atomic是Go内置原子操作包。下面是官方说明:
Package atomic provides low-level atomic memory primitives useful for implementing synchronization algorithms.
atomic包提供了用于实现同步机制的底层原子内存原语。
These functions require great care to be used correctly. Except for special, low-level applications, synchronization is better done with channels or the facilities of the sync package. Share memory by communicating; don't communicate by sharing memory
使用这些功能需要非常小心。除了特殊的底层应用程序外,最好使用通道或sync包来进行同步。通过通信来共享内存;不要通过共享内存来通信。
atomic包提供的操作可以分为三类:
T类型是int32、int64、uint32、uint64、uintptr其中一种。
func AddT(addr *T, delta T) (new T)
func CompareAndSwapT(addr *T, old, new T) (swapped bool)
func LoadT(addr *T) (val T)
func StoreT(addr *T, val T)
func SwapT(addr *T, new T) (old T)func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)atomic提供了atomic.Value类型,用来原子性加载和存储类型一致的值(consistently typed value)。atomic.Value提供了对任何类型的原则性操作。
func (v *Value) Load() (x interface{}) // 原子性返回刚刚存储的值,若没有值返回nil
func (v *Value) Store(x interface{}) // 原子性存储值x,x可以是nil,但需要每次存的值都必须是同一个具体类型。package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var count int32
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
atomic.AddInt32(&count, 1) // 原子性增加值
wg.Done()
}()
go func() {
fmt.Println(atomic.LoadInt32(&count)) // 原子性加载
}()
}
wg.Wait()
fmt.Println("count: ", count)
}package main
import (
"sync/atomic"
)
type spin int64
func (l *spin) lock() bool {
for {
if atomic.CompareAndSwapInt64((*int64)(l), 0, 1) {
return true
}
continue
}
}
func (l *spin) unlock() bool {
for {
if atomic.CompareAndSwapInt64((*int64)(l), 1, 0) {
return true
}
continue
}
}
func main() {
s := new(spin)
for i := 0; i < 5; i++ {
s.lock()
go func(i int) {
println(i)
s.unlock()
}(i)
}
for {
}
}对于Uint32和Uint64类型Add方法第二个参数只能接受相应的无符号整数,atomic包没有提供减法SubstractT操作:
func AddUint32(addr *uint32, delta uint32) (new uint32)
func AddUint64(addr *uint64, delta uint64) (new uint64)对于无符号整数V,我们可以传递-V给AddT方法第二个参数就可以实现减法操作。
package main
import (
"sync/atomic"
)
func main() {
var i uint64 = 100
var j uint64 = 10
var k = 5
atomic.AddUint64(&i, -j)
println(i)
atomic.AddUint64(&i, -uint64(k))
println(i)
// 下面这种操作是不可以的,会发生恐慌:constant -5 overflows uint64
// atomic.AddUint64(&i, -uint64(5))
}atomic包提供的三类操作的前两种都是直接通过汇编源码实现的(sync/atomic/asm.s):
#include "textflag.h"
TEXT ·SwapInt32(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Xchg(SB)
TEXT ·SwapUint32(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Xchg(SB)
...
TEXT ·StoreUintptr(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Storeuintptr(SB)从上面汇编代码可以看出来atomic操作通过JMP操作跳到runtime/internal/atomic目录下面的汇编实现。我们把目标转移到runtime/internal/atomic目录下面。
该目录包含针对不同平台的atomic汇编实现asm_xxx.s。这里面我们只关注amd64平台asm_amd64.s(runtime/internal/atomic/asm_amd64.s)和atomic_amd64.go(runtime/internal/atomic/atomic_amd64.go)。
| 函数 | 底层实现 |
|---|---|
| SwapInt32 / SwapUint32 | runtime∕internal∕atomic·Xchg |
| SwapInt64 / SwapUint64 / SwapUintptr | runtime∕internal∕atomic·Xchg64 |
| CompareAndSwapInt32 / CompareAndSwapUint32 | runtime∕internal∕atomic·Cas |
| CompareAndSwapUintptr / CompareAndSwapInt64 / CompareAndSwapUint64 | runtime∕internal∕atomic·Cas64 |
| AddInt32 / AddUint32 | runtime∕internal∕atomic·Xadd |
| AddUintptr / AddInt64 / AddUint64 | runtime∕internal∕atomic·Xadd64 |
| LoadInt32 / LoadUint32 | runtime∕internal∕atomic·Load |
| LoadInt64 / LoadUint64 / LoadUint64/ LoadUintptr | runtime∕internal∕atomic·Load64 |
| LoadPointer | runtime∕internal∕atomic·Loadp |
| StoreInt32 / StoreUint32 | runtime∕internal∕atomic·Store |
| StoreInt64 / StoreUint64 / StoreUintptr | runtime∕internal∕atomic·Store64 |
AddUintptr 、 AddInt64 以及 AddUint64都是由方法runtime∕internal∕atomic·Xadd64实现:
TEXT runtime∕internal∕atomic·Xadd64(SB), NOSPLIT, $0-24
MOVQ ptr+0(FP), BX // 第一个参数保存到BX
MOVQ delta+8(FP), AX // 第二个参数保存到AX
MOVQ AX, CX // 将第二个参数临时存到CX寄存器中
LOCK // LOCK指令进行锁住操作,实现对共享内存独占访问
XADDQ AX, 0(BX) // xaddq指令,实现寄存器AX的值与BX指向的内存存的值互换,
// 并将这两个值的和存在BX指向的内存中,此时AX寄存器存的是第一个参数指向的值
ADDQ CX, AX // 此时AX寄存器的值是Add操作之后的值,和0(BX)值一样
MOVQ AX, ret+16(FP) # 返回值
RETLOCK指令是一个指令前缀,其后是读-写性质的指令,在多处理器环境中,LOCK指令能够确保在执行LOCK随后的指令时,处理器拥有对数据的独占使用。若对应数据已经在cache line里,也就不用锁定总线,仅锁住缓存行即可,否则需要锁住总线来保证独占性。
XADDQ指令用于交换加操作,会将源操作数与目的操作数互换,并将两者的和保存到源操作数中。
AddInt32 、 AddUint32 都是由方法runtime∕internal∕atomic·Xadd实现,实现逻辑和runtime∕internal∕atomic·Xadd64一样,只是Xadd中相关数据操作指令后缀是L:
TEXT runtime∕internal∕atomic·Xadd(SB), NOSPLIT, $0-20
MOVQ ptr+0(FP), BX // 注意第一个参数是一个指针类型,是64位,所以还是MOVQ指令
MOVL delta+8(FP), AX // 第二个参数32位的,所以是MOVL指令
MOVL AX, CX
LOCK
XADDL AX, 0(BX)
ADDL CX, AX
MOVL AX, ret+16(FP)
RETStoreInt64、StoreUint64、StoreUintptr三个是runtime∕internal∕atomic·Store64方法实现:
TEXT runtime∕internal∕atomic·Store64(SB), NOSPLIT, $0-16
MOVQ ptr+0(FP), BX // 第一个参数保存到BX
MOVQ val+8(FP), AX // 第二个参数保存到AX
XCHGQ AX, 0(BX) // 将AX寄存器与BX寄存指向内存的值互换,
// 那么第一个参数指向的内存存的值为第二个参数
RETXCHGQ指令是交换指令,用于交换源操作数和目的操作数。
StoreInt32、StoreUint32是由runtime∕internal∕atomic·Store方法实现,与runtime∕internal∕atomic·Store64逻辑一样,这里不在赘述。
CompareAndSwapUintptr、CompareAndSwapInt64和CompareAndSwapUint64都是由runtime∕internal∕atomic·Cas64实现:
TEXT runtime∕internal∕atomic·Cas64(SB), NOSPLIT, $0-25
MOVQ ptr+0(FP), BX // 将第一个参数保存到BX
MOVQ old+8(FP), AX // 将第二个参数保存到AX
MOVQ new+16(FP), CX // 将第三个参数保存CX
LOCK // LOCK指令进行上锁操作
CMPXCHGQ CX, 0(BX) // BX寄存器指向的内存的值与AX寄存器值进行比较,若相等则把CX寄存器值存储到BX寄存器指向的内存中
SETEQ ret+24(FP)
RETCMPXCHGQ指令是比较并交换指令,它的用法是将目的操作数和累加寄存器AX进行比较,若相等,则将源操作数复制到目的操作数中,否则将目的操作复制到累加寄存器中。
SwapInt64、SwapUint64、SwapUintptr实现的方法是runtime∕internal∕atomic·Xchg64,SwapInt32和SwapUint32底层实现是runtime∕internal∕atomic·Xchg,这里面只分析64的操作:
TEXT runtime∕internal∕atomic·Xchg64(SB), NOSPLIT, $0-24
MOVQ ptr+0(FP), BX // 第一个参数保存到BX
MOVQ new+8(FP), AX // 第一个参数保存到AX中
XCHGQ AX, 0(BX) // XCHGQ指令交互AX值到0(BX)中
MOVQ AX, ret+16(FP) // 将旧值返回
RETLoadInt32、LoadUint32、LoadInt64 、 LoadUint64 、 LoadUint64、 LoadUintptr、LoadPointer实现都是Go实现的:
//go:linkname Load
//go:linkname Loadp
//go:linkname Load64
//go:nosplit
//go:noinline
func Load(ptr *uint32) uint32 {
return *ptr
}
//go:nosplit
//go:noinline
func Loadp(ptr unsafe.Pointer) unsafe.Pointer {
return *(*unsafe.Pointer)(ptr)
}
//go:nosplit
//go:noinline
func Load64(ptr *uint64) uint64 {
return *ptr
}最后我们来分析atomic.Value类型提供Load/Store操作。
atomic.Value类型定义如下:
type Value struct {
v interface{}
}
// ifaceWords是空接口底层表示
type ifaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}atomic.Value底层存储的是空接口类型,空接口底层结构如下:
type eface struct {
_type *_type // 空接口持有的类型
data unsafe.Pointer // 指向空接口持有类型变量的指针
}atomic.Value内存布局如下所示:
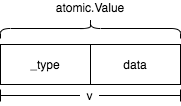
从上图可以看出来atomic.Value内部分为两部分,第一个部分是_type类型指针,第二个部分是unsafe.Pointer类型,两个部分大小都是8字节(64系统下)。我们可以通过以下代码进行测试:
type Value struct {
v interface{}
}
type ifaceWords struct {
typ unsafe.Pointer
data unsafe.Pointer
}
func main() {
func main() {
val := Value{v: 123456}
t := (*ifaceWords)(unsafe.Pointer(&val))
dp := (*t).data // dp是非安全指针类型变量
fmt.Println(*((*int)(dp))) // 输出123456
var val2 Value
t = (*ifaceWords)(unsafe.Pointer(&val2))
fmt.Println(t.typ) // 输出nil
}接下来我们看下Store方法:
func (v *Value) Store(x interface{}) {
if x == nil { // atomic.Value类型变量不能是nil
panic("sync/atomic: store of nil value into Value")
}
vp := (*ifaceWords)(unsafe.Pointer(v)) // 将指向atomic.Value类型指针转换成*ifaceWords类型
xp := (*ifaceWords)(unsafe.Pointer(&x)) // xp是*faceWords类型指针,指向传入参数x
for {
typ := LoadPointer(&vp.typ) // 原子性返回vp.typ
if typ == nil { // 第一次调用Store时候,atomic.Value底层结构体第一部分是nil,
// 我们可以从上面测试代码可以看出来
runtime_procPin() // pin process处理,防止M被抢占
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(^uintptr(0))) { // 通过cas操作,将atomic.Value的第一部分存储为unsafe.Pointer(^uintptr(0)),若没操作成功,继续操作
runtime_procUnpin() // unpin process处理,释放对当前M的锁定
continue
}
// vp.data == xp.data
// vp.typ == xp.typ
StorePointer(&vp.data, xp.data)
StorePointer(&vp.typ, xp.typ)
runtime_procUnpin()
return
}
if uintptr(typ) == ^uintptr(0) { // 此时说明第一次的Store操作未完成,正在处理中,此时其他的Store等待第一次操作完成
continue
}
if typ != xp.typ { // 再次Store操作时进行typ类型校验,确保每次Store数据对象都必须是同一类型
panic("sync/atomic: store of inconsistently typed value into Value")
}
StorePointer(&vp.data, xp.data) // vp.data == xp.data
return
}
}总结上面Store流程:
- 每次调用Store方法时候,会将传入参数转换成interface{}类型。当第一次调用Store方法时候,分两部分操作,分别将传入参数空接口类型的_typ和data,存储到Value类型中。
- 当再次调用Store类型时候,进行传入参数空接口类型的_type和Value的_type比较,若不一致直接panic,若一致则将data存储到Value类型中
从流程2可以看出来,每次调用Store方法时传入参数都必须是同一类型的变量。当Store完成之后,实现了“鸠占鹊巢”,atomic.Value底层存储的实际上是(interface{})x。
最后我们看看atomic.Value的Load操作:
func (v *Value) Load() (x interface{}) {
vp := (*ifaceWords)(unsafe.Pointer(v)) // 将指向v指针转换成*ifaceWords类型
typ := LoadPointer(&vp.typ)
if typ == nil || uintptr(typ) == ^uintptr(0) { // typ == nil 说明Store方法未调用过
// uintptr(typ) == ^uintptr(0) 说明第一Store方法调用正在进行中
return nil
}
data := LoadPointer(&vp.data)
xp := (*ifaceWords)(unsafe.Pointer(&x))
xp.typ = typ
xp.data = data
return
}