2D visulization of crowded cluster with ivis #119
Comments
|
Hi there, Generally speaking, in dimensionality reduction (DR) there is a trade-off between cluster separability and fidelity to actual data structure. Ivis was developed to prioritise the latter. For example, consider this figure: Ivis does a much better job at preserving L1 and L2 distances between observations across high- and low-dimensional space. This is not the case for many other DR techniques. Also, this:
In other words, the separability between data points (or lack of it) is a real phenomenon of the dataset and is not artificially optimised for by Ivis algorithm. We find this property of ivis much more useful in any downstream tasks from classification/regression to metric learning. We discuss this property in greater depth in our paper: https://www.nature.com/articles/s41598-019-45301-0 |
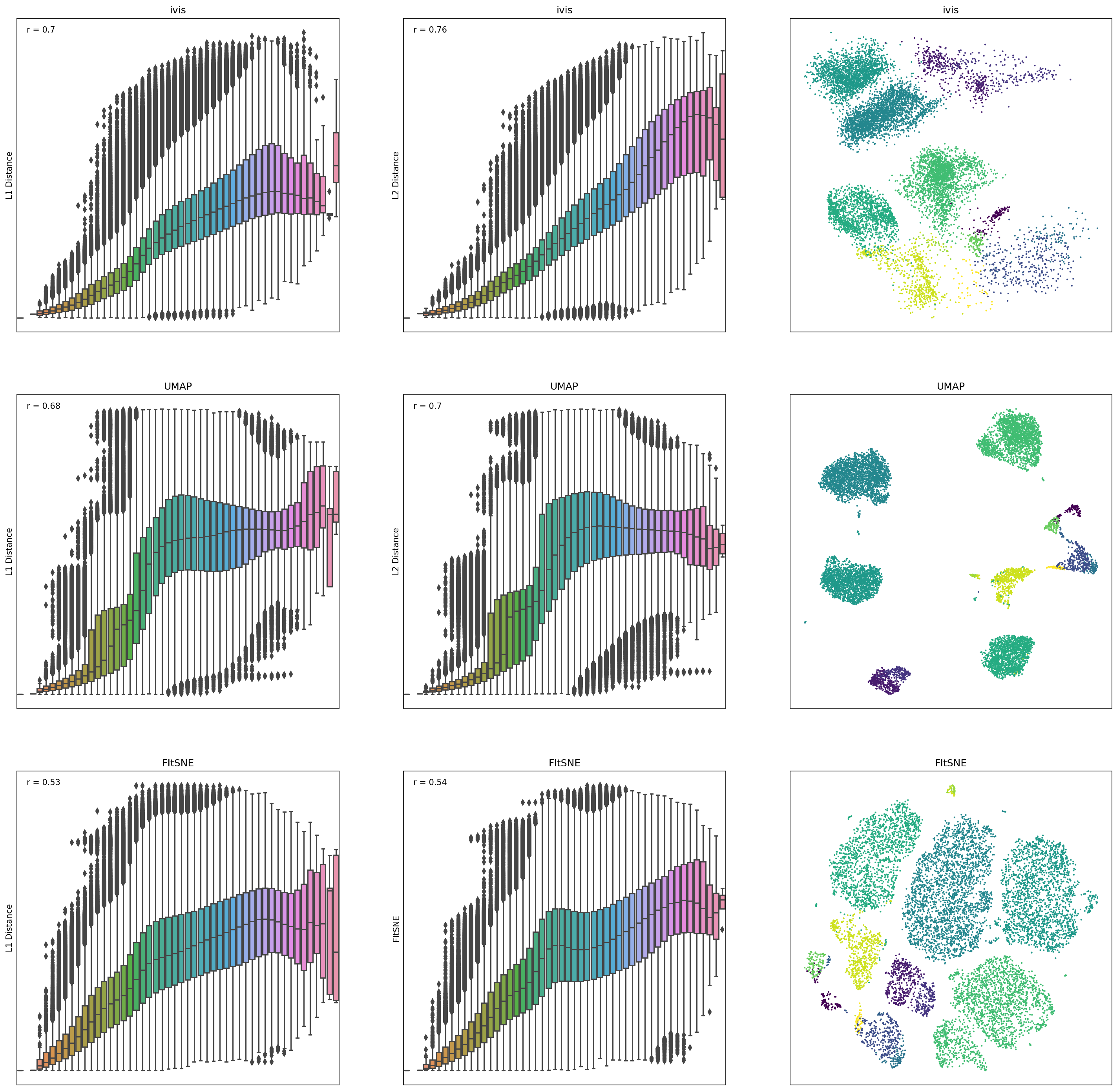

I test the 2D visulization of ivis with mnist dataset. I found the distribution of point is very crowded in the 2D figure, my code is below:
the result is below:

It is very different from the umap visulization:

I have test k=10,20,50,100,150 with ivis, the cluster of all digits is very crowded with little difference.In other word, I think the ideal result is few points should be overlapped like umap. Could you give some advices on how to solve this crowded problem? for example, the digit 1 should be away from any other digit but ivis lost this information in this sence.
The text was updated successfully, but these errors were encountered: