English | Tiếng Việt
- Demo: https://youtu.be/o5xpfwalEWw
- Demo source: https://github.com/ds4v/NomNaSite
The Vietnamese language, with its extremely diverse phonetics and the most robust writing system in East Asia, has undergone a journey from Confucian, Sino (Hán) characters to the Nôm script, and finally, the Quốc Ngữ alphabet based on the Latin writing system. Accompanying each type of script are glorious chapters of the nation's history.
After ending Thousand Years of Chinese Domination, our ancestors, with a consciousness of linguistic self-determination, created the Nôm script, an ideographic script based on the Hán characters to represent Vietnamese speech. Along with these Hán characters, the Nôm script was used to record the majority of Vietnamese documents for about 10 centuries. However, this heritage is currently at risk of extinction by the shift to the modern Vietnamese script (Quốc Ngữ).
"Today, less than 100 scholars world-wide can read Nôm. Much of Việt Nam's vast,
written history is, in effect, inaccessible to the 80 million speakers of the language"
(Vietnamese Nôm Preservation Foundation – VNPF)
To use this vast source of knowledge, it needs to be digitized and translated into modern Quốc Ngữ. Due to the difficulty and time-consuming nature of translation, along with a limited number of experts, these efforts cannot be accomplished in a short time.
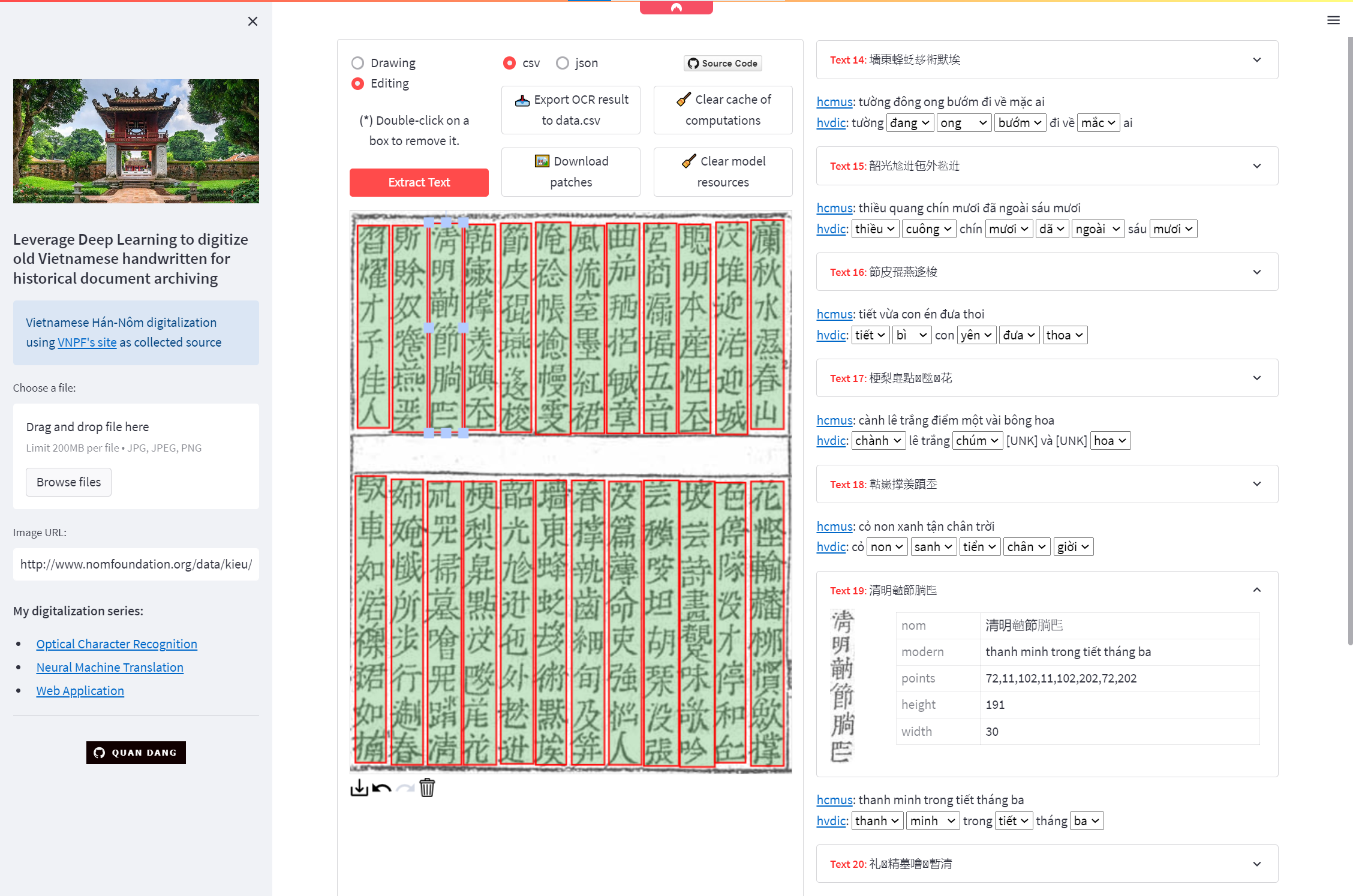
👉 To accelerate this digitization process, Optical Character Recognition (OCR) techniques are key to making all major works in Sino-Nom available online.
My teammate Nguyễn Đức Duy Anh and I have been working on this project for nearly 8 months under the dedicated guidance of Dr. Do Trong Hop (Faculty of Information Science and Engineering - VNUHCM UIT) and have obtained specific achievements:
-
Successful build of the NomNaOCR dataset:
- Serving 2 OCR problems of Text Detection and Text Recognition for historical documents written in Sino-Nom.
- The biggest dataset for Sino-Nom script at the moment, with 2953 Pages and 38318 Patches.
-
Successful build of an OCR pipeline on Sino-Nom text using Deep Learning.

-
Implement and experiment models on sequence level. This not only saves the cost for annotation but also helps us retain the semantics in the sequence, instead of just processing individual character like most previous works. Take a look at the following open-source projects if you need implementations on character level:

👉 You can take a look at this thesis_en.pdf file for a summary of the models used in this project.
II. The NomNaOCR Dataset

- Dataset: https://www.kaggle.com/datasets/quandang/nomnaocr
- Paper: https://ieeexplore.ieee.org/document/10013842
Note: You should use the NomNaTong font to be able to read the Sino-Nom content in the best way.
VNPF has digitized many famous Sino-Nom works with high historical value. To make use of these invaluable resources, I used Automa to create an automatic collection flow to collect:
- Images and their URLs.
- Phonetics with their digital characters and Vietnamese translation (if any).
Automa.mp4
I was lazy to write code at this step, so I did it a bit manually 😅.
- Import workflow.json into Automa.
- Choose the
New tabblock andEdit=> enter the URLs of the Sino-Nom works you want to collect EdittheTo numberfield of theLoop Datablock to specify the number of pages to be collected.EditCSS Selector of following blocks:Element exists: check if the page is empty.Blocks group: get the image URL and the text of the current page.
- Click
Executeto start collecting. - Run automa2txt.py to parse the obtained
automa.jsoninto 3 files:url.txt: contains the image URLs of the historical work.nom.txt: contains Sino-Nom text.modern.txt: contains the translated phonetics corresponding tonom.txt.
[*] For downloading images, I just simply use the Batch Download feature of Internet Download Manager.
| Document Name | Number of Pages |
|---|---|
| Lục Vân Tiên | 104 |
| Tale of Kiều ver 1866 | 100 |
| Tale of Kiều ver 1871 | 136 |
| Tale of Kiều ver 1872 | 163 |
| ĐVSKTT Quyển Thủ | 107 |
| ĐVSKTT Ngoại kỷ toàn thư | 178 |
| ĐVSKTT Bản kỷ toàn thư | 933 |
| ĐVSKTT Bản kỷ thực lục | 787 |
| ĐVSKTT Bản kỷ tục biên | 448 |
| Total | 2956 |
[*] ĐVSKTT: abbreviation of Đại Việt Sử Ký Toàn Thư (History of Greater Vietnam).
We used PPOCRLabel from the PaddleOCR ecosystem to assign bounding boxes automatically. This tool, by default, uses DBNet to detect text, which is also the model we planned to experiment with for Text Detection. Here, we have divided this tool into 2 versions:
- annotators.zip: For labelers, I removed unnecessary features like
Auto annotation, ... to avoid mistakes due to over-clicking during labeling and to make installation easier and less error-prone. - composer.zip: For guideline builders (who I'll call Composer) to run
Auto annotation, with quite fully functional compared to the original PPOCRLabel. I removed the Auto recognition computation when runningAuto annotationand usedTEMPORARYas the label for text. Additionally, I also implemented image rotation to match the input of the Recognition models when running theExport Recognition Resultfeature.
👉 Annotators will replace the TEMPORARY labels according to the guidelines for poetry and prose guidelines. Finally, they will map the actual labels collected from VNPF.

However, with images in NomNaOCR, PPOCRLabel will mainly detect text areas in horizontal orientation, so we rotated images at 90-degree angles to detect boxes:
- Depending on the documents, Composers chose to rotate the images by ±90 degrees or both directions.
- Run rotated_generator.py to generate the rotated images.
- Then, input them into PPOCRLabel to predict the
bounding boxes. - When the prediction is complete, run unrotated_convertor.py to rotate the
bounding boxesvertically again.
After the actual implementation, the NomNaOCR dataset obtained 2953 Pages (excluding 1 error-scanned page and 2 blank pages). By semi-manually annotating, we got additional 38,318 patches (1 Patch was ignored). Then, we used the formula of the IHR-NomDB dataset to acquire a similar distribution between the Train and Validate sets to split the Recognition data. The Synthetic Nom String set of this dataset was also used to perform Pretraining for Recognition models.
| Subset | Number of Records | Character Intersection |
|---|---|---|
| Train set | 30654 | 93.24% |
| Validate set | 7664 | 64.41% |

- For Detection, I used PaddleOCR for training with corresponding config files in the Text detection folder.
- For Recognition, during the PreTraining phase on the Synthetic Nom String set of IHR-NomDB, we found that when performing Skip Connection (SC) for the feature map with a layer X that has the same shape and is located as far away from this feature map as possible, it will significantly improve model performance. Therefore, we also experimented 2 fundamental Skip Connection methods: Addition and Concatenation for the most feasible models (those contain the aforementioned layer X).
👉 Download the weights of models here.

-
Metrics for evaluating Text Detection and End-to-End: We used a new method called CLEval to evaluate the effectiveness of both stages of Text Detection and Recognition (End-to-End). Moreover, this method can also evaluate Text Detection only, so depending on the problem, CLEval will vary in its computational components.
-
Metrics for evaluating Text Recognition only: We used similar metrics to previous related works at sequence level, including: Sequence Accuracy, Character Accuracy, and Character Error Rate (CER).
-
Additionally, for Recognition, I only keep the output of
notebooksor models that have the best results on theValidateset of NomNaOCR, including:- CRNNxCTC.ipynb: has the highest Sequence Accuracy.
- SC-CNNxTransformer_finetune.ipynb: has the highest Character Accuracy and CER.


👉 Check thesis_en.pdf for more information.




-
Members of the labeling team, who generously sacrificed a portion of their time to participate in this research and help us complete a high-quality dataset:
-
My friend, Nguyễn Ngọc Thịnh (Oriental Studies - VNUHCM USSH) for helping me answer questions about linguistic aspects of Sino-Nom characters in this project.
-
Mr. Nguyễn Đạt Phi, the founder of the HÙNG CA SỬ VIỆT channel, who has instilled in me a passion for our nation's history, which served as an inspiration for me to pursue this project. The stories about our ancestors, narrated with his emotive voice, have become an indispensable spiritual nourishment for me.
-
Finally, heartfelt thanks to VNPF for their wonderful works and contribution to the preservation of our national historical and cultural heritage.
-
Use Beam search or even further, a Language model to decode the output for Text Recognition, referencing projects by Harald Scheidl.
-
NomNaOCRpp: Experiment with more recent models or state-of-the-art (SOTA) models on famous benchmark datasets such as ICDAR 2013 and 2015.
-
NomNaSite: Develop a WebApp to apply implemented solutions in practical scenarios.
-
NomNaNMT: Develop the following 2 machine translation tasks.
- Translate Sino-Nom phonetics into Quốc Ngữ script: Already deployed by HCMUS.
- From the above Quốc Ngữ text, further translate into contemporary Vietnamese.

-
Record errors on VNPF into a file. During dataset creation, we discovered several errors in VNPF's translations, such as some translations not matching the current Page, incorrect translations compared to the image, translations with extra or missing words, ... Below are a few examples:
Error Description Work Page Location in Image Note The character 揆 in the dictionary does not mean "cõi" Tale of Kieu ver 1866 1 Sentence 1 The character 別 is different from the image Tale of Kieu ver 1866 9 Sentence 22 Variant of "别", appeared mostly in versions before 1902 The character 𥪞 is different from the image Tale of Kieu ver 1866 55 Sentence 15 The character is different from the image Tale of Kieu ver 1866 55 Sentence 15 There are 21 lines > 20 in the image Lục Vân Tiên 6 - There are 19 lines < 20 in the image Lục Vân Tiên 7 - The 5th character is displayed as [?] Lục Vân Tiên 7 Sentence 10

- Dive into Deep Learning book.
- OCR articles by Phạm Bá Cường Quốc.
- OCR articles by TheAILearner.
- OCR articles by Nanonets:
- OCR articles by Label Your Data:
- OCR articles by Gidi Shperber:
- Part 1 - A gentle introduction to OCR.
- Part 2 - OCR 101: All you need to know.
- Additionally, in
*.ipynband*.pyfiles, there are references noted for the corresponding implementations.