diff --git "a/docs/java/\346\265\201\347\250\213\347\274\226\346\216\222LiteFlow.md" "b/docs/java/\346\265\201\347\250\213\347\274\226\346\216\222LiteFlow.md"
index f79ba7c3..cc22eba4 100644
--- "a/docs/java/\346\265\201\347\250\213\347\274\226\346\216\222LiteFlow.md"
+++ "b/docs/java/\346\265\201\347\250\213\347\274\226\346\216\222LiteFlow.md"
@@ -2,17 +2,16 @@
LiteFlow真的是相见恨晚啊,之前做过的很多系统,都会用各种if else,switch这些来解决不同业务方提出的问题,有时候还要“切一个分支”来搞这些额外的事情,把代码搞得一团糟,毫无可读性而言。如何打破僵局?LiteFlow为解耦逻辑而生,为编排而生,在使用LiteFlow之后,你会发现打造一个低耦合,灵活的系统会变得易如反掌!
-## 背景
+另外, LiteFlow 和 Activiti 们并不是同一个东西,而是面向不同的使用场景和需求。LiteFlow 更加轻量灵活,适合需要简单流程管理和动态配置的场景;而 Activiti 则是一个全面的 BPM 引擎,适合需要复杂业务流程管理和任务管理的场景。根据具体业务需求,可以选择合适的工具来实现流程编排。
-之前做过一个数据分发系统,需要消费kafka的数据,下游有不同的业务,每个业务可能有共同的地方,也有不同的地方,在经过各类的处理之后,最后数据分发到下游里面去,真个流程如下。
+## 背景
-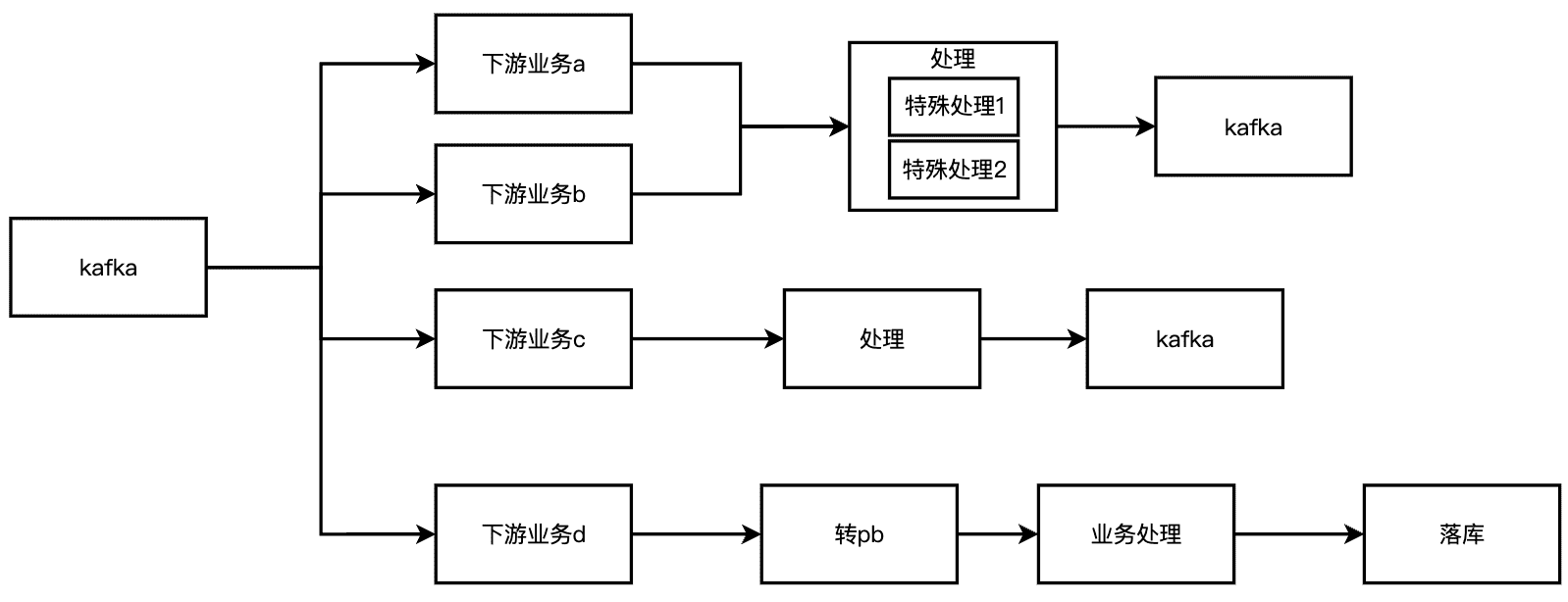
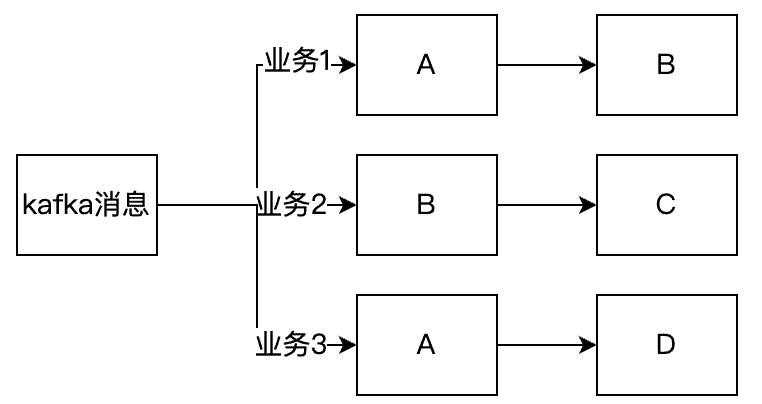
+之前做过一个数据分发系统,需要消费kafka的数据,下游有不同的业务,每个业务可能有共同的地方,也有不同的地方,在经过各类的处理之后,最后数据分发到下游里面去。为了简化代码方便理解,我们定义4个Handler(A、B、C、D),然后有3个不同的业务,需要经过不同的Handler,整个流程如下。
-如果要在一个代码实现上诉功能,我们第一反应可能是**责任链设计模式**,每个业务一条链路,
+ -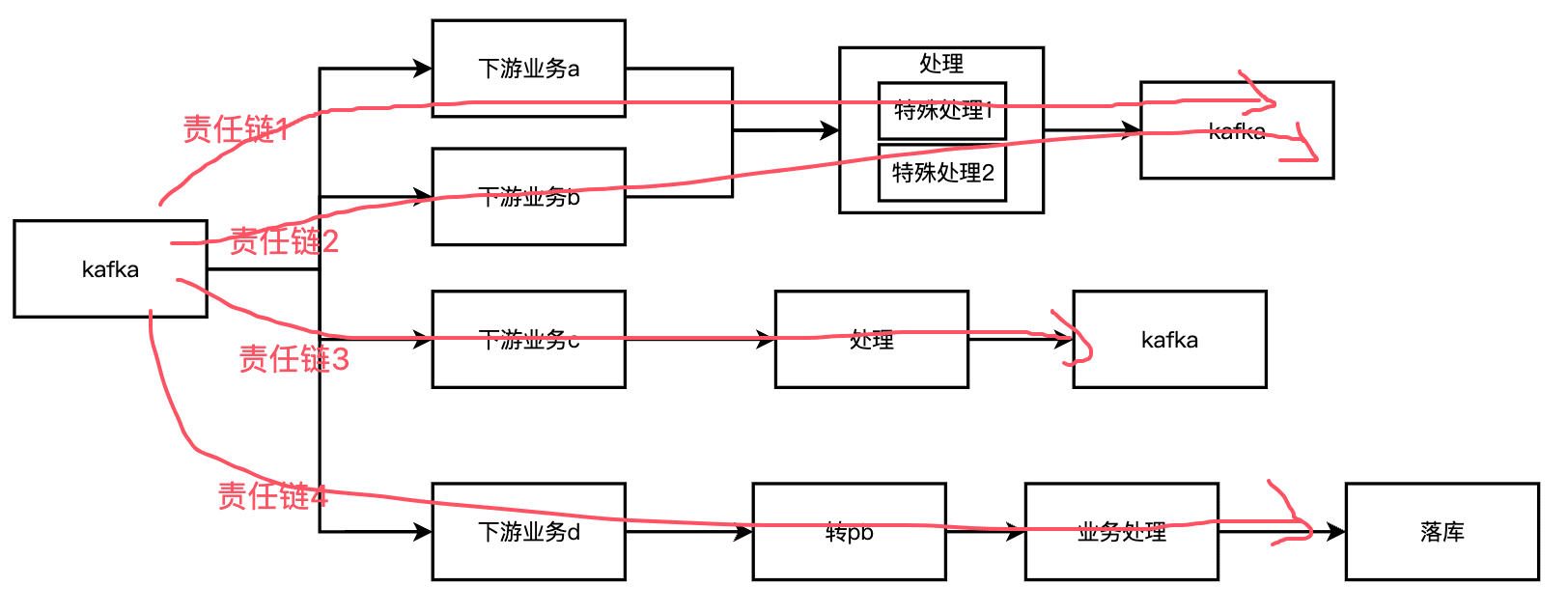
+如果要在一个代码实现上诉功能,我们第一反应可能是**责任链设计模式**,每个业务一条链路,在Spring中,类似下面的代码:
-在Spring中,类似下面的代码:
```java
public abstract class Handler {
abstract void handler(Request request);
@@ -70,7 +69,7 @@ public enum HandleBuz {
}
```
-通过配置责任链,可以灵活地组合处理对象,实现不同的处理流程,并且可以在运行时动态地改变处理的顺序,由于责任链模式遵循[开闭原则](https://zhida.zhihu.com/search?q=开闭原则&zhida_source=entity&is_preview=1),新的处理者可以随时被加入到责任链中,不需要修改已有代码,提供了良好的扩展性。但实际上面对各种需求的时候,没法做到完全的解耦,比如对于HandlerA,如果业务1和业务2都有定制化的需求,此时是应该再HandlerA中用if else解决,还是再额外开个HandlerA_1和HandlerA_2。这类特性需求会非常多,最终把代码可读性变得越来越低。
+通过配置责任链,可以灵活地组合处理对象,实现不同的处理流程,并且可以在运行时动态地改变处理的顺序,由于责任链模式遵循[开闭原则](https://zhida.zhihu.com/search?q=开闭原则&zhida_source=entity&is_preview=1),新的处理者可以随时被加入到责任链中,不需要修改已有代码,提供了良好的扩展性。但实际上面对各种需求的时候,没法做到完全的解耦,比如**对于HandlerA,如果业务1和业务2都有定制化的需求(来自产品提的临时或长期需求)**,此时是应该再HandlerA中用if else解决,还是再额外开个HandlerA_1和HandlerA_2。这类特性需求会非常多,最终把代码可读性变得越来越低。
## 一、为什么需要流程编排
@@ -84,35 +83,27 @@ LiteFlow由Baidu开源,专注于逻辑驱动流程编排,通过组件化方
## 二、它可以解决什么问题
-
-
-
-
-```xml
-
- THEN(
- SWTICH(分业务).to(
- )
- A, B,
- WHEN(
- THEN(C, WHEN(J, K)),
- D,
- THEN(H, I)
- ),
- SWITCH(X).to(
- M,
- N,
- WHEN(Q, THEN(P, R)).id("w01")
- ),
- Z
- );
-
-```
-
-
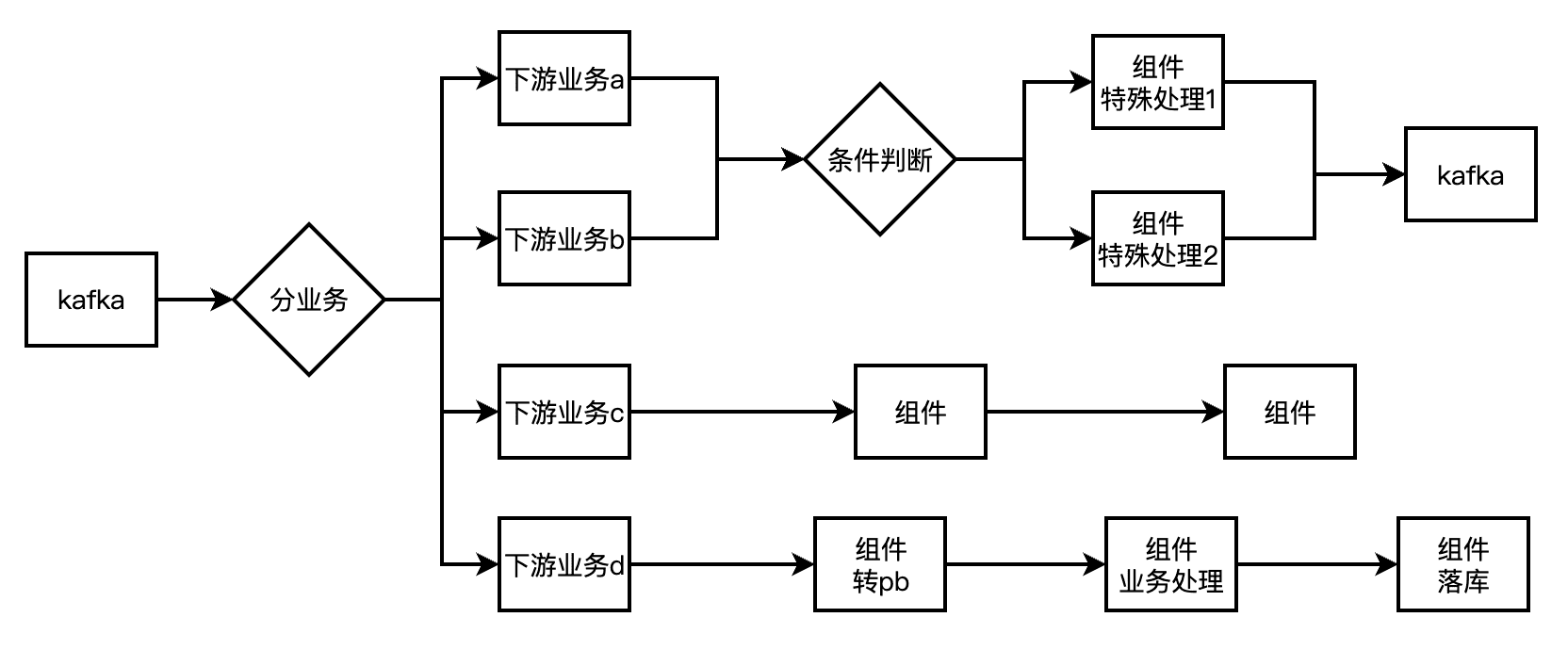
+对大部分不断迭代的代码来说,历史遗留的代码加上需要面对各类各样的需求,代码会变得越来越难维护,甚至变成屎山。我们想着不断的去进行解耦,不断的去进行切割拆分,还要兼顾新需求,就怕蝴蝶效应导致大故障,liteflow能帮我们在解耦上更加清晰一点。
+(1)复杂业务流程编排和管理
+在一些应用场景中,业务逻辑往往非常复杂,涉及多个步骤的执行,并且这些步骤之间具有复杂的依赖关系。LiteFlow 可以帮助开发者通过配置和代码相结合的方式定义和管理这些流程。
+(2)流程动态配置
+LiteFlow 允许通过配置文件或者数据库动态修改流程,而无需修改代码。这意味着可以根据不同的业务需求快速调整并发布新的流程,而不需要重新部署应用。
+(3)流程节点的复用和解耦
+在使用 LiteFlow 时,每个业务步骤都可以定义为一个独立的节点(Node),这些节点可以独立开发、测试和维护,并且可以在多个流程中复用。通过这种方式,可以实现业务逻辑的复用和解耦,提高代码的可维护性。
+(4)节点状态和错误处理
+LiteFlow 提供了丰富的节点状态管理和错误处理机制,允许开发者在流程执行过程中捕获和处理异常,从而确保系统的稳定性和健壮性。
+(5) 高扩展性和自定义能力
+LiteFlow 具有高度的扩展性,开发者可以根据自身业务的特殊需求定制节点、组件和插件,从而满足复杂场景的要求。
+
+以下是一些实际使用 LiteFlow 的示例场景:
+(1)**订单处理系统**:在电商系统中,订单处理涉及多个步骤,如库存检查、支付处理、订单确认和发货等。LiteFlow 可以帮助将这些步骤分开独立实现,然后通过流程引擎编排执行。
+(2)**审批流程**:在企业中,审批流程通常包括多个节点(如申请、审批、复核、归档等),并且这些节点之间可能有条件和依赖关系。LiteFlow 可以帮助动态配置和管理这些流程,提高审批效率。
+(3)**营销活动**:在一些营销活动中,不同的活动环节和逻辑可能会因用户行为和外部条件而变化。LiteFlow 可以帮助实现灵活的活动规则配置和执行。
## 三、LiteFlow改造之后
+首先定义并实现一些组件,确保SpringBoot会扫描到这些组件并注册进上下文。
+
```java
@Slf4j
@LiteflowComponent("a")
@@ -152,22 +143,63 @@ public class HandlerD extends NodeComponent {
```
+同时,你得在resources下的`config/flow.el.xml`中定义规则:
+```xml
+
+
+
+ THEN(
+ a,b
+ );
+
+
+ THEN(
+ b,c
+ );
+
+
+ THEN(
+ a,d
+ );
+
+
+```
-再配合LiteFlow的EL表达式使用
-
-
-
-
-
+最后,在消费kafka的时候,先定义一个ruleChainMap,用来判断根据唯一的id(业务id或者消息id)来判断走哪条chain、哪个组件等,甚至可以定义方法级别的组件。
+```java
+ private Map ruleChainMap = new HashMap<>();
+ @Resource
+ private FlowExecutor flowExecutor;
+
+ @PostConstruct
+ private void init() {
+ ruleChainMap.put(1, "业务1");
+ ruleChainMap.put(2, "业务2");
+ ruleChainMap.put(3, "业务3");
+ }
+ @KafkaListener(topics = "xxxx")
+ public void common(List> records) {
+ for (ConsumerRecord record : records) {
+ ...
+ String chainName = ruleChainMap.get("唯一id(可以是record里的,也可以全局定义的id)");
+ LiteflowResponse response = flowExecutor.execute2Resp(chainName, xxx, xxx, new TempContext());
+ }
+ }
+```
+由于篇幅的关系,这里不再讲解怎么传递上下文的关系,可以自己去官网研究一下。另外,上面的例子因为是简化之后的,如果你觉得不够形象,可以看看下面的实际业务。这个如果不使用liteflow,可能就得在主流程代码里增加各种if else,甚至后续改了一小块也不知道对别的地方有没有影响。
-## 文档
+
-1.【腾讯文档】业务处理复杂 https://docs.qq.com/flowchart/DZVFURmhCb0JFUHFD
+## 总结
+**后续,如果面对产品经理“来自大领导的一个想法,我不知道后续还会不会一直做下去,反正先做了再说”这类需求,就可以自己定义一个LiteFlow的组件,既不污染主流程的代码,后续下线了删掉即可,赏心悦目。**
-2.【腾讯文档】业务处理复杂2 https://docs.qq.com/flowchart/DZXVOaUV5VGRtc3ZD
+## 文档&参考
-3.[一文搞懂设计模式—责任链模式](https://zhuanlan.zhihu.com/p/680508137)
\ No newline at end of file
+1.【腾讯文档】业务处理复杂 https://docs.qq.com/flowchart/DZVFURmhCb0JFUHFD
+2.【腾讯文档】业务处理复杂2 https://docs.qq.com/flowchart/DZXVOaUV5VGRtc3ZD
+3.[一文搞懂设计模式—责任链模式](https://zhuanlan.zhihu.com/p/680508137)
+4.[LiteFlow官网](https://liteflow.cc/)
\ No newline at end of file
-
+如果要在一个代码实现上诉功能,我们第一反应可能是**责任链设计模式**,每个业务一条链路,在Spring中,类似下面的代码:
-在Spring中,类似下面的代码:
```java
public abstract class Handler {
abstract void handler(Request request);
@@ -70,7 +69,7 @@ public enum HandleBuz {
}
```
-通过配置责任链,可以灵活地组合处理对象,实现不同的处理流程,并且可以在运行时动态地改变处理的顺序,由于责任链模式遵循[开闭原则](https://zhida.zhihu.com/search?q=开闭原则&zhida_source=entity&is_preview=1),新的处理者可以随时被加入到责任链中,不需要修改已有代码,提供了良好的扩展性。但实际上面对各种需求的时候,没法做到完全的解耦,比如对于HandlerA,如果业务1和业务2都有定制化的需求,此时是应该再HandlerA中用if else解决,还是再额外开个HandlerA_1和HandlerA_2。这类特性需求会非常多,最终把代码可读性变得越来越低。
+通过配置责任链,可以灵活地组合处理对象,实现不同的处理流程,并且可以在运行时动态地改变处理的顺序,由于责任链模式遵循[开闭原则](https://zhida.zhihu.com/search?q=开闭原则&zhida_source=entity&is_preview=1),新的处理者可以随时被加入到责任链中,不需要修改已有代码,提供了良好的扩展性。但实际上面对各种需求的时候,没法做到完全的解耦,比如**对于HandlerA,如果业务1和业务2都有定制化的需求(来自产品提的临时或长期需求)**,此时是应该再HandlerA中用if else解决,还是再额外开个HandlerA_1和HandlerA_2。这类特性需求会非常多,最终把代码可读性变得越来越低。
## 一、为什么需要流程编排
@@ -84,35 +83,27 @@ LiteFlow由Baidu开源,专注于逻辑驱动流程编排,通过组件化方
## 二、它可以解决什么问题
-
-
-
-
-```xml
-
- THEN(
- SWTICH(分业务).to(
- )
- A, B,
- WHEN(
- THEN(C, WHEN(J, K)),
- D,
- THEN(H, I)
- ),
- SWITCH(X).to(
- M,
- N,
- WHEN(Q, THEN(P, R)).id("w01")
- ),
- Z
- );
-
-```
-
-
+对大部分不断迭代的代码来说,历史遗留的代码加上需要面对各类各样的需求,代码会变得越来越难维护,甚至变成屎山。我们想着不断的去进行解耦,不断的去进行切割拆分,还要兼顾新需求,就怕蝴蝶效应导致大故障,liteflow能帮我们在解耦上更加清晰一点。
+(1)复杂业务流程编排和管理
+在一些应用场景中,业务逻辑往往非常复杂,涉及多个步骤的执行,并且这些步骤之间具有复杂的依赖关系。LiteFlow 可以帮助开发者通过配置和代码相结合的方式定义和管理这些流程。
+(2)流程动态配置
+LiteFlow 允许通过配置文件或者数据库动态修改流程,而无需修改代码。这意味着可以根据不同的业务需求快速调整并发布新的流程,而不需要重新部署应用。
+(3)流程节点的复用和解耦
+在使用 LiteFlow 时,每个业务步骤都可以定义为一个独立的节点(Node),这些节点可以独立开发、测试和维护,并且可以在多个流程中复用。通过这种方式,可以实现业务逻辑的复用和解耦,提高代码的可维护性。
+(4)节点状态和错误处理
+LiteFlow 提供了丰富的节点状态管理和错误处理机制,允许开发者在流程执行过程中捕获和处理异常,从而确保系统的稳定性和健壮性。
+(5) 高扩展性和自定义能力
+LiteFlow 具有高度的扩展性,开发者可以根据自身业务的特殊需求定制节点、组件和插件,从而满足复杂场景的要求。
+
+以下是一些实际使用 LiteFlow 的示例场景:
+(1)**订单处理系统**:在电商系统中,订单处理涉及多个步骤,如库存检查、支付处理、订单确认和发货等。LiteFlow 可以帮助将这些步骤分开独立实现,然后通过流程引擎编排执行。
+(2)**审批流程**:在企业中,审批流程通常包括多个节点(如申请、审批、复核、归档等),并且这些节点之间可能有条件和依赖关系。LiteFlow 可以帮助动态配置和管理这些流程,提高审批效率。
+(3)**营销活动**:在一些营销活动中,不同的活动环节和逻辑可能会因用户行为和外部条件而变化。LiteFlow 可以帮助实现灵活的活动规则配置和执行。
## 三、LiteFlow改造之后
+首先定义并实现一些组件,确保SpringBoot会扫描到这些组件并注册进上下文。
+
```java
@Slf4j
@LiteflowComponent("a")
@@ -152,22 +143,63 @@ public class HandlerD extends NodeComponent {
```
+同时,你得在resources下的`config/flow.el.xml`中定义规则:
+```xml
+
+
+
+ THEN(
+ a,b
+ );
+
+
+ THEN(
+ b,c
+ );
+
+
+ THEN(
+ a,d
+ );
+
+
+```
-再配合LiteFlow的EL表达式使用
-
-
-
-
-
+最后,在消费kafka的时候,先定义一个ruleChainMap,用来判断根据唯一的id(业务id或者消息id)来判断走哪条chain、哪个组件等,甚至可以定义方法级别的组件。
+```java
+ private Map ruleChainMap = new HashMap<>();
+ @Resource
+ private FlowExecutor flowExecutor;
+
+ @PostConstruct
+ private void init() {
+ ruleChainMap.put(1, "业务1");
+ ruleChainMap.put(2, "业务2");
+ ruleChainMap.put(3, "业务3");
+ }
+ @KafkaListener(topics = "xxxx")
+ public void common(List> records) {
+ for (ConsumerRecord record : records) {
+ ...
+ String chainName = ruleChainMap.get("唯一id(可以是record里的,也可以全局定义的id)");
+ LiteflowResponse response = flowExecutor.execute2Resp(chainName, xxx, xxx, new TempContext());
+ }
+ }
+```
+由于篇幅的关系,这里不再讲解怎么传递上下文的关系,可以自己去官网研究一下。另外,上面的例子因为是简化之后的,如果你觉得不够形象,可以看看下面的实际业务。这个如果不使用liteflow,可能就得在主流程代码里增加各种if else,甚至后续改了一小块也不知道对别的地方有没有影响。
-## 文档
+
-1.【腾讯文档】业务处理复杂 https://docs.qq.com/flowchart/DZVFURmhCb0JFUHFD
+## 总结
+**后续,如果面对产品经理“来自大领导的一个想法,我不知道后续还会不会一直做下去,反正先做了再说”这类需求,就可以自己定义一个LiteFlow的组件,既不污染主流程的代码,后续下线了删掉即可,赏心悦目。**
-2.【腾讯文档】业务处理复杂2 https://docs.qq.com/flowchart/DZXVOaUV5VGRtc3ZD
+## 文档&参考
-3.[一文搞懂设计模式—责任链模式](https://zhuanlan.zhihu.com/p/680508137)
\ No newline at end of file
+1.【腾讯文档】业务处理复杂 https://docs.qq.com/flowchart/DZVFURmhCb0JFUHFD
+2.【腾讯文档】业务处理复杂2 https://docs.qq.com/flowchart/DZXVOaUV5VGRtc3ZD
+3.[一文搞懂设计模式—责任链模式](https://zhuanlan.zhihu.com/p/680508137)
+4.[LiteFlow官网](https://liteflow.cc/)
\ No newline at end of file