| title | date | categories | tags | permalink | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
分布式锁 |
2019-06-04 16:42:00 -0700 |
|
|
/pages/0eb5a899/ |
在计算机科学中,锁是在并发场景下用于强行限制资源访问的一种同步机制,即用于在并发控制中通过互斥手段来保证数据同步安全。
在 Java 进程中,可以使用 Lock、synchronized 等来支持并发锁。如果是同一台机器的不同进程,想要同时操作一个共享资源(例如修改同一个文件),可以使用操作系统提供的「文件锁」或「信号量」来做互斥。这些发生在同一台机器上的互斥操作,可以称为本地锁。
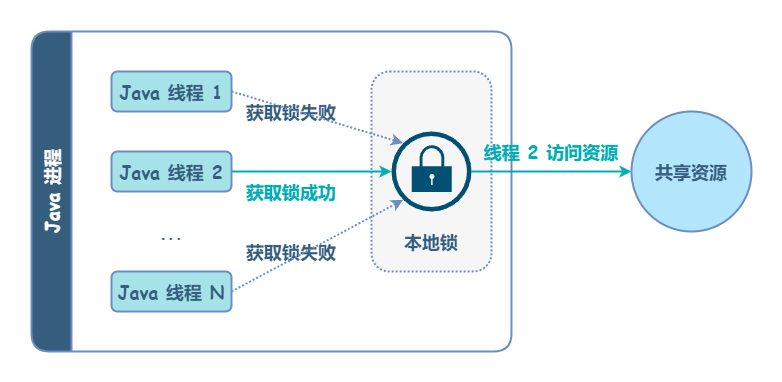
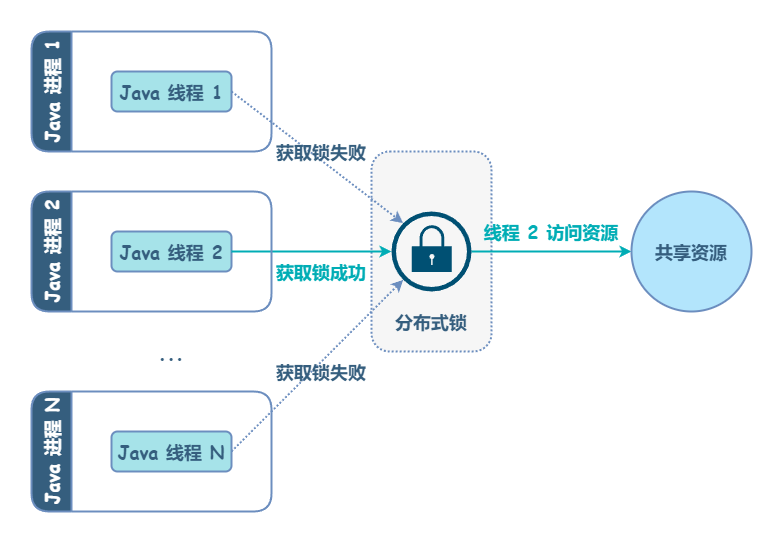
本地锁无法协同不同机器间的互斥操作。为了解决这个问题,需要引入分布式锁。
分布式锁,顾名思义,应用于分布式场景下,它和单进程中的锁并没有本质上的不同,只是控制对象由一个进程中的多个线程变成了多个进程中的多个线程。此外,临界区的资源也由进程内共享资源变成了分布式系统内部共享资源。
分布式锁典型应用场景是:
- 选举 Leader - 分布式锁可用于确保:在任何指定时间内,只有一个节点成为领导者。
- 任务调度 - 在分布式任务调度器中,分布式锁确保一个调度任务仅由一个 worker 节点执行,从而防止重复执行。
- 资源配置 - 在管理共享资源(如文件系统、网络 Socket 或硬件设备)时,分布式锁可确保一次只有一个进程可以访问资源。
- 微服务协调 - 当多个微服务需要执行协同操作时,例如更新不同数据库中的相关数据,分布式锁可以确保这些操作以可控和有序的方式执行。
- 库存管理 - 在电商系统中,分布式锁可以管理库存更新,以确保当多个用户尝试同时购买相同商品时,正确增减库存,防止超卖。
- 会话管理 - 在分布式环境中处理用户会话时,分布式锁可以确保用户会话一次只能由一个服务器修改,从而防止不一致。
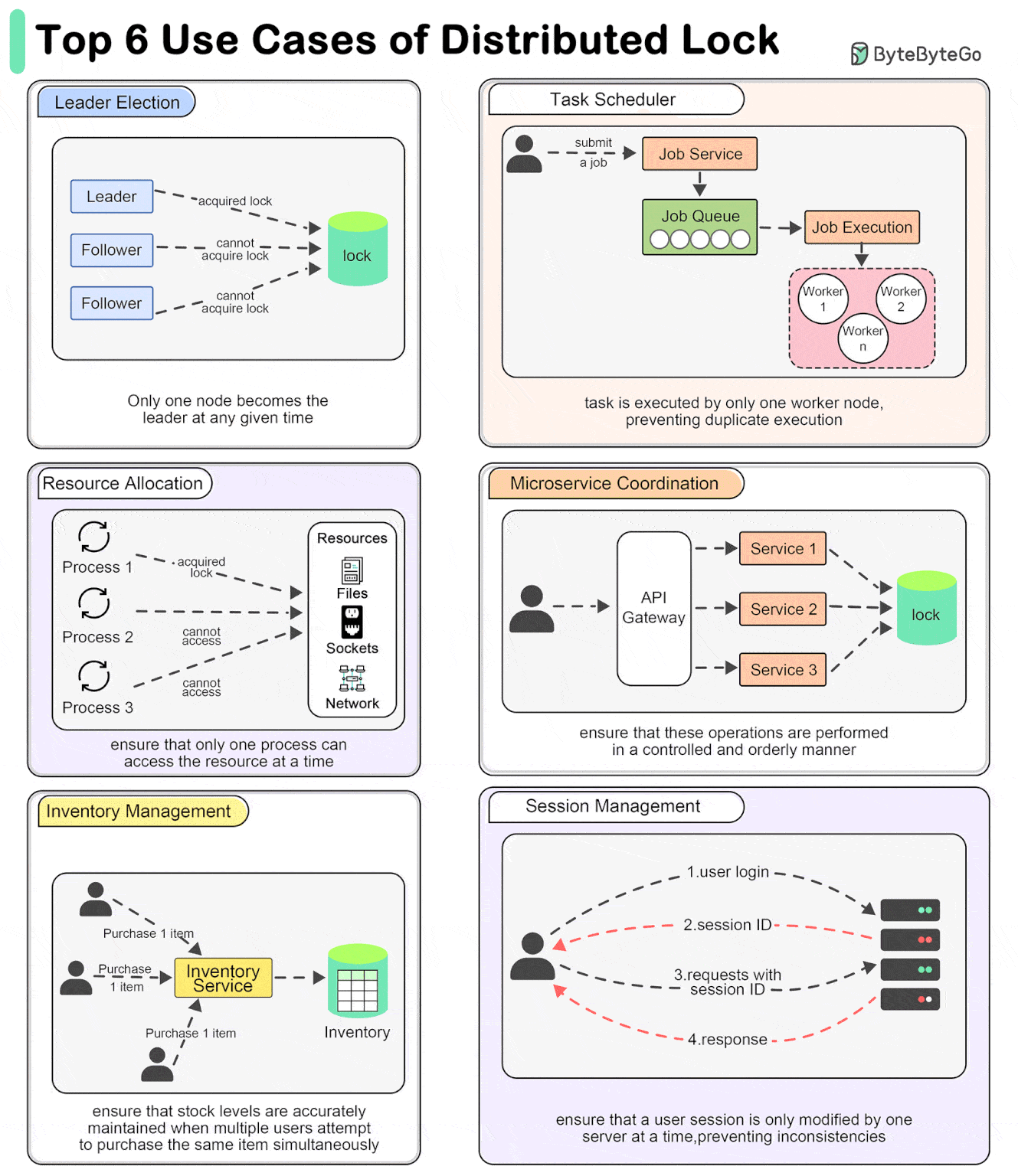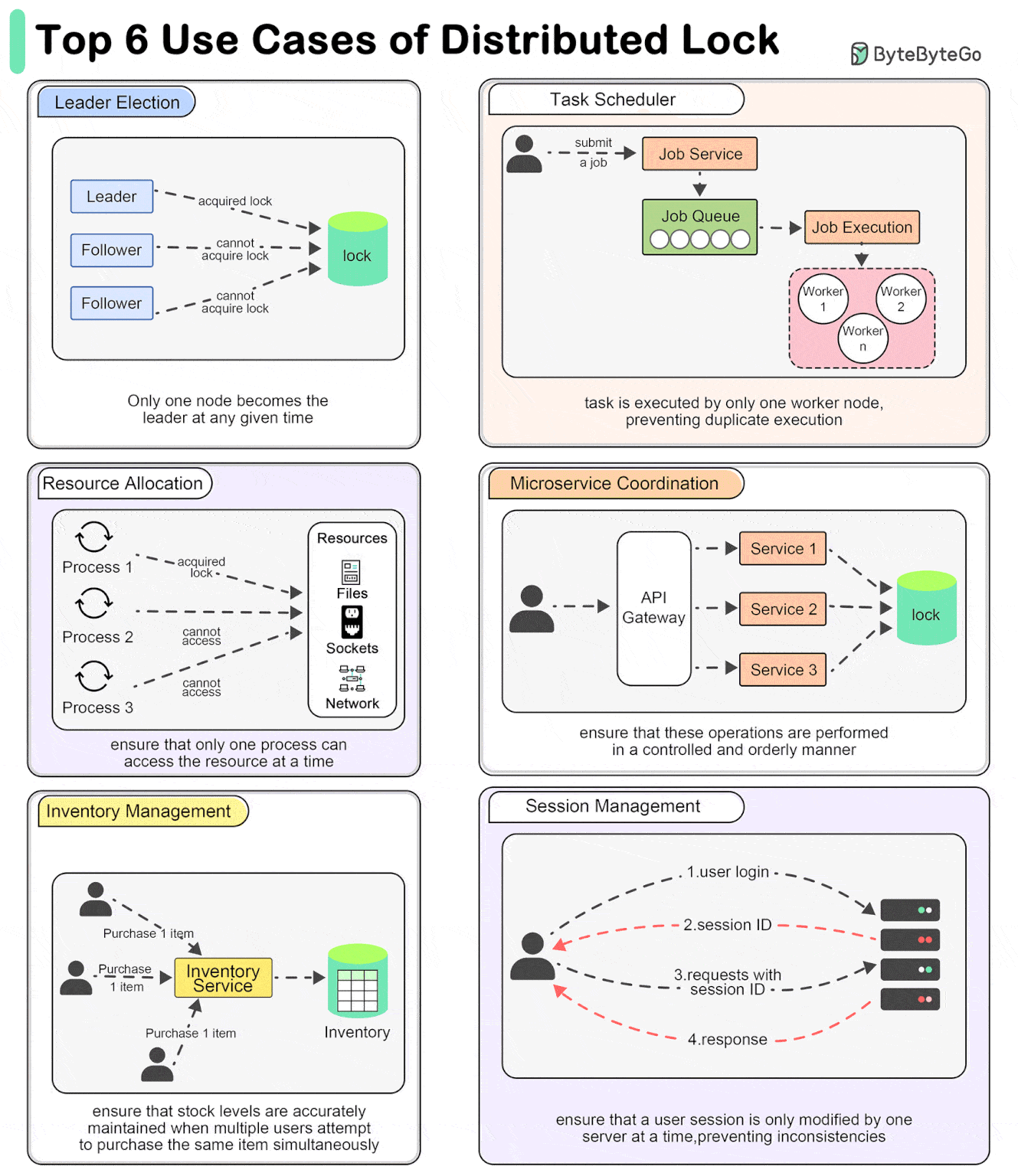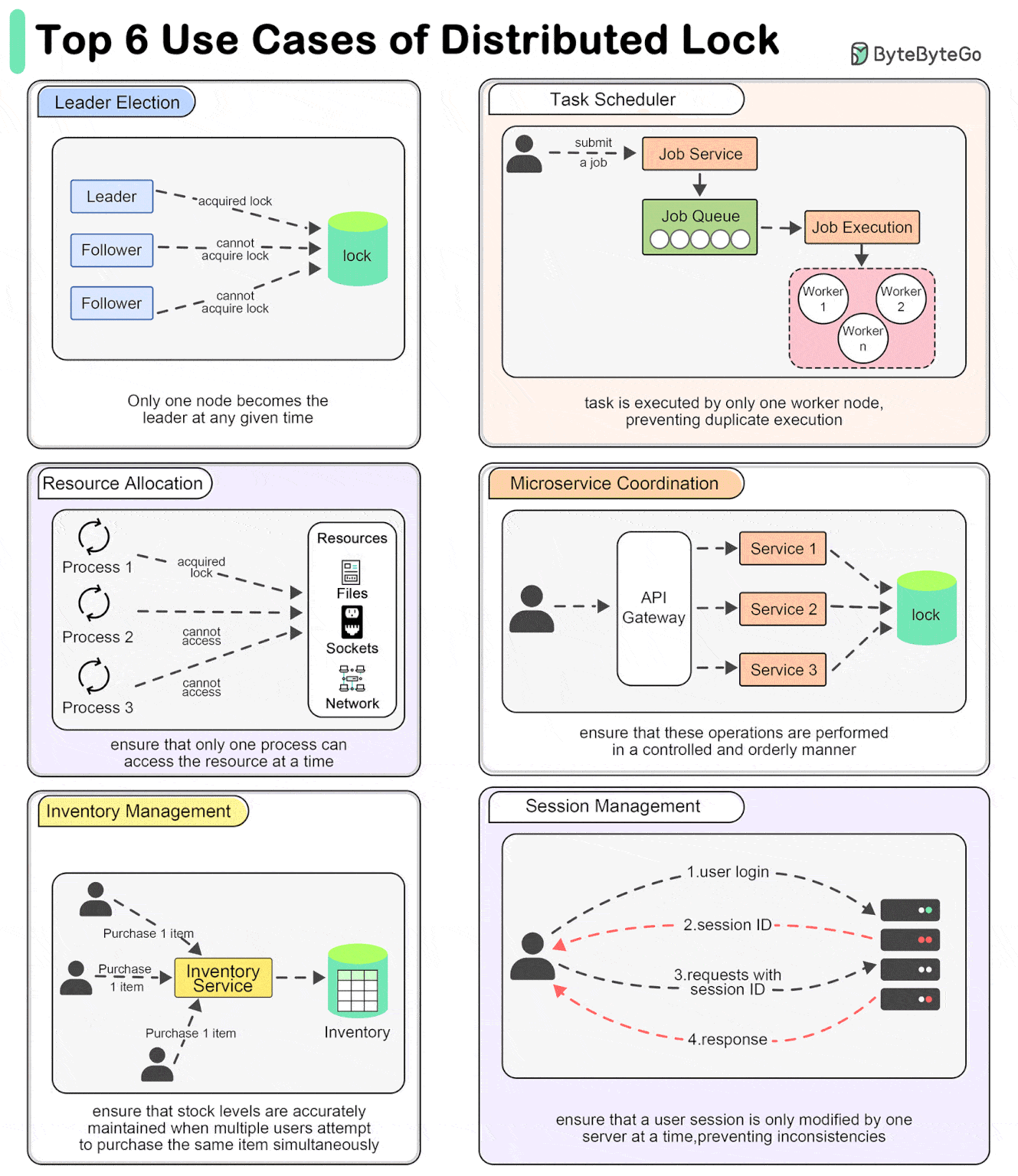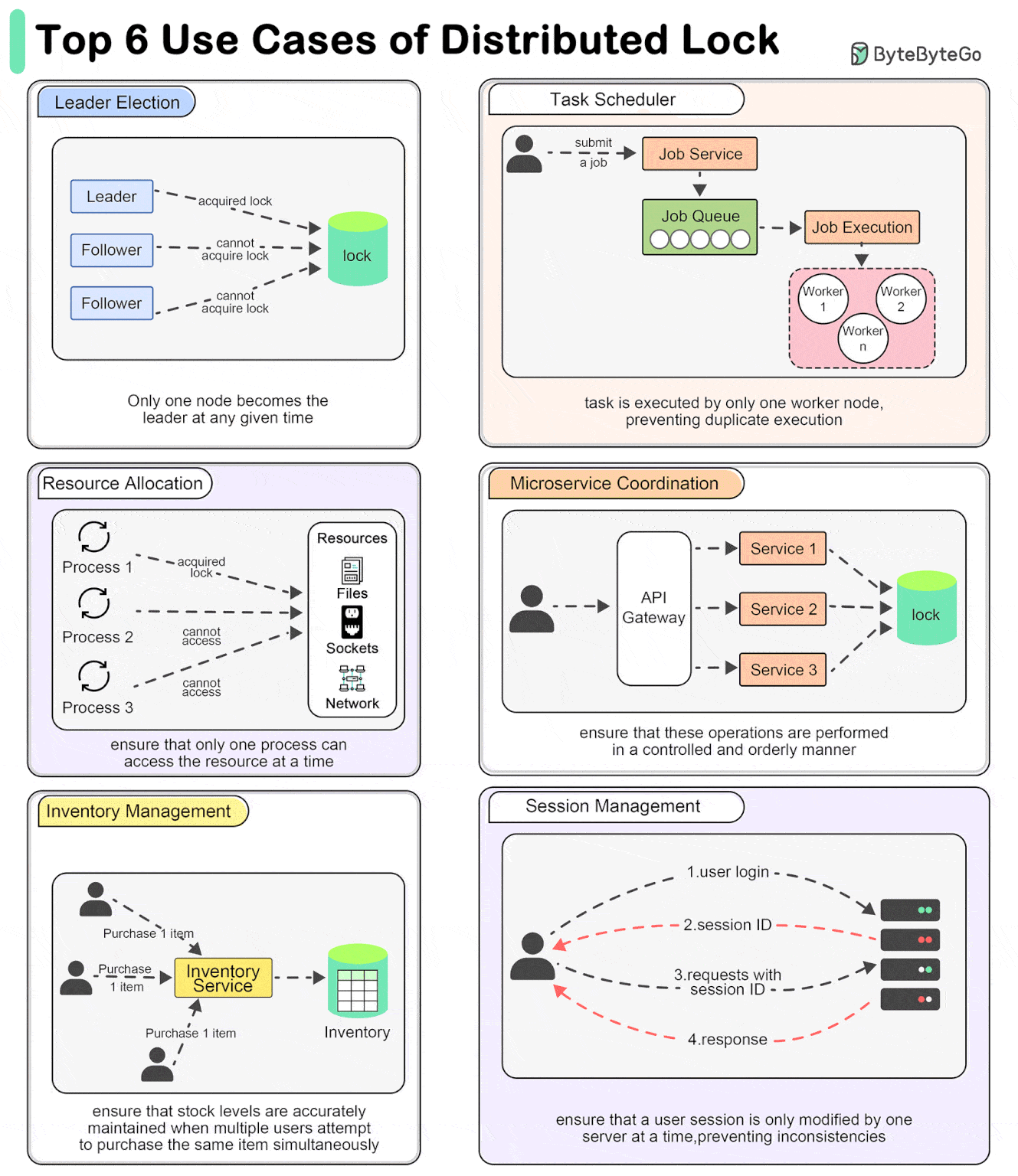
图来自:https://blog.bytebytego.com/i/149472287/why-do-we-need-to-use-a-distributed-lock
分布式锁的解决方案大致有以下几种:
- 基于数据库实现
- 基于缓存(Redis,Memcached 等)实现
- 基于 Zookeeper 实现
分布式锁的实现要点大同小异,仅在实现细节上有所不同。
分布式锁必须是独一无二的,表现形式为:向数据存储插入一个唯一的 key,一旦有一个线程插入这个 key,其他线程就不能再插入了。
- 保证 key 唯一性的最简单的方式是使用 UUID。
- 此外,可以参考 Snowflake ID(雪花算法),将机器地址(IP 地址、机器 ID、MAC 地址)、Jvm 进程 ID(应用 ID、服务 ID)、时间戳等关键信息拼接起来作为唯一标识。
- 应用自行保证
在分布式锁的场景中,部分失败和异步网络这两个问题是同时存在的。如果一个进程获得了锁,但是这个进程与锁服务之间的网络出现了问题,导致无法通信,那么这个情况下,如果锁服务让它一直持有锁,就会导致死锁的发生。
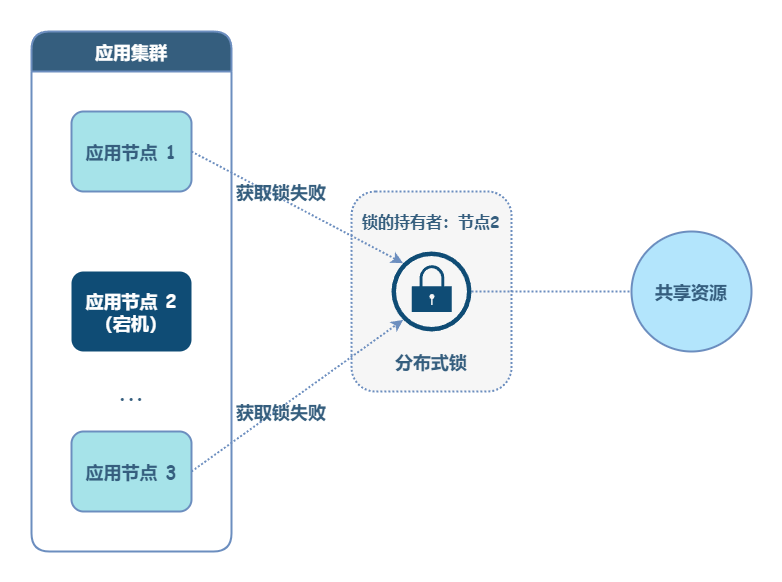
常见的解决思路是引入超时机制,即成功申请锁后,超过一定时间,锁失效(删除 key)。这样就不会出现锁一直不释放,导致其他线程无法获取锁的情况。Redis 分布式锁就采用了这种思路。
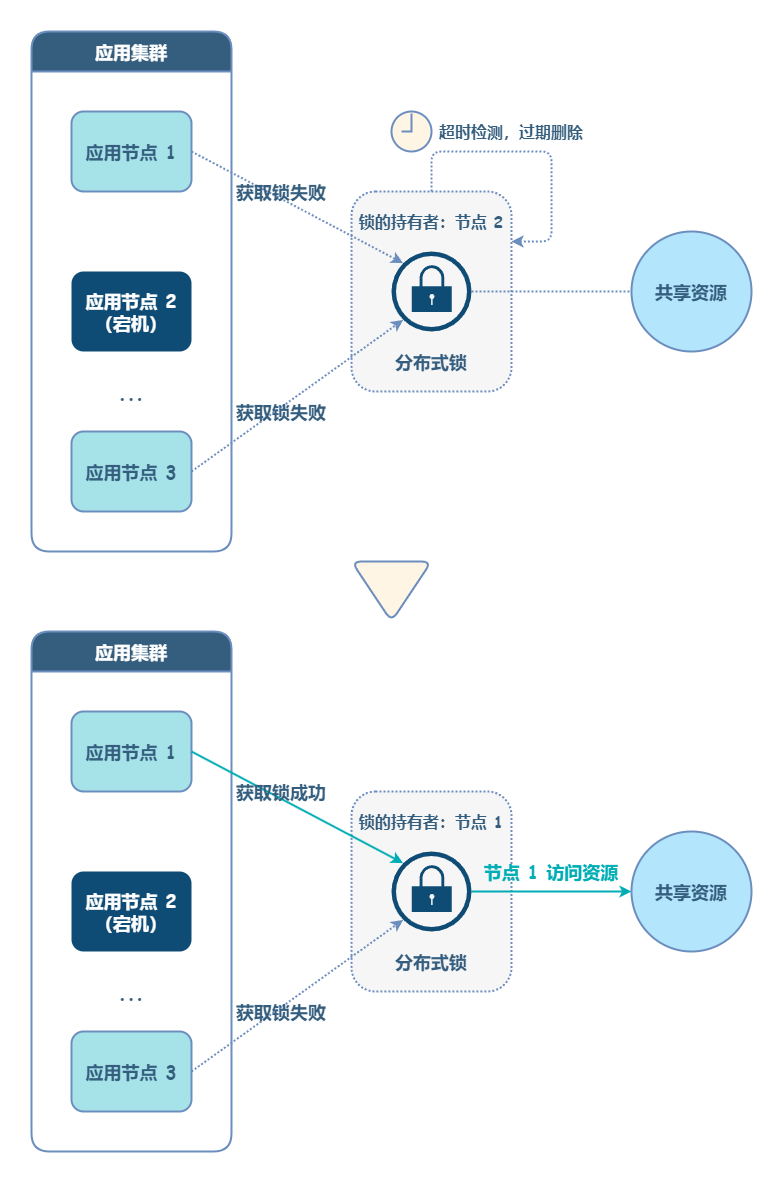
超时机制解锁了死锁问题,但又引入了一个新问题:如果应用加锁时,对于操作共享资源的时长估计不足,可能会出现:操作尚未执行完,但是锁没了的尴尬情况。为了解决这个问题,需要引入锁续期机制:当持有锁的线程尚未执行完操作前,不断周期性检测锁的超时时间,一旦发现快要过期,就自动为锁续期。
ZooKeeper 分布式锁避免死锁采用了另外一种思路。ZooKeeper 的存储单元叫 znode,它是以文件层级形式组织,天然就存在物理空间隔离。并且 ZooKeeper 支持临时节点 + Watch 机制,可以在客户端断连时主动删除临时节点,所以不存在死锁问题。
可重入指的是:同一个线程在没有释放锁之前,能否再次获得该锁。其实现方案是:只需在加锁的时候,记录好当前获取锁的节点 + 线程组合的唯一标识,然后在后续的加锁请求时,如果当前请求的节点 + 线程的唯一标识和当前持有锁的相同,那么就直接返回加锁成功;如果不相同,则按正常加锁流程处理。
当多个线程请求同一锁时,它们必须按照请求的顺序来获取锁,即先来先得的原则。锁的公平性的实现也非常简单,对于被阻塞的加锁请求,我们只要先记录好它们的顺序,在锁被释放后,按顺序颁发就可以了。
有时候,加锁失败可能只是由于网络波动、请求超时等原因,稍候就可以成功获取锁。为了应对这种情况,加锁操作需要支持重试机制。常见的做法是,设置一个加锁超时时间,在该时间范围内,不断自旋重试加锁操作,超时后再判定加锁失败。
分布式锁若存储在单一节点,一旦该节点宕机或失联,就会导致锁失效。将分布式锁存储在多数据库实例中,加锁时并发写入 N 个节点,只要 N / 2 + 1 个节点写入成功即视为加锁成功。
基于数据库实现分布式锁的思路是:维护一张锁记录表,为用于标识分布式锁的字段增加唯一性约束。利用唯一性约束的互斥性,当且仅当成功插入记录,即表示加锁成功。
(1)创建锁表
CREATE TABLE `distributed_lock` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '资源',
`count` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '锁次数,统计可重入锁',
`desc` TEXT DEFAULT NULL COMMENT '备注',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_resource`(`resource`)
)
ENGINE = InnoDB DEFAULT CHARSET = `utf8mb4`;(2)获取锁
想要锁住某个方法时,执行以下 SQL:
insert into methodLock(method_name,desc) values (‘method_name’,‘desc’)因为我们对 method_name 做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
成功插入则获取锁。
(3)释放锁
当方法执行完毕之后,想要释放锁的话,需要执行以下 Sql:
delete from methodLock where method_name ='method_name'数据库分布式锁的问题:
- 死锁:一旦释放锁操作失败,或持有锁的机器宕机、断连,就会导致锁记录一直存在,其他线程无法再获得锁。解决办法:为锁增加失效时间字段,启动一个定时任务,隔一段时间清除一次过期的数据。
- 非阻塞:因为
insert操作一旦失败就会报错,因此未获得锁的线程并不会进入排队队列,要想获得锁就要再次触发加锁操作。解决办法:循环重试,直到插入成功,这么做会产生一定额外开销。 - 非重入:同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。解决办法:在数据库表中加个字段,记录当前获得锁的节点信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
- 单点问题:如果数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。解决办法:单点问题可以用多数据库实例,同时写入
N个节点,N / 2 + 1个成功就加锁成功。
数据库分布式锁的利弊:
- 优点:直接借助数据库,简单易懂。
- 缺点:会有各种各样的问题,在解决问题的过程中会使整个方案变得越来越复杂。此外,数据库性能易成为瓶颈。
ZooKeeper 分布式锁的实现基于 ZooKeeper 的两个重要特性:
- 顺序临时节点:ZooKeeper 的存储类似于 DNS 那样的具有层级的命名空间。ZooKeeper 节点类型可以分为持久节点(
PERSISTENT)、临时节点(EPHEMERAL),每个节点还能被标记为有序性(SEQUENTIAL),一旦节点被标记为有序性,那么整个节点就具有顺序自增的特点。 - Watch 机制:ZooKeeper 允许用户在指定节点上注册一些
Watcher,并且在特定事件触发的时候,ZooKeeper 服务端会将事件通知给用户。
下面是 ZooKeeper 分布式锁的工作流程:
- 创建一个目录节点,比如叫做
/locks; - 线程 A 想获取锁,就在
/locks目录下创建临时顺序 zk 节点; - 获取
/locks目录下所有的子节点,检查是否存在比自己顺序更小的节点:若不存在,则说明当前线程创建的节点顺序最小,获取锁成功; - 此时,线程 B 试图获取锁,发现自己的节点顺序不是最小,设置监听锁号在自己前一位的节点;
- 线程 A 处理完,删除自己的节点。线程 B 监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
Apache Curator 提供了基于 ZooKeeper 实现的可重入公平锁 InterProcessMutex,它正是采用了上面所述的工作流程。
:::details ZooKeeper 分布式锁实现示例
下面是一个简单的 InterProcessMutex 封装示例:
import cn.hutool.core.collection.CollectionUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
@Slf4j
public class ZookeeperReentrantDistributedLock {
/**
* 锁路径,即锁的唯一标识,对应 zk 的一个 PERSISTENT 节点,加锁时会在该节点下新建 EPHEMERAL 节点
*/
private final String path;
/**
* zk 的客户端
*/
private final CuratorFramework client;
/**
* curator 客户端提供的 zk 可重入公平锁
*/
private final InterProcessMutex mutex;
public ZookeeperReentrantDistributedLock(String lockId, CuratorFramework client) {
this.client = client;
this.path = "/locks/" + lockId;
this.mutex = new InterProcessMutex(this.client, this.path);
}
public void lock() {
try {
mutex.acquire();
System.out.println("lock success");
} catch (Exception e) {
log.error("lock exception", e);
}
}
public boolean tryLock(long timeout, TimeUnit unit) {
try {
boolean isOk = mutex.acquire(timeout, unit);
if (isOk) {
System.out.println("tryLock success");
}
return isOk;
} catch (Exception e) {
log.error("tryLock exception", e);
return false;
}
}
public void unlock() {
try {
mutex.release();
System.out.println("unlock success");
} catch (Throwable e) {
log.error("unlock exception", e);
} finally {
// 清除根路径
// 生产环境中应指定线程池
CompletableFuture.runAsync(() -> {
try {
List<String> list = client.getChildren().forPath(path);
if (CollectionUtil.isEmpty(list)) {
client.delete().forPath(path);
}
} catch (Exception e) {
log.error("final unlock exception", e);
}
});
}
}
}测试代码:
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", retryPolicy);
client.start();
ZookeeperReentrantDistributedLock lock = new ZookeeperReentrantDistributedLock("订单流水号", client);
lock.lock();
System.out.println("do something");
lock.unlock();
client.close();:::
ZooKeeper 分布式锁的优点是较为可靠:
- 避免死锁:ZooKeeper 通过临时节点 + 监听机制,可以保证:如果持有临时节点的线程主动解锁或断连,Zk 会自动删除临时节点,这意味着锁的释放。所以,不存在锁永久不释放从而导致死锁的问题。
- 单点问题:ZooKeeper 采用主从架构,并确保主从同步是强一致的,因此不会出现单点问题。
ZooKeeper 分布式锁的缺点是:加锁、解锁操作,本质上是对 ZooKeeper 的写操作,全部由 ZooKeeper 主节点负责。如果加锁、解锁的吞吐量很大,容易出现单点写入瓶颈。
相比于用数据库来实现分布式锁,基于缓存实现的分布式锁的性能会更好。目前有很多成熟的分布式产品,包括 Redis、memcache、Tair 等。这里以 Redis 举例。
我们先来看一下,如何实现一个极简版本的 Redis 分布式锁。
(1)加锁
Redis 中的 setnx 命令,表示当且仅当 key 不存在时,才会写入 key。由于其互斥性,所以可以基于此来实现分布式锁。
执行 setnx key val,若返回 1,表示写入成功,即加锁成功;若返回 0,表示该 key 已存在,写入失败,即加锁失败。
(2)解锁
Redis 分布式锁如何解锁呢?
很简单,删除 key 就意味着释放锁,即执行 del key 命令。
极简版本的解决方案有一个很大的问题:存在死锁的可能。持有锁的节点如果执行业务过程中出现异常或机器宕机,都可能导致无法释放锁。这种情况下,其他节点永远也无法再获取锁。
对于异常,在 Java 中,可以通过 try...catch...finally 来保证:最终一定会释放锁,其他编程语言也有相似的语法特性。
对于机器宕机这种情况,如何处理呢?通常的对策是:为锁加上超时机制,过期自动删除。
在 Redis 中,expire 命令可以为 key 设置一个超时时间,一旦过期,Redis 会自动删除 key。如此看来,setnx + expire 组合使用,就能解决死锁问题了。可惜,没那么简单。Redis 只能保证单一命令的原子性,不保证组合命令的原子性。
那么,Redis 中有没有一条命令可以实现 setnx + expire 的组合语义呢?还真有,可以通过下面的命令来实现:
# 下面两条命令是等价的
SET key val NX PX 30000
SET key val NX EX 30参数说明:
NX:该参数表示当且仅当 key 不存在,才能写入成功PX:超时时间,单位毫秒EX:超时时间,单位秒
为了避免死锁,我们为锁添加了超时时间。但这里有一个问题,如果应用加锁时,对于操作共享资源的时长估计不足,可能会出现:操作尚未执行完,但是锁没了的尴尬情况。为了解决这个问题,很自然会想到,时间不够,就续期呗。
具体来说,如何续期呢?一种方案是:加锁后,启动一个定时任务,周期性检测锁是否快要过期,如果快要过期并且操作尚未结束,就对锁进行自动续期。自行实现这个方案似乎有点繁琐,好在开源 Redis 客户端 Redisson 中已经为锁的超时续期提供了一个成熟的机制——WatchDog(看门狗)。我们可以直接拿来主义即可。
前文提到了,解锁的操作,实际上就是 del key。这里存在一个问题:因为没有任何判断,任何节点都可以随意删除 key,换句话说,锁可能会被其他节点释放。如何避免这个问题呢?解决方法就是:为锁添加唯一性标识来进行互斥。唯一性标识可以是 UUID,可以是雪花算法 ID 等。
在 Redis 分布式锁中,唯一性标识的具体实现就是在 set key val 时,将唯一性标识 id 作为 val 写入。解锁前,先判断 key 的 value,必须和 set 时写入的 id 值保持一致,以此确认锁归属于自己。解锁的伪代码如下:
if (redis.get("key") == id)
redis.del("key");这里依然存在一个问题,由于需要在 Redis 中,先 get,后 del 操作,所以无法保证操作的原子性。为了保证原子性,可以将这段伪代码用 lua 脚本来实现,这么做的理由是 Redis 中支持原子性的执行 lua 脚本。下面是安全解锁的 lua 脚本代码:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end有时候,加锁失败可能只是由于网络波动、请求超时等原因,稍候就可以成功获取锁。为了应对这种情况,加锁操作需要支持重试机制。常见的做法是,设置一个加锁超时时间,在该时间范围内,不断自旋重试加锁操作,超时后再判定加锁失败。
下面是一个自旋重试获取锁的伪代码示例:
try {
long begin = System.currentTimeMillis();
while (true) {
String result = jedis.set(lockKey, uniqId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
// 加锁成功,执行业务操作
return true;
}
long time = System.currentTimeMillis() - begin;
if (time >= timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} catch (Exception e) {
// 异常处理
} finally {
// 释放锁
}在前文中,为了实现一个靠谱的 Redis 分布式锁,我们讨论了避免死锁、超时续期、安全解锁几个问题以及应对策略。但是,依然存在一些其他问题:
- 不可重入 - 同一个线程无法多次获取同一把锁。
- 单点问题 - Redis 主从同步存在延迟,有可能导致锁冲突。举例来说:线程一在主节点加锁,如果主节点尚未同步给从节点就发生宕机;此时,Redis 集群会选举一个从节点作为新的主节点。此时,新的主节点没有锁的数据,若有其他线程试图加锁,就可以成功获取锁,即出现同时有多个线程持有锁的情况。解决这个问题,可以使用 RedLock 算法。
RedLock 分布式锁,是 Redis 的作者 Antirez 提出的一种解决方案。
扩展:RedLock 官方文档
RedLock 分布式锁在普通 Redis 分布式锁的基础上,进行了扩展,其要点在于:
- (1)加锁操作不是写入单一节点,而是同时写入多个主节点,官方推荐集群中至少有 5 个主节点。
- (2)只要半数以上的主节点写入成功,即视为加锁成功。
- (3)大多数节点加锁的总耗时,要小于锁设置的过期时间。
- (4)解锁时,要向所有节点发起请求。
下面来逐一解释以上各要点的用意:
(1)RedLock 加锁时,为什么要同时写入多个主节点?
这是为了避免单点问题,即使有部分实例出现异常,依然可以正常提供加锁、解锁能力。
(2)为什么要半数以上的主节点写入成功,才视为加锁成功?
在分布式系统中,为了达成共识,常常采用“多数派”策略来进行决策:大多数节点认可的行为,就视为整体通过。
(3)为什么加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久。而且,网络情况是复杂的,可能存在延迟、丢包、超时等情况。网络请求越多,异常发生的概率就越大。所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经超过了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
(4)解锁时,为什么要向所有节点发起请求?
因为网络环境的复杂性,可能会存在这种情况:向某主节点写入锁信息,实际写入成功,但是响应超时或丢包。
所以,释放锁时,不管之前有没有加锁成功,需要释放所有节点的锁,以保证清理节点上残留的锁。
RedLock 分布式锁的解决方案看上去考虑的面面俱到,似乎已经万无一失了,但真的是如此吗?
分布式领域典中典著作《数据密集型应用系统设计》的作者 Martin 就曾对 RedLock 提出了质疑,他和 Redis 以及 RedLock 的作者 Antirez 掀起了一场激烈的争论。
二人的讨论文章如下,有兴趣可以看一下:
- Martin 质疑 RedLock 的文章:How to do distributed locking
- Antirez 的辩驳文章:Is Redlock safe?
Martin 的观点:
(1)RedLock 不能完全保证安全性
分布式系统会遇到三座大山:NPC
- N:Network Delay,网络延迟;
- P:Process Pause,进程暂停(GC);
- C:Clock Drift,时钟漂移。
RedLock 在遇到以上情况时,不能保证安全性。
(2)RedLock 加锁、解锁需要处理多个节点,代价太高
(3)提出 fencing token 的方案,保证正确性
这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个递增的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝后来者的请求
Antirez 的观点:
- 同意时钟跳跃对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。并且如果误差不大,也是可以接受的。
- Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
总结来说,已知的分布式锁,无论采用什么解决方案,在极端情况下,都无法保证百分百的安全。
Redisson 是一个流行的 Redis Java 客户端,它基于 Netty 开发,并提供了丰富的扩展功能,如:分布式计数器、分布式集合、分布式锁 等。
Redisson 支持的分布式锁有多种:Lock, FairLock, MultiLock, RedLock, ReadWriteLock, Semaphore, PermitExpirableSemaphore, CountDownLatch,可以根据场景需要去选择,非常方面。一般而言,使用 Redis 分布式锁,推荐直接使用 Redisson 提供的 API,功能全面且较为可靠。
下面是 Redisson Lock API 的一个简单示例:
RLock lock = redisson.getLock("myLock");
// traditional lock method
lock.lock();
// or acquire lock and automatically unlock it after 10 seconds
lock.lock(10, TimeUnit.SECONDS);
// or wait for lock aquisition up to 100 seconds
// and automatically unlock it after 10 seconds
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}下面是主流分布式锁技术方案的对比,可以在技术选型时作为参考:
| 数据库分布式锁 | Redis 分布式锁 | ZooKeeper 分布式锁 | |
|---|---|---|---|
| 方案要点 | 1. 维护一张锁表,为锁的唯一标识字段添加唯一性约束。 2. 只要 insert 成功,即视为加锁成功。 |
set lockKey randomValue NX PX/EX time 当且仅当 key 不存在时才可以写入,并且设定超时时间,以避免死锁。 |
加锁本质上是在 zk 中指定目录创建顺序临时接节点,序号最小即加锁成功。节点删除时,有监听通知机制告知申请锁的线程。 |
| 方案难度 | 实现简单、易于理解 | 较为简单,但要使其更可靠,需要有一些完善策略 | 应用简单,但 zk 内部机制并不简单 |
| 性能 | 性能最差,易成为瓶颈 | 性能最高 | 性能弱于 Redis |
| 可靠性 | 有锁表的风险 | 较为可靠(需要一些完善策略) | 可靠性最高 |
| 适用场景 | 一般不采用 | 适用于高并发的场景 | 适用于要求可靠,但并发量不高的场景 |
| 开源实现 | 无 | Redisson | Apache Curator |