由于$Inception$
(
(
核心思想$1$:用两个$3$×$3$的卷积代替$5$×$5$的卷积
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如$5$x$5$卷积核参数是$3$x$3$卷积核的$2$5$/$9$=$2.78$倍。为此,作者提出可以用$2个连续的$3$×$3$卷积层组成的小网络来代替单个的$5$x$5$卷积层,在保持感受野范围的同时又减少了参数量,如图1所示:

因此在原来的$Inception$

针对这种操作也许你会有一些疑问:
-这种替代会造成表达能力的下降吗?
作者在论文中做了大量实验可以表明不会造成表达缺失;
-$3$x$3$卷积之后还要再加激活吗?
作者也做了对比试验,表明添加非线性激活会提高性能。
核心思想$2$:用$n$×$1$和$1$×$n$卷积代替$n$×$n$卷积
从上面来看,大卷积核完全可以由一系列的小卷积核来替代,那能不能将小卷积分解的更小一点呢。在原论文中作者考虑到了$n$×$1$这种卷积如下图$3$所示:

进一步的,作者将$n$x$n$的卷积核分解成$1$×$n$和$n$×$1$两个矩阵来进一步减少计算量,如下图$4$所示。实际上,作者发现在网络的前期使用这种分解效果并不好,只有在中度大小的$feature$

核心思想$3$:模块中的滤波器组被扩展(即变得更宽而不是更深)
具体操作见图$5$所示,作者将$Inception$模块中的$3$×$3$卷积核分解成并行的$3$×$1$和$1$×$3$的卷积,用来平衡网络的宽度和深度。

核心思想$4$:引入辅助分类器,加速深度网络收敛
作者在文中提出辅助分类器在网络训练的早期不起作用,在网络训练的末期可以帮助获取更高的准确率。并且辅助分类分支起着正则化的作用,如果在侧分支使用$BN$层,那么网络的主分类器的性能会更好。但是只是单纯地使用$BN$层获得的增益还不明显,还需要一些相应的调整:增大学习速率并加快学习衰减速度以适用$BN$规范化后的数据;去除$Dropout$并减轻$L2$正则(因$BN$已起到正则化的作用);去除$LRN$;更彻底地对训练样本进行$shuffle$;减少数据增强过程中对数据的光学畸变(因为$BN$训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助)。在使用了这些措施后,$Inception$ $V2$在训练达到$Inception$ $V1$的准确率时快了$14$倍,并且模型在收敛时的准确率上限更高。如下图$6$所示,在侧分枝中使用了$BN$层。

核心思想$5$:避免使用瓶颈层
作者提出使用传统方法搭建卷积神经网络时候会使用一些池化操作以减小特征图大小。如图$7$左边先使用池化再进行卷积会导致瓶颈结构,违背$Inception$

核心思想$6$:减小特征图的尺寸
作者采用了一种并行的降维结构,在加宽卷积核组的同时减小特征图大小,既减少计算量又避免了瓶颈结构。如下图$8$所示:

最后我们来看一下在使用了以上的核心思想的$Inception$

核心思想$7$:Label Smoothing
主要是为了消除训练过程中$label$-$dropout$的边缘效应。
对于每一个训练$example$
网络结构展示:
以下为$Inception$

# BasicConv2d是这里定义的基本结构:Conv2D-->BN,下同。
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1) # 1
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionD(nn.Module):
def __init__(self, in_channels):
super(InceptionD, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)
class InceptionE(nn.Module):
def __init__(self, in_channels):
super(InceptionE, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)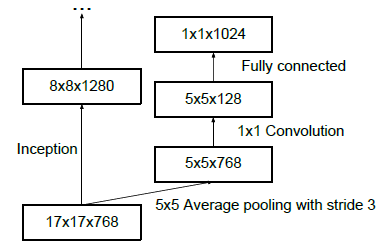
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# 17 x 17 x 768
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# 5 x 5 x 768
x = self.conv0(x)
# 5 x 5 x 128
x = self.conv1(x)
# 1 x 1 x 768
x = x.view(x.size(0), -1)
# 768
x = self.fc(x)
# 1000
return x在$Inception$
另一方面,在$Inception$
论文的链接放在了下文的引用中,大家自行提取哈。
- https://arxiv.org/abs/1512.00567
- https://zhuanlan.zhihu.com/p/30172532
- https://my.oschina.net/u/4597666/blog/4525757
- https://www.cnblogs.com/shouhuxianjian/p/7786760.html
- https://blog.csdn.net/weixin_44474718/article/details/99081062?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
- https://zhuxiaoxia.blog.csdn.net/article/details/79632721?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-10.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-10.control