机器语言是机器指令的集合。计算机的机器指令是一系列二进制数字。计算机将之转换为一系列高低电平脉冲信号来驱动硬件工作的
机器指令是由0和1组成的二进制指令,难以编写与记忆。汇编语言是二进制指令的文本形式,与机器指令一一对应,相当于机器指令的助记码。比如,加法的机器指令是00000011写成汇编语言就是ADD。汇编的指令格式由操作码和操作数组成。
将助记码标准化后称为assembly language,缩写为asm,中文译为汇编语言。
汇编语言大致可以分为两类:
-
基于x86架构处理器的汇编语言
- Intel 汇编
- DOS(8086处理器), Windows
- Windows 派系 -> VC 编译器
- AT&T 汇编
- Linux, Unix, Mac OS, iOS(模拟器)
- Unix派系 -> GCC编译器
- Intel 汇编
-
基于ARM 架构处理器的汇编语言
- ARM 汇编
汇编中数据单元大小可分为:
- 位 bit
- 半字节 Nibble
- 字节 Byte
- 字 Word 相当于两个字节
- 双字 Double Word 相当于2个字,4个字节
- 四字 Quadword 相当于4个字,8个字节
寄存器是CPU中存储数据的器件,起到数据缓存作用。内存按照内存层级(memory hierarchy)依次分为寄存器,L1 Cache, L2 Cache, L3 Cache,其读写延迟依次增加,实现成本依次降低。
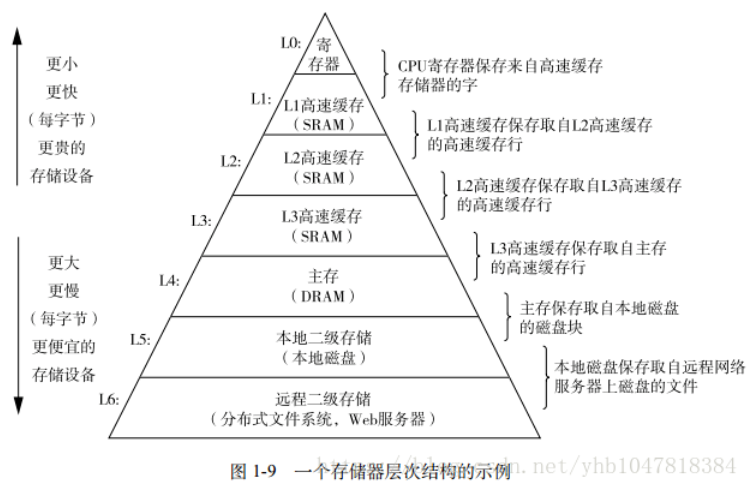
一个CPU中有多个寄存器。每一个寄存器都有自己的名称。寄存器按照种类分为通用寄存器和控制寄存器。其中通用寄存器有可细分为数据寄存器,指针寄存器,以及变址寄存器。
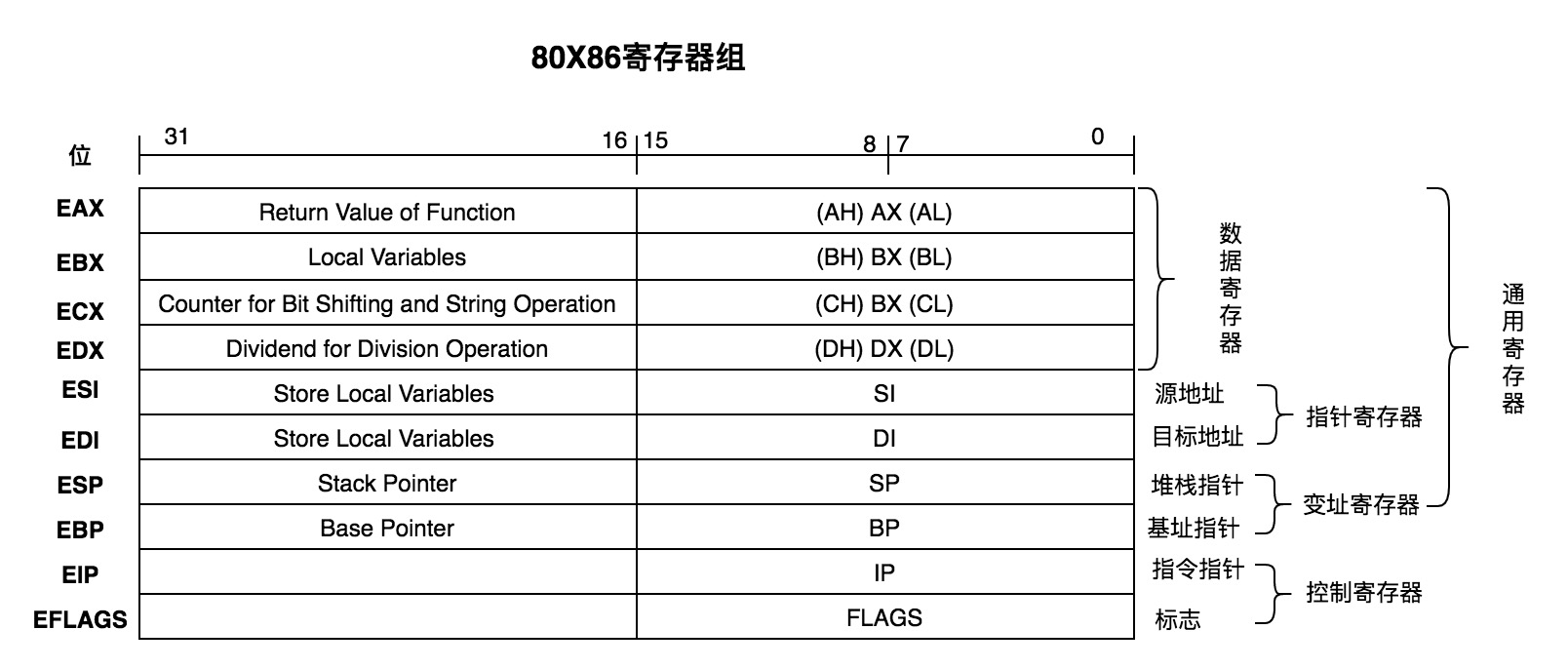
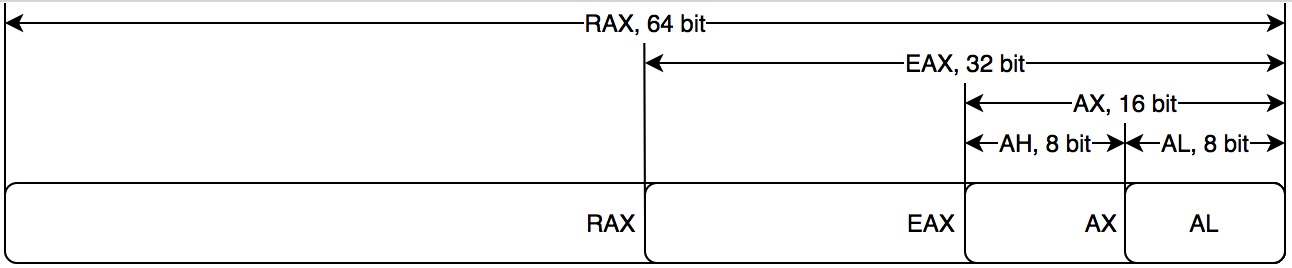
1979年因特尔推出8086架构的CPU,开始支持16位。为了兼容之前8008架构的8位CPU,8086架构中AX寄存器高8位称为AH,低8位称为AL,用来对应8008架构的8位的A寄存器。后来随着x86,以及x86-64 架构的CPU推出,开始支持32位以及64位,为了兼容并保留了旧名称,16位处理器的AX寄存器拓展成EAX(E代表拓展Extended的意思)。对于64位处理器的寄存器相应的RAX(R代表寄存器Register的意思)。其他指令也类似。
| 寄存器 | 功能 |
|---|---|
| AX | A代表累加器Accumulator,X是八位寄存器AH和AL的中H和L的占位符,表示AX由AH和AL组成。AX一般用于算术与逻辑运算,以及作为函数返回值 |
| BX | B代表Base,BX一般用于保存中间地址(hold indirect addresses) |
| CX | C代表Count,CX一般用于计数,比如使用它来计算循环中的迭代次数或指定字符串中的字符数 |
| DX | D代表Data,DX一般用于保存某些算术运算的溢出,并且在访问80x86 I/O总线上的数据时保存I/O地址 |
| DI | DI代表Destination Index,DI一般用于指针 |
| SI | SI代表Source Index,SI用途同DI一样 |
| SP | SP代表Stack Pointer,是栈指针寄存器,存放着执行函数对应栈帧的栈顶地址,且始终指向栈顶 |
| BP | BP代表Base Pointer,是栈帧基址指针寄存器,存放这执行函数对应栈帧的栈底地址,一般用于访问栈中的局部变量和参数 |
| IP | IP代表Instruction Pointer,是指令寄存器,指向处理器下条等待执行的指令地址(代码段内的偏移量),每次执行完相应汇编指令IP值就会增加;IP是个特殊寄存器,不能像访问通用寄存器那样访问它。IP可被jmp、call和ret等指令隐含地改变 |
| CS | CS代表是Code Segment,是代码段寄存器,CS与寄存器IP相配合获得当前线程代码执行到的内存位置 |
| DS | DS代表是Data Segment,是数据段寄存器,DS与各通用寄存器配合访问内存中的数据 |
| SS | SS代表Stack Segment,是栈段寄存器,SS与寄存器(E)SP、(E)BP配合访问线程的调用栈 |
| ES | ES代表Extra Segment,是扩展段寄存器,ES用于特定字符串指令(如MOVS或CMPS) |
| FS | FS是无特定的硬件用途的段寄存器,可以用作基指针地址,以便访问特殊的操作系统数据结构 |
| GS | 同FS类似 |
FS/GS用法
The FS segment is commonly used to address Thread Local Storage (TLS). FS is usually managed by runtime code or a threading library. Variables declared with the ‘__thread’ storage class specifier are instantiated per thread and the compiler emits the FS: address prefix for accesses to these variables. Each thread has its own FS base address so common code can be used without complex address offset calculations to access the per thread instances. Applications should not use FS for other purposes when they use runtimes or threading libraries which manage the per thread FS.
The GS segment has no common use and can be used freely by applications. GCC and Clang support GS based addressing via address space identifiers.
现代Linux x86-64下的fs/gs段寄存器的用途分别为:
- 用户态使用fs寄存器引用线程的glibc TLS和线程在用户态的stack canary;用户态的glibc不使用gs寄存器;应用可以自行决定是否使用该寄存器(这里存在潜在的、充满想象力的优化空间)。
- 内核态使用gs寄存器引用percpu变量和进程在内核态的stack canary;内核态不使用fs寄存器。
CPU要对数据进行读写,必须和外部器件进行以下三类信息的交互:
- 存储单元的地址(地址信息)
- 器件的选择、读或写命令(控制信息)
- 读或写的数据(数据信息)
总线是连接CPU和其他芯片的导线,逻辑上分为地址总线、数据总线、控制总线

CPU从内存单元中读写数据的过程:
- CPU通过地址线将地址信息发出;
- CPU通过控制线发出内存读命令,选中存储器芯片,并通知它将要从中读或写数据;
- 存储器将相应的地址单元中的数据通过数据线送入CPU或CPU通过数据线将数据送入相应的内存单元

CPU是通过地址总线指定存储单元,地址总线传送的能力决定了CPU对存储单元的寻址能力。对于32位CPU,其寻址能力为2^32=4G(存储单元的尺寸是Byte,32位地址可以寻址地址空间大小 = 2 ^ 32 * 1Byte = 4G)。
地址寄存器存储的是CPU当前要存取的数据或指令的地址,该地址是由地址总线传输到地址寄存器上的。
CPU通过数据总线来与内存等器件进行数据传送,数据总线的宽度决定了CPU和外界的数据传送速度。
控制总线是一些不同控制的集合,CPU通过控制总线对外部器件的控制。控制总线的宽度决定了CPU对外部器件的控制能力。
CPU位数与地址寄存器位数,以及数据总线的宽度是一致的。
地址总线的宽度并不一定与CPU位数一致。目前各种架构的64位CPU通常是42条地址线。
当应用程序运行起来时候,系统会将该应用加载到内存中,应用会独立的、完全的占用所有内存,这里内存指的是虚拟内存,对于32位系统,该虚拟内存大小是2^32 = 4G。虚拟内存最终一定会映射到物理内存,操作系统会完成虚拟内存到物理内存的映射处理工作,应用程序并不需要关心。进程加载到虚拟内存中,这就牵扯到进程在虚拟内存的布局。
进程在内存布局分为以下几大块
- Stack - 栈
- Heap - 堆
- BSS - 未初始化数据区,对应的汇编是(.section .bss)
- DS - 初始化化数据区, 对应的汇编是(.section .data)
- Text - 文本区,程序代码, 对应的汇编是(.section .text)
内存布局简图:
High Addresses ---> .----------------------.
| Environment |
|----------------------|
| | Functions and variable are declared
| STACK | on the stack.
base pointer -> | - - - - - - - - - - -|
| | |
| v |
: :
. . The stack grows down into unused space
. Empty . while the heap grows up.
. .
. . (other memory maps do occur here, such
. . as dynamic libraries, and different memory
: : allocate)
| ^ |
| | |
brk point -> | - - - - - - - - - - -| Dynamic memory is declared on the heap
| HEAP |
| |
|----------------------|
| BSS | Uninitialized data (BSS)
|----------------------|
| Data | Initialized data (DS)
|----------------------|
| Text | Binary code
Low Addresses ----> '----------------------'
详细图:
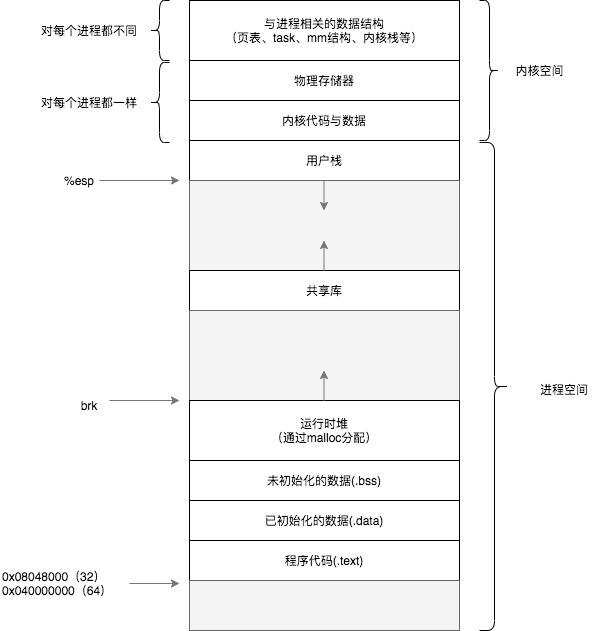
在32位系统中进程空间(即用户空间)范围为0x00000000 ~ 0xbfffffff,内核空间范围为0xc0000000 ~ 0xffffffff, 实际上分配的进程空间并不是从0x00000000开始的,而是从0x08048000开始,到0xbfffffff结束。进程实际的esp指向的地址并不是从0xbfffffff开始的,因为linux系统会在程序初始化前,将一些命令行参数及环境变量以及ELF辅助向量(ELF Auxiliary Vectors)等信息放到栈上。进程启动时,其空间布局如下所示(注意图示中地址是从低地址到高地址的):
stack pointer -> [ argc = number of args ] 4
[ argv[0] (pointer) ] 4 (program name)
[ argv[1] (pointer) ] 4
[ argv[..] (pointer) ] 4 * x
[ argv[n - 1] (pointer) ] 4
[ argv[n] (pointer) ] 4 (= NULL)
[ envp[0] (pointer) ] 4
[ envp[1] (pointer) ] 4
[ envp[..] (pointer) ] 4
[ envp[term] (pointer) ] 4 (= NULL)
[ auxv[0] (Elf32_auxv_t) ] 8
[ auxv[1] (Elf32_auxv_t) ] 8
[ auxv[..] (Elf32_auxv_t) ] 8
[ auxv[term] (Elf32_auxv_t) ] 8 (= AT_NULL vector)
[ padding ] 0 - 16
[ argument ASCIIZ strings ] >= 0
[ environment ASCIIZ strings ] >= 0
[ program name ASCIIZ strings ] >= 0
(0xbffffffc) [ end marker ] 4 (= NULL)
(0xc0000000) < bottom of stack > 0 (virtual)
多线程中每个线程都需要有单独的堆栈。主线程的堆栈都是从在内核边界的位置开始(32位系统下,内核空间占用1G大小)。下一个线程的堆栈从某个偏移量开始,该偏移量定义了主线程的最大堆栈大小。线程API允许设置堆栈大小。
|---| DLLs | code | data | heap |--> <--| stack 2 | <--| stack 1 | kernel |
0 3G 4G
(first page is never mapped to catch NULL dereferences)
从上图可以看出来stack 2的偏移定义了主线程stack 1的最大堆栈的大小。许多线程会占用大量虚拟空间,这在32位计算机上可能是个问题。例如。一个有2000个线程的程序,每个线程默认使用1M的堆栈大小,大约吃掉2G或虚拟内存,只剩下很少的堆空间。在这种情况下,应减少线程堆栈的大小。
更多内容参加Why stack grows down
AT&T汇编语法是类Unix的系统上的标准汇编语法,比如gcc、gdb中默认都是使用AT&T汇编语法。AT&T汇编的指令格式如下:
instruction src dst
其中instruction是指令助记符,也叫操作码,比如mov就是一个指令助记符,src是源操作数,dst是目的操作。
当引用寄存器时候,应在寄存器名称加前缀%,对于常数,则应加前缀 $。
寻址方式即指令中提供操作数或者操作数地址的方式。
| 寻址方式 | 寻址指令 | 解释 |
|---|---|---|
| 立即寻址 | movl $number, %eax | 将number直接存储到到寄存器或存储位置 |
| 直接寻址 | movl 0x123, %eax | 将内存地址0x123存储到到%eax寄存器中 |
| 索引寻址/变址寻址方式 | movl string_start(, %ecx, 1), %eax | 将string_start地址与1 * %ecx相加得到新地址,从该新地址加载数据到%eax寄存器中 |
| 间接寻址方式 | mov (%eax), %ebx | 从寄存器%eax中存储的地址加载值到%ebx寄存器中 |
| 基址寻址方式 | movl 4(%eax), %ebx | 将寄存器%eax中存储的地址加上4字节后得到地址,从该地址加载数据到寄存器%ebx中 |
| 汇编指令 | 逻辑表达式 | 含义 |
|---|---|---|
| mov $0x05, %ax | R[ax] = 0x05 | 将数值5存储到寄存器ax中 |
| mov %ax, -4(%bp) | mem[R[bp] -4] = R[ax] | 将ax寄存器中存储的数据存储到 bp寄存器存的地址减去4之后的内存地址中, |
| mov -4(%bp), %ax | R[ax] = mem[R[bp] -4] | bp寄存器存储的地址减去4值, 然后改地址对应的内存存储的信息存储到ax寄存器中 |
| mov $0x10, (%sp) | mem[R[sp]] = 0x10 | 将16存储到sp寄存器存储的地址对应的内存 |
| push $0x03 | mem[R[sp]] = 0x03 R[sp] = R[sp] - 4 |
将数值03入栈,然后sp寄存器存储的地址减去4 |
| pop | R[sp] = R[sp] + 4 | 将当前sp寄存器指向的地址的变量出栈, 并将sp寄存器存储的地址加4 |
| call func1 | --- | 调用函数func1 |
| ret | --- | 函数返回,将返回值存储到寄存器中或caller栈中, 并将return address弹出到ip寄存器中 |
当使用mov指令传递数据时,数据的大小由mov指令的后缀决定。
movb $123, %eax // 1 byte
movw $123, %eax // 2 byte
movl $123, %eax // 4 byte
movq $123, %eax // 8 byte| 指令 | 含义 |
|---|---|
| subl $0x05, %eax | R[eax] = R[eax] - 0x05 |
| subl %eax, -4(%ebp) | mem[R[ebp] -4] = mem[R[ebp] -4] - R[eax] |
| subl -4(%ebp), %eax | R[eax] = R[eax] - mem[R[ebp] -4] |
| test eax, ebx | 对于R[eax] 和R[ebx] 进行按位与操作 |
test指令会对操作数进行按位与操作,并根据计算结果设置相应的标志寄存器:
| 标志位 | 标志位名称 | =1 | =0 |
|---|---|---|---|
| CF | 进位标志/Carry Flag | CY/Carry/进位 | NC/No Carry/无进位 |
| PF | 奇偶标志/Parity Flag | PE/Parity Even/偶 | PO/Parity Odd/奇 |
| ZF | 零标志/Zero Flag | ZR/Zero/等于零 | NZ/Not Zero/不等于零 |
| SF | 符号标志/Sign Flag | NG/Negative/负 | PL/Positive/非负 |
test一个常见用法是测试寄存器的值是为0或者非0:
test eax, eax # 如果eax寄存器值为0,则ZF置为1,否则ZF值置为0
jz 0x458891 # 如果ZF值为1时,jz指令才会跳到0x458891
jnz 0x458875 # 如果ZF值为0时,jnz指令才会跳到0x458875
je 0x458325 # 如果ZF值为1时,je指令才会跳到0x458325| 指令 | 含义 |
|---|---|
| cmpl %eax %ebx | 计算 R[eax] - R[ebx], 然后设置flags寄存器 |
| jmp location | 无条件跳转到location |
| je location | 如果flags寄存器设置了相等标志,则跳转到location |
| jg, jge, jl, gle, jnz, ... location | 如果flags寄存器设置了>, >=, <, <=, != 0等标志,则跳转到location |
| 指令 | 含义 | 等同操作 |
|---|---|---|
| pushl %eax | 将R[eax]入栈 | subl $4, %esp; movl %eax, (%esp) |
| popl %eax | 将栈顶数据弹出,然后存储到R[eax] | movl (%esp), %eax addl $4, %esp |
| leave | Restore the callers stack pointer | movl %ebp, %esp pop %ebp |
| lea 8(%esp), %esi | 将R[esp]存放的地址加8,然后存储到R[esi] | R[esi] = R[esp] + 8 |
lea 是load effective address的缩写,用于将一个内存地址直接赋给目的操作数。
| 指令 | 含义 |
|---|---|
| call label | 调用函数,并将返回地址入栈 |
| ret | 从栈中弹出返回地址,并跳转至该返回地址 |
| leave | Restore the callers stack pointer |
注意: 以上指令分类并不规范和完整,比如call,ret都可以算作无条件跳转指令,这里面是按照功能放在函数调用这一分类了。完整指令分类可以参加百度百科汇编指令条目。
断点指令,即INT3指令,它是专门用来软件调试的一条指令,对应的机器码是0xCC。INT3的含义是3号中断,INT是interrupt一词的缩写。GDB等调试工具就是通过此指令工作的,当我们打断点时候,GDB会把设断点处的机器码指令的第一个字节改为0xCC(即INT3指令),并把原字节保存起来,当CPU执行到这条指令时候会产生中断异常,然后调用GDB提前注册的异常处理程序(通过ptrace系统调用实现)做进一步处理。
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。
栈帧的边界由栈帧基地址指针EBP和堆栈指针ESP界定(指针存放在相应寄存器中)。EBP指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此函数中对大部分数据的访问都基于EBP进行。
函数调用栈的典型内存布局如下图:
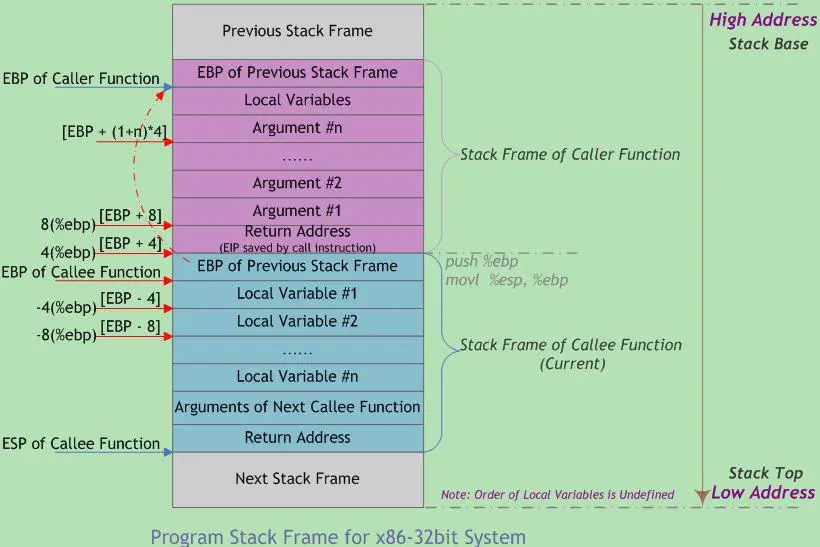
AT&T汇编代码示例:
// 计算 2 ^ 3
_start:
pushl $3 // 压入第二个参数
pushl $2 // 压入第一个参数
call power // 调用函数power
.....
power:
pushl %ebp // 保存旧基址指针
movl %esp, %ebp // 将基址指针设置为栈指针
subl $4, %esp // 为本地存储保留空间
..... // 核心逻辑处理
movl %ebp, %esp // 恢复栈指针
popl %ebp // 恢复基址指针
ret // 将控制权交还给caller,即_start上面代码中_start是入口函数,_start函数中通过call指令调用power函数,call指令会将当前指令(即call power)的下一指令地址入栈,并将power函数的入口地址保存到eip中。
power函数中先通过pushl %ebp保存旧基址指针,即_start函数的开始地址,然后movl %esp, %ebp将esp保存的栈顶指针地址保存到ebp中,之后可以就可以通过ebp可以访问power的栈信息。至此power完成函数执行的准备过程。
为什么要通过ebp访问power的栈信息,而不是通过esp访问栈信息?
这是因为在power的生命周期内,ebp是不变的,总是指向power栈帧开始位置 - 4的位置处。而esp总是随着栈的伸缩而变化。
power函数核心逻辑完成之后,需要完成返回过程。首先执行movl %ebp, %esp,恢复栈指针,然后执行popl %ebp,将堆栈中存储的caller的基址弹出,并将弹出的基址保存到ebp寄存器中。最后调用ret指令,交出控制权给caller,该指令相当于popl %eip。
power函数的准备过程以及返回过程是函数调用的通用逻辑处理。
在函数调用中,栈看起来如下:
参数 #N <--- N*4 + 4(%ebp)
......
参数2 <--- 12(%ebp)
参数1 <--- 8(%ebp)
返回地址 <--- 4(%ebp)
旧%ebp <--- (%ebp)
局部变量1 <--- -4(%ebp)
局部变量2 <--- -8(%ebp)
....... <--- %esp
注意:CALL指令和RET指令是配对出现的。CALL指令将返回地址压入堆栈,再把被调用过程的地址复制到指令指针寄存器。当过程准备返回时,它的RET指令从堆栈把返回地址弹回到指令指针寄存器
PC指的是程序计数器,是Program Counter的缩写,是一个中央处理器中的寄存器,用于指示计算机在其程序序列中的位置。在Intel x86和Itanium微处理器中,它叫做指令指针(instruction pointer,IP),有时又称为指令地址寄存器(instruction address register,IAR)
x86-32是32位Intel处理器,是从Intel 80386开始支持的。x86-32是兼容16位Intel x86架构的(比如 Intel 8086 - 80286 的CPU)。x86-32架构下的汇编称为IA-32 Assembly。
x86-64是64位Intel处理器,简称x64,是基于x86架构的拓展而来,向后兼容16位及32位的架构。x86-64也可以称为AMD 64。x86-32和x86-64都统称为x86。
AMD 64是amd最先开发出来的兼容x86的指令集。x86-64与AMD64基本相同但有细节上的区别,AMD 64是x86-64的实际标准。
苹果、RPM包管理、Arch Linux称之为x86-64或x86_64,甲骨文和微软称之为x64,BSD和其他Linux发行版称之为amd64。
系统调用(system call)指的是运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。
CPU特权级别一般来说总共有4个,从最高特权的Ring 0到最低特权的Ring 3。在大多数操作系统中,Ring 0拥有最高特权,并且可以和最多的硬件直接交互(比如CPU,内存)。这种分级保护策略称为CPU环(CPU Rings),是用来在发生故障时保护数据和功能,提升容错度,避免恶意操作,提升计算机安全的一种设计方式。

在Linux上用户态对应Ring 3,内核态对应Ring 0,当应用程序想要使用特权指令,控制中断、修改页表、访问设备等时候,应用程序就需要执行系统调用,完成CPU的运行级别从Ring 3到Ring 0的切换,然后跳转到系统调用对应的内核代码位置执行相关操作。
Linux 执行系统调用一共有三种方法:
- 使用软件中断(Software interrupt)触发系统调用
- 使用 SYSCALL / SYSENTER 等汇编指令触发系统调用
- 使用虚拟动态共享对象(virtual dynamic shared object、vDSO)执行系统调用
中断分成硬件和软件中断两种,硬件中断是由处理器外部的设备触发的电子信号;而软件中断是由处理器在执行特定指令时触发的。x86 的系统上,我们可以使用int $0x80指令来触发软件中断,完成系统调用。使用int $0x80进行调用时候的调用约定如下:
| system call number | 1st parameter | 2nd parameter | 3rd parameter | 4th parameter | 5th parameter | 6th parameter | result |
|---|---|---|---|---|---|---|---|
| eax | ebx | ecx | edx | esi | edi | ebp | eax |
int $0x80软性中断实现系统调用的性能不太好。
Linux为了解决软件中断实现的系统调用在 Pentium 4 的处理器上表现非常差的问题,Linux新版本使用了专有的系统调用指令来完成系统调用。在32位系统下,它们是SYSENTER / SYSEXIT指令;64位的操作系统下是SYSCALL / SYSRET指令。
与 INT 0x80 通过触发软件中断实现系统调用不同,SYSENTER 和 SYSCALL 是专门为系统调用设计的汇编指令,它们不需要在中断描述表(Interrupt Descriptor Table、IDT)中查找系统调用对应的执行过程,也不需要保存堆栈和返回地址等信息,所以能够减少所需要的额外开销。
SYSCALL指令的调用约定如下:
| system call number | 1st parameter | 2nd parameter | 3rd parameter | 4th parameter | 5th parameter | 6th parameter | result |
|---|---|---|---|---|---|---|---|
| rax | rdi | rsi | rdx | r10 | r8 | r9 | rax |
虚拟动态共享对象(virtual dynamic shared object、vDSO)是 Linux 内核对用户空间暴露内核空间部分函数的一种机制,简单来说,是将 Linux 内核中不涉及安全的系统调用直接映射到用户空间,这样用户空间中的应用程序在调用这些函数时就不需要切换到内核态以减少性能上的损失。vDSO 中含 gettimeofday、clock_gettime、clock_getres、rt_sigreturn 等系统调用
vDSO 使用了标准的链接和加载技术,作为一个动态链接库,它由 Linux 内核提供并映射到每一个正在执行的进程中,我们可以使用如下所示的命令查看该动态链接库在进程中的位置:
...
02078000-02099000 rw-p 00000000 00:00 0 [heap]
7f80c99f9000-7f80c99fa000 rw-p 00026000 fc:00 799776 /lib/x86_64-linux-gnu/ld-2.23.so
7f80c99fa000-7f80c99fb000 rw-p 00000000 00:00 0
7ffdcc361000-7ffdcc383000 rw-p 00000000 00:00 0 [stack]
7ffdcc3b6000-7ffdcc3b8000 r--p 00000000 00:00 0 [vvar]
7ffdcc3b8000-7ffdcc3ba000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
| 1st parameter | 2nd parameter | 3rd parameter | 4th parameter | 5th parameter | 6th parameter | result |
|---|---|---|---|---|---|---|
| rdi | rsi | rdx | rcx | r8 | r9 | rax |
指令周期(Instruction Cycle)指的CPU从内存取出一条指令并执行这条指令的时间总和。

字长是描述一个字(word)的长度的概念。在上面的数据单元大小中,介绍到在汇编中一个word(字)的长度是2个字节,也就是说字长是16位。
其实word在不同语义环境下,含义是不一样的,我们在实际过程中需要注意区别:
- processor word:在CPU 架构语境中,word代表是CPU word,此处字长为处理器寄存器长度(a "processor word" refers to the size of a processor register),对于64位CPU,字长是64位,对于32位CPU,字长是32位。我们在描述变量数据大小时应使用的是processor word。例如,Go 内置的数据结构占用空间:
- string (2 words)
- slice (3 words)
- interface (2 words)
- map (1 word)
- chan (1 word)
- func (1 word)
- Intel/AMD instruction set word: 即汇编语境中word,上面已介绍过。
Go 编译器会输出一种抽象可移植的汇编代码,这种汇编并不对应某种真实的硬件架构。Go 的汇编器会使用这种伪汇编,再为目标硬件生成具体的机器指令。伪汇编这一个额外层可以带来很多好处,最主要的一点是方便将 Go 移植到新的架构上。
要了解Go的汇编器最重要的是要知道Go的汇编器不是对底层机器的直接表示,即Go的汇 编器没有直接使用目标机器的汇编指令。Go汇编器所用的指令,一部分与目标机器的指令 一一对应,而另外一部分则不是。这是因为编译器套件不需要汇编器直接参与常规的编译 过程。相反,编译器使用了一种半抽象的指令集,并且部分指令是在代码生成后才被选择 的。汇编器基于这种半抽象的形式工作,所以虽然你看到的是一条MOV指令,但是工具链 针对对这条指令实际生成可能完全不是一个移动指令,也许会是清除或者加载。也有可能 精确的对应目标平台上同名的指令。概括来说,特定于机器的指令会以他们的本尊出现, 然而对于一些通用的操作,如内存的移动以及子程序的调用以及返回通常都做了抽象。细 节因架构不同而不一样,我们对这样的不精确性表示歉意,情况并不明确。
汇编器程序的工作是对这样半抽象指令集进行解析并将其转变为可以输入到链接器的指令。
Go 汇编还引入 4 个伪寄存器:
-
FP: Frame pointer: arguments and locals.
- 使用形如 symbol+offset(FP) 的方式,引用函数的输入参数。例如 arg0+0(FP),arg1+8(FP)
- offset是正值
-
PC: Program counter: jumps and branches.
- PC寄存器,在 x86 平台下对应 ip 寄存器,amd64 上则是 rip
-
SB: Static base pointer: global symbols.
- 全局静态基指针,一般用来声明函数或全局变量
-
SP: Stack pointer: top of stack.
-
SP寄存器指向当前栈帧的局部变量的开始位置,使用形如 symbol+offset(SP) 的方式,引用函数的局部变量。
-
offset是负值,offset 的合法取值是 [-framesize, 0)。
-
手写汇编代码时,如果是 symbol+offset(SP) 形式,则表示伪寄存器 SP。如果是 offset(SP) 则表示硬件寄存器 SP。对于编译输出(go tool compile -S / go tool objdump)的代码来讲,目前所有的 SP 都是硬件寄存器 SP,无论是否带 symbol。
-
参数大小+返回值大小
|
TEXT pkgname·add(SB),NOSPLIT,$32-16
| | |
包名 函数名 栈帧大小(局部变量+可能需要的额外调用函数的参数空间的总大小,但不包括调用其它函数时的 ret address 的大小)
-
TEXT指令声明了pagname.add是在.text段 -
pkgname·add中的·,是一个 unicode 的中点。在程序被链接之后,所有的中点·都会被替换为点号.。所以通过gdb调试打断点时候,应该是b pagname.add。 -
(SB): SB 是一个虚拟寄存器,保存了静态基地址(static-base) 指针,即我们程序地址空间的开始地址。 "".add(SB) 表明我们的符号位于某个固定的相对地址空间起始处的偏移位置 (最终是由链接器计算得到的)objdump -j .text -t test | grep 'main.add' # 可获得main.add的绝对地址
-
NOSPLIT: 向编译器表明不应该插入 stack-split 的用来检查栈需要扩张的前导指令。 在我们 add 函数的这种情况下,编译器自己帮我们插入了这个标记: 它足够聪明地意识到,由于 add 没有任何局部变量且没有它自己的栈帧,所以一定不会超出当前的栈;因此每次调用函数时在这里执行栈检查就是完全浪费 CPU 循环了 -
$32-16:$32代表即将分配的栈帧大小;而$16指定了调用方传入的参数与返回值的大小
package main
//go:noinline
func add(a, b int32) (int32, bool) { return a + b, true }
func main() { add(10, 32) }将这段代码编译到汇编:
$ GOOS=linux GOARCH=amd64 go tool compile -S direct_topfunc_call.go0x0000 TEXT "".add(SB), NOSPLIT, $0-16
0x0000 FUNCDATA $0, gclocals·f207267fbf96a0178e8758c6e3e0ce28(SB)
0x0000 FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 MOVL "".b+12(SP), AX
0x0004 MOVL "".a+8(SP), CX
0x0008 ADDL CX, AX
0x000a MOVL AX, "".~r2+16(SP)
0x000e MOVB $1, "".~r3+20(SP)
0x0013 RET
0x0000 TEXT "".main(SB), $24-0
;; ...omitted stack-split prologue...
0x000f SUBQ $24, SP
0x0013 MOVQ BP, 16(SP)
0x0018 LEAQ 16(SP), BP
0x001d FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d MOVQ $137438953482, AX
0x0027 MOVQ AX, (SP)
0x002b PCDATA $0, $0
0x002b CALL "".add(SB)
0x0030 MOVQ 16(SP), BP
0x0035 ADDQ $24, SP
0x0039 RET
;; ...omitted stack-split epilogue...接下来一行一行地对这两个函数进行解析来帮助我们理解编译器在编译期间都做了什么事情。
0x0000 TEXT "".add(SB), NOSPLIT, $0-16-
0x0000: 当前指令相对于当前函数的偏移量。 -
TEXT "".add:TEXT指令声明了"".add是.text段(程序代码在运行期会放在内存的 .text 段中)的一部分,并表明跟在这个声明后的是函数的函数体。 在链接期,""这个空字符会被替换为当前的包名: 也就是说,"".add在链接到二进制文件后会变成main.add。 -
(SB):SB是一个虚拟寄存器,保存了静态基地址(static-base) 指针,即我们程序地址空间的开始地址。"".add(SB)表明我们的符号位于某个固定的相对地址空间起始处的偏移位置 (最终是由链接器计算得到的)。换句话来讲,它有一个直接的绝对地址: 是一个全局的函数符号。objdump这个工具能帮我们确认上面这些结论:
$ objdump -j .text -t direct_topfunc_call | grep 'main.add'
000000000044d980 g F .text 000000000000000f main.add
所有用户定义的符号都被写为相对于伪寄存器FP(参数以及局部值)和SB(全局值)的偏移量。 SB伪寄存器可以被认为是内存的起始位置,所以对于符号foo(SB)就是名称foo在内存的地址。
NOSPLIT: 向编译器表明不应该插入 stack-split 的用来检查栈需要扩张的前导指令。 在我们add函数的这种情况下,编译器自己帮我们插入了这个标记: 它足够聪明地意识到,由于add没有任何局部变量且没有它自己的栈帧,所以一定不会超出当前的栈;因此每次调用函数时在这里执行栈检查就是完全浪费 CPU 循环了。
"NOSPLIT": 不会插入前导码来检查栈是否必须被分裂。协程上的栈帧,以及他所有的调用,都必须存放在栈顶的空闲空间。用来保护协程诸如栈分裂代码本身。
本章结束时会对 goroutines 和 stack-splits 进行简单介绍。
$0-16:$0代表即将分配的栈帧大小;而$16指定了调用方传入的参数大小。
通常来讲,帧大小后一般都跟随着一个参数大小,用减号分隔。(这不是一个减法操作,只是 一种特殊的语法)帧大小 $24-8 意味着这个函数有24个字节的帧以及8个字节的参数,位 于调用者的帧上。如果NOSPLIT没有在TEXT中指定,则必须提供参数大小。对于Go原型的 汇编函数,go vet会检查参数大小是否正确。
0x0000 FUNCDATA $0, gclocals·f207267fbf96a0178e8758c6e3e0ce28(SB)
0x0000 FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)FUNCDATA以及PCDATA指令包含有被垃圾回收所使用的信息;这些指令是被编译器加入的。
现在还不要对这个太上心;在本书深入探讨垃圾收集时,会再回来了解这些知识。
0x0000 MOVL "".b+12(SP), AX
0x0004 MOVL "".a+8(SP), CXGo 的调用规约要求每一个参数都通过栈来传递,这部分空间由 caller 在其栈帧(stack frame)上提供。
调用其它过程之前,caller 就需要按照参数和返回变量的大小来对应地增长(返回后收缩)栈。
Go 编译器不会生成任何 PUSH/POP 族的指令: 栈的增长和收缩是通过在栈指针寄存器 SP 上分别执行减法和加法指令来实现的。
SP伪寄存器是虚拟的栈指针,用于引用帧局部变量以及为函数调用准备的参数。 它指向局部栈帧的顶部,所以应用应该使用负的偏移且范围在[-framesize, 0): x-8(SP), y-4(SP), 等等。
尽管官方文档说 "All user-defined symbols are written as offsets to the pseudo-register FP(arguments and locals)",实际这个原则只是在手写的代码场景下才是有效的。 与大多数最近的编译器做法一样,Go 工具链总是在其生成的代码中,使用相对栈指针(stack-pointer)的偏移量来引用参数和局部变量。这样使得我们可以在那些寄存器数量较少的平台上(例如 x86),也可以将帧指针(frame-pointer)作为一个额外的通用寄存器。 如果你喜欢了解这些细节问题,可以参考本章后提供的 Stack frame layout on x86-64 一文。
"".b+12(SP) 和 "".a+8(SP) 分别指向栈的低 12 字节和低 8 字节位置(记住: 栈是向低位地址方向增长的!)。
.a 和 .b 是分配给引用地址的任意别名;尽管 它们没有任何语义上的含义 ,但在使用虚拟寄存器和相对地址时,这种别名是需要强制使用的。
虚拟寄存器帧指针(frame-pointer)的文档对此有所提及:
FP伪寄存器是虚拟的帧指针,用来对函数的参数做参考。编译器维护虚拟帧指针并将栈中 的参数作为该伪寄存器的偏移量。因此0(FP)是函数的第一个参数,8(FP)是第二个(在64 位机器上),等等。然而,当使用这种方式应用函数参数时,必须在开始的位置放置一个 名称,比如first_arg+0(FP) 以及 second_arg+8(FP). (偏移————相对于帧指针的偏 移————的意义是与SB中的偏移不一样的,它是相对于符号的偏移。)汇编器强制执行这种 约定,拒绝纯0(FP)以及8(FP)。实际名称与语义不想关,但应该用来记录参数的名字。
最后,有两个重点需要指出:
- 第一个变量
a的地址并不是0(SP),而是在8(SP);这是因为调用方通过使用CALL伪指令,把其返回地址保存在了0(SP)位置。 - 参数是反序传入的;也就是说,第一个参数和栈顶距离最近。
0x0008 ADDL CX, AX
0x000a MOVL AX, "".~r2+16(SP)
0x000e MOVB $1, "".~r3+20(SP)ADDL 进行实际的加法操作,L 这里代表 Long,4 字节的值,其将保存在 AX 和 CX 寄存器中的值进行相加,然后再保存进 AX 寄存器中。
这个结果之后被移动到 "".~r2+16(SP) 地址处,这是之前调用方专门为返回值预留的栈空间。这一次 "".~r2 同样没什么语义上的含义。
为了演示 Go 如何处理多返回值,我们同时返回了一个 bool 常量 true。
返回这个 bool 值的方法和之前返回数值的方法是一样的;只是相对于 SP 寄存器的偏移量发生了变化。
0x0013 RET最后的 RET 伪指令告诉 Go 汇编器插入一些指令,这些指令是对应的目标平台中的调用规约所要求的,从子过程中返回时所需要的指令。
一般情况下这样的指令会使在 0(SP) 寄存器中保存的函数返回地址被 pop 出栈,并跳回到该地址。
TEXT块的最后一条指令必须为某种形式的跳转,通常为RET(伪)指令。 (如果不是的话,链接器会添加一条跳转到自己的指令;TEXT块没有失败处理)
我们一次性需要消化的语法和语义细节有点多。下面将我们已经覆盖到的知识点作为注释加进了汇编代码中:
;; Declare global function symbol "".add (actually main.add once linked)
;; Do not insert stack-split preamble
;; 0 bytes of stack-frame, 16 bytes of arguments passed in
;; func add(a, b int32) (int32, bool)
0x0000 TEXT "".add(SB), NOSPLIT, $0-16
;; ...omitted FUNCDATA stuff...
0x0000 MOVL "".b+12(SP), AX ;; move second Long-word (4B) argument from caller's stack-frame into AX
0x0004 MOVL "".a+8(SP), CX ;; move first Long-word (4B) argument from caller's stack-frame into CX
0x0008 ADDL CX, AX ;; compute AX=CX+AX
0x000a MOVL AX, "".~r2+16(SP) ;; move addition result (AX) into caller's stack-frame
0x000e MOVB $1, "".~r3+20(SP) ;; move `true` boolean (constant) into caller's stack-frame
0x0013 RET ;; jump to return address stored at 0(SP)总之,下面是 main.add 即将执行 RET 指令时的栈的情况。
| +-------------------------+ <-- 32(SP)
| | |
G | | |
R | | |
O | | main.main's saved |
W | | frame-pointer (BP) |
S | |-------------------------| <-- 24(SP)
| | [alignment] |
D | | "".~r3 (bool) = 1/true | <-- 21(SP)
O | |-------------------------| <-- 20(SP)
W | | |
N | | "".~r2 (int32) = 42 |
W | |-------------------------| <-- 16(SP)
A | | |
R | | "".b (int32) = 32 |
D | |-------------------------| <-- 12(SP)
S | | |
| | "".a (int32) = 10 |
| |-------------------------| <-- 8(SP)
| | |
| | |
| | |
\ | / | return address to |
\|/ | main.main + 0x30 |
- +-------------------------+ <-- 0(SP) (TOP OF STACK)
(diagram made with https://textik.com)
这里略去了一些代码帮你节省滚鼠标的时间,我们再次回忆一下 main 函数的逆向结果:
0x0000 TEXT "".main(SB), $24-0
;; ...omitted stack-split prologue...
0x000f SUBQ $24, SP
0x0013 MOVQ BP, 16(SP)
0x0018 LEAQ 16(SP), BP
;; ...omitted FUNCDATA stuff...
0x001d MOVQ $137438953482, AX
0x0027 MOVQ AX, (SP)
;; ...omitted PCDATA stuff...
0x002b CALL "".add(SB)
0x0030 MOVQ 16(SP), BP
0x0035 ADDQ $24, SP
0x0039 RET
;; ...omitted stack-split epilogue...0x0000 TEXT "".main(SB), $24-0没什么新东西:
"".main(被链接之后名字会变成main.main) 是一个全局的函数符号,存储在.text段中,该函数的地址是相对于整个地址空间起始位置的一个固定的偏移量。- 它分配了 24 字节的栈帧,且不接收参数,不返回值。
0x000f SUBQ $24, SP
0x0013 MOVQ BP, 16(SP)
0x0018 LEAQ 16(SP), BP上面我们已经提到过,Go 的调用规约强制我们将所有参数都通过栈来进行传递。
main 作为调用者,通过对虚拟栈指针(stack-pointer)寄存器做减法,将其栈帧大小增加了 24 个字节(回忆一下栈是向低地址方向增长,所以这里的 SUBQ 指令是将栈帧的大小调整得更大了)。
这 24 个字节中:
- 8 个字节(
16(SP)-24(SP)) 用来存储当前帧指针BP(这是一个实际存在的寄存器)的值,以支持栈的展开和方便调试 - 1+3 个字节(
12(SP)-16(SP)) 是预留出的给第二个返回值 (bool) 的空间,除了类型本身的 1 个字节,在amd64平台上还额外需要 3 个字节来做对齐 - 4 个字节(
8(SP)-12(SP)) 预留给第一个返回值 (int32) - 4 个字节(
4(SP)-8(SP)) 是预留给传给被调用函数的参数b (int32) - 4 个字节(
0(SP)-4(SP)) 预留给传入参数a (int32)
最后,跟着栈的增长,LEAQ 指令计算出帧指针的新地址,并将其存储到 BP 寄存器中。
0x001d MOVQ $137438953482, AX
0x0027 MOVQ AX, (SP)调用方将被调用方需要的参数作为一个 Quad word(8 字节值)推到了刚刚增长的栈的栈顶。
尽管指令里出现的 137438953482 这个值看起来像是随机的垃圾值,实际上这个值对应的就是 10 和 32 这两个 4 字节值,它们两被连接成了一个 8 字节值。
$ echo 'obase=2;137438953482' | bc
10000000000000000000000000000000001010
\_____/\_____________________________/
32 10
0x002b CALL "".add(SB)我们使用相对于 static-base 指针的偏移量,来对 add 函数进行 CALL 调用: 这种调用实际上相当于直接跳到一个指定的地址。
注意 CALL 指令还会将函数的返回地址(8 字节值)也推到栈顶;所以每次我们在 add 函数中引用 SP 寄存器的时候还需要额外偏移 8 个字节!
例如,"".a 现在不是 0(SP) 了,而是在 8(SP) 位置。
0x0030 MOVQ 16(SP), BP
0x0035 ADDQ $24, SP
0x0039 RET最后,我们:
- 将帧指针(frame-pointer)下降一个栈帧(stack-frame)的大小(就是“向下”一级)
- 将栈收缩 24 个字节,回收之前分配的栈空间
- 请求 Go 汇编器插入子过程返回相关的指令
现在还不是能够深入 goroutine 内部实现的合适时间点(这部分会在之后讲解),不过随着我们一遍遍 dump 出程序的汇编代码,栈管理相关的指令会越来越熟悉。 这样我们就可以快速地看出代码的模式,并且可以理解这些代码一般情况下在做什么,为什么要做这些事情。
由于 Go 程序中的 goroutine 数目是不可确定的,并且实际场景可能会有百万级别的 goroutine,runtime 必须使用保守的思路来给 goroutine 分配空间以避免吃掉所有的可用内存。
也由于此,每个新的 goroutine 会被 runtime 分配初始为 2KB 大小的栈空间(Go 的栈在底层实际上是分配在堆空间上的)。
随着一个 goroutine 进行自己的工作,可能会超出最初分配的栈空间限制(就是栈溢出的意思)。 为了防止这种情况发生,runtime 确保 goroutine 在超出栈范围时,会创建一个相当于原来两倍大小的新栈,并将原来栈的上下文拷贝到新栈上。 这个过程被称为 栈分裂(stack-split),这样使得 goroutine 栈能够动态调整大小。
为了使栈分裂正常工作,编译器会在每一个函数的开头和结束位置插入指令来防止 goroutine 爆栈。
像我们本章早些看到的一样,为了避免不必要的开销,一定不会爆栈的函数会被标记上 NOSPLIT 来提示编译器不要在这些函数的开头和结束部分插入这些检查指令。
我们来看看之前的 main 函数,这次不再省略栈分裂的前导指令:
0x0000 TEXT "".main(SB), $24-0
;; stack-split prologue
0x0000 MOVQ (TLS), CX
0x0009 CMPQ SP, 16(CX)
0x000d JLS 58
0x000f SUBQ $24, SP
0x0013 MOVQ BP, 16(SP)
0x0018 LEAQ 16(SP), BP
;; ...omitted FUNCDATA stuff...
0x001d MOVQ $137438953482, AX
0x0027 MOVQ AX, (SP)
;; ...omitted PCDATA stuff...
0x002b CALL "".add(SB)
0x0030 MOVQ 16(SP), BP
0x0035 ADDQ $24, SP
0x0039 RET
;; stack-split epilogue
0x003a NOP
;; ...omitted PCDATA stuff...
0x003a CALL runtime.morestack_noctxt(SB)
0x003f JMP 0可以看到,栈分裂(stack-split)前导码被分成 prologue 和 epilogue 两个部分:
- prologue 会检查当前 goroutine 是否已经用完了所有的空间,然后如果确实用完了的话,会直接跳转到后部。
- epilogue 会触发栈增长(stack-growth),然后再跳回到前部。
这样就形成了一个反馈循环,使我们的栈在没有达到饥饿的 goroutine 要求之前不断地进行空间扩张。
Prologue
0x0000 MOVQ (TLS), CX ;; store current *g in CX
0x0009 CMPQ SP, 16(CX) ;; compare SP and g.stackguard0
0x000d JLS 58 ;; jumps to 0x3a if SP <= g.stackguard0TLS 是一个由 runtime 维护的虚拟寄存器,保存了指向当前 g 的指针,这个 g 的数据结构会跟踪 goroutine 运行时的所有状态值。
看一看 runtime 源代码中对于 g 的定义:
type g struct {
stack stack // 16 bytes
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
stackguard0 uintptr
stackguard1 uintptr
// ...omitted dozens of fields...
}我们可以看到 16(CX) 对应的是 g.stackguard0,是 runtime 维护的一个阈值,该值会被拿来与栈指针(stack-pointer)进行比较以判断一个 goroutine 是否马上要用完当前的栈空间。
因此 prologue 只要检查当前的 SP 的值是否小于或等于 stackguard0 的阈值就行了,如果是的话,就跳到 epilogue 部分去。
Epilogue
0x003a NOP
0x003a CALL runtime.morestack_noctxt(SB)
0x003f JMP 0epilogue 部分的代码就很直来直去了: 它直接调用 runtime 的函数,对应的函数会将栈进行扩张,然后再跳回到函数的第一条指令去(就是指 prologue部分)。
在 CALL 之前出现的 NOP 这个指令使 prologue 部分不会直接跳到 CALL 指令位置。在一些平台上,直接跳到 CALL 可能会有一些麻烦的问题;所以在调用位置插一个 noop 的指令并在跳转时跳到这个 NOP 位置是一种最佳实践。
Go汇编中函数调用的参数以及返回值都是由栈传递和保存的,这部分空间由caller在其栈帧(stack frame)上提供。Go汇编中没有使用PUSH/POP指令进行栈的伸缩处理,所有栈的增长和收缩是通过在栈指针寄存器SP上分别执行减法和加法指令来实现的。
caller
+------------------+
| |
+----------------------> |------------------|
| | caller parent BP |
| |------------------| <--------- BP(pseudo SP)
| | local Var0 |
| |------------------|
| | ......... |
| |------------------|
| | local VarN |
| |------------------|
| | temporarily |
| unused space |
caller stack frame |------------------|
| callee retN |
| |------------------|
| | ......... |
| |------------------|
| | callee ret0 |
| |------------------|
| | callee argN |
| |------------------|
| | ......... |
| |------------------|
| | callee arg0 |
| |------------------| <--------- FP(virtual register)
| | return addr |
+----------------------> |------------------| <----------------------+
| caller BP | |
BP(pseudo SP) ------> |------------------| |
| local Var0 | |
|------------------| |
| local Var1 |
|------------------| callee stack frame
| ......... |
|------------------| |
| local VarN | |
SP(Real Register) ------> |------------------| |
| | |
| | |
+------------------+ <----------------------+
callee
go代码示例:
package main
import "fmt"
//go:noinline
func add(a, b int) int {
return a + b
}
func main() {
c := add(3, 5)
fmt.Println(c)
}go tool compile -N -l -S main.go
GOOS=linux GOARCH=amd64 go tool compile -N -l -S main.go # 指定系统和架构- -N选项指示禁止优化
- -l选项指示禁止内联
- -S选项指示打印出汇编代码
若要禁止指定函数内联优化,可以在函数定义处加上noinline标签:
//go:noinline
func add(a, b int) int {
return a + b
}方法1: 根据目标文件反编译出汇编代码
go tool compile -N -l main.go # 生成main.o
go tool objdump main.o
go tool objdump -s "main.(main|add)" ./test # objdump支持搜索特定字符串方法2: 根据可执行文件反编译出汇编代码
go build -gcflags="-N -l" main.go -o test
go tool objdump main.ogo build -gcflags="-N -l -S" main.go- Go官方:A Quick Guide to Go's Assembler
- plan9 assembly 完全解析
- EAX x86 Register Meaning and History
- teh-cmc/go-internals中文版
- x86 Assembly/Interfacing with Linux
- 为什么系统调用会消耗较多资源
- x86 Assembly book
- LINUX SYSTEM CALL TABLE FOR X86 64
- Dropping down Go functions in assembly language
- A Readers Guide to x86 Assembly
- Go汇编笔记
- 理解 Golang 中函数调用的原理
- What is an ABI?
- Linux用户态是如何使用FS寄存器引用glibc TLS的?
- Using FS and GS segments in user space applications
- How many bits does a WORD contain in 32/64 bit OS respectively?
- x86 and amd64 instruction reference