-
Notifications
You must be signed in to change notification settings - Fork 1
/
Copy pathsearch.xml
230 lines (110 loc) · 64.8 KB
/
search.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
<?xml version="1.0" encoding="utf-8"?>
<search>
<entry>
<title>新的一年,裁员大年</title>
<link href="/2024/02/02/24Y-Q1-02-02-One-Year/"/>
<url>/2024/02/02/24Y-Q1-02-02-One-Year/</url>
<content type="html"><![CDATA[<p>狗裁员了,xbox裁员了。股票却涨了。</p>]]></content>
<tags>
<tag> 随笔 </tag>
</tags>
</entry>
<entry>
<title>Project #1: Buffer Pool Manager</title>
<link href="/2023/12/21/23Y-Q4-12-21-Project-1-Buffer-pool/"/>
<url>/2023/12/21/23Y-Q4-12-21-Project-1-Buffer-pool/</url>
<content type="html"><![CDATA[<h2 id="类图">类图</h2><pre class="mermaid">---title: Extendible Hashing Table---classDiagram HashTable <|-- ExtendibleHashTable ExtendibleHashTable *-- Bucket class HashTable{ Find(key,value) Remove(key,value) Insert(key,value) } class Bucket { + IsFull() bool + GetDepth() int + IncrementDepth() + GetItems() + Find(key, value) bool + Remove(key) bool + Insert(key,value) bool - size - depth_ - list_ } class ExtendibleHashTable { + GetGlobalDepth() + GetLocalDepth(int dir_index) + GetNumBuckets() + Find(key,value) + Insert(key,value) + Remove(key) - global_depth_ - bucket_size_ - num_buckets - latch_ - dir_ }</pre>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
</tags>
</entry>
<entry>
<title>Lecture #08: Trees Indexes</title>
<link href="/2023/11/24/23Y-Q4-11-24-Lecture-8-Trees-Indexes/"/>
<url>/2023/11/24/23Y-Q4-11-24-Lecture-8-Trees-Indexes/</url>
<content type="html"><![CDATA[<p><a href="https://www.youtube.com/watch?v=9QPr8Ufzt5M">refer to course</a></p><p><a href="https://15445.courses.cs.cmu.edu/fall2022/notes/08-trees.pdf">refer to Note</a></p><p><a href="https://15445.courses.cs.cmu.edu/fall2022/slides/08-trees.pdf">refer to Slide</a></p><p><img src="https://ipfs.io/ipfs/Qmf1iSgv1S3Y1zQdNMLv6vEYTuMkQFkar8qnXKS3KFbMgL" alt="cover"></p><p><div class="table-of-contents"><ul><li><a href="#1.-table-indexes">1. Table Indexes</a></li><li><a href="#2.-b%2B-tree">2. B+ Tree</a></li><li><a href="#3.-b%2B-tree-design-choices">3. B+ Tree Design Choices</a></li><li><a href="#4.-optimizations">4. Optimizations</a></li></ul></div></p><hr><h2 id="1-Table-Indexes">1. Table Indexes</h2><p>table index 是一份表属性的副本,主要用来加速。</p><p>table index 主要权衡两个方面的因素</p><ul class="lvl-0"><li class="lvl-2"><p>维护的代价</p></li><li class="lvl-2"><p>加速的效果</p></li></ul><hr><h2 id="2-B-Tree">2. B+ Tree</h2><p><img src="https://ipfs.io/ipfs/QmSUuU5ejZWCoJS9PasQHauYhRNFwi9Spa8Yot4MmPj5G8" alt="B+Tree_attribute"></p><p>B+ 树是一个自平衡的数据结构,查找插入等操作的事件复杂度通常在 $O(\log{n})$ ,并且这种数据结构针对比较大的数据块做了优化。</p><p>B+ 树是一个 <em><strong>M</strong></em>-叉搜索树有以下的特征:</p><ul class="lvl-0"><li class="lvl-2"><p>完美平衡(所有的叶子节点的层数都相同)</p></li><li class="lvl-2"><p>除了根节点外,左右节点的有 <code>M/2-1 <= #keys <= M-1</code></p></li><li class="lvl-2"><p>所有有 <strong><code>k</code></strong> 个 key 的节点都有 <strong><code>k+1</code></strong> 个非空子节点。</p></li></ul><p><img src="https://ipfs.io/ipfs/QmWky989uLPgXE4FEBGwb54HYFKGiefoSe12YVmxdMgvBQ" alt="B+Tree Example"></p><p>在 B+ 树中,叶子节点是存储最后我们需要的 key 的地方。因此我们如果要依据叶子节点去寻找最终的 val 的话,有以下两种方法。</p><ol><li class="lvl-3"><p>将 val 存在的地方用一个指针记录下地址</p></li><li class="lvl-3"><p>直接存储在叶子节点中。</p></li></ol><h3 id="B-Tree-VS-B-Tree">B-Tree VS. B+Tree</h3><p>B-树和B+树最主要区别是,B-树的 key 也存在于非叶子节点。因此B-树在利用存储空间上无疑相较于B+树更为优秀。</p><p>因此可能存在以下的一些问题。</p><ol><li class="lvl-3"><p>B-树在遍历的时候不得不在各个节点中来回跳跃。而B+树则可以直接扫描。</p></li><li class="lvl-3"><p>B-树,在使用将 val 存储在节点中的方法可能会导致查询过慢。</p></li></ol><h3 id="可视化">可视化</h3><p><a href="https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html">https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html</a></p><h3 id="INSERT">INSERT</h3><p>找到一个叶子节点进行插入。按照大小插入。</p><p>如果该节点有足够的空间容纳,那么则插入停止。如果没有足够的空间那么有以下两步操作。</p><ol><li class="lvl-3"><p>将该节点以中间值对半分为两个节点。</p></li><li class="lvl-3"><p>将该中间值向上推给父节点。若没有父节点,则创造父节点。然后对父节点执行同样的操作。</p></li></ol><h3 id="DELETE">DELETE</h3><p>找到叶子节点进行删除。</p><p>如果该叶子节点删除了该 key 之后至少有一半的容量,那么删除停止。</p><p>如果该叶子节点只有 <code>M/2-1</code> 个 key 了,那么有以下两种策略</p><ul class="lvl-0"><li class="lvl-2"><p>尝试将隔壁节点的值拿过来。</p></li><li class="lvl-2"><p>如果尝试失败那么则尝试将两个节点合并。</p></li></ul><h3 id="Selection-Conditions">Selection Conditions</h3><p>具有与树结构查询的优缺点。</p><h3 id="Duplicate-Keys">Duplicate Keys</h3><p>有两种方式来解决重复的 keys</p><ol><li class="lvl-3"><p>在所有的 key 后面加入 recorid ID 来确保每个 key 都是独一无二的。</p></li><li class="lvl-3"><p>使用一个可以溢出的节点来保存这些重复的信息。<br><img src="https://ipfs.io/ipfs/QmReRx1KBQZUxJdVHgSUSydanhj3gbLc8aeC2cJxknP83U" alt="溢出节点"></p></li></ol><h3 id="Clustered-Indexes">Clustered Indexes</h3><p>表通常依照 primary key 进行索引。</p><p>不过有一些数据库采用聚集索引,会为表加上一个隐藏的 primary key。别的数据库通常无法使用这个索引</p><hr><h2 id="3-B-Tree-Design-Choices">3. B+ Tree Design Choices</h2><h3 id="Node-Size">Node Size</h3><p>通常是存储设备越慢,采用的 node size 越大。</p><ul class="lvl-0"><li class="lvl-2"><p>HDD: ~1MB</p></li><li class="lvl-2"><p>SSD: ~10KB</p></li><li class="lvl-2"><p>In-Memory: ~512B</p></li></ul><h3 id="Merge-Threshold">Merge Threshold</h3><p>一些 DBMS 不会总是合并那些 half full 状态的节点。</p><p>因为,如果延迟合并操作的话,那么可能会减少重新平衡的开销。</p><p>维持一些比较小的节点并且周期性的重构树可能会更好。</p><h3 id="Variable-length-Keys">Variable length Keys</h3><ol><li class="lvl-3"><p>采用指针的方法,即在 B+树中仅仅存储指向值的指针。</p></li><li class="lvl-3"><p>采用可变长的节点。</p></li><li class="lvl-3"><p>将所有的值强制以一个固定大小存储在 B+ 树中。</p></li><li class="lvl-3"><p>采用 map 的形式来进行存储</p></li></ol><h3 id="Intra-Node-Search">Intra-Node Search</h3><ol><li class="lvl-3"><p>Linear</p><ul class="lvl-2"><li class="lvl-5">线性的扫描节点</li><li class="lvl-5">可以采用 SIMD 的技术增加扫描的数据量。</li></ul></li><li class="lvl-3"><p>Binary<br>采用二分法进行查找</p></li><li class="lvl-3"><p>Interpolation<br>通过值,从而知道位置在哪。<br><img src="https://ipfs.io/ipfs/Qmek3W8RpxgSAKQBJTMJ8dL5eKecVgzvfP7v7jUgRiA8Qa" alt="interpolation"></p></li></ol><hr><h2 id="4-Optimizations">4. Optimizations</h2><h3 id="Prefix-Compression">Prefix Compression</h3><p>通过提取出相同前缀的方式来进行压缩。</p><p><img src="https://ipfs.io/ipfs/QmUc1C6GuTTyiMunZxaXQip6iD28pwRfF8y7b9KBLNtG6a" alt="prefix compression"></p><h3 id="Deduplication">Deduplication</h3><p>在 index 不一定都是独一无二的所有的值中,可以通过将这些值合并为一个 key 。</p><p><img src="https://ipfs.io/ipfs/QmQWaQfTJfRDr8iyxYdPfg9dcM1uvNUVmrofmZk4b527BB" alt="deduplication"></p><h3 id="Suffix-Truncation">Suffix Truncation</h3><p>这种方式是通过在节点中选出可以进行区分比较的小的前缀长度,从而达到查找的目的。</p><p><img src="https://ipfs.io/ipfs/QmacamtjrbGWMzVdRwUg4nFWCop8FqCJTZohn5sLkCekxu" alt="truncation 1"></p><p><img src="https://ipfs.io/ipfs/QmUxU9Nb4Qqpn4xnow84NAcmdbxT2cwkjpfpmpyCHSLvAu" alt="truncation 2"></p><h3 id="Pointer-Swizzling">Pointer Swizzling</h3><p>将 B+ 树中的 page id 固定在 buffer pool 中,可以避免重复的读 disk 进而加快速度。然后将 page id 的指针替换为在 memory 中的真实的值,这样就可以绕过 buffer pool 的转换,进行直接访问。</p><h3 id="Bulk-Insert">Bulk Insert</h3><p>重建一个 b+ 树的方法最快的方法是从底层向上建树</p>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
</tags>
</entry>
<entry>
<title> Lecture #07: Hash Tables</title>
<link href="/2023/11/19/23Y-Q4-11-19-Lecture-7-Hash-Table/"/>
<url>/2023/11/19/23Y-Q4-11-19-Lecture-7-Hash-Table/</url>
<content type="html"><![CDATA[<p><a href="https://15445.courses.cs.cmu.edu/fall2022/notes/07-hashtables.pdf">refer to Note</a></p><p><a href="https://15445.courses.cs.cmu.edu/fall2022/slides/07-hashtables.pdf">refer to Slides</a></p><p><a href="https://www.youtube.com/watch?v=9yUlSabzVwQ">refet to courses</a></p><p><img src="https://ipfs.io/ipfs/QmQa6j1YLf7asoGhZVGnHVsEeCq3ieVXENzbHPhRqi9nPi" alt="cover"></p><p><div class="table-of-contents"><ul><li><a href="#1.-data-structure">1. Data Structure</a></li><li><a href="#2.-hash-table">2. Hash Table</a></li><li><a href="#3.-hash-function">3. Hash Function</a></li><li><a href="#4.-static-hashing-schemes">4. Static Hashing Schemes</a></li><li><a href="#5-dynamic-hashing-schemes">5 Dynamic Hashing Schemes</a></li></ul></div></p><hr><h2 id="1-Data-Structure">1. Data Structure</h2><p>DBMS 主要包括以下几种数据</p><ul class="lvl-0"><li class="lvl-2"><p>Internal Meta-Data : 记录有关数据库和系统的信息</p></li><li class="lvl-2"><p>Core Data Storage : 记录 tuple 的信息</p></li><li class="lvl-2"><p>Temporary Data Structures</p></li><li class="lvl-2"><p>Table Indices</p></li></ul><p>主要考虑以下两个问题</p><ol><li class="lvl-3"><p>数据组织</p></li><li class="lvl-3"><p>数据的可靠性</p></li></ol><hr><h2 id="2-Hash-Table">2. Hash Table</h2><p><img src="https://ipfs.io/ipfs/QmPLrgbKARDLJYZ7uHbat3H6eVfds7wpEWSGNJ5u8icjRs" alt="hash_table"></p><p><img src="https://ipfs.io/ipfs/QmTS14yPDLeGj28rz24AUXH68vmeunxLJfamF94xiqqusd" alt="hash_table_target"></p><p><strong>Hash Function</strong></p><ol><li class="lvl-3"><p>将值转化为一个较小的键</p></li><li class="lvl-3"><p>在 <em>速度</em> 和 <em>碰撞率</em> 之间进行权衡。</p></li></ol><p><strong>Hashing Scheme</strong></p><ol><li class="lvl-3"><p>该如何处置碰撞的情形</p></li><li class="lvl-3"><p>需要在 <em>哈希表大小</em> 与 <em>额外信息维护之间</em> 权衡</p></li></ol><hr><h2 id="3-Hash-Function">3. Hash Function</h2><p>不管输入的 key 是什么,输出一个 <strong>特别的</strong> <em>数字</em> 的函数。</p><p><img src="https://ipfs.io/ipfs/QmcgN4smq3GKho1E6jm2Z2yWvcwBR5GTuXV1Q6bBohCNJt" alt="Hash_Function"></p><p><img src="https://ipfs.io/ipfs/Qmbko8F5hZKV5NxAZJMbfmcc3jv26iBH9uvYVoxeFRTmeS" alt="Hash_Function bench_mark"></p><hr><h2 id="4-Static-Hashing-Schemes">4. Static Hashing Schemes</h2><h3 id="4-1-Linear-Probe-Hashing">4.1 Linear Probe Hashing</h3><p>线性探针</p><p>我们解决哈希冲突的方法是,如果我们的哈希函数返回的位置已经被占用了,那么则一直向下取一个位置,直到找到表中空的值。</p><p>在删除操作中,可能会出现一种情形,有的值并不是 hash function 产生的直接值,而是通过一直取下一个位置得到的值。</p><p>在这种情形下,我们所采取的方法有。</p><ol><li class="lvl-3"><p>将受到偏移影响的值往回调整。通过重新哈希的方式进行调整。效率比较低下。</p></li><li class="lvl-3"><p>将那些删除了的值标记为已删除。这些值可以在新的值需要使用的时候重新利用。不过需要周期性的垃圾回收。</p></li></ol><p><strong>存储相同的值</strong></p><p><img src="https://ipfs.io/ipfs/QmfB5t64wEpnMpyUKB8RKSeMjmmnkxs4uhEyLGrqC9ZcKA" alt="NON-UNIQUE-KEY"></p><p>存储相同的 key 但有不同的 value 的值的时候,我们可以有两种办法解决。</p><ol><li class="lvl-3"><p>对于每个 key 他们的 value 开辟出来一个单独的空间</p></li><li class="lvl-3"><p>所有的 key 都用 哈希函数 散列在一个存储空间中。</p></li></ol><h3 id="4-2-Robin-Hood-Hashing">4.2 Robin Hood Hashing</h3><p>这是线性探针算法的一个升级版,旨在解决分布不均的问题。在上面的算法中,可能存在一些 key,经过哈希计算后可能会聚集在一块导致哈希算法劣化。 Robin Hood hashing 解决冲突的方式会将部分 <em>rich</em> 的 key 分配给 <em>poor</em> key.</p><p>这种避免哈希碰撞的方法是,给每个值都记录一个偏移值,表中的每个值在向下搜索的时候,需要和表中的值进行对比。如果当前偏移值比表中值的偏移值大,那么则将当前值和表中值进行替换。直到找到空位结束。</p><figure class="highlight cpp"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br><span class="line">4</span><br><span class="line">5</span><br><span class="line">6</span><br><span class="line">7</span><br><span class="line">8</span><br><span class="line">9</span><br><span class="line">10</span><br><span class="line">11</span><br><span class="line">12</span><br><span class="line">13</span><br><span class="line">14</span><br><span class="line">15</span><br><span class="line">16</span><br><span class="line">17</span><br></pre></td><td class="code"><pre><span class="line"><span class="function"><span class="type">void</span> <span class="title">Robin_hood_Hashing</span><span class="params">(<span class="type">int</span> key)</span> </span>{</span><br><span class="line"> <span class="type">int</span> val = <span class="built_in">hash</span>(key);</span><br><span class="line"> <span class="type">int</span> offset = <span class="number">0</span>;</span><br><span class="line"> <span class="keyword">for</span> (<span class="type">int</span> i = val ; ; i ++ , offset ++ ) {</span><br><span class="line"> <span class="keyword">if</span>(hash_table-><span class="built_in">is_empty</span>(i)){ </span><br><span class="line"> hash_table-><span class="built_in">insert</span>(i , val , offset);</span><br><span class="line"> <span class="keyword">break</span>;</span><br><span class="line"> }</span><br><span class="line"></span><br><span class="line"> <span class="keyword">if</span>(hash_table-><span class="built_in">get_offset</span>(i) < offset) {</span><br><span class="line"> <span class="keyword">auto</span> [n_val , n_offset] = hash_table-><span class="built_in">get_data</span>(i);</span><br><span class="line"> hash_table-><span class="built_in">insert</span>(i , val , offset);</span><br><span class="line"> val = n_val , offset = n_offset;</span><br><span class="line"> }</span><br><span class="line"> <span class="keyword">if</span>(i == MAXSIZE) i = <span class="number">0</span>;</span><br><span class="line"> }</span><br><span class="line">}</span><br></pre></td></tr></table></figure><h3 id="4-3-Cuckoo-Hashing">4.3 Cuckoo Hashing</h3><p>这种解决碰撞的方法是使用两种哈希函数和两张哈希表完成的。</p><p>对于输入的 key 他会计算出 <code>val[0]</code> 和 <code>val[1]</code> 在不确定的情况下,会随机采用其中一个作为最终的结果,当其中一个触发冲突的时候,则采用一个哈希函数与哈希表。如果两个都冲突的话,那么则重新计算冲突的哈希,直到没有冲突。</p><p>采用这正方法,在查询的时候复杂度永远都是 $O(1)$ ,但插入的代价比加大。</p><p><a href="https://github.com/efficient/libcuckoo/tree/master">open-source CMU 实现</a></p><hr><h2 id="5-Dynamic-Hashing-Schemes">5 Dynamic Hashing Schemes</h2><p><a href="https://ipfs.io/ipfs/QmVuuRrFwfEo7bRCHfgd3DtECUyXR3RMuXGFFFYtB3Vwdd">observation</a></p><p>以上的的哈希表都基于固定大小的元素,所以需要一些动态的哈希表。</p><h3 id="5-1-Chained-Hashing">5.1 Chained Hashing</h3><p>对每个哈希值都维护一 个链表。将所有哈希值相同的键都放在一个 bucket 中。bucket 是通过链表的形式连接在一起的。</p><p><img src="https://ipfs.io/ipfs/QmVamwFnGeAMucAgSzyYbjn6AifDRv5utYpsm7A2ZhgGRN" alt="Chained Hashing"></p><h3 id="5-2-Extendible-Hashing">5.2 Extendible Hashing</h3><p>在 bucket 快 满的时候,通过二进制前缀开辟新的 bucket。</p><p><img src="https://ipfs.io/ipfs/QmNP81bLcQQmhPKKGK5dLqUsffYXTJjs7RjYmtnL9MYE8b" alt="splits"></p><p><a href="https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/">详解</a></p><h3 id="5-3-Linear-Hashing">5.3 Linear Hashing</h3><p>运行时动态扩容的一种哈希。</p><p><a href="https://ruby-china.org/topics/39466">详解</a></p>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
</tags>
</entry>
<entry>
<title>Lecture #06: Memory Management</title>
<link href="/2023/11/15/23Y-Q4-10-23-Lecture-6-Memory-Management/"/>
<url>/2023/11/15/23Y-Q4-10-23-Lecture-6-Memory-Management/</url>
<content type="html"><![CDATA[<p><a href="https://15445.courses.cs.cmu.edu/fall2022/notes/06-bufferpool.pdf">refer to Note</a></p><p><a href="https://15445.courses.cs.cmu.edu/fall2022/slides/06-bufferpool.pdf">refer to Slide</a></p><h2 id="1-Introduction">1. Introduction</h2><p>如何存储:</p><ul class="lvl-0"><li class="lvl-2"><p>我们的 pages 要存储在 disk 上的什么样的地方</p></li></ul><p>快速操作:</p><ul class="lvl-0"><li class="lvl-2"><p>对于 DBMS 来说,在进行操作数据之前需要将所有的的数据从 Disk 先转移到 Memory 中才可以进行操作。<br><img src="https://ipfs.io/ipfs/QmQj1jJ4oBaTXGSq2FYcHZKNz2y2aN3TmjcJqDECtCAxkq" alt="image"></p></li></ul><p><img src="https://ipfs.io/ipfs/QmSFSzXFhUmf3Md5ruAg9PNNQwDQo82TH3a2sbDuLduuPS" alt="image"></p><hr><h2 id="2-Locks-vs-Latches">2. Locks vs. Latches</h2><p><img src="https://ipfs.io/ipfs/Qmd4Ru91wEckAkCukc6gooxtsF5uid8wTkFNTRDsUz1MdD" alt="image"></p><hr><h2 id="3-Buffer-Pool">3. Buffer Pool</h2><p>Memory 中存储的是一个个固定大小的 pages。</p><p>其中的每一个记录称之为 <em>frame</em></p><p>当我们需要一个 page 的时候,我们会立刻复制一个 frame。</p><p>Dirty pages 不会立刻写回。(Write-Back Cache)</p><p><img src="https://ipfs.io/ipfs/QmZcfwGcz4kqLbfRsiMFjp7d2c9UVK7RvrxfyoEHuNAezh" alt="image"></p><h3 id="Buffer-Pool-Meta-data">Buffer Pool Meta-data</h3><p><img src="https://ipfs.io/ipfs/QmeudvGi34M1W8gBkn6meRA8vFCWSnYqpcfWgrqAu4GXzT" alt="image"></p><p><em>page table</em> 是用来跟踪哪些 pages 在 memory 中。</p><p>通常还有一些信息也会被保存在 page table 中</p><ul class="lvl-0"><li class="lvl-2"><p>Dirty Flag</p></li><li class="lvl-2"><p>Pin/Reference Counter</p></li></ul><p>Dirty Flag 用来表示这个页是否被写过。</p><p>Pin/Reference Counter 是用来固定 frame 来确保该页面不会被放回到 disk 中。</p><blockquote><p><strong>page directory</strong> 是一个将 page id 映射到 page location 的一个映射。所有信息必须存放在 disk 上,以便 DBMS 可以找到。</p><p><strong>page table</strong> 是一个将 page id 映射到 buffer pool 中的帧上的映射。这是一个 in-memory 的数据结构不需要存储在 disk 上。</p></blockquote><h3 id="Memory-Allocation-Policies">Memory Allocation Policies</h3><p><img src="https://ipfs.io/ipfs/QmPwVEC3FkiDvkkZtBLC6j1Bj2e7FaBsVCKuT2vGvfdW9P" alt="Allocation Policies"></p><p>全局策略</p><ul class="lvl-0"><li class="lvl-2"><p>为所有的操作负责,确保全局最优</p></li></ul><p>局部策略</p><ul class="lvl-0"><li class="lvl-2"><p>仅仅考虑当前的查询的效率而不考虑其对全局的影响</p></li></ul><hr><h2 id="4-Buffer-Pool-Optimizations">4. Buffer Pool Optimizations</h2><h3 id="Multiple-Buffer-Pools">Multiple Buffer Pools</h3><p>通常 DBMS 不总是仅仅有一个 buffer pool</p><p><img src="https://ipfs.io/ipfs/QmYcUwX9zREMD3WL3Dr7yMimPiYHmgiZddgeUdxazCU1ti" alt=""></p><p>DBMS 维护多个 buffer pool 是为了多种目的 (i.e per-database buffer pool, per-page type buffer pool)。然后每个缓冲池可以针对每个存储在其中的数量进行定制本地策略。</p><p>主要有两种方式访问不同的buffer Pool</p><ol><li class="lvl-3"><p>Object id<br>通过 Object Id 来识别不同的 buffer pool<br><img src="https://ipfs.io/ipfs/QmeUPyJ2nh5qVv9bQVGhtHS7rg9HCcdtsYkPdGV3C3zHLG" alt=""></p></li><li class="lvl-3"><p>Hashing<br>通过 hash page id 来识别不同的 buffer pool<br><img src="https://ipfs.io/ipfs/QmS7XuiwDB71XG25B1RLeVHQ4YstpxfYb6ECGeurKZNAuN" alt=""></p></li></ol><h3 id="Pre-fetching">Pre-fetching</h3><p>DBMS 可以基于查询提前交换页面,特别适用于</p><ul class="lvl-0"><li class="lvl-2"><p>顺序查询</p></li><li class="lvl-2"><p>索引查询</p></li></ul><blockquote><p><img src="https://ipfs.io/ipfs/QmWVEZBVH4uzkyPjPPAVitn9hQyJmuouHDUK382UFcHfKw" alt=""><br>查询到 page1 的时候 buffer pool 就将接下来需要解析的加载到 buffer pool中</p></blockquote><blockquote><p><img src="https://ipfs.io/ipfs/QmRjU4Vi8MT14NE2PbEKx4YvE9kiu1DaqefVX1ZaJMhpaA" alt=""><br>同样是可以提前加载</p></blockquote><h3 id="Scan-Sharing-Synchornized-Scans">Scan Sharing(Synchornized Scans)</h3><p>通常发生在多次查询同一个东西的时候。</p><p>如果第一个查询一张表,不久之后第二个也在查询同一张表,那么最终的情况会第二个查询会和第一个查询进行同步查询。在第一个查询结束后,第二个查询会补查漏掉的数据。</p><blockquote><p>在 Q1 查询到了一半的时候 Q2 也执行了同样的查询</p><p><img src="https://ipfs.io/ipfs/Qmbjt1dV3DPC9y5ktoyLm1Yq46fx9tBieGQFLtfjQn8iSY" alt="scan sharing_1"></p><p>由于 Q1 已经查询了一段距离,在 Buffer pool 中重新载入 page0 是非常浪费的。那么我们可以和 Q1 一起查询。</p><p><img src="https://ipfs.io/ipfs/QmPdiuvUbFdxx6gFpqN9EL5Pscs7CAp67Ne3RkTuRs99fK" alt="scan sharing_2"></p><p>在一起查询结束之后我们再去查询 Q2 剩下来的 page0-page2</p></blockquote><blockquote><p>如果启用这种策略进行查询到的话,那么最终的结果可能是不同的。因为我们的查询是无序的。对于一个顺序十分重要且确定的结构中,一般不会采用这种方式进行查询。</p><p><img src="https://ipfs.io/ipfs/QmWU6wBvP4bg6EnPPFBPPfWEDmeAzWMcimHk777gmZvdKq" alt="scan sharing_3" title="不同时间的查询的结果是不一样的"></p></blockquote><h3 id="Buffer-Pool-Bypass">Buffer Pool Bypass</h3><p>对于一些操作可能不会存储在 buffer pool 中,这样可以减少开销。</p><hr><h2 id="5-OS-Page-Cache">5. OS Page Cache</h2><p><img src="https://ipfs.io/ipfs/QmdakwRMowx1BTC2BSJnZSGdDtDxJQBBVfnEAUQ2A59Mxk" alt="OS Page Cache"></p><p>在 DBMS 中通常不会直接采用 OS 的的文件管理。</p><ul class="lvl-0"><li class="lvl-2"><p>减少 pages 的多次拷贝</p></li><li class="lvl-2"><p>减少 page 的退出策略</p></li><li class="lvl-2"><p>加强对 I/O 的控制</p></li></ul><hr><h2 id="6-Buffer-Replacement-Policies">6. Buffer Replacement Policies</h2><p><img src="https://ipfs.io/ipfs/QmTCesEwNanWC9JBFcVcRvTZgKMNDmiPYZ8RWrudxHc9o1" alt="Buffer Replacement Policies"></p><p>当 DBMS 需要将 buffer pool 里的 frame 给清除了,需要决定就近是哪个页退出。</p><p>所以 Buffer Replacement Policies 就是关于清除 frame 的算法。</p><p>它的主要目标是</p><ul class="lvl-0"><li class="lvl-2"><p>正确</p></li><li class="lvl-2"><p>一致</p></li><li class="lvl-2"><p>速度</p></li><li class="lvl-2"><p>元数据的开销</p></li></ul><h3 id="Least-Recently-Used-LRU">Least Recently Used (LRU)</h3><p><img src="https://ipfs.io/ipfs/QmdFFaYegTC4dTbMhuhRtYGKJSi4NCS4vkjNBXsunXfCVv" alt="LRU"></p><p>维护一个时间表来记录哪个 page 是最后被访问的,在需要置换 frame 的时候,将最后被访问的页面给置换出去。</p><h3 id="CLOCK">CLOCK</h3><p><img src="https://ipfs.io/ipfs/QmQLMPUdZkrwNJ76BofzxnrZo6KXEaJ547sZw6YM73UU1j" alt="CLOCK"></p><p>clock 算法是 LRU 的一种近似的产物。它的好处是不再需要一张时间表来记录各个 pages 了,而采用 bit 的形式记录。</p><p>Clock 是,将所有的页面以某种顺序进行记录,并且该顺序是首位相连的。初始时,将所有的页都标记为 0 ,在某个页访问的时候,将该页的 bit 标记为一。在寻找需要置换的页面时,也将顺序的找下去,如遇到 page 的 bit 为 1 那么就将该 bit 置为 0 , 如果该页的的 bit 为 0 ,那么则将该页置换下去。</p><figure class="highlight cpp"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br><span class="line">4</span><br><span class="line">5</span><br><span class="line">6</span><br><span class="line">7</span><br><span class="line">8</span><br><span class="line">9</span><br><span class="line">10</span><br><span class="line">11</span><br><span class="line">12</span><br><span class="line">13</span><br><span class="line">14</span><br><span class="line">15</span><br></pre></td><td class="code"><pre><span class="line"><span class="function">page_id <span class="title">clock_page</span><span class="params">()</span> </span>{</span><br><span class="line"></span><br><span class="line"><span class="type">static</span> page_id ref = <span class="number">0</span>;</span><br><span class="line"></span><br><span class="line"><span class="keyword">for</span> ( ; ; ref ++ ) {</span><br><span class="line"><span class="keyword">if</span>(ref >= BUFFER_POOL_SIZE) ref = <span class="number">0</span>;</span><br><span class="line"></span><br><span class="line"><span class="keyword">if</span> (bit[ref]) </span><br><span class="line">bit[ref] = <span class="number">0</span>;</span><br><span class="line"><span class="keyword">else</span> </span><br><span class="line"><span class="keyword">return</span> ref;</span><br><span class="line"></span><br><span class="line">}</span><br><span class="line"><span class="keyword">return</span> <span class="number">-1</span>;</span><br><span class="line">}</span><br></pre></td></tr></table></figure><h3 id="Alternatives">Alternatives</h3><p>不管是 <a href="#least-recently-used-lru">LRU</a> 还是 <a href="#clock">CLOCK</a> 都对 <strong>sequential flooding</strong> 操作影响较深。</p><ul class="lvl-0"><li class="lvl-2"><p>一种顺序查询所有页的操作</p></li><li class="lvl-2"><p>这种操作仅仅执行一次,并且不会再次进行访问</p></li></ul><p>这就会导致一种结果,Buffer pool 里面存储的数据不会是接下来需要用到的数据。</p><p>为了减少这种情况的发生我们通常会采用 LRU-K 来进行置换。</p><p><img src="https://ipfs.io/ipfs/Qmd5wfNRQZv3fqCxo9E6avNnus3Ds9r1fVMZKxkDEej9LM" alt="LRU-K"></p><p>追踪每个页面的最近 K 次访问。DBMS 根据这个记录来确定访问优先级。</p><h3 id="Dirty-Page">Dirty Page</h3><p><img src="https://ipfs.io/ipfs/QmSUPwbF9xn8Jb6aqFZcMS4N7Dkv278AJkAxPa9UB9xUEv?filename=image.png" alt="Dirty Page"></p><p>对于非 Dirty Page 而言,只需要将 page 丢掉即可,而 Dirty Page 则需要写回到 disk 上以保持持久性。</p><p>为了避免这一现象,有一种策略是通过周期性扫描 buffer pool 中的 dirty pages 并将其写回 disk 中,这样就可以较为安全的移除 dirty pin flag 。</p><hr><h2 id="7-Other-Memory-Pools">7. Other Memory Pools</h2><p><img src="https://ipfs.io/ipfs/Qmb1KVRbZLhGufcjPszvZzBx7VL9zfb3ZkVrqwMkCVgC2X?filename=image.png" alt="Other Buffer Pools"></p><hr><h2 id="Tasks">Tasks</h2><p><a href="https://15445.courses.cs.cmu.edu/fall2022/project1/">https://15445.courses.cs.cmu.edu/fall2022/project1/</a></p>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
</tags>
</entry>
<entry>
<title>《上个世纪的学校》 书摘</title>
<link href="/2023/10/23/23Y-Q4-10-23-%E4%B8%8A%E4%B8%AA%E4%B8%96%E7%BA%AA%E7%9A%84%E5%AD%A6%E6%A0%A1/"/>
<url>/2023/10/23/23Y-Q4-10-23-%E4%B8%8A%E4%B8%AA%E4%B8%96%E7%BA%AA%E7%9A%84%E5%AD%A6%E6%A0%A1/</url>
<content type="html"><![CDATA[<p>书源 《昨日的世界》 茨威格 , 数百年前的「现代」「教育」,「军事化」的教育</p><h2 id="Pt-1-填鸭式、流水线化的教育">Pt.1 填鸭式、流水线化的教育</h2><blockquote><p>然而,在那开明的自由主义时代,只有所谓高等学府的教育,即进入大学,才完全有真正的价值。因此,每个上流家庭都追慕在自己的儿子中至少有一个在名字前冠有博士学衔。但这条通往大学的道路却是相当漫长和一点都不令人感到愉快。因为在此之前必须坐在硬板凳上念完五年国民小学和八年中学,每天要坐五至六小时,课余时间则完全被作业占满,而且还要接受除了学校课程以外的常规教育,即,除了学习古典的希腊语和拉丁语以外还要学习活的语言—法语、英语、意大利语,也就是说,除了几何、物理和学校规定的其他课程以外还要学习五种语言。学习负担重得不能再重,几乎没有进行体育锻炼和散步的时间,更谈不上消遣和娱乐。</p></blockquote><p>大学?或者说,名校真的有所谓的用处吗?超极限的压榨式学习,这是我的写照。</p><hr><blockquote><p>学校对我们来说,意味着强迫、荒漠、无聊,是一处不得不在那里死记硬背那些仔细划分好了的毫无知识价值的科学的场所。我们从那些经院式或者装成经院式的内容中感觉到,它们和现实,和我们个人兴趣毫无关系。**那是一种无精打采、百无聊赖的学习,不是为生活而学习,而是为学习而学习,**是旧教育强加于我们身上的学习。而唯一真正令人欢欣鼓舞的幸福时刻,就是我永远离开学校的那一天—我得为它感谢学校。</p><p>这倒并不是我们奥地利的学校本身不好。恰恰相反,所谓教学计划是根据近一百年的经验认真制订的,倘若教学方法生动活泼,也确实能够奠定一个富有成效的相当广博的学习基础。但是正因为刻板的计划性和干巴巴的教条,使得我们的课死气沉沉和枯燥透顶。上课成了一种冷冰冰的学习器械,从来不依靠个人进行调节,而仅仅象一具标有良好、及格、不及格刻度的自动装置,以此来表示学生适应教学计划的要求达到了什么程度。</p><p>然而,**恰恰是这种索然无味、缺乏个性、对人漠不关心、兵营似的生活,无意之中使我们不胜痛苦。**我们必须学习规定的课程,而且凡是学过的东西都要考试。在八年之中没有一个教师问过我们一次,我们自己希望学些什么,更没有鼓励的意思,而这正是每个年轻人所悄悄盼望的。</p></blockquote><hr><blockquote><p>不过,那种令人沮丧的学校生活也不能怪我们的老师。对于他们,既不能说好,也不能说坏。 <strong>他们既不是暴君,也不是乐于助人的伙伴,而是一些可怜虫。他们是条条框框的奴隶,束缚于官署规定的教学计划,他们也象我们一样必须完成自己的课程。</strong> 我们清楚地感觉到:当中午学校的钟声一响,他们也像我们一样获得了自由,欢愉之情和我们没有什么两样。他们不爱我们,也不恨我们,之所以如此,是因为他们根本不了解我们。过了好几年,他们也还只知道我们中间极少数几个人的名字。而且,就当时的教学方法而言,他们除了批改出学生在上次作业中有多少错误以外,再也没有什么要关心的了。他们高高地坐在讲坛上,我们坐在台底下;他们提问,我们回答,除此以外,我们之前没有任何联系。因为在师生之间,在讲坛和课椅之间,在可以看得见的高高在上和可以看得见的眼皮底下之间,隔着那堵看不见的权威之墙,它阻碍着任何的接触。一个教员理应把学生当作一个希望对他自己的特殊个性有深入了解的人来看待,或者甚至象今天司空见惯的那样,有责任为学生写出报告,即把他观察到的学生的情况写出来,但在当时,这些是大大超出他的权限和能力的。更何况,私人谈话还会降低他的权威性,因为这样谈话很容易使我们这些学生和身为前辈的他平起平坐。我觉得,最能说明我们和教员之间在思想感情上毫不沾边的一点是,我早已把他们所有人的名字和面貌忘得一干二净。在我的记忆中,只清清楚楚保留着那座讲坛和那本我们始终想偷看一下的班级记事簿的形象,因为里面记着我们的分数。我今天还记得那本教员们主要用来评分的小小的红笔记本,记得那支用来记分的黑短铅笔,记得自己那些被教员用红墨水批改过的练习簿,但是我怎么也记不得他们之中任何一个人的脸—也许因为我们站在他们面前的时候总是低着头或者从不认真地看过他们一眼。</p><p>对学校的这种反感并不是一种个人的成见;我记不得在我的同学中有谁对这种一成不变的生活不反感的,它压抑和磨平了我们最好的志趣。不过,只是到了很久以后我才意识到,对我们它少年的教育采用这样一种冷漠无情的方法,并不是出于国家主管部门的疏忽,而是包藏着一种经过深思熟虑、秘而不宣的既定意图。我们面临的世界,或者说,主宰我们命运的世界,它把自己的一切想法都集中在追求一个太平盛肚的偶像上,它对青年一代是不喜欢的,说得更透彻一点,它对青年一代始终抱着怀疑。**对自己有条不紊的进步和秩序感到沾沾自喜的市民社会宣称,在一切生活领域中从容不迫和中庸节制是人的唯一能见成效的品德,所以,任何要把我们引导向前的急躁都应该避免。**奥地利是由一位自发苍苍的皇帝统治着和由年迈的大臣们管理着的一个古老的国家,是一个没有雄心壮志的国家,它只希望能防止各种激烈的变革,从而保住自己在欧洲范围内的安然无恙的地位。而年轻人的天性,就是要不断进行迅速、激烈的变革。因此他们也就成了一种令人忧虑的因素,这种因素必须尽可能长时间地被排斥在外或者压制下去。所以国家根本没有打算要使我们学生时代的生活过得愉快。我们应该通过耐心的等待才能得到任何形式的升迁。由于这种不断的往后推移,因此年龄也就像今天一样完全要用另一种标准来衡量。那时候,一个十八岁的中学生就像一个孩子似地被对待,如果当场抓住他在吸烟,就要受到惩罚,如果他因要解手而想要离开课椅,就得毕恭毕敬地先举手。 <strong>不过话又要说回来,在那个时候,纵然是一个三十岁的男子汉,也还会被看作是一只羽毛未丰的小鸟呢,而且即便到了四十岁,也还被认为不足以胜任一个负责的职位。</strong></p></blockquote><p>螺丝钉,似乎没有人能逃出。</p><hr><h2 id="Pt-2-权威「教育」">Pt.2 权威「教育」</h2><blockquote><p>唯有了解这样一种特殊的观念,才会明白,国家就是要充分利用学校作为维护自己权威的工具。<strong>学校首先就得教育我们把现存的一切尊为完美无缺的,教师的看法是万无一失的,父亲的话是不可反驳的,国家的一切设施都是绝对有效和与世永存的。</strong> ***这种教育的第二个基本原则,就是不应该让青年人太舒服。这一原则也在家庭中贯彻。***在给予青年人某些权利之前,他们首先应该懂得自己要尽义务,而且主要是尽完全服从的义务。从一开始就应该让我们牢牢记住:我们在一生中尚未有任何的贡献,没有丝毫的经验,唯有对给予我们的一切永铭感激之情,而没有资格提什么问题或者什么要求。在我那个时代,从孩提时候起就对人采用吓唬的蠢办法。女仆和愚蠢的母亲们在孩子三四岁的时候就吓唬他们,说什么如果他们再闹的话,就去叫警察。</p></blockquote><hr><h2 id="Pt3-脆弱">Pt3. 脆弱</h2><blockquote><p>在此之前,被我们错误地称为普遍的选举权,实际上只是赋予交纳了一定税款的有产阶级。然而,从这个阶级中挑选出来的律师们以及农场主们却真诚地相信,自己在国会里是民众的代表和发言人。他们为自己是受过教育的人,甚至大部分是受过高等学府教育的人而无比自傲。</p><p>他们讲究尊严、体面、高雅的谈吐,因此国会开会时就像一家高级俱乐部的晚间讨论会。这些资产阶级民主主义者出于自己对自由主义的信仰,真诚地相信通过宽容和理性必然会使世界进步,他们主张用小小的妥协和逐渐的改善,来促进全体子民们的福利,并认为这是最好的办法。 <strong>但他们完全忘记了自己仅仅代表大城市里五万或十万生活富裕的人,而并不代表全州儿十万和几百万人。</strong> 在此期间,机器生产也起到了作用,它把以往分散的工人集中到工业中来。在一位俊杰—维克托阿德勒博士的领导下,奥地利成立了一个社会主义政党,旨在实现无产阶级的各种要求;无产阶级要求有真正普遍和人人平等的选举权。可是,这种选举权刚一实行,或者更确切一点说,刚一被迫实行,人们就立刻发现,备受推崇的自由主义是何等的脆弱。随着自由主义的消失,公共政治生活中的和睦相处也就不复存在。现在处处是激烈的利害冲突。斗争开始了。</p></blockquote><blockquote><p>大商店和大规模生产,使小资产阶级和手工业企业的师傅们面临着破产。卡尔卢埃格尔博士—一位受人欢迎、机灵能干的领袖人物,利用这种不满和忧虑,提出了必须帮助小人物的口号,他把全体小市民和恼怒的小资产阶级吸引到自己身边; <strong>因为他们对自己将从有产者降为无产者的恐惧远远超过对有钱人物的嫉妒。</strong> 正是这个优心仲仲的社会阶层,后来成为希特勒周围的第一批广大群众。从某种意义上讲,卡尔卢埃格尔是希特勒的榜样,是他教会了希特勒随心所欲地利用反犹太主义的口号。这一口号为不满的小资产阶级树立了一个可见的敌人,同时却又悄悄转移了他们对大地主和封建华贵的仇恨。</p></blockquote><blockquote><p>然而我们这些年轻人却完全沉浸在自己的文学的志趣之中,对祖国的这些危险变化很少注意,在我们眼里只有书籍和绘画。我们对政治和社会问题丝毫不感兴趣。那种刺耳的不断争吵对我们的生活有什么意义呢当全城的人为了选举而兴奋激动时,我们却向图书馆走去,当群众举行暴动时,我们正在写作和讨论诗文。我们没有看到墙上着火的信号,而是象古时的伯沙撒国王一样,无忧无虑地品尝着各种珍贵的艺术佳肴,没有警惕地朝前看一眼,一直到几十年以后,当屋顶和墙垣倒塌到我们头顶上时,我们才认识到,墙基早已挖空,认识到:随着新世纪的开始,个人自由也已在欧洲开始没落。</p></blockquote><p>当年轻人无法再获得「被承诺」所获得的东西,当几代人积累的财富被窃取时,我们究竟该如何走下去。</p>]]></content>
<tags>
<tag> 散文 </tag>
</tags>
</entry>
<entry>
<title>Lecture #05: Storage Models & Compression</title>
<link href="/2023/10/19/23Y-Q4-10-19-Lecture-5-Storage-Models-Compression/"/>
<url>/2023/10/19/23Y-Q4-10-19-Lecture-5-Storage-Models-Compression/</url>
<content type="html"><![CDATA[<p><a href="https://15445.courses.cs.cmu.edu/fall2022/slides/05-storage3.pdf">refer to Slide</a></p><p><a href="https://15445.courses.cs.cmu.edu/fall2022/notes/05-storage3.pdf">refer to Note</a></p><pre class="mermaid">mindmaproot((Lecture 5)) Workloads OLTP OLAP HTAP Storage Models N-Ary DSM Columnar Compression Run-Length Encoding Bit-Packing Encoding Delta Encoding Incremental Encoding Dictionary Encoding</pre><h2 id="Database-workloads">Database workloads</h2><h3 id="OLTP">OLTP</h3><p>OLTP: On-Line Transaction Processing</p><p>每次快速的对一个小范围的数据进行读取、更新的操作。</p><p><img src="https://ipfs.io/ipfs/QmWjGBjz9tPJNKJsWvAJHn6S1Y1Zg4bzwUFh4rGbkmr7Nx" alt="OLTP"></p><h3 id="OLAP">OLAP</h3><p>OLAP: On-Line Analytical Processing</p><p>OLAP 是用来支持复杂的分析操作,提供决策支持等</p><p><img src="https://ipfs.io/ipfs/Qmcr9z7hT4zstPoYQrLUmicaivD5rt8dRqxARZu7U6DVHF" alt="image"></p><h3 id="HTAP">HTAP</h3><p>Hybrid Transaction + Analytical Processing</p><p>一种新的 workload ,将 OLTP 和 OOLAP 结合起来。</p><p><img src="https://ipfs.io/ipfs/QmSaQ4beZHaMzsfsMTe1tFL1ybqRSj7My4684j1kn1coer" alt="OLTP OLAP HTAP"></p><hr><h2 id="Stroage-Models">Stroage Models</h2><h3 id="N-Ary-Storage-Model-NSM">N-Ary Storage Model (NSM)</h3><p>在 <code>n-ary</code> 的存储模式中,DBMS 连续的存储所有的、包含所有 <code>arributes</code> 的 <code>tuple</code> 在一个单独的页面中。</p><p><img src="https://ipfs.io/ipfs/QmVYrVctydHbc4A1c5WwD3jczyYA94uhNExZgn6mYfAje8" alt="n-ary-model"></p><p>这对于 OLTP 来说是十分理想的。</p><p>Advantages:</p><ul class="lvl-0"><li class="lvl-2"><p>插入,更新,删除非常快</p></li><li class="lvl-2"><p>对于需要整个 <code>tuple</code> 的查询非常友好</p></li></ul><p>Disadvantages:</p><ul class="lvl-0"><li class="lvl-2"><p>对于需要扫描整个表或者只需要一个属性的查询非常不好</p></li></ul><blockquote></blockquote><p><img src="https://ipfs.io/ipfs/QmR8EJYooMcLuaGZLMzLeDK92r9svS3mk8ay2VcfTDgJY5" alt="image"></p><h3 id="Decompositrion-Storage-Model-DSM">Decompositrion Storage Model (DSM)</h3><p>将所有 <code>tuples</code> 中的每个 <code>attribute</code> 单独分出来进行存储</p><blockquote><p>也可以成为 “列存储 (column store)”</p></blockquote><p>对于只读的 OLAP 操作非常友好,尤其是那些只需要扫描部分 <code>attributes</code> 的操作来说。</p><p><img src="https://ipfs.io/ipfs/QmeW3ayCpBjFVx8rJvC4Ld5MQPuKPHT1kDciKLM1fPBeFc" alt="image"></p><p>Advantages:</p><ul class="lvl-0"><li class="lvl-2"><p>减少 I/O 的浪费</p></li><li class="lvl-2"><p>更好的进行查询以及将数据进行压缩</p></li></ul><p>Disadvantages:</p><ul class="lvl-0"><li class="lvl-2"><p>对于单点修改查询更新这些操作比较慢。</p></li></ul><p>为了实现这种操作通常有两种操作方法。</p><ol><li class="lvl-3"><p>为每个属性设置固定的字长,这样我们只需要得到 <code>offset</code> 就可以准确的查找到我们所需要的数据</p></li><li class="lvl-3"><p>一个更为罕见的操作是,使用一个形如 <code>(id : pos)</code> 的 tuple 来存储值,表示第 <code>id</code> 的值存储在 <code>pos</code> 位置上。</p></li></ol><p><img src="https://ipfs.io/ipfs/QmRyFvUztSXxLZKPfiEUnYBXsgh9ZfSyWfM8UcbjuM8cW4" alt="image"></p><h2 id="Database-Compression">Database Compression</h2><p>I/O 是非常耗时的,通常是整个数据库的瓶颈,所以 DBMS 中广泛的采用压缩算法来提高 DBMS 的表现。</p><p>通常我们需要在 <strong>速度</strong> 和 <strong>压缩率</strong> 之间进行取舍。</p><h3 id="压缩颗粒度">压缩颗粒度</h3><ul class="lvl-0"><li class="lvl-2"><p>Block Level</p></li><li class="lvl-2"><p>Tuple Level 对整个 <code>tuple</code> 进行压缩 (NSM Only)</p></li><li class="lvl-2"><p>Attribute Level</p></li><li class="lvl-2"><p>Columnar Level</p></li></ul><h2 id="Naive-Compression">Naive Compression</h2><p>使用 “general-purpose” 的压缩算法通常也是一种解决办法。不过一旦使用着这种方法之后,DBMS 就不知道我们进行操作的数据是什么,直到解压完。</p><p>provided as input:<br>→ LZO (1996), LZ4 (2011), Snappy (2011),<br>Oracle OZIP (2014), Zstd (2015)</p><p><img src="https://ipfs.io/ipfs/QmRU9XswYdyhkH7e6G5MhU1oFknSRU934udLUwMhryvpnC" alt="image"></p><p>为了提高速度,我们需要另外的压缩方法,即使是在压缩之后,我们也有办法获取其中的信息来加速。</p><p><img src="https://ipfs.io/ipfs/QmfWREJzu1jZZ1k9WbwDMCJxedBfqz9bdPWc25LWR5b1RE" alt="image"></p><h2 id="Columnar-Compression">Columnar Compression</h2><h3 id="Run-Length-Encoding-RLE">Run-Length Encoding(RLE)</h3><p>可以将一些连续出现在同一列上的值压缩成一个形如<code>(value : pos : num)</code> 的 <code>triplets</code>。</p><p>其中:</p><ol><li class="lvl-3"><p><code>value</code> 表示值</p></li><li class="lvl-3"><p><code>pos</code> 表示该值的起始位置</p></li><li class="lvl-3"><p><code>num</code> 表示该值重复的次数</p></li></ol><p><img src="https://ipfs.io/ipfs/QmeDPCDfxrA8q7pA3emRu5oX56W6PmUwGyG7V2GcGY6Rhw" alt="image"></p><blockquote><p>不过该方法可能存在一些缺陷</p></blockquote><p><img src="https://ipfs.io/ipfs/QmbNbjXVMavSqu2ct7UQF4MqXBXen6Bu5nAJ6FyqhokcHY" alt="image"></p><blockquote><p>经过转换后</p></blockquote><p><img src="https://ipfs.io/ipfs/Qmc8rLbNFkcyyEgb3WDL78U6BWXmyULhYF1eUhVHBctvub" alt="image"></p><h3 id="Bit-Packing-Encoding">Bit-Packing Encoding</h3><p>一些数据对我们来说是十分冗余的,我们可以通过 Bit-Packing 的方式来减少这些冗余。</p><p><img src="https://ipfs.io/ipfs/QmRLifwPj8CVwfxrQqLChyyMKWsAHsqvvJsbLpycA8SrAS" alt="image"></p><p>将 <code>int64</code> 转换为 <code>int8</code> 大大减少了需要的空间。</p><p>不过该方法存在一些缺陷,可能会存在部分信息有不符合 <code>int8</code> 的信息。</p><p>因此,我们需要如下的方式进行存储。</p><p><img src="https://ipfs.io/ipfs/QmbnGQ8AmVdWtJvqwA2zyZyqgwTTQqrugWo8EVmgsANCun" alt="image"></p><p>不过该方法只能在额外存储信息较少的时候进行使用。</p><h3 id="Bitmap-Encoding">Bitmap Encoding</h3><p>当我们每个 <code>attribute</code> 较少的时候,我们可以采用 Bitmap 的方式进行存储。</p><p>例如,只存在 <code>F</code> 和 <code>M</code> 两种值的时候,我们就可以是由 <code>01</code> 来表示是或者不是。</p><p><img src="https://ipfs.io/ipfs/QmVHXmXPg4af1uc5zZ8PT4S56cjMyXtn7Vux1WqHQRh3Zv" alt="image"></p><h3 id="Delta-Encoding">Delta Encoding</h3><p>在许多情况下,例如室温多少,我们的统计结果里可能存在较为密集的值在一定的范围内。</p><p>因此我们通过确定一个值后,往后的所有值都可以通过 <code>delta</code> 的形式存储</p><p><img src="https://ipfs.io/ipfs/QmQSzbJGqVgdzv37LYb7wKa2cpWHEyc83bBd45MXKsTCPD" alt="image"></p><h3 id="Incremental-Encoding">Incremental Encoding</h3><p>我们通常也可以通过取 <strong>前缀 / 后缀</strong> 的形式来得到我们的最终结果。</p><p><img src="https://ipfs.io/ipfs/QmU21hsowqjLrA3RpLyaxDvYanP6of77ZcnsTnmxJ48GsM" alt="image"></p><h3 id="Dictionary-Compression">Dictionary Compression</h3><p>当一张表中可能存在多个值,且这多个值存在在不同的地方,那么我们就可以通过字典的形式得到这些值所在的位置。</p><p><img src="https://ipfs.io/ipfs/QmaTr6bHJnc5GA4rCQkKxPqNvN9nzmtbzMRTsLhg863wEd" alt="image"></p><p>这也是最常用的压缩方法。</p>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
</tags>
</entry>
<entry>
<title>清泉之心</title>
<link href="/2023/10/15/23Y-Q4-10-15-heart-of-Clean-Springs/"/>
<url>/2023/10/15/23Y-Q4-10-15-heart-of-Clean-Springs/</url>
<content type="html"><![CDATA[<h2 id="剧情PV">剧情PV</h2><iframe width="854" height="480" src="https://www.youtube.com/embed/bdduDpNxknE" title="《原神》剧情PV-「清泉之心」" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe><p>人们望向流水,叹息时光匆匆流淌。而在清泉停驻的村庄,情思如湖光般澄亮。</p><blockquote><p>“等待的时候是不觉得苦的,可是如果你真的回头了,我会觉得这一路的等待还是漫长了些。”</p></blockquote><h2 id="游戏文本">游戏文本</h2><p><a href="https://wiki.hoyolab.com/pc/genshin/entry/2323"><i class="fa-brands fa-wikipedia-w fa-bounce"></i>HoyoWiki!</a></p><h3 id="第一卷">第一卷</h3><p>清泉镇猎人们口口相传的传说故事,讲述了泉水精灵与不知名少年的相遇。<br>如水的月光下,流泪的少年对清泉许下愿望。<br>远来的精灵客居无心的泉水之中,静静地倾听着无声的心愿。</p><p>泉水中的精灵并无悠远的记忆,也无深沉的梦想。她们来自水的精华,是无面目的天使之后裔。<br>因而,当好奇的精灵从清泉中现身,从泪滴中听到少年的心声,便立刻对这更加年轻而脆弱的生命产生了兴趣。<br>沉默的精灵伸出无形状的手指,轻触少年的额头与脸颊。同夜露一般冰凉,如失去的祝福一样柔软。</p><p>少年为陌生的感触惊醒,抬起头,正迎上精灵的目光。<br>「你能替我实现愿望吗?」少年问道。<br>泉水的精灵为唐突的发问惊讶不解,但她无法发声,只是轻轻点头。<br>少年心满意足地离去。</p><p>他未曾知道,泉水精灵是孤独的。她没有友伴与亲人,也失却了大部分智慧。<br>只有在泉水源源不断从石缝涌出,汇入池塘时,望着被涟漪击碎的月亮,她才渐渐获得思索的能力,渐渐能够模仿破碎的话语。<br>好奇的精灵张望着这个世界,带着纯净的爱与无知,带着幼稚的灵性。她为偷吃浆果的狐狸与松鼠而欣喜,也为遮蔽银河的乌云哀伤。</p><p>对于那夜的少年,一种复杂却不成熟的感情在她的心中涌流。<br>孤独的她既无力量也无智能,终究无法实现他的心愿。<br>但她可以分担愿望,从他的烦恼中汲取生命,与他一同分享。</p><hr><h3 id="第二卷">第二卷</h3><p>清泉镇猎人们口口相传的传说故事,讲述了泉水精灵与少年的相识。<br>望着涟漪中破碎的月光,少年向泉水倾诉真心。<br>从他的话语中,她得知了他的许多故事。<br>而从她的沉默中,他为自己坚定了信心。</p><p>泉水的精灵懵懂地明白,这世界上的美好不仅有月光与浆果,令人叹惋的黑暗也不仅有遮蔽夜空的层层乌云。<br>少年向她讲述森林、城市与高墙,同她分享他的欢乐、哀伤与恐慌。<br>而在倾听中,她为自己所新生的这个并不完美的世界日渐着迷。</p><p>当少年为自己的无力烦恼时,泉水的精灵温柔而沉默地替他拭去泪水。从他的泪水中,她对清泉之外的世界又多了几分理解。<br>泪水汇入池水,精灵将之净化,转变成为少年带来好梦的醴泉。少年则忘记了清醒时的一切伤痛,在梦中的清泉与沉默的精灵相会。</p><p>每当此时,月光溶融的池水中,安睡的精灵也展露笑颜。<br>清露滋润着少年的美梦,少年的梦想也润湿了孤独的精灵。<br>在梦中,泉水的精灵为少年讲述着遥远的水之国度,讲述着蓝宝石般的家乡,浅唱着流放者的乡愁,叹息着离乡与归宿。而少年则成了沉默的倾听者,为她的遭遇而流泪,为她的幸福而欣慰。</p><p>就这样,泉水精灵在少年的记忆与梦境中获得了言谈的能力。<br>就这样,她与少年成为了无言不欢的朋友。</p><hr><h3 id="第三卷">第三卷</h3><p>清泉镇猎人们口口相传的传说故事,讲述了泉水精灵与少年许下诺言的故事。<br>当夜风停止吹拂,池中的月亮复归圆满,少年第一次听到了精灵的声音。<br>精灵生来便是比人类更加纤细而敏感的生灵,少年不禁为她哀歌一般温柔的语言入迷。</p><p>但精灵毕竟生来便是比人类更加纤细而敏感的生灵,透过少年的眼眸,她望见了无法隐瞒的思慕,与即将脱口而出的诺言。</p><p>突然间,精灵惊慌失措。</p><p>凡人的生命顽强却短暂,少年终将成长,终会老去。等到他褪去青涩与纯真,又将如何对待元素的纯净后裔?等到他年岁将衰,是否会自我责备,因一个幼稚的诺言而枉度一生?</p><p>泉水的精灵纯净而善良,但她并不懂得人界之爱。她未曾见识过人的奇迹,而只将千百年的变迁视作等闲。也正因此,她格外恐惧离别。</p><p>在人类看来奇迹般的守候,于元素之精灵看来只是短暂的美好。而所爱之人的衰老,即使精灵的力量也无法挽回。</p><p>纤细的泉水精灵不忍目睹那一日不可逆转地降临,于是用一吻制止了少年。<br>少年何其愚钝,竟将精灵冰凉的拒绝之吻误以为对诺言的认可。</p><p>在那一刻,精灵下定决心终会忍心离开少年。<br>而少年则立下了永远陪伴在清泉旁边的誓言。</p><hr><h3 id="第四卷">第四卷</h3><p>清泉镇猎人们口口相传的传说故事,不再是少年的少年与不老的精灵终于面对苦涩的缺憾结局。<br>后来,再后来,少年渐渐成长,交了新的朋友,有了新的经历。<br>泉水的精灵依旧如同年轻时那样,为他安静地唱着每一首温柔的哀歌。</p><p>直到那一天,她终于离去,不再望向少年的方向。<br>泉水叮咚作响不再汇成语言,涟漪中破碎的月亮也不再在水面的脚印中复合。<br>泉水的精灵突然意识到,尽管找到了归宿,尽管经历了短暂的幸福,她仍然是孤独的。</p><p>不再是少年的少年没能意识到精灵的逃避,却将孤独归咎于自己。<br>「或许她只是一个幼稚的幻梦。」<br>听着清泉潺潺,他有时会这样想。</p><p>但那冰凉的一吻是真实的,就像曾戏弄她长发的夜风一般真实。<br>突然间,他意识到,即使与无数新朋友相交相别,经历过无数冒险与归乡,他仍然是孤独的。</p><p>于是,像多年前那样,少年的眼泪落入清净的池塘,打湿了破碎的月亮。<br>但这次,泉水精灵没有应约而来。<br>她固执地背过身去,宁愿自视为一个童年纯洁的梦,一个自遥远异乡流浪而来的暂居客,也不愿以近乎永恒的寿命辜负爱慕之人的约定。</p><p>传说每当大雨降下,落入池塘的雨滴中间总会混杂着泉水精灵的泪滴。<br>当少年终于老去,他依然对这样的无稽之谈深信不疑。<br>不幸的是,逃避真心的泉水精灵同样对这等事实无法质疑。</p>]]></content>
<tags>
<tag> game </tag>
</tags>
</entry>
<entry>
<title>CMU15445 Project 0 Trie_Tree</title>
<link href="/2023/09/27/23Y-Q4-09-27-CMU15445-project-0/"/>
<url>/2023/09/27/23Y-Q4-09-27-CMU15445-project-0/</url>
<content type="html"><![CDATA[<h2 id="实验目标">实验目标</h2><p>该实验为 <code>CMU 15-445/645</code> 的前置实现。主要考察 C++ 使用的功底。</p><p>我所采用的课程为 <a href="https://15445.courses.cs.cmu.edu/fall2022/">fall2022</a><sup class="footnote-ref"><a href="#fn1" id="fnref1">[1]</a></sup> 相关代码可以在 <a href="https://github.com/cmu-db/bustub/releases/tag/v20221128-2022fall">Release</a><sup class="footnote-ref"><a href="#fn2" id="fnref2">[2]</a></sup> 中下载</p><p>该课程主要涉及到两方面内容</p><ul class="lvl-0"><li class="lvl-2"><p>如何搭建环境</p></li><li class="lvl-2"><p>C++的使用</p></li></ul><pre class="mermaid">classDiagramclass TrieNode { + TrieNode(char keychar) + TrieNode(TrieNode &&orher_trie_node) + HasChild(char key_char) bool + HasChildren() bool + IsEndNode() bool + GetKeyChar() char + InsertChildNode(char key_char, unique_ptr~TrieNode~ && child) unque_ptr~TrieNode~ + GetChildNode(char key_char) unique_ptr~TrieNode~ + RemoveChildNode(char key_char) void + SetEndNode(bool is_end) void # char key_char_ # bool is_end_ # unordered_map |char, unique_ptr~TrieNode~| children_}class TrieNodeWithValue { - T value_ + TrieNodeWithValue(TrieNode &&trieNode, T value) + TrieNodeWithValue(char key_char, T value) + T GetValue() T}TrieNode <|-- TrieNodeWithValue</pre><pre class="mermaid">classDiagramclass Trie { - std::unique_ptr~TrieNode~ root_ - ReaderWriterLatch latch_ + Trie() + Insert(const std::string &key, T value) bool + Remove(const std::string &key,) bool + GetValue(const std::string &key, bool success) T}</pre><h2 id="环境的搭建">环境的搭建</h2><p>我采用的是使用虚拟机(Ubuntu) + 本地电脑ssh 的开发方式。</p><p>vscode 中安装如下几个插件</p><ul class="lvl-0"><li class="lvl-2"><p><code>C/C++</code></p></li><li class="lvl-2"><p><code>CMake</code></p></li><li class="lvl-2"><p><code>CMake Tools</code></p></li><li class="lvl-2"><p><code>Remote - SSH</code></p></li></ul><p>首先我们首先需要下载并解压所需要的 <a href="https://github.com/cmu-db/bustub/releases/tag/v20221128-2022fall">代码</a></p><figure class="highlight shell"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br></pre></td><td class="code"><pre><span class="line">wget https://github.com/cmu-db/bustub/archive/refs/tags/v20221128-2022fall.tar.gz</span><br><span class="line">tar -zxvf v20221128-2022fall.tar.gz </span><br></pre></td></tr></table></figure><p>然后直接用 <code>VScode</code> SSH直接进入远程的电脑的当前目录下。</p><p>之后安装必要的软件</p><figure class="highlight shell"><table><tr><td class="gutter"><pre><span class="line">1</span><br></pre></td><td class="code"><pre><span class="line">sudo build_support/packages.sh</span><br></pre></td></tr></table></figure><p>之后看 Vscode 几个选项需要我们设置一下</p><div id="tmp_tag"></div>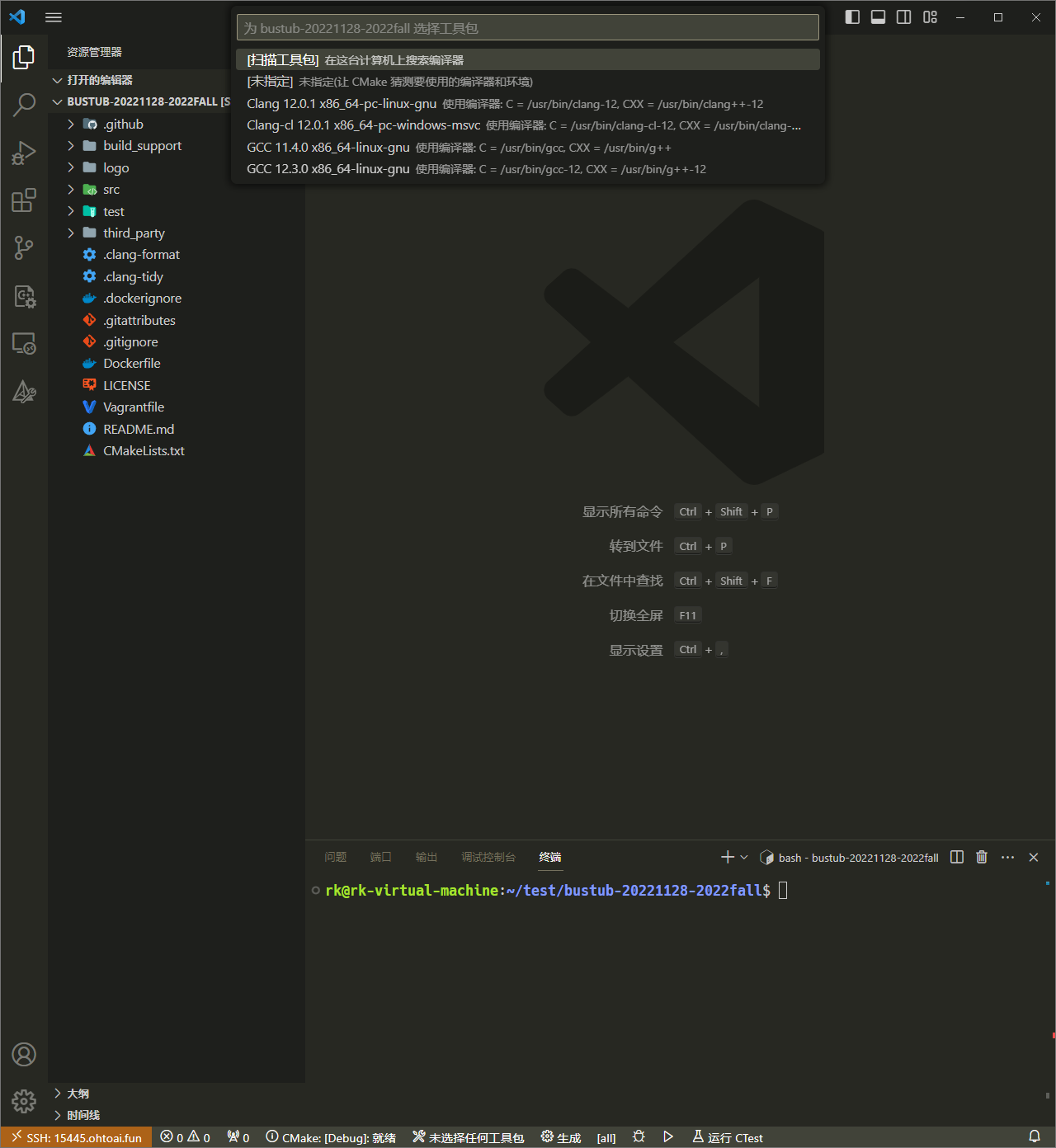<p>我们点击最下方的</p><p><a href="#tmp_tag"><i class="fa-solid fa-gear fa-beat"></i> 生成</a></p><p><img src="https://s2.loli.net/2023/10/01/RcEXkCSA9uOsj1I.png" alt="image-20231001205625799"></p><p>然后选择 <code>Clang 12.01 x86_64-pc-linux-gnu</code> 即可愉快的coding了。</p><h3 id="Debug">Debug</h3><p>在 <i class="fa-solid fa-gear fa-beat"></i> 生成旁边有个按钮 <code>[all]</code> 把他切换为你所需要的那个就可以了。</p><p><img src="https://s2.loli.net/2023/10/02/MRDE97WAlb5ht6w.png" alt=""></p><p>所采用的测试方法为 <code>GTest</code></p><p>只需要将目标 Test 文件下的 <code>DIABLE_</code> 删除就可以进行 Test 了</p><p>例如在路径 <code>/test/primer/starter_trie_test.cpp</code> 将所有 <code>DIABLE_</code> 删除,之后就可以尝试输出结果,按 <i class="fa-solid fa-bug"></i> 就可以在自己打的断点进行调试。按 <i class="fa-solid fa-play"></i> 就可以直接出结果</p><blockquote><p><i class="fa-solid fa-bug"></i> 调试<br><img src="https://s2.loli.net/2023/10/02/hXI9qEDSOpasglx.png" alt="Debug "你正在调试""></p></blockquote><blockquote><p><i class="fa-solid fa-play"></i> 运行结果<br><img src="https://s2.loli.net/2023/10/02/2F1ToQA6LgkyvID.png" alt="Run "运行代码的结果""></p></blockquote><h2 id="C-的使用">C++ 的使用</h2><p>这方面到没有太多可以讲的。</p><p>主要抓住 <code>std::unique_ptr</code> 的用法就可以了。</p><p>下面是几个个使用的例子。</p><p>遍历字典树的节点</p><figure class="highlight cpp"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br><span class="line">4</span><br><span class="line">5</span><br><span class="line">6</span><br><span class="line">7</span><br><span class="line">8</span><br></pre></td><td class="code"><pre><span class="line"><span class="keyword">auto</span> cur_node = &<span class="keyword">this</span>->root_; <span class="comment">// ! 指向智能指针的指针</span></span><br><span class="line"><span class="keyword">auto</span> par_node = cur_node;</span><br><span class="line"></span><br><span class="line"><span class="keyword">while</span>(cur_node != <span class="literal">nullptr</span>) {</span><br><span class="line"> cur_node = cur_node-><span class="built_in">get</span>()-> <span class="built_in">GetChildNode</span>(ch);</span><br><span class="line"> ...</span><br><span class="line"> par_node = cur_node;</span><br><span class="line">}</span><br></pre></td></tr></table></figure><p>如何在父类指针上动态构建子类节点</p><figure class="highlight cpp"><table><tr><td class="gutter"><pre><span class="line">1</span><br><span class="line">2</span><br><span class="line">3</span><br></pre></td><td class="code"><pre><span class="line"><span class="keyword">auto</span> tmp_node = std::<span class="built_in">make_unique</span><T>(std::<span class="built_in">move</span>(*cur_node) , value);</span><br><span class="line">par_node-> <span class="built_in">get</span>() -> <span class="built_in">InsertChildNode</span>(ch, std::<span class="built_in">move</span>(*tmp_node));</span><br><span class="line">cur_node = par_node-> <span class="built_in">GetChildNode</span>(ch);</span><br></pre></td></tr></table></figure><p>通过强制转换得到子类空间的值</p><figure class="highlight cpp"><table><tr><td class="gutter"><pre><span class="line">1</span><br></pre></td><td class="code"><pre><span class="line"><span class="keyword">auto</span> tmp_node = <span class="keyword">dynamic_cast</span><TrieNodeWithValue<T> *>(cur_node-><span class="built_in">get</span>());</span><br></pre></td></tr></table></figure><p>由于课程已经结束了,实在无法完成的话,可以参考我的<a href="/assets/others/CMU15445_project_0_c++_prime.cpp">代码</a>。</p><hr class="footnotes-sep"><section class="footnotes"><ol class="footnotes-list"><li id="fn1" class="footnote-item"><p>CMU 15-445/645 fall2022 官方网址 <a href="https://15445.courses.cs.cmu.edu/fall2022/">https://15445.courses.cs.cmu.edu/fall2022/</a> <a href="#fnref1" class="footnote-backref">↩︎</a></p></li><li id="fn2" class="footnote-item"><p>bustub 源码地址 <a href="https://github.com/cmu-db/bustub">https://github.com/cmu-db/bustub</a> <a href="#fnref2" class="footnote-backref">↩︎</a></p></li></ol></section>]]></content>
<categories>
<category> CMU15-445 </category>
</categories>
<tags>
<tag> CMU15-445 </tag>
<tag> 数据库 </tag>
<tag> C++ </tag>
<tag> Trie_Tree </tag>
</tags>
</entry>
</search>