diff --git a/nvidia_deeplearningexamples_resnext.md b/nvidia_deeplearningexamples_resnext.md
index 7de8bbd..ea8d6f8 100644
--- a/nvidia_deeplearningexamples_resnext.md
+++ b/nvidia_deeplearningexamples_resnext.md
@@ -18,32 +18,32 @@ demo-model-link: https://huggingface.co/spaces/pytorch/ResNeXt101
---
-### Model Description
+### 모델 설명
-The ***ResNeXt101-32x4d*** is a model introduced in the [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/pdf/1611.05431.pdf) paper.
+***ResNeXt101-32x4d***는 [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/pdf/1611.05431.pdf) 논문에 소개된 모델입니다.
-It is based on regular ResNet model, substituting 3x3 convolutions inside the bottleneck block for 3x3 grouped convolutions.
+이 모델은 일반적인 ResNet 모델에 기반을 두고 있으며 ResNet의 3x3 그룹 합성곱(Grouped Convolution) 계층을 병목 블록(Bottleneck Block) 내부의 3x3 합성곱 계층으로 대체합니다.
-This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 3x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
+ResNeXt101 모델은 Volta, Turing 및 NVIDIA Ampere 아키텍처에서 Tensor Core를 사용하여 혼합 정밀도(Mixed Precision) 방식[1]으로 학습됩니다. 따라서 연구자들은 혼합 정밀도 학습의 장점을 경험하는 동시에 Tensor Cores를 사용하지 않을 때보다 결과를 3배 빠르게 얻을 수 있습니다. 이 모델은 시간이 지남에도 지속적인 정확도와 성능을 유지하기 위해 월별 NGC 컨테이너 출시에 대해 테스트되고 있습니다.
-We use [NHWC data layout](https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html) when training using Mixed Precision.
+혼합 정밀도 학습에는 [NHWC 데이터 레이아웃](https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html)이 사용됩니다.
-Note that the ResNeXt101-32x4d model can be deployed for inference on the [NVIDIA Triton Inference Server](https://github.com/NVIDIA/trtis-inference-server) using TorchScript, ONNX Runtime or TensorRT as an execution backend. For details check [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:resnext_for_triton_from_pytorch)
+ResNeXt101-32x4d 모델은 추론을 위해 TorchScript, ONNX Runtime 또는 TensorRT를 실행 백엔드로 사용하고 [NVIDIA Triton Inference Server](https://github.com/NVIDIA/trtis-inference-server)에 배포할 수 있습니다. 자세한 내용은 [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnext_for_triton_from_pytorch)에서 확인하세요.
-#### Model architecture
+#### 모델 구조
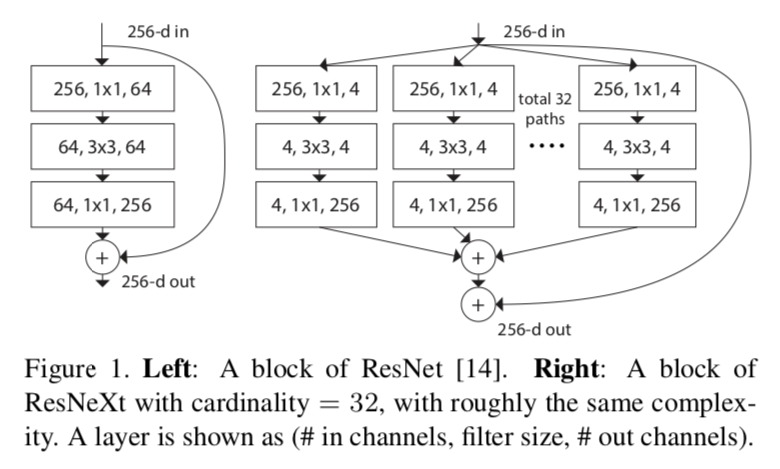
-_Image source: [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/pdf/1611.05431.pdf)_
+_이미지 출처: Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/pdf/1611.05431.pdf)_
-Image shows difference between ResNet bottleneck block and ResNeXt bottleneck block.
+위의 이미지는 ResNet 모델의 병목 블록과 ResNeXt 모델의 병목 블록의 차이를 나타냅니다.
-ResNeXt101-32x4d model's cardinality equals to 32 and bottleneck width equals to 4.
-### Example
+ResNeXt101-32x4d 모델의 카디널리티(Cardinality)는 32이고 병목 블록의 Width는 4입니다.
+### 예시
-In the example below we will use the pretrained ***ResNeXt101-32x4d*** model to perform inference on images and present the result.
+아래 예시에서 사전 학습된 ***ResNeXt101-32x4d***모델을 사용하여 이미지들에 대한 추론을 진행하고 결과를 제시합니다.
-To run the example you need some extra python packages installed. These are needed for preprocessing images and visualization.
+예시를 실행하려면 추가적인 파이썬 패키지들이 설치되어야 합니다. 이 패키지들은 이미지 전처리 및 시각화에 필요합니다.
```python
!pip install validators matplotlib
```
@@ -64,7 +64,7 @@ device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cp
print(f'Using {device} for inference')
```
-Load the model pretrained on IMAGENET dataset.
+IMAGENET 데이터셋으로 사전 학습된 모델을 불러옵니다.
```python
resneXt = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_resneXt')
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_convnets_processing_utils')
@@ -72,7 +72,7 @@ utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_convnets_
resneXt.eval().to(device)
```
-Prepare sample input data.
+샘플 입력 데이터를 준비합니다.
```python
uris = [
'http://images.cocodataset.org/test-stuff2017/000000024309.jpg',
@@ -87,7 +87,7 @@ batch = torch.cat(
).to(device)
```
-Run inference. Use `pick_n_best(predictions=output, n=topN)` helepr function to pick N most probably hypothesis according to the model.
+추론을 시작합니다. 헬퍼 함수 `pick_n_best(predictions=output, n=topN)`를 사용해 모델에 대한 N개의 가장 가능성이 높은 가설을 선택합니다.
```python
with torch.no_grad():
output = torch.nn.functional.softmax(resneXt(batch), dim=1)
@@ -95,7 +95,7 @@ with torch.no_grad():
results = utils.pick_n_best(predictions=output, n=5)
```
-Display the result.
+결과를 출력합니다.
```python
for uri, result in zip(uris, results):
img = Image.open(requests.get(uri, stream=True).raw)
@@ -106,15 +106,16 @@ for uri, result in zip(uris, results):
```
-### Details
-For detailed information on model input and output, training recipies, inference and performance visit:
-[github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/resnext101-32x4d)
-and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:resnext_for_pytorch)
+### 세부사항
+모델 입력 및 출력, 학습 방법, 추론 및 성능에 대한 자세한 내용은 [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/resnext101-32x4d)이나 [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnext_for_pytorch)에서 확인할 수 있습니다.
-### References
+### 참고문헌
- [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/pdf/1611.05431.pdf)
- [model on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/resnext101-32x4d)
- [model on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:resnext_for_pytorch)
- [pretrained model on NGC](https://ngc.nvidia.com/catalog/models/nvidia:resnext101_32x4d_pyt_amp)
+
+
+ [1]: 빠르고 효율적인 처리를 위해 16비트 부동소수점과 32비트 부동소수점을 함께 사용해 학습하는 방식.