelly, one can specify we want to stop at the start of the routine before the allocations.
(gdb) b main\nBreakpoint 2 at 0x219ea2: file saxpy.cpp, line 62.\n
We can now run our application again! (gdb) run\n[output] \nStarting program ...\n...\nBreakpoint 2, main() at saxpy.cpp:62\n62 int n=256;\n\n(gdb) p d_y\n[output] \n$1 = (float *) 0x13 <_start>\n
Should have intialized the pointer to NULL! It makes it easier to debug faulty alocations. In anycase, this is a very unlikely address - usually dynamic allocation live in a high address range, e.g. 0x123456789000.
(gdb) n\n[output] \n63 std::size_t size = sizeof(float)*n;\n\n(gdb) n\n[output] \nBreakpoint 1, main () at saxpy.cpp:67\n67 init(n, h_x, d_x);\n\n(gdb) p h_x\n[output] \n$2 = (float *) 0x219cd0 <_start>\n(gdb) p *h_x@5\n
Prints out the next 5 values pointed to by h_x
[output] \n$3 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n
Random values printed out \u2013 not initialized!
(gdb) b 56\n\n(gdb) c\n\n[output] \nThread 5 \u201csaxpy\u201d hit Breakpoint 3 \u2026.\n56 if (i < n)\n\n(gdb) info threads\n\nShows both CPU and GPU threads\n(gdb) p x\n\n[output] \n$4 = (const float *) 0x219cd0 <_start>\n\n(gdb) p *x@5\n
This can either yeild unintialized results or just complain that the address can't be accessed: [output] \n$5 = {-2.43e-33, 2.4e-33, -1.93e22, 556, 2.163e-36}\n\nor \n\nCannot access memory at address 0x13\n
Let's move to the next statement:
(gdb) n\n\n(gdb) n\n\n(gdb) n\n
Until reach line 57. We can now inspect the indexing and the array contents should the memory be accesible. (gdb) p i\n\n[output] \n$6 = 0\n\n(gdb) p y[0]\n\n[output] \n$7 = -2.12e14\n\n(gdb) p x[0]\n\n[output] \n$8 = -2.43e-33\n\n(gdb) p a\n[output] \n$9 = 1\n
We can see that there are multiple problems with this kernel. X and Y are not initialized. Each value of X is multiplied by 1.0 and then added to the existing value of Y.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#rocprof","title":"Rocprof","text":"Setup environment
salloc -N 1 --gpus=8 -p standard-g --exclusive -A project_465001362 -t 20:00 --reservation LUMItraining_G\n\nmodule load PrgEnv-cray\nmodule load craype-accel-amd-gfx90a\nmodule load rocm\n
Download examples repo and navigate to the HIPIFY exercises cd ~/HPCTrainingExamples/HIPIFY/mini-nbody/hip/\n
Compile and run one case. We are on the front-end node, so we have two ways to compile for the GPU that we want to run on.
- The first is to explicitly set the GPU archicture when compiling (We are effectively cross-compiling for a GPU that is present where we are compiling).
hipcc -I../ -DSHMOO --offload-arch=gfx90a nbody-orig.hip -o nbody-orig\n
- The other option is to compile on the compute node where the compiler will auto-detect which GPU is present. Note that the autodetection may fail if you do not have all the GPUs (depending on the ROCm version). If that occurs, you will need to set
export ROCM_GPU=gfx90a.
srun hipcc -I../ -DSHMOO nbody-orig.cpp -o nbody-orig\n
Now Run rocprof on nbody-orig to obtain hotspots list
srun rocprof --stats nbody-orig 65536\n
Check Results cat results.csv\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Using --basenames on will show only kernel names without their parameters. srun rocprof --stats --basenames on nbody-orig 65536\n
Check the statistics result file, one line per kernel, sorted in descending order of durations cat results.stats.csv\n
Trace HIP calls with --hip-trace srun rocprof --stats --hip-trace nbody-orig 65536\n
Check the new file results.hip_stats.csv cat results.hip_stats.csv\n
Profile also the HSA API with the --hsa-trace srun rocprof --stats --hip-trace --hsa-trace nbody-orig 65536\n
Check the new file results.hsa_stats.csv cat results.hsa_stats.csv\n
On your laptop, download results.json scp -i <HOME_DIRECTORY>/.ssh/<public ssh key file> <username>@lumi.csc.fi:<path_to_file>/results.json results.json\n
Open a browser and go to https://ui.perfetto.dev/. Click on Open trace file in the top left corner. Navigate to the results.json you just downloaded. Use the keystrokes W,A,S,D to zoom in and move right and left in the GUI Navigation\nw/s Zoom in/out\na/d Pan left/right\n
"},{"location":"4day-20241028/exercises_AMD_hackmd/#perfetto-issue","title":"Perfetto issue","text":"Perfetto seems to introduced a bug, Sam created a container with a perfetto version that works with the rocprof traces. If you want to use that one you need to run docker on your laptop.
From your laptop:
sudo dockerd\n
and in another terminal sudo docker run -it --rm -p 10000:10000 --name myperfetto sfantao/perfetto4rocm\n
The open your web browser to: http://localhost:10000/ and open the trace.
Read about hardware counters available for the GPU on this system (look for gfx90a section)
less $ROCM_PATH/lib/rocprofiler/gfx_metrics.xml\n
Create a rocprof_counters.txt file with the counters you would like to collect vi rocprof_counters.txt\n
Content for rocprof_counters.txt: pmc : Wavefronts VALUInsts\npmc : SALUInsts SFetchInsts GDSInsts\npmc : MemUnitBusy ALUStalledByLDS\n
Execute with the counters we just added: srun rocprof --timestamp on -i rocprof_counters.txt nbody-orig 65536\n
You'll notice that rocprof runs 3 passes, one for each set of counters we have in that file. Contents of rocprof_counters.csv
cat rocprof_counters.csv\n
"},{"location":"4day-20241028/exercises_AMD_hackmd/#omnitrace","title":"Omnitrace","text":" Omnitrace is known to work better with ROCm versions more recent than 5.2.3. So we use a ROCm 5.4.3 installation for this.
module load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omnitrace/1.10.3-rocm-5.4.x\n
- Allocate resources with
salloc
salloc -N 1 --ntasks=1 --partition=standard-g --gpus=1 -A project_465001362 --time=00:15:00 --reservation LUMItraining_G
- Check the various options and their values and also a second command for description
srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace srun -n 1 --gpus 1 omnitrace-avail --categories omnitrace --brief --description
- Create an Omnitrace configuration file with description per option
srun -n 1 omnitrace-avail -G omnitrace.cfg --all
- Declare to use this configuration file:
export OMNITRACE_CONFIG_FILE=/path/omnitrace.cfg
- Get the training examples:
cp -r /project/project_465001362/Exercises/AMD/HPCTrainingExamples/ .
-
Now build the code
make -f Makefile.craytime srun -n 1 --gpus 1 Jacobi_hip -g 1 1
-
Check the duration
"},{"location":"4day-20241028/exercises_AMD_hackmd/#dynamic-instrumentation","title":"Dynamic instrumentation","text":" - Execute dynamic instrumentation:
time srun -n 1 --gpus 1 omnitrace-instrument -- ./saxpy and check the duration
- About Jacobi example, as the dynamic instrumentation wuld take long time, check what the binary calls and gets instrumented:
nm --demangle Jacobi_hip | egrep -i ' (t|u) ' - Available functions to instrument:
srun -n 1 --gpus 1 omnitrace-instrument -v 1 --simulate --print-available functions -- ./Jacobi_hip -g 1 1 - the simulate option means that it will not execute the binary
"},{"location":"4day-20241028/exercises_AMD_hackmd/#binary-rewriting-to-be-used-with-mpi-codes-and-decreases-overhead","title":"Binary rewriting (to be used with MPI codes and decreases overhead)","text":" -
Binary rewriting: srun -n 1 --gpus 1 omnitrace-instrument -v -1 --print-available functions -o jacobi.inst -- ./Jacobi_hip
- We created a new instrumented binary called jacobi.inst
-
Executing the new instrumented binary: time srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and check the duration
- See the list of the instrumented GPU calls:
cat omnitrace-jacobi.inst-output/TIMESTAMP/roctracer.txt
"},{"location":"4day-20241028/exercises_AMD_hackmd/#visualization","title":"Visualization","text":" - Copy the
perfetto-trace.proto to your laptop, open the web page https://ui.perfetto.dev/ click to open the trace and select the file
"},{"location":"4day-20241028/exercises_AMD_hackmd/#hardware-counters","title":"Hardware counters","text":" - See a list of all the counters:
srun -n 1 --gpus 1 omnitrace-avail --all - Declare in your configuration file:
OMNITRACE_ROCM_EVENTS = GPUBusy,Wavefronts,VALUBusy,L2CacheHit,MemUnitBusy - Execute:
srun -n 1 --gpus 1 omnitrace-run -- ./jacobi.inst -g 1 1 and copy the perfetto file and visualize
"},{"location":"4day-20241028/exercises_AMD_hackmd/#sampling","title":"Sampling","text":"Activate in your configuration file OMNITRACE_USE_SAMPLING = true and OMNITRACE_SAMPLING_FREQ = 100, execute and visualize
"},{"location":"4day-20241028/exercises_AMD_hackmd/#kernel-timings","title":"Kernel timings","text":" - Open the file
omnitrace-binary-output/timestamp/wall_clock.txt (replace binary and timestamp with your information) - In order to see the kernels gathered in your configuration file, make sure that
OMNITRACE_USE_TIMEMORY = true and OMNITRACE_FLAT_PROFILE = true, execute the code and open again the file omnitrace-binary-output/timestamp/wall_clock.txt
"},{"location":"4day-20241028/exercises_AMD_hackmd/#call-stack","title":"Call-stack","text":"Edit your omnitrace.cfg:
OMNITRACE_USE_SAMPLING = true;\u00a0\nOMNITRACE_SAMPLING_FREQ = 100\n
Execute again the instrumented binary and now you can see the call-stack when you visualize with perfetto.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#omniperf","title":"Omniperf","text":" Omniperf is using a virtual environemtn to keep its python dependencies.
module load cray-python\nmodule load craype-accel-amd-gfx90a\nmodule load PrgEnv-amd\n\nmodule use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omniperf/1.0.10-rocm-5.4.x\n\nsource /pfs/lustrep2/projappl/project_462000125/samantao-public/omnitools/venv/bin/activate\n
- Reserve a GPU, compile the exercise and execute Omniperf, observe how many times the code is executed
salloc -N 1 --ntasks=1 --partition=small-g --gpus=1 -A project_465001362 --time=00:30:00\ncp -r /project/project_465001362/Exercises/AMD/HPCTrainingExamples/ .\ncd HPCTrainingExamples/HIP/dgemm/\nmkdir build\ncd build\ncmake ..\nmake\ncd bin\nsrun -n 1 omniperf profile -n dgemm -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv\n
-
Run srun -n 1 --gpus 1 omniperf profile -h to see all the options
-
Now is created a workload in the directory workloads with the name dgemm (the argument of the -n). So, we can analyze it
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ &> dgemm_analyze.txt\n
- If you want to only roofline analysis, then execute:
srun -n 1 omniperf profile -n dgemm --roof-only -- ./dgemm -m 8192 -n 8192 -k 8192 -i 1 -r 10 -d 0 -o dgemm.csv
There is no need for srun to analyze but we want to avoid everybody to use the login node. Explore the file dgemm_analyze.txt
- We can select specific IP Blocks, like:
srun -n 1 --gpus 1 omniperf analyze -p workloads/dgemm/mi200/ -b 7.1.2\n
But you need to know the code of the IP Block
- If you have installed Omniperf on your laptop (no ROCm required for analysis) then you can download the data and execute:
omniperf analyze -p workloads/dgemm/mi200/ --gui\n
- Open the web page: http://IP:8050/ The IP will be displayed in the output
For more exercises, visit here: https://github.com/amd/HPCTrainingExamples/tree/main/OmniperfExamples or locally HPCTrainingExamples/OmniperfExamples, there are 5 exercises, in each directory there is a readme file with instructions.
"},{"location":"4day-20241028/exercises_AMD_hackmd/#mnist-example","title":"MNIST example","text":"This example is supported by the files in /project/project_465000644/Exercises/AMD/Pytorch. These script experiment with different tools with a more realistic application. They cover PyTorch, how to install it, run it and then profile and debug a MNIST based training. We selected the one in https://github.com/kubeflow/examples/blob/master/pytorch_mnist/training/ddp/mnist/mnist_DDP.py but the concept would be similar for any PyTorch-based distributed training.
This is mostly based on a two node allocation.
-
Installing PyTorch directly on the filesystem using the system python installation. ./01-install-direct.sh
-
Installing PyTorch in a virtual environment based on the system python installation. ./02-install-venv.sh
-
Installing PyTorch in a condo environment based on the condo package python version. ./03-install-conda.sh
-
Installing PyTorch from source on top of a base condo environment. It builds with debug symbols which can be useful to facilitate debugging. ./04-install-source.sh
-
Testing a container prepared for LUMI that comprises PyTorch. ./05-test-container.sh
-
Test the right affinity settings. ./06-afinity-testing.sh
-
Complete example with MNIST training with all the trimmings to run it properly on LUMI. ./07-mnist-example.sh
-
Examples using rocprof, Omnitrace and Omniperf. ./08-mnist-rocprof.sh ./09-mnist-omnitrace.sh ./10-mnist-omnitrace-python.sh ./11-mnist-omniperf.sh
-
Example that debugs an hang in the application leveraging rocgdb. ./12-mnist-debug.sh
"},{"location":"4day-20241028/extra_1_00_Introduction/","title":"Introduction","text":"Presenters: J\u00f8rn Dietze (LUST), Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_01_HPE_Cray_EX_Architecture/","title":"HPE Cray EX Architecture","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_01_HPE_Cray_EX_Architecture/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_02_Programming_Environment_and_Modules/","title":"Programming Environment and Modules","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_02_Programming_Environment_and_Modules/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_03_Running_Applications/","title":"Running Applications","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_03_Running_Applications/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_04_Exercises_1/","title":"Exercise session 1: Running applications","text":""},{"location":"4day-20241028/extra_1_04_Exercises_1/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_1_04_Exercises_1/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_05_Compilers_and_Parallel_Programming_Models/","title":"Compilers and Parallel Programming Models","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_05_Compilers_and_Parallel_Programming_Models/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_06_Exercises_2/","title":"Exercise session 2: Compilers","text":"The exercises are basically the same as in session #1. You can now play with different programming models and optimisation options.
"},{"location":"4day-20241028/extra_1_06_Exercises_2/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_1_06_Exercises_2/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_07_Cray_Scientific_Libraries/","title":"Cray Scientific Libraries","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_07_Cray_Scientific_Libraries/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_08_Exercises_3/","title":"Exercise session 3: Cray Scientific Libraries","text":""},{"location":"4day-20241028/extra_1_08_Exercises_3/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_1_08_Exercises_3/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_1_09_Offload_CCE/","title":"CCE Offloading Models","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_1_09_Offload_CCE/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_01_Advanced_Application_Placement/","title":"Advanced Placement","text":"Presenter: Jean Pourroy (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_2_01_Advanced_Application_Placement/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_02_Exercises_4/","title":"Exercise session 4: Placement","text":""},{"location":"4day-20241028/extra_2_02_Exercises_4/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_2_02_Exercises_4/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_03_Debugging_at_Scale/","title":"Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat","text":"Presenter: Thierry Braconnier (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_2_03_Debugging_at_Scale/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_04_Exercises_5/","title":"Exercise session 5: Cray PE Debugging Tools","text":""},{"location":"4day-20241028/extra_2_04_Exercises_5/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_2_04_Exercises_5/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_05_Introduction_to_AMD_ROCm_Ecosystem/","title":"Introduction to the AMD ROCmTM Ecosystem","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_2_05_Introduction_to_AMD_ROCm_Ecosystem/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_06_Exercises_6/","title":"Exercise session 6: HIP tools","text":""},{"location":"4day-20241028/extra_2_06_Exercises_6/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_2_06_Exercises_6/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_2_07_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"Presenter: Kurt Lust (LUST)
Course materials will be provided during the course.
"},{"location":"4day-20241028/extra_2_07_LUMI_Software_Stacks/#additional-materials","title":"Additional materials","text":" -
The information in this talk is also partly covered by the following talks from the introductory courses:
-
Modules on LUMI
-
LUMI Software Stacks
-
The cotainr package was presented during the September 27, 2023 user coffee break
"},{"location":"4day-20241028/extra_2_07_LUMI_Software_Stacks/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_01_Introduction_to_Perftools/","title":"Introduction to Perftools","text":"Presenters: Thierry Braconnier (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_3_01_Introduction_to_Perftools/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_02_Exercises_7/","title":"Exercise session 7: perftools-lite","text":""},{"location":"4day-20241028/extra_3_02_Exercises_7/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_3_02_Exercises_7/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_03_Advanced_Performance_Analysis/","title":"Advanced Performance Analysis","text":"Presenter: Thierry Braconnier (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_3_03_Advanced_Performance_Analysis/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_04_Exercises_8/","title":"Exercise session 8: perftools","text":""},{"location":"4day-20241028/extra_3_04_Exercises_8/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_3_04_Exercises_8/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_05_Cray_MPI_on_Slingshot/","title":"MPI Topics on the HPE Cray EX Supercomputer","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_3_05_Cray_MPI_on_Slingshot/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_06_Exercises_9/","title":"Exercise session 9: Cray MPICH","text":""},{"location":"4day-20241028/extra_3_06_Exercises_9/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_3_06_Exercises_9/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_07_AMD_ROCgdb_Debugger/","title":"AMD ROCgdb debugger","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_3_07_AMD_ROCgdb_Debugger/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_08_Exercises_10/","title":"Exercise session 10: Debugging with ROCgdb","text":""},{"location":"4day-20241028/extra_3_08_Exercises_10/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_3_08_Exercises_10/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/","title":"Introduction to ROC-Profiler (rocprof)","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_3_10_Exercises_11/","title":"Exercise session 11: Profiling with AMD Rocprof","text":""},{"location":"4day-20241028/extra_3_10_Exercises_11/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_3_10_Exercises_11/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_01_Introduction_to_Python_on_Cray_EX/","title":"Introduction to Python on Cray EX","text":"Presenter: Jean Pourroy (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_01_Introduction_to_Python_on_Cray_EX/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_02_Porting_to_GPU/","title":"Porting Applications to GPU","text":"Presenter: Jean Pourroy (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_02_Porting_to_GPU/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_03_Performance_Optimization_Improving_Single_Core/","title":"Performance Optimization: Improving Single-core Efficiency","text":"Presenter: Jean Pourroy (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_03_Performance_Optimization_Improving_Single_Core/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_04_Exercises_12/","title":"Exercise session 12: Node-level performance","text":""},{"location":"4day-20241028/extra_4_04_Exercises_12/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_4_04_Exercises_12/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_05_IO_Optimization_Parallel_IO/","title":"I/O Optimization - Parallel I/O","text":"Presenter: Harvey Richardson (HPE)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_05_IO_Optimization_Parallel_IO/#links","title":"Links","text":" - The ExaIO project paper \"Transparent Asynchronous Parallel I/O Using Background Threads\".
"},{"location":"4day-20241028/extra_4_05_IO_Optimization_Parallel_IO/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_06_Exercises_13/","title":"Exercise session 13: Lustre I/O","text":""},{"location":"4day-20241028/extra_4_06_Exercises_13/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_4_06_Exercises_13/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_07_AMD_Omnitrace/","title":"Introduction to OmniTrace","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_07_AMD_Omnitrace/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_08_Exercises_14/","title":"Exercise session 14: Omnitrace","text":""},{"location":"4day-20241028/extra_4_08_Exercises_14/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_09_AMD_Omniperf/","title":"AMD Omniperf","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_09_AMD_Omniperf/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_10_Exercises_15/","title":"Exercise session 15: Omniperf","text":""},{"location":"4day-20241028/extra_4_10_Exercises_15/#materials","title":"Materials","text":"No materials available at the moment.
"},{"location":"4day-20241028/extra_4_10_Exercises_15/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_11_Best_Practices_GPU_Optimization/","title":"Best practices: GPU Optimization, tips & tricks / demo","text":"Presenter: Samuel Antao (AMD)
Course materials will be provided during and after the course.
"},{"location":"4day-20241028/extra_4_11_Best_Practices_GPU_Optimization/#qa","title":"Q&A","text":"/
"},{"location":"4day-20241028/extra_4_12_LUMI_Support_and_Documentation/","title":"LUMI User Support","text":"Presenter: J\u00f8rn Dietze (LUST)
Course materials will be provided during and after the course.
The information in this talk is also covered by the following talk from the introductory courses:
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
- Some remarks about using containers on LUMI.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack than your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with a not fully mature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: the option to use a partly coherent fully unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and is also rumoured to be in the Apple Silicon M-series but then without the NUMA character (except maybe for the Ultra version that consists of two dies).
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD compute GPUs while the visualisation nodes have NVIDIA rendering GPUs.
Given the rather novel interconnect and GPU we cannot expect that all system and application software is already fully mature and we need to be prepared for fast evolution, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 12 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 10 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a a talk in the EasyBuild user meeting in 2022.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised environments. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparent way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. Both have their own strengths and weaknesses. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be accustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place.
We do offer some help to set up Spack also but it is mostly offered \"as is\" and we will not do bug-fixing or development in Spack package files. Spack is very attractive for users who want to set up a personal environment with fully customised versions of the software rather than the rather fixed versions provided by EasyBuild for every version of the software stack. It is possible to specify versions for the main packages that you need and then let Spack figure out a minimal compatible set of dependencies to install those packages.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionnaire sent out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
Some restrictions coming from software licenses
-
Anaconda cannot be used legally on LUMI, neither can you use Miniconda to pull packages from the Anaconda Public Repository. You have to use alternatives such as conda-forge.
See point 2.1 of the \"Anaconda Terms of Service\".
-
The LUMI support team cannot really help much with VASP as most people in the support team are not covered by a valid VASP license. VASP licenses typically even contain a list of people who are allowed to touch the source code, and one person per license who can download the source code.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, the so-called Cassini provider, so any software compiled with an MPI library that requires UCX, or any other distributed memory model built on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intra-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-Bus comes to mind.
Also, the LUMI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses tens of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason LUMI also requires to containerize conda and Python installations. On LUMI three tools are offered for this.
- cotainr is a tool developed by the Danish LUMI-partner DeIC that helps with building some types of containers that can be built in user space. Its current version focusses on containerising a conda-installation.
- The second tool is a container-based wrapper generator that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the
cray-python module. On LUMI the tool is called lumi-container-wrapper but users of the CSC national systems will know it as Tykky. - SingularityCE supports the so-called unprivileged proot build process to build containers. With this process, it is also possible to add additional OS packages, etc., to the container.
Both cotainr and lumi-container-wrapper are pre-installed on the system as modules. Furthermore, there is also a module that provides the proot command needed by the SingularityCE unprivileged proot build process.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the minimal software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 3 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes and zen3 + MI250X for the LUMI-G partition. We were also planning to have a fourth version for the visualisation nodes with zen2 CPUs combined with NVIDIA GPUs, but that may never materialise and we may manage those differently.
We also have an extensible software stack based on Spack which has been pre-configured to use the compilers from the Cray PE. This stack is offered as-is for users who know how to use Spack, but we don't offer much support nor do we do any bugfixing in Spack.
Some partner organisations in the LUMI consortium also provide pre-installed software on LUMI. This software is not manages by the LUMI User Support Team and as a consequence of this, support is only provided through those organisations that manage the software. Though they did promise to offer some basic support for everybody, the level of support may be different depending on how your project ended up on LUMI as they receive no EuroHPC funding for this. There is also no guarantee that software in those stacks is compatible with anything else on LUMI. The stacks are provided by modules whose name starts with Local-. Currently there are two such stacks on LUMI:
-
Local-CSC: Enables software installed and maintained by CSC. Most of that software is available to all users, though some packages are restricted or only useful to users of other CSC services (e.g., the allas module).
Some of that software builds on software in the LUMI stacks, some is based on containers with wrapper scripts, and some is compiled outside of any software management environment on LUMI.
The names of the modules don't follow the conventions of the LUMI stacks, but those used on the Finnish national systems.
-
Local-quantum contains some packages of general use, but also some packages that are only relevant to Finnish researchers with an account on the Helmi quantum computer. Helmi is not a EuroHPC-JU computer so being eligible for an account on LUMI does not mean that you are also eligible for an account on Helmi.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It is also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/24.03, LUMI/23.12, LUMI/23.09, LUMI/23.03, LUMI/22.12 and LUMI/22.08 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes and partition/G for the AMD GPU nodes. There may be a separate partition for the visualisation nodes in the future but that is not clear yet.
There is also a hidden partition/common module in which software is installed that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
Supported stacks after the August 2024 system update
Since 24.03 is the only version of the Cray Programming Environment currently fully supported by HPE on LUMI, as it is the only version which is from the ground up built for ROCm/6.0, SUSE Enterprise 15 SP5, and the current version of the SlingShot software, it is also the only fully supported version of the LUMI software stacks.
The 23.12 and 23.09 version function reasonably well, but keep in mind that 23.09 was originally meant to be used with ROCm 5.2 or 5.5 depending on the SUSE version while you will now get a much newer version of the compilers that come with ROCm.
The even older stacks are only there for projects that were using them. We've had problems with them already in the past and they currently don't work properly anymore for installing software via EasyBuild.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. -
But Lmod also has other commands, module spider and module keyword, to search in the list of installed modules.
On LUMI, we had to restrict the search space of module spider. By default, module spider will only search in the Cray PE modules, the CrayEnv stack and the LUMI stacks. This is done for performance reasons. However, as we shall discuss later, you can load a module or set an environment variable to enable searching all installed modules. The behaviour is also not fully consistent. Lmod uses a cache which it refreshes once every 24 hours, or after manually clearing the cache. If a rebuild happens while modules from another software stack are available, that stack will also be indexed and results for that stack shown in the results of module spider. It is a price we had to pay though as due to the large number of modules and the many organisations managing modules, the user cache rebuild time became too long and system caches are hard to manage also.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1 (when infrastructure for a demo is available)
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail. All variants however will by default only check the Cray PE, the CrayEnv stack and the LUMI stacks, unless another software stack is loaded through a module or module use statement and the cache is regenerated during that period.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. It works both for packages and for the names of extensions. There is a subtlety though: If a match in the exact case is found, it will no longer look for extensions that may have the same name but in a different case.
-
The third use of module spider is with the full name of a module. In this case, we get the full information on how the module can be made available for loading if it is not yet available, and for packages also some help information about the package if the module includes this information.
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider CMake\nmodule spider gnuplot/5.4.10-cpeGNU-24.03\nmodule spider CMake/3.29.3\n
In the above display, the ARMForge module is currently available in only one version. The Autoconf package is offered in two versions, but in both cases as an extension of another module as the blue (E) in the output shows. The Blosc package is available in many versions, but they are not all shown as the ... suggests.
After a few more screens, we get the last one:
Let's now try for instance module spider gnuplot.
This shows 18 versions of GNUplot. There are 4 installations of GNUplot 5.4.3, five of 5.4.6, 6 of 5.4.8 and and 4 of 5.4.10 at the moment the slide was made. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake.
We see that there were four versions at the moment this slide was made, 3.24.0, 3.25.2, 3.27.7 and 3.29.3, that are shown in blue with an \"E\" behind the name. That is because these are not provided by a module called CMake on LUMI, but by another module that in this case contains a collection of popular build tools and that we will discover shortly.
Noe try module spider gnuplot/5.4.10-cpeGNU-24.03.
This now shows full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are three ways to load the module: By loading LUMI/24.03 combined with partition/C, by loading LUMI/23.03 combined with partition/G or by loading LUMI/24.03 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/24.03 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
Finally, try module spider CMake/3.29.3 (remember this was an extension of a module):
This now shows us that this tool is in the buildtools/24.03 module (among others) and gives us 4 different options to load that module as it is provided in the CrayEnv and the LUMI/24.03 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#module-keyword-command","title":"Module keyword command","text":"Lmod has a second way of searching for modules: module keyword. It searches in some of the information included in module files for the given keyword, and shows in which modules the keyword was found.
We do an effort to put enough information in the modules to make this a suitable additional way to discover software that is installed on the system.
Demo module keyword Try the following command:
module keyword https\n
cURL and wget are indeed two tools that can be used to fetch files from the internet.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"On some systems you will be taught to avoid module purge as many HPC systems do their default user configuration also through modules. This advice is often given on Cray systems as it is a common practice to preload a suitable set of target modules and a programming environment. On LUMI both are used. A default programming environment and set of target modules suitable for the login nodes is preloaded when you log in to the system, and next the init-lumi module is loaded which in turn makes the LUMI software stacks available that we will discuss in the next session.
Lmod however has a trick that helps to avoid removing necessary modules and it is called sticky modules. When issuing the module purge command these modules are automatically reloaded. It is very important to realise that those modules will not just be kept \"as is\" but are in fact unloaded and loaded again as we shall see later that this may have consequences. It is still possible to force unload all these modules using module --force purge or selectively unload those using module --force unload.
The sticky property is something that is defined in the module file and not used by the module files ot the HPE Cray Programming Environment, but we shall see that there is a partial workaround for this in some of the LUMI software stacks. The init-lumi module mentioned above though is a sticky module, as are the modules that activate a software stack so that you don't have to start from scratch if you have already chosen a software stack but want to clean up your environment.
Demo Try the following command immediately after login:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded, but we'll come back to that later also. The letter \"S\" denotes a sticky module.
Note also the two categories for the PE modules. The target modules get their own block which will be shown further down in the output.
The screen above also shows (5.0.2:5.1.0:5.2.0:5.2.3:5.5.1:5.7.0:6.0.0) next to the rocm module. This shows that the rocm/6.0.3 module can also be loaded as rocm/5.0.2 or any of the other versions in that list. Some of them were old versions that have been removed from the system in later updates, and we now load the newer version as often binaries of programs will still run that way. Others are versions that are hard-coded some of the Cray PE modules and other files, but have never been on the system as we had an already patched version. (E.g., the 24.03 version of the Cray PE will sometimes try to load rocm/6.0.0 while we have immediate had rocm/6.0.3 on the system which corrects some bugs).
The D next to modules that have multiple versions, denotes which version is currently the default. It is the version that will be loaded if you don't specify a module version. The default version may differ depending on which other modules are loaded already.
On the screen we also see the list of target modules. This screenshot was taken at login in the login environment, when those modules that are irrelevant to LUMI or to the chosen variant of the LUMI software stack are not yet hidden.
The above screen also shows the modules for the software stack that we have discussed earlier in this text.
And the screen above shows some extensions of modules (but the list is short at this point as most modules containing extensions only become available after loading one of the software stacks).
At the end of the output we also get some information about the meaning of the letters used in the display.
Try the following commands and carefully observe the output:
module load LUMI/24.03 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\nmodule av\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similarly in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
As the module extensions list in the output of module avail could potentially become very long over time (certainly if there would be Python or R modules installed with EasyBuild that show all included Python or R packages in that list) you may want to hide those. You can do this by loading the ModuleExtensions/hide module and undo this again by loading ModuleExtensions/show.
Demo Try the following commands:
module avail\nmodule load ModuleExtensions/hide\nmodule avail\nmodule load ModuleExtensions/show\nmodule avail\n
There are two ways to tell module spider to search in all installed modules. One is more meant as a temporary solution: Load
module load ModuleFullSpider/on\n
and this is turned off again by force-unloading this module or loading
module load ModuleFullSpider/off\n
The second and permanent way is to set add the line
export LUMI_FULL_SPIDER=1\n
to your .profile file and from then on, module spider will index all modules on the system. Note that this can have a large impact on the performance of the module spider and module avail commands that can easily \"hang\" for a minute or more if a cache rebuild is needed, which is the case after installing software with EasyBuild or once every 24 hours.
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/24.03 stack we prefer that users use the Cray programming environment modules that come with release 24.03 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Another way to show hidden modules also, is to use the --show_hidden flag of the module command with the avail subcommand: module --show_hidden avail.
With ModulePowerUser, all modules will be displayed as if they are regular modules, while module --show_hidden avail will still grey the hidden modules and add an (H) to them so that they are easily recognised.
Demo Try the following commands:
module load LUMI/24.03\nmodule avail\nmodule --show_hidden avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs (Red Hat Package Manager, a popular format to package Linux software distributed as binaries) or any other similar format for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. This is expected to happen especially with packages that require specific MPI versions or implementations. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And LUMI needs a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is the primary software installation tool. EasyBuild was selected as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain there would be problems with MPI. EasyBuild uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures with some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the classic Intel compilers will simply optimize for a two decades old CPU. The situation is better with the new LLVM-based compilers though, and it looks like very recent versions of MKL are less AMD-hostile. Problems have also been reported with Intel MPI running on LUMI.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system.
We also have the LUMI Software Library which documents all software for which we have EasyBuild recipes available. This includes both the pre-installed software and the software for which we provide recipes in the LUMI-EasyBuild-contrib GitHub repository, and even instructions for some software that is not suitable for installation through EasyBuild or Spack, e.g., because it likes to write in its own directories while running.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#easybuild-recipes-easyconfigs","title":"EasyBuild recipes - easyconfigs","text":"EasyBuild uses a build recipe for each individual package, or better said, each individual module as it is possible to install more than one software package in the same module. That installation description relies on either a generic or a specific installation process provided by an easyblock. The build recipes are called easyconfig files or simply easyconfigs and are Python files with the extension .eb.
The typical steps in an installation process are:
- Downloading sources and patches. For licensed software you may have to provide the sources as often they cannot be downloaded automatically.
- A typical configure - build - test - install process, where the test process is optional and depends on the package providing useable pre-installation tests.
- An extension mechanism can be used to install perl/python/R extension packages
- Then EasyBuild will do some simple checks (some default ones or checks defined in the recipe)
- And finally it will generate the module file using lots of information specified in the EasyBuild recipe.
Most or all of these steps can be influenced by parameters in the easyconfig.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#the-toolchain-concept","title":"The toolchain concept","text":"EasyBuild uses the toolchain concept. A toolchain consists of compilers, an MPI implementation and some basic mathematics libraries. The latter two are optional in a toolchain. All these components have a level of exchangeability as there are language standards, as MPI is standardised, and the math libraries that are typically included are those that provide a standard API for which several implementations exist. All these components also have in common that it is risky to combine pieces of code compiled with different sets of such libraries and compilers because there can be conflicts in names in the libraries.
On LUMI we don't use the standard EasyBuild toolchains but our own toolchains specifically for Cray and these are precisely the cpeCray, cpeGNU, cpeAOCC and cpeAMD modules already mentioned before.
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiling Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers (login nodes and LUMI-C only) PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) There is also a special toolchain called the SYSTEM toolchain that uses the compiler provided by the operating system. This toolchain does not fully function in the same way as the other toolchains when it comes to handling dependencies of a package and is therefore a bit harder to use. The EasyBuild designers had in mind that this compiler would only be used to bootstrap an EasyBuild-managed software stack, but we do use it for a bit more on LUMI as it offers us a relatively easy way to compile some packages also for the CrayEnv stack and do this in a way that they interact as little as possible with other software.
It is not possible to load packages from different cpe toolchains at the same time. This is an EasyBuild restriction, because mixing libraries compiled with different compilers does not always work. This could happen, e.g., if a package compiled with the Cray Compiling Environment and one compiled with the GNU compiler collection would both use a particular library, as these would have the same name and hence the last loaded one would be used by both executables (we don't use rpath or runpath linking in EasyBuild for those familiar with that technique).
However, as we did not implement a hierarchy in the Lmod implementation of our software stack at the toolchain level, the module system will not protect you from these mistakes. When we set up the software stack, most people in the support team considered it too misleading and difficult to ask users to first select the toolchain they want to use and then see the software for that toolchain.
It is however possible to combine packages compiled with one CPE-based toolchain with packages compiled with the system toolchain, but you should avoid mixing those when linking as that may cause problems. The reason that it works when running software is because static linking is used as much as possible in the SYSTEM toolchain so that these packages are as independent as possible.
And with some tricks it might also be possible to combine packages from the LUMI software stack with packages compiled with Spack, but one should make sure that no Spack packages are available when building as mixing libraries could cause problems. Spack uses rpath linking which is why this may work.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#easyconfig-names-and-module-names","title":"EasyConfig names and module names","text":"There is a convention for the naming of an EasyConfig as shown on the slide. This is not mandatory, but EasyBuild will fail to automatically locate easyconfigs for dependencies of a package that are not yet installed if the easyconfigs don't follow the naming convention. Each part of the name also corresponds to a parameter in the easyconfig file.
Consider, e.g., the easyconfig file GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb.
- The first part of the name,
GROMACS, is the name of the package, specified by the name parameter in the easyconfig, and is after installation also the name of the module. - The second part,
2024.3, is the version of GROMACS and specified by the version parameter in the easyconfig. -
The next part, cpeGNU-24.03 is the name and version of the toolchain, specified by the toolchain parameter in the easyconfig. The version of the toolchain must always correspond to the version of the LUMI stack. So this is an easyconfig for installation in LUMI/24.03.
This part is not present for the SYSTEM toolchain
-
The final part, -PLUMED-2.9.2-noPython-CPU, is the version suffix and used to provide additional information and distinguish different builds with different options of the same package. It is specified in the versionsuffix parameter of the easyconfig.
This part is optional.
The version, toolchain + toolchain version and versionsuffix together also combine to the version of the module that will be generated during the installation process. Hence this easyconfig file will generate the module GROMACS/2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#installing-software","title":"Installing software","text":""},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants of the project to solve a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"The next step is to configure your environment. First load the proper version of the LUMI stack for which you want to install software, and you may want to change to the proper partition also if you are cross-compiling.
Once you have selected the software stack and partition, all you need to do to activate EasyBuild to install additional software is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition.
Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module. It works correctly for a lot of CPU-only software, but fails more frequently for GPU software as the installation scripts will try to run scripts that detect which GPU is present, or try to run tests on the GPU, even if you tell which GPU type to use, which does not work on the login nodes.
Note that the EasyBuild-user module is only needed for the installation process. For using the software that is installed that way it is sufficient to ensure that EBU_USER_PREFIX has the proper value before loading the LUMI module.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes.
First we need to figure out for which versions of GROMACS we already have support. The easy way is to check the LUMI Software Library which lists all software that we manage via EasyBuild and make available either pre-installed on the system or as an EasyBuild recipe for user installation. A command-line alternative is to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
Results of the searches:
In the LUMI Software Library, after some scrolling through the page for GROMACS, the list of EasyBuild recipes is found in the \"User-installable modules (and EasyConfigs)\" section:
eb --search GROMACS produces:
while eb -S GROMACS produces:
The information provided by both variants of the search command is the same, but -S presents the information in a more compact form.
Now let's take the variant GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb. This is GROMACS 2024.3 with the PLUMED 2.9.2 plugin, built with the GNU compilers from LUMI/24.03, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS there already is a GPU version for AMD GPUs in active development so even before LUMI-G was active we chose to ensure that we could distinguish between GPU and CPU-only versions. To install it, we first run
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package.
The output of this command looks like:
Looking at the output we see that EasyBuild will also need to install PLUMED for us.
To install GROMACS and also automatically install missing dependencies (only PLUMED in this case), we run
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb -r\n
The -r argument tells EasyBuild to also look for dependencies in a preset search path and to install them. The installation of dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on.
Running EasyBuild to install GROMACS and dependency
The command
eb GROMACS-2024.3-cpeGNU-24.03-PLUMED-2.9.2-noPython-CPU.eb -r\n
results in:
EasyBuild detects PLUMED is a dependency and because of the -r option, it first installs the required version of PLUMED.
When the installation of PLUMED finishes, EasyBuild starts the installation of GROMACS. It mentions something we haven't seen when installing PLUMED:
== starting iteration #0\n
GROMACS can be installed in many configurations, and they generate executables with different names. Our EasyConfig combines 4 popular installations in one: Single and double precision and with and without MPI, so it will do 4 iterations. As EasyBuild is developed by geeks, counting starts from 0.
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
Lmod does keep a user cache of modules. EasyBuild will try to erase that cache after a software installation to ensure that the newly installed module(s) show up immediately. We have seen some very rare cases where clearing the cache did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment.
In case you see strange behaviour using modules you can also try to manually remove the Lmod user cache which is in $HOME/.cache/lmod. You can do this with
rm -rf $HOME/.cache/lmod\n
(With older versions of Lmod the cache directory is $HOME/.lmod.d/cache.)"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r . \n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.4.2 with the GNU compilers: eb VASP-6.4.2-cpeGNU-23.09-build02.eb \u2013r . \n
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greatest before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/UserRepo/easybuild/easyconfigs.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory (unless the sources are already available elsewhere where EasyBuild can find them, e.g., in the system EasyBuild sources directory), and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easyconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebfiles_repo. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebfiles_repo subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#easybuild-tips-tricks","title":"EasyBuild tips & tricks","text":"Updating the version of a package often requires only trivial changes in the easyconfig file. However, we do tend to use checksums for the sources so that we can detect if the available sources have changed. This may point to files being tampered with, or other changes that might need us to be a bit more careful when installing software and check a bit more again. Should the checksum sit in the way, you can always disable it by using --ignore-checksums with the eb command.
Updating an existing recipe to a new toolchain might be a bit more involving as you also have to make build recipes for all dependencies. When we update a toolchain on the system, we often bump the versions of all installed libraries to one of the latest versions to have most bug fixes and security patches in the software stack, so you need to check for those versions also to avoid installing yet another unneeded version of a library.
We provide documentation on the available software that is either pre-installed or can be user-installed with EasyBuild in the LUMI Software Library. For most packages this documentation does also contain information about the license. The user documentation for some packages gives more information about how to use the package on LUMI, or sometimes also about things that do not work. The documentation also shows all EasyBuild recipes, and for many packages there is also some technical documentation that is more geared towards users who want to build or modify recipes. It sometimes also tells why we did things in a particular way.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"I also want to give some pointers to more information in case you want to learn a lot more about, e.g., developing support for your code in EasyBuild, or for support people who want to adapt our EasyConfigs for users requesting a specific configuration of a package.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on tutorial.easybuild.io. The site also contains a LUST-specific tutorial oriented towards Cray systems.
There is also a later course developed by LUST for developers of EasyConfigs for LUMI that can be found on lumi-supercomputer.github.io/easybuild-tutorial.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of personpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI. This is only true if you transport software between sufficiently similar machines (which is why they do work very well in, e.g., the management nodes of a cluster, or a server farm).
First, computational results are almost never 100% reproducible because of the very nature of how computers work. If you use any floating point computation, you can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and with exactly the same software. Besides, by the very nature of floating point computations, you know that the results are wrong if you really want to work with real numbers. What matters is understanding how wrong the results are and reproduce results that fall within expected error margins for the computation. This is no different from reproducing a lab experiment where, e.g., each measurement instrument introduces errors. The only thing that containers do reproduce very well, is your software stack. But not without problems:
Containers are certainly not performance portable unless they have been designed to run optimally on a range of hardware and your hardware falls into that range. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
But even full portability is a myth, even if you wouldn't care much about performance (which is already a bad idea on an infrastructure as expensive as LUMI). Containers are really only guaranteed to be portable between similar systems. When well built, they are more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it ends. Containers are usually built for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware too, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the SlingShot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
Software installations that would otherwise be impossible. E.g., some software may not even be suited for installation in a multi-user HPC system as it uses fixed paths that are not compatible with installation in module-controlled software stacks. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and cannot be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
-
As an example, Conda installations are not appreciated on the main Lustre file system.
On one hand, Conda installations tend to generate lots of small files (and then even more due to a linking strategy that does not work on Lustre). So they need to be containerised just for storage manageability.
They also re-install lots of libraries that may already be on the system in a different version. The isolation offered by a container environment may be a good idea to ensure that all software picks up the right versions.
-
Another example where containers have proven to be useful on LUMI is to experiment with newer versions of ROCm than we can offer on the system.
This often comes with limitations though, as (a) that ROCm version is still limited by the drivers on the system and (b) we've seen incompatibilities between newer ROCm versions and the Cray MPICH libraries.
-
Isolation is often considered as an advantage of containers also. The isolation helps preventing that software picks up libraries it should not pick up. In a context with multiple services running on a single server, it limits problems when the security of a container is compromised to that container. However, it also comes with a big disadvantage in an HPC context: Debugging and performance profiling also becomes a lot harder.
In fact, with the current state of container technology, it is often a pain also when running MPI applications as it would be much better to have only a single container per node, running MPI inside the container at the node level and then between containers on different nodes.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't really like running multiple versions next to one another, and currently the version that we offer is determined by what is offered by the OS. Currently we offer Singularity Community Edition 4.1.3.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, bring in the container either by creating a tarball from a docker container on the remote system and then converting that to the singularity .sif format on LUMI or by copying the singularity .sif file, or use those container build features of singularity that can be supported on LUMI within the security constraints (which is why there are no user namespaces on LUMI).
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory. This can lead to exhaustion of your disk quota for your home directory. So you may want to use the environment variable SINGULARITY_CACHEDIR to put the cache in, e.g,, your scratch space (but even then you want to clean up after the pull operation so save on your storage billing units).
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently limited support for building containers on LUMI and I do not expect that to change quickly. Container build strategies that require elevated privileges, and even those that require fakeroot or user namespaces, cannot be supported for security reasons (with user namespaces in particular a huge security concern as the Linux implementation is riddled with security issues). Enabling features that are known to have had several serious security vulnerabilities in the recent past, or that themselves are unsecure by design and could allow users to do more on the system than a regular user should be able to do, will never be supported.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
There is some support for building on top of an existing singularity container using what the SingularityCE user guide calls \"unprivileged proot builds\". This requires loading the proot command which is provided by the systools module in CrayEnv or LUMI/23.09 or later. The SingularityCE user guide mentions several restrictions of this process. The general guideline from the manual is: \"Generally, if your definition file starts from an existing SIF/OCI container image, and adds software using system package managers, an unprivileged proot build is appropriate. If your definition file compiles and installs large complex software from source, you may wish to investigate --remote or --fakeroot builds instead.\" But as we just said, on LUMI we cannot yet provide --fakeroot builds due to security constraints.
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI (and some for ROCm are already there).
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the container indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and /dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, i.e., use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI SlingShot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We only have a partial solution for the CPU nodes that is not tested in all scenarios, and on the GPU nodes Open MPI is very problematic at the moment. This is due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE only started supporting recently on Cray EX systems and that we haven't been able to fully test. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and until version 5 full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the SlingShot 11 interconnect, so work is going on for better support for OFI in general and Cray SlingShot in particular and for full GPU support.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#bindings-for-singularity","title":"Bindings for singularity","text":"The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY_PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
You can also check the page for the singularity-bindings in the LUMI Software Library.
You may need to change the EasyConfig for your specific purpose though. E.g., the singularity command line option --rocm to import the ROCm installation from the system doesn't fully work (and in fact, as we have alternative ROCm versions on the system cannot work in all cases) but that can also be fixed by extending the singularity-bindings module (or by just manually setting the proper environment variables).
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#vnc-container","title":"VNC container","text":"The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks through the lumi-vnc module. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
For most users, the Open OnDemand web interface and tools offered in that interface will be a better alternative.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#cotainr-build-conda-containers-on-lumi","title":"cotainr: Build Conda containers on LUMI","text":"The third tool is cotainr, a tool developed by DeIC, the Danish partner in the LUMI consortium. It is a tool to pack a Conda installation into a container. It runs entirely in user space and doesn't need any special rights. (For the container specialists: It is based on the container sandbox idea to build containers in user space.)
Containers build with cotainr are used just as other containers, so through the singularity commands discussed before.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#container-wrapper-for-python-packages-and-conda","title":"Container wrapper for Python packages and conda","text":"The fourth tool is a container wrapper tool that users from Finland may also know as Tykky. It is a tool to wrap Python and conda installations in a container and then create wrapper scripts for the commands in the bin subdirectory so that for most practical use cases the commands can be used without directly using singularity commands. Whereas cotainr fully exposes the container to users and its software is accessed through the regular singularity commands, Tykky tries to hide this complexity with wrapper scripts that take care of all bindings and calling singularity. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run the tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation. So strictly speaking it does not create a container, but a SquashFS file that is then mounted in a small existing base container. However, the wrappers created for all commands in the bin subdirectory of the conda or Python installation take care of doing the proper bindings. If you want to use the container through singularity commands however, you'll have to do that mounting by hand.
We do strongly recommend to use the container wrapper tool or cotainr for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a tempororary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#pre-built-ai-containers","title":"Pre-built AI containers","text":"LUST with the help of AMD is also building some containers with popular AI software. These containers contain a ROCm version that is appropriate for the software, use Conda for some components, but have several of the performance critical components built specifically for LUMI for near-optimal performance. Depending on the software they also contain a RCCL library with the appropriate plugin to work well on the Slingshot 11 interconnect, or a horovod compiled to use Cray MPICH.
The containers are provided through a module which sets the SINGULARITY_BIND environment variable to ensure proper bindings (as they need, e.g., the libfabric library from the system and the proper \"CXI provider\" for libfabric to connect to the Slingshot interconnect). The module will also provide an environment variable to refer to the container (name with full path) to make it easy to refer to the container in job scripts.
These containers can be found through the LUMI Software Library and are marked with a container label.
"},{"location":"4day-20241028/notes_2_07_LUMI_Software_Stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance. Also, containers do not abstract the hardware unlike some virtual machine solutions.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in the container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH ABI the solution is often to tell it to use the Cray MPICH libraries from the system instead.
Likewise, for containers for distributed AI, one may need to inject an appropriate RCCL plugin to fully use the SlingShot 11 interconnect.
-
As containers rely on drivers in the kernel of the host OS, the AMD driver may also cause problems. AMD only guarantees compatibility of the driver with two minor versions before and after the ROCm release for which the driver was meant. Hence containers using a very old version of ROCm or a very new version compared to what is available on LUMI, may not always work as expected.
-
The support for building containers on LUMI is currently limited due to security concerns. Any build process that requires elevated privileges, fakeroot or user namespaces will not work.
"},{"location":"4day-20241028/schedule/","title":"Course schedule","text":" - Day 1
- Day 2
- Day 3
- Day 4 DAY 1 - Monday 28/10 09:00 CEST 10:00 EEST Welcome and introduction Presenters: J\u00f8rn Dietze (LUST), Harvey Richardson (HPE) 09:15 CEST 10:15 EEST HPE Cray EX architecture Presenter: Harvey Richardson (HPE) 10:15 CEST 11:15 EEST Programming Environment and Modules Presenter: Harvey Richardson (HPE) 10:45 CEST 11:45 EEST Break (15 minutes) 11:00 CEST 12:00 EEST First steps for running on Cray EX hardware
- Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
Presenter: Harvey Richardson (HPE) 11:20 CEST 12:20 EEST Exercises (session #1) 12:00 CEST 13:00 EEST Lunch break (90 minutes) 13:30 CEST 14:30 EEST Overview of Compilers and Parallel Programming Models - An introduction to the compiler suites available, including examples of how to get additional information about the compilation process.
- Cray Compilation Environment (CCE) and options relevant to porting and performance.
- Description of the Parallel Programming models.
Presenter: |Harvey Richardson (HPE) 14:30 CEST 15:30 EEST Exercises (session #2) 15:00 CEST 16:00 EEST Break (15 minutes) 15:15 CEST 16:15 EEST Cray Scientific Libraries - The Cray Scientific Libraries for CPU and GPU execution.
Presenter: Harvey Richardson (HPE) 15:45 CEST 14:45 EEST Exercises (session #3) 16:15 CEST 15:15 EEST OpenACC and OpenMP offload with Cray Compilation Environment - Directive-based approach for GPU offloading execution with the Cray Compilation Environment. Presenter: Harvey Richardson (HPE) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course day DAY 2 - Tuesday 29/10 09:00 CEST 10:00 EEST Advanced Placement
- More detailed treatment of Slurm binding technology and OpenMP controls.
Presenter: Jean Pourroy (HPE) 10:00 CEST 11:00 EEST Exercises (session #4) 10:30 CEST 11:30 EEST Break (15 minutes) 10:45 CEST 11:45 EEST Debugging at Scale \u2013 gdb4hpc, valgrind4hpc, ATP, stat Presenter: Thierry Braconnier (HPE) 11:30 CEST 12:30 EEST Exercises (session #5) 12:00 CEST 13:00 EEST Lunch break (80 minutes) 13:20 CEST 14:20 EEST Introduction to the AMD ROCm ecosystem and HIP The AMD ROCmTM ecosystem HIP programming
Presenter: Samuel Antao (AMD) 14:20 CEST 13:20 EEST Exercises (session #6) 14:50 CEST 15:50 EEST Break (20 minutes) 15:10 CEST 16:10 EEST LUMI Software Stacks - Software policy.
- Software environment on LUMI.
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LUST) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course day DAY 3 - Wednesday 30/10 09:00 CEST 10:00 EEST Introduction to Perftools - Overview of the Cray Performance and Analysis toolkit for profiling applications.
- Demo: Visualization of performance data with Apprentice2 Presenter: Thierry Braconnier (HPE) 09:40 CEST 10:40 EEST Exercises (session #7) 10:10 CEST 11:10 EEST Break (20 minutes) 10:30 CEST 11:30 EEST Advanced Performance Analysis
- Automatic performance analysis and loop work estimated with perftools
- Communication Imbalance, Hardware Counters, Perftools API, OpenMP
- Compiler feedback and variable scoping with Reveal
Presenter: Thierry Braconnier (HPE) 11:30 CEST 12:30 EEST Exercises (session #8) 12:00 CEST 13:00 EEST Lunch break 13:15 CEST 14:15 EEST MPI Topics on the HPE Cray EX Supercomputer - High level overview of Cray MPI on Slingshot
- Useful environment variable controls
- Rank reordering and MPMD application launch
Presenter: Harvey Richardson (HPE) 14:15 CEST 15:15 EEST Exercises (session #9) 14:45 CEST 15:45 EEST Break 15:00 CEST 15:00 EEST AMD Debugger: ROCgdb Presenter: Samuel Antao (AMD) 15:30 CEST 16:30 EEST Exercises (session #10) 16:00 CEST 17:00 EEST Introduction to ROC-Profiler (rocprof) Presenter: Samuel Antao (AMD) 16:30 CEST 17:30 EEST Exercises (session #11) 17:00 CEST 18:00 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 CEST 18:30 EEST End of the course day DAY 4 - Thursday 31/10 09:00 CEST 08:00 EEST Introduction to Python on Cray EX Cray Python for the Cray EX
Presenter: Jean Pourroy (HPE) 09:10 CEST 08:10 EEST Porting Applications to GPU Presenter: Jean Pourroy (HPE) 09:20 CEST 10:20 EEST Performance Optimization: Improving Single-core Efficiency Presenter: Jean Pourroy (HPE) 10:00 CEST 11:00 EEST Exercises (session #12) 10:15 CEST 11:15 EEST Break 10:30 CEST 11:30 EEST Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system.
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes.
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations
- Further considerations of parallel I/O and other APIs.
- Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson (HPE) 11:30 CEST 12:30 EEST Exercises (session #13) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 12:00 EEST Introduction to OmniTrace Presenter: Samuel Antao (AMD) 13:25 CEST 14:25 EEST Exercises (session #14) 13:45 CEST 12:45 EEST Introduction to Omniperf Presenter: Samuel Antao (AMD) 14:10 CEST 15:10 EEST Exercises (session #15) 14:30 CEST 15:30 EEST Break 14:45 CEST 15:45 EEST Best practices: GPU Optimization, tips & tricks / demo Presenter: Samuel Antao (AMD) 16:15 CEST 17:15 EEST LUMI User Support - What can we help you with and what not? How to get help, how to write good support requests.
- Some typical/frequent support questions of users on LUMI?
Presenter: J\u00f8rn Dietze (LUST) 16:45 CEST 17:45 EEST Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:15 CEST 18:15 EEST End of the course"},{"location":"4day-20241028/where_to_drink/","title":"Water, or something better?","text":"Disclaimer: This page is not written by a local, but by someone from Belgium who visits Amsterdam from time to time. Hence it is biased towards his interests.
I'm not so much in the kind of night entertainment offered at the \"Ouderzijds Voorburgwal\" and \"Ouderzijds Achterburgwal\" so no advice about that area. However, Amsterdam has more to offer at night. Though we, Belgians, used to compare Dutch beer with dirty water, nowadays the Netherlands in general and Amsterdam in particular have a nice craft beer scene. Most beers are more than decent, and some of those beers are truly excellent. So here are some breweries in the city with taprooms, and some other craft beer bars. They may very well give you a much cheaper evening than the entertainment at \"De Wallen\" and are as effective in forgetting the stress of a busy course day.
Map of the venues below on Google Maps.
"},{"location":"4day-20241028/where_to_drink/#breweries","title":"Breweries","text":"All those breweries also have a taproom unless otherwise indicated. I haven't tried them all yet though.
For some breweries, I also provide links to a web site that lists all their beers, including scores given by users of that web site. This is for all beers that they made through their recent history and does by no means imply that you can order all those beers now. If I know of a list that mirrors what is available now, I've included that list instead as the menu.
The list is sorted according to walking distance from the SURF building in Science Park, but you'll have to be a good swimmer for one of them (or take a ferry).
-
Poesiat & Kater. This brewery is just 1.4km walking from the SURF building in Science Park and so could be your first place to get some relief after a hard course day. They also serve food, but I haven't tried their restaurant yet.
(Google Maps) (Beer menu)
-
't IJ
The brewery has three taprooms:
-
De Molen in De Gooyer, at the original brewery. (There is now a second location 700m further but without a taproom.)
(Google Maps)
-
Caf\u00e9 Struis, next to De Molen
(Google Maps)
-
Proeflokaal \u2018t Blauwe Theehuis in the Vondelpark and close to the famous \"Museumplein\" with some of the main museums of Amsterdam.
(Google Maps)
If you want to know how their beers score, you can check the brewery page on Untappd.
-
Brouwerij Homeland: Located in a hotel-restaurant in the centre of Amsterdam. It is in a part of Amsterdam where battleships were made from the middle of the 17th century till the start of the first world war (in which The Netherlands were not occupied).
(Google Maps) (Beer menu)
-
Oedipus Craft Space is the taproom of Oedipus in Amsterdam-Noord, across the river IJ. This no longer really a small craft beer brewery, but has become rather large and is now a subsidiary of Heineken.
(Google Maps) (Scores of their beers on Untapped)
-
De Bierfabriek: Brewery and restaurant in the centre of the city, not far from the Rokin metro station.
(Google Maps) (Scores of their beers on Untappd)
-
De Prael is a brewery active in several cities in the Netherlands (also in Den Haag and Groningen). There is only one location left in Amsterdam, in the Oudezijds Armsteeg, right in the centre and a short walk from the central station.
(Google Maps) (Amsterdam beers on Untappd) (Den Haag beers on Untappd) (Groningen beers on Untappd)
-
Brouwerij Troost has two locations
-
Locatie De Pijp, at the Cornelis Troostplein, is where it all started. Nowadays it is their experimental brewery. They serve food also.
(Google Maps) (Full beer and food menu, hopefully up-to-date)
-
Locatie Westergas is their newer location. A formal industrial site used by the gas company now turned into an area with bars and lots of cultural activities. It is now also their main production site. They have a complete menu.
(Google Maps) (Full beer and food menu, hopfully up-to-date)
If you want to know how their beers score, you can check the brewery page on Untappd.
-
Two Chefs Restaurant and Taproom with the restaurant and taproom next to one another. Two chefs who started brewing their own beers to go with the food. The beers became so successful that nowadays it is brewed in a different location in the port of Amsterdam, but that location cannot be visited.
(Google Maps) (Scores of their beers)
-
Gebrouwen door Vrouwen BAR: Beer brewed by women. They have no brewery of their own, but use the installations of other breweries to brew beer according to their recipes.
(Google Maps) (Scores of their beers on Untappd)
-
Brouwerij Kleiburg at De Bijlmer and hence a bit outside the centre of Amsterdam. If you'd go there, look for \"De Proefzaak\".
(Google Maps) (Scores on Untappd)
-
Brouwerij de 7 deugden: A bit far outside the centre, and it closes at 6pm so it cannot be combined with the course unless you stay a bit longer in Amsterdam. It is also closed on Sundays so coming early won't help, nor will staying longer as November 1 is a public holiday and hence like a Sunday.
(Google Maps) (Scores of their beers)
"},{"location":"4day-20241028/where_to_drink/#craft-beer-bars","title":"Craft beer bars","text":"The first two are the ones I usually go to.
-
Bierproeflokaal In De Wildeman in a former distillery. Pleasantly close to the central station, so if you have time on Thursday evening after the course, you could still try it before catching the train. You can also snack a bit. The cheese platter is recommended, or you can try some Dutch \"Ossenworst\" to integrate with the locals (assuming you're not Dutch of course).
(Google Maps) (Beer menu)
-
Proeflokaal Arendsnest. Also a nice place to snack with a beer. I can highly recommend the cheese platter (I usuale take the 2.0).
(Google Maps) (Beer and snacks menu)
-
Craft & Draft. I haven't been there myself yet, but found the place recommended in various places.
(Google Maps) (Beer menu)
-
BeerTemple. I have never been at this place. The name sounds as one that should mostly attract tourists. But though their web site advertises as an \"American Beer Bar\", they have a nice selection of local beers also, and the typical Dutch snacks (did someone call for \"bitterballen\"?)
(Google Maps) (Beer menu)
"},{"location":"EasyBuild-CSC-20220509/","title":"EasyBuild course for CSC and local organisations (9-11 May 2022)","text":""},{"location":"EasyBuild-CSC-20220509/#downloads","title":"Downloads","text":""},{"location":"EasyBuild-CSC-20220509/#notes","title":"Notes","text":""},{"location":"Hackathon-20230417/","title":"LUMI-G hackathon April 2023","text":""},{"location":"Hackathon-20230417/#projects","title":"Projects","text":" - ALARO ACRANEB2: Project in the framework of Destination Earth, but the code is not in the public domain.
- FEniCSx with a team from Cambride University and Edinburgh University / EPCC.
- ICON: Icosahedral Nonhydrostatic Weather and Climate Model, with a team linked to DKRZ.
- TurboGAP data-driven atomistic simulation, with a team from CSC and Aalto University.
- waLBerla, with a team from Forschungszentrum J\u00fclich.
"},{"location":"Hackathon-20230417/#presentations","title":"Presentations","text":"Overview of the team's presentations at the start and end of the hackathon week:
Team Opening presentation Closing presentation ALARO ACRANEB2 / / FEniCSx / PDF ICON PDF PDF TurboGAP PDF PDF waLBerla PDF PDF"},{"location":"Hackathon-20241014/","title":"LUMI-G hackathon October 2024","text":""},{"location":"Hackathon-20241014/#hackathon-information","title":"Hackathon information","text":" -
Local information: The venue
-
Tentative schedule
-
Hedgedoc for collaboration (will become unavailable over time, so the link may be dead)
"},{"location":"Hackathon-20241014/#a-brief-introduction-to-belgian-culture","title":"A brief introduction to Belgian culture","text":" -
In Belgium, we discuss tough problems at the dinner table, not in a meeting room, zoom session or a sauna
-
Curing mental distress after a hard day on LUMI
-
See also this map on Google Maps for the restaurants and bars mentioned in the previous links.
"},{"location":"Hackathon-20241014/#projects","title":"Projects","text":"In alphabetical order:
-
Elmer
- Group: CSC (Finland)
- Domain: Finite Element Modeling
- Main programming languages and models: Fortran, with MPI, OpenMP and CUDA/HIP
- Code: Elmer and Elmer/Ice
- Presentations:
- Kickoff presentation
- Final presentation
-
Exciting
- Group: SOLgroup, Department of Physics, Humbold Universit\u00e4t zu Berlin (Germany)
- Domain: DFT
- Main programming languages and models: Fortran, with MPI and OpenMP offload
- Code: exciting
- Presentations:
- Kickoff presentation
- Final presentation
-
FAISER x ASTERIX
- Group: Space Physics Research Group, Particle Physics and Astrophysics, and Complex Systems Computation Group, Department of Computer Science, Helsinki University (Finland)
- Domain: AI and plasma physics
- Main programming languages and models: C++, Python, Rust and Julia
- Codes: Vlassiator and Asterix
- Presentations:
- Kickoff presentation
- Final presentation
-
FLEXI/GAL\u00c6XI
- Group: Numerics Research Group, Institute of Aerodynamics and Gas Dynamics, University of Stuttgart (Germany)
- Main programming languages and models: Fortranm with MPI and HIP for parallelization and GPU support
- Codes: GAL\u00c6XI, GPU version of FLEXI
- Presentations:
- Kickoff presentation
- Final presentation
-
Laplax: Scalable uncertainty quantification
- Group: DTU Compute (Denmark)
- Domain: AI
- Main programming languages and models: Python, using XLA-compiled JAX
- Code is not yet open
- Presentations:
- Kickoff presentation
- Final presentation
-
SAPIEN - Skilfull Atmospheric Prediction with IntelligEnt Networks
- Group: DMI (Denmark)
- Domain: AI
- Main programming languages and models: Python
- Codes: LDcast model and SHADECast model
- Presentations:
- Kickoff presentation
- Final presentation
-
SignLlava
- Group: Department of Cybernetics and NTIS, University of West Bohemia (Czech Republic)
- Domain: AI
- Main programming languages and models Python, HIP
- Code: Sign_LLaVA
- Presentations:
- Kickoff presentation
- Final presentation
-
SOD2D: Spectral high-Order coDe 2 solve partial Differential equations
- Groups: FLOW, Engineering Mechanics, KTH (Sweden) and Microprocessors and Digital Systems Laboratory, NTUA (Greece), but the code is also developed at BSC
- Domain: CFD
- Main programming languages and models: Fortran with MPI and OpenACC
- Code: SOD2D
- Presentations:
- Kickoff presentation
- Final presentation
-
SPH-EXA
- Group: High Performance Computing Group, Department of Mathematics and Compute Science, University of Basel (Switzerland), but CSCS and the Universit\u00e4t Zurich are also inbvolved with code development.
- Domain: Hydrodynamics simulations
- Main programming languages and models: C++ with MPI, OpenMP and HIP
- Code: SPH-EXA
- Presentations:
- Kickoff presentation
- Final presentation
"},{"location":"Hackathon-20241014/localinfo/","title":"Local information","text":"Venue: HOEK38, Leuvenseweg 38, 1000 Brussel, just behind the Belgian parliament and almost next to the Flemish Parliament. This is the building of the main scientific funding organisation for fundamental research in Flanders, FWO-Vlaanderen, who also sponsors the VSC - Vlaams Supercomputer Centrum, the local organiser for this hackathon.
The venue can easily be reached walking from the central station. Hotels near the Central Station or Grote Markt/Grande-Place are good options as you are both within walking distance of the venue and close to a nice area to spend some time at night.
The main airport of Belgium is Brussels Airport from which one has 6 trains per hour to the central station. Both Schiphol Airport in Amsterdam and Paris Charles de Gaulle have direct train connections to Brussels, but you will have to change trains in the Bruxelles Midi (Brussels South) station or, for some trains from Amsterdam, Bruxelles Nord (Brussels North). There is also an airport that is sometimes called Brussels South Airport but that one is really a significant distance from Brussels. A shuttle bus may be the best way to get to Brussels from there. Ryanair is one of the biggest companies serving that airport.
Most buses and all trams and metros in Brussels are operated by MIVB/STIB. Some lines that come from outside Brussels are operated by De Lijn (Flanders) or TEC (Wallonia), but most likely you will not need those buses. The easiest way to pay for the MIVB/STIB busses, trams and metros is likely contactless payment with your bank or credit card or certain smartphone payment systems.
"},{"location":"Hackathon-20241014/schedule/","title":"Schedule","text":" -
Monday October 14: Auditorium
-
From 12:00: Check in at the venue. A sandwich lunch is provided.
-
13:00: Welcome and information
-
13:15: Short and informal presentations of each project (10 minutes each)
-
15:00: Coffee break
-
Until 17:00: Group work
-
Tuesday till Thursday, October 15-17: 4 small meeting rooms
-
9:00: Status update (max 5min each group)
- What did you work on yesterday?
- What are you working on today?
- What issues are blocking you?
-
9:15\u201312:00: Group work
-
12:00\u201313:00: Lunch break
-
13:00\u201317:00: Group work
-
15:00: Coffee break
-
Friday October 18: Auditorium
"},{"location":"Hackathon-20241014/schedule/#other-information","title":"Other information","text":""},{"location":"Hackathon-20241014/where_to_drink/","title":"Curing mental distress after a hard day on LUMI","text":"The LUMI User Support Team realises that at night, you want to forget all the misery from the day. The hunting for bugs, the temperamental file system of LUMI that freezes when you want to save your file so that it takes ages to get out of the editor...
Belgium has a very famous non-prescription medicine for curing that mental distress. It is called \"beer\" and is available in large quantities all over the city, with something for every taste and budget. Some are even made for people who need a very strong medicine to forget. You cannot get it at pharmacies though (though the latter then have a remedy for the day after if you take an overdose of the medicine \"beer\"), but in specialised businesses called \"bar\" or \"caf\u00e9\".
The medicine is tolerated well in modest quantities by most people. However, should you be taking any other medication, please consult your doctor or pharmacist to ensure that there are no conflicts with the medication you're already using. Some side effects may occur, especially when the medicine is taken in large doses. These side effects include some drowsiness, and the day after, headache and intolerance for loud sounds. The medicine is also known to impair your ability to drive a vehicle. It is recommended to not drive a vehicle after using more than one glass of the medicine.
We realise that many participants to the hackathon are scientist or have a background in science. Hence it is only natural that you may want to set up experiments to study and compare the efficiency of the various recipes for the medicine that are available. In case you want to set up a full pharmaceutical study with three groups (one taking the medicine, one getting a placebo, and one not using anything), most places that sell the medicine will also be happy to sell you a placebo. The latter can usually be recognised by the writing \"0.0%\" or \"0.4%\" on the bottle. It is not always available in bulk though.
"},{"location":"Hackathon-20241014/where_to_drink/#where-to-get","title":"Where to get?","text":"See also this map on Google Maps.
The centre of the city is very touristic though and unfortunately this is not the place to find the best beer as too many tourists go for the cheaper volume stuff.
Note that most bars in Brussels will have some of the local microbrewery beers on their menu and not only the large-volume industrial beers.
Some especially noteworthy places near the city centre:
-
If you really, really want to be in the places where all tourists are (not my thing though), people usually mention:
I personally think that it is better to have 50 beers available that the staff knows than 2000 beers of which half are only available on the menu and not in the fridges, and that the staff does not know.
-
BrewDog Brussels (Putterie 20) is a subsidiary of the Brewdog group that you can find in many big cities in Europe.
Not bad if you are in an urgent need for some medicine when walking back from the hackathon venue to your hotel in the historic city centre, and it could be an option on Friday noon also if it is too early to leave to the airport but you want to be close to the station as you don't want to carry around your luggage.
So some of the places I like more:
-
Moeder Lambic Fontainas (Place Fontainas/Fontainasplein 8) is a good choice right in the city centre if you want a more typical place and not one that really aims at tourists as the places we mentioned before. Moeder Lambic cannot compete with these tourist places in number of beers, but they do have more than just the stuff from the large breweries.
-
La Porte Noir (Rue des Alexiens/Cellebroerstraat 67) is an underground bar in the basement of a former monastery. The selection is small, but they do have a selection of nice beers, both on tap and in the fridges. It is right next to the Brasserie des Alexiens (Rue des Alexiens/Cellebroersstraat 63) which is a highly recommended restaurant.
-
GIST (Oud Korenhuis/Place de la Vieille Halle aux Bl\u00e9s 30) You can check their menu here.
In summer, the place is open every day but it might be closed on Monday during the Hackathon.
-
Less a craft beer bar and more a nice pub with a large selection of beers: Poechenellekelder (Eikstraat/Rue du Ch\u00eane 5). It is very close to one of the main tourist attractions of Brussels though, Manneken Pis, so not my personal choice though.
There are lots of breweries with taprooms in Brussels. These are usually a bit further away from the historic city centre and outside the area known as the \"pentagon\" (look on a map and notice a more or less pentagonal area surrounded by bigger roads and you'll know what I mean). I mention those places that are closest to the city centre only:
-
The Wolf food court (Wolvengracht/Rue du Foss\u00e9 aus Loups 50). has its own microbrewery. You can order their beer in the middle of the hall. From all breweries and brewery taprooms mentioned here, this one is closest to the Grande Place and central station.
-
Brussels Beer Project started as a very small brewery but thanks to good marketing, they are now rather big.
-
Their original site and taproom is at Antoine Dansaertstraat/Rue Antoine Dansaert 188, still inside the Pentagon. When I last checked, the place was open Tuesday till Saturday.
-
They now also have a taproom in the Bailli area (Baljuwstraat/Rue du Bailli 1/A), easy to reach by tram from the park between the Parliament and Royal Palace near HOEK38.
-
Brasserie Surr\u00e9aliste at the Nieuwe Graanmarkt/Place du Nouveau March\u00e9 aux Grains 23 and housed in an Art Deco building from 1932, is a small brewery with taproom and restaurant. Open on Wednesday, Thursday and Friday from 5pm and Saturday from noon.
-
Saint-Gilles, south of the pentagon, is a very multicultural community. Yet there are some very nice beer bars.
-
L'Ermitage Saint-Gilles (Rue de Moscou/Moskoustraat 34) is now the main taproom of the L'Ermitage brewery as they outgrew their taproom at their original location (which in fact is only open in the weekend).
They serve pizza also and are open every day.
Two other places in Saint-Gilles that are not brewery taprooms but regular craft beer bars well worth a visit are:
-
Moeder Lambic Original (Savoistraat/Rue de Savoie 68). A good place to drink the beer type that the Brussels area is most known for, Geuze and Lambic.
-
An old favourite of mine is Dynamo - Bar de Soif at the Alsembergsesteenweg/Chauss\u00e9e d'Alsemberg 130. Most beers on tap are not Belgian though, and the place specialises somewhat in British beers. They do have more in their fridges though, also Belgian beers, and know what they sell.
(The menu I linked to may not be complete, at least it was not when I wrote this.)
-
There are some interesting developments going on just north of the north-west corner of the pentagon area, at the canal and close to the North station (which itself is a less pleasant area, on one side surrounded by large office buildings that are empty at night and on the other side the red light district and one of the more infamous areas of Brussels when it comes to safety).
Tour & taxis is a completely renovated old customs hall that now houses a food court and places for cultural events. There are also some new office buildings on the former site, including the main office building of the administration of the Flemish government.
Just north of that site there are two microbreweries with their own taproom:
-
Brasserie de la Senne (Anna Bochdreef/Dr\u00e8ve Anna Boch 19/21) is named after the river that flows through Brussels (under Brussels would be a better expression as it is covered almost everywhere). The taproom , called Zennebar, is open every day except Mondays. They do serve some food also, but I am not sure they do that on all opening days.
-
La Source (Dieudonn\u00e9 Lef\u00e8vrestraat/Rue Dieudonn\u00e9 Lev\u00e8vre 4) is my personal favourite small brewery in Brussels. The brewpub/taproom is a bit tricky to find: It is in the far left corner of a big hall named BE-HERE that you enter through a port. They typically have 5 beers from the tank and 13-14 beers on tap.
They brew a variety of styles and their beers rarely disappoint me. You'll find fruited sours, several IPA variants, porters or stouts, but often also their own lager beer. They're one of the few though where it may be hard to find the (near) alcohol-free variant.
During the evening, they do serve pizza also (until 21:30 except on Sundays, then until 20:30).
Closed on Monday and Tuesday though.
-
In case you would not fly back home on Friday afternoon and would like to learn how Lambic, the most famous beer type from the Brussels area, is brewed (and what the difference is between Geuze and Lambic), you can visit the Cantillon Brewery and Brussels Museum of the Geuze which is also not far outside the pentagon area.
They brew an excellent Lambic and Geuze, but the taste of it may be a bit on the extreme end of the Geuze/Lambic spectrum and not everyone's thing. Personally, I think the beers from. e.g., Oud Beersel and 3 Fonteinen are a bit more accessible to most and as a starter in this kind of beer. So depending on how adventurous you are when it comes to the taste of beer, you may be very happy or a bit disappointed. But it is certainly interesting to see how this beer is brewed and to learn that its production in the Brussels area is threatened by global warming...
The place is not open at night though.
"},{"location":"Hackathon-20241014/where_to_eat/","title":"Good places to discuss tough problems","text":"See also this map on Google Maps.
Just some suggestions. There are many more decent restaurants in Brussels especially if you are alone or only with a small group. In general most places that score a 4 or more on Google Maps are decent places. For vegetarians and certainly for vegans, the options may be a bit more limited. I couldn't check the menu of all these places, but often the choices are limited. Brussels feels more like a southern European place in that respect than a modern northern city. Traditional Belgian cuisine is very much focused on meat and fish dishes. Moreover, the vegetables that were traditionally grown in the area have mostly lost popularity so any dish based on them, has disappeared.
The first two are particular favourites of me, and after that I focus more on certain areas with lots of restaurants.
-
Brasserie des Alexiens (Rue des Alexiens/Cellebroersstraat 63) It opens only at 7pm. I've been there a few times with guests already who are always very satisfied. A highly recommended place. It is a bit more expensive, but then you also get a bit more space than in most other restaurants in this list. The place is in a former monastery.
- The bar La Porte Noir next door is a good option for a beer before or afterwards.
-
La porteuse d'eau (Avenue Jean Volders/Jean Voldersslaan 48) Interesting Art Deco building and interior, and the food is very much OK. It is a bit further away but still interesting for its architecture. There are more Art Deco restaurants in Brussels, but this one has the best reputation for the food. The vegetarian options are very limited though.
- Tip: Combine with the nearby bar L'Ermitage Saint-Gilles (Rue de Moscou/Moskoustraat 34) for a local beer, or simply have some pub food in the bar. This bar is from a brewery in Brussels that started the bar elsewhere as the location had become too small.
-
Near the corner of the Kartuizerstraat and Arteveldestraat, not far from the Beurs/La Bourse, which used to house the Brussels stock market:
- Fin de Sci\u00e8cle (Rue des Chartreux/Kartuizersstraat 9) The interior may not look nice at all but has character, and the food is good. It is a very busy place though, even during the week (which already shows that it likely offers good value for money). I've been there with guests also and they too liked it.
- Diagonally opposite, at the corner of the street, is 9 et Voisins, another busy place with a good reputation. Not as good as Fin de Sci\u00e8cle though (Google Maps)
- Next to Fin de Sci\u00e8cle is Brasserie Greenwich Brussels, also with an interesting interior. It used to be a pretty good place but I've heard less good things from them recently, and the place is definitely not as busy as it used to be which is already a sign.
-
And in the same area: Sint-Goriksplein/Place Saint-G\u00e9ry and in particular two streets leading to that place: Jules Van Praetstraat/Rue Jules Van Praet and Karperbrug/Rue du Pont de la Carpe are two streets with lots of restaurants, and in particular lots of Asian restaurants. As is often the case with streets with a high concentration of restaurants in the centre of Brussels and attracting lots of tourists also, there are very good places and some disappointments. So check review sites if possible. This may be one of the more interesting areas for vegetarians.
-
Another nearby popular area is Sint-Katelijneplein/Place Sainte-Catherine and surrounding streets, especially the Vlaamsesteenweg/Rue de Flandre. Most, but not all places there are decent . Personally, I don't thrust most of the fish restaurants on the corner of the big, long square (Vismarkt/March\u00e9 aux Poissons or Baksteenkaai/Quai aux Briques). They are too cheap to be able to offer a decent quality. On the Vlaamsesteenweg/Rue de Flandre there are also a couple of Asian restaurants which may be a good option for vegetarians.
-
The Rue du March\u00e9 au Charbon/Kolenmarkt is the gay street in Brussels, but it also has some nice places to eat where nobody has to feel uncomfortable.
- Caf\u00e9 Charbon (Rue du March\u00e9 au Charbon/Kolenmarkt 90) serves good food, and especially the daily specials (on the board against the wall) are highly recommended. I've been there with guests also before and they too were very satisfied.
- Brasserie Le Lombard on the corner with the Rue du Lombard/Lombardstraat has nice food also. You may have to order at the bar.
- Le Plattesteen on the opposite corner has also a decent reputation. Not spectacular, but a bit less expensive than many other places and the price/quality ratio is certainly OK. The reviews are certainly rather mixed and waiting times can be a bit longer, but I've always had a decent meal there. They also have some more simple traditional dishes, as Belgium is not only about \"steak frites\".
-
Restaurants in the neighbourhood of HOEK 38 that should be OK:
- La Tana (Rue de l'Enseignement/Onderrichtsstraat 27) is an Italian restaurant that also specialises in craft beers and has very nice Italian imports. The food is likely real Italian. E.g., the Pasta Carbonara that I had there, looked a lot more like what I would expect from reading the recipe rather than the typical cheese sauce with uncooked bacon or even ham you get in many places. It has very much an \"eat in the kitchen of an Italian\" atmosphere, without any luxury. But unfortunately the opening hours of the business are very limited, making it only an option on Wednesday and Thursday evening.
- Per Bacco (Rue de l'Enseignement/Onderrichtsstraat 31)
- Al Solito Posto (Rue de l'Enseignement/Onderrichtsstraat 73)
- Yuca Latina (Onderrichtstraat/Rue de l'Enseignement 18) is a South-American restaurant with rave reviews on Google Maps, but also always busy which is already an indication.
-
Beenhouwersstraat/Rue des Bouchers and in its extension, Gr\u00e9tystraat/Rue Gr\u00e9ty: This is the tourist trap area in Brussels when it comes to food. It may be fun to walk through especially the Rue des Bouchers, but but don't be tempted by the man at the door who lures you in with offers that seem interesting. Some of those places are really dishonest and what you get inside is very different from what you expect outside. Some places are OK though, so check review sites or Google Maps.
Some places that range from acceptable to very good:
- Le Marmiton: A very good restaurant at the corner of the Galerie de la Reine. A bit more pricey, and it may be hard to find a table there without a reservation. But it has been recommended to me by FWO and is a restaurant they often use for dinners with their review boards.
- Aux Armes de Bruxelles (Rue des Bouchers/Beenhouwersstraat 13) is a very large Belgian restaurant that tries to evoke an old-fashioned luxury atmosphere. It is OK but not spectacular. I've eaten there once. One dish I had was very good, the other was not a complete disappointment, but still a bit expensive for what I got. An easy choice though if you don't want to spent too much time looking for a place and want a varied menu.
- Chez L\u00e9on (Rue des Bouchers/Beenhouwersstraat 18) is another one that you will find in all tourist guides, and it is a very busy place. I wouldn't call it a tourist trap, but it is not as good as it should be for the price. They claim an old-style Brussels atmosphere of a \"frituur/friterie\" (chip shop).
- Not in the street but nearby: Mozart (Petit Rue des Bouchers/Korte Beenhouwersstraat 18) Specialises in ribs, and has a good reputation
-
Rue du March\u00e9 aux Fromages/Kaasmarkt is another street with restaurants very much oriented towards tourists. Contrary to the Rue des Bouchers, even some of the cheap places there serve very decent food for the price if you're travelling on a budget, e.g., Plaka, Hellas, Saffron and The Blue, and the Italians in that street also seem to be decent. These places are certainly not spectacular and they don't use first-class ingredients, but then they are relatively cheap for a city like Brussels.
Baladi, a Syrian restaurant in the nearby Rue des Chapeliers/Hoedenmakerstraat 16, is definitely worth a visit.
-
Kind of interesting if you don't need a big meal, is the Wolf food court (Wolvengracht/Rue du Foss\u00e9 aus Loups 50). Not all food stalls are as good though. The place does have its own microbrewery. You can order their beer in the middle of the hall.
"},{"location":"LUMI-G-20220823/","title":"LUMI-G Pilot Training, August 23, 2022","text":""},{"location":"LUMI-G-20220823/#downloads","title":"Downloads","text":" - Introduction to the AMD ROCmTM Ecosystem (PDF, 6.3M)
- Exercises for \"Introduction to the AMD ROCmTM Ecosystem\" (tar file, 56k)
"},{"location":"LUMI-G-20220823/#notes","title":"Notes","text":" - Notes from the hackmd page
"},{"location":"LUMI-G-20220823/hackmd_notes/","title":"LUMI-G Pilot Training","text":"23.8.2022 9:00--17:30 (CEST)
- LUMI-G Pilot Training
- General Information
- Next public HPC coffee break
- Schedule
- Slides and other material (temporary location)
- Q&A
- Ice breaker: What is the most important topic you want to learn about today?
- Introduction to the Cray EX Hardware and Programming Environment on LUMI-G
- First steps for running on LUMI-G
- Introduction to the AMD ROCm(TM) Ecosystem
- AMD hands-on exercises
- General Q&A
"},{"location":"LUMI-G-20220823/hackmd_notes/#general-information","title":"General Information","text":""},{"location":"LUMI-G-20220823/hackmd_notes/#next-public-hpc-coffee-break","title":"Next public HPC coffee break","text":"31.8.22, 13:00-13:45 (CEST), 14:00--14:45(EEST) Meet the LUMI user support team, discuss problems, give feedback or suggestions on how to improve services, and get advice for your projects.
Every last Wednesday in a month. Join via Zoom
"},{"location":"LUMI-G-20220823/hackmd_notes/#schedule","title":"Schedule","text":" - 9:00-9:10: Introduction
- Course organisation
- Demonstration of how to use hackmd
- 9:10-10:15: Introduction to the Cray EX Hardware and Programming Environment on LUMI-G ([name=Harvey])
- HPE Cray EX hardware architecture and software stack
- The Cray programming environment and compiler wrapper scripts
- An introduction to the compiler suites for GPUs
- 10:15-10:45: Break
- 10:45-12:00: First steps for running on LUMI-G
- Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
- MPI update for GPUs/SS11 (GPU-aware communications)
- Profiling tools
- 12:00-14:00: Lunch break
- 14:00-15:45: AMD topics ([name=George] & [name=Samuel])
- GPU Hardware intro
- Introduction to ROCm and HIP
- Porting Applications to HIP
- ROCm libraries
- Profiling
- Debugging
- 15:30-16:00: Break
- 16:00-16:45: Continuation of AMD topics + examples & hands-on exercises
- 16:45-17:30: General Questions & Answers
"},{"location":"LUMI-G-20220823/hackmd_notes/#slides-and-other-material-temporary-location","title":"Slides and other material (temporary location)","text":" - HPE slides and excercises on lumi at
/users/lazzaroa/hackathon - AMD slides: https://www.dropbox.com/s/umcjwr6hhn06ivl/LUMIG_training_AMD_ecosystem_23_08_2022.pdf?dl=0
- AMD excersises on lumi at
/users/gmarkoman/training The README contains basic instructions
"},{"location":"LUMI-G-20220823/hackmd_notes/#qa","title":"Q&A","text":""},{"location":"LUMI-G-20220823/hackmd_notes/#ice-breaker-what-is-the-most-important-topic-you-want-to-learn-about-today","title":"Ice breaker: What is the most important topic you want to learn about today?","text":" - I want to learn how to bind GPUs to CPU cores
- Profiling and Debugging +6
- AMD GPU Unified Memory performance, Page Migration Mechanism, memory prefetching (eg. hipMemPrefetchAsync), comparison of differences between the newest AMD and NVIDIA archs with respect to Unified Memory
- General use of the system
- Any significant ROCm issues known? +1
- GPU aware MPI on LUMI. +2
- How to compile my application for CPU/GPU execution
- How to build software in user's space under different software stacks?
-
What are the problems with LUMI-G that lead to the postponing of the pilot phase? Appart from hardware issues, can these issues impact users running in rocm containers?
-
How to edit this document (without logging in)?
- You can click the \"Pencil\" button in the top left.
"},{"location":"LUMI-G-20220823/hackmd_notes/#introduction-to-the-cray-ex-hardware-and-programming-environment-on-lumi-g","title":"Introduction to the Cray EX Hardware and Programming Environment on LUMI-G","text":" -
Will pilots be restricted to a max of 100 nodes/run or is larger possible?
- For the CPU pilots there were special arrangements for very big runs towards the end of the pilot phase so I guess that could be arranged
- Great, thanks, we (UTU) are very interested in very large runs
-
How are the MI250X seen in a program? 1 or 2 GPUs?
- 2, more description in the next lecture
- So a program will have to be multi-gpu to use it at maximum?
- Not sure I understand the question, let's discuss this in the next lecture. There are 4 Mi250X on the node, a total of 8 GCDs. From the software point of view these are 8 GPUs. You can use ranks attached to each gpu or use multi-gpu within the same process.
-
Benchmarks vs NVIDIA (node vs node & gpu vs gpu // fundamental ops & application ie pytorch)
- One of the purposes of the pilot phase is actually that you establish such benchmarks. We do not have much numbers yet.
-
Is Simultaneous Multi-Threading enabled on CPU
- Yes, there are 128 hardware threads
- You need to use the slurm option `--threads-per-core=2
-
Does slurm schedule multi-node jobs on nodes which have the lowest node to node latency in the dragonfly network?
- I doubt. It is not the case on the CPU nodes, so I doubt it will be the case on the GPUs. In fact, every dual GPU node blade connects to 4 switches but it is not clear to me if every node already connects to 4 swithces or if both nodes each connect to two switches. SLURM does try to give nodes that are close in the numbering which means that they are in one so-called group (within a rack). There are still other problems with the Slurm configuration though.
- You can configure Slurm to try to keep workloads to 'switches' (a Slurm concept). So you can associate a switch to a group of physical switches.
-
debugger: what's the maximum job size of ddt's license ?
- 256 MPI ranks (each rank can use 1 GPU), i.e. max 32 nodes. There is also the gdb4hpc debugger from HPE Cray, which has no limit
- We don't have a version that is ready for AMD GPUs though at the moment.
-
Known issues with ROCm / HIP complex numbers? What version of ROCm?
- Any issue in particular that you are referring to here?
-
What version of ROCm?
- Currently 5.0.2 but it changes all the time. We're still figuring out why 5.1 did not get installed as that should be supported on the version of the OS that we have.
-
Does the GPU-aware MPI do packing and unpacking for derived datatypes on the GPU? Does it support Unified Memory (passing pointers to UM)?
- The system has an unified memory pool - GPU memory pointer can not only be used in MPI but also in your CPU code.
- HPE is beeter position to answer how that packing/unpacking is implemented - not sure if that is offloaded to the GPU.
- (HPE) I will ask to MPI experts..
- Thanks! My experience is that for example with OpenMPI and MVAPCIH2-GDR with NVIDIA archs, the packing and unpacking for derived data types is not done on the GPUs. This means that with Unified Memory, recurring page faults occur (because packing/unpacking is done on the CPU, and requires CPU accessing the data from the GPU). This can make derived MPI datatypes very slow, and we actually had to move back to continuous MPI datatypes (eg. MPI_BYTE), this gave a huge performance increase (3x whole program performance) with CUDA and NVIDIA cards. But it would be good to know whether things are different with AMD cards and cray MPI implementation?
- [HPE] Can you provide a little more detail about the datatypes involved, are they vector constructions for example.
- MPI_Type_create_struct and MPI_Type_create_hvector are used at least I think, I don't remember the exact details anymore, the code is here: https://github.com/parflow/parflow/blob/master/pfsimulator/amps/mpi1/amps_pack.c
- (HPE) MPI expert reply: we currently do not offload datatype pack/unpact to the GPU. Users can allocate memory via hipMallocManaged or cudaMallocManaged and pass those pointers to MPI. Users need to set MPICH_GPU_MANAGED_MEMORY_SUPPORT_ENABLED=1 for such codes (check
man mpi for details). - Thanks, Will there be page faults, or is the data prefetched to the CPU without page faults for packing/unpacking? Does it crash if hipMalloc is used instead of hipMallocManaged when using those derived datatypes?
- Sorry, you have to try, we don't have performance numbers...
-
Maybe I mis - what is the difference between cray-python and python?
- cray-python is a just an installation that is linked to the cray libsci library for numpy/scipy/pandas
- System python should never be used, it comes with a miminum of packages and is not meant to be build upon.
- cray-python can be loaded with the module system
-
Will there be multiple rocm modules available?
- Likely through different versions of the programming environment, the Cray compilers and Cray MPICH require specific versions.
- (Kurt for LUST) I checked what the current rocm/5.0.2 module does and it actually does not even support multiple versions of ROCm on the system as it uses
/opt/rocm rather /opt/rocm-5.0.2 which in turn may have to do with a ROCm problem, i..e., hard-coded paths in the ROCm code that don't support installing in other directories. Now if tomorrow the sysadmins would install ROCm 5.2.0 and then use /etc/alternatives to make that version the default, the 5.0.2 module would actually be loading 5.2.0 instead...
-
What is the preferred way to monitor GPU usage and memory across multiple nodes?
- See later sessions, this is more a question for the end
- Usually
rocm-smi is how you go about this, or you can instrument your application to collect stats. I used to do monitoring by SSHing to the allocated nodes but that is not available on LUMI. A possibility is to create a script such as (rocm-monitor) : #!/bin/bash\n\nwhile true ; do\n date > ~/rocm-smi-$(hostname)\n rocm-smi >> ~/rocm-smi-$(hostname)\n sleep 1\ndone\n
then you can use in your submission script: mpids=''\nif [ $SLURM_LOCALID -eq 0 ] ; then\n rocm-monitor &\n mpids=$!\nfi\n\n... do your thing\n\nfor p in $mpids ; do\n kill $p\ndone\n
And in a login node you can watch -n1 cat ~/rocm-smi-*
-
Is there a difference between hipMalloc and hipMallocManaged for LUMI environment? If I remember right, the pointer to hipMalloc'd memory can be used in host code as well with AMD GPUs (this is different from NVIDIA archs).
- One difference is that with hipMallocManaged the migration happens with the declaration while with hipMalloc the migration will happen on demand. On the dev, the first access could be slighlty slower than the next ones.
Follow-up question: Can you confirm that with hipMalloc the migration happens only when the data is needed? This would be the opposite of how it works with NVIDIA archs.
- Yes, not every time, just the first time, then no need to migrate again
Insisting: Are you 100% sure you did not mix the hipMalloc and hipMallocManaged functions? With NVIDIA archs they work the other way around.
-
Trying to clarify:
hipmalloc - page lives in the GPU and is migrated to main memory on demandhiphostalloc - page lives in main memory and is migrated to the GPU on demandhipmallocmanaged - page is migrated when it is touch and then resides in the destination memory
-
I think what is meant is that the first time you touch memory allocated in the GPU in the GPU, you have a small hit in BW to have the shared memory system to workout the consistency logic.
-
Just for completion - unified memory is on by default on the nodes. If you disable it (HSA_XNACK=0) then a page fault will result in segfault in the first two cases. That could be useful if you want to make sure you are not relying on the unified memory by mistake, i.e you are not using a main memory pointer on the GPU or vice-versa.
-
craype-x86-rome: are the cpus of the cn zen3/milan cpus ? would you recommend to load craype-x86-milan instead ?
- Actually, there is
craype-x86-trento. More in the next slides
-
Will complete start to finish tutorials be available (i.e. MNIST JAX example including loading modules / installing packages / running)?
- Likely not, except probably for very specific packages. It is impossible to maintain such documentation with a small team as we are a small team and with the rapid rate of compiler updates that we can expect in the next year. We do try to develop EasyBuild recipes for software though, and offer Spack for those who know how to use it (but do not intend to implement packages in Spack ourselves). The reality is that given the very new technology on LUMI, it will be a rapidly changing system initially and not one for those who expect an environment that is stable for a longer period of time.
"},{"location":"LUMI-G-20220823/hackmd_notes/#first-steps-for-running-on-lumi-g","title":"First steps for running on LUMI-G","text":" -
How to profile python programs?
- (HPE) I'm not sure about this,
pat_run might tell you something, we plan to have a discussion about Python support in the CoE/LUST team so I will keep this in mind.
-
How to do MPI allreduce on pure GPUs and hybrid case?
- Copy data to GPU, then allreduce will be handled on GPU, also in hybrid case (if some data is in main memory)
-
About gpu_bind.sh: is there a reason why gpus are not attached to the numa nodes in a friendler way (gpu0 to numa0, etc...) ? because of the nic ?
- I guess hardware design and routing issues may have created this mess...
-
When I run the following simple test found in https://github.com/csc-training/summerschool/blob/master/gpu-hip/memory-prefetch/solution/prefetch.cpp on the NVIDIA-based system, I always get more or less the following kind of timings:
Mahti timings (NVIDIA A100)\nThe results are OK! (0.990s - ExplicitMemCopy)\nThe results are OK! (0.744s - ExplicitMemPinnedCopy)\nThe results are OK! (0.040s - ExplicitMemNoCopy)\nThe results are OK! (2.418s - UnifiedMemNoPrefetch)\nThe results are OK! (1.557s - UnifiedMemPrefetch)\nThe results are OK! (0.052s - UnifiedMemNoCopy)\n
However, on the LUMI with AMD GPUs, everything else looks good, but I don't understand why the latter two cases are so slow. For example, putting a hipMemPrefetchAsync (that should speed up things), looks to make it much slower in the second last case. In the last case, using hipMemset for a pointer to a Unified Memory appears extremely slow: LUMI timings\nThe results are OK! (0.748s - ExplicitMemCopy)\nThe results are OK! (0.537s - ExplicitMemPinnedCopy)\nThe results are OK! (0.044s - ExplicitMemNoCopy)\nThe results are OK! (0.609s - UnifiedMemNoPrefetch)\nThe results are OK! (3.561s - UnifiedMemPrefetch)\nThe results are OK! (18.889s - UnifiedMemNoCopy)\n
Any explanation? -
Do any modules need to be loaded to run rocm-smi? I get the following error:
ERROR:root:Driver not initialized (amdgpu not found in modules)\n
-
(HPE) Are you running on the compute node?
- R: Yes, but I think it should also run on the login node. I used to be able to run this both on compute nodes and login nodes.
-
(HPE) Login do not have GPUs and drivers. I'm running this (use your project ID):
srun --nodes=1 --ntasks-per-node=1 -p pilot -A project_462000031 -t \"00:10:00\" --ntasks=1 --gres=gpu:8 rocm-smi\n
On the login you can get the help though.
Ok thank you. But why do I need to run this with srun?
- The
srun command gets you to the compute node.
Ok sorry for the confusion. My question is why doesn't this work with salloc? I ask for an interactive session, then cannot run rocm-smi there.
Yes that is clear, thank you. On other clusters, salloc usually gives a shell on a compute node in my experience. But I assume this is not the case here because ssh is not enabled.
-
You can connect via srun shell, just in case... I think the difference in salloc is because the login nodes are shared between LUMI-C and LUMI-G...
-
(Someone from LUST) salloc on LUMI behaves as I am used from other clusters and a SLURM training we got from SchedMD at my home university so I am not that surprised. It has nothing to do with ssh. On the contrary, the reason why ssh is not enabled is that it does not necessarily take to the right CPU set and the resources that are controlled by SLURM.
-
(HPE) I think the salloc behaviour is site configurable.
-
I am wondering if the GPUDirect RDMA is supported on LUMI-G?
- I think the osu device to device copy that Alfio showed indicates this is the case.
- (HPE) Yes, it is supported.
-
Are containers supported on lumi-g? With rdma ?
- [HPE] this is something we are looking at, but I don't think we have checked on the current software stack.
"},{"location":"LUMI-G-20220823/hackmd_notes/#remarks-for-this-section","title":"Remarks for this section","text":" - There are xthi-like programs in the
lumi-CPEtools modules. Load the module and check man lumi-CPEtools for more information.
"},{"location":"LUMI-G-20220823/hackmd_notes/#introduction-to-the-amd-rocmtm-ecosystem","title":"Introduction to the AMD ROCm(TM) Ecosystem","text":" -
(Q): Is there a GPU memory pool allocator (that uses either hipMalloc or hipMallocManaged) for AMD GPUs?
(A): Can you clarify what exactly you are looking for - you mean an allocator for a given language or runtime?
(Q): The point of pool allocator is to allocate a large memory pool which is reused. So that recurrent alloc and free-calls do not recurrently allocate and free memory at the system level, but instead just reuse the memory pool. I think CUDA recently added memory pools (cf. cudaDeviceSetMemPool and cudaMallocAsync), but I have not used these yet. Previously I have used Rapids Memory Manager with NVIDIA cards. This is really important with applications which do recurring allocations and deallocations in a loop. For example in the paper \"Leveraging HPC accelerator architectures with modern techniques - huydrologic modeling on GPUs with ParFlow\", simply using GPU memory pool allocator gave additional 5x speed-up for the whole program performance (instead of allocating and freeing things recurringly with cudaMallocManaged and cudaFree).
(Q): I see, you have hipDeviceSetMemPool but that is in rocm 5.2.0, unfortunately that is not the version on LUMI but it is possible to install in user space and have it to work with the existing driver. Apart from that there are many runtimes that do similar things, I don't have an exaustive list. There are many libraries and portability layers that come up with their own memory management - if there is one in particular you think is worth us to look at I (Sam) am happy to do so.
(Q): Is that rocm5.2 also supporting memory pools for AMD GPUs, or only for NVIDIA GPUs? The whole point is really to avoid having to write your own memory manager and using an existing one, preferably one that is directly offered by HIP.
(A): Didn't try it but if it goes in HIP should be supported on AMD Instinct GPUs.
(Q): Do you know any libraries which would provide hipMallocManaged pool allocator for AMD GPUs? I am not sure if the CUDA/HIP pools in rocm5.2 support Unified Memory.
(A):Just found Umpire (https://computing.llnl.gov/projects/umpire) which appears to support HIP+Unified Memory pool allocation
-
Will tools like GPUFORT be available on LUMI?
- We strive to provide many development tools on LUMI-G, but in the beginning, during the pilot phase, you are expected to install some of the tools that you need by yourself. GPUFORT seems like a research project, so might not want to \"officially\" support itif it is difficult to use. Regarding OpenACC in general (the use case for GPUFORT?), Cray's Fortran compiler does support OpenACC offloading to the AMD GPUs, so this might be a better approach.
-
If there performance difference hipforrtran vs fortran + hip ?
- There should not - hipfortran is awrapper exactly for fortran + hip.
-
Question for HPE: Does the gcc that comes with the PE support OpenMP offload on AMD?
- No, the first version with Mi250X will be GCC 13. I do expect support in the PE when GNU will support the GPU.
-
(Q): Is there JAX support / tests?
(A): I'm not familiar with this or the XLA dependencies, else might be able to answer.
(Q): There is a known issue on AMD, seems to be unstable.
-
Does any AMD profiling app give backtrace for Unified Memory page fault locations?
- Unfortunatly, I am not aware of a way for one to do that with the profile. You can try disabling unified memory (
export HSA_XNACK=0) and see where code crashes and get the backtrace then.
-
Is Perfetto available as a desktop application? Or can I look at AMD profiles offline somehow?
- Even though Perfetto runs on the browser, it does run locally. If you want to have your instance served locally you can use a docker container, this is the image I use:
FROM eu.gcr.io/perfetto-ci/sandbox\n\nRUN set -eux ; \\\ncd /opt ; \\\ngit clone -b v20.1 https://github.com/google/perfetto\n\nWORKDIR /opt/perfetto\nRUN set -eux ; \\\ntools/install-build-deps --ui\n\nRUN set -eux ; \\\nui/build\n\nRUN set -eux ; \\\nsed -i 's/127\\.0\\.0\\.1/0.0.0.0/g' ui/build.js\n\nEXPOSE 10000\nENTRYPOINT []\nCMD [\"./ui/run-dev-server\", \"-n\"]\n
build with #!/bin/bash\n\ndocker network rm \\\nlan-restricted\n\ndocker network create \\\n-o \"com.docker.network.bridge.enable_ip_masquerade\"=\"false\" \\\nlan-restricted\n\ndocker run -p 10000:10000 --name myperfetto --network lan-restricted myperfetto\n
This will create a local server for Perfetto
-
Is the following warning expected when running rocm-smi?
======================= ROCm System Management Interface =======================\n================================= Concise Info =================================\nGPU Temp AvgPwr SCLK MCLK Fan Perf PwrCap VRAM% GPU% \n0 39.0c 88.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0% \n1 45.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0% \n2 43.0c 85.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0% \n3 41.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0% \n4 44.0c 82.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0% \n5 41.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0% \n6 41.0c 83.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0% \n7 40.0c N/A 800Mhz 1600Mhz 0% auto 0.0W 0% 0% \n================================================================================\nWARNING: One or more commands failed\n============================= End of ROCm SMI Log ==============================\n
- The warning likely comes from SLURM because
rocm-smi returns non-zero exit codes?
-
What is the timeline of the pilot phase? When exactly does it start and when does it end?
- It will start on September 26th and last for a month.
"},{"location":"LUMI-G-20220823/hackmd_notes/#amd-hands-on-exercises","title":"AMD hands-on exercises","text":"Files for excersises on lumi are available for download (tar file, 56k). The README contains basic instructions
"},{"location":"LUMI-G-20220823/hackmd_notes/#general-qa","title":"General Q&A","text":" -
How to bind correctly mpi-rank <-> gpu-id? select_gpu.sh
#!/bin/bash\n\nGPUSID=\"4 5 2 3 6 7 0 1\"\nGPUSID=(${GPUSID})\nif [ ${#GPUSID[@]} -gt 0 -a -n \"${SLURM_NTASKS_PER_NODE}\" ]; then\n export ROCR_VISIBLE_DEVICES=${GPUSID[$((SLURM_LOCALID / ($SLURM_NTASKS_PER_NODE / ${#GPUSID[@]})))]}\nfi\n\nexec $*\n
#SBATCH --job-name=NAME # <--- SET \n#SBATCH --output=\"NAME.%J.out\" # <--- SET\n#SBATCH --error=\"NAME.%J.err\" # <--- SET\n#SBATCH --nodes=2 # <--- SET: Number of nodes, each noode has 8 GPUs\n#SBATCH --ntasks=16 # <--- SET: Number of processes you want to use, MUST be nodes*8 !!!\n#SBATCH --gpus=16 # <--- SET: MUST be the same as ntasks !!!\n#SBATCH --time=15:00 # <--- SET: Walltime HH:MM:SS\n#SBATCH --mail-type=ALL\n#SBATCH --mail-user=your@email # <--- SET: if you want to get e-mail notification\n#SBATCH --partition=eap \n#SBATCH --account=project_465000150 \n#SBATCH --cpus-per-task=1 # Do not modify\n#SBATCH --ntasks-per-node=8 # Do not modify\n\n# Set environment\nexport MPICH_GPU_SUPPORT_ENABLED=1 \n\n# the simple call\nsrun -n 16 ./td-wslda-3d input.txt\n\n# I mapping provided above.\n\n--------------------------------------------------------------------\n# START OF THE MAIN FUNCTION\n# CODE: TD-WSLDA-3D\n# PROCESS ip=6 RUNNING ON NODE nid005100 USES device-id=6\n# PROCESS ip=1 RUNNING ON NODE nid005100 USES device-id=1\n# PROCESS ip=7 RUNNING ON NODE nid005100 USES device-id=7\n# PROCESS ip=5 RUNNING ON NODE nid005100 USES device-id=5\n# PROCESS ip=4 RUNNING ON NODE nid005100 USES device-id=4\n# PROCESS ip=3 RUNNING ON NODE nid005100 USES device-id=3\n# PROCESS ip=2 RUNNING ON NODE nid005100 USES device-id=2\n# PROCESS ip=12 RUNNING ON NODE nid005104 USES device-id=4\n# PROCESS ip=13 RUNNING ON NODE nid005104 USES device-id=5\n# PROCESS ip=15 RUNNING ON NODE nid005104 USES device-id=7\n# PROCESS ip=8 RUNNING ON NODE nid005104 USES device-id=0\n# PROCESS ip=14 RUNNING ON NODE nid005104 USES device-id=6\n# PROCESS ip=10 RUNNING ON NODE nid005104 USES device-id=2\n# PROCESS ip=11 RUNNING ON NODE nid005104 USES device-id=3\n# PROCESS ip=9 RUNNING ON NODE nid005104 USES device-id=1\n# PROCESS ip=0 RUNNING ON NODE nid005100 USES device-id=0\n...\n
-
What has changed over the past 2 weeks (software and or hardware) ? I was running PyTorch code using this container more or less reliably at the beginning of the pre pilot phase using rccl backend. I haven't touched it since and tried again today and I seem to have network issues:
nid005000:30599:30731 [0] /long_pathname_so_that_rpms_can_package_the_debug_info/data/driver/rccl/src/include/socket.h:415 NCCL WARN Net : Connect to 10.120.24.10<52061> failed : No route to host\n
Any ideas?
- (AMD): Try
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3 let RCCL focus on the right network interfaces. Also export NCCL_DEBUG=INFO to get more info. export NCCL_DEBUG_SUBSYS=INIT,COLL.
"},{"location":"LUMI-G-20230111/","title":"LUMI-G Training, January 11, 2023","text":""},{"location":"LUMI-G-20230111/#course-overview","title":"Course overview","text":""},{"location":"LUMI-G-20230111/#downloads","title":"Downloads","text":" - Slides Introduction to the AMD ROCmTM Ecosystem (PDF, 10M)
- Additional notes and exercises from the AMD session
- Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"LUMI-G-20230111/#other-material-only-available-on-lumi","title":"Other material only available on LUMI","text":"The following materials can only be found on LUMI and are only accessible to members of project_465000320:
- Introduction to the Cray EX Hardware and Programming Environment on LUMI-G
- Slides:
/project/project_465000320/slides/HPE/01_Intro_EX_Architecture_and_PE.pdf - Recording:
/project/project_465000320/recordings/01_Intro_EX_Architecture_and_PE.mp4
- Running Applications on LUMI-G
- Slides:
/project/project_465000320/slides/HPE/02_Running_Applications_and_Tools.pdf - Recording:
/project/project_465000320/recordings/02_Running_Applications_and_Tools.mp4
- Introduction to AMD ROCmTM Ecosystem
- Recording:
/project/project_465000320/recordings/03_Introduction_to_the_AMD_ROCmTM_ecosystem.mp4
- Exercises are in
/project/project_465000320/exercises
"},{"location":"LUMI-G-20230111/#notes","title":"Notes","text":" - Notes from the HedgeDOC page
"},{"location":"LUMI-G-20230111/#exercises","title":"Exercises","text":"Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- OSU benchmark
- Fortran OpenACC examples
- Fortran OpenMP examples
- Collections of examples in BabelStream
- hello_jobstep example
- Run OpenMP example in the HPE Suport Center
- ROCm HIP examples
"},{"location":"LUMI-G-20230111/hedgedoc_notes/","title":"Notes from the HedgeDoc page","text":"These are the notes from the LUMI-G training, 11.01.2023, 9:00--17:00 (CET) on Zoom.
- Notes from the HedgeDoc page
- General information
- Exercises
- LUMI user coffee break
- Slides and other material
- Q&A of the sessions
- Questions regarding organisation or LUMI in general
- Introduction to the Cray EX Hardware and Programming Environment on LUMI-G
- First steps for running on LUMI-G
- Exercises morning sessions
- GPU Hardware & Introduction to ROCm and HIP
- General Q&A
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#general-information","title":"General information","text":""},{"location":"LUMI-G-20230111/hedgedoc_notes/#exercises","title":"Exercises","text":"The exercise files are on lumi at project/project_465000320/exercises.Copy the files into your home directory and work from there.
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#lumi-user-coffee-break","title":"LUMI user coffee break","text":"25.1.23, 13:00-13:45 (CET), 14:00--14:45(EET) Meet the LUMI user support team, discuss problems, give feedback or suggestions on how to improve services, and get advice for your projects.
Every last Wednesday in a month. Join via Zoom
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#slides-and-other-material","title":"Slides and other material","text":"Slides from HPE are available on LUMI at project/project_465000320/slides You need to join the training project via the link you received in the email on Monday. Slides from the LUST talks are available on these pages
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#qa-of-the-sessions","title":"Q&A of the sessions","text":""},{"location":"LUMI-G-20230111/hedgedoc_notes/#questions-regarding-organisation-or-lumi-in-general","title":"Questions regarding organisation or LUMI in general","text":" -
I was on the waiting list for the training, and didn't seen to recieve the invitation link to the project. Any way to get the slides? (I have access to LUMI)
Answer
- This training was heavily overbooked, so it wasn't possible for everyone to get access.
- We will share the AMD slides on https://lumi-supercomputer.github.io/LUMI-training-materials/
- We are still debating on how to share the HPE slides with all LUMI users (everyone who joined the training project can access the slides on LUMI at
/project/project_465000320/slides. - I tried to see the slides at /project/project_465000320/slides, but permission denied.
- I managed to
cp the presentation slides to my ~/user/slides and then scp to my base PC with no problem. - Still can not access: cp: cannot stat '/project/project_465000320/slides': Permission denied
- same for me \"permission denied\"
-
Will the recorded training available after? I did not get the link and could join after 20 minutes.
Answer
- We are still debating on how to best share but we will definitely upload them to LUMI at
/project/project_465000320/recordings. - it will be unavailable for people with \"permission denied\"
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#introduction-to-the-cray-ex-hardware-and-programming-environment-on-lumi-g","title":"Introduction to the Cray EX Hardware and Programming Environment on LUMI-G","text":"Presenter: Harvey Richardson (HPE)
Info
The slides for this session are available on LUMI at 01_Intro_EX_Architecture_and_PE.pdf. There are also optional exercises on LUMI at /project/project_465000320/exercises/HPE
-
What's the topology of Slingshot in Lumi?
Answer
Question
- Do we have about 50 GPUs per switch?
Answer
- It's a bit more difficult than this as every board (with two nodes per board) is connected to multiple switches on the first level of switches, and I believe this actually results in multiple switches per node also. But the number is much less than 50 per switch. I'm not sure but I believe it is 16 at the first level, the other connections on those switches are used to build the dragonfly with some ports for in-group connections and others for connections between the groups.
- (Harvey) I will try to address this in future training, I still need to understand this myself as it varies by system and node type.
Question
- Is Slurm aware? Will it but tasks in one job to the same electric group?
Answer
- Not always as this would dramatically raise waiting times for jobs in the queue. Network groups are available as a Slurm feature of the compute node:
scontrol show node nid00XXXX -> \"ActiveFeatures=AMD_EPYC_7A53,x1101. In this example, x1101 is the identifier of the network group. User can request that a job use a particular group by using the Slurm --constraint=<feature> option. - (Harvey) You can configure slurm to be aware of the switch topology, I just checked and I don't think this is currently enabled but this is something we should consider.
-
How does SHMEM work with GPU memory? is there something similar to NVSHMEM?
Answer
- I don't think so, I don't think there is a GPU support. Good question for AMD people though...
- See ROC_SHMEM. It requires UCX so, it may not work on LUMI that relies on libfabric for communication.
-
What is the module name for the Cray Scientific and Math Libraries I can't find out how to load LAPACK and BLAS on LUMI
Answer
module load cray-libsci. This might be discussed later in the course and is part of our introductory courses. It is linked automatically when cray-libsci is loaded but there is more to it that is discussed in our \"big\" course like the one we had in November in Brussels or the online one we will have in February. All those modules also come with manual pages. In this case it is man intro_libsci (after module load cray-libsci) that is a good starting point.
Question
- Thank you! And then I can probably use
module show cray-libsci to locate the header files.
Answer
- The compiler wrappers should add the necessary
-I options automatically. But the mdoule does define a number of environment variables that point to the installation directory of the libraries, so you can develop Makefiles etc. that adapt to new releases on the system
-
Where can I get more information about GPU accelerated Sci libraries?
Answer
- Need to load the module first (cray-libsci_acc) and then you have a man page:
man -l /opt/cray/pe/libsci_acc/default/man/man3/intro_libsci_acc.3s
-
how can I check my project ID (I have two projects)?
Answer
groups command will tell your projectslumi-workspaces with module load lumi-workspaces will print all your projects with their directories.
-
Does LUMI support installation of software via Anaconda/conda?
Answer
- Yes but not directly. You can create conda environments in a container: https://docs.lumi-supercomputer.eu/software/installing/container-wrapper/
- It is not supported in the sense that we also solve problems with Conda. We have no control whatsoever over the binaries that Conda installs nor how they are build, so we cannot solve problems with those either. And just as with regular containers, as is discussed in the full courses, you can expect problems with, e.g., MPI which may not recognize the SlingShot network correctly and use it in the appropriate way.
-
I have a Finnish/CSC based Lumi account, and now also the myaccessid/puhuri based one. Is there way to combine or something?
Answer
- A solution is being rolled out (but still somewhat in a test phase). It is a direct result of the choice to use the myCSC system that is familiar to Finnish users to manage Finnish project on LUMI without integrating it with Puhuuri and use the authentication mechanisms that Puhuuri uses.
- I have managed to (No guarantees that you will be able to): https://docs.csc.fi/accounts/how-to-manage-user-information/. in myCSC you can link your myCSC account to myAccessID. So my access to the LUMI-G course is attached to myCSC account.
- I don't dare to push that before end of course to not to break anything with the existing dual accounts :-)
- Yes. No guarantees it works!
- Linking in My CSC worked for me nicely, can access the training directory with me regular CSC account.
-
Is mpi4py available in python? if so, which python module has mpi4py available?
Answer
-
Can I use cray compilers outside of LUMI?
Answer
- Cray compiler (CCE) is part of the HPE Cray Environment, so it is available only on HPE Cray systems
- If you are using the Cray C/C++ compiler it is very similar to Clang, which is freely available. The Fortran compiler, though, is HPE/Cray-specific.
Question
- Are there online docs to view cray specific compile flags and options? Or is it safe to assume that they are very similar to clang and that cray compiler are simply optimized versions
Answer
- There are online PDF documents which are very hard to find and not very enlighting. The Cray PE is mostly documented through man pages accessible via the man command on the system. That is also why man pages are mentioned throughout the talk of Harvey.
- The man pages to use are actually mentioned in our documentation at https://docs.lumi-supercomputer.eu in the relevant pages (though I note that those for the GPU compiler of AMD should still be added).
- (Harvey) We cover compilers in a lot of detailed in the longer training courses. There is a Fortran manual but for clang the manpage is just showing the additions, there is comprehensive clang documentation online.
-
Why do I have to export following to get the ROCm-aware MPI support not to error? I am running on AMD GPUs and MPI via Julia and need to explicitly export the following if I use ROCm-aware MPI features in the code. Thus I load following:
export LD_PRELOAD=${CRAY_MPICH_ROOTDIR}/gtl/lib/libmpi_gtl_hsa.so\n
module load CrayEnv\nmodule load craype-accel-amd-gfx90a # MI250x\nmodule load cray-mpich\nmodule load rocm\n
Answer
- Could you give more details? GTL is the GPU-Transfer-Library used by cray-mpich for GPU to GPU communications. MPI links with this library whenever the module
craype-accel-amd-gfx90a is loaded. - OK, so you are not using the compiler wrappers, therefore you have link with the GTL library to get MPI GPU-aware.
User answer
- Thanks for the info. Indeed, I am not using the wrapper indeed, as just launching Julia via
srun julia my_prog.jl
-
What do I need to load in order to get working OpenCL support?
Answer
User remark
- This makes libOpenCL.so and include files available (so things compile), but OpenCL depends on dynamically loading drivers that are normally listed in /etc/OpenCL/vendors. This dir does not exist on the GPU nodes. I can create my own in my home directory and set OCL_ICD_VENDORS environment variable to point at it (which libOpenCL picks up), but this seems rather hacky. Note that all this \"vendors\" directory contains is a file \"amdocl64_50002.icd\" containing the string \"libamdocl64.so\".
-
The compute nodes have rocm 5.1,while the log in nodes 5.0. This makes some problems with some compilations. Is there a plan to have the 5.1 available on the log in nodes as well?
Answer
- The official ROCm versions are actually 5.0 on login and 5.1 on compute nodes, and this is a configuration error of the system so it should be solved at some point. But currently the GPU nodes are still in the hands of HPE so we cannot yet do whatever we like. This is also why the current phase is called \"extended beta\". The 5.1 is a module that we build ourselves and that may not fully integrate with the HPE Cray PE.
Question
- Follow up: can/should the 5.1 module be used with hipcc? (Trying to build Jax..., I got a container for my app already, this was just an attempt to get a native build flying)
Answer
-
I'm not sure building Jax on LUMI is a good idea at the moment since the more recent versions require ROCm 5.3 or newer and the code for AMD in the older versions of Jax is even more immature. Some users use a container with ROCm 5.3 and a prebuilt Jax in it. ROCm 5.3 should still work fine on the driver version that we have on LUMI. And in any case I would build on a compute node and use 5.1 instead.
-
You can try to use prebuild wheels of jax:
wget https://a3s.fi/swift/v1/AUTH_ac5838fe86f043458516efa4b8235d7a/lumi-wheels/jaxlib-0.3.25-cp39-cp39-manylinux2014_x86_64.whl\nwget https://a3s.fi/swift/v1/AUTH_ac5838fe86f043458516efa4b8235d7a/lumi-wheels/jax-0.3.25-py3-none-any.whl\nmodule load cray-python\nmodule load rocm\npython -m venv --system-site-packages jaxenv\nsource jaxenv/bin/activate\npip install absl-py etils opt_einsum wheel typing_extensions\npip install --no-deps jax*.whl\n
Question
- Thanx, that receipe worked, as far as building and loading libraries. However, it doesn't seem to see the GPUs (I'm on dev-g):
Python 3.9.12 (main, Apr 18 2022, 21:29:31)\n[GCC 9.3.0 20200312 (Cray Inc.)] on linux\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> import jax\n>>> import jaxlib\n>>> jax.device_count()\n2023-01-11 11:50:57.816391: E external/org_tensorflow/tensorflow/compiler/xla/stream_executor/rocm/rocm_driver.cc:302] failed call to hipInit: HIP_ERROR_InvalidDevice\nWARNING:jax._src.lib.xla_bridge:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)\n1 \n
Answer
- The only way I can reproduce your result is by not requesting a GPU. Did you request a GPU when you submitted your job? Here is what I get:
$ srun -pdev-g --gres=gpu:1 --pty -t30:00 $SHELL\nsrun: job 2420138 queued and waiting for resources\nsrun: job 2420138 has been allocated resources\n\u2744\ufe0f (12:32) nid007565 [~/sandbox] $ source jaxenv/bin/activate\n(jaxenv) \u2744\ufe0f (12:32) nid007565 [~/sandbox] $ python\nPython 3.9.12 (main, Apr 18 2022, 21:29:31)\n[GCC 9.3.0 20200312 (Cray Inc.)] on linux\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> import jax\n>>> jax.device_count()\n1\n>>> jax.devices('gpu')\n[StreamExecutorGpuDevice(id=0, process_index=0, slice_index=0)]\n
- We also have a container with a JAX installation: https://a3s.fi/swift/v1/AUTH_ac5838fe86f043458516efa4b8235d7a/lumi-experimental-containers/jax/jax-0.3.25-rocm-5.3.sif
-
In the MI250x EAP phase the compiler names were not yet wrapped with \"CC\" etc, yet? Right? I've not been using wrong commands, have I? (Say, september 2022) (OpenMP)
Answer
- If you mean the MI100 EAP phase: the wrappers where there also but not OK.
- Once users where allowed on the MI250X everything was there. In September the wrappers where there already, and in fact this is also what HPE was using for the acceptance tests. The wrappers were actually explained in the course for Pilot users in August.
User remark
- I was just reading the web pages. I have \"amdclang\" as a compiler in my Makefile with
-fopenmp-targets=amdgcn-amd-amdhsa etc.
Answer
- Using the compilers without wrappers is possible but you have to know better what to do then to, e.g., ensure that MPI works properly (as shown in one of the questions above). The wrappers are just a convenience, not an absolute requirement. With older versions of some of the PE compilers the compiles sometimes had trouble finding their own include files though.
-
Does cray-libsci_acc work transparently with GPU pointers?
Answer
- Yes, in that case it will push the computation on the GPU. With CPU pointers, the library will apply some heuristics to check if it worth to move data to the GPU and do the computation there. Check the man page for more info.
-
Is it allowed to use Jupyter notebooks on Lumi GPUs? and if yes, how to log in to the allocated node and forward the port?
Answer
- In the (hopefully not too distant) future this will be possible with OpenOnDemand (see question 23)
- The prefered scenario, also with OpenOnDemand, will be though that the Jupyter notebooks are used to launch jobs and process what they return on resources reserved for interactive use, and that they are not used to block access to regular nodes for interactive work for a long time as having those expensive nodes idle waiting for user input is not what you want, and as you never can be sure that your allocation will actually start at a time that you will be available to use it. LUMI does have nodes that are set apart for interactive use and will be used by Open On Demand, but these are not the AMD GPU nodes.
-
Is there a prebuilt tensorflow & pytorch available that's optimized for the GPU architecture?
Answer
- AMD has optimized versions in containers that seem to work well but it is nearly impossible to build these packages from scratch ourselves as they have build environments that are developed for a totally different environment than an HPC cluster (even more so for TensorFlow than for PyTorch) and as build procedures and dependencies are not well documented, so expect that pre-built containers and/or wheels will be the way to go for a very long time.
-
Is there anything similar to PyCuda available?
Answer
- CuPY has some AMD GPU support. https://docs.cupy.dev/en/stable/install.html?highlight=AMD#using-cupy-on-amd-gpu-experimental
-
This may be linked to question #20 above: Harvey mentioned at the begining (interactive?) nodes for vizualisation, are these in production and where can we find more information?
Answer
- No, they are not in production yet.
- (Harvey) Sorry for any confusion but I was talking in general terms at that point and not being specific about node types on LUMI.
- CSC is working a OpenOnDemand solution to allow quick and easy access to LUMI-D (visualisation partition with Nvidia GPUs). We are hoping for a production phase in Q2 2023. This would also allow direct in browser Jupyter and R notebook access.
User remark
- Ok, thanks, so no interactive nodes with Radeon GPUs then?
Answer
- Maybe. As far as I know OpenOnDemand should also allow access to LUMI-G for calculations.
- (Kurt): As far as I know it will allow to launch jobs on all partitions, but there is no partition on LUMI-G with a job policy optimised for interactive work.
-
I used to have access to the eap partition. How can I see all partitions that I am allowed to use?
Answer
- All users of lumi have now access to the new partitions (standard-g, small-g, dev-g) but you will need allocated GPU hours
- Talk to your allocator to get GPU resources
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#first-steps-for-running-on-lumi-g","title":"First steps for running on LUMI-G","text":"Info
The slides for this session are available on LUMI at /project/project_465000320/slides/HPE/02_Running_Applications_and_Tools.pdf. There are also optional exercises on LUMI at /project/project_465000320/exercises/HPE
-
Is the famous slurm command available on Lumi?
Answer
- It is! A wrapper for e.g. sinfo.
-
In all theses examples the exact format of the \"project\" is omitted. Is it just the number or with \"project_nnnn\" format?
Answer
- project_XXXXXXX
- You can quickly see your projects by running the
groups command. It is the names as used in SLURM.
-
Is there any guarantee that the GPUs land on the same node?
Answer
- With
--gres yes. Using --gpus=<n> on the dev-g and small-g partitions no.
-
If I have an sbatch job running on a node e.g. nid012, is it possible to log in to that node and check e.g. rocm-smi status? It seems that slurm somehow isolates the GPUs of other jobs (e.g. via srun, requesting nid012) that land on the same node, so I can't check the status of the GPUs allocated to the first job.
Answer
- This would allow you to go into a given node but no GPU visibility:
srun --pty --jobid <your job id> -w <your node> --mem=0 --oversubscribe --gpus-per-task=0 -N 1 -n 1 -c 16 /usr/bin/bash -l - This would allow you to go to the first node of a given allocation with GPU visibility:
srun --jobid <your job id> --interactive --pty /bin/bash - Unfortunately the previous version ignores -w option to specify any node. There is a ticket on that.
- Our sysadmins are also working on allowing ssh access to allocated nodes. But this is still in the future.
-
What is the difference between --gres=gpu:N and e.g. --gpus=N. When should either be used
Answer
- The outcome will be similar. Also, using --gpus should instruct SLURM to allocate the specified number of GPUs. E.g.
-N $N --gpus $((N*8))
-
seff isn't on LUMI AFAIK. Why?
Answer
- This is not a standard Slurm command but something that has to be installed separately, and also requires certain rights to certain data in Slurm. We currently use a Slurm instance as pre-configured by HPE Cray that does not contain
seff. It is likely that it will be installed in the future as many people are requesting it. - Note also that
seff is no replacement for a decent profiler when you want to assess the efficiency of your job/code. E.g., so-called busy waiting is common in MPI implementations and OpemMP runtimes and seff would still give the impression that those jobs are efficient.
-
Why is SMT not enabled by default in Slurm?
Answer
- SMT is typically not faster for most HPC workloads.
-
Are the GPU interrupts something not bound to the computation? I just wonder because CPU0 is reserverd for system AND gpu interrupts of
Answer
- (Harvey) I'm not an expert on this but I think the interrupts relate to the driver and are in kernel space so not clear to me how this interacts with the 'computation'. You could ask this again later today as I think hardware will be covered again.
-
Is it possible to disable the low-noise mode?
Answer
- (Peter) No, not as a user.
- (Harvey) I expect we might see future developments here as we learn more and implement more features. I think that disabling 0 was a pretty recent change felt to be of benefit based on experience of running applications. It would be useful to get feedback on this.
- (Kurt) My guess is that it is probably needed for applications that scale over many nodes as any kind of OS jitter can them completely break scalability, but it is an annoyance for single node jobs. But since LUMI is build as a pre-exascale system that should accomodate huge jobs, it is a reasonable thing to have.
- (Kurt) If AMD is reading this: I know what you are doing for MI300 from the hints at the investor's day and CES, but for MI400 please give as yet another CPU die to run those processes, with quick access to some on-package LPDDR5 memory so that all OS code can be in a different part of memory from the user GPU application. An \"accelerator\" to run the OS code without interfering with user applications... Cloud companies can then use these cores to run the hypervisor.
-
Can I run examples/exercises using the LUMI-G training project?
Answer
- You can use it for the exercises this afternoon but not for other purposes as the amount of resources allocated to the project is very minimal.
- I just want to run the
xthi example :). I copied the files to my $HOME dir. xthi hardly consumes any resources. I believe you can actually try the program first on the login nodes.- And if you do
module spider lumi-CPEtools it will actually tell you about a module that contains a similar program that gives even a bit more information. I'm not sure it is there already for the GPU nodes though.
-
Shouldn't SLURM be doing this NUMA-GPU-CPU-NIC binding for us? At least for the default case?
Answer
- (Peter) Yes, ideally... Hopefully, it will be added to SLURM eventually.
- (Harvey) I'm not sure that there is a generic capability to discover all the hardware (maybe hwloc, or at least it was not there for AMD GPus to enable this to be developed in time.)
-
Could you please provide us with the handy script to select the proper GPU id with ROCR_VISIBLE_DEVICES?
Answer
- Do you mean the script in the slides?
- There is something similar in the LUMI user documentation on the page with GPU examples: https://docs.lumi-supercomputer.eu/runjobs/scheduled-jobs/lumig-job/
- The
xthi example talked about in the presentation is available: /projappl/project_465000320/exercises/HPE/xthi
-
Is it faster to MPI transfer data from GPU memory than host memory?
Answer
- Answered in slides. (a bit faster, not really significant.)
-
Does the programmer need to handle manually the communications between gpus on the same nodes or in different node? I mean if the suitable technology is automatically selected.(RDMA vs. peer2peer)
Answer
- The MPI implementation will handle that for you (MPICH_GPU_SUPPORT_ENABLED=1 needs to be set). Other libraries like RCCL will also detect topology and use the best approach for communication between GPUs. Having said that, if you are not planning on using these libs you need to manage the topology yourself.
- You may wish to take care on which ranks are on each node of course as you would for any MPI application to balance on or off- node traffic.
-
I tried running a simple NCCL example ported to HIP using the RCCL library within rocm. Compilation worked well but I had trouble running it when submitting it to the GPU queue. The first call to a library function, ncclCommInitRank(), returned an error reading \"unhandled system error\". I suspect something is wrong with my batch script, might be related to some MPI environment variable. Have you got any ideas what the problem could be?
Answer
- RCCL is using the wrong network interface. Please
export NCCL_SOCKET_IFNAME=hsn to select the slingshot NICs.
-
Can you also profile the energy consumption of GPU jobs? I assumed what was just shown is only for CPU?
Answer
- (Harvey) I have not checked this but the basic information for whole-job GPU energy consumption should be available. I'm not sure if either Slurm or perftools reports that and would have to check.
User remark
- OK, we have a research project where we want to look at the energy consumption of GPU jobs, so this would be very useful. I know with
rocm-smi we can see the current (at that specific point in time) GPU utilization and consumption, but might be hard to get for the whole job?
Answer
- The files are in
/sys/cray/pm_counters (on compute nodes). They update at 10Hz. See accel0_energy etc. for example
-
Is it possible to get memory peak on the GPU ?
Answer
- this is something CrayPAT can do for you. (This is actually a question for AMD, you can ask it in the afternoon).
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#exercises-morning-sessions","title":"Exercises morning sessions","text":"Info
The exercises can be found on LUMI at /project/project_465000320/exercises/HPE
-
Is there a way to get access to the exercices when not on the training project? (This is basically question 1)
Answer
- No, unfortunately at the moment not. We will reevaluate how to publish slides and exercises for future courses.
- If you have gotten all the emails in the last few days about the course, you should be able tojoin the project and then get access to the project folder on LUMI.
User remark
- I was on the waiting list and apparently didn't recieve a link to get the access. Should I open a ticket like suggested in the next question?
Answer
- It will take a few minutes (~15-30) after you joined for the synchronization to LUMI.
-
What should we do if we get permission denied when trying to access /project/project_465000320/?
Answer
- Check that you are using the right account (the Puhuri one)
User remark
- I see the project listed under the Puhuru portal. Should I sign in with another username than normally?
Answer
- Otherwise join the project or if you have problems with joining the project, please open a ticket at https://lumi-supercomputer.eu/user-support/need-help/generic/
-
Are there some instructions for the exercises? In what order should they be run?
Answer
- No instructions are provided, there are there only to reproduce what we showed in the slides.
- We are running ahead of expectation as last time I think we had way more discussion during the morning. Because we are switching to AMD presenters this afternoon I didn't want to suggest moving everything forward.
-
What is the recommended way of running Java code on LUMI? Can the Java Fork/Join framework be used directly or does one need to use something like aparapi?
Answer
- Question remained unanswered due to the lack of Java experts. After all, this is not a popular HPC tool...
-
I am trying to compile the implementation of BabelStream (\"ocl\"). After doing module load craype-accel-amd-gfx90a and module load rocm I try cmake -Bbuild -H. -DMODEL=ocl, but this fails with Could NOT find OpenCL (missing: OpenCL_LIBRARY) (found version \"2.2\"). The OpenCL libraries are certainly somewhere in /opt/rocm, but apparently not made available to cmake. What am I missing?
Answer
-
Any news on hipSYCL on Lumi?
Answer
- We have an EasyConfig for it, see the link to the LUMI software Library in the LUMI documentation: https://docs.lumi-supercomputer.eu/software/#the-lumi-software-library
-
Do we need to load modules in slurm batch script or set variables ? hello_jobstep after compilation (modified Makefile to use flags like frontier) during execution - error while loading shared libraries: libomp.so cannot open shared object file: No such file or directory
Answer
User remark
- Problem solved- do not change PrgEnv-cray during compilation to PrgEnv-amd for hello_jobstep. Only modification is in Makefile - there is no lumi, but flags from frontier worked
Answer
- Well, the problem is that libomp is under
/opt/rocm/llvm/lib, while the PrgEnv-amd module (5.0.2) is using /opt/rocm-5.0.2/llvm/lib and the 5.0.2 is not available on the compute nodes (only 5.1.0). You can do export LD_LIBRARY_PATH=/opt/rocm/llvm/lib:$LD_LIBRARY_PATH.
-
What exercises can I make public and which ones can I not? For example in a public repo on Github
Answer
- Those from HPE cannot be made public in any way. In fact, they can only be spread to users of LUMI.
- (Harvey) In some cases those exercises came from elsewhere in which case there is no problem and I migh have been a bit strong in my comments earlier based on examples used in other courses, We will check.
- I remember seeing an AMD repo in one of their accounts for ROCm that had exercises very similar to those of this afternoon, so I guess you can look up the license that covers that repository. The AMD people will only be around this afternoon.
- Check the slides, we basically took the slides from the repos, namely:
- OSU benchmark https://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.9.tar.gz
- Fortran OpenACC examples https://github.com/RonRahaman/openacc-mpi-demos
- Fortran OpenMP examples https://github.com/ye-luo/openmp-target
- Collections of examples in BabelStream https://github.com/UoB-HPC/BabelStream
- https://code.ornl.gov/olcf/hello_jobstep
- https://support.hpe.com/hpesc/public/docDisplay?docId=a00114008en_us&docLocale=en_US&page=Run_an_OpenMP_Application.html
-
except PrgEnv-xxx, Cray introduced also cpe module (Cray Programming environment). when is the cpe module used for compiling?
Answer
- (Alfio) cpe is a collection, for instance LUMI has 22.08 (year.month version). You can load the cpe, which will load PrgEnv-XXX versions (and all other modules)...
User remark
- but e.g PrgEnv-cray is loaded by default, if then load cpe, there is not any changed.
Answer
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#gpu-hardware-introduction-to-rocm-and-hip","title":"GPU Hardware & Introduction to ROCm and HIP","text":"Info
The slides for this session are available on LUMI at /project/project_465000320/slides/AMD/.
-
It seems that whenever I try to run a slurm job, I get the sbatch error AssocMaxSubmitJobLimit - \"Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits)\". I assume this means I need to be allocated more time and resources on LUMI.
Answer
- Are you submitting with your own project or the training one? (
--account=<project_XXXXXXXXXX> option)
User remark
-
Thanks. I get the same error whether I use my own project or the trainig project. I am submitting to partition \"small\" - perhaps I should be submitting to a different partition? Here's the batch file I'n trying to run:
#!/bin/bash \n#SBATCH -p small\n#SBATCH -A project_465000320\n#SBATCH --time=00:02:00\n#SBATCH --nodes=1\n#SBATCH --gres=gpu:1\n#SBATCH --exclusive\nsrun -n 1 rocm-smi\n
Answer
-
You should use small-g but the error message you should get is sbatch: error: Batch job submission failed: Requested node configuration is not available. What is your username?
-
You should be able to submit with project_465000320 and using the small-g partition. Your other project has no billing units. Maybe you have the SBATCH_ACCOUNT or SLURM_ACCOUNT environment variables set to this project as this is something we recommend in the documentation?
User remark
- Thank you. The problem was that my
SBATCH_ACCOUNT variable was set to my other project. Thanks for the help!
-
Are these advanced features like Matrix cores and packed FP32 already ported to libraries like PyTorch and TensorFlow (as they already have official ROCm ports)?
Answer
- Yes, these libs/frameworks leverage BLAS and MiOpen libs that comprise support for matrix ops.
-
When running multi-GPU (but single node, so up to 8 logical GPUs) batch ML training jobs using basic Keras/Tensorflow with ROCm, I'm noticing that it's quite unstable, often but not always the training crashes after a few steps. This does not occur (or occurs much more rarely) when using a single (logical) GPU. There are no useful messages in the log. Any ideas how to debug this?
Answer
- Any backtrace dumped when the crash happens? Several users have managed to run training on multiple GPUs and multiple nodes each using multiple GPUs.
-
If I need to synchronize only a subset of my threads, similar to what I'd do with a __syncwarp, should I abandon the optimization and do a __syncthreads, or is there an implicit wavefront-wide synchronisation?
Answer
- Cooperative groups are supported in recent ROCm versions. However on Instinct GPUs all threads in a wave front always execute in lock step. So cooperative groups is mostly a portability feature as on instinct GPUs threads do not diverge.
-
Why isn't there a HIP equivalent to CUDA fortran? (Out of curiosity)
Answer
- There is not, you have to call the HIP runtime through the C interface and launch kernels separately. There is a library with wrappers to facilitate this: https://github.com/ROCmSoftwarePlatform/hipfort
-
What are some good resources for running python code (torch/CUDA) on LUMI GPUs? The documentation does not have anything on it.
Answer
- https://docs.csc.fi/apps/pytorch/ has some comments on using pytorch on LUMI.
User remark
- Ok, so the package is available, but if changes in the code regarding running it on AMD GPUs are needed I cannot find that in the docs, right?
Answer
- You can run the same Python/PyTorch code on AMD.
- There are some AI/ML modules on LUMI (for AMD GPUs) created by CSC:
module use /appl/local/csc/soft/ai/modulefiles/, if you have any questions about this you can send a ticket to csc service desk (email: servicedesk@csc.fi).
-
There was at some point a HIP implementation that runs on the CPU (https://github.com/ROCm-Developer-Tools/HIP-CPU), which would be useful for portability, but it doesn't seem maintained. Is the project dead?
Answer
- Being a header only project I'd expect it to work in most cases as HIP standard didn't shift much. However, this is maintained on best effort and not officially supported. Having said that, we encourage users to file tickets if they are facing issues using it.
-
Can you obtain the information provided by rocminfo (CUs etc.) from an API simply useable in an OpenMP offload program?
Answer
- Yes, there is library which provides the
rocm-smi information: https://github.com/RadeonOpenCompute/rocm_smi_lib - Actually, if you look at the source of rocminfo, it's quite a small utility (~1K LoC). You can have a look and extract the part that you are interested in and include it in your application.
-
When I run Alfio's example on slide 8 of his slides, I get an output similar to that on his slide 9, but this is followed by the following errors:
srun: error: nid007244: task 0: Exited with exit code 2\nsrun: launch/slurm: _step_signal: Terminating StepId=2422727.0\n
Does anyone know what this is due to?
Answer
-
rocm-smi is exiting with a return code of 2 which slurm interprets as a failure.
harveyri@nid007307:~/workshop/2023_01> rocm-smi\n\n\n======================= ROCm System Management Interface =======================\n================================= Concise Info =================================\nGPU Temp AvgPwr SCLK MCLK Fan Perf PwrCap VRAM% GPU%\n0 40.0c 91.0W 800Mhz 1600Mhz 0% auto 560.0W 0% 0%\n================================================================================\n============================= End of ROCm SMI Log ==============================\nharveyri@nid007307:~/workshop/2023_01> echo $?\n2\n
User remark
- OK. Thanks. I assume rocm-smi is supposed to exit with code 2. At least, not something I need to worry about!
Answer
- (Harvey) I don't know but there is an issue reported on the return code in github for an invocation with -a so I expect this is not expected. It is not something to worry about in any case.
-
I am interested in running distributed trainings using pytorch, as we have a very large dataset. I am using the official Docker container for Pytorch with ROCm support. The communication between nodes/GPUs works at this moment. But, I get this error MIOpen Error: /long_pathname_so_that_rpms_can_package_the_debug_info/data/driver/MLOpen/src/sqlite_db.cpp:220: Internal error while accessing SQLite database: locking protocol for the trainings. I can set MIOPEN_DEBUG_DISABLE_FIND_DB=1, MIOPEN_DISABLE_CACHE=1, and MIOPEN_FIND_ENFORCE=5 to eliminate this issue. Any comments would be great.
Answer
-
This can be fixed if you add to each process instance something like:
export MIOPEN_USER_DB_PATH=\"/tmp/sam-miopen-cache-$SLURM_PROCID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=$MIOPEN_USER_DB_PATH\n\nrm -rf $MIOPEN_USER_DB_PATH\nmkdir -p $MIOPEN_USER_DB_PATH\n
the FS doesn't cope with the locks, so moving the DB to /tmp fixes the problem.
-
Please do some cleanup at the end of your job if you use this solution, i.e., remove the files rm -rf $MIOPEN_USER_DB_PATH as /tmp is a RAM disk and, at the moment, is not cleaned at the end of the job execution. As a consequence, leftover files may endup consuming the entire node memory.
-
Not sure which ROCm users space you use but you might be interested in enabling the libfabric plugin. Here's a module I maintain that provides that - not sure if there a generally available build:
module use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load aws-ofi-rccl/sam-rocm-5.3.3.lua\n
this will boost your internode BW.
Question
- Thank you for this answer. I get another error
nid007564:5809:6364 [6] /long_pathname_so_that_rpms_can_package_the_debug_info/data/driver/rccl/src/misc/rocm_smi_wrap.cc:38 NCCL WARN ROCm SMI init failure An error occurred during initialization, during monitor discovery or when when initializing internal data structures if MIOPEN_FIND_ENFORCE=5 is not set. Is this also related?
Answer
- Does it help if you set
export NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3?
User remark
- Unfortunately not --
NCCL_SOCKET_IFNAME=hsn is already set. Only thing seems to help is the enforce level 5, which seems to be related to this DB.
Answer
- RCCL attempts to initilaize all interfaces but the ones other than slingshot can't be initialized properly.
-
Is there a mechanism to profile shared libraries that use the GPUs? (My application is a python package, so everything is in a .so)
Answer
- rocprof will follow linked libraries, so the profiling method is not different than a regular map.
rocprof python ... is what you should be running. - for omnitrace with instrumentation you'd have to instrument the libraries you care about.
-
Using omniperf with Grafana is definitely interesting! So could we take this debugging and profiling information back locally and analyse on our own Grafana servers? Granted this is more advanced due to having your own Grafana server.
Answer
- Copying the information locally: According to AMD, yes.
- (Kurt from LUST) But no hope that LUST will offer omniperf in one way or another for now. I just heard from a colleague that there is a serious security problem which has to do with the basic concepts that omniperf uses, making it not suitable for a shared infrastructure as LUMI. We cannot stop you from installing yourself but be aware that you put your data at risk. We are working on omnitrace though.
-
If you had a working program (\"black box\"), how would you start profiling the program and what metrics would you first focus on to see if the program utilizes the GPUs correctly?
Answer
- Using plain
rocprof with your app is a good starting point - that will produce a list of the kernels ran on the GPU and that could give one hints if that is what one would expect. While running you can also monitor rocm-smi and see what PIDs use which GPUs and have an overview of the activity: memory being used and compute (which correlates to the GPU drawn power - up to 560W).
-
This is very heavy with lots of info. Is there a \"poor man\" way to use it. Like getting start it with something simple?
Answer
- Our more introductory 4-day course...
-
As an excercise I'm running rocgdb for my openMP offload code. Could someone interpret the general lines:
(gdb) run\nThe program being debugged has been started already.\nStart it from the beginning? (y or n) y\nStarting program: /pfs/lustrep2/users/---/prw/parallel_random_walk\n[Thread debugging using libthread_db enabled]\nUsing host libthread_db library \"/lib64/libthread_db.so.1\".\nOMP: Warning #234: OMP_NUM_THREADS: Invalid symbols found. Check the value \"\".\n[New Thread 0x1554aae22700 (LWP 61357)]\nMarkers 1000000 Steps 320000 Gridsize 10240.\n[New Thread 0x1554a37ff700 (LWP 61358)]\n[GPU Memory Error] Addr: 0x155673c00000 Reason: No Idea!\nMemory access fault by GPU node-4 (Agent handle: 0x3d4160) on address 0x155673c00000. Reason: Unknown.\n
Specifically [GPU Memory Error] Addr: 0x155673c00000 Reason: No Idea!Memory access fault by GPU node-4 (Agent handle: 0x3d4160) on address 0x155673c00000. Reason: Unknown.
Answer
- This is a memory access problem - some data not being accessed properly. Are you assuming unified memory?
User remark/question
- openMP...so no. The same code works with other compliler versions in Lumi.
- What's this:
OMP: Warning #234: OMP_NUM_THREADS: Invalid symbols found. Check the value \"\".?
Answer
- Have you tried OMP_NUM_THREADS=1? How do you declare it btw?
User remark/question
- That was a good question. Forgot to remove it from the script to bring the code to the debugger.
Answer
-
Can I submit tickets regarding what George discussed to LUST? In-depth questions about profiling, debugging etc in case I would like some support on roctrace, omniperf etc?
Answer
- Yes you can. When you submit a ticket it's also visible to AMD and HPE LUMI center of excellence members. So, either LUST or the vendors can answer depending on the complexity of your question
"},{"location":"LUMI-G-20230111/hedgedoc_notes/#general-qa","title":"General Q&A","text":" -
What is the status of LUMI? has it now being handed over to CSC/EuroHPC?
Answer
- LUMI-G is still owned by HPE and hasn't been handed over. That's also the reason why we are not in full production but in an extended beta phase.
-
What software will be first hand supported?
Answer
- We don't know yet. SW has to be quite stable for us to be supportable
- LUST is a very small team so we don't have much resources except for providing SW installation (easybuild) recipes.
- Medium term goal to produce some guide lines for most used SW packages.
- Long term goal to involve local consortium countries (centers and universities) to help support and tune software packages and write application guidelines.
"},{"location":"LUMI-G-20230111/schedule/","title":"Course schedule","text":"All times CET.
09:00\u00a0\u00a0 Introduction Presenter: J\u00f8rn Dietze (LUST) 09:10 Introduction to the Cray EX Hardware and Programming Environment on LUMI-G - The HPE Cray EX hardware architecture and software stack
- The Cray module environment and compiler wrapper scripts
- An introduction to the compiler suites for GPUs Presenter: Harvey Richardson (HPE) Slide files:
/project/project_465000320/slides/HPE/01_Intro_EX_Architecture_and_PE.pdf on LUMI only. Recording: /project/project_465000320/recordings/01_Intro_EX_Architecture_and_PE.mp4 on LUMI only. 10:15 break (30 minutes) 10:45 Running Applications on LUMI-G - Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement (CPU/GPU/NIC)
- MPI update for GPUs and SlingShot 11 (GPU-aware communications)
- Profiling tools
Presenter: Alfio Lazzaro (HPE) Slide file: /project/project_465000320/slides/HPE/02_Running_Applications_and_Tools.pdf on LUMI only. Recording: /project/project_465000320/recordings/02_Running_Applications_and_Tools.mp4 on LUMI only. 12:00 lunch break (60 minutes) 13:00 Introduction to AMD ROCmTM Ecosystem - GPU Hardware intro
- Introduction to ROCm and HIP
- Porting Applications to HIP
- ROCm libraries
Slides and additional notes and exercises Recording: /project/project_465000320/recordings/03_Introduction_to_the_AMD_ROCmTM_ecosystem.mp4 on LUMI only. 14:30 break (30 minutes) 15:00 Introduction to AMD ROCmTM Ecosystem (Ctd) - Profiling (Ctd)
- Debugging
Presenter: George Markomanolis (AMD) 16:30 General Questions & Answers 17:00 End of the course"},{"location":"PEAP-Q-20220427/","title":"Detailed introduction to the LUMI-C environment and architecture (April 27/28, 2022)","text":""},{"location":"PEAP-Q-20220427/#downloads","title":"Downloads","text":" - LUMI Software Stacks slides (PDF, 667k)
- Containers on LUMI (PDF, 243k)
- The LUMI documentation and help desk (PDF, 1.8M)
- Frequently asked support questions (PDF, 907 k)
"},{"location":"PEAP-Q-20220427/#notes","title":"Notes","text":" - Notes from the hackmd page
- LUMI Software Stacks
"},{"location":"PEAP-Q-20220427/demo_software_stakcs_mdp/","title":"Demo software stakcs mdp","text":"%title: LUMI Software Stacks (demos) %author: Kurt Lust %date: 2022-04-28
-> # module spider <-
module spider\n
- Long list of all installed software with short description
- Will also look into modules for \u201cextensions\u201d and show those also, marked with an \\\u201cE\\\u201d
-> # module spider <-
- With the (suspected) name of a package
module spider gnuplot\n
- Shows all versions of gnuplot on the system
- Case-insensitive
module spider GNUplot\n
-> # module spider <-
- With the (suspected) name of a package
module spider cmake\n
CMake turns out to be an extension but module spider still manages to tell which versions exist.
-> # module spider <-
- With the full module name of a package
module spider gnuplot/5.4.3-cpeGNU-21.12 \n
- Shows help information for the specific module, including what should be done to make the module available
- But this does not completely work with the Cray PE modules
-> # module spider <-
- With the name and version of an extension
module spider CMake/3.22.2 \n
- Will tell you which module contains CMake and how to load it
module spider buildtools/21.12\n
-> # module keyword <-
- Currently not yet very useful due to a bug in Cray Lmod
- It searches in the module short description and help for the keyword.
module keyword https\n
- We do try to put enough information in the modules to make this a suitable additional way to discover software that is already installed on the system
-> # sticky modules and module purge <-
- On some systems, you will be taught to avoid module purge (which unloads all modules)
- Sticky modules are modules that are not unloaded by
module purge, but reloaded. - They can be force-unloaded with
module \u2013-force purge and module \u2013-force unload
module list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
- Used on LUMI for the software stacks and modules that set the display style of the modules
- But keep in mind that the modules are reloaded, which implies that the target modules and partition module will be switched (back) to those for the current node.
module load init-lumi\nmodule list\n
-> # Changing the module list display <-
- You may have noticed that you don\u2019t see directories in the module view but descriptive texts
- This can be changed by loading a module
ModuleLabel/label: The default viewModuleLabel/PEhierarchy: Descriptive texts, but the PE hierarchy is unfoldedModuleLabel/system: Module directories
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
-> # Changing the module list display <-
- Turn colour on or off using ModuleColour/on or ModuleColour/off
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
-> # Changing the module list display <-
- Show some hidden modules with ModulePowerUser/LUMI This will also show undocumented/unsupported modules!
module load LUMI/21.12\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
- Note that we see a lot more Cray PE modules with ModulePowerUser!
-> # Demo moment 2 <-
-> # Install GROMACS <-
- Search for a GROMACS build recipe
module load LUMI/21.12 partition/C EasyBuild-user\neb --search GROMACS\neb -S GROMACS\n
- Let\u2019s take
GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb
eb -r GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb -D\neb -r GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb\n
- Now the module should be available
module avail GROMACS\n
"},{"location":"PEAP-Q-20220427/hackmd_notes/","title":"Copy of the shared notes for course \"Detailed introduction to LUMI-C architecture and environment (April 27/28)\"","text":" - Copy of the shared notes for course \"Detailed introduction to LUMI-C architecture and environment (April 27/28)\"
- Useful info
- Zoom
- Slides and Exercises
- Notes, questions & answers per session
- April 27 (all times CEST)
- 09:00 Welcome, introduction to the course
- 09:10 How the LUMI User Support Team works
- 09:20 Introduction to the HPE Cray Hardware and Programming Environment
- HPE Cray EX hardware talk
- Programming environment talk
- 10:30 break (30 minutes)
- 11:00 First steps to running on Cray EX Hardware
- 12:10 lunch break (80 minutes)
- 13:30 Overview of compilers and libraries
- 15:00 break (30 minutes)
- 15:30 Advanced Application Placement
- 16:30 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions)
- 17:00 End of first course day
- April 28 (all times CEST)
- 09:00 Performance and Debugging Tools incl exercises and a break
- 09:00 Introduction to Perftools -- Perftools-lite module and demo
- 09:55 Advanced Performance Analysis I/II \u2014 Perftools, variable scoping and compiler
- 10:45 Advanced Performance Analysis II/II \u2014 Communication Imbalance, Apprentice2, Hardware Counters, Perftools API, Feedback with Reveal, OpenMP, demo
- 11:30 Debugging at Scale -- gdb4hpc, valgrind4hpc, ATP, stat, demo
- 12:00 lunch break (60 minutes)
- 13:00 Understanding Cray MPI on Slingshot, rank reordering and MPMD launch
- 14:00 I/O Optimisation \u2014 Parallel I/O
- 14:45 break (30 minutes)
- 15:15 Additional software on LUMI-C
- 16:15 LUMI documentation, how to get help, how to write good support requests
- 16:20 What are typical/frequent support questions of users on LUMI-C?
- 16:35 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions)
- 17:00 End of second course day
- Any other notes
- Questions
"},{"location":"PEAP-Q-20220427/hackmd_notes/#useful-info","title":"Useful info","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#zoom","title":"Zoom","text":" - Link distributed via email
"},{"location":"PEAP-Q-20220427/hackmd_notes/#slides-and-exercises","title":"Slides and Exercises","text":" -
Links, info on how to access them will be provided directly to participants
-
Slides from the LUST presentations are on lumi-supercomputer.github.io/LUMI-training-materials, and in particular on this page.
During the course some materials were temprorarily available but do expect those to have become inaccessible when reading this:
- Slides appeared at:
/users/richards/workshop/slides - Exercise materials were available at
/users/richards/workshop/exercises and for the performance tools sessions at /users/anielloesp/exercises
The following instruction was only valid during the course. If you want to do this after the course you can no longer use the reservation and you have to submit regular jobs on a project you are member of in the regular partitions and queues:
- In the jobscripts please add
#SBATCH --reservation=lumi_course and use one of your project accounts, e.g., project_46{2,5}0000xx (#SBATCH -A project_46{2,5}000xyz). Remove/comment out #SBATCH -p standard and #SBATCH -q standard).
"},{"location":"PEAP-Q-20220427/hackmd_notes/#notes-questions-answers-per-session","title":"Notes, questions & answers per session","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#april-27-all-times-cest","title":"April 27 (all times CEST)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#0900-welcome-introduction-to-the-course","title":"09:00 Welcome, introduction to the course","text":"Q&A
- Q: 1.5h in a row is rather long (both morning and afternoon sessions) in one go. Will there be some excercises or other breaks in between? Just 5mins or so to stretch a bit.
- A: not planned, sorry (we will take this into account for a future course)
"},{"location":"PEAP-Q-20220427/hackmd_notes/#0910-how-the-lumi-user-support-team-works","title":"09:10 How the LUMI User Support Team works","text":"Q&A
- Q: who are the dedicated Experts in Sweden?
- A: Peter Larsson at KTH, Stockholm, is the LUST member for Sweden; but the idea behind LUST is not that the person from your country should answer your questions, but the person who has most experience with the topic.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#0920-introduction-to-the-hpe-cray-hardware-and-programming-environment","title":"09:20 Introduction to the HPE Cray Hardware and Programming Environment","text":"Session info: Focus on the HPE Cray EX hardware architecture and software stack. Tutorial on the Cray module environment and compiler wrapper scripts.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#hpe-cray-ex-hardware-talk","title":"HPE Cray EX hardware talk","text":"Q&A
-
Q: are you supporting or will you support interactive notebooks on compute nodes? (moving question to software session tomorrow)
- A: It is not yet supported now but part of the planned Open OnDemand service that will be rolled out after the summer. It may use just a few nodes meant specifically for data analysis and visualisation (LUMI-D), with the option to launch regular jobs from your notebooks.
-
Q: Is the AMD CPU on LUMI-G nodes the same as the one on LUMI-C nodes?
- A: no, GPU nodes have AMD Trento CPUs (more details at https://www.lumi-supercomputer.eu/lumis-full-system-architecture-revealed/ ... also https://docs.olcf.ornl.gov/systems/crusher_quick_start_guide.html#crusher-quick-start-guide may provide some insights about GPU nodes, but final design remains to be seen). Both CPUs are zen3 though, but with a special I/O die for the one on LUMI-G to provide the InfinityFabric connection to the GPUs for the unified cache coherent memory architecture.
-
Q: on the AMD GPUs, how will you handle the situation of commercial software extensively used MATLAB for instance (just one example) that don't have a version for that?
- A: As every machine in the world, not all software is compatible with all hardware and that is why EuroHPC has multiple clusters. There is in fact more than just the GPU that could cause compatibility problems with MATLAB. LUMI has specific requirements for MPI also that may not be met by software only available as binaries.
-
Q: Do you know what other EuroHPC cluster offers NVIDIA GPUs?
- A: Leonardo (pre-exascale), Meluxina (petascale), Vega (petascale), Karolina (petascale), Deucalion (when ready, petascale). An overview is on the EuroHPC JU web site, \"Discover EuroHPC JU\" page.
-
Q: Does the slingshot network handle IPMI (iLO and OOB management) as well?
- A: There is a separate network for system management as far as I know.
- A(Harvey, HPE): This is the answer I got from a colleague, don't shoot the messenger: Slides \"IPMI is dead, long live RedFish
-
Q: How is the boost of CPU's configured at Lumi-c by default.
- A: Slurm has the
--cpu-freq flag to control the CPU frequency (see here (--cpu-freq). In general you can expect boosting to be enabled on compute nodes but core boost policy is quite complex.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#programming-environment-talk","title":"Programming environment talk","text":" -
Remark 1: There is not only the CMake integration, but pkg-config is also Cray-specific. If you try to replace it with your own version the compiler wrappers may fail.
-
Remark 2: On licenses, LUMI has a license for ARM Forge but we are still struggling with the installation, so some patience required.
-
Remark 3: The AMD compiler modules on the system do not all work. AOCC 2.2 that came with the 21.05 version of the system works but will be removed at one of the next maintenance intervals. 3.0 has a module on the system but no binaries, and the module of 3.1.0 is broken. That can be dealt with by instead using the LUMI/21.12 software stack and then the cpeAOCC module (see a presentation on the second day about the LUMI software stacks).
Q&A
-
Q: Question about the Cray Developer Environment: Do the 3rd party packages have a different support deal that the ones developed by Cray?
- A: Unclear to LUST, we have not seen the contracts. But the installation files do come via HPE and we did notice that some builds are definitely HPE Cray-specific (choice of options and supported technologies, names of binaries to avoid conflicts with other tools, ...). But basically we cannot expect HPE to debug the GNU compiler while we can expect them to do bug fixes for the CCE compiler. And since AMD is also involved in the project, we can go to them with compiler bugs in the AMD compilers. ARM Forge is a different story, it is obtained from ARM directly and not via HPE.
- A(Harvey, HPE): The developers will forward bugs for some of the components not developed internally, it depends. For AMD we have a special relationship with them that we can use for LUMI. All of the integration pieces (modules) are supported.
-
Q: what about h5py?
-
Q: how about Julia, Rust, golang?
- A:
- We had Rust but removed it again from the software stack due to problems with installing Rust. The whole Rust installation process is very HPC-unfreiendly (and we are not the only one suffering with this, I know this from the meetings about the software management/installation tool that we use).
- Golang due to its poor memory use is not even an HPC language.
- Julia would be interesting, but for now it looks best to do this via containers as the installation process from sources is complicated.
- Comment: I guess one could place binaries of Julia in the work directory?
- Answer: I don't know, Julia binaries may require other libraries to be installed that are not installed on the Cray system. It does special things to link to some mathematical libraries and to MPI.
-
Q: There was a brief mention of singularity containers and using MPI with containers. Will HPE provide a basic singularity recipe for using MPI on LUMI? This would be a useful starting point for building containers for various application (e.g. machine learning with Horovod support). Experience shows it can be quite tricky to get this working, having right versions etc.
- A: We're working on that. Basically, currently Open MPI is a big problem and we have failed to get it to work reliably with our network and SLURM. For containers that support MPICH 3 we already have a (currently still undocumented) module available that users can adapt and then install to set some environment variables to tell the container to use the Cray MPICH library instaed (relying on ABI compatibility with plain MPICH). After the course, try
eb --search singularity-bindings (tomorrow we will explain what this means). You may even adapt this EasyConfig yourself before installing to include additional bindings that you may need before installing it with EasyBuild.
-
Q: Have you also considered conda environments, especially when it comes to complex Python dependencies?
- A: We are providing dedicated wrapper for containerized conda and pip based environments. It will be mentioned tomorrow afternoon. But again, not everything installed via Conda might work as Conda may try to use libraries that are not compatible with LUMI. More info in the LUMI documentation, lumi-container-wrapper page.
-
Q: Singularity is available but Docker does not seem to be available?
- A: Docker was mentioned from administration perspective. From the user perspective singularity is the choice. For most docker containers simple
singularity pull command should be enough for conversion. For instance singularity pull docker://julia
-
Q: Regarding MPI : is there any native OpenMPI implementation available?
- A: Not really. We have some workarounds but in large scale it is expected to fail.
-
Q: What with Intel compilers, MKL Intel and Julia language?
- A: Harvey will describe current status on the Intel development tools in the compilers talk.
- A: We have no support for Intel in our contract with HPE and Intel will also not support it on AMD processors. If the reason why you want Intel is the classic Fortran compiler, you should really consider modifying the code as their classic compiler is end-of-line anyway and the new one has a completely different front-end so different compatibility problems.
- A: MKL is known to produce wrong results on the AMD processors and there are performance problems that need hacks that are not user-friendly to force it to take an AVX2 code path rather than one for the Pentium 4 from 15 years ago. At the University of Antwerp, where I work, most DFT packages for instance produce wrong results with Intel on AMD Rome CPUs that we could correct by using FFTW instead of MKL for FFT. JuliA: see above, the question has already been asked, we'd like to support this but the installation procedure is a bit complicated and we cannot do everything in the first year.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1030-break-30-minutes","title":"10:30 break (30 minutes)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1100-first-steps-to-running-on-cray-ex-hardware","title":"11:00 First steps to running on Cray EX Hardware","text":"Session info: Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement. Exercises: about 40 minutes
Q&A
-
Q: you don't need to specify the number of tasks for this script? just the number of nodes?
- A: Just checked and the slide is indeed wrong. The #SBATCH lines will create only 2 task slots I think so srun will fail to then use 256. (Harvey: Which slide was this?) (Kurt: One of the first but I don't remember the page number, in the July version of the course it was slide 6 and the first example of a job script) Harvey: The jobs are specifying nodes (--nodes/N). We will check at end of talk.
-
Q: Does Gromacs get some benefits from the hardware threads (--hint)?
- A: Can you be a bit clearer? Turning threads on or off? My expectation is that it would be case dependend, but I doubt as GROMACS already puts a very high stress on the CPU. (And we know that some GROMACS jobs trigger a hardware problem in some nodes that HPE is still working on because of the high load they put on the CPU.)
-
Q: Using --exclusive on small/eap partitions would always reserve full nodes, right?
- A: For binding exercises/jobs this flag is needed.
- A: Using
--exclusive on small defeats the whole purpose of the small partition which is all about having resources available for programs that cannot use a whole node. Also note that you will be billed for the whole node of course. On the EAP it is very asocial behaviour as we have only few such nodes available so it should only be done for short jobs if there is really no other option available. Note also that the EAP is not really a benchmarking platform.
-
Q: Will --cpus-per-task set the OMP_NUM_THREADS variable?
- A: It does not. And while on some systems the Open MP runtime recognizes from the CPU sets how much threads should be created, this does not always work on LUMI as that mechanism cannot recognize between
--hint=multithread and --hint=nomultithread so you may get twice the number of threads you want. We'll put a program in the software stack that shows you what srun would do by running a quick program not requiring many billing units, but it is not yet there as I am waiting for some other software to go into the same module that is not finished yet. - A: SLURM does set
SLURM_THREADS_PER_CORE and SLURM_CPUS_PER_TASK environment variables that you can use to set OMP_NUM_THREADS.
-
Q: Is there \"seff\" command (exist in Puhti) to check resources used by batch job?
- A: No, it is something we've looked into but it turns out that that script needs a SLURM setup that we do not have on LUMI and that it is not something we could install without sysadmin support. And currently the LUMI sysadmins install the system the way HPE tells them to, which means that there are some SLURM plugins that are on puhti or mahti but not on LUMI. I guess we'll see the sacct command later in the course and that can tell you what the total and average CPU time consumed by a job is so that you can get some idea about efficiency.
-
Q: can we use mpprun instead of srun?
- A: No.
srun is the only parallel executor supported.
-
Q: Why is SMT not turned off by default if it is not beneficial in most cases?
- A: I would say it is turned off by default (for both
small and standard partitions). - A: SMT tends to be most beneficial for code that runs at a low \"instructions per clock\", so branchy code (like databases) or code that has very bad memory access patterns, and hence creates pipeline stalls. For well written scientific codes that do proper streaming of data it tends to make matters worse rather than better as you effectively half the amount of cache available per thread and as a single thread per core already keeps the memory units busy.
-
Q: Compiling the pi/C example gives warning: Cray does not optimize for target 'znver3' [-Wunsupported-target-opt] Is this something to worry about? Does it mean it will not optimize for AMD at all?
- A: I think you are using the wrong CCE module? The latest one (cce/13.0.0) that came with the 21.12 programming environment can optimise for zen3, but older versions didn't. Indeed, I had some other modules loaded. Just loading
PrgEnv-cray/8.1.0 makes the warning disappear.
-
Q: Bash completion for Slurm does not seem to be setup on Lumi? Are there plans to install it?
- A: No idea. This is something that has to be done at the sysadmin level, not at the level that the support team can do. Given the security constraints for a machine like LUMI and the desire to have a setup at the system level which is fully supported by HPE, there is a very strict border between what is possible at the user interface level and what sysadmins should do, and are willing to do as some features are turned off explicitly for security reasons. This, e.g., explains some of the restrictions there are on LUMI working with containers. But if you really really want it I guess you could install it in your account and activate from your .bashrc. Just sourcing the file seems to work.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1210-lunch-break-80-minutes","title":"12:10 lunch break (80 minutes)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1330-overview-of-compilers-and-libraries","title":"13:30 Overview of compilers and libraries","text":"Session info: An introduction to the compiler suites available. Including examples of how to get additional information about the compilation process. Special attention is given the Cray Compilation Environment (CCE) noting options relevant to porting and performance. CCE classic to Clang transition Exercises: about 20 minutes
Remark 1: Slide 7 (3 ways of dynamic linking) is a really important one. It implies that you will sometimes be using a different version of a library at run time than you think unless you use the third approach. It also implies the behaviour of a code may change when the default programming environment on the system is changed if you use the first apporach.
Remark 2: The Cray Fortran compiler is actually one of the most strict compilers around when it comes to standard compliance. Many codes that don't fully follow the standards fail to compile.
Q&A
-
Q: would one expect a more performant code with dynamic vs. static linking?
- A: I think on modern CPUs the main difference will be the performance during loading (static is faster as you have only one file to open and read). There are differences in the code generated (e.g., you have to use position independent code for a shared library) but I would expect that the performance impact of that will be very low or none on modern architectures as CPUs have simply been optimised to work well with the memory models for shared libraries. I haven't benchmarked it though.
-
Q: I am trying to compile my library on LUMI. According the recommendation, I have loaded PrgEnv-cray/8.2.0. Since I am using waf compiler tool, that does not recognise cc/CC wrappers, so I have specified clang++ to be c++ compiler.
onvysock@uan02:~/meric> CC --version\nCray clang version 13.0.0 (24b043d62639ddb4320c86db0b131600fdbc6ec6)\nTarget: x86_64-unknown-linux-gnu\nThread model: posix\nInstalledDir: /opt/cray/pe/cce/13.0.0/cce-clang/x86_64/share/../bin\n\nonvysock@uan02:~/meric> clang++ --version\nCray clang version 13.0.0 (24b043d62639ddb4320c86db0b131600fdbc6ec6)\nTarget: x86_64-unknown-linux-gnu\nThread model: posix\nInstalledDir: /opt/cray/pe/cce/13.0.0/cce-clang/x86_64/bin\n
Despite using the clang++ the compilation fails that it does not find C++ header file. It seems to me, that C compiler is used instead of C++. [ 2/82] Compiling src/meric/meric.cpp\n14:57:01 runner ['clang++', '-O0', '-g', '-std=c++11', '-fPIC', '-fopenmp', '-I/pfs/lustrep2/users/onvysock/meric/include/', '-DMERIC_PATH=\"/pfs/lustrep2/users/onvysock/meric\"', '-DVERBOSE', '../src/meric/meric.cpp', '-c', '-o/pfs/lustrep2/users/onvysock/meric/build/src/meric/meric.cpp.1.o']\n\nIn file included from ../src/meric/meric.cpp:2:\n../src/meric/meric.h:5:10: fatal error: 'iostream' file not found\n#include <iostream>\n ^~~~~~~~~~\n1 error generated.\n
Do you have any idea what can be wrong? - A: I was expecting this problem would be solved by now, but the Cray compilers need additional options to find their own include files. These are added automatically by the wrappers. I'm not sure if I have compiled programs with waf already on LUMI (I hate all those alternative tools that are incomplete) but most install utilities have a way to tell them which compiler to use.
cc can show the commands that it would generate using the -craype-verbose flag so you could see which libraries and include files it tries to use but from what I remember this is cumbersome. I checked the tool that we use to manage software installations and I do not that it seems to support Waf which means that there must be a way to set environmen variables or command line options to select the compiler. - A (Alfio): the flag is actually
-craype-verbose, e.g. $ CC -craype-verbose test.cc \nclang++ -march=znver2 -dynamic -D__CRAY_X86_ROME -D__CRAYXT_COMPUTE_LINUX_TARGET --gcc-toolchain=/opt/cray/pe/gcc/8.1.0/snos -isystem /opt/cray/pe/cce/13.0.0/cce-clang/x86_64/lib/clang/13.0.0/include -isystem /opt/cray/pe/cce/13.0.0/cce/x86_64/include/craylibs -Wl,-rpath=/opt/cray/pe/cce/13.0.0/cce/x86_64/lib -Wl,-rpath=/opt/cray/pe/gcc-libs test.cc -I/opt/cray/pe/libsci/21.08.1.2/CRAY/9.0/x86_64/include -I/opt/cray/pe/mpich/8.1.12/ofi/cray/10.0/include -I/opt/cray/pe/dsmml/0.2.2/dsmml//include -I/opt/cray/xpmem/2.2.40-2.1_3.9__g3cf3325.shasta/include -L/opt/cray/pe/libsci/21.08.1.2/CRAY/9.0/x86_64/lib -L/opt/cray/pe/mpich/8.1.12/ofi/cray/10.0/lib -L/opt/cray/pe/dsmml/0.2.2/dsmml//lib -L/opt/cray/pe/cce/13.0.0/cce/x86_64/lib/pkgconfig/../ -L/opt/cray/xpmem/2.2.40-2.1_3.9__g3cf3325.shasta/lib64 -Wl,--as-needed,-lsci_cray_mpi,--no-as-needed -Wl,--as-needed,-lsci_cray,--no-as-needed -ldl -Wl,--as-needed,-lmpi_cray,--no-as-needed -Wl,--as-needed,-ldsmml,--no-as-needed -lxpmem -Wl,--as-needed,-lstdc++,--no-as-needed -Wl,--as-needed,-lpgas-shmem,--no-as-needed -lquadmath -lmodules -lfi -lcraymath -lf -lu -lcsup -Wl,--as-needed,-lpthread,-latomic,--no-as-needed -Wl,--as-needed,-lm,--no-as-needed -Wl,--disable-new-dtags \n
- RE1: To be honest I am not sure, what is your advice. Should I add the include paths when compiling with clang++ (I did a fast browse and did not find the standard c++ headers in the paths mentioned in the Alfio's answer)? Should I wait for someone to fix the clang++ utility? Should I load a compiler module instead of PrgEnv module?
- A: (Alfio): I'm not really familiar with the tool, apologize in advance for any naive suggestion... Could you try
CXX=CC ../../waf configure build? I tried it with a simple C++ example in the waf repository and it correctly reports Checking for 'clang++' (C++ compiler) : CC - RE1.1: This is not a problem of waf. Try the following:
$ module load PrgEnv-cray/8.2.0\n$ vim hello.cpp\n #include <iostream>\n int main()\n {\n std::cout << \"Hello LUMI\\n\";\n return 0;\n }\n$ clang++ -std=c++11 hello.cpp\n hello.cpp:1:10: fatal error: 'iostream' file not found\n #include <iostream>\n ^~~~~~~\n 1 error generated.\n$ CC -std=c++11 hello.cpp\n$ ./a.out\nHello LUMI\n$\n
What solution do you suggest to use, if I do not want to use CC but directly clang++? If you prefer, we may use another channel for communication. - A: So, if you want directly use clang++, you should be aware that it comes from the Cray compiler, so you really need the wrappers. For instance:
$ which clang\n/opt/cray/pe/cce/13.0.0/cce-clang/x86_64/bin/clang\n
If you need a plain clang, then I suggest to use the AOCC clang: $ module load aocc-mixed\n
and then you can compile with clang++ the example above. - RE2: I did not do a deep research, so it could be possible, that waf support Cray compiler wrapper, however as an easy solution I did just specify the
clang++, which equals to CC. - A (Alfio): Have you seen this?
- RE2.1: My library compilation process supports clang++, but the CC wrapper is not working for me. I know how to tell waf, which compiler to use based on what the CC wrapper returns. The source of the problem is not in the waf, see RE1.1.
- A: I've checked what EasyBuild does, tested myself and also searched a bit on the web and it looks like Waf indeed simply uses the environment variables in the way that
configure does to specify the compilers so it should be possible to use statements like export CC='cc' and export CXX='CC' to tell Waf to use the wrappers. Using the waf command line options (if that is what you are doing) is NOT enough to say With this on a C++ demo program the output does show Checking for 'g++' (C++ compiler) : not found\nChecking for 'clang++' (C++ compiler) : CC\n
Whis is exactly what I want to see, and continuing this with waf configure build -vvv clearly shows once more that Waf is using the CC wrapper. In general, I'd say never trust autodetection of compilers when running configure/build tools because you'll often end up using the worst one on your system. Any decent tool has a way to specify the name of the compiler and compiler flags, at least when used in the proper way by the developers creating the build recipe. All the software we have at the moment on LUMI is build using the Cray wrappers except for software where I explicitly wanted the system gcc to be able to run completely independent of the Cray PE. - A: And
clang++ does not equal to CC. CC does a lot more. - RE2.2: Can you please share your wscript? The part that checks for the CXX.
- A: I simply ran some examples from the Waf examples, e.g., the C++ one with the current version of Waf (2.0.23) and telling it via the
CXX environment variable to use CC as I described above. I'm not a Waf specialist, but I guess it is the opt.load('compiler_cxx')\n
or conf.load('compiler_cxx')\n
lines that activate the routines that do the magic.
-
Q: Is the BLIS library available?
- A: We have a recipe so that a user can install it but we don't want to make it available by default in the central stack as it would conflict with libraries already build with Cray LibSci. A look at the symbols in Cray LibSci shows that is uses a mix of OpenBLAS and BLIS.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1500-break-30-minutes","title":"15:00 break (30 minutes)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1530-advanced-application-placement","title":"15:30 Advanced Application Placement","text":"Session info: More detailed treatment of Slurm binding technology and OpenMP controls. Exercises: about 30 minutes
Q&A
-
Q: If it is only \"marginally slower\" that suggest that very little extra perfomance can be obtained by doing the explicit binding? Ok, now he is saying something else. Suggest to ask at end of presentation.
- A: crossing socket boundaries may lead to significantly lower performance
- A: depends on the particular case
-
Q: (slide 16) Are you assuming --exclusive or other kind of full-node-access here?
-
Q: which binding mechanism has a higher priority OpenMP or SLURM?
- A: Slurm will set a cgroup, you can't escape that. But also depends on which plugins are enabled.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1630-open-questions-answers-participants-are-encouraged-to-continue-with-exercises-in-case-there-should-be-no-questions","title":"16:30 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions)","text":"Q&A
-
Q: Is there a mechanism for requesting packages such as MUMPS?
- A: should be addressed tomorrow.
- A: Checked for MUMPS. The likely reasons why we don't have that yet ready (besides that it has not yet been requested) is that we have given priority to packages for which a friendly site with a similar system provides build instructions in a way that we can easily adapt to LUMI, and a frightening element on the web site that actually asks you to specify some information about how MUMPS will be used before downloading which we as support people rather than users obviously cannot answer with any accuracy. Though it looks like the download isn't really protected.
-
Q: would you provide tools such as Extrae as modules? Or maybe users would install them?
- A: likely answered in tomorrows talk on additional software
- A: if someone struggles to build/install a software package LUST+CoE can help, for example, by asking around (what experiences on other systems have been made)
- A: The reality is also that the support team of 9 FTE is way too small to do all software installations for all projects as the expected number is very high given that many countries assign lots of small projects. We have to do more than just software installations, and we are only a fraction of the size of the software support team of larger centres as, e.g., J\u00fclich. So we have to rely a lot on users doing their own installations, possibly with the help of local support teams from the countries they come from, and hopefully then contributing their experiences so that we can make them available to others.
-
Q: I want to build/compile CP2K 9.1, may be need assistance for that
- A: we already have a recipe (easyconfig) for that, should be more clear after tomorrows talk on additional software
- A (Alfio, HPE): CoE has expertise with CP2K too. That's they way I use to install CP2K v9.1 on LUMI: +
module swap PrgEnv-cray PrgEnv-gnu (GNU is supported by CP2K) + module load cray-fftw + git clone --recursive --branch v9.1.0 https://github.com/cp2k/cp2k.git + cd cp2k/tools/toolchain + ./install_cp2k_toolchain.sh --enable-cray (use ./install_cp2k_toolchain.sh --help to get more help on what to install). Note that this takes a while to complete. + cp install/arch/local.psmp ../../arch/ + cd ../../ + Change the arch/local.psmp file by adding -fallow-argument-mismatch flag to FCDEBFLAGS variable + make ARCH=local VERSION=psmp - A: LUST may have had a support request for CP2K 9.1 recently
-
Q: will programs like LAMMPS, ABINIT, SIESTA be available as modules?
- A: Status for these applications:
- Limited support for LAMMPS, only few plugins, configuration based on input we got from CSCS who have a system similar to LUMI-C. Some of the plugins are supported by neither EasyBuild nor Spack, the two frameworks for HPC software installation that we use or consult for installation procedures.
- ABINIT is available as easyconfig and discussions are going on with the ABINIT authors to improve the installation. The developers have already got access via the Belgian share on LUMI.
- SIESTA: Kind of problematic. I've seen it fail on user tests even though the compile succeeded without any terrifying warning. They also had the brilliant idea to change the build process to one that is harder to support in tools such as Spack and EasyBuild. Therefore Spack for now stopped supporting Siesta at version 4.0.2 which is 4 years old. EasyBuild kind of supports newer versions but only in combination with some libraries that are different from what we use on the system, and do to the nature of the new build process it is difficult to adapt the EasyBuild code in a generic way but also to write a robust automated build process specifically for the Cray PE. We'd need working manual installation procedures before even looking at how we can automate the procedure and maintain it. There are some instructions to compile Siesta with PrgEnv-gnu on the Archer2 GitHub but we'd need a Siesta expert to see if this is just the most basic build or includes options that Siesta might provide. At first sight it does not include METIS, ELAP, MUMPS, PEXSI or flook that are mentioned in the 4.1.5 manual as libraries that provide additional functionality.
-
Q: Are there Easybuild recipes to install the Cray PE/tools?
- A: No. This is no free software and installed in a very different way. EasyBuild can use the the Cray PE as external software though.
-
Q: I think for Lammps and other softwares alike would be better to have a short guide suggesting the best combination of compilers, libraries and slurm options that would give the best performance in a general way
- A: not easy to provide general answers. The right combination of compilers and libraries and the right Slurm options will often depend on the particular test case. E.g., due to different vectorisation and loop unrolling strategies one compiler may be better on one problem that leads to shorter loops and another may be better on another problem with the same code that leads to longer loops. The amount of parallelism and certainly how to tune a hybrid run combining MPI with threads will depend a lot on the test case.
- A: maybe better to provide guidance on how to determine these options on a case by case basis
-
Q: is there a supercomputer similar to LUMI in the world?
- A: to some extend yes, Frontier (ORNL, US), Dardel (KTH, SE), Setonix (Pawsey, Australia), Adastra (CINES, Montpellier, France). For LUMI-C there is Archer2 (EPCC, UK) and Eiger (CSCS, Switzerland). The software stack for LUMI was originally developed on Eiger as otherwise it would have taken half a year or so from the start of the pilot to have something that is properly designed and working.
-
Q: What is important to participants in terms of applications (standard applications or own applications)?
- A: Looking at the proposals submitted in the latest round in Belgium, it was about 50-50.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1700-end-of-first-course-day","title":"17:00 End of first course day","text":"See you tomorrow at 07:00 UTC, 08:00 EPCC, 09:00 CEST or 10:00 EEST.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#april-28-all-times-cest","title":"April 28 (all times CEST)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#0900-performance-and-debugging-tools-incl-exercises-and-a-break","title":"09:00 Performance and Debugging Tools incl exercises and a break","text":"Session info: Includes following content broken up with Exercises/Demos and a break + Introduction to perftools + Pertfools lite modules + Loop work estimates + Reveal for performance data display, compiler feedback and automatedscoping + Debugging tools at scale
"},{"location":"PEAP-Q-20220427/hackmd_notes/#0900-introduction-to-perftools-perftools-lite-module-and-demo","title":"09:00 Introduction to Perftools -- Perftools-lite module and demo","text":"Q&A
-
Q: I would be really interested in some comments about HIP and OpenMP offload profiling as long as power consumption tracking with the tools
- A: Noted but this course is not about LUMI-G.
- A: Sure, we have EAP though
- A: These tools can be used with the AMD GPUs but we don't plan to cover that in this course.
- A: routine-level power consumption available, not sure about data transfers
-
Q: When do the GPU partition will be available? For early access and then production?
- A: LUMI-G: not before August (pilot), general availability fall 2022. The Early Access Platform, EAP, (MI100, available already, any existing project on LUMI-C has access). The EAP is designed for porting code, not for production runs or benchmarking. Especially inter-node communication is very poor at the moment which makes benchmarking this completely irrelevant, and the GPUs in the EAP are sufficiently different that much benchmarking and really fine-tuning on them may also prove to be irrelevant on the MI250X.
-
Q: Is there a tool to track specific I/O events (like volume of data written or read along the run) ?
- A: perftools reports include a table addressing I/O, this will be shown later.
-
Q: Do you also advise to compare the performance of the exec generated with perftools-lite (only sampling) with the original executable without any monitoring? In other words, can there be a significant overhead with just application sampling?
- A: always good to have one reference run
-
Q: Can the perftools-lite tools also be used with MPMD execution?
- A: yes, has been done in the past
-
Q: What should you do if you notice that perftools-lite introduces a significant overhead compared to an executable without any profiling hooks?
- A: More likely if you trace very small, frequently called functions, you can specify not to profile certain functions.
- Q2: Can this be done with perftools-lite?
- A: perftools is needed to select/exclude certain functions , however this applies to tracing, it is less likely that a lite sampling experiment will skew the performance.
-
Q: What is the purpose of the perftools-base module that is loaded by default?
- A:
man perftools-base (HPE Cray really likes man pages rather than web-based documentation). One of the functions is to make the other perftools modules available in the Lmod hierarchy. It is a rather common practice on Cray systems to load it by default, so we follow this \"convention\" so that people who are familiar with the Cray Programming Environment find more or less what they expect. - A: It provides the command-line tools but unlike the full perftools module it does not affect any compilations.
-
Q: Is it possible to install perftools-* in our machine so that we can get the interactive output? (I mean this \"Apprentice\" program)
- A: /opt/cray/pe/perftools/default/share/desktop_installers contains Apprentice2 for Windows and macOS and Reveal for macOS. Some remote connect capability of these does not work with ssh keys at the moment but you can run apprentice2 on .ap2 files you copy to your desktop/laptop.
- A: We also have the lumi-vnc module to run graphical programs on LUMI via a VNC client or web browser (try
module help lumi-vnc), and later this year (hopefully) there should also be Open OnDemand to offer a frontend to LUMI to run GUI programs without too much trouble. - Q2: but not a Linux version, it seems (I guess this would require the full Cray stack to be installed, though)
- A: This comes up from time to time but it is not clear how large the community is of people who want this and at the moment there is no commitment to provide Linux clients. We will feed this back.
- A: The problem may also be that release engineering for Linux can be very hard for GUI packages that are not spread through RPM or other repositories as you can never be sure which libraries are present on a Linux machine due to all the distributions and all the installation options. One of the reasons we are so slow in setting up GUI-based applications on LUMI and to get the visualisation nodes available to users is precisely that we run into these problems all the time. You may have to use one of the modern containerised solutions for that.
- C: The first argument is a bit surprizing, given that I would expect the HPC community to be a bit more Linux-oriented than the average public. But I totally agree that getting a GUI to run on Linux is a hell of a job, so thank you for your answers :)
- C: The reality is that macOS is very popular in the HPC community because it offers you a UNIX-like environment, good development tools, but also good office tools that you also need in your work, and that Windows is on the rise since it has become rather good for development on Linux also thanks to WSL and WSL2. ComputeCanada makes their HPC software stack that they serve via CernVM FS also available to their users in Canada on Windows simply via WSL2...
"},{"location":"PEAP-Q-20220427/hackmd_notes/#0955-advanced-performance-analysis-iii-perftools-variable-scoping-and-compiler","title":"09:55 Advanced Performance Analysis I/II \u2014 Perftools, variable scoping and compiler","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1045-advanced-performance-analysis-iiii-communication-imbalance-apprentice2-hardware-counters-perftools-api-feedback-with-reveal-openmp-demo","title":"10:45 Advanced Performance Analysis II/II \u2014 Communication Imbalance, Apprentice2, Hardware Counters, Perftools API, Feedback with Reveal, OpenMP, demo","text":"Q&A
-
Q: Is there a way to \"customize\" the profiling : for example if the runtime is n sec, start the profiling at t0 and stop it at t1 with 0<t0<t1<n, i. e. produce a profiling from t0 to t0+t1? it may be usefull for tracing for example a small number of it\u00e9rations (rather than all it\u00e9rations) and also for avoiding to generate too much data to proceed later with GUI.
- A: You can use an API to control which parts of an application are profiled (between begin/end calls). This is covered in the talk and one of the exercise directories. The two aspects of this are first that you can collection off and on, secondly wrapping particular parts of an application between begin/end calls such that this will appear separately in the report.
- A: Using specific time stamps is not directly possible with the API.
-
Q: Regarding the himeno example; What is the importance of distributing processes over NUMA domains?
- A: By default, processes are not cyclically distributed over NUMA domains. Might use
--cpu-bind=verbose as srun option to obtain binding information.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1130-debugging-at-scale-gdb4hpc-valgrind4hpc-atp-stat-demo","title":"11:30 Debugging at Scale -- gdb4hpc, valgrind4hpc, ATP, stat, demo","text":"Q&A
-
Q: Is there any reason not to setup ATP by default so that it can capture any unexpected crash?
- A: ATP has a low overhead, but it has some. So, it's up to the user to make the decision to include it or not.
- A: It adds a signal handler. That might interfere with the application.
-
Q: Will DDT be available on LUMI?
- A: Yes ARM forge will be available on LUMI. No ETA for the installation at the moment.
-
Q: Will totalview be also treated in the same way as DDT? Will the user have to bring its own license to use it on Lumi if I understood well?
- A: DDT will be available as a part of the ARM Forge. I do not believe TotalView would be available.
- A: No, we've looked at TotalView also but we cannot buy every debugger/profiler and in fact at that time there were not even realistic plans for support for the architecture that we have (didn't check if this has changed though).
-
Q: Is it possible/advised to enable by default both ATP and perftools-lite?
- A: ATP could be enabled by default, there might be the odd interaction with application signal handlers to watch out for.
- A: I (Harvey) don't recommend having profiling enabled by default as this affects how applications are built and run and generates extra data that people might not want.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1200-lunch-break-60-minutes","title":"12:00 lunch break (60 minutes)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1300-understanding-cray-mpi-on-slingshot-rank-reordering-and-mpmd-launch","title":"13:00 Understanding Cray MPI on Slingshot, rank reordering and MPMD launch","text":"Session info: High level overview of Cray MPI on Slingshot, useful environment variable controls. Rank reordering and MPMD application launch. Exercises: about 20 minutes
Q&A
-
Q: When will the Slingshot upgrade take place?
- A: ~ end of May, from then UCX won't be available
-
Q: Can MPICH_RANK_REORDER environment variables also be used to control binding inside a node, for example spreading across sockets?
- A: don't think so
- Q2: I phrased my question wrong. Suppose in a single node you bind processes to cores 0,32,64,96. Can you then use
MPICH_RANK_REORDER to control mapping of ranks to those processes? Admittedly, this will have a smaller impact compared to inter-node communication, but it is possible that communication between 0-64 is slower than between 0-32. - A: This is a very good question and I have been thinking we should start looking at this from the perspective of node structure in addtion to on/off node considerations.
-
Q: What is the difference between MPICH_RANK_REORDER_METHOD and srun --distribution? Apparently the former takes precedence over the latter.
- A: I'd say: srun will map Slurm tasks on the resources of the job, and
MPICH_RANK_REORDER_METHOD will then influence the mapping of MPI ranks on Slurm tasks with the default being rank i on task i. - A: (Harvey) I really need to test this as I could imagine that distribution to nodes could be done from scratch but the custom mapping might be done from SLURM-set mapping already there.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1400-io-optimisation-parallel-io","title":"14:00 I/O Optimisation \u2014 Parallel I/O","text":"Session info: Introduction into the structure of the Lustre Parallel file system. Tips for optimising parallel bandwidth for a variety of parallel I/O schemes. Examples of using MPI-IO to improve overall application performance.
Advanced Parallel I/O considerations + Further considerations of parallel I/O and other APIs.
Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Q&A
-
Q: What is the ratio between IO node to compute nodes on Lumi?
- What do you mean by IO node?
- IO nodes is probably not the right terminologiy here indeed. I used the terminology from the decommissioned BGQ system.
- I/O node == some node that is only used for I/O transfers???
- A: don't think that there are such special nodes on LUMI-C, however some other partition, for example, LUMI-K (?) might be used (don't know if these partitions have better network connections for I/O)
- A: The I/O servers on one of the slides where it said that you only do I/O from some processes are not hardware I/O servers, but your processes of which some take care of the I/O. Is that the source of the confusion?
- Probably. If I request a collective IO with MPIIO, which fraction of my processes will then be in charge of communicating with the file server?
- A: maybe depends on the implementation of MPI-IO (and stripe_size, stripe_count) \u2192 in other words: \"don't know\"
-
Q: What is the optimize number of files per compute nodes for MPIIO?
- A: maybe one file per process?
- Q2: This would overflow the meta data server if for instance 100 000 processes write 100 000 files at the same time. The other extreme would be 100 000 files wrting collectively in one single shared file. Is there an optimum where a subset of processes would write to their own share file?
- A: probably there is an optimum, but difficult to provide one answer to all possible scenarios
-
Q: It seems there is no metadata striping: lfs getdirstripe . gives lmv_stripe_count: 0 lmv_stripe_offset: 0 lmv_hash_type: none Is this a deliberate choice? How do you ensure load balancing across MDTs? I see generally MDT0000 already is used more than MDT0001.
- A: second MDT seems to be there for redundancy only
-
Q: What is performance for writing small files to MDTs (https://doc.lustre.org/lustre_manual.xhtml#dataonmdt)?
- A: It is probably a non-issue on LUMI as the file policies are such that the use of small files is strongly discouraged due to bad experiences on other CSC systems. You will be forced to use different strategies than putting 10M small files on the system.
-
Q: Do you use PFL (Progressive File Layouts - https://doc.lustre.org/lustre_manual.xhtml#pfl)? If so when do you recomend it?
- A: With
lfs getstripe -d . you can see the current settings; I see stripe_count=1 and no PFL. - A: (Harvey) I don't have the answer but we can ask about this. I would expect some delay in any case for features to be enabled in the Lustre that HPE provides even if they have been available for some time.
- A: I tried
lfs setstripe -E 4M -c 1 -E 64M -c 4 -E -1 -c -1 -i 4 /my/dir and it seems to work. So I think PFLs are possible, but the default striping settings do not use it.
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1445-break-30-minutes","title":"14:45 break (30 minutes)","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1515-additional-software-on-lumi-c","title":"15:15 Additional software on LUMI-C","text":"Session info:
- Software stacks and policies
- Advanced Lmod use
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Q&A
- Q: Are the EasyBlocks adapted for LUMI? Do you expect users will need to modify those as well?
- A1: some easyblocks have been adapted for LUMI, see https://github.com/Lumi-supercomputer/LUMI-SoftwareStack/tree/main/easybuild/easyblocks
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1615-lumi-documentation-how-to-get-help-how-to-write-good-support-requests","title":"16:15 LUMI documentation, how to get help, how to write good support requests","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1620-what-are-typicalfrequent-support-questions-of-users-on-lumi-c","title":"16:20 What are typical/frequent support questions of users on LUMI-C?","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#1635-open-questions-answers-participants-are-encouraged-to-continue-with-exercises-in-case-there-should-be-no-questions","title":"16:35 Open Questions & Answers (participants are encouraged to continue with exercises in case there should be no questions)","text":"Q&A
-
Q: Would LUST be interested in EB recipes contributed from users?
-
Q: Will mail server for slurm be installed on LUMI? so, when the calculation finish will notify by email (#SBATCH --mail-type=END)
- A: need to ask system admins
-
Q: A question about the material from yesterday: When is it safe to use the mixed compiler modules and when it is not? I would expect it to be safe for C, but can see problems combining C++ code from different compilers (name mangling issues?) or Fortran code. Can you give any advice?
- A: The real use case here is that you normally have a programming environment loaded and are using the wrappers but want to use another compiler to build something directly without the wrappers, typically PrgEnv-cray for the former and a newer-than-system gcc for the latter. For example you might want to build cmake with gcc but don't need to swap the whole environemnt to gnu and use the wrappers.
-
Q: Any plans for LUMI Users Group or something similar?
- A: Exchange of solutions, experiences, etc. I was thinking online.
-
Q: Quick question: to compile a code which targets Lumi-C, I suppose the modules LUMI/21.08 partition/C should be the right ones
- A: yes, but better start using
LUMI/21.12
-
Q: In my experience, EasyBuild is not necessarily the best tool to fix compilation problems. Do you have tips for when an existing easyblock does not work on LUMI? For example try a manual build first, and afterwards add it to EasyBuild for reproducibility?
"},{"location":"PEAP-Q-20220427/hackmd_notes/#1700-end-of-second-course-day","title":"17:00 End of second course day","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#any-other-notes","title":"Any other notes","text":""},{"location":"PEAP-Q-20220427/hackmd_notes/#course-page","title":"Course page","text":"https://www.lumi-supercomputer.eu/events/detailed-introduction-to-lumi-c-april-2022/
"},{"location":"PEAP-Q-20220427/hackmd_notes/#misc","title":"Misc","text":"Download the LUST slides
"},{"location":"PEAP-Q-20220427/hackmd_notes/#questions","title":"Questions","text":" -
Q: How to get login to LUMI? (for users with a Finnish allocation)
- A: See https://www.lumi-supercomputer.eu/get-started-2021/users-in-finland/
-
Q: I have registerd my public key to mycsc.fi page few days back, but I still not recived the username. Can I use my csc username (the one i use for puhti and mahti) to get login into lumi?
- A: Best option is to send a support request for this. If you let us know the username for puhti/mahti we might check if it is created on LUMI already.
"},{"location":"PEAP-Q-20220427/software_stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
"},{"location":"PEAP-Q-20220427/software_stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"PEAP-Q-20220427/software_stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: a fully cache-coherent unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in the Apple M1 but then without the NUMA character.
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a recent talk in an EasyBuild user meeting.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"PEAP-Q-20220427/software_stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparant way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be acustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an increasing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place. We do offer some help so set up Spack also but activating Spack for installation is your project directory is not yet automated.
"},{"location":"PEAP-Q-20220427/software_stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionaire send out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The final LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, so any software compiled with an MPI library that requires UCX, or any other distributed memory model build on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intro-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-bus comes to mind.
Also, the LUNI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that I did not yet mention is that software that accesses hundreds of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. The link to the documentation of the tool that we call lumi-container-wrapper but may by some from CSC also be known as Tykky is in the handout of the slides that you can get after the course.
"},{"location":"PEAP-Q-20220427/software_stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using the that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 4 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes, zen 2 combined with NVIDIA GPUs for the visualisation nodes and zen3 + MI250X for the LUMI-G partition. There is also some support for the early access platform which has zen2 CPUs combined with MI100 GPUs but we don't pre-install software in there at the moment except for some build tools and some necessary tools for ROCm as these nodes are not meant to run codes on and as due to installation restrictions we cannot yet use the GPU compilers with EasyBuild the way we should do that on the final system.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"PEAP-Q-20220427/software_stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"PEAP-Q-20220427/software_stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"PEAP-Q-20220427/software_stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It ia also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change. E.g., the PRgEnv-aocc/21.12 module can successfully use the aocc/3.1.0 compilers.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"PEAP-Q-20220427/software_stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/21.08 and LUMI/21.12 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes, partition/EAP for the early access platform and in the future we will have partition/D for the visualisation nodes and partition/G for the AMD GPU nodes.
There is also a hidden partition/common module in which we install software that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"PEAP-Q-20220427/software_stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"PEAP-Q-20220427/software_stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the few modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"PEAP-Q-20220427/software_stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 5 versions of GNUplot. There are two installations of GNUplot 5.4.2 and three of 5.4.3. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there are two versions, 3.21.2 and 3.22.2, but now they are shown in blue with an \"E\" behind the name. That is because there is no module called CMake on LUMI. Instead the tool is provided by another module that in this case contains a collection of popular build tools and that we will discover shortly.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.3-cpeGNU-21.12. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are two ways to load the module: By loading LUMI/21.12 combined with partition/C or by loading LUMI/21.12 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/21.12 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.22.2. This will now show us that this tool is in the buildtools/21.12 module and give us 6 different options to load that module as it is provided in the CrayEnv and the LUMI/211.12 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
"},{"location":"PEAP-Q-20220427/software_stacks/#module-keyword-command","title":"Module keyword command","text":"module keyword will search for a module using a keyword but it is currently not very useful on LUMI because of a bug in the current version of Cray Lmod which is solved in the more recent versions. Currently the output contains a lot of irrelevant modules, basically all extensions of modules on the system.
What module keyword really does is search in the module description and help for the word that you give as an argument. Try for instance module keyword https and you'll see two relevant tools, cURL and wget, two tools that can be used to download files to LUMI via several protocols in use on the internet.
On LUMI we do try to put enough information in the module files to make this a suitable additional way to discover software that is already installed on the system, more so than in regular EasyBuild installations.
"},{"location":"PEAP-Q-20220427/software_stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"You may have been taught that module purge is a command that unloads all modules and on some systems they might tell you in trainings not to use it because it may also remove some basic modules that you need to use the system. On LUMI for instance there is an init-lumi module that does some of the setup of the module system and should be reloaded after a normal module purge. On Cray systems module purge will also unload the target modules while those are typically not loaded by the PrgEnv modules so you'd need to reload them by hand before the PrgEnv modules would work.
Lmod however does have the concept of \"sticky modules\". These are not unloaded by module purge but are re-loaded, so unloaded and almost immediately loaded again, though you can always force-unload them with module --force purge or module --force unload for individual modules.
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similary in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"PEAP-Q-20220427/software_stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is calle system which shows you again the module directories.
We're also very much aware that the default colour view is not good for everybody. So far I don't know an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/21.12 stack we prefer that users use the Cray programming environment modules that come with release 21.12 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
"},{"location":"PEAP-Q-20220427/software_stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"PEAP-Q-20220427/software_stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. We expect this to happen especially with packages that require specific MPI versions. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And we need a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"PEAP-Q-20220427/software_stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is our primary software installation tool. We selected this as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the build-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain we would have problems with MPI. EasyBuild there uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost or the Intel compiler will simply optimize for a two decades old CPU.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system. We're also working on presenting a list of supported software in the documentation.
"},{"location":"PEAP-Q-20220427/software_stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .bash_profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
Once that environment variable is set, all you need to do to activate EasyBuild is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition. Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
"},{"location":"PEAP-Q-20220427/software_stacks/#step-2-install-the-software","title":"Step 2: Install the software.","text":"Demo moment 2
Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS we already have support. At the moment we have to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
This process is not optimal and will be improved in the future. We are developing a system that will instead give an overview of available EasyBuild recipes on the documentation web site. Now let's take the variant GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/21.12, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS we do expect that GPU builds for LUMI will become available early on in the deployment of LUMI-G so we've already added a so-called version suffix to distinguish between CPU and GPU versions. To install it, we first run
eb \u2013r GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The search for dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb \u2013r GROMACS-2021.4-cpeCray-21.12-PLUMED-2.8.0-CPU.eb\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
End of demo moment 2
"},{"location":"PEAP-Q-20220427/software_stacks/#step-2-install-the-software-note","title":"Step 2: Install the software - Note","text":"There is a little problem though that you may run into. Sometimes the module does not show up immediately. This is because Lmod keeps a cache when it feels that Lmod searches become too slow and often fails to detect that the cache is outdated. The easy solution is then to simply remove the cache which is in $HOME/.lmod.d/.cache, which you can do with
rm -rf $HOME/.lmod.d/.cache\n
And we have seen some very rare cases where even that did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment. Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work.
"},{"location":"PEAP-Q-20220427/software_stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb -r . my_recipe.eb\n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb \u2013r . VASP-6.3.0-cpeGNU-21.12.eb\n
"},{"location":"PEAP-Q-20220427/software_stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greates before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/easybuild/easyconfigs.
"},{"location":"PEAP-Q-20220427/software_stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory, and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software.
Moreover, EasyBuild also keeps copies of all installed easconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is also a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"PEAP-Q-20220427/software_stacks/#easybuild-training-for-support-team-members","title":"EasyBuild training for support team members","text":"Since there were a lot of registrations from local support team members, I want to dedicate one slide to them also.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
Lastly we are organising a training for CSC staff also open to other local support organisations on May 9 and 11, from 12:30 to 15:30 CEST. Notes from that training will likely also become available on the EasyBuilders training web site, or we will post them via a separate GitHub pages web site or so. If you want to join, contact LUMI support.
"},{"location":"PEAP-Q-20221123/","title":"Detailed introduction to the LUMI-C environment and architecture (November 23/24, 2022)","text":""},{"location":"PEAP-Q-20221123/#during-the-course","title":"During the course","text":" - Course schedule
- Notes from the HedgeDoc document with questions
- HedgeDoc collaborative document (may disappear over time)
- Where to eat?
"},{"location":"PEAP-Q-20221123/#course-materials","title":"Course materials","text":"Resources in italics on the list below are only available on LUMI and not via web download.
Presentation title slides notes recording Introduction slides / recording HPE Cray EX Architecture slides / recording Programming Environment and Modules slides / recording Running Applications slides / recording Compilers and Libraries slides / recording Advanced Placement slides / recording Introduction to Perftools slides / recording Advanced Performance Analysis part 1 slides / recording Advanced Performance Analysis part 2 slides / recording Debugging at Scale slides / recording MPI Topics on the HPE Cray EX Supercomputer slides / recording Optimizing Large Scale I/O slides / recording LUMI Software Stacks slides notes recording LUMI User Support slides / recording Day 2 General Q&A / / /"},{"location":"PEAP-Q-20221123/demo_software_stacks_mdp/","title":"Demo software stacks mdp","text":"%title: LUMI Software Stacks (demos) %author: Kurt Lust %date: 2022-11-24
-> # module spider <-
module spider\n
- Long list of all installed software with short description
- Will also look into modules for \u201cextensions\u201d and show those also, marked with an \\\u201cE\\\u201d
-> # module spider <-
- With the (suspected) name of a package
module spider gnuplot\n
- Shows all versions of gnuplot on the system
- Case-insensitive
module spider GNUplot\n
-> # module spider <-
- With the (suspected) name of a package
module spider cmake\n
CMake turns out to be an extension but module spider still manages to tell which versions exist.
-> # module spider <-
- With the full module name of a package
module spider gnuplot/5.4.3-cpeGNU-22.08 \n
- Shows help information for the specific module, including what should be done to make the module available
- But this does not completely work with the Cray PE modules
-> # module spider <-
- With the name and version of an extension
module spider CMake/3.24.0 \n
- Will tell you which module contains CMake and how to load it
module spider buildtools/21.08\n
-> # module keyword <-
- Currently not yet very useful due to a bug in Cray Lmod
- It searches in the module short description and help for the keyword.
module keyword https\n
- We do try to put enough information in the modules to make this a suitable additional way to discover software that is already installed on the system
-> # sticky modules and module purge <-
- On some systems, you will be taught to avoid module purge (which unloads all modules)
- Sticky modules are modules that are not unloaded by
module purge, but reloaded. - They can be force-unloaded with
module \u2013-force purge and module \u2013-force unload
module list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
- Used on LUMI for the software stacks and modules that set the display style of the modules
- But keep in mind that the modules are reloaded, which implies that the target modules and partition module will be switched (back) to those for the current node.
module load init-lumi\nmodule list\n
-> # Changing the module list display <-
- You may have noticed that you don\u2019t see directories in the module view but descriptive texts
- This can be changed by loading a module
ModuleLabel/label: The default viewModuleLabel/PEhierarchy: Descriptive texts, but the PE hierarchy is unfoldedModuleLabel/system: Module directories
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
-> # Changing the module list display <-
- Turn colour on or off using ModuleColour/on or ModuleColour/off
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
-> # Changing the module list display <-
- Show some hidden modules with ModulePowerUser/LUMI This will also show undocumented/unsupported modules!
module load LUMI/22.08\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
- Note that we see a lot more Cray PE modules with ModulePowerUser!
-> # Demo moment 2 <-
-> # Install GROMACS <-
- Search for a GROMACS build recipe
module load LUMI/22.08 partition/C EasyBuild-user\neb --search GROMACS\neb -S GROMACS\n
- Let\u2019s take
GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb
eb -r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb -D\neb -r GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb\n
- Now the module should be available
module avail GROMACS\n
"},{"location":"PEAP-Q-20221123/extra_00_Introduction/","title":"Welcome and introduction","text":"Presenters: Kurt Lust (LUST)
Additional materials
"},{"location":"PEAP-Q-20221123/extra_00_Introduction/#qa","title":"Q&A","text":" -
Do you know the current allocation per country ? (I wonder how much Belgium contributes to LUMI)
- Belgium: 7.4% of the total budget.
- Information about how to contact the Belgian team is https://www.enccb.be/LUMI
-
What do you mean the training project? like ssh to lumi? or the puhuri portal?
- Yes, there is a small allocation on LUMI associated with the course (i.e. yo can log in with SSH and run jobs). We send out an email on Monday with the puhuri link to join the training project. This is a different project from the one you may have from a project from EuroHPC or your national allocation. Please use this project only for the exercises, not to run your own code or we will run out of our allocation for the course.
- The information on how to join was sent out a few days before the course. We will mention the project number and slurm reservation before we start the exercises.
"},{"location":"PEAP-Q-20221123/extra_01_HPE_Cray_EX_Architecture/","title":"HPE Cray EX Architecture","text":""},{"location":"PEAP-Q-20221123/extra_01_HPE_Cray_EX_Architecture/#qa","title":"Q&A","text":" -
What's the expected CPU clock for a heavy all-core job?
- 2.45 GHz base clock rate (https://www.amd.com/en/product/10906)
- Don't expect any boost for a really heavy load. The effective clock is determined dynamically by the system depending on the heating/cooling situation. It can be complex, because heavy network/MPI traffic will also affect this, and the node tries to distribute power between the CPU cores, the IO die on the CPU, (the GPUs for LUMI-G), and the network cards on-the-fly to optimize for the best performance.
-
Regarding the CPU cores and threads : you said that the threads are hardware : should we run large runs on the number of threads, rather than the number of nodes ?
- Could you elaborate a bit more?
- My understanding is : a cpu that has 64 cores, shows 128 threads by multithreading, therefore cases that use the cpu 100% load during 100% of the time will be better tu run on 64 core, rather than the 128 threads to eliminate the overhead of the operating system due to scheduling the software threads to the hardware core.
- There are two sessions about SLURM in the course where it will be explained how to use hyperthreading etc.
- In general, hyperthreading doesn't offer much benefits on a good code, rather the contrary. It's really more lack of cache and memory bandwidth stat stops you from using hyperthreading. Hyperthreading is basically a way to hide latency in very branchy code such as databases. In fact there are codes that run faster using a given number of nodes and 75% of the cores than the same number of nodes and all cores per socket, without hyperthreading.
- OK I will wait for the next parts of the course. Thank you
"},{"location":"PEAP-Q-20221123/extra_02_Programming_Environment_and_Modules/","title":"Programming Environment and Modules","text":""},{"location":"PEAP-Q-20221123/extra_02_Programming_Environment_and_Modules/#qa","title":"Q&A","text":" -
At the ExaFoam summer school I was told that HDF5 parallel I/O does not scale to exa scale applications. Ist that correct Instead the exafoam project is working on an ADIOS-2 based system for parallel I/O in OpenFOAM. Feel free to answer this question at the most appropriate time in the course
- This is the current understanding, so I would say \"yes\" (even if I'm not a 100% expert).
- The HDF5 group had a BOF at SC22 about their future plans
- I would not rule out HDF5 parallel I/O at large scale on LUMI-C for runs of say 500 nodes or similar. The best approach would be to try to benchmark it first for your particular use case.
- It depends on what you would exactly need to do. If you need to write to file, I am not sure there are real alternatives. ADIOS would be great for in-situ processing.
- [Harvey] I have heard of some good experience about ADIOS-2 but have not tried it yet myself, on my list of things to do.
- One of the engines that ADIOS-2 can use is HDF5 so it is not necessarily more scalable. Just as for HDF5, it will depend much on how it is used and tuned for the particular simulation.
-
Will there be, for the exercises, shown on-screen (in the zoom session) terminal session which will show how to use all the commands, how to successfully complete the exercises, or will we be void of visual guide and will we only have to rely on the voice of the person presenting the exercises? What I mean - can we please have the presenter show interactively the commands and their usage and output?
- You can find exercises at
/project/project_465000297/exercises/ with Readme's. You can copy the directory in your area. Just follow them and let us know if you have questions. We will cover it during the next sessions.
"},{"location":"PEAP-Q-20221123/extra_03_Running_Applications_Slurm/","title":"Running Applications","text":""},{"location":"PEAP-Q-20221123/extra_03_Running_Applications_Slurm/#qa","title":"Q&A","text":" -
I would like to know whether it is possible to run FEM simulation software (e.g., COMSOL Multiphysics) on LUMI?
- As long as it is installed correctly then I see no reason why not. It has been run on other Cray EX systems. The only complication here will be the commerical license. LUMI does not have its own license, you would have to provide your own. There might be some complications right now, because the compute nodes do not have internet access, which would block access to the license server. We hope that internet access will be enabled on the compute nodes soon.
-
Is it something like MC (Midnight Commander) installed?
- No, and midnight commander specifically has some annoying dependencies so it will not come quickly in a way that integrates properly with all the other software on LUMI.
- You can see your files and transfer to and from LUMI using tools like filezilla and the host
sftp://lumi.csc.fi - And for people on a connection with sufficiently low latency Visual Studio Code also works. The client-server connection seems to fail easily though on connections with a higher latency. It is also more for editing remotely in a user friendly way than browsing files or running commands. But we do understand that mc is awesome for some people.
- In the future there will also be an Open OnDemand interface to LUMI.
-
MC is ok but Krusader is better
-
and WinSCP?
- That is client software to run on your PC. It should work.
- In general, until we have Open OnDemand, the support for running GUI software on LUMI is very limited. And after that it will not be brilliant either, as an interface such as GNOME is not ideal to run on multiuser login nodes due to the resources it needs but also due to how it works internally.
-
Would it be alright to test the building of licensed software such as VASP during the course and the EasyBuild system you have in place? (and benchmark with very small test run of course)
- Please don't run benchmarks of your own software on the project account. If you already have another project, use that one instead.
- You can install and run VASP but need to bring your own license file. See also here or the future page in the LUMI Software Library.
Exercise
Exercises are available at /project/project_465000297/exercises/ProgrammingModels/ Copy the files to your home folder before unpacking them.
"},{"location":"PEAP-Q-20221123/extra_03_Running_Applications_Slurm/#exercises","title":"Exercises","text":"A tar file with exercises is available as /appl/local/training/peap-q-20221123/files/exercises-1day-20221123.tar.gz.
"},{"location":"PEAP-Q-20221123/extra_04_Compilers_and_Libraries/","title":"Compilers and Libraries","text":""},{"location":"PEAP-Q-20221123/extra_04_Compilers_and_Libraries/#qa","title":"Q&A","text":" -
By default the libraries are shared (dynamic), so isn't it good practice to but the compiling part of the application in the slurm script job ?
- In general, no. The libraries on the system will not change that often, only after service breaks / upgrades of the Cray Programming Environment. It would also be inefficient to compile using compute node allocation if you have e.g. a wide parallel job with 100 compute nodes.
- You must also consider that it uses your allocated resources (from your project)
-
Question about the cray fortran compiler: I've been trying to use it now on some private code, and it crashes when it encounters preprocesseor statements like #ifdef which gfortran is happy about. Is this expected? Is there a way to handle this?
- What error does the compiler give?
ftn-100: This statement must begin with a label, a keyword or identifier, so it just seems to take the statement literally
- Did you use the right filename extension to activate the preprocessor or the -ep/-ez options shown in the presentation?
- That is probably the problem, I think I missed that comment, I will go back to the slides to look
- After loading PrgEnv-cray you can also get extensive help about all the command line options using man crayftn
- Source file extension needs to start with F and not f to automatically trigger the preprocessor.
- The other cause might be that sometimes there are subtle differences between wat a C and Fortran preprocessor allows but I believe there is an option for that also. I remember having such a ticket long ago.
- Thanks, the filename was actually the problem, I wasn't expecting that
- I may have another advice, just in case: the CCE produces modules with capital letters names (FOO.mod), you can use
-emf to get lowercase (like gfortran).
"},{"location":"PEAP-Q-20221123/extra_04_Compilers_and_Libraries/#exercises","title":"Exercises","text":"A tar file with exercises is available as /appl/local/training/peap-q-20221123/files/exercises-1day-20221123.tar.gz.
Try the compiler exercises in perftools/compiler_listings and try recompiling the exercises from earlier. You don't need to run any jobs.
"},{"location":"PEAP-Q-20221123/extra_05_Advanced_Placement/","title":"Advanced Placement","text":""},{"location":"PEAP-Q-20221123/extra_05_Advanced_Placement/#qa","title":"Q&A","text":" - I have a question regarding
srun: does it forward options to the underlying MPI implementation? with OpenMPI you can get a report of the binding using \u2014report-bindings - Yes, it forwards the options to pmi
- It is possible to get a report and we will mention tomorrow how to do that. But it can be done by option or environmental variable.
"},{"location":"PEAP-Q-20221123/extra_05_Advanced_Placement/#exercises","title":"Exercises","text":"A tar file with exercises is available as /appl/local/training/peap-q-20221123/files/exercises-1day-20221123.tar.gz.
Try the exercides in the Binding subdirectory.
"},{"location":"PEAP-Q-20221123/extra_06_introduction_to_perftools/","title":"Introduction to Perftools","text":""},{"location":"PEAP-Q-20221123/extra_06_introduction_to_perftools/#qa","title":"Q&A","text":" -
Can perftools-lite also be used with the gcc compilers?
- yes, there is support for all the compilers offered on the machine.
- the 'loops' variant only works with CCE as it needs extra information from the compiler.
-
Can perftools also output per-MPI-rank timings or only (as shown in the presentation) averaged over all processes?
* you can get per rank timings in the text output with appropriate options to pat_reoprt. Conversely, you can have a look at apprentice2 which has a nice way of showing per-rank timings.\n
- there is an option pe=ALL that will show timings per rank/PE
-
The output of the statistics will tell you the name of the subroutine, line number, will it also tell you the name of the file where this is from ?
- with the
-O ca+src option to pat_report you can get the source information.
"},{"location":"PEAP-Q-20221123/extra_06_introduction_to_perftools/#exercises","title":"Exercises","text":"The exercises for this session are in the perftools/perftools-lite subdirectory.
Apprentice2 and Reveal downloads
With perftools-base loaded (and it is loaded by default), you can also find the Apprentice2 downloads in $CRAYPAT_ROOT/share/desktop_installers or $CRAY_PERFTOOLS_PREFIX/share/desktop_installers. Copy them to your local machine and install them there.
"},{"location":"PEAP-Q-20221123/extra_07_advanced_performance_analysis_part1/","title":"Advanced Performance Analysis part 1","text":" -
Slide file in /appl/local/training/peap-q-20221123/files/07_advanced_performance_analysis_part1.pdf
-
Recording in /appl/local/training/peap-q-20221123/recordings/07_advanced_performance_analysis_part1.mp4
"},{"location":"PEAP-Q-20221123/extra_07_advanced_performance_analysis_part1/#qa","title":"Q&A","text":" -
I downloaded and installed \"Apprentice2\" under Windows. Even if I am able to connect to LUMI via SSH, I am not able to open a remote folder with Apprentice2 (connection failed). Is it something special to configure (I added the ssh keys to pageagent and also added a LUMI section in my ~/.ssh/config)?
- I think you will have to copy the files to the laptop as Windows has no concept of a generic ssh setup for a user as far as I know.
- Kurt I'd have to check when I can get access to a Windows machine (as my work machine is macOS), but Windows 10 and 11 come with OpenSSH and can use a regular config file in the .ssh subdirectory. And that could allow to define an alias with a parameter that points to the keu file. Windows 10 and 11 also have a built-in ssh agent equivalent that Windows Open?SSH can use.
"},{"location":"PEAP-Q-20221123/extra_08_advanced_performance_analysis_part2/","title":"Advanced Performance Analysis part 2","text":" -
Slide file in /appl/local/training/peap-q-20221123/files/08_advanced_performance_analysis_part2.pdf
-
Recording in /appl/local/training/peap-q-20221123/recordings/08_advanced_performance_analysis_part2.mp4
"},{"location":"PEAP-Q-20221123/extra_08_advanced_performance_analysis_part2/#qa","title":"Q&A","text":" -
If perftools runs on CLE/Mac/windows where can we get it/ find install instructions?
- Only apprentice2 and reveal are available as clients on mac/windows (basically the user interface components to interpret the collected data). These should be self-installing executables. Like
*.dmg on a MAC. - You can download the apprentice install files from LUMI (look at the info box above question 23)
-
I managed to install apprentice2 on my MAC. How can I connect to Lumi? I need to provide a password, but when connecting to Lumi via the terminal I just pass the local ssh key...
- There is no password access enabled, you have to setup ssh in a way that it is being picked up by apprentice
- It should work if you have a ssh config file with the hostname, username and identity file for lumi. Can you connect to lumi with just
ssh lumi? - Yes, I can connect to lumi with just
ssh lumi. However: apprentice2, open remote with host username@lumi.csc.fi prompts for a password
"},{"location":"PEAP-Q-20221123/extra_08_advanced_performance_analysis_part2/#exercises","title":"Exercises","text":"The exercises are in the perftools subdirectory.
"},{"location":"PEAP-Q-20221123/extra_09_debugging_at_scale/","title":"Debugging at Scale","text":""},{"location":"PEAP-Q-20221123/extra_09_debugging_at_scale/#qa","title":"Q&A","text":"/
"},{"location":"PEAP-Q-20221123/extra_11_cray_mpi_MPMD_short/","title":"MPI Topics on the HPE Cray EX Supercomputer","text":""},{"location":"PEAP-Q-20221123/extra_11_cray_mpi_MPMD_short/#qa","title":"Q&A","text":"/
"},{"location":"PEAP-Q-20221123/extra_12_IO_short_LUMI/","title":"Optimizing Large Scale I/O","text":""},{"location":"PEAP-Q-20221123/extra_12_IO_short_LUMI/#qa","title":"Q&A","text":" -
You mentioned that you are using a RAID array to have redundancy of storage (and I read RAID-6 in the slides), have you considered using the ZFS file system ? I don't know too much, but i read it could be more reliable and better performance.
- in ZFS you also chose a RAID level. I'm not sure what is used on LUMI, and it might be different for metadata and the storage targets. You will not solve the metadata problem with ZFS though. I know H?PE supports two backend file systems for Lustre but I'm not sure which one is used on LUMI.
-
This is really a question about the earlier session on performance tools, but I hope it's still OK to post it: I've tried using perftools-liteon my own code, but doing so it does not compile (it does without the modules). The linking seems to fail with WARNING: cannot acquire file status information for '-L/usr/lib64/libdl.so' [No such file or directory] Is this something that has been seen before? Any tips/hints on what is going on?
- without checking the code is hard to understand what it the problem. Do you really link with libdl.so in your compilation?
- Yes, doing ldd on a successful compile gives
libdl.so.2 => /lib64/libdl.so.2 (0x00007f228c3b0000) The other dl library symlinks to that one. - OK, the question is the line
-L/usr/lib64/libdl.so, I wonder if you are using somewhere in the makefile - Yes, this is a large cmake set-up though, but cmake has
CMakeCache.txt:LIBDL_LIBRARY:FILEPATH=/usr/lib64/libdl.so - Then we are hitting a situation where perftools-lite doesn't work... Try perftools, restricting to
-g - OK, thanks! Will try that.
"},{"location":"PEAP-Q-20221123/extra_13_LUMI_Software_Stacks/","title":"Additional software on LUMI","text":"Presenter: Kurt Lust (LUST)
Additional materials
"},{"location":"PEAP-Q-20221123/extra_13_LUMI_Software_Stacks/#qa","title":"Q&A","text":" -
Error: ~/exercises/VH1-io/VH1-io/run> sbatch run_vh1-io.slurm sbatch: error: Invalid directive found in batch script: e.g Do I need to change something in run_vh1-io.slurm before submitting?
- Yes, you have to at least adapt the account, partition and reservation. qos has to be deleted (reservation is also optional).
- The readme has some quick build instructions. It worked for me :)
- Okay, thank you.
-
More information about the python container wrapper can be found in the documentation.
-
Is easybuild with AMD compilers on the roadmap for EB?
- The AMD AOCC compiler is already available in the Cray and LUMI software stack. Either
PrgEnv-aocc or cpeAOCC/22.08. Additionally the AMD LLVM compiler is available via PrgEnv-amd. - Ok thanks! I thought one of Kurt's slides showed that EB currently only works with GNU or Intel
- No, it works with Cray, GNU and AOCC but intel is tricky and not recommended.
- Thanks!
- [Kurt] Clarification: Standard EasyBuild has a lot of toolchains for different compilers, but only build recipes \\9the EasyConfig files) for some specific toolchains, called the common toolchains. And they are based on GNU+OpenMPI+FlexiBLAS with OpenBLAS+FFTW and a few other libraries, or Intel (currently the classic compilers but that will change) with MKL and Intel MPI. This is what I pointed to with GNU and Intel in EasyBuild. For LUMI we build our own toolchain definitions which are an improved version of those used at CSCS and similar toolchains for an older version of the Cray PE included in EasyBuild.
- [Kurt] It is not on the roadmap of the EasyBuilders. They have toolchains for AMD compilers but doe not build specific EasyBuild recipes and don't do much specific testing. I am trying to push them to support at least default clang, but then the Fortran mess will have to be cleaned up first. Regular clang support would at least imply that a number of clang-specific configuration problems would get solved so that changing to the AMD toolchain would be a relatively small effort (and could work with
--try-toolchain). - Ok thanks again! :D
-
Julia (language) is installed?
- No, not in the central software stack available for everyone. It is quite easy to just download the Julia binaries in your home directory and just run it, though. Julia uses OpenBLAS by default, which is quite OK on AMD CPUs. If you want, you can also try to somewhat \"hidden\" Julia module installed with Spack.
module load spack/22.08; module load julia/1.7.2-gcc-vv. No guarantees on that one, though (unsupported/untested). - Another easy approach is to use existing containers. Unless GPU is used, generic container from DockerHub should work fine.
- It is not clear though if the communication across nodes is anywhere near optimal on LUMI at the moment. The problem is that Julia comes with very incomplete installation instructions. Both the Spack and EasyBuild teams are struggling with a proper installation from sources and neither seem to have enough resources to also fully test and benchmark to see if Julia is properly tuned.
-
Paraview is a data postprocessing software that employs a graphical user interface. Is it possible to use it with LUMI? Also, as explained in https://www.paraview.org/Wiki/PvPython_and_PvBatch,\u00a0Paraview functions may be accessed without using the GUI and just using python scripts. Is it feasible to use pvBatch and pvPython in LUMI to postprocess data with Paraview?
- Yes, you can use Paraview on LUMI. We have an EasyBuild recipe that is not yet present on the system but is available via the LUMI \"contrib\" Github repository. This easyconfig build the server components only and does CPU rendering via MESA. You need to run a client of the same version of the server on your local machine in order to interact with the server.
- Actually, the Paraview recipe is still missing in the repository but we will take care of that.
"},{"location":"PEAP-Q-20221123/extra_14_LUMI_User_Support/","title":"LUMI support and LUMI documentation","text":"Presenter: J\u00f8rn Dietze (LUST)
Additional materials
"},{"location":"PEAP-Q-20221123/extra_14_LUMI_User_Support/#qa","title":"Q&A","text":" -
Will porting calls be available just for academic users? What about (potential) industrial users?
- There are other EuroHPC inititiaves that specifically aim to support industrial users (like the national competence centres). An industrial project for the LUMI porting program could be considered if it is open research and the software is then publicly available for all (and I think without a big license cost).
- Good to know. Thanks for answering. I guess industrial users can always pay for porting if they wish to keep their software private.
- Indeed, but then the problem on our side would still be personpower. The payment could of course be used to hire additional people on our side, but that is also not always easy. I also don't know how much AMD and/or HPE would charge for their part in the support.
-
If I think I may need level-3 support is it still recommended to go through LUMI service desk?
- Hard to tell. At the moment we ourselves have no clear view on all the instances giving Level-3 support. If a ticket would end up with us we would do an effort to refer to the right instance, but the reality is that we hope there is already a lot more than we see. I am pretty sure that some centres are already offering some support to some of the users of their country without much contact with us.
- I guess to be clearer. Would LUST like to be kept 'in the loop' regarding these problems or is it more effort than necessary for LUST to forward these tickets to local centres?
- It would be nice for us to be in the loop as we can learn from it, but the reality is that it turned out to be difficult to integrate ticketing systems to make that easy and that the communication with some local teams is decent but is totally absent with others so we cannot efficiently pass things to the local centres. That is a communication problem that LUST and the LUMI project management needs to solve though.
"},{"location":"PEAP-Q-20221123/extra_15_Day_2_QandA/","title":"Day 2 General Q&A","text":" -
What is the libfabric module that is loaded by default upon login?
- It is the library necessary for the node interconnect (slingshot) to work. It will be automatically loaded if you load
craype-network-ofi module which is standard if you login or use one of the described Software stacks.
-
I know it is not the object of today course, but may I still ask how launch I a job on LUMI-G ? As Kurt said, first: reload LUMI/22.08 partition/G and then do I have to specify a specific --partition with the sbatch command ?
- Yes, you have to use
--partition=pilot but this only works at the moment if you are member of a GPU-pilot project. Alternatively you can use the eap partition which is available for everyone on LUMI and consists of the same GPU nodes, but has shorter walltime limits. eap is intended for testing only, not for production runs. - partition
gpu is shown but currently not available (it is for the HPE benchmarking) instead pilot and eap have to be used. - Thank you for the precision. My project is mostly GPU oriented, so we did not ask for CPU as we thought a minimum amount of CPU would be included. Will it be possible to launch jobs on LUMI-G without any CPU resources or should I ask for additional CPU resources ?
- [Kurt] In regular operation you will only need GPU billing units to run on the GPUs. However, at the moment, during the pilot, the situation is different:
- The Early Access Platform (partition
eap) does not require GPU billing units. It is also not charged, but usage is monitored and should remain reasonable, i.e., development and first benchmarking only. However, to get access to the queue, a minimal CPU allocation is needed. - The
pilot partition is for pilot users only and this one requires GPU billing units but no CPU allocation.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/","title":"Notes from the HedgeDoc page","text":"These are the notes from the LUMI-C training, 23.--24.11.2022, 9:30--17:30 (CET) Hybrid on Zoom and in person HOEK 38, Leuvenseweg 38, 1000 Brussels
- Notes from the HedgeDoc page
- General information
- Exercises
- LUMI user coffee break
- Slides and other material
- Q&A of the sessions on day 1
- Course introduction
- Introduction to the HPE Cray Hardware and Programming Environment
- First steps to running on Cray EX Hardware
- Overview of compilers and libraries
- Advanced Application Placement
- Q&A of the sessions on day 2
- Introduction to Perftools
- Advanced Performance Analysis I/II
- Advanced Performance Analysis II/II
- Debugging
- MPI Topics on the HPE Cray EX supercomputer
- Optimizing Large Scale I/O
- Lust presentation: LUMI software stack
- LUST presentation: LUMI support
- General Q&A
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#general-information","title":"General information","text":""},{"location":"PEAP-Q-20221123/hedgedoc_notes/#exercises","title":"Exercises","text":"The exercise files are on lumi at /project/project_465000297/exercises.Copy the files into your home directory and work from there.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#lumi-user-coffee-break","title":"LUMI user coffee break","text":"30.11.22, 13:00-13:45 (CET), 14:00--14:45(EET) Meet the LUMI user support team, discuss problems, give feedback or suggestions on how to improve services, and get advice for your projects.
Every last Wednesday in a month. Join via Zoom
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#slides-and-other-material","title":"Slides and other material","text":"Slides from HPE are available on LUMI at /project/project_465000297/slides You need to join the training project via the link you received in the email on Monday. Slides from the LUST talks are available on these pages
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#qa-of-the-sessions-on-day-1","title":"Q&A of the sessions on day 1","text":""},{"location":"PEAP-Q-20221123/hedgedoc_notes/#course-introduction","title":"Course introduction","text":"Presenter: Kurt Lust Slides
-
Do you know the current allocation per country ? (I wonder how much Belgium contributes to LUMI)
- Belgium: 7.4% of the total budget.
- Information about how to contact the Belgian team is https://www.enccb.be/LUMI
-
What do you mean the training project? like ssh to lumi? or the puhuri portal?
- Yes, there is a small allocation on LUMI associated with the course (i.e. yo can log in with SSH and run jobs). We send out an email on Monday with the puhuri link to join the training project. This is a different project from the one you may have from a project from EuroHPC or your national allocation. Please use this project only for the exercises, not to run your own code or we will run out of our allocation for the course.
- The information on how to join was sent out a few days before the course. We will mention the project number and slurm reservation before we start the exercises.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#introduction-to-the-hpe-cray-hardware-and-programming-environment","title":"Introduction to the HPE Cray Hardware and Programming Environment","text":"Presenter: Harvey Richardson (HPE) Slide files: /project/project_465000297/slides/01_EX_Architecture.pdf and /project/project_465000297/slides/02_PE_and_Modules.pdf
-
What's the expected CPU clock for a heavy all-core job?
- 2.45 GHz base clock rate (https://www.amd.com/en/product/10906)
- Don't expect any boost for a really heavy load. The effective clock is determined dynamically by the system depending on the heating/cooling situation. It can be complex, because heavy network/MPI traffic will also affect this, and the node tries to distribute power between the CPU cores, the IO die on the CPU, (the GPUs for LUMI-G), and the network cards on-the-fly to optimize for the best performance.
-
Regarding the CPU cores and threads : you said that the threads are hardware : should we run large runs on the number of threads, rather than the number of nodes ?
- Could you elaborate a bit more?
- My understanding is : a cpu that has 64 cores, shows 128 threads by multithreading, therefore cases that use the cpu 100% load during 100% of the time will be better tu run on 64 core, rather than the 128 threads to eliminate the overhead of the operating system due to scheduling the software threads to the hardware core.
- There are two sessions about SLURM in the course where it will be explained how to use hyperthreading etc.
- In general, hyperthreading doesn't offer much benefits on a good code, rather the contrary. It's really more lack of cache and memory bandwidth stat stops you from using hyperthreading. Hyperthreading is basically a way to hide latency in very branchy code such as databases. In fact there are codes that run faster using a given number of nodes and 75% of the cores than the same number of nodes and all cores per socket, without hyperthreading.
- OK I will wait for the next parts of the course. Thank you
-
At the ExaFoam summer school I was told that HDF5 parallel I/O does not scale to exa scale applications. Ist that correct Instead the exafoam project is working on an ADIOS-2 based system for parallel I/O in OpenFOAM. Feel free to answer this question at the most appropriate time in the course
- This is the current understanding, so I would say \"yes\" (even if I'm not a 100% expert).
- The HDF5 group had a BOF at SC22 about their future plans
- I would not rule out HDF5 parallel I/O at large scale on LUMI-C for runs of say 500 nodes or similar. The best approach would be to try to benchmark it first for your particular use case.
- It depends on what you would exactly need to do. If you need to write to file, I am not sure there are real alternatives. ADIOS would be great for in-situ processing.
- [Harvey] I have heard of some good experience about ADIOS-2 but have not tried it yet myself, on my list of things to do.
- One of the engines that ADIOS-2 can use is HDF5 so it is not necessarily more scalable. Just as for HDF5, it will depend much on how it is used and tuned for the particular simulation.
-
Will there be, for the exercises, shown on-screen (in the zoom session) terminal session which will show how to use all the commands, how to successfully complete the exercises, or will we be void of visual guide and will we only have to rely on the voice of the person presenting the exercises? What I mean - can we please have the presenter show interactively the commands and their usage and output?
- You can find exercises at
/project/project_465000297/exercises/ with Readme's. You can copy the directory in your area. Just follow them and let us know if you have questions. We will cover it during the next sessions.
-
Julia (language) is installed?
- No, not in the central software stack available for everyone. It is quite easy to just download the Julia binaries in your home directory and just run it, though. Julia uses OpenBLAS by default, which is quite OK on AMD CPUs. If you want, you can also try to somewhat \"hidden\" Julia module installed with Spack.
module load spack/22.08; module load julia/1.7.2-gcc-vv. No guarantees on that one, though (unsupported/untested). - Another easy approach is to use existing containers. Unless GPU is used, generic container from DockerHub should work fine.
- It is not clear though if the communication across nodes is anywhere near optimal on LUMI at the moment. The problem is that Julia comes with very incomplete installation instructions. Both the Spack and EasyBuild teams are struggling with a proper installation from sources and neither seem to have enough resources to also fully test and benchmark to see if Julia is properly tuned.
-
Paraview is a data postprocessing software that employs a graphical user interface. Is it possible to use it with LUMI? Also, as explained in https://www.paraview.org/Wiki/PvPython_and_PvBatch,\u00a0Paraview functions may be accessed without using the GUI and just using python scripts. Is it feasible to use pvBatch and pvPython in LUMI to postprocess data with Paraview?
- Yes, you can use Paraview on LUMI. We have an EasyBuild recipe that is not yet present on the system but is available via the LUMI \"contrib\" Github repository. This easyconfig build the server components only and does CPU rendering via MESA. You need to run a client of the same version of the server on your local machine in order to interact with the server.
- Actually, the Paraview recipe is still missing in the repository but we will take care of that.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#first-steps-to-running-on-cray-ex-hardware","title":"First steps to running on Cray EX Hardware","text":"Slide file: /project/project_465000297/slides/03_Running_Applications_Slurm.pdf
-
I would like to know whether it is possible to run FEM simulation software (e.g., COMSOL Multiphysics) on LUMI?
- As long as it is installed correctly then I see no reason why not. It has been run on other Cray EX systems. The only complication here will be the commerical license. LUMI does not have its own license, you would have to provide your own. There might be some complications right now, because the compute nodes do not have internet access, which would block access to the license server. We hope that internet access will be enabled on the compute nodes soon.
-
Is it something like MC (Midnight Commander) installed?
- No, and midnight commander specifically has some annoying dependencies so it will not come quickly in a way that integrates properly with all the other software on LUMI.
- You can see your files and transfer to and from LUMI using tools like filezilla and the host
sftp://lumi.csc.fi - And for people on a connection with sufficiently low latency Visual Studio Code also works. The client-server connection seems to fail easily though on connections with a higher latency. It is also more for editing remotely in a user friendly way than browsing files or running commands. But we do understand that mc is awesome for some people.
- In the future there will also be an Open OnDemand interface to LUMI.
-
MC is ok but Krusader is better
-
and WinSCP?
- That is client software to run on your PC. It should work.
- In general, until we have Open OnDemand, the support for running GUI software on LUMI is very limited. And after that it will not be brilliant either, as an interface such as GNOME is not ideal to run on multiuser login nodes due to the resources it needs but also due to how it works internally.
-
Would it be alright to test the building of licensed software such as VASP during the course and the EasyBuild system you have in place? (and benchmark with very small test run of course)
- Please don't run benchmarks of your own software on the project account. If you already have another project, use that one instead.
- You can install and run VASP but need to bring your own license file. See also here or the future page in the LUMI Software Library.
Exercise
Exercises are available at /project/project_465000297/exercises/ProgrammingModels/ Copy the files to your home folder before unpacking them.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#overview-of-compilers-and-libraries","title":"Overview of compilers and libraries","text":"Slide file: /project/project_465000297/slides/04_Compilers_and_Libraries.pdf
-
By default the libraries are shared (dynamic), so isn't it good practice to but the compiling part of the application in the slurm script job ?
- In general, no. The libraries on the system will not change that often, only after service breaks / upgrades of the Cray Programming Environment. It would also be inefficient to compile using compute node allocation if you have e.g. a wide parallel job with 100 compute nodes.
- You must also consider that it uses your allocated resources (from your project)
-
Question about the cray fortran compiler: I've been trying to use it now on some private code, and it crashes when it encounters preprocesseor statements like #ifdef which gfortran is happy about. Is this expected? Is there a way to handle this?
- What error does the compiler give?
ftn-100: This statement must begin with a label, a keyword or identifier, so it just seems to take the statement literally
- Did you use the right filename extension to activate the preprocessor or the -ep/-ez options shown in the presentation?
- That is probably the problem, I think I missed that comment, I will go back to the slides to look
- After loading PrgEnv-cray you can also get extensive help about all the command line options using man crayftn
- Source file extension needs to start with F and not f to automatically trigger the preprocessor.
- The other cause might be that sometimes there are subtle differences between wat a C and Fortran preprocessor allows but I believe there is an option for that also. I remember having such a ticket long ago.
- Thanks, the filename was actually the problem, I wasn't expecting that
- I may have another advice, just in case: the CCE produces modules with capital letters names (FOO.mod), you can use
-emf to get lowercase (like gfortran).
Exercise
Try the compiler exercises at /project/project_465000297/exercises/perftools/compiler_listings and recompiling the exercises from earlier. You don't need to run any jobs.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#advanced-application-placement","title":"Advanced Application Placement","text":"Presenter: Jean Pourroy (HPE) Slide file: /project/project_465000297/slides/05_Advanced_Placement.pdf
- I have a question regarding
srun: does it forward options to the underlying MPI implementation? with OpenMPI you can get a report of the binding using \u2014report-bindings - Yes, it forwards the options to pmi
- It is possible to get a report and we will mention tomorrow how to do that. But it can be done by option or environmental variable.
Exercise
Try out the exercises found under /project/project_465000297/exercises/Binding and ask questions here. All exercises are described in the pdf document there.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#qa-of-the-sessions-on-day-2","title":"Q&A of the sessions on day 2","text":""},{"location":"PEAP-Q-20221123/hedgedoc_notes/#introduction-to-perftools","title":"Introduction to Perftools","text":"Presenter: Alfio Lazarro Slide file: /project/project_465000297/slides/06_introduction_to_perftools.pdf
-
Can perftools-lite also be used with the gcc compilers?
- yes, there is support for all the compilers offered on the machine.
- the 'loops' variant only works with CCE as it needs extra information from the compiler.
-
Can perftools also output per-MPI-rank timings or only (as shown in the presentation) averaged over all processes?
* you can get per rank timings in the text output with appropriate options to pat_reoprt. Conversely, you can have a look at apprentice2 which has a nice way of showing per-rank timings.\n
- there is an option pe=ALL that will show timings per rank/PE
-
The output of the statistics will tell you the name of the subroutine, line number, will it also tell you the name of the file where this is from ?
- with the
-O ca+src option to pat_report you can get the source information.
Exercise
The exercise files are on lumi at /project/project_465000297/exercises/perftools/perftools-lite. Copy the files into your home directory and work from there.
Apprentice2 and Reveal downloads
With perftools-base loaded (and it is loaded by default), you can also find the Apprentice2 downloads in $CRAYPAT_ROOT/share/desktop_installers or
$CRAY_PERFTOOLS_PREFIX/share/desktop_installers. Copy them to your local machine and install them there.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#advanced-performance-analysis-iii","title":"Advanced Performance Analysis I/II","text":"Presenter: Thierry Braconnier (HPE) Slide file: /project/project_465000297/slides/07_advanced_performance_analysis_part1.pdf
-
I downloaded and installed \"Apprentice2\" under Windows. Even if I am able to connect to LUMI via SSH, I am not able to open a remote folder with Apprentice2 (connection failed). Is it something special to configure (I added the ssh keys to pageagent and also added a LUMI section in my ~/.ssh/config)?
- I think you will have to copy the files to the laptop as Windows has no concept of a generic ssh setup for a user as far as I know.
- [name=Kurt] I'd have to check when I can get access to a Windows machine (as my work machine is macOS), but Windows 10 and 11 come with OpenSSH and can use a regular config file in the .ssh subdirectory. And that could allow to define an alias with a parameter that points to the keu file. Windows 10 and 11 also have a built-in ssh agent equivalent that Windows Open?SSH can use.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#advanced-performance-analysis-iiii","title":"Advanced Performance Analysis II/II","text":"Presenter: Thierry Braconnier (HPE) Slide file: /project/project_465000297/slides/08_advanced_performance_analysis_part2.pdf
-
If perftools runs on CLE/Mac/windows where can we get it/ find install instructions?
- Only apprentice2 and reveal are available as clients on mac/windows (basically the user interface components to interpret the collected data). These should be self-installing executables. Like
*.dmg on a MAC. - You can download the apprentice install files from LUMI (look at the info box above question 23)
-
I managed to install apprentice2 on my MAC. How can I connect to Lumi? I need to provide a password, but when connecting to Lumi via the terminal I just pass the local ssh key...
- There is no password access enabled, you have to setup ssh in a way that it is being picked up by apprentice
- It should work if you have a ssh config file with the hostname, username and identity file for lumi. Can you connect to lumi with just
ssh lumi? - Yes, I can connect to lumi with just
ssh lumi. However: apprentice2, open remote with host username@lumi.csc.fi prompts for a password
Exercise
The exercise files are on lumi at /project/project_465000297/exercises/perftools/.Copy the files into your home directory and work from there.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#debugging","title":"Debugging","text":"Presenter: Alfio Lazarro (HPE) Slide file: /project/project_465000297/slides/09_debugging_at_scale.pdf
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#mpi-topics-on-the-hpe-cray-ex-supercomputer","title":"MPI Topics on the HPE Cray EX supercomputer","text":"Presenter: Harvey Richardson (HPE) Slide file: /project/project_465000297/slides/11_cray_mpi_MPMD_short.pdf
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#optimizing-large-scale-io","title":"Optimizing Large Scale I/O","text":"Presenter: Harvey Richardson (HPE) Slide file: /project/project_465000297/slides/12_IO_short_LUMI.pdf
-
You mentioned that you are using a RAID array to have redundancy of storage (and I read RAID-6 in the slides), have you considered using the ZFS file system ? I don't know too much, but i read it could be more reliable and better performance.
- in ZFS you also chose a RAID level. I'm not sure what is used on LUMI, and it might be different for metadata and the storage targets. You will not solve the metadata problem with ZFS though. I know H?PE supports two backend file systems for Lustre but I'm not sure which one is used on LUMI.
-
This is really a question about the earlier session on performance tools, but I hope it's still OK to post it: I've tried using perftools-liteon my own code, but doing so it does not compile (it does without the modules). The linking seems to fail with WARNING: cannot acquire file status information for '-L/usr/lib64/libdl.so' [No such file or directory] Is this something that has been seen before? Any tips/hints on what is going on?
- without checking the code is hard to understand what it the problem. Do you really link with libdl.so in your compilation?
- Yes, doing ldd on a successful compile gives
libdl.so.2 => /lib64/libdl.so.2 (0x00007f228c3b0000) The other dl library symlinks to that one. - OK, the question is the line
-L/usr/lib64/libdl.so, I wonder if you are using somewhere in the makefile - Yes, this is a large cmake set-up though, but cmake has
CMakeCache.txt:LIBDL_LIBRARY:FILEPATH=/usr/lib64/libdl.so - Then we are hitting a situation where perftools-lite doesn't work... Try perftools, restricting to
-g - OK, thanks! Will try that.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#lust-presentation-lumi-software-stack","title":"Lust presentation: LUMI software stack","text":"Presenter: Kurt Lust Slides and notes
-
Error: ~/exercises/VH1-io/VH1-io/run> sbatch run_vh1-io.slurm sbatch: error: Invalid directive found in batch script: e.g Do I need to change something in run_vh1-io.slurm before submitting?
- Yes, you have to at least adapt the account, partition and reservation. qos has to be deleted (reservation is also optional).
- The readme has some quick build instructions. It worked for me :)
- Okay, thank you.
-
More information about the python container wrapper can be found in the documentation.
-
Is easybuild with AMD compilers on the roadmap for EB?
- The AMD AOCC compiler is already available in the Cray and LUMI software stack. Either
PrgEnv-aocc or cpeAOCC/22.08. Additionally the AMD LLVM compiler is available via PrgEnv-amd. - Ok thanks! I thought one of Kurt's slides showed that EB currently only works with GNU or Intel
- No, it works with Cray, GNU and AOCC but intel is tricky and not recommended.
- Thanks!
- [Kurt] Clarification: Standard EasyBuild has a lot of toolchains for different compilers, but only build recipes \\9the EasyConfig files) for some specific toolchains, called the common toolchains. And they are based on GNU+OpenMPI+FlexiBLAS with OpenBLAS+FFTW and a few other libraries, or Intel (currently the classic compilers but that will change) with MKL and Intel MPI. This is what I pointed to with GNU and Intel in EasyBuild. For LUMI we build our own toolchain definitions which are an improved version of those used at CSCS and similar toolchains for an older version of the Cray PE included in EasyBuild.
- [Kurt] It is not on the roadmap of the EasyBuilders. They have toolchains for AMD compilers but doe not build specific EasyBuild recipes and don't do much specific testing. I am trying to push them to support at least default clang, but then the Fortran mess will have to be cleaned up first. Regular clang support would at least imply that a number of clang-specific configuration problems would get solved so that changing to the AMD toolchain would be a relatively small effort (and could work with
--try-toolchain). - Ok thanks again! :D
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#lust-presentation-lumi-support","title":"LUST presentation: LUMI support","text":"Presenter: Jorn Dietze Slides
-
Will porting calls be available just for academic users? What about (potential) industrial users?
- There are other EuroHPC inititiaves that specifically aim to support industrial users (like the national competence centres). An industrial project for the LUMI porting program could be considered if it is open research and the software is then publicly available for all (and I think without a big license cost).
- Good to know. Thanks for answering. I guess industrial users can always pay for porting if they wish to keep their software private.
- Indeed, but then the problem on our side would still be personpower. The payment could of course be used to hire additional people on our side, but that is also not always easy. I also don't know how much AMD and/or HPE would charge for their part in the support.
-
If I think I may need level-3 support is it still recommended to go through LUMI service desk?
- Hard to tell. At the moment we ourselves have no clear view on all the instances giving Level-3 support. If a ticket would end up with us we would do an effort to refer to the right instance, but the reality is that we hope there is already a lot more than we see. I am pretty sure that some centres are already offering some support to some of the users of their country without much contact with us.
- I guess to be clearer. Would LUST like to be kept 'in the loop' regarding these problems or is it more effort than necessary for LUST to forward these tickets to local centres?
- It would be nice for us to be in the loop as we can learn from it, but the reality is that it turned out to be difficult to integrate ticketing systems to make that easy and that the communication with some local teams is decent but is totally absent with others so we cannot efficiently pass things to the local centres. That is a communication problem that LUST and the LUMI project management needs to solve though.
"},{"location":"PEAP-Q-20221123/hedgedoc_notes/#general-qa","title":"General Q&A","text":" -
What is the libfabric module that is loaded by default upon login?
- It is the library necessary for the node interconnect (slingshot) to work. It will be automatically loaded if you load
craype-network-ofi module which is standard if you login or use one of the described Software stacks.
-
I know it is not the object of today course, but may I still ask how launch I a job on LUMI-G ? As Kurt said, first: reload LUMI/22.08 partition/G and then do I have to specify a specific --partition with the sbatch command ?
- Yes, you have to use
--partition=pilot but this only works at the moment if you are member of a GPU-pilot project. Alternatively you can use the eap partition which is available for everyone on LUMI and consists of the same GPU nodes, but has shorter walltime limits. eap is intended for testing only, not for production runs. - partition
gpu is shown but currently not available (it is for the HPE benchmarking) instead pilot and eap have to be used. - Thank you for the precision. My project is mostly GPU oriented, so we did not ask for CPU as we thought a minimum amount of CPU would be included. Will it be possible to launch jobs on LUMI-G without any CPU resources or should I ask for additional CPU resources ?
- [Kurt] In regular operation you will only need GPU billing units to run on the GPUs. However, at the moment, during the pilot, the situation is different:
- The Early Access Platform (partition
eap) does not require GPU billing units. It is also not charged, but usage is monitored and should remain reasonable, i.e., development and first benchmarking only. However, to get access to the queue, a minimal CPU allocation is needed. - The
pilot partition is for pilot users only and this one requires GPU billing units but no CPU allocation.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/","title":"LUMI Software Stacks","text":"In this part of the training, we cover:
- Software stacks on LUMI, where we discuss the organisation of the software stacks that we offer and some of the policies surrounding it
- Advanced Lmod use to make the best out of the software stacks
- Creating your customised environment with EasyBuild, the tool that we use to install most software.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#the-software-stacks-on-lumi","title":"The software stacks on LUMI","text":""},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#design-considerations","title":"Design considerations","text":" -
LUMI is a very leading edge and also an inhomogeneous machine. Leading edge often implies teething problems and inhomogeneous doesn't make life easier either.
- It uses a novel interconnect which is an extension of Ethernet rather than being based on InfiniBand, and that interconnect has a different software stack of your typical Mellanox InfiniBand cluster.
- It also uses a relatively new GPU architecture, AMD CDNA2, with an immature software ecosystem. The GPU nodes are really GPU-first, with the interconnect cards connected directly to the GPU packages and only one CPU socket, and another feature which is relatively new: a fully cache-coherent unified memory space between the CPU and GPUs, though of course very NUMA. This is a feature that has previously only been seen in some clusters with NVIDIA P100 and V100 GPUs and IBM Power 8 and 9 CPUs used for some USA pre-exascale systems, and of course in the Apple M1 but then without the NUMA character.
- LUMI is also inhomogeneous because some nodes have zen2 processors while the two main compute partitions have zen3-based CPUs, and the compute GPU nodes have AMD GPUs while the visualisation nodes have NVIDIA GPUs.
Given the novel interconnect and GPU we do expect that both system and application software will be immature at first and evolve quickly, hence we needed a setup that enables us to remain very agile, which leads to different compromises compared to a software stack for a more conventional and mature system as an x86 cluster with NVIDIA GPUs and Mellanox InfiniBand.
-
Users also come to LUMI from 11 different channels, not counting subchannels as some countries have multiple organisations managing allocations, and those channels all have different expectations about what LUMI should be and what kind of users should be served. For our major stakeholder, the EuroHPC JU, LUMI is a pre-exascale system meant to prepare users and applications to make use of future even large systems, while some of the LUMI consortium countries see LUMI more as an extension of their tier-1 or even tier-2 machines.
-
The central support team of LUMI is also relatively small compared to the nature of LUMI with its many different partitions and storage services and the expected number of projects and users. Support from users coming in via the national channels will rely a lot on efforts from local organisations also. So we must set up a system so that they can support their users without breaking things on LUMI, and to work with restricted rights. And in fact, LUMI User Support team members also have very limited additional rights on the machine compared to regular users or support people from the local organisations. LUST is currently 9 FTE. Compare this to 41 people in the J\u00fclich Supercomputer Centre for software installation and support only... (I give this number because it was mentioned in a recent talk in an EasyBuild user meeting.)
-
The Cray Programming Environment is also a key part of LUMI and the environment for which we get support from HPE Cray. It is however different from more traditional environments such as a typical Intel oneAPI installation of a typical installation build around the GNU Compiler Collection and Open MPI or MPICH. The programming environment is installed with the operating system rather than through the user application software stack hence not managed through the tools used for the application software stack, and it also works differently with its universal compiler wrappers that are typically configured through modules.
-
We also see an increasing need for customised setups. Everybody wants a central stack as long as their software is in there but not much more as otherwise it is hard to find, and as long as software is configured in the way they are used to. And everybody would like LUMI to look as much as possible as their home system. But this is of course impossible. Moreover, there are more and more conflicts between software packages and modules are only a partial solution to this problem. The success of containers, conda and Python virtual environments is certainly to some extent explained by the need for more customised setups and the need for multiple setups as it has become nearly impossible to combine everything in a single setup due to conflicts between packages and the dependencies they need.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#the-lumi-solution","title":"The LUMI solution","text":"We tried to take all these considerations into account and came up with a solution that may look a little unconventional to many users.
In principle there should be a high degree of compatibility between releases of the HPE Cray Programming Environment but we decided not to take the risk and build our software for a specific release of the programming environment, which is also a better fit with the typical tools used to manage a scientific software stack such as EasyBuild and Spack as they also prefer precise versions for all dependencies and compilers etc. We also made the stack very easy to extend. So we have many base libraries and some packages already pre-installed but also provide an easy and very transparant way to install additional packages in your project space in exactly the same way as we do for the central stack, with the same performance but the benefit that the installation can be customised more easily to the needs of your project. Not everybody needs the same configuration of GROMACS or LAMMPS or other big packages, and in fact a one-configuration-that-works-for-everybody may even be completely impossible due to conflicting options that cannot be used together.
For the module system we could chose between two systems supported by HPE Cray. They support Environment Modules with module files based on the TCL scripting language, but only the old version that is no longer really developed and not the newer versions 4 and 5 developed in France, and Lmod, a module system based on the LUA scripting language that also support many TCL module files through a translation layer. We chose to go with Lmod as LUA is an easier and more modern language to work with and as Lmod is much more powerful than Environment Modules 3, certainly for searching modules.
To manage the software installations we could chose between EasyBuild, which is mostly developed in Europe and hence a good match with a EuroHPC project as EuroHPC wants to develop a European HPC technology stack from hardware to application software, and Spack, a package developed in the USA national labs. We chose to go with EasyBuild as our primary tool for which we also do some development. However, as we shall see, our EasyBuild installation is not your typical EasyBuild installation that you may be acustomed with from clusters at your home institution. It uses toolchains specifically for the HPE Cray programming environment so recipes need to be adapted. We do offer an growing library of Cray-specific installation recipes though. The whole setup of EasyBuild is done such that you can build on top of the central software stack and such that your modules appear in your module view without having to add directories by hand to environment variables etc. You only need to point to the place where you want to install software for your project as we cannot automatically determine a suitable place. We have a pre-configured Spack installation also but do not do any package development in Spack ourselves. The setup is meant for users familiar with Spack who can also solve problems that occur on the road, but we already did the work of ensuring that Spack is correctly configured for the HPE Cray compilers.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#software-policies","title":"Software policies","text":"As any site, we also have a number of policies about software installation, and we're still further developing them as we gain experience in what we can do with the amount of people we have and what we cannot do.
LUMI uses a bring-your-on-license model except for a selection of tools that are useful to a larger community.
- This is partly caused by the distributed user management as we do not even have the necessary information to determine if a particular user can use a particular license, so we must shift that responsibility to people who have that information, which is often the PI of your project.
- You also have to take into account that up to 20% of LUMI is reserved for industry use which makes negotiations with software vendors rather difficult as they will want to push us onto the industrial rather than academic pricing as they have no guarantee that we will obey to the academic license restrictions.
- And lastly, we don't have an infinite budget. There was a questionaire send out to some groups even before the support team was assembled and that contained a number of packages that by themselves would likely consume our whole software budget for a single package if I look at the size of the company that produces the package and the potential size of their industrial market. So we'd have to make choices and with any choice for a very specialised package you favour a few groups. And there is also a political problem as without doubt the EuroHPC JU would prefer that we invest in packages that are developed by European companies or at least have large development teams in Europe.
The LUMI User Support Team tries to help with installations of recent software but porting or bug correction in software is not our task. As a user, you have to realise that not all Linux or even supercomputer software will work on LUMI. This holds even more for software that comes only as a binary. The biggest problems are the GPU and anything that uses distributed memory and requires high performance from the interconnect. For example,
- software that use NVIDIA proprietary programming models and libraries needs to be ported.
- Binaries that do only contain NVIDIA code paths, even if the programming model is supported on AMD GPUs, will not run on LUMI.
- The final LUMI interconnect requires libfabric using a specific provider for the NIC used on LUMI, so any software compiled with an MPI library that requires UCX, or any other distributed memory model build on top of UCX, will not work on LUMI, or at least not work efficiently as there might be a fallback path to TCP communications.
- Even intro-node interprocess communication can already cause problems as there are three different kernel extensions that provide more efficient interprocess messaging than the standard Linux mechanism. Many clusters use knem for that but on LUMI xpmem is used. So software that is not build to support xpmem will also fall back to the default mechanism or fail.
- Also, the MPI implementation needs to collaborate with certain modules in our Slurm installation to start correctly and experience has shown that this can also be a source of trouble as the fallback mechanisms that are often used do not work on LUMI.
- Containers solve none of these problems. There can be more subtle compatibility problems also. As has been discussed earlier in the course, LUMI runs SUSE Linux and not Ubuntu which is popular on workstations or a Red Hat-derived Linux popular on many clusters. Subtle differences between Linux versions can cause compatibility problems that in some cases can be solved with containers. But containers won't help you if they are build for different kernel extensions, driver versions and hardware interfaces.
- The compute nodes also lack some Linux daemons that may be present on smaller clusters. HPE Cray use an optimised Linux version called COS or Cray Operating System on the compute nodes. It is optimised to reduce OS jitter and hence to enhance scalability of applications as that is after all the primary goal of a pre-exascale machine. But that implies that certain Linux daemons that your software may expect to find are not present on the compute nodes. D-bus comes to mind.
Also, the LUNI user support team is too small to do all software installations which is why we currently state in our policy that a LUMI user should be capable of installing their software themselves or have another support channel. We cannot install every single piece of often badly documented research-quality code that was never meant to be used by people who don't understand the code.
Another soft compatibility problem that has not yet been mentioned is that software that accesses hundreds of thousands of small files and abuses the file system as a database rather than using structured data formats designed to organise data on supercomputers is not welcome on LUMI. For that reason we also require to containerize conda and Python installations. We do offer a container-based wrapper that offers a way to install conda packages or to install Python packages with pip on top of the Python provided by the cray-python module. The link to the documentation of the tool that we call lumi-container-wrapper but may by some from CSC also be known as Tykky is in the handout of the slides that you can get after the course.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#organisation-of-the-software-in-software-stacks","title":"Organisation of the software in software stacks","text":"On LUMI we have several software stacks.
CrayEnv is the software stack for users who only need the Cray Programming Environment but want a more recent set of build tools etc than the OS provides. We also take care of a few issues that we will discuss on the next slide that are present right after login on LUMI.
Next we have the stacks called \"LUMI\". Each one corresponds to a particular release of the HPE Cray Programming Environment. It is the stack in which we install software using the that programming environment and mostly EasyBuild. The Cray Programming Environment modules are still used, but they are accessed through a replacement for the PrgEnv modules that is managed by EasyBuild. We have tuned versions for the 4 types of hardware in the regular LUMI system: zen2 CPUs in the login nodes and large memory nodes, zen3 for the LUMI-C compute nodes, zen 2 combined with NVIDIA GPUs for the visualisation nodes and zen3 + MI250X for the LUMI-G partition. There is also some support for the early access platform which has zen2 CPUs combined with MI100 GPUs but we don't pre-install software in there at the moment except for some build tools and some necessary tools for ROCm as these nodes are not meant to run codes on and as due to installation restrictions we cannot yet use the GPU compilers with EasyBuild the way we should do that on the final system.
We also provide the spack modules which provide some support to install software with Spack. This stack is meant for users who are very familiar with Spack and can deal with the problems Spack may throw at you. We have no intent to debug or modify Spack package files ourselves, but did an effort to configure Spack to use the compilers provided by the HPE Cray PE.
In the far future we will also look at a stack based on the common EasyBuild toolchains as-is, but we do expect problems with MPI that will make this difficult to implement, and the common toolchains also do not yet support the AMD GPU ecosystem, so we make no promises whatsoever about a time frame for this development.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#3-ways-to-access-the-cray-programming-environment-on-lumi","title":"3 ways to access the Cray Programming environment on LUMI.","text":""},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#bare-environment-and-crayenv","title":"Bare environment and CrayEnv","text":"Right after login you have a very bare environment available with the Cray Programming Environment with the PrgEnv-cray module loaded. It gives you basically what you can expect on a typical Cray system. There aren't many tools available, basically mostly only the tools in the base OS image and some tools that we are sure will not impact software installed in one of the software stacks. The set of target modules loaded is the one for the login nodes and not tuned to any particular node type. As a user you're fully responsible for managing the target modules, reloading them when needed or loading the appropriate set for the hardware you're using or want to cross-compile for.
The second way to access the Cray Programming Environment is through the CrayEnv software stack. This stack offers an \"enriched\" version of the Cray environment. It takes care of the target modules: Loading or reloading CrayEnv will reload an optimal set of target modules for the node you're on. It also provides some additional tools like newer build tools than provided with the OS. They are offered here and not in the bare environment to be sure that those tools don't create conflicts with software in other stacks. But otherwise the Cray Programming Environment works exactly as you'd expect from this course.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#lumi-stack","title":"LUMI stack","text":"The third way to access the Cray Programming Environment is through the LUMI software stacks, where each stack is based on a particular release of the HPE Cray Programming Environment. We advise against mixing with modules that came with other versions of the Cray PE, but they remain accessible although they are hidden from the default view for regular users. It ia also better to not use the PrgEnv modules, but the equivalent LUMI EasyBuild toolchains instead as indicated by the following table:
HPE Cray PE LUMI toolchain What? PrgEnv-cray cpeCray Cray Compiler Environment PrgEnv-gnu cpeGNU GNU C/C++ and Fortran PrgEnv-aocc cpeAOCC AMD CPU compilers PrgEnv-amd cpeAMD AMD ROCm GPU compilers (LUMI-G only) The cpeCray etc modules also load the MPI libraries and Cray LibSci just as the PrgEnv modules do. And we sometimes use this to work around problems in Cray-provided modules that we cannot change. E.g., the PrgEnv-aocc/21.12 module can successfully use the aocc/3.1.0 compilers.
This is also the environment in which we install most software, and from the name of the modules you can see which compilers we used.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#lumi-stack-module-organisation","title":"LUMI stack module organisation","text":"To manage the heterogeneity in the hardware, the LUMI software stack uses two levels of modules
First there are the LUMI/21.12 and LUMI/22.08 modules. Each of the LUMI modules loads a particular version of the LUMI stack.
The second level consists of partition modules. There is partition/L for the login and large memory nodes, partition/C for the regular compute nodes, partition/G for the GPU nodes and in the future we may have partition/D for the visualisation nodes.
There is also a hidden partition/common module in which we install software that is available everywhere, but we advise you to be careful to install software in there in your own installs as it is risky to rely on software in one of the regular partitions, and impossible in our EasyBuild setup.
The LUMI module will automatically load the best partition module for the current hardware whenever it is loaded or reloaded. So if you want to cross-compile, you can do so by loading a different partition module after loading the LUMI module, but you'll have to reload every time you reload the LUMI module.
Hence you should also be very careful in your job scripts. On LUMI the environment from the login nodes is used when your job starts, so unless you switched to the suitable partition for the compute nodes, your job will start with the software stack for the login nodes. If in your job script you reload the LUMI module it will instead switch to the software stack that corresponds to the type of compute node you're using and more optimised binaries can be available. If for some reason you'd like to use the same software on LUMI-C and on the login or large memory nodes and don't want two copies of locally installed software, you'll have to make sure that after reloading the LUMI module in your job script you explicitly load the partition/L module.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#lmod-on-lumi","title":"Lmod on LUMI","text":""},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#exploring-modules-with-lmod","title":"Exploring modules with Lmod","text":"Contrary to some other module systems, or even some other Lmod installations, not all modules are immediately available for loading. So don't be disappointed by the small number of modules you will see with module available right after login. Lmod has a so-called hierarchical setup that tries to protect you from being confronted with all modules at the same time, even those that may conflict with each other, and we use that to some extent on LUMI. Lmod distinguishes between installed modules and available modules. Installed modules are all modules on the system that can be loaded one way or another, sometimes through loading other modules first. Available modules are all those modules that can be loaded at a given point in time without first loading other modules.
The HPE Cray Programming Environment also uses a hierarchy though it is not fully implemented in the way the Lmod developer intended so that some features do not function as they should.
- For example, the
cray-mpich module can only be loaded if both a network target module and a compiler module are loaded (and that is already the example that is implemented differently from what the Lmod developer had in mind). - Another example is the performance monitoring tools. Many of those tools only become available after loading the
perftools-base module. - Another example is the
cray-fftw module which requires a processor target module to be loaded first.
Lmod has several tools to search for modules.
- The
module avail command is one that is also present in the various Environment Modules implementations and is the command to search in the available modules. - But Lmod also has other commands,
module spider and module keyword, to search in the list of installed modules.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#module-spider-command","title":"Module spider command","text":"Demo moment 1 (when infrastructure for a demo is available)
(The content of this slide is really meant to be shown in practice on a command line.)
There are three ways to use module spider, discovering software in more and more detail.
-
module spider by itself will show a list of all installed software with a short description. Software is bundled by name of the module, and it shows the description taken from the default version. module spider will also look for \"extensions\" defined in a module and show those also and mark them with an \"E\". Extensions are a useful Lmod feature to make clear that a module offers features that one would not expect from its name. E.g., in a Python module the extensions could be a list of major Python packages installed in the module which would allow you to find NumPy if it were hidden in a module with a different name. This is also a very useful feature to make tools that are bundled in one module to reduce the module clutter findable.
-
module spider with the name of a package will show all versions of that package installed on the system. This is also case-insensitive. Let's try for instance module spider gnuplot. This will show 10 versions of GNUplot. There are two installations of GNUplot 5.4.2 and eight of 5.4.3. The remainder of the name shows us with what compilers gnuplot was compiled. The reason to have versions for two or three compilers is that no two compiler modules can be loaded simultaneously, and this offers a solution to use multiple tools without having to rebuild your environment for every tool, and hence also to combine tools.
Now try module spider CMake. We see that there are four versions, 3.21.2, 3.22.2, 3.23.2 and 3.24.0, but now they are shown in blue with an \"E\" behind the name. That is because there is no module called CMake on LUMI. Instead the tool is provided by another module that in this case contains a collection of popular build tools and that we will discover shortly.
-
The third use of module spider is with the full name of a module. Try for instance module spider gnuplot/5.4.3-cpeGNU-22.08. This will now show full help information for the specific module, including what should be done to make the module available. For this GNUplot module we see that there are two ways to load the module: By loading LUMI/22.08 combined with partition/C or by loading LUMI/22.08 combined with partition/L. So use only a single line, but chose it in function of the other modules that you will also need. In this case it means that that version of GNUplot is available in the LUMI/22.08 stack which we could already have guessed from its name, with binaries for the login and large memory nodes and the LUMI-C compute partition. This does however not always work with the Cray Programming Environment modules.
We can also use module spider with the name and version of an extension. So try module spider CMake/3.24.0. This will now show us that this tool is in the buildtools/22.08 module (among others) and give us 6 different options to load that module as it is provided in the CrayEnv and the LUMI/22.08 software stacks and for all partitions (basically because we don't do processor-specific optimisations for these tools).
Demo module spider Try the following commands:
module spider\nmodule spider gnuplot\nmodule spider cmake\nmodule spider gnuplot/5.4.3-cpeGNU-22.08\nmodule spider CMake/3.24.0\n
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#module-keyword-command","title":"Module keyword command","text":"module keyword will search for a module using a keyword but it is currently not very useful on LUMI because of a bug in the current version of Cray Lmod which is solved in the more recent versions. Currently the output contains a lot of irrelevant modules, basically all extensions of modules on the system.
What module keyword really does is search in the module description and help for the word that you give as an argument. Try for instance module keyword https and you'll see two relevant tools, cURL and wget, two tools that can be used to download files to LUMI via several protocols in use on the internet.
On LUMI we do try to put enough information in the module files to make this a suitable additional way to discover software that is already installed on the system, more so than in regular EasyBuild installations.
Demo module keyword Try the following command:
module keyword https\n
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#sticky-modules-and-module-purge","title":"Sticky modules and module purge","text":"You may have been taught that module purge is a command that unloads all modules and on some systems they might tell you in trainings not to use it because it may also remove some basic modules that you need to use the system. On LUMI for instance there is an init-lumi module that does some of the setup of the module system and should be reloaded after a normal module purge. On Cray systems module purge will also unload the target modules while those are typically not loaded by the PrgEnv modules so you'd need to reload them by hand before the PrgEnv modules would work.
Lmod however does have the concept of \"sticky modules\". These are not unloaded by module purge but are re-loaded, so unloaded and almost immediately loaded again, though you can always force-unload them with module --force purge or module --force unload for individual modules.
Demo Try the following command:
module av\n
Note the very descriptive titles in the above screenshot.
The letter \"D\" next to a name denotes that this is the default version, the letter \"L\" denotes that the module is loaded.
Try the following commands and carefully observe the output:
module load LUMI/22.08 buildtools\nmodule list\nmodule purge\nmodule list\nmodule --force unload ModuleLabel/label\nmodule list\n
The sticky property has to be declared in the module file so we cannot add it to for instance the Cray Programming Environment target modules, but we can and do use it in some modules that we control ourselves. We use it on LUMI for the software stacks themselves and for the modules that set the display style of the modules.
- In the
CrayEnv environment, module purge will clear the target modules also but as CrayEnv is not just left untouched but reloaded instead, the load of CrayEnv will load a suitable set of target modules for the node you're on again. But any customisations that you did for cross-compiling will be lost. - Similary in the LUMI stacks, as the
LUMI module itself is reloaded, it will also reload a partition module. However, that partition module might not be the one that you had loaded but it will be the one that the LUMI module deems the best for the node you're on, and you may see some confusing messages that look like an error message but are not.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#changing-how-the-module-list-is-displayed","title":"Changing how the module list is displayed","text":"You may have noticed already that by default you don't see the directories in which the module files reside as is the case on many other clusters. Instead we try to show labels that tell you what that group of modules actually is. And sometimes this also combines modules from multiple directories that have the same purpose. For instance, in the default view we collapse all modules from the Cray Programming Environment in two categories, the target modules and other programming environment modules. But you can customise this by loading one of the ModuleLabel modules. One version, the label version, is the default view. But we also have PEhierarchy which still provides descriptive texts but unfolds the whole hierarchy in the Cray Programming Environment. And the third style is called system which shows you again the module directories.
Demo Try the following commands:
module list\nmodule avail\nmodule load ModuleLabel/PEhiererachy\nmodule avail\nmodule load ModuleLabel/system\nmodule avail\nmodule load ModuleLabel/label\n
We're also very much aware that the default colour view is not good for everybody. So far we are not aware of an easy way to provide various colour schemes as one that is OK for people who like a black background on their monitor might not be OK for people who prefer a white background. But it is possible to turn colour off alltogether by loading the ModuleColour/off module, and you can always turn it on again with ModuleColour/on.
Demo Try the following commands:
module avail\nmodule load ModuleColour/off\nmodule avail\nmodule list\nmodule load ModuleColour/on\n
We also hide some modules from regular users because we think they are not useful at all for regular users or not useful in the context you're in at the moment. For instance, when working in the LUMI/22.08 stack we prefer that users use the Cray programming environment modules that come with release 22.08 of that environment, and cannot guarantee compatibility of other modules with already installed software, so we hide the other ones from view. You can still load them if you know they exist but you cannot see them with module available. It is possible though to still show most if not all of them by loading ModulePowerUser/LUMI. Use this at your own risk however, we will not help you to make things work or to use any module that was designed for us to maintain the system.
Demo Try the following commands:
module load LUMI/22.08\nmodule avail\nmodule load ModulePowerUser\nmodule avail\n
Note that we see a lot more Cray PE modules with ModulePowerUser!
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#easybuild-to-extend-the-lumi-software-stack","title":"EasyBuild to extend the LUMI software stack","text":""},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#installing-software-on-hpc-systems","title":"Installing software on HPC systems","text":"Software on HPC systems is rarely installed from RPMs for various reasons. Generic RPMs are rarely optimised for the specific CPU of the system as they have to work on a range of systems and as including optimised code paths in a single executable for multiple architectures is hard to even impossible. Secondly generic RPMs might not even work with the specific LUMI environment. They may not fully support the SlingShot interconnect and hence run at reduced speed, or they may need particular kernel modules or daemons that are not present on the system or they may not work well with the resource manager on the system. We expect this to happen especially with packages that require specific MPI versions. Moreover, LUMI is a multi-user system so there is usually no \"one version fits all\". And we need a small system image as nodes are diskless which means that RPMs need to be relocatable so that they can be installed elsewhere.
Spack and EasyBuild are the two most popular HPC-specific software build and installation frameworks. These two systems usually install packages from sources so that the software can be adapted to the underlying hardware and operating system. They do offer a mean to communicate and execute installation instructions easily so that in practice once a package is well supported by these tools a regular user can install them also. Both packages make software available via modules so that you can customise your environment and select appropriate versions for your work. And they do take care of dependency handling in a way that is compatible with modules.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#extending-the-lumi-stack-with-easybuild","title":"Extending the LUMI stack with EasyBuild","text":"On LUMI EasyBuild is our primary software installation tool. We selected this as there is already a lot of experience with EasyBuild in several LUMI consortium countries and as it is also a tool developed in Europe which makes it a nice fit with EuroHPC's goal of creating a fully European HPC ecosystem.
EasyBuild is fully integrated in the LUMI software stack. Loading the LUMI module will not only make centrally installed packages available, but also packages installed in your personal or project stack. Installing packages in that space is done by loading the EasyBuild-user module that will load a suitable version of EasyBuild and configure it for installation in a way that is compatible with the LUMI stack. EasyBuild will then use existing modules for dependencies if those are already on the system or in your personal or project stack.
Note however that the built-in easyconfig files that come with EasyBuild do not work on LUMI at the moment.
- For the GNU toolchain we would have problems with MPI. EasyBuild there uses Open MPI and that needs to be configured differently to work well on LUMI, and there are also still issues with getting it to collaborate with the resource manager as it is installed on LUMI.
- The Intel-based toolchains have their problems also. At the moment, the Intel compilers with the AMD CPUs are a problematic cocktail. There have recently been performance and correctness problems with the MKL math library and also failures some versions of Intel MPI, and you need to be careful selecting compiler options and not use
-xHost with the classic compilers or the Intel compiler will simply optimize for a two decades old CPU.
Instead we make our own EasyBuild build recipes that we also make available in the LUMI-EasyBuild-contrib GitHub repository. The EasyBuild configuration done by the EasyBuild-user module will find a copy of that repository on the system or in your own install directory. The latter is useful if you always want the very latest, before we deploy it on the system. We also maintain a list of all EasyBuild recipes installed in the central stack maintained by LUST or available in the main EasyConfig repository LUMI-EasyBuild-contrib in the LUMI Software Library.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#step-1-where-to-install","title":"Step 1: Where to install","text":"Let's now discuss how you can extend the central LUMI software stack with packages that you need for your project.
The default location for the EasyBuild user modules and software is in $HOME/EasyBuild. This is not the ideal place though as then the software is not available for other users in your project, and as the size of your home directory is also limited and cannot be expanded. The home file system on LUMI is simply not meant to install software. However, as LUMI users can have multiple projects there is no easy way to figure out automatically where else to install software.
The best place to install software is in your project directory so that it also becomes available for the whole project. After all, a project is meant to be a collaboration between all participants on a scientific problem. You'll need to point LUMI to the right location though and that has to be done by setting the environment variable EBU_USER_PREFIX to point to the location where you want to have your custom installation. Also don't forget to export that variable as otherwise the module system and EasyBuild will not find it when they need it. So a good choice would be something like export EBU_USER_PREFIX=/project/project_465000000/EasyBuild. You have to do this before loading the LUMI module as it is then already used to ensure that user modules are included in the module search path. You can do this in your .bash_profile or .bashrc. This variable is not only used by EasyBuild-user to know where to install software, but also by the LUMI - or actually the partition - module to find software so all users in your project who want to use the software should set that variable.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#step-2-configure-the-environment","title":"Step 2: Configure the environment","text":"Once that environment variable is set, all you need to do to activate EasyBuild is to load the LUMI module, load a partition module if you want a different one from the default, and then load the EasyBuild-user module. In fact, if you switch to a different partition or LUMI module after loading EasyBuild-user EasyBuild will still be correctly reconfigured for the new stack and new partition. Cross-compilation which is installing software for a different partition than the one you're working on does not always work since there is so much software around with installation scripts that don't follow good practices, but when it works it is easy to do on LUMI by simply loading a different partition module than the one that is auto-loaded by the LUMI module.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#step-3-install-the-software","title":"Step 3: Install the software.","text":"Demo moment 2
Let's look at GROMACS as an example. I will not try to do this completely live though as the installation takes 15 or 20 minutes. First we need to figure out for which versions of GROMACS we already have support. At the moment we have to use eb -S or eb --search for that. So in our example this is
eb --search GROMACS\n
This process is not optimal and will be improved in the future. We are developing a system that will instead give an overview of available EasyBuild recipes on the documentation web site. Now let's take the variant GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb. This is GROMACS 2021.4 with the PLUMED 2.8.0 plugin, build with the Cray compilers from LUMI/22.08, and a build meant for CPU-only systems. The -CPU extension is not always added for CPU-only system, but in case of GROMACS we do expect that GPU builds for LUMI will become available early on in the deployment of LUMI-G so we've already added a so-called version suffix to distinguish between CPU and GPU versions. To install it, we first run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb \u2013D\n
The -D flag tells EasyBuild to just perform a check for the dependencies that are needed when installing this package, while the -r argument is needed to tell EasyBuild to also look for dependencies in a preset search path. The search for dependencies is not automatic since there are scenarios where this is not desired and it cannot be turned off as easily as it can be turned on. Looking at the output we see that EasyBuild will also need to install PLUMED for us. But it will do so automatically when we run
eb GROMACS-2021.4-cpeCray-22.08-PLUMED-2.8.0-CPU.eb -r\n
This takes too long to wait for, but once it finished the software should be available and you should be able to see the module in the output of
module avail\n
Demo of the EasyBuild installation of GROMACS
End of demo moment 2
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#step-3-install-the-software-note","title":"Step 3: Install the software - Note","text":"There is a little problem though that you may run into. Sometimes the module does not show up immediately. This is because Lmod keeps a cache when it feels that Lmod searches become too slow and often fails to detect that the cache is outdated. The easy solution is then to simply remove the cache which is in $HOME/.lmod.d/.cache, which you can do with
rm -rf $HOME/.lmod.d/.cache\n
And we have seen some very rare cases where even that did not help likely because some internal data structures in Lmod where corrupt. The easiest way to solve this is to simply log out and log in again and rebuild your environment. Installing software this way is 100% equivalent to an installation in the central software tree. The application is compiled in exactly the same way as we would do and served from the same file systems. But it helps keep the output of module avail reasonably short and focused on your projects, and it puts you in control of installing updates. For instance, we may find out that something in a module does not work for some users and that it needs to be re-installed. Do this in the central stack and either you have to chose a different name or risk breaking running jobs as the software would become unavailable during the re-installation and also jobs may get confused if they all of a sudden find different binaries. However, have this in your own stack extension and you can update whenever it suits your project best or even not update at all if you figure out that the problem we discovered has no influence on your work. OFten you also don't need to be an EasyBuild expert to adapt the build recipe to install, e.g., a slgithly different version of the package that better suits your needs.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#more-advanced-work","title":"More advanced work","text":"You can also install some EasyBuild recipes that you got from support. For this it is best to create a subdirectory where you put those files, then go into that directory and run something like
eb my_recipe.eb -r .\n
The dot after the -r is very important here as it does tell EasyBuild to also look for dependencies in the current directory, the directory where you have put the recipes you got from support, but also in its subdirectories so for speed reasons you should not do this just in your home directory but in a subdirectory that only contains those files. In some cases you will have to download sources by hand as packages don't allow to download software unless you sign in to their web site first. This is the case for a lot of licensed software, for instance, for VASP. We'd likely be in violation of the license if we would put the download somewhere where EasyBuild can find it, and it is also a way for us to ensure that you have a license for VASP. For instance,
eb --search VASP\n
will tell you for which versions of VASP we already have build instructions, but you will still have to download the file that the EasyBuild recipe expects. Put it somewhere in a directory, and then from that directory run EasyBuild, for instance for VASP 6.3.0 with the GNU compilers: eb VASP-6.3.2-cpeGNU-22.08.eb -r .\n
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#more-advanced-work-2-repositories","title":"More advanced work (2): Repositories","text":"It is also possible to have your own clone of the LUMI-EasyBuild-contrib GitHub repository in your $EBU_USER_PREFIX subdirectory if you want the latest and greates before it is in the centrally maintained clone of the repository. All you need to do is
cd $EBU_USER_PREFIX\ngit clone https://github.com/Lumi-supercomputer/LUMI-EasyBuild-contrib.git\n
and then of course keep the repository up to date. And it is even possible to maintain your own GitHub repository. The only restrictions are that it should also be in $EBU_USER_PREFIX and that the subdirectory should be called UserRepo, but that doesn't stop you from using a different name for the repository on GitHub. After cloning your GitHub version you can always change the name of the directory. The structure should also be compatible with the structure that EasyBuild uses, so easyconfig files go in $EBU_USER_PREFIX/easybuild/easyconfigs.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#more-advanced-work-3-reproducibility","title":"More advanced work (3): Reproducibility","text":"EasyBuild also takes care of a high level of reproducibility of installations.
It will keep a copy of all the downloaded sources in the $EBU_USER_PREFIX/sources subdirectory, and use that source file again rather than downloading it again. Of course in some cases those \"sources\" could be downloaded tar files with binaries instead as EasyBuild can install downloaded binaries or relocatable RPMs. And if you know the structure of those directories, this is also a place where you could manually put the downloaded installation files for licensed software. Also, there are rare cases in which EasyBuild cannot save the sources because they are automatically downloaded during the installation procedure outside the control of EasyBuild with no way to teach EasyBuild where to download those files and place them to avoid them to be downloaded automatically. This is, e.g., often te case for software written in Rust.
Moreover, EasyBuild also keeps copies of all installed easconfig files in two locations.
- There is a copy in
$EBU_USER_PREFIX/ebrepo_files. And in fact, EasyBuild will use this version first if you try to re-install and did not delete this version first. This is also a policy we set on LUMI which has both its advantages and disadvantages. The advantage is that it ensures that the information that EasyBuild has about the installed application is compatible with what is in the module files. But the disadvantage of course is that if you install an EasyConfig file without being in the subdirectory that contains that file, it is easily overlooked that it is installing based on the EasyConfig in the ebrepo_files subdirectory and not based on the version of the recipe that you likely changed and is in your user repository or one of the other repositories that EasyBuild uses. - The second copy is with the installed software in
$EBU_USER_PREFIX/SW in a subdirectory called easybuild. This subdirectory is meant to have all information about how EasyBuild installed the application, also some other files that play a role in the installation process, and hence to help in reproducing an installation or checking what's in an existing installation. It is also the directory where you will find the extensive log file with all commands executed during the installation and their output.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#easybuild-training-for-advanced-users-and-developers","title":"EasyBuild training for advanced users and developers","text":"Since there were a lot of registrations from local support team members, I want to dedicate one slide to them also.
Pointers to all information about EasyBuild can be found on the EasyBuild web site easybuild.io. This page also includes links to training materials, both written and as recordings on YouTube, and the EasyBuild documentation.
Generic EasyBuild training materials are available on easybuilders.github.io/easybuild-tutorial. The site also contains a LUST-specific tutorial oriented towards Cray systems.
In the past we also organised a training for CSC staff and staff from other local support organisations. The latest version of the training materials is currently available on klust.github.io/easybuild-tutorial.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#containers-on-lumi","title":"Containers on LUMI","text":"Let's now switch to using containers on LUMI. This section is about using containers on the login nodes and compute nodes. Some of you may have heard that there were plans to also have an OpenShift Kubernetes container cloud platform for running microservices but at this point it is not clear if and when this will materialize due to a lack of manpower to get this running and then to support this.
In this section, we will
-
discuss what to expect from containers on LUMI: what can they do and what can't they do,
-
discuss how to get a container on LUMI,
-
discuss how to run a container on LUMI,
-
and discuss some enhancements we made to the LUMI environment that are based on containers or help you use containers.
Remember though that the compute nodes of LUMI are an HPC infrastructure and not a container cloud!
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#what-do-containers-not-provide","title":"What do containers not provide","text":"What is being discussed in this subsection may be a bit surprising. Containers are often marketed as a way to provide reproducible science and as an easy way to transfer software from one machine to another machine. However, containers are neither of those and this becomes very clear when using containers build on your typical Mellanox/NVIDIA InfiniBand based clusters with Intel processors and NVIDIA GPUs on LUMI.
First, computational results are almost never 100% reproducible because of the very nature of how computers work. You can only expect reproducibility of sequential codes between equal hardware. As soon as you change the CPU type, some floating point computations may produce slightly different results, and as soon as you go parallel this may even be the case between two runs on exactly the same hardware and software.
But full portability is a much greater myth. Containers are really only guaranteed to be portable between similar systems. They may be a little bit more portable than just a binary as you may be able to deal with missing or different libraries in the container, but that is where it stops. Containers are usually build for a particular CPU architecture and GPU architecture, two elements where everybody can easily see that if you change this, the container will not run. But there is in fact more: containers talk to other hardware to, and on an HPC system the first piece of hardware that comes to mind is the interconnect. And they use the kernel of the host and the kernel modules and drivers provided by that kernel. Those can be a problem. A container that is not build to support the SlingShot interconnect, may fall back to TCP sockets in MPI, completely killing scalability. Containers that expect the knem kernel extension for good intra-node MPI performance may not run as efficiently as LUMI uses xpmem instead.
Even if a container is portable to LUMI, it may not yet be performance portable. E.g., without proper support for the interconnect it may still run but in a much slower mode. But one should also realise that speed gains in the x86 family over the years come to a large extent from adding new instructions to the CPU set, and that two processors with the same instructions set extensions may still benefit from different optimisations by the compilers. Not using the proper instruction set extensions can have a lot of influence. At my local site we've seen GROMACS doubling its speed by choosing proper options, and the difference can even be bigger.
Many HPC sites try to build software as much as possible from sources to exploit the available hardware as much as possible. You may not care much about 10% or 20% performance difference on your PC, but 20% on a 160 million EURO investment represents 32 million EURO and a lot of science can be done for that money...
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#but-what-can-they-then-do-on-lumi","title":"But what can they then do on LUMI?","text":" -
A very important reason to use containers on LUMI is reducing the pressure on the file system by software that accesses many thousands of small files (Python and R users, you know who we are talking about). That software kills the metadata servers of almost any parallel file system when used at scale.
As a container on LUMI is a single file, the metadata servers of the parallel file system have far less work to do, and all the file caching mechanisms can also work much better.
-
When setting up very large software environments, e.g., some Python and R environments, they can still be very helpful, even if you may have to change some elements in your build recipes from your regular cluster or workstation. Some software may also be simply too hard to install from sources in the typical HPC way of working.
-
And related to the previous point is also that some software may not even be suited for installation in a multi-user HPC system. HPC systems want a lightweight /usr etc. structure as that part of the system software is often stored in a RAM disk, and to reduce boot times. Moreover, different users may need different versions of a software library so it cannot be installed in its default location in the system library. However, some software is ill-behaved and doesn't allowed to be relocated to a different directory, and in these cases containers help you to build a private installation that does not interfere with other software on the system.
Remember though that whenever you use containers, you are the system administrator and not LUST. We can impossibly support all different software that users want to run in containers, and all possible Linux distributions they may want to run in those containers. We provide some advice on how to build a proper container, but if you chose to neglect it it is up to you to solve the problems that occur.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#managing-containers","title":"Managing containers","text":"On LUMI, we currently support only one container runtime.
Docker is not available, and will never be on the regular compute nodes as it requires elevated privileges to run the container which cannot be given safely to regular users of the system.
Singularity is currently the only supported container runtime and is available on the login nodes and the compute nodes. It is a system command that is installed with the OS, so no module has to be loaded to enable it. We can also offer only a single version of singularity or its close cousin AppTainer as singularity/AppTainer simply don't support running multiple versions, and currently the version that we offer is determined by what is offered by the OS.
To work with containers on LUMI you will either need to pull the container from a container registry, e.g., DockerHub, or bring in the container by copying the singularity .sif file.
Singularity does offer a command to pull in a Docker container and to convert it to singularity format. E.g., to pull a container for the Julia language from DockerHub, you'd use
singularity pull docker://julia\n
Singularity uses a single flat sif file for storing containers. The singularity pull command does the conversion from Docker format to the singularity format.
Singularity caches files during pull operations and that may leave a mess of files in the .singularity cache directory or in $XDG_RUNTIME_DIR (works only on the login nodes). The former can lead to exhaustion of your storage quota, so check and clean up from time to time. You may also want to clean up $XDG_RUNTIME_DIR, but this directory is also automatically cleaned when you log out from your last running session on that (login) node.
Demo singularity pull Let's try the singularity pull docker://julia command:
We do get a lot of warnings but usually this is perfectly normal and usually they can be safely ignored.
The process ends with the creation of the file jula_latest.sif.
Note however that the process has left a considerable number of files in ~/.singularity also:
There is currently no support for building containers on LUMI and I do not expect that to change quickly. It would require enabling some features in the Linux kernel that have seen some very serious security vulnerabilities in recent years.
So you should pull containers from a container repository, or build the container on your own workstation and then transfer it to LUMI.
We are also working on a number of base images to build upon, where the base images are tested with the OS kernel on LUMI.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#interacting-with-containers","title":"Interacting with containers","text":"There are basically three ways to interact with containers.
If you have the sif file already on the system you can enter the container with an interactive shell:
singularity shell container.sif\n
Demo singularity shell
In this screenshot we checked the contents of the /opt directory before and after the singularity shell julia_latest.sif command. This shows that we are clearly in a different environment. Checking the /etc/os-release file only confirms this as LUMI runs SUSE Linux on the login nodes, not a version of Debian.
The second way is to execute a command in the container with singularity exec. E.g., assuming the container has the uname executable installed in it,
singularity exec container.sif uname -a\n
Demo singularity exec
In this screenshot we execute the uname -a command before and with the singularity exec julia_latest.sif command. There are some slight differences in the output though the same kernel version is reported as the container uses the host kernel. Executing
singularity exec julia_latest.sif cat /etc/os-release\n
confirms though that the commands are executed in the container.
The third option is often called running a container, which is done with singularity run:
singularity run container.sif\n
It does require the container to have a special script that tells singularity what running a container means. You can check if it is present and what it does with singularity inspect:
singularity inspect --runscript container.sif\n
Demo singularity run
In this screenshot we start the julia interface in the container using singularity run. The second command shows that the contianer indeed includes a script to tell singularity what singularity run should do.
You want your container to be able to interact with the files in your account on the system. Singularity will automatically mount $HOME, /tmp, /proc, /sys and dev in the container, but this is not enough as your home directory on LUMI is small and only meant to be used for storing program settings, etc., and not as your main work directory. (And it is also not billed and therefore no extension is allowed.) Most of the time you want to be able to access files in your project directories in /project, /scratch or /flash, or maybe even in /appl. To do this you need to tell singularity to also mount these directories in the container, either using the --bind src1:dest1,src2:dest2 flag or via the SINGULARITY_BIND or SINGULARITY_BINDPATH environment variables.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#running-containers-on-lumi","title":"Running containers on LUMI","text":"Just as for other jobs, you need to use Slurm to run containers on the compute nodes.
For MPI containers one should use srun to run the singularity exec command, e.g,,
srun singularity exec --bind ${BIND_ARGS} \\\n${CONTAINER_PATH} mp_mpi_binary ${APP_PARAMS}\n
(and replace the environment variables above with the proper bind arguments for --bind, container file and parameters for the command that you want to run in the container).
On LUMI, the software that you run in the container should be compatible with Cray MPICH, ie.e, use the MPICH ABI (currently Cray MPICH is based on MPICH 3.4). It is then possible to tell the container to use Cray MPICH (from outside the container) rather than the MPICH variant installed in the container, so that it can offer optimal performance on the LUMI SlingShot 11 interconnect.
Open MPI containers are currently not well supported on LUMI and we do not recommend using them. We have no good solutions at the moment to run them with good performance. We only have a partial solution for the CPU nodes, and on the GPU nodes Open MPI is very problematic at the moment. This is both due to some design issues in the design of Open MPI, and also to some piece of software that recent versions of Open MPI require but that HPE does not yet support on Cray EX systems. Open MPI has a slight preference for the UCX communication library over the OFI libraries, and currently full GPU support requires UCX. Moreover, binaries using Open MPI often use the so-called rpath linking process so that it becomes a lot harder to inject an Open MPI library that is installed elsewhere. The good news though is that the Open MPI developers of course also want Open MPI to work on biggest systems in the USA, and all three currently operating or planned exascale systems use the SlingShot 11 interconnect so work is going on for better support for OFI and for full GPU support on systems that rely on OFI and do not support UCX.
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#enhancements-to-the-environment","title":"Enhancements to the environment","text":"To make life easier, LUST with the support of CSC did implement some modules that are either based on containers or help you run software with containers.
The singularity-bindings/system module which can be installed via EasyBuild helps to set SINGULARITY_BIND and SINGULARITY_LD_LIBRARY__PATH to use Cray MPICH. Figuring out those settings is tricky, and sometimes changes to the module are needed for a specific situation because of dependency conflicts between Cray MPICH and other software in the container, which is why we don't provide it in the standard software stacks but instead make it available as an EasyBuild recipe that you can adapt to your situation and install.
As it needs to be installed through EasyBuild, it is really meant to be used in the context of a LUMI software stack (so not in CrayEnv). To find the EasyConfig files, load the EasyBuild-user module and run
eb --search singularity-bindings\n
Soon you'll also be able to find more information on the design of this module and the contents of the EasyConfig files in the software library documentation that we are developing and that will be made available via the \"Software\" section in the LUMI documentation.
The second tool is a container that we provide with some bash functions to start a VNC server as temporary way to be able to use some GUI programs on LUMI until the final setup which will be based on Open OnDemand is ready. It can be used in CrayEnv or in the LUMI stacks. The container also contains a poor men's window manager (and yes, we know that there are sometimes some problems with fonts). It is possible to connect to the VNC server either through a regular VNC client on your PC or a web browser, but in both cases you'll have to create an ssh tunnel to access the server. Try
module help lumi-vnc\n
for more information on how to use lumi-vnc.
The final tool is a container wrapper tool that users from Finland may also know as Tykky. It is a tool to wrap Python and conda installations in a limited number of files in a transparent way. On LUMI, it is provided by the lumi-container-wrapper module which is available in the CrayEnv environment and in the LUMI software stacks. It is also documented in the LUMI documentation.
The basic idea is that you run a tool to either do a conda installation or an installation of Python packages from a file that defines the environment in either standard conda format (a Yaml file) or in the requirements.txt format used by pip.
The container wrapper will then perform the installation in a work directory, create some wrapper commands in the bin subdirectory of the directory where you tell the container wrapper tool to do the installation, and it will use SquashFS to create as single file that contains the conda or Python installation.
We do strongly recommend to use the container wrapper tool for larger conda and Python installation. We will not raise your file quota if it is to house such installation in your /project directory.
Demo lumi-container-wrapper Create a subdirectory to experiment. In that subdirectory, create a file named env.yml with the content:
channels:\n - conda-forge\ndependencies:\n - python=3.8.8\n - scipy\n - nglview\n
and create an empty subdirectory conda-cont-1.
|Now you can follow the commands on the slides below:
On the slide above we prepared the environment.
Now lets run the command
conda-containerize new --prefix ./conda-cont-1 env.yml\n
and look at the output that scrolls over the screen. The screenshots don't show the full output as some parts of the screen get overwritten during the process:
The tool will first build the conda installation in a temprorary work directory and also uses a base container for that purpose.
The conda installation itself though is stored in a SquashFS file that is then used by the container.
In the slide above we see the installation contains both a singularity container and a SquashFS file. They work together to get a working conda installation.
The bin directory seems to contain the commands, but these are in fact scripts that run those commands in the container with the SquashFS file system mounted in it.
So as you can see above, we can simply use the python3 command without realising what goes on behind the screen...
The wrapper module also offers a pip-based command to build upon the Cray Python modules already present on the system
"},{"location":"PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/#conclusion-container-limitations-on-lumi-c","title":"Conclusion: Container limitations on LUMI-C","text":"To conclude the information on using singularity containers on LUMI, we want to repeat the limitations:
-
Containers use the host's operating system kernel which is likely different and may have different drivers and kernel extensions than your regular system. This may cause the container to fail or run with poor performance.
-
The LUMI hardware is almost certainly different from that of the systems on which you may have used the container before and that may also cause problems.
In particular a generic container may not offer sufficiently good support for the SlingShot 11 interconnect on LUMI which requires OFI (libfabric) with the right network provider (the so-called Cassini provider) for optimal performance. The software in teh container may fall back to TCP sockets resulting in poor performance and scalability for communication-heavy programs.
For containers with an MPI implementation that follows the MPICH aBI the solution is often to tell it to use the Cray MPICH libraries fro the system instead.
-
Building containers is currently not supported on LUMI due to security concerns.
"},{"location":"PEAP-Q-20221123/schedule/","title":"Course schedule","text":""},{"location":"PEAP-Q-20221123/schedule/#wednesday-november-23","title":"Wednesday November 23","text":"All times CET.
09:30\u00a0\u00a0 Welcome, introduction to the course Presenter: Kurt Lust (LUST) 09:45 Introduction to the HPE Cray Hardware and Programming Environment - The HPE Cray EX hardware architecture and software stack
- The Cray module environment and compiler wrapper scripts
Presenter: Harvey Richardson (HPE) 10:55 break (25 minutes) 11:20 Running Applications - Examples of using the Slurm Batch system, launching jobs on the front end and basic controls for job placement
- Exercises: about 45 minutes
12:40 lunch break (80 minutes) 14:00 Compilers and Libraries - An introduction to the compiler suites available
- How to get additional information about the compilation process
- Special attention is given the Cray Compilation Environment (CCE) noting options relevant to porting and performance. CCE classic to Clang transition
- Exercises: about 20 minutes
15:30 break (30 minutes) 16:00 Advanced Placement - More detailed treatment of Slurm binding technology and OpenMP controls
- Exercises: about 30 minutes
Presenter: Jean Pourroy 17:00 Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 End of first course day"},{"location":"PEAP-Q-20221123/schedule/#thursday-november-24","title":"Thursday November 24","text":"All times CET.
09:30\u00a0\u00a0 Introduction to Perftools, Performance Analysis Part 1 and Part 2, and Debugging at Scale - Introduction to perftools
- Pertfools lite modules
- Loop work estimates
- Reveal for performance data display, compiler feedback and automatedscoping
- Debugging tools at scale
Presenters: Alfio Lazarro and Thierry Braconnier (HPE) 12:15 lunch break (60 minutes) 13:15 MPI Topics on the HPE Cray EX Supercomputer - High level overview of Cray MPI on Slingshot, useful environment variable controls.
- Rank reordering and MPMD application launch.
- Exercises: about 20 minutes
Presenter: Harvey Richardson 14:15 Optimizing Large Scale I/O - Introduction into the structure of the Lustre Parallel file system
- Tips for optimising parallel bandwidth for a variety of parallel I/O schemes
- Examples of using MPI-IO to improve overall application performance.
- Advanced Parallel I/O considerations
- Further considerations of parallel I/O and other APIs.
- Being nice to Lustre
- Consideration of how to avoid certain situations in I/O usage that don\u2019t specifically relate to data movement.
Presenter: Harvey Richardson Slide file: /project/project_465000297/slides/12_IO_short_LUMI.pdf on LUMI only. 15:00 break (20 minutes) 15:20 LUMI Software Stacks - Software policy
- Software environment on LUMI
- Installing software with EasyBuild (concepts, contributed recipes)
- Containers for Python, R, VNC (container wrappers)
Presenter: Kurt Lust (LuST) 16:40 LUMI User Support - LUMI documentation
- What can we help you with and what not? How to get help, how to write good support requests
- Some typical/frequent support questions of users on LUMI-C?
Presenter: J\u00f8rn Dietze (LUST) 17:10 Open Questions & Answers Participants are encouraged to continue with exercises in case there should be no questions. 17:30 End of second course day"},{"location":"PEAP-Q-20221123/where_to_eat/","title":"Where to eat?","text":"Just some suggestions. There are many more decent restaurants in Brussels especially if you are alone or only with a small group. In general most places that score a 4 or more on Google Maps are decent places. Just some suggestions:
- Brasserie des Alexiens (Rue des Alexiens/Cellebroersstraat 63)
- Opens only at 7pm
- The bar La Porte Noir next door is a good option for a beer before or afterwards.
- Fin de Sci\u00e8cle (Rue des Chartreux/Kartuizersstraat 9)
- The interior may not look nice at all but has character, and the food is good
- La porteuse d'eau (Avenue JEan Volders/Jean Voldersslaan 48)
- Interesting Art Deco building and interior, and the food is very much OK. It is a bit further away but still interesting for its architecture. There are more Art Deco restaurants in Brussels, but this one has the best reputation for the food.
- Tip: Combine with the nearby bar L'Ermitage Saint-Gilles (Rue de Moscou/Moskoustraat 34) for a local beer, or simply have some pub food in the bar. This bar is from a brewery in Brussels that started the bar elsewhere as the location had become too small.
- Moeder Lambic Fontainas (Place Fontainas/Fontainasplein 8) is a good choice for decent food with a good Belgian beer. They have more than just the stuff from the large breweries.
- The Rue du March\u00e9 au Charbon/Kolenmarkt is the gay street in Brussels, but it also has some nice places to eat where nobody has to feel uncomfortable. Brasserie du Lombard on the corner with the Rue du Lombard/Lombardstraat has nice food. Order at the bar with your drinks. Le Plattesteen on the opposite corner has also a decent reputation. Caf\u00e9 Charbon (Rue du March\u00e9 au Charbon/Kolenmarkt 90) serves good food also, and the daily specials are definitely recommended.
- Restaurants in the neighbourhood of HOEK 38 that should be OK:
- La Tana (Rue de l'Enseignement/Onderrichtsstraat 27)
- Per Bacco (Rue de l'Enseignement/Onderrichtsstraat 31)
- La Bottega (Rue de l'Enseignement/Onderrichtsstraat )
- Aux Armes de Bruxelles (Rue des Bouchers/Beenhouwersstraat 13) and Chez L\u00e9on (Rue des Bouchers/Beenhouwersstraat 13)
- A very touristic street and with a bad reputation as many of the restaurants are true tourist traps. But if you want to eat there for the atmosphere of the street, these are two decent options, each with their own character.
- Mozart (Petit Rue des Bouchers/Korte Beenhouwersstraat 18) Specialises in ribs, and has a good reputation
- Rue du March\u00e9 aux Fromages/Kaasmarkt is another street with restaurants very much oriented towards tourists. Contrary to the Rue des Bouchers, even some of the cheap places there serve very decent food if you're travelling on a budget, e.g., Plaka, Hellas, Saffron and The Blue, and the Italians in that street also seem to be decent. Baladi, a Syrian restaurant in the nearby Rue des Chapeliers/Hoedenmakerstraat 16, is definitely worth a visit.
"},{"location":"Profiling-20230413/","title":"HPE and AMD profiling tools (April 13, 2023)","text":""},{"location":"Profiling-20230413/#course-organisation","title":"Course organisation","text":" -
Course schedule
The full filename for the slides and the video recording of each presentation is also mentioned in that table, if that file is only available on LUMI.
-
HedgeDoc for questions (during the course only)
"},{"location":"Profiling-20230413/#course-materials","title":"Course materials","text":"Presenatation slides recording Introduction / / Preparing an Application for Hybrid Supercomputing slides recording Introduction to ROC-Profiler (rocprof) slides recording Introduction to OmniTrace slides recording Introduction to Omniperf slides recording Exercises / /"},{"location":"Profiling-20230413/#extras","title":"Extras","text":"Extra downloads:
- Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
- vcopy.cpp example from the Omniperf presentation
- mini-nbody from the rocporf exercise
"},{"location":"Profiling-20230413/00_Introduction/","title":"Introduction","text":" - The video is also available as
/appl/local/training/profiling-20230413/recordings/00_Introduction.mp4
"},{"location":"Profiling-20230413/00_Introduction/#qa","title":"Q&A","text":" -
Can I ask for incresing the home directory capacity?
Answer: No. The home directory cannot be extended, not in capacity and not in number of files as it is also the only directory that is not billed. The home directory is only for stricly personal files and typically the type of stuff that Linux software tends to put in home directories such as caches. The project directory is the directory to install software, work on code, etc., and the scratch and flash directory are for temporary data. You can always create a subdirectory for yourself in your project directory and take away the group read rights if you need more personal space.
-
/project/project_465000502/slides is empty now, right? Thanks.
Answer Yes. HPE tends to upload the slides only at the end of the presentation. PDF file is now copied.
-
How one can see /project/project_465000502/ on LUMI? When I do ls in the terminal, I do not see this folder.
Answer Did you accept the project invite you got earlier this week? And if you have a Finnish user account you will now have a second userid and that is the one you have to use.
Did you try to cd into /project/project_465000502? That directory is not a subdirectory of your home directory!
cd /project/project_465000502\n
"},{"location":"Profiling-20230413/01_Preparing_an_Application_for_Hybrid_Supercomputing/","title":"Preparing an Application for Hybrid Supercomputing","text":""},{"location":"Profiling-20230413/01_Preparing_an_Application_for_Hybrid_Supercomputing/#qa","title":"Q&A","text":" -
Can the tools be used for profiling GPU code which is not directive-based, but written in CUDA/HIP?
Answer: Yes, we provide examples in perftools/perftools-for-hip (and clearly CUDA is supported too) and perftools-lite-gpu. Perftools-lite can give output like this for HIP code:
Table 2: Profile by Function Group and Function\n\n Time% | Time | Imb. | Imb. | Team | Calls | Group\n | | Time | Time% | Size | | Function=[MAX10]\n | | | | | | Thread=HIDE\n | | | | | | PE=HIDE\n\n 100.0% | 0.593195 | -- | -- | -- | 14,960.0 | Total\n|---------------------------------------------------------------------------\n| 57.5% | 0.341232 | -- | -- | -- | 18.0 | HIP\n||--------------------------------------------------------------------------\n|| 39.5% | 0.234131 | -- | -- | 1 | 3.0 | hipMemcpy\n|| 10.2% | 0.060392 | -- | -- | 1 | 2.0 | hipMalloc\n|| 7.2% | 0.042665 | -- | -- | 1 | 1.0 | hipKernel.saxpy_kernel\n||==========================================================================\n
-
Completely unrelated to this course, but, is it possible to use all 128GB of GPU memory on the chip from a single GCD? i.e. have processes running on one GCD access memory on the other GCD.
Answer Not sure if this is allowed. We never investigated since the performance will be really, really bad. The inter-die bandwidth is low compared to the memory bandwidth. BAsically 200 GB/s read and write (theoretical peak) while the theoretical memory bandwidth of a single die is 1.6 TB/s.
Follow up Yes, I appreciate it will be slow, but probably not as slow as swapping back and forwards with main memory? i.e. if I need the full 128GB I can just swap out stuff with DRAM, but that's really, really, really, really bad performance ;). So it'd be 8x slower than on a die, but 8x isn't really really bad. Anyway, I assumed it wasn't supported, just wanted to check if I'd missed something
Peter: but if you already have the data in memory on the other GCD, would it not make more sense to do the compute there in-place, rather than waiting for the kernel to finish on GCD 1 and then transfer the data to GCD 2? It is supported in the sense that it will work with managed memory. The kernel on GCD 1 can load data automatically from GCD 2 with decent bandwidth, typically 150 GB/s (see this paper).
George: some of the above are true if you use both GCDs, in your case is like you use only one.
"},{"location":"Profiling-20230413/02_Intro_rocprof/","title":"Introduction to ROC-Profiler (rocprof)","text":""},{"location":"Profiling-20230413/02_Intro_rocprof/#qa","title":"Q&A","text":" -
Can the PyTorch profiler be used without any specific things to take into account, see link?
Answer:
That is correct. Let us know if you come across any problems.
-
Could you give a rough estimate on the overhead in terms of percentage?
Answer
- Generally very low, but can be high in unusual cases.
- Hard to say exactly what the overhead is, depends usually on the ammount of data being collected. A code with a lot of smaller chunks of GPU activity are usually more pronoe to show more overhead.
"},{"location":"Profiling-20230413/03_Intro_OmniTrace/","title":"Introduction to OmniTrace","text":""},{"location":"Profiling-20230413/03_Intro_OmniTrace/#remarks","title":"Remarks","text":" - Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
"},{"location":"Profiling-20230413/03_Intro_OmniTrace/#qa","title":"Q&A","text":" -
Since there is support for OpenCL, does it support also SYCL? Or it will in the future?
Answer
- There currently no plans to support the SYCL programming models in the AMD tools. For SYCL you'd have to rely on the HIP/HSA activity it generates.
- Peter: I have tested HipSYCL code with rocprof, and you can see the kernels launching.
- OpenSYCL uses HIP for AMD GPUs, so it should be able to track.
-
On LUMI ROCm is only available on LUMI-G, correct? What about onmitrace/perf? Is this available on LUMI-C?
Answer
- Omnitrace could eventually be used to sample CPU code - omniperf is useless in no-GPU systems. These tools are not generally available but can be easily installed as indicated in the presentations.
- The AMD \u03bcProf tool is used for the AMD CPUs.
- The ROCm modules are available on LUMI-C and the login nodes also, but there was a problem with versions before the maintenance. If these tools connect to GPU-specific device drivers though they will fail on non-GPU nodes.
-
What is a reasonable maximum number of mpi processes for omnitrace/perf to deal with?
Answer
- Omniperf needs application replaying to collect multiple counters so the application would have to be replayed equally in all ranks. Omnitrace as MPI trace features and can use wil multiple ranks. In general, you'd be interested in profiling at the scale that is relevant for you and then maybe focus on more problematic/representative ranks, i.e. activate profile on only a given rank or set of ranks while using multiple ranks.
- A related question is how many MPI ranks to use per GPU - this depends but usually a rank por GCD is the choice for many apps. You can use more and the runtime/driver is ready for it without any requires wrapping. My recommendation however is to use ROCm 5.4+ if the intent is to overpopulate the GCDs with ranks.
- Omniperf requires 1 MPI process only. Omnitrace, can be large, not sure what limit except how to analyze the data.
-
Can you track memory usage with these tools? Thanks, will it give you maximum memory usage and where the memory is allocated in the code? Thanks
Answer
- Yes, omnitrace samples memory usage.
"},{"location":"Profiling-20230413/04_Intro_OmniPerf/","title":"Introduction to Omniperf","text":""},{"location":"Profiling-20230413/04_Intro_OmniPerf/#remarks","title":"Remarks","text":"Warning
For security reasons it is best to run omniperf analyze on a single user machine that is protected by a firewall (which is why we do not want to install it visibly on LUMI). It opens an unprotected port to a webserver so everybody with access to LUMI can easily guess the port number and get access to some of your data that way.
"},{"location":"Profiling-20230413/04_Intro_OmniPerf/#qa","title":"Q&A","text":" -
Not related to omniperf. On tranining/exercises/HPE/openacc-mpi-demos after doing sbatch job.slurm.
srun: error: CPU binding outside of job step allocation, allocated CPUs are: 0x01FFFFFFFFFFFFFE01FFFFFFFFFFFFFE.\nsrun: error: Task launch for StepId=3372350.2 failed on node nid007281: Unable to satisfy cpu bind request\nsrun: error: Application launch failed: Unable to satisfy cpu bind request\n
Answer
- let me fix it, I will report here when it is done (for the record, this is due to the today's change in Slurm)... done, please check.
- what change in slurm happened today?
- LUMI admins somehow reverted a change in Slurm that came in with the update where SLURM no longer propagates cpus-per-task if set in an SBATCH job comment into the srun. The old behaviour was restored but we tested the scripts yesterday. There was a user email this morning.
-
Slide 43, the kernels performance are good or not? There is a threshold in terms of distance from boundaries?
Answer
Will be in the recording. The performance is not very good (and take into account the scales are logarithmic so the dots are very far from the boundary).
"},{"location":"Profiling-20230413/05_Exercises/","title":"Exercises","text":" -
Files for the exercises are available in /appl/local/training/profiling-20230413/files/exercises-profiling-20230423.tar.gz
-
Exercises from HPE are available in /appl/local/training/profiling-20230413/files/05_Exercises_HPE.pdf
-
AMD exercidses are available as an online text (local web copy(PDF)) or as /appl/local/training/profiling-20230413/files/05_LUMI-G_Pre-Hackathon-AMD.pdf
-
Extra software that was made available by AMD is available in /appl/local/training/profiling-20230413/files/software-profiling-20230423.tar.gz. As the configuration of LUMI is continuously evolving, this software may not work anymore.
"},{"location":"Profiling-20230413/05_Exercises/#qa","title":"Q&A","text":"Info
AMD Exercises
You can find the instructions in this HackMD document
To run slurm jobs, set the necessary variables for this course by source /project/project_465000502/exercises/HPE/lumi_g.sh Note however that this script is for the reservation made for the course and needs to be adapted afterwards.
Info
HPE Exercises
- Exercise notes and files including pdf and Readme with instructions on LUMI are in the
exercises/HPE subdirectory after untarring the files for the exercises. - General examples
- Directories: openacc-mpi-demos, BabelStream \u2013 Try different parallel offload programming models (OpenACC, OpenMP, HIP) and examples
-
Tests based on the HIMENO benchmark
- Directory: cray_acc_debug
- Directory: compiler_listings
-
In some exercises you have source additional files to load the right modules necessary, check the README file.
-
Follow the Readme.md files in each subfolder
-
I am stuck on the first AMD one.
- I can compile the nbody-orig, and it runs without srun. With srun, it dies with
\"hipErrorNoBinaryForGpu: Unable to find code object for all current devices!\" - What does the
-DSHMOO flag mean for the hip compiler? - If I run
rocprof --stats nbody-orig 65536 (no srun), it dies with Exception: Could not run command: \"rocminfo\"
Answer
-
Please add --offload-arch=gfx90a in the compilation.
hipcc --offload-arch=gfx90a -I../ -DSHMOO nbody-orig.cpp -o nbody-orig\n
-
-D is the compiler flag for a C language family compiler to define a symbol for the preprocessor.
-
I did not get if Omnitrace is available from a module on LUMI or not, sorry! Should I install it?
Answer
No official module currently that fits nicely in the software stack, but for the exercises you can use
module use /project/project_465000502/software/omnitrace192/share/modulefiles/\nmodule load omnitrace/1.9.2\n
-
How can i get access to omniperf on LUMI?
Answer
module use /project/project_465000502/software/omnitrace192/share/modulefiles/\nmodule load omnitrace/1.9.2\n
module load cray-python\nmodule use /project/project_465000502/software/omniperf108/modules\nmodule load omniperf\nexport ROOFLINE_BIN=/project/project_465000502/software/omniperf108/bin/utils/rooflines/roofline-sle15sp3-mi200-rocm5\n
No plans to have it officially available due to the security issues mentioned earlier in this document.
-
I'm having a problem with perftools and OpenACC code
Instrumented code exits with \"pat[WARNING][0]: abort process 72108 because of signal 6 ...\"\n
This happens both with \"perftools-lite-gpu\" as well as with \"perftools\" + \"pat_build\". Uninstrumented code works fine.
- Can you try the latest perftools modules. You will have to unload them (including perftools-base) and reload the newer ones
Same with perftools-base/23.03.0
- Could you share the code?
Simple heat-equation toy code: https://github.com/cschpc/heat-equation I was using the \"3d/openacc/fortran\" version
-
I've tried with the following steps:
git clone https://github.com/cschpc/heat-equation\ncd heat-equation/3d/openacc/fortran\nmodule load PrgEnv-cray\nmodule swap cce cce/15.0.1 # better use always the newest compiler\nmodule load craype-accel-amd-gfx90a rocm\nmodule load perftools-lite-gpu\nmake COMP=cray\nsrun -n 1 --gres=gpu:8 ./heat_openacc\n
And got the error...
-
I will file a ticket for that...
-
(Harvey) Started to look at this, need to be sure the Fortran is valid first (checked: looks fine, the USEs have no circular chain). I'm sure I will run out of time so please put in the ticket.
-
Can I use the cray compiler with rocprof?
- I tried with an example and it works, I assume it could depend on what you want to do.
I would like to trace my application; I tried in the past but I did not manage to produce a .csv file for PERFETTO. I am trying again,
I used:
module load craype-accel-amd-gfx90a\nCC -x hip -o vcopy vcopy.cpp -L/opt/rocm/lib/ -lamdhip64\nsrun -n 1 rocprof --hip-trace ./vcopy 1048576 256\n
I get some errors I can not understand, regarding a HSA table already existing. I added -t ${PWD} to use the current directory, I see the temporary directories created but I get the same error and the directories contain only some .txt files
Traceback (most recent call last):\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/tblextr.py\", line 833, in <module>\n hsa_trace_found = fill_api_db('HSA', db, indir, 'hsa', HSA_PID, COPY_PID, kern_dep_list, {}, 0)\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/tblextr.py\", line 406, in fill_api_db\n table_handle = db.add_table(table_name, api_table_descr)\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/sqlitedb.py\", line 48, in add_table\n cursor.execute(stm)\nsqlite3.OperationalError: table HSA already exists \n Profiling data corrupted: ' /users/bellenta/work_dir/rocm/rpl_data_230413_165341_47398/input_results_230413_165341/results.txt \n
I deleted a results.db present in the directory, and now I see a results.csv file together with others (however still errors in the logfile).. maybe there is a flag to overwrite - This seems like rocprof get killes, can you provide the used command?
srun -N ${SLURM_NNODES} -n 4 rocprof -t ${PWD} --hip-trace --hsa-trace ./pw.x -i atom.in > atom.out.${SLURM_JOBID} 2>&
- Do you have the slides, you need to use a wrapper for multiple processes, could you try with 1 process?
Before I was using the wrapper, and it wasn't working as well but I'll try again. However, now without the wrapper I see a different folder for each mpi rank and it reports an error regarding profiling data corruption, maybe something in the code...
- Yes it is because is more than 1 process, if you try 1 process, it works, right?
yes! by launching with one process only, so no MPI distribution
-
It needs the wrapper, I believe.
WORK_DIR=${PWD}\nif [[ \"$SLURM_PROCID\" == 0 ]]; then\n rocprof -t ${WORK_DIR} --hsa-trace --hip-trace \\\n ./pw.x -i atom.in\nelse\n ./pw.x -i atom.in\nfi\n
-
This will isntrument only process 0, it depends on what you want to do.
This worked, thank you very much! I want to see data movements which should be the same for each MPI rank. Is it feasible to see all the GPUs together with rocprof?
- Omnitrace would be better
-
Trying out some code of my own I get this error when running \"MPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked\", is this a compile time issue?
Answer
-
Are you using hipcc? add this:
module load craype-accel-amd-gfx90a\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\n-I${MPICH_DIR}/include\n-L${MPICH_DIR}/lib -lmpi ${PE_MPICH_GTL_DIR_amd_gfx90a} ${PE_MPICH_GTL_LIBS_amd_gfx90a}\n
-
Perftools information for HIP code is not very useful
I was playing with simple C++ heat-equation toy code https://github.com/cschpc/heat-equation (3d/hip version), which launches kernels asynchronously. Pat_report shows all the time being spent in hipDeviceSynchronize, instead of the actual kernels:
|| 56.9% | 7.172922 | -- | -- | 500.0 | hipDeviceSynchronize\n...\n|| 0.0% | 0.001363 | -- | -- | 500.0 | hipKernel.evolve_interior_kernel\n|| 0.0% | 0.001353 | -- | -- | 500.0 | hipKernel.evolve_z_edges_kernel\n|| 0.0% | 0.001325 | -- | -- | 500.0 | hipKernel.evolve_x_edges_kernel\n|| 0.0% | 0.001306 | -- | -- | 500.0 | hipKernel.evolve_y_edges_kernel\n
Is there way to get the time actually spent in kernels?
- Is this tracing? (
-w flag for pat_build) You can also decide to mask a function (-T flag). Check man pat_build for more info. - You can collect timeseries data (PAT_RT_SUMMARY=0) and view a timeline in apprentice2 and this can show kernels.
Thanks, with tracing and timeseries apprentice2 does not show Time Line but gives \"Data server terminated\" error
-
Omnitrace-instrument seems to take ages to launch for the Jacobi example. Waitng about 10 mins now. Is it normal?
- I assume dynamic instrumentation? yes
- Do binary rewriting, I think the storage is not performing well
Thanks. Is there somewhere I can read about what this dynamic instrumetation means vs (I guess) static? I am a newbie :-)
- In the slides there is a command with
--simulate that show sall the libraries that access the dynamic instrumentation and they are a lot, so the binary rewriting makes profiling accessing onlyt he required libraries which are minimal.
-
I managed to get a roofline plot using the saxpy example, meaning that i can see the kernel \"points\" on the plot. However, i can't do the same with the vcopy example. I mean, it generates a report, so i guess that it works, but it does not show any point on the plot. Can you think of a reason about it? EDIT: because it doesn't have FP operation i guess...
- Yes, vcopy has 0 FLOPs, check more the other things than roofline for vcopy
I changed it to use dgemm
"},{"location":"Profiling-20230413/hedgedoc_notes/","title":"Notes from the HedgeDoc document","text":""},{"location":"Profiling-20230413/hedgedoc_notes/#questions-regarding-course-organisation-or-lumi-in-general","title":"Questions regarding course organisation or LUMI in general","text":" -
Can I ask for incresing the home directory capacity?
Answer: No. The home directory cannot be extended, not in capacity and not in number of files as it is also the only directory that is not billed. The home directory is only for stricly personal files and typically the type of stuff that Linux software tends to put in home directories such as caches. The project directory is the directory to install software, work on code, etc., and the scratch and flash directory are for temporary data. You can always create a subdirectory for yourself in your project directory and take away the group read rights if you need more personal space.
-
/project/project_465000502/slides is empty now, right? Thanks.
Answer Yes. HPE tends to upload the slides only at the end of the presentation. PDF file is now copied.
-
How one can see /project/project_465000502/ on LUMI? When I do ls in the terminal, I do not see this folder.
Answer Did you accept the project invite you got earlier this week? And if you have a Finnish user account you will now have a second userid and that is the one you have to use.
Did you try to cd into /project/project_465000502? That directory is not a subdirectory of your home directory!
cd /project/project_465000502\n
"},{"location":"Profiling-20230413/hedgedoc_notes/#hpe-cray-pe-tools","title":"HPE Cray PE tools","text":" -
Can the tools be used for profiling GPU code which is not directive-based, but written in CUDA/HIP?
Answer: Yes, we provide examples in perftools/perftools-for-hip (and clearly CUDA is supported too) and perftools-lite-gpu. Perftools-lite can give output like this for HIP code:
Table 2: Profile by Function Group and Function\n\n Time% | Time | Imb. | Imb. | Team | Calls | Group\n | | Time | Time% | Size | | Function=[MAX10]\n | | | | | | Thread=HIDE\n | | | | | | PE=HIDE\n\n 100.0% | 0.593195 | -- | -- | -- | 14,960.0 | Total\n|---------------------------------------------------------------------------\n| 57.5% | 0.341232 | -- | -- | -- | 18.0 | HIP\n||--------------------------------------------------------------------------\n|| 39.5% | 0.234131 | -- | -- | 1 | 3.0 | hipMemcpy\n|| 10.2% | 0.060392 | -- | -- | 1 | 2.0 | hipMalloc\n|| 7.2% | 0.042665 | -- | -- | 1 | 1.0 | hipKernel.saxpy_kernel\n||==========================================================================\n
-
Completely unrelated to this course, but, is it possible to use all 128GB of GPU memory on the chip from a single GCD? i.e. have processes running on one GCD access memory on the other GCD.
Answer Not sure if this is allowed. We never investigated since the performance will be really, really bad. The inter-die bandwidth is low compared to the memory bandwidth. BAsically 200 GB/s read and write (theoretical peak) while the theoretical memory bandwidth of a single die is 1.6 TB/s.
Follow up Yes, I appreciate it will be slow, but probably not as slow as swapping back and forwards with main memory? i.e. if I need the full 128GB I can just swap out stuff with DRAM, but that's really, really, really, really bad performance ;). So it'd be 8x slower than on a die, but 8x isn't really really bad. Anyway, I assumed it wasn't supported, just wanted to check if I'd missed something
Peter: but if you already have the data in memory on the other GCD, would it not make more sense to do the compute there in-place, rather than waiting for the kernel to finish on GCD 1 and then transfer the data to GCD 2? It is supported in the sense that it will work with managed memory. The kernel on GCD 1 can load data automatically from GCD 2 with decent bandwidth, typically 150 GB/s (see this paper).
George: some of the above are true if you use both GCDs, in your case is like you use only one.
"},{"location":"Profiling-20230413/hedgedoc_notes/#amd-rocm-profiling-tools","title":"AMD ROCM profiling tools","text":""},{"location":"Profiling-20230413/hedgedoc_notes/#rocprof","title":"ROCProf","text":" -
Can the PyTorch profiler be used without any specific things to take into account, see link?
Answer:
That is correct. Let us know if you come across any problems.
-
Could you give a rough estimate on the overhead in terms of percentage?
Answer
- Generally very low, but can be high in unusual cases.
- Hard to say exactly what the overhead is, depends usually on the ammount of data being collected. A code with a lot of smaller chunks of GPU activity are usually more pronoe to show more overhead.
"},{"location":"Profiling-20230413/hedgedoc_notes/#omnitrace","title":"Omnitrace","text":" -
Since there is support for OpenCL, does it support also SYCL? Or it will in the future?
Answer
- There currently no plans to support the SYCL programming models in the AMD tools. For SYCL you'd have to rely on the HIP/HSA activity it generates.
- Peter: I have tested HipSYCL code with rocprof, and you can see the kernels launching.
- OpenSYCL uses HIP for AMD GPUs, so it should be able to track.
-
On LUMI ROCm is only available on LUMI-G, correct? What about onmitrace/perf? Is this available on LUMI-C?
Answer
- Omnitrace could eventually be used to sample CPU code - omniperf is useless in no-GPU systems. These tools are not generally available but can be easily installed as indicated in the presentations.
- The AMD \u03bcProf tool is used for the AMD CPUs.
- The ROCm modules are available on LUMI-C and the login nodes also, but there was a problem with versions before the maintenance. If these tools connect to GPU-specific device drivers though they will fail on non-GPU nodes.
-
What is a reasonable maximum number of mpi processes for omnitrace/perf to deal with?
Answer
- Omniperf needs application replaying to collect multiple counters so the application would have to be replayed equally in all ranks. Omnitrace as MPI trace features and can use wil multiple ranks. In general, you'd be interested in profiling at the scale that is relevant for you and then maybe focus on more problematic/representative ranks, i.e. activate profile on only a given rank or set of ranks while using multiple ranks.
- A related question is how many MPI ranks to use per GPU - this depends but usually a rank por GCD is the choice for many apps. You can use more and the runtime/driver is ready for it without any requires wrapping. My recommendation however is to use ROCm 5.4+ if the intent is to overpopulate the GCDs with ranks.
- Omniperf requires 1 MPI process only. Omnitrace, can be large, not sure what limit except how to analyze the data.
-
Can you track memory usage with these tools? Thanks, will it give you maximum memory usage and where the memory is allocated in the code? Thanks
Answer
- Yes, omnitrace samples memory usage.
"},{"location":"Profiling-20230413/hedgedoc_notes/#omniperf","title":"Omniperf","text":" -
Not related to omniperf. On tranining/exercises/HPE/openacc-mpi-demos after doing sbatch job.slurm.
srun: error: CPU binding outside of job step allocation, allocated CPUs are: 0x01FFFFFFFFFFFFFE01FFFFFFFFFFFFFE.\nsrun: error: Task launch for StepId=3372350.2 failed on node nid007281: Unable to satisfy cpu bind request\nsrun: error: Application launch failed: Unable to satisfy cpu bind request\n
Answer
- let me fix it, I will report here when it is done (for the record, this is due to the today's change in Slurm)... done, please check.
- what change in slurm happened today?
- LUMI admins somehow reverted a change in Slurm that came in with the update where SLURM no longer propagates cpus-per-task if set in an SBATCH job comment into the srun. The old behaviour was restored but we tested the scripts yesterday. There was a user email this morning.
-
Slide 43, the kernels performance are good or not? There is a threshold in terms of distance from boundaries?
Answer
Will be in the recording. The performance is not very good (and take into account the scales are logarithmic so the dots are very far from the boundary).
Warning
For security reasons it is best to run omniperf analyze on a single user machine that is protected by a firewall (which is why we do not want to install it visibly on LUMI). It opens an unprotected port to a webserver so everybody with access to LUMI can easily guess the port number and get access to some of your data that way.
"},{"location":"Profiling-20230413/hedgedoc_notes/#exercises","title":"Exercises","text":"Info
AMD Exercises
You can find the instructions in this HackMD document
To run slurm jobs, set the necessary variables for this course by source /project/project_465000502/exercises/HPE/lumi_g.sh Note however that this script is for the reservation made for the course and needs to be adapted afterwards.
Info
HPE Exercises - Exercise notes and files including pdf and Readme with instructions on LUMI at /project/project_465000502/exercises/HPE/ - General examples - Directories: openacc-mpi-demos, BabelStream \u2013 Try different parallel offload programming models (OpenACC, OpenMP, HIP) and examples - Tests based on the HIMENO benchmark - Directory: cray_acc_debug - Directory: compiler_listings
- Copy the files to your home or project folder before working on the exercises.
-
In some exercises you have source additional files to load the right modules necessary, check the README file.
-
Follow the Readme.md files in each subfolder
-
To run slurm jobs, set the necessary variables for this course by source /project/project_465000502/exercises/HPE/lumi_g.sh. Note however that this script is for the reservation made for the course and needs to be adapted afterwards.
-
I am stuck on the first AMD one.
- I can compile the nbody-orig, and it runs without srun. With srun, it dies with
\"hipErrorNoBinaryForGpu: Unable to find code object for all current devices!\" - What does the
-DSHMOO flag mean for the hip compiler? - If I run
rocprof --stats nbody-orig 65536 (no srun), it dies with Exception: Could not run command: \"rocminfo\"
Answer
-
Please add --offload-arch=gfx90a in the compilation.
hipcc --offload-arch=gfx90a -I../ -DSHMOO nbody-orig.cpp -o nbody-orig\n
-
-D is the compiler flag for a C language family compiler to define a symbol for the preprocessor.
-
I did not get if Omnitrace is available from a module on LUMI or not, sorry! Should I install it?
Answer
No official module currently that fits nicely in the software stack, but for the exercises you can use
module use /project/project_465000502/software/omnitrace192/share/modulefiles/\nmodule load omnitrace/1.9.2\n
-
How can i get access to omniperf on LUMI?
Answer
module use /project/project_465000502/software/omnitrace192/share/modulefiles/\nmodule load omnitrace/1.9.2\n
module load cray-python\nmodule use /project/project_465000502/software/omniperf108/modules\nmodule load omniperf\nexport ROOFLINE_BIN=/project/project_465000502/software/omniperf108/bin/utils/rooflines/roofline-sle15sp3-mi200-rocm5\n
No plans to have it officially available due to the security issues mentioned earlier in this document.
-
I'm having a problem with perftools and OpenACC code
Instrumented code exits with \"pat[WARNING][0]: abort process 72108 because of signal 6 ...\"\n
This happens both with \"perftools-lite-gpu\" as well as with \"perftools\" + \"pat_build\". Uninstrumented code works fine.
- Can you try the latest perftools modules. You will have to unload them (including perftools-base) and reload the newer ones
Same with perftools-base/23.03.0
- Could you share the code?
Simple heat-equation toy code: https://github.com/cschpc/heat-equation I was using the \"3d/openacc/fortran\" version
-
I've tried with the following steps:
git clone https://github.com/cschpc/heat-equation\ncd heat-equation/3d/openacc/fortran\nmodule load PrgEnv-cray\nmodule swap cce cce/15.0.1 # better use always the newest compiler\nmodule load craype-accel-amd-gfx90a rocm\nmodule load perftools-lite-gpu\nmake COMP=cray\nsrun -n 1 --gres=gpu:8 ./heat_openacc\n
And got the error...
-
I will file a ticket for that...
-
(Harvey) Started to look at this, need to be sure the Fortran is valid first (checked: looks fine, the USEs have no circular chain). I'm sure I will run out of time so please put in the ticket.
-
Can I use the cray compiler with rocprof?
- I tried with an example and it works, I assume it could depend on what you want to do.
I would like to trace my application; I tried in the past but I did not manage to produce a .csv file for PERFETTO. I am trying again,
I used:
module load craype-accel-amd-gfx90a\nCC -x hip -o vcopy vcopy.cpp -L/opt/rocm/lib/ -lamdhip64\nsrun -n 1 rocprof --hip-trace ./vcopy 1048576 256\n
I get some errors I can not understand, regarding a HSA table already existing. I added -t ${PWD} to use the current directory, I see the temporary directories created but I get the same error and the directories contain only some .txt files
Traceback (most recent call last):\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/tblextr.py\", line 833, in <module>\n hsa_trace_found = fill_api_db('HSA', db, indir, 'hsa', HSA_PID, COPY_PID, kern_dep_list, {}, 0)\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/tblextr.py\", line 406, in fill_api_db\n table_handle = db.add_table(table_name, api_table_descr)\n File \"/pfs/lustrep3/appl/lumi/SW/LUMI-22.08/G/EB/rocm/5.3.3/libexec/rocprofiler/sqlitedb.py\", line 48, in add_table\n cursor.execute(stm)\nsqlite3.OperationalError: table HSA already exists \n Profiling data corrupted: ' /users/bellenta/work_dir/rocm/rpl_data_230413_165341_47398/input_results_230413_165341/results.txt \n
I deleted a results.db present in the directory, and now I see a results.csv file together with others (however still errors in the logfile).. maybe there is a flag to overwrite - This seems like rocprof get killes, can you provide the used command?
srun -N ${SLURM_NNODES} -n 4 rocprof -t ${PWD} --hip-trace --hsa-trace ./pw.x -i atom.in > atom.out.${SLURM_JOBID} 2>&
- Do you have the slides, you need to use a wrapper for multiple processes, could you try with 1 process?
Before I was using the wrapper, and it wasn't working as well but I'll try again. However, now without the wrapper I see a different folder for each mpi rank and it reports an error regarding profiling data corruption, maybe something in the code...
- Yes it is because is more than 1 process, if you try 1 process, it works, right?
yes! by launching with one process only, so no MPI distribution
-
It needs the wrapper, I believe.
WORK_DIR=${PWD}\nif [[ \"$SLURM_PROCID\" == 0 ]]; then\n rocprof -t ${WORK_DIR} --hsa-trace --hip-trace \\\n ./pw.x -i atom.in\nelse\n ./pw.x -i atom.in\nfi\n
-
This will isntrument only process 0, it depends on what you want to do.
This worked, thank you very much! I want to see data movements which should be the same for each MPI rank. Is it feasible to see all the GPUs together with rocprof?
- Omnitrace would be better
-
Trying out some code of my own I get this error when running \"MPIDI_CRAY_init: GPU_SUPPORT_ENABLED is requested, but GTL library is not linked\", is this a compile time issue?
Answer
-
Are you using hipcc? add this:
module load craype-accel-amd-gfx90a\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\n-I${MPICH_DIR}/include\n-L${MPICH_DIR}/lib -lmpi ${PE_MPICH_GTL_DIR_amd_gfx90a} ${PE_MPICH_GTL_LIBS_amd_gfx90a}\n
-
Perftools information for HIP code is not very useful
I was playing with simple C++ heat-equation toy code https://github.com/cschpc/heat-equation (3d/hip version), which launches kernels asynchronously. Pat_report shows all the time being spent in hipDeviceSynchronize, instead of the actual kernels:
|| 56.9% | 7.172922 | -- | -- | 500.0 | hipDeviceSynchronize\n...\n|| 0.0% | 0.001363 | -- | -- | 500.0 | hipKernel.evolve_interior_kernel\n|| 0.0% | 0.001353 | -- | -- | 500.0 | hipKernel.evolve_z_edges_kernel\n|| 0.0% | 0.001325 | -- | -- | 500.0 | hipKernel.evolve_x_edges_kernel\n|| 0.0% | 0.001306 | -- | -- | 500.0 | hipKernel.evolve_y_edges_kernel\n
Is there way to get the time actually spent in kernels?
- Is this tracing? (
-w flag for pat_build) You can also decide to mask a function (-T flag). Check man pat_build for more info. - You can collect timeseries data (PAT_RT_SUMMARY=0) and view a timeline in apprentice2 and this can show kernels.
Thanks, with tracing and timeseries apprentice2 does not show Time Line but gives \"Data server terminated\" error
-
Omnitrace-instrument seems to take ages to launch for the Jacobi example. Waitng about 10 mins now. Is it normal?
- I assume dynamic instrumentation? yes
- Do binary rewriting, I think the storage is not performing well
Thanks. Is there somewhere I can read about what this dynamic instrumetation means vs (I guess) static? I am a newbie :-)
- In the slides there is a command with
--simulate that show sall the libraries that access the dynamic instrumentation and they are a lot, so the binary rewriting makes profiling accessing onlyt he required libraries which are minimal.
-
I managed to get a roofline plot using the saxpy example, meaning that i can see the kernel \"points\" on the plot. However, i can't do the same with the vcopy example. I mean, it generates a report, so i guess that it works, but it does not show any point on the plot. Can you think of a reason about it? EDIT: because it doesn't have FP operation i guess...
- Yes, vcopy has 0 FLOPs, check more the other things than roofline for vcopy
I changed it to use dgemm
"},{"location":"Profiling-20230413/schedule/","title":"Course schedule","text":"10:15\u00a0\u00a0 Welcome and introduction Presenters: Emmanuel Ory (LUST), J\u00f8rn Dietze (LUST), Harvey Richardson (HPE)( Recording: /project/project_465000502/recordings/00_Introduction.mp4 on LUMI only. 10:30 Preparing an Application for Hybrid Supercomputing Presenter: John Levesque (HPE) 12:00 lunch break (60 minutes) 13:00 Introduction to ROC-prof profiler Presenter: George Markomanolis (AMD) 13:30 Introduction to OmniTrace Presenter: George Markomanolis (AMD) 14:10 5-minute break 14:15 Introduction to Omniperf and Hierarchical Roofline on AMD InstinctTM MI200 GPUs Presenter: George Markomanolis (AMD) 14:55 break 15:05 Hands-on with examples or own code 16:30 Close"},{"location":"Profiling-20231122/","title":"HPE and AMD profiling tools (November 22, 2023)","text":""},{"location":"Profiling-20231122/#schedule","title":"Schedule","text":"For each session, the schedule also contains a link to the page with downloadable materials and the recordings.
10:15\u00a0\u00a0 Welcome and introduction Presenter: J\u00f8rn Dietze (LUST) 10:25 HPE Cray PE tools introduction Presenter: Alfio Lazzaro (HPE) 12:00 lunch break (60 minutes) 13:00 AMD ROCmTM profiling tools Presenter: Samuel Antao (AMD) 14:45 break 15:05 Hands-on with examples or own code 16:30 Close"},{"location":"Profiling-20231122/#course-organisation","title":"Course organisation","text":" - HedgeDoc for questions (during the course only)
"},{"location":"Profiling-20231122/#extras","title":"Extras","text":"Extra downloads:
- Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
"},{"location":"Profiling-20231122/00_Introduction/","title":"Introduction","text":"Presenter: J\u00f8rn Dietze (LUST)
- The video is also available as
/appl/local/training/profiling-20231122/recordings/00_Introduction.mp4
"},{"location":"Profiling-20231122/00_Introduction/#qa","title":"Q&A","text":"/
"},{"location":"Profiling-20231122/01_HPE_Cray_PE_tools/","title":"HPE Cray PE tools introduction","text":"Presenter: Alfio Lazzaro (HPE)
-
Slides on LUMI in /appl/local/training/profiling-20231122/files/01_HPE_Cray_PE_tools.pdf
-
Files from the demo on LUMI in /appl/local/training/profiling-20231122/files/01_HPE_Demo.tar
-
Recordings: To make the presentations more accessible, the presentation has been split in 6 parts:
-
Introduction and LUMI hardware: slides 1-8: /appl/local/training/profiling-20231122/recordings/01a_HPE_Cray_PE_tools__Hardware.mp4
-
The HPE Cray Programming Environment: slides 9-38: /appl/local/training/profiling-20231122/recordings/01b_HPE_Cray_PE_tools__Programming_environment.mp4
-
Job placement: slides 39-51: /appl/local/training/profiling-20231122/recordings/01c_HPE_Cray_PE_tools__Job_placement.mp4
-
Cray MPICH for GPUs: slides 52-57: /appl/local/training/profiling-20231122/recordings/01d_HPE_Cray_PE_tools__MPICH_GPU.mp4
-
Performance Analysis: slides 58-92: /appl/local/training/profiling-20231122/recordings/01e_HPE_Cray_PE_tools__Performance_analysis.mp4
The \"GDB for HPC\" slides were not covered in the presentation.
HPE training materials can only be shared with other LUMI users and therefore are not available on the web.
"},{"location":"Profiling-20231122/01_HPE_Cray_PE_tools/#qa","title":"Q&A","text":" -
When specifying a single GCD, is the limit GPU memory 64 or 128 G ?
- The slide said 8 GPUS (remember he said the context in the talk was now that 'GPU'=GCD) so it is 64 per GCD.
- And due to the slow connection between two GCDs (basically 200 GB/s per direction) using all memory of a package is not supported.
- For completeness - memory in the GPU is coherent so it is possible for one GCD use memory from the other. E.g. in the current implementation, having a copy kernel that picks up data of the other GCD on the chip is the fastest way to move data between GPUs. So, one can use all the memory on the chip, but the GCD will have 1.6 TB/s (peak) for the HBM next to it and 200 GB/s (peak) from the HBM next to the other GCD.
-
Normally I use gdb4hpc to check what are my MPI processes and individual threads doing. Is there an alternative for this in hpe / cray toolset where I could really nicely get an overview of what all the threads are doing? There can be more of them and it's important to have it well visualized to find reasons for hangs in MPI during sends and receives and probes.
-
We also have ARM Forge (now Linaro) on LUMI.
-
I'm not clear on the request, you can list threads in gdb4hpc (at least for CPU). I expect it to work for GPU kernels but have not actually tried this myself. Are you just looking for a nicer display?
yes, that's what I'm normally using, just wondering if there is a better tool on the market, so I wanted to check if you know about anything.. visualization and really nice overview would be a plus, as sometimes it's hard to navigate in what these threads are up to. I want to try cray stat as well, but not sure what detail can it provide
- The AMD tools also give a thread view, maybe someone can do a demo during the hackathon for you if you have not seen this.
- Linaro Forge promises a lot, but the AMD GPU support is not yet spectacular. We'll upgrade our version of that as soon as it gets better.
Thanks, I should try it out then :)
That would be great. The GPU support of the debugger is not the biggest issue right now as the current issue that I'm looking into can be reproduced also in CPU-only regime, even though our code supports gpus and we're using all the GPUs on a node.
-
How to check if NIC is used when running GPU-aware MPI
- This is tricky. You can tell which NICs an MPI process has access to via the environment variable Alfio mentioned. Proving a particular NIC was used would be nontrivial and possibly involve performance counters.
-
Our application (as every distributed mem coupled cluster code) is relatively heavy on internode communication. How can I measure and analyze when the GPUs are waiting for internode communication, offloading and obtain an overview of what is the percentages of theoretical flop rates on both cpus and gpus? .. and analyze communication vs compute intensity
- Waiting in which API?
- We will cover both the Cray PE profiling tools and AMD profiling tools so you should get an idea of which tool is appropriate for a given investigation by the end of the day.
The code can wait on mpi communication (mpi is run from fortran) between the nodes (each with multiple mpi processes). Also can wait on offloading to a GPU (using HIP) and then the gpu does not get to more than 10% of theoretical peak flop rate on average, it's use-time is like 55%. I'd like to analyze, measure and visualize these bottlenecks. Not sure what you mean by which API. I want to use whatever tool does the job for the analysis. I see that the presented tools can do a lot on this, which is great.
- API, for example MPI, HIP (cpu to GPU) ?
Yes, MPI called from fortran and HIP. cpu to gpu, we tried gpu aware mpi comm for the first time a week ago, it's just in an experimental phase
-
Can I see the percentage use of theoretical GPU flop rate?
- No. For this kind of analysis, in particular roofline analysis, AMD omniperf is the tool to use.
-
Do you have any experience with OOD disconnection? I've tried several times VNC or VSCode and after a while I get a \"disconnected\" message. Thanks.
- After how much time? Sessions are by default for 4 hours I believe.
-
For development I use VSCode very often and with Lumi I often have the problem that VSCode cannot write files to disk. Do you have any experience with that? Thanks.
- Do you use VSCode + server on LUMI or OOD VSCode?
VSCode + ssh extension + VSCode server on cluster
-
Would it be possible to enable running Xorg on GPU nodes (Some applications require OpenGL for calculation)?
- Not on the AMD GPU nodes. They are compute GPUs, not render GPUs and typical graphics APIs are not supported. They don't even have the hardware to run those APIs with full hardware acceleration as much of the render pipeline is eliminated from their design to have more transistors available for compute. Time to switch APIs I think as, e.g., NVIDIA, is also more an more making a distiction between compute and render GPUs with the former missing the necessary hardware to support render APIs.
There is only problem with permission for running of Xorg :0, the example to allow Xorg running (CentOS7) - e.g. for prolog
{\n log_debug \"xorg_load\"\n echo \"allowed_users=anybody\" > /etc/X11/Xwrapper.config\n echo \"#%PAM-1.0\n auth sufficient pam_rootok.so\n auth sufficient pam_permit.so\n account required pam_permit.so\n session optional pam_keyinit.so force revoke\" > /etc/pam.d/xserver\n}\n
-
If something is not permitted, it is not permitted for a reason. So no hope we would change these permissions. Moreover, LUMI has an OS set up to run minimal services on the compute nodes to limit OS jitter. And there is more than a permissions problem. The next problem would be a driver problem as there is no driver for OpenGL (or graphics in general) on MI250X.
The name \"GPU\" is very misleading for MI100/MI200 (but in fact also for the NVIDIA H100). MI100 and MI200 are really vector- and matrix compute accelerators, but with an architecture similar to that of GPUs (in the AMD case an evolution of GCN/Vega), and not graphics processing units.
You might be able to run some kind of X server in a container (after all, this is what is done to run VNC on LUMI also as a VNC server is some sort of X server, at least the ones that we use) but that still would only give you software based rendering.
Use case for off-screen rendering (OpenGL/Vulkan): There is off-screen rendering/rasterization that is used as input to neural network algorithms. There are articles and research papers that need this use case for research.
-
Then I think you'll have to look at a different way of developing such software, splitting the parts that need rendering GPUs and compute GPUs, run on supercomputers with lots of rendering GPUs, or use different libraries that still perform decent on vector accelerators. The only rendering you could do on LUMI would be fully software-based anyway. Clusters that still have a battery of rendering GPUs, will probably also have the necessary hardware acceleration for AI in the forseeable future as AI is becomming business in the PC space also (though even that isn't sure as AMD in some of their PC APUs did not integrate matrix units in the GPU part for AI acceleration, but uses instead a dedicated accelerator for AI - called XDNA, just as most phone SOCs do). And large partitions with rendering GPUs are becoming rare in the supercomputer space...
-
There is HIP support for Prorender but that means you need to use that API instead of Vulkan/EGL: https://gpuopen.com/radeon-prorender-hip-updates/
-
For computer vision and AI - the GPU accelerated pre-processing can be accomlished with rocAL part of the MIVisionX suite (or on GitHub) that comes with ROCm.
"},{"location":"Profiling-20231122/02_AMD_tools/","title":"AMD ROCmTM profiling tools","text":"Presenter: Samuel Antao (AMD)
Part 1: rocprofPart 2: OmniTracePart 3: OmniPerf The recordings are also available on LUMI in /appl/local/training/profiling-20231122/recordings.
"},{"location":"Profiling-20231122/02_AMD_tools/#qa","title":"Q&A","text":" -
Can the tool used also for profiling ML framework, Tensforflow-Horovod
- Yes, omnitrace-python is the driver to be used in these cases ot see the Python call stack alongside the GPU activity.
-
In the first set of slides it was mentioned that rocmprof serialize the kernels execution. How does this affect the other tools? Is it possible to use the tools to profile a program that launches multiple kernels on different streams or even in different processes and see the overal performance?
- No, rocprof does not serialize kernels, what I tried to explain is that users should serialize kernels for counter readings to be meaningful.
-
Could you check the slide about installing of omniperf? I see different path in CMAKE_INSTALL_PREFIX and \"export PATH\". There is dependencies: Python 3.7 but default on Lumi is Python 3.6, which module is the best for that (e.g. cray-python)?
-
Cray-python should be fine. The exported PATH is a typo, it should be: export PATH=$INSTALL_DIR/1.0.10/bin:$PATH. For the exercises we use the following to provide omniperf for ROCm 5.4.3:
module use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/5.4.3 omniperf/1.0.10-rocm-5.4.x\n\nsource /pfs/lustrep2/projappl/project_462000125/samantao-public/omnitools/venv/bin/activate\n
"},{"location":"Profiling-20231122/03_Exercises/","title":"Exercises","text":"The main goal is to try out what you have learned in the course on your own code for the hackaton.
Alternatively, AMD exercises are available as an online text (or version saved as Chrome .mht file, may not open directly in your browser, also /appl/local/training/profiling-20231122/files/03_AMD_Excercise_notes.mht)
"},{"location":"Profiling-20231122/03_Exercises/#qa","title":"Q&A","text":"/
"},{"location":"Profiling-20241009/","title":"HPE and AMD profiling tools (October 9, 2024)","text":""},{"location":"Profiling-20241009/#schedule","title":"Schedule","text":"For each session, the schedule also contains a link to the page with downloadable materials and the recordings.
Original schedule (PDF)
10:15 CEST11:15 EEST Welcome and introduction Presenter: J\u00f8rn Dietze (LUST) and Harvey Richardson (HPE) 10:30 CEST11:30 EEST HPE Cray PE tools introduction Presenter: Harvey Richardson and Alfio Lazzaro (HPE) 12:00 CEST13:00 EEST lunch break (60 minutes) 13:00 CEST14:00 EEST AMD ROCmTM profiling tools Presenter: Samuel Antao (AMD) 14:45 CEST15:45 EEST break (15 minutes) 15:00 CEST16:00 EEST Hands-on with examples or own code 16:30 CEST17:30 EEST Close"},{"location":"Profiling-20241009/#course-organisation","title":"Course organisation","text":" - HedgeDoc for questions (during the course only)
- Project for the course:
project_465001361
"},{"location":"Profiling-20241009/#extras","title":"Extras","text":" -
Links to documentation of commands on LUMI
-
Perfetto, the \"program\" used to visualise the output of omnitrace, is not a regular application but a browser application. Some browsers nowadays offer the option to install it on your system in a way that makes it look and behave more like a regular application (Chrome, Edge among others).
Some of the exercises used in the course are based on exercises or other material available in various GitHub repositories:
"},{"location":"Profiling-20241009/00_Introduction/","title":"Introduction","text":"Presenters: J\u00f8rn Dietze (LUST) and Harvey Richardson (HPE)
- The video is also available as
/appl/local/training/profiling-20241009/recordings/00_Introduction.mp4
"},{"location":"Profiling-20241009/00_Introduction/#qa","title":"Q&A","text":" -
We have trouble creating our container on LUMI. Is it expected that it is in place before the Hackathon starts, or can we get help to do this in the beginning of the Hackathon. Preferrable, we would like to get some help before the Hackathon.
-
Did your LUST mentor contact you? They may offer some help. The more of those things are done before the hackathon, the more time can actually be spent on the goals of the hackathon.
-
There are also updated container images (prebuilt by us) at: /appl/local/containers/sif-images/
Okay, nice. How do we load one of these images to look what packages are available inside them?
-
They use a conda installation internally. So singularity shell <path to the .sif file> and then at the command prompt $WITH_CONDA. The latter is an environment variable that contains the commands that should be executed to activate the conda environment. Then you can just look around in the container and use the usual tools to, e.g., get a list of python packages (conda list).
-
In case, some packages are missing, also check out this presentation on how to extend our containers
"},{"location":"Profiling-20241009/01_HPE_Cray_PE_tools/","title":"HPE Cray PE tools introduction","text":"Presenters: Harvey Richardson and Alfio Lazzaro (HPE)
-
Slides on LUMI in /appl/local/training/profiling-20241009/files/01_HPE_Cray_PE_tools.pdf
-
Recordings: To make the presentations more accessible, the presentation has been split in 6 parts:
-
Introduction and LUMI hardware (Harvey Richardson): slides 1-8: /appl/local/training/profiling-20241009/recordings/01a_HPE_Cray_PE_tools__Hardware.mp4
-
The HPE Cray Programming Environment (Harvey Richardson): slides 9-38: /appl/local/training/profiling-20241009/recordings/01b_HPE_Cray_PE_tools__Programming_environment.mp4
-
Job placement (Harvey Richardson): slides 39-51: /appl/local/training/profiling-20241009/recordings/01c_HPE_Cray_PE_tools__Job_placement.mp4
-
Cray MPICH for GPUs (Harvey Richardson): slides 52-57: /appl/local/training/profiling-20241009/recordings/01d_HPE_Cray_PE_tools__MPICH_GPU.mp4
-
CCE Fortran and C/C++ & Offload to the GPUs (Alfio Lazzaro): slides 58-75 /appl/local/training/profiling-20241009/recordings/01e_HPE_Cray_PE_tools__CCE_Fortran_and_offload.mp4
-
Performance Analysis (Alfio Lazzaro): slides 76-113: /appl/local/training/profiling-20241009/recordings/01f_HPE_Cray_PE_tools__Performance_analysis.mp4
The \"GDB for HPC\" slides (114-127) were not covered in the presentation.
HPE training materials can only be shared with other LUMI users and therefore are not available on the web.
"},{"location":"Profiling-20241009/01_HPE_Cray_PE_tools/#qa","title":"Q&A","text":" -
Slide 25 may need an update. With the 24.03 edition it is better to use gcc-native-mixed to get the gcc installation specifically for this version of the PE. And then you have to use gcc-13 --version as gcc --version would give you the (ancient) system gcc.
- (Alfio) the comment is correct, then you have to use
gcc-13 instead of gcc. However, gcc-13 is always available, so don't need to load the gcc-native-mixed module. Proper linking to gcc has been fixed in PE 24.07 (not yet on LUMI).
-
How does ROCR_VISIBLE_DEVICES interact with OpenMP calls that detect the number of devices (\"omp_get_num_devices\") and set/get the default target device (\"omp_set_default_device\" and \"omp_get_default_device\")?
- It works at the lowest level of the ROCm stack and will limit what the OpenMP runtime can detect. For example you might only see one device from OpenMP (or a HIP program)
"},{"location":"Profiling-20241009/02_AMD_tools/","title":"AMD ROCmTM profiling tools","text":"Presenter: Samuel Antao (AMD)
Part 1: GPU timeline profilingPart 2: OmniPerf and the roofline modelPart 3: Tips and Tricks The recordings are also available on LUMI in /appl/local/training/profiling-20241009/recordings.
"},{"location":"Profiling-20241009/02_AMD_tools/#qa","title":"Q&A","text":"Slide 7
We now have a rocm/6.2.2 module on the system which is built by LUST, but there are compatibility problems with the CCE compilers as ROCm 6.2 is based on Clang/LLVM 18 which has some conflicts with Clang/LLVM 17 from the 24.03 CPE. You can find it in CrayEnv and LUMI/24.03 partition/G.
-
Can we give multiple kernel names for omniprof for the profiling?
- Yes you can usually up to 10 kernels but there could be more probably
-
Is there a way to capture the kernel running not every time, but in certain intervals. For example only profile \"my_great_kernel\" every 5 runs.
- I am not sure for every 5 but you can say profile the 5th execution, 10th, etc. so this is manual. However, it is improtant to know that all the kernels are running in the order that they are called, so 5th execution does not mean is the kernel we want, you need to identify first which call is for your kernel. Although they were planning to change it, I need to check if something is changed.
Thanks. This was exactly my question. a specific kernel's 5th and 10th invocation. I guess one can check the order of kernels that are and map the invocation to the specific kernel one wants to profile.
-
Which modules do I need to load in order to use rocprofv3?
-
You need ROCm 6.2 and later, then it is included there, no other module required
-
After loading rocm/6.2.2 (see above), it is in $EBROOTROCM/bin and also in the path. However, loading this will likely also cause your code to use libraries from ROCm 6.2.2 which may cause some problems with some codes.
-
pftrace files generated with rocprofv3 can quickly get rather large, I tried to upload one to perfetto which had 1 GB. Can the size of the output files be reduced easily?
-
I am not aware of a way to reduce the profile size. You can use, though, the offline trace processor tool. Perfetto UI will look for an instance of that trace processor. You can even choose to have the trace processor running remotelly (on LUMI) and forward that with SSH to your laptop.
-
(Harvey) I see rocprofv2 has a --trace-period option but that is not listed under help for rocprofv3. There is also a start and stop API call mentioned in the rocprof documentation but again I don't see that in the rocprofv3 equivalent webpage.
-
They are here (two sections)
"},{"location":"Profiling-20241009/03_Exercises/","title":"Exercises","text":"The main goal is to try out what you have learned in the course on your own code for the hackaton.
There are also AMD exercises available in three online documents:
-
AMD LUMI pre-hackathon training: Basic exercises
-
AMD LUMI pre-hackathon training Omniperf advanced exercises part 1
-
AMD LUMI pre-hackathon training Omniperf advanced exercises part 2
"},{"location":"Profiling-20241009/03_Exercises/#qa","title":"Q&A","text":"/
"},{"location":"Profiling-20241009/A01-Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"Profiling-20241009/A01-Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 23.02.7, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCD 3.11 User Guide
"},{"location":"Profiling-20241009/A01-Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"Profiling-20241009/A01-Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"Profiling-20241009/A01-Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"Profiling-20241009/A01-Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"User-Coffee-Breaks/","title":"LUMI User Coffee Break Talks","text":"In reverse chronological order:
-
LUMI Update Webinar (October 2, 2024)
-
HyperQueue (January 31, 2024)
-
Open OnDemand: A web interface for LUMI (November 29, 2023)
-
Cotainr on LUMI (September 27, 2023)
-
Spack on LUMI (August 30, 2023)
-
Current state of running AI workloads on LUMI (June 28, 2023)
"},{"location":"User-Coffee-Breaks/20230628-user-coffee-break-AI/","title":"Current state of running AI workloads on LUMI (June 28, 2023)","text":"Presenters: Christian Schou Oxvig and Ren\u00e9 L\u00f8we Jacobsen (LUST & DeiC)
"},{"location":"User-Coffee-Breaks/20230628-user-coffee-break-AI/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the AI-related questions.
-
Q: On this page https://github.com/Lumi-supercomputer/ml-examples/tree/main/tensorflow/hvd, options for installing Horovod are described. The first one uses cray-python and tensorflow-rocm from pip. But it does not explain what module is necessary to load for Horovod to function, despite that the environment is without a running mpirun executable (GPU-aware), required by Horovod. If OpenMPI is loaded first, the horovod package will not compile with NCCL support. Knowing what other packages than cray-python (and OpenMPI?) are necessary when installing horovod with pip and not a docker, would be helpful.
Answer:
-
Please, notice that that\u2019s not lumi\u2019s official documentation.
-
The idea there is to install horovod within the container. That\u2019s why it doesn\u2019t need any system modules loaded. The image already has a horovod installation, but somehow it doesn\u2019t work for us. We are only replacing it.
OpenMPI is used only as a launcher while all the communication is done via rccl.
Nevertherless, since you are having issues with those instructions, we will have a look to see if anything needs to be changed. We should probably update it to the latest image.
-
Q: On the same page, this script loads many modueles and sets environment variables. But they are not explained, which makes it difficult to experiment with new dockers. Likewise, it is not explained why some areas are mapped into the Singularity image (e.g., app). Where is this information available?
Answer: Maybe the sections Accessing the Slingshot interconnect and OpenMPI of the README.md have the information that you need.
-
Q: How can the package Accelerate from Huggingface be loaded, working with Pytorch2 and AMD infrastructure?
Answer: (Christian) One option is to use cotainr to build a Singularity/Apptainer container from a conda/pip environment. On LUMI you can module load LUMI, module load cotainr to get access to cotainr. You may use this (somewhat outdated) PyTorch+ROCm example as a starting point. Modify the conda environment YAML file to your needs, i.e. include the torch 2.0 and accelerate pip packages. You probably want to use a ROCm 5.3 based version for best compatibility with LUMI, i.e. use --extra-index-url https://download.pytorch.org/whl/rocm5.3. If you try this and it doesn\u2019t work, please submit a ticket to the LUMI user support team via https://lumi-supercomputer.eu/user-support/need-help/.
-
Q: I notice that aws-ofi-rccl automatically replaces Lmod \u201cPrgEnv-cray/8.3.3\u201d with \u201ccpeGNU/22.08\u201d when I load it. Could you explain this behavior, and if the GNU environment is necessary to use (also it terms of python version) when using Singuarlity dockers?
Answer: This is because the module has been built with EasyBuild using the cpeGNU/22.08 toolchain and that module may be needed for the AWS plugin to find the runtime libraries. You'd have to compile the plugin during the construction of the container with a C compiler in the container to avoid that.
"},{"location":"User-Coffee-Breaks/20230830-user-coffee-break-Spack/","title":"Spack on LUMI (August 30, 2023)","text":"Presenters: Peter Larsson (LUST & KTH PDC)
"},{"location":"User-Coffee-Breaks/20230830-user-coffee-break-Spack/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the Spack-related questions.
-
Q: I do not know all the limitations but if you create many spack instances in a project you can hit the quota regarding number of files, right?
Answer: Yes, it is true. For this reason we provide \u201ccentral\u201d spack installation with most common software pieces already available (so called upstream spack instance). If you use spack module then you wouldn\u2019t need to install everything in your own directory.
"},{"location":"User-Coffee-Breaks/20230927-user-coffee-break-cotainr/","title":"Cotainr on LUMI (September 27, 2023)","text":"Presenters: Christian Schou Oxvig (LUST & DeiC)
Materials:
"},{"location":"User-Coffee-Breaks/20230927-user-coffee-break-cotainr/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the cotainr-related questions.
-
Q: Is it recommended/possible to use multiprecision in my tensorflow models during training?
Answer: That's a question to ask to a Tensorflow specialist. It requires domain knowledge to answer. We are a small team and can impossibly have expertise in all applications and how they behave on LUMI.
However, the AMD GPUs are relatively strong in FP32 and very strong in FP64 but not so strong in lower precision formats so it may not pay off as much as you would expect from some other GPUs.
Comment on the answer: it is also a question on GPU type, with NVIDIA, the command: tf.keras.mixed_precision.set_global_policy(\"mixed_float16\") works transparently (and I am not specialist neither)
-
Q: For containr, where is the image stored (on which quota does it go)?
Answer: That depends on where you install it. We recommend that the image is stored in your project folder. The image will only be a single file.
-
Q: For my conda installation on LUMI, I followed the instructions provided on the LUMI container wrapper doc page, unlike containr build mentioned today. Seems like it did build on the file system. So should I do it again differently? The commands I used were:
$ module load LUMI\n$ module load lumi-container-wrapper\n$ mkdir MyEnv\n$ conda-containerize new --prefix MyEnv env.yaml\n$ which python\n{my project path}/MyEnv/bin/python\n
Answer: It does put some things on the file system like wrapper scripts but the main installation is done in a SquashFS file that will be among those files. But the container wrapper does, e.g., create wrapper scripts for everything in the bin directory in the container so that you don't need to use singularity commands to start something in the container.
Comment: You can use cotainr as an alternative to the LUMI container wrapper. Please take a look at the LUMI docs page Installing Python Packages for more details about the differences.
-
Q: Does the --system option installs ROCM GPU optimized BLAS/LAPACK releases when selecting lumi-g ?
Answer: The system flag defines a base image for your container. For LUMI-G it will include the full ROCm stack. You can use --base-image, if you want to specify your own base image.
-
Q: Is there a command similar to --post-install for cotainr that is present in the lumi-container-wrapper?
- The
--post-install command allows commands to be executed inside the container after creating the squashfs file. --post-install is not available in containr and for best practice you should re-build the container with the python file.
-
Q: Being new to containers in general, is it possible to have my \"core\" image built with containr, and when running it, pip install new packages to use in the container for one certain project? Thank you.
Answer Containers are read-only once created so pip install would do an installation outside the container in the default Python installation directories.
-
Q: I use conda env for the ML part of my code but I have also Cray compilers and tools to use with this. What are your suggestions for such mixed requirements ?
Answer I don't think there is a generic answer to that. The problem is that if you start to mix software compiled with different compilers, you can have conflicts between run-time libraries of compilers. Ideally you'd use the same compilers as those ML parts were built with, but that's something that you don't always know... Unfortunately compiling our own PyTorch and Tensorflow to ensure compatibility is outside what LUST can do given the size of the team, and is something that AMD advised us not to do as it is very difficult to get it right.
-
Q: As an addition to the question about post-install: Singularity has the option to make a \"sandbox\" image, so that you are able to install linux packages in the shell after creation. Wouldn't this be an easy addition, that doesn't make it too complicated for the basic user? A --sandbox option.
Answer Cotainr actually exploits sandbox to build the container. But it is not a good practice to build containers and then extend them afterwards as you may loose reproducibility as you don't have a definition file anymore that covers the whole container.
-
Q: Does cotainr works also with pipenv?
Answer Currently only Conda is supported, but the documentation does show a way to add pip packages to the environment.
-
Q: I am running an R code on LUMI-C using the small partition. How can I efficiently allocate a whole node in order to cut billing units?. Are there any specific commands to adjust the minimum number of GB per core to be allocated?
Answer It is possible to allocate a full node in the small partition by using the #SBATCH --exclusive flag in SLURM, but you might as well run in the standard partition as well, which allocated a full node by default. Same with memory: there are flags to specify the amount of memory per core, per rank, per GPU etc in SLURM (please see the sbatch man page).
-
Q: Is it easy to add something like \"module load\" in the cotainr build script, to start with a known group of packages?
Answer That doesn't make much sense in the spirit of containers as containers try to offer a self-contained environment. The primary use of modules is to support multiple versions of one package which is not of use in containers.
Packages also are not taken from the system, but currently from the Conda repositories and for containers in general from different software repositories.
-
Q: Does the LUMI container image include Cray compiler ? And if yes could, this container by use on our PC ?
Answer The Cray compiler is NOT public domain but licensed software so you cannot use it outside of LUMI or other systems that have a license for it. There actually exists a containerised version of the PE but it is given only to users who have signed heavy legal documents in a specific project.
So the Cray compiler is also not contained in the base images of cotainr and never will unless HPE would open source the PE which they will not do anytime soon as it is one of the selling points for their systems.
-
Q: With a singularity container built with cotainer based on a conda env, is it possible to add packages to the environment after the container is built?
Answer Please see the answers above.
-
Q: So is there container with gnu/llvm +rocm for building fortran code for LUMI in our PC ?
Answer Why not simply install the gnu compilers or ROCm + LLVM (the AMD compilers are LLVM-based) on your PC? ROCm in a container would still need an AMD GPU and driver installed in the PC if you want to test the software also and not only compile. In fact, not even all compiles would work as software installation scripts sometimes need the GPU to be present as they try to automatically check the type etc.
Comment The point was to have a good starting point, that User Support have already tested .
Reply Testing is not absolute anyway as a container still depends on the underlying hardware, OS kernel and drivers. It is a misconception that containers are fully portable. And having the software in a container can make development harder as you will always be mixing things in the container with things outside it.
Moreover, we don't have the resources to test such things thoroughly. It is already not possible to thoroughly test everything that runs on the system, let alone that we can test if things would also work on other systems.
-
Q: Has cotainr images access to all lustre filesystems?
Answer Yes, but you need to do the binding as explained in our singularity documentation.
"},{"location":"User-Coffee-Breaks/20231129-user-coffee-break-OoD/","title":"Open OnDemand: A web interface for LUMI (November 29, 2023)","text":"Presenters: Ren\u00e9 L\u00f8we Jacobsen (LUST & DeiC)
"},{"location":"User-Coffee-Breaks/20231129-user-coffee-break-OoD/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the questions from the Open OnDemand session.
"},{"location":"User-Coffee-Breaks/20231129-user-coffee-break-OoD/#open-ondemand","title":"Open OnDemand","text":" -
Are there plans to add other IDEs like PyCharm along with VSCode?
- You can install the PyCharm VScode plugin, but be careful that files are not all installed in your home (small file quota there)
-
How can you run Pytorch from OpenOnDemand?
- New documentation about PyTorch: https://lumi-supercomputer.github.io/LUMI-EasyBuild-docs/p/PyTorch/
- You can access your python virtual/conda environments from within the jupyter notebook.
-
Regarding Jupyter, why is it required to load a virtual environment to use python packages and not using system-wise installations instead?
-
LUMI is a multi-user system. There is no configuration that is good for everybody, so something systemwide does not make sense. Moreover, another restriction that limits what we can do system-wide, is that Python distributes packages in too many small files that puts a severe load on the file system, so we prefer Python in containers.
Virtual environments actually also became important simply because there are so many package conflicts in Python.
-
You can also install your python environment easily with the container wrapper: https://docs.lumi-supercomputer.eu/software/installing/container-wrapper/ . It encapsulates it nicely in a container and puts no strain on the LUMI file system
-
And as LUMI is a multi-user system, there are even multiple versions of Python itself. The system Python is for system management and hence the default version of SUSE, but then there are newer versions provided by modules. This is the very nature of an HPC system.
-
Comment: mlflow may be added to web interface, in addition to tensorboard. This could be useful also for pytorch users.
"},{"location":"User-Coffee-Breaks/20231129-user-coffee-break-OoD/#other-questions","title":"Other questions","text":" -
Can I have a tmux session persist after logout or ssh disconnect? I know there are plugins such as tmux-ressurect to save and restore sessions, but there are cases where I might be running a task in a tmux session which I would like to be able to resume or reconnect to after a logout. I understand some of the issues one can raise around this approach, but there are other less abusive uses of tmux like simply storing a working environment (inc. environment variables) which I find very useful. Hopefully you can help answer, or maybe suggest tools to restore the full working environment of several sessions. Thanks!
-
The tmux executable is on the system but we do not actively support it. The resources on the login nodes are limited and if everybody leaves things running, we're run out of resources.
Personally I have bash functions in my login environment that I use to initialise specific session types (modules and environment variables).
As the environment on LUMI sometimes changes it is also not a good idea to store it unless you understand very well the problems that can occur.
Not refreshing the environment also has other disadvantages. E.g., we've seen corrupt Lmod environments and logging out and in helps to clean things up. Or we change things on the system that are then not picked up, and if users keep using the same session for weeks and then submit tickets it's really not the first thing we think about as the cause of the problem.
-
We would like to use Gaussian quantum chemistry software on LUMI (I'm sure thre are more users who would be interested to use it). Gaussian doesn't support \"bring your own license\" approach, and they strictly determine the location where it is allowed to use. Gaussian customer support clarifed that our license is only valid on the licensed location (e.g. university campus). They also mentionned that CSC has a supercomputer center license, which allows external accademic users access to the binary code, but this license is not valid for LUMI. CSC has last year expressed an interst to obtaining a Gaussian license for LUMI as well, but so far, there has been no steps toward that. Can you clarify if and when Gaussian software will be available on LUMI?
-
LUST will not invest in the license. If CSC wants to for their users, they can, but we don't speak for CSC. It is not a very scalable code (its LINDA parallelisation technology is basically technology from the early '90s that does not exploit modern fast interconnects well) and unless you have a source code license, it may not even run on LUMI. We have very bad experiences with some other codes already that come as binaries. The interconnect can be a problem, but people should also realise that the compute nodes only run a subset of SUSE Linux as some daemons are disabled (and we know software that doesn't work or has limited functionality because of this). Software that can use the AMD GPUs has a higher priority for our central budget. They only support some NVIDIA GPUs and no AMD GPUs.
For a system whose prime focus is development of exascale technologies their license that forbids comparison with other codes is also not interesting.
-
I'm already in contact with support about this, so sorry if this is a repetition. I'm trying to get some multi-node pytorch code to run using torchrun but for some reason it fails with NCCL (connection) errors. The code works on a single node and I earlier on had a variety that (sometimes) worked with multiple nodes, but irregularily failed. Support has tried pytorch examples for multi-node code which seemed to work, but the code I have still fails. The code in
-
You are talking here to the same people as those who do the ticket so we really cannot say anything here more.
The message I got from AMD is that torchrun is actually not the ideal way to run PyTorch on LUMI. When they built the container for LUMI, they started PyTorch via Python itself.
Ok, but what way should be used then? handling it all manually, when there is a wrapper in place that should exactly care about all of these issues concerning multi-node settings?
- The script I have seen uses
srun outside the container with each container starting a Python process with access to 1 GPU.
I also tried one srun now within an allocation. Same issue.
-
Basically, the script I got is
#!/bin/bash -e\n\nwd=$(pwd)\njobid=$(squeue --me | head -2 | tail -n1 | awk '{print $1}')\n\n\n#\n# Example assume allocation was created, e.g.:\n# N=1 ; salloc -p standard-g --threads-per-core 1 --exclusive -N $N --gpus $((N*8)) -t 4:00:00 --mem 0\n#\n\nset -x\n\nSIF=/appl/local/containers/sif-images/lumi-pytorch-rocm-5.6.1-python-3.10-pytorch-v2.1.0.sif\n\n# Utility script to detect the master node\ncat > $wd/get-master.py << EOF\nimport argparse\ndef get_parser():\n parser = argparse.ArgumentParser(description=\"Extract master node name from Slurm node list\",\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\"nodelist\", help=\"Slurm nodelist\")\n return parser\n\n\nif __name__ == '__main__':\n parser = get_parser()\n args = parser.parse_args()\n\n first_nodelist = args.nodelist.split(',')[0]\n\n if '[' in first_nodelist:\n a = first_nodelist.split('[')\n first_node = a[0] + a[1].split('-')[0]\n\n else:\n first_node = first_nodelist\n\n print(first_node)\nEOF\n\nrm -rf $wd/run-me.sh\ncat > $wd/run-me.sh << EOF\n#!/bin/bash -e\n\n# Make sure GPUs are up\nif [ \\$SLURM_LOCALID -eq 0 ] ; then\n rocm-smi\nfi\nsleep 2\n\nexport MIOPEN_USER_DB_PATH=\"/tmp/$(whoami)-miopen-cache-\\$SLURM_NODEID\"\nexport MIOPEN_CUSTOM_CACHE_DIR=\\$MIOPEN_USER_DB_PATH\n\n# Set MIOpen cache to a temporary folder.\nif [ \\$SLURM_LOCALID -eq 0 ] ; then\n rm -rf \\$MIOPEN_USER_DB_PATH\n mkdir -p \\$MIOPEN_USER_DB_PATH\nfi\nsleep 2\n\n# Report affinity\necho \"Rank \\$SLURM_PROCID --> \\$(taskset -p \\$\\$)\"\n\n\n# Start conda environment inside the container\n\\$WITH_CONDA\n\n# Set interfaces to be used by RCCL.\nexport NCCL_SOCKET_IFNAME=hsn0,hsn1,hsn2,hsn3\n\n# Set environment for the app\nexport MASTER_ADDR=\\$(python /workdir/get-master.py \"\\$SLURM_NODELIST\")\nexport MASTER_PORT=29500\nexport WORLD_SIZE=\\$SLURM_NPROCS\nexport RANK=\\$SLURM_PROCID\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\n\n# Run app\ncd /workdir/mnist\npython -u mnist_DDP.py --gpu --modelpath /workdir/mnist/model\n\nEOF\nchmod +x $wd/run-me.sh\n\nc=fe\nMYMASKS=\"0x${c}000000000000,0x${c}00000000000000,0x${c}0000,0x${c}000000,0x${c},0x${c}00,0x${c}00000000,0x${c}0000000000\"\n\nNodes=4\nsrun --jobid=$jobid -N $((Nodes)) -n $((Nodes*8)) --gpus $((Nodes*8)) --cpu-bind=mask_cpu:$MYMASKS \\\n singularity exec \\\n -B /var/spool/slurmd \\\n -B /opt/cray \\\n -B /usr/lib64/libcxi.so.1 \\\n -B /usr/lib64/libjansson.so.4 \\\n -B $wd:/workdir \\\n $SIF /workdir/run-me.sh\n
that a colleague of mine tested.
It is also the basis of what we have tried to pack in a wrapper module for the PyTorch containers we got from AMD.
-
Will you look at supporting mojo programming language in the future, once the language has developed to a more mature level?
-
It is unfortuantely very difficult for us to support any packages and software packages as we are a very small team. Instead we provide a simple way for you to install the packages yourself using EasyBuild: https://docs.lumi-supercomputer.eu/software/installing/easybuild/
-
Once there is a Mojo Easyconfig available you can install it easily. maybe ask the developers to create one or send us a support request and we can have a look.
-
[Kurt] Well actually, I notice it is something for AI software with Python so it would have to go in those containers. And you can probably just instal it with pip on top of one of the existing containers...
"},{"location":"User-Coffee-Breaks/20240131-user-coffee-break-HyperQueue/","title":"HyperQueue (January 31, 2024)","text":"Presenters: Jakub Ber\u00e1nek and Ada B\u00f6hm (IT4Innovations)
"},{"location":"User-Coffee-Breaks/20240131-user-coffee-break-HyperQueue/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the questions from the HyperQueue session.
"},{"location":"User-Coffee-Breaks/20240131-user-coffee-break-HyperQueue/#hyperqueue-specific-questions","title":"HyperQueue-specific questions","text":" -
How does HyperQueue compare to other workflow managers such as Nomad (by Hashicorp)?
- The question was briefly touched in the presentation but without a full answer.
"},{"location":"User-Coffee-Breaks/20240131-user-coffee-break-HyperQueue/#other-questions","title":"Other questions","text":" -
Any progress regarding how to work with sensitive data on LUMI?
- \"An architecture draft will be reviewed in week 5. Implementation is planned for Spring/Summer 2024.\"
-
I am porting a code to run on LUMI-G, and encountered a strange data transfer issue (CPU-GPU) which I can't understand. The code is calling \"hiprandGenerateUniformDouble\" at this point and out of 8 MPI processes only RANK 0 is able to show the device generated random numbers on host after updating them from device. Rest of the ranks fail (Memory access fault message with C RAY_ACC_DEBUG variable) while updating data back to host from their respective devices. The data transfer is managed by OpenMP pragmas. I have verified (with omp_get_default_device() & hipGetDevice()) that all MPI ranks are well running on their own devices. I have this short test ready to quickly go through the issue. Would it be possible for someone to have a look at this issue with me during this coffee break session? Thanks
- It is not obvious for me what might be causing this. What comes to mind is a mismatch of set device IDs in the OpenMP runtime and the hipRAND handler. To narrow down the issues search space I'd make sure that each rank only sees a single GPU with ROCR_VISIBLE_DEVICES. For instance one can use: ROCR_VISIBLE_DEVICES=$SLURM_LOCALID. I'll (Sam from AMD) be in the coffee break and we can take a closer look.
-
We have recently undertaken the task of porting URANOS, a Computational Fluid Dynamics code, to AMD GPUs. While the code using the OpenACC standard. it was predominantly optimized for NVIDIA machines, so we have encountered some performance challenges on AMD cards. We are reaching out to inquire whether there are individuals within the LUMI staff who can share some pieces of kwnoledge in optimizing code performance specifically for AMD GPUs. We would greatly appreciate any assistance or guidance
- We may need HPE people to also chime in here. My experience with OpenACC comes from very flat codes. Here, the performance implications are a mix of runtime overheads and kernel performance. The former can be assessed with a trace of the GPU activity and the later can be done with a comparison of kernel execution time with other vendors. I've seen the Cray Compiler OpenACC runtime being a bit conservative on how to control dependencies with some redundant runtime calls that can be lifted. Other things might come from register pressure and some device specific tunning (loop tilling for example). The register pressure is connected with the setting of launch bounds - unfortunatelly setting the number threads is not sufficient and a thread limit clause needs to be used instead. Tilling requires change a bit the code. We can discuss further during the coffee break.
-
We try to understand why we don't the performance we exepct from the GPUs on LUMI-G but our software is too complicated to trace itself. So I'm looking for much simpler examples, to measure individual functionallities, such as data transfers, FFTs, bandwidth, etc. Is there a repository of simple to complex examples for GPU execution on LUMI-G?
- Not sure if it will cover everything needed but AMD has some examples used for training: https://github.com/amd/HPCTrainingExamples. There are also the AMD blog notes that can help with some trimmed down examples https://gpuopen.com/learn/amd-lab-notes/amd-lab-notes-readme/. These are not really benchmarks and not meant for performance assessment but could be helpful for testing along those lines.
"},{"location":"User-Coffee-Breaks/20241002-user-coffee-break-LUMI-update/","title":"LUMI Update Webinar (October 2, 2024)","text":"Presenters: Harvey Richardson (HPE), Kurt Lust (LUST), George Markomanolis (AMD)
Slides of the presentations:
-
HPE presentation
-
LUST presentation
-
AMD presentation
"},{"location":"User-Coffee-Breaks/20241002-user-coffee-break-LUMI-update/#qa","title":"Q&A","text":"Full archive of all LUMI Coffee Break questions. This page only shows the questions from the LUMI update session.
-
Any knowledge when EasyBuild-recipes for Pytorch Containers with ROCm 6 are coming?
- So far Kurt Lust made those recipes. It was a personal idea of him, as the people teaching the AI course preferred a different approach. But Kurt is rather busy this month with the Hackathon in Brussels and the course in Amsterdam. So no promises when he will have time to look into it unfortunately. Good to know that these modules are actually appreciated, we will try to put some time into it.
-
We observe about 30% slowdown in GPU MPI jobs compared to previous LUMI system. Is this expected? Now we use CC, previously used hipcc but we were not able to make it work after the update.
-
No. Most people report equal speed to a modest increase for GPU software.
-
Did you have the rocm module loaded? With the AMD compilers (amd/6.0.3 module now, amd/5.2.3 before the update) you didn't need to load the rocm module, but now you do for some ROCm functionality and GPU aware MPI. That could in fact explain why hipcc didn't work.
-
I've observed this same behaviour and already reported it, I find a 50% slowdown with ELPA.
-
Are you planning to build software that so far is only present as an Easybuild recipe? E.g. Paraview, it is a long build, could be easier to provide \"normal\" prebuilt modules for that.
-
ParaView is offered as a container in the web interface to LUMI, or at least, will be again as soon as the NVIDIA visualisation nodes are operational again.
-
We don't provide pre-built modules for software that is hard for us to test or may need different configurations to please everybody. A central installation is problematic to manage as you can only add to it and not remove as you don't know when people are using a package. So stuff that is broken for some but works for others sticks on the system forever. We follow the approach that is used in the big USA centres also more and more, i.e., not much centrally installed software for more flexibility in managing the stack and reparing broken installations. After all, if a apckage is in a project, the members in the project only need to talk to each other to find out when it can be updated.
-
Is there an estimate when ROCm 6.2 and the new profiling tools will be available on LUMI?
-
An equivalent to the modules that we had before, is still in the testing phase. It will appear either as a user installable module or in LUMI/24.03 partition/G.
Follow the updates in the LUMI software library
-
There is currently a very unofficial one with no guarantee that it will stay on the system:
module use /pfs/lustrep2/projappl/project_462000125/samantao-public/mymodules\nmodule load rocm/6.2.1\n
-
Will modules like singularity-filesystems etc become available by default or will we keep having to use module use /appl/local/training/modules/AI-20240529
-
We've already needed several specialised versions of it for users, so no. There is no single \"fits all\" configuration of this module.
-
Unfortunately, the central software stacks on LUMI have been designed in a way that prevents us from providing these modules as part of those stacks. We are looking at alterantive ways to provide something similar, but no timeline at this point unfortunately.
-
We have recently attempted to transition training LLMs from NVIDIA-based supercomputers to LUMI-G. The setup is based around Pytorch, along with some packages compiled from source using Hipify and Hipcc wrapped in a Singularity container. However, we observe a slowdown of over 200%, along with increased memory requirements for GPUs. Are there any tips or obvious mistakes users make when managing such transitions? (A100-40GB, bfloat16)
-
You can find training material (recordings, slides) from the last AI workshop here: 2-day Getting started with AI on LUMI workshop
Most of the material is still fairly accurate, but you may have to change versions of modules.
-
We will have another (updated) AI workshop in November, maybe that might be interesting for you
-
Otherwise you can also open a ticket describing your problem and we will have a look
-
You may need to review how RCCL is initialized. Batch sizes, etc., can also have a large influence on performance.
-
Is there training material for porting CUDA kernels into ROCm compatible?
-
What is the method to hand over (large) (collection of) files to the LUMI support team, now that `/tmp/* is mangled?
-
You can use LUMI web interface to create LUMI-O bucket and share it with us; use private buckets only!
-
Various academic service providers also offer file sender services similar to WeTransfer. This will require transfering files to a system where you can run the web browser first, but then since these are usually rather important files you should have a backup outside of LUMI anyway.
"},{"location":"User-Updates/","title":"User updates","text":" -
Update after the August-September 2024 maintenance
-
Update after the October-November 2023 maintenance
-
Update after the August 2023 maintenance
"},{"location":"User-Updates/Update-202308/","title":"Changes after the update of August 2023","text":"The main purpose of the August 2023 update of LUMI was to add in additional GPU hardware that will become gradually available to users (as extensions of the current partitions).
However, a few changes were made to the scheduler, one of which has a large impact on GPU jobs, and we also want to put more emphasis on proper and efficient use of the system as queue times have become rather long lately.
- Changes to the low-noise mode on LUMI-G. These changes have implications for job scripts so read carefully.
- Policy change on dev-g and eap
- Responsible use of LUMI-C and LUMI-G
"},{"location":"User-Updates/Update-202308/lumig-devg/","title":"The dev-g and eap partitions","text":""},{"location":"User-Updates/Update-202308/lumig-devg/#policy-change-of-dev-g","title":"Policy change of dev-g","text":"The dev-g partition was always meant for the development of GPU software, and in particular, to get a quick turnaround time if you need to run software under the control of a debugger or for short profiling runs. We have observed that the queue has been abused for production or near-production runs instead to bypass longer waiting times on the regular queue. This complicates the work of developers. Also, a maximum of 16 nodes per job has not always been enough for some debugging runs.
Therefore the following policy changes will be implemented:
- The maximum size for a job increases from 16 to 32 nodes.
- The maximum runtime (walltime) for a job is decreased from 6 to 3 hours.
- The maximum number of jobs is unmodified. Users can have only one running job in this partition.
User action: Some job scripts may require changes and you may have to move to a different partition if you were not using dev-g in the intended way.
"},{"location":"User-Updates/Update-202308/lumig-devg/#the-eap-partition","title":"The eap partition","text":"The EAP (Early Access Platform) partition was a leftover of the early days of LUMI when a GPU development system with MI100 nodes was attached to the system. As a transition measure a new eap partition was created on LUMI-G with the full MI250X hardware, and just as the original eap partition, it allowed development of GPU software without GPU billing units. However, we've recently seen abuse of this partition for regular runs, and developers have now had ample time to request development projects at EuroHPC or, for groups in LUMI consortium countries, their local resource allocators.
The eap partition was removed during the update and will not return. All users who want to experiment on the GPU nodes now need projects with GPU billing units.
User action: Request GPU billing units from your resource allocator. Depending on your use profile, use dev-g, small-g or standard-g instead.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/","title":"The low-noise mode on LUMI-G","text":""},{"location":"User-Updates/Update-202308/lumig-lownoise/#configuration-changes","title":"Configuration changes","text":"The configuration of LUMI-G has been made more symmetrical.
Previously, a low-noise mode was enabled reserving one core (core 0) for the operating system and drivers. This was needed because benchmarking before the pilot phase showed that the jitter caused by OS processes in the background stealing time from some cores that were in use by applications, had a very negative impact on scalability.
This created an asymmetry as one CCD (chiplet) of the CPU had 7 cores available while all others had 8 cores available. And this in turn almost forced users to do a fully manual CPU binding in standard-g, and gave very bad core allocations in small-g. Some changes have been made to the scheduler config to improve this situation.
What has changed:
-
The first core of each CCD is now reserved. As a result, only 56 cores are available to Slurm on each LUMI-G node. The reserved cores are 0, 8, 16, 24, 32, 40, 48 and 56.
-
The thread distribution and binding behaviour of --cpus-per-task has been improved. Even with the old distribution rules, --cpus-per-task=7 would now give a nice distribution on the standard-g partition with effectively each task on its own CCD, which in turn makes proper GPU mapping possible. However, in some cases, even with a lower value of --cpus-per-task you will still have nice mapping with tasks not spanning multiple CCDs (and if there are 8 tasks or less, each task on a separate CCD). You should experiment with this though as it is not true in all cases and as on small-g it is only the case if you happen to have a node that is empty.
What has not changed:
-
Proper binding is only possible on job-exclusive nodes, but that is the very nature of binding as it requires full control of all resources.
-
For those users who also work on Frontier: The configuration of the GPU nodes is now more similar but still not the same. E.g., the Slurm socket is still defined as the physical socket and not an L3 cache domain as on Frontier, because modifying this would have had implications for LUMI-C also. So don't expect that you can simply use the same strategy for resource requests for all cases on LUMI and Frontier.
-
--gpu-bind=closest still does not work as expected. On standard-g, it will not give you the proper GPUs (apart from other problems with Slurm doing the binding). On small-g, it will not enforce an allocation with the proper CPU cores for the GPUs in your allocation.
-
The Slurm GPU binding is still incompatible with shared memory communication between GPUs in different tasks, as is used by, e.g., GPU-aware Cray MPICH intra-node communication. So the trick of avoiding Slurm doing the binding and do a manual binding instead via the select_gpu script used in the LUMI documentation, is still needed.
User impact:
-
Any job script that in one way or another asks for more than 56 cores on a node of LUMI-G will fail.
-
Any job script that uses --cpu-bind=map_cpu: and that has one of the now unavailable cores in the map will fail.
The \"MPI-based job\" in the GPU examples in the LUMI documentation before the August 2023 update does no longer work. Also, the --cpu-bind=map_cpu: line that was shown on the \"Distribution and binding\" page does no longer work after the update. The documentation has been corrected.
-
Any job script that uses --cpu-bind=mask_gpu: and that includes a now unavailable core in the mask will fail.
The \"Hybrid MPI+OpenMP job\" example in \"GPU examples already took this into account and is still correct. The example mask on the \"Distribution and binding\" page is wrong and all occurrences of ff need to be modified to fe. The documentation has been corrected.
All training materials in the \"LUMI training materials\" archive web site reflect the state of LUMI at the time that the course was given. These materials are not updated after the course, so some job scripts for LUMI-G contained in those courses will be incorrect. As courses are lectured again, a new version of the course materials will be made available on this site and LUMI (as some materials cannot be published on the web).
In particular,
-
The latest materials for the 4-day comprehensive LUMI training are currently those of the May 30 - June 2 course in Tallinn, but a new version will become available some days after the training in Warsaw, October 3-6.
-
The latest materials of the 1-day introductory LUMI training are currently those of the course in early May 2023. A new edition has not yet been planned but is expected in the fall of 2023.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/#mpi-based-job-example","title":"MPI-based job example","text":"The example from the \"MPI-based job\" section on the \"GPU examples\" documentation page needs only an almost trivial modification on line 23:
#!/bin/bash -l\n#SBATCH --job-name=examplejob # Job name\n#SBATCH --output=examplejob.o%j # Name of stdout output file\n#SBATCH --error=examplejob.e%j # Name of stderr error file\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=2 # Total number of nodes \n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node, 16 total (2x8)\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=1-12:00:00 # Run time (d-hh:mm:ss)\n#SBATCH --mail-type=all # Send email at begin and end of job\n#SBATCH --account=project_<id> # Project for billing\n#SBATCH --mail-user=username@domain.com\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nCPU_BIND=\"map_cpu:49,57,17,25,1,9,33,41\"\n\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu <executable> <args>\nrm -rf ./select_gpu\n
Download runnable example Example: example-mpi.sh
Run with:
sbatch -A project_46YXXXXXX example-mpi.sh\n
Future updates of LUMI may invalidate this script.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/#hybrid-mpiopenmp-job","title":"Hybrid MPI+OpenMP job","text":"The mask in the example from the \"Hybrid MPI+OpenMP job\" section on the \"GPU examples\" documentation page is still correct:
#!/bin/bash -l\n#SBATCH --job-name=examplejob # Job name\n#SBATCH --output=examplejob.o%j # Name of stdout output file\n#SBATCH --error=examplejob.e%j # Name of stderr error file\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=2 # Total number of nodes \n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node, 16 total (2x8)\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=1-12:00:00 # Run time (d-hh:mm:ss)\n#SBATCH --mail-type=all # Send email at begin and end of job\n#SBATCH --account=project_<id> # Project for billing\n#SBATCH --mail-user=username@domain.com\n\ncat << EOF > select_gpu\n#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\n\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu:7e000000000000,7e00000000000000\"\nCPU_BIND=\"${CPU_BIND},7e0000,7e000000\"\nCPU_BIND=\"${CPU_BIND},7e,7e00\"\nCPU_BIND=\"${CPU_BIND},7e00000000,7e0000000000\"\n\nexport OMP_NUM_THREADS=6\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu <executable> <args>\nrm -rf ./select_gpu\n
The mask here is built up of 7e blocks which use cores 1 till 6 of each CCD, but do not use the reserved core 0 nor the available core 7. In general, any mask element with a 1, 3, 5, 7, 9, B, D or F in position 1, 3, 5, 7, 9, 11, 13 or 15 (counting from the right and starting with 1) is wrong as it would have a 1-bit on the position of core 0 of one of the CCDs. Or in other words, the odd positions (counting from the right and starting from 1) of each mask element should be an even hexadecimal number (including 0).
Download runnable example Example: example-hybrid.sh
Run with:
sbatch -A project_46YXXXXXX example-hybrid.sh\n
Future updates of LUMI may invalidate this script.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/#comprehensive-training-advanced-placement-lecture","title":"Comprehensive training \"Advanced Placement\" lecture","text":"Many of the slides of the GPU-related slides of the \"Advanced Placement\" lecture of the comprehensive LUMI course of May-June 2023 need changes.
Note that numbers refer to the page numbers on the slides themselves. Some slides are left out of the bundle so your PDF reader may show a second numbering.
-
The example on slide 61 which did not work (as explained on slide 62 and 63) will now actually work
#!/bin/bash\n#SBATCH -p <partition>\n#SBATCH -A <your_project>\n#SBATCH --time=00:02:00\n#SBATCH --nodes=2\n#SBATCH --gres=gpu:8 \n#SBATCH --exclusive\n#SBATCH --ntasks-per-node=8 \n#SBATCH --cpus-per-task=7 \n#SBATCH --hint=nomultithread\n\nexport OMP_PLACES=cores\nexport OMP_PROC_BIND=close\nexport OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK}\n\nsrun ./xthi | sort -n -k 4 -k 6\n
The mask shown on slide 63 is still correct though and that approach also works.
The Python script on slide 64 to generate masks is also correct as is the job script on slide 65 that uses that mask:
#!/bin/bash\n#SBATCH -p <partition> \n#SBATCH -A <your_project> \n#SBATCH --time=00:02:00 \n#SBATCH --nodes=1\n#SBATCH --gres=gpu:8 \n#SBATCH --exclusive\n#SBATCH --ntasks-per-node=8 \n#SBATCH --hint=nomultithread\n\nexport OMP_PLACES=cores\nexport OMP_PROC_BIND=close\nexport OMP_NUM_THREADS=7\n\nASRUN=\"srun --cpu-bind=mask_cpu:0xfe,0xfe00,0xfe0000,0xfe000000,0xfe00000000,0xfe0000000000,0xfe000000000000,0xfe00000000000000\"\n\n${ASRUN} ./xthi | sort -n -k 4 -k 6\n
(but the --cpus-per-task line on that slide is wrong and was wrong before as that should not be used together with manual binding based on maps or masks, so we also cannot rely on SLURM_CPUS_PER_TASK.)
-
The script on slide 72:
#!/bin/bash\n#SBATCH -p <partition>\n#SBATCH -A <your_project>\n#SBATCH --time=00:02:00\n#SBATCH --nodes=2\n#SBATCH --gres=gpu:8\n#SBATCH --exclusive\n#SBATCH --ntasks-per-node=8 \n#SBATCH --hint=nomultithread\n\nexport OMP_PLACES=cores\nexport OMP_PROC_BIND=close\nexport OMP_NUM_THREADS=7\n\nASRUN=\"srun --cpu-bind=mask_cpu:0xfe,0xfe00,0xfe0000,0xfe000000,0xfe00000000,0xfe0000000000,0xfe000000000000,0xfe00000000000000\"\n\n${ASRUN} ./select_gpu.sh <my_app>\n
with select_gpu.sh:
#!/bin/bash\n\nexport ROCR_VISIBLE_DEVICES=$SLURM_LOCALID\n\nexec $*\n
(and with the --cpus-per-task line removed)
will still give a correct CPU binding and the GPU binding is still too naive. It is corrected by the select_gpu.sh script on slide 74 which does not require any modifications either:
#!/bin/bash\nGPUSID=\"4 5 2 3 6 7 0 1\"\nGPUSID=(${GPUSID})\nif [ ${#GPUSID[@]} -gt 0 -a -n \"${SLURM_NTASKS_PER_NODE}\" ]; then\n if [ ${#GPUSID[@]} -gt $SLURM_NTASKS_PER_NODE ]; then\n export ROCR_VISIBLE_DEVICES=${GPUSID[$(($SLURM_LOCALID))]}\n else\n export ROCR_VISIBLE_DEVICES=${GPUSID[$(($SLURM_LOCALID / ($SLURM_NTASKS_PER_NODE / ${#GPUSID[@]})))]}\n fi \nfi\nexec $*\n
(Note that this script however assumes that the number of tasks per node is a multiple of the number of GPUs in the list.)
Download runnable example based on the script of slide 72-74 Example: example-cray.sh
Run with:
sbatch -A project_46YXXXXXX example-cray.sh\n
Future updates of LUMI may invalidate this script.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/#some-other-examples","title":"Some other examples","text":""},{"location":"User-Updates/Update-202308/lumig-lownoise/#mask-for-1-gpu-per-task-7-cores-per-task","title":"Mask for 1 GPU per task, 7 cores per task:","text":"#!/bin/bash -l\n#SBATCH --job-name=examplejob # Job name\n#SBATCH --output=examplejob.o%j # Name of stdout output file\n#SBATCH --error=examplejob.e%j # Name of stderr error file\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=2 # Total number of nodes \n#SBATCH --ntasks-per-node=8 # 8 MPI ranks per node, 16 total (2x8)\n#SBATCH --gpus-per-node=8 # Allocate one gpu per MPI rank\n#SBATCH --time=1-12:00:00 # Run time (d-hh:mm:ss)\n#SBATCH --mail-type=all # Send email at begin and end of job\n#SBATCH --account=project_<id> # Project for billing\n#SBATCH --mail-user=username@domain.com\n\ncat << EOF > select_gpu\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$SLURM_LOCALID\nexec \\$*\nEOF\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu\"\nCPU_BIND=\"${CPU_BIND}:00fe000000000000,fe00000000000000\" # CCD 6. 7\nCPU_BIND=\"${CPU_BIND},0000000000fe0000,00000000fe000000\" # CCD 2, 3\nCPU_BIND=\"${CPU_BIND},00000000000000fe,000000000000fe00\" # CCD 0, 1\nCPU_BIND=\"${CPU_BIND},000000fe00000000,0000fe0000000000\" # CCD 4, 5\n\nexport OMP_NUM_THREADS=7\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu <executable> <args>\nrm -rf ./select_gpu\n
This mask makes the first hardware thread on all 7 non-reserved cores of all CCDs available, one CCD per task. For hybrid OpenMP applications, use can then be restricted again by setting OMP_NUM_THREADS to a lower value.
Download runnable example Example: example-1gpt-7cpt.sh
Run with:
sbatch -A project_46YXXXXXX example-1gpt-7cpt.sh\n
Future updates of LUMI may invalidate this script.
"},{"location":"User-Updates/Update-202308/lumig-lownoise/#mask-for-2-tasks-per-gpu-3-cores-per-task","title":"Mask for 2 tasks per GPU, 3 cores per task","text":"#!/bin/bash -l\n#SBATCH --job-name=examplejob # Job name\n#SBATCH --output=examplejob.o%j # Name of stdout output file\n#SBATCH --error=examplejob.e%j # Name of stderr error file\n#SBATCH --partition=standard-g # Partition (queue) name\n#SBATCH --nodes=2 # Total number of nodes \n#SBATCH --ntasks-per-node=16 # 16 MPI ranks per node, 32 total (2x16)\n#SBATCH --gpus-per-node=8 # Allocate all eight GPUS in a node\n#SBATCH --time=1-12:00:00 # Run time (d-hh:mm:ss)\n#SBATCH --mail-type=all # Send email at begin and end of job\n#SBATCH --account=project_<id> # Project for billing\n#SBATCH --mail-user=username@domain.com\n\ncat << EOF > select_gpu\n#!/bin/bash\nexport ROCR_VISIBLE_DEVICES=\\$((SLURM_LOCALID/2))\nexec \\$*\nEOF\nchmod +x ./select_gpu\n\nCPU_BIND=\"mask_cpu\" #7766554433221100,7766554433221100\nCPU_BIND=\"${CPU_BIND}:000E000000000000,00E0000000000000\" # CCD 6\nCPU_BIND=\"${CPU_BIND},0E00000000000000,E000000000000000\" # CCD 7\nCPU_BIND=\"${CPU_BIND},00000000000E0000,0000000000E00000\" # CCD 2\nCPU_BIND=\"${CPU_BIND},000000000E000000,00000000E0000000\" # CCD 3\nCPU_BIND=\"${CPU_BIND},000000000000000E,00000000000000E0\" # CCD 0\nCPU_BIND=\"${CPU_BIND},0000000000000E00,000000000000E000\" # CCD 1\nCPU_BIND=\"${CPU_BIND},0000000E00000000,000000E000000000\" # CCD 4\nCPU_BIND=\"${CPU_BIND},00000E0000000000,0000E00000000000\" # CCD 5\n# 7766554433221100,7766554433221100\n\nexport OMP_NUM_THREADS=3\nexport MPICH_GPU_SUPPORT_ENABLED=1\n\nsrun --cpu-bind=${CPU_BIND} ./select_gpu <executable> <args>\nrm -rf ./select_gpu\n
This mask will use the first hardware thread of each core of core groups 1-3 and 5-7 of each CCD to place tasks (so hardware thread 1-3 in the Linux numbering for task 1, 5-7 for task 2, 9-11 for task 3, ...).
Download runnable example Example: example-2tpg-3cpt.sh
Run with:
sbatch -A project_46YXXXXXX example-2tpg-3cpt.sh\n
Future updates of LUMI may invalidate this script.
"},{"location":"User-Updates/Update-202308/responsible-use/","title":"Responsible use of LUMI-C and LUMI-G","text":"Responsible use of LUMI can help to reduce waiting times for everybody and helps the priority system to function as designed.
"},{"location":"User-Updates/Update-202308/responsible-use/#use-small-or-small-g-for-small-jobs","title":"Use small or small-g for small jobs","text":"The small and small-g partition support jobs that need up to four nodes. Though these partitions are allocatable by resources rather than allocatable by node, it is possible by adding some options to sbatch to use them in the same way as the standard and standard-g partitions.
You can get the same environment on the small and standard partitions by:
- Adding the option
--exclusive to the sbatch flags (as a command line argument or in an #SBATCH line), and - Requesting memory, e.g., using
--mem. For migrating from standard to small on LUMI-C, a good choice is --mem=224g and for migrating from standard-g to small-g, a good option is --mem=480g. This is needed because --exclusive does not yet give you access to memory in the same way as the standard and standard-g partition do, but instead still impose the regular restrictions of small and small-g.
These options should only be used if you indeed need job exclusive nodes and you will also be billed for the full node if you use these options as described here.
Job scripts using the above two options can still also run on standard and standard-g without negative consequences if you adapt the partition.
Lines for LUMI-C
#SBATCH --partition=small\n#SBATCH --exclusive\n#SBATCH --mem=224g\n
Lines for LUMI-G
#SBATCH --partition=small-g\n#SBATCH --exclusive\n#SBATCH --mem=480g\n
User action: We encourage users to consider using small instead of standard and small-g instead of standard-g for jobs that require 4 nodes or less, in particular if those jobs run for longer than one hour. Shorter low-nodecount jobs can run as backfill and do not so much affect queueing times for users with big jobs who can only use standard or standard-g.
"},{"location":"User-Updates/Update-202308/responsible-use/#dont-use-standard-g-if-you-cannot-use-all-gpus","title":"Don't use standard-g if you cannot use all GPUs","text":"A common error on LUMI-G is that users use a GPU node in the standard-g partition but cannot or do not use all GPUs. Standard-g is only allocatable per node. So if you have a job running on a node in standard-g, nor you nor any other user can use the remaining resources on that node (and you are in fact billed for the full node).
Common errors include:
-
Running on a GPU node but forgetting to request GPUs. In some cases, you will see a warning or even an error message from your application in your output, but in other cases the software will just run fine without a warning, as the same binary may support both GPU and non-GPU use.
-
Running software that is not built for a GPU. Software will not use a GPU in some magical way just because there is a GPU in the system but needs to be written and built for using a GPU. Most Python and R packages do not support GPU computing. And packages written for an NVIDIA GPU cannot run on an AMD GPU, just as software compiled for an x86 processor cannot run on an ARM processor.
If you use a package which is not written for GPU use, you will not get any warning as software does not give warnings if there is more hardware in the system than it needs or if it doesn't know a piece of hardware and doesn't need it.
-
Know your software. Not all software can use more than one GPU, let alone that it could use more than one GPU efficiently for the problem that you are trying to solve. And for all practical purposes one GPU is one GCD or half of an MI250X package.
Again, in many cases you won't get a warning as computers warn or produce error messages if they try to use something which is not available but don't produce warnings if some piece of software does not use all the hardware in the node (and that is a good thing as most shell commands would then also have to produce that warning).
"},{"location":"User-Updates/Update-202308/responsible-use/#proper-test-jobs-are-not-only-short-in-duration-but-also-small-in-size","title":"Proper test jobs are not only short in duration but also small in size","text":"Try to avoid running short test jobs that need a lot of nodes.
A supercomputer is never run in pre-emptive mode. Jobs run until they are finished and are not interrupted for other jobs.
Now assume you submit a 512-node job on LUMI-C, half the size of the standard partition, and assume that all other jobs in the system would be running for the maximum allowed walltime of 2 days. The scheduler will need to gather nodes as they become available for the 512-node job, so if all jobs would run for 2 days and you need half of the total number of nodes, then on average this could take one full day, with the first resources in the pool becoming available almost immediately but the last few of the requested nodes only when the job starts. On average nodes would have been kept idle for half a day, so you really loose the equivalent of 256 node-days of capacity.
You can see that this process makes a lot of resources unavailable for other jobs for a long time and leads to inefficient use of the supercomputer. Luckily LUMI also supports backfill, i.e., small and short jobs can still start if the scheduler knows these jobs will finish before it expects to be able to collect the nodes for the 512-node job, even if they have a much lower priority than the big job.
However, usually there are not enough suitable jobs for backfill, so very large jobs will usually lead to lots of nodes being idle for some time and hence inefficient use of resources. LUMI is built for research into jobs for the exascale area, so we do want to keep it possible to run large jobs. But users who do this should realise the consequences for the operation of the system and be responsible: Test on smaller configurations on a smaller number of nodes, then when you scale up for the large number of nodes go immediately for a long run and instead ensure that your job is cancelled properly if something goes wrong. 15-minute 512-node test jobs are a very bad idea. That job is worth just over 5 node days of production but can cost a large multiple of that in idle time as the scheduler gathers resources.
"},{"location":"User-Updates/Update-202308/responsible-use/#dont-use-large-jobs-just-for-the-fun-of-it","title":"Don't use large jobs just for the fun of it","text":"Sometimes you have the choice between using more nodes and getting a shorter runtime, or fewer nodes with a larger runtime. In general using fewer nodes will always be more efficient as parallel efficiency for a given problem size usually decreases with increasing node counts. So you'll likely get more from your allocation by using smaller jobs.
Also, the more nodes a job requires, the longer it may take to get scheduled, even just because it may take a while to gather the required number of nodes. Showing how well your code can scale may certainly be a worthwhile addition to your paper, but it does not mean that all runs have to be done at those extreme node counts.
And as already discussed, very large jobs also have a negative impact on the efficiency of the resource use of the scheduler, and hence on the waiting times for everybody.
If you need a big run requiring on the order of 80 nodes or more, do so responsibly and ensure that it can run for a while so that resources haven't been kept idle by the scheduler for basically nothing.
"},{"location":"User-Updates/Update-202308/responsible-use/#use-a-reasonable-estimate-for-the-walltime","title":"Use a reasonable estimate for the walltime","text":"Of course it is OK to use a good safety margin when estimating the walltime a job will need, but just taking the maximum allowed for a partition only to be as safe as possible is very asocial behaviour. It makes it impossible for a scheduler to properly use backfill to use resources that are idle while nodes are being collected for a big job. Not only are jobs that request the maximum allowed walltime not suitable as backfill (and hence cannot run earlier than can be expected based on their priority), but overestimating the walltime needed for a job will also needlessly delay that big job simply because the scheduler thinks the nodes will only be available at a later time than they actually are and hence will wrongly assume that it is still safe to start short lower priority jobs as backfill.
The maximum walltime on LUMI is high compared to many other large clusters in Europe that have a 24-hour limit for larger jobs. Don't abuse it.
"},{"location":"User-Updates/Update-202308/responsible-use/#core-and-memory-use-on-small-g-and-dev-g","title":"Core and memory use on small-g and dev-g","text":"The changes made to the configuration of LUMI are not yet reflected in the billing policy. However, to enable everybody to maximally exploit the nodes of LUMI-G, one should
- request at most 60 GB of CPU memory for every GPU requested as then all 8 GPUs can be used by jobs with a fair amount of system memory for everybody, and
- not request more than 7 cores for each GPU requested.
If all users do this, the GPUs in a node can be used maximally.
"},{"location":"User-Updates/Update-202311/","title":"Changes after the update of October-November 2023","text":"Last update of this document: November 17, 2023.
We advise to carefully test if all your software is still working properly before submitting large batches of jobs. Expect that some jobs that worked before the maintenance will fail now.
The main purpose of the update in late October and early November 2023 were the addition of 512 nodes to the LUMI-C standard partition and the installation of various patches in the operating system to further improve the stability of the system.
The notes of the August 2023 update are still relevant!
"},{"location":"User-Updates/Update-202311/#known-broken-features-workaround-available","title":"Known broken features (workaround available)","text":"The cray-mpich/8.1.18, cray-mpich/8.1.23 and cray-mpich/8.1.25 modules for the CCE compiler are currently broken on LUMI. This manifests itself in several ways:
-
The modules are invisible when one of the cce compiler modules is loaded.
-
Loading software for cpeCray/22.08, cpeCray/22.12 or cpeCray/23.03 in the LUMI software stacks produces errors.
-
Changing the default version of the PE to 22.08, 22.12 or 23.03 by loading the matching cpe module will fail if PrgEnv-cray is loaded. Likewise, switching to PrgEnv-cray with one of these cpe modules loaded, will fail.
-
The same hold when you try to load one of the cce modules by hand with one of the cray-mpich modules mentioned above loaded for a different compiler.
The root cause of the problems is that HPE Cray now makes libraries available for the LLVM ABI version 14.0. All packages on the system, also those for older versions of the Cray PE, were properly upgraded in the process except the MPICH packages for 22.08, 22.12 or 23.03.
"},{"location":"User-Updates/Update-202311/#update-monday-november-13-2023-workaround","title":"Update Monday November 13, 2023: Workaround","text":"Changes have been made to the module system to automatically replace any attempt to load cray-mpich/8.1.18, cray-mpich/8.1.23 or cray-mpich/8.1.25 with a load operation of cray-mpich/8.1.27. As it is not possible to do this selectively only for the Cray MPICH modules for the Cray Compilation Environment, the switch is done for all compilers.
The confusing bit is that you will still see these modules in the list of available modules, dependent on whether you have the LUMI stacks loaded or one of the other ones, on which cpe* module you have loaded in the LUMI stacks, or which compiler module you have loaded. You can however no longer load these modules, they will be replaced automatically by the cray-mpich/8.1.27 as this rule has precedence in Lmod.
Note that using cray-mpich/8.1.27 should be fine, also when using any compiler version from 22.08, 22.12, 23.03 (for CCE this would be cce/14.0.2, cce/15.0.0 or cce/15.0.1). In fact, as this is the default version, unless you enforce a particular version of Cray MPICH by prepending LD_LIBRARY_PATH with CRAY_LD_LIBRARY_PATH or using rpath-linking, you'll be running with libraries from this module anyway. Hence we expect a minimal impact on software already on the system, and certainly far less impact than the underlying problem has.
"},{"location":"User-Updates/Update-202311/#os-patches","title":"OS patches","text":"Several patches have been applied to the SUSE OS on the login nodes and Cray OS on the compute nodes (as both are in sync with the latter based on SUSE but with some features disabled that harm scalability). This version of the Cray operating system distribution is still based on the AMD GPU driver from ROCm 5.2.3. As a consequence of this, ROCm 5.2.3 is still the official version of ROCm on LUMI, whereas AMD also promises compatibility with versions 5.0 till 5.4. Many features of 5.5 and 5.6 work just fine if you install those versions in a container. Version 5.5 should also be compatible with the MPI libraries of the Cray PE version 23.09.
On LUMI we use the LTS (long-term service) releases of the HPE Cray operating system and management software stack. Support for a newer ROCm driver should be part of the next update of that stack expected to appear later this year, but after past bad experiences with bugs in the installation procedure slowing down the update process we do not want to be the first site installing this update.
"},{"location":"User-Updates/Update-202311/#2309-programming-environment","title":"23.09 programming environment","text":"The major novelty of this release of the Cray PE is the move to Clang/LLVM 16 as the base for the Cray Compiling Environment compilers. After a future update of the Cray OS it should also be possible to use the updated AOCC 4.0 compilers and ROCm 5.5 will also be fully supported. However, for this to happen we are waiting on a new Long-Term Service release of the HPE Cray system software stack for Cray EX systems.
Not all features of 23.09 are supported on the version of the OS on LUMI. In particular, though the newest versions of the Cray performance monitoring tools are installed on the system, they are not fully operational. Users should use the versions of Perftools and PAPI included with the 23.03 or earlier programming environments.
To make the modules of an older release of the Cray PE the default, load the matching cpe module twice in separate module load statements and ignore the warnings. E.g., to make the modules from the CPE 22.12 the default (and marked with a D in the output of module avail), run
module load cpe/22.12\nmodule load cpe/22.12\n
As it may be impossible to support programming environments older than 23.09 after the next system update, we encourage users to transfer to 23.09 when possible.
"},{"location":"User-Updates/Update-202311/#update-november-13-2023-this-now-also-works-again-for-prgenv-cray","title":"Update November 13, 2023: This now also works again for PrgEnv-cray.","text":"In the coming weeks, LUST will work on a set of base libraries and additional EasyBuild recipes for work with the 23.09 release of the Cray PE. However, as Clang 16, on which the new version of the Cray compilers is based, is a lot more strict about language compliance, rebuilding the software stack is not a smooth process.
The 23.09 version of the Cray PE should also be fully compatible with the next LTS release of the Cray OS and management software distribution except that at that time a newer version of ROCm will become the basis.
"},{"location":"User-Updates/Update-202311/#update-november-17-2023-software-stacks","title":"Update November 17, 2023: Software stacks","text":"A lot of base libraries have been pre-installed on the system in the LUMI/23.09 software stacks. At the moment, the cpeCray-23.09 version in particular is less extensive than usual. The reasons are twofold:
-
Boost currently fails to compile with cpeCray/23.09. It is currently unclear if this is caused to errors in the Boost configuration process or to a bug in the compiler returning a wrong value during configuration.
-
Some packages fail to compile due to sloppy code violating C or C++ language rules that have been in place for 20 or more years. Clang 16, the basis for the Cray Compilation Environment 16, is more strict imposing those language standards than previous compilers. In some cases we were able to disable the errors and the package compiled, but some software using Gnome GLib so far fails to compile.
Those packages may be added to the software stack at a later date if we find solutions to the problems, but there is no guarantee that these problems can be solved with the current versions of those packages and CPE.
We've also started the process of porting user-installable EasyBuild recipes. Some are already available on the system, others will follow, possibly on request.
"},{"location":"User-Updates/Update-202409/","title":"Changes after the update of August-September 2024","text":"See also the recording of the user update webinar of October 2, 2024.
Recent changes are in dark blue.
This page will be updated as we learn about problems with the system after the update and figure out workarounds for problems. Even though this time we had the opportunity to do more testing then during previous updates, most testing was not on the main system and the system was also not a full copy of LUMI. Moreover, it turns out that there are always users who use the system in a different way than we expected and run into problems that we did not expect.
Almost all software components on LUMI have received an update during the past system maintenance. The user-facing updates are:
-
The operating system is now SUSE Enterprise Linux 15 SP5 on the login nodes (formerly SP4), and the matching version of Cray Operating System on the compute nodes.
-
Slurm is upgraded to version 23.02.7.
-
The libfabric CXI provider has also been upgraded to a newer version.
-
ROCm 6.0.3 is now the system-installed and default ROCm version and ROCm 5.2.3 is no longer on the system.
The installed driver should be able to install ROCm version 5.6 to 6.2, but that does not imply that all of those versions will work with all versions of the Cray Programming Environment. Each version of the Cray Programming Environment has only been tested with one or two versions of ROCm.
-
Two new programming environments have been installed, see the next section.
As after previous maintenance periods, the visualisation nodes in the lumid partition are not yet available as they require a slightly different setup.
"},{"location":"User-Updates/Update-202409/#major-changes-to-the-programming-environments","title":"Major changes to the programming environments","text":""},{"location":"User-Updates/Update-202409/#unsupported-programming-environments","title":"(Un)supported programming environments","text":"Updating ROCm on LUMI is not as trivial as it seems. There are other components in the system that depend on ROCm also, and the most noteworthy of these is GPU-aware MPI. MPI is a very tricky piece of software on a supercomputer: It has to link with the applications on the system, but also needs to work closely together with the lower-level communication libraries on the system (libfabric and the CXI provider on LUMI), the GPU accelerator driver and libraries for GPU-aware MPI (so the ROCm stack on LUMI), and with shared memory communication/support libraries in the kernel (HPE uses xpmem). Any change to one of those components may require a change in the MPI library. So you can understand that updating a system is not as simple as it may appear, and the ROCm update has inevitably other consequences on the system:
-
The new 24.03 programming environment is the only programming environment that is fully supported by HPE on the new system configuration as it is the only programming environment on the system with official support for both the current version of the operating system and ROCm 6.0.
It is therefore also the system default version of the programming environment.
This implies that if you experience problems, the answer might be that you will have to move to 24.03 or at least try if the problems occur there too. The LUMI User Support Team will focus its efforts on making the software stack for 24.03 as complete as possible as soon as we can, and a lot of it is already on the system. We only support relatively recent versions of software though.
The CCE and ROCm compilers in this programming environment are both based on Clang/LLVM 17 while the AOCC compiler (module aocc/4.1.0) is based on Clang/LLVM 16.
-
The second new programming environment on the system is 23.12. This is offered \"as is\", and problems cannot be excluded, especially with GPU software, as this version does not officially support ROCm 6.0. This version of the CPE was designed by HPE for ROCm 5.7.
-
The 23.09 programming environment is also still on the system. It does support SUSE 15SP5, but it does not officially support ROCm 6.0. It was developed to be used with ROCm 5.2 or 5.5, depending on the version of the OS.
As originally we planned to move to ROCm 5.7 instead of 6.0, it was expected that we would still be able to support this version of the programming environment as the ROCm versions are close enough (this had worked in the past). However, due to the larger than expected upgrade of the system, moving directly to ROCm 6.0, this is not possible. It may be better to recompile all GPU software, and this will be particularly troublesome with PrgEnv-amd/cpeAMD as you now get a much newer but also much stricter compiler based on Clang 17 rather than Clang 14. The LUST has recompiled the central software stack for LUMI-G and had to remove some packages due to compatibility problems with the newer and more strict compilers. These packages return in newer versions in the 24.03 stack.
-
Older programming environments on the system are offered \"as is\" as they support neither the current version of the OS nor ROCm 6.
In fact, even repairing by trying to install the user-level libraries of older versions of ROCm may not be a solution, as the ROCm versions that are fully supported by those programming environments are not supported by the current ROCm driver on the system, and there can be only one driver.
Expect problems in particular with GPU code. In most, if not all cases, the proposed solution will be \"upgrade to 24.03\" as this is also the version for which we can receive upstream support. However, we even cannot guarantee the proper working of all CPU code, and recompiling may not be enough to solve problems. (In fact, we have had problems with some software on 22.08 already for over one year.)
"},{"location":"User-Updates/Update-202409/#some-major-changes-to-the-programming-environment","title":"Some major changes to the programming environment","text":" -
Just as after previous updates, the module system has been tuned to load the current ROCm module, rocm/6.0.3, when you try to load one of the previous system ROCm versions, including rocm/5.2.3. In some cases, programs will run just fine with the newer version, in other cases issues may appear.
Some version of the HPE Cray PE also try to load non-existing ROCm versions and this is also being handled by the module environment which will offer the rocm/6.0.3 and amd/6.0.3 modules instead.
-
The amd/6.0.3 module does not offer the complete ROCm environment as older versions did. So you may now have to load the rocm/6.0.3 module also as was already needed with the other programming environments for complete ROCm support.
-
23.12 and 24.03 use the gcc-native modules. They will, as older versions of the programming environment are phased out, completely replace the gcc modules.
The former gcc modules provided a version of the GNU compilers packaged by HPE and hence installed in /opt/cray. The new gcc-native modules provide the GNU compilers from development packages in the SUSE Linux distribution. Hence executables and runtime libraries have moved to the standard SUSE locations.
Note that using the GNU compilers without wrappers is therefore different from before in these modules. E.g., in gcc-native/12.3, the compilers are now called gcc-12, g++-12 and gfortran-12.
When using the GNU compilers with the wrappers, one should make sure that the right version of the wrappers is used with each type of GNU compiler module. If you are not using the LUMI stacks, it is best to use the proper cpe module to select a version of the programming environment and then use the default version of the craype wrapper module for that version of the CPE.
You will have to be extra careful when installing software and double check if the right compilers are used. Unless you tell the configuration process exactly which compilers to use, it may pick up the system gcc instead which is rather old and just there to ensure that there is a level of compatibility between system libraries for all SUSE 15 versions.
"},{"location":"User-Updates/Update-202409/#known-issues-with-the-programming-environment","title":"Known issues with the programming environment","text":" -
The intro_mpi manual page for the latest version of Cray MPICH (8.1.29) was missing. Instead, the one from version 8.1.28 is shown which does lack some new information.
The web version of the manual page offered by HPE is currently the one from version 8.1.29 though and very interesting reading.
-
It turns out that the Cray Fortran compilers 17.0.0 (23.12) and 17.0.1 (24.12) have some severe regressions compared to the 16.0.1 version (23.09). See, e.g., a list of issues identified on the Frontier supercomputer. Unfortunately LUMI has never had a ROCm 5.5 installation which is the best ROCm version for CCE 16.0.1 on the new version of the operating system.
-
The Fortran compiler of the cce/16.0.1 module does not always play nicely with the rocm/6.0.3 module. We have observed LLVM ERROR crashes. This is not unexpected as that compiler version was never tested by HPE Cray against ROCm 6 but was developed for use with ROCm 5.2 or 5.5.
A workaround is to load the rocm/5.4.6 module in CrayEnv or LUMI/23.09 partition/G and compile with that module loaded. This then however causes problems when running, with the executable failing to detect the GPUs, and that is then solved again by using the rocm/6.0.3 module when running the code. Note that ROCm 5.4 is not officially supported by the current driver, which may be the cause of the problems when running.
"},{"location":"User-Updates/Update-202409/#the-lumi-software-stacks","title":"The LUMI software stacks","text":"We are building new software stacks based on the 23.12 and 24.03 versions of the CPE. The LUMI/23.12 stack closely resembles the 23.09 stack as when we started preparing it, it was expected that this stack too would have been fully supported by HPE (but then we were planning an older version of ROCm), while the 24.03 stack contains more updates to packages in the central installation. Much of 24.03 and 23.12 was ready when the system was released again to users.
Note that the LUMI documentation will receive several updates in the first weeks after the maintenance. The LUMI Software Library is mostly consistent with what can be found on the system when it comes to the 23.12 and 24.03 versions of the LUMI stack, but you may find some EasyConfigs for packages that claim to be pre-installed but are not yet on the system.
Since the LUMI/24.03 software stack is sufficiently ready and since it is the only stack we can truly support, it is also the default software stack so that it also aligns with the system default version of the programming environment. In any case, we do encourage all users to never load the LUMI module without specifying a version, as that will better protect your jobscripts from future changes on the system.
Some enhancements were made to the EasyBuild configuration. Note that the name of the ebrepo_files subdirectory of $EBU_USER_PREFIX and /appl/lumi/mgmt is now changed to ebfiles_repo to align with the standard name used by EasyBuild on other systems. The first time you load the EasyBuild-user module, it will try to adapt the name in your installation. The new configuration now also supports custom easyblocks in all repositories that are searched for easyconfig files. On the login nodes, the level of parallelism for parallel build operations is restricted to 16 to not overload the login nodes and as a higher level of parallelism rarely generates much gains.
Note that we have put some effort in testing LUMI/23.09 and have rebuild the GPU version of the packages in the LUMI/23.09 central stack to as much as possible remove references to ROCm libraries that may cause problems. However, we will not invest time in solving problems with even older versions of the LUMI stacks for which we already indicated before the maintenance that there would be problems.
"},{"location":"User-Updates/Update-202409/#other-software-stacks","title":"Other software stacks","text":"Local software stacks, with the one provided in /appl/local/csc as the most prominent example, are not managed by the LUMI User Support Team. They have to be updated by the organisation who provides them and LUST cannot tell when they will do that.
Expect that modules my not function anymore or become unavailable for a while while updates are being made. If the package has an equivalent in the LUST-provided LUMI software stack and a new user-installable EasyBuild recipe is ready already (see the LUMI Software Library for all available software), you can consider switching to those.
"},{"location":"User-Updates/Update-202409/#how-to-get-running-again","title":"How to get running again?","text":"We encourage users to be extremely careful in order to not waste lots of billing units on jobs that hang or produce incorrect results for other reasons.
-
All GPU jobs have been put in \"user hold\" mode. It is up to you to release them when you are confident that they will work properly. We recommend to not release them all at once, as they may very well fail or even get stuck until the wall time expires, and this will lead to a lot of wasted billing units on your project that we cannot compensate for.
To release the jobs again, use the scontrol release command. It argument is a comma-separated list of jobids, or alternatively you can use \"jobname=\" with the job's name which would attempt to release all jobs with that name.
But first continue reading the text below...
-
First check if your software still works properly. This is best done by first running a single smaller problem, then scaling up to your intended problem size, and only after a successful representative run, submit more jobs.
You may want to cancel jobs that are still in the queue from before the maintenance.
-
As explained in the courses, by default the HPE Cray PE will use system default versions of MPI etc., which are those of the 24.03 PE, even if older modules are loaded. The idea behind this is that in most cases the latest one is the most bug-free one and best adapted to the current OS and drivers on the system.
If that causes problems, you can try running using the exact versions of the libraries that you actually selected.
For this, you either prepend LD_LIBRARY_PATH with CRAY_LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=$CRAY_LD_LIBRARY_PATH:$LD_LIBRARY_PATH\n
or, even simpler, load the module lumi-CrayPath after loading all modules and reload this module after every module change.
We expect mostly problems for GPU applications that have not been recompiled with 24.03 and ROCm 6 as there you might be mixing ROCm 5 libraries and ROCm 6 libraries as the latter are used by the default MPI libraries.
-
Something rather technical: Sometimes software installation procedures hard-code paths to libraries in the executable. The mechanisms that Linux uses for this are called rpath and runpath. Binaries compiled before the system update may now try to look for libraries in places where they no longer are, or may cause loading versions of libraries that are no longer compatible with the system while you may be thinking it will load a newer version through the modules that you selected or through the default libraries.
Applications and libraries with known problems now or in the past are OpenFOAM, CDO, NCO, PETSc and libdap.
This jobs will fail immediately so no billing units will be wasted.
There is no other solution to this problem than to completely reinstall these packages, and likely you'll have to use the latest compiler and/or LUMI stack to be fully safe.
-
Do consider recompiling GPU software, even if it still seems to work just fine. In fact, we have seen that for software that could be recompiled in the LUMI/23.09 stack, performance increased due to the much better optimisations in the much newer ROCm version.
-
Consider moving to the 24.03 programming environment, and if you are using the LUMI stacks, to the LUMI/24.03 stack, as soon as possible. Much work has already been done in preparing EasyBuild recipes for user-installable packages also.
-
For users using containers: Depending on how you bind Cray MPICH to the container and which version of Cray MPICH you use for that, you may have to bind additional packages from the system. Note that you may also run into runtime library conflicts between the version of ROCm in the container and the MPI libraries which may expect a different version. The LUST is also still gaining experience with this.
We will also update the AI containers in the coming weeks as especially for those applications, ROCm 6 should have great advantages and support (versions of) software that could not be supported before. The initial focus for AI-oriented containers will be on providing base images for containers based on ROCm 5.7 up to 6.2, and containers providing recent versions of PyTorch based on those ROCm versions, as PyTorch is the most used AI application on LUMI.
"},{"location":"User-Updates/Update-202409/#faq","title":"FAQ","text":"See the separate \"Frequently Asked Questions\" page compiled from questions asked by users after the first few user coffee breaks after the update.
"},{"location":"User-Updates/Update-202409/#other-documentation","title":"Other documentation","text":"See the separate \"Documentation links\" page for links to the relevant documentation for Slurm and CPE components.
"},{"location":"User-Updates/Update-202409/202409_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links specifically for the system as it is after the August-September 2024 update. It is taken from similar pages in the various LUMI trainings.
"},{"location":"User-Updates/Update-202409/202409_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 23.02.7, on the system at the time of the course
-
HPE Cray Programming Environment web documentation contains a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09 and aocc/4.1.0 in 23.12/24.03)
-
Clang 17.0.1 version (cce/17.0.0 in 23.12 and cce/17.0.1 in 24.03)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCE 4.1 User Guide
"},{"location":"User-Updates/Update-202409/202409_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
man cc (or latest version)
-
man CC (or latest version)
-
man ftn (or latest version)
-
OpenMP in CCE
man intro_openmp (or latest version)
-
OpenACC in CCE
man intro_openacc (or latest version)
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version. The links on this page are for the version on LUMI at the time of the course.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"User-Updates/Update-202409/202409_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"User-Updates/Update-202409/202409_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"User-Updates/Update-202409/202409_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"User-Updates/Update-202409/202409_FAQ/","title":"Frequently Asked Questions","text":"This document is based on questions asked during user coffee breaks after the system update.
-
How is the (driver) update schedule for LUMI looking in the future? Will there be more frequent updates than so far; or should we plan to stick with then ROCm 6.0-6.1 for a long time? Having at least ROCm 6.1 or newer would be nice to have (even if it is just AMD CLR 6.1).
-
We explain why this is not trivial in our update page.
-
The driver needs to be compatible with the OS.
-
The ROCm version needs to be compatible with the other compilers and MPI library.
And we need full upstream support from HPE and AMD for that combination.
-
A driver update can cause a cascade of other updates that need to be done first. Anybody wants another 3 weeks downtime anytime soon? Updating a system the size of LUMI is not the same as updating a workstation or server. Try updating firmware on 1000 switches, 12000 GPUs, 7000 CPUs, 15000 NICs and be sure that the update went fine on all... Some software updates actually require firmware updates also.
-
So we will probably stay on the ROCm 6.0 driver for some time but we are working on making newer ROCm version available through modules. This is on a \"use at your own risk\" basis as we cannot guarantee full compatibility with other libraries on the system. Also note that the driver supports 2 minor version up and down (5.6, 5.7, 6.0, 6.1, 6.2). We will also provide containers that provide ROCm 6.1 and 6.2.
-
I've noticed that LUMI/24.03 now includes PrgEnv-nvhpc/8.5.0 and PrgEnv-nvidia/8.5.0, but does not include PrgEnv-amd/8.5.0. For the NVHPC / NVIDIA variants, I expect that this is just a small issue and that they're not intended to be there. My question is if PrgEnv-amd/8.5.0 is a compiler environment which is (or will be) supported. This may influence our testing for our software and which installations we provide via EasyBuild for example. It does exist when just logging into LUMI (using CrayEnv).
-
We need to check while it is hidden. Note though that if you are using EasyBuild, you should not use any PrgEnv-* module directly and instead use the matching cpe* module (e.g., cpeAMD instead of PrgEnv-amd)
Note that which cpe* modules are available, also depends on the partition module that is loaded. cpeAMD is irrelevant in partition/L and partition/C and hence is not installed in those partitions, and cpeAOCC is irrelevant in partition/G and not installed there.
-
Not sure though if the PrgEnv-nvhpc/8.5.0 and PrgEnv-nvidia/8.5.0 would even function correctly on the NVIDIA visualisation nodes.
-
How can I compile an application with HIP support? Are there any changes to the previous method, it doesn't seem to be working for my application
-
You should be able to continue use the same tools in the same way.
What has changed though is the location of the header files. There has been a deprecation warning since ROCm 5.3 and on ROCm 6 the deprecated headers were removed. But if you neglected the warnings and did not make the necessary changes, you may indeed run into problems.
-
Is there a way to know the amount of GPU and CPU hours used by every project member?
-
No, and there are no plans to implement this.
LUMI projects are meant to be a close collaboration between the people in the project, where each user knows well what the others are doing, and then this is just not really needed. It is also not on the other CSC systems as far as I know, and the scripts used on LUMI are derived from those.
If what users do is so different that you'd like to manage a split of resources between users, these should have been different projects in the first place.
-
But you can get some unprocessed information via the Slurm sreport and sacct commands. This is rough data though and not in billing units.
The mapping between Slurm resource use and billing units actually happens offline on a different system. Slurm cannot really handle the formulas that are used, and take into account the different formulas for GPU and CPU nodes.
-
It seems natural that LUMI would provide a utility into which we feed the intended resources (as specified for SLURM) and what falls out is the number of billing units that will be used up. Is there such a tool yet?
-
It is trickier than it appears. The are more intricacies as the billing units depend also on the node type used and also on the exact parameters being used in the script. Especially with regards to core to memory ratio, see also https://docs.lumi-supercomputer.eu/runjobs/lumi_env/billing/.
It is not realistic to develop a system that would correctly interpret all options that one can give to Slurm and that may even be interpreted differently depending on the Slurm partition and command used.
The tool would also need to interpret the Slurm configuration files to understand all the defaults that Slurm would use.
-
Is there a plan or a possibility in a near future to mount the XXX (name your organisation) servers on LUMI? This way it will spare a lot of duplication of data for the case we can afford some delay for reading the files.
-
Is there a way to get job notification emails on Lumi? I have tried with #SBATCH --mail-type=ALL and my email address such #SBATCH --mail-user=user@email.com but I do not get any notification emails.
- There are also no plans to enable this function of Slurm email notifications. It is not that easy to do with architecture of LUMI based on isolated services, and also there has been abuse of this functionality on other systems. Moreover, the pattern of emails sent from LUMI would make it look like a spam bot to many systems, so there is not even a guarantee that the mails would ever arrive at your site, or worse, other CSC systems may also get blocked.
"},{"location":"ai-20240529/","title":"Moving your AI training jobs to LUMI workshop - Copenhagen, May 29-30 2024","text":""},{"location":"ai-20240529/#course-organisation","title":"Course organisation","text":" -
Location: NORDUNets, Kastruplundgade 22, DK-2770 Kastrup, Denmark
-
Schedule
-
HedgeDoc for questions
Questions with longer-term relevance have been incorporated into the pages linked below.
"},{"location":"ai-20240529/#setting-up-for-the-exercises","title":"Setting up for the exercises","text":""},{"location":"ai-20240529/#during-the-course","title":"During the course","text":"If you have an active project on LUMI, you should be able to make the exercises in that project. To reduce the waiting time during the workshop, use the SLURM reservations we provide (see above).
You can find all exercises on our AI workshop GitHub page
"},{"location":"ai-20240529/#after-the-termination-of-the-course-project","title":"After the termination of the course project","text":"Setting up for the exercises is a bit more elaborate now.
-
The containers used in some of the exercises are no longer available in /scratch/project_465001063/containers. You'll have to replace that directory now with /appl/local/training/software/ai-20240529.
Alternatively you can download the containers as a tar file and untar in a directory of your choice (and point the scripts to that directory where needed).
-
The exercises as they were during the course are available as the tag ai-202405291 in the GitHub repository. Whereas the repository could simply be cloned during the course, now you have to either:
-
Download the content of the repository as a tar file or bzip2-compressed tar file or from the GitHub release where you have a choice of formats,
-
or clone the repository and then check out the tag ai-202405291:
git clone https://github.com/Lumi-supercomputer/Getting_Started_with_AI_workshop.git\ncd Getting_Started_with_AI_workshop\ngit checkout ai-202405291\n
Note also that any reference to a reservation in Slurm has to be removed.
The exercises were thoroughly tested at the time of the course. LUMI is an evolving supercomputer though, so it is expected that some exercises may fail over time, and modules that need to be loaded, will also change as at every update we have to drop some versions of the LUMI module as the programming environment is no longer functional. Likewise it is expected that at some point the ROCm driver on the system may become incompatible with the ROCm versions used in the containers for the course.
"},{"location":"ai-20240529/#course-materials","title":"Course materials","text":"Note: Some links in the table below will remain invalid until after the course when all materials are uploaded.
Presentation Slides recording Welcome and course introduction / video Introduction to LUMI slides video Using the LUMI web-interface slides video Hands-on: Run a simple PyTorch example notebook / video Your first AI training job on LUMI slides video Hands-on: Run a simple single-GPU PyTorch AI training job / video Understanding GPU activity & checking jobs slides video Hands-on: Checking GPU usage interactively using rocm-smi / video Running containers on LUMI slides video Hands-on: Pull and run a container / video Building containers from Conda/pip environments slides video Hands-on: Creating a conda environment file and building a container using cotainr / / Extending containers with virtual environments for faster testing slides video Scaling AI training to multiple GPUs slides video Hands-on: Converting the PyTorch single GPU AI training job to use all GPUs in a single node via DDP / video Hyper-parameter tuning using Ray slides video Hands-on: Hyper-parameter tuning the PyTorch model using Ray / video Extreme scale AI slides video Demo/Hands-on: Using multiple nodes / video Loading training data from Lustre and LUMI-O slides video Coupling machine learning with HPC simulation slides video"},{"location":"ai-20240529/#web-links","title":"Web links","text":""},{"location":"ai-20240529/E02_Webinterface/","title":"Hands-on: Run a simple PyTorch example notebook","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E02_Webinterface/#qa","title":"Q&A","text":" -
Not directly related to the exercise, but is it possible to view the GPU / memory utilization in real time when running jobs ? Perhaps something similar to C3se implementation like this https://www.c3se.chalmers.se/documentation/monitoring/
- We will discuss some methods later today.
-
I already have a project on LUMI that I wanted to carry the exercises out on, but I run into some problems. I changed the \"HF_HOME\" variable to my own project (\"/scratch/project_465000956/hf-cache\"), but I get an error of OSError: [Errno 122] Disk quota exceeded. What am I doing wrong?
-
Check your disk quota with the lumi-workspaces command. You likely have a too large volume or too many files in your scratch or home folder.
-
UPDATE: (Lukas) There was an issue in the notebook that could cause this. This is now fixed, so you can update via git pull.
"},{"location":"ai-20240529/E03_FirstJob/","title":"Hands-on: Run a simple single-GPU PyTorch AI training job","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E03_FirstJob/#qa","title":"Q&A","text":" -
Is it alright/normal to always get the following message/warning in the start of our output file?
The following modules were not unloaded:\n (Use \"module --force purge\" to unload all):\n\n 1) ModuleLabel/label 2) lumi-tools/24.05 3) init-lumi/0.2\n\nThe following sticky modules could not be reloaded:\n\n 1) lumi-tools\n
-
Yes, that is completely normal. If you want to know more about how the module system works, we recommend our regular introductory courses. E.g., the lecture on modules of the recent Amsterdam training, currently our most recent training. It is not possible to compress all relevant material of that course in this 2-day course unfortunately.
Basically it is the result of some modules on LUMI being sticky, and all this is explained in this section of the notes of the modules talk of the Amsterdam intro course.
-
What is the rationele behind asking for 7 CPUs if you do the training on 1 GPU (Maybe it was mentioned during the presentation, but I lost connection at some point)?
- The nodes are configured to leave some CPUs free for GPU driver activity leaving 7 per GPU. It is useful to routinely ask for these so that if you are getting all the cpus associated with each GPU.
Thanks, so in principle you could just ask for just 1 cpu, but it would kind of waste the other 6?
- All GPU codes also launch from CPUs and in some cases that CPU part of the code is also multithreaded. Can't speak for your case, but earlier today a user wanted more than 7 cores per GPU... E.g., managing the loading of data is largely done by the CPU.
-
In the .py file, why do we specify remove_columns=[\"text\", \"label\"] - should not only \"label\" be removed? (it is in the train_dataset.map and eval_dataset.map functions)
- This is somewhat specific to the HuggingFace Trainer with this specific model, which expects the training data to be token ids, that is, integers, under key 'input_ids'. These are created during running the tokenizer in the script, but it means we can discard the actual
text afterwards.
-
The script has finished training correctly, but did not print the generated reviews. Same problem with the reference solution.
- With the suggested configuration / resource allocation, the script probably ran out of time to finish training and generating reviews. Check from the output log if it says in the end
JOB xyz ON nid... CANCELLED AT ... DUE TO TIME LIMIT. This is expected for this exercise. We will speed up the training using multiple GPUs in Session 08 tomorrow.
"},{"location":"ai-20240529/E04_Workarounds/","title":"Hands-on: Checking GPU usage interactively using rocm-smi","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E04_Workarounds/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/E05_RunningContainers/","title":"Hands-on: Pull and run a container","text":"Exercises on the course GitHub.
For the exercises, if you want to use the binding modules, use
module use /appl/local/training/modules/AI-20240529/\nmodule load singularity-userfilesystems singularity-CPEbits\n
"},{"location":"ai-20240529/E05_RunningContainers/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/E06_BuildingContainers/","title":"Hands-on: Creating a conda environment file and building a container using cotainr","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E06_BuildingContainers/#qa","title":"Q&A","text":" -
I get the following error ValueError: Invalid command cmd='bash conda_installer.sh -b -s -p /opt/conda' passed to Singularity resulted in the FATAL error: FATAL: container creation failed: mount /appl->/appl error: while mounting /appl: destination /appl doesn't exist in container when running cotainr build python312.sif --system=lumi-c --conda-env=python312.yml
-
Try logging in and out of LUMI. I have feeling that you have too many conflicting variables/modules set.
-
(Christian) It looks like you are trying to build a container using cotainr while having the singularity-userfilesystems module loaded. Unfortunately, this doesn't currently work because you try to bind mount a path inside the container during the build that isn't already in the container directory tree which results on a FATAL error. It's a bug in cotainr.
"},{"location":"ai-20240529/E08_MultipleGPUs/","title":"Hands-on: Converting the PyTorch single GPU AI training job to use all GPUs in a single node via DDP","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E08_MultipleGPUs/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/E09_Ray/","title":"Hands-on: Hyper-parameter tuning the PyTorch model using Ray","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E09_Ray/#qa","title":"Q&A","text":" -
In run.sh in the reference solution, memory is specified to be 0 (#SBATCH --mem=0). Why does this work? Why do we not need to specify e.g. 480G?
-
(Gregor) --mem=0 will use all the available memory on the node, it's just a faster way of specifying \"use all the available memory on the node\". --mem=480G works as well.
-
(Kurt) but it is actually better to specify that you want 480G as there is a subtle difference: Asking for 480G guarantees that you will get 480G. You can get a lot less with --mem=0 if, e.g., due to a memory leak in the system software - which has happened - more memory is consumed by the OS. So asking --mem=480G guarantees you a node that is healthy at least in that respect.
"},{"location":"ai-20240529/E10_ExtremeScale/","title":"Demo/Hands-on: Using multiple nodes","text":"Exercises on the course GitHub.
"},{"location":"ai-20240529/E10_ExtremeScale/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_00_Course_Introduction/","title":"Welcome and course introduction","text":"Presenters: J\u00f8rn Dietze (LUST) and Christian Schou Oxvig (LUST & DeiC)
"},{"location":"ai-20240529/extra_00_Course_Introduction/#qa","title":"Q&A","text":"Questions asked before the start of the course or in the wrong section of the HedgeDoc:
-
Is headless rendering supported on AMD/LUMI inside containers?
-
(Christian) If you mean rendering of graphics and visualizations, the AMD MI250X GPUs do not really support this. However, LUMI does a few LUMI-D nodes that features Nvidia A40 GPUs specifically designed for rendering and visualization.
-
(Kurt) But you can use pure software rendering of course.
-
Which container images are recommended for using Pytorch with rocm, i.e. can standard Docker containers be used?docker pull rocm/pytorch:rocm6.1.1_ubuntu22.04_py3.10_pytorch_release-2.1.2
- (Christian) Yes, you can use standard Docker containers, but they need to based on a ROCm version that is compatible with LUMI and you may not get optimal performance when using more than a single LUMI-G node. This will be covered in more detail in sessions throughout the workshop - including recommendations for which PyTorch containers to use with LUMI.
-
Do containers need to be built on your laptop and then uploaded or can the containers be built on LUMI itself?
- (Christian) On LUMI you can do rootless container builds, so you don't necessarily have to build containers on your laptop. More details will be given in the workshop sessions covering running and building containers on LUMI.
-
Are there specific driver versions for rocm which MUST to be used with the GPU hardware of LUMI?
- (Christian) Yes, you have to use versions of ROCm that are compatible with the version of the AMD GPU driver installed on LUMI. More details will be given in the workshop sessions.
"},{"location":"ai-20240529/extra_01_Introduction/","title":"Introduction to LUMI","text":"Presenter: J\u00f8rn Dietze (LUST)
"},{"location":"ai-20240529/extra_01_Introduction/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_01_Introduction/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_02_Webinterface/","title":"Using the LUMI web interface","text":"Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC)
"},{"location":"ai-20240529/extra_02_Webinterface/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_02_Webinterface/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_03_FirstJob/","title":"Your first training job on LUMI","text":"Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC)
"},{"location":"ai-20240529/extra_03_FirstJob/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_03_FirstJob/#qa","title":"Q&A","text":" -
Why in --mem-per-gpu=60G it is 60 GB, not 64?
-
Because the nodes have only 480 GB available per user of the 512 GB, so \u215bth of that is a fair use per GPU. Which gives 60 GB. Note that this is CPU memory and not GPU memory!
It was actually explained later in the presentation, after this question was asked.
-
Does AMD have some alternative to nvidia ngc? Premade singularity images?
-
AMD has a ROCm dockerHub project where the latests containers go, e.g. Pytorch.
-
There is also InfinityHub but this contains possibly more datated versions, so I recommend using DockerHub for AI-related images.
-
The other part of the equation here is that the publicly available containers do not (they can't because of license issues) the network related bits, so they are not ready to run efficiently accross nodes. For that, we recommend using the LUMI provided containers under /appl/local/containers/sif-images. The containers suggested for this training event are based on those. More details will be given in a later session today.
-
When I use this command from the slides, it gives error & I am not sure which form should the compute_node take:
$ srun --overlap --pty --jobid=7240318 bash \n@compute_node$ rocm-smi\n
Gives /usr/bin/bash: @compute_node$: No such file or directory. Should the \"@compute_node$\" be 1, or @1$, or @1, or small-g, or @small-g$ etc.?
-
If something ends on a $ at the start of a line it is meant to refer to the command line prompt. And in this case this notation was used to denote a compute node command line prompt, showing the number of the compute node.
-
So you should use srun --overlap --pty --jobid=7240318 bash to open a terminal on the same node that your job is running on, then use the rocm-smi command in that new terminal.
"},{"location":"ai-20240529/extra_04_Workarounds/","title":"Understanding GPU activity & checking jobs","text":"Presenter: Samuel A\u00f1tao (AMD)
"},{"location":"ai-20240529/extra_04_Workarounds/#extra-materials","title":"Extra materials","text":" -
Presentation slides
-
Hands-on exercises
"},{"location":"ai-20240529/extra_04_Workarounds/#qa","title":"Q&A","text":" -
Is nvtop available on LUM?
-
Not preinstalled but you can build it yourself using Easybuild, see nvtop in the LUMI Software Library. Also check our docs about how to setup Easybuild or watch the presentation on LUMI Software Stacks from the recent Amsterdam training (or check the notes linked on that page)
We restrict software in the central stack to things that are widely used and easy to maintain and explain as we need to be able to move fast after a system update and managing a central stack has serial bottlenecks to keep everything organised. The next system update is going to be a huge one and you will see afterwards what we mean as we expect a lot of repairs will be needed to the central stack...
After all, corrections in a central stack are not easy. You can simply delete a container and start over again as a user. You can delete your user software installation and start over again and it will only hurt your project. But you cannot simply delete stuff in a central stack and start over as users are using that stack at the moment and all those jobs would fail until there is a compatible stack in place... (to use an argument from the container presentation after this one)
"},{"location":"ai-20240529/extra_05_RunningContainers/","title":"Running containers on LUMI","text":"Presenter: Christian Schou Oxvig (LUST & DeiC)
"},{"location":"ai-20240529/extra_05_RunningContainers/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_05_RunningContainers/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_06_BuildingContainers/","title":"Building containers from Conda/pip environments","text":"Presenter: Christian Schou Oxvig (LUST & DeiC)
"},{"location":"ai-20240529/extra_06_BuildingContainers/#extra-materials","title":"Extra materials","text":" -
Presentation slides
-
Hands-on exercises
-
\"Bonus materials\" from the course GitHub contains among other things the files used to generate the container used in the course with the cotainr tool.
-
Further reading materials from the slides:
-
LUMI Docs containers page
-
LUMI Docs installing Python packages page
-
Cotainr conda env documentation
-
Conda environment documentation
-
Pip requirements.txt file specification
-
ROCm compatibility kernel / user space compatibility
-
The additional training materials mentioned in the \"Running containers\" page are relevant for this presentation also.
"},{"location":"ai-20240529/extra_06_BuildingContainers/#remarks-to-things-mentioned-in-the-recording","title":"Remarks to things mentioned in the recording","text":""},{"location":"ai-20240529/extra_06_BuildingContainers/#rocm-compatibility","title":"ROCm compatibility","text":"The compatibility situation is actually even more complicated than explained in this presentation. The kernel driver for the GPUs depends on certain kernel versions. The kernel version depends on the version of the management interface of LUMI. So basically to do the upgrade to the 5.7 driver we need to update nearly everything on LUMI.
Furthermore, we need to ensure that MPI also works. GPU-aware MPI also depends on versions of ROCm and driver. So before updating to a new ROCm version we also need versions of the HPE Programming Environment compatible with those ROCm versions or all users of traditional HPC simulation codes would be very unhappy. That is also a factor stopping the update, as the version that supports recent enough ROCm version has also come out just a few weeks ago. And breaks a lot of currently installed software...
"},{"location":"ai-20240529/extra_06_BuildingContainers/#images-in-appllocalcontainerssif-images","title":"Images in /appl/local/containers/sif-images","text":"It is important to realise that the base images in /appl/local/containers/sif-images are symbolic links to the actual containers and they vary over time without warning. That may be a problem if you build on top of them, as all of a sudden things that you install on top of them may be incompatible with new packages in that container. So if you do that (topic of the next presentation) it is better to make a copy of the container and use that one.
EasyBuild actually gets its container images from /appl/local/containers/easybuild-sif-images which contains copies from the container images as they were when the corresponding EasyConfig was created so that an EasyConfig with a given name will always use the same module. This to improve reproducibility. E.g., some more recent containers did require changes to the module to simulate the effect of $WITH_CONDA by injecting environment variables in the container.
It is possible to extend an existing container with a virtual environment (topic of the next presentation) and automate that with EasyBuild, but it is complex enough that it might require help from someone with enough EasyBuild experience. An example is this EasyConfig but this is not something that an unexperienced user should try to create.
"},{"location":"ai-20240529/extra_06_BuildingContainers/#what-does-the-tool-provided-by-lumi-container-wrapper-do","title":"What does the tool provided by lumi-container-wrapper do?","text":"The lumi-container-wrapper provides a tool that enables to do some pip and conda installations in a file system friendly way. It also uses a base container but that one does not have a ROCm in it so it is of little use for AI software unless you can use the ROCm from the system. It basically does not change the base container, but installs the software in a separate SquashFS file. Furthermore, for each command it can find in the container, it will create a wrapper script outside the container that will call singularity with the right bindings to run that command in the container. It is actually rather hard to start the container \"by hand\" using the singularity command as you will also have to create the right bindmount for the SquashFS file containing the actual software installation.
The cotainr tool on the other hand will take the selected base image and build a new container from it that can be used the way containers are normally used.
"},{"location":"ai-20240529/extra_06_BuildingContainers/#qa","title":"Q&A","text":" -
About installing environments/packages: How about if I work in a jupyter notebook for exploration and testing of data and algorithms and need some quite specific packages? Can I also not install them in that case?
- (Lukas) For early testing, you can install additional packages in a virtual environment. The next session will cover this. Just keep in mind that this stresses the network filesystem, so it shouldn't become your default option for package installation.
Alright thanks. I just need a good solution for trying out various networks, setting etc. before running a larger model. And there the notebooks are ideal!
- (Kurt) Actually there is a way to ensure that the virtual environment does not stress the file system (by then packing it in a SquashFS file and bindmounting that in the container) and some of the more recent EasyConfigs for PyTorch already install some scripts to make organising that easier as it is rather technical.
-
Can you use SingularityCE definition files to build containers on LUMI? As explained here https://docs.sylabs.io/guides/latest/user-guide/build_a_container.html
-
(Lukas): As far as I know, this often might not work, namely when the definition file performs any kind of installation step that would require superuser privileges on a normal system (e.g., installing software via one of the linux software/package managers), due to limitations in permissions/fakeroot on the system. It is usually easier to build these containers on your own system and then copy them to LUMI.
-
(Kurt) Some things might actually work with the \"unprivileged proot build process\" of SingularityCE 3.11, but the documentation is very unclear what works and what doesn't. We have already used it to extend an existing container with additional SUSE packages using the zypper command. See Demo 1 from the Amsterdam course earlier this month. But it is certainly not a solution that always works.
We now have the proot command in the systools/23.09 module (LUMI Software Library page) in the CrayEnv and LUMI/23.09 stacks.
-
Where will be the conda env files located inside the container when we're making it from environment.yml? I suppose it cannot be ~/.conda as the home directory by default is bind inside the container.
- (Lukas): When using cotainr, the environment is installed to
/opt/conda/envs/conda_container_env/ inside the container.
-
When I try to build my container in a LUMI-C node, I'm getting an error, which I surmise arises from a previous salloc command. Is there a way to avoid this, besides logging in/out?:
srun: error: Unable to confirm allocation for job 7241252: Invalid job id specified\nsrun: Check SLURM_JOB_ID environment variable. Expired or invalid job 7241252\n
salloc actually starts a new shell session with the SLURM environmental paramters set. Just write exit to exit that one and you should be back in your original one. You can check whether $SLURM_JOB_ID is still set.
exit worked, however the job had already expired, so i wouldn't have found a job id anyway. Thanks!
-
That's exactly the problem the variable is not unset/deleted even though it is not valid any longer.
-
The problem is partly also because Slurm commands communicate with one another via environment variables that can take precedence over command line options. So starting a new Slurm job in an existing one can transfer those environment variables to the new job and result in very strange error messages.
"},{"location":"ai-20240529/extra_07_VirtualEnvironments/","title":"Extending containers with virtual environments for faster testing","text":"Presenter: Gregor Decristoforo (LUST)
"},{"location":"ai-20240529/extra_07_VirtualEnvironments/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_07_VirtualEnvironments/#qa","title":"Q&A","text":" -
Maybe it will be discusses later, but what would then be a good workflow to develop a package? Build a container with necessary packages, then install (with -e option) your under-development package in the venv. Then you could develop on the login node and then test it in the container?
-
(Christian) Doing editable installs in a read-only container doesn't make much sense. If you need to do something like this, you can/should probably use the venv method, yes. I haven't tried it myself, though, so I don't know if it works or not.
-
(Kurt) My suggestion would be to actually create another bindmount in the container to the directory where you are doing development work, but indeed use the venv method if it is for Python packages. By using an additional bindmount you can even move your development installation around in your directories without breaking anything in the container. And this definitely works, I've used it already to install software that used PyTorch but could not be simply installed via conda or pip.
The problem you may have is to install proper development tools in the container as using those on LUMI would be problematic as they may not be fully compatible with software installed through conda. If the packages are provided by conda, you can try to build your own container. If these are regular SUSE packages, it is possible to extend the container via the \"unprivileged proot build process\" supported by Singularity CE. It is something I have also done already and it worked for me. There is some discussion in the course material of the \"Containers on LUMI-C and LUMI-G\" talk of the Amsterdam course in the \"Extending the containers\" section of the notes.
"},{"location":"ai-20240529/extra_08_MultipleGPUs/","title":"Scaling to multiple GPUs","text":"Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC)
"},{"location":"ai-20240529/extra_08_MultipleGPUs/#extra-materials","title":"Extra materials","text":" -
Presentation slides
-
Hands-on exercises
"},{"location":"ai-20240529/extra_08_MultipleGPUs/#qa","title":"Q&A","text":" -
If I reserve one GCD and 14 CPU cores, will I only be billed for one GCD?
-
No, you will be billed for 2 GCDs since your share of requested CPU cores corresponds to 14/56 = \u00bc of the node (2 CCDs out of 8). The same principle applies if you request more han \u215b of the memory for a single GCD. More details on the LUMI Docs billing policy page.
Basically the policy is that you get billed for everything that another user cannot use in a normal way because of the way you use the machine. So if you take a larger share of a particular resource (GCDs, CPU cores and CPU memory), that will be the basis on which you are billed as you can no longer fill up the node with other users who only ask a fair share of each resource.
-
If I use PyTorch DistributedDataParallel on LUMI, do I still need to specify NCCL and not RCCL as backend? (The slide says torch.distributed.init_process_group(backend='nccl'))
-
Yes, PyTorch uses the Nvidia terminology independently of whether you use AMD or Nvidia GPUs. If your PyTorch has been built against ROCm instead of CUDA, setting torch.distributed.init_process_group(backend='nccl') results in RCCL being used for communication.
-
The underlying reason is that AMD could not exactly copy CUDA because that is proprietary and protected technology. However, they could legally make a set of libraries where function calls have a different name but the same functionality. This is how HIP came to be. It mimics a large part of the CUDA functionality with functions that map one-to-one on CUDA functions to the extent that you can still compile your HIP code for NVIDIA GPUs by just adding a header file that converts those function names back to the CUDA ones. Similary, several libraries in the ROCm ecosystem just mimic NVIDIA libraries, and this is why PyTorch treats them the same.
-
In checking that we use all GPUs, do we primarily check the power oscillating around that recommended value ( 300-500 W) or psutil? Maybe I mix things...
- I think the first step is to check the GPU utilization, the GPU% part. It should be higher than 0, and also the GPU memory allocated should be higher than zero. Then if those things are OK, check the power as well, as that's a better indication of it doing something useful as well.
"},{"location":"ai-20240529/extra_09_Ray/","title":"Hyper-parameter tuning using Ray","text":"Presenter: Gregor Decristoforo (LUST)
"},{"location":"ai-20240529/extra_09_Ray/#extra-materials","title":"Extra materials","text":" -
Presentation slides
-
Hands-on exercises
"},{"location":"ai-20240529/extra_09_Ray/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_10_ExtremeScale/","title":"Extreme-scale AI","text":"Presenter: Samuel A\u00f1tao
"},{"location":"ai-20240529/extra_10_ExtremeScale/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_10_ExtremeScale/#remark-why-is-binding-not-easier-in-slurm","title":"Remark: Why is binding not easier in Slurm?","text":"There are some reaons why the situation with the binding is not better:
-
Slurm GPU binding is broken and uses a technique that breaks communication with RCCL and GPU-aware MPI
-
One change that would offer some improvement is system-wide and would have a large impact on LUMI-C also, necessitating retraining all users and probably making some use scenarios on that partition difficult.
-
It is not easy either because you can only do something with few environment variables or a pre-made script if every user would nicely request 7 cores per GPU requested. On small-g you now basically have a lot of fragmentation. I'm not sure if \"CPU\" could be redefined in Slurm to mean \"1 CCD\" but that might very well be the change that sysadmins told me would also be in effect on LUMI-C where it would not be appreciated by users.
-
And as we say in another course: \"Slurm is not a good scheduler, but we don't have a better one yet\". Current HPC schedulers were designed in the days that nodes had just one or 2 CPU cores and no accelerators and they don't sufficiently understand the hierarchy in resources and proximity between various components.
-
Preset are not easy. What may be ideal for some AI workflows may not work for others, or may not work for all the other users on LUMI that do simulation or other types of data processing and analysis.
"},{"location":"ai-20240529/extra_10_ExtremeScale/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_11_LUMIO/","title":"Loading training data from Lustre and LUMI-O","text":"Presenter: Harvey Richardson (HPE)
"},{"location":"ai-20240529/extra_11_LUMIO/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_11_LUMIO/#nice-to-knows","title":"Nice-to-knows","text":""},{"location":"ai-20240529/extra_11_LUMIO/#lumi-o","title":"LUMI-O","text":"Two nice things to know about LUMI-O
-
We actually use it during this course to serve you the slides and the videos. Though it is not meant to be a web server.
-
As the LUMI-O software is done by a different team at CSC and not by HPE, it is often still up when LUMI is down. We cannot give a guarantee, but when a long downtime is announced, in the past LUMI-O was still available almost the whole downtime. So you may still be able to access data on LUMI-O, but not on the Lustre file systems when LUMI is down for maintenance.
But it is not meant for long-time data archiving. Storage on LUMI-O also disappears 90 days after your project ends. For long-term archiving and data publishing you need to use specialised services.
"},{"location":"ai-20240529/extra_11_LUMIO/#auto-cleanup-of-scratch-and-flash","title":"Auto-cleanup of /scratch and /flash","text":"Clean-up is not yet implemented on LUMI because until now there hasn't been a need to do so as the storage is empty enough.
The limited size of /project is also because CSC wants to avoid that LUMI is used for long-term data storage.
The idea is indeed that data is stored longtime on LUMI-O and transported to /scratch or /flash as needed as the assumption was that the whole dataset is rarely needed at the same time.
Note that asking for more quota doesn't make sense if your project doesn't have the necessary storage billing units. Storing 20TB for one year on /scratch or /project would cost you 175,200 TB hours, so make sure you have enough storage billing units. There is enough storage on LUMI that resource allocators can grant decent amounts of storage, but it is not infinite. LUST cannot grant you storage billing units, that is something you need to negotiate with the instance that granted you your project on LUMI.
"},{"location":"ai-20240529/extra_11_LUMIO/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/extra_12_Coupling/","title":"Coupling machine learning with HPC simulation","text":"Presenter: Harvey Richardson (HPE)
"},{"location":"ai-20240529/extra_12_Coupling/#extra-materials","title":"Extra materials","text":""},{"location":"ai-20240529/extra_12_Coupling/#qa","title":"Q&A","text":"/
"},{"location":"ai-20240529/schedule/","title":"Schedule","text":" - Day 1
- Day 2 DAY 1 - Wednesday 29/05 09:00 CEST 10:00 EEST Welcome and Introduction Presenters: J\u00f8rn Dietze (LUST) and Christian Schou Oxvig (LUST and DeiC) 09:15 CEST 10:15 EEST Introduction to LUMI Presenter: J\u00f8rn Dietze (LUST) 09:45 CEST 10:45 EEST Using the LUMI web interface Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC) 10:05 CEST 11:05 EEST Hands-on: Run a simple PyTorch example notebook 10:35 CEST 11:35 EEST Break (25 minutes) 10:50 CEST 11:50 EEST Your first AI training job on LUMI Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC) 11:20 CEST 12:20 EEST Hands-on: Run a simple single-GPU PyTorch AI training job 12:05 CEST 13:05 EEST Lunch break (45 minutes) 12:50 CEST 13:50 EEST Understanding GPU activity & checking jobs Presenter: Samuel A\u00f1tao (AMD) 13:10 CEST 14:10 EEST Hands-on: Checking GPU usage interactively using rocm-smi 13:30 CEST 14:30 EEST Running containers on LUMI Presenter: Christian Schou Oxvig (LUST & DeiC) 13:50 CEST 14:50 EEST Hands-on: Pull and run a container 14:50 CEST 15:50 EEST Break (15 minutes) 14:25 CEST 15:25 EEST Building containers from conda/pip environments Presenter: Christian Schou Oxvig (LUST & DeiC) 14:45 CEST 15:45 EEST Hands-on: Creating a conda environment file and building a container using cotainr 15:05 CEST 16:05 EEST Extending containers with virtual environments for faster testing Presenter: Gregor Decristoforo (LUST) 15:25 CEST 16:25 EEST Getting started with your own project 16:25 CEST 17:25 EEST End of the course day DAY 2 - Thursday 30/05 09:00 CEST 10:00 EEST Scaling AI training to multiple GPUs Presenters: Mats Sj\u00f6berg (CSC) and Lukas Prediger (CSC) 09:30 CEST 10:30 EEST Hands-on: Converting the PyTorch single GPU AI training job to use all GPUs in a single node via DDP 10:00 CEST 11:00 EEST Hyper-parameter tuning using Ray on LUMI Presenter: Gregor Decristoforo (LUST) 10:20 CEST 11:20 EEST Hands-on: Hyper-parameter tuning the PyTorch model using Ray 10:40 CEST 11:40 EEST Break (15 minutes) 10:55 CEST 11:55 EEST Extreme scale AI Presenter: Samuel A\u00f1tao (AMD) 11:25 CEST 12:25 EEST Demo/Hands-on: Using multiple nodes 11:45 CEST 12:45 EEST Loading training data from Lustre and LUMI-O Presenter: Harvey Richardson (HPE) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 14:00 EEST Coupling machine learning with HPC simulation Presenter: Harvey Richardson (HPE) 13:30 CEST 14:30 EEST Advancing your own project 16:00 CEST 17:00 EEST End of the course day"},{"location":"paow-20240611/","title":"Performance Analysis and Optimization Workshop, Oslo, 11-2 June 2024","text":""},{"location":"paow-20240611/#course-organisation","title":"Course organisation","text":"
-
Location: University of Oslo, Ole-Johan Dahls hus, Gaustadall\u00e9en 23B, 0373 Oslo
-
Schedule
-
HedgeDoc for questions
-
Course project: project_465001154
-
Reservations:
"},{"location":"paow-20240611/#course-materials","title":"Course materials","text":"Materials will follow as the course progresses
Due to copyright issues some of the materials are only available to current LUMI users and have to be downloaded from LUMI.
Note: Some links in the table below are dead and will remain so until after the end of the course.
Presentation slides recording Introduction / recording Architecture, Programming and Runtime Environment slides recording Exercises #1 / / Performance Analysis with Perftools slides recording Improving Single-Core Efficiency slides recording Application Placement slides recording Demo and Exercises Part 1 slides recording Demo and Exercises Part 2 slides recording AMD Profiling Tools Overview & Omnitrace slides recording Exercises #2 / / Introduction to Omniperf slides recording Exercises #3 / / MPI Optimizations slides recording Exercises #4 / / I/O Optimizations slides recording Exercises #5 / / Appendix: Links to documentation / /"},{"location":"paow-20240611/#making-the-exercises-afer-the-course","title":"Making the exercises afer the course","text":""},{"location":"paow-20240611/#hpe","title":"HPE","text":"The exercise material remains available in the course archive on LUMI:
-
The PDF notes in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.pdf
-
The other files for the exercises in either a bzip2-compressed tar file /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.bz2 or an uncompressed tar file /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.
To reconstruct the exercise material in your own home, project or scratch directory, all you need to do is run:
tar -xf /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.bz2\n
in the directory where you want to work on the exercises. This will create the Exercises/HPE subdirectory from the training project.
However, instead of running the lumi_c.sh or lumi_g.sh scripts that only work for the course as they set the course project as the active project for Slurm and also set a reservation, use the lumi_c_after.sh and lumi_g_after.sh scripts instead, but first edit them to use one of your projects.
"},{"location":"paow-20240611/#amd","title":"AMD","text":"See the notes at each session.
There is no guarantee though that the software that is referred to on the system, will be there forever or will still work after an update of the system.
Warning
The software and exercises were tested thoroughly at the time of the course. LUMI however is in continuous evolution and changes to the system may break exercises and software
"},{"location":"paow-20240611/ME_1_01_HPE_PE/","title":"Exercises session 1","text":"Exercises on using the HPE Cray Programming Environment
"},{"location":"paow-20240611/ME_1_01_HPE_PE/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar
"},{"location":"paow-20240611/ME_2_01_AMD_tools_1/","title":"Exercises session 2: Omnitrace","text":"Exercises on AMD profiling tools and GPU optimizations.
"},{"location":"paow-20240611/ME_2_01_AMD_tools_1/#materials","title":"Materials","text":" -
Basic examples
Local copy as as HTML file1 or as as MHTML file2
-
Advanced Omnitrace examples
Local copy as as HTML file1 or as as MHTML file2
"},{"location":"paow-20240611/ME_2_01_AMD_tools_1/#qa","title":"Q&A","text":"/
-
Single-page HTML with embedded figures, but some layout issues.\u00a0\u21a9\u21a9
-
Supported by several Chromium-based browsers, but currently due to the way the pages are served, the page will be downloaded.\u00a0\u21a9\u21a9
"},{"location":"paow-20240611/ME_2_02_AMD_tools_2/","title":"Exercises session 3: Omniperf by example","text":"Exercises on AMD profiling tools and GPU optimizations.
"},{"location":"paow-20240611/ME_2_02_AMD_tools_2/#materials","title":"Materials","text":" -
Basic examples
Local copy as as HTML file1 or as as MHTML file2
-
Advanced Omniperf examples part 1: Exercises 1-4
Local copy as as HTML file1 or as as MHTML file2
-
Advanced Omniperf examples part 2: Exercise 5
Local copy as as HTML file1 or as as MHTML file2
"},{"location":"paow-20240611/ME_2_02_AMD_tools_2/#qa","title":"Q&A","text":"/
-
Single-page HTML with embedded figures, but some layout issues.\u00a0\u21a9\u21a9\u21a9
-
Supported by several Chromium-based browsers, but currently due to the way the pages are served, the page will be downloaded.\u00a0\u21a9\u21a9\u21a9
"},{"location":"paow-20240611/ME_2_03_MPI/","title":"Exercises (session 4)","text":"Exercises on MPI optimizations.
"},{"location":"paow-20240611/ME_2_03_MPI/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar
-
Recording: /appl/local/training/paow-20240611/recordings/E2_03_MPI.mp4
"},{"location":"paow-20240611/ME_2_04_IO/","title":"Exercises (session 5)","text":"Exercises on I/O optimizations.
"},{"location":"paow-20240611/ME_2_04_IO/#materials","title":"Materials","text":"Temporary web-available materials:
- Overview exercise assignments day 2 temporarily available on this link \u2192
Archived materials on LUMI:
-
Exercise assignments in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.pdf
-
Exercises as bizp2-compressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar.bz2
-
Exercises as uncompressed tar file in /appl/local/training/paow-20240611/files/LUMI-paow-20240611-Exercises_HPE.tar
-
Recording: /appl/local/training/paow-20240611/recordings/E2_04_IO.mp4
"},{"location":"paow-20240611/M_1_00_Course_Introduction/","title":"Welcome and introduction","text":"Presenters: J\u00f8rn Dietze (LUST) and Harvey Richardson (HPE)
"},{"location":"paow-20240611/M_1_01_HPE_PE/","title":"LUMI Architecture, Programming and Runtime Environment","text":"Presenter: Harvey Richardson (HPE)
"},{"location":"paow-20240611/M_1_01_HPE_PE/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_1_01_HPE_PE/#qa","title":"Q&A","text":" -
PAT only with the Cray compiler or all other back end ?
- Assuming by back-end you mean other compilers (GNU, AMD), the answer is yes. You should be able to use cray PAT with the different compilers.
-
How to control number of openmp threads for libsci if it called inside a nasted openmp loop?
- The library is \"OpenMP-aware\", so it will not spawn nested threads if it is already inside an OpenMP region.
Can you use nested OpenMP, e.g., on 16 cores use 4 threads at the outer level, having 4 threads for each LibSci routine? It is possible to set nested parallelism via OpenMP environment variables.
- It is not possible, the library will check that you are inside a parallel region and will do in serial only.
What if I really want to do it like this, other options for the libs could be used?
- (Kurt) You are of course free to compile any other BLAS and Lapack implementation which may support nested parallelism. But it does imply that you cannot use pre-compiled software on LUMI that is built with cray-libsci .
-
Question in the room about which target modules should be used:
-
The difference is likely not that large as there is not really an instruction set difference between zen2 and zen3, but there are differences in the cache architecture and in the latency of various instructions.
-
Technically speaking: craype-x86-milan on the regular compute nodes, craype-x86-rome on the login nodes and the nodes for data analytics (largemem and lumid Slurm partitions), and craype-x86-trento for the GPU nodes.
-
Question in the room about the limited number of packages in cray-python: Why these and no others?
- (Kurt) These are actually packages were linking to the Cray libraries is either essential (mpi4py) or where you need to take care to link to Cray LibSci if you want the performance offered by that library.
-
Fortran code for AMD GPU which compiler should be choose on LUMI?
a. OpenMP offload
-
Cray Fortran is defnitely more mature than the Fortran compiler included with ROCm (the latter in the amd module / PrgEnv-amd)
The system update that is planned to start on August 19 will be a big upgrade for ROCm and its compilers.
b. hipfort
- Hipfort is a library to facilitate the implementation of C bindings for the HIP runtime and libraries. You can use that with any compiler.
-
aocc flang, which flags could match the performance as gfortran (most of the code do with double complex number)?
- It is difficult to tell for sure what will improve performance to match or exceed some other compiler. This will always need experimentation. Compilers have different defaults to floating point operation ordering, heuristics controlling unrolling and inlining. So, I'd start there and see the flags that influence. We can look into something more specific if there is a repro to experiement with.
"},{"location":"paow-20240611/M_1_02_Perftools/","title":"Introduction to Performance Analysis with Perftools","text":"Presenter: Thierry Braconnier (HPE)
"},{"location":"paow-20240611/M_1_02_Perftools/#materials","title":"Materials","text":"Archived materials on LUMI:
-
Slides: /appl/local/training/paow-20240611/files/LUMI-paow-20240611-1_02_introduction_to_performance_analysis_with_perftools.pdf
-
Recording: /appl/local/training/paow-20240611/recordings/1_02_Perftools.mp4
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_1_02_Perftools/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_1_03_PerformanceOptimization/","title":"Performance Optimization: Improving Single-Core Efficiency","text":"Presenter: Jean-Yves Vet (HPE)
"},{"location":"paow-20240611/M_1_03_PerformanceOptimization/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_1_03_PerformanceOptimization/#links","title":"Links","text":" - Extended version of the talk in the 4-day comprehensive course of April 2024
"},{"location":"paow-20240611/M_1_03_PerformanceOptimization/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_1_04_ApplicationPlacement/","title":"Application Placement","text":"Presenter: Jean-Yves Vet (HPE)
"},{"location":"paow-20240611/M_1_04_ApplicationPlacement/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
Bash functions to convert between hexadecimal and binary (slide 17):
# Convert hexa to binary\n0x () {\n local val=$(tr '[a-z]' '[A-Z]' <<< $1)\n echo \"binary: `BC_LINE_LENGTH=0 bc <<< \\\"ibase=16;obase=2;$val\\\"`\" \n}\n# Convert binary to hexa\n0b () {\n local val=$(tr '[a-z]' '[A-Z]' <<< $1)\n echo \"hexa: `BC_LINE_LENGTH=0 bc <<< \\\"ibase=2;obase=10000;$val\\\"`\"\n}\n
"},{"location":"paow-20240611/M_1_04_ApplicationPlacement/#links","title":"Links","text":" - Extended version of the talk in the 4-day comprehensive course of April 2024
"},{"location":"paow-20240611/M_1_04_ApplicationPlacement/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_1_05_PerformanceAnalysisAtWork_1/","title":"Optimization/performance analysis demo and exercise part 1","text":"Presenter: Alfio Lazzaro (HPE)
"},{"location":"paow-20240611/M_1_05_PerformanceAnalysisAtWork_1/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_1_05_PerformanceAnalysisAtWork_1/#references","title":"References","text":"From slide 8:
-
AMD64 Architecture Programmer's Manual
-
AMD Documentation Hub
-
AMD64 Architecture Programmer's Manual Volume 2: System Programming (840 pages)
-
AMD64 Architecture Programmer's Manual Volume 3: General-Purpose and System Instructions (696 pages)
-
HPC Tuning Guide AMD EPYZ 7003 (70 pages)
-
Software optimization resources on Agner Fog's blog
-
Computer Architecture. A quantitative Approach. John L. Hennessy and David A. Patterson, 6th edition (2017)
-
Performance Optimization of Numerically Intensive Codes. Stefan Goedecker and Adolfy Hoisie, SIAM (2001)
-
Introduction to High Performance Computing for Scientists and Engineers. Georg Hager and Gerhard Wellein, CRC Press (2010)
"},{"location":"paow-20240611/M_1_05_PerformanceAnalysisAtWork_1/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_1_06_PerformanceAnalysisAtWork_2/","title":"Optimization/performance analysis demo and exercise part 2","text":"Presenter: Alfio Lazzaro (HPE)
"},{"location":"paow-20240611/M_1_06_PerformanceAnalysisAtWork_2/#materials","title":"Materials","text":"Except for the recording, the materials are the same as for part 1
Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_1_06_PerformanceAnalysisAtWork_2/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_2_01_AMD_tools_1/","title":"AMD Profiling Tools Overview & Omnitrace","text":"Presenter: Samuel Antao (AMD)
"},{"location":"paow-20240611/M_2_01_AMD_tools_1/#materials","title":"Materials","text":"Directly available as web downloads:
Archived materials on LUMI:
-
Slides first part of the presentation: Overview of the profiling tools: /appl/local/training/paow-20240611/files/LUMI-paow-20240611-2_01_profiler-tools-overview.pdf
-
Slides second part of the presentation: Omnitrace by example: /appl/local/training/paow-20240611/files/LUMI-paow-20240611-2_01_omnitrace-by-example.pdf
-
Recording: /appl/local/training/paow-20240611/recordings/2_01_AMD_tools_1.mp4
"},{"location":"paow-20240611/M_2_01_AMD_tools_1/#references-from-the-slides","title":"References (from the slides)","text":" -
Omnitrace documentation web site
-
Ghost Exhange OpenMP offload example suite on GitHub
-
ROCm docs
-
ROCm blog post \"Introduction to profiling tools for AMD hardware\"
-
AMD Instinct\u2122 GPU Training - Look for session 15, on day 4.
-
See also the materials linked in Exercise session #2
"},{"location":"paow-20240611/M_2_01_AMD_tools_1/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_2_02_AMD_tools_2/","title":"Introduction to Omniperf","text":"Presenter: Samuel Antao (AMD)
"},{"location":"paow-20240611/M_2_02_AMD_tools_2/#materials","title":"Materials","text":"Directly available as web downloads:
Archived materials on LUMI:
"},{"location":"paow-20240611/M_2_02_AMD_tools_2/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_2_03_MPI/","title":"MPI Optimizations","text":"Presenter: Harvey Richardson (HPE)
"},{"location":"paow-20240611/M_2_03_MPI/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_2_03_MPI/#references","title":"References","text":" - Longer version of the MPI presentation from the 4-day comprehensive course in April 2024
"},{"location":"paow-20240611/M_2_03_MPI/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_2_04_IO/","title":"I/O Optimizations","text":"Presenter: Harvey Richardson (HPE)
"},{"location":"paow-20240611/M_2_04_IO/#materials","title":"Materials","text":"Archived materials on LUMI:
These materials can only be distributed to actual users of LUMI (active user account).
"},{"location":"paow-20240611/M_2_04_IO/#qa","title":"Q&A","text":"/
"},{"location":"paow-20240611/M_2_05_OpenSession/","title":"Open session and Q&A","text":"Time to work on your own code while being able to ask for help from the experts in the room.
"},{"location":"paow-20240611/M_A01_Documentation/","title":"Documentation links","text":"Note that documentation, and especially web based documentation, is very fluid. Links change rapidly and were correct when this page was developed right after the course. However, there is no guarantee that they are still correct when you read this and will only be updated at the next course on the pages of that course.
This documentation page is far from complete but bundles a lot of links mentioned during the presentations, and some more.
"},{"location":"paow-20240611/M_A01_Documentation/#web-documentation","title":"Web documentation","text":" -
Slurm version 22.05.10, on the system at the time of the course
-
HPE Cray Programming Environment web documentation has only become available in May 2023 and is a work-in-progress. It does contain a lot of HTML-processed man pages in an easier-to-browse format than the man pages on the system.
The presentations on debugging and profiling tools referred a lot to pages that can be found on this web site. The manual pages mentioned in those presentations are also in the web documentation and are the easiest way to access that documentation.
-
Cray PE Github account with whitepapers and some documentation.
-
Cray DSMML - Distributed Symmetric Memory Management Library
-
Cray Library previously provides as TPSL build instructions
-
Clang latest version documentation (Usually for the latest version)
-
Clang 13.0.0 version (basis for aocc/3.2.0)
-
Clang 14.0.0 version (basis for rocm/5.2.3 and amd/5.2.3)
-
Clang 15.0.0 version (cce/15.0.0 and cce/15.0.1 in 22.12/23.03)
-
Clang 16.0.0 version (cce/16.0.0 in 23.09)
-
AMD Developer Information
-
ROCmTM documentation overview
-
HDF5 generic documentation
-
SingularityCD 3.11 User Guide
"},{"location":"paow-20240611/M_A01_Documentation/#man-pages","title":"Man pages","text":"A selection of man pages explicitly mentioned during the course:
-
Compilers
PrgEnv C C++ Fortran PrgEnv-cray man craycc man crayCC man crayftn PrgEnv-gnu man gcc man g++ man gfortran PrgEnv-aocc/PrgEnv-amd - - - Compiler wrappers man cc man CC man ftn -
Web-based versions of the compiler wrapper manual pages (the version on the system is currently hijacked by the GNU manual pages):
-
OpenMP in CCE
-
OpenACC in CCE
-
MPI:
-
LibSci
-
man intro_libsci and man intro_libsci_acc (no online manual page, load cray-libsci_acc to see the manual page on the system)
-
man intro_blas1, man intro_blas2, man intro_blas3, man intro_cblas
-
man intro_lapack
-
man intro_scalapack and man intro_blacs
-
man intro_irt
-
man intro_fftw3 (with cray-fftw loaded)
-
DSMML - Distributed Symmetric Memory Management Library
-
Slurm manual pages are also all on the web and are easily found by Google, but are usually those for the latest version.
-
man sbatch
-
man srun
-
man salloc
-
man squeue
-
man scancel
-
man sinfo
-
man sstat
-
man sacct
-
man scontrol
"},{"location":"paow-20240611/M_A01_Documentation/#via-the-module-system","title":"Via the module system","text":"Most HPE Cray PE modules contain links to further documentation. Try module help cce etc.
"},{"location":"paow-20240611/M_A01_Documentation/#from-the-commands-themselves","title":"From the commands themselves","text":"PrgEnv C C++ Fortran PrgEnv-cray craycc --helpcraycc --craype-help crayCC --helpcrayCC --craype-help crayftn --helpcrayftn --craype-help PrgEnv-gnu gcc --help g++ --help gfortran --help PrgEnv-aocc clang --help clang++ --help flang --help PrgEnv-amd amdclang --help amdclang++ --help amdflang --help Compiler wrappers cc --craype-helpcc --help CC --craype-helpCC --help ftn --craype-helpftn --help For the PrgEnv-gnu compiler, the --help option only shows a little bit of help information, but mentions further options to get help about specific topics.
Further commands that provide extensive help on the command line:
rocm-smi --help, even on the login nodes.
"},{"location":"paow-20240611/M_A01_Documentation/#documentation-of-other-cray-ex-systems","title":"Documentation of other Cray EX systems","text":"Note that these systems may be configured differently, and this especially applies to the scheduler. So not all documentations of those systems applies to LUMI. Yet these web sites do contain a lot of useful information.
-
Archer2 documentation. Archer2 is the national supercomputer of the UK, operated by EPCC. It is an AMD CPU-only cluster. Two important differences with LUMI are that (a) the cluster uses AMD Rome CPUs with groups of 4 instead of 8 cores sharing L3 cache and (b) the cluster uses Slingshot 10 instead of Slinshot 11 which has its own bugs and workarounds.
It includes a page on cray-python referred to during the course.
-
ORNL Frontier User Guide and ORNL Crusher Qucik-Start Guide. Frontier is the first USA exascale cluster and is built up of nodes that are very similar to the LUMI-G nodes (same CPA and GPUs but a different storage configuration) while Crusher is the 192-node early access system for Frontier. One important difference is the configuration of the scheduler which has 1 core reserved in each CCD to have a more regular structure than LUMI.
-
KTH Dardel documentation. Dardel is the Swedish \"baby-LUMI\" system. Its CPU nodes use the AMD Rome CPU instead of AMD Milan, but its GPU nodes are the same as in LUMI.
-
GENCI Adastra documentation. Adastra is another system similar to LUMI. Its GPU nodes are the same as on LUMI (but it also has a small partition with the newer MI300A APUs) while the CPU partition uses the newer zen4/Genoa generation AMD EPYC CPUs.
-
Setonix User Guide. Setonix is a Cray EX system at Pawsey Supercomputing Centre in Australia. The CPU and GPU compute nodes are the same as on LUMI.
"},{"location":"paow-20240611/schedule/","title":"Schedule","text":" - Day 1 - Tuesday 11/06/2024
- Day 2 - Wednesday 12/06/2024 DAY 1 - Tuesday 11/06/2024 09:00 CEST 10:00 EEST Welcome and Introduction Presenters: J\u00f8rn Dietze (LUST) and Harvey Richardson (HPE) 09:15 CEST 10:15 EEST LUMI Architecture, Programming and Runtime Environment Presenters: Harvey Richardson (HPE) 09:45 CEST 10:45 EEST Exercises (session 1) Presenter: Alfio Lazzaro (HPE) 10:15 CEST 11:15 EEST Break (15 minutes) 10:30 CEST 11:30 EEST Introduction to Performance Analysis with Perftools Presenters Thierry Braconnier (HPE) 11:10 CEST 12:10 EEST Performance Optimization: Improving Single-Core Efficiency Presenter: Jean-Yves Vet (HPE) 11:40 CEST 12:40 EEST Application Placement Presenters: Jean-Yves Vet (HPE) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 14:00 EEST Optimization/performance analysis demo and exercise Presenters: Alfio Lazzaro (HPE) 14:30 CEST 15:30 EEST Break (30 minutes) 15:00 CEST 16:00 EEST Optimization/performance analysis demo and exercise Presenters: Alfio Lazzaro (HPE) 16:30 CEST 17:30 EEST End of the workshop day DAY 2 - Wednesday 12/06/2024 09:00 CEST 10:00 EEST AMD Profiling Tools Overview & Omnitrace Presenter: Samuel A\u00f1tao (AMD) 10:00 CEST 11:00 EEST Exercises (session 2) Presenter: Samuel A\u00f1tao (AMD) 10:30 CEST 11:30 EEST Break (15 minutes) 10:45 CEST 11:45 EEST Introduction to Omniperf Presenters: Samuel A\u00f1tao (AMD) 11:30 CEST 12:#0 EEST Exercises (session 3) Presenter: Samuel A\u00f1tao (AMD) 12:00 CEST 13:00 EEST Lunch break (60 minutes) 13:00 CEST 14:00 EEST MPI Optimizations Presenters: Harvey Richardson (HPE) 13:30 CEST 14:30 EEST Exercises (session 4) Presenter: Harvey Richardson (HPE) 14:00 CEST 15:00 EEST IO Optimizations Presenters: Harvey Richardson (HPE) 14:35 CEST 15:35 EEST Exercises (session 5) Presenter: Harvey Richardson (HPE) 15:05 CEST 16:05 EEST Break (15 minutes) 15:20 CEST 16:20 EEST Open session and Q&A Option to work on your own code 16:30 CEST 17:30 EEST End of the workshop"}]}
\ No newline at end of file
diff --git a/sitemap.xml b/sitemap.xml
index d7a54b294..f84d08b5b 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -2,2212 +2,2232 @@
https://lumi-supercomputer.github.io/LUMI-training-materials/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/01_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/02_CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/03_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/04_Software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/05_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/06_Running_jobs/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/07_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/08_Lustre_intro/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/09_LUMI_support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/notes_20230509/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/notes_20230516/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_01_LUMI_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_02_HPE_Cray_Programming_Environment/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_03_Modules_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_04_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_06_Running_Jobs_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_08_Introduction_to_Lustre_and_Best_Practices/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230509/video_09_LUMI_User_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/01_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/02_CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/03_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/04_Software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/05_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/06_Running_jobs/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/07_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/08_Lustre_intro/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/09_LUMI_support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/notes_20230921/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_01_LUMI_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_02_HPE_Cray_Programming_Environment/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_03_Modules_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_04_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_06_Running_Jobs_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_08_Introduction_to_Lustre_and_Best_Practices/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20230921/video_09_LUMI_User_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/01_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/02_CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/03_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/04_Software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/05_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/06_Running_jobs/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/07_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/08_Lustre_intro/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/09_LUMI_support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/notes_20240208/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_01_LUMI_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_02_HPE_Cray_Programming_Environment/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_03_Modules_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_04_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_06_Running_Jobs_on_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_08_Introduction_to_Lustre_and_Best_Practices/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/1day-20240208/video_09_LUMI_User_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/01_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/02_CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/03_LUMI_access/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/04_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/05_Software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/06_Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/07_Binding/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/08_Lustre/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/09_Containers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/10_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/Demo1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/Demo2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/E03_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/E04_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/E05_Exercises_3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/E07_Exercises_4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_01_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_02_CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_03_LUMI_access/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_04_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_05_Software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_06_Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_07_Binding/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_08_Lustre/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_09_Containers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_10_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_11_Netherlands/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_12_What_else/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_13_WrapUpDay1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/extra_14_IntroductionDay2/
- 2024-10-22
+ 2024-10-25
+ daily
+
+
+ https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/index.links.noGit/
+ 2024-10-25
+ daily
+
+
+ https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/index.noLinks.noGit/
+ 2024-10-25
+ daily
+
+
+ https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/schedule.links.noGit/
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/schedule/
- 2024-10-22
+ 2024-10-25
+ daily
+
+
+ https://lumi-supercomputer.github.io/LUMI-training-materials/2day-20240502/schedule.noLinks.noGit/
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/00-Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/01-Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/02-CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/03-Access/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/04-Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/05-SoftwareStacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/06-Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/07-Binding/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/08-Lustre/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/09-Containers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/10-Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/A01-Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/Demo1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/Demo2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E02-CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E03-Access/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E04-Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E05-SoftwareStacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E06-Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/E07-Binding/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M01-Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M02-CPE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M03-Access/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M04-Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M05-SoftwareStacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M06-Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M07-Binding/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M08-Lustre/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M09-Containers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/M10-Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/ME03-Exercises-1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/ME04-Exercises-2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/ME05-Exercises-3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/ME07-Exercises-4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/MI01-IntroductionCourse/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/MI02-WrapUpDay1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/MI03-IntroductionDay2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/MI04-WhatElse/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/2day-next/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/hedgedoc_notes_day1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/hedgedoc_notes_day2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/hedgedoc_notes_day3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/hedgedoc_notes_day4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/video_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/video_09_LUMI_Software_Stack/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230214/video_10_LUMI_User_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_01_HPE_Cray_EX_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_02_Programming_Environment_and_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_03_Running_Applications/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_04_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_05_Compilers_and_Parallel_Programming_Models/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_06_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_07_Cray_Scientific_Libraries/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_08_Exercises_3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_1_09_Offload_CCE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_01_Debugging_at_Scale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_02_Exercises_4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_03_Advanced_Application_Placement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_04_Exercises_5/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_05_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_2_07_Exercises_6/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_01_Introduction_to_Perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_02_Exercises_7/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_03_Advanced_Performance_Analysis/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_04_Exercises_8/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_05_Cray_MPI_on_Slingshot/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_06_Exercises_9/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_07_AMD_ROCgdb_Debugger/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_08_Exercises_10/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_3_10_Exercises_11/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_01_Performance_Optimization_Improving_Single_Core/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_02_Introduction_to_Python_on_Cray_EX/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_03_Exercises_12/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_04_IO_Optimization_Parallel_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_05_Exercises_13/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_06_AMD_Ominitrace/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_07_Exercises_14/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_08_AMD_Ominiperf/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_09_Exercises_15/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_10_Best_Practices_GPU_Optimization/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/extra_4_11_LUMI_Support_and_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/notes_2_05_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20230530/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/exercises_AMD_hackmd/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_01_HPE_Cray_EX_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_02_Programming_Environment_and_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_03_Running_Applications/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_04_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_05_Compilers_and_Parallel_Programming_Models/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_06_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_07_Cray_Scientific_Libraries/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_08_Exercises_3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_1_09_Offload_CCE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_01_Advanced_Application_Placement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_02_Exercises_4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_03_Debugging_at_Scale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_04_Exercises_5/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_05_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_06_Introduction_to_AMD_ROCm_Ecosystem/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_2_07_Exercises_6/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_01_Introduction_to_Perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_02_Exercises_7/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_03_Advanced_Performance_Analysis/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_04_Exercises_8/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_05_Cray_MPI_on_Slingshot/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_06_Exercises_9/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_07_AMD_ROCgdb_Debugger/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_08_Exercises_10/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_3_10_Exercises_11/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_01_Introduction_to_Python_on_Cray_EX/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_02_Performance_Optimization_Improving_Single_Core/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_03_Exercises_12/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_04_IO_Optimization_Parallel_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_05_Exercises_13/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_06_AMD_Omnitrace/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_07_Exercises_14/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_08_AMD_Omniperf/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_09_Exercises_15/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_10_Best_Practices_GPU_Optimization/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/extra_4_11_LUMI_Support_and_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/notes_2_05_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20231003/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/A02_Misc_Questions/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/exercises_AMD_hackmd/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_01_HPE_Cray_EX_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_02_Programming_Environment_and_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_03_Running_Applications/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_04_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_05_Compilers_and_Parallel_Programming_Models/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_06_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_07_Cray_Scientific_Libraries/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_08_Exercises_3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_1_09_Offload_CCE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_01_Introduction_to_AMD_ROCm_Ecosystem/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_02_Exercises_4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_03_Debugging_at_Scale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_04_Exercises_5/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_05_Advanced_Application_Placement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_06_Exercises_6/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_2_07_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_01_Introduction_to_Perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_02_Exercises_7/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_03_Advanced_Performance_Analysis/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_04_Exercises_8/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_05_Cray_MPI_on_Slingshot/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_06_Exercises_9/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_07_AMD_ROCgdb_Debugger/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_08_Exercises_10/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_3_10_Exercises_11/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_01_Introduction_to_Python_on_Cray_EX/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_02_Porting_to_GPU/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_03_Performance_Optimization_Improving_Single_Core/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_04_Exercises_12/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_05_IO_Optimization_Parallel_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_06_Exercises_13/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_07_AMD_Omnitrace/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_08_Exercises_14/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_09_AMD_Omniperf/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_10_Exercises_15/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_11_Best_Practices_GPU_Optimization/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/extra_4_12_LUMI_Support_and_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/notes_2_07_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/notes_4_12_LUMI_Support_and_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20240423/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/A02_Misc_Questions/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/exercises_AMD_hackmd/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_01_HPE_Cray_EX_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_02_Programming_Environment_and_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_03_Running_Applications/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_04_Exercises_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_05_Compilers_and_Parallel_Programming_Models/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_06_Exercises_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_07_Cray_Scientific_Libraries/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_08_Exercises_3/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_1_09_Offload_CCE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_01_Advanced_Application_Placement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_02_Exercises_4/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_03_Debugging_at_Scale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_04_Exercises_5/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_05_Introduction_to_AMD_ROCm_Ecosystem/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_06_Exercises_6/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_2_07_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_01_Introduction_to_Perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_02_Exercises_7/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_03_Advanced_Performance_Analysis/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_04_Exercises_8/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_05_Cray_MPI_on_Slingshot/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_06_Exercises_9/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_07_AMD_ROCgdb_Debugger/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_08_Exercises_10/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_09_Introduction_to_Rocprof_Profiling_Tool/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_3_10_Exercises_11/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_01_Introduction_to_Python_on_Cray_EX/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_02_Porting_to_GPU/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_03_Performance_Optimization_Improving_Single_Core/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_04_Exercises_12/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_05_IO_Optimization_Parallel_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_06_Exercises_13/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_07_AMD_Omnitrace/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_08_Exercises_14/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_09_AMD_Omniperf/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_10_Exercises_15/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_11_Best_Practices_GPU_Optimization/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/extra_4_12_LUMI_Support_and_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/notes_2_07_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/4day-20241028/where_to_drink/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/EasyBuild-CSC-20220509/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20230417/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20241014/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20241014/localinfo/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20241014/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20241014/where_to_drink/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Hackathon-20241014/where_to_eat/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/LUMI-G-20220823/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/LUMI-G-20220823/hackmd_notes/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/LUMI-G-20230111/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/LUMI-G-20230111/hedgedoc_notes/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/LUMI-G-20230111/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20220427/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20220427/demo_software_stakcs_mdp/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20220427/hackmd_notes/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20220427/software_stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/demo_software_stacks_mdp/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_01_HPE_Cray_EX_Architecture/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_02_Programming_Environment_and_Modules/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_03_Running_Applications_Slurm/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_04_Compilers_and_Libraries/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_05_Advanced_Placement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_06_introduction_to_perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_07_advanced_performance_analysis_part1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_08_advanced_performance_analysis_part2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_09_debugging_at_scale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_11_cray_mpi_MPMD_short/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_12_IO_short_LUMI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_13_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_14_LUMI_User_Support/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/extra_15_Day_2_QandA/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/hedgedoc_notes/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/notes_13_LUMI_Software_Stacks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/PEAP-Q-20221123/where_to_eat/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/01_Preparing_an_Application_for_Hybrid_Supercomputing/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/02_Intro_rocprof/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/03_Intro_OmniTrace/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/04_Intro_OmniPerf/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/05_Exercises/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/hedgedoc_notes/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20230413/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20231122/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20231122/00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20231122/01_HPE_Cray_PE_tools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20231122/02_AMD_tools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20231122/03_Exercises/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/00_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/01_HPE_Cray_PE_tools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/02_AMD_tools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/03_Exercises/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/Profiling-20241009/A01-Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20230628-user-coffee-break-AI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20230830-user-coffee-break-Spack/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20230927-user-coffee-break-cotainr/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20231129-user-coffee-break-OoD/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20240131-user-coffee-break-HyperQueue/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Coffee-Breaks/20241002-user-coffee-break-LUMI-update/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202308/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202308/lumig-devg/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202308/lumig-lownoise/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202308/responsible-use/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202311/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202409/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202409/202409_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/User-Updates/Update-202409/202409_FAQ/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E02_Webinterface/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E03_FirstJob/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E04_Workarounds/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E05_RunningContainers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E06_BuildingContainers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E08_MultipleGPUs/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E09_Ray/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/E10_ExtremeScale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_00_Course_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_01_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_02_Webinterface/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_03_FirstJob/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_04_Workarounds/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_05_RunningContainers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_06_BuildingContainers/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_07_VirtualEnvironments/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_08_MultipleGPUs/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_09_Ray/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_10_ExtremeScale/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_11_LUMIO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/extra_12_Coupling/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/ai-20240529/schedule/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/ME_1_01_HPE_PE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/ME_2_01_AMD_tools_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/ME_2_02_AMD_tools_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/ME_2_03_MPI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/ME_2_04_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_00_Course_Introduction/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_01_HPE_PE/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_02_Perftools/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_03_PerformanceOptimization/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_04_ApplicationPlacement/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_05_PerformanceAnalysisAtWork_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_1_06_PerformanceAnalysisAtWork_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_2_01_AMD_tools_1/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_2_02_AMD_tools_2/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_2_03_MPI/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_2_04_IO/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_2_05_OpenSession/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/M_A01_Documentation/
- 2024-10-22
+ 2024-10-25
daily
https://lumi-supercomputer.github.io/LUMI-training-materials/paow-20240611/schedule/
- 2024-10-22
+ 2024-10-25
daily
\ No newline at end of file
diff --git a/sitemap.xml.gz b/sitemap.xml.gz
index dfc7426cf..2a2ebc576 100644
Binary files a/sitemap.xml.gz and b/sitemap.xml.gz differ

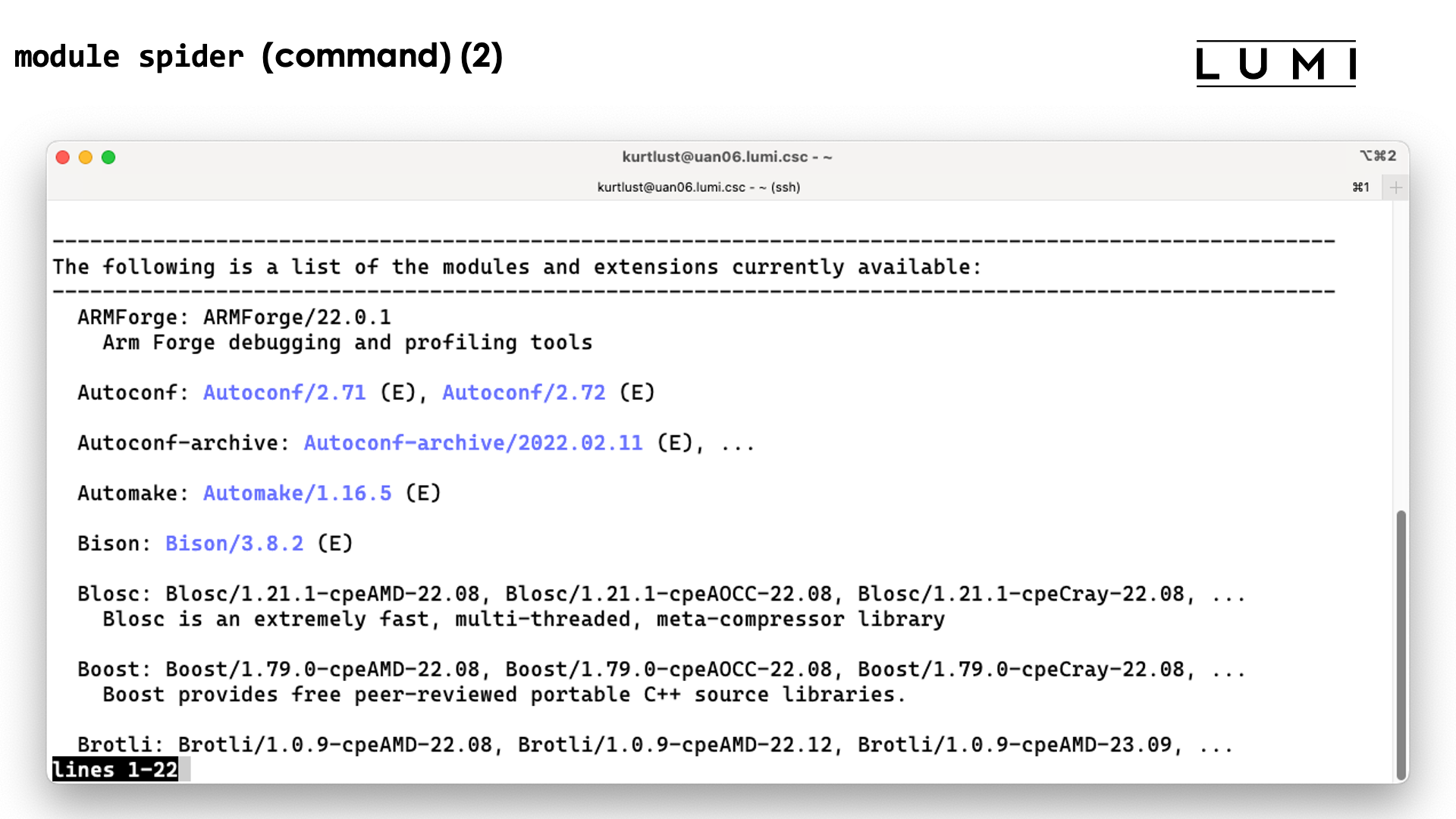
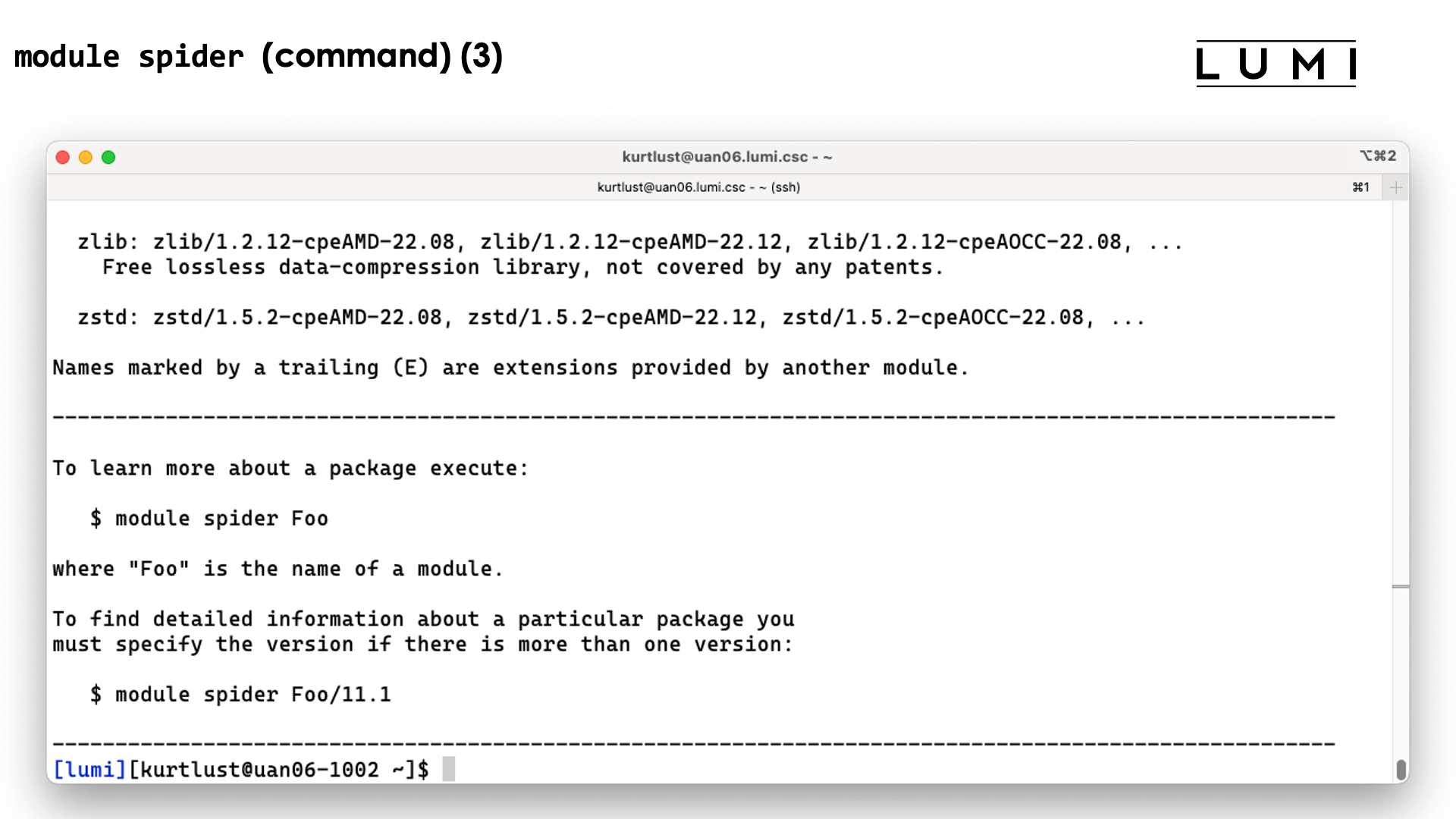
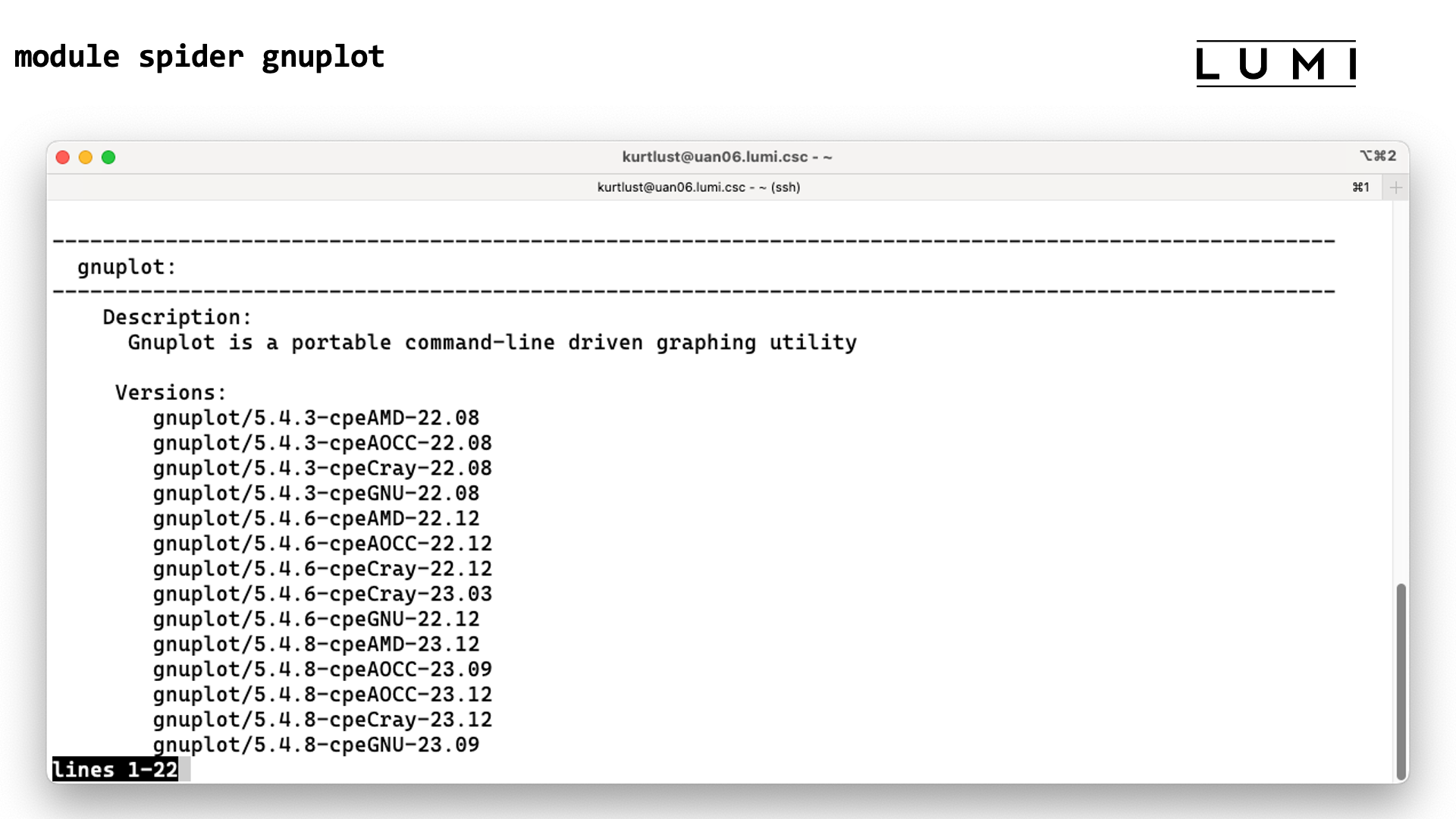
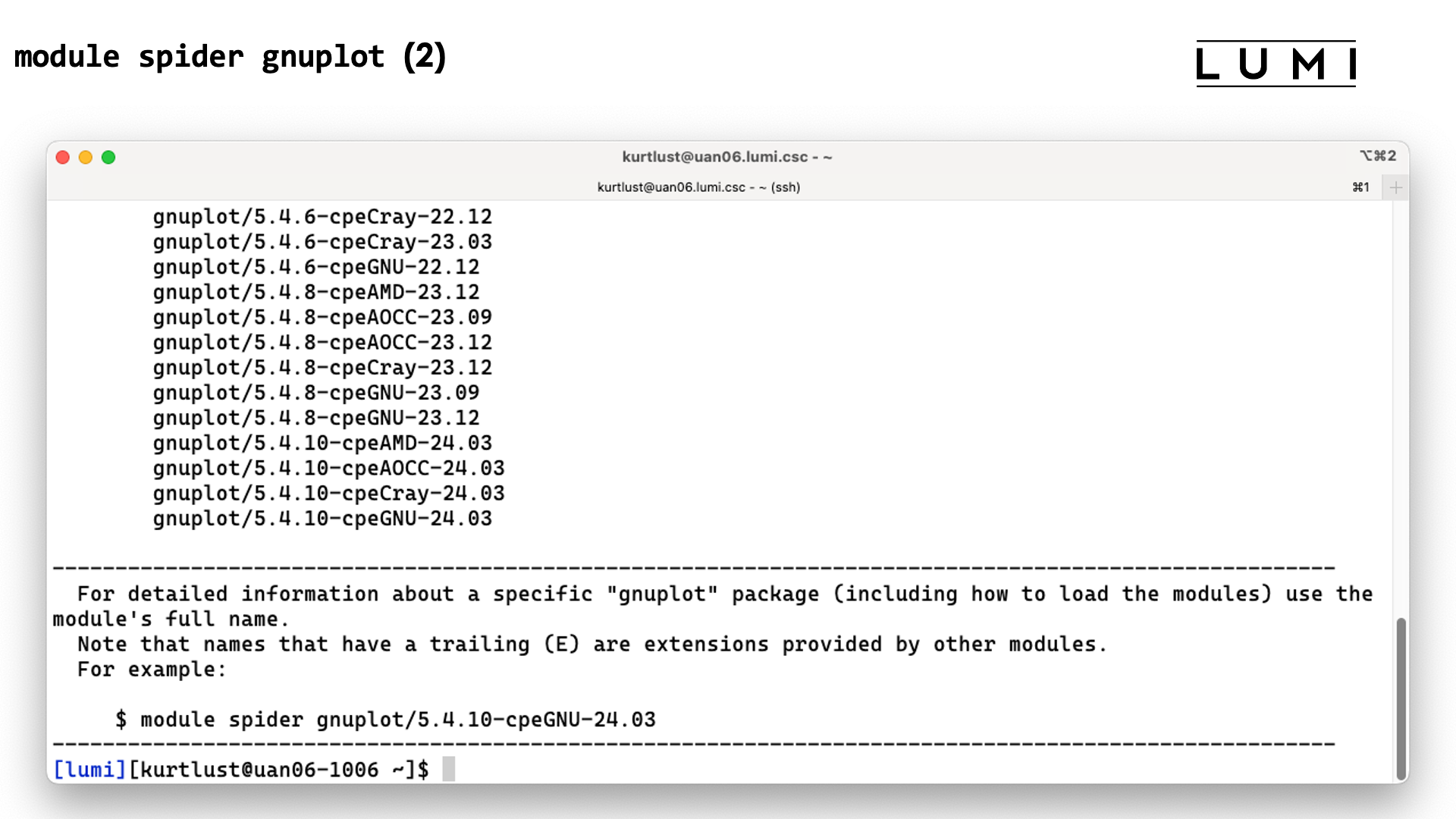
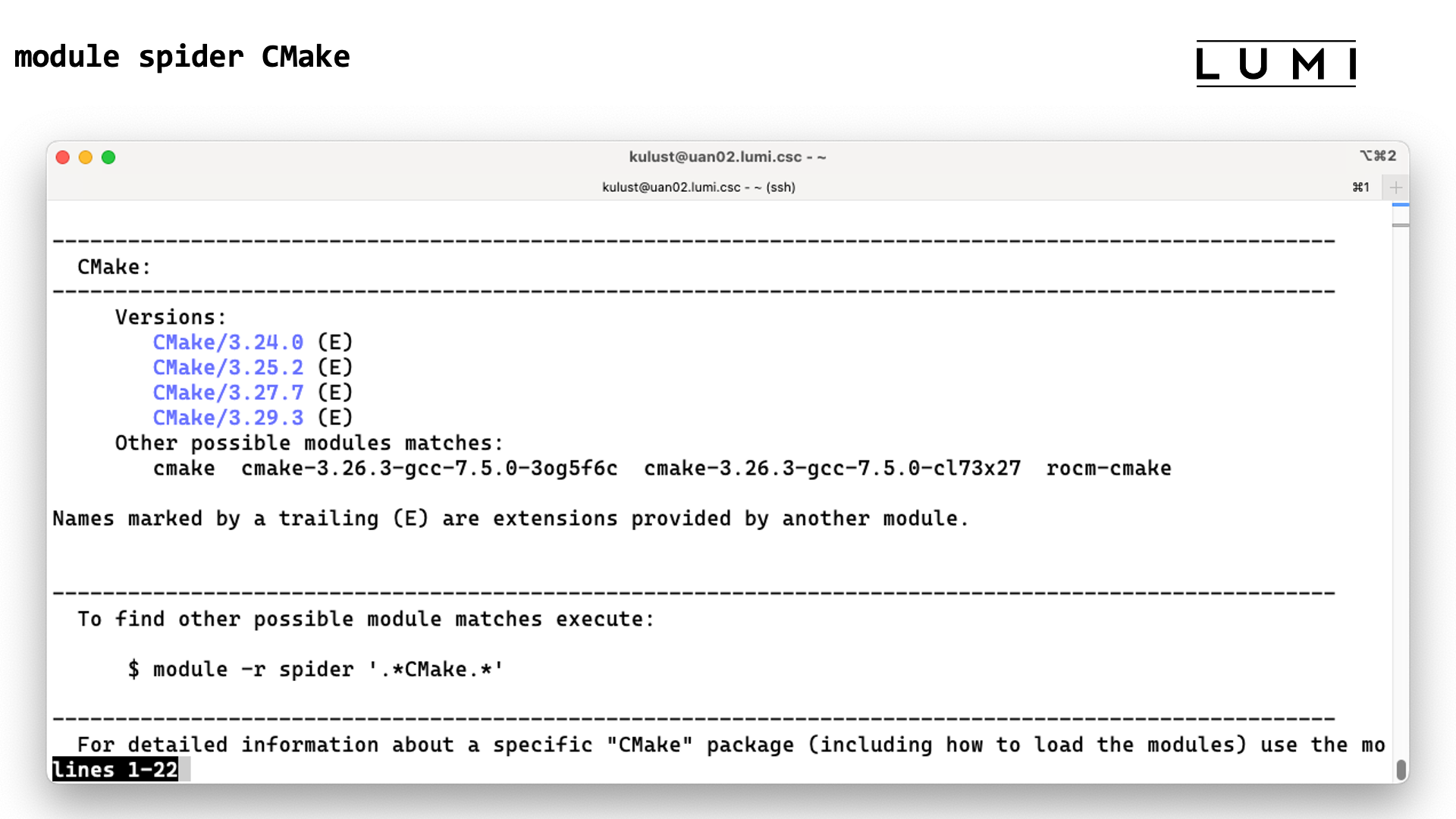
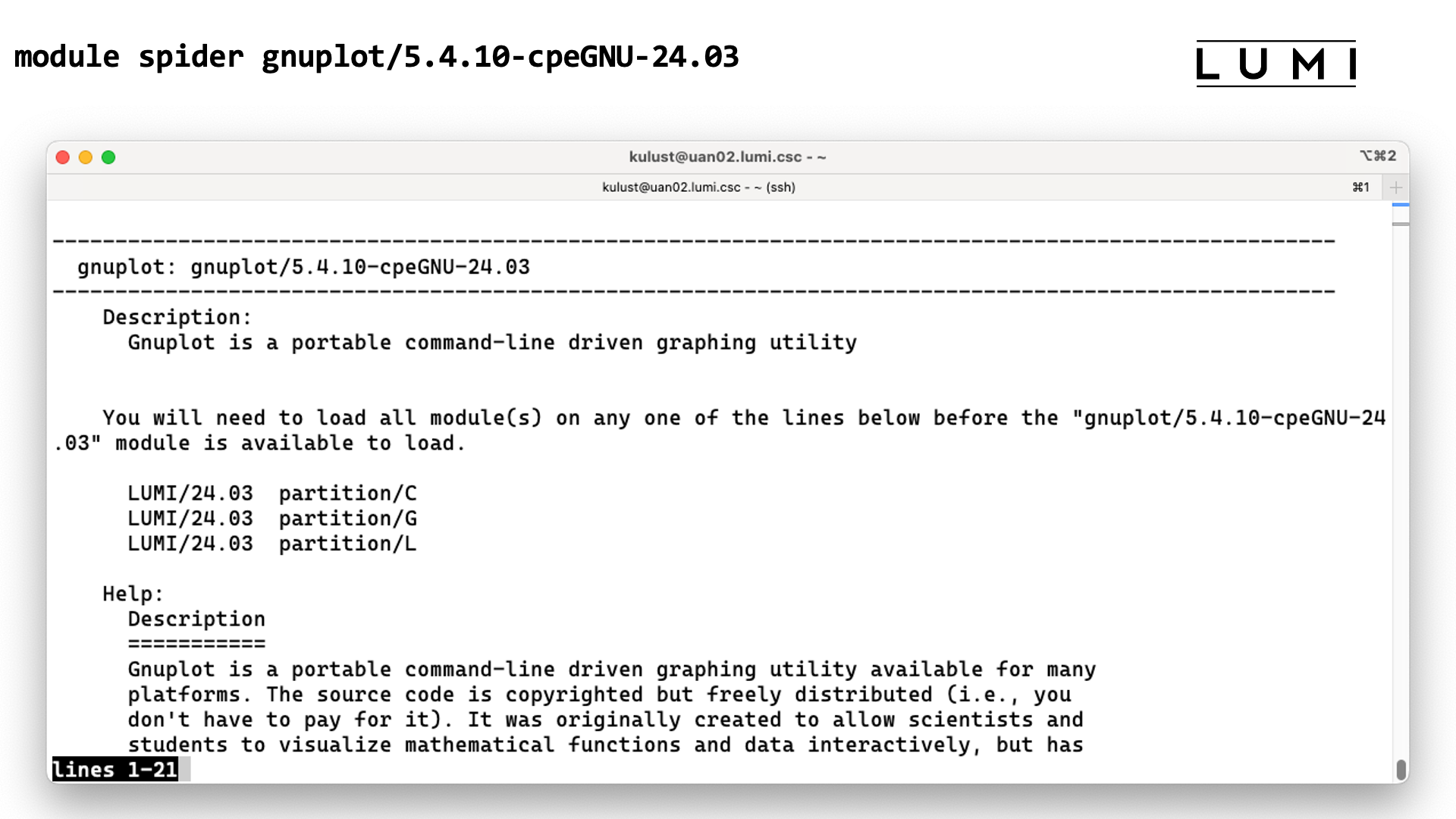
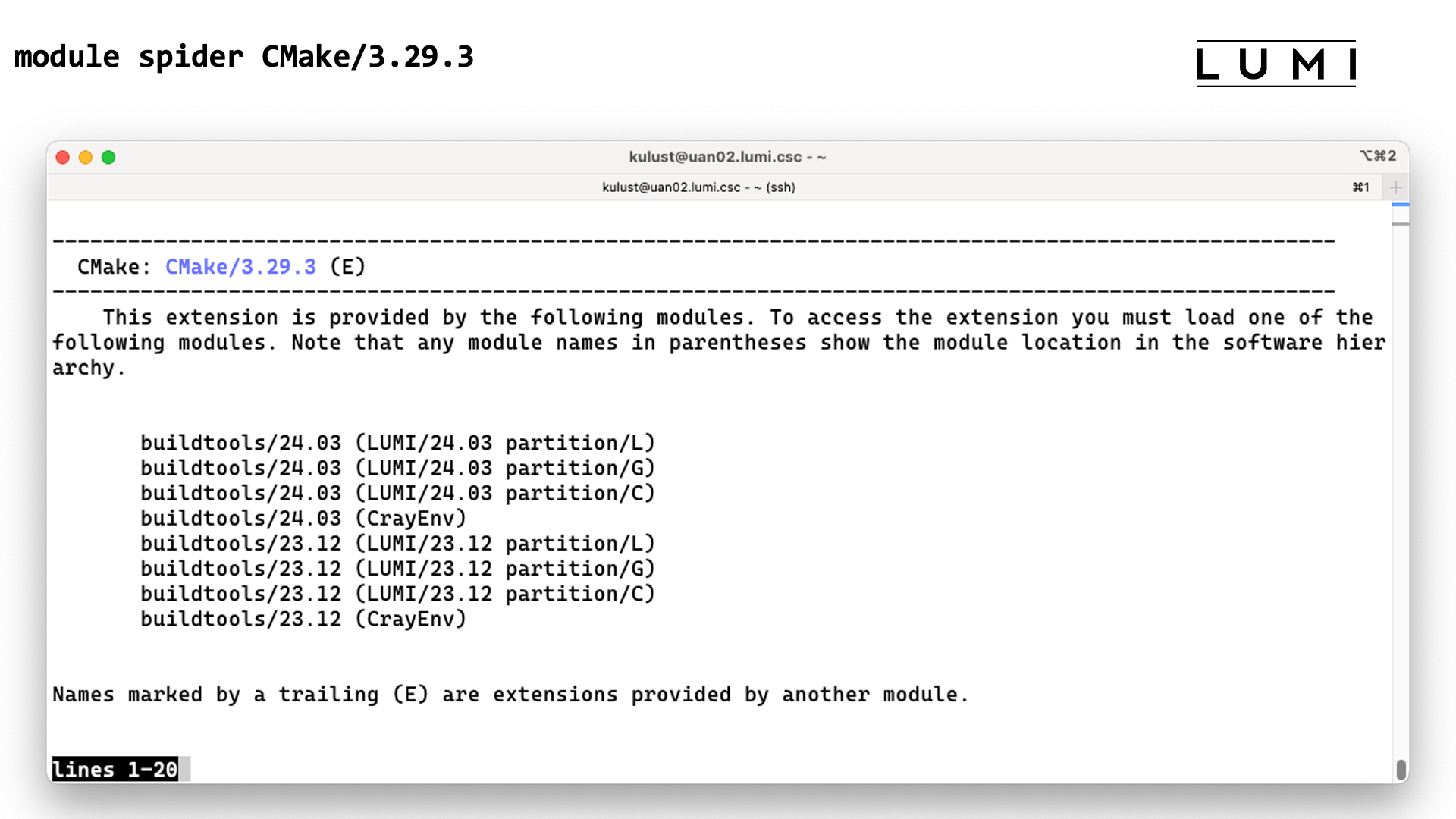
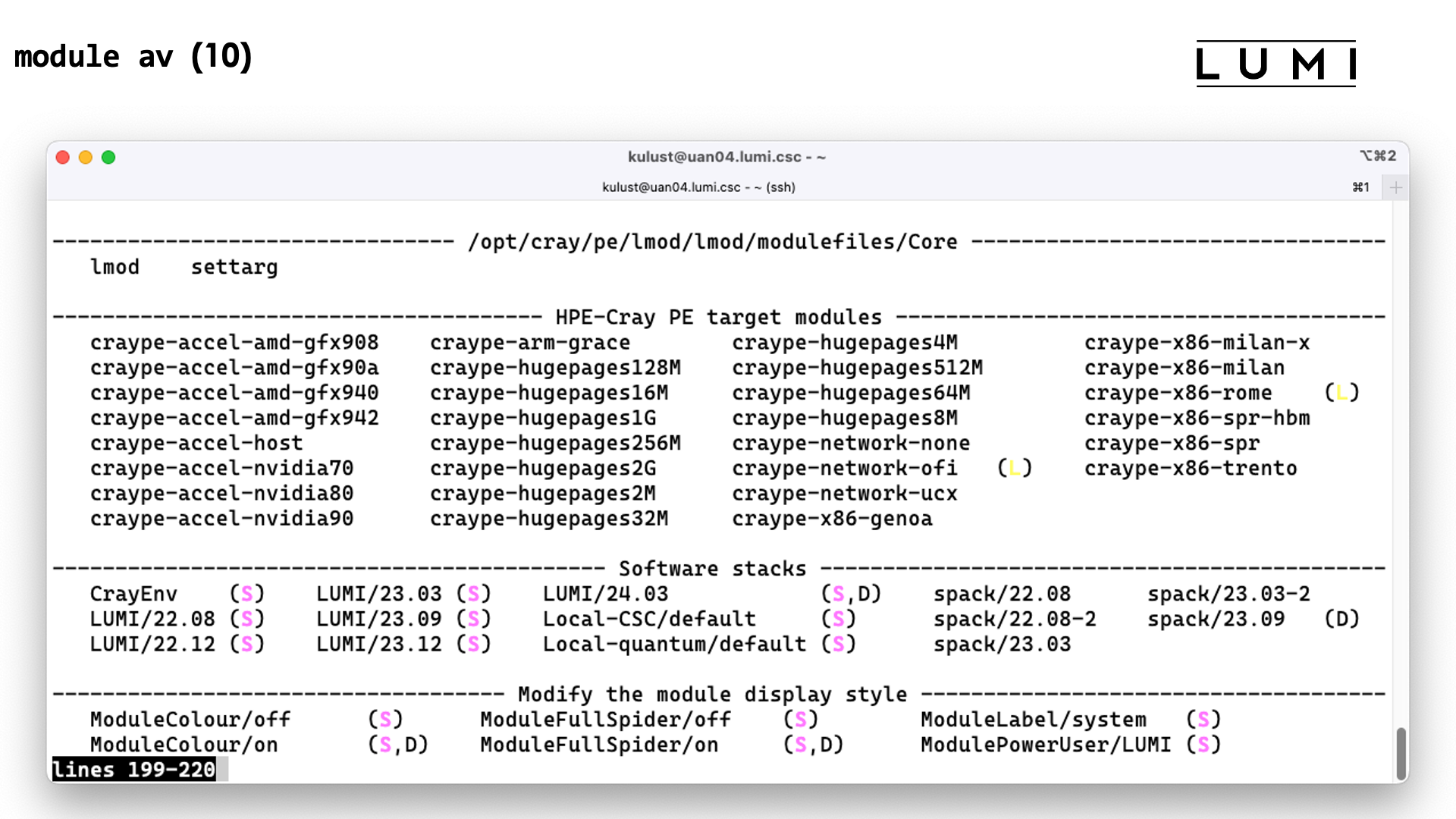
 -
- +
+  +
+ 

