【实践经验】基于CDH6.3.2独立部署Linkis1.0.3+DSS1.0.1 #2652
WenxiangFan
started this conversation in
Solicit Articles(征文)
Replies: 5 comments
-
|
这么保姆的文可是说是非常用心了 |
Beta Was this translation helpful? Give feedback.
0 replies
-
|
文档记录详细,亲测好用,感谢感谢! |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
-
作者:范文祥
微信:fan_wenxiang
一、前言
我司大数据开发平台基于CDH6.3.2,各个项目团队在实际的数据开发过程中苦恼于,没有统一的数据开发IDE环境,使用不同的大数据开发组件往往需要切换不同的开发工具。再加上CDH平台已开启kerberos认证,使得项目团队在数据开发过程中还需要进行kerberos认证,团队数据开发的过程变得更加繁琐。为了解决团队数据开发的痛点,提高数据开发的效率。我们基于微众Linkis和DSS进行了适配,并独立于CDH环境进行搭建,成功实现项目部署。
二、环境
1、CDH6.3.2环境
CDH6.3.2 各组件依赖版本
权限控制
2、硬件环境
三、编译
编译过程首先需要根据CDH相关版本进行适配调整,如hadoop、spark、hive等版本。版本调整后难免出现编译不通过的问题,需要根据实际报错信息添加或者删除依赖。
1、编译linkis1.0.3
代码改造(适配CDH6.3.2)
修改hadoop、hive 到CDH适配版本
由于CDH6.3.2源生的spark版本为2.4.3,此版本没有spark-sql。因此我们升级使用spark3.0.0,并且依赖scala 2.12,需升级scala到2.12.10
源代码中对于hive引擎由于版本中带有“-”,与linkis引擎路径解析关键字冲突需要进行调整,在hive引擎pom中增加
修改distribution.xml
编译打包
2、编译DSS1.0.1
手工编译,发现缺失jetty包,需要补上。
升级scala版本
由于我们使用的是zulujdk-1.8 需要手工下载jfxrt并添加到本地依赖
修改
dss-framework/dss-framework-orchestrator-server/pom.xml
dss-commons/dss-common/pom.xml
编译打包
四、单机版安装
前置工作
这里安装zulu-jdk8、mysql客户端、kerberos客户端无需求过多介绍。重点讲一下部署账号的创建:
1、首先我们需要在CDH上创建一个linkis账号,账号需要开通HDFS权限,并创建一个路径
2、在安装服务器上创建linkis账号,并授权免密sudo权限
CDH环境配置
1、将服务器改进行CDH环境配置改造,步骤相对简单。只需将配置包拷贝到服务器中并配置环境变量即可,配置完成后使用linkis用户进行以下测试,所有安装服务器均可以运行kerberos、hive、spark、hdfs等命令:
2、独立安装Spark 3.0.0
由于CDH6.3.2 使用的spark版本为spark2.4.3此版本不支持spark-sql。所以我们在安装服务器上使用独立部署并安装了Spark 3.0.0。配置模式采用spark on yarn client 。
五、安装linkis-1.0.3
安装过程官网文档已经有了详细的配置过程,此处就不做详细的介绍。重点说一下安装过程中遇到的问题。
1、配置kerberos认证配置问题
将下面的配置信息拷贝到所有涉及到的配置文件(所有用户的keytab都放到linkis用户目录下,并且将linkis作为所有者
涉及到的微服务的配置文件有:
各个引擎相关的配置文件:
2,由于公司安全要求需要,关闭actuator的endpoint
vi /app/data/Install/linkis1.0.3/conf/application-linkis.yml
将management.endpoints.web.exposure.include: 改为一个不存在的路径即可。
按照修复漏洞的方式disable掉endpoint不行,disable之后还会有info和health两个接口是可以免密使用的。
3、由于ECM启动时会报错SSLHandshakeException: No appropriate protocol,需要进行如下修改
编辑 删除掉红框部分

4、报错KrbException: Message stream modified (41)
删除 krb5.conf 配置文件里的 renew_lifetime = xxx 这行配置即可
启动linkis
启动过程中进入到 /app/data/Install/linkis1.0.3/logs里检查每一个日志文件,确保启动过程中没有任何异常出现,否则一定要先修复这些问题。
安装引擎
shell 引擎
./linkis-cli -engineType shell-1 -code "echo \"hello world\"" -codeType shell如果shell引擎能够起来,则说明linkis的整体框架起来了。改完了linkis的相关配置一定要测试一下shell引擎。
hive引擎
测试 hive 引擎
执行命令,如果可以查询到所有 表名,则说明hive引擎成功
./linkis-cli-hive -engineType hive-2.1.1_cdh6.3.2 -code "show tables;"由于前面修改了 hive打包路径需要 修改 linkis-cli-hive 文件中配置的hive引擎版本

python引擎
由于python2版本官方已经与2020年1月1日停止更新,所以我们直接使用python3作为默认版本。
安装Python引擎依赖包
配置python加载目录,修改python引擎的linkis-engineconn.properties,增加
测试Python引擎
Spark 引擎
1、修改 linkis-cli-spark-submit 中spark版本


vim /app/data/linkis/linkis-1.0.3/bin/linkis-cli-spark-submit
2 解决引擎报错
Caused by: java.lang.ClassCastException: org.apache.hadoop.fs.FsUrlConnection cannot be cast to java.net.HttpURLConnection
修改 spark3配置文件 vim /app/data/CDH-6.3.2/spark-conf/spark-defaults.conf增加
问题解决
4、修改spark引擎配置文件
vim /app/data/linkis/linkis-1.0.3/lib/linkis-engineconn-plugins/spark/dist/v3.0.0/conf/linkis-engineconn.properties #hadoopconfig hadoop.config.dir=/app/data/CDH6.3.2/hadoop-conf测试引擎
./linkis-cli-spark-sql -code "show tables;"如果可以查询到所有 表名,则说明hive引擎成功
JDBC引擎
linkis 1.0.3 版本默认是不会打包jdbc引擎的,需要单独进行编译或者在编译脚本中增加,jdbc引擎。
编译后生out.zip 压缩包,并上传到引擎安装目录
重启linkis服务
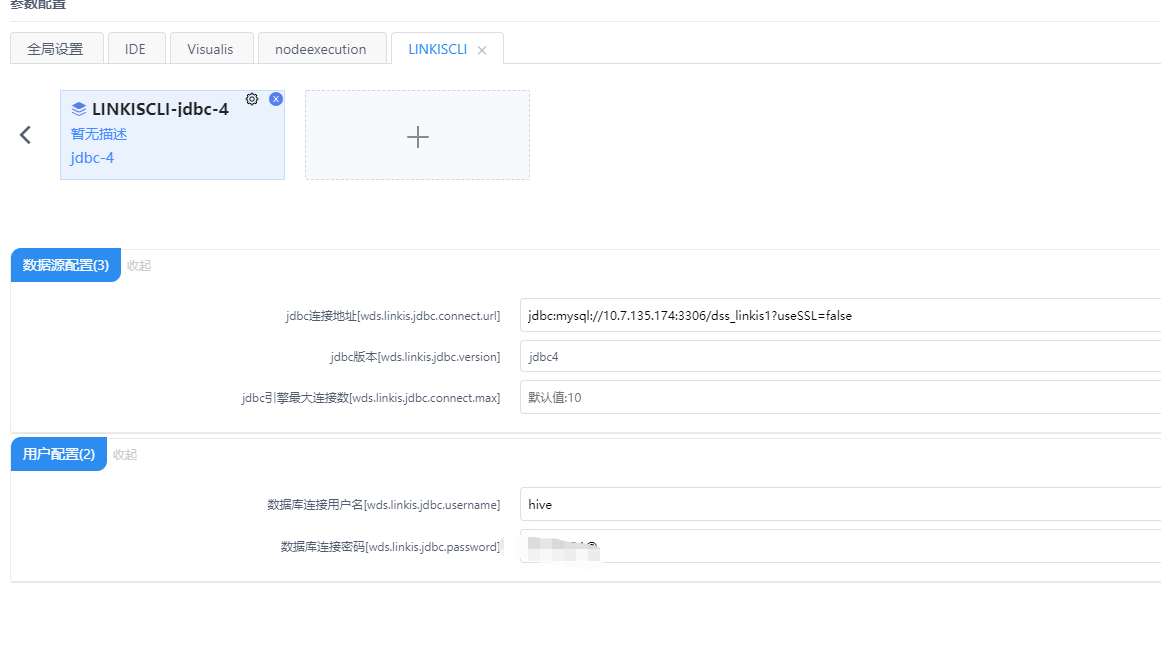
如果需要在通过CLI测试,数据库连接配置,控制台参数设置增加LINKISCLI应用类型,点击增加jdbc 引擎,页面点击配置好的JDBC引擎标签并维护数据库JDBC链接。
#测试引擎
调用linkis-cli,输入命令
./linkis-cli -engineType jdbc-4 -code "show databases" -codeType sql执行成功则配置生效
六、安装DSS 1.0.1
安装过程参考官网文档进行安装配置即可,这里说明一下遇到的问题和注意的事项。
1、将dss-gateway-support-1.0.1.jar拷贝到linkis的gateway服务下,并重启gateway服务,此包里实现有简单版的用户身份验证逻辑(如果dss和linkis都是自编译的,这个jar也有必要要在linkis重新覆盖一下)
七、测试集群部署规划
角色划分
将s1已经安装好的linkis和CDH配置包分别复制到S2和s3
配置并启动eureka服务
修改application-eureka.yml
S1节点
vim application-eureka.yml
spring: application: name: linkis-mg-eureka profiles: eureka debug: false server: port: 20303 eureka: instance: hostname: linkis-test-67 # preferIpAddress: true client: register-with-eureka: true fetch-registry: true serviceUrl: defaultZone: http://linkis-test-68:20303/eureka/ # server: # enableSelfPreservation: false # enable-self-preservation: false # eviction-interval-timer-in-ms: 3000 server: # response-cache-update-interval-ms: 2000 enable-self-preservation: true leaseRenewalIntervalInSeconds: 30 renewal-percent-threshold: 0.85 eviction-interval-timer-in-ms: 3000S2节点
vim application-eureka.yml
spring: application: name: linkis-mg-eureka profiles: eureka debug: false server: port: 20303 eureka: instance: hostname: linkis-test-68 # preferIpAddress: true client: register-with-eureka: true fetch-registry: true serviceUrl: defaultZone: http://linkis-test-67:20303/eureka/ # server: # enableSelfPreservation: false # enable-self-preservation: false # eviction-interval-timer-in-ms: 3000 server: # response-cache-update-interval-ms: 2000 enable-self-preservation: true leaseRenewalIntervalInSeconds: 30 renewal-percent-threshold: 0.85 eviction-interval-timer-in-ms: 3000修改 S1、S2、S3节点的application-linkis.yml
eureka: client: serviceUrl: defaultZone: http://linkis-test-67:20303/eureka/,http://linkis-test-68:20303/eureka/启动服务
su -l linkis cd /app/data/linkis/linkis-1.0.3/sbin/ ./linkis-daemon.sh restart mg-eureka查看启动日志是否存在异常
浏览器访问 http://linkis-test-68:20303/ 和 http://linkis-test-69:20303/ 查看服务列表
启动公共服务
分别修改S1、S2、S3 的配置文件中的euraka 注册地址
vim application-linkis.yml
vim linkis.properties
修改S1、S2、S3 的配置文件中的geteway 网关地址
vim linkis.properties
启动S1节点上的gateway
查看启动日志是否存在异常
启动S1节点上的其他服务
查看启动日志是否存在异常
由于除了S1节点除了cg-engineconnmanager,均需要启动可以先使用start-all脚本启动全部然后停止cg-linkismanager(注意:此方法需要先启动S2的eureka服务)
启动引擎服务
分别启动S2、S3上的引擎服务、查看启动日志是否存在异常
浏览器访问 http://linkis-test-68:20303/ 和 http://linkis-test-69:20303/ 查看服务启动个数
通过测试引擎验证服务是否启动成功
登录S1节点测试引擎
./linkis-cli-hive -engineType hive-2.1.1_cdh6.3.2 -code "show tables;"启动DSS服务
总结:
1、集群化部署启动过程一定要实时查看各个引擎的启动日志。
2、启动完成后检查eureka,业务服务启动情况。
3、完成后还需要进入dss页面进行引擎和功能的的验证和测试。
八、新用户配置
以linkis_test1账号为例,展示怎么在linkis&dss中添加此用户
1,创建用户linkis_test1,并添加到linkis组里
2,kerberos生成linkis_test1票据并将keytab文件拷贝到/home/linkis下
3、在hdfs,user_root 和 服务器user_root 中增加加linkis_test1目录
九、遇到的问题
1、由于我司采用的是sentry进行权限控制,但是DSS源数据模块使用hive matastore ,元数据表中的权限信息不足导致展示的数据库列表存在问题,因此这里改造为采用使用jdbc链接hive方式读取数据库列表。
2、数据结构的表统计信息,默认linkis使用的hive root账号读取。由于我司CDH账号要求相对较为严格,无法授权过高的hive权限。所以改造为使用当前用户读取。
Beta Was this translation helpful? Give feedback.
All reactions