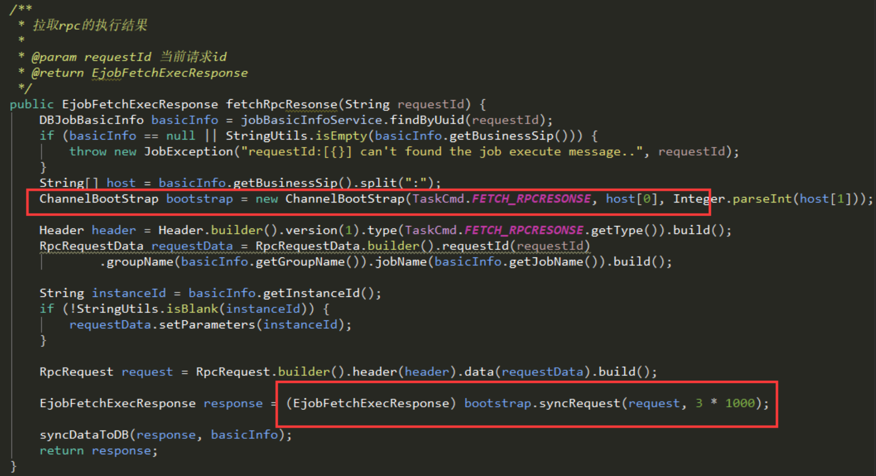
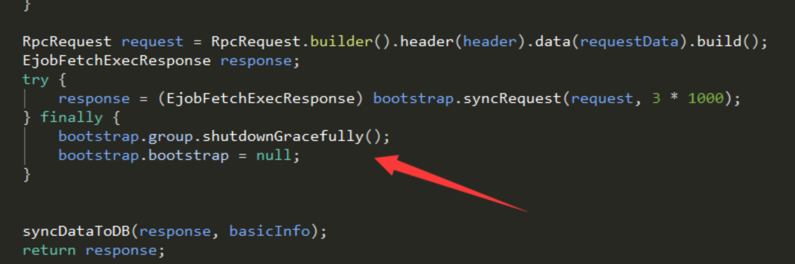
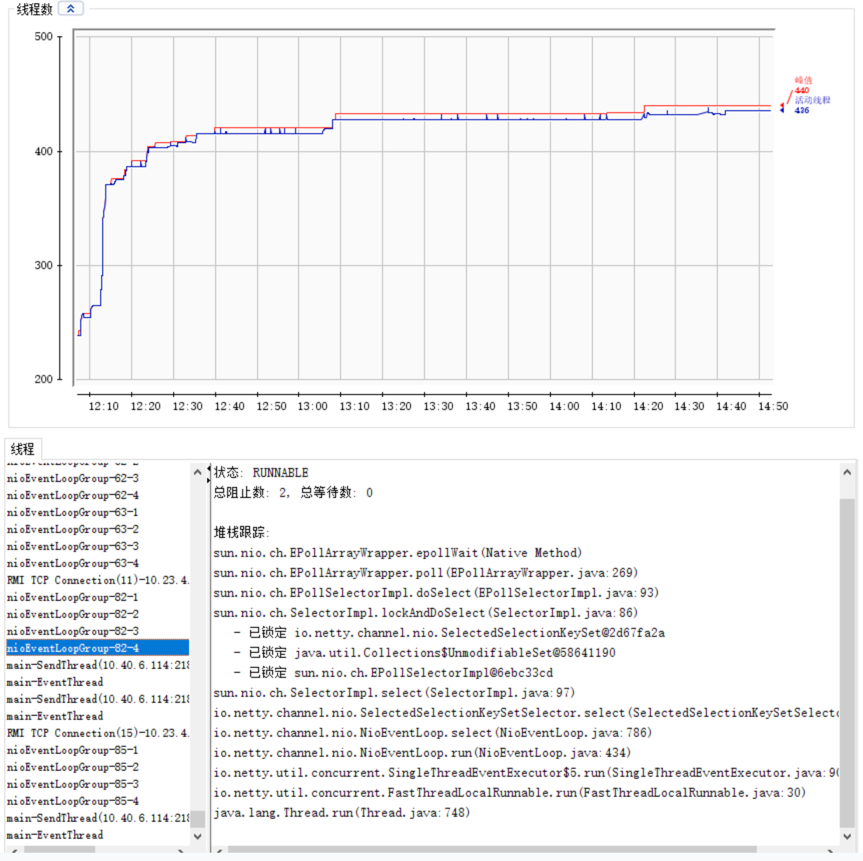
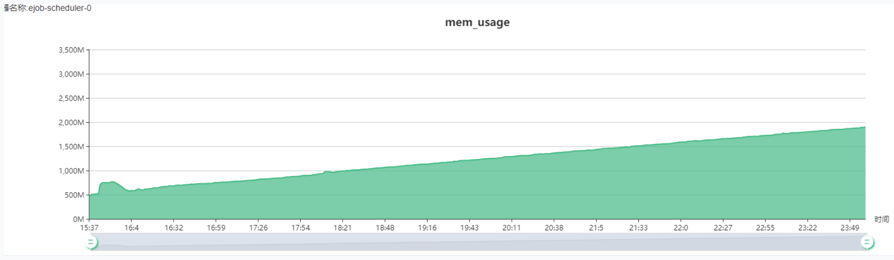
diff --git a/404.html b/404.html
new file mode 100644
index 00000000..555ea79f
--- /dev/null
+++ b/404.html
@@ -0,0 +1,46 @@
+
+
+
+ 个人博客
+ 关于我 | 个人博客
+ Personal Life | 个人博客
+ 自我介绍 | 个人博客
+ 文章 | 个人博客
+ 1.历史与架构 \\n各位大佬瞄一眼我的个人网站 呗 。如果觉得不错,希望能在GitHub上麻烦给个star,GitHub地址https://github.com/Zephery/newblog 。\\n大学的时候萌生的一个想法,就是建立一个个人网站,前前后后全部推翻重构了4、5遍,现在终于能看了,下面是目前的首页。
","autoDesc":true}');export{e as data};
diff --git "a/assets/1.\345\216\206\345\217\262\344\270\216\346\236\266\346\236\204.html-X_ZVzsKc.js" "b/assets/1.\345\216\206\345\217\262\344\270\216\346\236\266\346\236\204.html-X_ZVzsKc.js"
new file mode 100644
index 00000000..288afd89
--- /dev/null
+++ "b/assets/1.\345\216\206\345\217\262\344\270\216\346\236\266\346\236\204.html-X_ZVzsKc.js"
@@ -0,0 +1 @@
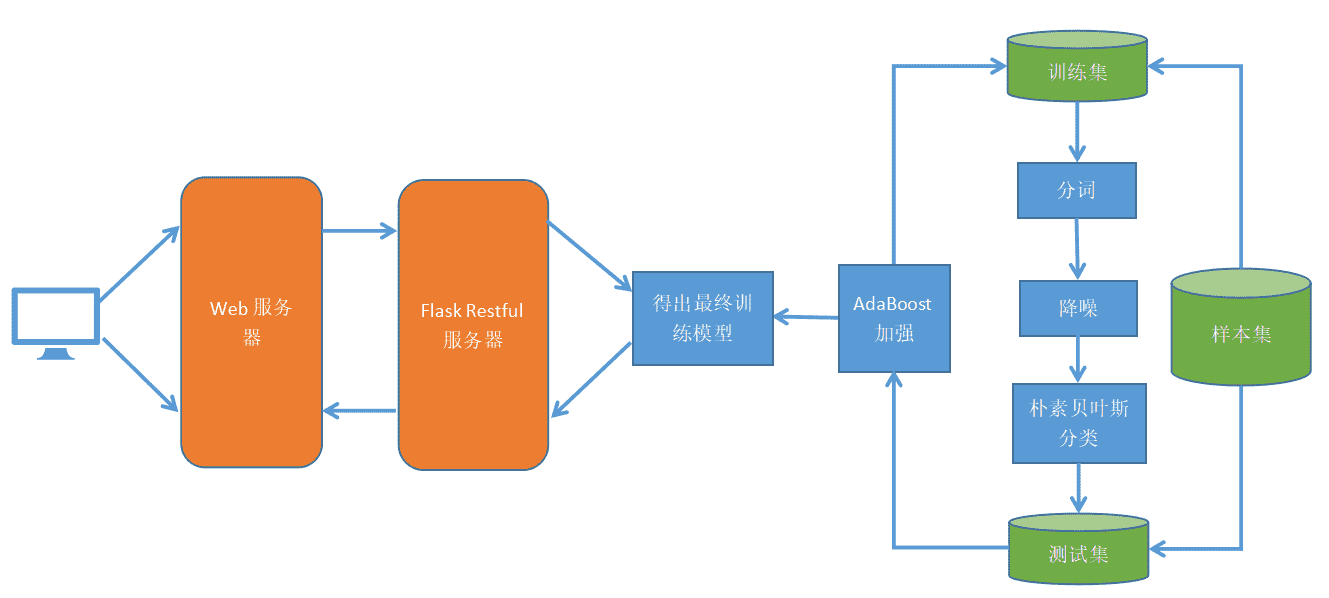
+import{_ as l}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as i,c as a,a as e,d as t,b as n,e as s}from"./app-cS6i7hsH.js";const h={},c=e("h1",{id:"_1-历史与架构",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_1-历史与架构","aria-hidden":"true"},"#"),t(" 1.历史与架构")],-1),d={href:"http://www.wenzhihuai.com/",target:"_blank",rel:"noopener noreferrer"},_={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},g=e("figure",null,[e("img",{src:"https://github-images.wenzhihuai.com/images/600-20240126113210252.png",alt:"",tabindex:"0",loading:"lazy"}),e("figcaption")],-1),p={href:"http://www.wenzhihuai.com/weibonlp.html",target:"_blank",rel:"noopener noreferrer"},b=e("br",null,null,-1),u={href:"https://github.com/Zephery/newblog/blob/master/doc/1.%E5%8E%86%E5%8F%B2%E4%B8%8E%E6%9E%B6%E6%9E%84.md",target:"_blank",rel:"noopener noreferrer"},f=e("br",null,null,-1),m={href:"https://github.com/Zephery/newblog/blob/master/doc/2.Lucene%E7%9A%84%E4%BD%BF%E7%94%A8.md",target:"_blank",rel:"noopener noreferrer"},w=e("br",null,null,-1),E={href:"https://github.com/Zephery/newblog/blob/master/doc/3.%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1.md",target:"_blank",rel:"noopener noreferrer"},B=e("br",null,null,-1),x={href:"https://github.com/Zephery/baidutongji/blob/master/README.md",target:"_blank",rel:"noopener noreferrer"},k=e("br",null,null,-1),y={href:"https://github.com/Zephery/newblog/blob/master/doc/6.%E5%B0%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.md",target:"_blank",rel:"noopener noreferrer"},z=e("br",null,null,-1),v=e("li",null,[t("[数据库]"),e("br")],-1),A=e("li",null,[t("使用机器学习对微博进行分析"),e("br")],-1),C=e("li",null,[t("网站性能优化"),e("br")],-1),P=e("li",null,[t("SEO优化"),e("br")],-1),S=e("h2",{id:"_1-建站故事与网站架构",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_1-建站故事与网站架构","aria-hidden":"true"},"#"),t(" 1.建站故事与网站架构")],-1),V=e("h3",{id:"_1-1建站过程",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_1-1建站过程","aria-hidden":"true"},"#"),t(" 1.1建站过程")],-1),I={href:"http://www.yangqq.com/",target:"_blank",rel:"noopener noreferrer"},j=e("figure",null,[e("img",{src:"https://github-images.wenzhihuai.com/images/500.png",alt:"",tabindex:"0",loading:"lazy"}),e("figcaption")],-1),H=e("p",null,"第二版的界面确实是这样的,只是把图片的切换变成了wowslider,也是简单的用bootstrap和pagehelper做了下分页,现在的最终版保留了它的header,然后评论框使用了多说(超级怀念多说)。后端也由原来的ssh变成了ssm,之后加上了lucene来对文章进行索引。之后,随着多说要关闭了,突然之间有很多div都不适应了(我写死了的。。。),再一次,没法看,不想看,一怒之下再次推翻重做,变成了现在这个版本。",-1),M={href:"https://tale.biezhi.me",target:"_blank",rel:"noopener noreferrer"},Z={href:"https://yusi123.com",target:"_blank",rel:"noopener noreferrer"},F=e("h3",{id:"_1-2-网站整体技术架构",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_1-2-网站整体技术架构","aria-hidden":"true"},"#"),t(" 1.2 网站整体技术架构")],-1),q=e("p",null,"最终版的技术架构图如下:",-1),G=e("figure",null,[e("img",{src:"https://github-images.wenzhihuai.com/images/awfawefwefwef.png",alt:"",tabindex:"0",loading:"lazy"}),e("figcaption")],-1),J={href:"http://jinnianshilongnian.iteye.com/blog/1594806",target:"_blank",rel:"noopener noreferrer"},R=s('运行流程分析
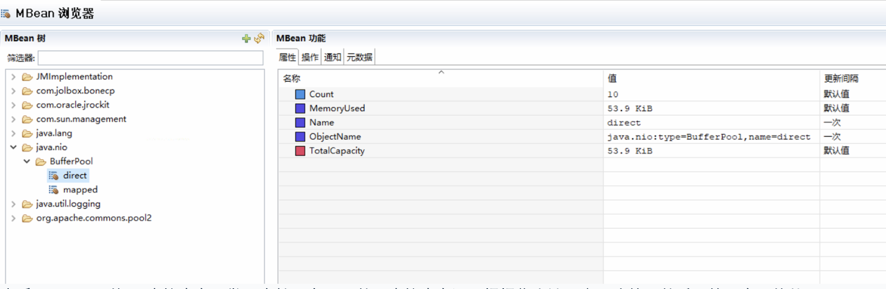
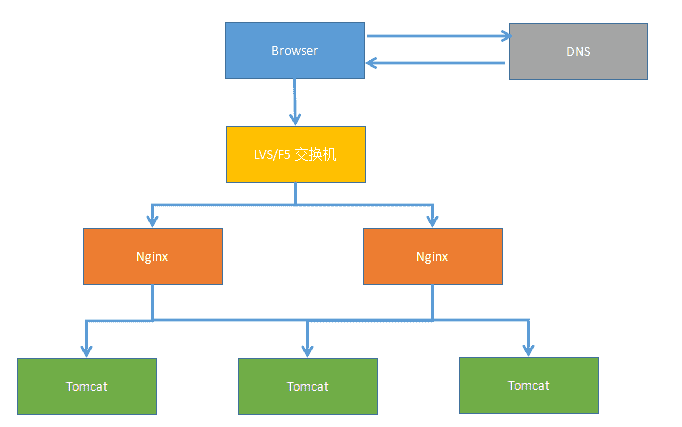
浏览器发送http请求。/blogdetail.html?blogid=1。 tomcat容器初始化,顺序为context-param>listener>filter>servlet,此时,spring中的bean还没有被注入的,不建议在此处加载bean,网站声明了两个类(IPFilter和CacheControlFilter),IPFilter用来拦截IP,CacheControlFilter用来缓存。 初始化Spring。 DispatcherServlet——>HandlerMapping进行请求到处理的映射,HandlerMapping将“/blogdetail”路径直接映射到名字为“/blogdetail”的Bean进行处理,即BlogController。 自定义拦截器,其中BaseIntercepter实现了HandleInterceptor的接口,用来记录每次访问的链接以及后台响应的时间。 DispatcherServlet——> SimpleControllerHandlerAdapter,SimpleControllerHandlerAdapter将HandlerExecutionChain中的处理器适配为BlogController。 BlogController执行查询,取得结果集返回数据。 blogdetail(ModelAndView的逻辑视图名)——>InternalResourceViewResolver, InternalResourceViewResolver使用JstlView,具体视图页面在/blogdetail.jsp。 JstlView(/blogdetail.jsp)——>渲染,将在处理器传入的模型数据(blog=Blog!)在视图中展示出来。 返回响应。 1.3 日志系统 日志系统架构如下:
10.网站重构 \\n因原本的
\\n","autoDesc":true}');export{e as data};
diff --git "a/assets/10.\347\275\221\347\253\231\351\207\215\346\236\204.html-vlubYdUg.js" "b/assets/10.\347\275\221\347\253\231\351\207\215\346\236\204.html-vlubYdUg.js"
new file mode 100644
index 00000000..724aac62
--- /dev/null
+++ "b/assets/10.\347\275\221\347\253\231\351\207\215\346\236\204.html-vlubYdUg.js"
@@ -0,0 +1 @@
+import{_}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as o,a as e,d as a}from"./app-cS6i7hsH.js";const c={},r=e("h1",{id:"_10-网站重构",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_10-网站重构","aria-hidden":"true"},"#"),a(" 10.网站重构")],-1),s=e("p",null,"因原本的",-1),n=[r,s];function d(i,l){return t(),o("div",null,n)}const m=_(c,[["render",d],["__file","10.网站重构.html.vue"]]);export{m as default};
diff --git a/assets/1mysql.html-OHVRcqVz.js b/assets/1mysql.html-OHVRcqVz.js
new file mode 100644
index 00000000..892c8876
--- /dev/null
+++ b/assets/1mysql.html-OHVRcqVz.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as s,c as a,a as e,d as o}from"./app-cS6i7hsH.js";const n="/assets/img-kuzmmtyE.png",c={},i=e("h1",{id:"mysql",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#mysql","aria-hidden":"true"},"#"),o(" mysql")],-1),r=e("figure",null,[e("img",{src:n,alt:"img",tabindex:"0",loading:"lazy"}),e("figcaption",null,"img")],-1),l=[i,r];function _(m,d){return s(),a("div",null,l)}const u=t(c,[["render",_],["__file","1mysql.html.vue"]]);export{u as default};
diff --git a/assets/1mysql.html-iiTeieOx.js b/assets/1mysql.html-iiTeieOx.js
new file mode 100644
index 00000000..c91affc3
--- /dev/null
+++ b/assets/1mysql.html-iiTeieOx.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-aa93dec0","path":"/database/mysql/1mysql.html","title":"mysql","lang":"zh-CN","frontmatter":{"description":"mysql img","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/mysql/1mysql.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"mysql"}],["meta",{"property":"og:description","content":"mysql img"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"mysql\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706092222000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.01,"words":3},"filePathRelative":"database/mysql/1mysql.md","localizedDate":"2024年1月24日","excerpt":" mysql \\nimg Lucene的整体架构 image 搜索引擎的几个重要概念: 倒排索引:将文档中的词作为关键字,建立词与文档的映射关系,通过对倒排索引的检索,可以根据词快速获取包含这个词的文档列表。倒排索引一般需要对句子做去除停用词。
停用词:在一段句子中,去掉之后对句子的表达意向没有印象的词语,如“非常”、“如果”,中文中主要包括冠词,副词等。
排序:搜索引擎在对一个关键词进行搜索时,可能会命中许多文档,这个时候,搜索引擎就需要快速的查找的用户所需要的文档,因此,相关度大的结果需要进行排序,这个设计到搜索引擎的相关度算法。
Lucene中的几个概念 文档(Document):文档是一系列域的组合,文档的域则代表一系列域文档相关的内容。 域(Field):每个文档可以包含一个或者多个不同名称的域。 词(Term):Term是搜索的基本单元,与Field相对应,包含了搜索的域的名称和关键词。 查询(Query):一系列Term的条件组合,成为TermQuery,但也有可能是短语查询等。 分词器(Analyzer):主要是用来做分词以及去除停用词的处理。 索引的建立
索引的搜索
lucene在本网站的使用: 搜索 2. 自动分词 一、搜索 注意:本文使用最新的lucene,版本6.6.0。lucene的版本更新很快,每跨越一次大版本,使用方式就不一样。首先需要导入lucene所使用的包。使用maven:
< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - core< / artifactId> < ! -- lucene核心-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - analyzers- common< / artifactId> < ! -- 分词器-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - analyzers- smartcn< / artifactId> < ! -- 中文分词器-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - queryparser< / artifactId> < ! -- 格式化-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - highlighter< / artifactId> < ! -- lucene高亮-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+构建索引 Directory dir = FSDirectory . open ( Paths . get ( "blog_index" ) ) ;
+SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+IndexWriterConfig config = new IndexWriterConfig ( analyzer) ;
+IndexWriter writer = new IndexWriter ( dir, config) ;
+Document doc = new Document ( ) ;
+doc. add ( new TextField ( "title" , blog. getTitle ( ) , Field. Store . YES ) ) ;
+doc. add ( new TextField ( "content" , Jsoup . parse ( blog. getContent ( ) ) . text ( ) , Field. Store . YES ) ) ;
+writer. addDocument ( doc) ;
+writer. close ( ) ;
+更新与删除 IndexWriter writer = getWriter ( ) ;
+Document doc = new Document ( ) ;
+doc. add ( new TextField ( "title" , blog. getTitle ( ) , Field. Store . YES ) ) ;
+doc. add ( new TextField ( "content" , Jsoup . parse ( blog. getContent ( ) ) . text ( ) , Field. Store . YES ) ) ;
+writer. updateDocument ( new Term ( "blogid" , String . valueOf ( blog. getBlogid ( ) ) ) , doc) ;
+writer. close ( ) ;
+查询 private static void search_index ( String keyword) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "blog_index" ) ) ;
+ IndexReader reader = DirectoryReader . open ( dir) ;
+ IndexSearcher searcher = new IndexSearcher ( reader) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ QueryParser parser = new QueryParser ( "content" , analyzer) ;
+ Query query = parser. parse ( keyword) ;
+ TopDocs docs = searcher. search ( query, 10 ) ;
+ for ( ScoreDoc scoreDoc : docs. scoreDocs) {
+ Document doc = searcher. doc ( scoreDoc. doc) ;
+ System . out. println ( doc. get ( "title" ) ) ;
+ }
+ reader. close ( ) ;
+ } catch ( IOException | ParseException e) {
+ logger. error ( e. toString ( ) ) ;
+ }
+}
+高亮 Fragmenter fragmenter = new SimpleSpanFragmenter ( scorer) ;
+SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter ( "<b><font color='red'>" , "</font></b>" ) ;
+Highlighter highlighter = new Highlighter ( simpleHTMLFormatter, scorer) ;
+highlighter. setTextFragmenter ( fragmenter) ;
+for ( ScoreDoc scoreDoc : docs. scoreDocs) {
+ Document doc = searcher. doc ( scoreDoc. doc) ;
+ String title = doc. get ( "title" ) ;
+ TokenStream tokenStream = analyzer. tokenStream ( "title" , new StringReader ( title) ) ;
+ String hTitle = highlighter. getBestFragment ( tokenStream, title) ;
+ System . out. println ( hTitle) ;
+}
+结果
< b> < fontcolor = ' red' > </ font> </ b> 分页 目前lucene分页的方式主要有两种: (1). 每次都全部查询,然后通过截取获得所需要的记录。由于采用了分词与倒排索引,所有速度是足够快的,但是在数据量过大的时候,占用内存过大,容易造成内存溢出 (2). 使用searchAfter把数据保存在缓存里面,然后再去取。这种方式对大量的数据友好,但是当数据量比较小的时候,速度会相对慢。 lucene中使用searchafter来筛选顺序 ScoreDoc lastBottom = null ;
+BooleanQuery. Builder booleanQuery = new BooleanQuery. Builder ( ) ;
+QueryParser parser1 = new QueryParser ( "title" , analyzer) ;
+Query query1 = parser1. parse ( q) ;
+booleanQuery. add ( query1, BooleanClause. Occur . SHOULD ) ;
+TopDocs hits = search. searchAfter ( lastBottom, booleanQuery. build ( ) , pagehits) ;
+ 使用: 导入maven包 < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 如果想将结果反序列化,声明实体类的时候要加上: public class Blog implements Serializable {
+实现InputIterator接口 InputIterator的几个方法:
+long weight():返回的权重值,大小会影响排序,默认是1L
+BytesRef payload():对某个对象进行序列化
+boolean hasPayloads():是否有设置payload信息
+Set<BytesRef> contexts():存入context,context里可以是任意的自定义数据,一般用于数据过滤
+boolean hasContexts():判断是否有下一个,默认为false
+public class BlogIterator implements InputIterator {
+
+ private static final Logger logger = LoggerFactory . getLogger ( BlogIterator . class ) ;
+ private Iterator < Blog > ;
+ private Blog currentBlog;
+
+ public BlogIterator ( Iterator < Blog > ) {
+ this . blogIterator = blogIterator;
+ }
+
+ @Override
+ public boolean hasContexts ( ) {
+ return true ;
+ }
+
+ @Override
+ public boolean hasPayloads ( ) {
+ return true ;
+ }
+
+ public Comparator < BytesRef > getComparator ( ) {
+ return null ;
+ }
+
+ @Override
+ public BytesRef next ( ) {
+ if ( blogIterator. hasNext ( ) ) {
+ currentBlog = blogIterator. next ( ) ;
+ try {
+
+ return new BytesRef ( Jsoup . parse ( currentBlog. getTitle ( ) ) . text ( ) . getBytes ( "utf8" ) ) ;
+ } catch ( Exception e) {
+ e. printStackTrace ( ) ;
+ return null ;
+ }
+ } else {
+ return null ;
+ }
+ }
+
+
+ @Override
+ public BytesRef payload ( ) {
+ try {
+ ByteArrayOutputStream bos = new ByteArrayOutputStream ( ) ;
+ ObjectOutputStream out = new ObjectOutputStream ( bos) ;
+ out. writeObject ( currentBlog) ;
+ out. close ( ) ;
+ BytesRef bytesRef = new BytesRef ( bos. toByteArray ( ) ) ;
+ return bytesRef;
+ } catch ( IOException e) {
+ logger. error ( "" , e) ;
+ return null ;
+ }
+ }
+
+
+ @Override
+ public Set < BytesRef > contexts ( ) {
+ try {
+ Set < BytesRef > = new HashSet < BytesRef > ( ) ;
+ regions. add ( new BytesRef ( currentBlog. getTitle ( ) . getBytes ( "UTF8" ) ) ) ;
+ return regions;
+ } catch ( UnsupportedEncodingException e) {
+ throw new RuntimeException ( "Couldn't convert to UTF-8" ) ;
+ }
+ }
+
+
+ @Override
+ public long weight ( ) {
+ return currentBlog. getHits ( ) ;
+ }
+}
+ajax 建立索引
+@Override
+public void ajaxbuild ( ) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "autocomplete" ) ) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester ( dir, analyzer) ;
+
+ List < Blog > = blogMapper. getAllBlog ( ) ;
+ suggester. build ( new BlogIterator ( blogs. iterator ( ) ) ) ;
+ } catch ( IOException e) {
+ System . err. println ( "Error!" ) ;
+ }
+}
+查找 @Override
+public Set < String > ajaxsearch ( String keyword) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "autocomplete" ) ) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester ( dir, analyzer) ;
+ List < String > = lookup ( suggester, keyword) ;
+ list. sort ( new Comparator < String > ( ) {
+ @Override
+ public int compare ( String o1, String o2) {
+ if ( o1. length ( ) > o2. length ( ) ) {
+ return 1 ;
+ } else {
+ return - 1 ;
+ }
+ }
+ } ) ;
+ Set < String > = new LinkedHashSet < > ( ) ;
+ for ( String string : list) {
+ set. add ( string) ;
+ }
+ ssubSet ( set, 7 ) ;
+ return set;
+ } catch ( IOException e) {
+ System . err. println ( "Error!" ) ;
+ return null ;
+ }
+}
+controller层 @RequestMapping ( "ajaxsearch" )
+public void ajaxsearch ( HttpServletRequest request, HttpServletResponse response) throws IOException {
+ String keyword = request. getParameter ( "keyword" ) ;
+ if ( StringUtils . isEmpty ( keyword) ) {
+ return ;
+ }
+ Set < String > = blogService. ajaxsearch ( keyword) ;
+ Gson gson = new Gson ( ) ;
+ response. getWriter ( ) . write ( gson. toJson ( set) ) ;
+}
+ajax来提交请求 autocomplete.js源代码与介绍:https://github.com/xdan/autocomplete < link rel= "stylesheet" href= "js/autocomplete/jquery.autocomplete.css" >
+< script src= "js/autocomplete/jquery.autocomplete.js" type= "text/javascript" > < / script>
+< script type= "text/javascript" >
+
+ $ ( '#remote_input' ) . autocomplete ( {
+ source : [
+ {
+ url : "ajaxsearch.html?keyword=%QUERY%" ,
+ type : 'remote'
+ }
+ ]
+ } ) ;
+
+< / script>
+效果: 2.Lucene的使用 \\n首先,帮忙点击一下我的网站http://www.wenzhihuai.com/ 。谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github.com/Zephery/newblog 。
","autoDesc":true}');export{e as data};
diff --git a/assets/2017.html-BbxR5q6z.js b/assets/2017.html-BbxR5q6z.js
new file mode 100644
index 00000000..93ee87aa
--- /dev/null
+++ b/assets/2017.html-BbxR5q6z.js
@@ -0,0 +1 @@
+import{_ as r}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as g,c as h,a,d as i,b as n,e as t}from"./app-cS6i7hsH.js";const p={},c=a("h1",{id:"_2017",tabindex:"-1"},[a("a",{class:"header-anchor",href:"#_2017","aria-hidden":"true"},"#"),i(" 2017")],-1),s=a("p",null,[i("2016年6月,大三,考完最后一科,默默的看着大四那群人一个一个的走了,想着想着,明年毕业的时候,自己将会失去你所拥有的一切,大学那群认识的人,可能这辈子都不会见到了——致远离家乡出省读书的娃。然而,我并没有想到,自己失去的,不仅仅是那群人,几乎是一切。。。。"),a("br"),i(" 17年1月,因为受不了北京雾霾(其实是次因),从实习的公司跑路了,很不舍,只是,感觉自己还有很多事要做,很多梦想要去实现,毕竟,看着身边的人,去了美团,拿着15k的月薪,有点不平衡,感觉他也不是很厉害吧,我努力努力10k应该没问题吧?")],-1),d=a("figure",null,[a("img",{src:"http://image.wenzhihuai.com/images/20171231044153.png",alt:"",tabindex:"0",loading:"lazy"}),a("figcaption")],-1),l=a("p",null,"回到学校,待了几天,那个整天给别人灌毒鸡汤的人还是不着急找工作:该有的时候总会有的啦,然后继续打游戏、那个天天喊着吃麻辣香锅的人,记忆中好像今年都没有吃上,哈哈、厕所还是那样偶尔炸一下,嗯,感觉一切都很熟悉,只是,我有了点伤感,毕竟身边又要换一群不认识的人了。考完试,终于能回广东了,一年没回了,开心不得了,更多的是,为了那个喜欢了好几年没有表白的妹纸,之前从没想过真的能每天跟一个妹纸道晚安,秒回,但是,对她,我还真做到了。1月份的广州,不热不冷,空气很清新,比北京、天津那股泥土味好多了,只是,我被拒了,男闺蜜还是男闺蜜,备胎还是备胎,那会还没想过放弃,直到...",-1),u={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},f=t(' 疲惫的面试历程 2月份底开始慢慢投简历,跑招聘会,深圳招聘的太少了,那就去广州,大学城,于是,开始了自己一周两天都在广深往返。有的公司笔试要跑一次广州,一面要跑一次,二面还要跑一次,每次看着路费,真的承受不起,但是有希望就行。乐观之下,到来的是一重又一重的打击。
**数码,很看好的公司,在广州也算是老品牌了,笔试的时候面试官没有带够卷子,就拿了大数据的做,还过了,面试的时候被面到union和union all的区别,答反了,还有left join和right join的原理,一脸懵逼,过后去了百度搜了搜,这东西哪来的原理?
然后是个企业建站的,笔试完了,面试官照着题问然后没说啥就让我走了,额,我好像还没自我介绍呢。
有点想回北京了,往北京投了一份,A轮公司,月薪10k,过了,觉得自己技术应该不差吧,不过还是拒了,因为一想起那里满脑子都是雾霾。
没事没事,下一家,某游戏公司,笔试过了,一面也过了,然后被问flume收集的时候断网处理机制、MD5和RSA原理、Angulajs和Vuejs用没用过、千万级的数据是如何存储的?额,跟你们想的一样,我一道也答出来,然后就挂了,面试官跟我说,你要是来早三个月这些都会啦,说的我很紧张,广东的同学都那么强么?
这个时候还没质疑自己的技术,去了趟深圳某家小公司,金融的,HR问我是不是培训过来的,心里开始突然间好苦涩,大学花那么多时间学习居然被别人用来和培训机构的人相提并论,笔试不知从哪整来的英文逻辑题,做完了然后上机笔试,做不出来不能见面试官,开始感觉这公司有点。。。。还是撤了撤了。
突然感觉面试面的绝望,是自己的问题么?是自己技术太菜了么?开始怀疑自己,感觉也是,已经3月份底了,毕竟别人都在实习,而我已经离职3个月没工作了,但是那些问题不是有点离谱了,一开始是开始心态爆炸觉得怎么可以对应届生问这些问题,不应该是基础么?算法什么的,后来是无奈了,开始上网搜各种不沾边的技术。
还有其他的面试。。。有的工资不高(6K不到),有的面试问题全答对就因为说了有点想做大数据就不要你,有的聊得很欢快却没消息,有的说招java但是笔试一道java题都没有全是前端的,有的打着互联网实际却是外包的公司。。。。 4月初真的很绝望很绝望,不想跟别人说话,是不是很可笑,一个从北京B+轮的公司回广东,面试近15个,居然只能拿到2个offer,其中之一国企外包的,都不知说什么好。13号要拍毕业照了,没有回去,大学四年,毕竟大家个个圈子之间没什么交流,没什么友谊,果然,整个专业的人只有2/3的人去拍了毕业照。4月23号,拉勾网深圳站,梦想着市集,抱着一点点的小希望,去投了5个,结果一个面试邀请都没有,换之而来的是一片绝望、黑暗。。。。
感情、我们毕业了 5月初回学校了赶毕业设计,回学校也是,天天往图书馆跑,为了面试,毕业设计拉下太多了。悠闲的时候,总会想起我喜欢的那个人,过的怎么样了,微信一开,好像自己被屏蔽了还是被删了?这三个月来的面试打击,真的不知道怎么应对,我更不知道怎么跟她聊天,以至于慢慢隔离,这段感情,或许只有我知道自己有多心疼,只有我自己sb得一点点的呵护着。想起上次跟她聊天是4月中,还是她提了个问题其他什么都没问,彼此之前已经没有关心了。删了吧删了吧,就这样一句再见都没有说,一句“祝福”都没有说。 5月底遇到两次还算开心的事,导师问我要不要评优秀论文,不是很想折腾,拒了,导师仍旧劝我,只是写个3页的小总结而已,评上的话能留图书馆收藏。另一个件是珍爱网打电话过来说我一面过了,什么时候二面,天啊,3月份一面,5月底才通知,心里想骂,但是真的好开心好开心,黑暗中的光芒,泪奔。。。。约到了6月15号面试。 6月初开始自己的回家倒计时,请那唯一一个跟我好的妹纸吃饭,忙完答辩,然后是优秀论文的小报告,13号下午交了上去,再回到宿舍,空无一人,一遍忍着不要悲伤,一遍收拾东西,然后向每个宿舍敲门,告别,一个人拖着行李箱,嗯,我要淡定。
准备了有点久,我以为自己准备好了,15号,深圳,珍爱网,被问到:有没有JVM调优经验 ?ZK是如何保持一致性的?有没有写过ELK索引经验?谈谈你对dubbo的理解。。。事后,得知自己没有过。心态真的炸了,通宵打了两天游戏。月底得知,优秀论文也没有被评上,已经没有骂人吐槽的想法,只是哦的一声,6月,宣告了自己春招结束,宣告自己要去外包,同时也宣告自己大学这些努力全部白费,跟那个灌毒鸡汤天天打游戏的人同一起跑线。
996的工作 七月初入职的时候,问了问那些一起应届入职的同学,跟别人交流一下面试被问的问题,只有线程池,JVM回收算法,他们也没用过,我无奈,为什么我被问到的,全是Angularjs、MD5加密算法、ZK一致性原理这种奇葩的问题。。。。。
',16),m={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},_=t('决心先好好呆着,学习学习,把公司的产品业务技术专研专研,7、8月份是挺开心的,没怎么加班,虽然下班我都留在公司学习,虽然公司的产品不咋地,但是还是有可学之处的,随后,我没想到的是,公司要实行996,,,9月份至12月,每天都是改bug,开发模块,写业务,全都是增删改查,没有涉及redis、rabbitmq,就真的只有使用Hibernate、spring,而做出的东西,要使用JDK6来运行,至今都能看到sun的类。每天的状态就是累累累,我们组还不是最惨的,隔壁项目组,一周通宵两次,9月到10都是如此,国庆加班,每次经过他们组,我都觉得自己还算是幸福。很厌恶这种不把员工当人看的行为,有同事调侃,明年估计我们这些应届过来的,是不是要走掉2/3的人?疯狂加班的代价是牺牲积极性,我问过那些一周通宵两次的人,敲代码,程序员你喜欢这份工作么?不喜欢!!!有那么一两次,实在是太累了,我都感觉自己有点不行了,想离职,可是,会有公司要我么?会有公司不问那些奇葩的问题么?
双十一,花了500多买了十本书,神书啊,计算机届的圣经啊,然而至今一本都没看完,甚至是都没怎么翻,每天下班回去之后就是9点半了,烧水,洗澡,洗衣服,近11点了,躺床上,一遍看书一遍看鹌鹑直播,一小时才翻几页,996真的太累了,实在看不下书。经过这几个月的加班,感觉自己技术增长为负数,也病了几次,同学见我,都感觉我老了不少,心里不平,可是又没有什么办法。
孤独 珠江新城,一年四季都那么美,今晚应该又是万人一起倒计时了吧?已经好久没跟别人一起出去玩过了。今年貌似得了自闭症?社交全靠黄段子。想找人出门走走,然而手机已经没有那种几年的朋友,大学同学一个都不在,哈哈哈,别人说社交软件让人离得更近,我怎么发现我自己一个好朋友都没有了呢,哭笑ing。或许是自己的确不善于跟别人保持联系吧,这个要改,一定要改!!! 远看:
近看:
题外话: 有些时候,遇到不顺,感觉自己不是神,没必要忍住,就开始宣泄自己的情绪,比如疯狂打游戏,只能这样度过了吧。
期望 想起初中,老师让我在黑板写自己的英文作文,好像是信件,描述什么状况来这?最后夸了夸我在文章后面加的一段大概是劝别人不要悲伤要灿烂。也想起一个故事,二战以后,德国满目疮痍,他们处在这样一个凄惨的境地,还能想到在桌上摆设一些花,就一定能在废墟上重建家园。我所看到的是即使在再黑暗的状态下,要永远抱着希望。明年要更加努力的学习,而不是工作,是该挽留一些人了,多运动。说了那么多,其实,我只希望自己的运气不要再差了,再差就没法活了。人在遇到不顺的时候,往往最难过的一关便是自己。哈哈哈,只能学我那个同学给自己灌毒鸡汤了。加油加油↖(^ω^)↗
2017 \\n2016年6月,大三,考完最后一科,默默的看着大四那群人一个一个的走了,想着想着,明年毕业的时候,自己将会失去你所拥有的一切,大学那群认识的人,可能这辈子都不会见到了——致远离家乡出省读书的娃。然而,我并没有想到,自己失去的,不仅仅是那群人,几乎是一切。。。。
\\nand ... 广州拜拜,晚上人少的时候,跟妹纸去珠江新城真的很美好
工作工作 入职的时候是做日志收集的,就是flume+kafka+es这一套,遇到了不少大佬,嗯,感觉挺好的,打算好好干,一个半月后不知怎么滴,被拉去做容器云了,然后就开始了天天调jenkins、gitlab这些没什么用的api,开始了增删改查的历程,很烦,研究jenkins、gitlab对于自己的技术没什么提升,又不得不做,而且大小周+加班这么做,回到家自己看java、netty、golang的书籍,可是没项目做没实践,过几个月就忘光了,有段时间真的很烦很烦,根本不想工作,天天调api,而且是jenkins、gitlab这些没什么卵用的api,至今也没找到什么办法。。。。 公司发展太快,也实在让人不知所措,一不小心部门被架空了,什么预兆都没有,被分到其他部门,然后发现这个部门领导内斗真的是,“三国争霸”吧,无奈成为炮灰,不同的领导不同的要求,安安静静敲个代码怎么这么难。。。。 去年的学习拉下了不少,文章也写的少了,总写那些入门的文章确实没有什么意思,买的书虽然没有17年的多吧,不过也不少了,也看了挺多本书的,虽然我还是不满意自己的阅读量。 这几年要开始抓准一个框架了,好好专研一下,也要开始学习一下go了,希望能参与一些github的项目,好好努力吧。
跑步跑步 平时没事总是宅在家里打游戏,差不多持续到下半年吧,那会打游戏去楼下吃东西的时候老是觉得眼神恍惚,盯着电子产品太多了,然后就跟别人跑步去了,每周去一次人才公园,跑步健身,人才公园真的是深圳跑步最好的一个地方了,桥上总有一群摄影师,好想在深圳湾买一套房子,看了看房价,算了算了,深圳的房,真的贵的离谱。19年也要多多运动,健康第一健康第一。
Others 拿到了深圳户口,全程只花了15天,感谢学妹and家人 买了第一台MacBook Pro,对于Java的我真心不好用 盼了好几年的老姐结婚,18年终于了解了这心事 养了只猫,在经历了好几个月的早起之后,晚上睡觉锁厨房,终于安分了,对不起了哈哈哈 2019 想不起来还有什么要说的了,毕竟程序员,好像每天的生活都一样,就展望一下19年吧。今年,最最重要的是家里人以及身边还有所有人都健健康康的,哈哈哈。然后是安安静静的敲代码~~就酱
',13);function u(m,b){const i=r("ExternalLinkIcon");return o(),h("div",null,[l,d,e("p",null,[a("想着17年12月31号写的那篇文章"),e("a",p,[a("https://www.cnblogs.com/w1570631036/p/8158284.html"),n(i)]),a(",感叹18年还算恢复了点。")]),g,e("p",null,[a("其实校招过去的那家公司,真的不是很喜欢,996、技术差、产品差,实在受不了,春节前提出了离职,老大也挽留了下,以“来了个阿里的带我们重构,能学不了东西”来挽留,虽然我对技术比较痴迷,但离职去深圳的决心还是没有动摇,嗯,就这么开始了自己的裸辞过程。3月8号拿到离职,回公司的时候跟跟同事吹吹水,吃个饭,某同事还喊:“周末来公司玩玩么,我给你开门”,哈哈哈,泼出去的水,回不去了,偶尔有点伤感。 去深圳面试,第一家随手记,之前超级想去这家公司的,金融这一块,有钱,只可惜,没过,一面面试官一直夸我,我觉得稳了,二面没转过来,就这么挂了,有点不甘心吧,在这,感谢那个内推我的人吧,"),e("a",f,[a("面经在这"),n(i)]),a(",之后就是大大小小的面试,联想、恒大、期待金融什么的,都没拿到offer,裸辞真的慌得一比,一天没工作,感觉一年没有工作没人要的样子。。。。没面试就跑去广州图书馆,复习,反思,一天一天的过着,回家就去楼下吃烧烤,打游戏,2点3点才睡觉,boss直聘、拉勾网见一个问一个,迷迷糊糊慌慌张张,那段期间真的想有点把所有书卖掉回家啃老的想法,好在最后联系了一家公司,电商、大小周,知乎上全是差评,不过评价的都不是技术的,更重要的是,岗位是中间件的,嗯,去吧。")]),_])}const k=t(s,[["render",u],["__file","2018.html.vue"]]);export{k as default};
diff --git a/assets/2018.html-pd4XfNXB.js b/assets/2018.html-pd4XfNXB.js
new file mode 100644
index 00000000..87f5292d
--- /dev/null
+++ b/assets/2018.html-pd4XfNXB.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-1f7a720c","path":"/life/2018.html","title":"2018","lang":"zh-CN","frontmatter":{"description":"2018 年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。 想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.html,感叹18年还算恢复了点。 心惊胆战的裸辞经历","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/life/2018.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"2018"}],["meta",{"property":"og:description","content":"2018 年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。 想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.html,感叹18年还算恢复了点。 心惊胆战的裸辞经历"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T04:53:47.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T04:53:47.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"2018\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T04:53:47.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"心惊胆战的裸辞经历","slug":"心惊胆战的裸辞经历","link":"#心惊胆战的裸辞经历","children":[]},{"level":2,"title":"工作工作","slug":"工作工作","link":"#工作工作","children":[]},{"level":2,"title":"跑步跑步","slug":"跑步跑步","link":"#跑步跑步","children":[]},{"level":2,"title":"Others","slug":"others","link":"#others","children":[]},{"level":2,"title":"2019","slug":"_2019","link":"#_2019","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706244827000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":4.35,"words":1306},"filePathRelative":"life/2018.md","localizedDate":"2024年1月24日","excerpt":" 2018 \\n年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。
\\n想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.html ,感叹18年还算恢复了点。
\\n 心惊胆战的裸辞经历 ","autoDesc":true}');export{e as data};
diff --git a/assets/2019.html-mLTyb7PF.js b/assets/2019.html-mLTyb7PF.js
new file mode 100644
index 00000000..8fdb72f7
--- /dev/null
+++ b/assets/2019.html-mLTyb7PF.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-1c10c0ce","path":"/life/2019.html","title":"2019","lang":"zh-CN","frontmatter":{"description":"2019 2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。 19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。 工作 从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/life/2019.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"2019"}],["meta",{"property":"og:description","content":"2019 2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。 19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。 工作 从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T04:53:47.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T04:53:47.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"2019\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T04:53:47.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"工作","slug":"工作","link":"#工作","children":[]},{"level":2,"title":"学习","slug":"学习","link":"#学习","children":[]},{"level":2,"title":"感情","slug":"感情","link":"#感情","children":[]},{"level":2,"title":"运动","slug":"运动","link":"#运动","children":[]},{"level":2,"title":"其他","slug":"其他","link":"#其他","children":[]},{"level":2,"title":"2020展望","slug":"_2020展望","link":"#_2020展望","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706244827000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":4.43,"words":1329},"filePathRelative":"life/2019.md","localizedDate":"2024年1月24日","excerpt":" 2019 \\n2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。\\n19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。
\\n 工作 \\n从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。
","autoDesc":true}');export{e as data};
diff --git a/assets/2019.html-ogBQCkli.js b/assets/2019.html-ogBQCkli.js
new file mode 100644
index 00000000..583dec10
--- /dev/null
+++ b/assets/2019.html-ogBQCkli.js
@@ -0,0 +1 @@
+import{_ as a}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as e,c as i,e as n}from"./app-cS6i7hsH.js";const r={},t=n(' 2019 2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。 19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。
工作 从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。
之后有了点起色,然后开始着重强调了DevOps的重要性,期初也没人理解,还被骂天天研究技术不干活。。。这东西没技术,但是真的是公司十分需要的公司好么!!可惜公司对这个产品很失望,也不给人,期间还说要暂停项目,唉,这么大的项目就给几个人怎么做,谁都不乐意,就这么过的很憋屈吧,开始了维护的日子。。。
工作上,蛮多人对我挺好的,领导,同事,不过有时候憋屈的时候还是有了点情绪化,有时候有点悲伤的想法,浮躁、暴躁,出去面试了几次,感觉不是自己能力不好,而是市场上的真的需要3+年以上的。。。。不过感觉自己能在这里憋屈的过了这么久,也是很佩服自己的,哈哈,用同事的话来说就是:当做游戏里的练级,锻炼自己哈哈哈
学习 项目的方向错误,导致自己写的代码都是很简单的增删改查,没有技术含量的那种,也最终导致自己浪费了不少时间,上半年算是很气愤吧,不想就这么浪费掉这些时间,虽然期间看了各种各样的东西,比如Netty、Go、操作系统什么的,最终发现,如果不在项目中使用的话,真的会忘,而且很快就忘掉,最后的还是决定学习项目相关度比较大的东西了,比如Go,如果项目不是很大,小项目的话,就用Go来写,这么做感觉提升还是挺大的。 过去一年往南山图书馆借了不少书,省了不少钱,虽然没怎么看,但我至少有个奋斗的心啊,哈哈哈哈哈哈哈哈,文章写得少了,因为感觉写不出好东西,总是入门的那种,不深,不值得学习,想想到时候把别人给坑了,也不好意思。 操作系统感觉还是要好好学学了,加油
Kubernetes就是未来的方向,有时候翻开源码看看,又不敢往下面看了,对底层不熟吧,今年要多多研究下Kubernetes的源码了,至于Spring那一套,也不知道该不该放弃,或者都学习一下?云原生就是趋势。
感情 吵架了,没心思写
运动 过去一年还是把运动算是坚持了下来,每个月必去深圳湾跑一次。还是没怎么睡好,工作感情上都有点不顺,加上自己本身就难以入睡,有时候躺床上就是怎么也睡不着,还长了痘痘,要跑去医院那种,可怕,老了,还是要早点睡觉,多走走多运动,好久没打羽毛球了,自己也不想有空的时候只会打游戏,今年继续加油,多运动吧。
还爬了两次南山
其他 看了周围蛮多同事去了腾讯阿里,有点心动,好想去csig,没到3年真的让人很抓狂。 过去一年过的蛮憋屈的,特别是工作不顺,加上跟女朋友吵架,心态爆炸。。。
2020展望 每年这个时候,都不敢有太大的期望了,祝大家都健健康康的,工作顺利!!
当然,如果有可能的话,我想去CSIG
',23),h=[t];function d(c,p){return e(),i("div",null,h)}const g=a(r,[["render",d],["__file","2019.html.vue"]]);export{g as default};
diff --git "a/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-73kuTv_z.js" "b/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-73kuTv_z.js"
new file mode 100644
index 00000000..d6464a02
--- /dev/null
+++ "b/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-73kuTv_z.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-731a76b6","path":"/personalWebsite/3.%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1.html","title":"3.定时任务","lang":"zh-CN","frontmatter":{"description":"3.定时任务 先看一下Quartz的架构图: 一.特点: 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求; 灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式; 分布式和集群能力。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/3.%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"3.定时任务"}],["meta",{"property":"og:description","content":"3.定时任务 先看一下Quartz的架构图: 一.特点: 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求; 灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式; 分布式和集群能力。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"3.定时任务\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":3,"title":"一.特点:","slug":"一-特点","link":"#一-特点","children":[]},{"level":3,"title":"二.主要组成部分","slug":"二-主要组成部分","link":"#二-主要组成部分","children":[]},{"level":3,"title":"三、Quartz设计","slug":"三、quartz设计","link":"#三、quartz设计","children":[]},{"level":3,"title":"四、使用","slug":"四、使用","link":"#四、使用","children":[]},{"level":2,"title":"Spring的高级特性之定时任务","slug":"spring的高级特性之定时任务","link":"#spring的高级特性之定时任务","children":[]}],"git":{"createdTime":1706182936000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":3.55,"words":1064},"filePathRelative":"personalWebsite/3.定时任务.md","localizedDate":"2024年1月25日","excerpt":" 3.定时任务 \\n先看一下Quartz的架构图:
\\n 一.特点: \\n\\n强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求; \\n灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式; \\n分布式和集群能力。 \\n ","autoDesc":true}');export{e as data};
diff --git "a/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-CtCjmCiV.js" "b/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-CtCjmCiV.js"
new file mode 100644
index 00000000..b9a139d4
--- /dev/null
+++ "b/assets/3.\345\256\232\346\227\266\344\273\273\345\212\241.html-CtCjmCiV.js"
@@ -0,0 +1,71 @@
+import{_ as p}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as l,c,a as n,d as a,b as t,e}from"./app-cS6i7hsH.js";const i={},u=e(' 3.定时任务 先看一下Quartz的架构图:
一.特点: 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求; 灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式; 分布式和集群能力。 二.主要组成部分 JobDetail:需实现该接口定义的人物,其中JobExecutionContext提供了上下文的各种信息。 JobDetail:QUartz的执行任务的类,通过newInstance的反射机制实例化Job。 Trigger: Job的时间触发规则。主要有SimpleTriggerImpl和CronTriggerImpl两个实现类。 Calendar:org.quartz.Calendar和java.util.Calendar不同,它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。 Scheduler:由上图可以看出,Scheduler是Quartz独立运行的容器。其中,Trigger和JobDetail可以注册到Scheduler中。 ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。 三、Quartz设计 ',8),r=n("br",null,null,-1),k={href:"http://www.quartz-scheduler.org/documentation/quartz-2.2.x/quick-start.html",target:"_blank",rel:"noopener noreferrer"},d=n("li",null,null,-1),g=e(` 四、使用 hello world!代码在这 本网站中使用quartz来对数据库进行备份,与Spring结合 (1)导入spring的拓展包,其协助spring集成第三方库:邮件服务、定时任务、缓存等。。。 < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> (2)导入quartz包
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> (3)mysql远程备份 使用命令行工具仅仅需要一行:
mysqldump -u [username] -p[password] -h [hostip] database > file
+但是java不能直接执行linux的命令,仍旧需要依赖第三方库ganymed
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 完整代码如下:
@Component ( "mysqlService" )
+public class MysqlUtil {
+ . . .
+ StringBuffer sb = new StringBuffer ( ) ;
+ sb. append ( "mysqldump -u " + username + " -p" + password + " -h " + host + " " +
+ database + " >" + file) ;
+ String sql = sb. toString ( ) ;
+ Connection connection = new Connection ( s_host) ;
+ connection. connect ( ) ;
+ boolean isAuth = connection. authenticateWithPassword ( s_username, s_password) ;
+ if ( ! isAuth) {
+ logger. error ( "server login error" ) ;
+ }
+ Session session = connection. openSession ( ) ;
+ session. execCommand ( sql) ;
+ InputStream stdout = new StreamGobbler ( session. getStdout ( ) ) ;
+ BufferedReader br = new BufferedReader ( new InputStreamReader ( stdout) ) ;
+ . . .
+}
+(4)spring中配置quartz
< beanid = " jobDetail" class = " org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean" > < propertyname = " targetObject" ref = " mysqlService" /> < propertyname = " targetMethod" value = " exportDataBase" /> </ bean> < beanid = " myTrigger" class = " org.springframework.scheduling.quartz.CronTriggerFactoryBean" > < propertyname = " jobDetail" ref = " jobDetail" /> < propertyname = " cronExpression" value = " 0 59 2 ? * FRI" /> </ bean> < beanid = " scheduler" class = " org.springframework.scheduling.quartz.SchedulerFactoryBean" > < propertyname = " triggers" > < list> < refbean = " myTrigger" /> </ list> </ property> </ bean> Spring的高级特性之定时任务 java ee项目的定时任务中除了运行quartz之外,spring3+还提供了task,可以看做是一个轻量级的Quartz,而且使用起来比Quartz简单的多。
(1)spring配置文件中配置:
< task: annotation-driven/> (2)最简单的例子,在所需要的函数上添加定时任务即可运行
@Scheduled ( fixedRate = 5000 )
+ public void reportCurrentTime ( ) {
+ System . out. println ( "每隔5秒运行一次" + sdf. format ( new Date ( ) ) ) ;
+ }
+(3)运行的时候会报错:
org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type [org.springframework.scheduling.TaskScheduler] is defined
+ at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:372)
+ at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:332)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.finishRegistration(ScheduledAnnotationBeanPostProcessor.java:192)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.onApplicationEvent(ScheduledAnnotationBeanPostProcessor.java:171)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.onApplicationEvent(ScheduledAnnotationBeanPostProcessor.java:86)
+ at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:163)
+ at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:136)
+ at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:380)
+1.尝试从配置中找到一个TaskScheduler Bean
2.寻找ScheduledExecutorService Bean
3.使用默认的scheduler 修改log4j.properties即可: log4j.logger.org.springframework.scheduling=INFO
每隔5秒运行一次14:44:34
+每隔5秒运行一次14:44:39
+每隔5秒运行一次14:44:44
+ 1.网站代码安装 先在百度统计 中注册登录之后,进入管理页面,新增网站,然后在代码管理中获取安装代码,大部分人的代码都是类似的,除了hm.js?后面的参数,是记录该网站的唯一标识。
< script>
+var _hmt = _hmt || [ ] ;
+( function ( ) {
+ var hm = document. createElement ( "script" ) ;
+ hm. src = "https://hm.baidu.com/hm.js?code" ;
+ var s = document. getElementsByTagName ( "script" ) [ 0 ] ;
+ s. parentNode. insertBefore ( hm, s) ;
+} ) ( ) ;
+ </ script> 同时,需要在申请其他设置->数据导出服务中开通数据导出服务,百度统计Tongji API可以为网站接入者提供便捷的获取网站流量数据的通道。
至此,我们获得了username、password、token,然后开始使用三个参数来获取数据。
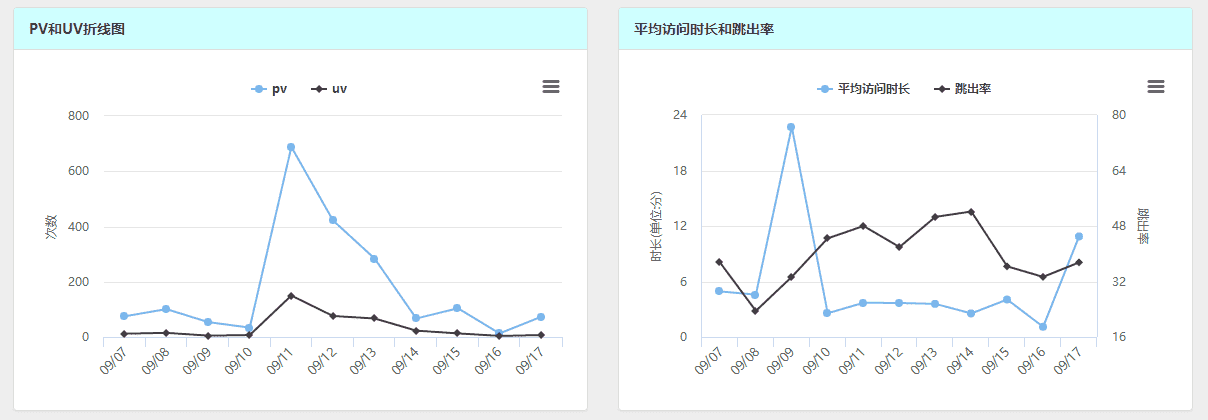
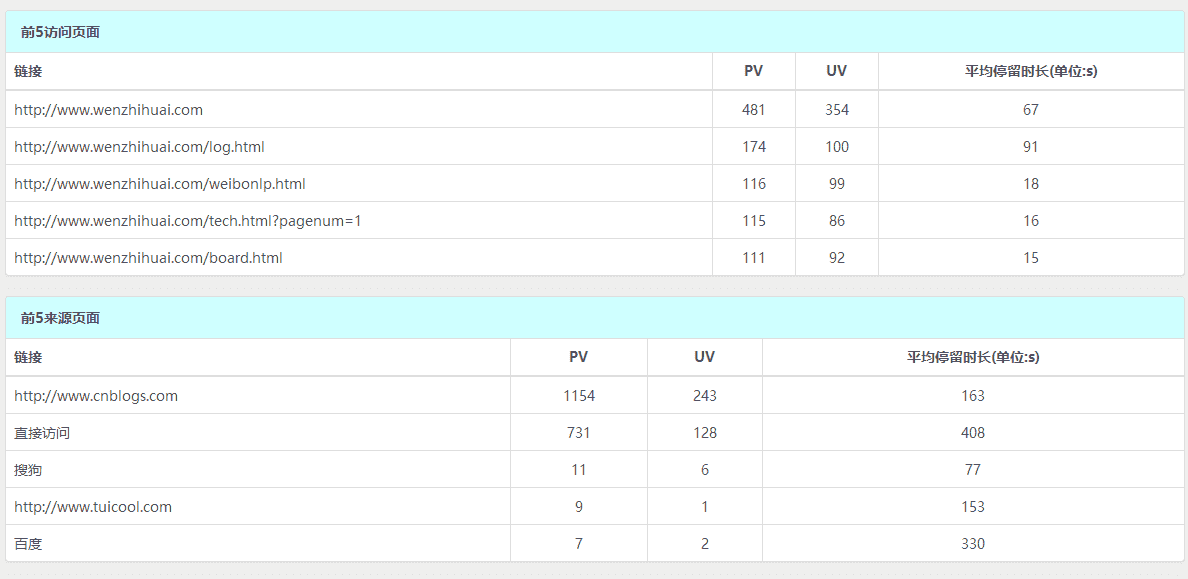
2.根据API获取数据 `,7),f={href:"https://tongji.baidu.com/dataapi/file/TongjiApiFile.pdf",target:"_blank",rel:"noopener noreferrer"},w={href:"https://api.baidu.com/json/tongji/v1/ReportService/getData",target:"_blank",rel:"noopener noreferrer"},x={href:"https://tongji.baidu.com/dataapi/file/TongjiApiFile.pdf",title:"百度统计",target:"_blank",rel:"noopener noreferrer"},j=p(`参数名称 参数类型 描述 method string 要查询的报告 start_date string 查询起始时间 end_date string 查询结束时间 metrics string 自定义指标
其中,参数start_date和end_date的规定为:yyyyMMdd,这里我们使用python的原生库,datetime、time,获取昨天的时间以及前七天的日期。
today = datetime. date. today( )
+yesterday = today - datetime. timedelta( days= 1 )
+fifteenago = today - datetime. timedelta( days= 7 )
+end, start = str ( yesterday) . replace( "-" , "" ) , str ( fifteenago) . replace( "-" , "" )
+ 3.构建请求 说明:siteId可以根据个人百度统计的链接获取,也可以使用Tongji API的第一个接口列表获取用户的站点列表。首先,我们构建一个类,由于username、password、token都是通用的,所以我们将它设置为构造方法的参数。
class Baidu ( object ) :
+ def __init__ ( self, siteId, username, password, token) :
+ self. siteId = siteId
+ self. username = username
+ self. password = password
+ self. token = token
+然后构建一个共同的方法,用来获取提交数据之后返回的结果,其中提供了4个可变参数,分别是(start_date:起始日期,end_date:结束日期,method:方法,metrics:指标),返回的是字节,最后需要decode("utf-8")一下变成字符:
def getresult ( self, start_date, end_date, method, metrics) :
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date,
+ "metrics" : metrics} }
+ data = bytes ( json. dumps( body) , 'utf8' )
+ req = urllib. request. Request( base_url, data)
+ response = urllib. request. urlopen( req)
+ the_page = response. read( )
+ return the_page. decode( "utf-8" )
+def getresult ( self, start_date, end_date, method, metrics, ** kw) :
+ base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date, "metrics" : metrics} }
+ for key in kw:
+ body[ 'body' ] [ key] = kw[ key]
+使用方式:
result = self. getresult( start, end, "source/all/a" ,
+ "pv_count,visitor_count,avg_visit_time" , viewType= 'visitor' )
+(2)获取的数据如何解析 百度统计返回的结果比较简洁而又反人类,以获取概览中的pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time为例子:
result = bd. getresult( start, end, "overview/getTimeTrendRpt" ,
+ "pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time" )
+返回的结果是:
[[['2017/09/12'], ['2017/09/13'], ['2017/09/14'], ['2017/09/15'], ['2017/09/16'], ['2017/09/17'], ['2017/09/18']],
+[[422, 76, 76, 41.94, 221],
+ [284, 67, 65, 50.63, 215],
+ [67, 23, 22, 52.17, 153],
+ [104, 13, 13, 36.36, 243],
+ [13, 4, 4, 33.33, 66],
+ [73, 7, 6, 37.5, 652],
+ [63, 11, 11, 33.33, 385]
+ ], [], []]
+即:翻译成人话就是:
[[[date1,date2,...]],
+ [[date1的pv_count, date1的visitor_count, date1的ip_count, date1的bounce_ratio, date1的avg_visit_time],
+ [date2的pv_count, date2的visitor_count, date2的ip_count, date2的bounce_ratio, date2的avg_visit_time],
+ ...,[]
+ ],[],[]]
+极其反人类的设计。还好用的python,python数组的特性实在太强了。出了可以运用[x for x in range]这类语法之外,还能与三元符(x if y else x+1,如果y成立,那么结果是x,如果y不成立,那么结果是x+1)一起使用,这里注意:如果当天访问量为0,其返回的json结果是'--',所以要判断是不是为'--',归0化,才能在折线图等各种图上显示。下面是pv_count的例子:
pv_count = [ x[ 0 ] if x[ 0 ] != '--' else 0 for x in result[ 1 ] ]
+(3)每周限制2000次 在开通数据导出服务的时候,不知道大家有没有注意到它的说明,即我们是不能实时监控的,只能将它放在临时数据库中,这里我们选择了Redis,并在centos里定义一个定时任务,每天全部更新一次即可。
python中redis的使用方法很简单,连接跟mysql类似:
+pool = redis. ConnectionPool( host= 'your host ip' , port= port, password= 'your auth' )
+r = redis. Redis( connection_pool= pool)
+本网站使用redis的数据结构只有set,方法也很简单,就是定义一个key,然后value是数组的字符串获取json。
ip_count = [ x[ 2 ] if x[ 2 ] != '--' else 0 for x in result[ 1 ] ]
+r. set ( "ip_count" , ip_count)
+
+name = [ item[ 0 ] [ 'name' ] for item in data[ 0 ] ]
+count = 0
+tojson = [ ]
+for item in data[ 1 ] :
+ temp = { }
+ temp[ "name" ] = name[ count]
+ temp[ "pv_count" ] = item[ 0 ]
+ temp[ "visitor_count" ] = item[ 1 ]
+ temp[ "average_stay_time" ] = item[ 2 ]
+ tojson. append( temp)
+ count = count + 1
+r. set ( "rukouyemian" , json. dumps( tojson[ : 5 ] ) )
+ 5.基本代码 `,18),E={href:"https://github.com/Zephery/baidutongji/blob/master/demo.py",target:"_blank",rel:"noopener noreferrer"},R=p(`import json
+import time
+import datetime
+import urllib. parse
+import urllib. request
+
+base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+
+class Baidu ( object ) :
+ def __init__ ( self, siteId, username, password, token) :
+ self. siteId = siteId
+ self. username = username
+ self. password = password
+ self. token = token
+
+ def getresult ( self, start_date, end_date, method, metrics, ** kw) :
+ base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date, "metrics" : metrics} }
+ for key in kw:
+ body[ 'body' ] [ key] = kw[ key]
+ data = bytes ( json. dumps( body) , 'utf8' )
+ req = urllib. request. Request( base_url, data)
+ response = urllib. request. urlopen( req)
+ the_page = response. read( )
+ return the_page. decode( "utf-8" )
+
+if __name__ == '__main__' :
+
+ today = datetime. date. today( )
+ yesterday = today - datetime. timedelta( days= 1 )
+ fifteenago = today - datetime. timedelta( days= 7 )
+ end, start = str ( yesterday) . replace( "-" , "" ) , str ( fifteenago) . replace( "-" , "" )
+
+ bd = Baidu( yoursiteid, "username" , "password" , "token" )
+ result = bd. getresult( start, end, "overview/getTimeTrendRpt" ,
+ "pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time" )
+ result = json. loads( result)
+ base = result[ "body" ] [ "data" ] [ 0 ] [ "result" ] [ "items" ]
+ print ( base)
+
+ 6.展示数据 `,2),V={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},B=p(`String pv_count = jedis. get ( "pv_count" ) ;
+String visitor_count = jedis. get ( "visitor_count" ) ;
+mv. addObject ( "pv_count" , pv_count) ;
+mv. addObject ( "visitor_count" , visitor_count) ;
+jsp中的使用如下:
< divclass = " panel-heading" style = " background-color : rgba ( 187, 255, 255, 0.7) " > < divclass = " card-title" > < strong> </ strong> < divclass = " panel-body" > < divid = " linecontainer" style = " width : auto; height : 330px" > < script>
+ var chart = new Highcharts. Chart ( 'linecontainer' , {
+ title : {
+ text : null
+ } ,
+ credits : {
+ enabled : false
+ } ,
+ xAxis : {
+ categories : ${ daterange}
+ } ,
+ yAxis : {
+ title : {
+ text : '次数'
+ } ,
+ plotLines : [ {
+ value : 0 ,
+ width : 1 ,
+ color : '#808080'
+ } ]
+ } ,
+ tooltip : {
+ valueSuffix : '次'
+ } ,
+ legend : {
+ borderWidth : 0 ,
+ align : "center" ,
+ verticalAlign : "top" ,
+ x : 0 ,
+ y : 0
+ } ,
+ series : [ {
+ name : 'pv' ,
+ data : ${ pv_count}
+ } , {
+ name : 'uv' ,
+ data : ${ visitor_count}
+ } ]
+ } )
+ </ script> 效果如下:
(2)地域访问量 在python代码中先获取地域的数据,其结果如下,百度统计跟echarts都是百度的,果然,自家人对自己人的支持真是特别友好的。
[{'pv_count': 649, 'pv_ratio': 7, 'visitor_count': 2684, 'name': '广东'}, {'pv_count': 2, 'pv_ratio': 2, 'visitor_count': 76, 'name': '四川'}, {'pv_count': 1, 'pv_ratio': 1, 'visitor_count': 3, 'name': '江苏'}]
+<script type="text/javascript">
+ var myChart = echarts.init(document.getElementById('diyu'));
+ option = {
+ tooltip: {
+ trigger: 'item'
+ },
+ legend: {
+ orient: 'vertical',
+ left: 'left'
+ },
+ visualMap: {
+ min: 0,
+ max:\${diyumax},
+ left: 'left',
+ top: 'bottom',
+ text: ['高', '低'], // 文本,默认为数值文本
+ calculable: true
+ },
+ toolbox: {
+ show: true,
+ orient: 'vertical',
+ left: 'right',
+ top: 'center',
+ feature: {
+ dataView: {readOnly: false},
+ restore: {},
+ saveAsImage: {}
+ }
+ },
+ series: [
+ {
+ name: '访问量',
+ type: 'map',
+ mapType: 'china',
+ roam: false,
+ label: {
+ normal: {
+ show: true
+ },
+ emphasis: {
+ show: true
+ }
+ },
+ data: [
+ <c:forEach var="diyu" items="\${diyu}">
+ {name: '\${diyu.name}', value: \${to.pv_count}},
+ </c:forEach>
+ ]
+ }
+ ]
+ };
+ myChart.setOption(option);
+</script>
+结果如下:
结语 `,3),N=n("br",null,null,-1),O={href:"http://www.wenzhihuai.com/log.html",target:"_blank",rel:"noopener noreferrer"},C=n("br",null,null,-1),G={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},H=n("br",null,null,-1),M={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},K=n("br",null,null,-1),U={href:"https://github.com/Zephery/baidutongji",target:"_blank",rel:"noopener noreferrer"},F=n("br",null,null,-1);function Y(J,W){const a=o("ExternalLinkIcon");return c(),i("div",null,[u,n("p",null,[s("欢迎访问我的网站"),n("a",r,[s("http://www.wenzhihuai.com/"),t(a)]),s(" 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址"),n("a",d,[s("https://github.com/Zephery/newblog"),t(a)]),s(" 。")]),n("p",null,[s("建立网站少不了日志系统,用来查看网站的访问次数、停留时间、抓取量、目录抓取统计、页面抓取统计等,其中,最常用的方法还是使用ELK,但是,本网站的服务器配置实在太低了(1GHZ、2G内存),压根就跑不起ELK,所以只能寻求其他方式,目前最常用的有"),n("a",k,[s("百度统计"),t(a)]),s("和"),n("a",v,[s("友盟"),t(a)]),s(",这里,本人使用的是百度统计,提供了API给开发者使用,能够将自己所需要的图表移植到自己的网站上。日志是网站及其重要的文件,通过对日志进行统计、分析、综合,就能有效地掌握网站运行状况,发现和排除错误原因,了解客户访问分布等,更好的加强系统的维护和管理。下面是我的百度统计的概览页面:")]),m,n("p",null,[s("企业级的网站日志不能公开,但是我的是个人网站,用来跟大家一起学习的,所以,需要将百度的统计页面展示出来,但是,百度并不提供日志的图像,只提供API给开发者调用,而且还限制访问次数,一天不能超过2000次,这个对于实时统计来说,确实不够,所以只能展示前几天的访问统计。这里的日志系统分为三个步骤:1.API获取数据;2.存储数据;3.展示数据。页面效果如下,也可以点开我的网站的"),n("a",b,[s("日志系统"),t(a)]),s(":")]),g,h,_,n("p",null,[s("百度统计提供了Tongji API的Java和Python版本,这两个版本及其复杂,可用性极低,所以,本人用Python写了个及其简单的通用版本,整体只有28行,代码在这,"),n("a",y,[s("https://github.com/Zephery/baidutongji"),t(a)]),s("。下面是具体过程")]),q,n("p",null,[n("a",f,[s("官网的API"),t(a)]),s("详细的记录了接口的参数以及解释, 链接:"),n("a",w,[s("https://api.baidu.com/json/tongji/v1/ReportService/getData"),t(a)]),s(",详细的官方报告请访问官网"),n("a",x,[s("TongjiApi"),t(a)]),s(" 所需参数(必须):")]),j,n("p",null,[s("至此,python获取百度统计的过程基本就没了,没错,就是那么简简单单的几行,完整代码见"),n("a",z,[s("https://github.com/Zephery/baidutongji/blob/master/baidu.py"),t(a)]),s(",但是,想要实现获取各种数据,仍需要做很多工作。")]),I,T,A,n("p",null,[s("python中提供了个可变参数来解决这一烦恼,详细请看"),n("a",P,[s("http://www.jianshu.com/p/98f7e34845b5"),t(a)]),s(",可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple,而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。")]),Z,n("p",null,[s("下面是基本的使用代码,完整的使用代码就不贴了,有兴趣可以去我的github上看看,"),n("a",E,[s("完整代码"),t(a)]),s(",希望能给个star哈哈哈,感谢")]),R,n("p",null,[s("在将数据存进redis中之后,我们需要在博客中使用这些数据来制作图表。在"),n("a",V,[s("newblog"),t(a)]),s("中使用方式也很简单,大概就是使用jedis读取数据,然后使用echarts或者highcharts展示。其中折线图以及线型图我都使用了highcharts,确实比echarts好看的多,但是地域图还是选择了echarts,毕竟中国的产品还是对中国的支持较好。 (1)PV、UV折线图 以图表PV、UV为例,由于存储进redis的是一个数组,所以,可以直接从redis中读取然后放到一个attribute里即可:")]),B,n("p",null,[s("地域图目前支持最好的还是百度的echarts,使用方法见echarts的官网吧,这里不再阐述,展示"),S,s("的时候需要获取下载两个文件,"),n("a",L,[s("china.js"),t(a)]),s("(其提供了js和json,这里使用的js),"),n("a",$,[s("echarts.js"),t(a)]),s("。 部分代码:")]),D,n("p",null,[s("网上关于日志系统的几乎都是ELK,对于小网站的,隐私不是很重要的还是可以用用百度统计的,这套系统也折磨了我挺久的,特别是它那反人类的返回数据。期初本来是想使用百度统计的,后来考虑了一下ELK,尝试之后发现,服务器配置跑不起来,还是安安稳稳的使用了百度统计,于此做成了这个系统,美观度还是不高,颜色需要优化一下。最后,希望能在GitHub上给我个star吧。"),N,s(" 日志系统地址:"),n("a",O,[s("http://www.wenzhihuai.com/log.html"),t(a)]),C,s(" 个人网站网址:"),n("a",G,[s("http://www.wenzhihuai.com"),t(a)]),H,s(" 个人网站代码地址:"),n("a",M,[s("https://github.com/Zephery/newblog"),t(a)]),K,s(" 百度统计python代码地址:"),n("a",U,[s("https://github.com/Zephery/baidutongji"),t(a)]),F,s(" 万分感谢")])])}const nn=e(l,[["render",Y],["__file","4.日志系统.html.vue"]]);export{nn as default};
diff --git "a/assets/4.\346\227\245\345\277\227\347\263\273\347\273\237.html-k-_vSI4k.js" "b/assets/4.\346\227\245\345\277\227\347\263\273\347\273\237.html-k-_vSI4k.js"
new file mode 100644
index 00000000..64cae355
--- /dev/null
+++ "b/assets/4.\346\227\245\345\277\227\347\263\273\347\273\237.html-k-_vSI4k.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-bea2ce1e","path":"/personalWebsite/4.%E6%97%A5%E5%BF%97%E7%B3%BB%E7%BB%9F.html","title":"4.日志系统.md","lang":"zh-CN","frontmatter":{"description":"4.日志系统.md 欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/4.%E6%97%A5%E5%BF%97%E7%B3%BB%E7%BB%9F.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"4.日志系统.md"}],["meta",{"property":"og:description","content":"4.日志系统.md 欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"4.日志系统.md\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"1.网站代码安装","slug":"_1-网站代码安装","link":"#_1-网站代码安装","children":[]},{"level":2,"title":"2.根据API获取数据","slug":"_2-根据api获取数据","link":"#_2-根据api获取数据","children":[]},{"level":2,"title":"3.构建请求","slug":"_3-构建请求","link":"#_3-构建请求","children":[]},{"level":2,"title":"4.实际运用","slug":"_4-实际运用","link":"#_4-实际运用","children":[]},{"level":2,"title":"5.基本代码","slug":"_5-基本代码","link":"#_5-基本代码","children":[]},{"level":2,"title":"6.展示数据","slug":"_6-展示数据","link":"#_6-展示数据","children":[]}],"git":{"createdTime":1706182936000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":9.64,"words":2891},"filePathRelative":"personalWebsite/4.日志系统.md","localizedDate":"2024年1月25日","excerpt":" 4.日志系统.md \\n欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。
","autoDesc":true}');export{e as data};
diff --git a/assets/404.html-WhIsgby4.js b/assets/404.html-WhIsgby4.js
new file mode 100644
index 00000000..ffb11d95
--- /dev/null
+++ b/assets/404.html-WhIsgby4.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-3706649a","path":"/404.html","title":"","lang":"zh-CN","frontmatter":{"layout":"NotFound","description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/404.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":0},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{t as data};
diff --git a/assets/404.html-tbxpD8LH.js b/assets/404.html-tbxpD8LH.js
new file mode 100644
index 00000000..63b92ac1
--- /dev/null
+++ b/assets/404.html-tbxpD8LH.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(_,n){return t(),c("div")}const f=e(o,[["render",r],["__file","404.html.vue"]]);export{f as default};
diff --git "a/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-ZTiwy8Ji.js" "b/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-ZTiwy8Ji.js"
new file mode 100644
index 00000000..d37837be
--- /dev/null
+++ "b/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-ZTiwy8Ji.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-3efc517e","path":"/personalWebsite/5.%E5%B0%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.html","title":"5.小集群部署.md","lang":"zh-CN","frontmatter":{"description":"5.小集群部署.md 欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com,个人网站代码地址:https://github.com/Zephery/newblog。 洋洋洒洒的买了两个服务器,用来学习分布式、集群之类的东西,整来整去,感觉分布式这种东西没人指导一下真的是太抽象了,先从网站的分布式部署一步一步学起来吧,虽然网站本身的访问量不大==。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/5.%E5%B0%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"5.小集群部署.md"}],["meta",{"property":"og:description","content":"5.小集群部署.md 欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com,个人网站代码地址:https://github.com/Zephery/newblog。 洋洋洒洒的买了两个服务器,用来学习分布式、集群之类的东西,整来整去,感觉分布式这种东西没人指导一下真的是太抽象了,先从网站的分布式部署一步一步学起来吧,虽然网站本身的访问量不大==。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"5.小集群部署.md\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"1.1 Nginx的安装","slug":"_1-1-nginx的安装","link":"#_1-1-nginx的安装","children":[]},{"level":2,"title":"1.2 Nginx的配置","slug":"_1-2-nginx的配置","link":"#_1-2-nginx的配置","children":[]},{"level":2,"title":"测试:","slug":"测试","link":"#测试","children":[]}],"git":{"createdTime":1706182936000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":9.5,"words":2849},"filePathRelative":"personalWebsite/5.小集群部署.md","localizedDate":"2024年1月25日","excerpt":" 5.小集群部署.md \\n欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com ,个人网站代码地址:https://github.com/Zephery/newblog 。
","autoDesc":true}');export{e as data};
diff --git "a/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-z5KJNYuo.js" "b/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-z5KJNYuo.js"
new file mode 100644
index 00000000..84df5a47
--- /dev/null
+++ "b/assets/5.\345\260\217\351\233\206\347\276\244\351\203\250\347\275\262.html-z5KJNYuo.js"
@@ -0,0 +1,105 @@
+import{_ as p}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as i,o,c as l,a as n,d as s,b as t,e}from"./app-cS6i7hsH.js";const c={},u=n("h1",{id:"_5-小集群部署-md",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#_5-小集群部署-md","aria-hidden":"true"},"#"),s(" 5.小集群部署.md")],-1),r={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},d={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},g=n("br",null,null,-1),k=n("h1",{id:"nginx负载均衡",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#nginx负载均衡","aria-hidden":"true"},"#"),s(" nginx负载均衡")],-1),m={href:"http://jinnianshilongnian.iteye.com/",target:"_blank",rel:"noopener noreferrer"},v=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171018044732.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),h=n("p",null,"本站并没有那么多的服务器,目前只有两台,搭建不了那么大型的架构,就简陋的用两台服务器来模拟一下负载均衡的搭建。下图是本站的简单架构:",-1),b=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171018051437.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),_=n("p",null,"其中服务器A(119.23.46.71)为深圳节点,服务器B(47.95.10.139)为北京节点,搭建Nginx之后流量是这么走的:user->A->B-A->user或者user->A->user,第一条中A将请求转发给B,然后B返回的是其运行结果的静态资源。因为这里仅仅是用来学习,所以请不要考虑因为地域导致延时的问题。。。。下面是过程。",-1),f=n("h2",{id:"_1-1-nginx的安装",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#_1-1-nginx的安装","aria-hidden":"true"},"#"),s(" 1.1 Nginx的安装")],-1),q={href:"https://pkgs.org/download/nginx",target:"_blank",rel:"noopener noreferrer"},x=e(`启动后页面如下:
记一下常用命令
启动nginx,由于是采用rpm方式,所以环境变量什么的都配置好了。
+[root@beijingali ~]# nginx #启动nginx
+[root@beijingali ~]# nginx -s reload #重启nginx
+[root@beijingali ~]# nginx -t #校验nginx配置文件
+nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
+nginx: configuration file /etc/nginx/nginx.conf test is successful
+ 1.2 Nginx的配置 1.2.1 负载均衡算法 `,7),w={href:"http://blog.csdn.net/qh_java/article/details/45955923",target:"_blank",rel:"noopener noreferrer"},y=e(`http{
+ ...
+ upstream backend {
+ hash $uri;
+ # 北京节点
+ server 47.95.10.139:8080;
+ # 深圳节点
+ server 119.23.46.71:8080;
+ }
+
+ server {
+ ...
+ location / {
+ root html;
+ index index.html index.htm;
+ proxy_pass http://backend;
+ ...
+ }
+ ...
+ 1.2.2 日志格式 之前有使用过ELK来跟踪日志,所以将日志格式化成了json的格式,这里贴一下吧
...
+ log_format main '{"@timestamp":"$time_iso8601",'
+ '"host":"$server_addr",'
+ '"clientip":"$remote_addr",'
+ '"size":$body_bytes_sent,'
+ '"responsetime":$request_time,'
+ '"upstreamtime":"$upstream_response_time",'
+ '"upstreamhost":"$upstream_addr",'
+ '"http_host":"$host",'
+ '"url":"$uri",'
+ '"xff":"$http_x_forwarded_for",'
+ '"referer":"$http_referer",'
+ '"agent":"$http_user_agent",'
+ '"status":"$status"}';
+ access_log logs/access.log main;
+ ...
+ 1.2.3 HTTP反向代理 `,5),S={href:"http://blog.csdn.net/bao19901210/article/details/52537279",target:"_blank",rel:"noopener noreferrer"},$=e(` location / {
+ root html;
+ index index.html index.htm;
+ proxy_pass http://backend;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ proxy_set_header Host $host;
+ proxy_set_header REMOTE-HOST $remote_addr;
+ }
+(1)proxy_set_header X-real-ip $remote_addr;
(2)proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
X-Forwarded-For:squid开发的,用于识别通过HTTP代理或负载平衡器原始IP一个连接到Web服务器的客户机地址的非rfc标准,这个不是默认有的,其经过代理转发之后,格式为client1, proxy1, proxy2,如果想通过这个变量来获取用户的ip,那么需要和$proxy_add_x_forwarded_for一起使用。
1.2.4 HTTPS `,5),z={href:"https://baike.baidu.com/item/https/285356?fr=aladdin",target:"_blank",rel:"noopener noreferrer"},T=e(`首先需要下载证书,放在nginx.conf相同目录下,nginx上的配置也需要有所改变,在nginx.conf中设置listen 443 ssl;开启https。然后配置证书和私钥:
ssl_certificate 1_www.wenzhihuai.com_bundle.crt; #主要文件路径
+ ssl_certificate_key 2_www.wenzhihuai.com.key;
+ ssl_session_timeout 5m; # 超时时间
+ ssl_protocols TLSv1 TLSv1.1 TLSv1.2; #按照这个协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;#按照这个套件配置
+ ssl_prefer_server_ciphers on;
+至此,可以使用https来访问了。https带来的安全性(保证信息安全、识别钓鱼网站等)是http远远不能比拟的,目前大部分网站都是实现全站https,还能将http自动重定向为https,此处,需要在server中添加rewrite ^(.*) https://$server_name$1 permanent;即可
1.2.5 失败重试 配置好了负载均衡之后,如果有一台服务器挂了怎么办?nginx中提供了可配置的服务器存活的识别,主要是通过max_fails失败请求次数,fail_timeout超时时间,weight为权重,下面的配置的意思是当服务器超时10秒,并失败了两次的时候,nginx将认为上游服务器不可用,将会摘掉上游服务器,fail_timeout时间后会再次将该服务器加入到存活上游服务器列表进行重试
upstream backend_server {
+ server 10.23.46.71:8080 max_fails=2 fail_timeout=10s weight=1;
+ server 47.95.10.139:8080 max_fails=2 fail_timeout=10s weight=1;
+}
+ session共享 `,8),H={href:"http://blog.csdn.net/qh_java/article/details/45955923",target:"_blank",rel:"noopener noreferrer"},F={href:"https://docs.spring.io/spring-session/docs/2.0.0.BUILD-SNAPSHOT/reference/html5/",target:"_blank",rel:"noopener noreferrer"},I=e(`首先,添加相关依赖
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> < type> </ type> </ dependency> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 新建一个session.xml,然后在spring的配置文件中添加该文件,然后在session.xml中添加:
+ < beanid = " jedisPoolConfig" class = " redis.clients.jedis.JedisPoolConfig" > </ bean> < beanid = " jedisConnectionFactory" class = " org.springframework.data.redis.connection.jedis.JedisConnectionFactory" > < propertyname = " hostName" value = " \${host}" /> < propertyname = " port" value = " \${port}" /> < propertyname = " password" value = " \${password}" /> < propertyname = " timeout" value = " \${timeout}" /> < propertyname = " poolConfig" ref = " jedisPoolConfig" /> < propertyname = " usePool" value = " true" /> </ bean> < beanid = " redisTemplate" class = " org.springframework.data.redis.core.StringRedisTemplate" > < propertyname = " connectionFactory" ref = " jedisConnectionFactory" /> </ bean> < beanid = " redisHttpSessionConfiguration" class = " org.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfiguration" > < propertyname = " maxInactiveIntervalInSeconds" value = " 1800" /> </ bean> 然后我们需要保证servlet容器(tomcat)针对每一个请求都使用springSessionRepositoryFilter来拦截
< filter> < filter-name> </ filter-name> < filter-class> </ filter-class> </ filter> < filter-mapping> < filter-name> </ filter-name> < url-pattern> </ url-pattern> < dispatcher> </ dispatcher> < dispatcher> </ dispatcher> </ filter-mapping> 配置完成,使用RedisDesktopManager查看结果:
测试: 访问http://www.wenzhihuai.com
访问技术杂谈页面,此时nginx将请求转发到119.23.46.71服务器,session为28424f91-5bc5-4bba-99ec-f725401d7318。
点击生活笔记页面,转发到的服务器为47.95.10.139,session为28424f91-5bc5-4bba-99ec-f725401d7318,与上面相同。session已保持一致。
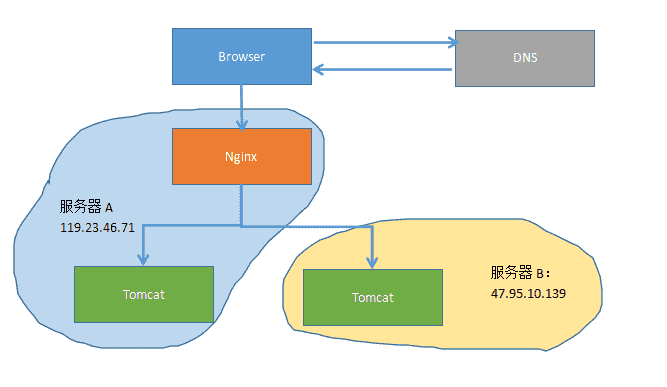
6.数据库备份 \\n先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
\\n由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:
","autoDesc":true}');export{e as data};
diff --git "a/assets/6.\346\225\260\346\215\256\345\272\223\345\244\207\344\273\275.html-GrbFXSWT.js" "b/assets/6.\346\225\260\346\215\256\345\272\223\345\244\207\344\273\275.html-GrbFXSWT.js"
new file mode 100644
index 00000000..16387227
--- /dev/null
+++ "b/assets/6.\346\225\260\346\215\256\345\272\223\345\244\207\344\273\275.html-GrbFXSWT.js"
@@ -0,0 +1,65 @@
+import{_ as s}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as l,o as r,c as d,a as i,d as e,b as a,e as t}from"./app-cS6i7hsH.js";const m={},c=t(` 6.数据库备份 先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:
果然,36ms。。。看起来挺小的,但是对比一下sql执行语句的时间:
大部分都能在10ms内完成,而最长的语句是insert语句,可见,由于异地导致的36ms延时还是比较大的,捣鼓了一下,最后还是选择换个架构,每个服务器读取自己的数据库,然后数据库底层做一下主主复制,让数据同步。最终架构如下:
一、MySql的复制 数据库复制的基本问题就是让一台服务器的数据与其他服务器保持同步。MySql目前支持两种复制方式:基于行的复制和基于语句的复制,这两者的基本过程都是在主库上记录二进制的日志、在备库上重放日志的方式来实现异步的数据复制。其过程分为三步:
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。 下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。 SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。 此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。 MySql的基本复制方式有主从复制、主主复制,主主复制即把主从复制的配置倒过来再配置一遍即可,下面的配置则是主从复制的过程,到时候可自行改为主主复制。其他的架构如:一主库多备库、环形复制、树或者金字塔型都是基于这两种方式,可参考《高性能MySql》。
二、配置过程 2.1 创建所用的复制账号 由于是个自己的小网站,就不做过多的操作了,直接使用root账号
2.2 配置master 接下来要对mysql的serverID,日志位置,复制方式等进行操作,使用vim打开my.cnf。
[client]
+default-character-set=utf8
+
+[mysqld]
+character_set_server=utf8
+init_connect= SET NAMES utf8
+
+datadir=/var/lib/mysql
+socket=/var/lib/mysql/mysql.sock
+
+symbolic-links=0
+
+log-error=/var/log/mysqld.log
+pid-file=/var/run/mysqld/mysqld.pid
+
+# master
+log-bin=mysql-bin
+# 设为基于行的复制
+binlog-format=ROW
+# 设置server的唯一id
+server-id=2
+# 忽略的数据库,不使用备份
+binlog-ignore-db=information_schema
+binlog-ignore-db=cluster
+binlog-ignore-db=mysql
+# 要进行备份的数据库
+binlog-do-db=myblog
+重启Mysql之后,查看主库状态,show master status。
其中,File为日志文件,指定Slave从哪个日志文件开始读复制数据,Position为偏移,从哪个POSITION号开始读,Binlog_Do_DB为要备份的数据库。
2.3 配置slave 从库的配置跟主库类似,vim /etc/my.cnf配置从库信息。
+[client]
+default-character-set=utf8
+
+[mysqld]
+character_set_server=utf8
+init_connect= SET NAMES utf8
+
+datadir=/var/lib/mysql
+socket=/var/lib/mysql/mysql.sock
+
+symbolic-links=0
+
+log-error=/var/log/mysqld.log
+pid-file=/var/run/mysqld/mysqld.pid
+
+# slave
+log-bin=mysql-bin
+# 服务器唯一id
+server-id=3
+# 不备份的数据库
+binlog-ignore-db=information_schema
+binlog-ignore-db=cluster
+binlog-ignore-db=mysql
+# 需要备份的数据库
+replicate-do-db=myblog
+# 其他相关信息
+slave-skip-errors=all
+slave-net-timeout=60
+# 开启中继日志
+relay_log = mysql-relay-bin
+#
+log_slave_updates = 1
+# 防止改变数据
+read_only = 1
+重启slave,同时启动复制,还需要调整一下命令。
mysql> CHANGE MASTER TO MASTER_HOST = '119.23.46.71', MASTER_USER = 'root', MASTER_PASSWORD = 'helloroot', MASTER_PORT = 3306, MASTER_LOG_FILE = 'mysql-bin.000009', MASTER_LOG_POS = 346180;
+
+可以看见slave已经开始进行同步了。我们使用show slave status\\G来查看slave的状态。
其中日志文件和POSITION不一致是合理的,配置好了的话,即使重启,也不会影响到主从复制的配置。
某天在Github上漂游,发现了阿里的canal,同时才知道上面这个业务是叫异地跨机房同步,早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。下面是基本的原理:
原理相对比较简单:
1.canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
`,34),v={href:"https://github.com/alibaba/canal",target:"_blank",rel:"noopener noreferrer"},o=i("figure",null,[i("img",{src:"https://github-images.wenzhihuai.com/images/20171120100237.png",alt:"",tabindex:"0",loading:"lazy"}),i("figcaption")],-1),u={href:"https://github.com/alibaba/otter",target:"_blank",rel:"noopener noreferrer"},b=i("p",null,"公司又要996了,实在是忙不过来,感觉自己写的还是急躁了点,困==",-1);function g(h,p){const n=l("ExternalLinkIcon");return r(),d("div",null,[c,i("p",null,[e("其中,配置过程如下:"),i("a",v,[e("https://github.com/alibaba/canal"),a(n)]),e(",可以搭配Zookeeper使用。在ZKUI中能够查看到节点:")]),o,i("p",null,[e("一般情况下,还要配合阿里的另一个开源产品使用"),i("a",u,[e("otter"),a(n)]),e(",相关文档还是找找GitHub吧,个人搭建完了之后,用起来还是不如直接使用mysql的主主复制,而且异地机房同步这种大企业才有的业务。")]),b])}const y=s(m,[["render",g],["__file","6.数据库备份.html.vue"]]);export{y as default};
diff --git "a/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-QSPIBlp6.js" "b/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-QSPIBlp6.js"
new file mode 100644
index 00000000..bbf9d080
--- /dev/null
+++ "b/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-QSPIBlp6.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-8658e60a","path":"/personalWebsite/7.%E9%82%A3%E4%BA%9B%E7%89%9B%E9%80%BC%E7%9A%84%E6%8F%92%E4%BB%B6.html","title":"7.那些牛逼的插件","lang":"zh-CN","frontmatter":{"description":"7.那些牛逼的插件 欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。 建站的一开始,我也想自己全部实现,各种布局,各种炫丽的效果,想做点能让大家佩服的UI出来,但是,事实上,自己作为专注Java的程序员,前端的东西一碰脑子就有“我又不是前端,浪费时间在这合适么?”这种想法,捣鼓来捣鼓去,做出的东西实在是没法看,我就觉得,如果自己的“产品”连自己都看不下去了,那还好意思给别人看?特别是留言板那块,初版的页面简直low的要死。所以,还是踏踏实实的“站在巨人的肩膀上”吧,改用别人的插件。但不要纯粹的使用别人的博客模板了,如hexo,wordpress这些,就算是自己拼凑过来的也比这些强。下面是本博客中所用到的插件,给大家介绍介绍,共同学习学习。 本站主要用到的插件有: 1.wowslider 2.畅言 3.Editor.md 4.highchart、echart 5.百度分享 6.waterfall.js 7.心知天气 8.标签云","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/7.%E9%82%A3%E4%BA%9B%E7%89%9B%E9%80%BC%E7%9A%84%E6%8F%92%E4%BB%B6.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"7.那些牛逼的插件"}],["meta",{"property":"og:description","content":"7.那些牛逼的插件 欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。 建站的一开始,我也想自己全部实现,各种布局,各种炫丽的效果,想做点能让大家佩服的UI出来,但是,事实上,自己作为专注Java的程序员,前端的东西一碰脑子就有“我又不是前端,浪费时间在这合适么?”这种想法,捣鼓来捣鼓去,做出的东西实在是没法看,我就觉得,如果自己的“产品”连自己都看不下去了,那还好意思给别人看?特别是留言板那块,初版的页面简直low的要死。所以,还是踏踏实实的“站在巨人的肩膀上”吧,改用别人的插件。但不要纯粹的使用别人的博客模板了,如hexo,wordpress这些,就算是自己拼凑过来的也比这些强。下面是本博客中所用到的插件,给大家介绍介绍,共同学习学习。 本站主要用到的插件有: 1.wowslider 2.畅言 3.Editor.md 4.highchart、echart 5.百度分享 6.waterfall.js 7.心知天气 8.标签云"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"7.那些牛逼的插件\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"wowslider","slug":"wowslider","link":"#wowslider","children":[]},{"level":2,"title":"畅言","slug":"畅言","link":"#畅言","children":[]},{"level":2,"title":"Editor.md","slug":"editor-md","link":"#editor-md","children":[]},{"level":2,"title":"图表","slug":"图表","link":"#图表","children":[]},{"level":2,"title":"百度分享","slug":"百度分享","link":"#百度分享","children":[]},{"level":2,"title":"瀑布流","slug":"瀑布流","link":"#瀑布流","children":[]},{"level":2,"title":"天气插件","slug":"天气插件","link":"#天气插件","children":[]},{"level":2,"title":"标签云","slug":"标签云","link":"#标签云","children":[]}],"git":{"createdTime":1706182936000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":7.24,"words":2173},"filePathRelative":"personalWebsite/7.那些牛逼的插件.md","localizedDate":"2024年1月25日","excerpt":" 7.那些牛逼的插件 \\n欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。
","autoDesc":true}');export{e as data};
diff --git "a/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-xUNU4jTw.js" "b/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-xUNU4jTw.js"
new file mode 100644
index 00000000..f41159a0
--- /dev/null
+++ "b/assets/7.\351\202\243\344\272\233\347\211\233\351\200\274\347\232\204\346\217\222\344\273\266.html-xUNU4jTw.js"
@@ -0,0 +1,14 @@
+import{_ as i}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as r,c as l,a as n,d as e,b as t,e as s}from"./app-cS6i7hsH.js";const c={},h=n("h1",{id:"_7-那些牛逼的插件",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#_7-那些牛逼的插件","aria-hidden":"true"},"#"),e(" 7.那些牛逼的插件")],-1),p={href:"http://www.wenzhihuai.com/",target:"_blank",rel:"noopener noreferrer"},d={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},u=n("br",null,null,-1),g=n("br",null,null,-1),_=n("br",null,null,-1),m=n("br",null,null,-1),b=n("br",null,null,-1),f=n("br",null,null,-1),w=n("br",null,null,-1),k=n("br",null,null,-1),v=n("br",null,null,-1),x=n("h2",{id:"wowslider",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#wowslider","aria-hidden":"true"},"#"),e(" wowslider")],-1),z={href:"http://wowslider.com/",target:"_blank",rel:"noopener noreferrer"},y={href:"https://github.com/WOWSlider/WOWSlider",target:"_blank",rel:"noopener noreferrer"},j={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},S=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171121023427.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),E=n("p",null,[n("strong",null,"不过还有个值得注意的问题,就是wowslider里面带有一个googleapis的服务,即https://fonts.googleapis.com/css?family=Arimo&subset=latin,cyrillic,latin-ext,由于一般用户不能访问谷歌,会导致网页加载速度及其缓慢,所以,去掉为妙")],-1),W=n("h2",{id:"畅言",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#畅言","aria-hidden":"true"},"#"),e(" 畅言")],-1),Z={href:"http://www.wenzhihuai.com/board.html",target:"_blank",rel:"noopener noreferrer"},H=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171121024358.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),R=n("h2",{id:"editor-md",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#editor-md","aria-hidden":"true"},"#"),e(" Editor.md")],-1),G={href:"https://github.com/pandao/editor.md",target:"_blank",rel:"noopener noreferrer"},O=s('代码样式,这一点是不如WORDPRESS的插件了,不过已经可以了。
图表 目前最常用的是highcharts跟echart,目前个人博客中的日志系统主要还是采用了highcharts,主要还是颜色什么的格调比较相符吧,其次是因为对echarts印象不太友好,比如下面做这张,打开网页后,缩小浏览器,百度的地域图却不能自适应,出现了越界,而highcharts的全部都能自适应调整。想起有次面试,我说我用的highcharts,面试官一脸嫌弃。。。(网上这么多人鄙视百度是假的?)
不过地图确确实实是echarts的优势,毕竟还是自家的东西了解自家,不过前段时间去看了看echarts的官网,已经不提供下载了。如果有需要,还是去csdn上搜索吧,或者替换为highmap。
百度分享 ',9),P={href:"http://www.jiathis.com/",target:"_blank",rel:"noopener noreferrer"},D={href:"http://share.baidu.com/code/advance#tools",target:"_blank",rel:"noopener noreferrer"},I=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171121022116.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),N={href:"https://github.com/Zephery/newblog/blob/master/src/main/webapp/board.jsp",target:"_blank",rel:"noopener noreferrer"},V=s(`#share a {
+ width : 34px;
+ height : 34px;
+ padding : 0;
+ margin : 6px;
+ border-radius : 25px;
+ transition : all .4s;
+}
+
+#share a.bds_qzone {
+ background : url ( http://image.wenzhihuai.com/t_QQZone.png) ;
+ background-size : 34px 34px;
+}
+改完之后的效果。
瀑布流 `,4),B={href:"https://www.zhihu.com/question/20653270",target:"_blank",rel:"noopener noreferrer"},M=n("a",{href:""},"waterfall.js",-1),Q=n("a",{href:""},"masory.js",-1),q=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171125103716.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),C=n("h2",{id:"天气插件",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#天气插件","aria-hidden":"true"},"#"),e(" 天气插件")],-1),L={href:"http://cj.weather.com.cn/",target:"_blank",rel:"noopener noreferrer"},U={href:"https://www.seniverse.com/widget/intro",target:"_blank",rel:"noopener noreferrer"},A=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171125105127.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),J=n("h2",{id:"标签云",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#标签云","aria-hidden":"true"},"#"),e(" 标签云")],-1),T=n("p",null,"标签云,弄得好的话应该说是一个网站的点缀。现在好像比较流行3D的标签云?像下面这种。",-1),F=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171127033202.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),K={href:"https://github.com/Zephery/newblog/blob/master/src/main/webapp/css/newlypublished.css",target:"_blank",rel:"noopener noreferrer"},X=n("figure",null,[n("img",{src:"https://github-images.wenzhihuai.com/images/20171127033945.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),Y=n("h1",{id:"总结",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#总结","aria-hidden":"true"},"#"),e(" 总结")],-1),$=n("p",null,"作为一个后端人员,调css和js真是痛苦==,好在坚持下来了,虽然还是很多不足,以后有时间慢慢改。说了那么多,感觉自己还是菜的抠脚。 题外话,搭建一个博客,对于一个新近程序员来说真的是锻炼自己的一个好机会,能够认识到从前端、java后台、linux、jvm等等知识,只是真的有点耗时间(还不如把时间耗在Spring源码),如果不采用别人的框架的话,付出的代价还是蛮大的(所以不要鄙视我啦)。没有什么能够一举两得,看自己的取舍吧。加油💪(ง •_•)ง",-1),nn={href:"http://www.wenzhihuai.com/",target:"_blank",rel:"noopener noreferrer"},en={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"};function an(tn,sn){const a=o("ExternalLinkIcon");return r(),l("div",null,[h,n("p",null,[e("欢迎访问我的网站"),n("a",p,[e("http://www.wenzhihuai.com/"),t(a)]),e(" 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址"),n("a",d,[e("https://github.com/Zephery/newblog"),t(a)]),e(" 。"),u,e(" 建站的一开始,我也想自己全部实现,各种布局,各种炫丽的效果,想做点能让大家佩服的UI出来,但是,事实上,自己作为专注Java的程序员,前端的东西一碰脑子就有“我又不是前端,浪费时间在这合适么?”这种想法,捣鼓来捣鼓去,做出的东西实在是没法看,我就觉得,如果自己的“产品”连自己都看不下去了,那还好意思给别人看?特别是留言板那块,初版的页面简直low的要死。所以,还是踏踏实实的“站在巨人的肩膀上”吧,改用别人的插件。但不要纯粹的使用别人的博客模板了,如hexo,wordpress这些,就算是自己拼凑过来的也比这些强。下面是本博客中所用到的插件,给大家介绍介绍,共同学习学习。"),g,e(" 本站主要用到的插件有:"),_,e(" 1.wowslider"),m,e(" 2.畅言"),b,e(" 3.Editor.md"),f,e(" 4.highchart、echart 5.百度分享"),w,e(" 6.waterfall.js"),k,e(" 7.心知天气"),v,e(" 8.标签云")]),x,n("p",null,[e("可能是我这网站中最炫的东西了,图片能够自动像幻灯片一样自动滚动,让网站的首页一看起来就高大上,简直就是建站必备的东西,而且安装也及其简单,有兴趣可以点击"),n("a",z,[e("官网"),t(a)]),e("看看。GitHub里也开放了"),n("a",y,[e("源代码"),t(a)]),e("。安装过程:自己选择“幻灯片”切换效果,保存为html就行了,WORDPREESS中好像有集成这个插件的,做的还更好。感兴趣可以点击"),n("a",j,[e("我的博客首页"),t(a)]),e("看一看。")]),S,E,W,n("p",null,[e("作为社交评论的工具,虽然说表示还是想念以前的多说,但是畅言现在做得还是好了,有评论审核,评论导出导入等功能,如果浏览量大的话,还能提供广告服务,让站长也能拿到一丢丢的广告费。本博客中使用了畅言的基本评论、获取某篇文章评论数的功能。可以到我这里"),n("a",Z,[e("留言"),t(a)]),e("哈")]),H,R,n("p",null,[e("一款能将markdown解析为html的插件,国人的作品,博客的文章编辑器一开始想使用的是markdown,想法是:写文章、保存数据库都是markdown格式的,保存在数据库中,读取时有需要解析markdown,这个过程是有点耗时的,但是相比把html式的网页保存在数据库中友好点吧,因为如果一篇文章比较长的话,转成html的格式,光是大小估计也得超过几十kb?所以,还是本人选择的是一切都用源markdown。 "),n("a",G,[e("editor.md"),t(a)]),e(",是一款开源的、可嵌入的 Markdown 在线编辑器(组件),基于 CodeMirror、jQuery 和 Marked 构建。页面看起来还是美观的,相比WORDPRESS的那些牛逼插件还差那么一点点,不过从普通人的眼光来看,应该是可以的了。此处,我用它作为解析网页的利器,还有就是后台编辑也是用的这个。")]),O,n("p",null,[e("作为一个以博客为主的网站,免不了使用一些社会化分享的工具,目前主要是"),n("a",P,[e("jiathis"),t(a)]),e("和百度分享,这两者的ui都是相似的(丑爆了)。凭我个人的感觉,jiathis加载实在是太过于缓慢,这点是无法让人忍受的,只好投靠百度。百度分享类似于jiathis,安装也很简单,具体见官网"),n("a",D,[e("http://share.baidu.com/code/advance#tools"),t(a)]),e("。一直点点点,配置完之后,就是下图这种,丑爆了是不是?")]),I,n("p",null,[e("好在对它的美观改变不是很难,此处参考了别人的UI设计,原作者我忘记怎么联系他了。其原理主要是使用图片来替换掉原本的东西。完整的源码可以点击"),n("a",N,[e("此处"),t(a)]),e("。")]),V,n("p",null,[e("有段时间,瀑布流特别流行?还有段时间,瀑布流开始遭到各种抵制。。。"),n("a",B,[e("看看知乎的人怎么说"),t(a)]),e(",大部分人不喜欢的原因是让人觉得视觉疲劳,不过瀑布流最大的好处还是有的:提高发现好图的效率以及图片列表页极强的视觉感染力。没错,我还是想把自己的网站弄得铉一些==,所以采用了瀑布流(不过效果不是很好,某些浏览器甚至加载出错),这个大bug有时间再改,毕竟花了很多时间做的这个,效果确实不咋地。目前主要的瀑布流有"),M,e("和"),Q,e("。这一块目前还不是很完善,希望能得到各位大佬的指点。")]),q,C,n("p",null,[e("此类咨询服务还是网上还是挺多的,这一块不知道是不是所谓的“画蛇添足”这部分,主要是我觉得网站右边这部分老是少了点什么,所以加上了天气插件。目前常用的天气插件有"),n("a",L,[e("中国天气网"),t(a)]),e(","),n("a",U,[e("心知天气"),t(a)]),e("等。安装方式见各自的官网,这里不再阐述,我使用的是心知天气。注意:心知天气限制流量的,一个小时内只能使用400次,如果超出了会失效,当然也可以付费使用。")]),A,J,T,F,n("p",null,[e("从个人的网站风格来看,比较适应PHP形式的,有点颜色而又不绚丽的即可,之前用的跟分类的一样的样式,即双纵列的样式,美观度还行,虽然老是感觉有点怪怪的,如果某个标签的字数过长怎么办,岂不是要顶出div了。所以还是选择换另一种风格,最终偶然一次找到了下面这种,能够自适应宽度,颜色虽然鲜艳了点(以后有空再调一下吧),源码见"),n("a",K,[e("style.css"),t(a)]),e("。 下图为目前的标签页。")]),X,Y,$,n("p",null,[e("欢迎访问我的网站"),n("a",nn,[e("http://www.wenzhihuai.com/"),t(a)]),e(" 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址"),n("a",en,[e("https://github.com/Zephery/newblog"),t(a)]),e(" 。")])])}const ln=i(c,[["render",an],["__file","7.那些牛逼的插件.html.vue"]]);export{ln as default};
diff --git "a/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-DmNVFgOS.js" "b/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-DmNVFgOS.js"
new file mode 100644
index 00000000..ba7bc5bb
--- /dev/null
+++ "b/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-DmNVFgOS.js"
@@ -0,0 +1 @@
+import{_}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as a,a as e,d as o}from"./app-cS6i7hsH.js";const r={},c=e("h1",{id:"_8-基于贝叶斯的情感分析",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_8-基于贝叶斯的情感分析","aria-hidden":"true"},"#"),o(" 8.基于贝叶斯的情感分析")],-1),s=[c];function n(d,i){return t(),a("div",null,s)}const f=_(r,[["render",n],["__file","8.基于贝叶斯的情感分析.html.vue"]]);export{f as default};
diff --git "a/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-O9J2qs51.js" "b/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-O9J2qs51.js"
new file mode 100644
index 00000000..cde75a8d
--- /dev/null
+++ "b/assets/8.\345\237\272\344\272\216\350\264\235\345\217\266\346\226\257\347\232\204\346\203\205\346\204\237\345\210\206\346\236\220.html-O9J2qs51.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-7e9e4a32","path":"/personalWebsite/8.%E5%9F%BA%E4%BA%8E%E8%B4%9D%E5%8F%B6%E6%96%AF%E7%9A%84%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90.html","title":"8.基于贝叶斯的情感分析","lang":"zh-CN","frontmatter":{"description":"8.基于贝叶斯的情感分析","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/8.%E5%9F%BA%E4%BA%8E%E8%B4%9D%E5%8F%B6%E6%96%AF%E7%9A%84%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"8.基于贝叶斯的情感分析"}],["meta",{"property":"og:description","content":"8.基于贝叶斯的情感分析"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"8.基于贝叶斯的情感分析\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706182936000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.04,"words":11},"filePathRelative":"personalWebsite/8.基于贝叶斯的情感分析.md","localizedDate":"2024年1月25日","excerpt":" 8.基于贝叶斯的情感分析 \\n","autoDesc":true}');export{e as data};
diff --git "a/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-MC-9j6vs.js" "b/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-MC-9j6vs.js"
new file mode 100644
index 00000000..92150283
--- /dev/null
+++ "b/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-MC-9j6vs.js"
@@ -0,0 +1 @@
+import{_}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as a,a as e,d as o}from"./app-cS6i7hsH.js";const r={},c=e("h1",{id:"_9-网站性能优化",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#_9-网站性能优化","aria-hidden":"true"},"#"),o(" 9.网站性能优化")],-1),s=[c];function n(d,i){return t(),a("div",null,s)}const f=_(r,[["render",n],["__file","9.网站性能优化.html.vue"]]);export{f as default};
diff --git "a/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-npDz6nv1.js" "b/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-npDz6nv1.js"
new file mode 100644
index 00000000..fff9322a
--- /dev/null
+++ "b/assets/9.\347\275\221\347\253\231\346\200\247\350\203\275\344\274\230\345\214\226.html-npDz6nv1.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-0b62f72e","path":"/personalWebsite/9.%E7%BD%91%E7%AB%99%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.html","title":"9.网站性能优化","lang":"zh-CN","frontmatter":{"description":"9.网站性能优化","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/personalWebsite/9.%E7%BD%91%E7%AB%99%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"9.网站性能优化"}],["meta",{"property":"og:description","content":"9.网站性能优化"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"9.网站性能优化\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706182936000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.02,"words":7},"filePathRelative":"personalWebsite/9.网站性能优化.md","localizedDate":"2024年1月25日","excerpt":" 9.网站性能优化 \\n","autoDesc":true}');export{e as data};
diff --git "a/assets/JVM\350\260\203\344\274\230\345\217\202\346\225\260.html-RmR4uDpi.js" "b/assets/JVM\350\260\203\344\274\230\345\217\202\346\225\260.html-RmR4uDpi.js"
new file mode 100644
index 00000000..48bb1fe6
--- /dev/null
+++ "b/assets/JVM\350\260\203\344\274\230\345\217\202\346\225\260.html-RmR4uDpi.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-0a27b598","path":"/java/JVM%E8%B0%83%E4%BC%98%E5%8F%82%E6%95%B0.html","title":"JVM调优参数","lang":"zh-CN","frontmatter":{"description":"JVM调优参数 一、堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。 典型设置: java -Xmx3550m -Xms3550m -Xmn2g -Xss128k","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/JVM%E8%B0%83%E4%BC%98%E5%8F%82%E6%95%B0.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"JVM调优参数"}],["meta",{"property":"og:description","content":"JVM调优参数 一、堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。 典型设置: java -Xmx3550m -Xms3550m -Xmn2g -Xss128k"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T10:30:22.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T10:30:22.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"JVM调优参数\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T10:30:22.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、堆大小设置","slug":"一、堆大小设置","link":"#一、堆大小设置","children":[{"level":3,"title":"典型设置:","slug":"典型设置","link":"#典型设置","children":[]}]},{"level":2,"title":"二、回收器选择","slug":"二、回收器选择","link":"#二、回收器选择","children":[{"level":3,"title":"2.1 吞吐量优先的并行收集器","slug":"_2-1-吞吐量优先的并行收集器","link":"#_2-1-吞吐量优先的并行收集器","children":[]},{"level":3,"title":"2.2 响应时间优先的并发收集器","slug":"_2-2-响应时间优先的并发收集器","link":"#_2-2-响应时间优先的并发收集器","children":[]}]},{"level":2,"title":"三、辅助信息","slug":"三、辅助信息","link":"#三、辅助信息","children":[{"level":3,"title":"3.1 堆设置","slug":"_3-1-堆设置","link":"#_3-1-堆设置","children":[]},{"level":3,"title":"3.2 收集器设置","slug":"_3-2-收集器设置","link":"#_3-2-收集器设置","children":[]},{"level":3,"title":"3.3 垃圾回收统计信息","slug":"_3-3-垃圾回收统计信息","link":"#_3-3-垃圾回收统计信息","children":[]},{"level":3,"title":"3.4 并行收集器设置","slug":"_3-4-并行收集器设置","link":"#_3-4-并行收集器设置","children":[]},{"level":3,"title":"3.5 并发收集器设置","slug":"_3-5-并发收集器设置","link":"#_3-5-并发收集器设置","children":[]}]},{"level":2,"title":"四、调优总结","slug":"四、调优总结","link":"#四、调优总结","children":[{"level":3,"title":"4.1 年轻代大小选择","slug":"_4-1-年轻代大小选择","link":"#_4-1-年轻代大小选择","children":[]},{"level":3,"title":"4.2 年老代大小选择","slug":"_4-2-年老代大小选择","link":"#_4-2-年老代大小选择","children":[]},{"level":3,"title":"4.3 较小堆引起的碎片问题","slug":"_4-3-较小堆引起的碎片问题","link":"#_4-3-较小堆引起的碎片问题","children":[]}]}],"git":{"createdTime":1706066758000,"updatedTime":1706092222000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":9.13,"words":2739},"filePathRelative":"java/JVM调优参数.md","localizedDate":"2024年1月24日","excerpt":" JVM调优参数 \\n 一、堆大小设置 \\nJVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
\\n 典型设置: \\njava -Xmx3550m -Xms3550m -Xmn2g -Xss128k \\n JVM调优参数 一、堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置: java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
+-Xmx3550m:设置JVM最大可用内存为3550M。
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio = 4 -XX:SurvivorRatio = 4 -XX:MaxPermSize = 16m -XX:MaxTenuringThreshold = 0
+-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
二、回收器选择 JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
2.1 吞吐量优先的并行收集器 如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads = 20
+-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。 -XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads = 20 -XX:+UseParallelOldGC
+-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis = 100
+-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis = 100 -XX:+UseAdaptiveSizePolicy
+-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
2.2 响应时间优先的并发收集器 如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。 典型配置:
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads = 20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
+-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction = 5 -XX:+UseCMSCompactAtFullCollection
+-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。 -XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
三、辅助信息 JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些: -XX:+PrintGC 输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用 输出形式:Application time: 0.5291524 seconds -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用 输出形式:Total time for which application threads were stopped: 0.0468229 seconds -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息 输出形式:
34.702: [GC {Heap before gc invocations=7:
+ def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
+eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
+from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
+ to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
+ tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
+the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
+ compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
+ the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
+ ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
+ rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
+34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
+ def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
+eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
+ from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
+ to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
+ tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
+the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
+ compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
+ the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
+ ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
+ rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
+}
+, 0.0757599 secs]
+-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。 常见配置汇总
3.1 堆设置 -Xms:初始堆大小 -Xmx:最大堆大小 -XX:NewSize=n:设置年轻代大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n:设置持久代大小
3.2 收集器设置 -XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器
3.3 垃圾回收统计信息 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename
3.4 并行收集器设置 -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
3.5 并发收集器设置 -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
四、调优总结 4.1 年轻代大小选择 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
4.2 年老代大小选择 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得: 并发垃圾收集信息 持久代并发收集次数 传统GC信息 花在年轻代和年老代回收上的时间比例 减少年轻代和年老代花费的时间,一般会提高应用的效率 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
4.3 较小堆引起的碎片问题 因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他 会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么 并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置: -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。 -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
`,49),l=[i];function d(p,t){return e(),s("div",null,l)}const m=a(r,[["render",d],["__file","JVM调优参数.html.vue"]]);export{m as default};
diff --git a/assets/SearchResult-Uuauwwzf.js b/assets/SearchResult-Uuauwwzf.js
new file mode 100644
index 00000000..7dd7b8f4
--- /dev/null
+++ b/assets/SearchResult-Uuauwwzf.js
@@ -0,0 +1 @@
+import{u as U,f as ee,g as Y,h as j,Y as se,i as ae,t as le,j as te,k as D,l as A,m as re,n as B,p as a,q as _,s as F,v as I,x as ue,y as ie,z as ne,A as oe,R as ce,O as ve,B as pe,C as he,D as ye,E as de,F as me,G as fe,H as E,I as ge}from"./app-cS6i7hsH.js";const He="SEARCH_PRO_QUERY_HISTORY",y=U(He,[]),Re=()=>{const{queryHistoryCount:u}=E,o=u>0;return{enabled:o,queryHistory:y,addQueryHistory:t=>{o&&(y.value.length{y.value=[...y.value.slice(0,t),...y.value.slice(t+1)]}}},ke="SEARCH_PRO_RESULT_HISTORY",{resultHistoryCount:$}=E,d=U(ke,[]),Qe=()=>{const u=Y(),o=$>0,t=l=>u.resolve({name:l.key,..."anchor"in l?{hash:`#${l.anchor}`}:{}}).fullPath;return{enabled:o,resultHistory:d,addResultHistory:l=>{if(o){const i={link:t(l),display:l.display};"header"in l&&(i.header=l.header),d.value.length<$?d.value=[i,...d.value]:d.value=[i,...d.value.slice(0,$-1)]}},removeResultHistory:l=>{d.value=[...d.value.slice(0,l),...d.value.slice(l+1)]}}},xe=u=>{const o=ce(),t=j(),{search:l,terminate:i}=ve(),f=D(!1),g=pe([]);return he(()=>{const m=()=>{g.value=[],f.value=!1},x=ge(H=>{f.value=!0,H?l({type:"search",query:H,locale:t.value,options:o}).then(h=>{g.value=h,f.value=!1}).catch(h=>{console.error(h),m()}):m()},E.searchDelay);B([u,t],()=>x(u.value),{immediate:!0}),ye(()=>{i()})}),{searching:f,results:g}};var Se=ee({name:"SearchResult",props:{query:{type:String,required:!0},isFocusing:Boolean},emits:["close","updateQuery"],setup(u,{emit:o}){const t=Y(),l=j(),i=se(ae),{enabled:f,addQueryHistory:g,queryHistory:m,removeQueryHistory:x}=Re(),{enabled:H,resultHistory:h,addResultHistory:b,removeResultHistory:M}=Qe(),O=f||H,w=le(u,"query"),{results:R,searching:z}=xe(w),r=te({isQuery:!0,index:0}),p=D(0),c=D(0),P=A(()=>O&&(m.value.length>0||h.value.length>0)),S=A(()=>R.value.length>0),q=A(()=>R.value[p.value]||null),T=e=>t.resolve({name:e.key,..."anchor"in e?{hash:`#${e.anchor}`}:{}}).fullPath,G=()=>{const{isQuery:e,index:s}=r;s===0?(r.isQuery=!e,r.index=e?h.value.length-1:m.value.length-1):r.index=s-1},V=()=>{const{isQuery:e,index:s}=r;s===(e?m.value.length-1:h.value.length-1)?(r.isQuery=!e,r.index=0):r.index=s+1},J=()=>{p.value=p.value>0?p.value-1:R.value.length-1,c.value=q.value.contents.length-1},K=()=>{p.value=p.value{c.value{c.value>0?c.value=c.value-1:J()},C=e=>e.map(s=>de(s)?s:a(s[0],s[1])),X=e=>{if(e.type==="customField"){const s=me[e.index]||"$content",[n,Q=""]=fe(s)?s[l.value].split("$content"):s.split("$content");return e.display.map(v=>a("div",C([n,...v,Q])))}return e.display.map(s=>a("div",C(s)))},k=()=>{p.value=0,c.value=0,o("updateQuery",""),o("close")};return re("keydown",e=>{if(u.isFocusing){if(S.value){if(e.key==="ArrowUp")W();else if(e.key==="ArrowDown")N();else if(e.key==="Enter"){const s=q.value.contents[c.value],n=T(s);g(u.query),b(s),t.push(n),k()}}else if(H){if(e.key==="ArrowUp")G();else if(e.key==="ArrowDown")V();else if(e.key==="Enter"){const{index:s}=r;r.isQuery?(o("updateQuery",m.value[s]),e.preventDefault()):(t.push(h.value[s].link),k())}}}}),B([p,c],()=>{var e;(e=document.querySelector(".search-pro-result-list-item.active .search-pro-result-item.active"))==null||e.scrollIntoView(!1)},{flush:"post"}),()=>a("div",{class:["search-pro-result-wrapper",{empty:w.value?!S.value:!P.value}],id:"search-pro-results"},w.value===""?O?P.value?[f?a("ul",{class:"search-pro-result-list"},a("li",{class:"search-pro-result-list-item"},[a("div",{class:"search-pro-result-title"},i.value.queryHistory),m.value.map((e,s)=>a("div",{class:["search-pro-result-item",{active:r.isQuery&&r.index===s}],onClick:()=>{o("updateQuery",e)}},[a(_,{class:"search-pro-result-type"}),a("div",{class:"search-pro-result-content"},e),a("button",{class:"search-pro-remove-icon",innerHTML:F,onClick:n=>{n.preventDefault(),n.stopPropagation(),x(s)}})]))])):null,H?a("ul",{class:"search-pro-result-list"},a("li",{class:"search-pro-result-list-item"},[a("div",{class:"search-pro-result-title"},i.value.resultHistory),h.value.map((e,s)=>a(I,{to:e.link,class:["search-pro-result-item",{active:!r.isQuery&&r.index===s}],onClick:()=>{k()}},()=>[a(_,{class:"search-pro-result-type"}),a("div",{class:"search-pro-result-content"},[e.header?a("div",{class:"content-header"},e.header):null,a("div",e.display.map(n=>C(n)).flat())]),a("button",{class:"search-pro-remove-icon",innerHTML:F,onClick:n=>{n.preventDefault(),n.stopPropagation(),M(s)}})]))])):null]:i.value.emptyHistory:i.value.emptyResult:z.value?a(ue,{hint:i.value.searching}):S.value?a("ul",{class:"search-pro-result-list"},R.value.map(({title:e,contents:s},n)=>{const Q=p.value===n;return a("li",{class:["search-pro-result-list-item",{active:Q}]},[a("div",{class:"search-pro-result-title"},e||i.value.defaultTitle),s.map((v,Z)=>{const L=Q&&c.value===Z;return a(I,{to:T(v),class:["search-pro-result-item",{active:L,"aria-selected":L}],onClick:()=>{g(u.query),b(v),k()}},()=>[v.type==="text"?null:a(v.type==="title"?ie:v.type==="heading"?ne:oe,{class:"search-pro-result-type"}),a("div",{class:"search-pro-result-content"},[v.type==="text"&&v.header?a("div",{class:"content-header"},v.header):null,a("div",X(v))])])})])})):i.value.emptyResult)}});export{Se as default};
diff --git a/assets/app-cS6i7hsH.js b/assets/app-cS6i7hsH.js
new file mode 100644
index 00000000..55a5a149
--- /dev/null
+++ b/assets/app-cS6i7hsH.js
@@ -0,0 +1,229 @@
+/**
+* @vue/shared v3.4.15
+* (c) 2018-present Yuxi (Evan) You and Vue contributors
+* @license MIT
+**/function ll(e,t){const n=new Set(e.split(","));return t?r=>n.has(r.toLowerCase()):r=>n.has(r)}const Te={},vn=[],et=()=>{},Yu=()=>!1,ar=e=>e.charCodeAt(0)===111&&e.charCodeAt(1)===110&&(e.charCodeAt(2)>122||e.charCodeAt(2)<97),ol=e=>e.startsWith("onUpdate:"),Ie=Object.assign,sl=(e,t)=>{const n=e.indexOf(t);n>-1&&e.splice(n,1)},Xu=Object.prototype.hasOwnProperty,pe=(e,t)=>Xu.call(e,t),Q=Array.isArray,Hn=e=>Xr(e)==="[object Map]",Ju=e=>Xr(e)==="[object Set]",re=e=>typeof e=="function",oe=e=>typeof e=="string",Yr=e=>typeof e=="symbol",Le=e=>e!==null&&typeof e=="object",Os=e=>(Le(e)||re(e))&&re(e.then)&&re(e.catch),Qu=Object.prototype.toString,Xr=e=>Qu.call(e),e1=e=>Xr(e).slice(8,-1),t1=e=>Xr(e)==="[object Object]",il=e=>oe(e)&&e!=="NaN"&&e[0]!=="-"&&""+parseInt(e,10)===e,Fn=ll(",key,ref,ref_for,ref_key,onVnodeBeforeMount,onVnodeMounted,onVnodeBeforeUpdate,onVnodeUpdated,onVnodeBeforeUnmount,onVnodeUnmounted"),Jr=e=>{const t=Object.create(null);return n=>t[n]||(t[n]=e(n))},n1=/-(\w)/g,at=Jr(e=>e.replace(n1,(t,n)=>n?n.toUpperCase():"")),r1=/\B([A-Z])/g,An=Jr(e=>e.replace(r1,"-$1").toLowerCase()),lr=Jr(e=>e.charAt(0).toUpperCase()+e.slice(1)),fa=Jr(e=>e?`on${lr(e)}`:""),Ht=(e,t)=>!Object.is(e,t),pa=(e,t)=>{for(let n=0;n{Object.defineProperty(e,t,{configurable:!0,enumerable:!1,value:n})},a1=e=>{const t=parseFloat(e);return isNaN(t)?e:t},l1=e=>{const t=oe(e)?Number(e):NaN;return isNaN(t)?e:t};let uo;const Ms=()=>uo||(uo=typeof globalThis<"u"?globalThis:typeof self<"u"?self:typeof window<"u"?window:typeof global<"u"?global:{});function cl(e){if(Q(e)){const t={};for(let n=0;n{if(n){const r=n.split(s1);r.length>1&&(t[r[0].trim()]=r[1].trim())}}),t}function ul(e){let t="";if(oe(e))t=e;else if(Q(e))for(let n=0;n=2))break}this._dirtyLevel<2&&(this._dirtyLevel=0),rn()}return this._dirtyLevel>=2}set dirty(t){this._dirtyLevel=t?2:0}run(){if(this._dirtyLevel=0,!this.active)return this.fn();let t=Nt,n=Qt;try{return Nt=!0,Qt=this,this._runnings++,fo(this),this.fn()}finally{po(this),this._runnings--,Qt=n,Nt=t}}stop(){var t;this.active&&(fo(this),po(this),(t=this.onStop)==null||t.call(this),this.active=!1)}}function v1(e){return e.value}function fo(e){e._trackId++,e._depsLength=0}function po(e){if(e.deps&&e.deps.length>e._depsLength){for(let t=e._depsLength;t{const n=new Map;return n.cleanup=e,n.computed=t,n},Nr=new WeakMap,en=Symbol(""),Va=Symbol("");function Ge(e,t,n){if(Nt&&Qt){let r=Nr.get(e);r||Nr.set(e,r=new Map);let a=r.get(n);a||r.set(n,a=Fs(()=>r.delete(n))),Ns(Qt,a)}}function Tt(e,t,n,r,a,l){const o=Nr.get(e);if(!o)return;let i=[];if(t==="clear")i=[...o.values()];else if(n==="length"&&Q(e)){const c=Number(r);o.forEach((u,d)=>{(d==="length"||!Yr(d)&&d>=c)&&i.push(u)})}else switch(n!==void 0&&i.push(o.get(n)),t){case"add":Q(e)?il(n)&&i.push(o.get("length")):(i.push(o.get(en)),Hn(e)&&i.push(o.get(Va)));break;case"delete":Q(e)||(i.push(o.get(en)),Hn(e)&&i.push(o.get(Va)));break;case"set":Hn(e)&&i.push(o.get(en));break}fl();for(const c of i)c&&zs(c,2);pl()}function m1(e,t){var n;return(n=Nr.get(e))==null?void 0:n.get(t)}const g1=ll("__proto__,__v_isRef,__isVue"),js=new Set(Object.getOwnPropertyNames(Symbol).filter(e=>e!=="arguments"&&e!=="caller").map(e=>Symbol[e]).filter(Yr)),ho=b1();function b1(){const e={};return["includes","indexOf","lastIndexOf"].forEach(t=>{e[t]=function(...n){const r=ce(this);for(let l=0,o=this.length;l{e[t]=function(...n){nn(),fl();const r=ce(this)[t].apply(this,n);return pl(),rn(),r}}),e}function y1(e){const t=ce(this);return Ge(t,"has",e),t.hasOwnProperty(e)}class Ws{constructor(t=!1,n=!1){this._isReadonly=t,this._shallow=n}get(t,n,r){const a=this._isReadonly,l=this._shallow;if(n==="__v_isReactive")return!a;if(n==="__v_isReadonly")return a;if(n==="__v_isShallow")return l;if(n==="__v_raw")return r===(a?l?R1:Us:l?qs:Ks).get(t)||Object.getPrototypeOf(t)===Object.getPrototypeOf(r)?t:void 0;const o=Q(t);if(!a){if(o&&pe(ho,n))return Reflect.get(ho,n,r);if(n==="hasOwnProperty")return y1}const i=Reflect.get(t,n,r);return(Yr(n)?js.has(n):g1(n))||(a||Ge(t,"get",n),l)?i:$e(i)?o&&il(n)?i:i.value:Le(i)?a?an(i):or(i):i}}class Gs extends Ws{constructor(t=!1){super(!1,t)}set(t,n,r,a){let l=t[n];if(!this._shallow){const c=_n(l);if(!zr(r)&&!_n(r)&&(l=ce(l),r=ce(r)),!Q(t)&&$e(l)&&!$e(r))return c?!1:(l.value=r,!0)}const o=Q(t)&&il(n)?Number(n)e,Qr=e=>Reflect.getPrototypeOf(e);function Er(e,t,n=!1,r=!1){e=e.__v_raw;const a=ce(e),l=ce(t);n||(Ht(t,l)&&Ge(a,"get",t),Ge(a,"get",l));const{has:o}=Qr(a),i=r?hl:n?gl:Yn;if(o.call(a,t))return i(e.get(t));if(o.call(a,l))return i(e.get(l));e!==a&&e.get(t)}function kr(e,t=!1){const n=this.__v_raw,r=ce(n),a=ce(e);return t||(Ht(e,a)&&Ge(r,"has",e),Ge(r,"has",a)),e===a?n.has(e):n.has(e)||n.has(a)}function xr(e,t=!1){return e=e.__v_raw,!t&&Ge(ce(e),"iterate",en),Reflect.get(e,"size",e)}function vo(e){e=ce(e);const t=ce(this);return Qr(t).has.call(t,e)||(t.add(e),Tt(t,"add",e,e)),this}function mo(e,t){t=ce(t);const n=ce(this),{has:r,get:a}=Qr(n);let l=r.call(n,e);l||(e=ce(e),l=r.call(n,e));const o=a.call(n,e);return n.set(e,t),l?Ht(t,o)&&Tt(n,"set",e,t):Tt(n,"add",e,t),this}function go(e){const t=ce(this),{has:n,get:r}=Qr(t);let a=n.call(t,e);a||(e=ce(e),a=n.call(t,e)),r&&r.call(t,e);const l=t.delete(e);return a&&Tt(t,"delete",e,void 0),l}function bo(){const e=ce(this),t=e.size!==0,n=e.clear();return t&&Tt(e,"clear",void 0,void 0),n}function Tr(e,t){return function(r,a){const l=this,o=l.__v_raw,i=ce(o),c=t?hl:e?gl:Yn;return!e&&Ge(i,"iterate",en),o.forEach((u,d)=>r.call(a,c(u),c(d),l))}}function Lr(e,t,n){return function(...r){const a=this.__v_raw,l=ce(a),o=Hn(l),i=e==="entries"||e===Symbol.iterator&&o,c=e==="keys"&&o,u=a[e](...r),d=n?hl:t?gl:Yn;return!t&&Ge(l,"iterate",c?Va:en),{next(){const{value:f,done:p}=u.next();return p?{value:f,done:p}:{value:i?[d(f[0]),d(f[1])]:d(f),done:p}},[Symbol.iterator](){return this}}}}function Pt(e){return function(...t){return e==="delete"?!1:e==="clear"?void 0:this}}function x1(){const e={get(l){return Er(this,l)},get size(){return xr(this)},has:kr,add:vo,set:mo,delete:go,clear:bo,forEach:Tr(!1,!1)},t={get(l){return Er(this,l,!1,!0)},get size(){return xr(this)},has:kr,add:vo,set:mo,delete:go,clear:bo,forEach:Tr(!1,!0)},n={get(l){return Er(this,l,!0)},get size(){return xr(this,!0)},has(l){return kr.call(this,l,!0)},add:Pt("add"),set:Pt("set"),delete:Pt("delete"),clear:Pt("clear"),forEach:Tr(!0,!1)},r={get(l){return Er(this,l,!0,!0)},get size(){return xr(this,!0)},has(l){return kr.call(this,l,!0)},add:Pt("add"),set:Pt("set"),delete:Pt("delete"),clear:Pt("clear"),forEach:Tr(!0,!0)};return["keys","values","entries",Symbol.iterator].forEach(l=>{e[l]=Lr(l,!1,!1),n[l]=Lr(l,!0,!1),t[l]=Lr(l,!1,!0),r[l]=Lr(l,!0,!0)}),[e,n,t,r]}const[T1,L1,A1,S1]=x1();function vl(e,t){const n=t?e?S1:A1:e?L1:T1;return(r,a,l)=>a==="__v_isReactive"?!e:a==="__v_isReadonly"?e:a==="__v_raw"?r:Reflect.get(pe(n,a)&&a in r?n:r,a,l)}const C1={get:vl(!1,!1)},P1={get:vl(!1,!0)},I1={get:vl(!0,!1)},Ks=new WeakMap,qs=new WeakMap,Us=new WeakMap,R1=new WeakMap;function O1(e){switch(e){case"Object":case"Array":return 1;case"Map":case"Set":case"WeakMap":case"WeakSet":return 2;default:return 0}}function M1(e){return e.__v_skip||!Object.isExtensible(e)?0:O1(e1(e))}function or(e){return _n(e)?e:ml(e,!1,w1,C1,Ks)}function Zs(e){return ml(e,!1,k1,P1,qs)}function an(e){return ml(e,!0,E1,I1,Us)}function ml(e,t,n,r,a){if(!Le(e)||e.__v_raw&&!(t&&e.__v_isReactive))return e;const l=a.get(e);if(l)return l;const o=M1(e);if(o===0)return e;const i=new Proxy(e,o===2?r:n);return a.set(e,i),i}function mn(e){return _n(e)?mn(e.__v_raw):!!(e&&e.__v_isReactive)}function _n(e){return!!(e&&e.__v_isReadonly)}function zr(e){return!!(e&&e.__v_isShallow)}function Ys(e){return mn(e)||_n(e)}function ce(e){const t=e&&e.__v_raw;return t?ce(t):e}function Xs(e){return Br(e,"__v_skip",!0),e}const Yn=e=>Le(e)?or(e):e,gl=e=>Le(e)?an(e):e;class Js{constructor(t,n,r,a){this._setter=n,this.dep=void 0,this.__v_isRef=!0,this.__v_isReadonly=!1,this.effect=new dl(()=>t(this._value),()=>jn(this,1),()=>this.dep&&Hs(this.dep)),this.effect.computed=this,this.effect.active=this._cacheable=!a,this.__v_isReadonly=r}get value(){const t=ce(this);return(!t._cacheable||t.effect.dirty)&&Ht(t._value,t._value=t.effect.run())&&jn(t,2),bl(t),t.effect._dirtyLevel>=1&&jn(t,1),t._value}set value(t){this._setter(t)}get _dirty(){return this.effect.dirty}set _dirty(t){this.effect.dirty=t}}function $1(e,t,n=!1){let r,a;const l=re(e);return l?(r=e,a=et):(r=e.get,a=e.set),new Js(r,a,l||!a,n)}function bl(e){Nt&&Qt&&(e=ce(e),Ns(Qt,e.dep||(e.dep=Fs(()=>e.dep=void 0,e instanceof Js?e:void 0))))}function jn(e,t=2,n){e=ce(e);const r=e.dep;r&&zs(r,t)}function $e(e){return!!(e&&e.__v_isRef===!0)}function Z(e){return Qs(e,!1)}function lt(e){return Qs(e,!0)}function Qs(e,t){return $e(e)?e:new D1(e,t)}class D1{constructor(t,n){this.__v_isShallow=n,this.dep=void 0,this.__v_isRef=!0,this._rawValue=n?t:ce(t),this._value=n?t:Yn(t)}get value(){return bl(this),this._value}set value(t){const n=this.__v_isShallow||zr(t)||_n(t);t=n?t:ce(t),Ht(t,this._rawValue)&&(this._rawValue=t,this._value=n?t:Yn(t),jn(this,2))}}function tn(e){return $e(e)?e.value:e}const V1={get:(e,t,n)=>tn(Reflect.get(e,t,n)),set:(e,t,n,r)=>{const a=e[t];return $e(a)&&!$e(n)?(a.value=n,!0):Reflect.set(e,t,n,r)}};function ei(e){return mn(e)?e:new Proxy(e,V1)}class B1{constructor(t){this.dep=void 0,this.__v_isRef=!0;const{get:n,set:r}=t(()=>bl(this),()=>jn(this));this._get=n,this._set=r}get value(){return this._get()}set value(t){this._set(t)}}function ti(e){return new B1(e)}class N1{constructor(t,n,r){this._object=t,this._key=n,this._defaultValue=r,this.__v_isRef=!0}get value(){const t=this._object[this._key];return t===void 0?this._defaultValue:t}set value(t){this._object[this._key]=t}get dep(){return m1(ce(this._object),this._key)}}class z1{constructor(t){this._getter=t,this.__v_isRef=!0,this.__v_isReadonly=!0}get value(){return this._getter()}}function Sn(e,t,n){return $e(e)?e:re(e)?new z1(e):Le(e)&&arguments.length>1?H1(e,t,n):Z(e)}function H1(e,t,n){const r=e[t];return $e(r)?r:new N1(e,t,n)}/**
+* @vue/runtime-core v3.4.15
+* (c) 2018-present Yuxi (Evan) You and Vue contributors
+* @license MIT
+**/function zt(e,t,n,r){let a;try{a=r?e(...r):e()}catch(l){sr(l,t,n)}return a}function nt(e,t,n,r){if(re(e)){const l=zt(e,t,n,r);return l&&Os(l)&&l.catch(o=>{sr(o,t,n)}),l}const a=[];for(let l=0;l>>1,a=Be[r],l=Jn(a);lmt&&Be.splice(t,1)}function G1(e){Q(e)?gn.push(...e):(!Mt||!Mt.includes(e,e.allowRecurse?Yt+1:Yt))&&gn.push(e),ri()}function yo(e,t,n=Xn?mt+1:0){for(;nJn(n)-Jn(r));if(gn.length=0,Mt){Mt.push(...t);return}for(Mt=t,Yt=0;Yte.id==null?1/0:e.id,K1=(e,t)=>{const n=Jn(e)-Jn(t);if(n===0){if(e.pre&&!t.pre)return-1;if(t.pre&&!e.pre)return 1}return n};function ai(e){Ba=!1,Xn=!0,Be.sort(K1);try{for(mt=0;mtoe(h)?h.trim():h)),f&&(a=n.map(a1))}let i,c=r[i=fa(t)]||r[i=fa(at(t))];!c&&l&&(c=r[i=fa(An(t))]),c&&nt(c,e,6,a);const u=r[i+"Once"];if(u){if(!e.emitted)e.emitted={};else if(e.emitted[i])return;e.emitted[i]=!0,nt(u,e,6,a)}}function li(e,t,n=!1){const r=t.emitsCache,a=r.get(e);if(a!==void 0)return a;const l=e.emits;let o={},i=!1;if(!re(e)){const c=u=>{const d=li(u,t,!0);d&&(i=!0,Ie(o,d))};!n&&t.mixins.length&&t.mixins.forEach(c),e.extends&&c(e.extends),e.mixins&&e.mixins.forEach(c)}return!l&&!i?(Le(e)&&r.set(e,null),null):(Q(l)?l.forEach(c=>o[c]=null):Ie(o,l),Le(e)&&r.set(e,o),o)}function ta(e,t){return!e||!ar(t)?!1:(t=t.slice(2).replace(/Once$/,""),pe(e,t[0].toLowerCase()+t.slice(1))||pe(e,An(t))||pe(e,t))}let tt=null,oi=null;function Fr(e){const t=tt;return tt=e,oi=e&&e.type.__scopeId||null,t}function U1(e,t=tt,n){if(!t||e._n)return e;const r=(...a)=>{r._d&&Io(-1);const l=Fr(t);let o;try{o=e(...a)}finally{Fr(l),r._d&&Io(1)}return o};return r._n=!0,r._c=!0,r._d=!0,r}function ha(e){const{type:t,vnode:n,proxy:r,withProxy:a,props:l,propsOptions:[o],slots:i,attrs:c,emit:u,render:d,renderCache:f,data:p,setupState:h,ctx:g,inheritAttrs:w}=e;let E,b;const L=Fr(e);try{if(n.shapeFlag&4){const A=a||r,V=A;E=ct(d.call(V,A,f,l,h,p,g)),b=c}else{const A=t;E=ct(A.length>1?A(l,{attrs:c,slots:i,emit:u}):A(l,null)),b=t.props?c:Z1(c)}}catch(A){qn.length=0,sr(A,e,1),E=Re(gt)}let _=E;if(b&&w!==!1){const A=Object.keys(b),{shapeFlag:V}=_;A.length&&V&7&&(o&&A.some(ol)&&(b=Y1(b,o)),_=Ft(_,b))}return n.dirs&&(_=Ft(_),_.dirs=_.dirs?_.dirs.concat(n.dirs):n.dirs),n.transition&&(_.transition=n.transition),E=_,Fr(L),E}const Z1=e=>{let t;for(const n in e)(n==="class"||n==="style"||ar(n))&&((t||(t={}))[n]=e[n]);return t},Y1=(e,t)=>{const n={};for(const r in e)(!ol(r)||!(r.slice(9)in t))&&(n[r]=e[r]);return n};function X1(e,t,n){const{props:r,children:a,component:l}=e,{props:o,children:i,patchFlag:c}=t,u=l.emitsOptions;if(t.dirs||t.transition)return!0;if(n&&c>=0){if(c&1024)return!0;if(c&16)return r?_o(r,o,u):!!o;if(c&8){const d=t.dynamicProps;for(let f=0;fe.__isSuspense;function ii(e,t){t&&t.pendingBranch?Q(e)?t.effects.push(...e):t.effects.push(e):G1(e)}const nd=Symbol.for("v-scx"),rd=()=>ue(nd);function _l(e,t){return wl(e,null,t)}const Ar={};function ve(e,t,n){return wl(e,t,n)}function wl(e,t,{immediate:n,deep:r,flush:a,once:l,onTrack:o,onTrigger:i}=Te){if(t&&l){const T=t;t=(...K)=>{T(...K),V()}}const c=Me,u=T=>r===!0?T:pn(T,r===!1?1:void 0);let d,f=!1,p=!1;if($e(e)?(d=()=>e.value,f=zr(e)):mn(e)?(d=()=>u(e),f=!0):Q(e)?(p=!0,f=e.some(T=>mn(T)||zr(T)),d=()=>e.map(T=>{if($e(T))return T.value;if(mn(T))return u(T);if(re(T))return zt(T,c,2)})):re(e)?t?d=()=>zt(e,c,2):d=()=>(h&&h(),nt(e,c,3,[g])):d=et,t&&r){const T=d;d=()=>pn(T())}let h,g=T=>{h=_.onStop=()=>{zt(T,c,4),h=_.onStop=void 0}},w;if(ur)if(g=et,t?n&&nt(t,c,3,[d(),p?[]:void 0,g]):d(),a==="sync"){const T=rd();w=T.__watcherHandles||(T.__watcherHandles=[])}else return et;let E=p?new Array(e.length).fill(Ar):Ar;const b=()=>{if(!(!_.active||!_.dirty))if(t){const T=_.run();(r||f||(p?T.some((K,B)=>Ht(K,E[B])):Ht(T,E)))&&(h&&h(),nt(t,c,3,[T,E===Ar?void 0:p&&E[0]===Ar?[]:E,g]),E=T)}else _.run()};b.allowRecurse=!!t;let L;a==="sync"?L=b:a==="post"?L=()=>Fe(b,c&&c.suspense):(b.pre=!0,c&&(b.id=c.uid),L=()=>ea(b));const _=new dl(d,et,L),A=Ds(),V=()=>{_.stop(),A&&sl(A.effects,_)};return t?n?b():E=_.run():a==="post"?Fe(_.run.bind(_),c&&c.suspense):_.run(),w&&w.push(V),V}function ad(e,t,n){const r=this.proxy,a=oe(e)?e.includes(".")?ci(r,e):()=>r[e]:e.bind(r,r);let l;re(t)?l=t:(l=t.handler,n=t);const o=cr(this),i=wl(a,l.bind(r),n);return o(),i}function ci(e,t){const n=t.split(".");return()=>{let r=e;for(let a=0;a0){if(n>=t)return e;n++}if(r=r||new Set,r.has(e))return e;if(r.add(e),$e(e))pn(e.value,t,n,r);else if(Q(e))for(let a=0;a{pn(a,t,n,r)});else if(t1(e))for(const a in e)pn(e[a],t,n,r);return e}function vt(e,t,n,r){const a=e.dirs,l=t&&t.dirs;for(let o=0;o{e.isMounted=!0}),kl(()=>{e.isUnmounting=!0}),e}const Je=[Function,Array],di={mode:String,appear:Boolean,persisted:Boolean,onBeforeEnter:Je,onEnter:Je,onAfterEnter:Je,onEnterCancelled:Je,onBeforeLeave:Je,onLeave:Je,onAfterLeave:Je,onLeaveCancelled:Je,onBeforeAppear:Je,onAppear:Je,onAfterAppear:Je,onAppearCancelled:Je},ld={name:"BaseTransition",props:di,setup(e,{slots:t}){const n=ln(),r=ui();let a;return()=>{const l=t.default&&El(t.default(),!0);if(!l||!l.length)return;let o=l[0];if(l.length>1){for(const w of l)if(w.type!==gt){o=w;break}}const i=ce(e),{mode:c}=i;if(r.isLeaving)return va(o);const u=Eo(o);if(!u)return va(o);const d=Qn(u,i,r,n);er(u,d);const f=n.subTree,p=f&&Eo(f);let h=!1;const{getTransitionKey:g}=u.type;if(g){const w=g();a===void 0?a=w:w!==a&&(a=w,h=!0)}if(p&&p.type!==gt&&(!Xt(u,p)||h)){const w=Qn(p,i,r,n);if(er(p,w),c==="out-in")return r.isLeaving=!0,w.afterLeave=()=>{r.isLeaving=!1,n.update.active!==!1&&(n.effect.dirty=!0,n.update())},va(o);c==="in-out"&&u.type!==gt&&(w.delayLeave=(E,b,L)=>{const _=fi(r,p);_[String(p.key)]=p,E[$t]=()=>{b(),E[$t]=void 0,delete d.delayedLeave},d.delayedLeave=L})}return o}}},od=ld;function fi(e,t){const{leavingVNodes:n}=e;let r=n.get(t.type);return r||(r=Object.create(null),n.set(t.type,r)),r}function Qn(e,t,n,r){const{appear:a,mode:l,persisted:o=!1,onBeforeEnter:i,onEnter:c,onAfterEnter:u,onEnterCancelled:d,onBeforeLeave:f,onLeave:p,onAfterLeave:h,onLeaveCancelled:g,onBeforeAppear:w,onAppear:E,onAfterAppear:b,onAppearCancelled:L}=t,_=String(e.key),A=fi(n,e),V=(B,M)=>{B&&nt(B,r,9,M)},T=(B,M)=>{const N=M[1];V(B,M),Q(B)?B.every(ne=>ne.length<=1)&&N():B.length<=1&&N()},K={mode:l,persisted:o,beforeEnter(B){let M=i;if(!n.isMounted)if(a)M=w||i;else return;B[$t]&&B[$t](!0);const N=A[_];N&&Xt(e,N)&&N.el[$t]&&N.el[$t](),V(M,[B])},enter(B){let M=c,N=u,ne=d;if(!n.isMounted)if(a)M=E||c,N=b||u,ne=L||d;else return;let z=!1;const ee=B[Sr]=Ae=>{z||(z=!0,Ae?V(ne,[B]):V(N,[B]),K.delayedLeave&&K.delayedLeave(),B[Sr]=void 0)};M?T(M,[B,ee]):ee()},leave(B,M){const N=String(e.key);if(B[Sr]&&B[Sr](!0),n.isUnmounting)return M();V(f,[B]);let ne=!1;const z=B[$t]=ee=>{ne||(ne=!0,M(),ee?V(g,[B]):V(h,[B]),B[$t]=void 0,A[N]===e&&delete A[N])};A[N]=e,p?T(p,[B,z]):z()},clone(B){return Qn(B,t,n,r)}};return K}function va(e){if(ir(e))return e=Ft(e),e.children=null,e}function Eo(e){return ir(e)?e.children?e.children[0]:void 0:e}function er(e,t){e.shapeFlag&6&&e.component?er(e.component.subTree,t):e.shapeFlag&128?(e.ssContent.transition=t.clone(e.ssContent),e.ssFallback.transition=t.clone(e.ssFallback)):e.transition=t}function El(e,t=!1,n){let r=[],a=0;for(let l=0;l1)for(let l=0;l!!e.type.__asyncLoader;/*! #__NO_SIDE_EFFECTS__ */function j(e){re(e)&&(e={loader:e});const{loader:t,loadingComponent:n,errorComponent:r,delay:a=200,timeout:l,suspensible:o=!0,onError:i}=e;let c=null,u,d=0;const f=()=>(d++,c=null,p()),p=()=>{let h;return c||(h=c=t().catch(g=>{if(g=g instanceof Error?g:new Error(String(g)),i)return new Promise((w,E)=>{i(g,()=>w(f()),()=>E(g),d+1)});throw g}).then(g=>h!==c&&c?c:(g&&(g.__esModule||g[Symbol.toStringTag]==="Module")&&(g=g.default),u=g,g)))};return D({name:"AsyncComponentWrapper",__asyncLoader:p,get __asyncResolved(){return u},setup(){const h=Me;if(u)return()=>ma(u,h);const g=L=>{c=null,sr(L,h,13,!r)};if(o&&h.suspense||ur)return p().then(L=>()=>ma(L,h)).catch(L=>(g(L),()=>r?Re(r,{error:L}):null));const w=Z(!1),E=Z(),b=Z(!!a);return a&&setTimeout(()=>{b.value=!1},a),l!=null&&setTimeout(()=>{if(!w.value&&!E.value){const L=new Error(`Async component timed out after ${l}ms.`);g(L),E.value=L}},l),p().then(()=>{w.value=!0,h.parent&&ir(h.parent.vnode)&&(h.parent.effect.dirty=!0,ea(h.parent.update))}).catch(L=>{g(L),E.value=L}),()=>{if(w.value&&u)return ma(u,h);if(E.value&&r)return Re(r,{error:E.value});if(n&&!b.value)return Re(n)}}})}function ma(e,t){const{ref:n,props:r,children:a,ce:l}=t.vnode,o=Re(e,r,a);return o.ref=n,o.ce=l,delete t.vnode.ce,o}const ir=e=>e.type.__isKeepAlive;function sd(e,t){pi(e,"a",t)}function id(e,t){pi(e,"da",t)}function pi(e,t,n=Me){const r=e.__wdc||(e.__wdc=()=>{let a=n;for(;a;){if(a.isDeactivated)return;a=a.parent}return e()});if(na(t,r,n),n){let a=n.parent;for(;a&&a.parent;)ir(a.parent.vnode)&&cd(r,t,n,a),a=a.parent}}function cd(e,t,n,r){const a=na(t,e,r,!0);Cn(()=>{sl(r[t],a)},n)}function na(e,t,n=Me,r=!1){if(n){const a=n[e]||(n[e]=[]),l=t.__weh||(t.__weh=(...o)=>{if(n.isUnmounted)return;nn();const i=cr(n),c=nt(t,n,e,o);return i(),rn(),c});return r?a.unshift(l):a.push(l),l}}const St=e=>(t,n=Me)=>(!ur||e==="sp")&&na(e,(...r)=>t(...r),n),ud=St("bm"),ge=St("m"),dd=St("bu"),hi=St("u"),kl=St("bum"),Cn=St("um"),fd=St("sp"),pd=St("rtg"),hd=St("rtc");function vd(e,t=Me){na("ec",e,t)}const Na=e=>e?Si(e)?Al(e)||e.proxy:Na(e.parent):null,Gn=Ie(Object.create(null),{$:e=>e,$el:e=>e.vnode.el,$data:e=>e.data,$props:e=>e.props,$attrs:e=>e.attrs,$slots:e=>e.slots,$refs:e=>e.refs,$parent:e=>Na(e.parent),$root:e=>Na(e.root),$emit:e=>e.emit,$options:e=>xl(e),$forceUpdate:e=>e.f||(e.f=()=>{e.effect.dirty=!0,ea(e.update)}),$nextTick:e=>e.n||(e.n=Gt.bind(e.proxy)),$watch:e=>ad.bind(e)}),ga=(e,t)=>e!==Te&&!e.__isScriptSetup&&pe(e,t),md={get({_:e},t){const{ctx:n,setupState:r,data:a,props:l,accessCache:o,type:i,appContext:c}=e;let u;if(t[0]!=="$"){const h=o[t];if(h!==void 0)switch(h){case 1:return r[t];case 2:return a[t];case 4:return n[t];case 3:return l[t]}else{if(ga(r,t))return o[t]=1,r[t];if(a!==Te&&pe(a,t))return o[t]=2,a[t];if((u=e.propsOptions[0])&&pe(u,t))return o[t]=3,l[t];if(n!==Te&&pe(n,t))return o[t]=4,n[t];za&&(o[t]=0)}}const d=Gn[t];let f,p;if(d)return t==="$attrs"&&Ge(e,"get",t),d(e);if((f=i.__cssModules)&&(f=f[t]))return f;if(n!==Te&&pe(n,t))return o[t]=4,n[t];if(p=c.config.globalProperties,pe(p,t))return p[t]},set({_:e},t,n){const{data:r,setupState:a,ctx:l}=e;return ga(a,t)?(a[t]=n,!0):r!==Te&&pe(r,t)?(r[t]=n,!0):pe(e.props,t)||t[0]==="$"&&t.slice(1)in e?!1:(l[t]=n,!0)},has({_:{data:e,setupState:t,accessCache:n,ctx:r,appContext:a,propsOptions:l}},o){let i;return!!n[o]||e!==Te&&pe(e,o)||ga(t,o)||(i=l[0])&&pe(i,o)||pe(r,o)||pe(Gn,o)||pe(a.config.globalProperties,o)},defineProperty(e,t,n){return n.get!=null?e._.accessCache[t]=0:pe(n,"value")&&this.set(e,t,n.value,null),Reflect.defineProperty(e,t,n)}};function ko(e){return Q(e)?e.reduce((t,n)=>(t[n]=null,t),{}):e}let za=!0;function gd(e){const t=xl(e),n=e.proxy,r=e.ctx;za=!1,t.beforeCreate&&xo(t.beforeCreate,e,"bc");const{data:a,computed:l,methods:o,watch:i,provide:c,inject:u,created:d,beforeMount:f,mounted:p,beforeUpdate:h,updated:g,activated:w,deactivated:E,beforeDestroy:b,beforeUnmount:L,destroyed:_,unmounted:A,render:V,renderTracked:T,renderTriggered:K,errorCaptured:B,serverPrefetch:M,expose:N,inheritAttrs:ne,components:z,directives:ee,filters:Ae}=t;if(u&&bd(u,r,null),o)for(const ae in o){const U=o[ae];re(U)&&(r[ae]=U.bind(n))}if(a){const ae=a.call(n,n);Le(ae)&&(e.data=or(ae))}if(za=!0,l)for(const ae in l){const U=l[ae],st=re(U)?U.bind(n,n):re(U.get)?U.get.bind(n,n):et,Ct=!re(U)&&re(U.set)?U.set.bind(n):et,pt=y({get:st,set:Ct});Object.defineProperty(r,ae,{enumerable:!0,configurable:!0,get:()=>pt.value,set:He=>pt.value=He})}if(i)for(const ae in i)vi(i[ae],r,n,ae);if(c){const ae=re(c)?c.call(n):c;Reflect.ownKeys(ae).forEach(U=>{rt(U,ae[U])})}d&&xo(d,e,"c");function Y(ae,U){Q(U)?U.forEach(st=>ae(st.bind(n))):U&&ae(U.bind(n))}if(Y(ud,f),Y(ge,p),Y(dd,h),Y(hi,g),Y(sd,w),Y(id,E),Y(vd,B),Y(hd,T),Y(pd,K),Y(kl,L),Y(Cn,A),Y(fd,M),Q(N))if(N.length){const ae=e.exposed||(e.exposed={});N.forEach(U=>{Object.defineProperty(ae,U,{get:()=>n[U],set:st=>n[U]=st})})}else e.exposed||(e.exposed={});V&&e.render===et&&(e.render=V),ne!=null&&(e.inheritAttrs=ne),z&&(e.components=z),ee&&(e.directives=ee)}function bd(e,t,n=et){Q(e)&&(e=Ha(e));for(const r in e){const a=e[r];let l;Le(a)?"default"in a?l=ue(a.from||r,a.default,!0):l=ue(a.from||r):l=ue(a),$e(l)?Object.defineProperty(t,r,{enumerable:!0,configurable:!0,get:()=>l.value,set:o=>l.value=o}):t[r]=l}}function xo(e,t,n){nt(Q(e)?e.map(r=>r.bind(t.proxy)):e.bind(t.proxy),t,n)}function vi(e,t,n,r){const a=r.includes(".")?ci(n,r):()=>n[r];if(oe(e)){const l=t[e];re(l)&&ve(a,l)}else if(re(e))ve(a,e.bind(n));else if(Le(e))if(Q(e))e.forEach(l=>vi(l,t,n,r));else{const l=re(e.handler)?e.handler.bind(n):t[e.handler];re(l)&&ve(a,l,e)}}function xl(e){const t=e.type,{mixins:n,extends:r}=t,{mixins:a,optionsCache:l,config:{optionMergeStrategies:o}}=e.appContext,i=l.get(t);let c;return i?c=i:!a.length&&!n&&!r?c=t:(c={},a.length&&a.forEach(u=>jr(c,u,o,!0)),jr(c,t,o)),Le(t)&&l.set(t,c),c}function jr(e,t,n,r=!1){const{mixins:a,extends:l}=t;l&&jr(e,l,n,!0),a&&a.forEach(o=>jr(e,o,n,!0));for(const o in t)if(!(r&&o==="expose")){const i=yd[o]||n&&n[o];e[o]=i?i(e[o],t[o]):t[o]}return e}const yd={data:To,props:Lo,emits:Lo,methods:zn,computed:zn,beforeCreate:Ne,created:Ne,beforeMount:Ne,mounted:Ne,beforeUpdate:Ne,updated:Ne,beforeDestroy:Ne,beforeUnmount:Ne,destroyed:Ne,unmounted:Ne,activated:Ne,deactivated:Ne,errorCaptured:Ne,serverPrefetch:Ne,components:zn,directives:zn,watch:wd,provide:To,inject:_d};function To(e,t){return t?e?function(){return Ie(re(e)?e.call(this,this):e,re(t)?t.call(this,this):t)}:t:e}function _d(e,t){return zn(Ha(e),Ha(t))}function Ha(e){if(Q(e)){const t={};for(let n=0;n1)return n&&re(t)?t.call(r&&r.proxy):t}}function xd(e,t,n,r=!1){const a={},l={};Br(l,ra,1),e.propsDefaults=Object.create(null),gi(e,t,a,l);for(const o in e.propsOptions[0])o in a||(a[o]=void 0);n?e.props=r?a:Zs(a):e.type.props?e.props=a:e.props=l,e.attrs=l}function Td(e,t,n,r){const{props:a,attrs:l,vnode:{patchFlag:o}}=e,i=ce(a),[c]=e.propsOptions;let u=!1;if((r||o>0)&&!(o&16)){if(o&8){const d=e.vnode.dynamicProps;for(let f=0;f{c=!0;const[p,h]=bi(f,t,!0);Ie(o,p),h&&i.push(...h)};!n&&t.mixins.length&&t.mixins.forEach(d),e.extends&&d(e.extends),e.mixins&&e.mixins.forEach(d)}if(!l&&!c)return Le(e)&&r.set(e,vn),vn;if(Q(l))for(let d=0;d-1,h[1]=w<0||g-1||pe(h,"default"))&&i.push(f)}}}const u=[o,i];return Le(e)&&r.set(e,u),u}function Ao(e){return e[0]!=="$"}function So(e){const t=e&&e.toString().match(/^\s*(function|class) (\w+)/);return t?t[2]:e===null?"null":""}function Co(e,t){return So(e)===So(t)}function Po(e,t){return Q(t)?t.findIndex(n=>Co(n,e)):re(t)&&Co(t,e)?0:-1}const yi=e=>e[0]==="_"||e==="$stable",Tl=e=>Q(e)?e.map(ct):[ct(e)],Ld=(e,t,n)=>{if(t._n)return t;const r=U1((...a)=>Tl(t(...a)),n);return r._c=!1,r},_i=(e,t,n)=>{const r=e._ctx;for(const a in e){if(yi(a))continue;const l=e[a];if(re(l))t[a]=Ld(a,l,r);else if(l!=null){const o=Tl(l);t[a]=()=>o}}},wi=(e,t)=>{const n=Tl(t);e.slots.default=()=>n},Ad=(e,t)=>{if(e.vnode.shapeFlag&32){const n=t._;n?(e.slots=ce(t),Br(t,"_",n)):_i(t,e.slots={})}else e.slots={},t&&wi(e,t);Br(e.slots,ra,1)},Sd=(e,t,n)=>{const{vnode:r,slots:a}=e;let l=!0,o=Te;if(r.shapeFlag&32){const i=t._;i?n&&i===1?l=!1:(Ie(a,t),!n&&i===1&&delete a._):(l=!t.$stable,_i(t,a)),o=t}else t&&(wi(e,t),o={default:1});if(l)for(const i in a)!yi(i)&&o[i]==null&&delete a[i]};function Gr(e,t,n,r,a=!1){if(Q(e)){e.forEach((p,h)=>Gr(p,t&&(Q(t)?t[h]:t),n,r,a));return}if(Wn(r)&&!a)return;const l=r.shapeFlag&4?Al(r.component)||r.component.proxy:r.el,o=a?null:l,{i,r:c}=e,u=t&&t.r,d=i.refs===Te?i.refs={}:i.refs,f=i.setupState;if(u!=null&&u!==c&&(oe(u)?(d[u]=null,pe(f,u)&&(f[u]=null)):$e(u)&&(u.value=null)),re(c))zt(c,i,12,[o,d]);else{const p=oe(c),h=$e(c),g=e.f;if(p||h){const w=()=>{if(g){const E=p?pe(f,c)?f[c]:d[c]:c.value;a?Q(E)&&sl(E,l):Q(E)?E.includes(l)||E.push(l):p?(d[c]=[l],pe(f,c)&&(f[c]=d[c])):(c.value=[l],e.k&&(d[e.k]=c.value))}else p?(d[c]=o,pe(f,c)&&(f[c]=o)):h&&(c.value=o,e.k&&(d[e.k]=o))};a||g?w():(w.id=-1,Fe(w,n))}}}let It=!1;const Cd=e=>e.namespaceURI.includes("svg")&&e.tagName!=="foreignObject",Pd=e=>e.namespaceURI.includes("MathML"),Cr=e=>{if(Cd(e))return"svg";if(Pd(e))return"mathml"},Pr=e=>e.nodeType===8;function Id(e){const{mt:t,p:n,o:{patchProp:r,createText:a,nextSibling:l,parentNode:o,remove:i,insert:c,createComment:u}}=e,d=(_,A)=>{if(!A.hasChildNodes()){n(null,_,A),Hr(),A._vnode=_;return}It=!1,f(A.firstChild,_,null,null,null),Hr(),A._vnode=_,It&&console.error("Hydration completed but contains mismatches.")},f=(_,A,V,T,K,B=!1)=>{const M=Pr(_)&&_.data==="[",N=()=>w(_,A,V,T,K,M),{type:ne,ref:z,shapeFlag:ee,patchFlag:Ae}=A;let Se=_.nodeType;A.el=_,Ae===-2&&(B=!1,A.dynamicChildren=null);let Y=null;switch(ne){case wn:Se!==3?A.children===""?(c(A.el=a(""),o(_),_),Y=_):Y=N():(_.data!==A.children&&(It=!0,_.data=A.children),Y=l(_));break;case gt:L(_)?(Y=l(_),b(A.el=_.content.firstChild,_,V)):Se!==8||M?Y=N():Y=l(_);break;case Kn:if(M&&(_=l(_),Se=_.nodeType),Se===1||Se===3){Y=_;const ae=!A.children.length;for(let U=0;U{B=B||!!A.dynamicChildren;const{type:M,props:N,patchFlag:ne,shapeFlag:z,dirs:ee,transition:Ae}=A,Se=M==="input"||M==="option";if(Se||ne!==-1){ee&&vt(A,null,V,"created");let Y=!1;if(L(_)){Y=Ei(T,Ae)&&V&&V.vnode.props&&V.vnode.props.appear;const U=_.content.firstChild;Y&&Ae.beforeEnter(U),b(U,_,V),A.el=_=U}if(z&16&&!(N&&(N.innerHTML||N.textContent))){let U=h(_.firstChild,A,_,V,T,K,B);for(;U;){It=!0;const st=U;U=U.nextSibling,i(st)}}else z&8&&_.textContent!==A.children&&(It=!0,_.textContent=A.children);if(N)if(Se||!B||ne&48)for(const U in N)(Se&&(U.endsWith("value")||U==="indeterminate")||ar(U)&&!Fn(U)||U[0]===".")&&r(_,U,null,N[U],void 0,void 0,V);else N.onClick&&r(_,"onClick",null,N.onClick,void 0,void 0,V);let ae;(ae=N&&N.onVnodeBeforeMount)&&Qe(ae,V,A),ee&&vt(A,null,V,"beforeMount"),((ae=N&&N.onVnodeMounted)||ee||Y)&&ii(()=>{ae&&Qe(ae,V,A),Y&&Ae.enter(_),ee&&vt(A,null,V,"mounted")},T)}return _.nextSibling},h=(_,A,V,T,K,B,M)=>{M=M||!!A.dynamicChildren;const N=A.children,ne=N.length;for(let z=0;z{const{slotScopeIds:M}=A;M&&(K=K?K.concat(M):M);const N=o(_),ne=h(l(_),A,N,V,T,K,B);return ne&&Pr(ne)&&ne.data==="]"?l(A.anchor=ne):(It=!0,c(A.anchor=u("]"),N,ne),ne)},w=(_,A,V,T,K,B)=>{if(It=!0,A.el=null,B){const ne=E(_);for(;;){const z=l(_);if(z&&z!==ne)i(z);else break}}const M=l(_),N=o(_);return i(_),n(null,A,N,M,V,T,Cr(N),K),M},E=(_,A="[",V="]")=>{let T=0;for(;_;)if(_=l(_),_&&Pr(_)&&(_.data===A&&T++,_.data===V)){if(T===0)return l(_);T--}return _},b=(_,A,V)=>{const T=A.parentNode;T&&T.replaceChild(_,A);let K=V;for(;K;)K.vnode.el===A&&(K.vnode.el=K.subTree.el=_),K=K.parent},L=_=>_.nodeType===1&&_.tagName.toLowerCase()==="template";return[d,f]}const Fe=ii;function Rd(e){return Od(e,Id)}function Od(e,t){const n=Ms();n.__VUE__=!0;const{insert:r,remove:a,patchProp:l,createElement:o,createText:i,createComment:c,setText:u,setElementText:d,parentNode:f,nextSibling:p,setScopeId:h=et,insertStaticContent:g}=e,w=(v,m,k,P=null,S=null,O=null,F=void 0,R=null,$=!!m.dynamicChildren)=>{if(v===m)return;v&&!Xt(v,m)&&(P=C(v),He(v,S,O,!0),v=null),m.patchFlag===-2&&($=!1,m.dynamicChildren=null);const{type:I,ref:G,shapeFlag:J}=m;switch(I){case wn:E(v,m,k,P);break;case gt:b(v,m,k,P);break;case Kn:v==null&&L(m,k,P,F);break;case Ue:z(v,m,k,P,S,O,F,R,$);break;default:J&1?V(v,m,k,P,S,O,F,R,$):J&6?ee(v,m,k,P,S,O,F,R,$):(J&64||J&128)&&I.process(v,m,k,P,S,O,F,R,$,q)}G!=null&&S&&Gr(G,v&&v.ref,O,m||v,!m)},E=(v,m,k,P)=>{if(v==null)r(m.el=i(m.children),k,P);else{const S=m.el=v.el;m.children!==v.children&&u(S,m.children)}},b=(v,m,k,P)=>{v==null?r(m.el=c(m.children||""),k,P):m.el=v.el},L=(v,m,k,P)=>{[v.el,v.anchor]=g(v.children,m,k,P,v.el,v.anchor)},_=({el:v,anchor:m},k,P)=>{let S;for(;v&&v!==m;)S=p(v),r(v,k,P),v=S;r(m,k,P)},A=({el:v,anchor:m})=>{let k;for(;v&&v!==m;)k=p(v),a(v),v=k;a(m)},V=(v,m,k,P,S,O,F,R,$)=>{m.type==="svg"?F="svg":m.type==="math"&&(F="mathml"),v==null?T(m,k,P,S,O,F,R,$):M(v,m,S,O,F,R,$)},T=(v,m,k,P,S,O,F,R)=>{let $,I;const{props:G,shapeFlag:J,transition:X,dirs:te}=v;if($=v.el=o(v.type,O,G&&G.is,G),J&8?d($,v.children):J&16&&B(v.children,$,null,P,S,ba(v,O),F,R),te&&vt(v,null,P,"created"),K($,v,v.scopeId,F,P),G){for(const _e in G)_e!=="value"&&!Fn(_e)&&l($,_e,null,G[_e],O,v.children,P,S,Ve);"value"in G&&l($,"value",null,G.value,O),(I=G.onVnodeBeforeMount)&&Qe(I,P,v)}te&&vt(v,null,P,"beforeMount");const le=Ei(S,X);le&&X.beforeEnter($),r($,m,k),((I=G&&G.onVnodeMounted)||le||te)&&Fe(()=>{I&&Qe(I,P,v),le&&X.enter($),te&&vt(v,null,P,"mounted")},S)},K=(v,m,k,P,S)=>{if(k&&h(v,k),P)for(let O=0;O{for(let I=$;I{const R=m.el=v.el;let{patchFlag:$,dynamicChildren:I,dirs:G}=m;$|=v.patchFlag&16;const J=v.props||Te,X=m.props||Te;let te;if(k&&Ut(k,!1),(te=X.onVnodeBeforeUpdate)&&Qe(te,k,m,v),G&&vt(m,v,k,"beforeUpdate"),k&&Ut(k,!0),I?N(v.dynamicChildren,I,R,k,P,ba(m,S),O):F||U(v,m,R,null,k,P,ba(m,S),O,!1),$>0){if($&16)ne(R,m,J,X,k,P,S);else if($&2&&J.class!==X.class&&l(R,"class",null,X.class,S),$&4&&l(R,"style",J.style,X.style,S),$&8){const le=m.dynamicProps;for(let _e=0;_e{te&&Qe(te,k,m,v),G&&vt(m,v,k,"updated")},P)},N=(v,m,k,P,S,O,F)=>{for(let R=0;R{if(k!==P){if(k!==Te)for(const R in k)!Fn(R)&&!(R in P)&&l(v,R,k[R],null,F,m.children,S,O,Ve);for(const R in P){if(Fn(R))continue;const $=P[R],I=k[R];$!==I&&R!=="value"&&l(v,R,I,$,F,m.children,S,O,Ve)}"value"in P&&l(v,"value",k.value,P.value,F)}},z=(v,m,k,P,S,O,F,R,$)=>{const I=m.el=v?v.el:i(""),G=m.anchor=v?v.anchor:i("");let{patchFlag:J,dynamicChildren:X,slotScopeIds:te}=m;te&&(R=R?R.concat(te):te),v==null?(r(I,k,P),r(G,k,P),B(m.children||[],k,G,S,O,F,R,$)):J>0&&J&64&&X&&v.dynamicChildren?(N(v.dynamicChildren,X,k,S,O,F,R),(m.key!=null||S&&m===S.subTree)&&ki(v,m,!0)):U(v,m,k,G,S,O,F,R,$)},ee=(v,m,k,P,S,O,F,R,$)=>{m.slotScopeIds=R,v==null?m.shapeFlag&512?S.ctx.activate(m,k,P,F,$):Ae(m,k,P,S,O,F,$):Se(v,m,$)},Ae=(v,m,k,P,S,O,F)=>{const R=v.component=jd(v,P,S);if(ir(v)&&(R.ctx.renderer=q),Wd(R),R.asyncDep){if(S&&S.registerDep(R,Y),!v.el){const $=R.subTree=Re(gt);b(null,$,m,k)}}else Y(R,v,m,k,S,O,F)},Se=(v,m,k)=>{const P=m.component=v.component;if(X1(v,m,k))if(P.asyncDep&&!P.asyncResolved){ae(P,m,k);return}else P.next=m,W1(P.update),P.effect.dirty=!0,P.update();else m.el=v.el,P.vnode=m},Y=(v,m,k,P,S,O,F)=>{const R=()=>{if(v.isMounted){let{next:G,bu:J,u:X,parent:te,vnode:le}=v;{const dn=xi(v);if(dn){G&&(G.el=le.el,ae(v,G,F)),dn.asyncDep.then(()=>{v.isUnmounted||R()});return}}let _e=G,xe;Ut(v,!1),G?(G.el=le.el,ae(v,G,F)):G=le,J&&pa(J),(xe=G.props&&G.props.onVnodeBeforeUpdate)&&Qe(xe,te,G,le),Ut(v,!0);const Oe=ha(v),it=v.subTree;v.subTree=Oe,w(it,Oe,f(it.el),C(it),v,S,O),G.el=Oe.el,_e===null&&J1(v,Oe.el),X&&Fe(X,S),(xe=G.props&&G.props.onVnodeUpdated)&&Fe(()=>Qe(xe,te,G,le),S)}else{let G;const{el:J,props:X}=m,{bm:te,m:le,parent:_e}=v,xe=Wn(m);if(Ut(v,!1),te&&pa(te),!xe&&(G=X&&X.onVnodeBeforeMount)&&Qe(G,_e,m),Ut(v,!0),J&&ke){const Oe=()=>{v.subTree=ha(v),ke(J,v.subTree,v,S,null)};xe?m.type.__asyncLoader().then(()=>!v.isUnmounted&&Oe()):Oe()}else{const Oe=v.subTree=ha(v);w(null,Oe,k,P,v,S,O),m.el=Oe.el}if(le&&Fe(le,S),!xe&&(G=X&&X.onVnodeMounted)){const Oe=m;Fe(()=>Qe(G,_e,Oe),S)}(m.shapeFlag&256||_e&&Wn(_e.vnode)&&_e.vnode.shapeFlag&256)&&v.a&&Fe(v.a,S),v.isMounted=!0,m=k=P=null}},$=v.effect=new dl(R,et,()=>ea(I),v.scope),I=v.update=()=>{$.dirty&&$.run()};I.id=v.uid,Ut(v,!0),I()},ae=(v,m,k)=>{m.component=v;const P=v.vnode.props;v.vnode=m,v.next=null,Td(v,m.props,P,k),Sd(v,m.children,k),nn(),yo(v),rn()},U=(v,m,k,P,S,O,F,R,$=!1)=>{const I=v&&v.children,G=v?v.shapeFlag:0,J=m.children,{patchFlag:X,shapeFlag:te}=m;if(X>0){if(X&128){Ct(I,J,k,P,S,O,F,R,$);return}else if(X&256){st(I,J,k,P,S,O,F,R,$);return}}te&8?(G&16&&Ve(I,S,O),J!==I&&d(k,J)):G&16?te&16?Ct(I,J,k,P,S,O,F,R,$):Ve(I,S,O,!0):(G&8&&d(k,""),te&16&&B(J,k,P,S,O,F,R,$))},st=(v,m,k,P,S,O,F,R,$)=>{v=v||vn,m=m||vn;const I=v.length,G=m.length,J=Math.min(I,G);let X;for(X=0;XG?Ve(v,S,O,!0,!1,J):B(m,k,P,S,O,F,R,$,J)},Ct=(v,m,k,P,S,O,F,R,$)=>{let I=0;const G=m.length;let J=v.length-1,X=G-1;for(;I<=J&&I<=X;){const te=v[I],le=m[I]=$?Dt(m[I]):ct(m[I]);if(Xt(te,le))w(te,le,k,null,S,O,F,R,$);else break;I++}for(;I<=J&&I<=X;){const te=v[J],le=m[X]=$?Dt(m[X]):ct(m[X]);if(Xt(te,le))w(te,le,k,null,S,O,F,R,$);else break;J--,X--}if(I>J){if(I<=X){const te=X+1,le=teX)for(;I<=J;)He(v[I],S,O,!0),I++;else{const te=I,le=I,_e=new Map;for(I=le;I<=X;I++){const Ke=m[I]=$?Dt(m[I]):ct(m[I]);Ke.key!=null&&_e.set(Ke.key,I)}let xe,Oe=0;const it=X-le+1;let dn=!1,so=0;const Dn=new Array(it);for(I=0;I=it){He(Ke,S,O,!0);continue}let ht;if(Ke.key!=null)ht=_e.get(Ke.key);else for(xe=le;xe<=X;xe++)if(Dn[xe-le]===0&&Xt(Ke,m[xe])){ht=xe;break}ht===void 0?He(Ke,S,O,!0):(Dn[ht-le]=I+1,ht>=so?so=ht:dn=!0,w(Ke,m[ht],k,null,S,O,F,R,$),Oe++)}const io=dn?Md(Dn):vn;for(xe=io.length-1,I=it-1;I>=0;I--){const Ke=le+I,ht=m[Ke],co=Ke+1{const{el:O,type:F,transition:R,children:$,shapeFlag:I}=v;if(I&6){pt(v.component.subTree,m,k,P);return}if(I&128){v.suspense.move(m,k,P);return}if(I&64){F.move(v,m,k,q);return}if(F===Ue){r(O,m,k);for(let J=0;J<$.length;J++)pt($[J],m,k,P);r(v.anchor,m,k);return}if(F===Kn){_(v,m,k);return}if(P!==2&&I&1&&R)if(P===0)R.beforeEnter(O),r(O,m,k),Fe(()=>R.enter(O),S);else{const{leave:J,delayLeave:X,afterLeave:te}=R,le=()=>r(O,m,k),_e=()=>{J(O,()=>{le(),te&&te()})};X?X(O,le,_e):_e()}else r(O,m,k)},He=(v,m,k,P=!1,S=!1)=>{const{type:O,props:F,ref:R,children:$,dynamicChildren:I,shapeFlag:G,patchFlag:J,dirs:X}=v;if(R!=null&&Gr(R,null,k,v,!0),G&256){m.ctx.deactivate(v);return}const te=G&1&&X,le=!Wn(v);let _e;if(le&&(_e=F&&F.onVnodeBeforeUnmount)&&Qe(_e,m,v),G&6)wr(v.component,k,P);else{if(G&128){v.suspense.unmount(k,P);return}te&&vt(v,null,m,"beforeUnmount"),G&64?v.type.remove(v,m,k,S,q,P):I&&(O!==Ue||J>0&&J&64)?Ve(I,m,k,!1,!0):(O===Ue&&J&384||!S&&G&16)&&Ve($,m,k),P&&cn(v)}(le&&(_e=F&&F.onVnodeUnmounted)||te)&&Fe(()=>{_e&&Qe(_e,m,v),te&&vt(v,null,m,"unmounted")},k)},cn=v=>{const{type:m,el:k,anchor:P,transition:S}=v;if(m===Ue){un(k,P);return}if(m===Kn){A(v);return}const O=()=>{a(k),S&&!S.persisted&&S.afterLeave&&S.afterLeave()};if(v.shapeFlag&1&&S&&!S.persisted){const{leave:F,delayLeave:R}=S,$=()=>F(k,O);R?R(v.el,O,$):$()}else O()},un=(v,m)=>{let k;for(;v!==m;)k=p(v),a(v),v=k;a(m)},wr=(v,m,k)=>{const{bum:P,scope:S,update:O,subTree:F,um:R}=v;P&&pa(P),S.stop(),O&&(O.active=!1,He(F,v,m,k)),R&&Fe(R,m),Fe(()=>{v.isUnmounted=!0},m),m&&m.pendingBranch&&!m.isUnmounted&&v.asyncDep&&!v.asyncResolved&&v.suspenseId===m.pendingId&&(m.deps--,m.deps===0&&m.resolve())},Ve=(v,m,k,P=!1,S=!1,O=0)=>{for(let F=O;Fv.shapeFlag&6?C(v.component.subTree):v.shapeFlag&128?v.suspense.next():p(v.anchor||v.el);let W=!1;const H=(v,m,k)=>{v==null?m._vnode&&He(m._vnode,null,null,!0):w(m._vnode||null,v,m,null,null,null,k),W||(W=!0,yo(),Hr(),W=!1),m._vnode=v},q={p:w,um:He,m:pt,r:cn,mt:Ae,mc:B,pc:U,pbc:N,n:C,o:e};let me,ke;return t&&([me,ke]=t(q)),{render:H,hydrate:me,createApp:kd(H,me)}}function ba({type:e,props:t},n){return n==="svg"&&e==="foreignObject"||n==="mathml"&&e==="annotation-xml"&&t&&t.encoding&&t.encoding.includes("html")?void 0:n}function Ut({effect:e,update:t},n){e.allowRecurse=t.allowRecurse=n}function Ei(e,t){return(!e||e&&!e.pendingBranch)&&t&&!t.persisted}function ki(e,t,n=!1){const r=e.children,a=t.children;if(Q(r)&&Q(a))for(let l=0;l>1,e[n[i]]0&&(t[r]=n[l-1]),n[l]=r)}}for(l=n.length,o=n[l-1];l-- >0;)n[l]=o,o=t[o];return n}function xi(e){const t=e.subTree.component;if(t)return t.asyncDep&&!t.asyncResolved?t:xi(t)}const $d=e=>e.__isTeleport,Ue=Symbol.for("v-fgt"),wn=Symbol.for("v-txt"),gt=Symbol.for("v-cmt"),Kn=Symbol.for("v-stc"),qn=[];let ut=null;function O3(e=!1){qn.push(ut=e?null:[])}function Dd(){qn.pop(),ut=qn[qn.length-1]||null}let tr=1;function Io(e){tr+=e}function Vd(e){return e.dynamicChildren=tr>0?ut||vn:null,Dd(),tr>0&&ut&&ut.push(e),e}function M3(e,t,n,r,a,l){return Vd(Li(e,t,n,r,a,l,!0))}function ja(e){return e?e.__v_isVNode===!0:!1}function Xt(e,t){return e.type===t.type&&e.key===t.key}const ra="__vInternal",Ti=({key:e})=>e??null,Vr=({ref:e,ref_key:t,ref_for:n})=>(typeof e=="number"&&(e=""+e),e!=null?oe(e)||$e(e)||re(e)?{i:tt,r:e,k:t,f:!!n}:e:null);function Li(e,t=null,n=null,r=0,a=null,l=e===Ue?0:1,o=!1,i=!1){const c={__v_isVNode:!0,__v_skip:!0,type:e,props:t,key:t&&Ti(t),ref:t&&Vr(t),scopeId:oi,slotScopeIds:null,children:n,component:null,suspense:null,ssContent:null,ssFallback:null,dirs:null,transition:null,el:null,anchor:null,target:null,targetAnchor:null,staticCount:0,shapeFlag:l,patchFlag:r,dynamicProps:a,dynamicChildren:null,appContext:null,ctx:tt};return i?(Ll(c,n),l&128&&e.normalize(c)):n&&(c.shapeFlag|=oe(n)?8:16),tr>0&&!o&&ut&&(c.patchFlag>0||l&6)&&c.patchFlag!==32&&ut.push(c),c}const Re=Bd;function Bd(e,t=null,n=null,r=0,a=null,l=!1){if((!e||e===Q1)&&(e=gt),ja(e)){const i=Ft(e,t,!0);return n&&Ll(i,n),tr>0&&!l&&ut&&(i.shapeFlag&6?ut[ut.indexOf(e)]=i:ut.push(i)),i.patchFlag|=-2,i}if(Zd(e)&&(e=e.__vccOpts),t){t=Nd(t);let{class:i,style:c}=t;i&&!oe(i)&&(t.class=ul(i)),Le(c)&&(Ys(c)&&!Q(c)&&(c=Ie({},c)),t.style=cl(c))}const o=oe(e)?1:td(e)?128:$d(e)?64:Le(e)?4:re(e)?2:0;return Li(e,t,n,r,a,o,l,!0)}function Nd(e){return e?Ys(e)||ra in e?Ie({},e):e:null}function Ft(e,t,n=!1){const{props:r,ref:a,patchFlag:l,children:o}=e,i=t?zd(r||{},t):r;return{__v_isVNode:!0,__v_skip:!0,type:e.type,props:i,key:i&&Ti(i),ref:t&&t.ref?n&&a?Q(a)?a.concat(Vr(t)):[a,Vr(t)]:Vr(t):a,scopeId:e.scopeId,slotScopeIds:e.slotScopeIds,children:o,target:e.target,targetAnchor:e.targetAnchor,staticCount:e.staticCount,shapeFlag:e.shapeFlag,patchFlag:t&&e.type!==Ue?l===-1?16:l|16:l,dynamicProps:e.dynamicProps,dynamicChildren:e.dynamicChildren,appContext:e.appContext,dirs:e.dirs,transition:e.transition,component:e.component,suspense:e.suspense,ssContent:e.ssContent&&Ft(e.ssContent),ssFallback:e.ssFallback&&Ft(e.ssFallback),el:e.el,anchor:e.anchor,ctx:e.ctx,ce:e.ce}}function Ai(e=" ",t=0){return Re(wn,null,e,t)}function $3(e,t){const n=Re(Kn,null,e);return n.staticCount=t,n}function ct(e){return e==null||typeof e=="boolean"?Re(gt):Q(e)?Re(Ue,null,e.slice()):typeof e=="object"?Dt(e):Re(wn,null,String(e))}function Dt(e){return e.el===null&&e.patchFlag!==-1||e.memo?e:Ft(e)}function Ll(e,t){let n=0;const{shapeFlag:r}=e;if(t==null)t=null;else if(Q(t))n=16;else if(typeof t=="object")if(r&65){const a=t.default;a&&(a._c&&(a._d=!1),Ll(e,a()),a._c&&(a._d=!0));return}else{n=32;const a=t._;!a&&!(ra in t)?t._ctx=tt:a===3&&tt&&(tt.slots._===1?t._=1:(t._=2,e.patchFlag|=1024))}else re(t)?(t={default:t,_ctx:tt},n=32):(t=String(t),r&64?(n=16,t=[Ai(t)]):n=8);e.children=t,e.shapeFlag|=n}function zd(...e){const t={};for(let n=0;nMe||tt;let Kr,Wa;{const e=Ms(),t=(n,r)=>{let a;return(a=e[n])||(a=e[n]=[]),a.push(r),l=>{a.length>1?a.forEach(o=>o(l)):a[0](l)}};Kr=t("__VUE_INSTANCE_SETTERS__",n=>Me=n),Wa=t("__VUE_SSR_SETTERS__",n=>ur=n)}const cr=e=>{const t=Me;return Kr(e),e.scope.on(),()=>{e.scope.off(),Kr(t)}},Ro=()=>{Me&&Me.scope.off(),Kr(null)};function Si(e){return e.vnode.shapeFlag&4}let ur=!1;function Wd(e,t=!1){t&&Wa(t);const{props:n,children:r}=e.vnode,a=Si(e);xd(e,n,a,t),Ad(e,r);const l=a?Gd(e,t):void 0;return t&&Wa(!1),l}function Gd(e,t){const n=e.type;e.accessCache=Object.create(null),e.proxy=Xs(new Proxy(e.ctx,md));const{setup:r}=n;if(r){const a=e.setupContext=r.length>1?qd(e):null,l=cr(e);nn();const o=zt(r,e,0,[e.props,a]);if(rn(),l(),Os(o)){if(o.then(Ro,Ro),t)return o.then(i=>{Oo(e,i,t)}).catch(i=>{sr(i,e,0)});e.asyncDep=o}else Oo(e,o,t)}else Ci(e,t)}function Oo(e,t,n){re(t)?e.type.__ssrInlineRender?e.ssrRender=t:e.render=t:Le(t)&&(e.setupState=ei(t)),Ci(e,n)}let Mo;function Ci(e,t,n){const r=e.type;if(!e.render){if(!t&&Mo&&!r.render){const a=r.template||xl(e).template;if(a){const{isCustomElement:l,compilerOptions:o}=e.appContext.config,{delimiters:i,compilerOptions:c}=r,u=Ie(Ie({isCustomElement:l,delimiters:i},o),c);r.render=Mo(a,u)}}e.render=r.render||et}{const a=cr(e);nn();try{gd(e)}finally{rn(),a()}}}function Kd(e){return e.attrsProxy||(e.attrsProxy=new Proxy(e.attrs,{get(t,n){return Ge(e,"get","$attrs"),t[n]}}))}function qd(e){const t=n=>{e.exposed=n||{}};return{get attrs(){return Kd(e)},slots:e.slots,emit:e.emit,expose:t}}function Al(e){if(e.exposed)return e.exposeProxy||(e.exposeProxy=new Proxy(ei(Xs(e.exposed)),{get(t,n){if(n in t)return t[n];if(n in Gn)return Gn[n](e)},has(t,n){return n in t||n in Gn}}))}function Ud(e,t=!0){return re(e)?e.displayName||e.name:e.name||t&&e.__name}function Zd(e){return re(e)&&"__vccOpts"in e}const y=(e,t)=>$1(e,t,ur);function s(e,t,n){const r=arguments.length;return r===2?Le(t)&&!Q(t)?ja(t)?Re(e,null,[t]):Re(e,t):Re(e,null,t):(r>3?n=Array.prototype.slice.call(arguments,2):r===3&&ja(n)&&(n=[n]),Re(e,t,n))}const Yd="3.4.15";/**
+* @vue/runtime-dom v3.4.15
+* (c) 2018-present Yuxi (Evan) You and Vue contributors
+* @license MIT
+**/const Xd="http://www.w3.org/2000/svg",Jd="http://www.w3.org/1998/Math/MathML",Vt=typeof document<"u"?document:null,$o=Vt&&Vt.createElement("template"),Qd={insert:(e,t,n)=>{t.insertBefore(e,n||null)},remove:e=>{const t=e.parentNode;t&&t.removeChild(e)},createElement:(e,t,n,r)=>{const a=t==="svg"?Vt.createElementNS(Xd,e):t==="mathml"?Vt.createElementNS(Jd,e):Vt.createElement(e,n?{is:n}:void 0);return e==="select"&&r&&r.multiple!=null&&a.setAttribute("multiple",r.multiple),a},createText:e=>Vt.createTextNode(e),createComment:e=>Vt.createComment(e),setText:(e,t)=>{e.nodeValue=t},setElementText:(e,t)=>{e.textContent=t},parentNode:e=>e.parentNode,nextSibling:e=>e.nextSibling,querySelector:e=>Vt.querySelector(e),setScopeId(e,t){e.setAttribute(t,"")},insertStaticContent(e,t,n,r,a,l){const o=n?n.previousSibling:t.lastChild;if(a&&(a===l||a.nextSibling))for(;t.insertBefore(a.cloneNode(!0),n),!(a===l||!(a=a.nextSibling)););else{$o.innerHTML=r==="svg"?`${e} `:r==="mathml"?`${e} `:e;const i=$o.content;if(r==="svg"||r==="mathml"){const c=i.firstChild;for(;c.firstChild;)i.appendChild(c.firstChild);i.removeChild(c)}t.insertBefore(i,n)}return[o?o.nextSibling:t.firstChild,n?n.previousSibling:t.lastChild]}},Rt="transition",Vn="animation",En=Symbol("_vtc"),jt=(e,{slots:t})=>s(od,Ii(e),t);jt.displayName="Transition";const Pi={name:String,type:String,css:{type:Boolean,default:!0},duration:[String,Number,Object],enterFromClass:String,enterActiveClass:String,enterToClass:String,appearFromClass:String,appearActiveClass:String,appearToClass:String,leaveFromClass:String,leaveActiveClass:String,leaveToClass:String},ef=jt.props=Ie({},di,Pi),Zt=(e,t=[])=>{Q(e)?e.forEach(n=>n(...t)):e&&e(...t)},Do=e=>e?Q(e)?e.some(t=>t.length>1):e.length>1:!1;function Ii(e){const t={};for(const z in e)z in Pi||(t[z]=e[z]);if(e.css===!1)return t;const{name:n="v",type:r,duration:a,enterFromClass:l=`${n}-enter-from`,enterActiveClass:o=`${n}-enter-active`,enterToClass:i=`${n}-enter-to`,appearFromClass:c=l,appearActiveClass:u=o,appearToClass:d=i,leaveFromClass:f=`${n}-leave-from`,leaveActiveClass:p=`${n}-leave-active`,leaveToClass:h=`${n}-leave-to`}=e,g=tf(a),w=g&&g[0],E=g&&g[1],{onBeforeEnter:b,onEnter:L,onEnterCancelled:_,onLeave:A,onLeaveCancelled:V,onBeforeAppear:T=b,onAppear:K=L,onAppearCancelled:B=_}=t,M=(z,ee,Ae)=>{Ot(z,ee?d:i),Ot(z,ee?u:o),Ae&&Ae()},N=(z,ee)=>{z._isLeaving=!1,Ot(z,f),Ot(z,h),Ot(z,p),ee&&ee()},ne=z=>(ee,Ae)=>{const Se=z?K:L,Y=()=>M(ee,z,Ae);Zt(Se,[ee,Y]),Vo(()=>{Ot(ee,z?c:l),Et(ee,z?d:i),Do(Se)||Bo(ee,r,w,Y)})};return Ie(t,{onBeforeEnter(z){Zt(b,[z]),Et(z,l),Et(z,o)},onBeforeAppear(z){Zt(T,[z]),Et(z,c),Et(z,u)},onEnter:ne(!1),onAppear:ne(!0),onLeave(z,ee){z._isLeaving=!0;const Ae=()=>N(z,ee);Et(z,f),Oi(),Et(z,p),Vo(()=>{z._isLeaving&&(Ot(z,f),Et(z,h),Do(A)||Bo(z,r,E,Ae))}),Zt(A,[z,Ae])},onEnterCancelled(z){M(z,!1),Zt(_,[z])},onAppearCancelled(z){M(z,!0),Zt(B,[z])},onLeaveCancelled(z){N(z),Zt(V,[z])}})}function tf(e){if(e==null)return null;if(Le(e))return[ya(e.enter),ya(e.leave)];{const t=ya(e);return[t,t]}}function ya(e){return l1(e)}function Et(e,t){t.split(/\s+/).forEach(n=>n&&e.classList.add(n)),(e[En]||(e[En]=new Set)).add(t)}function Ot(e,t){t.split(/\s+/).forEach(r=>r&&e.classList.remove(r));const n=e[En];n&&(n.delete(t),n.size||(e[En]=void 0))}function Vo(e){requestAnimationFrame(()=>{requestAnimationFrame(e)})}let nf=0;function Bo(e,t,n,r){const a=e._endId=++nf,l=()=>{a===e._endId&&r()};if(n)return setTimeout(l,n);const{type:o,timeout:i,propCount:c}=Ri(e,t);if(!o)return r();const u=o+"end";let d=0;const f=()=>{e.removeEventListener(u,p),l()},p=h=>{h.target===e&&++d>=c&&f()};setTimeout(()=>{d(n[g]||"").split(", "),a=r(`${Rt}Delay`),l=r(`${Rt}Duration`),o=No(a,l),i=r(`${Vn}Delay`),c=r(`${Vn}Duration`),u=No(i,c);let d=null,f=0,p=0;t===Rt?o>0&&(d=Rt,f=o,p=l.length):t===Vn?u>0&&(d=Vn,f=u,p=c.length):(f=Math.max(o,u),d=f>0?o>u?Rt:Vn:null,p=d?d===Rt?l.length:c.length:0);const h=d===Rt&&/\b(transform|all)(,|$)/.test(r(`${Rt}Property`).toString());return{type:d,timeout:f,propCount:p,hasTransform:h}}function No(e,t){for(;e.lengthzo(n)+zo(e[r])))}function zo(e){return e==="auto"?0:Number(e.slice(0,-1).replace(",","."))*1e3}function Oi(){return document.body.offsetHeight}function rf(e,t,n){const r=e[En];r&&(t=(t?[t,...r]:[...r]).join(" ")),t==null?e.removeAttribute("class"):n?e.setAttribute("class",t):e.className=t}const af=Symbol("_vod"),lf=Symbol("");function of(e,t,n){const r=e.style,a=r.display,l=oe(n);if(n&&!l){if(t&&!oe(t))for(const o in t)n[o]==null&&Ga(r,o,"");for(const o in n)Ga(r,o,n[o])}else if(l){if(t!==n){const o=r[lf];o&&(n+=";"+o),r.cssText=n}}else t&&e.removeAttribute("style");af in e&&(r.display=a)}const Ho=/\s*!important$/;function Ga(e,t,n){if(Q(n))n.forEach(r=>Ga(e,t,r));else if(n==null&&(n=""),t.startsWith("--"))e.setProperty(t,n);else{const r=sf(e,t);Ho.test(n)?e.setProperty(An(r),n.replace(Ho,""),"important"):e[r]=n}}const Fo=["Webkit","Moz","ms"],_a={};function sf(e,t){const n=_a[t];if(n)return n;let r=at(t);if(r!=="filter"&&r in e)return _a[t]=r;r=lr(r);for(let a=0;awa||(vf.then(()=>wa=0),wa=Date.now());function gf(e,t){const n=r=>{if(!r._vts)r._vts=Date.now();else if(r._vts<=n.attached)return;nt(bf(r,n.value),t,5,[r])};return n.value=e,n.attached=mf(),n}function bf(e,t){if(Q(t)){const n=e.stopImmediatePropagation;return e.stopImmediatePropagation=()=>{n.call(e),e._stopped=!0},t.map(r=>a=>!a._stopped&&r&&r(a))}else return t}const Ko=e=>e.charCodeAt(0)===111&&e.charCodeAt(1)===110&&e.charCodeAt(2)>96&&e.charCodeAt(2)<123,yf=(e,t,n,r,a,l,o,i,c)=>{const u=a==="svg";t==="class"?rf(e,r,u):t==="style"?of(e,n,r):ar(t)?ol(t)||pf(e,t,n,r,o):(t[0]==="."?(t=t.slice(1),!0):t[0]==="^"?(t=t.slice(1),!1):_f(e,t,r,u))?uf(e,t,r,l,o,i,c):(t==="true-value"?e._trueValue=r:t==="false-value"&&(e._falseValue=r),cf(e,t,r,u))};function _f(e,t,n,r){if(r)return!!(t==="innerHTML"||t==="textContent"||t in e&&Ko(t)&&re(n));if(t==="spellcheck"||t==="draggable"||t==="translate"||t==="form"||t==="list"&&e.tagName==="INPUT"||t==="type"&&e.tagName==="TEXTAREA")return!1;if(t==="width"||t==="height"){const a=e.tagName;if(a==="IMG"||a==="VIDEO"||a==="CANVAS"||a==="SOURCE")return!1}return Ko(t)&&oe(n)?!1:t in e}const Mi=new WeakMap,$i=new WeakMap,qr=Symbol("_moveCb"),qo=Symbol("_enterCb"),Di={name:"TransitionGroup",props:Ie({},ef,{tag:String,moveClass:String}),setup(e,{slots:t}){const n=ln(),r=ui();let a,l;return hi(()=>{if(!a.length)return;const o=e.moveClass||`${e.name||"v"}-move`;if(!Tf(a[0].el,n.vnode.el,o))return;a.forEach(Ef),a.forEach(kf);const i=a.filter(xf);Oi(),i.forEach(c=>{const u=c.el,d=u.style;Et(u,o),d.transform=d.webkitTransform=d.transitionDuration="";const f=u[qr]=p=>{p&&p.target!==u||(!p||/transform$/.test(p.propertyName))&&(u.removeEventListener("transitionend",f),u[qr]=null,Ot(u,o))};u.addEventListener("transitionend",f)})}),()=>{const o=ce(e),i=Ii(o);let c=o.tag||Ue;a=l,l=t.default?El(t.default()):[];for(let u=0;udelete e.mode;Di.props;const Vi=Di;function Ef(e){const t=e.el;t[qr]&&t[qr](),t[qo]&&t[qo]()}function kf(e){$i.set(e,e.el.getBoundingClientRect())}function xf(e){const t=Mi.get(e),n=$i.get(e),r=t.left-n.left,a=t.top-n.top;if(r||a){const l=e.el.style;return l.transform=l.webkitTransform=`translate(${r}px,${a}px)`,l.transitionDuration="0s",e}}function Tf(e,t,n){const r=e.cloneNode(),a=e[En];a&&a.forEach(i=>{i.split(/\s+/).forEach(c=>c&&r.classList.remove(c))}),n.split(/\s+/).forEach(i=>i&&r.classList.add(i)),r.style.display="none";const l=t.nodeType===1?t:t.parentNode;l.appendChild(r);const{hasTransform:o}=Ri(r);return l.removeChild(r),o}const Lf=Ie({patchProp:yf},Qd);let Ea,Uo=!1;function Af(){return Ea=Uo?Ea:Rd(Lf),Uo=!0,Ea}const Sf=(...e)=>{const t=Af().createApp(...e),{mount:n}=t;return t.mount=r=>{const a=Pf(r);if(a)return n(a,!0,Cf(a))},t};function Cf(e){if(e instanceof SVGElement)return"svg";if(typeof MathMLElement=="function"&&e instanceof MathMLElement)return"mathml"}function Pf(e){return oe(e)?document.querySelector(e):e}const If="modulepreload",Rf=function(e){return"/"+e},Zo={},x=function(t,n,r){let a=Promise.resolve();if(n&&n.length>0){const l=document.getElementsByTagName("link");a=Promise.all(n.map(o=>{if(o=Rf(o),o in Zo)return;Zo[o]=!0;const i=o.endsWith(".css"),c=i?'[rel="stylesheet"]':"";if(!!r)for(let f=l.length-1;f>=0;f--){const p=l[f];if(p.href===o&&(!i||p.rel==="stylesheet"))return}else if(document.querySelector(`link[href="${o}"]${c}`))return;const d=document.createElement("link");if(d.rel=i?"stylesheet":If,i||(d.as="script",d.crossOrigin=""),d.href=o,document.head.appendChild(d),i)return new Promise((f,p)=>{d.addEventListener("load",f),d.addEventListener("error",()=>p(new Error(`Unable to preload CSS for ${o}`)))})}))}return a.then(()=>t()).catch(l=>{const o=new Event("vite:preloadError",{cancelable:!0});if(o.payload=l,window.dispatchEvent(o),!o.defaultPrevented)throw l})},Of={"v-8daa1a0e":()=>x(()=>import("./index.html-6A2xto4n.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-728c3a8f":()=>x(()=>import("./index.html-t2KDSwiJ.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-cfe8b6c8":()=>x(()=>import("./index.html-N_67P6-s.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-2e25198a":()=>x(()=>import("./index.html-2xQqwR-V.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-71fde78e":()=>x(()=>import("./index.html-zEn3PTqR.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-580db9be":()=>x(()=>import("./devops-ping-tai.html-abOd7AV0.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-06d5cd4c":()=>x(()=>import("./gitlab-ci.html-HyFv5Ls3.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-132efcd1":()=>x(()=>import("./jenkins-x.html-gi90zyZ8.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-1a2ca7a7":()=>x(()=>import("./tekton.html-7q40Qc0_.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-50cb12f2":()=>x(()=>import("./index.html-HoKSYW3I.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-091223ce":()=>x(()=>import("./tiktok2023.html-GIHWTkgC.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-0a27b598":()=>x(()=>import("./JVM调优参数.html-RmR4uDpi.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-478d0de6":()=>x(()=>import("./lucene搜索原理.html-xqazIHll.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-60eda44c":()=>x(()=>import("./serverlog.html-9M0lHfZ_.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-399e07b6":()=>x(()=>import("./一次jvm调优过程.html-G6NlySyS.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-660266c1":()=>x(()=>import("./内存屏障.html-YpsEGPcG.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-90f2343c":()=>x(()=>import("./在 Spring 6 中使用虚拟线程.html-aSy3Jyqy.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-0b5d4df0":()=>x(()=>import("./基于kubernetes的分布式限流.html-SsVfGmol.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-21e54510":()=>x(()=>import("./index.html-k7gT6RRu.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-57ae83ac":()=>x(()=>import("./spark on k8s operator.html-keQuD2fg.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-22e4234a":()=>x(()=>import("./2017.html-cyR93hTD.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-1f7a720c":()=>x(()=>import("./2018.html-pd4XfNXB.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-1c10c0ce":()=>x(()=>import("./2019.html-mLTyb7PF.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-258f309e":()=>x(()=>import("./index.html-xgoJibcf.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-510415f9":()=>x(()=>import("./chatgpt.html-ynpK4pK0.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-3c114a75":()=>x(()=>import("./tesla.html-NVSkMPRC.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-37ac02fe":()=>x(()=>import("./1.历史与架构.html-6w7Lm3Xl.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-523e9724":()=>x(()=>import("./10.网站重构.html-8BbyrcnW.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-65b5c81c":()=>x(()=>import("./2.Lucene的使用.html-E5Y3Wetu.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-731a76b6":()=>x(()=>import("./3.定时任务.html-73kuTv_z.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-bea2ce1e":()=>x(()=>import("./4.日志系统.html-k-_vSI4k.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-3efc517e":()=>x(()=>import("./5.小集群部署.html-ZTiwy8Ji.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-79ad699f":()=>x(()=>import("./6.数据库备份.html-6hO0TA2i.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-8658e60a":()=>x(()=>import("./7.那些牛逼的插件.html-QSPIBlp6.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-7e9e4a32":()=>x(()=>import("./8.基于贝叶斯的情感分析.html-O9J2qs51.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-0b62f72e":()=>x(()=>import("./9.网站性能优化.html-npDz6nv1.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-dc384366":()=>x(()=>import("./index.html-5Ud_mAI1.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-70796e0a":()=>x(()=>import("./redis缓存.html-wXDEeG8X.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-43e9e6b0":()=>x(()=>import("./wewe.html-wLcqOgAE.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-04e32b44":()=>x(()=>import("./elastic-spark.html-5RlCSmjx.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-d73a9aee":()=>x(()=>import("./elasticsearch源码debug.html-Z9uKxlVb.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-3f2a15ee":()=>x(()=>import("./【elasticsearch】搜索过程详解.html-6moNXOiY.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-aa93dec0":()=>x(()=>import("./1mysql.html-iiTeieOx.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-3192e5a0":()=>x(()=>import("./gap锁.html-i4faTCf2.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-2675bfdc":()=>x(()=>import("./执行计划explain.html-v0f75n9M.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-0a0b7a54":()=>x(()=>import("./数据库缓存.html-k3XJyHqW.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-d7d7df80":()=>x(()=>import("./kafka.html-K4MxmLWF.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-7d9b9318":()=>x(()=>import("./zookeeper.html-YcPoe8IG.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-3706649a":()=>x(()=>import("./404.html-WhIsgby4.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-71b3ae87":()=>x(()=>import("./index.html-vgYoWX9F.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-14c69af4":()=>x(()=>import("./index.html-yuZKtvix.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-14e6315a":()=>x(()=>import("./index.html-T5wPpx5i.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-25b47c13":()=>x(()=>import("./index.html-zdhpQIq5.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-525c5e4d":()=>x(()=>import("./index.html-hCmlVboM.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-5d3e6196":()=>x(()=>import("./index.html-SLeyy5iI.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-60fc7530":()=>x(()=>import("./index.html-5KP2soWP.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-02bc92be":()=>x(()=>import("./index.html-8MJuJxlA.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-380c630d":()=>x(()=>import("./index.html-TuBE6nT4.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-21ba2ec8":()=>x(()=>import("./index.html-DLDIhIzm.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-a32329e6":()=>x(()=>import("./index.html-NPk7ZlMe.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-4d194044":()=>x(()=>import("./index.html-Prj9iPTA.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-6e21a4b2":()=>x(()=>import("./index.html-VZNNIAqy.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-5bc93818":()=>x(()=>import("./index.html-KA0_6BkE.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-744d024e":()=>x(()=>import("./index.html-48vkkelG.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-e52c881c":()=>x(()=>import("./index.html-IZIHDPXq.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-154dc4c4":()=>x(()=>import("./index.html-XULjGA2d.js"),__vite__mapDeps([])).then(({data:e})=>e),"v-01560935":()=>x(()=>import("./index.html-P7BZhZZ3.js"),__vite__mapDeps([])).then(({data:e})=>e)},Mf=JSON.parse('{"base":"/","lang":"zh-CN","title":"个人博客","description":"个人博客","head":[["script",{"data-ad-client":"ca-pub-9037099208128116","async":true,"src":"https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"}],["meta",{"name":"robots","content":"all"}],["meta",{"name":"author","content":"个人博客"}],["meta",{"http-equiv":"Cache-Control","content":"no-cache, no-store, must-revalidate"}],["meta",{"http-equiv":"Pragma","content":"no-cache"}],["meta",{"http-equiv":"Expires","content":"0"}],["meta",{"name":"keywords","content":"Java基础, 多线程, JVM, 虚拟机, 数据库, MySQL, Spring, Redis, MyBatis, 系统设计, 分布式, RPC, 高可用, 高并发"}],["meta",{"name":"description","content":"Java基础, 多线程, JVM, 虚拟机, 数据库, MySQL, Spring, Redis, MyBatis, 系统设计, 分布式, RPC, 高可用, 高并发"}],["meta",{"name":"apple-mobile-web-app-capable","content":"yes"}],["script",{},"var _hmt = _hmt || [];\\n (function() {\\n var hm = document.createElement(\\"script\\");\\n hm.src = \\"https://hm.baidu.com/hm.js?e580b8db831811a4aaf4a8f3e30034dc\\";\\n var s = document.getElementsByTagName(\\"script\\")[0]; \\n s.parentNode.insertBefore(hm, s);\\n })();"],["link",{"rel":"icon","href":"/favicon.ico"}]],"locales":{}}');var $f=([e,t,n])=>e==="meta"&&t.name?`${e}.${t.name}`:["title","base"].includes(e)?e:e==="template"&&t.id?`${e}.${t.id}`:JSON.stringify([e,t,n]),Df=e=>{const t=new Set,n=[];return e.forEach(r=>{const a=$f(r);t.has(a)||(t.add(a),n.push(r))}),n},Vf=e=>e[0]==="/"?e:`/${e}`,Bi=e=>e[e.length-1]==="/"||e.endsWith(".html")?e:`${e}/`,on=e=>/^(https?:)?\/\//.test(e),Bf=/.md((\?|#).*)?$/,Ur=(e,t="/")=>!!(on(e)||e.startsWith("/")&&!e.startsWith(t)&&!Bf.test(e)),Ni=e=>/^[a-z][a-z0-9+.-]*:/.test(e),Sl=e=>Object.prototype.toString.call(e)==="[object Object]",Cl=e=>e[e.length-1]==="/"?e.slice(0,-1):e,zi=e=>e[0]==="/"?e.slice(1):e,Nf=(e,t)=>{const n=Object.keys(e).sort((r,a)=>{const l=a.split("/").length-r.split("/").length;return l!==0?l:a.length-r.length});for(const r of n)if(t.startsWith(r))return r;return"/"};const Hi={"v-8daa1a0e":j(()=>x(()=>import("./index.html-GO9KhDWT.js"),__vite__mapDeps([0,1]))),"v-728c3a8f":j(()=>x(()=>import("./index.html--YxqP697.js"),__vite__mapDeps([2,1]))),"v-cfe8b6c8":j(()=>x(()=>import("./index.html-CmwrSuW4.js"),__vite__mapDeps([3,1]))),"v-2e25198a":j(()=>x(()=>import("./index.html-OXmsW7Ba.js"),__vite__mapDeps([4,1]))),"v-71fde78e":j(()=>x(()=>import("./index.html-7Jwn4Cbi.js"),__vite__mapDeps([5,1]))),"v-580db9be":j(()=>x(()=>import("./devops-ping-tai.html-Pr-n_ibi.js"),__vite__mapDeps([6,1]))),"v-06d5cd4c":j(()=>x(()=>import("./gitlab-ci.html-9dvcTJNs.js"),__vite__mapDeps([7,1]))),"v-132efcd1":j(()=>x(()=>import("./jenkins-x.html--QxcKVNb.js"),__vite__mapDeps([8,1]))),"v-1a2ca7a7":j(()=>x(()=>import("./tekton.html-5SA8R3wN.js"),__vite__mapDeps([9,1]))),"v-50cb12f2":j(()=>x(()=>import("./index.html-2mdvLUFa.js"),__vite__mapDeps([10,1]))),"v-091223ce":j(()=>x(()=>import("./tiktok2023.html-Ih4GrSaS.js"),__vite__mapDeps([11,1]))),"v-0a27b598":j(()=>x(()=>import("./JVM调优参数.html-adpG87p4.js"),__vite__mapDeps([12,1]))),"v-478d0de6":j(()=>x(()=>import("./lucene搜索原理.html-xLQYDnip.js"),__vite__mapDeps([13,1]))),"v-60eda44c":j(()=>x(()=>import("./serverlog.html-f8i7CjpW.js"),__vite__mapDeps([14,1]))),"v-399e07b6":j(()=>x(()=>import("./一次jvm调优过程.html-ObKNMeJg.js"),__vite__mapDeps([15,1]))),"v-660266c1":j(()=>x(()=>import("./内存屏障.html-P7fE8DoQ.js"),__vite__mapDeps([16,1]))),"v-90f2343c":j(()=>x(()=>import("./在 Spring 6 中使用虚拟线程.html-lrPVTD8u.js"),__vite__mapDeps([17,1]))),"v-0b5d4df0":j(()=>x(()=>import("./基于kubernetes的分布式限流.html-FM9j_CKw.js"),__vite__mapDeps([18,1]))),"v-21e54510":j(()=>x(()=>import("./index.html-1G2UU7KQ.js"),__vite__mapDeps([19,1]))),"v-57ae83ac":j(()=>x(()=>import("./spark on k8s operator.html-oBat6Q5m.js"),__vite__mapDeps([20,1]))),"v-22e4234a":j(()=>x(()=>import("./2017.html-BbxR5q6z.js"),__vite__mapDeps([21,1]))),"v-1f7a720c":j(()=>x(()=>import("./2018.html-iLHJNmQ1.js"),__vite__mapDeps([22,1]))),"v-1c10c0ce":j(()=>x(()=>import("./2019.html-ogBQCkli.js"),__vite__mapDeps([23,1]))),"v-258f309e":j(()=>x(()=>import("./index.html-YcQRCdzL.js"),__vite__mapDeps([24,1]))),"v-510415f9":j(()=>x(()=>import("./chatgpt.html-lQQa_oJF.js"),__vite__mapDeps([25,1]))),"v-3c114a75":j(()=>x(()=>import("./tesla.html-2Y58-poF.js"),__vite__mapDeps([26,1]))),"v-37ac02fe":j(()=>x(()=>import("./1.历史与架构.html-X_ZVzsKc.js"),__vite__mapDeps([27,1]))),"v-523e9724":j(()=>x(()=>import("./10.网站重构.html-vlubYdUg.js"),__vite__mapDeps([28,1]))),"v-65b5c81c":j(()=>x(()=>import("./2.Lucene的使用.html-5sj9Z-FP.js"),__vite__mapDeps([29,1]))),"v-731a76b6":j(()=>x(()=>import("./3.定时任务.html-CtCjmCiV.js"),__vite__mapDeps([30,1]))),"v-bea2ce1e":j(()=>x(()=>import("./4.日志系统.html-Gyuvpz3_.js"),__vite__mapDeps([31,1]))),"v-3efc517e":j(()=>x(()=>import("./5.小集群部署.html-z5KJNYuo.js"),__vite__mapDeps([32,1]))),"v-79ad699f":j(()=>x(()=>import("./6.数据库备份.html-GrbFXSWT.js"),__vite__mapDeps([33,1]))),"v-8658e60a":j(()=>x(()=>import("./7.那些牛逼的插件.html-xUNU4jTw.js"),__vite__mapDeps([34,1]))),"v-7e9e4a32":j(()=>x(()=>import("./8.基于贝叶斯的情感分析.html-DmNVFgOS.js"),__vite__mapDeps([35,1]))),"v-0b62f72e":j(()=>x(()=>import("./9.网站性能优化.html-MC-9j6vs.js"),__vite__mapDeps([36,1]))),"v-dc384366":j(()=>x(()=>import("./index.html-9KTewoYW.js"),__vite__mapDeps([37,1]))),"v-70796e0a":j(()=>x(()=>import("./redis缓存.html-2QC7Jkrn.js"),__vite__mapDeps([38,1]))),"v-43e9e6b0":j(()=>x(()=>import("./wewe.html-MSrbCURC.js"),__vite__mapDeps([39,1]))),"v-04e32b44":j(()=>x(()=>import("./elastic-spark.html-NDvsW2Dx.js"),__vite__mapDeps([40,1]))),"v-d73a9aee":j(()=>x(()=>import("./elasticsearch源码debug.html-riyCnJZU.js"),__vite__mapDeps([41,1]))),"v-3f2a15ee":j(()=>x(()=>import("./【elasticsearch】搜索过程详解.html-ga4ihhfd.js"),__vite__mapDeps([42,1]))),"v-aa93dec0":j(()=>x(()=>import("./1mysql.html-OHVRcqVz.js"),__vite__mapDeps([43,1]))),"v-3192e5a0":j(()=>x(()=>import("./gap锁.html-0qMpGSdo.js"),__vite__mapDeps([44,1]))),"v-2675bfdc":j(()=>x(()=>import("./执行计划explain.html-y5jML1O_.js"),__vite__mapDeps([45,1]))),"v-0a0b7a54":j(()=>x(()=>import("./数据库缓存.html-fj1Jh_qh.js"),__vite__mapDeps([46,1]))),"v-d7d7df80":j(()=>x(()=>import("./kafka.html-FefoBwLN.js"),__vite__mapDeps([47,1]))),"v-7d9b9318":j(()=>x(()=>import("./zookeeper.html-bxhlqtiT.js"),__vite__mapDeps([48,1]))),"v-3706649a":j(()=>x(()=>import("./404.html-tbxpD8LH.js"),__vite__mapDeps([49,1]))),"v-71b3ae87":j(()=>x(()=>import("./index.html-JRhiMr7F.js"),__vite__mapDeps([50,1]))),"v-14c69af4":j(()=>x(()=>import("./index.html-UdEIAh49.js"),__vite__mapDeps([51,1]))),"v-14e6315a":j(()=>x(()=>import("./index.html-GqCa2uIM.js"),__vite__mapDeps([52,1]))),"v-25b47c13":j(()=>x(()=>import("./index.html-Pmc9G9cb.js"),__vite__mapDeps([53,1]))),"v-525c5e4d":j(()=>x(()=>import("./index.html-OwsuoqvI.js"),__vite__mapDeps([54,1]))),"v-5d3e6196":j(()=>x(()=>import("./index.html-dfS5oaDz.js"),__vite__mapDeps([55,1]))),"v-60fc7530":j(()=>x(()=>import("./index.html-AOPdgBmB.js"),__vite__mapDeps([56,1]))),"v-02bc92be":j(()=>x(()=>import("./index.html-Pv8xpMqr.js"),__vite__mapDeps([57,1]))),"v-380c630d":j(()=>x(()=>import("./index.html-IuOpNwku.js"),__vite__mapDeps([58,1]))),"v-21ba2ec8":j(()=>x(()=>import("./index.html-PzLMN4bj.js"),__vite__mapDeps([59,1]))),"v-a32329e6":j(()=>x(()=>import("./index.html-6QAvnWzZ.js"),__vite__mapDeps([60,1]))),"v-4d194044":j(()=>x(()=>import("./index.html-jG6_D9tR.js"),__vite__mapDeps([61,1]))),"v-6e21a4b2":j(()=>x(()=>import("./index.html-L2EY0waG.js"),__vite__mapDeps([62,1]))),"v-5bc93818":j(()=>x(()=>import("./index.html-_KtgcszN.js"),__vite__mapDeps([63,1]))),"v-744d024e":j(()=>x(()=>import("./index.html-IefXkqnJ.js"),__vite__mapDeps([64,1]))),"v-e52c881c":j(()=>x(()=>import("./index.html-GqC77IMP.js"),__vite__mapDeps([65,1]))),"v-154dc4c4":j(()=>x(()=>import("./index.html-QFJKSvrT.js"),__vite__mapDeps([66,1]))),"v-01560935":j(()=>x(()=>import("./index.html--QH2zN9-.js"),__vite__mapDeps([67,1])))};var zf=Symbol(""),Fi=Symbol(""),Hf=an({key:"",path:"",title:"",lang:"",frontmatter:{},headers:[]}),se=()=>{const e=ue(Fi);if(!e)throw new Error("pageData() is called without provider.");return e},ji=Symbol(""),ye=()=>{const e=ue(ji);if(!e)throw new Error("usePageFrontmatter() is called without provider.");return e},Wi=Symbol(""),Ff=()=>{const e=ue(Wi);if(!e)throw new Error("usePageHead() is called without provider.");return e},jf=Symbol(""),Gi=Symbol(""),Pl=()=>{const e=ue(Gi);if(!e)throw new Error("usePageLang() is called without provider.");return e},Ki=Symbol(""),Wf=()=>{const e=ue(Ki);if(!e)throw new Error("usePageLayout() is called without provider.");return e},Gf=Z(Of),Il=Symbol(""),ft=()=>{const e=ue(Il);if(!e)throw new Error("useRouteLocale() is called without provider.");return e},hn=Z(Mf),qi=()=>hn,Ui=Symbol(""),Pn=()=>{const e=ue(Ui);if(!e)throw new Error("useSiteLocaleData() is called without provider.");return e},Kf=Symbol(""),qf="Layout",Uf="NotFound",kt=or({resolveLayouts:e=>e.reduce((t,n)=>({...t,...n.layouts}),{}),resolvePageData:async e=>{const t=Gf.value[e];return await(t==null?void 0:t())??Hf},resolvePageFrontmatter:e=>e.frontmatter,resolvePageHead:(e,t,n)=>{const r=oe(t.description)?t.description:n.description,a=[...Q(t.head)?t.head:[],...n.head,["title",{},e],["meta",{name:"description",content:r}]];return Df(a)},resolvePageHeadTitle:(e,t)=>[e.title,t.title].filter(n=>!!n).join(" | "),resolvePageLang:(e,t)=>e.lang||t.lang||"en-US",resolvePageLayout:(e,t)=>{let n;if(e.path){const r=e.frontmatter.layout;oe(r)?n=r:n=qf}else n=Uf;return t[n]},resolveRouteLocale:(e,t)=>Nf(e,t),resolveSiteLocaleData:(e,t)=>({...e,...e.locales[t]})}),aa=D({name:"ClientOnly",setup(e,t){const n=Z(!1);return ge(()=>{n.value=!0}),()=>{var r,a;return n.value?(a=(r=t.slots).default)==null?void 0:a.call(r):null}}}),Zi=D({name:"Content",props:{pageKey:{type:String,required:!1,default:""}},setup(e){const t=se(),n=y(()=>Hi[e.pageKey||t.value.key]);return()=>n.value?s(n.value):s("div","404 Not Found")}}),Xe=(e={})=>e,Ee=e=>on(e)?e:`/${zi(e)}`;const Zf={};/*!
+ * vue-router v4.2.5
+ * (c) 2023 Eduardo San Martin Morote
+ * @license MIT
+ */const fn=typeof window<"u";function Yf(e){return e.__esModule||e[Symbol.toStringTag]==="Module"}const be=Object.assign;function ka(e,t){const n={};for(const r in t){const a=t[r];n[r]=dt(a)?a.map(e):e(a)}return n}const Un=()=>{},dt=Array.isArray,Xf=/\/$/,Jf=e=>e.replace(Xf,"");function xa(e,t,n="/"){let r,a={},l="",o="";const i=t.indexOf("#");let c=t.indexOf("?");return i=0&&(c=-1),c>-1&&(r=t.slice(0,c),l=t.slice(c+1,i>-1?i:t.length),a=e(l)),i>-1&&(r=r||t.slice(0,i),o=t.slice(i,t.length)),r=np(r??t,n),{fullPath:r+(l&&"?")+l+o,path:r,query:a,hash:o}}function Qf(e,t){const n=t.query?e(t.query):"";return t.path+(n&&"?")+n+(t.hash||"")}function Yo(e,t){return!t||!e.toLowerCase().startsWith(t.toLowerCase())?e:e.slice(t.length)||"/"}function ep(e,t,n){const r=t.matched.length-1,a=n.matched.length-1;return r>-1&&r===a&&kn(t.matched[r],n.matched[a])&&Yi(t.params,n.params)&&e(t.query)===e(n.query)&&t.hash===n.hash}function kn(e,t){return(e.aliasOf||e)===(t.aliasOf||t)}function Yi(e,t){if(Object.keys(e).length!==Object.keys(t).length)return!1;for(const n in e)if(!tp(e[n],t[n]))return!1;return!0}function tp(e,t){return dt(e)?Xo(e,t):dt(t)?Xo(t,e):e===t}function Xo(e,t){return dt(t)?e.length===t.length&&e.every((n,r)=>n===t[r]):e.length===1&&e[0]===t}function np(e,t){if(e.startsWith("/"))return e;if(!e)return t;const n=t.split("/"),r=e.split("/"),a=r[r.length-1];(a===".."||a===".")&&r.push("");let l=n.length-1,o,i;for(o=0;o1&&l--;else break;return n.slice(0,l).join("/")+"/"+r.slice(o-(o===r.length?1:0)).join("/")}var nr;(function(e){e.pop="pop",e.push="push"})(nr||(nr={}));var Zn;(function(e){e.back="back",e.forward="forward",e.unknown=""})(Zn||(Zn={}));function rp(e){if(!e)if(fn){const t=document.querySelector("base");e=t&&t.getAttribute("href")||"/",e=e.replace(/^\w+:\/\/[^\/]+/,"")}else e="/";return e[0]!=="/"&&e[0]!=="#"&&(e="/"+e),Jf(e)}const ap=/^[^#]+#/;function lp(e,t){return e.replace(ap,"#")+t}function op(e,t){const n=document.documentElement.getBoundingClientRect(),r=e.getBoundingClientRect();return{behavior:t.behavior,left:r.left-n.left-(t.left||0),top:r.top-n.top-(t.top||0)}}const la=()=>({left:window.pageXOffset,top:window.pageYOffset});function sp(e){let t;if("el"in e){const n=e.el,r=typeof n=="string"&&n.startsWith("#"),a=typeof n=="string"?r?document.getElementById(n.slice(1)):document.querySelector(n):n;if(!a)return;t=op(a,e)}else t=e;"scrollBehavior"in document.documentElement.style?window.scrollTo(t):window.scrollTo(t.left!=null?t.left:window.pageXOffset,t.top!=null?t.top:window.pageYOffset)}function Jo(e,t){return(history.state?history.state.position-t:-1)+e}const Ka=new Map;function ip(e,t){Ka.set(e,t)}function cp(e){const t=Ka.get(e);return Ka.delete(e),t}let up=()=>location.protocol+"//"+location.host;function Xi(e,t){const{pathname:n,search:r,hash:a}=t,l=e.indexOf("#");if(l>-1){let i=a.includes(e.slice(l))?e.slice(l).length:1,c=a.slice(i);return c[0]!=="/"&&(c="/"+c),Yo(c,"")}return Yo(n,e)+r+a}function dp(e,t,n,r){let a=[],l=[],o=null;const i=({state:p})=>{const h=Xi(e,location),g=n.value,w=t.value;let E=0;if(p){if(n.value=h,t.value=p,o&&o===g){o=null;return}E=w?p.position-w.position:0}else r(h);a.forEach(b=>{b(n.value,g,{delta:E,type:nr.pop,direction:E?E>0?Zn.forward:Zn.back:Zn.unknown})})};function c(){o=n.value}function u(p){a.push(p);const h=()=>{const g=a.indexOf(p);g>-1&&a.splice(g,1)};return l.push(h),h}function d(){const{history:p}=window;p.state&&p.replaceState(be({},p.state,{scroll:la()}),"")}function f(){for(const p of l)p();l=[],window.removeEventListener("popstate",i),window.removeEventListener("beforeunload",d)}return window.addEventListener("popstate",i),window.addEventListener("beforeunload",d,{passive:!0}),{pauseListeners:c,listen:u,destroy:f}}function Qo(e,t,n,r=!1,a=!1){return{back:e,current:t,forward:n,replaced:r,position:window.history.length,scroll:a?la():null}}function fp(e){const{history:t,location:n}=window,r={value:Xi(e,n)},a={value:t.state};a.value||l(r.value,{back:null,current:r.value,forward:null,position:t.length-1,replaced:!0,scroll:null},!0);function l(c,u,d){const f=e.indexOf("#"),p=f>-1?(n.host&&document.querySelector("base")?e:e.slice(f))+c:up()+e+c;try{t[d?"replaceState":"pushState"](u,"",p),a.value=u}catch(h){console.error(h),n[d?"replace":"assign"](p)}}function o(c,u){const d=be({},t.state,Qo(a.value.back,c,a.value.forward,!0),u,{position:a.value.position});l(c,d,!0),r.value=c}function i(c,u){const d=be({},a.value,t.state,{forward:c,scroll:la()});l(d.current,d,!0);const f=be({},Qo(r.value,c,null),{position:d.position+1},u);l(c,f,!1),r.value=c}return{location:r,state:a,push:i,replace:o}}function pp(e){e=rp(e);const t=fp(e),n=dp(e,t.state,t.location,t.replace);function r(l,o=!0){o||n.pauseListeners(),history.go(l)}const a=be({location:"",base:e,go:r,createHref:lp.bind(null,e)},t,n);return Object.defineProperty(a,"location",{enumerable:!0,get:()=>t.location.value}),Object.defineProperty(a,"state",{enumerable:!0,get:()=>t.state.value}),a}function hp(e){return typeof e=="string"||e&&typeof e=="object"}function Ji(e){return typeof e=="string"||typeof e=="symbol"}const xt={path:"/",name:void 0,params:{},query:{},hash:"",fullPath:"/",matched:[],meta:{},redirectedFrom:void 0},Qi=Symbol("");var es;(function(e){e[e.aborted=4]="aborted",e[e.cancelled=8]="cancelled",e[e.duplicated=16]="duplicated"})(es||(es={}));function xn(e,t){return be(new Error,{type:e,[Qi]:!0},t)}function wt(e,t){return e instanceof Error&&Qi in e&&(t==null||!!(e.type&t))}const ts="[^/]+?",vp={sensitive:!1,strict:!1,start:!0,end:!0},mp=/[.+*?^${}()[\]/\\]/g;function gp(e,t){const n=be({},vp,t),r=[];let a=n.start?"^":"";const l=[];for(const u of e){const d=u.length?[]:[90];n.strict&&!u.length&&(a+="/");for(let f=0;ft.length?t.length===1&&t[0]===80?1:-1:0}function yp(e,t){let n=0;const r=e.score,a=t.score;for(;n0&&t[t.length-1]<0}const _p={type:0,value:""},wp=/[a-zA-Z0-9_]/;function Ep(e){if(!e)return[[]];if(e==="/")return[[_p]];if(!e.startsWith("/"))throw new Error(`Invalid path "${e}"`);function t(h){throw new Error(`ERR (${n})/"${u}": ${h}`)}let n=0,r=n;const a=[];let l;function o(){l&&a.push(l),l=[]}let i=0,c,u="",d="";function f(){u&&(n===0?l.push({type:0,value:u}):n===1||n===2||n===3?(l.length>1&&(c==="*"||c==="+")&&t(`A repeatable param (${u}) must be alone in its segment. eg: '/:ids+.`),l.push({type:1,value:u,regexp:d,repeatable:c==="*"||c==="+",optional:c==="*"||c==="?"})):t("Invalid state to consume buffer"),u="")}function p(){u+=c}for(;i{o(L)}:Un}function o(d){if(Ji(d)){const f=r.get(d);f&&(r.delete(d),n.splice(n.indexOf(f),1),f.children.forEach(o),f.alias.forEach(o))}else{const f=n.indexOf(d);f>-1&&(n.splice(f,1),d.record.name&&r.delete(d.record.name),d.children.forEach(o),d.alias.forEach(o))}}function i(){return n}function c(d){let f=0;for(;f=0&&(d.record.path!==n[f].record.path||!ec(d,n[f]));)f++;n.splice(f,0,d),d.record.name&&!as(d)&&r.set(d.record.name,d)}function u(d,f){let p,h={},g,w;if("name"in d&&d.name){if(p=r.get(d.name),!p)throw xn(1,{location:d});w=p.record.name,h=be(rs(f.params,p.keys.filter(L=>!L.optional).map(L=>L.name)),d.params&&rs(d.params,p.keys.map(L=>L.name))),g=p.stringify(h)}else if("path"in d)g=d.path,p=n.find(L=>L.re.test(g)),p&&(h=p.parse(g),w=p.record.name);else{if(p=f.name?r.get(f.name):n.find(L=>L.re.test(f.path)),!p)throw xn(1,{location:d,currentLocation:f});w=p.record.name,h=be({},f.params,d.params),g=p.stringify(h)}const E=[];let b=p;for(;b;)E.unshift(b.record),b=b.parent;return{name:w,path:g,params:h,matched:E,meta:Ap(E)}}return e.forEach(d=>l(d)),{addRoute:l,resolve:u,removeRoute:o,getRoutes:i,getRecordMatcher:a}}function rs(e,t){const n={};for(const r of t)r in e&&(n[r]=e[r]);return n}function Tp(e){return{path:e.path,redirect:e.redirect,name:e.name,meta:e.meta||{},aliasOf:void 0,beforeEnter:e.beforeEnter,props:Lp(e),children:e.children||[],instances:{},leaveGuards:new Set,updateGuards:new Set,enterCallbacks:{},components:"components"in e?e.components||null:e.component&&{default:e.component}}}function Lp(e){const t={},n=e.props||!1;if("component"in e)t.default=n;else for(const r in e.components)t[r]=typeof n=="object"?n[r]:n;return t}function as(e){for(;e;){if(e.record.aliasOf)return!0;e=e.parent}return!1}function Ap(e){return e.reduce((t,n)=>be(t,n.meta),{})}function ls(e,t){const n={};for(const r in e)n[r]=r in t?t[r]:e[r];return n}function ec(e,t){return t.children.some(n=>n===e||ec(e,n))}const tc=/#/g,Sp=/&/g,Cp=/\//g,Pp=/=/g,Ip=/\?/g,nc=/\+/g,Rp=/%5B/g,Op=/%5D/g,rc=/%5E/g,Mp=/%60/g,ac=/%7B/g,$p=/%7C/g,lc=/%7D/g,Dp=/%20/g;function Rl(e){return encodeURI(""+e).replace($p,"|").replace(Rp,"[").replace(Op,"]")}function Vp(e){return Rl(e).replace(ac,"{").replace(lc,"}").replace(rc,"^")}function qa(e){return Rl(e).replace(nc,"%2B").replace(Dp,"+").replace(tc,"%23").replace(Sp,"%26").replace(Mp,"`").replace(ac,"{").replace(lc,"}").replace(rc,"^")}function Bp(e){return qa(e).replace(Pp,"%3D")}function Np(e){return Rl(e).replace(tc,"%23").replace(Ip,"%3F")}function zp(e){return e==null?"":Np(e).replace(Cp,"%2F")}function Zr(e){try{return decodeURIComponent(""+e)}catch{}return""+e}function Hp(e){const t={};if(e===""||e==="?")return t;const r=(e[0]==="?"?e.slice(1):e).split("&");for(let a=0;al&&qa(l)):[r&&qa(r)]).forEach(l=>{l!==void 0&&(t+=(t.length?"&":"")+n,l!=null&&(t+="="+l))})}return t}function Fp(e){const t={};for(const n in e){const r=e[n];r!==void 0&&(t[n]=dt(r)?r.map(a=>a==null?null:""+a):r==null?r:""+r)}return t}const jp=Symbol(""),ss=Symbol(""),oa=Symbol(""),Ol=Symbol(""),Ua=Symbol("");function Bn(){let e=[];function t(r){return e.push(r),()=>{const a=e.indexOf(r);a>-1&&e.splice(a,1)}}function n(){e=[]}return{add:t,list:()=>e.slice(),reset:n}}function Bt(e,t,n,r,a){const l=r&&(r.enterCallbacks[a]=r.enterCallbacks[a]||[]);return()=>new Promise((o,i)=>{const c=f=>{f===!1?i(xn(4,{from:n,to:t})):f instanceof Error?i(f):hp(f)?i(xn(2,{from:t,to:f})):(l&&r.enterCallbacks[a]===l&&typeof f=="function"&&l.push(f),o())},u=e.call(r&&r.instances[a],t,n,c);let d=Promise.resolve(u);e.length<3&&(d=d.then(c)),d.catch(f=>i(f))})}function Ta(e,t,n,r){const a=[];for(const l of e)for(const o in l.components){let i=l.components[o];if(!(t!=="beforeRouteEnter"&&!l.instances[o]))if(Wp(i)){const u=(i.__vccOpts||i)[t];u&&a.push(Bt(u,n,r,l,o))}else{let c=i();a.push(()=>c.then(u=>{if(!u)return Promise.reject(new Error(`Couldn't resolve component "${o}" at "${l.path}"`));const d=Yf(u)?u.default:u;l.components[o]=d;const p=(d.__vccOpts||d)[t];return p&&Bt(p,n,r,l,o)()}))}}return a}function Wp(e){return typeof e=="object"||"displayName"in e||"props"in e||"__vccOpts"in e}function Za(e){const t=ue(oa),n=ue(Ol),r=y(()=>t.resolve(tn(e.to))),a=y(()=>{const{matched:c}=r.value,{length:u}=c,d=c[u-1],f=n.matched;if(!d||!f.length)return-1;const p=f.findIndex(kn.bind(null,d));if(p>-1)return p;const h=is(c[u-2]);return u>1&&is(d)===h&&f[f.length-1].path!==h?f.findIndex(kn.bind(null,c[u-2])):p}),l=y(()=>a.value>-1&&Up(n.params,r.value.params)),o=y(()=>a.value>-1&&a.value===n.matched.length-1&&Yi(n.params,r.value.params));function i(c={}){return qp(c)?t[tn(e.replace)?"replace":"push"](tn(e.to)).catch(Un):Promise.resolve()}return{route:r,href:y(()=>r.value.href),isActive:l,isExactActive:o,navigate:i}}const Gp=D({name:"RouterLink",compatConfig:{MODE:3},props:{to:{type:[String,Object],required:!0},replace:Boolean,activeClass:String,exactActiveClass:String,custom:Boolean,ariaCurrentValue:{type:String,default:"page"}},useLink:Za,setup(e,{slots:t}){const n=or(Za(e)),{options:r}=ue(oa),a=y(()=>({[cs(e.activeClass,r.linkActiveClass,"router-link-active")]:n.isActive,[cs(e.exactActiveClass,r.linkExactActiveClass,"router-link-exact-active")]:n.isExactActive}));return()=>{const l=t.default&&t.default(n);return e.custom?l:s("a",{"aria-current":n.isExactActive?e.ariaCurrentValue:null,href:n.href,onClick:n.navigate,class:a.value},l)}}}),Kp=Gp;function qp(e){if(!(e.metaKey||e.altKey||e.ctrlKey||e.shiftKey)&&!e.defaultPrevented&&!(e.button!==void 0&&e.button!==0)){if(e.currentTarget&&e.currentTarget.getAttribute){const t=e.currentTarget.getAttribute("target");if(/\b_blank\b/i.test(t))return}return e.preventDefault&&e.preventDefault(),!0}}function Up(e,t){for(const n in t){const r=t[n],a=e[n];if(typeof r=="string"){if(r!==a)return!1}else if(!dt(a)||a.length!==r.length||r.some((l,o)=>l!==a[o]))return!1}return!0}function is(e){return e?e.aliasOf?e.aliasOf.path:e.path:""}const cs=(e,t,n)=>e??t??n,Zp=D({name:"RouterView",inheritAttrs:!1,props:{name:{type:String,default:"default"},route:Object},compatConfig:{MODE:3},setup(e,{attrs:t,slots:n}){const r=ue(Ua),a=y(()=>e.route||r.value),l=ue(ss,0),o=y(()=>{let u=tn(l);const{matched:d}=a.value;let f;for(;(f=d[u])&&!f.components;)u++;return u}),i=y(()=>a.value.matched[o.value]);rt(ss,y(()=>o.value+1)),rt(jp,i),rt(Ua,a);const c=Z();return ve(()=>[c.value,i.value,e.name],([u,d,f],[p,h,g])=>{d&&(d.instances[f]=u,h&&h!==d&&u&&u===p&&(d.leaveGuards.size||(d.leaveGuards=h.leaveGuards),d.updateGuards.size||(d.updateGuards=h.updateGuards))),u&&d&&(!h||!kn(d,h)||!p)&&(d.enterCallbacks[f]||[]).forEach(w=>w(u))},{flush:"post"}),()=>{const u=a.value,d=e.name,f=i.value,p=f&&f.components[d];if(!p)return us(n.default,{Component:p,route:u});const h=f.props[d],g=h?h===!0?u.params:typeof h=="function"?h(u):h:null,E=s(p,be({},g,t,{onVnodeUnmounted:b=>{b.component.isUnmounted&&(f.instances[d]=null)},ref:c}));return us(n.default,{Component:E,route:u})||E}}});function us(e,t){if(!e)return null;const n=e(t);return n.length===1?n[0]:n}const oc=Zp;function Yp(e){const t=xp(e.routes,e),n=e.parseQuery||Hp,r=e.stringifyQuery||os,a=e.history,l=Bn(),o=Bn(),i=Bn(),c=lt(xt);let u=xt;fn&&e.scrollBehavior&&"scrollRestoration"in history&&(history.scrollRestoration="manual");const d=ka.bind(null,C=>""+C),f=ka.bind(null,zp),p=ka.bind(null,Zr);function h(C,W){let H,q;return Ji(C)?(H=t.getRecordMatcher(C),q=W):q=C,t.addRoute(q,H)}function g(C){const W=t.getRecordMatcher(C);W&&t.removeRoute(W)}function w(){return t.getRoutes().map(C=>C.record)}function E(C){return!!t.getRecordMatcher(C)}function b(C,W){if(W=be({},W||c.value),typeof C=="string"){const m=xa(n,C,W.path),k=t.resolve({path:m.path},W),P=a.createHref(m.fullPath);return be(m,k,{params:p(k.params),hash:Zr(m.hash),redirectedFrom:void 0,href:P})}let H;if("path"in C)H=be({},C,{path:xa(n,C.path,W.path).path});else{const m=be({},C.params);for(const k in m)m[k]==null&&delete m[k];H=be({},C,{params:f(m)}),W.params=f(W.params)}const q=t.resolve(H,W),me=C.hash||"";q.params=d(p(q.params));const ke=Qf(r,be({},C,{hash:Vp(me),path:q.path})),v=a.createHref(ke);return be({fullPath:ke,hash:me,query:r===os?Fp(C.query):C.query||{}},q,{redirectedFrom:void 0,href:v})}function L(C){return typeof C=="string"?xa(n,C,c.value.path):be({},C)}function _(C,W){if(u!==C)return xn(8,{from:W,to:C})}function A(C){return K(C)}function V(C){return A(be(L(C),{replace:!0}))}function T(C){const W=C.matched[C.matched.length-1];if(W&&W.redirect){const{redirect:H}=W;let q=typeof H=="function"?H(C):H;return typeof q=="string"&&(q=q.includes("?")||q.includes("#")?q=L(q):{path:q},q.params={}),be({query:C.query,hash:C.hash,params:"path"in q?{}:C.params},q)}}function K(C,W){const H=u=b(C),q=c.value,me=C.state,ke=C.force,v=C.replace===!0,m=T(H);if(m)return K(be(L(m),{state:typeof m=="object"?be({},me,m.state):me,force:ke,replace:v}),W||H);const k=H;k.redirectedFrom=W;let P;return!ke&&ep(r,q,H)&&(P=xn(16,{to:k,from:q}),pt(q,q,!0,!1)),(P?Promise.resolve(P):N(k,q)).catch(S=>wt(S)?wt(S,2)?S:Ct(S):U(S,k,q)).then(S=>{if(S){if(wt(S,2))return K(be({replace:v},L(S.to),{state:typeof S.to=="object"?be({},me,S.to.state):me,force:ke}),W||k)}else S=z(k,q,!0,v,me);return ne(k,q,S),S})}function B(C,W){const H=_(C,W);return H?Promise.reject(H):Promise.resolve()}function M(C){const W=un.values().next().value;return W&&typeof W.runWithContext=="function"?W.runWithContext(C):C()}function N(C,W){let H;const[q,me,ke]=Xp(C,W);H=Ta(q.reverse(),"beforeRouteLeave",C,W);for(const m of q)m.leaveGuards.forEach(k=>{H.push(Bt(k,C,W))});const v=B.bind(null,C,W);return H.push(v),Ve(H).then(()=>{H=[];for(const m of l.list())H.push(Bt(m,C,W));return H.push(v),Ve(H)}).then(()=>{H=Ta(me,"beforeRouteUpdate",C,W);for(const m of me)m.updateGuards.forEach(k=>{H.push(Bt(k,C,W))});return H.push(v),Ve(H)}).then(()=>{H=[];for(const m of ke)if(m.beforeEnter)if(dt(m.beforeEnter))for(const k of m.beforeEnter)H.push(Bt(k,C,W));else H.push(Bt(m.beforeEnter,C,W));return H.push(v),Ve(H)}).then(()=>(C.matched.forEach(m=>m.enterCallbacks={}),H=Ta(ke,"beforeRouteEnter",C,W),H.push(v),Ve(H))).then(()=>{H=[];for(const m of o.list())H.push(Bt(m,C,W));return H.push(v),Ve(H)}).catch(m=>wt(m,8)?m:Promise.reject(m))}function ne(C,W,H){i.list().forEach(q=>M(()=>q(C,W,H)))}function z(C,W,H,q,me){const ke=_(C,W);if(ke)return ke;const v=W===xt,m=fn?history.state:{};H&&(q||v?a.replace(C.fullPath,be({scroll:v&&m&&m.scroll},me)):a.push(C.fullPath,me)),c.value=C,pt(C,W,H,v),Ct()}let ee;function Ae(){ee||(ee=a.listen((C,W,H)=>{if(!wr.listening)return;const q=b(C),me=T(q);if(me){K(be(me,{replace:!0}),q).catch(Un);return}u=q;const ke=c.value;fn&&ip(Jo(ke.fullPath,H.delta),la()),N(q,ke).catch(v=>wt(v,12)?v:wt(v,2)?(K(v.to,q).then(m=>{wt(m,20)&&!H.delta&&H.type===nr.pop&&a.go(-1,!1)}).catch(Un),Promise.reject()):(H.delta&&a.go(-H.delta,!1),U(v,q,ke))).then(v=>{v=v||z(q,ke,!1),v&&(H.delta&&!wt(v,8)?a.go(-H.delta,!1):H.type===nr.pop&&wt(v,20)&&a.go(-1,!1)),ne(q,ke,v)}).catch(Un)}))}let Se=Bn(),Y=Bn(),ae;function U(C,W,H){Ct(C);const q=Y.list();return q.length?q.forEach(me=>me(C,W,H)):console.error(C),Promise.reject(C)}function st(){return ae&&c.value!==xt?Promise.resolve():new Promise((C,W)=>{Se.add([C,W])})}function Ct(C){return ae||(ae=!C,Ae(),Se.list().forEach(([W,H])=>C?H(C):W()),Se.reset()),C}function pt(C,W,H,q){const{scrollBehavior:me}=e;if(!fn||!me)return Promise.resolve();const ke=!H&&cp(Jo(C.fullPath,0))||(q||!H)&&history.state&&history.state.scroll||null;return Gt().then(()=>me(C,W,ke)).then(v=>v&&sp(v)).catch(v=>U(v,C,W))}const He=C=>a.go(C);let cn;const un=new Set,wr={currentRoute:c,listening:!0,addRoute:h,removeRoute:g,hasRoute:E,getRoutes:w,resolve:b,options:e,push:A,replace:V,go:He,back:()=>He(-1),forward:()=>He(1),beforeEach:l.add,beforeResolve:o.add,afterEach:i.add,onError:Y.add,isReady:st,install(C){const W=this;C.component("RouterLink",Kp),C.component("RouterView",oc),C.config.globalProperties.$router=W,Object.defineProperty(C.config.globalProperties,"$route",{enumerable:!0,get:()=>tn(c)}),fn&&!cn&&c.value===xt&&(cn=!0,A(a.location).catch(me=>{}));const H={};for(const me in xt)Object.defineProperty(H,me,{get:()=>c.value[me],enumerable:!0});C.provide(oa,W),C.provide(Ol,Zs(H)),C.provide(Ua,c);const q=C.unmount;un.add(C),C.unmount=function(){un.delete(C),un.size<1&&(u=xt,ee&&ee(),ee=null,c.value=xt,cn=!1,ae=!1),q()}}};function Ve(C){return C.reduce((W,H)=>W.then(()=>M(H)),Promise.resolve())}return wr}function Xp(e,t){const n=[],r=[],a=[],l=Math.max(t.matched.length,e.matched.length);for(let o=0;okn(u,i))?r.push(i):n.push(i));const c=e.matched[o];c&&(t.matched.find(u=>kn(u,c))||a.push(c))}return[n,r,a]}function De(){return ue(oa)}function ot(){return ue(Ol)}const de=({name:e="",color:t="currentColor"},{slots:n})=>{var r;return s("svg",{xmlns:"http://www.w3.org/2000/svg",class:["icon",`${e}-icon`],viewBox:"0 0 1024 1024",fill:t,"aria-label":`${e} icon`},(r=n.default)==null?void 0:r.call(n))};de.displayName="IconBase";const sc=({size:e=48,stroke:t=4,wrapper:n=!0,height:r=2*e})=>{const a=s("svg",{xmlns:"http://www.w3.org/2000/svg",width:e,height:e,preserveAspectRatio:"xMidYMid",viewBox:"25 25 50 50"},[s("animateTransform",{attributeName:"transform",type:"rotate",dur:"2s",keyTimes:"0;1",repeatCount:"indefinite",values:"0;360"}),s("circle",{cx:"50",cy:"50",r:"20",fill:"none",stroke:"currentColor","stroke-width":t,"stroke-linecap":"round"},[s("animate",{attributeName:"stroke-dasharray",dur:"1.5s",keyTimes:"0;0.5;1",repeatCount:"indefinite",values:"1,200;90,200;1,200"}),s("animate",{attributeName:"stroke-dashoffset",dur:"1.5s",keyTimes:"0;0.5;1",repeatCount:"indefinite",values:"0;-35px;-125px"})])]);return n?s("div",{class:"loading-icon-wrapper",style:`display:flex;align-items:center;justify-content:center;height:${r}px`},a):a};sc.displayName="LoadingIcon";const ic=(e,{slots:t})=>{var n;return(n=t.default)==null?void 0:n.call(t)},Ml=(e="")=>{if(e){if(typeof e=="number")return new Date(e);const t=Date.parse(e.toString());if(!Number.isNaN(t))return new Date(t)}return null},sa=(e,t)=>{let n=1;for(let r=0;r>6;return n+=n<<3,n^=n>>11,n%t},cc=Array.isArray,Jp=e=>typeof e=="function",Qp=e=>typeof e=="string";var dr=e=>/^(https?:)?\/\//.test(e),e0=/.md((\?|#).*)?$/,t0=(e,t="/")=>!!(dr(e)||e.startsWith("/")&&!e.startsWith(t)&&!e0.test(e)),$l=e=>Object.prototype.toString.call(e)==="[object Object]",n0=e=>e[e.length-1]==="/"?e.slice(0,-1):e;function r0(){const e=Z(!1);return ln()&&ge(()=>{e.value=!0}),e}function a0(e){return r0(),y(()=>!!e())}const La=e=>typeof e=="number",bt=e=>typeof e=="string",Wt=(e,t)=>bt(e)&&e.startsWith(t),Ir=(e,t)=>bt(e)&&e.endsWith(t),In=Object.entries,l0=Object.fromEntries,yt=Object.keys,o0=e=>(e.endsWith(".md")&&(e=`${e.slice(0,-3)}.html`),!e.endsWith("/")&&!e.endsWith(".html")&&(e=`${e}.html`),e=e.replace(/(^|\/)(?:README|index).html$/i,"$1"),e),uc=e=>{const[t,n=""]=e.split("#");return t?`${o0(t)}${n?`#${n}`:""}`:e},ds=e=>$l(e)&&bt(e.name),rr=(e,t=!1)=>e?cc(e)?e.map(n=>bt(n)?{name:n}:ds(n)?n:null).filter(n=>n!==null):bt(e)?[{name:e}]:ds(e)?[e]:(console.error(`Expect "author" to be \`AuthorInfo[] | AuthorInfo | string[] | string ${t?"":"| false"} | undefined\`, but got`,e),[]):[],dc=(e,t)=>{if(e){if(cc(e)&&e.every(bt))return e;if(bt(e))return[e];console.error(`Expect ${t||"value"} to be \`string[] | string | undefined\`, but got`,e)}return[]},fc=e=>dc(e,"category"),pc=e=>dc(e,"tag"),Rn=e=>Wt(e,"/");let s0=class{constructor(){this.messageElements={};const t="message-container",n=document.getElementById(t);n?this.containerElement=n:(this.containerElement=document.createElement("div"),this.containerElement.id=t,document.body.appendChild(this.containerElement))}pop(t,n=2e3){const r=document.createElement("div"),a=Date.now();return r.className="message move-in",r.innerHTML=t,this.containerElement.appendChild(r),this.messageElements[a]=r,n>0&&setTimeout(()=>{this.close(a)},n),a}close(t){if(t){const n=this.messageElements[t];n.classList.remove("move-in"),n.classList.add("move-out"),n.addEventListener("animationend",()=>{n.remove(),delete this.messageElements[t]})}else yt(this.messageElements).forEach(n=>this.close(Number(n)))}destroy(){document.body.removeChild(this.containerElement)}};const hc=/#.*$/u,i0=e=>{const t=hc.exec(e);return t?t[0]:""},fs=e=>decodeURI(e).replace(hc,"").replace(/(index)?\.html$/i,"").replace(/(README|index)?\.md$/i,""),vc=(e,t)=>{if(t===void 0)return!1;const n=fs(e.path),r=fs(t),a=i0(t);return a?a===e.hash&&(!r||n===r):n===r},c0=e=>dr(e)?e:`https://github.com/${e}`,mc=e=>!dr(e)||/github\.com/.test(e)?"GitHub":/bitbucket\.org/.test(e)?"Bitbucket":/gitlab\.com/.test(e)?"GitLab":/gitee\.com/.test(e)?"Gitee":null,Tn=(e,...t)=>{const n=e.resolve(...t),r=n.matched[n.matched.length-1];if(!(r!=null&&r.redirect))return n;const{redirect:a}=r,l=Jp(a)?a(n):a,o=Qp(l)?{path:l}:l;return Tn(e,{hash:n.hash,query:n.query,params:n.params,...o})},u0=e=>{var t;if(!(e.metaKey||e.altKey||e.ctrlKey||e.shiftKey)&&!e.defaultPrevented&&!(e.button!==void 0&&e.button!==0)&&!(e.currentTarget&&((t=e.currentTarget.getAttribute("target"))!=null&&t.match(/\b_blank\b/i))))return e.preventDefault(),!0},Pe=({to:e="",class:t="",...n},{slots:r})=>{var i;const a=De(),l=uc(e),o=(c={})=>u0(c)?a.push(e).catch():Promise.resolve();return s("a",{...n,class:["vp-link",t],href:Wt(l,"/")?Ee(l):l,onClick:o},(i=r.default)==null?void 0:i.call(r))};Pe.displayName="VPLink";const gc=()=>s(de,{name:"github"},()=>s("path",{d:"M511.957 21.333C241.024 21.333 21.333 240.981 21.333 512c0 216.832 140.544 400.725 335.574 465.664 24.49 4.395 32.256-10.07 32.256-23.083 0-11.69.256-44.245 0-85.205-136.448 29.61-164.736-64.64-164.736-64.64-22.315-56.704-54.4-71.765-54.4-71.765-44.587-30.464 3.285-29.824 3.285-29.824 49.195 3.413 75.179 50.517 75.179 50.517 43.776 75.008 114.816 53.333 142.762 40.79 4.523-31.66 17.152-53.377 31.19-65.537-108.971-12.458-223.488-54.485-223.488-242.602 0-53.547 19.114-97.323 50.517-131.67-5.035-12.33-21.93-62.293 4.779-129.834 0 0 41.258-13.184 134.912 50.346a469.803 469.803 0 0 1 122.88-16.554c41.642.213 83.626 5.632 122.88 16.554 93.653-63.488 134.784-50.346 134.784-50.346 26.752 67.541 9.898 117.504 4.864 129.834 31.402 34.347 50.474 78.123 50.474 131.67 0 188.586-114.73 230.016-224.042 242.09 17.578 15.232 33.578 44.672 33.578 90.454v135.85c0 13.142 7.936 27.606 32.854 22.87C862.25 912.597 1002.667 728.747 1002.667 512c0-271.019-219.648-490.667-490.71-490.667z"}));gc.displayName="GitHubIcon";const bc=()=>s(de,{name:"gitlab"},()=>s("path",{d:"M229.333 78.688C223.52 62 199.895 62 193.895 78.688L87.958 406.438h247.5c-.188 0-106.125-327.75-106.125-327.75zM33.77 571.438c-4.875 15 .563 31.687 13.313 41.25l464.812 345L87.77 406.438zm301.5-165 176.813 551.25 176.812-551.25zm655.125 165-54-165-424.312 551.25 464.812-345c12.938-9.563 18.188-26.25 13.5-41.25zM830.27 78.688c-5.812-16.688-29.437-16.688-35.437 0l-106.125 327.75h247.5z"}));bc.displayName="GitLabIcon";const yc=()=>s(de,{name:"gitee"},()=>s("path",{d:"M512 992C246.92 992 32 777.08 32 512S246.92 32 512 32s480 214.92 480 480-214.92 480-480 480zm242.97-533.34H482.39a23.7 23.7 0 0 0-23.7 23.7l-.03 59.28c0 13.08 10.59 23.7 23.7 23.7h165.96a23.7 23.7 0 0 1 23.7 23.7v11.85a71.1 71.1 0 0 1-71.1 71.1H375.71a23.7 23.7 0 0 1-23.7-23.7V423.11a71.1 71.1 0 0 1 71.1-71.1h331.8a23.7 23.7 0 0 0 23.7-23.7l.06-59.25a23.73 23.73 0 0 0-23.7-23.73H423.11a177.78 177.78 0 0 0-177.78 177.75v331.83c0 13.08 10.62 23.7 23.7 23.7h349.62a159.99 159.99 0 0 0 159.99-159.99V482.33a23.7 23.7 0 0 0-23.7-23.7z"}));yc.displayName="GiteeIcon";const _c=()=>s(de,{name:"bitbucket"},()=>s("path",{d:"M575.256 490.862c6.29 47.981-52.005 85.723-92.563 61.147-45.714-20.004-45.714-92.562-1.133-113.152 38.29-23.442 93.696 7.424 93.696 52.005zm63.451-11.996c-10.276-81.152-102.29-134.839-177.152-101.156-47.433 21.138-79.433 71.424-77.129 124.562 2.853 69.705 69.157 126.866 138.862 120.576S647.3 548.571 638.708 478.83zm136.558-309.723c-25.161-33.134-67.986-38.839-105.728-45.13-106.862-17.151-216.576-17.7-323.438 1.134-35.438 5.706-75.447 11.996-97.719 43.996 36.572 34.304 88.576 39.424 135.424 45.129 84.553 10.862 171.447 11.447 256 .585 47.433-5.705 99.987-10.276 135.424-45.714zm32.585 591.433c-16.018 55.99-6.839 131.438-66.304 163.986-102.29 56.576-226.304 62.867-338.87 42.862-59.43-10.862-129.135-29.696-161.72-85.723-14.3-54.858-23.442-110.848-32.585-166.84l3.438-9.142 10.276-5.157c170.277 112.567 408.576 112.567 579.438 0 26.844 8.01 6.84 40.558 6.29 60.014zm103.424-549.157c-19.42 125.148-41.728 249.71-63.415 374.272-6.29 36.572-41.728 57.162-71.424 72.558-106.862 53.724-231.424 62.866-348.562 50.286-79.433-8.558-160.585-29.696-225.134-79.433-30.28-23.443-30.28-63.415-35.986-97.134-20.005-117.138-42.862-234.277-57.161-352.585 6.839-51.42 64.585-73.728 107.447-89.71 57.16-21.138 118.272-30.866 178.87-36.571 129.134-12.58 261.157-8.01 386.304 28.562 44.581 13.13 92.563 31.415 122.844 69.705 13.714 17.7 9.143 40.01 6.29 60.014z"}));_c.displayName="BitbucketIcon";const wc=()=>s(de,{name:"source"},()=>s("path",{d:"M601.92 475.2c0 76.428-8.91 83.754-28.512 99.594-14.652 11.88-43.956 14.058-78.012 16.434-18.81 1.386-40.392 2.97-62.172 6.534-18.612 2.97-36.432 9.306-53.064 17.424V299.772c37.818-21.978 63.36-62.766 63.36-109.692 0-69.894-56.826-126.72-126.72-126.72S190.08 120.186 190.08 190.08c0 46.926 25.542 87.714 63.36 109.692v414.216c-37.818 21.978-63.36 62.766-63.36 109.692 0 69.894 56.826 126.72 126.72 126.72s126.72-56.826 126.72-126.72c0-31.086-11.286-59.598-29.7-81.576 13.266-9.504 27.522-17.226 39.996-19.206 16.038-2.574 32.868-3.762 50.688-5.148 48.312-3.366 103.158-7.326 148.896-44.55 61.182-49.698 74.25-103.158 75.24-187.902V475.2h-126.72zM316.8 126.72c34.848 0 63.36 28.512 63.36 63.36s-28.512 63.36-63.36 63.36-63.36-28.512-63.36-63.36 28.512-63.36 63.36-63.36zm0 760.32c-34.848 0-63.36-28.512-63.36-63.36s28.512-63.36 63.36-63.36 63.36 28.512 63.36 63.36-28.512 63.36-63.36 63.36zM823.68 158.4h-95.04V63.36h-126.72v95.04h-95.04v126.72h95.04v95.04h126.72v-95.04h95.04z"}));wc.displayName="SourceIcon";const Lt=(e,t)=>{var r;const n=(r=(t==null?void 0:t._instance)||ln())==null?void 0:r.appContext.components;return n?e in n||at(e)in n||lr(at(e))in n:!1},d0=()=>a0(()=>typeof window<"u"&&window.navigator&&"userAgent"in window.navigator),f0=()=>{const e=d0();return y(()=>e.value&&/\b(?:Android|iPhone)/i.test(navigator.userAgent))},On=e=>{const t=ft();return y(()=>e[t.value])},Ec=({type:e="info",text:t="",vertical:n,color:r},{slots:a})=>{var l;return s("span",{class:["vp-badge",e,{diy:r}],style:{verticalAlign:n??!1,backgroundColor:r??!1}},((l=a.default)==null?void 0:l.call(a))||t)};Ec.displayName="Badge";var p0=D({name:"FontIcon",props:{icon:{type:String,default:""},color:{type:String,default:""},size:{type:[String,Number],default:""}},setup(e){const t=y(()=>{const r=["font-icon icon"],a=`${e.icon}`;return r.push(a),r}),n=y(()=>{const r={};return e.color&&(r.color=e.color),e.size&&(r["font-size"]=Number.isNaN(Number(e.size))?e.size:`${e.size}px`),yt(r).length?r:null});return()=>e.icon?s("span",{key:e.icon,class:t.value,style:n.value}):null}});function ps(e,t){var n;const r=lt();return _l(()=>{r.value=e()},{...t,flush:(n=t==null?void 0:t.flush)!=null?n:"sync"}),an(r)}function Dl(e,t){let n,r,a;const l=Z(!0),o=()=>{l.value=!0,a()};ve(e,o,{flush:"sync"});const i=typeof t=="function"?t:t.get,c=typeof t=="function"?void 0:t.set,u=ti((d,f)=>(r=d,a=f,{get(){return l.value&&(n=i(),l.value=!1),r(),n},set(p){c==null||c(p)}}));return Object.isExtensible(u)&&(u.trigger=o),u}function Mn(e){return Ds()?(h1(e),!0):!1}function je(e){return typeof e=="function"?e():tn(e)}const fr=typeof window<"u"&&typeof document<"u";typeof WorkerGlobalScope<"u"&&globalThis instanceof WorkerGlobalScope;const h0=Object.prototype.toString,v0=e=>h0.call(e)==="[object Object]",At=()=>{},Ya=m0();function m0(){var e,t;return fr&&((e=window==null?void 0:window.navigator)==null?void 0:e.userAgent)&&(/iP(ad|hone|od)/.test(window.navigator.userAgent)||((t=window==null?void 0:window.navigator)==null?void 0:t.maxTouchPoints)>2&&/iPad|Macintosh/.test(window==null?void 0:window.navigator.userAgent))}function Vl(e,t){function n(...r){return new Promise((a,l)=>{Promise.resolve(e(()=>t.apply(this,r),{fn:t,thisArg:this,args:r})).then(a).catch(l)})}return n}const kc=e=>e();function g0(e,t={}){let n,r,a=At;const l=i=>{clearTimeout(i),a(),a=At};return i=>{const c=je(e),u=je(t.maxWait);return n&&l(n),c<=0||u!==void 0&&u<=0?(r&&(l(r),r=null),Promise.resolve(i())):new Promise((d,f)=>{a=t.rejectOnCancel?f:d,u&&!r&&(r=setTimeout(()=>{n&&l(n),r=null,d(i())},u)),n=setTimeout(()=>{r&&l(r),r=null,d(i())},c)})}}function b0(e,t=!0,n=!0,r=!1){let a=0,l,o=!0,i=At,c;const u=()=>{l&&(clearTimeout(l),l=void 0,i(),i=At)};return f=>{const p=je(e),h=Date.now()-a,g=()=>c=f();return u(),p<=0?(a=Date.now(),g()):(h>p&&(n||!o)?(a=Date.now(),g()):t&&(c=new Promise((w,E)=>{i=r?E:w,l=setTimeout(()=>{a=Date.now(),o=!0,w(g()),u()},Math.max(0,p-h))})),!n&&!l&&(l=setTimeout(()=>o=!0,p)),o=!1,c)}}function y0(e=kc){const t=Z(!0);function n(){t.value=!1}function r(){t.value=!0}const a=(...l)=>{t.value&&e(...l)};return{isActive:an(t),pause:n,resume:r,eventFilter:a}}function _0(e){let t;function n(){return t||(t=e()),t}return n.reset=async()=>{const r=t;t=void 0,r&&await r},n}function w0(e){return e||ln()}function E0(...e){if(e.length!==1)return Sn(...e);const t=e[0];return typeof t=="function"?an(ti(()=>({get:t,set:At}))):Z(t)}function k0(e,t=200,n={}){return Vl(g0(t,n),e)}function x0(e,t=200,n=!1,r=!0,a=!1){return Vl(b0(t,n,r,a),e)}function T0(e,t,n={}){const{eventFilter:r=kc,...a}=n;return ve(e,Vl(r,t),a)}function L0(e,t,n={}){const{eventFilter:r,...a}=n,{eventFilter:l,pause:o,resume:i,isActive:c}=y0(r);return{stop:T0(e,t,{...a,eventFilter:l}),pause:o,resume:i,isActive:c}}function Bl(e,t=!0,n){w0()?ge(e,n):t?e():Gt(e)}function A0(e,t,n={}){const{immediate:r=!0}=n,a=Z(!1);let l=null;function o(){l&&(clearTimeout(l),l=null)}function i(){a.value=!1,o()}function c(...u){o(),a.value=!0,l=setTimeout(()=>{a.value=!1,l=null,e(...u)},je(t))}return r&&(a.value=!0,fr&&c()),Mn(i),{isPending:an(a),start:c,stop:i}}function hs(e=!1,t={}){const{truthyValue:n=!0,falsyValue:r=!1}=t,a=$e(e),l=Z(e);function o(i){if(arguments.length)return l.value=i,l.value;{const c=je(n);return l.value=l.value===c?je(r):c,l.value}}return a?o:[l,o]}function Ze(e){var t;const n=je(e);return(t=n==null?void 0:n.$el)!=null?t:n}const _t=fr?window:void 0,S0=fr?window.document:void 0,xc=fr?window.navigator:void 0;function Ce(...e){let t,n,r,a;if(typeof e[0]=="string"||Array.isArray(e[0])?([n,r,a]=e,t=_t):[t,n,r,a]=e,!t)return At;Array.isArray(n)||(n=[n]),Array.isArray(r)||(r=[r]);const l=[],o=()=>{l.forEach(d=>d()),l.length=0},i=(d,f,p,h)=>(d.addEventListener(f,p,h),()=>d.removeEventListener(f,p,h)),c=ve(()=>[Ze(t),je(a)],([d,f])=>{if(o(),!d)return;const p=v0(f)?{...f}:f;l.push(...n.flatMap(h=>r.map(g=>i(d,h,g,p))))},{immediate:!0,flush:"post"}),u=()=>{c(),o()};return Mn(u),u}let vs=!1;function C0(e,t,n={}){const{window:r=_t,ignore:a=[],capture:l=!0,detectIframe:o=!1}=n;if(!r)return At;Ya&&!vs&&(vs=!0,Array.from(r.document.body.children).forEach(p=>p.addEventListener("click",At)),r.document.documentElement.addEventListener("click",At));let i=!0;const c=p=>a.some(h=>{if(typeof h=="string")return Array.from(r.document.querySelectorAll(h)).some(g=>g===p.target||p.composedPath().includes(g));{const g=Ze(h);return g&&(p.target===g||p.composedPath().includes(g))}}),d=[Ce(r,"click",p=>{const h=Ze(e);if(!(!h||h===p.target||p.composedPath().includes(h))){if(p.detail===0&&(i=!c(p)),!i){i=!0;return}t(p)}},{passive:!0,capture:l}),Ce(r,"pointerdown",p=>{const h=Ze(e);i=!c(p)&&!!(h&&!p.composedPath().includes(h))},{passive:!0}),o&&Ce(r,"blur",p=>{setTimeout(()=>{var h;const g=Ze(e);((h=r.document.activeElement)==null?void 0:h.tagName)==="IFRAME"&&!(g!=null&&g.contains(r.document.activeElement))&&t(p)},0)})].filter(Boolean);return()=>d.forEach(p=>p())}function P0(){const e=Z(!1);return ln()&&ge(()=>{e.value=!0}),e}function pr(e){const t=P0();return y(()=>(t.value,!!e()))}function Tc(e,t={}){const{window:n=_t}=t,r=pr(()=>n&&"matchMedia"in n&&typeof n.matchMedia=="function");let a;const l=Z(!1),o=u=>{l.value=u.matches},i=()=>{a&&("removeEventListener"in a?a.removeEventListener("change",o):a.removeListener(o))},c=_l(()=>{r.value&&(i(),a=n.matchMedia(je(e)),"addEventListener"in a?a.addEventListener("change",o):a.addListener(o),l.value=a.matches)});return Mn(()=>{c(),i(),a=void 0}),l}function ms(e,t={}){const{controls:n=!1,navigator:r=xc}=t,a=pr(()=>r&&"permissions"in r);let l;const o=typeof e=="string"?{name:e}:e,i=Z(),c=()=>{l&&(i.value=l.state)},u=_0(async()=>{if(a.value){if(!l)try{l=await r.permissions.query(o),Ce(l,"change",c),c()}catch{i.value="prompt"}return l}});return u(),n?{state:i,isSupported:a,query:u}:i}function I0(e={}){const{navigator:t=xc,read:n=!1,source:r,copiedDuring:a=1500,legacy:l=!1}=e,o=pr(()=>t&&"clipboard"in t),i=ms("clipboard-read"),c=ms("clipboard-write"),u=y(()=>o.value||l),d=Z(""),f=Z(!1),p=A0(()=>f.value=!1,a);function h(){o.value&&i.value!=="denied"?t.clipboard.readText().then(b=>{d.value=b}):d.value=E()}u.value&&n&&Ce(["copy","cut"],h);async function g(b=je(r)){u.value&&b!=null&&(o.value&&c.value!=="denied"?await t.clipboard.writeText(b):w(b),d.value=b,f.value=!0,p.start())}function w(b){const L=document.createElement("textarea");L.value=b??"",L.style.position="absolute",L.style.opacity="0",document.body.appendChild(L),L.select(),document.execCommand("copy"),L.remove()}function E(){var b,L,_;return(_=(L=(b=document==null?void 0:document.getSelection)==null?void 0:b.call(document))==null?void 0:L.toString())!=null?_:""}return{isSupported:u,text:d,copied:f,copy:g}}const Rr=typeof globalThis<"u"?globalThis:typeof window<"u"?window:typeof global<"u"?global:typeof self<"u"?self:{},Or="__vueuse_ssr_handlers__",R0=O0();function O0(){return Or in Rr||(Rr[Or]=Rr[Or]||{}),Rr[Or]}function M0(e,t){return R0[e]||t}function $0(e){return e==null?"any":e instanceof Set?"set":e instanceof Map?"map":e instanceof Date?"date":typeof e=="boolean"?"boolean":typeof e=="string"?"string":typeof e=="object"?"object":Number.isNaN(e)?"any":"number"}const D0={boolean:{read:e=>e==="true",write:e=>String(e)},object:{read:e=>JSON.parse(e),write:e=>JSON.stringify(e)},number:{read:e=>Number.parseFloat(e),write:e=>String(e)},any:{read:e=>e,write:e=>String(e)},string:{read:e=>e,write:e=>String(e)},map:{read:e=>new Map(JSON.parse(e)),write:e=>JSON.stringify(Array.from(e.entries()))},set:{read:e=>new Set(JSON.parse(e)),write:e=>JSON.stringify(Array.from(e))},date:{read:e=>new Date(e),write:e=>e.toISOString()}},gs="vueuse-storage";function Lc(e,t,n,r={}){var a;const{flush:l="pre",deep:o=!0,listenToStorageChanges:i=!0,writeDefaults:c=!0,mergeDefaults:u=!1,shallow:d,window:f=_t,eventFilter:p,onError:h=M=>{console.error(M)},initOnMounted:g}=r,w=(d?lt:Z)(typeof t=="function"?t():t);if(!n)try{n=M0("getDefaultStorage",()=>{var M;return(M=_t)==null?void 0:M.localStorage})()}catch(M){h(M)}if(!n)return w;const E=je(t),b=$0(E),L=(a=r.serializer)!=null?a:D0[b],{pause:_,resume:A}=L0(w,()=>V(w.value),{flush:l,deep:o,eventFilter:p});return f&&i&&Bl(()=>{Ce(f,"storage",B),Ce(f,gs,K),g&&B()}),g||B(),w;function V(M){try{if(M==null)n.removeItem(e);else{const N=L.write(M),ne=n.getItem(e);ne!==N&&(n.setItem(e,N),f&&f.dispatchEvent(new CustomEvent(gs,{detail:{key:e,oldValue:ne,newValue:N,storageArea:n}})))}}catch(N){h(N)}}function T(M){const N=M?M.newValue:n.getItem(e);if(N==null)return c&&E!=null&&n.setItem(e,L.write(E)),E;if(!M&&u){const ne=L.read(N);return typeof u=="function"?u(ne,E):b==="object"&&!Array.isArray(ne)?{...E,...ne}:ne}else return typeof N!="string"?N:L.read(N)}function K(M){B(M.detail)}function B(M){if(!(M&&M.storageArea!==n)){if(M&&M.key==null){w.value=E;return}if(!(M&&M.key!==e)){_();try{(M==null?void 0:M.newValue)!==L.write(w.value)&&(w.value=T(M))}catch(N){h(N)}finally{M?Gt(A):A()}}}}}function V0(e){return Tc("(prefers-color-scheme: dark)",e)}function B0(e,t,n={}){const{window:r=_t,...a}=n;let l;const o=pr(()=>r&&"ResizeObserver"in r),i=()=>{l&&(l.disconnect(),l=void 0)},c=y(()=>Array.isArray(e)?e.map(f=>Ze(f)):[Ze(e)]),u=ve(c,f=>{if(i(),o.value&&r){l=new ResizeObserver(t);for(const p of f)p&&l.observe(p,a)}},{immediate:!0,flush:"post",deep:!0}),d=()=>{i(),u()};return Mn(d),{isSupported:o,stop:d}}function N0(e,t={width:0,height:0},n={}){const{window:r=_t,box:a="content-box"}=n,l=y(()=>{var f,p;return(p=(f=Ze(e))==null?void 0:f.namespaceURI)==null?void 0:p.includes("svg")}),o=Z(t.width),i=Z(t.height),{stop:c}=B0(e,([f])=>{const p=a==="border-box"?f.borderBoxSize:a==="content-box"?f.contentBoxSize:f.devicePixelContentBoxSize;if(r&&l.value){const h=Ze(e);if(h){const g=r.getComputedStyle(h);o.value=Number.parseFloat(g.width),i.value=Number.parseFloat(g.height)}}else if(p){const h=Array.isArray(p)?p:[p];o.value=h.reduce((g,{inlineSize:w})=>g+w,0),i.value=h.reduce((g,{blockSize:w})=>g+w,0)}else o.value=f.contentRect.width,i.value=f.contentRect.height},n);Bl(()=>{const f=Ze(e);f&&(o.value="offsetWidth"in f?f.offsetWidth:t.width,i.value="offsetHeight"in f?f.offsetHeight:t.height)});const u=ve(()=>Ze(e),f=>{o.value=f?t.width:0,i.value=f?t.height:0});function d(){c(),u()}return{width:o,height:i,stop:d}}const bs=["fullscreenchange","webkitfullscreenchange","webkitendfullscreen","mozfullscreenchange","MSFullscreenChange"];function Nl(e,t={}){const{document:n=S0,autoExit:r=!1}=t,a=y(()=>{var b;return(b=Ze(e))!=null?b:n==null?void 0:n.querySelector("html")}),l=Z(!1),o=y(()=>["requestFullscreen","webkitRequestFullscreen","webkitEnterFullscreen","webkitEnterFullScreen","webkitRequestFullScreen","mozRequestFullScreen","msRequestFullscreen"].find(b=>n&&b in n||a.value&&b in a.value)),i=y(()=>["exitFullscreen","webkitExitFullscreen","webkitExitFullScreen","webkitCancelFullScreen","mozCancelFullScreen","msExitFullscreen"].find(b=>n&&b in n||a.value&&b in a.value)),c=y(()=>["fullScreen","webkitIsFullScreen","webkitDisplayingFullscreen","mozFullScreen","msFullscreenElement"].find(b=>n&&b in n||a.value&&b in a.value)),u=["fullscreenElement","webkitFullscreenElement","mozFullScreenElement","msFullscreenElement"].find(b=>n&&b in n),d=pr(()=>a.value&&n&&o.value!==void 0&&i.value!==void 0&&c.value!==void 0),f=()=>u?(n==null?void 0:n[u])===a.value:!1,p=()=>{if(c.value){if(n&&n[c.value]!=null)return n[c.value];{const b=a.value;if((b==null?void 0:b[c.value])!=null)return!!b[c.value]}}return!1};async function h(){if(!(!d.value||!l.value)){if(i.value)if((n==null?void 0:n[i.value])!=null)await n[i.value]();else{const b=a.value;(b==null?void 0:b[i.value])!=null&&await b[i.value]()}l.value=!1}}async function g(){if(!d.value||l.value)return;p()&&await h();const b=a.value;o.value&&(b==null?void 0:b[o.value])!=null&&(await b[o.value](),l.value=!0)}async function w(){await(l.value?h():g())}const E=()=>{const b=p();(!b||b&&f())&&(l.value=b)};return Ce(n,bs,E,!1),Ce(()=>Ze(a),bs,E,!1),r&&Mn(h),{isSupported:d,isFullscreen:l,enter:g,exit:h,toggle:w}}function Aa(e){return typeof Window<"u"&&e instanceof Window?e.document.documentElement:typeof Document<"u"&&e instanceof Document?e.documentElement:e}function V3(e,t,n={}){const{window:r=_t}=n;return Lc(e,t,r==null?void 0:r.localStorage,n)}function Ac(e){const t=window.getComputedStyle(e);if(t.overflowX==="scroll"||t.overflowY==="scroll"||t.overflowX==="auto"&&e.clientWidth1?!0:(t.preventDefault&&t.preventDefault(),!1)}const Mr=new WeakMap;function zl(e,t=!1){const n=Z(t);let r=null,a;ve(E0(e),i=>{const c=Aa(je(i));if(c){const u=c;Mr.get(u)||Mr.set(u,a),n.value&&(u.style.overflow="hidden")}},{immediate:!0});const l=()=>{const i=Aa(je(e));!i||n.value||(Ya&&(r=Ce(i,"touchmove",c=>{z0(c)},{passive:!1})),i.style.overflow="hidden",n.value=!0)},o=()=>{var i;const c=Aa(je(e));!c||!n.value||(Ya&&(r==null||r()),c.style.overflow=(i=Mr.get(c))!=null?i:"",Mr.delete(c),n.value=!1)};return Mn(o),y({get(){return n.value},set(i){i?l():o()}})}function H0(e={}){const{window:t=_t,behavior:n="auto"}=e;if(!t)return{x:Z(0),y:Z(0)};const r=Z(t.scrollX),a=Z(t.scrollY),l=y({get(){return r.value},set(i){scrollTo({left:i,behavior:n})}}),o=y({get(){return a.value},set(i){scrollTo({top:i,behavior:n})}});return Ce(t,"scroll",()=>{r.value=t.scrollX,a.value=t.scrollY},{capture:!1,passive:!0}),{x:l,y:o}}function F0(e={}){const{window:t=_t,initialWidth:n=Number.POSITIVE_INFINITY,initialHeight:r=Number.POSITIVE_INFINITY,listenOrientation:a=!0,includeScrollbar:l=!0}=e,o=Z(n),i=Z(r),c=()=>{t&&(l?(o.value=t.innerWidth,i.value=t.innerHeight):(o.value=t.document.documentElement.clientWidth,i.value=t.document.documentElement.clientHeight))};if(c(),Bl(c),Ce("resize",c,{passive:!0}),a){const u=Tc("(orientation: portrait)");ve(u,()=>c())}return{width:o,height:i}}const Sc=()=>s(de,{name:"back-to-top"},()=>[s("path",{d:"M512 843.2c-36.2 0-66.4-13.6-85.8-21.8-10.8-4.6-22.6 3.6-21.8 15.2l7 102c.4 6.2 7.6 9.4 12.6 5.6l29-22c3.6-2.8 9-1.8 11.4 2l41 64.2c3 4.8 10.2 4.8 13.2 0l41-64.2c2.4-3.8 7.8-4.8 11.4-2l29 22c5 3.8 12.2.6 12.6-5.6l7-102c.8-11.6-11-20-21.8-15.2-19.6 8.2-49.6 21.8-85.8 21.8z"}),s("path",{d:"m795.4 586.2-96-98.2C699.4 172 513 32 513 32S324.8 172 324.8 488l-96 98.2c-3.6 3.6-5.2 9-4.4 14.2L261.2 824c1.8 11.4 14.2 17 23.6 10.8L419 744s41.4 40 94.2 40c52.8 0 92.2-40 92.2-40l134.2 90.8c9.2 6.2 21.6.6 23.6-10.8l37-223.8c.4-5.2-1.2-10.4-4.8-14zM513 384c-34 0-61.4-28.6-61.4-64s27.6-64 61.4-64c34 0 61.4 28.6 61.4 64S547 384 513 384z"})]);Sc.displayName="BackToTopIcon";const Cc=()=>s(de,{name:"close"},()=>s("path",{d:"m925.468 822.294-303.27-310.288L925.51 201.674c34.683-27.842 38.3-75.802 8.122-107.217-30.135-31.37-82.733-34.259-117.408-6.463L512.001 399.257 207.777 87.993C173.1 60.197 120.504 63.087 90.369 94.456c-30.179 31.415-26.561 79.376 8.122 107.217L401.8 512.005l-303.27 310.29c-34.724 27.82-38.34 75.846-8.117 107.194 30.135 31.437 82.729 34.327 117.408 6.486L512 624.756l304.177 311.22c34.68 27.84 87.272 24.95 117.408-6.487 30.223-31.348 26.56-79.375-8.118-107.195z"}));Cc.displayName="CloseIcon";var j0={"/":{backToTop:"返回顶部"}},W0=D({name:"BackToTop",props:{threshold:{type:Number,default:100},noProgress:Boolean},setup(e){const t=ye(),n=On(j0),r=lt(),{height:a}=N0(r),{height:l}=F0(),{y:o}=H0(),i=y(()=>t.value.backToTop!==!1&&o.value>e.threshold),c=y(()=>o.value/(a.value-l.value)*100);return ge(()=>{r.value=document.body}),()=>s(jt,{name:"fade"},()=>i.value?s("button",{type:"button",class:"vp-back-to-top-button","aria-label":n.value.backToTop,"data-balloon-pos":"left",onClick:()=>{window.scrollTo({top:0,behavior:"smooth"})}},[e.noProgress?null:s("span",{class:"vp-scroll-progress",role:"progressbar","aria-labelledby":"loadinglabel","aria-valuenow":c.value},s("svg",s("circle",{cx:"50%",cy:"50%",style:{"stroke-dasharray":`calc(${Math.PI*c.value}% - ${4*Math.PI}px) calc(${Math.PI*100}% - ${4*Math.PI}px)`}}))),s(Sc)]):null)}}),G0=D({name:"NoticeItem",props:{path:{type:String,default:""},match:{type:String,default:""},title:{type:String,required:!0},content:{type:String,required:!0},actions:{type:Array,default:()=>[]},noticeKey:{type:String,default:""},showOnce:Boolean,confirm:Boolean,fullscreen:Boolean},setup(e){const t=ot(),n=De(),r=Z(!1),a=y(()=>e.noticeKey?`notice-${e.noticeKey}`:`${e.title}${e.content}`),l=y(()=>e.match?new RegExp(e.match).test(t.path):Wt(t.path,e.path));ge(()=>{const c=(e.showOnce?localStorage:sessionStorage).getItem(a.value);r.value=!c});const o=()=>{r.value=!1,(e.showOnce?localStorage:sessionStorage).setItem(a.value,"true")},i=c=>{c&&(Rn(c)?n.push(c):dr(c)&&window.open(c)),o()};return()=>s(Vi,{name:"notice-fade"},()=>l.value&&r.value?[e.fullscreen?s("div",{key:"mask",class:"vp-notice-mask",onClick:()=>{e.confirm||o()}}):null,s("div",{key:"popup",class:["vp-notice-wrapper",{fullscreen:e.fullscreen}]},[s("header",{class:"vp-notice-title"},[e.confirm?null:s(Cc,{onClick:()=>o()}),s("span",{innerHTML:e.title})]),s("div",{class:"vp-notice-content",innerHTML:e.content}),s("div",{class:"vp-notice-footer"},e.actions.map(({text:c,link:u,type:d=""})=>s("button",{type:"button",class:["vp-notice-footer-action",d],onClick:()=>i(u),innerHTML:c})))])]:[])}});const Xa=({config:e})=>{const t=ot(),n=e.find(r=>"match"in r?new RegExp(r.match).test(t.path):Wt(t.path,r.path));return n?s(G0,n):null};Xa.displayName="Notice",Xa.props={config:{type:Array,required:!0}};const K0=Xe({enhance:({app:e})=>{Lt("Badge")||e.component("Badge",Ec),Lt("FontIcon")||e.component("FontIcon",p0)},setup:()=>{},rootComponents:[()=>s(W0,{}),()=>s(Xa,{config:[]})]});function q0(e,t,n){var r,a,l;t===void 0&&(t=50),n===void 0&&(n={});var o=(r=n.isImmediate)!=null&&r,i=(a=n.callback)!=null&&a,c=n.maxWait,u=Date.now(),d=[];function f(){if(c!==void 0){var h=Date.now()-u;if(h+t>=c)return c-h}return t}var p=function(){var h=[].slice.call(arguments),g=this;return new Promise(function(w,E){var b=o&&l===void 0;if(l!==void 0&&clearTimeout(l),l=setTimeout(function(){if(l=void 0,u=Date.now(),!o){var _=e.apply(g,h);i&&i(_),d.forEach(function(A){return(0,A.resolve)(_)}),d=[]}},f()),b){var L=e.apply(g,h);return i&&i(L),w(L)}d.push({resolve:w,reject:E})})};return p.cancel=function(h){l!==void 0&&clearTimeout(l),d.forEach(function(g){return(0,g.reject)(h)}),d=[]},p}const U0=({headerLinkSelector:e,headerAnchorSelector:t,delay:n,offset:r=5})=>{const a=De(),o=q0(()=>{var w,E;const i=Math.max(window.scrollY,document.documentElement.scrollTop,document.body.scrollTop);if(Math.abs(i-0)p.some(L=>L.hash===b.hash));for(let b=0;b=(((w=L.parentElement)==null?void 0:w.offsetTop)??0)-r,V=!_||i<(((E=_.parentElement)==null?void 0:E.offsetTop)??0)-r;if(!(A&&V))continue;const K=decodeURIComponent(a.currentRoute.value.hash),B=decodeURIComponent(L.hash);if(K===B)return;if(f){for(let M=b+1;M{window.addEventListener("scroll",o)}),kl(()=>{window.removeEventListener("scroll",o)})},ys=async(e,t)=>{const{scrollBehavior:n}=e.options;e.options.scrollBehavior=void 0,await e.replace({query:e.currentRoute.value.query,hash:t}).finally(()=>e.options.scrollBehavior=n)},Z0=".vp-sidebar-link, .toc-link",Y0=".header-anchor",X0=200,J0=5,Q0=Xe({setup(){U0({headerLinkSelector:Z0,headerAnchorSelector:Y0,delay:X0,offset:J0})}});let Pc=e=>oe(e.title)?{title:e.title}:null;const Ic=Symbol(""),e2=e=>{Pc=e},t2=()=>ue(Ic),n2=e=>{e.provide(Ic,Pc)};var r2={"/":{title:"目录",empty:"暂无目录"}},a2=D({name:"AutoCatalog",props:{base:{type:String,default:""},level:{type:Number,default:3},index:Boolean,hideHeading:Boolean},setup(e){const t=t2(),n=On(r2),r=se(),a=De(),l=qi(),o=Z(a.getRoutes().map(({meta:u,path:d})=>{const f=t(u);if(!f)return null;const p=d.split("/").length;return{level:Ir(d,"/")?p-2:p-1,base:d.replace(/\/[^/]+\/?$/,"/"),path:d,...f}}).filter(u=>$l(u)&&oe(u.title))),i=()=>{const u=e.base?Vf(Bi(e.base)):r.value.path.replace(/\/[^/]+$/,"/"),d=u.split("/").length-2,f=[];return o.value.filter(({level:p,path:h})=>{if(!Wt(h,u)||h===u)return!1;if(u==="/"){const g=yt(l.value.locales).filter(w=>w!=="/");if(h==="/404.html"||g.some(w=>Wt(h,w)))return!1}return p-d<=e.level&&(Ir(h,".html")&&!Ir(h,"/index.html")||Ir(h,"/"))}).sort(({title:p,level:h,order:g},{title:w,level:E,order:b})=>h-E||(La(g)?La(b)?g>0?b>0?g-b:-1:b<0?g-b:1:g:La(b)?b:p.localeCompare(w))).forEach(p=>{var w;const{base:h,level:g}=p;switch(g-d){case 1:f.push(p);break;case 2:{const E=f.find(b=>b.path===h);E&&(E.children??(E.children=[])).push(p);break}default:{const E=f.find(b=>b.path===h.replace(/\/[^/]+\/$/,"/"));if(E){const b=(w=E.children)==null?void 0:w.find(L=>L.path===h);b&&(b.children??(b.children=[])).push(p)}}}}),f},c=y(()=>i());return()=>{const u=c.value.some(d=>d.children);return s("div",{class:["vp-catalog-wrapper",{index:e.index}]},[e.hideHeading?null:s("h2",{class:"vp-catalog-main-title"},n.value.title),c.value.length?s(e.index?"ol":"ul",{class:["vp-catalogs",{deep:u}]},c.value.map(({children:d=[],title:f,path:p,content:h})=>{const g=s(Pe,{class:"vp-catalog-title",to:p},()=>h?s(h):f);return s("li",{class:"vp-catalog"},u?[s("h3",{id:f,class:["vp-catalog-child-title",{"has-children":d.length}]},[s("a",{href:`#${f}`,class:"header-anchor","aria-hidden":!0},"#"),g]),d.length?s(e.index?"ol":"ul",{class:"vp-child-catalogs"},d.map(({children:w=[],content:E,path:b,title:L})=>s("li",{class:"vp-child-catalog"},[s("div",{class:["vp-catalog-sub-title",{"has-children":w.length}]},[s("a",{href:`#${L}`,class:"header-anchor"},"#"),s(Pe,{class:"vp-catalog-title",to:b},()=>E?s(E):L)]),w.length?s(e.index?"ol":"div",{class:e.index?"vp-sub-catalogs":"vp-sub-catalogs-wrapper"},w.map(({content:_,path:A,title:V})=>e.index?s("li",{class:"vp-sub-catalog"},s(Pe,{to:A},()=>_?s(_):V)):s(Pe,{class:"vp-sub-catalog-link",to:A},()=>_?s(_):V))):null]))):null]:s("div",{class:"vp-catalog-child-title"},g))})):s("p",{class:"vp-empty-catalog"},n.value.empty)])}}}),l2=Xe({enhance:({app:e})=>{n2(e),Lt("AutoCatalog",e)||e.component("AutoCatalog",a2)}});const o2=s("svg",{class:"external-link-icon",xmlns:"http://www.w3.org/2000/svg","aria-hidden":"true",focusable:"false",x:"0px",y:"0px",viewBox:"0 0 100 100",width:"15",height:"15"},[s("path",{fill:"currentColor",d:"M18.8,85.1h56l0,0c2.2,0,4-1.8,4-4v-32h-8v28h-48v-48h28v-8h-32l0,0c-2.2,0-4,1.8-4,4v56C14.8,83.3,16.6,85.1,18.8,85.1z"}),s("polygon",{fill:"currentColor",points:"45.7,48.7 51.3,54.3 77.2,28.5 77.2,37.2 85.2,37.2 85.2,14.9 62.8,14.9 62.8,22.9 71.5,22.9"})]),Rc=D({name:"ExternalLinkIcon",props:{locales:{type:Object,required:!1,default:()=>({})}},setup(e){const t=ft(),n=y(()=>e.locales[t.value]??{openInNewWindow:"open in new window"});return()=>s("span",[o2,s("span",{class:"external-link-icon-sr-only"},n.value.openInNewWindow)])}});var s2={};const i2=s2,c2=Xe({enhance({app:e}){e.component("ExternalLinkIcon",s(Rc,{locales:i2}))}});/**
+ * NProgress, (c) 2013, 2014 Rico Sta. Cruz - http://ricostacruz.com/nprogress
+ * @license MIT
+ */const fe={settings:{minimum:.08,easing:"ease",speed:200,trickle:!0,trickleRate:.02,trickleSpeed:800,barSelector:'[role="bar"]',parent:"body",template:'
'},status:null,set:e=>{const t=fe.isStarted();e=Sa(e,fe.settings.minimum,1),fe.status=e===1?null:e;const n=fe.render(!t),r=n.querySelector(fe.settings.barSelector),a=fe.settings.speed,l=fe.settings.easing;return n.offsetWidth,u2(o=>{$r(r,{transform:"translate3d("+_s(e)+"%,0,0)",transition:"all "+a+"ms "+l}),e===1?($r(n,{transition:"none",opacity:"1"}),n.offsetWidth,setTimeout(function(){$r(n,{transition:"all "+a+"ms linear",opacity:"0"}),setTimeout(function(){fe.remove(),o()},a)},a)):setTimeout(()=>o(),a)}),fe},isStarted:()=>typeof fe.status=="number",start:()=>{fe.status||fe.set(0);const e=()=>{setTimeout(()=>{fe.status&&(fe.trickle(),e())},fe.settings.trickleSpeed)};return fe.settings.trickle&&e(),fe},done:e=>!e&&!fe.status?fe:fe.inc(.3+.5*Math.random()).set(1),inc:e=>{let t=fe.status;return t?(typeof e!="number"&&(e=(1-t)*Sa(Math.random()*t,.1,.95)),t=Sa(t+e,0,.994),fe.set(t)):fe.start()},trickle:()=>fe.inc(Math.random()*fe.settings.trickleRate),render:e=>{if(fe.isRendered())return document.getElementById("nprogress");ws(document.documentElement,"nprogress-busy");const t=document.createElement("div");t.id="nprogress",t.innerHTML=fe.settings.template;const n=t.querySelector(fe.settings.barSelector),r=e?"-100":_s(fe.status||0),a=document.querySelector(fe.settings.parent);return $r(n,{transition:"all 0 linear",transform:"translate3d("+r+"%,0,0)"}),a!==document.body&&ws(a,"nprogress-custom-parent"),a==null||a.appendChild(t),t},remove:()=>{Es(document.documentElement,"nprogress-busy"),Es(document.querySelector(fe.settings.parent),"nprogress-custom-parent");const e=document.getElementById("nprogress");e&&d2(e)},isRendered:()=>!!document.getElementById("nprogress")},Sa=(e,t,n)=>en?n:e,_s=e=>(-1+e)*100,u2=function(){const e=[];function t(){const n=e.shift();n&&n(t)}return function(n){e.push(n),e.length===1&&t()}}(),$r=function(){const e=["Webkit","O","Moz","ms"],t={};function n(o){return o.replace(/^-ms-/,"ms-").replace(/-([\da-z])/gi,function(i,c){return c.toUpperCase()})}function r(o){const i=document.body.style;if(o in i)return o;let c=e.length;const u=o.charAt(0).toUpperCase()+o.slice(1);let d;for(;c--;)if(d=e[c]+u,d in i)return d;return o}function a(o){return o=n(o),t[o]??(t[o]=r(o))}function l(o,i,c){i=a(i),o.style[i]=c}return function(o,i){for(const c in i){const u=i[c];u!==void 0&&Object.prototype.hasOwnProperty.call(i,c)&&l(o,c,u)}}}(),Oc=(e,t)=>(typeof e=="string"?e:Hl(e)).indexOf(" "+t+" ")>=0,ws=(e,t)=>{const n=Hl(e),r=n+t;Oc(n,t)||(e.className=r.substring(1))},Es=(e,t)=>{const n=Hl(e);if(!Oc(e,t))return;const r=n.replace(" "+t+" "," ");e.className=r.substring(1,r.length-1)},Hl=e=>(" "+(e.className||"")+" ").replace(/\s+/gi," "),d2=e=>{e&&e.parentNode&&e.parentNode.removeChild(e)},f2=()=>{ge(()=>{const e=De(),t=new Set;t.add(e.currentRoute.value.path),e.beforeEach(n=>{t.has(n.path)||fe.start()}),e.afterEach(n=>{t.add(n.path),fe.done()})})},p2=Xe({setup(){f2()}}),h2=JSON.parse('{"encrypt":{},"logo":"/logo.png","author":{"name":"Zephery","url":"https://wenzhihuai.com/article/"},"repo":"https://github.com/Zephery/MyWebsite","docsDir":"docs","pure":true,"breadcrumb":false,"footer":"粤ICP备17092242号-1 ","displayFooter":true,"pageInfo":["Author","Category","Tag","Original","Word","ReadingTime"],"blog":{"intro":"/about-the-author/","sidebarDisplay":"mobile","medias":{"Zhihu":"https://www.zhihu.com/people/javaZephery","Github":"https://github.com/Zephery","Gitee":"https://gitee.com/Zephery"}},"locales":{"/":{"lang":"zh-CN","navbarLocales":{"langName":"简体中文","selectLangAriaLabel":"选择语言"},"metaLocales":{"author":"作者","date":"写作日期","origin":"原创","views":"访问量","category":"分类","tag":"标签","readingTime":"阅读时间","words":"字数","toc":"此页内容","prev":"上一页","next":"下一页","lastUpdated":"上次编辑于","contributors":"贡献者","editLink":"编辑此页","print":"打印"},"blogLocales":{"article":"文章","articleList":"文章列表","category":"分类","tag":"标签","timeline":"时间轴","timelineTitle":"昨日不在","all":"全部","intro":"个人介绍","star":"星标","empty":"$text 为空"},"paginationLocales":{"prev":"上一页","next":"下一页","navigate":"跳转到","action":"前往","errorText":"请输入 1 到 $page 之前的页码!"},"outlookLocales":{"themeColor":"主题色","darkmode":"外观","fullscreen":"全屏"},"routeLocales":{"skipToContent":"跳至主要內容","notFoundTitle":"页面不存在","notFoundMsg":["这里什么也没有","我们是怎么来到这儿的?","这 是 四 零 四 !","看起来你访问了一个失效的链接"],"back":"返回上一页","home":"带我回家","openInNewWindow":"Open in new window"},"navbar":[{"text":"Java","icon":"java","link":"/index"},{"text":"中间件","icon":"middleware","link":"/middleware/"},{"text":"数据库","icon":"database","link":"/database/"},{"text":"大数据","icon":"bigdata","link":"/bigdata/"},{"text":"Kubernetes","icon":"Kubernetes","link":"/kubernetes/"},{"text":"个人网站","icon":"personalWebsite.ts","link":"/personalWebsite/"},{"text":"其他","icon":"others","link":"/others/"},{"text":"捐赠","icon":"donate","link":"/donate/"},{"text":"网站相关","icon":"about","children":[{"text":"关于作者","icon":"zuozhe","link":"/about-the-author/"}]}],"sidebar":{"/database/":[{"text":"MySQL","prefix":"mysql/","icon":"mysql","collapsible":false,"children":"structure"},{"text":"Redis","prefix":"redis/","icon":"redis","collapsible":false,"children":"structure"},{"text":"Elasticsearch","prefix":"elasticsearch/","icon":"elasticsearch","collapsible":false,"children":"structure"},{"text":"MongoDB","prefix":"mongodb/","icon":"mongodb","collapsible":false,"children":"structure"}],"/bigdata/":[{"text":"Spark","prefix":"spark/","icon":"bigdata","collapsible":false,"children":"structure"}],"/middleware/":[{"text":"Kafka","prefix":"kafka/","icon":"kafka","collapsible":false,"children":"structure"},{"text":"Zookeeper","prefix":"zookeeper/","icon":"zookeeper","collapsible":false,"children":"structure"}],"/personalWebsite/":[{"text":"个人网站","icon":"personalWebsite","collapsible":false,"children":"structure"}],"/kubernetes/":[{"text":"Kubernetes","icon":"kubernetes","collapsible":false,"children":["spark on k8s operator.md"]}],"/books/":[{"text":"计算机基础","link":"cs-basics","icon":"computer"},{"text":"数据库","link":"database","icon":"database"},{"text":"搜索引擎","link":"search-engine","icon":"search"},{"text":"Java","link":"java","icon":"java"},{"text":"软件质量","link":"software-quality","icon":"highavailable"},{"text":"分布式","link":"distributed-system","icon":"distributed-network"}],"/donate/":[{"text":"微信支付","link":"README","icon":"README"}],"/life/":[{"text":"生活","icon":"life","collapsible":false,"children":"structure"}],"/others/":[{"text":"其他","collapsible":false,"children":"structure"}],"/about-the-author/":[{"text":"个人生活","icon":"experience","prefix":"personal-life/","collapsible":false,"children":"structure"},{"text":"杂谈","icon":"chat","prefix":"talking/","collapsible":false,"children":"structure"}],"/high-quality-technical-articles/":[{"text":"练级攻略","icon":"et-performance","prefix":"advanced-programmer/","collapsible":false,"children":["programmer-quickly-learn-new-technology","the-growth-strategy-of-the-technological-giant","ten-years-of-dachang-growth-road","meituan-three-year-summary-lesson-10","seven-tips-for-becoming-an-advanced-programmer","20-bad-habits-of-bad-programmers","thinking-about-technology-and-business-after-five-years-of-work"]},{"text":"个人经历","icon":"experience","prefix":"personal-experience/","collapsible":false,"children":["four-year-work-in-tencent-summary","two-years-of-back-end-develop--experience-in-didi-and-toutiao","8-years-programmer-work-summary","huawei-od-275-days"]},{"text":"程序员","icon":"code","prefix":"programmer/","collapsible":false,"children":["how-do-programmers-publish-a-technical-book","efficient-book-publishing-and-practice-Zephery"]},{"text":"面试","icon":"interview","prefix":"interview/","collapsible":true,"children":["the-experience-of-get-offer-from-over-20-big-companies","the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer","technical-preliminary-preparation","screen-candidates-for-packaging","summary-of-spring-recruitment","my-personal-experience-in-2021","how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology","some-secrets-about-alibaba-interview"]},{"text":"工作","icon":"work","prefix":"work/","collapsible":true,"children":["get-into-work-mode-quickly-when-you-join-a-company","32-tips-improving-career","employee-performance"]}],"/zhuanlan/":["java-mian-shi-zhi-bei","back-end-interview-high-frequency-system-design-and-scenario-questions","handwritten-rpc-framework","source-code-reading"],"/":[{"text":"Java","icon":"java","collapsible":false,"prefix":"java/","children":"structure"}]}}}}'),v2=Z(h2),Mc=()=>v2,$c=Symbol(""),m2=()=>{const e=ue($c);if(!e)throw new Error("useThemeLocaleData() is called without provider.");return e},g2=(e,t)=>{const{locales:n,...r}=e;return{...r,...n==null?void 0:n[t]}},b2=Xe({enhance({app:e}){const t=Mc(),n=e._context.provides[Il],r=y(()=>g2(t.value,n.value));e.provide($c,r),Object.defineProperties(e.config.globalProperties,{$theme:{get(){return t.value}},$themeLocale:{get(){return r.value}}})}});var y2={"/":{copy:"复制代码",copied:"已复制",hint:"复制成功"}},_2=['.theme-hope-content div[class*="language-"] pre'];const w2=800,E2=2e3,k2=y2,x2=_2,ks=!1,Ca=new Map,T2=()=>{const{copy:e}=I0({legacy:!0}),t=On(k2),n=se(),r=f0(),a=i=>{if(!i.hasAttribute("copy-code-registered")){const c=document.createElement("button");c.type="button",c.classList.add("copy-code-button"),c.innerHTML='
',c.setAttribute("aria-label",t.value.copy),c.setAttribute("data-copied",t.value.copied),i.parentElement&&i.parentElement.insertBefore(c,i),i.setAttribute("copy-code-registered","")}},l=()=>Gt().then(()=>new Promise(i=>{setTimeout(()=>{x2.forEach(c=>{document.querySelectorAll(c).forEach(a)}),i()},w2)})),o=(i,c,u)=>{let{innerText:d=""}=c;/language-(shellscript|shell|bash|sh|zsh)/.test(i.classList.toString())&&(d=d.replace(/^ *(\$|>) /gm,"")),e(d).then(()=>{u.classList.add("copied"),clearTimeout(Ca.get(u));const f=setTimeout(()=>{u.classList.remove("copied"),u.blur(),Ca.delete(u)},E2);Ca.set(u,f)})};ge(()=>{(!r.value||ks)&&l(),Ce("click",i=>{const c=i.target;if(c.matches('div[class*="language-"] > button.copy')){const u=c.parentElement,d=c.nextElementSibling;d&&o(u,d,c)}else if(c.matches('div[class*="language-"] div.copy-icon')){const u=c.parentElement,d=u.parentElement,f=u.nextElementSibling;f&&o(d,f,u)}}),ve(()=>n.value.path,()=>{(!r.value||ks)&&l()})})};var L2=Xe({setup:()=>{T2()}}),A2={"/":{author:"著作权归:author所有",license:"基于:license协议",link:"原文链接::link"}};const Pa="https://wenzhihuai.com/",S2=()=>{const e=ye(),t=On(A2),n=se(),r=y(()=>!!e.value.copy||e.value.copy!==!1&&!0),a=y(()=>$l(e.value.copy)?e.value.copy:null),l=y(()=>{var h;return((h=a.value)==null?void 0:h.disableCopy)??!1}),o=y(()=>{var h;return r.value?((h=a.value)==null?void 0:h.disableSelection)??!1:!1}),i=y(()=>{var h;return r.value?((h=a.value)==null?void 0:h.maxLength)??700:0}),c=y(()=>{var h;return((h=a.value)==null?void 0:h.triggerLength)??100}),u=()=>`${n0(dr(Pa)?Pa:`https://${Pa}`)}${n.value.path}`,d=(h,g)=>{const{author:w,license:E,link:b}=t.value;return[h?w.replace(":author",h):"",g?E.replace(":license",g):"",b.replace(":link",u())].filter(L=>L).join(`
+`)},f=()=>{if(bt(n.value.copyright))return n.value.copyright.replace(":link",u());const{author:h,license:g}=n.value.copyright||{};return d(h??"wenzhihuai.com",g??"MIT")},p=h=>{const g=getSelection();if(g){const w=g.getRangeAt(0);if(r.value){const E=w.toString().length;if(l.value||i.value&&E>i.value)return h.preventDefault();if(E>=c.value){h.preventDefault();const b=f(),L=document.createElement("div");L.appendChild(g.getRangeAt(0).cloneContents()),h.clipboardData&&(h.clipboardData.setData("text/html",`${L.innerHTML}${b.replace(/\\n/g,"
`),h.clipboardData.setData("text/plain",`${g.getRangeAt(0).cloneContents().textContent||""}
+------
+${b}`))}}}};ge(()=>{const h=document.querySelector("#app");Ce(h,"copy",p),_l(()=>{h.style.userSelect=o.value?"none":"auto"})})};var C2=Xe({setup:()=>{S2()}});let P2={};const Dc=Symbol(""),I2=()=>ue(Dc),R2=e=>{e.provide(Dc,P2)};var O2={"/":{closeTitle:"关闭",downloadTitle:"下载图片",fullscreenTitle:"切换全屏",zoomTitle:"缩放",arrowPrevTitle:"上一个 (左箭头)",arrowNextTitle:"下一个 (右箭头)"}};const M2=".theme-hope-content :not(a) > img:not([no-view])",$2=O2,D2=800,V2='',B2=e=>oe(e)?Array.from(document.querySelectorAll(e)):e.map(t=>Array.from(document.querySelectorAll(t))).flat(),Vc=e=>new Promise((t,n)=>{e.complete?t({type:"image",element:e,src:e.src,width:e.naturalWidth,height:e.naturalHeight,alt:e.alt,msrc:e.src}):(e.onload=()=>t(Vc(e)),e.onerror=r=>n(r))}),N2=()=>{const e=On($2),t=ye(),n=se(),{isSupported:r,toggle:a}=Nl(),l=I2();let o;const i=y(()=>t.value.photoSwipe===!1?!1:t.value.photoSwipe||M2),c=d=>{d.on("uiRegister",()=>{r&&d.ui.registerElement({name:"fullscreen",order:7,isButton:!0,html:'{p.goTo(h.indexOf(b.target))},h.push(E),f.appendChild(E)}p.on("change",()=>{g>=0&&h[g].classList.remove("active"),h[p.currIndex].classList.add("active"),g=p.currIndex})}})})},u=async()=>{if(i.value)return Promise.all([x(()=>import("./photoswipe.esm-08_zHRDQ.js"),__vite__mapDeps([])),Gt().then(()=>new Promise(d=>setTimeout(d,D2)).then(()=>B2(i.value)))]).then(([{default:d},f])=>{const p=f.map(h=>({html:V2,element:h,msrc:h.src}));f.forEach((h,g)=>{const w=()=>{o=new d({preloaderDelay:0,showHideAnimationType:"zoom",...e.value,...l,dataSource:p,index:g,closeOnVerticalDrag:!0,wheelToZoom:!1}),c(o),o.addFilter("thumbEl",()=>h),o.addFilter("placeholderSrc",()=>h.src),o.init()};h.style.cursor="zoom-in",h.addEventListener("click",()=>{w()}),h.addEventListener("keypress",({key:E})=>{E==="Enter"&&w()})}),f.forEach((h,g)=>{Vc(h).then(w=>{p.splice(g,1,w),o==null||o.refreshSlideContent(g)})})})};ge(()=>{Ce("wheel",()=>{o==null||o.close()}),ve(()=>n.value.path,u,{immediate:!0})})};var z2=Xe({enhance:({app:e})=>{R2(e)},setup:()=>{N2()}}),xs={"/":{word:"约 $word 字",less1Minute:"小于 1 分钟",time:"大约 $time 分钟"}};const Bc=()=>{const e=se();return y(()=>e.value.readingTime??null)},Ja=typeof xs>"u"?null:xs,Nc=(e,t)=>{const{minutes:n,words:r}=e,{less1Minute:a,word:l,time:o}=t;return{time:n<1?a:o.replace("$time",Math.round(n).toString()),words:l.replace("$word",r.toString())}},Ts={words:"",time:""},zc=()=>Ja?On(Ja):y(()=>null),H2=()=>{if(typeof Ja>"u")return y(()=>Ts);const e=Bc(),t=zc();return y(()=>e.value&&t.value?Nc(e.value,t.value):Ts)},Kt=()=>Mc(),ie=()=>m2(),sn=()=>y(()=>!!Kt().value.pure);var Ia=D({name:"EmptyComponent",setup:()=>()=>null});const F2="719px",j2="1440px",W2="true",Fl={mobileBreakPoint:F2,pcBreakPoint:j2,enableThemeColor:W2,"theme-1":"#2196f3","theme-2":"#f26d6d","theme-3":"#3eaf7c","theme-4":"#fb9b5f"},jl={"/database/mysql/":["gap锁","1mysql","执行计划explain","数据库缓存"],"/database/redis/":[],"/database/elasticsearch/":["【elasticsearch】搜索过程详解","elasticsearch源码debug"],"/database/mongodb/":[],"/bigdata/spark/":["elastic-spark"],"/middleware/kafka/":["kafka"],"/middleware/zookeeper/":["zookeeper"],"/personalWebsite/":["1.历史与架构","2.Lucene的使用","3.定时任务","4.日志系统","5.小集群部署","6.数据库备份","7.那些牛逼的插件","8.基于贝叶斯的情感分析","9.网站性能优化","10.网站重构"],"/life/":["2017","2018","2019"],"/others/":["tesla","chatgpt"],"/about-the-author/personal-life/":["wewe"],"/about-the-author/talking/":[],"/java/":["JVM调优参数","lucene搜索原理","一次jvm调优过程","内存屏障","在 Spring 6 中使用虚拟线程","基于kubernetes的分布式限流","serverlog"]},Hc=e=>{const{icon:t="",color:n,size:r}=e,a={};return n&&(a.color=n),r&&(a.height=Number.isNaN(Number(r))?r:`${r}px`),on(t)?s("img",{class:"icon",src:t,"no-view":"",style:a}):Rn(t)?s("img",{class:"icon",src:Ee(t),"aria-hidden":"","no-view":"",style:a}):s(Ye("FontIcon"),e)};Hc.displayName="HopeIcon";var ze=Hc;const hr=()=>{const e=De(),t=ot();return n=>{if(n)if(Rn(n))t.path!==n&&e.push(n);else if(Ni(n))window&&window.open(n);else{const r=t.path.slice(0,t.path.lastIndexOf("/"));e.push(`${r}/${encodeURI(n)}`)}}},Fc=()=>{const e=ie(),t=ye();return y(()=>{const{author:n}=t.value;return n?rr(n):n===!1?[]:rr(e.value.author,!1)})},G2=()=>{const e=ye();return y(()=>fc(e.value.category).map(t=>{var n,r;return{name:t,path:((r=(n=ue(Symbol.for("categoryMap")))==null?void 0:n.value.map[t])==null?void 0:r.path)||""}}))},K2=()=>{const e=ye();return y(()=>pc(e.value.tag).map(t=>{var n,r;return{name:t,path:((r=(n=ue(Symbol.for("tagMap")))==null?void 0:n.value.map[t])==null?void 0:r.path)||""}}))},q2=()=>{const e=ye(),t=se();return y(()=>{const n=Ml(e.value.date);if(n)return n;const{createdTime:r}=t.value.git||{};return r?new Date(r):null})},U2=()=>{const e=ie(),t=se(),n=ye(),r=Fc(),a=G2(),l=K2(),o=q2(),i=Bc(),c=H2(),u=y(()=>({author:r.value,category:a.value,date:o.value,localizedDate:t.value.localizedDate,tag:l.value,isOriginal:n.value.isOriginal||!1,readingTime:i.value,readingTimeLocale:c.value,pageview:"pageview"in n.value?n.value.pageview:!0})),d=y(()=>"pageInfo"in n.value?n.value.pageInfo:"pageInfo"in e.value?e.value.pageInfo:null);return{info:u,items:d}},{mobileBreakPoint:Z2,pcBreakPoint:Y2}=Fl,Ls=e=>e.endsWith("px")?Number(e.slice(0,-2)):null,vr=()=>{const e=Z(!1),t=Z(!1),n=()=>{e.value=window.innerWidth<=(Ls(Z2)??719),t.value=window.innerWidth>=(Ls(Y2)??1440)};return ge(()=>{n(),Ce("resize",n,!1),Ce("orientationchange",n,!1)}),{isMobile:e,isPC:t}},jc=Symbol(""),mr=()=>{const e=ue(jc);if(!e)throw new Error("useDarkmode() is called without provider.");return e},X2=e=>{const t=Kt(),n=V0(),r=Lc("vuepress-theme-hope-scheme","auto"),a=y(()=>t.value.darkmode||"switch"),l=y(()=>{const i=a.value;return i==="disable"?!1:i==="enable"?!0:i==="auto"?n.value:i==="toggle"?r.value==="dark":r.value==="dark"||r.value==="auto"&&n.value}),o=y(()=>{const i=a.value;return i==="switch"||i==="toggle"});e.provide(jc,{canToggle:o,config:a,isDarkmode:l,status:r}),Object.defineProperties(e.config.globalProperties,{$isDarkmode:{get:()=>l.value}})},J2=()=>{const{isDarkmode:e}=mr(),t=(n=e.value)=>document.documentElement.setAttribute("data-theme",n?"dark":"light");ge(()=>{ve(e,t,{immediate:!0})})};var We=D({name:"AutoLink",inheritAttrs:!1,props:{config:{type:Object,required:!0},exact:Boolean,noExternalLinkIcon:Boolean},emits:["focusout"],slots:Object,setup(e,{attrs:t,emit:n,slots:r}){const a=ot(),l=qi(),o=Sn(e,"config"),i=y(()=>on(o.value.link)),c=y(()=>!i.value&&Ni(o.value.link)),u=y(()=>o.value.target||(i.value?"_blank":void 0)),d=y(()=>u.value==="_blank"),f=y(()=>!i.value&&!c.value&&!d.value),p=y(()=>o.value.rel||(d.value?"noopener noreferrer":void 0)),h=y(()=>o.value.ariaLabel||o.value.text),g=y(()=>{if(e.exact)return!1;const E=yt(l.value.locales);return E.length?E.every(b=>b!==o.value.link):o.value.link!=="/"}),w=y(()=>f.value?o.value.activeMatch?new RegExp(o.value.activeMatch).test(a.path):g.value?Wt(a.path,o.value.link):a.path===o.value.link:!1);return()=>{const{before:E,after:b,default:L}=r,{text:_,icon:A,link:V}=o.value;return f.value?s(Pe,{to:V,"aria-label":h.value,...t,class:["nav-link",{active:w.value},t.class],onFocusout:()=>n("focusout")},()=>L?L():[E?E():s(ze,{icon:A}),_,b==null?void 0:b()]):s("a",{href:V,rel:p.value,target:u.value,"aria-label":h.value,...t,class:["nav-link",t.class],onFocusout:()=>n("focusout")},L?L():[E?E():s(ze,{icon:A}),_,e.noExternalLinkIcon?null:s(Rc),b==null?void 0:b()])}}});const Ln=(e,t,n=!1)=>"activeMatch"in t?new RegExp(t.activeMatch).test(e.path):vc(e,t.link)?!0:t.children&&!n?t.children.some(r=>Ln(e,r)):!1,Wc=(e,t)=>t.type==="group"?t.children.some(n=>n.type==="group"?Wc(e,n):n.type==="page"&&Ln(e,n,!0))||"prefix"in t&&vc(e,t.prefix):!1,Gc=(e,t)=>oe(e.link)?s(We,{...t,config:e}):s("p",t,[s(ze,{icon:e.icon}),e.text]),Kc=e=>{const t=ot();return e?s("ul",{class:"vp-sidebar-sub-headers"},e.map(n=>s("li",{class:"vp-sidebar-sub-header"},[Gc(n,{class:["vp-sidebar-link","vp-heading",{active:Ln(t,n,!0)}]}),Kc(n.children)]))):null};var we=(e=>(e.type="y",e.title="t",e.shortTitle="s",e.icon="i",e.author="a",e.date="d",e.localizedDate="l",e.category="c",e.tag="g",e.isEncrypted="n",e.isOriginal="o",e.readingTime="r",e.excerpt="e",e.sticky="u",e.cover="v",e.index="I",e.order="O",e))(we||{}),qc=(e=>(e.article="a",e.home="h",e.slide="s",e.page="p",e))(qc||{});const Jt=(e="",t="")=>Rn(t)?t:`${Bi(e)}${t}`,bn=(e,t,n=!1)=>{let r=Tn(e,uc(encodeURI(t)));r.name==="404"&&(r=Tn(e,t));const{fullPath:a,meta:l,name:o}=r;return{text:!n&&l[we.shortTitle]?l[we.shortTitle]:l[we.title]||t,link:o==="404"?t:a,...l[we.icon]?{icon:l[we.icon]}:{}}},Q2=(e,t)=>{const n=se();return{type:"heading",text:e.title,link:`${n.value.path}#${e.slug}`,children:Wl(e.children,t)}},Wl=(e,t)=>t>0?e.map(n=>Q2(n,t-1)):[],Uc=e=>{const t=se();return Wl(t.value.headers,e)},Qa=(e,t,n="")=>{const r=De(),a=se(),l=(o,i=n)=>{var u;const c=oe(o)?bn(r,Jt(i,o)):o.link?{...o,...Ur(o.link)?{}:{link:bn(r,Jt(i,o.link)).link}}:o;if("children"in c){const d=Jt(i,c.prefix),f=c.children==="structure"?jl[d]:c.children;return{type:"group",...c,prefix:d,children:f.map(p=>l(p,d))}}return{type:"page",...c,children:c.link===a.value.path?Wl(((u=a.value.headers[0])==null?void 0:u.level)===1?a.value.headers[0].children:a.value.headers,t):[]}};return e.map(o=>l(o))},eh=(e,t)=>{const n=se(),r=yt(e).sort((a,l)=>l.length-a.length);for(const a of r)if(Wt(decodeURI(n.value.path),a)){const l=e[a];return l?Qa(l==="structure"?jl[a]:l==="heading"?Uc(t):l,t,a):[]}return console.warn(`${n.value.path} is missing sidebar config.`),[]},th=(e,t)=>{const n=ft();return e===!1?[]:e==="heading"?Uc(t):e==="structure"?Qa(jl[n.value],t,n.value):Q(e)?Qa(e,t):Sl(e)?eh(e,t):[]},Zc=Symbol(""),nh=()=>{const e=ye(),t=ie(),n=se(),r=y(()=>e.value.home?!1:e.value.sidebar??t.value.sidebar??"structure"),a=y(()=>e.value.headerDepth??t.value.headerDepth??2),l=Dl(()=>[r.value,a.value,n.value.path,null],()=>th(r.value,a.value));rt(Zc,l)},Gl=()=>{const e=ue(Zc);if(!e)throw new Error("useSidebarItems() is called without provider.");return e};var rh=D({name:"PageFooter",setup(){const e=Kt(),t=ie(),n=ye(),r=Fc(),a=y(()=>{const{copyright:u,footer:d}=n.value;return d!==!1&&!!(u||d||t.value.displayFooter)}),l=y(()=>{const{footer:u}=n.value;return u===!1?!1:oe(u)?u:t.value.footer||""}),o=y(()=>r.value.map(({name:u})=>u).join(", ")),i=u=>`Copyright © ${new Date().getFullYear()} ${o.value} ${u?`${u} Licensed`:""}`,c=y(()=>{const{copyright:u,license:d=""}=n.value,{license:f}=e.value,{copyright:p}=t.value;return u??(d?i(d):oe(p)?p:o.value||f?i(f):!1)});return()=>a.value?s("footer",{class:"vp-footer-wrapper"},[l.value?s("div",{class:"vp-footer",innerHTML:l.value}):null,c.value?s("div",{class:"vp-copyright",innerHTML:c.value}):null]):null}}),ah=D({name:"NavbarDropdownLink",props:{config:{type:Object,required:!0}},slots:Object,setup(e,{slots:t}){const n=se(),r=Sn(e,"config"),a=y(()=>r.value.ariaLabel||r.value.text),l=Z(!1);ve(()=>n.value.path,()=>{l.value=!1});const o=i=>{i.detail===0&&(l.value=!l.value)};return()=>{var i;return s("div",{class:["dropdown-wrapper",{open:l.value}]},[s("button",{type:"button",class:"dropdown-title","aria-label":a.value,onClick:o},[((i=t.title)==null?void 0:i.call(t))||s("span",{class:"title"},[s(ze,{icon:r.value.icon}),e.config.text]),s("span",{class:"arrow"}),s("ul",{class:"nav-dropdown"},r.value.children.map((c,u)=>{const d=u===r.value.children.length-1;return s("li",{class:"dropdown-item"},"children"in c?[s("h4",{class:"dropdown-subtitle"},c.link?s(We,{config:c,onFocusout:()=>{c.children.length===0&&d&&(l.value=!1)}}):s("span",c.text)),s("ul",{class:"dropdown-subitem-wrapper"},c.children.map((f,p)=>s("li",{class:"dropdown-subitem"},s(We,{config:f,onFocusout:()=>{p===c.children.length-1&&d&&(l.value=!1)}}))))]:s(We,{config:c,onFocusout:()=>{d&&(l.value=!1)}}))}))])])}}});const Yc=(e,t,n="")=>oe(t)?bn(e,Jt(n,t)):"children"in t?{...t,...t.link&&!Ur(t.link)?bn(e,Jt(n,t.link)):{},children:t.children.map(r=>Yc(e,r,Jt(n,t.prefix)))}:{...t,link:Ur(t.link)?t.link:bn(e,Jt(n,t.link)).link},Xc=()=>{const e=ie(),t=De(),n=()=>(e.value.navbar||[]).map(r=>Yc(t,r));return Dl(()=>e.value.navbar,()=>n())},lh=()=>{const e=ie(),t=y(()=>e.value.repo||null),n=y(()=>t.value?c0(t.value):null),r=y(()=>t.value?mc(t.value):null),a=y(()=>n.value?e.value.repoLabel??(r.value===null?"Source":r.value):null);return y(()=>!n.value||!a.value||e.value.repoDisplay===!1?null:{type:r.value||"Source",label:a.value,link:n.value})};var oh=D({name:"NavScreenDropdown",props:{config:{type:Object,required:!0}},setup(e){const t=se(),n=Sn(e,"config"),r=y(()=>n.value.ariaLabel||n.value.text),a=Z(!1);ve(()=>t.value.path,()=>{a.value=!1});const l=(o,i)=>i[i.length-1]===o;return()=>[s("button",{type:"button",class:["nav-screen-dropdown-title",{active:a.value}],"aria-label":r.value,onClick:()=>{a.value=!a.value}},[s("span",{class:"title"},[s(ze,{icon:n.value.icon}),e.config.text]),s("span",{class:["arrow",a.value?"down":"end"]})]),s("ul",{class:["nav-screen-dropdown",{hide:!a.value}]},n.value.children.map(o=>s("li",{class:"dropdown-item"},"children"in o?[s("h4",{class:"dropdown-subtitle"},o.link?s(We,{config:o,onFocusout:()=>{l(o,n.value.children)&&o.children.length===0&&(a.value=!1)}}):s("span",o.text)),s("ul",{class:"dropdown-subitem-wrapper"},o.children.map(i=>s("li",{class:"dropdown-subitem"},s(We,{config:i,onFocusout:()=>{l(i,o.children)&&l(o,n.value.children)&&(a.value=!1)}}))))]:s(We,{config:o,onFocusout:()=>{l(o,n.value.children)&&(a.value=!1)}}))))]}}),sh=D({name:"NavScreenLinks",setup(){const e=Xc();return()=>e.value.length?s("nav",{class:"nav-screen-links"},e.value.map(t=>s("div",{class:"navbar-links-item"},"children"in t?s(oh,{config:t}):s(We,{config:t})))):null}});const Jc=()=>s(de,{name:"dark"},()=>s("path",{d:"M524.8 938.667h-4.267a439.893 439.893 0 0 1-313.173-134.4 446.293 446.293 0 0 1-11.093-597.334A432.213 432.213 0 0 1 366.933 90.027a42.667 42.667 0 0 1 45.227 9.386 42.667 42.667 0 0 1 10.24 42.667 358.4 358.4 0 0 0 82.773 375.893 361.387 361.387 0 0 0 376.747 82.774 42.667 42.667 0 0 1 54.187 55.04 433.493 433.493 0 0 1-99.84 154.88 438.613 438.613 0 0 1-311.467 128z"}));Jc.displayName="DarkIcon";const Qc=()=>s(de,{name:"light"},()=>s("path",{d:"M952 552h-80a40 40 0 0 1 0-80h80a40 40 0 0 1 0 80zM801.88 280.08a41 41 0 0 1-57.96-57.96l57.96-58a41.04 41.04 0 0 1 58 58l-58 57.96zM512 752a240 240 0 1 1 0-480 240 240 0 0 1 0 480zm0-560a40 40 0 0 1-40-40V72a40 40 0 0 1 80 0v80a40 40 0 0 1-40 40zm-289.88 88.08-58-57.96a41.04 41.04 0 0 1 58-58l57.96 58a41 41 0 0 1-57.96 57.96zM192 512a40 40 0 0 1-40 40H72a40 40 0 0 1 0-80h80a40 40 0 0 1 40 40zm30.12 231.92a41 41 0 0 1 57.96 57.96l-57.96 58a41.04 41.04 0 0 1-58-58l58-57.96zM512 832a40 40 0 0 1 40 40v80a40 40 0 0 1-80 0v-80a40 40 0 0 1 40-40zm289.88-88.08 58 57.96a41.04 41.04 0 0 1-58 58l-57.96-58a41 41 0 0 1 57.96-57.96z"}));Qc.displayName="LightIcon";const eu=()=>s(de,{name:"auto"},()=>s("path",{d:"M512 992C246.92 992 32 777.08 32 512S246.92 32 512 32s480 214.92 480 480-214.92 480-480 480zm0-840c-198.78 0-360 161.22-360 360 0 198.84 161.22 360 360 360s360-161.16 360-360c0-198.78-161.22-360-360-360zm0 660V212c165.72 0 300 134.34 300 300 0 165.72-134.28 300-300 300z"}));eu.displayName="AutoIcon";const tu=()=>s(de,{name:"enter-fullscreen"},()=>s("path",{d:"M762.773 90.24h-497.28c-96.106 0-174.4 78.293-174.4 174.4v497.28c0 96.107 78.294 174.4 174.4 174.4h497.28c96.107 0 175.04-78.293 174.4-174.4V264.64c0-96.213-78.186-174.4-174.4-174.4zm-387.2 761.173H215.04c-21.867 0-40.427-17.92-41.067-41.066V649.92c0-22.507 17.92-40.427 40.427-40.427 11.307 0 21.227 4.694 28.48 11.947 7.253 7.253 11.947 17.92 11.947 28.48v62.293l145.28-145.28c15.893-15.893 41.813-15.893 57.706 0 15.894 15.894 15.894 41.814 0 57.707l-145.28 145.28h62.294c22.506 0 40.426 17.92 40.426 40.427s-17.173 41.066-39.68 41.066zM650.24 165.76h160.427c21.866 0 40.426 17.92 41.066 41.067v160.426c0 22.507-17.92 40.427-40.426 40.427-11.307 0-21.227-4.693-28.48-11.947-7.254-7.253-11.947-17.92-11.947-28.48v-62.186L625.6 450.347c-15.893 15.893-41.813 15.893-57.707 0-15.893-15.894-15.893-41.814 0-57.707l145.28-145.28H650.88c-22.507 0-40.427-17.92-40.427-40.427s17.174-41.173 39.787-41.173z"}));tu.displayName="EnterFullScreenIcon";const nu=()=>s(de,{name:"cancel-fullscreen"},()=>s("path",{d:"M778.468 78.62H247.922c-102.514 0-186.027 83.513-186.027 186.027V795.08c0 102.514 83.513 186.027 186.027 186.027h530.432c102.514 0 186.71-83.513 186.026-186.027V264.647C964.494 162.02 880.981 78.62 778.468 78.62zM250.88 574.35h171.122c23.324 0 43.122 19.115 43.804 43.805v171.121c0 24.008-19.114 43.122-43.122 43.122-12.06 0-22.641-5.006-30.378-12.743s-12.743-19.115-12.743-30.379V722.83L224.597 877.91c-16.953 16.952-44.6 16.952-61.553 0-16.953-16.954-16.953-44.602 0-61.554L318.009 661.39h-66.446c-24.007 0-43.122-19.114-43.122-43.122 0-24.12 18.432-43.918 42.439-43.918zm521.899-98.873H601.657c-23.325 0-43.122-19.114-43.805-43.804V260.55c0-24.007 19.115-43.122 43.122-43.122 12.06 0 22.642 5.007 30.379 12.743s12.743 19.115 12.743 30.38v66.445l154.965-154.965c16.953-16.953 44.601-16.953 61.554 0 16.953 16.953 16.953 44.6 0 61.554L705.536 388.55h66.446c24.007 0 43.122 19.115 43.122 43.122.114 24.007-18.318 43.804-42.325 43.804z"}));nu.displayName="CancelFullScreenIcon";const ru=()=>s(de,{name:"outlook"},()=>[s("path",{d:"M224 800c0 9.6 3.2 44.8 6.4 54.4 6.4 48-48 76.8-48 76.8s80 41.6 147.2 0 134.4-134.4 38.4-195.2c-22.4-12.8-41.6-19.2-57.6-19.2C259.2 716.8 227.2 761.6 224 800zM560 675.2l-32 51.2c-51.2 51.2-83.2 32-83.2 32 25.6 67.2 0 112-12.8 128 25.6 6.4 51.2 9.6 80 9.6 54.4 0 102.4-9.6 150.4-32l0 0c3.2 0 3.2-3.2 3.2-3.2 22.4-16 12.8-35.2 6.4-44.8-9.6-12.8-12.8-25.6-12.8-41.6 0-54.4 60.8-99.2 137.6-99.2 6.4 0 12.8 0 22.4 0 12.8 0 38.4 9.6 48-25.6 0-3.2 0-3.2 3.2-6.4 0-3.2 3.2-6.4 3.2-6.4 6.4-16 6.4-16 6.4-19.2 9.6-35.2 16-73.6 16-115.2 0-105.6-41.6-198.4-108.8-268.8C704 396.8 560 675.2 560 675.2zM224 419.2c0-28.8 22.4-51.2 51.2-51.2 28.8 0 51.2 22.4 51.2 51.2 0 28.8-22.4 51.2-51.2 51.2C246.4 470.4 224 448 224 419.2zM320 284.8c0-22.4 19.2-41.6 41.6-41.6 22.4 0 41.6 19.2 41.6 41.6 0 22.4-19.2 41.6-41.6 41.6C339.2 326.4 320 307.2 320 284.8zM457.6 208c0-12.8 12.8-25.6 25.6-25.6 12.8 0 25.6 12.8 25.6 25.6 0 12.8-12.8 25.6-25.6 25.6C470.4 233.6 457.6 220.8 457.6 208zM128 505.6C128 592 153.6 672 201.6 736c28.8-60.8 112-60.8 124.8-60.8-16-51.2 16-99.2 16-99.2l316.8-422.4c-48-19.2-99.2-32-150.4-32C297.6 118.4 128 291.2 128 505.6zM764.8 86.4c-22.4 19.2-390.4 518.4-390.4 518.4-22.4 28.8-12.8 76.8 22.4 99.2l9.6 6.4c35.2 22.4 80 12.8 99.2-25.6 0 0 6.4-12.8 9.6-19.2 54.4-105.6 275.2-524.8 288-553.6 6.4-19.2-3.2-32-19.2-32C777.6 76.8 771.2 80 764.8 86.4z"})]);ru.displayName="OutlookIcon";var au=D({name:"AppearanceSwitch",setup(){const{config:e,isDarkmode:t,status:n}=mr(),r=sn(),a=()=>{e.value==="switch"?n.value={light:"dark",dark:"auto",auto:"light"}[n.value]:n.value=n.value==="light"?"dark":"light"},l=async o=>{if(!(document.startViewTransition&&!window.matchMedia("(prefers-reduced-motion: reduce)").matches&&!r.value)||!o){a();return}const i=o.clientX,c=o.clientY,u=Math.hypot(Math.max(i,innerWidth-i),Math.max(c,innerHeight-c)),d=t.value;await document.startViewTransition(async()=>{a(),await Gt()}).ready,t.value!==d&&document.documentElement.animate({clipPath:t.value?[`circle(${u}px at ${i}px ${c}px)`,`circle(0px at ${i}px ${c}px)`]:[`circle(0px at ${i}px ${c}px)`,`circle(${u}px at ${i}px ${c}px)`]},{duration:400,pseudoElement:t.value?"::view-transition-old(root)":"::view-transition-new(root)"})};return()=>s("button",{type:"button",id:"appearance-switch",onClick:l},[s(eu,{style:{display:n.value==="auto"?"block":"none"}}),s(Jc,{style:{display:n.value==="dark"?"block":"none"}}),s(Qc,{style:{display:n.value==="light"?"block":"none"}})])}}),ih=D({name:"AppearanceMode",setup(){const e=ie(),{canToggle:t}=mr(),n=y(()=>e.value.outlookLocales.darkmode);return()=>t.value?s("div",{class:"appearance-wrapper"},[s("label",{class:"appearance-title",for:"appearance-switch"},n.value),s(au)]):null}});const Ra="VUEPRESS_THEME_COLOR";var ch=D({name:"ThemeColorPicker",props:{themeColor:{type:Object,required:!0}},setup(e){const t=(n="")=>{const r=document.documentElement.classList,a=yt(e.themeColor);if(!n){localStorage.removeItem(Ra),r.remove(...a);return}r.remove(...a.filter(l=>l!==n)),r.add(n),localStorage.setItem(Ra,n)};return ge(()=>{const n=localStorage.getItem(Ra);n&&t(n)}),()=>s("ul",{id:"theme-color-picker"},[s("li",s("span",{class:"theme-color",onClick:()=>t()})),In(e.themeColor).map(([n,r])=>s("li",s("span",{style:{background:r},onClick:()=>t(n)})))])}});const yn=Fl.enableThemeColor==="true",uh=yn?l0(In(Fl).filter(([e])=>e.startsWith("theme-"))):{};var dh=D({name:"ThemeColor",setup(){const e=ie(),t=y(()=>e.value.outlookLocales.themeColor);return()=>yn?s("div",{class:"theme-color-wrapper"},[s("label",{class:"theme-color-title",for:"theme-color-picker"},t.value),s(ch,{themeColor:uh})]):null}}),lu=D({name:"ToggleFullScreenButton",setup(){const e=ie(),{isSupported:t,isFullscreen:n,toggle:r}=Nl(),a=y(()=>e.value.outlookLocales.fullscreen);return()=>t?s("div",{class:"full-screen-wrapper"},[s("label",{class:"full-screen-title",for:"full-screen-switch"},a.value),s("button",{type:"button",id:"full-screen-switch",class:"full-screen",ariaPressed:n.value,onClick:()=>r()},n.value?s(nu):s(tu))]):null}}),ou=D({name:"OutlookSettings",setup(){const e=Kt(),t=sn(),n=y(()=>!t.value&&e.value.fullscreen);return()=>s(aa,()=>[yn?s(dh):null,s(ih),n.value?s(lu):null])}}),fh=D({name:"NavScreen",props:{show:Boolean},emits:["close"],slots:Object,setup(e,{emit:t,slots:n}){const r=se(),{isMobile:a}=vr(),l=lt(),o=zl(l);return ge(()=>{l.value=document.body,ve(a,i=>{!i&&e.show&&(o.value=!1,t("close"))}),ve(()=>r.value.path,()=>{o.value=!1,t("close")})}),Cn(()=>{o.value=!1}),()=>s(jt,{name:"fade",onEnter:()=>{o.value=!0},onAfterLeave:()=>{o.value=!1}},()=>{var i,c;return e.show?s("div",{id:"nav-screen"},s("div",{class:"vp-nav-screen-container"},[(i=n.before)==null?void 0:i.call(n),s(sh),s("div",{class:"vp-outlook-wrapper"},s(ou)),(c=n.after)==null?void 0:c.call(n)])):null})}}),ph=D({name:"NavbarBrand",setup(){const e=ft(),t=Pn(),n=ie(),r=y(()=>n.value.home||e.value),a=y(()=>t.value.title),l=y(()=>n.value.navTitle??a.value),o=y(()=>n.value.logo?Ee(n.value.logo):null),i=y(()=>n.value.logoDark?Ee(n.value.logoDark):null);return()=>s(Pe,{to:r.value,class:"vp-brand"},()=>[o.value?s("img",{class:["vp-nav-logo",{light:!!i.value}],src:o.value,alt:""}):null,i.value?s("img",{class:["vp-nav-logo dark"],src:i.value,alt:""}):null,l.value?s("span",{class:["vp-site-name",{"hide-in-pad":o.value&&n.value.hideSiteNameOnMobile!==!1}]},l.value):null])}}),hh=D({name:"NavbarLinks",setup(){const e=Xc();return()=>e.value.length?s("nav",{class:"vp-nav-links"},e.value.map(t=>s("div",{class:"nav-item hide-in-mobile"},"children"in t?s(ah,{config:t}):s(We,{config:t})))):null}}),vh=D({name:"RepoLink",components:{BitbucketIcon:_c,GiteeIcon:yc,GitHubIcon:gc,GitLabIcon:bc,SourceIcon:wc},setup(){const e=lh();return()=>e.value?s("div",{class:"nav-item vp-repo"},s("a",{class:"vp-repo-link",href:e.value.link,target:"_blank",rel:"noopener noreferrer","aria-label":e.value.label},s(Ye(`${e.value.type}Icon`),{style:{width:"1.25rem",height:"1.25rem",verticalAlign:"middle"}}))):null}});const su=({active:e=!1},{emit:t})=>s("button",{type:"button",class:["vp-toggle-navbar-button",{"is-active":e}],"aria-label":"Toggle Navbar","aria-expanded":e,"aria-controls":"nav-screen",onClick:()=>t("toggle")},s("span",[s("span",{class:"vp-top"}),s("span",{class:"vp-middle"}),s("span",{class:"vp-bottom"})]));su.displayName="ToggleNavbarButton";var mh=su;const el=(e,{emit:t})=>s("button",{type:"button",class:"vp-toggle-sidebar-button",title:"Toggle Sidebar",onClick:()=>t("toggle")},s("span",{class:"icon"}));el.displayName="ToggleSidebarButton",el.emits=["toggle"];var gh=el,bh=D({name:"OutlookButton",setup(){const{isSupported:e}=Nl(),t=Kt(),n=sn(),r=se(),{canToggle:a}=mr(),l=Z(!1),o=y(()=>!n.value&&t.value.fullscreen&&e);return ve(()=>r.value.path,()=>{l.value=!1}),()=>a.value||o.value||yn?s("div",{class:"nav-item hide-in-mobile"},a.value&&!o.value&&!yn?s(au):o.value&&!a.value&&!yn?s(lu):s("button",{type:"button",class:["outlook-button",{open:l.value}],tabindex:"-1","aria-hidden":!0},[s(ru),s("div",{class:"outlook-dropdown"},s(ou))])):null}}),yh=D({name:"NavBar",emits:["toggleSidebar"],slots:Object,setup(e,{emit:t,slots:n}){const r=ie(),{isMobile:a}=vr(),l=Z(!1),o=y(()=>{const{navbarAutoHide:d="mobile"}=r.value;return d!=="none"&&(d==="always"||a.value)}),i=y(()=>r.value.navbarLayout||{start:["Brand"],center:["Links"],end:["Language","Repo","Outlook","Search"]}),c={Brand:ph,Language:Ia,Links:hh,Repo:vh,Outlook:bh,Search:Lt("Docsearch")?Ye("Docsearch"):Lt("SearchBox")?Ye("SearchBox"):Ia},u=d=>c[d]??(Lt(d)?Ye(d):Ia);return()=>{var d,f,p,h,g,w;return[s("header",{id:"navbar",class:["vp-navbar",{"auto-hide":o.value,"hide-icon":r.value.navbarIcon===!1}]},[s("div",{class:"vp-navbar-start"},[s(gh,{onToggle:()=>{l.value&&(l.value=!1),t("toggleSidebar")}}),(d=n.startBefore)==null?void 0:d.call(n),(i.value.start||[]).map(E=>s(u(E))),(f=n.startAfter)==null?void 0:f.call(n)]),s("div",{class:"vp-navbar-center"},[(p=n.centerBefore)==null?void 0:p.call(n),(i.value.center||[]).map(E=>s(u(E))),(h=n.centerAfter)==null?void 0:h.call(n)]),s("div",{class:"vp-navbar-end"},[(g=n.endBefore)==null?void 0:g.call(n),(i.value.end||[]).map(E=>s(u(E))),(w=n.endAfter)==null?void 0:w.call(n),s(mh,{active:l.value,onToggle:()=>{l.value=!l.value}})])]),s(fh,{show:l.value,onClose:()=>{l.value=!1}},{before:()=>{var E;return(E=n.screenTop)==null?void 0:E.call(n)},after:()=>{var E;return(E=n.screenBottom)==null?void 0:E.call(n)}})]}}}),_h=D({name:"SidebarChild",props:{config:{type:Object,required:!0}},setup(e){const t=ot();return()=>[Gc(e.config,{class:["vp-sidebar-link",`vp-sidebar-${e.config.type}`,{active:Ln(t,e.config,!0)}],exact:!0}),Kc(e.config.children)]}}),wh=D({name:"SidebarGroup",props:{config:{type:Object,required:!0},open:{type:Boolean,required:!0}},emits:["toggle"],setup(e,{emit:t}){const n=ot(),r=y(()=>Ln(n,e.config)),a=y(()=>Ln(n,e.config,!0));return()=>{const{collapsible:l,children:o=[],icon:i,prefix:c,link:u,text:d}=e.config;return s("section",{class:"vp-sidebar-group"},[s(l?"button":"p",{class:["vp-sidebar-heading",{clickable:l||u,exact:a.value,active:r.value}],...l?{type:"button",onClick:()=>t("toggle"),onKeydown:f=>{f.key==="Enter"&&t("toggle")}}:{}},[s(ze,{icon:i}),u?s(We,{class:"vp-sidebar-title",config:{text:d,link:u},noExternalLinkIcon:!0}):s("span",{class:"vp-sidebar-title"},d),l?s("span",{class:["vp-arrow",e.open?"down":"end"]}):null]),e.open||!l?s(iu,{key:c,config:o}):null])}}}),iu=D({name:"SidebarLinks",props:{config:{type:Array,required:!0}},setup(e){const t=ot(),n=Z(-1),r=a=>{n.value=a===n.value?-1:a};return ve(()=>t.path,()=>{const a=e.config.findIndex(l=>Wc(t,l));n.value=a},{immediate:!0,flush:"post"}),()=>s("ul",{class:"vp-sidebar-links"},e.config.map((a,l)=>s("li",a.type==="group"?s(wh,{config:a,open:l===n.value,onToggle:()=>r(l)}):s(_h,{config:a}))))}}),Eh=D({name:"SideBar",slots:Object,setup(e,{slots:t}){const n=ot(),r=ie(),a=Gl(),l=lt();return ge(()=>{ve(()=>n.hash,o=>{const i=document.querySelector(`.vp-sidebar a.vp-sidebar-link[href="${n.path}${o}"]`);if(!i)return;const{top:c,height:u}=l.value.getBoundingClientRect(),{top:d,height:f}=i.getBoundingClientRect();dc+u&&i.scrollIntoView(!1)},{immediate:!0})}),()=>{var o,i,c;return s("aside",{ref:l,id:"sidebar",class:["vp-sidebar",{"hide-icon":r.value.sidebarIcon===!1}]},[(o=t.top)==null?void 0:o.call(t),((i=t.default)==null?void 0:i.call(t))||s(iu,{config:a.value}),(c=t.bottom)==null?void 0:c.call(t)])}}}),Kl=D({name:"CommonWrapper",props:{containerClass:{type:String,default:""},noNavbar:Boolean,noSidebar:Boolean,noToc:Boolean},slots:Object,setup(e,{slots:t}){const n=De(),r=se(),a=ye(),l=ie(),{isMobile:o,isPC:i}=vr(),[c,u]=hs(!1),[d,f]=hs(!1),p=Gl(),h=Z(!1),g=y(()=>e.noNavbar||a.value.navbar===!1||l.value.navbar===!1?!1:!!(r.value.title||l.value.logo||l.value.repo||l.value.navbar)),w=y(()=>e.noSidebar?!1:a.value.sidebar!==!1&&p.value.length!==0&&!a.value.home),E=y(()=>e.noToc||a.value.home?!1:a.value.toc||l.value.toc!==!1&&a.value.toc!==!1),b={x:0,y:0},L=T=>{b.x=T.changedTouches[0].clientX,b.y=T.changedTouches[0].clientY},_=T=>{const K=T.changedTouches[0].clientX-b.x,B=T.changedTouches[0].clientY-b.y;Math.abs(K)>Math.abs(B)*1.5&&Math.abs(K)>40&&(K>0&&b.x<=80?u(!0):u(!1))},A=()=>window.pageYOffset||document.documentElement.scrollTop||document.body.scrollTop||0;let V=0;return Ce("scroll",x0(()=>{const T=A();T<=58||T{T||u(!1)}),ge(()=>{const T=zl(document.body);ve(c,B=>{T.value=B});const K=n.afterEach(()=>{u(!1)});Cn(()=>{T.value=!1,K()})}),()=>s(Lt("GlobalEncrypt")?Ye("GlobalEncrypt"):ic,()=>s("div",{class:["theme-container",{"no-navbar":!g.value,"no-sidebar":!w.value&&!(t.sidebar||t.sidebarTop||t.sidebarBottom),"has-toc":E.value,"hide-navbar":h.value,"sidebar-collapsed":!o.value&&!i.value&&d.value,"sidebar-open":o.value&&c.value},e.containerClass,a.value.containerClass||""],onTouchStart:L,onTouchEnd:_},[g.value?s(yh,{onToggleSidebar:()=>u()},{startBefore:()=>{var T;return(T=t.navbarStartBefore)==null?void 0:T.call(t)},startAfter:()=>{var T;return(T=t.navbarStartAfter)==null?void 0:T.call(t)},centerBefore:()=>{var T;return(T=t.navbarCenterBefore)==null?void 0:T.call(t)},centerAfter:()=>{var T;return(T=t.navbarCenterAfter)==null?void 0:T.call(t)},endBefore:()=>{var T;return(T=t.navbarEndBefore)==null?void 0:T.call(t)},endAfter:()=>{var T;return(T=t.navbarEndAfter)==null?void 0:T.call(t)},screenTop:()=>{var T;return(T=t.navScreenTop)==null?void 0:T.call(t)},screenBottom:()=>{var T;return(T=t.navScreenBottom)==null?void 0:T.call(t)}}):null,s(jt,{name:"fade"},()=>c.value?s("div",{class:"vp-sidebar-mask",onClick:()=>u(!1)}):null),s(jt,{name:"fade"},()=>o.value?null:s("div",{class:"toggle-sidebar-wrapper",onClick:()=>f()},s("span",{class:["arrow",d.value?"end":"start"]}))),s(Eh,{},{...t.sidebar?{default:()=>t.sidebar()}:{},top:()=>{var T;return(T=t.sidebarTop)==null?void 0:T.call(t)},bottom:()=>{var T;return(T=t.sidebarBottom)==null?void 0:T.call(t)}}),t.default(),s(rh)]))}}),he=D({name:"DropTransition",props:{type:{type:String,default:"single"},delay:{type:Number,default:0},duration:{type:Number,default:.25},appear:Boolean},slots:Object,setup(e,{slots:t}){const n=a=>{a.style.transition=`transform ${e.duration}s ease-in-out ${e.delay}s, opacity ${e.duration}s ease-in-out ${e.delay}s`,a.style.transform="translateY(-20px)",a.style.opacity="0"},r=a=>{a.style.transform="translateY(0)",a.style.opacity="1"};return()=>s(e.type==="single"?jt:Vi,{name:"drop",appear:e.appear,onAppear:n,onAfterAppear:r,onEnter:n,onAfterEnter:r,onBeforeLeave:n},()=>t.default())}});const tl=({custom:e})=>s(Zi,{class:["theme-hope-content",{custom:e}]});tl.displayName="MarkdownContent",tl.props={custom:Boolean};var ql=tl;const cu=()=>s(de,{name:"author"},()=>s("path",{d:"M649.6 633.6c86.4-48 147.2-144 147.2-249.6 0-160-128-288-288-288s-288 128-288 288c0 108.8 57.6 201.6 147.2 249.6-121.6 48-214.4 153.6-240 288-3.2 9.6 0 19.2 6.4 25.6 3.2 9.6 12.8 12.8 22.4 12.8h704c9.6 0 19.2-3.2 25.6-12.8 6.4-6.4 9.6-16 6.4-25.6-25.6-134.4-121.6-240-243.2-288z"}));cu.displayName="AuthorIcon";const uu=()=>s(de,{name:"calendar"},()=>s("path",{d:"M716.4 110.137c0-18.753-14.72-33.473-33.472-33.473-18.753 0-33.473 14.72-33.473 33.473v33.473h66.993v-33.473zm-334.87 0c0-18.753-14.72-33.473-33.473-33.473s-33.52 14.72-33.52 33.473v33.473h66.993v-33.473zm468.81 33.52H716.4v100.465c0 18.753-14.72 33.473-33.472 33.473a33.145 33.145 0 01-33.473-33.473V143.657H381.53v100.465c0 18.753-14.72 33.473-33.473 33.473a33.145 33.145 0 01-33.473-33.473V143.657H180.6A134.314 134.314 0 0046.66 277.595v535.756A134.314 134.314 0 00180.6 947.289h669.74a134.36 134.36 0 00133.94-133.938V277.595a134.314 134.314 0 00-133.94-133.938zm33.473 267.877H147.126a33.145 33.145 0 01-33.473-33.473c0-18.752 14.72-33.473 33.473-33.473h736.687c18.752 0 33.472 14.72 33.472 33.473a33.145 33.145 0 01-33.472 33.473z"}));uu.displayName="CalendarIcon";const du=()=>s(de,{name:"category"},()=>s("path",{d:"M148.41 106.992h282.176c22.263 0 40.31 18.048 40.31 40.31V429.48c0 22.263-18.047 40.31-40.31 40.31H148.41c-22.263 0-40.311-18.047-40.311-40.31V147.302c0-22.263 18.048-40.31 40.311-40.31zM147.556 553.478H429.73c22.263 0 40.311 18.048 40.311 40.31v282.176c0 22.263-18.048 40.312-40.31 40.312H147.555c-22.263 0-40.311-18.049-40.311-40.312V593.79c0-22.263 18.048-40.311 40.31-40.311zM593.927 106.992h282.176c22.263 0 40.31 18.048 40.31 40.31V429.48c0 22.263-18.047 40.31-40.31 40.31H593.927c-22.263 0-40.311-18.047-40.311-40.31V147.302c0-22.263 18.048-40.31 40.31-40.31zM730.22 920.502H623.926c-40.925 0-74.22-33.388-74.22-74.425V623.992c0-41.038 33.387-74.424 74.425-74.424h222.085c41.038 0 74.424 33.226 74.424 74.067v114.233c0 10.244-8.304 18.548-18.547 18.548s-18.548-8.304-18.548-18.548V623.635c0-20.388-16.746-36.974-37.33-36.974H624.13c-20.585 0-37.331 16.747-37.331 37.33v222.086c0 20.585 16.654 37.331 37.126 37.331H730.22c10.243 0 18.547 8.304 18.547 18.547 0 10.244-8.304 18.547-18.547 18.547z"}));du.displayName="CategoryIcon";const fu=()=>s(de,{name:"print"},()=>s("path",{d:"M819.2 364.8h-44.8V128c0-17.067-14.933-32-32-32H281.6c-17.067 0-32 14.933-32 32v236.8h-44.8C145.067 364.8 96 413.867 96 473.6v192c0 59.733 49.067 108.8 108.8 108.8h44.8V896c0 17.067 14.933 32 32 32h460.8c17.067 0 32-14.933 32-32V774.4h44.8c59.733 0 108.8-49.067 108.8-108.8v-192c0-59.733-49.067-108.8-108.8-108.8zM313.6 160h396.8v204.8H313.6V160zm396.8 704H313.6V620.8h396.8V864zM864 665.6c0 25.6-19.2 44.8-44.8 44.8h-44.8V588.8c0-17.067-14.933-32-32-32H281.6c-17.067 0-32 14.933-32 32v121.6h-44.8c-25.6 0-44.8-19.2-44.8-44.8v-192c0-25.6 19.2-44.8 44.8-44.8h614.4c25.6 0 44.8 19.2 44.8 44.8v192z"}));fu.displayName="PrintIcon";const pu=()=>s(de,{name:"tag"},()=>s("path",{d:"M939.902 458.563L910.17 144.567c-1.507-16.272-14.465-29.13-30.737-30.737L565.438 84.098h-.402c-3.215 0-5.726 1.005-7.634 2.913l-470.39 470.39a10.004 10.004 0 000 14.164l365.423 365.424c1.909 1.908 4.42 2.913 7.132 2.913s5.223-1.005 7.132-2.913l470.39-470.39c2.01-2.11 3.014-5.023 2.813-8.036zm-240.067-72.121c-35.458 0-64.286-28.828-64.286-64.286s28.828-64.285 64.286-64.285 64.286 28.828 64.286 64.285-28.829 64.286-64.286 64.286z"}));pu.displayName="TagIcon";const hu=()=>s(de,{name:"timer"},()=>s("path",{d:"M799.387 122.15c4.402-2.978 7.38-7.897 7.38-13.463v-1.165c0-8.933-7.38-16.312-16.312-16.312H256.33c-8.933 0-16.311 7.38-16.311 16.312v1.165c0 5.825 2.977 10.874 7.637 13.592 4.143 194.44 97.22 354.963 220.201 392.763-122.204 37.542-214.893 196.511-220.2 389.397-4.661 5.049-7.638 11.651-7.638 19.03v5.825h566.49v-5.825c0-7.379-2.849-13.981-7.509-18.9-5.049-193.016-97.867-351.985-220.2-389.527 123.24-37.67 216.446-198.453 220.588-392.892zM531.16 450.445v352.632c117.674 1.553 211.787 40.778 211.787 88.676H304.097c0-48.286 95.149-87.382 213.728-88.676V450.445c-93.077-3.107-167.901-81.297-167.901-177.093 0-8.803 6.99-15.793 15.793-15.793 8.803 0 15.794 6.99 15.794 15.793 0 80.261 63.69 145.635 142.01 145.635s142.011-65.374 142.011-145.635c0-8.803 6.99-15.793 15.794-15.793s15.793 6.99 15.793 15.793c0 95.019-73.789 172.82-165.96 177.093z"}));hu.displayName="TimerIcon";const vu=()=>s(de,{name:"word"},()=>[s("path",{d:"M518.217 432.64V73.143A73.143 73.143 0 01603.43 1.097a512 512 0 01419.474 419.474 73.143 73.143 0 01-72.046 85.212H591.36a73.143 73.143 0 01-73.143-73.143z"}),s("path",{d:"M493.714 566.857h340.297a73.143 73.143 0 0173.143 85.577A457.143 457.143 0 11371.566 117.76a73.143 73.143 0 0185.577 73.143v339.383a36.571 36.571 0 0036.571 36.571z"})]);vu.displayName="WordIcon";const qt=()=>{const e=ie();return y(()=>e.value.metaLocales)};var kh=D({name:"AuthorInfo",inheritAttrs:!1,props:{author:{type:Array,required:!0},pure:Boolean},setup(e){const t=qt();return()=>e.author.length?s("span",{class:"page-author-info","aria-label":`${t.value.author}${e.pure?"":"🖊"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(cu),s("span",e.author.map(n=>n.url?s("a",{class:"page-author-item",href:n.url,target:"_blank",rel:"noopener noreferrer"},n.name):s("span",{class:"page-author-item"},n.name))),s("span",{property:"author",content:e.author.map(n=>n.name).join(", ")})]):null}}),xh=D({name:"CategoryInfo",inheritAttrs:!1,props:{category:{type:Array,required:!0},pure:Boolean},setup(e){const t=De(),n=se(),r=qt(),a=(l,o="")=>{o&&n.value.path!==o&&(l.preventDefault(),t.push(o))};return()=>e.category.length?s("span",{class:"page-category-info","aria-label":`${r.value.category}${e.pure?"":"🌈"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(du),e.category.map(({name:l,path:o})=>s("span",{class:["page-category-item",{[`category${sa(l,9)}`]:!e.pure,clickable:o}],role:o?"navigation":"",onClick:i=>a(i,o)},l)),s("meta",{property:"articleSection",content:e.category.map(({name:l})=>l).join(",")})]):null}}),Th=D({name:"DateInfo",inheritAttrs:!1,props:{date:{type:Object,default:null},localizedDate:{type:String,default:""},pure:Boolean},setup(e){const t=Pl(),n=qt();return()=>e.date?s("span",{class:"page-date-info","aria-label":`${n.value.date}${e.pure?"":"📅"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(uu),s("span",s(aa,()=>e.localizedDate||e.date.toLocaleDateString(t.value))),s("meta",{property:"datePublished",content:e.date.toISOString()||""})]):null}}),Lh=D({name:"OriginalInfo",inheritAttrs:!1,props:{isOriginal:Boolean},setup(e){const t=qt();return()=>e.isOriginal?s("span",{class:"page-original-info"},t.value.origin):null}}),Ah=D({name:"ReadingTimeInfo",inheritAttrs:!1,props:{readingTime:{type:Object,default:()=>null},readingTimeLocale:{type:Object,default:()=>null},pure:Boolean},setup(e){const t=qt(),n=y(()=>{if(!e.readingTime)return null;const{minutes:r}=e.readingTime;return r<1?"PT1M":`PT${Math.round(r)}M`});return()=>{var r,a;return(r=e.readingTimeLocale)!=null&&r.time?s("span",{class:"page-reading-time-info","aria-label":`${t.value.readingTime}${e.pure?"":"⌛"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(hu),s("span",(a=e.readingTimeLocale)==null?void 0:a.time),s("meta",{property:"timeRequired",content:n.value})]):null}}}),Sh=D({name:"TagInfo",inheritAttrs:!1,props:{tag:{type:Array,default:()=>[]},pure:Boolean},setup(e){const t=De(),n=se(),r=qt(),a=(l,o="")=>{o&&n.value.path!==o&&(l.preventDefault(),t.push(o))};return()=>e.tag.length?s("span",{class:"page-tag-info","aria-label":`${r.value.tag}${e.pure?"":"🏷"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(pu),e.tag.map(({name:l,path:o})=>s("span",{class:["page-tag-item",{[`tag${sa(l,9)}`]:!e.pure,clickable:o}],role:o?"navigation":"",onClick:i=>a(i,o)},l)),s("meta",{property:"keywords",content:e.tag.map(({name:l})=>l).join(",")})]):null}}),Ch=D({name:"ReadTimeInfo",inheritAttrs:!1,props:{readingTime:{type:Object,default:()=>null},readingTimeLocale:{type:Object,default:()=>null},pure:Boolean},setup(e){const t=qt();return()=>{var n,r,a;return(n=e.readingTimeLocale)!=null&&n.words?s("span",{class:"page-word-info","aria-label":`${t.value.words}${e.pure?"":"🔠"}`,...e.pure?{}:{"data-balloon-pos":"down"}},[s(vu),s("span",(r=e.readingTimeLocale)==null?void 0:r.words),s("meta",{property:"wordCount",content:(a=e.readingTime)==null?void 0:a.words})]):null}}}),mu=D({name:"PageInfo",components:{AuthorInfo:kh,CategoryInfo:xh,DateInfo:Th,OriginalInfo:Lh,PageViewInfo:()=>null,ReadingTimeInfo:Ah,TagInfo:Sh,WordInfo:Ch},props:{items:{type:[Array,Boolean],default:()=>["Author","Original","Date","PageView","ReadingTime","Category","Tag"]},info:{type:Object,required:!0}},setup(e){const t=sn();return()=>e.items?s("div",{class:"page-info"},e.items.map(n=>s(Ye(`${n}Info`),{...e.info,pure:t.value}))):null}}),Ph=D({name:"PrintButton",setup(){const e=Kt(),t=ie();return()=>e.value.print===!1?null:s("button",{type:"button",class:"print-button",title:t.value.metaLocales.print,onClick:()=>{window.print()}},s(fu))}});const Ih=({title:e,level:t,slug:n})=>s(Pe,{to:`#${n}`,class:["toc-link",`level${t}`]},()=>e),nl=(e,t)=>{const n=ot();return e.length&&t>0?s("ul",{class:"toc-list"},e.map(r=>{const a=nl(r.children,t-1);return[s("li",{class:["toc-item",{active:n.hash===`#${r.slug}`}]},Ih(r)),a?s("li",a):null]})):null};var gu=D({name:"TOC",props:{items:{type:Array,default:()=>[]},headerDepth:{type:Number,default:2}},slots:Object,setup(e,{slots:t}){const n=ot(),r=se(),a=qt(),l=lt(),o=Z("-1.7rem"),i=u=>{var d;(d=l.value)==null||d.scrollTo({top:u,behavior:"smooth"})},c=()=>{if(l.value){const u=document.querySelector(".toc-item.active");u?o.value=`${u.getBoundingClientRect().top-l.value.getBoundingClientRect().top+l.value.scrollTop}px`:o.value="-1.7rem"}else o.value="-1.7rem"};return ge(()=>{ve(()=>n.hash,u=>{if(l.value){const d=document.querySelector(`#toc a.toc-link[href$="${u}"]`);if(!d)return;const{top:f,height:p}=l.value.getBoundingClientRect(),{top:h,height:g}=d.getBoundingClientRect();hf+p&&i(l.value.scrollTop+h+g-f-p)}}),ve(()=>n.fullPath,c,{flush:"post",immediate:!0})}),()=>{var d,f;const u=e.items.length?nl(e.items,e.headerDepth):r.value.headers?nl(r.value.headers,e.headerDepth):null;return u?s("div",{class:"toc-place-holder"},[s("aside",{id:"toc"},[(d=t.before)==null?void 0:d.call(t),s("div",{class:"toc-header"},[a.value.toc,s(Ph)]),s("div",{class:"toc-wrapper",ref:l},[u,s("div",{class:"toc-marker",style:{top:o.value}})]),(f=t.after)==null?void 0:f.call(t)])]):null}}}),Ul=D({name:"SkipLink",props:{content:{type:String,default:"main-content"}},setup(e){const t=se(),n=ie(),r=lt(),a=({target:l})=>{const o=document.querySelector(l.hash);if(o){const i=()=>{o.removeAttribute("tabindex"),o.removeEventListener("blur",i)};o.setAttribute("tabindex","-1"),o.addEventListener("blur",i),o.focus(),window.scrollTo(0,0)}};return ge(()=>{ve(()=>t.value.path,()=>r.value.focus())}),()=>[s("span",{ref:r,tabindex:"-1"}),s("a",{href:`#${e.content}`,class:"vp-skip-link sr-only",onClick:a},n.value.routeLocales.skipToContent)]}});let Oa=null,Nn=null;const Rh={wait:()=>Oa,pending:()=>{Oa=new Promise(e=>Nn=e)},resolve:()=>{Nn==null||Nn(),Oa=null,Nn=null}},bu=()=>Rh;var Oh=D({name:"FadeSlideY",slots:Object,setup(e,{slots:t}){const{resolve:n,pending:r}=bu();return()=>s(jt,{name:"fade-slide-y",mode:"out-in",onBeforeEnter:n,onBeforeLeave:r},()=>{var a;return(a=t.default)==null?void 0:a.call(t)})}});const Mh=(e,t)=>{const n=e.replace(t,"/").split("/"),r=[];let a=Cl(t);return n.forEach((l,o)=>{o!==n.length-1?(a+=`${l}/`,r.push({link:a,name:l||"Home"})):l!==""&&(a+=l,r.push({link:a,name:l}))}),r},yu=(e,{slots:t})=>{var f,p;const{bgImage:n,bgImageDark:r,bgImageStyle:a,color:l,description:o,image:i,imageDark:c,header:u,features:d=[]}=e;return s("div",{class:"vp-feature-wrapper"},[n?s("div",{class:["vp-feature-bg",{light:r}],style:[{"background-image":`url(${n})`},a]}):null,r?s("div",{class:"vp-feature-bg dark",style:[{"background-image":`url(${r})`},a]}):null,s("div",{class:"vp-feature",style:l?{color:l}:{}},[((f=t.image)==null?void 0:f.call(t,e))||[i?s("img",{class:["vp-feature-image",{light:c}],src:Ee(i),alt:""}):null,c?s("img",{class:"vp-feature-image dark",src:Ee(c),alt:""}):null],((p=t.info)==null?void 0:p.call(t,e))||[u?s("h2",{class:"vp-feature-header"},u):null,o?s("p",{class:"vp-feature-description",innerHTML:o}):null],d.length?s("div",{class:"vp-features"},d.map(({icon:h,title:g,details:w,link:E})=>{const b=[s("h3",{class:"vp-feature-title"},[s(ze,{icon:h}),s("span",{innerHTML:g})]),s("p",{class:"vp-feature-details",innerHTML:w})];return E?Ur(E)?s("a",{class:"vp-feature-item link",href:E,"aria-label":g,target:"_blank"},b):s(Pe,{class:"vp-feature-item link",to:E,"aria-label":g},()=>b):s("div",{class:"vp-feature-item"},b)})):null])])};yu.displayName="FeaturePanel";var As=yu;const _u=e=>{const{icon:t="",color:n,size:r}=e,a={};return n&&(a.color=n),r&&(a.height=Number.isNaN(Number(r))?r:`${r}px`),on(t)?s("img",{class:"icon",src:t,"no-view":"",style:a}):Rn(t)?s("img",{class:"icon",src:Ee(t),"aria-hidden":"","no-view":"",style:a}):s(Ye("FontIcon"),e)};_u.displayName="HopeIcon";var $h=_u,Dh=D({name:"HeroInfo",slots:Object,setup(e,{slots:t}){const n=ye(),r=Pn(),a=y(()=>n.value.heroFullScreen??!1),l=y(()=>{const{heroText:u,tagline:d}=n.value;return{text:u??r.value.title??"Hello",tagline:d??r.value.description??"",isFullScreen:a.value}}),o=y(()=>{const{heroText:u,heroImage:d,heroImageDark:f,heroAlt:p,heroImageStyle:h}=n.value;return{image:d?Ee(d):null,imageDark:f?Ee(f):null,heroStyle:h,alt:p||u||"",isFullScreen:a.value}}),i=y(()=>{const{bgImage:u,bgImageDark:d,bgImageStyle:f}=n.value;return{image:bt(u)?Ee(u):null,imageDark:bt(d)?Ee(d):null,bgStyle:f,isFullScreen:a.value}}),c=y(()=>n.value.actions??[]);return()=>{var u,d,f;return s("header",{class:["vp-hero-info-wrapper",{fullscreen:a.value}]},[((u=t.heroBg)==null?void 0:u.call(t,i.value))||[i.value.image?s("div",{class:["vp-hero-mask",{light:i.value.imageDark}],style:[{"background-image":`url(${i.value.image})`},i.value.bgStyle]}):null,i.value.imageDark?s("div",{class:"vp-hero-mask dark",style:[{"background-image":`url(${i.value.imageDark})`},i.value.bgStyle]}):null],s("div",{class:"vp-hero-info"},[((d=t.heroImage)==null?void 0:d.call(t,o.value))||s(he,{appear:!0,type:"group"},()=>[o.value.image?s("img",{key:"light",class:["vp-hero-image",{light:o.value.imageDark}],style:o.value.heroStyle,src:o.value.image,alt:o.value.alt}):null,o.value.imageDark?s("img",{key:"dark",class:"vp-hero-image dark",style:o.value.heroStyle,src:o.value.imageDark,alt:o.value.alt}):null]),((f=t.heroInfo)==null?void 0:f.call(t,l.value))??s("div",{class:"vp-hero-infos"},[l.value.text?s(he,{appear:!0,delay:.04},()=>s("h1",{id:"main-title"},l.value.text)):null,l.value.tagline?s(he,{appear:!0,delay:.08},()=>s("p",{id:"main-description",innerHTML:l.value.tagline})):null,c.value.length?s(he,{appear:!0,delay:.12},()=>s("p",{class:"vp-hero-actions"},c.value.map(p=>s(We,{class:["vp-hero-action",p.type||"default"],config:p,noExternalLinkIcon:!0},p.icon?{before:()=>s($h,{icon:p.icon})}:{})))):null])])])}}});const wu=(e,{slots:t})=>{var p,h,g;const{bgImage:n,bgImageDark:r,bgImageStyle:a,color:l,description:o,image:i,imageDark:c,header:u,highlights:d=[],type:f="un-order"}=e;return s("div",{class:"vp-highlight-wrapper",style:l?{color:l}:{}},[n?s("div",{class:["vp-highlight-bg",{light:r}],style:[{"background-image":`url(${n})`},a]}):null,r?s("div",{class:"vp-highlight-bg dark",style:[{"background-image":`url(${r})`},a]}):null,s("div",{class:"vp-highlight"},[((p=t.image)==null?void 0:p.call(t,e))||[i?s("img",{class:["vp-highlight-image",{light:c}],src:Ee(i),alt:""}):null,c?s("img",{class:"vp-highlight-image dark",src:Ee(c),alt:""}):null],((h=t.info)==null?void 0:h.call(t,e))||[s("div",{class:"vp-highlight-info-wrapper"},s("div",{class:"vp-highlight-info"},[u?s("h2",{class:"vp-highlight-header",innerHTML:u}):null,o?s("p",{class:"vp-highlight-description",innerHTML:o}):null,((g=t.highlights)==null?void 0:g.call(t,d))||s(f==="order"?"ol":f==="no-order"?"dl":"ul",{class:"vp-highlights"},d.map(({icon:w,title:E,details:b,link:L})=>{const _=[s(f==="no-order"?"dt":"h3",{class:"vp-highlight-title"},[w?s(ze,{class:"vp-highlight-icon",icon:w}):null,s("span",{innerHTML:E})]),b?s(f==="no-order"?"dd":"p",{class:"vp-highlight-details",innerHTML:b}):null];return s(f==="no-order"?"div":"li",{class:["vp-highlight-item-wrapper",{link:L}]},L?t0(L)?s("a",{class:"vp-highlight-item link",href:L,"aria-label":E,target:"_blank"},_):s(Pe,{class:"vp-highlight-item link",to:L,"aria-label":E},()=>_):s("div",{class:"vp-highlight-item"},_))}))]))]])])};wu.displayName="HighlightPanel";var Vh=wu,Bh=D({name:"HomePage",slots:Object,setup(e,{slots:t}){const n=sn(),r=ye(),a=y(()=>{const{features:o}=r.value;return Q(o)?o:null}),l=y(()=>{const{highlights:o}=r.value;return Q(o)?o:null});return()=>{var o,i,c,u;return s("main",{id:"main-content",class:["vp-project-home ",{pure:n.value}],"aria-labelledby":r.value.heroText===null?"":"main-title"},[(o=t.top)==null?void 0:o.call(t),s(Dh),((i=l.value)==null?void 0:i.map(d=>"features"in d?s(As,d):s(Vh,d)))||(a.value?s(he,{appear:!0,delay:.24},()=>s(As,{features:a.value})):null),(c=t.center)==null?void 0:c.call(t),s(he,{appear:!0,delay:.32},()=>s(ql)),(u=t.bottom)==null?void 0:u.call(t)])}}}),Nh=D({name:"BreadCrumb",setup(){const e=De(),t=se(),n=ft(),r=ye(),a=ie(),l=lt([]),o=y(()=>(r.value.breadcrumb||r.value.breadcrumb!==!1&&a.value.breadcrumb!==!1)&&l.value.length>1),i=y(()=>r.value.breadcrumbIcon||r.value.breadcrumbIcon!==!1&&a.value.breadcrumbIcon!==!1),c=()=>{const u=e.getRoutes(),d=Mh(t.value.path,n.value).map(({link:f,name:p})=>{const h=u.find(g=>g.path===f);if(h){const{meta:g,path:w}=Tn(e,h.path);return{title:g[we.shortTitle]||g[we.title]||p,icon:g[we.icon],path:w}}return null}).filter(f=>f!==null);d.length>1&&(l.value=d)};return ge(()=>{ve(()=>t.value.path,c,{immediate:!0})}),()=>s("nav",{class:["vp-breadcrumb",{disable:!o.value}]},o.value?s("ol",{vocab:"https://schema.org/",typeof:"BreadcrumbList"},l.value.map((u,d)=>s("li",{class:{"is-active":l.value.length-1===d},property:"itemListElement",typeof:"ListItem"},[s(Pe,{to:u.path,property:"item",typeof:"WebPage"},()=>[i.value?s(ze,{icon:u.icon}):null,s("span",{property:"name"},u.title||"Unknown")]),s("meta",{property:"position",content:d+1})]))):[])}});const Ss=e=>{const t=De();return e===!1?!1:oe(e)?bn(t,e,!0):Sl(e)?e:null},rl=(e,t,n)=>{const r=e.findIndex(a=>a.link===t);if(r!==-1){const a=e[r+n];return a!=null&&a.link?a:null}for(const a of e)if(a.children){const l=rl(a.children,t,n);if(l)return l}return null};var zh=D({name:"PageNav",setup(){const e=ie(),t=ye(),n=Gl(),r=se(),a=hr(),l=y(()=>{const i=Ss(t.value.prev);return i===!1?null:i||(e.value.prevLink===!1?null:rl(n.value,r.value.path,-1))}),o=y(()=>{const i=Ss(t.value.next);return i===!1?null:i||(e.value.nextLink===!1?null:rl(n.value,r.value.path,1))});return Ce("keydown",i=>{i.altKey&&(i.key==="ArrowRight"?o.value&&(a(o.value.link),i.preventDefault()):i.key==="ArrowLeft"&&l.value&&(a(l.value.link),i.preventDefault()))}),()=>l.value||o.value?s("nav",{class:"vp-page-nav"},[l.value?s(We,{class:"prev",config:l.value},()=>{var i,c;return[s("div",{class:"hint"},[s("span",{class:"arrow start"}),e.value.metaLocales.prev]),s("div",{class:"link"},[s(ze,{icon:(i=l.value)==null?void 0:i.icon}),(c=l.value)==null?void 0:c.text])]}):null,o.value?s(We,{class:"next",config:o.value},()=>{var i,c;return[s("div",{class:"hint"},[e.value.metaLocales.next,s("span",{class:"arrow end"})]),s("div",{class:"link"},[(i=o.value)==null?void 0:i.text,s(ze,{icon:(c=o.value)==null?void 0:c.icon})])]}):null]):null}});const Hh={GitHub:":repo/edit/:branch/:path",GitLab:":repo/-/edit/:branch/:path",Gitee:":repo/edit/:branch/:path",Bitbucket:":repo/src/:branch/:path?mode=edit&spa=0&at=:branch&fileviewer=file-view-default"},Fh=({docsRepo:e,docsBranch:t,docsDir:n,filePathRelative:r,editLinkPattern:a})=>{if(!r)return null;const l=mc(e);let o;return a?o=a:l!==null&&(o=Hh[l]),o?o.replace(/:repo/,on(e)?e:`https://github.com/${e}`).replace(/:branch/,t).replace(/:path/,zi(`${Cl(n)}/${r}`)):null},jh=()=>{const e=ie(),t=se(),n=ye();return y(()=>{const{repo:r,docsRepo:a=r,docsBranch:l="main",docsDir:o="",editLink:i,editLinkPattern:c=""}=e.value;if(!(n.value.editLink??i??!0)||!a)return null;const u=Fh({docsRepo:a,docsBranch:l,docsDir:o,editLinkPattern:c,filePathRelative:t.value.filePathRelative});return u?{text:e.value.metaLocales.editLink,link:u}:null})},Wh=()=>{const e=Pn(),t=ie(),n=se(),r=ye();return y(()=>{var a,l;return!(r.value.lastUpdated??t.value.lastUpdated??!0)||!((a=n.value.git)!=null&&a.updatedTime)?null:new Date((l=n.value.git)==null?void 0:l.updatedTime).toLocaleString(e.value.lang)})},Gh=()=>{const e=ie(),t=se(),n=ye();return y(()=>{var r;return n.value.contributors??e.value.contributors??!0?((r=t.value.git)==null?void 0:r.contributors)??null:null})};var Kh=D({name:"PageTitle",setup(){const e=se(),t=ye(),n=ie(),{info:r,items:a}=U2();return()=>s("div",{class:"vp-page-title"},[s("h1",[n.value.titleIcon===!1?null:s(ze,{icon:t.value.icon}),e.value.title]),s(mu,{info:r.value,...a.value===null?{}:{items:a.value}}),s("hr")])}});const Eu=()=>s(de,{name:"edit"},()=>[s("path",{d:"M430.818 653.65a60.46 60.46 0 0 1-50.96-93.281l71.69-114.012 7.773-10.365L816.038 80.138A60.46 60.46 0 0 1 859.225 62a60.46 60.46 0 0 1 43.186 18.138l43.186 43.186a60.46 60.46 0 0 1 0 86.373L588.879 565.55l-8.637 8.637-117.466 68.234a60.46 60.46 0 0 1-31.958 11.229z"}),s("path",{d:"M728.802 962H252.891A190.883 190.883 0 0 1 62.008 771.98V296.934a190.883 190.883 0 0 1 190.883-192.61h267.754a60.46 60.46 0 0 1 0 120.92H252.891a69.962 69.962 0 0 0-69.098 69.099V771.98a69.962 69.962 0 0 0 69.098 69.098h475.911A69.962 69.962 0 0 0 797.9 771.98V503.363a60.46 60.46 0 1 1 120.922 0V771.98A190.883 190.883 0 0 1 728.802 962z"})]);Eu.displayName="EditIcon";var qh=D({name:"PageMeta",setup(){const e=ie(),t=jh(),n=Wh(),r=Gh();return()=>{const{metaLocales:a}=e.value;return s("footer",{class:"page-meta"},[t.value?s("div",{class:"meta-item edit-link"},s(We,{class:"label",config:t.value},{before:()=>s(Eu)})):null,s("div",{class:"meta-item git-info"},[n.value?s("div",{class:"update-time"},[s("span",{class:"label"},`${a.lastUpdated}: `),s(aa,()=>s("span",{class:"info"},n.value))]):null,r.value&&r.value.length?s("div",{class:"contributors"},[s("span",{class:"label"},`${a.contributors}: `),r.value.map(({email:l,name:o},i)=>[s("span",{class:"contributor",title:`email: ${l}`},o),i!==r.value.length-1?",":""])]):null])])}}}),Uh=D({name:"NormalPage",slots:Object,setup(e,{slots:t}){const n=ye(),{isDarkmode:r}=mr(),a=ie(),l=y(()=>n.value.toc||n.value.toc!==!1&&a.value.toc!==!1);return()=>s("main",{id:"main-content",class:"vp-page"},s(Lt("LocalEncrypt")?Ye("LocalEncrypt"):ic,()=>{var o,i,c,u;return[(o=t.top)==null?void 0:o.call(t),n.value.cover?s("div",{class:"page-cover"},s("img",{src:Ee(n.value.cover),alt:"","no-view":""})):null,s(Nh),s(Kh),l.value?s(gu,{headerDepth:n.value.headerDepth??a.value.headerDepth??2},{before:()=>{var d;return(d=t.tocBefore)==null?void 0:d.call(t)},after:()=>{var d;return(d=t.tocAfter)==null?void 0:d.call(t)}}):null,(i=t.contentBefore)==null?void 0:i.call(t),s(ql),(c=t.contentAfter)==null?void 0:c.call(t),s(qh),s(zh),Lt("CommentService")?s(Ye("CommentService"),{darkmode:r.value}):null,(u=t.bottom)==null?void 0:u.call(t)]}))}}),Zh=D({name:"Layout",slots:Object,setup(e,{slots:t}){const n=Kt(),r=ie(),a=se(),l=ye(),{isMobile:o}=vr(),i=y(()=>{var c,u;return((c=r.value.blog)==null?void 0:c.sidebarDisplay)||((u=n.value.blog)==null?void 0:u.sidebarDisplay)||"mobile"});return()=>[s(Ul),s(Kl,{},{default:()=>{var c;return((c=t.default)==null?void 0:c.call(t))||(l.value.home?s(Bh):s(Oh,()=>s(Uh,{key:a.value.path},{top:()=>{var u;return(u=t.top)==null?void 0:u.call(t)},bottom:()=>{var u;return(u=t.bottom)==null?void 0:u.call(t)},contentBefore:()=>{var u;return(u=t.contentBefore)==null?void 0:u.call(t)},contentAfter:()=>{var u;return(u=t.contentAfter)==null?void 0:u.call(t)},tocBefore:()=>{var u;return(u=t.tocBefore)==null?void 0:u.call(t)},tocAfter:()=>{var u;return(u=t.tocAfter)==null?void 0:u.call(t)}})))},...i.value!=="none"?{navScreenBottom:()=>s(Ye("BloggerInfo"))}:{},...!o.value&&i.value==="always"?{sidebar:()=>s(Ye("BloggerInfo"))}:{}})]}}),Yh=D({name:"NotFoundHint",setup(){const e=ie(),t=()=>{const n=e.value.routeLocales.notFoundMsg;return n[Math.floor(Math.random()*n.length)]};return()=>s("div",{class:"not-found-hint"},[s("p",{class:"error-code"},"404"),s("h1",{class:"error-title"},e.value.routeLocales.notFoundTitle),s("p",{class:"error-hint"},t())])}}),Xh=D({name:"NotFound",slots:Object,setup(e,{slots:t}){const n=ft(),r=ie(),{navigate:a}=Za({to:r.value.home??n.value});return()=>[s(Ul),s(Kl,{noSidebar:!0},()=>{var l;return s("main",{id:"main-content",class:"vp-page not-found"},((l=t.default)==null?void 0:l.call(t))||[s(Yh),s("div",{class:"actions"},[s("button",{type:"button",class:"action-button",onClick:()=>{window.history.go(-1)}},r.value.routeLocales.back),s("button",{type:"button",class:"action-button",onClick:()=>a()},r.value.routeLocales.home)])])})]}});const Jh={Zhihu:'{const{current:h}=e;let g=1,w=o.value;const E=[];o.value>=7&&(h<=4&&h4&&h>=o.value-3?(w=o.value,g=o.value-4):o.value>7&&(g=h-2,w=h+2));for(let b=g;b<=w;b++)E.push(b);return E}),f=h=>t("updateCurrentPage",h),p=h=>{const g=parseInt(h);g<=o.value&&g>0?f(g):n.pop(`f(e.current+1)},l.value.next):null]),s("div",{class:"vp-pagination-nav"},[s("label",{for:"navigation-text"},`${l.value.navigate}: `),s("input",{id:"navigation-text",value:a.value,onInput:({target:h})=>{a.value=h.value},onKeydown:h=>{h.key==="Enter"&&(h.preventDefault(),p(a.value))}}),s("button",{class:"vp-pagination-button",role:"navigation",title:l.value.action,onClick:()=>p(a.value)},l.value.action)])]):[])}}),to=D({name:"ArticleList",props:{items:{type:Array,default:()=>[]}},setup(e){const t=ot(),n=De(),r=br(),a=Z(1),l=y(()=>r.value.articlePerPage||10),o=y(()=>e.items.slice((a.value-1)*l.value,a.value*l.value)),i=async c=>{a.value=c;const u={...t.query};!(u.page===c.toString()||c===1&&!u.page)&&(c===1?delete u.page:u.page=c.toString(),await n.push({path:t.path,query:u}))};return ge(()=>{const{page:c}=t.query;console.log("mounted"),i(c?Number(c):1),ve(a,()=>{const u=document.querySelector("#article-list").getBoundingClientRect().top+window.scrollY;setTimeout(()=>{window.scrollTo(0,u)},100)})}),()=>s("div",{id:"article-list",class:"vp-article-list",role:"feed"},o.value.length?[...o.value.map(({info:c,path:u},d)=>s(he,{appear:!0,delay:d*.04},()=>s(h4,{key:u,info:c,path:u}))),s(v4,{current:a.value,perPage:l.value,total:e.items.length,onUpdateCurrentPage:i})]:s($u))}}),Vu=D({name:"CategoryList",setup(){const e=se(),t=gr();return()=>s("ul",{class:"vp-category-list"},In(t.value.map).sort(([,n],[,r])=>r.items.length-n.items.length).map(([n,{path:r,items:a}])=>s("li",{class:["vp-category",`vp-category${sa(n,9)}`,{active:r===e.value.path}]},s(Pe,{to:r},()=>[n,s("span",{class:"count"},a.length)]))))}}),Bu=D({name:"TagList",setup(){const e=ye(),t=yr(),n=r=>{var a;return r===((a=e.value.blog)==null?void 0:a.name)};return()=>s("ul",{class:"tag-list-wrapper"},In(t.value.map).sort(([,r],[,a])=>a.items.length-r.items.length).map(([r,{path:a,items:l}])=>s("li",{class:["tag",`tag${sa(r,9)}`,{active:n(r)}]},s(Pe,{to:a},()=>[r,s("span",{class:"tag-num"},l.length)]))))}}),m4=D({name:"TimelineList",setup(){const e=ie(),t=Yl(),n=hr(),r=y(()=>e.value.blogLocales.timeline);return()=>s("div",{class:"timeline-list-wrapper"},[s("div",{class:"timeline-list-title",onClick:()=>n(t.value.path)},[s(eo),s("span",{class:"num"},t.value.items.length),r.value]),s("hr"),s("div",{class:"timeline-content"},s("ul",{class:"timeline-list"},t.value.config.map(({year:a,items:l},o)=>s(he,{appear:!0,delay:.08*(o+1)},()=>s("li",[s("h3",{class:"timeline-year"},a),s("ul",{class:"timeline-year-wrapper"},l.map(({date:i,info:c,path:u})=>s("li",{class:"timeline-item"},[s("span",{class:"timeline-date"},i),s(Pe,{class:"timeline-title",to:u},()=>c[we.title])])))])))))])}});const g4={article:ca,category:Jl,tag:Ql,timeline:eo};var Nu=D({name:"InfoList",setup(){const e=ie(),t=_r(),n=gr(),r=y(()=>yt(n.value.map).length),a=Zl(),l=yr(),o=y(()=>yt(l.value.map).length),i=hr(),c=Z("article"),u=y(()=>e.value.blogLocales);return()=>s("div",{class:"vp-blog-infos"},[s("div",{class:"vp-blog-type-switcher"},In(g4).map(([d,f])=>s("button",{type:"button",class:"vp-blog-type-button",onClick:()=>{c.value=d}},s("div",{class:["icon-wrapper",{active:c.value===d}],"aria-label":u.value[d],"data-balloon-pos":"up"},s(f))))),s(he,()=>c.value==="article"?s("div",{class:"vp-star-article-wrapper"},[s("div",{class:"title",onClick:()=>i(t.value.path)},[s(ca),s("span",{class:"num"},t.value.items.length),u.value.article]),s("hr"),a.value.items.length?s("ul",{class:"vp-star-articles"},a.value.items.map(({info:d,path:f},p)=>s(he,{appear:!0,delay:.08*(p+1)},()=>s("li",{class:"vp-star-article"},s(Pe,{to:f},()=>d[we.title]))))):s("div",{class:"vp-star-article-empty"},u.value.empty.replace("$text",u.value.star))]):c.value==="category"?s("div",{class:"vp-category-wrapper"},[r.value?[s("div",{class:"title",onClick:()=>i(n.value.path)},[s(Jl),s("span",{class:"num"},r.value),u.value.category]),s("hr"),s(he,{delay:.04},()=>s(Vu))]:s("div",{class:"vp-category-empty"},u.value.empty.replace("$text",u.value.category))]):c.value==="tag"?s("div",{class:"vp-tag-wrapper"},[o.value?[s("div",{class:"title",onClick:()=>i(l.value.path)},[s(Ql),s("span",{class:"num"},o.value),u.value.tag]),s("hr"),s(he,{delay:.04},()=>s(Bu))]:s("div",{class:"vp-tag-empty"},u.value.empty.replace("$text",u.value.tag))]):s(he,()=>s(m4)))])}}),ua=D({name:"BlogWrapper",slots:Object,setup(e,{slots:t}){const{isMobile:n}=vr();return()=>[s(Ul),s(Kl,{noSidebar:!0,noToc:!0},{default:()=>t.default(),navScreenBottom:()=>s(Xl),...n.value?{sidebar:()=>s(Nu)}:{}})]}});const zu=()=>s("aside",{class:"vp-blog-info-wrapper"},[s(he,()=>s(Xl)),s(he,{delay:.04},()=>s(Nu))]);zu.displayName="InfoPanel";var da=zu,b4=D({name:"BlogPage",setup(){const e=se(),t=ye(),n=gr(),r=yr();return()=>{const{key:a="",name:l=""}=t.value.blog||{},o=l?a==="category"?n.value.map[l].items:a==="tag"?r.value.map[l].items:[]:[];return s(ua,()=>s("div",{class:"vp-page vp-blog"},s("div",{class:"blog-page-wrapper"},[s("main",{id:"main-content",class:"vp-blog-main"},[s(he,()=>a==="category"?s(Vu):a==="tag"?s(Bu):null),l?s(he,{appear:!0,delay:.24},()=>s(to,{key:e.value.path,items:o})):null]),s(he,{delay:.16},()=>s(da,{key:"blog"}))])))}}});const y4="//theme-hope-assets.vuejs.press/hero/default.jpg";var _4=D({name:"BlogHero",slots:Object,setup(e,{slots:t}){const n=ye(),r=Pn(),a=lt(),l=y(()=>n.value.heroFullScreen??!1),o=y(()=>{const{heroText:c,heroImage:u,heroImageDark:d,heroAlt:f,heroImageStyle:p,tagline:h}=n.value;return{text:c??r.value.title??"Hello",image:u?Ee(u):null,imageDark:d?Ee(d):null,heroStyle:p,alt:f||c||"",tagline:h??"",isFullScreen:l.value}}),i=y(()=>{const{bgImage:c,bgImageDark:u,bgImageStyle:d}=n.value;return{image:oe(c)?Ee(c):c===!1?null:y4,imageDark:oe(u)?Ee(u):null,bgStyle:d,isFullScreen:l.value}});return()=>{var c,u;return n.value.hero===!1?null:s("div",{ref:a,class:["vp-blog-hero",{fullscreen:l.value,"no-bg":!i.value.image}]},[((c=t.heroBg)==null?void 0:c.call(t,i.value))||[i.value.image?s("div",{class:["vp-blog-mask",{light:i.value.imageDark}],style:[{background:`url(${i.value.image}) center/cover no-repeat`},i.value.bgStyle]}):null,i.value.imageDark?s("div",{class:"vp-blog-mask dark",style:[{background:`url(${i.value.imageDark}) center/cover no-repeat`},i.value.bgStyle]}):null],((u=t.heroInfo)==null?void 0:u.call(t,o.value))||[s(he,{appear:!0,type:"group",delay:.04},()=>[o.value.image?s("img",{key:"light",class:["vp-blog-hero-image",{light:o.value.imageDark}],style:o.value.heroStyle,src:o.value.image,alt:o.value.alt}):null,o.value.imageDark?s("img",{key:"dark",class:"vp-blog-hero-image dark",style:o.value.heroStyle,src:o.value.imageDark,alt:o.value.alt}):null]),s(he,{appear:!0,delay:.08},()=>o.value.text?s("h1",{class:"vp-blog-hero-title"},o.value.text):null),s(he,{appear:!0,delay:.12},()=>o.value.tagline?s("p",{class:"vp-blog-hero-description",innerHTML:o.value.tagline}):null)],o.value.isFullScreen?s("button",{type:"button",class:"slide-down-button",onClick:()=>{window.scrollTo({top:a.value.clientHeight,behavior:"smooth"})}},[s(al),s(al)]):null])}}});const w4=["link","article","book","project","friend"];var E4=D({name:"ProjectPanel",components:{ArticleIcon:ca,BookIcon:Iu,FriendIcon:Mu,LinkIcon:Ru,ProjectIcon:Ou},props:{items:{type:Array,required:!0}},setup(e){const t=sn(),n=hr(),r=(a="",l="icon")=>w4.includes(a)?s(Ye(`${a}-icon`)):on(a)?s("img",{class:"vp-project-image",src:a,alt:l}):Rn(a)?s("img",{class:"vp-project-image",src:Ee(a),alt:l}):s(ze,{icon:a});return()=>s("div",{class:"vp-project-panel"},e.items.map(({icon:a,link:l,name:o,desc:i},c)=>s("div",{class:["vp-project-card",{[`project${c%9}`]:!t.value}],onClick:()=>n(l)},[r(a,o),s("div",{class:"vp-project-name"},o),s("div",{class:"vp-project-desc"},i)])))}}),k4=D({name:"BlogHome",setup(){const e=_r(),t=ye(),n=y(()=>t.value.projects??[]);return()=>s("div",{class:"vp-page vp-blog"},[s(_4),s("div",{class:"blog-page-wrapper"},[s("main",{id:"main-content",class:"vp-blog-main"},[n.value.length?s(he,{appear:!0,delay:.16},()=>s(E4,{items:n.value})):null,s(he,{appear:!0,delay:.24},()=>s(to,{items:e.value.items}))]),s(he,{appear:!0,delay:.16},()=>s(da,{key:"blog"}))]),s(he,{appear:!0,delay:.28},()=>s(ql))])}});const Hu=()=>s(ua,()=>s(k4));Hu.displayName="BlogHomeLayout";var x4=Hu,T4=D({name:"ArticleType",setup(){const e=se(),t=ft(),n=ie(),r=_r(),a=Zl(),l=y(()=>{const o=n.value.blogLocales;return[{text:o.all,path:r.value.path},{text:o.star,path:a.value.path},...t4.map(({key:i,path:c})=>({text:o[i],path:c.replace(/^\//,t.value)}))]});return()=>s("ul",{class:"vp-article-type-wrapper"},l.value.map(o=>s("li",{class:["vp-article-type",{active:o.path===e.value.path}]},s(Pe,{to:o.path},()=>o.text))))}}),L4=D({name:"BlogPage",setup(){const e=ia(),t=ye(),n=se(),r=_r(),a=Zl(),l=y(()=>{const{key:o="",type:i}=t.value.blog||{};return o==="star"?a.value.items:i==="type"&&o?e.value.items:r.value.items});return()=>s(ua,()=>s("div",{class:"vp-page vp-blog"},s("div",{class:"blog-page-wrapper"},[s("main",{id:"main-content",class:"vp-blog-main"},[s(he,()=>s(T4)),s(he,{appear:!0,delay:.24},()=>s(to,{key:n.value.path,items:l.value}))]),s(he,{delay:.16},()=>s(da,{key:"blog"}))])))}}),A4=D({name:"TimelineItems",setup(){const e=br(),t=ie(),n=Yl(),r=y(()=>e.value.timeline||t.value.blogLocales.timelineTitle),a=y(()=>n.value.config.map(({year:l})=>({title:l.toString(),level:2,slug:l.toString(),children:[]})));return()=>s("div",{class:"timeline-wrapper"},s("ul",{class:"timeline-content"},[s(he,()=>s("li",{class:"motto"},r.value)),s(gu,{items:a.value}),n.value.config.map(({year:l,items:o},i)=>s(he,{appear:!0,delay:.08*(i+1),type:"group"},()=>[s("h3",{key:"title",id:l,class:"timeline-year-title"},s("span",l)),s("li",{key:"content",class:"timeline-year-list"},[s("ul",{class:"timeline-year-wrapper"},o.map(({date:c,info:u,path:d})=>s("li",{class:"timeline-item"},[s("span",{class:"timeline-date"},c),s(Pe,{class:"timeline-title",to:d},()=>u[we.title])])))])]))]))}});const Fu=()=>s(ua,()=>s("div",{class:"vp-page vp-blog"},s("div",{class:"blog-page-wrapper"},[s("main",{id:"main-content",class:"vp-blog-main"},[s(he,{appear:!0,delay:.24},()=>s(A4))]),s(he,{delay:.16},()=>s(da,{key:"blog"}))])));Fu.displayName="Timeline";var S4=Fu;e2(e=>{const t=e.t,n=e.I!==!1,r=e.i;return n?{title:t,content:r?()=>[s(ze,{icon:r}),t]:null,order:e.O,index:e.I}:null});const C4=Xe({enhance:({app:e,router:t})=>{const{scrollBehavior:n}=t.options;t.options.scrollBehavior=async(...r)=>(await bu().wait(),n(...r)),X2(e),e.component("HopeIcon",ze),e.component("VPLink",Pe),e.component("BloggerInfo",Xl)},setup:()=>{J2(),nh(),f4()},layouts:{Layout:Zh,NotFound:Xh,BlogCategory:b4,BlogHome:x4,BlogType:L4,Timeline:S4}}),P4=Xe({enhance:({app:e})=>{},setup:()=>{}}),$n=({name:e="",color:t="currentColor"},{slots:n})=>{var r;return s("svg",{xmlns:"http://www.w3.org/2000/svg",class:["icon",`${e}-icon`],viewBox:"0 0 1024 1024",fill:t,"aria-label":`${e} icon`},(r=n.default)==null?void 0:r.call(n))};$n.displayName="IconBase";const I4=e=>[/\((ipad);[-\w),; ]+apple/i,/applecoremedia\/[\w.]+ \((ipad)/i,/\b(ipad)\d\d?,\d\d?[;\]].+ios/i].some(t=>t.test(e)),R4=e=>[/ip[honead]{2,4}\b(?:.*os ([\w]+) like mac|; opera)/i,/cfnetwork\/.+darwin/i].some(t=>t.test(e)),O4=e=>[/(mac os x) ?([\w. ]*)/i,/(macintosh|mac_powerpc\b)(?!.+haiku)/i].some(t=>t.test(e));function M4(){const e=Z(!1);return ln()&&ge(()=>{e.value=!0}),e}function $4(e){return M4(),y(()=>!!e())}const D4=e=>typeof e=="string",ju=(e,t)=>D4(e)&&e.startsWith(t),V4=e=>(e.endsWith(".md")&&(e=`${e.slice(0,-3)}.html`),!e.endsWith("/")&&!e.endsWith(".html")&&(e=`${e}.html`),e=e.replace(/(^|\/)(?:README|index).html$/i,"$1"),e),B4=e=>{const[t,n=""]=e.split("#");return t?`${V4(t)}${n?`#${n}`:""}`:e},N4=e=>{var t;if(!(e.metaKey||e.altKey||e.ctrlKey||e.shiftKey)&&!e.defaultPrevented&&!(e.button!==void 0&&e.button!==0)&&!(e.currentTarget&&((t=e.currentTarget.getAttribute("target"))!=null&&t.match(/\b_blank\b/i))))return e.preventDefault(),!0},z4=({to:e="",class:t="",...n},{slots:r})=>{var i;const a=De(),l=B4(e),o=(c={})=>N4(c)?a.push(e).catch():Promise.resolve();return s("a",{...n,class:["vp-link",t],href:ju(l,"/")?Ee(l):l,onClick:o},(i=r.default)==null?void 0:i.call(r))};z4.displayName="VPLink";const H4=()=>$4(()=>typeof window<"u"&&window.navigator&&"userAgent"in window.navigator),F4=()=>{const e=H4();return y(()=>e.value&&/\b(?:Android|iPhone)/i.test(navigator.userAgent))},no=e=>{const t=ft();return y(()=>e[t.value])},j4=()=>s($n,{name:"heading"},()=>s("path",{d:"M250.4 704.6H64V595.4h202.4l26.2-166.6H94V319.6h214.4L352 64h127.8l-43.6 255.4h211.2L691 64h126.2l-43.6 255.4H960v109.2H756.2l-24.6 166.6H930v109.2H717L672 960H545.8l43.6-255.4H376.6L333 960H206.8l43.6-255.4zm168.4-276L394 595.4h211.2l24.6-166.6h-211z"}));j4.displayName="HeadingIcon";const W4=()=>s($n,{name:"heart"},()=>s("path",{d:"M1024 358.156C1024 195.698 892.3 64 729.844 64c-86.362 0-164.03 37.218-217.844 96.49C458.186 101.218 380.518 64 294.156 64 131.698 64 0 195.698 0 358.156 0 444.518 37.218 522.186 96.49 576H96l320 320c32 32 64 64 96 64s64-32 96-64l320-320h-.49c59.272-53.814 96.49-131.482 96.49-217.844zM841.468 481.232 517.49 805.49a2981.962 2981.962 0 0 1-5.49 5.48c-1.96-1.95-3.814-3.802-5.49-5.48L182.532 481.234C147.366 449.306 128 405.596 128 358.156 128 266.538 202.538 192 294.156 192c47.44 0 91.15 19.366 123.076 54.532L512 350.912l94.768-104.378C638.696 211.366 682.404 192 729.844 192 821.462 192 896 266.538 896 358.156c0 47.44-19.368 91.15-54.532 123.076z"}));W4.displayName="HeartIcon";const G4=()=>s($n,{name:"history"},()=>s("path",{d:"M512 1024a512 512 0 1 1 512-512 512 512 0 0 1-512 512zm0-896a384 384 0 1 0 384 384 384 384 0 0 0-384-384zm192 448H512a64 64 0 0 1-64-64V320a64 64 0 0 1 128 0v128h128a64 64 0 0 1 0 128z"}));G4.displayName="HistoryIcon";const K4=()=>s($n,{name:"title"},()=>s("path",{d:"M512 256c70.656 0 134.656 28.672 180.992 75.008A254.933 254.933 0 0 1 768 512c0 83.968-41.024 157.888-103.488 204.48C688.96 748.736 704 788.48 704 832c0 105.984-86.016 192-192 192-106.048 0-192-86.016-192-192h128a64 64 0 1 0 128 0 64 64 0 0 0-64-64 255.19 255.19 0 0 1-181.056-75.008A255.403 255.403 0 0 1 256 512c0-83.968 41.024-157.824 103.488-204.544C335.04 275.264 320 235.584 320 192A192 192 0 0 1 512 0c105.984 0 192 85.952 192 192H576a64.021 64.021 0 0 0-128 0c0 35.328 28.672 64 64 64zM384 512c0 70.656 57.344 128 128 128s128-57.344 128-128-57.344-128-128-128-128 57.344-128 128z"}));K4.displayName="TitleIcon";const ro=()=>s($n,{name:"search"},()=>s("path",{d:"M192 480a256 256 0 1 1 512 0 256 256 0 0 1-512 0m631.776 362.496-143.2-143.168A318.464 318.464 0 0 0 768 480c0-176.736-143.264-320-320-320S128 303.264 128 480s143.264 320 320 320a318.016 318.016 0 0 0 184.16-58.592l146.336 146.368c12.512 12.48 32.768 12.48 45.28 0 12.48-12.512 12.48-32.768 0-45.28"}));ro.displayName="SearchIcon";const Wu=()=>s("svg",{xmlns:"http://www.w3.org/2000/svg",width:"32",height:"32",preserveAspectRatio:"xMidYMid",viewBox:"0 0 100 100"},[s("circle",{cx:"28",cy:"75",r:"11",fill:"currentColor"},s("animate",{attributeName:"fill-opacity",begin:"0s",dur:"1s",keyTimes:"0;0.2;1",repeatCount:"indefinite",values:"0;1;1"})),s("path",{fill:"none",stroke:"#88baf0","stroke-width":"10",d:"M28 47a28 28 0 0 1 28 28"},s("animate",{attributeName:"stroke-opacity",begin:"0.1s",dur:"1s",keyTimes:"0;0.2;1",repeatCount:"indefinite",values:"0;1;1"})),s("path",{fill:"none",stroke:"#88baf0","stroke-width":"10",d:"M28 25a50 50 0 0 1 50 50"},s("animate",{attributeName:"stroke-opacity",begin:"0.2s",dur:"1s",keyTimes:"0;0.2;1",repeatCount:"indefinite",values:"0;1;1"}))]);Wu.displayName="LoadingIcon";const Gu=({hint:e})=>s("div",{class:"search-pro-result-wrapper loading"},[s(Wu),e]);Gu.displayName="SearchLoading";const q4='{t||(n.value=0)}),{index:n,item:r,prev:a,next:l}},oo=Symbol(""),n3=()=>{const e=Z(!1);rt(oo,e)},r3=e=>e instanceof Element?document.activeElement===e&&(["TEXTAREA","SELECT","INPUT"].includes(e.tagName)||e.hasAttribute("contenteditable")):!1,a3=e=>Ku.some(t=>{const{key:n,ctrl:r=!1,shift:a=!1,alt:l=!1,meta:o=!1}=t;return n===e.key&&r===e.ctrlKey&&a===e.shiftKey&&l===e.altKey&&o===e.metaKey}),l3=' 关于我
+留空
+`,r:{minutes:.02,words:5},y:"a",t:"关于我"},["/about-the-author/README.md"]],["v-cfe8b6c8","/cloudnative/",{d:1706066758e3,y:"a",t:""},["/cloudnative/README.md"]],["v-2e25198a","/database/",{d:1706182936e3,e:`
+`,r:{minutes:.05,words:15},y:"a",t:""},["/database/README.md"]],["v-71fde78e","/devops/",{d:1706066758e3,e:` 三、DevOps
+`,r:{minutes:.08,words:24},y:"a",t:"三、DevOps"},["/devops/README.md"]],["v-580db9be","/devops/devops-ping-tai.html",{d:1706066758e3,e:` 3.1 DevOps平台.md
+DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
+公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。
`,r:{minutes:11.93,words:3580},y:"a",t:"3.1 DevOps平台.md"},[":md"]],["v-06d5cd4c","/devops/gitlab-ci.html",{d:1706066758e3,e:` Git
+`,r:{minutes:0,words:1},y:"a",t:"Git"},[":md"]],["v-132efcd1","/devops/jenkins-x.html",{d:1706066758e3,e:` jenkins-x
+`,r:{minutes:.01,words:2},y:"a",t:"jenkins-x"},[":md"]],["v-1a2ca7a7","/devops/tekton.html",{d:1706066758e3,e:` tekton
+`,r:{minutes:0,words:1},y:"a",t:"tekton"},[":md"]],["v-50cb12f2","/donate/",{d:1706182936e3,e:` 微信支付
+微信支付 tt一面:
+1.全程项目
+2.lc3,最长无重复子串,滑动窗口解决
+tt二面:
+全程基础,一直追问
+1.java内存模型介绍一下
+2.volatile原理
+3.内存屏障,使用场景?(我提了在gc中有使用)
+4.gc中具体是怎么使用内存屏障的,详细介绍
+5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么
+6.线程内存分配方式,tlab相关
+7.happens-before介绍一下
+8.总线风暴是什么,怎么解决
+9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决
+10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222
+11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作
`,r:{minutes:1.15,words:344},y:"a",t:""},[":md"]],["v-0a27b598","/java/JVM%E8%B0%83%E4%BC%98%E5%8F%82%E6%95%B0.html",{d:1706066758e3,e:` JVM调优参数
+ 一、堆大小设置
+JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
+ 典型设置:
+java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
+ lucene搜索原理
+`,r:{minutes:.02,words:5},y:"a",t:"lucene搜索原理"},["/java/lucene搜索原理.html","/java/lucene搜索原理.md",":md"]],["v-60eda44c","/java/serverlog.html",{d:1706066758e3,e:` 被挖矿攻击
+服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看:
`,r:{minutes:.57,words:172},y:"a",t:"被挖矿攻击"},[":md"]],["v-399e07b6","/java/%E4%B8%80%E6%AC%A1jvm%E8%B0%83%E4%BC%98%E8%BF%87%E7%A8%8B.html",{d:1706066758e3,e:` 一次jvm调优过程
+前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。
+该程序task主要分为三个模块:
+console进行一些cron的配置(表达式、任务名称、任务组等);
+schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发;
+client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。
+整体架构跟github上开源的xxl-job类似,也可以参考一下。
`,r:{minutes:6.23,words:1870},y:"a",t:"一次jvm调优过程"},["/java/一次jvm调优过程.html","/java/一次jvm调优过程.md",":md"]],["v-660266c1","/java/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C.html",{d:1706066758e3,e:` 内存屏障
+四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad
+在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值
+在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。
`,r:{minutes:.69,words:208},y:"a",t:"内存屏障"},["/java/内存屏障.html","/java/内存屏障.md",":md"]],["v-90f2343c","/java/%E5%9C%A8%20Spring%206%20%E4%B8%AD%E4%BD%BF%E7%94%A8%E8%99%9A%E6%8B%9F%E7%BA%BF%E7%A8%8B.html",{d:1706186538e3,e:` 在 Spring 6 中使用虚拟线程
+ 一、简介
+在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。
+虚拟线程是Java 19 的预览功能 ,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本 最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。
`,r:{minutes:4.83,words:1448},y:"a",t:"在 Spring 6 中使用虚拟线程"},["/java/在 Spring 6 中使用虚拟线程.html","/java/在 Spring 6 中使用虚拟线程.md",":md"]],["v-0b5d4df0","/java/%E5%9F%BA%E4%BA%8Ekubernetes%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81.html",{d:1706066758e3,e:` 基于kubernetes的分布式限流
+做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
+ 一、概念
+限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。
+ 1.1 使用场景
+限流可以应对:
+
+热点业务带来的突发请求;
+调用方 bug 导致的突发请求;
+恶意攻击请求。
+ `,r:{minutes:7.18,words:2155},y:"a",t:"基于kubernetes的分布式限流"},["/java/基于kubernetes的分布式限流.html","/java/基于kubernetes的分布式限流.md",":md"]],["v-21e54510","/kubernetes/",{d:1706066758e3,y:"a",t:""},["/kubernetes/README.md"]],["v-57ae83ac","/kubernetes/spark%20on%20k8s%20operator.html",{d:1706066758e3,e:` spark on k8s operator
+Spark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。
+使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。
+Spark Operator包括如下几个组件:
`,r:{minutes:3.5,words:1050},y:"a",t:"spark on k8s operator"},["/kubernetes/spark on k8s operator.html","/kubernetes/spark on k8s operator.md",":md"]],["v-22e4234a","/life/2017.html",{d:1706066758e3,e:` 2017
+2016年6月,大三,考完最后一科,默默的看着大四那群人一个一个的走了,想着想着,明年毕业的时候,自己将会失去你所拥有的一切,大学那群认识的人,可能这辈子都不会见到了——致远离家乡出省读书的娃。然而,我并没有想到,自己失去的,不仅仅是那群人,几乎是一切。。。。
+ 2018
+年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。
+想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.html ,感叹18年还算恢复了点。
+ 心惊胆战的裸辞经历 `,r:{minutes:4.35,words:1306},y:"a",t:"2018"},[":md"]],["v-1c10c0ce","/life/2019.html",{d:1706066758e3,e:` 2019
+2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。
+19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。
+ 工作
+从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。
`,r:{minutes:4.43,words:1329},y:"a",t:"2019"},[":md"]],["v-258f309e","/open-source-project/",{d:1706092222e3,e:`jfaowejfoewj
+`,r:{minutes:0,words:1},y:"a",t:""},["/open-source-project/README.md"]],["v-510415f9","/others/chatgpt.html",{d:1706186538e3,e:` 微信公众号-chatgpt智能客服搭建
+想体验的可以去微信上搜索【旅行的树】公众号。
+ 一、ChatGPT注册
+ 1.1 短信手机号申请
+openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。
+国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。
+国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。
+`,r:{minutes:9.96,words:2987},y:"a",t:"微信公众号-chatgpt智能客服搭建"},[":md"]],["v-3c114a75","/others/tesla.html",{d:1706186538e3,e:` Tesla api
+ 一、特斯拉应用申请
+ 1.1 创建 Tesla 账户
+如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。
+正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.
+ 1.历史与架构
+各位大佬瞄一眼我的个人网站 呗 。如果觉得不错,希望能在GitHub上麻烦给个star,GitHub地址https://github.com/Zephery/newblog 。
+大学的时候萌生的一个想法,就是建立一个个人网站,前前后后全部推翻重构了4、5遍,现在终于能看了,下面是目前的首页。
`,r:{minutes:6.79,words:2038},y:"a",t:"1.历史与架构"},["/personalWebsite/1.历史与架构.html","/personalWebsite/1.历史与架构.md",":md"]],["v-523e9724","/personalWebsite/10.%E7%BD%91%E7%AB%99%E9%87%8D%E6%9E%84.html",{d:1706182936e3,e:` 10.网站重构
+因原本的
+`,r:{minutes:.03,words:9},y:"a",t:"10.网站重构"},["/personalWebsite/10.网站重构.html","/personalWebsite/10.网站重构.md",":md"]],["v-65b5c81c","/personalWebsite/2.Lucene%E7%9A%84%E4%BD%BF%E7%94%A8.html",{d:1706182936e3,e:` 2.Lucene的使用
+首先,帮忙点击一下我的网站http://www.wenzhihuai.com/ 。谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github.com/Zephery/newblog 。
`,r:{minutes:6.82,words:2046},y:"a",t:"2.Lucene的使用"},["/personalWebsite/2.Lucene的使用.html","/personalWebsite/2.Lucene的使用.md",":md"]],["v-731a76b6","/personalWebsite/3.%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1.html",{d:1706182936e3,e:` 3.定时任务
+先看一下Quartz的架构图:
+ 一.特点:
+
+强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求;
+灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式;
+分布式和集群能力。
+ `,r:{minutes:3.55,words:1064},y:"a",t:"3.定时任务"},["/personalWebsite/3.定时任务.html","/personalWebsite/3.定时任务.md",":md"]],["v-bea2ce1e","/personalWebsite/4.%E6%97%A5%E5%BF%97%E7%B3%BB%E7%BB%9F.html",{d:1706182936e3,e:` 4.日志系统.md
+欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。
`,r:{minutes:9.64,words:2891},y:"a",t:"4.日志系统.md"},["/personalWebsite/4.日志系统.html","/personalWebsite/4.日志系统.md",":md"]],["v-3efc517e","/personalWebsite/5.%E5%B0%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.html",{d:1706182936e3,e:` 5.小集群部署.md
+欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com ,个人网站代码地址:https://github.com/Zephery/newblog 。
`,r:{minutes:9.5,words:2849},y:"a",t:"5.小集群部署.md"},["/personalWebsite/5.小集群部署.html","/personalWebsite/5.小集群部署.md",":md"]],["v-79ad699f","/personalWebsite/6.%E6%95%B0%E6%8D%AE%E5%BA%93%E5%A4%87%E4%BB%BD.html",{d:1706182936e3,e:` 6.数据库备份
+先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
+由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:
`,r:{minutes:5.77,words:1732},y:"a",t:"6.数据库备份"},["/personalWebsite/6.数据库备份.html","/personalWebsite/6.数据库备份.md",":md"]],["v-8658e60a","/personalWebsite/7.%E9%82%A3%E4%BA%9B%E7%89%9B%E9%80%BC%E7%9A%84%E6%8F%92%E4%BB%B6.html",{d:1706182936e3,e:` 7.那些牛逼的插件
+欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。
`,r:{minutes:7.24,words:2173},y:"a",t:"7.那些牛逼的插件"},["/personalWebsite/7.那些牛逼的插件.html","/personalWebsite/7.那些牛逼的插件.md",":md"]],["v-7e9e4a32","/personalWebsite/8.%E5%9F%BA%E4%BA%8E%E8%B4%9D%E5%8F%B6%E6%96%AF%E7%9A%84%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90.html",{d:1706182936e3,e:` 8.基于贝叶斯的情感分析
+`,r:{minutes:.04,words:11},y:"a",t:"8.基于贝叶斯的情感分析"},["/personalWebsite/8.基于贝叶斯的情感分析.html","/personalWebsite/8.基于贝叶斯的情感分析.md",":md"]],["v-0b62f72e","/personalWebsite/9.%E7%BD%91%E7%AB%99%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.html",{d:1706182936e3,e:` 9.网站性能优化
+`,r:{minutes:.02,words:7},y:"a",t:"9.网站性能优化"},["/personalWebsite/9.网站性能优化.html","/personalWebsite/9.网站性能优化.md",":md"]],["v-dc384366","/redis/",{d:1706066758e3,y:"a",t:""},["/redis/README.md"]],["v-70796e0a","/redis/redis%E7%BC%93%E5%AD%98.html",{d:1706066758e3,e:` 一、概述
+ 1.1 缓存介绍
+系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。
+缓存常用语:
+数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透
+可查看Redis实战(一) 使用缓存合理性
`,r:{minutes:11.96,words:3588},y:"a",t:"一、概述"},["/redis/redis缓存.html","/redis/redis缓存.md",":md"]],["v-43e9e6b0","/about-the-author/personal-life/wewe.html",{d:1706244827e3,e:` 自我介绍
+oifjwoiej
+`,r:{minutes:.02,words:5},y:"a",t:"自我介绍"},[":md"]],["v-04e32b44","/bigdata/spark/elastic-spark.html",{d:1706182936e3,e:` elastic spark
+Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有:
+(1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv
`,r:{minutes:1.71,words:514},y:"a",t:"elastic spark"},[":md"]],["v-d73a9aee","/database/elasticsearch/elasticsearch%E6%BA%90%E7%A0%81debug.html",{d:1706186538e3,e:` 【elasticsearch】源码debug
+ 一、下载源代码
+直接用idea下载代码https://github.com/elastic/elasticsearch.git
+
+切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好
+
`,r:{minutes:.52,words:157},y:"a",t:"【elasticsearch】源码debug"},["/database/elasticsearch/elasticsearch源码debug.html","/database/elasticsearch/elasticsearch源码debug.md",":md"]],["v-3f2a15ee","/database/elasticsearch/%E3%80%90elasticsearch%E3%80%91%E6%90%9C%E7%B4%A2%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.html",{d:1706183164e3,e:` 【elasticsearch】搜索过程详解
+本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。
+ SearchType
+QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。
+DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。
`,r:{minutes:8.92,words:2676},y:"a",t:"【elasticsearch】搜索过程详解"},["/database/elasticsearch/【elasticsearch】搜索过程详解.html","/database/elasticsearch/【elasticsearch】搜索过程详解.md",":md"]],["v-aa93dec0","/database/mysql/1mysql.html",{d:1706092222e3,e:` mysql
+img gap锁
+`,r:{minutes:.01,words:2},y:"a",t:"gap锁"},["/database/mysql/gap锁.html","/database/mysql/gap锁.md",":md"]],["v-2675bfdc","/database/mysql/%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92explain.html",{d:1706092222e3,e:` 执行计划explain
+第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain
+`,r:{minutes:.14,words:41},y:"a",t:"执行计划explain"},["/database/mysql/执行计划explain.html","/database/mysql/执行计划explain.md",":md"]],["v-0a0b7a54","/database/mysql/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%BC%93%E5%AD%98.html",{d:1706092222e3,e:` 数据库缓存
+在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。
+将select语句和语句的结果做hash 映射关系后保存在一定的内存区域内。
+禁用原因:
+1.命中率低
+2.写时所有都失效
+禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。
`,r:{minutes:.34,words:101},y:"a",t:"数据库缓存"},["/database/mysql/数据库缓存.html","/database/mysql/数据库缓存.md",":md"]],["v-d7d7df80","/middleware/kafka/kafka.html",{d:1706204085e3,e:` kafka面试题
+1、请说明什么是Apache Kafka?
+Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。
+2、说说Kafka的使用场景?
+①异步处理
+②应用解耦
+③流量削峰
+④日志处理
+⑤消息通讯等。
+3、使用Kafka有什么优点和缺点?
+优点:
+①支持跨数据中心的消息复制;
+②单机吞吐量:十万级,最大的优点,就是吞吐量高;
+③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源;
+④时效性:ms级;
+⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用;
+⑥消息可靠性:经过参数优化配置,消息可以做到0丢失;
+⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
`,r:{minutes:17.01,words:5103},y:"a",t:"kafka面试题"},[":md"]],["v-7d9b9318","/middleware/zookeeper/zookeeper.html",{d:1706204085e3,e:` Zookeeper
+留空
+`,r:{minutes:.01,words:3},y:"a",t:"Zookeeper"},[":md"]],["v-3706649a","/404.html",{y:"p",t:""},[]],["v-71b3ae87","/interview/",{y:"p",t:"Interview"},[]],["v-14c69af4","/java/",{y:"p",t:"Java"},[]],["v-14e6315a","/life/",{y:"p",t:"Life"},[]],["v-25b47c13","/others/",{y:"p",t:"Others"},[]],["v-525c5e4d","/personalWebsite/",{y:"p",t:"Personal Website"},[]],["v-5d3e6196","/about-the-author/personal-life/",{y:"p",t:"Personal Life"},[]],["v-60fc7530","/bigdata/spark/",{y:"p",t:"Spark"},[]],["v-02bc92be","/bigdata/",{y:"p",t:"Bigdata"},[]],["v-380c630d","/database/elasticsearch/",{y:"p",t:"Elasticsearch"},[]],["v-21ba2ec8","/database/mysql/",{y:"p",t:"Mysql"},[]],["v-a32329e6","/middleware/kafka/",{y:"p",t:"Kafka"},[]],["v-4d194044","/middleware/",{y:"p",t:"Middleware"},[]],["v-6e21a4b2","/middleware/zookeeper/",{y:"p",t:"Zookeeper"},[]],["v-5bc93818","/category/",{y:"p",t:"分类",I:!1},[]],["v-744d024e","/tag/",{y:"p",t:"标签",I:!1},[]],["v-e52c881c","/article/",{y:"p",t:"文章",I:!1},[]],["v-154dc4c4","/star/",{y:"p",t:"星标",I:!1},[]],["v-01560935","/timeline/",{y:"p",t:"时间轴",I:!1},[]]];var Rs=D({name:"Vuepress",setup(){const e=Wf();return()=>s(e.value)}}),k3=()=>E3.reduce((e,[t,n,r,a])=>(e.push({name:t,path:n,component:Rs,meta:r},{path:n.endsWith("/")?n+"index.html":n.substring(0,n.length-5),redirect:n},...a.map(l=>({path:l===":md"?n.substring(0,n.length-5)+".md":l,redirect:n}))),e),[{name:"404",path:"/:catchAll(.*)",component:Rs}]),x3=pp,T3=()=>{const e=Yp({history:x3(Cl("/")),routes:k3(),scrollBehavior:(t,n,r)=>r||(t.hash?{el:t.hash}:{top:0})});return e.beforeResolve(async(t,n)=>{var r;(t.path!==n.path||n===xt)&&([t.meta._data]=await Promise.all([kt.resolvePageData(t.name),(r=Hi[t.name])==null?void 0:r.__asyncLoader()]))}),e},L3=e=>{e.component("ClientOnly",aa),e.component("Content",Zi)},A3=(e,t,n)=>{const r=ps(()=>t.currentRoute.value.path),a=ps(()=>kt.resolveRouteLocale(hn.value.locales,r.value)),l=Dl(r,()=>t.currentRoute.value.meta._data),o=y(()=>kt.resolveLayouts(n)),i=y(()=>kt.resolveSiteLocaleData(hn.value,a.value)),c=y(()=>kt.resolvePageFrontmatter(l.value)),u=y(()=>kt.resolvePageHeadTitle(l.value,i.value)),d=y(()=>kt.resolvePageHead(u.value,c.value,i.value)),f=y(()=>kt.resolvePageLang(l.value,i.value)),p=y(()=>kt.resolvePageLayout(l.value,o.value));return e.provide(zf,o),e.provide(Fi,l),e.provide(ji,c),e.provide(jf,u),e.provide(Wi,d),e.provide(Gi,f),e.provide(Ki,p),e.provide(Il,a),e.provide(Ui,i),Object.defineProperties(e.config.globalProperties,{$frontmatter:{get:()=>c.value},$head:{get:()=>d.value},$headTitle:{get:()=>u.value},$lang:{get:()=>f.value},$page:{get:()=>l.value},$routeLocale:{get:()=>a.value},$site:{get:()=>hn.value},$siteLocale:{get:()=>i.value},$withBase:{get:()=>Ee}}),{layouts:o,pageData:l,pageFrontmatter:c,pageHead:d,pageHeadTitle:u,pageLang:f,pageLayout:p,routeLocale:a,siteData:hn,siteLocaleData:i}},S3=()=>{const e=Ff(),t=Pl(),n=Z([]),r=()=>{e.value.forEach(l=>{const o=C3(l);o&&n.value.push(o)})},a=()=>{document.documentElement.lang=t.value,n.value.forEach(l=>{l.parentNode===document.head&&document.head.removeChild(l)}),n.value.splice(0,n.value.length),e.value.forEach(l=>{const o=P3(l);o!==null&&(document.head.appendChild(o),n.value.push(o))})};rt(Kf,a),ge(()=>{r(),a(),ve(()=>e.value,a)})},C3=([e,t,n=""])=>{const r=Object.entries(t).map(([i,c])=>oe(c)?`[${i}=${JSON.stringify(c)}]`:c===!0?`[${i}]`:"").join(""),a=`head > ${e}${r}`;return Array.from(document.querySelectorAll(a)).find(i=>i.innerText===n)||null},P3=([e,t,n])=>{if(!oe(e))return null;const r=document.createElement(e);return Sl(t)&&Object.entries(t).forEach(([a,l])=>{oe(l)?r.setAttribute(a,l):l===!0&&r.setAttribute(a,"")}),oe(n)&&r.appendChild(document.createTextNode(n)),r},I3=Sf,R3=async()=>{var n;const e=I3({name:"VuepressApp",setup(){var r;S3();for(const a of Dr)(r=a.setup)==null||r.call(a);return()=>[s(oc),...Dr.flatMap(({rootComponents:a=[]})=>a.map(l=>s(l)))]}}),t=T3();L3(e),A3(e,t,Dr);for(const r of Dr)await((n=r.enhance)==null?void 0:n.call(r,{app:e,router:t,siteData:hn}));return e.use(t),{app:e,router:t}};R3().then(({app:e,router:t})=>{t.isReady().then(()=>{e.mount("#app")})});export{W4 as A,lt as B,ge as C,Cn as D,oe as E,B3 as F,Sl as G,ao as H,k0 as I,e3 as O,J4 as R,no as Y,Li as a,Re as b,M3 as c,R3 as createVueApp,Ai as d,$3 as e,D as f,De as g,ft as h,lo as i,or as j,Z as k,y as l,Ce as m,ve as n,O3 as o,s as p,G4 as q,Ye as r,q4 as s,Sn as t,V3 as u,z4 as v,U1 as w,Gu as x,K4 as y,j4 as z};
+function __vite__mapDeps(indexes) {
+ if (!__vite__mapDeps.viteFileDeps) {
+ __vite__mapDeps.viteFileDeps = ["assets/index.html-GO9KhDWT.js","assets/plugin-vue_export-helper-x3n3nnut.js","assets/index.html--YxqP697.js","assets/index.html-CmwrSuW4.js","assets/index.html-OXmsW7Ba.js","assets/index.html-7Jwn4Cbi.js","assets/devops-ping-tai.html-Pr-n_ibi.js","assets/gitlab-ci.html-9dvcTJNs.js","assets/jenkins-x.html--QxcKVNb.js","assets/tekton.html-5SA8R3wN.js","assets/index.html-2mdvLUFa.js","assets/tiktok2023.html-Ih4GrSaS.js","assets/JVM调优参数.html-adpG87p4.js","assets/lucene搜索原理.html-xLQYDnip.js","assets/serverlog.html-f8i7CjpW.js","assets/一次jvm调优过程.html-ObKNMeJg.js","assets/内存屏障.html-P7fE8DoQ.js","assets/在 Spring 6 中使用虚拟线程.html-lrPVTD8u.js","assets/基于kubernetes的分布式限流.html-FM9j_CKw.js","assets/index.html-1G2UU7KQ.js","assets/spark on k8s operator.html-oBat6Q5m.js","assets/2017.html-BbxR5q6z.js","assets/2018.html-iLHJNmQ1.js","assets/2019.html-ogBQCkli.js","assets/index.html-YcQRCdzL.js","assets/chatgpt.html-lQQa_oJF.js","assets/tesla.html-2Y58-poF.js","assets/1.历史与架构.html-X_ZVzsKc.js","assets/10.网站重构.html-vlubYdUg.js","assets/2.Lucene的使用.html-5sj9Z-FP.js","assets/3.定时任务.html-CtCjmCiV.js","assets/4.日志系统.html-Gyuvpz3_.js","assets/5.小集群部署.html-z5KJNYuo.js","assets/6.数据库备份.html-GrbFXSWT.js","assets/7.那些牛逼的插件.html-xUNU4jTw.js","assets/8.基于贝叶斯的情感分析.html-DmNVFgOS.js","assets/9.网站性能优化.html-MC-9j6vs.js","assets/index.html-9KTewoYW.js","assets/redis缓存.html-2QC7Jkrn.js","assets/wewe.html-MSrbCURC.js","assets/elastic-spark.html-NDvsW2Dx.js","assets/elasticsearch源码debug.html-riyCnJZU.js","assets/【elasticsearch】搜索过程详解.html-ga4ihhfd.js","assets/1mysql.html-OHVRcqVz.js","assets/gap锁.html-0qMpGSdo.js","assets/执行计划explain.html-y5jML1O_.js","assets/数据库缓存.html-fj1Jh_qh.js","assets/kafka.html-FefoBwLN.js","assets/zookeeper.html-bxhlqtiT.js","assets/404.html-tbxpD8LH.js","assets/index.html-JRhiMr7F.js","assets/index.html-UdEIAh49.js","assets/index.html-GqCa2uIM.js","assets/index.html-Pmc9G9cb.js","assets/index.html-OwsuoqvI.js","assets/index.html-dfS5oaDz.js","assets/index.html-AOPdgBmB.js","assets/index.html-Pv8xpMqr.js","assets/index.html-IuOpNwku.js","assets/index.html-PzLMN4bj.js","assets/index.html-6QAvnWzZ.js","assets/index.html-jG6_D9tR.js","assets/index.html-L2EY0waG.js","assets/index.html-_KtgcszN.js","assets/index.html-IefXkqnJ.js","assets/index.html-GqC77IMP.js","assets/index.html-QFJKSvrT.js","assets/index.html--QH2zN9-.js"]
+ }
+ return indexes.map((i) => __vite__mapDeps.viteFileDeps[i])
+}
diff --git a/assets/chatgpt.html-lQQa_oJF.js b/assets/chatgpt.html-lQQa_oJF.js
new file mode 100644
index 00000000..05f55471
--- /dev/null
+++ b/assets/chatgpt.html-lQQa_oJF.js
@@ -0,0 +1,110 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as p,o,c as i,a as s,d as n,b as c,e as a}from"./app-cS6i7hsH.js";const l={},r=a(` 微信公众号-chatgpt智能客服搭建 想体验的可以去微信上搜索【旅行的树】公众号。
一、ChatGPT注册 1.1 短信手机号申请 openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。
国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。
国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。
之后再搜索框填openai进行下单购买即可。
1.2 云服务器申请 openai在国内不提供服务的,而且也通过ip识别是不是在国内,解决办法用vpn也行,或者,自己去买一台国外的服务器也行。我这里使用的是腾讯云轻量服务器,最低配置54元/月,选择windows的主要原因毕竟需要注册openai,需要看页面,同时也可以搭建nginx,当然,用ubuntu如果能自己搞界面也行。
1.3 ChatGPT注册 购买完之后,就可以直接打开openai的官网了,然后去https://platform.openai.com/signup官网里注册,注册过程具体就不讲了,讲下核心问题——短信验证码
然后回sms查看验证码。
注册成功之后就可以在chatgpt里聊天啦,能够识别各种语言,发起多轮会话的时候,可能回出现访问超过限制什么的。
通过chatgpt聊天不是我们最终想要的,我们需要的是在微信公众号也提供智能客服的聊天回复,所以我们需要在通过openai的api来进行调用。
二、搭建nginx服务器 跟页面一样,OpenAI的调用也是不能再国内访问的,这里,我们使用同一台服务器来搭建nginx,还是保留使用windows吧,主要还是得注意下面这段话,如果API key被泄露了,OpenAI可能会自动重新更新你的API key,这个规则似乎是API key如果被多个ip使用,就会触发这个规则,调试阶段还是尽量使用windows的服务器吧,万一被更新了,还能去页面上重新找到。
Do not share your API key with others, or expose it in the browser or other client-side code. In order to protect the security of your account, OpenAI may also automatically rotate any API key that we've found has leaked publicly.
+windows的安装过程参考网上的来,我们只需要添加下面这个配置即可,原理主要是将调用OpenAI的接口全部往官网转发。
location /v1/completions{
+ proxy_pass https://api.openai.com/v1/completions;
+ }
+然后使用下面的方法进行调试即可:
POST http://YOUR IP/v1/completions
+
+
+
+{
+ "model" : "text-davinci-003" ,
+ "prompt" : "Say this is a test" ,
+ "max_tokens" : 7 ,
+ "temperature" : 0
+}
+ 三、公众号开发 网上有很多关于微信通过chatgpt回复的文章,有些使用自己微信号直接做为载体,因为要扫码网页登陆,而且是网页端在国外,很容易被封;有些是使用公众号,相对来说,公众号被封也不至于导致个人微信号出问题。
3.1 微信云托管 微信公众平台提供了微信云托管,无需鉴权,比其他方式都方便不少,可以免费试用3个月,继续薅羊毛,当然,如果自己开发能力足够,也可以自己从0开始开发。
提供了各种语言的模版,方便快速开发,OpenAI官方提供的sdk是node和python,这里我们选择express(node)。
3.2 一个简单ChatGPT简单回复 微信官方的源码在这,https://github.com/WeixinCloud/wxcloudrun-express,我们直接fork一份自己来开发。
一个简单的消息回复功能(无db),直接在我们的index.js里添加如下代码。
const configuration = new Configuration ( {
+ apiKey : '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' ,
+ basePath : 'http://43.153.15.174/v1'
+} ) ;
+const openai = new OpenAIApi ( configuration) ;
+
+async function simpleResponse ( prompt ) {
+ const completion = await openai. createCompletion ( {
+ model : 'text-davinci-003' ,
+ prompt,
+ max_tokens : 1024 ,
+ temperature : 0.1 ,
+ } ) ;
+ const response = ( completion?. data?. choices?. [ 0 ] . text || 'AI 挂了' ) . trim ( ) ;
+ return strip ( response, [ '\\n' , 'A: ' ] ) ;
+}
+
+app. post ( "/message/simple" , async ( req, res ) => {
+ console. log ( '消息推送' , req. body)
+
+ const appid = req. headers[ 'x-wx-from-appid' ] || ''
+ const { ToUserName, FromUserName, MsgType, Content, CreateTime} = req. body
+ console. log ( '推送接收的账号' , ToUserName, '创建时间' , CreateTime)
+ if ( MsgType === 'text' ) {
+ message = await simpleResponse ( Content)
+ res. send ( {
+ ToUserName : FromUserName,
+ FromUserName : ToUserName,
+ CreateTime : CreateTime,
+ MsgType : 'text' ,
+ Content : message,
+ } )
+ } else {
+ res. send ( 'success' )
+ }
+} )
+本地可以直接使用http请求测试,成功调用之后直接提交发布即可,在微信云托管上需要先授权代码库,即可使用云托管的流水线,一键发布。注意,api_base和api_key可以填写在服务设置-基础信息那里,一个是OPENAI_API_BASE,一个是OPENAI_API_KEY,服务会自动从环境变量里取。
3.3 服务部署 提交代码只github或者gitee都可以,值得注意的是,OpenAI判断key泄露的规则,不知道是不是判断调用的ip地址不一样,还是github的提交记录里含有这块,有点玄学,同样的key本地调用一次,然后在云托管也调用的话,OpenAI就很容易把key给重新更新。
部署完之后,云托管也提供了云端调试功能,相当于在服务里发送了http请求。这一步很重要,如果没有调用成功,则无法进行云托管消息推送。
这里填上你自己的url,我们这里配置的是/meesage/simple,如果没有成功,需要进行下面步骤进行排查:
(1)服务有没有正常启动,看日志
(2)端口有没有设置错误,这个很多次没有注意到
保存成功之后,就可以在微信公众号里测试了。
体验还可以
四、没有回复(超时回复问题) 很多OpenAI的回答都要几十秒,有的甚至更久,比如对chatgpt问“写一篇1000字关于深圳的文章”,就需要几十秒,而微信的主动回复接口,是需要我们3s内返回给用户。
订阅号的消息推送分几种:
被动消息回复 :指用户给公众号发一条消息,系统接收到后,可以回复一条消息。主动回复/客服消息 :可以脱离被动消息的5秒超时权限,在48小时内可以主动回复。但需要公众号完成微信认证。根据微信官方文档,没有认证的公众号是没有调用主动回复接口权限的,https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Explanation_of_interface_privileges.html
对于有微信认证的订阅号或者服务号,可以调用微信官方的/cgi-bin/message/custom/send接口来实现主动回复,但是对于个人的公众号,没有权限调用,只能尝试别的办法。想来想去,只能在3s内返回让用户重新复制发送的信息,同时后台里保存记录异步调用,用户重新发送的时候再从数据库里提取回复。
1.先往数据库存一条 回复记录,把用户的提问存下来,以便后续查询。设置回复的内容为空,设置状态为 回复中(thinking)。
+ await Message. create ( {
+ fromUser : FromUserName,
+ response : '' ,
+ request : Content,
+ aiType : AI_TYPE_TEXT ,
+ } ) ;
+2.抽象一个 chatGPT 请求方法 getAIMessage,函数内部得到 GPT 响应后,会更新之前那条记录(通过用户id & 用户提问 查询),把状态更新为 已回答(answered),并把回复内容更新上。
+ await Message. update (
+ {
+ response : response,
+ status : MESSAGE_STATUS_ANSWERED ,
+ } ,
+ {
+ where : {
+ fromUser : FromUserName,
+ request : Content,
+ } ,
+ } ,
+ ) ;
+3.前置增加一些判断,当用户在请求时,如果 AI 还没完成响应,直接回复用户 AI 还在响应,让用户过一会儿再重试。如果 AI 此时已响应完成,则直接把 内容返回给用户。
+ const message = await Message. findOne ( {
+ where : {
+ fromUser : FromUserName,
+ request : Content,
+ } ,
+ } ) ;
+
+
+ if ( message?. status === MESSAGE_STATUS_ANSWERED ) {
+ return \` [GPT]: \${ message?. response} \` ;
+ }
+
+
+ if ( message?. status === MESSAGE_STATUS_THINKING ) {
+ return AI_THINKING_MESSAGE ;
+ }
+4.最后就是一个 Promise.race
const message = await Promise. race ( [
+
+ sleep ( 2900 ) . then ( ( ) => AI_THINKING_MESSAGE ) ,
+ getAIMessage ( { Content, FromUserName } ) ,
+ ] ) ;
+这样子大概就能实现超时之前返回了。
五、会话保存 掉接口是一次性的,一次接口调用完之后怎么做到下一次通话的时候,还能继续保持会话,是不是应该类似客户端与服务端那种有个session这种,但是实际上在openai里是没有session这种东西的,令人震惊的是,chatgpt里是通过前几次会话拼接起来一起发送给chatgpt里的,需要通过回车符来拼接。
async function buildCtxPrompt ( { FromUserName } ) {
+
+ const messages = await Message. findAll ( {
+ where : {
+ fromUser : FromUserName,
+ aiType : AI_TYPE_TEXT ,
+ } ,
+ limit : 10 ,
+ order : [ [ 'updatedAt' , 'ASC' ] ] ,
+ } ) ;
+
+ return messages. length === 1
+ ? messages[ 0 ] . request
+ : messages
+ . map ( ( { response, request } ) => \` Q: \${ request} \\n A: \${ response} \` )
+ . join ( '\\n' ) ;
+}
+之后就可以实现会话之间的保存通信了。
六、其他问题 6.1 限频 chatgpt毕竟也是新上线的,火热是肯定的,聊天窗口只能开几个,api调用的话,也是有限频的,但是规则具体没有找到,只是在调用次数过多的时候会报429的错误,出现之后就需要等待一个小时左右。
对于这个的解决办法只能是多开几个账号,一旦429就只能换个账号重试了。
6.2 秘钥key被更新 没有找到详细的规则,凭个人经验的话,可能github提交的代码会被扫描,可能ip调用的来源不一样,最好还是开发一个秘钥,生产一个秘钥吧。
6.3 为啥和官网的回复不一样 我们这里用的模型算法是text-davinci-003,具体可以参考:https://platform.openai.com/docs/models/overview,也算是一个比较老的样本了吧
6.4 玄学挂掉 有时候消息没有回复,真的不是我们的问题,chatgpt毕竟太火了,官网的这个能力都经常挂掉,也可以订阅官网修复的通知,一旦修复则会发邮件告知你。
参考:https://juejin.cn/post/7200769439335546935
最后 记得去微信关注【旅行的树】公众号体验
',6);function m(v,h){const t=p("ExternalLinkIcon");return o(),i("div",null,[r,s("p",null,[n("从官方文档来看,官方服务版的 ChatGPT 的模型并非基础版的"),u,n(",而是经过了「微调:fine-tunes」。文档地址在这:"),s("a",d,[n("platform.openai.com/docs/guides…"),c(t)])]),k])}const y=e(l,[["render",m],["__file","chatgpt.html.vue"]]);export{y as default};
diff --git a/assets/chatgpt.html-ynpK4pK0.js b/assets/chatgpt.html-ynpK4pK0.js
new file mode 100644
index 00000000..4a3f813d
--- /dev/null
+++ b/assets/chatgpt.html-ynpK4pK0.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-510415f9","path":"/others/chatgpt.html","title":"微信公众号-chatgpt智能客服搭建","lang":"zh-CN","frontmatter":{"description":"微信公众号-chatgpt智能客服搭建 想体验的可以去微信上搜索【旅行的树】公众号。 一、ChatGPT注册 1.1 短信手机号申请 openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。 国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。 国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/others/chatgpt.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"微信公众号-chatgpt智能客服搭建"}],["meta",{"property":"og:description","content":"微信公众号-chatgpt智能客服搭建 想体验的可以去微信上搜索【旅行的树】公众号。 一、ChatGPT注册 1.1 短信手机号申请 openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。 国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。 国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"微信公众号-chatgpt智能客服搭建\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、ChatGPT注册","slug":"一、chatgpt注册","link":"#一、chatgpt注册","children":[{"level":3,"title":"1.1 短信手机号申请","slug":"_1-1-短信手机号申请","link":"#_1-1-短信手机号申请","children":[]},{"level":3,"title":"1.2 云服务器申请","slug":"_1-2-云服务器申请","link":"#_1-2-云服务器申请","children":[]},{"level":3,"title":"1.3 ChatGPT注册","slug":"_1-3-chatgpt注册","link":"#_1-3-chatgpt注册","children":[]}]},{"level":2,"title":"二、搭建nginx服务器","slug":"二、搭建nginx服务器","link":"#二、搭建nginx服务器","children":[]},{"level":2,"title":"三、公众号开发","slug":"三、公众号开发","link":"#三、公众号开发","children":[{"level":3,"title":"3.1 微信云托管","slug":"_3-1-微信云托管","link":"#_3-1-微信云托管","children":[]},{"level":3,"title":"3.2 一个简单ChatGPT简单回复","slug":"_3-2-一个简单chatgpt简单回复","link":"#_3-2-一个简单chatgpt简单回复","children":[]},{"level":3,"title":"3.3 服务部署","slug":"_3-3-服务部署","link":"#_3-3-服务部署","children":[]}]},{"level":2,"title":"四、没有回复(超时回复问题)","slug":"四、没有回复-超时回复问题","link":"#四、没有回复-超时回复问题","children":[]},{"level":2,"title":"五、会话保存","slug":"五、会话保存","link":"#五、会话保存","children":[]},{"level":2,"title":"六、其他问题","slug":"六、其他问题","link":"#六、其他问题","children":[{"level":3,"title":"6.1 限频","slug":"_6-1-限频","link":"#_6-1-限频","children":[]},{"level":3,"title":"6.2 秘钥key被更新","slug":"_6-2-秘钥key被更新","link":"#_6-2-秘钥key被更新","children":[]},{"level":3,"title":"6.3 为啥和官网的回复不一样","slug":"_6-3-为啥和官网的回复不一样","link":"#_6-3-为啥和官网的回复不一样","children":[]},{"level":3,"title":"6.4 玄学挂掉","slug":"_6-4-玄学挂掉","link":"#_6-4-玄学挂掉","children":[]}]},{"level":2,"title":"最后","slug":"最后","link":"#最后","children":[]}],"git":{"createdTime":1706186538000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":5}]},"readingTime":{"minutes":9.96,"words":2987},"filePathRelative":"others/chatgpt.md","localizedDate":"2024年1月25日","excerpt":" 微信公众号-chatgpt智能客服搭建 \\n想体验的可以去微信上搜索【旅行的树】公众号。
\\n 一、ChatGPT注册 \\n 1.1 短信手机号申请 \\nopenai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。
\\n国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。
\\n国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。
\\n","autoDesc":true}');export{t as data};
diff --git a/assets/devops-ping-tai.html-Pr-n_ibi.js b/assets/devops-ping-tai.html-Pr-n_ibi.js
new file mode 100644
index 00000000..26718294
--- /dev/null
+++ b/assets/devops-ping-tai.html-Pr-n_ibi.js
@@ -0,0 +1,246 @@
+import{_ as i}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as l,o as p,c,a as n,d as s,b as e,e as t}from"./app-cS6i7hsH.js";const o={},u=n("h1",{id:"_3-1-devops平台-md",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#_3-1-devops平台-md","aria-hidden":"true"},"#"),s(" 3.1 DevOps平台.md")],-1),d=n("p",null,"DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。",-1),r=n("p",null,"公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。",-1),v=n("h2",{id:"一、自由风格的软件项目",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#一、自由风格的软件项目","aria-hidden":"true"},"#"),s(" 一、自由风格的软件项目")],-1),m={href:"https://www.cnblogs.com/w1570631036/p/9861473.html",target:"_blank",rel:"noopener noreferrer"},g=t(`完成了以上的东西,不过由于太过于简单,导致只能进行单条线的CICD,而且CI仅仅实现了打包,没有将CD的过程一同串行起来。简单来说就是,用户点击了构建只是能够打出一个镜像,但是如果要部署到kubernetes,还是需要在应用里手动更换一下镜像版本。总体而言,这个版本的jenkins我们使用的还是单点的,不足以支撑构建量比较大的情况,甚至如果当前服务挂了,断网了,整一块的构建功能都不能用。
< project> < actions/> < description> </ description> < properties> < hudson.model.ParametersDefinitionProperty> < parameterDefinitions> < hudson.model.TextParameterDefinition> < name> </ name> < defaultValue> </ defaultValue> </ hudson.model.TextParameterDefinition> < hudson.model.TextParameterDefinition> < name> </ name> < defaultValue> </ defaultValue> </ hudson.model.TextParameterDefinition> </ parameterDefinitions> </ hudson.model.ParametersDefinitionProperty> </ properties> < scmclass = " hudson.plugins.git.GitSCM" > < configVersion> </ configVersion> < userRemoteConfigs> < hudson.plugins.git.UserRemoteConfig> < url> </ url> < credentialsId> </ credentialsId> </ hudson.plugins.git.UserRemoteConfig> </ userRemoteConfigs> < branches> < hudson.plugins.git.BranchSpec> < name> </ name> </ hudson.plugins.git.BranchSpec> </ branches> < doGenerateSubmoduleConfigurations> </ doGenerateSubmoduleConfigurations> < extensions/> </ scm> < builders> < hudson.tasks.Shell> < command> </ command> </ hudson.tasks.Shell> < hudson.tasks.Maven> < targets> </ targets> < mavenName> </ mavenName> </ hudson.tasks.Maven> < com.cloudbees.dockerpublish.DockerBuilder> < server> < uri> </ uri> </ server> < registry> < url> </ url> </ registry> < repoName> </ repoName> < forcePull> </ forcePull> < dockerfilePath> </ dockerfilePath> < repoTag> </ repoTag> < skipTagLatest> </ skipTagLatest> </ com.cloudbees.dockerpublish.DockerBuilder> </ builders> < publishers> < com.xxxx.notifications.Notifier/> </ publishers> </ project> 二、优化之后的CICD 上面的过程也仍然没有没住DevOps的流程,人工干预的东西依旧很多,由于上级急需产出,所以只能将就着继续下去。我们将构建、部署每个当做一个小块,一个CICD的过程可以选择构建、部署,花了很大的精力,完成了串行化的别样的CICD。 以下图为例,整个流程的底层为:paas平台-jenkins-kakfa-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发构建-jenkins-kafka-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发部署。
目前实现了串行化的CICD构建部署,之后考虑实现多个CICD并行,并且一个CICD能够调用另一个CICD,实际运行中,出现了一大堆问题。由于经过的组件太多,一次cicd的运行报错,却很难排查到问题出现的原因,业务方的投诉也开始慢慢多了起来,只能说劝导他们不要用这个功能。
没有CICD,就无法帮助公司上容器云,无法合理的利用容器云的特性,更无法走上云原生的道路。于是,我们决定另谋出路。
三、调研期 由于之前的CICD问题太多,特别是经过的组件太多了,导致出现问题的时候无法正常排查,为了能够更加稳定可靠,还是决定了要更换一下底层。 我们重新审视了下pipeline,觉得这才是正确的做法,可惜不知道如果做成一个产品样子的东西,用户方Dockerfile都不怎么会写,你让他写一个Jenkinsfile?不合理!在此之外,我们看到了serverless jenkins、谷歌的tekton。 GitLab-CICD Gitlab中自带了cicd的工具,需要配置一下runner,然后配置一下.gitlab-ci.yml写一下程序的cicd过程即可,构建镜像的时候我们使用的是kaniko,整个gitlab的cicd在我们公司小项目中大范围使用,但是学习成本过高,尤其是引入了kaniko之后,还是寻找一个产品化的CICD方案。
`,9),k=n("strong",null,"分布式构建jenkins x",-1),b={href:"https://github.com/jenkins-x/jenkins-x-image",target:"_blank",rel:"noopener noreferrer"},h=n("figure",null,[n("img",{src:"http://image.wenzhihuai.com/images/201908170612301464716259.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),x=n("p",null,[n("strong",null,"serverless jenkins"),s(" 好像跟谷歌的tekton相关,用了下,没调通,只能用于GitHub。感觉还不如直接使用tekton。")],-1),q=n("p",null,[n("strong",null,"阿里云云效"),s(" 提供了图形化配置DevOps流程,支持定时触发,可惜没有跟gitlab触发结合,如果需要个公司级的DevOps,需要将公司的jira、gitlab、jenkins等集合起来,但是图形化jenkins pipeline是个特别好的参考方向,可以结合阿里云云效来做一个自己的DevOps产品。")],-1),f=n("p",null,[n("strong",null,"微软Pipeline"),s(" 微软也是提供了DevOps解决方案的,也是提供了yaml格式的写法,即:在右边填写完之后会转化成yaml。如果想把DevOps打造成一款产品,这样的设计显然不是最好的。")],-1),_=n("figure",null,[n("img",{src:"http://image.wenzhihuai.com/images/201908100346011648784131.png",alt:"",tabindex:"0",loading:"lazy"}),n("figcaption")],-1),D=n("strong",null,"谷歌tekton",-1),y={href:"https://www.jianshu.com/p/8871b7ea7d6e",target:"_blank",rel:"noopener noreferrer"},j=t(` 四、产品化后的DevOps平台 在调研DockOne以及各个产商的DevOps产品时,发现,真的只有阿里云的云效才是真正比较完美的DevOps产品,用户不需要知道pipeline的语法,也不需要掌握kubernetes的相关知识,甚至不用写yaml文件,对于开发、测试来说简直就是神一样的存在了。云效对小公司(创业公司)免费,但是有一定的量之后,就要开始收费了。在调研了一番云效的东西之后,发现云效也是基于jenkins x改造的,不过阿里毕竟人多,虽然能约莫看出是pipeline的语法,但是阿里彻底改造成了能够使用yaml来与后台交互。 下面是以阿里云的云效界面以及配合jenkins的pipeline语法来讲解:
4.1 Java代码扫描 PMD是一款可拓展的静态代码分析器它不仅可以对代码分析器,它不仅可以对代码风格进行检查,还可以检查设计、多线程、性能等方面的问题。阿里云的是简单的集成了一下而已,对于我们来说,底层使用了sonar来接入,所有的代码扫描结果都接入了sonar。
stage('Clone') {
+ steps{
+ git branch: 'master', credentialsId: 'xxxx', url: "xxx"
+ }
+}
+stage('check') {
+ steps{
+ container('maven') {
+ echo "mvn pmd:pmd"
+ }
+ }
+}
+ 4.2 Java单元测试 Java的单元测试一般用的是Junit,在阿里云中,使用了surefire插件,用来在maven构建生命周期的test phase执行一个应用的单元测试。它会产生两种不同形式的测试结果报告。我这里就简单的过一下,使用"mvn test"命令来代替。
+stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxx', url: "xxxxxx"
+ }
+}
+stage('test') {
+ steps{
+ container('maven') {
+ sh "mvn test"
+ }
+ }
+}
+ 4.3 Java构建并上传镜像 镜像的构建比较想使用kaniko,尝试找了不少方法,到最后还是只能使用dind(docker in docker),挂载宿主机的docker来进行构建,如果能有其他方案,希望能提醒下。目前jenkins x使用的是dind,挂载的时候需要配置一下config.json,然后挂载到容器的/root/.docker目录,才能在容器中使用docker。
为什么不推荐dind:挂载了宿主机的docker,就可以使用docker ps查看正在运行的容器,也就意味着可以使用docker stop、docker rm来控制宿主机的容器,虽然kubernetes会重新调度起来,但是这一段的重启时间极大的影响业务。
+stage('下载代码') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxx', url: "xxxxxx"
+ script {
+ build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
+ }
+ }
+}
+stage('打包并构建镜像') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn clean install -Dmaven.test.skip=true"
+ sh "docker build -f xxx/Dockerfile -t xxxxxx:\${build_tag} ."
+ sh "docker push xxxxxx:\${build_tag}"
+ }
+ }
+}
+
+ 4.4 部署到阿里云k8s CD过程有点困难,由于我们的kubernetes平台是图形化的,类似于阿里云,用户根本不需要自己写deployment,只需要在图形化界面做一下操作即可部署。对于CD过程来说,如果应用存在的话,就可以直接替换掉镜像版本即可,如果没有应用,就提供个简单的界面让用户新建应用。当然,在容器最初推行的时候,对于用户来说,一下子需要接受docker、kubernetes、helm等概念是十分困难的,不能一个一个帮他们写deployment这些yaml文件,只能用helm创建一个通用的spring boot或者其他的模板,然后让业务方修改自己的配置,每次构建的时候只需要替换镜像即可。
def tmp = sh (
+ returnStdout: true,
+ script: "kubectl get deployment -n \${namespace} | grep \${JOB_NAME} | awk '{print \\$1}'"
+)
+//如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置
+if(tmp.equals('')){
+ sh "helm init --client-only"
+ sh """helm repo add mychartmuseum http://xxxxxx \\
+ --username myuser \\
+ --password=mypass"""
+ sh """helm install --set name=\${JOB_NAME} \\
+ --set namespace=\${namespace} \\
+ --set deployment.image=\${image} \\
+ --set deployment.imagePullSecrets=\${harborProject} \\
+ --name \${namespace}-\${JOB_NAME} \\
+ mychartmuseum/soa-template"""
+}else{
+ println "已经存在,替换镜像"
+ //epaas中一个pod的容器名称需要带上"-0"来区分
+ sh "kubectl set image deployment/\${JOB_NAME} \${JOB_NAME}-0=\${image} -n \${namespace}"
+}
+
+ 4.5 整体流程 代码扫描,单元测试,构建镜像三个并行运行,等三个完成之后,在进行部署
pipeline:
pipeline {
+ agent {
+ label "jenkins-maven"
+ }
+ stages{
+ stage('代码扫描,单元测试,镜像构建'){
+ parallel {
+ stage('并行任务一') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('Java代码扫描') {
+ stage('Clone') {
+ steps{
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ }
+ }
+ stage('check') {
+ steps{
+ container('maven') {
+ echo "$BUILD_NUMBER"
+ }
+ }
+ }
+ }
+ }
+ stage('并行任务二') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('Java单元测试') {
+ stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ }
+ }
+ stage('test') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn -v"
+ }
+ }
+ }
+ }
+ }
+ stage('并行任务三') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('java构建镜像') {
+ stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ script {
+ build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
+ }
+ }
+ }
+ stage('Build') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn clean install -Dmaven.test.skip=true"
+ sh "docker build -f epaas-portal/Dockerfile -t hub.gcloud.lab/rongqiyun/epaas:\${build_tag} ."
+ sh "docker push hub.gcloud.lab/rongqiyun/epaas:\${build_tag}"
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ stage('部署'){
+ stages('部署到容器云') {
+ stage('check') {
+ steps{
+ container('maven') {
+ script{
+ if (deploy_app == "true"){
+ def tmp = sh (
+ returnStdout: true,
+ script: "kubectl get deployment -n \${namespace} | grep \${JOB_NAME} | awk '{print \\$1}'"
+ )
+ //如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置
+ if(tmp.equals('')){
+ sh "helm init --client-only"
+ sh """helm repo add mychartmuseum http://xxxxxx \\
+ --username myuser \\
+ --password=mypass"""
+ sh """helm install --set name=\${JOB_NAME} \\
+ --set namespace=\${namespace} \\
+ --set deployment.image=\${image} \\
+ --set deployment.imagePullSecrets=\${harborProject} \\
+ --name \${namespace}-\${JOB_NAME} \\
+ mychartmuseum/soa-template"""
+ }else{
+ println "已经存在,替换镜像"
+ //epaas中一个pod的容器名称需要带上"-0"来区分
+ sh "kubectl set image deployment/\${JOB_NAME} \${JOB_NAME}-0=\${image} -n \${namespace}"
+ }
+ }else{
+ println "用户选择不部署代码"
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+}
+在jenkins x中查看:
4.4 日志 jenkins blue ocean步骤日志:
云效中的日志:
4.5 定时触发 triggers {
+ cron('H H * * *') //每天
+ }
+ 五、其他 5.1 Gitlab触发 pipeline中除了有对于时间的trigger,还支持了gitlab的触发,需要各种配置,不过如果真的对于gitlab的cicd有要求,直接使用gitlab-ci会更好,我们同时也对gitlab进行了runner的配置来支持gitlab的cicd。gitlab的cicd也提供了构建完后即销毁的过程。
六、总结 功能最强大的过程莫过于自己使用pipeline脚本实现,选取最适合自己的,但是对于一个公司来说,如果要求业务方来掌握这些,特别是IT流动性大的时候,既需要重新培训,同个问题又会被问多遍,所以,只能将DevOps实现成一个图形化的东西,方便,简单,相对来说功能还算强大。
DevOps最难的可能都不是以上这些,关键是让用户接受,容器云最初推行时,公司原本传统的很多发版方式都需要进行改变,有些业务方不愿意改,或者有些代码把持久化的东西存到了代码中而不是分布式存储里,甚至有些用户方都不愿意维护老代码,看都不想看然后想上容器,一个公司在做技术架构的时候,过于混乱到最后填坑要么需要耗费太多精力甚至大换血。
最后,DevOps是云原生的必经之路!!!
文章同步:
`,40);function C($,O){const a=l("ExternalLinkIcon");return p(),c("div",null,[u,d,r,v,n("p",null,[s("主要还是基于jenkins里面构建一个自由风格的软件项目,当时参考的是阿里的codepipeline,就是对jenkins封装一层,包括创建job、立即构建、获取构建进度等都进行封装,并将需要的东西进行存库,没有想到码代码的时候,一堆的坑,比如: 1.连续点击立即构建,jenkins是不按顺序返回的,(分布式锁解决) 2.跨域调用,csrf,这个还好,不过容易把jenkins搞的无法登录(注意配置,具体可以点击"),n("a",m,[s("这里"),e(a)]),s(") 3.创建job的时候只支持xml格式,还要转换一下,超级坑(xstream强行转换) 4.docker构建的时候,需要挂载宿主机的docker(想过用远程的,但效率不高) 5.数据库与jenkins的job一致性问题,任务创建失败,批量删除太慢(目前没想好怎么解决) 6.由于使用了数据库,需要检测job是否构建完成,为了自定义参数,我们自写了个通知插件,将构建状态返回到kafka,然后管理平台在进行消息处理。")]),g,n("p",null,[k,s(" 首先要解决的是多个构建同时运行的问题,很久之前就调研过jenkins x,它必须要使用在kubernetes上,由于当时官方文档不全,而且我们的DevOps项目处于初始期,所有没有使用。jenkins的master slave结构就不多说了。jenkins x应该说是个全家桶,包含了helm仓库、nexus仓库、docker registry等,代码是"),n("a",b,[s("jenkins-x-image"),e(a)]),s("。")]),h,x,q,f,_,n("p",null,[D,s(" kubernetes的官方cicd,目前已用于kubernetes的release发版过程,目前也仅仅是与GitHub相结合,gitlab无法使用,全过程可使用yaml文件来创建,跑起来就是类似kubernetes的job一样,用完即销毁,可惜目前比较新,依旧处于alpha版本,无法用于生产。有兴趣可以参考下:"),n("a",y,[s("Knative 初体验:CICD 极速入门 "),e(a)])]),j])}const B=i(o,[["render",C],["__file","devops-ping-tai.html.vue"]]);export{B as default};
diff --git a/assets/devops-ping-tai.html-abOd7AV0.js b/assets/devops-ping-tai.html-abOd7AV0.js
new file mode 100644
index 00000000..bd6bfdc1
--- /dev/null
+++ b/assets/devops-ping-tai.html-abOd7AV0.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-580db9be","path":"/devops/devops-ping-tai.html","title":"3.1 DevOps平台.md","lang":"zh-CN","frontmatter":{"description":"3.1 DevOps平台.md DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。 公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/devops/devops-ping-tai.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"3.1 DevOps平台.md"}],["meta",{"property":"og:description","content":"3.1 DevOps平台.md DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。 公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"3.1 DevOps平台.md\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、自由风格的软件项目","slug":"一、自由风格的软件项目","link":"#一、自由风格的软件项目","children":[]},{"level":2,"title":"二、优化之后的CICD","slug":"二、优化之后的cicd","link":"#二、优化之后的cicd","children":[]},{"level":2,"title":"三、调研期","slug":"三、调研期","link":"#三、调研期","children":[]},{"level":2,"title":"四、产品化后的DevOps平台","slug":"四、产品化后的devops平台","link":"#四、产品化后的devops平台","children":[{"level":3,"title":"4.1 Java代码扫描","slug":"_4-1-java代码扫描","link":"#_4-1-java代码扫描","children":[]},{"level":3,"title":"4.2 Java单元测试","slug":"_4-2-java单元测试","link":"#_4-2-java单元测试","children":[]},{"level":3,"title":"4.3 Java构建并上传镜像","slug":"_4-3-java构建并上传镜像","link":"#_4-3-java构建并上传镜像","children":[]},{"level":3,"title":"4.4 部署到阿里云k8s","slug":"_4-4-部署到阿里云k8s","link":"#_4-4-部署到阿里云k8s","children":[]},{"level":3,"title":"4.5 整体流程","slug":"_4-5-整体流程","link":"#_4-5-整体流程","children":[]},{"level":3,"title":"4.4 日志","slug":"_4-4-日志","link":"#_4-4-日志","children":[]},{"level":3,"title":"4.5 定时触发","slug":"_4-5-定时触发","link":"#_4-5-定时触发","children":[]}]},{"level":2,"title":"五、其他","slug":"五、其他","link":"#五、其他","children":[{"level":3,"title":"5.1 Gitlab触发","slug":"_5-1-gitlab触发","link":"#_5-1-gitlab触发","children":[]}]},{"level":2,"title":"六、总结","slug":"六、总结","link":"#六、总结","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":11.93,"words":3580},"filePathRelative":"devops/devops-ping-tai.md","localizedDate":"2024年1月24日","excerpt":" 3.1 DevOps平台.md \\nDevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
\\n公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。
","autoDesc":true}');export{e as data};
diff --git a/assets/elastic-spark.html-5RlCSmjx.js b/assets/elastic-spark.html-5RlCSmjx.js
new file mode 100644
index 00000000..0b35437c
--- /dev/null
+++ b/assets/elastic-spark.html-5RlCSmjx.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-04e32b44","path":"/bigdata/spark/elastic-spark.html","title":"elastic spark","lang":"zh-CN","frontmatter":{"description":"elastic spark Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有: (1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv (2)数据RDBMS:mysql、oracle、mssql (3)NOSQL数据库:HBase、ES、Redis (4)消息对象:Redis","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/bigdata/spark/elastic-spark.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"elastic spark"}],["meta",{"property":"og:description","content":"elastic spark Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有: (1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv (2)数据RDBMS:mysql、oracle、mssql (3)NOSQL数据库:HBase、ES、Redis (4)消息对象:Redis"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"elastic spark\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、原生RDD支持","slug":"一、原生rdd支持","link":"#一、原生rdd支持","children":[{"level":3,"title":"1.1 基础配置","slug":"_1-1-基础配置","link":"#_1-1-基础配置","children":[]},{"level":3,"title":"1.2 读取es数据","slug":"_1-2-读取es数据","link":"#_1-2-读取es数据","children":[]},{"level":3,"title":"1.3 写数据","slug":"_1-3-写数据","link":"#_1-3-写数据","children":[]}]},{"level":2,"title":"二、Spark Streaming","slug":"二、spark-streaming","link":"#二、spark-streaming","children":[]},{"level":2,"title":"三、Spark SQL","slug":"三、spark-sql","link":"#三、spark-sql","children":[]},{"level":2,"title":"四、Spark Structure Streaming","slug":"四、spark-structure-streaming","link":"#四、spark-structure-streaming","children":[]},{"level":2,"title":"五、Spark on kubernetes Operator","slug":"五、spark-on-kubernetes-operator","link":"#五、spark-on-kubernetes-operator","children":[]}],"git":{"createdTime":1706182936000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":1.71,"words":514},"filePathRelative":"bigdata/spark/elastic-spark.md","localizedDate":"2024年1月25日","excerpt":" elastic spark \\nHadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有:\\n(1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv
","autoDesc":true}');export{e as data};
diff --git a/assets/elastic-spark.html-NDvsW2Dx.js b/assets/elastic-spark.html-NDvsW2Dx.js
new file mode 100644
index 00000000..cd56dd93
--- /dev/null
+++ b/assets/elastic-spark.html-NDvsW2Dx.js
@@ -0,0 +1,31 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as c,c as l,a,d as n,b as t,e as p}from"./app-cS6i7hsH.js";const i={},u=p(` elastic spark Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有: (1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv
elasticsearch相对hdfs来说,容易搭建、并且有可视化kibana支持,非常方便spark的初学入门,本文主要讲解用elasticsearch-spark的入门。
Spark - Apache Spark 一、原生RDD支持 1.1 基础配置 相关库引入:
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> public static SparkConf getSparkConf ( ) {
+ SparkConf sparkConf = new SparkConf ( ) . setAppName ( "elasticsearch-spark-demo" ) ;
+ sparkConf. set ( "es.nodes" , "host" )
+ . set ( "es.port" , "xxxxxx" )
+ . set ( "es.nodes.wan.only" , "true" )
+ . set ( "es.net.http.auth.user" , "elxxxxastic" )
+ . set ( "es.net.http.auth.pass" , "xxxx" )
+ . setMaster ( "local[*]" ) ;
+ return sparkConf;
+}
+ 1.2 读取es数据 这里用的是kibana提供的sample data里面的索引kibana_sample_data_ecommerce,也可以替换成自己的索引。
public static void main ( String [ ] args) {
+ SparkConf conf = getSparkConf ( ) ;
+ try ( JavaSparkContext jsc = new JavaSparkContext ( conf) ) {
+
+ JavaPairRDD < String , Map < String , Object > > =
+ JavaEsSpark . esRDD ( jsc, "kibana_sample_data_ecommerce" ) ;
+ esRDD. collect ( ) . forEach ( System . out:: println ) ;
+ }
+}
+esRDD同时也支持query语句esRDD(final JavaSparkContext jsc, final String resource, final String query),一般对es的查询都需要根据时间筛选一下,不过相对于es的官方sdk,并没有那么友好的api,只能直接使用原生的dsl语句。
1.3 写数据 支持序列化对象、json,并且能够使用占位符动态索引写入数据(使用较少),不过多介绍了。
public static void jsonWrite ( ) {
+ String json1 = "{\\"reason\\" : \\"business\\",\\"airport\\" : \\"SFO\\"}" ;
+ String json2 = "{\\"participants\\" : 5,\\"airport\\" : \\"OTP\\"}" ;
+ JavaRDD < String > = jsc. parallelize ( ImmutableList . of ( json1, json2) ) ;
+ JavaEsSpark . saveJsonToEs ( stringRDD, "spark-json" ) ;
+}
+比较常用的读写也就这些,更多可以看下官网相关介绍。
二、Spark Streaming spark的实时处理,es5.0的时候开始支持,目前
三、Spark SQL 四、Spark Structure Streaming 五、Spark on kubernetes Operator 参考: `,15),h={href:"https://www.elastic.co/Zephery/en/elasticsearch/hadoop/current/spark.html",target:"_blank",rel:"noopener noreferrer"},m={href:"https://github.com/elastic/elasticsearch-hadoop",target:"_blank",rel:"noopener noreferrer"},v={href:"https://www.jianshu.com/p/996c60f0492a",target:"_blank",rel:"noopener noreferrer"};function g(b,f){const s=o("ExternalLinkIcon");return c(),l("div",null,[u,a("p",null,[n("SparkConf配置,更多详细的请点击"),a("a",r,[n("这里"),t(s)]),n("或者源码"),a("a",k,[n("ConfigurationOptions"),t(s)]),n("。")]),d,a("p",null,[n("1."),a("a",h,[n("Apache Spark support"),t(s)])]),a("p",null,[n("2."),a("a",m,[n("elasticsearch-hadoop"),t(s)])]),a("p",null,[n("3."),a("a",v,[n("使用SparkSQL操作Elasticsearch - Spark入门教程"),t(s)])])])}const _=e(i,[["render",g],["__file","elastic-spark.html.vue"]]);export{_ as default};
diff --git "a/assets/elasticsearch\346\272\220\347\240\201debug.html-Z9uKxlVb.js" "b/assets/elasticsearch\346\272\220\347\240\201debug.html-Z9uKxlVb.js"
new file mode 100644
index 00000000..1a8fef1e
--- /dev/null
+++ "b/assets/elasticsearch\346\272\220\347\240\201debug.html-Z9uKxlVb.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-d73a9aee","path":"/database/elasticsearch/elasticsearch%E6%BA%90%E7%A0%81debug.html","title":"【elasticsearch】源码debug","lang":"zh-CN","frontmatter":{"description":"【elasticsearch】源码debug 一、下载源代码 直接用idea下载代码https://github.com/elastic/elasticsearch.git 切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/elasticsearch/elasticsearch%E6%BA%90%E7%A0%81debug.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"【elasticsearch】源码debug"}],["meta",{"property":"og:description","content":"【elasticsearch】源码debug 一、下载源代码 直接用idea下载代码https://github.com/elastic/elasticsearch.git 切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"【elasticsearch】源码debug\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706186538000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":4}]},"readingTime":{"minutes":0.52,"words":157},"filePathRelative":"database/elasticsearch/elasticsearch源码debug.md","localizedDate":"2024年1月25日","excerpt":" 【elasticsearch】源码debug \\n 一、下载源代码 \\n直接用idea下载代码https://github.com/elastic/elasticsearch.git\\n
\\n切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好\\n
","autoDesc":true}');export{e as data};
diff --git "a/assets/elasticsearch\346\272\220\347\240\201debug.html-riyCnJZU.js" "b/assets/elasticsearch\346\272\220\347\240\201debug.html-riyCnJZU.js"
new file mode 100644
index 00000000..edcc9d7d
--- /dev/null
+++ "b/assets/elasticsearch\346\272\220\347\240\201debug.html-riyCnJZU.js"
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as a,c as i,e as s}from"./app-cS6i7hsH.js";const t={},r=s(' 【elasticsearch】源码debug 一、下载源代码 直接用idea下载代码https://github.com/elastic/elasticsearch.git
切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好
二、修改设置(可选) 为了方便, 在 gradle/run.gradle 中关闭 Auth 认证:
setting 'xpack.security.enabled', 'false'
或者使用其中的用户名密码:
user username: 'elastic-admin', password: 'elastic-password', role: 'superuser'
三、启动 先启动上面的 remote debug, 然后用 gradlew 启动项目:
./gradlew :run --debug-jvm 打开浏览器http://localhost:9200即可看到es相关信息了
',12),h=[r];function c(d,l){return a(),i("div",null,h)}const o=e(t,[["render",c],["__file","elasticsearch源码debug.html.vue"]]);export{o as default};
diff --git "a/assets/gap\351\224\201.html-0qMpGSdo.js" "b/assets/gap\351\224\201.html-0qMpGSdo.js"
new file mode 100644
index 00000000..4fb5781a
--- /dev/null
+++ "b/assets/gap\351\224\201.html-0qMpGSdo.js"
@@ -0,0 +1 @@
+import{_ as a}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as o,a as e,d as r}from"./app-cS6i7hsH.js";const c={},s=e("h1",{id:"gap锁",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#gap锁","aria-hidden":"true"},"#"),r(" gap锁")],-1),_=[s];function n(d,i){return t(),o("div",null,_)}const p=a(c,[["render",n],["__file","gap锁.html.vue"]]);export{p as default};
diff --git "a/assets/gap\351\224\201.html-i4faTCf2.js" "b/assets/gap\351\224\201.html-i4faTCf2.js"
new file mode 100644
index 00000000..463eedc1
--- /dev/null
+++ "b/assets/gap\351\224\201.html-i4faTCf2.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-3192e5a0","path":"/database/mysql/gap%E9%94%81.html","title":"gap锁","lang":"zh-CN","frontmatter":{"description":"gap锁","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/mysql/gap%E9%94%81.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"gap锁"}],["meta",{"property":"og:description","content":"gap锁"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"gap锁\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706092222000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.01,"words":2},"filePathRelative":"database/mysql/gap锁.md","localizedDate":"2024年1月24日","excerpt":" gap锁 \\n","autoDesc":true}');export{e as data};
diff --git a/assets/giscus-NkhROb6B.js b/assets/giscus-NkhROb6B.js
new file mode 100644
index 00000000..28de2fa3
--- /dev/null
+++ b/assets/giscus-NkhROb6B.js
@@ -0,0 +1,66 @@
+/**
+ * @license
+ * Copyright 2019 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const H=globalThis,q=H.ShadowRoot&&(H.ShadyCSS===void 0||H.ShadyCSS.nativeShadow)&&"adoptedStyleSheets"in Document.prototype&&"replace"in CSSStyleSheet.prototype,K=Symbol(),J=new WeakMap;let ot=class{constructor(t,e,s){if(this._$cssResult$=!0,s!==K)throw Error("CSSResult is not constructable. Use `unsafeCSS` or `css` instead.");this.cssText=t,this.t=e}get styleSheet(){let t=this.o;const e=this.t;if(q&&t===void 0){const s=e!==void 0&&e.length===1;s&&(t=J.get(e)),t===void 0&&((this.o=t=new CSSStyleSheet).replaceSync(this.cssText),s&&J.set(e,t))}return t}toString(){return this.cssText}};const ut=i=>new ot(typeof i=="string"?i:i+"",void 0,K),$t=(i,...t)=>{const e=i.length===1?i[0]:t.reduce((s,r,o)=>s+(n=>{if(n._$cssResult$===!0)return n.cssText;if(typeof n=="number")return n;throw Error("Value passed to 'css' function must be a 'css' function result: "+n+". Use 'unsafeCSS' to pass non-literal values, but take care to ensure page security.")})(r)+i[o+1],i[0]);return new ot(e,i,K)},_t=(i,t)=>{if(q)i.adoptedStyleSheets=t.map(e=>e instanceof CSSStyleSheet?e:e.styleSheet);else for(const e of t){const s=document.createElement("style"),r=H.litNonce;r!==void 0&&s.setAttribute("nonce",r),s.textContent=e.cssText,i.appendChild(s)}},F=q?i=>i:i=>i instanceof CSSStyleSheet?(t=>{let e="";for(const s of t.cssRules)e+=s.cssText;return ut(e)})(i):i;/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const{is:gt,defineProperty:ft,getOwnPropertyDescriptor:mt,getOwnPropertyNames:At,getOwnPropertySymbols:yt,getPrototypeOf:St}=Object,A=globalThis,Q=A.trustedTypes,vt=Q?Q.emptyScript:"",z=A.reactiveElementPolyfillSupport,U=(i,t)=>i,L={toAttribute(i,t){switch(t){case Boolean:i=i?vt:null;break;case Object:case Array:i=i==null?i:JSON.stringify(i)}return i},fromAttribute(i,t){let e=i;switch(t){case Boolean:e=i!==null;break;case Number:e=i===null?null:Number(i);break;case Object:case Array:try{e=JSON.parse(i)}catch{e=null}}return e}},Y=(i,t)=>!gt(i,t),Z={attribute:!0,type:String,converter:L,reflect:!1,hasChanged:Y};Symbol.metadata??(Symbol.metadata=Symbol("metadata")),A.litPropertyMetadata??(A.litPropertyMetadata=new WeakMap);class E extends HTMLElement{static addInitializer(t){this._$Ei(),(this.l??(this.l=[])).push(t)}static get observedAttributes(){return this.finalize(),this._$Eh&&[...this._$Eh.keys()]}static createProperty(t,e=Z){if(e.state&&(e.attribute=!1),this._$Ei(),this.elementProperties.set(t,e),!e.noAccessor){const s=Symbol(),r=this.getPropertyDescriptor(t,s,e);r!==void 0&&ft(this.prototype,t,r)}}static getPropertyDescriptor(t,e,s){const{get:r,set:o}=mt(this.prototype,t)??{get(){return this[e]},set(n){this[e]=n}};return{get(){return r==null?void 0:r.call(this)},set(n){const a=r==null?void 0:r.call(this);o.call(this,n),this.requestUpdate(t,a,s)},configurable:!0,enumerable:!0}}static getPropertyOptions(t){return this.elementProperties.get(t)??Z}static _$Ei(){if(this.hasOwnProperty(U("elementProperties")))return;const t=St(this);t.finalize(),t.l!==void 0&&(this.l=[...t.l]),this.elementProperties=new Map(t.elementProperties)}static finalize(){if(this.hasOwnProperty(U("finalized")))return;if(this.finalized=!0,this._$Ei(),this.hasOwnProperty(U("properties"))){const e=this.properties,s=[...At(e),...yt(e)];for(const r of s)this.createProperty(r,e[r])}const t=this[Symbol.metadata];if(t!==null){const e=litPropertyMetadata.get(t);if(e!==void 0)for(const[s,r]of e)this.elementProperties.set(s,r)}this._$Eh=new Map;for(const[e,s]of this.elementProperties){const r=this._$Eu(e,s);r!==void 0&&this._$Eh.set(r,e)}this.elementStyles=this.finalizeStyles(this.styles)}static finalizeStyles(t){const e=[];if(Array.isArray(t)){const s=new Set(t.flat(1/0).reverse());for(const r of s)e.unshift(F(r))}else t!==void 0&&e.push(F(t));return e}static _$Eu(t,e){const s=e.attribute;return s===!1?void 0:typeof s=="string"?s:typeof t=="string"?t.toLowerCase():void 0}constructor(){super(),this._$Ep=void 0,this.isUpdatePending=!1,this.hasUpdated=!1,this._$Em=null,this._$Ev()}_$Ev(){var t;this._$Eg=new Promise(e=>this.enableUpdating=e),this._$AL=new Map,this._$ES(),this.requestUpdate(),(t=this.constructor.l)==null||t.forEach(e=>e(this))}addController(t){var e;(this._$E_??(this._$E_=new Set)).add(t),this.renderRoot!==void 0&&this.isConnected&&((e=t.hostConnected)==null||e.call(t))}removeController(t){var e;(e=this._$E_)==null||e.delete(t)}_$ES(){const t=new Map,e=this.constructor.elementProperties;for(const s of e.keys())this.hasOwnProperty(s)&&(t.set(s,this[s]),delete this[s]);t.size>0&&(this._$Ep=t)}createRenderRoot(){const t=this.shadowRoot??this.attachShadow(this.constructor.shadowRootOptions);return _t(t,this.constructor.elementStyles),t}connectedCallback(){var t;this.renderRoot??(this.renderRoot=this.createRenderRoot()),this.enableUpdating(!0),(t=this._$E_)==null||t.forEach(e=>{var s;return(s=e.hostConnected)==null?void 0:s.call(e)})}enableUpdating(t){}disconnectedCallback(){var t;(t=this._$E_)==null||t.forEach(e=>{var s;return(s=e.hostDisconnected)==null?void 0:s.call(e)})}attributeChangedCallback(t,e,s){this._$AK(t,s)}_$EO(t,e){var o;const s=this.constructor.elementProperties.get(t),r=this.constructor._$Eu(t,s);if(r!==void 0&&s.reflect===!0){const n=(((o=s.converter)==null?void 0:o.toAttribute)!==void 0?s.converter:L).toAttribute(e,s.type);this._$Em=t,n==null?this.removeAttribute(r):this.setAttribute(r,n),this._$Em=null}}_$AK(t,e){var o;const s=this.constructor,r=s._$Eh.get(t);if(r!==void 0&&this._$Em!==r){const n=s.getPropertyOptions(r),a=typeof n.converter=="function"?{fromAttribute:n.converter}:((o=n.converter)==null?void 0:o.fromAttribute)!==void 0?n.converter:L;this._$Em=r,this[r]=a.fromAttribute(e,n.type),this._$Em=null}}requestUpdate(t,e,s){if(t!==void 0){if(s??(s=this.constructor.getPropertyOptions(t)),!(s.hasChanged??Y)(this[t],e))return;this.C(t,e,s)}this.isUpdatePending===!1&&(this._$Eg=this._$EP())}C(t,e,s){this._$AL.has(t)||this._$AL.set(t,e),s.reflect===!0&&this._$Em!==t&&(this._$ET??(this._$ET=new Set)).add(t)}async _$EP(){this.isUpdatePending=!0;try{await this._$Eg}catch(e){Promise.reject(e)}const t=this.scheduleUpdate();return t!=null&&await t,!this.isUpdatePending}scheduleUpdate(){return this.performUpdate()}performUpdate(){var s;if(!this.isUpdatePending)return;if(!this.hasUpdated){if(this.renderRoot??(this.renderRoot=this.createRenderRoot()),this._$Ep){for(const[o,n]of this._$Ep)this[o]=n;this._$Ep=void 0}const r=this.constructor.elementProperties;if(r.size>0)for(const[o,n]of r)n.wrapped!==!0||this._$AL.has(o)||this[o]===void 0||this.C(o,this[o],n)}let t=!1;const e=this._$AL;try{t=this.shouldUpdate(e),t?(this.willUpdate(e),(s=this._$E_)==null||s.forEach(r=>{var o;return(o=r.hostUpdate)==null?void 0:o.call(r)}),this.update(e)):this._$Ej()}catch(r){throw t=!1,this._$Ej(),r}t&&this._$AE(e)}willUpdate(t){}_$AE(t){var e;(e=this._$E_)==null||e.forEach(s=>{var r;return(r=s.hostUpdated)==null?void 0:r.call(s)}),this.hasUpdated||(this.hasUpdated=!0,this.firstUpdated(t)),this.updated(t)}_$Ej(){this._$AL=new Map,this.isUpdatePending=!1}get updateComplete(){return this.getUpdateComplete()}getUpdateComplete(){return this._$Eg}shouldUpdate(t){return!0}update(t){this._$ET&&(this._$ET=this._$ET.forEach(e=>this._$EO(e,this[e]))),this._$Ej()}updated(t){}firstUpdated(t){}}E.elementStyles=[],E.shadowRootOptions={mode:"open"},E[U("elementProperties")]=new Map,E[U("finalized")]=new Map,z==null||z({ReactiveElement:E}),(A.reactiveElementVersions??(A.reactiveElementVersions=[])).push("2.0.3");/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const P=globalThis,k=P.trustedTypes,X=k?k.createPolicy("lit-html",{createHTML:i=>i}):void 0,ht="$lit$",m=`lit$${(Math.random()+"").slice(9)}$`,at="?"+m,Et=`<${at}>`,v=document,N=()=>v.createComment(""),R=i=>i===null||typeof i!="object"&&typeof i!="function",ct=Array.isArray,bt=i=>ct(i)||typeof(i==null?void 0:i[Symbol.iterator])=="function",B=`[
+\f\r]`,w=/<(?:(!--|\/[^a-zA-Z])|(\/?[a-zA-Z][^>\s]*)|(\/?$))/g,tt=/-->/g,et=/>/g,y=RegExp(`>|${B}(?:([^\\s"'>=/]+)(${B}*=${B}*(?:[^
+\f\r"'\`<>=]|("|')|))|$)`,"g"),st=/'/g,it=/"/g,lt=/^(?:script|style|textarea|title)$/i,Ct=i=>(t,...e)=>({_$litType$:i,strings:t,values:e}),wt=Ct(1),b=Symbol.for("lit-noChange"),l=Symbol.for("lit-nothing"),rt=new WeakMap,S=v.createTreeWalker(v,129);function dt(i,t){if(!Array.isArray(i)||!i.hasOwnProperty("raw"))throw Error("invalid template strings array");return X!==void 0?X.createHTML(t):t}const Ut=(i,t)=>{const e=i.length-1,s=[];let r,o=t===2?"":"",n=w;for(let a=0;a"?(n=r??w,c=-1):u[1]===void 0?c=-2:(c=n.lastIndex-u[2].length,d=u[1],n=u[3]===void 0?y:u[3]==='"'?it:st):n===it||n===st?n=y:n===tt||n===et?n=w:(n=y,r=void 0);const f=n===y&&i[a+1].startsWith("/>")?" ":"";o+=n===w?h+Et:c>=0?(s.push(d),h.slice(0,c)+ht+h.slice(c)+m+f):h+m+(c===-2?a:f)}return[dt(i,o+(i[e]||"")+(t===2?" ":"")),s]};class I{constructor({strings:t,_$litType$:e},s){let r;this.parts=[];let o=0,n=0;const a=t.length-1,h=this.parts,[d,u]=Ut(t,e);if(this.el=I.createElement(d,s),S.currentNode=this.el.content,e===2){const c=this.el.content.firstChild;c.replaceWith(...c.childNodes)}for(;(r=S.nextNode())!==null&&h.length0){r.textContent=k?k.emptyScript:"";for(let f=0;f2||s[0]!==""||s[1]!==""?(this._$AH=Array(s.length-1).fill(new String),this.strings=s):this._$AH=l}_$AI(t,e=this,s,r){const o=this.strings;let n=!1;if(o===void 0)t=C(this,t,e,0),n=!R(t)||t!==this._$AH&&t!==b,n&&(this._$AH=t);else{const a=t;let h,d;for(t=o[0],h=0;h{const s=(e==null?void 0:e.renderBefore)??t;let r=s._$litPart$;if(r===void 0){const o=(e==null?void 0:e.renderBefore)??null;s._$litPart$=r=new M(t.insertBefore(N(),o),o,void 0,e??{})}return r._$AI(i),r};/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */let O=class extends E{constructor(){super(...arguments),this.renderOptions={host:this},this._$Do=void 0}createRenderRoot(){var e;const t=super.createRenderRoot();return(e=this.renderOptions).renderBefore??(e.renderBefore=t.firstChild),t}update(t){const e=this.render();this.hasUpdated||(this.renderOptions.isConnected=this.isConnected),super.update(t),this._$Do=It(e,this.renderRoot,this.renderOptions)}connectedCallback(){var t;super.connectedCallback(),(t=this._$Do)==null||t.setConnected(!0)}disconnectedCallback(){var t;super.disconnectedCallback(),(t=this._$Do)==null||t.setConnected(!1)}render(){return b}};var nt;O._$litElement$=!0,O.finalized=!0,(nt=globalThis.litElementHydrateSupport)==null||nt.call(globalThis,{LitElement:O});const W=globalThis.litElementPolyfillSupport;W==null||W({LitElement:O});(globalThis.litElementVersions??(globalThis.litElementVersions=[])).push("4.0.3");/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const Mt=i=>(t,e)=>{e!==void 0?e.addInitializer(()=>{customElements.define(i,t)}):customElements.define(i,t)};/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const xt={attribute:!0,type:String,converter:L,reflect:!1,hasChanged:Y},Ht=(i=xt,t,e)=>{const{kind:s,metadata:r}=e;let o=globalThis.litPropertyMetadata.get(r);if(o===void 0&&globalThis.litPropertyMetadata.set(r,o=new Map),o.set(e.name,i),s==="accessor"){const{name:n}=e;return{set(a){const h=t.get.call(this);t.set.call(this,a),this.requestUpdate(n,h,i)},init(a){return a!==void 0&&this.C(n,void 0,i),a}}}if(s==="setter"){const{name:n}=e;return function(a){const h=this[n];t.call(this,a),this.requestUpdate(n,h,i)}}throw Error("Unsupported decorator location: "+s)};function _(i){return(t,e)=>typeof e=="object"?Ht(i,t,e):((s,r,o)=>{const n=r.hasOwnProperty(o);return r.constructor.createProperty(o,n?{...s,wrapped:!0}:s),n?Object.getOwnPropertyDescriptor(r,o):void 0})(i,t,e)}/**
+ * @license
+ * Copyright 2020 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const Lt=i=>i.strings===void 0;/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const kt={ATTRIBUTE:1,CHILD:2,PROPERTY:3,BOOLEAN_ATTRIBUTE:4,EVENT:5,ELEMENT:6},Gt=i=>(...t)=>({_$litDirective$:i,values:t});let Dt=class{constructor(t){}get _$AU(){return this._$AM._$AU}_$AT(t,e,s){this._$Ct=t,this._$AM=e,this._$Ci=s}_$AS(t,e){return this.update(t,e)}update(t,e){return this.render(...e)}};/**
+ * @license
+ * Copyright 2017 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const T=(i,t)=>{var s;const e=i._$AN;if(e===void 0)return!1;for(const r of e)(s=r._$AO)==null||s.call(r,t,!1),T(r,t);return!0},G=i=>{let t,e;do{if((t=i._$AM)===void 0)break;e=t._$AN,e.delete(i),i=t}while((e==null?void 0:e.size)===0)},pt=i=>{for(let t;t=i._$AM;i=t){let e=t._$AN;if(e===void 0)t._$AN=e=new Set;else if(e.has(i))break;e.add(i),jt(t)}};function zt(i){this._$AN!==void 0?(G(this),this._$AM=i,pt(this)):this._$AM=i}function Bt(i,t=!1,e=0){const s=this._$AH,r=this._$AN;if(r!==void 0&&r.size!==0)if(t)if(Array.isArray(s))for(let o=e;o{i.type==kt.CHILD&&(i._$AP??(i._$AP=Bt),i._$AQ??(i._$AQ=zt))};class Wt extends Dt{constructor(){super(...arguments),this._$AN=void 0}_$AT(t,e,s){super._$AT(t,e,s),pt(this),this.isConnected=t._$AU}_$AO(t,e=!0){var s,r;t!==this.isConnected&&(this.isConnected=t,t?(s=this.reconnected)==null||s.call(this):(r=this.disconnected)==null||r.call(this)),e&&(T(this,t),G(this))}setValue(t){if(Lt(this._$Ct))this._$Ct._$AI(t,this);else{const e=[...this._$Ct._$AH];e[this._$Ci]=t,this._$Ct._$AI(e,this,0)}}disconnected(){}reconnected(){}}/**
+ * @license
+ * Copyright 2020 Google LLC
+ * SPDX-License-Identifier: BSD-3-Clause
+ */const Vt=()=>new qt;class qt{}const V=new WeakMap,Kt=Gt(class extends Wt{render(i){return l}update(i,[t]){var s;const e=t!==this.G;return e&&this.G!==void 0&&this.ot(void 0),(e||this.rt!==this.lt)&&(this.G=t,this.ct=(s=i.options)==null?void 0:s.host,this.ot(this.lt=i.element)),l}ot(i){if(typeof this.G=="function"){const t=this.ct??globalThis;let e=V.get(t);e===void 0&&(e=new WeakMap,V.set(t,e)),e.get(this.G)!==void 0&&this.G.call(this.ct,void 0),e.set(this.G,i),i!==void 0&&this.G.call(this.ct,i)}else this.G.value=i}get rt(){var i,t;return typeof this.G=="function"?(i=V.get(this.ct??globalThis))==null?void 0:i.get(this.G):(t=this.G)==null?void 0:t.value}disconnected(){this.rt===this.lt&&this.ot(void 0)}reconnected(){this.ot(this.lt)}});var Yt=Object.defineProperty,Jt=Object.getOwnPropertyDescriptor,$=(i,t,e,s)=>{for(var r=s>1?void 0:s?Jt(t,e):t,o=i.length-1,n;o>=0;o--)(n=i[o])&&(r=(s?n(t,e,r):n(r))||r);return s&&r&&Yt(t,e,r),r};function Ft(i){return customElements.get(i)?t=>t:Mt(i)}let p=class extends O{constructor(){super(),this.GISCUS_SESSION_KEY="giscus-session",this.GISCUS_DEFAULT_HOST="https://giscus.app",this.ERROR_SUGGESTION="Please consider reporting this error at https://github.com/giscus/giscus/issues/new.",this.__session="",this._iframeRef=Vt(),this.messageEventHandler=this.handleMessageEvent.bind(this),this.hasLoaded=!1,this.host=this.GISCUS_DEFAULT_HOST,this.strict="0",this.reactionsEnabled="1",this.emitMetadata="0",this.inputPosition="bottom",this.theme="light",this.lang="en",this.loading="eager",this.setupSession(),window.addEventListener("message",this.messageEventHandler)}get iframeRef(){var i;return(i=this._iframeRef)==null?void 0:i.value}get _host(){try{return new URL(this.host),this.host}catch{return this.GISCUS_DEFAULT_HOST}}disconnectedCallback(){super.disconnectedCallback(),window.removeEventListener("message",this.messageEventHandler)}_formatError(i){return`[giscus] An error occurred. Error message: "${i}".`}setupSession(){const i=location.href,t=new URL(i),e=localStorage.getItem(this.GISCUS_SESSION_KEY),s=t.searchParams.get("giscus")??"";if(this.__session="",s){localStorage.setItem(this.GISCUS_SESSION_KEY,JSON.stringify(s)),this.__session=s,t.searchParams.delete("giscus"),t.hash="",history.replaceState(void 0,document.title,t.toString());return}if(e)try{this.__session=JSON.parse(e)}catch(r){localStorage.removeItem(this.GISCUS_SESSION_KEY),console.warn(`${this._formatError(r==null?void 0:r.message)} Session has been cleared.`)}}signOut(){localStorage.removeItem(this.GISCUS_SESSION_KEY),this.__session="",this.update(new Map)}handleMessageEvent(i){if(i.origin!==this._host)return;const{data:t}=i;if(!(typeof t=="object"&&t.giscus))return;if(this.iframeRef&&t.giscus.resizeHeight&&(this.iframeRef.style.height=`${t.giscus.resizeHeight}px`),t.giscus.signOut){console.info("[giscus] User has logged out. Session has been cleared."),this.signOut();return}if(!t.giscus.error)return;const e=t.giscus.error;if(e.includes("Bad credentials")||e.includes("Invalid state value")||e.includes("State has expired")){if(localStorage.getItem(this.GISCUS_SESSION_KEY)!==null){console.warn(`${this._formatError(e)} Session has been cleared.`),this.signOut();return}console.error(`${this._formatError(e)} No session is stored initially. ${this.ERROR_SUGGESTION}`)}if(e.includes("Discussion not found")){console.warn(`[giscus] ${e}. A new discussion will be created if a comment/reaction is submitted.`);return}console.error(`${this._formatError(e)} ${this.ERROR_SUGGESTION}`)}sendMessage(i){var t;!((t=this.iframeRef)!=null&&t.contentWindow)||!this.hasLoaded||this.iframeRef.contentWindow.postMessage({giscus:i},this._host)}updateConfig(){const i={setConfig:{repo:this.repo,repoId:this.repoId,category:this.category,categoryId:this.categoryId,term:this.getTerm(),number:+this.getNumber(),strict:this.strict==="1",reactionsEnabled:this.reactionsEnabled==="1",emitMetadata:this.emitMetadata==="1",inputPosition:this.inputPosition,theme:this.theme,lang:this.lang}};this.sendMessage(i)}firstUpdated(){var i;(i=this.iframeRef)==null||i.addEventListener("load",()=>{var t;(t=this.iframeRef)==null||t.classList.remove("loading"),this.hasLoaded=!0,this.updateConfig()})}requestUpdate(i,t,e){if(!this.hasUpdated||i==="host"){super.requestUpdate(i,t,e);return}this.updateConfig()}getMetaContent(i,t=!1){const e=t?`meta[property='og:${i}'],`:"",s=document.querySelector(e+`meta[name='${i}']`);return s?s.content:""}_getCleanedUrl(){const i=new URL(location.href);return i.searchParams.delete("giscus"),i.hash="",i}getTerm(){switch(this.mapping){case"url":return this._getCleanedUrl().toString();case"title":return document.title;case"og:title":return this.getMetaContent("title",!0);case"specific":return this.term??"";case"number":return"";case"pathname":default:return location.pathname.length<2?"index":location.pathname.substring(1).replace(/\.\w+$/,"")}}getNumber(){return this.mapping==="number"?this.term??"":""}getIframeSrc(){const i=this._getCleanedUrl().toString(),t=`${i}${this.id?"#"+this.id:""}`,e=this.getMetaContent("description",!0),s=this.getMetaContent("giscus:backlink")||i,r={origin:t,session:this.__session,repo:this.repo,repoId:this.repoId??"",category:this.category??"",categoryId:this.categoryId??"",term:this.getTerm(),number:this.getNumber(),strict:this.strict,reactionsEnabled:this.reactionsEnabled,emitMetadata:this.emitMetadata,inputPosition:this.inputPosition,theme:this.theme,description:e,backLink:s},o=this._host,n=this.lang?`/${this.lang}`:"",a=new URLSearchParams(r);return`${o}${n}/widget?${a.toString()}`}render(){return wt`
+
+ `}};p.styles=$t`
+ :host,
+ iframe {
+ width: 100%;
+ border: none;
+ min-height: 150px;
+ color-scheme: light dark;
+ }
+
+ iframe.loading {
+ opacity: 0;
+ }
+ `;$([_({reflect:!0})],p.prototype,"host",2);$([_({reflect:!0})],p.prototype,"repo",2);$([_({reflect:!0})],p.prototype,"repoId",2);$([_({reflect:!0})],p.prototype,"category",2);$([_({reflect:!0})],p.prototype,"categoryId",2);$([_({reflect:!0})],p.prototype,"mapping",2);$([_({reflect:!0})],p.prototype,"term",2);$([_({reflect:!0})],p.prototype,"strict",2);$([_({reflect:!0})],p.prototype,"reactionsEnabled",2);$([_({reflect:!0})],p.prototype,"emitMetadata",2);$([_({reflect:!0})],p.prototype,"inputPosition",2);$([_({reflect:!0})],p.prototype,"theme",2);$([_({reflect:!0})],p.prototype,"lang",2);$([_({reflect:!0})],p.prototype,"loading",2);p=$([Ft("giscus-widget")],p);export{p as GiscusWidget};
diff --git a/assets/gitlab-ci.html-9dvcTJNs.js b/assets/gitlab-ci.html-9dvcTJNs.js
new file mode 100644
index 00000000..0b71bf7d
--- /dev/null
+++ b/assets/gitlab-ci.html-9dvcTJNs.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as a,c,a as e,d as o}from"./app-cS6i7hsH.js";const r={},i=e("h1",{id:"git",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#git","aria-hidden":"true"},"#"),o(" Git")],-1),s=[i];function n(_,d){return a(),c("div",null,s)}const f=t(r,[["render",n],["__file","gitlab-ci.html.vue"]]);export{f as default};
diff --git a/assets/gitlab-ci.html-HyFv5Ls3.js b/assets/gitlab-ci.html-HyFv5Ls3.js
new file mode 100644
index 00000000..6397a4ab
--- /dev/null
+++ b/assets/gitlab-ci.html-HyFv5Ls3.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-06d5cd4c","path":"/devops/gitlab-ci.html","title":"Git","lang":"zh-CN","frontmatter":{"description":"Git","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/devops/gitlab-ci.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Git"}],["meta",{"property":"og:description","content":"Git"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"Git\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0,"words":1},"filePathRelative":"devops/gitlab-ci.md","localizedDate":"2024年1月24日","excerpt":" Git \\n","autoDesc":true}');export{t as data};
diff --git a/assets/icon/apple-icon-152.png b/assets/icon/apple-icon-152.png
new file mode 100644
index 00000000..f53c6c55
Binary files /dev/null and b/assets/icon/apple-icon-152.png differ
diff --git a/assets/icon/chrome-192.png b/assets/icon/chrome-192.png
new file mode 100644
index 00000000..57096280
Binary files /dev/null and b/assets/icon/chrome-192.png differ
diff --git a/assets/icon/chrome-512.png b/assets/icon/chrome-512.png
new file mode 100644
index 00000000..2db62c29
Binary files /dev/null and b/assets/icon/chrome-512.png differ
diff --git a/assets/icon/chrome-mask-192.png b/assets/icon/chrome-mask-192.png
new file mode 100644
index 00000000..77c39a2a
Binary files /dev/null and b/assets/icon/chrome-mask-192.png differ
diff --git a/assets/icon/chrome-mask-512.png b/assets/icon/chrome-mask-512.png
new file mode 100644
index 00000000..b8349f4e
Binary files /dev/null and b/assets/icon/chrome-mask-512.png differ
diff --git a/assets/icon/guide-maskable.png b/assets/icon/guide-maskable.png
new file mode 100644
index 00000000..230798a3
Binary files /dev/null and b/assets/icon/guide-maskable.png differ
diff --git a/assets/icon/guide-monochrome.png b/assets/icon/guide-monochrome.png
new file mode 100644
index 00000000..e12403e2
Binary files /dev/null and b/assets/icon/guide-monochrome.png differ
diff --git a/assets/icon/ms-icon-144.png b/assets/icon/ms-icon-144.png
new file mode 100644
index 00000000..681cde6f
Binary files /dev/null and b/assets/icon/ms-icon-144.png differ
diff --git a/assets/img-kuzmmtyE.png b/assets/img-kuzmmtyE.png
new file mode 100644
index 00000000..fccce293
Binary files /dev/null and b/assets/img-kuzmmtyE.png differ
diff --git a/assets/img_1-mEcVW6nR.png b/assets/img_1-mEcVW6nR.png
new file mode 100644
index 00000000..64cf87d5
Binary files /dev/null and b/assets/img_1-mEcVW6nR.png differ
diff --git a/assets/index.html--QH2zN9-.js b/assets/index.html--QH2zN9-.js
new file mode 100644
index 00000000..93577862
--- /dev/null
+++ b/assets/index.html--QH2zN9-.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(n,_){return t(),c("div")}const f=e(o,[["render",r],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html--YxqP697.js b/assets/index.html--YxqP697.js
new file mode 100644
index 00000000..536f6584
--- /dev/null
+++ b/assets/index.html--YxqP697.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o,c as a,a as e,d as c}from"./app-cS6i7hsH.js";const n={},r=e("h1",{id:"关于我",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#关于我","aria-hidden":"true"},"#"),c(" 关于我")],-1),s=e("p",null,"留空",-1),_=[r,s];function d(i,l){return o(),a("div",null,_)}const m=t(n,[["render",d],["__file","index.html.vue"]]);export{m as default};
diff --git a/assets/index.html-1G2UU7KQ.js b/assets/index.html-1G2UU7KQ.js
new file mode 100644
index 00000000..93577862
--- /dev/null
+++ b/assets/index.html-1G2UU7KQ.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(n,_){return t(),c("div")}const f=e(o,[["render",r],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html-2mdvLUFa.js b/assets/index.html-2mdvLUFa.js
new file mode 100644
index 00000000..76fac78b
--- /dev/null
+++ b/assets/index.html-2mdvLUFa.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as a,c as n,a as e,d as o}from"./app-cS6i7hsH.js";const s="/assets/img_1-mEcVW6nR.png",c={},i=e("h1",{id:"微信支付",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#微信支付","aria-hidden":"true"},"#"),o(" 微信支付")],-1),r=e("figure",null,[e("img",{src:s,alt:"微信支付",tabindex:"0",loading:"lazy"}),e("figcaption",null,"微信支付")],-1),_=[i,r];function d(l,m){return a(),n("div",null,_)}const u=t(c,[["render",d],["__file","index.html.vue"]]);export{u as default};
diff --git a/assets/index.html-2xQqwR-V.js b/assets/index.html-2xQqwR-V.js
new file mode 100644
index 00000000..3e89b994
--- /dev/null
+++ b/assets/index.html-2xQqwR-V.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-2e25198a","path":"/database/","title":"","lang":"zh-CN","frontmatter":{"description":"八、mysql 8.1 mysql缓存.md","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:description","content":"八、mysql 8.1 mysql缓存.md"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706182936000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.05,"words":15},"filePathRelative":"database/README.md","localizedDate":"2024年1月25日","excerpt":"\\n","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-48vkkelG.js b/assets/index.html-48vkkelG.js
new file mode 100644
index 00000000..d5872d8a
--- /dev/null
+++ b/assets/index.html-48vkkelG.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-744d024e","path":"/tag/","title":"标签","lang":"zh-CN","frontmatter":{"title":"标签","dir":{"index":false},"index":false,"feed":false,"sitemap":false,"blog":{"type":"category","key":"tag"},"layout":"BlogCategory","description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/tag/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"标签"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"标签\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":0},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-5KP2soWP.js b/assets/index.html-5KP2soWP.js
new file mode 100644
index 00000000..6a8deec4
--- /dev/null
+++ b/assets/index.html-5KP2soWP.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-60fc7530","path":"/bigdata/spark/","title":"Spark","lang":"zh-CN","frontmatter":{"title":"Spark","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/bigdata/spark/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Spark"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Spark\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{t as data};
diff --git a/assets/index.html-5Ud_mAI1.js b/assets/index.html-5Ud_mAI1.js
new file mode 100644
index 00000000..2ac1e94d
--- /dev/null
+++ b/assets/index.html-5Ud_mAI1.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-dc384366","path":"/redis/","title":"","lang":"zh-CN","frontmatter":{"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/redis/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0,"words":0},"filePathRelative":"redis/README.md","localizedDate":"2024年1月24日","excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-6A2xto4n.js b/assets/index.html-6A2xto4n.js
new file mode 100644
index 00000000..8fbfc45c
--- /dev/null
+++ b/assets/index.html-6A2xto4n.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-8daa1a0e","path":"/","title":"","lang":"zh-CN","frontmatter":{"description":"目录 一、Java 1.1 一次jvm调优过程.md 1.2 JVM调优参数.md 1.3 serverlog.md 1.5 基于kubernetes的分布式限流","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:description","content":"目录 一、Java 1.1 一次jvm调优过程.md 1.2 JVM调优参数.md 1.3 serverlog.md 1.5 基于kubernetes的分布式限流"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T17:34:45.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T17:34:45.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T17:34:45.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706204085000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":6}]},"readingTime":{"minutes":0.21,"words":62},"filePathRelative":"README.md","localizedDate":"2024年1月24日","excerpt":"\\n","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-6QAvnWzZ.js b/assets/index.html-6QAvnWzZ.js
new file mode 100644
index 00000000..8b446c54
--- /dev/null
+++ b/assets/index.html-6QAvnWzZ.js
@@ -0,0 +1 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as t,o as n,c,b as r}from"./app-cS6i7hsH.js";const a={};function _(s,l){const e=t("AutoCatalog");return n(),c("div",null,[r(e)])}const i=o(a,[["render",_],["__file","index.html.vue"]]);export{i as default};
diff --git a/assets/index.html-7Jwn4Cbi.js b/assets/index.html-7Jwn4Cbi.js
new file mode 100644
index 00000000..f7385e50
--- /dev/null
+++ b/assets/index.html-7Jwn4Cbi.js
@@ -0,0 +1 @@
+import{_ as n}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as a,o as c,c as l,a as e,d as o,b as t}from"./app-cS6i7hsH.js";const s={},d=e("h1",{id:"三、devops",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#三、devops","aria-hidden":"true"},"#"),o(" 三、DevOps")],-1),i={href:"https://github.com/Zephery/book/tree/64e9606b37cc2743260cbab2f6d7a4f3667c1aa9/devops/DevOps%E5%B9%B3%E5%8F%B0.md",target:"_blank",rel:"noopener noreferrer"},h={href:"https://github.com/Zephery/book/tree/64e9606b37cc2743260cbab2f6d7a4f3667c1aa9/devops/gitlab-ci.md",target:"_blank",rel:"noopener noreferrer"},p={href:"https://github.com/Zephery/book/tree/64e9606b37cc2743260cbab2f6d7a4f3667c1aa9/devops/jenkins-x.md",target:"_blank",rel:"noopener noreferrer"},b={href:"https://github.com/Zephery/book/tree/64e9606b37cc2743260cbab2f6d7a4f3667c1aa9/devops/tekton.md",target:"_blank",rel:"noopener noreferrer"};function _(f,m){const r=a("ExternalLinkIcon");return c(),l("div",null,[d,e("ul",null,[e("li",null,[o("DevOps "),e("ul",null,[e("li",null,[e("a",i,[o("DevOps平台"),t(r)])]),e("li",null,[e("a",h,[o("Gitlab-ci"),t(r)])]),e("li",null,[e("a",p,[o("jenkins-x.md"),t(r)])]),e("li",null,[e("a",b,[o("tekton"),t(r)])])])])])])}const v=n(s,[["render",_],["__file","index.html.vue"]]);export{v as default};
diff --git a/assets/index.html-8MJuJxlA.js b/assets/index.html-8MJuJxlA.js
new file mode 100644
index 00000000..6afc9e69
--- /dev/null
+++ b/assets/index.html-8MJuJxlA.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-02bc92be","path":"/bigdata/","title":"Bigdata","lang":"zh-CN","frontmatter":{"title":"Bigdata","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/bigdata/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Bigdata"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Bigdata\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{t as data};
diff --git a/assets/index.html-9KTewoYW.js b/assets/index.html-9KTewoYW.js
new file mode 100644
index 00000000..93577862
--- /dev/null
+++ b/assets/index.html-9KTewoYW.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(n,_){return t(),c("div")}const f=e(o,[["render",r],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html-AOPdgBmB.js b/assets/index.html-AOPdgBmB.js
new file mode 100644
index 00000000..8b446c54
--- /dev/null
+++ b/assets/index.html-AOPdgBmB.js
@@ -0,0 +1 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as t,o as n,c,b as r}from"./app-cS6i7hsH.js";const a={};function _(s,l){const e=t("AutoCatalog");return n(),c("div",null,[r(e)])}const i=o(a,[["render",_],["__file","index.html.vue"]]);export{i as default};
diff --git a/assets/index.html-CmwrSuW4.js b/assets/index.html-CmwrSuW4.js
new file mode 100644
index 00000000..93577862
--- /dev/null
+++ b/assets/index.html-CmwrSuW4.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(n,_){return t(),c("div")}const f=e(o,[["render",r],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html-DLDIhIzm.js b/assets/index.html-DLDIhIzm.js
new file mode 100644
index 00000000..dd75be91
--- /dev/null
+++ b/assets/index.html-DLDIhIzm.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-21ba2ec8","path":"/database/mysql/","title":"Mysql","lang":"zh-CN","frontmatter":{"title":"Mysql","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/mysql/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Mysql"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Mysql\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-GO9KhDWT.js b/assets/index.html-GO9KhDWT.js
new file mode 100644
index 00000000..b9d1c947
--- /dev/null
+++ b/assets/index.html-GO9KhDWT.js
@@ -0,0 +1 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as u,o as r,c as s,a as e,b as t,w as a,d as n}from"./app-cS6i7hsH.js";const _={},c=e("nav",{class:"table-of-contents"},[e("ul")],-1);function d(E,m){const l=u("RouterLink");return r(),s("div",null,[c,e("ul",null,[e("li",null,[e("p",null,[t(l,{to:"/"},{default:a(()=>[n("目录")]),_:1})])]),e("li",null,[e("p",null,[t(l,{to:"/java/"},{default:a(()=>[n("一、Java")]),_:1})]),e("ul",null,[e("li",null,[t(l,{to:"/java/%E4%B8%80%E6%AC%A1jvm%E8%B0%83%E4%BC%98%E8%BF%87%E7%A8%8B.html"},{default:a(()=>[n("1.1 一次jvm调优过程.md")]),_:1})]),e("li",null,[t(l,{to:"/java/JVM%E8%B0%83%E4%BC%98%E5%8F%82%E6%95%B0.html"},{default:a(()=>[n("1.2 JVM调优参数.md")]),_:1})]),e("li",null,[t(l,{to:"/java/serverlog.html"},{default:a(()=>[n("1.3 serverlog.md")]),_:1})]),e("li",null,[t(l,{to:"/java/%E5%9F%BA%E4%BA%8Ekubernetes%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81.html"},{default:a(()=>[n("1.5 基于kubernetes的分布式限流")]),_:1})])])])])])}const f=o(_,[["render",d],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html-GqC77IMP.js b/assets/index.html-GqC77IMP.js
new file mode 100644
index 00000000..93577862
--- /dev/null
+++ b/assets/index.html-GqC77IMP.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c}from"./app-cS6i7hsH.js";const o={};function r(n,_){return t(),c("div")}const f=e(o,[["render",r],["__file","index.html.vue"]]);export{f as default};
diff --git a/assets/index.html-GqCa2uIM.js b/assets/index.html-GqCa2uIM.js
new file mode 100644
index 00000000..8b446c54
--- /dev/null
+++ b/assets/index.html-GqCa2uIM.js
@@ -0,0 +1 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as t,o as n,c,b as r}from"./app-cS6i7hsH.js";const a={};function _(s,l){const e=t("AutoCatalog");return n(),c("div",null,[r(e)])}const i=o(a,[["render",_],["__file","index.html.vue"]]);export{i as default};
diff --git a/assets/index.html-HoKSYW3I.js b/assets/index.html-HoKSYW3I.js
new file mode 100644
index 00000000..63f7890f
--- /dev/null
+++ b/assets/index.html-HoKSYW3I.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-50cb12f2","path":"/donate/","title":"微信支付","lang":"zh-CN","frontmatter":{"description":"微信支付 微信支付","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/donate/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"微信支付"}],["meta",{"property":"og:description","content":"微信支付 微信支付"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"微信支付\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706182936000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.03,"words":9},"filePathRelative":"donate/README.md","localizedDate":"2024年1月25日","excerpt":" 微信支付 \\n微信支付 关于我 \\n留空
\\n","autoDesc":true}');export{t as data};
diff --git a/assets/index.html-vgYoWX9F.js b/assets/index.html-vgYoWX9F.js
new file mode 100644
index 00000000..b5b4d971
--- /dev/null
+++ b/assets/index.html-vgYoWX9F.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-71b3ae87","path":"/interview/","title":"Interview","lang":"zh-CN","frontmatter":{"title":"Interview","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/interview/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Interview"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Interview\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-xgoJibcf.js b/assets/index.html-xgoJibcf.js
new file mode 100644
index 00000000..a67d4303
--- /dev/null
+++ b/assets/index.html-xgoJibcf.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-258f309e","path":"/open-source-project/","title":"","lang":"zh-CN","frontmatter":{"description":"jfaowejfoewj","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/open-source-project/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:description","content":"jfaowejfoewj"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T10:30:22.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T10:30:22.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T10:30:22.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706092222000,"updatedTime":1706092222000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0,"words":1},"filePathRelative":"open-source-project/README.md","localizedDate":"2024年1月24日","excerpt":"jfaowejfoewj
\\n","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-yuZKtvix.js b/assets/index.html-yuZKtvix.js
new file mode 100644
index 00000000..266ce1bb
--- /dev/null
+++ b/assets/index.html-yuZKtvix.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-14c69af4","path":"/java/","title":"Java","lang":"zh-CN","frontmatter":{"title":"Java","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Java"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Java\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-zEn3PTqR.js b/assets/index.html-zEn3PTqR.js
new file mode 100644
index 00000000..80418a6c
--- /dev/null
+++ b/assets/index.html-zEn3PTqR.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-71fde78e","path":"/devops/","title":"三、DevOps","lang":"zh-CN","frontmatter":{"description":"三、DevOps DevOps DevOps平台 Gitlab-ci jenkins-x.md tekton","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/devops/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"三、DevOps"}],["meta",{"property":"og:description","content":"三、DevOps DevOps DevOps平台 Gitlab-ci jenkins-x.md tekton"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"三、DevOps\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.08,"words":24},"filePathRelative":"devops/README.md","localizedDate":"2024年1月24日","excerpt":" 三、DevOps \\n","autoDesc":true}');export{e as data};
diff --git a/assets/index.html-zdhpQIq5.js b/assets/index.html-zdhpQIq5.js
new file mode 100644
index 00000000..c0b39189
--- /dev/null
+++ b/assets/index.html-zdhpQIq5.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-25b47c13","path":"/others/","title":"Others","lang":"zh-CN","frontmatter":{"title":"Others","article":false,"feed":false,"sitemap":false,"description":"","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/others/"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Others"}],["meta",{"property":"og:type","content":"website"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"article:author","content":"Zephery"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"WebPage\\",\\"name\\":\\"Others\\"}"]]},"headers":[],"git":{},"readingTime":{"minutes":0,"words":1},"filePathRelative":null,"excerpt":"","autoDesc":true}');export{e as data};
diff --git a/assets/jenkins-x.html--QxcKVNb.js b/assets/jenkins-x.html--QxcKVNb.js
new file mode 100644
index 00000000..75fe09a5
--- /dev/null
+++ b/assets/jenkins-x.html--QxcKVNb.js
@@ -0,0 +1 @@
+import{_ as n}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as s,c as t,a as e,d as a}from"./app-cS6i7hsH.js";const o={},r=e("h1",{id:"jenkins-x",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#jenkins-x","aria-hidden":"true"},"#"),a(" jenkins-x")],-1),c=[r];function i(_,d){return s(),t("div",null,c)}const f=n(o,[["render",i],["__file","jenkins-x.html.vue"]]);export{f as default};
diff --git a/assets/jenkins-x.html-gi90zyZ8.js b/assets/jenkins-x.html-gi90zyZ8.js
new file mode 100644
index 00000000..03dd6c23
--- /dev/null
+++ b/assets/jenkins-x.html-gi90zyZ8.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-132efcd1","path":"/devops/jenkins-x.html","title":"jenkins-x","lang":"zh-CN","frontmatter":{"description":"jenkins-x","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/devops/jenkins-x.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"jenkins-x"}],["meta",{"property":"og:description","content":"jenkins-x"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"jenkins-x\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.01,"words":2},"filePathRelative":"devops/jenkins-x.md","localizedDate":"2024年1月24日","excerpt":" jenkins-x \\n","autoDesc":true}');export{e as data};
diff --git a/assets/kafka.html-FefoBwLN.js b/assets/kafka.html-FefoBwLN.js
new file mode 100644
index 00000000..197b649a
--- /dev/null
+++ b/assets/kafka.html-FefoBwLN.js
@@ -0,0 +1 @@
+import{_ as a}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as e,c as k,e as r}from"./app-cS6i7hsH.js";const o={},p=r(' kafka面试题 1、请说明什么是Apache Kafka? Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。
2、说说Kafka的使用场景? ①异步处理 ②应用解耦 ③流量削峰 ④日志处理 ⑤消息通讯等。
3、使用Kafka有什么优点和缺点? 优点: ①支持跨数据中心的消息复制; ②单机吞吐量:十万级,最大的优点,就是吞吐量高; ③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源; ④时效性:ms级; ⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用; ⑥消息可靠性:经过参数优化配置,消息可以做到0丢失; ⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
缺点: ①由于是批量发送,数据并非真正的实时; 仅支持统一分区内消息有序,无法实现全局消息有序; ②有可能消息重复消费; ③依赖zookeeper进行元数据管理,等等。
4、为什么说Kafka性能很好,体现在哪里? ①顺序读写 ②零拷贝 ③分区 ④批量发送 ⑤数据压缩
5、请说明什么是传统的消息传递方法? 传统的消息传递方法包括两种: 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。 发布-订阅:在这个模型中,消息被广播给所有的用户。
6、请说明Kafka相对传统技术有什么优势? ①快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。 ②可伸缩:在一组机器上对数据进行分区 ③和简化,以支持更大的数据 ④持久:消息是持久性的,并在集群中进 ⑤行复制,以防止数据丢失。 ⑥设计:它提供了容错保证和持久性
7、解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗? Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。 不,不可能越过Zookeeper,直接联系Kafka broker。一旦Zookeeper停止工作,它就不能服务客户端请求。 Zookeeper主要用于在集群中不同节点之间进行通信 在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取 除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
8、解释Kafka的用户如何消费信息? 在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节从套接口转移到磁盘,通过内核空间保存副本,并在内核用户之间调用内核。
9、解释如何提高远程用户的吞吐量? 如果用户位于与broker不同的数据中心,则可能需要调优套接口缓冲区大小,以对长网络延迟进行摊销。
10、解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息? 在数据中,为了精确地获得Kafka的消息,你必须遵循两件事: 在数据消耗期间避免重复,在数据生产过程中避免重复。 这里有两种方法,可以在数据生成时准确地获得一个语义: 每个分区使用一个单独的写入器,每当你发现一个网络错误,检查该分区中的最后一条消息,以查看您的最后一次写入是否成功 在消息中包含一个主键(UUID或其他),并在用户中进行反复制
11、解释如何减少ISR中的扰动?broker什么时候离开ISR? ISR是一组与leaders完全同步的消息副本,也就是说ISR中包含了所有提交的消息。ISR应该总是包含所有的副本,直到出现真正的故障。如果一个副本从leader中脱离出来,将会从ISR中删除。
12、Kafka为什么需要复制? Kafka的信息复制确保了任何已发布的消息不会丢失,并且可以在机器错误、程序错误或更常见些的软件升级中使用。
13、如果副本在ISR中停留了很长时间表明什么? 如果一个副本在ISR中保留了很长一段时间,那么它就表明,跟踪器无法像在leader收集数据那样快速地获取数据。
14、请说明如果首选的副本不在ISR中会发生什么? 如果首选的副本不在ISR中,控制器将无法将leadership转移到首选的副本。
15、有可能在生产后发生消息偏移吗? 在大多数队列系统中,作为生产者的类无法做到这一点,它的作用是触发并忘记消息。broker将完成剩下的工作,比如使用id进行适当的元数据处理、偏移量等。
作为消息的用户,你可以从Kafka broker中获得补偿。如果你注视SimpleConsumer类,你会注意到它会获取包括偏移量作为列表的MultiFetchResponse对象。此外,当你对Kafka消息进行迭代时,你会拥有包括偏移量和消息发送的MessageAndOffset对象。
16、Kafka的设计时什么样的呢? Kafka将消息以topic为单位进行归纳 将向Kafka topic发布消息的程序成为producers. 将预订topics并消费消息的程序成为consumer. Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群向消费者提供消息
17、数据传输的事物定义有哪三种? (1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输 (2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输. (3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
18、Kafka判断一个节点是否还活着有那两个条件? (1)节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接 (2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
19、producer是否直接将数据发送到broker的leader(主节点)? producer直接将数据发送到broker的leader(主节点),不需要在多个节点进行分发,为了帮助producer做到这点,所有的Kafka节点都可以及时的告知:哪些节点是活动的,目标topic目标分区的leader在哪。这样producer就可以直接将消息发送到目的地了。
20、Kafa consumer是否可以消费指定分区消息? Kafa consumer消费消息时,向broker发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
21、Kafka消息是采用Pull模式,还是Push模式? Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式
Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略
Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
22、Kafka存储在硬盘上的消息格式是什么? 消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。 消息长度: 4 bytes (value: 1+4+n) 版本号: 1 byte CRC校验码: 4 bytes 具体的消息: n bytes
23、Kafka高效文件存储设计特点: (1).Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。 (2).通过索引信息可以快速定位message和确定response的最大大小。 (3).通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。 (4).通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
24、Kafka 与传统消息系统之间有三个关键区别 (1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留 (2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性 (3).Kafka 支持实时的流式处理
25、Kafka创建Topic时如何将分区放置到不同的Broker中 副本因子不能大于 Broker 的个数; 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的; 其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推; 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的
26、Kafka新建的分区会在哪个目录下创建 在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。 当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。 如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。 但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
27、partition的数据如何保存到硬盘 topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增, 且消息有序 Partition文件下有多个segment(xxx.index,xxx.log) segment 文件里的 大小和配置文件大小一致可以根据要求修改 默认为1g 如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
28、kafka的ack机制 request.required.acks有三个值 0 1 -1 0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱当server挂掉的时候就会丢数据 1:服务端会等待ack值 leader副本确认接收到消息后发送ack但是如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢失 -1:同样在1的基础上 服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢失
29、Kafka的消费者如何消费数据 消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置 等到下次消费时,他会接着上次位置继续消费。同时也可以按照指定的offset进行重新消费。
30、消费者负载均衡策略 结合consumer的加入和退出进行再平衡策略。
31、kafka消息数据是否有序? 消费者组里某具体分区是有序的,所以要保证有序只能建一个分区,但是实际这样会存在性能问题,具体业务具体分析后确认。
32、kafaka生产数据时数据的分组策略,生产者决定数据产生到集群的哪个partition中 每一条消息都是以(key,value)格式 Key是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个partition
33、kafka consumer 什么情况会触发再平衡reblance? ①一旦消费者加入或退出消费组,导致消费组成员列表发生变化,消费组中的所有消费者都要执行再平衡。 ②订阅主题分区发生变化,所有消费者也都要再平衡。
34、描述下kafka consumer 再平衡步骤? ①关闭数据拉取线程,情空队列和消息流,提交偏移量; ②释放分区所有权,删除zk中分区和消费者的所有者关系; ③将所有分区重新分配给每个消费者,每个消费者都会分到不同分区; ④将分区对应的消费者所有关系写入ZK,记录分区的所有权信息; ⑤重启消费者拉取线程管理器,管理每个分区的拉取线程。
35、Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么 36、Kafka中的HW、LEO、LSO、LW等分别代表什么? 37、Kafka中是怎么体现消息顺序性的? 38、Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么? 39、Kafka生产者客户端的整体结构是什么样子的? 40、Kafka生产者客户端中使用了几个线程来处理?分别是什么? 41、Kafka的旧版Scala的消费者客户端的设计有什么缺陷? 42、“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段? 43、消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1? 44、有哪些情形会造成重复消费? 45、那些情景下会造成消息漏消费? 46、KafkaConsumer是非线程安全的,那么怎么样实现多线程消费? 47、简述消费者与消费组之间的关系 48、当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑? 49、topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么? 50、topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么? 51、创建topic时如何选择合适的分区数? 52、Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么? 53、优先副本是什么?它有什么特殊的作用? 54、Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理 55、简述Kafka的日志目录结构 56、Kafka中有那些索引文件? 57、如果我指定了一个offset,Kafka怎么查找到对应的消息? 58、如果我指定了一个timestamp,Kafka怎么查找到对应的消息? 59、聊一聊你对Kafka的Log Retention的理解 60、聊一聊你对Kafka的Log Compaction的理解 61、聊一聊你对Kafka底层存储的理解(页缓存、内核层、块层、设备层) 62、聊一聊Kafka的延时操作的原理 63、聊一聊Kafka控制器的作用 64、消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器) 65、Kafka中的幂等是怎么实现的 66、Kafka中的事务是怎么实现的(这题我去面试6家被问4次,照着答案念也要念十几分钟,面试官简直凑不要脸。实在记不住的话...只要简历上不写精通Kafka一般不会问到,我简历上写的是“熟悉Kafka,了解RabbitMQ....”) 67、Kafka中有那些地方需要选举?这些地方的选举策略又有哪些? 68、失效副本是指什么?有那些应对措施? 69、多副本下,各个副本中的HW和LEO的演变过程 70、为什么Kafka不支持读写分离? 71、Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch) 72、Kafka中怎么实现死信队列和重试队列? 73、Kafka中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会Kafka,那你说说延迟队列怎么实现?) 74、Kafka中怎么做消息审计? 75、Kafka中怎么做消息轨迹? 76、Kafka中有那些配置参数比较有意思?聊一聊你的看法 77、Kafka中有那些命名比较有意思?聊一聊你的看法 78、Kafka有哪些指标需要着重关注? 79、怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同) 80、Kafka的那些设计让它有如此高的性能? 81、Kafka有什么优缺点? 82、还用过什么同质类的其它产品,与Kafka相比有什么优缺点? 83、为什么选择Kafka? 84、在使用Kafka的过程中遇到过什么困难?怎么解决的? 85、怎么样才能确保Kafka极大程度上的可靠性? 86、聊一聊你对Kafka生态的理解
',40),f=[p];function K(t,c){return e(),k("div",null,f)}const n=a(o,[["render",K],["__file","kafka.html.vue"]]);export{n as default};
diff --git a/assets/kafka.html-K4MxmLWF.js b/assets/kafka.html-K4MxmLWF.js
new file mode 100644
index 00000000..e729904a
--- /dev/null
+++ b/assets/kafka.html-K4MxmLWF.js
@@ -0,0 +1 @@
+const a=JSON.parse('{"key":"v-d7d7df80","path":"/middleware/kafka/kafka.html","title":"kafka面试题","lang":"zh-CN","frontmatter":{"description":"kafka面试题 1、请说明什么是Apache Kafka? Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。 2、说说Kafka的使用场景? ①异步处理 ②应用解耦 ③流量削峰 ④日志处理 ⑤消息通讯等。 3、使用Kafka有什么优点和缺点? 优点: ①支持跨数据中心的消息复制; ②单机吞吐量:十万级,最大的优点,就是吞吐量高; ③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源; ④时效性:ms级; ⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用; ⑥消息可靠性:经过参数优化配置,消息可以做到0丢失; ⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/middleware/kafka/kafka.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"kafka面试题"}],["meta",{"property":"og:description","content":"kafka面试题 1、请说明什么是Apache Kafka? Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。 2、说说Kafka的使用场景? ①异步处理 ②应用解耦 ③流量削峰 ④日志处理 ⑤消息通讯等。 3、使用Kafka有什么优点和缺点? 优点: ①支持跨数据中心的消息复制; ②单机吞吐量:十万级,最大的优点,就是吞吐量高; ③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源; ④时效性:ms级; ⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用; ⑥消息可靠性:经过参数优化配置,消息可以做到0丢失; ⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T17:34:45.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T17:34:45.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"kafka面试题\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T17:34:45.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706204085000,"updatedTime":1706204085000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":17.01,"words":5103},"filePathRelative":"middleware/kafka/kafka.md","localizedDate":"2024年1月25日","excerpt":" kafka面试题 \\n1、请说明什么是Apache Kafka?\\nApache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。
\\n2、说说Kafka的使用场景?\\n①异步处理\\n②应用解耦\\n③流量削峰\\n④日志处理\\n⑤消息通讯等。
\\n3、使用Kafka有什么优点和缺点?\\n优点:\\n①支持跨数据中心的消息复制;\\n②单机吞吐量:十万级,最大的优点,就是吞吐量高;\\n③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源;\\n④时效性:ms级;\\n⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用;\\n⑥消息可靠性:经过参数优化配置,消息可以做到0丢失;\\n⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
","autoDesc":true}');export{a as data};
diff --git "a/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xLQYDnip.js" "b/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xLQYDnip.js"
new file mode 100644
index 00000000..aa11d27e
--- /dev/null
+++ "b/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xLQYDnip.js"
@@ -0,0 +1 @@
+import{_ as c}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as a,a as e,d as n}from"./app-cS6i7hsH.js";const o={},r=e("h1",{id:"lucene搜索原理",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#lucene搜索原理","aria-hidden":"true"},"#"),n(" lucene搜索原理")],-1),_=[r];function s(l,d){return t(),a("div",null,_)}const h=c(o,[["render",s],["__file","lucene搜索原理.html.vue"]]);export{h as default};
diff --git "a/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xqazIHll.js" "b/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xqazIHll.js"
new file mode 100644
index 00000000..eca52cfc
--- /dev/null
+++ "b/assets/lucene\346\220\234\347\264\242\345\216\237\347\220\206.html-xqazIHll.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-478d0de6","path":"/java/lucene%E6%90%9C%E7%B4%A2%E5%8E%9F%E7%90%86.html","title":"lucene搜索原理","lang":"zh-CN","frontmatter":{"description":"lucene搜索原理","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/lucene%E6%90%9C%E7%B4%A2%E5%8E%9F%E7%90%86.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"lucene搜索原理"}],["meta",{"property":"og:description","content":"lucene搜索原理"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"lucene搜索原理\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.02,"words":5},"filePathRelative":"java/lucene搜索原理.md","localizedDate":"2024年1月24日","excerpt":" lucene搜索原理 \\n","autoDesc":true}');export{e as data};
diff --git a/assets/photoswipe.esm-08_zHRDQ.js b/assets/photoswipe.esm-08_zHRDQ.js
new file mode 100644
index 00000000..4048314e
--- /dev/null
+++ b/assets/photoswipe.esm-08_zHRDQ.js
@@ -0,0 +1,4 @@
+/*!
+ * PhotoSwipe 5.4.3 - https://photoswipe.com
+ * (c) 2023 Dmytro Semenov
+ */function f(r,t,i){const e=document.createElement(t);return r&&(e.className=r),i&&i.appendChild(e),e}function p(r,t){return r.x=t.x,r.y=t.y,t.id!==void 0&&(r.id=t.id),r}function M(r){r.x=Math.round(r.x),r.y=Math.round(r.y)}function A(r,t){const i=Math.abs(r.x-t.x),e=Math.abs(r.y-t.y);return Math.sqrt(i*i+e*e)}function x(r,t){return r.x===t.x&&r.y===t.y}function I(r,t,i){return Math.min(Math.max(r,t),i)}function b(r,t,i){let e=`translate3d(${r}px,${t||0}px,0)`;return i!==void 0&&(e+=` scale3d(${i},${i},1)`),e}function y(r,t,i,e){r.style.transform=b(t,i,e)}const $="cubic-bezier(.4,0,.22,1)";function R(r,t,i,e){r.style.transition=t?`${t} ${i}ms ${e||$}`:"none"}function L(r,t,i){r.style.width=typeof t=="number"?`${t}px`:t,r.style.height=typeof i=="number"?`${i}px`:i}function U(r){R(r)}function q(r){return"decode"in r?r.decode().catch(()=>{}):r.complete?Promise.resolve(r):new Promise((t,i)=>{r.onload=()=>t(r),r.onerror=i})}const _={IDLE:"idle",LOADING:"loading",LOADED:"loaded",ERROR:"error"};function G(r){return"button"in r&&r.button===1||r.ctrlKey||r.metaKey||r.altKey||r.shiftKey}function K(r,t,i=document){let e=[];if(r instanceof Element)e=[r];else if(r instanceof NodeList||Array.isArray(r))e=Array.from(r);else{const s=typeof r=="string"?r:t;s&&(e=Array.from(i.querySelectorAll(s)))}return e}function C(){return!!(navigator.vendor&&navigator.vendor.match(/apple/i))}let F=!1;try{window.addEventListener("test",null,Object.defineProperty({},"passive",{get:()=>{F=!0}}))}catch{}class X{constructor(){this._pool=[]}add(t,i,e,s){this._toggleListener(t,i,e,s)}remove(t,i,e,s){this._toggleListener(t,i,e,s,!0)}removeAll(){this._pool.forEach(t=>{this._toggleListener(t.target,t.type,t.listener,t.passive,!0,!0)}),this._pool=[]}_toggleListener(t,i,e,s,n,o){if(!t)return;const a=n?"removeEventListener":"addEventListener";i.split(" ").forEach(l=>{if(l){o||(n?this._pool=this._pool.filter(d=>d.type!==l||d.listener!==e||d.target!==t):this._pool.push({target:t,type:l,listener:e,passive:s}));const c=F?{passive:s||!1}:!1;t[a](l,e,c)}})}}function B(r,t){if(r.getViewportSizeFn){const i=r.getViewportSizeFn(r,t);if(i)return i}return{x:document.documentElement.clientWidth,y:window.innerHeight}}function S(r,t,i,e,s){let n=0;if(t.paddingFn)n=t.paddingFn(i,e,s)[r];else if(t.padding)n=t.padding[r];else{const o="padding"+r[0].toUpperCase()+r.slice(1);t[o]&&(n=t[o])}return Number(n)||0}function N(r,t,i,e){return{x:t.x-S("left",r,t,i,e)-S("right",r,t,i,e),y:t.y-S("top",r,t,i,e)-S("bottom",r,t,i,e)}}class Y{constructor(t){this.slide=t,this.currZoomLevel=1,this.center={x:0,y:0},this.max={x:0,y:0},this.min={x:0,y:0}}update(t){this.currZoomLevel=t,this.slide.width?(this._updateAxis("x"),this._updateAxis("y"),this.slide.pswp.dispatch("calcBounds",{slide:this.slide})):this.reset()}_updateAxis(t){const{pswp:i}=this.slide,e=this.slide[t==="x"?"width":"height"]*this.currZoomLevel,n=S(t==="x"?"left":"top",i.options,i.viewportSize,this.slide.data,this.slide.index),o=this.slide.panAreaSize[t];this.center[t]=Math.round((o-e)/2)+n,this.max[t]=e>o?Math.round(o-e)+n:this.center[t],this.min[t]=e>o?n:this.center[t]}reset(){this.center.x=0,this.center.y=0,this.max.x=0,this.max.y=0,this.min.x=0,this.min.y=0}correctPan(t,i){return I(i,this.max[t],this.min[t])}}const T=4e3;class k{constructor(t,i,e,s){this.pswp=s,this.options=t,this.itemData=i,this.index=e,this.panAreaSize=null,this.elementSize=null,this.fit=1,this.fill=1,this.vFill=1,this.initial=1,this.secondary=1,this.max=1,this.min=1}update(t,i,e){const s={x:t,y:i};this.elementSize=s,this.panAreaSize=e;const n=e.x/s.x,o=e.y/s.y;this.fit=Math.min(1,no?n:o),this.vFill=Math.min(1,o),this.initial=this._getInitial(),this.secondary=this._getSecondary(),this.max=Math.max(this.initial,this.secondary,this._getMax()),this.min=Math.min(this.fit,this.initial,this.secondary),this.pswp&&this.pswp.dispatch("zoomLevelsUpdate",{zoomLevels:this,slideData:this.itemData})}_parseZoomLevelOption(t){const i=t+"ZoomLevel",e=this.options[i];if(e)return typeof e=="function"?e(this):e==="fill"?this.fill:e==="fit"?this.fit:Number(e)}_getSecondary(){let t=this._parseZoomLevelOption("secondary");return t||(t=Math.min(1,this.fit*3),this.elementSize&&t*this.elementSize.x>T&&(t=T/this.elementSize.x),t)}_getInitial(){return this._parseZoomLevelOption("initial")||this.fit}_getMax(){return this._parseZoomLevelOption("max")||Math.max(1,this.fit*4)}}class j{constructor(t,i,e){this.data=t,this.index=i,this.pswp=e,this.isActive=i===e.currIndex,this.currentResolution=0,this.panAreaSize={x:0,y:0},this.pan={x:0,y:0},this.isFirstSlide=this.isActive&&!e.opener.isOpen,this.zoomLevels=new k(e.options,t,i,e),this.pswp.dispatch("gettingData",{slide:this,data:this.data,index:i}),this.content=this.pswp.contentLoader.getContentBySlide(this),this.container=f("pswp__zoom-wrap","div"),this.holderElement=null,this.currZoomLevel=1,this.width=this.content.width,this.height=this.content.height,this.heavyAppended=!1,this.bounds=new Y(this),this.prevDisplayedWidth=-1,this.prevDisplayedHeight=-1,this.pswp.dispatch("slideInit",{slide:this})}setIsActive(t){t&&!this.isActive?this.activate():!t&&this.isActive&&this.deactivate()}append(t){this.holderElement=t,this.container.style.transformOrigin="0 0",this.data&&(this.calculateSize(),this.load(),this.updateContentSize(),this.appendHeavy(),this.holderElement.appendChild(this.container),this.zoomAndPanToInitial(),this.pswp.dispatch("firstZoomPan",{slide:this}),this.applyCurrentZoomPan(),this.pswp.dispatch("afterSetContent",{slide:this}),this.isActive&&this.activate())}load(){this.content.load(!1),this.pswp.dispatch("slideLoad",{slide:this})}appendHeavy(){const{pswp:t}=this;this.heavyAppended||!t.opener.isOpen||t.mainScroll.isShifted()||!this.isActive&&!!0||this.pswp.dispatch("appendHeavy",{slide:this}).defaultPrevented||(this.heavyAppended=!0,this.content.append(),this.pswp.dispatch("appendHeavyContent",{slide:this}))}activate(){this.isActive=!0,this.appendHeavy(),this.content.activate(),this.pswp.dispatch("slideActivate",{slide:this})}deactivate(){this.isActive=!1,this.content.deactivate(),this.currZoomLevel!==this.zoomLevels.initial&&this.calculateSize(),this.currentResolution=0,this.zoomAndPanToInitial(),this.applyCurrentZoomPan(),this.updateContentSize(),this.pswp.dispatch("slideDeactivate",{slide:this})}destroy(){this.content.hasSlide=!1,this.content.remove(),this.container.remove(),this.pswp.dispatch("slideDestroy",{slide:this})}resize(){this.currZoomLevel===this.zoomLevels.initial||!this.isActive?(this.calculateSize(),this.currentResolution=0,this.zoomAndPanToInitial(),this.applyCurrentZoomPan(),this.updateContentSize()):(this.calculateSize(),this.bounds.update(this.currZoomLevel),this.panTo(this.pan.x,this.pan.y))}updateContentSize(t){const i=this.currentResolution||this.zoomLevels.initial;if(!i)return;const e=Math.round(this.width*i)||this.pswp.viewportSize.x,s=Math.round(this.height*i)||this.pswp.viewportSize.y;!this.sizeChanged(e,s)&&!t||this.content.setDisplayedSize(e,s)}sizeChanged(t,i){return t!==this.prevDisplayedWidth||i!==this.prevDisplayedHeight?(this.prevDisplayedWidth=t,this.prevDisplayedHeight=i,!0):!1}getPlaceholderElement(){var t;return(t=this.content.placeholder)===null||t===void 0?void 0:t.element}zoomTo(t,i,e,s){const{pswp:n}=this;if(!this.isZoomable()||n.mainScroll.isShifted())return;n.dispatch("beforeZoomTo",{destZoomLevel:t,centerPoint:i,transitionDuration:e}),n.animations.stopAllPan();const o=this.currZoomLevel;s||(t=I(t,this.zoomLevels.min,this.zoomLevels.max)),this.setZoomLevel(t),this.pan.x=this.calculateZoomToPanOffset("x",i,o),this.pan.y=this.calculateZoomToPanOffset("y",i,o),M(this.pan);const a=()=>{this._setResolution(t),this.applyCurrentZoomPan()};e?n.animations.startTransition({isPan:!0,name:"zoomTo",target:this.container,transform:this.getCurrentTransform(),onComplete:a,duration:e,easing:n.options.easing}):a()}toggleZoom(t){this.zoomTo(this.currZoomLevel===this.zoomLevels.initial?this.zoomLevels.secondary:this.zoomLevels.initial,t,this.pswp.options.zoomAnimationDuration)}setZoomLevel(t){this.currZoomLevel=t,this.bounds.update(this.currZoomLevel)}calculateZoomToPanOffset(t,i,e){if(this.bounds.max[t]-this.bounds.min[t]===0)return this.bounds.center[t];i||(i=this.pswp.getViewportCenterPoint()),e||(e=this.zoomLevels.initial);const n=this.currZoomLevel/e;return this.bounds.correctPan(t,(this.pan[t]-i[t])*n+i[t])}panTo(t,i){this.pan.x=this.bounds.correctPan("x",t),this.pan.y=this.bounds.correctPan("y",i),this.applyCurrentZoomPan()}isPannable(){return!!this.width&&this.currZoomLevel>this.zoomLevels.fit}isZoomable(){return!!this.width&&this.content.isZoomable()}applyCurrentZoomPan(){this._applyZoomTransform(this.pan.x,this.pan.y,this.currZoomLevel),this===this.pswp.currSlide&&this.pswp.dispatch("zoomPanUpdate",{slide:this})}zoomAndPanToInitial(){this.currZoomLevel=this.zoomLevels.initial,this.bounds.update(this.currZoomLevel),p(this.pan,this.bounds.center),this.pswp.dispatch("initialZoomPan",{slide:this})}_applyZoomTransform(t,i,e){e/=this.currentResolution||this.zoomLevels.initial,y(this.container,t,i,e)}calculateSize(){const{pswp:t}=this;p(this.panAreaSize,N(t.options,t.viewportSize,this.data,this.index)),this.zoomLevels.update(this.width,this.height,this.panAreaSize),t.dispatch("calcSlideSize",{slide:this})}getCurrentTransform(){const t=this.currZoomLevel/(this.currentResolution||this.zoomLevels.initial);return b(this.pan.x,this.pan.y,t)}_setResolution(t){t!==this.currentResolution&&(this.currentResolution=t,this.updateContentSize(),this.pswp.dispatch("resolutionChanged"))}}const Q=.35,J=.6,z=.4,E=.5;function tt(r,t){return r*t/(1-t)}class it{constructor(t){this.gestures=t,this.pswp=t.pswp,this.startPan={x:0,y:0}}start(){this.pswp.currSlide&&p(this.startPan,this.pswp.currSlide.pan),this.pswp.animations.stopAll()}change(){const{p1:t,prevP1:i,dragAxis:e}=this.gestures,{currSlide:s}=this.pswp;if(e==="y"&&this.pswp.options.closeOnVerticalDrag&&s&&s.currZoomLevel<=s.zoomLevels.fit&&!this.gestures.isMultitouch){const n=s.pan.y+(t.y-i.y);if(!this.pswp.dispatch("verticalDrag",{panY:n}).defaultPrevented){this._setPanWithFriction("y",n,J);const o=1-Math.abs(this._getVerticalDragRatio(s.pan.y));this.pswp.applyBgOpacity(o),s.applyCurrentZoomPan()}}else this._panOrMoveMainScroll("x")||(this._panOrMoveMainScroll("y"),s&&(M(s.pan),s.applyCurrentZoomPan()))}end(){const{velocity:t}=this.gestures,{mainScroll:i,currSlide:e}=this.pswp;let s=0;if(this.pswp.animations.stopAll(),i.isShifted()){const o=(i.x-i.getCurrSlideX())/this.pswp.viewportSize.x;t.x<-E&&o<0||t.x<.1&&o<-.5?(s=1,t.x=Math.min(t.x,0)):(t.x>E&&o>0||t.x>-.1&&o>.5)&&(s=-1,t.x=Math.max(t.x,0)),i.moveIndexBy(s,!0,t.x)}e&&e.currZoomLevel>e.zoomLevels.max||this.gestures.isMultitouch?this.gestures.zoomLevels.correctZoomPan(!0):(this._finishPanGestureForAxis("x"),this._finishPanGestureForAxis("y"))}_finishPanGestureForAxis(t){const{velocity:i}=this.gestures,{currSlide:e}=this.pswp;if(!e)return;const{pan:s,bounds:n}=e,o=s[t],a=this.pswp.bgOpacity<1&&t==="y",l=o+tt(i[t],.995);if(a){const v=this._getVerticalDragRatio(o),w=this._getVerticalDragRatio(l);if(v<0&&w<-z||v>0&&w>z){this.pswp.close();return}}const c=n.correctPan(t,l);if(o===c)return;const d=c===l?1:.82,u=this.pswp.bgOpacity,m=c-o;this.pswp.animations.startSpring({name:"panGesture"+t,isPan:!0,start:o,end:c,velocity:i[t],dampingRatio:d,onUpdate:v=>{if(a&&this.pswp.bgOpacity<1){const w=1-(c-v)/m;this.pswp.applyBgOpacity(I(u+(1-u)*w,0,1))}s[t]=Math.floor(v),e.applyCurrentZoomPan()}})}_panOrMoveMainScroll(t){const{p1:i,dragAxis:e,prevP1:s,isMultitouch:n}=this.gestures,{currSlide:o,mainScroll:a}=this.pswp,h=i[t]-s[t],l=a.x+h;if(!h||!o)return!1;if(t==="x"&&!o.isPannable()&&!n)return a.moveTo(l,!0),!0;const{bounds:c}=o,d=o.pan[t]+h;if(this.pswp.options.allowPanToNext&&e==="x"&&t==="x"&&!n){const u=a.getCurrSlideX(),m=a.x-u,v=h>0,w=!v;if(d>c.min[t]&&v){if(c.min[t]<=this.startPan[t])return a.moveTo(l,!0),!0;this._setPanWithFriction(t,d)}else if(d0)return a.moveTo(Math.max(l,u),!0),!0;if(m<0)return a.moveTo(Math.min(l,u),!0),!0}else this._setPanWithFriction(t,d)}else t==="y"?!a.isShifted()&&c.min.y!==c.max.y&&this._setPanWithFriction(t,d):this._setPanWithFriction(t,d);return!1}_getVerticalDragRatio(t){var i,e;return(t-((i=(e=this.pswp.currSlide)===null||e===void 0?void 0:e.bounds.center.y)!==null&&i!==void 0?i:0))/(this.pswp.viewportSize.y/3)}_setPanWithFriction(t,i,e){const{currSlide:s}=this.pswp;if(!s)return;const{pan:n,bounds:o}=s;if(o.correctPan(t,i)!==i||e){const h=Math.round(i-n[t]);n[t]+=h*(e||Q)}else n[t]=i}}const et=.05,st=.15;function O(r,t,i){return r.x=(t.x+i.x)/2,r.y=(t.y+i.y)/2,r}class nt{constructor(t){this.gestures=t,this._startPan={x:0,y:0},this._startZoomPoint={x:0,y:0},this._zoomPoint={x:0,y:0},this._wasOverFitZoomLevel=!1,this._startZoomLevel=1}start(){const{currSlide:t}=this.gestures.pswp;t&&(this._startZoomLevel=t.currZoomLevel,p(this._startPan,t.pan)),this.gestures.pswp.animations.stopAllPan(),this._wasOverFitZoomLevel=!1}change(){const{p1:t,startP1:i,p2:e,startP2:s,pswp:n}=this.gestures,{currSlide:o}=n;if(!o)return;const a=o.zoomLevels.min,h=o.zoomLevels.max;if(!o.isZoomable()||n.mainScroll.isShifted())return;O(this._startZoomPoint,i,s),O(this._zoomPoint,t,e);let l=1/A(i,s)*A(t,e)*this._startZoomLevel;if(l>o.zoomLevels.initial+o.zoomLevels.initial/15&&(this._wasOverFitZoomLevel=!0),lh&&(l=h+(l-h)*et);o.pan.x=this._calculatePanForZoomLevel("x",l),o.pan.y=this._calculatePanForZoomLevel("y",l),o.setZoomLevel(l),o.applyCurrentZoomPan()}end(){const{pswp:t}=this.gestures,{currSlide:i}=t;(!i||i.currZoomLevele.zoomLevels.max?n=e.zoomLevels.max:(o=!1,n=s);const a=i.bgOpacity,h=i.bgOpacity<1,l=p({x:0,y:0},e.pan);let c=p({x:0,y:0},l);t&&(this._zoomPoint.x=0,this._zoomPoint.y=0,this._startZoomPoint.x=0,this._startZoomPoint.y=0,this._startZoomLevel=s,p(this._startPan,l)),o&&(c={x:this._calculatePanForZoomLevel("x",n),y:this._calculatePanForZoomLevel("y",n)}),e.setZoomLevel(n),c={x:e.bounds.correctPan("x",c.x),y:e.bounds.correctPan("y",c.y)},e.setZoomLevel(s);const d=!x(c,l);if(!d&&!o&&!h){e._setResolution(n),e.applyCurrentZoomPan();return}i.animations.stopAllPan(),i.animations.startSpring({isPan:!0,start:0,end:1e3,velocity:0,dampingRatio:1,naturalFrequency:40,onUpdate:u=>{if(u/=1e3,d||o){if(d&&(e.pan.x=l.x+(c.x-l.x)*u,e.pan.y=l.y+(c.y-l.y)*u),o){const m=s+(n-s)*u;e.setZoomLevel(m)}e.applyCurrentZoomPan()}h&&i.bgOpacity<1&&i.applyBgOpacity(I(a+(1-a)*u,0,1))},onComplete:()=>{e._setResolution(n),e.applyCurrentZoomPan()}})}}function Z(r){return!!r.target.closest(".pswp__container")}class ot{constructor(t){this.gestures=t}click(t,i){const e=i.target.classList,s=e.contains("pswp__img"),n=e.contains("pswp__item")||e.contains("pswp__zoom-wrap");s?this._doClickOrTapAction("imageClick",t,i):n&&this._doClickOrTapAction("bgClick",t,i)}tap(t,i){Z(i)&&this._doClickOrTapAction("tap",t,i)}doubleTap(t,i){Z(i)&&this._doClickOrTapAction("doubleTap",t,i)}_doClickOrTapAction(t,i,e){var s;const{pswp:n}=this.gestures,{currSlide:o}=n,a=t+"Action",h=n.options[a];if(!n.dispatch(a,{point:i,originalEvent:e}).defaultPrevented){if(typeof h=="function"){h.call(n,i,e);return}switch(h){case"close":case"next":n[h]();break;case"zoom":o==null||o.toggleZoom(i);break;case"zoom-or-close":o!=null&&o.isZoomable()&&o.zoomLevels.secondary!==o.zoomLevels.initial?o.toggleZoom(i):n.options.clickToCloseNonZoomable&&n.close();break;case"toggle-controls":(s=this.gestures.pswp.element)===null||s===void 0||s.classList.toggle("pswp--ui-visible");break}}}}const rt=10,at=300,ht=25;class lt{constructor(t){this.pswp=t,this.dragAxis=null,this.p1={x:0,y:0},this.p2={x:0,y:0},this.prevP1={x:0,y:0},this.prevP2={x:0,y:0},this.startP1={x:0,y:0},this.startP2={x:0,y:0},this.velocity={x:0,y:0},this._lastStartP1={x:0,y:0},this._intervalP1={x:0,y:0},this._numActivePoints=0,this._ongoingPointers=[],this._touchEventEnabled="ontouchstart"in window,this._pointerEventEnabled=!!window.PointerEvent,this.supportsTouch=this._touchEventEnabled||this._pointerEventEnabled&&navigator.maxTouchPoints>1,this._numActivePoints=0,this._intervalTime=0,this._velocityCalculated=!1,this.isMultitouch=!1,this.isDragging=!1,this.isZooming=!1,this.raf=null,this._tapTimer=null,this.supportsTouch||(t.options.allowPanToNext=!1),this.drag=new it(this),this.zoomLevels=new nt(this),this.tapHandler=new ot(this),t.on("bindEvents",()=>{t.events.add(t.scrollWrap,"click",this._onClick.bind(this)),this._pointerEventEnabled?this._bindEvents("pointer","down","up","cancel"):this._touchEventEnabled?(this._bindEvents("touch","start","end","cancel"),t.scrollWrap&&(t.scrollWrap.ontouchmove=()=>{},t.scrollWrap.ontouchend=()=>{})):this._bindEvents("mouse","down","up")})}_bindEvents(t,i,e,s){const{pswp:n}=this,{events:o}=n,a=s?t+s:"";o.add(n.scrollWrap,t+i,this.onPointerDown.bind(this)),o.add(window,t+"move",this.onPointerMove.bind(this)),o.add(window,t+e,this.onPointerUp.bind(this)),a&&o.add(n.scrollWrap,a,this.onPointerUp.bind(this))}onPointerDown(t){const i=t.type==="mousedown"||t.pointerType==="mouse";if(i&&t.button>0)return;const{pswp:e}=this;if(!e.opener.isOpen){t.preventDefault();return}e.dispatch("pointerDown",{originalEvent:t}).defaultPrevented||(i&&(e.mouseDetected(),this._preventPointerEventBehaviour(t,"down")),e.animations.stopAll(),this._updatePoints(t,"down"),this._numActivePoints===1&&(this.dragAxis=null,p(this.startP1,this.p1)),this._numActivePoints>1?(this._clearTapTimer(),this.isMultitouch=!0):this.isMultitouch=!1)}onPointerMove(t){this._preventPointerEventBehaviour(t,"move"),this._numActivePoints&&(this._updatePoints(t,"move"),!this.pswp.dispatch("pointerMove",{originalEvent:t}).defaultPrevented&&(this._numActivePoints===1&&!this.isDragging?(this.dragAxis||this._calculateDragDirection(),this.dragAxis&&!this.isDragging&&(this.isZooming&&(this.isZooming=!1,this.zoomLevels.end()),this.isDragging=!0,this._clearTapTimer(),this._updateStartPoints(),this._intervalTime=Date.now(),this._velocityCalculated=!1,p(this._intervalP1,this.p1),this.velocity.x=0,this.velocity.y=0,this.drag.start(),this._rafStopLoop(),this._rafRenderLoop())):this._numActivePoints>1&&!this.isZooming&&(this._finishDrag(),this.isZooming=!0,this._updateStartPoints(),this.zoomLevels.start(),this._rafStopLoop(),this._rafRenderLoop())))}_finishDrag(){this.isDragging&&(this.isDragging=!1,this._velocityCalculated||this._updateVelocity(!0),this.drag.end(),this.dragAxis=null)}onPointerUp(t){this._numActivePoints&&(this._updatePoints(t,"up"),!this.pswp.dispatch("pointerUp",{originalEvent:t}).defaultPrevented&&(this._numActivePoints===0&&(this._rafStopLoop(),this.isDragging?this._finishDrag():!this.isZooming&&!this.isMultitouch&&this._finishTap(t)),this._numActivePoints<2&&this.isZooming&&(this.isZooming=!1,this.zoomLevels.end(),this._numActivePoints===1&&(this.dragAxis=null,this._updateStartPoints()))))}_rafRenderLoop(){(this.isDragging||this.isZooming)&&(this._updateVelocity(),this.isDragging?x(this.p1,this.prevP1)||this.drag.change():(!x(this.p1,this.prevP1)||!x(this.p2,this.prevP2))&&this.zoomLevels.change(),this._updatePrevPoints(),this.raf=requestAnimationFrame(this._rafRenderLoop.bind(this)))}_updateVelocity(t){const i=Date.now(),e=i-this._intervalTime;e<50&&!t||(this.velocity.x=this._getVelocity("x",e),this.velocity.y=this._getVelocity("y",e),this._intervalTime=i,p(this._intervalP1,this.p1),this._velocityCalculated=!0)}_finishTap(t){const{mainScroll:i}=this.pswp;if(i.isShifted()){i.moveIndexBy(0,!0);return}if(t.type.indexOf("cancel")>0)return;if(t.type==="mouseup"||t.pointerType==="mouse"){this.tapHandler.click(this.startP1,t);return}const e=this.pswp.options.doubleTapAction?at:0;this._tapTimer?(this._clearTapTimer(),A(this._lastStartP1,this.startP1){this.tapHandler.tap(this.startP1,t),this._clearTapTimer()},e))}_clearTapTimer(){this._tapTimer&&(clearTimeout(this._tapTimer),this._tapTimer=null)}_getVelocity(t,i){const e=this.p1[t]-this._intervalP1[t];return Math.abs(e)>1&&i>5?e/i:0}_rafStopLoop(){this.raf&&(cancelAnimationFrame(this.raf),this.raf=null)}_preventPointerEventBehaviour(t,i){this.pswp.applyFilters("preventPointerEvent",!0,t,i)&&t.preventDefault()}_updatePoints(t,i){if(this._pointerEventEnabled){const e=t,s=this._ongoingPointers.findIndex(n=>n.id===e.pointerId);i==="up"&&s>-1?this._ongoingPointers.splice(s,1):i==="down"&&s===-1?this._ongoingPointers.push(this._convertEventPosToPoint(e,{x:0,y:0})):s>-1&&this._convertEventPosToPoint(e,this._ongoingPointers[s]),this._numActivePoints=this._ongoingPointers.length,this._numActivePoints>0&&p(this.p1,this._ongoingPointers[0]),this._numActivePoints>1&&p(this.p2,this._ongoingPointers[1])}else{const e=t;this._numActivePoints=0,e.type.indexOf("touch")>-1?e.touches&&e.touches.length>0&&(this._convertEventPosToPoint(e.touches[0],this.p1),this._numActivePoints++,e.touches.length>1&&(this._convertEventPosToPoint(e.touches[1],this.p2),this._numActivePoints++)):(this._convertEventPosToPoint(t,this.p1),i==="up"?this._numActivePoints=0:this._numActivePoints++)}}_updatePrevPoints(){p(this.prevP1,this.p1),p(this.prevP2,this.p2)}_updateStartPoints(){p(this.startP1,this.p1),p(this.startP2,this.p2),this._updatePrevPoints()}_calculateDragDirection(){if(this.pswp.mainScroll.isShifted())this.dragAxis="x";else{const t=Math.abs(this.p1.x-this.startP1.x)-Math.abs(this.p1.y-this.startP1.y);if(t!==0){const i=t>0?"x":"y";Math.abs(this.p1[i]-this.startP1[i])>=rt&&(this.dragAxis=i)}}}_convertEventPosToPoint(t,i){return i.x=t.pageX-this.pswp.offset.x,i.y=t.pageY-this.pswp.offset.y,"pointerId"in t?i.id=t.pointerId:t.identifier!==void 0&&(i.id=t.identifier),i}_onClick(t){this.pswp.mainScroll.isShifted()&&(t.preventDefault(),t.stopPropagation())}}const ct=.35;class dt{constructor(t){this.pswp=t,this.x=0,this.slideWidth=0,this._currPositionIndex=0,this._prevPositionIndex=0,this._containerShiftIndex=-1,this.itemHolders=[]}resize(t){const{pswp:i}=this,e=Math.round(i.viewportSize.x+i.viewportSize.x*i.options.spacing),s=e!==this.slideWidth;s&&(this.slideWidth=e,this.moveTo(this.getCurrSlideX())),this.itemHolders.forEach((n,o)=>{s&&y(n.el,(o+this._containerShiftIndex)*this.slideWidth),t&&n.slide&&n.slide.resize()})}resetPosition(){this._currPositionIndex=0,this._prevPositionIndex=0,this.slideWidth=0,this._containerShiftIndex=-1}appendHolders(){this.itemHolders=[];for(let t=0;t<3;t++){const i=f("pswp__item","div",this.pswp.container);i.setAttribute("role","group"),i.setAttribute("aria-roledescription","slide"),i.setAttribute("aria-hidden","true"),i.style.display=t===1?"block":"none",this.itemHolders.push({el:i})}}canBeSwiped(){return this.pswp.getNumItems()>1}moveIndexBy(t,i,e){const{pswp:s}=this;let n=s.potentialIndex+t;const o=s.getNumItems();if(s.canLoop()){n=s.getLoopedIndex(n);const h=(t+o)%o;h<=o/2?t=h:t=h-o}else n<0?n=0:n>=o&&(n=o-1),t=n-s.potentialIndex;s.potentialIndex=n,this._currPositionIndex-=t,s.animations.stopMainScroll();const a=this.getCurrSlideX();if(!i)this.moveTo(a),this.updateCurrItem();else{s.animations.startSpring({isMainScroll:!0,start:this.x,end:a,velocity:e||0,naturalFrequency:30,dampingRatio:1,onUpdate:l=>{this.moveTo(l)},onComplete:()=>{this.updateCurrItem(),s.appendHeavy()}});let h=s.potentialIndex-s.currIndex;if(s.canLoop()){const l=(h+o)%o;l<=o/2?h=l:h=l-o}Math.abs(h)>1&&this.updateCurrItem()}return!!t}getCurrSlideX(){return this.slideWidth*this._currPositionIndex}isShifted(){return this.x!==this.getCurrSlideX()}updateCurrItem(){var t;const{pswp:i}=this,e=this._prevPositionIndex-this._currPositionIndex;if(!e)return;this._prevPositionIndex=this._currPositionIndex,i.currIndex=i.potentialIndex;let s=Math.abs(e),n;s>=3&&(this._containerShiftIndex+=e+(e>0?-3:3),s=3);for(let o=0;o0?(n=this.itemHolders.shift(),n&&(this.itemHolders[2]=n,this._containerShiftIndex++,y(n.el,(this._containerShiftIndex+2)*this.slideWidth),i.setContent(n,i.currIndex-s+o+2))):(n=this.itemHolders.pop(),n&&(this.itemHolders.unshift(n),this._containerShiftIndex--,y(n.el,this._containerShiftIndex*this.slideWidth),i.setContent(n,i.currIndex+s-o-2)));Math.abs(this._containerShiftIndex)>50&&!this.isShifted()&&(this.resetPosition(),this.resize()),i.animations.stopAllPan(),this.itemHolders.forEach((o,a)=>{o.slide&&o.slide.setIsActive(a===1)}),i.currSlide=(t=this.itemHolders[1])===null||t===void 0?void 0:t.slide,i.contentLoader.updateLazy(e),i.currSlide&&i.currSlide.applyCurrentZoomPan(),i.dispatch("change")}moveTo(t,i){if(!this.pswp.canLoop()&&i){let e=(this.slideWidth*this._currPositionIndex-t)/this.slideWidth;e+=this.pswp.currIndex;const s=Math.round(t-this.x);(e<0&&s>0||e>=this.pswp.getNumItems()-1&&s<0)&&(t=this.x+s*ct)}this.x=t,this.pswp.container&&y(this.pswp.container,t),this.pswp.dispatch("moveMainScroll",{x:t,dragging:i??!1})}}const pt={Escape:27,z:90,ArrowLeft:37,ArrowUp:38,ArrowRight:39,ArrowDown:40,Tab:9},g=(r,t)=>t?r:pt[r];class ut{constructor(t){this.pswp=t,this._wasFocused=!1,t.on("bindEvents",()=>{t.options.trapFocus&&(t.options.initialPointerPos||this._focusRoot(),t.events.add(document,"focusin",this._onFocusIn.bind(this))),t.events.add(document,"keydown",this._onKeyDown.bind(this))});const i=document.activeElement;t.on("destroy",()=>{t.options.returnFocus&&i&&this._wasFocused&&i.focus()})}_focusRoot(){!this._wasFocused&&this.pswp.element&&(this.pswp.element.focus(),this._wasFocused=!0)}_onKeyDown(t){const{pswp:i}=this;if(i.dispatch("keydown",{originalEvent:t}).defaultPrevented||G(t))return;let e,s,n=!1;const o="key"in t;switch(o?t.key:t.keyCode){case g("Escape",o):i.options.escKey&&(e="close");break;case g("z",o):e="toggleZoom";break;case g("ArrowLeft",o):s="x";break;case g("ArrowUp",o):s="y";break;case g("ArrowRight",o):s="x",n=!0;break;case g("ArrowDown",o):n=!0,s="y";break;case g("Tab",o):this._focusRoot();break}if(s){t.preventDefault();const{currSlide:a}=i;i.options.arrowKeys&&s==="x"&&i.getNumItems()>1?e=n?"next":"prev":a&&a.currZoomLevel>a.zoomLevels.fit&&(a.pan[s]+=n?-80:80,a.panTo(a.pan.x,a.pan.y))}e&&(t.preventDefault(),i[e]())}_onFocusIn(t){const{template:i}=this.pswp;i&&document!==t.target&&i!==t.target&&!i.contains(t.target)&&i.focus()}}const mt="cubic-bezier(.4,0,.22,1)";class ft{constructor(t){var i;this.props=t;const{target:e,onComplete:s,transform:n,onFinish:o=()=>{},duration:a=333,easing:h=mt}=t;this.onFinish=o;const l=n?"transform":"opacity",c=(i=t[l])!==null&&i!==void 0?i:"";this._target=e,this._onComplete=s,this._finished=!1,this._onTransitionEnd=this._onTransitionEnd.bind(this),this._helperTimeout=setTimeout(()=>{R(e,l,a,h),this._helperTimeout=setTimeout(()=>{e.addEventListener("transitionend",this._onTransitionEnd,!1),e.addEventListener("transitioncancel",this._onTransitionEnd,!1),this._helperTimeout=setTimeout(()=>{this._finalizeAnimation()},a+500),e.style[l]=c},30)},0)}_onTransitionEnd(t){t.target===this._target&&this._finalizeAnimation()}_finalizeAnimation(){this._finished||(this._finished=!0,this.onFinish(),this._onComplete&&this._onComplete())}destroy(){this._helperTimeout&&clearTimeout(this._helperTimeout),U(this._target),this._target.removeEventListener("transitionend",this._onTransitionEnd,!1),this._target.removeEventListener("transitioncancel",this._onTransitionEnd,!1),this._finished||this._finalizeAnimation()}}const _t=12,vt=.75;class gt{constructor(t,i,e){this.velocity=t*1e3,this._dampingRatio=i||vt,this._naturalFrequency=e||_t,this._dampedFrequency=this._naturalFrequency,this._dampingRatio<1&&(this._dampedFrequency*=Math.sqrt(1-this._dampingRatio*this._dampingRatio))}easeFrame(t,i){let e=0,s;i/=1e3;const n=Math.E**(-this._dampingRatio*this._naturalFrequency*i);if(this._dampingRatio===1)s=this.velocity+this._naturalFrequency*t,e=(t+s*i)*n,this.velocity=e*-this._naturalFrequency+s*n;else if(this._dampingRatio<1){s=1/this._dampedFrequency*(this._dampingRatio*this._naturalFrequency*t+this.velocity);const o=Math.cos(this._dampedFrequency*i),a=Math.sin(this._dampedFrequency*i);e=n*(t*o+s*a),this.velocity=e*-this._naturalFrequency*this._dampingRatio+n*(-this._dampedFrequency*t*a+this._dampedFrequency*s*o)}return e}}class yt{constructor(t){this.props=t,this._raf=0;const{start:i,end:e,velocity:s,onUpdate:n,onComplete:o,onFinish:a=()=>{},dampingRatio:h,naturalFrequency:l}=t;this.onFinish=a;const c=new gt(s,h,l);let d=Date.now(),u=i-e;const m=()=>{this._raf&&(u=c.easeFrame(u,Date.now()-d),Math.abs(u)<1&&Math.abs(c.velocity)<50?(n(e),o&&o(),this.onFinish()):(d=Date.now(),n(u+e),this._raf=requestAnimationFrame(m)))};this._raf=requestAnimationFrame(m)}destroy(){this._raf>=0&&cancelAnimationFrame(this._raf),this._raf=0}}class wt{constructor(){this.activeAnimations=[]}startSpring(t){this._start(t,!0)}startTransition(t){this._start(t)}_start(t,i){const e=i?new yt(t):new ft(t);return this.activeAnimations.push(e),e.onFinish=()=>this.stop(e),e}stop(t){t.destroy();const i=this.activeAnimations.indexOf(t);i>-1&&this.activeAnimations.splice(i,1)}stopAll(){this.activeAnimations.forEach(t=>{t.destroy()}),this.activeAnimations=[]}stopAllPan(){this.activeAnimations=this.activeAnimations.filter(t=>t.props.isPan?(t.destroy(),!1):!0)}stopMainScroll(){this.activeAnimations=this.activeAnimations.filter(t=>t.props.isMainScroll?(t.destroy(),!1):!0)}isPanRunning(){return this.activeAnimations.some(t=>t.props.isPan)}}class Pt{constructor(t){this.pswp=t,t.events.add(t.element,"wheel",this._onWheel.bind(this))}_onWheel(t){t.preventDefault();const{currSlide:i}=this.pswp;let{deltaX:e,deltaY:s}=t;if(i&&!this.pswp.dispatch("wheel",{originalEvent:t}).defaultPrevented)if(t.ctrlKey||this.pswp.options.wheelToZoom){if(i.isZoomable()){let n=-s;t.deltaMode===1?n*=.05:n*=t.deltaMode?1:.002,n=2**n;const o=i.currZoomLevel*n;i.zoomTo(o,{x:t.clientX,y:t.clientY})}}else i.isPannable()&&(t.deltaMode===1&&(e*=18,s*=18),i.panTo(i.pan.x-e,i.pan.y-s))}}function St(r){if(typeof r=="string")return r;if(!r||!r.isCustomSVG)return"";const t=r;let i='';return i=i.split("%d").join(t.size||32),t.outlineID&&(i+=' ",i}class xt{constructor(t,i){var e;const s=i.name||i.className;let n=i.html;if(t.options[s]===!1)return;typeof t.options[s+"SVG"]=="string"&&(n=t.options[s+"SVG"]),t.dispatch("uiElementCreate",{data:i});let o="";i.isButton?(o+="pswp__button ",o+=i.className||`pswp__button--${i.name}`):o+=i.className||`pswp__${i.name}`;let a=i.isButton?i.tagName||"button":i.tagName||"div";a=a.toLowerCase();const h=f(o,a);if(i.isButton){a==="button"&&(h.type="button");let{title:d}=i;const{ariaLabel:u}=i;typeof t.options[s+"Title"]=="string"&&(d=t.options[s+"Title"]),d&&(h.title=d);const m=u||d;m&&h.setAttribute("aria-label",m)}h.innerHTML=St(n),i.onInit&&i.onInit(h,t),i.onClick&&(h.onclick=d=>{typeof i.onClick=="string"?t[i.onClick]():typeof i.onClick=="function"&&i.onClick(d,h,t)});const l=i.appendTo||"bar";let c=t.element;l==="bar"?(t.topBar||(t.topBar=f("pswp__top-bar pswp__hide-on-close","div",t.scrollWrap)),c=t.topBar):(h.classList.add("pswp__hide-on-close"),l==="wrapper"&&(c=t.scrollWrap)),(e=c)===null||e===void 0||e.appendChild(t.applyFilters("uiElement",h,i))}}function H(r,t,i){r.classList.add("pswp__button--arrow"),r.setAttribute("aria-controls","pswp__items"),t.on("change",()=>{t.options.loop||(i?r.disabled=!(t.currIndex0))})}const bt={name:"arrowPrev",className:"pswp__button--arrow--prev",title:"Previous",order:10,isButton:!0,appendTo:"wrapper",html:{isCustomSVG:!0,size:60,inner:' 1.2 本站缓存架构 从没有使用缓存,到使用mybatis缓存,然后使用了ehcache,再然后是mybatis+redis缓存。
步骤: (1)用户发送一个请求到nginx,nginx对请求进行分发。 (2)请求进入controller,service,service中查询缓存,如果命中,则直接返回结果,否则去调用mybatis。 (3)mybatis的缓存调用步骤:二级缓存->一级缓存->直接查询数据库。 (4)查询数据库的时候,mysql作了主主备份。
二、Mybatis缓存 2.1 mybatis一级缓存 Mybatis的一级缓存是指Session回话级别的缓存,也称作本地缓存。一级缓存的作用域是一个SqlSession。Mybatis默认开启一级缓存。在同一个SqlSession中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。当执行SQL时两次查询中间发生了增删改操作,则SqlSession的缓存清空。Mybatis 默认支持一级缓存,不需要在配置文件中配置。
我们来查看一下源码的类图,具体的源码分析简单概括一下:SqlSession实际上是使用PerpetualCache来维护的,PerpetualCache中定义了一个HashMap来进行缓存。
2.2 mybatis二级缓存 Mybatis的二级缓存是指mapper映射文件,为Application应用级别的缓存,生命周期长。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。在同一个namespace下的mapper文件中,执行相同的查询SQL。实现二级缓存,关键是要对Executor对象做文章,Mybatis给Executor对象加上了一个CachingExecutor,使用了设计模式中的装饰者模式,
2.2.1 MyBatis二级缓存的划分 MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下: a.为每一个Mapper分配一个Cache缓存对象; b.多个Mapper共用一个Cache缓存对象;
2.2.2 二级缓存的开启 在mybatis的配置文件中添加:
< settings> < settingname = " cacheEnabled" value = " true" /> </ settings> 然后再需要开启二级缓存的mapper.xml中添加(本站使用了LRU算法,时间为120000毫秒):
< cacheeviction = " LRU" type = " org.apache.ibatis.cache.impl.PerpetualCache" flushInterval = " 120000" size = " 1024" readOnly = " true" /> 2.2.3 使用第三方支持的二级缓存的实现 MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached、Redis的集成,总之,使用MyBatis的二级缓存有三个选择:
`,22),g=a("li",null,"MyBatis自身提供的缓存实现;",-1),m=a("li",null,"用户自定义的Cache接口实现;",-1),h=a("br",null,null,-1),v={href:"http://blog.csdn.net/xiadi934/article/details/50786293",target:"_blank",rel:"noopener noreferrer"},b={href:"http://blog.csdn.net/luanlouis/article/details/41390801",target:"_blank",rel:"noopener noreferrer"},y=e(` 2.3 Mybatis在分布式环境下脏读问题 (1)如果是一级缓存,在多个SqlSession或者分布式的环境下,数据库的写操作会引起脏数据,多数情况可以通过设置缓存级别为Statement来解决。
下面将介绍使用Redis集中式缓存在个人网站的应用。
三、Redis缓存 Redis运行于独立的进程,通过网络协议和应用交互,将数据保存在内存中,并提供多种手段持久化内存的数据。同时具备服务器的水平拆分、复制等分布式特性,使得其成为缓存服务器的主流。为了与Spring更好的结合使用,我们使用的是Spring-Data-Redis。此处省略安装过程和Redis的命令讲解。
3.1 Spring Cache Spring 3.1 引入了激动人心的基于注释(annotation)的缓存(cache)技术,它本质上不是一个具体的缓存实现方案(例如EHCache 或者 OSCache),而是一个对缓存使用的抽象,通过在既有代码中添加少量它定义的各种 annotation,即能够达到缓存方法的返回对象的效果。Spring 的缓存技术还具备相当的灵活性,不仅能够使用 **SpEL(Spring Expression Language)**来定义缓存的 key 和各种 condition,还提供开箱即用的缓存临时存储方案,也支持和主流的专业缓存例如 EHCache 集成。 下面是Spring Cache常用的注解:
(1)@Cacheable @Cacheable 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”)
(2)@CachePut @CachePut 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”)
(3)@CacheEvict @CachEvict 的作用 主要针对方法配置,能够根据一定的条件对缓存进行清空
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”) allEntries 是否清空所有缓存内容,默认为false @CachEvict(value=”testcache”,allEntries=true) beforeInvocation 是否在方法执行前就清空,缺省为 false @CachEvict(value=”testcache”,beforeInvocation=true)
但是有个问题: Spring官方认为:缓存过期时间由各个产商决定,所以并不提供缓存过期时间的注解。所以,如果想实现各个元素过期时间不同,就需要自己重写一下Spring cache。
3.2 引入包 一般是Spring常用的包+Spring data redis的包,记得注意去掉所有冲突的包,之前才过坑,Spring-data-MongoDB已经有SpEL的库了,和自己新引进去的冲突,搞得我以为自己是配置配错了,真是个坑,注意,开发过程中一定要去除掉所有冲突的包!!!
3.3 ApplicationContext.xml 需要启用缓存的注解开关,并配置好Redis。序列化方式也要带上,否则会碰到幽灵bug。
+ < cache: annotation-driven/> < beanid = " jedisConnectionFactory" class = " org.springframework.data.redis.connection.jedis.JedisConnectionFactory" > < propertyname = " hostName" value = " \${host}" /> < propertyname = " port" value = " \${port}" /> < propertyname = " password" value = " \${password}" /> < propertyname = " database" value = " \${redis.default.db}" /> < propertyname = " timeout" value = " \${timeout}" /> < propertyname = " poolConfig" ref = " jedisPoolConfig" /> < propertyname = " usePool" value = " true" /> </ bean> < beanid = " redisTemplate" class = " org.springframework.data.redis.core.StringRedisTemplate" > < propertyname = " connectionFactory" ref = " jedisConnectionFactory" /> < propertyname = " keySerializer" > < beanclass = " org.springframework.data.redis.serializer.StringRedisSerializer" /> </ property> < propertyname = " hashKeySerializer" > < beanclass = " org.springframework.data.redis.serializer.StringRedisSerializer" /> </ property> < propertyname = " valueSerializer" > < beanclass = " org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" /> </ property> < propertyname = " hashValueSerializer" > < beanclass = " org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" /> </ property> </ bean> < beanid = " cacheManager" class = " org.springframework.data.redis.cache.RedisCacheManager" > < constructor-argname = " redisOperations" ref = " redisTemplate" /> < propertyname = " defaultExpiration" value = " \${redis.defaultExpiration}" /> </ bean> 3.5 自定义KeyGenerator 在分布式系统中,很容易存在不同类相同名字的方法,如A.getAll(),B.getAll(),默认的key(getAll)都是一样的,会很容易产生问题,所以,需要自定义key来实现分布式环境下的不同。
@Component ( "customKeyGenerator" )
+public class CustomKeyGenerator implements KeyGenerator {
+ @Override
+ public Object generate ( Object o, Method method, Object . . . objects) {
+ StringBuilder sb = new StringBuilder ( ) ;
+ sb. append ( o. getClass ( ) . getName ( ) ) ;
+ sb. append ( "." ) ;
+ sb. append ( method. getName ( ) ) ;
+ for ( Object obj : objects) {
+ sb. append ( obj. toString ( ) ) ;
+ }
+ return sb. toString ( ) ;
+ }
+}
+之后,存储的key就变为:com.myblog.service.impl.BlogServiceImpl.getBanner。
3.4 添加注解 在所需要的方法上添加注解,比如,首页中的那几张幻灯片,每次进入首页都需要查询数据库,这里,我们直接放入缓存里,减少数据库的压力,还有就是那些热门文章,访问量比较大的,也放进数据库里。
@Override
+ @Cacheable ( value = "getBanner" , keyGenerator = "customKeyGenerator" )
+ public List < Blog > getBanner ( ) {
+ return blogMapper. getBanner ( ) ;
+ }
+ @Override
+ @Cacheable ( value = "getBlogDetail" , key = "'blogid'.concat(#blogid)" )
+ public Blog getBlogDetail ( Integer blogid) {
+ Blog blog = blogMapper. selectByPrimaryKey ( blogid) ;
+ if ( blog == null ) {
+ return null ;
+ }
+ Category category = categoryMapper. selectByPrimaryKey ( blog. getCategoryid ( ) ) ;
+ blog. setCategory ( category) ;
+ List < Tag > = tagMapper. getTagByBlogId ( blog. getBlogid ( ) ) ;
+ blog. setTags ( tags. size ( ) > 0 ? tags : null ) ;
+ asyncService. updatebloghits ( blogid) ;
+ logger. info ( "没有走缓存" ) ;
+ return blog;
+ }
+ 3.5 测试 我们调用一个getBlogDetail(获取博客详情)100次来对比一下时间。连接的数据库在深圳,本人在广州,还是有那么一丢丢的网路延时的。
public class SpringTest {
+ @Test
+ public void init ( ) {
+ ApplicationContext ctx = new FileSystemXmlApplicationContext ( "classpath:spring-test.xml" ) ;
+ IBlogService blogService = ( IBlogService ) ctx. getBean ( "blogService" ) ;
+ long startTime = System . currentTimeMillis ( ) ;
+ for ( int i = 0 ; i < 100 ; i++ ) {
+ blogService. getBlogDetail ( 615 ) ;
+ }
+ System . out. println ( System . currentTimeMillis ( ) - startTime) ;
+ }
+}
+为了做一下对比,我们同时使用mybatis自身缓存来进行测试。
3.6 实验结果 统计出结果如下:
没有使用任何缓存(mybatis一级缓存没有关闭):18305
+使用远程Redis缓存:12727
+使用Mybatis缓存:6649
+使用本地Redis缓存:5818
+由结果看出,缓存的使用大大较少了获取数据的时间。
部署进个人博客之后,redis已经缓存的数据:
3.7 分页的数据怎么办 个人网站中共有两个栏目,一个是技术杂谈,另一个是生活笔记,每点击一次栏目的时候,会根据页数从数据库中查询数据,百度了下,大概有三种方法: (1)以页码作为Key,然后缓存整个页面。 (2)分条存取,只从数据库中获取分页的文章ID序列,然后从service(缓存策略在service中实现)中获取。 第一种,由于使用了第三方的插件PageHelper,分页获取的话会比较麻烦,同时整页缓存对内存压力也蛮大的,毕竟服务器只有2g。第二条实现方式简单,缺陷是依旧需要查询数据库,想了想还是放弃了。缓存的初衷是对请求频繁又不易变的数据,实际使用中很少会反复的请求同一页的数据(查询条件也相同),当然对数据中某些字段做缓存还是有必要的。
四、如何解决脏读? `,40),q={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},f=a("h1",{id:"五、题外话",tabindex:"-1"},[a("a",{class:"header-anchor",href:"#五、题外话","aria-hidden":"true"},"#"),n(" 五、题外话")],-1),_=a("p",null,"兄弟姐妹们啊,个人网站只是个小项目,纯属为了学习而用的,文章可以看看,但是,就不要抓取了吧。。。。一个小时抓取6万次宝宝心脏真的受不了,虽然服务器一切都还稳定==",-1),S=a("figure",null,[a("img",{src:"http://image.wenzhihuai.com/images/20180119044345.png",alt:"",tabindex:"0",loading:"lazy"}),a("figcaption")],-1),x=a("strong",null,"个人网站",-1),C={href:"http://www.wenzhihuai.com",target:"_blank",rel:"noopener noreferrer"},w=a("br",null,null,-1),M=a("strong",null,"个人网站源码,希望能给个star",-1),B={href:"https://github.com/Zephery/newblog",target:"_blank",rel:"noopener noreferrer"},z=a("br",null,null,-1),E={href:"http://blog.csdn.net/luanlouis/article/details/41390801",target:"_blank",rel:"noopener noreferrer"},R=a("br",null,null,-1),j={href:"http://blog.csdn.net/luanlouis/article/details/41408341",target:"_blank",rel:"noopener noreferrer"},L=a("br",null,null,-1),I={href:"https://mp.weixin.qq.com/s/Ju4d71VrL0omGkV3s3U_1Q",target:"_blank",rel:"noopener noreferrer"},N=a("br",null,null,-1),T={href:"https://www.jianshu.com/p/0b00cbba40f3",target:"_blank",rel:"noopener noreferrer"},P=a("br",null,null,-1),O={href:"http://blog.csdn.net/xiadi934/article/details/50786293",target:"_blank",rel:"noopener noreferrer"},K=a("br",null,null,-1);function A(V,D){const s=o("ExternalLinkIcon");return c(),l("div",null,[u,r,a("p",null,[n("系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。 缓存常用语: 数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透 可查看"),a("a",k,[n("Redis实战(一) 使用缓存合理性"),t(s)])]),d,a("ol",null,[g,m,a("li",null,[n("跟第三方内存缓存库的集成;"),h,n(" 具体的实现,可参照:"),a("a",v,[n("SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置"),t(s)])])]),a("p",null,[n("MyBatis中一级缓存和二级缓存的组织如下图所示(图片来自"),a("a",b,[n("深入理解mybatis原理"),t(s)]),n("):")]),y,a("p",null,[n("对于文章来说,内容是不经常更新的,没有涉及到缓存一致性,但是对于文章的阅读量,用户每点击一次,就应该更新浏览量的。对于文章的缓存,常规的设计是将文章存储进数据库中,然后读取的时候放入缓存中,然后将浏览量以文章ID+浏览量的结构实时的存入redis服务器中。本站当初设计不合理,直接将浏览量作为一个字段,用户每点击一次的时候就异步更新浏览量,但是此处没有更新缓存,如果手动更新缓存的话,基本上每点击一次都得执行更新操作,同样也不合理。所以,目前本站,你们在页面上看到的浏览量和数据库中的浏览量并不是一致的。有兴趣的可以点击"),a("a",q,[n("我的网站"),t(s)]),n("玩玩~~")]),f,_,S,a("p",null,[x,n(":"),a("a",C,[n("http://www.wenzhihuai.com"),t(s)]),w,M,n(":"),a("a",B,[n("https://github.com/Zephery/newblog"),t(s)])]),a("p",null,[n("参考:"),z,n(" 1."),a("a",E,[n("《深入理解mybatis原理》 MyBatis的一级缓存实现详解"),t(s)]),R,n(" 2."),a("a",j,[n("《深入理解mybatis原理》 MyBatis的二级缓存的设计原理"),t(s)]),L,n(" 3."),a("a",I,[n("聊聊Mybatis缓存机制"),t(s)]),N,n(" 4."),a("a",T,[n("Spring思维导图"),t(s)]),P,n(" 5."),a("a",O,[n("SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置"),t(s)]),K,n(" 6.《深入分布式缓存:从原理到实践》")])])}const Q=p(i,[["render",A],["__file","redis缓存.html.vue"]]);export{Q as default};
diff --git "a/assets/redis\347\274\223\345\255\230.html-wXDEeG8X.js" "b/assets/redis\347\274\223\345\255\230.html-wXDEeG8X.js"
new file mode 100644
index 00000000..ecde00ec
--- /dev/null
+++ "b/assets/redis\347\274\223\345\255\230.html-wXDEeG8X.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-70796e0a","path":"/redis/redis%E7%BC%93%E5%AD%98.html","title":"一、概述","lang":"zh-CN","frontmatter":{"description":"一、概述 1.1 缓存介绍 系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。 缓存常用语: 数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透 可查看Redis实战(一) 使用缓存合理性","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/redis/redis%E7%BC%93%E5%AD%98.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"一、概述"}],["meta",{"property":"og:description","content":"一、概述 1.1 缓存介绍 系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。 缓存常用语: 数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透 可查看Redis实战(一) 使用缓存合理性"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T11:34:08.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T11:34:08.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"一、概述\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T11:34:08.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"1.1 缓存介绍","slug":"_1-1-缓存介绍","link":"#_1-1-缓存介绍","children":[]},{"level":2,"title":"1.2 本站缓存架构","slug":"_1-2-本站缓存架构","link":"#_1-2-本站缓存架构","children":[]},{"level":2,"title":"2.1 mybatis一级缓存","slug":"_2-1-mybatis一级缓存","link":"#_2-1-mybatis一级缓存","children":[]},{"level":2,"title":"2.2 mybatis二级缓存","slug":"_2-2-mybatis二级缓存","link":"#_2-2-mybatis二级缓存","children":[{"level":3,"title":"2.2.1 MyBatis二级缓存的划分","slug":"_2-2-1-mybatis二级缓存的划分","link":"#_2-2-1-mybatis二级缓存的划分","children":[]},{"level":3,"title":"2.2.2 二级缓存的开启","slug":"_2-2-2-二级缓存的开启","link":"#_2-2-2-二级缓存的开启","children":[]},{"level":3,"title":"2.2.3 使用第三方支持的二级缓存的实现","slug":"_2-2-3-使用第三方支持的二级缓存的实现","link":"#_2-2-3-使用第三方支持的二级缓存的实现","children":[]}]},{"level":2,"title":"2.3 Mybatis在分布式环境下脏读问题","slug":"_2-3-mybatis在分布式环境下脏读问题","link":"#_2-3-mybatis在分布式环境下脏读问题","children":[]},{"level":2,"title":"3.1 Spring Cache","slug":"_3-1-spring-cache","link":"#_3-1-spring-cache","children":[]},{"level":2,"title":"3.2 引入包","slug":"_3-2-引入包","link":"#_3-2-引入包","children":[]},{"level":2,"title":"3.3 ApplicationContext.xml","slug":"_3-3-applicationcontext-xml","link":"#_3-3-applicationcontext-xml","children":[]},{"level":2,"title":"3.5 自定义KeyGenerator","slug":"_3-5-自定义keygenerator","link":"#_3-5-自定义keygenerator","children":[]},{"level":2,"title":"3.4 添加注解","slug":"_3-4-添加注解","link":"#_3-4-添加注解","children":[]},{"level":2,"title":"3.5 测试","slug":"_3-5-测试","link":"#_3-5-测试","children":[]},{"level":2,"title":"3.6 实验结果","slug":"_3-6-实验结果","link":"#_3-6-实验结果","children":[]},{"level":2,"title":"3.7 分页的数据怎么办","slug":"_3-7-分页的数据怎么办","link":"#_3-7-分页的数据怎么办","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706096048000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":3}]},"readingTime":{"minutes":11.96,"words":3588},"filePathRelative":"redis/redis缓存.md","localizedDate":"2024年1月24日","excerpt":" 一、概述 \\n 1.1 缓存介绍 \\n系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。\\n缓存常用语:\\n数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透\\n可查看Redis实战(一) 使用缓存合理性
","autoDesc":true}');export{e as data};
diff --git a/assets/serverlog.html-9M0lHfZ_.js b/assets/serverlog.html-9M0lHfZ_.js
new file mode 100644
index 00000000..f31502da
--- /dev/null
+++ b/assets/serverlog.html-9M0lHfZ_.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-60eda44c","path":"/java/serverlog.html","title":"被挖矿攻击","lang":"zh-CN","frontmatter":{"description":"被挖矿攻击 服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看: stratum+tcp://get.bi-chi.com:3333 -u 47EAoaBc5TWDZKVaAYvQ7Y4ZfoJMFathAR882gabJ43wHEfxEp81vfJ3J3j6FQGJxJNQTAwvmJYS2Ei8dbkKcwfPFst8FhG","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/serverlog.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"被挖矿攻击"}],["meta",{"property":"og:description","content":"被挖矿攻击 服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看: stratum+tcp://get.bi-chi.com:3333 -u 47EAoaBc5TWDZKVaAYvQ7Y4ZfoJMFathAR882gabJ43wHEfxEp81vfJ3J3j6FQGJxJNQTAwvmJYS2Ei8dbkKcwfPFst8FhG"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T10:30:22.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T10:30:22.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"被挖矿攻击\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T10:30:22.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706092222000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.57,"words":172},"filePathRelative":"java/serverlog.md","localizedDate":"2024年1月24日","excerpt":" 被挖矿攻击 \\n服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看:
","autoDesc":true}');export{t as data};
diff --git a/assets/serverlog.html-f8i7CjpW.js b/assets/serverlog.html-f8i7CjpW.js
new file mode 100644
index 00000000..6afa5639
--- /dev/null
+++ b/assets/serverlog.html-f8i7CjpW.js
@@ -0,0 +1,3 @@
+import{_ as n}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as s,o,c,a,d as e,b as t,e as r}from"./app-cS6i7hsH.js";const p={},h=r(' 被挖矿攻击 服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看:
使用top查看:
iptables -A INPUT -s xmr.crypto-pool.fr -j DROP
+iptables -A OUTPUT -d xmr.crypto-pool.fr -j DROP
+ 2017-10-02 再次遭到挖矿攻击 2017-11-20 19号添加mongodb之后,20号重启了服务器,但是忘记启动mongodb,导致后台一直在重连mongodb,也就导致了服务访问超级超级慢,记住要启动所需要的组件。
2017-12-03 2017-12-05 wipefs spark on k8s operator \\nSpark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。
\\n使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。
\\nSpark Operator包括如下几个组件:
","autoDesc":true}');export{e as data};
diff --git a/assets/spark on k8s operator.html-oBat6Q5m.js b/assets/spark on k8s operator.html-oBat6Q5m.js
new file mode 100644
index 00000000..07b4bf88
--- /dev/null
+++ b/assets/spark on k8s operator.html-oBat6Q5m.js
@@ -0,0 +1,73 @@
+import{_ as p}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as c,c as l,a as n,d as s,b as t,e}from"./app-cS6i7hsH.js";const i={},u=e(` spark on k8s operator Spark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。
使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。
Spark Operator包括如下几个组件:
SparkApplication控制器:该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作。 Submission Runner:负责调用spark-submit提交Spark作业,作业提交的流程完全复用Spark on K8s的模式。 Spark Pod Monitor:监控Spark作业相关Pod的状态,并同步到控制器中。 Mutating Admission Webhook:可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求。 SparkCtl:用于和Spark Operator交互的命令行工具。 安装
+helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
+
+helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace
+这个时候如果直接执行kubectl apply -f examples/spark-pi.yaml调用样例,会出现以下报错,需要创建对象的serviceaccount。
forbidden: error looking up service account default/spark: serviceaccount \\"spark\\" not found.\\n\\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport.requestFailure(OperationSupport.java:568)\\n\\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport
+同时也要安装rbac
`,10),r={href:"https://github.com/Zephery/spark-java-demo/blob/master/k8s/rbac.yaml",target:"_blank",rel:"noopener noreferrer"},k=e(`执行脚本,这里用的app.jar是一个读取es数据源,然后计算,为了展示效果,在程序的后面用了TimeUnit.HOURS.sleep(1)方便观察。
代码如下:
SparkConf sparkConf = new SparkConf ( ) . setAppName ( "Spark WordCount Application (java)" ) ;
+ sparkConf. set ( "es.nodes" , "xxx" )
+ . set ( "es.port" , "8xx0" )
+ . set ( "es.nodes.wan.only" , "true" )
+ . set ( "es.net.http.auth.user" , "xxx" )
+ . set ( "es.net.http.auth.pass" , "xxx-xxx" ) ;
+ try ( JavaSparkContext jsc = new JavaSparkContext ( sparkConf) ) {
+ JavaRDD < Map < String , Object > > = JavaEsSpark . esRDD ( jsc, "kibana_sample_data_ecommerce" ) . values ( ) ;
+
+ System . out. println ( esRDD. partitions ( ) . size ( ) ) ;
+
+ esRDD. map ( x -> x. get ( "customer_full_name" ) )
+ . countByValue ( )
+ . forEach ( ( x, y) -> System . out. println ( x + ":" + y) ) ;
+ TimeUnit . HOURS . sleep ( 1 ) ;
+
+ } catch ( InterruptedException e) {
+ throw new RuntimeException ( e) ;
+ }
+打包之后kubectl create -f k8s.yaml即可
apiVersion : "sparkoperator.k8s.io/v1beta2"
+kind : SparkApplication
+metadata :
+ name : spark- demo
+ namespace : default
+spec :
+ type : Scala
+ mode : cluster
+ image : fewfew- docker.pkg.coding.net/spark- java- demo/spark- java- demo- new/spark- java- demo: master- 1d8c164bced70a1c66837ea5c0180c61dfb48ac3
+ imagePullPolicy : Always
+ mainClass : com.spark.es.demo.EsReadGroupByName
+ mainApplicationFile : "local:///opt/spark/examples/jars/app.jar"
+ sparkVersion : "3.1.1"
+ restartPolicy :
+ type : Never
+ driver :
+
+ coreRequest : "100m"
+ coreLimit : "1200m"
+ memory : "512m"
+ labels :
+ version : 3.1.1
+ serviceAccount : sparkoperator
+ executor :
+
+ coreRequest : "100m"
+ instances : 1
+ memory : "512m"
+ labels :
+ version : 3.1.1
+spark-demo-driver 1/1 Running 0 2m30s
+spark-wordcount-application-java-0ac352810a9728e1-exec-1 1/1 Running 0 2m1s
+同时会自动生成相应的service。
image-20220528203941897 Spark on k8s operator大大减少了spark的部署与运维成本,用容器的调度来替换掉yarn,
源码解析 Spark Operator的主要组件如下:
1、SparkApplication Controller : 用于监控并相应SparkApplication的相关对象的创建、更新和删除事件;
2、Submission Runner:用于接收Controller的提交指令,并通过spark-submit 来提交Spark作业到K8S集群并创建Driver Pod,driver正常运行之后将启动Executor Pod;
3、Spark Pod Monitor:实时监控Spark作业相关Pod(Driver、Executor)的运行状态,并将这些状态信息同步到Controller ;
4、Mutating Admission Webhook:可选模块,但是在Spark Operator中基本上所有的有关Spark pod在Kubernetes上的定制化功能都需要使用到该模块,因此建议将enableWebhook这个选项设置为true。
5、sparkctl: 基于Spark Operator的情况下可以不再使用kubectl来管理Spark作业了,而是采用Spark Operator专用的作业管理工具sparkctl,该工具功能较kubectl功能更为强大、方便易用。
apis:用户编写yaml时的解析
Batchscheduler:批处理的调度,提供了支持volcano的接口
Client:
leader的选举
electionCfg := leaderelection. LeaderElectionConfig{
+ Lock: resourceLock,
+ LeaseDuration: * leaderElectionLeaseDuration,
+ RenewDeadline: * leaderElectionRenewDeadline,
+ RetryPeriod: * leaderElectionRetryPeriod,
+ Callbacks: leaderelection. LeaderCallbacks{
+ OnStartedLeading: func ( c context. Context) {
+ close ( startCh)
+ } ,
+ OnStoppedLeading: func ( ) {
+ close ( stopCh)
+ } ,
+ } ,
+}
+
+elector, err := leaderelection. NewLeaderElector ( electionCfg)
+参考:
`,25),d={href:"https://blog.csdn.net/chengyinwu/article/details/121049750",target:"_blank",rel:"noopener noreferrer"},m={href:"https://www.cnblogs.com/zhangmingcheng/p/15846133.html",target:"_blank",rel:"noopener noreferrer"};function v(b,g){const a=o("ExternalLinkIcon");return c(),l("div",null,[u,n("p",null,[s("rbac的文件在manifest/spark-operator-install/spark-operator-rbac.yaml,需要把namespace全部改为需要运行的namespace,这里我们任务放在default命名空间下,所以全部改为default,源文件见"),n("a",r,[s("rbac.yaml"),t(a)])]),k,n("p",null,[s("1."),n("a",d,[s("k8s client-go中Leader选举实现"),t(a)])]),n("p",null,[s("2.["),n("a",m,[s("Kubernetes基于leaderelection选举策略实现组件高可用"),t(a)])])])}const f=p(i,[["render",v],["__file","spark on k8s operator.html.vue"]]);export{f as default};
diff --git a/assets/style-hJpTPrwX.css b/assets/style-hJpTPrwX.css
new file mode 100644
index 00000000..91ee2078
--- /dev/null
+++ b/assets/style-hJpTPrwX.css
@@ -0,0 +1 @@
+html[data-theme=dark]{--text-color: #9e9e9e;--bg-color: #0d1117;--bg-color-secondary: #161b22;--bg-color-tertiary: #21262c;--border-color: #30363d;--box-shadow: #282a32;--card-shadow: rgba(0, 0, 0, .3);--black: #fff;--dark-grey: #999;--light-grey: #666;--white: #000;--grey3: #bbb;--grey12: #333;--grey14: #111;--bg-color-light: #161b22;--bg-color-back: #0d1117;--bg-color-float: #161b22;--bg-color-blur: rgba(13, 17, 23, .9);--bg-color-float-blur: rgba(22, 27, 34, .9);--text-color-light: #a8a8a8;--text-color-lighter: #b1b1b1;--text-color-bright: #c5c5c5;--border-color-light: #2e333a;--border-color-dark: #394048}:root{--theme-color: #2980b9;--text-color: #2c3e50;--bg-color: #fff;--bg-color-secondary: #f8f8f8;--bg-color-tertiary: #efeef4;--border-color: #eaecef;--box-shadow: #f0f1f2;--card-shadow: rgba(0, 0, 0, .15);--black: #000;--dark-grey: #666;--light-grey: #999;--white: #fff;--grey3: #333;--grey12: #bbb;--grey14: #eee;--navbar-height: 3.75rem;--navbar-horizontal-padding: 1.5rem;--navbar-vertical-padding: .7rem;--navbar-mobile-height: 3.25rem;--navbar-mobile-horizontal-padding: 1rem;--navbar-mobile-vertical-padding: .5rem;--sidebar-width: 20rem;--sidebar-mobile-width: 16rem;--content-width: 780px;--home-page-width: 1160px;--font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen, Ubuntu, Cantarell, "Fira Sans", "Droid Sans", "Helvetica Neue", STHeiti, "Microsoft YaHei", SimSun, sans-serif;--font-family-heading: Georgia Pro, Crimson, Georgia, -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen, Ubuntu, Cantarell, "Fira Sans", "Droid Sans", "Helvetica Neue", STHeiti, "Microsoft YaHei", SimSun, sans-serif;--font-family-mono: Consolas, Monaco, "Andale Mono", "Ubuntu Mono", monospace;--line-numbers-width: 2.5rem;--color-transition: .3s ease;--transform-transition: .3s ease;--vp-bg: var(--bg-color);--vp-bgl: var(--bg-color-light);--vp-bglt: var(--bg-color-tertiary);--vp-c: var(--text-color);--vp-cl: var(--text-color-light);--vp-clt: var(--text-color-lighter);--vp-brc: var(--border-color);--vp-brcd: var(--border-color-dark);--vp-tc: var(--theme-color);--vp-tcl: var(--theme-color-light);--vp-ct: var(--color-transition);--vp-tt: var(--transform-transition);--bg-color-light: #fff;--bg-color-back: #f8f8f8;--bg-color-float: #fff;--bg-color-blur: rgba(255, 255, 255, .9);--bg-color-float-blur: rgba(255, 255, 255, .9);--text-color-light: #3a5169;--text-color-lighter: #476582;--text-color-bright: #6a8bad;--border-color-light: #eceef1;--border-color-dark: #cfd4db;--theme-color-dark: #2573a7;--theme-color-light: #2e90d0;--theme-color-mask: rgba(41, 128, 185, .15)}:root{--badge-tip-color: #42b983;--badge-warning-color: #f4cd00;--badge-danger-color: #f55;--badge-info-color: #0295ff;--badge-note-color: #666}.vp-badge{display:inline-block;vertical-align:center;height:18px;padding:0 6px;border-radius:3px;background:var(--vp-tc);color:var(--white);font-size:14px;line-height:18px;transition:background var(--vp-ct),color var(--vp-ct)}.vp-badge+.vp-badge{margin-inline-start:5px}h1 .vp-badge,h2 .vp-badge,h3 .vp-badge,h4 .vp-badge,h5 .vp-badge,h6 .vp-badge{vertical-align:top}.vp-badge.tip{background:var(--badge-tip-color)}.vp-badge.warning{background:var(--badge-warning-color)}.vp-badge.danger{background:var(--badge-danger-color)}.vp-badge.info{background:var(--badge-info-color)}.vp-badge.note{background:var(--badge-note-color)}.font-icon{display:inline-block}.theme-hope-content .font-icon{vertical-align:middle}:root{--balloon-border-radius: 2px;--balloon-color: rgba(16, 16, 16, .95);--balloon-text-color: #fff;--balloon-font-size: 12px;--balloon-move: 4px}button[aria-label][data-balloon-pos]{overflow:visible}[aria-label][data-balloon-pos]{position:relative;cursor:pointer}[aria-label][data-balloon-pos]:after{opacity:0;pointer-events:none;transition:all .18s ease-out .18s;text-indent:0;font-family:-apple-system,BlinkMacSystemFont,Segoe UI,Roboto,Oxygen,Ubuntu,Cantarell,Open Sans,Helvetica Neue,sans-serif;font-weight:400;font-style:normal;text-shadow:none;font-size:var(--balloon-font-size);background:var(--balloon-color);border-radius:2px;color:var(--balloon-text-color);border-radius:var(--balloon-border-radius);content:attr(aria-label);padding:.5em 1em;position:absolute;white-space:nowrap;z-index:10}[aria-label][data-balloon-pos]:before{width:0;height:0;border:5px solid transparent;border-top-color:var(--balloon-color);opacity:0;pointer-events:none;transition:all .18s ease-out .18s;content:"";position:absolute;z-index:10}[aria-label][data-balloon-pos]:hover:before,[aria-label][data-balloon-pos]:hover:after,[aria-label][data-balloon-pos][data-balloon-visible]:before,[aria-label][data-balloon-pos][data-balloon-visible]:after,[aria-label][data-balloon-pos]:not([data-balloon-nofocus]):focus:before,[aria-label][data-balloon-pos]:not([data-balloon-nofocus]):focus:after{opacity:1;pointer-events:none}[aria-label][data-balloon-pos].font-awesome:after{font-family:FontAwesome,-apple-system,BlinkMacSystemFont,Segoe UI,Roboto,Oxygen,Ubuntu,Cantarell,Open Sans,Helvetica Neue,sans-serif}[aria-label][data-balloon-pos][data-balloon-break]:after{white-space:pre}[aria-label][data-balloon-pos][data-balloon-break][data-balloon-length]:after{white-space:pre-line;word-break:break-word}[aria-label][data-balloon-pos][data-balloon-blunt]:before,[aria-label][data-balloon-pos][data-balloon-blunt]:after{transition:none}[aria-label][data-balloon-pos][data-balloon-pos=up]:hover:after,[aria-label][data-balloon-pos][data-balloon-pos=up][data-balloon-visible]:after,[aria-label][data-balloon-pos][data-balloon-pos=down]:hover:after,[aria-label][data-balloon-pos][data-balloon-pos=down][data-balloon-visible]:after{transform:translate(-50%)}[aria-label][data-balloon-pos][data-balloon-pos=up]:hover:before,[aria-label][data-balloon-pos][data-balloon-pos=up][data-balloon-visible]:before,[aria-label][data-balloon-pos][data-balloon-pos=down]:hover:before,[aria-label][data-balloon-pos][data-balloon-pos=down][data-balloon-visible]:before{transform:translate(-50%)}[aria-label][data-balloon-pos][data-balloon-pos*=-left]:after{left:0}[aria-label][data-balloon-pos][data-balloon-pos*=-left]:before{left:5px}[aria-label][data-balloon-pos][data-balloon-pos*=-right]:after{right:0}[aria-label][data-balloon-pos][data-balloon-pos*=-right]:before{right:5px}[aria-label][data-balloon-pos][data-balloon-po*=-left]:hover:after,[aria-label][data-balloon-pos][data-balloon-po*=-left][data-balloon-visible]:after,[aria-label][data-balloon-pos][data-balloon-pos*=-right]:hover:after,[aria-label][data-balloon-pos][data-balloon-pos*=-right][data-balloon-visible]:after{transform:translate(0)}[aria-label][data-balloon-pos][data-balloon-po*=-left]:hover:before,[aria-label][data-balloon-pos][data-balloon-po*=-left][data-balloon-visible]:before,[aria-label][data-balloon-pos][data-balloon-pos*=-right]:hover:before,[aria-label][data-balloon-pos][data-balloon-pos*=-right][data-balloon-visible]:before{transform:translate(0)}[aria-label][data-balloon-pos][data-balloon-pos^=up]:before,[aria-label][data-balloon-pos][data-balloon-pos^=up]:after{bottom:100%;transform-origin:top;transform:translateY(var(--balloon-move))}[aria-label][data-balloon-pos][data-balloon-pos^=up]:after{margin-bottom:10px}[aria-label][data-balloon-pos][data-balloon-pos=up]:before,[aria-label][data-balloon-pos][data-balloon-pos=up]:after{left:50%;transform:translate(-50%,var(--balloon-move))}[aria-label][data-balloon-pos][data-balloon-pos^=down]:before,[aria-label][data-balloon-pos][data-balloon-pos^=down]:after{top:100%;transform:translateY(calc(var(--balloon-move) * -1))}[aria-label][data-balloon-pos][data-balloon-pos^=down]:after{margin-top:10px}[aria-label][data-balloon-pos][data-balloon-pos^=down]:before{width:0;height:0;border:5px solid transparent;border-bottom-color:var(--balloon-color)}[aria-label][data-balloon-pos][data-balloon-pos=down]:after,[aria-label][data-balloon-pos][data-balloon-pos=down]:before{left:50%;transform:translate(-50%,calc(var(--balloon-move) * -1))}[aria-label][data-balloon-pos][data-balloon-pos=left]:hover:after,[aria-label][data-balloon-pos][data-balloon-pos=left][data-balloon-visible]:after,[aria-label][data-balloon-pos][data-balloon-pos=right]:hover:after,[aria-label][data-balloon-pos][data-balloon-pos=right][data-balloon-visible]:after{transform:translateY(-50%)}[aria-label][data-balloon-pos][data-balloon-pos=left]:hover:before,[aria-label][data-balloon-pos][data-balloon-pos=left][data-balloon-visible]:before,[aria-label][data-balloon-pos][data-balloon-pos=right]:hover:before,[aria-label][data-balloon-pos][data-balloon-pos=right][data-balloon-visible]:before{transform:translateY(-50%)}[aria-label][data-balloon-pos][data-balloon-pos=left]:after,[aria-label][data-balloon-pos][data-balloon-pos=left]:before{right:100%;top:50%;transform:translate(var(--balloon-move),-50%)}[aria-label][data-balloon-pos][data-balloon-pos=left]:after{margin-right:10px}[aria-label][data-balloon-pos][data-balloon-pos=left]:before{width:0;height:0;border:5px solid transparent;border-left-color:var(--balloon-color)}[aria-label][data-balloon-pos][data-balloon-pos=right]:after,[aria-label][data-balloon-pos][data-balloon-pos=right]:before{left:100%;top:50%;transform:translate(calc(var(--balloon-move) * -1),-50%)}[aria-label][data-balloon-pos][data-balloon-pos=right]:after{margin-left:10px}[aria-label][data-balloon-pos][data-balloon-pos=right]:before{width:0;height:0;border:5px solid transparent;border-right-color:var(--balloon-color)}[aria-label][data-balloon-pos][data-balloon-length]:after{white-space:normal}[aria-label][data-balloon-pos][data-balloon-length=small]:after{width:80px}[aria-label][data-balloon-pos][data-balloon-length=medium]:after{width:150px}[aria-label][data-balloon-pos][data-balloon-length=large]:after{width:260px}[aria-label][data-balloon-pos][data-balloon-length=xlarge]:after{width:380px}@media screen and (max-width: 768px){[aria-label][data-balloon-pos][data-balloon-length=xlarge]:after{width:90vw}}[aria-label][data-balloon-pos][data-balloon-length=fit]:after{width:100%}.vp-back-to-top-button{border-width:0;background:transparent;cursor:pointer;position:fixed!important;bottom:64px;inset-inline-end:1rem;z-index:100;width:48px;height:48px;padding:8px;border-radius:50%;background:var(--vp-bg);color:var(--vp-tc);box-shadow:2px 2px 10px 4px var(--card-shadow);transition:background var(--vp-ct),color var(--vp-ct),box-shadow var(--vp-ct)}@media (max-width: 719px){.vp-back-to-top-button{width:36px;height:36px}}@media print{.vp-back-to-top-button{display:none}}.vp-back-to-top-button:hover{color:var(--vp-tcl)}.vp-back-to-top-button .back-to-top-icon{overflow:hidden;width:100%;border-radius:50%;fill:currentcolor}.vp-scroll-progress{position:absolute;right:-2px;bottom:-2px;width:52px;height:52px}@media (max-width: 719px){.vp-scroll-progress{width:40px;height:40px}}.vp-scroll-progress svg{width:100%;height:100%}.vp-scroll-progress circle{opacity:.9;fill:none;stroke:var(--vp-tc);transform:rotate(-90deg);transform-origin:50% 50%;r:22;stroke-dasharray:0% 314.1593%;stroke-width:3px}@media (max-width: 719px){.vp-scroll-progress circle{r:18}}.fade-enter-active,.fade-leave-active{transition:opacity var(--vp-ct)}.fade-enter-from,.fade-leave-to{opacity:0}:root{--notice-width: 250px}.notice-fade-enter-active,.notice-fade-leave-active{transition:opacity .5s}.notice-fade-enter,.notice-fade-leave-to{opacity:0}.vp-notice-mask{position:fixed;top:0;right:0;bottom:0;left:0;z-index:1499;-webkit-backdrop-filter:blur(10px);backdrop-filter:blur(10px)}@media print{.vp-notice-mask{display:none}}.vp-notice-wrapper{position:fixed;top:80px;inset-inline-end:20px;z-index:1500;overflow:hidden;width:var(--notice-width);border-radius:8px;background:var(--vp-bg);box-shadow:0 2px 6px 0 var(--card-shadow)}@media print{.vp-notice-wrapper{display:none}}.vp-notice-wrapper.fullscreen{top:50vh;right:50vw;left:unset;transform:translate(50%,-50%)}.vp-notice-title{position:relative;margin:0;padding:8px 12px;background:var(--vp-tc);color:var(--white);font-weight:500;text-align:start}.vp-notice-title .close-icon{vertical-align:middle;float:right;width:1em;height:1em;margin:auto;padding:4px;border-radius:50%;background-color:#0003;color:var(--white);cursor:pointer}html[dir=rtl] .vp-notice-title .close-icon{float:left}.vp-notice-title .close-icon:hover{background-color:#0000004d}.vp-notice-content{margin:1rem .75rem;font-size:14px;line-height:1.5}.vp-notice-footer{padding-bottom:8px;text-align:center}.vp-notice-footer-action{display:inline-block;margin:4px;padding:8px 12px;border:none;border-radius:8px;background-color:var(--vp-bglt);color:var(--vp-c);cursor:pointer}.vp-notice-footer-action:hover{background-color:var(--vp-bgl)}.vp-notice-footer-action.primary{background-color:var(--vp-tc);color:var(--white)}.vp-notice-footer-action.primary:hover{background-color:var(--vp-tcl)}@media screen{.sr-only{position:absolute;overflow:hidden;clip:rect 0,0,0,0;width:1px;height:1px;margin:-1px;padding:0;border:0}}@media print{.sr-only{display:none}}.vp-catalog-wrapper{margin-top:8px;margin-bottom:8px}.vp-catalog-wrapper.index ol{padding-inline-start:0}.vp-catalog-wrapper.index li{list-style-type:none}.vp-catalog-wrapper.index .vp-catalogs{padding-inline-start:0}.vp-catalog-wrapper.index .vp-catalog{list-style-type:none}.vp-catalog-wrapper.index .vp-catalog-title:before{content:"§" counter(catalog-item,upper-roman) " "}.vp-catalog-wrapper.index .vp-child-catalogs{counter-reset:child-catalog}.vp-catalog-wrapper.index .vp-child-catalog{counter-increment:child-catalog}.vp-catalog-wrapper.index .vp-child-catalog .vp-catalog-title:before{content:counter(catalog-item) "." counter(child-catalog) " "}.vp-catalog-wrapper.index .vp-sub-catalogs{padding-inline-start:.5rem}.vp-catalogs{margin:0;counter-reset:catalog-item}.vp-catalogs.deep{padding-inline-start:0}.vp-catalogs.deep .vp-catalog{list-style-type:none}.vp-catalogs .font-icon{vertical-align:baseline;margin-inline-end:.25rem}.vp-catalog{counter-increment:catalog-item}.vp-catalog-main-title{margin-top:calc(.5rem - var(--navbar-height, 3.6rem));margin-bottom:.5rem;padding-top:var(--navbar-height, 3.6rem);font-weight:500;font-size:1.75rem}.vp-catalog-main-title:first-child{margin-bottom:.5rem!important}.vp-catalog-main-title:only-child{margin-bottom:0!important}.vp-catalog-child-title{margin-bottom:.5rem!important}.vp-catalog-child-title.has-children{margin-top:calc(.5rem - var(--navbar-height, 3.6rem));padding-top:var(--navbar-height, 3.6rem);border-bottom:1px solid var(--vp-brc);font-weight:500;font-size:1.3rem;transition:border-color var(--vp-ct)}.vp-catalog-child-title.has-children:only-child{margin-bottom:0!important}.vp-catalog-sub-title{font-weight:500;font-size:1.1rem}.vp-catalog-sub-title:only-child{margin-bottom:0!important}.vp-catalog-title{color:inherit;text-decoration:none}.vp-catalog-title:hover{color:var(--vp-tc)}.vp-child-catalogs{margin:0}.vp-child-catalog{list-style-type:disc}.vp-sub-catalogs{counter-reset:sub-catalog}.vp-sub-catalog{counter-increment:sub-catalog}.vp-sub-catalog .vp-link:before{content:counter(catalog-item) "." counter(child-catalog) "." counter(sub-catalog) " "}.vp-sub-catalogs-wrapper{display:flex;flex-wrap:wrap}.vp-sub-catalog-link{display:inline-block;margin:4px 8px;padding:4px 8px;border-radius:6px;background-color:var(--vp-bgl);line-height:1.5;overflow-wrap:break-word;transition:background-color var(--vp-ct),color var(--vp-ct)}.vp-sub-catalog-link:hover{background-color:var(--vp-tcl);color:var(--vp-bg);text-decoration:none!important}.vp-empty-catalog{font-size:1.25rem;text-align:center}:root{--external-link-icon-color: #aaa}.external-link-icon{position:relative;display:inline-block;color:var(--external-link-icon-color);vertical-align:middle;top:-1px}@media print{.external-link-icon{display:none}}.external-link-icon-sr-only{position:absolute;width:1px;height:1px;padding:0;margin:-1px;overflow:hidden;clip:rect(0,0,0,0);white-space:nowrap;border-width:0;-webkit-user-select:none;-moz-user-select:none;user-select:none}:root{--nprogress-color: #29d;--nprogress-z-index: 1031}#nprogress{pointer-events:none}#nprogress .bar{background:var(--nprogress-color);position:fixed;z-index:var(--nprogress-z-index);top:0;left:0;width:100%;height:2px}:root{--copy-icon: url("data:image/svg+xml;utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24' fill='none' height='20' width='20' stroke='rgba(128,128,128,1)' stroke-width='2'%3E%3Cpath stroke-linecap='round' stroke-linejoin='round' d='M9 5H7a2 2 0 0 0-2 2v12a2 2 0 0 0 2 2h10a2 2 0 0 0 2-2V7a2 2 0 0 0-2-2h-2M9 5a2 2 0 0 0 2 2h2a2 2 0 0 0 2-2M9 5a2 2 0 0 1 2-2h2a2 2 0 0 1 2 2'/%3E%3C/svg%3E");--copied-icon: url("data:image/svg+xml;utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24' fill='none' height='20' width='20' stroke='rgba(128,128,128,1)' stroke-width='2'%3E%3Cpath stroke-linecap='round' stroke-linejoin='round' d='M9 5H7a2 2 0 0 0-2 2v12a2 2 0 0 0 2 2h10a2 2 0 0 0 2-2V7a2 2 0 0 0-2-2h-2M9 5a2 2 0 0 0 2 2h2a2 2 0 0 0 2-2M9 5a2 2 0 0 1 2-2h2a2 2 0 0 1 2 2m-6 9 2 2 4-4'/%3E%3C/svg%3E")}div[class*=language-]>button.copy-code-button{border-width:0;background:transparent;position:absolute;outline:none;cursor:pointer}@media print{div[class*=language-]>button.copy-code-button{display:none}}div[class*=language-]>button.copy-code-button .copy-icon{background:currentcolor;-webkit-mask-image:var(--copy-icon);mask-image:var(--copy-icon);-webkit-mask-position:50%;mask-position:50%;-webkit-mask-repeat:no-repeat;mask-repeat:no-repeat;-webkit-mask-size:1em;mask-size:1em}div[class*=language-]>button.copy-code-button:not(.fancy){border-width:0;background:transparent;cursor:pointer;position:absolute;top:.5em;right:.5em;z-index:5;width:2.5rem;height:2.5rem;padding:0;border-radius:.5rem;opacity:0;transition:opacity .4s}div[class*=language-]>button.copy-code-button:not(.fancy):hover,div[class*=language-]>button.copy-code-button:not(.fancy).copied{background:var(--code-hl-bg-color, rgba(0, 0, 0, .66))}div[class*=language-]>button.copy-code-button:not(.fancy):focus,div[class*=language-]>button.copy-code-button:not(.fancy).copied{opacity:1}div[class*=language-]>button.copy-code-button:not(.fancy).copied:after{content:attr(data-copied);position:absolute;top:0;right:calc(100% + .25rem);display:block;height:1.25rem;padding:.625rem;border-radius:.5rem;background:var(--code-hl-bg-color, rgba(0, 0, 0, .66));color:var(--code-ln-color, #9e9e9e);font-weight:500;line-height:1.25rem;white-space:nowrap}div[class*=language-]>button.copy-code-button:not(.fancy) .copy-icon{width:1.25rem;height:1.25rem;padding:.625rem;color:var(--code-ln-color, #9e9e9e);font-size:1.25rem}div[class*=language-]>button.copy-code-button.fancy{right:-14px;bottom:-14px;z-index:5;width:2rem;height:2rem;padding:7px 8px;border-radius:50%;background:#339af0;color:#fff}@media (max-width: 419px){div[class*=language-]>button.copy-code-button.fancy{right:0;bottom:0;width:28px;height:28px;border-radius:50% 10% 0}}div[class*=language-]>button.copy-code-button.fancy:hover{background:#228be6}div[class*=language-]>button.copy-code-button.fancy .copy-icon{width:100%;height:100%;color:#fff;font-size:1.25rem}@media (max-width: 419px){div[class*=language-]>button.copy-code-button.fancy .copy-icon{position:relative;top:2px;left:2px}}div[class*=language-]>button.copy-code-button.copied .copy-icon{-webkit-mask-image:var(--copied-icon);mask-image:var(--copied-icon)}div[class*=language-]:hover:before{display:none}div[class*=language-]:hover>button.copy-code-button:not(.fancy){opacity:1}/*! PhotoSwipe main CSS by Dmytro Semenov | photoswipe.com */.pswp{--pswp-bg: #000;--pswp-placeholder-bg: #222;--pswp-root-z-index: 100000;--pswp-preloader-color: rgba(79, 79, 79, .4);--pswp-preloader-color-secondary: rgba(255, 255, 255, .9);--pswp-icon-color: #fff;--pswp-icon-color-secondary: #4f4f4f;--pswp-icon-stroke-color: #4f4f4f;--pswp-icon-stroke-width: 2px;--pswp-error-text-color: var(--pswp-icon-color)}.pswp{position:fixed;top:0;left:0;width:100%;height:100%;z-index:var(--pswp-root-z-index);display:none;touch-action:none;outline:0;opacity:.003;contain:layout style size;-webkit-tap-highlight-color:rgba(0,0,0,0)}.pswp:focus{outline:0}.pswp *{box-sizing:border-box}.pswp img{max-width:none}.pswp--open{display:block}.pswp,.pswp__bg{transform:translateZ(0);will-change:opacity}.pswp__bg{opacity:.005;background:var(--pswp-bg)}.pswp,.pswp__scroll-wrap{overflow:hidden}.pswp__scroll-wrap,.pswp__bg,.pswp__container,.pswp__item,.pswp__content,.pswp__img,.pswp__zoom-wrap{position:absolute;top:0;left:0;width:100%;height:100%}.pswp__img,.pswp__zoom-wrap{width:auto;height:auto}.pswp--click-to-zoom.pswp--zoom-allowed .pswp__img{cursor:zoom-in}.pswp--click-to-zoom.pswp--zoomed-in .pswp__img{cursor:move;cursor:grab}.pswp--click-to-zoom.pswp--zoomed-in .pswp__img:active{cursor:grabbing}.pswp--no-mouse-drag.pswp--zoomed-in .pswp__img,.pswp--no-mouse-drag.pswp--zoomed-in .pswp__img:active,.pswp__img{cursor:zoom-out}.pswp__container,.pswp__img,.pswp__button,.pswp__counter{-webkit-user-select:none;-moz-user-select:none;user-select:none}.pswp__item{z-index:1;overflow:hidden}.pswp__hidden{display:none!important}.pswp__content{pointer-events:none}.pswp__content>*{pointer-events:auto}.pswp__error-msg-container{display:grid}.pswp__error-msg{margin:auto;font-size:1em;line-height:1;color:var(--pswp-error-text-color)}.pswp .pswp__hide-on-close{opacity:.005;will-change:opacity;transition:opacity var(--pswp-transition-duration) cubic-bezier(.4,0,.22,1);z-index:10;pointer-events:none}.pswp--ui-visible .pswp__hide-on-close{opacity:1;pointer-events:auto}.pswp__button{position:relative;display:block;width:50px;height:60px;padding:0;margin:0;overflow:hidden;cursor:pointer;background:none;border:0;box-shadow:none;opacity:.85;-webkit-appearance:none;-webkit-touch-callout:none}.pswp__button:hover,.pswp__button:active,.pswp__button:focus{transition:none;padding:0;background:none;border:0;box-shadow:none;opacity:1}.pswp__button:disabled{opacity:.3;cursor:auto}.pswp__icn{fill:var(--pswp-icon-color);color:var(--pswp-icon-color-secondary)}.pswp__icn{position:absolute;top:14px;left:9px;width:32px;height:32px;overflow:hidden;pointer-events:none}.pswp__icn-shadow{stroke:var(--pswp-icon-stroke-color);stroke-width:var(--pswp-icon-stroke-width);fill:none}.pswp__icn:focus{outline:0}div.pswp__img--placeholder,.pswp__img--with-bg{background:var(--pswp-placeholder-bg)}.pswp__top-bar{position:absolute;left:0;top:0;width:100%;height:60px;display:flex;flex-direction:row;justify-content:flex-end;z-index:10;pointer-events:none!important}.pswp__top-bar>*{pointer-events:auto;will-change:opacity}.pswp__button--close{margin-right:6px}.pswp__button--arrow{position:absolute;width:75px;height:100px;top:50%;margin-top:-50px}.pswp__button--arrow:disabled{display:none;cursor:default}.pswp__button--arrow .pswp__icn{top:50%;margin-top:-30px;width:60px;height:60px;background:none;border-radius:0}.pswp--one-slide .pswp__button--arrow{display:none}.pswp--touch .pswp__button--arrow{visibility:hidden}.pswp--has_mouse .pswp__button--arrow{visibility:visible}.pswp__button--arrow--prev{right:auto;left:0}.pswp__button--arrow--next{right:0}.pswp__button--arrow--next .pswp__icn{left:auto;right:14px;transform:scaleX(-1)}.pswp__button--zoom{display:none}.pswp--zoom-allowed .pswp__button--zoom{display:block}.pswp--zoomed-in .pswp__zoom-icn-bar-v{display:none}.pswp__preloader{position:relative;overflow:hidden;width:50px;height:60px;margin-right:auto}.pswp__preloader .pswp__icn{opacity:0;transition:opacity .2s linear;animation:pswp-clockwise .6s linear infinite}.pswp__preloader--active .pswp__icn{opacity:.85}@keyframes pswp-clockwise{0%{transform:rotate(0)}to{transform:rotate(360deg)}}.pswp__counter{height:30px;margin-top:15px;margin-inline-start:20px;font-size:14px;line-height:30px;color:var(--pswp-icon-color);text-shadow:1px 1px 3px var(--pswp-icon-color-secondary);opacity:.85}.pswp--one-slide .pswp__counter{display:none}.photo-swipe-loading{position:absolute;top:0;right:0;bottom:0;left:0;display:flex;align-items:center;justify-content:center}.photo-swipe-bullets-indicator{position:absolute;bottom:30px;left:50%;display:flex;flex-direction:row;align-items:center;transform:translate(-50%)}.photo-swipe-bullet{width:12px;height:6px;margin:0 5px;border-radius:3px;background:#fff;transition:width var(--vp-tt),color var(--vp-ct)}.photo-swipe-bullet.active{width:30px;background:var(--vp-tc)}@keyframes message-move-in{0%{opacity:0;transform:translateY(-100%)}to{opacity:1;transform:translateY(0)}}@keyframes message-move-out{0%{opacity:1;transform:translateY(0)}to{opacity:0;transform:translateY(-100%)}}#message-container{position:fixed;inset:calc(var(--navbar-height, 3.6rem) + 1rem) 0 auto;z-index:75;text-align:center}#message-container .message{display:inline-block;padding:8px 10px;border-radius:3px;background:var(--vp-bg);color:var(--vp-c);box-shadow:0 0 10px 0 var(--box-shadow, #f0f1f2);font-size:14px}#message-container .message.move-in{animation:message-move-in .3s ease-in-out}#message-container .message.move-out{animation:message-move-out .3s ease-in-out;animation-fill-mode:forwards}#message-container .message svg{position:relative;bottom:-.125em;margin-inline-end:5px}.vp-article-wrapper{position:relative;box-sizing:border-box;width:100%;margin:0 auto 1.25rem;text-align:start;overflow-wrap:break-word}@media (max-width: 959px){.vp-article-wrapper{margin:0 auto 1rem}}.vp-article-wrapper:last-child{margin-bottom:0}.vp-article-item{display:block;padding:.75rem 1.25rem;border-radius:.4rem;background:var(--bg-color-float);color:inherit;box-shadow:0 1px 3px 1px var(--card-shadow);transition:background var(--color-transition),box-shadow var(--color-transition)}@media (max-width: 959px){.vp-article-item{padding:.75rem 1rem}}@media (max-width: 419px){.vp-article-item{border-radius:0}}.vp-article-item:hover{box-shadow:0 2px 6px 2px var(--card-shadow)}.vp-article-item .sticky-icon{position:absolute;top:0;inset-inline-end:0;width:1.5rem;height:1.5rem;color:var(--theme-color)}.vp-article-item .page-info>span{display:flex;flex-shrink:0;align-items:center;margin-inline-end:.5em;line-height:1.8}.vp-article-item .page-info>span:after{--balloon-font-size: 8px;padding:.3em .6em!important}.vp-article-hr{margin-block:.375em .375em}.vp-article-title{position:relative;display:inline-block;color:var(--text-color);font-size:1.25rem;font-family:var(--font-family-heading);line-height:1.6;cursor:pointer}.vp-article-title:after{content:"";position:absolute;inset:auto 0 0;height:2px;background:var(--theme-color);visibility:hidden;transition:transform .3s ease-in-out;transform:scaleX(0)}.vp-article-title:hover{cursor:pointer}.vp-article-title:hover:after{visibility:visible;transform:scaleX(1)}.vp-article-title a{color:inherit;font-weight:600}.vp-article-title .lock-icon,.vp-article-title .slides-icon{position:relative;bottom:-.125em;display:inline-block;vertical-align:baseline;width:1em;height:1em;margin-inline-end:.25em;color:var(--theme-color)}.vp-article-title>span{word-break:break-word}.vp-article-cover{width:calc(100% + 2.5rem);margin:-.75rem -1.25rem .75rem;border-top-left-radius:.4rem;border-top-right-radius:.4rem}@media (max-width: 959px){.vp-article-cover{width:calc(100% + 2rem);margin:-.75rem -1rem .75rem}}@media (max-width: 419px){.vp-article-cover{border-radius:0}}.vp-article-excerpt{overflow:hidden;line-height:1.6;cursor:default}@media (max-width: 959px){.vp-article-excerpt{font-size:15px}}@media (max-width: 419px){.vp-article-excerpt{font-size:14px}}.vp-article-excerpt h1{display:none}.vp-article-excerpt h2{font-size:1.4em}.vp-article-excerpt h3{font-size:1.2em}.vp-article-excerpt h1,.vp-article-excerpt h2,.vp-article-excerpt h3,.vp-article-excerpt h4,.vp-article-excerpt h5,.vp-article-excerpt h6{margin-top:.5em;margin-bottom:.5em}.vp-article-excerpt h1+p{margin-top:.5em}.vp-article-excerpt p:first-child{margin-top:.5em}.vp-article-excerpt p:last-child{margin-bottom:.5em}.vp-article-excerpt div[class*=language-]{overflow:auto hidden}.vp-article-excerpt div[class*=language-] pre{margin:.85rem 0;line-height:1.375}.vp-article-excerpt div[class*=language-] pre code{padding:0;background:transparent}.vp-article-excerpt div[class*=language-].line-numbers-mode .line-numbers{padding:.85rem 0}.vp-article-excerpt .code-demo-wrapper,.vp-article-excerpt .external-link-icon,.vp-article-excerpt .footnote-anchor{display:none}.vp-article-excerpt section.footnotes{display:none}.vp-article-excerpt img{max-width:100%}.vp-article-excerpt figure{display:flex;flex-direction:column;width:auto;margin:1rem auto;text-align:center;transition:transform var(--transform-transition)}.vp-article-excerpt figure img{overflow:hidden;margin:0 auto;border-radius:8px}.vp-article-excerpt figure figcaption{display:inline-block;margin:6px auto;font-size:.8rem}.vp-article-excerpt figure figcaption:only-child{display:none}.vp-article-list{margin-top:calc(-.5rem - var(--navbar-height));padding-top:calc(var(--navbar-height) + .5rem);text-align:center}.vp-article-list:first-child{margin-top:calc(0rem - var(--navbar-height))}.vp-article-list .empty{max-width:560px;margin:0 auto;text-align:center}.vp-article-type-wrapper{position:relative;z-index:2;display:flex;align-items:center;justify-content:center;padding-inline-start:0;list-style:none;font-weight:600;font-size:18px}@media (max-width: 419px){.vp-article-type-wrapper{font-size:16px}}.vp-article-type{position:relative;vertical-align:middle;margin:.3em .8em;line-height:1.2;cursor:pointer}.vp-article-type:after{content:" ";position:absolute;inset:auto 50% -6px;height:2px;border-radius:1px;background:var(--theme-color);visibility:hidden;transition:inset .2s ease-in-out}.vp-article-type a{display:inline-block;color:inherit;transition:all .3s ease-in-out}.vp-article-type.active{position:relative}.vp-article-type.active a{color:var(--theme-color);transform:scale(1.1)}.vp-article-type:hover:after,.vp-article-type.active:after{inset:auto calc(50% - 8px) -6px;visibility:visible}.vp-blog-hero{position:relative;display:flex;flex-direction:column;justify-content:center;height:450px;margin-bottom:1rem;color:#eee;font-family:var(--font-family-heading)}@media (max-width: 719px){.vp-blog-hero{height:350px}}@media (max-width: 419px){.vp-blog-hero{margin:0 0 1rem}}.vp-blog-hero.no-bg{color:var(--text-color)}.vp-blog-hero>:not(.vp-blog-mask){position:relative;z-index:2}.vp-blog-hero .slide-down-button{border-width:0;background:transparent;cursor:pointer;position:absolute;bottom:0;left:calc(50vw - 30px);display:none;width:60px;height:60px;padding:10px}.vp-blog-hero .slide-down-button .icon{width:30px;margin:-15px 0;animation-name:bounce-down;animation-duration:1.5s;animation-timing-function:linear;animation-iteration-count:infinite;animation-direction:alternate}.vp-blog-hero .slide-down-button .icon:first-child{color:#ffffff26}.vp-blog-hero .slide-down-button .icon:nth-child(2){color:#ffffff80}.vp-blog-hero.fullscreen{height:calc(100vh - var(--navbar-height))!important}.vp-blog-hero.fullscreen .vp-blog-mask{background-position-y:top!important}.vp-blog-hero.fullscreen .slide-down-button{display:block}.vp-blog-mask{position:absolute;top:0;right:0;bottom:0;left:0}.vp-blog-mask:after{content:" ";position:absolute;top:0;right:0;bottom:0;left:0;z-index:1;display:block;background:var(--light-grey);opacity:.2}.vp-blog-mask.light{display:block}html[data-theme=dark] .vp-blog-mask.light,.vp-blog-mask.dark{display:none}html[data-theme=dark] .vp-blog-mask.dark{display:block}.vp-blog-hero-title{margin:.5rem auto;font-weight:700;font-size:2rem}@media (min-width: 1440px){.vp-blog-hero-title{font-size:2.25rem}}@media (max-width: 719px){.vp-blog-hero-title{font-size:1.75rem}}.vp-blog-hero-image{display:block;max-width:100%;max-height:15rem;margin:1.5rem auto}@media (max-width: 719px){.vp-blog-hero-image{max-height:12rem}}.vp-blog-hero-image.light{display:block}html[data-theme=dark] .vp-blog-hero-image.light,.vp-blog-hero-image.dark{display:none}html[data-theme=dark] .vp-blog-hero-image.dark{display:block}.vp-blog-hero-image+.vp-blog-hero-title{margin:0 auto}.vp-blog-hero-description{margin:1.2rem auto 0;font-size:1.5rem}@media (max-width: 719px){.vp-blog-hero-description{font-size:1.25rem}}@keyframes bounce-down{0%{transform:translateY(-5px)}to{transform:translateY(5px)}}.vp-blogger-info{padding:.5rem;font-family:var(--font-family-heading);overflow-wrap:break-word}.vp-page .vp-blogger-info{background:var(--bg-color-float);transition:background var(--color-transition)}.vp-sidebar .vp-blogger-info.mobile{display:none}@media (max-width: 719px){.vp-sidebar .vp-blogger-info.mobile{display:block}}.vp-sidebar .vp-blogger-info.mobile+hr{display:none}@media (max-width: 719px){.vp-sidebar .vp-blogger-info.mobile+hr{display:block;margin-top:1rem}}.vp-blogger{padding:.5rem;text-align:center}.vp-blogger-avatar{width:8rem;height:8rem;margin:0 auto}.vp-blogger-avatar.round{border-radius:50%}.vp-blogger-name{margin:1rem auto;font-size:22px}.vp-blogger-description{margin:1rem auto;font-size:14px}.vp-blog-counts{display:flex;width:80%;margin:0 auto 1rem}.vp-blog-count{display:block;width:25%;color:inherit;font-size:13px;text-align:center;cursor:pointer;transition:color var(--color-transition)}.vp-blog-count:hover{color:var(--theme-color)}.vp-blog-count .count{position:relative;margin-bottom:.5rem;font-weight:600;font-size:20px}.vp-category-list{position:relative;z-index:2;padding-inline-start:0;list-style:none;font-size:14px}.vp-category{display:inline-block;vertical-align:middle;overflow:hidden;margin:.3rem .6rem .8rem;padding:.4rem .8rem;border-radius:.25rem;color:var(--dark-grey);box-shadow:0 1px 4px 0 var(--card-shadow);word-break:break-word;cursor:pointer;transition:background var(--color-transition),color var(--color-transition)}@media (max-width: 419px){.vp-category{font-size:.9rem}}.vp-category a{color:inherit}.vp-category .count{display:inline-block;min-width:1rem;height:1.2rem;margin-inline-start:.2em;padding:0 .1rem;border-radius:.6rem;color:var(--white);font-size:.7rem;line-height:1.2rem;text-align:center}.vp-category0{background:#fde5e7;color:#ba111f}html[data-theme=dark] .vp-category0{background:#340509;color:#ec2f3e}.vp-category0:hover{background:#f9bec3}html[data-theme=dark] .vp-category0:hover{background:#53080e}.vp-category0.active{background:#cf1322;color:#fff}html[data-theme=dark] .vp-category0.active{background:#a60f1b;color:var(--bg-color)}.vp-category0.active .count{background:var(--bg-color);color:#cf1322}.vp-category0 .count{background:#cf1322}.vp-category1{background:#ffeee8;color:#f54205}html[data-theme=dark] .vp-category1{background:#441201;color:#fb7649}.vp-category1:hover{background:#fed4c6}html[data-theme=dark] .vp-category1:hover{background:#6d1d02}.vp-category1.active{background:#fa541c;color:#fff}html[data-theme=dark] .vp-category1.active{background:#da3a05;color:var(--bg-color)}.vp-category1.active .count{background:var(--bg-color);color:#fa541c}.vp-category1 .count{background:#fa541c}.vp-category2{background:#fef5e7;color:#e08e0b}html[data-theme=dark] .vp-category2{background:#3e2703;color:#f5b041}.vp-category2:hover{background:#fce6c4}html[data-theme=dark] .vp-category2:hover{background:#633f05}.vp-category2.active{background:#f39c12;color:#fff}html[data-theme=dark] .vp-category2.active{background:#c77e0a;color:var(--bg-color)}.vp-category2.active .count{background:var(--bg-color);color:#f39c12}.vp-category2 .count{background:#f39c12}.vp-category3{background:#eafaf1;color:#29b866}html[data-theme=dark] .vp-category3{background:#0c331c;color:#55d98d}.vp-category3:hover{background:#caf3db}html[data-theme=dark] .vp-category3:hover{background:#12522d}.vp-category3.active{background:#2ecc71;color:#fff}html[data-theme=dark] .vp-category3.active{background:#25a35a;color:var(--bg-color)}.vp-category3.active .count{background:var(--bg-color);color:#2ecc71}.vp-category3 .count{background:#2ecc71}.vp-category4{background:#e6f9ee;color:#219552}html[data-theme=dark] .vp-category4{background:#092917;color:#36d278}.vp-category4:hover{background:#c0f1d5}html[data-theme=dark] .vp-category4:hover{background:#0f4224}.vp-category4.active{background:#25a55b;color:#fff}html[data-theme=dark] .vp-category4.active{background:#1e8449;color:var(--bg-color)}.vp-category4.active .count{background:var(--bg-color);color:#25a55b}.vp-category4 .count{background:#25a55b}.vp-category5{background:#e1fcfc;color:#0e9595}html[data-theme=dark] .vp-category5{background:#042929;color:#16e1e1}.vp-category5:hover{background:#b4f8f8}html[data-theme=dark] .vp-category5:hover{background:#064242}.vp-category5.active{background:#10a5a5;color:#fff}html[data-theme=dark] .vp-category5.active{background:#0d8484;color:var(--bg-color)}.vp-category5.active .count{background:var(--bg-color);color:#10a5a5}.vp-category5 .count{background:#10a5a5}.vp-category6{background:#e4f0fe;color:#0862c3}html[data-theme=dark] .vp-category6{background:#021b36;color:#2589f6}.vp-category6:hover{background:#bbdafc}html[data-theme=dark] .vp-category6:hover{background:#042c57}.vp-category6.active{background:#096dd9;color:#fff}html[data-theme=dark] .vp-category6.active{background:#0757ae;color:var(--bg-color)}.vp-category6.active .count{background:var(--bg-color);color:#096dd9}.vp-category6 .count{background:#096dd9}.vp-category7{background:#f7f1fd;color:#9851e4}html[data-theme=dark] .vp-category7{background:#2a0b4b;color:#bb8ced}.vp-category7:hover{background:#eadbfa}html[data-theme=dark] .vp-category7:hover{background:#431277}.vp-category7.active{background:#aa6fe9;color:#fff}html[data-theme=dark] .vp-category7.active{background:#8733e0;color:var(--bg-color)}.vp-category7.active .count{background:var(--bg-color);color:#aa6fe9}.vp-category7 .count{background:#aa6fe9}.vp-category8{background:#fdeaf5;color:#e81689}html[data-theme=dark] .vp-category8{background:#400626;color:#ef59ab}.vp-category8:hover{background:#facbe5}html[data-theme=dark] .vp-category8:hover{background:#670a3d}.vp-category8.active{background:#eb2f96;color:#fff}html[data-theme=dark] .vp-category8.active{background:#ce147a;color:var(--bg-color)}.vp-category8.active .count{background:var(--bg-color);color:#eb2f96}.vp-category8 .count{background:#eb2f96}html[data-theme=dark] .empty-icon g.people{opacity:.8}html[data-theme=dark] .empty-icon g:not(.people){filter:invert(80%)}.vp-page.vp-blog .vp-blog-home{flex:1;width:0;max-width:780px}.vp-page.vp-blog .theme-hope-content:empty{padding:0}.vp-blog-infos{margin:8px auto;padding:8px 16px}.vp-page .vp-blog-infos{border-radius:6px;background:var(--bg-color-float);box-shadow:0 1px 3px 1px var(--card-shadow);transition:background var(--color-transition),box-shadow var(--color-transition)}.vp-page .vp-blog-infos:hover{box-shadow:0 2px 6px 2px var(--card-shadow)}.vp-blog-infos .timeline-list-wrapper .content{max-height:60vh}.vp-blog-type-switcher{display:flex;justify-content:center;margin-bottom:8px}.vp-blog-type-button{border-width:0;background:transparent;cursor:pointer;width:44px;height:44px;margin:0 8px;padding:4px;color:var(--grey3);transition:color var(--color-transition)}.vp-blog-type-button:focus{outline:none}.vp-blog-type-button .icon-wrapper{width:20px;height:20px;padding:8px;border-radius:50%;background:#7f7f7f26;transition:background var(--color-transition)}html[data-theme=dark] .vp-blog-type-button .icon-wrapper{background:#ffffff26}.vp-blog-type-button .icon-wrapper:hover{cursor:pointer}.vp-blog-type-button .icon-wrapper.active{background:var(--theme-color-light)}html[data-theme=dark] .vp-blog-type-button .icon-wrapper.active{background:var(--theme-color-dark)}.vp-blog-type-button .icon{width:100%;height:100%}.vp-sidebar.hide-icon .vp-blog-type-button .icon{display:block!important}.vp-star-article-wrapper,.vp-category-wrapper,.vp-tag-wrapper{padding:8px 0}.vp-star-article-wrapper .title,.vp-category-wrapper .title,.vp-tag-wrapper .title{cursor:pointer}.vp-star-article-wrapper .title .icon,.vp-category-wrapper .title .icon,.vp-tag-wrapper .title .icon{position:relative;bottom:-.125rem;width:16px;height:16px;margin:0 6px}.vp-star-article-wrapper .title .num,.vp-category-wrapper .title .num,.vp-tag-wrapper .title .num{position:relative;margin:0 2px;font-size:22px;font-family:var(--font-family-heading)}.vp-star-articles{overflow-y:auto;max-height:80vh;margin:8px auto;line-height:1.5}.vp-star-article{padding:12px 8px 4px;border-bottom:1px dashed var(--grey);transition:border-color var(--color-transition),color var(--color-transition)}.vp-star-article a{color:inherit}.vp-star-article:hover{cursor:pointer}.vp-star-article:hover a{color:var(--theme-color)}.vp-category-wrapper .category-list-wrapper,.vp-tag-wrapper .tag-list-wrapper{overflow-y:auto;max-height:80vh;margin:8px auto}.vp-sidebar .vp-blog-info-wrapper .vp-blogger-info{display:none}.vp-page .vp-blog-info-wrapper{position:sticky;top:calc(var(--navbar-height) + .75rem);flex:0 0 300px;box-sizing:border-box;width:300px;height:auto;margin-top:.75rem;margin-bottom:.75rem;margin-inline-start:1rem;transition:all .3s}@media (max-width: 719px){.vp-page .vp-blog-info-wrapper{display:none}}.vp-page .vp-blog-info-wrapper .vp-blogger-info{margin-bottom:16px;padding:8px 0;border-radius:8px;box-shadow:0 1px 3px 1px var(--card-shadow)}.vp-page .vp-blog-info-wrapper .vp-blogger-info:hover{box-shadow:0 2px 6px 2px var(--card-shadow)}.theme-container .vp-page.vp-blog{display:flex;flex-direction:column;justify-content:space-between;box-sizing:border-box;padding-top:var(--navbar-height);padding-bottom:2rem;background:var(--bg-color-back);transition:background var(--color-transition)}@media (min-width: 1440px){.theme-container.has-toc .vp-page.vp-blog{padding-inline-end:0}}.blog-page-wrapper{display:flex;align-items:flex-start;justify-content:center;box-sizing:border-box;width:100%;margin:0 auto;padding:0 2rem}@media (max-width: 959px){.blog-page-wrapper{padding:0 1rem}}@media (max-width: 419px){.blog-page-wrapper{padding:0}}.vp-blog-main{flex:1;width:0;max-width:780px}.vp-pagination{margin:1.25rem 0 .75rem;font-weight:600;font-size:15px;line-height:2}.vp-pagination-list{display:flex;flex-wrap:wrap;align-items:center;justify-content:space-evenly;-webkit-user-select:none;-moz-user-select:none;user-select:none}.vp-pagination-number{display:flex;align-items:stretch;overflow:hidden;height:30px;margin:0 .5rem;border:1px solid var(--border-color);border-radius:.25rem}.vp-pagination-number div{position:relative;padding:0 .5rem;background:var(--bg-color);color:var(--theme-color);cursor:pointer}.vp-pagination-number div:before{content:" ";position:absolute;top:0;bottom:0;inset-inline-start:0;width:1px;background:var(--border-color)}.vp-pagination-number div:first-child:before{background:transparent}.vp-pagination-number div:hover{color:var(--theme-color-light)}.vp-pagination-number div.active{background:var(--theme-color);color:var(--white)}.vp-pagination-number div.active:before{background:var(--theme-color)}.vp-pagination-number div.active+div:before{background:var(--theme-color)}.vp-pagination-number div.prev,.vp-pagination-number div.next{font-size:13px;line-height:30px}.vp-pagination-number div.active,.vp-pagination-number div.ellipsis{cursor:default}.vp-pagination-nav{display:flex;align-items:center;justify-content:center;margin:.5rem}.vp-pagination-nav input{width:3.5rem;margin:6px 5px;border:1px solid var(--border-color);border-radius:.25em;background:var(--bg-color);color:var(--text-color);outline:none;line-height:2;text-align:center}.vp-pagination-button{overflow:hidden;padding:0 .75em;border:1px solid var(--border-color);border-radius:.25em;background:var(--bg-color);color:var(--theme-color);outline:none;font-weight:600;font-size:15px;line-height:2;cursor:pointer}.vp-pagination-button:hover{color:var(--theme-color-light)}.vp-project-panel{position:relative;z-index:2;display:flex;flex-wrap:wrap;align-items:stretch;place-content:stretch flex-start;margin-bottom:12px}.vp-project-panel:empty{margin-bottom:0}.vp-project-card{position:relative;width:calc(33% - 40px);margin:6px 8px;padding:12px;border-radius:8px;background:var(--bg-color-float);transition:background var(--color-transition),transform var(--transform-transition)}@media (max-width: 959px){.vp-project-card{width:calc(50% - 40px)}}@media (min-width: 1440px){.vp-project-card{width:calc(25% - 40px)}}.vp-project-card:hover{cursor:pointer;transform:scale(.98)}.vp-project-card .icon{position:relative;z-index:2;float:right;width:20px;height:20px}html[dir=rtl] .vp-project-card .icon{float:left}.vp-project-card.project0{background:#fde5e7}.vp-project-card.project0:hover{background:#f9bec3}html[data-theme=dark] .vp-project-card.project0{background:#340509}html[data-theme=dark] .vp-project-card.project0:hover{background:#53080e}.vp-project-card.project1{background:#ffeee8}.vp-project-card.project1:hover{background:#fed4c6}html[data-theme=dark] .vp-project-card.project1{background:#441201}html[data-theme=dark] .vp-project-card.project1:hover{background:#6d1d02}.vp-project-card.project2{background:#fef5e7}.vp-project-card.project2:hover{background:#fce6c4}html[data-theme=dark] .vp-project-card.project2{background:#3e2703}html[data-theme=dark] .vp-project-card.project2:hover{background:#633f05}.vp-project-card.project3{background:#eafaf1}.vp-project-card.project3:hover{background:#caf3db}html[data-theme=dark] .vp-project-card.project3{background:#0c331c}html[data-theme=dark] .vp-project-card.project3:hover{background:#12522d}.vp-project-card.project4{background:#e6f9ee}.vp-project-card.project4:hover{background:#c0f1d5}html[data-theme=dark] .vp-project-card.project4{background:#092917}html[data-theme=dark] .vp-project-card.project4:hover{background:#0f4224}.vp-project-card.project5{background:#e1fcfc}.vp-project-card.project5:hover{background:#b4f8f8}html[data-theme=dark] .vp-project-card.project5{background:#042929}html[data-theme=dark] .vp-project-card.project5:hover{background:#064242}.vp-project-card.project6{background:#e4f0fe}.vp-project-card.project6:hover{background:#bbdafc}html[data-theme=dark] .vp-project-card.project6{background:#021b36}html[data-theme=dark] .vp-project-card.project6:hover{background:#042c57}.vp-project-card.project7{background:#f7f1fd}.vp-project-card.project7:hover{background:#eadbfa}html[data-theme=dark] .vp-project-card.project7{background:#2a0b4b}html[data-theme=dark] .vp-project-card.project7:hover{background:#431277}.vp-project-card.project8{background:#fdeaf5}.vp-project-card.project8:hover{background:#facbe5}html[data-theme=dark] .vp-project-card.project8{background:#400626}html[data-theme=dark] .vp-project-card.project8:hover{background:#670a3d}.vp-project-name{position:relative;z-index:2;color:var(--grey3);font-weight:500;font-size:16px;transition:color var(--color-transition)}.vp-project-desc{position:relative;z-index:2;margin:6px 0;color:var(--dark-grey);font-size:13px}.vp-project-image{position:relative;z-index:2;float:right;width:40px;height:40px}html[dir=rtl] .vp-project-image{float:left}.vp-social-medias{display:flex;flex-wrap:wrap;justify-content:center;margin:8px auto}.vp-social-media{width:26px;height:26px;margin:4px;transition:transform .18s ease-out .18s;transform:scale(1)}.vp-social-media:hover{cursor:pointer;transform:scale(1.2)}.vp-social-media:after{--balloon-font-size: 8px;padding:.3em .6em}.vp-social-media .icon{width:100%;height:100%}.tag-list-wrapper{position:relative;z-index:2;display:flex;flex-wrap:wrap;justify-content:flex-start;padding-inline-start:0;list-style:none}.tag-list-wrapper a{color:inherit}.tag-list-wrapper .tag{position:relative;display:inline-block;vertical-align:middle;overflow:hidden;min-width:24px;margin:4px 6px;padding:3px 8px;border-radius:8px;color:var(--white);box-shadow:0 1px 6px 0 var(--box-shadow);font-size:12px;text-align:center;word-break:break-word;cursor:pointer;transition:background var(--color-transition),box-shadow var(--color-transition),transform var(--color-transition)}.tag-list-wrapper .tag:hover{cursor:pointer}.tag-list-wrapper .tag.active{transform:scale(1.1)}.tag-list-wrapper .tag-num{margin-inline-start:.5em}.tag-list-wrapper .tag0{background:#e91526}.tag-list-wrapper .tag0:hover,.tag-list-wrapper .tag0.active,html[data-theme=dark] .tag-list-wrapper .tag0{background:#c51220}html[data-theme=dark] .tag-list-wrapper .tag0:hover,html[data-theme=dark] .tag-list-wrapper .tag0.active{background:#e91526}.tag-list-wrapper .tag1{background:#fb6533}.tag-list-wrapper .tag1:hover,.tag-list-wrapper .tag1.active,html[data-theme=dark] .tag-list-wrapper .tag1{background:#fa4a0e}html[data-theme=dark] .tag-list-wrapper .tag1:hover,html[data-theme=dark] .tag-list-wrapper .tag1.active{background:#fb6533}.tag-list-wrapper .tag2{background:#f4a62a}.tag-list-wrapper .tag2:hover,.tag-list-wrapper .tag2.active,html[data-theme=dark] .tag-list-wrapper .tag2{background:#ec950c}html[data-theme=dark] .tag-list-wrapper .tag2:hover,html[data-theme=dark] .tag-list-wrapper .tag2.active{background:#f4a62a}.tag-list-wrapper .tag3{background:#40d47f}.tag-list-wrapper .tag3:hover,.tag-list-wrapper .tag3.active,html[data-theme=dark] .tag-list-wrapper .tag3{background:#2cc26b}html[data-theme=dark] .tag-list-wrapper .tag3:hover,html[data-theme=dark] .tag-list-wrapper .tag3.active{background:#40d47f}.tag-list-wrapper .tag4{background:#2bbe69}.tag-list-wrapper .tag4:hover,.tag-list-wrapper .tag4.active,html[data-theme=dark] .tag-list-wrapper .tag4{background:#239d56}html[data-theme=dark] .tag-list-wrapper .tag4:hover,html[data-theme=dark] .tag-list-wrapper .tag4.active{background:#2bbe69}.tag-list-wrapper .tag5{background:#13c3c3}.tag-list-wrapper .tag5:hover,.tag-list-wrapper .tag5.active,html[data-theme=dark] .tag-list-wrapper .tag5{background:#0f9d9d}html[data-theme=dark] .tag-list-wrapper .tag5:hover,html[data-theme=dark] .tag-list-wrapper .tag5.active{background:#13c3c3}.tag-list-wrapper .tag6{background:#0a7bf4}.tag-list-wrapper .tag6:hover,.tag-list-wrapper .tag6.active,html[data-theme=dark] .tag-list-wrapper .tag6{background:#0968ce}html[data-theme=dark] .tag-list-wrapper .tag6:hover,html[data-theme=dark] .tag-list-wrapper .tag6.active{background:#0a7bf4}.tag-list-wrapper .tag7{background:#b37deb}.tag-list-wrapper .tag7:hover,.tag-list-wrapper .tag7.active,html[data-theme=dark] .tag-list-wrapper .tag7{background:#a160e7}html[data-theme=dark] .tag-list-wrapper .tag7:hover,html[data-theme=dark] .tag-list-wrapper .tag7.active{background:#b37deb}.tag-list-wrapper .tag8{background:#ed44a1}.tag-list-wrapper .tag8:hover,.tag-list-wrapper .tag8.active,html[data-theme=dark] .tag-list-wrapper .tag8{background:#ea2290}html[data-theme=dark] .tag-list-wrapper .tag8:hover,html[data-theme=dark] .tag-list-wrapper .tag8.active{background:#ed44a1}.timeline-wrapper{--dot-color: #fff;--dot-bar-color: #eaecef;--dot-border-color: #ddd;max-width:740px;margin:0 auto;padding:40px 0}@media (max-width: 719px){.timeline-wrapper{margin:0 1.2rem}}html[data-theme=dark] .timeline-wrapper{--dot-color: #444;--dot-bar-color: #333;--dot-border-color: #555}.timeline-wrapper #toc{inset-inline:unset 0;min-width:0}.timeline-wrapper .toc-wrapper{position:relative;z-index:10}.timeline-wrapper .timeline-content{position:relative;box-sizing:border-box;padding-inline-start:76px;list-style:none}.timeline-wrapper .timeline-content:after{content:" ";position:absolute;top:14px;inset-inline-start:64px;z-index:-1;width:4px;height:calc(100% - 38px);margin-inline-end:-2px;background:var(--dot-bar-color);transition:background var(--color-transition)}.timeline-wrapper .motto{position:relative;color:var(--text-color);font-size:18px;transition:color var(--color-transition)}@media (min-width: 1280px){.timeline-wrapper .motto{font-size:20px}}.timeline-wrapper .motto:before{content:" ";position:absolute;top:50%;z-index:2;margin-top:-6px;margin-inline-start:-6px;border:2px solid var(--dot-border-color);border-radius:50%;background:var(--dot-color);transition:background var(--color-transition),border-color var(--color-transition);inset-inline-start:-10px;width:8px;height:8px}.timeline-wrapper .timeline-year-title{margin-top:calc(3rem - var(--navbar-height));margin-bottom:.5rem;padding-top:var(--navbar-height);color:var(--text-color);font-weight:700;font-size:26px;font-family:var(--font-family-heading);transition:color var(--color-transition)}.timeline-wrapper .timeline-year-title span{position:relative}.timeline-wrapper .timeline-year-title span:before{content:" ";position:absolute;top:50%;z-index:2;margin-top:-6px;margin-inline-start:-6px;border:2px solid var(--dot-border-color);border-radius:50%;background:var(--dot-color);transition:background var(--color-transition),border-color var(--color-transition);inset-inline-start:-10px;width:8px;height:8px}.timeline-wrapper .timeline-year-wrapper{padding-inline-start:0!important}.timeline-wrapper .timeline-date{position:absolute;inset-inline-end:calc(100% + 24px);width:50px;font-size:14px;line-height:30px;text-align:end}.timeline-wrapper .timeline-date:before{content:" ";position:absolute;top:50%;z-index:2;margin-top:-6px;margin-inline-start:-6px;border:2px solid var(--dot-border-color);border-radius:50%;background:var(--dot-color);transition:background var(--color-transition),border-color var(--color-transition);inset-inline-end:-19px;width:6px;height:6px}.timeline-wrapper .timeline-title{position:relative;display:block;color:inherit;font-size:16px;line-height:30px;transition:color var(--color-transition),font-size var(--transform-transition)}.timeline-wrapper .timeline-item{position:relative;z-index:3;display:flex;padding:30px 0 10px;border-bottom:1px dashed var(--border-color);list-style:none;transition:border-color var(--color-transition)}.timeline-wrapper .timeline-item:hover{cursor:pointer}.timeline-wrapper .timeline-item:hover .timeline-date{font-size:16px;transition:border-color var(--color-transition),color var(--color-transition),font-size var(--transform-transition)}.timeline-wrapper .timeline-item:hover .timeline-date:before{border-color:var(--theme-color);background:var(--bg-color-secondary)}.timeline-wrapper .timeline-item:hover .timeline-title{color:var(--theme-color);font-size:18px}.timeline-list-wrapper{--dot-color: #fff;--dot-bar-color: #eaecef;--dot-border-color: #ddd;padding:8px 0}html[data-theme=dark] .timeline-list-wrapper{--dot-color: #444;--dot-bar-color: #333;--dot-border-color: #555}.timeline-list-wrapper .timeline-list-title{cursor:pointer}.timeline-list-wrapper .timeline-list-title .icon{position:relative;bottom:-.125rem;width:16px;height:16px;margin:0 6px}.timeline-list-wrapper .timeline-list-title .num{position:relative;margin:0 2px;font-size:22px}.timeline-list-wrapper .timeline-content{overflow-y:auto;max-height:80vh}.timeline-list-wrapper .timeline-content::-webkit-scrollbar-track-piece{background:transparent}.timeline-list-wrapper .timeline-list{position:relative;box-sizing:border-box;margin:0 8px;list-style:none}.timeline-list-wrapper .timeline-list:after{content:" ";position:absolute;top:14px;inset-inline-start:0;z-index:-1;width:4px;height:calc(100% - 14px);margin-inline-start:-2px;background:var(--dot-bar-color);transition:background var(--color-transition)}.timeline-list-wrapper .timeline-year{position:relative;margin:20px 0 0;color:var(--text-color);font-weight:700;font-size:20px}.timeline-list-wrapper .timeline-year:before{content:" ";position:absolute;z-index:2;border:1px solid var(--dot-border-color);border-radius:50%;background:var(--dot-color);transition:background var(--color-transition),border-color var(--color-transition);top:50%;inset-inline-start:-20px;width:8px;height:8px;margin-top:-4px;margin-inline-start:-4px}.timeline-list-wrapper .timeline-year-wrapper{padding-inline-start:0!important}.timeline-list-wrapper .timeline-date{display:inline-block;vertical-align:bottom;width:36px;font-size:12px;line-height:32px;transition:color var(--color-transition)}.timeline-list-wrapper .timeline-date:before{content:" ";position:absolute;z-index:2;border:1px solid var(--dot-border-color);border-radius:50%;background:var(--dot-color);transition:background var(--color-transition),border-color var(--color-transition);top:24px;inset-inline-start:-19px;width:6px;height:6px;margin-inline-start:-4px}.timeline-list-wrapper .timeline-title{color:inherit;font-size:14px;line-height:32px;cursor:pointer;transition:color var(--color-transition)}.timeline-list-wrapper .timeline-item{position:relative;display:flex;padding:12px 0 4px;border-bottom:1px dashed var(--border-color);list-style:none;transition:border-color var(--color-transition)}.timeline-list-wrapper .timeline-item:hover .timeline-date{color:var(--theme-color)}.timeline-list-wrapper .timeline-item:hover .timeline-date:before{border-color:var(--dot-color);background:var(--theme-color)}.timeline-list-wrapper .timeline-item:hover .timeline-title{color:var(--theme-color)}:root{--navbar-bg-color: var(--bg-color-float-blur);--sidebar-bg-color: var(--bg-color-blur)}html[data-theme=dark]{--navbar-bg-color: var(--bg-color-blur);--sidebar-bg-color: var(--bg-color-blur)}#app{--code-hl-bg-color: var(--code-highlight-line-color);--code-ln-color: var(--code-line-color);--code-ln-wrapper-width: var(--line-numbers-width);--code-tabs-nav-text-color: var(--code-color);--code-tabs-nav-bg-color: var(--code-border-color);--code-tabs-nav-hover-color: var(--code-highlight-line-color);--sidebar-space: var(--sidebar-width)}@media (max-width: 959px){#app{--navbar-height: var(--navbar-mobile-height);--navbar-vertical-padding: var(--navbar-mobile-vertical-padding);--navbar-horizontal-padding: var(--navbar-mobile-horizontal-padding);--sidebar-width: var(--sidebar-mobile-width)}}@media (min-width: 1440px){#app{--sidebar-space: clamp( var(--sidebar-width), max(0px, calc((100vw - var(--content-width)) / 2 - 2rem)) , 100vw )}}.DocSearch-Button,.DocSearch{--docsearch-primary-color: var(--vp-tc);--docsearch-text-color: var(--vp-c);--docsearch-highlight-color: var(--vp-tc);--docsearch-muted-color: var(--light-grey);--docsearch-container-background: rgb(9 10 17 / 80%);--docsearch-modal-background: var(--bg-color-float);--docsearch-searchbox-background: var(--bg-color-secondary);--docsearch-searchbox-focus-background: var(--vp-bg);--docsearch-searchbox-shadow: inset 0 0 0 2px var(--vp-tc);--docsearch-hit-color: var(--vp-cl);--docsearch-hit-active-color: var(--vp-bg);--docsearch-hit-background: var(--vp-bg);--docsearch-hit-shadow: 0 1px 3px 0 var(--border-color);--docsearch-footer-background: var(--vp-bg)}html[data-theme=dark] .DocSearch-Button,html[data-theme=dark] .DocSearch{--docsearch-logo-color: var(--vp-c);--docsearch-modal-shadow: inset 1px 1px 0 0 #2c2e40, 0 3px 8px 0 #000309;--docsearch-key-shadow: inset 0 -2px 0 0 #282d55, inset 0 0 1px 1px #51577d, 0 2px 2px 0 rgb(3 4 9 / 30%);--docsearch-key-gradient: linear-gradient(-225deg, #444950, #1c1e21);--docsearch-footer-shadow: inset 0 1px 0 0 rgb(73 76 106 / 50%), 0 -4px 8px 0 rgb(0 0 0 / 20%)}#nprogress{--nprogress-color: var(--vp-tc)}.search-box{--search-bg-color: var(--vp-bg);--search-accent-color: var(--vp-tc);--search-text-color: var(--vp-c);--search-border-color: var(--border-color);--search-item-text-color: var(--vp-clt);--search-item-focus-bg-color: var(--bg-color-secondary)}.external-link-icon{--external-link-icon-color: var(--light-grey)}html,body{margin:0;padding:0;background:#fff}html{font-size:16px;font-display:optional;-webkit-font-smoothing:antialiased;-moz-osx-font-smoothing:grayscale;-webkit-tap-highlight-color:transparent}@media print{html{font-size:12pt}}body{min-height:100vh;color:#2c3e50}a{color:#3eaf7c;font-weight:500;text-decoration:none;overflow-wrap:break-word}kbd{display:inline-block;min-width:1em;margin-inline:.125rem;padding:.25em;border:1px solid #eee;border-radius:.25em;box-shadow:1px 1px 4px #00000026;line-height:1;letter-spacing:-.1em;text-align:center}code{margin:0;padding:.2rem .4rem;border-radius:5px;background:#7f7f7f1f;font-size:.85em;overflow-wrap:break-word}table code{padding:.1rem .4rem}p a code{color:#3eaf7c;font-weight:400}strong{font-weight:600}h1,h2,h3,h4,h5,h6{font-weight:500;line-height:1.25;overflow-wrap:break-word}h1:hover .header-anchor,h2:hover .header-anchor,h3:hover .header-anchor,h4:hover .header-anchor,h5:hover .header-anchor,h6:hover .header-anchor{opacity:1}h1{font-size:2rem}h2{padding-bottom:.3rem;border-bottom:1px solid #eaecef;font-size:1.65rem}h3{font-size:1.35rem}h4{font-size:1.15rem}h5{font-size:1.05rem}h6{font-size:1rem}a.header-anchor{float:left;margin-top:.125em;margin-inline-start:-.87em;padding-inline-end:.23em;font-size:.85em;opacity:0;transition:opacity .2s}@media print{a.header-anchor{display:none!important}}a.header-anchor:hover{text-decoration:none}a.header-anchor:focus-visible{opacity:1}p,ul,ol{line-height:1.6;overflow-wrap:break-word}@media print{p,ul,ol{line-height:1.5}}ul,ol{padding-inline-start:1.2em}blockquote{margin:1rem 0;padding:.25rem 0 .25rem 1rem;border-inline-start:.2rem solid #ddd;color:#666;font-size:1rem;overflow-wrap:break-word}blockquote>p{margin:0}hr{border:0;border-top:1px solid #eaecef}table{display:block;overflow-x:auto;margin:1rem 0;border-collapse:collapse}tr:nth-child(2n){background:#f6f8fa}th,td{padding:.6em 1em;border:1px solid #dfe2e5}pre{direction:ltr}@page{margin:2cm;font-size:12pt;size:a4}@media print{*,:after,:before{box-shadow:none!important;text-shadow:none!important}h2,h3,p{orphans:3;widows:3}h2,h3{page-break-after:avoid}a{color:inherit;font-weight:inherit!important;font-size:inherit!important;text-decoration:underline}a[href^="http://"]:after,a[href^="https://"]:after{content:" (" attr(href) ") "}abbr[title]:after{content:" (" attr(title) ")"}pre{border:1px solid #eee;white-space:pre-wrap!important}pre>code{white-space:pre-wrap!important}blockquote{border-inline-start:.2rem solid #ddd;color:inherit}blockquote,pre{orphans:5;widows:5}img,tr,canvas{page-break-inside:avoid}}@font-face{font-weight:400;font-style:normal;font-family:Crimson;src:url(data:font/truetype;charset=utf-8;base64,AAEAAAANAIAAAwBQRkZUTYr5mwEAAAyMAAAAHEdERUYAKQATAAAMbAAAAB5PUy8yVsJ0MgAAAVgAAABgY21hcBiKDzgAAAHcAAABWGdhc3D//wADAAAMZAAAAAhnbHlmr+DBdQAAA1AAAAdsaGVhZBZwt+8AAADcAAAANmhoZWEFawEuAAABFAAAACRobXR4BksA9gAAAbgAAAAibG9jYQlsC24AAAM0AAAAHG1heHAAEQBZAAABOAAAACBuYW1lLaFDVAAACrwAAAFrcG9zdAC1AHoAAAwoAAAAPAABAAAAAQAAqBd2H18PPPUACwQAAAAAANqqufwAAAAA2qq5/AAb/9wB4QMeAAAACAACAAAAAAAAAAEAAAMs/ywAXAH9AAAAAAHhAAEAAAAAAAAAAAAAAAAAAAAEAAEAAAANAFkAAwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAH1AZAABQAAApkCzAAAAI8CmQLMAAAB6wAzAQkAAAIABgMAAAAAAAAAAAABEAAAAAAAAAAAAAAAUGZFZADAADAAOQMs/ywAXAMsANQAAAABAAAAAAMYAAAAAAAgAAEBpwAfAAAAAAFVAAAB/QAfAH0ALQA+ABsAPgAyACgAPgAxAAAAAAADAAAAAwAAABwAAQAAAAAAUgADAAEAAAAcAAQANgAAAAQABAABAAAAOf//AAAAL///AAAAAQAEAAAAAAADAAQABQAGAAcACAAJAAoACwAMAAABBgAAAQAAAAAAAAABAgAAAAIAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAwQFBgcICQoLDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACYAJgAmAGIAwAEeAZIBzgJAApYC2gNiA7YAAQAf/9wBhwMeABIAAAEGBwYHATAXFjM2NzY3ASYnJjcBgxwLCgH+zgMECxIKCgIBLgEDAwMDHhQFBgP85wMEAQgJBgMOAwMDEwAAAAIAH//9Ad0CkAAQACEAABMWFxYXNjc2NzQnJicGBwYHNyY3NjcWFxYXFAcGByYnJjcfATo6amo7OQE5OmxrOjkBXQIlJEE5IyIBIyJEOSQjAgFOkV5eBAReXoqJXl4EBF5eggJ0UlEDA09Qe3xVVgMDU1OEAAAAAAEAff/9AYACkQA+AAA3FAcGBwYHBiMGFQYXNjc2MzIXFhc2JzQnIicmJyY1JjURNjc2MSYnJicjBgcGBwYVFBUUFxYXNjc2NzIXFhXkAQEEBRgYDAMBBB4ZGhweGxofBAEDDBgZBQQBAQMEAQIDBAIFNTZCAgMDBA0XFw0LBQV3GBMVDAgEBAUKCgUCAQICAQIFCgoFBAQIDBUTGAGnLxkbBAYFAQIZGh4BAgECBQUEAwUHBwEICRYAAAAAAQAtAAAB0QKRADoAADcGFxYXITY3NjcmJyYjIgcGBwYHBisBNjc2NzY3NjUmJyYnBgcGBxQXFhc2NzY3FhcWFxYHBgcGBwYHLgEEAwMBYwURERADBwYFBAMDAg8VEx/LJkBAOhsQDwIxMkxSMjIHCAYGCSYmPTIfHwEBCgoeLkJBQg8EBQQCETAwKQICAgEBBCgUEylJSUYhJicsRDIzAgY1NRoEBQYBEyEhAwEjIjYlJCQtQlBQSAAAAAABAD7/+wG+ApEASgAANwYXFhcWFxYzNjc2NyYnJic2NzY3JicmIwYHBgcUFxYXNjc2NxYXFhcGBwYHBgcUFRQXNjc2NxYXFhcGBwYnIicmJyYnJiciBwYXPwEIBwUaHB0VZU5NBAMvLi8eIB4DAywsKzwrKxgEAwUIHR4wLRscAQMvLz8BAQYKEhEQNSYmAgImJSsWExQPCw0NFREMDQE7DgsLBQwFBgE8PWpMKSoGECQkMkAiIQIdHyUHBwcBCRscAwEbGSpCIyUOAgMCAwwIAwUEAQEoKD9XJSQBBQYODg8PAQ0NFQAAAgAb//oB4QKTACIAJQAANxQXFhchFRQXFjMyNzYjNTM2NzY1NCcmJyMRNCcmIwYHBgcBExEbAgMFASEJCRIdCAkBRgIBAQUEBTwFAwgHCQkG/vjmxgUGBgOwBQIBAwKzAgQDCBAMDQEBlAYGBgEICQf+cwEs/tQAAQA+//sBvgKTAEoAADcGFxYXFhcWMzY3NjcmJyYnIgcGBzY3NjczMjc2NzY3NjU0JyYnBgcGByMGBwYHFBcWMzY3NjMWFxYHBgcGJyInJicmJyYnIgcGFz8BCAcFGhwdFWVOTQQBMjJbFx8gFwoJCQlWKB0dFQ4JCAQDBQMdHSKXCREQEgMCBA4bGhNYJyUBAiYlKxYTFA8LDQ0VEQwNATsOCwsFDAUGATw9akU2NwMFBggrMC8uAgICExcZBgQCAgMBAwQBMVNUWAUFBAYFBAMxMTNZIyQBBQYODg8PAQ0NFQAAAgAy//oBzQKXACAAMwAANxQXFhc2NzY3NicmJyIHBgc2NzY3NCcmJwYHBgcGBwYXNyY3Njc2FxYXFgcGBwYHJicmNzM1NV5aOTsCAioqahoiIRsnWFhFAwIHQ0tMOTAZGQFbBAQaGxkXRB8fAQEfIDE9Hh4E511FRwQDPT1ZPEJBBQwLF4Y9PRMGCwwBEiwsPDZFRkkTHyAbCAcBAjAwREYsLQEFREVQAAAAAAEAKP/7AdUCiwApAAATFhcWMzI3Njc2NzYzIQYHBgcWFxYzMjcBNjc2NzQnJiMiBwYjIQYHBgcoAwYHAwYDAwELEBEdAQUJYWJXAQ8PDgcDAQ4LCQgBAQEEBhUVFv7JBgsNDAH6DQMCAQEFKRITFMjHjQcFBgMCPxYSEwoEAgMBAhkrKiAAAAADAD7/9wG/ApIAKABBAFgAADcGFxYXNjc2NyYnJicmJzQ3Njc2NyYnJiMGBwYHFhcWFxYVFAcGBwYHNyY3Njc2MzIzMhcyFxYXFhcGBwYHIicmNxMmNzY3FhcWFRQHBgcGByIjIicmJyY3PwE1M1ZQODgDAykpMQIBAyYlJQMCMC9HRjExAgIiIiMCAiMvLwNTBBQTKgEBAQECAQIBEjU1CAEdHjMrISICGAMYGSYvGxoTEx8CAQIBBAMfJCQBoU8tLQECMjFPOC4uGwIBAgEWJiU7SCYoAjEwQzopKhMBAgECEykpQAQsIiEbAQEBBywsQjUeHQEiI0QBZSMhIAECJiYvKh8gFAEBAhAfIEYAAAIAMf/6AcsClwAgADMAABMGFxYXMjc2NwYHBgcUFxYXNjc2NzY3NjUmJyYnBgcGBzcmNzY3FhcWFRQHBgcGJyYnJjc0AyopahoiIRsoV1hFAwIHQ0tMODEZGQE2NF5ZOjoBWgMfHzE9Hh4EGhoaF0QeHwUBy0dBQgUMCxeFPj0SBwsLAREsLD01RkVPV0dFBQQ8PU8UPCwtAQVFRUklIRsHCAECMDBPAAAADACWAAEAAAAAAAEABwAQAAEAAAAAAAIABwAoAAEAAAAAAAMABwBAAAEAAAAAAAQABwBYAAEAAAAAAAUAHgCeAAEAAAAAAAYABwDNAAMAAQQJAAEADgAAAAMAAQQJAAIADgAYAAMAAQQJAAMADgAwAAMAAQQJAAQADgBIAAMAAQQJAAUAPABgAAMAAQQJAAYADgC9AEMAcgBpAG0AcwBvAG4AAENyaW1zb24AAEMAcgBpAG0AcwBvAG4AAENyaW1zb24AAEMAcgBpAG0AcwBvAG4AAENyaW1zb24AAEMAcgBpAG0AcwBvAG4AAENyaW1zb24AAFYAZQByAHMAaQBvAG4AIAAxAC4AMAA7ACAARgBvAG4AdABFAGQAaQB0AG8AcgAgACgAdgAxAC4AMAApAABWZXJzaW9uIDEuMDsgRm9udEVkaXRvciAodjEuMCkAAEMAcgBpAG0AcwBvAG4AAENyaW1zb24AAAACAAAAAAAAADIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA0AAAABAAIAEwAUABUAFgAXABgAGQAaABsAHAAAAAH//wACAAEAAAAMAAAAFgAAAAIAAQADAAwAAQAEAAAAAgAAAAAAAAABAAAAANWkJwgAAAAA2qq5/AAAAADaqrn8) format("truetype")}html,body{background:var(--bg-color);transition:background var(--color-transition)}:root{color-scheme:light}html[data-theme=dark]{color-scheme:dark}body{color:var(--text-color);font-family:var(--font-family)}@media (min-width: 1440px){body{font-size:17px}}a{color:var(--theme-color)}kbd{border-color:var(--border-color-dark);background:var(--bg-color-secondary);font-family:var(--font-family-mono)}code{font-family:var(--font-family-mono);transition:background var(--color-transition),color var(--color-transition)}html[data-theme=dark] code{background:#333}p a code{color:var(--theme-color)}blockquote{border-color:#eee;color:#666;transition:border-color var(--color-transition),color var(--color-transition)}html[data-theme=dark] blockquote{border-color:#333}h1,h2,h3,h4,h5,h6{font-family:var(--font-family-heading)}@media (max-width: 419px){h1{font-size:1.9rem}}h2{border-color:var(--border-color);transition:border-bottom-color var(--color-transition)}hr{border-color:var(--border-color);transition:border-top-color var(--color-transition)}tr:nth-child(2n){background:var(--bg-color-secondary)}th,td{border-color:var(--border-color-dark)}@media print{@page{--text-color: #000 !important;--bg-color: #fff !important}div[class*=language-]{position:relative!important}}.theme-hope-content:not(.custom)>*:first-child{margin-top:0}.vp-breadcrumb{max-width:var(--content-width, 740px);margin-inline:auto;padding-inline:2.5rem;position:relative;z-index:2;padding-top:1rem;font-size:15px}@media (max-width: 959px){.vp-breadcrumb{padding-inline:1.5rem}}@media print{.vp-breadcrumb{max-width:unset}}@media (max-width: 959px){.vp-breadcrumb{font-size:14px}}@media (max-width: 419px){.vp-breadcrumb{padding-top:.5rem;font-size:12.8px}}@media print{.vp-breadcrumb{display:none}}.vp-breadcrumb .icon{margin-inline-end:.25em;font-size:1em}.vp-breadcrumb img.icon{vertical-align:-.125em;height:1em}.vp-breadcrumb a{display:inline-block;padding:0 .5em}.vp-breadcrumb a:before{position:relative;bottom:.125rem;margin-inline-end:.25em}.vp-breadcrumb a:hover{color:var(--theme-color)}.vp-breadcrumb ol{margin:0;padding-inline-start:0;list-style:none}.vp-breadcrumb li{display:inline-block;line-height:1.5}.vp-breadcrumb li:first-child a{padding-inline-start:0}.vp-breadcrumb li:last-child a{padding-inline-end:0}.vp-breadcrumb li.is-active a{color:var(--light-grey);cursor:default;pointer-events:none}.vp-breadcrumb li+li:before{content:"/";color:var(--light-grey)}.toggle-sidebar-wrapper{position:fixed;top:var(--navbar-height);bottom:0;inset-inline-start:var(--sidebar-space);z-index:100;display:flex;align-items:center;justify-content:center;font-size:2rem;transition:inset-inline-start var(--transform-transition)}@media (max-width: 719px){.toggle-sidebar-wrapper{display:none}}@media (min-width: 1440px){.toggle-sidebar-wrapper{display:none}}.toggle-sidebar-wrapper:hover{background:#7f7f7f0d;cursor:pointer}.toggle-sidebar-wrapper .arrow{display:inline-block;vertical-align:middle;width:1em;height:1em;background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(0,0,0,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E");background-position:center;background-repeat:no-repeat;line-height:normal;transition:all .3s}html[data-theme=dark] .toggle-sidebar-wrapper .arrow{background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(255,255,255,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E")}.toggle-sidebar-wrapper .arrow.down{transform:rotate(180deg)}html[dir=rtl] .toggle-sidebar-wrapper .arrow.down{transform:rotate(-180deg)}.toggle-sidebar-wrapper .arrow.end{transform:rotate(90deg)}html[dir=rtl] .toggle-sidebar-wrapper .arrow.end,.toggle-sidebar-wrapper .arrow.start{transform:rotate(-90deg)}html[dir=rtl] .toggle-sidebar-wrapper .arrow.start{transform:rotate(90deg)}.theme-container{display:flex;flex-direction:column;justify-content:space-between;min-height:100vh}.theme-container .vp-page{padding-top:var(--navbar-height);padding-inline-start:calc(var(--sidebar-space) + 2rem)}@media (max-width: 719px){.theme-container .vp-page{padding-inline:0}}@media (min-width: 1440px){.theme-container .vp-page{padding-inline-end:calc(100vw - var(--content-width) - var(--sidebar-space) - 6rem)}}.theme-container .vp-sidebar{top:var(--navbar-height)}.theme-container.no-navbar .vp-page{padding-top:0}.theme-container.no-navbar .vp-sidebar{top:0}@media (max-width: 719px){.theme-container.no-navbar .vp-sidebar{top:0}}@media (max-width: 719px){.theme-container.hide-navbar .vp-sidebar{top:0}}.theme-container.sidebar-collapsed .vp-page{padding-inline-start:0}.theme-container.sidebar-collapsed .vp-sidebar{box-shadow:none;transform:translate(-100%)}html[dir=rtl] .theme-container.sidebar-collapsed .vp-sidebar{transform:translate(100%)}.theme-container.sidebar-collapsed .toggle-sidebar-wrapper{inset-inline-start:0}.theme-container.no-sidebar .vp-page{padding-inline:0}@media (min-width: 1440px){.theme-container.no-sidebar.has-toc .vp-page{padding-inline-end:16rem}}.theme-container.no-sidebar .vp-toggle-sidebar-button,.theme-container.no-sidebar .toggle-sidebar-wrapper,.theme-container.no-sidebar .vp-sidebar{display:none}.theme-container.sidebar-open .vp-sidebar{box-shadow:2px 0 8px var(--card-shadow);transform:translate(0)}.fade-slide-y-enter-active{transition:all .3s ease!important}.fade-slide-y-leave-active{transition:all .3s cubic-bezier(1,.5,.8,1)!important}.fade-slide-y-enter-from,.fade-slide-y-leave-to{opacity:0;transform:translateY(10px)}.vp-feature-wrapper{position:relative}.vp-feature-bg{position:absolute;top:0;right:0;bottom:0;left:0;z-index:0;background-attachment:fixed;background-position:50%;background-size:cover}.vp-feature-bg.light{display:inline-block}.vp-feature-bg.dark,html[data-theme=dark] .vp-feature-bg.light{display:none}html[data-theme=dark] .vp-feature-bg.dark{display:inline-block}.vp-feature{position:relative;z-index:1;margin:0 auto;padding:1.5rem 1rem;color:var(--text-color-lighter);text-align:center}.vp-feature-bg+.vp-feature{color:#222}html[data-theme=dark] .vp-feature-bg+.vp-feature{color:#eee}.vp-feature-bg+.vp-feature .icon{color:inherit}.vp-feature-image{height:10rem;margin:0 auto}@media (max-width: 959px){.vp-feature-image{height:8rem}}.vp-feature-image.light{display:inline-block}.vp-feature-image.dark,html[data-theme=dark] .vp-feature-image.light{display:none}html[data-theme=dark] .vp-feature-image.dark{display:inline-block}.vp-feature-header{margin-bottom:1.5rem;border-bottom:none;font-size:3rem;font-family:var(--font-family);text-align:center}@media (max-width: 959px){.vp-feature-header{font-size:2.5rem}}@media (max-width: 719px){.vp-feature-header{font-size:2.25rem}}@media (max-width: 419px){.vp-feature-header{font-size:2rem}}.vp-feature-description{font-size:1.125rem}.vp-features{z-index:1;display:flex;flex-wrap:wrap;align-items:stretch;place-content:stretch center;margin:1rem 0;text-align:start}@media print{.vp-features{display:block}}.vp-features:first-child{border-top:1px solid var(--border-color);transition:border-color var(--color-transition)}.vp-feature-item{position:relative;display:block;flex-basis:calc(33% - 3rem);margin:.5rem;padding:1rem;border-radius:.5rem;color:inherit;transition:background var(--color-transition),box-shadow var(--color-transition),transform var(--transform-transition)}@media (min-width: 1440px){.vp-feature-item{flex-basis:calc(25% - 3rem)}}@media (max-width: 959px){.vp-feature-item{flex-basis:calc(50% - 3rem)}}@media (max-width: 719px){.vp-feature-item{flex-basis:100%;font-size:.95rem}}@media (max-width: 419px){.vp-feature-item{margin:.5rem 0;font-size:.9rem}}.vp-feature-item.link{cursor:pointer}@media print{.vp-feature-item.link{text-decoration:none}}.vp-feature-item .icon{display:inline-block;height:1.1em;margin-inline-end:.5rem;color:var(--theme-color);font-weight:400;font-size:1.1em}.vp-feature-item:hover{background-color:var(--bg-color-secondary);box-shadow:0 2px 12px 0 var(--card-shadow);transform:translate(-2px,-2px);transform:scale(1.05)}.vp-feature-bg+.vp-feature .vp-feature-item:hover{background-color:transparent}.vp-feature-item:only-child{flex-basis:100%}.vp-feature-item:first-child:nth-last-child(2),.vp-feature-item:nth-child(2):last-child{flex-basis:calc(50% - 3rem)}@media (max-width: 719px){.vp-feature-item:first-child:nth-last-child(2),.vp-feature-item:nth-child(2):last-child{flex-basis:100%}}.vp-feature-title{margin:.25rem 0 .5rem;font-weight:700;font-size:1.3rem;font-family:var(--font-family)}@media (max-width: 419px){.vp-feature-title{font-size:1.2rem}}.vp-feature-details{margin:0;line-height:1.4}.vp-footer-wrapper{position:relative;display:flex;flex-wrap:wrap;align-items:center;justify-content:space-evenly;padding-block:.75rem;padding-inline:calc(var(--sidebar-space) + 2rem) 2rem;border-top:1px solid var(--border-color);background:var(--bg-color);color:var(--dark-grey);text-align:center;transition:border-top-color var(--color-transition),background var(--color-transition),padding var(--transform-transition)}@media (max-width: 719px){.vp-footer-wrapper{padding-inline-start:2rem}}@media (min-width: 1440px){.vp-footer-wrapper{z-index:50;padding-inline-start:2rem}}@media print{.vp-footer-wrapper{margin:0!important;padding:0!important}}@media (max-width: 419px){.vp-footer-wrapper{display:block}}.no-sidebar .vp-footer-wrapper,.sidebar-collapsed .vp-footer-wrapper{padding-inline-start:2rem}.vp-footer{margin:.5rem 1rem;font-size:14px}@media print{.vp-footer{display:none}}.vp-copyright{margin:6px 0;font-size:13px}.vp-page:not(.not-found)+.vp-footer-wrapper{margin-top:-2rem}.vp-hero-info-wrapper{position:relative;display:flex;align-items:center;justify-content:center;margin-inline:auto}.vp-hero-info-wrapper.fullscreen{height:calc(100vh - var(--navbar-height))!important}.vp-hero-info{z-index:1;width:100%;padding-inline:2.5rem}@media (max-width: 959px){.vp-hero-info{padding-inline:1.5rem}}@media (min-width: 959px){.vp-hero-info{display:flex;align-items:center;justify-content:space-evenly}}.vp-hero-mask{position:absolute;top:0;right:0;bottom:0;left:0;z-index:0;background-position:50%;background-size:cover}.vp-hero-mask:after{content:" ";position:absolute;top:0;right:0;bottom:0;left:0;z-index:1;display:block}.vp-hero-mask.light{display:block}html[data-theme=dark] .vp-hero-mask.light,.vp-hero-mask.dark{display:none}html[data-theme=dark] .vp-hero-mask.dark{display:block}.vp-hero-infos{z-index:1;margin:0 .5rem}.vp-hero-image{display:block;max-width:100%;max-height:18rem;margin:1rem}@media (max-width: 959px){.vp-hero-image{margin:2rem auto}}@media (max-width: 719px){.vp-hero-image{max-height:16rem;margin:1.5rem auto}}@media (max-width: 419px){.vp-hero-image{max-height:14rem}}.vp-hero-image.light{display:block}html[data-theme=dark] .vp-hero-image.light,.vp-hero-image.dark{display:none}html[data-theme=dark] .vp-hero-image.dark{display:block}#main-title{margin:.5rem 0;background:linear-gradient(120deg,var(--theme-color-light),var(--theme-color) 30%,#6229b9 100%);-webkit-background-clip:text;background-clip:text;font-weight:700;font-size:3.6rem;font-family:var(--font-family);line-height:1.5;-webkit-text-fill-color:transparent}@media (max-width: 719px){#main-title{margin:0}}@media (max-width: 959px){#main-title{font-size:2.5rem;text-align:center}}@media (max-width: 719px){#main-title{font-size:2.25rem;text-align:center}}@media (max-width: 419px){#main-title{margin:0 auto;font-size:2rem}}#main-description,.vp-hero-actions{margin:1.8rem 0}@media (max-width: 719px){#main-description,.vp-hero-actions{margin:1.5rem 0}}@media (max-width: 959px){#main-description,.vp-hero-actions{margin:1.5rem auto;text-align:center}}@media (max-width: 419px){#main-description,.vp-hero-actions{margin:1.2rem 0}}#main-description{max-width:35rem;color:var(--text-color-light);font-weight:500;font-size:1.6rem;line-height:1.3}@media (max-width: 719px){#main-description{font-size:1.4rem}}@media (max-width: 419px){#main-description{font-size:1.2rem}}.vp-hero-action{display:inline-block;overflow:hidden;min-width:4rem;margin:.5rem;padding:.5em 1.5rem;border-radius:2rem;background:var(--bg-color-secondary);color:var(--text-color);font-size:1.2rem;text-align:center;transition:color var(--color-transition),color var(--color-transition),transform var(--transform-transition)}@media (max-width: 719px){.vp-hero-action{padding:.5rem 1rem;font-size:1.1rem}}@media (max-width: 419px){.vp-hero-action{font-size:1rem}}@media print{.vp-hero-action{text-decoration:none}}.vp-hero-action:hover{background:var(--bg-color-tertiary)}.vp-hero-action.primary{border-color:var(--theme-color);background:var(--theme-color);color:var(--white)}.vp-hero-action.primary:hover{border-color:var(--theme-color-light);background:var(--theme-color-light)}.vp-project-home:not(.pure) .vp-hero-action:active{transform:scale(.96)}.vp-hero-action .icon{margin-inline-end:.25em}.vp-highlight-wrapper{position:relative;display:flex;align-items:center;justify-content:center}.vp-highlight-wrapper:nth-child(2n) .vp-highlight{flex-direction:row-reverse}.vp-highlight{z-index:1;display:flex;flex:1;align-items:center;justify-content:flex-end;max-width:var(--home-page-width);margin:0 auto;padding:1.5rem 2.5rem;color:#222}@media (max-width: 719px){.vp-highlight{display:block;padding-inline:1.5rem;text-align:center}}html[data-theme=dark] .vp-highlight{color:#eee}.vp-highlight-bg{position:absolute;top:0;right:0;bottom:0;left:0;z-index:0;background-attachment:fixed;background-position:50%;background-size:cover}.vp-highlight-bg.light{display:inline-block}.vp-highlight-bg.dark,html[data-theme=dark] .vp-highlight-bg.light{display:none}html[data-theme=dark] .vp-highlight-bg.dark{display:inline-block}.vp-highlight-image{width:12rem;margin:2rem 4rem}@media (max-width: 959px){.vp-highlight-image{width:10rem}}@media (max-width: 719px){.vp-highlight-image{width:8rem;margin:0 auto}}.vp-highlight-image.light{display:inline-block}.vp-highlight-image.dark,html[data-theme=dark] .vp-highlight-image.light{display:none}html[data-theme=dark] .vp-highlight-image.dark{display:inline-block}.vp-highlight-info-wrapper{display:flex;flex:1;justify-content:center;padding:2rem}@media (max-width: 719px){.vp-highlight-info-wrapper{padding:1rem 0}}.vp-highlight-info-wrapper:only-child{flex:1 0 100%}.vp-highlight-info{text-align:start}.vp-highlight-header{margin-bottom:1.5rem;border-bottom:none;font-size:3rem;font-family:var(--font-family)}@media (max-width: 959px){.vp-highlight-header{font-size:2.5rem}}@media (max-width: 719px){.vp-highlight-header{font-size:2.25rem;text-align:center}}@media (max-width: 419px){.vp-highlight-header{font-size:2rem}}.vp-highlight-description{font-size:1.125rem}.vp-highlights{margin-inline-start:-1.25em;padding-inline-start:0}.vp-highlight-item-wrapper{padding:.5em .5em .5em 1.75em;border-radius:.5rem;list-style:none}.vp-highlight-item-wrapper.link{cursor:pointer}.vp-highlight-item-wrapper:hover{background-color:var(--bg-color-secondary);box-shadow:0 2px 12px 0 var(--card-shadow);transition:transform var(--transform-transition);transform:translate(-2px,-2px)}.vp-highlight-bg+.vp-highlight .vp-highlight-item-wrapper:hover{background-color:transparent}.vp-highlight-item-wrapper::marker{font-weight:700}.vp-highlight-item{display:list-item;color:inherit;list-style:initial}@media print{.vp-highlight-item{text-decoration:none}}.vp-highlight-title{margin:0;font-weight:600;font-size:1.125rem;font-family:var(--font-family)}.vp-highlight-title .icon{margin-inline-end:.25em;font-size:1em}.vp-highlight-title img.icon{vertical-align:-.125em;height:1em}.vp-highlight-details{margin:.5rem 0 0}.vp-project-home{--content-width: var(--home-page-width);display:block;flex:1;padding-top:var(--navbar-height)}@media screen{.vp-project-home .vp-hero-info-wrapper:not(.fullscreen) .vp-hero-info{max-width:var(--home-page-width)}}@media screen{.vp-project-home .vp-feature{max-width:var(--home-page-width)}}.vp-project-home .theme-hope-content{padding-bottom:1.5rem!important}.vp-project-home .theme-hope-content:empty{padding:0!important}.not-found-hint{padding:2rem}.not-found-hint .error-code{margin:0;font-weight:700;font-size:4rem;line-height:4rem}.not-found-hint .error-title{font-weight:700}.not-found-hint .error-hint{margin:0;padding:12px 0;font-weight:600;font-size:20px;line-height:20px;letter-spacing:2px}.vp-page.not-found{display:flex;flex-direction:column;align-items:center;justify-content:center;box-sizing:border-box;width:100vw;max-width:var(--home-page-width);margin:0 auto;padding:calc(var(--navbar-height) + 1rem) 1rem 1rem!important;text-align:center}.vp-page.not-found .action-button{display:inline-block;box-sizing:border-box;margin:.25rem;padding:.75rem 1rem;border-width:0;border-bottom:1px solid var(--theme-color-dark);border-radius:3rem;background:var(--theme-color);color:var(--white);outline:none;font-size:1rem;transition:background .1s ease}.vp-page.not-found .action-button:hover{background:var(--theme-color-light);cursor:pointer}.vp-page-nav{display:flex;flex-wrap:wrap;min-height:2rem;margin-top:0;padding-block:.5rem;padding-inline:2rem;border-top:1px solid var(--border-color);transition:border-top var(--color-transition)}@media (max-width: 959px){.vp-page-nav{padding-inline:1rem}}@media print{.vp-page-nav{display:none}}.vp-page-nav .nav-link{display:inline-block;flex-grow:1;margin:.25rem;padding:.25rem .5rem;border:1px solid var(--border-color);border-radius:.25rem}.vp-page-nav .nav-link:hover{background:var(--bg-color-secondary)}.vp-page-nav .nav-link .hint{color:var(--light-grey);font-size:.875rem;line-height:2}.vp-page-nav .nav-link .arrow{display:inline-block;vertical-align:middle;width:1em;height:1em;background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(0,0,0,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E");background-position:center;background-repeat:no-repeat;line-height:normal;transition:all .3s;font-size:.75rem}html[data-theme=dark] .vp-page-nav .nav-link .arrow{background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(255,255,255,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E")}.vp-page-nav .nav-link .arrow.down{transform:rotate(180deg)}html[dir=rtl] .vp-page-nav .nav-link .arrow.down{transform:rotate(-180deg)}.vp-page-nav .nav-link .arrow.end{transform:rotate(90deg)}html[dir=rtl] .vp-page-nav .nav-link .arrow.end,.vp-page-nav .nav-link .arrow.start{transform:rotate(-90deg)}html[dir=rtl] .vp-page-nav .nav-link .arrow.start{transform:rotate(90deg)}.vp-page-nav .prev{text-align:start}.vp-page-nav .prev .icon{margin-inline-end:.25em;font-size:1em}.vp-page-nav .prev img.icon{vertical-align:-.125em;height:1em}.vp-page-nav .next{text-align:end}.vp-page-nav .next .icon{margin-inline-start:.25em;font-size:1em}.vp-page-nav .next img.icon{vertical-align:-.125em;height:1em}.vp-page-title{max-width:var(--content-width, 740px);margin-inline:auto;padding-inline:2.5rem;position:relative;z-index:1;padding-top:1rem;padding-bottom:0}@media (max-width: 959px){.vp-page-title{padding-inline:1.5rem}}@media print{.vp-page-title{max-width:unset}}@media print{.vp-page-title{padding-inline:0!important}}@media (max-width: 959px){.vp-page-title{padding-top:.5rem}}.vp-page-title h1{margin-top:calc(0px - var(--navbar-height))!important;margin-bottom:1rem;padding-top:var(--navbar-height)!important;font-size:2.2rem}@media (max-width: 959px){.vp-page-title h1{margin-bottom:.5rem}}.vp-page-title h1 .icon{margin-inline-end:.25em;color:var(--theme-color);font-size:.9em}.vp-page-title h1 img.icon{vertical-align:-.125em;height:1em}.theme-hope-content:not(.custom){padding-top:0!important}.theme-hope-content:not(.custom) h1:first-child,.theme-hope-content:not(.custom) h2:first-child,.theme-hope-content:not(.custom) h3:first-child,.theme-hope-content:not(.custom) h4:first-child,.theme-hope-content:not(.custom) h5:first-child,.theme-hope-content:not(.custom) h6:first-child{margin-top:calc(.5rem - var(--navbar-height))!important;padding-top:var(--navbar-height)!important}.theme-hope-content:not(.custom)>h1:first-child{display:none}.vp-page{display:block;flex-grow:1;padding-bottom:2rem;transition:padding var(--transform-transition)}@media print{.vp-page{min-height:auto!important;margin:0!important;padding:0!important}}.page-cover{width:var(--content-width);margin-inline:auto}@media (max-width: 719px){.page-cover{width:100%}}.page-cover img{-o-object-fit:cover;object-fit:cover;width:100%;max-height:25vh;border-radius:.5rem}@media (max-width: 719px){.page-cover img{border-radius:0}}.vp-skip-link{top:.25rem;inset-inline-start:.25rem;z-index:999;padding:.65rem 1.5rem;border-radius:.5rem;background:var(--bg-color);color:var(--theme-color);box-shadow:var(--card-shadow);font-weight:700;font-size:.9em;text-decoration:none}@media print{.vp-skip-link{display:none}}.vp-skip-link:focus{clip:auto;width:auto;height:auto;-webkit-clip-path:none;clip-path:none}.theme-hope-content pre{overflow:auto;margin:.85rem 0;padding:1rem;border-radius:6px;line-height:1.375}.theme-hope-content pre code{padding:0;border-radius:0;background:transparent!important;color:var(--code-color);font-family:var(--font-family-mono);text-align:left;white-space:pre;word-spacing:normal;word-wrap:normal;word-break:normal;overflow-wrap:unset;-webkit-hyphens:none;hyphens:none;transition:color var(--color-transition);-webkit-font-smoothing:auto;-moz-osx-font-smoothing:auto}@media print{.theme-hope-content pre code{white-space:pre-wrap}}.theme-hope-content .line-number{font-family:var(--font-family-mono)}div[class*=language-]{position:relative;border-radius:6px;background:var(--code-bg-color);font-size:16px;transition:background var(--color-transition)}@media (max-width: 419px){.theme-hope-content>div[class*=language-]{margin:.85rem -1.5rem;border-radius:0}}div[class*=language-]:before{content:attr(data-ext);position:absolute;top:0;right:1em;z-index:3;color:var(--code-line-color);font-size:.75rem;transition:color var(--color-transition)}div[class*=language-] pre{position:relative;z-index:1;scrollbar-gutter:stable}div[class*=language-] .highlight-lines{position:absolute;top:0;bottom:0;left:0;width:100%;padding:1rem 0;line-height:1.375;-webkit-user-select:none;-moz-user-select:none;user-select:none}div[class*=language-] .highlight-line{background:var(--code-highlight-line-color);transition:background var(--color-transition)}div[class*=language-].line-numbers-mode:after{content:"";position:absolute;top:0;bottom:0;left:0;z-index:2;width:var(--line-numbers-width);border-right:1px solid var(--code-highlight-line-color);border-radius:6px 0 0 6px;transition:border-color var(--color-transition)}@media (max-width: 419px){div[class*=language-].line-numbers-mode:after{border-radius:0}}@media print{div[class*=language-].line-numbers-mode:after{display:none}}div[class*=language-].line-numbers-mode .highlight-line{position:relative}div[class*=language-].line-numbers-mode .highlight-line:before{content:" ";position:absolute;top:0;left:0;z-index:3;display:block;width:var(--line-numbers-width);height:100%}div[class*=language-].line-numbers-mode pre{vertical-align:middle;margin-left:var(--line-numbers-width);padding-left:.5rem}@media print{div[class*=language-].line-numbers-mode pre{margin-left:0;padding-left:1rem}}div[class*=language-].line-numbers-mode .line-numbers{position:absolute;top:0;bottom:0;left:0;display:flex;flex-direction:column;width:var(--line-numbers-width);padding:1rem 0;color:var(--code-line-color);counter-reset:line-number;text-align:center;transition:color var(--color-transition)}@media print{div[class*=language-].line-numbers-mode .line-numbers{display:none}}div[class*=language-].line-numbers-mode .line-number{position:relative;z-index:4;display:flex;flex:1;align-items:center;justify-content:center;-webkit-user-select:none;-moz-user-select:none;user-select:none}div[class*=language-].line-numbers-mode .line-number:before{content:counter(line-number);display:block;font-size:.8em;line-height:1;counter-increment:line-number}div[class*=language-]:not(.line-numbers-mode) .line-numbers{display:none}html[data-theme=light] #app{--code-color: #383a42;--code-line-color: rgba(56, 58, 66, .67);--code-bg-color: #ecf4fa;--code-border-color: #c3def3;--code-highlight-line-color: #d8e9f6}html[data-theme=light] code[class*=language-],html[data-theme=light] pre[class*=language-]{-moz-tab-size:2;-o-tab-size:2;tab-size:2}html[data-theme=light] code[class*=language-]::-moz-selection,html[data-theme=light] code[class*=language-] ::-moz-selection,html[data-theme=light] pre[class*=language-]::-moz-selection,html[data-theme=light] pre[class*=language-] ::-moz-selection{background:#e5e5e6;color:inherit}html[data-theme=light] code[class*=language-]::selection,html[data-theme=light] code[class*=language-] ::selection,html[data-theme=light] pre[class*=language-]::selection,html[data-theme=light] pre[class*=language-] ::selection{background:#e5e5e6;color:inherit}html[data-theme=light] .token.comment,html[data-theme=light] .token.prolog,html[data-theme=light] .token.cdata{color:#a0a1a7}html[data-theme=light] .token.doctype,html[data-theme=light] .token.punctuation,html[data-theme=light] .token.entity{color:#383a42}html[data-theme=light] .token.attr-name,html[data-theme=light] .token.class-name,html[data-theme=light] .token.boolean,html[data-theme=light] .token.constant,html[data-theme=light] .token.number,html[data-theme=light] .token.atrule{color:#b76b01}html[data-theme=light] .token.keyword{color:#a626a4}html[data-theme=light] .token.property,html[data-theme=light] .token.tag,html[data-theme=light] .token.symbol,html[data-theme=light] .token.deleted,html[data-theme=light] .token.important{color:#e45649}html[data-theme=light] .token.selector,html[data-theme=light] .token.string,html[data-theme=light] .token.char,html[data-theme=light] .token.builtin,html[data-theme=light] .token.inserted,html[data-theme=light] .token.regex,html[data-theme=light] .token.attr-value,html[data-theme=light] .token.attr-value>.token.punctuation{color:#50a14f}html[data-theme=light] .token.variable,html[data-theme=light] .token.operator,html[data-theme=light] .token.function{color:#4078f2}html[data-theme=light] .token.url{color:#0184bc}html[data-theme=light] .token.attr-value>.token.punctuation.attr-equals,html[data-theme=light] .token.special-attr>.token.attr-value>.token.value.css{color:#383a42}html[data-theme=light] .language-css .token.selector{color:#e45649}html[data-theme=light] .language-css .token.property{color:#383a42}html[data-theme=light] .language-css .token.function,html[data-theme=light] .language-css .token.url>.token.function{color:#0184bc}html[data-theme=light] .language-css .token.url>.token.string.url{color:#50a14f}html[data-theme=light] .language-css .token.important,html[data-theme=light] .language-css .token.atrule .token.rule,html[data-theme=light] .language-javascript .token.operator{color:#a626a4}html[data-theme=light] .language-javascript .token.template-string>.token.interpolation>.token.interpolation-punctuation.punctuation{color:#ca1243}html[data-theme=light] .language-json .token.operator{color:#383a42}html[data-theme=light] .language-json .token.null.keyword{color:#b76b01}html[data-theme=light] .language-markdown .token.url,html[data-theme=light] .language-markdown .token.url>.token.operator,html[data-theme=light] .language-markdown .token.url-reference.url>.token.string{color:#383a42}html[data-theme=light] .language-markdown .token.url>.token.content{color:#4078f2}html[data-theme=light] .language-markdown .token.url>.token.url,html[data-theme=light] .language-markdown .token.url-reference.url{color:#0184bc}html[data-theme=light] .language-markdown .token.blockquote.punctuation,html[data-theme=light] .language-markdown .token.hr.punctuation{color:#a0a1a7;font-style:italic}html[data-theme=light] .language-markdown .token.code-snippet{color:#50a14f}html[data-theme=light] .language-markdown .token.bold .token.content{color:#b76b01}html[data-theme=light] .language-markdown .token.italic .token.content{color:#a626a4}html[data-theme=light] .language-markdown .token.strike .token.content,html[data-theme=light] .language-markdown .token.strike .token.punctuation,html[data-theme=light] .language-markdown .token.list.punctuation,html[data-theme=light] .language-markdown .token.title.important>.token.punctuation{color:#e45649}html[data-theme=light] .token.bold{font-weight:700}html[data-theme=light] .token.comment,html[data-theme=light] .token.italic{font-style:italic}html[data-theme=light] .token.entity{cursor:help}html[data-theme=light] .token.namespace{opacity:.8}html[data-theme=dark] #app{--code-color: #abb2bf;--code-line-color: rgba(171, 178, 191, .67);--code-bg-color: #282c34;--code-border-color: #343e51;--code-highlight-line-color: #2f3542}html[data-theme=dark] code[class*=language-],html[data-theme=dark] pre[class*=language-]{text-shadow:0 1px rgba(0,0,0,.3);-moz-tab-size:2;-o-tab-size:2;tab-size:2}@media print{html[data-theme=dark] code[class*=language-],html[data-theme=dark] pre[class*=language-]{text-shadow:none}}html[data-theme=dark] code[class*=language-]::-moz-selection,html[data-theme=dark] code[class*=language-] ::-moz-selection,html[data-theme=dark] pre[class*=language-]::-moz-selection,html[data-theme=dark] pre[class*=language-] ::-moz-selection{background:#3e4451;color:inherit;text-shadow:none}html[data-theme=dark] code[class*=language-]::selection,html[data-theme=dark] code[class*=language-] ::selection,html[data-theme=dark] pre[class*=language-]::selection,html[data-theme=dark] pre[class*=language-] ::selection{background:#3e4451;color:inherit;text-shadow:none}html[data-theme=dark] .token.comment,html[data-theme=dark] .token.prolog,html[data-theme=dark] .token.cdata{color:#5c6370}html[data-theme=dark] .token.doctype,html[data-theme=dark] .token.punctuation,html[data-theme=dark] .token.entity{color:#abb2bf}html[data-theme=dark] .token.attr-name,html[data-theme=dark] .token.class-name,html[data-theme=dark] .token.boolean,html[data-theme=dark] .token.constant,html[data-theme=dark] .token.number,html[data-theme=dark] .token.atrule{color:#d19a66}html[data-theme=dark] .token.keyword{color:#c678dd}html[data-theme=dark] .token.property,html[data-theme=dark] .token.tag,html[data-theme=dark] .token.symbol,html[data-theme=dark] .token.deleted,html[data-theme=dark] .token.important{color:#e06c75}html[data-theme=dark] .token.selector,html[data-theme=dark] .token.string,html[data-theme=dark] .token.char,html[data-theme=dark] .token.builtin,html[data-theme=dark] .token.inserted,html[data-theme=dark] .token.regex,html[data-theme=dark] .token.attr-value,html[data-theme=dark] .token.attr-value>.token.punctuation{color:#98c379}html[data-theme=dark] .token.variable,html[data-theme=dark] .token.operator,html[data-theme=dark] .token.function{color:#61afef}html[data-theme=dark] .token.url{color:#56b6c2}html[data-theme=dark] .token.attr-value>.token.punctuation.attr-equals,html[data-theme=dark] .token.special-attr>.token.attr-value>.token.value.css{color:#abb2bf}html[data-theme=dark] .language-css .token.selector{color:#e06c75}html[data-theme=dark] .language-css .token.property{color:#abb2bf}html[data-theme=dark] .language-css .token.function,html[data-theme=dark] .language-css .token.url>.token.function{color:#56b6c2}html[data-theme=dark] .language-css .token.url>.token.string.url{color:#98c379}html[data-theme=dark] .language-css .token.important,html[data-theme=dark] .language-css .token.atrule .token.rule,html[data-theme=dark] .language-javascript .token.operator{color:#c678dd}html[data-theme=dark] .language-javascript .token.template-string>.token.interpolation>.token.interpolation-punctuation.punctuation{color:#be5046}html[data-theme=dark] .language-json .token.operator{color:#abb2bf}html[data-theme=dark] .language-json .token.null.keyword{color:#d19a66}html[data-theme=dark] .language-markdown .token.url,html[data-theme=dark] .language-markdown .token.url>.token.operator,html[data-theme=dark] .language-markdown .token.url-reference.url>.token.string{color:#abb2bf}html[data-theme=dark] .language-markdown .token.url>.token.content{color:#61afef}html[data-theme=dark] .language-markdown .token.url>.token.url,html[data-theme=dark] .language-markdown .token.url-reference.url{color:#56b6c2}html[data-theme=dark] .language-markdown .token.blockquote.punctuation,html[data-theme=dark] .language-markdown .token.hr.punctuation{color:#5c6370;font-style:italic}html[data-theme=dark] .language-markdown .token.code-snippet{color:#98c379}html[data-theme=dark] .language-markdown .token.bold .token.content{color:#d19a66}html[data-theme=dark] .language-markdown .token.italic .token.content{color:#c678dd}html[data-theme=dark] .language-markdown .token.strike .token.content,html[data-theme=dark] .language-markdown .token.strike .token.punctuation,html[data-theme=dark] .language-markdown .token.list.punctuation,html[data-theme=dark] .language-markdown .token.title.important>.token.punctuation{color:#e06c75}html[data-theme=dark] .token.bold{font-weight:700}html[data-theme=dark] .token.comment,html[data-theme=dark] .token.italic{font-style:italic}html[data-theme=dark] .token.entity{cursor:help}html[data-theme=dark] .token.namespace{opacity:.8}.sr-only{position:absolute;overflow:hidden;clip:rect(0,0,0,0);width:1px;height:1px;margin:-1px;padding:0;border-width:0;white-space:nowrap;-webkit-user-select:none;-moz-user-select:none;user-select:none}@media print{.theme-hope-content{margin:0!important;padding-inline:0!important}}.theme-hope-content.custom{margin:0;padding:0}.theme-hope-content:not(.custom){max-width:var(--content-width, 740px);margin:0 auto;padding:2rem 2.5rem;padding-top:0}@media (max-width: 959px){.theme-hope-content:not(.custom){padding:1.5rem}}@media (max-width: 419px){.theme-hope-content:not(.custom){padding:1rem 1.5rem}}@media print{.theme-hope-content:not(.custom){max-width:unset}}.theme-hope-content:not(.custom)>h1,.theme-hope-content:not(.custom)>h2,.theme-hope-content:not(.custom)>h3,.theme-hope-content:not(.custom)>h4,.theme-hope-content:not(.custom)>h5,.theme-hope-content:not(.custom)>h6{margin-top:calc(.5rem - var(--navbar-height));margin-bottom:.5rem;padding-top:calc(1rem + var(--navbar-height));outline:none}.theme-container.no-navbar .theme-hope-content:not(.custom)>h1,.theme-container.no-navbar .theme-hope-content:not(.custom)>h2,.theme-container.no-navbar .theme-hope-content:not(.custom)>h3,.theme-container.no-navbar .theme-hope-content:not(.custom)>h4,.theme-container.no-navbar .theme-hope-content:not(.custom)>h5,.theme-container.no-navbar .theme-hope-content:not(.custom)>h6{margin-top:1.5rem;padding-top:0}.theme-hope-content:not(.custom)>p,.theme-hope-content:not(.custom)>ul p,.theme-hope-content:not(.custom)>ol p{text-align:justify;overflow-wrap:break-word;-webkit-hyphens:auto;hyphens:auto}@media (max-width: 419px){.theme-hope-content:not(.custom)>p,.theme-hope-content:not(.custom)>ul p,.theme-hope-content:not(.custom)>ol p{text-align:start}}@media print{.theme-hope-content:not(.custom)>p,.theme-hope-content:not(.custom)>ul p,.theme-hope-content:not(.custom)>ol p{text-align:start}}.theme-hope-content a:hover{text-decoration:underline}.theme-hope-content img{max-width:100%}::view-transition-old(root),::view-transition-new(root){animation:none;mix-blend-mode:normal}html[data-theme=light]::view-transition-old(root),html[data-theme=dark]::view-transition-new(root){z-index:1}html[data-theme=light]::view-transition-new(root),html[data-theme=dark]::view-transition-old(root){z-index:99999}@media (min-width: 1280px){.chart-wrapper::-webkit-scrollbar,.flowchart-wrapper::-webkit-scrollbar,.mermaid-wrapper::-webkit-scrollbar{width:8px;height:8px}.chart-wrapper::-webkit-scrollbar-track-piece,.flowchart-wrapper::-webkit-scrollbar-track-piece,.mermaid-wrapper::-webkit-scrollbar-track-piece{border-radius:8px;background:#0000001a}}html[dir=rtl] a.header-anchor{float:right}#docsearch-container{min-width:145.7px!important}@media (max-width: 959px){#docsearch-container{min-width:36px!important}}.DocSearch.DocSearch-Button{margin-left:0}@media (max-width: 959px){.DocSearch.DocSearch-Button{min-width:36px!important}}.DocSearch .DocSearch-Button-Placeholder{display:inline-block;padding:4px 12px 4px 6px;font-size:14px}@media (max-width: 719px){.DocSearch .DocSearch-Button-Placeholder{display:none}}.DocSearch .DocSearch-Search-Icon{width:1.25em;height:1.25em}@media (max-width: 959px){.DocSearch .DocSearch-Button-Keys{display:none}}.DocSearch .DocSearch-Button-Key{background:var(--bg-color);box-shadow:none}:root{scrollbar-width:thin}@media (prefers-reduced-motion: no-preference){:root{scroll-behavior:smooth}}::-webkit-scrollbar{width:6px;height:6px}::-webkit-scrollbar-track-piece{border-radius:6px;background:#0000001a}::-webkit-scrollbar-thumb{border-radius:6px;background:var(--theme-color)}::-webkit-scrollbar-thumb:active{background:var(--theme-color-light)}@media (max-width: 719px){.hide-in-mobile{display:none!important}}@media (max-width: 959px){.hide-in-pad{display:none!important}}.page-author-item{display:inline-block;margin:0 4px;font-weight:400;overflow-wrap:break-word}.page-category-info{flex-wrap:wrap}.page-category-item{display:inline-block;margin:.125em .25em;padding:0 .25em;border-radius:.25em;background:var(--bg-color-secondary);color:var(--text-color-light);font-weight:700;font-size:.75rem;line-height:2;transition:background var(--color-transition),color var(--color-transition)}@media print{.page-category-item{padding:0;font-weight:400}.page-category-item:after{content:", "}.page-category-item:last-of-type:after{content:""}}.page-category-item.clickable>span:hover{color:var(--theme-color);cursor:pointer}.page-category-item.category0{background:#fde5e7;color:#ec2f3e}html[data-theme=dark] .page-category-item.category0{background:#340509;color:#ba111f}.page-category-item.category0:hover{background:#f9bec3}html[data-theme=dark] .page-category-item.category0:hover{background:#53080e}.page-category-item.category1{background:#ffeee8;color:#fb7649}html[data-theme=dark] .page-category-item.category1{background:#441201;color:#f54205}.page-category-item.category1:hover{background:#fed4c6}html[data-theme=dark] .page-category-item.category1:hover{background:#6d1d02}.page-category-item.category2{background:#fef5e7;color:#f5b041}html[data-theme=dark] .page-category-item.category2{background:#3e2703;color:#e08e0b}.page-category-item.category2:hover{background:#fce6c4}html[data-theme=dark] .page-category-item.category2:hover{background:#633f05}.page-category-item.category3{background:#eafaf1;color:#55d98d}html[data-theme=dark] .page-category-item.category3{background:#0c331c;color:#29b866}.page-category-item.category3:hover{background:#caf3db}html[data-theme=dark] .page-category-item.category3:hover{background:#12522d}.page-category-item.category4{background:#e6f9ee;color:#36d278}html[data-theme=dark] .page-category-item.category4{background:#092917;color:#219552}.page-category-item.category4:hover{background:#c0f1d5}html[data-theme=dark] .page-category-item.category4:hover{background:#0f4224}.page-category-item.category5{background:#e1fcfc;color:#16e1e1}html[data-theme=dark] .page-category-item.category5{background:#042929;color:#0e9595}.page-category-item.category5:hover{background:#b4f8f8}html[data-theme=dark] .page-category-item.category5:hover{background:#064242}.page-category-item.category6{background:#e4f0fe;color:#2589f6}html[data-theme=dark] .page-category-item.category6{background:#021b36;color:#0862c3}.page-category-item.category6:hover{background:#bbdafc}html[data-theme=dark] .page-category-item.category6:hover{background:#042c57}.page-category-item.category7{background:#f7f1fd;color:#bb8ced}html[data-theme=dark] .page-category-item.category7{background:#2a0b4b;color:#9851e4}.page-category-item.category7:hover{background:#eadbfa}html[data-theme=dark] .page-category-item.category7:hover{background:#431277}.page-category-item.category8{background:#fdeaf5;color:#ef59ab}html[data-theme=dark] .page-category-item.category8{background:#400626;color:#e81689}.page-category-item.category8:hover{background:#facbe5}html[data-theme=dark] .page-category-item.category8:hover{background:#670a3d}.page-original-info{position:relative;display:inline-block;vertical-align:middle;overflow:hidden;padding:0 .5em;border:.5px solid var(--dark-grey);border-radius:.75em;background:var(--bg-color);font-size:.75em;line-height:1.5!important}.page-info{display:flex;flex-wrap:wrap;align-items:center;place-content:stretch flex-start;color:var(--dark-grey);font-size:14px}@media print{.page-info{display:flex!important}}.page-info>span{display:flex;align-items:center;max-width:100%;margin-inline-end:.5em;line-height:2}@media (min-width: 1440px){.page-info>span{font-size:1.1em}}@media (max-width: 419px){.page-info>span{margin-inline-end:.3em;font-size:.875em}}@media print{.page-info>span{display:flex!important}}.page-info .icon{position:relative;display:inline-block;vertical-align:middle;width:1em;height:1em;margin-inline-end:.25em}.page-info a{color:inherit}.page-info a:hover,.page-info a:active{color:var(--theme-color)}.page-meta{max-width:var(--content-width, 740px);margin-inline:auto;padding-inline:2.5rem;display:flex;flex-wrap:wrap;justify-content:space-between;overflow:auto;padding-top:.75rem;padding-bottom:.75rem}@media (max-width: 959px){.page-meta{padding-inline:1.5rem}}@media print{.page-meta{max-width:unset}}@media print{.page-meta{margin:0!important;padding-inline:0!important}}@media (max-width: 719px){.page-meta{display:block}}.page-meta .meta-item{flex-grow:1}.page-meta .meta-item .label{font-weight:500}.page-meta .meta-item .label:not(a){color:var(--text-color-lighter)}.page-meta .meta-item .info{color:var(--dark-grey);font-weight:400}.page-meta .git-info{text-align:end}.page-meta .edit-link{margin-top:.25rem;margin-bottom:.25rem;margin-inline-end:.5rem;font-size:14px}@media print{.page-meta .edit-link{display:none}}.page-meta .edit-link .icon{position:relative;bottom:-.125em;width:1em;height:1em;margin-inline-end:.25em}.page-meta .update-time,.page-meta .contributors{margin-top:.25rem;margin-bottom:.25rem;font-size:14px}@media (max-width: 719px){.page-meta .update-time,.page-meta .contributors{font-size:13px;text-align:start}}.print-button{border-width:0;background:transparent;cursor:pointer;box-sizing:content-box;width:1rem;height:1rem;padding:.5rem;border-radius:.25em;color:inherit;font-size:1rem;transform:translateY(.25rem)}@media print{.print-button{display:none}}.page-tag-info{flex-wrap:wrap}.page-tag-item{position:relative;display:inline-block;vertical-align:middle;overflow:hidden;min-width:1.5rem;margin:.125rem;padding:.125rem .25rem .125rem .625rem;background:var(--bg-color-secondary);background:linear-gradient(135deg,transparent .75em,var(--bg-color-secondary) 0) top,linear-gradient(45deg,transparent .75em,var(--bg-color-secondary) 0) bottom;background-size:100% 52%!important;background-repeat:no-repeat!important;color:var(--text-color-light);font-weight:700;font-size:.625rem;line-height:1.5;text-align:center;transition:background var(--color-transition),color var(--color-transition)}@media print{.page-tag-item{padding:0;font-weight:400}.page-tag-item:after{content:", "}.page-tag-item:last-of-type:after{content:""}}.page-tag-item.clickable:hover{cursor:pointer}.page-tag-item.tag0{background:#fde5e7;background:linear-gradient(135deg,transparent .75em,#fde5e7 0) top,linear-gradient(45deg,transparent .75em,#fde5e7 0) bottom;color:#ec2f3e}html[data-theme=dark] .page-tag-item.tag0{background:#340509;background:linear-gradient(135deg,transparent .75em,#340509 0) top,linear-gradient(45deg,transparent .75em,#340509 0) bottom;color:#ba111f}.page-tag-item.tag0.clickable:hover{background:#f9bec3;background:linear-gradient(135deg,transparent .75em,#f9bec3 0) top,linear-gradient(45deg,transparent .75em,#f9bec3 0) bottom}html[data-theme=dark] .page-tag-item.tag0.clickable:hover{background:#53080e;background:linear-gradient(135deg,transparent .75em,#53080e 0) top,linear-gradient(45deg,transparent .75em,#53080e 0) bottom}.page-tag-item.tag1{background:#ffeee8;background:linear-gradient(135deg,transparent .75em,#ffeee8 0) top,linear-gradient(45deg,transparent .75em,#ffeee8 0) bottom;color:#fb7649}html[data-theme=dark] .page-tag-item.tag1{background:#441201;background:linear-gradient(135deg,transparent .75em,#441201 0) top,linear-gradient(45deg,transparent .75em,#441201 0) bottom;color:#f54205}.page-tag-item.tag1.clickable:hover{background:#fed4c6;background:linear-gradient(135deg,transparent .75em,#fed4c6 0) top,linear-gradient(45deg,transparent .75em,#fed4c6 0) bottom}html[data-theme=dark] .page-tag-item.tag1.clickable:hover{background:#6d1d02;background:linear-gradient(135deg,transparent .75em,#6d1d02 0) top,linear-gradient(45deg,transparent .75em,#6d1d02 0) bottom}.page-tag-item.tag2{background:#fef5e7;background:linear-gradient(135deg,transparent .75em,#fef5e7 0) top,linear-gradient(45deg,transparent .75em,#fef5e7 0) bottom;color:#f5b041}html[data-theme=dark] .page-tag-item.tag2{background:#3e2703;background:linear-gradient(135deg,transparent .75em,#3e2703 0) top,linear-gradient(45deg,transparent .75em,#3e2703 0) bottom;color:#e08e0b}.page-tag-item.tag2.clickable:hover{background:#fce6c4;background:linear-gradient(135deg,transparent .75em,#fce6c4 0) top,linear-gradient(45deg,transparent .75em,#fce6c4 0) bottom}html[data-theme=dark] .page-tag-item.tag2.clickable:hover{background:#633f05;background:linear-gradient(135deg,transparent .75em,#633f05 0) top,linear-gradient(45deg,transparent .75em,#633f05 0) bottom}.page-tag-item.tag3{background:#eafaf1;background:linear-gradient(135deg,transparent .75em,#eafaf1 0) top,linear-gradient(45deg,transparent .75em,#eafaf1 0) bottom;color:#55d98d}html[data-theme=dark] .page-tag-item.tag3{background:#0c331c;background:linear-gradient(135deg,transparent .75em,#0c331c 0) top,linear-gradient(45deg,transparent .75em,#0c331c 0) bottom;color:#29b866}.page-tag-item.tag3.clickable:hover{background:#caf3db;background:linear-gradient(135deg,transparent .75em,#caf3db 0) top,linear-gradient(45deg,transparent .75em,#caf3db 0) bottom}html[data-theme=dark] .page-tag-item.tag3.clickable:hover{background:#12522d;background:linear-gradient(135deg,transparent .75em,#12522d 0) top,linear-gradient(45deg,transparent .75em,#12522d 0) bottom}.page-tag-item.tag4{background:#e6f9ee;background:linear-gradient(135deg,transparent .75em,#e6f9ee 0) top,linear-gradient(45deg,transparent .75em,#e6f9ee 0) bottom;color:#36d278}html[data-theme=dark] .page-tag-item.tag4{background:#092917;background:linear-gradient(135deg,transparent .75em,#092917 0) top,linear-gradient(45deg,transparent .75em,#092917 0) bottom;color:#219552}.page-tag-item.tag4.clickable:hover{background:#c0f1d5;background:linear-gradient(135deg,transparent .75em,#c0f1d5 0) top,linear-gradient(45deg,transparent .75em,#c0f1d5 0) bottom}html[data-theme=dark] .page-tag-item.tag4.clickable:hover{background:#0f4224;background:linear-gradient(135deg,transparent .75em,#0f4224 0) top,linear-gradient(45deg,transparent .75em,#0f4224 0) bottom}.page-tag-item.tag5{background:#e1fcfc;background:linear-gradient(135deg,transparent .75em,#e1fcfc 0) top,linear-gradient(45deg,transparent .75em,#e1fcfc 0) bottom;color:#16e1e1}html[data-theme=dark] .page-tag-item.tag5{background:#042929;background:linear-gradient(135deg,transparent .75em,#042929 0) top,linear-gradient(45deg,transparent .75em,#042929 0) bottom;color:#0e9595}.page-tag-item.tag5.clickable:hover{background:#b4f8f8;background:linear-gradient(135deg,transparent .75em,#b4f8f8 0) top,linear-gradient(45deg,transparent .75em,#b4f8f8 0) bottom}html[data-theme=dark] .page-tag-item.tag5.clickable:hover{background:#064242;background:linear-gradient(135deg,transparent .75em,#064242 0) top,linear-gradient(45deg,transparent .75em,#064242 0) bottom}.page-tag-item.tag6{background:#e4f0fe;background:linear-gradient(135deg,transparent .75em,#e4f0fe 0) top,linear-gradient(45deg,transparent .75em,#e4f0fe 0) bottom;color:#2589f6}html[data-theme=dark] .page-tag-item.tag6{background:#021b36;background:linear-gradient(135deg,transparent .75em,#021b36 0) top,linear-gradient(45deg,transparent .75em,#021b36 0) bottom;color:#0862c3}.page-tag-item.tag6.clickable:hover{background:#bbdafc;background:linear-gradient(135deg,transparent .75em,#bbdafc 0) top,linear-gradient(45deg,transparent .75em,#bbdafc 0) bottom}html[data-theme=dark] .page-tag-item.tag6.clickable:hover{background:#042c57;background:linear-gradient(135deg,transparent .75em,#042c57 0) top,linear-gradient(45deg,transparent .75em,#042c57 0) bottom}.page-tag-item.tag7{background:#f7f1fd;background:linear-gradient(135deg,transparent .75em,#f7f1fd 0) top,linear-gradient(45deg,transparent .75em,#f7f1fd 0) bottom;color:#bb8ced}html[data-theme=dark] .page-tag-item.tag7{background:#2a0b4b;background:linear-gradient(135deg,transparent .75em,#2a0b4b 0) top,linear-gradient(45deg,transparent .75em,#2a0b4b 0) bottom;color:#9851e4}.page-tag-item.tag7.clickable:hover{background:#eadbfa;background:linear-gradient(135deg,transparent .75em,#eadbfa 0) top,linear-gradient(45deg,transparent .75em,#eadbfa 0) bottom}html[data-theme=dark] .page-tag-item.tag7.clickable:hover{background:#431277;background:linear-gradient(135deg,transparent .75em,#431277 0) top,linear-gradient(45deg,transparent .75em,#431277 0) bottom}.page-tag-item.tag8{background:#fdeaf5;background:linear-gradient(135deg,transparent .75em,#fdeaf5 0) top,linear-gradient(45deg,transparent .75em,#fdeaf5 0) bottom;color:#ef59ab}html[data-theme=dark] .page-tag-item.tag8{background:#400626;background:linear-gradient(135deg,transparent .75em,#400626 0) top,linear-gradient(45deg,transparent .75em,#400626 0) bottom;color:#e81689}.page-tag-item.tag8.clickable:hover{background:#facbe5;background:linear-gradient(135deg,transparent .75em,#facbe5 0) top,linear-gradient(45deg,transparent .75em,#facbe5 0) bottom}html[data-theme=dark] .page-tag-item.tag8.clickable:hover{background:#670a3d;background:linear-gradient(135deg,transparent .75em,#670a3d 0) top,linear-gradient(45deg,transparent .75em,#670a3d 0) bottom}.toc-place-holder{margin-inline:auto;padding-inline:2.5rem;position:sticky;top:calc(var(--navbar-height) + 2rem);z-index:99;max-width:var(--content-width, 740px)}@media (max-width: 959px){.toc-place-holder{padding-inline:1.5rem}}@media print{.toc-place-holder{max-width:unset}}.toc-place-holder+.theme-hope-content:not(.custom){padding-top:0}#toc{position:absolute;inset-inline-start:calc(100% + 1rem);display:none;min-width:10rem;max-width:15rem}@media (min-width: 1440px){.has-toc #toc{display:block}}@media print{#toc{display:none!important}}#toc .toc-header{margin-bottom:.75rem;margin-inline-start:.5rem;font-weight:600;font-size:.875rem}#toc .toc-wrapper{position:relative;overflow:hidden auto;max-height:75vh;margin:0 .5rem;padding-inline-start:8px;text-overflow:ellipsis;white-space:nowrap;scroll-behavior:smooth}#toc .toc-wrapper::-webkit-scrollbar-track-piece{background:transparent}#toc .toc-wrapper::-webkit-scrollbar{width:3px}#toc .toc-wrapper::-webkit-scrollbar-thumb:vertical{background:#ddd}html[data-theme=dark] #toc .toc-wrapper::-webkit-scrollbar-thumb:vertical{background:#333}#toc .toc-wrapper:before{content:" ";position:absolute;top:0;bottom:0;inset-inline-start:0;z-index:-1;width:2px;background:var(--border-color)}#toc .toc-list{position:relative;margin:0;padding:0}#toc .toc-marker{content:" ";position:absolute;top:0;inset-inline-start:-8px;z-index:2;width:2px;height:1.7rem;background:var(--theme-color);transition:top var(--vp-tt)}#toc .toc-link{position:relative;display:block;overflow:hidden;max-width:100%;color:var(--light-grey);line-height:inherit;text-overflow:ellipsis;white-space:nowrap}#toc .toc-link.level2{padding-inline-start:0px;font-size:14px}#toc .toc-link.level3{padding-inline-start:8px;font-size:13px}#toc .toc-link.level4{padding-inline-start:16px;font-size:12px}#toc .toc-link.level5{padding-inline-start:24px;font-size:11px}#toc .toc-link.level6{padding-inline-start:32px;font-size:10px}#toc .toc-item{position:relative;box-sizing:border-box;height:1.7rem;padding:0 .5rem;list-style:none;line-height:1.7rem}#toc .toc-item:hover>.toc-link{color:var(--theme-color)}#toc .toc-item.active>.toc-link{color:var(--theme-color);font-weight:700}.dropdown-wrapper{cursor:pointer}.dropdown-wrapper:not(:hover) .arrow{transform:rotate(-180deg)}.dropdown-wrapper .dropdown-title{border-width:0;background:transparent;cursor:pointer;padding:0 .25rem;color:var(--dark-grey);font-weight:500;font-size:inherit;font-family:inherit;line-height:inherit;cursor:inherit}.dropdown-wrapper .dropdown-title:hover{border-color:transparent}.dropdown-wrapper .dropdown-title .icon{margin-inline-end:.25em;font-size:1em}.dropdown-wrapper .dropdown-title .arrow{display:inline-block;vertical-align:middle;width:1em;height:1em;background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(0,0,0,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E");background-position:center;background-repeat:no-repeat;line-height:normal;transition:all .3s;font-size:1.2em}html[data-theme=dark] .dropdown-wrapper .dropdown-title .arrow{background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(255,255,255,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E")}.dropdown-wrapper .dropdown-title .arrow.down{transform:rotate(180deg)}html[dir=rtl] .dropdown-wrapper .dropdown-title .arrow.down{transform:rotate(-180deg)}.dropdown-wrapper .dropdown-title .arrow.end{transform:rotate(90deg)}html[dir=rtl] .dropdown-wrapper .dropdown-title .arrow.end,.dropdown-wrapper .dropdown-title .arrow.start{transform:rotate(-90deg)}html[dir=rtl] .dropdown-wrapper .dropdown-title .arrow.start{transform:rotate(90deg)}.dropdown-wrapper ul{margin:0;padding:0;list-style-type:none}.dropdown-wrapper .nav-dropdown{position:absolute;top:100%;inset-inline-end:0;overflow-y:auto;box-sizing:border-box;min-width:6rem;max-height:calc(100vh - var(--navbar-height));margin:0;padding:.5rem .75rem;border:1px solid var(--grey14);border-radius:.5rem;background:var(--bg-color);box-shadow:2px 2px 10px var(--card-shadow);text-align:start;white-space:nowrap;opacity:0;visibility:hidden;transition:all .18s ease-out;transform:scale(.9)}.dropdown-wrapper:hover .nav-dropdown,.dropdown-wrapper.open .nav-dropdown{z-index:2;opacity:1;visibility:visible;transform:none}.dropdown-wrapper .nav-link{position:relative;display:block;margin-bottom:0;border-bottom:none;color:var(--dark-grey);font-weight:400;font-size:.875rem;line-height:1.7rem;transition:color var(--color-transition)}.dropdown-wrapper .nav-link:hover,.dropdown-wrapper .nav-link.active{color:var(--theme-color)}.dropdown-wrapper .dropdown-subtitle{margin:0;padding:.5rem .25rem 0;color:var(--light-grey);font-weight:600;font-size:.75rem;line-height:2;text-transform:uppercase;transition:color var(--color-transition)}.dropdown-wrapper .dropdown-subitem-wrapper{padding:0 0 .25rem}.dropdown-wrapper .dropdown-item{color:inherit;line-height:1.7rem}.dropdown-wrapper .dropdown-item:last-child .dropdown-subtitle{padding-top:0}.dropdown-wrapper .dropdown-item:last-child .dropdown-subitem-wrapper{padding-bottom:0}.nav-screen-dropdown-title{border-width:0;background:transparent;position:relative;display:flex;align-items:center;width:100%;padding:0;color:var(--dark-grey);font-size:inherit;font-family:inherit;text-align:start;cursor:pointer}.nav-screen-dropdown-title:hover,.nav-screen-dropdown-title.active{color:var(--text-color)}.nav-screen-dropdown-title .title{flex:1}.nav-screen-dropdown-title .arrow{display:inline-block;vertical-align:middle;width:1em;height:1em;background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(0,0,0,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E");background-position:center;background-repeat:no-repeat;line-height:normal;transition:all .3s}html[data-theme=dark] .nav-screen-dropdown-title .arrow{background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(255,255,255,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E")}.nav-screen-dropdown-title .arrow.down{transform:rotate(180deg)}html[dir=rtl] .nav-screen-dropdown-title .arrow.down{transform:rotate(-180deg)}.nav-screen-dropdown-title .arrow.end{transform:rotate(90deg)}html[dir=rtl] .nav-screen-dropdown-title .arrow.end,.nav-screen-dropdown-title .arrow.start{transform:rotate(-90deg)}html[dir=rtl] .nav-screen-dropdown-title .arrow.start{transform:rotate(90deg)}.nav-screen-dropdown{overflow:hidden;margin:.5rem 0 0;padding:0;list-style:none;transition:transform .1s ease-out;transform:scaleY(1);transform-origin:top}.nav-screen-dropdown.hide{height:0;margin:0;transform:scaleY(0)}.nav-screen-dropdown .nav-link{position:relative;display:block;padding-inline-start:.5rem;font-weight:400;line-height:2}.nav-screen-dropdown .nav-link:hover,.nav-screen-dropdown .nav-link.active{color:var(--theme-color)}.nav-screen-dropdown .nav-link .icon{font-size:1em}.nav-screen-dropdown .dropdown-item{color:inherit;line-height:1.7rem}.nav-screen-dropdown .dropdown-subtitle{margin:0;padding-inline-start:.25rem;color:var(--light-grey);font-weight:600;font-size:.75rem;line-height:2;text-transform:uppercase;transition:color var(--color-transition)}.nav-screen-dropdown .dropdown-subtitle .nav-link{padding:0}.nav-screen-dropdown .dropdown-subitem-wrapper{margin:0;padding:0;list-style:none}.nav-screen-dropdown .dropdown-subitem{padding-inline-start:.5rem;font-size:.9em}.nav-screen-links{display:none;padding-bottom:.75rem}@media (max-width: 719px){.nav-screen-links{display:block}}.nav-screen-links .navbar-links-item{position:relative;display:block;padding:12px 4px 11px 0;border-bottom:1px solid var(--border-color);font-size:16px;line-height:1.5rem;transition:border-bottom-color var(--color-transition)}.nav-screen-links .nav-link{display:inline-block;width:100%;color:var(--dark-grey);font-weight:400}.nav-screen-links .nav-link:hover{color:var(--text-color)}.nav-screen-links .nav-link.active{color:var(--theme-color)}.vp-nav-screen-container{max-width:320px;margin:0 auto;padding:2rem 0 4rem}#nav-screen{position:fixed;inset:var(--navbar-height) 0 0 0;z-index:150;display:none;overflow-y:auto;padding:0 2rem;background:var(--bg-color);transition:background .5s}@media (max-width: 719px){#nav-screen{display:block}}#nav-screen.fade-enter-active,#nav-screen.fade-leave-active{transition:opacity .25s}#nav-screen.fade-enter-active .vp-nav-screen-container,#nav-screen.fade-leave-active .vp-nav-screen-container{transition:transform .25s ease}#nav-screen.fade-enter-from,#nav-screen.fade-leave-to{opacity:0}#nav-screen.fade-enter-from .vp-nav-screen-container,#nav-screen.fade-leave-to .vp-nav-screen-container{transform:translateY(-8px)}#nav-screen .icon{margin-inline-end:.25em;font-size:1em}#nav-screen img.icon{vertical-align:-.125em;height:1em}.vp-outlook-wrapper{display:flex;justify-content:space-around}.vp-nav-logo{vertical-align:top;height:var(--navbar-line-height);margin-inline-end:.8rem}.vp-nav-logo.light{display:inline-block}.vp-nav-logo.dark,html[data-theme=dark] .vp-nav-logo.light{display:none}html[data-theme=dark] .vp-nav-logo.dark{display:inline-block}.vp-site-name{position:relative;color:var(--text-color);font-size:1.25rem}@media (max-width: 719px){.vp-site-name{overflow:hidden;width:calc(100vw - 9.4rem);text-overflow:ellipsis;white-space:nowrap}}.vp-brand:hover .vp-site-name{color:var(--theme-color)}.vp-navbar .vp-nav-links{display:flex;align-items:center;font-size:.875rem}.vp-navbar .nav-item{position:relative;margin:0 .25rem;line-height:2rem}.vp-navbar .nav-item:first-child{margin-inline-start:0}.vp-navbar .nav-item:last-child{margin-inline-end:0}.vp-navbar .nav-item>.nav-link{color:var(--dark-grey)}.vp-navbar .nav-item>.nav-link:after{content:" ";position:absolute;inset:auto 50% 0;height:2px;border-radius:1px;background:var(--theme-color-light);visibility:hidden;transition:inset .2s ease-in-out}.vp-navbar .nav-item>.nav-link.active{color:var(--theme-color)}.vp-navbar .nav-item>.nav-link:hover:after,.vp-navbar .nav-item>.nav-link.active:after{inset:auto 0 0;visibility:visible}.vp-navbar{--navbar-line-height: calc( var(--navbar-height) - var(--navbar-vertical-padding) * 2 );position:fixed;inset:0 0 auto;z-index:175;display:flex;align-items:center;justify-content:space-between;box-sizing:border-box;height:var(--navbar-height);padding:var(--navbar-vertical-padding) var(--navbar-horizontal-padding);background:var(--navbar-bg-color);box-shadow:0 2px 8px var(--card-shadow);line-height:var(--navbar-line-height);white-space:nowrap;transition:transform ease-in-out .3s,background var(--color-transition),box-shadow var(--color-transition);-webkit-backdrop-filter:saturate(150%) blur(12px);backdrop-filter:saturate(150%) blur(12px)}@media print{.vp-navbar{display:none}}.hide-navbar .vp-navbar.auto-hide{transform:translateY(-100%)}.vp-navbar .nav-link{padding:0 .25rem;color:var(--dark-grey)}.vp-navbar .nav-link.active{color:var(--theme-color)}.vp-navbar .nav-link .icon{margin-inline-end:.25em;font-size:1em}.vp-navbar .nav-link img.icon{vertical-align:-.125em;height:1em}.vp-navbar.hide-icon .vp-nav-links .icon{display:none!important}.vp-navbar-start,.vp-navbar-end,.vp-navbar-center{display:flex;flex:1;align-items:center}.vp-navbar-start>*,.vp-navbar-end>*,.vp-navbar-center>*{position:relative;margin:0 .25rem!important}.vp-navbar-start>*:first-child,.vp-navbar-end>*:first-child,.vp-navbar-center>*:first-child{margin-inline-start:0!important}.vp-navbar-start>*:last-child,.vp-navbar-end>*:last-child,.vp-navbar-center>*:last-child{margin-inline-end:0!important}.vp-navbar-start{justify-content:start}.vp-navbar-center{justify-content:center}.vp-navbar-end{justify-content:end}.vp-navbar .vp-repo{margin:0!important}.vp-navbar .vp-repo-link{display:inline-block;margin:auto;padding:6px;color:var(--dark-grey);line-height:1}.vp-navbar .vp-repo-link:hover,.vp-navbar .vp-repo-link:active{color:var(--theme-color)}.vp-toggle-navbar-button{border-width:0;background:transparent;cursor:pointer;position:relative;display:none;align-items:center;justify-content:center;padding:6px}@media screen and (max-width: 719px){.vp-toggle-navbar-button{display:flex}}.vp-toggle-navbar-button>span{position:relative;overflow:hidden;width:16px;height:14px}.vp-toggle-navbar-button .vp-top,.vp-toggle-navbar-button .vp-middle,.vp-toggle-navbar-button .vp-bottom{position:absolute;width:16px;height:2px;background:var(--dark-grey);transition:top .25s,background .5s,transform .25s}.vp-toggle-navbar-button .vp-top{top:0;left:0;transform:translate(0)}.vp-toggle-navbar-button .vp-middle{top:6px;left:0;transform:translate(8px)}.vp-toggle-navbar-button .vp-bottom{top:12px;left:0;transform:translate(4px)}.vp-toggle-navbar-button:hover .vp-top{top:0;left:0;transform:translate(4px)}.vp-toggle-navbar-button:hover .vp-middle{top:6;left:0;transform:translate(0)}.vp-toggle-navbar-button:hover .vp-bottom{top:12px;left:0;transform:translate(8px)}.vp-toggle-navbar-button.is-active .vp-top{top:6px;transform:translate(0) rotate(225deg)}.vp-toggle-navbar-button.is-active .vp-middle{top:6px;transform:translate(16px)}.vp-toggle-navbar-button.is-active .vp-bottom{top:6px;transform:translate(0) rotate(135deg)}.vp-toggle-navbar-button.is-active:hover .vp-top,.vp-toggle-navbar-button.is-active:hover .vp-middle,.vp-toggle-navbar-button.is-active:hover .vp-bottom{background:var(--theme-color);transition:top .25s,background .25s,transform .25s}.vp-toggle-sidebar-button{border-width:0;background:transparent;cursor:pointer;display:none;vertical-align:middle;box-sizing:content-box;width:1rem;height:1rem;padding:.5rem;font:unset;transition:transform .2s ease-in-out}@media screen and (max-width: 719px){.vp-toggle-sidebar-button{display:block;padding-inline-end:var(--navbar-mobile-horizontal-padding)}}.vp-toggle-sidebar-button:before,.vp-toggle-sidebar-button:after,.vp-toggle-sidebar-button .icon{display:block;width:100%;height:2px;border-radius:.05em;background:var(--dark-grey);transition:transform .2s ease-in-out}.vp-toggle-sidebar-button:before{content:" ";margin-top:.125em}.sidebar-open .vp-toggle-sidebar-button:before{transform:translateY(.34rem) rotate(135deg)}.vp-toggle-sidebar-button:after{content:" ";margin-bottom:.125em}.sidebar-open .vp-toggle-sidebar-button:after{transform:translateY(-.34rem) rotate(-135deg)}.vp-toggle-sidebar-button .icon{margin:.2em 0}.sidebar-open .vp-toggle-sidebar-button .icon{transform:scale(0)}.appearance-title{display:block;margin:0;padding:0 .25rem;color:var(--light-grey);font-weight:600;font-size:.75rem;line-height:2;transition:color var(--color-transition)}#appearance-switch{border-width:0;background:transparent;vertical-align:middle;padding:6px;color:var(--dark-grey);cursor:pointer;transition:color var(--color-transition)}#appearance-switch:hover{color:var(--theme-color)}#appearance-switch .icon{width:1.25rem;height:1.25rem}.outlook-button{border-width:0;background:transparent;cursor:pointer;position:relative;padding:.375rem;color:var(--dark-grey)}.outlook-button .icon{vertical-align:middle;width:1.25rem;height:1.25rem}.outlook-dropdown{position:absolute;top:100%;inset-inline-end:0;overflow-y:auto;box-sizing:border-box;min-width:100px;margin:0;padding:.5rem .75rem;border:1px solid var(--grey14);border-radius:.25rem;background:var(--bg-color);box-shadow:2px 2px 10px var(--card-shadow);text-align:start;white-space:nowrap;opacity:0;visibility:hidden;transition:all .18s ease-out;transform:scale(.8)}.outlook-dropdown>*:not(:last-child){padding-bottom:.5rem;border-bottom:1px solid var(--grey14)}.outlook-button:hover .outlook-dropdown,.outlook-button.open .outlook-dropdown{z-index:2;opacity:1;visibility:visible;transform:scale(1)}.theme-color-title{display:block;margin:0;padding:0 .25rem;color:var(--light-grey);font-weight:600;font-size:.75rem;line-height:2;transition:color var(--color-transition)}#theme-color-picker{display:flex;margin:0;padding:0;list-style-type:none;font-size:14px}#theme-color-picker li span{display:inline-block;vertical-align:middle;width:15px;height:15px;margin:0 2px;border-radius:2px}#theme-color-picker li span.theme-color,#theme-color-picker li span.theme-color html[data-theme=dark]{background:#2980b9}:root.theme-1{--theme-color: #2196f3;--theme-color-light: #37a1f4;--theme-color-dark: #0d89ec;--theme-color-mask: rgba(33, 150, 243, .15)}:root.theme-2{--theme-color: #f26d6d;--theme-color-light: #f37c7c;--theme-color-dark: #ef4d4d;--theme-color-mask: rgba(242, 109, 109, .15)}:root.theme-3{--theme-color: #3eaf7c;--theme-color-light: #4abf8a;--theme-color-dark: #389e70;--theme-color-mask: rgba(62, 175, 124, .15)}:root.theme-4{--theme-color: #fb9b5f;--theme-color-light: #fba56f;--theme-color-dark: #fa863d;--theme-color-mask: rgba(251, 155, 95, .15)}@media print{.full-screen-wrapper{display:none}}.full-screen-title{display:block;margin:0;padding:0 .25rem;color:var(--light-grey);font-weight:600;font-size:.75rem;line-height:2;transition:color var(--color-transition)}.full-screen,.cancel-full-screen{border-width:0;background:transparent;vertical-align:middle;padding:.375rem;color:var(--dark-grey);cursor:pointer}.full-screen:hover,.cancel-full-screen:hover{color:var(--theme-color)}.full-screen .icon,.cancel-full-screen .icon{width:1.25rem;height:1.25rem}.enter-fullscreen-icon:hover,.cancel-fullscreen-icon{color:var(--theme-color)}.cancel-fullscreen-icon:hover{color:var(--dark-grey)}.vp-sidebar-heading{display:flex;align-items:center;overflow:hidden;box-sizing:border-box;width:calc(100% - 1rem);margin:0;margin-inline:.5rem;padding:.25rem .5rem;border-width:0;border-radius:.375rem;background:transparent;color:var(--text-color);font-size:1.1em;line-height:1.5;-webkit-user-select:none;-moz-user-select:none;user-select:none;transition:color .15s ease;transform:rotate(0)}.vp-sidebar-heading.open{color:inherit}.vp-sidebar-heading.clickable:hover{background:var(--bg-color-secondary)}.vp-sidebar-heading.clickable.exact{border-inline-start-color:var(--theme-color);color:var(--theme-color)}.vp-sidebar-heading.clickable.exact a{color:inherit}.vp-sidebar-heading .vp-sidebar-title{flex:1}.vp-sidebar-heading .vp-arrow{display:inline-block;vertical-align:middle;width:1em;height:1em;background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(0,0,0,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E");background-position:center;background-repeat:no-repeat;line-height:normal;transition:all .3s;font-size:1.5em}html[data-theme=dark] .vp-sidebar-heading .vp-arrow{background-image:url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 24 24'%3E%3Cpath fill='rgba(255,255,255,0.5)' d='M7.41 15.41L12 10.83l4.59 4.58L18 14l-6-6-6 6z'/%3E%3C/svg%3E")}.vp-sidebar-heading .vp-arrow.down{transform:rotate(180deg)}html[dir=rtl] .vp-sidebar-heading .vp-arrow.down{transform:rotate(-180deg)}.vp-sidebar-heading .vp-arrow.end{transform:rotate(90deg)}html[dir=rtl] .vp-sidebar-heading .vp-arrow.end,.vp-sidebar-heading .vp-arrow.start{transform:rotate(-90deg)}html[dir=rtl] .vp-sidebar-heading .vp-arrow.start{transform:rotate(90deg)}button.vp-sidebar-heading{outline:none;font-weight:inherit;font-family:inherit;line-height:inherit;text-align:start;cursor:pointer}.vp-sidebar-link{display:inline-block;box-sizing:border-box;width:calc(100% - 1rem);margin-inline:.5rem;padding:.25rem .5rem;border-radius:.375rem;color:var(--text-color);font-weight:400;font-size:1em;line-height:1.5}.vp-sidebar-link:hover{background:var(--bg-color-secondary)}.vp-sidebar-link.active{background:var(--theme-color-mask);color:var(--theme-color);font-weight:500}.vp-sidebar-link.active .icon{color:var(--theme-color)}.vp-sidebar-sub-headers .vp-sidebar-link{padding-top:.25rem;padding-bottom:.25rem;border-inline-start:none}.vp-sidebar-sub-headers .vp-sidebar-link.active{background:transparent;font-weight:500}.vp-sidebar-group:not(.collapsible) .vp-sidebar-heading:not(.clickable){color:inherit;cursor:auto}.vp-sidebar-group .vp-sidebar-group{padding-inline-start:.75rem}.vp-sidebar-group .vp-sidebar-group .vp-sidebar-heading{font-size:1em}.vp-sidebar-group .vp-sidebar-link{padding-inline-start:1.25rem}.vp-sidebar-links,.vp-sidebar-links ul{margin:0;padding:0}.vp-sidebar-links ul.vp-sidebar-sub-headers{padding-inline-start:.75rem;font-size:.95em}@media (min-width: 1440px){.has-toc .vp-sidebar-links ul.vp-sidebar-sub-headers{display:none}}.vp-sidebar-links li{list-style-type:none}.vp-sidebar>.vp-sidebar-links{padding:1.5rem 0}@media (max-width: 719px){.vp-sidebar>.vp-sidebar-links{padding:1rem 0}}.vp-sidebar>.vp-sidebar-links>li>.vp-sidebar-link{font-size:1.1em}.vp-sidebar>.vp-sidebar-links>li:not(:first-child){margin-top:.5rem}.vp-sidebar{position:fixed;top:0;bottom:0;inset-inline-start:0;z-index:1;overflow-y:auto;width:var(--sidebar-width);margin:0;padding-inline-start:calc(var(--sidebar-space) - var(--sidebar-width));background:var(--sidebar-bg-color);box-shadow:2px 0 8px var(--card-shadow);font-size:.94rem;transition:background var(--color-transition),box-shadow var(--color-transition),padding var(--transform-transition),transform var(--transform-transition);-webkit-backdrop-filter:saturate(150%) blur(12px);backdrop-filter:saturate(150%) blur(12px);scrollbar-color:var(--theme-color) var(--border-color);scrollbar-width:thin}@media (max-width: 959px){.vp-sidebar{font-size:.86em}}@media (max-width: 719px){.vp-sidebar{z-index:125;box-shadow:none;transform:translate(-100%)}html[dir=rtl] .vp-sidebar{transform:translate(100%)}}@media (min-width: 1440px){.vp-sidebar{padding-bottom:3rem;box-shadow:none;font-size:1rem}}@media print{.vp-sidebar{display:none}}.vp-sidebar a{display:inline-block;color:var(--text-color);font-weight:400}.vp-sidebar .icon{margin-inline-end:.25em;font-size:1em}.vp-sidebar img.icon{vertical-align:-.125em;height:1em}.vp-sidebar.hide-icon .icon{display:none!important}.vp-sidebar-mask{position:fixed;top:0;right:0;bottom:0;left:0;z-index:9;background:#00000026}.vp-sidebar-mask.fade-enter-active,.vp-sidebar-mask.fade-leave-active{transition:opacity .25s}.vp-sidebar-mask.fade-enter-from,.vp-sidebar-mask.fade-leave-to{opacity:0}@media (min-width: 1440px){body{font-size:16px}}:root{--font-family: gitbook-content-font, -apple-system, BlinkMacSystemFont, "Segoe UI", Helvetica, Arial, sans-serif;--font-family-heading: gitbook-content-font, -apple-system, BlinkMacSystemFont, "Segoe UI", Helvetica, Arial, sans-serif}html[data-theme=dark]{--text-color: #FFFFFF}.theme-hope-content figure{position:relative;display:flex;flex-direction:column;width:auto;margin:1rem auto;text-align:center;transition:transform var(--vp-tt)}.theme-hope-content figure img{overflow:hidden;margin:0 auto;border-radius:8px}.theme-hope-content figure img[tabindex]:hover,.theme-hope-content figure img[tabindex]:focus{box-shadow:2px 2px 10px 0 var(--card-shadow)}@media print{.theme-hope-content figure>a[href^="http://"]:after,.theme-hope-content figure>a[href^="https://"]:after{content:""}}.theme-hope-content figure>a .external-link-icon{display:none}.theme-hope-content figure figcaption{display:inline-block;margin:6px auto;font-size:.8rem}html[data-theme=light] figure:has(img[data-mode=darkmode-only]),html[data-theme=light] img[data-mode=darkmode-only]{display:none!important}html[data-theme=dark] figure:has(img[data-mode=lightmode-only]),html[data-theme=dark] img[data-mode=lightmode-only]{display:none!important}.search-pro-button{border-width:0;background:transparent;display:inline-flex;align-items:center;box-sizing:content-box;height:1.25rem;margin-inline:1rem 0;margin-top:0;margin-bottom:0;padding:.5rem;border:0;border:1px solid var(--vp-bgl);border-radius:1rem;background:var(--vp-bgl);color:var(--vp-c);font-weight:500;cursor:pointer;transition:background var(--vp-ct),color var(--vp-ct)}@media print{.search-pro-button{display:none}}@media (max-width: 959px){.search-pro-button{border-radius:50%}}.search-pro-button:hover{border:1px solid var(--vp-tc);background-color:var(--vp-bglt);color:var(--vp-clt)}.search-pro-button .search-icon{width:1.25rem;height:1.25rem}.search-pro-placeholder{margin-inline:.25rem;font-size:1rem}@media (max-width: 959px){.search-pro-placeholder{display:none}}.search-pro-key-hints{font-size:.75rem}@media (max-width: 959px){.search-pro-key-hints{display:none}}.search-pro-key{display:inline-block;min-width:1em;margin-inline:.125rem;padding:.25rem;border:1px solid var(--vp-brc);border-radius:4px;box-shadow:1px 1px 4px 0 var(--card-shadow);line-height:1;letter-spacing:-.1em;transition:background var(--vp-ct),color var(--vp-ct),border var(--vp-ct) box-shadow var(--vp-ct)}@keyframes search-pro-fade-in{0%{opacity:.2}to{opacity:1}}.search-pro-modal-wrapper{position:fixed;top:0;right:0;bottom:0;left:0;z-index:997;display:flex;align-items:center;justify-content:center;overflow:auto;cursor:default}.search-pro-mask{position:fixed;top:0;right:0;bottom:0;left:0;z-index:998;animation:.25s search-pro-fade-in;-webkit-backdrop-filter:blur(10px);backdrop-filter:blur(10px)}.search-pro-modal{position:absolute;z-index:999;display:flex;flex-direction:column;width:calc(100% - 6rem);max-width:50em;border-radius:10px;background:var(--vp-bg);box-shadow:2px 2px 10px 0 var(--card-shadow);transition:background var(--vp-ct);animation:.15s pwa-opened}@media (max-width: 1280px){.search-pro-modal{animation:.25s pwa-mobile}}@media (max-width: 719px){.search-pro-modal{width:100vw;max-width:unset;height:100vh}}.search-pro-box{display:flex;margin:1rem}.search-pro-box form{position:relative;display:flex;flex:1}.search-pro-box label{position:absolute;top:calc(50% - .75rem);inset-inline-start:.5rem;color:var(--vp-tc)}.search-pro-box label .search-icon{width:1.5rem;height:1.5rem}.search-pro-clear-button{border-width:0;background:transparent;cursor:pointer;position:absolute;top:calc(50% - 10px);inset-inline-end:.75rem;padding:0;color:var(--vp-tc)}.search-pro-clear-button:hover{border-radius:50%;background-color:#0000001a}.search-pro-close-button{border-width:0;background:transparent;cursor:pointer;display:none;margin-inline:.5rem -.5rem;padding:.5rem;color:var(--grey3);font-size:1rem}@media (max-width: 719px){.search-pro-close-button{display:block}}.search-pro-input{flex:1;width:0;margin:0;padding-block:.25rem;padding-inline:2.5rem 2rem;border:0;border:2px solid var(--vp-tc);border-radius:8px;background:var(--vp-bg);color:var(--vp-c);outline:none;font-size:1.25rem;line-height:2.5;-webkit-appearance:none;-moz-appearance:none;appearance:none}.search-pro-input::-webkit-search-cancel-button{display:none}.search-pro-suggestions{position:absolute;inset:calc(100% + 4px) 0 auto;z-index:20;overflow:visible;overflow-y:auto;max-height:50vh;margin:0;padding:0;border-radius:.5rem;background-color:var(--vp-bg);box-shadow:2px 2px 10px 0 var(--card-shadow);list-style:none;line-height:1.5}.search-pro-suggestion{padding:.25rem 1rem;border-top:1px solid var(--vp-brc);cursor:pointer}.search-pro-suggestion:first-child{border-top:none}.search-pro-suggestion.active,.search-pro-suggestion:hover{background-color:var(--vp-bglt)}.search-pro-auto-complete{display:none;float:right;margin:0 .5rem;padding:4px;border:1px solid var(--vp-brc);border-radius:4px;box-shadow:1px 1px 4px 0 var(--card-shadow);font-size:12px;line-height:1}.search-pro-suggestion.active .search-pro-auto-complete{display:block}.search-pro-result-wrapper{flex-grow:1;overflow-y:auto;min-height:40vh;max-height:calc(80vh - 10rem);padding:0 1rem}@media (max-width: 719px){.search-pro-result-wrapper{min-height:unset;max-height:unset}}.search-pro-result-wrapper.loading,.search-pro-result-wrapper.empty{display:flex;align-items:center;justify-content:center;padding:1.5rem;font-weight:600;font-size:22px;text-align:center}.search-pro-hints{margin-top:1rem;padding:.75rem .5rem;box-shadow:0 -1px 4px 0 var(--card-shadow);line-height:1}.search-pro-hint{display:inline-flex;align-items:center;margin:0 .5rem}.search-pro-hint kbd{margin:0 .5rem;padding:2px;border:1px solid var(--vp-brc);border-radius:4px;box-shadow:1px 1px 4px 0 var(--card-shadow)}.search-pro-hint kbd+kbd{margin-inline-start:-.25rem}.search-pro-hint svg{display:block;width:15px;height:15px}.giscus-wrapper{max-width:var(--content-width, 740px);margin:0 auto;padding:2rem 2.5rem}@media (max-width: 959px){.giscus-wrapper{padding:1.5rem}}@media (max-width: 419px){.giscus-wrapper{padding:1rem 1.5rem}}@media print{.giscus-wrapper{max-width:unset}}@media print{.giscus-wrapper{display:none!important}}.giscus-wrapper.input-top .giscus{margin-bottom:-3rem}.search-pro-result-wrapper{scrollbar-color:var(--vp-tc) var(--vp-brc);scrollbar-width:thin}@media (max-width: 419px){.search-pro-result-wrapper{font-size:14px}}.search-pro-result-wrapper::-webkit-scrollbar{width:6px;height:6px}.search-pro-result-wrapper::-webkit-scrollbar-track-piece{border-radius:6px;background:#0000001a}.search-pro-result-wrapper::-webkit-scrollbar-thumb{border-radius:6px;background:var(--vp-tc)}.search-pro-result-wrapper::-webkit-scrollbar-thumb:active{background:var(--vp-tcl)}.search-pro-result-wrapper mark{border-radius:.25em;line-height:1}.search-pro-result-list{margin:0;padding:0}.search-pro-result-list-item{display:block;list-style:none}.search-pro-result-title{position:sticky;top:-2px;z-index:10;margin:-4px;margin-bottom:.25rem;padding:4px;background:var(--vp-bg);color:var(--vp-tc);font-weight:600;font-size:.85em;line-height:2rem;text-indent:.5em}.search-pro-result-item.active .search-pro-result-title{color:var(--vp-tc)}.search-pro-result-type{display:block;width:1rem;height:1rem;margin-inline-start:-.5rem;padding:.5rem;color:var(--vp-tc)}.search-pro-remove-icon{border-width:0;background:transparent;cursor:pointer;box-sizing:content-box;height:1.5rem;padding:0;border-radius:50%;color:var(--vp-tc);font-size:1rem}.search-pro-remove-icon svg{width:1.5rem;height:1.5rem}.search-pro-remove-icon:hover{background:#8080804d}.search-pro-result-content{display:flex;flex-grow:1;flex-direction:column;align-items:stretch;justify-content:center;line-height:1.5}.search-pro-result-content .content-header{margin-bottom:.25rem;border-bottom:1px solid var(--vp-brcd);font-size:.9em}.search-pro-result-item{display:flex;align-items:center;margin:.5rem 0;padding:.5rem .75rem;border-radius:.25rem;background:var(--vp-bgl);color:inherit;box-shadow:0 1px 3px 0 var(--card-shadow);font-weight:400;white-space:pre-wrap;word-wrap:break-word}.search-pro-result-item strong{color:var(--vp-tc)}.search-pro-result-item:hover,.search-pro-result-item.active{background-color:var(--vp-tcl);color:var(--white);cursor:pointer}.search-pro-result-item:hover .search-pro-result-type,.search-pro-result-item:hover .search-pro-remove-icon,.search-pro-result-item:hover strong,.search-pro-result-item.active .search-pro-result-type,.search-pro-result-item.active .search-pro-remove-icon,.search-pro-result-item.active strong{color:var(--white)}
diff --git a/assets/tekton.html-5SA8R3wN.js b/assets/tekton.html-5SA8R3wN.js
new file mode 100644
index 00000000..1a761263
--- /dev/null
+++ b/assets/tekton.html-5SA8R3wN.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o,c as a,a as e,d as n}from"./app-cS6i7hsH.js";const r={},c=e("h1",{id:"tekton",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#tekton","aria-hidden":"true"},"#"),n(" tekton")],-1),s=[c];function _(d,i){return o(),a("div",null,s)}const f=t(r,[["render",_],["__file","tekton.html.vue"]]);export{f as default};
diff --git a/assets/tekton.html-7q40Qc0_.js b/assets/tekton.html-7q40Qc0_.js
new file mode 100644
index 00000000..4469cff7
--- /dev/null
+++ b/assets/tekton.html-7q40Qc0_.js
@@ -0,0 +1 @@
+const t=JSON.parse('{"key":"v-1a2ca7a7","path":"/devops/tekton.html","title":"tekton","lang":"zh-CN","frontmatter":{"description":"tekton","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/devops/tekton.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"tekton"}],["meta",{"property":"og:description","content":"tekton"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"tekton\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0,"words":1},"filePathRelative":"devops/tekton.md","localizedDate":"2024年1月24日","excerpt":" tekton \\n","autoDesc":true}');export{t as data};
diff --git a/assets/tesla.html-2Y58-poF.js b/assets/tesla.html-2Y58-poF.js
new file mode 100644
index 00000000..6d620bd7
--- /dev/null
+++ b/assets/tesla.html-2Y58-poF.js
@@ -0,0 +1,30 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as i,o as p,c as l,a as e,d as a,b as o,e as n}from"./app-cS6i7hsH.js";const r={},c=n(' Tesla api 一、特斯拉应用申请 1.1 创建 Tesla 账户 如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。
正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.
注意点:(1)不要用自己车辆的邮箱来注册(2)有些邮箱不是特斯拉开发者的邮箱,可能用这些有些无法正常提交访问请求。
1.2 提交访问请求 点击下方的“提交请求”按钮,请求应用程序访问权限。登录后,请提供您的合法企业详细信息、应用程序名称及描述和使用目的。在您提交了详细信息之后,我们会审核您的请求并通过电子邮件向您发送状态更新。
这一步很坑,多次尝试之后都无果,原因也不知道是为啥,只能自己去看返回报文琢磨,太难受了,下面是自己踩的坑
(1)Invalid domain
无效的域名,这里我用的域名是腾讯云个人服务器的域名,证书是腾讯云免费一年的证书,印象中第一申请的时候还是能过的,第二次的时候就不行了,可能被识别到免费的ssl证书不符合规范,还是需要由合法机构的颁发证书才行。所以,为了金快速申请通过,先填个https://baidu.com吧。当然,后续需要彻底解决自己域名证书的问题,我改为使用阿里云的ssl证书,3个月到期的那种。
(2)Unable to Onboard
应用无法上架,可能原因为邮箱不对,用了之前消费者账号(即自己的车辆账号),建议换别的邮箱试试。
(3) Rejected
这一步尝试了很多次,具体原因为国内还无法正常使用tesla api,只能切换至美国服务器申请下(截止2023-11-15),后续留意官网通知。
1.3 访问应用程序凭据 一旦获得批准,将为您的应用程序生成可在登录后访问的客户端 ID 和客户端密钥。使用这些凭据,通过 OAuth 2.0 身份验证获取用户访问令牌。访问令牌可用于对提供私人用户账户信息或代表其他账户执行操作的请求进行身份验证。
申请好就可以在自己的账号下看到自己的应用了,
1.4 开始 API 集成 按照 API 文档和设置说明将您的应用程序与 Tesla 车队 API 集成。您需要生成并注册公钥,请求用户授权并按照规格要求拨打电话。完成后您将能够与 API 进行交互,并开始围绕 Tesla 设备构建集成。
二、开发之前的准备 由于特斯拉刚推出,并且国内进展缓慢,很多都申请不下来,下面内容均以北美区域进行调用。
2.1 认识token app与特斯拉交互的共有两个令牌(token)方式,在调用api的时候,特别需要注意使用的是哪种token,下面是两种token的说明:
(1)合作伙伴身份验证令牌:这个就是你申请的app的令牌
(2)客户生成第三方令牌:这个是消费者在你这个app下授权之后的令牌。
',32),d={href:"https://fleet-api.prd.cn.vn.cloud.tesla.cn/",target:"_blank",rel:"noopener noreferrer"},u=n(` 2.2 获取第三方应用token 这一步官网列的很详细,就不在详述了。
CLIENT_ID = < command to obtain a client_id>
+CLIENT_SECRET = < secure command to obtain a client_secret>
+AUDIENCE = "https://fleet-api.prd.na.vn.cloud.tesla.com"
+
+curl --request POST \\
+ --header 'Content-Type: application/x-www-form-urlencoded' \\
+ --data-urlencode 'grant_type=client_credentials' \\
+ --data-urlencode "client_id=$CLIENT_ID " \\
+ --data-urlencode "client_secret=$CLIENT_SECRET " \\
+ --data-urlencode 'scope=openid vehicle_device_data vehicle_cmds vehicle_charging_cmds' \\
+ --data-urlencode "audience=$AUDIENCE " \\
+ 'https://auth.tesla.com/oauth2/v3/token'
+
+ 2.3 验证域名归属 2.1.1 Register 完成注册合作方账号之后才可以访问API. 每个developer.tesla.cn上的应用程序都必须完成此步骤。官网挂了一个github的代码,看了半天,以为要搞很多东西,实际上只需要几步就可以了。
cd vehicle-command/cmd/tesla-keygen
+go build .
+./tesla-keygen -f -keyring-debug -key-file= private create > public_key.pem
+这里只是生成了公钥,需要把公钥挂载到域名之下,我们用的是nginx,所以只要指向pem文件就可以了,注意下nginx是否可以访问到改文件,如果不行,把nginx的user改为root。
location ~ ^/.well-known {
+ default_type text/html;
+ alias /root/vehicle-command/cmd/tesla-keygen/public_key.pem;
+ }
+随后,便是向tesla注册你的域名,域名必须和你申请的时候填的一样。
curl --header 'Content-Type: application/json' \\
+ --header "Authorization: Bearer $TESLA_API_TOKEN " \\
+ --data '{"domain":"string"}' \\
+ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts'
+
+ 2.1.2 public_key 最后,验证一下是否真的注册成功(GET /api/1/partner_accounts/public_key)
curl --header 'Content-Type: application/json' \\
+ --header "Authorization: Bearer $TESLA_API_TOKEN" \\
+ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts/public_key'
+得到下面内容就代表成功了
{ "response" : { "public_key" : "xxxx" } }
+至此,我们的开发准备就完成了,接下来就是正常的开发与用户交互的api。
`,17);function h(m,v){const s=i("ExternalLinkIcon");return p(),l("div",null,[c,e("p",null,[a("此外,还需要注意下,中国大陆地区对应的api地址是 "),e("a",d,[a("https://fleet-api.prd.cn.vn.cloud.tesla.cn"),o(s)]),a(",不要调到别的地址去了。")]),u])}const k=t(r,[["render",h],["__file","tesla.html.vue"]]);export{k as default};
diff --git a/assets/tesla.html-NVSkMPRC.js b/assets/tesla.html-NVSkMPRC.js
new file mode 100644
index 00000000..186a2cf5
--- /dev/null
+++ b/assets/tesla.html-NVSkMPRC.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-3c114a75","path":"/others/tesla.html","title":"Tesla api","lang":"zh-CN","frontmatter":{"description":"Tesla api 一、特斯拉应用申请 1.1 创建 Tesla 账户 如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。 正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/others/tesla.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Tesla api"}],["meta",{"property":"og:description","content":"Tesla api 一、特斯拉应用申请 1.1 创建 Tesla 账户 如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。 正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator."}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"Tesla api\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、特斯拉应用申请","slug":"一、特斯拉应用申请","link":"#一、特斯拉应用申请","children":[{"level":3,"title":"1.1 创建 Tesla 账户","slug":"_1-1-创建-tesla-账户","link":"#_1-1-创建-tesla-账户","children":[]},{"level":3,"title":"1.2 提交访问请求","slug":"_1-2-提交访问请求","link":"#_1-2-提交访问请求","children":[]},{"level":3,"title":"1.3 访问应用程序凭据","slug":"_1-3-访问应用程序凭据","link":"#_1-3-访问应用程序凭据","children":[]},{"level":3,"title":"1.4 开始 API 集成","slug":"_1-4-开始-api-集成","link":"#_1-4-开始-api-集成","children":[]},{"level":3,"title":"2.1 认识token","slug":"_2-1-认识token","link":"#_2-1-认识token","children":[]},{"level":3,"title":"2.2 获取第三方应用token","slug":"_2-2-获取第三方应用token","link":"#_2-2-获取第三方应用token","children":[]},{"level":3,"title":"2.3 验证域名归属","slug":"_2-3-验证域名归属","link":"#_2-3-验证域名归属","children":[]}]}],"git":{"createdTime":1706186538000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":4}]},"readingTime":{"minutes":4.5,"words":1351},"filePathRelative":"others/tesla.md","localizedDate":"2024年1月25日","excerpt":" Tesla api \\n 一、特斯拉应用申请 \\n 1.1 创建 Tesla 账户 \\n如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。
\\n正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.
\\ntt一面:\\n1.全程项目\\n2.lc3,最长无重复子串,滑动窗口解决
\\ntt二面:\\n全程基础,一直追问\\n1.java内存模型介绍一下\\n2.volatile原理\\n3.内存屏障,使用场景?(我提了在gc中有使用)\\n4.gc中具体是怎么使用内存屏障的,详细介绍\\n5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么\\n6.线程内存分配方式,tlab相关\\n7.happens-before介绍一下\\n8.总线风暴是什么,怎么解决\\n9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决\\n10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222\\n11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作
","autoDesc":true}');export{e as data};
diff --git a/assets/tiktok2023.html-Ih4GrSaS.js b/assets/tiktok2023.html-Ih4GrSaS.js
new file mode 100644
index 00000000..db593f7c
--- /dev/null
+++ b/assets/tiktok2023.html-Ih4GrSaS.js
@@ -0,0 +1 @@
+import{_ as e}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as c,c as o,a as t}from"./app-cS6i7hsH.js";const s={},l=t("p",null,"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决",-1),n=t("p",null,"tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作",-1),_=t("p",null,"tt三面: 大部分聊项目,基础随便问了问 1.分布式事务,两阶段三阶段流程,区别 2.mysql主从,同步复制,半同步复制,异步复制 3.算法题,k个一组翻转链表,类似lc25,区别是最后一组不足k个也要翻转 4.场景题,设计一个评论系统,包含发布评论,回复评论,评论点赞等功能,用户过亿,qps百万",-1),a=[l,n,_];function i(r,m){return c(),o("div",null,a)}const f=e(s,[["render",i],["__file","tiktok2023.html.vue"]]);export{f as default};
diff --git a/assets/wewe.html-MSrbCURC.js b/assets/wewe.html-MSrbCURC.js
new file mode 100644
index 00000000..4cb90731
--- /dev/null
+++ b/assets/wewe.html-MSrbCURC.js
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o,c as a,a as e,d as c}from"./app-cS6i7hsH.js";const r={},s=e("h1",{id:"自我介绍",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#自我介绍","aria-hidden":"true"},"#"),c(" 自我介绍")],-1),n=e("p",null,"oifjwoiej",-1),_=[s,n];function d(i,l){return o(),a("div",null,_)}const m=t(r,[["render",d],["__file","wewe.html.vue"]]);export{m as default};
diff --git a/assets/wewe.html-wLcqOgAE.js b/assets/wewe.html-wLcqOgAE.js
new file mode 100644
index 00000000..cee953ff
--- /dev/null
+++ b/assets/wewe.html-wLcqOgAE.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-43e9e6b0","path":"/about-the-author/personal-life/wewe.html","title":"自我介绍","lang":"zh-CN","frontmatter":{"description":"自我介绍 oifjwoiej","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/about-the-author/personal-life/wewe.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"自我介绍"}],["meta",{"property":"og:description","content":"自我介绍 oifjwoiej"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T04:53:47.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T04:53:47.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"自我介绍\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T04:53:47.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706244827000,"updatedTime":1706244827000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.02,"words":5},"filePathRelative":"about-the-author/personal-life/wewe.md","localizedDate":"2024年1月26日","excerpt":" 自我介绍 \\noifjwoiej
\\n","autoDesc":true}');export{e as data};
diff --git a/assets/zookeeper.html-YcPoe8IG.js b/assets/zookeeper.html-YcPoe8IG.js
new file mode 100644
index 00000000..46357549
--- /dev/null
+++ b/assets/zookeeper.html-YcPoe8IG.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-7d9b9318","path":"/middleware/zookeeper/zookeeper.html","title":"Zookeeper","lang":"zh-CN","frontmatter":{"description":"Zookeeper 留空","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/middleware/zookeeper/zookeeper.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"Zookeeper"}],["meta",{"property":"og:description","content":"Zookeeper 留空"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T17:34:45.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T17:34:45.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"Zookeeper\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T17:34:45.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706204085000,"updatedTime":1706204085000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":0.01,"words":3},"filePathRelative":"middleware/zookeeper/zookeeper.md","localizedDate":"2024年1月25日","excerpt":" Zookeeper \\n留空
\\n","autoDesc":true}');export{e as data};
diff --git a/assets/zookeeper.html-bxhlqtiT.js b/assets/zookeeper.html-bxhlqtiT.js
new file mode 100644
index 00000000..08c7cdc1
--- /dev/null
+++ b/assets/zookeeper.html-bxhlqtiT.js
@@ -0,0 +1 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as r,c as t,a as e,d as a}from"./app-cS6i7hsH.js";const c={},s=e("h1",{id:"zookeeper",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#zookeeper","aria-hidden":"true"},"#"),a(" Zookeeper")],-1),n=e("p",null,"留空",-1),_=[s,n];function d(i,l){return r(),t("div",null,_)}const f=o(c,[["render",d],["__file","zookeeper.html.vue"]]);export{f as default};
diff --git "a/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-6moNXOiY.js" "b/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-6moNXOiY.js"
new file mode 100644
index 00000000..11dea2eb
--- /dev/null
+++ "b/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-6moNXOiY.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-3f2a15ee","path":"/database/elasticsearch/%E3%80%90elasticsearch%E3%80%91%E6%90%9C%E7%B4%A2%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.html","title":"【elasticsearch】搜索过程详解","lang":"zh-CN","frontmatter":{"description":"【elasticsearch】搜索过程详解 本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。 SearchType QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。 DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/elasticsearch/%E3%80%90elasticsearch%E3%80%91%E6%90%9C%E7%B4%A2%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"【elasticsearch】搜索过程详解"}],["meta",{"property":"og:description","content":"【elasticsearch】搜索过程详解 本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。 SearchType QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。 DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T04:05:46.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T04:05:46.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"【elasticsearch】搜索过程详解\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T04:05:46.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":3,"title":"SearchType","slug":"searchtype","link":"#searchtype","children":[]},{"level":2,"title":"搜索入口:","slug":"搜索入口","link":"#搜索入口","children":[]},{"level":2,"title":"3.1 query阶段","slug":"_3-1-query阶段","link":"#_3-1-query阶段","children":[]},{"level":2,"title":"3.2 Fetch阶段","slug":"_3-2-fetch阶段","link":"#_3-2-fetch阶段","children":[{"level":3,"title":"3.2.1 FetchSearchPhase(对应上面的1)","slug":"_3-2-1-fetchsearchphase-对应上面的1","link":"#_3-2-1-fetchsearchphase-对应上面的1","children":[]},{"level":3,"title":"3.2.2 ExpandSearchPhase(对应上图的2)","slug":"_3-2-2-expandsearchphase-对应上图的2","link":"#_3-2-2-expandsearchphase-对应上图的2","children":[]}]},{"level":2,"title":"4.1 执行query、fetch流程","slug":"_4-1-执行query、fetch流程","link":"#_4-1-执行query、fetch流程","children":[]}],"git":{"createdTime":1706183164000,"updatedTime":1706241946000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":5}]},"readingTime":{"minutes":8.92,"words":2676},"filePathRelative":"database/elasticsearch/【elasticsearch】搜索过程详解.md","localizedDate":"2024年1月25日","excerpt":" 【elasticsearch】搜索过程详解 \\n本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。
\\n SearchType \\nQUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。\\nDFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。
","autoDesc":true}');export{e as data};
diff --git "a/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-ga4ihhfd.js" "b/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-ga4ihhfd.js"
new file mode 100644
index 00000000..45737a80
--- /dev/null
+++ "b/assets/\343\200\220elasticsearch\343\200\221\346\220\234\347\264\242\350\277\207\347\250\213\350\257\246\350\247\243.html-ga4ihhfd.js"
@@ -0,0 +1,300 @@
+import{_ as p}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as c,o,c as i,a as n,d as s,b as t,e}from"./app-cS6i7hsH.js";const u={},l=e(` 【elasticsearch】搜索过程详解 本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。
SearchType QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。 DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。
为了能够深刻了解es的搜索过程,首先创建3个索引,每个索引指定一天的一条记录。
POST aaaa-16/_doc
+{
+ "@timestamp": "2022-02-16T16:21:15.000Z",
+ "word":"16"
+}
+
+
+POST aaaa-17/_doc
+{
+ "@timestamp": "2022-02-17T16:21:15.000Z",
+ "word":"17"
+}
+
+POST aaaa-18/_doc
+{
+ "@timestamp": "2022-02-18T16:21:15.000Z",
+ "word":"18"
+}
+即可在kibana上看到3条数据
image-20220219195141327 此时,假设我们用一个索引+星号来搜索,es内部的搜索是怎么样的呢?
GET aaaa*/_search
+{
+ "query": {
+ "range": {
+ "@timestamp": {
+ "gte": "2022-02-18T10:21:15.000Z",
+ "lte": "2022-02-18T17:21:15.000Z"
+ }
+ }
+ }
+}
+正好命中一条记录返回。
{
+ "took" : 2 ,
+ "timed_out" : false ,
+ "_shards" : {
+ "total" : 3 ,
+ "successful" : 3 ,
+ "skipped" : 0 ,
+ "failed" : 0
+ } ,
+ "hits" : {
+ "total" : {
+ "value" : 1 ,
+ "relation" : "eq"
+ } ,
+ "max_score" : 1.0 ,
+ "hits" : [
+ {
+ "_index" : "aaaa-18" ,
+ "_id" : "0zB2O38BoMIMP8QzHgdq" ,
+ "_score" : 1.0 ,
+ "_source" : {
+ "@timestamp" : "2022-02-18T16:21:15.000Z" ,
+ "word" : "18"
+ }
+ }
+ ]
+ }
+}
+
+ 一、es的分布式搜索过程 `,13),r={href:"https://weread.qq.com/web/reader/f9c32dc07184876ef9cdeb6k7f33291023d7f39f8317e0b",target:"_blank",rel:"noopener noreferrer"},d=e(`2 搜索入口: 整个http请求的入口,主要使用的是Netty4HttpRequestHandler。
@ChannelHandler.Sharable
+class Netty4HttpRequestHandler extends SimpleChannelInboundHandler < HttpPipelinedRequest > {
+ @Override
+ protected void channelRead0 ( ChannelHandlerContext ctx, HttpPipelinedRequest httpRequest) {
+ final Netty4HttpChannel channel = ctx. channel ( ) . attr ( Netty4HttpServerTransport . HTTP_CHANNEL_KEY ) . get ( ) ;
+ boolean success = false ;
+ try {
+ serverTransport. incomingRequest ( httpRequest, channel) ;
+ success = true ;
+ } finally {
+ if ( success == false ) {
+ httpRequest. release ( ) ;
+ }
+ }
+ }
+}
+ 二、初步调用流程 调用链路过程:Netty4HttpRequestHandler.channelRead0->AbstractHttpServerTransport.incomingRequest->AbstractHttpServerTransport.handleIncomingRequest->AbstractHttpServerTransport.dispatchRequest->RestController.dispatchRequest(实现了HttpServerTransport.Dispatcher)->SecurityRestFilter.handleRequest->BaseRestHandler.handleRequest->action.accept(channel)->RestCancellableNodeClient.doExecute->NodeClient.executeLocally->RequestFilterChain.proceed->TransportAction.proceed->TransportSearchAction.doExecute->TransportSearchAction.executeRequest(判断是本地执行还是远程执行)->TransportSearchAction.searchAsyncAction
协调节点的主要功能是接收请求,解析并构建目的的shard列表,然后异步发送到数据节点进行请求查询。具体就不细讲了,可按着debug的来慢慢调试。
特别注意下RestCancellableNodeClient.doExecute,从executeLocally执行所有的查询过程,并注册监听listener.onResponse(response),然后响应。
public < Request extends ActionRequest , Response extends ActionResponse > void doExecute ( . . . ) {
+ . . .
+ TaskHolder taskHolder = new TaskHolder ( ) ;
+ Task task = client. executeLocally ( action, request, new ActionListener < > ( ) {
+ @Override
+ public void onResponse ( Response response) {
+ try {
+ closeListener. unregisterTask ( taskHolder) ;
+ } finally {
+ listener. onResponse ( response) ;
+ }
+ }
+ } ) ;
+ . . .
+}
+其次要注意的是:TransportSearchAction.searchAsyncAction才开始真正的搜索过程
private SearchPhase searchAsyncAction ( . . . ) {
+ . . .
+ final QueryPhaseResultConsumer queryResultConsumer = searchPhaseController. newSearchPhaseResults ( ) ;
+ AbstractSearchAsyncAction < ? extends SearchPhaseResult > = switch ( searchRequest. searchType ( ) ) {
+ case DFS_QUERY_THEN_FETCH -> new SearchDfsQueryThenFetchAsyncAction ( . . . ) ;
+ case QUERY_THEN_FETCH -> new SearchQueryThenFetchAsyncAction ( . . . ) ;
+ } ;
+ return searchAsyncAction;
+ . . .
+}
+之后就是执行AbstractSearchAsyncAction.start,启动AbstractSearchAsyncAction.executePhase的查询动作。
此处的SearchPhase 实现类为SearchQueryThenFetchAsyncAction
+private void executePhase ( SearchPhase phase) {
+ try {
+ phase. run ( ) ;
+ } catch ( Exception e) {
+ if ( logger. isDebugEnabled ( ) ) {
+ logger. debug ( new ParameterizedMessage ( "Failed to execute [{}] while moving to [{}] phase" , request, phase. getName ( ) ) , e) ;
+ }
+ onPhaseFailure ( phase, "" , e) ;
+ }
+}
+ 三、协调节点 两阶段相应的实现位置:查询(Query)阶段—search.SearchQueryThenFetchAsyncAction;取回(Fetch)阶段—search.FetchSearchPhase。它们都继承自SearchPhase,如下图所示。
23 3.1 query阶段 `,17),k={href:"https://www.elastic.co/Zephery/en/elasticsearch/Zephery/current/_query_phase.html",target:"_blank",rel:"noopener noreferrer"},v=e(`12 (1)客户端发送一个search请求到node3,node3创建一个大小为from,to的优先级队列。 (2)node3转发转发search请求至索引的主分片或者副本,每个分片执行查询请求,并且将结果放到一个排序之后的from、to大小的优先级队列。 (3)每个分片把文档id和排序之后的值返回给协调节点node3,node3把结果合并然后创建一个全局排序之后的结果。
在RestSearchAction#prepareRequest方法中将请求体解析为SearchRequest 数据结构:
+public RestChannelConsumer prepareRequest(.. .) {
+ SearchRequest searchRequest = new SearchRequest();
+ request.withContentOrSourceParamParserOrNull (parser ->
+ parseSearchRequest (searchRequest, request, parser, setSize));
+ ...
+}
+ 3.1.1 构造目的shard列表 将请求涉及的本集群shard列表和远程集群的shard列表(远程集群用于跨集群访问)合并:
private void executeSearch ( . . . ) {
+ . . .
+ final GroupShardsIterator < SearchShardIterator > = mergeShardsIterators ( localShardIterators, remoteShardIterators) ;
+ localShardIterators = StreamSupport . stream ( localShardRoutings. spliterator ( ) , false ) . map ( it -> {
+ OriginalIndices finalIndices = finalIndicesMap. get ( it. shardId ( ) . getIndex ( ) . getUUID ( ) ) ;
+ assert finalIndices != null ;
+ return new SearchShardIterator ( searchRequest. getLocalClusterAlias ( ) , it. shardId ( ) , it. getShardRoutings ( ) , finalIndices) ;
+ } ) . collect ( Collectors . toList ( ) ) ;
+ . . .
+}
+查看结果
241 3.1.2 对所有分片进行搜索 AbstractSearchAsyncAction . run
+对每个分片进行搜索查询
+for ( int i = 0 ; i < shardsIts. size ( ) ; i++ ) {
+ final SearchShardIterator shardRoutings = shardsIts. get ( i) ;
+ assert shardRoutings. skip ( ) == false ;
+ assert shardIndexMap. containsKey ( shardRoutings) ;
+ int shardIndex = shardIndexMap. get ( shardRoutings) ;
+ performPhaseOnShard ( shardIndex, shardRoutings, shardRoutings. nextOrNull ( ) ) ;
+}
+其中shardsIts是所有aaaa*的所有索引+其中一个副本
2141 3.1.3 分片具体的搜索过程 AbstractSearchAsyncAction . performPhaseOnShard
+private void performPhaseOnShard ( . . . ) {
+ executePhaseOnShard ( . . . ) {
+
+ public void inne rOnResponse ( FirstResult result) {
+ maybeFork ( thread, ( ) -> onShardResult ( result,shardIt) ) ;
+ }
+
+ public void onFailure ( Exception t) {
+ maybeFork ( thread, ( ) -> onShardFailure ( shardIndex, shard, shard. currentNodeId ( ) ,shardIt, t) ) ;
+ }
+ } ) ;
+}
+分片结果,当前线程
+. . .
+private void onShardResult ( FirstResult result, SearchShardIterator shardIt) {
+ onShardSuccess ( result) ;
+ success fulShardExecution ( shardIt) ;
+}
+. . .
+
+private void successfulShardExecution ( SearchShardIterator shardsIt) {
+
+ final int xTotalOps = totalOps. addAndGet ( remainingOpsOnIterator) ;
+
+ if ( xTotalOps == expectedTotalOps) {
+ onPhaseDone ( ) ;
+ } else if ( xTota1Ops > expectedTotal0ps) {
+ throw new AssertionError ( . . . ) ;
+ }
+}
+
+412 此处忽略了搜索结果totalHits为0的结果,并将结果进行累加,当xTotalOps等于expectedTotalOps时开始AbstractSearchAsyncAction.onPhaseDone再进行AbstractSearchAsyncAction.executeNextPhase取回阶段
3.2 Fetch阶段 `,19),h={href:"https://www.elastic.co/Zephery/en/elasticsearch/Zephery/current/_fetch_phase.html",target:"_blank",rel:"noopener noreferrer"},m=e(`412412 (1)各个shard 返回的只是各文档的id和排序值 IDs and sort values ,coordinate node根据这些id&sort values 构建完priority queue之后,然后把程序需要的document 的id发送mget请求去所有shard上获取对应的document
(2)各个shard将document返回给coordinate node
(3)coordinate node将合并后的document结果返回给client客户端
3.2.1 FetchSearchPhase(对应上面的1) Query阶段的executeNextPhase方法触发Fetch阶段,Fetch阶段的起点为FetchSearchPhase#innerRun函数,从查询阶段的shard列表中遍历,跳过查询结果为空的shard,对特定目标shard执行executeFetch来获取数据,其中包括分页信息。对scroll请求的处理也在FetchSearchPhase#innerRun函数中。
private void innerRun ( ) throws Exception {
+ final int numShards = context. getNumShards ( ) ;
+ final boolean isScrollSearch = context. getRequest ( ) . scroll ( ) != null ;
+ final List < SearchPhaseResult > = queryResults. asList ( ) ;
+ final SearchPhaseController. ReducedQueryPhase reducedQueryPhase = resultConsumer. reduce ( ) ;
+ final boolean queryAndFetchOptimization = queryResults. length ( ) == 1 ;
+ final Runnable finishPhase = ( ) -> moveToNextPhase (
+ searchPhaseController,
+ queryResults,
+ reducedQueryPhase,
+ queryAndFetchOptimization ? queryResults : fetchResults. getAtomicArray ( )
+ ) ;
+ for ( int i = 0 ; i < docIdsToLoad. length; i++ ) {
+ IntArrayList entry = docIdsToLoad[ i] ;
+ SearchPhaseResult queryResult = queryResults. get ( i) ;
+ if ( entry == null ) {
+ if ( queryResult != null ) {
+ releaseIrrelevantSearchContext ( queryResult. queryResult ( ) ) ;
+ progressListener. notifyFetchResult ( i) ;
+ }
+ counter. countDown ( ) ;
+ } else {
+ executeFetch (
+ queryResult. getShardIndex ( ) ,
+ shardTarget,
+ counter,
+ fetchSearchRequest,
+ queryResult. queryResult ( ) ,
+ connection
+ ) ;
+ }
+ }
+ }
+}
+再看源码:
启动一个线程来fetch
+AbstractSearchAsyncAction . executePhase-> FetchSearchPhase . run-> FetchSearchPhase . innerRun-> FetchSearchPhase . executeFetch
+
+private void executeFetch ( . . . ) {
+ context. getSearchTransport ( )
+ . sendExecuteFetch (
+ connection,
+ fetchSearchRequest,
+ context. getTask ( ) ,
+ new SearchActionListener < FetchSearchResult > ( shardTarget, shardIndex) {
+ @Override
+ public void innerOnResponse ( FetchSearchResult result) {
+ progressListener. notifyFetchResult ( shardIndex) ;
+ counter. onResult ( result) ;
+ }
+
+ @Override
+ public void onFailure ( Exception e) {
+ progressListener. notifyFetchFailure ( shardIndex, shardTarget, e) ;
+ counter. onFailure ( shardIndex, shardTarget, e) ;
+ }
+ }
+ ) ;
+}
+
+13413 counter是一个收集器CountedCollector,onResult(result)主要是每次收到的shard数据存放,并且执行一次countDown,当所有shard数据收集完之后,然后触发一次finishPhase。
# CountedCollector.class
+void countDown() {
+ assert counter.isCountedDown() == false : "more operations executed than specified";
+ if (counter.countDown()) {
+ onFinish.run();
+ }
+}
+moveToNextPhase方法执行下一阶段,下-阶段要执行的任务定义在FetchSearchPhase构造 函数中,主要是触发ExpandSearchPhase。
3.2.2 ExpandSearchPhase(对应上图的2) AbstractSearchAsyncAction.executePhase->ExpandSearchPhase.run。取回阶段完成之后执行ExpandSearchPhase#run,主要判断是否启用字段折叠,根据需要实现字段折叠功能,如果没有实现字段折叠,则直接返回给客户端。
image-20220317000858513 ExpandSearchPhase执行完之后回复客户端,在AbstractSearchAsyncAction.sendSearchResponse方法中实现:
412412 四、数据节点 4.1 执行query、fetch流程 执行本流程的线程池: search。
对各种Query请求的处理入口注册于SearchTransportService.registerRequestHandler。
public static void registerRequestHandler ( TransportService transportService, SearchService searchService) {
+ . . .
+ transportService. registerRequestHandler (
+ QUERY_ACTION_NAME ,
+ ThreadPool. Names . SAME ,
+ ShardSearchRequest :: new ,
+ ( request, channel, task) -> searchService. executeQueryPhase (
+ request,
+ ( SearchShardTask ) task,
+ new ChannelActionListener < > ( channel, QUERY_ACTION_NAME , request)
+ )
+ ) ;
+ . . .
+}
+ 4.1.1 执行query请求 # SearchService
+public void executeQueryPhase ( ShardSearchRequest request, SearchShardTask task, ActionListener < SearchPhaseResult > ) {
+ assert request. canReturnNullResponseIfMatchNoDocs ( ) == false || request. numberOfShards ( ) > 1
+ : "empty responses require more than one shard" ;
+ final IndexShard shard = getShard ( request) ;
+ rewriteAndFetchShardRequest ( shard, request, listener. delegateFailure ( ( l, orig) -> {
+ ensureAfterSeqNoRefreshed ( shard, orig, ( ) -> executeQueryPhase ( orig, task) , l) ;
+ } ) ) ;
+}
+其中ensureAfterSeqNoRefreshed是把request任务放到一个名为search的线程池里面执行,容量大小为1000。
1 主要是用来执行SearchService.executeQueryPhase->SearchService.loadOrExecuteQueryPhase->QueryPhase.execute。核心的查询封装在queryPhase.execute(context)中,其中调用Lucene实现检索,同时实现聚合:
public void execute ( SearchContext searchContext) {
+ aggregationPhase. preProcess ( searchContext) ;
+ boolean rescore = execute ( searchContext, searchContext. searcher ( ) , searcher:: setCheckCancelled , indexSort) ;
+ if ( rescore) {
+ rescorePhase. execute ( searchContext) ;
+ suggestPhase. execute ( searchContext) ;
+ aggregationPhase. execute ( searchContext) ;
+ }
+}
+其中包含几个核心功能:
execute(),调用Lucene、searcher.search()实现搜索 rescorePhase,全文检索且需要打分 suggestPhase,自动补全及纠错 aggregationPhase,实现聚合 4.1.2 fetch流程 对各种Fetch请求的处理入口注册于SearchTransportService.registerRequestHandler。
transportService. registerRequestHandler (
+ QUERY_FETCH_SCROLL_ACTION_NAME ,
+ ThreadPool. Names . SAME ,
+ InternalScrollSearchRequest :: new ,
+ ( request, channel, task) -> {
+ searchService. executeFetchPhase (
+ request,
+ ( SearchShardTask ) task,
+ new ChannelActionListener < > ( channel, QUERY_FETCH_SCROLL_ACTION_NAME , request)
+ ) ;
+ }
+) ;
+对Fetch响应的实现封装在SearchService.executeFetchPhase中,核心是调用fetchPhase.execute(context)。按照命中的doc取得相关数据,填充到SearchHits中,最终封装到FetchSearchResult中。
# FetchPhase
+public void execute ( SearchContext context) {
+ Profiler profiler = context. getProfilers ( ) == null ? Profiler . NOOP : context. getProfilers ( ) . startProfilingFetchPhase ( ) ;
+ SearchHits hits = null ;
+ try {
+
+ hits = buildSearchHits ( context, profiler) ;
+ } finally {
+ ProfileResult profileResult = profiler. finish ( ) ;
+
+ if ( hits != null ) {
+ context. fetchResult ( ) . shardResult ( hits, profileResult) ;
+ }
+ }
+}
+ 五、数据返回 入口:RestCancellableNodeClient.doExecute Task task = client.executeLocally主要执行查询,并使用了ActionListener来进行监听
其中onResponse的调用链路如下:RestActionListener.onResponse->RestResponseListener.processResponse->RestController.sendResponse->DefaultRestChannel.sendResponse->Netty4HttpChannel.sendResponse
public void sendResponse ( RestResponse restResponse) {
+ . . .
+ httpChannel. sendResponse ( httpResponse, listener) ;
+ . . .
+}
+
+最后由Netty4HttpChannel.sendResponse来响应请求。
六、总结 当我们以aaaa*这样来搜索的时候,实际上查询了所有匹配以aaaa开头的索引,并且对所有的索引的分片都进行了一次Query,再然后对有结果的分片进行一次fetch,最终才能展示结果。可能觉得好奇,对所有分片都进行一次搜索,遍历分片所有的Lucene分段,会不会太过于消耗资源,因此合并Lucene分段对搜索性能有好处,这里下篇文章在讲吧。同时,聚合是发生在fetch过程中的,并不是lucene。
本文参考 `,44),b={href:"https://weread.qq.com/web/reader/f9c32dc07184876ef9cdeb6k7f33291023d7f39f8317e0b",target:"_blank",rel:"noopener noreferrer"},g={href:"https://www.jianshu.com/p/b77e80d6c18e",target:"_blank",rel:"noopener noreferrer"},f={href:"https://www.jianshu.com/p/7174cf716790",target:"_blank",rel:"noopener noreferrer"},y={href:"https://www.jianshu.com/p/f5a61653708e",target:"_blank",rel:"noopener noreferrer"},q={href:"https://zhuanlan.zhihu.com/p/36940048",target:"_blank",rel:"noopener noreferrer"},w={href:"https://juejin.cn/post/6994755077659426846",target:"_blank",rel:"noopener noreferrer"};function x(S,R){const a=c("ExternalLinkIcon");return o(),i("div",null,[l,n("p",null,[s("一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。当搜索任务执行在分布式系统上时,整体流程如下图所示。图片来源"),n("a",r,[s("Elasitcsearch源码解析与优化实战"),t(a)])]),d,n("p",null,[s("图片来源"),n("a",k,[s("官网"),t(a)]),s(",比较旧,但任然可用")]),v,n("p",null,[s("取回阶段,图片来自"),n("a",h,[s("官网"),t(a)]),s(",")]),m,n("ol",null,[n("li",null,[n("a",b,[s("Elasitcsearch源码解析与优化实战"),t(a)])]),n("li",null,[n("a",g,[s("Elasticsearch源码分析-搜索分析(一)"),t(a)])]),n("li",null,[n("a",f,[s("Elasticsearch源码分析-搜索分析(二)"),t(a)])]),n("li",null,[n("a",y,[s("Elasticsearch源码分析-搜索分析(三)"),t(a)])]),n("li",null,[n("a",q,[s("Elasticsearch 通信模块的分析"),t(a)])]),n("li",null,[n("a",w,[s("Elasticsearch 网络通信线程分析"),t(a)])])])])}const P=p(u,[["render",x],["__file","【elasticsearch】搜索过程详解.html.vue"]]);export{P as default};
diff --git "a/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-G6NlySyS.js" "b/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-G6NlySyS.js"
new file mode 100644
index 00000000..8ef92840
--- /dev/null
+++ "b/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-G6NlySyS.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-399e07b6","path":"/java/%E4%B8%80%E6%AC%A1jvm%E8%B0%83%E4%BC%98%E8%BF%87%E7%A8%8B.html","title":"一次jvm调优过程","lang":"zh-CN","frontmatter":{"description":"一次jvm调优过程 前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。 该程序task主要分为三个模块: console进行一些cron的配置(表达式、任务名称、任务组等); schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发; client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。 整体架构跟github上开源的xxl-job类似,也可以参考一下。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/%E4%B8%80%E6%AC%A1jvm%E8%B0%83%E4%BC%98%E8%BF%87%E7%A8%8B.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"一次jvm调优过程"}],["meta",{"property":"og:description","content":"一次jvm调优过程 前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。 该程序task主要分为三个模块: console进行一些cron的配置(表达式、任务名称、任务组等); schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发; client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。 整体架构跟github上开源的xxl-job类似,也可以参考一下。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T10:30:22.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T10:30:22.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"一次jvm调优过程\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T10:30:22.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"1. 启用jmx和远程debug模式","slug":"_1-启用jmx和远程debug模式","link":"#_1-启用jmx和远程debug模式","children":[]},{"level":2,"title":"2. memory analyzer、jprofiler进行堆内存分析","slug":"_2-memory-analyzer、jprofiler进行堆内存分析","link":"#_2-memory-analyzer、jprofiler进行堆内存分析","children":[]},{"level":2,"title":"3. netty的方面的考虑","slug":"_3-netty的方面的考虑","link":"#_3-netty的方面的考虑","children":[]},{"level":2,"title":"4. 直接内存排查","slug":"_4-直接内存排查","link":"#_4-直接内存排查","children":[]},{"level":2,"title":"5. 推荐的直接内存排查方法","slug":"_5-推荐的直接内存排查方法","link":"#_5-推荐的直接内存排查方法","children":[]},{"level":2,"title":"6. 意外的结果","slug":"_6-意外的结果","link":"#_6-意外的结果","children":[]},{"level":2,"title":"总结","slug":"总结","link":"#总结","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706092222000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":6.23,"words":1870},"filePathRelative":"java/一次jvm调优过程.md","localizedDate":"2024年1月24日","excerpt":" 一次jvm调优过程 \\n前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。\\n该程序task主要分为三个模块:\\nconsole进行一些cron的配置(表达式、任务名称、任务组等);\\nschedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发;\\nclient接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。\\n整体架构跟github上开源的xxl-job类似,也可以参考一下。
","autoDesc":true}');export{e as data};
diff --git "a/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-ObKNMeJg.js" "b/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-ObKNMeJg.js"
new file mode 100644
index 00000000..b2c1d3f4
--- /dev/null
+++ "b/assets/\344\270\200\346\254\241jvm\350\260\203\344\274\230\350\277\207\347\250\213.html-ObKNMeJg.js"
@@ -0,0 +1,9 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as i,o as r,c as o,a as e,d as a,b as s,e as p}from"./app-cS6i7hsH.js";const l={},c=p(` 一次jvm调优过程 前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。 该程序task主要分为三个模块: console进行一些cron的配置(表达式、任务名称、任务组等); schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发; client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。 整体架构跟github上开源的xxl-job类似,也可以参考一下。
1. 启用jmx和远程debug模式 容器的网络使用了BGP,打通了公司的内网,所以可以直接通过ip来进行程序的调试,主要是在启动的jvm参数中添加:
JAVA_DEBUG_OPTS = " -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=0.0.0.0:8000,server=y,suspend=n "
+JAVA_JMX_OPTS = " -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false "
+其中,调试模式的address最好加上0.0.0.0,有时候通过netstat查看端口的时候,该位置显示为127.0.0.1,导致无法正常debug,开启了jmx之后,可以初步观察堆内存的情况。
堆内存(特别是cms的old gen),初步看代码觉得是由于用了大量的map,本地缓存了大量数据,怀疑是每次定时调度的信息都进行了保存。
2. memory analyzer、jprofiler进行堆内存分析 先从容器中dump出堆内存
jmap -dump:live,format= b,file= heap.hprof 58
+由图片可以看出,这些大对象不过也就10M,并没有想象中的那么大,所以并不是大对象的问题,后续继续看了下代码,虽然每次请求都会把信息放进map里,如果能正常调通的话,就会移除map中保存的记录,由于是测试环境,执行端很多时候都没有正常运行,甚至说业务方关闭了程序,导致调度一直出现问题,所以map的只会保留大量的错误请求。不过相对于该程序的堆内存来说,不是主要问题。
3. netty的方面的考虑 另一个小伙伴一直怀疑的是netty这一块有错误,着重看了下。该程序用netty自己实现了一套rpc,调度端每次进行命令下发的时候都会通过netty的rpc来进行通信,整个过程逻辑写的很混乱,下面开始排查。 首先是查看堆内存的中占比:
可以看出,io.netty.channel.nio.NioEventLoop的占比达到了40%左右,再然后是io.netty.buffer.PoolThreadCache,占比大概达到33%左右。猜想可能是传输的channel没有关闭,还是NioEventLoop没有关闭。再跑去看一下jmx的线程数:
达到了惊人的1000个左右,而且一直在增长,没有过下降的趋势,再次猜想到可能是NioEventLoop没有关闭,在代码中全局搜索NioEventLoop,找到一处比较可疑的地方。
声明了一个NioEventLoopGroup的成员变量,通过构造方法进行了初始化,但是在执行syncRequest完之后并没有进行对group进行shutdownGracefully操作,外面对其的操作并没有对该类的group对象进行关闭,导致线程数一直在增长。
最终解决办法: 在调用完syncRequest方法时,对ChannelBootStrap的group对象进行行shutdownGracefully
提交代码,容器中继续测试,可以基本看出,线程基本处于稳定状态,并不会出现一直增长的情况了
还原本以为基本解决了,到最后还是发现,堆内存还算稳定,但是,直接内存依旧打到了100%,虽然程序没有挂掉,所以,上面做的,可能仅仅是为这个程序续命了而已,感觉并没有彻底解决掉问题。
4. 直接内存排查 第一个想到的就是netty的直接内存,关掉,命令如下:
-Dio.netty.noPreferDirect = true -Dio.netty.leakDetectionLevel = advanced
+查看了一下java的nio直接内存,发现也就几十kb,然而直接内存还是慢慢往上涨。毫无头绪,然后开始了自己的从linux层面开始排查问题
5. 推荐的直接内存排查方法 5.1 pmap 一般配合pmap使用,从内核中读取内存块,然后使用views 内存块来判断错误,我简单试了下,乱码,都是二进制的东西,看不出所以然来。
pmap -d 58 | sort -n -k2
+pmap -x 58 | sort -n -k3
+grep rw-p /proc/$1 /maps | sed -n 's/^\\([0-9a-f]*\\)-\\([0-9a-f]*\\) .*$/\\1 \\2/p' | while read start stop; do gdb --batch --pid $1 -ex "dump memory $1 -$start -$stop .dump 0x$start 0x$stop " ; done
+这个时候真的懵了,不知道从何入手了,难道是linux操作系统方面的问题?
起初,在网上看到有人说是因为linux自带的glibc版本太低了,导致的内存溢出,考虑一下。初步觉得也可能是因为这个问题,所以开始慢慢排查。oracle官方有一个jemalloc用来替换linux自带的,谷歌那边也有一个tcmalloc,据说性能比glibc、jemalloc都强,开始换一下。 根据网上说的,在容器里装libunwind,然后再装perf-tools,然后各种捣鼓,到最后发现,执行不了,
pprof --text /usr/bin/java java_58.0001.heap
+看着工具高大上的,似乎能找出linux的调用栈,
6. 意外的结果 毫无头绪的时候,回想到了linux的top命令以及日志情况,测试环境是由于太多执行端业务方都没有维护,导致调度系统一直会出错,一出错就会导致大量刷错误日志,平均一天一个容器大概就有3G的日志,cron一旦到准点,就会有大量的任务要同时执行,而且容器中是做了对io的限制,磁盘也限制为10G,导致大量的日志都堆积在buff/cache里面,最终直接内存一直在涨,这个时候,系统不会挂,但是先会一直显示内存使用率达到100%。 修复后的结果如下图所示:
总结 定时调度这个系统当时并没有考虑到公司的系统会用的这么多,设计的时候也仅仅是为了实现上千的量,没想到到最后变成了一天的调度都有几百万次。最初那批开发也就使用了大量的本地缓存map来临时存储数据,然后面向简历编程各种用netty自己实现了通信的方式,一堆坑都留给了后人。目前也算是解决掉了一个由于线程过多导致系统不可用的情况而已,但是由于存在大量的map,系统还是得偶尔重启一下比较好。
`,50),d=e("br",null,null,-1),u={href:"https://www.cnblogs.com/testfan2019/p/11151008.html",target:"_blank",rel:"noopener noreferrer"},g=e("br",null,null,-1),h={href:"https://coldwalker.com/2018/08//troubleshooter_native_memory_increase/",target:"_blank",rel:"noopener noreferrer"},m=e("br",null,null,-1),f={href:"https://static.rainfocus.com/oracle/oow18/sess/1524505564465001W0mS/PF/Troubleshooting_native_memory_leaks_1540301908390001k6DR.pdf",target:"_blank",rel:"noopener noreferrer"};function b(v,k){const n=i("ExternalLinkIcon");return r(),o("div",null,[c,e("p",null,[a("参考:"),d,a(" 1."),e("a",u,[a("记一次线上内存泄漏问题的排查过程"),s(n)]),g,a(" 2."),e("a",h,[a("Java堆外内存增长问题排查Case"),s(n)]),m,a(" 3."),e("a",f,[a("Troubleshooting Native Memory Leaks in Java Applications"),s(n)])])])}const y=t(l,[["render",b],["__file","一次jvm调优过程.html.vue"]]);export{y as default};
diff --git "a/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-P7fE8DoQ.js" "b/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-P7fE8DoQ.js"
new file mode 100644
index 00000000..0eeb9457
--- /dev/null
+++ "b/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-P7fE8DoQ.js"
@@ -0,0 +1 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as a,c as d,a as e,d as o}from"./app-cS6i7hsH.js";const r={},l=e("h1",{id:"内存屏障",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#内存屏障","aria-hidden":"true"},"#"),o(" 内存屏障")],-1),_=e("p",null,[o("四个内存屏障指令:LoadLoad"),e("code",null,","),o("StoreStore"),e("code",null,","),o("LoadStore"),e("code",null,","),o("StoreLoad")],-1),c=e("p",null,"在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值",-1),n=e("p",null,"在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。",-1),s=[l,_,c,n];function i(h,u){return a(),d("div",null,s)}const p=t(r,[["render",i],["__file","内存屏障.html.vue"]]);export{p as default};
diff --git "a/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-YpsEGPcG.js" "b/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-YpsEGPcG.js"
new file mode 100644
index 00000000..fa8cee42
--- /dev/null
+++ "b/assets/\345\206\205\345\255\230\345\261\217\351\232\234.html-YpsEGPcG.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-660266c1","path":"/java/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C.html","title":"内存屏障","lang":"zh-CN","frontmatter":{"description":"内存屏障 四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad 在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值 在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"内存屏障"}],["meta",{"property":"og:description","content":"内存屏障 四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad 在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值 在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T10:30:22.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T10:30:22.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"内存屏障\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T10:30:22.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706092222000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.69,"words":208},"filePathRelative":"java/内存屏障.md","localizedDate":"2024年1月24日","excerpt":" 内存屏障 \\n四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad
\\n在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值
\\n在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。
","autoDesc":true}');export{e as data};
diff --git "a/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-aSy3Jyqy.js" "b/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-aSy3Jyqy.js"
new file mode 100644
index 00000000..d89e7e93
--- /dev/null
+++ "b/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-aSy3Jyqy.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-90f2343c","path":"/java/%E5%9C%A8%20Spring%206%20%E4%B8%AD%E4%BD%BF%E7%94%A8%E8%99%9A%E6%8B%9F%E7%BA%BF%E7%A8%8B.html","title":"在 Spring 6 中使用虚拟线程","lang":"zh-CN","frontmatter":{"description":"在 Spring 6 中使用虚拟线程 一、简介 在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。 虚拟线程是Java 19 的预览功能,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/%E5%9C%A8%20Spring%206%20%E4%B8%AD%E4%BD%BF%E7%94%A8%E8%99%9A%E6%8B%9F%E7%BA%BF%E7%A8%8B.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"在 Spring 6 中使用虚拟线程"}],["meta",{"property":"og:description","content":"在 Spring 6 中使用虚拟线程 一、简介 在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。 虚拟线程是Java 19 的预览功能,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"在 Spring 6 中使用虚拟线程\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、简介","slug":"一、简介","link":"#一、简介","children":[]},{"level":2,"title":"二、 虚拟线程与平台线程","slug":"二、-虚拟线程与平台线程","link":"#二、-虚拟线程与平台线程","children":[]},{"level":2,"title":"三、在Spring 6中使用虚拟线程","slug":"三、在spring-6中使用虚拟线程","link":"#三、在spring-6中使用虚拟线程","children":[]},{"level":2,"title":"四、性能比较","slug":"四、性能比较","link":"#四、性能比较","children":[]}],"git":{"createdTime":1706186538000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":4}]},"readingTime":{"minutes":4.83,"words":1448},"filePathRelative":"java/在 Spring 6 中使用虚拟线程.md","localizedDate":"2024年1月25日","excerpt":" 在 Spring 6 中使用虚拟线程 \\n 一、简介 \\n在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。
\\n虚拟线程是Java 19 的预览功能 ,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本 最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。
","autoDesc":true}');export{e as data};
diff --git "a/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-lrPVTD8u.js" "b/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-lrPVTD8u.js"
new file mode 100644
index 00000000..d4b14e55
--- /dev/null
+++ "b/assets/\345\234\250 Spring 6 \344\270\255\344\275\277\347\224\250\350\231\232\346\213\237\347\272\277\347\250\213.html-lrPVTD8u.js"
@@ -0,0 +1,60 @@
+import{_ as o}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as p,o as c,c as i,a as n,d as a,b as e,e as t}from"./app-cS6i7hsH.js";const l={},r=n("h1",{id:"在-spring-6-中使用虚拟线程",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#在-spring-6-中使用虚拟线程","aria-hidden":"true"},"#"),a(" 在 Spring 6 中使用虚拟线程")],-1),u=n("h2",{id:"一、简介",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#一、简介","aria-hidden":"true"},"#"),a(" 一、简介")],-1),d=n("p",null,"在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。",-1),k={href:"https://openjdk.org/jeps/425",target:"_blank",rel:"noopener noreferrer"},g={href:"https://spring.io/blog/2022/10/11/embracing-virtual-threads",target:"_blank",rel:"noopener noreferrer"},v=n("p",null,"首先,我们将看到“平台线程”和“虚拟线程”之间的主要区别。接下来,我们将使用虚拟线程从头开始构建一个 Spring-Boot 应用程序。最后,我们将创建一个小型测试套件,以查看简单 Web 应用程序吞吐量的最终改进。",-1),m=n("h2",{id:"二、-虚拟线程与平台线程",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#二、-虚拟线程与平台线程","aria-hidden":"true"},"#"),a(" 二、 虚拟线程与平台线程")],-1),h={href:"https://www.baeldung.com/java-virtual-thread-vs-thread",target:"_blank",rel:"noopener noreferrer"},b=n("p",null,"对于本教程来说,必须了解虚拟线程的运行成本远低于平台线程。它们消耗的分配内存量要少得多。这就是为什么可以创建数百万个虚拟线程而不会出现内存不足问题,而不是使用标准平台(或内核)线程创建几百个虚拟线程。",-1),_=n("p",null,"从理论上讲,这赋予了开发人员一种超能力:无需依赖异步代码即可管理高度可扩展的应用程序。",-1),f=n("h2",{id:"三、在spring-6中使用虚拟线程",tabindex:"-1"},[n("a",{class:"header-anchor",href:"#三、在spring-6中使用虚拟线程","aria-hidden":"true"},"#"),a(" 三、在Spring 6中使用虚拟线程")],-1),w={href:"https://www.baeldung.com/java-preview-features",target:"_blank",rel:"noopener noreferrer"},y=n("em",null,"代码",-1),x=t(`< build> < plugins> < plugin> < groupId> . apache. maven. plugins< / groupId>
+ < artifactId> - compiler- plugin< / artifactId>
+ < configuration> < source> 19 < / source>
+ < target> 19 < / target>
+ < compilerArgs> -- enable- preview
+ < / compilerArgs>
+ < / configuration>
+ < / plugin>
+ < / plugins>
+< / build>
+从 Java 的角度来看,要使用 Apache Tomcat 和虚拟线程,我们需要一个带有几个 bean 的简单配置类:
@EnableAsync
+@Configuration
+@ConditionalOnProperty (
+ value = "spring.thread-executor" ,
+ havingValue = "virtual"
+)
+public class ThreadConfig {
+ @Bean
+ public AsyncTaskExecutor applicationTaskExecutor ( ) {
+ return new TaskExecutorAdapter ( Executors . newVirtualThreadPerTaskExecutor ( ) ) ;
+ }
+
+ @Bean
+ public TomcatProtocolHandlerCustomizer < ? > protocolHandlerVirtualThreadExecutorCustomizer ( ) {
+ return protocolHandler -> {
+ protocolHandler. setExecutor ( Executors . newVirtualThreadPerTaskExecutor ( ) ) ;
+ } ;
+ }
+}
+spring :
+ thread-executor : virtual
+ //...
+我们来测试一下Spring Boot应用程序是否使用虚拟线程来处理Web请求调用。为此,我们需要构建一个简单的控制器来返回所需的信息:
@RestController
+@RequestMapping ( "/thread" )
+public class ThreadController {
+ @GetMapping ( "/name" )
+ public String getThreadName ( ) {
+ return Thread . currentThread ( ) . toString ( ) ;
+ }
+}
+$ curl -s http://localhost:8080/thread/name
+$ VirtualThread[
+正如我们所看到的,响应明确表示我们正在使用虚拟线程来处理此 Web 请求。换句话说,*Thread.currentThread()*调用返回虚拟线程类的实例。现在让我们通过简单但有效的负载测试来看看虚拟线程的有效性。
四、性能比较 `,3),I={href:"https://www.baeldung.com/jmeter",target:"_blank",rel:"noopener noreferrer"},J=t(`在这种特殊的场景中,我们将调用Rest Controller 中的一个端点,该端点将简单地让执行休眠一秒钟,模拟复杂的异步任务:
@RestController
+@RequestMapping ( "/load" )
+public class LoadTestController {
+
+ private static final Logger LOG = LoggerFactory . getLogger ( LoadTestController . class ) ;
+
+ @GetMapping
+ public void doSomething ( ) throws InterruptedException {
+ LOG . info ( "hey, I'm doing something" ) ;
+ Thread . sleep ( 1000 ) ;
+ }
+}
+请记住,由于*@ConditionalOnProperty* 注释,我们只需更改 application.yaml 中变量的值即可在虚拟线程和标准线程之间切换 。
JMeter 测试将仅包含一个线程组,模拟 1000 个并发用户访问*/load* 端点 100 秒:
image-20230827193431807 在本例中,采用这一新功能所带来的性能提升是显而易见的。让我们比较不同实现的“响应时间图”。这是标准线程的响应图。我们可以看到,立即完成一次调用所需的时间达到 5000 毫秒:
image-20230827193511176 发生这种情况是因为平台线程是一种有限的资源,当所有计划的和池化的线程都忙时,Spring 应用程序除了将请求搁置直到一个线程空闲之外别无选择。
让我们看看虚拟线程会发生什么:
image-20230827193533565 正如我们所看到的,响应稳定在 1000 毫秒。虚拟线程在请求后立即创建和使用,因为从资源的角度来看它们非常便宜。在本例中,我们正在比较 spring 默认固定标准线程池(默认为 200)和 spring 默认无界虚拟线程池的使用情况。
**这种性能提升之所以可能,是因为场景过于简单,并且没有考虑 Spring Boot 应用程序可以执行的全部操作。**从底层操作系统基础设施中采用这种抽象可能是有好处的,但并非在所有情况下都是如此。
`,12);function M(H,N){const s=p("ExternalLinkIcon");return c(),i("div",null,[r,u,d,n("p",null,[a("虚拟线程是Java 19 的"),n("a",k,[a("预览功能"),e(s)]),a(",这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。"),n("a",g,[a("Spring 6 版本"),e(s)]),a("最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。")]),v,m,n("p",null,[a("主要区别在于"),n("a",h,[a("虚拟线程"),e(s)]),a("在其操作周期中不依赖于操作系统线程:它们与硬件解耦,因此有了“虚拟”这个词。这种解耦是由 JVM 提供的抽象层实现的。")]),b,_,f,n("p",null,[a("从 Spring Framework 6(和 Spring Boot 3)开始,虚拟线程功能正式公开,但虚拟线程是Java 19 的"),n("a",w,[a("预览功能。"),e(s)]),a("这意味着我们需要告诉 JVM 我们要在应用程序中启用它们。由于我们使用 Maven 来构建应用程序,因此我们希望确保在 pom.xml 中包含以下"),y,a(":")]),x,n("p",null,[a("第一个 Spring Bean "),T,a("将取代标准的*"),n("a",j,[a("ApplicationTaskExecutor"),e(s)]),a("* ,提供为每个任务启动新虚拟线程的"),E,a("。第二个 bean,名为"),n("em",null,[a("ProtocolHandlerVirtualThreadExecutorCustomizer,"),S,n("a",C,[a("TomcatProtocolHandler 。"),e(s)]),q,n("a",V,[a("@ConditionalOnProperty,"),e(s)]),a("**以通过切换application.yaml")]),a("文件中配置属性的值来按需启用虚拟线程:")]),B,n("p",null,[a("*"),n("a",P,[a("Thread"),e(s)]),a("*对象的toString *()*方法将返回我们需要的所有信息:线程 ID、线程名称、线程组和优先级。让我们通过一个"),n("a",L,[z,e(s)]),a("请求来访问这个端点:")]),A,n("p",null,[a("对于此负载测试,我们将使用"),n("a",I,[a("JMeter"),e(s)]),a("。这不是虚拟线程和标准线程之间的完整性能比较,而是我们可以使用不同参数构建其他测试的起点。")]),J])}const G=o(l,[["render",M],["__file","在 Spring 6 中使用虚拟线程.html.vue"]]);export{G as default};
diff --git "a/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-FM9j_CKw.js" "b/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-FM9j_CKw.js"
new file mode 100644
index 00000000..10249c31
--- /dev/null
+++ "b/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-FM9j_CKw.js"
@@ -0,0 +1,54 @@
+import{_ as t}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as p,o as i,c as o,a as s,d as n,b as e,e as c}from"./app-cS6i7hsH.js";const l={},u=c(` 基于kubernetes的分布式限流 做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
一、概念 限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。
1.1 使用场景 限流可以应对:
热点业务带来的突发请求; 调用方 bug 导致的突发请求; 恶意攻击请求。 1.2 维度 对于限流场景,一般需要考虑两个维度的信息: 时间 限流基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定 资源 基于可用资源的限制,比如设定最大访问次数,或最高可用连接数。 限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。
image.png 1.3 分布式限流 分布式限流相比于单机限流,只是把限流频次分配到各个节点中,比如限制某个服务访问100qps,如果有10个节点,那么每个节点理论上能够平均被访问10次,如果超过了则进行频率限制。
二、分布式限流常用方案 基于Guava的客户端限流 Guava是一个客户端组件,在其多线程模块下提供了以RateLimiter为首的几个限流支持类。它只能对“当前”服务进行限流,即它不属于分布式限流的解决方案。
网关层限流 服务网关,作为整个分布式链路中的第一道关卡,承接了所有用户来访请求。我们在网关层进行限流,就可以达到了整体限流的目的了。目前,主流的网关层有以软件为代表的Nginx,还有Spring Cloud中的Gateway和Zuul这类网关层组件,也有以硬件为代表的F5。
中间件限流 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。
限流组件 目前也有一些开源组件提供了限流的功能,比如Sentinel就是一个不错的选择。Sentinel是阿里出品的开源组件,并且包含在了Spring Cloud Alibaba组件库中。Hystrix也具有限流的功能。
Guava的Ratelimiter设计实现相当不错,可惜只能支持单机,网关层限流如果是单机则不太满足高可用,并且分布式网关的话还是需要依赖中间件限流,而redis之类的网络通信需要占用一小部分的网络消耗。阿里的Sentinel也是同理,底层使用的是redis或者zookeeper,每次访问都需要调用一次redis或者zk的接口。那么在云原生场景下,我们有没有什么更好的办法呢?
对于极致追求高性能的服务不需要考虑熔断、降级来说,是需要尽量减少网络之间的IO,那么是否可以通过一个总限频然后分配到具体的单机里面去,在单机中实现平均的限流,比如限制某个ip的qps为100,服务总共有10个节点,那么平均到每个服务里就是10qps,此时就可以通过guava的ratelimiter来实现了,甚至说如果服务的节点动态调整,单个服务的qps也能动态调整。
三、基于kubernetes的分布式限流 在Spring Boot应用中,定义一个filter,获取请求参数里的key(ip、userId等),然后根据key来获取rateLimiter,其中,rateLimiter的创建由数据库定义的限频数和副本数来判断,最后,再通过rateLimiter.tryAcquire来判断是否可以通过。
企业微信截图_868136b4-f9e2-4813-bc02-281a66756ecd.png 3.1 kubernetes中的副本数 在实际的服务中,数据上报服务一般无法确定客户端的上报时间、上报量,特别是对于这种要求高性能,服务一般都会用到HPA来实现动态扩缩容,所以,需要去间隔一段时间去获取服务的副本数。
func CountDeploymentSize ( namespace string , deploymentName string ) * int32 {
+ deployment, err := client. AppsV1 ( ) . Deployments ( namespace) . Get ( context. TODO ( ) , deploymentName, metav1. GetOptions{ } )
+ if err != nil {
+ return nil
+ }
+ return deployment. Spec. Replicas
+}
+用法:GET host/namespaces/test/deployments/k8s-rest-api直接即可。
3.2 rateLimiter的创建 在RateLimiterService中定义一个LoadingCache<String, RateLimiter>,其中,key可以为ip、userId等,并且,在多线程的情况下,使用refreshAfterWrite只阻塞加载数据的线程,其他线程则返回旧数据,极致发挥缓存的作用。
private final LoadingCache < String , RateLimiter > = Caffeine . newBuilder ( )
+ . maximumSize ( 10_000 )
+ . refreshAfterWrite ( 20 , TimeUnit . MINUTES )
+ . build ( this :: createRateLimit ) ;
+
+private static final Integer minQpsLimit = 3000 ;
+之后是创建rateLimiter,获取总限频数totalLimit和副本数replicas,之后是自己所需的逻辑判断,可以根据totalLimit和replicas的情况来进行qps的限定。
public RateLimiter createRateLimit ( String key) {
+ log. info ( "createRateLimit,key:{}" , key) ;
+ int totalLimit = 获取总限频数,可以在数据库中定义
+ Integer replicas = kubernetesService. getDeploymentReplicas ( ) ;
+ RateLimiter rateLimiter;
+ if ( totalLimit > 0 && replicas == null ) {
+ rateLimiter = RateLimiter . create ( totalLimit) ;
+ } else if ( totalLimit > 0 ) {
+ int nodeQpsLimit = totalLimit / replicas;
+ rateLimiter = RateLimiter . create ( nodeQpsLimit > minQpsLimit ? nodeQpsLimit : minQpsLimit) ;
+ } else {
+ rateLimiter = RateLimiter . create ( minQpsLimit) ;
+ }
+ log. info ( "create rateLimiter success,key:{},rateLimiter:{}" , key, rateLimiter) ;
+ return rateLimiter;
+}
+ 3.3 rateLimiter的获取 根据key获取RateLimiter,如果有特殊需求的话,需要判断key不存在的尝尽
public RateLimiter getRateLimiter ( String key) {
+ return loadingCache. get ( key) ;
+}
+ 3.4 filter里的判断 最后一步,就是使用rateLimiter来进行限流,如果rateLimiter.tryAcquire()为true,则进行filterChain.doFilter(request, response),如果为false,则返回HttpStatus.TOO_MANY_REQUESTS
public class RateLimiterFilter implements Filter {
+ @Resource
+ private RateLimiterService rateLimiterService;
+
+ @Override
+ public void doFilter ( ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException , ServletException {
+ HttpServletRequest httpServletRequest = ( HttpServletRequest ) request;
+ HttpServletResponse httpServletResponse = ( HttpServletResponse ) response;
+ String key = httpServletRequest. getHeader ( "key" ) ;
+ RateLimiter rateLimiter = rateLimiterService. getRateLimiter ( key) ;
+ if ( rateLimiter != null ) {
+ if ( rateLimiter. tryAcquire ( ) ) {
+ filterChain. doFilter ( request, response) ;
+ } else {
+ httpServletResponse. setStatus ( HttpStatus . TOO_MANY_REQUESTS . value ( ) ) ;
+ }
+ } else {
+ filterChain. doFilter ( request, response) ;
+ }
+ }
+}
+ 四、性能压测 为了方便对比性能之间的差距,我们在本地单机做了下列测试,其中,总限频都设置为3万。
无限流
企业微信截图_ea1b7815-3b89-43bf-aed7-240e135bdad1.png 使用redis限流
其中,ping redis大概6-7ms左右,对应的,每次请求需要访问redis,时延都有大概6-7ms,性能下降明显
企业微信截图_9118c4e0-c7f3-4e74-9649-4cd4d56fda79.png 自研限流
性能几乎追平无限流的场景,guava的rateLimiter确实表现卓越
企业微信截图_9f6510bd-be9e-438b-aa9d-bdd13ebca953.png 五、其他问题 5.1 对于保证qps限频准确的时候,应该怎么解决呢?
在k8s中,服务是动态扩缩容的,相应的,每个节点应该都要有所变化,如果对外宣称限频100qps,而且后续业务方真的要求百分百准确,只能把LoadingCache<String, RateLimiter>的过期时间调小一点,让它能够近实时的更新单节点的qps。这里还需要考虑一下k8s的压力,因为每次都要获取副本数,这里也是需要做缓存的
5.2 服务从1个节点动态扩为4个节点,这个时候新节点识别为4,但其实有些并没有启动完,会不会造成某个节点承受了太大的压力
理论上是存在这个可能的,这个时候需要考虑一下初始的副本数的,扩缩容不能一蹴而就,一下子从1变为4变为几十个这种。一般的话,生产环境肯定是不能只有一个节点,并且要考虑扩缩容的话,至于要有多个副本预备的
5.3 如果有多个副本,怎么保证请求是均匀的
这个是依赖于k8s的service负载均衡策略的,这个我们之前做过实验,流量确实是能够均匀的落到节点上的。还有就是,我们整个限流都是基于k8s的,如果k8s出现问题,那就是整个集群所有服务都有可能出现问题了。
参考 `,55),r={href:"https://blog.csdn.net/hou_ge/article/details/113869419",target:"_blank",rel:"noopener noreferrer"},k=s("br",null,null,-1),d={href:"https://www.infoq.cn/article/qg2tx8fyw5vt-f3hh673",target:"_blank",rel:"noopener noreferrer"},m=s("br",null,null,-1),v={href:"https://www.cnblogs.com/huilei/p/13773557.html",target:"_blank",rel:"noopener noreferrer"};function g(h,b){const a=p("ExternalLinkIcon");return i(),o("div",null,[u,s("p",null,[n("1."),s("a",r,[n("常见的分布式限流解决方案"),e(a)]),k,n(" 2."),s("a",d,[n("分布式服务限流实战"),e(a)]),m,n(" 3."),s("a",v,[n("高性能"),e(a)])])])}const _=t(l,[["render",g],["__file","基于kubernetes的分布式限流.html.vue"]]);export{_ as default};
diff --git "a/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-SsVfGmol.js" "b/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-SsVfGmol.js"
new file mode 100644
index 00000000..a8828206
--- /dev/null
+++ "b/assets/\345\237\272\344\272\216kubernetes\347\232\204\345\210\206\345\270\203\345\274\217\351\231\220\346\265\201.html-SsVfGmol.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-0b5d4df0","path":"/java/%E5%9F%BA%E4%BA%8Ekubernetes%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81.html","title":"基于kubernetes的分布式限流","lang":"zh-CN","frontmatter":{"description":"基于kubernetes的分布式限流 做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。 一、概念 限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。 1.1 使用场景 限流可以应对: 热点业务带来的突发请求; 调用方 bug 导致的突发请求; 恶意攻击请求。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/java/%E5%9F%BA%E4%BA%8Ekubernetes%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"基于kubernetes的分布式限流"}],["meta",{"property":"og:description","content":"基于kubernetes的分布式限流 做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。 一、概念 限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。 1.1 使用场景 限流可以应对: 热点业务带来的突发请求; 调用方 bug 导致的突发请求; 恶意攻击请求。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-26T03:58:56.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-26T03:58:56.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"基于kubernetes的分布式限流\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-26T03:58:56.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[{"level":2,"title":"一、概念","slug":"一、概念","link":"#一、概念","children":[{"level":3,"title":"1.1 使用场景","slug":"_1-1-使用场景","link":"#_1-1-使用场景","children":[]},{"level":3,"title":"1.2 维度","slug":"_1-2-维度","link":"#_1-2-维度","children":[]},{"level":3,"title":"1.3 分布式限流","slug":"_1-3-分布式限流","link":"#_1-3-分布式限流","children":[]}]},{"level":2,"title":"二、分布式限流常用方案","slug":"二、分布式限流常用方案","link":"#二、分布式限流常用方案","children":[]},{"level":2,"title":"三、基于kubernetes的分布式限流","slug":"三、基于kubernetes的分布式限流","link":"#三、基于kubernetes的分布式限流","children":[{"level":3,"title":"3.1 kubernetes中的副本数","slug":"_3-1-kubernetes中的副本数","link":"#_3-1-kubernetes中的副本数","children":[]},{"level":3,"title":"3.2 rateLimiter的创建","slug":"_3-2-ratelimiter的创建","link":"#_3-2-ratelimiter的创建","children":[]},{"level":3,"title":"3.3 rateLimiter的获取","slug":"_3-3-ratelimiter的获取","link":"#_3-3-ratelimiter的获取","children":[]},{"level":3,"title":"3.4 filter里的判断","slug":"_3-4-filter里的判断","link":"#_3-4-filter里的判断","children":[]}]},{"level":2,"title":"四、性能压测","slug":"四、性能压测","link":"#四、性能压测","children":[]},{"level":2,"title":"五、其他问题","slug":"五、其他问题","link":"#五、其他问题","children":[]},{"level":2,"title":"参考","slug":"参考","link":"#参考","children":[]}],"git":{"createdTime":1706066758000,"updatedTime":1706241536000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":4}]},"readingTime":{"minutes":7.18,"words":2155},"filePathRelative":"java/基于kubernetes的分布式限流.md","localizedDate":"2024年1月24日","excerpt":" 基于kubernetes的分布式限流 \\n做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
\\n 一、概念 \\n限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。
\\n 1.1 使用场景 \\n限流可以应对:
\\n\\n热点业务带来的突发请求; \\n调用方 bug 导致的突发请求; \\n恶意攻击请求。 \\n ","autoDesc":true}');export{e as data};
diff --git "a/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-v0f75n9M.js" "b/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-v0f75n9M.js"
new file mode 100644
index 00000000..bdd3ce33
--- /dev/null
+++ "b/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-v0f75n9M.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-2675bfdc","path":"/database/mysql/%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92explain.html","title":"执行计划explain","lang":"zh-CN","frontmatter":{"description":"执行计划explain 第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/mysql/%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92explain.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"执行计划explain"}],["meta",{"property":"og:description","content":"执行计划explain 第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"执行计划explain\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706092222000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.14,"words":41},"filePathRelative":"database/mysql/执行计划explain.md","localizedDate":"2024年1月24日","excerpt":" 执行计划explain \\n第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain
\\n","autoDesc":true}');export{e as data};
diff --git "a/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-y5jML1O_.js" "b/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-y5jML1O_.js"
new file mode 100644
index 00000000..f018d8a0
--- /dev/null
+++ "b/assets/\346\211\247\350\241\214\350\256\241\345\210\222explain.html-y5jML1O_.js"
@@ -0,0 +1 @@
+import{_ as a}from"./plugin-vue_export-helper-x3n3nnut.js";import{o as t,c as n,a as e,d as o}from"./app-cS6i7hsH.js";const _={},c=e("h1",{id:"执行计划explain",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#执行计划explain","aria-hidden":"true"},"#"),o(" 执行计划explain")],-1),r=e("p",null,"第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain",-1),s=[c,r];function i(l,d){return t(),n("div",null,s)}const x=a(_,[["render",i],["__file","执行计划explain.html.vue"]]);export{x as default};
diff --git "a/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-fj1Jh_qh.js" "b/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-fj1Jh_qh.js"
new file mode 100644
index 00000000..dff6e58b
--- /dev/null
+++ "b/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-fj1Jh_qh.js"
@@ -0,0 +1 @@
+import{_ as s}from"./plugin-vue_export-helper-x3n3nnut.js";import{r as o,o as c,c as _,a as e,d as t,b as a}from"./app-cS6i7hsH.js";const r={},l=e("h1",{id:"数据库缓存",tabindex:"-1"},[e("a",{class:"header-anchor",href:"#数据库缓存","aria-hidden":"true"},"#"),t(" 数据库缓存")],-1),d=e("p",null,"在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。",-1),h={href:"https://so.csdn.net/so/search?q=hash&spm=1001.2101.3001.7020",target:"_blank",rel:"noopener noreferrer"},i=e("p",null,"禁用原因:",-1),p=e("p",null,"1.命中率低",-1),m=e("p",null,"2.写时所有都失效",-1),u=e("p",null,"禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。",-1),f=e("p",null,"查询缓存讲解:https://blog.csdn.net/zzddada/article/details/124116182",-1);function x(k,b){const n=o("ExternalLinkIcon");return c(),_("div",null,[l,d,e("p",null,[t("将select语句和语句的结果做"),e("a",h,[t("hash"),a(n)]),t("映射关系后保存在一定的内存区域内。")]),i,p,m,u,f])}const L=s(r,[["render",x],["__file","数据库缓存.html.vue"]]);export{L as default};
diff --git "a/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-k3XJyHqW.js" "b/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-k3XJyHqW.js"
new file mode 100644
index 00000000..dd540894
--- /dev/null
+++ "b/assets/\346\225\260\346\215\256\345\272\223\347\274\223\345\255\230.html-k3XJyHqW.js"
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-0a0b7a54","path":"/database/mysql/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%BC%93%E5%AD%98.html","title":"数据库缓存","lang":"zh-CN","frontmatter":{"description":"数据库缓存 在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。 将select语句和语句的结果做hash映射关系后保存在一定的内存区域内。 禁用原因: 1.命中率低 2.写时所有都失效 禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/database/mysql/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%BC%93%E5%AD%98.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:title","content":"数据库缓存"}],["meta",{"property":"og:description","content":"数据库缓存 在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。 将select语句和语句的结果做hash映射关系后保存在一定的内存区域内。 禁用原因: 1.命中率低 2.写时所有都失效 禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-25T11:42:16.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-25T11:42:16.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"数据库缓存\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-25T11:42:16.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706092222000,"updatedTime":1706182936000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":2}]},"readingTime":{"minutes":0.34,"words":101},"filePathRelative":"database/mysql/数据库缓存.md","localizedDate":"2024年1月24日","excerpt":" 数据库缓存 \\n在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。
\\n将select语句和语句的结果做hash 映射关系后保存在一定的内存区域内。
\\n禁用原因:
\\n1.命中率低
\\n2.写时所有都失效
\\n禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。
","autoDesc":true}');export{e as data};
diff --git a/bigdata/index.html b/bigdata/index.html
new file mode 100644
index 00000000..351c493b
--- /dev/null
+++ b/bigdata/index.html
@@ -0,0 +1,46 @@
+
+
+
+ Bigdata | 个人博客
+ elastic spark | 个人博客
+ 跳至主要內容 elastic spark Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有: (1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv
elasticsearch相对hdfs来说,容易搭建、并且有可视化kibana支持,非常方便spark的初学入门,本文主要讲解用elasticsearch-spark的入门。
Spark - Apache Spark 一、原生RDD支持 1.1 基础配置 相关库引入:
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> SparkConf配置,更多详细的请点击这里open in new window 或者源码ConfigurationOptionsopen in new window 。
public static SparkConf getSparkConf ( ) {
+ SparkConf sparkConf = new SparkConf ( ) . setAppName ( "elasticsearch-spark-demo" ) ;
+ sparkConf. set ( "es.nodes" , "host" )
+ . set ( "es.port" , "xxxxxx" )
+ . set ( "es.nodes.wan.only" , "true" )
+ . set ( "es.net.http.auth.user" , "elxxxxastic" )
+ . set ( "es.net.http.auth.pass" , "xxxx" )
+ . setMaster ( "local[*]" ) ;
+ return sparkConf;
+}
+ 1.2 读取es数据 这里用的是kibana提供的sample data里面的索引kibana_sample_data_ecommerce,也可以替换成自己的索引。
public static void main ( String [ ] args) {
+ SparkConf conf = getSparkConf ( ) ;
+ try ( JavaSparkContext jsc = new JavaSparkContext ( conf) ) {
+
+ JavaPairRDD < String , Map < String , Object > > =
+ JavaEsSpark . esRDD ( jsc, "kibana_sample_data_ecommerce" ) ;
+ esRDD. collect ( ) . forEach ( System . out:: println ) ;
+ }
+}
+esRDD同时也支持query语句esRDD(final JavaSparkContext jsc, final String resource, final String query),一般对es的查询都需要根据时间筛选一下,不过相对于es的官方sdk,并没有那么友好的api,只能直接使用原生的dsl语句。
1.3 写数据 支持序列化对象、json,并且能够使用占位符动态索引写入数据(使用较少),不过多介绍了。
public static void jsonWrite ( ) {
+ String json1 = "{\"reason\" : \"business\",\"airport\" : \"SFO\"}" ;
+ String json2 = "{\"participants\" : 5,\"airport\" : \"OTP\"}" ;
+ JavaRDD < String > = jsc. parallelize ( ImmutableList . of ( json1, json2) ) ;
+ JavaEsSpark . saveJsonToEs ( stringRDD, "spark-json" ) ;
+}
+比较常用的读写也就这些,更多可以看下官网相关介绍。
二、Spark Streaming spark的实时处理,es5.0的时候开始支持,目前
三、Spark SQL 四、Spark Structure Streaming 五、Spark on kubernetes Operator 参考: 1.Apache Spark supportopen in new window
2.elasticsearch-hadoopopen in new window
3.使用SparkSQL操作Elasticsearch - Spark入门教程open in new window
Spark | 个人博客
+ 分类 | 个人博客
+ 个人博客
+ 【elasticsearch】源码debug | 个人博客
+ 跳至主要內容 【elasticsearch】源码debug 一、下载源代码 直接用idea下载代码https://github.com/elastic/elasticsearch.git
切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好
二、修改设置(可选) 为了方便, 在 gradle/run.gradle 中关闭 Auth 认证:
setting 'xpack.security.enabled', 'false'
或者使用其中的用户名密码:
user username: 'elastic-admin', password: 'elastic-password', role: 'superuser'
三、启动 先启动上面的 remote debug, 然后用 gradlew 启动项目:
./gradlew :run --debug-jvm 打开浏览器http://localhost:9200即可看到es相关信息了
【elasticsearch】搜索过程详解
Elasticsearch | 个人博客
+ 【elasticsearch】搜索过程详解 | 个人博客
+ 跳至主要內容 【elasticsearch】搜索过程详解 本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。
SearchType QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。 DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。
为了能够深刻了解es的搜索过程,首先创建3个索引,每个索引指定一天的一条记录。
POST aaaa-16/_doc
+{
+ "@timestamp": "2022-02-16T16:21:15.000Z",
+ "word":"16"
+}
+
+
+POST aaaa-17/_doc
+{
+ "@timestamp": "2022-02-17T16:21:15.000Z",
+ "word":"17"
+}
+
+POST aaaa-18/_doc
+{
+ "@timestamp": "2022-02-18T16:21:15.000Z",
+ "word":"18"
+}
+即可在kibana上看到3条数据
image-20220219195141327 此时,假设我们用一个索引+星号来搜索,es内部的搜索是怎么样的呢?
GET aaaa*/_search
+{
+ "query": {
+ "range": {
+ "@timestamp": {
+ "gte": "2022-02-18T10:21:15.000Z",
+ "lte": "2022-02-18T17:21:15.000Z"
+ }
+ }
+ }
+}
+正好命中一条记录返回。
{
+ "took" : 2 ,
+ "timed_out" : false ,
+ "_shards" : {
+ "total" : 3 ,
+ "successful" : 3 ,
+ "skipped" : 0 ,
+ "failed" : 0
+ } ,
+ "hits" : {
+ "total" : {
+ "value" : 1 ,
+ "relation" : "eq"
+ } ,
+ "max_score" : 1.0 ,
+ "hits" : [
+ {
+ "_index" : "aaaa-18" ,
+ "_id" : "0zB2O38BoMIMP8QzHgdq" ,
+ "_score" : 1.0 ,
+ "_source" : {
+ "@timestamp" : "2022-02-18T16:21:15.000Z" ,
+ "word" : "18"
+ }
+ }
+ ]
+ }
+}
+
+ 一、es的分布式搜索过程 一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。当搜索任务执行在分布式系统上时,整体流程如下图所示。图片来源Elasitcsearch源码解析与优化实战open in new window
2 搜索入口: 整个http请求的入口,主要使用的是Netty4HttpRequestHandler。
@ChannelHandler.Sharable
+class Netty4HttpRequestHandler extends SimpleChannelInboundHandler < HttpPipelinedRequest > {
+ @Override
+ protected void channelRead0 ( ChannelHandlerContext ctx, HttpPipelinedRequest httpRequest) {
+ final Netty4HttpChannel channel = ctx. channel ( ) . attr ( Netty4HttpServerTransport . HTTP_CHANNEL_KEY ) . get ( ) ;
+ boolean success = false ;
+ try {
+ serverTransport. incomingRequest ( httpRequest, channel) ;
+ success = true ;
+ } finally {
+ if ( success == false ) {
+ httpRequest. release ( ) ;
+ }
+ }
+ }
+}
+ 二、初步调用流程 调用链路过程:Netty4HttpRequestHandler.channelRead0->AbstractHttpServerTransport.incomingRequest->AbstractHttpServerTransport.handleIncomingRequest->AbstractHttpServerTransport.dispatchRequest->RestController.dispatchRequest(实现了HttpServerTransport.Dispatcher)->SecurityRestFilter.handleRequest->BaseRestHandler.handleRequest->action.accept(channel)->RestCancellableNodeClient.doExecute->NodeClient.executeLocally->RequestFilterChain.proceed->TransportAction.proceed->TransportSearchAction.doExecute->TransportSearchAction.executeRequest(判断是本地执行还是远程执行)->TransportSearchAction.searchAsyncAction
协调节点的主要功能是接收请求,解析并构建目的的shard列表,然后异步发送到数据节点进行请求查询。具体就不细讲了,可按着debug的来慢慢调试。
特别注意下RestCancellableNodeClient.doExecute,从executeLocally执行所有的查询过程,并注册监听listener.onResponse(response),然后响应。
public < Request extends ActionRequest , Response extends ActionResponse > void doExecute ( . . . ) {
+ . . .
+ TaskHolder taskHolder = new TaskHolder ( ) ;
+ Task task = client. executeLocally ( action, request, new ActionListener < > ( ) {
+ @Override
+ public void onResponse ( Response response) {
+ try {
+ closeListener. unregisterTask ( taskHolder) ;
+ } finally {
+ listener. onResponse ( response) ;
+ }
+ }
+ } ) ;
+ . . .
+}
+其次要注意的是:TransportSearchAction.searchAsyncAction才开始真正的搜索过程
private SearchPhase searchAsyncAction ( . . . ) {
+ . . .
+ final QueryPhaseResultConsumer queryResultConsumer = searchPhaseController. newSearchPhaseResults ( ) ;
+ AbstractSearchAsyncAction < ? extends SearchPhaseResult > = switch ( searchRequest. searchType ( ) ) {
+ case DFS_QUERY_THEN_FETCH -> new SearchDfsQueryThenFetchAsyncAction ( . . . ) ;
+ case QUERY_THEN_FETCH -> new SearchQueryThenFetchAsyncAction ( . . . ) ;
+ } ;
+ return searchAsyncAction;
+ . . .
+}
+之后就是执行AbstractSearchAsyncAction.start,启动AbstractSearchAsyncAction.executePhase的查询动作。
此处的SearchPhase 实现类为SearchQueryThenFetchAsyncAction
+private void executePhase ( SearchPhase phase) {
+ try {
+ phase. run ( ) ;
+ } catch ( Exception e) {
+ if ( logger. isDebugEnabled ( ) ) {
+ logger. debug ( new ParameterizedMessage ( "Failed to execute [{}] while moving to [{}] phase" , request, phase. getName ( ) ) , e) ;
+ }
+ onPhaseFailure ( phase, "" , e) ;
+ }
+}
+ 三、协调节点 两阶段相应的实现位置:查询(Query)阶段—search.SearchQueryThenFetchAsyncAction;取回(Fetch)阶段—search.FetchSearchPhase。它们都继承自SearchPhase,如下图所示。
23 3.1 query阶段 图片来源官网open in new window ,比较旧,但任然可用
12 (1)客户端发送一个search请求到node3,node3创建一个大小为from,to的优先级队列。 (2)node3转发转发search请求至索引的主分片或者副本,每个分片执行查询请求,并且将结果放到一个排序之后的from、to大小的优先级队列。 (3)每个分片把文档id和排序之后的值返回给协调节点node3,node3把结果合并然后创建一个全局排序之后的结果。
在RestSearchAction#prepareRequest方法中将请求体解析为SearchRequest 数据结构:
+public RestChannelConsumer prepareRequest(.. .) {
+ SearchRequest searchRequest = new SearchRequest();
+ request.withContentOrSourceParamParserOrNull (parser ->
+ parseSearchRequest (searchRequest, request, parser, setSize));
+ ...
+}
+ 3.1.1 构造目的shard列表 将请求涉及的本集群shard列表和远程集群的shard列表(远程集群用于跨集群访问)合并:
private void executeSearch ( . . . ) {
+ . . .
+ final GroupShardsIterator < SearchShardIterator > = mergeShardsIterators ( localShardIterators, remoteShardIterators) ;
+ localShardIterators = StreamSupport . stream ( localShardRoutings. spliterator ( ) , false ) . map ( it -> {
+ OriginalIndices finalIndices = finalIndicesMap. get ( it. shardId ( ) . getIndex ( ) . getUUID ( ) ) ;
+ assert finalIndices != null ;
+ return new SearchShardIterator ( searchRequest. getLocalClusterAlias ( ) , it. shardId ( ) , it. getShardRoutings ( ) , finalIndices) ;
+ } ) . collect ( Collectors . toList ( ) ) ;
+ . . .
+}
+查看结果
241 3.1.2 对所有分片进行搜索 AbstractSearchAsyncAction . run
+对每个分片进行搜索查询
+for ( int i = 0 ; i < shardsIts. size ( ) ; i++ ) {
+ final SearchShardIterator shardRoutings = shardsIts. get ( i) ;
+ assert shardRoutings. skip ( ) == false ;
+ assert shardIndexMap. containsKey ( shardRoutings) ;
+ int shardIndex = shardIndexMap. get ( shardRoutings) ;
+ performPhaseOnShard ( shardIndex, shardRoutings, shardRoutings. nextOrNull ( ) ) ;
+}
+其中shardsIts是所有aaaa*的所有索引+其中一个副本
2141 3.1.3 分片具体的搜索过程 AbstractSearchAsyncAction . performPhaseOnShard
+private void performPhaseOnShard ( . . . ) {
+ executePhaseOnShard ( . . . ) {
+
+ public void inne rOnResponse ( FirstResult result) {
+ maybeFork ( thread, ( ) -> onShardResult ( result,shardIt) ) ;
+ }
+
+ public void onFailure ( Exception t) {
+ maybeFork ( thread, ( ) -> onShardFailure ( shardIndex, shard, shard. currentNodeId ( ) ,shardIt, t) ) ;
+ }
+ } ) ;
+}
+分片结果,当前线程
+. . .
+private void onShardResult ( FirstResult result, SearchShardIterator shardIt) {
+ onShardSuccess ( result) ;
+ success fulShardExecution ( shardIt) ;
+}
+. . .
+
+private void successfulShardExecution ( SearchShardIterator shardsIt) {
+
+ final int xTotalOps = totalOps. addAndGet ( remainingOpsOnIterator) ;
+
+ if ( xTotalOps == expectedTotalOps) {
+ onPhaseDone ( ) ;
+ } else if ( xTota1Ops > expectedTotal0ps) {
+ throw new AssertionError ( . . . ) ;
+ }
+}
+
+412 此处忽略了搜索结果totalHits为0的结果,并将结果进行累加,当xTotalOps等于expectedTotalOps时开始AbstractSearchAsyncAction.onPhaseDone再进行AbstractSearchAsyncAction.executeNextPhase取回阶段
3.2 Fetch阶段 取回阶段,图片来自官网open in new window ,
412412 (1)各个shard 返回的只是各文档的id和排序值 IDs and sort values ,coordinate node根据这些id&sort values 构建完priority queue之后,然后把程序需要的document 的id发送mget请求去所有shard上获取对应的document
(2)各个shard将document返回给coordinate node
(3)coordinate node将合并后的document结果返回给client客户端
3.2.1 FetchSearchPhase(对应上面的1) Query阶段的executeNextPhase方法触发Fetch阶段,Fetch阶段的起点为FetchSearchPhase#innerRun函数,从查询阶段的shard列表中遍历,跳过查询结果为空的shard,对特定目标shard执行executeFetch来获取数据,其中包括分页信息。对scroll请求的处理也在FetchSearchPhase#innerRun函数中。
private void innerRun ( ) throws Exception {
+ final int numShards = context. getNumShards ( ) ;
+ final boolean isScrollSearch = context. getRequest ( ) . scroll ( ) != null ;
+ final List < SearchPhaseResult > = queryResults. asList ( ) ;
+ final SearchPhaseController. ReducedQueryPhase reducedQueryPhase = resultConsumer. reduce ( ) ;
+ final boolean queryAndFetchOptimization = queryResults. length ( ) == 1 ;
+ final Runnable finishPhase = ( ) -> moveToNextPhase (
+ searchPhaseController,
+ queryResults,
+ reducedQueryPhase,
+ queryAndFetchOptimization ? queryResults : fetchResults. getAtomicArray ( )
+ ) ;
+ for ( int i = 0 ; i < docIdsToLoad. length; i++ ) {
+ IntArrayList entry = docIdsToLoad[ i] ;
+ SearchPhaseResult queryResult = queryResults. get ( i) ;
+ if ( entry == null ) {
+ if ( queryResult != null ) {
+ releaseIrrelevantSearchContext ( queryResult. queryResult ( ) ) ;
+ progressListener. notifyFetchResult ( i) ;
+ }
+ counter. countDown ( ) ;
+ } else {
+ executeFetch (
+ queryResult. getShardIndex ( ) ,
+ shardTarget,
+ counter,
+ fetchSearchRequest,
+ queryResult. queryResult ( ) ,
+ connection
+ ) ;
+ }
+ }
+ }
+}
+再看源码:
启动一个线程来fetch
+AbstractSearchAsyncAction . executePhase-> FetchSearchPhase . run-> FetchSearchPhase . innerRun-> FetchSearchPhase . executeFetch
+
+private void executeFetch ( . . . ) {
+ context. getSearchTransport ( )
+ . sendExecuteFetch (
+ connection,
+ fetchSearchRequest,
+ context. getTask ( ) ,
+ new SearchActionListener < FetchSearchResult > ( shardTarget, shardIndex) {
+ @Override
+ public void innerOnResponse ( FetchSearchResult result) {
+ progressListener. notifyFetchResult ( shardIndex) ;
+ counter. onResult ( result) ;
+ }
+
+ @Override
+ public void onFailure ( Exception e) {
+ progressListener. notifyFetchFailure ( shardIndex, shardTarget, e) ;
+ counter. onFailure ( shardIndex, shardTarget, e) ;
+ }
+ }
+ ) ;
+}
+
+13413 counter是一个收集器CountedCollector,onResult(result)主要是每次收到的shard数据存放,并且执行一次countDown,当所有shard数据收集完之后,然后触发一次finishPhase。
# CountedCollector.class
+void countDown() {
+ assert counter.isCountedDown() == false : "more operations executed than specified";
+ if (counter.countDown()) {
+ onFinish.run();
+ }
+}
+moveToNextPhase方法执行下一阶段,下-阶段要执行的任务定义在FetchSearchPhase构造 函数中,主要是触发ExpandSearchPhase。
3.2.2 ExpandSearchPhase(对应上图的2) AbstractSearchAsyncAction.executePhase->ExpandSearchPhase.run。取回阶段完成之后执行ExpandSearchPhase#run,主要判断是否启用字段折叠,根据需要实现字段折叠功能,如果没有实现字段折叠,则直接返回给客户端。
image-20220317000858513 ExpandSearchPhase执行完之后回复客户端,在AbstractSearchAsyncAction.sendSearchResponse方法中实现:
412412 四、数据节点 4.1 执行query、fetch流程 执行本流程的线程池: search。
对各种Query请求的处理入口注册于SearchTransportService.registerRequestHandler。
public static void registerRequestHandler ( TransportService transportService, SearchService searchService) {
+ . . .
+ transportService. registerRequestHandler (
+ QUERY_ACTION_NAME ,
+ ThreadPool. Names . SAME ,
+ ShardSearchRequest :: new ,
+ ( request, channel, task) -> searchService. executeQueryPhase (
+ request,
+ ( SearchShardTask ) task,
+ new ChannelActionListener < > ( channel, QUERY_ACTION_NAME , request)
+ )
+ ) ;
+ . . .
+}
+ 4.1.1 执行query请求 # SearchService
+public void executeQueryPhase ( ShardSearchRequest request, SearchShardTask task, ActionListener < SearchPhaseResult > ) {
+ assert request. canReturnNullResponseIfMatchNoDocs ( ) == false || request. numberOfShards ( ) > 1
+ : "empty responses require more than one shard" ;
+ final IndexShard shard = getShard ( request) ;
+ rewriteAndFetchShardRequest ( shard, request, listener. delegateFailure ( ( l, orig) -> {
+ ensureAfterSeqNoRefreshed ( shard, orig, ( ) -> executeQueryPhase ( orig, task) , l) ;
+ } ) ) ;
+}
+其中ensureAfterSeqNoRefreshed是把request任务放到一个名为search的线程池里面执行,容量大小为1000。
1 主要是用来执行SearchService.executeQueryPhase->SearchService.loadOrExecuteQueryPhase->QueryPhase.execute。核心的查询封装在queryPhase.execute(context)中,其中调用Lucene实现检索,同时实现聚合:
public void execute ( SearchContext searchContext) {
+ aggregationPhase. preProcess ( searchContext) ;
+ boolean rescore = execute ( searchContext, searchContext. searcher ( ) , searcher:: setCheckCancelled , indexSort) ;
+ if ( rescore) {
+ rescorePhase. execute ( searchContext) ;
+ suggestPhase. execute ( searchContext) ;
+ aggregationPhase. execute ( searchContext) ;
+ }
+}
+其中包含几个核心功能:
execute(),调用Lucene、searcher.search()实现搜索 rescorePhase,全文检索且需要打分 suggestPhase,自动补全及纠错 aggregationPhase,实现聚合 4.1.2 fetch流程 对各种Fetch请求的处理入口注册于SearchTransportService.registerRequestHandler。
transportService. registerRequestHandler (
+ QUERY_FETCH_SCROLL_ACTION_NAME ,
+ ThreadPool. Names . SAME ,
+ InternalScrollSearchRequest :: new ,
+ ( request, channel, task) -> {
+ searchService. executeFetchPhase (
+ request,
+ ( SearchShardTask ) task,
+ new ChannelActionListener < > ( channel, QUERY_FETCH_SCROLL_ACTION_NAME , request)
+ ) ;
+ }
+) ;
+对Fetch响应的实现封装在SearchService.executeFetchPhase中,核心是调用fetchPhase.execute(context)。按照命中的doc取得相关数据,填充到SearchHits中,最终封装到FetchSearchResult中。
# FetchPhase
+public void execute ( SearchContext context) {
+ Profiler profiler = context. getProfilers ( ) == null ? Profiler . NOOP : context. getProfilers ( ) . startProfilingFetchPhase ( ) ;
+ SearchHits hits = null ;
+ try {
+
+ hits = buildSearchHits ( context, profiler) ;
+ } finally {
+ ProfileResult profileResult = profiler. finish ( ) ;
+
+ if ( hits != null ) {
+ context. fetchResult ( ) . shardResult ( hits, profileResult) ;
+ }
+ }
+}
+ 五、数据返回 入口:RestCancellableNodeClient.doExecute Task task = client.executeLocally主要执行查询,并使用了ActionListener来进行监听
其中onResponse的调用链路如下:RestActionListener.onResponse->RestResponseListener.processResponse->RestController.sendResponse->DefaultRestChannel.sendResponse->Netty4HttpChannel.sendResponse
public void sendResponse ( RestResponse restResponse) {
+ . . .
+ httpChannel. sendResponse ( httpResponse, listener) ;
+ . . .
+}
+
+最后由Netty4HttpChannel.sendResponse来响应请求。
六、总结 当我们以aaaa*这样来搜索的时候,实际上查询了所有匹配以aaaa开头的索引,并且对所有的索引的分片都进行了一次Query,再然后对有结果的分片进行一次fetch,最终才能展示结果。可能觉得好奇,对所有分片都进行一次搜索,遍历分片所有的Lucene分段,会不会太过于消耗资源,因此合并Lucene分段对搜索性能有好处,这里下篇文章在讲吧。同时,聚合是发生在fetch过程中的,并不是lucene。
本文参考 Elasitcsearch源码解析与优化实战open in new window Elasticsearch源码分析-搜索分析(一)open in new window Elasticsearch源码分析-搜索分析(二)open in new window Elasticsearch源码分析-搜索分析(三)open in new window Elasticsearch 通信模块的分析open in new window Elasticsearch 网络通信线程分析open in new window 下一页
【elasticsearch】源码debug
个人博客
+ mysql | 个人博客
+ gap锁 | 个人博客
+ Mysql | 个人博客
+ 执行计划explain | 个人博客
+ 数据库缓存 | 个人博客
+ 跳至主要內容 数据库缓存 在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。
将select语句和语句的结果做hashopen in new window 映射关系后保存在一定的内存区域内。
禁用原因:
1.命中率低
2.写时所有都失效
禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。
查询缓存讲解:https://blog.csdn.net/zzddada/article/details/124116182
执行计划explain
3.1 DevOps平台.md | 个人博客
+ 跳至主要內容 3.1 DevOps平台.md DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。
一、自由风格的软件项目 主要还是基于jenkins里面构建一个自由风格的软件项目,当时参考的是阿里的codepipeline,就是对jenkins封装一层,包括创建job、立即构建、获取构建进度等都进行封装,并将需要的东西进行存库,没有想到码代码的时候,一堆的坑,比如: 1.连续点击立即构建,jenkins是不按顺序返回的,(分布式锁解决) 2.跨域调用,csrf,这个还好,不过容易把jenkins搞的无法登录(注意配置,具体可以点击这里open in new window ) 3.创建job的时候只支持xml格式,还要转换一下,超级坑(xstream强行转换) 4.docker构建的时候,需要挂载宿主机的docker(想过用远程的,但效率不高) 5.数据库与jenkins的job一致性问题,任务创建失败,批量删除太慢(目前没想好怎么解决) 6.由于使用了数据库,需要检测job是否构建完成,为了自定义参数,我们自写了个通知插件,将构建状态返回到kafka,然后管理平台在进行消息处理。
完成了以上的东西,不过由于太过于简单,导致只能进行单条线的CICD,而且CI仅仅实现了打包,没有将CD的过程一同串行起来。简单来说就是,用户点击了构建只是能够打出一个镜像,但是如果要部署到kubernetes,还是需要在应用里手动更换一下镜像版本。总体而言,这个版本的jenkins我们使用的还是单点的,不足以支撑构建量比较大的情况,甚至如果当前服务挂了,断网了,整一块的构建功能都不能用。
< project> < actions/> < description> </ description> < properties> < hudson.model.ParametersDefinitionProperty> < parameterDefinitions> < hudson.model.TextParameterDefinition> < name> </ name> < defaultValue> </ defaultValue> </ hudson.model.TextParameterDefinition> < hudson.model.TextParameterDefinition> < name> </ name> < defaultValue> </ defaultValue> </ hudson.model.TextParameterDefinition> </ parameterDefinitions> </ hudson.model.ParametersDefinitionProperty> </ properties> < scmclass = " hudson.plugins.git.GitSCM" > < configVersion> </ configVersion> < userRemoteConfigs> < hudson.plugins.git.UserRemoteConfig> < url> </ url> < credentialsId> </ credentialsId> </ hudson.plugins.git.UserRemoteConfig> </ userRemoteConfigs> < branches> < hudson.plugins.git.BranchSpec> < name> </ name> </ hudson.plugins.git.BranchSpec> </ branches> < doGenerateSubmoduleConfigurations> </ doGenerateSubmoduleConfigurations> < extensions/> </ scm> < builders> < hudson.tasks.Shell> < command> </ command> </ hudson.tasks.Shell> < hudson.tasks.Maven> < targets> </ targets> < mavenName> </ mavenName> </ hudson.tasks.Maven> < com.cloudbees.dockerpublish.DockerBuilder> < server> < uri> </ uri> </ server> < registry> < url> </ url> </ registry> < repoName> </ repoName> < forcePull> </ forcePull> < dockerfilePath> </ dockerfilePath> < repoTag> </ repoTag> < skipTagLatest> </ skipTagLatest> </ com.cloudbees.dockerpublish.DockerBuilder> </ builders> < publishers> < com.xxxx.notifications.Notifier/> </ publishers> </ project> 二、优化之后的CICD 上面的过程也仍然没有没住DevOps的流程,人工干预的东西依旧很多,由于上级急需产出,所以只能将就着继续下去。我们将构建、部署每个当做一个小块,一个CICD的过程可以选择构建、部署,花了很大的精力,完成了串行化的别样的CICD。 以下图为例,整个流程的底层为:paas平台-jenkins-kakfa-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发构建-jenkins-kafka-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发部署。
目前实现了串行化的CICD构建部署,之后考虑实现多个CICD并行,并且一个CICD能够调用另一个CICD,实际运行中,出现了一大堆问题。由于经过的组件太多,一次cicd的运行报错,却很难排查到问题出现的原因,业务方的投诉也开始慢慢多了起来,只能说劝导他们不要用这个功能。
没有CICD,就无法帮助公司上容器云,无法合理的利用容器云的特性,更无法走上云原生的道路。于是,我们决定另谋出路。
三、调研期 由于之前的CICD问题太多,特别是经过的组件太多了,导致出现问题的时候无法正常排查,为了能够更加稳定可靠,还是决定了要更换一下底层。 我们重新审视了下pipeline,觉得这才是正确的做法,可惜不知道如果做成一个产品样子的东西,用户方Dockerfile都不怎么会写,你让他写一个Jenkinsfile?不合理!在此之外,我们看到了serverless jenkins、谷歌的tekton。 GitLab-CICD Gitlab中自带了cicd的工具,需要配置一下runner,然后配置一下.gitlab-ci.yml写一下程序的cicd过程即可,构建镜像的时候我们使用的是kaniko,整个gitlab的cicd在我们公司小项目中大范围使用,但是学习成本过高,尤其是引入了kaniko之后,还是寻找一个产品化的CICD方案。
分布式构建jenkins x 首先要解决的是多个构建同时运行的问题,很久之前就调研过jenkins x,它必须要使用在kubernetes上,由于当时官方文档不全,而且我们的DevOps项目处于初始期,所有没有使用。jenkins的master slave结构就不多说了。jenkins x应该说是个全家桶,包含了helm仓库、nexus仓库、docker registry等,代码是jenkins-x-imageopen in new window 。
serverless jenkins 好像跟谷歌的tekton相关,用了下,没调通,只能用于GitHub。感觉还不如直接使用tekton。
阿里云云效 提供了图形化配置DevOps流程,支持定时触发,可惜没有跟gitlab触发结合,如果需要个公司级的DevOps,需要将公司的jira、gitlab、jenkins等集合起来,但是图形化jenkins pipeline是个特别好的参考方向,可以结合阿里云云效来做一个自己的DevOps产品。
微软Pipeline 微软也是提供了DevOps解决方案的,也是提供了yaml格式的写法,即:在右边填写完之后会转化成yaml。如果想把DevOps打造成一款产品,这样的设计显然不是最好的。
谷歌tekton kubernetes的官方cicd,目前已用于kubernetes的release发版过程,目前也仅仅是与GitHub相结合,gitlab无法使用,全过程可使用yaml文件来创建,跑起来就是类似kubernetes的job一样,用完即销毁,可惜目前比较新,依旧处于alpha版本,无法用于生产。有兴趣可以参考下:Knative 初体验:CICD 极速入门 open in new window
四、产品化后的DevOps平台 在调研DockOne以及各个产商的DevOps产品时,发现,真的只有阿里云的云效才是真正比较完美的DevOps产品,用户不需要知道pipeline的语法,也不需要掌握kubernetes的相关知识,甚至不用写yaml文件,对于开发、测试来说简直就是神一样的存在了。云效对小公司(创业公司)免费,但是有一定的量之后,就要开始收费了。在调研了一番云效的东西之后,发现云效也是基于jenkins x改造的,不过阿里毕竟人多,虽然能约莫看出是pipeline的语法,但是阿里彻底改造成了能够使用yaml来与后台交互。 下面是以阿里云的云效界面以及配合jenkins的pipeline语法来讲解:
4.1 Java代码扫描 PMD是一款可拓展的静态代码分析器它不仅可以对代码分析器,它不仅可以对代码风格进行检查,还可以检查设计、多线程、性能等方面的问题。阿里云的是简单的集成了一下而已,对于我们来说,底层使用了sonar来接入,所有的代码扫描结果都接入了sonar。
stage('Clone') {
+ steps{
+ git branch: 'master', credentialsId: 'xxxx', url: "xxx"
+ }
+}
+stage('check') {
+ steps{
+ container('maven') {
+ echo "mvn pmd:pmd"
+ }
+ }
+}
+ 4.2 Java单元测试 Java的单元测试一般用的是Junit,在阿里云中,使用了surefire插件,用来在maven构建生命周期的test phase执行一个应用的单元测试。它会产生两种不同形式的测试结果报告。我这里就简单的过一下,使用"mvn test"命令来代替。
+stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxx', url: "xxxxxx"
+ }
+}
+stage('test') {
+ steps{
+ container('maven') {
+ sh "mvn test"
+ }
+ }
+}
+ 4.3 Java构建并上传镜像 镜像的构建比较想使用kaniko,尝试找了不少方法,到最后还是只能使用dind(docker in docker),挂载宿主机的docker来进行构建,如果能有其他方案,希望能提醒下。目前jenkins x使用的是dind,挂载的时候需要配置一下config.json,然后挂载到容器的/root/.docker目录,才能在容器中使用docker。
为什么不推荐dind:挂载了宿主机的docker,就可以使用docker ps查看正在运行的容器,也就意味着可以使用docker stop、docker rm来控制宿主机的容器,虽然kubernetes会重新调度起来,但是这一段的重启时间极大的影响业务。
+stage('下载代码') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxx', url: "xxxxxx"
+ script {
+ build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
+ }
+ }
+}
+stage('打包并构建镜像') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn clean install -Dmaven.test.skip=true"
+ sh "docker build -f xxx/Dockerfile -t xxxxxx:${build_tag} ."
+ sh "docker push xxxxxx:${build_tag}"
+ }
+ }
+}
+
+ 4.4 部署到阿里云k8s CD过程有点困难,由于我们的kubernetes平台是图形化的,类似于阿里云,用户根本不需要自己写deployment,只需要在图形化界面做一下操作即可部署。对于CD过程来说,如果应用存在的话,就可以直接替换掉镜像版本即可,如果没有应用,就提供个简单的界面让用户新建应用。当然,在容器最初推行的时候,对于用户来说,一下子需要接受docker、kubernetes、helm等概念是十分困难的,不能一个一个帮他们写deployment这些yaml文件,只能用helm创建一个通用的spring boot或者其他的模板,然后让业务方修改自己的配置,每次构建的时候只需要替换镜像即可。
def tmp = sh (
+ returnStdout: true,
+ script: "kubectl get deployment -n ${namespace} | grep ${JOB_NAME} | awk '{print \$1}'"
+)
+//如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置
+if(tmp.equals('')){
+ sh "helm init --client-only"
+ sh """helm repo add mychartmuseum http://xxxxxx \
+ --username myuser \
+ --password=mypass"""
+ sh """helm install --set name=${JOB_NAME} \
+ --set namespace=${namespace} \
+ --set deployment.image=${image} \
+ --set deployment.imagePullSecrets=${harborProject} \
+ --name ${namespace}-${JOB_NAME} \
+ mychartmuseum/soa-template"""
+}else{
+ println "已经存在,替换镜像"
+ //epaas中一个pod的容器名称需要带上"-0"来区分
+ sh "kubectl set image deployment/${JOB_NAME} ${JOB_NAME}-0=${image} -n ${namespace}"
+}
+
+ 4.5 整体流程 代码扫描,单元测试,构建镜像三个并行运行,等三个完成之后,在进行部署
pipeline:
pipeline {
+ agent {
+ label "jenkins-maven"
+ }
+ stages{
+ stage('代码扫描,单元测试,镜像构建'){
+ parallel {
+ stage('并行任务一') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('Java代码扫描') {
+ stage('Clone') {
+ steps{
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ }
+ }
+ stage('check') {
+ steps{
+ container('maven') {
+ echo "$BUILD_NUMBER"
+ }
+ }
+ }
+ }
+ }
+ stage('并行任务二') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('Java单元测试') {
+ stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ }
+ }
+ stage('test') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn -v"
+ }
+ }
+ }
+ }
+ }
+ stage('并行任务三') {
+ agent {
+ label "jenkins-maven"
+ }
+ stages('java构建镜像') {
+ stage('Clone') {
+ steps{
+ echo "1.Clone Stage"
+ git branch: 'master', credentialsId: 'xxxxxxx', url: "xxxxxxx"
+ script {
+ build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
+ }
+ }
+ }
+ stage('Build') {
+ steps{
+ container('maven') {
+ echo "3.Build Docker Image Stage"
+ sh "mvn clean install -Dmaven.test.skip=true"
+ sh "docker build -f epaas-portal/Dockerfile -t hub.gcloud.lab/rongqiyun/epaas:${build_tag} ."
+ sh "docker push hub.gcloud.lab/rongqiyun/epaas:${build_tag}"
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ stage('部署'){
+ stages('部署到容器云') {
+ stage('check') {
+ steps{
+ container('maven') {
+ script{
+ if (deploy_app == "true"){
+ def tmp = sh (
+ returnStdout: true,
+ script: "kubectl get deployment -n ${namespace} | grep ${JOB_NAME} | awk '{print \$1}'"
+ )
+ //如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置
+ if(tmp.equals('')){
+ sh "helm init --client-only"
+ sh """helm repo add mychartmuseum http://xxxxxx \
+ --username myuser \
+ --password=mypass"""
+ sh """helm install --set name=${JOB_NAME} \
+ --set namespace=${namespace} \
+ --set deployment.image=${image} \
+ --set deployment.imagePullSecrets=${harborProject} \
+ --name ${namespace}-${JOB_NAME} \
+ mychartmuseum/soa-template"""
+ }else{
+ println "已经存在,替换镜像"
+ //epaas中一个pod的容器名称需要带上"-0"来区分
+ sh "kubectl set image deployment/${JOB_NAME} ${JOB_NAME}-0=${image} -n ${namespace}"
+ }
+ }else{
+ println "用户选择不部署代码"
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+ }
+}
+在jenkins x中查看:
4.4 日志 jenkins blue ocean步骤日志:
云效中的日志:
4.5 定时触发 triggers {
+ cron('H H * * *') //每天
+ }
+ 五、其他 5.1 Gitlab触发 pipeline中除了有对于时间的trigger,还支持了gitlab的触发,需要各种配置,不过如果真的对于gitlab的cicd有要求,直接使用gitlab-ci会更好,我们同时也对gitlab进行了runner的配置来支持gitlab的cicd。gitlab的cicd也提供了构建完后即销毁的过程。
六、总结 功能最强大的过程莫过于自己使用pipeline脚本实现,选取最适合自己的,但是对于一个公司来说,如果要求业务方来掌握这些,特别是IT流动性大的时候,既需要重新培训,同个问题又会被问多遍,所以,只能将DevOps实现成一个图形化的东西,方便,简单,相对来说功能还算强大。
DevOps最难的可能都不是以上这些,关键是让用户接受,容器云最初推行时,公司原本传统的很多发版方式都需要进行改变,有些业务方不愿意改,或者有些代码把持久化的东西存到了代码中而不是分布式存储里,甚至有些用户方都不愿意维护老代码,看都不想看然后想上容器,一个公司在做技术架构的时候,过于混乱到最后填坑要么需要耗费太多精力甚至大换血。
最后,DevOps是云原生的必经之路!!!
文章同步:
Git | 个人博客
+ 三、DevOps | 个人博客
+ jenkins-x | 个人博客
+ tekton | 个人博客
+ 微信支付 | 个人博客
+ 个人博客
+ Interview | 个人博客
+ 个人博客
+ 跳至主要內容 tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决
tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作
tt三面: 大部分聊项目,基础随便问了问 1.分布式事务,两阶段三阶段流程,区别 2.mysql主从,同步复制,半同步复制,异步复制 3.算法题,k个一组翻转链表,类似lc25,区别是最后一组不足k个也要翻转 4.场景题,设计一个评论系统,包含发布评论,回复评论,评论点赞等功能,用户过亿,qps百万
JVM调优参数 | 个人博客
+ 跳至主要內容 JVM调优参数 一、堆大小设置 JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置: java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
+-Xmx3550m:设置JVM最大可用内存为3550M。
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio = 4 -XX:SurvivorRatio = 4 -XX:MaxPermSize = 16m -XX:MaxTenuringThreshold = 0
+-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
二、回收器选择 JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
2.1 吞吐量优先的并行收集器 如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads = 20
+-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。 -XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads = 20 -XX:+UseParallelOldGC
+-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis = 100
+-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis = 100 -XX:+UseAdaptiveSizePolicy
+-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
2.2 响应时间优先的并发收集器 如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。 典型配置:
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads = 20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
+-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction = 5 -XX:+UseCMSCompactAtFullCollection
+-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。 -XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
三、辅助信息 JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些: -XX:+PrintGC 输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用 输出形式:Application time: 0.5291524 seconds -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用 输出形式:Total time for which application threads were stopped: 0.0468229 seconds -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息 输出形式:
34.702: [GC {Heap before gc invocations=7:
+ def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
+eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
+from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
+ to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
+ tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
+the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
+ compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
+ the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
+ ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
+ rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
+34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
+ def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
+eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
+ from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
+ to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
+ tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
+the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
+ compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
+ the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
+ ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
+ rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
+}
+, 0.0757599 secs]
+-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。 常见配置汇总
3.1 堆设置 -Xms:初始堆大小 -Xmx:最大堆大小 -XX:NewSize=n:设置年轻代大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n:设置持久代大小
3.2 收集器设置 -XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器
3.3 垃圾回收统计信息 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename
3.4 并行收集器设置 -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
3.5 并发收集器设置 -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
四、调优总结 4.1 年轻代大小选择 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
4.2 年老代大小选择 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得: 并发垃圾收集信息 持久代并发收集次数 传统GC信息 花在年轻代和年老代回收上的时间比例 减少年轻代和年老代花费的时间,一般会提高应用的效率 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
4.3 较小堆引起的碎片问题 因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他 会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么 并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置: -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。 -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
下一页
lucene搜索原理
Java | 个人博客
+ lucene搜索原理 | 个人博客
+ 被挖矿攻击 | 个人博客
+ 一次jvm调优过程 | 个人博客
+ 跳至主要內容 一次jvm调优过程 前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。 该程序task主要分为三个模块: console进行一些cron的配置(表达式、任务名称、任务组等); schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发; client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。 整体架构跟github上开源的xxl-job类似,也可以参考一下。
1. 启用jmx和远程debug模式 容器的网络使用了BGP,打通了公司的内网,所以可以直接通过ip来进行程序的调试,主要是在启动的jvm参数中添加:
JAVA_DEBUG_OPTS = " -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=0.0.0.0:8000,server=y,suspend=n "
+JAVA_JMX_OPTS = " -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false "
+其中,调试模式的address最好加上0.0.0.0,有时候通过netstat查看端口的时候,该位置显示为127.0.0.1,导致无法正常debug,开启了jmx之后,可以初步观察堆内存的情况。
堆内存(特别是cms的old gen),初步看代码觉得是由于用了大量的map,本地缓存了大量数据,怀疑是每次定时调度的信息都进行了保存。
2. memory analyzer、jprofiler进行堆内存分析 先从容器中dump出堆内存
jmap -dump:live,format= b,file= heap.hprof 58
+由图片可以看出,这些大对象不过也就10M,并没有想象中的那么大,所以并不是大对象的问题,后续继续看了下代码,虽然每次请求都会把信息放进map里,如果能正常调通的话,就会移除map中保存的记录,由于是测试环境,执行端很多时候都没有正常运行,甚至说业务方关闭了程序,导致调度一直出现问题,所以map的只会保留大量的错误请求。不过相对于该程序的堆内存来说,不是主要问题。
3. netty的方面的考虑 另一个小伙伴一直怀疑的是netty这一块有错误,着重看了下。该程序用netty自己实现了一套rpc,调度端每次进行命令下发的时候都会通过netty的rpc来进行通信,整个过程逻辑写的很混乱,下面开始排查。 首先是查看堆内存的中占比:
可以看出,io.netty.channel.nio.NioEventLoop的占比达到了40%左右,再然后是io.netty.buffer.PoolThreadCache,占比大概达到33%左右。猜想可能是传输的channel没有关闭,还是NioEventLoop没有关闭。再跑去看一下jmx的线程数:
达到了惊人的1000个左右,而且一直在增长,没有过下降的趋势,再次猜想到可能是NioEventLoop没有关闭,在代码中全局搜索NioEventLoop,找到一处比较可疑的地方。
声明了一个NioEventLoopGroup的成员变量,通过构造方法进行了初始化,但是在执行syncRequest完之后并没有进行对group进行shutdownGracefully操作,外面对其的操作并没有对该类的group对象进行关闭,导致线程数一直在增长。
最终解决办法: 在调用完syncRequest方法时,对ChannelBootStrap的group对象进行行shutdownGracefully
提交代码,容器中继续测试,可以基本看出,线程基本处于稳定状态,并不会出现一直增长的情况了
还原本以为基本解决了,到最后还是发现,堆内存还算稳定,但是,直接内存依旧打到了100%,虽然程序没有挂掉,所以,上面做的,可能仅仅是为这个程序续命了而已,感觉并没有彻底解决掉问题。
4. 直接内存排查 第一个想到的就是netty的直接内存,关掉,命令如下:
-Dio.netty.noPreferDirect = true -Dio.netty.leakDetectionLevel = advanced
+查看了一下java的nio直接内存,发现也就几十kb,然而直接内存还是慢慢往上涨。毫无头绪,然后开始了自己的从linux层面开始排查问题
5. 推荐的直接内存排查方法 5.1 pmap 一般配合pmap使用,从内核中读取内存块,然后使用views 内存块来判断错误,我简单试了下,乱码,都是二进制的东西,看不出所以然来。
pmap -d 58 | sort -n -k2
+pmap -x 58 | sort -n -k3
+grep rw-p /proc/$1 /maps | sed -n 's/^\([0-9a-f]*\)-\([0-9a-f]*\) .*$/\1 \2/p' | while read start stop; do gdb --batch --pid $1 -ex "dump memory $1 -$start -$stop .dump 0x$start 0x$stop " ; done
+这个时候真的懵了,不知道从何入手了,难道是linux操作系统方面的问题?
起初,在网上看到有人说是因为linux自带的glibc版本太低了,导致的内存溢出,考虑一下。初步觉得也可能是因为这个问题,所以开始慢慢排查。oracle官方有一个jemalloc用来替换linux自带的,谷歌那边也有一个tcmalloc,据说性能比glibc、jemalloc都强,开始换一下。 根据网上说的,在容器里装libunwind,然后再装perf-tools,然后各种捣鼓,到最后发现,执行不了,
pprof --text /usr/bin/java java_58.0001.heap
+看着工具高大上的,似乎能找出linux的调用栈,
6. 意外的结果 毫无头绪的时候,回想到了linux的top命令以及日志情况,测试环境是由于太多执行端业务方都没有维护,导致调度系统一直会出错,一出错就会导致大量刷错误日志,平均一天一个容器大概就有3G的日志,cron一旦到准点,就会有大量的任务要同时执行,而且容器中是做了对io的限制,磁盘也限制为10G,导致大量的日志都堆积在buff/cache里面,最终直接内存一直在涨,这个时候,系统不会挂,但是先会一直显示内存使用率达到100%。 修复后的结果如下图所示:
总结 定时调度这个系统当时并没有考虑到公司的系统会用的这么多,设计的时候也仅仅是为了实现上千的量,没想到到最后变成了一天的调度都有几百万次。最初那批开发也就使用了大量的本地缓存map来临时存储数据,然后面向简历编程各种用netty自己实现了通信的方式,一堆坑都留给了后人。目前也算是解决掉了一个由于线程过多导致系统不可用的情况而已,但是由于存在大量的map,系统还是得偶尔重启一下比较好。
参考:记一次线上内存泄漏问题的排查过程open in new window Java堆外内存增长问题排查Caseopen in new window Troubleshooting Native Memory Leaks in Java Applicationsopen in new window
lucene搜索原理
下一页
内存屏障
内存屏障 | 个人博客
+ 跳至主要內容 内存屏障 四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad
在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值
在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。
一次jvm调优过程
下一页
在 Spring 6 中使用虚拟线程
在 Spring 6 中使用虚拟线程 | 个人博客
+ 跳至主要內容 在 Spring 6 中使用虚拟线程 一、简介 在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。
虚拟线程是Java 19 的预览功能open in new window ,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本open in new window 最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。
首先,我们将看到“平台线程”和“虚拟线程”之间的主要区别。接下来,我们将使用虚拟线程从头开始构建一个 Spring-Boot 应用程序。最后,我们将创建一个小型测试套件,以查看简单 Web 应用程序吞吐量的最终改进。
二、 虚拟线程与平台线程 主要区别在于虚拟线程open in new window 在其操作周期中不依赖于操作系统线程:它们与硬件解耦,因此有了“虚拟”这个词。这种解耦是由 JVM 提供的抽象层实现的。
对于本教程来说,必须了解虚拟线程的运行成本远低于平台线程。它们消耗的分配内存量要少得多。这就是为什么可以创建数百万个虚拟线程而不会出现内存不足问题,而不是使用标准平台(或内核)线程创建几百个虚拟线程。
从理论上讲,这赋予了开发人员一种超能力:无需依赖异步代码即可管理高度可扩展的应用程序。
三、在Spring 6中使用虚拟线程 从 Spring Framework 6(和 Spring Boot 3)开始,虚拟线程功能正式公开,但虚拟线程是Java 19 的预览功能。open in new window 这意味着我们需要告诉 JVM 我们要在应用程序中启用它们。由于我们使用 Maven 来构建应用程序,因此我们希望确保在 pom.xml 中包含以下代码 :
< build> < plugins> < plugin> < groupId> . apache. maven. plugins< / groupId>
+ < artifactId> - compiler- plugin< / artifactId>
+ < configuration> < source> 19 < / source>
+ < target> 19 < / target>
+ < compilerArgs> -- enable- preview
+ < / compilerArgs>
+ < / configuration>
+ < / plugin>
+ < / plugins>
+< / build>
+从 Java 的角度来看,要使用 Apache Tomcat 和虚拟线程,我们需要一个带有几个 bean 的简单配置类:
@EnableAsync
+@Configuration
+@ConditionalOnProperty (
+ value = "spring.thread-executor" ,
+ havingValue = "virtual"
+)
+public class ThreadConfig {
+ @Bean
+ public AsyncTaskExecutor applicationTaskExecutor ( ) {
+ return new TaskExecutorAdapter ( Executors . newVirtualThreadPerTaskExecutor ( ) ) ;
+ }
+
+ @Bean
+ public TomcatProtocolHandlerCustomizer < ? > protocolHandlerVirtualThreadExecutorCustomizer ( ) {
+ return protocolHandler -> {
+ protocolHandler. setExecutor ( Executors . newVirtualThreadPerTaskExecutor ( ) ) ;
+ } ;
+ }
+}
+第一个 Spring Bean ApplicationTaskExecutor 将取代标准的*ApplicationTaskExecutoropen in new window * ,提供为每个任务启动新虚拟线程的Executor 。第二个 bean,名为ProtocolHandlerVirtualThreadExecutorCustomizer,将以相同的方式 自定义标准 TomcatProtocolHandler 。open in new window 我们还添加了注释 @ConditionalOnProperty,open in new window **以通过切换application.yaml 文件中配置属性的值来按需启用虚拟线程:
spring :
+ thread-executor : virtual
+ //...
+我们来测试一下Spring Boot应用程序是否使用虚拟线程来处理Web请求调用。为此,我们需要构建一个简单的控制器来返回所需的信息:
@RestController
+@RequestMapping ( "/thread" )
+public class ThreadController {
+ @GetMapping ( "/name" )
+ public String getThreadName ( ) {
+ return Thread . currentThread ( ) . toString ( ) ;
+ }
+}
+*Threadopen in new window *对象的toString *()*方法将返回我们需要的所有信息:线程 ID、线程名称、线程组和优先级。让我们通过一个curl open in new window
$ curl -s http://localhost:8080/thread/name
+$ VirtualThread[
+正如我们所看到的,响应明确表示我们正在使用虚拟线程来处理此 Web 请求。换句话说,*Thread.currentThread()*调用返回虚拟线程类的实例。现在让我们通过简单但有效的负载测试来看看虚拟线程的有效性。
四、性能比较 对于此负载测试,我们将使用JMeteropen in new window 。这不是虚拟线程和标准线程之间的完整性能比较,而是我们可以使用不同参数构建其他测试的起点。
在这种特殊的场景中,我们将调用Rest Controller 中的一个端点,该端点将简单地让执行休眠一秒钟,模拟复杂的异步任务:
@RestController
+@RequestMapping ( "/load" )
+public class LoadTestController {
+
+ private static final Logger LOG = LoggerFactory . getLogger ( LoadTestController . class ) ;
+
+ @GetMapping
+ public void doSomething ( ) throws InterruptedException {
+ LOG . info ( "hey, I'm doing something" ) ;
+ Thread . sleep ( 1000 ) ;
+ }
+}
+请记住,由于*@ConditionalOnProperty* 注释,我们只需更改 application.yaml 中变量的值即可在虚拟线程和标准线程之间切换 。
JMeter 测试将仅包含一个线程组,模拟 1000 个并发用户访问*/load* 端点 100 秒:
image-20230827193431807 在本例中,采用这一新功能所带来的性能提升是显而易见的。让我们比较不同实现的“响应时间图”。这是标准线程的响应图。我们可以看到,立即完成一次调用所需的时间达到 5000 毫秒:
image-20230827193511176 发生这种情况是因为平台线程是一种有限的资源,当所有计划的和池化的线程都忙时,Spring 应用程序除了将请求搁置直到一个线程空闲之外别无选择。
让我们看看虚拟线程会发生什么:
image-20230827193533565 正如我们所看到的,响应稳定在 1000 毫秒。虚拟线程在请求后立即创建和使用,因为从资源的角度来看它们非常便宜。在本例中,我们正在比较 spring 默认固定标准线程池(默认为 200)和 spring 默认无界虚拟线程池的使用情况。
**这种性能提升之所以可能,是因为场景过于简单,并且没有考虑 Spring Boot 应用程序可以执行的全部操作。**从底层操作系统基础设施中采用这种抽象可能是有好处的,但并非在所有情况下都是如此。
内存屏障
下一页
基于kubernetes的分布式限流
基于kubernetes的分布式限流 | 个人博客
+ 跳至主要內容 基于kubernetes的分布式限流 做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。
一、概念 限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。
1.1 使用场景 限流可以应对:
热点业务带来的突发请求; 调用方 bug 导致的突发请求; 恶意攻击请求。 1.2 维度 对于限流场景,一般需要考虑两个维度的信息: 时间 限流基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定 资源 基于可用资源的限制,比如设定最大访问次数,或最高可用连接数。 限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。
image.png 1.3 分布式限流 分布式限流相比于单机限流,只是把限流频次分配到各个节点中,比如限制某个服务访问100qps,如果有10个节点,那么每个节点理论上能够平均被访问10次,如果超过了则进行频率限制。
二、分布式限流常用方案 基于Guava的客户端限流 Guava是一个客户端组件,在其多线程模块下提供了以RateLimiter为首的几个限流支持类。它只能对“当前”服务进行限流,即它不属于分布式限流的解决方案。
网关层限流 服务网关,作为整个分布式链路中的第一道关卡,承接了所有用户来访请求。我们在网关层进行限流,就可以达到了整体限流的目的了。目前,主流的网关层有以软件为代表的Nginx,还有Spring Cloud中的Gateway和Zuul这类网关层组件,也有以硬件为代表的F5。
中间件限流 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。
限流组件 目前也有一些开源组件提供了限流的功能,比如Sentinel就是一个不错的选择。Sentinel是阿里出品的开源组件,并且包含在了Spring Cloud Alibaba组件库中。Hystrix也具有限流的功能。
Guava的Ratelimiter设计实现相当不错,可惜只能支持单机,网关层限流如果是单机则不太满足高可用,并且分布式网关的话还是需要依赖中间件限流,而redis之类的网络通信需要占用一小部分的网络消耗。阿里的Sentinel也是同理,底层使用的是redis或者zookeeper,每次访问都需要调用一次redis或者zk的接口。那么在云原生场景下,我们有没有什么更好的办法呢?
对于极致追求高性能的服务不需要考虑熔断、降级来说,是需要尽量减少网络之间的IO,那么是否可以通过一个总限频然后分配到具体的单机里面去,在单机中实现平均的限流,比如限制某个ip的qps为100,服务总共有10个节点,那么平均到每个服务里就是10qps,此时就可以通过guava的ratelimiter来实现了,甚至说如果服务的节点动态调整,单个服务的qps也能动态调整。
三、基于kubernetes的分布式限流 在Spring Boot应用中,定义一个filter,获取请求参数里的key(ip、userId等),然后根据key来获取rateLimiter,其中,rateLimiter的创建由数据库定义的限频数和副本数来判断,最后,再通过rateLimiter.tryAcquire来判断是否可以通过。
企业微信截图_868136b4-f9e2-4813-bc02-281a66756ecd.png 3.1 kubernetes中的副本数 在实际的服务中,数据上报服务一般无法确定客户端的上报时间、上报量,特别是对于这种要求高性能,服务一般都会用到HPA来实现动态扩缩容,所以,需要去间隔一段时间去获取服务的副本数。
func CountDeploymentSize ( namespace string , deploymentName string ) * int32 {
+ deployment, err := client. AppsV1 ( ) . Deployments ( namespace) . Get ( context. TODO ( ) , deploymentName, metav1. GetOptions{ } )
+ if err != nil {
+ return nil
+ }
+ return deployment. Spec. Replicas
+}
+用法:GET host/namespaces/test/deployments/k8s-rest-api直接即可。
3.2 rateLimiter的创建 在RateLimiterService中定义一个LoadingCache<String, RateLimiter>,其中,key可以为ip、userId等,并且,在多线程的情况下,使用refreshAfterWrite只阻塞加载数据的线程,其他线程则返回旧数据,极致发挥缓存的作用。
private final LoadingCache < String , RateLimiter > = Caffeine . newBuilder ( )
+ . maximumSize ( 10_000 )
+ . refreshAfterWrite ( 20 , TimeUnit . MINUTES )
+ . build ( this :: createRateLimit ) ;
+
+private static final Integer minQpsLimit = 3000 ;
+之后是创建rateLimiter,获取总限频数totalLimit和副本数replicas,之后是自己所需的逻辑判断,可以根据totalLimit和replicas的情况来进行qps的限定。
public RateLimiter createRateLimit ( String key) {
+ log. info ( "createRateLimit,key:{}" , key) ;
+ int totalLimit = 获取总限频数,可以在数据库中定义
+ Integer replicas = kubernetesService. getDeploymentReplicas ( ) ;
+ RateLimiter rateLimiter;
+ if ( totalLimit > 0 && replicas == null ) {
+ rateLimiter = RateLimiter . create ( totalLimit) ;
+ } else if ( totalLimit > 0 ) {
+ int nodeQpsLimit = totalLimit / replicas;
+ rateLimiter = RateLimiter . create ( nodeQpsLimit > minQpsLimit ? nodeQpsLimit : minQpsLimit) ;
+ } else {
+ rateLimiter = RateLimiter . create ( minQpsLimit) ;
+ }
+ log. info ( "create rateLimiter success,key:{},rateLimiter:{}" , key, rateLimiter) ;
+ return rateLimiter;
+}
+ 3.3 rateLimiter的获取 根据key获取RateLimiter,如果有特殊需求的话,需要判断key不存在的尝尽
public RateLimiter getRateLimiter ( String key) {
+ return loadingCache. get ( key) ;
+}
+ 3.4 filter里的判断 最后一步,就是使用rateLimiter来进行限流,如果rateLimiter.tryAcquire()为true,则进行filterChain.doFilter(request, response),如果为false,则返回HttpStatus.TOO_MANY_REQUESTS
public class RateLimiterFilter implements Filter {
+ @Resource
+ private RateLimiterService rateLimiterService;
+
+ @Override
+ public void doFilter ( ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException , ServletException {
+ HttpServletRequest httpServletRequest = ( HttpServletRequest ) request;
+ HttpServletResponse httpServletResponse = ( HttpServletResponse ) response;
+ String key = httpServletRequest. getHeader ( "key" ) ;
+ RateLimiter rateLimiter = rateLimiterService. getRateLimiter ( key) ;
+ if ( rateLimiter != null ) {
+ if ( rateLimiter. tryAcquire ( ) ) {
+ filterChain. doFilter ( request, response) ;
+ } else {
+ httpServletResponse. setStatus ( HttpStatus . TOO_MANY_REQUESTS . value ( ) ) ;
+ }
+ } else {
+ filterChain. doFilter ( request, response) ;
+ }
+ }
+}
+ 四、性能压测 为了方便对比性能之间的差距,我们在本地单机做了下列测试,其中,总限频都设置为3万。
无限流
企业微信截图_ea1b7815-3b89-43bf-aed7-240e135bdad1.png 使用redis限流
其中,ping redis大概6-7ms左右,对应的,每次请求需要访问redis,时延都有大概6-7ms,性能下降明显
企业微信截图_9118c4e0-c7f3-4e74-9649-4cd4d56fda79.png 自研限流
性能几乎追平无限流的场景,guava的rateLimiter确实表现卓越
企业微信截图_9f6510bd-be9e-438b-aa9d-bdd13ebca953.png 五、其他问题 5.1 对于保证qps限频准确的时候,应该怎么解决呢?
在k8s中,服务是动态扩缩容的,相应的,每个节点应该都要有所变化,如果对外宣称限频100qps,而且后续业务方真的要求百分百准确,只能把LoadingCache<String, RateLimiter>的过期时间调小一点,让它能够近实时的更新单节点的qps。这里还需要考虑一下k8s的压力,因为每次都要获取副本数,这里也是需要做缓存的
5.2 服务从1个节点动态扩为4个节点,这个时候新节点识别为4,但其实有些并没有启动完,会不会造成某个节点承受了太大的压力
理论上是存在这个可能的,这个时候需要考虑一下初始的副本数的,扩缩容不能一蹴而就,一下子从1变为4变为几十个这种。一般的话,生产环境肯定是不能只有一个节点,并且要考虑扩缩容的话,至于要有多个副本预备的
5.3 如果有多个副本,怎么保证请求是均匀的
这个是依赖于k8s的service负载均衡策略的,这个我们之前做过实验,流量确实是能够均匀的落到节点上的。还有就是,我们整个限流都是基于k8s的,如果k8s出现问题,那就是整个集群所有服务都有可能出现问题了。
参考 1.常见的分布式限流解决方案open in new window 分布式服务限流实战open in new window 高性能open in new window
在 Spring 6 中使用虚拟线程
下一页
被挖矿攻击
个人博客
+ spark on k8s operator | 个人博客
+ 跳至主要內容 spark on k8s operator Spark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。
使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。
Spark Operator包括如下几个组件:
SparkApplication控制器:该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作。 Submission Runner:负责调用spark-submit提交Spark作业,作业提交的流程完全复用Spark on K8s的模式。 Spark Pod Monitor:监控Spark作业相关Pod的状态,并同步到控制器中。 Mutating Admission Webhook:可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求。 SparkCtl:用于和Spark Operator交互的命令行工具。 安装
+helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
+
+helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace
+这个时候如果直接执行kubectl apply -f examples/spark-pi.yaml调用样例,会出现以下报错,需要创建对象的serviceaccount。
forbidden: error looking up service account default/spark: serviceaccount \"spark\" not found.\n\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport.requestFailure(OperationSupport.java:568)\n\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport
+同时也要安装rbac
rbac的文件在manifest/spark-operator-install/spark-operator-rbac.yaml,需要把namespace全部改为需要运行的namespace,这里我们任务放在default命名空间下,所以全部改为default,源文件见rbac.yamlopen in new window
执行脚本,这里用的app.jar是一个读取es数据源,然后计算,为了展示效果,在程序的后面用了TimeUnit.HOURS.sleep(1)方便观察。
代码如下:
SparkConf sparkConf = new SparkConf ( ) . setAppName ( "Spark WordCount Application (java)" ) ;
+ sparkConf. set ( "es.nodes" , "xxx" )
+ . set ( "es.port" , "8xx0" )
+ . set ( "es.nodes.wan.only" , "true" )
+ . set ( "es.net.http.auth.user" , "xxx" )
+ . set ( "es.net.http.auth.pass" , "xxx-xxx" ) ;
+ try ( JavaSparkContext jsc = new JavaSparkContext ( sparkConf) ) {
+ JavaRDD < Map < String , Object > > = JavaEsSpark . esRDD ( jsc, "kibana_sample_data_ecommerce" ) . values ( ) ;
+
+ System . out. println ( esRDD. partitions ( ) . size ( ) ) ;
+
+ esRDD. map ( x -> x. get ( "customer_full_name" ) )
+ . countByValue ( )
+ . forEach ( ( x, y) -> System . out. println ( x + ":" + y) ) ;
+ TimeUnit . HOURS . sleep ( 1 ) ;
+
+ } catch ( InterruptedException e) {
+ throw new RuntimeException ( e) ;
+ }
+打包之后kubectl create -f k8s.yaml即可
apiVersion : "sparkoperator.k8s.io/v1beta2"
+kind : SparkApplication
+metadata :
+ name : spark- demo
+ namespace : default
+spec :
+ type : Scala
+ mode : cluster
+ image : fewfew- docker.pkg.coding.net/spark- java- demo/spark- java- demo- new/spark- java- demo: master- 1d8c164bced70a1c66837ea5c0180c61dfb48ac3
+ imagePullPolicy : Always
+ mainClass : com.spark.es.demo.EsReadGroupByName
+ mainApplicationFile : "local:///opt/spark/examples/jars/app.jar"
+ sparkVersion : "3.1.1"
+ restartPolicy :
+ type : Never
+ driver :
+
+ coreRequest : "100m"
+ coreLimit : "1200m"
+ memory : "512m"
+ labels :
+ version : 3.1.1
+ serviceAccount : sparkoperator
+ executor :
+
+ coreRequest : "100m"
+ instances : 1
+ memory : "512m"
+ labels :
+ version : 3.1.1
+spark-demo-driver 1/1 Running 0 2m30s
+spark-wordcount-application-java-0ac352810a9728e1-exec-1 1/1 Running 0 2m1s
+同时会自动生成相应的service。
image-20220528203941897 Spark on k8s operator大大减少了spark的部署与运维成本,用容器的调度来替换掉yarn,
源码解析 Spark Operator的主要组件如下:
1、SparkApplication Controller : 用于监控并相应SparkApplication的相关对象的创建、更新和删除事件;
2、Submission Runner:用于接收Controller的提交指令,并通过spark-submit 来提交Spark作业到K8S集群并创建Driver Pod,driver正常运行之后将启动Executor Pod;
3、Spark Pod Monitor:实时监控Spark作业相关Pod(Driver、Executor)的运行状态,并将这些状态信息同步到Controller ;
4、Mutating Admission Webhook:可选模块,但是在Spark Operator中基本上所有的有关Spark pod在Kubernetes上的定制化功能都需要使用到该模块,因此建议将enableWebhook这个选项设置为true。
5、sparkctl: 基于Spark Operator的情况下可以不再使用kubectl来管理Spark作业了,而是采用Spark Operator专用的作业管理工具sparkctl,该工具功能较kubectl功能更为强大、方便易用。
apis:用户编写yaml时的解析
Batchscheduler:批处理的调度,提供了支持volcano的接口
Client:
leader的选举
electionCfg := leaderelection. LeaderElectionConfig{
+ Lock: resourceLock,
+ LeaseDuration: * leaderElectionLeaseDuration,
+ RenewDeadline: * leaderElectionRenewDeadline,
+ RetryPeriod: * leaderElectionRetryPeriod,
+ Callbacks: leaderelection. LeaderCallbacks{
+ OnStartedLeading: func ( c context. Context) {
+ close ( startCh)
+ } ,
+ OnStoppedLeading: func ( ) {
+ close ( stopCh)
+ } ,
+ } ,
+}
+
+elector, err := leaderelection. NewLeaderElector ( electionCfg)
+参考:
1.k8s client-go中Leader选举实现open in new window
2.[Kubernetes基于leaderelection选举策略实现组件高可用open in new window
2017 | 个人博客
+ 跳至主要內容 2017 2016年6月,大三,考完最后一科,默默的看着大四那群人一个一个的走了,想着想着,明年毕业的时候,自己将会失去你所拥有的一切,大学那群认识的人,可能这辈子都不会见到了——致远离家乡出省读书的娃。然而,我并没有想到,自己失去的,不仅仅是那群人,几乎是一切。。。。
回到学校,待了几天,那个整天给别人灌毒鸡汤的人还是不着急找工作:该有的时候总会有的啦,然后继续打游戏、那个天天喊着吃麻辣香锅的人,记忆中好像今年都没有吃上,哈哈、厕所还是那样偶尔炸一下,嗯,感觉一切都很熟悉,只是,我有了点伤感,毕竟身边又要换一群不认识的人了。考完试,终于能回广东了,一年没回了,开心不得了,更多的是,为了那个喜欢了好几年没有表白的妹纸,之前从没想过真的能每天跟一个妹纸道晚安,秒回,但是,对她,我还真做到了。1月份的广州,不热不冷,空气很清新,比北京、天津那股泥土味好多了,只是,我被拒了,男闺蜜还是男闺蜜,备胎还是备胎,那会还没想过放弃,直到...
春节期间,把自己的网站open in new window 整理了一下,看了看JVM和并发的知识,偶尔刷刷牛客网的题,觉得自己没多大问题了,跟同学出发,去深圳,我并没有一个做马化腾、马云的梦,但是我想,要做出点东西,至少,不是个平庸的人。投了几个,第一个面试,知道是培训兼外包后果断弃了,春招还没开始,再多准备准备,有时间就往深圳图书馆里跑,找个位置,静静的复习,那会,感觉自己一定能去个大公司吧,搞搞分布式、大数据之类的~
疲惫的面试历程 2月份底开始慢慢投简历,跑招聘会,深圳招聘的太少了,那就去广州,大学城,于是,开始了自己一周两天都在广深往返。有的公司笔试要跑一次广州,一面要跑一次,二面还要跑一次,每次看着路费,真的承受不起,但是有希望就行。乐观之下,到来的是一重又一重的打击。
**数码,很看好的公司,在广州也算是老品牌了,笔试的时候面试官没有带够卷子,就拿了大数据的做,还过了,面试的时候被面到union和union all的区别,答反了,还有left join和right join的原理,一脸懵逼,过后去了百度搜了搜,这东西哪来的原理?
然后是个企业建站的,笔试完了,面试官照着题问然后没说啥就让我走了,额,我好像还没自我介绍呢。
有点想回北京了,往北京投了一份,A轮公司,月薪10k,过了,觉得自己技术应该不差吧,不过还是拒了,因为一想起那里满脑子都是雾霾。
没事没事,下一家,某游戏公司,笔试过了,一面也过了,然后被问flume收集的时候断网处理机制、MD5和RSA原理、Angulajs和Vuejs用没用过、千万级的数据是如何存储的?额,跟你们想的一样,我一道也答出来,然后就挂了,面试官跟我说,你要是来早三个月这些都会啦,说的我很紧张,广东的同学都那么强么?
这个时候还没质疑自己的技术,去了趟深圳某家小公司,金融的,HR问我是不是培训过来的,心里开始突然间好苦涩,大学花那么多时间学习居然被别人用来和培训机构的人相提并论,笔试不知从哪整来的英文逻辑题,做完了然后上机笔试,做不出来不能见面试官,开始感觉这公司有点。。。。还是撤了撤了。
突然感觉面试面的绝望,是自己的问题么?是自己技术太菜了么?开始怀疑自己,感觉也是,已经3月份底了,毕竟别人都在实习,而我已经离职3个月没工作了,但是那些问题不是有点离谱了,一开始是开始心态爆炸觉得怎么可以对应届生问这些问题,不应该是基础么?算法什么的,后来是无奈了,开始上网搜各种不沾边的技术。
还有其他的面试。。。有的工资不高(6K不到),有的面试问题全答对就因为说了有点想做大数据就不要你,有的聊得很欢快却没消息,有的说招java但是笔试一道java题都没有全是前端的,有的打着互联网实际却是外包的公司。。。。 4月初真的很绝望很绝望,不想跟别人说话,是不是很可笑,一个从北京B+轮的公司回广东,面试近15个,居然只能拿到2个offer,其中之一国企外包的,都不知说什么好。13号要拍毕业照了,没有回去,大学四年,毕竟大家个个圈子之间没什么交流,没什么友谊,果然,整个专业的人只有2/3的人去拍了毕业照。4月23号,拉勾网深圳站,梦想着市集,抱着一点点的小希望,去投了5个,结果一个面试邀请都没有,换之而来的是一片绝望、黑暗。。。。
感情、我们毕业了 5月初回学校了赶毕业设计,回学校也是,天天往图书馆跑,为了面试,毕业设计拉下太多了。悠闲的时候,总会想起我喜欢的那个人,过的怎么样了,微信一开,好像自己被屏蔽了还是被删了?这三个月来的面试打击,真的不知道怎么应对,我更不知道怎么跟她聊天,以至于慢慢隔离,这段感情,或许只有我知道自己有多心疼,只有我自己sb得一点点的呵护着。想起上次跟她聊天是4月中,还是她提了个问题其他什么都没问,彼此之前已经没有关心了。删了吧删了吧,就这样一句再见都没有说,一句“祝福”都没有说。 5月底遇到两次还算开心的事,导师问我要不要评优秀论文,不是很想折腾,拒了,导师仍旧劝我,只是写个3页的小总结而已,评上的话能留图书馆收藏。另一个件是珍爱网打电话过来说我一面过了,什么时候二面,天啊,3月份一面,5月底才通知,心里想骂,但是真的好开心好开心,黑暗中的光芒,泪奔。。。。约到了6月15号面试。 6月初开始自己的回家倒计时,请那唯一一个跟我好的妹纸吃饭,忙完答辩,然后是优秀论文的小报告,13号下午交了上去,再回到宿舍,空无一人,一遍忍着不要悲伤,一遍收拾东西,然后向每个宿舍敲门,告别,一个人拖着行李箱,嗯,我要淡定。
准备了有点久,我以为自己准备好了,15号,深圳,珍爱网,被问到:有没有JVM调优经验 ?ZK是如何保持一致性的?有没有写过ELK索引经验?谈谈你对dubbo的理解。。。事后,得知自己没有过。心态真的炸了,通宵打了两天游戏。月底得知,优秀论文也没有被评上,已经没有骂人吐槽的想法,只是哦的一声,6月,宣告了自己春招结束,宣告自己要去外包,同时也宣告自己大学这些努力全部白费,跟那个灌毒鸡汤天天打游戏的人同一起跑线。
996的工作 七月初入职的时候,问了问那些一起应届入职的同学,跟别人交流一下面试被问的问题,只有线程池,JVM回收算法,他们也没用过,我无奈,为什么我被问到的,全是Angularjs、MD5加密算法、ZK一致性原理这种奇葩的问题。。。。。
没有环境,就自己创造,下班有时间就改改自己的网站http://www.wenzhihuai.comopen in new window ,GitHub目前有154个star了,感觉也是个小作品吧,把常用的Java技术栈(RabbitMQ、MongoDB等)加了上去,虽然没啥使用场景,但是自己好好努力吧,毕竟高并发、高可用是自己的梦想。今年GitHub自己的提交次数。
决心先好好呆着,学习学习,把公司的产品业务技术专研专研,7、8月份是挺开心的,没怎么加班,虽然下班我都留在公司学习,虽然公司的产品不咋地,但是还是有可学之处的,随后,我没想到的是,公司要实行996,,,9月份至12月,每天都是改bug,开发模块,写业务,全都是增删改查,没有涉及redis、rabbitmq,就真的只有使用Hibernate、spring,而做出的东西,要使用JDK6来运行,至今都能看到sun的类。每天的状态就是累累累,我们组还不是最惨的,隔壁项目组,一周通宵两次,9月到10都是如此,国庆加班,每次经过他们组,我都觉得自己还算是幸福。很厌恶这种不把员工当人看的行为,有同事调侃,明年估计我们这些应届过来的,是不是要走掉2/3的人?疯狂加班的代价是牺牲积极性,我问过那些一周通宵两次的人,敲代码,程序员你喜欢这份工作么?不喜欢!!!有那么一两次,实在是太累了,我都感觉自己有点不行了,想离职,可是,会有公司要我么?会有公司不问那些奇葩的问题么?
双十一,花了500多买了十本书,神书啊,计算机届的圣经啊,然而至今一本都没看完,甚至是都没怎么翻,每天下班回去之后就是9点半了,烧水,洗澡,洗衣服,近11点了,躺床上,一遍看书一遍看鹌鹑直播,一小时才翻几页,996真的太累了,实在看不下书。经过这几个月的加班,感觉自己技术增长为负数,也病了几次,同学见我,都感觉我老了不少,心里不平,可是又没有什么办法。
孤独 珠江新城,一年四季都那么美,今晚应该又是万人一起倒计时了吧?已经好久没跟别人一起出去玩过了。今年貌似得了自闭症?社交全靠黄段子。想找人出门走走,然而手机已经没有那种几年的朋友,大学同学一个都不在,哈哈哈,别人说社交软件让人离得更近,我怎么发现我自己一个好朋友都没有了呢,哭笑ing。或许是自己的确不善于跟别人保持联系吧,这个要改,一定要改!!! 远看:
近看:
题外话: 有些时候,遇到不顺,感觉自己不是神,没必要忍住,就开始宣泄自己的情绪,比如疯狂打游戏,只能这样度过了吧。
期望 想起初中,老师让我在黑板写自己的英文作文,好像是信件,描述什么状况来这?最后夸了夸我在文章后面加的一段大概是劝别人不要悲伤要灿烂。也想起一个故事,二战以后,德国满目疮痍,他们处在这样一个凄惨的境地,还能想到在桌上摆设一些花,就一定能在废墟上重建家园。我所看到的是即使在再黑暗的状态下,要永远抱着希望。明年要更加努力的学习,而不是工作,是该挽留一些人了,多运动。说了那么多,其实,我只希望自己的运气不要再差了,再差就没法活了。人在遇到不顺的时候,往往最难过的一关便是自己。哈哈哈,只能学我那个同学给自己灌毒鸡汤了。加油加油↖(^ω^)↗
下一页
2018
2018 | 个人博客
+ 跳至主要內容 2018 年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。
想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.htmlopen in new window ,感叹18年还算恢复了点。
心惊胆战的裸辞经历 其实校招过去的那家公司,真的不是很喜欢,996、技术差、产品差,实在受不了,春节前提出了离职,老大也挽留了下,以“来了个阿里的带我们重构,能学不了东西”来挽留,虽然我对技术比较痴迷,但离职去深圳的决心还是没有动摇,嗯,就这么开始了自己的裸辞过程。3月8号拿到离职,回公司的时候跟跟同事吹吹水,吃个饭,某同事还喊:“周末来公司玩玩么,我给你开门”,哈哈哈,泼出去的水,回不去了,偶尔有点伤感。 去深圳面试,第一家随手记,之前超级想去这家公司的,金融这一块,有钱,只可惜,没过,一面面试官一直夸我,我觉得稳了,二面没转过来,就这么挂了,有点不甘心吧,在这,感谢那个内推我的人吧,面经在这open in new window ,之后就是大大小小的面试,联想、恒大、期待金融什么的,都没拿到offer,裸辞真的慌得一比,一天没工作,感觉一年没有工作没人要的样子。。。。没面试就跑去广州图书馆,复习,反思,一天一天的过着,回家就去楼下吃烧烤,打游戏,2点3点才睡觉,boss直聘、拉勾网见一个问一个,迷迷糊糊慌慌张张,那段期间真的想有点把所有书卖掉回家啃老的想法,好在最后联系了一家公司,电商、大小周,知乎上全是差评,不过评价的都不是技术的,更重要的是,岗位是中间件的,嗯,去吧。
and ... 广州拜拜,晚上人少的时候,跟妹纸去珠江新城真的很美好
工作工作 入职的时候是做日志收集的,就是flume+kafka+es这一套,遇到了不少大佬,嗯,感觉挺好的,打算好好干,一个半月后不知怎么滴,被拉去做容器云了,然后就开始了天天调jenkins、gitlab这些没什么用的api,开始了增删改查的历程,很烦,研究jenkins、gitlab对于自己的技术没什么提升,又不得不做,而且大小周+加班这么做,回到家自己看java、netty、golang的书籍,可是没项目做没实践,过几个月就忘光了,有段时间真的很烦很烦,根本不想工作,天天调api,而且是jenkins、gitlab这些没什么卵用的api,至今也没找到什么办法。。。。 公司发展太快,也实在让人不知所措,一不小心部门被架空了,什么预兆都没有,被分到其他部门,然后发现这个部门领导内斗真的是,“三国争霸”吧,无奈成为炮灰,不同的领导不同的要求,安安静静敲个代码怎么这么难。。。。 去年的学习拉下了不少,文章也写的少了,总写那些入门的文章确实没有什么意思,买的书虽然没有17年的多吧,不过也不少了,也看了挺多本书的,虽然我还是不满意自己的阅读量。 这几年要开始抓准一个框架了,好好专研一下,也要开始学习一下go了,希望能参与一些github的项目,好好努力吧。
跑步跑步 平时没事总是宅在家里打游戏,差不多持续到下半年吧,那会打游戏去楼下吃东西的时候老是觉得眼神恍惚,盯着电子产品太多了,然后就跟别人跑步去了,每周去一次人才公园,跑步健身,人才公园真的是深圳跑步最好的一个地方了,桥上总有一群摄影师,好想在深圳湾买一套房子,看了看房价,算了算了,深圳的房,真的贵的离谱。19年也要多多运动,健康第一健康第一。
Others 拿到了深圳户口,全程只花了15天,感谢学妹and家人 买了第一台MacBook Pro,对于Java的我真心不好用 盼了好几年的老姐结婚,18年终于了解了这心事 养了只猫,在经历了好几个月的早起之后,晚上睡觉锁厨房,终于安分了,对不起了哈哈哈 2019 想不起来还有什么要说的了,毕竟程序员,好像每天的生活都一样,就展望一下19年吧。今年,最最重要的是家里人以及身边还有所有人都健健康康的,哈哈哈。然后是安安静静的敲代码~~就酱
2017
下一页
2019
2019 | 个人博客
+ 跳至主要內容 2019 2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。 19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。
工作 从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。
之后有了点起色,然后开始着重强调了DevOps的重要性,期初也没人理解,还被骂天天研究技术不干活。。。这东西没技术,但是真的是公司十分需要的公司好么!!可惜公司对这个产品很失望,也不给人,期间还说要暂停项目,唉,这么大的项目就给几个人怎么做,谁都不乐意,就这么过的很憋屈吧,开始了维护的日子。。。
工作上,蛮多人对我挺好的,领导,同事,不过有时候憋屈的时候还是有了点情绪化,有时候有点悲伤的想法,浮躁、暴躁,出去面试了几次,感觉不是自己能力不好,而是市场上的真的需要3+年以上的。。。。不过感觉自己能在这里憋屈的过了这么久,也是很佩服自己的,哈哈,用同事的话来说就是:当做游戏里的练级,锻炼自己哈哈哈
学习 项目的方向错误,导致自己写的代码都是很简单的增删改查,没有技术含量的那种,也最终导致自己浪费了不少时间,上半年算是很气愤吧,不想就这么浪费掉这些时间,虽然期间看了各种各样的东西,比如Netty、Go、操作系统什么的,最终发现,如果不在项目中使用的话,真的会忘,而且很快就忘掉,最后的还是决定学习项目相关度比较大的东西了,比如Go,如果项目不是很大,小项目的话,就用Go来写,这么做感觉提升还是挺大的。 过去一年往南山图书馆借了不少书,省了不少钱,虽然没怎么看,但我至少有个奋斗的心啊,哈哈哈哈哈哈哈哈,文章写得少了,因为感觉写不出好东西,总是入门的那种,不深,不值得学习,想想到时候把别人给坑了,也不好意思。 操作系统感觉还是要好好学学了,加油
Kubernetes就是未来的方向,有时候翻开源码看看,又不敢往下面看了,对底层不熟吧,今年要多多研究下Kubernetes的源码了,至于Spring那一套,也不知道该不该放弃,或者都学习一下?云原生就是趋势。
感情 吵架了,没心思写
运动 过去一年还是把运动算是坚持了下来,每个月必去深圳湾跑一次。还是没怎么睡好,工作感情上都有点不顺,加上自己本身就难以入睡,有时候躺床上就是怎么也睡不着,还长了痘痘,要跑去医院那种,可怕,老了,还是要早点睡觉,多走走多运动,好久没打羽毛球了,自己也不想有空的时候只会打游戏,今年继续加油,多运动吧。
还爬了两次南山
其他 看了周围蛮多同事去了腾讯阿里,有点心动,好想去csig,没到3年真的让人很抓狂。 过去一年过的蛮憋屈的,特别是工作不顺,加上跟女朋友吵架,心态爆炸。。。
2020展望 每年这个时候,都不敢有太大的期望了,祝大家都健健康康的,工作顺利!!
当然,如果有可能的话,我想去CSIG
2018
Life | 个人博客
+
+
\ No newline at end of file
diff --git a/middleware/index.html b/middleware/index.html
new file mode 100644
index 00000000..595b75ab
--- /dev/null
+++ b/middleware/index.html
@@ -0,0 +1,46 @@
+
+
+
+ Middleware | 个人博客
+ Kafka | 个人博客
+ kafka面试题 | 个人博客
+ 跳至主要內容 kafka面试题 1、请说明什么是Apache Kafka? Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。
2、说说Kafka的使用场景? ①异步处理 ②应用解耦 ③流量削峰 ④日志处理 ⑤消息通讯等。
3、使用Kafka有什么优点和缺点? 优点: ①支持跨数据中心的消息复制; ②单机吞吐量:十万级,最大的优点,就是吞吐量高; ③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源; ④时效性:ms级; ⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用; ⑥消息可靠性:经过参数优化配置,消息可以做到0丢失; ⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
缺点: ①由于是批量发送,数据并非真正的实时; 仅支持统一分区内消息有序,无法实现全局消息有序; ②有可能消息重复消费; ③依赖zookeeper进行元数据管理,等等。
4、为什么说Kafka性能很好,体现在哪里? ①顺序读写 ②零拷贝 ③分区 ④批量发送 ⑤数据压缩
5、请说明什么是传统的消息传递方法? 传统的消息传递方法包括两种: 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。 发布-订阅:在这个模型中,消息被广播给所有的用户。
6、请说明Kafka相对传统技术有什么优势? ①快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。 ②可伸缩:在一组机器上对数据进行分区 ③和简化,以支持更大的数据 ④持久:消息是持久性的,并在集群中进 ⑤行复制,以防止数据丢失。 ⑥设计:它提供了容错保证和持久性
7、解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗? Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。 不,不可能越过Zookeeper,直接联系Kafka broker。一旦Zookeeper停止工作,它就不能服务客户端请求。 Zookeeper主要用于在集群中不同节点之间进行通信 在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取 除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
8、解释Kafka的用户如何消费信息? 在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节从套接口转移到磁盘,通过内核空间保存副本,并在内核用户之间调用内核。
9、解释如何提高远程用户的吞吐量? 如果用户位于与broker不同的数据中心,则可能需要调优套接口缓冲区大小,以对长网络延迟进行摊销。
10、解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息? 在数据中,为了精确地获得Kafka的消息,你必须遵循两件事: 在数据消耗期间避免重复,在数据生产过程中避免重复。 这里有两种方法,可以在数据生成时准确地获得一个语义: 每个分区使用一个单独的写入器,每当你发现一个网络错误,检查该分区中的最后一条消息,以查看您的最后一次写入是否成功 在消息中包含一个主键(UUID或其他),并在用户中进行反复制
11、解释如何减少ISR中的扰动?broker什么时候离开ISR? ISR是一组与leaders完全同步的消息副本,也就是说ISR中包含了所有提交的消息。ISR应该总是包含所有的副本,直到出现真正的故障。如果一个副本从leader中脱离出来,将会从ISR中删除。
12、Kafka为什么需要复制? Kafka的信息复制确保了任何已发布的消息不会丢失,并且可以在机器错误、程序错误或更常见些的软件升级中使用。
13、如果副本在ISR中停留了很长时间表明什么? 如果一个副本在ISR中保留了很长一段时间,那么它就表明,跟踪器无法像在leader收集数据那样快速地获取数据。
14、请说明如果首选的副本不在ISR中会发生什么? 如果首选的副本不在ISR中,控制器将无法将leadership转移到首选的副本。
15、有可能在生产后发生消息偏移吗? 在大多数队列系统中,作为生产者的类无法做到这一点,它的作用是触发并忘记消息。broker将完成剩下的工作,比如使用id进行适当的元数据处理、偏移量等。
作为消息的用户,你可以从Kafka broker中获得补偿。如果你注视SimpleConsumer类,你会注意到它会获取包括偏移量作为列表的MultiFetchResponse对象。此外,当你对Kafka消息进行迭代时,你会拥有包括偏移量和消息发送的MessageAndOffset对象。
16、Kafka的设计时什么样的呢? Kafka将消息以topic为单位进行归纳 将向Kafka topic发布消息的程序成为producers. 将预订topics并消费消息的程序成为consumer. Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群向消费者提供消息
17、数据传输的事物定义有哪三种? (1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输 (2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输. (3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
18、Kafka判断一个节点是否还活着有那两个条件? (1)节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接 (2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
19、producer是否直接将数据发送到broker的leader(主节点)? producer直接将数据发送到broker的leader(主节点),不需要在多个节点进行分发,为了帮助producer做到这点,所有的Kafka节点都可以及时的告知:哪些节点是活动的,目标topic目标分区的leader在哪。这样producer就可以直接将消息发送到目的地了。
20、Kafa consumer是否可以消费指定分区消息? Kafa consumer消费消息时,向broker发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
21、Kafka消息是采用Pull模式,还是Push模式? Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式
Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略
Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
22、Kafka存储在硬盘上的消息格式是什么? 消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。 消息长度: 4 bytes (value: 1+4+n) 版本号: 1 byte CRC校验码: 4 bytes 具体的消息: n bytes
23、Kafka高效文件存储设计特点: (1).Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。 (2).通过索引信息可以快速定位message和确定response的最大大小。 (3).通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。 (4).通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
24、Kafka 与传统消息系统之间有三个关键区别 (1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留 (2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性 (3).Kafka 支持实时的流式处理
25、Kafka创建Topic时如何将分区放置到不同的Broker中 副本因子不能大于 Broker 的个数; 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的; 其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推; 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的
26、Kafka新建的分区会在哪个目录下创建 在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。 当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。 如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。 但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
27、partition的数据如何保存到硬盘 topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增, 且消息有序 Partition文件下有多个segment(xxx.index,xxx.log) segment 文件里的 大小和配置文件大小一致可以根据要求修改 默认为1g 如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
28、kafka的ack机制 request.required.acks有三个值 0 1 -1 0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱当server挂掉的时候就会丢数据 1:服务端会等待ack值 leader副本确认接收到消息后发送ack但是如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢失 -1:同样在1的基础上 服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢失
29、Kafka的消费者如何消费数据 消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置 等到下次消费时,他会接着上次位置继续消费。同时也可以按照指定的offset进行重新消费。
30、消费者负载均衡策略 结合consumer的加入和退出进行再平衡策略。
31、kafka消息数据是否有序? 消费者组里某具体分区是有序的,所以要保证有序只能建一个分区,但是实际这样会存在性能问题,具体业务具体分析后确认。
32、kafaka生产数据时数据的分组策略,生产者决定数据产生到集群的哪个partition中 每一条消息都是以(key,value)格式 Key是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个partition
33、kafka consumer 什么情况会触发再平衡reblance? ①一旦消费者加入或退出消费组,导致消费组成员列表发生变化,消费组中的所有消费者都要执行再平衡。 ②订阅主题分区发生变化,所有消费者也都要再平衡。
34、描述下kafka consumer 再平衡步骤? ①关闭数据拉取线程,情空队列和消息流,提交偏移量; ②释放分区所有权,删除zk中分区和消费者的所有者关系; ③将所有分区重新分配给每个消费者,每个消费者都会分到不同分区; ④将分区对应的消费者所有关系写入ZK,记录分区的所有权信息; ⑤重启消费者拉取线程管理器,管理每个分区的拉取线程。
35、Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么 36、Kafka中的HW、LEO、LSO、LW等分别代表什么? 37、Kafka中是怎么体现消息顺序性的? 38、Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么? 39、Kafka生产者客户端的整体结构是什么样子的? 40、Kafka生产者客户端中使用了几个线程来处理?分别是什么? 41、Kafka的旧版Scala的消费者客户端的设计有什么缺陷? 42、“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段? 43、消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1? 44、有哪些情形会造成重复消费? 45、那些情景下会造成消息漏消费? 46、KafkaConsumer是非线程安全的,那么怎么样实现多线程消费? 47、简述消费者与消费组之间的关系 48、当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑? 49、topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么? 50、topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么? 51、创建topic时如何选择合适的分区数? 52、Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么? 53、优先副本是什么?它有什么特殊的作用? 54、Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理 55、简述Kafka的日志目录结构 56、Kafka中有那些索引文件? 57、如果我指定了一个offset,Kafka怎么查找到对应的消息? 58、如果我指定了一个timestamp,Kafka怎么查找到对应的消息? 59、聊一聊你对Kafka的Log Retention的理解 60、聊一聊你对Kafka的Log Compaction的理解 61、聊一聊你对Kafka底层存储的理解(页缓存、内核层、块层、设备层) 62、聊一聊Kafka的延时操作的原理 63、聊一聊Kafka控制器的作用 64、消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器) 65、Kafka中的幂等是怎么实现的 66、Kafka中的事务是怎么实现的(这题我去面试6家被问4次,照着答案念也要念十几分钟,面试官简直凑不要脸。实在记不住的话...只要简历上不写精通Kafka一般不会问到,我简历上写的是“熟悉Kafka,了解RabbitMQ....”) 67、Kafka中有那些地方需要选举?这些地方的选举策略又有哪些? 68、失效副本是指什么?有那些应对措施? 69、多副本下,各个副本中的HW和LEO的演变过程 70、为什么Kafka不支持读写分离? 71、Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch) 72、Kafka中怎么实现死信队列和重试队列? 73、Kafka中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会Kafka,那你说说延迟队列怎么实现?) 74、Kafka中怎么做消息审计? 75、Kafka中怎么做消息轨迹? 76、Kafka中有那些配置参数比较有意思?聊一聊你的看法 77、Kafka中有那些命名比较有意思?聊一聊你的看法 78、Kafka有哪些指标需要着重关注? 79、怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同) 80、Kafka的那些设计让它有如此高的性能? 81、Kafka有什么优缺点? 82、还用过什么同质类的其它产品,与Kafka相比有什么优缺点? 83、为什么选择Kafka? 84、在使用Kafka的过程中遇到过什么困难?怎么解决的? 85、怎么样才能确保Kafka极大程度上的可靠性? 86、聊一聊你对Kafka生态的理解
Zookeeper | 个人博客
+ Zookeeper | 个人博客
+ 个人博客
+ 微信公众号-chatgpt智能客服搭建 | 个人博客
+ 跳至主要內容 微信公众号-chatgpt智能客服搭建 想体验的可以去微信上搜索【旅行的树】公众号。
一、ChatGPT注册 1.1 短信手机号申请 openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。
国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。
国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。
之后再搜索框填openai进行下单购买即可。
1.2 云服务器申请 openai在国内不提供服务的,而且也通过ip识别是不是在国内,解决办法用vpn也行,或者,自己去买一台国外的服务器也行。我这里使用的是腾讯云轻量服务器,最低配置54元/月,选择windows的主要原因毕竟需要注册openai,需要看页面,同时也可以搭建nginx,当然,用ubuntu如果能自己搞界面也行。
1.3 ChatGPT注册 购买完之后,就可以直接打开openai的官网了,然后去https://platform.openai.com/signup官网里注册,注册过程具体就不讲了,讲下核心问题——短信验证码
然后回sms查看验证码。
注册成功之后就可以在chatgpt里聊天啦,能够识别各种语言,发起多轮会话的时候,可能回出现访问超过限制什么的。
通过chatgpt聊天不是我们最终想要的,我们需要的是在微信公众号也提供智能客服的聊天回复,所以我们需要在通过openai的api来进行调用。
二、搭建nginx服务器 跟页面一样,OpenAI的调用也是不能再国内访问的,这里,我们使用同一台服务器来搭建nginx,还是保留使用windows吧,主要还是得注意下面这段话,如果API key被泄露了,OpenAI可能会自动重新更新你的API key,这个规则似乎是API key如果被多个ip使用,就会触发这个规则,调试阶段还是尽量使用windows的服务器吧,万一被更新了,还能去页面上重新找到。
Do not share your API key with others, or expose it in the browser or other client-side code. In order to protect the security of your account, OpenAI may also automatically rotate any API key that we've found has leaked publicly.
+windows的安装过程参考网上的来,我们只需要添加下面这个配置即可,原理主要是将调用OpenAI的接口全部往官网转发。
location /v1/completions{
+ proxy_pass https://api.openai.com/v1/completions;
+ }
+然后使用下面的方法进行调试即可:
POST http://YOUR IP/v1/completions
+
+
+
+{
+ "model" : "text-davinci-003" ,
+ "prompt" : "Say this is a test" ,
+ "max_tokens" : 7 ,
+ "temperature" : 0
+}
+ 三、公众号开发 网上有很多关于微信通过chatgpt回复的文章,有些使用自己微信号直接做为载体,因为要扫码网页登陆,而且是网页端在国外,很容易被封;有些是使用公众号,相对来说,公众号被封也不至于导致个人微信号出问题。
3.1 微信云托管 微信公众平台提供了微信云托管,无需鉴权,比其他方式都方便不少,可以免费试用3个月,继续薅羊毛,当然,如果自己开发能力足够,也可以自己从0开始开发。
提供了各种语言的模版,方便快速开发,OpenAI官方提供的sdk是node和python,这里我们选择express(node)。
3.2 一个简单ChatGPT简单回复 微信官方的源码在这,https://github.com/WeixinCloud/wxcloudrun-express,我们直接fork一份自己来开发。
一个简单的消息回复功能(无db),直接在我们的index.js里添加如下代码。
const configuration = new Configuration ( {
+ apiKey : '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' ,
+ basePath : 'http://43.153.15.174/v1'
+} ) ;
+const openai = new OpenAIApi ( configuration) ;
+
+async function simpleResponse ( prompt ) {
+ const completion = await openai. createCompletion ( {
+ model : 'text-davinci-003' ,
+ prompt,
+ max_tokens : 1024 ,
+ temperature : 0.1 ,
+ } ) ;
+ const response = ( completion?. data?. choices?. [ 0 ] . text || 'AI 挂了' ) . trim ( ) ;
+ return strip ( response, [ '\n' , 'A: ' ] ) ;
+}
+
+app. post ( "/message/simple" , async ( req, res ) => {
+ console. log ( '消息推送' , req. body)
+
+ const appid = req. headers[ 'x-wx-from-appid' ] || ''
+ const { ToUserName, FromUserName, MsgType, Content, CreateTime} = req. body
+ console. log ( '推送接收的账号' , ToUserName, '创建时间' , CreateTime)
+ if ( MsgType === 'text' ) {
+ message = await simpleResponse ( Content)
+ res. send ( {
+ ToUserName : FromUserName,
+ FromUserName : ToUserName,
+ CreateTime : CreateTime,
+ MsgType : 'text' ,
+ Content : message,
+ } )
+ } else {
+ res. send ( 'success' )
+ }
+} )
+本地可以直接使用http请求测试,成功调用之后直接提交发布即可,在微信云托管上需要先授权代码库,即可使用云托管的流水线,一键发布。注意,api_base和api_key可以填写在服务设置-基础信息那里,一个是OPENAI_API_BASE,一个是OPENAI_API_KEY,服务会自动从环境变量里取。
3.3 服务部署 提交代码只github或者gitee都可以,值得注意的是,OpenAI判断key泄露的规则,不知道是不是判断调用的ip地址不一样,还是github的提交记录里含有这块,有点玄学,同样的key本地调用一次,然后在云托管也调用的话,OpenAI就很容易把key给重新更新。
部署完之后,云托管也提供了云端调试功能,相当于在服务里发送了http请求。这一步很重要,如果没有调用成功,则无法进行云托管消息推送。
这里填上你自己的url,我们这里配置的是/meesage/simple,如果没有成功,需要进行下面步骤进行排查:
(1)服务有没有正常启动,看日志
(2)端口有没有设置错误,这个很多次没有注意到
保存成功之后,就可以在微信公众号里测试了。
体验还可以
四、没有回复(超时回复问题) 很多OpenAI的回答都要几十秒,有的甚至更久,比如对chatgpt问“写一篇1000字关于深圳的文章”,就需要几十秒,而微信的主动回复接口,是需要我们3s内返回给用户。
订阅号的消息推送分几种:
被动消息回复 :指用户给公众号发一条消息,系统接收到后,可以回复一条消息。主动回复/客服消息 :可以脱离被动消息的5秒超时权限,在48小时内可以主动回复。但需要公众号完成微信认证。根据微信官方文档,没有认证的公众号是没有调用主动回复接口权限的,https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Explanation_of_interface_privileges.html
对于有微信认证的订阅号或者服务号,可以调用微信官方的/cgi-bin/message/custom/send接口来实现主动回复,但是对于个人的公众号,没有权限调用,只能尝试别的办法。想来想去,只能在3s内返回让用户重新复制发送的信息,同时后台里保存记录异步调用,用户重新发送的时候再从数据库里提取回复。
1.先往数据库存一条 回复记录,把用户的提问存下来,以便后续查询。设置回复的内容为空,设置状态为 回复中(thinking)。
+ await Message. create ( {
+ fromUser : FromUserName,
+ response : '' ,
+ request : Content,
+ aiType : AI_TYPE_TEXT ,
+ } ) ;
+2.抽象一个 chatGPT 请求方法 getAIMessage,函数内部得到 GPT 响应后,会更新之前那条记录(通过用户id & 用户提问 查询),把状态更新为 已回答(answered),并把回复内容更新上。
+ await Message. update (
+ {
+ response : response,
+ status : MESSAGE_STATUS_ANSWERED ,
+ } ,
+ {
+ where : {
+ fromUser : FromUserName,
+ request : Content,
+ } ,
+ } ,
+ ) ;
+3.前置增加一些判断,当用户在请求时,如果 AI 还没完成响应,直接回复用户 AI 还在响应,让用户过一会儿再重试。如果 AI 此时已响应完成,则直接把 内容返回给用户。
+ const message = await Message. findOne ( {
+ where : {
+ fromUser : FromUserName,
+ request : Content,
+ } ,
+ } ) ;
+
+
+ if ( message?. status === MESSAGE_STATUS_ANSWERED ) {
+ return ` [GPT]: ${ message?. response} ` ;
+ }
+
+
+ if ( message?. status === MESSAGE_STATUS_THINKING ) {
+ return AI_THINKING_MESSAGE ;
+ }
+4.最后就是一个 Promise.race
const message = await Promise. race ( [
+
+ sleep ( 2900 ) . then ( ( ) => AI_THINKING_MESSAGE ) ,
+ getAIMessage ( { Content, FromUserName } ) ,
+ ] ) ;
+这样子大概就能实现超时之前返回了。
五、会话保存 掉接口是一次性的,一次接口调用完之后怎么做到下一次通话的时候,还能继续保持会话,是不是应该类似客户端与服务端那种有个session这种,但是实际上在openai里是没有session这种东西的,令人震惊的是,chatgpt里是通过前几次会话拼接起来一起发送给chatgpt里的,需要通过回车符来拼接。
async function buildCtxPrompt ( { FromUserName } ) {
+
+ const messages = await Message. findAll ( {
+ where : {
+ fromUser : FromUserName,
+ aiType : AI_TYPE_TEXT ,
+ } ,
+ limit : 10 ,
+ order : [ [ 'updatedAt' , 'ASC' ] ] ,
+ } ) ;
+
+ return messages. length === 1
+ ? messages[ 0 ] . request
+ : messages
+ . map ( ( { response, request } ) => ` Q: ${ request} \n A: ${ response} ` )
+ . join ( '\n' ) ;
+}
+之后就可以实现会话之间的保存通信了。
六、其他问题 6.1 限频 chatgpt毕竟也是新上线的,火热是肯定的,聊天窗口只能开几个,api调用的话,也是有限频的,但是规则具体没有找到,只是在调用次数过多的时候会报429的错误,出现之后就需要等待一个小时左右。
对于这个的解决办法只能是多开几个账号,一旦429就只能换个账号重试了。
6.2 秘钥key被更新 没有找到详细的规则,凭个人经验的话,可能github提交的代码会被扫描,可能ip调用的来源不一样,最好还是开发一个秘钥,生产一个秘钥吧。
6.3 为啥和官网的回复不一样 我们这里用的模型算法是text-davinci-003,具体可以参考:https://platform.openai.com/docs/models/overview,也算是一个比较老的样本了吧
从官方文档来看,官方服务版的 ChatGPT 的模型并非基础版的text-davinci-003,而是经过了「微调:fine-tunes」。文档地址在这:platform.openai.com/docs/guides…open in new window
6.4 玄学挂掉 有时候消息没有回复,真的不是我们的问题,chatgpt毕竟太火了,官网的这个能力都经常挂掉,也可以订阅官网修复的通知,一旦修复则会发邮件告知你。
参考:https://juejin.cn/post/7200769439335546935
最后 记得去微信关注【旅行的树】公众号体验
Tesla api
Others | 个人博客
+ Tesla api | 个人博客
+ 跳至主要內容 Tesla api 一、特斯拉应用申请 1.1 创建 Tesla 账户 如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。
正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.
注意点:(1)不要用自己车辆的邮箱来注册(2)有些邮箱不是特斯拉开发者的邮箱,可能用这些有些无法正常提交访问请求。
1.2 提交访问请求 点击下方的“提交请求”按钮,请求应用程序访问权限。登录后,请提供您的合法企业详细信息、应用程序名称及描述和使用目的。在您提交了详细信息之后,我们会审核您的请求并通过电子邮件向您发送状态更新。
这一步很坑,多次尝试之后都无果,原因也不知道是为啥,只能自己去看返回报文琢磨,太难受了,下面是自己踩的坑
(1)Invalid domain
无效的域名,这里我用的域名是腾讯云个人服务器的域名,证书是腾讯云免费一年的证书,印象中第一申请的时候还是能过的,第二次的时候就不行了,可能被识别到免费的ssl证书不符合规范,还是需要由合法机构的颁发证书才行。所以,为了金快速申请通过,先填个https://baidu.com吧。当然,后续需要彻底解决自己域名证书的问题,我改为使用阿里云的ssl证书,3个月到期的那种。
(2)Unable to Onboard
应用无法上架,可能原因为邮箱不对,用了之前消费者账号(即自己的车辆账号),建议换别的邮箱试试。
(3) Rejected
这一步尝试了很多次,具体原因为国内还无法正常使用tesla api,只能切换至美国服务器申请下(截止2023-11-15),后续留意官网通知。
1.3 访问应用程序凭据 一旦获得批准,将为您的应用程序生成可在登录后访问的客户端 ID 和客户端密钥。使用这些凭据,通过 OAuth 2.0 身份验证获取用户访问令牌。访问令牌可用于对提供私人用户账户信息或代表其他账户执行操作的请求进行身份验证。
申请好就可以在自己的账号下看到自己的应用了,
1.4 开始 API 集成 按照 API 文档和设置说明将您的应用程序与 Tesla 车队 API 集成。您需要生成并注册公钥,请求用户授权并按照规格要求拨打电话。完成后您将能够与 API 进行交互,并开始围绕 Tesla 设备构建集成。
二、开发之前的准备 由于特斯拉刚推出,并且国内进展缓慢,很多都申请不下来,下面内容均以北美区域进行调用。
2.1 认识token app与特斯拉交互的共有两个令牌(token)方式,在调用api的时候,特别需要注意使用的是哪种token,下面是两种token的说明:
(1)合作伙伴身份验证令牌:这个就是你申请的app的令牌
(2)客户生成第三方令牌:这个是消费者在你这个app下授权之后的令牌。
此外,还需要注意下,中国大陆地区对应的api地址是 https://fleet-api.prd.cn.vn.cloud.tesla.cnopen in new window ,不要调到别的地址去了。
2.2 获取第三方应用token 这一步官网列的很详细,就不在详述了。
CLIENT_ID = < command to obtain a client_id>
+CLIENT_SECRET = < secure command to obtain a client_secret>
+AUDIENCE = "https://fleet-api.prd.na.vn.cloud.tesla.com"
+
+curl --request POST \
+ --header 'Content-Type: application/x-www-form-urlencoded' \
+ --data-urlencode 'grant_type=client_credentials' \
+ --data-urlencode "client_id=$CLIENT_ID " \
+ --data-urlencode "client_secret=$CLIENT_SECRET " \
+ --data-urlencode 'scope=openid vehicle_device_data vehicle_cmds vehicle_charging_cmds' \
+ --data-urlencode "audience=$AUDIENCE " \
+ 'https://auth.tesla.com/oauth2/v3/token'
+
+ 2.3 验证域名归属 2.1.1 Register 完成注册合作方账号之后才可以访问API. 每个developer.tesla.cn上的应用程序都必须完成此步骤。官网挂了一个github的代码,看了半天,以为要搞很多东西,实际上只需要几步就可以了。
cd vehicle-command/cmd/tesla-keygen
+go build .
+./tesla-keygen -f -keyring-debug -key-file= private create > public_key.pem
+这里只是生成了公钥,需要把公钥挂载到域名之下,我们用的是nginx,所以只要指向pem文件就可以了,注意下nginx是否可以访问到改文件,如果不行,把nginx的user改为root。
location ~ ^/.well-known {
+ default_type text/html;
+ alias /root/vehicle-command/cmd/tesla-keygen/public_key.pem;
+ }
+随后,便是向tesla注册你的域名,域名必须和你申请的时候填的一样。
curl --header 'Content-Type: application/json' \
+ --header "Authorization: Bearer $TESLA_API_TOKEN " \
+ --data '{"domain":"string"}' \
+ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts'
+
+ 2.1.2 public_key 最后,验证一下是否真的注册成功(GET /api/1/partner_accounts/public_key)
curl --header 'Content-Type: application/json' \
+ --header "Authorization: Bearer $TESLA_API_TOKEN" \
+ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts/public_key'
+得到下面内容就代表成功了
{ "response" : { "public_key" : "xxxx" } }
+至此,我们的开发准备就完成了,接下来就是正常的开发与用户交互的api。
下一页
微信公众号-chatgpt智能客服搭建
1.历史与架构 | 个人博客
+ 跳至主要內容 1.历史与架构 各位大佬瞄一眼我的个人网站open in new window 呗 。如果觉得不错,希望能在GitHub上麻烦给个star,GitHub地址https://github.com/Zephery/newblogopen in new window 。 大学的时候萌生的一个想法,就是建立一个个人网站,前前后后全部推翻重构了4、5遍,现在终于能看了,下面是目前的首页。
由原本的ssh变成ssm,再变成ssm+shiro+lucene,到现在的前后台分离。前台使用ssm+lucene,后台使用spring boot+shiro。其中,使用pagehelper作为分页,lucene用来搜索和自动补全,使用百度统计的API做了个日志系统,统计pv和uv什么的,同时,还有使用了JMX来观察JVM的使用和cpu的使用率,机器学习方面,使用了adaboost和朴素贝叶斯对微博进行分类,有兴趣的可以点点有点意思open in new window 这个页面。 本文从下面这几个方面来讲讲网站的建立:
建站故事与网站架构open in new window lucene搜索的使用open in new window 使用quartz来定时备份数据库open in new window 使用百度统计api做日志系统open in new window Nginx小集群的搭建open in new window [数据库] 使用机器学习对微博进行分析 网站性能优化 SEO优化 1.建站故事与网站架构 1.1建站过程 起初,是因为学习的时候老是找不到什么好玩而又有挑战性的项目,看着struts、spring、hibernate的书,全都是一些小项目,做了感觉也没啥意义,有时候在博客园看到别人还有自己的网站,特羡慕,最终就选择了自己做一个个人网站。期初刚学的ssh,于是开始了自己的ssh搭建个人网站的行程,但是对于一个后端的人来说,前端是个大问题啊。。。。所以初版的时候差不多全是纯生的html、css、js,至少发博客这个功能实现了,但是确实没法看。前前后后折腾了一个多月,决定推翻重做,到百度看看别人怎么做的。首先看到的是杨青open in new window 的网站,已经好几年没更新了,前端的代码看起来比较简单,也是自己能够掌握的,但是不够美观,继续找,在模板之家发现了一个高大上的模板。
第二版的界面确实是这样的,只是把图片的切换变成了wowslider,也是简单的用bootstrap和pagehelper做了下分页,现在的最终版保留了它的header,然后评论框使用了多说(超级怀念多说)。后端也由原来的ssh变成了ssm,之后加上了lucene来对文章进行索引。之后,随着多说要关闭了,突然之间有很多div都不适应了(我写死了的。。。),再一次,没法看,不想看,一怒之下再次推翻重做,变成了现在这个版本。
最终版本在考虑时,也找了很多模板,影响深刻的是taleopen in new window 和欲思open in new window 这两个主题,期中,tale使用的是java语言写的,刚知道的那一刻我就没好感了,java后端我是要自己全部写的,tale这个页面简洁但是不够炫,而且内容量太低,可能就只是个纯博客,之后发现了欲思,拓展性强,只可惜没有静态的版本,后台是纯生的PHP(嗯,PHP是世界上最好的语言),看了看,没事,保存网页,前端自己改,后端自己全部重写,最终变成了现在这个版本,虽然拼接的时候各种css、js混入。。。。还好在做网站性能优化的时候差不多全部去掉了。最终版加入redis、quartz、shiro等,还有python机器学习、flask的restful api,可谓是大杂烩了。 页面看着还算凑合,至少不是那种看都看不过去的那种了,但是仔细看看,还是有不少问题的,比如瀑布流,还有排版什么的。只能等自己什么时候想认真学学前端的东西了。 已经部署在腾讯云服务器上,存储使用了七牛云的cdn。
1.2 网站整体技术架构 最终版的技术架构图如下:
网站核心主要采用Spring SpringMVC和Mybatis,下图是当访问一篇博客的时候的运行流程,参考了张开涛open in new window 的博客。
运行流程分析
浏览器发送http请求。/blogdetail.html?blogid=1。 tomcat容器初始化,顺序为context-param>listener>filter>servlet,此时,spring中的bean还没有被注入的,不建议在此处加载bean,网站声明了两个类(IPFilter和CacheControlFilter),IPFilter用来拦截IP,CacheControlFilter用来缓存。 初始化Spring。 DispatcherServlet——>HandlerMapping进行请求到处理的映射,HandlerMapping将“/blogdetail”路径直接映射到名字为“/blogdetail”的Bean进行处理,即BlogController。 自定义拦截器,其中BaseIntercepter实现了HandleInterceptor的接口,用来记录每次访问的链接以及后台响应的时间。 DispatcherServlet——> SimpleControllerHandlerAdapter,SimpleControllerHandlerAdapter将HandlerExecutionChain中的处理器适配为BlogController。 BlogController执行查询,取得结果集返回数据。 blogdetail(ModelAndView的逻辑视图名)——>InternalResourceViewResolver, InternalResourceViewResolver使用JstlView,具体视图页面在/blogdetail.jsp。 JstlView(/blogdetail.jsp)——>渲染,将在处理器传入的模型数据(blog=Blog!)在视图中展示出来。 返回响应。 1.3 日志系统 日志系统架构如下:
日志系统open in new window 曾经尝试采用过ELK,实时监控实在是让人不能不称赞,本地也跑起来了,但是一到服务器,卡卡卡,毕竟(1Ghz CPU、1G内存),只能放弃ELK,采用百度统计。百度统计提供了Tongji API供开发者使用,只是有次数限制,2000/日,实时的话实在有点低,只能统计前几天的PV、UV等开放出来。其实这个存放在mysql也行,不过这些零碎的数据还是放在redis中,方便管理。 出了日志系统,自己对服务器的一些使用率也是挺关心的,毕竟服务器配置太低,于是利用了使用了tomcat的JMX来对CPU和jvm使用情况进行监控,这两个都是实时的。出了这两个,对内存的分配做了监控,Eden、Survivor、Tenured的使用情况。
1.4 【有点意思】自然语言处理 本人大学里的毕业设计就是基于AdaBoost算法的情感分类,学到的东西还是要经常拿出来看看,要不然真的浪费了我这么久努力做的毕业设计啊。构建了一个基本的情感分类小系统,每天抓取微博进行分类存储在MySql上,并使用flask提供Restful API给java调用,可以点击这里open in new window 尝试(请忽略Google的图片)。目前分类效果不是很明显,准确率大概只有百分之70%,因为训练样本只有500条(找不到训练样本),机器学习真的太依赖样本的标注。这个,只能请教各位路人大神指导指导了。
总结 断断续续,也总算做了一个能拿得出手仍要遮遮掩掩才能给别人看的网站,哈哈哈哈哈,也劳烦各位帮忙找找bug。前前后后从初学Java EE就一直设想的事也还算有了个了结,以后要多多看书,写点精品文章。PS:GitHub上求给个Staropen in new window ,以后面试能讲讲这个网站。
下一页
2.Lucene的使用
10.网站重构 | 个人博客
+ 2.Lucene的使用 | 个人博客
+ 跳至主要內容 2.Lucene的使用 首先,帮忙点击一下我的网站http://www.wenzhihuai.com/open in new window 。谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github.com/Zephery/newblogopen in new window 。
Lucene的整体架构 image 搜索引擎的几个重要概念: 倒排索引:将文档中的词作为关键字,建立词与文档的映射关系,通过对倒排索引的检索,可以根据词快速获取包含这个词的文档列表。倒排索引一般需要对句子做去除停用词。
停用词:在一段句子中,去掉之后对句子的表达意向没有印象的词语,如“非常”、“如果”,中文中主要包括冠词,副词等。
排序:搜索引擎在对一个关键词进行搜索时,可能会命中许多文档,这个时候,搜索引擎就需要快速的查找的用户所需要的文档,因此,相关度大的结果需要进行排序,这个设计到搜索引擎的相关度算法。
Lucene中的几个概念 文档(Document):文档是一系列域的组合,文档的域则代表一系列域文档相关的内容。 域(Field):每个文档可以包含一个或者多个不同名称的域。 词(Term):Term是搜索的基本单元,与Field相对应,包含了搜索的域的名称和关键词。 查询(Query):一系列Term的条件组合,成为TermQuery,但也有可能是短语查询等。 分词器(Analyzer):主要是用来做分词以及去除停用词的处理。 索引的建立
索引的搜索
lucene在本网站的使用: 搜索 2. 自动分词 一、搜索 注意:本文使用最新的lucene,版本6.6.0。lucene的版本更新很快,每跨越一次大版本,使用方式就不一样。首先需要导入lucene所使用的包。使用maven:
< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - core< / artifactId> < ! -- lucene核心-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - analyzers- common< / artifactId> < ! -- 分词器-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - analyzers- smartcn< / artifactId> < ! -- 中文分词器-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - queryparser< / artifactId> < ! -- 格式化-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+< dependency> < groupId> . apache. lucene< / groupId>
+ < artifactId> - highlighter< / artifactId> < ! -- lucene高亮-- >
+ < version> { lucene. version} < / version>
+< / dependency>
+构建索引 Directory dir = FSDirectory . open ( Paths . get ( "blog_index" ) ) ;
+SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+IndexWriterConfig config = new IndexWriterConfig ( analyzer) ;
+IndexWriter writer = new IndexWriter ( dir, config) ;
+Document doc = new Document ( ) ;
+doc. add ( new TextField ( "title" , blog. getTitle ( ) , Field. Store . YES ) ) ;
+doc. add ( new TextField ( "content" , Jsoup . parse ( blog. getContent ( ) ) . text ( ) , Field. Store . YES ) ) ;
+writer. addDocument ( doc) ;
+writer. close ( ) ;
+更新与删除 IndexWriter writer = getWriter ( ) ;
+Document doc = new Document ( ) ;
+doc. add ( new TextField ( "title" , blog. getTitle ( ) , Field. Store . YES ) ) ;
+doc. add ( new TextField ( "content" , Jsoup . parse ( blog. getContent ( ) ) . text ( ) , Field. Store . YES ) ) ;
+writer. updateDocument ( new Term ( "blogid" , String . valueOf ( blog. getBlogid ( ) ) ) , doc) ;
+writer. close ( ) ;
+查询 private static void search_index ( String keyword) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "blog_index" ) ) ;
+ IndexReader reader = DirectoryReader . open ( dir) ;
+ IndexSearcher searcher = new IndexSearcher ( reader) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ QueryParser parser = new QueryParser ( "content" , analyzer) ;
+ Query query = parser. parse ( keyword) ;
+ TopDocs docs = searcher. search ( query, 10 ) ;
+ for ( ScoreDoc scoreDoc : docs. scoreDocs) {
+ Document doc = searcher. doc ( scoreDoc. doc) ;
+ System . out. println ( doc. get ( "title" ) ) ;
+ }
+ reader. close ( ) ;
+ } catch ( IOException | ParseException e) {
+ logger. error ( e. toString ( ) ) ;
+ }
+}
+高亮 Fragmenter fragmenter = new SimpleSpanFragmenter ( scorer) ;
+SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter ( "<b><font color='red'>" , "</font></b>" ) ;
+Highlighter highlighter = new Highlighter ( simpleHTMLFormatter, scorer) ;
+highlighter. setTextFragmenter ( fragmenter) ;
+for ( ScoreDoc scoreDoc : docs. scoreDocs) {
+ Document doc = searcher. doc ( scoreDoc. doc) ;
+ String title = doc. get ( "title" ) ;
+ TokenStream tokenStream = analyzer. tokenStream ( "title" , new StringReader ( title) ) ;
+ String hTitle = highlighter. getBestFragment ( tokenStream, title) ;
+ System . out. println ( hTitle) ;
+}
+结果
< b> < fontcolor = ' red' > </ font> </ b> 分页 目前lucene分页的方式主要有两种: (1). 每次都全部查询,然后通过截取获得所需要的记录。由于采用了分词与倒排索引,所有速度是足够快的,但是在数据量过大的时候,占用内存过大,容易造成内存溢出 (2). 使用searchAfter把数据保存在缓存里面,然后再去取。这种方式对大量的数据友好,但是当数据量比较小的时候,速度会相对慢。 lucene中使用searchafter来筛选顺序 ScoreDoc lastBottom = null ;
+BooleanQuery. Builder booleanQuery = new BooleanQuery. Builder ( ) ;
+QueryParser parser1 = new QueryParser ( "title" , analyzer) ;
+Query query1 = parser1. parse ( q) ;
+booleanQuery. add ( query1, BooleanClause. Occur . SHOULD ) ;
+TopDocs hits = search. searchAfter ( lastBottom, booleanQuery. build ( ) , pagehits) ;
+使用效果 全部代码放在这里open in new window ,代码写的不太好,光从代码规范上就不咋地。在网页上的使用效果如下: 二、lucene自动补全 百度、谷歌等在输入文字的时候会弹出补全框,如下图:
在搭建lucene自动补全的时候,也有考虑过使用SQL语句中使用like来进行,主要还是like对数据库压力会大,而且相关度没有lucene的高。主要使用了官方suggest库以及autocompelte.jsopen in new window 这个插件。 suggest的原理看这open in new window ,以及索引结构看这open in new window 。
使用: 导入maven包 < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 如果想将结果反序列化,声明实体类的时候要加上: public class Blog implements Serializable {
+实现InputIterator接口 InputIterator的几个方法:
+long weight():返回的权重值,大小会影响排序,默认是1L
+BytesRef payload():对某个对象进行序列化
+boolean hasPayloads():是否有设置payload信息
+Set<BytesRef> contexts():存入context,context里可以是任意的自定义数据,一般用于数据过滤
+boolean hasContexts():判断是否有下一个,默认为false
+public class BlogIterator implements InputIterator {
+
+ private static final Logger logger = LoggerFactory . getLogger ( BlogIterator . class ) ;
+ private Iterator < Blog > ;
+ private Blog currentBlog;
+
+ public BlogIterator ( Iterator < Blog > ) {
+ this . blogIterator = blogIterator;
+ }
+
+ @Override
+ public boolean hasContexts ( ) {
+ return true ;
+ }
+
+ @Override
+ public boolean hasPayloads ( ) {
+ return true ;
+ }
+
+ public Comparator < BytesRef > getComparator ( ) {
+ return null ;
+ }
+
+ @Override
+ public BytesRef next ( ) {
+ if ( blogIterator. hasNext ( ) ) {
+ currentBlog = blogIterator. next ( ) ;
+ try {
+
+ return new BytesRef ( Jsoup . parse ( currentBlog. getTitle ( ) ) . text ( ) . getBytes ( "utf8" ) ) ;
+ } catch ( Exception e) {
+ e. printStackTrace ( ) ;
+ return null ;
+ }
+ } else {
+ return null ;
+ }
+ }
+
+
+ @Override
+ public BytesRef payload ( ) {
+ try {
+ ByteArrayOutputStream bos = new ByteArrayOutputStream ( ) ;
+ ObjectOutputStream out = new ObjectOutputStream ( bos) ;
+ out. writeObject ( currentBlog) ;
+ out. close ( ) ;
+ BytesRef bytesRef = new BytesRef ( bos. toByteArray ( ) ) ;
+ return bytesRef;
+ } catch ( IOException e) {
+ logger. error ( "" , e) ;
+ return null ;
+ }
+ }
+
+
+ @Override
+ public Set < BytesRef > contexts ( ) {
+ try {
+ Set < BytesRef > = new HashSet < BytesRef > ( ) ;
+ regions. add ( new BytesRef ( currentBlog. getTitle ( ) . getBytes ( "UTF8" ) ) ) ;
+ return regions;
+ } catch ( UnsupportedEncodingException e) {
+ throw new RuntimeException ( "Couldn't convert to UTF-8" ) ;
+ }
+ }
+
+
+ @Override
+ public long weight ( ) {
+ return currentBlog. getHits ( ) ;
+ }
+}
+ajax 建立索引
+@Override
+public void ajaxbuild ( ) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "autocomplete" ) ) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester ( dir, analyzer) ;
+
+ List < Blog > = blogMapper. getAllBlog ( ) ;
+ suggester. build ( new BlogIterator ( blogs. iterator ( ) ) ) ;
+ } catch ( IOException e) {
+ System . err. println ( "Error!" ) ;
+ }
+}
+查找 @Override
+public Set < String > ajaxsearch ( String keyword) {
+ try {
+ Directory dir = FSDirectory . open ( Paths . get ( "autocomplete" ) ) ;
+ SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer ( ) ;
+ AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester ( dir, analyzer) ;
+ List < String > = lookup ( suggester, keyword) ;
+ list. sort ( new Comparator < String > ( ) {
+ @Override
+ public int compare ( String o1, String o2) {
+ if ( o1. length ( ) > o2. length ( ) ) {
+ return 1 ;
+ } else {
+ return - 1 ;
+ }
+ }
+ } ) ;
+ Set < String > = new LinkedHashSet < > ( ) ;
+ for ( String string : list) {
+ set. add ( string) ;
+ }
+ ssubSet ( set, 7 ) ;
+ return set;
+ } catch ( IOException e) {
+ System . err. println ( "Error!" ) ;
+ return null ;
+ }
+}
+controller层 @RequestMapping ( "ajaxsearch" )
+public void ajaxsearch ( HttpServletRequest request, HttpServletResponse response) throws IOException {
+ String keyword = request. getParameter ( "keyword" ) ;
+ if ( StringUtils . isEmpty ( keyword) ) {
+ return ;
+ }
+ Set < String > = blogService. ajaxsearch ( keyword) ;
+ Gson gson = new Gson ( ) ;
+ response. getWriter ( ) . write ( gson. toJson ( set) ) ;
+}
+ajax来提交请求 autocomplete.js源代码与介绍:https://github.com/xdan/autocomplete < link rel= "stylesheet" href= "js/autocomplete/jquery.autocomplete.css" >
+< script src= "js/autocomplete/jquery.autocomplete.js" type= "text/javascript" > < / script>
+< script type= "text/javascript" >
+
+ $ ( '#remote_input' ) . autocomplete ( {
+ source : [
+ {
+ url : "ajaxsearch.html?keyword=%QUERY%" ,
+ type : 'remote'
+ }
+ ]
+ } ) ;
+
+< / script>
+效果: 参考:
http://iamyida.iteye.com/blog/2205114
1.历史与架构
下一页
3.定时任务
3.定时任务 | 个人博客
+ 跳至主要內容 3.定时任务 先看一下Quartz的架构图:
一.特点: 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求; 灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式; 分布式和集群能力。 二.主要组成部分 JobDetail:需实现该接口定义的人物,其中JobExecutionContext提供了上下文的各种信息。 JobDetail:QUartz的执行任务的类,通过newInstance的反射机制实例化Job。 Trigger: Job的时间触发规则。主要有SimpleTriggerImpl和CronTriggerImpl两个实现类。 Calendar:org.quartz.Calendar和java.util.Calendar不同,它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。 Scheduler:由上图可以看出,Scheduler是Quartz独立运行的容器。其中,Trigger和JobDetail可以注册到Scheduler中。 ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。 三、Quartz设计 properties file官网open in new window 中表明:quartz中使用了quartz.properties来对quartz进行配置,并保留在其jar包中,如果没有定义则默认使用改文件。 四、使用 hello world!代码在这 本网站中使用quartz来对数据库进行备份,与Spring结合 (1)导入spring的拓展包,其协助spring集成第三方库:邮件服务、定时任务、缓存等。。。 < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> (2)导入quartz包
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> (3)mysql远程备份 使用命令行工具仅仅需要一行:
mysqldump -u [username] -p[password] -h [hostip] database > file
+但是java不能直接执行linux的命令,仍旧需要依赖第三方库ganymed
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 完整代码如下:
@Component ( "mysqlService" )
+public class MysqlUtil {
+ . . .
+ StringBuffer sb = new StringBuffer ( ) ;
+ sb. append ( "mysqldump -u " + username + " -p" + password + " -h " + host + " " +
+ database + " >" + file) ;
+ String sql = sb. toString ( ) ;
+ Connection connection = new Connection ( s_host) ;
+ connection. connect ( ) ;
+ boolean isAuth = connection. authenticateWithPassword ( s_username, s_password) ;
+ if ( ! isAuth) {
+ logger. error ( "server login error" ) ;
+ }
+ Session session = connection. openSession ( ) ;
+ session. execCommand ( sql) ;
+ InputStream stdout = new StreamGobbler ( session. getStdout ( ) ) ;
+ BufferedReader br = new BufferedReader ( new InputStreamReader ( stdout) ) ;
+ . . .
+}
+(4)spring中配置quartz
< beanid = " jobDetail" class = " org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean" > < propertyname = " targetObject" ref = " mysqlService" /> < propertyname = " targetMethod" value = " exportDataBase" /> </ bean> < beanid = " myTrigger" class = " org.springframework.scheduling.quartz.CronTriggerFactoryBean" > < propertyname = " jobDetail" ref = " jobDetail" /> < propertyname = " cronExpression" value = " 0 59 2 ? * FRI" /> </ bean> < beanid = " scheduler" class = " org.springframework.scheduling.quartz.SchedulerFactoryBean" > < propertyname = " triggers" > < list> < refbean = " myTrigger" /> </ list> </ property> </ bean> (5)java完整文件在这open in new window
Spring的高级特性之定时任务 java ee项目的定时任务中除了运行quartz之外,spring3+还提供了task,可以看做是一个轻量级的Quartz,而且使用起来比Quartz简单的多。
(1)spring配置文件中配置:
< task: annotation-driven/> (2)最简单的例子,在所需要的函数上添加定时任务即可运行
@Scheduled ( fixedRate = 5000 )
+ public void reportCurrentTime ( ) {
+ System . out. println ( "每隔5秒运行一次" + sdf. format ( new Date ( ) ) ) ;
+ }
+(3)运行的时候会报错:
org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type [org.springframework.scheduling.TaskScheduler] is defined
+ at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:372)
+ at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBean(DefaultListableBeanFactory.java:332)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.finishRegistration(ScheduledAnnotationBeanPostProcessor.java:192)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.onApplicationEvent(ScheduledAnnotationBeanPostProcessor.java:171)
+ at org.springframework.scheduling.annotation.ScheduledAnnotationBeanPostProcessor.onApplicationEvent(ScheduledAnnotationBeanPostProcessor.java:86)
+ at org.springframework.context.event.SimpleApplicationEventMulticaster.invokeListener(SimpleApplicationEventMulticaster.java:163)
+ at org.springframework.context.event.SimpleApplicationEventMulticaster.multicastEvent(SimpleApplicationEventMulticaster.java:136)
+ at org.springframework.context.support.AbstractApplicationContext.publishEvent(AbstractApplicationContext.java:380)
+参考:http://blog.csdn.net/oarsman/article/details/52801877open in new window http://stackoverflow.com/questions/31199888/spring-task-scheduler-no-qualifying-bean-of-type-org-springframework-scheduliopen in new window
1.尝试从配置中找到一个TaskScheduler Bean
2.寻找ScheduledExecutorService Bean
3.使用默认的scheduler 修改log4j.properties即可: log4j.logger.org.springframework.scheduling=INFO
每隔5秒运行一次14:44:34
+每隔5秒运行一次14:44:39
+每隔5秒运行一次14:44:44
+
2.Lucene的使用
下一页
4.日志系统.md
4.日志系统.md | 个人博客
+ 跳至主要內容 4.日志系统.md 欢迎访问我的网站http://www.wenzhihuai.com/open in new window 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblogopen in new window 。
建立网站少不了日志系统,用来查看网站的访问次数、停留时间、抓取量、目录抓取统计、页面抓取统计等,其中,最常用的方法还是使用ELK,但是,本网站的服务器配置实在太低了(1GHZ、2G内存),压根就跑不起ELK,所以只能寻求其他方式,目前最常用的有百度统计open in new window 和友盟open in new window ,这里,本人使用的是百度统计,提供了API给开发者使用,能够将自己所需要的图表移植到自己的网站上。日志是网站及其重要的文件,通过对日志进行统计、分析、综合,就能有效地掌握网站运行状况,发现和排除错误原因,了解客户访问分布等,更好的加强系统的维护和管理。下面是我的百度统计的概览页面:
企业级的网站日志不能公开,但是我的是个人网站,用来跟大家一起学习的,所以,需要将百度的统计页面展示出来,但是,百度并不提供日志的图像,只提供API给开发者调用,而且还限制访问次数,一天不能超过2000次,这个对于实时统计来说,确实不够,所以只能展示前几天的访问统计。这里的日志系统分为三个步骤:1.API获取数据;2.存储数据;3.展示数据。页面效果如下,也可以点开我的网站的日志系统open in new window :
百度统计提供了Tongji API的Java和Python版本,这两个版本及其复杂,可用性极低,所以,本人用Python写了个及其简单的通用版本,整体只有28行,代码在这,https://github.com/Zephery/baidutongjiopen in new window 。下面是具体过程
1.网站代码安装 先在百度统计 中注册登录之后,进入管理页面,新增网站,然后在代码管理中获取安装代码,大部分人的代码都是类似的,除了hm.js?后面的参数,是记录该网站的唯一标识。
< script>
+var _hmt = _hmt || [ ] ;
+( function ( ) {
+ var hm = document. createElement ( "script" ) ;
+ hm. src = "https://hm.baidu.com/hm.js?code" ;
+ var s = document. getElementsByTagName ( "script" ) [ 0 ] ;
+ s. parentNode. insertBefore ( hm, s) ;
+} ) ( ) ;
+ </ script> 同时,需要在申请其他设置->数据导出服务中开通数据导出服务,百度统计Tongji API可以为网站接入者提供便捷的获取网站流量数据的通道。
至此,我们获得了username、password、token,然后开始使用三个参数来获取数据。
2.根据API获取数据 官网的APIopen in new window 详细的记录了接口的参数以及解释, 链接:https://api.baidu.com/json/tongji/v1/ReportService/getDataopen in new window ,详细的官方报告请访问官网TongjiApiopen in new window 所需参数(必须):
参数名称 参数类型 描述 method string 要查询的报告 start_date string 查询起始时间 end_date string 查询结束时间 metrics string 自定义指标
其中,参数start_date和end_date的规定为:yyyyMMdd,这里我们使用python的原生库,datetime、time,获取昨天的时间以及前七天的日期。
today = datetime. date. today( )
+yesterday = today - datetime. timedelta( days= 1 )
+fifteenago = today - datetime. timedelta( days= 7 )
+end, start = str ( yesterday) . replace( "-" , "" ) , str ( fifteenago) . replace( "-" , "" )
+ 3.构建请求 说明:siteId可以根据个人百度统计的链接获取,也可以使用Tongji API的第一个接口列表获取用户的站点列表。首先,我们构建一个类,由于username、password、token都是通用的,所以我们将它设置为构造方法的参数。
class Baidu ( object ) :
+ def __init__ ( self, siteId, username, password, token) :
+ self. siteId = siteId
+ self. username = username
+ self. password = password
+ self. token = token
+然后构建一个共同的方法,用来获取提交数据之后返回的结果,其中提供了4个可变参数,分别是(start_date:起始日期,end_date:结束日期,method:方法,metrics:指标),返回的是字节,最后需要decode("utf-8")一下变成字符:
def getresult ( self, start_date, end_date, method, metrics) :
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date,
+ "metrics" : metrics} }
+ data = bytes ( json. dumps( body) , 'utf8' )
+ req = urllib. request. Request( base_url, data)
+ response = urllib. request. urlopen( req)
+ the_page = response. read( )
+ return the_page. decode( "utf-8" )
+至此,python获取百度统计的过程基本就没了,没错,就是那么简简单单的几行,完整代码见https://github.com/Zephery/baidutongji/blob/master/baidu.pyopen in new window ,但是,想要实现获取各种数据,仍需要做很多工作。
4.实际运用 (1)需要使用其他参数怎么办
python中提供了个可变参数来解决这一烦恼,详细请看http://www.jianshu.com/p/98f7e34845b5open in new window ,可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple,而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def getresult ( self, start_date, end_date, method, metrics, ** kw) :
+ base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date, "metrics" : metrics} }
+ for key in kw:
+ body[ 'body' ] [ key] = kw[ key]
+使用方式:
result = self. getresult( start, end, "source/all/a" ,
+ "pv_count,visitor_count,avg_visit_time" , viewType= 'visitor' )
+(2)获取的数据如何解析 百度统计返回的结果比较简洁而又反人类,以获取概览中的pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time为例子:
result = bd. getresult( start, end, "overview/getTimeTrendRpt" ,
+ "pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time" )
+返回的结果是:
[[['2017/09/12'], ['2017/09/13'], ['2017/09/14'], ['2017/09/15'], ['2017/09/16'], ['2017/09/17'], ['2017/09/18']],
+[[422, 76, 76, 41.94, 221],
+ [284, 67, 65, 50.63, 215],
+ [67, 23, 22, 52.17, 153],
+ [104, 13, 13, 36.36, 243],
+ [13, 4, 4, 33.33, 66],
+ [73, 7, 6, 37.5, 652],
+ [63, 11, 11, 33.33, 385]
+ ], [], []]
+即:翻译成人话就是:
[[[date1,date2,...]],
+ [[date1的pv_count, date1的visitor_count, date1的ip_count, date1的bounce_ratio, date1的avg_visit_time],
+ [date2的pv_count, date2的visitor_count, date2的ip_count, date2的bounce_ratio, date2的avg_visit_time],
+ ...,[]
+ ],[],[]]
+极其反人类的设计。还好用的python,python数组的特性实在太强了。出了可以运用[x for x in range]这类语法之外,还能与三元符(x if y else x+1,如果y成立,那么结果是x,如果y不成立,那么结果是x+1)一起使用,这里注意:如果当天访问量为0,其返回的json结果是'--',所以要判断是不是为'--',归0化,才能在折线图等各种图上显示。下面是pv_count的例子:
pv_count = [ x[ 0 ] if x[ 0 ] != '--' else 0 for x in result[ 1 ] ]
+(3)每周限制2000次 在开通数据导出服务的时候,不知道大家有没有注意到它的说明,即我们是不能实时监控的,只能将它放在临时数据库中,这里我们选择了Redis,并在centos里定义一个定时任务,每天全部更新一次即可。
python中redis的使用方法很简单,连接跟mysql类似:
+pool = redis. ConnectionPool( host= 'your host ip' , port= port, password= 'your auth' )
+r = redis. Redis( connection_pool= pool)
+本网站使用redis的数据结构只有set,方法也很简单,就是定义一个key,然后value是数组的字符串获取json。
ip_count = [ x[ 2 ] if x[ 2 ] != '--' else 0 for x in result[ 1 ] ]
+r. set ( "ip_count" , ip_count)
+
+name = [ item[ 0 ] [ 'name' ] for item in data[ 0 ] ]
+count = 0
+tojson = [ ]
+for item in data[ 1 ] :
+ temp = { }
+ temp[ "name" ] = name[ count]
+ temp[ "pv_count" ] = item[ 0 ]
+ temp[ "visitor_count" ] = item[ 1 ]
+ temp[ "average_stay_time" ] = item[ 2 ]
+ tojson. append( temp)
+ count = count + 1
+r. set ( "rukouyemian" , json. dumps( tojson[ : 5 ] ) )
+ 5.基本代码 下面是基本的使用代码,完整的使用代码就不贴了,有兴趣可以去我的github上看看,完整代码open in new window ,希望能给个star哈哈哈,感谢
import json
+import time
+import datetime
+import urllib. parse
+import urllib. request
+
+base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+
+class Baidu ( object ) :
+ def __init__ ( self, siteId, username, password, token) :
+ self. siteId = siteId
+ self. username = username
+ self. password = password
+ self. token = token
+
+ def getresult ( self, start_date, end_date, method, metrics, ** kw) :
+ base_url = "https://api.baidu.com/json/tongji/v1/ReportService/getData"
+ body = { "header" : { "account_type" : 1 , "password" : self. password, "token" : self. token,
+ "username" : self. username} ,
+ "body" : { "siteId" : self. siteId, "method" : method, "start_date" : start_date,
+ "end_date" : end_date, "metrics" : metrics} }
+ for key in kw:
+ body[ 'body' ] [ key] = kw[ key]
+ data = bytes ( json. dumps( body) , 'utf8' )
+ req = urllib. request. Request( base_url, data)
+ response = urllib. request. urlopen( req)
+ the_page = response. read( )
+ return the_page. decode( "utf-8" )
+
+if __name__ == '__main__' :
+
+ today = datetime. date. today( )
+ yesterday = today - datetime. timedelta( days= 1 )
+ fifteenago = today - datetime. timedelta( days= 7 )
+ end, start = str ( yesterday) . replace( "-" , "" ) , str ( fifteenago) . replace( "-" , "" )
+
+ bd = Baidu( yoursiteid, "username" , "password" , "token" )
+ result = bd. getresult( start, end, "overview/getTimeTrendRpt" ,
+ "pv_count,visitor_count,ip_count,bounce_ratio,avg_visit_time" )
+ result = json. loads( result)
+ base = result[ "body" ] [ "data" ] [ 0 ] [ "result" ] [ "items" ]
+ print ( base)
+
+ 6.展示数据 在将数据存进redis中之后,我们需要在博客中使用这些数据来制作图表。在newblogopen in new window 中使用方式也很简单,大概就是使用jedis读取数据,然后使用echarts或者highcharts展示。其中折线图以及线型图我都使用了highcharts,确实比echarts好看的多,但是地域图还是选择了echarts,毕竟中国的产品还是对中国的支持较好。 (1)PV、UV折线图 以图表PV、UV为例,由于存储进redis的是一个数组,所以,可以直接从redis中读取然后放到一个attribute里即可:
String pv_count = jedis. get ( "pv_count" ) ;
+String visitor_count = jedis. get ( "visitor_count" ) ;
+mv. addObject ( "pv_count" , pv_count) ;
+mv. addObject ( "visitor_count" , visitor_count) ;
+jsp中的使用如下:
< divclass = " panel-heading" style = " background-color : rgba ( 187, 255, 255, 0.7) " > < divclass = " card-title" > < strong> </ strong> < divclass = " panel-body" > < divid = " linecontainer" style = " width : auto; height : 330px" > < script>
+ var chart = new Highcharts. Chart ( 'linecontainer' , {
+ title : {
+ text : null
+ } ,
+ credits : {
+ enabled : false
+ } ,
+ xAxis : {
+ categories : ${ daterange}
+ } ,
+ yAxis : {
+ title : {
+ text : '次数'
+ } ,
+ plotLines : [ {
+ value : 0 ,
+ width : 1 ,
+ color : '#808080'
+ } ]
+ } ,
+ tooltip : {
+ valueSuffix : '次'
+ } ,
+ legend : {
+ borderWidth : 0 ,
+ align : "center" ,
+ verticalAlign : "top" ,
+ x : 0 ,
+ y : 0
+ } ,
+ series : [ {
+ name : 'pv' ,
+ data : ${ pv_count}
+ } , {
+ name : 'uv' ,
+ data : ${ visitor_count}
+ } ]
+ } )
+ </ script> 效果如下:
(2)地域访问量 在python代码中先获取地域的数据,其结果如下,百度统计跟echarts都是百度的,果然,自家人对自己人的支持真是特别友好的。
[{'pv_count': 649, 'pv_ratio': 7, 'visitor_count': 2684, 'name': '广东'}, {'pv_count': 2, 'pv_ratio': 2, 'visitor_count': 76, 'name': '四川'}, {'pv_count': 1, 'pv_ratio': 1, 'visitor_count': 3, 'name': '江苏'}]
+地域图目前支持最好的还是百度的echarts,使用方法见echarts的官网吧,这里不再阐述,展示地域图 的时候需要获取下载两个文件,china.jsopen in new window (其提供了js和json,这里使用的js),echarts.jsopen in new window 。 部分代码:
<script type="text/javascript">
+ var myChart = echarts.init(document.getElementById('diyu'));
+ option = {
+ tooltip: {
+ trigger: 'item'
+ },
+ legend: {
+ orient: 'vertical',
+ left: 'left'
+ },
+ visualMap: {
+ min: 0,
+ max:${diyumax},
+ left: 'left',
+ top: 'bottom',
+ text: ['高', '低'], // 文本,默认为数值文本
+ calculable: true
+ },
+ toolbox: {
+ show: true,
+ orient: 'vertical',
+ left: 'right',
+ top: 'center',
+ feature: {
+ dataView: {readOnly: false},
+ restore: {},
+ saveAsImage: {}
+ }
+ },
+ series: [
+ {
+ name: '访问量',
+ type: 'map',
+ mapType: 'china',
+ roam: false,
+ label: {
+ normal: {
+ show: true
+ },
+ emphasis: {
+ show: true
+ }
+ },
+ data: [
+ <c:forEach var="diyu" items="${diyu}">
+ {name: '${diyu.name}', value: ${to.pv_count}},
+ </c:forEach>
+ ]
+ }
+ ]
+ };
+ myChart.setOption(option);
+</script>
+结果如下:
结语 网上关于日志系统的几乎都是ELK,对于小网站的,隐私不是很重要的还是可以用用百度统计的,这套系统也折磨了我挺久的,特别是它那反人类的返回数据。期初本来是想使用百度统计的,后来考虑了一下ELK,尝试之后发现,服务器配置跑不起来,还是安安稳稳的使用了百度统计,于此做成了这个系统,美观度还是不高,颜色需要优化一下。最后,希望能在GitHub上给我个star吧。http://www.wenzhihuai.com/log.htmlopen in new window http://www.wenzhihuai.comopen in new window https://github.com/Zephery/newblogopen in new window https://github.com/Zephery/baidutongjiopen in new window
3.定时任务
下一页
5.小集群部署.md
5.小集群部署.md | 个人博客
+ 跳至主要內容 5.小集群部署.md 欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.comopen in new window ,个人网站代码地址:https://github.com/Zephery/newblogopen in new window 。
nginx负载均衡 一般情况下,当单实例无法支撑起用户的请求时,就需要就行扩容,部署的服务器可以分机房、分地域。而分地域会导致请求分配到太远的地区,比如:深圳的用户却访问到了北京的节点,然后还得从北京返回处理之后的数据,光是来回就至少得30ms。这部分可以通过智能DNS(就近访问)解决。而分机房,需要将请求合理的分配到不同的服务器,这部分就是我们所需要处理的。 通常,负载均衡分为硬件和软件两种,硬件层的比较牛逼,将4-7层负载均衡功能做到一个硬件里面,如F5,梭子鱼等。目前主流的软件负载均衡分为四层和七层,LVS属于四层负载均衡,工作在tcp/ip协议栈上,通过修改网络包的ip地址和端口来转发, 由于效率比七层高,一般放在架构的前端。七层的负载均衡有nginx, haproxy, apache等,虽然nginx自1.9.0版本后也开始支持四层的负载均衡,但是暂不讨论(我木有硬件条件)。下图来自张开涛open in new window 的《亿级流量网站架构核心技术》
本站并没有那么多的服务器,目前只有两台,搭建不了那么大型的架构,就简陋的用两台服务器来模拟一下负载均衡的搭建。下图是本站的简单架构:
其中服务器A(119.23.46.71)为深圳节点,服务器B(47.95.10.139)为北京节点,搭建Nginx之后流量是这么走的:user->A->B-A->user或者user->A->user,第一条中A将请求转发给B,然后B返回的是其运行结果的静态资源。因为这里仅仅是用来学习,所以请不要考虑因为地域导致延时的问题。。。。下面是过程。
1.1 Nginx的安装 可以选择tar.gz、yum、rpm安装等,这里,由于编译、nginx配置比较复杂,要是没有把握还是使用rpm来安装吧,比较简单。从https://pkgs.org/download/nginxopen in new window 可以找到最新的rpm包,然后rpm -ivh 文件,然后在命令行中输入nginx即可启动,可以使用netstat检查一下端口。
启动后页面如下:
记一下常用命令
启动nginx,由于是采用rpm方式,所以环境变量什么的都配置好了。
+[root@beijingali ~]# nginx #启动nginx
+[root@beijingali ~]# nginx -s reload #重启nginx
+[root@beijingali ~]# nginx -t #校验nginx配置文件
+nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
+nginx: configuration file /etc/nginx/nginx.conf test is successful
+ 1.2 Nginx的配置 1.2.1 负载均衡算法 Nginx常用的算法有: (1)round-robin:轮询,nginx默认的算法,从词语上可以看出,轮流访问服务器,也可以通过weight来控制访问次数。 (2)ip_hash:根据访客的ip,一个ip地址对应一个服务器。 (3)hash算法:hash算法常用的方式有根据uri、动态指定的consistent_key两种。 使用hash算法的缺点是当添加服务器的时候,只有少部分的uri能够被重新分配到新的服务器。这里,本站使用的是hash uri的算法,将不同的uri分配到不同的服务器,但是由于是不同的服务器,tomcat中的session是不一致,解决办法是tomcat sessionopen in new window 的共享。额。。。可惜本站目前没有什么能够涉及到登陆什么session的问题。
http{
+ ...
+ upstream backend {
+ hash $uri;
+ # 北京节点
+ server 47.95.10.139:8080;
+ # 深圳节点
+ server 119.23.46.71:8080;
+ }
+
+ server {
+ ...
+ location / {
+ root html;
+ index index.html index.htm;
+ proxy_pass http://backend;
+ ...
+ }
+ ...
+ 1.2.2 日志格式 之前有使用过ELK来跟踪日志,所以将日志格式化成了json的格式,这里贴一下吧
...
+ log_format main '{"@timestamp":"$time_iso8601",'
+ '"host":"$server_addr",'
+ '"clientip":"$remote_addr",'
+ '"size":$body_bytes_sent,'
+ '"responsetime":$request_time,'
+ '"upstreamtime":"$upstream_response_time",'
+ '"upstreamhost":"$upstream_addr",'
+ '"http_host":"$host",'
+ '"url":"$uri",'
+ '"xff":"$http_x_forwarded_for",'
+ '"referer":"$http_referer",'
+ '"agent":"$http_user_agent",'
+ '"status":"$status"}';
+ access_log logs/access.log main;
+ ...
+ 1.2.3 HTTP反向代理 配置完上流服务器之后,需要配置Http的代理,将请求的端口转发到proxy_pass设定的上流服务器,即当我们访问http://wwww.wenzhihuai.com的时候,请求会被转发到backend中配置的服务器,此处为http://47.95.10.139:8080或者http://119.23.46.71:8080。但是,仔细注意之后,我们会发现,tomcat中的访问日志ip来源都是127.0.0.1,相当于本地访问自己的资源。由于后台中有处理ip的代码,对客户端的ip、访问uri等记录下来,所以需要设置nginx来获取用户的实际ip,参考nginx 配置open in new window 。参考文中的一句话:经过反向代理后,由于在客户端和web服务器之间增加了中间层,因此web服务器无法直接拿到客户端的ip,通过$remote_addr变量拿到的将是反向代理服务器的ip地址”。nginx是可以获得用户的真实ip的,也就是说nginx使用$remote_addr变量时获得的是用户的真实ip,如果我们想要在web端获得用户的真实ip,就必须在nginx这里作一个赋值操作,如下:
location / {
+ root html;
+ index index.html index.htm;
+ proxy_pass http://backend;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ proxy_set_header Host $host;
+ proxy_set_header REMOTE-HOST $remote_addr;
+ }
+(1)proxy_set_header X-real-ip $remote_addr;
(2)proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
X-Forwarded-For:squid开发的,用于识别通过HTTP代理或负载平衡器原始IP一个连接到Web服务器的客户机地址的非rfc标准,这个不是默认有的,其经过代理转发之后,格式为client1, proxy1, proxy2,如果想通过这个变量来获取用户的ip,那么需要和$proxy_add_x_forwarded_for一起使用。
1.2.4 HTTPS HTTPSopen in new window (全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。一般情况下,能通过服务器的ssh来生成ssl证书,但是如果使用是自己的,一般浏览器(谷歌、360等)都会报证书不安全的错误,正常用户都不敢访问吧==,所以现在使用的是腾讯跟别的机构颁发的:
首先需要下载证书,放在nginx.conf相同目录下,nginx上的配置也需要有所改变,在nginx.conf中设置listen 443 ssl;开启https。然后配置证书和私钥:
ssl_certificate 1_www.wenzhihuai.com_bundle.crt; #主要文件路径
+ ssl_certificate_key 2_www.wenzhihuai.com.key;
+ ssl_session_timeout 5m; # 超时时间
+ ssl_protocols TLSv1 TLSv1.1 TLSv1.2; #按照这个协议配置
+ ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;#按照这个套件配置
+ ssl_prefer_server_ciphers on;
+至此,可以使用https来访问了。https带来的安全性(保证信息安全、识别钓鱼网站等)是http远远不能比拟的,目前大部分网站都是实现全站https,还能将http自动重定向为https,此处,需要在server中添加rewrite ^(.*) https://$server_name$1 permanent;即可
1.2.5 失败重试 配置好了负载均衡之后,如果有一台服务器挂了怎么办?nginx中提供了可配置的服务器存活的识别,主要是通过max_fails失败请求次数,fail_timeout超时时间,weight为权重,下面的配置的意思是当服务器超时10秒,并失败了两次的时候,nginx将认为上游服务器不可用,将会摘掉上游服务器,fail_timeout时间后会再次将该服务器加入到存活上游服务器列表进行重试
upstream backend_server {
+ server 10.23.46.71:8080 max_fails=2 fail_timeout=10s weight=1;
+ server 47.95.10.139:8080 max_fails=2 fail_timeout=10s weight=1;
+}
+ session共享 分布式情况下难免会要解决session共享的问题,目前推荐的方法基本上都是使用redis,网上查找的方法目前流行的有下面四种,参考自tomcat 集群中 session 共open in new window : 1.使用 filter 方法存储。(推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简单容易控制。) 2.使用 tomcat sessionmanager 方法存储。(直接配置即可) 3.使用 terracotta 服务器共享。(不知道,不了解) 4.使用spring-session。(spring的一个小项目,其原理也和第一种基本一致)
本站使用spring-session,毕竟是spring下的子项目,学习下还是挺好的。参考Spring-Session官网open in new window 。官方文档提供了spring-boot、spring等例子,可以参考参考。目前最新版本是2.0.0,不同版本使用方式不同,建议看官网的文档吧。
首先,添加相关依赖
< dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> < type> </ type> </ dependency> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> 新建一个session.xml,然后在spring的配置文件中添加该文件,然后在session.xml中添加:
+ < beanid = " jedisPoolConfig" class = " redis.clients.jedis.JedisPoolConfig" > </ bean> < beanid = " jedisConnectionFactory" class = " org.springframework.data.redis.connection.jedis.JedisConnectionFactory" > < propertyname = " hostName" value = " ${host}" /> < propertyname = " port" value = " ${port}" /> < propertyname = " password" value = " ${password}" /> < propertyname = " timeout" value = " ${timeout}" /> < propertyname = " poolConfig" ref = " jedisPoolConfig" /> < propertyname = " usePool" value = " true" /> </ bean> < beanid = " redisTemplate" class = " org.springframework.data.redis.core.StringRedisTemplate" > < propertyname = " connectionFactory" ref = " jedisConnectionFactory" /> </ bean> < beanid = " redisHttpSessionConfiguration" class = " org.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfiguration" > < propertyname = " maxInactiveIntervalInSeconds" value = " 1800" /> </ bean> 然后我们需要保证servlet容器(tomcat)针对每一个请求都使用springSessionRepositoryFilter来拦截
< filter> < filter-name> </ filter-name> < filter-class> </ filter-class> </ filter> < filter-mapping> < filter-name> </ filter-name> < url-pattern> </ url-pattern> < dispatcher> </ dispatcher> < dispatcher> </ dispatcher> </ filter-mapping> 配置完成,使用RedisDesktopManager查看结果:
测试: 访问http://www.wenzhihuai.com
访问技术杂谈页面,此时nginx将请求转发到119.23.46.71服务器,session为28424f91-5bc5-4bba-99ec-f725401d7318。
点击生活笔记页面,转发到的服务器为47.95.10.139,session为28424f91-5bc5-4bba-99ec-f725401d7318,与上面相同。session已保持一致。
值得注意的是:同一个浏览器,在没有关闭的情况下,即使通过域名访问和ip访问得到的session是不同的。 欢迎访问我的个人网站O(∩_∩)O哈哈~希望能给个star 个人网站网址:http://www.wenzhihuai.comopen in new window https://github.com/Zephery/newblogopen in new window
4.日志系统.md
下一页
6.数据库备份
6.数据库备份 | 个人博客
+ 跳至主要內容 6.数据库备份 先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:
由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:
果然,36ms。。。看起来挺小的,但是对比一下sql执行语句的时间:
大部分都能在10ms内完成,而最长的语句是insert语句,可见,由于异地导致的36ms延时还是比较大的,捣鼓了一下,最后还是选择换个架构,每个服务器读取自己的数据库,然后数据库底层做一下主主复制,让数据同步。最终架构如下:
一、MySql的复制 数据库复制的基本问题就是让一台服务器的数据与其他服务器保持同步。MySql目前支持两种复制方式:基于行的复制和基于语句的复制,这两者的基本过程都是在主库上记录二进制的日志、在备库上重放日志的方式来实现异步的数据复制。其过程分为三步:
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。 下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。 SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。 此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。 MySql的基本复制方式有主从复制、主主复制,主主复制即把主从复制的配置倒过来再配置一遍即可,下面的配置则是主从复制的过程,到时候可自行改为主主复制。其他的架构如:一主库多备库、环形复制、树或者金字塔型都是基于这两种方式,可参考《高性能MySql》。
二、配置过程 2.1 创建所用的复制账号 由于是个自己的小网站,就不做过多的操作了,直接使用root账号
2.2 配置master 接下来要对mysql的serverID,日志位置,复制方式等进行操作,使用vim打开my.cnf。
[client]
+default-character-set=utf8
+
+[mysqld]
+character_set_server=utf8
+init_connect= SET NAMES utf8
+
+datadir=/var/lib/mysql
+socket=/var/lib/mysql/mysql.sock
+
+symbolic-links=0
+
+log-error=/var/log/mysqld.log
+pid-file=/var/run/mysqld/mysqld.pid
+
+# master
+log-bin=mysql-bin
+# 设为基于行的复制
+binlog-format=ROW
+# 设置server的唯一id
+server-id=2
+# 忽略的数据库,不使用备份
+binlog-ignore-db=information_schema
+binlog-ignore-db=cluster
+binlog-ignore-db=mysql
+# 要进行备份的数据库
+binlog-do-db=myblog
+重启Mysql之后,查看主库状态,show master status。
其中,File为日志文件,指定Slave从哪个日志文件开始读复制数据,Position为偏移,从哪个POSITION号开始读,Binlog_Do_DB为要备份的数据库。
2.3 配置slave 从库的配置跟主库类似,vim /etc/my.cnf配置从库信息。
+[client]
+default-character-set=utf8
+
+[mysqld]
+character_set_server=utf8
+init_connect= SET NAMES utf8
+
+datadir=/var/lib/mysql
+socket=/var/lib/mysql/mysql.sock
+
+symbolic-links=0
+
+log-error=/var/log/mysqld.log
+pid-file=/var/run/mysqld/mysqld.pid
+
+# slave
+log-bin=mysql-bin
+# 服务器唯一id
+server-id=3
+# 不备份的数据库
+binlog-ignore-db=information_schema
+binlog-ignore-db=cluster
+binlog-ignore-db=mysql
+# 需要备份的数据库
+replicate-do-db=myblog
+# 其他相关信息
+slave-skip-errors=all
+slave-net-timeout=60
+# 开启中继日志
+relay_log = mysql-relay-bin
+#
+log_slave_updates = 1
+# 防止改变数据
+read_only = 1
+重启slave,同时启动复制,还需要调整一下命令。
mysql> CHANGE MASTER TO MASTER_HOST = '119.23.46.71', MASTER_USER = 'root', MASTER_PASSWORD = 'helloroot', MASTER_PORT = 3306, MASTER_LOG_FILE = 'mysql-bin.000009', MASTER_LOG_POS = 346180;
+
+可以看见slave已经开始进行同步了。我们使用show slave status\G来查看slave的状态。
其中日志文件和POSITION不一致是合理的,配置好了的话,即使重启,也不会影响到主从复制的配置。
某天在Github上漂游,发现了阿里的canal,同时才知道上面这个业务是叫异地跨机房同步,早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。下面是基本的原理:
原理相对比较简单:
1.canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
其中,配置过程如下:https://github.com/alibaba/canalopen in new window ,可以搭配Zookeeper使用。在ZKUI中能够查看到节点:
一般情况下,还要配合阿里的另一个开源产品使用otteropen in new window ,相关文档还是找找GitHub吧,个人搭建完了之后,用起来还是不如直接使用mysql的主主复制,而且异地机房同步这种大企业才有的业务。
公司又要996了,实在是忙不过来,感觉自己写的还是急躁了点,困==
5.小集群部署.md
下一页
7.那些牛逼的插件
7.那些牛逼的插件 | 个人博客
+ 跳至主要內容 7.那些牛逼的插件 欢迎访问我的网站http://www.wenzhihuai.com/open in new window 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblogopen in new window 。
wowslider 可能是我这网站中最炫的东西了,图片能够自动像幻灯片一样自动滚动,让网站的首页一看起来就高大上,简直就是建站必备的东西,而且安装也及其简单,有兴趣可以点击官网open in new window 看看。GitHub里也开放了源代码open in new window 。安装过程:自己选择“幻灯片”切换效果,保存为html就行了,WORDPREESS中好像有集成这个插件的,做的还更好。感兴趣可以点击我的博客首页open in new window 看一看。
不过还有个值得注意的问题,就是wowslider里面带有一个googleapis的服务,即https://fonts.googleapis.com/css?family=Arimo&subset=latin,cyrillic,latin-ext,由于一般用户不能访问谷歌,会导致网页加载速度及其缓慢,所以,去掉为妙
畅言 作为社交评论的工具,虽然说表示还是想念以前的多说,但是畅言现在做得还是好了,有评论审核,评论导出导入等功能,如果浏览量大的话,还能提供广告服务,让站长也能拿到一丢丢的广告费。本博客中使用了畅言的基本评论、获取某篇文章评论数的功能。可以到我这里留言open in new window 哈
Editor.md 一款能将markdown解析为html的插件,国人的作品,博客的文章编辑器一开始想使用的是markdown,想法是:写文章、保存数据库都是markdown格式的,保存在数据库中,读取时有需要解析markdown,这个过程是有点耗时的,但是相比把html式的网页保存在数据库中友好点吧,因为如果一篇文章比较长的话,转成html的格式,光是大小估计也得超过几十kb?所以,还是本人选择的是一切都用源markdown。 editor.mdopen in new window ,是一款开源的、可嵌入的 Markdown 在线编辑器(组件),基于 CodeMirror、jQuery 和 Marked 构建。页面看起来还是美观的,相比WORDPRESS的那些牛逼插件还差那么一点点,不过从普通人的眼光来看,应该是可以的了。此处,我用它作为解析网页的利器,还有就是后台编辑也是用的这个。
代码样式,这一点是不如WORDPRESS的插件了,不过已经可以了。
图表 目前最常用的是highcharts跟echart,目前个人博客中的日志系统主要还是采用了highcharts,主要还是颜色什么的格调比较相符吧,其次是因为对echarts印象不太友好,比如下面做这张,打开网页后,缩小浏览器,百度的地域图却不能自适应,出现了越界,而highcharts的全部都能自适应调整。想起有次面试,我说我用的highcharts,面试官一脸嫌弃。。。(网上这么多人鄙视百度是假的?)
不过地图确确实实是echarts的优势,毕竟还是自家的东西了解自家,不过前段时间去看了看echarts的官网,已经不提供下载了。如果有需要,还是去csdn上搜索吧,或者替换为highmap。
百度分享 作为一个以博客为主的网站,免不了使用一些社会化分享的工具,目前主要是jiathisopen in new window 和百度分享,这两者的ui都是相似的(丑爆了)。凭我个人的感觉,jiathis加载实在是太过于缓慢,这点是无法让人忍受的,只好投靠百度。百度分享类似于jiathis,安装也很简单,具体见官网http://share.baidu.com/code/advance#toolsopen in new window 。一直点点点,配置完之后,就是下图这种,丑爆了是不是?
好在对它的美观改变不是很难,此处参考了别人的UI设计,原作者我忘记怎么联系他了。其原理主要是使用图片来替换掉原本的东西。完整的源码可以点击此处open in new window 。
#share a {
+ width : 34px;
+ height : 34px;
+ padding : 0;
+ margin : 6px;
+ border-radius : 25px;
+ transition : all .4s;
+}
+
+#share a.bds_qzone {
+ background : url ( http://image.wenzhihuai.com/t_QQZone.png) ;
+ background-size : 34px 34px;
+}
+改完之后的效果。
瀑布流 有段时间,瀑布流特别流行?还有段时间,瀑布流开始遭到各种抵制。。。看看知乎的人怎么说open in new window ,大部分人不喜欢的原因是让人觉得视觉疲劳,不过瀑布流最大的好处还是有的:提高发现好图的效率以及图片列表页极强的视觉感染力。没错,我还是想把自己的网站弄得铉一些==,所以采用了瀑布流(不过效果不是很好,某些浏览器甚至加载出错),这个大bug有时间再改,毕竟花了很多时间做的这个,效果确实不咋地。目前主要的瀑布流有waterfall.js 和masory.js 。这一块目前还不是很完善,希望能得到各位大佬的指点。
天气插件 此类咨询服务还是网上还是挺多的,这一块不知道是不是所谓的“画蛇添足”这部分,主要是我觉得网站右边这部分老是少了点什么,所以加上了天气插件。目前常用的天气插件有中国天气网open in new window ,心知天气open in new window 等。安装方式见各自的官网,这里不再阐述,我使用的是心知天气。注意:心知天气限制流量的,一个小时内只能使用400次,如果超出了会失效,当然也可以付费使用。
标签云 标签云,弄得好的话应该说是一个网站的点缀。现在好像比较流行3D的标签云?像下面这种。
从个人的网站风格来看,比较适应PHP形式的,有点颜色而又不绚丽的即可,之前用的跟分类的一样的样式,即双纵列的样式,美观度还行,虽然老是感觉有点怪怪的,如果某个标签的字数过长怎么办,岂不是要顶出div了。所以还是选择换另一种风格,最终偶然一次找到了下面这种,能够自适应宽度,颜色虽然鲜艳了点(以后有空再调一下吧),源码见style.cssopen in new window 。 下图为目前的标签页。
总结 作为一个后端人员,调css和js真是痛苦==,好在坚持下来了,虽然还是很多不足,以后有时间慢慢改。说了那么多,感觉自己还是菜的抠脚。 题外话,搭建一个博客,对于一个新近程序员来说真的是锻炼自己的一个好机会,能够认识到从前端、java后台、linux、jvm等等知识,只是真的有点耗时间(还不如把时间耗在Spring源码),如果不采用别人的框架的话,付出的代价还是蛮大的(所以不要鄙视我啦)。没有什么能够一举两得,看自己的取舍吧。加油💪(ง •_•)ง
欢迎访问我的网站http://www.wenzhihuai.com/open in new window 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblogopen in new window 。
6.数据库备份
下一页
8.基于贝叶斯的情感分析
8.基于贝叶斯的情感分析 | 个人博客
+ 9.网站性能优化 | 个人博客
+ Personal Website | 个人博客
+ 个人博客
+ 一、概述 | 个人博客
+ 跳至主要內容 一、概述 1.1 缓存介绍 系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。 缓存常用语: 数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透 可查看Redis实战(一) 使用缓存合理性open in new window
1.2 本站缓存架构 从没有使用缓存,到使用mybatis缓存,然后使用了ehcache,再然后是mybatis+redis缓存。
步骤: (1)用户发送一个请求到nginx,nginx对请求进行分发。 (2)请求进入controller,service,service中查询缓存,如果命中,则直接返回结果,否则去调用mybatis。 (3)mybatis的缓存调用步骤:二级缓存->一级缓存->直接查询数据库。 (4)查询数据库的时候,mysql作了主主备份。
二、Mybatis缓存 2.1 mybatis一级缓存 Mybatis的一级缓存是指Session回话级别的缓存,也称作本地缓存。一级缓存的作用域是一个SqlSession。Mybatis默认开启一级缓存。在同一个SqlSession中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。当执行SQL时两次查询中间发生了增删改操作,则SqlSession的缓存清空。Mybatis 默认支持一级缓存,不需要在配置文件中配置。
我们来查看一下源码的类图,具体的源码分析简单概括一下:SqlSession实际上是使用PerpetualCache来维护的,PerpetualCache中定义了一个HashMap来进行缓存。
2.2 mybatis二级缓存 Mybatis的二级缓存是指mapper映射文件,为Application应用级别的缓存,生命周期长。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。在同一个namespace下的mapper文件中,执行相同的查询SQL。实现二级缓存,关键是要对Executor对象做文章,Mybatis给Executor对象加上了一个CachingExecutor,使用了设计模式中的装饰者模式,
2.2.1 MyBatis二级缓存的划分 MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下: a.为每一个Mapper分配一个Cache缓存对象; b.多个Mapper共用一个Cache缓存对象;
2.2.2 二级缓存的开启 在mybatis的配置文件中添加:
< settings> < settingname = " cacheEnabled" value = " true" /> </ settings> 然后再需要开启二级缓存的mapper.xml中添加(本站使用了LRU算法,时间为120000毫秒):
< cacheeviction = " LRU" type = " org.apache.ibatis.cache.impl.PerpetualCache" flushInterval = " 120000" size = " 1024" readOnly = " true" /> 2.2.3 使用第三方支持的二级缓存的实现 MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached、Redis的集成,总之,使用MyBatis的二级缓存有三个选择:
MyBatis自身提供的缓存实现; 用户自定义的Cache接口实现; 跟第三方内存缓存库的集成;SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置open in new window MyBatis中一级缓存和二级缓存的组织如下图所示(图片来自深入理解mybatis原理open in new window ):
2.3 Mybatis在分布式环境下脏读问题 (1)如果是一级缓存,在多个SqlSession或者分布式的环境下,数据库的写操作会引起脏数据,多数情况可以通过设置缓存级别为Statement来解决。
下面将介绍使用Redis集中式缓存在个人网站的应用。
三、Redis缓存 Redis运行于独立的进程,通过网络协议和应用交互,将数据保存在内存中,并提供多种手段持久化内存的数据。同时具备服务器的水平拆分、复制等分布式特性,使得其成为缓存服务器的主流。为了与Spring更好的结合使用,我们使用的是Spring-Data-Redis。此处省略安装过程和Redis的命令讲解。
3.1 Spring Cache Spring 3.1 引入了激动人心的基于注释(annotation)的缓存(cache)技术,它本质上不是一个具体的缓存实现方案(例如EHCache 或者 OSCache),而是一个对缓存使用的抽象,通过在既有代码中添加少量它定义的各种 annotation,即能够达到缓存方法的返回对象的效果。Spring 的缓存技术还具备相当的灵活性,不仅能够使用 **SpEL(Spring Expression Language)**来定义缓存的 key 和各种 condition,还提供开箱即用的缓存临时存储方案,也支持和主流的专业缓存例如 EHCache 集成。 下面是Spring Cache常用的注解:
(1)@Cacheable @Cacheable 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”)
(2)@CachePut @CachePut 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”)
(3)@CacheEvict @CachEvict 的作用 主要针对方法配置,能够根据一定的条件对缓存进行清空
属性 介绍 例子 value 缓存的名称,必选 @Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”} key 缓存的key,可选,需要按照SpEL表达式填写 @Cacheable(value=”testcache”,key=”#userName”) condition 缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存 @Cacheable(value=”testcache”,key=”#userName”) allEntries 是否清空所有缓存内容,默认为false @CachEvict(value=”testcache”,allEntries=true) beforeInvocation 是否在方法执行前就清空,缺省为 false @CachEvict(value=”testcache”,beforeInvocation=true)
但是有个问题: Spring官方认为:缓存过期时间由各个产商决定,所以并不提供缓存过期时间的注解。所以,如果想实现各个元素过期时间不同,就需要自己重写一下Spring cache。
3.2 引入包 一般是Spring常用的包+Spring data redis的包,记得注意去掉所有冲突的包,之前才过坑,Spring-data-MongoDB已经有SpEL的库了,和自己新引进去的冲突,搞得我以为自己是配置配错了,真是个坑,注意,开发过程中一定要去除掉所有冲突的包!!!
3.3 ApplicationContext.xml 需要启用缓存的注解开关,并配置好Redis。序列化方式也要带上,否则会碰到幽灵bug。
+ < cache: annotation-driven/> < beanid = " jedisConnectionFactory" class = " org.springframework.data.redis.connection.jedis.JedisConnectionFactory" > < propertyname = " hostName" value = " ${host}" /> < propertyname = " port" value = " ${port}" /> < propertyname = " password" value = " ${password}" /> < propertyname = " database" value = " ${redis.default.db}" /> < propertyname = " timeout" value = " ${timeout}" /> < propertyname = " poolConfig" ref = " jedisPoolConfig" /> < propertyname = " usePool" value = " true" /> </ bean> < beanid = " redisTemplate" class = " org.springframework.data.redis.core.StringRedisTemplate" > < propertyname = " connectionFactory" ref = " jedisConnectionFactory" /> < propertyname = " keySerializer" > < beanclass = " org.springframework.data.redis.serializer.StringRedisSerializer" /> </ property> < propertyname = " hashKeySerializer" > < beanclass = " org.springframework.data.redis.serializer.StringRedisSerializer" /> </ property> < propertyname = " valueSerializer" > < beanclass = " org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" /> </ property> < propertyname = " hashValueSerializer" > < beanclass = " org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" /> </ property> </ bean> < beanid = " cacheManager" class = " org.springframework.data.redis.cache.RedisCacheManager" > < constructor-argname = " redisOperations" ref = " redisTemplate" /> < propertyname = " defaultExpiration" value = " ${redis.defaultExpiration}" /> </ bean> 3.5 自定义KeyGenerator 在分布式系统中,很容易存在不同类相同名字的方法,如A.getAll(),B.getAll(),默认的key(getAll)都是一样的,会很容易产生问题,所以,需要自定义key来实现分布式环境下的不同。
@Component ( "customKeyGenerator" )
+public class CustomKeyGenerator implements KeyGenerator {
+ @Override
+ public Object generate ( Object o, Method method, Object . . . objects) {
+ StringBuilder sb = new StringBuilder ( ) ;
+ sb. append ( o. getClass ( ) . getName ( ) ) ;
+ sb. append ( "." ) ;
+ sb. append ( method. getName ( ) ) ;
+ for ( Object obj : objects) {
+ sb. append ( obj. toString ( ) ) ;
+ }
+ return sb. toString ( ) ;
+ }
+}
+之后,存储的key就变为:com.myblog.service.impl.BlogServiceImpl.getBanner。
3.4 添加注解 在所需要的方法上添加注解,比如,首页中的那几张幻灯片,每次进入首页都需要查询数据库,这里,我们直接放入缓存里,减少数据库的压力,还有就是那些热门文章,访问量比较大的,也放进数据库里。
@Override
+ @Cacheable ( value = "getBanner" , keyGenerator = "customKeyGenerator" )
+ public List < Blog > getBanner ( ) {
+ return blogMapper. getBanner ( ) ;
+ }
+ @Override
+ @Cacheable ( value = "getBlogDetail" , key = "'blogid'.concat(#blogid)" )
+ public Blog getBlogDetail ( Integer blogid) {
+ Blog blog = blogMapper. selectByPrimaryKey ( blogid) ;
+ if ( blog == null ) {
+ return null ;
+ }
+ Category category = categoryMapper. selectByPrimaryKey ( blog. getCategoryid ( ) ) ;
+ blog. setCategory ( category) ;
+ List < Tag > = tagMapper. getTagByBlogId ( blog. getBlogid ( ) ) ;
+ blog. setTags ( tags. size ( ) > 0 ? tags : null ) ;
+ asyncService. updatebloghits ( blogid) ;
+ logger. info ( "没有走缓存" ) ;
+ return blog;
+ }
+ 3.5 测试 我们调用一个getBlogDetail(获取博客详情)100次来对比一下时间。连接的数据库在深圳,本人在广州,还是有那么一丢丢的网路延时的。
public class SpringTest {
+ @Test
+ public void init ( ) {
+ ApplicationContext ctx = new FileSystemXmlApplicationContext ( "classpath:spring-test.xml" ) ;
+ IBlogService blogService = ( IBlogService ) ctx. getBean ( "blogService" ) ;
+ long startTime = System . currentTimeMillis ( ) ;
+ for ( int i = 0 ; i < 100 ; i++ ) {
+ blogService. getBlogDetail ( 615 ) ;
+ }
+ System . out. println ( System . currentTimeMillis ( ) - startTime) ;
+ }
+}
+为了做一下对比,我们同时使用mybatis自身缓存来进行测试。
3.6 实验结果 统计出结果如下:
没有使用任何缓存(mybatis一级缓存没有关闭):18305
+使用远程Redis缓存:12727
+使用Mybatis缓存:6649
+使用本地Redis缓存:5818
+由结果看出,缓存的使用大大较少了获取数据的时间。
部署进个人博客之后,redis已经缓存的数据:
3.7 分页的数据怎么办 个人网站中共有两个栏目,一个是技术杂谈,另一个是生活笔记,每点击一次栏目的时候,会根据页数从数据库中查询数据,百度了下,大概有三种方法: (1)以页码作为Key,然后缓存整个页面。 (2)分条存取,只从数据库中获取分页的文章ID序列,然后从service(缓存策略在service中实现)中获取。 第一种,由于使用了第三方的插件PageHelper,分页获取的话会比较麻烦,同时整页缓存对内存压力也蛮大的,毕竟服务器只有2g。第二条实现方式简单,缺陷是依旧需要查询数据库,想了想还是放弃了。缓存的初衷是对请求频繁又不易变的数据,实际使用中很少会反复的请求同一页的数据(查询条件也相同),当然对数据中某些字段做缓存还是有必要的。
四、如何解决脏读? 对于文章来说,内容是不经常更新的,没有涉及到缓存一致性,但是对于文章的阅读量,用户每点击一次,就应该更新浏览量的。对于文章的缓存,常规的设计是将文章存储进数据库中,然后读取的时候放入缓存中,然后将浏览量以文章ID+浏览量的结构实时的存入redis服务器中。本站当初设计不合理,直接将浏览量作为一个字段,用户每点击一次的时候就异步更新浏览量,但是此处没有更新缓存,如果手动更新缓存的话,基本上每点击一次都得执行更新操作,同样也不合理。所以,目前本站,你们在页面上看到的浏览量和数据库中的浏览量并不是一致的。有兴趣的可以点击我的网站open in new window 玩玩~~
五、题外话 兄弟姐妹们啊,个人网站只是个小项目,纯属为了学习而用的,文章可以看看,但是,就不要抓取了吧。。。。一个小时抓取6万次宝宝心脏真的受不了,虽然服务器一切都还稳定==
个人网站 :http://www.wenzhihuai.comopen in new window 个人网站源码,希望能给个star :https://github.com/Zephery/newblogopen in new window
参考:《深入理解mybatis原理》 MyBatis的一级缓存实现详解open in new window 《深入理解mybatis原理》 MyBatis的二级缓存的设计原理open in new window 聊聊Mybatis缓存机制open in new window Spring思维导图open in new window SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置open in new window
{const d=o*i;t:for(const l of e.keys())if(l===F){const a=u[d-1];a<=s&&n.set(r,[e.get(l),a])}else{let a=o;for(let h=0;hs)continue t}R(e.get(l),t,s,n,u,a,i,r+l)}};class C{_tree;_prefix;_size=void 0;constructor(t=new Map,s=""){this._tree=t,this._prefix=s}atPrefix(t){if(!t.startsWith(this._prefix))throw new Error("Mismatched prefix");const[s,n]=x(this._tree,t.slice(this._prefix.length));if(s===void 0){const[u,o]=M(n);for(const i of u.keys())if(i!==F&&i.startsWith(o)){const r=new Map;return r.set(i.slice(o.length),u.get(i)),new C(r,t)}}return new C(s,t)}clear(){this._size=void 0,this._tree.clear()}delete(t){return this._size=void 0,ot(this._tree,t)}entries(){return new D(this,nt)}forEach(t){for(const[s,n]of this)t(s,n,this)}fuzzyGet(t,s){return ut(this._tree,t,s)}get(t){const s=I(this._tree,t);return s!==void 0?s.get(F):void 0}has(t){const s=I(this._tree,t);return s!==void 0&&s.has(F)}keys(){return new D(this,V)}set(t,s){if(typeof t!="string")throw new Error("key must be a string");return this._size=void 0,O(this._tree,t).set(F,s),this}get size(){if(this._size)return this._size;this._size=0;const t=this.entries();for(;!t.next().done;)this._size+=1;return this._size}update(t,s){if(typeof t!="string")throw new Error("key must be a string");this._size=void 0;const n=O(this._tree,t);return n.set(F,s(n.get(F))),this}fetch(t,s){if(typeof t!="string")throw new Error("key must be a string");this._size=void 0;const n=O(this._tree,t);let u=n.get(F);return u===void 0&&n.set(F,u=s()),u}values(){return new D(this,T)}[Symbol.iterator](){return this.entries()}static from(t){const s=new C;for(const[n,u]of t)s.set(n,u);return s}static fromObject(t){return C.from(Object.entries(t))}}const x=(e,t,s=[])=>{if(t.length===0||e==null)return[e,s];for(const n of e.keys())if(n!==F&&t.startsWith(n))return s.push([e,n]),x(e.get(n),t.slice(n.length),s);return s.push([e,t]),x(void 0,"",s)},I=(e,t)=>{if(t.length===0||e==null)return e;for(const s of e.keys())if(s!==F&&t.startsWith(s))return I(e.get(s),t.slice(s.length))},O=(e,t)=>{const s=t.length;t:for(let n=0;e&&n{const[s,n]=x(e,t);if(s!==void 0){if(s.delete(F),s.size===0)W(n);else if(s.size===1){const[u,o]=s.entries().next().value;q(n,u,o)}}},W=e=>{if(e.length===0)return;const[t,s]=M(e);if(t.delete(s),t.size===0)W(e.slice(0,-1));else if(t.size===1){const[n,u]=t.entries().next().value;n!==F&&q(e.slice(0,-1),n,u)}},q=(e,t,s)=>{if(e.length===0)return;const[n,u]=M(e);n.set(u+t,s),n.delete(u)},M=e=>e[e.length-1],it=(e,t)=>{const s=e._idToShortId.get(t);if(s!=null)return e._storedFields.get(s)},rt=/[\n\r -#%-*,-/:;?@[-\]_{}\u00A0\u00A1\u00A7\u00AB\u00B6\u00B7\u00BB\u00BF\u037E\u0387\u055A-\u055F\u0589\u058A\u05BE\u05C0\u05C3\u05C6\u05F3\u05F4\u0609\u060A\u060C\u060D\u061B\u061E\u061F\u066A-\u066D\u06D4\u0700-\u070D\u07F7-\u07F9\u0830-\u083E\u085E\u0964\u0965\u0970\u09FD\u0A76\u0AF0\u0C77\u0C84\u0DF4\u0E4F\u0E5A\u0E5B\u0F04-\u0F12\u0F14\u0F3A-\u0F3D\u0F85\u0FD0-\u0FD4\u0FD9\u0FDA\u104A-\u104F\u10FB\u1360-\u1368\u1400\u166E\u1680\u169B\u169C\u16EB-\u16ED\u1735\u1736\u17D4-\u17D6\u17D8-\u17DA\u1800-\u180A\u1944\u1945\u1A1E\u1A1F\u1AA0-\u1AA6\u1AA8-\u1AAD\u1B5A-\u1B60\u1BFC-\u1BFF\u1C3B-\u1C3F\u1C7E\u1C7F\u1CC0-\u1CC7\u1CD3\u2000-\u200A\u2010-\u2029\u202F-\u2043\u2045-\u2051\u2053-\u205F\u207D\u207E\u208D\u208E\u2308-\u230B\u2329\u232A\u2768-\u2775\u27C5\u27C6\u27E6-\u27EF\u2983-\u2998\u29D8-\u29DB\u29FC\u29FD\u2CF9-\u2CFC\u2CFE\u2CFF\u2D70\u2E00-\u2E2E\u2E30-\u2E4F\u3000-\u3003\u3008-\u3011\u3014-\u301F\u3030\u303D\u30A0\u30FB\uA4FE\uA4FF\uA60D-\uA60F\uA673\uA67E\uA6F2-\uA6F7\uA874-\uA877\uA8CE\uA8CF\uA8F8-\uA8FA\uA8FC\uA92E\uA92F\uA95F\uA9C1-\uA9CD\uA9DE\uA9DF\uAA5C-\uAA5F\uAADE\uAADF\uAAF0\uAAF1\uABEB\uFD3E\uFD3F\uFE10-\uFE19\uFE30-\uFE52\uFE54-\uFE61\uFE63\uFE68\uFE6A\uFE6B\uFF01-\uFF03\uFF05-\uFF0A\uFF0C-\uFF0F\uFF1A\uFF1B\uFF1F\uFF20\uFF3B-\uFF3D\uFF3F\uFF5B\uFF5D\uFF5F-\uFF65]+/u,S="or",$="and",ct="and_not",lt=(e,t)=>{e.includes(t)||e.push(t)},P=(e,t)=>{for(const s of t)e.includes(s)||e.push(s)},G=({score:e},{score:t})=>t-e,ht=()=>new Map,k=e=>{const t=new Map;for(const s of Object.keys(e))t.set(parseInt(s,10),e[s]);return t},N=(e,t)=>Object.prototype.hasOwnProperty.call(e,t)?e[t]:void 0,dt={[S]:(e,t)=>{for(const s of t.keys()){const n=e.get(s);if(n==null)e.set(s,t.get(s));else{const{score:u,terms:o,match:i}=t.get(s);n.score=n.score+u,n.match=Object.assign(n.match,i),P(n.terms,o)}}return e},[$]:(e,t)=>{const s=new Map;for(const n of t.keys()){const u=e.get(n);if(u==null)continue;const{score:o,terms:i,match:r}=t.get(n);P(u.terms,i),s.set(n,{score:u.score+o,terms:u.terms,match:Object.assign(u.match,r)})}return s},[ct]:(e,t)=>{for(const s of t.keys())e.delete(s);return e}},at=(e,t,s,n,u,o)=>{const{k:i,b:r,d}=o;return Math.log(1+(s-t+.5)/(t+.5))*(d+e*(i+1)/(e+i*(1-r+r*n/u)))},ft=e=>(t,s,n)=>{const u=typeof e.fuzzy=="function"?e.fuzzy(t,s,n):e.fuzzy||!1,o=typeof e.prefix=="function"?e.prefix(t,s,n):e.prefix===!0;return{term:t,fuzzy:u,prefix:o}},H=(e,t,s,n)=>{for(const u of Object.keys(e._fieldIds))if(e._fieldIds[u]===s){e._options.logger("warn",`SlimSearch: document with ID ${e._documentIds.get(t)} has changed before removal: term "${n}" was not present in field "${u}". Removing a document after it has changed can corrupt the index!`,"version_conflict");return}},gt=(e,t,s,n)=>{if(!e._index.has(n)){H(e,s,t,n);return}const u=e._index.fetch(n,ht),o=u.get(t);o==null||o.get(s)==null?H(e,s,t,n):o.get(s)<=1?o.size<=1?u.delete(t):o.delete(s):o.set(s,o.get(s)-1),e._index.get(n).size===0&&e._index.delete(n)},mt={k:1.2,b:.7,d:.5},pt={idField:"id",extractField:(e,t)=>e[t],tokenize:e=>e.split(rt),processTerm:e=>e.toLowerCase(),fields:void 0,searchOptions:void 0,storeFields:[],logger:(e,t)=>{typeof console?.[e]=="function"&&console[e](t)},autoVacuum:!0},J={combineWith:S,prefix:!1,fuzzy:!1,maxFuzzy:6,boost:{},weights:{fuzzy:.45,prefix:.375},bm25:mt},Ft={combineWith:$,prefix:(e,t,s)=>t===s.length-1},_t={batchSize:1e3,batchWait:10},U={minDirtFactor:.1,minDirtCount:20},yt={..._t,...U},Y=(e,t=S)=>{if(e.length===0)return new Map;const s=t.toLowerCase();return e.reduce(dt[s])||new Map},B=(e,t,s,n,u,o,i,r,d=new Map)=>{if(u==null)return d;for(const l of Object.keys(o)){const a=o[l],h=e._fieldIds[l],m=u.get(h);if(m==null)continue;let p=m.size;const f=e._avgFieldLength[h];for(const c of m.keys()){if(!e._documentIds.has(c)){gt(e,h,c,s),p-=1;continue}const g=i?i(e._documentIds.get(c),s,e._storedFields.get(c)):1;if(!g)continue;const _=m.get(c),y=e._fieldLength.get(c)[h],b=at(_,p,e._documentCount,y,f,r),z=n*a*g*b,A=d.get(c);if(A){A.score+=z,lt(A.terms,t);const w=N(A.match,s);w?w.push(l):A.match[s]=[l]}else d.set(c,{score:z,terms:[t],match:{[s]:[l]}})}}return d},At=(e,t,s)=>{const n={...e._options.searchOptions,...s},u=(n.fields||e._options.fields).reduce((c,g)=>({...c,[g]:N(n.boost,g)||1}),{}),{boostDocument:o,weights:i,maxFuzzy:r,bm25:d}=n,{fuzzy:l,prefix:a}={...J.weights,...i},h=e._index.get(t.term),m=B(e,t.term,t.term,1,h,u,o,d);let p,f;if(t.prefix&&(p=e._index.atPrefix(t.term)),t.fuzzy){const c=t.fuzzy===!0?.2:t.fuzzy,g=c<1?Math.min(r,Math.round(t.term.length*c)):c;g&&(f=e._index.fuzzyGet(t.term,g))}if(p)for(const[c,g]of p){const _=c.length-t.term.length;if(!_)continue;f?.delete(c);const y=a*c.length/(c.length+.3*_);B(e,t.term,c,y,g,u,o,d,m)}if(f)for(const c of f.keys()){const[g,_]=f.get(c);if(!_)continue;const y=l*c.length/(c.length+_);B(e,t.term,c,y,g,u,o,d,m)}return m},X=(e,t,s={})=>{if(typeof t!="string"){const a={...s,...t,queries:void 0},h=t.queries.map(m=>X(e,m,a));return Y(h,a.combineWith)}const{tokenize:n,processTerm:u,searchOptions:o}=e._options,i={tokenize:n,processTerm:u,...o,...s},{tokenize:r,processTerm:d}=i,l=r(t).flatMap(a=>d(a)).filter(a=>!!a).map(ft(i)).map(a=>At(e,a,i));return Y(l,i.combineWith)},K=(e,t,s={})=>{const n=X(e,t,s),u=[];for(const[o,{score:i,terms:r,match:d}]of n){const l=r.length,a={id:e._documentIds.get(o),score:i*l,terms:Object.keys(d),match:d};Object.assign(a,e._storedFields.get(o)),(s.filter==null||s.filter(a))&&u.push(a)}return u.sort(G),u},Ct=(e,t,s={})=>{s={...e._options.autoSuggestOptions,...s};const n=new Map;for(const{score:o,terms:i}of K(e,t,s)){const r=i.join(" "),d=n.get(r);d!=null?(d.score+=o,d.count+=1):n.set(r,{score:o,terms:i,count:1})}const u=[];for(const[o,{score:i,terms:r,count:d}]of n)u.push({suggestion:o,terms:r,score:i/d});return u.sort(G),u};class Et{_options;_index;_documentCount;_documentIds;_idToShortId;_fieldIds;_fieldLength;_avgFieldLength;_nextId;_storedFields;_dirtCount;_currentVacuum;_enqueuedVacuum;_enqueuedVacuumConditions;constructor(t){if(t?.fields==null)throw new Error('SlimSearch: option "fields" must be provided');const s=t.autoVacuum==null||t.autoVacuum===!0?yt:t.autoVacuum;this._options={...pt,...t,autoVacuum:s,searchOptions:{...J,...t.searchOptions||{}},autoSuggestOptions:{...Ft,...t.autoSuggestOptions||{}}},this._index=new C,this._documentCount=0,this._documentIds=new Map,this._idToShortId=new Map,this._fieldIds={},this._fieldLength=new Map,this._avgFieldLength=[],this._nextId=0,this._storedFields=new Map,this._dirtCount=0,this._currentVacuum=null,this._enqueuedVacuum=null,this._enqueuedVacuumConditions=U,this.addFields(this._options.fields)}get isVacuuming(){return this._currentVacuum!=null}get dirtCount(){return this._dirtCount}get dirtFactor(){return this._dirtCount/(1+this._documentCount+this._dirtCount)}get documentCount(){return this._documentCount}get termCount(){return this._index.size}toJSON(){const t=[];for(const[s,n]of this._index){const u={};for(const[o,i]of n)u[o]=Object.fromEntries(i);t.push([s,u])}return{documentCount:this._documentCount,nextId:this._nextId,documentIds:Object.fromEntries(this._documentIds),fieldIds:this._fieldIds,fieldLength:Object.fromEntries(this._fieldLength),averageFieldLength:this._avgFieldLength,storedFields:Object.fromEntries(this._storedFields),dirtCount:this._dirtCount,index:t,serializationVersion:2}}addFields(t){for(let s=0;s{if(l!==1&&l!==2)throw new Error("SlimSearch: cannot deserialize an index created with an incompatible version");const h=new Et(a);h._documentCount=t,h._nextId=s,h._documentIds=k(n),h._idToShortId=new Map,h._fieldIds=u,h._fieldLength=k(o),h._avgFieldLength=i,h._storedFields=k(r),h._dirtCount=d||0,h._index=new C;for(const[m,p]of h._documentIds)h._idToShortId.set(p,m);for(const[m,p]of e){const f=new Map;for(const c of Object.keys(p)){let g=p[c];l===1&&(g=g.ds),f.set(parseInt(c,10),k(g))}h._index.set(m,f)}return h},Q=Object.entries,wt=Object.fromEntries,j=(e,t)=>{const s=e.toLowerCase(),n=t.toLowerCase(),u=[];let o=0,i=0;const r=(l,a=!1)=>{let h="";i===0?h=l.length>20?`… ${l.slice(-20)}`:l:a?h=l.length+i>100?`${l.slice(0,100-i)}… `:l:h=l.length>20?`${l.slice(0,20)} … ${l.slice(-20)}`:l,h&&u.push(h),i+=h.length,a||(u.push(["mark",t]),i+=t.length,i>=100&&u.push(" …"))};let d=s.indexOf(n,o);if(d===-1)return null;for(;d>=0;){const l=d+n.length;if(r(e.slice(o,d)),o=l,i>100)break;d=s.indexOf(n,o)}return i<100&&r(e.slice(o),!0),u},Z=/[\u4e00-\u9fa5]/g,tt=(e={})=>({fuzzy:.2,prefix:!0,processTerm:t=>{const s=t.match(Z)||[],n=t.replace(Z,"").toLowerCase();return n?[n,...s]:[...s]},...e}),xt=(e,t)=>t.contents.reduce((s,[,n])=>s+n,0)-e.contents.reduce((s,[,n])=>s+n,0),kt=(e,t)=>Math.max(...t.contents.map(([,s])=>s))-Math.max(...e.contents.map(([,s])=>s)),et=(e,t,s={})=>{const n={};return K(t,e,tt({boost:{h:2,t:1,c:4},...s})).forEach(u=>{const{id:o,terms:i,score:r}=u,d=o.includes("@"),l=o.includes("#"),[a,h]=o.split(/[#@]/),m=i.sort((f,c)=>f.length-c.length).filter((f,c)=>i.slice(c+1).every(g=>!g.includes(f))),{contents:p}=n[a]??={title:"",contents:[]};if(d)p.push([{type:"customField",key:a,index:h,display:m.map(f=>u.c.map(c=>j(c,f))).flat().filter(f=>f!==null)},r]);else{const f=m.map(c=>j(u.h,c)).filter(c=>c!==null);if(f.length&&p.push([{type:l?"heading":"title",key:a,...l&&{anchor:h},display:f},r]),"t"in u)for(const c of u.t){const g=m.map(_=>j(c,_)).filter(_=>_!==null);g.length&&p.push([{type:"text",key:a,...l&&{anchor:h},display:g},r])}}}),Q(n).sort(([,u],[,o])=>"max"==="total"?xt(u,o):kt(u,o)).map(([u,{title:o,contents:i}])=>{if(!o){const r=it(t,u);r&&(o=r.h)}return{title:o,contents:i.map(([r])=>r)}})},st=(e,t,s={})=>Ct(t,e,tt(s)).map(({suggestion:n})=>n),v=wt(Q(JSON.parse("{\"/\":{\"documentCount\":236,\"nextId\":236,\"documentIds\":{\"0\":\"v-8daa1a0e\",\"1\":\"v-728c3a8f\",\"2\":\"v-2e25198a\",\"3\":\"v-71fde78e\",\"4\":\"v-580db9be\",\"5\":\"v-580db9be#一、自由风格的软件项目\",\"6\":\"v-580db9be#二、优化之后的cicd\",\"7\":\"v-580db9be#三、调研期\",\"8\":\"v-580db9be#四、产品化后的devops平台\",\"9\":\"v-580db9be#_4-1-java代码扫描\",\"10\":\"v-580db9be#_4-2-java单元测试\",\"11\":\"v-580db9be#_4-3-java构建并上传镜像\",\"12\":\"v-580db9be#_4-4-部署到阿里云k8s\",\"13\":\"v-580db9be#_4-5-整体流程\",\"14\":\"v-580db9be#_4-4-日志\",\"15\":\"v-580db9be#_4-5-定时触发\",\"16\":\"v-580db9be#五、其他\",\"17\":\"v-580db9be#_5-1-gitlab触发\",\"18\":\"v-580db9be#六、总结\",\"19\":\"v-06d5cd4c\",\"20\":\"v-132efcd1\",\"21\":\"v-1a2ca7a7\",\"22\":\"v-50cb12f2\",\"23\":\"v-091223ce\",\"24\":\"v-0a27b598\",\"25\":\"v-0a27b598#一、堆大小设置\",\"26\":\"v-0a27b598#典型设置\",\"27\":\"v-0a27b598#二、回收器选择\",\"28\":\"v-0a27b598#_2-1-吞吐量优先的并行收集器\",\"29\":\"v-0a27b598#_2-2-响应时间优先的并发收集器\",\"30\":\"v-0a27b598#三、辅助信息\",\"31\":\"v-0a27b598#_3-1-堆设置\",\"32\":\"v-0a27b598#_3-2-收集器设置\",\"33\":\"v-0a27b598#_3-3-垃圾回收统计信息\",\"34\":\"v-0a27b598#_3-4-并行收集器设置\",\"35\":\"v-0a27b598#_3-5-并发收集器设置\",\"36\":\"v-0a27b598#四、调优总结\",\"37\":\"v-0a27b598#_4-1-年轻代大小选择\",\"38\":\"v-0a27b598#_4-2-年老代大小选择\",\"39\":\"v-0a27b598#_4-3-较小堆引起的碎片问题\",\"40\":\"v-478d0de6\",\"41\":\"v-60eda44c\",\"42\":\"v-399e07b6\",\"43\":\"v-399e07b6#_1-启用jmx和远程debug模式\",\"44\":\"v-399e07b6#_2-memory-analyzer、jprofiler进行堆内存分析\",\"45\":\"v-399e07b6#_3-netty的方面的考虑\",\"46\":\"v-399e07b6#_4-直接内存排查\",\"47\":\"v-399e07b6#_5-推荐的直接内存排查方法\",\"48\":\"v-399e07b6#_5-1-pmap\",\"49\":\"v-399e07b6#_5-2-gperftools-https-github-com-gperftools-gperftools\",\"50\":\"v-399e07b6#_6-意外的结果\",\"51\":\"v-399e07b6#总结\",\"52\":\"v-660266c1\",\"53\":\"v-90f2343c\",\"54\":\"v-90f2343c#一、简介\",\"55\":\"v-90f2343c#二、-虚拟线程与平台线程\",\"56\":\"v-90f2343c#三、在spring-6中使用虚拟线程\",\"57\":\"v-90f2343c#四、性能比较\",\"58\":\"v-0b5d4df0\",\"59\":\"v-0b5d4df0#一、概念\",\"60\":\"v-0b5d4df0#_1-1-使用场景\",\"61\":\"v-0b5d4df0#_1-2-维度\",\"62\":\"v-0b5d4df0#_1-3-分布式限流\",\"63\":\"v-0b5d4df0#二、分布式限流常用方案\",\"64\":\"v-0b5d4df0#三、基于kubernetes的分布式限流\",\"65\":\"v-0b5d4df0#_3-1-kubernetes中的副本数\",\"66\":\"v-0b5d4df0#_3-2-ratelimiter的创建\",\"67\":\"v-0b5d4df0#_3-3-ratelimiter的获取\",\"68\":\"v-0b5d4df0#_3-4-filter里的判断\",\"69\":\"v-0b5d4df0#四、性能压测\",\"70\":\"v-0b5d4df0#五、其他问题\",\"71\":\"v-0b5d4df0#参考\",\"72\":\"v-57ae83ac\",\"73\":\"v-22e4234a\",\"74\":\"v-22e4234a#疲惫的面试历程\",\"75\":\"v-22e4234a#感情、我们毕业了\",\"76\":\"v-22e4234a#_996的工作\",\"77\":\"v-22e4234a#孤独\",\"78\":\"v-22e4234a#期望\",\"79\":\"v-1f7a720c\",\"80\":\"v-1f7a720c#心惊胆战的裸辞经历\",\"81\":\"v-1f7a720c#工作工作\",\"82\":\"v-1f7a720c#跑步跑步\",\"83\":\"v-1f7a720c#others\",\"84\":\"v-1f7a720c#_2019\",\"85\":\"v-1c10c0ce\",\"86\":\"v-1c10c0ce#工作\",\"87\":\"v-1c10c0ce#学习\",\"88\":\"v-1c10c0ce#感情\",\"89\":\"v-1c10c0ce#运动\",\"90\":\"v-1c10c0ce#其他\",\"91\":\"v-1c10c0ce#_2020展望\",\"92\":\"v-258f309e\",\"93\":\"v-510415f9\",\"94\":\"v-510415f9#一、chatgpt注册\",\"95\":\"v-510415f9#_1-1-短信手机号申请\",\"96\":\"v-510415f9#_1-2-云服务器申请\",\"97\":\"v-510415f9#_1-3-chatgpt注册\",\"98\":\"v-510415f9#二、搭建nginx服务器\",\"99\":\"v-510415f9#三、公众号开发\",\"100\":\"v-510415f9#_3-1-微信云托管\",\"101\":\"v-510415f9#_3-2-一个简单chatgpt简单回复\",\"102\":\"v-510415f9#_3-3-服务部署\",\"103\":\"v-510415f9#四、没有回复-超时回复问题\",\"104\":\"v-510415f9#五、会话保存\",\"105\":\"v-510415f9#六、其他问题\",\"106\":\"v-510415f9#_6-1-限频\",\"107\":\"v-510415f9#_6-2-秘钥key被更新\",\"108\":\"v-510415f9#_6-3-为啥和官网的回复不一样\",\"109\":\"v-510415f9#_6-4-玄学挂掉\",\"110\":\"v-510415f9#最后\",\"111\":\"v-3c114a75\",\"112\":\"v-3c114a75#一、特斯拉应用申请\",\"113\":\"v-3c114a75#_1-1-创建-tesla-账户\",\"114\":\"v-3c114a75#_1-2-提交访问请求\",\"115\":\"v-3c114a75#_1-3-访问应用程序凭据\",\"116\":\"v-3c114a75#_1-4-开始-api-集成\",\"117\":\"v-3c114a75#_2-1-认识token\",\"118\":\"v-3c114a75#_2-2-获取第三方应用token\",\"119\":\"v-3c114a75#_2-3-验证域名归属\",\"120\":\"v-3c114a75#_2-1-1-register\",\"121\":\"v-3c114a75#_2-1-2-public-key\",\"122\":\"v-37ac02fe\",\"123\":\"v-37ac02fe#_1-建站故事与网站架构\",\"124\":\"v-37ac02fe#_1-1建站过程\",\"125\":\"v-37ac02fe#_1-2-网站整体技术架构\",\"126\":\"v-37ac02fe#_1-3-日志系统\",\"127\":\"v-37ac02fe#_1-4-【有点意思】自然语言处理\",\"128\":\"v-37ac02fe#总结\",\"129\":\"v-523e9724\",\"130\":\"v-65b5c81c\",\"131\":\"v-65b5c81c#lucene的整体架构\",\"132\":\"v-65b5c81c#搜索引擎的几个重要概念\",\"133\":\"v-65b5c81c#lucene中的几个概念\",\"134\":\"v-65b5c81c#lucene在本网站的使用\",\"135\":\"v-65b5c81c#一、搜索\",\"136\":\"v-65b5c81c#二、lucene自动补全\",\"137\":\"v-65b5c81c#使用\",\"138\":\"v-65b5c81c#欢迎访问我的个人网站\",\"139\":\"v-731a76b6\",\"140\":\"v-731a76b6#一-特点\",\"141\":\"v-731a76b6#二-主要组成部分\",\"142\":\"v-731a76b6#三、quartz设计\",\"143\":\"v-731a76b6#四、使用\",\"144\":\"v-731a76b6#spring的高级特性之定时任务\",\"145\":\"v-bea2ce1e\",\"146\":\"v-bea2ce1e#_1-网站代码安装\",\"147\":\"v-bea2ce1e#_2-根据api获取数据\",\"148\":\"v-bea2ce1e#_3-构建请求\",\"149\":\"v-bea2ce1e#_4-实际运用\",\"150\":\"v-bea2ce1e#_5-基本代码\",\"151\":\"v-bea2ce1e#_6-展示数据\",\"152\":\"v-3efc517e\",\"153\":\"v-3efc517e#_1-1-nginx的安装\",\"154\":\"v-3efc517e#_1-2-nginx的配置\",\"155\":\"v-3efc517e#_1-2-1-负载均衡算法\",\"156\":\"v-3efc517e#_1-2-2-日志格式\",\"157\":\"v-3efc517e#_1-2-3-http反向代理\",\"158\":\"v-3efc517e#_1-2-4-https\",\"159\":\"v-3efc517e#_1-2-5-失败重试\",\"160\":\"v-3efc517e#测试\",\"161\":\"v-79ad699f\",\"162\":\"v-79ad699f#_2-1-创建所用的复制账号\",\"163\":\"v-79ad699f#_2-2-配置master\",\"164\":\"v-79ad699f#_2-3-配置slave\",\"165\":\"v-8658e60a\",\"166\":\"v-8658e60a#wowslider\",\"167\":\"v-8658e60a#畅言\",\"168\":\"v-8658e60a#editor-md\",\"169\":\"v-8658e60a#图表\",\"170\":\"v-8658e60a#百度分享\",\"171\":\"v-8658e60a#瀑布流\",\"172\":\"v-8658e60a#天气插件\",\"173\":\"v-8658e60a#标签云\",\"174\":\"v-7e9e4a32\",\"175\":\"v-0b62f72e\",\"176\":\"v-70796e0a\",\"177\":\"v-70796e0a#_1-1-缓存介绍\",\"178\":\"v-70796e0a#_1-2-本站缓存架构\",\"179\":\"v-70796e0a#_2-1-mybatis一级缓存\",\"180\":\"v-70796e0a#_2-2-mybatis二级缓存\",\"181\":\"v-70796e0a#_2-2-1-mybatis二级缓存的划分\",\"182\":\"v-70796e0a#_2-2-2-二级缓存的开启\",\"183\":\"v-70796e0a#_2-2-3-使用第三方支持的二级缓存的实现\",\"184\":\"v-70796e0a#_2-3-mybatis在分布式环境下脏读问题\",\"185\":\"v-70796e0a#_3-1-spring-cache\",\"186\":\"v-70796e0a#_3-2-引入包\",\"187\":\"v-70796e0a#_3-3-applicationcontext-xml\",\"188\":\"v-70796e0a#_3-5-自定义keygenerator\",\"189\":\"v-70796e0a#_3-4-添加注解\",\"190\":\"v-70796e0a#_3-5-测试\",\"191\":\"v-70796e0a#_3-6-实验结果\",\"192\":\"v-70796e0a#_3-7-分页的数据怎么办\",\"193\":\"v-43e9e6b0\",\"194\":\"v-04e32b44\",\"195\":\"v-04e32b44#一、原生rdd支持\",\"196\":\"v-04e32b44#_1-1-基础配置\",\"197\":\"v-04e32b44#_1-2-读取es数据\",\"198\":\"v-04e32b44#_1-3-写数据\",\"199\":\"v-04e32b44#二、spark-streaming\",\"200\":\"v-04e32b44#三、spark-sql\",\"201\":\"v-04e32b44#四、spark-structure-streaming\",\"202\":\"v-04e32b44#五、spark-on-kubernetes-operator\",\"203\":\"v-d73a9aee\",\"204\":\"v-3f2a15ee\",\"205\":\"v-3f2a15ee#searchtype\",\"206\":\"v-3f2a15ee#搜索入口\",\"207\":\"v-3f2a15ee#_3-1-query阶段\",\"208\":\"v-3f2a15ee#_3-1-1-构造目的shard列表\",\"209\":\"v-3f2a15ee#_3-1-2-对所有分片进行搜索\",\"210\":\"v-3f2a15ee#_3-1-3-分片具体的搜索过程\",\"211\":\"v-3f2a15ee#_3-2-fetch阶段\",\"212\":\"v-3f2a15ee#_3-2-1-fetchsearchphase-对应上面的1\",\"213\":\"v-3f2a15ee#_3-2-2-expandsearchphase-对应上图的2\",\"214\":\"v-3f2a15ee#_4-1-执行query、fetch流程\",\"215\":\"v-3f2a15ee#_4-1-1-执行query请求\",\"216\":\"v-3f2a15ee#_4-1-2-fetch流程\",\"217\":\"v-aa93dec0\",\"218\":\"v-3192e5a0\",\"219\":\"v-2675bfdc\",\"220\":\"v-0a0b7a54\",\"221\":\"v-d7d7df80\",\"222\":\"v-7d9b9318\",\"223\":\"v-71b3ae87\",\"224\":\"v-14c69af4\",\"225\":\"v-14e6315a\",\"226\":\"v-25b47c13\",\"227\":\"v-525c5e4d\",\"228\":\"v-5d3e6196\",\"229\":\"v-60fc7530\",\"230\":\"v-02bc92be\",\"231\":\"v-380c630d\",\"232\":\"v-21ba2ec8\",\"233\":\"v-a32329e6\",\"234\":\"v-4d194044\",\"235\":\"v-6e21a4b2\"},\"fieldIds\":{\"h\":0,\"t\":1,\"c\":2},\"fieldLength\":{\"0\":[0,24],\"1\":[2,1],\"2\":[0,9],\"3\":[3,12],\"4\":[6,95],\"5\":[7,276],\"6\":[6,121],\"7\":[4,246],\"8\":[7,93],\"9\":[5,70],\"10\":[4,67],\"11\":[7,140],\"12\":[7,158],\"13\":[4,166],\"14\":[3,11],\"15\":[4,12],\"16\":[3],\"17\":[4,42],\"18\":[3,149],\"19\":[1],\"20\":[3],\"21\":[1],\"22\":[2,2],\"23\":[0,154],\"24\":[3],\"25\":[5,55],\"26\":[3,158],\"27\":[5,52],\"28\":[7,112],\"29\":[8,112],\"30\":[4,187],\"31\":[4,49],\"32\":[4,16],\"33\":[6,10],\"34\":[5,35],\"35\":[5,31],\"36\":[5],\"37\":[6,57],\"38\":[6,95],\"39\":[8,82],\"40\":[3],\"41\":[3,88],\"42\":[4,116],\"43\":[8,115],\"44\":[10,95],\"45\":[6,170],\"46\":[5,48],\"47\":[8],\"48\":[3,93],\"49\":[13,83],\"50\":[5,89],\"51\":[1,108],\"52\":[2,56],\"53\":[8],\"54\":[3,80],\"55\":[7,94],\"56\":[10,214],\"57\":[4,208],\"58\":[5,44],\"59\":[3,28],\"60\":[4,20],\"61\":[3,56],\"62\":[4,39],\"63\":[6,198],\"64\":[7,58],\"65\":[7,84],\"66\":[5,113],\"67\":[5,31],\"68\":[6,68],\"69\":[4,83],\"70\":[4,146],\"71\":[1,12],\"72\":[5,438],\"73\":[1,263],\"74\":[4,330],\"75\":[5,241],\"76\":[3,280],\"77\":[1,128],\"78\":[1,115],\"79\":[1,63],\"80\":[4,204],\"81\":[1,164],\"82\":[1,70],\"83\":[1,52],\"84\":[1,37],\"85\":[1,98],\"86\":[1,191],\"87\":[1,145],\"88\":[1,6],\"89\":[1,68],\"90\":[1,40],\"91\":[2,26],\"92\":[0,1],\"93\":[8,15],\"94\":[4],\"95\":[5,69],\"96\":[5,58],\"97\":[4,77],\"98\":[5,162],\"99\":[5,46],\"100\":[4,55],\"101\":[6,183],\"102\":[4,111],\"103\":[8,253],\"104\":[5,116],\"105\":[4],\"106\":[3,52],\"107\":[6,30],\"108\":[9,58],\"109\":[4,43],\"110\":[1,25],\"111\":[3],\"112\":[5],\"113\":[5,58],\"114\":[5,169],\"115\":[5,55],\"116\":[5,59],\"117\":[4,68],\"118\":[6,78],\"119\":[5],\"120\":[3,141],\"121\":[5,70],\"122\":[4,144],\"123\":[6],\"124\":[3,266],\"125\":[6,141],\"126\":[4,110],\"127\":[8,94],\"128\":[1,57],\"129\":[3,3],\"130\":[4,38],\"131\":[4,1],\"132\":[6,79],\"133\":[5,61],\"134\":[7,5],\"135\":[3,291],\"136\":[5,60],\"137\":[2,309],\"138\":[7,23],\"139\":[3,6],\"140\":[4,32],\"141\":[4,92],\"142\":[4,30],\"143\":[3,203],\"144\":[7,182],\"145\":[5,187],\"146\":[4,102],\"147\":[4,92],\"148\":[3,150],\"149\":[3,316],\"150\":[3,133],\"151\":[3,335],\"152\":[6,250],\"153\":[5,91],\"154\":[5],\"155\":[5,111],\"156\":[4,68],\"157\":[5,203],\"158\":[3,179],\"159\":[4,250],\"160\":[2,103],\"161\":[3,259],\"162\":[7,19],\"163\":[4,103],\"164\":[4,276],\"165\":[6,159],\"166\":[1,114],\"167\":[1,59],\"168\":[3,122],\"169\":[1,99],\"170\":[2,151],\"171\":[2,100],\"172\":[2,70],\"173\":[2,194],\"174\":[6],\"175\":[4],\"176\":[3],\"177\":[4,78],\"178\":[5,58],\"179\":[5,123],\"180\":[4,52],\"181\":[6,41],\"182\":[5,54],\"183\":[8,93],\"184\":[8,118],\"185\":[4,168],\"186\":[4,47],\"187\":[5,94],\"188\":[4,83],\"189\":[4,100],\"190\":[3,83],\"191\":[4,42],\"192\":[6,243],\"193\":[1,1],\"194\":[3,85],\"195\":[5],\"196\":[4,72],\"197\":[5,87],\"198\":[4,74],\"199\":[5,11],\"200\":[5],\"201\":[6],\"202\":[7,16],\"203\":[5,88],\"204\":[6,51],\"205\":[1,197],\"206\":[3,215],\"207\":[4,91],\"208\":[6,65],\"209\":[7,47],\"210\":[7,90],\"211\":[4,59],\"212\":[9,171],\"213\":[9,43],\"214\":[7,52],\"215\":[5,110],\"216\":[4,202],\"217\":[1,1],\"218\":[2],\"219\":[3,20],\"220\":[2,63],\"221\":[2,1012],\"222\":[1,1],\"223\":[1],\"224\":[1],\"225\":[1],\"226\":[1],\"227\":[3],\"228\":[3],\"229\":[1],\"230\":[1],\"231\":[1],\"232\":[1],\"233\":[1],\"234\":[1],\"235\":[1]},\"averageFieldLength\":[4.07627118644068,106.36333493842162],\"storedFields\":{\"0\":{\"h\":\"\",\"t\":[\"目录\",\"一、Java\",\"1.1 一次jvm调优过程.md\",\"1.2 JVM调优参数.md\",\"1.3 serverlog.md\",\"1.5 基于kubernetes的分布式限流\"]},\"1\":{\"h\":\"关于我\",\"t\":[\"留空\"]},\"2\":{\"h\":\"\",\"t\":[\"八、mysql\",\"8.1 mysql缓存.md\"]},\"3\":{\"h\":\"三、DevOps\",\"t\":[\"DevOps \",\"DevOps平台\",\"Gitlab-ci\",\"jenkins-x.md\",\"tekton\"]},\"4\":{\"h\":\"3.1 DevOps平台.md\",\"t\":[\"DevOps定义(来自维基百科): DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。\",\"公司技术部目前几百人左右吧,但是整个技术栈还是比较落后的,尤其是DevOps、容器这一块,需要将全线打通,当时进来也主要是负责DevOps这一块的工作,应该说也是没怎么做好,其中也走了不少弯路,下面主要是自己踩过的坑吧。\"]},\"5\":{\"h\":\"一、自由风格的软件项目\",\"t\":[\"主要还是基于jenkins里面构建一个自由风格的软件项目,当时参考的是阿里的codepipeline,就是对jenkins封装一层,包括创建job、立即构建、获取构建进度等都进行封装,并将需要的东西进行存库,没有想到码代码的时候,一堆的坑,比如: 1.连续点击立即构建,jenkins是不按顺序返回的,(分布式锁解决) 2.跨域调用,csrf,这个还好,不过容易把jenkins搞的无法登录(注意配置,具体可以点击这里) 3.创建job的时候只支持xml格式,还要转换一下,超级坑(xstream强行转换) 4.docker构建的时候,需要挂载宿主机的docker(想过用远程的,但效率不高) 5.数据库与jenkins的job一致性问题,任务创建失败,批量删除太慢(目前没想好怎么解决) 6.由于使用了数据库,需要检测job是否构建完成,为了自定义参数,我们自写了个通知插件,将构建状态返回到kafka,然后管理平台在进行消息处理。\",\"完成了以上的东西,不过由于太过于简单,导致只能进行单条线的CICD,而且CI仅仅实现了打包,没有将CD的过程一同串行起来。简单来说就是,用户点击了构建只是能够打出一个镜像,但是如果要部署到kubernetes,还是需要在应用里手动更换一下镜像版本。总体而言,这个版本的jenkins我们使用的还是单点的,不足以支撑构建量比较大的情况,甚至如果当前服务挂了,断网了,整一块的构建功能都不能用。\",\" xxx buildParam v1 codeBranch master 2 http://xxxxx.git 002367566a4eb4bb016a4eb723550054 ${codeBranch} false ls clean package install -Dmaven.test.skip=true mvn3.5.4 unix:///var/run/docker.sock http://xxxx xxx/xx true Dockerfile ${buildParam} true \"]},\"6\":{\"h\":\"二、优化之后的CICD\",\"t\":[\"上面的过程也仍然没有没住DevOps的流程,人工干预的东西依旧很多,由于上级急需产出,所以只能将就着继续下去。我们将构建、部署每个当做一个小块,一个CICD的过程可以选择构建、部署,花了很大的精力,完成了串行化的别样的CICD。 以下图为例,整个流程的底层为:paas平台-jenkins-kakfa-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发构建-jenkins-kafka-管理平台(选择cicd的下一步)-kafka-cicd组件调用管理平台触发部署。\",\"目前实现了串行化的CICD构建部署,之后考虑实现多个CICD并行,并且一个CICD能够调用另一个CICD,实际运行中,出现了一大堆问题。由于经过的组件太多,一次cicd的运行报错,却很难排查到问题出现的原因,业务方的投诉也开始慢慢多了起来,只能说劝导他们不要用这个功能。\",\"没有CICD,就无法帮助公司上容器云,无法合理的利用容器云的特性,更无法走上云原生的道路。于是,我们决定另谋出路。\"]},\"7\":{\"h\":\"三、调研期\",\"t\":[\"由于之前的CICD问题太多,特别是经过的组件太多了,导致出现问题的时候无法正常排查,为了能够更加稳定可靠,还是决定了要更换一下底层。 我们重新审视了下pipeline,觉得这才是正确的做法,可惜不知道如果做成一个产品样子的东西,用户方Dockerfile都不怎么会写,你让他写一个Jenkinsfile?不合理!在此之外,我们看到了serverless jenkins、谷歌的tekton。 GitLab-CICD Gitlab中自带了cicd的工具,需要配置一下runner,然后配置一下.gitlab-ci.yml写一下程序的cicd过程即可,构建镜像的时候我们使用的是kaniko,整个gitlab的cicd在我们公司小项目中大范围使用,但是学习成本过高,尤其是引入了kaniko之后,还是寻找一个产品化的CICD方案。\",\"分布式构建jenkins x 首先要解决的是多个构建同时运行的问题,很久之前就调研过jenkins x,它必须要使用在kubernetes上,由于当时官方文档不全,而且我们的DevOps项目处于初始期,所有没有使用。jenkins的master slave结构就不多说了。jenkins x应该说是个全家桶,包含了helm仓库、nexus仓库、docker registry等,代码是jenkins-x-image。\",\"serverless jenkins 好像跟谷歌的tekton相关,用了下,没调通,只能用于GitHub。感觉还不如直接使用tekton。\",\"阿里云云效 提供了图形化配置DevOps流程,支持定时触发,可惜没有跟gitlab触发结合,如果需要个公司级的DevOps,需要将公司的jira、gitlab、jenkins等集合起来,但是图形化jenkins pipeline是个特别好的参考方向,可以结合阿里云云效来做一个自己的DevOps产品。\",\"微软Pipeline 微软也是提供了DevOps解决方案的,也是提供了yaml格式的写法,即:在右边填写完之后会转化成yaml。如果想把DevOps打造成一款产品,这样的设计显然不是最好的。\",\"谷歌tekton kubernetes的官方cicd,目前已用于kubernetes的release发版过程,目前也仅仅是与GitHub相结合,gitlab无法使用,全过程可使用yaml文件来创建,跑起来就是类似kubernetes的job一样,用完即销毁,可惜目前比较新,依旧处于alpha版本,无法用于生产。有兴趣可以参考下:Knative 初体验:CICD 极速入门 \"]},\"8\":{\"h\":\"四、产品化后的DevOps平台\",\"t\":[\"在调研DockOne以及各个产商的DevOps产品时,发现,真的只有阿里云的云效才是真正比较完美的DevOps产品,用户不需要知道pipeline的语法,也不需要掌握kubernetes的相关知识,甚至不用写yaml文件,对于开发、测试来说简直就是神一样的存在了。云效对小公司(创业公司)免费,但是有一定的量之后,就要开始收费了。在调研了一番云效的东西之后,发现云效也是基于jenkins x改造的,不过阿里毕竟人多,虽然能约莫看出是pipeline的语法,但是阿里彻底改造成了能够使用yaml来与后台交互。 下面是以阿里云的云效界面以及配合jenkins的pipeline语法来讲解:\"]},\"9\":{\"h\":\"4.1 Java代码扫描\",\"t\":[\"PMD是一款可拓展的静态代码分析器它不仅可以对代码分析器,它不仅可以对代码风格进行检查,还可以检查设计、多线程、性能等方面的问题。阿里云的是简单的集成了一下而已,对于我们来说,底层使用了sonar来接入,所有的代码扫描结果都接入了sonar。\",\"stage('Clone') { steps{ git branch: 'master', credentialsId: 'xxxx', url: \\\"xxx\\\" } } stage('check') { steps{ container('maven') { echo \\\"mvn pmd:pmd\\\" } } } \"]},\"10\":{\"h\":\"4.2 Java单元测试\",\"t\":[\"Java的单元测试一般用的是Junit,在阿里云中,使用了surefire插件,用来在maven构建生命周期的test phase执行一个应用的单元测试。它会产生两种不同形式的测试结果报告。我这里就简单的过一下,使用\\\"mvn test\\\"命令来代替。\",\" stage('Clone') { steps{ echo \\\"1.Clone Stage\\\" git branch: 'master', credentialsId: 'xxxxx', url: \\\"xxxxxx\\\" } } stage('test') { steps{ container('maven') { sh \\\"mvn test\\\" } } } \"]},\"11\":{\"h\":\"4.3 Java构建并上传镜像\",\"t\":[\"镜像的构建比较想使用kaniko,尝试找了不少方法,到最后还是只能使用dind(docker in docker),挂载宿主机的docker来进行构建,如果能有其他方案,希望能提醒下。目前jenkins x使用的是dind,挂载的时候需要配置一下config.json,然后挂载到容器的/root/.docker目录,才能在容器中使用docker。\",\"为什么不推荐dind:挂载了宿主机的docker,就可以使用docker ps查看正在运行的容器,也就意味着可以使用docker stop、docker rm来控制宿主机的容器,虽然kubernetes会重新调度起来,但是这一段的重启时间极大的影响业务。\",\" stage('下载代码') { steps{ echo \\\"1.Clone Stage\\\" git branch: 'master', credentialsId: 'xxxxx', url: \\\"xxxxxx\\\" script { build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim() } } } stage('打包并构建镜像') { steps{ container('maven') { echo \\\"3.Build Docker Image Stage\\\" sh \\\"mvn clean install -Dmaven.test.skip=true\\\" sh \\\"docker build -f xxx/Dockerfile -t xxxxxx:${build_tag} .\\\" sh \\\"docker push xxxxxx:${build_tag}\\\" } } } \"]},\"12\":{\"h\":\"4.4 部署到阿里云k8s\",\"t\":[\"CD过程有点困难,由于我们的kubernetes平台是图形化的,类似于阿里云,用户根本不需要自己写deployment,只需要在图形化界面做一下操作即可部署。对于CD过程来说,如果应用存在的话,就可以直接替换掉镜像版本即可,如果没有应用,就提供个简单的界面让用户新建应用。当然,在容器最初推行的时候,对于用户来说,一下子需要接受docker、kubernetes、helm等概念是十分困难的,不能一个一个帮他们写deployment这些yaml文件,只能用helm创建一个通用的spring boot或者其他的模板,然后让业务方修改自己的配置,每次构建的时候只需要替换镜像即可。\",\"def tmp = sh ( returnStdout: true, script: \\\"kubectl get deployment -n ${namespace} | grep ${JOB_NAME} | awk '{print \\\\$1}'\\\" ) //如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置 if(tmp.equals('')){ sh \\\"helm init --client-only\\\" sh \\\"\\\"\\\"helm repo add mychartmuseum http://xxxxxx \\\\ --username myuser \\\\ --password=mypass\\\"\\\"\\\" sh \\\"\\\"\\\"helm install --set name=${JOB_NAME} \\\\ --set namespace=${namespace} \\\\ --set deployment.image=${image} \\\\ --set deployment.imagePullSecrets=${harborProject} \\\\ --name ${namespace}-${JOB_NAME} \\\\ mychartmuseum/soa-template\\\"\\\"\\\" }else{ println \\\"已经存在,替换镜像\\\" //epaas中一个pod的容器名称需要带上\\\"-0\\\"来区分 sh \\\"kubectl set image deployment/${JOB_NAME} ${JOB_NAME}-0=${image} -n ${namespace}\\\" } \"]},\"13\":{\"h\":\"4.5 整体流程\",\"t\":[\"代码扫描,单元测试,构建镜像三个并行运行,等三个完成之后,在进行部署\",\"pipeline:\",\"pipeline { agent { label \\\"jenkins-maven\\\" } stages{ stage('代码扫描,单元测试,镜像构建'){ parallel { stage('并行任务一') { agent { label \\\"jenkins-maven\\\" } stages('Java代码扫描') { stage('Clone') { steps{ git branch: 'master', credentialsId: 'xxxxxxx', url: \\\"xxxxxxx\\\" } } stage('check') { steps{ container('maven') { echo \\\"$BUILD_NUMBER\\\" } } } } } stage('并行任务二') { agent { label \\\"jenkins-maven\\\" } stages('Java单元测试') { stage('Clone') { steps{ echo \\\"1.Clone Stage\\\" git branch: 'master', credentialsId: 'xxxxxxx', url: \\\"xxxxxxx\\\" } } stage('test') { steps{ container('maven') { echo \\\"3.Build Docker Image Stage\\\" sh \\\"mvn -v\\\" } } } } } stage('并行任务三') { agent { label \\\"jenkins-maven\\\" } stages('java构建镜像') { stage('Clone') { steps{ echo \\\"1.Clone Stage\\\" git branch: 'master', credentialsId: 'xxxxxxx', url: \\\"xxxxxxx\\\" script { build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim() } } } stage('Build') { steps{ container('maven') { echo \\\"3.Build Docker Image Stage\\\" sh \\\"mvn clean install -Dmaven.test.skip=true\\\" sh \\\"docker build -f epaas-portal/Dockerfile -t hub.gcloud.lab/rongqiyun/epaas:${build_tag} .\\\" sh \\\"docker push hub.gcloud.lab/rongqiyun/epaas:${build_tag}\\\" } } } } } } } stage('部署'){ stages('部署到容器云') { stage('check') { steps{ container('maven') { script{ if (deploy_app == \\\"true\\\"){ def tmp = sh ( returnStdout: true, script: \\\"kubectl get deployment -n ${namespace} | grep ${JOB_NAME} | awk '{print \\\\$1}'\\\" ) //如果是第一次,则使用helm模板创建,创建完后需要去epaas修改pod的配置 if(tmp.equals('')){ sh \\\"helm init --client-only\\\" sh \\\"\\\"\\\"helm repo add mychartmuseum http://xxxxxx \\\\ --username myuser \\\\ --password=mypass\\\"\\\"\\\" sh \\\"\\\"\\\"helm install --set name=${JOB_NAME} \\\\ --set namespace=${namespace} \\\\ --set deployment.image=${image} \\\\ --set deployment.imagePullSecrets=${harborProject} \\\\ --name ${namespace}-${JOB_NAME} \\\\ mychartmuseum/soa-template\\\"\\\"\\\" }else{ println \\\"已经存在,替换镜像\\\" //epaas中一个pod的容器名称需要带上\\\"-0\\\"来区分 sh \\\"kubectl set image deployment/${JOB_NAME} ${JOB_NAME}-0=${image} -n ${namespace}\\\" } }else{ println \\\"用户选择不部署代码\\\" } } } } } } } } } \",\"在jenkins x中查看:\"]},\"14\":{\"h\":\"4.4 日志\",\"t\":[\"jenkins blue ocean步骤日志:\",\"云效中的日志:\"]},\"15\":{\"h\":\"4.5 定时触发\",\"t\":[\" triggers { cron('H H * * *') //每天 } \"]},\"16\":{\"h\":\"五、其他\"},\"17\":{\"h\":\"5.1 Gitlab触发\",\"t\":[\"pipeline中除了有对于时间的trigger,还支持了gitlab的触发,需要各种配置,不过如果真的对于gitlab的cicd有要求,直接使用gitlab-ci会更好,我们同时也对gitlab进行了runner的配置来支持gitlab的cicd。gitlab的cicd也提供了构建完后即销毁的过程。\"]},\"18\":{\"h\":\"六、总结\",\"t\":[\"功能最强大的过程莫过于自己使用pipeline脚本实现,选取最适合自己的,但是对于一个公司来说,如果要求业务方来掌握这些,特别是IT流动性大的时候,既需要重新培训,同个问题又会被问多遍,所以,只能将DevOps实现成一个图形化的东西,方便,简单,相对来说功能还算强大。\",\"DevOps最难的可能都不是以上这些,关键是让用户接受,容器云最初推行时,公司原本传统的很多发版方式都需要进行改变,有些业务方不愿意改,或者有些代码把持久化的东西存到了代码中而不是分布式存储里,甚至有些用户方都不愿意维护老代码,看都不想看然后想上容器,一个公司在做技术架构的时候,过于混乱到最后填坑要么需要耗费太多精力甚至大换血。\",\"最后,DevOps是云原生的必经之路!!!\",\"文章同步:\\n博客园:https://www.cnblogs.com/w1570631036/p/11524673.html\\n个人网站:http://www.wenzhihuai.com/getblogdetail.html?blogid=663\\ngitbook:https://gitbook.wenzhihuai.com/devops/devops-ping-tai\"]},\"19\":{\"h\":\"Git\"},\"20\":{\"h\":\"jenkins-x\"},\"21\":{\"h\":\"tekton\"},\"22\":{\"h\":\"微信支付\",\"t\":[\"微信支付\"]},\"23\":{\"h\":\"\",\"t\":[\"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决\",\"tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作\",\"tt三面:\\n大部分聊项目,基础随便问了问\\n1.分布式事务,两阶段三阶段流程,区别\\n2.mysql主从,同步复制,半同步复制,异步复制\\n3.算法题,k个一组翻转链表,类似lc25,区别是最后一组不足k个也要翻转\\n4.场景题,设计一个评论系统,包含发布评论,回复评论,评论点赞等功能,用户过亿,qps百万\"]},\"24\":{\"h\":\"JVM调优参数\"},\"25\":{\"h\":\"一、堆大小设置\",\"t\":[\"JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统 下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。\"]},\"26\":{\"h\":\"典型设置:\",\"t\":[\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k \",\"-Xmx3550m:设置JVM最大可用内存为3550M。 -Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。 -Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。 -Xss128k: 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内 存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。\",\"java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0 \",\"-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 -XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6 -XX:MaxPermSize=16m:设置持久代大小为16m。 -XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。\"]},\"27\":{\"h\":\"二、回收器选择\",\"t\":[\"JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。\"]},\"28\":{\"h\":\"2.1 吞吐量优先的并行收集器\",\"t\":[\"如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。 典型配置:\",\"java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 \",\"-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。 -XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。\",\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC \",\"-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。\",\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 \",\"-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。\",\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy \",\"-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。\"]},\"29\":{\"h\":\"2.2 响应时间优先的并发收集器\",\"t\":[\"如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。 典型配置:\",\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC \",\"-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。 -XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。\",\"java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection \",\"-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。 -XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片\"]},\"30\":{\"h\":\"三、辅助信息\",\"t\":[\"JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些: -XX:+PrintGC 输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]\",\"-XX:+PrintGCDetails 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]\",\"-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用 输出形式:Application time: 0.5291524 seconds -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用 输出形式:Total time for which application threads were stopped: 0.0468229 seconds -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息 输出形式:\",\"34.702: [GC {Heap before gc invocations=7: def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000) eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000) from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000) to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000) tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000) the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000) compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000) the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000) ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000) rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000) 34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8: def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000) eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000) from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000) to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000) tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000) the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000) compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000) the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000) ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000) rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000) } , 0.0757599 secs] \",\"-Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。 常见配置汇总\"]},\"31\":{\"h\":\"3.1 堆设置\",\"t\":[\"-Xms:初始堆大小 -Xmx:最大堆大小 -XX:NewSize=n:设置年轻代大小 -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n:设置持久代大小\"]},\"32\":{\"h\":\"3.2 收集器设置\",\"t\":[\"-XX:+UseSerialGC:设置串行收集器 -XX:+UseParallelGC:设置并行收集器 -XX:+UseParalledlOldGC:设置并行年老代收集器 -XX:+UseConcMarkSweepGC:设置并发收集器\"]},\"33\":{\"h\":\"3.3 垃圾回收统计信息\",\"t\":[\"-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename\"]},\"34\":{\"h\":\"3.4 并行收集器设置\",\"t\":[\"-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)\"]},\"35\":{\"h\":\"3.5 并发收集器设置\",\"t\":[\"-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。\"]},\"36\":{\"h\":\"四、调优总结\"},\"37\":{\"h\":\"4.1 年轻代大小选择\",\"t\":[\"响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。\"]},\"38\":{\"h\":\"4.2 年老代大小选择\",\"t\":[\"响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得: 并发垃圾收集信息 持久代并发收集次数 传统GC信息 花在年轻代和年老代回收上的时间比例 减少年轻代和年老代花费的时间,一般会提高应用的效率 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。\"]},\"39\":{\"h\":\"4.3 较小堆引起的碎片问题\",\"t\":[\"因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他 会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后,就会出现“碎片”,如果并发收集器找不到足够的空间,那么 并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:\\n-XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。\\n-XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩\"]},\"40\":{\"h\":\"lucene搜索原理\"},\"41\":{\"h\":\"被挖矿攻击\",\"t\":[\"服务器被黑,进程占用率高达99%,查看了一下,是/usr/sbin/bashd的原因,怎么删也删不掉,使用ps查看: stratum+tcp://get.bi-chi.com:3333 -u 47EAoaBc5TWDZKVaAYvQ7Y4ZfoJMFathAR882gabJ43wHEfxEp81vfJ3J3j6FQGJxJNQTAwvmJYS2Ei8dbkKcwfPFst8FhG\",\"使用top查看:\",\"启动iptables,参考http://www.setphp.com/981.htmlhttp://www.setphp.com/981.html\",\"iptables -A INPUT -s xmr.crypto-pool.fr -j DROP iptables -A OUTPUT -d xmr.crypto-pool.fr -j DROP \",\"19号添加mongodb之后,20号重启了服务器,但是忘记启动mongodb,导致后台一直在重连mongodb,也就导致了服务访问超级超级慢,记住要启动所需要的组件。\"]},\"42\":{\"h\":\"一次jvm调优过程\",\"t\":[\"前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,kubernetes也没有将该容器自动重启。业务方基本每天都在反馈task不稳定,后续就协助接手看了下,先主要讲下该程序的架构吧。 该程序task主要分为三个模块: console进行一些cron的配置(表达式、任务名称、任务组等); schedule主要从数据库中读取配置然后装载到quartz再然后进行命令下发; client接收任务执行,然后向schedule返回运行的信息(成功、失败原因等)。 整体架构跟github上开源的xxl-job类似,也可以参考一下。\"]},\"43\":{\"h\":\"1. 启用jmx和远程debug模式\",\"t\":[\"容器的网络使用了BGP,打通了公司的内网,所以可以直接通过ip来进行程序的调试,主要是在启动的jvm参数中添加:\",\"JAVA_DEBUG_OPTS=\\\" -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=0.0.0.0:8000,server=y,suspend=n \\\" JAVA_JMX_OPTS=\\\" -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false \\\" \",\"其中,调试模式的address最好加上0.0.0.0,有时候通过netstat查看端口的时候,该位置显示为127.0.0.1,导致无法正常debug,开启了jmx之后,可以初步观察堆内存的情况。\",\"堆内存(特别是cms的old gen),初步看代码觉得是由于用了大量的map,本地缓存了大量数据,怀疑是每次定时调度的信息都进行了保存。\"]},\"44\":{\"h\":\"2. memory analyzer、jprofiler进行堆内存分析\",\"t\":[\"先从容器中dump出堆内存\",\"jmap -dump:live,format=b,file=heap.hprof 58 \",\"由图片可以看出,这些大对象不过也就10M,并没有想象中的那么大,所以并不是大对象的问题,后续继续看了下代码,虽然每次请求都会把信息放进map里,如果能正常调通的话,就会移除map中保存的记录,由于是测试环境,执行端很多时候都没有正常运行,甚至说业务方关闭了程序,导致调度一直出现问题,所以map的只会保留大量的错误请求。不过相对于该程序的堆内存来说,不是主要问题。\"]},\"45\":{\"h\":\"3. netty的方面的考虑\",\"t\":[\"另一个小伙伴一直怀疑的是netty这一块有错误,着重看了下。该程序用netty自己实现了一套rpc,调度端每次进行命令下发的时候都会通过netty的rpc来进行通信,整个过程逻辑写的很混乱,下面开始排查。 首先是查看堆内存的中占比:\",\"可以看出,io.netty.channel.nio.NioEventLoop的占比达到了40%左右,再然后是io.netty.buffer.PoolThreadCache,占比大概达到33%左右。猜想可能是传输的channel没有关闭,还是NioEventLoop没有关闭。再跑去看一下jmx的线程数:\",\"达到了惊人的1000个左右,而且一直在增长,没有过下降的趋势,再次猜想到可能是NioEventLoop没有关闭,在代码中全局搜索NioEventLoop,找到一处比较可疑的地方。\",\"声明了一个NioEventLoopGroup的成员变量,通过构造方法进行了初始化,但是在执行syncRequest完之后并没有进行对group进行shutdownGracefully操作,外面对其的操作并没有对该类的group对象进行关闭,导致线程数一直在增长。\",\"最终解决办法: 在调用完syncRequest方法时,对ChannelBootStrap的group对象进行行shutdownGracefully\",\"提交代码,容器中继续测试,可以基本看出,线程基本处于稳定状态,并不会出现一直增长的情况了\",\"还原本以为基本解决了,到最后还是发现,堆内存还算稳定,但是,直接内存依旧打到了100%,虽然程序没有挂掉,所以,上面做的,可能仅仅是为这个程序续命了而已,感觉并没有彻底解决掉问题。\"]},\"46\":{\"h\":\"4. 直接内存排查\",\"t\":[\"第一个想到的就是netty的直接内存,关掉,命令如下:\",\"-Dio.netty.noPreferDirect=true -Dio.netty.leakDetectionLevel=advanced \",\"查看了一下java的nio直接内存,发现也就几十kb,然而直接内存还是慢慢往上涨。毫无头绪,然后开始了自己的从linux层面开始排查问题\"]},\"47\":{\"h\":\"5. 推荐的直接内存排查方法\"},\"48\":{\"h\":\"5.1 pmap\",\"t\":[\"一般配合pmap使用,从内核中读取内存块,然后使用views 内存块来判断错误,我简单试了下,乱码,都是二进制的东西,看不出所以然来。\",\"pmap -d 58 | sort -n -k2 pmap -x 58 | sort -n -k3 grep rw-p /proc/$1/maps | sed -n 's/^\\\\([0-9a-f]*\\\\)-\\\\([0-9a-f]*\\\\) .*$/\\\\1 \\\\2/p' | while read start stop; do gdb --batch --pid $1 -ex \\\"dump memory $1-$start-$stop.dump 0x$start 0x$stop\\\"; done \",\"这个时候真的懵了,不知道从何入手了,难道是linux操作系统方面的问题?\"]},\"49\":{\"h\":\"5.2 [gperftools](https://github.com/gperftools/gperftools)\",\"t\":[\"起初,在网上看到有人说是因为linux自带的glibc版本太低了,导致的内存溢出,考虑一下。初步觉得也可能是因为这个问题,所以开始慢慢排查。oracle官方有一个jemalloc用来替换linux自带的,谷歌那边也有一个tcmalloc,据说性能比glibc、jemalloc都强,开始换一下。 根据网上说的,在容器里装libunwind,然后再装perf-tools,然后各种捣鼓,到最后发现,执行不了,\",\"pprof --text /usr/bin/java java_58.0001.heap \",\"看着工具高大上的,似乎能找出linux的调用栈,\"]},\"50\":{\"h\":\"6. 意外的结果\",\"t\":[\"毫无头绪的时候,回想到了linux的top命令以及日志情况,测试环境是由于太多执行端业务方都没有维护,导致调度系统一直会出错,一出错就会导致大量刷错误日志,平均一天一个容器大概就有3G的日志,cron一旦到准点,就会有大量的任务要同时执行,而且容器中是做了对io的限制,磁盘也限制为10G,导致大量的日志都堆积在buff/cache里面,最终直接内存一直在涨,这个时候,系统不会挂,但是先会一直显示内存使用率达到100%。 修复后的结果如下图所示:\"]},\"51\":{\"h\":\"总结\",\"t\":[\"定时调度这个系统当时并没有考虑到公司的系统会用的这么多,设计的时候也仅仅是为了实现上千的量,没想到到最后变成了一天的调度都有几百万次。最初那批开发也就使用了大量的本地缓存map来临时存储数据,然后面向简历编程各种用netty自己实现了通信的方式,一堆坑都留给了后人。目前也算是解决掉了一个由于线程过多导致系统不可用的情况而已,但是由于存在大量的map,系统还是得偶尔重启一下比较好。\",\"参考:\\n1.记一次线上内存泄漏问题的排查过程\\n2.Java堆外内存增长问题排查Case\\n3.Troubleshooting Native Memory Leaks in Java Applications\"]},\"52\":{\"h\":\"内存屏障\",\"t\":[\"四个内存屏障指令:LoadLoad,StoreStore,LoadStore,StoreLoad\",\"在每个volatile写操作前插入StoreStore屏障,这样就能让其他线程修改A变量后,把修改的值对当前线程可见,在写操作后插入StoreLoad屏障,这样就能让其他线程获取A变量的时候,能够获取到已经被当前线程修改的值\",\"在每个volatile读操作前插入LoadLoad屏障,这样就能让当前线程获取A变量的时候,保证其他线程也都能获取到相同的值,这样所有的线程读取的数据就一样了,在读操作后插入LoadStore屏障;这样就能让当前线程在其他线程修改A变量的值之前,获取到主内存里面A变量的的值。\"]},\"53\":{\"h\":\"在 Spring 6 中使用虚拟线程\"},\"54\":{\"h\":\"一、简介\",\"t\":[\"在这个简短的教程中,我们将了解如何在 Spring Boot 应用程序中利用虚拟线程的强大功能。\",\"虚拟线程是Java 19 的预览功能,这意味着它们将在未来 12 个月内包含在官方 JDK 版本中。Spring 6 版本最初由 Project Loom 引入,为开发人员提供了开始尝试这一出色功能的选项。\",\"首先,我们将看到“平台线程”和“虚拟线程”之间的主要区别。接下来,我们将使用虚拟线程从头开始构建一个 Spring-Boot 应用程序。最后,我们将创建一个小型测试套件,以查看简单 Web 应用程序吞吐量的最终改进。\"]},\"55\":{\"h\":\"二、 虚拟线程与平台线程\",\"t\":[\"主要区别在于虚拟线程在其操作周期中不依赖于操作系统线程:它们与硬件解耦,因此有了“虚拟”这个词。这种解耦是由 JVM 提供的抽象层实现的。\",\"对于本教程来说,必须了解虚拟线程的运行成本远低于平台线程。它们消耗的分配内存量要少得多。这就是为什么可以创建数百万个虚拟线程而不会出现内存不足问题,而不是使用标准平台(或内核)线程创建几百个虚拟线程。\",\"从理论上讲,这赋予了开发人员一种超能力:无需依赖异步代码即可管理高度可扩展的应用程序。\"]},\"56\":{\"h\":\"三、在Spring 6中使用虚拟线程\",\"t\":[\"从 Spring Framework 6(和 Spring Boot 3)开始,虚拟线程功能正式公开,但虚拟线程是Java 19 的预览功能。这意味着我们需要告诉 JVM 我们要在应用程序中启用它们。由于我们使用 Maven 来构建应用程序,因此我们希望确保在 pom.xml 中包含以下代码:\",\" org.apache.maven.plugins maven-compiler-plugin 19 19 --enable-preview \",\"从 Java 的角度来看,要使用 Apache Tomcat 和虚拟线程,我们需要一个带有几个 bean 的简单配置类:\",\"@EnableAsync @Configuration @ConditionalOnProperty( value = \\\"spring.thread-executor\\\", havingValue = \\\"virtual\\\" ) public class ThreadConfig { @Bean public AsyncTaskExecutor applicationTaskExecutor() { return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor()); } @Bean public TomcatProtocolHandlerCustomizer protocolHandlerVirtualThreadExecutorCustomizer() { return protocolHandler -> { protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor()); }; } } \",\"第一个 Spring Bean ApplicationTaskExecutor将取代标准的*ApplicationTaskExecutor* ,提供为每个任务启动新虚拟线程的Executor。第二个 bean,名为ProtocolHandlerVirtualThreadExecutorCustomizer,将以相同的方式 自定义标准TomcatProtocolHandler 。我们还添加了注释@ConditionalOnProperty,**以通过切换application.yaml文件中配置属性的值来按需启用虚拟线程:\",\"spring: thread-executor: virtual //... \",\"我们来测试一下Spring Boot应用程序是否使用虚拟线程来处理Web请求调用。为此,我们需要构建一个简单的控制器来返回所需的信息:\",\"@RestController @RequestMapping(\\\"/thread\\\") public class ThreadController { @GetMapping(\\\"/name\\\") public String getThreadName() { return Thread.currentThread().toString(); } } \",\"*Thread*对象的toString *()*方法将返回我们需要的所有信息:线程 ID、线程名称、线程组和优先级。让我们通过一个curl请求来访问这个端点:\",\"$ curl -s http://localhost:8080/thread/name $ VirtualThread[#171]/runnable@ForkJoinPool-1-worker-4 \",\"正如我们所看到的,响应明确表示我们正在使用虚拟线程来处理此 Web 请求。换句话说,*Thread.currentThread()*调用返回虚拟线程类的实例。现在让我们通过简单但有效的负载测试来看看虚拟线程的有效性。\"]},\"57\":{\"h\":\"四、性能比较\",\"t\":[\"对于此负载测试,我们将使用JMeter。这不是虚拟线程和标准线程之间的完整性能比较,而是我们可以使用不同参数构建其他测试的起点。\",\"在这种特殊的场景中,我们将调用Rest Controller中的一个端点,该端点将简单地让执行休眠一秒钟,模拟复杂的异步任务:\",\"@RestController @RequestMapping(\\\"/load\\\") public class LoadTestController { private static final Logger LOG = LoggerFactory.getLogger(LoadTestController.class); @GetMapping public void doSomething() throws InterruptedException { LOG.info(\\\"hey, I'm doing something\\\"); Thread.sleep(1000); } } \",\"请记住,由于*@ConditionalOnProperty* 注释,我们只需更改 application.yaml 中变量的值即可在虚拟线程和标准线程之间切换。\",\"JMeter 测试将仅包含一个线程组,模拟 1000 个并发用户访问*/load* 端点 100 秒:\",\"image-20230827193431807\",\"在本例中,采用这一新功能所带来的性能提升是显而易见的。让我们比较不同实现的“响应时间图”。这是标准线程的响应图。我们可以看到,立即完成一次调用所需的时间达到 5000 毫秒:\",\"image-20230827193511176\",\"发生这种情况是因为平台线程是一种有限的资源,当所有计划的和池化的线程都忙时,Spring 应用程序除了将请求搁置直到一个线程空闲之外别无选择。\",\"让我们看看虚拟线程会发生什么:\",\"image-20230827193533565\",\"正如我们所看到的,响应稳定在 1000 毫秒。虚拟线程在请求后立即创建和使用,因为从资源的角度来看它们非常便宜。在本例中,我们正在比较 spring 默认固定标准线程池(默认为 200)和 spring 默认无界虚拟线程池的使用情况。\",\"**这种性能提升之所以可能,是因为场景过于简单,并且没有考虑 Spring Boot 应用程序可以执行的全部操作。**从底层操作系统基础设施中采用这种抽象可能是有好处的,但并非在所有情况下都是如此。\"]},\"58\":{\"h\":\"基于kubernetes的分布式限流\",\"t\":[\"做为一个数据上报系统,随着接入量越来越大,由于 API 接口无法控制调用方的行为,因此当遇到瞬时请求量激增时,会导致接口占用过多服务器资源,使得其他请求响应速度降低或是超时,更有甚者可能导致服务器宕机。\"]},\"59\":{\"h\":\"一、概念\",\"t\":[\"限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。\"]},\"60\":{\"h\":\"1.1 使用场景\",\"t\":[\"限流可以应对:\",\"热点业务带来的突发请求;\",\"调用方 bug 导致的突发请求;\",\"恶意攻击请求。\"]},\"61\":{\"h\":\"1.2 维度\",\"t\":[\"对于限流场景,一般需要考虑两个维度的信息: 时间 限流基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定 资源 基于可用资源的限制,比如设定最大访问次数,或最高可用连接数。 限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。\",\"image.png\"]},\"62\":{\"h\":\"1.3 分布式限流\",\"t\":[\"分布式限流相比于单机限流,只是把限流频次分配到各个节点中,比如限制某个服务访问100qps,如果有10个节点,那么每个节点理论上能够平均被访问10次,如果超过了则进行频率限制。\"]},\"63\":{\"h\":\"二、分布式限流常用方案\",\"t\":[\"基于Guava的客户端限流 Guava是一个客户端组件,在其多线程模块下提供了以RateLimiter为首的几个限流支持类。它只能对“当前”服务进行限流,即它不属于分布式限流的解决方案。\",\"网关层限流 服务网关,作为整个分布式链路中的第一道关卡,承接了所有用户来访请求。我们在网关层进行限流,就可以达到了整体限流的目的了。目前,主流的网关层有以软件为代表的Nginx,还有Spring Cloud中的Gateway和Zuul这类网关层组件,也有以硬件为代表的F5。\",\"中间件限流 将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。\",\"限流组件 目前也有一些开源组件提供了限流的功能,比如Sentinel就是一个不错的选择。Sentinel是阿里出品的开源组件,并且包含在了Spring Cloud Alibaba组件库中。Hystrix也具有限流的功能。\",\"Guava的Ratelimiter设计实现相当不错,可惜只能支持单机,网关层限流如果是单机则不太满足高可用,并且分布式网关的话还是需要依赖中间件限流,而redis之类的网络通信需要占用一小部分的网络消耗。阿里的Sentinel也是同理,底层使用的是redis或者zookeeper,每次访问都需要调用一次redis或者zk的接口。那么在云原生场景下,我们有没有什么更好的办法呢?\",\"对于极致追求高性能的服务不需要考虑熔断、降级来说,是需要尽量减少网络之间的IO,那么是否可以通过一个总限频然后分配到具体的单机里面去,在单机中实现平均的限流,比如限制某个ip的qps为100,服务总共有10个节点,那么平均到每个服务里就是10qps,此时就可以通过guava的ratelimiter来实现了,甚至说如果服务的节点动态调整,单个服务的qps也能动态调整。\"]},\"64\":{\"h\":\"三、基于kubernetes的分布式限流\",\"t\":[\"在Spring Boot应用中,定义一个filter,获取请求参数里的key(ip、userId等),然后根据key来获取rateLimiter,其中,rateLimiter的创建由数据库定义的限频数和副本数来判断,最后,再通过rateLimiter.tryAcquire来判断是否可以通过。\",\"企业微信截图_868136b4-f9e2-4813-bc02-281a66756ecd.png\"]},\"65\":{\"h\":\"3.1 kubernetes中的副本数\",\"t\":[\"在实际的服务中,数据上报服务一般无法确定客户端的上报时间、上报量,特别是对于这种要求高性能,服务一般都会用到HPA来实现动态扩缩容,所以,需要去间隔一段时间去获取服务的副本数。\",\"func CountDeploymentSize(namespace string, deploymentName string) *int32 { deployment, err := client.AppsV1().Deployments(namespace).Get(context.TODO(), deploymentName, metav1.GetOptions{}) if err != nil { return nil } return deployment.Spec.Replicas } \",\"用法:GET host/namespaces/test/deployments/k8s-rest-api直接即可。\"]},\"66\":{\"h\":\"3.2 rateLimiter的创建\",\"t\":[\"在RateLimiterService中定义一个LoadingCache,其中,key可以为ip、userId等,并且,在多线程的情况下,使用refreshAfterWrite只阻塞加载数据的线程,其他线程则返回旧数据,极致发挥缓存的作用。\",\"private final LoadingCache loadingCache = Caffeine.newBuilder() .maximumSize(10_000) .refreshAfterWrite(20, TimeUnit.MINUTES) .build(this::createRateLimit); //定义一个默认最小的QPS private static final Integer minQpsLimit = 3000; \",\"之后是创建rateLimiter,获取总限频数totalLimit和副本数replicas,之后是自己所需的逻辑判断,可以根据totalLimit和replicas的情况来进行qps的限定。\",\"public RateLimiter createRateLimit(String key) { log.info(\\\"createRateLimit,key:{}\\\", key); int totalLimit = 获取总限频数,可以在数据库中定义 Integer replicas = kubernetesService.getDeploymentReplicas(); RateLimiter rateLimiter; if (totalLimit > 0 && replicas == null) { rateLimiter = RateLimiter.create(totalLimit); } else if (totalLimit > 0) { int nodeQpsLimit = totalLimit / replicas; rateLimiter = RateLimiter.create(nodeQpsLimit > minQpsLimit ? nodeQpsLimit : minQpsLimit); } else { rateLimiter = RateLimiter.create(minQpsLimit); } log.info(\\\"create rateLimiter success,key:{},rateLimiter:{}\\\", key, rateLimiter); return rateLimiter; } \"]},\"67\":{\"h\":\"3.3 rateLimiter的获取\",\"t\":[\"根据key获取RateLimiter,如果有特殊需求的话,需要判断key不存在的尝尽\",\"public RateLimiter getRateLimiter(String key) { return loadingCache.get(key); } \"]},\"68\":{\"h\":\"3.4 filter里的判断\",\"t\":[\"最后一步,就是使用rateLimiter来进行限流,如果rateLimiter.tryAcquire()为true,则进行filterChain.doFilter(request, response),如果为false,则返回HttpStatus.TOO_MANY_REQUESTS\",\"public class RateLimiterFilter implements Filter { @Resource private RateLimiterService rateLimiterService; @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException { HttpServletRequest httpServletRequest = (HttpServletRequest) request; HttpServletResponse httpServletResponse = (HttpServletResponse) response; String key = httpServletRequest.getHeader(\\\"key\\\"); RateLimiter rateLimiter = rateLimiterService.getRateLimiter(key); if (rateLimiter != null) { if (rateLimiter.tryAcquire()) { filterChain.doFilter(request, response); } else { httpServletResponse.setStatus(HttpStatus.TOO_MANY_REQUESTS.value()); } } else { filterChain.doFilter(request, response); } } } \"]},\"69\":{\"h\":\"四、性能压测\",\"t\":[\"为了方便对比性能之间的差距,我们在本地单机做了下列测试,其中,总限频都设置为3万。\",\"无限流\",\"企业微信截图_ea1b7815-3b89-43bf-aed7-240e135bdad1.png\",\"使用redis限流\",\"其中,ping redis大概6-7ms左右,对应的,每次请求需要访问redis,时延都有大概6-7ms,性能下降明显\",\"企业微信截图_9118c4e0-c7f3-4e74-9649-4cd4d56fda79.png\",\"自研限流\",\"性能几乎追平无限流的场景,guava的rateLimiter确实表现卓越\",\"企业微信截图_9f6510bd-be9e-438b-aa9d-bdd13ebca953.png\"]},\"70\":{\"h\":\"五、其他问题\",\"t\":[\"5.1 对于保证qps限频准确的时候,应该怎么解决呢?\",\"在k8s中,服务是动态扩缩容的,相应的,每个节点应该都要有所变化,如果对外宣称限频100qps,而且后续业务方真的要求百分百准确,只能把LoadingCache的过期时间调小一点,让它能够近实时的更新单节点的qps。这里还需要考虑一下k8s的压力,因为每次都要获取副本数,这里也是需要做缓存的\",\"5.2 服务从1个节点动态扩为4个节点,这个时候新节点识别为4,但其实有些并没有启动完,会不会造成某个节点承受了太大的压力\",\"理论上是存在这个可能的,这个时候需要考虑一下初始的副本数的,扩缩容不能一蹴而就,一下子从1变为4变为几十个这种。一般的话,生产环境肯定是不能只有一个节点,并且要考虑扩缩容的话,至于要有多个副本预备的\",\"5.3 如果有多个副本,怎么保证请求是均匀的\",\"这个是依赖于k8s的service负载均衡策略的,这个我们之前做过实验,流量确实是能够均匀的落到节点上的。还有就是,我们整个限流都是基于k8s的,如果k8s出现问题,那就是整个集群所有服务都有可能出现问题了。\"]},\"71\":{\"h\":\"参考\",\"t\":[\"1.常见的分布式限流解决方案\\n2.分布式服务限流实战\\n3.高性能\"]},\"72\":{\"h\":\"spark on k8s operator\",\"t\":[\"Spark operator是一个管理Kubernetes上的Apache Spark应用程序生命周期的operator,旨在像在Kubernetes上运行其他工作负载一样简单的指定和运行spark应用程序。\",\"使用Spark Operator管理Spark应用,能更好的利用Kubernetes原生能力控制和管理Spark应用的生命周期,包括应用状态监控、日志获取、应用运行控制等,弥补Spark on Kubernetes方案在集成Kubernetes上与其他类型的负载之间存在的差距。\",\"Spark Operator包括如下几个组件:\",\"SparkApplication控制器:该控制器用于创建、更新、删除SparkApplication对象,同时控制器还会监控相应的事件,执行相应的动作。\",\"Submission Runner:负责调用spark-submit提交Spark作业,作业提交的流程完全复用Spark on K8s的模式。\",\"Spark Pod Monitor:监控Spark作业相关Pod的状态,并同步到控制器中。\",\"Mutating Admission Webhook:可选模块,基于注解来实现Driver/Executor Pod的一些定制化需求。\",\"SparkCtl:用于和Spark Operator交互的命令行工具。\",\"安装\",\"# 添加源 helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator # 安装 helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace \",\"这个时候如果直接执行kubectl apply -f examples/spark-pi.yaml调用样例,会出现以下报错,需要创建对象的serviceaccount。\",\"forbidden: error looking up service account default/spark: serviceaccount \\\\\\\"spark\\\\\\\" not found.\\\\n\\\\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport.requestFailure(OperationSupport.java:568)\\\\n\\\\tat io.fabric8.kubernetes.client.dsl.base.OperationSupport \",\"同时也要安装rbac\",\"rbac的文件在manifest/spark-operator-install/spark-operator-rbac.yaml,需要把namespace全部改为需要运行的namespace,这里我们任务放在default命名空间下,所以全部改为default,源文件见rbac.yaml\",\"执行脚本,这里用的app.jar是一个读取es数据源,然后计算,为了展示效果,在程序的后面用了TimeUnit.HOURS.sleep(1)方便观察。\",\"代码如下:\",\" SparkConf sparkConf = new SparkConf().setAppName(\\\"Spark WordCount Application (java)\\\"); sparkConf.set(\\\"es.nodes\\\", \\\"xxx\\\") .set(\\\"es.port\\\", \\\"8xx0\\\") .set(\\\"es.nodes.wan.only\\\", \\\"true\\\") .set(\\\"es.net.http.auth.user\\\", \\\"xxx\\\") .set(\\\"es.net.http.auth.pass\\\", \\\"xxx-xxx\\\"); try (JavaSparkContext jsc = new JavaSparkContext(sparkConf)) { JavaRDD> esRDD = JavaEsSpark.esRDD(jsc, \\\"kibana_sample_data_ecommerce\\\").values(); System.out.println(esRDD.partitions().size()); esRDD.map(x -> x.get(\\\"customer_full_name\\\")) .countByValue() .forEach((x, y) -> System.out.println(x + \\\":\\\" + y)); TimeUnit.HOURS.sleep(1); } catch (InterruptedException e) { throw new RuntimeException(e); } \",\"打包之后kubectl create -f k8s.yaml即可\",\"apiVersion: \\\"sparkoperator.k8s.io/v1beta2\\\" kind: SparkApplication metadata: name: spark-demo namespace: default spec: type: Scala mode: cluster image: fewfew-docker.pkg.coding.net/spark-java-demo/spark-java-demo-new/spark-java-demo:master-1d8c164bced70a1c66837ea5c0180c61dfb48ac3 imagePullPolicy: Always mainClass: com.spark.es.demo.EsReadGroupByName mainApplicationFile: \\\"local:///opt/spark/examples/jars/app.jar\\\" sparkVersion: \\\"3.1.1\\\" restartPolicy: type: Never driver: # 用cores必须要大于等于1,这里用coreRequest coreRequest: \\\"100m\\\" coreLimit: \\\"1200m\\\" memory: \\\"512m\\\" labels: version: 3.1.1 serviceAccount: sparkoperator executor: # 用cores必须要大于等于1,这里用coreRequest coreRequest: \\\"100m\\\" instances: 1 memory: \\\"512m\\\" labels: version: 3.1.1 \",\"spark-demo-driver 1/1 Running 0 2m30s spark-wordcount-application-java-0ac352810a9728e1-exec-1 1/1 Running 0 2m1s \",\"同时会自动生成相应的service。\",\"image-20220528203941897\",\"Spark on k8s operator大大减少了spark的部署与运维成本,用容器的调度来替换掉yarn,\",\"Spark Operator的主要组件如下:\",\"1、SparkApplication Controller : 用于监控并相应SparkApplication的相关对象的创建、更新和删除事件;\",\"2、Submission Runner:用于接收Controller的提交指令,并通过spark-submit 来提交Spark作业到K8S集群并创建Driver Pod,driver正常运行之后将启动Executor Pod;\",\"3、Spark Pod Monitor:实时监控Spark作业相关Pod(Driver、Executor)的运行状态,并将这些状态信息同步到Controller ;\",\"4、Mutating Admission Webhook:可选模块,但是在Spark Operator中基本上所有的有关Spark pod在Kubernetes上的定制化功能都需要使用到该模块,因此建议将enableWebhook这个选项设置为true。\",\"5、sparkctl: 基于Spark Operator的情况下可以不再使用kubectl来管理Spark作业了,而是采用Spark Operator专用的作业管理工具sparkctl,该工具功能较kubectl功能更为强大、方便易用。\",\"apis:用户编写yaml时的解析\",\"Batchscheduler:批处理的调度,提供了支持volcano的接口\",\"Client:\",\"leader的选举\",\"electionCfg := leaderelection.LeaderElectionConfig{ Lock: resourceLock, LeaseDuration: *leaderElectionLeaseDuration, RenewDeadline: *leaderElectionRenewDeadline, RetryPeriod: *leaderElectionRetryPeriod, Callbacks: leaderelection.LeaderCallbacks{ OnStartedLeading: func(c context.Context) { close(startCh) }, OnStoppedLeading: func() { close(stopCh) }, }, } elector, err := leaderelection.NewLeaderElector(electionCfg) \",\"参考:\",\"1.k8s client-go中Leader选举实现\",\"2.[Kubernetes基于leaderelection选举策略实现组件高可用\"]},\"73\":{\"h\":\"2017\",\"t\":[\"2016年6月,大三,考完最后一科,默默的看着大四那群人一个一个的走了,想着想着,明年毕业的时候,自己将会失去你所拥有的一切,大学那群认识的人,可能这辈子都不会见到了——致远离家乡出省读书的娃。然而,我并没有想到,自己失去的,不仅仅是那群人,几乎是一切。。。。 17年1月,因为受不了北京雾霾(其实是次因),从实习的公司跑路了,很不舍,只是,感觉自己还有很多事要做,很多梦想要去实现,毕竟,看着身边的人,去了美团,拿着15k的月薪,有点不平衡,感觉他也不是很厉害吧,我努力努力10k应该没问题吧?\",\"回到学校,待了几天,那个整天给别人灌毒鸡汤的人还是不着急找工作:该有的时候总会有的啦,然后继续打游戏、那个天天喊着吃麻辣香锅的人,记忆中好像今年都没有吃上,哈哈、厕所还是那样偶尔炸一下,嗯,感觉一切都很熟悉,只是,我有了点伤感,毕竟身边又要换一群不认识的人了。考完试,终于能回广东了,一年没回了,开心不得了,更多的是,为了那个喜欢了好几年没有表白的妹纸,之前从没想过真的能每天跟一个妹纸道晚安,秒回,但是,对她,我还真做到了。1月份的广州,不热不冷,空气很清新,比北京、天津那股泥土味好多了,只是,我被拒了,男闺蜜还是男闺蜜,备胎还是备胎,那会还没想过放弃,直到...\",\"春节期间,把自己的网站整理了一下,看了看JVM和并发的知识,偶尔刷刷牛客网的题,觉得自己没多大问题了,跟同学出发,去深圳,我并没有一个做马化腾、马云的梦,但是我想,要做出点东西,至少,不是个平庸的人。投了几个,第一个面试,知道是培训兼外包后果断弃了,春招还没开始,再多准备准备,有时间就往深圳图书馆里跑,找个位置,静静的复习,那会,感觉自己一定能去个大公司吧,搞搞分布式、大数据之类的~\"]},\"74\":{\"h\":\"疲惫的面试历程\",\"t\":[\"2月份底开始慢慢投简历,跑招聘会,深圳招聘的太少了,那就去广州,大学城,于是,开始了自己一周两天都在广深往返。有的公司笔试要跑一次广州,一面要跑一次,二面还要跑一次,每次看着路费,真的承受不起,但是有希望就行。乐观之下,到来的是一重又一重的打击。\",\"**数码,很看好的公司,在广州也算是老品牌了,笔试的时候面试官没有带够卷子,就拿了大数据的做,还过了,面试的时候被面到union和union all的区别,答反了,还有left join和right join的原理,一脸懵逼,过后去了百度搜了搜,这东西哪来的原理?\",\"然后是个企业建站的,笔试完了,面试官照着题问然后没说啥就让我走了,额,我好像还没自我介绍呢。\",\"有点想回北京了,往北京投了一份,A轮公司,月薪10k,过了,觉得自己技术应该不差吧,不过还是拒了,因为一想起那里满脑子都是雾霾。\",\"没事没事,下一家,某游戏公司,笔试过了,一面也过了,然后被问flume收集的时候断网处理机制、MD5和RSA原理、Angulajs和Vuejs用没用过、千万级的数据是如何存储的?额,跟你们想的一样,我一道也答出来,然后就挂了,面试官跟我说,你要是来早三个月这些都会啦,说的我很紧张,广东的同学都那么强么?\",\"这个时候还没质疑自己的技术,去了趟深圳某家小公司,金融的,HR问我是不是培训过来的,心里开始突然间好苦涩,大学花那么多时间学习居然被别人用来和培训机构的人相提并论,笔试不知从哪整来的英文逻辑题,做完了然后上机笔试,做不出来不能见面试官,开始感觉这公司有点。。。。还是撤了撤了。\",\"突然感觉面试面的绝望,是自己的问题么?是自己技术太菜了么?开始怀疑自己,感觉也是,已经3月份底了,毕竟别人都在实习,而我已经离职3个月没工作了,但是那些问题不是有点离谱了,一开始是开始心态爆炸觉得怎么可以对应届生问这些问题,不应该是基础么?算法什么的,后来是无奈了,开始上网搜各种不沾边的技术。\",\"还有其他的面试。。。有的工资不高(6K不到),有的面试问题全答对就因为说了有点想做大数据就不要你,有的聊得很欢快却没消息,有的说招java但是笔试一道java题都没有全是前端的,有的打着互联网实际却是外包的公司。。。。 4月初真的很绝望很绝望,不想跟别人说话,是不是很可笑,一个从北京B+轮的公司回广东,面试近15个,居然只能拿到2个offer,其中之一国企外包的,都不知说什么好。13号要拍毕业照了,没有回去,大学四年,毕竟大家个个圈子之间没什么交流,没什么友谊,果然,整个专业的人只有2/3的人去拍了毕业照。4月23号,拉勾网深圳站,梦想着市集,抱着一点点的小希望,去投了5个,结果一个面试邀请都没有,换之而来的是一片绝望、黑暗。。。。\"]},\"75\":{\"h\":\"感情、我们毕业了\",\"t\":[\"5月初回学校了赶毕业设计,回学校也是,天天往图书馆跑,为了面试,毕业设计拉下太多了。悠闲的时候,总会想起我喜欢的那个人,过的怎么样了,微信一开,好像自己被屏蔽了还是被删了?这三个月来的面试打击,真的不知道怎么应对,我更不知道怎么跟她聊天,以至于慢慢隔离,这段感情,或许只有我知道自己有多心疼,只有我自己sb得一点点的呵护着。想起上次跟她聊天是4月中,还是她提了个问题其他什么都没问,彼此之前已经没有关心了。删了吧删了吧,就这样一句再见都没有说,一句“祝福”都没有说。 5月底遇到两次还算开心的事,导师问我要不要评优秀论文,不是很想折腾,拒了,导师仍旧劝我,只是写个3页的小总结而已,评上的话能留图书馆收藏。另一个件是珍爱网打电话过来说我一面过了,什么时候二面,天啊,3月份一面,5月底才通知,心里想骂,但是真的好开心好开心,黑暗中的光芒,泪奔。。。。约到了6月15号面试。 6月初开始自己的回家倒计时,请那唯一一个跟我好的妹纸吃饭,忙完答辩,然后是优秀论文的小报告,13号下午交了上去,再回到宿舍,空无一人,一遍忍着不要悲伤,一遍收拾东西,然后向每个宿舍敲门,告别,一个人拖着行李箱,嗯,我要淡定。\",\"准备了有点久,我以为自己准备好了,15号,深圳,珍爱网,被问到:有没有JVM调优经验?ZK是如何保持一致性的?有没有写过ELK索引经验?谈谈你对dubbo的理解。。。事后,得知自己没有过。心态真的炸了,通宵打了两天游戏。月底得知,优秀论文也没有被评上,已经没有骂人吐槽的想法,只是哦的一声,6月,宣告了自己春招结束,宣告自己要去外包,同时也宣告自己大学这些努力全部白费,跟那个灌毒鸡汤天天打游戏的人同一起跑线。\"]},\"76\":{\"h\":\"996的工作\",\"t\":[\"七月初入职的时候,问了问那些一起应届入职的同学,跟别人交流一下面试被问的问题,只有线程池,JVM回收算法,他们也没用过,我无奈,为什么我被问到的,全是Angularjs、MD5加密算法、ZK一致性原理这种奇葩的问题。。。。。\",\"没有环境,就自己创造,下班有时间就改改自己的网站http://www.wenzhihuai.com,GitHub目前有154个star了,感觉也是个小作品吧,把常用的Java技术栈(RabbitMQ、MongoDB等)加了上去,虽然没啥使用场景,但是自己好好努力吧,毕竟高并发、高可用是自己的梦想。今年GitHub自己的提交次数。\",\"决心先好好呆着,学习学习,把公司的产品业务技术专研专研,7、8月份是挺开心的,没怎么加班,虽然下班我都留在公司学习,虽然公司的产品不咋地,但是还是有可学之处的,随后,我没想到的是,公司要实行996,,,9月份至12月,每天都是改bug,开发模块,写业务,全都是增删改查,没有涉及redis、rabbitmq,就真的只有使用Hibernate、spring,而做出的东西,要使用JDK6来运行,至今都能看到sun的类。每天的状态就是累累累,我们组还不是最惨的,隔壁项目组,一周通宵两次,9月到10都是如此,国庆加班,每次经过他们组,我都觉得自己还算是幸福。很厌恶这种不把员工当人看的行为,有同事调侃,明年估计我们这些应届过来的,是不是要走掉2/3的人?疯狂加班的代价是牺牲积极性,我问过那些一周通宵两次的人,敲代码,程序员你喜欢这份工作么?不喜欢!!!有那么一两次,实在是太累了,我都感觉自己有点不行了,想离职,可是,会有公司要我么?会有公司不问那些奇葩的问题么?\",\"双十一,花了500多买了十本书,神书啊,计算机届的圣经啊,然而至今一本都没看完,甚至是都没怎么翻,每天下班回去之后就是9点半了,烧水,洗澡,洗衣服,近11点了,躺床上,一遍看书一遍看鹌鹑直播,一小时才翻几页,996真的太累了,实在看不下书。经过这几个月的加班,感觉自己技术增长为负数,也病了几次,同学见我,都感觉我老了不少,心里不平,可是又没有什么办法。\"]},\"77\":{\"h\":\"孤独\",\"t\":[\"珠江新城,一年四季都那么美,今晚应该又是万人一起倒计时了吧?已经好久没跟别人一起出去玩过了。今年貌似得了自闭症?社交全靠黄段子。想找人出门走走,然而手机已经没有那种几年的朋友,大学同学一个都不在,哈哈哈,别人说社交软件让人离得更近,我怎么发现我自己一个好朋友都没有了呢,哭笑ing。或许是自己的确不善于跟别人保持联系吧,这个要改,一定要改!!! 远看:\",\"近看:\",\"题外话: 有些时候,遇到不顺,感觉自己不是神,没必要忍住,就开始宣泄自己的情绪,比如疯狂打游戏,只能这样度过了吧。 今年听过最多的一句话,你好厉害,你好牛逼==我感觉也是,可惜,要被业务耽误了不少时间吧。。 《企业IT架构转型之道》是今年最好的架构图书,没有之一。\"]},\"78\":{\"h\":\"期望\",\"t\":[\"想起初中,老师让我在黑板写自己的英文作文,好像是信件,描述什么状况来这?最后夸了夸我在文章后面加的一段大概是劝别人不要悲伤要灿烂。也想起一个故事,二战以后,德国满目疮痍,他们处在这样一个凄惨的境地,还能想到在桌上摆设一些花,就一定能在废墟上重建家园。我所看到的是即使在再黑暗的状态下,要永远抱着希望。明年要更加努力的学习,而不是工作,是该挽留一些人了,多运动。说了那么多,其实,我只希望自己的运气不要再差了,再差就没法活了。人在遇到不顺的时候,往往最难过的一关便是自己。哈哈哈,只能学我那个同学给自己灌毒鸡汤了。加油加油↖(^ω^)↗\"]},\"79\":{\"h\":\"2018\",\"t\":[\"年底老姐结婚,跑回家去了,忙着一直没写,本来想回深圳的时候空余的时候写写,没想到一直加班,嗯,9点半下班那种,偶尔也趁着间隙的时间,一段一段的凑着吧。\",\"想着17年12月31号写的那篇文章https://www.cnblogs.com/w1570631036/p/8158284.html,感叹18年还算恢复了点。\"]},\"80\":{\"h\":\"心惊胆战的裸辞经历\",\"t\":[\"其实校招过去的那家公司,真的不是很喜欢,996、技术差、产品差,实在受不了,春节前提出了离职,老大也挽留了下,以“来了个阿里的带我们重构,能学不了东西”来挽留,虽然我对技术比较痴迷,但离职去深圳的决心还是没有动摇,嗯,就这么开始了自己的裸辞过程。3月8号拿到离职,回公司的时候跟跟同事吹吹水,吃个饭,某同事还喊:“周末来公司玩玩么,我给你开门”,哈哈哈,泼出去的水,回不去了,偶尔有点伤感。 去深圳面试,第一家随手记,之前超级想去这家公司的,金融这一块,有钱,只可惜,没过,一面面试官一直夸我,我觉得稳了,二面没转过来,就这么挂了,有点不甘心吧,在这,感谢那个内推我的人吧,面经在这,之后就是大大小小的面试,联想、恒大、期待金融什么的,都没拿到offer,裸辞真的慌得一比,一天没工作,感觉一年没有工作没人要的样子。。。。没面试就跑去广州图书馆,复习,反思,一天一天的过着,回家就去楼下吃烧烤,打游戏,2点3点才睡觉,boss直聘、拉勾网见一个问一个,迷迷糊糊慌慌张张,那段期间真的想有点把所有书卖掉回家啃老的想法,好在最后联系了一家公司,电商、大小周,知乎上全是差评,不过评价的都不是技术的,更重要的是,岗位是中间件的,嗯,去吧。\",\"and ... 广州拜拜,晚上人少的时候,跟妹纸去珠江新城真的很美好\"]},\"81\":{\"h\":\"工作工作\",\"t\":[\"入职的时候是做日志收集的,就是flume+kafka+es这一套,遇到了不少大佬,嗯,感觉挺好的,打算好好干,一个半月后不知怎么滴,被拉去做容器云了,然后就开始了天天调jenkins、gitlab这些没什么用的api,开始了增删改查的历程,很烦,研究jenkins、gitlab对于自己的技术没什么提升,又不得不做,而且大小周+加班这么做,回到家自己看java、netty、golang的书籍,可是没项目做没实践,过几个月就忘光了,有段时间真的很烦很烦,根本不想工作,天天调api,而且是jenkins、gitlab这些没什么卵用的api,至今也没找到什么办法。。。。 公司发展太快,也实在让人不知所措,一不小心部门被架空了,什么预兆都没有,被分到其他部门,然后发现这个部门领导内斗真的是,“三国争霸”吧,无奈成为炮灰,不同的领导不同的要求,安安静静敲个代码怎么这么难。。。。 去年的学习拉下了不少,文章也写的少了,总写那些入门的文章确实没有什么意思,买的书虽然没有17年的多吧,不过也不少了,也看了挺多本书的,虽然我还是不满意自己的阅读量。 这几年要开始抓准一个框架了,好好专研一下,也要开始学习一下go了,希望能参与一些github的项目,好好努力吧。\"]},\"82\":{\"h\":\"跑步跑步\",\"t\":[\"平时没事总是宅在家里打游戏,差不多持续到下半年吧,那会打游戏去楼下吃东西的时候老是觉得眼神恍惚,盯着电子产品太多了,然后就跟别人跑步去了,每周去一次人才公园,跑步健身,人才公园真的是深圳跑步最好的一个地方了,桥上总有一群摄影师,好想在深圳湾买一套房子,看了看房价,算了算了,深圳的房,真的贵的离谱。19年也要多多运动,健康第一健康第一。\"]},\"83\":{\"h\":\"Others\",\"t\":[\"拿到了深圳户口,全程只花了15天,感谢学妹and家人\",\"买了第一台MacBook Pro,对于Java的我真心不好用\",\"盼了好几年的老姐结婚,18年终于了解了这心事\",\"养了只猫,在经历了好几个月的早起之后,晚上睡觉锁厨房,终于安分了,对不起了哈哈哈\"]},\"84\":{\"h\":\"2019\",\"t\":[\"想不起来还有什么要说的了,毕竟程序员,好像每天的生活都一样,就展望一下19年吧。今年,最最重要的是家里人以及身边还有所有人都健健康康的,哈哈哈。然后是安安静静的敲代码~~就酱\"]},\"85\":{\"h\":\"2019\",\"t\":[\"2019,本命年,1字头开头的年份,就这么过去了,迎来了2开头的十年,12月过的不是很好,每隔几天就吵架,都没怎么想起写自己的年终总结了,对这个跨年也不是很重视,貌似有点浑浑噩噩的样子。今天1号,就继续来公司学习学习,就写写文章吧。 19年一月,没发生什么事,对老板也算是失望,打算过完春节就出去外面试试,完全的架构错误啊,怎么守得了,然后开了个年会,没什么好看的,唯一的例外就是看见漂漂亮亮的她,可惜不敢搭话,就这么的呗。2月以奇奇怪怪的方式走到了一起,开心,又有点伤心,然后就开始了这个欢喜而又悲剧的本命年。\"]},\"86\":{\"h\":\"工作\",\"t\":[\"从18年底开始吧,大概就知道领导对容器云这么快的完全架构设计错误,就是一个完完全全错误的产品,其他人也觉得有点很有问题,但老板就是固执不听,结果一个跑路,一个被压得懒得反抗,然后我一个人跟老板和项目经理怼了前前后后半年,真是惨啊,还要被骂,各种拉到小黑屋里批斗,一直在对他们强调:没有这么做的!!!然后被以年轻人,不懂事,不要抱怨,长大了以后就领会了怼回来,当时气得真是无语。。。。。自己调研的阿里云、腾讯云、青云,还有其他小公司的容器,发现真的只有我们这么设计,完全错误的方向,,,,直到老板走了之后,才开始决定重构,走上正轨。\",\"之后有了点起色,然后开始着重强调了DevOps的重要性,期初也没人理解,还被骂天天研究技术不干活。。。这东西没技术,但是真的是公司十分需要的公司好么!!可惜公司对这个产品很失望,也不给人,期间还说要暂停项目,唉,这么大的项目就给几个人怎么做,谁都不乐意,就这么过的很憋屈吧,开始了维护的日子。。。\",\"工作上,蛮多人对我挺好的,领导,同事,不过有时候憋屈的时候还是有了点情绪化,有时候有点悲伤的想法,浮躁、暴躁,出去面试了几次,感觉不是自己能力不好,而是市场上的真的需要3+年以上的。。。。不过感觉自己能在这里憋屈的过了这么久,也是很佩服自己的,哈哈,用同事的话来说就是:当做游戏里的练级,锻炼自己哈哈哈\"]},\"87\":{\"h\":\"学习\",\"t\":[\"项目的方向错误,导致自己写的代码都是很简单的增删改查,没有技术含量的那种,也最终导致自己浪费了不少时间,上半年算是很气愤吧,不想就这么浪费掉这些时间,虽然期间看了各种各样的东西,比如Netty、Go、操作系统什么的,最终发现,如果不在项目中使用的话,真的会忘,而且很快就忘掉,最后的还是决定学习项目相关度比较大的东西了,比如Go,如果项目不是很大,小项目的话,就用Go来写,这么做感觉提升还是挺大的。 过去一年往南山图书馆借了不少书,省了不少钱,虽然没怎么看,但我至少有个奋斗的心啊,哈哈哈哈哈哈哈哈,文章写得少了,因为感觉写不出好东西,总是入门的那种,不深,不值得学习,想想到时候把别人给坑了,也不好意思。 操作系统感觉还是要好好学学了,加油\",\"Kubernetes就是未来的方向,有时候翻开源码看看,又不敢往下面看了,对底层不熟吧,今年要多多研究下Kubernetes的源码了,至于Spring那一套,也不知道该不该放弃,或者都学习一下?云原生就是趋势。\"]},\"88\":{\"h\":\"感情\",\"t\":[\"吵架了,没心思写\"]},\"89\":{\"h\":\"运动\",\"t\":[\"过去一年还是把运动算是坚持了下来,每个月必去深圳湾跑一次。还是没怎么睡好,工作感情上都有点不顺,加上自己本身就难以入睡,有时候躺床上就是怎么也睡不着,还长了痘痘,要跑去医院那种,可怕,老了,还是要早点睡觉,多走走多运动,好久没打羽毛球了,自己也不想有空的时候只会打游戏,今年继续加油,多运动吧。\",\"还爬了两次南山\"]},\"90\":{\"h\":\"其他\",\"t\":[\"看了周围蛮多同事去了腾讯阿里,有点心动,好想去csig,没到3年真的让人很抓狂。 过去一年过的蛮憋屈的,特别是工作不顺,加上跟女朋友吵架,心态爆炸。。。\"]},\"91\":{\"h\":\"2020展望\",\"t\":[\"每年这个时候,都不敢有太大的期望了,祝大家都健健康康的,工作顺利!!\",\"当然,如果有可能的话,我想去CSIG\"]},\"92\":{\"h\":\"\",\"t\":[\"jfaowejfoewj\"]},\"93\":{\"h\":\"微信公众号-chatgpt智能客服搭建\",\"t\":[\"想体验的可以去微信上搜索【旅行的树】公众号。\"]},\"94\":{\"h\":\"一、ChatGPT注册\"},\"95\":{\"h\":\"1.1 短信手机号申请\",\"t\":[\"openai提供服务的区域,美国最好,这个解决办法是搞个翻墙,或者买一台美国的服务器更好。\",\"国外邮箱,hotmail或者google最好,qq邮箱可能会对这些平台进行邮件过滤。\",\"国外手机号,没有的话也可以去https://sms-activate.org,费用大概需要1美元,这个网站记得也用国外邮箱注册,需要先充值,使用支付宝支付。\",\"之后再搜索框填openai进行下单购买即可。\"]},\"96\":{\"h\":\"1.2 云服务器申请\",\"t\":[\"openai在国内不提供服务的,而且也通过ip识别是不是在国内,解决办法用vpn也行,或者,自己去买一台国外的服务器也行。我这里使用的是腾讯云轻量服务器,最低配置54元/月,选择windows的主要原因毕竟需要注册openai,需要看页面,同时也可以搭建nginx,当然,用ubuntu如果能自己搞界面也行。\"]},\"97\":{\"h\":\"1.3 ChatGPT注册\",\"t\":[\"购买完之后,就可以直接打开openai的官网了,然后去https://platform.openai.com/signup官网里注册,注册过程具体就不讲了,讲下核心问题——短信验证码\",\"然后回sms查看验证码。\",\"注册成功之后就可以在chatgpt里聊天啦,能够识别各种语言,发起多轮会话的时候,可能回出现访问超过限制什么的。\",\"通过chatgpt聊天不是我们最终想要的,我们需要的是在微信公众号也提供智能客服的聊天回复,所以我们需要在通过openai的api来进行调用。\"]},\"98\":{\"h\":\"二、搭建nginx服务器\",\"t\":[\"跟页面一样,OpenAI的调用也是不能再国内访问的,这里,我们使用同一台服务器来搭建nginx,还是保留使用windows吧,主要还是得注意下面这段话,如果API key被泄露了,OpenAI可能会自动重新更新你的API key,这个规则似乎是API key如果被多个ip使用,就会触发这个规则,调试阶段还是尽量使用windows的服务器吧,万一被更新了,还能去页面上重新找到。\",\"Do not share your API key with others, or expose it in the browser or other client-side code. In order to protect the security of your account, OpenAI may also automatically rotate any API key that we've found has leaked publicly. \",\"windows的安装过程参考网上的来,我们只需要添加下面这个配置即可,原理主要是将调用OpenAI的接口全部往官网转发。\",\" location /v1/completions { proxy_pass https://api.openai.com/v1/completions; } \",\"然后使用下面的方法进行调试即可:\",\"POST http://YOUR IP/v1/completions Authorization: Bearer YOUR_API_KEY Content-Type: application/json { \\\"model\\\": \\\"text-davinci-003\\\", \\\"prompt\\\": \\\"Say this is a test\\\", \\\"max_tokens\\\": 7, \\\"temperature\\\": 0 } \"]},\"99\":{\"h\":\"三、公众号开发\",\"t\":[\"网上有很多关于微信通过chatgpt回复的文章,有些使用自己微信号直接做为载体,因为要扫码网页登陆,而且是网页端在国外,很容易被封;有些是使用公众号,相对来说,公众号被封也不至于导致个人微信号出问题。\"]},\"100\":{\"h\":\"3.1 微信云托管\",\"t\":[\"微信公众平台提供了微信云托管,无需鉴权,比其他方式都方便不少,可以免费试用3个月,继续薅羊毛,当然,如果自己开发能力足够,也可以自己从0开始开发。\",\"提供了各种语言的模版,方便快速开发,OpenAI官方提供的sdk是node和python,这里我们选择express(node)。\"]},\"101\":{\"h\":\"3.2 一个简单ChatGPT简单回复\",\"t\":[\"微信官方的源码在这,https://github.com/WeixinCloud/wxcloudrun-express,我们直接fork一份自己来开发。\",\"一个简单的消息回复功能(无db),直接在我们的index.js里添加如下代码。\",\"const configuration = new Configuration({ apiKey: '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', basePath: 'http://43.153.15.174/v1' }); const openai = new OpenAIApi(configuration); async function simpleResponse(prompt) { const completion = await openai.createCompletion({ model: 'text-davinci-003', prompt, max_tokens: 1024, temperature: 0.1, }); const response = (completion?.data?.choices?.[0].text || 'AI 挂了').trim(); return strip(response, ['\\\\n', 'A: ']); } app.post(\\\"/message/simple\\\", async (req, res) => { console.log('消息推送', req.body) // 从 header 中取appid,如果 from-appid 不存在,则不是资源复用场景,可以直接传空字符串,使用环境所属账号发起云调用 const appid = req.headers['x-wx-from-appid'] || '' const {ToUserName, FromUserName, MsgType, Content, CreateTime} = req.body console.log('推送接收的账号', ToUserName, '创建时间', CreateTime) if (MsgType === 'text') { message = await simpleResponse(Content) res.send({ ToUserName: FromUserName, FromUserName: ToUserName, CreateTime: CreateTime, MsgType: 'text', Content: message, }) } else { res.send('success') } }) \",\"本地可以直接使用http请求测试,成功调用之后直接提交发布即可,在微信云托管上需要先授权代码库,即可使用云托管的流水线,一键发布。注意,api_base和api_key可以填写在服务设置-基础信息那里,一个是OPENAI_API_BASE,一个是OPENAI_API_KEY,服务会自动从环境变量里取。\"]},\"102\":{\"h\":\"3.3 服务部署\",\"t\":[\"提交代码只github或者gitee都可以,值得注意的是,OpenAI判断key泄露的规则,不知道是不是判断调用的ip地址不一样,还是github的提交记录里含有这块,有点玄学,同样的key本地调用一次,然后在云托管也调用的话,OpenAI就很容易把key给重新更新。\",\"部署完之后,云托管也提供了云端调试功能,相当于在服务里发送了http请求。这一步很重要,如果没有调用成功,则无法进行云托管消息推送。\",\"这里填上你自己的url,我们这里配置的是/meesage/simple,如果没有成功,需要进行下面步骤进行排查:\",\"(1)服务有没有正常启动,看日志\",\"(2)端口有没有设置错误,这个很多次没有注意到\",\"保存成功之后,就可以在微信公众号里测试了。\",\"体验还可以\"]},\"103\":{\"h\":\"四、没有回复(超时回复问题)\",\"t\":[\"很多OpenAI的回答都要几十秒,有的甚至更久,比如对chatgpt问“写一篇1000字关于深圳的文章”,就需要几十秒,而微信的主动回复接口,是需要我们3s内返回给用户。\",\"订阅号的消息推送分几种:\",\"被动消息回复:指用户给公众号发一条消息,系统接收到后,可以回复一条消息。\",\"主动回复/客服消息:可以脱离被动消息的5秒超时权限,在48小时内可以主动回复。但需要公众号完成微信认证。\",\"根据微信官方文档,没有认证的公众号是没有调用主动回复接口权限的,https://developers.weixin.qq.com/doc/offiaccount/Getting_Started/Explanation_of_interface_privileges.html\",\"对于有微信认证的订阅号或者服务号,可以调用微信官方的/cgi-bin/message/custom/send接口来实现主动回复,但是对于个人的公众号,没有权限调用,只能尝试别的办法。想来想去,只能在3s内返回让用户重新复制发送的信息,同时后台里保存记录异步调用,用户重新发送的时候再从数据库里提取回复。\",\"1.先往数据库存一条 回复记录,把用户的提问存下来,以便后续查询。设置回复的内容为空,设置状态为 回复中(thinking)。\",\" // 因为AI响应比较慢,容易超时,先插入一条记录,维持状态,待后续更新记录。 await Message.create({ fromUser: FromUserName, response: '', request: Content, aiType: AI_TYPE_TEXT, // 为其他AI回复拓展,比如AI作画 }); \",\"2.抽象一个 chatGPT 请求方法 getAIMessage,函数内部得到 GPT 响应后,会更新之前那条记录(通过用户id & 用户提问 查询),把状态更新为 已回答(answered),并把回复内容更新上。\",\" // 成功后,更新记录 await Message.update( { response: response, status: MESSAGE_STATUS_ANSWERED, }, { where: { fromUser: FromUserName, request: Content, }, }, ); \",\"3.前置增加一些判断,当用户在请求时,如果 AI 还没完成响应,直接回复用户 AI 还在响应,让用户过一会儿再重试。如果 AI 此时已响应完成,则直接把 内容返回给用户。\",\" // 找一下,是否已有记录 const message = await Message.findOne({ where: { fromUser: FromUserName, request: Content, }, }); // 已回答,直接返回消息 if (message?.status === MESSAGE_STATUS_ANSWERED) { return `[GPT]: ${message?.response}`; } // 在回答中 if (message?.status === MESSAGE_STATUS_THINKING) { return AI_THINKING_MESSAGE; } \",\"4.最后就是一个 Promise.race\",\" const message = await Promise.race([ // 3秒微信服务器就会超时,超过2.9秒要提示用户重试 sleep(2900).then(() => AI_THINKING_MESSAGE), getAIMessage({ Content, FromUserName }), ]); \",\"这样子大概就能实现超时之前返回了。\"]},\"104\":{\"h\":\"五、会话保存\",\"t\":[\"掉接口是一次性的,一次接口调用完之后怎么做到下一次通话的时候,还能继续保持会话,是不是应该类似客户端与服务端那种有个session这种,但是实际上在openai里是没有session这种东西的,令人震惊的是,chatgpt里是通过前几次会话拼接起来一起发送给chatgpt里的,需要通过回车符来拼接。\",\"async function buildCtxPrompt({ FromUserName }) { // 获取最近10条对话 const messages = await Message.findAll({ where: { fromUser: FromUserName, aiType: AI_TYPE_TEXT, }, limit: 10, order: [['updatedAt', 'ASC']], }); // 只有一条的时候,就不用封装上下文了 return messages.length === 1 ? messages[0].request : messages .map(({ response, request }) => `Q: ${request}\\\\n A: ${response}`) .join('\\\\n'); } \",\"之后就可以实现会话之间的保存通信了。\"]},\"105\":{\"h\":\"六、其他问题\"},\"106\":{\"h\":\"6.1 限频\",\"t\":[\"chatgpt毕竟也是新上线的,火热是肯定的,聊天窗口只能开几个,api调用的话,也是有限频的,但是规则具体没有找到,只是在调用次数过多的时候会报429的错误,出现之后就需要等待一个小时左右。\",\"对于这个的解决办法只能是多开几个账号,一旦429就只能换个账号重试了。\"]},\"107\":{\"h\":\"6.2 秘钥key被更新\",\"t\":[\"没有找到详细的规则,凭个人经验的话,可能github提交的代码会被扫描,可能ip调用的来源不一样,最好还是开发一个秘钥,生产一个秘钥吧。\"]},\"108\":{\"h\":\"6.3 为啥和官网的回复不一样\",\"t\":[\"我们这里用的模型算法是text-davinci-003,具体可以参考:https://platform.openai.com/docs/models/overview,也算是一个比较老的样本了吧\",\"从官方文档来看,官方服务版的 ChatGPT 的模型并非基础版的text-davinci-003,而是经过了「微调:fine-tunes」。文档地址在这:platform.openai.com/docs/guides…\"]},\"109\":{\"h\":\"6.4 玄学挂掉\",\"t\":[\"有时候消息没有回复,真的不是我们的问题,chatgpt毕竟太火了,官网的这个能力都经常挂掉,也可以订阅官网修复的通知,一旦修复则会发邮件告知你。\",\"参考:https://juejin.cn/post/7200769439335546935\"]},\"110\":{\"h\":\"最后\",\"t\":[\"记得去微信关注【旅行的树】公众号体验\\n代码地址:https://github.com/Zephery/wechat-gpt\"]},\"111\":{\"h\":\"Tesla api\"},\"112\":{\"h\":\"一、特斯拉应用申请\"},\"113\":{\"h\":\"1.1 创建 Tesla 账户\",\"t\":[\"如果您还没有 Tesla 账户,请创建账户。验证您的电子邮件并设置多重身份验证。\",\"正常创建用户就好,然后需要开启多重身份认证,这边常用的是mircrosoft的Authenticator.\",\"注意点:(1)不要用自己车辆的邮箱来注册(2)有些邮箱不是特斯拉开发者的邮箱,可能用这些有些无法正常提交访问请求。\"]},\"114\":{\"h\":\"1.2 提交访问请求\",\"t\":[\"点击下方的“提交请求”按钮,请求应用程序访问权限。登录后,请提供您的合法企业详细信息、应用程序名称及描述和使用目的。在您提交了详细信息之后,我们会审核您的请求并通过电子邮件向您发送状态更新。\",\"这一步很坑,多次尝试之后都无果,原因也不知道是为啥,只能自己去看返回报文琢磨,太难受了,下面是自己踩的坑\",\"(1)Invalid domain\",\"无效的域名,这里我用的域名是腾讯云个人服务器的域名,证书是腾讯云免费一年的证书,印象中第一申请的时候还是能过的,第二次的时候就不行了,可能被识别到免费的ssl证书不符合规范,还是需要由合法机构的颁发证书才行。所以,为了金快速申请通过,先填个https://baidu.com吧。当然,后续需要彻底解决自己域名证书的问题,我改为使用阿里云的ssl证书,3个月到期的那种。\",\"(2)Unable to Onboard\",\"应用无法上架,可能原因为邮箱不对,用了之前消费者账号(即自己的车辆账号),建议换别的邮箱试试。\",\"(3) Rejected\",\"这一步尝试了很多次,具体原因为国内还无法正常使用tesla api,只能切换至美国服务器申请下(截止2023-11-15),后续留意官网通知。\"]},\"115\":{\"h\":\"1.3 访问应用程序凭据\",\"t\":[\"一旦获得批准,将为您的应用程序生成可在登录后访问的客户端 ID 和客户端密钥。使用这些凭据,通过 OAuth 2.0 身份验证获取用户访问令牌。访问令牌可用于对提供私人用户账户信息或代表其他账户执行操作的请求进行身份验证。\",\"申请好就可以在自己的账号下看到自己的应用了,\"]},\"116\":{\"h\":\"1.4 开始 API 集成\",\"t\":[\"按照 API 文档和设置说明将您的应用程序与 Tesla 车队 API 集成。您需要生成并注册公钥,请求用户授权并按照规格要求拨打电话。完成后您将能够与 API 进行交互,并开始围绕 Tesla 设备构建集成。\",\"由于特斯拉刚推出,并且国内进展缓慢,很多都申请不下来,下面内容均以北美区域进行调用。\"]},\"117\":{\"h\":\"2.1 认识token\",\"t\":[\"app与特斯拉交互的共有两个令牌(token)方式,在调用api的时候,特别需要注意使用的是哪种token,下面是两种token的说明:\",\"(1)合作伙伴身份验证令牌:这个就是你申请的app的令牌\",\"(2)客户生成第三方令牌:这个是消费者在你这个app下授权之后的令牌。\",\"此外,还需要注意下,中国大陆地区对应的api地址是 https://fleet-api.prd.cn.vn.cloud.tesla.cn,不要调到别的地址去了。\"]},\"118\":{\"h\":\"2.2 获取第三方应用token\",\"t\":[\"这一步官网列的很详细,就不在详述了。\",\"CLIENT_ID= CLIENT_SECRET= AUDIENCE=\\\"https://fleet-api.prd.na.vn.cloud.tesla.com\\\" # Partner authentication token request curl --request POST \\\\ --header 'Content-Type: application/x-www-form-urlencoded' \\\\ --data-urlencode 'grant_type=client_credentials' \\\\ --data-urlencode \\\"client_id=$CLIENT_ID\\\" \\\\ --data-urlencode \\\"client_secret=$CLIENT_SECRET\\\" \\\\ --data-urlencode 'scope=openid vehicle_device_data vehicle_cmds vehicle_charging_cmds' \\\\ --data-urlencode \\\"audience=$AUDIENCE\\\" \\\\ 'https://auth.tesla.com/oauth2/v3/token' \"]},\"119\":{\"h\":\"2.3 验证域名归属\"},\"120\":{\"h\":\"2.1.1 Register\",\"t\":[\"完成注册合作方账号之后才可以访问API. 每个developer.tesla.cn上的应用程序都必须完成此步骤。官网挂了一个github的代码,看了半天,以为要搞很多东西,实际上只需要几步就可以了。\",\"cd vehicle-command/cmd/tesla-keygen go build . ./tesla-keygen -f -keyring-debug -key-file=private create > public_key.pem \",\"这里只是生成了公钥,需要把公钥挂载到域名之下,我们用的是nginx,所以只要指向pem文件就可以了,注意下nginx是否可以访问到改文件,如果不行,把nginx的user改为root。\",\" location ~ ^/.well-known { default_type text/html; alias /root/vehicle-command/cmd/tesla-keygen/public_key.pem; } \",\"随后,便是向tesla注册你的域名,域名必须和你申请的时候填的一样。\",\"curl --header 'Content-Type: application/json' \\\\ --header \\\"Authorization: Bearer $TESLA_API_TOKEN\\\" \\\\ --data '{\\\"domain\\\":\\\"string\\\"}' \\\\ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts' \"]},\"121\":{\"h\":\"2.1.2 public_key\",\"t\":[\"最后,验证一下是否真的注册成功(GET /api/1/partner_accounts/public_key)\",\"curl --header 'Content-Type: application/json' \\\\ --header \\\"Authorization: Bearer $TESLA_API_TOKEN\\\" \\\\ 'https://fleet-api.prd.na.vn.cloud.tesla.com/api/1/partner_accounts/public_key' \",\"得到下面内容就代表成功了\",\"{\\\"response\\\":{\\\"public_key\\\":\\\"xxxx\\\"}} \",\"至此,我们的开发准备就完成了,接下来就是正常的开发与用户交互的api。\"]},\"122\":{\"h\":\"1.历史与架构\",\"t\":[\"各位大佬瞄一眼我的个人网站呗 。如果觉得不错,希望能在GitHub上麻烦给个star,GitHub地址https://github.com/Zephery/newblog 。 大学的时候萌生的一个想法,就是建立一个个人网站,前前后后全部推翻重构了4、5遍,现在终于能看了,下面是目前的首页。\",\"由原本的ssh变成ssm,再变成ssm+shiro+lucene,到现在的前后台分离。前台使用ssm+lucene,后台使用spring boot+shiro。其中,使用pagehelper作为分页,lucene用来搜索和自动补全,使用百度统计的API做了个日志系统,统计pv和uv什么的,同时,还有使用了JMX来观察JVM的使用和cpu的使用率,机器学习方面,使用了adaboost和朴素贝叶斯对微博进行分类,有兴趣的可以点点有点意思这个页面。 本文从下面这几个方面来讲讲网站的建立:\",\"建站故事与网站架构\",\"lucene搜索的使用\",\"使用quartz来定时备份数据库\",\"使用百度统计api做日志系统\",\"Nginx小集群的搭建\",\"[数据库]\",\"使用机器学习对微博进行分析\",\"网站性能优化\",\"SEO优化\"]},\"123\":{\"h\":\"1.建站故事与网站架构\"},\"124\":{\"h\":\"1.1建站过程\",\"t\":[\"起初,是因为学习的时候老是找不到什么好玩而又有挑战性的项目,看着struts、spring、hibernate的书,全都是一些小项目,做了感觉也没啥意义,有时候在博客园看到别人还有自己的网站,特羡慕,最终就选择了自己做一个个人网站。期初刚学的ssh,于是开始了自己的ssh搭建个人网站的行程,但是对于一个后端的人来说,前端是个大问题啊。。。。所以初版的时候差不多全是纯生的html、css、js,至少发博客这个功能实现了,但是确实没法看。前前后后折腾了一个多月,决定推翻重做,到百度看看别人怎么做的。首先看到的是杨青的网站,已经好几年没更新了,前端的代码看起来比较简单,也是自己能够掌握的,但是不够美观,继续找,在模板之家发现了一个高大上的模板。\",\"第二版的界面确实是这样的,只是把图片的切换变成了wowslider,也是简单的用bootstrap和pagehelper做了下分页,现在的最终版保留了它的header,然后评论框使用了多说(超级怀念多说)。后端也由原来的ssh变成了ssm,之后加上了lucene来对文章进行索引。之后,随着多说要关闭了,突然之间有很多div都不适应了(我写死了的。。。),再一次,没法看,不想看,一怒之下再次推翻重做,变成了现在这个版本。\",\"最终版本在考虑时,也找了很多模板,影响深刻的是tale和欲思这两个主题,期中,tale使用的是java语言写的,刚知道的那一刻我就没好感了,java后端我是要自己全部写的,tale这个页面简洁但是不够炫,而且内容量太低,可能就只是个纯博客,之后发现了欲思,拓展性强,只可惜没有静态的版本,后台是纯生的PHP(嗯,PHP是世界上最好的语言),看了看,没事,保存网页,前端自己改,后端自己全部重写,最终变成了现在这个版本,虽然拼接的时候各种css、js混入。。。。还好在做网站性能优化的时候差不多全部去掉了。最终版加入redis、quartz、shiro等,还有python机器学习、flask的restful api,可谓是大杂烩了。 页面看着还算凑合,至少不是那种看都看不过去的那种了,但是仔细看看,还是有不少问题的,比如瀑布流,还有排版什么的。只能等自己什么时候想认真学学前端的东西了。 已经部署在腾讯云服务器上,存储使用了七牛云的cdn。\"]},\"125\":{\"h\":\"1.2 网站整体技术架构\",\"t\":[\"最终版的技术架构图如下:\",\"网站核心主要采用Spring SpringMVC和Mybatis,下图是当访问一篇博客的时候的运行流程,参考了张开涛的博客。\",\"运行流程分析\",\"浏览器发送http请求。/blogdetail.html?blogid=1。\",\"tomcat容器初始化,顺序为context-param>listener>filter>servlet,此时,spring中的bean还没有被注入的,不建议在此处加载bean,网站声明了两个类(IPFilter和CacheControlFilter),IPFilter用来拦截IP,CacheControlFilter用来缓存。\",\"初始化Spring。\",\"DispatcherServlet——>HandlerMapping进行请求到处理的映射,HandlerMapping将“/blogdetail”路径直接映射到名字为“/blogdetail”的Bean进行处理,即BlogController。\",\"自定义拦截器,其中BaseIntercepter实现了HandleInterceptor的接口,用来记录每次访问的链接以及后台响应的时间。\",\"DispatcherServlet——> SimpleControllerHandlerAdapter,SimpleControllerHandlerAdapter将HandlerExecutionChain中的处理器适配为BlogController。\",\"BlogController执行查询,取得结果集返回数据。\",\"blogdetail(ModelAndView的逻辑视图名)——>InternalResourceViewResolver, InternalResourceViewResolver使用JstlView,具体视图页面在/blogdetail.jsp。\",\"JstlView(/blogdetail.jsp)——>渲染,将在处理器传入的模型数据(blog=Blog!)在视图中展示出来。\",\"返回响应。\"]},\"126\":{\"h\":\"1.3 日志系统\",\"t\":[\"日志系统架构如下:\",\"日志系统曾经尝试采用过ELK,实时监控实在是让人不能不称赞,本地也跑起来了,但是一到服务器,卡卡卡,毕竟(1Ghz CPU、1G内存),只能放弃ELK,采用百度统计。百度统计提供了Tongji API供开发者使用,只是有次数限制,2000/日,实时的话实在有点低,只能统计前几天的PV、UV等开放出来。其实这个存放在mysql也行,不过这些零碎的数据还是放在redis中,方便管理。 出了日志系统,自己对服务器的一些使用率也是挺关心的,毕竟服务器配置太低,于是利用了使用了tomcat的JMX来对CPU和jvm使用情况进行监控,这两个都是实时的。出了这两个,对内存的分配做了监控,Eden、Survivor、Tenured的使用情况。\"]},\"127\":{\"h\":\"1.4 【有点意思】自然语言处理\",\"t\":[\"本人大学里的毕业设计就是基于AdaBoost算法的情感分类,学到的东西还是要经常拿出来看看,要不然真的浪费了我这么久努力做的毕业设计啊。构建了一个基本的情感分类小系统,每天抓取微博进行分类存储在MySql上,并使用flask提供Restful API给java调用,可以点击这里尝试(请忽略Google的图片)。目前分类效果不是很明显,准确率大概只有百分之70%,因为训练样本只有500条(找不到训练样本),机器学习真的太依赖样本的标注。这个,只能请教各位路人大神指导指导了。\"]},\"128\":{\"h\":\"总结\",\"t\":[\"断断续续,也总算做了一个能拿得出手仍要遮遮掩掩才能给别人看的网站,哈哈哈哈哈,也劳烦各位帮忙找找bug。前前后后从初学Java EE就一直设想的事也还算有了个了结,以后要多多看书,写点精品文章。PS:GitHub上求给个Star,以后面试能讲讲这个网站。\"]},\"129\":{\"h\":\"10.网站重构\",\"t\":[\"因原本的\"]},\"130\":{\"h\":\"2.Lucene的使用\",\"t\":[\"首先,帮忙点击一下我的网站http://www.wenzhihuai.com/ 。谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github.com/Zephery/newblog 。\"]},\"131\":{\"h\":\"Lucene的整体架构\",\"t\":[\"image\"]},\"132\":{\"h\":\"搜索引擎的几个重要概念:\",\"t\":[\"倒排索引:将文档中的词作为关键字,建立词与文档的映射关系,通过对倒排索引的检索,可以根据词快速获取包含这个词的文档列表。倒排索引一般需要对句子做去除停用词。 \",\"停用词:在一段句子中,去掉之后对句子的表达意向没有印象的词语,如“非常”、“如果”,中文中主要包括冠词,副词等。\",\"排序:搜索引擎在对一个关键词进行搜索时,可能会命中许多文档,这个时候,搜索引擎就需要快速的查找的用户所需要的文档,因此,相关度大的结果需要进行排序,这个设计到搜索引擎的相关度算法。\"]},\"133\":{\"h\":\"Lucene中的几个概念\",\"t\":[\"文档(Document):文档是一系列域的组合,文档的域则代表一系列域文档相关的内容。\",\"域(Field):每个文档可以包含一个或者多个不同名称的域。\",\"词(Term):Term是搜索的基本单元,与Field相对应,包含了搜索的域的名称和关键词。\",\"查询(Query):一系列Term的条件组合,成为TermQuery,但也有可能是短语查询等。\",\"分词器(Analyzer):主要是用来做分词以及去除停用词的处理。\",\"索引的建立\",\"索引的搜索\"]},\"134\":{\"h\":\"lucene在本网站的使用:\",\"t\":[\"搜索 2. 自动分词\"]},\"135\":{\"h\":\"一、搜索\",\"t\":[\"注意:本文使用最新的lucene,版本6.6.0。lucene的版本更新很快,每跨越一次大版本,使用方式就不一样。首先需要导入lucene所使用的包。使用maven:\",\" org.apache.lucene lucene-core ${lucene.version} org.apache.lucene lucene-analyzers-common ${lucene.version} org.apache.lucene lucene-analyzers-smartcn ${lucene.version} org.apache.lucene lucene-queryparser ${lucene.version} org.apache.lucene lucene-highlighter ${lucene.version} \",\"构建索引\",\"Directory dir = FSDirectory.open(Paths.get(\\\"blog_index\\\"));//索引存储的位置 SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();//简单的分词器 IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter writer = new IndexWriter(dir, config); Document doc = new Document(); doc.add(new TextField(\\\"title\\\", blog.getTitle(), Field.Store.YES)); //对标题做索引 doc.add(new TextField(\\\"content\\\", Jsoup.parse(blog.getContent()).text(), Field.Store.YES));//对文章内容做索引 writer.addDocument(doc); writer.close(); \",\"更新与删除\",\"IndexWriter writer = getWriter(); Document doc = new Document(); doc.add(new TextField(\\\"title\\\", blog.getTitle(), Field.Store.YES)); doc.add(new TextField(\\\"content\\\", Jsoup.parse(blog.getContent()).text(), Field.Store.YES)); writer.updateDocument(new Term(\\\"blogid\\\", String.valueOf(blog.getBlogid())), doc); //更新索引 writer.close(); \",\"查询\",\"private static void search_index(String keyword) { try { Directory dir = FSDirectory.open(Paths.get(\\\"blog_index\\\")); //获取要查询的路径,也就是索引所在的位置 IndexReader reader = DirectoryReader.open(dir); IndexSearcher searcher = new IndexSearcher(reader); SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer(); QueryParser parser = new QueryParser(\\\"content\\\", analyzer); //查询解析器 Query query = parser.parse(keyword); //通过解析要查询的String,获取查询对象 TopDocs docs = searcher.search(query, 10);//开始查询,查询前10条数据,将记录保存在docs中, for (ScoreDoc scoreDoc : docs.scoreDocs) { //取出每条查询结果 Document doc = searcher.doc(scoreDoc.doc); //scoreDoc.doc相当于docID,根据这个docID来获取文档 System.out.println(doc.get(\\\"title\\\")); //fullPath是刚刚建立索引的时候我们定义的一个字段 } reader.close(); } catch (IOException | ParseException e) { logger.error(e.toString()); } } \",\"高亮\",\"Fragmenter fragmenter = new SimpleSpanFragmenter(scorer); SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter(\\\"\\\", \\\" Java org.apache.lucene lucene-suggest 6.6.0 \",\"如果想将结果反序列化,声明实体类的时候要加上:\",\"public class Blog implements Serializable { \",\"实现InputIterator接口\",\"InputIterator的几个方法: long weight():返回的权重值,大小会影响排序,默认是1L BytesRef payload():对某个对象进行序列化 boolean hasPayloads():是否有设置payload信息 Set contexts():存入context,context里可以是任意的自定义数据,一般用于数据过滤 boolean hasContexts():判断是否有下一个,默认为false \",\"public class BlogIterator implements InputIterator { /** * logger */ private static final Logger logger = LoggerFactory.getLogger(BlogIterator.class); private Iterator blogIterator; private Blog currentBlog; public BlogIterator(Iterator blogIterator) { this.blogIterator = blogIterator; } @Override public boolean hasContexts() { return true; } @Override public boolean hasPayloads() { return true; } public Comparator getComparator() { return null; } @Override public BytesRef next() { if (blogIterator.hasNext()) { currentBlog = blogIterator.next(); try { //返回当前Project的name值,把blog类的name属性值作为key return new BytesRef(Jsoup.parse(currentBlog.getTitle()).text().getBytes(\\\"utf8\\\")); } catch (Exception e) { e.printStackTrace(); return null; } } else { return null; } } /** * 将Blog对象序列化存入payload * 可以只将所需要的字段存入payload,这里对整个实体类进行序列化,方便以后需求,不建议采用这种方法 */ @Override public BytesRef payload() { try { ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(bos); out.writeObject(currentBlog); out.close(); BytesRef bytesRef = new BytesRef(bos.toByteArray()); return bytesRef; } catch (IOException e) { logger.error(\\\"\\\", e); return null; } } /** * 文章标题 */ @Override public Set contexts() { try { Set regions = new HashSet(); regions.add(new BytesRef(currentBlog.getTitle().getBytes(\\\"UTF8\\\"))); return regions; } catch (UnsupportedEncodingException e) { throw new RuntimeException(\\\"Couldn't convert to UTF-8\\\"); } } /** * 返回权重值,这个值会影响排序 * 这里以产品的销售量作为权重值,weight值即最终返回的热词列表里每个热词的权重值 */ @Override public long weight() { return currentBlog.getHits(); //change to hits } } \",\"ajax 建立索引\",\"/** * ajax建立索引 */ @Override public void ajaxbuild() { try { Directory dir = FSDirectory.open(Paths.get(\\\"autocomplete\\\")); SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer(); AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(dir, analyzer); //创建Blog测试数据 List blogs = blogMapper.getAllBlog(); suggester.build(new BlogIterator(blogs.iterator())); } catch (IOException e) { System.err.println(\\\"Error!\\\"); } } \",\"查找 因为有些文章的标题是一样的,先对list排序,将标题短的放前面,长的放后面,然后使用LinkHashSet来存储。\",\"@Override public Set ajaxsearch(String keyword) { try { Directory dir = FSDirectory.open(Paths.get(\\\"autocomplete\\\")); SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer(); AnalyzingInfixSuggester suggester = new AnalyzingInfixSuggester(dir, analyzer); List list = lookup(suggester, keyword); list.sort(new Comparator() { @Override public int compare(String o1, String o2) { if (o1.length() > o2.length()) { return 1; } else { return -1; } } }); Set set = new LinkedHashSet<>(); for (String string : list) { set.add(string); } ssubSet(set, 7); return set; } catch (IOException e) { System.err.println(\\\"Error!\\\"); return null; } } \",\"controller层\",\"@RequestMapping(\\\"ajaxsearch\\\") public void ajaxsearch(HttpServletRequest request, HttpServletResponse response) throws IOException { String keyword = request.getParameter(\\\"keyword\\\"); if (StringUtils.isEmpty(keyword)) { return; } Set set = blogService.ajaxsearch(keyword); Gson gson = new Gson(); response.getWriter().write(gson.toJson(set));//返回的数据使用json } \",\"ajax来提交请求 autocomplete.js源代码与介绍:https://github.com/xdan/autocomplete\",\" org.springframework spring-context-support 4.2.6.RELEASE \",\"(2)导入quartz包\",\" org.quartz-scheduler quartz 2.3.0 \",\"(3)mysql远程备份 使用命令行工具仅仅需要一行:\",\"mysqldump -u [username] -p[password] -h [hostip] database > file \",\"但是java不能直接执行linux的命令,仍旧需要依赖第三方库ganymed\",\" ch.ethz.ganymed ganymed-ssh2 262 \",\"完整代码如下:\",\"@Component(\\\"mysqlService\\\")//在spring中注册一个mysqlService的Bean public class MysqlUtil { ... StringBuffer sb = new StringBuffer(); sb.append(\\\"mysqldump -u \\\" + username + \\\" -p\\\" + password + \\\" -h \\\" + host + \\\" \\\" + database + \\\" >\\\" + file); String sql = sb.toString(); Connection connection = new Connection(s_host); connection.connect(); boolean isAuth = connection.authenticateWithPassword(s_username, s_password);//进行远程服务器登陆认证 if (!isAuth) { logger.error(\\\"server login error\\\"); } Session session = connection.openSession(); session.execCommand(sql);//执行linux语句 InputStream stdout = new StreamGobbler(session.getStdout()); BufferedReader br = new BufferedReader(new InputStreamReader(stdout)); ... } \",\"(4)spring中配置quartz\",\" [ ]
\",\"(5)java完整文件在这\"]},\"144\":{\"h\":\"Spring的高级特性之定时任务\",\"t\":[\"java ee项目的定时任务中除了运行quartz之外,spring3+还提供了task,可以看做是一个轻量级的Quartz,而且使用起来比Quartz简单的多。\",\"(1)spring配置文件中配置:\",\" PV和UV折线图 \",\"效果如下:\",\"(2)地域访问量 在python代码中先获取地域的数据,其结果如下,百度统计跟echarts都是百度的,果然,自家人对自己人的支持真是特别友好的。\",\"[{'pv_count': 649, 'pv_ratio': 7, 'visitor_count': 2684, 'name': '广东'}, {'pv_count': 2, 'pv_ratio': 2, 'visitor_count': 76, 'name': '四川'}, {'pv_count': 1, 'pv_ratio': 1, 'visitor_count': 3, 'name': '江苏'}] \",\"地域图目前支持最好的还是百度的echarts,使用方法见echarts的官网吧,这里不再阐述,展示地域图的时候需要获取下载两个文件,china.js(其提供了js和json,这里使用的js),echarts.js。 部分代码:\",\" \",\"结果如下: \",\"网上关于日志系统的几乎都是ELK,对于小网站的,隐私不是很重要的还是可以用用百度统计的,这套系统也折磨了我挺久的,特别是它那反人类的返回数据。期初本来是想使用百度统计的,后来考虑了一下ELK,尝试之后发现,服务器配置跑不起来,还是安安稳稳的使用了百度统计,于此做成了这个系统,美观度还是不高,颜色需要优化一下。最后,希望能在GitHub上给我个star吧。\\n日志系统地址:http://www.wenzhihuai.com/log.html\\n个人网站网址:http://www.wenzhihuai.com\\n个人网站代码地址:https://github.com/Zephery/newblog\\n百度统计python代码地址:https://github.com/Zephery/baidutongji\\n万分感谢\"]},\"152\":{\"h\":\"5.小集群部署.md\",\"t\":[\"欢迎访问我的个人网站O(∩_∩)O哈哈~希望大佬们能给个star,个人网站网址:http://www.wenzhihuai.com,个人网站代码地址:https://github.com/Zephery/newblog。 洋洋洒洒的买了两个服务器,用来学习分布式、集群之类的东西,整来整去,感觉分布式这种东西没人指导一下真的是太抽象了,先从网站的分布式部署一步一步学起来吧,虽然网站本身的访问量不大==。\",\"一般情况下,当单实例无法支撑起用户的请求时,就需要就行扩容,部署的服务器可以分机房、分地域。而分地域会导致请求分配到太远的地区,比如:深圳的用户却访问到了北京的节点,然后还得从北京返回处理之后的数据,光是来回就至少得30ms。这部分可以通过智能DNS(就近访问)解决。而分机房,需要将请求合理的分配到不同的服务器,这部分就是我们所需要处理的。 通常,负载均衡分为硬件和软件两种,硬件层的比较牛逼,将4-7层负载均衡功能做到一个硬件里面,如F5,梭子鱼等。目前主流的软件负载均衡分为四层和七层,LVS属于四层负载均衡,工作在tcp/ip协议栈上,通过修改网络包的ip地址和端口来转发, 由于效率比七层高,一般放在架构的前端。七层的负载均衡有nginx, haproxy, apache等,虽然nginx自1.9.0版本后也开始支持四层的负载均衡,但是暂不讨论(我木有硬件条件)。下图来自张开涛的《亿级流量网站架构核心技术》\",\"本站并没有那么多的服务器,目前只有两台,搭建不了那么大型的架构,就简陋的用两台服务器来模拟一下负载均衡的搭建。下图是本站的简单架构:\",\"其中服务器A(119.23.46.71)为深圳节点,服务器B(47.95.10.139)为北京节点,搭建Nginx之后流量是这么走的:user->A->B-A->user或者user->A->user,第一条中A将请求转发给B,然后B返回的是其运行结果的静态资源。因为这里仅仅是用来学习,所以请不要考虑因为地域导致延时的问题。。。。下面是过程。\"]},\"153\":{\"h\":\"1.1 Nginx的安装\",\"t\":[\"可以选择tar.gz、yum、rpm安装等,这里,由于编译、nginx配置比较复杂,要是没有把握还是使用rpm来安装吧,比较简单。从https://pkgs.org/download/nginx可以找到最新的rpm包,然后rpm -ivh 文件,然后在命令行中输入nginx即可启动,可以使用netstat检查一下端口。\",\"启动后页面如下:\",\"记一下常用命令\",\"启动nginx,由于是采用rpm方式,所以环境变量什么的都配置好了。 [root@beijingali ~]# nginx #启动nginx [root@beijingali ~]# nginx -s reload #重启nginx [root@beijingali ~]# nginx -t #校验nginx配置文件 nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful \"]},\"154\":{\"h\":\"1.2 Nginx的配置\"},\"155\":{\"h\":\"1.2.1 负载均衡算法\",\"t\":[\"Nginx常用的算法有: (1)round-robin:轮询,nginx默认的算法,从词语上可以看出,轮流访问服务器,也可以通过weight来控制访问次数。 (2)ip_hash:根据访客的ip,一个ip地址对应一个服务器。 (3)hash算法:hash算法常用的方式有根据uri、动态指定的consistent_key两种。 使用hash算法的缺点是当添加服务器的时候,只有少部分的uri能够被重新分配到新的服务器。这里,本站使用的是hash uri的算法,将不同的uri分配到不同的服务器,但是由于是不同的服务器,tomcat中的session是不一致,解决办法是tomcat session的共享。额。。。可惜本站目前没有什么能够涉及到登陆什么session的问题。\",\"http{ ... upstream backend { hash $uri; # 北京节点 server 47.95.10.139:8080; # 深圳节点 server 119.23.46.71:8080; } server { ... location / { root html; index index.html index.htm; proxy_pass http://backend; ... } ... \"]},\"156\":{\"h\":\"1.2.2 日志格式\",\"t\":[\"之前有使用过ELK来跟踪日志,所以将日志格式化成了json的格式,这里贴一下吧\",\" ... log_format main '{\\\"@timestamp\\\":\\\"$time_iso8601\\\",' '\\\"host\\\":\\\"$server_addr\\\",' '\\\"clientip\\\":\\\"$remote_addr\\\",' '\\\"size\\\":$body_bytes_sent,' '\\\"responsetime\\\":$request_time,' '\\\"upstreamtime\\\":\\\"$upstream_response_time\\\",' '\\\"upstreamhost\\\":\\\"$upstream_addr\\\",' '\\\"http_host\\\":\\\"$host\\\",' '\\\"url\\\":\\\"$uri\\\",' '\\\"xff\\\":\\\"$http_x_forwarded_for\\\",' '\\\"referer\\\":\\\"$http_referer\\\",' '\\\"agent\\\":\\\"$http_user_agent\\\",' '\\\"status\\\":\\\"$status\\\"}'; access_log logs/access.log main; ... \"]},\"157\":{\"h\":\"1.2.3 HTTP反向代理\",\"t\":[\"配置完上流服务器之后,需要配置Http的代理,将请求的端口转发到proxy_pass设定的上流服务器,即当我们访问http://wwww.wenzhihuai.com的时候,请求会被转发到backend中配置的服务器,此处为http://47.95.10.139:8080或者http://119.23.46.71:8080。但是,仔细注意之后,我们会发现,tomcat中的访问日志ip来源都是127.0.0.1,相当于本地访问自己的资源。由于后台中有处理ip的代码,对客户端的ip、访问uri等记录下来,所以需要设置nginx来获取用户的实际ip,参考nginx 配置。参考文中的一句话:经过反向代理后,由于在客户端和web服务器之间增加了中间层,因此web服务器无法直接拿到客户端的ip,通过$remote_addr变量拿到的将是反向代理服务器的ip地址”。nginx是可以获得用户的真实ip的,也就是说nginx使用$remote_addr变量时获得的是用户的真实ip,如果我们想要在web端获得用户的真实ip,就必须在nginx这里作一个赋值操作,如下:\",\" location / { root html; index index.html index.htm; proxy_pass http://backend; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $host; proxy_set_header REMOTE-HOST $remote_addr; } \",\"(1)proxy_set_header X-real-ip $remote_addr; 其中这个X-real-ip是一个自定义的变量名,名字可以随意取,这样做完之后,用户的真实ip就被放在X-real-ip这个变量里了,然后,在web端可以这样获取: request.getAttribute(\\\"X-real-ip\\\")\",\"(2)proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;\",\"X-Forwarded-For:squid开发的,用于识别通过HTTP代理或负载平衡器原始IP一个连接到Web服务器的客户机地址的非rfc标准,这个不是默认有的,其经过代理转发之后,格式为client1, proxy1, proxy2,如果想通过这个变量来获取用户的ip,那么需要和$proxy_add_x_forwarded_for一起使用。 $proxy_add_x_forwarded_for:现在的$proxy_add_x_forwarded_for变量,X-Forwarded-For部分包含的是用户的真实ip,$remote_addr部分的值是上一台nginx的ip地址,于是通过这个赋值以后现在的X-Forwarded-For的值就变成了“用户的真实ip,第一台nginx的ip”。\"]},\"158\":{\"h\":\"1.2.4 HTTPS\",\"t\":[\"HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。一般情况下,能通过服务器的ssh来生成ssl证书,但是如果使用是自己的,一般浏览器(谷歌、360等)都会报证书不安全的错误,正常用户都不敢访问吧==,所以现在使用的是腾讯跟别的机构颁发的:\",\"首先需要下载证书,放在nginx.conf相同目录下,nginx上的配置也需要有所改变,在nginx.conf中设置listen 443 ssl;开启https。然后配置证书和私钥:\",\" ssl_certificate 1_www.wenzhihuai.com_bundle.crt; #主要文件路径 ssl_certificate_key 2_www.wenzhihuai.com.key; ssl_session_timeout 5m; # 超时时间 ssl_protocols TLSv1 TLSv1.1 TLSv1.2; #按照这个协议配置 ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;#按照这个套件配置 ssl_prefer_server_ciphers on; \",\"至此,可以使用https来访问了。https带来的安全性(保证信息安全、识别钓鱼网站等)是http远远不能比拟的,目前大部分网站都是实现全站https,还能将http自动重定向为https,此处,需要在server中添加rewrite ^(.*) https://$server_name$1 permanent;即可\"]},\"159\":{\"h\":\"1.2.5 失败重试\",\"t\":[\"配置好了负载均衡之后,如果有一台服务器挂了怎么办?nginx中提供了可配置的服务器存活的识别,主要是通过max_fails失败请求次数,fail_timeout超时时间,weight为权重,下面的配置的意思是当服务器超时10秒,并失败了两次的时候,nginx将认为上游服务器不可用,将会摘掉上游服务器,fail_timeout时间后会再次将该服务器加入到存活上游服务器列表进行重试\",\"upstream backend_server { server 10.23.46.71:8080 max_fails=2 fail_timeout=10s weight=1; server 47.95.10.139:8080 max_fails=2 fail_timeout=10s weight=1; } \",\"分布式情况下难免会要解决session共享的问题,目前推荐的方法基本上都是使用redis,网上查找的方法目前流行的有下面四种,参考自tomcat 集群中 session 共: 1.使用 filter 方法存储。(推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简单容易控制。) 2.使用 tomcat sessionmanager 方法存储。(直接配置即可) 3.使用 terracotta 服务器共享。(不知道,不了解) 4.使用spring-session。(spring的一个小项目,其原理也和第一种基本一致)\",\"本站使用spring-session,毕竟是spring下的子项目,学习下还是挺好的。参考Spring-Session官网。官方文档提供了spring-boot、spring等例子,可以参考参考。目前最新版本是2.0.0,不同版本使用方式不同,建议看官网的文档吧。\",\"首先,添加相关依赖\",\"
org.springframework.session spring-session-data-redis 1.3.1.RELEASE pom redis.clients jedis ${jedis.version} \",\"新建一个session.xml,然后在spring的配置文件中添加该文件,然后在session.xml中添加:\",\"
\",\"然后我们需要保证servlet容器(tomcat)针对每一个请求都使用springSessionRepositoryFilter来拦截\",\"
springSessionRepositoryFilter org.springframework.web.filter.DelegatingFilterProxy springSessionRepositoryFilter /* REQUEST ERROR \",\"配置完成,使用RedisDesktopManager查看结果:\"]},\"160\":{\"h\":\"测试:\",\"t\":[\"访问http://www.wenzhihuai.com tail -f localhost_access_log.2017-11-05.txt查看日志,然后清空一下当前记录\",\"访问技术杂谈页面,此时nginx将请求转发到119.23.46.71服务器,session为28424f91-5bc5-4bba-99ec-f725401d7318。\",\"点击生活笔记页面,转发到的服务器为47.95.10.139,session为28424f91-5bc5-4bba-99ec-f725401d7318,与上面相同。session已保持一致。\",\"值得注意的是:同一个浏览器,在没有关闭的情况下,即使通过域名访问和ip访问得到的session是不同的。\\n欢迎访问我的个人网站O(∩_∩)O哈哈~希望能给个star\\n个人网站网址:http://www.wenzhihuai.com\\n个人网站代码地址:https://github.com/Zephery/newblog\"]},\"161\":{\"h\":\"6.数据库备份\",\"t\":[\"先来回顾一下上一篇的小集群架构,tomcat集群,nginx进行反向代理,服务器异地:\",\"由上一篇讲到,部署的时候,将war部署在不同的服务器里,通过spring-session实现了session共享,基本的分布式部署还算是完善了点,但是想了想数据库的访问会不会延迟太大,毕竟一个服务器在北京,一个在深圳,然后试着ping了一下:\",\"果然,36ms。。。看起来挺小的,但是对比一下sql执行语句的时间:\",\"大部分都能在10ms内完成,而最长的语句是insert语句,可见,由于异地导致的36ms延时还是比较大的,捣鼓了一下,最后还是选择换个架构,每个服务器读取自己的数据库,然后数据库底层做一下主主复制,让数据同步。最终架构如下:\",\"数据库复制的基本问题就是让一台服务器的数据与其他服务器保持同步。MySql目前支持两种复制方式:基于行的复制和基于语句的复制,这两者的基本过程都是在主库上记录二进制的日志、在备库上重放日志的方式来实现异步的数据复制。其过程分为三步: (1)master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events); (2)slave将master的binary log events拷贝到它的中继日志(relay log); (3)slave重做中继日志中的事件,将改变反映它自己的数据。\",\"该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。 下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。 SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。 此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。 MySql的基本复制方式有主从复制、主主复制,主主复制即把主从复制的配置倒过来再配置一遍即可,下面的配置则是主从复制的过程,到时候可自行改为主主复制。其他的架构如:一主库多备库、环形复制、树或者金字塔型都是基于这两种方式,可参考《高性能MySql》。\"]},\"162\":{\"h\":\"2.1 创建所用的复制账号\",\"t\":[\"由于是个自己的小网站,就不做过多的操作了,直接使用root账号\"]},\"163\":{\"h\":\"2.2 配置master\",\"t\":[\"接下来要对mysql的serverID,日志位置,复制方式等进行操作,使用vim打开my.cnf。\",\"[client] default-character-set=utf8 [mysqld] character_set_server=utf8 init_connect= SET NAMES utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock symbolic-links=0 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid # master log-bin=mysql-bin # 设为基于行的复制 binlog-format=ROW # 设置server的唯一id server-id=2 # 忽略的数据库,不使用备份 binlog-ignore-db=information_schema binlog-ignore-db=cluster binlog-ignore-db=mysql # 要进行备份的数据库 binlog-do-db=myblog \",\"重启Mysql之后,查看主库状态,show master status。\",\"其中,File为日志文件,指定Slave从哪个日志文件开始读复制数据,Position为偏移,从哪个POSITION号开始读,Binlog_Do_DB为要备份的数据库。\"]},\"164\":{\"h\":\"2.3 配置slave\",\"t\":[\"从库的配置跟主库类似,vim /etc/my.cnf配置从库信息。\",\" [client] default-character-set=utf8 [mysqld] character_set_server=utf8 init_connect= SET NAMES utf8 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock symbolic-links=0 log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid # slave log-bin=mysql-bin # 服务器唯一id server-id=3 # 不备份的数据库 binlog-ignore-db=information_schema binlog-ignore-db=cluster binlog-ignore-db=mysql # 需要备份的数据库 replicate-do-db=myblog # 其他相关信息 slave-skip-errors=all slave-net-timeout=60 # 开启中继日志 relay_log = mysql-relay-bin # log_slave_updates = 1 # 防止改变数据 read_only = 1 \",\"重启slave,同时启动复制,还需要调整一下命令。\",\"mysql> CHANGE MASTER TO MASTER_HOST = '119.23.46.71', MASTER_USER = 'root', MASTER_PASSWORD = 'helloroot', MASTER_PORT = 3306, MASTER_LOG_FILE = 'mysql-bin.000009', MASTER_LOG_POS = 346180; \",\"可以看见slave已经开始进行同步了。我们使用show slave status\\\\G来查看slave的状态。\",\"其中日志文件和POSITION不一致是合理的,配置好了的话,即使重启,也不会影响到主从复制的配置。\",\"某天在Github上漂游,发现了阿里的canal,同时才知道上面这个业务是叫异地跨机房同步,早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。下面是基本的原理:\",\"原理相对比较简单:\",\"1.canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议 2.mysql master收到dump请求,开始推送binary log给slave(也就是canal) 3.canal解析binary log对象(原始为byte流)\",\"其中,配置过程如下:https://github.com/alibaba/canal,可以搭配Zookeeper使用。在ZKUI中能够查看到节点:\",\"一般情况下,还要配合阿里的另一个开源产品使用otter,相关文档还是找找GitHub吧,个人搭建完了之后,用起来还是不如直接使用mysql的主主复制,而且异地机房同步这种大企业才有的业务。\",\"公司又要996了,实在是忙不过来,感觉自己写的还是急躁了点,困==\"]},\"165\":{\"h\":\"7.那些牛逼的插件\",\"t\":[\"欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。 建站的一开始,我也想自己全部实现,各种布局,各种炫丽的效果,想做点能让大家佩服的UI出来,但是,事实上,自己作为专注Java的程序员,前端的东西一碰脑子就有“我又不是前端,浪费时间在这合适么?”这种想法,捣鼓来捣鼓去,做出的东西实在是没法看,我就觉得,如果自己的“产品”连自己都看不下去了,那还好意思给别人看?特别是留言板那块,初版的页面简直low的要死。所以,还是踏踏实实的“站在巨人的肩膀上”吧,改用别人的插件。但不要纯粹的使用别人的博客模板了,如hexo,wordpress这些,就算是自己拼凑过来的也比这些强。下面是本博客中所用到的插件,给大家介绍介绍,共同学习学习。 本站主要用到的插件有: 1.wowslider 2.畅言 3.Editor.md 4.highchart、echart 5.百度分享 6.waterfall.js 7.心知天气 8.标签云\"]},\"166\":{\"h\":\"wowslider\",\"t\":[\"可能是我这网站中最炫的东西了,图片能够自动像幻灯片一样自动滚动,让网站的首页一看起来就高大上,简直就是建站必备的东西,而且安装也及其简单,有兴趣可以点击官网看看。GitHub里也开放了源代码。安装过程:自己选择“幻灯片”切换效果,保存为html就行了,WORDPREESS中好像有集成这个插件的,做的还更好。感兴趣可以点击我的博客首页看一看。\",\"不过还有个值得注意的问题,就是wowslider里面带有一个googleapis的服务,即https://fonts.googleapis.com/css?family=Arimo&subset=latin,cyrillic,latin-ext,由于一般用户不能访问谷歌,会导致网页加载速度及其缓慢,所以,去掉为妙\"]},\"167\":{\"h\":\"畅言\",\"t\":[\"作为社交评论的工具,虽然说表示还是想念以前的多说,但是畅言现在做得还是好了,有评论审核,评论导出导入等功能,如果浏览量大的话,还能提供广告服务,让站长也能拿到一丢丢的广告费。本博客中使用了畅言的基本评论、获取某篇文章评论数的功能。可以到我这里留言哈\"]},\"168\":{\"h\":\"Editor.md\",\"t\":[\"一款能将markdown解析为html的插件,国人的作品,博客的文章编辑器一开始想使用的是markdown,想法是:写文章、保存数据库都是markdown格式的,保存在数据库中,读取时有需要解析markdown,这个过程是有点耗时的,但是相比把html式的网页保存在数据库中友好点吧,因为如果一篇文章比较长的话,转成html的格式,光是大小估计也得超过几十kb?所以,还是本人选择的是一切都用源markdown。 editor.md,是一款开源的、可嵌入的 Markdown 在线编辑器(组件),基于 CodeMirror、jQuery 和 Marked 构建。页面看起来还是美观的,相比WORDPRESS的那些牛逼插件还差那么一点点,不过从普通人的眼光来看,应该是可以的了。此处,我用它作为解析网页的利器,还有就是后台编辑也是用的这个。\",\"代码样式,这一点是不如WORDPRESS的插件了,不过已经可以了。\"]},\"169\":{\"h\":\"图表\",\"t\":[\"目前最常用的是highcharts跟echart,目前个人博客中的日志系统主要还是采用了highcharts,主要还是颜色什么的格调比较相符吧,其次是因为对echarts印象不太友好,比如下面做这张,打开网页后,缩小浏览器,百度的地域图却不能自适应,出现了越界,而highcharts的全部都能自适应调整。想起有次面试,我说我用的highcharts,面试官一脸嫌弃。。。(网上这么多人鄙视百度是假的?)\",\"不过地图确确实实是echarts的优势,毕竟还是自家的东西了解自家,不过前段时间去看了看echarts的官网,已经不提供下载了。如果有需要,还是去csdn上搜索吧,或者替换为highmap。\"]},\"170\":{\"h\":\"百度分享\",\"t\":[\"作为一个以博客为主的网站,免不了使用一些社会化分享的工具,目前主要是jiathis和百度分享,这两者的ui都是相似的(丑爆了)。凭我个人的感觉,jiathis加载实在是太过于缓慢,这点是无法让人忍受的,只好投靠百度。百度分享类似于jiathis,安装也很简单,具体见官网http://share.baidu.com/code/advance#tools。一直点点点,配置完之后,就是下图这种,丑爆了是不是?\",\"好在对它的美观改变不是很难,此处参考了别人的UI设计,原作者我忘记怎么联系他了。其原理主要是使用图片来替换掉原本的东西。完整的源码可以点击此处。\",\"#share a { width: 34px; height: 34px; padding: 0; margin: 6px; border-radius: 25px; transition: all .4s; } /*主要的是替换掉backgound的背景图片*/ #share a.bds_qzone { background: url(http://image.wenzhihuai.com/t_QQZone.png) no-repeat; background-size: 34px 34px; } \",\"改完之后的效果。\"]},\"171\":{\"h\":\"瀑布流\",\"t\":[\"有段时间,瀑布流特别流行?还有段时间,瀑布流开始遭到各种抵制。。。看看知乎的人怎么说,大部分人不喜欢的原因是让人觉得视觉疲劳,不过瀑布流最大的好处还是有的:提高发现好图的效率以及图片列表页极强的视觉感染力。没错,我还是想把自己的网站弄得铉一些==,所以采用了瀑布流(不过效果不是很好,某些浏览器甚至加载出错),这个大bug有时间再改,毕竟花了很多时间做的这个,效果确实不咋地。目前主要的瀑布流有waterfall.js和masory.js。这一块目前还不是很完善,希望能得到各位大佬的指点。\"]},\"172\":{\"h\":\"天气插件\",\"t\":[\"此类咨询服务还是网上还是挺多的,这一块不知道是不是所谓的“画蛇添足”这部分,主要是我觉得网站右边这部分老是少了点什么,所以加上了天气插件。目前常用的天气插件有中国天气网,心知天气等。安装方式见各自的官网,这里不再阐述,我使用的是心知天气。注意:心知天气限制流量的,一个小时内只能使用400次,如果超出了会失效,当然也可以付费使用。\"]},\"173\":{\"h\":\"标签云\",\"t\":[\"标签云,弄得好的话应该说是一个网站的点缀。现在好像比较流行3D的标签云?像下面这种。\",\"从个人的网站风格来看,比较适应PHP形式的,有点颜色而又不绚丽的即可,之前用的跟分类的一样的样式,即双纵列的样式,美观度还行,虽然老是感觉有点怪怪的,如果某个标签的字数过长怎么办,岂不是要顶出div了。所以还是选择换另一种风格,最终偶然一次找到了下面这种,能够自适应宽度,颜色虽然鲜艳了点(以后有空再调一下吧),源码见style.css。 下图为目前的标签页。\",\"作为一个后端人员,调css和js真是痛苦==,好在坚持下来了,虽然还是很多不足,以后有时间慢慢改。说了那么多,感觉自己还是菜的抠脚。 题外话,搭建一个博客,对于一个新近程序员来说真的是锻炼自己的一个好机会,能够认识到从前端、java后台、linux、jvm等等知识,只是真的有点耗时间(还不如把时间耗在Spring源码),如果不采用别人的框架的话,付出的代价还是蛮大的(所以不要鄙视我啦)。没有什么能够一举两得,看自己的取舍吧。加油💪(ง •_•)ง\",\"欢迎访问我的网站http://www.wenzhihuai.com/ 。感谢,如果可以,希望能在GitHub上给个star,GitHub地址https://github.com/Zephery/newblog 。\"]},\"174\":{\"h\":\"8.基于贝叶斯的情感分析\"},\"175\":{\"h\":\"9.网站性能优化\"},\"176\":{\"h\":\"一、概述\"},\"177\":{\"h\":\"1.1 缓存介绍\",\"t\":[\"系统的性能指标一般包括响应时间、延迟时间、吞吐量,并发用户数和资源利用率等。在应用运行过程中,我们有可能在一次数据库会话中,执行多次查询条件完全相同的SQL,MyBatis提供了一级缓存的方案优化这部分场景,如果是相同的SQL语句,会优先命中一级缓存,避免直接对数据库进行查询,提高性能。 缓存常用语: 数据不一致性、缓存更新机制、缓存可用性、缓存服务降级、缓存预热、缓存穿透 可查看Redis实战(一) 使用缓存合理性\"]},\"178\":{\"h\":\"1.2 本站缓存架构\",\"t\":[\"从没有使用缓存,到使用mybatis缓存,然后使用了ehcache,再然后是mybatis+redis缓存。\",\"步骤: (1)用户发送一个请求到nginx,nginx对请求进行分发。 (2)请求进入controller,service,service中查询缓存,如果命中,则直接返回结果,否则去调用mybatis。 (3)mybatis的缓存调用步骤:二级缓存->一级缓存->直接查询数据库。 (4)查询数据库的时候,mysql作了主主备份。\"]},\"179\":{\"h\":\"2.1 mybatis一级缓存\",\"t\":[\"Mybatis的一级缓存是指Session回话级别的缓存,也称作本地缓存。一级缓存的作用域是一个SqlSession。Mybatis默认开启一级缓存。在同一个SqlSession中,执行相同的查询SQL,第一次会去查询数据库,并写到缓存中;第二次直接从缓存中取。当执行SQL时两次查询中间发生了增删改操作,则SqlSession的缓存清空。Mybatis 默认支持一级缓存,不需要在配置文件中配置。\",\"我们来查看一下源码的类图,具体的源码分析简单概括一下:SqlSession实际上是使用PerpetualCache来维护的,PerpetualCache中定义了一个HashMap来进行缓存。 (1)当会话开始时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象; (2)对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果。如果命中,则返回结果,如果没有命中,则去数据库中查询,再将结果存储到cache中,最后返回结果。如果执行增删改,则执行flushCacheIfRequired方法刷新缓存。 (3)当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。\"]},\"180\":{\"h\":\"2.2 mybatis二级缓存\",\"t\":[\"Mybatis的二级缓存是指mapper映射文件,为Application应用级别的缓存,生命周期长。二级缓存的作用域是同一个namespace下的mapper映射文件内容,多个SqlSession共享。Mybatis需要手动设置启动二级缓存。在同一个namespace下的mapper文件中,执行相同的查询SQL。实现二级缓存,关键是要对Executor对象做文章,Mybatis给Executor对象加上了一个CachingExecutor,使用了设计模式中的装饰者模式,\"]},\"181\":{\"h\":\"2.2.1 MyBatis二级缓存的划分\",\"t\":[\"MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下: a.为每一个Mapper分配一个Cache缓存对象; b.多个Mapper共用一个Cache缓存对象;\"]},\"182\":{\"h\":\"2.2.2 二级缓存的开启\",\"t\":[\"在mybatis的配置文件中添加:\",\"
\",\"然后再需要开启二级缓存的mapper.xml中添加(本站使用了LRU算法,时间为120000毫秒):\",\"
\"]},\"183\":{\"h\":\"2.2.3 使用第三方支持的二级缓存的实现\",\"t\":[\"MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached、Redis的集成,总之,使用MyBatis的二级缓存有三个选择:\",\"MyBatis自身提供的缓存实现;\",\"用户自定义的Cache接口实现;\",\"跟第三方内存缓存库的集成; 具体的实现,可参照:SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置\",\"MyBatis中一级缓存和二级缓存的组织如下图所示(图片来自深入理解mybatis原理):\"]},\"184\":{\"h\":\"2.3 Mybatis在分布式环境下脏读问题\",\"t\":[\"(1)如果是一级缓存,在多个SqlSession或者分布式的环境下,数据库的写操作会引起脏数据,多数情况可以通过设置缓存级别为Statement来解决。 (2)如果是二级缓存,虽然粒度比一级缓存更细,但是在进行多表查询时,依旧可能会出现脏数据。 (3)Mybatis的缓存默认是本地的,分布式环境下出现脏读问题是不可避免的,虽然可以通过实现Mybatis的Cache接口,但还不如直接使用集中式缓存如Redis、Memcached好。\",\"下面将介绍使用Redis集中式缓存在个人网站的应用。\",\"Redis运行于独立的进程,通过网络协议和应用交互,将数据保存在内存中,并提供多种手段持久化内存的数据。同时具备服务器的水平拆分、复制等分布式特性,使得其成为缓存服务器的主流。为了与Spring更好的结合使用,我们使用的是Spring-Data-Redis。此处省略安装过程和Redis的命令讲解。 \"]},\"185\":{\"h\":\"3.1 Spring Cache\",\"t\":[\"Spring 3.1 引入了激动人心的基于注释(annotation)的缓存(cache)技术,它本质上不是一个具体的缓存实现方案(例如EHCache 或者 OSCache),而是一个对缓存使用的抽象,通过在既有代码中添加少量它定义的各种 annotation,即能够达到缓存方法的返回对象的效果。Spring 的缓存技术还具备相当的灵活性,不仅能够使用 **SpEL(Spring Expression Language)**来定义缓存的 key 和各种 condition,还提供开箱即用的缓存临时存储方案,也支持和主流的专业缓存例如 EHCache 集成。 下面是Spring Cache常用的注解:\",\"(1)@Cacheable @Cacheable 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存\",\"属性\",\"介绍\",\"例子\",\"value\",\"缓存的名称,必选\",\"@Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”}\",\"key\",\"缓存的key,可选,需要按照SpEL表达式填写\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"condition\",\"缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"(2)@CachePut @CachePut 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用\",\"属性\",\"介绍\",\"例子\",\"value\",\"缓存的名称,必选\",\"@Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”}\",\"key\",\"缓存的key,可选,需要按照SpEL表达式填写\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"condition\",\"缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"(3)@CacheEvict @CachEvict 的作用 主要针对方法配置,能够根据一定的条件对缓存进行清空\",\"属性\",\"介绍\",\"例子\",\"value\",\"缓存的名称,必选\",\"@Cacheable(value=”mycache”) 或者@Cacheable(value={”cache1”,”cache2”}\",\"key\",\"缓存的key,可选,需要按照SpEL表达式填写\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"condition\",\"缓存的条件,可以为空,使用 SpEL 编写,只有为 true 才进行缓存\",\"@Cacheable(value=”testcache”,key=”#userName”)\",\"allEntries\",\"是否清空所有缓存内容,默认为false\",\"@CachEvict(value=”testcache”,allEntries=true)\",\"beforeInvocation\",\"是否在方法执行前就清空,缺省为 false\",\"@CachEvict(value=”testcache”,beforeInvocation=true)\",\"但是有个问题: Spring官方认为:缓存过期时间由各个产商决定,所以并不提供缓存过期时间的注解。所以,如果想实现各个元素过期时间不同,就需要自己重写一下Spring cache。\"]},\"186\":{\"h\":\"3.2 引入包\",\"t\":[\"一般是Spring常用的包+Spring data redis的包,记得注意去掉所有冲突的包,之前才过坑,Spring-data-MongoDB已经有SpEL的库了,和自己新引进去的冲突,搞得我以为自己是配置配错了,真是个坑,注意,开发过程中一定要去除掉所有冲突的包!!!\"]},\"187\":{\"h\":\"3.3 ApplicationContext.xml\",\"t\":[\"需要启用缓存的注解开关,并配置好Redis。序列化方式也要带上,否则会碰到幽灵bug。\",\" \"]},\"188\":{\"h\":\"3.5 自定义KeyGenerator\",\"t\":[\"在分布式系统中,很容易存在不同类相同名字的方法,如A.getAll(),B.getAll(),默认的key(getAll)都是一样的,会很容易产生问题,所以,需要自定义key来实现分布式环境下的不同。\",\"@Component(\\\"customKeyGenerator\\\") public class CustomKeyGenerator implements KeyGenerator { @Override public Object generate(Object o, Method method, Object... objects) { StringBuilder sb = new StringBuilder(); sb.append(o.getClass().getName()); sb.append(\\\".\\\"); sb.append(method.getName()); for (Object obj : objects) { sb.append(obj.toString()); } return sb.toString(); } } \",\"之后,存储的key就变为:com.myblog.service.impl.BlogServiceImpl.getBanner。\"]},\"189\":{\"h\":\"3.4 添加注解\",\"t\":[\"在所需要的方法上添加注解,比如,首页中的那几张幻灯片,每次进入首页都需要查询数据库,这里,我们直接放入缓存里,减少数据库的压力,还有就是那些热门文章,访问量比较大的,也放进数据库里。\",\" @Override @Cacheable(value = \\\"getBanner\\\", keyGenerator = \\\"customKeyGenerator\\\") public List getBanner() { return blogMapper.getBanner(); } @Override @Cacheable(value = \\\"getBlogDetail\\\", key = \\\"'blogid'.concat(#blogid)\\\") public Blog getBlogDetail(Integer blogid) { Blog blog = blogMapper.selectByPrimaryKey(blogid); if (blog == null) { return null; } Category category = categoryMapper.selectByPrimaryKey(blog.getCategoryid()); blog.setCategory(category); List tags = tagMapper.getTagByBlogId(blog.getBlogid()); blog.setTags(tags.size() > 0 ? tags : null); asyncService.updatebloghits(blogid);//异步更新阅读次数 logger.info(\\\"没有走缓存\\\"); return blog; } \"]},\"190\":{\"h\":\"3.5 测试\",\"t\":[\"我们调用一个getBlogDetail(获取博客详情)100次来对比一下时间。连接的数据库在深圳,本人在广州,还是有那么一丢丢的网路延时的。\",\"public class SpringTest { @Test public void init() { ApplicationContext ctx = new FileSystemXmlApplicationContext(\\\"classpath:spring-test.xml\\\"); IBlogService blogService = (IBlogService) ctx.getBean(\\\"blogService\\\"); long startTime = System.currentTimeMillis(); for (int i = 0; i < 100; i++) { blogService.getBlogDetail(615); } System.out.println(System.currentTimeMillis() - startTime); } } \",\"为了做一下对比,我们同时使用mybatis自身缓存来进行测试。\"]},\"191\":{\"h\":\"3.6 实验结果\",\"t\":[\"统计出结果如下:\",\"没有使用任何缓存(mybatis一级缓存没有关闭):18305 使用远程Redis缓存:12727 使用Mybatis缓存:6649 使用本地Redis缓存:5818 \",\"由结果看出,缓存的使用大大较少了获取数据的时间。\",\"部署进个人博客之后,redis已经缓存的数据:\"]},\"192\":{\"h\":\"3.7 分页的数据怎么办\",\"t\":[\"个人网站中共有两个栏目,一个是技术杂谈,另一个是生活笔记,每点击一次栏目的时候,会根据页数从数据库中查询数据,百度了下,大概有三种方法: (1)以页码作为Key,然后缓存整个页面。 (2)分条存取,只从数据库中获取分页的文章ID序列,然后从service(缓存策略在service中实现)中获取。 第一种,由于使用了第三方的插件PageHelper,分页获取的话会比较麻烦,同时整页缓存对内存压力也蛮大的,毕竟服务器只有2g。第二条实现方式简单,缺陷是依旧需要查询数据库,想了想还是放弃了。缓存的初衷是对请求频繁又不易变的数据,实际使用中很少会反复的请求同一页的数据(查询条件也相同),当然对数据中某些字段做缓存还是有必要的。\",\"对于文章来说,内容是不经常更新的,没有涉及到缓存一致性,但是对于文章的阅读量,用户每点击一次,就应该更新浏览量的。对于文章的缓存,常规的设计是将文章存储进数据库中,然后读取的时候放入缓存中,然后将浏览量以文章ID+浏览量的结构实时的存入redis服务器中。本站当初设计不合理,直接将浏览量作为一个字段,用户每点击一次的时候就异步更新浏览量,但是此处没有更新缓存,如果手动更新缓存的话,基本上每点击一次都得执行更新操作,同样也不合理。所以,目前本站,你们在页面上看到的浏览量和数据库中的浏览量并不是一致的。有兴趣的可以点击我的网站玩玩~~\",\"兄弟姐妹们啊,个人网站只是个小项目,纯属为了学习而用的,文章可以看看,但是,就不要抓取了吧。。。。一个小时抓取6万次宝宝心脏真的受不了,虽然服务器一切都还稳定==\",\"个人网站:http://www.wenzhihuai.com个人网站源码,希望能给个star:https://github.com/Zephery/newblog\",\"参考:\\n1.《深入理解mybatis原理》 MyBatis的一级缓存实现详解\\n2.《深入理解mybatis原理》 MyBatis的二级缓存的设计原理\\n3.聊聊Mybatis缓存机制\\n4.Spring思维导图\\n5.SpringMVC + MyBatis + Mysql + Redis(作为二级缓存) 配置\\n6.《深入分布式缓存:从原理到实践》\"]},\"193\":{\"h\":\"自我介绍\",\"t\":[\"oifjwoiej\"]},\"194\":{\"h\":\"elastic spark\",\"t\":[\"Hadoop允许Elasticsearch在Spark中以两种方式使用:通过自2.1以来的原生RDD支持,或者通过自2.0以来的Map/Reduce桥接器。从5.0版本开始,elasticsearch-hadoop就支持Spark 2.0。目前spark支持的数据源有: (1)文件系统:LocalFS、HDFS、Hive、text、parquet、orc、json、csv (2)数据RDBMS:mysql、oracle、mssql (3)NOSQL数据库:HBase、ES、Redis (4)消息对象:Redis\",\"elasticsearch相对hdfs来说,容易搭建、并且有可视化kibana支持,非常方便spark的初学入门,本文主要讲解用elasticsearch-spark的入门。\",\"Spark - Apache Spark\"]},\"195\":{\"h\":\"一、原生RDD支持\"},\"196\":{\"h\":\"1.1 基础配置\",\"t\":[\"相关库引入:\",\" org.elasticsearch elasticsearch-spark-30_2.13 8.1.3 \",\"SparkConf配置,更多详细的请点击这里或者源码ConfigurationOptions。\",\"public static SparkConf getSparkConf() { SparkConf sparkConf = new SparkConf().setAppName(\\\"elasticsearch-spark-demo\\\"); sparkConf.set(\\\"es.nodes\\\", \\\"host\\\") .set(\\\"es.port\\\", \\\"xxxxxx\\\") .set(\\\"es.nodes.wan.only\\\", \\\"true\\\") .set(\\\"es.net.http.auth.user\\\", \\\"elxxxxastic\\\") .set(\\\"es.net.http.auth.pass\\\", \\\"xxxx\\\") .setMaster(\\\"local[*]\\\"); return sparkConf; } \"]},\"197\":{\"h\":\"1.2 读取es数据\",\"t\":[\"这里用的是kibana提供的sample data里面的索引kibana_sample_data_ecommerce,也可以替换成自己的索引。\",\"public static void main(String[] args) { SparkConf conf = getSparkConf(); try (JavaSparkContext jsc = new JavaSparkContext(conf)) { JavaPairRDD> esRDD = JavaEsSpark.esRDD(jsc, \\\"kibana_sample_data_ecommerce\\\"); esRDD.collect().forEach(System.out::println); } } \",\"esRDD同时也支持query语句esRDD(final JavaSparkContext jsc, final String resource, final String query),一般对es的查询都需要根据时间筛选一下,不过相对于es的官方sdk,并没有那么友好的api,只能直接使用原生的dsl语句。\"]},\"198\":{\"h\":\"1.3 写数据\",\"t\":[\"支持序列化对象、json,并且能够使用占位符动态索引写入数据(使用较少),不过多介绍了。\",\"public static void jsonWrite(){ String json1 = \\\"{\\\\\\\"reason\\\\\\\" : \\\\\\\"business\\\\\\\",\\\\\\\"airport\\\\\\\" : \\\\\\\"SFO\\\\\\\"}\\\"; String json2 = \\\"{\\\\\\\"participants\\\\\\\" : 5,\\\\\\\"airport\\\\\\\" : \\\\\\\"OTP\\\\\\\"}\\\"; JavaRDD stringRDD = jsc.parallelize(ImmutableList.of(json1, json2)); JavaEsSpark.saveJsonToEs(stringRDD, \\\"spark-json\\\"); } \",\"比较常用的读写也就这些,更多可以看下官网相关介绍。\"]},\"199\":{\"h\":\"二、Spark Streaming\",\"t\":[\"spark的实时处理,es5.0的时候开始支持,目前\"]},\"200\":{\"h\":\"三、Spark SQL\"},\"201\":{\"h\":\"四、Spark Structure Streaming\"},\"202\":{\"h\":\"五、Spark on kubernetes Operator\",\"t\":[\"1.Apache Spark support\",\"2.elasticsearch-hadoop\",\"3.使用SparkSQL操作Elasticsearch - Spark入门教程\"]},\"203\":{\"h\":\"【elasticsearch】源码debug\",\"t\":[\"直接用idea下载代码https://github.com/elastic/elasticsearch.git \",\"切换到特定版本的分支:比如7.17,之后idea会自己加上Run/Debug Elasitcsearch的,配置可以不用改,默认就好 \",\"为了方便, 在 gradle/run.gradle 中关闭 Auth 认证:\",\"setting 'xpack.security.enabled', 'false'\",\"或者使用其中的用户名密码:\",\"user username: 'elastic-admin', password: 'elastic-password', role: 'superuser'\",\"先启动上面的 remote debug, 然后用 gradlew 启动项目:\",\"./gradlew :run --debug-jvm\\n打开浏览器http://localhost:9200即可看到es相关信息了\\n\"]},\"204\":{\"h\":\"【elasticsearch】搜索过程详解\",\"t\":[\"本文基于elasticsearch8.1。在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的进行搜索呢还是仅仅根据时间找出索引,然后才遍历索引进行搜索。在了解其原理前先了解一些基本知识。\"]},\"205\":{\"h\":\"SearchType\",\"t\":[\"QUERY_THEN_FETCH(默认):第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。 DFS_QUERY_THEN_FETCH:比第1种方式多了一个初始化散发(initial scatter)步骤。\",\"为了能够深刻了解es的搜索过程,首先创建3个索引,每个索引指定一天的一条记录。\",\"POST aaaa-16/_doc { \\\"@timestamp\\\": \\\"2022-02-16T16:21:15.000Z\\\", \\\"word\\\":\\\"16\\\" } POST aaaa-17/_doc { \\\"@timestamp\\\": \\\"2022-02-17T16:21:15.000Z\\\", \\\"word\\\":\\\"17\\\" } POST aaaa-18/_doc { \\\"@timestamp\\\": \\\"2022-02-18T16:21:15.000Z\\\", \\\"word\\\":\\\"18\\\" } \",\"即可在kibana上看到3条数据\",\"image-20220219195141327\",\"此时,假设我们用一个索引+星号来搜索,es内部的搜索是怎么样的呢?\",\"GET aaaa*/_search { \\\"query\\\": { \\\"range\\\": { \\\"@timestamp\\\": { \\\"gte\\\": \\\"2022-02-18T10:21:15.000Z\\\", \\\"lte\\\": \\\"2022-02-18T17:21:15.000Z\\\" } } } } \",\"正好命中一条记录返回。\",\"{ \\\"took\\\" : 2, \\\"timed_out\\\" : false, \\\"_shards\\\" : { \\\"total\\\" : 3, \\\"successful\\\" : 3, \\\"skipped\\\" : 0, \\\"failed\\\" : 0 }, \\\"hits\\\" : { \\\"total\\\" : { \\\"value\\\" : 1, \\\"relation\\\" : \\\"eq\\\" }, \\\"max_score\\\" : 1.0, \\\"hits\\\" : [ { \\\"_index\\\" : \\\"aaaa-18\\\", \\\"_id\\\" : \\\"0zB2O38BoMIMP8QzHgdq\\\", \\\"_score\\\" : 1.0, \\\"_source\\\" : { \\\"@timestamp\\\" : \\\"2022-02-18T16:21:15.000Z\\\", \\\"word\\\" : \\\"18\\\" } } ] } } \",\"一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配。假设一个索引有5个主分片,每个主分片有1个副分片,共10个分片,一次搜索请求会由5个分片来共同完成,它们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。当搜索任务执行在分布式系统上时,整体流程如下图所示。图片来源Elasitcsearch源码解析与优化实战\",\"2\"]},\"206\":{\"h\":\"搜索入口:\",\"t\":[\"整个http请求的入口,主要使用的是Netty4HttpRequestHandler。\",\"@ChannelHandler.Sharable class Netty4HttpRequestHandler extends SimpleChannelInboundHandler { @Override protected void channelRead0(ChannelHandlerContext ctx, HttpPipelinedRequest httpRequest) { final Netty4HttpChannel channel = ctx.channel().attr(Netty4HttpServerTransport.HTTP_CHANNEL_KEY).get(); boolean success = false; try { serverTransport.incomingRequest(httpRequest, channel); success = true; } finally { if (success == false) { httpRequest.release(); } } } } \",\"调用链路过程:Netty4HttpRequestHandler.channelRead0->AbstractHttpServerTransport.incomingRequest->AbstractHttpServerTransport.handleIncomingRequest->AbstractHttpServerTransport.dispatchRequest->RestController.dispatchRequest(实现了HttpServerTransport.Dispatcher)->SecurityRestFilter.handleRequest->BaseRestHandler.handleRequest->action.accept(channel)->RestCancellableNodeClient.doExecute->NodeClient.executeLocally->RequestFilterChain.proceed->TransportAction.proceed->TransportSearchAction.doExecute->TransportSearchAction.executeRequest(判断是本地执行还是远程执行)->TransportSearchAction.searchAsyncAction\",\"协调节点的主要功能是接收请求,解析并构建目的的shard列表,然后异步发送到数据节点进行请求查询。具体就不细讲了,可按着debug的来慢慢调试。\",\"特别注意下RestCancellableNodeClient.doExecute,从executeLocally执行所有的查询过程,并注册监听listener.onResponse(response),然后响应。\",\"public void doExecute(...) { ... TaskHolder taskHolder = new TaskHolder(); Task task = client.executeLocally(action, request, new ActionListener<>() { @Override public void onResponse(Response response) { try { closeListener.unregisterTask(taskHolder); } finally { listener.onResponse(response); } } }); ... } \",\"其次要注意的是:TransportSearchAction.searchAsyncAction才开始真正的搜索过程\",\"private SearchPhase searchAsyncAction(...) { ... final QueryPhaseResultConsumer queryResultConsumer = searchPhaseController.newSearchPhaseResults(); AbstractSearchAsyncAction searchAsyncAction = switch (searchRequest.searchType()) { case DFS_QUERY_THEN_FETCH -> new SearchDfsQueryThenFetchAsyncAction(...); case QUERY_THEN_FETCH -> new SearchQueryThenFetchAsyncAction(...); }; return searchAsyncAction; ... } \",\"之后就是执行AbstractSearchAsyncAction.start,启动AbstractSearchAsyncAction.executePhase的查询动作。\",\"此处的SearchPhase实现类为SearchQueryThenFetchAsyncAction private void executePhase(SearchPhase phase) { try { phase.run(); } catch (Exception e) { if (logger.isDebugEnabled()) { logger.debug(new ParameterizedMessage(\\\"Failed to execute [{}] while moving to [{}] phase\\\", request, phase.getName()), e); } onPhaseFailure(phase, \\\"\\\", e); } } \",\"两阶段相应的实现位置:查询(Query)阶段—search.SearchQueryThenFetchAsyncAction;取回(Fetch)阶段—search.FetchSearchPhase。它们都继承自SearchPhase,如下图所示。\",\"23\"]},\"207\":{\"h\":\"3.1 query阶段\",\"t\":[\"图片来源官网,比较旧,但任然可用\",\"12\",\"(1)客户端发送一个search请求到node3,node3创建一个大小为from,to的优先级队列。 (2)node3转发转发search请求至索引的主分片或者副本,每个分片执行查询请求,并且将结果放到一个排序之后的from、to大小的优先级队列。 (3)每个分片把文档id和排序之后的值返回给协调节点node3,node3把结果合并然后创建一个全局排序之后的结果。\",\"在RestSearchAction#prepareRequest方法中将请求体解析为SearchRequest 数据结构: public RestChannelConsumer prepareRequest(.. .) { SearchRequest searchRequest = new SearchRequest(); request.withContentOrSourceParamParserOrNull (parser -> parseSearchRequest (searchRequest, request, parser, setSize)); ... } \"]},\"208\":{\"h\":\"3.1.1 构造目的shard列表\",\"t\":[\"将请求涉及的本集群shard列表和远程集群的shard列表(远程集群用于跨集群访问)合并:\",\"private void executeSearch(.. .) { ... final GroupShardsIterator shardIterators = mergeShardsIterators(localShardIterators, remoteShardIterators); localShardIterators = StreamSupport.stream(localShardRoutings.spliterator(), false).map(it -> { OriginalIndices finalIndices = finalIndicesMap.get(it.shardId().getIndex().getUUID()); assert finalIndices != null; return new SearchShardIterator(searchRequest.getLocalClusterAlias(), it.shardId(), it.getShardRoutings(), finalIndices); }).collect(Collectors.toList()); ... } \",\"查看结果\",\"241\"]},\"209\":{\"h\":\"3.1.2 对所有分片进行搜索\",\"t\":[\"AbstractSearchAsyncAction.run 对每个分片进行搜索查询 for (int i = 0; i < shardsIts.size(); i++) { final SearchShardIterator shardRoutings = shardsIts.get(i); assert shardRoutings.skip() == false; assert shardIndexMap.containsKey(shardRoutings); int shardIndex = shardIndexMap.get(shardRoutings); performPhaseOnShard(shardIndex, shardRoutings, shardRoutings.nextOrNull()); } \",\"其中shardsIts是所有aaaa*的所有索引+其中一个副本\",\"2141\"]},\"210\":{\"h\":\"3.1.3 分片具体的搜索过程\",\"t\":[\"AbstractSearchAsyncAction.performPhaseOnShard private void performPhaseOnShard(. ..) { executePhaseOnShard(.. .) { //收到执行成功的回复 public void inne rOnResponse (FirstResult result) { maybeFork (thread, () -> onShardResult (result,shardIt) ); } //收到执行失败的回复 public void onFailure (Exception t) { maybeFork(thread, () -> onShardFailure (shardIndex, shard, shard. currentNodeId(),shardIt, t)); } }); } \",\"分片结果,当前线程\",\"//AbstractSearchAsyncAction.onShardResult ... private void onShardResult (FirstResult result, SearchShardIterator shardIt) { onShardSuccess(result); success fulShardExecution(shardIt); } ... //AbstractSearchAsyncAction.onShardResultConsumed private void successfulShardExecution (SearchShardIterator shardsIt) { //计数器累加. final int xTotalOps = totalOps.addAndGet (remainingOpsOnIterator); //检查是否收到全部回复 if (xTotalOps == expectedTotalOps) { onPhaseDone (); } else if (xTota1Ops > expectedTotal0ps) { throw new AssertionError(. ..); } } \",\"412\",\"此处忽略了搜索结果totalHits为0的结果,并将结果进行累加,当xTotalOps等于expectedTotalOps时开始AbstractSearchAsyncAction.onPhaseDone再进行AbstractSearchAsyncAction.executeNextPhase取回阶段\"]},\"211\":{\"h\":\"3.2 Fetch阶段\",\"t\":[\"取回阶段,图片来自官网,\",\"412412\",\"(1)各个shard 返回的只是各文档的id和排序值 IDs and sort values ,coordinate node根据这些id&sort values 构建完priority queue之后,然后把程序需要的document 的id发送mget请求去所有shard上获取对应的document\",\"(2)各个shard将document返回给coordinate node\",\"(3)coordinate node将合并后的document结果返回给client客户端\"]},\"212\":{\"h\":\"3.2.1 FetchSearchPhase(对应上面的1)\",\"t\":[\"Query阶段的executeNextPhase方法触发Fetch阶段,Fetch阶段的起点为FetchSearchPhase#innerRun函数,从查询阶段的shard列表中遍历,跳过查询结果为空的shard,对特定目标shard执行executeFetch来获取数据,其中包括分页信息。对scroll请求的处理也在FetchSearchPhase#innerRun函数中。\",\"private void innerRun() throws Exception { final int numShards = context.getNumShards(); final boolean isScrollSearch = context.getRequest().scroll() != null; final List phaseResults = queryResults.asList(); final SearchPhaseController.ReducedQueryPhase reducedQueryPhase = resultConsumer.reduce(); final boolean queryAndFetchOptimization = queryResults.length() == 1; final Runnable finishPhase = () -> moveToNextPhase( searchPhaseController, queryResults, reducedQueryPhase, queryAndFetchOptimization ? queryResults : fetchResults.getAtomicArray() ); for (int i = 0; i < docIdsToLoad.length; i++) { IntArrayList entry = docIdsToLoad[i]; SearchPhaseResult queryResult = queryResults.get(i); if (entry == null) { if (queryResult != null) { releaseIrrelevantSearchContext(queryResult.queryResult()); progressListener.notifyFetchResult(i); } counter.countDown(); }else{ executeFetch( queryResult.getShardIndex(), shardTarget, counter, fetchSearchRequest, queryResult.queryResult(), connection ); } } } } \",\"再看源码:\",\"启动一个线程来fetch AbstractSearchAsyncAction.executePhase->FetchSearchPhase.run->FetchSearchPhase.innerRun->FetchSearchPhase.executeFetch private void executeFetch(...) { context.getSearchTransport() .sendExecuteFetch( connection, fetchSearchRequest, context.getTask(), new SearchActionListener(shardTarget, shardIndex) { @Override public void innerOnResponse(FetchSearchResult result) { progressListener.notifyFetchResult(shardIndex); counter.onResult(result); } @Override public void onFailure(Exception e) { progressListener.notifyFetchFailure(shardIndex, shardTarget, e); counter.onFailure(shardIndex, shardTarget, e); } } ); } \",\"13413\",\"counter是一个收集器CountedCollector,onResult(result)主要是每次收到的shard数据存放,并且执行一次countDown,当所有shard数据收集完之后,然后触发一次finishPhase。\",\"# CountedCollector.class void countDown() { assert counter.isCountedDown() == false : \\\"more operations executed than specified\\\"; if (counter.countDown()) { onFinish.run(); } } \",\"moveToNextPhase方法执行下一阶段,下-阶段要执行的任务定义在FetchSearchPhase构造 函数中,主要是触发ExpandSearchPhase。\"]},\"213\":{\"h\":\"3.2.2 ExpandSearchPhase(对应上图的2)\",\"t\":[\"AbstractSearchAsyncAction.executePhase->ExpandSearchPhase.run。取回阶段完成之后执行ExpandSearchPhase#run,主要判断是否启用字段折叠,根据需要实现字段折叠功能,如果没有实现字段折叠,则直接返回给客户端。\",\"image-20220317000858513\",\"ExpandSearchPhase执行完之后回复客户端,在AbstractSearchAsyncAction.sendSearchResponse方法中实现:\",\"412412\"]},\"214\":{\"h\":\"4.1 执行query、fetch流程\",\"t\":[\"执行本流程的线程池: search。\",\"对各种Query请求的处理入口注册于SearchTransportService.registerRequestHandler。\",\"public static void registerRequestHandler(TransportService transportService, SearchService searchService) { ... transportService.registerRequestHandler( QUERY_ACTION_NAME, ThreadPool.Names.SAME, ShardSearchRequest::new, (request, channel, task) -> searchService.executeQueryPhase( request, (SearchShardTask) task, new ChannelActionListener<>(channel, QUERY_ACTION_NAME, request) ) ); ... } \"]},\"215\":{\"h\":\"4.1.1 执行query请求\",\"t\":[\"# SearchService public void executeQueryPhase(ShardSearchRequest request, SearchShardTask task, ActionListener listener) { assert request.canReturnNullResponseIfMatchNoDocs() == false || request.numberOfShards() > 1 : \\\"empty responses require more than one shard\\\"; final IndexShard shard = getShard(request); rewriteAndFetchShardRequest(shard, request, listener.delegateFailure((l, orig) -> { ensureAfterSeqNoRefreshed(shard, orig, () -> executeQueryPhase(orig, task), l); })); } \",\"其中ensureAfterSeqNoRefreshed是把request任务放到一个名为search的线程池里面执行,容量大小为1000。\",\"1\",\"主要是用来执行SearchService.executeQueryPhase->SearchService.loadOrExecuteQueryPhase->QueryPhase.execute。核心的查询封装在queryPhase.execute(context)中,其中调用Lucene实现检索,同时实现聚合:\",\"public void execute (SearchContext searchContext) { aggregationPhase.preProcess (searchContext); boolean rescore = execute ( searchContext, searchContext.searcher(), searcher::setCheckCancelled, indexSort); if (rescore) { rescorePhase.execute (searchContext); suggestPhase.execute (searchContext); aggregationPhase.execute (searchContext); } } \",\"其中包含几个核心功能:\",\"execute(),调用Lucene、searcher.search()实现搜索\",\"rescorePhase,全文检索且需要打分\",\"suggestPhase,自动补全及纠错\",\"aggregationPhase,实现聚合\"]},\"216\":{\"h\":\"4.1.2 fetch流程\",\"t\":[\"对各种Fetch请求的处理入口注册于SearchTransportService.registerRequestHandler。\",\"transportService.registerRequestHandler( QUERY_FETCH_SCROLL_ACTION_NAME, ThreadPool.Names.SAME, InternalScrollSearchRequest::new, (request, channel, task) -> { searchService.executeFetchPhase( request, (SearchShardTask) task, new ChannelActionListener<>(channel, QUERY_FETCH_SCROLL_ACTION_NAME, request) ); } ); \",\"对Fetch响应的实现封装在SearchService.executeFetchPhase中,核心是调用fetchPhase.execute(context)。按照命中的doc取得相关数据,填充到SearchHits中,最终封装到FetchSearchResult中。\",\"# FetchPhase public void execute(SearchContext context) { Profiler profiler = context.getProfilers() == null ? Profiler.NOOP : context.getProfilers().startProfilingFetchPhase(); SearchHits hits = null; try { //lucene构建搜索的结果 hits = buildSearchHits(context, profiler); } finally { ProfileResult profileResult = profiler.finish(); // Only set the shardResults if building search hits was successful if (hits != null) { context.fetchResult().shardResult(hits, profileResult); } } } \",\"入口:RestCancellableNodeClient.doExecute Task task = client.executeLocally主要执行查询,并使用了ActionListener来进行监听 \",\"其中onResponse的调用链路如下:RestActionListener.onResponse->RestResponseListener.processResponse->RestController.sendResponse->DefaultRestChannel.sendResponse->Netty4HttpChannel.sendResponse\",\"public void sendResponse(RestResponse restResponse) { ... httpChannel.sendResponse(httpResponse, listener); ... } \",\"最后由Netty4HttpChannel.sendResponse来响应请求。\",\"当我们以aaaa*这样来搜索的时候,实际上查询了所有匹配以aaaa开头的索引,并且对所有的索引的分片都进行了一次Query,再然后对有结果的分片进行一次fetch,最终才能展示结果。可能觉得好奇,对所有分片都进行一次搜索,遍历分片所有的Lucene分段,会不会太过于消耗资源,因此合并Lucene分段对搜索性能有好处,这里下篇文章在讲吧。同时,聚合是发生在fetch过程中的,并不是lucene。\",\"Elasitcsearch源码解析与优化实战\",\"Elasticsearch源码分析-搜索分析(一)\",\"Elasticsearch源码分析-搜索分析(二)\",\"Elasticsearch源码分析-搜索分析(三)\",\"Elasticsearch 通信模块的分析\",\"Elasticsearch 网络通信线程分析\"]},\"217\":{\"h\":\"mysql\",\"t\":[\"img\"]},\"218\":{\"h\":\"gap锁\"},\"219\":{\"h\":\"执行计划explain\",\"t\":[\"第一次听到执行计划还是挺懵的,感觉像是存储函数什么样的东西,后来发现,居然是explain\"]},\"220\":{\"h\":\"数据库缓存\",\"t\":[\"在MySQL 5.6开始,就已经默认禁用查询缓存了。在MySQL 8.0,就已经删除查询缓存功能了。\",\"将select语句和语句的结果做hash映射关系后保存在一定的内存区域内。\",\"禁用原因:\",\"1.命中率低\",\"2.写时所有都失效\",\"禁用了:https://mp.weixin.qq.com/s/_EXXmciNdgXswSVzKyO4xg。\",\"查询缓存讲解:https://blog.csdn.net/zzddada/article/details/124116182\"]},\"221\":{\"h\":\"kafka面试题\",\"t\":[\"1、请说明什么是Apache Kafka? Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。\",\"2、说说Kafka的使用场景? ①异步处理 ②应用解耦 ③流量削峰 ④日志处理 ⑤消息通讯等。\",\"3、使用Kafka有什么优点和缺点? 优点: ①支持跨数据中心的消息复制; ②单机吞吐量:十万级,最大的优点,就是吞吐量高; ③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源; ④时效性:ms级; ⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用; ⑥消息可靠性:经过参数优化配置,消息可以做到0丢失; ⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。\",\"缺点: ①由于是批量发送,数据并非真正的实时; 仅支持统一分区内消息有序,无法实现全局消息有序; ②有可能消息重复消费; ③依赖zookeeper进行元数据管理,等等。\",\"4、为什么说Kafka性能很好,体现在哪里? ①顺序读写 ②零拷贝 ③分区 ④批量发送 ⑤数据压缩\",\"5、请说明什么是传统的消息传递方法? 传统的消息传递方法包括两种: 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。 发布-订阅:在这个模型中,消息被广播给所有的用户。\",\"6、请说明Kafka相对传统技术有什么优势? ①快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。 ②可伸缩:在一组机器上对数据进行分区 ③和简化,以支持更大的数据 ④持久:消息是持久性的,并在集群中进 ⑤行复制,以防止数据丢失。 ⑥设计:它提供了容错保证和持久性\",\"7、解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗? Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。 不,不可能越过Zookeeper,直接联系Kafka broker。一旦Zookeeper停止工作,它就不能服务客户端请求。 Zookeeper主要用于在集群中不同节点之间进行通信 在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取 除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。\",\"8、解释Kafka的用户如何消费信息? 在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节从套接口转移到磁盘,通过内核空间保存副本,并在内核用户之间调用内核。\",\"9、解释如何提高远程用户的吞吐量? 如果用户位于与broker不同的数据中心,则可能需要调优套接口缓冲区大小,以对长网络延迟进行摊销。\",\"10、解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息? 在数据中,为了精确地获得Kafka的消息,你必须遵循两件事: 在数据消耗期间避免重复,在数据生产过程中避免重复。 这里有两种方法,可以在数据生成时准确地获得一个语义: 每个分区使用一个单独的写入器,每当你发现一个网络错误,检查该分区中的最后一条消息,以查看您的最后一次写入是否成功 在消息中包含一个主键(UUID或其他),并在用户中进行反复制\",\"11、解释如何减少ISR中的扰动?broker什么时候离开ISR? ISR是一组与leaders完全同步的消息副本,也就是说ISR中包含了所有提交的消息。ISR应该总是包含所有的副本,直到出现真正的故障。如果一个副本从leader中脱离出来,将会从ISR中删除。\",\"12、Kafka为什么需要复制? Kafka的信息复制确保了任何已发布的消息不会丢失,并且可以在机器错误、程序错误或更常见些的软件升级中使用。\",\"13、如果副本在ISR中停留了很长时间表明什么? 如果一个副本在ISR中保留了很长一段时间,那么它就表明,跟踪器无法像在leader收集数据那样快速地获取数据。\",\"14、请说明如果首选的副本不在ISR中会发生什么? 如果首选的副本不在ISR中,控制器将无法将leadership转移到首选的副本。\",\"15、有可能在生产后发生消息偏移吗? 在大多数队列系统中,作为生产者的类无法做到这一点,它的作用是触发并忘记消息。broker将完成剩下的工作,比如使用id进行适当的元数据处理、偏移量等。\",\"作为消息的用户,你可以从Kafka broker中获得补偿。如果你注视SimpleConsumer类,你会注意到它会获取包括偏移量作为列表的MultiFetchResponse对象。此外,当你对Kafka消息进行迭代时,你会拥有包括偏移量和消息发送的MessageAndOffset对象。\",\"16、Kafka的设计时什么样的呢? Kafka将消息以topic为单位进行归纳 将向Kafka topic发布消息的程序成为producers. 将预订topics并消费消息的程序成为consumer. Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker. producers通过网络将消息发送到Kafka集群,集群向消费者提供消息\",\"17、数据传输的事物定义有哪三种? (1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输 (2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输. (3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的\",\"18、Kafka判断一个节点是否还活着有那两个条件? (1)节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接 (2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久\",\"19、producer是否直接将数据发送到broker的leader(主节点)? producer直接将数据发送到broker的leader(主节点),不需要在多个节点进行分发,为了帮助producer做到这点,所有的Kafka节点都可以及时的告知:哪些节点是活动的,目标topic目标分区的leader在哪。这样producer就可以直接将消息发送到目的地了。\",\"20、Kafa consumer是否可以消费指定分区消息? Kafa consumer消费消息时,向broker发出\\\"fetch\\\"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的\",\"21、Kafka消息是采用Pull模式,还是Push模式? Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式\",\"Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略\",\"Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发\",\"22、Kafka存储在硬盘上的消息格式是什么? 消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。 消息长度: 4 bytes (value: 1+4+n) 版本号: 1 byte CRC校验码: 4 bytes 具体的消息: n bytes\",\"23、Kafka高效文件存储设计特点: (1).Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。 (2).通过索引信息可以快速定位message和确定response的最大大小。 (3).通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。 (4).通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。\",\"24、Kafka 与传统消息系统之间有三个关键区别 (1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留 (2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性 (3).Kafka 支持实时的流式处理\",\"25、Kafka创建Topic时如何将分区放置到不同的Broker中 副本因子不能大于 Broker 的个数; 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的; 其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推; 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的\",\"26、Kafka新建的分区会在哪个目录下创建 在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。 当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。 如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。 但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。\",\"27、partition的数据如何保存到硬盘 topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增, 且消息有序 Partition文件下有多个segment(xxx.index,xxx.log) segment 文件里的 大小和配置文件大小一致可以根据要求修改 默认为1g 如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名\",\"28、kafka的ack机制 request.required.acks有三个值 0 1 -1 0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱当server挂掉的时候就会丢数据 1:服务端会等待ack值 leader副本确认接收到消息后发送ack但是如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢失 -1:同样在1的基础上 服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢失\",\"29、Kafka的消费者如何消费数据 消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置 等到下次消费时,他会接着上次位置继续消费。同时也可以按照指定的offset进行重新消费。\",\"30、消费者负载均衡策略 结合consumer的加入和退出进行再平衡策略。\",\"31、kafka消息数据是否有序? 消费者组里某具体分区是有序的,所以要保证有序只能建一个分区,但是实际这样会存在性能问题,具体业务具体分析后确认。\",\"32、kafaka生产数据时数据的分组策略,生产者决定数据产生到集群的哪个partition中 每一条消息都是以(key,value)格式 Key是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个partition\",\"33、kafka consumer 什么情况会触发再平衡reblance? ①一旦消费者加入或退出消费组,导致消费组成员列表发生变化,消费组中的所有消费者都要执行再平衡。 ②订阅主题分区发生变化,所有消费者也都要再平衡。\",\"34、描述下kafka consumer 再平衡步骤? ①关闭数据拉取线程,情空队列和消息流,提交偏移量; ②释放分区所有权,删除zk中分区和消费者的所有者关系; ③将所有分区重新分配给每个消费者,每个消费者都会分到不同分区; ④将分区对应的消费者所有关系写入ZK,记录分区的所有权信息; ⑤重启消费者拉取线程管理器,管理每个分区的拉取线程。\",\"35、Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么\\n36、Kafka中的HW、LEO、LSO、LW等分别代表什么?\\n37、Kafka中是怎么体现消息顺序性的?\\n38、Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?\\n39、Kafka生产者客户端的整体结构是什么样子的?\\n40、Kafka生产者客户端中使用了几个线程来处理?分别是什么?\\n41、Kafka的旧版Scala的消费者客户端的设计有什么缺陷?\\n42、“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?\\n43、消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?\\n44、有哪些情形会造成重复消费?\\n45、那些情景下会造成消息漏消费?\\n46、KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?\\n47、简述消费者与消费组之间的关系\\n48、当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?\\n49、topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?\\n50、topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?\\n51、创建topic时如何选择合适的分区数?\\n52、Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么?\\n53、优先副本是什么?它有什么特殊的作用?\\n54、Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理\\n55、简述Kafka的日志目录结构\\n56、Kafka中有那些索引文件?\\n57、如果我指定了一个offset,Kafka怎么查找到对应的消息?\\n58、如果我指定了一个timestamp,Kafka怎么查找到对应的消息?\\n59、聊一聊你对Kafka的Log Retention的理解\\n60、聊一聊你对Kafka的Log Compaction的理解\\n61、聊一聊你对Kafka底层存储的理解(页缓存、内核层、块层、设备层)\\n62、聊一聊Kafka的延时操作的原理\\n63、聊一聊Kafka控制器的作用\\n64、消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)\\n65、Kafka中的幂等是怎么实现的\\n66、Kafka中的事务是怎么实现的(这题我去面试6家被问4次,照着答案念也要念十几分钟,面试官简直凑不要脸。实在记不住的话...只要简历上不写精通Kafka一般不会问到,我简历上写的是“熟悉Kafka,了解RabbitMQ....”)\\n67、Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?\\n68、失效副本是指什么?有那些应对措施?\\n69、多副本下,各个副本中的HW和LEO的演变过程\\n70、为什么Kafka不支持读写分离?\\n71、Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)\\n72、Kafka中怎么实现死信队列和重试队列?\\n73、Kafka中的延迟队列怎么实现(这题被问的比事务那题还要多!!!听说你会Kafka,那你说说延迟队列怎么实现?)\\n74、Kafka中怎么做消息审计?\\n75、Kafka中怎么做消息轨迹?\\n76、Kafka中有那些配置参数比较有意思?聊一聊你的看法\\n77、Kafka中有那些命名比较有意思?聊一聊你的看法\\n78、Kafka有哪些指标需要着重关注?\\n79、怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)\\n80、Kafka的那些设计让它有如此高的性能?\\n81、Kafka有什么优缺点?\\n82、还用过什么同质类的其它产品,与Kafka相比有什么优缺点?\\n83、为什么选择Kafka?\\n84、在使用Kafka的过程中遇到过什么困难?怎么解决的?\\n85、怎么样才能确保Kafka极大程度上的可靠性?\\n86、聊一聊你对Kafka生态的理解\"]},\"222\":{\"h\":\"Zookeeper\",\"t\":[\"留空\"]},\"223\":{\"h\":\"Interview\"},\"224\":{\"h\":\"Java\"},\"225\":{\"h\":\"Life\"},\"226\":{\"h\":\"Others\"},\"227\":{\"h\":\"Personal Website\"},\"228\":{\"h\":\"Personal Life\"},\"229\":{\"h\":\"Spark\"},\"230\":{\"h\":\"Bigdata\"},\"231\":{\"h\":\"Elasticsearch\"},\"232\":{\"h\":\"Mysql\"},\"233\":{\"h\":\"Kafka\"},\"234\":{\"h\":\"Middleware\"},\"235\":{\"h\":\"Zookeeper\"}},\"dirtCount\":0,\"index\":[[\"轨迹\",{\"1\":{\"221\":1}}],[\"演变\",{\"1\":{\"221\":1}}],[\"措施\",{\"1\":{\"221\":1}}],[\"念\",{\"1\":{\"221\":1}}],[\"幂\",{\"1\":{\"221\":1}}],[\"背后\",{\"1\":{\"221\":1}}],[\"背景图片\",{\"1\":{\"170\":1}}],[\"句\",{\"1\":{\"221\":1}}],[\"句子\",{\"1\":{\"132\":3}}],[\"退出\",{\"1\":{\"221\":2}}],[\"受到\",{\"1\":{\"221\":2}}],[\"受不了\",{\"1\":{\"73\":1,\"80\":1,\"192\":1}}],[\"递增\",{\"1\":{\"221\":1}}],[\"序号\",{\"1\":{\"221\":1}}],[\"序列\",{\"1\":{\"192\":1}}],[\"序列化\",{\"1\":{\"137\":4,\"187\":2,\"198\":1,\"221\":1}}],[\"逗号\",{\"1\":{\"221\":1}}],[\"剩余\",{\"1\":{\"221\":1}}],[\"剩下\",{\"1\":{\"221\":1}}],[\"稀疏\",{\"1\":{\"221\":1}}],[\"\",{\"1\":{\"221\":8}}],[\"头部\",{\"1\":{\"221\":2}}],[\"头绪\",{\"1\":{\"46\":1,\"50\":1}}],[\"硬盘\",{\"1\":{\"221\":2}}],[\"硬件\",{\"1\":{\"55\":1,\"63\":1,\"152\":4}}],[\"达\",{\"1\":{\"221\":1}}],[\"达到\",{\"1\":{\"45\":3,\"50\":1,\"57\":1,\"63\":1,\"185\":1,\"221\":1}}],[\"达到目标\",{\"1\":{\"28\":1}}],[\"循环\",{\"1\":{\"221\":1}}],[\"崩溃\",{\"1\":{\"221\":2}}],[\"恐怕\",{\"1\":{\"221\":1}}],[\"致力于\",{\"1\":{\"221\":1}}],[\"致远\",{\"1\":{\"73\":1}}],[\"速率\",{\"1\":{\"221\":6}}],[\"速度\",{\"1\":{\"135\":2,\"166\":1}}],[\"坏处\",{\"1\":{\"221\":1}}],[\"漏\",{\"1\":{\"221\":3}}],[\"迭代\",{\"1\":{\"221\":1}}],[\"补偿\",{\"1\":{\"221\":1}}],[\"补全\",{\"0\":{\"136\":1},\"1\":{\"122\":1,\"136\":2,\"215\":1}}],[\"升级\",{\"1\":{\"221\":1}}],[\"些\",{\"1\":{\"221\":1}}],[\"故障\",{\"1\":{\"221\":1}}],[\"故事\",{\"0\":{\"123\":1},\"1\":{\"78\":1,\"122\":1}}],[\"扰动\",{\"1\":{\"221\":1}}],[\"制\",{\"1\":{\"221\":1}}],[\"制作\",{\"1\":{\"151\":1,\"221\":1}}],[\"遵循\",{\"1\":{\"221\":2}}],[\"摊销\",{\"1\":{\"221\":1}}],[\"何时\",{\"1\":{\"221\":1}}],[\"伸缩\",{\"1\":{\"221\":3}}],[\"拷贝\",{\"1\":{\"221\":1}}],[\"拷贝到\",{\"1\":{\"161\":2}}],[\"零\",{\"1\":{\"221\":1}}],[\"零碎\",{\"1\":{\"126\":1}}],[\"采集\",{\"1\":{\"221\":1}}],[\"采用\",{\"1\":{\"57\":2,\"72\":1,\"125\":1,\"126\":2,\"135\":1,\"137\":1,\"153\":1,\"169\":1,\"171\":1,\"173\":1,\"187\":1,\"204\":1,\"221\":3}}],[\"⑦\",{\"1\":{\"221\":1}}],[\"⑥\",{\"1\":{\"221\":2}}],[\"⑤\",{\"1\":{\"221\":5}}],[\"④\",{\"1\":{\"221\":5}}],[\"削峰\",{\"1\":{\"221\":1}}],[\"③\",{\"1\":{\"221\":6}}],[\"②\",{\"1\":{\"221\":7}}],[\"①\",{\"1\":{\"221\":7}}],[\"禁用\",{\"1\":{\"220\":3}}],[\"纠错\",{\"1\":{\"215\":1}}],[\"且\",{\"1\":{\"215\":1,\"221\":1}}],[\"聚合\",{\"1\":{\"215\":2,\"216\":1}}],[\"跳过\",{\"1\":{\"212\":1}}],[\"体现\",{\"1\":{\"221\":2}}],[\"体\",{\"1\":{\"207\":1}}],[\"体验\",{\"1\":{\"93\":1,\"102\":1,\"110\":1}}],[\"队列\",{\"1\":{\"207\":2,\"221\":7}}],[\"继承\",{\"1\":{\"206\":1}}],[\"继续\",{\"1\":{\"44\":1,\"45\":1,\"73\":1,\"85\":1,\"89\":1,\"100\":1,\"104\":1,\"124\":1,\"221\":1}}],[\"继续下去\",{\"1\":{\"6\":1}}],[\"监听\",{\"1\":{\"206\":1,\"216\":1}}],[\"监控\",{\"1\":{\"72\":5,\"126\":3,\"149\":1}}],[\"询问\",{\"1\":{\"205\":1}}],[\"假设\",{\"1\":{\"205\":2,\"221\":1}}],[\"假的\",{\"1\":{\"169\":1}}],[\"散发\",{\"1\":{\"205\":1}}],[\"种\",{\"1\":{\"205\":1}}],[\"匹配\",{\"1\":{\"204\":1,\"205\":1,\"216\":1}}],[\"戳\",{\"1\":{\"204\":1}}],[\"星号\",{\"1\":{\"204\":1,\"205\":1}}],[\"密码\",{\"1\":{\"203\":1}}],[\"密钥\",{\"1\":{\"115\":1}}],[\"桥接器\",{\"1\":{\"194\":1}}],[\"桥上\",{\"1\":{\"82\":1}}],[\"思维\",{\"1\":{\"192\":1}}],[\"宝宝\",{\"1\":{\"192\":1}}],[\"兄弟姐妹\",{\"1\":{\"192\":1}}],[\"栏目\",{\"1\":{\"192\":2}}],[\"统一\",{\"1\":{\"187\":1,\"221\":1}}],[\"统计\",{\"0\":{\"33\":1},\"1\":{\"63\":1,\"122\":3,\"126\":3,\"145\":10,\"146\":2,\"148\":2,\"149\":1,\"151\":5,\"191\":1}}],[\"幽灵\",{\"1\":{\"187\":1}}],[\"碰到\",{\"1\":{\"187\":1}}],[\"冲突\",{\"1\":{\"186\":3}}],[\"缺陷\",{\"1\":{\"192\":1,\"221\":1}}],[\"缺省\",{\"1\":{\"185\":1}}],[\"缺点\",{\"1\":{\"155\":1,\"221\":3}}],[\"激动人心\",{\"1\":{\"185\":1}}],[\"激增\",{\"1\":{\"58\":1}}],[\"拆分\",{\"1\":{\"184\":1}}],[\"粒度\",{\"1\":{\"184\":1}}],[\"脏读\",{\"1\":{\"184\":1}}],[\"脏\",{\"1\":{\"184\":2}}],[\"细\",{\"1\":{\"181\":1}}],[\"划分\",{\"0\":{\"181\":1},\"1\":{\"181\":1}}],[\"装饰\",{\"1\":{\"180\":1}}],[\"装载\",{\"1\":{\"42\":1}}],[\"释放\",{\"1\":{\"179\":1,\"221\":1}}],[\"称作\",{\"1\":{\"179\":1}}],[\"称赞\",{\"1\":{\"126\":1}}],[\"否则\",{\"1\":{\"178\":1,\"187\":1}}],[\"穿透\",{\"1\":{\"177\":1}}],[\"•\",{\"1\":{\"173\":2}}],[\"ง\",{\"1\":{\"173\":2}}],[\"💪\",{\"1\":{\"173\":1}}],[\"付出\",{\"1\":{\"173\":1}}],[\"付费\",{\"1\":{\"172\":1}}],[\"脚\",{\"1\":{\"173\":1}}],[\"脚本\",{\"1\":{\"18\":1,\"72\":1}}],[\"抠\",{\"1\":{\"173\":1}}],[\"菜\",{\"1\":{\"173\":1}}],[\"痛苦\",{\"1\":{\"173\":1}}],[\"鲜艳\",{\"1\":{\"173\":1}}],[\"宽度\",{\"1\":{\"173\":1}}],[\"偶然\",{\"1\":{\"173\":1}}],[\"偶尔\",{\"1\":{\"51\":1,\"73\":2,\"79\":1,\"80\":1}}],[\"顶\",{\"1\":{\"173\":1}}],[\"岂\",{\"1\":{\"173\":1}}],[\"怪怪的\",{\"1\":{\"173\":1}}],[\"纵列\",{\"1\":{\"173\":1}}],[\"绚丽\",{\"1\":{\"173\":1}}],[\"画蛇添足\",{\"1\":{\"172\":1}}],[\"咨询服务\",{\"1\":{\"172\":1}}],[\"疲劳\",{\"1\":{\"171\":1}}],[\"疲惫\",{\"0\":{\"74\":1}}],[\"视觉\",{\"1\":{\"171\":2}}],[\"视图\",{\"1\":{\"125\":3}}],[\"抵制\",{\"1\":{\"171\":1}}],[\"遭到\",{\"1\":{\"171\":1}}],[\"爆\",{\"1\":{\"170\":1}}],[\"爆炸\",{\"1\":{\"74\":1,\"90\":1}}],[\"丑爆\",{\"1\":{\"170\":1}}],[\"丑\",{\"1\":{\"170\":1}}],[\"社会化\",{\"1\":{\"170\":1}}],[\"社交\",{\"1\":{\"77\":2,\"167\":1}}],[\"免不了\",{\"1\":{\"170\":1}}],[\"免费\",{\"1\":{\"8\":1,\"100\":1,\"114\":2}}],[\"鄙视\",{\"1\":{\"169\":1,\"173\":1}}],[\"嫌弃\",{\"1\":{\"169\":1}}],[\"越过\",{\"1\":{\"221\":1}}],[\"越界\",{\"1\":{\"169\":1}}],[\"越来越\",{\"1\":{\"58\":1}}],[\"缩小\",{\"1\":{\"169\":1}}],[\"格调\",{\"1\":{\"169\":1}}],[\"格式化\",{\"1\":{\"135\":1,\"147\":1,\"156\":1}}],[\"格式\",{\"0\":{\"156\":1},\"1\":{\"5\":1,\"7\":1,\"147\":1,\"156\":1,\"157\":1,\"168\":2,\"221\":2}}],[\"利器\",{\"1\":{\"168\":1}}],[\"利用率\",{\"1\":{\"177\":1}}],[\"利用\",{\"1\":{\"6\":1,\"54\":1,\"72\":1,\"126\":1}}],[\"眼光\",{\"1\":{\"168\":1}}],[\"眼神\",{\"1\":{\"82\":1}}],[\"嵌入\",{\"1\":{\"168\":1}}],[\"式\",{\"1\":{\"168\":1}}],[\"耗在\",{\"1\":{\"173\":1}}],[\"耗时间\",{\"1\":{\"173\":1}}],[\"耗时\",{\"1\":{\"168\":1}}],[\"耗费\",{\"1\":{\"18\":1}}],[\"哈\",{\"1\":{\"167\":1}}],[\"哈哈哈哈\",{\"1\":{\"87\":2}}],[\"哈哈哈\",{\"1\":{\"77\":1,\"78\":1,\"80\":1,\"83\":1,\"84\":1,\"86\":1,\"128\":1,\"150\":1}}],[\"哈哈\",{\"1\":{\"73\":1,\"86\":1,\"128\":1,\"152\":1,\"160\":1}}],[\"丢失\",{\"1\":{\"221\":6}}],[\"丢\",{\"1\":{\"167\":2,\"190\":2,\"221\":1}}],[\"丢弃\",{\"1\":{\"59\":1}}],[\"浏览量\",{\"1\":{\"167\":1,\"192\":7}}],[\"浏览器\",{\"1\":{\"125\":1,\"158\":1,\"160\":1,\"169\":1,\"171\":1,\"203\":1}}],[\"滚动\",{\"1\":{\"166\":1,\"221\":1}}],[\"幻灯片\",{\"1\":{\"166\":2,\"189\":1}}],[\"畅言\",{\"0\":{\"167\":1},\"1\":{\"165\":1,\"167\":2}}],[\"拼凑\",{\"1\":{\"165\":1}}],[\"拼接\",{\"1\":{\"104\":2,\"124\":1}}],[\"肩膀\",{\"1\":{\"165\":1}}],[\"巨人\",{\"1\":{\"165\":1}}],[\"踏踏实实\",{\"1\":{\"165\":1}}],[\"脑子\",{\"1\":{\"165\":1}}],[\"布局\",{\"1\":{\"165\":1}}],[\"困\",{\"1\":{\"164\":1}}],[\"困难\",{\"1\":{\"12\":1,\"221\":1}}],[\"急躁\",{\"1\":{\"164\":1}}],[\"急需\",{\"1\":{\"6\":1}}],[\"伪装\",{\"1\":{\"164\":1}}],[\"衍生\",{\"1\":{\"164\":1}}],[\"逐步\",{\"1\":{\"164\":1}}],[\"系\",{\"1\":{\"164\":1}}],[\"系统配置\",{\"1\":{\"27\":1,\"29\":1}}],[\"系统\",{\"0\":{\"126\":1,\"145\":1},\"1\":{\"23\":1,\"25\":4,\"28\":1,\"37\":1,\"42\":1,\"50\":2,\"51\":3,\"58\":1,\"103\":1,\"122\":2,\"126\":3,\"127\":1,\"145\":4,\"151\":4,\"169\":1,\"177\":1,\"221\":6}}],[\"双\",{\"1\":{\"164\":1,\"173\":1}}],[\"双十\",{\"1\":{\"76\":1}}],[\"杭州\",{\"1\":{\"164\":1}}],[\"叫\",{\"1\":{\"164\":1}}],[\"叫做\",{\"1\":{\"161\":1,\"221\":1}}],[\"漂游\",{\"1\":{\"164\":1}}],[\"漂漂亮亮\",{\"1\":{\"85\":1}}],[\"防止\",{\"1\":{\"164\":1,\"221\":1}}],[\"偏移量\",{\"1\":{\"221\":9}}],[\"偏移\",{\"1\":{\"163\":1,\"221\":1}}],[\"型\",{\"1\":{\"161\":1}}],[\"树\",{\"1\":{\"161\":1}}],[\"环形\",{\"1\":{\"161\":1}}],[\"环境变量\",{\"1\":{\"101\":1,\"153\":1}}],[\"环境\",{\"0\":{\"184\":1},\"1\":{\"63\":1,\"70\":1,\"76\":1,\"101\":1,\"184\":2,\"188\":1}}],[\"普通人\",{\"1\":{\"168\":1}}],[\"普通\",{\"1\":{\"161\":1}}],[\"延迟时间\",{\"1\":{\"177\":1}}],[\"延迟\",{\"1\":{\"161\":1,\"221\":4}}],[\"延时\",{\"1\":{\"152\":1,\"161\":1,\"190\":1,\"221\":2}}],[\"异地\",{\"1\":{\"161\":2,\"164\":2}}],[\"异步\",{\"1\":{\"23\":1,\"55\":1,\"57\":1,\"103\":1,\"161\":1,\"189\":1,\"192\":1,\"206\":1,\"221\":1}}],[\"杂谈\",{\"1\":{\"160\":1,\"192\":1}}],[\"子项目\",{\"1\":{\"159\":1}}],[\"子串\",{\"1\":{\"23\":1}}],[\"摘掉\",{\"1\":{\"159\":1}}],[\"钓鱼\",{\"1\":{\"158\":1}}],[\"私钥\",{\"1\":{\"158\":1}}],[\"私人\",{\"1\":{\"115\":1}}],[\"非\",{\"1\":{\"157\":1}}],[\"非常灵活\",{\"1\":{\"183\":1}}],[\"非常\",{\"1\":{\"57\":1,\"132\":1,\"194\":1,\"221\":1}}],[\"赋值\",{\"1\":{\"157\":2}}],[\"赋予\",{\"1\":{\"55\":1}}],[\"访客\",{\"1\":{\"155\":1}}],[\"访问量\",{\"1\":{\"149\":1,\"151\":2,\"152\":1,\"189\":1}}],[\"访问\",{\"0\":{\"114\":1,\"115\":1,\"138\":1},\"1\":{\"41\":1,\"56\":1,\"57\":1,\"61\":3,\"62\":2,\"63\":1,\"69\":1,\"97\":1,\"98\":1,\"113\":1,\"114\":1,\"115\":3,\"120\":2,\"125\":2,\"145\":5,\"147\":1,\"152\":3,\"155\":2,\"157\":4,\"158\":2,\"160\":5,\"161\":1,\"165\":1,\"166\":1,\"173\":1,\"208\":1}}],[\"校验码\",{\"1\":{\"221\":2}}],[\"校验\",{\"1\":{\"153\":1}}],[\"校招\",{\"1\":{\"80\":1}}],[\"木\",{\"1\":{\"152\":1}}],[\"讨论\",{\"1\":{\"152\":1}}],[\"暂\",{\"1\":{\"152\":1}}],[\"暂停\",{\"1\":{\"30\":1,\"34\":1,\"38\":1,\"86\":1}}],[\"协调\",{\"1\":{\"206\":1,\"207\":1,\"221\":3}}],[\"协议\",{\"1\":{\"152\":1,\"158\":1,\"164\":2}}],[\"协助\",{\"1\":{\"42\":1,\"143\":1}}],[\"梭子鱼\",{\"1\":{\"152\":1}}],[\"洋洋洒洒\",{\"1\":{\"152\":1}}],[\"们\",{\"1\":{\"152\":1,\"192\":1}}],[\"∩\",{\"1\":{\"152\":2,\"160\":2}}],[\"颜色\",{\"1\":{\"151\":1,\"169\":1,\"173\":2}}],[\"度\",{\"1\":{\"151\":1,\"173\":1}}],[\"度过\",{\"1\":{\"77\":1}}],[\"隐私\",{\"1\":{\"151\":1}}],[\"阐述\",{\"1\":{\"151\":1,\"172\":1}}],[\"江苏\",{\"1\":{\"151\":1}}],[\"轴\",{\"1\":{\"151\":2}}],[\"垂直\",{\"1\":{\"151\":1}}],[\"贴\",{\"1\":{\"150\":1,\"156\":1}}],[\"折叠\",{\"1\":{\"213\":3}}],[\"折磨\",{\"1\":{\"151\":1}}],[\"折线图\",{\"1\":{\"149\":1,\"151\":3}}],[\"折腾\",{\"1\":{\"75\":1,\"124\":1}}],[\"归纳\",{\"1\":{\"221\":1}}],[\"归\",{\"1\":{\"149\":1}}],[\"归属\",{\"0\":{\"119\":1}}],[\"符\",{\"1\":{\"149\":1,\"198\":1}}],[\"符合规范\",{\"1\":{\"114\":1}}],[\"含义\",{\"1\":{\"221\":1}}],[\"含\",{\"1\":{\"149\":1}}],[\"含有\",{\"1\":{\"102\":1,\"221\":1}}],[\"允许\",{\"1\":{\"149\":2,\"183\":1,\"194\":1}}],[\"烦恼\",{\"1\":{\"149\":1}}],[\"昨天\",{\"1\":{\"147\":2}}],[\"者\",{\"1\":{\"146\":1,\"180\":1}}],[\"综合\",{\"1\":{\"145\":1}}],[\"移植\",{\"1\":{\"145\":1}}],[\"移除\",{\"1\":{\"44\":1}}],[\"寻求\",{\"1\":{\"145\":1}}],[\"寻找\",{\"1\":{\"7\":1,\"144\":1}}],[\"共用\",{\"1\":{\"181\":1}}],[\"共\",{\"1\":{\"159\":1,\"205\":1}}],[\"共同完成\",{\"1\":{\"205\":1}}],[\"共同\",{\"1\":{\"148\":1,\"165\":1,\"221\":1}}],[\"共享\",{\"1\":{\"141\":1,\"155\":1,\"159\":2,\"161\":1,\"180\":1}}],[\"共有\",{\"1\":{\"117\":1}}],[\"独立\",{\"1\":{\"141\":1,\"184\":1}}],[\"灵活性\",{\"1\":{\"185\":1}}],[\"灵活\",{\"1\":{\"140\":1,\"221\":1}}],[\"丰富\",{\"1\":{\"140\":1}}],[\"热门\",{\"1\":{\"189\":1}}],[\"热词\",{\"1\":{\"137\":2}}],[\"热点\",{\"1\":{\"60\":1}}],[\"销售量\",{\"1\":{\"137\":1}}],[\"销毁\",{\"1\":{\"7\":1,\"17\":1}}],[\"段\",{\"1\":{\"137\":1,\"221\":2}}],[\"段时间\",{\"1\":{\"61\":1,\"81\":1,\"171\":2}}],[\"任然\",{\"1\":{\"207\":1}}],[\"任何\",{\"1\":{\"191\":1,\"221\":2}}],[\"任意\",{\"1\":{\"137\":1,\"149\":2}}],[\"任务调度\",{\"1\":{\"144\":2}}],[\"任务\",{\"0\":{\"139\":1,\"144\":1},\"1\":{\"5\":1,\"42\":3,\"50\":1,\"56\":1,\"57\":1,\"72\":1,\"140\":1,\"141\":3,\"143\":1,\"144\":2,\"149\":1,\"205\":1,\"212\":1,\"215\":1}}],[\"权重\",{\"1\":{\"137\":4,\"159\":1}}],[\"权限\",{\"1\":{\"103\":3,\"114\":1}}],[\"输入\",{\"1\":{\"136\":1,\"153\":1}}],[\"输出\",{\"1\":{\"30\":6}}],[\"光是\",{\"1\":{\"152\":1,\"168\":1}}],[\"光\",{\"1\":{\"135\":1}}],[\"光芒\",{\"1\":{\"75\":1}}],[\"筛选\",{\"1\":{\"135\":1,\"197\":1}}],[\"友盟\",{\"1\":{\"145\":1}}],[\"友好\",{\"1\":{\"135\":1,\"151\":1,\"168\":1,\"169\":1,\"197\":1}}],[\"友谊\",{\"1\":{\"74\":1}}],[\"笔记\",{\"1\":{\"135\":1,\"160\":1,\"192\":1}}],[\"笔试\",{\"1\":{\"74\":7}}],[\"域\",{\"1\":{\"133\":6}}],[\"域名\",{\"0\":{\"119\":1},\"1\":{\"114\":4,\"120\":3,\"160\":1}}],[\"许多\",{\"1\":{\"132\":1}}],[\"副\",{\"1\":{\"205\":3,\"221\":1}}],[\"副词\",{\"1\":{\"132\":1}}],[\"副本\",{\"0\":{\"65\":1},\"1\":{\"64\":1,\"65\":1,\"66\":1,\"70\":4,\"205\":1,\"207\":1,\"209\":1,\"221\":20}}],[\"冠词\",{\"1\":{\"132\":1}}],[\"列表\",{\"0\":{\"208\":1},\"1\":{\"132\":1,\"137\":1,\"148\":2,\"159\":1,\"171\":1,\"206\":1,\"208\":2,\"212\":1,\"221\":2}}],[\"倒\",{\"1\":{\"161\":1}}],[\"倒排\",{\"1\":{\"132\":3,\"135\":1}}],[\"倒计时\",{\"1\":{\"75\":1,\"77\":1}}],[\"谢谢\",{\"1\":{\"130\":1}}],[\"精通\",{\"1\":{\"221\":1}}],[\"精确\",{\"1\":{\"221\":2}}],[\"精品\",{\"1\":{\"128\":1}}],[\"精力\",{\"1\":{\"6\":1,\"18\":1}}],[\"劳烦\",{\"1\":{\"128\":1}}],[\"遮遮掩掩\",{\"1\":{\"128\":1}}],[\"断断续续\",{\"1\":{\"128\":1}}],[\"断网\",{\"1\":{\"5\":1,\"74\":1}}],[\"训练样本\",{\"1\":{\"127\":2}}],[\"忽略\",{\"1\":{\"127\":1,\"163\":1,\"210\":1}}],[\"卡卡\",{\"1\":{\"126\":1}}],[\"卡\",{\"1\":{\"126\":1}}],[\"曾经\",{\"1\":{\"126\":1}}],[\"渲染\",{\"1\":{\"125\":1}}],[\"取回\",{\"1\":{\"206\":1,\"210\":1,\"211\":1,\"213\":1}}],[\"取前\",{\"1\":{\"205\":1}}],[\"取舍\",{\"1\":{\"173\":1}}],[\"取\",{\"1\":{\"157\":1,\"205\":1}}],[\"取出\",{\"1\":{\"135\":2,\"179\":1}}],[\"取得\",{\"1\":{\"125\":1,\"216\":1}}],[\"取代\",{\"1\":{\"23\":1,\"56\":1}}],[\"映射\",{\"1\":{\"125\":2,\"132\":1,\"180\":2,\"220\":1,\"221\":1}}],[\"拦截器\",{\"1\":{\"125\":1,\"221\":1}}],[\"拦截\",{\"1\":{\"125\":1,\"159\":1}}],[\"涛的\",{\"1\":{\"152\":1}}],[\"涛\",{\"1\":{\"125\":1}}],[\"张开\",{\"1\":{\"125\":1,\"152\":1}}],[\"七层\",{\"1\":{\"152\":3}}],[\"七天\",{\"1\":{\"147\":2}}],[\"七\",{\"1\":{\"124\":1}}],[\"七月\",{\"1\":{\"76\":1}}],[\"排队\",{\"1\":{\"221\":1}}],[\"排名\",{\"1\":{\"205\":2}}],[\"排除\",{\"1\":{\"145\":1}}],[\"排序\",{\"1\":{\"132\":2,\"137\":3,\"205\":2,\"207\":3,\"211\":1}}],[\"排版\",{\"1\":{\"124\":1}}],[\"排查\",{\"0\":{\"46\":1,\"47\":1},\"1\":{\"6\":1,\"7\":1,\"45\":1,\"46\":1,\"49\":1,\"51\":2,\"102\":1}}],[\"瀑布\",{\"0\":{\"171\":1},\"1\":{\"124\":1,\"171\":5}}],[\"仔细\",{\"1\":{\"124\":1,\"157\":1}}],[\"世界\",{\"1\":{\"124\":1}}],[\"性的\",{\"1\":{\"221\":1}}],[\"性强\",{\"1\":{\"124\":1}}],[\"性能指标\",{\"1\":{\"177\":1}}],[\"性能比\",{\"1\":{\"49\":1}}],[\"性能\",{\"0\":{\"57\":1,\"69\":1,\"175\":1},\"1\":{\"9\":1,\"26\":1,\"29\":1,\"57\":3,\"69\":3,\"122\":1,\"124\":1,\"177\":1,\"216\":1,\"221\":4}}],[\"纯属\",{\"1\":{\"192\":1}}],[\"纯粹\",{\"1\":{\"165\":1}}],[\"纯\",{\"1\":{\"124\":1}}],[\"纯生\",{\"1\":{\"124\":2}}],[\"低\",{\"1\":{\"124\":1,\"126\":1,\"151\":1,\"220\":1,\"221\":1}}],[\"低于\",{\"1\":{\"55\":1}}],[\"炫丽\",{\"1\":{\"165\":1}}],[\"炫\",{\"1\":{\"124\":1,\"166\":1}}],[\"欲思\",{\"1\":{\"124\":2}}],[\"深入\",{\"1\":{\"183\":1,\"192\":3}}],[\"深刻\",{\"1\":{\"124\":1,\"205\":1}}],[\"深圳湾\",{\"1\":{\"82\":1,\"89\":1}}],[\"深圳\",{\"1\":{\"73\":2,\"74\":3,\"75\":1,\"79\":1,\"80\":2,\"82\":2,\"83\":1,\"103\":1,\"152\":2,\"155\":1,\"161\":1,\"190\":1}}],[\"死信\",{\"1\":{\"221\":1}}],[\"死\",{\"1\":{\"124\":1}}],[\"怀念\",{\"1\":{\"124\":1}}],[\"怀疑\",{\"1\":{\"43\":1,\"45\":1,\"74\":1}}],[\"杨青\",{\"1\":{\"124\":1}}],[\"博客\",{\"1\":{\"124\":2,\"125\":2,\"151\":1,\"165\":2,\"166\":1,\"167\":1,\"168\":1,\"169\":1,\"170\":1,\"173\":1,\"190\":1,\"191\":1}}],[\"博客园\",{\"1\":{\"18\":1,\"124\":1}}],[\"羡慕\",{\"1\":{\"124\":1}}],[\"挑战性\",{\"1\":{\"124\":1}}],[\"备\",{\"1\":{\"161\":1}}],[\"备份\",{\"0\":{\"161\":1},\"1\":{\"122\":1,\"143\":2,\"163\":3,\"164\":2,\"178\":1}}],[\"备胎\",{\"1\":{\"73\":2}}],[\"贝叶斯\",{\"0\":{\"174\":1},\"1\":{\"122\":1}}],[\"朴素\",{\"1\":{\"122\":1}}],[\"首选\",{\"1\":{\"221\":3}}],[\"首页\",{\"1\":{\"122\":1,\"166\":2,\"189\":2}}],[\"首先\",{\"1\":{\"7\":1,\"45\":1,\"54\":1,\"124\":1,\"130\":1,\"135\":1,\"148\":1,\"158\":1,\"159\":1,\"161\":1,\"205\":1}}],[\"遍历\",{\"1\":{\"149\":1,\"204\":1,\"212\":1,\"216\":1}}],[\"遍\",{\"1\":{\"122\":1}}],[\"萌生\",{\"1\":{\"122\":1}}],[\"麻烦\",{\"1\":{\"122\":1,\"130\":1,\"192\":1}}],[\"麻辣\",{\"1\":{\"73\":1}}],[\"瞄\",{\"1\":{\"122\":1}}],[\"历史\",{\"0\":{\"122\":1}}],[\"历程\",{\"0\":{\"74\":1},\"1\":{\"81\":1}}],[\"详解\",{\"0\":{\"204\":1},\"1\":{\"192\":1}}],[\"详情\",{\"1\":{\"190\":1}}],[\"详述\",{\"1\":{\"118\":1}}],[\"详细信息\",{\"1\":{\"114\":2}}],[\"详细\",{\"1\":{\"23\":1,\"30\":1,\"107\":1,\"118\":1,\"147\":2,\"149\":1,\"158\":1,\"196\":1}}],[\"北美\",{\"1\":{\"116\":1}}],[\"北京\",{\"1\":{\"73\":2,\"74\":3,\"152\":3,\"155\":1,\"161\":1}}],[\"缓冲区\",{\"1\":{\"221\":1}}],[\"缓慢\",{\"1\":{\"116\":1,\"166\":1,\"170\":1}}],[\"缓存\",{\"0\":{\"177\":1,\"178\":1,\"179\":1,\"220\":1},\"1\":{\"2\":1,\"43\":1,\"51\":1,\"63\":1,\"66\":1,\"70\":1,\"125\":1,\"135\":1,\"143\":1,\"161\":1,\"177\":9,\"178\":6,\"179\":13,\"180\":1,\"181\":4,\"183\":6,\"184\":7,\"185\":26,\"187\":2,\"189\":2,\"190\":1,\"191\":7,\"192\":13,\"220\":3,\"221\":2}}],[\"刚刚\",{\"1\":{\"135\":1}}],[\"刚学\",{\"1\":{\"124\":1}}],[\"刚\",{\"1\":{\"116\":1,\"124\":1}}],[\"围绕\",{\"1\":{\"116\":1}}],[\"拨打\",{\"1\":{\"116\":1}}],[\"车队\",{\"1\":{\"116\":1}}],[\"车辆\",{\"1\":{\"113\":1,\"114\":1}}],[\"令牌\",{\"1\":{\"115\":2,\"117\":5}}],[\"令人震惊\",{\"1\":{\"104\":1}}],[\"截取\",{\"1\":{\"135\":1}}],[\"截止\",{\"1\":{\"114\":1}}],[\"截图\",{\"1\":{\"64\":1,\"69\":3}}],[\"金字塔\",{\"1\":{\"161\":1}}],[\"金\",{\"1\":{\"114\":1}}],[\"金融\",{\"1\":{\"74\":1,\"80\":2}}],[\"颁发\",{\"1\":{\"114\":1,\"158\":1}}],[\"印象\",{\"1\":{\"114\":1,\"132\":1,\"169\":1}}],[\"证书\",{\"1\":{\"114\":6,\"158\":4}}],[\"琢磨\",{\"1\":{\"114\":1}}],[\"审计\",{\"1\":{\"221\":1}}],[\"审核\",{\"1\":{\"114\":1,\"167\":1}}],[\"审视\",{\"1\":{\"7\":1}}],[\"及时\",{\"1\":{\"221\":2}}],[\"及其\",{\"1\":{\"145\":3,\"166\":2,\"179\":1}}],[\"及\",{\"1\":{\"114\":1,\"140\":1,\"215\":1,\"221\":1}}],[\"身份\",{\"1\":{\"113\":1}}],[\"身份验证\",{\"1\":{\"113\":1,\"115\":2,\"117\":1}}],[\"身边\",{\"1\":{\"73\":2,\"84\":1}}],[\"验证\",{\"0\":{\"119\":1},\"1\":{\"113\":1,\"121\":1}}],[\"验证码\",{\"1\":{\"97\":2}}],[\"您\",{\"1\":{\"113\":2,\"114\":4,\"115\":1,\"116\":3,\"221\":1}}],[\"账户\",{\"0\":{\"113\":1},\"1\":{\"113\":2,\"115\":2}}],[\"账号\",{\"0\":{\"162\":1},\"1\":{\"101\":2,\"106\":2,\"114\":2,\"115\":1,\"120\":1,\"162\":1}}],[\"…\",{\"1\":{\"108\":1}}],[\"」\",{\"1\":{\"108\":1}}],[\"「\",{\"1\":{\"108\":1}}],[\"版\",{\"1\":{\"108\":2,\"124\":1,\"158\":1}}],[\"版本号\",{\"1\":{\"221\":2}}],[\"版本\",{\"1\":{\"5\":2,\"7\":1,\"12\":1,\"49\":1,\"54\":2,\"124\":4,\"135\":3,\"145\":3,\"152\":1,\"159\":2,\"194\":1,\"203\":1}}],[\"凭据\",{\"0\":{\"115\":1},\"1\":{\"115\":1}}],[\"凭\",{\"1\":{\"107\":1,\"170\":1}}],[\"秘钥\",{\"0\":{\"107\":1},\"1\":{\"107\":2}}],[\"火热\",{\"1\":{\"106\":1}}],[\"条件\",{\"1\":{\"133\":1,\"152\":1,\"177\":1,\"185\":4,\"192\":1,\"221\":1}}],[\"条\",{\"1\":{\"104\":1,\"127\":1,\"135\":1,\"192\":1,\"205\":1}}],[\"`\",{\"1\":{\"103\":2,\"104\":2}}],[\"函数调用\",{\"1\":{\"149\":1}}],[\"函数\",{\"1\":{\"103\":1,\"144\":1,\"149\":1,\"212\":3,\"219\":1}}],[\"查找\",{\"1\":{\"132\":1,\"137\":1,\"159\":1,\"221\":2}}],[\"查询数据库\",{\"1\":{\"178\":2,\"179\":1,\"189\":1,\"192\":1}}],[\"查询\",{\"1\":{\"103\":2,\"125\":1,\"133\":2,\"135\":10,\"147\":3,\"177\":2,\"178\":1,\"179\":4,\"180\":1,\"184\":1,\"192\":2,\"197\":1,\"206\":4,\"207\":1,\"209\":1,\"212\":2,\"215\":1,\"216\":2,\"220\":3}}],[\"查看\",{\"1\":{\"11\":1,\"13\":1,\"41\":3,\"43\":1,\"45\":1,\"46\":1,\"54\":1,\"97\":1,\"145\":1,\"159\":1,\"160\":1,\"163\":1,\"164\":2,\"177\":1,\"179\":1,\"208\":1,\"221\":1}}],[\"认为\",{\"1\":{\"159\":1,\"185\":1}}],[\"认真\",{\"1\":{\"124\":1}}],[\"认证\",{\"1\":{\"103\":3,\"113\":1,\"143\":1,\"203\":1}}],[\"认识\",{\"0\":{\"117\":1},\"1\":{\"73\":2,\"173\":1}}],[\"脱离\",{\"1\":{\"103\":1,\"221\":1}}],[\"订阅\",{\"1\":{\"103\":2,\"109\":1,\"164\":1,\"221\":3}}],[\"玄学\",{\"0\":{\"109\":1},\"1\":{\"102\":1}}],[\"库如\",{\"1\":{\"183\":1}}],[\"库\",{\"1\":{\"101\":1,\"136\":1,\"143\":2,\"147\":1,\"161\":1,\"183\":1,\"186\":1,\"196\":1}}],[\"库中\",{\"1\":{\"63\":1}}],[\"授权\",{\"1\":{\"101\":1,\"116\":1,\"117\":1}}],[\"字数\",{\"1\":{\"173\":1}}],[\"字符\",{\"1\":{\"148\":1}}],[\"字符串\",{\"1\":{\"101\":1,\"149\":2}}],[\"字节\",{\"1\":{\"148\":1,\"221\":3}}],[\"字段\",{\"1\":{\"135\":1,\"192\":2,\"213\":3}}],[\"字\",{\"1\":{\"103\":1,\"137\":1}}],[\"字头\",{\"1\":{\"85\":1}}],[\"羊毛\",{\"1\":{\"100\":1}}],[\"薅\",{\"1\":{\"100\":1}}],[\"鉴权\",{\"1\":{\"100\":1}}],[\"托管\",{\"0\":{\"100\":1},\"1\":{\"100\":1,\"101\":2,\"102\":3}}],[\"封\",{\"1\":{\"99\":1}}],[\"封装\",{\"1\":{\"5\":2,\"104\":1,\"215\":1,\"216\":2}}],[\"登陆\",{\"1\":{\"99\":1,\"143\":1,\"155\":1}}],[\"登录\",{\"1\":{\"5\":1,\"114\":1,\"115\":1,\"146\":1}}],[\"扫码\",{\"1\":{\"99\":1}}],[\"扫描\",{\"0\":{\"9\":1},\"1\":{\"9\":1,\"13\":3,\"107\":1}}],[\"载体\",{\"1\":{\"99\":1}}],[\"规范\",{\"1\":{\"135\":1}}],[\"规格\",{\"1\":{\"116\":1}}],[\"规则\",{\"1\":{\"98\":2,\"102\":1,\"106\":1,\"107\":1,\"141\":1}}],[\"规定\",{\"1\":{\"28\":1,\"147\":1}}],[\"泄露\",{\"1\":{\"98\":1,\"102\":1}}],[\"泄漏\",{\"1\":{\"51\":1}}],[\"台\",{\"1\":{\"98\":1,\"122\":1}}],[\"语义\",{\"1\":{\"221\":1}}],[\"语句\",{\"1\":{\"136\":1,\"143\":1,\"161\":5,\"177\":1,\"197\":2,\"220\":2}}],[\"语言\",{\"1\":{\"97\":1,\"100\":1,\"124\":2}}],[\"语法\",{\"1\":{\"8\":3,\"149\":1}}],[\"核心技术\",{\"1\":{\"152\":1}}],[\"核心\",{\"1\":{\"97\":1,\"125\":1,\"135\":1,\"215\":2,\"216\":1}}],[\"官\",{\"1\":{\"151\":1}}],[\"官网列\",{\"1\":{\"118\":1}}],[\"官网\",{\"0\":{\"108\":1},\"1\":{\"97\":2,\"109\":2,\"114\":1,\"120\":1,\"142\":1,\"147\":2,\"159\":1,\"166\":1,\"169\":1,\"170\":1,\"172\":1,\"207\":1,\"211\":1}}],[\"官方\",{\"1\":{\"7\":2,\"26\":1,\"49\":1,\"54\":1,\"100\":1,\"101\":1,\"103\":2,\"108\":2,\"136\":1,\"147\":1,\"159\":1,\"185\":1,\"197\":1}}],[\"元素\",{\"1\":{\"185\":1}}],[\"元\",{\"1\":{\"96\":1,\"221\":4}}],[\"轻量级\",{\"1\":{\"144\":1}}],[\"轻量\",{\"1\":{\"96\":1}}],[\"购买\",{\"1\":{\"95\":1,\"97\":1}}],[\"框\",{\"1\":{\"124\":1,\"136\":1}}],[\"框填\",{\"1\":{\"95\":1}}],[\"框架\",{\"1\":{\"81\":1,\"173\":1}}],[\"充值\",{\"1\":{\"95\":1}}],[\"费用\",{\"1\":{\"95\":1}}],[\"邮件\",{\"1\":{\"95\":1,\"143\":1}}],[\"邮箱\",{\"1\":{\"95\":3,\"113\":3,\"114\":2}}],[\"申请\",{\"0\":{\"95\":1,\"96\":1,\"112\":1},\"1\":{\"114\":3,\"115\":1,\"116\":1,\"117\":1,\"120\":1,\"146\":1}}],[\"短\",{\"1\":{\"137\":1}}],[\"短语\",{\"1\":{\"133\":1}}],[\"短信\",{\"0\":{\"95\":1},\"1\":{\"97\":1}}],[\"短期\",{\"1\":{\"38\":1}}],[\"】\",{\"0\":{\"127\":1,\"203\":1,\"204\":1},\"1\":{\"93\":1,\"110\":1}}],[\"旅行\",{\"1\":{\"93\":1,\"110\":1}}],[\"【\",{\"0\":{\"127\":1,\"203\":1,\"204\":1},\"1\":{\"93\":1,\"110\":1}}],[\"搭配\",{\"1\":{\"164\":1}}],[\"搭建\",{\"0\":{\"93\":1,\"98\":1},\"1\":{\"96\":1,\"98\":1,\"122\":1,\"124\":1,\"136\":1,\"152\":3,\"164\":1,\"173\":1,\"194\":1}}],[\"搭话\",{\"1\":{\"85\":1}}],[\"客户机\",{\"1\":{\"157\":1}}],[\"客户\",{\"1\":{\"117\":1,\"145\":1}}],[\"客户端\",{\"1\":{\"63\":2,\"65\":1,\"104\":1,\"115\":2,\"157\":3,\"207\":1,\"211\":1,\"213\":2,\"221\":5}}],[\"客服\",{\"0\":{\"93\":1},\"1\":{\"97\":1,\"103\":1}}],[\"智能\",{\"0\":{\"93\":1},\"1\":{\"97\":1,\"152\":1}}],[\"顺利\",{\"1\":{\"91\":1}}],[\"顺序\",{\"1\":{\"5\":1,\"125\":1,\"135\":1,\"221\":3}}],[\"祝\",{\"1\":{\"91\":1}}],[\"祝福\",{\"1\":{\"75\":1}}],[\"女朋友\",{\"1\":{\"90\":1}}],[\"蛮大的\",{\"1\":{\"173\":1}}],[\"蛮\",{\"1\":{\"90\":1,\"192\":1}}],[\"蛮多\",{\"1\":{\"90\":1}}],[\"蛮多人\",{\"1\":{\"86\":1}}],[\"抓取\",{\"1\":{\"127\":1,\"145\":3,\"192\":2}}],[\"抓狂\",{\"1\":{\"90\":1}}],[\"抓准\",{\"1\":{\"81\":1}}],[\"爬\",{\"1\":{\"89\":1}}],[\"羽毛球\",{\"1\":{\"89\":1}}],[\"医院\",{\"1\":{\"89\":1}}],[\"痘痘\",{\"1\":{\"89\":1}}],[\"睡眠\",{\"1\":{\"161\":1}}],[\"睡不着\",{\"1\":{\"89\":1}}],[\"睡好\",{\"1\":{\"89\":1}}],[\"睡觉\",{\"1\":{\"80\":1,\"83\":1,\"89\":1}}],[\"坚持\",{\"1\":{\"89\":1,\"173\":1}}],[\"奋斗\",{\"1\":{\"87\":1}}],[\"钱\",{\"1\":{\"87\":1}}],[\"省略\",{\"1\":{\"184\":1}}],[\"省\",{\"1\":{\"87\":1}}],[\"借\",{\"1\":{\"87\":1}}],[\"南山\",{\"1\":{\"87\":1,\"89\":1}}],[\"气愤\",{\"1\":{\"87\":1}}],[\"气得\",{\"1\":{\"86\":1}}],[\"浪费时间\",{\"1\":{\"165\":1}}],[\"浪费\",{\"1\":{\"87\":2,\"127\":1,\"221\":1}}],[\"锻炼\",{\"1\":{\"86\":1,\"173\":1}}],[\"练级\",{\"1\":{\"86\":1}}],[\"佩服\",{\"1\":{\"86\":1,\"165\":1}}],[\"市场\",{\"1\":{\"86\":1}}],[\"市集\",{\"1\":{\"74\":1}}],[\"暴躁\",{\"1\":{\"86\":1}}],[\"浮躁\",{\"1\":{\"86\":1}}],[\"日期\",{\"1\":{\"147\":4,\"148\":2,\"150\":2}}],[\"日历\",{\"1\":{\"141\":2}}],[\"日\",{\"1\":{\"126\":1}}],[\"日子\",{\"1\":{\"86\":1}}],[\"日志\",{\"0\":{\"14\":1,\"126\":1,\"145\":1,\"156\":1},\"1\":{\"14\":2,\"30\":1,\"42\":1,\"50\":4,\"72\":1,\"81\":1,\"102\":1,\"122\":2,\"126\":3,\"145\":7,\"151\":2,\"156\":2,\"157\":1,\"160\":1,\"161\":16,\"163\":3,\"164\":3,\"169\":1,\"221\":7}}],[\"憋屈\",{\"1\":{\"86\":3,\"90\":1}}],[\"谁\",{\"1\":{\"86\":1}}],[\"唉\",{\"1\":{\"86\":1}}],[\"青云\",{\"1\":{\"86\":1}}],[\"腾讯\",{\"1\":{\"86\":1,\"90\":1,\"96\":1,\"114\":2,\"124\":1,\"158\":1}}],[\"长度\",{\"1\":{\"221\":3}}],[\"长时间\",{\"1\":{\"221\":1}}],[\"长\",{\"1\":{\"137\":1,\"168\":1,\"180\":1}}],[\"长大\",{\"1\":{\"86\":1}}],[\"长期\",{\"1\":{\"38\":1}}],[\"屋里\",{\"1\":{\"86\":1}}],[\"惨\",{\"1\":{\"86\":1}}],[\"怼\",{\"1\":{\"86\":2}}],[\"懒得\",{\"1\":{\"86\":1}}],[\"听说\",{\"1\":{\"221\":1}}],[\"听到\",{\"1\":{\"219\":1}}],[\"听\",{\"1\":{\"86\":1}}],[\"听过\",{\"1\":{\"77\":1}}],[\"固执\",{\"1\":{\"86\":1}}],[\"固定\",{\"1\":{\"26\":1,\"57\":1,\"221\":1}}],[\"悲剧\",{\"1\":{\"85\":1}}],[\"悲伤\",{\"1\":{\"75\":1,\"78\":1,\"86\":1}}],[\"欢迎\",{\"0\":{\"138\":1},\"1\":{\"145\":1,\"152\":1,\"160\":1,\"165\":1,\"173\":1}}],[\"欢喜\",{\"1\":{\"85\":1}}],[\"欢快\",{\"1\":{\"74\":1}}],[\"伤心\",{\"1\":{\"85\":1}}],[\"伤感\",{\"1\":{\"73\":1,\"80\":1}}],[\"奇奇怪怪\",{\"1\":{\"85\":1}}],[\"奇葩\",{\"1\":{\"76\":2}}],[\"呗\",{\"1\":{\"85\":1,\"122\":1}}],[\"例子\",{\"1\":{\"144\":1,\"149\":2,\"159\":1,\"185\":3}}],[\"例外\",{\"1\":{\"85\":1}}],[\"例如\",{\"1\":{\"59\":1,\"140\":2,\"185\":2}}],[\"守得\",{\"1\":{\"85\":1}}],[\"浑浑噩噩\",{\"1\":{\"85\":1}}],[\"跨\",{\"1\":{\"164\":2,\"208\":1,\"221\":1}}],[\"跨越\",{\"1\":{\"135\":1}}],[\"跨年\",{\"1\":{\"85\":1}}],[\"跨域\",{\"1\":{\"5\":1}}],[\"吵架\",{\"1\":{\"85\":1,\"88\":1,\"90\":1}}],[\"迎来\",{\"1\":{\"85\":1}}],[\"酱\",{\"1\":{\"84\":1}}],[\"展望\",{\"0\":{\"91\":1},\"1\":{\"84\":1}}],[\"展示\",{\"0\":{\"151\":1},\"1\":{\"72\":1,\"125\":1,\"145\":3,\"151\":2,\"216\":1}}],[\"厨房\",{\"1\":{\"83\":1}}],[\"猫\",{\"1\":{\"83\":1}}],[\"养\",{\"1\":{\"83\":1}}],[\"盼\",{\"1\":{\"83\":1}}],[\"户口\",{\"1\":{\"83\":1}}],[\"健健康康\",{\"1\":{\"84\":1,\"91\":1}}],[\"健康\",{\"1\":{\"82\":2}}],[\"健身\",{\"1\":{\"82\":1}}],[\"贵\",{\"1\":{\"82\":1}}],[\"房\",{\"1\":{\"82\":1}}],[\"房价\",{\"1\":{\"82\":1}}],[\"房子\",{\"1\":{\"82\":1}}],[\"摄影师\",{\"1\":{\"82\":1}}],[\"盯\",{\"1\":{\"82\":1}}],[\"恍惚\",{\"1\":{\"82\":1}}],[\"宅\",{\"1\":{\"82\":1}}],[\"阅读\",{\"1\":{\"81\":1,\"189\":1,\"192\":1}}],[\"安全性\",{\"1\":{\"158\":1}}],[\"安全\",{\"1\":{\"158\":4,\"221\":1}}],[\"安安稳稳\",{\"1\":{\"151\":1}}],[\"安安静静\",{\"1\":{\"81\":1,\"84\":1}}],[\"安分\",{\"1\":{\"83\":1}}],[\"安装\",{\"0\":{\"146\":1,\"153\":1},\"1\":{\"72\":3,\"98\":1,\"146\":1,\"153\":2,\"166\":2,\"170\":1,\"172\":1,\"184\":1}}],[\"炮灰\",{\"1\":{\"81\":1}}],[\"争霸\",{\"1\":{\"81\":1}}],[\"领会\",{\"1\":{\"86\":1}}],[\"领导\",{\"1\":{\"81\":2,\"86\":2}}],[\"领域\",{\"1\":{\"29\":1,\"221\":1}}],[\"架空\",{\"1\":{\"81\":1}}],[\"架构图\",{\"1\":{\"125\":1,\"139\":1}}],[\"架构设计\",{\"1\":{\"86\":1}}],[\"架构\",{\"0\":{\"122\":1,\"123\":1,\"125\":1,\"131\":1,\"178\":1},\"1\":{\"4\":1,\"18\":1,\"42\":2,\"77\":2,\"85\":1,\"122\":1,\"126\":1,\"152\":4,\"161\":4}}],[\"部分\",{\"1\":{\"151\":1,\"157\":2,\"161\":1}}],[\"部门\",{\"1\":{\"81\":3}}],[\"部署\",{\"0\":{\"12\":1,\"102\":1,\"152\":1},\"1\":{\"5\":1,\"6\":4,\"12\":1,\"13\":4,\"42\":1,\"72\":1,\"102\":1,\"124\":1,\"152\":2,\"161\":3,\"164\":1,\"191\":1}}],[\"卵用\",{\"1\":{\"81\":1}}],[\"忘掉\",{\"1\":{\"87\":1}}],[\"忘\",{\"1\":{\"87\":1}}],[\"忘光\",{\"1\":{\"81\":1}}],[\"忘记\",{\"1\":{\"41\":1,\"170\":1,\"221\":1}}],[\"研究\",{\"1\":{\"81\":1,\"86\":1,\"87\":1}}],[\"滴\",{\"1\":{\"81\":1}}],[\"干活\",{\"1\":{\"86\":1}}],[\"干\",{\"1\":{\"81\":1}}],[\"晚上\",{\"1\":{\"80\":1,\"83\":1}}],[\"晚安\",{\"1\":{\"73\":1}}],[\"拜拜\",{\"1\":{\"80\":1}}],[\"岗位\",{\"1\":{\"80\":1}}],[\"电话\",{\"1\":{\"116\":1}}],[\"电子邮件\",{\"1\":{\"113\":1,\"114\":1}}],[\"电子产品\",{\"1\":{\"82\":1}}],[\"电商\",{\"1\":{\"80\":1}}],[\"电信\",{\"1\":{\"29\":1}}],[\"联系\",{\"1\":{\"80\":1,\"170\":1,\"221\":1}}],[\"联想\",{\"1\":{\"80\":1}}],[\"啃\",{\"1\":{\"80\":1}}],[\"卖掉\",{\"1\":{\"80\":1}}],[\"慌慌张张\",{\"1\":{\"80\":1}}],[\"慌得\",{\"1\":{\"80\":1}}],[\"迷迷糊糊\",{\"1\":{\"80\":1}}],[\"烧烤\",{\"1\":{\"80\":1}}],[\"烧水\",{\"1\":{\"76\":1}}],[\"楼下\",{\"1\":{\"80\":1,\"82\":1}}],[\"反复\",{\"1\":{\"192\":1,\"221\":1}}],[\"反映\",{\"1\":{\"161\":1}}],[\"反向\",{\"0\":{\"157\":1},\"1\":{\"157\":2,\"161\":1}}],[\"反射\",{\"1\":{\"141\":1}}],[\"反\",{\"1\":{\"137\":1,\"149\":2,\"151\":1}}],[\"反抗\",{\"1\":{\"86\":1}}],[\"反思\",{\"1\":{\"80\":1}}],[\"反馈\",{\"1\":{\"42\":1}}],[\"恒\",{\"1\":{\"80\":1}}],[\"甘心\",{\"1\":{\"80\":1}}],[\"稳\",{\"1\":{\"80\":1}}],[\"稳定\",{\"1\":{\"7\":1,\"42\":1,\"45\":2,\"57\":1,\"192\":1}}],[\"水平\",{\"1\":{\"184\":1}}],[\"水\",{\"1\":{\"80\":1}}],[\"泼出去\",{\"1\":{\"80\":1}}],[\"玩玩\",{\"1\":{\"80\":1,\"192\":1}}],[\"周围\",{\"1\":{\"90\":1}}],[\"周\",{\"1\":{\"80\":1,\"81\":1}}],[\"周末\",{\"1\":{\"80\":1}}],[\"周期\",{\"1\":{\"55\":1}}],[\"饭\",{\"1\":{\"80\":1}}],[\"吹水\",{\"1\":{\"80\":1}}],[\"吹\",{\"1\":{\"80\":1}}],[\"痴迷\",{\"1\":{\"80\":1}}],[\"裸辞\",{\"0\":{\"80\":1},\"1\":{\"80\":2}}],[\"恢复\",{\"1\":{\"79\":1}}],[\"篇文章\",{\"1\":{\"79\":1,\"167\":1,\"216\":1}}],[\"凑合\",{\"1\":{\"124\":1}}],[\"凑\",{\"1\":{\"79\":1,\"221\":1}}],[\"趁着\",{\"1\":{\"79\":1}}],[\"↗\",{\"1\":{\"78\":1}}],[\"ω\",{\"1\":{\"78\":1}}],[\"↖\",{\"1\":{\"78\":1}}],[\"便捷\",{\"1\":{\"146\":1}}],[\"便是\",{\"1\":{\"78\":1,\"120\":1,\"149\":1}}],[\"便宜\",{\"1\":{\"57\":1}}],[\"活着\",{\"1\":{\"221\":1}}],[\"活动\",{\"1\":{\"221\":2}}],[\"活\",{\"1\":{\"78\":1}}],[\"差不多\",{\"1\":{\"82\":1,\"124\":2}}],[\"差评\",{\"1\":{\"80\":1}}],[\"差\",{\"1\":{\"78\":2,\"80\":2,\"168\":1}}],[\"差距\",{\"1\":{\"69\":1,\"72\":1}}],[\"挽留\",{\"1\":{\"78\":1,\"80\":2}}],[\"永远\",{\"1\":{\"78\":1}}],[\"废墟\",{\"1\":{\"78\":1}}],[\"摆设\",{\"1\":{\"78\":1}}],[\"桌上\",{\"1\":{\"78\":1}}],[\"境地\",{\"1\":{\"78\":1}}],[\"凄惨\",{\"1\":{\"78\":1}}],[\"德国\",{\"1\":{\"78\":1}}],[\"灿烂\",{\"1\":{\"78\":1}}],[\"夸\",{\"1\":{\"78\":2,\"80\":1}}],[\"状况\",{\"1\":{\"78\":1}}],[\"状态\",{\"1\":{\"5\":1,\"45\":1,\"72\":4,\"76\":1,\"78\":1,\"103\":3,\"114\":1,\"163\":1,\"164\":1,\"221\":2}}],[\"描述\",{\"1\":{\"78\":1,\"114\":1,\"147\":1,\"221\":1}}],[\"信号\",{\"1\":{\"99\":2}}],[\"信件\",{\"1\":{\"78\":1}}],[\"信息安全\",{\"1\":{\"158\":1}}],[\"信息\",{\"0\":{\"30\":1,\"33\":1},\"1\":{\"30\":2,\"38\":2,\"42\":1,\"43\":1,\"44\":1,\"56\":2,\"61\":1,\"63\":1,\"72\":1,\"101\":1,\"103\":1,\"115\":1,\"137\":1,\"141\":1,\"164\":2,\"203\":1,\"205\":1,\"212\":1,\"221\":5}}],[\"》\",{\"1\":{\"77\":1,\"152\":1,\"161\":1,\"192\":3}}],[\"《\",{\"1\":{\"77\":1,\"152\":1,\"161\":1,\"192\":3}}],[\"耽误\",{\"1\":{\"77\":1}}],[\"牛云\",{\"1\":{\"124\":1}}],[\"牛\",{\"0\":{\"165\":1},\"1\":{\"77\":1,\"152\":1,\"168\":1}}],[\"牛客\",{\"1\":{\"73\":1}}],[\"情景\",{\"1\":{\"221\":1}}],[\"情形\",{\"1\":{\"221\":1}}],[\"情空\",{\"1\":{\"221\":1}}],[\"情感\",{\"0\":{\"174\":1},\"1\":{\"127\":2}}],[\"情绪化\",{\"1\":{\"86\":1}}],[\"情绪\",{\"1\":{\"77\":1}}],[\"情况\",{\"1\":{\"5\":1,\"27\":2,\"35\":1,\"37\":2,\"39\":1,\"43\":1,\"45\":1,\"50\":1,\"51\":1,\"57\":3,\"66\":2,\"72\":1,\"126\":2,\"152\":1,\"158\":1,\"159\":1,\"160\":1,\"164\":1,\"184\":1,\"221\":4}}],[\"忍受\",{\"1\":{\"170\":1}}],[\"忍住\",{\"1\":{\"77\":1}}],[\"忍着\",{\"1\":{\"75\":1}}],[\"善于\",{\"1\":{\"77\":1}}],[\"笑\",{\"1\":{\"77\":1}}],[\"哭\",{\"1\":{\"77\":1}}],[\"朋友\",{\"1\":{\"77\":2}}],[\"朋友圈\",{\"1\":{\"23\":1}}],[\"手段\",{\"1\":{\"221\":1}}],[\"手机号\",{\"0\":{\"95\":1},\"1\":{\"95\":1}}],[\"手机\",{\"1\":{\"77\":1}}],[\"手动\",{\"1\":{\"5\":1,\"180\":1,\"192\":1}}],[\"黄段子\",{\"1\":{\"77\":1}}],[\"貌似\",{\"1\":{\"77\":1,\"85\":1}}],[\"今天\",{\"1\":{\"85\":1,\"147\":1}}],[\"今晚\",{\"1\":{\"77\":1}}],[\"今年\",{\"1\":{\"73\":1,\"76\":1,\"77\":3,\"84\":1,\"87\":1,\"89\":1}}],[\"美观\",{\"1\":{\"124\":1,\"151\":1,\"168\":1,\"170\":1,\"173\":1}}],[\"美元\",{\"1\":{\"95\":1}}],[\"美国\",{\"1\":{\"95\":2,\"114\":1,\"164\":1}}],[\"美好\",{\"1\":{\"80\":1}}],[\"美\",{\"1\":{\"77\":1}}],[\"美团\",{\"1\":{\"73\":1}}],[\"珠江\",{\"1\":{\"77\":1,\"80\":1}}],[\"孤独\",{\"0\":{\"77\":1}}],[\"病\",{\"1\":{\"76\":1}}],[\"书籍\",{\"1\":{\"81\":1}}],[\"书\",{\"1\":{\"76\":1,\"80\":1,\"81\":1,\"87\":1,\"124\":1}}],[\"鹌鹑\",{\"1\":{\"76\":1}}],[\"床上\",{\"1\":{\"76\":1,\"89\":1}}],[\"躺\",{\"1\":{\"76\":1,\"89\":1}}],[\"洗衣服\",{\"1\":{\"76\":1}}],[\"洗澡\",{\"1\":{\"76\":1}}],[\"翻译\",{\"1\":{\"149\":1}}],[\"翻墙\",{\"1\":{\"95\":1}}],[\"翻开\",{\"1\":{\"87\":1}}],[\"翻\",{\"1\":{\"76\":2}}],[\"翻转\",{\"1\":{\"23\":2}}],[\"圣经\",{\"1\":{\"76\":1}}],[\"届\",{\"1\":{\"76\":1}}],[\"十几分钟\",{\"1\":{\"221\":1}}],[\"十万\",{\"1\":{\"221\":1}}],[\"十分\",{\"1\":{\"86\":1}}],[\"十分困难\",{\"1\":{\"12\":1}}],[\"十年\",{\"1\":{\"85\":1}}],[\"十\",{\"1\":{\"76\":1}}],[\"买\",{\"1\":{\"76\":1,\"81\":1,\"82\":1,\"83\":1,\"95\":1,\"96\":1,\"152\":1}}],[\"敲个\",{\"1\":{\"81\":1}}],[\"敲\",{\"1\":{\"76\":1,\"84\":1}}],[\"敲门\",{\"1\":{\"75\":1}}],[\"积极性\",{\"1\":{\"76\":1}}],[\"牺牲\",{\"1\":{\"76\":1}}],[\"疯狂\",{\"1\":{\"76\":1,\"77\":1}}],[\"估计\",{\"1\":{\"76\":1,\"168\":1}}],[\"员工\",{\"1\":{\"76\":1}}],[\"厌恶\",{\"1\":{\"76\":1}}],[\"幸福\",{\"1\":{\"76\":1}}],[\"国人\",{\"1\":{\"168\":1}}],[\"国内\",{\"1\":{\"96\":2,\"98\":1,\"114\":1,\"116\":1}}],[\"国外\",{\"1\":{\"95\":3,\"96\":1,\"99\":1}}],[\"国庆\",{\"1\":{\"76\":1}}],[\"国企\",{\"1\":{\"74\":1}}],[\"隔壁\",{\"1\":{\"76\":1}}],[\"隔离\",{\"1\":{\"75\":1}}],[\"累加\",{\"1\":{\"210\":2}}],[\"累累\",{\"1\":{\"76\":1}}],[\"累\",{\"1\":{\"76\":1}}],[\"涉及\",{\"1\":{\"76\":1,\"155\":1,\"192\":1,\"208\":1}}],[\"咋\",{\"1\":{\"76\":1,\"135\":1,\"171\":1}}],[\"挺大\",{\"1\":{\"87\":1}}],[\"挺\",{\"1\":{\"76\":1,\"81\":2,\"86\":1,\"126\":1,\"151\":1,\"159\":1,\"161\":1,\"172\":1,\"219\":1}}],[\"呆\",{\"1\":{\"76\":1}}],[\"决心\",{\"1\":{\"76\":1,\"80\":1}}],[\"决定\",{\"1\":{\"6\":1,\"7\":1,\"63\":1,\"86\":1,\"87\":1,\"124\":1,\"185\":1,\"221\":7}}],[\"职\",{\"1\":{\"76\":1}}],[\"白费\",{\"1\":{\"75\":1}}],[\"宣泄\",{\"1\":{\"77\":1}}],[\"宣告\",{\"1\":{\"75\":3}}],[\"宣称\",{\"1\":{\"70\":1}}],[\"哦\",{\"1\":{\"75\":1}}],[\"吐槽\",{\"1\":{\"75\":1}}],[\"理解\",{\"1\":{\"75\":1,\"86\":1,\"183\":1,\"192\":2,\"221\":4}}],[\"理论\",{\"1\":{\"55\":1,\"62\":1,\"70\":1}}],[\"谈谈\",{\"1\":{\"75\":1}}],[\"索引\",{\"1\":{\"75\":1,\"124\":1,\"132\":3,\"133\":2,\"135\":8,\"136\":1,\"137\":2,\"197\":2,\"198\":1,\"204\":3,\"205\":5,\"207\":1,\"209\":1,\"216\":2,\"221\":3}}],[\"久\",{\"1\":{\"75\":1,\"151\":1}}],[\"淡定\",{\"1\":{\"75\":1}}],[\"拖\",{\"1\":{\"75\":1}}],[\"告知\",{\"1\":{\"109\":1,\"221\":1}}],[\"告别\",{\"1\":{\"75\":1}}],[\"告诉\",{\"1\":{\"56\":1}}],[\"宿舍\",{\"1\":{\"75\":2}}],[\"宿主机\",{\"1\":{\"5\":1,\"11\":3}}],[\"唯一\",{\"1\":{\"75\":1,\"85\":1,\"146\":1,\"163\":1,\"164\":1}}],[\"约\",{\"1\":{\"75\":1}}],[\"约莫\",{\"1\":{\"8\":1}}],[\"泪奔\",{\"1\":{\"75\":1}}],[\"骂人\",{\"1\":{\"75\":1}}],[\"骂\",{\"1\":{\"75\":1,\"86\":2}}],[\"啊\",{\"1\":{\"75\":1,\"76\":2,\"85\":1,\"86\":1,\"87\":1,\"124\":1,\"127\":1,\"130\":1,\"192\":1}}],[\"珍爱\",{\"1\":{\"75\":2}}],[\"件\",{\"1\":{\"75\":1}}],[\"页码\",{\"1\":{\"192\":1}}],[\"页数\",{\"1\":{\"192\":1}}],[\"页面\",{\"1\":{\"96\":1,\"98\":2,\"122\":1,\"124\":2,\"125\":1,\"145\":4,\"146\":1,\"153\":1,\"160\":2,\"165\":1,\"168\":1,\"192\":2}}],[\"页\",{\"1\":{\"75\":1,\"171\":1,\"173\":1,\"221\":1}}],[\"劝\",{\"1\":{\"75\":1,\"78\":1}}],[\"劝导\",{\"1\":{\"6\":1}}],[\"评价\",{\"1\":{\"80\":1}}],[\"评上\",{\"1\":{\"75\":1}}],[\"评\",{\"1\":{\"75\":1}}],[\"评论\",{\"1\":{\"23\":5,\"124\":1,\"167\":5}}],[\"导图\",{\"1\":{\"192\":1}}],[\"导出\",{\"1\":{\"146\":2,\"149\":1,\"167\":1}}],[\"导入\",{\"1\":{\"135\":1,\"137\":1,\"143\":2,\"167\":1}}],[\"导师\",{\"1\":{\"75\":2}}],[\"导致系统\",{\"1\":{\"51\":1}}],[\"导致\",{\"1\":{\"5\":1,\"7\":1,\"41\":2,\"42\":1,\"43\":1,\"44\":1,\"45\":1,\"49\":1,\"50\":3,\"58\":2,\"60\":1,\"87\":2,\"99\":1,\"152\":2,\"161\":1,\"166\":1,\"221\":5}}],[\"彼此\",{\"1\":{\"75\":1}}],[\"呵护\",{\"1\":{\"75\":1}}],[\"屏蔽\",{\"1\":{\"75\":1}}],[\"屏障\",{\"0\":{\"52\":1},\"1\":{\"23\":2,\"52\":5}}],[\"悠闲\",{\"1\":{\"75\":1}}],[\"拉取\",{\"1\":{\"221\":6}}],[\"拉到\",{\"1\":{\"86\":1}}],[\"拉下\",{\"1\":{\"75\":1,\"81\":1}}],[\"拉勾\",{\"1\":{\"74\":1,\"80\":1}}],[\"赶\",{\"1\":{\"75\":1}}],[\"感染力\",{\"1\":{\"171\":1}}],[\"感兴趣\",{\"1\":{\"166\":1}}],[\"感谢\",{\"1\":{\"80\":1,\"83\":1,\"145\":1,\"150\":1,\"151\":1,\"165\":1,\"173\":1}}],[\"感叹\",{\"1\":{\"79\":1}}],[\"感情\",{\"0\":{\"75\":1,\"88\":1},\"1\":{\"75\":1,\"89\":1}}],[\"感觉\",{\"1\":{\"7\":1,\"45\":1,\"73\":4,\"74\":3,\"76\":4,\"77\":2,\"80\":1,\"81\":1,\"86\":2,\"87\":3,\"124\":1,\"152\":1,\"164\":1,\"170\":1,\"173\":2,\"219\":1}}],[\"邀请\",{\"1\":{\"74\":1}}],[\"抱怨\",{\"1\":{\"86\":1}}],[\"抱\",{\"1\":{\"74\":1,\"78\":1}}],[\"站长\",{\"1\":{\"167\":1}}],[\"站点\",{\"1\":{\"148\":1}}],[\"站\",{\"1\":{\"74\":1,\"165\":1}}],[\"专注\",{\"1\":{\"165\":1}}],[\"专研\",{\"1\":{\"76\":2,\"81\":1}}],[\"专业\",{\"1\":{\"74\":1,\"185\":1}}],[\"专用\",{\"1\":{\"72\":1}}],[\"果然\",{\"1\":{\"74\":1,\"151\":1,\"161\":1}}],[\"果断\",{\"1\":{\"73\":1}}],[\"圈子\",{\"1\":{\"74\":1}}],[\"照\",{\"1\":{\"74\":2}}],[\"照着\",{\"1\":{\"74\":1,\"221\":1}}],[\"拍\",{\"1\":{\"74\":2}}],[\"外包\",{\"1\":{\"74\":2,\"75\":1}}],[\"外面\",{\"1\":{\"45\":1,\"85\":1}}],[\"互联网\",{\"1\":{\"74\":1}}],[\"招\",{\"1\":{\"74\":1}}],[\"招聘\",{\"1\":{\"74\":1}}],[\"招聘会\",{\"1\":{\"74\":1}}],[\"沾边\",{\"1\":{\"74\":1}}],[\"心跳\",{\"1\":{\"221\":1}}],[\"心脏\",{\"1\":{\"192\":1}}],[\"心知\",{\"1\":{\"165\":1,\"172\":2}}],[\"心动\",{\"1\":{\"90\":1}}],[\"心思\",{\"1\":{\"88\":1}}],[\"心\",{\"1\":{\"87\":1,\"172\":1}}],[\"心事\",{\"1\":{\"83\":1}}],[\"心惊胆战\",{\"0\":{\"80\":1}}],[\"心疼\",{\"1\":{\"75\":1}}],[\"心态\",{\"1\":{\"74\":1,\"75\":1,\"90\":1}}],[\"心里\",{\"1\":{\"74\":1,\"75\":1,\"76\":1}}],[\"么\",{\"1\":{\"74\":2,\"76\":2,\"80\":1,\"165\":1}}],[\"绝望\",{\"1\":{\"74\":4}}],[\"撤\",{\"1\":{\"74\":2}}],[\"英文\",{\"1\":{\"74\":1,\"78\":1}}],[\"哪些\",{\"1\":{\"221\":5}}],[\"哪里\",{\"1\":{\"221\":1}}],[\"哪个\",{\"1\":{\"163\":2,\"221\":4}}],[\"哪种\",{\"1\":{\"117\":1}}],[\"哪\",{\"1\":{\"74\":1,\"221\":3}}],[\"哪来\",{\"1\":{\"74\":1}}],[\"机会\",{\"1\":{\"173\":1}}],[\"机房\",{\"1\":{\"152\":2,\"164\":4}}],[\"机器\",{\"1\":{\"122\":2,\"124\":1,\"127\":1,\"221\":5}}],[\"机构\",{\"1\":{\"74\":1,\"114\":1,\"158\":1}}],[\"机制\",{\"1\":{\"74\":1,\"141\":1,\"177\":1,\"192\":1,\"221\":2}}],[\"居然\",{\"1\":{\"74\":2,\"219\":1}}],[\"苦涩\",{\"1\":{\"74\":1}}],[\"间隙\",{\"1\":{\"79\":1}}],[\"间\",{\"1\":{\"74\":1}}],[\"间隔\",{\"1\":{\"65\":1,\"151\":4}}],[\"突然\",{\"1\":{\"74\":2,\"124\":1}}],[\"突发\",{\"1\":{\"60\":2}}],[\"家人\",{\"1\":{\"83\":1}}],[\"家里人\",{\"1\":{\"84\":1}}],[\"家里\",{\"1\":{\"82\":1}}],[\"家\",{\"1\":{\"81\":1,\"221\":1}}],[\"家小\",{\"1\":{\"74\":1}}],[\"家乡\",{\"1\":{\"73\":1}}],[\"趟\",{\"1\":{\"74\":1}}],[\"质疑\",{\"1\":{\"74\":1}}],[\"紧张\",{\"1\":{\"74\":1}}],[\"早期\",{\"1\":{\"164\":2}}],[\"早点\",{\"1\":{\"89\":1}}],[\"早起\",{\"1\":{\"83\":1}}],[\"早\",{\"1\":{\"74\":1}}],[\"答案\",{\"1\":{\"221\":2}}],[\"答辩\",{\"1\":{\"75\":1}}],[\"答对\",{\"1\":{\"74\":1}}],[\"答出来\",{\"1\":{\"74\":1}}],[\"答反\",{\"1\":{\"74\":1}}],[\"千万级\",{\"1\":{\"74\":1}}],[\"游戏\",{\"1\":{\"74\":1,\"75\":1,\"86\":1}}],[\"霾\",{\"1\":{\"74\":1}}],[\"雾\",{\"1\":{\"74\":1}}],[\"雾霾\",{\"1\":{\"73\":1}}],[\"满意\",{\"1\":{\"81\":1}}],[\"满目疮痍\",{\"1\":{\"78\":1}}],[\"满脑子\",{\"1\":{\"74\":1}}],[\"满足\",{\"1\":{\"28\":2,\"63\":1,\"140\":1}}],[\"轮流\",{\"1\":{\"155\":1}}],[\"轮询\",{\"1\":{\"155\":1,\"221\":1}}],[\"轮\",{\"1\":{\"74\":2}}],[\"额\",{\"1\":{\"74\":2,\"155\":1}}],[\"啥\",{\"1\":{\"74\":1,\"76\":1,\"124\":1}}],[\"建\",{\"1\":{\"221\":1}}],[\"建立\",{\"1\":{\"122\":2,\"132\":1,\"133\":1,\"135\":1,\"137\":2,\"145\":1}}],[\"建站\",{\"0\":{\"123\":1,\"124\":1},\"1\":{\"74\":1,\"122\":1,\"165\":1,\"166\":1}}],[\"建议\",{\"1\":{\"28\":1,\"72\":1,\"114\":1,\"125\":1,\"137\":1,\"159\":1,\"187\":1}}],[\"搜\",{\"1\":{\"74\":2}}],[\"搜索引擎\",{\"0\":{\"132\":1},\"1\":{\"132\":3}}],[\"搜索\",{\"0\":{\"40\":1,\"135\":1,\"204\":1,\"206\":1,\"209\":1,\"210\":1},\"1\":{\"45\":1,\"93\":1,\"95\":1,\"122\":2,\"132\":1,\"133\":3,\"134\":1,\"135\":1,\"169\":1,\"204\":4,\"205\":7,\"206\":1,\"209\":1,\"210\":1,\"215\":1,\"216\":7}}],[\"逼\",{\"0\":{\"165\":1},\"1\":{\"74\":1,\"77\":1,\"152\":1,\"168\":1}}],[\"卷子\",{\"1\":{\"74\":1}}],[\"品牌\",{\"1\":{\"74\":1}}],[\"乐观\",{\"1\":{\"74\":1}}],[\"底\",{\"1\":{\"74\":2}}],[\"底层\",{\"1\":{\"6\":1,\"7\":1,\"9\":1,\"57\":1,\"63\":1,\"87\":1,\"161\":1,\"221\":1}}],[\"静静的\",{\"1\":{\"73\":1}}],[\"静态\",{\"1\":{\"9\":1,\"124\":1,\"152\":1}}],[\"春招\",{\"1\":{\"73\":1,\"75\":1}}],[\"春节\",{\"1\":{\"73\":1,\"80\":1,\"85\":1}}],[\"弃\",{\"1\":{\"73\":1}}],[\"兼外\",{\"1\":{\"73\":1}}],[\"面经\",{\"1\":{\"80\":1}}],[\"面\",{\"1\":{\"74\":1}}],[\"面到\",{\"1\":{\"74\":1}}],[\"面试题\",{\"0\":{\"221\":1}}],[\"面试官\",{\"1\":{\"74\":4,\"80\":1,\"169\":1,\"221\":1}}],[\"面试\",{\"0\":{\"74\":1},\"1\":{\"73\":1,\"74\":6,\"75\":3,\"76\":1,\"80\":3,\"86\":1,\"128\":1,\"130\":1,\"169\":1,\"221\":1}}],[\"面向\",{\"1\":{\"51\":1}}],[\"投靠\",{\"1\":{\"170\":1}}],[\"投\",{\"1\":{\"74\":2}}],[\"投了\",{\"1\":{\"73\":1,\"74\":1}}],[\"投诉\",{\"1\":{\"6\":1}}],[\"至此\",{\"1\":{\"121\":1,\"146\":1,\"148\":1,\"158\":1}}],[\"至今\",{\"1\":{\"76\":2,\"81\":1}}],[\"至\",{\"1\":{\"76\":1,\"114\":1,\"207\":1}}],[\"至少\",{\"1\":{\"73\":1,\"87\":1,\"124\":2,\"152\":1}}],[\"至于\",{\"1\":{\"70\":1,\"87\":1}}],[\"梦\",{\"1\":{\"73\":1}}],[\"梦想\",{\"1\":{\"73\":1,\"74\":1,\"76\":1}}],[\"马\",{\"1\":{\"73\":1}}],[\"马化腾\",{\"1\":{\"73\":1}}],[\"男闺蜜\",{\"1\":{\"73\":2}}],[\"拒\",{\"1\":{\"73\":1,\"74\":1,\"75\":1}}],[\"拒绝服务\",{\"1\":{\"63\":1}}],[\"味\",{\"1\":{\"73\":1}}],[\"泥土\",{\"1\":{\"73\":1}}],[\"天气\",{\"0\":{\"172\":1},\"1\":{\"165\":1,\"172\":6}}],[\"天\",{\"1\":{\"75\":1,\"83\":1}}],[\"天津\",{\"1\":{\"73\":1}}],[\"天天\",{\"1\":{\"73\":1,\"75\":2,\"81\":2,\"86\":1}}],[\"清空\",{\"1\":{\"160\":1,\"179\":1,\"185\":3}}],[\"清新\",{\"1\":{\"73\":1}}],[\"清除\",{\"1\":{\"38\":1,\"39\":2,\"221\":1}}],[\"冷\",{\"1\":{\"73\":1}}],[\"广播\",{\"1\":{\"221\":1}}],[\"广告费\",{\"1\":{\"167\":1}}],[\"广告\",{\"1\":{\"167\":1}}],[\"广深\",{\"1\":{\"74\":1}}],[\"广州\",{\"1\":{\"73\":1,\"74\":3,\"80\":2,\"190\":1}}],[\"广东\",{\"1\":{\"73\":1,\"74\":2,\"151\":1}}],[\"她\",{\"1\":{\"73\":1,\"75\":3,\"85\":1}}],[\"道\",{\"1\":{\"73\":1}}],[\"道路\",{\"1\":{\"6\":1}}],[\"妹纸\",{\"1\":{\"73\":2,\"75\":1,\"80\":1}}],[\"喜欢\",{\"1\":{\"73\":1,\"75\":1,\"76\":2,\"80\":1,\"171\":1}}],[\"终于\",{\"1\":{\"73\":1,\"83\":2,\"122\":1}}],[\"终端\",{\"1\":{\"42\":1}}],[\"熟悉\",{\"1\":{\"73\":1,\"221\":1}}],[\"嗯\",{\"1\":{\"73\":1,\"75\":1,\"79\":1,\"80\":2,\"81\":1,\"124\":1}}],[\"炸\",{\"1\":{\"73\":1,\"75\":1}}],[\"厕所\",{\"1\":{\"73\":1}}],[\"香锅\",{\"1\":{\"73\":1}}],[\"吃个\",{\"1\":{\"80\":1}}],[\"吃饭\",{\"1\":{\"75\":1}}],[\"吃\",{\"1\":{\"73\":2,\"80\":1,\"82\":1}}],[\"喊\",{\"1\":{\"73\":1}}],[\"啦\",{\"1\":{\"73\":1,\"74\":1,\"97\":1}}],[\"鸡汤\",{\"1\":{\"73\":1,\"75\":1,\"78\":1}}],[\"灌毒\",{\"1\":{\"73\":1,\"75\":1,\"78\":1}}],[\"待\",{\"1\":{\"73\":1,\"103\":1}}],[\"学到\",{\"1\":{\"127\":1}}],[\"学学\",{\"1\":{\"87\":1,\"124\":1}}],[\"学妹\",{\"1\":{\"83\":1}}],[\"学\",{\"1\":{\"78\":1,\"152\":1}}],[\"学校\",{\"1\":{\"73\":1,\"75\":2}}],[\"学习\",{\"0\":{\"87\":1},\"1\":{\"7\":1,\"74\":1,\"76\":3,\"78\":1,\"81\":2,\"85\":2,\"87\":3,\"122\":2,\"124\":2,\"127\":1,\"145\":1,\"152\":2,\"159\":1,\"165\":2,\"192\":1}}],[\"努力\",{\"1\":{\"73\":2,\"75\":1,\"76\":1,\"78\":1,\"81\":1,\"127\":1}}],[\"厉害\",{\"1\":{\"73\":1,\"77\":1}}],[\"拿到\",{\"1\":{\"74\":1,\"80\":1,\"83\":1,\"157\":2,\"167\":1}}],[\"拿\",{\"1\":{\"73\":1,\"74\":1,\"127\":1,\"128\":1}}],[\"路径\",{\"1\":{\"125\":1,\"135\":1,\"158\":1}}],[\"路费\",{\"1\":{\"74\":1}}],[\"路\",{\"1\":{\"73\":1,\"86\":1,\"127\":1}}],[\"娃\",{\"1\":{\"73\":1}}],[\"离开\",{\"1\":{\"221\":2}}],[\"离谱\",{\"1\":{\"74\":1,\"82\":1}}],[\"离职\",{\"1\":{\"74\":1,\"76\":1,\"80\":3}}],[\"离\",{\"1\":{\"73\":1}}],[\"—\",{\"1\":{\"73\":2,\"97\":2,\"125\":8,\"141\":2,\"161\":4,\"206\":2}}],[\"拥有\",{\"1\":{\"73\":1,\"181\":1,\"221\":3}}],[\"毕业设计\",{\"1\":{\"75\":2,\"127\":2}}],[\"毕业\",{\"0\":{\"75\":1},\"1\":{\"73\":1,\"74\":2}}],[\"毕竟\",{\"1\":{\"8\":1,\"73\":2,\"74\":2,\"76\":1,\"84\":1,\"96\":1,\"106\":1,\"109\":1,\"126\":2,\"151\":1,\"159\":1,\"161\":1,\"169\":1,\"171\":1,\"192\":1}}],[\"默默\",{\"1\":{\"73\":1}}],[\"默认\",{\"1\":{\"27\":1,\"57\":3,\"66\":1,\"137\":2,\"142\":1,\"144\":1,\"151\":1,\"155\":1,\"157\":1,\"179\":2,\"184\":1,\"185\":1,\"188\":1,\"203\":1,\"205\":1,\"220\":1,\"221\":1}}],[\"考完试\",{\"1\":{\"73\":1}}],[\"考完\",{\"1\":{\"73\":1}}],[\"考虑一下\",{\"1\":{\"49\":1,\"70\":2}}],[\"考虑\",{\"0\":{\"45\":1},\"1\":{\"6\":1,\"38\":1,\"51\":1,\"57\":1,\"61\":1,\"63\":1,\"70\":1,\"124\":1,\"136\":1,\"151\":1,\"152\":1,\"221\":1}}],[\"批准\",{\"1\":{\"115\":1}}],[\"批斗\",{\"1\":{\"86\":1}}],[\"批处理\",{\"1\":{\"72\":1}}],[\"批量\",{\"1\":{\"5\":1,\"221\":5}}],[\"编号\",{\"1\":{\"221\":1}}],[\"编辑\",{\"1\":{\"168\":1}}],[\"编辑器\",{\"1\":{\"168\":2}}],[\"编译\",{\"1\":{\"153\":1}}],[\"编写\",{\"1\":{\"72\":1,\"185\":3}}],[\"编程\",{\"1\":{\"51\":1}}],[\"易用\",{\"1\":{\"72\":1}}],[\"计数器\",{\"1\":{\"210\":1}}],[\"计算机\",{\"1\":{\"76\":1}}],[\"计算\",{\"1\":{\"72\":1,\"221\":2}}],[\"计划\",{\"0\":{\"219\":1},\"1\":{\"57\":1,\"219\":1}}],[\"见到\",{\"1\":{\"73\":1}}],[\"见\",{\"1\":{\"72\":1,\"74\":1,\"76\":1,\"148\":1,\"151\":1,\"170\":1,\"172\":1,\"173\":1}}],[\"命中率\",{\"1\":{\"220\":1}}],[\"命中\",{\"1\":{\"132\":1,\"177\":1,\"178\":1,\"179\":2,\"205\":2,\"216\":1}}],[\"命名\",{\"1\":{\"72\":1,\"221\":2}}],[\"命令行\",{\"1\":{\"30\":1,\"72\":1,\"143\":1,\"153\":1}}],[\"命令\",{\"1\":{\"10\":1,\"42\":1,\"45\":1,\"46\":1,\"50\":1,\"143\":1,\"164\":1,\"184\":1}}],[\"样式\",{\"1\":{\"168\":1,\"173\":2}}],[\"样本\",{\"1\":{\"108\":1,\"127\":1}}],[\"样例\",{\"1\":{\"72\":1}}],[\"样子\",{\"1\":{\"7\":1,\"80\":1,\"85\":1,\"103\":1,\"221\":1}}],[\"源代码\",{\"1\":{\"137\":1,\"166\":1}}],[\"源码\",{\"0\":{\"203\":1},\"1\":{\"87\":2,\"101\":1,\"170\":1,\"173\":2,\"179\":2,\"192\":1,\"196\":1,\"205\":1,\"212\":1,\"216\":4}}],[\"源文件\",{\"1\":{\"72\":1}}],[\"源\",{\"1\":{\"72\":1}}],[\"事物\",{\"1\":{\"221\":1}}],[\"事实上\",{\"1\":{\"165\":1}}],[\"事后\",{\"1\":{\"75\":1}}],[\"事\",{\"1\":{\"75\":1,\"85\":1,\"128\":1}}],[\"事要\",{\"1\":{\"73\":1}}],[\"事件\",{\"1\":{\"72\":2,\"161\":7}}],[\"事务\",{\"1\":{\"23\":1,\"161\":4,\"221\":2}}],[\"弥补\",{\"1\":{\"72\":1}}],[\"像是\",{\"1\":{\"219\":1}}],[\"像\",{\"1\":{\"72\":1,\"166\":1,\"173\":1,\"221\":1}}],[\"旨在\",{\"1\":{\"72\":1}}],[\"落到\",{\"1\":{\"70\":1}}],[\"策略\",{\"1\":{\"70\":1,\"72\":1,\"183\":1,\"192\":1,\"221\":6}}],[\"均\",{\"1\":{\"116\":1}}],[\"均衡\",{\"0\":{\"155\":1},\"1\":{\"70\":1,\"152\":7,\"159\":1,\"221\":2}}],[\"均匀\",{\"1\":{\"70\":2}}],[\"预订\",{\"1\":{\"221\":1}}],[\"预热\",{\"1\":{\"177\":1}}],[\"预兆\",{\"1\":{\"81\":1}}],[\"预备\",{\"1\":{\"70\":1}}],[\"预览\",{\"1\":{\"54\":1,\"56\":1}}],[\"肯定\",{\"1\":{\"70\":1,\"106\":1,\"221\":2}}],[\"承受\",{\"1\":{\"70\":1,\"74\":1}}],[\"承接\",{\"1\":{\"63\":1}}],[\"识别\",{\"1\":{\"70\":1,\"96\":1,\"97\":1,\"114\":1,\"157\":1,\"158\":1,\"159\":1,\"221\":1}}],[\"近看\",{\"1\":{\"77\":1}}],[\"近\",{\"1\":{\"70\":1,\"74\":1,\"76\":1,\"77\":1}}],[\"准备\",{\"1\":{\"73\":2,\"75\":2,\"121\":1}}],[\"准确率\",{\"1\":{\"127\":1}}],[\"准确\",{\"1\":{\"70\":2,\"221\":2}}],[\"准点\",{\"1\":{\"50\":1}}],[\"卓越\",{\"1\":{\"69\":1}}],[\"明年\",{\"1\":{\"73\":1,\"76\":1,\"78\":1}}],[\"明显\",{\"1\":{\"69\":1,\"127\":1}}],[\"明确\",{\"1\":{\"56\":1}}],[\"万次\",{\"1\":{\"192\":1}}],[\"万分\",{\"1\":{\"151\":1}}],[\"万一\",{\"1\":{\"98\":1}}],[\"万人\",{\"1\":{\"77\":1}}],[\"万\",{\"1\":{\"69\":1}}],[\"压根\",{\"1\":{\"145\":1}}],[\"压得\",{\"1\":{\"86\":1}}],[\"压力\",{\"1\":{\"70\":2,\"136\":1,\"189\":1,\"192\":1}}],[\"压测\",{\"0\":{\"69\":1}}],[\"压缩\",{\"1\":{\"29\":3,\"39\":3}}],[\"尝\",{\"1\":{\"67\":1}}],[\"尝试\",{\"1\":{\"11\":1,\"54\":1,\"103\":1,\"114\":2,\"126\":1,\"127\":1,\"144\":3,\"151\":1,\"164\":1}}],[\"&\",{\"1\":{\"66\":2,\"103\":1,\"164\":1,\"166\":1,\"211\":1}}],[\"作\",{\"1\":{\"157\":1,\"178\":1}}],[\"作画\",{\"1\":{\"103\":1}}],[\"作文\",{\"1\":{\"78\":1}}],[\"作品\",{\"1\":{\"76\":1,\"168\":1}}],[\"作业管理\",{\"1\":{\"72\":1}}],[\"作业\",{\"1\":{\"72\":6}}],[\"作用域\",{\"1\":{\"179\":1,\"180\":1}}],[\"作用\",{\"1\":{\"66\":1,\"185\":3,\"221\":4}}],[\"作为\",{\"1\":{\"63\":1,\"122\":1,\"132\":1,\"137\":2,\"141\":1,\"165\":1,\"167\":1,\"168\":1,\"170\":1,\"173\":1,\"183\":1,\"192\":3,\"221\":3}}],[\"旧版\",{\"1\":{\"221\":1}}],[\"旧\",{\"1\":{\"66\":1,\"207\":1}}],[\"阻塞\",{\"1\":{\"66\":1,\"221\":2}}],[\"!\",{\"1\":{\"65\":1,\"68\":1,\"135\":5,\"137\":2,\"143\":4,\"149\":2,\"158\":4,\"159\":2,\"182\":1,\"186\":3,\"187\":3,\"208\":1,\"212\":2,\"216\":1}}],[\"扩容\",{\"1\":{\"152\":1}}],[\"扩为\",{\"1\":{\"70\":1}}],[\"扩缩容\",{\"1\":{\"65\":1,\"70\":3}}],[\"扩展\",{\"1\":{\"55\":1}}],[\"确认\",{\"1\":{\"221\":2}}],[\"确确实实\",{\"1\":{\"169\":1}}],[\"确实\",{\"1\":{\"69\":1,\"70\":1,\"81\":1,\"124\":2,\"145\":1,\"151\":1,\"171\":1}}],[\"确定\",{\"1\":{\"65\":1,\"221\":1}}],[\"确保\",{\"1\":{\"56\":1,\"221\":3}}],[\"企业级\",{\"1\":{\"145\":1}}],[\"企业\",{\"1\":{\"64\":1,\"69\":3,\"74\":1,\"77\":1,\"114\":1,\"164\":1}}],[\"动摇\",{\"1\":{\"80\":1}}],[\"动作\",{\"1\":{\"72\":1,\"206\":1}}],[\"动态\",{\"1\":{\"63\":2,\"65\":1,\"70\":2,\"155\":1,\"198\":1}}],[\"动不动\",{\"1\":{\"42\":1}}],[\"尽量\",{\"1\":{\"98\":1,\"221\":1}}],[\"尽量减少\",{\"1\":{\"63\":1}}],[\"尽\",{\"1\":{\"67\":1}}],[\"尽可能\",{\"1\":{\"37\":2,\"38\":1}}],[\"降级\",{\"1\":{\"63\":1,\"177\":1}}],[\"降低\",{\"1\":{\"29\":1,\"58\":1,\"221\":1}}],[\"熔断\",{\"1\":{\"63\":1}}],[\"追平\",{\"1\":{\"69\":1}}],[\"追求\",{\"1\":{\"63\":1}}],[\"追问\",{\"1\":{\"23\":1}}],[\"呢\",{\"1\":{\"63\":1,\"70\":1,\"74\":1,\"77\":1,\"204\":1,\"221\":1}}],[\"办法\",{\"1\":{\"63\":1,\"76\":1,\"81\":1,\"103\":1}}],[\"zzddada\",{\"1\":{\"220\":1}}],[\"zb2o38bomimp8qzhgdq\",{\"1\":{\"205\":1}}],[\"z\",{\"1\":{\"205\":6}}],[\"zephery\",{\"1\":{\"110\":1,\"122\":1,\"130\":1,\"145\":2,\"148\":1,\"151\":2,\"152\":1,\"160\":1,\"165\":1,\"173\":1,\"192\":1}}],[\"zkui\",{\"1\":{\"164\":1}}],[\"zk\",{\"1\":{\"63\":1,\"75\":1,\"76\":1,\"221\":2}}],[\"zookeeper\",{\"0\":{\"222\":1,\"235\":1},\"1\":{\"63\":1,\"164\":1,\"221\":9}}],[\"zuul\",{\"1\":{\"63\":1}}],[\"具备\",{\"1\":{\"184\":1,\"185\":1}}],[\"具有\",{\"1\":{\"63\":1}}],[\"具体分析\",{\"1\":{\"221\":1}}],[\"具体\",{\"0\":{\"210\":1},\"1\":{\"5\":1,\"23\":1,\"63\":1,\"97\":1,\"106\":1,\"108\":1,\"114\":1,\"125\":1,\"145\":1,\"170\":1,\"179\":1,\"181\":1,\"183\":1,\"185\":1,\"206\":1,\"221\":3}}],[\"放置\",{\"1\":{\"221\":4}}],[\"放入\",{\"1\":{\"159\":1,\"189\":1,\"192\":1}}],[\"放到\",{\"1\":{\"151\":1,\"207\":1,\"215\":1}}],[\"放\",{\"1\":{\"137\":2,\"161\":1}}],[\"放弃\",{\"1\":{\"73\":1,\"87\":1,\"126\":1,\"192\":1}}],[\"放在\",{\"1\":{\"72\":1,\"126\":1,\"135\":1,\"149\":1,\"152\":1,\"157\":1,\"158\":1,\"221\":4}}],[\"放行\",{\"1\":{\"63\":1}}],[\"放进\",{\"1\":{\"44\":1,\"189\":1}}],[\"链接\",{\"1\":{\"125\":1,\"147\":1,\"148\":1}}],[\"链路\",{\"1\":{\"63\":1,\"206\":1,\"216\":1}}],[\"链表\",{\"1\":{\"23\":1}}],[\"属于\",{\"1\":{\"63\":1,\"152\":1}}],[\"属性\",{\"1\":{\"56\":1,\"137\":1,\"183\":1,\"185\":3}}],[\"节点\",{\"1\":{\"62\":3,\"63\":2,\"70\":8,\"152\":3,\"155\":2,\"164\":1,\"183\":1,\"206\":2,\"207\":1,\"221\":13}}],[\"连\",{\"1\":{\"165\":1}}],[\"连接\",{\"1\":{\"149\":1,\"157\":1,\"161\":3,\"190\":1,\"221\":3}}],[\"连接数\",{\"1\":{\"61\":1}}],[\"连续\",{\"1\":{\"5\":1}}],[\"常规\",{\"1\":{\"140\":1,\"192\":1}}],[\"常量\",{\"1\":{\"135\":1}}],[\"常用语\",{\"1\":{\"177\":1}}],[\"常用命令\",{\"1\":{\"153\":1}}],[\"常用\",{\"0\":{\"63\":1},\"1\":{\"76\":1,\"113\":1,\"145\":2,\"155\":2,\"169\":1,\"172\":1,\"185\":1,\"186\":1,\"198\":1}}],[\"常说的\",{\"1\":{\"61\":1}}],[\"常见\",{\"1\":{\"30\":1,\"71\":1,\"221\":1}}],[\"某些\",{\"1\":{\"171\":1,\"192\":1}}],[\"某天\",{\"1\":{\"164\":1}}],[\"某个\",{\"1\":{\"61\":2,\"62\":1,\"63\":2,\"70\":1,\"137\":1,\"173\":1,\"179\":1,\"205\":1,\"221\":1}}],[\"某\",{\"1\":{\"61\":1,\"74\":2,\"80\":1,\"167\":1,\"221\":1}}],[\"某一\",{\"1\":{\"59\":1}}],[\"恶意\",{\"1\":{\"60\":1}}],[\"快\",{\"1\":{\"86\":1,\"135\":1}}],[\"快速\",{\"1\":{\"59\":1,\"100\":1,\"114\":1,\"132\":2,\"221\":4}}],[\"快捷\",{\"1\":{\"4\":1}}],[\"指点\",{\"1\":{\"171\":1}}],[\"指标\",{\"1\":{\"147\":1,\"148\":1,\"221\":1}}],[\"指导\",{\"1\":{\"127\":2,\"152\":1}}],[\"指向\",{\"1\":{\"120\":1}}],[\"指\",{\"1\":{\"103\":1,\"141\":1,\"179\":1,\"180\":1,\"221\":2}}],[\"指定\",{\"1\":{\"72\":1,\"155\":1,\"163\":1,\"205\":1,\"221\":5}}],[\"指对\",{\"1\":{\"59\":1}}],[\"指令\",{\"1\":{\"52\":1,\"72\":1}}],[\"宕机\",{\"1\":{\"58\":1,\"221\":1}}],[\"瞬时\",{\"1\":{\"58\":1}}],[\"遇到\",{\"1\":{\"58\":1,\"75\":1,\"77\":1,\"78\":1,\"81\":1,\"221\":1}}],[\"随机\",{\"1\":{\"221\":2}}],[\"随意\",{\"1\":{\"157\":1}}],[\"随手\",{\"1\":{\"80\":1}}],[\"随后\",{\"1\":{\"76\":1,\"120\":1}}],[\"随着\",{\"1\":{\"58\":1,\"124\":1}}],[\"随便\",{\"1\":{\"23\":1}}],[\"池中\",{\"1\":{\"141\":1}}],[\"池\",{\"1\":{\"57\":2,\"76\":1,\"135\":1,\"141\":1,\"214\":1,\"215\":1}}],[\"池化\",{\"1\":{\"57\":1}}],[\"别的\",{\"1\":{\"103\":1,\"114\":1,\"117\":1,\"158\":1}}],[\"别人\",{\"1\":{\"73\":1,\"74\":3,\"76\":1,\"77\":3,\"78\":1,\"82\":1,\"87\":1,\"124\":2,\"128\":1,\"165\":3,\"170\":1,\"173\":1}}],[\"别无选择\",{\"1\":{\"57\":1}}],[\"别样\",{\"1\":{\"6\":1}}],[\"空余\",{\"1\":{\"79\":1}}],[\"空无一人\",{\"1\":{\"75\":1}}],[\"空气\",{\"1\":{\"73\":1}}],[\"空闲\",{\"1\":{\"57\":1}}],[\"空间\",{\"1\":{\"39\":3,\"72\":1,\"221\":2}}],[\"搁置\",{\"1\":{\"57\":1}}],[\"忙不过来\",{\"1\":{\"164\":1}}],[\"忙\",{\"1\":{\"57\":1,\"75\":1,\"79\":1}}],[\"资源\",{\"1\":{\"57\":2,\"61\":3,\"101\":1,\"152\":1,\"157\":1,\"177\":1,\"216\":1,\"221\":1}}],[\"毫秒\",{\"1\":{\"57\":2,\"182\":1}}],[\"毫无\",{\"1\":{\"46\":1,\"50\":1}}],[\"秒\",{\"1\":{\"57\":1,\"73\":1,\"103\":3,\"144\":4,\"159\":1}}],[\"请教\",{\"1\":{\"127\":1}}],[\"请\",{\"1\":{\"57\":1,\"75\":1,\"113\":1,\"114\":1,\"127\":1,\"147\":1,\"149\":1,\"152\":1,\"196\":1,\"221\":4}}],[\"请求\",{\"0\":{\"114\":1,\"148\":1,\"215\":1},\"1\":{\"44\":2,\"56\":3,\"57\":2,\"58\":2,\"59\":3,\"60\":3,\"61\":1,\"63\":1,\"64\":1,\"69\":1,\"70\":1,\"101\":1,\"102\":1,\"103\":2,\"113\":1,\"114\":3,\"115\":1,\"116\":1,\"125\":2,\"137\":1,\"152\":4,\"157\":2,\"159\":2,\"160\":1,\"164\":1,\"178\":3,\"185\":2,\"192\":2,\"204\":1,\"205\":4,\"206\":3,\"207\":4,\"208\":1,\"211\":1,\"212\":1,\"214\":1,\"216\":2,\"221\":2}}],[\"复习\",{\"1\":{\"73\":1,\"80\":1}}],[\"复用\",{\"1\":{\"72\":1,\"101\":1}}],[\"复杂\",{\"1\":{\"57\":1,\"145\":1}}],[\"复制\",{\"0\":{\"162\":1},\"1\":{\"23\":3,\"26\":1,\"103\":1,\"161\":13,\"163\":3,\"164\":2,\"184\":1,\"221\":7}}],[\"休眠\",{\"1\":{\"57\":1}}],[\"负数\",{\"1\":{\"76\":1}}],[\"负载平衡\",{\"1\":{\"157\":1}}],[\"负载\",{\"0\":{\"155\":1},\"1\":{\"56\":1,\"57\":1,\"70\":1,\"72\":2,\"152\":7,\"159\":1,\"221\":1}}],[\"负责\",{\"1\":{\"4\":1,\"72\":1}}],[\"现在\",{\"1\":{\"56\":1,\"122\":2,\"124\":3,\"157\":2,\"158\":1,\"167\":1,\"173\":1}}],[\"#\",{\"1\":{\"56\":1,\"72\":4,\"118\":1,\"137\":1,\"147\":4,\"149\":5,\"150\":2,\"151\":1,\"153\":6,\"155\":2,\"158\":4,\"163\":5,\"164\":8,\"170\":3,\"185\":6,\"189\":1,\"207\":1,\"212\":3,\"213\":1,\"215\":1,\"216\":1}}],[\"需求\",{\"1\":{\"67\":1,\"72\":1,\"137\":1,\"140\":1,\"164\":1}}],[\"需\",{\"1\":{\"56\":2,\"57\":2,\"66\":1,\"141\":1}}],[\"需要\",{\"1\":{\"4\":1,\"5\":4,\"7\":3,\"8\":2,\"11\":1,\"12\":6,\"13\":2,\"17\":1,\"18\":3,\"27\":1,\"38\":3,\"39\":1,\"41\":1,\"56\":4,\"61\":1,\"63\":5,\"65\":1,\"67\":1,\"69\":1,\"70\":3,\"72\":4,\"86\":2,\"95\":2,\"96\":2,\"97\":2,\"98\":1,\"101\":1,\"102\":1,\"103\":3,\"104\":1,\"106\":1,\"113\":1,\"114\":2,\"116\":1,\"117\":2,\"120\":2,\"132\":4,\"135\":2,\"137\":1,\"143\":2,\"144\":1,\"145\":2,\"146\":1,\"148\":2,\"149\":1,\"151\":3,\"152\":3,\"157\":3,\"158\":4,\"159\":1,\"164\":2,\"168\":1,\"169\":1,\"179\":1,\"180\":1,\"182\":1,\"183\":1,\"185\":4,\"187\":1,\"188\":1,\"189\":2,\"192\":1,\"197\":1,\"211\":1,\"213\":1,\"215\":1,\"221\":8}}],[\"切换\",{\"1\":{\"56\":1,\"57\":1,\"114\":1,\"124\":1,\"166\":1,\"203\":1}}],[\"注视\",{\"1\":{\"221\":1}}],[\"注入\",{\"1\":{\"125\":1}}],[\"注册\",{\"0\":{\"94\":1,\"97\":1},\"1\":{\"95\":1,\"96\":1,\"97\":3,\"113\":1,\"116\":1,\"120\":2,\"121\":1,\"141\":1,\"143\":1,\"144\":2,\"146\":1,\"206\":1,\"214\":1,\"216\":1}}],[\"注解\",{\"0\":{\"189\":1},\"1\":{\"72\":1,\"185\":2,\"187\":2,\"189\":1}}],[\"注释\",{\"1\":{\"56\":1,\"57\":1,\"185\":1}}],[\"注意\",{\"1\":{\"5\":1,\"23\":1,\"31\":1,\"98\":1,\"101\":1,\"102\":1,\"113\":1,\"117\":2,\"120\":1,\"135\":1,\"149\":2,\"157\":1,\"172\":1,\"186\":2,\"205\":1,\"206\":2,\"221\":3}}],[\"名\",{\"1\":{\"125\":1,\"149\":1,\"221\":1}}],[\"名字\",{\"1\":{\"125\":1,\"157\":1,\"188\":1}}],[\"名为\",{\"1\":{\"56\":1,\"215\":1,\"221\":1}}],[\"名称\",{\"1\":{\"12\":1,\"13\":1,\"42\":1,\"56\":1,\"114\":1,\"133\":2,\"147\":1,\"185\":3}}],[\"第三个\",{\"1\":{\"221\":1}}],[\"第三方\",{\"0\":{\"118\":1,\"183\":1},\"1\":{\"117\":1,\"143\":2,\"183\":2,\"192\":1}}],[\"第五个\",{\"1\":{\"221\":1}}],[\"第四个\",{\"1\":{\"221\":2}}],[\"第\",{\"1\":{\"205\":1,\"221\":1}}],[\"第二步\",{\"1\":{\"205\":1}}],[\"第二条\",{\"1\":{\"192\":1}}],[\"第二\",{\"1\":{\"124\":1}}],[\"第二次\",{\"1\":{\"114\":1,\"179\":1}}],[\"第二个\",{\"1\":{\"56\":1,\"221\":2}}],[\"第一步\",{\"1\":{\"205\":1}}],[\"第一种\",{\"1\":{\"159\":1,\"192\":1}}],[\"第一条\",{\"1\":{\"152\":1}}],[\"第一台\",{\"1\":{\"83\":1,\"157\":1}}],[\"第一\",{\"1\":{\"82\":2,\"114\":1,\"161\":1}}],[\"第一家\",{\"1\":{\"80\":1}}],[\"第一道\",{\"1\":{\"63\":1}}],[\"第一个\",{\"1\":{\"46\":1,\"56\":1,\"73\":1,\"148\":1,\"221\":6}}],[\"第一次\",{\"1\":{\"12\":1,\"13\":1,\"179\":1,\"219\":1}}],[\"@\",{\"1\":{\"56\":10,\"57\":4,\"68\":2,\"137\":10,\"143\":1,\"144\":1,\"153\":3,\"156\":1,\"185\":21,\"188\":2,\"189\":4,\"190\":1,\"205\":5,\"206\":3,\"212\":2}}],[\"类推\",{\"1\":{\"221\":1}}],[\"类为\",{\"1\":{\"206\":1}}],[\"类图\",{\"1\":{\"179\":1}}],[\"类型\",{\"1\":{\"72\":1,\"147\":1}}],[\"类\",{\"1\":{\"56\":2,\"63\":1,\"76\":1,\"125\":1,\"137\":1,\"141\":2,\"143\":1,\"148\":1,\"183\":2,\"188\":1,\"221\":3}}],[\"类似\",{\"1\":{\"7\":1,\"12\":1,\"23\":1,\"42\":1,\"104\":1,\"146\":1,\"149\":1,\"164\":1,\"170\":1}}],[\"角度\",{\"1\":{\"56\":1,\"57\":1}}],[\"超出\",{\"1\":{\"172\":1}}],[\"超过\",{\"1\":{\"59\":1,\"62\":1,\"97\":1,\"103\":1,\"145\":1,\"168\":1,\"221\":1}}],[\"超时\",{\"0\":{\"103\":1},\"1\":{\"58\":1,\"103\":4,\"158\":1,\"159\":2}}],[\"超能力\",{\"1\":{\"55\":1}}],[\"超级\",{\"1\":{\"5\":1,\"41\":2,\"80\":1,\"124\":1}}],[\"标签\",{\"0\":{\"173\":1},\"1\":{\"165\":1,\"173\":4}}],[\"标的\",{\"1\":{\"151\":2}}],[\"标识\",{\"1\":{\"146\":1}}],[\"标题\",{\"1\":{\"135\":2,\"137\":3}}],[\"标注\",{\"1\":{\"127\":1}}],[\"标准\",{\"1\":{\"55\":1,\"56\":2,\"57\":4,\"157\":1}}],[\"标记\",{\"1\":{\"38\":1,\"39\":2}}],[\"少数\",{\"1\":{\"221\":1}}],[\"少量\",{\"1\":{\"185\":1}}],[\"少部分\",{\"1\":{\"155\":1}}],[\"少不了\",{\"1\":{\"145\":1}}],[\"少\",{\"1\":{\"55\":1,\"81\":1,\"172\":1}}],[\"远大于\",{\"1\":{\"221\":1}}],[\"远远\",{\"1\":{\"158\":1}}],[\"远看\",{\"1\":{\"77\":1}}],[\"远\",{\"1\":{\"55\":1}}],[\"远程\",{\"0\":{\"43\":1},\"1\":{\"5\":1,\"143\":2,\"191\":1,\"206\":1,\"208\":2,\"221\":1}}],[\"本相\",{\"1\":{\"221\":1}}],[\"本质\",{\"1\":{\"185\":1}}],[\"本站\",{\"0\":{\"178\":1},\"1\":{\"152\":2,\"155\":2,\"159\":1,\"165\":1,\"182\":1,\"192\":2}}],[\"本人\",{\"1\":{\"127\":1,\"145\":2,\"168\":1,\"190\":1}}],[\"本文\",{\"1\":{\"122\":1,\"135\":1,\"194\":1,\"204\":1}}],[\"本身\",{\"1\":{\"89\":1,\"152\":1}}],[\"本命年\",{\"1\":{\"85\":2}}],[\"本来\",{\"1\":{\"79\":1,\"151\":1,\"205\":1}}],[\"本书\",{\"1\":{\"76\":1,\"81\":1}}],[\"本例\",{\"1\":{\"57\":2}}],[\"本\",{\"0\":{\"134\":1},\"1\":{\"55\":1,\"143\":1,\"145\":1,\"149\":1,\"165\":1,\"167\":1,\"208\":1,\"214\":1}}],[\"本地\",{\"1\":{\"43\":1,\"51\":1,\"69\":1,\"101\":1,\"102\":1,\"126\":1,\"157\":1,\"179\":1,\"184\":1,\"191\":1,\"206\":1}}],[\"层\",{\"1\":{\"55\":1,\"63\":5,\"137\":1,\"152\":2,\"158\":1,\"221\":3}}],[\"层面\",{\"1\":{\"46\":1}}],[\"抽象\",{\"1\":{\"55\":1,\"57\":1,\"103\":1,\"152\":1,\"185\":1}}],[\"因子\",{\"1\":{\"221\":1}}],[\"因\",{\"1\":{\"129\":1}}],[\"因此\",{\"1\":{\"55\":1,\"56\":1,\"58\":1,\"72\":1,\"132\":1,\"157\":1,\"158\":1,\"216\":1,\"221\":1}}],[\"因为\",{\"1\":{\"37\":1,\"39\":1,\"57\":1,\"70\":1,\"73\":1,\"74\":2,\"87\":1,\"99\":1,\"103\":1,\"127\":1,\"137\":1,\"152\":2,\"159\":1,\"164\":1,\"168\":1}}],[\"耦是\",{\"1\":{\"55\":1}}],[\"耦\",{\"1\":{\"55\":1,\"221\":1}}],[\"解释一下\",{\"1\":{\"221\":1}}],[\"解释\",{\"1\":{\"147\":1,\"221\":4}}],[\"解析器\",{\"1\":{\"135\":1}}],[\"解析\",{\"1\":{\"72\":1,\"135\":1,\"149\":1,\"164\":2,\"168\":3,\"205\":1,\"206\":1,\"207\":1,\"216\":1}}],[\"解\",{\"1\":{\"55\":2,\"221\":1}}],[\"解决办法\",{\"1\":{\"45\":1,\"95\":1,\"96\":1,\"106\":1,\"155\":1}}],[\"解决方案\",{\"1\":{\"7\":1,\"63\":1,\"71\":1}}],[\"解决\",{\"1\":{\"5\":2,\"7\":1,\"23\":3,\"45\":1,\"51\":1,\"70\":1,\"149\":1,\"152\":1,\"159\":1,\"184\":1,\"221\":1}}],[\"依次\",{\"1\":{\"221\":2}}],[\"依赖\",{\"1\":{\"55\":1,\"63\":1,\"127\":1,\"143\":1,\"159\":1,\"221\":1}}],[\"依赖于\",{\"1\":{\"55\":1,\"70\":1}}],[\"依旧\",{\"1\":{\"6\":1,\"7\":1,\"45\":1,\"184\":1,\"192\":1}}],[\"套件\",{\"1\":{\"54\":1,\"158\":1}}],[\"月底\",{\"1\":{\"75\":3}}],[\"月初\",{\"1\":{\"74\":1,\"75\":2}}],[\"月份\",{\"1\":{\"73\":1,\"74\":2,\"75\":1,\"76\":2}}],[\"月薪\",{\"1\":{\"73\":1,\"74\":1}}],[\"月\",{\"1\":{\"54\":1,\"73\":2,\"74\":3,\"75\":4,\"76\":3,\"79\":1,\"80\":1,\"81\":1,\"83\":1,\"85\":2,\"89\":1,\"96\":1,\"100\":1,\"114\":1}}],[\"教程\",{\"1\":{\"54\":1,\"55\":1}}],[\"虚拟\",{\"0\":{\"53\":1,\"55\":1,\"56\":1},\"1\":{\"54\":4,\"55\":5,\"56\":9,\"57\":5}}],[\"虚拟内存\",{\"1\":{\"25\":1}}],[\"读写操作\",{\"1\":{\"221\":1}}],[\"读写\",{\"1\":{\"198\":1,\"221\":3}}],[\"读书\",{\"1\":{\"73\":1}}],[\"读\",{\"1\":{\"52\":1,\"163\":2}}],[\"读取数据\",{\"1\":{\"151\":1}}],[\"读取\",{\"0\":{\"197\":1},\"1\":{\"42\":1,\"48\":1,\"52\":1,\"72\":1,\"151\":1,\"161\":3,\"168\":1,\"192\":1,\"221\":2}}],[\"插入\",{\"1\":{\"52\":4,\"103\":1}}],[\"插件\",{\"0\":{\"165\":1,\"172\":1},\"1\":{\"5\":1,\"10\":1,\"136\":1,\"165\":3,\"166\":1,\"168\":3,\"172\":2,\"192\":1}}],[\"得铉\",{\"1\":{\"171\":1}}],[\"得到\",{\"1\":{\"103\":1,\"121\":1,\"160\":1,\"171\":1,\"221\":1}}],[\"得知\",{\"1\":{\"75\":2}}],[\"得\",{\"1\":{\"51\":1,\"55\":1,\"75\":1,\"77\":2,\"98\":1,\"128\":1,\"152\":2,\"167\":1,\"168\":1,\"186\":1,\"192\":1}}],[\"算了算\",{\"1\":{\"82\":1}}],[\"算\",{\"1\":{\"79\":1,\"128\":1}}],[\"算是\",{\"1\":{\"51\":1,\"74\":1,\"76\":1,\"85\":1,\"87\":1,\"89\":1,\"108\":1,\"161\":1}}],[\"算法\",{\"0\":{\"155\":1},\"1\":{\"23\":2,\"39\":1,\"74\":1,\"76\":1,\"108\":1,\"127\":1,\"132\":1,\"155\":6,\"182\":1}}],[\"留言\",{\"1\":{\"167\":1}}],[\"留言板\",{\"1\":{\"165\":1}}],[\"留意\",{\"1\":{\"114\":1}}],[\"留在\",{\"1\":{\"76\":1}}],[\"留给\",{\"1\":{\"51\":1}}],[\"留空\",{\"1\":{\"1\":1,\"222\":1}}],[\"临时\",{\"1\":{\"51\":1,\"149\":1,\"185\":1}}],[\"修复\",{\"1\":{\"50\":1,\"109\":2}}],[\"修改\",{\"1\":{\"12\":2,\"13\":1,\"52\":4,\"144\":1,\"152\":1,\"221\":1}}],[\"涨\",{\"1\":{\"50\":1}}],[\"磁盘操作\",{\"1\":{\"221\":1}}],[\"磁盘\",{\"1\":{\"50\":1,\"221\":7}}],[\"平时\",{\"1\":{\"82\":1}}],[\"平庸\",{\"1\":{\"73\":1}}],[\"平衡\",{\"1\":{\"73\":1,\"221\":5}}],[\"平均\",{\"1\":{\"50\":1,\"62\":1,\"63\":2}}],[\"平台\",{\"0\":{\"4\":1,\"8\":1,\"55\":1},\"1\":{\"3\":1,\"5\":1,\"6\":5,\"12\":1,\"54\":1,\"55\":2,\"57\":1,\"95\":1,\"100\":1}}],[\"意向\",{\"1\":{\"132\":1}}],[\"意义\",{\"1\":{\"124\":1,\"221\":1}}],[\"意思\",{\"0\":{\"127\":1},\"1\":{\"81\":1,\"122\":1,\"159\":1}}],[\"意外\",{\"0\":{\"50\":1}}],[\"意味着\",{\"1\":{\"11\":1,\"54\":1,\"56\":1}}],[\"似乎\",{\"1\":{\"49\":1,\"98\":1}}],[\"捣鼓\",{\"1\":{\"49\":1,\"161\":1,\"165\":2}}],[\"换个\",{\"1\":{\"106\":1,\"161\":1}}],[\"换句话说\",{\"1\":{\"56\":1}}],[\"换\",{\"1\":{\"49\":1,\"73\":1,\"74\":1,\"114\":1,\"173\":1}}],[\"换血\",{\"1\":{\"18\":1}}],[\"据说\",{\"1\":{\"49\":1}}],[\"那题\",{\"1\":{\"221\":1}}],[\"那块\",{\"1\":{\"165\":1}}],[\"那一刻\",{\"1\":{\"124\":1}}],[\"那条\",{\"1\":{\"103\":1}}],[\"那段\",{\"1\":{\"80\":1}}],[\"那家\",{\"1\":{\"80\":1}}],[\"那种\",{\"1\":{\"77\":1,\"79\":1,\"87\":2,\"89\":1,\"104\":1,\"114\":1,\"124\":2}}],[\"那些\",{\"0\":{\"165\":1},\"1\":{\"74\":1,\"76\":3,\"81\":1,\"168\":1,\"189\":1,\"221\":8}}],[\"那里\",{\"1\":{\"74\":1,\"101\":1}}],[\"那会\",{\"1\":{\"73\":2,\"82\":1}}],[\"那股\",{\"1\":{\"73\":1}}],[\"那样\",{\"1\":{\"73\":1,\"221\":1}}],[\"那个\",{\"1\":{\"73\":3,\"75\":2,\"78\":1,\"80\":1}}],[\"那群\",{\"1\":{\"73\":1}}],[\"那群人\",{\"1\":{\"73\":2}}],[\"那\",{\"1\":{\"70\":1,\"74\":1,\"75\":1,\"79\":1,\"87\":1,\"151\":1,\"165\":1,\"189\":1,\"221\":4}}],[\"那批\",{\"1\":{\"51\":1}}],[\"那边\",{\"1\":{\"49\":1}}],[\"那么\",{\"1\":{\"39\":1,\"44\":1,\"62\":1,\"63\":3,\"74\":2,\"76\":1,\"77\":1,\"78\":1,\"143\":1,\"148\":1,\"149\":2,\"152\":2,\"157\":1,\"168\":1,\"173\":1,\"190\":1,\"197\":1,\"221\":7}}],[\"起\",{\"1\":{\"152\":1}}],[\"起始\",{\"1\":{\"147\":1,\"148\":1}}],[\"起色\",{\"1\":{\"86\":1}}],[\"起跑线\",{\"1\":{\"75\":1}}],[\"起点\",{\"1\":{\"57\":1,\"212\":1}}],[\"起初\",{\"1\":{\"49\":1,\"124\":1}}],[\"起来\",{\"1\":{\"5\":1,\"6\":1,\"7\":1,\"11\":1,\"104\":1,\"126\":1,\"144\":1,\"151\":1,\"152\":1,\"164\":1}}],[\"入口\",{\"0\":{\"206\":1},\"1\":{\"206\":1,\"214\":1,\"216\":2}}],[\"入睡\",{\"1\":{\"89\":1}}],[\"入职\",{\"1\":{\"76\":1,\"81\":1}}],[\"入手\",{\"1\":{\"48\":1}}],[\"入门教程\",{\"1\":{\"202\":1}}],[\"入门\",{\"1\":{\"7\":1,\"81\":1,\"87\":1,\"194\":2}}],[\"懵\",{\"1\":{\"48\":1,\"74\":1,\"219\":1}}],[\";\",{\"1\":{\"48\":2,\"56\":4,\"57\":3,\"66\":11,\"67\":1,\"68\":8,\"72\":8,\"98\":1,\"101\":5,\"103\":6,\"104\":2,\"120\":2,\"135\":41,\"137\":50,\"143\":11,\"144\":1,\"146\":6,\"151\":8,\"155\":6,\"156\":2,\"157\":9,\"158\":8,\"159\":2,\"164\":1,\"170\":8,\"188\":6,\"189\":10,\"190\":7,\"196\":3,\"197\":3,\"198\":4,\"206\":17,\"207\":2,\"208\":5,\"209\":7,\"210\":8,\"212\":21,\"214\":1,\"215\":9,\"216\":8,\"221\":5}}],[\"^\",{\"1\":{\"48\":1,\"78\":2,\"120\":1,\"158\":1}}],[\"乱码\",{\"1\":{\"48\":1}}],[\"试着\",{\"1\":{\"161\":1}}],[\"试用\",{\"1\":{\"100\":1}}],[\"试试\",{\"1\":{\"85\":1,\"114\":1}}],[\"试\",{\"1\":{\"48\":1}}],[\"块\",{\"1\":{\"48\":2,\"221\":1}}],[\"往官\",{\"1\":{\"98\":1}}],[\"往下面\",{\"1\":{\"87\":1}}],[\"往往\",{\"1\":{\"78\":1}}],[\"往返\",{\"1\":{\"74\":1}}],[\"往\",{\"1\":{\"46\":1,\"73\":1,\"74\":1,\"75\":1,\"87\":1,\"149\":1,\"221\":1}}],[\"然而\",{\"1\":{\"46\":1,\"73\":1,\"76\":1,\"77\":1}}],[\"然后\",{\"1\":{\"5\":1,\"7\":1,\"11\":1,\"12\":1,\"18\":1,\"39\":1,\"42\":3,\"45\":1,\"46\":1,\"48\":1,\"49\":2,\"51\":1,\"63\":1,\"64\":1,\"72\":1,\"73\":1,\"74\":5,\"75\":2,\"81\":2,\"82\":1,\"84\":1,\"85\":2,\"86\":3,\"97\":2,\"98\":1,\"102\":1,\"113\":1,\"124\":1,\"135\":2,\"137\":1,\"146\":2,\"148\":1,\"149\":1,\"151\":2,\"152\":2,\"153\":2,\"157\":1,\"158\":1,\"159\":3,\"160\":1,\"161\":3,\"178\":2,\"182\":1,\"183\":1,\"192\":4,\"203\":1,\"204\":1,\"205\":2,\"206\":2,\"207\":1,\"211\":1,\"212\":1,\"216\":1}}],[\"续命\",{\"1\":{\"45\":1}}],[\"行程\",{\"1\":{\"124\":1}}],[\"行李箱\",{\"1\":{\"75\":1}}],[\"行为\",{\"1\":{\"58\":1,\"76\":1}}],[\"行\",{\"1\":{\"45\":1,\"96\":3,\"126\":1,\"145\":1,\"161\":1,\"163\":1,\"221\":1}}],[\"构造\",{\"0\":{\"208\":1},\"1\":{\"212\":1}}],[\"构造方法\",{\"1\":{\"45\":1,\"148\":1}}],[\"构建\",{\"0\":{\"11\":1,\"148\":1},\"1\":{\"4\":1,\"5\":10,\"6\":4,\"7\":3,\"10\":1,\"11\":3,\"12\":1,\"13\":3,\"17\":1,\"54\":1,\"56\":2,\"57\":1,\"116\":1,\"127\":1,\"135\":1,\"148\":2,\"168\":1,\"179\":1,\"206\":1,\"211\":1,\"216\":1}}],[\"变\",{\"1\":{\"192\":1}}],[\"变为\",{\"1\":{\"70\":2,\"188\":1}}],[\"变化\",{\"1\":{\"70\":1}}],[\"变成\",{\"1\":{\"51\":1,\"122\":2,\"124\":4,\"148\":1,\"157\":1}}],[\"变量名\",{\"1\":{\"157\":1}}],[\"变量\",{\"1\":{\"45\":1,\"52\":5,\"57\":1,\"157\":5}}],[\"变更\",{\"1\":{\"4\":1,\"164\":2}}],[\"声明\",{\"1\":{\"45\":1,\"125\":1,\"137\":1}}],[\"趋势\",{\"1\":{\"45\":1,\"87\":1}}],[\"惊人\",{\"1\":{\"45\":1}}],[\"传递\",{\"1\":{\"221\":1}}],[\"传入\",{\"1\":{\"125\":1,\"149\":2,\"221\":1}}],[\"传空\",{\"1\":{\"101\":1}}],[\"传输\",{\"1\":{\"45\":1,\"221\":8}}],[\"传统\",{\"1\":{\"18\":1,\"38\":2,\"39\":1,\"221\":6}}],[\"猜想到\",{\"1\":{\"45\":1}}],[\"猜想\",{\"1\":{\"45\":1}}],[\"逻辑\",{\"1\":{\"45\":1,\"66\":1,\"74\":1,\"125\":1,\"221\":1}}],[\"端的\",{\"1\":{\"124\":1}}],[\"端点\",{\"1\":{\"56\":1,\"57\":3}}],[\"端\",{\"1\":{\"44\":1,\"45\":1,\"50\":1,\"99\":1,\"157\":2}}],[\"端口\",{\"1\":{\"43\":1,\"102\":1,\"152\":1,\"153\":1,\"157\":1}}],[\"由此\",{\"1\":{\"164\":1}}],[\"由\",{\"1\":{\"44\":1,\"54\":1,\"55\":1,\"64\":1,\"114\":1,\"122\":1,\"124\":1,\"141\":1,\"161\":1,\"185\":1,\"191\":1,\"205\":1,\"216\":1,\"221\":6}}],[\"由于\",{\"1\":{\"5\":2,\"6\":2,\"7\":2,\"12\":1,\"29\":1,\"43\":1,\"44\":1,\"50\":1,\"51\":2,\"56\":1,\"57\":1,\"58\":1,\"116\":1,\"135\":1,\"148\":1,\"151\":1,\"152\":1,\"153\":2,\"155\":1,\"157\":2,\"161\":1,\"162\":1,\"166\":1,\"192\":1,\"221\":1}}],[\"保持一致\",{\"1\":{\"160\":1,\"161\":1}}],[\"保持联系\",{\"1\":{\"77\":1}}],[\"保持\",{\"1\":{\"75\":1,\"104\":1,\"161\":1}}],[\"保证\",{\"1\":{\"52\":1,\"70\":2,\"158\":1,\"159\":1,\"221\":4}}],[\"保证系统\",{\"1\":{\"29\":1}}],[\"保留\",{\"1\":{\"44\":1,\"98\":1,\"124\":1,\"142\":1,\"221\":2}}],[\"保存\",{\"0\":{\"104\":1},\"1\":{\"43\":1,\"44\":1,\"102\":1,\"103\":1,\"104\":1,\"124\":1,\"135\":2,\"166\":1,\"168\":3,\"184\":1,\"220\":1,\"221\":3}}],[\"观察\",{\"1\":{\"43\":1,\"72\":1,\"122\":1}}],[\"显而易见\",{\"1\":{\"57\":1}}],[\"显示\",{\"1\":{\"43\":1,\"50\":1,\"149\":1}}],[\"显然\",{\"1\":{\"7\":1}}],[\"加密\",{\"1\":{\"158\":1}}],[\"加密算法\",{\"1\":{\"76\":1}}],[\"加强\",{\"1\":{\"145\":1}}],[\"加油\",{\"1\":{\"78\":2,\"87\":1,\"89\":1,\"173\":1}}],[\"加班\",{\"1\":{\"76\":4,\"79\":1,\"81\":1}}],[\"加\",{\"1\":{\"76\":1,\"78\":1}}],[\"加载\",{\"1\":{\"66\":1,\"125\":1,\"166\":1,\"170\":1,\"171\":1}}],[\"加上\",{\"1\":{\"43\":1,\"89\":1,\"90\":1,\"124\":1,\"137\":1,\"172\":1,\"180\":1,\"203\":1}}],[\"加入\",{\"1\":{\"27\":1,\"124\":1,\"149\":1,\"158\":1,\"159\":1,\"221\":2}}],[\"启用\",{\"0\":{\"43\":1},\"1\":{\"56\":2,\"187\":2,\"213\":1}}],[\"启动\",{\"1\":{\"27\":1,\"41\":3,\"43\":1,\"56\":1,\"70\":1,\"72\":1,\"102\":1,\"143\":1,\"153\":4,\"164\":1,\"180\":1,\"203\":2,\"206\":1,\"212\":1,\"221\":1}}],[\"向\",{\"1\":{\"42\":1,\"75\":1,\"114\":1,\"120\":1,\"164\":1,\"221\":4}}],[\"qzone\",{\"1\":{\"170\":1}}],[\"queue\",{\"1\":{\"211\":1}}],[\"questions\",{\"1\":{\"144\":1}}],[\"queryandfetchoptimization\",{\"1\":{\"212\":2}}],[\"queryresult\",{\"1\":{\"212\":7}}],[\"queryresults\",{\"1\":{\"212\":5}}],[\"queryresultconsumer\",{\"1\":{\"206\":1}}],[\"queryphase\",{\"1\":{\"215\":2}}],[\"queryphaseresultconsumer\",{\"1\":{\"206\":1}}],[\"queryparser\",{\"1\":{\"135\":5}}],[\"query1\",{\"1\":{\"135\":2}}],[\"query\",{\"0\":{\"207\":1,\"214\":1,\"215\":1},\"1\":{\"133\":1,\"135\":4,\"137\":1,\"197\":2,\"205\":3,\"206\":3,\"212\":1,\"214\":3,\"216\":3}}],[\"qualifying\",{\"1\":{\"144\":2}}],[\"quartz\",{\"0\":{\"142\":1},\"1\":{\"42\":1,\"122\":1,\"124\":1,\"139\":1,\"141\":5,\"142\":3,\"143\":8,\"144\":3}}],[\"q\",{\"1\":{\"104\":1,\"135\":1}}],[\"qqzone\",{\"1\":{\"170\":1}}],[\"qq\",{\"1\":{\"95\":1,\"103\":1,\"220\":1}}],[\"qps\",{\"1\":{\"23\":1,\"62\":1,\"63\":3,\"66\":2,\"70\":3}}],[\"从套\",{\"1\":{\"221\":1}}],[\"从库\",{\"1\":{\"164\":2}}],[\"从没\",{\"1\":{\"73\":1}}],[\"从而\",{\"1\":{\"63\":1}}],[\"从头开始\",{\"1\":{\"54\":1}}],[\"从何\",{\"1\":{\"48\":1}}],[\"从\",{\"1\":{\"42\":1,\"44\":1,\"46\":1,\"48\":1,\"55\":1,\"56\":2,\"57\":2,\"63\":1,\"70\":2,\"73\":1,\"74\":2,\"86\":1,\"100\":1,\"101\":2,\"103\":1,\"108\":1,\"122\":1,\"128\":1,\"135\":1,\"144\":1,\"151\":1,\"152\":2,\"153\":1,\"155\":1,\"161\":2,\"163\":2,\"164\":1,\"168\":1,\"173\":2,\"178\":1,\"179\":1,\"192\":4,\"194\":1,\"206\":1,\"212\":1,\"221\":13}}],[\"表明\",{\"1\":{\"142\":1,\"221\":2}}],[\"表达\",{\"1\":{\"132\":1}}],[\"表达式\",{\"1\":{\"42\":1,\"143\":1,\"185\":3}}],[\"表白\",{\"1\":{\"73\":1}}],[\"表现\",{\"1\":{\"69\":1}}],[\"表示\",{\"1\":{\"31\":2,\"56\":1,\"167\":1}}],[\"讲到\",{\"1\":{\"161\":1}}],[\"讲讲\",{\"1\":{\"122\":1,\"128\":1,\"130\":1}}],[\"讲\",{\"1\":{\"55\":1,\"97\":1,\"158\":1,\"206\":1,\"216\":1}}],[\"讲下\",{\"1\":{\"42\":1,\"97\":1}}],[\"讲解\",{\"1\":{\"8\":1,\"184\":1,\"194\":1,\"220\":1}}],[\"先向\",{\"1\":{\"205\":1}}],[\"先来\",{\"1\":{\"161\":1}}],[\"先看\",{\"1\":{\"139\":1}}],[\"先对\",{\"1\":{\"137\":1}}],[\"先往\",{\"1\":{\"103\":1}}],[\"先会\",{\"1\":{\"50\":1}}],[\"先\",{\"1\":{\"42\":1,\"44\":1,\"76\":1,\"95\":1,\"101\":1,\"103\":1,\"114\":1,\"146\":1,\"152\":1,\"203\":1,\"221\":1}}],[\"该不该\",{\"1\":{\"87\":1}}],[\"该类\",{\"1\":{\"45\":1}}],[\"该\",{\"1\":{\"42\":3,\"43\":1,\"44\":1,\"45\":1,\"57\":1,\"72\":3,\"73\":1,\"78\":1,\"141\":1,\"146\":1,\"159\":2,\"161\":3,\"221\":1}}],[\"错误\",{\"1\":{\"42\":1,\"44\":1,\"45\":1,\"48\":1,\"50\":1,\"85\":1,\"86\":3,\"87\":1,\"102\":1,\"106\":1,\"145\":1,\"158\":1,\"221\":3}}],[\"刷新\",{\"1\":{\"179\":1,\"183\":1}}],[\"刷刷\",{\"1\":{\"73\":1}}],[\"刷\",{\"1\":{\"42\":1,\"50\":1}}],[\"溢出\",{\"1\":{\"42\":1,\"49\":1,\"135\":1}}],[\"弄得好\",{\"1\":{\"173\":1}}],[\"弄\",{\"1\":{\"42\":1,\"171\":1}}],[\"记不住\",{\"1\":{\"221\":1}}],[\"记得\",{\"1\":{\"95\":1,\"110\":1,\"186\":1}}],[\"记忆\",{\"1\":{\"73\":1}}],[\"记\",{\"1\":{\"51\":1,\"80\":1,\"153\":1}}],[\"记住\",{\"1\":{\"41\":1,\"57\":1}}],[\"记录下来\",{\"1\":{\"157\":1}}],[\"记录\",{\"1\":{\"30\":1,\"44\":1,\"102\":1,\"103\":7,\"125\":1,\"135\":2,\"146\":1,\"147\":1,\"160\":1,\"161\":5,\"205\":2,\"221\":2}}],[\"慢\",{\"1\":{\"41\":1,\"135\":1}}],[\"慢慢\",{\"1\":{\"6\":1,\"46\":1,\"49\":1,\"74\":1,\"75\":1,\"173\":1,\"206\":1}}],[\"添加\",{\"0\":{\"189\":1},\"1\":{\"41\":1,\"43\":1,\"56\":1,\"72\":1,\"98\":1,\"101\":1,\"144\":1,\"155\":1,\"158\":1,\"159\":3,\"182\":2,\"185\":1,\"189\":1}}],[\"号发\",{\"1\":{\"103\":1}}],[\"号\",{\"0\":{\"93\":1,\"99\":1},\"1\":{\"41\":2,\"74\":2,\"75\":3,\"79\":1,\"80\":1,\"85\":1,\"93\":1,\"97\":1,\"99\":2,\"102\":1,\"103\":6,\"110\":1,\"163\":1}}],[\"删不掉\",{\"1\":{\"41\":1}}],[\"删\",{\"1\":{\"41\":1,\"75\":2}}],[\"删除\",{\"1\":{\"5\":1,\"72\":2,\"135\":1,\"220\":1,\"221\":4}}],[\"黑板\",{\"1\":{\"78\":1}}],[\"黑暗\",{\"1\":{\"74\":1,\"75\":1,\"78\":1}}],[\"黑\",{\"1\":{\"41\":1}}],[\"攻击\",{\"0\":{\"41\":1},\"1\":{\"60\":1}}],[\"挖矿\",{\"0\":{\"41\":1}}],[\"停留\",{\"1\":{\"221\":1}}],[\"停留时间\",{\"1\":{\"145\":1}}],[\"停\",{\"1\":{\"132\":2,\"133\":1}}],[\"停止\",{\"1\":{\"39\":1,\"221\":1}}],[\"停顿\",{\"1\":{\"29\":1}}],[\"足够\",{\"1\":{\"39\":1,\"100\":1,\"135\":1}}],[\"引进\",{\"1\":{\"186\":1}}],[\"引擎\",{\"1\":{\"161\":1}}],[\"引起\",{\"0\":{\"39\":1},\"1\":{\"184\":1}}],[\"引入\",{\"0\":{\"186\":1},\"1\":{\"7\":1,\"54\":1,\"185\":1,\"196\":1}}],[\"获得\",{\"1\":{\"38\":1,\"115\":1,\"135\":1,\"146\":1,\"157\":3,\"221\":3}}],[\"获取数据\",{\"0\":{\"147\":1},\"1\":{\"145\":1,\"146\":1,\"191\":1,\"212\":1,\"221\":1}}],[\"获取\",{\"0\":{\"67\":1,\"118\":1},\"1\":{\"5\":1,\"52\":5,\"63\":1,\"64\":2,\"65\":1,\"66\":2,\"67\":1,\"70\":1,\"72\":1,\"104\":1,\"115\":1,\"132\":1,\"135\":4,\"144\":3,\"146\":2,\"147\":4,\"148\":5,\"149\":3,\"151\":2,\"157\":3,\"164\":2,\"167\":1,\"190\":1,\"192\":3,\"211\":1,\"221\":2}}],[\"较为简单\",{\"1\":{\"221\":1}}],[\"较少\",{\"1\":{\"191\":1,\"198\":1,\"221\":1}}],[\"较\",{\"0\":{\"39\":1},\"1\":{\"38\":1,\"39\":1,\"72\":1,\"151\":1,\"221\":1}}],[\"较长\",{\"1\":{\"38\":1}}],[\"较大\",{\"1\":{\"26\":2,\"39\":1}}],[\"高可用性\",{\"1\":{\"221\":1}}],[\"高效\",{\"1\":{\"221\":1}}],[\"高级\",{\"0\":{\"144\":1}}],[\"高亮\",{\"1\":{\"135\":2}}],[\"高性能\",{\"1\":{\"63\":1,\"65\":1,\"71\":1,\"161\":1,\"221\":1}}],[\"高度\",{\"1\":{\"55\":1}}],[\"高大\",{\"1\":{\"49\":1,\"124\":1,\"166\":1}}],[\"高达\",{\"1\":{\"41\":1}}],[\"高\",{\"1\":{\"38\":1,\"63\":1,\"72\":1,\"76\":2,\"136\":1,\"151\":1,\"152\":1,\"221\":3}}],[\"持有\",{\"1\":{\"179\":1}}],[\"持续\",{\"1\":{\"82\":1}}],[\"持续时间\",{\"1\":{\"38\":1}}],[\"持久性\",{\"1\":{\"221\":2}}],[\"持久\",{\"1\":{\"18\":1,\"26\":4,\"31\":1,\"38\":1,\"184\":1,\"221\":2}}],[\"话\",{\"0\":{\"104\":1},\"1\":{\"38\":1,\"77\":1,\"149\":1,\"157\":1,\"179\":2,\"221\":1}}],[\"率\",{\"1\":{\"38\":1}}],[\"程度\",{\"1\":{\"37\":1,\"151\":1,\"221\":1}}],[\"程序员\",{\"1\":{\"76\":1,\"84\":1,\"165\":1,\"173\":1}}],[\"程序运行\",{\"1\":{\"34\":1}}],[\"程序\",{\"1\":{\"7\":1,\"30\":2,\"42\":3,\"43\":1,\"44\":2,\"45\":3,\"72\":1,\"143\":1,\"211\":1,\"221\":3}}],[\"直聘\",{\"1\":{\"80\":1}}],[\"直播\",{\"1\":{\"76\":1}}],[\"直到\",{\"1\":{\"37\":1,\"57\":1,\"73\":1,\"86\":1,\"221\":3}}],[\"直接\",{\"0\":{\"46\":1,\"47\":1},\"1\":{\"7\":1,\"12\":1,\"17\":1,\"26\":1,\"43\":1,\"45\":1,\"46\":3,\"50\":1,\"65\":1,\"72\":1,\"97\":1,\"99\":1,\"101\":5,\"103\":3,\"125\":1,\"143\":1,\"151\":1,\"157\":1,\"159\":1,\"162\":1,\"164\":1,\"177\":1,\"178\":2,\"179\":1,\"184\":1,\"189\":1,\"192\":1,\"197\":1,\"203\":1,\"213\":1,\"221\":4}}],[\"公钥\",{\"1\":{\"116\":1,\"120\":2}}],[\"公众\",{\"0\":{\"93\":1,\"99\":1},\"1\":{\"93\":1,\"97\":1,\"99\":2,\"100\":1,\"102\":1,\"103\":4,\"110\":1}}],[\"公园\",{\"1\":{\"82\":2}}],[\"公开\",{\"1\":{\"56\":1,\"145\":1}}],[\"公式\",{\"1\":{\"34\":1}}],[\"公司\",{\"1\":{\"4\":1,\"6\":1,\"7\":3,\"8\":2,\"18\":3,\"42\":1,\"43\":1,\"51\":1,\"73\":2,\"74\":8,\"76\":6,\"80\":5,\"81\":1,\"85\":1,\"86\":4,\"164\":3}}],[\"百度\",{\"0\":{\"170\":1},\"1\":{\"122\":2,\"124\":1,\"126\":2,\"136\":1,\"145\":6,\"146\":2,\"148\":2,\"149\":1,\"151\":7,\"165\":1,\"169\":2,\"170\":3,\"192\":1}}],[\"百度搜\",{\"1\":{\"74\":1}}],[\"百分之\",{\"1\":{\"127\":1}}],[\"百分百\",{\"1\":{\"70\":1}}],[\"百分比\",{\"1\":{\"34\":1}}],[\"百万\",{\"1\":{\"23\":1}}],[\"汇总\",{\"1\":{\"30\":1}}],[\"几处\",{\"1\":{\"221\":1}}],[\"几张\",{\"1\":{\"189\":1}}],[\"几行\",{\"1\":{\"148\":1}}],[\"几步\",{\"1\":{\"120\":1}}],[\"几种\",{\"1\":{\"103\":1}}],[\"几年\",{\"1\":{\"77\":1,\"81\":1}}],[\"几次\",{\"1\":{\"76\":1,\"86\":1}}],[\"几页\",{\"1\":{\"76\":1}}],[\"几天\",{\"1\":{\"73\":1,\"85\":1,\"126\":1,\"145\":1}}],[\"几乎\",{\"1\":{\"69\":1,\"73\":1,\"151\":1}}],[\"几百个\",{\"1\":{\"55\":1,\"221\":1}}],[\"几百万\",{\"1\":{\"51\":1}}],[\"几百人\",{\"1\":{\"4\":1}}],[\"几十秒\",{\"1\":{\"103\":2}}],[\"几十个\",{\"1\":{\"70\":1,\"221\":1}}],[\"几十\",{\"1\":{\"46\":1,\"168\":1}}],[\"几个\",{\"0\":{\"132\":1,\"133\":1},\"1\":{\"30\":1,\"56\":1,\"63\":1,\"72\":1,\"73\":1,\"76\":1,\"81\":1,\"86\":1,\"106\":2,\"122\":1,\"137\":1,\"215\":1,\"221\":1}}],[\"%\",{\"1\":{\"30\":14,\"41\":1,\"45\":3,\"50\":1,\"127\":1,\"137\":2}}],[\"未来\",{\"1\":{\"54\":1,\"87\":1}}],[\"未\",{\"1\":{\"30\":1}}],[\"前先\",{\"1\":{\"204\":1}}],[\"前段时间\",{\"1\":{\"169\":1}}],[\"前面\",{\"1\":{\"137\":1}}],[\"前台\",{\"1\":{\"122\":1}}],[\"前几次\",{\"1\":{\"104\":1}}],[\"前置\",{\"1\":{\"103\":1}}],[\"前前后后\",{\"1\":{\"86\":1,\"122\":1,\"124\":1,\"128\":1}}],[\"前端\",{\"1\":{\"42\":1,\"74\":1,\"124\":4,\"152\":1,\"165\":2,\"173\":1}}],[\"前后\",{\"1\":{\"30\":1,\"122\":1}}],[\"前\",{\"1\":{\"30\":1,\"80\":1,\"126\":1,\"135\":1,\"145\":1,\"147\":2,\"185\":1}}],[\"混入\",{\"1\":{\"124\":1}}],[\"混合\",{\"1\":{\"30\":3}}],[\"混乱\",{\"1\":{\"18\":1,\"45\":1}}],[\"9200\",{\"1\":{\"203\":1}}],[\"9649\",{\"1\":{\"69\":1}}],[\"9118\",{\"1\":{\"69\":1}}],[\"9\",{\"1\":{\"48\":2,\"69\":1,\"76\":3,\"79\":1,\"221\":1}}],[\"98\",{\"1\":{\"149\":1}}],[\"981.\",{\"1\":{\"41\":2}}],[\"98328\",{\"1\":{\"30\":1}}],[\"996\",{\"0\":{\"76\":1},\"1\":{\"76\":2,\"80\":1,\"164\":1}}],[\"99\",{\"1\":{\"30\":1,\"41\":1,\"160\":2}}],[\"93620\",{\"1\":{\"30\":1}}],[\"9088\",{\"1\":{\"30\":2}}],[\"9.\",{\"0\":{\"175\":1},\"1\":{\"23\":1}}],[\"79\",{\"1\":{\"221\":1}}],[\"78\",{\"1\":{\"221\":1}}],[\"781\",{\"1\":{\"30\":1}}],[\"77\",{\"1\":{\"221\":1}}],[\"75\",{\"1\":{\"221\":1}}],[\"74\",{\"1\":{\"221\":1}}],[\"72\",{\"1\":{\"221\":1}}],[\"7200769439335546935\",{\"1\":{\"109\":1}}],[\"71\",{\"1\":{\"221\":1}}],[\"73\",{\"1\":{\"149\":1,\"221\":1}}],[\"76\",{\"1\":{\"149\":2,\"151\":1,\"221\":1}}],[\"70\",{\"1\":{\"127\":1,\"221\":1}}],[\"7\",{\"1\":{\"30\":1,\"69\":2,\"76\":1,\"98\":1,\"137\":1,\"147\":1,\"149\":1,\"150\":1,\"151\":1,\"152\":1,\"221\":1}}],[\"7.17\",{\"1\":{\"203\":1}}],[\"7.\",{\"0\":{\"165\":1},\"1\":{\"23\":1,\"165\":1}}],[\"]\",{\"0\":{\"49\":1},\"1\":{\"30\":10,\"48\":2,\"56\":1,\"101\":3,\"103\":2,\"104\":3,\"122\":1,\"137\":1,\"143\":3,\"144\":1,\"146\":2,\"149\":55,\"150\":8,\"151\":6,\"153\":3,\"163\":2,\"164\":2,\"196\":1,\"197\":1,\"205\":1,\"206\":2,\"212\":1}}],[\"[\",{\"0\":{\"49\":1},\"1\":{\"30\":30,\"48\":2,\"56\":1,\"72\":1,\"101\":3,\"103\":2,\"104\":3,\"122\":1,\"137\":1,\"143\":3,\"144\":1,\"146\":2,\"149\":55,\"150\":8,\"151\":6,\"153\":3,\"163\":2,\"164\":2,\"196\":1,\"197\":1,\"205\":1,\"206\":2,\"212\":1}}],[\"供\",{\"1\":{\"30\":1,\"126\":1}}],[\"辅助\",{\"0\":{\"30\":1}}],[\"消费\",{\"1\":{\"164\":1,\"221\":35}}],[\"消费者\",{\"1\":{\"114\":1,\"117\":1,\"221\":20}}],[\"消耗\",{\"1\":{\"55\":1,\"63\":1,\"216\":1,\"221\":1}}],[\"消除\",{\"1\":{\"29\":1}}],[\"消息传递\",{\"1\":{\"221\":2}}],[\"消息\",{\"1\":{\"5\":1,\"74\":1,\"101\":2,\"102\":1,\"103\":7,\"109\":1,\"194\":1,\"221\":73}}],[\"次来\",{\"1\":{\"190\":1}}],[\"次因\",{\"1\":{\"73\":1}}],[\"次数\",{\"1\":{\"38\":1,\"61\":1,\"76\":1,\"106\":1,\"126\":1,\"145\":2,\"151\":1,\"155\":1,\"159\":1,\"189\":1}}],[\"次\",{\"1\":{\"29\":1,\"39\":1,\"51\":1,\"62\":1,\"145\":1,\"149\":1,\"151\":1,\"172\":1,\"221\":1}}],[\"碎片\",{\"0\":{\"39\":1},\"1\":{\"29\":2,\"38\":1,\"39\":2}}],[\"失望\",{\"1\":{\"85\":1,\"86\":1}}],[\"失去\",{\"1\":{\"73\":2}}],[\"失效\",{\"1\":{\"29\":1,\"172\":1,\"220\":1,\"221\":1}}],[\"失败\",{\"0\":{\"159\":1},\"1\":{\"5\":1,\"42\":1,\"59\":1,\"159\":2,\"210\":1,\"221\":1}}],[\"减少\",{\"1\":{\"29\":1,\"37\":1,\"38\":2,\"189\":1,\"221\":4}}],[\"减小\",{\"1\":{\"26\":2}}],[\"响应速度\",{\"1\":{\"58\":1}}],[\"响应\",{\"0\":{\"29\":1},\"1\":{\"29\":1,\"37\":3,\"38\":1,\"56\":1,\"57\":3,\"103\":5,\"125\":2,\"177\":1,\"206\":1,\"216\":2}}],[\"频\",{\"1\":{\"106\":1}}],[\"频数\",{\"1\":{\"64\":1,\"66\":2}}],[\"频次\",{\"1\":{\"62\":1}}],[\"频率\",{\"1\":{\"28\":1,\"37\":1,\"38\":1,\"62\":1}}],[\"频繁\",{\"1\":{\"4\":1,\"192\":1}}],[\"仍\",{\"1\":{\"148\":1}}],[\"仍要\",{\"1\":{\"128\":1}}],[\"仍旧\",{\"1\":{\"28\":1,\"75\":1,\"143\":1}}],[\"仍然\",{\"1\":{\"6\":1}}],[\"仅\",{\"1\":{\"28\":1,\"57\":1,\"221\":1}}],[\"仅仅\",{\"1\":{\"5\":1,\"7\":1,\"45\":1,\"51\":1,\"143\":1,\"152\":1,\"204\":1,\"221\":1}}],[\"科学技术\",{\"1\":{\"28\":1}}],[\"优缺点\",{\"1\":{\"221\":2}}],[\"优点\",{\"1\":{\"221\":3}}],[\"优势\",{\"1\":{\"169\":1,\"221\":1}}],[\"优秀论文\",{\"1\":{\"75\":3}}],[\"优\",{\"0\":{\"36\":1}}],[\"优先级\",{\"1\":{\"56\":1,\"207\":2}}],[\"优先\",{\"0\":{\"28\":1,\"29\":1},\"1\":{\"37\":2,\"38\":3,\"177\":1,\"221\":1}}],[\"优化\",{\"0\":{\"6\":1,\"175\":1},\"1\":{\"122\":2,\"124\":1,\"151\":1,\"177\":1,\"205\":1,\"216\":1,\"221\":1}}],[\"吞吐量\",{\"0\":{\"28\":1},\"1\":{\"28\":1,\"37\":1,\"38\":2,\"54\":1,\"177\":1,\"221\":5}}],[\"判断\",{\"0\":{\"68\":1},\"1\":{\"27\":1,\"48\":1,\"64\":2,\"66\":1,\"67\":1,\"102\":2,\"103\":1,\"137\":1,\"149\":1,\"206\":1,\"213\":1,\"221\":1}}],[\"根据\",{\"0\":{\"147\":1},\"1\":{\"27\":1,\"29\":1,\"37\":1,\"49\":1,\"64\":1,\"66\":1,\"67\":1,\"103\":1,\"132\":1,\"135\":2,\"148\":1,\"155\":2,\"179\":2,\"185\":3,\"192\":1,\"197\":1,\"204\":1,\"211\":1,\"213\":1,\"221\":2}}],[\"根本\",{\"1\":{\"12\":1,\"81\":1}}],[\"针对\",{\"1\":{\"27\":1,\"159\":1,\"185\":3}}],[\"适当\",{\"1\":{\"221\":1}}],[\"适配\",{\"1\":{\"125\":1}}],[\"适应\",{\"1\":{\"124\":1,\"169\":2,\"173\":2}}],[\"适用\",{\"1\":{\"27\":1,\"28\":1,\"29\":1,\"35\":1}}],[\"适合\",{\"1\":{\"18\":1,\"37\":1}}],[\"收到\",{\"1\":{\"164\":1,\"210\":3,\"212\":1}}],[\"收拾\",{\"1\":{\"75\":1}}],[\"收藏\",{\"1\":{\"75\":1}}],[\"收集\",{\"1\":{\"28\":6,\"29\":4,\"34\":3,\"35\":3,\"37\":2,\"38\":3,\"74\":1,\"81\":1,\"212\":1,\"221\":1}}],[\"收集器\",{\"0\":{\"28\":1,\"29\":1,\"32\":1,\"34\":1,\"35\":1},\"1\":{\"27\":8,\"28\":6,\"29\":2,\"32\":4,\"34\":1,\"35\":1,\"38\":1,\"39\":5,\"212\":1}}],[\"收费\",{\"1\":{\"8\":1}}],[\"器会\",{\"1\":{\"144\":1}}],[\"器\",{\"0\":{\"27\":1},\"1\":{\"157\":1,\"221\":5}}],[\"概括\",{\"1\":{\"179\":1}}],[\"概述\",{\"0\":{\"176\":1}}],[\"概览\",{\"1\":{\"145\":1,\"149\":1}}],[\"概论\",{\"1\":{\"26\":1}}],[\"概念\",{\"0\":{\"59\":1,\"132\":1,\"133\":1},\"1\":{\"12\":1,\"221\":1}}],[\"再调\",{\"1\":{\"173\":1}}],[\"再见\",{\"1\":{\"75\":1}}],[\"再装\",{\"1\":{\"49\":1}}],[\"再次\",{\"1\":{\"45\":1,\"124\":1,\"159\":1}}],[\"再\",{\"1\":{\"26\":1,\"29\":1,\"42\":1,\"45\":2,\"64\":1,\"73\":1,\"75\":1,\"78\":3,\"95\":1,\"98\":1,\"103\":2,\"122\":1,\"124\":1,\"135\":1,\"161\":1,\"171\":1,\"178\":1,\"179\":1,\"182\":1,\"210\":1,\"212\":1,\"216\":1,\"221\":6}}],[\"增删\",{\"1\":{\"76\":1,\"81\":1,\"87\":1,\"179\":2}}],[\"增长\",{\"1\":{\"45\":3,\"51\":1,\"76\":1}}],[\"增量\",{\"1\":{\"35\":1,\"164\":3}}],[\"增加\",{\"1\":{\"26\":2,\"103\":1,\"157\":1,\"221\":3}}],[\"增大\",{\"1\":{\"26\":1}}],[\"值去\",{\"1\":{\"179\":1}}],[\"值即\",{\"1\":{\"137\":1}}],[\"值会\",{\"1\":{\"137\":1}}],[\"值得注意\",{\"1\":{\"102\":1,\"160\":1,\"166\":1}}],[\"值得\",{\"1\":{\"87\":1}}],[\"值来\",{\"1\":{\"56\":1}}],[\"值\",{\"1\":{\"26\":1,\"52\":5,\"57\":1,\"137\":6,\"157\":2,\"179\":2,\"207\":1,\"211\":1,\"221\":2}}],[\"值能\",{\"1\":{\"26\":1}}],[\"占位\",{\"1\":{\"198\":1}}],[\"占用\",{\"1\":{\"58\":1,\"63\":1,\"135\":1,\"221\":2}}],[\"占用率\",{\"1\":{\"41\":1}}],[\"占比\",{\"1\":{\"45\":1}}],[\"占\",{\"1\":{\"26\":2,\"31\":1,\"34\":1,\"45\":2}}],[\"除掉\",{\"1\":{\"186\":1}}],[\"除此之外\",{\"1\":{\"183\":1,\"221\":1}}],[\"除去\",{\"1\":{\"26\":1}}],[\"除了\",{\"1\":{\"17\":1,\"57\":1,\"144\":1,\"146\":1}}],[\"49\",{\"1\":{\"221\":1}}],[\"49152\",{\"1\":{\"30\":2}}],[\"45\",{\"1\":{\"221\":1}}],[\"41\",{\"1\":{\"221\":1}}],[\"412412\",{\"1\":{\"211\":1,\"213\":1}}],[\"412\",{\"1\":{\"210\":1}}],[\"41.94\",{\"1\":{\"149\":1}}],[\"42\",{\"1\":{\"221\":1}}],[\"422\",{\"1\":{\"149\":1}}],[\"429\",{\"1\":{\"106\":2}}],[\"443\",{\"1\":{\"158\":1}}],[\"44\",{\"1\":{\"144\":4,\"221\":1}}],[\"48\",{\"1\":{\"103\":1,\"221\":1}}],[\"4813\",{\"1\":{\"64\":1}}],[\"43.153.15.174\",{\"1\":{\"101\":1}}],[\"438\",{\"1\":{\"69\":1}}],[\"43\",{\"1\":{\"69\":1,\"221\":1}}],[\"400\",{\"1\":{\"172\":1}}],[\"40\",{\"1\":{\"45\":1,\"221\":1}}],[\"47.95.10.139\",{\"1\":{\"152\":1,\"155\":1,\"157\":1,\"159\":1,\"160\":1}}],[\"47\",{\"1\":{\"41\":1,\"221\":1}}],[\"46\",{\"1\":{\"30\":2,\"221\":1}}],[\"4\",{\"1\":{\"26\":8,\"29\":1,\"30\":1,\"31\":1,\"56\":1,\"69\":2,\"70\":3,\"72\":1,\"74\":2,\"75\":1,\"122\":1,\"143\":1,\"144\":1,\"148\":1,\"149\":2,\"152\":1,\"160\":2,\"170\":1,\"178\":1,\"194\":1,\"221\":6}}],[\"4.5\",{\"0\":{\"13\":1,\"15\":1}}],[\"4.4\",{\"0\":{\"12\":1,\"14\":1}}],[\"4.3\",{\"0\":{\"11\":1,\"39\":1}}],[\"4.2.6.\",{\"1\":{\"143\":1}}],[\"4.2\",{\"0\":{\"10\":1,\"38\":1}}],[\"4.1.2\",{\"0\":{\"216\":1}}],[\"4.1.1\",{\"0\":{\"215\":1}}],[\"4.1\",{\"0\":{\"9\":1,\"37\":1,\"214\":1}}],[\"4.\",{\"0\":{\"46\":1,\"145\":1,\"149\":1},\"1\":{\"5\":1,\"23\":2,\"103\":1,\"159\":1,\"165\":1,\"192\":1}}],[\"57\",{\"1\":{\"221\":1}}],[\"56\",{\"1\":{\"221\":1}}],[\"568\",{\"1\":{\"72\":1}}],[\"53\",{\"1\":{\"221\":1}}],[\"51\",{\"1\":{\"221\":1}}],[\"512\",{\"1\":{\"72\":2}}],[\"50\",{\"1\":{\"221\":1}}],[\"50.63\",{\"1\":{\"149\":1}}],[\"500\",{\"1\":{\"76\":1,\"127\":1}}],[\"5000\",{\"1\":{\"26\":1,\"57\":1,\"144\":1}}],[\"52\",{\"1\":{\"221\":1}}],[\"52.17\",{\"1\":{\"149\":1}}],[\"52801877\",{\"1\":{\"144\":1}}],[\"52568\",{\"1\":{\"30\":2}}],[\"59\",{\"1\":{\"143\":2,\"221\":1}}],[\"54\",{\"1\":{\"96\":1,\"221\":1}}],[\"5818\",{\"1\":{\"191\":1}}],[\"58.0001.\",{\"1\":{\"49\":1}}],[\"58\",{\"1\":{\"44\":1,\"48\":2,\"221\":1}}],[\"55264\",{\"1\":{\"30\":1}}],[\"55296\",{\"1\":{\"30\":3}}],[\"55\",{\"1\":{\"30\":2,\"221\":1}}],[\"5\",{\"1\":{\"26\":1,\"29\":1,\"31\":1,\"72\":1,\"74\":1,\"75\":3,\"103\":1,\"122\":1,\"143\":1,\"144\":4,\"149\":1,\"158\":1,\"160\":2,\"198\":1,\"205\":2,\"221\":3}}],[\"5.6\",{\"1\":{\"220\":1}}],[\"5.0\",{\"1\":{\"194\":1}}],[\"5.3\",{\"1\":{\"70\":1}}],[\"5.2\",{\"0\":{\"49\":1},\"1\":{\"70\":1}}],[\"5.1\",{\"0\":{\"17\":1,\"48\":1},\"1\":{\"70\":1}}],[\"5.4\",{\"1\":{\"5\":1}}],[\"5.\",{\"0\":{\"47\":1,\"150\":1,\"152\":1},\"1\":{\"5\":1,\"23\":1,\"165\":1,\"192\":1}}],[\"经常\",{\"1\":{\"109\":1,\"127\":1,\"192\":1,\"204\":1}}],[\"经历\",{\"0\":{\"80\":1},\"1\":{\"83\":1}}],[\"经验\",{\"1\":{\"75\":2,\"107\":1}}],[\"经验值\",{\"1\":{\"26\":1}}],[\"经过\",{\"1\":{\"6\":1,\"7\":1,\"26\":1,\"76\":2,\"108\":1,\"157\":2,\"221\":1}}],[\"内部\",{\"1\":{\"103\":1,\"149\":1,\"179\":1,\"183\":1,\"205\":1,\"221\":2}}],[\"内容\",{\"1\":{\"103\":3,\"116\":1,\"121\":1,\"124\":1,\"133\":1,\"158\":1,\"180\":1,\"185\":1,\"192\":1}}],[\"内斗\",{\"1\":{\"81\":1}}],[\"内核\",{\"1\":{\"48\":1,\"55\":1,\"221\":4}}],[\"内网\",{\"1\":{\"43\":1}}],[\"内\",{\"1\":{\"26\":2,\"54\":1,\"80\":1,\"103\":3,\"161\":1,\"172\":1,\"220\":1}}],[\"内存不足\",{\"1\":{\"55\":1}}],[\"内存空间\",{\"1\":{\"29\":2}}],[\"内存大小\",{\"1\":{\"26\":2}}],[\"内存\",{\"0\":{\"44\":1,\"46\":1,\"47\":1,\"52\":1},\"1\":{\"23\":4,\"25\":3,\"26\":1,\"38\":1,\"43\":2,\"44\":2,\"45\":3,\"46\":3,\"48\":2,\"49\":1,\"50\":2,\"51\":2,\"52\":2,\"126\":2,\"135\":2,\"145\":1,\"183\":2,\"184\":2,\"192\":1,\"220\":1}}],[\"85\",{\"1\":{\"221\":1}}],[\"84\",{\"1\":{\"221\":1}}],[\"83\",{\"1\":{\"221\":1}}],[\"82\",{\"1\":{\"221\":1}}],[\"81\",{\"1\":{\"221\":1}}],[\"8158284.\",{\"1\":{\"79\":1}}],[\"8192\",{\"1\":{\"30\":6}}],[\"86\",{\"1\":{\"144\":1,\"221\":1}}],[\"868136\",{\"1\":{\"64\":1}}],[\"8614\",{\"1\":{\"30\":3}}],[\"80\",{\"1\":{\"221\":1}}],[\"808080\",{\"1\":{\"151\":1}}],[\"8080\",{\"1\":{\"56\":1,\"155\":2,\"157\":2,\"159\":2}}],[\"8000\",{\"1\":{\"43\":1}}],[\"8\",{\"1\":{\"26\":1,\"30\":1,\"37\":1,\"72\":1,\"76\":1,\"80\":1,\"137\":1,\"148\":2,\"150\":1,\"221\":1}}],[\"8.0\",{\"1\":{\"220\":1}}],[\"8.\",{\"0\":{\"174\":1},\"1\":{\"23\":1,\"165\":1}}],[\"8.1.3\",{\"1\":{\"196\":1}}],[\"8.1\",{\"1\":{\"2\":1}}],[\"年会\",{\"1\":{\"85\":1}}],[\"年终总结\",{\"1\":{\"85\":1}}],[\"年份\",{\"1\":{\"85\":1}}],[\"年底\",{\"1\":{\"79\":1,\"86\":1}}],[\"年\",{\"1\":{\"73\":2,\"79\":2,\"81\":1,\"82\":1,\"83\":1,\"84\":1,\"85\":1,\"86\":1,\"90\":1,\"164\":1}}],[\"年龄\",{\"1\":{\"26\":1}}],[\"年老\",{\"0\":{\"38\":1},\"1\":{\"26\":6,\"28\":3,\"29\":2,\"31\":3,\"32\":1,\"37\":1,\"38\":5,\"39\":3}}],[\"年轻人\",{\"1\":{\"86\":1}}],[\"年轻\",{\"0\":{\"37\":1},\"1\":{\"26\":12,\"28\":5,\"29\":2,\"31\":7,\"35\":1,\"37\":1,\"38\":3}}],[\"+\",{\"1\":{\"26\":2,\"28\":9,\"29\":7,\"30\":6,\"32\":4,\"33\":3,\"34\":1,\"35\":1,\"39\":1,\"41\":1,\"72\":2,\"74\":1,\"81\":3,\"86\":1,\"122\":4,\"143\":9,\"144\":2,\"149\":3,\"178\":1,\"183\":3,\"186\":1,\"190\":2,\"192\":4,\"204\":1,\"205\":1,\"209\":3,\"212\":2,\"221\":4}}],[\"回滚\",{\"1\":{\"221\":1}}],[\"回话\",{\"1\":{\"179\":1}}],[\"回顾\",{\"1\":{\"161\":1}}],[\"回车符\",{\"1\":{\"104\":1}}],[\"回答\",{\"1\":{\"103\":4}}],[\"回来\",{\"1\":{\"86\":1}}],[\"回不去\",{\"1\":{\"80\":1}}],[\"回家\",{\"1\":{\"75\":1,\"79\":1,\"80\":2}}],[\"回去\",{\"1\":{\"74\":1,\"76\":1}}],[\"回\",{\"1\":{\"73\":1,\"74\":1,\"75\":2,\"80\":1,\"97\":2}}],[\"回到\",{\"1\":{\"73\":1,\"75\":1,\"81\":1}}],[\"回想到\",{\"1\":{\"50\":1}}],[\"回收\",{\"0\":{\"27\":1,\"33\":1},\"1\":{\"26\":2,\"28\":2,\"30\":2,\"34\":1,\"38\":3,\"39\":2,\"76\":1}}],[\"回复\",{\"0\":{\"101\":1,\"103\":2,\"108\":1},\"1\":{\"23\":1,\"97\":1,\"99\":1,\"101\":1,\"103\":14,\"109\":1,\"210\":3,\"213\":1}}],[\"垃圾\",{\"0\":{\"33\":1},\"1\":{\"26\":2,\"28\":4,\"29\":1,\"30\":2,\"34\":1,\"37\":1,\"38\":1}}],[\"避免\",{\"1\":{\"26\":1,\"177\":1,\"221\":5}}],[\"促使\",{\"1\":{\"26\":1}}],[\"典型\",{\"0\":{\"26\":1},\"1\":{\"28\":1,\"29\":1}}],[\"~\",{\"1\":{\"25\":1,\"26\":1,\"73\":1,\"84\":2,\"120\":1,\"152\":1,\"153\":3,\"160\":1,\"192\":2}}],[\"位移\",{\"1\":{\"221\":1}}],[\"位于\",{\"1\":{\"161\":1,\"221\":1}}],[\"位置\",{\"1\":{\"43\":1,\"73\":1,\"135\":2,\"163\":1,\"206\":1,\"221\":6}}],[\"位\",{\"1\":{\"25\":1}}],[\"物理\",{\"1\":{\"25\":2,\"26\":1,\"221\":1}}],[\";\",{\"1\":{\"25\":3,\"38\":1,\"42\":2,\"52\":1,\"60\":2,\"72\":2,\"99\":1,\"140\":2,\"145\":2,\"161\":2,\"179\":2,\"181\":2,\"183\":5,\"206\":1,\"221\":13}}],[\"36\",{\"1\":{\"161\":2,\"221\":1}}],[\"360\",{\"1\":{\"158\":1}}],[\"36.36\",{\"1\":{\"149\":1}}],[\"30\",{\"1\":{\"152\":1,\"196\":1,\"221\":1}}],[\"3000\",{\"1\":{\"26\":1,\"66\":1}}],[\"38\",{\"1\":{\"221\":1}}],[\"385\",{\"1\":{\"149\":1}}],[\"380\",{\"1\":{\"144\":1}}],[\"37\",{\"1\":{\"221\":1}}],[\"37.5\",{\"1\":{\"149\":1}}],[\"372\",{\"1\":{\"144\":1}}],[\"39\",{\"1\":{\"144\":1,\"221\":1}}],[\"31199888\",{\"1\":{\"144\":1}}],[\"31\",{\"1\":{\"79\":1,\"221\":1}}],[\"3182\",{\"1\":{\"30\":1}}],[\"3306\",{\"1\":{\"164\":1}}],[\"330\",{\"1\":{\"151\":1}}],[\"33.33\",{\"1\":{\"149\":2}}],[\"332\",{\"1\":{\"144\":1}}],[\"33\",{\"1\":{\"45\":1,\"221\":1}}],[\"3333\",{\"1\":{\"41\":1}}],[\"346180\",{\"1\":{\"164\":1}}],[\"34\",{\"1\":{\"144\":1,\"170\":4,\"221\":1}}],[\"3433\",{\"1\":{\"30\":2}}],[\"34.735\",{\"1\":{\"30\":1}}],[\"34.702\",{\"1\":{\"30\":1}}],[\"35\",{\"1\":{\"30\":2,\"221\":1}}],[\"3550\",{\"1\":{\"26\":2}}],[\"3\",{\"1\":{\"26\":1,\"30\":1,\"31\":4,\"50\":1,\"56\":1,\"69\":2,\"72\":1,\"74\":3,\"75\":2,\"76\":1,\"80\":2,\"86\":1,\"90\":1,\"100\":1,\"103\":3,\"114\":2,\"143\":1,\"144\":1,\"149\":1,\"151\":1,\"155\":1,\"161\":1,\"164\":1,\"173\":1,\"178\":1,\"179\":1,\"184\":1,\"185\":1,\"194\":1,\"205\":4,\"207\":1,\"211\":1,\"221\":4}}],[\"32\",{\"1\":{\"25\":2,\"221\":1}}],[\"3.7\",{\"0\":{\"192\":1}}],[\"3.6\",{\"0\":{\"191\":1}}],[\"3.4\",{\"0\":{\"34\":1,\"68\":1,\"189\":1}}],[\"3.3\",{\"0\":{\"33\":1,\"67\":1,\"102\":1,\"187\":1}}],[\"3.2.2\",{\"0\":{\"213\":1}}],[\"3.2.1\",{\"0\":{\"212\":1}}],[\"3.2\",{\"0\":{\"32\":1,\"66\":1,\"101\":1,\"186\":1,\"211\":1}}],[\"3.5\",{\"0\":{\"35\":1,\"188\":1,\"190\":1},\"1\":{\"25\":1}}],[\"3.\",{\"0\":{\"45\":1,\"139\":1,\"148\":1},\"1\":{\"5\":1,\"11\":1,\"13\":2,\"23\":2,\"51\":1,\"71\":1,\"103\":1,\"144\":1,\"145\":1,\"159\":1,\"164\":1,\"165\":1,\"192\":1,\"202\":1}}],[\"3.1.3\",{\"0\":{\"210\":1}}],[\"3.1.2\",{\"0\":{\"209\":1}}],[\"3.1.1\",{\"0\":{\"208\":1},\"1\":{\"72\":3}}],[\"3.1\",{\"0\":{\"4\":1,\"31\":1,\"65\":1,\"100\":1,\"185\":1,\"207\":1},\"1\":{\"185\":1}}],[\"限于\",{\"1\":{\"159\":1}}],[\"限频\",{\"0\":{\"106\":1},\"1\":{\"70\":2}}],[\"限\",{\"1\":{\"64\":1}}],[\"限定\",{\"1\":{\"61\":1,\"66\":1}}],[\"限制\",{\"1\":{\"25\":6,\"26\":1,\"37\":1,\"50\":2,\"59\":3,\"61\":2,\"62\":2,\"63\":1,\"97\":1,\"126\":1,\"145\":1,\"149\":1,\"161\":1,\"172\":1}}],[\"限流\",{\"0\":{\"58\":1,\"62\":1,\"63\":1,\"64\":1},\"1\":{\"0\":1,\"59\":1,\"60\":1,\"61\":3,\"62\":3,\"63\":15,\"68\":1,\"69\":2,\"70\":1,\"71\":2}}],[\"设为\",{\"1\":{\"163\":1}}],[\"设想\",{\"1\":{\"128\":1}}],[\"设备\",{\"1\":{\"116\":1,\"221\":1}}],[\"设定\",{\"1\":{\"61\":2,\"157\":1}}],[\"设大\",{\"1\":{\"37\":1}}],[\"设置\",{\"0\":{\"25\":1,\"26\":1,\"31\":1,\"32\":1,\"34\":1,\"35\":1},\"1\":{\"25\":1,\"26\":13,\"28\":2,\"29\":6,\"31\":3,\"32\":4,\"34\":3,\"35\":2,\"37\":1,\"38\":2,\"39\":1,\"69\":1,\"72\":1,\"101\":1,\"102\":1,\"103\":2,\"113\":1,\"116\":1,\"137\":1,\"146\":1,\"148\":1,\"157\":1,\"158\":1,\"163\":1,\"180\":1,\"184\":1,\"221\":1}}],[\"设计模式\",{\"1\":{\"180\":1}}],[\"设计\",{\"0\":{\"142\":1},\"1\":{\"7\":1,\"9\":1,\"23\":2,\"51\":1,\"63\":1,\"86\":1,\"132\":1,\"149\":1,\"170\":1,\"183\":1,\"192\":3,\"221\":6}}],[\"堆外\",{\"1\":{\"51\":1}}],[\"堆积\",{\"1\":{\"50\":1}}],[\"堆大\",{\"1\":{\"38\":1}}],[\"堆栈\",{\"1\":{\"26\":4,\"30\":1}}],[\"堆\",{\"0\":{\"25\":1,\"31\":1,\"44\":1},\"1\":{\"25\":1,\"26\":1,\"31\":2,\"38\":1,\"43\":2,\"44\":1,\"45\":2,\"135\":1}}],[\"亿\",{\"1\":{\"23\":1,\"152\":1}}],[\"半天\",{\"1\":{\"120\":1}}],[\"半年\",{\"1\":{\"86\":1}}],[\"半\",{\"1\":{\"23\":1}}],[\"主键\",{\"1\":{\"221\":1}}],[\"主库\",{\"1\":{\"161\":2,\"163\":1,\"164\":1}}],[\"主主\",{\"1\":{\"161\":2,\"164\":1,\"178\":1}}],[\"主题\",{\"1\":{\"124\":1,\"221\":1}}],[\"主动\",{\"1\":{\"103\":5}}],[\"主流\",{\"1\":{\"63\":1,\"152\":1,\"184\":1,\"185\":1}}],[\"主\",{\"1\":{\"52\":1,\"161\":3,\"205\":2,\"207\":1,\"221\":2}}],[\"主从复制\",{\"1\":{\"161\":3,\"164\":1}}],[\"主从\",{\"1\":{\"23\":1}}],[\"主要\",{\"0\":{\"141\":1},\"1\":{\"4\":2,\"5\":1,\"27\":1,\"28\":1,\"29\":1,\"30\":1,\"42\":3,\"43\":1,\"44\":1,\"54\":1,\"55\":1,\"72\":1,\"96\":1,\"98\":2,\"125\":1,\"132\":1,\"133\":1,\"135\":1,\"136\":2,\"141\":1,\"158\":1,\"159\":1,\"164\":1,\"165\":1,\"169\":2,\"170\":3,\"171\":1,\"172\":1,\"185\":3,\"194\":1,\"206\":2,\"212\":2,\"213\":1,\"215\":1,\"216\":1,\"221\":2}}],[\"区内\",{\"1\":{\"221\":1}}],[\"区域\",{\"1\":{\"95\":1,\"116\":1,\"220\":1}}],[\"区有\",{\"1\":{\"31\":1}}],[\"区\",{\"1\":{\"26\":8,\"28\":1,\"31\":3}}],[\"区别\",{\"1\":{\"23\":2,\"54\":1,\"55\":1,\"74\":1,\"221\":1}}],[\"区分\",{\"1\":{\"12\":1,\"13\":1}}],[\"阶段\",{\"0\":{\"207\":1,\"211\":1},\"1\":{\"23\":2,\"98\":1,\"206\":3,\"210\":1,\"211\":1,\"212\":5,\"213\":1}}],[\"两件事\",{\"1\":{\"221\":1}}],[\"两者\",{\"1\":{\"161\":1,\"170\":1}}],[\"两台\",{\"1\":{\"152\":2}}],[\"两次\",{\"1\":{\"75\":1,\"76\":2,\"89\":1,\"159\":1,\"179\":1}}],[\"两天\",{\"1\":{\"74\":1,\"75\":1}}],[\"两个\",{\"1\":{\"26\":2,\"30\":1,\"31\":2,\"61\":1,\"117\":1,\"124\":1,\"125\":1,\"126\":2,\"141\":1,\"145\":1,\"151\":1,\"152\":1,\"192\":1,\"221\":1}}],[\"两\",{\"1\":{\"23\":1,\"206\":1}}],[\"两种\",{\"1\":{\"10\":1,\"117\":1,\"135\":1,\"152\":1,\"155\":1,\"161\":2,\"194\":1,\"221\":2}}],[\"聊聊\",{\"1\":{\"192\":1}}],[\"聊天\",{\"1\":{\"75\":2,\"97\":3,\"106\":1}}],[\"聊得\",{\"1\":{\"74\":1}}],[\"聊\",{\"1\":{\"23\":1,\"221\":16}}],[\"点缀\",{\"1\":{\"173\":1}}],[\"点开\",{\"1\":{\"145\":1}}],[\"点点\",{\"1\":{\"122\":1,\"170\":1}}],[\"点才\",{\"1\":{\"80\":1}}],[\"点半\",{\"1\":{\"76\":1,\"79\":1}}],[\"点\",{\"1\":{\"61\":1,\"73\":2,\"76\":1,\"79\":1,\"80\":1,\"86\":2,\"113\":1,\"141\":2,\"143\":1,\"161\":1,\"164\":1,\"165\":1,\"168\":1,\"170\":1,\"172\":1}}],[\"点赞\",{\"1\":{\"23\":2}}],[\"点击\",{\"1\":{\"5\":3,\"114\":1,\"127\":1,\"130\":1,\"160\":1,\"166\":2,\"170\":1,\"192\":5,\"196\":1}}],[\"如此\",{\"1\":{\"57\":1,\"76\":1,\"221\":1}}],[\"如何\",{\"1\":{\"54\":1,\"74\":1,\"75\":1,\"149\":1,\"221\":8}}],[\"如下\",{\"1\":{\"39\":1,\"46\":1,\"50\":1,\"72\":3,\"101\":1,\"125\":1,\"126\":1,\"135\":1,\"136\":1,\"143\":1,\"144\":1,\"145\":1,\"151\":4,\"153\":1,\"157\":1,\"161\":1,\"164\":1,\"181\":1,\"183\":1,\"191\":1,\"205\":1,\"206\":1,\"216\":1}}],[\"如上\",{\"1\":{\"28\":1,\"29\":1}}],[\"如\",{\"1\":{\"23\":1,\"31\":2,\"132\":1,\"152\":1,\"161\":1,\"165\":1,\"183\":1,\"184\":1,\"188\":1,\"221\":1}}],[\"如果\",{\"1\":{\"5\":2,\"7\":3,\"11\":1,\"12\":3,\"13\":1,\"17\":1,\"18\":1,\"26\":2,\"27\":1,\"28\":1,\"38\":2,\"39\":2,\"44\":1,\"62\":2,\"63\":2,\"67\":1,\"68\":2,\"70\":3,\"72\":1,\"87\":2,\"91\":1,\"96\":1,\"98\":2,\"100\":1,\"101\":1,\"102\":2,\"103\":2,\"113\":1,\"120\":1,\"122\":1,\"130\":1,\"132\":1,\"137\":1,\"142\":1,\"143\":1,\"145\":1,\"149\":4,\"157\":2,\"158\":1,\"159\":1,\"161\":1,\"165\":2,\"167\":1,\"168\":1,\"169\":1,\"172\":1,\"173\":3,\"177\":1,\"178\":1,\"179\":3,\"184\":2,\"185\":1,\"192\":1,\"213\":1,\"221\":26}}],[\"边界\",{\"1\":{\"23\":1}}],[\"出手\",{\"1\":{\"128\":1}}],[\"出去\",{\"1\":{\"85\":1,\"86\":1}}],[\"出去玩\",{\"1\":{\"77\":1}}],[\"出门\",{\"1\":{\"77\":1}}],[\"出来\",{\"1\":{\"74\":1,\"125\":1,\"126\":1,\"127\":1,\"145\":1,\"165\":1,\"221\":1}}],[\"出发\",{\"1\":{\"73\":1}}],[\"出省\",{\"1\":{\"73\":1}}],[\"出品\",{\"1\":{\"63\":1}}],[\"出色\",{\"1\":{\"54\":1}}],[\"出错\",{\"1\":{\"50\":2,\"171\":1}}],[\"出堆\",{\"1\":{\"44\":1}}],[\"出\",{\"1\":{\"23\":1,\"99\":1,\"126\":2,\"136\":1,\"149\":1,\"164\":1,\"173\":1,\"191\":1}}],[\"出现\",{\"1\":{\"6\":2,\"7\":1,\"39\":2,\"42\":1,\"44\":1,\"45\":1,\"55\":1,\"70\":2,\"72\":1,\"97\":1,\"106\":1,\"169\":1,\"184\":2,\"221\":1}}],[\"求用\",{\"1\":{\"23\":1}}],[\"数兆\",{\"1\":{\"221\":1}}],[\"数量\",{\"1\":{\"221\":3}}],[\"数值\",{\"1\":{\"151\":1}}],[\"数组\",{\"1\":{\"149\":2,\"151\":1,\"221\":1}}],[\"数码\",{\"1\":{\"74\":1}}],[\"数来\",{\"1\":{\"64\":1}}],[\"数百万个\",{\"1\":{\"55\":1}}],[\"数目\",{\"1\":{\"28\":1}}],[\"数\",{\"0\":{\"65\":1},\"1\":{\"26\":1,\"28\":1,\"34\":2,\"35\":2,\"45\":2,\"65\":1,\"66\":1,\"70\":2,\"167\":1,\"221\":4}}],[\"数据传输\",{\"1\":{\"221\":1}}],[\"数据处理\",{\"1\":{\"221\":1}}],[\"数据压缩\",{\"1\":{\"221\":1}}],[\"数据管理\",{\"1\":{\"221\":1}}],[\"数据中心\",{\"1\":{\"221\":2}}],[\"数据结构\",{\"1\":{\"149\":1,\"207\":1}}],[\"数据源\",{\"1\":{\"72\":1,\"194\":1}}],[\"数据\",{\"0\":{\"151\":1,\"192\":1,\"197\":1,\"198\":1},\"1\":{\"38\":1,\"43\":1,\"51\":1,\"52\":1,\"58\":1,\"65\":1,\"66\":2,\"73\":1,\"74\":3,\"125\":2,\"126\":1,\"135\":4,\"137\":2,\"140\":1,\"145\":2,\"146\":3,\"148\":2,\"149\":2,\"151\":4,\"152\":1,\"161\":7,\"163\":1,\"164\":1,\"177\":1,\"184\":4,\"191\":1,\"192\":4,\"194\":1,\"198\":1,\"205\":1,\"206\":1,\"212\":2,\"216\":1,\"221\":34}}],[\"数据量\",{\"1\":{\"27\":1,\"135\":1}}],[\"数据模型\",{\"1\":{\"25\":1}}],[\"数据库\",{\"0\":{\"161\":1,\"220\":1},\"1\":{\"5\":2,\"42\":1,\"64\":1,\"66\":1,\"103\":2,\"122\":2,\"136\":1,\"143\":1,\"149\":1,\"161\":4,\"163\":3,\"164\":4,\"168\":3,\"177\":2,\"179\":1,\"184\":1,\"189\":2,\"190\":1,\"192\":4,\"194\":1}}],[\"数字\",{\"1\":{\"23\":3}}],[\"给\",{\"1\":{\"23\":1,\"27\":1,\"39\":1,\"73\":1,\"78\":1,\"80\":1,\"86\":2,\"87\":1,\"102\":1,\"103\":3,\"122\":1,\"127\":1,\"128\":2,\"130\":1,\"145\":3,\"150\":1,\"151\":1,\"152\":1,\"160\":1,\"164\":1,\"165\":3,\"173\":1,\"180\":1,\"192\":1,\"207\":1,\"211\":2,\"213\":1,\"221\":3}}],[\"题外话\",{\"1\":{\"77\":1,\"173\":1}}],[\"题问\",{\"1\":{\"74\":1}}],[\"题\",{\"1\":{\"23\":4,\"73\":1,\"74\":2,\"221\":2}}],[\"带\",{\"1\":{\"80\":1}}],[\"带够\",{\"1\":{\"74\":1}}],[\"带有\",{\"1\":{\"56\":1,\"166\":1}}],[\"带来\",{\"1\":{\"23\":1,\"57\":1,\"60\":1,\"158\":1}}],[\"带上\",{\"1\":{\"12\":1,\"13\":1,\"187\":1}}],[\"网路\",{\"1\":{\"190\":1}}],[\"网址\",{\"1\":{\"151\":1,\"152\":1,\"160\":1}}],[\"网吧\",{\"1\":{\"151\":1}}],[\"网页\",{\"1\":{\"99\":2,\"124\":1,\"135\":1,\"166\":1,\"168\":2,\"169\":1}}],[\"网见\",{\"1\":{\"80\":1}}],[\"网\",{\"1\":{\"73\":1,\"74\":1,\"75\":2,\"98\":1,\"159\":1,\"172\":1,\"198\":1}}],[\"网关\",{\"1\":{\"63\":7}}],[\"网上\",{\"1\":{\"49\":2,\"98\":1,\"99\":1,\"151\":1,\"159\":1,\"169\":1,\"172\":1}}],[\"网络协议\",{\"1\":{\"184\":1}}],[\"网络通信\",{\"1\":{\"63\":1,\"216\":1}}],[\"网络\",{\"1\":{\"23\":1,\"43\":1,\"63\":2,\"152\":1,\"221\":3}}],[\"网站\",{\"0\":{\"123\":1,\"125\":1,\"129\":1,\"134\":1,\"138\":1,\"146\":1,\"175\":1},\"1\":{\"18\":1,\"73\":1,\"76\":1,\"95\":1,\"122\":5,\"124\":5,\"125\":2,\"128\":2,\"130\":1,\"143\":1,\"145\":10,\"146\":4,\"149\":1,\"151\":3,\"152\":6,\"158\":2,\"160\":3,\"162\":1,\"165\":1,\"166\":2,\"170\":1,\"171\":1,\"172\":1,\"173\":3,\"184\":1,\"192\":5}}],[\"风暴\",{\"1\":{\"23\":1}}],[\"风格\",{\"0\":{\"5\":1},\"1\":{\"5\":1,\"9\":1,\"173\":2}}],[\"什么样\",{\"1\":{\"219\":1,\"221\":1}}],[\"什么\",{\"1\":{\"23\":2,\"57\":1,\"63\":1,\"74\":2,\"75\":2,\"76\":1,\"78\":1,\"80\":1,\"81\":3,\"84\":1,\"85\":1,\"87\":1,\"97\":1,\"122\":1,\"124\":3,\"153\":1,\"155\":2,\"169\":1,\"172\":1,\"173\":1,\"221\":29}}],[\"吗\",{\"1\":{\"23\":1,\"221\":2}}],[\"场景\",{\"0\":{\"60\":1},\"1\":{\"23\":4,\"57\":2,\"61\":1,\"63\":1,\"69\":1,\"76\":1,\"101\":1,\"177\":1,\"221\":1}}],[\"介绍\",{\"0\":{\"177\":1},\"1\":{\"23\":4,\"137\":1,\"165\":2,\"184\":1,\"185\":3,\"198\":2}}],[\"模版\",{\"1\":{\"100\":1}}],[\"模拟\",{\"1\":{\"57\":2,\"152\":1,\"164\":1}}],[\"模块\",{\"1\":{\"42\":1,\"63\":1,\"72\":3,\"76\":1,\"216\":1}}],[\"模式\",{\"0\":{\"43\":1},\"1\":{\"35\":1,\"72\":1,\"180\":1,\"221\":8}}],[\"模型\",{\"1\":{\"23\":1,\"108\":2,\"125\":1,\"221\":1}}],[\"模板\",{\"1\":{\"12\":2,\"13\":1,\"124\":3,\"165\":1}}],[\"基本知识\",{\"1\":{\"204\":1}}],[\"基本一致\",{\"1\":{\"159\":1}}],[\"基本上\",{\"1\":{\"72\":1,\"159\":1,\"192\":1}}],[\"基本\",{\"0\":{\"150\":1},\"1\":{\"42\":1,\"45\":3,\"127\":1,\"133\":1,\"148\":1,\"150\":1,\"161\":4,\"164\":1,\"167\":1}}],[\"基础设施\",{\"1\":{\"57\":1,\"141\":1}}],[\"基础\",{\"0\":{\"196\":1},\"1\":{\"23\":2,\"74\":1,\"101\":1,\"108\":1,\"158\":1,\"221\":1}}],[\"基于\",{\"0\":{\"58\":1,\"64\":1,\"174\":1},\"1\":{\"0\":1,\"5\":1,\"8\":1,\"61\":2,\"63\":1,\"70\":1,\"72\":3,\"127\":1,\"161\":3,\"163\":1,\"164\":2,\"168\":1,\"185\":1,\"204\":1}}],[\"窗口\",{\"1\":{\"23\":1,\"61\":3,\"106\":1}}],[\"滑动\",{\"1\":{\"23\":1}}],[\"无效\",{\"1\":{\"114\":1}}],[\"无果\",{\"1\":{\"114\":1}}],[\"无语\",{\"1\":{\"86\":1}}],[\"无奈\",{\"1\":{\"74\":1,\"76\":1,\"81\":1}}],[\"无界\",{\"1\":{\"57\":1}}],[\"无需\",{\"1\":{\"29\":1,\"55\":1,\"100\":1}}],[\"无限期\",{\"1\":{\"221\":1}}],[\"无限\",{\"1\":{\"26\":1,\"69\":2}}],[\"无\",{\"1\":{\"23\":1,\"25\":1,\"101\":1,\"141\":1}}],[\"无法控制\",{\"1\":{\"58\":1}}],[\"无法\",{\"1\":{\"5\":1,\"6\":3,\"7\":3,\"28\":1,\"42\":1,\"43\":1,\"65\":1,\"102\":1,\"113\":1,\"114\":2,\"152\":1,\"157\":1,\"170\":1,\"221\":4}}],[\"微博\",{\"1\":{\"122\":2,\"127\":1}}],[\"微调\",{\"1\":{\"108\":1}}],[\"微\",{\"1\":{\"99\":2}}],[\"微信云\",{\"0\":{\"100\":1},\"1\":{\"100\":1,\"101\":1}}],[\"微信\",{\"0\":{\"22\":1,\"93\":1},\"1\":{\"22\":1,\"23\":1,\"64\":1,\"69\":3,\"75\":1,\"93\":1,\"97\":1,\"99\":1,\"100\":1,\"101\":1,\"102\":1,\"103\":6,\"110\":1}}],[\"微软\",{\"1\":{\"7\":2}}],[\"69\",{\"1\":{\"221\":1}}],[\"69632\",{\"1\":{\"30\":4}}],[\"68\",{\"1\":{\"221\":1}}],[\"62\",{\"1\":{\"221\":1}}],[\"61\",{\"1\":{\"221\":1}}],[\"615\",{\"1\":{\"190\":1}}],[\"6144\",{\"1\":{\"30\":4}}],[\"60\",{\"1\":{\"164\":1,\"221\":1}}],[\"63\",{\"1\":{\"149\":1,\"221\":1}}],[\"652\",{\"1\":{\"149\":1}}],[\"65\",{\"1\":{\"149\":1,\"221\":1}}],[\"67\",{\"1\":{\"149\":2,\"221\":1}}],[\"6649\",{\"1\":{\"191\":1}}],[\"6615\",{\"1\":{\"30\":1}}],[\"66\",{\"1\":{\"30\":2,\"149\":1,\"221\":1}}],[\"663\",{\"1\":{\"18\":1}}],[\"6\",{\"0\":{\"53\":1,\"56\":1},\"1\":{\"26\":1,\"54\":1,\"56\":1,\"69\":2,\"73\":1,\"74\":1,\"75\":3,\"149\":1,\"170\":1,\"192\":1,\"221\":2}}],[\"649\",{\"1\":{\"151\":1}}],[\"64\",{\"1\":{\"25\":2,\"26\":1,\"221\":1}}],[\"6.6.0\",{\"1\":{\"135\":1,\"137\":1}}],[\"6.4\",{\"0\":{\"109\":1}}],[\"6.3\",{\"0\":{\"108\":1}}],[\"6.2\",{\"0\":{\"107\":1}}],[\"6.1\",{\"0\":{\"106\":1}}],[\"6.\",{\"0\":{\"50\":1,\"151\":1,\"161\":1},\"1\":{\"5\":1,\"23\":1,\"165\":1,\"192\":1}}],[\"?\",{\"1\":{\"18\":1,\"56\":1,\"66\":1,\"101\":3,\"103\":3,\"104\":1,\"125\":1,\"137\":1,\"143\":1,\"146\":2,\"166\":1,\"189\":1,\"206\":1,\"212\":1,\"216\":1,\"221\":18}}],[\"write\",{\"1\":{\"137\":1}}],[\"writeobject\",{\"1\":{\"137\":1}}],[\"writer\",{\"1\":{\"135\":6}}],[\"wowslider\",{\"0\":{\"166\":1},\"1\":{\"124\":1,\"165\":1,\"166\":1}}],[\"word\",{\"1\":{\"205\":4}}],[\"wordpreess\",{\"1\":{\"166\":1}}],[\"wordpress\",{\"1\":{\"165\":1,\"168\":2}}],[\"wordcount\",{\"1\":{\"72\":2}}],[\"world\",{\"1\":{\"143\":1}}],[\"worker\",{\"1\":{\"56\":1}}],[\"where\",{\"1\":{\"103\":2,\"104\":1}}],[\"while\",{\"1\":{\"48\":1,\"206\":1}}],[\"which\",{\"1\":{\"30\":1}}],[\"wx\",{\"1\":{\"101\":1}}],[\"wxcloudrun\",{\"1\":{\"101\":1}}],[\"width\",{\"1\":{\"151\":2,\"170\":1}}],[\"withcontentorsourceparamparserornull\",{\"1\":{\"207\":1}}],[\"with\",{\"1\":{\"98\":1}}],[\"windows\",{\"1\":{\"25\":1,\"96\":1,\"98\":3}}],[\"was\",{\"1\":{\"216\":1}}],[\"waterfall\",{\"1\":{\"165\":1,\"171\":1}}],[\"war\",{\"1\":{\"161\":1}}],[\"wan\",{\"1\":{\"72\":1,\"196\":1}}],[\"wait\",{\"1\":{\"23\":2}}],[\"weight\",{\"1\":{\"137\":3,\"155\":1,\"159\":3}}],[\"weixin\",{\"1\":{\"103\":1,\"220\":1}}],[\"weixincloud\",{\"1\":{\"101\":1}}],[\"well\",{\"1\":{\"120\":1}}],[\"wechat\",{\"1\":{\"110\":1}}],[\"we\",{\"1\":{\"98\":1}}],[\"website\",{\"0\":{\"227\":1}}],[\"webhook\",{\"1\":{\"72\":2}}],[\"web\",{\"1\":{\"54\":1,\"56\":2,\"157\":5,\"159\":2}}],[\"were\",{\"1\":{\"30\":1}}],[\"wenzhihuai\",{\"1\":{\"18\":2,\"76\":1,\"130\":1,\"145\":1,\"151\":2,\"152\":1,\"157\":1,\"158\":2,\"160\":2,\"165\":1,\"170\":1,\"173\":1,\"192\":1}}],[\"w1570631036\",{\"1\":{\"18\":1,\"79\":1}}],[\"wwww\",{\"1\":{\"157\":1}}],[\"www\",{\"1\":{\"18\":2,\"41\":2,\"76\":1,\"79\":1,\"118\":1,\"130\":1,\"138\":1,\"145\":1,\"149\":1,\"151\":2,\"152\":1,\"158\":2,\"160\":2,\"165\":1,\"173\":1,\"192\":1}}],[\"\\n\",{\"1\":{\"18\":3,\"23\":5,\"39\":2,\"51\":3,\"71\":2,\"110\":1,\"151\":5,\"160\":3,\"192\":6,\"203\":2,\"221\":51}}],[\"必选\",{\"1\":{\"185\":3}}],[\"必备\",{\"1\":{\"166\":1}}],[\"必去\",{\"1\":{\"89\":1}}],[\"必要\",{\"1\":{\"77\":1,\"192\":1}}],[\"必经之路\",{\"1\":{\"18\":1}}],[\"必须\",{\"1\":{\"7\":1,\"55\":1,\"72\":2,\"120\":2,\"147\":1,\"157\":1,\"205\":1,\"221\":4}}],[\"填充\",{\"1\":{\"216\":1}}],[\"填\",{\"1\":{\"120\":1}}],[\"填个\",{\"1\":{\"114\":1}}],[\"填上\",{\"1\":{\"102\":1}}],[\"填坑\",{\"1\":{\"18\":1}}],[\"填写\",{\"1\":{\"7\":1,\"101\":1,\"185\":3}}],[\"老板\",{\"1\":{\"85\":1,\"86\":3}}],[\"老是\",{\"1\":{\"82\":1,\"124\":1,\"172\":1,\"173\":1}}],[\"老大\",{\"1\":{\"80\":1}}],[\"老姐\",{\"1\":{\"79\":1,\"83\":1}}],[\"老师\",{\"1\":{\"78\":1}}],[\"老\",{\"1\":{\"18\":1,\"74\":1,\"76\":1,\"80\":1,\"89\":1,\"108\":1}}],[\"维持\",{\"1\":{\"103\":1}}],[\"维度\",{\"0\":{\"61\":1},\"1\":{\"61\":1}}],[\"维护\",{\"1\":{\"18\":1,\"50\":1,\"86\":1,\"145\":1,\"179\":1,\"221\":1}}],[\"维基百科\",{\"1\":{\"4\":1}}],[\"化\",{\"1\":{\"18\":1,\"72\":2,\"141\":1,\"149\":1,\"184\":1,\"221\":1}}],[\"愿意\",{\"1\":{\"18\":2}}],[\"改完\",{\"1\":{\"170\":1}}],[\"改用\",{\"1\":{\"165\":1}}],[\"改查\",{\"1\":{\"76\":1,\"81\":1,\"87\":1}}],[\"改改\",{\"1\":{\"76\":1}}],[\"改为\",{\"1\":{\"72\":2,\"114\":1,\"120\":1}}],[\"改进\",{\"1\":{\"54\":1,\"221\":1}}],[\"改\",{\"1\":{\"18\":1,\"76\":1,\"77\":1,\"120\":1,\"124\":1,\"142\":1,\"161\":1,\"171\":1,\"173\":1,\"179\":2,\"203\":1}}],[\"改变\",{\"1\":{\"18\":1,\"158\":1,\"161\":3,\"164\":1,\"170\":1}}],[\"改造\",{\"1\":{\"8\":2}}],[\"关系\",{\"1\":{\"132\":1,\"220\":1,\"221\":3}}],[\"关注\",{\"1\":{\"110\":1,\"221\":1}}],[\"关心\",{\"1\":{\"75\":1,\"126\":1}}],[\"关卡\",{\"1\":{\"63\":1}}],[\"关掉\",{\"1\":{\"46\":1}}],[\"关闭\",{\"1\":{\"44\":1,\"45\":4,\"124\":1,\"160\":1,\"191\":1,\"203\":1,\"221\":1}}],[\"关键词\",{\"1\":{\"132\":1,\"133\":1}}],[\"关键字\",{\"1\":{\"132\":1,\"149\":2}}],[\"关键\",{\"1\":{\"18\":1,\"180\":1,\"221\":1}}],[\"关于\",{\"0\":{\"1\":1},\"1\":{\"99\":1,\"103\":1,\"151\":1}}],[\"问过\",{\"1\":{\"76\":1}}],[\"问到\",{\"1\":{\"75\":1,\"76\":1,\"221\":1}}],[\"问\",{\"1\":{\"18\":1,\"23\":2,\"74\":3,\"75\":2,\"76\":3,\"80\":1,\"103\":1,\"221\":2}}],[\"问题\",{\"0\":{\"39\":1,\"70\":1,\"103\":1,\"105\":1,\"184\":1},\"1\":{\"5\":1,\"6\":2,\"7\":3,\"9\":1,\"18\":1,\"42\":1,\"44\":3,\"45\":1,\"46\":1,\"48\":1,\"49\":1,\"51\":2,\"55\":1,\"70\":2,\"73\":2,\"74\":4,\"75\":1,\"76\":3,\"86\":1,\"97\":1,\"99\":1,\"109\":1,\"114\":1,\"124\":2,\"152\":1,\"155\":1,\"159\":1,\"161\":1,\"166\":1,\"184\":1,\"185\":1,\"188\":1,\"221\":2}}],[\"被动\",{\"1\":{\"103\":2}}],[\"被封\",{\"1\":{\"99\":1}}],[\"被拉去\",{\"1\":{\"81\":1}}],[\"被评\",{\"1\":{\"75\":1}}],[\"被删\",{\"1\":{\"75\":1}}],[\"被\",{\"0\":{\"41\":1,\"107\":1},\"1\":{\"18\":1,\"26\":1,\"41\":1,\"52\":1,\"62\":1,\"73\":1,\"74\":3,\"75\":2,\"76\":2,\"77\":1,\"81\":2,\"86\":4,\"98\":3,\"99\":1,\"107\":1,\"114\":1,\"125\":1,\"155\":1,\"157\":2,\"221\":13}}],[\"又\",{\"1\":{\"18\":1,\"73\":1,\"74\":1,\"76\":1,\"77\":1,\"81\":1,\"85\":2,\"87\":1,\"124\":1,\"149\":1,\"164\":1,\"165\":1,\"173\":1,\"192\":1,\"221\":6}}],[\"同质\",{\"1\":{\"221\":1}}],[\"同等\",{\"1\":{\"221\":1}}],[\"同\",{\"1\":{\"192\":1}}],[\"同样\",{\"1\":{\"102\":1,\"192\":1,\"221\":1}}],[\"同事\",{\"1\":{\"76\":1,\"80\":2,\"86\":2,\"90\":1}}],[\"同一个\",{\"1\":{\"160\":1,\"179\":1,\"180\":2}}],[\"同一\",{\"1\":{\"75\":1,\"98\":1}}],[\"同学\",{\"1\":{\"73\":1,\"74\":1,\"76\":2,\"77\":1,\"78\":1}}],[\"同理\",{\"1\":{\"63\":1}}],[\"同步\",{\"1\":{\"18\":1,\"23\":2,\"72\":2,\"161\":2,\"164\":6,\"221\":3}}],[\"同个\",{\"1\":{\"18\":1}}],[\"同时\",{\"1\":{\"7\":1,\"17\":1,\"28\":1,\"29\":1,\"37\":1,\"50\":1,\"72\":3,\"75\":1,\"96\":1,\"103\":1,\"122\":1,\"146\":1,\"164\":2,\"184\":1,\"190\":1,\"192\":1,\"197\":1,\"215\":1,\"216\":1,\"221\":1}}],[\"培训\",{\"1\":{\"18\":1,\"73\":1,\"74\":2}}],[\"既有\",{\"1\":{\"185\":1}}],[\"既\",{\"1\":{\"18\":1}}],[\"流式\",{\"1\":{\"221\":1}}],[\"流有\",{\"1\":{\"171\":1}}],[\"流行\",{\"1\":{\"159\":1,\"171\":1,\"173\":1}}],[\"流水线\",{\"1\":{\"101\":1}}],[\"流\",{\"0\":{\"171\":1},\"1\":{\"69\":2,\"124\":1,\"164\":1,\"171\":4,\"221\":1}}],[\"流量\",{\"1\":{\"63\":2,\"70\":1,\"146\":1,\"152\":2,\"172\":1,\"221\":1}}],[\"流拉取\",{\"1\":{\"23\":1}}],[\"流动性\",{\"1\":{\"18\":1}}],[\"流程\",{\"0\":{\"13\":1,\"214\":1,\"216\":1},\"1\":{\"4\":1,\"6\":2,\"7\":1,\"23\":1,\"72\":1,\"125\":2,\"205\":1,\"214\":1}}],[\"选举\",{\"1\":{\"72\":3,\"221\":2}}],[\"选\",{\"1\":{\"72\":2}}],[\"选项\",{\"1\":{\"28\":1,\"54\":1,\"72\":1}}],[\"选取\",{\"1\":{\"18\":1,\"221\":1}}],[\"选择\",{\"0\":{\"27\":1,\"37\":1,\"38\":1},\"1\":{\"6\":3,\"13\":1,\"27\":2,\"28\":2,\"37\":1,\"63\":1,\"96\":1,\"100\":1,\"124\":1,\"149\":1,\"151\":1,\"153\":1,\"161\":1,\"166\":1,\"168\":1,\"173\":1,\"183\":1,\"221\":3}}],[\"莫过于\",{\"1\":{\"18\":1}}],[\"强调\",{\"1\":{\"86\":1}}],[\"强么\",{\"1\":{\"74\":1}}],[\"强\",{\"1\":{\"49\":1,\"165\":1}}],[\"强大\",{\"1\":{\"18\":2,\"54\":1,\"72\":1,\"140\":1}}],[\"强行\",{\"1\":{\"5\":1}}],[\"总数\",{\"1\":{\"221\":1}}],[\"总之\",{\"1\":{\"183\":1}}],[\"总\",{\"1\":{\"143\":1}}],[\"总算\",{\"1\":{\"128\":1}}],[\"总有\",{\"1\":{\"82\":1}}],[\"总是\",{\"1\":{\"82\":1,\"87\":1,\"221\":1}}],[\"总写\",{\"1\":{\"81\":1}}],[\"总会\",{\"1\":{\"73\":1,\"75\":1}}],[\"总限\",{\"1\":{\"66\":2}}],[\"总限频\",{\"1\":{\"63\":1,\"69\":1}}],[\"总共\",{\"1\":{\"63\":1}}],[\"总线\",{\"1\":{\"23\":1}}],[\"总结\",{\"0\":{\"18\":1,\"36\":1,\"51\":1,\"128\":1},\"1\":{\"75\":1}}],[\"总体而言\",{\"1\":{\"5\":1}}],[\"六\",{\"0\":{\"18\":1,\"105\":1}}],[\"各\",{\"1\":{\"205\":2,\"211\":1}}],[\"各位\",{\"1\":{\"23\":1,\"122\":1,\"127\":1,\"128\":1,\"171\":1}}],[\"各自\",{\"1\":{\"23\":1,\"172\":1,\"221\":1}}],[\"各种各样\",{\"1\":{\"87\":1}}],[\"各种\",{\"1\":{\"17\":1,\"49\":1,\"51\":1,\"74\":1,\"86\":1,\"97\":1,\"100\":1,\"124\":1,\"140\":1,\"141\":1,\"148\":1,\"149\":1,\"165\":2,\"171\":1,\"183\":1,\"185\":2,\"214\":1,\"216\":1}}],[\"各个\",{\"1\":{\"8\":1,\"62\":1,\"185\":2,\"211\":2,\"221\":2}}],[\"五\",{\"0\":{\"16\":1,\"70\":1,\"104\":1,\"202\":1}}],[\"*\",{\"1\":{\"15\":3,\"48\":3,\"56\":10,\"57\":8,\"65\":1,\"72\":3,\"74\":2,\"137\":105,\"143\":1,\"149\":2,\"150\":2,\"158\":1,\"159\":1,\"170\":2,\"185\":4,\"196\":1,\"204\":1,\"205\":1,\"209\":1,\"216\":1}}],[\"步骤\",{\"1\":{\"14\":1,\"102\":1,\"120\":1,\"144\":1,\"145\":1,\"178\":2,\"205\":1,\"221\":1}}],[\"lw\",{\"1\":{\"221\":1}}],[\"lte\",{\"1\":{\"205\":1}}],[\"lru\",{\"1\":{\"182\":2,\"183\":1}}],[\"lvs\",{\"1\":{\"152\":1}}],[\"l\",{\"1\":{\"137\":1,\"215\":2}}],[\"lag\",{\"1\":{\"221\":1}}],[\"language\",{\"1\":{\"185\":1}}],[\"latin\",{\"1\":{\"166\":2}}],[\"layer\",{\"1\":{\"158\":1}}],[\"lazy\",{\"1\":{\"143\":1}}],[\"lastbottom\",{\"1\":{\"135\":3}}],[\"lab\",{\"1\":{\"13\":2}}],[\"labels\",{\"1\":{\"72\":2}}],[\"label\",{\"1\":{\"13\":4,\"151\":1}}],[\"leo\",{\"1\":{\"221\":2}}],[\"legend\",{\"1\":{\"151\":2}}],[\"length\",{\"1\":{\"104\":1,\"137\":2,\"212\":2}}],[\"left\",{\"1\":{\"74\":1,\"151\":5}}],[\"leaseduration\",{\"1\":{\"72\":1}}],[\"leaderepoch\",{\"1\":{\"221\":1}}],[\"leaderelectionretryperiod\",{\"1\":{\"72\":1}}],[\"leaderelectionrenewdeadline\",{\"1\":{\"72\":1}}],[\"leaderelectionleaseduration\",{\"1\":{\"72\":1}}],[\"leaderelectionconfig\",{\"1\":{\"72\":1}}],[\"leaderelection\",{\"1\":{\"72\":4}}],[\"leadership\",{\"1\":{\"221\":1}}],[\"leaders\",{\"1\":{\"221\":1}}],[\"leadercallbacks\",{\"1\":{\"72\":1}}],[\"leader\",{\"1\":{\"72\":2,\"221\":11}}],[\"leaked\",{\"1\":{\"98\":1}}],[\"leaks\",{\"1\":{\"51\":1}}],[\"leakdetectionlevel\",{\"1\":{\"46\":1}}],[\"low\",{\"1\":{\"165\":1}}],[\"lo\",{\"1\":{\"138\":1}}],[\"long\",{\"1\":{\"137\":2,\"190\":1}}],[\"location\",{\"1\":{\"98\":1,\"120\":1,\"155\":1,\"157\":1}}],[\"localshardroutings\",{\"1\":{\"208\":1}}],[\"localsharditerators\",{\"1\":{\"208\":2}}],[\"localfs\",{\"1\":{\"194\":1}}],[\"local\",{\"1\":{\"72\":1,\"196\":1}}],[\"localhost\",{\"1\":{\"56\":1,\"160\":1,\"203\":1}}],[\"lock\",{\"1\":{\"72\":1}}],[\"lookup\",{\"1\":{\"137\":1}}],[\"looking\",{\"1\":{\"72\":1}}],[\"loom\",{\"1\":{\"54\":1}}],[\"logs\",{\"1\":{\"156\":1}}],[\"log4j\",{\"1\":{\"144\":2}}],[\"login\",{\"1\":{\"143\":1}}],[\"log\",{\"1\":{\"57\":2,\"66\":2,\"101\":2,\"151\":1,\"156\":3,\"160\":1,\"161\":5,\"163\":4,\"164\":10,\"221\":8}}],[\"loggerfactory\",{\"1\":{\"57\":1,\"137\":1}}],[\"logger\",{\"1\":{\"57\":1,\"135\":1,\"137\":4,\"143\":1,\"144\":1,\"189\":1,\"206\":2}}],[\"loadorexecutequeryphase\",{\"1\":{\"215\":1}}],[\"loads\",{\"1\":{\"150\":1}}],[\"loadstore\",{\"1\":{\"52\":2}}],[\"loadingcache\",{\"1\":{\"66\":3,\"67\":1,\"70\":1}}],[\"loadtestcontroller\",{\"1\":{\"57\":2}}],[\"load\",{\"1\":{\"57\":2}}],[\"loadload\",{\"1\":{\"52\":2}}],[\"life\",{\"0\":{\"225\":1,\"228\":1}}],[\"lib\",{\"1\":{\"163\":2,\"164\":2}}],[\"libunwind\",{\"1\":{\"49\":1}}],[\"linecontainer\",{\"1\":{\"151\":2}}],[\"links\",{\"1\":{\"163\":1,\"164\":1}}],[\"link\",{\"1\":{\"137\":1}}],[\"linkedhashset\",{\"1\":{\"137\":1}}],[\"linkhashset\",{\"1\":{\"137\":1}}],[\"linux\",{\"1\":{\"46\":1,\"48\":1,\"49\":3,\"50\":1,\"143\":2,\"173\":1}}],[\"listen\",{\"1\":{\"158\":1}}],[\"listener\",{\"1\":{\"125\":1,\"206\":2,\"215\":2,\"216\":1}}],[\"list\",{\"1\":{\"137\":6,\"143\":2,\"189\":2,\"212\":1}}],[\"like\",{\"1\":{\"136\":2}}],[\"limit\",{\"1\":{\"104\":1}}],[\"live\",{\"1\":{\"44\":1}}],[\"lucene1\",{\"1\":{\"138\":1}}],[\"lucene\",{\"0\":{\"40\":1,\"130\":1,\"131\":1,\"133\":1,\"134\":1,\"136\":1},\"1\":{\"122\":4,\"124\":1,\"135\":22,\"136\":2,\"137\":2,\"215\":2,\"216\":4}}],[\"lc25\",{\"1\":{\"23\":1}}],[\"lc3\",{\"1\":{\"23\":1}}],[\"lso\",{\"1\":{\"221\":1}}],[\"ls\",{\"1\":{\"5\":1}}],[\"02\",{\"1\":{\"205\":6}}],[\"05.\",{\"1\":{\"160\":1}}],[\"09\",{\"1\":{\"149\":7}}],[\"003\",{\"1\":{\"98\":1,\"101\":1,\"108\":2}}],[\"000009\",{\"1\":{\"164\":1}}],[\"000\",{\"1\":{\"66\":1}}],[\"002367566\",{\"1\":{\"5\":1}}],[\"0.7\",{\"1\":{\"151\":1}}],[\"0.1\",{\"1\":{\"101\":1}}],[\"0.5291524\",{\"1\":{\"30\":1}}],[\"0.0.0.0\",{\"1\":{\"43\":2}}],[\"0.0757599\",{\"1\":{\"30\":1}}],[\"0.0468229\",{\"1\":{\"30\":1}}],[\"0.0436268\",{\"1\":{\"30\":1}}],[\"0.0433488\",{\"1\":{\"30\":1}}],[\"0.0072126\",{\"1\":{\"30\":1}}],[\"0.0082960\",{\"1\":{\"30\":1}}],[\"0.0000665\",{\"1\":{\"30\":1}}],[\"0.0094143\",{\"1\":{\"30\":1}}],[\"0.0124633\",{\"1\":{\"30\":1}}],[\"0.0123035\",{\"1\":{\"30\":1}}],[\"0.0650971\",{\"1\":{\"30\":1}}],[\"0\",{\"1\":{\"12\":2,\"13\":2,\"25\":1,\"26\":4,\"27\":2,\"28\":1,\"29\":1,\"30\":71,\"39\":1,\"48\":4,\"66\":2,\"72\":3,\"98\":1,\"100\":1,\"101\":1,\"104\":1,\"143\":1,\"146\":1,\"149\":12,\"150\":1,\"151\":5,\"163\":1,\"164\":1,\"170\":1,\"189\":1,\"190\":1,\"199\":1,\"205\":3,\"209\":1,\"210\":1,\"212\":1,\"221\":6}}],[\"oifjwoiej\",{\"1\":{\"193\":1}}],[\"otp\",{\"1\":{\"198\":1}}],[\"otter\",{\"1\":{\"164\":1}}],[\"other\",{\"1\":{\"98\":1}}],[\"others\",{\"0\":{\"83\":1,\"226\":1},\"1\":{\"98\":1}}],[\"oscache\",{\"1\":{\"185\":1}}],[\"os\",{\"1\":{\"161\":1}}],[\"ok\",{\"1\":{\"153\":1}}],[\"o\",{\"1\":{\"152\":2,\"160\":2,\"161\":4,\"188\":2}}],[\"oarsman\",{\"1\":{\"144\":1}}],[\"oauth2\",{\"1\":{\"118\":1}}],[\"oauth\",{\"1\":{\"115\":1}}],[\"o2\",{\"1\":{\"137\":2}}],[\"o1\",{\"1\":{\"137\":2}}],[\"occur\",{\"1\":{\"135\":1}}],[\"ocean\",{\"1\":{\"14\":1}}],[\"obj\",{\"1\":{\"188\":2}}],[\"objects\",{\"1\":{\"188\":2}}],[\"objectoutputstream\",{\"1\":{\"137\":2}}],[\"object\",{\"1\":{\"72\":1,\"148\":1,\"150\":1,\"188\":4,\"197\":1}}],[\"obtain\",{\"1\":{\"118\":2}}],[\"over\",{\"1\":{\"158\":1}}],[\"overview\",{\"1\":{\"108\":1,\"149\":1,\"150\":1}}],[\"override\",{\"1\":{\"68\":1,\"137\":9,\"188\":1,\"189\":2,\"206\":2,\"212\":2}}],[\"offset\",{\"1\":{\"221\":7}}],[\"offiaccount\",{\"1\":{\"103\":1}}],[\"offer\",{\"1\":{\"74\":1,\"80\":1}}],[\"of\",{\"1\":{\"98\":1,\"103\":1,\"144\":2,\"198\":1}}],[\"out\",{\"1\":{\"72\":2,\"135\":2,\"137\":3,\"144\":1,\"190\":1,\"197\":1,\"205\":1}}],[\"output\",{\"1\":{\"41\":1}}],[\"once\",{\"1\":{\"221\":1}}],[\"one\",{\"1\":{\"215\":1}}],[\"onfinish\",{\"1\":{\"212\":1}}],[\"onfailure\",{\"1\":{\"210\":1,\"212\":2}}],[\"onresult\",{\"1\":{\"212\":2}}],[\"onresponse\",{\"1\":{\"206\":3,\"216\":2}}],[\"onphasedone\",{\"1\":{\"210\":2}}],[\"onphasefailure\",{\"1\":{\"206\":1}}],[\"onshardsuccess\",{\"1\":{\"210\":1}}],[\"onshardfailure\",{\"1\":{\"210\":1}}],[\"onshardresultconsumed\",{\"1\":{\"210\":1}}],[\"onshardresult\",{\"1\":{\"210\":3}}],[\"onstoppedleading\",{\"1\":{\"72\":1}}],[\"onstartedleading\",{\"1\":{\"72\":1}}],[\"onapplicationevent\",{\"1\":{\"144\":2}}],[\"onboard\",{\"1\":{\"114\":1}}],[\"on\",{\"0\":{\"72\":1,\"202\":1},\"1\":{\"72\":4,\"158\":1}}],[\"only\",{\"1\":{\"12\":1,\"13\":1,\"72\":1,\"164\":1,\"196\":1,\"216\":1}}],[\"orig\",{\"1\":{\"215\":3}}],[\"originalindices\",{\"1\":{\"208\":1}}],[\"orient\",{\"1\":{\"151\":2}}],[\"orc\",{\"1\":{\"194\":1}}],[\"order\",{\"1\":{\"98\":1,\"104\":1}}],[\"or\",{\"1\":{\"98\":2}}],[\"org\",{\"1\":{\"56\":1,\"95\":1,\"135\":5,\"137\":1,\"141\":3,\"143\":5,\"144\":12,\"153\":1,\"159\":5,\"182\":1,\"183\":1,\"187\":7,\"196\":1}}],[\"oracle\",{\"1\":{\"49\":1,\"194\":1}}],[\"old\",{\"1\":{\"43\":1}}],[\"opensession\",{\"1\":{\"143\":1}}],[\"open\",{\"1\":{\"135\":3,\"137\":2}}],[\"openid\",{\"1\":{\"118\":1}}],[\"openaiapi\",{\"1\":{\"101\":1}}],[\"openai\",{\"1\":{\"95\":2,\"96\":2,\"97\":3,\"98\":5,\"100\":1,\"101\":4,\"102\":2,\"103\":1,\"104\":1,\"108\":2}}],[\"operator\",{\"0\":{\"72\":1,\"202\":1},\"1\":{\"72\":17}}],[\"operationsupport\",{\"1\":{\"72\":3}}],[\"operations\",{\"1\":{\"4\":1,\"212\":1}}],[\"option\",{\"1\":{\"151\":2}}],[\"opt\",{\"1\":{\"72\":1}}],[\"opts\",{\"1\":{\"43\":2}}],[\"ops\",{\"1\":{\"4\":1}}],[\"去取\",{\"1\":{\"135\":1}}],[\"去除\",{\"1\":{\"132\":1,\"133\":1}}],[\"去掉\",{\"1\":{\"124\":1,\"132\":1,\"166\":1,\"186\":1}}],[\"去年\",{\"1\":{\"81\":1}}],[\"去\",{\"1\":{\"12\":1,\"13\":1,\"45\":1,\"63\":1,\"65\":2,\"73\":4,\"74\":5,\"75\":1,\"79\":1,\"80\":7,\"82\":3,\"89\":1,\"90\":2,\"91\":1,\"93\":1,\"95\":1,\"96\":1,\"97\":1,\"98\":1,\"110\":1,\"114\":1,\"117\":1,\"150\":1,\"165\":1,\"169\":2,\"178\":1,\"179\":2,\"186\":2,\"205\":1,\"211\":1,\"221\":4}}],[\"则\",{\"1\":{\"12\":1,\"13\":1,\"26\":4,\"38\":1,\"59\":1,\"62\":1,\"63\":1,\"66\":1,\"68\":2,\"101\":1,\"102\":1,\"103\":1,\"109\":1,\"133\":1,\"142\":1,\"161\":1,\"178\":1,\"179\":4,\"213\":1,\"221\":1}}],[\"14\",{\"1\":{\"144\":3,\"149\":1,\"221\":1}}],[\"1478\",{\"1\":{\"25\":1}}],[\"18305\",{\"1\":{\"191\":1}}],[\"1800\",{\"1\":{\"159\":1}}],[\"187\",{\"1\":{\"151\":1}}],[\"18\",{\"1\":{\"79\":1,\"83\":1,\"86\":1,\"149\":1,\"205\":8,\"221\":1}}],[\"13413\",{\"1\":{\"212\":1}}],[\"136\",{\"1\":{\"144\":1}}],[\"13\",{\"1\":{\"74\":1,\"75\":1,\"149\":4,\"221\":1}}],[\"130112\",{\"1\":{\"30\":5}}],[\"15.000\",{\"1\":{\"205\":6}}],[\"153\",{\"1\":{\"149\":1}}],[\"154\",{\"1\":{\"76\":1}}],[\"15\",{\"1\":{\"73\":1,\"74\":1,\"75\":2,\"83\":1,\"114\":1,\"149\":1,\"221\":1}}],[\"17\",{\"1\":{\"73\":1,\"79\":1,\"81\":1,\"149\":1,\"205\":3,\"221\":1}}],[\"171\",{\"1\":{\"56\":1,\"144\":1}}],[\"192\",{\"1\":{\"144\":1}}],[\"19\",{\"1\":{\"41\":1,\"54\":1,\"56\":3,\"82\":1,\"84\":1,\"85\":1,\"221\":1}}],[\"124116182\",{\"1\":{\"220\":1}}],[\"124928\",{\"1\":{\"30\":1}}],[\"12727\",{\"1\":{\"191\":1}}],[\"127.0.0.1\",{\"1\":{\"43\":1,\"157\":1}}],[\"120000\",{\"1\":{\"182\":2}}],[\"1200\",{\"1\":{\"72\":1}}],[\"12\",{\"1\":{\"54\":1,\"76\":1,\"79\":1,\"85\":1,\"149\":1,\"207\":1,\"221\":1}}],[\"12288\",{\"1\":{\"30\":2}}],[\"121024\",{\"1\":{\"30\":1}}],[\"121376\",{\"1\":{\"30\":2}}],[\"104\",{\"1\":{\"149\":1}}],[\"10414\",{\"1\":{\"30\":3}}],[\"1024\",{\"1\":{\"101\":1,\"182\":1}}],[\"10\",{\"1\":{\"44\":1,\"50\":1,\"62\":2,\"63\":2,\"66\":1,\"73\":1,\"74\":1,\"76\":1,\"104\":2,\"135\":2,\"159\":3,\"161\":1,\"205\":1,\"221\":1}}],[\"1099\",{\"1\":{\"43\":1}}],[\"1000\",{\"1\":{\"45\":1,\"57\":3,\"103\":1,\"215\":1}}],[\"100\",{\"1\":{\"28\":3,\"45\":1,\"50\":1,\"57\":1,\"59\":1,\"61\":1,\"62\":1,\"63\":1,\"70\":1,\"72\":2,\"190\":2}}],[\"10.23.46.71\",{\"1\":{\"159\":1}}],[\"10.\",{\"0\":{\"129\":1},\"1\":{\"23\":1}}],[\"163\",{\"1\":{\"144\":1}}],[\"16\",{\"1\":{\"26\":3,\"149\":1,\"205\":3,\"221\":1}}],[\"119.23.46.71\",{\"1\":{\"152\":1,\"155\":1,\"157\":1,\"160\":1,\"164\":1}}],[\"11\",{\"1\":{\"76\":1,\"114\":1,\"149\":2,\"160\":1,\"221\":1}}],[\"112761\",{\"1\":{\"30\":1}}],[\"113543\",{\"1\":{\"30\":2}}],[\"118250\",{\"1\":{\"30\":2}}],[\"11.851\",{\"1\":{\"30\":1}}],[\"11.\",{\"1\":{\"23\":1}}],[\"11524673.\",{\"1\":{\"18\":1}}],[\"1\",{\"0\":{\"212\":1},\"1\":{\"12\":1,\"13\":1,\"26\":4,\"31\":3,\"34\":2,\"48\":4,\"56\":1,\"70\":2,\"72\":12,\"73\":2,\"85\":2,\"95\":1,\"102\":1,\"104\":1,\"113\":1,\"114\":1,\"117\":1,\"120\":1,\"121\":2,\"125\":1,\"126\":2,\"135\":1,\"137\":3,\"143\":1,\"144\":1,\"145\":1,\"147\":1,\"148\":1,\"149\":9,\"150\":2,\"151\":4,\"155\":1,\"157\":1,\"158\":3,\"159\":2,\"161\":1,\"164\":2,\"178\":1,\"179\":1,\"184\":1,\"185\":1,\"192\":1,\"194\":1,\"204\":1,\"205\":3,\"207\":1,\"211\":1,\"212\":1,\"215\":2,\"221\":15}}],[\"1.0\",{\"1\":{\"205\":2}}],[\"1.9.0\",{\"1\":{\"152\":1}}],[\"1.4\",{\"0\":{\"116\":1,\"127\":1}}],[\"1.\",{\"0\":{\"43\":1,\"122\":1,\"123\":1,\"146\":1},\"1\":{\"5\":1,\"10\":1,\"11\":1,\"13\":2,\"23\":3,\"51\":1,\"71\":1,\"72\":1,\"103\":1,\"144\":2,\"145\":1,\"159\":1,\"164\":1,\"165\":1,\"192\":1,\"202\":1,\"220\":1}}],[\"1.5\",{\"1\":{\"0\":1,\"25\":1}}],[\"1.3.1.\",{\"1\":{\"159\":1}}],[\"1.3\",{\"0\":{\"62\":1,\"97\":1,\"115\":1,\"126\":1,\"198\":1},\"1\":{\"0\":1}}],[\"1.2.5\",{\"0\":{\"159\":1}}],[\"1.2.4\",{\"0\":{\"158\":1}}],[\"1.2.3\",{\"0\":{\"157\":1}}],[\"1.2.2\",{\"0\":{\"156\":1}}],[\"1.2.1\",{\"0\":{\"155\":1}}],[\"1.2\",{\"0\":{\"61\":1,\"96\":1,\"114\":1,\"125\":1,\"154\":1,\"178\":1,\"197\":1},\"1\":{\"0\":1}}],[\"1.1\",{\"0\":{\"60\":1,\"95\":1,\"113\":1,\"124\":1,\"153\":1,\"177\":1,\"196\":1},\"1\":{\"0\":1}}],[\"\\\\\",{\"1\":{\"12\":8,\"13\":8,\"48\":6,\"72\":6,\"101\":1,\"104\":2,\"118\":7,\"120\":3,\"121\":2,\"164\":1,\"198\":14}}],[\"|\",{\"1\":{\"12\":2,\"13\":2,\"48\":4,\"101\":4,\"135\":1,\"146\":2,\"215\":2}}],[\"gte\",{\"1\":{\"205\":1}}],[\"gz\",{\"1\":{\"153\":1}}],[\"gap\",{\"0\":{\"218\":1}}],[\"ganymed\",{\"1\":{\"143\":3}}],[\"gateway\",{\"1\":{\"63\":1}}],[\"gson\",{\"1\":{\"137\":4}}],[\"ghz\",{\"1\":{\"126\":1,\"145\":1}}],[\"guides\",{\"1\":{\"108\":1}}],[\"guava\",{\"1\":{\"63\":4,\"69\":1}}],[\"gpt\",{\"1\":{\"103\":2,\"110\":1}}],[\"gperftools\",{\"0\":{\"49\":3}}],[\"googleapis\",{\"1\":{\"166\":2}}],[\"google\",{\"1\":{\"95\":1,\"127\":1}}],[\"googlecloudplatform\",{\"1\":{\"72\":1}}],[\"golang\",{\"1\":{\"81\":1}}],[\"go\",{\"1\":{\"72\":1,\"81\":1,\"87\":3,\"120\":1}}],[\"glibc\",{\"1\":{\"49\":2}}],[\"gdb\",{\"1\":{\"48\":1}}],[\"gradlew\",{\"1\":{\"203\":2}}],[\"gradle\",{\"1\":{\"203\":2}}],[\"grant\",{\"1\":{\"118\":1}}],[\"groupshardsiterator\",{\"1\":{\"208\":1}}],[\"groupid\",{\"1\":{\"56\":2,\"135\":10,\"137\":2,\"143\":6,\"159\":4,\"196\":2}}],[\"group\",{\"1\":{\"45\":3}}],[\"grep\",{\"1\":{\"12\":1,\"13\":1,\"48\":1}}],[\"gbit\",{\"1\":{\"37\":1}}],[\"generate\",{\"1\":{\"188\":1}}],[\"generation\",{\"1\":{\"30\":4}}],[\"gen\",{\"1\":{\"30\":2,\"43\":1}}],[\"getprofilers\",{\"1\":{\"216\":2}}],[\"getparameter\",{\"1\":{\"137\":1}}],[\"getnumshards\",{\"1\":{\"212\":1}}],[\"getname\",{\"1\":{\"188\":2,\"206\":1}}],[\"getlocalclusteralias\",{\"1\":{\"208\":1}}],[\"getlogger\",{\"1\":{\"57\":1,\"137\":1}}],[\"getuuid\",{\"1\":{\"208\":1}}],[\"getindex\",{\"1\":{\"208\":1}}],[\"getsearchtransport\",{\"1\":{\"212\":1}}],[\"getshard\",{\"1\":{\"215\":1}}],[\"getshardindex\",{\"1\":{\"212\":1}}],[\"getshardroutings\",{\"1\":{\"208\":1}}],[\"getsparkconf\",{\"1\":{\"196\":1,\"197\":1}}],[\"getstdout\",{\"1\":{\"143\":1}}],[\"getcategoryid\",{\"1\":{\"189\":1}}],[\"getclass\",{\"1\":{\"188\":1}}],[\"getcomparator\",{\"1\":{\"137\":1}}],[\"getcontent\",{\"1\":{\"135\":2}}],[\"getelementbyid\",{\"1\":{\"151\":1}}],[\"getelementsbytagname\",{\"1\":{\"146\":1}}],[\"getrequest\",{\"1\":{\"212\":1}}],[\"getresult\",{\"1\":{\"148\":1,\"149\":3,\"150\":2}}],[\"getratelimiter\",{\"1\":{\"67\":1,\"68\":1}}],[\"getdata\",{\"1\":{\"147\":1,\"149\":1,\"150\":2}}],[\"getdeploymentreplicas\",{\"1\":{\"66\":1}}],[\"getatomicarray\",{\"1\":{\"212\":1}}],[\"getattribute\",{\"1\":{\"157\":1}}],[\"getall\",{\"1\":{\"188\":3}}],[\"getallblog\",{\"1\":{\"137\":1}}],[\"getaimessage\",{\"1\":{\"103\":2}}],[\"gethits\",{\"1\":{\"137\":1}}],[\"getheader\",{\"1\":{\"68\":1}}],[\"getbanner\",{\"1\":{\"188\":1,\"189\":3}}],[\"getbean\",{\"1\":{\"144\":3,\"190\":1}}],[\"getbestfragment\",{\"1\":{\"135\":1}}],[\"getbytes\",{\"1\":{\"137\":2}}],[\"getblogid\",{\"1\":{\"135\":1,\"189\":1}}],[\"getblogdetail\",{\"1\":{\"18\":1,\"189\":2,\"190\":2}}],[\"getwriter\",{\"1\":{\"135\":1,\"137\":1}}],[\"gettask\",{\"1\":{\"212\":1}}],[\"gettagbyblogid\",{\"1\":{\"189\":1}}],[\"gettimetrendrpt\",{\"1\":{\"149\":1,\"150\":1}}],[\"gettitle\",{\"1\":{\"135\":2,\"137\":2}}],[\"getting\",{\"1\":{\"103\":1}}],[\"getthreadname\",{\"1\":{\"56\":1}}],[\"getoptions\",{\"1\":{\"65\":1}}],[\"getmapping\",{\"1\":{\"56\":1,\"57\":1}}],[\"get\",{\"1\":{\"12\":1,\"13\":1,\"41\":1,\"65\":2,\"67\":1,\"72\":1,\"121\":1,\"135\":4,\"137\":2,\"151\":2,\"205\":1,\"206\":1,\"208\":1,\"209\":2,\"212\":1}}],[\"g\",{\"1\":{\"25\":3,\"26\":1,\"50\":2,\"126\":1,\"145\":1,\"164\":1,\"192\":1,\"221\":2}}],[\"g1\",{\"1\":{\"23\":3}}],[\"gcm\",{\"1\":{\"158\":1}}],[\"gctimeratio\",{\"1\":{\"34\":1}}],[\"gc\",{\"1\":{\"23\":2,\"29\":1,\"30\":9,\"38\":1,\"39\":1}}],[\"gcloud\",{\"1\":{\"13\":2}}],[\"gitee\",{\"1\":{\"102\":1}}],[\"gitbook\",{\"1\":{\"18\":2}}],[\"github\",{\"0\":{\"49\":1},\"1\":{\"7\":2,\"42\":1,\"72\":1,\"76\":2,\"81\":1,\"101\":1,\"102\":2,\"107\":1,\"110\":1,\"120\":1,\"122\":3,\"128\":1,\"130\":3,\"137\":1,\"145\":4,\"148\":1,\"150\":1,\"151\":3,\"152\":1,\"160\":1,\"164\":3,\"165\":3,\"166\":1,\"173\":3,\"192\":1,\"203\":1}}],[\"gitscm\",{\"1\":{\"5\":1}}],[\"git\",{\"0\":{\"19\":1},\"1\":{\"5\":6,\"9\":1,\"10\":1,\"11\":2,\"13\":4,\"203\":1}}],[\"gitlab\",{\"0\":{\"17\":1},\"1\":{\"3\":1,\"7\":7,\"17\":6,\"81\":3}}],[\"每当\",{\"1\":{\"221\":1}}],[\"每条\",{\"1\":{\"135\":2,\"221\":2}}],[\"每\",{\"1\":{\"135\":1,\"159\":1,\"181\":2,\"192\":4,\"221\":1}}],[\"每年\",{\"1\":{\"91\":1}}],[\"每隔\",{\"1\":{\"85\":1,\"144\":4}}],[\"每周五\",{\"1\":{\"143\":1}}],[\"每周\",{\"1\":{\"82\":1,\"149\":1}}],[\"每分钟\",{\"1\":{\"61\":1}}],[\"每秒钟\",{\"1\":{\"61\":1}}],[\"每秒\",{\"1\":{\"59\":1,\"61\":1,\"221\":1}}],[\"每天\",{\"1\":{\"15\":1,\"42\":1,\"73\":1,\"76\":3,\"84\":1,\"127\":1,\"149\":1}}],[\"每次\",{\"1\":{\"12\":1,\"26\":1,\"28\":1,\"30\":1,\"43\":1,\"44\":1,\"45\":1,\"63\":1,\"69\":1,\"70\":1,\"74\":1,\"76\":1,\"125\":1,\"135\":1,\"185\":1,\"189\":1,\"212\":1,\"221\":1}}],[\"每个\",{\"1\":{\"6\":1,\"26\":3,\"52\":2,\"56\":1,\"62\":1,\"63\":2,\"70\":1,\"75\":1,\"89\":1,\"120\":1,\"133\":1,\"137\":1,\"161\":2,\"205\":2,\"207\":2,\"209\":1,\"221\":8}}],[\"通讯\",{\"1\":{\"221\":1}}],[\"通常\",{\"1\":{\"152\":1,\"161\":1,\"221\":1}}],[\"通道\",{\"1\":{\"146\":1,\"158\":1}}],[\"通话\",{\"1\":{\"104\":1}}],[\"通宵\",{\"1\":{\"75\":1,\"76\":2}}],[\"通信\",{\"1\":{\"45\":1,\"51\":1,\"104\":1,\"216\":1,\"221\":1}}],[\"通过\",{\"1\":{\"43\":2,\"45\":2,\"56\":3,\"63\":2,\"64\":2,\"72\":1,\"96\":1,\"97\":2,\"99\":1,\"103\":1,\"104\":2,\"114\":2,\"115\":1,\"132\":1,\"135\":2,\"141\":2,\"144\":1,\"145\":1,\"152\":2,\"155\":1,\"157\":4,\"158\":1,\"159\":1,\"160\":1,\"161\":1,\"184\":3,\"185\":1,\"194\":2,\"221\":9}}],[\"通用\",{\"1\":{\"12\":1,\"145\":1,\"148\":1}}],[\"通知\",{\"1\":{\"5\":1,\"75\":1,\"109\":1,\"114\":1,\"161\":1}}],[\"帮忙\",{\"1\":{\"128\":1,\"130\":1}}],[\"帮\",{\"1\":{\"12\":1}}],[\"帮助\",{\"1\":{\"6\":1,\"221\":1}}],[\"接着\",{\"1\":{\"221\":1}}],[\"接口定义\",{\"1\":{\"141\":1}}],[\"接口\",{\"1\":{\"58\":2,\"59\":1,\"63\":1,\"72\":1,\"98\":1,\"103\":3,\"104\":2,\"125\":1,\"137\":1,\"147\":1,\"148\":1,\"183\":3,\"184\":1,\"221\":2}}],[\"接下来\",{\"1\":{\"54\":1,\"121\":1,\"163\":1}}],[\"接收\",{\"1\":{\"42\":1,\"72\":1,\"101\":1,\"103\":1,\"206\":1,\"221\":1}}],[\"接手\",{\"1\":{\"42\":1}}],[\"接近\",{\"1\":{\"37\":1}}],[\"接受\",{\"1\":{\"12\":1,\"18\":1}}],[\"接入\",{\"1\":{\"9\":2,\"58\":1,\"146\":1}}],[\"推翻\",{\"1\":{\"122\":1,\"124\":2}}],[\"推出\",{\"1\":{\"116\":1}}],[\"推送\",{\"1\":{\"101\":2,\"102\":1,\"103\":1,\"164\":1,\"221\":9}}],[\"推\",{\"1\":{\"80\":1}}],[\"推行\",{\"1\":{\"12\":1,\"18\":1}}],[\"推荐\",{\"0\":{\"47\":1},\"1\":{\"11\":1,\"26\":1,\"159\":2}}],[\"掉\",{\"1\":{\"12\":1,\"38\":1,\"45\":1,\"51\":1,\"72\":1,\"87\":1,\"104\":1,\"170\":2,\"179\":1}}],[\"替换成\",{\"1\":{\"197\":1}}],[\"替换\",{\"1\":{\"12\":3,\"13\":1,\"49\":1,\"72\":1,\"169\":1,\"170\":2}}],[\"操作前\",{\"1\":{\"52\":2}}],[\"操作系统\",{\"1\":{\"25\":2,\"26\":1,\"48\":1,\"55\":1,\"57\":1,\"87\":2}}],[\"操作\",{\"1\":{\"12\":1,\"23\":1,\"45\":2,\"52\":2,\"55\":1,\"57\":1,\"115\":1,\"157\":1,\"161\":1,\"162\":1,\"163\":1,\"179\":1,\"184\":1,\"192\":1,\"202\":1,\"221\":2}}],[\"于此\",{\"1\":{\"151\":1}}],[\"于单\",{\"1\":{\"35\":1}}],[\"于\",{\"1\":{\"12\":1,\"27\":1,\"28\":1,\"29\":1,\"44\":1,\"62\":1,\"170\":1,\"184\":1,\"197\":1,\"214\":1,\"216\":1,\"221\":1}}],[\"于是\",{\"1\":{\"6\":1,\"74\":1,\"124\":1,\"126\":1,\"157\":1}}],[\"_\",{\"0\":{\"121\":1},\"1\":{\"11\":3,\"12\":5,\"13\":10,\"23\":2,\"43\":5,\"49\":1,\"64\":1,\"66\":1,\"68\":4,\"69\":3,\"72\":5,\"98\":4,\"101\":7,\"103\":16,\"104\":2,\"118\":15,\"120\":6,\"121\":7,\"135\":3,\"137\":1,\"143\":3,\"146\":2,\"147\":4,\"148\":16,\"149\":46,\"150\":30,\"151\":20,\"152\":1,\"155\":3,\"156\":18,\"157\":40,\"158\":14,\"159\":8,\"160\":3,\"163\":6,\"164\":16,\"170\":2,\"173\":1,\"196\":1,\"197\":6,\"205\":16,\"206\":7,\"214\":4,\"216\":8,\"220\":1,\"221\":2}}],[\"影响\",{\"1\":{\"11\":1,\"23\":1,\"26\":1,\"29\":1,\"124\":1,\"137\":2,\"144\":1,\"164\":1,\"221\":1}}],[\"极强\",{\"1\":{\"171\":1}}],[\"极其\",{\"1\":{\"149\":1}}],[\"极低\",{\"1\":{\"145\":1}}],[\"极致\",{\"1\":{\"63\":1,\"66\":1}}],[\"极大\",{\"1\":{\"11\":1,\"221\":1}}],[\"极速\",{\"1\":{\"7\":1}}],[\"控制权\",{\"1\":{\"221\":1}}],[\"控制器\",{\"1\":{\"56\":1,\"72\":4,\"221\":2}}],[\"控制\",{\"1\":{\"11\":1,\"72\":2,\"155\":1,\"159\":1}}],[\"提示\",{\"1\":{\"103\":1,\"221\":1}}],[\"提问\",{\"1\":{\"103\":2}}],[\"提取\",{\"1\":{\"103\":1}}],[\"提出\",{\"1\":{\"80\":1}}],[\"提升\",{\"1\":{\"57\":2,\"81\":1,\"87\":1,\"221\":1}}],[\"提交\",{\"0\":{\"114\":1},\"1\":{\"45\":1,\"72\":4,\"76\":1,\"101\":1,\"102\":2,\"107\":1,\"113\":1,\"114\":2,\"137\":1,\"148\":1,\"161\":1,\"221\":7}}],[\"提高\",{\"1\":{\"38\":1,\"141\":1,\"171\":1,\"177\":1,\"221\":2}}],[\"提高效率\",{\"1\":{\"26\":1}}],[\"提\",{\"1\":{\"23\":1,\"75\":1}}],[\"提醒\",{\"1\":{\"11\":1}}],[\"提供\",{\"1\":{\"7\":3,\"12\":1,\"17\":1,\"30\":1,\"54\":1,\"55\":1,\"56\":1,\"63\":2,\"72\":1,\"95\":1,\"96\":1,\"97\":1,\"100\":3,\"102\":1,\"114\":1,\"115\":1,\"126\":1,\"127\":1,\"141\":1,\"144\":1,\"145\":4,\"146\":1,\"148\":1,\"149\":1,\"151\":1,\"159\":2,\"167\":1,\"169\":1,\"177\":1,\"183\":2,\"184\":1,\"185\":2,\"197\":1,\"221\":2}}],[\"希望\",{\"1\":{\"11\":1,\"56\":1,\"74\":2,\"78\":2,\"81\":1,\"122\":1,\"145\":1,\"150\":1,\"151\":1,\"152\":1,\"160\":1,\"165\":1,\"171\":1,\"173\":1,\"192\":1}}],[\"其值\",{\"1\":{\"221\":1}}],[\"其次\",{\"1\":{\"169\":1,\"206\":1}}],[\"其它\",{\"1\":{\"161\":1,\"221\":1}}],[\"其实\",{\"1\":{\"70\":1,\"73\":1,\"78\":1,\"80\":1,\"126\":1,\"144\":1,\"221\":1}}],[\"其\",{\"1\":{\"38\":1,\"45\":1,\"55\":1,\"63\":1,\"142\":1,\"143\":1,\"149\":1,\"151\":2,\"152\":1,\"157\":1,\"159\":1,\"161\":2,\"170\":1,\"184\":1,\"185\":2,\"204\":1}}],[\"其他人\",{\"1\":{\"86\":1}}],[\"其他\",{\"0\":{\"16\":1,\"70\":1,\"90\":1,\"105\":1},\"1\":{\"11\":1,\"12\":1,\"27\":1,\"52\":4,\"57\":1,\"58\":1,\"66\":1,\"72\":2,\"74\":1,\"75\":1,\"81\":1,\"86\":1,\"100\":1,\"103\":1,\"115\":1,\"145\":1,\"146\":1,\"149\":1,\"161\":2,\"164\":1,\"221\":3}}],[\"其中\",{\"1\":{\"4\":1,\"43\":1,\"64\":1,\"66\":1,\"69\":2,\"74\":1,\"122\":1,\"125\":1,\"141\":2,\"145\":1,\"147\":1,\"148\":1,\"149\":1,\"151\":1,\"152\":1,\"157\":1,\"163\":1,\"164\":2,\"203\":1,\"209\":2,\"212\":1,\"215\":3,\"216\":1,\"221\":2}}],[\"最弱\",{\"1\":{\"221\":1}}],[\"最少\",{\"1\":{\"221\":6}}],[\"最新消息\",{\"1\":{\"221\":1}}],[\"最新\",{\"1\":{\"135\":1,\"153\":1,\"159\":1}}],[\"最近\",{\"1\":{\"104\":1}}],[\"最最\",{\"1\":{\"84\":1}}],[\"最惨\",{\"1\":{\"76\":1}}],[\"最多\",{\"1\":{\"61\":1,\"221\":1}}],[\"最高\",{\"1\":{\"61\":1}}],[\"最终版\",{\"1\":{\"124\":2,\"125\":1}}],[\"最终\",{\"1\":{\"45\":1,\"50\":1,\"54\":1,\"87\":2,\"97\":1,\"124\":3,\"137\":1,\"161\":1,\"173\":1,\"216\":2,\"221\":1}}],[\"最优化\",{\"1\":{\"38\":1}}],[\"最小\",{\"1\":{\"37\":1,\"66\":1}}],[\"最低\",{\"1\":{\"28\":1,\"37\":1,\"96\":1,\"221\":1}}],[\"最大\",{\"1\":{\"23\":1,\"25\":2,\"26\":2,\"31\":1,\"34\":1,\"61\":1,\"171\":1,\"221\":3}}],[\"最长\",{\"1\":{\"23\":1,\"28\":1,\"161\":1}}],[\"最难\",{\"1\":{\"18\":1}}],[\"最\",{\"1\":{\"18\":2,\"77\":1,\"78\":1,\"144\":1,\"145\":2,\"166\":1,\"169\":1,\"221\":2}}],[\"最初\",{\"1\":{\"12\":1,\"18\":1,\"51\":1,\"54\":1,\"221\":1}}],[\"最后\",{\"0\":{\"110\":1},\"1\":{\"11\":1,\"18\":2,\"23\":1,\"45\":1,\"49\":1,\"51\":1,\"54\":1,\"64\":1,\"68\":1,\"73\":1,\"78\":1,\"80\":1,\"87\":1,\"103\":1,\"121\":1,\"148\":1,\"151\":1,\"161\":2,\"179\":1,\"216\":1,\"221\":3}}],[\"最好\",{\"1\":{\"7\":1,\"28\":1,\"29\":1,\"43\":1,\"77\":1,\"82\":1,\"95\":2,\"107\":1,\"124\":1,\"151\":1}}],[\"找个\",{\"1\":{\"73\":1}}],[\"找出\",{\"1\":{\"49\":1,\"204\":1}}],[\"找到\",{\"1\":{\"45\":1,\"81\":1,\"98\":1,\"106\":1,\"107\":1,\"144\":1,\"153\":1,\"173\":1}}],[\"找\",{\"1\":{\"11\":1,\"39\":1,\"73\":1,\"77\":1,\"103\":1,\"124\":3,\"127\":1,\"128\":2,\"164\":2}}],[\"代理服务器\",{\"1\":{\"157\":1}}],[\"代理\",{\"0\":{\"157\":1},\"1\":{\"157\":4,\"161\":1,\"221\":1}}],[\"代价\",{\"1\":{\"76\":1,\"173\":1}}],[\"代表\",{\"1\":{\"63\":2,\"115\":1,\"121\":1,\"133\":1,\"141\":1,\"221\":2}}],[\"代尽\",{\"1\":{\"38\":1}}],[\"代为\",{\"1\":{\"29\":2}}],[\"代区\",{\"1\":{\"28\":1}}],[\"代即\",{\"1\":{\"26\":1}}],[\"代中\",{\"1\":{\"26\":1,\"31\":1}}],[\"代占\",{\"1\":{\"26\":1,\"31\":1}}],[\"代所\",{\"1\":{\"26\":1}}],[\"代与\",{\"1\":{\"26\":1,\"31\":1}}],[\"代后\",{\"1\":{\"26\":1}}],[\"代\",{\"0\":{\"37\":1,\"38\":1},\"1\":{\"26\":16,\"28\":7,\"29\":2,\"31\":8,\"32\":1,\"35\":1,\"37\":2,\"38\":8,\"39\":3}}],[\"代替\",{\"1\":{\"10\":1}}],[\"代码\",{\"0\":{\"9\":1,\"146\":1,\"150\":1},\"1\":{\"5\":1,\"7\":1,\"9\":4,\"11\":1,\"13\":4,\"18\":3,\"43\":1,\"44\":1,\"45\":2,\"55\":1,\"56\":1,\"72\":1,\"76\":1,\"81\":1,\"84\":1,\"87\":1,\"101\":2,\"102\":1,\"107\":1,\"110\":1,\"120\":1,\"124\":1,\"135\":3,\"143\":2,\"145\":1,\"146\":3,\"148\":1,\"150\":3,\"151\":4,\"152\":1,\"157\":1,\"160\":1,\"168\":1,\"185\":1,\"203\":1}}],[\"报\",{\"1\":{\"158\":1}}],[\"报文\",{\"1\":{\"114\":1}}],[\"报告\",{\"1\":{\"10\":1,\"75\":1,\"147\":2}}],[\"报错\",{\"1\":{\"6\":1,\"72\":1,\"144\":1}}],[\"形式\",{\"1\":{\"10\":1,\"30\":6,\"173\":1,\"221\":1}}],[\"执行\",{\"0\":{\"214\":1,\"215\":1,\"219\":1},\"1\":{\"10\":1,\"30\":1,\"42\":1,\"44\":1,\"45\":1,\"49\":1,\"50\":2,\"57\":2,\"72\":3,\"115\":1,\"125\":1,\"141\":1,\"143\":3,\"161\":2,\"177\":1,\"179\":4,\"180\":1,\"185\":1,\"192\":1,\"205\":1,\"206\":4,\"207\":1,\"210\":2,\"212\":4,\"213\":2,\"214\":1,\"215\":2,\"216\":1,\"219\":1,\"221\":3}}],[\"生态\",{\"1\":{\"221\":1}}],[\"生活\",{\"1\":{\"84\":1,\"160\":1,\"192\":1}}],[\"生成\",{\"1\":{\"26\":2,\"72\":1,\"115\":1,\"116\":1,\"117\":1,\"120\":1,\"158\":1,\"221\":1}}],[\"生命周期\",{\"1\":{\"10\":1,\"72\":2,\"180\":1}}],[\"生产者\",{\"1\":{\"221\":7}}],[\"生产\",{\"1\":{\"7\":1,\"70\":1,\"107\":1,\"221\":3}}],[\"empty\",{\"1\":{\"215\":1}}],[\"emphasis\",{\"1\":{\"151\":1}}],[\"eq\",{\"1\":{\"205\":1}}],[\"equals\",{\"1\":{\"12\":1,\"13\":1}}],[\"eviction\",{\"1\":{\"182\":1}}],[\"events\",{\"1\":{\"161\":2}}],[\"event\",{\"1\":{\"144\":2}}],[\"ehcache\",{\"1\":{\"178\":1,\"185\":2}}],[\"editor\",{\"0\":{\"168\":1},\"1\":{\"165\":1,\"168\":1}}],[\"eden\",{\"1\":{\"26\":3,\"30\":2,\"31\":2,\"126\":1}}],[\"etc\",{\"1\":{\"153\":2,\"164\":1}}],[\"ethz\",{\"1\":{\"143\":1}}],[\"ensureafterseqnorefreshed\",{\"1\":{\"215\":2}}],[\"entry\",{\"1\":{\"212\":2}}],[\"end\",{\"1\":{\"137\":1,\"147\":3,\"148\":4,\"149\":5,\"150\":5}}],[\"enabled\",{\"1\":{\"151\":1,\"203\":1}}],[\"enablewebhook\",{\"1\":{\"72\":1}}],[\"enableasync\",{\"1\":{\"56\":1}}],[\"enable\",{\"1\":{\"56\":1}}],[\"ee\",{\"1\":{\"128\":1,\"144\":1}}],[\"elasitcsearch\",{\"1\":{\"203\":1,\"205\":1,\"216\":1}}],[\"elasticsearch8\",{\"1\":{\"204\":1}}],[\"elasticsearch\",{\"0\":{\"203\":1,\"204\":1,\"231\":1},\"1\":{\"194\":4,\"196\":3,\"202\":2,\"203\":1,\"216\":5}}],[\"elastic\",{\"0\":{\"194\":1},\"1\":{\"203\":3}}],[\"elxxxxastic\",{\"1\":{\"196\":1}}],[\"elk\",{\"1\":{\"75\":1,\"126\":2,\"145\":2,\"151\":2,\"156\":1}}],[\"elector\",{\"1\":{\"72\":1}}],[\"electioncfg\",{\"1\":{\"72\":2}}],[\"else\",{\"1\":{\"12\":1,\"13\":2,\"66\":2,\"68\":2,\"101\":1,\"137\":2,\"149\":3,\"210\":1,\"212\":1}}],[\"e\",{\"1\":{\"72\":2,\"135\":2,\"137\":7,\"206\":3,\"212\":3}}],[\"ec\",{\"1\":{\"160\":2}}],[\"ecdhe\",{\"1\":{\"158\":1}}],[\"echart\",{\"1\":{\"165\":1,\"169\":1}}],[\"echarts\",{\"1\":{\"151\":8,\"169\":3}}],[\"echo\",{\"1\":{\"9\":1,\"10\":1,\"11\":2,\"13\":5}}],[\"ecommerce\",{\"1\":{\"72\":1,\"197\":2}}],[\"es5\",{\"1\":{\"199\":1}}],[\"esreadgroupbyname\",{\"1\":{\"72\":1}}],[\"esrdd\",{\"1\":{\"72\":4,\"197\":5}}],[\"es\",{\"0\":{\"197\":1},\"1\":{\"72\":7,\"81\":1,\"194\":1,\"196\":5,\"197\":2,\"203\":1,\"204\":2,\"205\":2}}],[\"e74\",{\"1\":{\"69\":1}}],[\"e135bdad1\",{\"1\":{\"69\":1}}],[\"ea1b7815\",{\"1\":{\"69\":1}}],[\"eaoabc5twdzkvaayvq7y4zfojmfathar882gabj43whefxep81vfj3j3j6fqgjxjnqtawvmjys2ei8dbkkcwfpfst8fhg\",{\"1\":{\"41\":1}}],[\"errors\",{\"1\":{\"164\":1}}],[\"error\",{\"1\":{\"72\":1,\"135\":1,\"137\":3,\"143\":2,\"159\":1,\"163\":1,\"164\":1}}],[\"err\",{\"1\":{\"65\":2,\"72\":1,\"137\":2}}],[\"exactly\",{\"1\":{\"221\":1}}],[\"examples\",{\"1\":{\"72\":2}}],[\"exxmcindgxswsvzkyo4xg\",{\"1\":{\"220\":1}}],[\"extends\",{\"1\":{\"206\":4}}],[\"extensions\",{\"1\":{\"5\":1}}],[\"ext\",{\"1\":{\"166\":1}}],[\"exception\",{\"1\":{\"137\":1,\"206\":1,\"210\":1,\"212\":2}}],[\"explain\",{\"0\":{\"219\":1},\"1\":{\"219\":1}}],[\"explanation\",{\"1\":{\"103\":1}}],[\"expandsearchphase\",{\"0\":{\"213\":1},\"1\":{\"212\":1,\"213\":3}}],[\"expectedtotal0ps\",{\"1\":{\"210\":1}}],[\"expectedtotalops\",{\"1\":{\"210\":2}}],[\"exportdatabase\",{\"1\":{\"143\":1}}],[\"expose\",{\"1\":{\"98\":1}}],[\"expression\",{\"1\":{\"185\":1}}],[\"express\",{\"1\":{\"100\":1,\"101\":1}}],[\"executequeryphase\",{\"1\":{\"214\":1,\"215\":3}}],[\"executed\",{\"1\":{\"212\":1}}],[\"executefetchphase\",{\"1\":{\"216\":2}}],[\"executefetch\",{\"1\":{\"212\":4}}],[\"executenextphase\",{\"1\":{\"210\":1,\"212\":1}}],[\"executesearch\",{\"1\":{\"208\":1}}],[\"execute\",{\"1\":{\"206\":1,\"215\":8,\"216\":2}}],[\"executephaseonshard\",{\"1\":{\"210\":1}}],[\"executephase\",{\"1\":{\"206\":2,\"212\":1,\"213\":1}}],[\"executerequest\",{\"1\":{\"206\":1}}],[\"executelocally\",{\"1\":{\"206\":3,\"216\":1}}],[\"executors\",{\"1\":{\"56\":2}}],[\"executor\",{\"1\":{\"56\":3,\"72\":4,\"179\":3,\"180\":2}}],[\"execcommand\",{\"1\":{\"143\":1}}],[\"exec\",{\"1\":{\"72\":1}}],[\"ex\",{\"1\":{\"48\":1}}],[\"epaas\",{\"1\":{\"12\":2,\"13\":5}}],[\")\",{\"1\":{\"9\":3,\"10\":3,\"11\":6,\"12\":3,\"13\":26,\"15\":1,\"30\":30,\"34\":1,\"48\":2,\"56\":14,\"57\":5,\"59\":1,\"65\":5,\"66\":13,\"67\":2,\"68\":14,\"72\":31,\"78\":1,\"101\":15,\"103\":10,\"104\":5,\"121\":1,\"125\":1,\"135\":67,\"137\":81,\"143\":15,\"144\":13,\"146\":6,\"147\":7,\"148\":11,\"149\":10,\"150\":20,\"151\":9,\"152\":1,\"157\":1,\"158\":1,\"160\":1,\"161\":5,\"164\":2,\"170\":1,\"173\":1,\"182\":1,\"183\":1,\"185\":11,\"188\":15,\"189\":17,\"190\":9,\"192\":1,\"196\":9,\"197\":8,\"198\":4,\"205\":3,\"206\":33,\"207\":4,\"208\":16,\"209\":8,\"210\":21,\"212\":38,\"214\":6,\"215\":21,\"216\":20,\"221\":12}}],[\"'\",{\"1\":{\"9\":10,\"10\":10,\"11\":12,\"12\":4,\"13\":58,\"15\":2,\"48\":2,\"57\":1,\"98\":1,\"101\":28,\"103\":2,\"104\":6,\"118\":8,\"120\":6,\"121\":4,\"135\":4,\"137\":5,\"143\":2,\"148\":2,\"149\":32,\"150\":6,\"151\":72,\"156\":26,\"164\":8,\"189\":2,\"203\":10}}],[\"(\",{\"1\":{\"9\":3,\"10\":3,\"11\":6,\"12\":3,\"13\":26,\"15\":1,\"30\":10,\"34\":1,\"48\":2,\"56\":14,\"57\":5,\"59\":1,\"65\":5,\"66\":13,\"67\":2,\"68\":14,\"72\":31,\"78\":1,\"101\":15,\"103\":10,\"104\":5,\"125\":1,\"135\":67,\"137\":81,\"143\":15,\"144\":13,\"146\":6,\"147\":7,\"148\":11,\"149\":10,\"150\":20,\"151\":9,\"152\":1,\"157\":1,\"158\":1,\"160\":1,\"161\":5,\"164\":2,\"170\":1,\"173\":1,\"182\":1,\"183\":1,\"185\":14,\"188\":15,\"189\":17,\"190\":9,\"192\":1,\"196\":9,\"197\":8,\"198\":4,\"205\":2,\"206\":33,\"207\":4,\"208\":16,\"209\":8,\"210\":20,\"212\":38,\"214\":6,\"215\":21,\"216\":20,\"221\":13}}],[\"而用\",{\"1\":{\"192\":1}}],[\"而分\",{\"1\":{\"152\":2}}],[\"而是\",{\"1\":{\"57\":1,\"72\":1,\"86\":1,\"108\":1,\"185\":1}}],[\"而\",{\"1\":{\"18\":1,\"28\":1,\"38\":2,\"55\":2,\"63\":1,\"74\":2,\"76\":1,\"78\":1,\"85\":1,\"103\":1,\"124\":1,\"149\":2,\"161\":1,\"169\":1,\"173\":1,\"221\":4}}],[\"而已\",{\"1\":{\"9\":1,\"45\":1,\"51\":1,\"75\":1}}],[\"而且\",{\"1\":{\"5\":1,\"7\":1,\"45\":1,\"50\":1,\"70\":1,\"81\":2,\"87\":1,\"96\":1,\"99\":1,\"124\":1,\"136\":1,\"144\":1,\"145\":1,\"159\":1,\"164\":1,\"166\":1,\"221\":1}}],[\"集中式\",{\"1\":{\"184\":2}}],[\"集合\",{\"1\":{\"141\":2}}],[\"集合起来\",{\"1\":{\"7\":1}}],[\"集\",{\"1\":{\"125\":1}}],[\"集群\",{\"0\":{\"152\":1},\"1\":{\"70\":1,\"72\":1,\"122\":1,\"140\":1,\"152\":1,\"159\":1,\"161\":2,\"208\":4,\"221\":10}}],[\"集成\",{\"0\":{\"116\":1},\"1\":{\"9\":1,\"72\":1,\"116\":2,\"143\":1,\"166\":1,\"183\":2,\"185\":1}}],[\"检索\",{\"1\":{\"132\":1,\"215\":1}}],[\"检查一下\",{\"1\":{\"153\":1}}],[\"检查\",{\"1\":{\"9\":2,\"210\":1,\"221\":2}}],[\"检测\",{\"1\":{\"5\":1,\"221\":1}}],[\"分组\",{\"1\":{\"221\":1}}],[\"分隔\",{\"1\":{\"221\":1}}],[\"分成\",{\"1\":{\"221\":1}}],[\"分区\",{\"1\":{\"221\":44}}],[\"分段\",{\"1\":{\"216\":2}}],[\"分数\",{\"1\":{\"205\":1}}],[\"分片\",{\"0\":{\"209\":1,\"210\":1},\"1\":{\"205\":11,\"207\":3,\"209\":1,\"210\":1,\"216\":4}}],[\"分支\",{\"1\":{\"203\":1}}],[\"分发\",{\"1\":{\"178\":1,\"221\":1}}],[\"分享\",{\"0\":{\"170\":1},\"1\":{\"165\":1,\"170\":3}}],[\"分别\",{\"1\":{\"148\":1,\"221\":2}}],[\"分布\",{\"1\":{\"145\":1,\"221\":1}}],[\"分布式应用\",{\"1\":{\"221\":1}}],[\"分布式系统\",{\"1\":{\"188\":1,\"205\":1,\"221\":1}}],[\"分布式服务\",{\"1\":{\"71\":1}}],[\"分布式\",{\"0\":{\"58\":1,\"62\":1,\"63\":1,\"64\":1,\"184\":1},\"1\":{\"0\":1,\"5\":1,\"7\":1,\"18\":1,\"23\":1,\"42\":1,\"62\":1,\"63\":4,\"71\":1,\"73\":1,\"140\":1,\"152\":3,\"159\":1,\"161\":1,\"184\":3,\"188\":1,\"192\":1,\"221\":3}}],[\"分词\",{\"1\":{\"133\":1,\"134\":1,\"135\":1}}],[\"分词器\",{\"1\":{\"133\":1,\"135\":3}}],[\"分类\",{\"1\":{\"122\":1,\"127\":4,\"173\":1}}],[\"分页\",{\"0\":{\"192\":1},\"1\":{\"122\":1,\"124\":1,\"135\":2,\"192\":2,\"212\":1}}],[\"分离\",{\"1\":{\"122\":1,\"221\":1}}],[\"分\",{\"1\":{\"103\":1,\"143\":1,\"152\":2,\"192\":1,\"221\":1}}],[\"分到\",{\"1\":{\"81\":1,\"221\":1}}],[\"分为\",{\"1\":{\"42\":1,\"145\":1,\"152\":2,\"161\":1}}],[\"分析\",{\"0\":{\"44\":1,\"174\":1},\"1\":{\"30\":1,\"122\":1,\"125\":1,\"145\":1,\"179\":1,\"216\":8}}],[\"分析器\",{\"1\":{\"9\":2}}],[\"分配内存\",{\"1\":{\"26\":1,\"55\":1}}],[\"分配\",{\"1\":{\"23\":1,\"39\":1,\"62\":1,\"63\":1,\"126\":1,\"152\":2,\"155\":1,\"181\":1,\"221\":2}}],[\"拓展\",{\"1\":{\"9\":1,\"103\":1,\"124\":1,\"143\":1}}],[\"配错\",{\"1\":{\"186\":1}}],[\"配合\",{\"1\":{\"8\":1,\"30\":1,\"48\":1,\"164\":1}}],[\"配置管理\",{\"1\":{\"221\":1}}],[\"配置文件\",{\"1\":{\"144\":1,\"153\":1,\"159\":1,\"179\":1,\"182\":1,\"221\":1}}],[\"配置\",{\"0\":{\"154\":1,\"163\":1,\"164\":1,\"196\":1},\"1\":{\"5\":1,\"7\":3,\"11\":1,\"12\":2,\"13\":1,\"17\":2,\"26\":1,\"28\":6,\"29\":3,\"30\":1,\"39\":2,\"42\":2,\"56\":2,\"96\":1,\"98\":1,\"102\":1,\"126\":1,\"142\":1,\"143\":1,\"144\":2,\"145\":1,\"151\":1,\"153\":2,\"157\":4,\"158\":4,\"159\":5,\"161\":3,\"164\":5,\"170\":1,\"179\":1,\"183\":2,\"185\":3,\"186\":1,\"187\":1,\"192\":1,\"196\":1,\"203\":1,\"221\":7}}],[\"界面\",{\"1\":{\"8\":1,\"12\":2,\"96\":1,\"124\":1}}],[\"交叉\",{\"1\":{\"161\":1}}],[\"交了\",{\"1\":{\"75\":1}}],[\"交流\",{\"1\":{\"74\":1,\"76\":1}}],[\"交互\",{\"1\":{\"8\":1,\"72\":1,\"116\":1,\"117\":1,\"121\":1,\"164\":1,\"184\":1}}],[\"交付\",{\"1\":{\"4\":1}}],[\"成千上万\",{\"1\":{\"221\":1}}],[\"成立\",{\"1\":{\"149\":2}}],[\"成人\",{\"1\":{\"149\":1}}],[\"成为\",{\"1\":{\"81\":1,\"133\":1,\"184\":1,\"221\":2}}],[\"成员\",{\"1\":{\"45\":1}}],[\"成功\",{\"1\":{\"42\":1,\"97\":1,\"101\":1,\"102\":3,\"103\":1,\"121\":2,\"210\":1,\"221\":1}}],[\"成\",{\"1\":{\"8\":1,\"18\":1,\"147\":1,\"156\":1}}],[\"成本\",{\"1\":{\"7\":1,\"55\":1,\"72\":1}}],[\"彻底解决\",{\"1\":{\"45\":1,\"114\":1}}],[\"彻底\",{\"1\":{\"8\":1}}],[\"看法\",{\"1\":{\"221\":2}}],[\"看一看\",{\"1\":{\"166\":1}}],[\"看官\",{\"1\":{\"159\":1}}],[\"看做\",{\"1\":{\"144\":1}}],[\"看作\",{\"1\":{\"141\":1}}],[\"看不下去\",{\"1\":{\"165\":1}}],[\"看不过去\",{\"1\":{\"124\":1}}],[\"看不出\",{\"1\":{\"48\":1}}],[\"看起来\",{\"1\":{\"124\":1,\"161\":1,\"166\":1,\"168\":1}}],[\"看见\",{\"1\":{\"85\":1,\"164\":1}}],[\"看书\",{\"1\":{\"76\":1,\"128\":1}}],[\"看好\",{\"1\":{\"74\":1}}],[\"看看\",{\"1\":{\"56\":1,\"57\":1,\"87\":1,\"124\":2,\"127\":1,\"150\":1,\"166\":1,\"171\":1,\"192\":1}}],[\"看着\",{\"1\":{\"49\":1,\"73\":2,\"74\":1,\"124\":2}}],[\"看\",{\"1\":{\"18\":2,\"42\":1,\"43\":1,\"44\":1,\"45\":2,\"73\":2,\"76\":4,\"81\":2,\"82\":2,\"87\":3,\"90\":1,\"96\":1,\"102\":1,\"114\":1,\"120\":1,\"122\":1,\"124\":6,\"128\":1,\"136\":2,\"149\":1,\"165\":2,\"169\":2,\"173\":1,\"198\":1,\"212\":1}}],[\"看出\",{\"1\":{\"8\":1,\"44\":1,\"45\":2,\"141\":1,\"155\":1,\"191\":1}}],[\"看到\",{\"1\":{\"7\":1,\"49\":1,\"54\":1,\"56\":1,\"57\":2,\"76\":1,\"78\":1,\"115\":1,\"124\":2,\"192\":1,\"203\":1,\"205\":1}}],[\"能过\",{\"1\":{\"114\":1}}],[\"能学\",{\"1\":{\"80\":1}}],[\"能留\",{\"1\":{\"75\":1}}],[\"能回\",{\"1\":{\"73\":1}}],[\"能力\",{\"1\":{\"72\":1,\"86\":1,\"100\":1,\"109\":1,\"140\":1,\"221\":3}}],[\"能\",{\"1\":{\"8\":1,\"11\":2,\"23\":1,\"44\":1,\"49\":1,\"52\":5,\"63\":1,\"72\":1,\"73\":2,\"76\":1,\"78\":2,\"81\":1,\"86\":1,\"96\":1,\"98\":1,\"103\":1,\"104\":1,\"122\":2,\"128\":2,\"130\":1,\"145\":2,\"149\":1,\"150\":1,\"151\":1,\"152\":1,\"158\":2,\"160\":1,\"161\":1,\"165\":2,\"167\":2,\"168\":1,\"169\":1,\"171\":1,\"173\":1,\"192\":1,\"221\":2}}],[\"能够\",{\"1\":{\"4\":1,\"5\":1,\"6\":1,\"7\":1,\"8\":1,\"52\":1,\"62\":1,\"70\":2,\"97\":1,\"116\":1,\"124\":1,\"145\":1,\"155\":2,\"164\":1,\"166\":1,\"173\":3,\"185\":5,\"198\":1,\"205\":1}}],[\"虽然\",{\"1\":{\"8\":1,\"11\":1,\"44\":1,\"45\":1,\"76\":3,\"80\":1,\"81\":2,\"87\":2,\"124\":1,\"152\":2,\"167\":1,\"173\":3,\"184\":2,\"192\":1}}],[\"人员\",{\"1\":{\"173\":1}}],[\"人类\",{\"1\":{\"149\":2,\"151\":1}}],[\"人物\",{\"1\":{\"141\":1}}],[\"人大\",{\"1\":{\"127\":1}}],[\"人才\",{\"1\":{\"82\":2}}],[\"人少\",{\"1\":{\"80\":1}}],[\"人离\",{\"1\":{\"77\":1}}],[\"人\",{\"1\":{\"73\":6,\"74\":3,\"75\":3,\"76\":1,\"77\":1,\"78\":2,\"80\":1,\"81\":1,\"86\":3,\"90\":1,\"124\":1,\"126\":1,\"146\":1,\"151\":1,\"170\":1,\"171\":3,\"221\":1}}],[\"人多\",{\"1\":{\"8\":1}}],[\"人工干预\",{\"1\":{\"6\":1}}],[\"创造\",{\"1\":{\"76\":1}}],[\"创业\",{\"1\":{\"8\":1}}],[\"创建对象\",{\"1\":{\"72\":1}}],[\"创建\",{\"0\":{\"66\":1,\"113\":1,\"162\":1},\"1\":{\"5\":3,\"7\":1,\"12\":3,\"13\":2,\"54\":1,\"55\":2,\"57\":1,\"64\":1,\"66\":1,\"72\":3,\"101\":1,\"113\":2,\"137\":1,\"179\":1,\"205\":1,\"207\":2,\"221\":8}}],[\"存取\",{\"1\":{\"192\":1}}],[\"存进\",{\"1\":{\"151\":1}}],[\"存入\",{\"1\":{\"137\":3,\"192\":1}}],[\"存\",{\"1\":{\"103\":2}}],[\"存放数据\",{\"1\":{\"221\":1}}],[\"存放\",{\"1\":{\"38\":1,\"126\":1,\"212\":1,\"221\":1}}],[\"存活\",{\"1\":{\"26\":1,\"38\":1,\"159\":2}}],[\"存下\",{\"1\":{\"26\":1}}],[\"存储\",{\"1\":{\"18\":1,\"51\":1,\"63\":1,\"74\":1,\"124\":1,\"127\":1,\"135\":1,\"137\":1,\"140\":1,\"145\":1,\"151\":1,\"159\":2,\"161\":1,\"179\":2,\"185\":1,\"188\":1,\"192\":1,\"219\":1,\"221\":5}}],[\"存到\",{\"1\":{\"18\":1}}],[\"存在\",{\"1\":{\"8\":1,\"12\":2,\"13\":1,\"51\":1,\"67\":1,\"70\":1,\"72\":1,\"101\":1,\"164\":2,\"188\":1,\"221\":1}}],[\"存库\",{\"1\":{\"5\":1}}],[\"神书\",{\"1\":{\"76\":1}}],[\"神\",{\"1\":{\"8\":1,\"77\":1,\"127\":1}}],[\"简述\",{\"1\":{\"221\":3}}],[\"简化\",{\"1\":{\"221\":1}}],[\"简陋\",{\"1\":{\"152\":1}}],[\"简简单单\",{\"1\":{\"148\":1}}],[\"简洁\",{\"1\":{\"124\":1,\"149\":1}}],[\"简短\",{\"1\":{\"54\":1}}],[\"简介\",{\"0\":{\"54\":1}}],[\"简历\",{\"1\":{\"51\":1,\"74\":1,\"221\":2}}],[\"简直\",{\"1\":{\"8\":1,\"165\":1,\"166\":1,\"221\":1}}],[\"简单\",{\"0\":{\"101\":2},\"1\":{\"5\":2,\"9\":1,\"10\":1,\"12\":1,\"18\":1,\"48\":1,\"54\":1,\"56\":3,\"57\":2,\"72\":1,\"87\":1,\"101\":1,\"124\":1,\"135\":1,\"141\":1,\"144\":2,\"145\":1,\"149\":2,\"151\":1,\"152\":1,\"158\":1,\"166\":1,\"170\":1,\"179\":1,\"181\":1,\"192\":1,\"221\":1}}],[\"知\",{\"1\":{\"172\":1}}],[\"知乎\",{\"1\":{\"80\":1,\"171\":1}}],[\"知识\",{\"1\":{\"8\":1,\"73\":1,\"173\":1}}],[\"知道\",{\"1\":{\"7\":1,\"8\":1,\"48\":1,\"73\":1,\"75\":3,\"86\":1,\"87\":1,\"102\":1,\"114\":1,\"124\":1,\"149\":1,\"159\":1,\"164\":1,\"172\":1,\"221\":3}}],[\"掌握\",{\"1\":{\"8\":1,\"18\":1,\"124\":1,\"145\":1}}],[\"真实\",{\"1\":{\"157\":6,\"185\":1}}],[\"真是\",{\"1\":{\"86\":2,\"151\":1,\"173\":1,\"186\":1}}],[\"真心\",{\"1\":{\"83\":1}}],[\"真\",{\"1\":{\"73\":1}}],[\"真正\",{\"1\":{\"8\":1,\"206\":1,\"221\":2}}],[\"真的\",{\"1\":{\"8\":1,\"17\":1,\"48\":1,\"70\":1,\"73\":1,\"74\":2,\"75\":3,\"76\":2,\"80\":4,\"81\":2,\"82\":2,\"86\":3,\"87\":1,\"90\":1,\"109\":1,\"121\":1,\"127\":2,\"152\":1,\"173\":2,\"192\":1}}],[\"才行\",{\"1\":{\"114\":1}}],[\"才能\",{\"1\":{\"11\":1,\"128\":1,\"149\":1,\"216\":1,\"221\":1}}],[\"才\",{\"1\":{\"8\":1,\"75\":1,\"76\":1,\"86\":1,\"120\":1,\"164\":2,\"185\":3,\"186\":1,\"204\":1,\"206\":1,\"221\":1}}],[\"时效性\",{\"1\":{\"221\":1}}],[\"时有\",{\"1\":{\"168\":1}}],[\"时延\",{\"1\":{\"69\":1}}],[\"时刻\",{\"1\":{\"63\":1}}],[\"时间\",{\"0\":{\"29\":1},\"1\":{\"11\":1,\"17\":1,\"26\":1,\"28\":3,\"29\":2,\"30\":2,\"34\":3,\"37\":3,\"38\":4,\"42\":1,\"57\":2,\"61\":5,\"65\":1,\"70\":1,\"73\":1,\"74\":1,\"76\":1,\"77\":1,\"79\":1,\"87\":2,\"101\":1,\"125\":1,\"141\":3,\"143\":1,\"147\":3,\"158\":1,\"159\":2,\"161\":1,\"171\":2,\"173\":2,\"177\":1,\"182\":1,\"185\":3,\"187\":1,\"190\":1,\"191\":1,\"197\":1,\"204\":2}}],[\"时\",{\"1\":{\"8\":1,\"18\":1,\"27\":1,\"28\":1,\"29\":1,\"34\":1,\"35\":1,\"39\":2,\"45\":1,\"57\":1,\"58\":1,\"72\":1,\"103\":1,\"124\":1,\"132\":1,\"149\":1,\"152\":1,\"157\":1,\"179\":3,\"184\":1,\"210\":1,\"221\":11}}],[\"时候\",{\"1\":{\"5\":3,\"7\":2,\"11\":1,\"12\":2,\"18\":2,\"43\":1,\"44\":1,\"45\":1,\"48\":1,\"50\":2,\"51\":1,\"52\":2,\"70\":3,\"72\":1,\"73\":2,\"74\":4,\"75\":2,\"76\":1,\"77\":1,\"78\":1,\"79\":2,\"80\":2,\"81\":1,\"82\":1,\"86\":1,\"89\":1,\"91\":1,\"97\":1,\"103\":1,\"104\":2,\"106\":1,\"114\":2,\"117\":1,\"120\":1,\"122\":1,\"124\":5,\"125\":1,\"132\":1,\"135\":3,\"136\":2,\"137\":1,\"144\":1,\"149\":1,\"151\":1,\"155\":1,\"157\":1,\"159\":1,\"161\":1,\"178\":1,\"192\":3,\"199\":1,\"216\":1,\"221\":4}}],[\"后移\",{\"1\":{\"221\":1}}],[\"后会\",{\"1\":{\"159\":1}}],[\"后端\",{\"1\":{\"124\":3,\"173\":1}}],[\"后来\",{\"1\":{\"74\":1,\"151\":1,\"219\":1}}],[\"后面\",{\"1\":{\"72\":1,\"78\":1,\"137\":1,\"141\":1,\"146\":1}}],[\"后人\",{\"1\":{\"51\":1}}],[\"后续\",{\"1\":{\"42\":1,\"44\":1,\"70\":1,\"103\":2,\"114\":2}}],[\"后台\",{\"1\":{\"8\":1,\"28\":1,\"41\":1,\"103\":1,\"122\":1,\"124\":1,\"125\":1,\"157\":1,\"168\":1,\"173\":1}}],[\"后\",{\"0\":{\"8\":1},\"1\":{\"26\":1,\"28\":1,\"39\":1,\"50\":1,\"52\":3,\"57\":1,\"81\":1,\"103\":3,\"114\":1,\"115\":1,\"116\":1,\"124\":1,\"152\":1,\"153\":1,\"157\":1,\"161\":1,\"169\":1,\"211\":1,\"220\":1,\"221\":6}}],[\"四种\",{\"1\":{\"159\":1}}],[\"四层\",{\"1\":{\"152\":3}}],[\"四川\",{\"1\":{\"151\":1}}],[\"四年\",{\"1\":{\"74\":1}}],[\"四个\",{\"1\":{\"52\":1}}],[\"四\",{\"0\":{\"8\":1,\"36\":1,\"57\":1,\"69\":1,\"103\":1,\"143\":1,\"201\":1}}],[\"初衷\",{\"1\":{\"192\":1}}],[\"初学\",{\"1\":{\"128\":1,\"194\":1}}],[\"初版\",{\"1\":{\"124\":1,\"165\":1}}],[\"初中\",{\"1\":{\"78\":1}}],[\"初入\",{\"1\":{\"76\":1}}],[\"初步\",{\"1\":{\"43\":2,\"49\":1}}],[\"初体验\",{\"1\":{\"7\":1}}],[\"初始化\",{\"1\":{\"45\":1,\"125\":2,\"205\":1}}],[\"初始\",{\"1\":{\"7\":1,\"31\":1,\"70\":1}}],[\"兴趣\",{\"1\":{\"7\":1,\"122\":1,\"150\":1,\"166\":1,\"192\":1}}],[\"有意思\",{\"1\":{\"221\":2}}],[\"有序\",{\"1\":{\"221\":6}}],[\"有的\",{\"1\":{\"171\":1}}],[\"有次\",{\"1\":{\"169\":1}}],[\"有下\",{\"1\":{\"137\":1}}],[\"有太大\",{\"1\":{\"91\":1}}],[\"有空\",{\"1\":{\"89\":1,\"173\":1}}],[\"有个\",{\"1\":{\"87\":1,\"104\":1,\"185\":1,\"221\":2}}],[\"有钱\",{\"1\":{\"80\":1}}],[\"有关\",{\"1\":{\"72\":1}}],[\"有所\",{\"1\":{\"70\":1,\"158\":1}}],[\"有没有\",{\"1\":{\"63\":1,\"75\":2,\"102\":2,\"149\":1,\"221\":1}}],[\"有限\",{\"1\":{\"57\":1,\"106\":1}}],[\"有了\",{\"1\":{\"55\":1}}],[\"有人\",{\"1\":{\"49\":1}}],[\"有时候\",{\"1\":{\"43\":1,\"86\":2,\"87\":1,\"89\":1,\"109\":1,\"124\":1}}],[\"有效性\",{\"1\":{\"56\":1}}],[\"有效\",{\"1\":{\"28\":1,\"56\":1,\"145\":1}}],[\"有些\",{\"1\":{\"18\":3,\"70\":1,\"77\":1,\"99\":2,\"113\":2,\"137\":1}}],[\"有点\",{\"0\":{\"127\":1},\"1\":{\"12\":1,\"73\":1,\"74\":4,\"75\":1,\"76\":1,\"80\":3,\"85\":2,\"86\":2,\"89\":1,\"90\":1,\"102\":1,\"122\":1,\"126\":1,\"168\":1,\"173\":3}}],[\"有\",{\"1\":{\"7\":1,\"8\":1,\"11\":1,\"17\":2,\"25\":1,\"26\":1,\"30\":1,\"38\":1,\"45\":1,\"49\":2,\"50\":2,\"51\":1,\"57\":1,\"62\":1,\"63\":4,\"67\":1,\"69\":1,\"70\":3,\"73\":4,\"74\":7,\"75\":1,\"76\":7,\"81\":1,\"86\":3,\"91\":1,\"99\":1,\"103\":2,\"122\":1,\"124\":3,\"126\":1,\"128\":1,\"133\":1,\"135\":1,\"136\":1,\"137\":1,\"141\":1,\"145\":1,\"149\":1,\"150\":1,\"152\":2,\"155\":2,\"156\":1,\"157\":1,\"159\":2,\"161\":3,\"164\":1,\"165\":1,\"166\":2,\"167\":1,\"169\":1,\"171\":2,\"172\":1,\"173\":1,\"177\":1,\"179\":1,\"183\":1,\"186\":1,\"190\":1,\"192\":4,\"194\":2,\"205\":2,\"216\":2,\"221\":29}}],[\"新近\",{\"1\":{\"173\":1}}],[\"新增\",{\"1\":{\"146\":1,\"221\":1}}],[\"新城\",{\"1\":{\"77\":1,\"80\":1}}],[\"新建\",{\"1\":{\"12\":1,\"159\":1,\"221\":1}}],[\"新\",{\"1\":{\"7\":1,\"56\":1,\"70\":1,\"106\":1,\"155\":1,\"161\":1,\"179\":3,\"186\":1,\"221\":10}}],[\"跑步\",{\"0\":{\"82\":2},\"1\":{\"82\":3}}],[\"跑\",{\"1\":{\"7\":1,\"45\":1,\"73\":2,\"74\":4,\"75\":1,\"79\":1,\"80\":1,\"86\":1,\"89\":2,\"126\":1,\"145\":1,\"151\":1}}],[\"相似\",{\"1\":{\"170\":1}}],[\"相符\",{\"1\":{\"169\":1}}],[\"相提并论\",{\"1\":{\"74\":1}}],[\"相当于\",{\"1\":{\"102\":1,\"135\":3,\"157\":1}}],[\"相当\",{\"1\":{\"63\":1,\"185\":1}}],[\"相比\",{\"1\":{\"62\":1,\"168\":2,\"221\":1}}],[\"相对\",{\"1\":{\"44\":1,\"133\":1,\"135\":1,\"164\":1,\"194\":1,\"197\":1,\"221\":2}}],[\"相对来说\",{\"1\":{\"18\":1,\"99\":1}}],[\"相邻\",{\"1\":{\"39\":1}}],[\"相等\",{\"1\":{\"28\":1,\"205\":1}}],[\"相应\",{\"1\":{\"27\":1,\"28\":2,\"70\":1,\"72\":4,\"206\":1}}],[\"相同\",{\"1\":{\"26\":2,\"52\":1,\"56\":1,\"158\":1,\"160\":1,\"177\":1,\"179\":1,\"180\":1,\"188\":1,\"192\":1}}],[\"相结合\",{\"1\":{\"7\":1}}],[\"相关度\",{\"1\":{\"87\":1,\"132\":2,\"136\":1}}],[\"相关\",{\"1\":{\"7\":1,\"8\":1,\"23\":2,\"25\":1,\"30\":1,\"72\":3,\"133\":1,\"159\":1,\"164\":2,\"196\":1,\"198\":1,\"203\":1,\"205\":2,\"216\":1}}],[\"发出\",{\"1\":{\"221\":2}}],[\"发出请求\",{\"1\":{\"205\":1}}],[\"发\",{\"1\":{\"124\":1,\"221\":1}}],[\"发邮件\",{\"1\":{\"109\":1}}],[\"发送数据\",{\"1\":{\"221\":1}}],[\"发送到\",{\"1\":{\"206\":1,\"221\":4}}],[\"发送给\",{\"1\":{\"104\":1,\"221\":1}}],[\"发送\",{\"1\":{\"102\":1,\"103\":2,\"114\":1,\"125\":1,\"164\":1,\"178\":1,\"207\":1,\"211\":1,\"221\":6}}],[\"发起\",{\"1\":{\"97\":1,\"101\":1}}],[\"发展\",{\"1\":{\"81\":1}}],[\"发挥\",{\"1\":{\"66\":1}}],[\"发生变化\",{\"1\":{\"221\":2}}],[\"发生\",{\"1\":{\"37\":1,\"57\":2,\"85\":1,\"179\":1,\"216\":1,\"221\":2}}],[\"发现\",{\"1\":{\"8\":2,\"45\":1,\"46\":1,\"49\":1,\"77\":1,\"81\":1,\"86\":1,\"87\":1,\"124\":2,\"145\":1,\"151\":1,\"157\":1,\"164\":1,\"171\":1,\"219\":1,\"221\":1}}],[\"发版\",{\"1\":{\"7\":1,\"18\":1}}],[\"发布\",{\"1\":{\"4\":1,\"23\":1,\"101\":2,\"221\":4}}],[\"已有\",{\"1\":{\"103\":1}}],[\"已经\",{\"1\":{\"12\":1,\"13\":1,\"52\":1,\"74\":2,\"75\":2,\"77\":2,\"124\":2,\"161\":1,\"164\":1,\"168\":1,\"169\":1,\"186\":1,\"191\":1,\"220\":2,\"221\":1}}],[\"已\",{\"1\":{\"7\":1,\"103\":3,\"160\":1,\"221\":1}}],[\"造成\",{\"1\":{\"7\":1,\"38\":1,\"70\":1,\"135\":1,\"221\":3}}],[\"转移\",{\"1\":{\"221\":2}}],[\"转成\",{\"1\":{\"168\":1}}],[\"转过\",{\"1\":{\"80\":1}}],[\"转型\",{\"1\":{\"77\":1}}],[\"转发给\",{\"1\":{\"152\":1}}],[\"转发\",{\"1\":{\"23\":1,\"98\":1,\"152\":1,\"157\":3,\"160\":2,\"207\":2}}],[\"转化成\",{\"1\":{\"7\":1}}],[\"转换\",{\"1\":{\"5\":2}}],[\"完善\",{\"1\":{\"161\":1,\"171\":1}}],[\"完完全全\",{\"1\":{\"86\":1}}],[\"完全相同\",{\"1\":{\"177\":1}}],[\"完全\",{\"1\":{\"72\":1,\"85\":1,\"86\":2,\"221\":1}}],[\"完整\",{\"1\":{\"57\":1,\"143\":2,\"148\":1,\"150\":2,\"170\":1}}],[\"完后\",{\"1\":{\"12\":1,\"13\":1,\"17\":1}}],[\"完美\",{\"1\":{\"8\":1}}],[\"完即\",{\"1\":{\"7\":1}}],[\"完\",{\"1\":{\"7\":1,\"45\":2,\"70\":1,\"74\":2,\"75\":1,\"76\":1,\"85\":1,\"97\":1,\"102\":1,\"104\":1,\"157\":2,\"164\":1,\"170\":1,\"211\":1,\"212\":1,\"213\":1,\"221\":1}}],[\"完成\",{\"1\":{\"5\":2,\"6\":1,\"13\":1,\"26\":1,\"57\":1,\"103\":3,\"116\":1,\"120\":2,\"121\":1,\"159\":1,\"161\":3,\"213\":1,\"221\":3}}],[\"右边\",{\"1\":{\"7\":1,\"172\":1}}],[\"即用\",{\"1\":{\"185\":1}}],[\"即当\",{\"1\":{\"157\":1}}],[\"即使\",{\"1\":{\"78\":1,\"160\":1,\"161\":1,\"164\":1}}],[\"即\",{\"1\":{\"7\":1,\"17\":1,\"28\":2,\"63\":1,\"114\":1,\"125\":1,\"141\":1,\"149\":2,\"158\":1,\"161\":1,\"166\":1,\"173\":1,\"181\":2,\"185\":1}}],[\"即可\",{\"1\":{\"7\":1,\"12\":3,\"55\":1,\"57\":1,\"65\":1,\"72\":1,\"95\":1,\"98\":2,\"101\":2,\"144\":2,\"149\":1,\"151\":1,\"153\":1,\"158\":1,\"159\":1,\"161\":1,\"173\":1,\"183\":1,\"203\":1,\"205\":1,\"221\":1}}],[\"yum\",{\"1\":{\"153\":1}}],[\"yyyymmdd\",{\"1\":{\"147\":2}}],[\"yesterday\",{\"1\":{\"147\":2,\"150\":2}}],[\"yes\",{\"1\":{\"135\":4}}],[\"yoursiteid\",{\"1\":{\"150\":1}}],[\"your\",{\"1\":{\"98\":4,\"149\":2}}],[\"yaxis\",{\"1\":{\"151\":1}}],[\"yarn\",{\"1\":{\"72\":1}}],[\"yaml\",{\"1\":{\"7\":3,\"8\":2,\"12\":1,\"56\":1,\"57\":1,\"72\":5}}],[\"y\",{\"1\":{\"43\":1,\"72\":2,\"149\":3,\"151\":2}}],[\"yml\",{\"1\":{\"7\":1}}],[\"级别\",{\"1\":{\"179\":1,\"180\":1,\"181\":1,\"184\":1}}],[\"级\",{\"1\":{\"7\":1,\"152\":1,\"221\":2}}],[\"结婚\",{\"1\":{\"79\":1,\"83\":1}}],[\"结束\",{\"1\":{\"75\":1,\"147\":1,\"148\":1,\"150\":1,\"179\":1}}],[\"结果\",{\"0\":{\"50\":1,\"191\":1},\"1\":{\"9\":1,\"10\":1,\"50\":1,\"74\":1,\"86\":1,\"125\":1,\"132\":1,\"135\":3,\"137\":1,\"144\":1,\"148\":1,\"149\":5,\"151\":2,\"152\":1,\"159\":1,\"178\":1,\"179\":4,\"185\":2,\"191\":2,\"207\":3,\"208\":1,\"210\":4,\"211\":1,\"212\":1,\"216\":3,\"220\":1}}],[\"结合\",{\"1\":{\"7\":2,\"143\":1,\"184\":1,\"221\":1}}],[\"结构\",{\"1\":{\"7\":1,\"136\":1,\"192\":1,\"221\":2}}],[\"定位\",{\"1\":{\"221\":1}}],[\"定期\",{\"1\":{\"221\":1}}],[\"定制\",{\"1\":{\"72\":2}}],[\"定时器\",{\"1\":{\"144\":1}}],[\"定时\",{\"0\":{\"15\":1,\"139\":1,\"144\":1},\"1\":{\"7\":1,\"42\":1,\"43\":1,\"51\":1,\"122\":1,\"143\":1,\"144\":3,\"149\":1}}],[\"定义数据\",{\"1\":{\"137\":1}}],[\"定义\",{\"1\":{\"4\":1,\"64\":2,\"66\":3,\"135\":1,\"142\":1,\"143\":1,\"149\":2,\"179\":1,\"185\":2,\"212\":1,\"221\":1}}],[\"图上\",{\"1\":{\"149\":1}}],[\"图像\",{\"1\":{\"145\":1}}],[\"图表\",{\"0\":{\"169\":1},\"1\":{\"145\":1,\"151\":2}}],[\"图书\",{\"1\":{\"77\":1}}],[\"图书馆\",{\"1\":{\"73\":1,\"75\":2,\"80\":1,\"87\":1}}],[\"图\",{\"1\":{\"50\":1,\"57\":2,\"136\":1,\"141\":1,\"151\":4,\"169\":1,\"183\":1,\"205\":1,\"206\":1}}],[\"图片\",{\"1\":{\"44\":1,\"124\":1,\"127\":1,\"166\":1,\"170\":1,\"171\":1,\"183\":1,\"205\":1,\"207\":1,\"211\":1}}],[\"图形化\",{\"1\":{\"7\":2,\"12\":2,\"18\":1}}],[\"图为例\",{\"1\":{\"6\":1}}],[\"效果\",{\"1\":{\"72\":1,\"127\":1,\"135\":2,\"137\":1,\"145\":1,\"151\":1,\"165\":1,\"166\":1,\"170\":1,\"171\":2,\"185\":1}}],[\"效来\",{\"1\":{\"7\":1}}],[\"效\",{\"1\":{\"7\":1}}],[\"效率\",{\"1\":{\"5\":1,\"29\":1,\"38\":1,\"141\":1,\"152\":1,\"171\":1}}],[\"跟上\",{\"1\":{\"161\":1}}],[\"跟踪器\",{\"1\":{\"221\":1}}],[\"跟踪\",{\"1\":{\"156\":1}}],[\"跟\",{\"1\":{\"7\":2,\"42\":1,\"73\":2,\"74\":3,\"75\":4,\"76\":1,\"77\":2,\"80\":3,\"82\":1,\"86\":1,\"90\":1,\"98\":1,\"145\":1,\"149\":1,\"151\":1,\"158\":1,\"164\":1,\"169\":1,\"173\":1,\"183\":2}}],[\"仓库\",{\"1\":{\"7\":2}}],[\"包中\",{\"1\":{\"142\":1}}],[\"包\",{\"0\":{\"186\":1},\"1\":{\"135\":1,\"137\":1,\"143\":2,\"152\":1,\"153\":1,\"186\":4}}],[\"包后\",{\"1\":{\"73\":1}}],[\"包含\",{\"1\":{\"7\":1,\"23\":2,\"54\":1,\"56\":1,\"57\":1,\"63\":1,\"132\":1,\"133\":2,\"157\":1,\"215\":1,\"221\":4}}],[\"包括\",{\"1\":{\"5\":1,\"26\":1,\"72\":2,\"132\":1,\"177\":1,\"205\":1,\"212\":1,\"221\":3}}],[\"桶\",{\"1\":{\"7\":1}}],[\"全文检索\",{\"1\":{\"215\":1}}],[\"全站\",{\"1\":{\"158\":1}}],[\"全称\",{\"1\":{\"158\":1}}],[\"全靠\",{\"1\":{\"77\":1}}],[\"全都\",{\"1\":{\"76\":1,\"124\":1}}],[\"全是\",{\"1\":{\"74\":1,\"76\":1,\"80\":1,\"124\":1}}],[\"全\",{\"1\":{\"74\":1}}],[\"全部\",{\"1\":{\"57\":1,\"72\":2,\"75\":1,\"98\":1,\"122\":1,\"124\":3,\"135\":2,\"149\":1,\"165\":1,\"169\":1,\"210\":1,\"221\":1}}],[\"全局\",{\"1\":{\"45\":1,\"207\":1,\"221\":1}}],[\"全程\",{\"1\":{\"23\":2,\"83\":1}}],[\"全过程\",{\"1\":{\"7\":1}}],[\"全家\",{\"1\":{\"7\":1}}],[\"全线\",{\"1\":{\"4\":1}}],[\"所谓\",{\"1\":{\"172\":1}}],[\"所用\",{\"0\":{\"162\":1},\"1\":{\"165\":1}}],[\"所在\",{\"1\":{\"135\":1}}],[\"所属\",{\"1\":{\"101\":1}}],[\"所示\",{\"1\":{\"50\":1,\"183\":1,\"205\":1,\"206\":1}}],[\"所\",{\"1\":{\"41\":1,\"56\":2,\"57\":3,\"66\":1,\"73\":1,\"78\":1,\"132\":1,\"135\":2,\"137\":1,\"144\":1,\"145\":1,\"152\":1,\"189\":1,\"221\":1}}],[\"所述\",{\"1\":{\"28\":1,\"29\":1}}],[\"所需\",{\"1\":{\"26\":1,\"147\":1}}],[\"所有者\",{\"1\":{\"221\":1}}],[\"所有权\",{\"1\":{\"221\":2}}],[\"所有人\",{\"1\":{\"84\":1}}],[\"所有\",{\"0\":{\"209\":1},\"1\":{\"7\":1,\"9\":1,\"52\":1,\"56\":1,\"57\":2,\"63\":1,\"70\":1,\"72\":1,\"80\":1,\"135\":1,\"185\":1,\"186\":2,\"205\":3,\"206\":1,\"209\":2,\"211\":1,\"212\":1,\"216\":4,\"220\":1,\"221\":9}}],[\"所以然\",{\"1\":{\"48\":1}}],[\"所以\",{\"1\":{\"6\":1,\"18\":1,\"26\":1,\"27\":1,\"29\":3,\"38\":1,\"39\":1,\"43\":1,\"44\":2,\"45\":1,\"49\":1,\"65\":1,\"72\":1,\"97\":1,\"114\":1,\"120\":1,\"124\":1,\"145\":4,\"148\":1,\"149\":1,\"151\":1,\"152\":1,\"153\":1,\"156\":1,\"157\":1,\"158\":1,\"161\":1,\"165\":1,\"166\":1,\"168\":1,\"171\":1,\"172\":1,\"173\":2,\"185\":2,\"188\":1,\"192\":1,\"221\":3}}],[\"处在\",{\"1\":{\"78\":1}}],[\"处于\",{\"1\":{\"7\":2,\"45\":1}}],[\"处理器\",{\"1\":{\"28\":1,\"125\":2}}],[\"处理\",{\"0\":{\"127\":1},\"1\":{\"5\":1,\"28\":1,\"56\":2,\"74\":1,\"125\":2,\"133\":1,\"152\":2,\"157\":1,\"161\":1,\"204\":1,\"212\":1,\"214\":1,\"216\":1,\"221\":8}}],[\"文中\",{\"1\":{\"157\":1}}],[\"文本\",{\"1\":{\"151\":2}}],[\"文字\",{\"1\":{\"136\":1}}],[\"文\",{\"1\":{\"28\":1,\"29\":1}}],[\"文章内容\",{\"1\":{\"135\":1}}],[\"文章\",{\"1\":{\"18\":1,\"78\":1,\"81\":2,\"85\":1,\"87\":1,\"99\":1,\"103\":1,\"124\":1,\"128\":1,\"135\":1,\"137\":2,\"168\":2,\"189\":1,\"192\":7}}],[\"文件夹\",{\"1\":{\"221\":5}}],[\"文件系统\",{\"1\":{\"194\":1}}],[\"文件\",{\"1\":{\"7\":1,\"8\":1,\"12\":1,\"30\":1,\"56\":1,\"72\":1,\"120\":2,\"142\":1,\"143\":1,\"145\":1,\"151\":1,\"153\":1,\"158\":1,\"159\":1,\"163\":2,\"164\":1,\"180\":3,\"221\":10}}],[\"文档\",{\"1\":{\"7\":1,\"103\":1,\"108\":2,\"116\":1,\"132\":5,\"133\":5,\"135\":2,\"159\":2,\"164\":1,\"205\":2,\"207\":1,\"211\":1}}],[\"文化\",{\"1\":{\"4\":1}}],[\"它们\",{\"1\":{\"54\":1,\"55\":2,\"56\":1,\"57\":1,\"205\":1,\"206\":1,\"221\":2}}],[\"它会\",{\"1\":{\"10\":1,\"144\":1,\"161\":1}}],[\"它\",{\"1\":{\"7\":1,\"9\":2,\"63\":2,\"70\":1,\"124\":1,\"141\":1,\"148\":1,\"149\":2,\"151\":1,\"159\":1,\"161\":3,\"168\":1,\"170\":1,\"181\":1,\"183\":1,\"185\":3,\"221\":14}}],[\"范围\",{\"1\":{\"7\":1,\"61\":1,\"159\":1}}],[\"小黑\",{\"1\":{\"86\":1}}],[\"小型\",{\"1\":{\"54\":1}}],[\"小伙伴\",{\"1\":{\"45\":1}}],[\"小时\",{\"1\":{\"39\":1,\"76\":1,\"103\":1,\"106\":1,\"172\":1,\"192\":1}}],[\"小堆\",{\"0\":{\"39\":1}}],[\"小心\",{\"1\":{\"38\":1}}],[\"小于\",{\"1\":{\"23\":1}}],[\"小\",{\"0\":{\"152\":1},\"1\":{\"7\":1,\"8\":1,\"27\":1,\"38\":2,\"74\":1,\"75\":2,\"76\":1,\"86\":1,\"87\":1,\"122\":1,\"124\":1,\"127\":1,\"135\":1,\"151\":1,\"159\":1,\"161\":2,\"162\":1,\"192\":1,\"221\":2}}],[\"小块\",{\"1\":{\"6\":1}}],[\"工资\",{\"1\":{\"74\":1}}],[\"工具\",{\"1\":{\"7\":1,\"49\":1,\"72\":3,\"143\":1,\"167\":1,\"170\":1}}],[\"工作\",{\"0\":{\"76\":1,\"81\":2,\"86\":1},\"1\":{\"4\":1,\"72\":1,\"73\":1,\"74\":1,\"76\":1,\"78\":1,\"80\":2,\"81\":1,\"86\":1,\"89\":1,\"90\":1,\"91\":1,\"148\":1,\"152\":1,\"161\":2,\"221\":2}}],[\"歌\",{\"1\":{\"7\":1,\"136\":1,\"158\":1}}],[\"谷歌\",{\"1\":{\"7\":2,\"49\":1,\"166\":1}}],[\"谷\",{\"1\":{\"7\":1,\"136\":1,\"158\":1}}],[\"此类\",{\"1\":{\"172\":1}}],[\"此处\",{\"1\":{\"125\":1,\"157\":1,\"158\":1,\"168\":1,\"170\":2,\"184\":1,\"187\":1,\"192\":1,\"206\":1,\"210\":1}}],[\"此外\",{\"1\":{\"117\":1,\"161\":1,\"221\":1}}],[\"此种\",{\"1\":{\"37\":1}}],[\"此时\",{\"1\":{\"29\":1,\"63\":1,\"103\":1,\"125\":1,\"160\":1,\"205\":1}}],[\"此值\",{\"1\":{\"26\":3,\"28\":3,\"29\":2}}],[\"此\",{\"1\":{\"7\":1,\"28\":3,\"56\":1,\"57\":1,\"120\":1}}],[\"!\",{\"1\":{\"7\":1,\"18\":3,\"76\":3,\"77\":3,\"86\":5,\"91\":2,\"125\":1,\"143\":1,\"221\":4}}],[\"?\",{\"1\":{\"7\":1,\"23\":2,\"48\":1,\"63\":1,\"70\":1,\"73\":1,\"74\":6,\"75\":4,\"76\":4,\"77\":2,\"78\":1,\"87\":1,\"159\":1,\"165\":2,\"168\":1,\"169\":1,\"170\":1,\"171\":1,\"173\":1,\"204\":1,\"205\":1,\"221\":63}}],[\"他会\",{\"1\":{\"221\":1}}],[\"他\",{\"1\":{\"7\":1,\"39\":1,\"73\":1,\"170\":1,\"221\":2}}],[\"他们\",{\"1\":{\"6\":1,\"12\":1,\"76\":2,\"78\":1,\"86\":1}}],[\"让\",{\"1\":{\"7\":1,\"12\":2,\"18\":1,\"52\":4,\"56\":2,\"57\":3,\"70\":1,\"77\":1,\"78\":1,\"81\":1,\"90\":1,\"103\":2,\"126\":1,\"161\":2,\"165\":1,\"166\":1,\"167\":1,\"170\":1,\"171\":1,\"221\":3}}],[\"你好\",{\"1\":{\"77\":2}}],[\"你们\",{\"1\":{\"74\":1,\"192\":1}}],[\"你\",{\"1\":{\"7\":1,\"23\":1,\"73\":1,\"74\":2,\"75\":1,\"76\":1,\"80\":1,\"98\":1,\"102\":1,\"109\":1,\"117\":2,\"120\":2,\"149\":2,\"221\":18}}],[\"写的是\",{\"1\":{\"221\":1}}],[\"写时\",{\"1\":{\"220\":1}}],[\"写文章\",{\"1\":{\"168\":1}}],[\"写入\",{\"1\":{\"161\":3,\"198\":1,\"221\":3}}],[\"写点\",{\"1\":{\"128\":1}}],[\"写不出\",{\"1\":{\"87\":1}}],[\"写得少\",{\"1\":{\"87\":1}}],[\"写写\",{\"1\":{\"79\":1,\"85\":1}}],[\"写过\",{\"1\":{\"75\":1}}],[\"写个\",{\"1\":{\"75\":1}}],[\"写法\",{\"1\":{\"7\":1}}],[\"写\",{\"0\":{\"198\":1},\"1\":{\"7\":3,\"8\":1,\"12\":2,\"45\":1,\"52\":2,\"76\":1,\"78\":1,\"79\":1,\"81\":1,\"85\":1,\"87\":2,\"88\":1,\"103\":1,\"124\":3,\"135\":1,\"145\":1,\"164\":1,\"179\":1,\"184\":1,\"221\":2}}],[\"会大\",{\"1\":{\"136\":1}}],[\"会弹\",{\"1\":{\"136\":1}}],[\"会报\",{\"1\":{\"106\":1}}],[\"会用\",{\"1\":{\"51\":1}}],[\"会话\",{\"1\":{\"38\":1,\"97\":1,\"104\":3,\"177\":1}}],[\"会\",{\"0\":{\"104\":1},\"1\":{\"7\":2,\"11\":1,\"17\":1,\"18\":1,\"26\":1,\"27\":1,\"28\":2,\"29\":3,\"38\":3,\"39\":2,\"44\":2,\"45\":1,\"50\":3,\"57\":1,\"58\":1,\"65\":1,\"70\":1,\"72\":2,\"74\":1,\"76\":2,\"87\":1,\"95\":1,\"98\":2,\"101\":1,\"103\":2,\"107\":1,\"109\":1,\"114\":1,\"132\":1,\"135\":1,\"137\":1,\"143\":1,\"144\":1,\"152\":1,\"157\":2,\"158\":1,\"161\":3,\"166\":1,\"172\":1,\"177\":1,\"179\":4,\"184\":2,\"185\":1,\"187\":1,\"188\":1,\"192\":3,\"203\":1,\"204\":1,\"205\":1,\"216\":1,\"221\":21}}],[\"产生\",{\"1\":{\"10\":1,\"23\":1,\"29\":1,\"161\":1,\"188\":1,\"221\":3}}],[\"产商\",{\"1\":{\"8\":1,\"185\":1}}],[\"产品化\",{\"0\":{\"8\":1},\"1\":{\"7\":1}}],[\"产品\",{\"1\":{\"7\":3,\"8\":2,\"76\":2,\"80\":1,\"86\":2,\"137\":1,\"151\":1,\"164\":1,\"165\":1,\"221\":1}}],[\"产出\",{\"1\":{\"6\":1}}],[\"做文章\",{\"1\":{\"180\":1}}],[\"做的\",{\"1\":{\"86\":1}}],[\"做出\",{\"1\":{\"73\":1,\"76\":1,\"165\":1}}],[\"做到\",{\"1\":{\"73\":1,\"104\":1,\"152\":1,\"221\":3}}],[\"做过\",{\"1\":{\"70\":1}}],[\"做\",{\"1\":{\"7\":1,\"12\":1,\"18\":1,\"45\":1,\"50\":1,\"58\":1,\"61\":2,\"69\":1,\"70\":1,\"73\":2,\"74\":4,\"81\":5,\"86\":1,\"87\":1,\"99\":1,\"122\":2,\"124\":5,\"126\":1,\"127\":1,\"128\":1,\"132\":1,\"133\":1,\"135\":2,\"144\":1,\"148\":1,\"157\":1,\"161\":1,\"162\":1,\"165\":1,\"166\":1,\"167\":1,\"169\":1,\"171\":1,\"190\":1,\"192\":1,\"220\":1,\"221\":4}}],[\"做成\",{\"1\":{\"7\":1,\"151\":1}}],[\"做法\",{\"1\":{\"7\":1}}],[\"做好\",{\"1\":{\"4\":1}}],[\"正好\",{\"1\":{\"205\":1}}],[\"正如\",{\"1\":{\"56\":1,\"57\":1}}],[\"正式\",{\"1\":{\"56\":1}}],[\"正在\",{\"1\":{\"11\":1,\"56\":1,\"57\":1}}],[\"正确\",{\"1\":{\"7\":1,\"221\":2}}],[\"正常\",{\"1\":{\"7\":1,\"43\":1,\"44\":2,\"72\":1,\"102\":1,\"113\":2,\"114\":1,\"121\":1,\"158\":1}}],[\"觉得\",{\"1\":{\"7\":1,\"43\":1,\"49\":1,\"73\":1,\"74\":2,\"76\":1,\"80\":1,\"82\":1,\"86\":1,\"122\":1,\"165\":1,\"171\":1,\"172\":1,\"216\":1}}],[\"重\",{\"1\":{\"161\":1}}],[\"重定向\",{\"1\":{\"158\":1}}],[\"重写\",{\"1\":{\"124\":1,\"185\":1}}],[\"重做\",{\"1\":{\"124\":2,\"161\":1}}],[\"重试\",{\"0\":{\"159\":1},\"1\":{\"103\":2,\"106\":1,\"159\":1,\"221\":1}}],[\"重要性\",{\"1\":{\"86\":1}}],[\"重要\",{\"0\":{\"132\":1},\"1\":{\"80\":1,\"84\":1,\"102\":1,\"145\":1,\"151\":1,\"161\":1}}],[\"重构\",{\"0\":{\"129\":1},\"1\":{\"80\":1,\"86\":1,\"122\":1}}],[\"重建家园\",{\"1\":{\"78\":1}}],[\"重连\",{\"1\":{\"41\":1}}],[\"重复\",{\"1\":{\"23\":1,\"221\":8}}],[\"重启\",{\"1\":{\"11\":1,\"41\":1,\"42\":1,\"51\":1,\"153\":1,\"163\":1,\"164\":2,\"221\":1}}],[\"重新分配\",{\"1\":{\"155\":1,\"221\":1}}],[\"重新\",{\"1\":{\"7\":1,\"11\":1,\"18\":1,\"26\":1,\"98\":2,\"102\":1,\"103\":2,\"205\":1,\"221\":2}}],[\"重视\",{\"1\":{\"4\":1,\"85\":1}}],[\"特征\",{\"1\":{\"221\":1}}],[\"特定\",{\"1\":{\"141\":1,\"203\":1,\"212\":1,\"221\":2}}],[\"特点\",{\"0\":{\"140\":1},\"1\":{\"221\":1}}],[\"特\",{\"1\":{\"124\":1}}],[\"特斯拉\",{\"0\":{\"112\":1},\"1\":{\"113\":1,\"116\":1,\"117\":1}}],[\"特殊\",{\"1\":{\"57\":1,\"67\":1,\"140\":1,\"141\":1,\"221\":1}}],[\"特别\",{\"1\":{\"7\":2,\"18\":1,\"42\":1,\"43\":1,\"65\":1,\"90\":1,\"117\":1,\"151\":2,\"165\":1,\"171\":1,\"206\":1}}],[\"特性\",{\"0\":{\"144\":1},\"1\":{\"6\":1,\"149\":1,\"184\":1}}],[\"期中\",{\"1\":{\"124\":1}}],[\"期初\",{\"1\":{\"86\":1,\"124\":1,\"151\":1}}],[\"期待\",{\"1\":{\"80\":1}}],[\"期望\",{\"0\":{\"78\":1},\"1\":{\"91\":1,\"221\":1}}],[\"期间\",{\"1\":{\"30\":1,\"73\":1,\"80\":1,\"86\":1,\"87\":1,\"221\":1}}],[\"期\",{\"0\":{\"7\":1},\"1\":{\"7\":1}}],[\"原作者\",{\"1\":{\"170\":1}}],[\"原始\",{\"1\":{\"157\":1,\"164\":1}}],[\"原来\",{\"1\":{\"124\":1}}],[\"原理\",{\"0\":{\"40\":1},\"1\":{\"23\":1,\"74\":3,\"76\":1,\"98\":1,\"136\":1,\"159\":2,\"164\":2,\"170\":1,\"183\":1,\"192\":4,\"204\":1,\"221\":3}}],[\"原本\",{\"1\":{\"18\":1,\"45\":1,\"122\":1,\"129\":1,\"170\":1}}],[\"原生\",{\"0\":{\"195\":1},\"1\":{\"6\":1,\"18\":1,\"63\":1,\"72\":1,\"87\":1,\"147\":1,\"194\":1,\"197\":1}}],[\"原因\",{\"1\":{\"6\":1,\"23\":1,\"29\":1,\"38\":1,\"41\":1,\"42\":1,\"96\":1,\"114\":3,\"145\":1,\"171\":1,\"220\":1}}],[\"合适\",{\"1\":{\"165\":1,\"221\":1}}],[\"合法\",{\"1\":{\"114\":2}}],[\"合并\",{\"1\":{\"39\":1,\"207\":1,\"208\":1,\"211\":1,\"216\":1}}],[\"合理性\",{\"1\":{\"177\":1}}],[\"合理\",{\"1\":{\"6\":1,\"152\":1,\"164\":1}}],[\"合作方\",{\"1\":{\"120\":1}}],[\"合作伙伴\",{\"1\":{\"117\":1}}],[\"合作\",{\"1\":{\"4\":1}}],[\"云端\",{\"1\":{\"102\":1}}],[\"云中\",{\"1\":{\"10\":1}}],[\"云效\",{\"1\":{\"8\":5,\"14\":1}}],[\"云云\",{\"1\":{\"7\":2}}],[\"云\",{\"0\":{\"12\":1,\"96\":1,\"173\":1},\"1\":{\"6\":3,\"8\":2,\"9\":1,\"12\":1,\"13\":1,\"18\":2,\"42\":1,\"63\":1,\"73\":1,\"81\":1,\"86\":3,\"87\":1,\"96\":1,\"101\":2,\"102\":3,\"114\":3,\"124\":1,\"165\":1,\"173\":2}}],[\"多表\",{\"1\":{\"184\":1}}],[\"多数\",{\"1\":{\"184\":1}}],[\"多人\",{\"1\":{\"169\":1}}],[\"多备库\",{\"1\":{\"161\":1}}],[\"多种手段\",{\"1\":{\"184\":1}}],[\"多种\",{\"1\":{\"140\":2}}],[\"多样\",{\"1\":{\"140\":1}}],[\"多说\",{\"1\":{\"124\":2}}],[\"多重\",{\"1\":{\"113\":2}}],[\"多开\",{\"1\":{\"106\":1}}],[\"多轮\",{\"1\":{\"97\":1}}],[\"多多\",{\"1\":{\"82\":1,\"87\":1,\"128\":1}}],[\"多少\",{\"1\":{\"28\":1,\"29\":1,\"39\":1}}],[\"多次\",{\"1\":{\"26\":1,\"102\":1,\"114\":2,\"177\":1}}],[\"多遍\",{\"1\":{\"18\":1}}],[\"多线程\",{\"1\":{\"9\":1,\"63\":1,\"66\":1,\"221\":1}}],[\"多\",{\"1\":{\"6\":1,\"7\":1,\"26\":2,\"51\":1,\"55\":1,\"73\":2,\"74\":1,\"75\":1,\"76\":1,\"77\":1,\"78\":2,\"81\":2,\"89\":3,\"124\":1,\"144\":1,\"151\":1,\"152\":1,\"159\":1,\"162\":1,\"167\":1,\"172\":1,\"173\":1,\"196\":1,\"198\":2,\"205\":1,\"221\":4}}],[\"多个\",{\"1\":{\"6\":1,\"7\":1,\"70\":2,\"98\":1,\"133\":1,\"180\":1,\"181\":1,\"184\":1,\"221\":9}}],[\"开关\",{\"1\":{\"187\":2}}],[\"开箱\",{\"1\":{\"185\":1}}],[\"开销\",{\"1\":{\"161\":1}}],[\"开通\",{\"1\":{\"146\":1,\"149\":1}}],[\"开放源码\",{\"1\":{\"221\":1}}],[\"开放\",{\"1\":{\"126\":1,\"166\":1}}],[\"开\",{\"1\":{\"106\":1}}],[\"开了个\",{\"1\":{\"85\":1}}],[\"开头\",{\"1\":{\"85\":2,\"216\":1}}],[\"开门\",{\"1\":{\"80\":1}}],[\"开心\",{\"1\":{\"73\":1,\"75\":1,\"76\":1,\"85\":1}}],[\"开源\",{\"1\":{\"42\":1,\"63\":2,\"164\":1,\"168\":1}}],[\"开启\",{\"0\":{\"182\":1},\"1\":{\"39\":2,\"43\":1,\"113\":1,\"158\":1,\"164\":1,\"179\":1,\"182\":2}}],[\"开发者\",{\"1\":{\"113\":1,\"126\":1,\"145\":2}}],[\"开发\",{\"0\":{\"99\":1},\"1\":{\"8\":1,\"51\":1,\"76\":1,\"100\":3,\"101\":1,\"107\":1,\"121\":2,\"157\":1,\"186\":1,\"221\":1}}],[\"开发人员\",{\"1\":{\"4\":1,\"54\":1,\"55\":1}}],[\"开始\",{\"0\":{\"116\":1},\"1\":{\"6\":1,\"8\":1,\"45\":1,\"46\":2,\"49\":2,\"54\":1,\"56\":1,\"73\":1,\"74\":8,\"75\":1,\"77\":1,\"80\":1,\"81\":4,\"85\":1,\"86\":4,\"100\":1,\"116\":1,\"124\":1,\"135\":1,\"146\":1,\"150\":1,\"152\":1,\"161\":3,\"163\":2,\"164\":4,\"165\":1,\"168\":1,\"171\":1,\"179\":1,\"194\":1,\"199\":1,\"206\":1,\"210\":1,\"220\":1,\"221\":1}}],[\"方都\",{\"1\":{\"18\":1,\"50\":1}}],[\"方不\",{\"1\":{\"18\":1}}],[\"方式\",{\"1\":{\"18\":1,\"23\":1,\"28\":1,\"35\":1,\"38\":1,\"39\":1,\"51\":1,\"56\":1,\"85\":1,\"100\":1,\"117\":1,\"135\":3,\"140\":3,\"145\":1,\"149\":1,\"151\":1,\"153\":1,\"155\":1,\"159\":1,\"161\":4,\"163\":1,\"164\":1,\"172\":1,\"187\":2,\"192\":1,\"194\":1,\"205\":2,\"221\":2}}],[\"方便管理\",{\"1\":{\"126\":1}}],[\"方便\",{\"1\":{\"18\":1,\"69\":1,\"72\":2,\"100\":2,\"137\":1,\"194\":1,\"203\":1}}],[\"方来\",{\"1\":{\"18\":1}}],[\"方法\",{\"0\":{\"47\":1},\"1\":{\"11\":1,\"45\":1,\"56\":1,\"98\":1,\"103\":1,\"137\":2,\"140\":1,\"144\":1,\"145\":1,\"148\":2,\"149\":2,\"151\":1,\"159\":4,\"179\":1,\"185\":8,\"188\":1,\"189\":1,\"192\":1,\"207\":1,\"212\":2,\"213\":1,\"221\":3}}],[\"方面\",{\"0\":{\"45\":1},\"1\":{\"9\":1,\"25\":1,\"48\":1,\"122\":2,\"221\":1}}],[\"方向\",{\"1\":{\"7\":1,\"86\":1,\"87\":2}}],[\"方案\",{\"0\":{\"63\":1},\"1\":{\"7\":1,\"11\":1,\"38\":1,\"72\":1,\"177\":1,\"185\":2}}],[\"方\",{\"1\":{\"6\":1,\"7\":1,\"12\":1,\"42\":1,\"44\":1,\"58\":1,\"60\":1,\"70\":1}}],[\"业务\",{\"1\":{\"6\":1,\"11\":1,\"12\":1,\"18\":2,\"42\":1,\"44\":1,\"50\":1,\"60\":1,\"70\":1,\"76\":2,\"77\":1,\"164\":5,\"221\":1}}],[\"难免会\",{\"1\":{\"159\":1}}],[\"难以\",{\"1\":{\"89\":1}}],[\"难过\",{\"1\":{\"78\":1}}],[\"难道\",{\"1\":{\"48\":1}}],[\"难\",{\"1\":{\"6\":1,\"81\":1}}],[\"却是\",{\"1\":{\"74\":1}}],[\"却\",{\"1\":{\"6\":1,\"74\":1,\"152\":1,\"169\":1}}],[\"中进\",{\"1\":{\"221\":1}}],[\"中将\",{\"1\":{\"207\":1}}],[\"中以\",{\"1\":{\"194\":1}}],[\"中共\",{\"1\":{\"192\":1}}],[\"中会\",{\"1\":{\"179\":1,\"221\":1}}],[\"中继\",{\"1\":{\"161\":7,\"164\":1}}],[\"中间\",{\"1\":{\"179\":1}}],[\"中间层\",{\"1\":{\"157\":1}}],[\"中间件\",{\"1\":{\"63\":3,\"80\":1}}],[\"中先\",{\"1\":{\"151\":1}}],[\"中文\",{\"1\":{\"132\":1,\"135\":1}}],[\"中国\",{\"1\":{\"117\":1,\"151\":2,\"172\":1}}],[\"中取\",{\"1\":{\"101\":1,\"179\":1}}],[\"中是\",{\"1\":{\"50\":1,\"204\":1,\"221\":1}}],[\"中期\",{\"1\":{\"38\":1}}],[\"中断\",{\"1\":{\"30\":1}}],[\"中有\",{\"1\":{\"23\":1,\"157\":1,\"221\":4}}],[\"中大\",{\"1\":{\"7\":1}}],[\"中\",{\"0\":{\"53\":1,\"56\":1,\"65\":1,\"133\":1},\"1\":{\"6\":1,\"7\":1,\"11\":1,\"12\":1,\"13\":2,\"14\":1,\"17\":1,\"18\":1,\"23\":1,\"25\":1,\"29\":1,\"42\":1,\"43\":1,\"44\":3,\"45\":3,\"48\":1,\"54\":3,\"55\":1,\"56\":3,\"57\":6,\"62\":1,\"63\":4,\"64\":1,\"65\":1,\"66\":2,\"70\":1,\"72\":3,\"73\":1,\"75\":2,\"87\":1,\"103\":2,\"114\":1,\"125\":3,\"126\":1,\"132\":3,\"135\":2,\"136\":1,\"141\":1,\"142\":2,\"143\":3,\"144\":3,\"146\":3,\"149\":5,\"151\":5,\"152\":1,\"153\":1,\"155\":1,\"157\":2,\"158\":2,\"159\":4,\"161\":8,\"164\":1,\"165\":1,\"166\":2,\"167\":1,\"168\":2,\"169\":1,\"177\":2,\"178\":1,\"179\":8,\"180\":2,\"182\":2,\"183\":1,\"184\":1,\"185\":1,\"186\":1,\"188\":1,\"189\":1,\"192\":10,\"203\":1,\"204\":1,\"205\":2,\"212\":3,\"213\":1,\"215\":1,\"216\":4,\"221\":44}}],[\"实体类\",{\"1\":{\"137\":2}}],[\"实践\",{\"1\":{\"81\":1,\"192\":1}}],[\"实在\",{\"1\":{\"76\":2,\"80\":1,\"81\":1,\"126\":2,\"145\":1,\"149\":1,\"164\":1,\"165\":1,\"170\":1,\"221\":1}}],[\"实行\",{\"1\":{\"76\":1}}],[\"实习\",{\"1\":{\"73\":1,\"74\":1}}],[\"实战\",{\"1\":{\"71\":1,\"177\":1,\"205\":1,\"216\":1}}],[\"实验\",{\"0\":{\"191\":1},\"1\":{\"70\":1}}],[\"实时处理\",{\"1\":{\"199\":1}}],[\"实时\",{\"1\":{\"70\":1,\"72\":1,\"126\":3,\"145\":1,\"149\":1,\"192\":1,\"221\":4}}],[\"实例\",{\"1\":{\"56\":1,\"141\":1,\"152\":1}}],[\"实际上\",{\"1\":{\"104\":1,\"120\":1,\"179\":1,\"216\":1}}],[\"实际\",{\"0\":{\"149\":1},\"1\":{\"6\":1,\"37\":1,\"65\":1,\"74\":1,\"157\":1,\"192\":1,\"221\":1}}],[\"实现\",{\"0\":{\"183\":1},\"1\":{\"5\":1,\"6\":2,\"18\":2,\"45\":1,\"51\":2,\"55\":1,\"57\":1,\"63\":3,\"65\":1,\"72\":3,\"73\":1,\"103\":2,\"104\":1,\"124\":1,\"125\":1,\"137\":1,\"141\":2,\"148\":1,\"158\":1,\"159\":1,\"161\":2,\"165\":1,\"180\":1,\"183\":8,\"184\":1,\"185\":2,\"188\":1,\"192\":3,\"206\":3,\"213\":3,\"215\":4,\"216\":1,\"221\":7}}],[\"另外\",{\"1\":{\"183\":1,\"221\":1}}],[\"另谋出路\",{\"1\":{\"6\":1}}],[\"另\",{\"1\":{\"6\":1,\"45\":1,\"75\":1,\"164\":1,\"173\":1,\"192\":1}}],[\"触发\",{\"0\":{\"15\":1,\"17\":1},\"1\":{\"6\":2,\"7\":2,\"17\":1,\"98\":1,\"141\":1,\"143\":1,\"185\":1,\"212\":3,\"221\":2}}],[\"组中\",{\"1\":{\"221\":2}}],[\"组里\",{\"1\":{\"221\":1}}],[\"组成员\",{\"1\":{\"221\":1}}],[\"组成\",{\"1\":{\"221\":2}}],[\"组成部分\",{\"0\":{\"141\":1}}],[\"组织\",{\"1\":{\"183\":1}}],[\"组装\",{\"1\":{\"149\":2}}],[\"组\",{\"1\":{\"57\":1,\"76\":2,\"221\":3}}],[\"组和\",{\"1\":{\"56\":1}}],[\"组等\",{\"1\":{\"42\":1}}],[\"组件\",{\"1\":{\"6\":3,\"7\":1,\"41\":1,\"63\":7,\"72\":3,\"168\":1}}],[\"组合\",{\"1\":{\"4\":1,\"23\":1,\"133\":2,\"140\":1}}],[\"下会\",{\"1\":{\"221\":1}}],[\"下次\",{\"1\":{\"221\":1}}],[\"下有\",{\"1\":{\"221\":1}}],[\"下游\",{\"1\":{\"221\":2}}],[\"下一阶段\",{\"1\":{\"212\":1}}],[\"下官\",{\"1\":{\"198\":1}}],[\"下脏读\",{\"0\":{\"184\":1}}],[\"下图\",{\"1\":{\"125\":1,\"152\":2,\"170\":1,\"173\":1}}],[\"下方\",{\"1\":{\"114\":1}}],[\"下单\",{\"1\":{\"95\":1}}],[\"下来\",{\"1\":{\"89\":1,\"103\":1,\"116\":1,\"173\":1}}],[\"下半年\",{\"1\":{\"82\":1}}],[\"下班\",{\"1\":{\"76\":3,\"79\":1}}],[\"下午\",{\"1\":{\"75\":1}}],[\"下列\",{\"1\":{\"69\":1}}],[\"下降\",{\"1\":{\"45\":1,\"69\":1,\"221\":1}}],[\"下发\",{\"1\":{\"42\":1,\"45\":1}}],[\"下载\",{\"1\":{\"11\":1,\"151\":1,\"158\":1,\"169\":1,\"203\":1}}],[\"下\",{\"1\":{\"6\":2,\"7\":3,\"11\":1,\"25\":2,\"27\":1,\"28\":1,\"37\":1,\"39\":1,\"42\":1,\"44\":1,\"45\":1,\"48\":1,\"57\":1,\"63\":2,\"66\":1,\"72\":2,\"74\":1,\"78\":1,\"80\":1,\"87\":1,\"104\":1,\"114\":1,\"115\":1,\"117\":2,\"120\":1,\"124\":1,\"152\":1,\"158\":3,\"159\":3,\"160\":1,\"161\":1,\"164\":1,\"180\":2,\"184\":2,\"188\":1,\"192\":1,\"206\":1,\"212\":1,\"216\":1,\"221\":11}}],[\"下面\",{\"1\":{\"4\":1,\"8\":1,\"45\":1,\"98\":3,\"102\":1,\"114\":1,\"116\":1,\"117\":1,\"121\":1,\"122\":2,\"145\":2,\"149\":1,\"150\":1,\"152\":1,\"159\":2,\"161\":1,\"164\":1,\"165\":1,\"169\":1,\"173\":2,\"184\":1,\"185\":1}}],[\"为止\",{\"1\":{\"221\":1}}],[\"为妙\",{\"1\":{\"166\":1}}],[\"为主\",{\"1\":{\"161\":1,\"170\":1}}],[\"为例\",{\"1\":{\"151\":1}}],[\"为啥\",{\"0\":{\"108\":1},\"1\":{\"114\":1}}],[\"为空\",{\"1\":{\"103\":1,\"185\":3,\"212\":1}}],[\"为首\",{\"1\":{\"63\":1}}],[\"为此\",{\"1\":{\"56\":1}}],[\"为什么\",{\"1\":{\"11\":1,\"55\":1,\"76\":1,\"221\":6}}],[\"为\",{\"1\":{\"6\":1,\"25\":2,\"26\":14,\"28\":3,\"31\":2,\"34\":1,\"35\":2,\"43\":1,\"45\":1,\"50\":1,\"54\":1,\"56\":1,\"57\":1,\"58\":1,\"59\":1,\"63\":3,\"66\":1,\"68\":2,\"69\":1,\"70\":1,\"72\":1,\"76\":1,\"99\":1,\"103\":3,\"114\":2,\"115\":1,\"125\":3,\"137\":1,\"146\":1,\"147\":1,\"148\":1,\"149\":5,\"151\":1,\"152\":2,\"157\":2,\"158\":2,\"159\":1,\"160\":3,\"163\":3,\"164\":2,\"166\":1,\"168\":1,\"169\":1,\"173\":1,\"180\":1,\"181\":1,\"182\":1,\"184\":1,\"185\":5,\"207\":2,\"210\":1,\"212\":1,\"215\":1,\"221\":3}}],[\"为了\",{\"1\":{\"5\":1,\"7\":1,\"51\":1,\"69\":1,\"72\":1,\"73\":1,\"75\":1,\"114\":1,\"184\":1,\"190\":1,\"192\":1,\"203\":1,\"205\":1,\"221\":4}}],[\"以来\",{\"1\":{\"194\":2}}],[\"以至于\",{\"1\":{\"75\":1}}],[\"以为\",{\"1\":{\"45\":1,\"75\":1,\"120\":1,\"186\":1}}],[\"以便\",{\"1\":{\"30\":1,\"103\":1}}],[\"以前\",{\"1\":{\"26\":1,\"27\":1,\"167\":1}}],[\"以后\",{\"1\":{\"26\":1,\"27\":1,\"29\":3,\"39\":1,\"78\":1,\"86\":1,\"128\":2,\"130\":1,\"137\":1,\"157\":1,\"173\":2}}],[\"以\",{\"1\":{\"8\":1,\"26\":1,\"28\":3,\"54\":1,\"56\":2,\"63\":3,\"80\":1,\"85\":1,\"86\":1,\"116\":1,\"137\":1,\"149\":1,\"151\":1,\"158\":1,\"170\":1,\"192\":2,\"216\":2,\"221\":9}}],[\"以及\",{\"1\":{\"8\":2,\"38\":1,\"50\":1,\"84\":1,\"125\":1,\"133\":1,\"136\":2,\"147\":2,\"151\":1,\"171\":1,\"221\":1}}],[\"以下\",{\"1\":{\"6\":1,\"30\":1,\"38\":1,\"56\":1,\"72\":1}}],[\"以上\",{\"1\":{\"5\":1,\"18\":1,\"29\":1,\"37\":1,\"86\":1,\"221\":1}}],[\"很长\",{\"1\":{\"221\":1}}],[\"很少\",{\"1\":{\"192\":1}}],[\"很难\",{\"1\":{\"170\":1}}],[\"很小\",{\"1\":{\"161\":1}}],[\"很坑\",{\"1\":{\"114\":1}}],[\"很快\",{\"1\":{\"87\":1,\"135\":1}}],[\"很烦\",{\"1\":{\"81\":3}}],[\"很想\",{\"1\":{\"75\":1}}],[\"很不舍\",{\"1\":{\"73\":1}}],[\"很久\",{\"1\":{\"7\":1}}],[\"很\",{\"1\":{\"6\":1,\"45\":1,\"73\":3,\"74\":6,\"76\":1,\"80\":2,\"85\":2,\"86\":4,\"87\":2,\"90\":1,\"99\":1,\"102\":3,\"114\":1,\"118\":1,\"127\":1,\"149\":2,\"151\":2,\"161\":1,\"170\":1,\"171\":2,\"188\":2,\"221\":3}}],[\"很大\",{\"1\":{\"6\":1,\"38\":1,\"87\":1}}],[\"很多\",{\"1\":{\"6\":1,\"18\":1,\"44\":1,\"73\":2,\"99\":1,\"103\":1,\"116\":1,\"120\":1,\"124\":2,\"148\":1,\"171\":1,\"173\":1}}],[\"花费\",{\"1\":{\"38\":1}}],[\"花\",{\"1\":{\"6\":1,\"38\":1,\"74\":1,\"76\":1,\"78\":1,\"171\":1}}],[\"着急\",{\"1\":{\"73\":1}}],[\"着重强调\",{\"1\":{\"86\":1}}],[\"着重\",{\"1\":{\"45\":1,\"221\":1}}],[\"着\",{\"1\":{\"6\":1,\"73\":2,\"74\":2,\"75\":2,\"76\":1,\"78\":1,\"79\":2,\"80\":1,\"82\":1}}],[\"就算\",{\"1\":{\"165\":1}}],[\"就有\",{\"1\":{\"165\":1}}],[\"就近\",{\"1\":{\"152\":1}}],[\"就让\",{\"1\":{\"74\":1}}],[\"就行了\",{\"1\":{\"166\":1}}],[\"就行\",{\"1\":{\"74\":1,\"152\":1}}],[\"就要\",{\"1\":{\"8\":1,\"221\":1}}],[\"就\",{\"1\":{\"6\":2,\"7\":2,\"10\":1,\"11\":2,\"12\":2,\"39\":1,\"41\":1,\"42\":2,\"44\":2,\"46\":1,\"50\":3,\"51\":1,\"52\":5,\"63\":2,\"73\":1,\"74\":5,\"75\":1,\"76\":3,\"77\":1,\"78\":2,\"80\":4,\"81\":2,\"82\":1,\"84\":2,\"85\":7,\"86\":4,\"87\":3,\"89\":1,\"97\":3,\"98\":1,\"102\":2,\"103\":3,\"104\":2,\"106\":2,\"113\":1,\"114\":1,\"115\":1,\"118\":1,\"120\":2,\"121\":2,\"124\":3,\"128\":1,\"132\":1,\"135\":2,\"143\":1,\"145\":2,\"148\":1,\"149\":1,\"150\":1,\"152\":3,\"157\":3,\"158\":1,\"162\":1,\"165\":1,\"166\":1,\"181\":1,\"185\":2,\"188\":1,\"192\":3,\"194\":1,\"198\":1,\"203\":1,\"206\":1,\"220\":2,\"221\":10}}],[\"就是\",{\"1\":{\"5\":2,\"7\":1,\"8\":1,\"46\":1,\"55\":1,\"61\":2,\"63\":2,\"68\":1,\"70\":2,\"76\":2,\"80\":1,\"81\":1,\"85\":1,\"86\":3,\"87\":2,\"89\":1,\"103\":1,\"117\":1,\"121\":1,\"122\":1,\"127\":1,\"135\":1,\"148\":1,\"149\":2,\"151\":1,\"152\":1,\"161\":3,\"164\":1,\"166\":2,\"168\":1,\"170\":1,\"189\":1,\"206\":1,\"221\":3}}],[\"上图\",{\"0\":{\"213\":1}}],[\"上时\",{\"1\":{\"205\":1}}],[\"上游\",{\"1\":{\"159\":3}}],[\"上流\",{\"1\":{\"157\":2}}],[\"上求\",{\"1\":{\"128\":1}}],[\"上架\",{\"1\":{\"114\":1}}],[\"上线\",{\"1\":{\"106\":1}}],[\"上下文\",{\"1\":{\"104\":1,\"141\":1}}],[\"上半年\",{\"1\":{\"87\":1}}],[\"上去\",{\"1\":{\"75\":1,\"76\":1}}],[\"上次\",{\"1\":{\"75\":1,\"221\":1}}],[\"上网\",{\"1\":{\"74\":1}}],[\"上机\",{\"1\":{\"74\":1}}],[\"上报\",{\"1\":{\"58\":1,\"65\":3}}],[\"上千\",{\"1\":{\"51\":1}}],[\"上涨\",{\"1\":{\"46\":1}}],[\"上述\",{\"1\":{\"28\":1}}],[\"上传\",{\"0\":{\"11\":1}}],[\"上\",{\"1\":{\"6\":1,\"7\":1,\"18\":1,\"23\":1,\"38\":1,\"42\":2,\"49\":1,\"55\":1,\"62\":1,\"70\":2,\"72\":4,\"73\":1,\"75\":1,\"78\":1,\"80\":1,\"86\":2,\"89\":1,\"93\":1,\"98\":1,\"101\":1,\"103\":1,\"120\":1,\"122\":1,\"124\":3,\"127\":1,\"130\":1,\"135\":2,\"141\":1,\"144\":1,\"145\":2,\"150\":1,\"151\":1,\"155\":1,\"157\":1,\"158\":1,\"161\":8,\"164\":1,\"165\":2,\"166\":1,\"169\":1,\"173\":1,\"183\":1,\"185\":1,\"189\":1,\"192\":1,\"205\":1,\"211\":1,\"221\":13}}],[\"上级\",{\"1\":{\"6\":1}}],[\"上面\",{\"0\":{\"212\":1},\"1\":{\"6\":1,\"30\":4,\"39\":1,\"45\":1,\"160\":1,\"164\":1,\"203\":1}}],[\"之家\",{\"1\":{\"124\":1}}],[\"之道\",{\"1\":{\"77\":1}}],[\"之处\",{\"1\":{\"76\":1}}],[\"之\",{\"0\":{\"144\":1},\"1\":{\"74\":1}}],[\"之一\",{\"1\":{\"74\":1,\"77\":1}}],[\"之下\",{\"1\":{\"74\":1,\"120\":1}}],[\"之类\",{\"1\":{\"63\":1,\"73\":1,\"152\":1}}],[\"之所以\",{\"1\":{\"57\":1}}],[\"之外\",{\"1\":{\"7\":1,\"57\":1,\"144\":1,\"149\":1}}],[\"之前\",{\"1\":{\"7\":2,\"52\":1,\"70\":1,\"73\":1,\"75\":1,\"80\":1,\"103\":2,\"114\":1,\"156\":1,\"161\":1,\"173\":1,\"186\":1,\"221\":3}}],[\"之后\",{\"0\":{\"6\":1},\"1\":{\"6\":1,\"7\":2,\"8\":2,\"13\":1,\"41\":1,\"43\":1,\"45\":1,\"66\":2,\"72\":2,\"76\":1,\"80\":1,\"83\":1,\"86\":2,\"95\":1,\"97\":2,\"101\":1,\"102\":2,\"104\":2,\"106\":1,\"114\":2,\"117\":1,\"120\":1,\"124\":3,\"132\":1,\"146\":1,\"148\":1,\"151\":2,\"152\":2,\"157\":4,\"159\":1,\"163\":1,\"164\":1,\"170\":2,\"188\":1,\"191\":1,\"203\":1,\"206\":1,\"207\":3,\"211\":1,\"212\":1,\"213\":2,\"221\":2}}],[\"之间\",{\"1\":{\"4\":1,\"54\":1,\"57\":2,\"63\":1,\"69\":1,\"72\":1,\"74\":1,\"104\":1,\"124\":1,\"221\":6}}],[\"二级缓存\",{\"0\":{\"180\":1,\"181\":1,\"182\":1,\"183\":1},\"1\":{\"178\":1,\"180\":4,\"182\":2,\"183\":4,\"184\":1,\"192\":2}}],[\"二战\",{\"1\":{\"78\":1}}],[\"二进制\",{\"1\":{\"48\":1,\"161\":7}}],[\"二面\",{\"1\":{\"23\":1,\"74\":1,\"75\":1,\"80\":1}}],[\"二\",{\"0\":{\"6\":1,\"27\":1,\"55\":1,\"63\":1,\"98\":1,\"136\":1,\"141\":1,\"199\":1},\"1\":{\"13\":1,\"161\":1,\"216\":1}}],[\"numshards\",{\"1\":{\"212\":1}}],[\"numberofshards\",{\"1\":{\"215\":1}}],[\"number\",{\"1\":{\"13\":1}}],[\"null\",{\"1\":{\"66\":1,\"68\":1,\"135\":1,\"137\":5,\"151\":1,\"189\":3,\"208\":1,\"212\":3,\"216\":3}}],[\"nil\",{\"1\":{\"65\":2}}],[\"nioeventloopgroup\",{\"1\":{\"45\":1}}],[\"nioeventloop\",{\"1\":{\"45\":4}}],[\"nio\",{\"1\":{\"45\":1,\"46\":1}}],[\"nginx\",{\"0\":{\"98\":1,\"153\":1,\"154\":1},\"1\":{\"63\":1,\"96\":1,\"98\":1,\"120\":3,\"122\":1,\"152\":3,\"153\":16,\"155\":2,\"157\":7,\"158\":3,\"159\":2,\"160\":1,\"161\":1,\"178\":2}}],[\"na\",{\"1\":{\"118\":1,\"120\":1,\"121\":1}}],[\"native\",{\"1\":{\"51\":1}}],[\"names\",{\"1\":{\"163\":1,\"164\":1,\"214\":1,\"216\":1}}],[\"namespaces\",{\"1\":{\"65\":1}}],[\"namespace\",{\"1\":{\"12\":5,\"13\":5,\"65\":2,\"72\":5,\"180\":2}}],[\"name\",{\"1\":{\"5\":6,\"12\":7,\"13\":7,\"56\":2,\"72\":2,\"137\":2,\"143\":5,\"149\":4,\"150\":1,\"151\":8,\"158\":1,\"159\":12,\"182\":1,\"187\":14,\"214\":2,\"216\":2}}],[\"noop\",{\"1\":{\"216\":1}}],[\"nosql\",{\"1\":{\"194\":1}}],[\"nosuchbeandefinitionexception\",{\"1\":{\"144\":1}}],[\"normal\",{\"1\":{\"151\":1}}],[\"no\",{\"1\":{\"144\":2,\"170\":1}}],[\"node3\",{\"1\":{\"207\":5}}],[\"nodeclient\",{\"1\":{\"206\":1}}],[\"node\",{\"1\":{\"100\":2,\"211\":3}}],[\"nodes\",{\"1\":{\"72\":2,\"196\":2}}],[\"nodeqpslimit\",{\"1\":{\"66\":3}}],[\"notifyfetchfailure\",{\"1\":{\"212\":1}}],[\"notifyfetchresult\",{\"1\":{\"212\":2}}],[\"notifier\",{\"1\":{\"5\":1}}],[\"notifications\",{\"1\":{\"5\":1}}],[\"not\",{\"1\":{\"72\":1,\"98\":1}}],[\"nopreferdirect\",{\"1\":{\"46\":1}}],[\"none\",{\"1\":{\"43\":1}}],[\"nextreplicashift\",{\"1\":{\"221\":1}}],[\"nextornull\",{\"1\":{\"209\":1}}],[\"next\",{\"1\":{\"137\":2}}],[\"nexus\",{\"1\":{\"7\":1}}],[\"never\",{\"1\":{\"72\":1}}],[\"net\",{\"1\":{\"72\":3,\"144\":1,\"164\":1,\"196\":2,\"220\":1}}],[\"netty4httpservertransport\",{\"1\":{\"206\":1}}],[\"netty4httpchannel\",{\"1\":{\"206\":1,\"216\":2}}],[\"netty4httprequesthandler\",{\"1\":{\"206\":3}}],[\"netty\",{\"0\":{\"45\":1},\"1\":{\"45\":5,\"46\":3,\"51\":1,\"81\":1,\"87\":1}}],[\"netstat\",{\"1\":{\"43\":1,\"153\":1}}],[\"newsearchphaseresults\",{\"1\":{\"206\":1}}],[\"newsize\",{\"1\":{\"31\":1}}],[\"newinstance\",{\"1\":{\"141\":1}}],[\"newblog\",{\"1\":{\"122\":1,\"130\":1,\"145\":1,\"151\":2,\"152\":1,\"160\":1,\"165\":1,\"173\":1,\"192\":1}}],[\"newbuilder\",{\"1\":{\"66\":1}}],[\"newleaderelector\",{\"1\":{\"72\":1}}],[\"newvirtualthreadpertaskexecutor\",{\"1\":{\"56\":2}}],[\"new\",{\"1\":{\"30\":2,\"56\":1,\"72\":4,\"101\":2,\"135\":19,\"137\":15,\"143\":5,\"144\":1,\"151\":1,\"188\":1,\"190\":1,\"196\":1,\"197\":1,\"206\":5,\"207\":1,\"208\":1,\"210\":1,\"212\":1,\"214\":2,\"216\":2}}],[\"newratio\",{\"1\":{\"26\":2,\"29\":1,\"31\":1}}],[\"n\",{\"1\":{\"12\":2,\"13\":2,\"23\":3,\"31\":4,\"34\":4,\"35\":1,\"43\":1,\"48\":3,\"72\":2,\"101\":1,\"104\":2,\"221\":2}}],[\"f725401d7318\",{\"1\":{\"160\":2}}],[\"f7e34845b5\",{\"1\":{\"149\":1}}],[\"f91\",{\"1\":{\"160\":2}}],[\"f9e2\",{\"1\":{\"64\":1}}],[\"fsdirectory\",{\"1\":{\"135\":2,\"137\":2}}],[\"flushinterval\",{\"1\":{\"182\":1}}],[\"flushcacheifrequired\",{\"1\":{\"179\":1}}],[\"flume\",{\"1\":{\"74\":1,\"81\":1,\"221\":1}}],[\"flask\",{\"1\":{\"124\":1,\"127\":1}}],[\"fleet\",{\"1\":{\"117\":1,\"118\":1,\"120\":1,\"121\":1}}],[\"fetchresult\",{\"1\":{\"216\":1}}],[\"fetchresults\",{\"1\":{\"212\":1}}],[\"fetchphase\",{\"1\":{\"216\":2}}],[\"fetchsearchresult\",{\"1\":{\"212\":2,\"216\":1}}],[\"fetchsearchrequest\",{\"1\":{\"212\":2}}],[\"fetchsearchphase\",{\"0\":{\"212\":1},\"1\":{\"206\":1,\"212\":6}}],[\"fetch\",{\"0\":{\"211\":1,\"214\":1,\"216\":1},\"1\":{\"205\":2,\"206\":3,\"212\":3,\"216\":6,\"221\":1}}],[\"feature\",{\"1\":{\"151\":1}}],[\"fewfew\",{\"1\":{\"72\":1}}],[\"feed\",{\"1\":{\"23\":1}}],[\"family\",{\"1\":{\"166\":1}}],[\"failed\",{\"1\":{\"205\":1,\"206\":1}}],[\"fail\",{\"1\":{\"159\":4}}],[\"fails\",{\"1\":{\"159\":3}}],[\"factory\",{\"1\":{\"144\":3}}],[\"fabric8\",{\"1\":{\"72\":2}}],[\"false\",{\"1\":{\"5\":1,\"43\":2,\"68\":1,\"137\":1,\"143\":1,\"151\":3,\"185\":2,\"203\":1,\"205\":1,\"206\":2,\"208\":1,\"209\":1,\"212\":1,\"215\":1}}],[\"follower\",{\"1\":{\"221\":2}}],[\"fonts\",{\"1\":{\"166\":1}}],[\"font\",{\"1\":{\"135\":4}}],[\"found\",{\"1\":{\"72\":1,\"98\":1}}],[\"forwarded\",{\"1\":{\"156\":1,\"157\":10}}],[\"form\",{\"1\":{\"118\":1}}],[\"format\",{\"1\":{\"44\":1,\"144\":1,\"156\":1,\"163\":1}}],[\"fork\",{\"1\":{\"101\":1}}],[\"forkjoinpool\",{\"1\":{\"56\":1}}],[\"foreach\",{\"1\":{\"72\":1,\"151\":2,\"197\":1}}],[\"forbidden\",{\"1\":{\"72\":1}}],[\"for\",{\"1\":{\"30\":1,\"135\":2,\"137\":1,\"149\":6,\"150\":1,\"156\":1,\"157\":10,\"188\":1,\"190\":1,\"209\":1,\"212\":1}}],[\"forcepull\",{\"1\":{\"5\":2}}],[\"f6510bd\",{\"1\":{\"69\":1}}],[\"fulshardexecution\",{\"1\":{\"210\":1}}],[\"fullpath\",{\"1\":{\"135\":1}}],[\"full\",{\"1\":{\"30\":1,\"39\":1,\"72\":1}}],[\"function\",{\"1\":{\"101\":1,\"104\":1,\"146\":1}}],[\"func\",{\"1\":{\"65\":1,\"72\":2}}],[\"f5\",{\"1\":{\"63\":1,\"152\":1}}],[\"firstresult\",{\"1\":{\"210\":2}}],[\"fifo\",{\"1\":{\"183\":1}}],[\"fifteenago\",{\"1\":{\"147\":2,\"150\":2}}],[\"fixedrate\",{\"1\":{\"144\":1}}],[\"field\",{\"1\":{\"133\":2,\"135\":4}}],[\"finish\",{\"1\":{\"216\":1}}],[\"finishphase\",{\"1\":{\"212\":2}}],[\"finishregistration\",{\"1\":{\"144\":1}}],[\"fine\",{\"1\":{\"108\":1}}],[\"findall\",{\"1\":{\"104\":1}}],[\"findone\",{\"1\":{\"103\":1}}],[\"finalindicesmap\",{\"1\":{\"208\":1}}],[\"finalindices\",{\"1\":{\"208\":3}}],[\"finally\",{\"1\":{\"206\":2,\"216\":1}}],[\"final\",{\"1\":{\"57\":1,\"66\":2,\"137\":1,\"197\":3,\"206\":2,\"208\":1,\"209\":1,\"210\":1,\"212\":6,\"215\":1}}],[\"filterchain\",{\"1\":{\"68\":5}}],[\"filter\",{\"0\":{\"68\":1},\"1\":{\"64\":1,\"68\":1,\"125\":1,\"159\":12}}],[\"filesystemxmlapplicationcontext\",{\"1\":{\"190\":1}}],[\"file\",{\"1\":{\"44\":1,\"120\":1,\"142\":1,\"143\":2,\"153\":2,\"163\":2,\"164\":2,\"221\":1}}],[\"filename\",{\"1\":{\"30\":1,\"33\":1}}],[\"fri\",{\"1\":{\"143\":1}}],[\"fragmenter\",{\"1\":{\"135\":3}}],[\"framework\",{\"1\":{\"56\":1}}],[\"fr\",{\"1\":{\"41\":2}}],[\"fromuser\",{\"1\":{\"103\":3,\"104\":1}}],[\"fromusername\",{\"1\":{\"101\":3,\"103\":4,\"104\":2}}],[\"from\",{\"1\":{\"30\":2,\"101\":2,\"207\":2}}],[\"f\",{\"1\":{\"11\":1,\"13\":1,\"48\":2,\"72\":2,\"120\":1,\"160\":1}}],[\"rdbms\",{\"1\":{\"194\":1}}],[\"rdd\",{\"0\":{\"195\":1},\"1\":{\"194\":1}}],[\"rc4\",{\"1\":{\"158\":1}}],[\"rfc\",{\"1\":{\"157\":1}}],[\"rpm\",{\"1\":{\"153\":5}}],[\"rpc\",{\"1\":{\"45\":2}}],[\"rgba\",{\"1\":{\"151\":1}}],[\"rukouyemian\",{\"1\":{\"149\":1}}],[\"runtimeexception\",{\"1\":{\"72\":1,\"137\":1}}],[\"running\",{\"1\":{\"72\":2}}],[\"runnable\",{\"1\":{\"56\":1,\"212\":1}}],[\"runner\",{\"1\":{\"7\":1,\"17\":1,\"72\":2}}],[\"run\",{\"1\":{\"5\":1,\"163\":1,\"164\":1,\"203\":3,\"206\":1,\"209\":1,\"212\":2,\"213\":2}}],[\"r\",{\"1\":{\"149\":3}}],[\"radius\",{\"1\":{\"170\":1}}],[\"range\",{\"1\":{\"149\":1,\"205\":1}}],[\"ratio\",{\"1\":{\"149\":4,\"150\":1,\"151\":3}}],[\"ratelimiterfilter\",{\"1\":{\"68\":1}}],[\"ratelimiterservice\",{\"1\":{\"66\":1,\"68\":3}}],[\"ratelimiter\",{\"0\":{\"66\":1,\"67\":1},\"1\":{\"63\":3,\"64\":3,\"66\":16,\"67\":2,\"68\":6,\"69\":1,\"70\":1}}],[\"ratelimiting\",{\"1\":{\"59\":1}}],[\"race\",{\"1\":{\"103\":2}}],[\"rabbitmq\",{\"1\":{\"76\":2,\"221\":1}}],[\"rsa\",{\"1\":{\"74\":1,\"158\":1}}],[\"right\",{\"1\":{\"74\":1,\"151\":1}}],[\"rbac\",{\"1\":{\"72\":4}}],[\"rw\",{\"1\":{\"30\":2,\"48\":1}}],[\"ronresponse\",{\"1\":{\"210\":1}}],[\"rongqiyun\",{\"1\":{\"13\":2}}],[\"role\",{\"1\":{\"203\":1}}],[\"rowbounds\",{\"1\":{\"179\":1}}],[\"row\",{\"1\":{\"163\":1}}],[\"robin\",{\"1\":{\"155\":1}}],[\"round\",{\"1\":{\"155\":1}}],[\"roam\",{\"1\":{\"151\":1}}],[\"rotate\",{\"1\":{\"98\":1}}],[\"ro\",{\"1\":{\"30\":2}}],[\"root\",{\"1\":{\"11\":1,\"120\":2,\"153\":3,\"155\":1,\"157\":1,\"162\":1,\"164\":1}}],[\"rm\",{\"1\":{\"11\":1}}],[\"reblance\",{\"1\":{\"221\":1}}],[\"remainingopsoniterator\",{\"1\":{\"210\":1}}],[\"remotesharditerators\",{\"1\":{\"208\":1}}],[\"remote\",{\"1\":{\"137\":4,\"156\":1,\"157\":7,\"203\":1}}],[\"rewriteandfetchshardrequest\",{\"1\":{\"215\":1}}],[\"rewrite\",{\"1\":{\"158\":1}}],[\"reason\",{\"1\":{\"198\":1}}],[\"real\",{\"1\":{\"157\":5}}],[\"readonly\",{\"1\":{\"151\":1,\"182\":1}}],[\"reader\",{\"1\":{\"135\":3}}],[\"read\",{\"1\":{\"48\":1,\"148\":1,\"150\":1,\"164\":1,\"221\":2}}],[\"referer\",{\"1\":{\"156\":2}}],[\"ref\",{\"1\":{\"143\":3,\"159\":2,\"187\":3}}],[\"refreshafterwrite\",{\"1\":{\"66\":2}}],[\"relation\",{\"1\":{\"205\":1}}],[\"relay\",{\"1\":{\"161\":1,\"164\":2}}],[\"reload\",{\"1\":{\"153\":1}}],[\"rel\",{\"1\":{\"137\":1}}],[\"releaseirrelevantsearchcontext\",{\"1\":{\"212\":1}}],[\"release\",{\"1\":{\"7\":1,\"72\":1,\"143\":1,\"159\":1,\"206\":1}}],[\"regions\",{\"1\":{\"137\":3}}],[\"registerrequesthandler\",{\"1\":{\"214\":3,\"216\":2}}],[\"register\",{\"0\":{\"120\":1}}],[\"registry\",{\"1\":{\"5\":2,\"7\":1}}],[\"reducedqueryphase\",{\"1\":{\"212\":3}}],[\"reduce\",{\"1\":{\"194\":1,\"212\":1}}],[\"red\",{\"1\":{\"135\":2}}],[\"redisoperations\",{\"1\":{\"187\":1}}],[\"rediscachemanager\",{\"1\":{\"187\":1}}],[\"redisdesktopmanager\",{\"1\":{\"159\":1}}],[\"redishttpsessionconfiguration\",{\"1\":{\"159\":2}}],[\"redistemplate\",{\"1\":{\"159\":1,\"187\":2}}],[\"redis\",{\"1\":{\"63\":4,\"69\":3,\"76\":1,\"124\":1,\"126\":1,\"149\":7,\"151\":3,\"159\":9,\"177\":1,\"178\":1,\"183\":2,\"184\":5,\"186\":1,\"187\":10,\"191\":3,\"192\":2,\"194\":2}}],[\"rejected\",{\"1\":{\"114\":1}}],[\"required\",{\"1\":{\"221\":1}}],[\"require\",{\"1\":{\"215\":1}}],[\"requestfilterchain\",{\"1\":{\"206\":1}}],[\"requestfailure\",{\"1\":{\"72\":1}}],[\"requests\",{\"1\":{\"68\":2}}],[\"request\",{\"1\":{\"68\":5,\"103\":3,\"104\":3,\"118\":2,\"137\":2,\"148\":3,\"150\":4,\"156\":1,\"157\":1,\"159\":1,\"206\":3,\"207\":2,\"214\":3,\"215\":6,\"216\":3,\"221\":1}}],[\"requestmapping\",{\"1\":{\"56\":1,\"57\":1,\"137\":1}}],[\"req\",{\"1\":{\"101\":4,\"148\":2,\"150\":2}}],[\"retention\",{\"1\":{\"221\":1}}],[\"retryperiod\",{\"1\":{\"72\":1}}],[\"return\",{\"1\":{\"56\":3,\"65\":2,\"66\":1,\"67\":1,\"101\":1,\"103\":2,\"104\":1,\"137\":15,\"148\":1,\"150\":1,\"188\":1,\"189\":3,\"196\":1,\"206\":1,\"208\":1}}],[\"returnstdout\",{\"1\":{\"11\":1,\"12\":1,\"13\":2}}],[\"renewdeadline\",{\"1\":{\"72\":1}}],[\"rescorephase\",{\"1\":{\"215\":2}}],[\"rescore\",{\"1\":{\"215\":2}}],[\"resultconsumer\",{\"1\":{\"212\":1}}],[\"result\",{\"1\":{\"149\":4,\"150\":5,\"210\":4,\"212\":3}}],[\"res\",{\"1\":{\"101\":3}}],[\"resourcelock\",{\"1\":{\"72\":1}}],[\"resource\",{\"1\":{\"68\":1,\"197\":1}}],[\"responses\",{\"1\":{\"215\":1}}],[\"responsetime\",{\"1\":{\"156\":1}}],[\"response\",{\"1\":{\"68\":5,\"101\":2,\"103\":4,\"104\":2,\"121\":1,\"137\":2,\"148\":2,\"150\":2,\"156\":1,\"206\":5,\"221\":1}}],[\"restresponse\",{\"1\":{\"216\":2}}],[\"restresponselistener\",{\"1\":{\"216\":1}}],[\"restactionlistener\",{\"1\":{\"216\":1}}],[\"restartpolicy\",{\"1\":{\"72\":1}}],[\"restsearchaction\",{\"1\":{\"207\":1}}],[\"restchannelconsumer\",{\"1\":{\"207\":1}}],[\"restcancellablenodeclient\",{\"1\":{\"206\":2,\"216\":1}}],[\"restcontroller\",{\"1\":{\"56\":1,\"57\":1,\"206\":1,\"216\":1}}],[\"restore\",{\"1\":{\"151\":1}}],[\"restful\",{\"1\":{\"124\":1,\"127\":1}}],[\"rest\",{\"1\":{\"57\":1,\"65\":1}}],[\"repeat\",{\"1\":{\"170\":1}}],[\"replicate\",{\"1\":{\"164\":1}}],[\"replicas\",{\"1\":{\"65\":1,\"66\":5}}],[\"replace\",{\"1\":{\"147\":2,\"150\":2}}],[\"reportservice\",{\"1\":{\"147\":1,\"149\":1,\"150\":2}}],[\"reportcurrenttime\",{\"1\":{\"144\":1}}],[\"repo\",{\"1\":{\"12\":1,\"13\":1,\"72\":1}}],[\"repotag\",{\"1\":{\"5\":2}}],[\"reponame\",{\"1\":{\"5\":2}}],[\"rev\",{\"1\":{\"11\":1,\"13\":1}}],[\"v3\",{\"1\":{\"118\":1}}],[\"vn\",{\"1\":{\"117\":1,\"118\":1,\"120\":1,\"121\":1}}],[\"vjuv1z3nbbemx9qjzrlzt3blbkfjkapjvqujfr2wi8cxserq\",{\"1\":{\"101\":1}}],[\"vertical\",{\"1\":{\"151\":2}}],[\"verticalalign\",{\"1\":{\"151\":1}}],[\"version\",{\"1\":{\"72\":2,\"135\":15,\"137\":2,\"143\":6,\"159\":5,\"196\":2}}],[\"vehicle\",{\"1\":{\"118\":3,\"120\":2}}],[\"ve\",{\"1\":{\"98\":1}}],[\"vpn\",{\"1\":{\"96\":1}}],[\"vuejs\",{\"1\":{\"74\":1}}],[\"volcano\",{\"1\":{\"72\":1}}],[\"volatile\",{\"1\":{\"23\":1,\"52\":2}}],[\"void\",{\"1\":{\"57\":1,\"68\":1,\"135\":1,\"137\":2,\"144\":1,\"190\":1,\"197\":1,\"198\":1,\"206\":4,\"208\":1,\"210\":5,\"212\":5,\"214\":1,\"215\":2,\"216\":2}}],[\"vim\",{\"1\":{\"163\":1,\"164\":1}}],[\"visualmap\",{\"1\":{\"151\":1}}],[\"visit\",{\"1\":{\"149\":5,\"150\":1}}],[\"visitor\",{\"1\":{\"149\":7,\"150\":1,\"151\":8}}],[\"viewtype\",{\"1\":{\"149\":2}}],[\"views\",{\"1\":{\"48\":1}}],[\"virtualthread\",{\"1\":{\"56\":1}}],[\"virtual\",{\"1\":{\"56\":2}}],[\"valueof\",{\"1\":{\"135\":1}}],[\"valueserializer\",{\"1\":{\"187\":1}}],[\"valuesuffix\",{\"1\":{\"151\":1}}],[\"values\",{\"1\":{\"72\":1,\"211\":2}}],[\"value\",{\"1\":{\"56\":1,\"68\":1,\"143\":2,\"149\":1,\"151\":2,\"159\":6,\"182\":1,\"185\":17,\"187\":7,\"189\":2,\"205\":1,\"221\":2}}],[\"var\",{\"1\":{\"5\":1,\"146\":3,\"151\":3,\"163\":4,\"164\":4}}],[\"v\",{\"1\":{\"13\":1}}],[\"v1beta2\",{\"1\":{\"72\":1}}],[\"v1\",{\"1\":{\"5\":1,\"98\":3,\"101\":1,\"147\":1,\"149\":1,\"150\":2}}],[\"iblogservice\",{\"1\":{\"190\":2}}],[\"ibatis\",{\"1\":{\"182\":1,\"183\":1}}],[\"ibm\",{\"1\":{\"138\":1}}],[\"ignore\",{\"1\":{\"163\":3,\"164\":3}}],[\"ivh\",{\"1\":{\"153\":1}}],[\"iamyida\",{\"1\":{\"138\":1}}],[\"isr\",{\"1\":{\"221\":12}}],[\"iscounteddown\",{\"1\":{\"212\":1}}],[\"isscrollsearch\",{\"1\":{\"212\":1}}],[\"isdebugenabled\",{\"1\":{\"206\":1}}],[\"iso8601\",{\"1\":{\"156\":1}}],[\"isauth\",{\"1\":{\"143\":2}}],[\"isempty\",{\"1\":{\"137\":1}}],[\"is\",{\"1\":{\"98\":1,\"144\":1,\"153\":2}}],[\"img\",{\"1\":{\"217\":1}}],[\"immutablelist\",{\"1\":{\"198\":1}}],[\"impl\",{\"1\":{\"182\":1,\"188\":1}}],[\"implements\",{\"1\":{\"68\":1,\"137\":2,\"188\":1}}],[\"import\",{\"1\":{\"150\":5}}],[\"imagepullpolicy\",{\"1\":{\"72\":1}}],[\"imagepullsecrets\",{\"1\":{\"12\":1,\"13\":1}}],[\"image\",{\"1\":{\"7\":1,\"11\":1,\"12\":4,\"13\":6,\"57\":3,\"61\":1,\"72\":2,\"131\":1,\"170\":1,\"205\":1,\"213\":1}}],[\"i\",{\"1\":{\"57\":1,\"161\":4,\"190\":3,\"209\":4,\"212\":6}}],[\"ids\",{\"1\":{\"211\":1}}],[\"idea\",{\"1\":{\"203\":2}}],[\"id\",{\"1\":{\"56\":1,\"103\":1,\"115\":1,\"118\":4,\"143\":3,\"151\":1,\"159\":4,\"163\":2,\"164\":2,\"187\":3,\"192\":2,\"205\":1,\"207\":1,\"211\":3,\"221\":2}}],[\"ioexception\",{\"1\":{\"68\":1,\"135\":1,\"137\":4}}],[\"io\",{\"1\":{\"45\":2,\"50\":1,\"63\":1,\"72\":4,\"221\":1}}],[\"ipfilter\",{\"1\":{\"125\":2}}],[\"ip\",{\"1\":{\"43\":1,\"63\":1,\"64\":1,\"66\":1,\"96\":1,\"98\":2,\"102\":1,\"107\":1,\"125\":1,\"149\":8,\"150\":1,\"152\":2,\"155\":3,\"157\":21,\"160\":1}}],[\"iptables\",{\"1\":{\"41\":3}}],[\"if\",{\"1\":{\"12\":1,\"13\":2,\"65\":1,\"66\":2,\"68\":2,\"101\":1,\"103\":2,\"137\":3,\"143\":1,\"149\":3,\"150\":1,\"189\":1,\"206\":2,\"210\":2,\"212\":3,\"215\":1,\"216\":2}}],[\"inneronresponse\",{\"1\":{\"212\":1}}],[\"innerrun\",{\"1\":{\"212\":4}}],[\"inne\",{\"1\":{\"210\":1}}],[\"incomingrequest\",{\"1\":{\"206\":2}}],[\"insert\",{\"1\":{\"161\":1}}],[\"insertbefore\",{\"1\":{\"146\":1}}],[\"instances\",{\"1\":{\"72\":1}}],[\"install\",{\"1\":{\"5\":1,\"11\":1,\"12\":1,\"13\":2,\"72\":2}}],[\"invokelistener\",{\"1\":{\"144\":1}}],[\"invocations\",{\"1\":{\"30\":2}}],[\"invalid\",{\"1\":{\"114\":1}}],[\"indexsort\",{\"1\":{\"215\":1}}],[\"indexshard\",{\"1\":{\"215\":1}}],[\"indexsearcher\",{\"1\":{\"135\":2}}],[\"indexreader\",{\"1\":{\"135\":1}}],[\"indexwriter\",{\"1\":{\"135\":3}}],[\"indexwriterconfig\",{\"1\":{\"135\":2}}],[\"index\",{\"1\":{\"101\":1,\"135\":3,\"155\":3,\"157\":3,\"205\":1,\"221\":3}}],[\"ing\",{\"1\":{\"77\":1}}],[\"intarraylist\",{\"1\":{\"212\":1}}],[\"int\",{\"1\":{\"66\":2,\"137\":1,\"190\":1,\"209\":2,\"210\":1,\"212\":2}}],[\"interview\",{\"0\":{\"223\":1}}],[\"internalscrollsearchrequest\",{\"1\":{\"216\":1}}],[\"internalresourceviewresolver\",{\"1\":{\"125\":2}}],[\"interface\",{\"1\":{\"103\":1}}],[\"interruptedexception\",{\"1\":{\"57\":1,\"72\":1}}],[\"integer\",{\"1\":{\"66\":2,\"189\":1}}],[\"int32\",{\"1\":{\"65\":1}}],[\"information\",{\"1\":{\"163\":1,\"164\":1}}],[\"info\",{\"1\":{\"57\":1,\"66\":2,\"144\":1,\"189\":1}}],[\"inputstreamreader\",{\"1\":{\"143\":1}}],[\"inputstream\",{\"1\":{\"143\":1}}],[\"inputiterator\",{\"1\":{\"137\":3}}],[\"input\",{\"1\":{\"41\":1,\"137\":1}}],[\"initial\",{\"1\":{\"205\":1}}],[\"init\",{\"1\":{\"12\":1,\"13\":1,\"143\":1,\"148\":1,\"150\":1,\"151\":1,\"163\":1,\"164\":1,\"190\":1}}],[\"in\",{\"1\":{\"11\":1,\"51\":1,\"98\":2,\"149\":6,\"150\":1}}],[\"items\",{\"1\":{\"150\":1,\"151\":1}}],[\"item\",{\"1\":{\"149\":6,\"151\":1}}],[\"iteye\",{\"1\":{\"138\":1}}],[\"iterator\",{\"1\":{\"137\":3}}],[\"it\",{\"1\":{\"4\":1,\"18\":1,\"77\":1,\"98\":1,\"208\":4}}],[\"t17\",{\"1\":{\"205\":1}}],[\"t10\",{\"1\":{\"205\":1}}],[\"t16\",{\"1\":{\"205\":4}}],[\"txt\",{\"1\":{\"160\":1}}],[\"tlsv1\",{\"1\":{\"158\":3}}],[\"tlab\",{\"1\":{\"23\":1}}],[\"tuple\",{\"1\":{\"149\":1}}],[\"tunes\",{\"1\":{\"108\":1}}],[\"title\",{\"1\":{\"135\":9,\"151\":3}}],[\"timed\",{\"1\":{\"205\":1}}],[\"timedelta\",{\"1\":{\"147\":2,\"150\":2}}],[\"timeout\",{\"1\":{\"158\":1,\"159\":6,\"164\":1,\"187\":2}}],[\"timestamp\",{\"1\":{\"156\":1,\"205\":5,\"221\":1}}],[\"timeunit\",{\"1\":{\"66\":1,\"72\":2}}],[\"time\",{\"1\":{\"23\":1,\"30\":2,\"147\":1,\"149\":6,\"150\":2,\"156\":3}}],[\"type\",{\"1\":{\"72\":2,\"98\":1,\"103\":1,\"104\":1,\"118\":2,\"120\":2,\"121\":1,\"137\":3,\"144\":2,\"148\":1,\"149\":1,\"150\":1,\"151\":2,\"159\":2,\"182\":1,\"183\":1}}],[\"tcmalloc\",{\"1\":{\"49\":1}}],[\"tcp\",{\"1\":{\"41\":1,\"152\":1}}],[\"than\",{\"1\":{\"212\":1,\"215\":1}}],[\"that\",{\"1\":{\"98\":1}}],[\"thinking\",{\"1\":{\"103\":4}}],[\"this\",{\"1\":{\"66\":1,\"98\":1,\"137\":1}}],[\"throw\",{\"1\":{\"72\":1,\"137\":1,\"210\":1}}],[\"throws\",{\"1\":{\"57\":1,\"68\":1,\"137\":1,\"212\":1}}],[\"threadpool\",{\"1\":{\"141\":1,\"214\":1,\"216\":1}}],[\"threadcontroller\",{\"1\":{\"56\":1}}],[\"threadconfig\",{\"1\":{\"56\":1}}],[\"thread\",{\"1\":{\"56\":7,\"57\":1,\"161\":1,\"210\":2}}],[\"threads\",{\"1\":{\"30\":1}}],[\"then\",{\"1\":{\"103\":1,\"205\":2,\"206\":2}}],[\"the\",{\"1\":{\"30\":4,\"98\":2,\"148\":2,\"150\":2,\"153\":1,\"216\":1}}],[\"tolist\",{\"1\":{\"208\":1}}],[\"today\",{\"1\":{\"147\":4,\"150\":4}}],[\"todo\",{\"1\":{\"65\":1,\"149\":1}}],[\"tojson\",{\"1\":{\"137\":1,\"149\":3}}],[\"tobytearray\",{\"1\":{\"137\":1}}],[\"tongjiapi\",{\"1\":{\"147\":1}}],[\"tongji\",{\"1\":{\"126\":1,\"145\":1,\"146\":1,\"147\":1,\"148\":1,\"149\":1,\"150\":2}}],[\"token\",{\"0\":{\"117\":1,\"118\":1},\"1\":{\"117\":3,\"118\":2,\"120\":1,\"121\":1,\"146\":1,\"148\":6,\"149\":2,\"150\":6}}],[\"tokenstream\",{\"1\":{\"135\":4}}],[\"tokens\",{\"1\":{\"98\":1,\"101\":1}}],[\"tousername\",{\"1\":{\"101\":4}}],[\"took\",{\"1\":{\"205\":1}}],[\"toolbox\",{\"1\":{\"151\":1}}],[\"tooltip\",{\"1\":{\"151\":2}}],[\"tools\",{\"1\":{\"49\":1,\"170\":1}}],[\"too\",{\"1\":{\"68\":2}}],[\"tostring\",{\"1\":{\"56\":2,\"135\":1,\"143\":1,\"188\":2}}],[\"tomcatprotocolhandler\",{\"1\":{\"56\":1}}],[\"tomcatprotocolhandlercustomizer\",{\"1\":{\"56\":1}}],[\"tomcat\",{\"1\":{\"56\":1,\"125\":1,\"126\":1,\"155\":2,\"157\":1,\"159\":4,\"161\":1}}],[\"topics\",{\"1\":{\"221\":2}}],[\"topic\",{\"1\":{\"221\":17}}],[\"topdocs\",{\"1\":{\"135\":2}}],[\"top\",{\"1\":{\"41\":1,\"50\":1,\"151\":3}}],[\"to\",{\"1\":{\"30\":2,\"98\":1,\"114\":1,\"118\":2,\"137\":2,\"151\":1,\"164\":1,\"206\":2,\"207\":2}}],[\"totalhits\",{\"1\":{\"210\":1}}],[\"totalops\",{\"1\":{\"210\":1}}],[\"totallimit\",{\"1\":{\"66\":7}}],[\"total\",{\"1\":{\"30\":7,\"205\":2}}],[\"tt\",{\"1\":{\"23\":3}}],[\"tmp\",{\"1\":{\"12\":2,\"13\":2}}],[\"t\",{\"1\":{\"11\":1,\"13\":1,\"137\":1,\"153\":1,\"170\":1,\"210\":2,\"221\":1}}],[\"transition\",{\"1\":{\"170\":1}}],[\"transfer\",{\"1\":{\"158\":1}}],[\"transportservice\",{\"1\":{\"214\":3,\"216\":1}}],[\"transportsearchaction\",{\"1\":{\"206\":4}}],[\"transportaction\",{\"1\":{\"206\":1}}],[\"transport\",{\"1\":{\"43\":1}}],[\"try\",{\"1\":{\"72\":1,\"135\":1,\"137\":5,\"197\":1,\"206\":3,\"216\":1}}],[\"tryacquire\",{\"1\":{\"64\":1,\"68\":2}}],[\"troubleshooting\",{\"1\":{\"51\":1}}],[\"trigger\",{\"1\":{\"17\":1,\"141\":2,\"151\":1,\"164\":1}}],[\"triggers\",{\"1\":{\"15\":1,\"143\":1}}],[\"trim\",{\"1\":{\"11\":1,\"13\":1,\"101\":1}}],[\"true\",{\"1\":{\"5\":3,\"11\":2,\"12\":1,\"13\":4,\"46\":1,\"68\":1,\"72\":2,\"137\":2,\"151\":4,\"159\":1,\"182\":2,\"185\":5,\"187\":1,\"196\":1,\"206\":1}}],[\"tar\",{\"1\":{\"153\":1}}],[\"targetmethod\",{\"1\":{\"143\":1}}],[\"targetobject\",{\"1\":{\"143\":1}}],[\"target\",{\"1\":{\"56\":2}}],[\"targets\",{\"1\":{\"5\":2}}],[\"tale\",{\"1\":{\"124\":3}}],[\"tat\",{\"1\":{\"72\":2}}],[\"taskholder\",{\"1\":{\"206\":4}}],[\"taskexecutoradapter\",{\"1\":{\"56\":1}}],[\"task\",{\"1\":{\"42\":2,\"144\":4,\"206\":2,\"214\":2,\"215\":2,\"216\":4}}],[\"taskscheduler\",{\"1\":{\"144\":2}}],[\"tasks\",{\"1\":{\"5\":4}}],[\"tail\",{\"1\":{\"160\":1}}],[\"tai\",{\"1\":{\"18\":1}}],[\"tagmapper\",{\"1\":{\"189\":1}}],[\"tags\",{\"1\":{\"189\":3}}],[\"tag\",{\"1\":{\"11\":3,\"13\":3,\"189\":1}}],[\"terracotta\",{\"1\":{\"159\":1}}],[\"termquery\",{\"1\":{\"133\":1}}],[\"term\",{\"1\":{\"133\":3,\"135\":1}}],[\"tesla\",{\"0\":{\"111\":1,\"113\":1},\"1\":{\"113\":1,\"114\":1,\"116\":2,\"117\":1,\"118\":2,\"120\":7,\"121\":2}}],[\"testcache\",{\"1\":{\"185\":8}}],[\"test\",{\"1\":{\"5\":1,\"10\":4,\"11\":1,\"13\":2,\"65\":1,\"98\":1,\"153\":1,\"190\":2}}],[\"temp\",{\"1\":{\"149\":6}}],[\"temperature\",{\"1\":{\"98\":1,\"101\":1}}],[\"template\",{\"1\":{\"12\":1,\"13\":1}}],[\"textfield\",{\"1\":{\"135\":4}}],[\"text\",{\"1\":{\"49\":1,\"98\":1,\"101\":4,\"103\":1,\"104\":1,\"108\":2,\"120\":1,\"135\":2,\"137\":3,\"151\":4,\"158\":1,\"194\":1}}],[\"textparameterdefinition\",{\"1\":{\"5\":4}}],[\"tenured\",{\"1\":{\"30\":3,\"126\":1}}],[\"tekton\",{\"0\":{\"21\":1},\"1\":{\"3\":1,\"7\":4}}],[\"}\",{\"1\":{\"5\":2,\"9\":5,\"10\":5,\"11\":8,\"12\":15,\"13\":55,\"15\":1,\"30\":1,\"56\":6,\"57\":2,\"65\":3,\"66\":7,\"67\":1,\"68\":6,\"72\":6,\"98\":2,\"101\":8,\"103\":10,\"104\":7,\"120\":2,\"121\":2,\"135\":10,\"137\":32,\"143\":2,\"144\":1,\"146\":1,\"148\":3,\"149\":4,\"150\":3,\"151\":35,\"155\":2,\"156\":1,\"157\":1,\"159\":6,\"170\":2,\"185\":3,\"187\":6,\"188\":3,\"189\":3,\"190\":3,\"196\":1,\"197\":2,\"198\":3,\"205\":13,\"206\":18,\"207\":1,\"208\":2,\"209\":1,\"210\":8,\"212\":12,\"214\":1,\"215\":4,\"216\":6}}],[\"{\",{\"1\":{\"5\":2,\"9\":5,\"10\":5,\"11\":8,\"12\":15,\"13\":55,\"15\":1,\"30\":1,\"56\":6,\"57\":2,\"65\":3,\"66\":7,\"67\":1,\"68\":6,\"72\":6,\"98\":2,\"101\":8,\"103\":10,\"104\":7,\"120\":2,\"121\":2,\"135\":10,\"137\":33,\"143\":2,\"144\":1,\"146\":1,\"148\":3,\"149\":4,\"150\":3,\"151\":35,\"155\":4,\"156\":1,\"157\":1,\"159\":6,\"170\":2,\"185\":3,\"187\":6,\"188\":3,\"189\":3,\"190\":3,\"196\":1,\"197\":2,\"198\":3,\"205\":13,\"206\":18,\"207\":1,\"208\":2,\"209\":1,\"210\":8,\"212\":11,\"214\":1,\"215\":4,\"216\":6}}],[\"$\",{\"1\":{\"5\":2,\"11\":2,\"12\":13,\"13\":16,\"48\":8,\"56\":2,\"103\":1,\"104\":2,\"118\":3,\"120\":1,\"121\":1,\"135\":5,\"137\":1,\"151\":7,\"155\":1,\"156\":13,\"157\":12,\"158\":2,\"159\":5,\"187\":6}}],[\"b2b\",{\"1\":{\"164\":1}}],[\"bba\",{\"1\":{\"160\":2}}],[\"bc5\",{\"1\":{\"160\":2}}],[\"bc02\",{\"1\":{\"64\":1}}],[\"bds\",{\"1\":{\"170\":1}}],[\"bd\",{\"1\":{\"149\":1,\"150\":2}}],[\"bdd13ebca953\",{\"1\":{\"69\":1}}],[\"byte\",{\"1\":{\"164\":1,\"221\":1}}],[\"bytes\",{\"1\":{\"148\":1,\"150\":1,\"156\":1,\"221\":3}}],[\"bytesref\",{\"1\":{\"137\":14}}],[\"bytearrayoutputstream\",{\"1\":{\"137\":2}}],[\"brokes\",{\"1\":{\"221\":1}}],[\"brokerlist\",{\"1\":{\"221\":1}}],[\"brokers\",{\"1\":{\"221\":1}}],[\"broker\",{\"1\":{\"221\":25}}],[\"browser\",{\"1\":{\"98\":1}}],[\"br\",{\"1\":{\"143\":1}}],[\"branch\",{\"1\":{\"9\":1,\"10\":1,\"11\":1,\"13\":3}}],[\"branchspec\",{\"1\":{\"5\":2}}],[\"branches\",{\"1\":{\"5\":2}}],[\"border\",{\"1\":{\"170\":1}}],[\"borderwidth\",{\"1\":{\"151\":1}}],[\"bottom\",{\"1\":{\"151\":1}}],[\"bounce\",{\"1\":{\"149\":4,\"150\":1}}],[\"bos\",{\"1\":{\"137\":3}}],[\"boss\",{\"1\":{\"80\":1}}],[\"boolean\",{\"1\":{\"137\":4,\"143\":1,\"206\":1,\"212\":2,\"215\":1}}],[\"booleanclause\",{\"1\":{\"135\":1}}],[\"booleanquery\",{\"1\":{\"135\":5}}],[\"bootstrap\",{\"1\":{\"124\":1}}],[\"boot\",{\"1\":{\"12\":1,\"54\":2,\"56\":2,\"57\":1,\"64\":1,\"122\":1,\"159\":1}}],[\"body\",{\"1\":{\"101\":2,\"148\":3,\"149\":5,\"150\":6,\"151\":1,\"156\":1}}],[\"bf\",{\"1\":{\"69\":1}}],[\"b89\",{\"1\":{\"69\":1}}],[\"b4\",{\"1\":{\"64\":1}}],[\"beijingali\",{\"1\":{\"153\":3}}],[\"bearer\",{\"1\":{\"98\":1,\"120\":1,\"121\":1}}],[\"beanfactory\",{\"1\":{\"144\":1}}],[\"beans\",{\"1\":{\"144\":3}}],[\"bean\",{\"1\":{\"56\":5,\"125\":3,\"143\":8,\"144\":5,\"159\":8,\"187\":10}}],[\"be9e\",{\"1\":{\"69\":1}}],[\"beforeinvocation\",{\"1\":{\"185\":2}}],[\"before\",{\"1\":{\"23\":1,\"30\":1}}],[\"backgound\",{\"1\":{\"170\":1}}],[\"background\",{\"1\":{\"151\":1,\"170\":2}}],[\"backend\",{\"1\":{\"155\":2,\"157\":2,\"159\":1}}],[\"baidutongji\",{\"1\":{\"145\":1,\"148\":1,\"151\":1}}],[\"baidu\",{\"1\":{\"114\":1,\"146\":1,\"147\":1,\"148\":2,\"149\":1,\"150\":4,\"170\":1}}],[\"baseresthandler\",{\"1\":{\"206\":1}}],[\"baseintercepter\",{\"1\":{\"125\":1}}],[\"basepath\",{\"1\":{\"101\":1}}],[\"base\",{\"1\":{\"72\":2,\"101\":2,\"148\":1,\"149\":1,\"150\":5}}],[\"bashd\",{\"1\":{\"41\":1}}],[\"batchscheduler\",{\"1\":{\"72\":1}}],[\"batch\",{\"1\":{\"48\":1}}],[\"business\",{\"1\":{\"198\":1}}],[\"bundle\",{\"1\":{\"158\":1}}],[\"bug\",{\"1\":{\"60\":1,\"76\":1,\"128\":1,\"171\":1,\"187\":1}}],[\"buff\",{\"1\":{\"50\":1}}],[\"bufferedreader\",{\"1\":{\"143\":2}}],[\"buffer\",{\"1\":{\"45\":1}}],[\"building\",{\"1\":{\"216\":1}}],[\"buildsearchhits\",{\"1\":{\"216\":1}}],[\"builder\",{\"1\":{\"135\":2}}],[\"builders\",{\"1\":{\"5\":2}}],[\"buildctxprompt\",{\"1\":{\"104\":1}}],[\"build\",{\"1\":{\"11\":5,\"13\":8,\"56\":2,\"66\":1,\"120\":1,\"135\":1,\"137\":1}}],[\"buildparam\",{\"1\":{\"5\":2}}],[\"b\",{\"1\":{\"44\":1,\"69\":1,\"74\":1,\"135\":4,\"152\":4,\"181\":1,\"188\":1}}],[\"bgp\",{\"1\":{\"43\":1}}],[\"bigdata\",{\"0\":{\"230\":1}}],[\"binlog\",{\"1\":{\"161\":2,\"163\":6,\"164\":3}}],[\"binary\",{\"1\":{\"161\":4,\"164\":2}}],[\"bin\",{\"1\":{\"49\":1,\"103\":1,\"163\":2,\"164\":4}}],[\"bi\",{\"1\":{\"41\":1}}],[\"bit\",{\"1\":{\"25\":1}}],[\"bt\",{\"1\":{\"25\":1}}],[\"blob\",{\"1\":{\"148\":1}}],[\"blogmapper\",{\"1\":{\"137\":1,\"189\":2}}],[\"blogserviceimpl\",{\"1\":{\"188\":1}}],[\"blogservice\",{\"1\":{\"137\":1,\"190\":3}}],[\"blogs\",{\"1\":{\"137\":2}}],[\"blogiterator\",{\"1\":{\"137\":10}}],[\"blogid\",{\"1\":{\"18\":1,\"125\":1,\"135\":1,\"189\":5}}],[\"blog\",{\"1\":{\"125\":2,\"135\":7,\"137\":8,\"138\":1,\"144\":1,\"189\":10,\"220\":1}}],[\"blogcontroller\",{\"1\":{\"125\":3}}],[\"blogdetail\",{\"1\":{\"125\":6}}],[\"blue\",{\"1\":{\"14\":1}}],[\"aggregationphase\",{\"1\":{\"215\":3}}],[\"agent\",{\"1\":{\"13\":4,\"156\":2}}],[\"abstractsearchasyncaction\",{\"1\":{\"206\":3,\"209\":1,\"210\":5,\"212\":1,\"213\":2}}],[\"abstracthttpservertransport\",{\"1\":{\"206\":3}}],[\"abstractapplicationcontext\",{\"1\":{\"144\":2}}],[\"aaaa\",{\"1\":{\"204\":1,\"205\":5,\"209\":1,\"216\":2}}],[\"aa9d\",{\"1\":{\"69\":1}}],[\"ar\",{\"1\":{\"221\":1}}],[\"args\",{\"1\":{\"197\":1}}],[\"arg\",{\"1\":{\"187\":1}}],[\"arimo\",{\"1\":{\"166\":1}}],[\"article\",{\"1\":{\"144\":1,\"220\":1}}],[\"artifactid\",{\"1\":{\"56\":2,\"135\":10,\"137\":2,\"143\":6,\"159\":4,\"196\":2}}],[\"aes128\",{\"1\":{\"158\":1}}],[\"aed7\",{\"1\":{\"69\":1}}],[\"average\",{\"1\":{\"149\":1}}],[\"avg\",{\"1\":{\"149\":5,\"150\":1}}],[\"attr\",{\"1\":{\"206\":1}}],[\"attribute\",{\"1\":{\"151\":1}}],[\"at\",{\"1\":{\"144\":8}}],[\"ajaxsearch\",{\"1\":{\"137\":5}}],[\"ajaxbuild\",{\"1\":{\"137\":1}}],[\"ajax\",{\"1\":{\"137\":3}}],[\"audience\",{\"1\":{\"118\":3}}],[\"auto\",{\"1\":{\"151\":1}}],[\"autocomplete\",{\"1\":{\"137\":9}}],[\"autocompelte\",{\"1\":{\"136\":1}}],[\"automatically\",{\"1\":{\"98\":1}}],[\"authentication\",{\"1\":{\"118\":1}}],[\"authenticator\",{\"1\":{\"113\":1}}],[\"authenticatewithpassword\",{\"1\":{\"143\":1}}],[\"authenticate\",{\"1\":{\"43\":1}}],[\"authorization\",{\"1\":{\"98\":1,\"120\":1,\"121\":1}}],[\"auth\",{\"1\":{\"72\":2,\"118\":1,\"149\":1,\"196\":2,\"203\":1}}],[\"aslist\",{\"1\":{\"212\":1}}],[\"assertionerror\",{\"1\":{\"210\":1}}],[\"assert\",{\"1\":{\"208\":1,\"209\":2,\"212\":1,\"215\":1}}],[\"asc\",{\"1\":{\"104\":1}}],[\"asyncservice\",{\"1\":{\"189\":1}}],[\"async\",{\"1\":{\"101\":2,\"104\":1}}],[\"asynctaskexecutor\",{\"1\":{\"56\":1}}],[\"airport\",{\"1\":{\"198\":2}}],[\"aitype\",{\"1\":{\"103\":1,\"104\":1}}],[\"ai\",{\"1\":{\"101\":1,\"103\":9,\"104\":1}}],[\"await\",{\"1\":{\"101\":2,\"103\":4,\"104\":1}}],[\"awk\",{\"1\":{\"12\":1,\"13\":1}}],[\"anull\",{\"1\":{\"158\":1}}],[\"annotation\",{\"1\":{\"144\":4,\"159\":1,\"185\":2,\"187\":1}}],[\"analyzinginfixsuggester\",{\"1\":{\"137\":4}}],[\"analyzers\",{\"1\":{\"135\":2}}],[\"analyzer\",{\"0\":{\"44\":1},\"1\":{\"133\":1,\"135\":6,\"137\":4}}],[\"answered\",{\"1\":{\"103\":3}}],[\"any\",{\"1\":{\"98\":1}}],[\"and\",{\"1\":{\"80\":1,\"83\":1,\"211\":1}}],[\"angularjs\",{\"1\":{\"76\":1}}],[\"angulajs\",{\"1\":{\"74\":1}}],[\"acks\",{\"1\":{\"221\":1}}],[\"ack\",{\"1\":{\"221\":5}}],[\"accept\",{\"1\":{\"206\":1}}],[\"access\",{\"1\":{\"156\":2,\"160\":1}}],[\"accounts\",{\"1\":{\"120\":1,\"121\":2}}],[\"account\",{\"1\":{\"72\":1,\"98\":1,\"148\":1,\"149\":1,\"150\":1}}],[\"actionlistener\",{\"1\":{\"206\":1,\"215\":1,\"216\":1}}],[\"actionresponse\",{\"1\":{\"206\":1}}],[\"actionrequest\",{\"1\":{\"206\":1}}],[\"action\",{\"1\":{\"206\":2,\"214\":2,\"216\":2}}],[\"actions\",{\"1\":{\"5\":1}}],[\"activate\",{\"1\":{\"95\":1}}],[\"ac352810a9728e1\",{\"1\":{\"72\":1}}],[\"a66756ecd\",{\"1\":{\"64\":1}}],[\"align\",{\"1\":{\"151\":1}}],[\"alias\",{\"1\":{\"120\":1}}],[\"alibaba\",{\"1\":{\"63\":1,\"164\":1}}],[\"also\",{\"1\":{\"98\":1}}],[\"allentries\",{\"1\":{\"185\":2}}],[\"all\",{\"1\":{\"74\":1,\"149\":1,\"164\":1,\"170\":1}}],[\"always\",{\"1\":{\"72\":1}}],[\"alpha\",{\"1\":{\"7\":1}}],[\"apikey\",{\"1\":{\"101\":1}}],[\"apis\",{\"1\":{\"72\":1}}],[\"apiversion\",{\"1\":{\"72\":1}}],[\"api\",{\"0\":{\"111\":1,\"116\":1,\"147\":1},\"1\":{\"58\":1,\"65\":1,\"81\":3,\"97\":1,\"98\":7,\"101\":4,\"106\":1,\"114\":1,\"116\":3,\"117\":3,\"118\":1,\"120\":4,\"121\":5,\"122\":2,\"124\":1,\"126\":1,\"127\":1,\"145\":4,\"146\":1,\"147\":2,\"148\":1,\"149\":1,\"150\":2,\"197\":1,\"221\":1}}],[\"apache\",{\"1\":{\"56\":2,\"72\":1,\"135\":5,\"137\":1,\"152\":1,\"182\":1,\"183\":1,\"194\":1,\"202\":1,\"221\":4}}],[\"append\",{\"1\":{\"143\":1,\"149\":1,\"188\":4}}],[\"appid\",{\"1\":{\"101\":4}}],[\"apply\",{\"1\":{\"72\":1}}],[\"applicationcontext\",{\"0\":{\"187\":1},\"1\":{\"190\":1}}],[\"applicationtaskexecutor\",{\"1\":{\"56\":3}}],[\"applications\",{\"1\":{\"51\":1}}],[\"application\",{\"1\":{\"30\":2,\"56\":1,\"57\":1,\"72\":2,\"98\":1,\"118\":1,\"120\":1,\"121\":1,\"180\":1,\"181\":1}}],[\"appsv1\",{\"1\":{\"65\":1}}],[\"app\",{\"1\":{\"13\":1,\"72\":2,\"101\":1,\"117\":3}}],[\"admin\",{\"1\":{\"203\":1}}],[\"admission\",{\"1\":{\"72\":2}}],[\"advance\",{\"1\":{\"170\":1}}],[\"advanced\",{\"1\":{\"46\":1}}],[\"adaboost\",{\"1\":{\"122\":1,\"127\":1}}],[\"addandget\",{\"1\":{\"210\":1}}],[\"addr\",{\"1\":{\"156\":3,\"157\":6}}],[\"address\",{\"1\":{\"43\":2}}],[\"addobject\",{\"1\":{\"151\":2}}],[\"adddocument\",{\"1\":{\"135\":1}}],[\"add\",{\"1\":{\"12\":1,\"13\":1,\"72\":1,\"135\":5,\"137\":2,\"157\":5}}],[\"a\",{\"1\":{\"41\":2,\"48\":2,\"52\":5,\"74\":1,\"98\":1,\"101\":1,\"104\":1,\"118\":2,\"149\":1,\"152\":5,\"170\":2,\"181\":1,\"188\":1}}],[\"after\",{\"1\":{\"30\":1}}],[\"a4eb4bb016a4eb723550054\",{\"1\":{\"5\":1}}],[\":\",{\"0\":{\"49\":1},\"1\":{\"5\":3,\"9\":4,\"10\":3,\"11\":7,\"12\":3,\"13\":16,\"18\":3,\"26\":11,\"28\":16,\"29\":12,\"30\":22,\"31\":11,\"32\":8,\"33\":4,\"34\":6,\"35\":4,\"39\":2,\"41\":4,\"43\":2,\"44\":1,\"56\":4,\"65\":1,\"66\":6,\"72\":45,\"76\":1,\"79\":1,\"95\":1,\"97\":1,\"98\":8,\"101\":13,\"103\":14,\"104\":8,\"108\":1,\"109\":1,\"110\":1,\"114\":1,\"117\":1,\"118\":3,\"120\":4,\"121\":5,\"122\":1,\"130\":2,\"135\":2,\"137\":10,\"138\":2,\"144\":18,\"145\":4,\"146\":1,\"147\":1,\"148\":15,\"149\":17,\"150\":18,\"151\":83,\"152\":2,\"153\":3,\"155\":3,\"156\":13,\"157\":6,\"158\":6,\"159\":2,\"160\":3,\"164\":1,\"165\":2,\"166\":1,\"170\":10,\"173\":2,\"183\":1,\"187\":1,\"188\":1,\"189\":1,\"190\":1,\"192\":2,\"197\":2,\"198\":4,\"203\":10,\"205\":42,\"207\":1,\"212\":2,\"214\":3,\"215\":4,\"216\":3,\"220\":2,\"221\":17}}],[\"hw\",{\"1\":{\"221\":3}}],[\"hbase\",{\"1\":{\"194\":1}}],[\"hdfs\",{\"1\":{\"194\":2}}],[\"hyper\",{\"1\":{\"158\":1}}],[\"hystrix\",{\"1\":{\"63\":1}}],[\"hmt\",{\"1\":{\"146\":2}}],[\"hm\",{\"1\":{\"146\":6}}],[\"hive\",{\"1\":{\"194\":1}}],[\"highmap\",{\"1\":{\"169\":1}}],[\"highchart\",{\"1\":{\"165\":1}}],[\"highcharts\",{\"1\":{\"151\":3,\"169\":4}}],[\"high\",{\"1\":{\"158\":1}}],[\"highlighter\",{\"1\":{\"135\":6}}],[\"hits\",{\"1\":{\"135\":1,\"137\":1,\"205\":2,\"216\":5}}],[\"hibernate\",{\"1\":{\"76\":1,\"124\":1}}],[\"href\",{\"1\":{\"137\":1}}],[\"hr\",{\"1\":{\"74\":1}}],[\"hotmail\",{\"1\":{\"95\":1}}],[\"hours\",{\"1\":{\"72\":2}}],[\"hostname\",{\"1\":{\"159\":1,\"187\":1}}],[\"hostip\",{\"1\":{\"143\":1}}],[\"host\",{\"1\":{\"65\":1,\"143\":2,\"149\":2,\"156\":3,\"157\":3,\"159\":1,\"164\":1,\"187\":1,\"196\":1}}],[\"hpa\",{\"1\":{\"65\":1}}],[\"hprof\",{\"1\":{\"44\":1}}],[\"hack\",{\"1\":{\"221\":1}}],[\"hadoop\",{\"1\":{\"194\":2,\"202\":1}}],[\"haproxy\",{\"1\":{\"152\":1}}],[\"happens\",{\"1\":{\"23\":1}}],[\"handleincomingrequest\",{\"1\":{\"206\":1}}],[\"handleinterceptor\",{\"1\":{\"125\":1}}],[\"handlerequest\",{\"1\":{\"206\":2}}],[\"handlerexecutionchain\",{\"1\":{\"125\":1}}],[\"handlermapping\",{\"1\":{\"125\":2}}],[\"hashvalueserializer\",{\"1\":{\"187\":1}}],[\"hashkeyserializer\",{\"1\":{\"187\":1}}],[\"hashkey\",{\"1\":{\"187\":1}}],[\"hashmap\",{\"1\":{\"179\":1}}],[\"hash\",{\"1\":{\"155\":6,\"220\":1}}],[\"hashset\",{\"1\":{\"137\":1}}],[\"hasnext\",{\"1\":{\"137\":1}}],[\"hascontexts\",{\"1\":{\"137\":2}}],[\"haspayloads\",{\"1\":{\"137\":2}}],[\"has\",{\"1\":{\"98\":1}}],[\"havingvalue\",{\"1\":{\"56\":1}}],[\"harborproject\",{\"1\":{\"12\":1,\"13\":1}}],[\"htm\",{\"1\":{\"155\":1,\"157\":1}}],[\"htmlhttp\",{\"1\":{\"41\":1}}],[\"html\",{\"1\":{\"18\":2,\"41\":1,\"79\":1,\"103\":1,\"120\":1,\"124\":1,\"125\":1,\"137\":1,\"151\":1,\"155\":2,\"157\":2,\"166\":1,\"168\":3}}],[\"htitle\",{\"1\":{\"135\":2}}],[\"httpresponse\",{\"1\":{\"216\":1}}],[\"httprequest\",{\"1\":{\"206\":3}}],[\"httpchannel\",{\"1\":{\"216\":1}}],[\"httppipelinedrequest\",{\"1\":{\"206\":2}}],[\"httpservertransport\",{\"1\":{\"206\":1}}],[\"httpservletresponse\",{\"1\":{\"68\":4,\"137\":1}}],[\"httpservletrequest\",{\"1\":{\"68\":4,\"137\":1}}],[\"httpstatus\",{\"1\":{\"68\":2}}],[\"https\",{\"0\":{\"49\":1,\"158\":1},\"1\":{\"18\":2,\"72\":1,\"79\":1,\"95\":1,\"97\":1,\"98\":1,\"101\":1,\"103\":1,\"108\":1,\"109\":1,\"110\":1,\"114\":1,\"117\":1,\"118\":2,\"120\":1,\"121\":1,\"122\":1,\"130\":1,\"137\":1,\"138\":1,\"145\":2,\"146\":1,\"147\":1,\"148\":1,\"149\":1,\"150\":2,\"151\":2,\"152\":1,\"153\":1,\"158\":8,\"160\":1,\"164\":1,\"165\":1,\"166\":1,\"173\":1,\"192\":1,\"203\":1,\"220\":2}}],[\"http\",{\"0\":{\"157\":1},\"1\":{\"5\":2,\"12\":1,\"13\":1,\"18\":1,\"41\":1,\"56\":1,\"72\":2,\"76\":1,\"98\":1,\"101\":2,\"102\":1,\"125\":1,\"130\":1,\"138\":1,\"144\":2,\"145\":1,\"149\":1,\"151\":2,\"152\":1,\"155\":2,\"156\":4,\"157\":6,\"158\":5,\"159\":1,\"160\":2,\"165\":1,\"170\":2,\"173\":1,\"192\":1,\"196\":2,\"203\":1,\"206\":2}}],[\"h\",{\"1\":{\"15\":2,\"143\":2}}],[\"hub\",{\"1\":{\"13\":2}}],[\"hudson\",{\"1\":{\"5\":15}}],[\"hexo\",{\"1\":{\"165\":1}}],[\"height\",{\"1\":{\"151\":1,\"170\":1}}],[\"helloroot\",{\"1\":{\"164\":1}}],[\"hello\",{\"1\":{\"143\":1}}],[\"helm\",{\"1\":{\"7\":1,\"12\":6,\"13\":4,\"72\":2}}],[\"hey\",{\"1\":{\"57\":1}}],[\"heap\",{\"1\":{\"30\":2,\"44\":1,\"49\":1}}],[\"heading\",{\"1\":{\"151\":1}}],[\"headers\",{\"1\":{\"101\":1}}],[\"header\",{\"1\":{\"101\":1,\"118\":1,\"120\":2,\"121\":2,\"124\":1,\"148\":1,\"149\":1,\"150\":1,\"157\":6}}],[\"head\",{\"1\":{\"11\":1,\"13\":1}}],[\"uuid\",{\"1\":{\"221\":1}}],[\"ui\",{\"1\":{\"165\":1,\"170\":2}}],[\"util\",{\"1\":{\"141\":3}}],[\"utf\",{\"1\":{\"137\":1,\"148\":2,\"150\":1}}],[\"utf8\",{\"1\":{\"137\":2,\"148\":1,\"150\":1,\"163\":3,\"164\":3}}],[\"uv\",{\"1\":{\"122\":1,\"126\":1,\"151\":4}}],[\"uncommitted\",{\"1\":{\"221\":1}}],[\"unregistertask\",{\"1\":{\"206\":1}}],[\"unsupportedencodingexception\",{\"1\":{\"137\":1}}],[\"unable\",{\"1\":{\"114\":1}}],[\"union\",{\"1\":{\"74\":2}}],[\"unix\",{\"1\":{\"5\":1}}],[\"ubuntu\",{\"1\":{\"96\":1}}],[\"upstreamhost\",{\"1\":{\"156\":1}}],[\"upstreamtime\",{\"1\":{\"156\":1}}],[\"upstream\",{\"1\":{\"155\":1,\"156\":2,\"159\":1}}],[\"updatebloghits\",{\"1\":{\"189\":1}}],[\"updates\",{\"1\":{\"164\":1}}],[\"updatedocument\",{\"1\":{\"135\":1}}],[\"updatedat\",{\"1\":{\"104\":1}}],[\"update\",{\"1\":{\"103\":1}}],[\"up\",{\"1\":{\"72\":1}}],[\"u\",{\"1\":{\"41\":1,\"143\":2}}],[\"usr\",{\"1\":{\"41\":1,\"49\":1}}],[\"usepool\",{\"1\":{\"159\":1,\"187\":1}}],[\"useparalledloldgc\",{\"1\":{\"32\":1}}],[\"useparalleloldgc\",{\"1\":{\"28\":2}}],[\"useparallelgc\",{\"1\":{\"28\":5,\"32\":1}}],[\"useparnewgc\",{\"1\":{\"29\":2}}],[\"useserialgc\",{\"1\":{\"32\":1}}],[\"used\",{\"1\":{\"30\":20}}],[\"usecmscompactatfullcollection\",{\"1\":{\"29\":2,\"39\":1}}],[\"useconcmarksweepgc\",{\"1\":{\"29\":3,\"32\":1}}],[\"useadaptivesizepolicy\",{\"1\":{\"28\":2}}],[\"user\",{\"1\":{\"72\":1,\"120\":1,\"152\":4,\"156\":1,\"164\":1,\"196\":1,\"203\":1}}],[\"userid\",{\"1\":{\"64\":1,\"66\":1}}],[\"username\",{\"1\":{\"12\":1,\"13\":1,\"143\":3,\"146\":1,\"148\":6,\"149\":2,\"150\":6,\"185\":6,\"203\":1}}],[\"userremoteconfig\",{\"1\":{\"5\":2}}],[\"userremoteconfigs\",{\"1\":{\"5\":2}}],[\"uri\",{\"1\":{\"5\":2,\"155\":5,\"156\":1,\"157\":1}}],[\"urlopen\",{\"1\":{\"148\":1,\"150\":1}}],[\"urllib\",{\"1\":{\"148\":2,\"150\":4}}],[\"urlencode\",{\"1\":{\"118\":5}}],[\"urlencoded\",{\"1\":{\"118\":1}}],[\"url\",{\"1\":{\"5\":4,\"9\":1,\"10\":1,\"11\":1,\"13\":3,\"102\":1,\"137\":1,\"148\":1,\"149\":1,\"150\":3,\"156\":1,\"159\":2,\"170\":1}}],[\"29\",{\"1\":{\"221\":1}}],[\"2900\",{\"1\":{\"103\":1}}],[\"27\",{\"1\":{\"221\":1}}],[\"2141\",{\"1\":{\"209\":1}}],[\"21\",{\"1\":{\"205\":6,\"221\":1}}],[\"215\",{\"1\":{\"149\":1}}],[\"25\",{\"1\":{\"170\":1,\"221\":1}}],[\"255\",{\"1\":{\"151\":2}}],[\"256\",{\"1\":{\"26\":1}}],[\"24\",{\"1\":{\"221\":1}}],[\"241\",{\"1\":{\"208\":1}}],[\"243\",{\"1\":{\"149\":1}}],[\"240\",{\"1\":{\"69\":1}}],[\"26\",{\"1\":{\"221\":1}}],[\"2684\",{\"1\":{\"151\":1}}],[\"262\",{\"1\":{\"143\":1}}],[\"2696\",{\"1\":{\"30\":1}}],[\"22\",{\"1\":{\"149\":1,\"221\":1}}],[\"221\",{\"1\":{\"149\":1}}],[\"2205114\",{\"1\":{\"138\":1}}],[\"2222\",{\"1\":{\"23\":1}}],[\"23\",{\"1\":{\"74\":1,\"149\":1,\"206\":1,\"221\":1}}],[\"28424\",{\"1\":{\"160\":2}}],[\"284\",{\"1\":{\"149\":1}}],[\"28\",{\"1\":{\"145\":1,\"221\":1}}],[\"281\",{\"1\":{\"64\":1}}],[\"2898\",{\"1\":{\"30\":2}}],[\"2010\",{\"1\":{\"164\":1}}],[\"2019\",{\"0\":{\"84\":1,\"85\":1},\"1\":{\"85\":1}}],[\"2018\",{\"0\":{\"79\":1}}],[\"2016\",{\"1\":{\"73\":1}}],[\"2017\",{\"0\":{\"73\":1},\"1\":{\"149\":7,\"160\":1}}],[\"20220317000858513\",{\"1\":{\"213\":1}}],[\"20220219195141327\",{\"1\":{\"205\":1}}],[\"20220528203941897\",{\"1\":{\"72\":1}}],[\"2022\",{\"1\":{\"205\":6}}],[\"2023\",{\"1\":{\"114\":1}}],[\"20230827193533565\",{\"1\":{\"57\":1}}],[\"20230827193511176\",{\"1\":{\"57\":1}}],[\"20230827193431807\",{\"1\":{\"57\":1}}],[\"2020\",{\"0\":{\"91\":1}}],[\"2000\",{\"1\":{\"126\":1,\"145\":1,\"149\":1}}],[\"200\",{\"1\":{\"57\":1}}],[\"2003\",{\"1\":{\"25\":1}}],[\"20\",{\"1\":{\"28\":3,\"29\":1,\"41\":1,\"66\":1,\"221\":1}}],[\"2\",{\"0\":{\"213\":1},\"1\":{\"5\":1,\"25\":1,\"26\":2,\"31\":1,\"48\":1,\"72\":3,\"74\":3,\"76\":1,\"80\":1,\"85\":2,\"102\":1,\"113\":1,\"114\":1,\"117\":1,\"135\":1,\"143\":3,\"144\":1,\"145\":1,\"149\":4,\"151\":3,\"155\":1,\"157\":1,\"158\":2,\"159\":2,\"161\":1,\"163\":1,\"178\":1,\"179\":1,\"184\":1,\"185\":1,\"192\":2,\"194\":1,\"205\":2,\"207\":1,\"211\":1,\"221\":5}}],[\"2.3.0\",{\"1\":{\"143\":1}}],[\"2.3\",{\"0\":{\"119\":1,\"164\":1,\"184\":1}}],[\"2.0.0\",{\"1\":{\"159\":1}}],[\"2.0\",{\"1\":{\"115\":1,\"194\":2}}],[\"2.9\",{\"1\":{\"103\":1}}],[\"2.2.3\",{\"0\":{\"183\":1}}],[\"2.2.2\",{\"0\":{\"182\":1}}],[\"2.2.1\",{\"0\":{\"181\":1}}],[\"2.2\",{\"0\":{\"29\":1,\"118\":1,\"163\":1,\"180\":1}}],[\"2.13\",{\"1\":{\"196\":1}}],[\"2.1.2\",{\"0\":{\"121\":1}}],[\"2.1.1\",{\"0\":{\"120\":1}}],[\"2.1\",{\"0\":{\"28\":1,\"117\":1,\"162\":1,\"179\":1},\"1\":{\"194\":1}}],[\"2.\",{\"0\":{\"44\":1,\"130\":1,\"147\":1},\"1\":{\"5\":1,\"23\":3,\"51\":1,\"71\":1,\"72\":1,\"103\":1,\"134\":1,\"144\":2,\"145\":1,\"159\":1,\"164\":1,\"165\":1,\"192\":1,\"202\":1,\"220\":1}}],[\"\\\"\",{\"1\":{\"5\":2,\"9\":4,\"10\":8,\"11\":12,\"12\":22,\"13\":58,\"43\":4,\"48\":2,\"56\":8,\"57\":4,\"66\":4,\"68\":2,\"72\":46,\"98\":12,\"101\":2,\"118\":8,\"120\":6,\"121\":8,\"135\":28,\"137\":32,\"143\":46,\"144\":2,\"146\":6,\"147\":8,\"148\":26,\"149\":44,\"150\":54,\"151\":30,\"156\":48,\"157\":2,\"159\":48,\"182\":14,\"187\":68,\"188\":4,\"189\":10,\"190\":4,\"196\":24,\"197\":2,\"198\":20,\"205\":86,\"206\":4,\"212\":2,\"215\":2,\"221\":2}}],[\"=\",{\"1\":{\"5\":2,\"11\":2,\"12\":7,\"13\":11,\"18\":1,\"26\":9,\"28\":6,\"29\":3,\"30\":2,\"31\":5,\"34\":3,\"35\":1,\"39\":1,\"43\":10,\"44\":2,\"46\":2,\"56\":2,\"57\":1,\"65\":2,\"66\":10,\"68\":5,\"72\":5,\"77\":2,\"101\":11,\"103\":9,\"104\":5,\"118\":8,\"120\":1,\"125\":2,\"135\":29,\"137\":25,\"143\":24,\"144\":2,\"146\":4,\"147\":6,\"148\":9,\"149\":25,\"150\":24,\"151\":14,\"152\":2,\"158\":2,\"159\":30,\"163\":15,\"164\":27,\"166\":2,\"171\":2,\"173\":2,\"182\":7,\"185\":22,\"187\":34,\"188\":1,\"189\":9,\"190\":4,\"192\":2,\"196\":1,\"197\":3,\"198\":3,\"206\":9,\"207\":1,\"208\":4,\"209\":5,\"210\":3,\"212\":17,\"215\":4,\"216\":8}}],[\"switch\",{\"1\":{\"206\":1}}],[\"sfo\",{\"1\":{\"198\":1}}],[\"squid\",{\"1\":{\"157\":1}}],[\"sqlsession\",{\"1\":{\"179\":7,\"180\":1,\"184\":1}}],[\"sql\",{\"0\":{\"200\":1},\"1\":{\"136\":1,\"143\":2,\"161\":3,\"177\":2,\"179\":2,\"180\":1}}],[\"sdf\",{\"1\":{\"144\":1}}],[\"sdk\",{\"1\":{\"100\":1,\"197\":1}}],[\"src\",{\"1\":{\"137\":1,\"146\":1}}],[\"smartchineseanalyzer\",{\"1\":{\"135\":4,\"137\":4}}],[\"smartcn\",{\"1\":{\"135\":1}}],[\"sms\",{\"1\":{\"95\":1,\"97\":1}}],[\"ssubset\",{\"1\":{\"137\":1}}],[\"ssm\",{\"1\":{\"122\":3,\"124\":1}}],[\"ssh2\",{\"1\":{\"143\":1}}],[\"ssh\",{\"1\":{\"122\":1,\"124\":3,\"158\":1}}],[\"ssl\",{\"1\":{\"43\":1,\"114\":2,\"158\":11}}],[\"sk\",{\"1\":{\"101\":1}}],[\"skipped\",{\"1\":{\"205\":1}}],[\"skiptaglatest\",{\"1\":{\"5\":2}}],[\"skip\",{\"1\":{\"5\":1,\"11\":1,\"13\":1,\"164\":1,\"209\":1}}],[\"same\",{\"1\":{\"214\":1,\"216\":1}}],[\"sample\",{\"1\":{\"72\":1,\"197\":3}}],[\"savejsontoes\",{\"1\":{\"198\":1}}],[\"saveasimage\",{\"1\":{\"151\":1}}],[\"say\",{\"1\":{\"98\":1}}],[\"siteid\",{\"1\":{\"148\":6,\"149\":2,\"150\":5}}],[\"simpleconsumer\",{\"1\":{\"221\":1}}],[\"simplecontrollerhandleradapter\",{\"1\":{\"125\":2}}],[\"simplechannelinboundhandler\",{\"1\":{\"206\":1}}],[\"simpleapplicationeventmulticaster\",{\"1\":{\"144\":4}}],[\"simpletriggerimpl\",{\"1\":{\"141\":1}}],[\"simplehtmlformatter\",{\"1\":{\"135\":4}}],[\"simplespanfragmenter\",{\"1\":{\"135\":1}}],[\"simple\",{\"1\":{\"101\":1,\"102\":1}}],[\"simpleresponse\",{\"1\":{\"101\":2}}],[\"side\",{\"1\":{\"98\":1}}],[\"signup\",{\"1\":{\"97\":1}}],[\"size\",{\"1\":{\"72\":1,\"156\":1,\"170\":1,\"182\":1,\"189\":1,\"205\":2,\"209\":1}}],[\"sb\",{\"1\":{\"75\":1,\"143\":3,\"188\":6}}],[\"sbin\",{\"1\":{\"41\":1}}],[\"symbolic\",{\"1\":{\"163\":1,\"164\":1}}],[\"syntax\",{\"1\":{\"153\":1}}],[\"syncrequest\",{\"1\":{\"45\":2}}],[\"system\",{\"1\":{\"72\":2,\"135\":2,\"137\":2,\"144\":1,\"190\":3,\"197\":1}}],[\"sleep\",{\"1\":{\"57\":1,\"72\":2,\"103\":1}}],[\"slave\",{\"0\":{\"164\":1},\"1\":{\"7\":1,\"161\":9,\"163\":1,\"164\":11}}],[\"s\",{\"1\":{\"41\":1,\"48\":1,\"56\":1,\"103\":2,\"143\":3,\"146\":3,\"153\":1,\"159\":2,\"170\":1,\"220\":1}}],[\"spliterator\",{\"1\":{\"208\":1}}],[\"spel\",{\"1\":{\"185\":7,\"186\":1}}],[\"specified\",{\"1\":{\"212\":1}}],[\"spec\",{\"1\":{\"65\":1,\"72\":1}}],[\"sparksql\",{\"1\":{\"202\":1}}],[\"sparkversion\",{\"1\":{\"72\":1}}],[\"sparkoperator\",{\"1\":{\"72\":2}}],[\"sparkconf\",{\"1\":{\"72\":5,\"196\":7,\"197\":1}}],[\"sparkctl\",{\"1\":{\"72\":3}}],[\"sparkapplication\",{\"1\":{\"72\":5}}],[\"spark\",{\"0\":{\"72\":1,\"194\":1,\"199\":1,\"200\":1,\"201\":1,\"202\":1,\"229\":1},\"1\":{\"72\":45,\"194\":7,\"196\":2,\"198\":1,\"199\":1,\"202\":2}}],[\"space\",{\"1\":{\"30\":14}}],[\"springtest\",{\"1\":{\"190\":1}}],[\"springsessionrepositoryfilter\",{\"1\":{\"159\":3}}],[\"spring3\",{\"1\":{\"144\":1}}],[\"springframework\",{\"1\":{\"143\":4,\"144\":12,\"159\":5,\"187\":7}}],[\"springmvc\",{\"1\":{\"125\":1,\"183\":1,\"192\":1}}],[\"spring\",{\"0\":{\"53\":1,\"56\":1,\"144\":1,\"185\":1},\"1\":{\"12\":1,\"54\":3,\"56\":6,\"57\":4,\"63\":2,\"64\":1,\"76\":1,\"87\":1,\"122\":1,\"124\":1,\"125\":3,\"143\":6,\"144\":3,\"159\":9,\"161\":1,\"173\":1,\"184\":2,\"185\":6,\"186\":3,\"190\":1,\"192\":1}}],[\"superuser\",{\"1\":{\"203\":1}}],[\"support\",{\"1\":{\"143\":1,\"144\":3,\"202\":1}}],[\"subset\",{\"1\":{\"166\":1}}],[\"submit\",{\"1\":{\"72\":2}}],[\"submission\",{\"1\":{\"72\":2}}],[\"suggestphase\",{\"1\":{\"215\":2}}],[\"suggester\",{\"1\":{\"137\":4}}],[\"suggest\",{\"1\":{\"136\":2,\"137\":1}}],[\"successfulshardexecution\",{\"1\":{\"210\":1}}],[\"successful\",{\"1\":{\"153\":1,\"205\":1,\"216\":1}}],[\"success\",{\"1\":{\"66\":1,\"101\":1,\"206\":3,\"210\":1}}],[\"suspend\",{\"1\":{\"43\":1}}],[\"survivor\",{\"1\":{\"26\":6,\"28\":1,\"31\":4,\"126\":1}}],[\"survivorratio\",{\"1\":{\"26\":2,\"31\":1}}],[\"surefire\",{\"1\":{\"10\":1}}],[\"sun\",{\"1\":{\"26\":1,\"43\":3,\"76\":1}}],[\"segment\",{\"1\":{\"221\":5}}],[\"select\",{\"1\":{\"220\":1}}],[\"selectbyprimarykey\",{\"1\":{\"189\":2}}],[\"self\",{\"1\":{\"148\":10,\"149\":6,\"150\":10}}],[\"serializer\",{\"1\":{\"187\":4}}],[\"serializable\",{\"1\":{\"137\":1}}],[\"series\",{\"1\":{\"151\":2}}],[\"serviceaccount\",{\"1\":{\"72\":3}}],[\"service\",{\"1\":{\"70\":1,\"72\":2,\"178\":2,\"188\":1,\"192\":2}}],[\"servlet\",{\"1\":{\"125\":1,\"159\":1}}],[\"servletexception\",{\"1\":{\"68\":1}}],[\"servletresponse\",{\"1\":{\"68\":1}}],[\"servletrequest\",{\"1\":{\"68\":1}}],[\"servertransport\",{\"1\":{\"206\":1}}],[\"serverid\",{\"1\":{\"163\":1}}],[\"serverless\",{\"1\":{\"7\":2}}],[\"serverlog\",{\"1\":{\"0\":1}}],[\"server\",{\"1\":{\"5\":2,\"25\":1,\"43\":1,\"143\":1,\"155\":3,\"156\":1,\"158\":3,\"159\":3,\"163\":3,\"164\":2,\"221\":1}}],[\"searchhits\",{\"1\":{\"216\":2}}],[\"searchcontext\",{\"1\":{\"215\":8,\"216\":1}}],[\"searchshardtask\",{\"1\":{\"214\":1,\"215\":1,\"216\":1}}],[\"searchsharditerator\",{\"1\":{\"208\":2,\"209\":1,\"210\":2}}],[\"searchservice\",{\"1\":{\"214\":3,\"215\":3,\"216\":2}}],[\"searchtransportservice\",{\"1\":{\"214\":1,\"216\":1}}],[\"searchtype\",{\"0\":{\"205\":1},\"1\":{\"206\":1}}],[\"searchquerythenfetchasyncaction\",{\"1\":{\"206\":3}}],[\"searchdfsquerythenfetchasyncaction\",{\"1\":{\"206\":1}}],[\"searchrequest\",{\"1\":{\"206\":1,\"207\":5,\"208\":1}}],[\"searchphaseresult\",{\"1\":{\"206\":1,\"212\":2,\"215\":1}}],[\"searchphasecontroller\",{\"1\":{\"206\":1,\"212\":2}}],[\"searchphase\",{\"1\":{\"206\":4}}],[\"searchactionlistener\",{\"1\":{\"212\":1}}],[\"searchasyncaction\",{\"1\":{\"206\":5}}],[\"searchafter\",{\"1\":{\"135\":3}}],[\"searcher\",{\"1\":{\"135\":4,\"215\":3}}],[\"search\",{\"1\":{\"135\":3,\"205\":1,\"206\":2,\"207\":2,\"214\":1,\"215\":2,\"216\":1}}],[\"seo\",{\"1\":{\"122\":1}}],[\"sessionmanager\",{\"1\":{\"159\":1}}],[\"session\",{\"1\":{\"104\":2,\"143\":4,\"155\":3,\"158\":1,\"159\":11,\"160\":4,\"161\":2,\"179\":1}}],[\"sent\",{\"1\":{\"156\":1}}],[\"sentinel\",{\"1\":{\"63\":3}}],[\"sendfile\",{\"1\":{\"221\":1}}],[\"sendresponse\",{\"1\":{\"216\":6}}],[\"sendsearchresponse\",{\"1\":{\"213\":1}}],[\"sendexecutefetch\",{\"1\":{\"212\":1}}],[\"send\",{\"1\":{\"101\":2,\"103\":1}}],[\"sed\",{\"1\":{\"48\":1}}],[\"secure\",{\"1\":{\"118\":1,\"158\":1}}],[\"securityrestfilter\",{\"1\":{\"206\":1}}],[\"security\",{\"1\":{\"98\":1,\"203\":1}}],[\"secret\",{\"1\":{\"118\":4}}],[\"seconds\",{\"1\":{\"30\":2}}],[\"secs\",{\"1\":{\"30\":10}}],[\"setcheckcancelled\",{\"1\":{\"215\":1}}],[\"setcategory\",{\"1\":{\"189\":1}}],[\"setsize\",{\"1\":{\"207\":1}}],[\"setstatus\",{\"1\":{\"68\":1}}],[\"setmaster\",{\"1\":{\"196\":1}}],[\"settags\",{\"1\":{\"189\":1}}],[\"setting\",{\"1\":{\"182\":1,\"203\":1}}],[\"settings\",{\"1\":{\"182\":2}}],[\"settextfragmenter\",{\"1\":{\"135\":1}}],[\"setoption\",{\"1\":{\"151\":1}}],[\"setappname\",{\"1\":{\"72\":1,\"196\":1}}],[\"setexecutor\",{\"1\":{\"56\":1}}],[\"setphp\",{\"1\":{\"41\":2}}],[\"set\",{\"1\":{\"12\":5,\"13\":5,\"72\":5,\"137\":12,\"149\":3,\"157\":6,\"163\":3,\"164\":3,\"196\":5,\"216\":1}}],[\"scribe\",{\"1\":{\"221\":1}}],[\"script\",{\"1\":{\"11\":2,\"12\":1,\"13\":4,\"137\":4,\"146\":4,\"151\":4}}],[\"scroll\",{\"1\":{\"212\":2,\"216\":2}}],[\"scatter\",{\"1\":{\"205\":1}}],[\"scala\",{\"1\":{\"72\":1,\"221\":1}}],[\"schema\",{\"1\":{\"163\":1,\"164\":1}}],[\"scheduli\",{\"1\":{\"144\":1}}],[\"scheduling\",{\"1\":{\"143\":3,\"144\":5}}],[\"scheduledexecutorservice\",{\"1\":{\"144\":1}}],[\"scheduledannotationbeanpostprocessor\",{\"1\":{\"144\":6}}],[\"scheduled\",{\"1\":{\"144\":1}}],[\"schedulerfactorybean\",{\"1\":{\"143\":1}}],[\"scheduler\",{\"1\":{\"141\":4,\"143\":2,\"144\":4}}],[\"schedule\",{\"1\":{\"42\":2}}],[\"score\",{\"1\":{\"205\":2}}],[\"scorer\",{\"1\":{\"135\":2}}],[\"scoredocs\",{\"1\":{\"135\":2}}],[\"scoredoc\",{\"1\":{\"135\":9}}],[\"scope\",{\"1\":{\"118\":1}}],[\"scm\",{\"1\":{\"5\":2}}],[\"sharable\",{\"1\":{\"206\":1}}],[\"shardresult\",{\"1\":{\"216\":1}}],[\"shardresults\",{\"1\":{\"216\":1}}],[\"shardroutings\",{\"1\":{\"209\":6}}],[\"shardtarget\",{\"1\":{\"212\":4}}],[\"shardit\",{\"1\":{\"210\":4}}],[\"sharditerators\",{\"1\":{\"208\":1}}],[\"shardindex\",{\"1\":{\"209\":2,\"210\":1,\"212\":4}}],[\"shardindexmap\",{\"1\":{\"209\":2}}],[\"shardid\",{\"1\":{\"208\":2}}],[\"shardsearchrequest\",{\"1\":{\"214\":1,\"215\":1}}],[\"shardsit\",{\"1\":{\"210\":1}}],[\"shardsits\",{\"1\":{\"209\":3}}],[\"shards\",{\"1\":{\"205\":1}}],[\"shard\",{\"0\":{\"208\":1},\"1\":{\"205\":2,\"206\":1,\"208\":2,\"210\":2,\"211\":3,\"212\":5,\"215\":4}}],[\"share\",{\"1\":{\"98\":1,\"170\":3}}],[\"sha256\",{\"1\":{\"158\":1}}],[\"show\",{\"1\":{\"151\":3,\"163\":1,\"164\":1}}],[\"should\",{\"1\":{\"135\":1}}],[\"short\",{\"1\":{\"11\":1,\"13\":1}}],[\"shiro\",{\"1\":{\"122\":2,\"124\":1}}],[\"shutdowngracefully\",{\"1\":{\"45\":2}}],[\"sh\",{\"1\":{\"10\":1,\"11\":4,\"12\":5,\"13\":10,\"221\":1}}],[\"shell\",{\"1\":{\"5\":2}}],[\"style\",{\"1\":{\"151\":2,\"173\":1}}],[\"stylesheet\",{\"1\":{\"137\":1}}],[\"stdout\",{\"1\":{\"143\":2}}],[\"structure\",{\"0\":{\"201\":1}}],[\"struts\",{\"1\":{\"124\":1}}],[\"stream\",{\"1\":{\"208\":1}}],[\"streamsupport\",{\"1\":{\"208\":1}}],[\"streaming\",{\"0\":{\"199\":1,\"201\":1}}],[\"streamgobbler\",{\"1\":{\"143\":1}}],[\"strong\",{\"1\":{\"151\":2}}],[\"str\",{\"1\":{\"147\":2,\"150\":2}}],[\"strip\",{\"1\":{\"101\":1}}],[\"stringrdd\",{\"1\":{\"198\":2}}],[\"stringredisserializer\",{\"1\":{\"187\":3}}],[\"stringredistemplate\",{\"1\":{\"159\":1,\"187\":1}}],[\"stringreader\",{\"1\":{\"135\":1}}],[\"stringbuilder\",{\"1\":{\"188\":2}}],[\"stringbuffer\",{\"1\":{\"143\":2}}],[\"stringutils\",{\"1\":{\"137\":1}}],[\"string\",{\"1\":{\"56\":1,\"65\":2,\"66\":3,\"67\":1,\"68\":1,\"70\":1,\"72\":1,\"120\":1,\"135\":5,\"137\":12,\"143\":1,\"147\":4,\"151\":2,\"197\":5,\"198\":3}}],[\"stratum\",{\"1\":{\"41\":1}}],[\"store\",{\"1\":{\"135\":4}}],[\"storeload\",{\"1\":{\"52\":2}}],[\"storestore\",{\"1\":{\"52\":2}}],[\"stopch\",{\"1\":{\"72\":1}}],[\"stopped\",{\"1\":{\"30\":1}}],[\"stop\",{\"1\":{\"11\":1,\"48\":3}}],[\"stay\",{\"1\":{\"149\":1}}],[\"stackoverflow\",{\"1\":{\"144\":1}}],[\"statement\",{\"1\":{\"184\":1}}],[\"statementid\",{\"1\":{\"179\":1}}],[\"status\",{\"1\":{\"103\":6,\"156\":2,\"163\":1,\"164\":1}}],[\"static\",{\"1\":{\"57\":1,\"66\":1,\"135\":1,\"137\":1,\"196\":1,\"197\":1,\"198\":1,\"214\":1}}],[\"star\",{\"1\":{\"76\":1,\"122\":1,\"128\":1,\"130\":1,\"145\":1,\"150\":1,\"151\":1,\"152\":1,\"160\":1,\"165\":1,\"173\":1,\"192\":1}}],[\"startprofilingfetchphase\",{\"1\":{\"216\":1}}],[\"starttime\",{\"1\":{\"190\":2}}],[\"started\",{\"1\":{\"103\":1}}],[\"startch\",{\"1\":{\"72\":1}}],[\"start\",{\"1\":{\"48\":3,\"137\":1,\"147\":3,\"148\":4,\"149\":5,\"150\":5,\"206\":1}}],[\"stages\",{\"1\":{\"13\":5}}],[\"stage\",{\"1\":{\"9\":2,\"10\":3,\"11\":4,\"13\":16}}],[\"steps\",{\"1\":{\"9\":2,\"10\":2,\"11\":2,\"13\":7}}],[\"something\",{\"1\":{\"57\":1}}],[\"source\",{\"1\":{\"56\":2,\"137\":1,\"149\":1,\"205\":1}}],[\"sort\",{\"1\":{\"48\":2,\"137\":1,\"211\":2}}],[\"soa\",{\"1\":{\"12\":1,\"13\":1}}],[\"sonar\",{\"1\":{\"9\":2}}],[\"socket\",{\"1\":{\"43\":1,\"158\":1,\"163\":1,\"164\":1}}],[\"sock\",{\"1\":{\"5\":1,\"163\":1,\"164\":1}}],[\"px\",{\"1\":{\"151\":1,\"170\":6}}],[\"py\",{\"1\":{\"148\":1}}],[\"python\",{\"1\":{\"100\":1,\"124\":1,\"145\":2,\"147\":1,\"148\":1,\"149\":4,\"151\":2}}],[\"php\",{\"1\":{\"124\":2,\"173\":1}}],[\"phaseresults\",{\"1\":{\"212\":1}}],[\"phase\",{\"1\":{\"10\":1,\"206\":5}}],[\"pv\",{\"1\":{\"122\":1,\"126\":1,\"149\":8,\"150\":1,\"151\":16}}],[\"pem\",{\"1\":{\"120\":3}}],[\"personal\",{\"0\":{\"227\":1,\"228\":1}}],[\"perpetualcache\",{\"1\":{\"179\":4,\"182\":1}}],[\"performphaseonshard\",{\"1\":{\"209\":1,\"210\":2}}],[\"perf\",{\"1\":{\"49\":1}}],[\"permanent\",{\"1\":{\"158\":1}}],[\"perm\",{\"1\":{\"30\":2}}],[\"plotlines\",{\"1\":{\"151\":1}}],[\"platform\",{\"1\":{\"97\":1,\"108\":2}}],[\"plugin\",{\"1\":{\"56\":3}}],[\"plugins\",{\"1\":{\"5\":5,\"56\":3}}],[\"pkgs\",{\"1\":{\"153\":1}}],[\"pkg\",{\"1\":{\"72\":1}}],[\"png\",{\"1\":{\"61\":1,\"64\":1,\"69\":3,\"170\":1}}],[\"pprof\",{\"1\":{\"49\":1}}],[\"pmap\",{\"0\":{\"48\":1},\"1\":{\"48\":3}}],[\"pmd\",{\"1\":{\"9\":3}}],[\"pi\",{\"1\":{\"72\":1}}],[\"pid\",{\"1\":{\"48\":1,\"163\":2,\"164\":2}}],[\"ping\",{\"1\":{\"18\":1,\"69\":1,\"161\":1}}],[\"pipeline\",{\"1\":{\"7\":3,\"8\":3,\"13\":2,\"17\":1,\"18\":1}}],[\"p\",{\"1\":{\"18\":1,\"48\":2,\"79\":1,\"143\":2,\"149\":1}}],[\"pos\",{\"1\":{\"164\":1}}],[\"position\",{\"1\":{\"163\":2,\"164\":1}}],[\"post\",{\"1\":{\"98\":1,\"101\":1,\"109\":1,\"118\":1,\"205\":3}}],[\"pom\",{\"1\":{\"56\":1,\"159\":1}}],[\"port\",{\"1\":{\"43\":1,\"72\":1,\"149\":2,\"159\":2,\"164\":1,\"187\":2,\"196\":1}}],[\"portal\",{\"1\":{\"13\":1}}],[\"poolconfig\",{\"1\":{\"159\":1,\"187\":1}}],[\"poolthreadcache\",{\"1\":{\"45\":1}}],[\"pool\",{\"1\":{\"41\":2,\"149\":3}}],[\"pod\",{\"1\":{\"12\":2,\"13\":2,\"72\":8}}],[\"preprocess\",{\"1\":{\"215\":1}}],[\"preparerequest\",{\"1\":{\"207\":2}}],[\"prefer\",{\"1\":{\"158\":1}}],[\"preview\",{\"1\":{\"56\":1}}],[\"prd\",{\"1\":{\"117\":1,\"118\":1,\"120\":1,\"121\":1}}],[\"priority\",{\"1\":{\"211\":1}}],[\"privileges\",{\"1\":{\"103\":1}}],[\"private\",{\"1\":{\"57\":1,\"66\":2,\"68\":1,\"120\":1,\"135\":1,\"137\":3,\"206\":2,\"208\":1,\"210\":3,\"212\":2}}],[\"printstacktrace\",{\"1\":{\"137\":1}}],[\"printheapatgc\",{\"1\":{\"30\":1}}],[\"printgcapplicationstoppedtime\",{\"1\":{\"30\":1}}],[\"printgcapplicationconcurrenttime\",{\"1\":{\"30\":1}}],[\"printgctimestamps\",{\"1\":{\"30\":2,\"33\":1}}],[\"printgcdetails\",{\"1\":{\"30\":1,\"33\":1}}],[\"printgc\",{\"1\":{\"30\":2,\"33\":1}}],[\"println\",{\"1\":{\"12\":1,\"13\":2,\"72\":2,\"135\":2,\"137\":2,\"144\":1,\"190\":1,\"197\":1}}],[\"print\",{\"1\":{\"12\":1,\"13\":1,\"150\":1}}],[\"producer\",{\"1\":{\"221\":5}}],[\"producers\",{\"1\":{\"221\":2}}],[\"profileresult\",{\"1\":{\"216\":3}}],[\"profiler\",{\"1\":{\"216\":5}}],[\"progresslistener\",{\"1\":{\"212\":3}}],[\"property\",{\"1\":{\"143\":6,\"159\":8,\"187\":17}}],[\"properties\",{\"1\":{\"5\":2,\"142\":2,\"144\":1}}],[\"promise\",{\"1\":{\"103\":2}}],[\"prompt\",{\"1\":{\"98\":1,\"101\":2}}],[\"proxy2\",{\"1\":{\"157\":1}}],[\"proxy1\",{\"1\":{\"157\":1}}],[\"proxy\",{\"1\":{\"98\":1,\"155\":1,\"157\":13}}],[\"protocols\",{\"1\":{\"158\":1}}],[\"protocol\",{\"1\":{\"158\":1}}],[\"protocolhandler\",{\"1\":{\"56\":2}}],[\"protocolhandlervirtualthreadexecutorcustomizer\",{\"1\":{\"56\":2}}],[\"protected\",{\"1\":{\"206\":1}}],[\"protect\",{\"1\":{\"98\":1}}],[\"pro\",{\"1\":{\"83\":1}}],[\"proceed\",{\"1\":{\"206\":2}}],[\"processresponse\",{\"1\":{\"216\":1}}],[\"process\",{\"1\":{\"161\":2}}],[\"proc\",{\"1\":{\"48\":1}}],[\"project\",{\"1\":{\"5\":2,\"54\":1,\"137\":1}}],[\"pull\",{\"1\":{\"221\":6}}],[\"publishevent\",{\"1\":{\"144\":1}}],[\"publishers\",{\"1\":{\"5\":2}}],[\"publicly\",{\"1\":{\"98\":1}}],[\"public\",{\"0\":{\"121\":1},\"1\":{\"56\":5,\"57\":2,\"66\":1,\"67\":1,\"68\":2,\"120\":2,\"121\":3,\"137\":14,\"143\":1,\"144\":1,\"188\":2,\"189\":2,\"190\":2,\"196\":1,\"197\":1,\"198\":1,\"206\":2,\"207\":1,\"210\":2,\"212\":2,\"214\":1,\"215\":2,\"216\":2}}],[\"push\",{\"1\":{\"11\":1,\"13\":1,\"221\":5}}],[\"ps\",{\"1\":{\"11\":1,\"41\":1,\"128\":1}}],[\"padding\",{\"1\":{\"170\":1}}],[\"pattern\",{\"1\":{\"159\":2}}],[\"paths\",{\"1\":{\"135\":2,\"137\":2}}],[\"panel\",{\"1\":{\"151\":2}}],[\"payload\",{\"1\":{\"137\":5}}],[\"page\",{\"1\":{\"148\":2,\"150\":2}}],[\"pagenum\",{\"1\":{\"135\":1}}],[\"pagehits\",{\"1\":{\"135\":2}}],[\"pagehelper\",{\"1\":{\"122\":1,\"124\":1,\"192\":1}}],[\"pagesize\",{\"1\":{\"135\":2}}],[\"pass\",{\"1\":{\"72\":1,\"98\":1,\"155\":1,\"157\":2,\"196\":1}}],[\"password\",{\"1\":{\"12\":1,\"13\":1,\"143\":3,\"146\":1,\"148\":6,\"149\":3,\"150\":6,\"159\":2,\"164\":1,\"187\":2,\"203\":2}}],[\"parition\",{\"1\":{\"221\":1}}],[\"parquet\",{\"1\":{\"194\":1}}],[\"parentnode\",{\"1\":{\"146\":1}}],[\"partition\",{\"1\":{\"221\":5}}],[\"partitions\",{\"1\":{\"72\":1}}],[\"participants\",{\"1\":{\"198\":1}}],[\"partner\",{\"1\":{\"118\":1,\"120\":1,\"121\":2}}],[\"params\",{\"1\":{\"179\":1}}],[\"param\",{\"1\":{\"125\":1}}],[\"parameterizedmessage\",{\"1\":{\"206\":1}}],[\"parameterdefinitions\",{\"1\":{\"5\":2}}],[\"parametersdefinitionproperty\",{\"1\":{\"5\":2}}],[\"parallelize\",{\"1\":{\"198\":1}}],[\"parallelgcthreads\",{\"1\":{\"28\":3,\"29\":1,\"34\":1,\"35\":1}}],[\"parallel\",{\"1\":{\"13\":1}}],[\"parsesearchrequest\",{\"1\":{\"207\":1}}],[\"parseexception\",{\"1\":{\"135\":1}}],[\"parser1\",{\"1\":{\"135\":2}}],[\"parser\",{\"1\":{\"135\":2,\"207\":2}}],[\"parse\",{\"1\":{\"11\":1,\"13\":1,\"135\":4,\"137\":1,\"150\":1}}],[\"paas\",{\"1\":{\"6\":1}}],[\"package\",{\"1\":{\"5\":1}}],[\"/\",{\"0\":{\"49\":4},\"1\":{\"5\":51,\"11\":3,\"12\":8,\"13\":13,\"15\":2,\"18\":12,\"26\":3,\"31\":2,\"34\":1,\"41\":11,\"48\":6,\"49\":3,\"50\":1,\"56\":18,\"57\":2,\"65\":4,\"66\":3,\"72\":22,\"74\":1,\"76\":3,\"79\":5,\"95\":2,\"96\":1,\"97\":3,\"98\":11,\"101\":11,\"102\":2,\"103\":25,\"104\":4,\"108\":7,\"109\":4,\"110\":4,\"114\":2,\"117\":2,\"118\":8,\"120\":16,\"121\":11,\"122\":4,\"125\":5,\"126\":1,\"130\":7,\"135\":58,\"137\":38,\"138\":11,\"143\":28,\"144\":12,\"145\":11,\"146\":4,\"147\":7,\"148\":7,\"149\":28,\"150\":15,\"151\":28,\"152\":7,\"153\":10,\"155\":3,\"156\":1,\"157\":9,\"158\":2,\"159\":30,\"160\":8,\"161\":4,\"163\":14,\"164\":20,\"165\":7,\"166\":3,\"170\":9,\"173\":7,\"182\":3,\"187\":23,\"189\":2,\"192\":6,\"194\":1,\"196\":4,\"203\":9,\"205\":4,\"210\":12,\"216\":4,\"220\":10}}],[\">\",{\"1\":{\"5\":79,\"30\":10,\"56\":20,\"66\":5,\"70\":1,\"72\":4,\"101\":1,\"103\":1,\"104\":1,\"118\":2,\"120\":1,\"125\":7,\"135\":53,\"137\":28,\"143\":44,\"144\":1,\"146\":3,\"151\":12,\"152\":5,\"159\":52,\"164\":1,\"178\":2,\"182\":5,\"187\":32,\"189\":3,\"196\":8,\"197\":2,\"198\":1,\"206\":20,\"207\":1,\"208\":2,\"210\":3,\"212\":6,\"213\":1,\"214\":2,\"215\":6,\"216\":6}}],[\"<\",{\"1\":{\"5\":79,\"56\":19,\"66\":2,\"70\":1,\"72\":2,\"118\":2,\"135\":53,\"137\":27,\"143\":42,\"144\":1,\"146\":2,\"151\":12,\"159\":52,\"182\":5,\"187\":32,\"189\":2,\"190\":1,\"196\":8,\"197\":2,\"198\":1,\"206\":4,\"208\":1,\"209\":1,\"212\":3,\"214\":1,\"215\":1,\"216\":1}}],[\"功能\",{\"1\":{\"5\":1,\"6\":1,\"18\":2,\"23\":2,\"54\":3,\"56\":2,\"57\":1,\"63\":2,\"72\":3,\"101\":1,\"102\":1,\"124\":1,\"140\":1,\"144\":2,\"152\":1,\"167\":2,\"206\":1,\"213\":1,\"215\":1,\"220\":1,\"221\":3}}],[\"整页\",{\"1\":{\"192\":1}}],[\"整来整去\",{\"1\":{\"152\":1}}],[\"整来\",{\"1\":{\"74\":1}}],[\"整天\",{\"1\":{\"73\":1}}],[\"整理\",{\"1\":{\"29\":2,\"73\":1}}],[\"整体\",{\"0\":{\"13\":1,\"125\":1,\"131\":1},\"1\":{\"42\":1,\"63\":1,\"145\":1,\"205\":1,\"221\":1}}],[\"整\",{\"1\":{\"5\":1}}],[\"整个\",{\"1\":{\"4\":1,\"6\":1,\"7\":1,\"26\":4,\"31\":2,\"45\":1,\"63\":1,\"70\":2,\"74\":1,\"137\":1,\"181\":1,\"192\":1,\"206\":1}}],[\"挂掉\",{\"0\":{\"109\":1},\"1\":{\"45\":1,\"109\":1,\"221\":2}}],[\"挂\",{\"1\":{\"5\":1,\"50\":1,\"74\":1,\"80\":1,\"101\":1,\"120\":1,\"159\":1}}],[\"挂载\",{\"1\":{\"5\":1,\"11\":4,\"120\":1}}],[\"服务端\",{\"1\":{\"104\":1,\"221\":2}}],[\"服务器之间\",{\"1\":{\"157\":1}}],[\"服务器资源\",{\"1\":{\"58\":1}}],[\"服务器\",{\"0\":{\"96\":1,\"98\":1},\"1\":{\"41\":2,\"58\":1,\"95\":1,\"96\":2,\"98\":2,\"103\":1,\"114\":2,\"124\":1,\"126\":3,\"143\":1,\"145\":1,\"151\":1,\"152\":7,\"155\":6,\"157\":5,\"158\":1,\"159\":9,\"160\":2,\"161\":6,\"164\":1,\"184\":2,\"192\":3,\"221\":1}}],[\"服务\",{\"0\":{\"102\":1},\"1\":{\"5\":1,\"41\":1,\"62\":1,\"63\":7,\"65\":4,\"70\":3,\"95\":1,\"96\":1,\"101\":2,\"102\":2,\"103\":1,\"108\":1,\"143\":1,\"146\":2,\"149\":1,\"166\":1,\"167\":1,\"177\":1,\"221\":5}}],[\"当初\",{\"1\":{\"192\":1}}],[\"当单\",{\"1\":{\"152\":1}}],[\"当天\",{\"1\":{\"149\":1}}],[\"当人\",{\"1\":{\"76\":1}}],[\"当堆\",{\"1\":{\"39\":1}}],[\"当\",{\"1\":{\"39\":1,\"57\":1,\"58\":1,\"103\":1,\"125\":1,\"135\":1,\"155\":1,\"159\":1,\"179\":3,\"205\":1,\"210\":1,\"212\":1,\"216\":1,\"221\":4}}],[\"当然\",{\"1\":{\"12\":1,\"91\":1,\"96\":1,\"100\":1,\"114\":1,\"172\":1,\"192\":1,\"221\":2}}],[\"当做\",{\"1\":{\"6\":1,\"86\":1}}],[\"当前\",{\"1\":{\"5\":1,\"27\":1,\"52\":4,\"63\":2,\"137\":1,\"160\":1,\"210\":1,\"221\":1}}],[\"当时\",{\"1\":{\"4\":1,\"5\":1,\"7\":1,\"51\":1,\"86\":1}}],[\"甚至\",{\"1\":{\"5\":1,\"8\":1,\"18\":2,\"44\":1,\"63\":1,\"76\":1,\"103\":1,\"171\":1}}],[\"大致\",{\"1\":{\"221\":1}}],[\"大幅\",{\"1\":{\"221\":1}}],[\"大幅度\",{\"1\":{\"221\":1}}],[\"大多数\",{\"1\":{\"221\":1}}],[\"大规模\",{\"1\":{\"221\":2}}],[\"大型\",{\"1\":{\"152\":1}}],[\"大杂烩\",{\"1\":{\"124\":1}}],[\"大陆\",{\"1\":{\"117\":1}}],[\"大佬\",{\"1\":{\"81\":1,\"122\":1,\"152\":1,\"171\":1}}],[\"大大\",{\"1\":{\"191\":1}}],[\"大大小小\",{\"1\":{\"80\":1}}],[\"大大减少\",{\"1\":{\"72\":1}}],[\"大家\",{\"1\":{\"74\":1,\"91\":1,\"145\":1,\"149\":1,\"165\":2,\"221\":1}}],[\"大学城\",{\"1\":{\"74\":1}}],[\"大学\",{\"1\":{\"73\":1,\"74\":2,\"75\":1,\"77\":1,\"122\":1,\"127\":1}}],[\"大四\",{\"1\":{\"73\":1}}],[\"大三\",{\"1\":{\"73\":1}}],[\"大于\",{\"1\":{\"72\":2,\"221\":2}}],[\"大概\",{\"1\":{\"45\":1,\"50\":1,\"69\":2,\"78\":1,\"86\":1,\"95\":1,\"103\":1,\"127\":1,\"151\":1,\"192\":1}}],[\"大量\",{\"1\":{\"30\":1,\"43\":2,\"44\":1,\"50\":3,\"51\":2,\"135\":1}}],[\"大小\",{\"0\":{\"25\":1,\"37\":1,\"38\":1},\"1\":{\"25\":1,\"26\":11,\"28\":2,\"29\":1,\"31\":4,\"38\":1,\"80\":1,\"81\":1,\"137\":1,\"168\":1,\"207\":2,\"215\":1,\"221\":6}}],[\"大部分\",{\"1\":{\"23\":1,\"38\":1,\"146\":1,\"158\":1,\"161\":1,\"171\":1,\"221\":1}}],[\"大\",{\"1\":{\"5\":1,\"18\":2,\"37\":1,\"44\":3,\"58\":1,\"73\":2,\"74\":2,\"80\":1,\"86\":1,\"87\":1,\"124\":1,\"132\":1,\"135\":1,\"161\":1,\"164\":1,\"167\":1,\"171\":1,\"189\":1,\"192\":1,\"221\":2}}],[\"量过大\",{\"1\":{\"135\":1}}],[\"量\",{\"1\":{\"5\":1,\"8\":1,\"51\":1,\"55\":1,\"58\":2,\"65\":1,\"81\":1,\"124\":1,\"145\":1,\"192\":1,\"221\":1}}],[\"支付宝\",{\"1\":{\"95\":1}}],[\"支付\",{\"0\":{\"22\":1},\"1\":{\"22\":1,\"95\":1}}],[\"支撑\",{\"1\":{\"5\":1,\"152\":1,\"221\":1}}],[\"支持\",{\"0\":{\"183\":1,\"195\":1},\"1\":{\"5\":1,\"7\":1,\"17\":2,\"28\":1,\"63\":2,\"72\":1,\"140\":3,\"151\":3,\"152\":1,\"161\":1,\"179\":1,\"183\":1,\"185\":1,\"194\":4,\"197\":1,\"198\":1,\"199\":1,\"221\":8}}],[\"单位\",{\"1\":{\"221\":1}}],[\"单独\",{\"1\":{\"221\":1}}],[\"单一\",{\"1\":{\"221\":1}}],[\"单元\",{\"1\":{\"133\":1}}],[\"单元测试\",{\"0\":{\"10\":1},\"1\":{\"10\":2,\"13\":3}}],[\"单\",{\"1\":{\"70\":1}}],[\"单个\",{\"1\":{\"63\":1}}],[\"单机\",{\"1\":{\"62\":1,\"63\":4,\"69\":1,\"221\":1}}],[\"单点\",{\"1\":{\"5\":1}}],[\"单条\",{\"1\":{\"5\":1}}],[\"更大\",{\"1\":{\"221\":1}}],[\"更细\",{\"1\":{\"184\":1}}],[\"更久\",{\"1\":{\"103\":1}}],[\"更为\",{\"1\":{\"72\":1}}],[\"更新\",{\"0\":{\"107\":1},\"1\":{\"70\":1,\"72\":2,\"98\":2,\"102\":1,\"103\":5,\"114\":1,\"124\":1,\"135\":3,\"149\":1,\"161\":3,\"177\":1,\"189\":1,\"192\":6}}],[\"更有甚者\",{\"1\":{\"58\":1}}],[\"更改\",{\"1\":{\"57\":1}}],[\"更具\",{\"1\":{\"26\":1}}],[\"更好\",{\"1\":{\"17\":1,\"63\":1,\"72\":1,\"95\":1,\"145\":1,\"166\":1,\"184\":1}}],[\"更\",{\"1\":{\"6\":1,\"26\":1,\"73\":1,\"75\":1,\"77\":1,\"80\":1,\"181\":1,\"196\":1,\"198\":1,\"221\":2}}],[\"更换\",{\"1\":{\"5\":1,\"7\":1}}],[\"更加\",{\"1\":{\"4\":1,\"7\":1,\"78\":1}}],[\"里取\",{\"1\":{\"101\":1}}],[\"里装\",{\"1\":{\"49\":1}}],[\"里\",{\"0\":{\"68\":1},\"1\":{\"5\":1,\"18\":1,\"44\":1,\"63\":2,\"64\":1,\"73\":1,\"86\":1,\"97\":2,\"101\":1,\"102\":3,\"103\":2,\"104\":3,\"127\":1,\"137\":2,\"149\":1,\"151\":1,\"157\":1,\"161\":1,\"166\":1,\"189\":2,\"221\":1}}],[\"里面\",{\"1\":{\"5\":1,\"50\":1,\"52\":1,\"63\":1,\"135\":1,\"152\":1,\"166\":1,\"197\":1,\"215\":1}}],[\"应\",{\"1\":{\"133\":1}}],[\"应届\",{\"1\":{\"76\":2}}],[\"应届生\",{\"1\":{\"74\":1}}],[\"应对\",{\"1\":{\"60\":1,\"75\":1,\"221\":1}}],[\"应用服务\",{\"1\":{\"59\":1}}],[\"应用服务器\",{\"1\":{\"29\":1}}],[\"应用程序\",{\"0\":{\"115\":1},\"1\":{\"54\":3,\"55\":1,\"56\":3,\"57\":2,\"72\":2,\"114\":2,\"115\":1,\"116\":1,\"120\":1}}],[\"应用\",{\"0\":{\"112\":1,\"118\":1},\"1\":{\"5\":1,\"10\":1,\"12\":3,\"26\":2,\"37\":3,\"38\":5,\"64\":1,\"72\":4,\"114\":1,\"115\":1,\"140\":1,\"177\":1,\"180\":1,\"184\":2,\"221\":1}}],[\"应该\",{\"1\":{\"4\":1,\"7\":1,\"70\":2,\"73\":1,\"74\":2,\"77\":1,\"104\":1,\"168\":1,\"173\":1,\"192\":1,\"221\":2}}],[\"要念\",{\"1\":{\"221\":1}}],[\"要死\",{\"1\":{\"165\":1}}],[\"要不然\",{\"1\":{\"127\":1}}],[\"要说\",{\"1\":{\"84\":1}}],[\"要改\",{\"1\":{\"77\":1}}],[\"要是\",{\"1\":{\"74\":1,\"153\":1}}],[\"要么\",{\"1\":{\"18\":1}}],[\"要求\",{\"1\":{\"17\":1,\"18\":1,\"37\":1,\"65\":1,\"70\":1,\"81\":1,\"116\":1,\"205\":1,\"221\":1}}],[\"要\",{\"1\":{\"5\":1,\"7\":3,\"23\":1,\"38\":1,\"41\":1,\"50\":1,\"55\":1,\"56\":2,\"70\":4,\"72\":3,\"73\":3,\"74\":3,\"75\":2,\"76\":4,\"77\":2,\"78\":3,\"81\":2,\"82\":1,\"86\":1,\"87\":2,\"89\":2,\"99\":1,\"103\":2,\"120\":1,\"124\":2,\"127\":1,\"128\":1,\"135\":2,\"137\":1,\"147\":1,\"149\":1,\"159\":1,\"163\":3,\"164\":1,\"173\":1,\"180\":1,\"186\":1,\"187\":1,\"206\":1,\"212\":1,\"221\":4}}],[\"镜像\",{\"0\":{\"11\":1},\"1\":{\"5\":2,\"7\":1,\"11\":2,\"12\":3,\"13\":4}}],[\"串行化\",{\"1\":{\"6\":2,\"161\":1}}],[\"串行\",{\"1\":{\"5\":1,\"27\":3,\"28\":1,\"32\":1,\"161\":1}}],[\"打分\",{\"1\":{\"215\":1}}],[\"打算\",{\"1\":{\"81\":1,\"85\":1}}],[\"打电话\",{\"1\":{\"75\":1}}],[\"打着\",{\"1\":{\"74\":1}}],[\"打击\",{\"1\":{\"74\":1,\"75\":1}}],[\"打游戏\",{\"1\":{\"73\":1,\"75\":1,\"77\":1,\"80\":1,\"82\":2,\"89\":1}}],[\"打到\",{\"1\":{\"45\":1}}],[\"打印\",{\"1\":{\"30\":3}}],[\"打印信息\",{\"1\":{\"30\":1}}],[\"打开\",{\"1\":{\"28\":1,\"29\":1,\"97\":1,\"161\":2,\"163\":1,\"169\":1,\"203\":1}}],[\"打\",{\"1\":{\"7\":1,\"75\":1,\"89\":1}}],[\"打出\",{\"1\":{\"5\":1}}],[\"打包\",{\"1\":{\"5\":1,\"11\":1,\"72\":1}}],[\"打通\",{\"1\":{\"4\":1,\"43\":1}}],[\"线型\",{\"1\":{\"151\":1}}],[\"线上\",{\"1\":{\"51\":1}}],[\"线程\",{\"0\":{\"53\":1,\"55\":2,\"56\":1},\"1\":{\"23\":1,\"26\":6,\"28\":2,\"34\":1,\"35\":1,\"45\":3,\"51\":1,\"52\":9,\"54\":5,\"55\":7,\"56\":12,\"57\":13,\"66\":2,\"76\":1,\"141\":3,\"161\":9,\"210\":1,\"212\":1,\"214\":1,\"215\":1,\"216\":1,\"221\":5}}],[\"线\",{\"1\":{\"5\":1}}],[\"太久\",{\"1\":{\"221\":1}}],[\"太远\",{\"1\":{\"152\":1}}],[\"太强\",{\"1\":{\"149\":1}}],[\"太难受\",{\"1\":{\"114\":1}}],[\"太火\",{\"1\":{\"109\":1}}],[\"太快\",{\"1\":{\"81\":1}}],[\"太累\",{\"1\":{\"76\":2}}],[\"太菜\",{\"1\":{\"74\":1}}],[\"太少\",{\"1\":{\"74\":1}}],[\"太大\",{\"1\":{\"70\":1,\"161\":1}}],[\"太低了\",{\"1\":{\"145\":1}}],[\"太低\",{\"1\":{\"49\":1,\"126\":1}}],[\"太多\",{\"1\":{\"6\":1,\"7\":2,\"18\":1,\"50\":1,\"75\":1,\"82\":1}}],[\"太\",{\"1\":{\"5\":1,\"63\":1,\"124\":1,\"127\":1,\"152\":1,\"170\":1,\"216\":1}}],[\"太慢\",{\"1\":{\"5\":1}}],[\"在线\",{\"1\":{\"168\":1}}],[\"在于\",{\"1\":{\"55\":1}}],[\"在读\",{\"1\":{\"52\":1}}],[\"在\",{\"0\":{\"53\":1,\"56\":1,\"134\":1,\"184\":1},\"1\":{\"5\":2,\"7\":4,\"8\":2,\"10\":2,\"11\":1,\"12\":2,\"13\":2,\"18\":1,\"23\":1,\"25\":2,\"26\":4,\"27\":1,\"37\":1,\"38\":1,\"41\":1,\"42\":4,\"43\":1,\"45\":5,\"49\":2,\"50\":2,\"52\":4,\"54\":4,\"55\":1,\"56\":2,\"57\":7,\"61\":1,\"63\":6,\"64\":1,\"65\":1,\"66\":3,\"69\":1,\"70\":1,\"72\":6,\"74\":3,\"77\":1,\"78\":6,\"80\":3,\"82\":2,\"83\":1,\"86\":2,\"87\":1,\"96\":2,\"97\":3,\"99\":1,\"101\":4,\"102\":3,\"103\":5,\"104\":1,\"106\":1,\"108\":1,\"114\":1,\"115\":2,\"117\":2,\"118\":1,\"122\":1,\"124\":5,\"125\":4,\"126\":1,\"127\":1,\"132\":2,\"135\":4,\"136\":2,\"142\":1,\"143\":3,\"144\":1,\"145\":2,\"146\":3,\"149\":5,\"151\":5,\"152\":1,\"153\":1,\"157\":4,\"158\":2,\"159\":2,\"160\":1,\"161\":14,\"164\":2,\"165\":3,\"168\":2,\"170\":1,\"173\":2,\"177\":2,\"179\":2,\"180\":1,\"182\":1,\"183\":1,\"184\":4,\"185\":2,\"188\":1,\"189\":1,\"190\":2,\"192\":2,\"194\":1,\"203\":1,\"204\":3,\"205\":2,\"207\":1,\"212\":2,\"213\":1,\"215\":1,\"216\":3,\"220\":3,\"221\":46}}],[\"管理器\",{\"1\":{\"221\":1}}],[\"管理\",{\"1\":{\"5\":1,\"6\":4,\"55\":1,\"72\":4,\"143\":1,\"145\":1,\"146\":2,\"221\":1}}],[\"kw\",{\"1\":{\"149\":3,\"150\":3}}],[\"known\",{\"1\":{\"120\":1}}],[\"knative\",{\"1\":{\"7\":1}}],[\"kind\",{\"1\":{\"72\":1}}],[\"kibana\",{\"1\":{\"72\":1,\"194\":1,\"197\":3,\"205\":1}}],[\"keyserializer\",{\"1\":{\"187\":1}}],[\"keyword\",{\"1\":{\"135\":2,\"137\":7}}],[\"keyring\",{\"1\":{\"120\":1}}],[\"keygenerator\",{\"0\":{\"188\":1},\"1\":{\"187\":1,\"188\":1,\"189\":1}}],[\"keygen\",{\"1\":{\"120\":3}}],[\"key\",{\"0\":{\"107\":1,\"121\":1},\"1\":{\"64\":2,\"66\":6,\"67\":4,\"68\":3,\"98\":6,\"101\":2,\"102\":3,\"120\":3,\"121\":3,\"137\":1,\"149\":4,\"150\":3,\"155\":1,\"158\":2,\"179\":3,\"185\":13,\"187\":1,\"188\":3,\"189\":1,\"192\":1,\"206\":1,\"221\":3}}],[\"k3\",{\"1\":{\"48\":1}}],[\"k2\",{\"1\":{\"48\":1}}],[\"kb\",{\"1\":{\"46\":1,\"168\":1}}],[\"k\",{\"1\":{\"23\":2,\"26\":1,\"30\":56,\"73\":2,\"74\":2}}],[\"kubectl\",{\"1\":{\"12\":2,\"13\":2,\"72\":4}}],[\"kubernetesservice\",{\"1\":{\"66\":1}}],[\"kubernetes\",{\"0\":{\"58\":1,\"64\":1,\"65\":1,\"202\":1},\"1\":{\"0\":1,\"5\":1,\"7\":4,\"8\":1,\"11\":1,\"12\":2,\"42\":2,\"72\":9,\"87\":2}}],[\"k8s\",{\"0\":{\"12\":1,\"72\":1},\"1\":{\"65\":1,\"70\":5,\"72\":7}}],[\"kafaka\",{\"1\":{\"221\":1}}],[\"kafa\",{\"1\":{\"221\":2}}],[\"kafkaconsumer\",{\"1\":{\"221\":1}}],[\"kafka\",{\"0\":{\"221\":1,\"233\":1},\"1\":{\"5\":1,\"6\":3,\"81\":1,\"221\":94}}],[\"kaniko\",{\"1\":{\"7\":2,\"11\":1}}],[\"kakfa\",{\"1\":{\"6\":1}}],[\"到期\",{\"1\":{\"114\":1}}],[\"到时候\",{\"1\":{\"87\":1,\"161\":1}}],[\"到来\",{\"1\":{\"74\":1}}],[\"到达\",{\"1\":{\"28\":1,\"37\":2,\"221\":1}}],[\"到\",{\"0\":{\"12\":1},\"1\":{\"5\":2,\"6\":1,\"11\":2,\"13\":1,\"18\":1,\"30\":1,\"42\":1,\"45\":1,\"49\":1,\"50\":1,\"51\":2,\"52\":3,\"62\":1,\"63\":3,\"72\":4,\"75\":1,\"76\":1,\"82\":1,\"102\":1,\"103\":1,\"114\":1,\"120\":2,\"122\":1,\"124\":1,\"125\":2,\"132\":1,\"141\":1,\"145\":1,\"149\":1,\"152\":3,\"155\":3,\"157\":3,\"159\":1,\"160\":2,\"161\":1,\"164\":2,\"165\":1,\"167\":1,\"173\":1,\"178\":2,\"179\":2,\"192\":2,\"203\":1,\"207\":1,\"216\":2,\"221\":19}}],[\"个数\",{\"1\":{\"221\":2}}],[\"个主\",{\"1\":{\"205\":1}}],[\"个个\",{\"1\":{\"74\":1}}],[\"个人\",{\"0\":{\"138\":1},\"1\":{\"18\":1,\"99\":1,\"103\":1,\"107\":1,\"114\":1,\"122\":2,\"124\":2,\"145\":1,\"148\":1,\"151\":2,\"152\":3,\"160\":3,\"164\":1,\"169\":1,\"170\":1,\"173\":1,\"184\":1,\"191\":1,\"192\":4}}],[\"个\",{\"1\":{\"5\":1,\"7\":3,\"12\":1,\"23\":2,\"28\":1,\"45\":1,\"54\":1,\"57\":1,\"59\":1,\"61\":1,\"62\":1,\"63\":1,\"70\":2,\"73\":2,\"74\":5,\"75\":1,\"76\":2,\"80\":1,\"95\":1,\"100\":1,\"114\":1,\"122\":2,\"124\":2,\"128\":2,\"130\":1,\"145\":2,\"148\":1,\"149\":5,\"150\":1,\"151\":1,\"152\":1,\"160\":1,\"162\":1,\"165\":1,\"166\":1,\"173\":1,\"186\":1,\"192\":2,\"205\":5,\"221\":4}}],[\"使\",{\"1\":{\"161\":1}}],[\"使用量\",{\"1\":{\"221\":1}}],[\"使用率\",{\"1\":{\"50\":1,\"122\":1,\"126\":1}}],[\"使用\",{\"0\":{\"53\":1,\"56\":1,\"60\":1,\"130\":1,\"134\":1,\"137\":1,\"143\":1,\"183\":1},\"1\":{\"5\":2,\"7\":7,\"8\":1,\"9\":1,\"10\":2,\"11\":6,\"12\":1,\"13\":1,\"17\":1,\"18\":1,\"23\":4,\"27\":2,\"28\":3,\"29\":1,\"30\":5,\"34\":1,\"35\":1,\"38\":2,\"39\":3,\"41\":2,\"43\":1,\"48\":2,\"51\":1,\"54\":1,\"55\":1,\"56\":4,\"57\":4,\"63\":1,\"66\":1,\"68\":1,\"69\":1,\"72\":3,\"76\":3,\"87\":1,\"95\":1,\"96\":1,\"98\":5,\"99\":2,\"101\":3,\"114\":3,\"115\":1,\"117\":1,\"122\":11,\"124\":3,\"125\":1,\"126\":4,\"127\":1,\"135\":8,\"136\":3,\"137\":2,\"141\":1,\"142\":2,\"143\":2,\"144\":2,\"145\":3,\"146\":1,\"147\":1,\"148\":1,\"149\":5,\"150\":2,\"151\":10,\"153\":2,\"155\":2,\"156\":1,\"157\":2,\"158\":3,\"159\":10,\"162\":1,\"163\":2,\"164\":4,\"165\":1,\"167\":1,\"168\":1,\"170\":2,\"172\":3,\"177\":1,\"178\":3,\"179\":1,\"180\":1,\"182\":1,\"183\":1,\"184\":4,\"185\":5,\"190\":1,\"191\":5,\"192\":2,\"194\":1,\"197\":1,\"198\":2,\"202\":1,\"203\":1,\"204\":1,\"206\":1,\"216\":1,\"221\":12}}],[\"使得\",{\"1\":{\"4\":1,\"29\":1,\"58\":1,\"161\":1,\"184\":1}}],[\"好奇\",{\"1\":{\"216\":1}}],[\"好图\",{\"1\":{\"171\":1}}],[\"好意思\",{\"1\":{\"165\":1}}],[\"好感\",{\"1\":{\"124\":1}}],[\"好玩\",{\"1\":{\"124\":1}}],[\"好么\",{\"1\":{\"86\":1}}],[\"好看\",{\"1\":{\"85\":1,\"151\":1}}],[\"好几个\",{\"1\":{\"83\":1}}],[\"好几年\",{\"1\":{\"73\":1,\"83\":1,\"124\":1}}],[\"好久没\",{\"1\":{\"77\":1,\"89\":1}}],[\"好好\",{\"1\":{\"76\":2,\"81\":3,\"87\":1}}],[\"好开心\",{\"1\":{\"75\":2}}],[\"好多\",{\"1\":{\"73\":1}}],[\"好处\",{\"1\":{\"57\":1,\"171\":1,\"216\":1,\"221\":2}}],[\"好像\",{\"1\":{\"7\":1,\"73\":1,\"74\":1,\"75\":1,\"78\":1,\"84\":1,\"166\":1,\"173\":1}}],[\"好\",{\"1\":{\"5\":1,\"7\":1,\"51\":1,\"74\":2,\"75\":2,\"77\":1,\"80\":1,\"81\":1,\"82\":1,\"85\":1,\"86\":1,\"87\":1,\"90\":1,\"113\":1,\"115\":1,\"151\":1,\"153\":1,\"159\":2,\"164\":1,\"167\":1,\"170\":1,\"171\":1,\"173\":2,\"184\":1,\"187\":1,\"203\":1,\"221\":2}}],[\"与\",{\"0\":{\"55\":1,\"122\":1,\"123\":1},\"1\":{\"5\":1,\"7\":1,\"8\":1,\"26\":4,\"28\":1,\"29\":1,\"30\":4,\"31\":1,\"55\":1,\"72\":2,\"104\":1,\"116\":2,\"117\":1,\"121\":1,\"122\":1,\"132\":1,\"133\":1,\"135\":2,\"137\":1,\"143\":1,\"149\":1,\"160\":1,\"161\":3,\"184\":1,\"205\":2,\"216\":1,\"221\":5}}],[\"但\",{\"1\":{\"5\":1,\"56\":2,\"57\":1,\"70\":1,\"80\":1,\"86\":1,\"87\":1,\"103\":1,\"133\":1,\"165\":1,\"184\":1,\"207\":1,\"221\":3}}],[\"但是\",{\"1\":{\"4\":1,\"5\":1,\"7\":2,\"8\":2,\"11\":1,\"18\":1,\"26\":1,\"27\":1,\"29\":1,\"39\":1,\"41\":1,\"45\":2,\"50\":1,\"51\":1,\"72\":1,\"73\":2,\"74\":3,\"75\":1,\"76\":2,\"86\":1,\"103\":1,\"104\":1,\"106\":1,\"124\":5,\"126\":1,\"135\":2,\"143\":1,\"145\":3,\"148\":1,\"151\":1,\"152\":1,\"155\":1,\"157\":1,\"158\":1,\"161\":2,\"165\":1,\"167\":1,\"168\":1,\"184\":1,\"185\":1,\"192\":3,\"221\":4}}],[\"用源\",{\"1\":{\"168\":1}}],[\"用用\",{\"1\":{\"151\":1}}],[\"用词\",{\"1\":{\"132\":2,\"133\":1}}],[\"用法\",{\"1\":{\"65\":1}}],[\"用到\",{\"1\":{\"65\":1,\"165\":1}}],[\"用来\",{\"1\":{\"10\":1,\"49\":1,\"74\":1,\"122\":1,\"125\":3,\"133\":1,\"145\":2,\"148\":1,\"152\":2,\"215\":1}}],[\"用于\",{\"1\":{\"7\":3,\"72\":4,\"115\":1,\"137\":1,\"157\":1,\"208\":1,\"221\":5}}],[\"用户名\",{\"1\":{\"203\":1}}],[\"用户数\",{\"1\":{\"177\":1}}],[\"用户\",{\"1\":{\"5\":1,\"7\":1,\"8\":1,\"12\":3,\"13\":1,\"18\":2,\"23\":1,\"57\":1,\"63\":1,\"72\":1,\"103\":12,\"113\":1,\"115\":2,\"116\":1,\"121\":1,\"132\":1,\"148\":1,\"152\":2,\"157\":8,\"158\":1,\"166\":1,\"178\":1,\"183\":3,\"192\":2,\"205\":1,\"221\":8}}],[\"用\",{\"1\":{\"5\":2,\"6\":1,\"7\":2,\"10\":1,\"12\":1,\"29\":1,\"42\":1,\"43\":1,\"45\":1,\"51\":2,\"72\":7,\"74\":1,\"81\":1,\"83\":1,\"86\":1,\"87\":1,\"95\":1,\"96\":2,\"108\":1,\"113\":2,\"114\":1,\"120\":1,\"124\":1,\"145\":1,\"149\":1,\"152\":1,\"159\":1,\"164\":1,\"168\":1,\"169\":1,\"173\":1,\"194\":1,\"197\":1,\"203\":2,\"205\":1,\"221\":2}}],[\"想念\",{\"1\":{\"167\":1}}],[\"想来想去\",{\"1\":{\"103\":1}}],[\"想要\",{\"1\":{\"97\":1,\"148\":1,\"157\":1}}],[\"想想\",{\"1\":{\"87\":1}}],[\"想不起来\",{\"1\":{\"84\":1}}],[\"想法\",{\"1\":{\"75\":1,\"80\":1,\"86\":1,\"122\":1,\"165\":1,\"168\":1}}],[\"想起\",{\"1\":{\"74\":1,\"75\":2,\"78\":2,\"85\":1,\"169\":1}}],[\"想回\",{\"1\":{\"74\":1,\"79\":1}}],[\"想过\",{\"1\":{\"73\":1}}],[\"想着\",{\"1\":{\"73\":2,\"79\":1}}],[\"想象\",{\"1\":{\"44\":1}}],[\"想\",{\"1\":{\"5\":1,\"7\":1,\"11\":1,\"18\":1,\"27\":1,\"73\":1,\"74\":2,\"75\":1,\"76\":1,\"77\":1,\"80\":2,\"82\":1,\"90\":1,\"91\":1,\"93\":1,\"124\":1,\"137\":1,\"151\":1,\"157\":1,\"161\":2,\"165\":2,\"168\":1,\"171\":1,\"185\":1,\"192\":2}}],[\"想到\",{\"1\":{\"5\":1,\"46\":1,\"73\":1,\"78\":1}}],[\"dfs\",{\"1\":{\"205\":1,\"206\":1}}],[\"dhe\",{\"1\":{\"158\":1}}],[\"dns\",{\"1\":{\"152\":1}}],[\"db\",{\"1\":{\"101\":1,\"163\":5,\"164\":4,\"187\":1}}],[\"days\",{\"1\":{\"147\":2,\"150\":2}}],[\"daterange\",{\"1\":{\"151\":1}}],[\"date2\",{\"1\":{\"149\":6}}],[\"date1\",{\"1\":{\"149\":6}}],[\"datetime\",{\"1\":{\"147\":4,\"150\":4}}],[\"date\",{\"1\":{\"144\":1,\"147\":5,\"148\":8,\"149\":6,\"150\":7}}],[\"datadir\",{\"1\":{\"163\":1,\"164\":1}}],[\"dataview\",{\"1\":{\"151\":1}}],[\"database\",{\"1\":{\"143\":2,\"187\":1}}],[\"data\",{\"1\":{\"72\":1,\"101\":1,\"118\":6,\"120\":1,\"148\":2,\"149\":2,\"150\":3,\"151\":3,\"159\":4,\"184\":1,\"186\":2,\"187\":7,\"197\":3}}],[\"davinci\",{\"1\":{\"98\":1,\"101\":1,\"108\":2}}],[\"dubbo\",{\"1\":{\"75\":1}}],[\"dumps\",{\"1\":{\"148\":1,\"149\":1,\"150\":1}}],[\"dump\",{\"1\":{\"44\":2,\"48\":2,\"161\":2,\"164\":2}}],[\"d8c164bced70a1c66837ea5c0180c61dfb48ac3\",{\"1\":{\"72\":1}}],[\"dsl\",{\"1\":{\"72\":2,\"197\":1}}],[\"driven\",{\"1\":{\"144\":1,\"187\":1}}],[\"driver\",{\"1\":{\"72\":6}}],[\"drop\",{\"1\":{\"41\":2}}],[\"dispatchrequest\",{\"1\":{\"206\":2}}],[\"dispatcher\",{\"1\":{\"159\":4,\"206\":1}}],[\"dispatcherservlet\",{\"1\":{\"125\":2}}],[\"diyumax\",{\"1\":{\"151\":1}}],[\"diyu\",{\"1\":{\"151\":4}}],[\"dict\",{\"1\":{\"149\":1}}],[\"dirs\",{\"1\":{\"221\":4}}],[\"dir\",{\"1\":{\"135\":4,\"137\":4,\"221\":1}}],[\"directoryreader\",{\"1\":{\"135\":1}}],[\"directory\",{\"1\":{\"135\":2,\"137\":2}}],[\"div\",{\"1\":{\"124\":1,\"151\":4,\"173\":1}}],[\"dio\",{\"1\":{\"46\":2}}],[\"dind\",{\"1\":{\"11\":3}}],[\"dcom\",{\"1\":{\"43\":3}}],[\"dt\",{\"1\":{\"43\":1}}],[\"djava\",{\"1\":{\"43\":1}}],[\"d\",{\"1\":{\"41\":1,\"48\":1,\"173\":1}}],[\"dmaven\",{\"1\":{\"5\":1,\"11\":1,\"13\":1}}],[\"doexecute\",{\"1\":{\"206\":4,\"216\":1}}],[\"download\",{\"1\":{\"153\":1}}],[\"domain\",{\"1\":{\"114\":1,\"120\":1}}],[\"docidstoload\",{\"1\":{\"212\":2}}],[\"docid\",{\"1\":{\"135\":4}}],[\"document\",{\"1\":{\"133\":1,\"135\":6,\"146\":2,\"151\":1,\"205\":3,\"211\":4}}],[\"docs\",{\"1\":{\"108\":2,\"135\":4}}],[\"doc\",{\"1\":{\"103\":1,\"135\":18,\"205\":3,\"216\":1}}],[\"dockone\",{\"1\":{\"8\":1}}],[\"dockerfile\",{\"1\":{\"5\":1,\"7\":1,\"11\":1,\"13\":1}}],[\"dockerfilepath\",{\"1\":{\"5\":2}}],[\"dockerbuilder\",{\"1\":{\"5\":2}}],[\"dockerpublish\",{\"1\":{\"5\":2}}],[\"docker\",{\"1\":{\"5\":3,\"7\":1,\"11\":12,\"12\":1,\"13\":4,\"72\":1}}],[\"dofilter\",{\"1\":{\"68\":4}}],[\"doing\",{\"1\":{\"57\":1}}],[\"dosomething\",{\"1\":{\"57\":1}}],[\"done\",{\"1\":{\"48\":1}}],[\"do\",{\"1\":{\"48\":1,\"98\":1,\"163\":2,\"164\":1}}],[\"dogeneratesubmoduleconfigurations\",{\"1\":{\"5\":2}}],[\"delegatefailure\",{\"1\":{\"215\":1}}],[\"delegatingfilterproxy\",{\"1\":{\"159\":1}}],[\"decode\",{\"1\":{\"148\":2,\"150\":1}}],[\"details\",{\"1\":{\"144\":1,\"220\":1}}],[\"dependency\",{\"1\":{\"135\":10,\"137\":2,\"143\":6,\"159\":4,\"196\":2}}],[\"deploy\",{\"1\":{\"13\":1}}],[\"deployments\",{\"1\":{\"65\":2}}],[\"deploymentname\",{\"1\":{\"65\":2}}],[\"deployment\",{\"1\":{\"12\":6,\"13\":4,\"65\":2}}],[\"demo\",{\"1\":{\"72\":6,\"196\":1}}],[\"debug\",{\"0\":{\"43\":1,\"203\":1},\"1\":{\"43\":2,\"120\":1,\"203\":3,\"206\":2}}],[\"defined\",{\"1\":{\"144\":1}}],[\"defaultrestchannel\",{\"1\":{\"216\":1}}],[\"defaultexpiration\",{\"1\":{\"187\":2}}],[\"defaultlistablebeanfactory\",{\"1\":{\"144\":4}}],[\"default\",{\"1\":{\"72\":4,\"120\":1,\"163\":1,\"164\":1,\"187\":1}}],[\"defaultvalue\",{\"1\":{\"5\":4}}],[\"defnew\",{\"1\":{\"30\":3}}],[\"def\",{\"1\":{\"12\":1,\"13\":1,\"30\":2,\"148\":2,\"149\":1,\"150\":2}}],[\"description\",{\"1\":{\"5\":2}}],[\"device\",{\"1\":{\"118\":1}}],[\"developerworks\",{\"1\":{\"138\":1}}],[\"developer\",{\"1\":{\"120\":1}}],[\"developers\",{\"1\":{\"103\":1}}],[\"development\",{\"1\":{\"4\":1}}],[\"dev\",{\"1\":{\"4\":1}}],[\"devops\",{\"0\":{\"3\":1,\"4\":1,\"8\":1},\"1\":{\"3\":2,\"4\":4,\"6\":1,\"7\":6,\"8\":2,\"18\":5,\"86\":1}}],[\"只好\",{\"1\":{\"170\":1}}],[\"只要\",{\"1\":{\"120\":1,\"161\":1,\"221\":1}}],[\"只花\",{\"1\":{\"83\":1}}],[\"只会\",{\"1\":{\"44\":1,\"89\":1,\"205\":1}}],[\"只有\",{\"1\":{\"8\":1,\"70\":1,\"74\":1,\"75\":2,\"76\":2,\"86\":1,\"104\":1,\"127\":2,\"145\":1,\"149\":1,\"152\":1,\"155\":1,\"181\":1,\"185\":3,\"192\":1}}],[\"只是\",{\"1\":{\"5\":1,\"62\":1,\"73\":3,\"75\":2,\"106\":1,\"120\":1,\"124\":2,\"126\":1,\"173\":1,\"192\":1,\"211\":1}}],[\"只能\",{\"1\":{\"5\":1,\"6\":2,\"7\":1,\"11\":1,\"12\":1,\"18\":1,\"63\":2,\"70\":1,\"74\":1,\"77\":1,\"78\":1,\"103\":2,\"106\":3,\"114\":2,\"124\":1,\"126\":2,\"127\":1,\"145\":2,\"149\":1,\"172\":1,\"197\":1,\"221\":2}}],[\"只\",{\"1\":{\"5\":1,\"12\":2,\"27\":1,\"57\":1,\"66\":1,\"78\":1,\"80\":1,\"83\":1,\"98\":1,\"102\":1,\"120\":1,\"124\":1,\"137\":1,\"145\":1,\"192\":1,\"205\":1,\"221\":3}}],[\"可不可以\",{\"1\":{\"221\":2}}],[\"可供\",{\"1\":{\"221\":1}}],[\"可视化\",{\"1\":{\"194\":1}}],[\"可选\",{\"1\":{\"185\":3}}],[\"可变\",{\"1\":{\"148\":1,\"149\":5,\"221\":1}}],[\"可谓\",{\"1\":{\"124\":1}}],[\"可怕\",{\"1\":{\"89\":1}}],[\"可是\",{\"1\":{\"76\":2,\"81\":1}}],[\"可学\",{\"1\":{\"76\":1}}],[\"可笑\",{\"1\":{\"74\":1}}],[\"可见\",{\"1\":{\"52\":1,\"161\":1}}],[\"可疑\",{\"1\":{\"45\":1}}],[\"可用性\",{\"1\":{\"145\":1,\"177\":1,\"221\":1}}],[\"可用内存\",{\"1\":{\"26\":1}}],[\"可用\",{\"1\":{\"25\":2,\"61\":2,\"63\":1,\"72\":1,\"76\":1,\"207\":1}}],[\"可能\",{\"1\":{\"18\":1,\"29\":1,\"37\":1,\"39\":1,\"45\":3,\"49\":1,\"57\":2,\"58\":1,\"70\":2,\"73\":1,\"91\":1,\"95\":1,\"97\":1,\"98\":1,\"107\":2,\"113\":1,\"114\":2,\"124\":1,\"132\":1,\"133\":1,\"166\":1,\"177\":1,\"184\":1,\"205\":2,\"216\":1,\"221\":7}}],[\"可\",{\"1\":{\"7\":1,\"9\":1,\"25\":1,\"29\":1,\"30\":3,\"55\":1,\"72\":2,\"115\":2,\"159\":1,\"161\":2,\"168\":1,\"177\":1,\"183\":1,\"187\":1,\"206\":1,\"221\":2}}],[\"可惜\",{\"1\":{\"7\":3,\"63\":1,\"77\":1,\"80\":1,\"85\":1,\"86\":1,\"124\":1,\"155\":1}}],[\"可以\",{\"1\":{\"5\":1,\"6\":1,\"7\":2,\"9\":3,\"11\":2,\"12\":1,\"26\":3,\"29\":1,\"37\":1,\"38\":2,\"39\":1,\"42\":1,\"43\":2,\"44\":1,\"45\":2,\"55\":1,\"57\":3,\"60\":1,\"63\":4,\"64\":1,\"66\":3,\"72\":1,\"74\":1,\"93\":1,\"95\":1,\"96\":1,\"97\":2,\"100\":2,\"101\":3,\"102\":3,\"103\":4,\"104\":1,\"108\":1,\"109\":1,\"115\":1,\"120\":4,\"122\":1,\"127\":1,\"130\":1,\"132\":1,\"133\":1,\"137\":2,\"140\":1,\"141\":3,\"144\":1,\"145\":2,\"146\":1,\"148\":2,\"149\":1,\"150\":1,\"151\":2,\"152\":2,\"153\":3,\"155\":2,\"157\":3,\"158\":1,\"159\":1,\"164\":2,\"165\":1,\"166\":2,\"167\":1,\"168\":2,\"170\":1,\"172\":1,\"173\":1,\"181\":1,\"184\":2,\"185\":3,\"192\":2,\"197\":1,\"198\":1,\"203\":1,\"221\":33}}],[\"可靠性\",{\"1\":{\"221\":3}}],[\"可靠\",{\"1\":{\"4\":1,\"7\":1}}],[\"搞搞\",{\"1\":{\"73\":1}}],[\"搞\",{\"1\":{\"5\":1,\"95\":1,\"96\":1,\"120\":1,\"186\":1}}],[\"把握\",{\"1\":{\"153\":1}}],[\"把\",{\"1\":{\"5\":1,\"7\":1,\"18\":1,\"30\":1,\"39\":1,\"42\":1,\"44\":1,\"52\":1,\"62\":1,\"70\":1,\"72\":1,\"73\":1,\"76\":3,\"80\":1,\"87\":1,\"89\":1,\"102\":1,\"103\":4,\"120\":2,\"124\":1,\"135\":1,\"137\":1,\"161\":1,\"168\":1,\"171\":1,\"173\":1,\"207\":2,\"211\":1,\"215\":1,\"221\":1}}],[\"容错\",{\"1\":{\"221\":2}}],[\"容量\",{\"1\":{\"215\":1}}],[\"容易\",{\"1\":{\"5\":1,\"42\":1,\"99\":1,\"102\":1,\"103\":1,\"135\":1,\"159\":1,\"188\":2,\"194\":1,\"221\":1}}],[\"容器\",{\"1\":{\"4\":1,\"6\":2,\"11\":4,\"12\":2,\"13\":2,\"18\":2,\"42\":3,\"43\":1,\"44\":1,\"45\":1,\"49\":1,\"50\":2,\"72\":1,\"81\":1,\"86\":2,\"125\":1,\"141\":1,\"143\":1,\"159\":1}}],[\"还行\",{\"1\":{\"173\":1}}],[\"还长\",{\"1\":{\"89\":1}}],[\"还喊\",{\"1\":{\"80\":1}}],[\"还会\",{\"1\":{\"72\":1}}],[\"还有\",{\"1\":{\"63\":1,\"70\":1,\"73\":1,\"74\":2,\"84\":2,\"86\":1,\"122\":1,\"124\":3,\"166\":1,\"168\":1,\"171\":1,\"179\":1,\"189\":1}}],[\"还算\",{\"1\":{\"18\":1,\"45\":1,\"75\":1,\"124\":1}}],[\"还\",{\"1\":{\"7\":1,\"9\":1,\"17\":1,\"45\":1,\"56\":1,\"70\":1,\"73\":3,\"74\":3,\"76\":2,\"78\":1,\"79\":1,\"86\":2,\"89\":1,\"98\":1,\"102\":1,\"103\":2,\"104\":1,\"113\":1,\"114\":1,\"117\":1,\"125\":1,\"128\":1,\"144\":1,\"145\":1,\"149\":1,\"152\":1,\"158\":1,\"161\":1,\"164\":1,\"165\":1,\"166\":1,\"167\":1,\"168\":1,\"171\":1,\"173\":1,\"183\":2,\"184\":1,\"185\":2,\"192\":1,\"221\":4}}],[\"还要\",{\"1\":{\"5\":1,\"74\":1,\"86\":1,\"164\":1,\"221\":1}}],[\"还好\",{\"1\":{\"5\":1,\"124\":1,\"149\":1}}],[\"还是\",{\"1\":{\"4\":1,\"5\":3,\"7\":2,\"11\":1,\"25\":1,\"26\":1,\"45\":2,\"46\":1,\"51\":1,\"63\":2,\"73\":4,\"74\":2,\"75\":2,\"76\":1,\"80\":1,\"81\":1,\"86\":1,\"87\":3,\"89\":3,\"98\":3,\"102\":1,\"107\":1,\"114\":2,\"124\":1,\"126\":1,\"127\":1,\"136\":1,\"145\":1,\"151\":6,\"153\":1,\"159\":1,\"161\":2,\"164\":3,\"165\":1,\"167\":2,\"168\":2,\"169\":4,\"171\":2,\"172\":2,\"173\":4,\"190\":1,\"192\":2,\"204\":1,\"206\":1,\"219\":1,\"221\":5}}],[\"调到\",{\"1\":{\"117\":1}}],[\"调侃\",{\"1\":{\"76\":1}}],[\"调小\",{\"1\":{\"70\":1}}],[\"调\",{\"0\":{\"36\":1},\"1\":{\"81\":2,\"173\":1}}],[\"调试模式\",{\"1\":{\"43\":1}}],[\"调试\",{\"1\":{\"30\":1,\"43\":1,\"98\":2,\"102\":1,\"206\":1}}],[\"调整\",{\"1\":{\"26\":1,\"28\":1,\"63\":2,\"164\":1,\"169\":1}}],[\"调度\",{\"1\":{\"11\":1,\"42\":1,\"43\":1,\"44\":1,\"45\":1,\"50\":1,\"51\":2,\"72\":2,\"140\":4,\"143\":1}}],[\"调通\",{\"1\":{\"7\":1,\"44\":1}}],[\"调研\",{\"0\":{\"7\":1},\"1\":{\"7\":1,\"8\":2,\"86\":1}}],[\"调用\",{\"1\":{\"5\":1,\"6\":3,\"45\":1,\"49\":1,\"56\":2,\"57\":2,\"58\":1,\"60\":1,\"63\":1,\"72\":2,\"97\":1,\"98\":2,\"101\":2,\"102\":4,\"103\":4,\"104\":1,\"106\":2,\"107\":1,\"116\":1,\"117\":1,\"127\":1,\"145\":1,\"178\":2,\"185\":1,\"190\":1,\"206\":1,\"215\":2,\"216\":2,\"221\":1}}],[\"调优套\",{\"1\":{\"221\":1}}],[\"调优\",{\"0\":{\"24\":1,\"42\":1},\"1\":{\"0\":2,\"75\":1}}],[\"锁\",{\"0\":{\"218\":1},\"1\":{\"5\":1,\"83\":1}}],[\"返回\",{\"1\":{\"5\":2,\"42\":1,\"56\":3,\"66\":1,\"68\":1,\"103\":5,\"114\":1,\"125\":2,\"137\":5,\"148\":2,\"149\":3,\"151\":1,\"152\":2,\"178\":1,\"179\":2,\"185\":1,\"205\":4,\"207\":1,\"211\":3,\"213\":1}}],[\"按着\",{\"1\":{\"206\":1}}],[\"按照\",{\"1\":{\"116\":2,\"158\":2,\"185\":3,\"205\":1,\"216\":1,\"221\":1}}],[\"按钮\",{\"1\":{\"114\":1}}],[\"按\",{\"1\":{\"5\":1,\"56\":1}}],[\"不断\",{\"1\":{\"221\":1}}],[\"不幸\",{\"1\":{\"221\":1}}],[\"不细\",{\"1\":{\"206\":1}}],[\"不易\",{\"1\":{\"192\":1}}],[\"不一致性\",{\"1\":{\"177\":1}}],[\"不太\",{\"1\":{\"169\":1}}],[\"不太好\",{\"1\":{\"135\":1,\"221\":1}}],[\"不大\",{\"1\":{\"152\":1}}],[\"不够\",{\"1\":{\"124\":2,\"145\":1}}],[\"不至于\",{\"1\":{\"99\":1}}],[\"不熟\",{\"1\":{\"87\":1}}],[\"不深\",{\"1\":{\"87\":1}}],[\"不乐意\",{\"1\":{\"86\":1}}],[\"不懂事\",{\"1\":{\"86\":1}}],[\"不敢\",{\"1\":{\"85\":1,\"87\":1,\"91\":1,\"158\":1}}],[\"不好意思\",{\"1\":{\"87\":1}}],[\"不好\",{\"1\":{\"83\":1,\"86\":1}}],[\"不得不\",{\"1\":{\"81\":1}}],[\"不得了\",{\"1\":{\"73\":1}}],[\"不顺\",{\"1\":{\"77\":1,\"78\":1,\"89\":1,\"90\":1}}],[\"不平\",{\"1\":{\"76\":1}}],[\"不下\",{\"1\":{\"76\":1}}],[\"不问\",{\"1\":{\"76\":1}}],[\"不行\",{\"1\":{\"76\":1,\"114\":1,\"120\":1}}],[\"不知所措\",{\"1\":{\"81\":1}}],[\"不知\",{\"1\":{\"74\":2,\"81\":1}}],[\"不差\",{\"1\":{\"74\":1}}],[\"不起\",{\"1\":{\"74\":1,\"145\":1}}],[\"不热\",{\"1\":{\"73\":1}}],[\"不再\",{\"1\":{\"72\":1,\"151\":1,\"172\":1}}],[\"不错\",{\"1\":{\"63\":2,\"122\":1}}],[\"不了\",{\"1\":{\"49\":1,\"80\":1,\"152\":1}}],[\"不可避免\",{\"1\":{\"184\":1}}],[\"不可\",{\"1\":{\"42\":1,\"51\":1,\"159\":1,\"221\":1}}],[\"不到\",{\"1\":{\"39\":1,\"74\":1,\"124\":1,\"127\":1,\"221\":1}}],[\"不会\",{\"1\":{\"39\":1,\"45\":1,\"50\":1,\"55\":1,\"70\":1,\"73\":1,\"161\":1,\"164\":1,\"216\":1,\"221\":10}}],[\"不明\",{\"1\":{\"29\":1}}],[\"不足\",{\"1\":{\"23\":1,\"173\":1}}],[\"不足以\",{\"1\":{\"5\":1}}],[\"不想\",{\"1\":{\"18\":1,\"74\":1,\"81\":1,\"87\":1,\"89\":1,\"124\":1}}],[\"不同\",{\"1\":{\"10\":1,\"57\":2,\"81\":2,\"133\":1,\"141\":1,\"152\":1,\"155\":3,\"159\":2,\"160\":1,\"161\":1,\"185\":2,\"188\":2,\"221\":7}}],[\"不仅仅\",{\"1\":{\"73\":1}}],[\"不仅\",{\"1\":{\"9\":2,\"159\":1,\"185\":1}}],[\"不用\",{\"1\":{\"8\":1,\"104\":1,\"203\":1}}],[\"不是\",{\"1\":{\"7\":1,\"18\":2,\"44\":2,\"55\":1,\"57\":1,\"73\":2,\"74\":1,\"75\":1,\"76\":1,\"77\":1,\"78\":1,\"80\":2,\"85\":2,\"86\":1,\"87\":1,\"97\":1,\"101\":1,\"109\":1,\"113\":1,\"124\":1,\"127\":1,\"151\":1,\"157\":1,\"165\":1,\"170\":1,\"171\":2,\"173\":1,\"181\":1,\"185\":1,\"192\":1,\"216\":1,\"221\":2}}],[\"不如\",{\"1\":{\"7\":1,\"164\":1,\"168\":1,\"173\":1,\"184\":1}}],[\"不全\",{\"1\":{\"7\":1}}],[\"不合理\",{\"1\":{\"7\":1,\"192\":2}}],[\"不怎么\",{\"1\":{\"7\":1}}],[\"不要脸\",{\"1\":{\"221\":1}}],[\"不要\",{\"1\":{\"6\":1,\"74\":1,\"75\":2,\"78\":2,\"86\":1,\"113\":1,\"117\":1,\"152\":1,\"165\":1,\"173\":1,\"192\":1,\"221\":1}}],[\"不能不\",{\"1\":{\"126\":1}}],[\"不能\",{\"1\":{\"5\":1,\"12\":1,\"26\":1,\"70\":2,\"74\":1,\"98\":1,\"143\":1,\"145\":2,\"149\":1,\"158\":1,\"161\":1,\"166\":1,\"169\":1,\"221\":3}}],[\"不高\",{\"1\":{\"5\":1,\"74\":1,\"151\":1}}],[\"不过\",{\"1\":{\"5\":2,\"8\":1,\"17\":1,\"44\":2,\"74\":1,\"80\":1,\"81\":1,\"86\":2,\"126\":1,\"164\":2,\"166\":1,\"168\":2,\"169\":2,\"171\":2,\"197\":1,\"198\":1}}],[\"不\",{\"0\":{\"108\":1},\"1\":{\"5\":1,\"7\":2,\"8\":2,\"11\":1,\"12\":1,\"13\":1,\"18\":1,\"26\":1,\"29\":1,\"42\":1,\"48\":1,\"55\":1,\"63\":3,\"67\":1,\"73\":4,\"74\":3,\"75\":2,\"76\":3,\"77\":2,\"80\":1,\"81\":1,\"86\":3,\"87\":3,\"96\":1,\"97\":1,\"101\":1,\"102\":2,\"107\":1,\"114\":3,\"116\":1,\"118\":1,\"124\":1,\"125\":1,\"135\":2,\"137\":1,\"144\":1,\"145\":1,\"149\":2,\"150\":1,\"151\":1,\"152\":1,\"155\":1,\"158\":1,\"159\":2,\"162\":1,\"163\":1,\"164\":2,\"169\":1,\"171\":2,\"172\":1,\"173\":2,\"179\":1,\"185\":1,\"192\":1,\"205\":1,\"221\":13}}],[\"不少\",{\"1\":{\"4\":1,\"11\":1,\"76\":1,\"77\":1,\"81\":3,\"87\":3,\"100\":1,\"124\":1}}],[\"比拟\",{\"1\":{\"158\":1}}],[\"比\",{\"1\":{\"45\":2,\"73\":1,\"100\":1,\"144\":1,\"151\":1,\"152\":1,\"165\":1,\"184\":1,\"205\":1,\"221\":1}}],[\"比例\",{\"1\":{\"28\":1,\"38\":1}}],[\"比值\",{\"1\":{\"26\":4,\"31\":3}}],[\"比较复杂\",{\"1\":{\"153\":1}}],[\"比较简单\",{\"1\":{\"124\":1,\"153\":1,\"159\":1,\"164\":1}}],[\"比较慢\",{\"1\":{\"103\":1}}],[\"比较\",{\"0\":{\"57\":1},\"1\":{\"5\":1,\"7\":1,\"8\":1,\"11\":1,\"26\":1,\"45\":1,\"51\":1,\"57\":3,\"80\":1,\"87\":1,\"108\":1,\"135\":1,\"149\":1,\"152\":1,\"159\":1,\"161\":1,\"168\":1,\"169\":1,\"173\":2,\"189\":1,\"192\":1,\"198\":1,\"207\":1,\"221\":2}}],[\"比较落后\",{\"1\":{\"4\":1}}],[\"比如\",{\"1\":{\"5\":1,\"61\":3,\"62\":1,\"63\":3,\"77\":1,\"87\":2,\"103\":2,\"124\":1,\"152\":1,\"169\":1,\"189\":1,\"203\":1,\"204\":1,\"221\":2}}],[\"码\",{\"1\":{\"5\":1}}],[\"东西\",{\"1\":{\"5\":2,\"6\":1,\"7\":1,\"8\":1,\"18\":2,\"48\":1,\"73\":1,\"74\":1,\"75\":1,\"76\":1,\"80\":1,\"82\":1,\"86\":1,\"87\":3,\"104\":1,\"120\":1,\"124\":1,\"127\":1,\"152\":2,\"165\":2,\"166\":2,\"169\":1,\"170\":1,\"219\":1}}],[\"并非\",{\"1\":{\"57\":1,\"108\":1,\"221\":1}}],[\"并发\",{\"0\":{\"29\":1,\"35\":1},\"1\":{\"27\":2,\"28\":1,\"29\":3,\"32\":1,\"35\":1,\"38\":4,\"39\":4,\"57\":1,\"73\":1,\"76\":1,\"177\":1}}],[\"并且\",{\"1\":{\"6\":1,\"57\":1,\"63\":2,\"66\":1,\"70\":1,\"116\":1,\"194\":1,\"198\":1,\"207\":1,\"212\":1,\"216\":1,\"221\":2}}],[\"并行操作\",{\"1\":{\"161\":1}}],[\"并行任务\",{\"1\":{\"13\":3}}],[\"并行\",{\"0\":{\"28\":1,\"34\":1},\"1\":{\"6\":1,\"13\":1,\"27\":2,\"28\":7,\"29\":1,\"32\":2,\"34\":3,\"35\":2,\"37\":1,\"161\":1}}],[\"并\",{\"0\":{\"11\":1},\"1\":{\"5\":1,\"11\":1,\"44\":2,\"45\":4,\"51\":1,\"70\":1,\"72\":5,\"73\":2,\"103\":1,\"113\":1,\"114\":1,\"116\":3,\"127\":1,\"142\":1,\"145\":1,\"149\":1,\"152\":1,\"159\":1,\"161\":1,\"179\":1,\"181\":1,\"183\":1,\"184\":1,\"185\":1,\"187\":1,\"192\":1,\"197\":1,\"206\":2,\"210\":1,\"216\":2,\"221\":5}}],[\"都\",{\"1\":{\"5\":2,\"7\":1,\"9\":1,\"18\":3,\"27\":1,\"38\":1,\"42\":1,\"43\":1,\"44\":2,\"45\":1,\"48\":1,\"49\":1,\"50\":1,\"51\":2,\"52\":1,\"57\":2,\"63\":2,\"65\":1,\"69\":2,\"70\":4,\"72\":1,\"73\":3,\"74\":8,\"75\":3,\"76\":9,\"77\":3,\"80\":2,\"81\":1,\"84\":2,\"85\":1,\"86\":1,\"87\":2,\"89\":1,\"91\":2,\"100\":1,\"102\":1,\"103\":1,\"109\":1,\"114\":1,\"116\":1,\"120\":1,\"124\":2,\"126\":1,\"135\":1,\"146\":1,\"148\":1,\"151\":3,\"153\":1,\"157\":1,\"158\":3,\"159\":2,\"161\":4,\"165\":1,\"168\":2,\"169\":1,\"170\":1,\"181\":1,\"185\":1,\"188\":1,\"189\":1,\"192\":2,\"197\":1,\"206\":1,\"216\":2,\"220\":1,\"221\":13}}],[\"等到\",{\"1\":{\"221\":1}}],[\"等等\",{\"1\":{\"173\":1,\"183\":1,\"221\":2}}],[\"等待\",{\"1\":{\"106\":1,\"161\":1,\"221\":2}}],[\"等于\",{\"1\":{\"72\":2,\"210\":1}}],[\"等\",{\"1\":{\"5\":1,\"7\":2,\"9\":1,\"12\":1,\"13\":1,\"23\":2,\"28\":2,\"29\":1,\"38\":1,\"42\":1,\"64\":1,\"66\":1,\"72\":1,\"76\":1,\"124\":2,\"126\":1,\"132\":1,\"133\":1,\"136\":1,\"143\":1,\"145\":2,\"149\":1,\"152\":2,\"153\":1,\"157\":1,\"158\":2,\"159\":1,\"163\":1,\"167\":1,\"172\":1,\"177\":1,\"184\":1,\"221\":5}}],[\"进\",{\"1\":{\"151\":1,\"191\":1,\"192\":1}}],[\"进展\",{\"1\":{\"116\":1}}],[\"进入\",{\"1\":{\"26\":1,\"42\":1,\"146\":1,\"178\":1,\"189\":1}}],[\"进程\",{\"1\":{\"26\":1,\"41\":1,\"184\":1}}],[\"进行\",{\"0\":{\"44\":1,\"209\":1},\"1\":{\"5\":4,\"9\":1,\"11\":1,\"13\":1,\"17\":1,\"18\":1,\"26\":2,\"27\":1,\"28\":1,\"29\":2,\"37\":1,\"39\":5,\"42\":2,\"43\":2,\"45\":7,\"59\":2,\"62\":1,\"63\":2,\"66\":1,\"68\":2,\"95\":2,\"97\":1,\"98\":1,\"102\":3,\"115\":1,\"116\":2,\"122\":2,\"124\":1,\"125\":2,\"126\":1,\"127\":1,\"132\":2,\"135\":1,\"136\":1,\"137\":2,\"142\":1,\"143\":2,\"145\":1,\"149\":1,\"159\":1,\"161\":1,\"163\":2,\"164\":2,\"177\":1,\"178\":1,\"179\":1,\"184\":1,\"185\":6,\"190\":1,\"204\":3,\"205\":3,\"206\":1,\"209\":1,\"210\":2,\"216\":4,\"221\":11}}],[\"进度\",{\"1\":{\"5\":1}}],[\"进来\",{\"1\":{\"4\":1}}],[\"立即\",{\"1\":{\"5\":2,\"57\":2,\"221\":1}}],[\"对长\",{\"1\":{\"221\":1}}],[\"对话\",{\"1\":{\"104\":1}}],[\"对不起\",{\"1\":{\"83\":1}}],[\"对外\",{\"1\":{\"70\":1}}],[\"对应\",{\"0\":{\"212\":1,\"213\":1},\"1\":{\"69\":1,\"117\":1,\"155\":1,\"179\":1,\"211\":1,\"221\":3}}],[\"对比\",{\"1\":{\"69\":1,\"161\":1,\"190\":2}}],[\"对堆\",{\"1\":{\"39\":1}}],[\"对象\",{\"1\":{\"26\":3,\"37\":1,\"38\":3,\"39\":1,\"44\":2,\"45\":2,\"56\":1,\"72\":2,\"135\":1,\"137\":2,\"164\":1,\"179\":8,\"180\":2,\"181\":4,\"185\":1,\"194\":1,\"198\":1,\"221\":2}}],[\"对系统\",{\"1\":{\"26\":1}}],[\"对于\",{\"1\":{\"8\":1,\"9\":1,\"12\":2,\"17\":2,\"18\":1,\"26\":1,\"55\":1,\"57\":1,\"61\":1,\"63\":1,\"65\":1,\"70\":1,\"81\":1,\"83\":1,\"103\":2,\"106\":1,\"124\":1,\"145\":1,\"151\":1,\"173\":1,\"179\":1,\"192\":3,\"221\":2}}],[\"对\",{\"0\":{\"209\":1},\"1\":{\"5\":1,\"8\":1,\"9\":2,\"17\":1,\"25\":1,\"26\":1,\"28\":2,\"29\":3,\"37\":1,\"39\":2,\"45\":4,\"50\":1,\"52\":1,\"59\":1,\"61\":2,\"63\":1,\"73\":1,\"74\":1,\"75\":1,\"80\":1,\"85\":2,\"86\":4,\"87\":1,\"95\":1,\"103\":1,\"114\":1,\"115\":1,\"122\":2,\"124\":1,\"126\":3,\"132\":4,\"135\":4,\"136\":1,\"137\":2,\"142\":1,\"143\":1,\"145\":1,\"149\":1,\"151\":2,\"157\":1,\"163\":1,\"169\":1,\"170\":1,\"177\":1,\"178\":1,\"180\":1,\"181\":1,\"183\":1,\"185\":4,\"192\":3,\"197\":1,\"204\":1,\"209\":1,\"212\":2,\"214\":1,\"216\":6,\"221\":6}}],[\"ctx\",{\"1\":{\"190\":2,\"206\":2}}],[\"cyrillic\",{\"1\":{\"166\":1}}],[\"certificate\",{\"1\":{\"158\":2}}],[\"center\",{\"1\":{\"151\":2}}],[\"centos\",{\"1\":{\"149\":1}}],[\"cmd\",{\"1\":{\"120\":2}}],[\"cmds\",{\"1\":{\"118\":2}}],[\"cmsincrementalmode\",{\"1\":{\"35\":1}}],[\"cmsfullgcsbeforecompaction\",{\"1\":{\"29\":2,\"39\":1}}],[\"cms\",{\"1\":{\"23\":3,\"29\":1,\"43\":1}}],[\"cnf\",{\"1\":{\"163\":1,\"164\":1}}],[\"cn\",{\"1\":{\"109\":1,\"117\":2,\"120\":1,\"138\":1}}],[\"cnblogs\",{\"1\":{\"18\":1,\"79\":1}}],[\"cgi\",{\"1\":{\"103\":1}}],[\"csv\",{\"1\":{\"194\":1}}],[\"csdn\",{\"1\":{\"144\":1,\"169\":1,\"220\":1}}],[\"css\",{\"1\":{\"124\":2,\"137\":1,\"166\":1,\"173\":2}}],[\"csig\",{\"1\":{\"90\":1,\"91\":1}}],[\"csrf\",{\"1\":{\"5\":1}}],[\"c\",{\"1\":{\"72\":1,\"151\":2}}],[\"customkeygenerator\",{\"1\":{\"188\":2,\"189\":1}}],[\"custom\",{\"1\":{\"103\":1}}],[\"customer\",{\"1\":{\"72\":1,\"221\":2}}],[\"currentnodeid\",{\"1\":{\"210\":1}}],[\"currenttimemillis\",{\"1\":{\"190\":2}}],[\"currentthread\",{\"1\":{\"56\":2}}],[\"currentblog\",{\"1\":{\"137\":6}}],[\"curl\",{\"1\":{\"56\":2,\"118\":1,\"120\":1,\"121\":1}}],[\"c7f3\",{\"1\":{\"69\":1}}],[\"c4e0\",{\"1\":{\"69\":1}}],[\"canreturnnullresponseifmatchnodocs\",{\"1\":{\"215\":1}}],[\"canal\",{\"1\":{\"164\":5}}],[\"cachingexecutor\",{\"1\":{\"180\":1}}],[\"cachemanager\",{\"1\":{\"187\":1}}],[\"cachevict\",{\"1\":{\"185\":3}}],[\"cacheevict\",{\"1\":{\"185\":1}}],[\"cacheenabled\",{\"1\":{\"182\":1}}],[\"cacheput\",{\"1\":{\"185\":2}}],[\"cache2\",{\"1\":{\"185\":3}}],[\"cache1\",{\"1\":{\"185\":3}}],[\"cacheable\",{\"1\":{\"185\":15,\"189\":2}}],[\"cachecontrolfilter\",{\"1\":{\"125\":2}}],[\"cache\",{\"0\":{\"185\":1},\"1\":{\"50\":1,\"179\":2,\"181\":4,\"182\":2,\"183\":6,\"184\":1,\"185\":3,\"187\":2}}],[\"categorymapper\",{\"1\":{\"189\":1}}],[\"category\",{\"1\":{\"189\":3}}],[\"categories\",{\"1\":{\"151\":1}}],[\"catch\",{\"1\":{\"72\":1,\"135\":1,\"137\":5,\"206\":1}}],[\"card\",{\"1\":{\"151\":1}}],[\"calculable\",{\"1\":{\"151\":1}}],[\"calendar\",{\"1\":{\"141\":8}}],[\"callbacks\",{\"1\":{\"72\":1}}],[\"caffeine\",{\"1\":{\"66\":1}}],[\"case\",{\"1\":{\"23\":1,\"51\":1,\"206\":2}}],[\"ch\",{\"1\":{\"143\":1}}],[\"choices\",{\"1\":{\"101\":1}}],[\"character\",{\"1\":{\"163\":2,\"164\":2}}],[\"chart\",{\"1\":{\"151\":2}}],[\"charging\",{\"1\":{\"118\":1}}],[\"change\",{\"1\":{\"137\":1,\"164\":1}}],[\"channelactionlistener\",{\"1\":{\"214\":1,\"216\":1}}],[\"channelread0\",{\"1\":{\"206\":2}}],[\"channelhandlercontext\",{\"1\":{\"206\":1}}],[\"channelhandler\",{\"1\":{\"206\":1}}],[\"channelbootstrap\",{\"1\":{\"45\":1}}],[\"channel\",{\"1\":{\"45\":2,\"206\":5,\"214\":2,\"216\":2}}],[\"chatgpt\",{\"0\":{\"93\":1,\"94\":1,\"97\":1,\"101\":1},\"1\":{\"97\":2,\"99\":1,\"103\":2,\"104\":2,\"106\":1,\"108\":1,\"109\":1}}],[\"china\",{\"1\":{\"151\":2}}],[\"chi\",{\"1\":{\"41\":1}}],[\"check\",{\"1\":{\"9\":1,\"13\":2}}],[\"cpu\",{\"1\":{\"34\":1,\"35\":2,\"37\":1,\"122\":1,\"126\":2}}],[\"crc\",{\"1\":{\"221\":1}}],[\"crc32\",{\"1\":{\"221\":1}}],[\"crt\",{\"1\":{\"158\":1}}],[\"credits\",{\"1\":{\"151\":1}}],[\"credentials\",{\"1\":{\"118\":1}}],[\"credentialsid\",{\"1\":{\"5\":2,\"9\":1,\"10\":1,\"11\":1,\"13\":3}}],[\"createelement\",{\"1\":{\"146\":1}}],[\"createtime\",{\"1\":{\"101\":4}}],[\"createcompletion\",{\"1\":{\"101\":1}}],[\"create\",{\"1\":{\"66\":4,\"72\":2,\"103\":1,\"120\":1}}],[\"createratelimit\",{\"1\":{\"66\":3}}],[\"crypto\",{\"1\":{\"41\":2}}],[\"cronexpression\",{\"1\":{\"143\":1}}],[\"crontriggerfactorybean\",{\"1\":{\"143\":1}}],[\"crontriggerimpl\",{\"1\":{\"141\":1}}],[\"cron\",{\"1\":{\"15\":1,\"42\":1,\"50\":1,\"143\":1}}],[\"cluster\",{\"1\":{\"72\":1,\"163\":1,\"164\":1}}],[\"clients\",{\"1\":{\"159\":2}}],[\"client1\",{\"1\":{\"157\":1}}],[\"clientip\",{\"1\":{\"156\":1}}],[\"client\",{\"1\":{\"12\":1,\"13\":1,\"42\":1,\"65\":1,\"72\":4,\"98\":1,\"118\":9,\"163\":1,\"164\":1,\"206\":1,\"211\":1,\"216\":1}}],[\"cloud\",{\"1\":{\"63\":2,\"117\":1,\"118\":1,\"120\":1,\"121\":1}}],[\"cloudbees\",{\"1\":{\"5\":2}}],[\"closelistener\",{\"1\":{\"206\":1}}],[\"close\",{\"1\":{\"23\":1,\"72\":2,\"135\":3,\"137\":1}}],[\"clone\",{\"1\":{\"9\":1,\"10\":2,\"11\":1,\"13\":5}}],[\"clean\",{\"1\":{\"5\":1,\"11\":1,\"13\":1}}],[\"classpath\",{\"1\":{\"190\":1}}],[\"class\",{\"1\":{\"5\":1,\"56\":2,\"57\":2,\"68\":1,\"137\":3,\"143\":4,\"148\":1,\"150\":1,\"151\":3,\"159\":6,\"187\":7,\"188\":1,\"190\":1,\"206\":1,\"212\":1}}],[\"coordinate\",{\"1\":{\"211\":3}}],[\"collectors\",{\"1\":{\"208\":1}}],[\"collect\",{\"1\":{\"197\":1,\"208\":1}}],[\"color\",{\"1\":{\"135\":2,\"151\":2}}],[\"couldn\",{\"1\":{\"137\":1}}],[\"countedcollector\",{\"1\":{\"212\":2}}],[\"counter\",{\"1\":{\"212\":7}}],[\"countdown\",{\"1\":{\"212\":4}}],[\"countdeploymentsize\",{\"1\":{\"65\":1}}],[\"count\",{\"1\":{\"149\":25,\"150\":3,\"151\":17}}],[\"countbyvalue\",{\"1\":{\"72\":1}}],[\"core\",{\"1\":{\"135\":1,\"159\":1,\"187\":1}}],[\"corelimit\",{\"1\":{\"72\":1}}],[\"corerequest\",{\"1\":{\"72\":4}}],[\"cores\",{\"1\":{\"72\":2}}],[\"coding\",{\"1\":{\"72\":1}}],[\"codemirror\",{\"1\":{\"168\":1}}],[\"code\",{\"1\":{\"98\":1,\"146\":1,\"170\":1}}],[\"codebranch\",{\"1\":{\"5\":2}}],[\"codepipeline\",{\"1\":{\"5\":1}}],[\"concat\",{\"1\":{\"189\":1}}],[\"condition\",{\"1\":{\"185\":4}}],[\"conditionalonproperty\",{\"1\":{\"56\":2,\"57\":1}}],[\"conf\",{\"1\":{\"153\":2,\"158\":2,\"197\":2}}],[\"configurationoptions\",{\"1\":{\"196\":1}}],[\"configuration\",{\"1\":{\"56\":3,\"101\":3,\"153\":2}}],[\"config\",{\"1\":{\"11\":1,\"135\":2,\"159\":1}}],[\"configversion\",{\"1\":{\"5\":2}}],[\"connect\",{\"1\":{\"143\":1,\"163\":1,\"164\":1}}],[\"connectionfactory\",{\"1\":{\"159\":1,\"187\":1}}],[\"connectionpool\",{\"1\":{\"149\":1}}],[\"connection\",{\"1\":{\"143\":6,\"149\":1,\"159\":1,\"187\":1,\"212\":2}}],[\"convert\",{\"1\":{\"137\":1}}],[\"consumer\",{\"1\":{\"221\":20}}],[\"consistent\",{\"1\":{\"155\":1}}],[\"constructor\",{\"1\":{\"187\":1}}],[\"const\",{\"1\":{\"101\":6,\"103\":2,\"104\":1}}],[\"console\",{\"1\":{\"42\":1,\"101\":2}}],[\"containskey\",{\"1\":{\"209\":1}}],[\"container\",{\"1\":{\"9\":1,\"10\":1,\"11\":1,\"13\":4}}],[\"content\",{\"1\":{\"98\":1,\"101\":3,\"103\":4,\"118\":1,\"120\":1,\"121\":1,\"135\":3}}],[\"contexts\",{\"1\":{\"137\":2}}],[\"context\",{\"1\":{\"65\":1,\"72\":2,\"125\":1,\"137\":2,\"143\":1,\"144\":3,\"212\":4,\"215\":1,\"216\":6}}],[\"controller\",{\"1\":{\"57\":1,\"72\":3,\"137\":1,\"178\":1}}],[\"committed\",{\"1\":{\"221\":1}}],[\"common\",{\"1\":{\"135\":1}}],[\"command\",{\"1\":{\"5\":2,\"118\":2,\"120\":2}}],[\"component\",{\"1\":{\"143\":1,\"188\":1}}],[\"compaction\",{\"1\":{\"221\":1}}],[\"compacting\",{\"1\":{\"30\":2}}],[\"compare\",{\"1\":{\"137\":1}}],[\"comparator\",{\"1\":{\"137\":2}}],[\"completion\",{\"1\":{\"101\":2}}],[\"completions\",{\"1\":{\"98\":3}}],[\"compilerargs\",{\"1\":{\"56\":2}}],[\"compiler\",{\"1\":{\"43\":1,\"56\":1}}],[\"com\",{\"0\":{\"49\":1},\"1\":{\"5\":3,\"18\":3,\"41\":3,\"72\":1,\"76\":1,\"79\":1,\"97\":1,\"98\":1,\"101\":1,\"103\":1,\"108\":2,\"110\":1,\"114\":1,\"118\":2,\"120\":1,\"121\":1,\"122\":1,\"130\":2,\"137\":1,\"138\":2,\"144\":1,\"145\":3,\"146\":1,\"147\":1,\"148\":1,\"149\":2,\"150\":2,\"151\":4,\"152\":2,\"157\":1,\"158\":2,\"160\":3,\"164\":1,\"165\":2,\"166\":1,\"170\":2,\"173\":2,\"188\":1,\"192\":2,\"203\":1,\"220\":1}}],[\"cdn\",{\"1\":{\"124\":1}}],[\"cd4d56fda79\",{\"1\":{\"69\":1}}],[\"cd\",{\"1\":{\"5\":1,\"12\":2,\"120\":1}}],[\"ciphers\",{\"1\":{\"158\":2}}],[\"cicd\",{\"0\":{\"6\":1},\"1\":{\"5\":1,\"6\":12,\"7\":8,\"17\":3}}],[\"ci\",{\"1\":{\"3\":1,\"5\":1,\"7\":1,\"17\":1}}],[\"阿里巴巴\",{\"1\":{\"164\":1}}],[\"阿里\",{\"0\":{\"12\":1},\"1\":{\"5\":1,\"7\":2,\"8\":4,\"9\":1,\"10\":1,\"12\":1,\"63\":2,\"80\":1,\"86\":1,\"90\":1,\"114\":1,\"164\":3}}],[\"参照\",{\"1\":{\"183\":1}}],[\"参与\",{\"1\":{\"81\":1}}],[\"参考\",{\"0\":{\"71\":1},\"1\":{\"5\":1,\"7\":2,\"38\":1,\"41\":1,\"42\":1,\"51\":1,\"72\":1,\"98\":1,\"108\":1,\"109\":1,\"125\":1,\"138\":1,\"144\":1,\"157\":2,\"159\":4,\"161\":1,\"170\":1,\"192\":1}}],[\"参数\",{\"0\":{\"24\":1},\"1\":{\"0\":1,\"5\":1,\"27\":1,\"30\":1,\"38\":1,\"43\":1,\"57\":1,\"64\":1,\"146\":2,\"147\":5,\"148\":2,\"149\":11,\"185\":2,\"221\":9}}],[\"项目经理\",{\"1\":{\"86\":1}}],[\"项目组\",{\"1\":{\"76\":1}}],[\"项目\",{\"0\":{\"5\":1},\"1\":{\"5\":1,\"7\":2,\"23\":2,\"81\":2,\"86\":2,\"87\":5,\"124\":2,\"130\":1,\"144\":1,\"159\":1,\"192\":1,\"203\":1}}],[\"坑\",{\"1\":{\"4\":1,\"5\":2,\"51\":1,\"87\":1,\"114\":1,\"186\":2}}],[\"过长\",{\"1\":{\"173\":1}}],[\"过大\",{\"1\":{\"135\":1}}],[\"过滤\",{\"1\":{\"95\":1,\"137\":1}}],[\"过去\",{\"1\":{\"80\":1,\"85\":1,\"87\":1,\"89\":1,\"90\":1}}],[\"过来\",{\"1\":{\"74\":1,\"75\":1,\"76\":1,\"161\":1,\"165\":1}}],[\"过后\",{\"1\":{\"74\":1}}],[\"过期\",{\"1\":{\"70\":1,\"185\":3,\"187\":1}}],[\"过多\",{\"1\":{\"51\":1,\"58\":1,\"106\":1,\"221\":1}}],[\"过高\",{\"1\":{\"7\":1}}],[\"过于\",{\"1\":{\"5\":1,\"18\":1,\"57\":1,\"170\":1,\"216\":1}}],[\"过\",{\"1\":{\"4\":1,\"5\":1,\"7\":1,\"10\":1,\"23\":1,\"45\":1,\"73\":1,\"74\":4,\"75\":3,\"77\":1,\"80\":1,\"81\":1,\"85\":2,\"86\":2,\"90\":1,\"103\":1,\"126\":1,\"136\":1,\"144\":2,\"156\":1,\"162\":1,\"186\":1,\"221\":2}}],[\"过程\",{\"0\":{\"42\":1,\"124\":1,\"204\":1,\"210\":1},\"1\":{\"0\":1,\"5\":1,\"6\":2,\"7\":2,\"12\":2,\"17\":1,\"18\":1,\"45\":1,\"51\":1,\"80\":1,\"97\":1,\"98\":1,\"145\":1,\"148\":1,\"152\":1,\"161\":6,\"164\":1,\"166\":1,\"168\":1,\"177\":1,\"184\":1,\"186\":1,\"205\":1,\"206\":3,\"216\":1,\"221\":5}}],[\"踩\",{\"1\":{\"4\":1,\"114\":1}}],[\"自主\",{\"1\":{\"221\":1}}],[\"自身\",{\"1\":{\"183\":1,\"190\":1}}],[\"自家\",{\"1\":{\"169\":2}}],[\"自家人\",{\"1\":{\"151\":1}}],[\"自\",{\"1\":{\"137\":1,\"152\":1,\"159\":1,\"169\":2,\"173\":1,\"194\":2,\"206\":1}}],[\"自然语言\",{\"0\":{\"127\":1}}],[\"自闭症\",{\"1\":{\"77\":1}}],[\"自我介绍\",{\"0\":{\"193\":1},\"1\":{\"74\":1}}],[\"自研\",{\"1\":{\"69\":1}}],[\"自行\",{\"1\":{\"29\":1,\"161\":1}}],[\"自动\",{\"0\":{\"136\":1},\"1\":{\"28\":2,\"42\":1,\"72\":1,\"98\":1,\"101\":1,\"122\":1,\"134\":1,\"136\":1,\"149\":2,\"158\":1,\"166\":2,\"215\":1}}],[\"自动化\",{\"1\":{\"4\":1}}],[\"自带\",{\"1\":{\"7\":1,\"49\":2}}],[\"自写\",{\"1\":{\"5\":1}}],[\"自定义\",{\"0\":{\"188\":1},\"1\":{\"5\":1,\"56\":1,\"125\":1,\"147\":1,\"157\":1,\"183\":2,\"187\":1,\"188\":1}}],[\"自由\",{\"0\":{\"5\":1},\"1\":{\"5\":1}}],[\"自己\",{\"1\":{\"4\":1,\"7\":1,\"12\":2,\"18\":2,\"45\":1,\"46\":1,\"51\":1,\"66\":1,\"73\":6,\"74\":6,\"75\":9,\"76\":8,\"77\":4,\"78\":4,\"80\":1,\"81\":3,\"85\":1,\"86\":5,\"87\":2,\"89\":2,\"96\":2,\"99\":1,\"100\":2,\"101\":1,\"102\":1,\"113\":1,\"114\":4,\"115\":2,\"124\":8,\"126\":1,\"145\":2,\"151\":1,\"157\":1,\"158\":1,\"161\":3,\"162\":1,\"164\":2,\"165\":5,\"166\":1,\"171\":1,\"173\":3,\"183\":1,\"185\":1,\"186\":2,\"197\":1,\"203\":1,\"221\":1}}],[\"弯路\",{\"1\":{\"4\":1}}],[\"了点\",{\"1\":{\"173\":1}}],[\"了结\",{\"1\":{\"128\":1}}],[\"了吧\",{\"1\":{\"77\":1}}],[\"了么\",{\"1\":{\"74\":1}}],[\"了解\",{\"1\":{\"54\":1,\"55\":1,\"83\":1,\"145\":1,\"159\":1,\"169\":1,\"204\":2,\"205\":1,\"221\":2}}],[\"了\",{\"0\":{\"75\":1},\"1\":{\"4\":1,\"5\":7,\"6\":5,\"7\":12,\"8\":4,\"9\":3,\"10\":1,\"11\":2,\"17\":3,\"18\":1,\"23\":2,\"27\":1,\"29\":1,\"30\":1,\"38\":2,\"41\":3,\"42\":2,\"43\":6,\"44\":2,\"45\":10,\"46\":2,\"48\":3,\"49\":1,\"50\":2,\"51\":5,\"52\":1,\"54\":1,\"55\":1,\"56\":1,\"62\":1,\"63\":7,\"69\":1,\"70\":2,\"72\":4,\"73\":17,\"74\":28,\"75\":17,\"76\":12,\"77\":5,\"78\":6,\"79\":2,\"80\":8,\"81\":12,\"82\":5,\"83\":9,\"84\":1,\"85\":6,\"86\":10,\"87\":10,\"88\":1,\"89\":5,\"90\":2,\"91\":1,\"97\":2,\"98\":2,\"100\":2,\"101\":1,\"102\":3,\"103\":1,\"104\":2,\"106\":1,\"108\":2,\"109\":1,\"114\":5,\"115\":1,\"117\":1,\"118\":1,\"120\":5,\"121\":2,\"122\":5,\"124\":27,\"125\":3,\"126\":7,\"127\":3,\"128\":2,\"133\":1,\"135\":1,\"136\":1,\"141\":1,\"142\":1,\"144\":1,\"145\":3,\"146\":1,\"147\":1,\"148\":2,\"149\":4,\"150\":1,\"151\":7,\"152\":3,\"153\":1,\"156\":1,\"157\":3,\"158\":1,\"159\":5,\"161\":5,\"162\":1,\"164\":7,\"165\":2,\"166\":2,\"167\":2,\"168\":3,\"169\":4,\"170\":4,\"171\":2,\"172\":3,\"173\":4,\"177\":1,\"178\":2,\"179\":2,\"180\":2,\"182\":1,\"183\":2,\"185\":1,\"186\":2,\"191\":1,\"192\":5,\"198\":1,\"203\":1,\"205\":1,\"206\":2,\"210\":1,\"216\":3,\"220\":3,\"221\":23}}],[\"走的\",{\"1\":{\"152\":1}}],[\"走到\",{\"1\":{\"85\":1}}],[\"走走\",{\"1\":{\"77\":1,\"89\":1}}],[\"走掉\",{\"1\":{\"76\":1}}],[\"走上正轨\",{\"1\":{\"86\":1}}],[\"走上\",{\"1\":{\"6\":1}}],[\"走\",{\"1\":{\"4\":1,\"73\":1,\"74\":1,\"86\":1,\"189\":1}}],[\"怎么办\",{\"0\":{\"192\":1},\"1\":{\"149\":1,\"159\":1,\"173\":1}}],[\"怎么样\",{\"1\":{\"75\":1,\"205\":1,\"221\":2}}],[\"怎么\",{\"1\":{\"4\":1,\"5\":1,\"23\":3,\"41\":1,\"70\":2,\"74\":1,\"75\":2,\"76\":2,\"77\":1,\"81\":2,\"85\":2,\"86\":1,\"87\":1,\"89\":2,\"104\":1,\"124\":1,\"170\":1,\"171\":1,\"204\":1,\"221\":14}}],[\"没错\",{\"1\":{\"148\":1,\"171\":1}}],[\"没到\",{\"1\":{\"90\":1}}],[\"没人\",{\"1\":{\"86\":1,\"152\":1}}],[\"没人要\",{\"1\":{\"80\":1}}],[\"没拿到\",{\"1\":{\"80\":1}}],[\"没过\",{\"1\":{\"80\":1}}],[\"没写\",{\"1\":{\"79\":1}}],[\"没法\",{\"1\":{\"78\":1,\"124\":2,\"165\":1}}],[\"没什么\",{\"1\":{\"74\":2,\"81\":3,\"85\":1}}],[\"没用过\",{\"1\":{\"74\":1,\"76\":1}}],[\"没事\",{\"1\":{\"74\":2,\"82\":1,\"124\":1}}],[\"没说\",{\"1\":{\"74\":1}}],[\"没多大\",{\"1\":{\"73\":1}}],[\"没回\",{\"1\":{\"73\":1}}],[\"没住\",{\"1\":{\"6\":1}}],[\"没想到\",{\"1\":{\"51\":1,\"76\":1,\"79\":1}}],[\"没想\",{\"1\":{\"5\":1,\"73\":1}}],[\"没有\",{\"0\":{\"103\":1},\"1\":{\"5\":2,\"6\":2,\"7\":2,\"12\":1,\"37\":1,\"42\":1,\"44\":2,\"45\":8,\"50\":1,\"51\":1,\"57\":1,\"70\":1,\"73\":4,\"74\":4,\"75\":6,\"76\":3,\"77\":3,\"80\":2,\"81\":3,\"86\":1,\"87\":1,\"95\":1,\"102\":3,\"103\":3,\"104\":1,\"106\":1,\"107\":1,\"109\":1,\"113\":1,\"124\":1,\"125\":1,\"132\":1,\"136\":1,\"142\":1,\"152\":1,\"153\":1,\"155\":1,\"160\":1,\"173\":1,\"178\":1,\"179\":1,\"189\":1,\"191\":2,\"192\":2,\"197\":1,\"213\":1,\"221\":2}}],[\"没\",{\"1\":{\"4\":1,\"7\":1,\"73\":2,\"74\":4,\"75\":1,\"76\":4,\"77\":1,\"80\":3,\"81\":3,\"85\":2,\"86\":1,\"87\":1,\"88\":1,\"89\":1,\"103\":1,\"124\":3,\"148\":1}}],[\"说明\",{\"1\":{\"116\":1,\"117\":1,\"141\":1,\"148\":1,\"149\":1,\"221\":4}}],[\"说话\",{\"1\":{\"74\":1}}],[\"说\",{\"1\":{\"4\":1,\"6\":1,\"7\":2,\"44\":1,\"49\":2,\"63\":1,\"74\":5,\"75\":3,\"77\":1,\"78\":1,\"86\":1,\"124\":1,\"167\":2,\"169\":1,\"171\":1,\"173\":2,\"221\":5}}],[\"也就是说\",{\"1\":{\"157\":1,\"161\":1,\"205\":1,\"221\":2}}],[\"也\",{\"1\":{\"4\":3,\"6\":2,\"7\":3,\"8\":2,\"11\":1,\"17\":2,\"23\":1,\"37\":1,\"41\":2,\"42\":2,\"44\":1,\"46\":1,\"49\":2,\"50\":1,\"51\":3,\"52\":1,\"61\":1,\"63\":5,\"70\":1,\"72\":1,\"73\":1,\"74\":4,\"75\":3,\"76\":3,\"77\":1,\"78\":1,\"79\":1,\"80\":1,\"81\":6,\"82\":1,\"85\":2,\"86\":4,\"87\":3,\"89\":2,\"95\":2,\"96\":5,\"97\":1,\"98\":1,\"99\":1,\"100\":1,\"102\":2,\"106\":2,\"108\":1,\"109\":1,\"114\":1,\"124\":5,\"126\":3,\"128\":3,\"133\":1,\"135\":1,\"136\":1,\"145\":1,\"148\":1,\"149\":1,\"151\":2,\"152\":1,\"155\":1,\"158\":1,\"159\":1,\"161\":2,\"164\":2,\"165\":2,\"166\":2,\"167\":1,\"168\":2,\"170\":1,\"172\":1,\"179\":2,\"185\":1,\"187\":1,\"189\":1,\"192\":3,\"197\":2,\"198\":1,\"205\":1,\"212\":1,\"221\":13}}],[\"将会\",{\"1\":{\"26\":1,\"39\":1,\"73\":1,\"159\":1,\"221\":4}}],[\"将\",{\"1\":{\"4\":1,\"5\":3,\"6\":2,\"7\":1,\"18\":1,\"26\":1,\"42\":1,\"54\":5,\"56\":3,\"57\":5,\"63\":1,\"72\":3,\"98\":1,\"115\":1,\"116\":2,\"125\":3,\"132\":1,\"135\":1,\"137\":4,\"141\":1,\"143\":1,\"145\":2,\"148\":1,\"149\":1,\"151\":1,\"152\":3,\"155\":1,\"156\":1,\"157\":2,\"158\":1,\"159\":3,\"160\":1,\"161\":7,\"168\":1,\"179\":1,\"181\":1,\"183\":1,\"184\":2,\"192\":3,\"207\":1,\"208\":1,\"210\":1,\"211\":2,\"220\":1,\"221\":19}}],[\"这方面\",{\"1\":{\"221\":1}}],[\"这点\",{\"1\":{\"170\":1,\"221\":2}}],[\"这张\",{\"1\":{\"169\":1}}],[\"这部分\",{\"1\":{\"152\":2,\"172\":2,\"177\":1}}],[\"这套\",{\"1\":{\"151\":1}}],[\"这边\",{\"1\":{\"113\":1}}],[\"这块\",{\"1\":{\"102\":1}}],[\"这家\",{\"1\":{\"80\":1}}],[\"这份\",{\"1\":{\"76\":1}}],[\"这段话\",{\"1\":{\"98\":1}}],[\"这段\",{\"1\":{\"75\":1}}],[\"这辈子\",{\"1\":{\"73\":1}}],[\"这类\",{\"1\":{\"63\":1,\"149\":1,\"204\":1}}],[\"这是\",{\"1\":{\"57\":1,\"221\":1}}],[\"这种\",{\"1\":{\"55\":1,\"57\":4,\"65\":1,\"70\":1,\"76\":2,\"104\":2,\"135\":1,\"137\":1,\"152\":1,\"164\":1,\"165\":1,\"170\":1,\"173\":2,\"205\":1}}],[\"这一\",{\"1\":{\"54\":1,\"149\":1}}],[\"这么久\",{\"1\":{\"86\":1,\"127\":1}}],[\"这么\",{\"1\":{\"51\":1,\"80\":2,\"81\":2,\"85\":2,\"86\":5,\"87\":2,\"152\":1,\"169\":1}}],[\"这些\",{\"1\":{\"12\":1,\"18\":2,\"44\":1,\"72\":1,\"74\":2,\"75\":1,\"76\":1,\"81\":2,\"87\":1,\"95\":1,\"113\":1,\"115\":1,\"126\":1,\"149\":2,\"151\":1,\"161\":3,\"165\":2,\"198\":1,\"211\":1,\"221\":4}}],[\"这样\",{\"1\":{\"7\":1,\"26\":1,\"38\":1,\"39\":1,\"52\":5,\"75\":1,\"77\":1,\"78\":1,\"124\":1,\"157\":2,\"216\":1,\"221\":5}}],[\"这才\",{\"1\":{\"7\":1}}],[\"这里\",{\"1\":{\"5\":1,\"10\":1,\"27\":1,\"39\":1,\"63\":1,\"70\":2,\"72\":4,\"86\":1,\"96\":1,\"98\":1,\"100\":1,\"102\":2,\"108\":1,\"114\":1,\"120\":1,\"127\":1,\"135\":1,\"137\":2,\"145\":2,\"147\":1,\"149\":2,\"151\":2,\"152\":1,\"153\":1,\"155\":1,\"156\":1,\"157\":1,\"167\":1,\"172\":1,\"189\":1,\"196\":1,\"197\":1,\"216\":1,\"221\":1}}],[\"这个\",{\"1\":{\"5\":2,\"6\":1,\"23\":1,\"26\":1,\"29\":1,\"45\":1,\"48\":1,\"49\":1,\"50\":1,\"51\":1,\"54\":1,\"55\":1,\"56\":1,\"70\":5,\"72\":2,\"74\":1,\"77\":1,\"81\":1,\"85\":2,\"86\":1,\"91\":1,\"95\":2,\"98\":3,\"102\":1,\"106\":1,\"109\":1,\"117\":3,\"122\":1,\"124\":4,\"126\":1,\"127\":1,\"128\":1,\"130\":1,\"132\":3,\"135\":2,\"136\":1,\"137\":1,\"144\":1,\"145\":1,\"151\":1,\"157\":5,\"158\":2,\"164\":1,\"166\":1,\"168\":2,\"171\":2,\"179\":1,\"221\":8}}],[\"这\",{\"1\":{\"4\":2,\"11\":1,\"45\":1,\"54\":1,\"55\":2,\"56\":1,\"57\":2,\"74\":2,\"75\":1,\"76\":1,\"78\":1,\"80\":3,\"81\":2,\"83\":1,\"86\":1,\"101\":1,\"102\":1,\"103\":1,\"108\":1,\"114\":2,\"118\":1,\"122\":1,\"124\":1,\"126\":2,\"136\":2,\"143\":2,\"145\":2,\"161\":2,\"165\":1,\"166\":1,\"168\":1,\"170\":1,\"171\":1,\"172\":1,\"221\":5}}],[\"尤其\",{\"1\":{\"4\":1,\"7\":1}}],[\"栈上\",{\"1\":{\"152\":1}}],[\"栈\",{\"1\":{\"4\":1,\"49\":1,\"76\":1,\"135\":1}}],[\"吧\",{\"1\":{\"4\":2,\"42\":1,\"73\":3,\"74\":1,\"75\":2,\"76\":2,\"77\":3,\"79\":1,\"80\":3,\"81\":3,\"82\":1,\"84\":1,\"85\":1,\"86\":2,\"87\":2,\"89\":1,\"98\":2,\"107\":1,\"108\":1,\"114\":1,\"151\":1,\"152\":1,\"153\":1,\"156\":1,\"158\":1,\"159\":1,\"164\":1,\"165\":1,\"168\":1,\"169\":2,\"173\":2,\"192\":1,\"216\":1}}],[\"左右\",{\"1\":{\"4\":1,\"26\":1,\"45\":3,\"69\":1,\"106\":1}}],[\"目的地\",{\"1\":{\"221\":1}}],[\"目的\",{\"0\":{\"208\":1},\"1\":{\"63\":1,\"114\":1,\"206\":1}}],[\"目标\",{\"1\":{\"28\":1,\"151\":2,\"158\":1,\"212\":1,\"221\":2}}],[\"目前\",{\"1\":{\"4\":1,\"5\":1,\"6\":1,\"7\":3,\"11\":1,\"51\":1,\"63\":2,\"76\":1,\"122\":1,\"127\":1,\"135\":1,\"145\":1,\"151\":1,\"152\":2,\"155\":1,\"158\":1,\"159\":3,\"161\":1,\"169\":2,\"170\":1,\"171\":2,\"172\":1,\"173\":1,\"192\":1,\"194\":1,\"199\":1,\"221\":1}}],[\"目录\",{\"1\":{\"0\":1,\"11\":1,\"145\":1,\"158\":1,\"221\":18}}],[\"技术含量\",{\"1\":{\"87\":1}}],[\"技术\",{\"0\":{\"125\":1},\"1\":{\"4\":1,\"18\":1,\"74\":4,\"76\":3,\"80\":3,\"81\":1,\"86\":2,\"125\":1,\"160\":1,\"185\":2,\"192\":1,\"221\":1}}],[\"技术部\",{\"1\":{\"4\":1}}],[\"技术人员\",{\"1\":{\"4\":1}}],[\"地图\",{\"1\":{\"169\":1}}],[\"地位\",{\"1\":{\"151\":2}}],[\"地域\",{\"1\":{\"151\":5,\"152\":3,\"169\":1}}],[\"地区\",{\"1\":{\"117\":1,\"152\":1}}],[\"地址\",{\"1\":{\"102\":1,\"108\":1,\"110\":1,\"117\":2,\"122\":1,\"130\":1,\"145\":1,\"149\":1,\"151\":3,\"152\":2,\"155\":1,\"157\":3,\"160\":1,\"165\":1,\"173\":1}}],[\"地方\",{\"1\":{\"45\":1,\"82\":1,\"221\":3}}],[\"地\",{\"1\":{\"4\":1,\"57\":1,\"76\":1,\"135\":1,\"141\":1,\"145\":1,\"171\":1,\"181\":1,\"221\":3}}],[\"测试数据\",{\"1\":{\"137\":1}}],[\"测试环境\",{\"1\":{\"44\":1,\"50\":1}}],[\"测试\",{\"0\":{\"160\":1,\"190\":1},\"1\":{\"4\":1,\"8\":1,\"10\":1,\"25\":1,\"29\":1,\"45\":1,\"54\":1,\"56\":2,\"57\":3,\"69\":1,\"101\":1,\"102\":1,\"190\":1}}],[\"来回\",{\"1\":{\"152\":1}}],[\"来源\",{\"1\":{\"107\":1,\"157\":1,\"205\":1,\"207\":1}}],[\"来访\",{\"1\":{\"63\":1}}],[\"来看\",{\"1\":{\"56\":1,\"57\":1,\"108\":1,\"168\":1,\"173\":1}}],[\"来说\",{\"1\":{\"5\":1,\"8\":1,\"9\":1,\"12\":2,\"18\":1,\"44\":1,\"55\":1,\"63\":1,\"86\":1,\"124\":1,\"145\":1,\"173\":1,\"192\":1,\"194\":1}}],[\"来\",{\"1\":{\"4\":1,\"7\":1,\"8\":2,\"9\":1,\"10\":1,\"11\":2,\"12\":1,\"13\":1,\"17\":1,\"43\":1,\"45\":1,\"48\":2,\"51\":1,\"56\":7,\"63\":1,\"64\":2,\"65\":1,\"66\":1,\"68\":1,\"72\":4,\"74\":2,\"75\":1,\"76\":1,\"78\":1,\"80\":4,\"85\":1,\"87\":1,\"97\":1,\"98\":2,\"101\":1,\"103\":1,\"104\":1,\"113\":1,\"122\":3,\"124\":1,\"126\":1,\"135\":3,\"136\":1,\"137\":2,\"142\":1,\"143\":1,\"144\":2,\"146\":1,\"149\":1,\"151\":1,\"152\":2,\"153\":1,\"155\":1,\"156\":1,\"157\":2,\"158\":2,\"159\":1,\"161\":1,\"164\":1,\"165\":1,\"170\":1,\"179\":4,\"184\":1,\"185\":1,\"188\":1,\"190\":1,\"204\":1,\"205\":2,\"206\":1,\"212\":2,\"216\":3,\"221\":1}}],[\"来自\",{\"1\":{\"4\":1,\"152\":1,\"183\":1,\"211\":1}}],[\",\",{\"1\":{\"4\":8,\"5\":36,\"6\":19,\"7\":44,\"8\":12,\"9\":5,\"10\":4,\"11\":12,\"12\":18,\"13\":9,\"17\":5,\"18\":21,\"23\":35,\"25\":4,\"26\":18,\"27\":5,\"28\":12,\"29\":10,\"30\":4,\"31\":4,\"35\":1,\"37\":6,\"38\":9,\"39\":13,\"41\":10,\"42\":11,\"43\":12,\"44\":13,\"45\":31,\"46\":5,\"48\":8,\"49\":15,\"50\":14,\"51\":6,\"52\":10,\"54\":7,\"55\":4,\"56\":12,\"57\":18,\"58\":6,\"59\":1,\"61\":6,\"62\":5,\"63\":28,\"64\":7,\"65\":5,\"66\":11,\"67\":2,\"68\":5,\"69\":9,\"70\":25,\"72\":31,\"73\":75,\"74\":88,\"75\":60,\"76\":77,\"77\":21,\"78\":17,\"79\":9,\"80\":58,\"81\":40,\"82\":14,\"83\":8,\"84\":5,\"85\":24,\"86\":48,\"87\":36,\"88\":1,\"89\":14,\"90\":6,\"91\":5,\"95\":10,\"96\":10,\"97\":9,\"98\":14,\"99\":6,\"100\":10,\"101\":15,\"102\":18,\"103\":38,\"104\":8,\"106\":8,\"107\":5,\"108\":4,\"109\":5,\"113\":4,\"114\":25,\"115\":3,\"116\":5,\"117\":6,\"118\":1,\"120\":11,\"121\":3,\"122\":18,\"124\":61,\"125\":18,\"126\":19,\"127\":9,\"128\":6,\"130\":5,\"132\":13,\"133\":5,\"135\":18,\"136\":4,\"137\":16,\"140\":4,\"141\":7,\"142\":2,\"143\":4,\"144\":6,\"145\":40,\"146\":10,\"147\":5,\"148\":19,\"149\":26,\"150\":5,\"151\":32,\"152\":27,\"153\":9,\"155\":11,\"156\":2,\"157\":34,\"158\":17,\"159\":26,\"160\":8,\"161\":42,\"162\":2,\"163\":11,\"164\":29,\"165\":25,\"166\":14,\"167\":7,\"168\":20,\"169\":16,\"170\":13,\"171\":11,\"172\":9,\"173\":28,\"177\":8,\"178\":10,\"179\":20,\"180\":8,\"181\":4,\"182\":1,\"183\":10,\"184\":14,\"185\":33,\"186\":8,\"187\":3,\"188\":7,\"189\":9,\"190\":3,\"191\":2,\"192\":40,\"194\":5,\"196\":1,\"197\":5,\"198\":3,\"199\":2,\"203\":3,\"204\":4,\"205\":17,\"206\":9,\"207\":7,\"210\":5,\"211\":4,\"212\":11,\"213\":5,\"215\":7,\"216\":15,\"219\":3,\"220\":2,\"221\":162}}],[\"透过\",{\"1\":{\"4\":1}}],[\"。\",{\"1\":{\"4\":3,\"5\":4,\"6\":7,\"7\":12,\"8\":3,\"9\":2,\"10\":3,\"11\":3,\"12\":3,\"17\":2,\"18\":2,\"25\":3,\"26\":19,\"27\":3,\"28\":10,\"29\":11,\"30\":4,\"31\":3,\"34\":3,\"35\":4,\"37\":5,\"38\":4,\"39\":4,\"41\":1,\"42\":4,\"43\":2,\"44\":2,\"45\":7,\"46\":1,\"48\":1,\"49\":3,\"50\":1,\"51\":3,\"52\":1,\"54\":6,\"55\":6,\"56\":9,\"57\":12,\"58\":1,\"59\":1,\"60\":1,\"61\":2,\"62\":1,\"63\":12,\"64\":1,\"65\":2,\"66\":2,\"69\":1,\"70\":4,\"72\":12,\"73\":8,\"74\":24,\"75\":17,\"76\":11,\"77\":7,\"78\":7,\"79\":2,\"80\":7,\"81\":10,\"82\":2,\"84\":2,\"85\":4,\"86\":16,\"87\":3,\"89\":2,\"90\":4,\"93\":1,\"95\":4,\"96\":2,\"97\":3,\"98\":2,\"99\":1,\"100\":2,\"101\":4,\"102\":4,\"103\":13,\"104\":2,\"106\":2,\"107\":1,\"108\":1,\"109\":1,\"113\":3,\"114\":8,\"115\":3,\"116\":4,\"117\":2,\"118\":1,\"120\":4,\"121\":1,\"122\":6,\"124\":23,\"125\":12,\"126\":5,\"127\":4,\"128\":3,\"130\":2,\"132\":4,\"133\":5,\"135\":7,\"136\":3,\"137\":1,\"140\":1,\"141\":8,\"142\":1,\"143\":3,\"144\":2,\"145\":7,\"146\":3,\"147\":1,\"148\":3,\"149\":6,\"151\":8,\"152\":16,\"153\":3,\"155\":9,\"157\":6,\"158\":4,\"159\":9,\"160\":4,\"161\":23,\"163\":3,\"164\":9,\"165\":6,\"166\":4,\"167\":2,\"168\":5,\"169\":6,\"170\":7,\"171\":7,\"172\":4,\"173\":11,\"177\":2,\"178\":5,\"179\":11,\"180\":4,\"184\":8,\"185\":4,\"187\":3,\"188\":2,\"189\":1,\"190\":3,\"191\":1,\"192\":13,\"194\":3,\"196\":1,\"197\":2,\"198\":2,\"204\":3,\"205\":10,\"206\":7,\"207\":3,\"212\":4,\"213\":2,\"214\":2,\"215\":2,\"216\":7,\"220\":4,\"221\":60}}],[\"惯例\",{\"1\":{\"4\":1}}],[\"或许\",{\"1\":{\"75\":1,\"77\":1}}],[\"或是\",{\"1\":{\"58\":1}}],[\"或者\",{\"1\":{\"12\":1,\"18\":1,\"28\":1,\"61\":1,\"63\":2,\"87\":1,\"95\":2,\"96\":1,\"102\":1,\"103\":1,\"133\":1,\"151\":1,\"152\":1,\"157\":1,\"161\":1,\"169\":1,\"184\":1,\"185\":4,\"194\":1,\"196\":1,\"203\":1,\"207\":1}}],[\"或\",{\"1\":{\"4\":1,\"55\":1,\"59\":1,\"61\":1,\"115\":1,\"149\":2,\"157\":1,\"221\":6}}],[\"运用\",{\"0\":{\"149\":1},\"1\":{\"149\":1}}],[\"运气\",{\"1\":{\"78\":1}}],[\"运行状况\",{\"1\":{\"145\":1}}],[\"运行\",{\"1\":{\"6\":2,\"7\":1,\"11\":1,\"13\":1,\"29\":3,\"39\":1,\"42\":2,\"44\":1,\"55\":1,\"72\":6,\"76\":1,\"125\":2,\"141\":3,\"143\":1,\"144\":7,\"152\":1,\"177\":1,\"184\":1,\"221\":2}}],[\"运动\",{\"0\":{\"89\":1},\"1\":{\"4\":1,\"78\":1,\"82\":1,\"89\":3}}],[\"运维\",{\"1\":{\"4\":1,\"72\":1}}],[\"沟通\",{\"1\":{\"4\":1}}],[\"”\",{\"1\":{\"4\":4,\"29\":1,\"39\":2,\"54\":2,\"55\":1,\"57\":1,\"61\":1,\"63\":1,\"75\":1,\"80\":2,\"81\":1,\"103\":1,\"114\":1,\"125\":2,\"132\":2,\"157\":2,\"165\":3,\"166\":1,\"172\":1,\"185\":46,\"221\":2}}],[\"软件\",{\"0\":{\"5\":1},\"1\":{\"4\":3,\"5\":1,\"63\":1,\"77\":1,\"152\":2,\"221\":1}}],[\"“\",{\"1\":{\"4\":4,\"29\":1,\"39\":2,\"54\":2,\"55\":1,\"57\":1,\"61\":1,\"63\":1,\"75\":1,\"80\":2,\"81\":1,\"103\":1,\"114\":1,\"125\":2,\"132\":2,\"157\":1,\"165\":3,\"166\":1,\"172\":1,\"221\":2}}],[\"是非\",{\"1\":{\"221\":1}}],[\"是以\",{\"1\":{\"221\":1}}],[\"是不是\",{\"1\":{\"74\":2,\"76\":1,\"96\":1,\"102\":1,\"104\":1,\"149\":1,\"170\":1,\"172\":1}}],[\"是因为\",{\"1\":{\"49\":2,\"57\":2,\"124\":1,\"169\":1}}],[\"是否\",{\"1\":{\"5\":1,\"56\":1,\"63\":1,\"64\":1,\"103\":1,\"120\":1,\"121\":1,\"137\":2,\"185\":2,\"210\":1,\"213\":1,\"221\":9}}],[\"是\",{\"1\":{\"4\":5,\"5\":2,\"7\":11,\"8\":4,\"9\":2,\"10\":1,\"11\":1,\"12\":3,\"13\":1,\"18\":3,\"23\":4,\"27\":1,\"29\":1,\"37\":1,\"38\":1,\"41\":1,\"43\":4,\"44\":1,\"45\":6,\"48\":2,\"50\":1,\"51\":1,\"54\":1,\"56\":1,\"57\":4,\"63\":7,\"65\":1,\"66\":2,\"70\":8,\"72\":2,\"73\":5,\"74\":11,\"75\":5,\"76\":10,\"77\":4,\"78\":4,\"80\":2,\"81\":3,\"82\":1,\"84\":2,\"86\":2,\"87\":1,\"90\":1,\"95\":1,\"96\":1,\"97\":1,\"98\":3,\"99\":2,\"100\":1,\"101\":2,\"102\":2,\"103\":2,\"104\":4,\"106\":4,\"108\":1,\"113\":1,\"114\":4,\"117\":4,\"120\":1,\"122\":1,\"124\":12,\"125\":1,\"126\":3,\"133\":4,\"135\":2,\"137\":3,\"141\":2,\"144\":1,\"145\":5,\"146\":2,\"148\":3,\"149\":7,\"150\":1,\"151\":5,\"152\":6,\"153\":1,\"155\":5,\"157\":7,\"158\":7,\"159\":5,\"160\":1,\"161\":6,\"162\":1,\"164\":5,\"165\":4,\"166\":1,\"168\":9,\"169\":3,\"170\":6,\"171\":1,\"172\":2,\"173\":2,\"177\":1,\"178\":1,\"179\":3,\"180\":3,\"181\":1,\"183\":1,\"184\":5,\"185\":2,\"186\":2,\"188\":1,\"192\":6,\"197\":1,\"204\":1,\"205\":4,\"206\":3,\"209\":1,\"212\":3,\"215\":2,\"216\":2,\"219\":1,\"221\":45}}],[\"词语\",{\"1\":{\"132\":1,\"155\":1}}],[\"词\",{\"1\":{\"4\":1,\"55\":1,\"132\":4,\"133\":1}}],[\"和\",{\"0\":{\"43\":1,\"108\":1},\"1\":{\"4\":4,\"23\":2,\"26\":1,\"27\":1,\"28\":2,\"31\":2,\"38\":4,\"54\":1,\"56\":2,\"57\":5,\"63\":1,\"64\":1,\"66\":2,\"72\":4,\"73\":1,\"74\":5,\"86\":1,\"100\":1,\"101\":1,\"114\":1,\"115\":1,\"116\":1,\"120\":1,\"122\":4,\"124\":2,\"125\":2,\"126\":1,\"133\":1,\"135\":1,\"140\":2,\"141\":3,\"145\":4,\"147\":1,\"151\":2,\"152\":3,\"157\":2,\"158\":1,\"159\":1,\"160\":1,\"161\":2,\"164\":2,\"168\":1,\"170\":1,\"171\":1,\"173\":1,\"177\":1,\"183\":1,\"184\":2,\"185\":3,\"186\":1,\"192\":1,\"205\":2,\"207\":1,\"208\":1,\"211\":1,\"220\":1,\"221\":21}}],[\":\",{\"0\":{\"26\":1,\"132\":1,\"134\":1,\"137\":1,\"140\":1,\"160\":1,\"206\":1},\"1\":{\"4\":1,\"5\":1,\"6\":1,\"7\":3,\"8\":1,\"11\":1,\"13\":2,\"14\":2,\"18\":4,\"23\":3,\"25\":1,\"26\":7,\"27\":1,\"28\":6,\"29\":4,\"30\":9,\"31\":4,\"37\":2,\"38\":3,\"39\":3,\"41\":2,\"42\":1,\"43\":1,\"45\":3,\"46\":1,\"50\":1,\"51\":1,\"52\":1,\"55\":2,\"56\":6,\"57\":4,\"60\":1,\"61\":1,\"65\":1,\"72\":16,\"73\":1,\"75\":1,\"77\":3,\"80\":1,\"86\":2,\"98\":1,\"102\":1,\"103\":3,\"108\":3,\"109\":1,\"110\":1,\"113\":1,\"117\":3,\"122\":1,\"125\":1,\"126\":1,\"128\":1,\"132\":3,\"133\":5,\"135\":4,\"136\":1,\"137\":4,\"138\":1,\"139\":1,\"141\":6,\"142\":1,\"143\":3,\"144\":6,\"145\":2,\"147\":3,\"148\":6,\"149\":8,\"151\":8,\"152\":5,\"153\":1,\"155\":4,\"157\":5,\"158\":3,\"159\":3,\"160\":3,\"161\":8,\"164\":4,\"165\":1,\"166\":1,\"168\":1,\"171\":1,\"172\":1,\"177\":1,\"178\":2,\"179\":1,\"181\":1,\"182\":2,\"183\":2,\"185\":3,\"188\":1,\"191\":6,\"192\":5,\"194\":6,\"196\":1,\"203\":1,\"205\":2,\"206\":3,\"208\":1,\"212\":1,\"213\":1,\"215\":1,\"216\":2,\"220\":3,\"221\":19}}],[\")\",{\"0\":{\"49\":1,\"103\":1,\"212\":1,\"213\":1},\"1\":{\"4\":4,\"5\":5,\"6\":2,\"8\":1,\"23\":1,\"25\":1,\"26\":2,\"37\":1,\"42\":2,\"43\":1,\"55\":1,\"56\":1,\"57\":1,\"63\":1,\"64\":1,\"72\":1,\"73\":1,\"74\":1,\"76\":1,\"100\":1,\"101\":1,\"102\":2,\"103\":3,\"113\":2,\"114\":5,\"117\":3,\"124\":3,\"125\":3,\"126\":1,\"127\":2,\"133\":5,\"135\":2,\"141\":1,\"143\":5,\"144\":4,\"145\":1,\"147\":1,\"149\":3,\"151\":3,\"152\":4,\"155\":3,\"157\":2,\"158\":3,\"159\":5,\"161\":1,\"168\":1,\"169\":1,\"170\":1,\"171\":1,\"173\":3,\"177\":1,\"178\":4,\"179\":3,\"183\":1,\"184\":3,\"185\":7,\"188\":1,\"190\":1,\"191\":1,\"192\":4,\"194\":4,\"198\":1,\"206\":2,\"207\":3,\"211\":3,\"221\":18}}],[\"(\",{\"0\":{\"49\":1,\"103\":1,\"212\":1,\"213\":1},\"1\":{\"4\":4,\"5\":5,\"6\":2,\"8\":1,\"23\":1,\"25\":1,\"26\":2,\"37\":1,\"42\":2,\"43\":1,\"55\":1,\"56\":1,\"57\":1,\"63\":1,\"64\":1,\"72\":1,\"73\":1,\"74\":1,\"76\":1,\"100\":1,\"101\":1,\"102\":2,\"103\":3,\"113\":2,\"114\":5,\"117\":3,\"121\":1,\"124\":3,\"125\":3,\"126\":1,\"127\":2,\"133\":5,\"135\":2,\"141\":1,\"143\":5,\"144\":4,\"145\":1,\"147\":1,\"149\":3,\"151\":3,\"152\":4,\"155\":3,\"157\":2,\"158\":3,\"159\":5,\"161\":1,\"168\":1,\"169\":1,\"170\":1,\"171\":1,\"173\":3,\"177\":1,\"178\":4,\"179\":3,\"183\":1,\"184\":3,\"185\":7,\"188\":1,\"190\":1,\"191\":1,\"192\":4,\"194\":4,\"198\":1,\"205\":1,\"206\":2,\"207\":3,\"211\":3,\"221\":18}}],[\"xtota1ops\",{\"1\":{\"210\":1}}],[\"xtotalops\",{\"1\":{\"210\":3}}],[\"xpack\",{\"1\":{\"203\":1}}],[\"xff\",{\"1\":{\"156\":1}}],[\"xaxis\",{\"1\":{\"151\":1}}],[\"xdan\",{\"1\":{\"137\":1}}],[\"xdebug\",{\"1\":{\"43\":1}}],[\"xrunjdwp\",{\"1\":{\"43\":1}}],[\"xnoagent\",{\"1\":{\"43\":1}}],[\"xloggc\",{\"1\":{\"30\":1,\"33\":1}}],[\"x21f2a5e8\",{\"1\":{\"30\":1}}],[\"x21bd0000\",{\"1\":{\"30\":5}}],[\"x21bce430\",{\"1\":{\"30\":1}}],[\"x2bfd0000\",{\"1\":{\"30\":2}}],[\"x2b972200\",{\"1\":{\"30\":2}}],[\"x2b972060\",{\"1\":{\"30\":2}}],[\"x2b3d0000\",{\"1\":{\"30\":4}}],[\"x2b12be00\",{\"1\":{\"30\":2}}],[\"x2b12bcc0\",{\"1\":{\"30\":2}}],[\"x26ea4c00\",{\"1\":{\"30\":2}}],[\"x26ea4ba8\",{\"1\":{\"30\":2}}],[\"x26bd0000\",{\"1\":{\"30\":10}}],[\"x2abd0000\",{\"1\":{\"30\":4}}],[\"x273d0000\",{\"1\":{\"30\":4}}],[\"x22aeba00\",{\"1\":{\"30\":1}}],[\"x22aeb958\",{\"1\":{\"30\":1}}],[\"x22a72200\",{\"1\":{\"30\":1}}],[\"x22a720f8\",{\"1\":{\"30\":1}}],[\"x22527e10\",{\"1\":{\"30\":1}}],[\"x221d0000\",{\"1\":{\"30\":5}}],[\"x227d0000\",{\"1\":{\"30\":10}}],[\"x1ebd0000\",{\"1\":{\"30\":5}}],[\"xss128k\",{\"1\":{\"26\":3,\"28\":4,\"29\":2}}],[\"xstream\",{\"1\":{\"5\":1}}],[\"xmr\",{\"1\":{\"41\":2}}],[\"xms\",{\"1\":{\"31\":1}}],[\"xms3800m\",{\"1\":{\"28\":1}}],[\"xms3550m\",{\"1\":{\"26\":3,\"28\":3,\"29\":2}}],[\"xmn\",{\"1\":{\"29\":1}}],[\"xmn2g\",{\"1\":{\"26\":2,\"28\":4,\"29\":2}}],[\"xmx3800m\",{\"1\":{\"28\":1}}],[\"xmx3550m\",{\"1\":{\"26\":3,\"28\":3,\"29\":2}}],[\"xmx\",{\"1\":{\"26\":1,\"31\":1}}],[\"xml\",{\"0\":{\"187\":1},\"1\":{\"5\":1,\"56\":1,\"159\":2,\"182\":1,\"190\":1}}],[\"xx0\",{\"1\":{\"72\":1}}],[\"xxl\",{\"1\":{\"42\":1}}],[\"xx\",{\"1\":{\"5\":1,\"26\":8,\"28\":15,\"29\":11,\"30\":7,\"31\":4,\"32\":4,\"33\":3,\"34\":3,\"35\":2,\"39\":2}}],[\"xxxx\",{\"1\":{\"5\":2,\"9\":1,\"121\":1,\"196\":1}}],[\"xxxxxxx\",{\"1\":{\"13\":6}}],[\"xxxxxx\",{\"1\":{\"10\":1,\"11\":3,\"12\":1,\"13\":1,\"196\":1}}],[\"xxxxx\",{\"1\":{\"5\":1,\"10\":1,\"11\":1}}],[\"xxx\",{\"1\":{\"5\":2,\"9\":1,\"11\":1,\"72\":4,\"221\":2}}],[\"x\",{\"0\":{\"20\":1},\"1\":{\"3\":1,\"7\":4,\"8\":1,\"11\":1,\"13\":1,\"48\":3,\"72\":4,\"101\":1,\"118\":1,\"149\":12,\"151\":2,\"156\":1,\"157\":15}}],[\"-\",{\"0\":{\"20\":1,\"93\":1},\"1\":{\"3\":2,\"5\":1,\"6\":10,\"7\":4,\"11\":6,\"12\":23,\"13\":35,\"17\":1,\"18\":2,\"23\":1,\"25\":2,\"26\":20,\"28\":31,\"29\":20,\"30\":18,\"31\":6,\"32\":4,\"33\":4,\"34\":3,\"35\":2,\"39\":2,\"41\":10,\"42\":1,\"43\":7,\"44\":1,\"46\":2,\"48\":20,\"49\":3,\"54\":1,\"56\":12,\"57\":3,\"64\":4,\"65\":2,\"69\":14,\"72\":45,\"95\":1,\"98\":4,\"101\":9,\"103\":1,\"108\":5,\"110\":1,\"114\":2,\"117\":1,\"118\":24,\"120\":19,\"121\":6,\"125\":1,\"135\":27,\"137\":3,\"138\":2,\"143\":23,\"144\":11,\"146\":1,\"147\":4,\"148\":2,\"149\":8,\"150\":5,\"151\":4,\"152\":7,\"153\":3,\"155\":1,\"157\":21,\"158\":4,\"159\":25,\"160\":11,\"161\":1,\"163\":17,\"164\":23,\"166\":1,\"170\":3,\"178\":2,\"182\":4,\"184\":2,\"186\":2,\"187\":14,\"190\":2,\"194\":3,\"196\":4,\"198\":1,\"202\":2,\"203\":5,\"204\":1,\"205\":17,\"206\":16,\"207\":1,\"208\":1,\"210\":2,\"212\":5,\"213\":2,\"214\":1,\"215\":4,\"216\":8,\"221\":4}}],[\"三步\",{\"1\":{\"161\":1}}],[\"三元\",{\"1\":{\"149\":1}}],[\"三国\",{\"1\":{\"81\":1}}],[\"三种\",{\"1\":{\"27\":1,\"192\":1,\"221\":1}}],[\"三面\",{\"1\":{\"23\":1}}],[\"三个\",{\"1\":{\"13\":2,\"42\":1,\"74\":1,\"75\":1,\"145\":1,\"146\":1,\"183\":1,\"221\":2}}],[\"三\",{\"0\":{\"3\":1,\"7\":1,\"30\":1,\"56\":1,\"64\":1,\"99\":1,\"142\":1,\"200\":1},\"1\":{\"13\":1,\"23\":1,\"25\":1,\"216\":1}}],[\"mq\",{\"1\":{\"221\":1}}],[\"mp\",{\"1\":{\"220\":1}}],[\"mget\",{\"1\":{\"211\":1}}],[\"mv\",{\"1\":{\"151\":2}}],[\"mvn\",{\"1\":{\"9\":1,\"10\":2,\"11\":1,\"13\":2}}],[\"mvn3\",{\"1\":{\"5\":1}}],[\"multifetchresponse\",{\"1\":{\"221\":1}}],[\"multicastevent\",{\"1\":{\"144\":1}}],[\"mutating\",{\"1\":{\"72\":2}}],[\"middleware\",{\"0\":{\"234\":1}}],[\"mircrosoft\",{\"1\":{\"113\":1}}],[\"min\",{\"1\":{\"151\":1}}],[\"minqpslimit\",{\"1\":{\"66\":4}}],[\"minutes\",{\"1\":{\"66\":1}}],[\"m1s\",{\"1\":{\"72\":1}}],[\"m30s\",{\"1\":{\"72\":1}}],[\"mssql\",{\"1\":{\"194\":1}}],[\"msgtype\",{\"1\":{\"101\":3}}],[\"ms\",{\"1\":{\"69\":2,\"152\":1,\"161\":3,\"221\":1}}],[\"mergeshardsiterators\",{\"1\":{\"208\":1}}],[\"memcached\",{\"1\":{\"184\":1}}],[\"memecached\",{\"1\":{\"183\":1}}],[\"memory\",{\"0\":{\"44\":1},\"1\":{\"48\":1,\"51\":1,\"72\":2,\"221\":1}}],[\"metrics\",{\"1\":{\"147\":1,\"148\":4,\"149\":3,\"150\":3}}],[\"method\",{\"1\":{\"147\":1,\"148\":4,\"149\":3,\"150\":3,\"188\":3}}],[\"methodinvokingjobdetailfactorybean\",{\"1\":{\"143\":1}}],[\"metadata\",{\"1\":{\"72\":1}}],[\"metav1\",{\"1\":{\"65\":1}}],[\"meesage\",{\"1\":{\"102\":1}}],[\"messageandoffset\",{\"1\":{\"221\":1}}],[\"messages\",{\"1\":{\"104\":4}}],[\"message\",{\"1\":{\"101\":3,\"103\":14,\"104\":1,\"221\":1}}],[\"more\",{\"1\":{\"212\":1,\"215\":1}}],[\"movetonextphase\",{\"1\":{\"212\":2}}],[\"moving\",{\"1\":{\"206\":1}}],[\"mode\",{\"1\":{\"72\":1}}],[\"modelandview\",{\"1\":{\"125\":1}}],[\"models\",{\"1\":{\"108\":1}}],[\"model\",{\"1\":{\"5\":6,\"98\":1,\"101\":1}}],[\"monitor\",{\"1\":{\"72\":2}}],[\"mongodb\",{\"1\":{\"41\":3,\"76\":1,\"186\":1}}],[\"m\",{\"1\":{\"23\":1,\"25\":1,\"26\":7,\"44\":1,\"57\":1,\"72\":5,\"158\":1}}],[\"mycache\",{\"1\":{\"185\":3}}],[\"mychart\",{\"1\":{\"151\":2}}],[\"mychartmuseum\",{\"1\":{\"12\":2,\"13\":2}}],[\"myblog\",{\"1\":{\"163\":1,\"164\":1,\"188\":1}}],[\"mybatis\",{\"0\":{\"179\":1,\"180\":1,\"181\":1,\"184\":1},\"1\":{\"125\":1,\"177\":1,\"178\":4,\"179\":3,\"180\":3,\"181\":1,\"182\":1,\"183\":8,\"184\":2,\"190\":1,\"191\":2,\"192\":6}}],[\"mytrigger\",{\"1\":{\"143\":2}}],[\"my\",{\"1\":{\"72\":1,\"163\":1,\"164\":1}}],[\"mypass\",{\"1\":{\"12\":1,\"13\":1}}],[\"myuser\",{\"1\":{\"12\":1,\"13\":1}}],[\"mysqld\",{\"1\":{\"163\":4,\"164\":4}}],[\"mysqldump\",{\"1\":{\"143\":2}}],[\"mysqlutil\",{\"1\":{\"143\":1}}],[\"mysqlservice\",{\"1\":{\"143\":3}}],[\"mysql\",{\"0\":{\"217\":1,\"232\":1},\"1\":{\"2\":2,\"23\":1,\"126\":1,\"127\":1,\"143\":1,\"149\":1,\"161\":5,\"163\":7,\"164\":13,\"178\":1,\"183\":1,\"192\":1,\"194\":1,\"220\":2}}],[\"masory\",{\"1\":{\"171\":1}}],[\"master\",{\"0\":{\"163\":1},\"1\":{\"5\":1,\"7\":1,\"9\":1,\"10\":1,\"11\":1,\"13\":3,\"72\":1,\"148\":1,\"161\":15,\"163\":2,\"164\":9}}],[\"margin\",{\"1\":{\"170\":1}}],[\"marked\",{\"1\":{\"168\":1}}],[\"markdown\",{\"1\":{\"168\":6}}],[\"maybefork\",{\"1\":{\"210\":2}}],[\"may\",{\"1\":{\"98\":1}}],[\"macbook\",{\"1\":{\"83\":1}}],[\"main\",{\"1\":{\"150\":1,\"156\":2,\"197\":1}}],[\"mainapplicationfile\",{\"1\":{\"72\":1}}],[\"mainclass\",{\"1\":{\"72\":1}}],[\"manifest\",{\"1\":{\"72\":1}}],[\"many\",{\"1\":{\"68\":2}}],[\"management\",{\"1\":{\"43\":3}}],[\"mapper\",{\"1\":{\"180\":3,\"181\":4,\"182\":1}}],[\"mapping\",{\"1\":{\"159\":2}}],[\"maptype\",{\"1\":{\"151\":1}}],[\"maps\",{\"1\":{\"48\":1}}],[\"map\",{\"1\":{\"43\":1,\"44\":3,\"51\":2,\"72\":2,\"104\":1,\"151\":1,\"194\":1,\"197\":1,\"208\":1}}],[\"maxinactiveintervalinseconds\",{\"1\":{\"159\":1}}],[\"maximumsize\",{\"1\":{\"66\":1}}],[\"max\",{\"1\":{\"98\":1,\"101\":1,\"151\":1,\"159\":3,\"205\":1}}],[\"maxgcpausemillis\",{\"1\":{\"28\":3,\"34\":1}}],[\"maxtenuringthreshold\",{\"1\":{\"26\":2}}],[\"maxpermsize\",{\"1\":{\"26\":2,\"31\":1}}],[\"mavenname\",{\"1\":{\"5\":2}}],[\"maven\",{\"1\":{\"5\":2,\"9\":1,\"10\":2,\"11\":1,\"13\":8,\"56\":3,\"135\":1,\"137\":1}}],[\"md5\",{\"1\":{\"74\":1,\"76\":1,\"158\":1}}],[\"md\",{\"0\":{\"4\":1,\"145\":1,\"152\":1,\"168\":1},\"1\":{\"0\":3,\"2\":1,\"3\":1,\"165\":1,\"168\":1}}],[\"八\",{\"1\":{\"2\":1}}],[\"我啦\",{\"1\":{\"173\":1}}],[\"我用\",{\"1\":{\"114\":1,\"168\":1}}],[\"我么\",{\"1\":{\"76\":1}}],[\"我要\",{\"1\":{\"75\":1}}],[\"我们\",{\"0\":{\"75\":1},\"1\":{\"5\":2,\"6\":2,\"7\":5,\"9\":1,\"12\":1,\"17\":1,\"54\":4,\"56\":13,\"57\":9,\"61\":1,\"63\":2,\"69\":1,\"70\":2,\"72\":1,\"76\":2,\"80\":1,\"86\":1,\"97\":3,\"98\":2,\"100\":1,\"101\":2,\"102\":1,\"103\":1,\"108\":1,\"109\":1,\"114\":1,\"120\":1,\"121\":1,\"135\":1,\"146\":1,\"147\":1,\"148\":2,\"149\":2,\"151\":1,\"152\":1,\"157\":3,\"159\":1,\"164\":1,\"177\":1,\"179\":1,\"184\":1,\"189\":1,\"190\":2,\"205\":1,\"216\":1,\"221\":4}}],[\"我\",{\"0\":{\"1\":1,\"138\":1},\"1\":{\"10\":1,\"23\":1,\"25\":1,\"48\":1,\"73\":7,\"74\":7,\"75\":9,\"76\":9,\"77\":3,\"78\":5,\"80\":5,\"81\":1,\"83\":1,\"86\":2,\"87\":1,\"91\":1,\"96\":1,\"114\":1,\"122\":1,\"124\":3,\"127\":1,\"130\":1,\"145\":4,\"150\":1,\"151\":3,\"152\":2,\"160\":1,\"165\":4,\"166\":2,\"167\":1,\"169\":2,\"170\":2,\"171\":1,\"172\":2,\"173\":1,\"186\":1,\"192\":1,\"221\":4}}],[\"的呢\",{\"1\":{\"204\":1,\"205\":1,\"221\":1}}],[\"的是\",{\"1\":{\"160\":1,\"206\":1}}],[\"的树\",{\"1\":{\"93\":1,\"110\":1}}],[\"的确\",{\"1\":{\"77\":1}}],[\"的人\",{\"1\":{\"76\":1}}],[\"的话\",{\"1\":{\"12\":1,\"26\":1,\"44\":1,\"63\":1,\"67\":1,\"70\":2,\"75\":1,\"86\":1,\"87\":2,\"91\":1,\"95\":1,\"102\":1,\"106\":1,\"107\":1,\"126\":1,\"149\":1,\"164\":1,\"167\":1,\"168\":1,\"173\":2,\"192\":2,\"221\":1}}],[\"的\",{\"0\":{\"5\":1,\"6\":1,\"8\":1,\"28\":1,\"29\":1,\"39\":1,\"45\":2,\"47\":1,\"50\":1,\"58\":1,\"64\":1,\"65\":1,\"66\":1,\"67\":1,\"68\":1,\"74\":1,\"76\":1,\"80\":1,\"108\":1,\"130\":1,\"131\":1,\"132\":1,\"133\":1,\"134\":1,\"138\":1,\"144\":1,\"153\":1,\"154\":1,\"162\":1,\"165\":1,\"174\":1,\"181\":1,\"182\":1,\"183\":2,\"192\":1,\"210\":1,\"212\":1,\"213\":1},\"1\":{\"0\":1,\"4\":6,\"5\":21,\"6\":18,\"7\":28,\"8\":12,\"9\":5,\"10\":6,\"11\":10,\"12\":11,\"13\":2,\"14\":1,\"17\":7,\"18\":9,\"23\":7,\"25\":3,\"26\":14,\"27\":2,\"28\":5,\"29\":4,\"30\":3,\"31\":4,\"34\":2,\"35\":1,\"37\":9,\"38\":12,\"39\":7,\"41\":2,\"42\":7,\"43\":10,\"44\":6,\"45\":17,\"46\":4,\"48\":2,\"49\":6,\"50\":7,\"51\":10,\"52\":10,\"54\":6,\"55\":5,\"56\":15,\"57\":19,\"58\":1,\"59\":3,\"60\":2,\"61\":3,\"63\":29,\"64\":3,\"65\":3,\"66\":7,\"67\":1,\"69\":4,\"70\":19,\"71\":1,\"72\":35,\"73\":24,\"74\":41,\"75\":16,\"76\":25,\"77\":4,\"78\":9,\"79\":5,\"80\":18,\"81\":18,\"82\":4,\"83\":3,\"84\":5,\"85\":12,\"86\":18,\"87\":13,\"89\":1,\"90\":2,\"91\":2,\"93\":1,\"95\":2,\"96\":4,\"97\":7,\"98\":8,\"99\":1,\"100\":2,\"101\":5,\"102\":7,\"103\":15,\"104\":7,\"106\":6,\"107\":3,\"108\":5,\"109\":3,\"113\":5,\"114\":17,\"115\":5,\"116\":1,\"117\":8,\"118\":1,\"120\":7,\"121\":3,\"122\":14,\"124\":39,\"125\":14,\"126\":8,\"127\":7,\"128\":2,\"129\":1,\"130\":1,\"132\":11,\"133\":11,\"135\":18,\"136\":4,\"137\":15,\"139\":1,\"140\":5,\"141\":12,\"143\":3,\"144\":13,\"145\":24,\"146\":6,\"147\":12,\"148\":10,\"149\":26,\"150\":3,\"151\":24,\"152\":28,\"153\":2,\"155\":17,\"156\":1,\"157\":35,\"158\":12,\"159\":16,\"160\":5,\"161\":46,\"162\":2,\"163\":6,\"164\":19,\"165\":18,\"166\":8,\"167\":5,\"168\":18,\"169\":9,\"170\":13,\"171\":9,\"172\":6,\"173\":17,\"177\":4,\"178\":2,\"179\":14,\"180\":7,\"181\":2,\"182\":2,\"183\":10,\"184\":14,\"185\":31,\"186\":6,\"187\":1,\"188\":5,\"189\":4,\"190\":3,\"191\":3,\"192\":27,\"194\":5,\"196\":1,\"197\":8,\"198\":1,\"199\":2,\"203\":4,\"204\":1,\"205\":13,\"206\":10,\"207\":6,\"208\":2,\"209\":1,\"210\":3,\"211\":6,\"212\":7,\"214\":2,\"215\":2,\"216\":13,\"219\":2,\"220\":2,\"221\":213}}],[\".\",{\"0\":{\"4\":1,\"49\":1,\"140\":1,\"141\":1,\"145\":1,\"152\":1,\"168\":1,\"187\":1},\"1\":{\"0\":3,\"2\":1,\"3\":1,\"5\":49,\"7\":2,\"11\":6,\"12\":3,\"13\":11,\"18\":7,\"25\":1,\"26\":1,\"27\":2,\"28\":1,\"29\":1,\"41\":10,\"43\":13,\"44\":1,\"45\":7,\"46\":4,\"48\":2,\"56\":15,\"57\":5,\"61\":1,\"64\":2,\"65\":7,\"66\":11,\"67\":1,\"68\":11,\"69\":3,\"72\":71,\"73\":3,\"76\":2,\"79\":2,\"80\":3,\"95\":1,\"97\":2,\"98\":4,\"101\":16,\"103\":13,\"104\":5,\"108\":4,\"109\":1,\"110\":1,\"113\":1,\"114\":1,\"117\":6,\"118\":8,\"120\":14,\"121\":6,\"122\":1,\"125\":3,\"130\":3,\"135\":79,\"136\":1,\"137\":49,\"138\":4,\"141\":12,\"142\":1,\"143\":30,\"144\":69,\"145\":4,\"146\":9,\"147\":8,\"148\":17,\"149\":22,\"150\":29,\"151\":19,\"152\":3,\"153\":4,\"155\":14,\"156\":7,\"157\":5,\"158\":11,\"159\":33,\"160\":6,\"163\":4,\"164\":6,\"165\":5,\"166\":2,\"168\":1,\"170\":7,\"171\":2,\"173\":4,\"181\":2,\"182\":6,\"183\":4,\"187\":39,\"188\":20,\"189\":12,\"190\":7,\"192\":3,\"196\":21,\"197\":4,\"198\":3,\"199\":1,\"203\":6,\"204\":1,\"206\":63,\"207\":7,\"208\":21,\"209\":7,\"210\":23,\"212\":33,\"213\":3,\"214\":11,\"215\":13,\"216\":29,\"220\":5,\"221\":28}}],[\"jiathis\",{\"1\":{\"170\":3}}],[\"jianshu\",{\"1\":{\"149\":1}}],[\"jira\",{\"1\":{\"7\":1}}],[\"jquery\",{\"1\":{\"137\":2,\"168\":1}}],[\"juejin\",{\"1\":{\"109\":1}}],[\"junit\",{\"1\":{\"10\":1}}],[\"jfaowejfoewj\",{\"1\":{\"92\":1}}],[\"join\",{\"1\":{\"74\":2,\"104\":1}}],[\"jobexecutioncontext\",{\"1\":{\"141\":1}}],[\"jobdetail\",{\"1\":{\"141\":3,\"143\":3}}],[\"job\",{\"1\":{\"5\":4,\"7\":1,\"12\":5,\"13\":5,\"42\":1,\"141\":2}}],[\"jsoup\",{\"1\":{\"135\":2,\"137\":1}}],[\"json2\",{\"1\":{\"198\":2}}],[\"json1\",{\"1\":{\"198\":2}}],[\"jsonwrite\",{\"1\":{\"198\":1}}],[\"json\",{\"1\":{\"11\":1,\"98\":1,\"120\":1,\"121\":1,\"137\":1,\"147\":1,\"148\":1,\"149\":5,\"150\":5,\"151\":1,\"156\":1,\"194\":1,\"198\":2}}],[\"jsp\",{\"1\":{\"125\":2,\"151\":1}}],[\"jstlview\",{\"1\":{\"125\":2}}],[\"js\",{\"1\":{\"101\":1,\"124\":2,\"136\":1,\"137\":4,\"146\":2,\"151\":4,\"165\":1,\"171\":2,\"173\":1}}],[\"jsc\",{\"1\":{\"72\":2,\"197\":3,\"198\":1}}],[\"jars\",{\"1\":{\"72\":1}}],[\"jar\",{\"1\":{\"72\":2,\"142\":1}}],[\"javapairrdd\",{\"1\":{\"197\":1}}],[\"javascript\",{\"1\":{\"137\":2,\"151\":1}}],[\"javasparkcontext\",{\"1\":{\"72\":2,\"197\":3}}],[\"javaesspark\",{\"1\":{\"72\":1,\"197\":1,\"198\":1}}],[\"javardd\",{\"1\":{\"72\":1,\"198\":1}}],[\"java\",{\"0\":{\"9\":1,\"10\":1,\"11\":1,\"224\":1},\"1\":{\"0\":1,\"10\":1,\"13\":3,\"23\":1,\"26\":2,\"28\":4,\"29\":2,\"43\":2,\"46\":1,\"49\":2,\"51\":2,\"54\":1,\"56\":2,\"72\":6,\"74\":2,\"76\":1,\"81\":1,\"83\":1,\"124\":2,\"127\":1,\"128\":1,\"135\":1,\"138\":1,\"141\":3,\"143\":2,\"144\":9,\"145\":1,\"165\":1,\"173\":1}}],[\"jedisconnectionfactory\",{\"1\":{\"159\":3,\"187\":3}}],[\"jedispoolconfig\",{\"1\":{\"159\":3,\"187\":1}}],[\"jedis\",{\"1\":{\"151\":3,\"159\":4,\"187\":1}}],[\"jemalloc\",{\"1\":{\"49\":2}}],[\"jenkinsfile\",{\"1\":{\"7\":1}}],[\"jenkins\",{\"0\":{\"20\":1},\"1\":{\"3\":1,\"5\":6,\"6\":2,\"7\":9,\"8\":2,\"11\":1,\"13\":5,\"14\":1,\"81\":3}}],[\"jmeter\",{\"1\":{\"57\":2}}],[\"jmap\",{\"1\":{\"44\":1}}],[\"jmxremote\",{\"1\":{\"43\":3}}],[\"jmx\",{\"0\":{\"43\":1},\"1\":{\"43\":2,\"45\":1,\"122\":1,\"126\":1}}],[\"jprofiler\",{\"0\":{\"44\":1}}],[\"j\",{\"1\":{\"41\":2,\"138\":1}}],[\"jdkserializationredisserializer\",{\"1\":{\"187\":2}}],[\"jdk\",{\"1\":{\"54\":1}}],[\"jdk6\",{\"1\":{\"28\":1,\"76\":1}}],[\"jdk5\",{\"1\":{\"25\":1,\"26\":1,\"27\":2,\"29\":1}}],[\"jvm\",{\"0\":{\"24\":1,\"42\":1},\"1\":{\"0\":2,\"25\":1,\"26\":4,\"27\":2,\"28\":1,\"29\":1,\"30\":1,\"42\":1,\"43\":1,\"55\":1,\"56\":1,\"73\":1,\"75\":1,\"76\":1,\"122\":1,\"126\":1,\"173\":1,\"203\":1}}],[\" \",{\"0\":{\"4\":1,\"9\":1,\"10\":1,\"11\":1,\"12\":1,\"13\":1,\"14\":1,\"15\":1,\"17\":1,\"28\":1,\"29\":1,\"31\":1,\"32\":1,\"33\":1,\"34\":1,\"35\":1,\"37\":1,\"38\":1,\"39\":1,\"43\":1,\"44\":2,\"45\":1,\"46\":1,\"47\":1,\"48\":1,\"49\":1,\"50\":1,\"53\":3,\"55\":1,\"56\":1,\"60\":1,\"61\":1,\"62\":1,\"65\":1,\"66\":1,\"67\":1,\"68\":1,\"72\":3,\"95\":1,\"96\":1,\"97\":1,\"100\":1,\"101\":1,\"102\":1,\"106\":1,\"107\":1,\"108\":1,\"109\":1,\"111\":1,\"113\":3,\"114\":1,\"115\":1,\"116\":3,\"117\":1,\"118\":1,\"119\":1,\"120\":1,\"121\":1,\"125\":1,\"126\":1,\"127\":1,\"138\":1,\"153\":1,\"154\":1,\"155\":1,\"156\":1,\"157\":1,\"158\":1,\"159\":1,\"162\":1,\"163\":1,\"164\":1,\"177\":1,\"178\":1,\"179\":1,\"180\":1,\"181\":1,\"182\":1,\"183\":1,\"184\":1,\"185\":2,\"186\":1,\"187\":1,\"188\":1,\"189\":1,\"190\":1,\"191\":1,\"192\":1,\"194\":1,\"196\":1,\"197\":1,\"198\":1,\"199\":1,\"200\":1,\"201\":2,\"202\":3,\"207\":1,\"208\":1,\"209\":1,\"210\":1,\"211\":1,\"212\":1,\"213\":1,\"214\":1,\"215\":1,\"216\":1,\"227\":1,\"228\":1},\"1\":{\"0\":4,\"2\":2,\"3\":1,\"4\":1,\"5\":69,\"6\":1,\"7\":19,\"8\":2,\"9\":23,\"10\":29,\"11\":64,\"12\":71,\"13\":252,\"14\":2,\"15\":10,\"23\":14,\"25\":5,\"26\":25,\"28\":32,\"29\":19,\"30\":251,\"31\":5,\"32\":3,\"33\":3,\"34\":2,\"35\":1,\"37\":1,\"38\":6,\"39\":3,\"41\":17,\"42\":5,\"43\":12,\"44\":3,\"45\":2,\"46\":2,\"48\":41,\"49\":5,\"50\":1,\"51\":6,\"54\":18,\"55\":2,\"56\":109,\"57\":50,\"58\":2,\"59\":2,\"60\":2,\"61\":5,\"63\":7,\"64\":1,\"65\":25,\"66\":86,\"67\":8,\"68\":65,\"69\":1,\"70\":4,\"72\":220,\"73\":1,\"74\":4,\"75\":2,\"77\":4,\"80\":3,\"81\":3,\"83\":1,\"85\":1,\"87\":2,\"90\":1,\"98\":73,\"101\":104,\"103\":109,\"104\":47,\"108\":2,\"113\":2,\"114\":5,\"115\":5,\"116\":10,\"117\":1,\"118\":44,\"120\":37,\"121\":13,\"122\":5,\"124\":3,\"125\":3,\"126\":3,\"127\":1,\"128\":1,\"130\":2,\"132\":1,\"134\":2,\"135\":240,\"136\":2,\"137\":386,\"138\":1,\"141\":1,\"142\":1,\"143\":148,\"144\":55,\"145\":3,\"146\":25,\"147\":30,\"148\":65,\"149\":208,\"150\":135,\"151\":228,\"152\":5,\"153\":33,\"155\":38,\"156\":21,\"157\":34,\"158\":31,\"159\":106,\"160\":3,\"161\":20,\"163\":32,\"164\":79,\"165\":12,\"168\":7,\"170\":28,\"173\":5,\"177\":4,\"178\":4,\"179\":4,\"181\":2,\"182\":13,\"183\":8,\"184\":3,\"185\":45,\"186\":2,\"187\":73,\"188\":37,\"189\":60,\"190\":40,\"191\":4,\"192\":12,\"194\":8,\"196\":30,\"197\":36,\"198\":28,\"202\":4,\"203\":23,\"205\":106,\"206\":154,\"207\":24,\"208\":35,\"209\":31,\"210\":94,\"211\":13,\"212\":158,\"214\":30,\"215\":75,\"216\":93,\"220\":2,\"221\":184}}],[\"、\",{\"0\":{\"3\":1,\"5\":1,\"6\":1,\"7\":1,\"8\":1,\"16\":1,\"18\":1,\"25\":1,\"27\":1,\"30\":1,\"36\":1,\"44\":1,\"54\":1,\"55\":1,\"56\":1,\"57\":1,\"59\":1,\"63\":1,\"64\":1,\"69\":1,\"70\":1,\"75\":1,\"94\":1,\"98\":1,\"99\":1,\"103\":1,\"104\":1,\"105\":1,\"112\":1,\"135\":1,\"136\":1,\"142\":1,\"143\":1,\"176\":1,\"195\":1,\"199\":1,\"200\":1,\"201\":1,\"202\":1,\"214\":1},\"1\":{\"0\":1,\"2\":1,\"4\":5,\"5\":2,\"6\":2,\"7\":5,\"8\":1,\"9\":2,\"11\":1,\"12\":2,\"27\":2,\"29\":3,\"38\":1,\"39\":2,\"42\":3,\"49\":1,\"56\":2,\"61\":1,\"63\":1,\"64\":1,\"65\":1,\"66\":1,\"72\":12,\"73\":5,\"74\":4,\"76\":7,\"80\":6,\"81\":5,\"86\":3,\"87\":2,\"114\":1,\"122\":1,\"124\":8,\"126\":4,\"132\":1,\"136\":1,\"143\":2,\"145\":7,\"146\":2,\"147\":1,\"148\":2,\"151\":2,\"152\":2,\"153\":3,\"155\":1,\"157\":1,\"158\":2,\"159\":1,\"161\":4,\"165\":1,\"167\":1,\"168\":3,\"173\":3,\"177\":7,\"183\":1,\"184\":2,\"194\":12,\"198\":1,\"207\":1,\"215\":1,\"221\":104}}],[\"一页\",{\"1\":{\"192\":1}}],[\"一并\",{\"1\":{\"179\":1}}],[\"一级\",{\"0\":{\"179\":1},\"1\":{\"177\":2,\"178\":1,\"179\":4,\"183\":1,\"184\":2,\"191\":1,\"192\":1}}],[\"一举两得\",{\"1\":{\"173\":1}}],[\"一碰\",{\"1\":{\"165\":1}}],[\"一致\",{\"1\":{\"155\":1,\"161\":1,\"164\":1,\"192\":1,\"221\":1}}],[\"一致性\",{\"1\":{\"5\":1,\"75\":1,\"76\":1,\"192\":1}}],[\"一行\",{\"1\":{\"143\":1}}],[\"一系列\",{\"1\":{\"133\":3,\"183\":1}}],[\"一到\",{\"1\":{\"126\":1}}],[\"一怒之下\",{\"1\":{\"124\":1}}],[\"一眼\",{\"1\":{\"122\":1}}],[\"一会儿\",{\"1\":{\"103\":1}}],[\"一条\",{\"1\":{\"103\":4,\"104\":1,\"205\":2,\"221\":3}}],[\"一篇\",{\"1\":{\"103\":1,\"125\":1,\"161\":2,\"168\":1}}],[\"一键\",{\"1\":{\"101\":1}}],[\"一台\",{\"1\":{\"95\":1,\"96\":1,\"157\":1,\"159\":1,\"161\":1}}],[\"一月\",{\"1\":{\"85\":1}}],[\"一不小心\",{\"1\":{\"81\":1}}],[\"一比\",{\"1\":{\"80\":1}}],[\"一关\",{\"1\":{\"78\":1}}],[\"一本\",{\"1\":{\"76\":1}}],[\"一两次\",{\"1\":{\"76\":1}}],[\"一声\",{\"1\":{\"75\":1}}],[\"一遍\",{\"1\":{\"75\":2,\"76\":2,\"161\":1}}],[\"一句\",{\"1\":{\"75\":2,\"77\":1,\"157\":1}}],[\"一开\",{\"1\":{\"75\":1}}],[\"一片\",{\"1\":{\"74\":1}}],[\"一道\",{\"1\":{\"74\":2}}],[\"一家\",{\"1\":{\"74\":1,\"80\":1}}],[\"一份\",{\"1\":{\"74\":1,\"101\":1}}],[\"一脸\",{\"1\":{\"74\":1,\"169\":1}}],[\"一重\",{\"1\":{\"74\":2}}],[\"一周\",{\"1\":{\"74\":1,\"76\":2}}],[\"一年四季\",{\"1\":{\"77\":1}}],[\"一年\",{\"1\":{\"73\":1,\"80\":1,\"87\":1,\"89\":1,\"90\":1,\"114\":1}}],[\"一群\",{\"1\":{\"73\":1,\"82\":1}}],[\"一切\",{\"1\":{\"73\":3,\"168\":1,\"192\":1}}],[\"一科\",{\"1\":{\"73\":1}}],[\"一蹴而就\",{\"1\":{\"70\":1}}],[\"一点点\",{\"1\":{\"74\":1,\"75\":1,\"168\":1}}],[\"一点\",{\"1\":{\"70\":1,\"168\":1,\"221\":1}}],[\"一小部分\",{\"1\":{\"63\":1}}],[\"一新\",{\"1\":{\"57\":1}}],[\"一秒钟\",{\"1\":{\"57\":1}}],[\"一旦\",{\"1\":{\"50\":1,\"106\":1,\"109\":1,\"115\":1,\"221\":2}}],[\"一天\",{\"1\":{\"50\":1,\"51\":1,\"80\":3,\"145\":1,\"205\":1}}],[\"一处\",{\"1\":{\"45\":1}}],[\"一套\",{\"1\":{\"45\":1,\"81\":1,\"82\":1,\"87\":1}}],[\"一些\",{\"1\":{\"30\":1,\"38\":1,\"42\":1,\"63\":1,\"72\":1,\"78\":2,\"81\":1,\"103\":1,\"124\":1,\"126\":1,\"141\":1,\"170\":1,\"171\":1,\"204\":1,\"221\":1}}],[\"一起\",{\"1\":{\"28\":1,\"76\":1,\"77\":2,\"85\":1,\"104\":1,\"145\":1,\"149\":1,\"157\":1}}],[\"一组\",{\"1\":{\"23\":2,\"221\":3}}],[\"一直\",{\"1\":{\"23\":1,\"28\":1,\"41\":1,\"42\":1,\"44\":1,\"45\":4,\"50\":3,\"79\":2,\"80\":1,\"86\":1,\"128\":1,\"170\":1}}],[\"一面\",{\"1\":{\"23\":1,\"74\":2,\"75\":2,\"80\":1}}],[\"一段时间\",{\"1\":{\"29\":1,\"39\":1,\"65\":1,\"221\":1}}],[\"一段\",{\"1\":{\"11\":1,\"78\":1,\"79\":2,\"132\":1}}],[\"一般\",{\"1\":{\"10\":1,\"25\":1,\"26\":1,\"37\":1,\"38\":4,\"48\":1,\"61\":1,\"65\":2,\"70\":1,\"132\":1,\"137\":1,\"152\":2,\"158\":2,\"164\":1,\"166\":1,\"177\":1,\"186\":1,\"197\":1,\"221\":1}}],[\"一番\",{\"1\":{\"8\":1}}],[\"一定\",{\"1\":{\"8\":1,\"28\":1,\"73\":1,\"77\":1,\"78\":1,\"185\":1,\"186\":1,\"220\":1}}],[\"一样\",{\"0\":{\"108\":1},\"1\":{\"7\":1,\"8\":1,\"52\":1,\"72\":1,\"74\":1,\"84\":1,\"98\":1,\"102\":1,\"107\":1,\"120\":1,\"135\":1,\"137\":1,\"161\":1,\"166\":1,\"173\":1,\"188\":1,\"221\":1}}],[\"一款\",{\"1\":{\"7\":1,\"9\":1,\"168\":2}}],[\"一大堆\",{\"1\":{\"6\":1}}],[\"一步\",{\"1\":{\"6\":2,\"68\":1,\"102\":1,\"114\":2,\"118\":1,\"152\":2,\"161\":2}}],[\"一同\",{\"1\":{\"5\":1}}],[\"一下子\",{\"1\":{\"12\":1,\"70\":1}}],[\"一下\",{\"1\":{\"5\":2,\"7\":4,\"9\":1,\"10\":1,\"11\":1,\"12\":1,\"23\":3,\"41\":1,\"42\":1,\"45\":1,\"46\":1,\"49\":1,\"51\":1,\"56\":1,\"73\":2,\"76\":1,\"81\":2,\"84\":1,\"87\":1,\"103\":1,\"121\":1,\"130\":1,\"139\":1,\"148\":1,\"151\":2,\"152\":2,\"153\":1,\"156\":1,\"160\":1,\"161\":5,\"164\":1,\"173\":1,\"179\":2,\"185\":1,\"190\":2,\"197\":1}}],[\"一堆\",{\"1\":{\"5\":1,\"51\":1}}],[\"一层\",{\"1\":{\"5\":1}}],[\"一个多月\",{\"1\":{\"124\":1}}],[\"一个半月\",{\"1\":{\"81\":1}}],[\"一个\",{\"0\":{\"101\":1},\"1\":{\"5\":2,\"6\":4,\"7\":4,\"10\":1,\"12\":4,\"13\":1,\"18\":3,\"23\":3,\"26\":4,\"31\":1,\"38\":2,\"42\":1,\"45\":2,\"49\":2,\"50\":1,\"51\":1,\"54\":2,\"56\":3,\"57\":3,\"58\":1,\"63\":3,\"64\":1,\"66\":2,\"70\":1,\"72\":2,\"73\":4,\"74\":2,\"75\":3,\"77\":2,\"78\":2,\"80\":2,\"81\":1,\"82\":1,\"86\":4,\"101\":3,\"103\":2,\"106\":1,\"107\":2,\"108\":1,\"120\":1,\"122\":2,\"124\":3,\"127\":1,\"128\":1,\"132\":1,\"133\":1,\"135\":1,\"137\":1,\"141\":2,\"143\":1,\"144\":4,\"148\":2,\"149\":4,\"151\":2,\"152\":1,\"155\":2,\"157\":3,\"159\":3,\"161\":8,\"164\":1,\"166\":1,\"170\":1,\"172\":1,\"173\":5,\"178\":1,\"179\":6,\"180\":1,\"181\":6,\"185\":2,\"190\":1,\"192\":4,\"205\":5,\"207\":4,\"209\":1,\"212\":2,\"215\":1,\"221\":27}}],[\"一块\",{\"1\":{\"4\":2,\"5\":1,\"45\":1,\"80\":1,\"171\":1,\"172\":1}}],[\"一种\",{\"1\":{\"4\":1,\"55\":1,\"57\":1,\"173\":1,\"221\":2}}],[\"一次性\",{\"1\":{\"104\":1}}],[\"一次\",{\"0\":{\"42\":1},\"1\":{\"0\":1,\"6\":1,\"51\":1,\"57\":1,\"63\":1,\"74\":3,\"82\":1,\"89\":1,\"102\":1,\"104\":2,\"124\":1,\"135\":1,\"144\":4,\"149\":1,\"173\":1,\"177\":1,\"192\":4,\"205\":2,\"212\":2,\"216\":3,\"221\":10}}],[\"一\",{\"0\":{\"5\":1,\"25\":1,\"54\":1,\"59\":1,\"94\":1,\"112\":1,\"135\":1,\"140\":1,\"176\":1,\"195\":1},\"1\":{\"0\":1,\"13\":1,\"50\":1,\"74\":2,\"76\":2,\"161\":1,\"165\":1,\"166\":1,\"167\":1,\"168\":1,\"177\":1,\"190\":1,\"216\":1,\"221\":8}}],[\",\",{\"1\":{\"0\":5,\"2\":1,\"3\":4,\"4\":1,\"5\":2,\"6\":2,\"7\":5,\"9\":3,\"10\":3,\"11\":5,\"12\":2,\"13\":11,\"14\":1,\"18\":3,\"23\":3,\"26\":3,\"28\":8,\"29\":4,\"30\":82,\"41\":5,\"43\":6,\"44\":4,\"45\":6,\"46\":2,\"48\":2,\"49\":2,\"51\":1,\"52\":5,\"54\":2,\"55\":2,\"56\":11,\"57\":13,\"59\":1,\"60\":3,\"61\":1,\"63\":5,\"64\":1,\"65\":6,\"66\":12,\"67\":1,\"68\":7,\"69\":8,\"70\":6,\"72\":52,\"73\":2,\"74\":7,\"75\":1,\"76\":3,\"77\":2,\"79\":1,\"80\":1,\"83\":3,\"86\":2,\"87\":1,\"89\":1,\"91\":1,\"95\":3,\"97\":3,\"98\":10,\"100\":1,\"101\":25,\"102\":6,\"103\":31,\"104\":9,\"106\":1,\"108\":1,\"109\":1,\"113\":2,\"114\":7,\"115\":1,\"116\":1,\"117\":3,\"118\":1,\"120\":5,\"121\":4,\"122\":10,\"124\":2,\"125\":12,\"126\":1,\"132\":2,\"133\":6,\"135\":38,\"136\":2,\"137\":23,\"138\":1,\"140\":2,\"141\":5,\"143\":14,\"144\":11,\"145\":3,\"146\":4,\"147\":22,\"148\":22,\"149\":112,\"150\":34,\"151\":68,\"152\":13,\"153\":3,\"155\":1,\"156\":13,\"157\":6,\"158\":3,\"159\":10,\"160\":3,\"161\":5,\"163\":3,\"164\":16,\"166\":3,\"168\":1,\"169\":1,\"170\":3,\"173\":3,\"178\":1,\"179\":3,\"182\":3,\"183\":4,\"184\":2,\"185\":59,\"187\":1,\"188\":5,\"189\":3,\"190\":2,\"191\":3,\"192\":4,\"194\":2,\"196\":8,\"197\":7,\"198\":6,\"202\":2,\"203\":12,\"205\":27,\"206\":21,\"207\":6,\"208\":8,\"209\":4,\"210\":10,\"211\":4,\"212\":23,\"213\":3,\"214\":12,\"215\":21,\"216\":26,\"220\":6,\"221\":42}}]],\"serializationVersion\":2}}")).map(([e,t])=>[e,zt(t,{fields:["h","t","c"],storeFields:["h","t","c"]})]));self.onmessage=({data:{type:e="all",query:t,locale:s,options:n}})=>{e==="suggest"?self.postMessage(st(t,v[s],n)):e==="search"?self.postMessage(et(t,v[s],n)):self.postMessage({suggestions:st(t,v[s],n),results:et(t,v[s],n)})};
+//# sourceMappingURL=index.js.map
diff --git a/sitemap.xml b/sitemap.xml
new file mode 100644
index 00000000..3c8db27c
--- /dev/null
+++ b/sitemap.xml
@@ -0,0 +1,3 @@
+
+
+http://www.wenzhihuai.com/ 2024-01-25T17:34:45.000Z daily http://www.wenzhihuai.com/about-the-author/ 2024-01-25T17:34:45.000Z daily http://www.wenzhihuai.com/cloudnative/ 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/database/ 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/devops/ 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/devops/devops-ping-tai.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/devops/gitlab-ci.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/devops/jenkins-x.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/devops/tekton.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/donate/ 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/interview/tiktok2023.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/java/JVM%E8%B0%83%E4%BC%98%E5%8F%82%E6%95%B0.html 2024-01-24T10:30:22.000Z daily http://www.wenzhihuai.com/java/lucene%E6%90%9C%E7%B4%A2%E5%8E%9F%E7%90%86.html 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/java/serverlog.html 2024-01-24T10:30:22.000Z daily http://www.wenzhihuai.com/java/%E4%B8%80%E6%AC%A1jvm%E8%B0%83%E4%BC%98%E8%BF%87%E7%A8%8B.html 2024-01-24T10:30:22.000Z daily http://www.wenzhihuai.com/java/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C.html 2024-01-24T10:30:22.000Z daily http://www.wenzhihuai.com/java/%E5%9C%A8%20Spring%206%20%E4%B8%AD%E4%BD%BF%E7%94%A8%E8%99%9A%E6%8B%9F%E7%BA%BF%E7%A8%8B.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/java/%E5%9F%BA%E4%BA%8Ekubernetes%E7%9A%84%E5%88%86%E5%B8%83%E5%BC%8F%E9%99%90%E6%B5%81.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/kubernetes/ 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/kubernetes/spark%20on%20k8s%20operator.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/life/2017.html 2024-01-26T04:53:47.000Z daily http://www.wenzhihuai.com/life/2018.html 2024-01-26T04:53:47.000Z daily http://www.wenzhihuai.com/life/2019.html 2024-01-26T04:53:47.000Z daily http://www.wenzhihuai.com/open-source-project/ 2024-01-24T10:30:22.000Z daily http://www.wenzhihuai.com/others/chatgpt.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/others/tesla.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/1.%E5%8E%86%E5%8F%B2%E4%B8%8E%E6%9E%B6%E6%9E%84.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/10.%E7%BD%91%E7%AB%99%E9%87%8D%E6%9E%84.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/2.Lucene%E7%9A%84%E4%BD%BF%E7%94%A8.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/3.%E5%AE%9A%E6%97%B6%E4%BB%BB%E5%8A%A1.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/4.%E6%97%A5%E5%BF%97%E7%B3%BB%E7%BB%9F.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/5.%E5%B0%8F%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/6.%E6%95%B0%E6%8D%AE%E5%BA%93%E5%A4%87%E4%BB%BD.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/7.%E9%82%A3%E4%BA%9B%E7%89%9B%E9%80%BC%E7%9A%84%E6%8F%92%E4%BB%B6.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/personalWebsite/8.%E5%9F%BA%E4%BA%8E%E8%B4%9D%E5%8F%B6%E6%96%AF%E7%9A%84%E6%83%85%E6%84%9F%E5%88%86%E6%9E%90.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/personalWebsite/9.%E7%BD%91%E7%AB%99%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/redis/ 2024-01-24T03:25:58.000Z daily http://www.wenzhihuai.com/redis/redis%E7%BC%93%E5%AD%98.html 2024-01-24T11:34:08.000Z daily http://www.wenzhihuai.com/about-the-author/personal-life/wewe.html 2024-01-26T04:53:47.000Z daily http://www.wenzhihuai.com/bigdata/spark/elastic-spark.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/database/elasticsearch/elasticsearch%E6%BA%90%E7%A0%81debug.html 2024-01-26T03:58:56.000Z daily http://www.wenzhihuai.com/database/elasticsearch/%E3%80%90elasticsearch%E3%80%91%E6%90%9C%E7%B4%A2%E8%BF%87%E7%A8%8B%E8%AF%A6%E8%A7%A3.html 2024-01-26T04:05:46.000Z daily http://www.wenzhihuai.com/database/mysql/1mysql.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/database/mysql/gap%E9%94%81.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/database/mysql/%E6%89%A7%E8%A1%8C%E8%AE%A1%E5%88%92explain.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/database/mysql/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%BC%93%E5%AD%98.html 2024-01-25T11:42:16.000Z daily http://www.wenzhihuai.com/middleware/kafka/kafka.html 2024-01-25T17:34:45.000Z daily http://www.wenzhihuai.com/middleware/zookeeper/zookeeper.html 2024-01-25T17:34:45.000Z daily
+
+
+
+ XML Sitemap
+ XML Sitemap
+
+
+ URLs list
+
+
+
+
+ Priority
+ Change Frequency
+ Last Updated Time
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 0.5
+
+
+
+
+
+
+
+
+ -
+
+
+
+
+
+
+
+
+
+
+
diff --git a/star/index.html b/star/index.html
new file mode 100644
index 00000000..14715cb5
--- /dev/null
+++ b/star/index.html
@@ -0,0 +1,46 @@
+
+
+
+ 星标 | 个人博客
+ 标签 | 个人博客
+ 时间轴 | 个人博客
+ 
 +
+
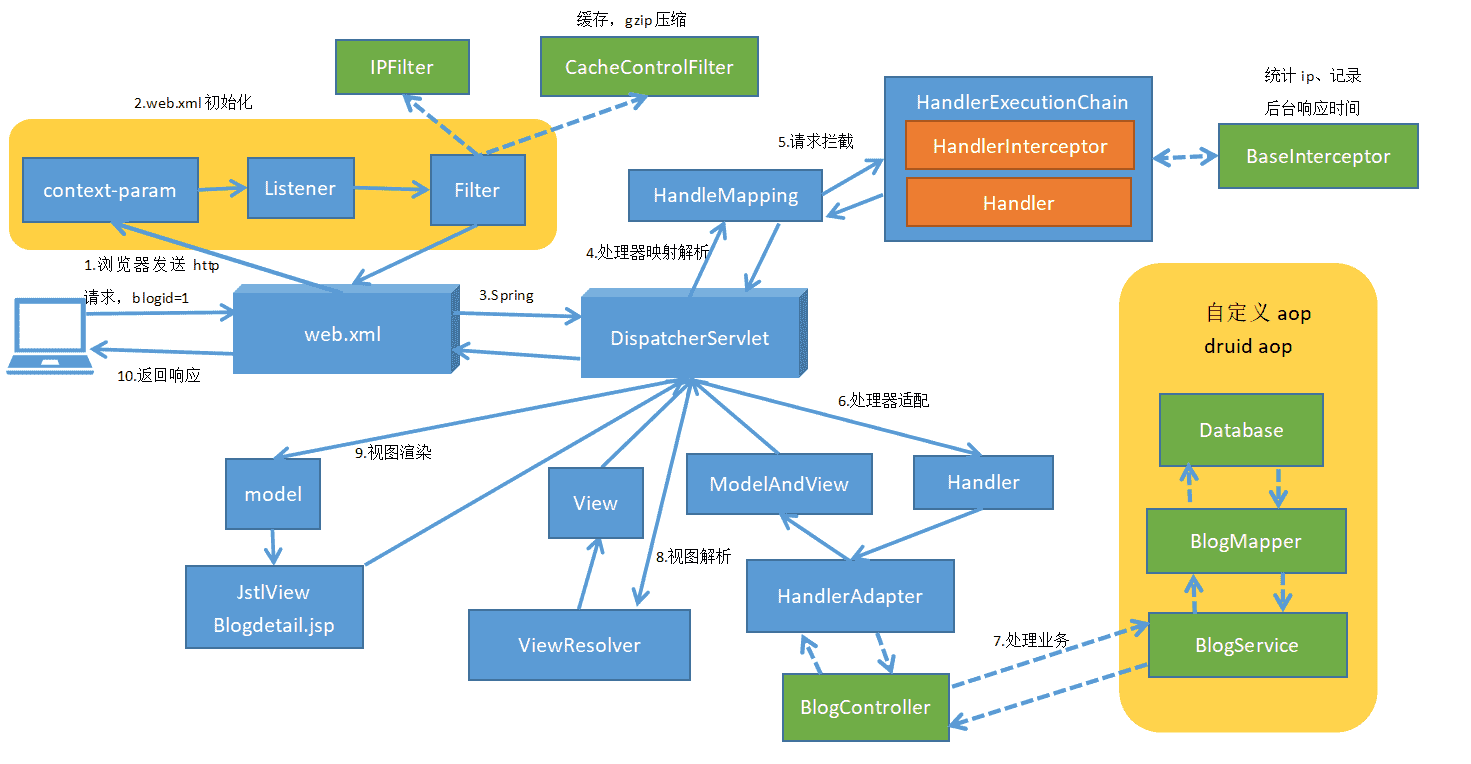
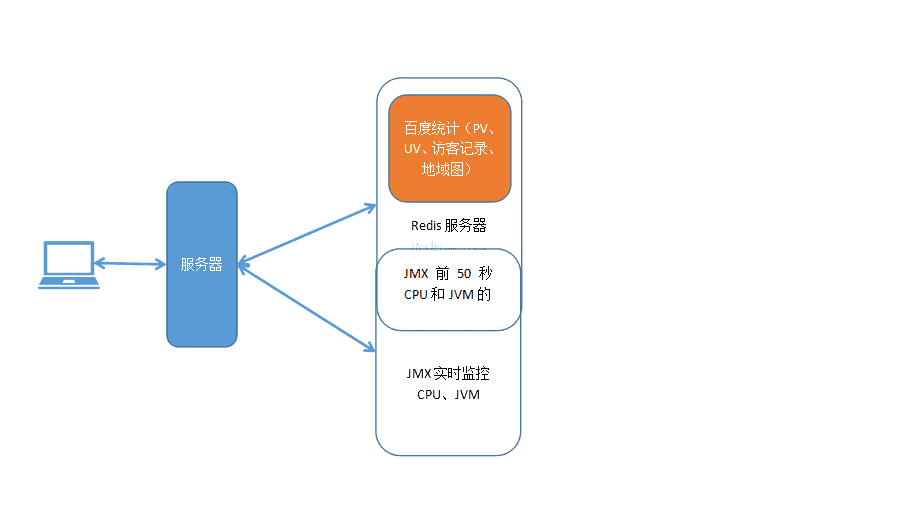
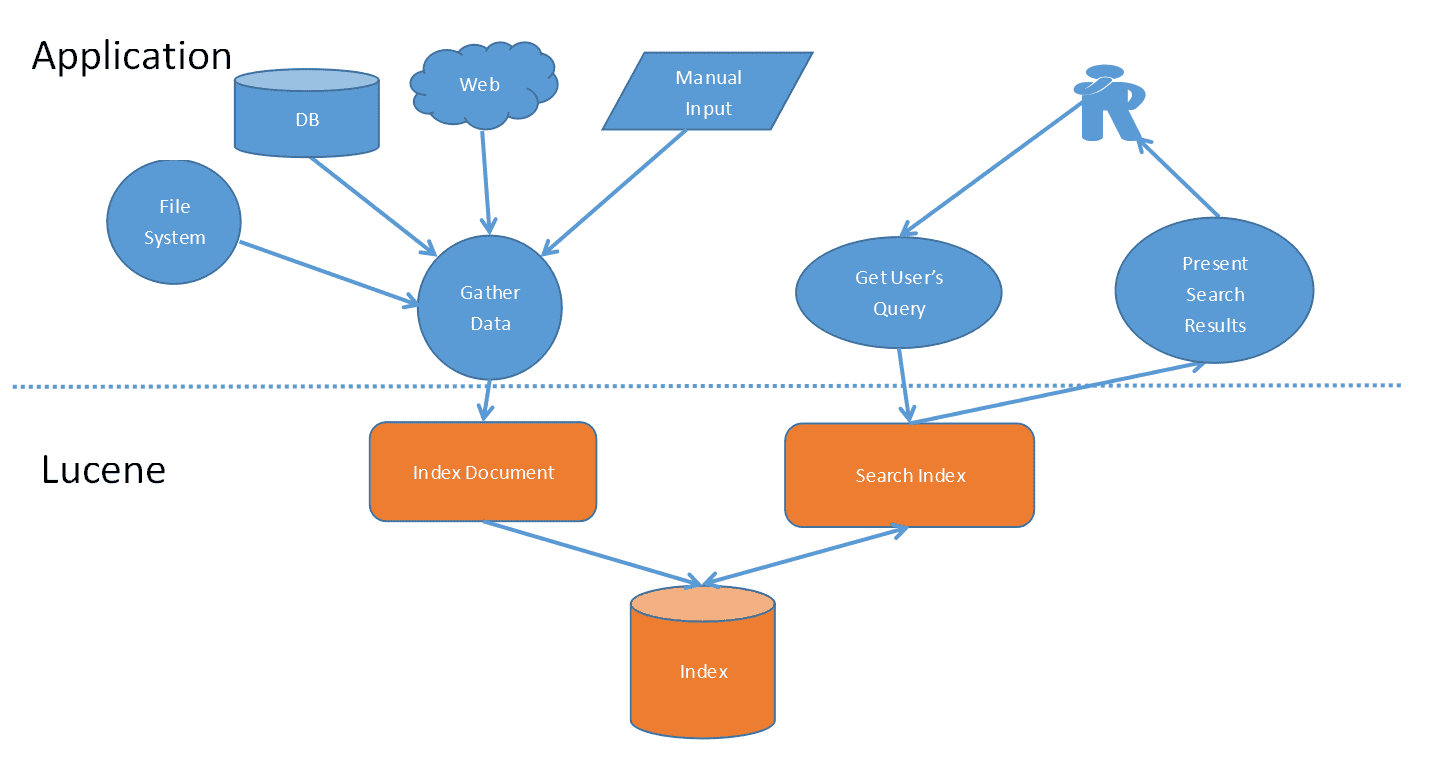
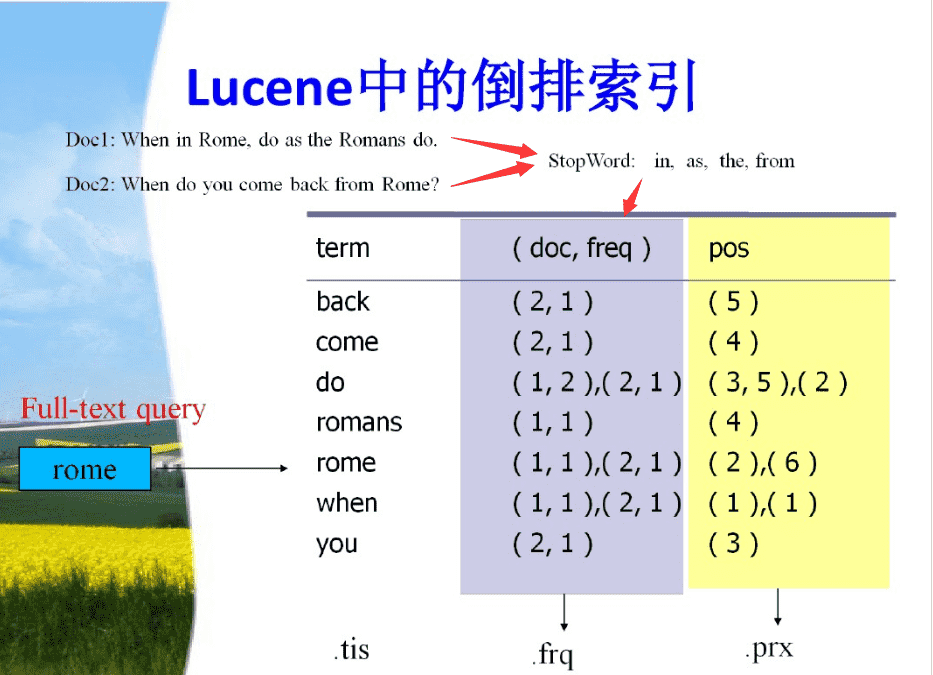
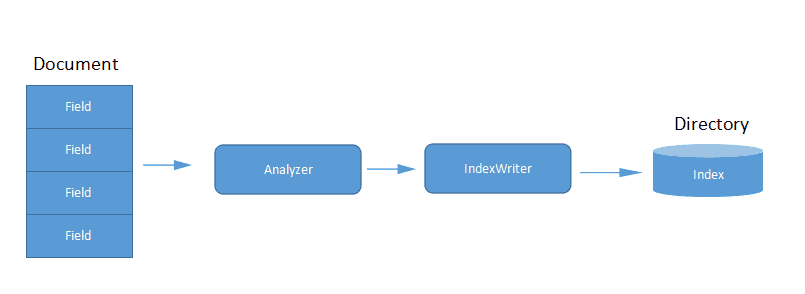
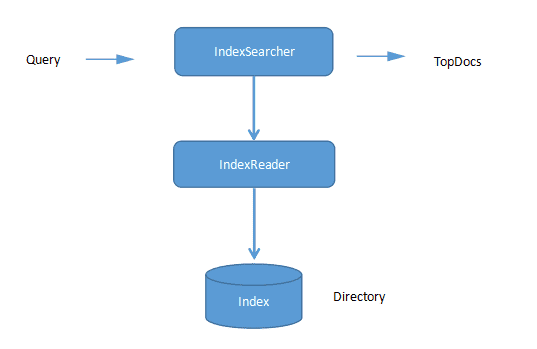















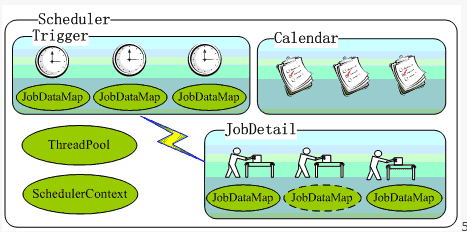
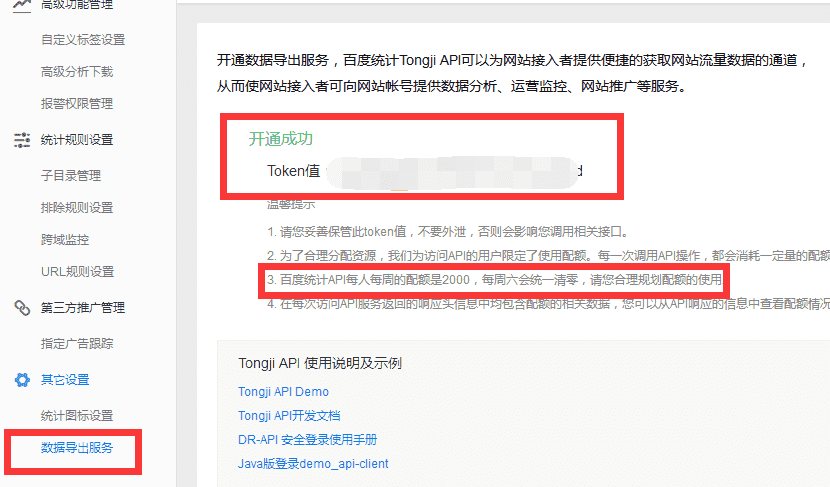

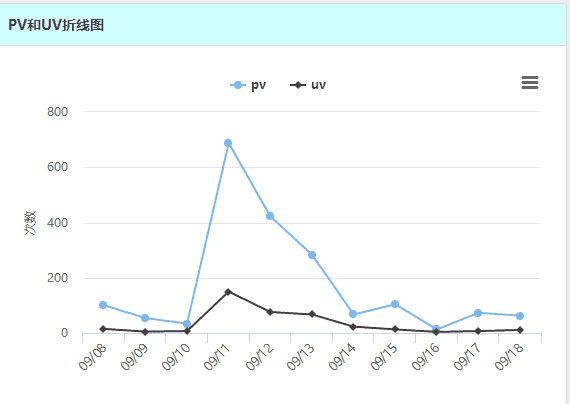
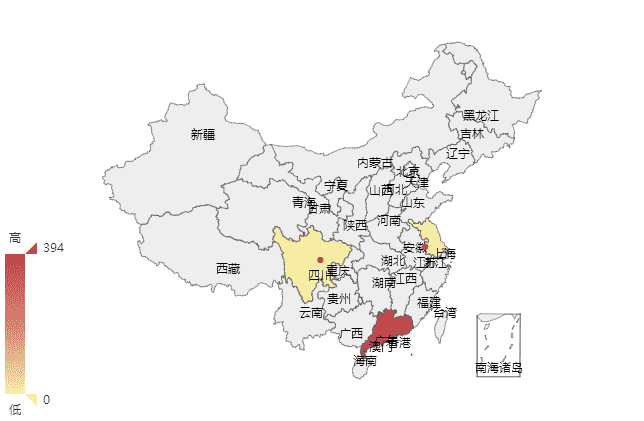
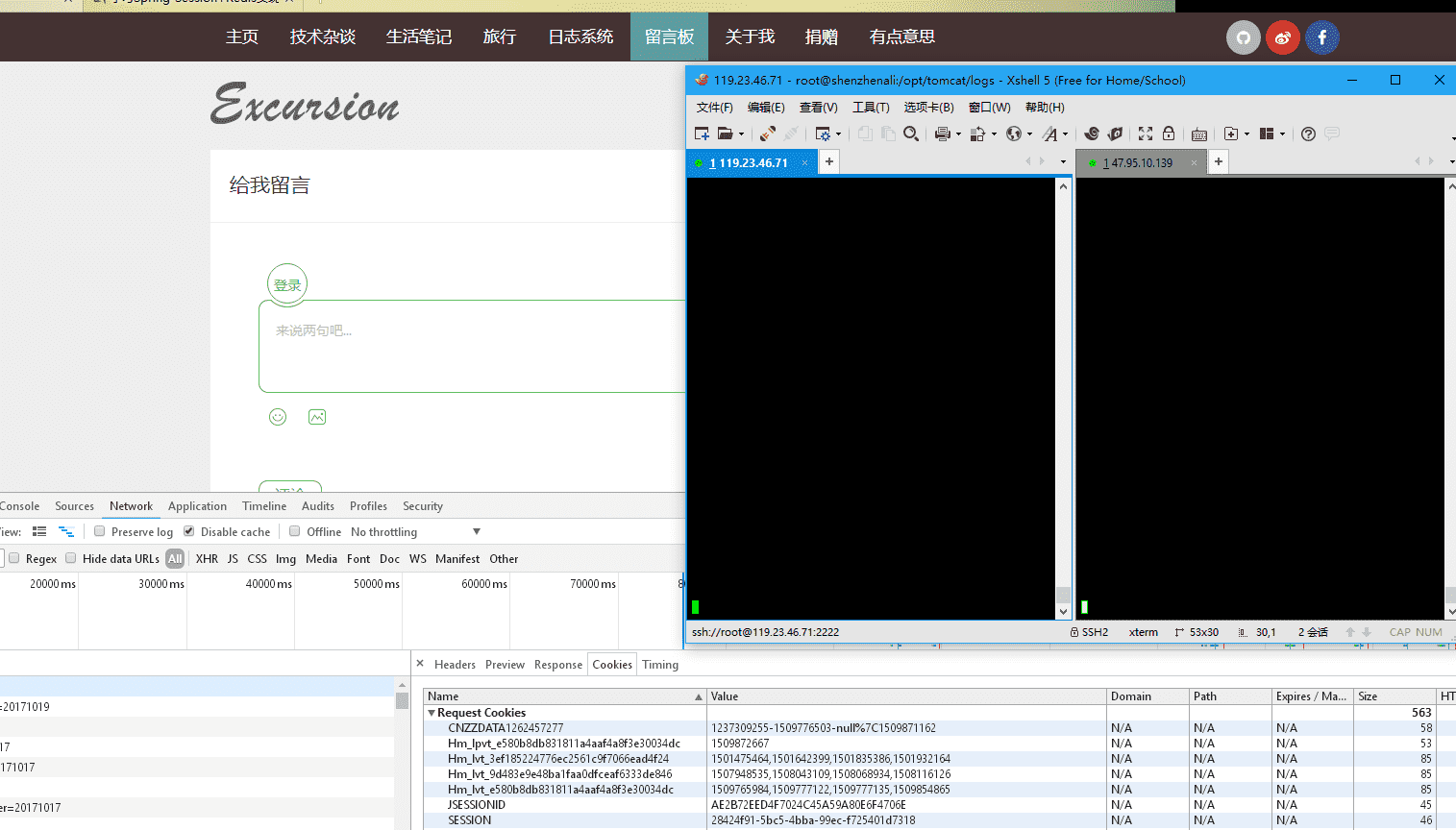
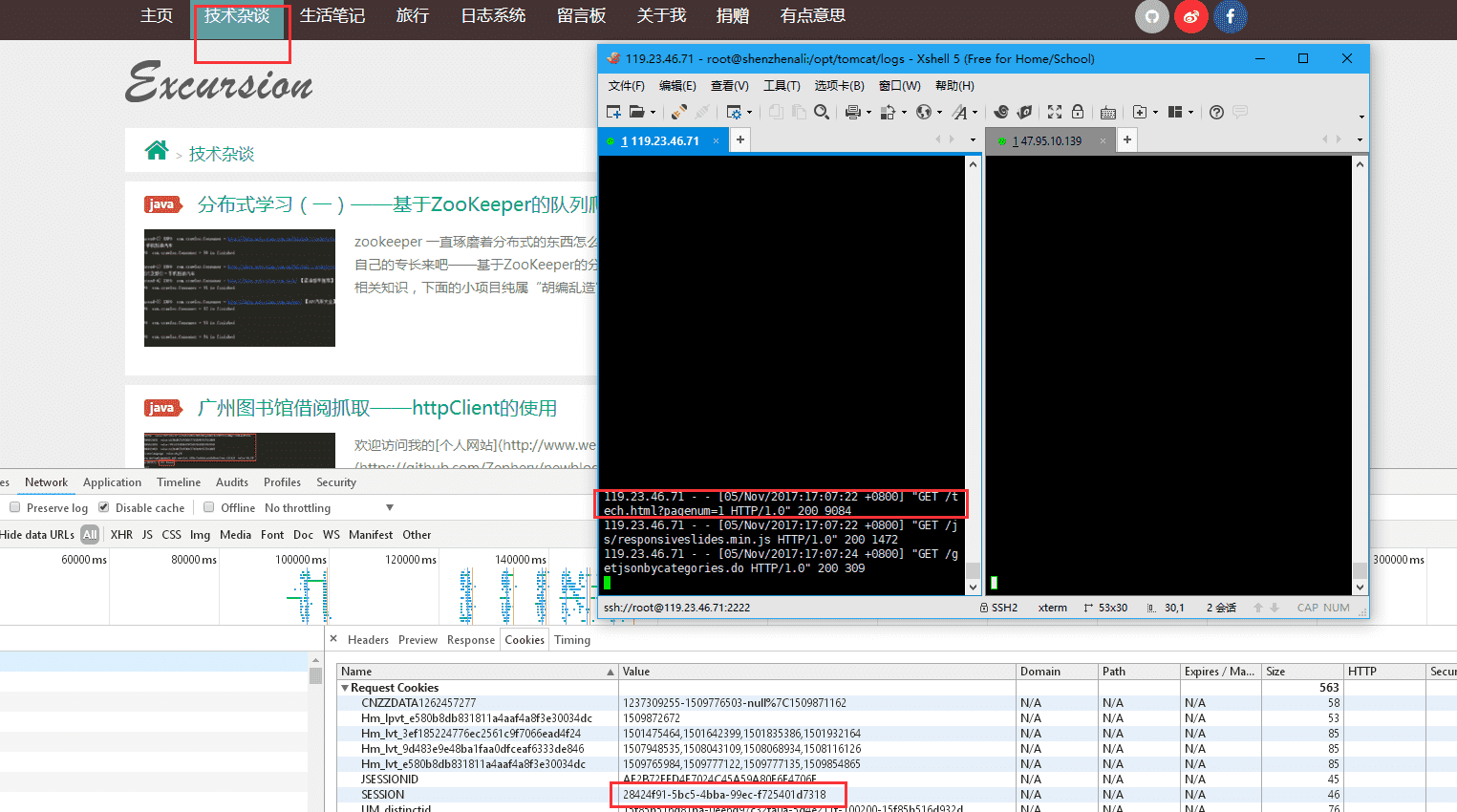
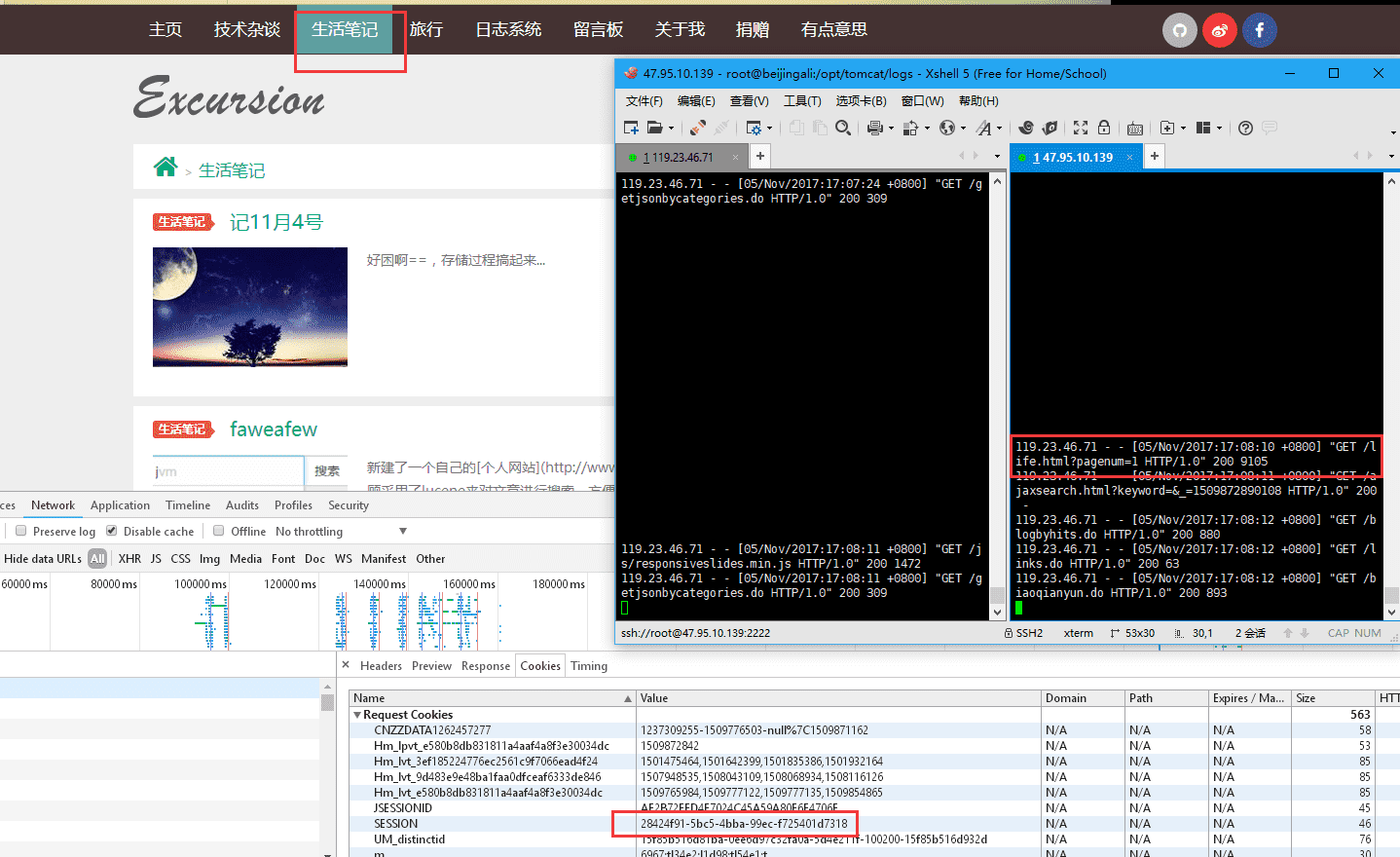

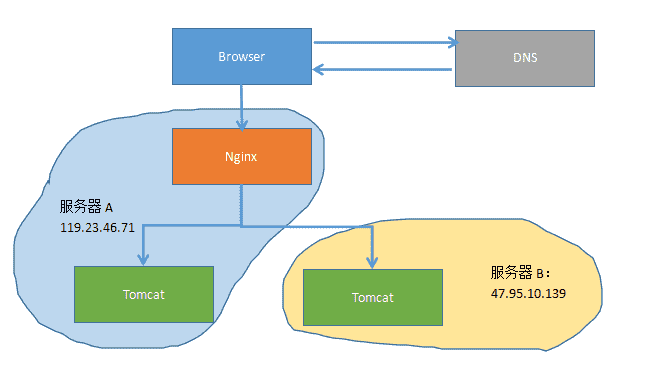


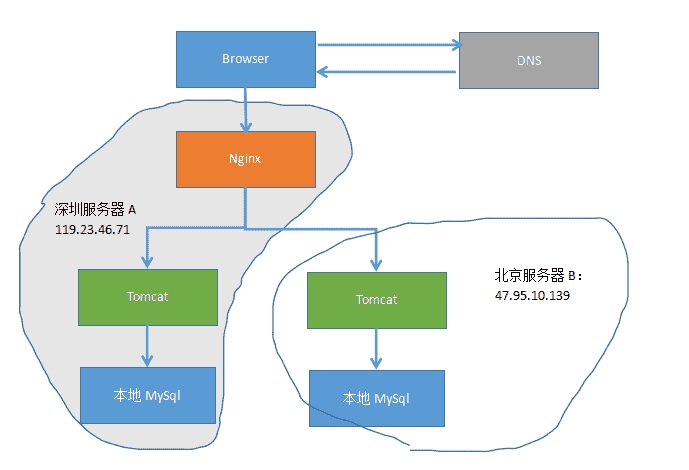
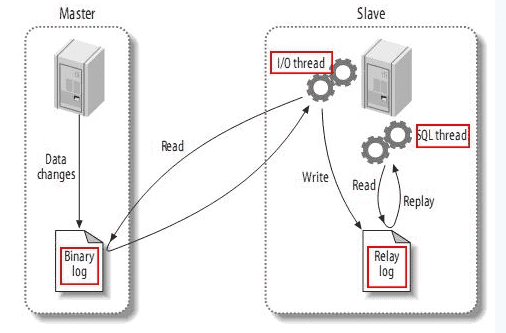

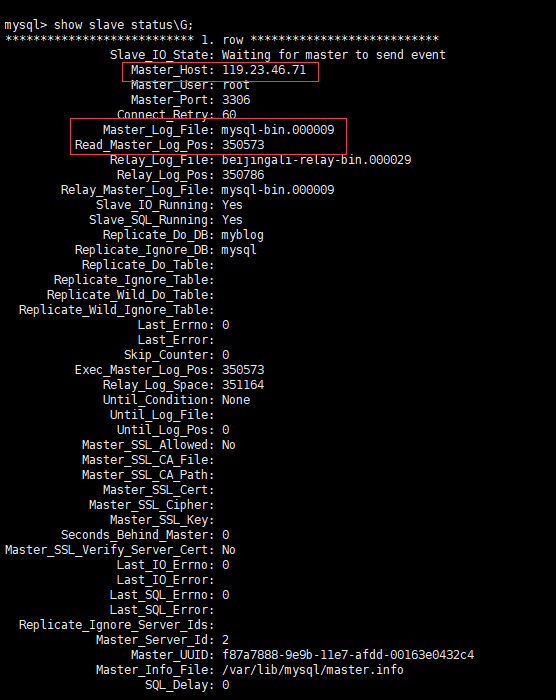
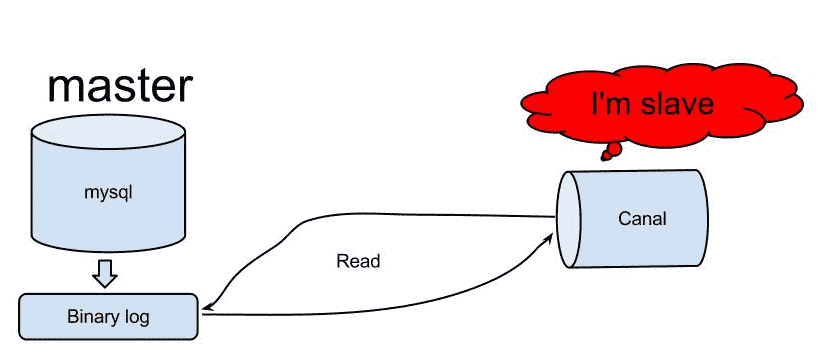

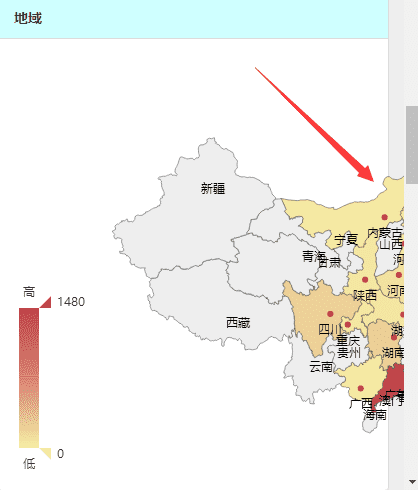




 `,83),u=s("code",null,"text-davinci-003",-1),d={href:"https://link.juejin.cn/?target=https%3A%2F%2Fplatform.openai.com%2Fdocs%2Fguides%2Ffine-tuning",target:"_blank",rel:"noopener noreferrer"},k=a('
`,83),u=s("code",null,"text-davinci-003",-1),d={href:"https://link.juejin.cn/?target=https%3A%2F%2Fplatform.openai.com%2Fdocs%2Fguides%2Ffine-tuning",target:"_blank",rel:"noopener noreferrer"},k=a('


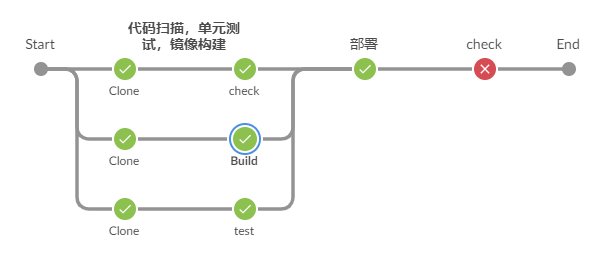


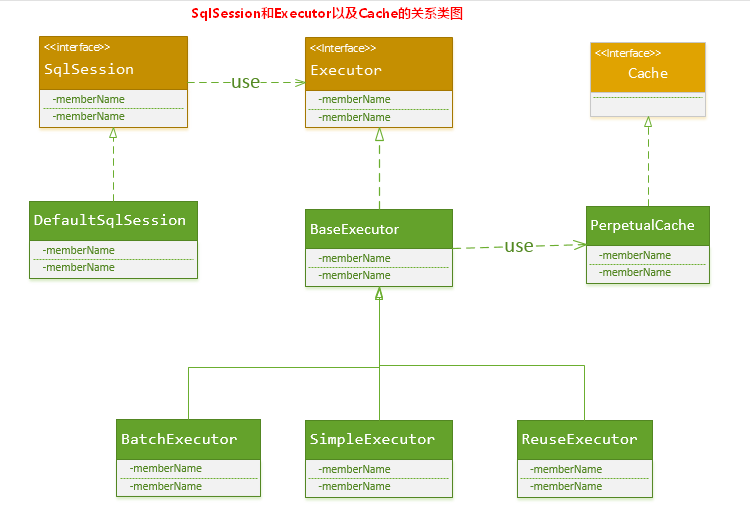
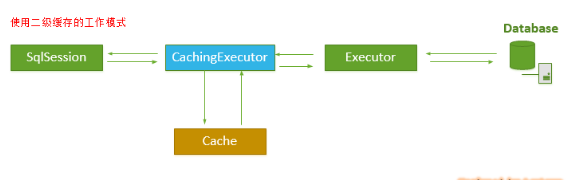
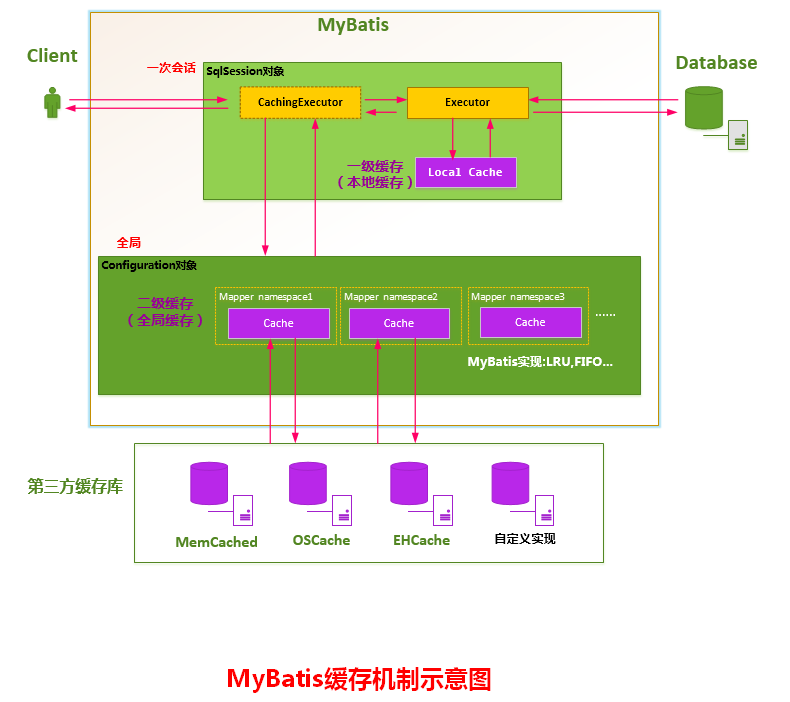









 \\n
\\n ","autoDesc":true}');export{e as data};
diff --git a/assets/tiktok2023.html-GIHWTkgC.js b/assets/tiktok2023.html-GIHWTkgC.js
new file mode 100644
index 00000000..3e4c69a8
--- /dev/null
+++ b/assets/tiktok2023.html-GIHWTkgC.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-091223ce","path":"/interview/tiktok2023.html","title":"","lang":"zh-CN","frontmatter":{"description":"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决 tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/interview/tiktok2023.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:description","content":"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决 tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":1.15,"words":344},"filePathRelative":"interview/tiktok2023.md","localizedDate":"2024年1月24日","excerpt":"
","autoDesc":true}');export{e as data};
diff --git a/assets/tiktok2023.html-GIHWTkgC.js b/assets/tiktok2023.html-GIHWTkgC.js
new file mode 100644
index 00000000..3e4c69a8
--- /dev/null
+++ b/assets/tiktok2023.html-GIHWTkgC.js
@@ -0,0 +1 @@
+const e=JSON.parse('{"key":"v-091223ce","path":"/interview/tiktok2023.html","title":"","lang":"zh-CN","frontmatter":{"description":"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决 tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作","head":[["meta",{"property":"og:url","content":"http://www.wenzhihuai.com/interview/tiktok2023.html"}],["meta",{"property":"og:site_name","content":"个人博客"}],["meta",{"property":"og:description","content":"tt一面: 1.全程项目 2.lc3,最长无重复子串,滑动窗口解决 tt二面: 全程基础,一直追问 1.java内存模型介绍一下 2.volatile原理 3.内存屏障,使用场景?(我提了在gc中有使用) 4.gc中具体是怎么使用内存屏障的,详细介绍 5.cms和g1介绍一下,g1能取代cms吗?g1和cms各自的使用场景是什么 6.线程内存分配方式,tlab相关 7.happens-before介绍一下 8.总线风暴是什么,怎么解决 9.网络相关,time_wait,close_wait产生原因,带来的影响,怎么解决 10.算法题,给你一个数字n,求用这个n的各位上的数字组合出最大的小于n的数字m,注意边界case,如2222 11.场景题,设计一个微信朋友圈,功能包含feed流拉取,评论,转发,点赞等操作"}],["meta",{"property":"og:type","content":"article"}],["meta",{"property":"og:locale","content":"zh-CN"}],["meta",{"property":"og:updated_time","content":"2024-01-24T03:25:58.000Z"}],["meta",{"property":"article:author","content":"Zephery"}],["meta",{"property":"article:modified_time","content":"2024-01-24T03:25:58.000Z"}],["script",{"type":"application/ld+json"},"{\\"@context\\":\\"https://schema.org\\",\\"@type\\":\\"Article\\",\\"headline\\":\\"\\",\\"image\\":[\\"\\"],\\"dateModified\\":\\"2024-01-24T03:25:58.000Z\\",\\"author\\":[{\\"@type\\":\\"Person\\",\\"name\\":\\"Zephery\\",\\"url\\":\\"https://wenzhihuai.com/article/\\"}]}"]]},"headers":[],"git":{"createdTime":1706066758000,"updatedTime":1706066758000,"contributors":[{"name":"zhihuaiwen","email":"zhihuaiwen@tencent.com","commits":1}]},"readingTime":{"minutes":1.15,"words":344},"filePathRelative":"interview/tiktok2023.md","localizedDate":"2024年1月24日","excerpt":"