diff --git a/docs/package_reference/sentence_transformer/evaluation.md b/docs/package_reference/sentence_transformer/evaluation.md
index df5fb258c..861718ef5 100644
--- a/docs/package_reference/sentence_transformer/evaluation.md
+++ b/docs/package_reference/sentence_transformer/evaluation.md
@@ -16,6 +16,11 @@
.. autoclass:: sentence_transformers.evaluation.InformationRetrievalEvaluator
```
+## NanoBEIREvaluator
+```eval_rst
+.. autoclass:: sentence_transformers.evaluation.NanoBEIREvaluator
+```
+
## MSEEvaluator
```eval_rst
.. autoclass:: sentence_transformers.evaluation.MSEEvaluator
diff --git a/docs/sentence_transformer/training/examples.rst b/docs/sentence_transformer/training/examples.rst
index f78d5916b..331ac4666 100644
--- a/docs/sentence_transformer/training/examples.rst
+++ b/docs/sentence_transformer/training/examples.rst
@@ -16,6 +16,7 @@ Training Examples
../../../examples/training/multilingual/README
../../../examples/training/distillation/README
../../../examples/training/data_augmentation/README
+ ../../../examples/training/prompts/README
.. toctree::
:maxdepth: 1
diff --git a/examples/training/prompts/README.md b/examples/training/prompts/README.md
new file mode 100644
index 000000000..81779e78a
--- /dev/null
+++ b/examples/training/prompts/README.md
@@ -0,0 +1,177 @@
+# Training with Prompts
+
+## What are Prompts?
+Many modern embedding models are trained with "instructions" or "prompts" following the [INSTRUCTOR paper](https://arxiv.org/abs/2212.09741). These prompts are strings, prefixed to each text to be embedded, allowing the model to distinguish between different types of text.
+
+For example, the [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) model was trained with `Represent this sentence for searching relevant passages: ` as the prompt for all queries. This prompt is stored in the [model configuration](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1/blob/main/config_sentence_transformers.json) under the prompt name `"query"`, so users can specify that `prompt_name` in `model.encode`:
+
+```python
+from sentence_transformers import SentenceTransformer
+
+model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1")
+query_embedding = model.encode("What are Pandas?", prompt_name="query")
+# or
+# query_embedding = model.encode("What are Pandas?", prompt="Represent this sentence for searching relevant passages: ")
+document_embeddings = model.encode([
+ "Pandas is a software library written for the Python programming language for data manipulation and analysis.",
+ "Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
+ "Koala bears are not actually bears, they are marsupials native to Australia.",
+])
+similarity = model.similarity(query_embedding, document_embeddings)
+print(similarity)
+# => tensor([[0.7594, 0.7560, 0.4674]])
+```
+See [Prompt Templates](https://sbert.net/examples/applications/computing-embeddings/README.html#prompt-templates) for more information about inference with prompts.
+
+## Why would we train with Prompts?
+
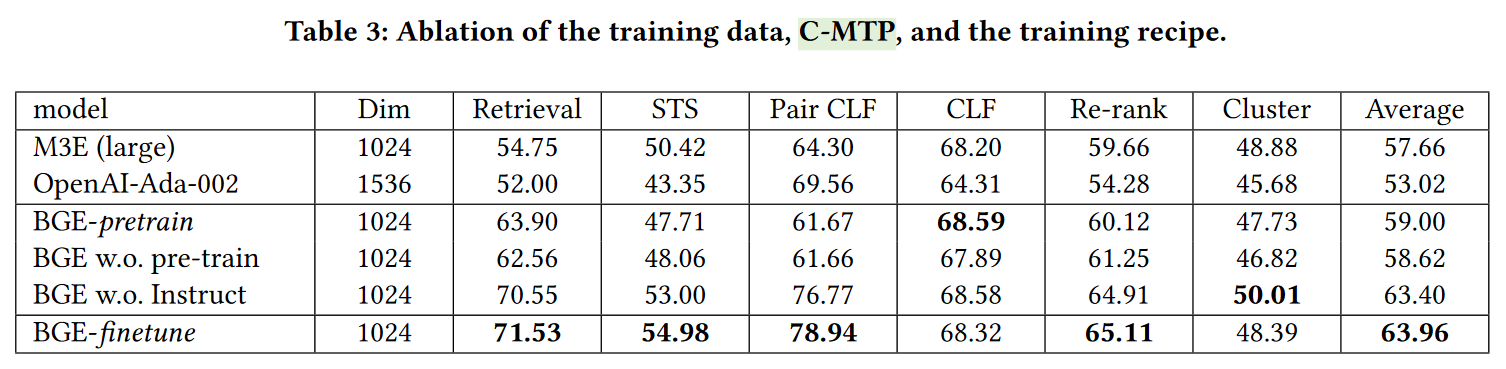
+The [INSTRUCTOR paper](https://arxiv.org/abs/2212.09741) showed that adding prompts or instructions before each text could improve model performance by an average of ~6%, with major gains especially for classification, clustering, and semantic textual similarity. Note that the performance improvements for retrieval are notably lower at 0.4% and 2.7% for small and large models, respectively.
+
+
+
+
+
+
 +
+ Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: `tomaarsen/mpnet-base-nq-prompts#natural-questions `_.
+
+ .. important::
+ If you train with prompts, then it's heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the :class:`~sentence_transformers.SentenceTransformer` with a ``prompts`` dictionary before saving it, updating the ``model.prompts`` of a loaded model before saving it, and/or updating the `config_sentence_transformers.json `_ file of the saved model.
+
+ After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes::
+
+ from sentence_transformers import SentenceTransformer
+
+ model = SentenceTransformer("tomaarsen/mpnet-base-nq-prompts")
+ query_embedding = model.encode("What are Pandas?", prompt_name="query")
+ document_embeddings = model.encode([
+ "Pandas is a software library written for the Python programming language for data manipulation and analysis.",
+ "Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
+ "Koala bears are not actually bears, they are marsupials native to Australia.",
+ ],
+ prompt_name="document",
+ )
+ similarity = model.similarity(query_embedding, document_embeddings)
+ print(similarity)
+ # => tensor([[0.4725, 0.7339, 0.4369]])
+
+.. tab:: Experiments with ``bert-base-uncased``
+
+ Running the script under various settings resulted in these checkpoints:
+
+ * `tomaarsen/bert-base-nq `_
+ * `tomaarsen/bert-base-nq-prompts `_
+ * `tomaarsen/bert-base-nq-prompts-exclude-pooling-prompts `_
+
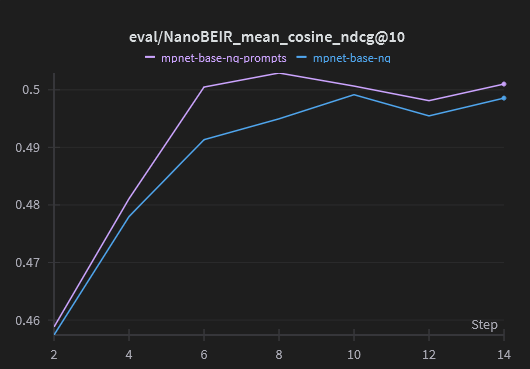
+ For these three models, the model trained with prompts consistently outperforms the baseline model all throughout training, except for the very first evaluation. The model that excludes the prompt in the mean pooling consistently performs notably worse than either of the other two.
+
+ .. raw:: html
+
+
+
+ Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: `tomaarsen/mpnet-base-nq-prompts#natural-questions `_.
+
+ .. important::
+ If you train with prompts, then it's heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the :class:`~sentence_transformers.SentenceTransformer` with a ``prompts`` dictionary before saving it, updating the ``model.prompts`` of a loaded model before saving it, and/or updating the `config_sentence_transformers.json `_ file of the saved model.
+
+ After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes::
+
+ from sentence_transformers import SentenceTransformer
+
+ model = SentenceTransformer("tomaarsen/mpnet-base-nq-prompts")
+ query_embedding = model.encode("What are Pandas?", prompt_name="query")
+ document_embeddings = model.encode([
+ "Pandas is a software library written for the Python programming language for data manipulation and analysis.",
+ "Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
+ "Koala bears are not actually bears, they are marsupials native to Australia.",
+ ],
+ prompt_name="document",
+ )
+ similarity = model.similarity(query_embedding, document_embeddings)
+ print(similarity)
+ # => tensor([[0.4725, 0.7339, 0.4369]])
+
+.. tab:: Experiments with ``bert-base-uncased``
+
+ Running the script under various settings resulted in these checkpoints:
+
+ * `tomaarsen/bert-base-nq `_
+ * `tomaarsen/bert-base-nq-prompts `_
+ * `tomaarsen/bert-base-nq-prompts-exclude-pooling-prompts `_
+
+ For these three models, the model trained with prompts consistently outperforms the baseline model all throughout training, except for the very first evaluation. The model that excludes the prompt in the mean pooling consistently performs notably worse than either of the other two.
+
+ .. raw:: html
+
+  +
+ Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: `tomaarsen/bert-base-nq-prompts#natural-questions `_.
+
+ .. important::
+ If you train with prompts, then it's heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the :class:`~sentence_transformers.SentenceTransformer` with a ``prompts`` dictionary before saving it, updating the ``model.prompts`` of a loaded model before saving it, and/or updating the `config_sentence_transformers.json `_ file of the saved model.
+
+ After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes::
+
+ from sentence_transformers import SentenceTransformer
+
+ model = SentenceTransformer("tomaarsen/bert-base-nq-prompts")
+ query_embedding = model.encode("What are Pandas?", prompt_name="query")
+ document_embeddings = model.encode([
+ "Pandas is a software library written for the Python programming language for data manipulation and analysis.",
+ "Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
+ "Koala bears are not actually bears, they are marsupials native to Australia.",
+ ],
+ prompt_name="document",
+ )
+ similarity = model.similarity(query_embedding, document_embeddings)
+ print(similarity)
+ # => tensor([[0.3955, 0.8226, 0.5706]])
+```
\ No newline at end of file
diff --git a/examples/training/prompts/training_nq_prompts.py b/examples/training/prompts/training_nq_prompts.py
new file mode 100644
index 000000000..65d0013ca
--- /dev/null
+++ b/examples/training/prompts/training_nq_prompts.py
@@ -0,0 +1,114 @@
+# See https://huggingface.co/collections/tomaarsen/training-with-prompts-672ce423c85b4d39aed52853 for some already trained models
+
+import logging
+import random
+
+import numpy
+import torch
+from datasets import Dataset, load_dataset
+
+from sentence_transformers import (
+ SentenceTransformer,
+ SentenceTransformerModelCardData,
+ SentenceTransformerTrainer,
+ SentenceTransformerTrainingArguments,
+)
+from sentence_transformers.evaluation import NanoBEIREvaluator
+from sentence_transformers.losses import CachedMultipleNegativesRankingLoss
+from sentence_transformers.training_args import BatchSamplers
+
+logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
+random.seed(12)
+torch.manual_seed(12)
+numpy.random.seed(12)
+
+# Feel free to adjust these variables:
+use_prompts = True
+include_prompts_in_pooling = True
+
+# 1. Load a model to finetune with 2. (Optional) model card data
+model = SentenceTransformer(
+ "microsoft/mpnet-base",
+ model_card_data=SentenceTransformerModelCardData(
+ language="en",
+ license="apache-2.0",
+ model_name="MPNet base trained on Natural Questions pairs",
+ ),
+)
+model.set_pooling_include_prompt(include_prompts_in_pooling)
+
+# 2. (Optional) Define prompts
+if use_prompts:
+ query_prompt = "query: "
+ corpus_prompt = "document: "
+ prompts = {
+ "query": query_prompt,
+ "answer": corpus_prompt,
+ }
+
+# 3. Load a dataset to finetune on
+dataset = load_dataset("sentence-transformers/natural-questions", split="train")
+dataset_dict = dataset.train_test_split(test_size=1_000, seed=12)
+train_dataset: Dataset = dataset_dict["train"]
+eval_dataset: Dataset = dataset_dict["test"]
+
+# 4. Define a loss function
+loss = CachedMultipleNegativesRankingLoss(model, mini_batch_size=16)
+
+# 5. (Optional) Specify training arguments
+run_name = "mpnet-base-nq"
+if use_prompts:
+ run_name += "-prompts"
+if not include_prompts_in_pooling:
+ run_name += "-exclude-pooling-prompts"
+args = SentenceTransformerTrainingArguments(
+ # Required parameter:
+ output_dir=f"models/{run_name}",
+ # Optional training parameters:
+ num_train_epochs=1,
+ per_device_train_batch_size=256,
+ per_device_eval_batch_size=256,
+ learning_rate=2e-5,
+ warmup_ratio=0.1,
+ fp16=False, # Set to False if you get an error that your GPU can't run on FP16
+ bf16=True, # Set to True if you have a GPU that supports BF16
+ batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicate samples in a batch
+ # Optional tracking/debugging parameters:
+ eval_strategy="steps",
+ eval_steps=50,
+ save_strategy="steps",
+ save_steps=50,
+ save_total_limit=2,
+ logging_steps=5,
+ logging_first_step=True,
+ run_name=run_name, # Will be used in W&B if `wandb` is installed
+ seed=12,
+ prompts=prompts if use_prompts else None,
+)
+
+# 6. (Optional) Create an evaluator & evaluate the base model
+dev_evaluator = NanoBEIREvaluator(
+ query_prompts=query_prompt if use_prompts else None,
+ corpus_prompts=corpus_prompt if use_prompts else None,
+)
+dev_evaluator(model)
+
+# 7. Create a trainer & train
+trainer = SentenceTransformerTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ loss=loss,
+ evaluator=dev_evaluator,
+)
+trainer.train()
+
+# (Optional) Evaluate the trained model on the evaluator after training
+dev_evaluator(model)
+
+# 8. Save the trained model
+model.save_pretrained(f"models/{run_name}/final")
+
+# 9. (Optional) Push it to the Hugging Face Hub
+model.push_to_hub(run_name)
diff --git a/index.rst b/index.rst
index b1f3b3843..efd65f44f 100644
--- a/index.rst
+++ b/index.rst
@@ -1,6 +1,10 @@
-.. tip::
+.. note::
- Sentence Transformers v3.2 just released, introducing the ONNX and OpenVINO backends for Sentence Transformer models. Read `SentenceTransformer > Usage > Speeding up Inference `_ to learn more about the new backends and what they can mean for your inference speed.
+ Sentence Transformers v3.2 recently released, introducing the ONNX and OpenVINO backends for Sentence Transformer models. Read `SentenceTransformer > Usage > Speeding up Inference `_ to learn more about the new backends and what they can mean for your inference speed.
+
+.. note::
+
+ Sentence Transformers v3.3 just released, introducing training with Prompts. Read `SentenceTransformer > Training Examples > Training with Prompts `_ to learn more about how you can use them to train stronger models.
SentenceTransformers Documentation
==================================
diff --git a/sentence_transformers/data_collator.py b/sentence_transformers/data_collator.py
index 071fac7a6..83445fe7e 100644
--- a/sentence_transformers/data_collator.py
+++ b/sentence_transformers/data_collator.py
@@ -46,11 +46,16 @@ def __call__(self, features: list[dict[str, Any]]) -> dict[str, torch.Tensor]:
column_names.remove(label_column)
break
- # Extract the feature columns
for column_name in column_names:
+ # If the prompt length has been set, we should add it to the batch
+ if column_name.endswith("_prompt_length") and column_name[: -len("_prompt_length")] in column_names:
+ batch[column_name] = torch.tensor([row[column_name] for row in features], dtype=torch.int)
+ continue
+
tokenized = self.tokenize_fn([row[column_name] for row in features])
for key, value in tokenized.items():
batch[f"{column_name}_{key}"] = value
+
return batch
def maybe_warn_about_column_order(self, column_names: list[str]) -> None:
diff --git a/sentence_transformers/evaluation/NanoBEIREvaluator.py b/sentence_transformers/evaluation/NanoBEIREvaluator.py
index 1e21f2254..9b5669cb6 100644
--- a/sentence_transformers/evaluation/NanoBEIREvaluator.py
+++ b/sentence_transformers/evaluation/NanoBEIREvaluator.py
@@ -88,8 +88,8 @@ class NanoBEIREvaluator(SentenceEvaluator):
datasets = ["QuoraRetrieval", "MSMARCO"]
query_prompts = {
- "QuoraRetrieval": "Instruct: Given a question, retrieve questions that are semantically equivalent to the given question\nQuery: ",
- "MSMARCO": "Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: "
+ "QuoraRetrieval": "Instruct: Given a question, retrieve questions that are semantically equivalent to the given question\\nQuery: ",
+ "MSMARCO": "Instruct: Given a web search query, retrieve relevant passages that answer the query\\nQuery: "
}
evaluator = NanoBEIREvaluator(
diff --git a/sentence_transformers/model_card.py b/sentence_transformers/model_card.py
index dd7c0e96b..fdd3f86f1 100644
--- a/sentence_transformers/model_card.py
+++ b/sentence_transformers/model_card.py
@@ -422,9 +422,7 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
columns = [
column
for column, feature in dataset[dataset_name].features.items()
- if isinstance(feature, Value)
- and (feature.dtype == "string" or feature.dtype == "large_string")
- and column != "dataset_name"
+ if isinstance(feature, Value) and feature.dtype in {"string", "large_string"}
]
str_dataset = dataset[dataset_name].select_columns(columns)
dataset_size = len(str_dataset)
@@ -435,7 +433,11 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
for idx, sample in enumerate(
str_dataset.select(random.sample(range(dataset_size), k=min(num_samples_to_check, dataset_size)))
):
- lengths[idx] = sum(len(value) for value in sample.values())
+ lengths[idx] = sum(
+ len(value)
+ for key, value in sample.items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ )
indices, _ = zip(*sorted(lengths.items(), key=lambda x: x[1]))
target_indices, backup_indices = indices[:num_samples], list(indices[num_samples:][::-1])
@@ -443,10 +445,18 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
# We want 4 texts, so we take texts from the backup indices, short texts first
for idx in target_indices:
# This is anywhere between 1 and n texts
- sentences = list(str_dataset[idx].values())
+ sentences = [
+ sentence
+ for key, sentence in str_dataset[idx].items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ ]
while len(sentences) < 4 and backup_indices:
backup_idx = backup_indices.pop()
- backup_sample = list(str_dataset[backup_idx].values())
+ backup_sample = [
+ sentence
+ for key, sentence in str_dataset[backup_idx].items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ ]
if len(backup_sample) == 1:
# If there is only one text in the backup sample, we take it
sentences.extend(backup_sample)
@@ -604,9 +614,9 @@ def compute_dataset_metrics(
dataset_info["stats"][column] = {
"dtype": "float",
"data": {
- "min": round(min(dataset[column]), 2),
- "mean": round(sum(dataset[column]) / len(dataset), 2),
- "max": round(max(dataset[column]), 2),
+ "min": round(min(subsection), 2),
+ "mean": round(sum(subsection) / len(subsection), 2),
+ "max": round(max(subsection), 2),
},
}
elif isinstance(first, list):
diff --git a/sentence_transformers/models/Pooling.py b/sentence_transformers/models/Pooling.py
index 4e24a1c92..21cfb617c 100644
--- a/sentence_transformers/models/Pooling.py
+++ b/sentence_transformers/models/Pooling.py
@@ -1,251 +1,260 @@
-from __future__ import annotations
-
-import json
-import os
-from typing import Any
-
-import torch
-from torch import Tensor, nn
-
-
-class Pooling(nn.Module):
- """
- Performs pooling (max or mean) on the token embeddings.
-
- Using pooling, it generates from a variable sized sentence a fixed sized sentence embedding. This layer also allows
- to use the CLS token if it is returned by the underlying word embedding model. You can concatenate multiple poolings
- together.
-
- Args:
- word_embedding_dimension: Dimensions for the word embeddings
- pooling_mode: Either "cls", "lasttoken", "max", "mean",
- "mean_sqrt_len_tokens", or "weightedmean". If set,
- overwrites the other pooling_mode_* settings
- pooling_mode_cls_token: Use the first token (CLS token) as text
- representations
- pooling_mode_max_tokens: Use max in each dimension over all
- tokens.
- pooling_mode_mean_tokens: Perform mean-pooling
- pooling_mode_mean_sqrt_len_tokens: Perform mean-pooling, but
- divide by sqrt(input_length).
- pooling_mode_weightedmean_tokens: Perform (position) weighted
- mean pooling. See `SGPT: GPT Sentence Embeddings for
- Semantic Search `_.
- pooling_mode_lasttoken: Perform last token pooling. See `SGPT:
- GPT Sentence Embeddings for Semantic Search
- `_ and `Text and Code
- Embeddings by Contrastive Pre-Training
- `_.
- include_prompt: If set to false, the prompt tokens are not
- included in the pooling. This is useful for reproducing
- work that does not include the prompt tokens in the pooling
- like INSTRUCTOR, but otherwise not recommended.
- """
-
- POOLING_MODES = (
- "cls",
- "lasttoken",
- "max",
- "mean",
- "mean_sqrt_len_tokens",
- "weightedmean",
- )
-
- def __init__(
- self,
- word_embedding_dimension: int,
- pooling_mode: str = None,
- pooling_mode_cls_token: bool = False,
- pooling_mode_max_tokens: bool = False,
- pooling_mode_mean_tokens: bool = True,
- pooling_mode_mean_sqrt_len_tokens: bool = False,
- pooling_mode_weightedmean_tokens: bool = False,
- pooling_mode_lasttoken: bool = False,
- include_prompt: bool = True,
- ) -> None:
- super().__init__()
-
- self.config_keys = [
- "word_embedding_dimension",
- "pooling_mode_cls_token",
- "pooling_mode_mean_tokens",
- "pooling_mode_max_tokens",
- "pooling_mode_mean_sqrt_len_tokens",
- "pooling_mode_weightedmean_tokens",
- "pooling_mode_lasttoken",
- "include_prompt",
- ]
-
- if pooling_mode is not None: # Set pooling mode by string
- pooling_mode = pooling_mode.lower()
-
- if pooling_mode not in self.POOLING_MODES:
- raise ValueError(
- f"Set invalid pooling mode: {pooling_mode}. Valid pooling modes are: {self.POOLING_MODES}."
- )
-
- pooling_mode_cls_token = pooling_mode == "cls"
- pooling_mode_max_tokens = pooling_mode == "max"
- pooling_mode_mean_tokens = pooling_mode == "mean"
- pooling_mode_mean_sqrt_len_tokens = pooling_mode == "mean_sqrt_len_tokens"
- pooling_mode_weightedmean_tokens = pooling_mode == "weightedmean"
- pooling_mode_lasttoken = pooling_mode == "lasttoken"
-
- self.word_embedding_dimension = word_embedding_dimension
- self.pooling_mode_cls_token = pooling_mode_cls_token
- self.pooling_mode_mean_tokens = pooling_mode_mean_tokens
- self.pooling_mode_max_tokens = pooling_mode_max_tokens
- self.pooling_mode_mean_sqrt_len_tokens = pooling_mode_mean_sqrt_len_tokens
- self.pooling_mode_weightedmean_tokens = pooling_mode_weightedmean_tokens
- self.pooling_mode_lasttoken = pooling_mode_lasttoken
-
- self.include_prompt = include_prompt
-
- pooling_mode_multiplier = sum(
- [
- pooling_mode_cls_token,
- pooling_mode_max_tokens,
- pooling_mode_mean_tokens,
- pooling_mode_mean_sqrt_len_tokens,
- pooling_mode_weightedmean_tokens,
- pooling_mode_lasttoken,
- ]
- )
- self.pooling_output_dimension = pooling_mode_multiplier * word_embedding_dimension
-
- def __repr__(self) -> str:
- return f"Pooling({self.get_config_dict()})"
-
- def get_pooling_mode_str(self) -> str:
- """Returns the pooling mode as string"""
- modes = []
- if self.pooling_mode_cls_token:
- modes.append("cls")
- if self.pooling_mode_mean_tokens:
- modes.append("mean")
- if self.pooling_mode_max_tokens:
- modes.append("max")
- if self.pooling_mode_mean_sqrt_len_tokens:
- modes.append("mean_sqrt_len_tokens")
- if self.pooling_mode_weightedmean_tokens:
- modes.append("weightedmean")
- if self.pooling_mode_lasttoken:
- modes.append("lasttoken")
-
- return "+".join(modes)
-
- def forward(self, features: dict[str, Tensor]) -> dict[str, Tensor]:
- token_embeddings = features["token_embeddings"]
- attention_mask = (
- features["attention_mask"]
- if "attention_mask" in features
- else torch.ones(token_embeddings.shape[:-1], device=token_embeddings.device, dtype=torch.int64)
- )
- if not self.include_prompt and "prompt_length" in features:
- attention_mask[:, : features["prompt_length"]] = 0
-
- ## Pooling strategy
- output_vectors = []
- if self.pooling_mode_cls_token:
- cls_token = features.get("cls_token_embeddings", token_embeddings[:, 0]) # Take first token by default
- output_vectors.append(cls_token)
- if self.pooling_mode_max_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
- max_over_time = torch.max(token_embeddings, 1)[0]
- output_vectors.append(max_over_time)
- if self.pooling_mode_mean_tokens or self.pooling_mode_mean_sqrt_len_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
-
- # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
- if "token_weights_sum" in features:
- sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
- else:
- sum_mask = input_mask_expanded.sum(1)
-
- sum_mask = torch.clamp(sum_mask, min=1e-9)
-
- if self.pooling_mode_mean_tokens:
- output_vectors.append(sum_embeddings / sum_mask)
- if self.pooling_mode_mean_sqrt_len_tokens:
- output_vectors.append(sum_embeddings / torch.sqrt(sum_mask))
- if self.pooling_mode_weightedmean_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- # token_embeddings shape: bs, seq, hidden_dim
- weights = (
- torch.arange(start=1, end=token_embeddings.shape[1] + 1)
- .unsqueeze(0)
- .unsqueeze(-1)
- .expand(token_embeddings.size())
- .to(token_embeddings.dtype)
- .to(token_embeddings.device)
- )
- assert weights.shape == token_embeddings.shape == input_mask_expanded.shape
- input_mask_expanded = input_mask_expanded * weights
-
- sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
-
- # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
- if "token_weights_sum" in features:
- sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
- else:
- sum_mask = input_mask_expanded.sum(1)
-
- sum_mask = torch.clamp(sum_mask, min=1e-9)
- output_vectors.append(sum_embeddings / sum_mask)
- if self.pooling_mode_lasttoken:
- bs, seq_len, hidden_dim = token_embeddings.shape
- # attention_mask shape: (bs, seq_len)
- # Get shape [bs] indices of the last token (i.e. the last token for each batch item)
- # Use flip and max() to get the last index of 1 in the attention mask
-
- if torch.jit.is_tracing():
- # Avoid tracing the argmax with int64 input that can not be handled by ONNX Runtime: https://github.com/microsoft/onnxruntime/issues/10068
- attention_mask = attention_mask.to(torch.int32)
-
- values, indices = attention_mask.flip(1).max(1)
- indices = torch.where(values == 0, seq_len - 1, indices)
- gather_indices = seq_len - indices - 1
-
- # Turn indices from shape [bs] --> [bs, 1, hidden_dim]
- gather_indices = gather_indices.unsqueeze(-1).repeat(1, hidden_dim)
- gather_indices = gather_indices.unsqueeze(1)
- assert gather_indices.shape == (bs, 1, hidden_dim)
-
- # Gather along the 1st dim (seq_len) (bs, seq_len, hidden_dim -> bs, hidden_dim)
- # Actually no need for the attention mask as we gather the last token where attn_mask = 1
- # but as we set some indices (which shouldn't be attended to) to 0 with clamp, we
- # use the attention mask to ignore them again
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- embedding = torch.gather(token_embeddings * input_mask_expanded, 1, gather_indices).squeeze(dim=1)
- output_vectors.append(embedding)
-
- output_vector = torch.cat(output_vectors, 1)
- features["sentence_embedding"] = output_vector
- return features
-
- def get_sentence_embedding_dimension(self) -> int:
- return self.pooling_output_dimension
-
- def get_config_dict(self) -> dict[str, Any]:
- return {key: self.__dict__[key] for key in self.config_keys}
-
- def save(self, output_path) -> None:
- with open(os.path.join(output_path, "config.json"), "w") as fOut:
- json.dump(self.get_config_dict(), fOut, indent=2)
-
- @staticmethod
- def load(input_path) -> Pooling:
- with open(os.path.join(input_path, "config.json")) as fIn:
- config = json.load(fIn)
-
- return Pooling(**config)
+from __future__ import annotations
+
+import json
+import os
+from typing import Any
+
+import torch
+from torch import Tensor, nn
+
+
+class Pooling(nn.Module):
+ """
+ Performs pooling (max or mean) on the token embeddings.
+
+ Using pooling, it generates from a variable sized sentence a fixed sized sentence embedding. This layer also allows
+ to use the CLS token if it is returned by the underlying word embedding model. You can concatenate multiple poolings
+ together.
+
+ Args:
+ word_embedding_dimension: Dimensions for the word embeddings
+ pooling_mode: Either "cls", "lasttoken", "max", "mean",
+ "mean_sqrt_len_tokens", or "weightedmean". If set,
+ overwrites the other pooling_mode_* settings
+ pooling_mode_cls_token: Use the first token (CLS token) as text
+ representations
+ pooling_mode_max_tokens: Use max in each dimension over all
+ tokens.
+ pooling_mode_mean_tokens: Perform mean-pooling
+ pooling_mode_mean_sqrt_len_tokens: Perform mean-pooling, but
+ divide by sqrt(input_length).
+ pooling_mode_weightedmean_tokens: Perform (position) weighted
+ mean pooling. See `SGPT: GPT Sentence Embeddings for
+ Semantic Search `_.
+ pooling_mode_lasttoken: Perform last token pooling. See `SGPT:
+ GPT Sentence Embeddings for Semantic Search
+ `_ and `Text and Code
+ Embeddings by Contrastive Pre-Training
+ `_.
+ include_prompt: If set to false, the prompt tokens are not
+ included in the pooling. This is useful for reproducing
+ work that does not include the prompt tokens in the pooling
+ like INSTRUCTOR, but otherwise not recommended.
+ """
+
+ POOLING_MODES = (
+ "cls",
+ "lasttoken",
+ "max",
+ "mean",
+ "mean_sqrt_len_tokens",
+ "weightedmean",
+ )
+
+ def __init__(
+ self,
+ word_embedding_dimension: int,
+ pooling_mode: str = None,
+ pooling_mode_cls_token: bool = False,
+ pooling_mode_max_tokens: bool = False,
+ pooling_mode_mean_tokens: bool = True,
+ pooling_mode_mean_sqrt_len_tokens: bool = False,
+ pooling_mode_weightedmean_tokens: bool = False,
+ pooling_mode_lasttoken: bool = False,
+ include_prompt: bool = True,
+ ) -> None:
+ super().__init__()
+
+ self.config_keys = [
+ "word_embedding_dimension",
+ "pooling_mode_cls_token",
+ "pooling_mode_mean_tokens",
+ "pooling_mode_max_tokens",
+ "pooling_mode_mean_sqrt_len_tokens",
+ "pooling_mode_weightedmean_tokens",
+ "pooling_mode_lasttoken",
+ "include_prompt",
+ ]
+
+ if pooling_mode is not None: # Set pooling mode by string
+ pooling_mode = pooling_mode.lower()
+
+ if pooling_mode not in self.POOLING_MODES:
+ raise ValueError(
+ f"Set invalid pooling mode: {pooling_mode}. Valid pooling modes are: {self.POOLING_MODES}."
+ )
+
+ pooling_mode_cls_token = pooling_mode == "cls"
+ pooling_mode_max_tokens = pooling_mode == "max"
+ pooling_mode_mean_tokens = pooling_mode == "mean"
+ pooling_mode_mean_sqrt_len_tokens = pooling_mode == "mean_sqrt_len_tokens"
+ pooling_mode_weightedmean_tokens = pooling_mode == "weightedmean"
+ pooling_mode_lasttoken = pooling_mode == "lasttoken"
+
+ self.word_embedding_dimension = word_embedding_dimension
+ self.pooling_mode_cls_token = pooling_mode_cls_token
+ self.pooling_mode_mean_tokens = pooling_mode_mean_tokens
+ self.pooling_mode_max_tokens = pooling_mode_max_tokens
+ self.pooling_mode_mean_sqrt_len_tokens = pooling_mode_mean_sqrt_len_tokens
+ self.pooling_mode_weightedmean_tokens = pooling_mode_weightedmean_tokens
+ self.pooling_mode_lasttoken = pooling_mode_lasttoken
+
+ self.include_prompt = include_prompt
+
+ pooling_mode_multiplier = sum(
+ [
+ pooling_mode_cls_token,
+ pooling_mode_max_tokens,
+ pooling_mode_mean_tokens,
+ pooling_mode_mean_sqrt_len_tokens,
+ pooling_mode_weightedmean_tokens,
+ pooling_mode_lasttoken,
+ ]
+ )
+ self.pooling_output_dimension = pooling_mode_multiplier * word_embedding_dimension
+
+ def __repr__(self) -> str:
+ return f"Pooling({self.get_config_dict()})"
+
+ def get_pooling_mode_str(self) -> str:
+ """Returns the pooling mode as string"""
+ modes = []
+ if self.pooling_mode_cls_token:
+ modes.append("cls")
+ if self.pooling_mode_mean_tokens:
+ modes.append("mean")
+ if self.pooling_mode_max_tokens:
+ modes.append("max")
+ if self.pooling_mode_mean_sqrt_len_tokens:
+ modes.append("mean_sqrt_len_tokens")
+ if self.pooling_mode_weightedmean_tokens:
+ modes.append("weightedmean")
+ if self.pooling_mode_lasttoken:
+ modes.append("lasttoken")
+
+ return "+".join(modes)
+
+ def forward(self, features: dict[str, Tensor]) -> dict[str, Tensor]:
+ token_embeddings = features["token_embeddings"]
+ attention_mask = (
+ features["attention_mask"]
+ if "attention_mask" in features
+ else torch.ones(token_embeddings.shape[:-1], device=token_embeddings.device, dtype=torch.int64)
+ )
+ if not self.include_prompt and "prompt_length" in features:
+ prompt_length = features["prompt_length"]
+ # prompt_length is either:
+ # * an int (in inference)
+ # * a tensor of shape (bs), all the same value (in training with an IterableDataset)
+ # * a tensor of shape (1) (in training with a Dataset)
+ # We turn all into an int
+ if isinstance(prompt_length, torch.Tensor):
+ prompt_length = prompt_length[0].item()
+
+ attention_mask[:, :prompt_length] = 0
+
+ ## Pooling strategy
+ output_vectors = []
+ if self.pooling_mode_cls_token:
+ cls_token = features.get("cls_token_embeddings", token_embeddings[:, 0]) # Take first token by default
+ output_vectors.append(cls_token)
+ if self.pooling_mode_max_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
+ max_over_time = torch.max(token_embeddings, 1)[0]
+ output_vectors.append(max_over_time)
+ if self.pooling_mode_mean_tokens or self.pooling_mode_mean_sqrt_len_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
+
+ # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
+ if "token_weights_sum" in features:
+ sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
+ else:
+ sum_mask = input_mask_expanded.sum(1)
+
+ sum_mask = torch.clamp(sum_mask, min=1e-9)
+
+ if self.pooling_mode_mean_tokens:
+ output_vectors.append(sum_embeddings / sum_mask)
+ if self.pooling_mode_mean_sqrt_len_tokens:
+ output_vectors.append(sum_embeddings / torch.sqrt(sum_mask))
+ if self.pooling_mode_weightedmean_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ # token_embeddings shape: bs, seq, hidden_dim
+ weights = (
+ torch.arange(start=1, end=token_embeddings.shape[1] + 1)
+ .unsqueeze(0)
+ .unsqueeze(-1)
+ .expand(token_embeddings.size())
+ .to(token_embeddings.dtype)
+ .to(token_embeddings.device)
+ )
+ assert weights.shape == token_embeddings.shape == input_mask_expanded.shape
+ input_mask_expanded = input_mask_expanded * weights
+
+ sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
+
+ # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
+ if "token_weights_sum" in features:
+ sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
+ else:
+ sum_mask = input_mask_expanded.sum(1)
+
+ sum_mask = torch.clamp(sum_mask, min=1e-9)
+ output_vectors.append(sum_embeddings / sum_mask)
+ if self.pooling_mode_lasttoken:
+ bs, seq_len, hidden_dim = token_embeddings.shape
+ # attention_mask shape: (bs, seq_len)
+ # Get shape [bs] indices of the last token (i.e. the last token for each batch item)
+ # Use flip and max() to get the last index of 1 in the attention mask
+
+ if torch.jit.is_tracing():
+ # Avoid tracing the argmax with int64 input that can not be handled by ONNX Runtime: https://github.com/microsoft/onnxruntime/issues/10068
+ attention_mask = attention_mask.to(torch.int32)
+
+ values, indices = attention_mask.flip(1).max(1)
+ indices = torch.where(values == 0, seq_len - 1, indices)
+ gather_indices = seq_len - indices - 1
+
+ # Turn indices from shape [bs] --> [bs, 1, hidden_dim]
+ gather_indices = gather_indices.unsqueeze(-1).repeat(1, hidden_dim)
+ gather_indices = gather_indices.unsqueeze(1)
+ assert gather_indices.shape == (bs, 1, hidden_dim)
+
+ # Gather along the 1st dim (seq_len) (bs, seq_len, hidden_dim -> bs, hidden_dim)
+ # Actually no need for the attention mask as we gather the last token where attn_mask = 1
+ # but as we set some indices (which shouldn't be attended to) to 0 with clamp, we
+ # use the attention mask to ignore them again
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ embedding = torch.gather(token_embeddings * input_mask_expanded, 1, gather_indices).squeeze(dim=1)
+ output_vectors.append(embedding)
+
+ output_vector = torch.cat(output_vectors, 1)
+ features["sentence_embedding"] = output_vector
+ return features
+
+ def get_sentence_embedding_dimension(self) -> int:
+ return self.pooling_output_dimension
+
+ def get_config_dict(self) -> dict[str, Any]:
+ return {key: self.__dict__[key] for key in self.config_keys}
+
+ def save(self, output_path) -> None:
+ with open(os.path.join(output_path, "config.json"), "w") as fOut:
+ json.dump(self.get_config_dict(), fOut, indent=2)
+
+ @staticmethod
+ def load(input_path) -> Pooling:
+ with open(os.path.join(input_path, "config.json")) as fIn:
+ config = json.load(fIn)
+
+ return Pooling(**config)
diff --git a/sentence_transformers/sampler.py b/sentence_transformers/sampler.py
index f78623c5a..7efc19bf1 100644
--- a/sentence_transformers/sampler.py
+++ b/sentence_transformers/sampler.py
@@ -167,7 +167,7 @@ def __init__(
seed (int, optional): Seed for the random number generator to ensure reproducibility.
"""
super().__init__(dataset, batch_size, drop_last)
- if label_columns := set(dataset.column_names) & (set(valid_label_columns) | {"dataset_name"}):
+ if label_columns := set(dataset.column_names) & set(valid_label_columns):
dataset = dataset.remove_columns(label_columns)
self.dataset = dataset
self.batch_size = batch_size
@@ -189,7 +189,11 @@ def __iter__(self) -> Iterator[list[int]]:
batch_values = set()
batch_indices = []
for index in remaining_indices:
- sample_values = set(self.dataset[index].values())
+ sample_values = {
+ value
+ for key, value in self.dataset[index].items()
+ if not key.endswith("_prompt_length") and key != "dataset_name"
+ }
if sample_values & batch_values:
continue
diff --git a/sentence_transformers/trainer.py b/sentence_transformers/trainer.py
index 090d6d454..68a60edbf 100644
--- a/sentence_transformers/trainer.py
+++ b/sentence_transformers/trainer.py
@@ -4,6 +4,7 @@
import os
from collections import OrderedDict
from contextlib import nullcontext
+from functools import partial
from typing import TYPE_CHECKING, Any, Callable
import torch
@@ -21,6 +22,7 @@
from sentence_transformers.evaluation import SentenceEvaluator, SequentialEvaluator
from sentence_transformers.losses.CoSENTLoss import CoSENTLoss
from sentence_transformers.model_card import ModelCardCallback
+from sentence_transformers.models import Pooling
from sentence_transformers.models.Transformer import Transformer
from sentence_transformers.sampler import (
DefaultBatchSampler,
@@ -77,10 +79,10 @@ class SentenceTransformerTrainer(Trainer):
loss (Optional[Union[:class:`torch.nn.Module`, Dict[str, :class:`torch.nn.Module`],\
Callable[[:class:`~sentence_transformers.SentenceTransformer`], :class:`torch.nn.Module`],\
Dict[str, Callable[[:class:`~sentence_transformers.SentenceTransformer`]]]], *optional*):
- The loss function to use for training. Can either be a loss class instance, a dictionary mapping dataset names to
- loss class instances, a function that returns a loss class instance given a model, or a dictionary mapping
- dataset names to functions that return a loss class instance given a model. In practice, the latter two
- are primarily used for hyper-parameter optimization. Will default to
+ The loss function to use for training. Can either be a loss class instance, a dictionary mapping
+ dataset names to loss class instances, a function that returns a loss class instance given a model,
+ or a dictionary mapping dataset names to functions that return a loss class instance given a model.
+ In practice, the latter two are primarily used for hyper-parameter optimization. Will default to
:class:`~sentence_transformers.losses.CoSENTLoss` if no ``loss`` is provided.
evaluator (Union[:class:`~sentence_transformers.evaluation.SentenceEvaluator`,\
List[:class:`~sentence_transformers.evaluation.SentenceEvaluator`]], *optional*):
@@ -232,6 +234,8 @@ def __init__(
# to avoid having to specify it in the data collator or model's forward
self.can_return_loss = True
+ self._prompt_length_mapping = {}
+
self.model: SentenceTransformer
self.args: SentenceTransformerTrainingArguments
self.data_collator: SentenceTransformerDataCollator
@@ -259,11 +263,21 @@ def __init__(
)
else:
self.loss = self.prepare_loss(loss, model)
+
# If evaluator is a list, we wrap it in a SequentialEvaluator
if evaluator is not None and not isinstance(evaluator, SentenceEvaluator):
evaluator = SequentialEvaluator(evaluator)
self.evaluator = evaluator
+ if self.train_dataset is not None:
+ self.train_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ train_dataset, args.prompts, dataset_name="train"
+ )
+ if self.eval_dataset is not None:
+ self.eval_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ eval_dataset, args.prompts, dataset_name="eval"
+ )
+
# Add a callback responsible for automatically tracking data required for the automatic model card generation
model_card_callback = ModelCardCallback(self, default_args_dict)
self.add_callback(model_card_callback)
@@ -410,9 +424,12 @@ def evaluate(
ignore_keys: list[str] | None = None,
metric_key_prefix: str = "eval",
) -> dict[str, float]:
- eval_dataset = eval_dataset if eval_dataset is not None else self.eval_dataset
- if isinstance(eval_dataset, DatasetDict) and isinstance(self.loss, dict):
- eval_dataset = self.add_dataset_name_column(eval_dataset)
+ if eval_dataset:
+ eval_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ eval_dataset, self.args.prompts, dataset_name="eval"
+ )
+ else:
+ eval_dataset = self.eval_dataset
return super().evaluate(eval_dataset, ignore_keys, metric_key_prefix)
def evaluation_loop(
@@ -483,7 +500,12 @@ def _load_best_model(self) -> None:
self.model = full_model
self.model[0].auto_model = loaded_auto_model
- def validate_column_names(self, dataset: Dataset, dataset_name: str | None = None) -> bool:
+ def validate_column_names(self, dataset: Dataset, dataset_name: str | None = None) -> None:
+ if isinstance(dataset, dict):
+ for dataset_name, dataset in dataset.items():
+ self.validate_column_names(dataset, dataset_name=dataset_name)
+ return
+
if overlap := set(dataset.column_names) & {"return_loss", "dataset_name"}:
raise ValueError(
f"The following column names are invalid in your {dataset_name + ' ' if dataset_name else ''}dataset: {list(overlap)}."
@@ -593,7 +615,7 @@ def get_train_dataloader(self) -> DataLoader:
Subclass and override this method if you want to inject some custom behavior.
"""
if self.train_dataset is None:
- raise ValueError("Trainer: training requires a train_dataset.")
+ raise ValueError("Training requires specifying a train_dataset to the SentenceTransformerTrainer.")
train_dataset = self.train_dataset
data_collator = self.data_collator
@@ -617,6 +639,8 @@ def get_train_dataloader(self) -> DataLoader:
"drop_last": self.args.dataloader_drop_last,
}
)
+ if self.args.batch_sampler != BatchSamplers.BATCH_SAMPLER:
+ logger.warning("When using an IterableDataset, you cannot specify a batch sampler.")
elif isinstance(train_dataset, IterableDatasetDict):
raise ValueError(
@@ -624,14 +648,12 @@ def get_train_dataloader(self) -> DataLoader:
)
elif isinstance(train_dataset, DatasetDict):
- for dataset_name, dataset in train_dataset.items():
- self.validate_column_names(dataset, dataset_name=dataset_name)
+ for dataset in train_dataset.values():
if isinstance(dataset, IterableDataset):
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- train_dataset = self.add_dataset_name_column(train_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -653,8 +675,6 @@ def get_train_dataloader(self) -> DataLoader:
dataloader_params["batch_sampler"] = batch_sampler
elif isinstance(train_dataset, Dataset):
- self.validate_column_names(train_dataset)
-
batch_sampler = self.get_batch_sampler(
train_dataset,
batch_size=self.args.train_batch_size,
@@ -675,7 +695,7 @@ def get_train_dataloader(self) -> DataLoader:
self._train_dataloader = self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params))
return self._train_dataloader
- def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader:
+ def get_eval_dataloader(self, eval_dataset: Dataset | DatasetDict | IterableDataset | None = None) -> DataLoader:
"""
Returns the evaluation [`~torch.utils.data.DataLoader`].
@@ -690,7 +710,8 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
# Prevent errors if the evaluator is set but no eval_dataset is provided
if self.evaluator is not None:
return DataLoader([])
- raise ValueError("Trainer: evaluation requires an eval_dataset.")
+ raise ValueError("Evaluation requires specifying an eval_dataset to the SentenceTransformerTrainer.")
+
eval_dataset = eval_dataset if eval_dataset is not None else self.eval_dataset
data_collator = self.data_collator
@@ -724,8 +745,7 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- eval_dataset = self.add_dataset_name_column(eval_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -767,7 +787,7 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
self.accelerator.even_batches = True
return self.accelerator.prepare(DataLoader(eval_dataset, **dataloader_params))
- def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
+ def get_test_dataloader(self, test_dataset: Dataset | DatasetDict | IterableDataset) -> DataLoader:
"""
Returns the training [`~torch.utils.data.DataLoader`].
@@ -806,14 +826,12 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
)
elif isinstance(test_dataset, DatasetDict):
- for dataset_name, dataset in test_dataset.items():
- self.validate_column_names(dataset, dataset_name=dataset_name)
+ for dataset in test_dataset.values():
if isinstance(dataset, IterableDataset):
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- test_dataset = self.add_dataset_name_column(test_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -835,8 +853,6 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
dataloader_params["batch_sampler"] = batch_sampler
elif isinstance(test_dataset, Dataset):
- self.validate_column_names(test_dataset)
-
batch_sampler = self.get_batch_sampler(
test_dataset,
batch_size=self.args.eval_batch_size,
@@ -852,11 +868,10 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
)
# If 'even_batches' is True, it will use the initial few samples to pad out the last sample. This can
- # cause issues with multi-dataset training, so we want to set this to False.
- # For evaluation, setting 'even_batches' to False results in hanging, so we keep it as True there.
- self.accelerator.even_batches = False
- self._train_dataloader = self.accelerator.prepare(DataLoader(test_dataset, **dataloader_params))
- return self._train_dataloader
+ # cause issues with multi-dataset training, so we want to set this to False during training.
+ # For evaluation, setting 'even_batches' to False results in hanging, so we keep it as True here.
+ self.accelerator.even_batches = True
+ return self.accelerator.prepare(DataLoader(test_dataset, **dataloader_params))
def _save(self, output_dir: str | None = None, state_dict=None) -> None:
# If we are executing this function, we are the process zero, so we don't check for that.
@@ -883,6 +898,243 @@ def _load_from_checkpoint(self, checkpoint_path: str) -> None:
loaded_model = SentenceTransformer(checkpoint_path, trust_remote_code=self.model.trust_remote_code)
self.model.load_state_dict(loaded_model.state_dict())
+ def _get_prompt_length(self, prompt: str) -> int:
+ try:
+ return self._prompt_length_mapping[prompt]
+ except KeyError:
+ prompt_length = self.model.tokenize([prompt])["input_ids"].shape[-1] - 1
+ self._prompt_length_mapping[prompt] = prompt_length
+ return prompt_length
+
+ def _include_prompt_length(self) -> bool:
+ """
+ Return whether the prompt length should be passed to the model's forward method.
+
+ True if the model does not include the prompt in the pooling layer. Can be
+ overridden by the user if it's useful to include the prompt length.
+ """
+ for module in self.model:
+ if isinstance(module, Pooling):
+ return not module.include_prompt
+ return False
+
+ @staticmethod
+ def add_prompts_or_dataset_name_transform(
+ batch: dict[str, list[Any]],
+ prompts: dict[str, str] | str | None = None,
+ prompt_lengths: dict[str, int] | int | None = None,
+ dataset_name: str | None = None,
+ transform: Callable[[dict[str, list[Any]]], dict[str, list[Any]]] = None,
+ **kwargs,
+ ) -> dict[str, list[Any]]:
+ """A transform/map function that adds prompts or dataset names to the batch.
+
+ Args:
+ batch (dict[str, list[Any]]): The batch of data, where each key is a column name and each value
+ is a list of values.
+ prompts (dict[str, str] | str | None, optional): An optional mapping of column names to string
+ prompts, or a string prompt for all columns. Defaults to None.
+ prompt_lengths (dict[str, int] | int | None, optional): An optional mapping of prompts names to
+ prompt token length, or a prompt token length if the prompt is a string. Defaults to None.
+ dataset_name (str | None, optional): The name of this dataset, only if there are multiple datasets
+ that use a different loss. Defaults to None.
+ transform (Callable[[dict[str, list[Any]]], dict[str, list[Any]]], optional): An optional transform
+ function to apply on the batch before adding prompts, etc. Defaults to None.
+
+ Returns:
+ dict[str, list[Any]]: The "just-in-time" transformed batch with prompts and/or dataset names added.
+ """
+ # If the dataset is a Dataset(Dict), then we use set_transform and we want to also apply any
+ # previous transform if it exists
+ if transform:
+ batch = transform(batch)
+
+ # Return if the batch has no columns...
+ if not batch:
+ return batch
+
+ # ... or if it's empty
+ first_column = list(batch.keys())[0]
+ if not batch[first_column]:
+ return batch
+
+ # Apply one prompt to all columns...
+ if isinstance(prompts, str):
+ for column_name, column in list(batch.items()):
+ if isinstance(column[0], str):
+ batch[column_name] = [prompts + value for value in column]
+
+ if prompt_lengths is not None:
+ batch[f"{column_name}_prompt_length"] = [prompt_lengths] * len(column)
+
+ # ... or a column-specific prompt
+ if isinstance(prompts, dict):
+ for column_name, prompt in prompts.items():
+ if column_name in batch:
+ batch[column_name] = [prompt + value for value in batch[column_name]]
+
+ if prompt_lengths:
+ batch[f"{column_name}_prompt_length"] = [prompt_lengths[prompt]] * len(batch[column_name])
+
+ # If we have multiple losses, then we need to add the dataset name to the batch
+ if dataset_name:
+ batch["dataset_name"] = [dataset_name] * len(batch[first_column])
+
+ return batch
+
+ def maybe_add_prompts_or_dataset_name_column(
+ self,
+ dataset_dict: DatasetDict | Dataset | None,
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None = None,
+ dataset_name: str | None = None,
+ ) -> DatasetDict | Dataset | None:
+ """
+ Maybe add prompts or dataset names to the dataset. We add the dataset_name column to the dataset if:
+
+ 1. The loss is a dictionary and the dataset is a DatasetDict, or
+ 2. The prompts contain a mapping to dataset names.
+
+ There are 4 cases for the prompts:
+
+ 1. `str`: One prompt for all datasets and columns.
+ 2. `dict[str, str]`: A column to prompt mapping.
+ 3. `dict[str, str]`: A dataset to prompt mapping.
+ 4. `dict[str, dict[str, str]]`: A dataset to column to prompt mapping.
+
+ And 2 cases for the dataset:
+
+ A. `Dataset`: A single dataset.
+ B. `DatasetDict`: A dictionary of datasets.
+
+ 3A is not allowed, and 2A doesn't make sense.
+
+ Args:
+ dataset_dict (DatasetDict | Dataset | None): The dataset to add prompts or dataset names to.
+
+ Returns:
+ DatasetDict | Dataset | None: The dataset with prompts or dataset names added.
+ """
+ if dataset_dict is None:
+ return None
+
+ include_dataset_name = isinstance(self.loss, dict)
+
+ # If we've already added the transform to this (iterable) dataset, don't add it again
+ if hasattr(dataset_dict, "_sentence_transformers_preprocessed"):
+ return dataset_dict
+
+ # Ensure that there's no "dataset_name"/"return_loss" columns in the unprocessed datasets
+ self.validate_column_names(dataset_dict, dataset_name=dataset_name)
+
+ # Only add if 1) we have prompts or 2) we need the dataset name for the loss dictionary
+ if prompts or include_dataset_name:
+ include_prompt_lengths = self._include_prompt_length()
+ dataset_dict = self.add_prompts_or_dataset_name_column(
+ dataset_dict,
+ prompts=prompts,
+ include_prompt_lengths=include_prompt_lengths,
+ include_dataset_name=include_dataset_name,
+ )
+ return dataset_dict
+
+ def add_prompts_or_dataset_name_column(
+ self,
+ dataset_dict: DatasetDict | IterableDatasetDict | Dataset | IterableDataset,
+ prompts: dict[str, str] | str | None = None,
+ dataset_name: str | None = None,
+ include_prompt_lengths: bool = False,
+ include_dataset_name: bool = False,
+ ) -> DatasetDict | Dataset | None:
+ # If we have DatasetDict, recurse
+ if isinstance(dataset_dict, (IterableDatasetDict, DatasetDict)):
+ for dataset_name, dataset in dataset_dict.items():
+ # If prompts is a dictionary that matches the dataset names, then take the nested prompts
+ nested_prompts = prompts.get(dataset_name, prompts) if isinstance(prompts, dict) else prompts
+ dataset_dict[dataset_name] = self.add_prompts_or_dataset_name_column(
+ dataset_dict=dataset,
+ prompts=nested_prompts,
+ dataset_name=dataset_name if include_dataset_name else None,
+ include_prompt_lengths=include_prompt_lengths,
+ include_dataset_name=include_dataset_name,
+ )
+ return dataset_dict
+
+ # Get the prompt lengths if needed for the pooling layer
+ prompt_lengths = None
+ if prompts:
+ if isinstance(prompts, str):
+ if include_prompt_lengths:
+ prompt_lengths = self._get_prompt_length(prompts)
+ elif isinstance(prompts, dict):
+ first_key = list(prompts.keys())[0]
+ if isinstance(prompts[first_key], dict):
+ raise ValueError(
+ "The prompts provided to the trainer are a nested dictionary. In this setting, the first "
+ "level of the dictionary should map to dataset names and the second level to column names. "
+ "However, as the provided dataset is a not a DatasetDict, no dataset names can be inferred. "
+ f"The keys to the provided prompts dictionary are {list(prompts.keys())!r}"
+ )
+ if include_prompt_lengths:
+ # If prompt columns exist, add the prompt length column
+ prompt_lengths = {
+ prompt: self._get_prompt_length(prompt)
+ for column_name, prompt in prompts.items()
+ if column_name in dataset_dict.column_names
+ }
+
+ # If we have a Dataset, we can set the transform directly...
+ if isinstance(dataset_dict, Dataset):
+ dataset_dict.set_transform(
+ partial(
+ self.add_prompts_or_dataset_name_transform,
+ prompts=prompts,
+ prompt_lengths=prompt_lengths,
+ dataset_name=dataset_name,
+ **dataset_dict._format_kwargs,
+ )
+ )
+
+ # ... otherwise, we have an IterableDataset and we need to map it, which performs the same operation as above
+ elif isinstance(dataset_dict, IterableDataset):
+ # Update the features to include the new columns
+ features = dataset_dict.features
+ if dataset_name:
+ features["dataset_name"] = Value("string")
+ if prompt_lengths:
+ if isinstance(prompts, str):
+ for column_name in dataset_dict.column_names:
+ feature = features[column_name]
+ if isinstance(feature, Value) and feature.dtype in ("string", "large_string"):
+ features[f"{column_name}_prompt_length"] = Value("int16")
+ elif isinstance(prompts, dict):
+ for column_name, prompt in prompts.items():
+ feature = features[column_name]
+ if (
+ prompt in prompt_lengths
+ and isinstance(feature, Value)
+ and feature.dtype in ("string", "large_string")
+ ):
+ features[f"{column_name}_prompt_length"] = Value("int16")
+
+ dataset_dict = dataset_dict.map(
+ partial(
+ self.add_prompts_or_dataset_name_transform,
+ prompts=prompts,
+ prompt_lengths=prompt_lengths,
+ dataset_name=dataset_name,
+ ),
+ batched=True,
+ features=features,
+ )
+
+ else:
+ raise ValueError("Unsupported dataset type.")
+
+ # Add a tag to the dataset to indicate that it has been preprocessed, to ensure that we don't apply the map or
+ # transform multiple times.
+ dataset_dict._sentence_transformers_preprocessed = True
+ return dataset_dict
+
def create_model_card(
self,
language: str | None = None,
diff --git a/sentence_transformers/training_args.py b/sentence_transformers/training_args.py
index ca1e15da8..68a659e30 100644
--- a/sentence_transformers/training_args.py
+++ b/sentence_transformers/training_args.py
@@ -149,6 +149,19 @@ class SentenceTransformerTrainingArguments(TransformersTrainingArguments):
Args:
output_dir (`str`):
The output directory where the model checkpoints will be written.
+ prompts (`Union[Dict[str, Dict[str, str]], Dict[str, str], str]`, *optional*):
+ The prompts to use for each column in the training, evaluation and test datasets. Four formats are accepted:
+
+ 1. `str`: A single prompt to use for all columns in the datasets, regardless of whether the training/evaluation/test
+ datasets are :class:`datasets.Dataset` or a :class:`datasets.DatasetDict`.
+ 2. `Dict[str, str]`: A dictionary mapping column names to prompts, regardless of whether the training/evaluation/test
+ datasets are :class:`datasets.Dataset` or a :class:`datasets.DatasetDict`.
+ 3. `Dict[str, str]`: A dictionary mapping dataset names to prompts. This should only be used if your training/evaluation/test
+ datasets are a :class:`datasets.DatasetDict` or a dictionary of :class:`datasets.Dataset`.
+ 4. `Dict[str, Dict[str, str]]`: A dictionary mapping dataset names to dictionaries mapping column names to
+ prompts. This should only be used if your training/evaluation/test datasets are a
+ :class:`datasets.DatasetDict` or a dictionary of :class:`datasets.Dataset`.
+
batch_sampler (Union[:class:`~sentence_transformers.training_args.BatchSamplers`, `str`], *optional*):
The batch sampler to use. See :class:`~sentence_transformers.training_args.BatchSamplers` for valid options.
Defaults to ``BatchSamplers.BATCH_SAMPLER``.
@@ -157,6 +170,7 @@ class SentenceTransformerTrainingArguments(TransformersTrainingArguments):
for valid options. Defaults to ``MultiDatasetBatchSamplers.PROPORTIONAL``.
"""
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None = None
batch_sampler: BatchSamplers | str = field(
default=BatchSamplers.BATCH_SAMPLER, metadata={"help": "The batch sampler to use."}
)
diff --git a/tests/test_sentence_transformer.py b/tests/test_sentence_transformer.py
index 3253bf2f9..588195b2a 100644
--- a/tests/test_sentence_transformer.py
+++ b/tests/test_sentence_transformer.py
@@ -284,12 +284,12 @@ def test_load_with_revision() -> None:
assert not torch.equal(main_embeddings, older_model.encode(test_sentence, convert_to_tensor=True))
-def test_load_local_without_normalize_directory() -> None:
- tiny_model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
- tiny_model.add_module("Normalize", Normalize())
+def test_load_local_without_normalize_directory(stsb_bert_tiny_model: SentenceTransformer) -> None:
+ model = stsb_bert_tiny_model
+ model.add_module("Normalize", Normalize())
with SafeTemporaryDirectory() as tmp_folder:
model_path = Path(tmp_folder) / "tiny_model_local"
- tiny_model.save(str(model_path))
+ model.save(str(model_path))
assert (model_path / "2_Normalize").exists()
os.rmdir(model_path / "2_Normalize")
@@ -300,8 +300,8 @@ def test_load_local_without_normalize_directory() -> None:
assert isinstance(fresh_tiny_model, SentenceTransformer)
-def test_prompts(caplog: pytest.LogCaptureFixture) -> None:
- model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
+def test_prompts(stsb_bert_tiny_model: SentenceTransformer, caplog: pytest.LogCaptureFixture) -> None:
+ model = stsb_bert_tiny_model
assert model.prompts == {}
assert model.default_prompt_name is None
texts = ["How to bake a chocolate cake", "Symptoms of the flu"]
@@ -469,13 +469,14 @@ def test_encode_quantization(
@pytest.mark.parametrize("normalize_embeddings", [True, False])
@pytest.mark.parametrize("output_value", ["sentence_embedding", None])
def test_encode_truncate(
+ stsb_bert_tiny_model_reused: SentenceTransformer,
sentences: str | list[str],
convert_to_tensor: bool,
convert_to_numpy: bool,
normalize_embeddings: bool,
output_value: Literal["sentence_embedding"] | None,
) -> None:
- model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
+ model = stsb_bert_tiny_model_reused
embeddings_full_unnormalized: torch.Tensor = model.encode(
sentences, convert_to_numpy=False, convert_to_tensor=True
) # These are raw embeddings which serve as the reference to test against
diff --git a/tests/test_trainer.py b/tests/test_trainer.py
index e7e9827d5..a978d8f5e 100644
--- a/tests/test_trainer.py
+++ b/tests/test_trainer.py
@@ -12,18 +12,21 @@
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
+from sentence_transformers.losses import MultipleNegativesRankingLoss
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
from sentence_transformers.util import is_datasets_available, is_training_available
from tests.utils import SafeTemporaryDirectory
if is_datasets_available():
- from datasets import DatasetDict, load_dataset
+ from datasets import Dataset, DatasetDict, IterableDatasetDict, load_dataset
+
+if not is_training_available():
+ pytest.skip(
+ reason='Sentence Transformers was not installed with the `["train"]` extra.',
+ allow_module_level=True,
+ )
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_trainer_multi_dataset_errors(
stsb_bert_tiny_model: SentenceTransformer, stsb_dataset_dict: DatasetDict
) -> None:
@@ -89,25 +92,20 @@ def test_trainer_multi_dataset_errors(
)
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_trainer_invalid_column_names(
stsb_bert_tiny_model: SentenceTransformer, stsb_dataset_dict: DatasetDict
) -> None:
train_dataset = stsb_dataset_dict["train"]
for column_name in ("return_loss", "dataset_name"):
invalid_train_dataset = train_dataset.rename_column("sentence1", column_name)
- trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
with pytest.raises(
ValueError,
match=re.escape(
- f"The following column names are invalid in your dataset: ['{column_name}']."
- " Avoid using these column names, as they are reserved for internal use."
+ f"The following column names are invalid in your train dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use.",
),
):
- trainer.train()
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
invalid_train_dataset = DatasetDict(
{
@@ -115,7 +113,6 @@ def test_trainer_invalid_column_names(
"stsb-2": train_dataset,
}
)
- trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
with pytest.raises(
ValueError,
match=re.escape(
@@ -123,13 +120,61 @@ def test_trainer_invalid_column_names(
" Avoid using these column names, as they are reserved for internal use."
),
):
- trainer.train()
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
+
+ train_dataset = stsb_dataset_dict["train"]
+ eval_dataset = stsb_dataset_dict["validation"]
+ for column_name in ("return_loss", "dataset_name"):
+ invalid_eval_dataset = eval_dataset.rename_column("sentence1", column_name)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your eval dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer = SentenceTransformerTrainer(
+ model=stsb_bert_tiny_model, train_dataset=train_dataset, eval_dataset=invalid_eval_dataset
+ )
+
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=train_dataset)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your eval dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer.evaluate(eval_dataset=invalid_eval_dataset)
+
+ invalid_eval_dataset = DatasetDict(
+ {
+ "stsb": eval_dataset.rename_column("sentence1", column_name),
+ "stsb-2": eval_dataset,
+ }
+ )
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your stsb dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer = SentenceTransformerTrainer(
+ model=stsb_bert_tiny_model, train_dataset=train_dataset, eval_dataset=invalid_eval_dataset
+ )
+
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=train_dataset)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your stsb dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer.evaluate(eval_dataset=invalid_eval_dataset)
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_model_card_reuse(stsb_bert_tiny_model: SentenceTransformer):
assert stsb_bert_tiny_model._model_card_text
# Reuse the model card if no training was done
@@ -153,10 +198,6 @@ def test_model_card_reuse(stsb_bert_tiny_model: SentenceTransformer):
assert model_card_text != stsb_bert_tiny_model._model_card_text
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
@pytest.mark.parametrize("streaming", [False, True])
@pytest.mark.parametrize("train_dict", [False, True])
@pytest.mark.parametrize("eval_dict", [False, True])
@@ -234,6 +275,346 @@ def test_trainer(
assert not torch.equal(original_embeddings, new_embeddings)
+@pytest.mark.slow
+@pytest.mark.parametrize("train_dict", [False, True])
+@pytest.mark.parametrize("eval_dict", [False, True])
+@pytest.mark.parametrize("loss_dict", [False, True])
+@pytest.mark.parametrize("pool_include_prompt", [False, True])
+@pytest.mark.parametrize("add_transform", [False, True])
+@pytest.mark.parametrize("streaming", [False, True])
+@pytest.mark.parametrize(
+ "prompts",
+ [
+ None, # No prompt
+ "Prompt: ", # Single prompt to all columns and all datasets
+ {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "}, # Different prompts for different datasets
+ {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "}, # Different prompts for different columns
+ {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ }, # Different prompts for different datasets and columns
+ ],
+)
+def test_trainer_prompts(
+ stsb_bert_tiny_model_reused: SentenceTransformer,
+ train_dict: bool,
+ eval_dict: bool,
+ loss_dict: bool,
+ pool_include_prompt: bool,
+ add_transform: bool,
+ streaming: bool,
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None,
+):
+ if loss_dict and (not train_dict or not eval_dict):
+ pytest.skip(
+ "Skipping test because loss_dict=True requires train_dict=True and eval_dict=True; already tested via test_trainer."
+ )
+
+ model = stsb_bert_tiny_model_reused
+ model[1].include_prompt = pool_include_prompt
+
+ train_dataset_1 = Dataset.from_dict(
+ {
+ "sentence1": ["train 1 sentence 1a", "train 1 sentence 1b"],
+ "sentence2": ["train 1 sentence 2a", "train 1 sentence 2b"],
+ }
+ )
+ train_dataset_2 = Dataset.from_dict(
+ {
+ "sentence1": ["train 2 sentence 1a", "train 2 sentence 1b"],
+ "sentence2": ["train 2 sentence 2a", "train 2 sentence 2b"],
+ }
+ )
+ eval_dataset_1 = Dataset.from_dict(
+ {
+ "sentence1": ["eval 1 sentence 1a", "eval 1 sentence 1b"],
+ "sentence2": ["eval 1 sentence 2a", "eval 1 sentence 2b"],
+ }
+ )
+ eval_dataset_2 = Dataset.from_dict(
+ {
+ "sentence1": ["eval 2 sentence 1a", "eval 2 sentence 1b"],
+ "sentence2": ["eval 2 sentence 2a", "eval 2 sentence 2b"],
+ }
+ )
+ tracked_forward_keys = set()
+
+ class EmptyLoss(MultipleNegativesRankingLoss):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def forward(self, features, *args, **kwargs):
+ tracked_forward_keys.update(set(features[0].keys()))
+ return super().forward(features, *args, **kwargs)
+
+ loss = EmptyLoss(model=model)
+ # loss = MultipleNegativesRankingLoss(model=model)
+
+ tracked_texts = []
+ old_tokenize = model.tokenize
+
+ def tokenize_tracker(texts, *args, **kwargs):
+ tracked_texts.extend(texts)
+ return old_tokenize(texts, *args, **kwargs)
+
+ model.tokenize = tokenize_tracker
+
+ if train_dict:
+ if streaming:
+ train_dataset = IterableDatasetDict({"stsb-1": train_dataset_1, "stsb-2": train_dataset_2})
+ else:
+ train_dataset = DatasetDict({"stsb-1": train_dataset_1, "stsb-2": train_dataset_2})
+ else:
+ if streaming:
+ train_dataset = train_dataset_1.to_iterable_dataset()
+ else:
+ train_dataset = train_dataset_1
+
+ if eval_dict:
+ if streaming:
+ eval_dataset = IterableDatasetDict({"stsb-1": eval_dataset_1, "stsb-2": eval_dataset_2})
+ else:
+ eval_dataset = DatasetDict({"stsb-1": eval_dataset_1, "stsb-2": eval_dataset_2})
+ else:
+ if streaming:
+ eval_dataset = eval_dataset_1.to_iterable_dataset()
+ else:
+ eval_dataset = eval_dataset_1
+
+ def upper_transform(batch):
+ for column_name, column in batch.items():
+ batch[column_name] = [text.upper() for text in column]
+ return batch
+
+ if add_transform:
+ if streaming:
+ if train_dict:
+ train_dataset = IterableDatasetDict(
+ {
+ dataset_name: dataset.map(upper_transform, batched=True, features=dataset.features)
+ for dataset_name, dataset in train_dataset.items()
+ }
+ )
+ else:
+ train_dataset = train_dataset.map(upper_transform, batched=True, features=train_dataset.features)
+ if eval_dict:
+ eval_dataset = IterableDatasetDict(
+ {
+ dataset_name: dataset.map(upper_transform, batched=True, features=dataset.features)
+ for dataset_name, dataset in eval_dataset.items()
+ }
+ )
+ else:
+ eval_dataset = eval_dataset.map(upper_transform, batched=True, features=eval_dataset.features)
+ else:
+ train_dataset.set_transform(upper_transform)
+ eval_dataset.set_transform(upper_transform)
+
+ if loss_dict:
+ loss = {
+ "stsb-1": loss,
+ "stsb-2": loss,
+ }
+
+ # Variables to more easily track the expected outputs. Uppercased if add_transform is True as we expect
+ # the transform to be applied to the data.
+ all_train_1_1 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_1["sentence1"]}
+ all_train_1_2 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_1["sentence2"]}
+ all_train_2_1 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_2["sentence1"]}
+ all_train_2_2 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_2["sentence2"]}
+ all_eval_1_1 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_1["sentence1"]}
+ all_eval_1_2 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_1["sentence2"]}
+ all_eval_2_1 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_2["sentence1"]}
+ all_eval_2_2 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_2["sentence2"]}
+ all_train_1 = all_train_1_1 | all_train_1_2
+ all_train_2 = all_train_2_1 | all_train_2_2
+ all_eval_1 = all_eval_1_1 | all_eval_1_2
+ all_eval_2 = all_eval_2_1 | all_eval_2_2
+ all_train = all_train_1 | all_train_2
+ all_eval = all_eval_1 | all_eval_2
+
+ if prompts == {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ } and (train_dict, eval_dict) != (True, True):
+ context = pytest.raises(
+ ValueError,
+ match="The prompts provided to the trainer are a nested dictionary. In this setting, the first "
+ "level of the dictionary should map to dataset names and the second level to column names. "
+ "However, as the provided dataset is a not a DatasetDict, no dataset names can be inferred. "
+ "The keys to the provided prompts dictionary are .*",
+ )
+ else:
+ context = nullcontext()
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+ args = SentenceTransformerTrainingArguments(
+ output_dir=str(temp_dir),
+ prompts=prompts,
+ max_steps=2,
+ eval_steps=2,
+ eval_strategy="steps",
+ per_device_train_batch_size=1,
+ per_device_eval_batch_size=1,
+ report_to=["none"],
+ )
+ with context:
+ trainer = SentenceTransformerTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ loss=loss,
+ )
+ if not isinstance(context, nullcontext):
+ return
+
+ datacollator_keys = set()
+ old_compute_loss = trainer.compute_loss
+
+ def compute_loss_tracker(model, inputs, **kwargs):
+ datacollator_keys.update(set(inputs.keys()))
+ loss = old_compute_loss(model, inputs, **kwargs)
+ return loss
+
+ trainer.compute_loss = compute_loss_tracker
+ trainer.train()
+
+ # In this one edge case, the prompts won't be used because the datasets aren't dictionaries, so the prompts
+ # are seen as column names & ignored as they don't exist.
+ if (
+ prompts
+ and not pool_include_prompt
+ and not (
+ prompts == {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "} and (train_dict, eval_dict) == (False, False)
+ )
+ ):
+ assert "prompt_length" in tracked_forward_keys
+ else:
+ assert "prompt_length" not in tracked_forward_keys
+
+ # We only need the dataset_name if the loss requires it
+ if loss_dict:
+ assert "dataset_name" in datacollator_keys
+ else:
+ assert "dataset_name" not in datacollator_keys
+
+ if prompts is None:
+ if (train_dict, eval_dict) == (False, False):
+ expected = all_train_1 | all_eval_1
+ elif (train_dict, eval_dict) == (True, False):
+ expected = all_train | all_eval_1
+ if (train_dict, eval_dict) == (False, True):
+ expected = all_train_1 | all_eval
+ elif (train_dict, eval_dict) == (True, True):
+ expected = all_train | all_eval
+
+ elif prompts == "Prompt: ":
+ if (train_dict, eval_dict) == (False, False):
+ expected = {prompts + sample for sample in all_train_1} | {prompts + sample for sample in all_eval_1}
+ elif (train_dict, eval_dict) == (True, False):
+ expected = {prompts + sample for sample in all_train} | {prompts + sample for sample in all_eval_1}
+ if (train_dict, eval_dict) == (False, True):
+ expected = {prompts + sample for sample in all_train_1} | {prompts + sample for sample in all_eval}
+ elif (train_dict, eval_dict) == (True, True):
+ expected = {prompts + sample for sample in all_train} | {prompts + sample for sample in all_eval}
+
+ if not pool_include_prompt:
+ expected.add(prompts)
+
+ elif prompts == {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "}:
+ # If we don't have dataset dictionaries, the prompts will be seen as column names
+ if (train_dict, eval_dict) == (False, False):
+ expected = all_train_1 | all_eval_1
+ elif (train_dict, eval_dict) == (True, False):
+ expected = (
+ {prompts["stsb-1"] + sample for sample in all_train_1}
+ | {prompts["stsb-2"] + sample for sample in all_train_2}
+ | all_eval_1
+ )
+ if (train_dict, eval_dict) == (False, True):
+ expected = (
+ all_train_1
+ | {prompts["stsb-1"] + sample for sample in all_eval_1}
+ | {prompts["stsb-2"] + sample for sample in all_eval_2}
+ )
+ elif (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["stsb-1"] + sample for sample in all_train_1}
+ | {prompts["stsb-2"] + sample for sample in all_train_2}
+ | {prompts["stsb-1"] + sample for sample in all_eval_1}
+ | {prompts["stsb-2"] + sample for sample in all_eval_2}
+ )
+
+ # We need to add the prompt to the expected set because we need to collect prompt lengths if
+ # not pool_include_prompt, except if the datasets aren't dictionaries
+ if (train_dict, eval_dict) != (False, False) and not pool_include_prompt:
+ expected.update(set(prompts.values()))
+
+ elif prompts == {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "}:
+ if (train_dict, eval_dict) == (False, False):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ )
+ elif (train_dict, eval_dict) == (True, False):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ )
+ if (train_dict, eval_dict) == (False, True):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_2_2}
+ )
+ elif (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_2_2}
+ )
+
+ if not pool_include_prompt:
+ expected.update(set(prompts.values()))
+
+ elif prompts == {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ }:
+ # All other cases are tested above with the ValueError context
+ if (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["stsb-1"]["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["stsb-1"]["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["stsb-2"]["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["stsb-2"]["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["stsb-1"]["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["stsb-1"]["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["stsb-2"]["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["stsb-2"]["sentence2"] + sample for sample in all_eval_2_2}
+ )
+
+ if not pool_include_prompt:
+ expected.update({prompt for inner_dict in prompts.values() for prompt in inner_dict.values()})
+
+ assert set(tracked_texts) == expected
+
+
@pytest.mark.parametrize("use_eval_dataset", [True, False])
@pytest.mark.parametrize("use_evaluator", [True, False])
def test_trainer_no_eval_dataset_with_eval_strategy(
+
+ Additionally, the model trained with prompts includes these prompts in the training dataset details in the automatically generated model card: `tomaarsen/bert-base-nq-prompts#natural-questions `_.
+
+ .. important::
+ If you train with prompts, then it's heavily recommended to store prompts in the model configuration as a mapping of prompt names to prompt strings. You can do this by initializing the :class:`~sentence_transformers.SentenceTransformer` with a ``prompts`` dictionary before saving it, updating the ``model.prompts`` of a loaded model before saving it, and/or updating the `config_sentence_transformers.json `_ file of the saved model.
+
+ After adding the prompts in the model configuration, the final usage of the prompt-trained model becomes::
+
+ from sentence_transformers import SentenceTransformer
+
+ model = SentenceTransformer("tomaarsen/bert-base-nq-prompts")
+ query_embedding = model.encode("What are Pandas?", prompt_name="query")
+ document_embeddings = model.encode([
+ "Pandas is a software library written for the Python programming language for data manipulation and analysis.",
+ "Pandas are a species of bear native to South Central China. They are also known as the giant panda or simply panda.",
+ "Koala bears are not actually bears, they are marsupials native to Australia.",
+ ],
+ prompt_name="document",
+ )
+ similarity = model.similarity(query_embedding, document_embeddings)
+ print(similarity)
+ # => tensor([[0.3955, 0.8226, 0.5706]])
+```
\ No newline at end of file
diff --git a/examples/training/prompts/training_nq_prompts.py b/examples/training/prompts/training_nq_prompts.py
new file mode 100644
index 000000000..65d0013ca
--- /dev/null
+++ b/examples/training/prompts/training_nq_prompts.py
@@ -0,0 +1,114 @@
+# See https://huggingface.co/collections/tomaarsen/training-with-prompts-672ce423c85b4d39aed52853 for some already trained models
+
+import logging
+import random
+
+import numpy
+import torch
+from datasets import Dataset, load_dataset
+
+from sentence_transformers import (
+ SentenceTransformer,
+ SentenceTransformerModelCardData,
+ SentenceTransformerTrainer,
+ SentenceTransformerTrainingArguments,
+)
+from sentence_transformers.evaluation import NanoBEIREvaluator
+from sentence_transformers.losses import CachedMultipleNegativesRankingLoss
+from sentence_transformers.training_args import BatchSamplers
+
+logging.basicConfig(format="%(asctime)s - %(message)s", datefmt="%Y-%m-%d %H:%M:%S", level=logging.INFO)
+random.seed(12)
+torch.manual_seed(12)
+numpy.random.seed(12)
+
+# Feel free to adjust these variables:
+use_prompts = True
+include_prompts_in_pooling = True
+
+# 1. Load a model to finetune with 2. (Optional) model card data
+model = SentenceTransformer(
+ "microsoft/mpnet-base",
+ model_card_data=SentenceTransformerModelCardData(
+ language="en",
+ license="apache-2.0",
+ model_name="MPNet base trained on Natural Questions pairs",
+ ),
+)
+model.set_pooling_include_prompt(include_prompts_in_pooling)
+
+# 2. (Optional) Define prompts
+if use_prompts:
+ query_prompt = "query: "
+ corpus_prompt = "document: "
+ prompts = {
+ "query": query_prompt,
+ "answer": corpus_prompt,
+ }
+
+# 3. Load a dataset to finetune on
+dataset = load_dataset("sentence-transformers/natural-questions", split="train")
+dataset_dict = dataset.train_test_split(test_size=1_000, seed=12)
+train_dataset: Dataset = dataset_dict["train"]
+eval_dataset: Dataset = dataset_dict["test"]
+
+# 4. Define a loss function
+loss = CachedMultipleNegativesRankingLoss(model, mini_batch_size=16)
+
+# 5. (Optional) Specify training arguments
+run_name = "mpnet-base-nq"
+if use_prompts:
+ run_name += "-prompts"
+if not include_prompts_in_pooling:
+ run_name += "-exclude-pooling-prompts"
+args = SentenceTransformerTrainingArguments(
+ # Required parameter:
+ output_dir=f"models/{run_name}",
+ # Optional training parameters:
+ num_train_epochs=1,
+ per_device_train_batch_size=256,
+ per_device_eval_batch_size=256,
+ learning_rate=2e-5,
+ warmup_ratio=0.1,
+ fp16=False, # Set to False if you get an error that your GPU can't run on FP16
+ bf16=True, # Set to True if you have a GPU that supports BF16
+ batch_sampler=BatchSamplers.NO_DUPLICATES, # MultipleNegativesRankingLoss benefits from no duplicate samples in a batch
+ # Optional tracking/debugging parameters:
+ eval_strategy="steps",
+ eval_steps=50,
+ save_strategy="steps",
+ save_steps=50,
+ save_total_limit=2,
+ logging_steps=5,
+ logging_first_step=True,
+ run_name=run_name, # Will be used in W&B if `wandb` is installed
+ seed=12,
+ prompts=prompts if use_prompts else None,
+)
+
+# 6. (Optional) Create an evaluator & evaluate the base model
+dev_evaluator = NanoBEIREvaluator(
+ query_prompts=query_prompt if use_prompts else None,
+ corpus_prompts=corpus_prompt if use_prompts else None,
+)
+dev_evaluator(model)
+
+# 7. Create a trainer & train
+trainer = SentenceTransformerTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ loss=loss,
+ evaluator=dev_evaluator,
+)
+trainer.train()
+
+# (Optional) Evaluate the trained model on the evaluator after training
+dev_evaluator(model)
+
+# 8. Save the trained model
+model.save_pretrained(f"models/{run_name}/final")
+
+# 9. (Optional) Push it to the Hugging Face Hub
+model.push_to_hub(run_name)
diff --git a/index.rst b/index.rst
index b1f3b3843..efd65f44f 100644
--- a/index.rst
+++ b/index.rst
@@ -1,6 +1,10 @@
-.. tip::
+.. note::
- Sentence Transformers v3.2 just released, introducing the ONNX and OpenVINO backends for Sentence Transformer models. Read `SentenceTransformer > Usage > Speeding up Inference `_ to learn more about the new backends and what they can mean for your inference speed.
+ Sentence Transformers v3.2 recently released, introducing the ONNX and OpenVINO backends for Sentence Transformer models. Read `SentenceTransformer > Usage > Speeding up Inference `_ to learn more about the new backends and what they can mean for your inference speed.
+
+.. note::
+
+ Sentence Transformers v3.3 just released, introducing training with Prompts. Read `SentenceTransformer > Training Examples > Training with Prompts `_ to learn more about how you can use them to train stronger models.
SentenceTransformers Documentation
==================================
diff --git a/sentence_transformers/data_collator.py b/sentence_transformers/data_collator.py
index 071fac7a6..83445fe7e 100644
--- a/sentence_transformers/data_collator.py
+++ b/sentence_transformers/data_collator.py
@@ -46,11 +46,16 @@ def __call__(self, features: list[dict[str, Any]]) -> dict[str, torch.Tensor]:
column_names.remove(label_column)
break
- # Extract the feature columns
for column_name in column_names:
+ # If the prompt length has been set, we should add it to the batch
+ if column_name.endswith("_prompt_length") and column_name[: -len("_prompt_length")] in column_names:
+ batch[column_name] = torch.tensor([row[column_name] for row in features], dtype=torch.int)
+ continue
+
tokenized = self.tokenize_fn([row[column_name] for row in features])
for key, value in tokenized.items():
batch[f"{column_name}_{key}"] = value
+
return batch
def maybe_warn_about_column_order(self, column_names: list[str]) -> None:
diff --git a/sentence_transformers/evaluation/NanoBEIREvaluator.py b/sentence_transformers/evaluation/NanoBEIREvaluator.py
index 1e21f2254..9b5669cb6 100644
--- a/sentence_transformers/evaluation/NanoBEIREvaluator.py
+++ b/sentence_transformers/evaluation/NanoBEIREvaluator.py
@@ -88,8 +88,8 @@ class NanoBEIREvaluator(SentenceEvaluator):
datasets = ["QuoraRetrieval", "MSMARCO"]
query_prompts = {
- "QuoraRetrieval": "Instruct: Given a question, retrieve questions that are semantically equivalent to the given question\nQuery: ",
- "MSMARCO": "Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: "
+ "QuoraRetrieval": "Instruct: Given a question, retrieve questions that are semantically equivalent to the given question\\nQuery: ",
+ "MSMARCO": "Instruct: Given a web search query, retrieve relevant passages that answer the query\\nQuery: "
}
evaluator = NanoBEIREvaluator(
diff --git a/sentence_transformers/model_card.py b/sentence_transformers/model_card.py
index dd7c0e96b..fdd3f86f1 100644
--- a/sentence_transformers/model_card.py
+++ b/sentence_transformers/model_card.py
@@ -422,9 +422,7 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
columns = [
column
for column, feature in dataset[dataset_name].features.items()
- if isinstance(feature, Value)
- and (feature.dtype == "string" or feature.dtype == "large_string")
- and column != "dataset_name"
+ if isinstance(feature, Value) and feature.dtype in {"string", "large_string"}
]
str_dataset = dataset[dataset_name].select_columns(columns)
dataset_size = len(str_dataset)
@@ -435,7 +433,11 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
for idx, sample in enumerate(
str_dataset.select(random.sample(range(dataset_size), k=min(num_samples_to_check, dataset_size)))
):
- lengths[idx] = sum(len(value) for value in sample.values())
+ lengths[idx] = sum(
+ len(value)
+ for key, value in sample.items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ )
indices, _ = zip(*sorted(lengths.items(), key=lambda x: x[1]))
target_indices, backup_indices = indices[:num_samples], list(indices[num_samples:][::-1])
@@ -443,10 +445,18 @@ def set_widget_examples(self, dataset: Dataset | DatasetDict) -> None:
# We want 4 texts, so we take texts from the backup indices, short texts first
for idx in target_indices:
# This is anywhere between 1 and n texts
- sentences = list(str_dataset[idx].values())
+ sentences = [
+ sentence
+ for key, sentence in str_dataset[idx].items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ ]
while len(sentences) < 4 and backup_indices:
backup_idx = backup_indices.pop()
- backup_sample = list(str_dataset[backup_idx].values())
+ backup_sample = [
+ sentence
+ for key, sentence in str_dataset[backup_idx].items()
+ if key != "dataset_name" and not key.endswith("_prompt_length")
+ ]
if len(backup_sample) == 1:
# If there is only one text in the backup sample, we take it
sentences.extend(backup_sample)
@@ -604,9 +614,9 @@ def compute_dataset_metrics(
dataset_info["stats"][column] = {
"dtype": "float",
"data": {
- "min": round(min(dataset[column]), 2),
- "mean": round(sum(dataset[column]) / len(dataset), 2),
- "max": round(max(dataset[column]), 2),
+ "min": round(min(subsection), 2),
+ "mean": round(sum(subsection) / len(subsection), 2),
+ "max": round(max(subsection), 2),
},
}
elif isinstance(first, list):
diff --git a/sentence_transformers/models/Pooling.py b/sentence_transformers/models/Pooling.py
index 4e24a1c92..21cfb617c 100644
--- a/sentence_transformers/models/Pooling.py
+++ b/sentence_transformers/models/Pooling.py
@@ -1,251 +1,260 @@
-from __future__ import annotations
-
-import json
-import os
-from typing import Any
-
-import torch
-from torch import Tensor, nn
-
-
-class Pooling(nn.Module):
- """
- Performs pooling (max or mean) on the token embeddings.
-
- Using pooling, it generates from a variable sized sentence a fixed sized sentence embedding. This layer also allows
- to use the CLS token if it is returned by the underlying word embedding model. You can concatenate multiple poolings
- together.
-
- Args:
- word_embedding_dimension: Dimensions for the word embeddings
- pooling_mode: Either "cls", "lasttoken", "max", "mean",
- "mean_sqrt_len_tokens", or "weightedmean". If set,
- overwrites the other pooling_mode_* settings
- pooling_mode_cls_token: Use the first token (CLS token) as text
- representations
- pooling_mode_max_tokens: Use max in each dimension over all
- tokens.
- pooling_mode_mean_tokens: Perform mean-pooling
- pooling_mode_mean_sqrt_len_tokens: Perform mean-pooling, but
- divide by sqrt(input_length).
- pooling_mode_weightedmean_tokens: Perform (position) weighted
- mean pooling. See `SGPT: GPT Sentence Embeddings for
- Semantic Search `_.
- pooling_mode_lasttoken: Perform last token pooling. See `SGPT:
- GPT Sentence Embeddings for Semantic Search
- `_ and `Text and Code
- Embeddings by Contrastive Pre-Training
- `_.
- include_prompt: If set to false, the prompt tokens are not
- included in the pooling. This is useful for reproducing
- work that does not include the prompt tokens in the pooling
- like INSTRUCTOR, but otherwise not recommended.
- """
-
- POOLING_MODES = (
- "cls",
- "lasttoken",
- "max",
- "mean",
- "mean_sqrt_len_tokens",
- "weightedmean",
- )
-
- def __init__(
- self,
- word_embedding_dimension: int,
- pooling_mode: str = None,
- pooling_mode_cls_token: bool = False,
- pooling_mode_max_tokens: bool = False,
- pooling_mode_mean_tokens: bool = True,
- pooling_mode_mean_sqrt_len_tokens: bool = False,
- pooling_mode_weightedmean_tokens: bool = False,
- pooling_mode_lasttoken: bool = False,
- include_prompt: bool = True,
- ) -> None:
- super().__init__()
-
- self.config_keys = [
- "word_embedding_dimension",
- "pooling_mode_cls_token",
- "pooling_mode_mean_tokens",
- "pooling_mode_max_tokens",
- "pooling_mode_mean_sqrt_len_tokens",
- "pooling_mode_weightedmean_tokens",
- "pooling_mode_lasttoken",
- "include_prompt",
- ]
-
- if pooling_mode is not None: # Set pooling mode by string
- pooling_mode = pooling_mode.lower()
-
- if pooling_mode not in self.POOLING_MODES:
- raise ValueError(
- f"Set invalid pooling mode: {pooling_mode}. Valid pooling modes are: {self.POOLING_MODES}."
- )
-
- pooling_mode_cls_token = pooling_mode == "cls"
- pooling_mode_max_tokens = pooling_mode == "max"
- pooling_mode_mean_tokens = pooling_mode == "mean"
- pooling_mode_mean_sqrt_len_tokens = pooling_mode == "mean_sqrt_len_tokens"
- pooling_mode_weightedmean_tokens = pooling_mode == "weightedmean"
- pooling_mode_lasttoken = pooling_mode == "lasttoken"
-
- self.word_embedding_dimension = word_embedding_dimension
- self.pooling_mode_cls_token = pooling_mode_cls_token
- self.pooling_mode_mean_tokens = pooling_mode_mean_tokens
- self.pooling_mode_max_tokens = pooling_mode_max_tokens
- self.pooling_mode_mean_sqrt_len_tokens = pooling_mode_mean_sqrt_len_tokens
- self.pooling_mode_weightedmean_tokens = pooling_mode_weightedmean_tokens
- self.pooling_mode_lasttoken = pooling_mode_lasttoken
-
- self.include_prompt = include_prompt
-
- pooling_mode_multiplier = sum(
- [
- pooling_mode_cls_token,
- pooling_mode_max_tokens,
- pooling_mode_mean_tokens,
- pooling_mode_mean_sqrt_len_tokens,
- pooling_mode_weightedmean_tokens,
- pooling_mode_lasttoken,
- ]
- )
- self.pooling_output_dimension = pooling_mode_multiplier * word_embedding_dimension
-
- def __repr__(self) -> str:
- return f"Pooling({self.get_config_dict()})"
-
- def get_pooling_mode_str(self) -> str:
- """Returns the pooling mode as string"""
- modes = []
- if self.pooling_mode_cls_token:
- modes.append("cls")
- if self.pooling_mode_mean_tokens:
- modes.append("mean")
- if self.pooling_mode_max_tokens:
- modes.append("max")
- if self.pooling_mode_mean_sqrt_len_tokens:
- modes.append("mean_sqrt_len_tokens")
- if self.pooling_mode_weightedmean_tokens:
- modes.append("weightedmean")
- if self.pooling_mode_lasttoken:
- modes.append("lasttoken")
-
- return "+".join(modes)
-
- def forward(self, features: dict[str, Tensor]) -> dict[str, Tensor]:
- token_embeddings = features["token_embeddings"]
- attention_mask = (
- features["attention_mask"]
- if "attention_mask" in features
- else torch.ones(token_embeddings.shape[:-1], device=token_embeddings.device, dtype=torch.int64)
- )
- if not self.include_prompt and "prompt_length" in features:
- attention_mask[:, : features["prompt_length"]] = 0
-
- ## Pooling strategy
- output_vectors = []
- if self.pooling_mode_cls_token:
- cls_token = features.get("cls_token_embeddings", token_embeddings[:, 0]) # Take first token by default
- output_vectors.append(cls_token)
- if self.pooling_mode_max_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
- max_over_time = torch.max(token_embeddings, 1)[0]
- output_vectors.append(max_over_time)
- if self.pooling_mode_mean_tokens or self.pooling_mode_mean_sqrt_len_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
-
- # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
- if "token_weights_sum" in features:
- sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
- else:
- sum_mask = input_mask_expanded.sum(1)
-
- sum_mask = torch.clamp(sum_mask, min=1e-9)
-
- if self.pooling_mode_mean_tokens:
- output_vectors.append(sum_embeddings / sum_mask)
- if self.pooling_mode_mean_sqrt_len_tokens:
- output_vectors.append(sum_embeddings / torch.sqrt(sum_mask))
- if self.pooling_mode_weightedmean_tokens:
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- # token_embeddings shape: bs, seq, hidden_dim
- weights = (
- torch.arange(start=1, end=token_embeddings.shape[1] + 1)
- .unsqueeze(0)
- .unsqueeze(-1)
- .expand(token_embeddings.size())
- .to(token_embeddings.dtype)
- .to(token_embeddings.device)
- )
- assert weights.shape == token_embeddings.shape == input_mask_expanded.shape
- input_mask_expanded = input_mask_expanded * weights
-
- sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
-
- # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
- if "token_weights_sum" in features:
- sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
- else:
- sum_mask = input_mask_expanded.sum(1)
-
- sum_mask = torch.clamp(sum_mask, min=1e-9)
- output_vectors.append(sum_embeddings / sum_mask)
- if self.pooling_mode_lasttoken:
- bs, seq_len, hidden_dim = token_embeddings.shape
- # attention_mask shape: (bs, seq_len)
- # Get shape [bs] indices of the last token (i.e. the last token for each batch item)
- # Use flip and max() to get the last index of 1 in the attention mask
-
- if torch.jit.is_tracing():
- # Avoid tracing the argmax with int64 input that can not be handled by ONNX Runtime: https://github.com/microsoft/onnxruntime/issues/10068
- attention_mask = attention_mask.to(torch.int32)
-
- values, indices = attention_mask.flip(1).max(1)
- indices = torch.where(values == 0, seq_len - 1, indices)
- gather_indices = seq_len - indices - 1
-
- # Turn indices from shape [bs] --> [bs, 1, hidden_dim]
- gather_indices = gather_indices.unsqueeze(-1).repeat(1, hidden_dim)
- gather_indices = gather_indices.unsqueeze(1)
- assert gather_indices.shape == (bs, 1, hidden_dim)
-
- # Gather along the 1st dim (seq_len) (bs, seq_len, hidden_dim -> bs, hidden_dim)
- # Actually no need for the attention mask as we gather the last token where attn_mask = 1
- # but as we set some indices (which shouldn't be attended to) to 0 with clamp, we
- # use the attention mask to ignore them again
- input_mask_expanded = (
- attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
- )
- embedding = torch.gather(token_embeddings * input_mask_expanded, 1, gather_indices).squeeze(dim=1)
- output_vectors.append(embedding)
-
- output_vector = torch.cat(output_vectors, 1)
- features["sentence_embedding"] = output_vector
- return features
-
- def get_sentence_embedding_dimension(self) -> int:
- return self.pooling_output_dimension
-
- def get_config_dict(self) -> dict[str, Any]:
- return {key: self.__dict__[key] for key in self.config_keys}
-
- def save(self, output_path) -> None:
- with open(os.path.join(output_path, "config.json"), "w") as fOut:
- json.dump(self.get_config_dict(), fOut, indent=2)
-
- @staticmethod
- def load(input_path) -> Pooling:
- with open(os.path.join(input_path, "config.json")) as fIn:
- config = json.load(fIn)
-
- return Pooling(**config)
+from __future__ import annotations
+
+import json
+import os
+from typing import Any
+
+import torch
+from torch import Tensor, nn
+
+
+class Pooling(nn.Module):
+ """
+ Performs pooling (max or mean) on the token embeddings.
+
+ Using pooling, it generates from a variable sized sentence a fixed sized sentence embedding. This layer also allows
+ to use the CLS token if it is returned by the underlying word embedding model. You can concatenate multiple poolings
+ together.
+
+ Args:
+ word_embedding_dimension: Dimensions for the word embeddings
+ pooling_mode: Either "cls", "lasttoken", "max", "mean",
+ "mean_sqrt_len_tokens", or "weightedmean". If set,
+ overwrites the other pooling_mode_* settings
+ pooling_mode_cls_token: Use the first token (CLS token) as text
+ representations
+ pooling_mode_max_tokens: Use max in each dimension over all
+ tokens.
+ pooling_mode_mean_tokens: Perform mean-pooling
+ pooling_mode_mean_sqrt_len_tokens: Perform mean-pooling, but
+ divide by sqrt(input_length).
+ pooling_mode_weightedmean_tokens: Perform (position) weighted
+ mean pooling. See `SGPT: GPT Sentence Embeddings for
+ Semantic Search `_.
+ pooling_mode_lasttoken: Perform last token pooling. See `SGPT:
+ GPT Sentence Embeddings for Semantic Search
+ `_ and `Text and Code
+ Embeddings by Contrastive Pre-Training
+ `_.
+ include_prompt: If set to false, the prompt tokens are not
+ included in the pooling. This is useful for reproducing
+ work that does not include the prompt tokens in the pooling
+ like INSTRUCTOR, but otherwise not recommended.
+ """
+
+ POOLING_MODES = (
+ "cls",
+ "lasttoken",
+ "max",
+ "mean",
+ "mean_sqrt_len_tokens",
+ "weightedmean",
+ )
+
+ def __init__(
+ self,
+ word_embedding_dimension: int,
+ pooling_mode: str = None,
+ pooling_mode_cls_token: bool = False,
+ pooling_mode_max_tokens: bool = False,
+ pooling_mode_mean_tokens: bool = True,
+ pooling_mode_mean_sqrt_len_tokens: bool = False,
+ pooling_mode_weightedmean_tokens: bool = False,
+ pooling_mode_lasttoken: bool = False,
+ include_prompt: bool = True,
+ ) -> None:
+ super().__init__()
+
+ self.config_keys = [
+ "word_embedding_dimension",
+ "pooling_mode_cls_token",
+ "pooling_mode_mean_tokens",
+ "pooling_mode_max_tokens",
+ "pooling_mode_mean_sqrt_len_tokens",
+ "pooling_mode_weightedmean_tokens",
+ "pooling_mode_lasttoken",
+ "include_prompt",
+ ]
+
+ if pooling_mode is not None: # Set pooling mode by string
+ pooling_mode = pooling_mode.lower()
+
+ if pooling_mode not in self.POOLING_MODES:
+ raise ValueError(
+ f"Set invalid pooling mode: {pooling_mode}. Valid pooling modes are: {self.POOLING_MODES}."
+ )
+
+ pooling_mode_cls_token = pooling_mode == "cls"
+ pooling_mode_max_tokens = pooling_mode == "max"
+ pooling_mode_mean_tokens = pooling_mode == "mean"
+ pooling_mode_mean_sqrt_len_tokens = pooling_mode == "mean_sqrt_len_tokens"
+ pooling_mode_weightedmean_tokens = pooling_mode == "weightedmean"
+ pooling_mode_lasttoken = pooling_mode == "lasttoken"
+
+ self.word_embedding_dimension = word_embedding_dimension
+ self.pooling_mode_cls_token = pooling_mode_cls_token
+ self.pooling_mode_mean_tokens = pooling_mode_mean_tokens
+ self.pooling_mode_max_tokens = pooling_mode_max_tokens
+ self.pooling_mode_mean_sqrt_len_tokens = pooling_mode_mean_sqrt_len_tokens
+ self.pooling_mode_weightedmean_tokens = pooling_mode_weightedmean_tokens
+ self.pooling_mode_lasttoken = pooling_mode_lasttoken
+
+ self.include_prompt = include_prompt
+
+ pooling_mode_multiplier = sum(
+ [
+ pooling_mode_cls_token,
+ pooling_mode_max_tokens,
+ pooling_mode_mean_tokens,
+ pooling_mode_mean_sqrt_len_tokens,
+ pooling_mode_weightedmean_tokens,
+ pooling_mode_lasttoken,
+ ]
+ )
+ self.pooling_output_dimension = pooling_mode_multiplier * word_embedding_dimension
+
+ def __repr__(self) -> str:
+ return f"Pooling({self.get_config_dict()})"
+
+ def get_pooling_mode_str(self) -> str:
+ """Returns the pooling mode as string"""
+ modes = []
+ if self.pooling_mode_cls_token:
+ modes.append("cls")
+ if self.pooling_mode_mean_tokens:
+ modes.append("mean")
+ if self.pooling_mode_max_tokens:
+ modes.append("max")
+ if self.pooling_mode_mean_sqrt_len_tokens:
+ modes.append("mean_sqrt_len_tokens")
+ if self.pooling_mode_weightedmean_tokens:
+ modes.append("weightedmean")
+ if self.pooling_mode_lasttoken:
+ modes.append("lasttoken")
+
+ return "+".join(modes)
+
+ def forward(self, features: dict[str, Tensor]) -> dict[str, Tensor]:
+ token_embeddings = features["token_embeddings"]
+ attention_mask = (
+ features["attention_mask"]
+ if "attention_mask" in features
+ else torch.ones(token_embeddings.shape[:-1], device=token_embeddings.device, dtype=torch.int64)
+ )
+ if not self.include_prompt and "prompt_length" in features:
+ prompt_length = features["prompt_length"]
+ # prompt_length is either:
+ # * an int (in inference)
+ # * a tensor of shape (bs), all the same value (in training with an IterableDataset)
+ # * a tensor of shape (1) (in training with a Dataset)
+ # We turn all into an int
+ if isinstance(prompt_length, torch.Tensor):
+ prompt_length = prompt_length[0].item()
+
+ attention_mask[:, :prompt_length] = 0
+
+ ## Pooling strategy
+ output_vectors = []
+ if self.pooling_mode_cls_token:
+ cls_token = features.get("cls_token_embeddings", token_embeddings[:, 0]) # Take first token by default
+ output_vectors.append(cls_token)
+ if self.pooling_mode_max_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
+ max_over_time = torch.max(token_embeddings, 1)[0]
+ output_vectors.append(max_over_time)
+ if self.pooling_mode_mean_tokens or self.pooling_mode_mean_sqrt_len_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
+
+ # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
+ if "token_weights_sum" in features:
+ sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
+ else:
+ sum_mask = input_mask_expanded.sum(1)
+
+ sum_mask = torch.clamp(sum_mask, min=1e-9)
+
+ if self.pooling_mode_mean_tokens:
+ output_vectors.append(sum_embeddings / sum_mask)
+ if self.pooling_mode_mean_sqrt_len_tokens:
+ output_vectors.append(sum_embeddings / torch.sqrt(sum_mask))
+ if self.pooling_mode_weightedmean_tokens:
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ # token_embeddings shape: bs, seq, hidden_dim
+ weights = (
+ torch.arange(start=1, end=token_embeddings.shape[1] + 1)
+ .unsqueeze(0)
+ .unsqueeze(-1)
+ .expand(token_embeddings.size())
+ .to(token_embeddings.dtype)
+ .to(token_embeddings.device)
+ )
+ assert weights.shape == token_embeddings.shape == input_mask_expanded.shape
+ input_mask_expanded = input_mask_expanded * weights
+
+ sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
+
+ # If tokens are weighted (by WordWeights layer), feature 'token_weights_sum' will be present
+ if "token_weights_sum" in features:
+ sum_mask = features["token_weights_sum"].unsqueeze(-1).expand(sum_embeddings.size())
+ else:
+ sum_mask = input_mask_expanded.sum(1)
+
+ sum_mask = torch.clamp(sum_mask, min=1e-9)
+ output_vectors.append(sum_embeddings / sum_mask)
+ if self.pooling_mode_lasttoken:
+ bs, seq_len, hidden_dim = token_embeddings.shape
+ # attention_mask shape: (bs, seq_len)
+ # Get shape [bs] indices of the last token (i.e. the last token for each batch item)
+ # Use flip and max() to get the last index of 1 in the attention mask
+
+ if torch.jit.is_tracing():
+ # Avoid tracing the argmax with int64 input that can not be handled by ONNX Runtime: https://github.com/microsoft/onnxruntime/issues/10068
+ attention_mask = attention_mask.to(torch.int32)
+
+ values, indices = attention_mask.flip(1).max(1)
+ indices = torch.where(values == 0, seq_len - 1, indices)
+ gather_indices = seq_len - indices - 1
+
+ # Turn indices from shape [bs] --> [bs, 1, hidden_dim]
+ gather_indices = gather_indices.unsqueeze(-1).repeat(1, hidden_dim)
+ gather_indices = gather_indices.unsqueeze(1)
+ assert gather_indices.shape == (bs, 1, hidden_dim)
+
+ # Gather along the 1st dim (seq_len) (bs, seq_len, hidden_dim -> bs, hidden_dim)
+ # Actually no need for the attention mask as we gather the last token where attn_mask = 1
+ # but as we set some indices (which shouldn't be attended to) to 0 with clamp, we
+ # use the attention mask to ignore them again
+ input_mask_expanded = (
+ attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype)
+ )
+ embedding = torch.gather(token_embeddings * input_mask_expanded, 1, gather_indices).squeeze(dim=1)
+ output_vectors.append(embedding)
+
+ output_vector = torch.cat(output_vectors, 1)
+ features["sentence_embedding"] = output_vector
+ return features
+
+ def get_sentence_embedding_dimension(self) -> int:
+ return self.pooling_output_dimension
+
+ def get_config_dict(self) -> dict[str, Any]:
+ return {key: self.__dict__[key] for key in self.config_keys}
+
+ def save(self, output_path) -> None:
+ with open(os.path.join(output_path, "config.json"), "w") as fOut:
+ json.dump(self.get_config_dict(), fOut, indent=2)
+
+ @staticmethod
+ def load(input_path) -> Pooling:
+ with open(os.path.join(input_path, "config.json")) as fIn:
+ config = json.load(fIn)
+
+ return Pooling(**config)
diff --git a/sentence_transformers/sampler.py b/sentence_transformers/sampler.py
index f78623c5a..7efc19bf1 100644
--- a/sentence_transformers/sampler.py
+++ b/sentence_transformers/sampler.py
@@ -167,7 +167,7 @@ def __init__(
seed (int, optional): Seed for the random number generator to ensure reproducibility.
"""
super().__init__(dataset, batch_size, drop_last)
- if label_columns := set(dataset.column_names) & (set(valid_label_columns) | {"dataset_name"}):
+ if label_columns := set(dataset.column_names) & set(valid_label_columns):
dataset = dataset.remove_columns(label_columns)
self.dataset = dataset
self.batch_size = batch_size
@@ -189,7 +189,11 @@ def __iter__(self) -> Iterator[list[int]]:
batch_values = set()
batch_indices = []
for index in remaining_indices:
- sample_values = set(self.dataset[index].values())
+ sample_values = {
+ value
+ for key, value in self.dataset[index].items()
+ if not key.endswith("_prompt_length") and key != "dataset_name"
+ }
if sample_values & batch_values:
continue
diff --git a/sentence_transformers/trainer.py b/sentence_transformers/trainer.py
index 090d6d454..68a60edbf 100644
--- a/sentence_transformers/trainer.py
+++ b/sentence_transformers/trainer.py
@@ -4,6 +4,7 @@
import os
from collections import OrderedDict
from contextlib import nullcontext
+from functools import partial
from typing import TYPE_CHECKING, Any, Callable
import torch
@@ -21,6 +22,7 @@
from sentence_transformers.evaluation import SentenceEvaluator, SequentialEvaluator
from sentence_transformers.losses.CoSENTLoss import CoSENTLoss
from sentence_transformers.model_card import ModelCardCallback
+from sentence_transformers.models import Pooling
from sentence_transformers.models.Transformer import Transformer
from sentence_transformers.sampler import (
DefaultBatchSampler,
@@ -77,10 +79,10 @@ class SentenceTransformerTrainer(Trainer):
loss (Optional[Union[:class:`torch.nn.Module`, Dict[str, :class:`torch.nn.Module`],\
Callable[[:class:`~sentence_transformers.SentenceTransformer`], :class:`torch.nn.Module`],\
Dict[str, Callable[[:class:`~sentence_transformers.SentenceTransformer`]]]], *optional*):
- The loss function to use for training. Can either be a loss class instance, a dictionary mapping dataset names to
- loss class instances, a function that returns a loss class instance given a model, or a dictionary mapping
- dataset names to functions that return a loss class instance given a model. In practice, the latter two
- are primarily used for hyper-parameter optimization. Will default to
+ The loss function to use for training. Can either be a loss class instance, a dictionary mapping
+ dataset names to loss class instances, a function that returns a loss class instance given a model,
+ or a dictionary mapping dataset names to functions that return a loss class instance given a model.
+ In practice, the latter two are primarily used for hyper-parameter optimization. Will default to
:class:`~sentence_transformers.losses.CoSENTLoss` if no ``loss`` is provided.
evaluator (Union[:class:`~sentence_transformers.evaluation.SentenceEvaluator`,\
List[:class:`~sentence_transformers.evaluation.SentenceEvaluator`]], *optional*):
@@ -232,6 +234,8 @@ def __init__(
# to avoid having to specify it in the data collator or model's forward
self.can_return_loss = True
+ self._prompt_length_mapping = {}
+
self.model: SentenceTransformer
self.args: SentenceTransformerTrainingArguments
self.data_collator: SentenceTransformerDataCollator
@@ -259,11 +263,21 @@ def __init__(
)
else:
self.loss = self.prepare_loss(loss, model)
+
# If evaluator is a list, we wrap it in a SequentialEvaluator
if evaluator is not None and not isinstance(evaluator, SentenceEvaluator):
evaluator = SequentialEvaluator(evaluator)
self.evaluator = evaluator
+ if self.train_dataset is not None:
+ self.train_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ train_dataset, args.prompts, dataset_name="train"
+ )
+ if self.eval_dataset is not None:
+ self.eval_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ eval_dataset, args.prompts, dataset_name="eval"
+ )
+
# Add a callback responsible for automatically tracking data required for the automatic model card generation
model_card_callback = ModelCardCallback(self, default_args_dict)
self.add_callback(model_card_callback)
@@ -410,9 +424,12 @@ def evaluate(
ignore_keys: list[str] | None = None,
metric_key_prefix: str = "eval",
) -> dict[str, float]:
- eval_dataset = eval_dataset if eval_dataset is not None else self.eval_dataset
- if isinstance(eval_dataset, DatasetDict) and isinstance(self.loss, dict):
- eval_dataset = self.add_dataset_name_column(eval_dataset)
+ if eval_dataset:
+ eval_dataset = self.maybe_add_prompts_or_dataset_name_column(
+ eval_dataset, self.args.prompts, dataset_name="eval"
+ )
+ else:
+ eval_dataset = self.eval_dataset
return super().evaluate(eval_dataset, ignore_keys, metric_key_prefix)
def evaluation_loop(
@@ -483,7 +500,12 @@ def _load_best_model(self) -> None:
self.model = full_model
self.model[0].auto_model = loaded_auto_model
- def validate_column_names(self, dataset: Dataset, dataset_name: str | None = None) -> bool:
+ def validate_column_names(self, dataset: Dataset, dataset_name: str | None = None) -> None:
+ if isinstance(dataset, dict):
+ for dataset_name, dataset in dataset.items():
+ self.validate_column_names(dataset, dataset_name=dataset_name)
+ return
+
if overlap := set(dataset.column_names) & {"return_loss", "dataset_name"}:
raise ValueError(
f"The following column names are invalid in your {dataset_name + ' ' if dataset_name else ''}dataset: {list(overlap)}."
@@ -593,7 +615,7 @@ def get_train_dataloader(self) -> DataLoader:
Subclass and override this method if you want to inject some custom behavior.
"""
if self.train_dataset is None:
- raise ValueError("Trainer: training requires a train_dataset.")
+ raise ValueError("Training requires specifying a train_dataset to the SentenceTransformerTrainer.")
train_dataset = self.train_dataset
data_collator = self.data_collator
@@ -617,6 +639,8 @@ def get_train_dataloader(self) -> DataLoader:
"drop_last": self.args.dataloader_drop_last,
}
)
+ if self.args.batch_sampler != BatchSamplers.BATCH_SAMPLER:
+ logger.warning("When using an IterableDataset, you cannot specify a batch sampler.")
elif isinstance(train_dataset, IterableDatasetDict):
raise ValueError(
@@ -624,14 +648,12 @@ def get_train_dataloader(self) -> DataLoader:
)
elif isinstance(train_dataset, DatasetDict):
- for dataset_name, dataset in train_dataset.items():
- self.validate_column_names(dataset, dataset_name=dataset_name)
+ for dataset in train_dataset.values():
if isinstance(dataset, IterableDataset):
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- train_dataset = self.add_dataset_name_column(train_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -653,8 +675,6 @@ def get_train_dataloader(self) -> DataLoader:
dataloader_params["batch_sampler"] = batch_sampler
elif isinstance(train_dataset, Dataset):
- self.validate_column_names(train_dataset)
-
batch_sampler = self.get_batch_sampler(
train_dataset,
batch_size=self.args.train_batch_size,
@@ -675,7 +695,7 @@ def get_train_dataloader(self) -> DataLoader:
self._train_dataloader = self.accelerator.prepare(DataLoader(train_dataset, **dataloader_params))
return self._train_dataloader
- def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader:
+ def get_eval_dataloader(self, eval_dataset: Dataset | DatasetDict | IterableDataset | None = None) -> DataLoader:
"""
Returns the evaluation [`~torch.utils.data.DataLoader`].
@@ -690,7 +710,8 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
# Prevent errors if the evaluator is set but no eval_dataset is provided
if self.evaluator is not None:
return DataLoader([])
- raise ValueError("Trainer: evaluation requires an eval_dataset.")
+ raise ValueError("Evaluation requires specifying an eval_dataset to the SentenceTransformerTrainer.")
+
eval_dataset = eval_dataset if eval_dataset is not None else self.eval_dataset
data_collator = self.data_collator
@@ -724,8 +745,7 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- eval_dataset = self.add_dataset_name_column(eval_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -767,7 +787,7 @@ def get_eval_dataloader(self, eval_dataset: Dataset | None = None) -> DataLoader
self.accelerator.even_batches = True
return self.accelerator.prepare(DataLoader(eval_dataset, **dataloader_params))
- def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
+ def get_test_dataloader(self, test_dataset: Dataset | DatasetDict | IterableDataset) -> DataLoader:
"""
Returns the training [`~torch.utils.data.DataLoader`].
@@ -806,14 +826,12 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
)
elif isinstance(test_dataset, DatasetDict):
- for dataset_name, dataset in test_dataset.items():
- self.validate_column_names(dataset, dataset_name=dataset_name)
+ for dataset in test_dataset.values():
if isinstance(dataset, IterableDataset):
raise ValueError(
"Sentence Transformers is not compatible with a DatasetDict containing an IterableDataset."
)
- if isinstance(self.loss, dict):
- test_dataset = self.add_dataset_name_column(test_dataset)
+
batch_samplers = [
self.get_batch_sampler(
dataset,
@@ -835,8 +853,6 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
dataloader_params["batch_sampler"] = batch_sampler
elif isinstance(test_dataset, Dataset):
- self.validate_column_names(test_dataset)
-
batch_sampler = self.get_batch_sampler(
test_dataset,
batch_size=self.args.eval_batch_size,
@@ -852,11 +868,10 @@ def get_test_dataloader(self, test_dataset: Dataset) -> DataLoader:
)
# If 'even_batches' is True, it will use the initial few samples to pad out the last sample. This can
- # cause issues with multi-dataset training, so we want to set this to False.
- # For evaluation, setting 'even_batches' to False results in hanging, so we keep it as True there.
- self.accelerator.even_batches = False
- self._train_dataloader = self.accelerator.prepare(DataLoader(test_dataset, **dataloader_params))
- return self._train_dataloader
+ # cause issues with multi-dataset training, so we want to set this to False during training.
+ # For evaluation, setting 'even_batches' to False results in hanging, so we keep it as True here.
+ self.accelerator.even_batches = True
+ return self.accelerator.prepare(DataLoader(test_dataset, **dataloader_params))
def _save(self, output_dir: str | None = None, state_dict=None) -> None:
# If we are executing this function, we are the process zero, so we don't check for that.
@@ -883,6 +898,243 @@ def _load_from_checkpoint(self, checkpoint_path: str) -> None:
loaded_model = SentenceTransformer(checkpoint_path, trust_remote_code=self.model.trust_remote_code)
self.model.load_state_dict(loaded_model.state_dict())
+ def _get_prompt_length(self, prompt: str) -> int:
+ try:
+ return self._prompt_length_mapping[prompt]
+ except KeyError:
+ prompt_length = self.model.tokenize([prompt])["input_ids"].shape[-1] - 1
+ self._prompt_length_mapping[prompt] = prompt_length
+ return prompt_length
+
+ def _include_prompt_length(self) -> bool:
+ """
+ Return whether the prompt length should be passed to the model's forward method.
+
+ True if the model does not include the prompt in the pooling layer. Can be
+ overridden by the user if it's useful to include the prompt length.
+ """
+ for module in self.model:
+ if isinstance(module, Pooling):
+ return not module.include_prompt
+ return False
+
+ @staticmethod
+ def add_prompts_or_dataset_name_transform(
+ batch: dict[str, list[Any]],
+ prompts: dict[str, str] | str | None = None,
+ prompt_lengths: dict[str, int] | int | None = None,
+ dataset_name: str | None = None,
+ transform: Callable[[dict[str, list[Any]]], dict[str, list[Any]]] = None,
+ **kwargs,
+ ) -> dict[str, list[Any]]:
+ """A transform/map function that adds prompts or dataset names to the batch.
+
+ Args:
+ batch (dict[str, list[Any]]): The batch of data, where each key is a column name and each value
+ is a list of values.
+ prompts (dict[str, str] | str | None, optional): An optional mapping of column names to string
+ prompts, or a string prompt for all columns. Defaults to None.
+ prompt_lengths (dict[str, int] | int | None, optional): An optional mapping of prompts names to
+ prompt token length, or a prompt token length if the prompt is a string. Defaults to None.
+ dataset_name (str | None, optional): The name of this dataset, only if there are multiple datasets
+ that use a different loss. Defaults to None.
+ transform (Callable[[dict[str, list[Any]]], dict[str, list[Any]]], optional): An optional transform
+ function to apply on the batch before adding prompts, etc. Defaults to None.
+
+ Returns:
+ dict[str, list[Any]]: The "just-in-time" transformed batch with prompts and/or dataset names added.
+ """
+ # If the dataset is a Dataset(Dict), then we use set_transform and we want to also apply any
+ # previous transform if it exists
+ if transform:
+ batch = transform(batch)
+
+ # Return if the batch has no columns...
+ if not batch:
+ return batch
+
+ # ... or if it's empty
+ first_column = list(batch.keys())[0]
+ if not batch[first_column]:
+ return batch
+
+ # Apply one prompt to all columns...
+ if isinstance(prompts, str):
+ for column_name, column in list(batch.items()):
+ if isinstance(column[0], str):
+ batch[column_name] = [prompts + value for value in column]
+
+ if prompt_lengths is not None:
+ batch[f"{column_name}_prompt_length"] = [prompt_lengths] * len(column)
+
+ # ... or a column-specific prompt
+ if isinstance(prompts, dict):
+ for column_name, prompt in prompts.items():
+ if column_name in batch:
+ batch[column_name] = [prompt + value for value in batch[column_name]]
+
+ if prompt_lengths:
+ batch[f"{column_name}_prompt_length"] = [prompt_lengths[prompt]] * len(batch[column_name])
+
+ # If we have multiple losses, then we need to add the dataset name to the batch
+ if dataset_name:
+ batch["dataset_name"] = [dataset_name] * len(batch[first_column])
+
+ return batch
+
+ def maybe_add_prompts_or_dataset_name_column(
+ self,
+ dataset_dict: DatasetDict | Dataset | None,
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None = None,
+ dataset_name: str | None = None,
+ ) -> DatasetDict | Dataset | None:
+ """
+ Maybe add prompts or dataset names to the dataset. We add the dataset_name column to the dataset if:
+
+ 1. The loss is a dictionary and the dataset is a DatasetDict, or
+ 2. The prompts contain a mapping to dataset names.
+
+ There are 4 cases for the prompts:
+
+ 1. `str`: One prompt for all datasets and columns.
+ 2. `dict[str, str]`: A column to prompt mapping.
+ 3. `dict[str, str]`: A dataset to prompt mapping.
+ 4. `dict[str, dict[str, str]]`: A dataset to column to prompt mapping.
+
+ And 2 cases for the dataset:
+
+ A. `Dataset`: A single dataset.
+ B. `DatasetDict`: A dictionary of datasets.
+
+ 3A is not allowed, and 2A doesn't make sense.
+
+ Args:
+ dataset_dict (DatasetDict | Dataset | None): The dataset to add prompts or dataset names to.
+
+ Returns:
+ DatasetDict | Dataset | None: The dataset with prompts or dataset names added.
+ """
+ if dataset_dict is None:
+ return None
+
+ include_dataset_name = isinstance(self.loss, dict)
+
+ # If we've already added the transform to this (iterable) dataset, don't add it again
+ if hasattr(dataset_dict, "_sentence_transformers_preprocessed"):
+ return dataset_dict
+
+ # Ensure that there's no "dataset_name"/"return_loss" columns in the unprocessed datasets
+ self.validate_column_names(dataset_dict, dataset_name=dataset_name)
+
+ # Only add if 1) we have prompts or 2) we need the dataset name for the loss dictionary
+ if prompts or include_dataset_name:
+ include_prompt_lengths = self._include_prompt_length()
+ dataset_dict = self.add_prompts_or_dataset_name_column(
+ dataset_dict,
+ prompts=prompts,
+ include_prompt_lengths=include_prompt_lengths,
+ include_dataset_name=include_dataset_name,
+ )
+ return dataset_dict
+
+ def add_prompts_or_dataset_name_column(
+ self,
+ dataset_dict: DatasetDict | IterableDatasetDict | Dataset | IterableDataset,
+ prompts: dict[str, str] | str | None = None,
+ dataset_name: str | None = None,
+ include_prompt_lengths: bool = False,
+ include_dataset_name: bool = False,
+ ) -> DatasetDict | Dataset | None:
+ # If we have DatasetDict, recurse
+ if isinstance(dataset_dict, (IterableDatasetDict, DatasetDict)):
+ for dataset_name, dataset in dataset_dict.items():
+ # If prompts is a dictionary that matches the dataset names, then take the nested prompts
+ nested_prompts = prompts.get(dataset_name, prompts) if isinstance(prompts, dict) else prompts
+ dataset_dict[dataset_name] = self.add_prompts_or_dataset_name_column(
+ dataset_dict=dataset,
+ prompts=nested_prompts,
+ dataset_name=dataset_name if include_dataset_name else None,
+ include_prompt_lengths=include_prompt_lengths,
+ include_dataset_name=include_dataset_name,
+ )
+ return dataset_dict
+
+ # Get the prompt lengths if needed for the pooling layer
+ prompt_lengths = None
+ if prompts:
+ if isinstance(prompts, str):
+ if include_prompt_lengths:
+ prompt_lengths = self._get_prompt_length(prompts)
+ elif isinstance(prompts, dict):
+ first_key = list(prompts.keys())[0]
+ if isinstance(prompts[first_key], dict):
+ raise ValueError(
+ "The prompts provided to the trainer are a nested dictionary. In this setting, the first "
+ "level of the dictionary should map to dataset names and the second level to column names. "
+ "However, as the provided dataset is a not a DatasetDict, no dataset names can be inferred. "
+ f"The keys to the provided prompts dictionary are {list(prompts.keys())!r}"
+ )
+ if include_prompt_lengths:
+ # If prompt columns exist, add the prompt length column
+ prompt_lengths = {
+ prompt: self._get_prompt_length(prompt)
+ for column_name, prompt in prompts.items()
+ if column_name in dataset_dict.column_names
+ }
+
+ # If we have a Dataset, we can set the transform directly...
+ if isinstance(dataset_dict, Dataset):
+ dataset_dict.set_transform(
+ partial(
+ self.add_prompts_or_dataset_name_transform,
+ prompts=prompts,
+ prompt_lengths=prompt_lengths,
+ dataset_name=dataset_name,
+ **dataset_dict._format_kwargs,
+ )
+ )
+
+ # ... otherwise, we have an IterableDataset and we need to map it, which performs the same operation as above
+ elif isinstance(dataset_dict, IterableDataset):
+ # Update the features to include the new columns
+ features = dataset_dict.features
+ if dataset_name:
+ features["dataset_name"] = Value("string")
+ if prompt_lengths:
+ if isinstance(prompts, str):
+ for column_name in dataset_dict.column_names:
+ feature = features[column_name]
+ if isinstance(feature, Value) and feature.dtype in ("string", "large_string"):
+ features[f"{column_name}_prompt_length"] = Value("int16")
+ elif isinstance(prompts, dict):
+ for column_name, prompt in prompts.items():
+ feature = features[column_name]
+ if (
+ prompt in prompt_lengths
+ and isinstance(feature, Value)
+ and feature.dtype in ("string", "large_string")
+ ):
+ features[f"{column_name}_prompt_length"] = Value("int16")
+
+ dataset_dict = dataset_dict.map(
+ partial(
+ self.add_prompts_or_dataset_name_transform,
+ prompts=prompts,
+ prompt_lengths=prompt_lengths,
+ dataset_name=dataset_name,
+ ),
+ batched=True,
+ features=features,
+ )
+
+ else:
+ raise ValueError("Unsupported dataset type.")
+
+ # Add a tag to the dataset to indicate that it has been preprocessed, to ensure that we don't apply the map or
+ # transform multiple times.
+ dataset_dict._sentence_transformers_preprocessed = True
+ return dataset_dict
+
def create_model_card(
self,
language: str | None = None,
diff --git a/sentence_transformers/training_args.py b/sentence_transformers/training_args.py
index ca1e15da8..68a659e30 100644
--- a/sentence_transformers/training_args.py
+++ b/sentence_transformers/training_args.py
@@ -149,6 +149,19 @@ class SentenceTransformerTrainingArguments(TransformersTrainingArguments):
Args:
output_dir (`str`):
The output directory where the model checkpoints will be written.
+ prompts (`Union[Dict[str, Dict[str, str]], Dict[str, str], str]`, *optional*):
+ The prompts to use for each column in the training, evaluation and test datasets. Four formats are accepted:
+
+ 1. `str`: A single prompt to use for all columns in the datasets, regardless of whether the training/evaluation/test
+ datasets are :class:`datasets.Dataset` or a :class:`datasets.DatasetDict`.
+ 2. `Dict[str, str]`: A dictionary mapping column names to prompts, regardless of whether the training/evaluation/test
+ datasets are :class:`datasets.Dataset` or a :class:`datasets.DatasetDict`.
+ 3. `Dict[str, str]`: A dictionary mapping dataset names to prompts. This should only be used if your training/evaluation/test
+ datasets are a :class:`datasets.DatasetDict` or a dictionary of :class:`datasets.Dataset`.
+ 4. `Dict[str, Dict[str, str]]`: A dictionary mapping dataset names to dictionaries mapping column names to
+ prompts. This should only be used if your training/evaluation/test datasets are a
+ :class:`datasets.DatasetDict` or a dictionary of :class:`datasets.Dataset`.
+
batch_sampler (Union[:class:`~sentence_transformers.training_args.BatchSamplers`, `str`], *optional*):
The batch sampler to use. See :class:`~sentence_transformers.training_args.BatchSamplers` for valid options.
Defaults to ``BatchSamplers.BATCH_SAMPLER``.
@@ -157,6 +170,7 @@ class SentenceTransformerTrainingArguments(TransformersTrainingArguments):
for valid options. Defaults to ``MultiDatasetBatchSamplers.PROPORTIONAL``.
"""
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None = None
batch_sampler: BatchSamplers | str = field(
default=BatchSamplers.BATCH_SAMPLER, metadata={"help": "The batch sampler to use."}
)
diff --git a/tests/test_sentence_transformer.py b/tests/test_sentence_transformer.py
index 3253bf2f9..588195b2a 100644
--- a/tests/test_sentence_transformer.py
+++ b/tests/test_sentence_transformer.py
@@ -284,12 +284,12 @@ def test_load_with_revision() -> None:
assert not torch.equal(main_embeddings, older_model.encode(test_sentence, convert_to_tensor=True))
-def test_load_local_without_normalize_directory() -> None:
- tiny_model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
- tiny_model.add_module("Normalize", Normalize())
+def test_load_local_without_normalize_directory(stsb_bert_tiny_model: SentenceTransformer) -> None:
+ model = stsb_bert_tiny_model
+ model.add_module("Normalize", Normalize())
with SafeTemporaryDirectory() as tmp_folder:
model_path = Path(tmp_folder) / "tiny_model_local"
- tiny_model.save(str(model_path))
+ model.save(str(model_path))
assert (model_path / "2_Normalize").exists()
os.rmdir(model_path / "2_Normalize")
@@ -300,8 +300,8 @@ def test_load_local_without_normalize_directory() -> None:
assert isinstance(fresh_tiny_model, SentenceTransformer)
-def test_prompts(caplog: pytest.LogCaptureFixture) -> None:
- model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
+def test_prompts(stsb_bert_tiny_model: SentenceTransformer, caplog: pytest.LogCaptureFixture) -> None:
+ model = stsb_bert_tiny_model
assert model.prompts == {}
assert model.default_prompt_name is None
texts = ["How to bake a chocolate cake", "Symptoms of the flu"]
@@ -469,13 +469,14 @@ def test_encode_quantization(
@pytest.mark.parametrize("normalize_embeddings", [True, False])
@pytest.mark.parametrize("output_value", ["sentence_embedding", None])
def test_encode_truncate(
+ stsb_bert_tiny_model_reused: SentenceTransformer,
sentences: str | list[str],
convert_to_tensor: bool,
convert_to_numpy: bool,
normalize_embeddings: bool,
output_value: Literal["sentence_embedding"] | None,
) -> None:
- model = SentenceTransformer("sentence-transformers-testing/stsb-bert-tiny-safetensors")
+ model = stsb_bert_tiny_model_reused
embeddings_full_unnormalized: torch.Tensor = model.encode(
sentences, convert_to_numpy=False, convert_to_tensor=True
) # These are raw embeddings which serve as the reference to test against
diff --git a/tests/test_trainer.py b/tests/test_trainer.py
index e7e9827d5..a978d8f5e 100644
--- a/tests/test_trainer.py
+++ b/tests/test_trainer.py
@@ -12,18 +12,21 @@
from sentence_transformers import SentenceTransformer, SentenceTransformerTrainer, losses
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
+from sentence_transformers.losses import MultipleNegativesRankingLoss
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
from sentence_transformers.util import is_datasets_available, is_training_available
from tests.utils import SafeTemporaryDirectory
if is_datasets_available():
- from datasets import DatasetDict, load_dataset
+ from datasets import Dataset, DatasetDict, IterableDatasetDict, load_dataset
+
+if not is_training_available():
+ pytest.skip(
+ reason='Sentence Transformers was not installed with the `["train"]` extra.',
+ allow_module_level=True,
+ )
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_trainer_multi_dataset_errors(
stsb_bert_tiny_model: SentenceTransformer, stsb_dataset_dict: DatasetDict
) -> None:
@@ -89,25 +92,20 @@ def test_trainer_multi_dataset_errors(
)
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_trainer_invalid_column_names(
stsb_bert_tiny_model: SentenceTransformer, stsb_dataset_dict: DatasetDict
) -> None:
train_dataset = stsb_dataset_dict["train"]
for column_name in ("return_loss", "dataset_name"):
invalid_train_dataset = train_dataset.rename_column("sentence1", column_name)
- trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
with pytest.raises(
ValueError,
match=re.escape(
- f"The following column names are invalid in your dataset: ['{column_name}']."
- " Avoid using these column names, as they are reserved for internal use."
+ f"The following column names are invalid in your train dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use.",
),
):
- trainer.train()
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
invalid_train_dataset = DatasetDict(
{
@@ -115,7 +113,6 @@ def test_trainer_invalid_column_names(
"stsb-2": train_dataset,
}
)
- trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
with pytest.raises(
ValueError,
match=re.escape(
@@ -123,13 +120,61 @@ def test_trainer_invalid_column_names(
" Avoid using these column names, as they are reserved for internal use."
),
):
- trainer.train()
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=invalid_train_dataset)
+
+ train_dataset = stsb_dataset_dict["train"]
+ eval_dataset = stsb_dataset_dict["validation"]
+ for column_name in ("return_loss", "dataset_name"):
+ invalid_eval_dataset = eval_dataset.rename_column("sentence1", column_name)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your eval dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer = SentenceTransformerTrainer(
+ model=stsb_bert_tiny_model, train_dataset=train_dataset, eval_dataset=invalid_eval_dataset
+ )
+
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=train_dataset)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your eval dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer.evaluate(eval_dataset=invalid_eval_dataset)
+
+ invalid_eval_dataset = DatasetDict(
+ {
+ "stsb": eval_dataset.rename_column("sentence1", column_name),
+ "stsb-2": eval_dataset,
+ }
+ )
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your stsb dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer = SentenceTransformerTrainer(
+ model=stsb_bert_tiny_model, train_dataset=train_dataset, eval_dataset=invalid_eval_dataset
+ )
+
+ trainer = SentenceTransformerTrainer(model=stsb_bert_tiny_model, train_dataset=train_dataset)
+ with pytest.raises(
+ ValueError,
+ match=re.escape(
+ f"The following column names are invalid in your stsb dataset: ['{column_name}']."
+ " Avoid using these column names, as they are reserved for internal use."
+ ),
+ ):
+ trainer.evaluate(eval_dataset=invalid_eval_dataset)
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
def test_model_card_reuse(stsb_bert_tiny_model: SentenceTransformer):
assert stsb_bert_tiny_model._model_card_text
# Reuse the model card if no training was done
@@ -153,10 +198,6 @@ def test_model_card_reuse(stsb_bert_tiny_model: SentenceTransformer):
assert model_card_text != stsb_bert_tiny_model._model_card_text
-@pytest.mark.skipif(
- not is_training_available(),
- reason='Sentence Transformers was not installed with the `["train"]` extra.',
-)
@pytest.mark.parametrize("streaming", [False, True])
@pytest.mark.parametrize("train_dict", [False, True])
@pytest.mark.parametrize("eval_dict", [False, True])
@@ -234,6 +275,346 @@ def test_trainer(
assert not torch.equal(original_embeddings, new_embeddings)
+@pytest.mark.slow
+@pytest.mark.parametrize("train_dict", [False, True])
+@pytest.mark.parametrize("eval_dict", [False, True])
+@pytest.mark.parametrize("loss_dict", [False, True])
+@pytest.mark.parametrize("pool_include_prompt", [False, True])
+@pytest.mark.parametrize("add_transform", [False, True])
+@pytest.mark.parametrize("streaming", [False, True])
+@pytest.mark.parametrize(
+ "prompts",
+ [
+ None, # No prompt
+ "Prompt: ", # Single prompt to all columns and all datasets
+ {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "}, # Different prompts for different datasets
+ {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "}, # Different prompts for different columns
+ {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ }, # Different prompts for different datasets and columns
+ ],
+)
+def test_trainer_prompts(
+ stsb_bert_tiny_model_reused: SentenceTransformer,
+ train_dict: bool,
+ eval_dict: bool,
+ loss_dict: bool,
+ pool_include_prompt: bool,
+ add_transform: bool,
+ streaming: bool,
+ prompts: dict[str, dict[str, str]] | dict[str, str] | str | None,
+):
+ if loss_dict and (not train_dict or not eval_dict):
+ pytest.skip(
+ "Skipping test because loss_dict=True requires train_dict=True and eval_dict=True; already tested via test_trainer."
+ )
+
+ model = stsb_bert_tiny_model_reused
+ model[1].include_prompt = pool_include_prompt
+
+ train_dataset_1 = Dataset.from_dict(
+ {
+ "sentence1": ["train 1 sentence 1a", "train 1 sentence 1b"],
+ "sentence2": ["train 1 sentence 2a", "train 1 sentence 2b"],
+ }
+ )
+ train_dataset_2 = Dataset.from_dict(
+ {
+ "sentence1": ["train 2 sentence 1a", "train 2 sentence 1b"],
+ "sentence2": ["train 2 sentence 2a", "train 2 sentence 2b"],
+ }
+ )
+ eval_dataset_1 = Dataset.from_dict(
+ {
+ "sentence1": ["eval 1 sentence 1a", "eval 1 sentence 1b"],
+ "sentence2": ["eval 1 sentence 2a", "eval 1 sentence 2b"],
+ }
+ )
+ eval_dataset_2 = Dataset.from_dict(
+ {
+ "sentence1": ["eval 2 sentence 1a", "eval 2 sentence 1b"],
+ "sentence2": ["eval 2 sentence 2a", "eval 2 sentence 2b"],
+ }
+ )
+ tracked_forward_keys = set()
+
+ class EmptyLoss(MultipleNegativesRankingLoss):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def forward(self, features, *args, **kwargs):
+ tracked_forward_keys.update(set(features[0].keys()))
+ return super().forward(features, *args, **kwargs)
+
+ loss = EmptyLoss(model=model)
+ # loss = MultipleNegativesRankingLoss(model=model)
+
+ tracked_texts = []
+ old_tokenize = model.tokenize
+
+ def tokenize_tracker(texts, *args, **kwargs):
+ tracked_texts.extend(texts)
+ return old_tokenize(texts, *args, **kwargs)
+
+ model.tokenize = tokenize_tracker
+
+ if train_dict:
+ if streaming:
+ train_dataset = IterableDatasetDict({"stsb-1": train_dataset_1, "stsb-2": train_dataset_2})
+ else:
+ train_dataset = DatasetDict({"stsb-1": train_dataset_1, "stsb-2": train_dataset_2})
+ else:
+ if streaming:
+ train_dataset = train_dataset_1.to_iterable_dataset()
+ else:
+ train_dataset = train_dataset_1
+
+ if eval_dict:
+ if streaming:
+ eval_dataset = IterableDatasetDict({"stsb-1": eval_dataset_1, "stsb-2": eval_dataset_2})
+ else:
+ eval_dataset = DatasetDict({"stsb-1": eval_dataset_1, "stsb-2": eval_dataset_2})
+ else:
+ if streaming:
+ eval_dataset = eval_dataset_1.to_iterable_dataset()
+ else:
+ eval_dataset = eval_dataset_1
+
+ def upper_transform(batch):
+ for column_name, column in batch.items():
+ batch[column_name] = [text.upper() for text in column]
+ return batch
+
+ if add_transform:
+ if streaming:
+ if train_dict:
+ train_dataset = IterableDatasetDict(
+ {
+ dataset_name: dataset.map(upper_transform, batched=True, features=dataset.features)
+ for dataset_name, dataset in train_dataset.items()
+ }
+ )
+ else:
+ train_dataset = train_dataset.map(upper_transform, batched=True, features=train_dataset.features)
+ if eval_dict:
+ eval_dataset = IterableDatasetDict(
+ {
+ dataset_name: dataset.map(upper_transform, batched=True, features=dataset.features)
+ for dataset_name, dataset in eval_dataset.items()
+ }
+ )
+ else:
+ eval_dataset = eval_dataset.map(upper_transform, batched=True, features=eval_dataset.features)
+ else:
+ train_dataset.set_transform(upper_transform)
+ eval_dataset.set_transform(upper_transform)
+
+ if loss_dict:
+ loss = {
+ "stsb-1": loss,
+ "stsb-2": loss,
+ }
+
+ # Variables to more easily track the expected outputs. Uppercased if add_transform is True as we expect
+ # the transform to be applied to the data.
+ all_train_1_1 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_1["sentence1"]}
+ all_train_1_2 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_1["sentence2"]}
+ all_train_2_1 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_2["sentence1"]}
+ all_train_2_2 = {sentence.upper() if add_transform else sentence for sentence in train_dataset_2["sentence2"]}
+ all_eval_1_1 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_1["sentence1"]}
+ all_eval_1_2 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_1["sentence2"]}
+ all_eval_2_1 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_2["sentence1"]}
+ all_eval_2_2 = {sentence.upper() if add_transform else sentence for sentence in eval_dataset_2["sentence2"]}
+ all_train_1 = all_train_1_1 | all_train_1_2
+ all_train_2 = all_train_2_1 | all_train_2_2
+ all_eval_1 = all_eval_1_1 | all_eval_1_2
+ all_eval_2 = all_eval_2_1 | all_eval_2_2
+ all_train = all_train_1 | all_train_2
+ all_eval = all_eval_1 | all_eval_2
+
+ if prompts == {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ } and (train_dict, eval_dict) != (True, True):
+ context = pytest.raises(
+ ValueError,
+ match="The prompts provided to the trainer are a nested dictionary. In this setting, the first "
+ "level of the dictionary should map to dataset names and the second level to column names. "
+ "However, as the provided dataset is a not a DatasetDict, no dataset names can be inferred. "
+ "The keys to the provided prompts dictionary are .*",
+ )
+ else:
+ context = nullcontext()
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+ args = SentenceTransformerTrainingArguments(
+ output_dir=str(temp_dir),
+ prompts=prompts,
+ max_steps=2,
+ eval_steps=2,
+ eval_strategy="steps",
+ per_device_train_batch_size=1,
+ per_device_eval_batch_size=1,
+ report_to=["none"],
+ )
+ with context:
+ trainer = SentenceTransformerTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ loss=loss,
+ )
+ if not isinstance(context, nullcontext):
+ return
+
+ datacollator_keys = set()
+ old_compute_loss = trainer.compute_loss
+
+ def compute_loss_tracker(model, inputs, **kwargs):
+ datacollator_keys.update(set(inputs.keys()))
+ loss = old_compute_loss(model, inputs, **kwargs)
+ return loss
+
+ trainer.compute_loss = compute_loss_tracker
+ trainer.train()
+
+ # In this one edge case, the prompts won't be used because the datasets aren't dictionaries, so the prompts
+ # are seen as column names & ignored as they don't exist.
+ if (
+ prompts
+ and not pool_include_prompt
+ and not (
+ prompts == {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "} and (train_dict, eval_dict) == (False, False)
+ )
+ ):
+ assert "prompt_length" in tracked_forward_keys
+ else:
+ assert "prompt_length" not in tracked_forward_keys
+
+ # We only need the dataset_name if the loss requires it
+ if loss_dict:
+ assert "dataset_name" in datacollator_keys
+ else:
+ assert "dataset_name" not in datacollator_keys
+
+ if prompts is None:
+ if (train_dict, eval_dict) == (False, False):
+ expected = all_train_1 | all_eval_1
+ elif (train_dict, eval_dict) == (True, False):
+ expected = all_train | all_eval_1
+ if (train_dict, eval_dict) == (False, True):
+ expected = all_train_1 | all_eval
+ elif (train_dict, eval_dict) == (True, True):
+ expected = all_train | all_eval
+
+ elif prompts == "Prompt: ":
+ if (train_dict, eval_dict) == (False, False):
+ expected = {prompts + sample for sample in all_train_1} | {prompts + sample for sample in all_eval_1}
+ elif (train_dict, eval_dict) == (True, False):
+ expected = {prompts + sample for sample in all_train} | {prompts + sample for sample in all_eval_1}
+ if (train_dict, eval_dict) == (False, True):
+ expected = {prompts + sample for sample in all_train_1} | {prompts + sample for sample in all_eval}
+ elif (train_dict, eval_dict) == (True, True):
+ expected = {prompts + sample for sample in all_train} | {prompts + sample for sample in all_eval}
+
+ if not pool_include_prompt:
+ expected.add(prompts)
+
+ elif prompts == {"stsb-1": "Prompt 1: ", "stsb-2": "Prompt 2: "}:
+ # If we don't have dataset dictionaries, the prompts will be seen as column names
+ if (train_dict, eval_dict) == (False, False):
+ expected = all_train_1 | all_eval_1
+ elif (train_dict, eval_dict) == (True, False):
+ expected = (
+ {prompts["stsb-1"] + sample for sample in all_train_1}
+ | {prompts["stsb-2"] + sample for sample in all_train_2}
+ | all_eval_1
+ )
+ if (train_dict, eval_dict) == (False, True):
+ expected = (
+ all_train_1
+ | {prompts["stsb-1"] + sample for sample in all_eval_1}
+ | {prompts["stsb-2"] + sample for sample in all_eval_2}
+ )
+ elif (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["stsb-1"] + sample for sample in all_train_1}
+ | {prompts["stsb-2"] + sample for sample in all_train_2}
+ | {prompts["stsb-1"] + sample for sample in all_eval_1}
+ | {prompts["stsb-2"] + sample for sample in all_eval_2}
+ )
+
+ # We need to add the prompt to the expected set because we need to collect prompt lengths if
+ # not pool_include_prompt, except if the datasets aren't dictionaries
+ if (train_dict, eval_dict) != (False, False) and not pool_include_prompt:
+ expected.update(set(prompts.values()))
+
+ elif prompts == {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "}:
+ if (train_dict, eval_dict) == (False, False):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ )
+ elif (train_dict, eval_dict) == (True, False):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ )
+ if (train_dict, eval_dict) == (False, True):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_2_2}
+ )
+ elif (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["sentence2"] + sample for sample in all_eval_2_2}
+ )
+
+ if not pool_include_prompt:
+ expected.update(set(prompts.values()))
+
+ elif prompts == {
+ "stsb-1": {"sentence1": "Prompt 1: ", "sentence2": "Prompt 2: "},
+ "stsb-2": {"sentence1": "Prompt 3: ", "sentence2": "Prompt 4: "},
+ }:
+ # All other cases are tested above with the ValueError context
+ if (train_dict, eval_dict) == (True, True):
+ expected = (
+ {prompts["stsb-1"]["sentence1"] + sample for sample in all_train_1_1}
+ | {prompts["stsb-1"]["sentence2"] + sample for sample in all_train_1_2}
+ | {prompts["stsb-2"]["sentence1"] + sample for sample in all_train_2_1}
+ | {prompts["stsb-2"]["sentence2"] + sample for sample in all_train_2_2}
+ | {prompts["stsb-1"]["sentence1"] + sample for sample in all_eval_1_1}
+ | {prompts["stsb-1"]["sentence2"] + sample for sample in all_eval_1_2}
+ | {prompts["stsb-2"]["sentence1"] + sample for sample in all_eval_2_1}
+ | {prompts["stsb-2"]["sentence2"] + sample for sample in all_eval_2_2}
+ )
+
+ if not pool_include_prompt:
+ expected.update({prompt for inner_dict in prompts.values() for prompt in inner_dict.values()})
+
+ assert set(tracked_texts) == expected
+
+
@pytest.mark.parametrize("use_eval_dataset", [True, False])
@pytest.mark.parametrize("use_evaluator", [True, False])
def test_trainer_no_eval_dataset_with_eval_strategy(