This code example shows how you can run Cloud Dataflow pipelines from App Engine apps, as a replacement for the older GAE Python MapReduce libraries, as well as do much more.
The example shows how to periodically launch a Python Dataflow pipeline from GAE, to analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
This example uses Dataflow Templates to launch the pipeline jobs. Since we're simply calling the Templates REST API to launch the jobs, we can build an App Engine standard app.
For an example that uses the same pipeline, but uses the Dataflow SDK to launch the pipeline jobs, see the sdk_launch directory. Because of its use of the SDK, that example requires App Engine Flex.
Now that Dataflow Templates are available for Python Dataflow, they are often the more straightforward option for this type of use case. See the Templates documentation for more detail.
The Python Dataflow pipeline reads recent tweets from the past N days from Cloud Datastore, then essentially splits into three processing branches. It finds the top N most popular words in terms of the percentage of tweets they were found in, calculates the top N most popular URLs in terms of their count, and then derives relevant word co-occurrences (bigrams) using an approximation to a tf*idf ranking metric. It writes the results to three BigQuery tables.

Follow the "Before you begin" steps on this page. Note your project and bucket name; you will need them in a moment.
Then, follow the next section on the same page to [install pip and the Dataflow SDK](https://cloud.google.com/dataflow/docs/quickstarts/quickstart- python#Setup). We'll need this to create our Dataflow Template.
The app will write its analytic results to BigQuery. In your project, create a new dataset to use for this purpose, or note the name of an existing dataset that you will use.
Create a Twitter application.. Note the credentials under the 'Keys and Access Tokens' tag: 'Consumer Key (API Key)', 'Consumer Secret (API Secret)', 'Access Token', and 'Access Token Secret'. You'll need these in moment.
We need to 'vendor' the libraries used by the app's frontend.
Install the dependencies into the app's lib subdirectory like this:
pip install --target=lib -r standard_requirements.txt(Take a look at appengine_config.py to see where we specify to GAE to add those libs).
Now we're set to run the template creation script. It expects PROJECT, BUCKET, and DATASET environment variables to be set. Edit the following and paste at the command line:
export DATASET=your-dataset
export BUCKET=your-bucket
export PROJECT=your-projectThen, run the template creation script:
python create_template.pyNote the resulting Google Cloud Storage (GCS)
template path that is output to the command line. By default the GCS filename should be:
<PROJECT> + '-twproc_tmpl', but you can change that in the script if you like.
The template creation script accesses the pipeline definition in dfpipe/pipe.py to build the template. As part of the pipeline definition, it's specified that the pipeline takes a
runtime argument,
timestamp. (This value is used to filter out tweets N days older than the timestamp, so that the analysis is only run over recent activity).
class UserOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_value_provider_argument('--timestamp', type=str)Then, the pipeline code can access that runtime parameter, e.g.:
user_options = pipeline_options.view_as(UserOptions)
...
wc_records = top_percents | 'format' >> beam.FlatMap(
lambda x: [{'word': xx[0], 'percent': xx[1],
'ts': user_options.timestamp.get()} for xx in x])Now that you've created a pipeline template, you can test it out by launching a job based on that template from the Cloud Console. (You could also do this via the gcloud command-line tool).
While it's not strictly necessary to do this prior to deploying your GAE app, it's a good sanity check.
Note that the pipeline won't do anything interesting unless you already have tweet data in the Datastore.
Go to the Dataflow pane of the Cloud Console, and click on "Create Job From Template".
 _Creating a Dataflow job from a template._
_Creating a Dataflow job from a template._
Select "Custom Template", then browse to your new template's location in GCS. This info was output when you ran
create_template.py. (The pulldown menu includes some predefined templates as well, that you may want to explore).
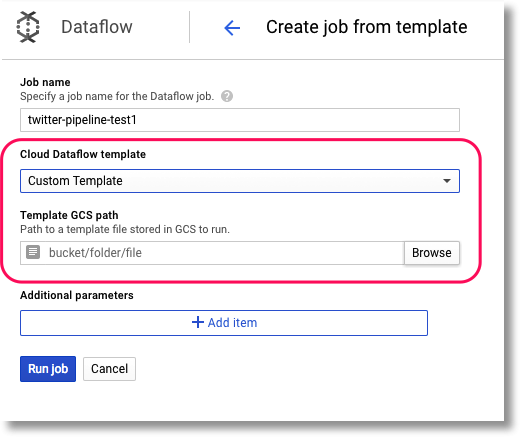 _Select "Custom Template", and indicate the path to it._
_Select "Custom Template", and indicate the path to it._
Finally, set your pipeline's runtime parameter(s). In this case, we have one: timestamp. The pipeline is expecting a value in a format like this: 2017-10-22 10:18:13.491543 (you can generate such a string in python via
str(datetime.datetime.now())).
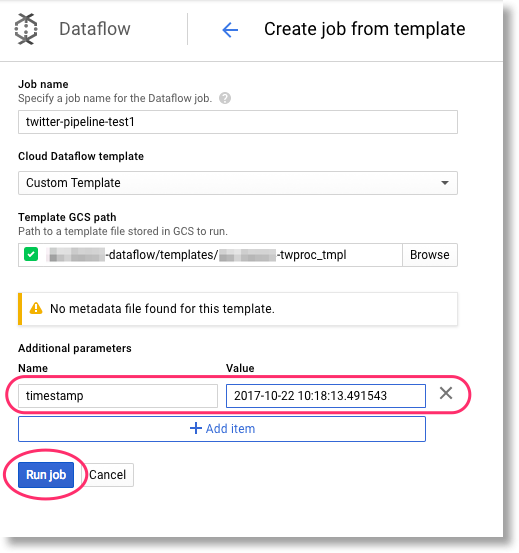 _Set your pipeline's runtime parameter(s) before running the job._
_Set your pipeline's runtime parameter(s) before running the job._
Note that while we don't show it here, you can extend your templates with additional metadata so that custom parameters may be validated when the template is executed.
Once you click 'Run', you should be able to see your job running in the Cloud Console.
Finally, edit app.yaml. Add the Twitter app credentials that you generated above. Then, fill in your PROJECT, DATASET, and BUCKET names.
Next, add your TEMPLATE name. By default, it will be <PROJECT>-twproc_templ, where <PROJECT> is replaced with your project name.
Now we're ready to deploy the GAE app. Deploy the app.yaml spec:
$ gcloud app deploy app.yaml.. and then the cron.yaml spec:
$ gcloud app deploy cron.yamlTo test your deployment, manually trigger the cron jobs. To do this, go to the cloud console for your project, and visit the App Engine pane. Then, click on 'Task Queues' in the left navbar, then the 'Cron Jobs' tab in the center pane.
Then, click Run now for the /timeline cron job. This is the job that fetches tweets and stores
them in the Datastore. After it runs, you should be able to see Tweet entities in the Datastore.
Visit the Datastore pane in the Cloud
Console, and select Tweet from the 'Entities' pull-down menu. You can also try a GQL query:
select * from Tweet order by created_at desc
Once you know that the 'fetch tweets' cron is running successfully and populating the Datastore,
click Run now for the
/launchtemplatejob cron. This should kick off a Dataflow job and return within a few seconds. You
should be able to see the job running in the Dataflow pane
of the Cloud Console. It should finish in a few minutes. Check that it finishes without error.
Once it has finished, you ought to see three new tables in your BigQuery dataset: urls,
word_counts, and word_cooccur.
If you see any problems, make sure that you've configured the app.yaml as described above, and check the logs for clues.
Note: the /launchtemplatejob request handler is configured to return without launching the pipeline
if the request has not originated as a cron request. You can comment out that logic in main.py,
in the LaunchJob class, if you'd like to override that behavior.
Once our example app is up and running, it periodically writes the results of its analysis to BigQuery. Then, we can run some fun queries on the data.
For example, we can find recent word co-occurrences that are 'interesting' by our metric:

Or look for emerging word pairs, that have become 'interesting' in the last day or so (as of early April 2017):

We can contrast the 'interesting' word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):

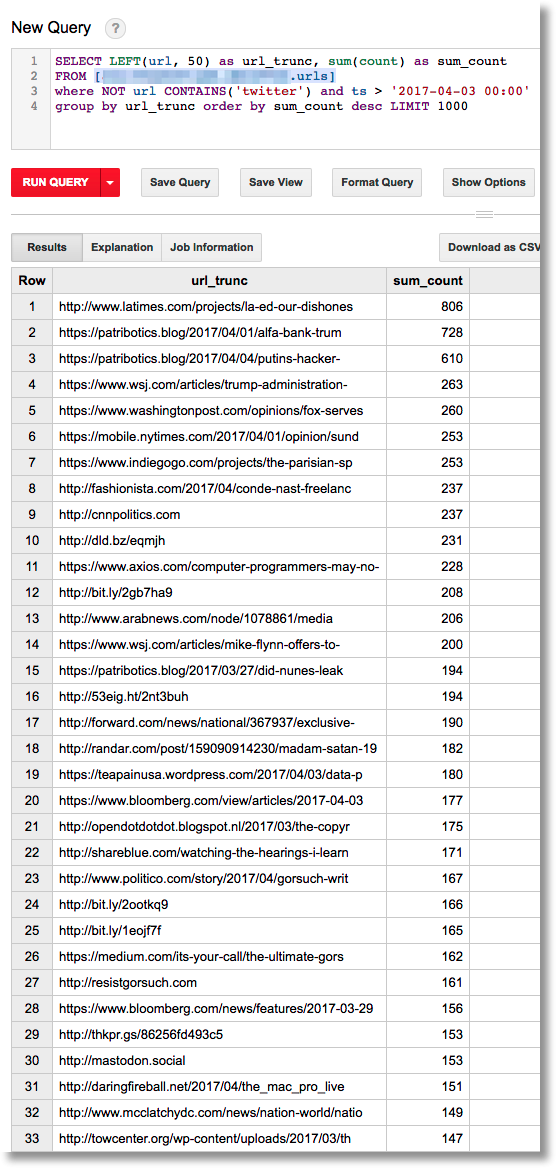
Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
This example walks through how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app, in order to support a range of processing and analytics tasks.
There are lots of interesting ways that this example could be extended. For example, you could add a user-facing frontend to the web app, that fetches and displays results from BigQuery. You might also look at trends over time (e.g. for bigrams) -- either from BigQuery, or by extending the Dataflow pipeline.
Contributions are not currently accepted. This is not an official Google product.