Question about U-net architecture for segmentation #464
Comments
|
Hi @ericspod , Could you please help provide more information here as you initialized the UNet code? |
|
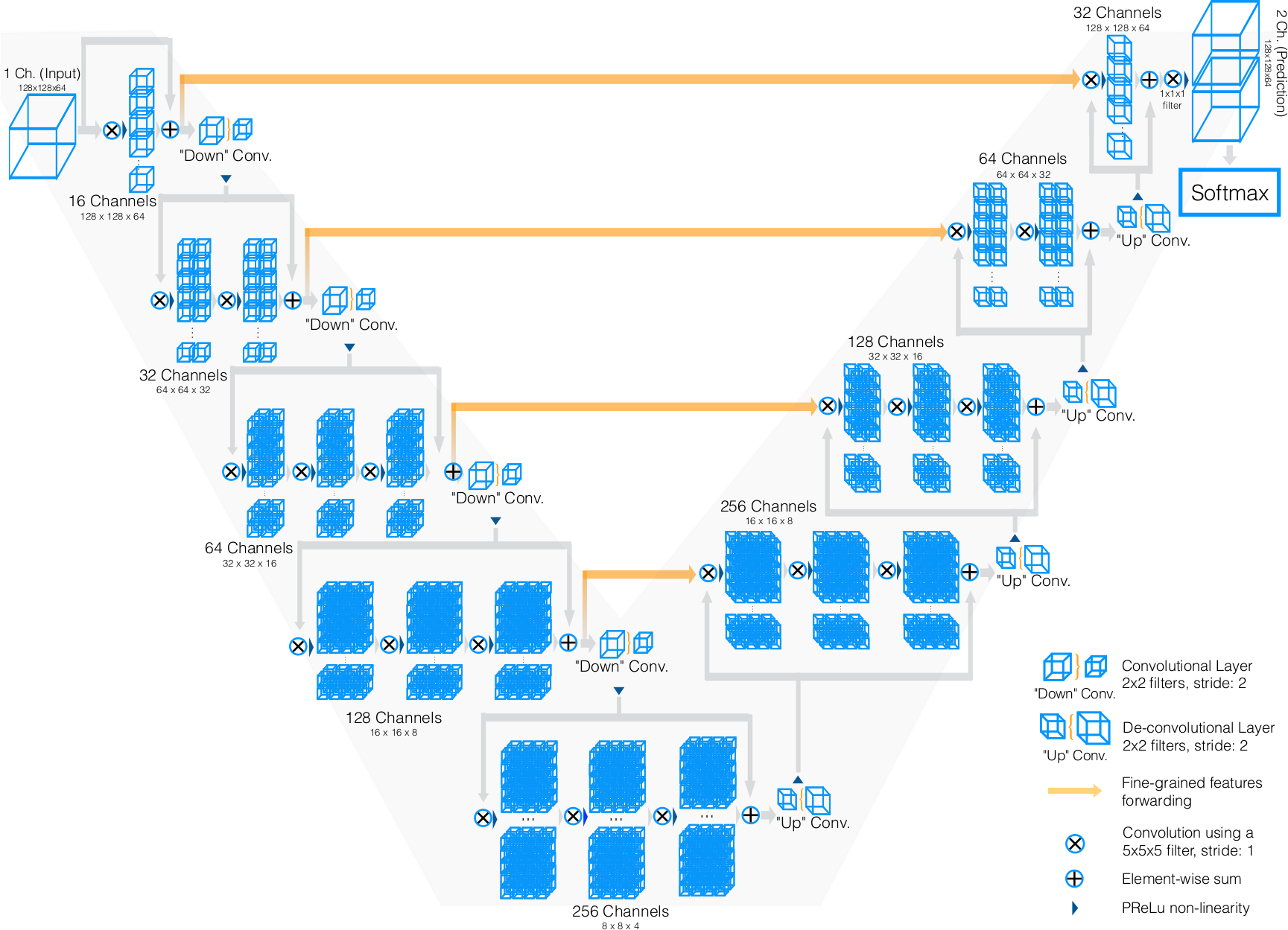
Hi, I initialized the UNet with this code: When visualising the computational graph in Tensorboard I noticed there are no max pooling layers and that the downsampling is done by the strided convolutions. Also on the upsampling part I am a bit confused as to where the residual layers are and how they connect. It seems to me that is it kind a similar to the model below. Is there a schematic visualisation of the model somewhere? That would really help me to understand the model better. Joris Wuts |
|
Hi @joriswuts, What this boils down to is a sequence of layers comprised of transpose convolution, normalization, activation, followed by a residual unit with a single sequence of convolution-normalization-activation layers. A way of thinking about UNet is that it is a tower of large layers containing one level of the encode and decode paths with the skip connection between them. You can then describe the structure of the layer and then the whole network as a stack of these. I've attached a diagram of this I've used in other papers, it's very similar to your configuration other than the use of instance norm.
|

|
@ericspod Kind regards, |
|
@ericspod, Just to be completely sure. Could it be that the residual connection in my model have a stride one convolution in them instead of a simple identity operation. I added an image of the first downsampling block in tensorboard. I noticed that a stride 1 convolution in the residual layer is also proposed in several papers that got referenced in the documents of DLTK and MONAI. (e.g. https://arxiv.org/pdf/1603.05027.pdf) |

{kind=link}
|
Residual units are implemented in UNet with the ResidualUnit class, the residual part uses a convolution to change the input dimensions to match the output dimensions if this is necessary but will use |
|
@ericspod Is it possible to find the see the settings used in the references paper (Left-Ventricle Quantification Using Residual U-Net) e.g. optimizer, learning rate, weight decay, learning rate scheduler ect. ? :) |
|
I used Adam with a learning rate of 0.001 with default values otherwise. I didn't do learning rate scheduling in this paper. |
Thanks, that is also what I have most luck with using :D |
Hey there, I am currently in the same spot as you, writing a thesis for my biomed. engineering studies. I am using the MONAI U-Net, too, and yes, it seems, the max pooling operations are replaced by strided convolutions. I cam to the same conclusion by printing out the model sequences. |
Hi,
I am a master student biomedical engineering at the University of Ghent. I have been using MONAI for my master thesis the last couple of months which is about the segmentation of bone lesions from multi-modal whole body MRI. When comparing the model architecture of MONAI with most U-nets that are described in literature I noticed that the MONAI U-net used strided convolutions instead of max-pooling for downsampling. I was wondering why that is and if there is are any reference papers suggesting to do this.
Kind regards,
Joris Wuts
The text was updated successfully, but these errors were encountered: