_3主3从的`Redis集群`搭建(下)
_3主3从的Redis集群搭建(下)
进入主机6381
++redis-cli -p 6381
+
.assets\image-20220509100727145.png) +
+查看集群信息
++cluster info
+
.assets\image-20220509101055861.png) +
+查看主机和从机之间的主从关系
+++cluster nodes
+
.assets\image-20220509101455220.png)
.assets\image-20220509101455220.png) +
+本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Research • 呓语!

++redis-cli -p 6381
+
+++cluster info
+
+查看主机和从机之间的主从关系
+++cluster nodes
+
.assets\image-20220509101455220.png)
+Redis集群搭建之哈希槽算法解决一致性哈希算法数据倾斜问题
是一个数组,数组[0,2^14-1]形成hash slot空间
+解决均匀分配问题,在数据和节点之间加入一层(哈希槽slot)用于管理数据和节点之间的关系,现在相当于节点里放槽,槽里放数据
+ +
+方便数据移动
+哈希解决的映射问题,使用key的哈希值来计算所在的槽,便于数据分配
+一个集群只能有16384个槽,编号0-16383(0-2^14-1)
+这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。
+接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。
以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
+Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上
+首先有几个redis就把0-16383分成几个
+.bmp) +
+Redis集群搭建(上)docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 63861 | docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381 |
运行成功,使用docker ps查看
进入容器redis-node-1并为6台机器构建集群关系
+进入一台redis进行配置docker exec -it redis-node-1 bash
#进入后执行
+redis-cli --cluster create 8.142.144.75:6381 8.142.144.75:6382 8.142.144.75:6383 8.142.144.75:6384 8.142.144.75:6385 8.142.144.75:6386 --cluster-replicas 1
+
+ --cluster create 构建集群
+ --cluster-replicas 1 集群关联一比一的关系
+
+--cluster-replicas 1 表示为每个master创建一个slave节点
+# 注意:上面的ip为真实IP
+有下面的绿色ok字样显示运行成功
+.assets\image-20220507145226431.png) +
+++如果运行不成功,一直显示
+Waiting for the cluster to join..一直………………………………….,则是端口没有全部开放,防火墙也要开放端口,以阿里云为例
就是需要在安全组上面配置6381~6386的6个端口,还需要配置16381~16386的6个端口,共12个端口都要开放,不然会一直提示等待
+++注意:
+jdk8需要和Dockerfile放到同一个文件夹
1 | FROM centos:7 |
++仓库名和标签名全部为
+的镜像
碰到它还是进行删除的好
+使用docker image ls -f dangling=true查找虚悬镜像
使用docker image prune删除镜像
新建主服务器容器实例3307
+1 | docker run -p 3307:3306 --name mysql-master -v /mydata/mysql-master/log/:/var/log/mysql -v /mydata/mysql-master/data:/var/lib/mysql -v /mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 |
进入/mydata/mysql-master/conf目录下新建my.cnf把下面内容粘贴到my.cnf
1 | [mysqld] |
修改完配置后重启master容器
+master容器实例内创建数据同步用户
+1 | 建立一个用户 |
 +
+新建从服务器实例3308
+1 | docker run -p 3308:3306 --name mysql-slave -v /mydata/mysql-slave/log/:/var/log/mysql -v /mydata/mysql-slave/data:/var/lib/mysql -v /mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 |
进入/mydata/mysql-slave/conf目录下新建my.cnf
+1 | # 设置使用的二进制日志格式(mixed,statement,row) |
重启从机实例docker restart mysql-slave
在主数据库中查看主从同步状态show master status;
进入mysql-slave从机容器
+在从数据库中配置主从复制change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;
1 | 说明: |
在从数据库中查看主从同步状态show slave status \G;
在从数据库中开启主从同步start slave
查看从数据库状态发现已经同步
+ +
+主从复制测试
+主机创建数据库,创建表,插入数据,搜索表的数据
+从机直接搜索标的数据
+++注意:进入集群环境后,不能使用单机版的
+redis-cli -p 6381
因为这样会在增加数据时有error报错出现
 +
+使用set k1 v1错误是因为1号主机里面的编号是0到5460,超过了这个范围就会报错
++正确进入的方法
+redis-cli -p 6381 -c-c 的作用是优化路由
+
 +
+++注:可以进入任意一台主机 + + +redis-cli —cluster check 8.142.144.75:6381
+
 +
+++主机宕机,从机自动切换成主机
+
启动docker
+++systemctl start docker
+
停止docker
+++systemctl stop docker
+
查看docker状态
+++systemctl status docker
+
重启 docker,没有任何提示说明启动成功
+++systemctl restart docker
+
docker 开机启动
+++systemctl enable docker
+
查看 docker 概要信息
+++docker info
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker info |
查看 docker 总体帮助文档
+++docker —help
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker --help |
++docker images
+
OPTIONS说明:+
+- +
+
+- a 列出本地所有的镜像(含历史镜像)
+- +
+
+- q 只显示镜像ID
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images |
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images -a |
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images -q |
++docker search 镜像名称
+
STARS 点赞数
OFFICIAL 官方认证
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker search hello-world |
++docker search —limit n 镜像名称
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker search --limit 5 redis |
++docker pull 镜像名称:标签版本号
+
没有tag就是最新版1
2
3
4
5
6
7
8
9
10
11
12
13[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker pull redis:6.0.8
6.0.8: Pulling from library/redis
bb79b6b2107f: Pull complete
1ed3521a5dcb: Pull complete
5999b99cee8f: Pull complete
3f806f5245c9: Pull complete
f8a4497572b2: Pull complete
eafe3b6b8d06: Pull complete
Digest: sha256:21db12e5ab3cc343e9376d655e8eabbdbe5516801373e95a8a9e66010c5b8819
Status: Downloaded newer image for redis:6.0.8
docker.io/library/redis:6.0.8
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
++docker system df
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker system df |
++docker rmi 镜像ID
+
```shell
+Error response from daemon: conflict: unable to delete feb5d9fea6a5 (must be forced) - image is being used by stopped container 13111f725991
+说明之前运行过这个镜像,生成了容器,需要先删除容器,再删除镜像
+++docker rmi -f 镜像id
+
++xxxxxxxxxx # 没有任何提示说明启动成功[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# systemctl restart docker[root@iZ8vbfaek3x3ogtpxnpnwfZ /]#shell
+
++docker rmi -f $(docker images -qa)
+
1 | 创建redis-node-7 |
docker exec -it redis-node-1 bash进入redis-node-1里面redis-cli --cluster add-node 8.142.144.75:6387 8.142.144.75:6381 +
+6387 新加入的节点
+6381 相当于6387的领路人
+redis-cli --cluster check 8.142.144.75:6381检查 +
+++redis-cli —cluster reshard IP地址:端口号
+
 +
+ +
+在重新加载过程会碰到Do you want to proceed with the proposed reshard plan (yes/no)?一句话,选择yes就可以
 +
+ +
+++redis-cli —cluster add-node ip:新slave端口 ip:新master端口 —cluster-slave —cluster-master-id 新主机节点ID
+
 +
+ +
+++redis-cli —cluster check 8.142.144.75:6382
+
 +
+++redis-cli —cluster del-node ip:从机端口 从机6388节点ID
+
 +
+redis-cli --cluster check 8.142.144.75:6382进行集群检查 +
+6388删除成功
+本例将清出来的槽号都给6381
+使用redis-cli --cluster reshard ip:6381进行节点的重组
 +
+上图中1输入的4096是6387主机所拥有的槽点数量,把他们全部拿出来分掉
+上图的2输入的ID是接收6387主机所放出的槽点数的主机id
+上图中3输入的ID是放出槽点数的6387主机的id
+上图中4输入的done指的是已经输入完所有的节点
+redis-cli --cluster check 8.142.144.75:6382进行集群检查 +
+++redis-cli —cluster del-node ip:端口 6387节点ID
+
 +
+redis-cli --cluster check 8.142.144.75:6382进行集群检查 +
+使用docker pull mysql:5.7拉取mysql 5.7镜像
使用docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7运行镜像创建容器
++因为linux系统自己装了mysql,避免端口冲突,先运行ps -ef|grep mysql查询
+
使用docker ps查询容器编号
使用docker exec -it 容器编号 bash进入mysql容器
使用mysql -uroot -p,输入密码,登录mysql
show databases
1 | mysql> show databases |
1 | INSERT INTo t1 VALUES(3, "张三"); |
1 | mysql> SHOW VARIABLES LIKE 'character%'; |
在宿主机的/ggls/mysql/conf目录下vim my.cnf文件,通过容器卷同步给容器实例
1 | [client] |
SHOW VARIABLES LIKE 'character%';验证工作使用版启动容器方法
+1 | docker run -d -p 3306:3306 --privileged=true |
使用docker pull redis:6.0.8拉取redis:6.0.8镜像
创建容器
+++容器卷要加入
+--privileged=true
在宿主机下新建目录mkdir -p /app/redis
首先把tomcat在镜像源中pull下来,使用docker images 查看镜像
使用docker run -d -p 8080:8080 tomcat:9.0新建容器运行tomcat
++运行后使用本地PC使用阿里云的ip和端口访问docker上面的
+tomcat
 +
+使用docker ps查询到容器编号,docker exec -it 容器编号 bash 打开容器
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps |
使用ls-l查看文件列表
1 | root@c52ab6b8b8df:/usr/local/tomcat# ls -l |
从列表可以看到有两个文件夹webapps和webapps.dist,数据全部在webapps.dist里面,需要将webapps删除,把webapps.dist重命名成webapps即可访问
使用rm -rf webapps删除webapps文件夹
使用mv webapps.dist webapps重命名
再次使用本地访问
+ +
+++docker pull billygoo/tomcat8-jdk8
+docker run -d -p 8080:8080 —name tomcat8 billygoo/tomcat8-jdk8
+
1 | docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 |
++宿主vs容器之间映射添加容器卷
+
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 添加1 | docker run -it --privileged=true -v /tmp/host_data:/tmp/docker_data --name=ui ubuntu |
1 | `在容器内部创建一个dockerin.txt文件 |
1 | docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:ro 镜像名 |
++卷的继承和共享
+
1 | docker run -it --privileged=true --volumes-from 父类 --name u2 ubuntu |
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker images |
docker run -it ubuntu:15.10 /bin/bash
/bin/bash 希望有交互式shell 就用/bin/bash
++docker ps [OPTIONS]
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a |
OPTIONS:
+1 | List containers |
run进入容器,exit退出容器, 容器停止
+run进入容器,exit退出容器, 容器不停止1
2
3
4
5
6[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker run -it ubuntu bash
root@562278524cda:/# [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
562278524cda ubuntu "bash" 16 seconds ago Up 15 seconds loving_dewdney
(问题):使用docker run -d ubuntu命令启动后台模式的容器ubuntu,然后用docker ps 查询提示没有找到运行的容器
+++Docker容器后台运行就必须有一个前台进程,不然容器没事做,会自杀
+
解决方法:将运行的程序以前台进程的方式运行
常见方式:命令行模式
++docker logs 容器id
+
++docker top 容器id
+
++docker inspect 容器id
+
进入正在运行的容器并以命令行交互
+++docker exec -it 容器id bashShell
+
重新进入
+++docker attach 容器id
+
(区别)
attach直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止
exec是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器的停止
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps |
++docker cp 容器id:容器地址 主机地址
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker cp 26191ecfb227:/tmp/a.txt /opt/ab.txt |
export 导出容器的内容留作为一个tar归档文件[对应import命令]
+++docker export 容器id > 自定义文件名.tar
+
import从tar包中的内容创建一个新的文件系统再导入为镜像[export]
+++cat 文件名.tar | docker import - 自定义/镜像名:3.5(3.5是自定义)
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ opt]# docker ps |
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ opt]# docker ps |
++docker start 容器id/容器名
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a |
++docker restart 容器id/容器名
+
++docker stop 容器id/容器名
+
++docker kill 容器id/容器名
+
++docker rm 容器id
+
注:xargs是linux系统的可变参数,把分隔符前面的结果传给xargs里面,然后执行分隔符后面的命令1
2
3
4
5
6
7
8
9
10
11[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
562278524cda ubuntu "bash" 20 minutes ago Up 20 minutes loving_dewdney
cdee90a8c77d ubuntu "bash" 45 minutes ago Up 15 minutes ubuntu
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a -q | xargs docker rm -f
562278524cda
cdee90a8c77d
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
++步骤
+
1 | docker pull registry |
1 | docker run -d -p 5000:5000 -v/ggls/myregistry/:/tmp/registry --privileged=true registry |
新启动ubuntu容器,新增ifconfig命令
apt-get update命令apt-get install net-tools命令容器外部执行docker commit -m="ifconfig cmd add" -a="ggls" ffcc5edf5071 ubuntu:1.6命令
curl验证私服库上有什么镜像
+1 | curl -XGET http://8.142.144.75:5000/v2/_catalog |
1 | docker tag 镜像:Tag Host:Port/Repository:Tag |
修改配置文件使之支持http
+++docker 默认不允许
+http方式推送镜像,通过此配置取消这个限制,若不生效,重启docker
vim /etc/docker/daemon.json打开配置文件json1 | { |
push推送到私服库
+1 | docker push 符合私服库格式的镜像名称:tag |
pull到本地并运行1 | docker pull 8.142.144.75:5000/ubuntu:1.6 |
使用docker进行对docker镜像功能的新增后,需要发布到阿里云上对镜像进行同步,下次pull镜像就不要pull缩减版的镜像,直接pull更新后的镜像,方便后续使用
然后在基本信息上面就可以看到仓库指南
+++根据指南进行操作
++ + ++
 +
+ +
+docker镜像是最小的,被精简过的Linux系统,是不带vim命令的
+++使用命令 ‘vim a.txt’ 进行新建编辑a.txt文件,就会提示找不到命令
+
更新镜像
+++apt-get update
+
下载vim功能
+++apt-get -y install vim
+
提交副本使成为一个新镜像
+++docker commit -m=”提交的描述信息” -a=”作者” 容器id 要创建的目标镜像名:[标签名]
+
1 | [root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker ps |
今天使用PyCharm下载一个模块pip.exe install locust,有错误提示
1 | https://visualstudio.microsoft.com/visual-cpp-build-tools/ |
++缺少对应的
+whl文件
碰到了这个错误ERROR: Failed building wheel for psutil,就需要下载psutil.whl
在下载网站点击进入网站
+下载psutil-5.9.0-cp38-cp38-win_amd64.whl文件
然后使用(pip install 文件的绝对路径)进行安装,然后使用pip.exe install locust正常安装
1 |
|
添加录制器“HTTP(S) Test Script Recorder”
+添加线程组“Thread Group”
+添加录制控制器“Recording Controller”,
+录制脚本的配置(Test Plan Creation)
+Port=8088Target Controller = TestPlan > Tread Group > Recording Controller录制脚本的配置(Requests Filtering 请求过滤器)
+URl Patterns to Include上添加正则.*\.(baidu\.com).*;表示只抓取百度URL的内容,不抓取其他网站的URl Patterns to Exclude上添加正则.*\.(js|css|PNG|jpg|jpeg|ico|png|gif).*;去掉一些静态请求单击保存按钮,将Jmeter脚本存储
+http://localhost:8088,然后就可以进行访问录制了Recording Controller下面看到,然后停止录制录制结束后,要对录制的代码进行校验
+运行录制的代码,在查看结果树上查看运行的结果
+1 | #字符串 |
回显的结果是:
+1 | { username: 'admin', |
1 | forceStr: !!str 123 |
回显的结果是:
+1 | forceStr: '123', |
1 | #数组 |
回显的结果是:
+1 | myFavourite: [ 'backaetball', 'football' ], |
1 | #对象 |
回显的结果是:
+1 | autotest: { username: 'root', password: 'root', age: 18, male: true }, |
1 | #复合结构 |
回显的结果是:
+1 | companies: |
1 | #引用 |
回显的结果是:
+1 | father: { lastName: '周' }, |
接口响应时间
+吞吐量
+TPS: 事务处理能力,每秒处理事务数(打开页面、登录、选择商品、加入购物车、下单、付款)
+注意:“日活” 每日活跃用户数,是运营数据,与性能无关
+八二原则
+++计算QPS/TPS
+
相信80%会集中在20%时间内,24小时的流量集中在白天8小时内,同时在午高峰达到高峰
+根据相应耗时计算公式预估所需并发,一次请求100ms
+根据 QPS = Vue * Rt
1000000 80% / 8 3600 * 20% = 277 QPS
+需要27个并发
+在linux创建helloworld.sh文件,在文件内输入:
1 | !/bin/bash |
然后保存该文件
+运行.sh文件时,有两种方法可以运行
1 | chmod +x ./helloworld.sh |
运行文件:./ 不能省略
+1 | ./helloworld.sh |
bash或sh 文件路径运行该文件1 | bash helloworld.sh |
$HOME 获取当前用户的家目录
$PWD 获取当前目录的路径
$SHELL 获取shell的执行引擎
$USER 获取当前用户的名称
在linux系统中定义变量A=1,等号两边不能有空格,使用echo $A显示A的值
使用unset A命令,撤销变量
定义只读变量readonly b=3,使用echo $b显示b的值,不能unset
export命令进行设置全局变量,可以让其他shell命令进行使用
定义
+n表示数字,范围是0~9,$0表示脚本名称,$1~9表示1~9个参数,10以上的参数要用花括号包裹,如${10}
运行apple.sh文件时可以传递参数
举个栗子
+1 | !/bin/bash |
运行后传递参数bash apple.sh 001 002 test "test sss" "hsgd_dee"
定义
+获取所有输入参数的个数,常用于循环
+举个栗子
+1 | !/bin/bash |
定义
+$*代表命令行中所有参数,把参数作为一个整体
$@代表命令行中所有参数,把参数区分对待
定义
+最后一次命令的返回状态,如果返回变量的值为0,则表示最后一次命令执行正确,如果变量的值非0,则证明上一条变量返回不正确
+举个栗子
+1 | [root@b09ed0cc2c9d opt]# $? |
首先创建test_shell.sh文件
1 | touch test_shell.sh |
在test_shell.sh文件输入shell脚本
使用shell创建banzhang.txt文件
在文件中追加数据echo "aabbccdd" >> banzhang.txt
1 | !/bin/bash |
在config目录下创建environment.yaml文件
+1 | username: 周杰伦 |
首先创建yaml_config文件,为了方便自动化后面的引用,需要创建一个类,在__init__里面打开yaml文件,使用yaml.load(文件名称, Loader=yaml.FullLoader )方法获取数据
打印出字典格式的数据{'username': '周杰伦', 'password': 123456}
1 | import yaml |
现在使用的是相对路径,后期如果换系统,或者更换文件位置,就需要自己获得文件路径,下面对代码进行优化
+创建get_project_path方法,获取项目根目录的绝对路径
首先定义一个变量,变量的值是项目的名称project_name = "trading_system_autotest"
获取当前文件的所在目录的绝对路径,需要使用python的os模块file_path=os.path.dirname(__file__)
在绝对路径中找到项目名称的下标位置file_path.find(project_name)
找到项目所在目录的绝对路径下标+项目名称的长度=项目根目录的绝对路径的下标file_path.find(project_name)+len(project_name)
然后对所在目录的绝对路径file_path进行切片获得项目根目录的绝对路径
file_path[: file_path.find(project_name)+len(project_name)]
1 | def get_project_path(): |
创建sep(path, add_sep_before=False, add_sep_after=False)方法,获得文件和目录的拼接
变量
+path变量需要传输一个列表,列表里面是文件所在目录和文件名称,如[文件所在目录,文件名称]
首先使用os.sep.join对列表的字段进行拼接all_path = os.sep.join(path)
对add_sep_before进行判断,如果是True,就在前面添加拼接符:all_path = os.sep + all_path
对add_sep_after进行判断,如果是True,就在后面添加拼接符:all_path = all_path + os.sep
windows格式拼接符有可能错误,就要对拼接符转换格式all_path = all_path.replace('\\', '/'),就算没有这个代码,也可以运行出来,只是调试该代码看起来不好看
然后返回all_path
1 | def sep(path, add_sep_before=False, add_sep_after=False): |
1 | class GetConf: |
1 | basename [string/ pathname][文件后缀] |
basename命令会删掉所有的前缀,只留一个文件名
+选项:
+如果指定后缀,basename会将pathname或string中的文件后缀去掉
+截取该/opt/banzhang.txt路径的文件名称
1 | [root@b09ed0cc2c9d opt]# basename /opt/banzhang.txt |
1 | dirname 文件绝对路径 |
从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录部分)
+1 | [root@b09ed0cc2c9d opt]# dirname /opt/banzhang.txt |
1 | [function] funname[()] |
1 | !/bin/bash |
++用于剪切数据
+
cut[选项参数] filename
+说明:默认分隔符是制表符
+| 选项参数 | +功能 | +
|---|---|
| -f | +列号,提取第几列 | +
| -d | +分隔符,按照指定分隔符分割列 | +
准备数据
+1 | [root@b09ed0cc2c9d local]# touch cut.txt |
切割第一列数据
+1 | [root@b09ed0cc2c9d local]# cut -d " " -f 1 cut.txt |
切割第二,三列
+1 | [root@b09ed0cc2c9d local]# cut -d " " -f 2,3 cut.txt |
在cut.txt文件切割出guan
+1 | [root@b09ed0cc2c9d local]# cat cut.txt |
选取系统PATH变量值,第二个“:”之后的所有路径
+1 | [root@b09ed0cc2c9d local]# echo $PATH |
切割ifconfig后打印的IP地址
+1 | [root@b09ed0cc2c9d local]# ifconfig |
++一种流编辑器,一次处理一行内容
+
sed [选项参数] command filename
选项参数说明
+| 选项参数 | +功能 | +
|---|---|
| -a | +直接在指定列模式上进行sed的动作编辑 | +
命令功能描述
+| 命令 | +功能描述 | +
|---|---|
| a | +新增,a的后面可以接字串,在下一行出现 | +
| d | +删除 | +
| s | +查找并替换 | +
数据准备
+1 | [root@b09ed0cc2c9d opt]# touch sed.txt |
将mei nv 这个单词插入到 sed.txt 第二行下,打印
+1 | [root@b09ed0cc2c9d opt]# sed "2a mei nv" sed.txt |
删除sed.txt文件所有包含 wo 的行
+1 | [root@b09ed0cc2c9d opt]# sed "/wo/d" sed.txt |
将sed.txt文件中 wo 替换为 ni
+1 | [root@b09ed0cc2c9d opt]# sed "s/wo/ni/g" sed.txt |
将sed.txt文件中的第二行删除并将wo替换成ni
+1 | [root@b09ed0cc2c9d opt]# sed -e "2d" -e "s/wo/ni/g" sed.txt |
[ condition ] (注意,condition 前后要有空格)
+注意:条件非空即为 true,[ atguigu ]返回 true, [] 返回 false.
+1 | = 字符串比较 |
举个栗子
+1 | [23 -lt 80] |
1 | -r 读 |
举个栗子
+1 | [ -w 1.sh ] |
1 | -f 文件存在且是一个常规文件 |
举个栗子
+1 | [ -e 2.sh ] |
$$$$ 与 ,前对,才执行后
+|| 或
[ 条件判断式 ],中括号和条件判断式之间必须有空格
+if后要有空格
+1 | if [ 条件判断式 ]:then |
输入一个数字,如果是1,则输出 banzhang zhen shuai,如果是2,则输出 cls zhen mei ,如果是其他,则什么都不输出
+1 | !/bin/bash |
1 | case $变量名 in |
输入一个数字,如果是 1,则输出 banzhang,如果是 2,则输出 cls,如果是其他,输出 renyao
+1 | !/bin/bash |
1 | for(( 初始值;循环控制添加;变量变化 )) |
输出从1加到100的值
+1 | !/bin/bash |
1 | for 变量 in 值1 值2 值3... |
打印所有输入参数
+1 | !/bin/bash |
1 | while[ 条件判断式 ] |
输出从1加到100的值
+1 | !/bin/bash |
1 | read(选项)(参数) |
提示7秒内,读取控制台输入的名称
+1 | !/bin/bash |
1 | expr 3 + 2 |
需要使用键盘左上角的`,把需要提前运算的包起来
+1 | expr `expr 2 + 3` \* 4 |
或者
+1 | s=$[(2+3)*4] |
++强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
+
awk [选项参数] ‘pattern1{action1}’ filename
+| 选项参数 | +功能 | +
|---|---|
| -F | +指定输入文件分隔符 | +
| -v | +赋值一个用户定义变量 | +
数据准备的是/etc/passwd
1 | [root@b09ed0cc2c9d opt]# cat passwd |
搜素passwd文件以root关键字开头的所有航,并输出该行的第7列
+1 | [root@b09ed0cc2c9d opt]# awk -F : '/^root/{print $7}' passwd |
搜素passwd文件以root关键字开头的所有航,并输出该行的第1列和第7列,输出时以逗号分隔
+1 | [root@b09ed0cc2c9d opt]# awk -F : '/^root/{print $1","$7}' passwd |
只显示/etc/passwd的第一列和第7列,以逗号分隔,且在所有航前面添加列名 user,shell在最后一行添加 ddd, /bin/zuishuai
+1 | [root@b09ed0cc2c9d opt]# awk -F : 'BEGIN{print "user,shell"} {print $1","$7} END{print "ddd,bin/zuishuai"}' passwd |
将passwd 文件中的用户id增加数值1并输出
+1 | [root@b09ed0cc2c9d opt]# awk -F : -v i=1 '{print $3+i}' passwd |
| 变量 | +说明 | +
|---|---|
| filename | +文件名 | +
| nr | +已读的记录数 | +
| nf | +浏览记录的域的个数 | +
数据准备
+1 | [root@b09ed0cc2c9d opt]# cat sed.txt |
统计passwd文件名,每行的行号,每列的列数
+1 | [root@b09ed0cc2c9d opt]# awk -F : '{print FILENAME "," NR "," NF}' passwd |
打印空行所在的行号
+1 | awk '/^$/ {print NR}' sed.txt |
++文件排序
+
sort(选项)(参数)
+| 选项 | +说明 | +
|---|---|
| -n | +按照数值大小排序 | +
| -r | +以相反的顺序排序 | +
| -t | +设置排序使用的分隔字符 | +
| -k | +指定需要排序的列 | +
参数是指定待排序文件列表
++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
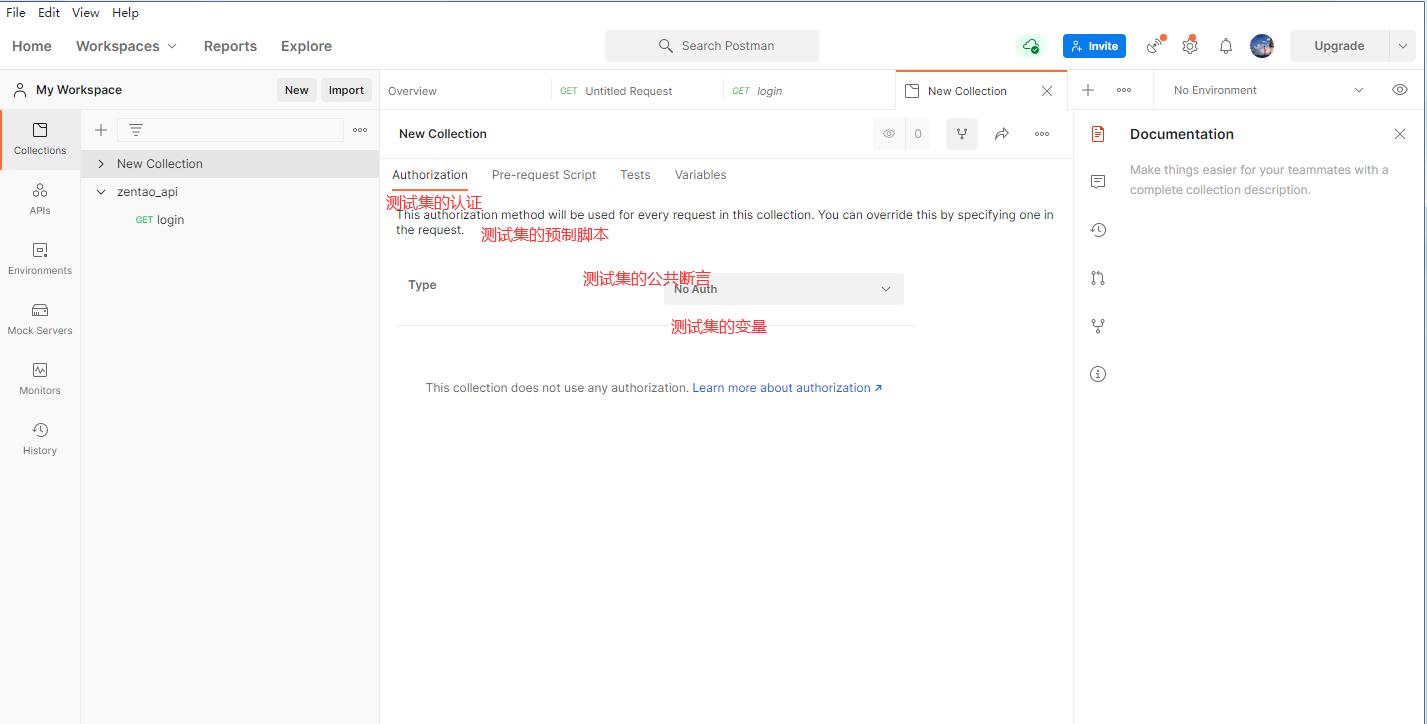
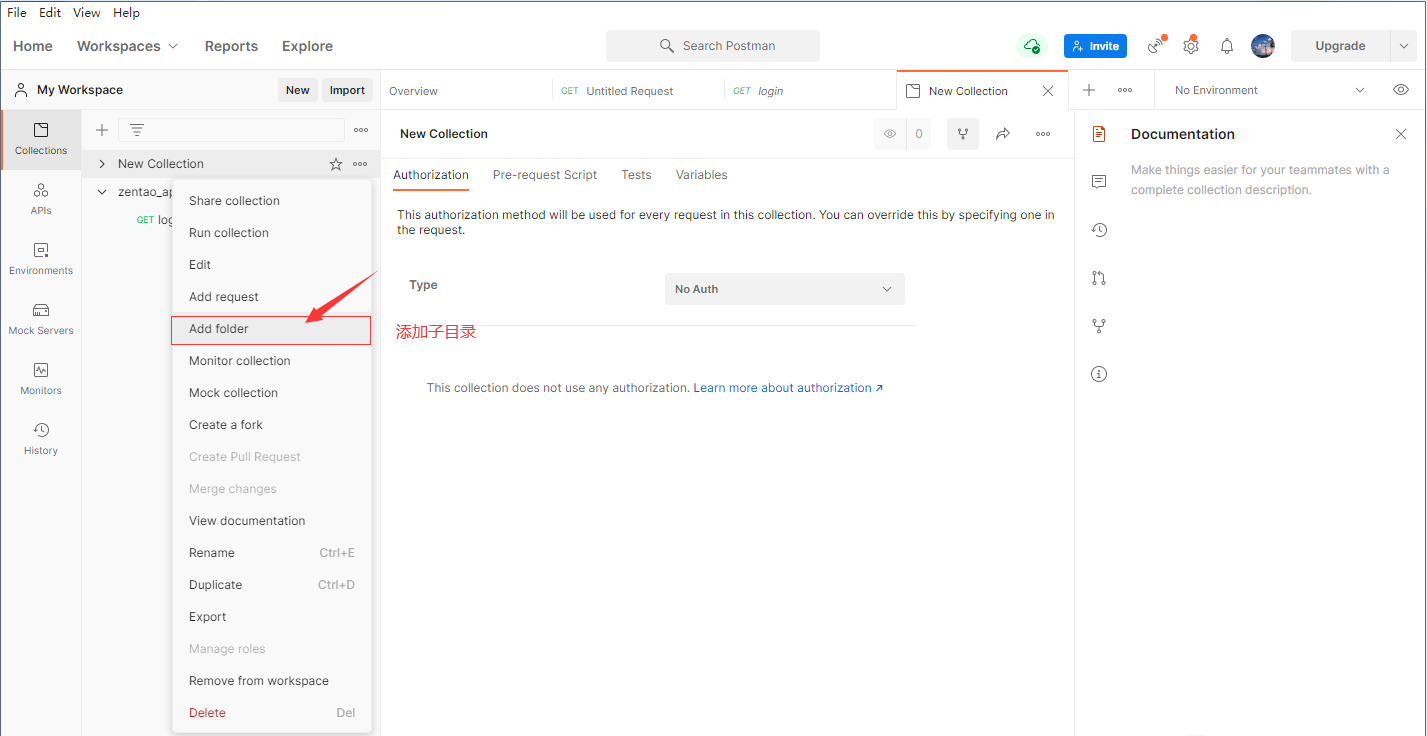
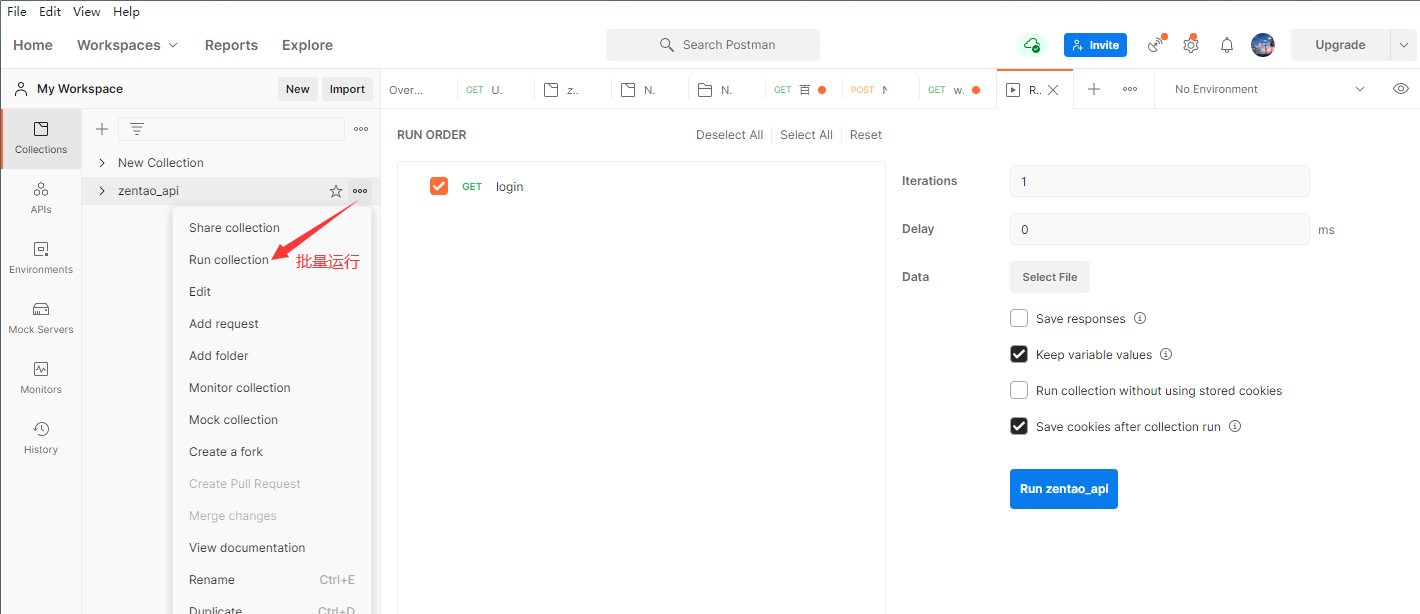
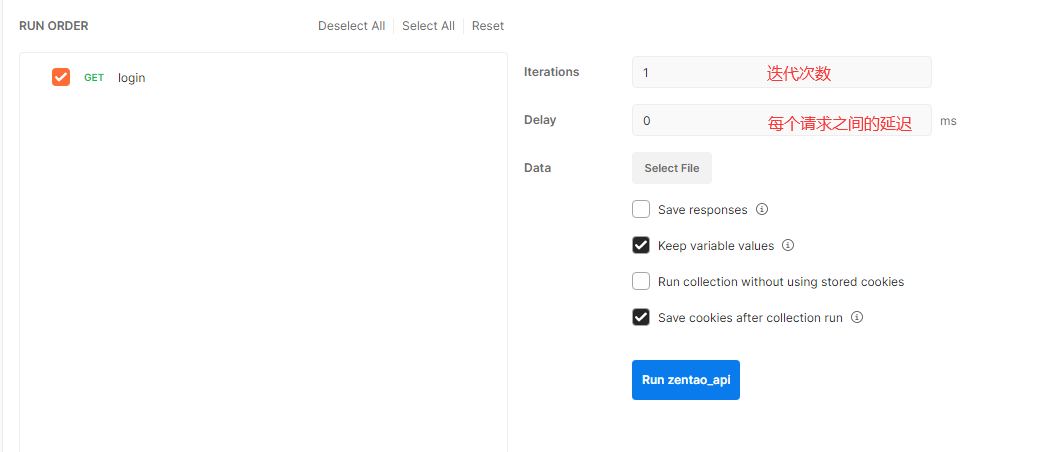
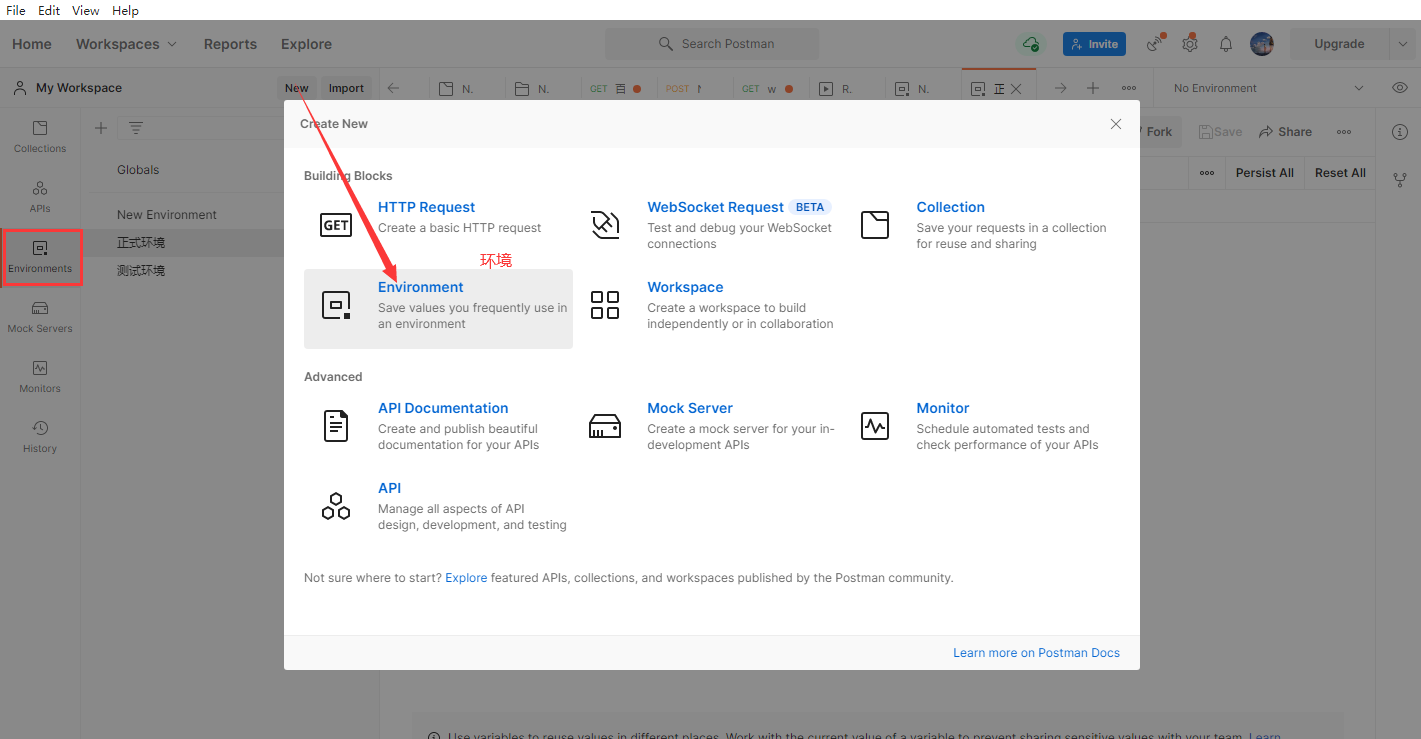
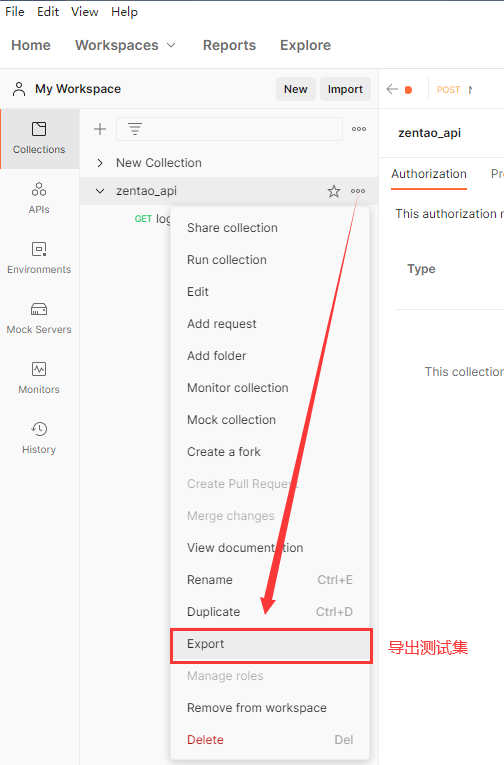
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.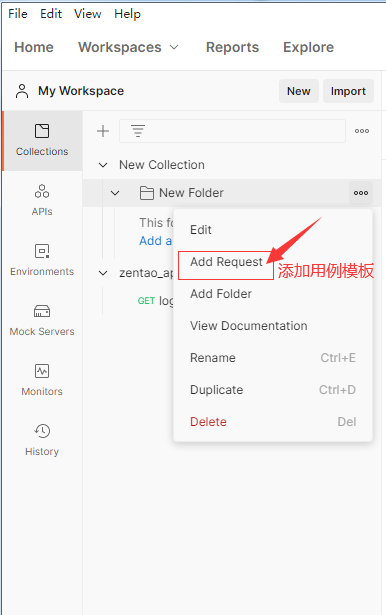
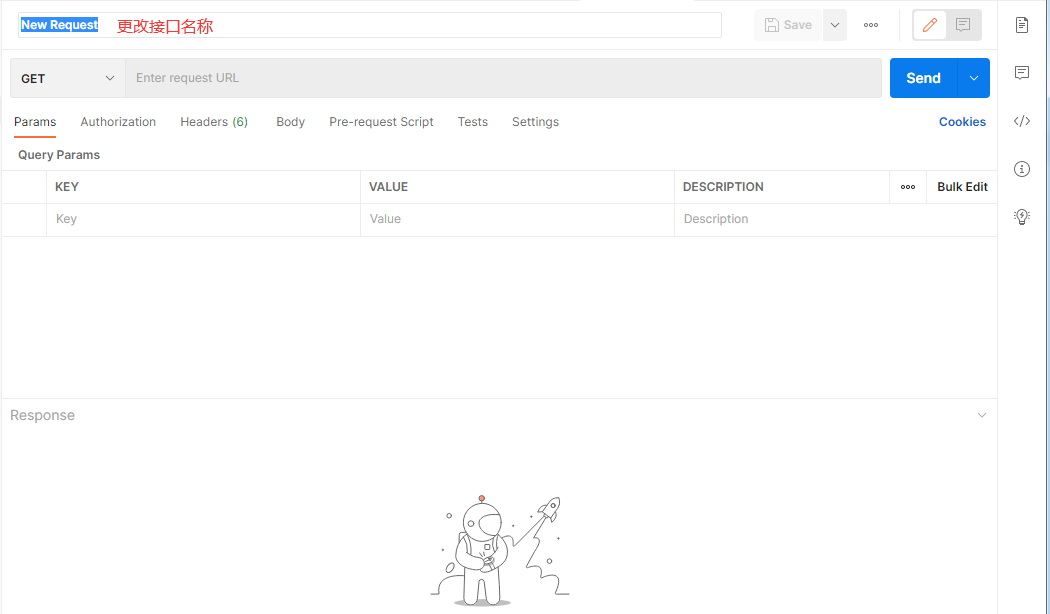
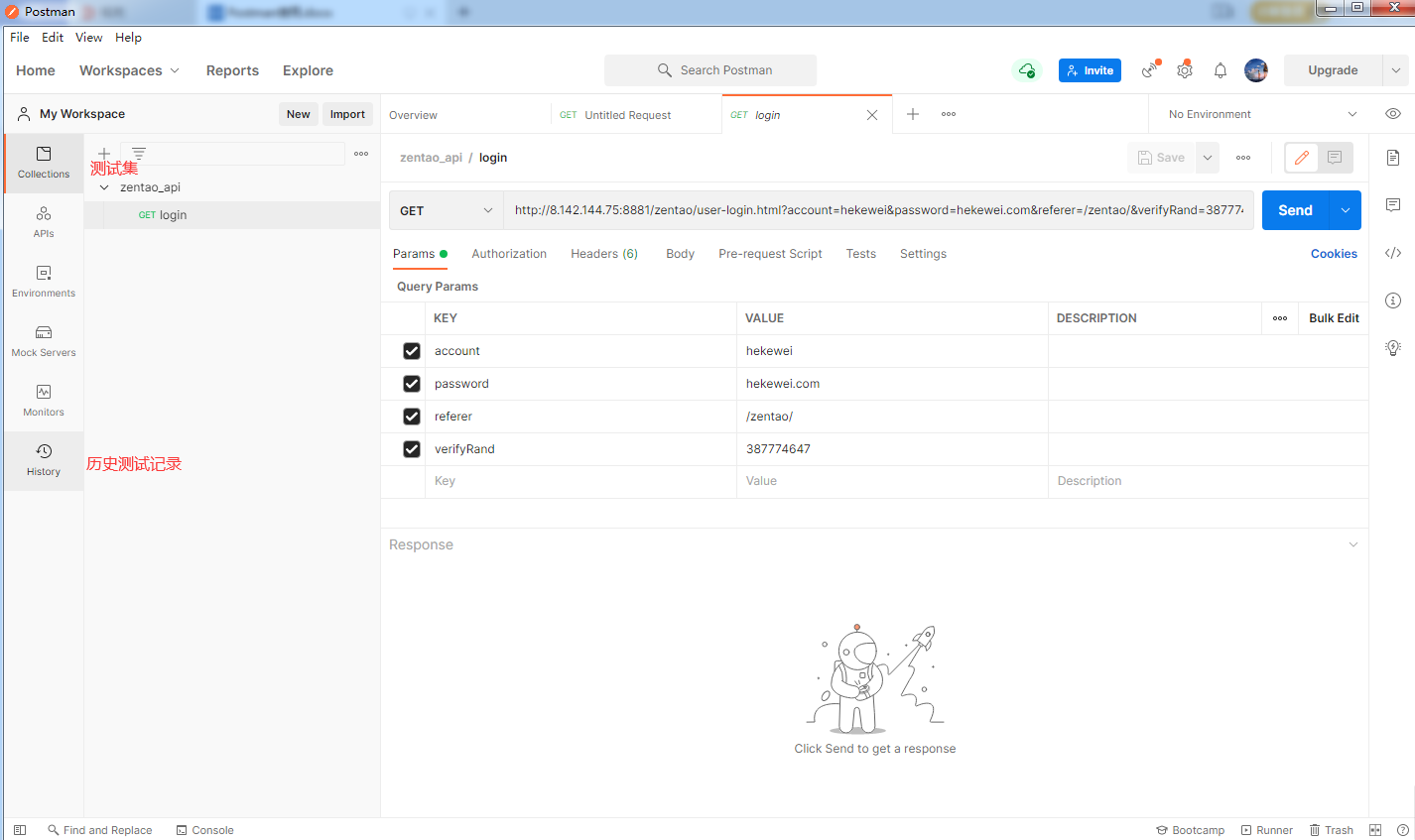
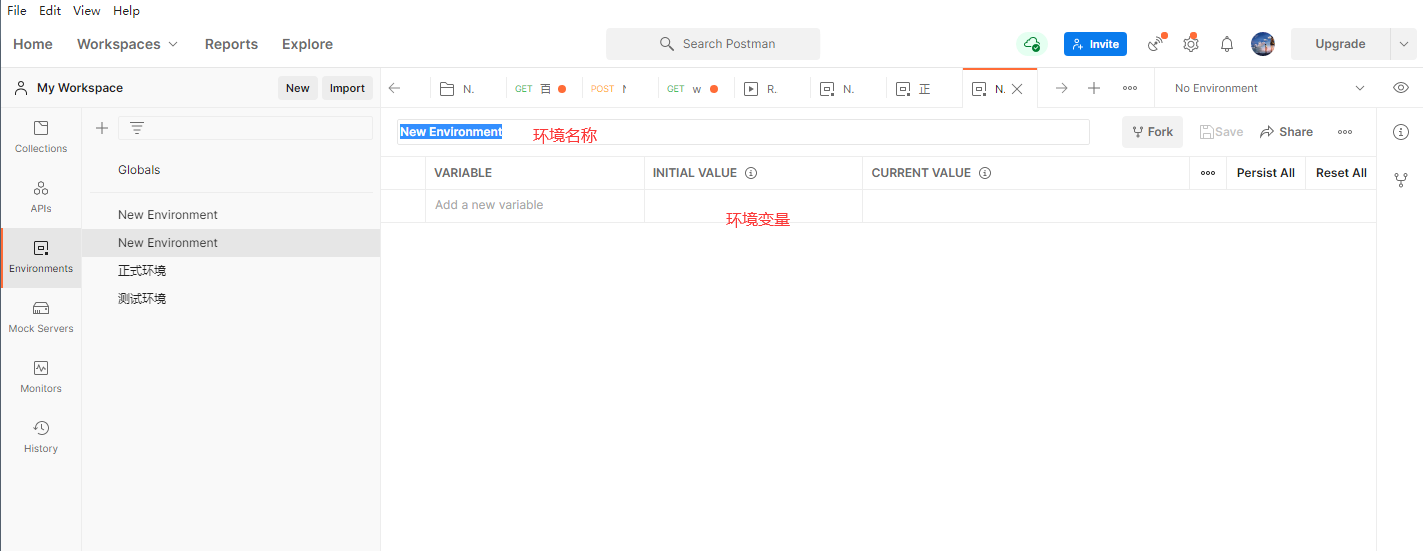
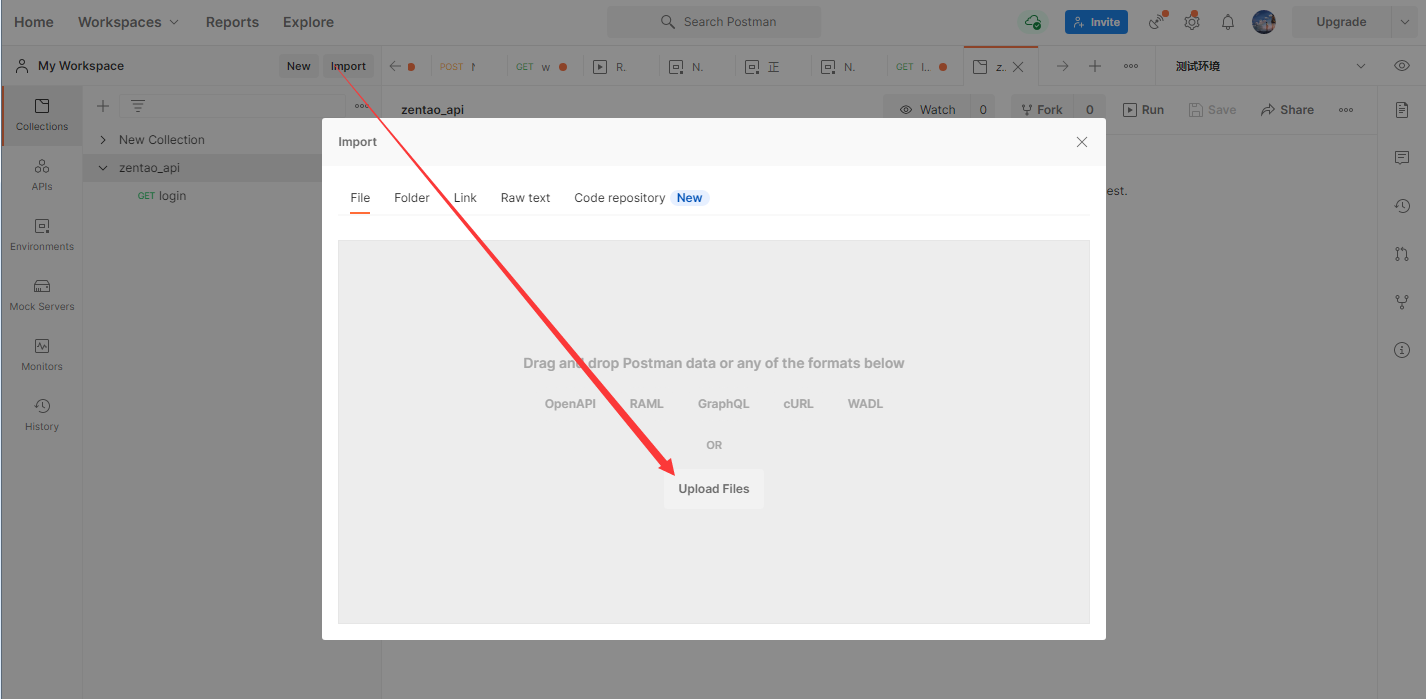
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求: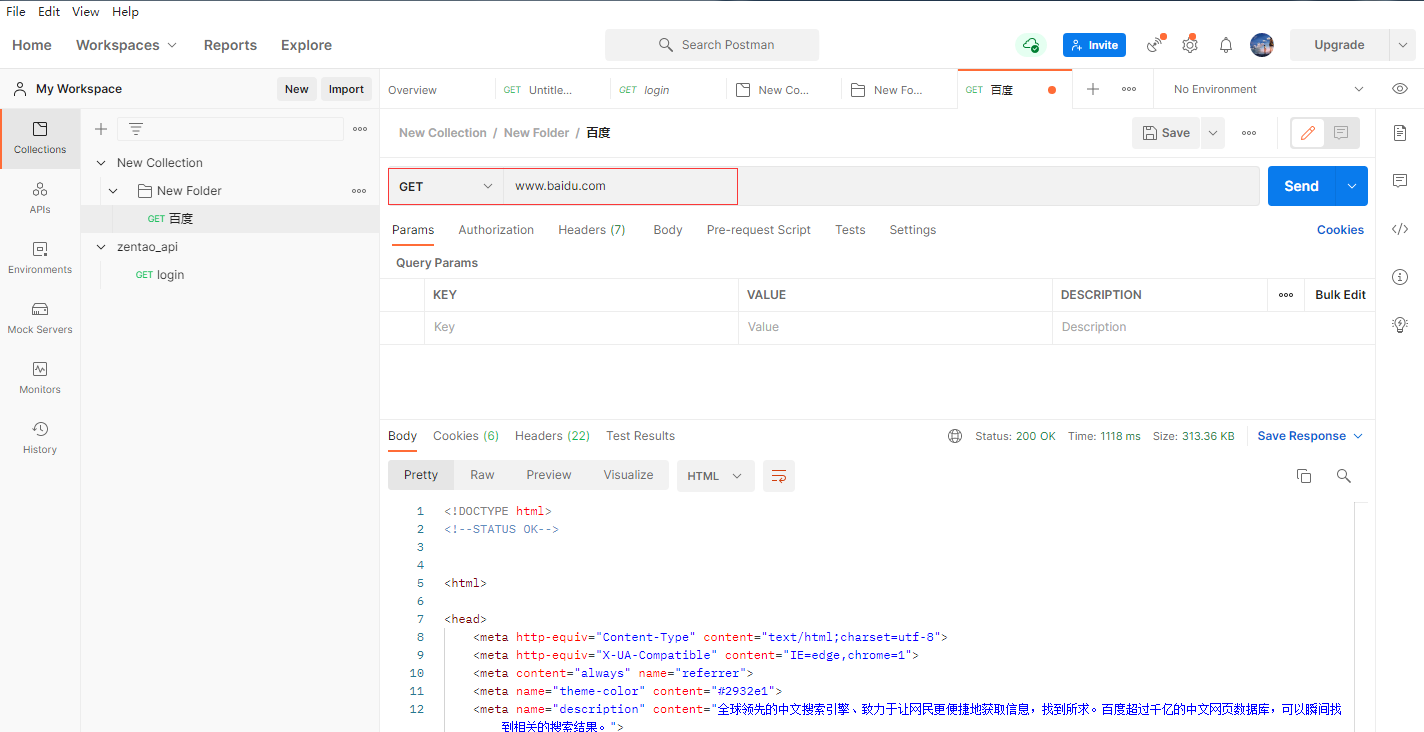
发送需要认证的get接口: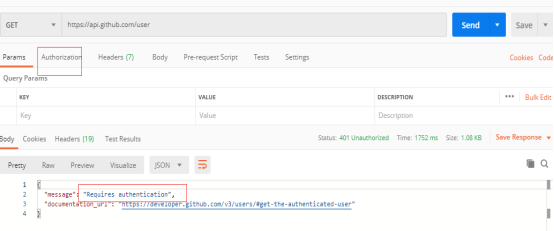
------------恢复内容开始------------
## Postman安装 +++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求:
发送需要认证的get接口:
选择请求格式为post
传参:

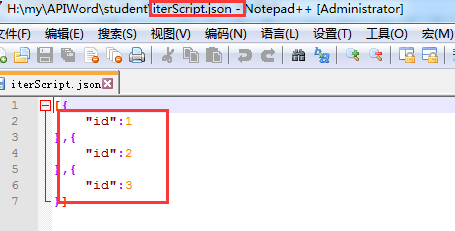
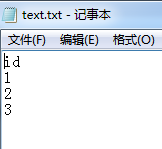
使用参数时,变量名称要与文件里的变量名保持一致
引用环境信息:
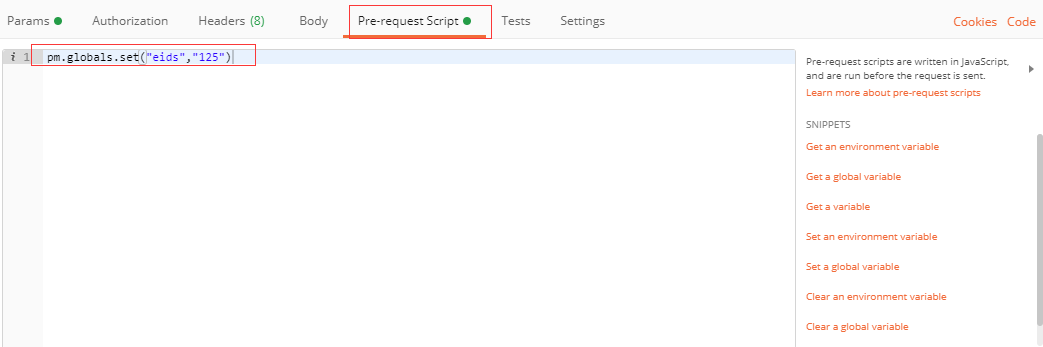
也可以用javascript写变量: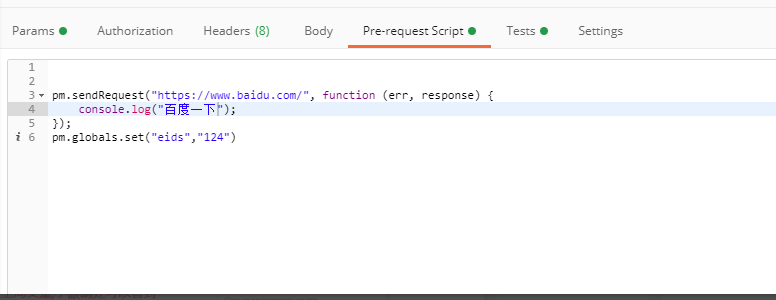
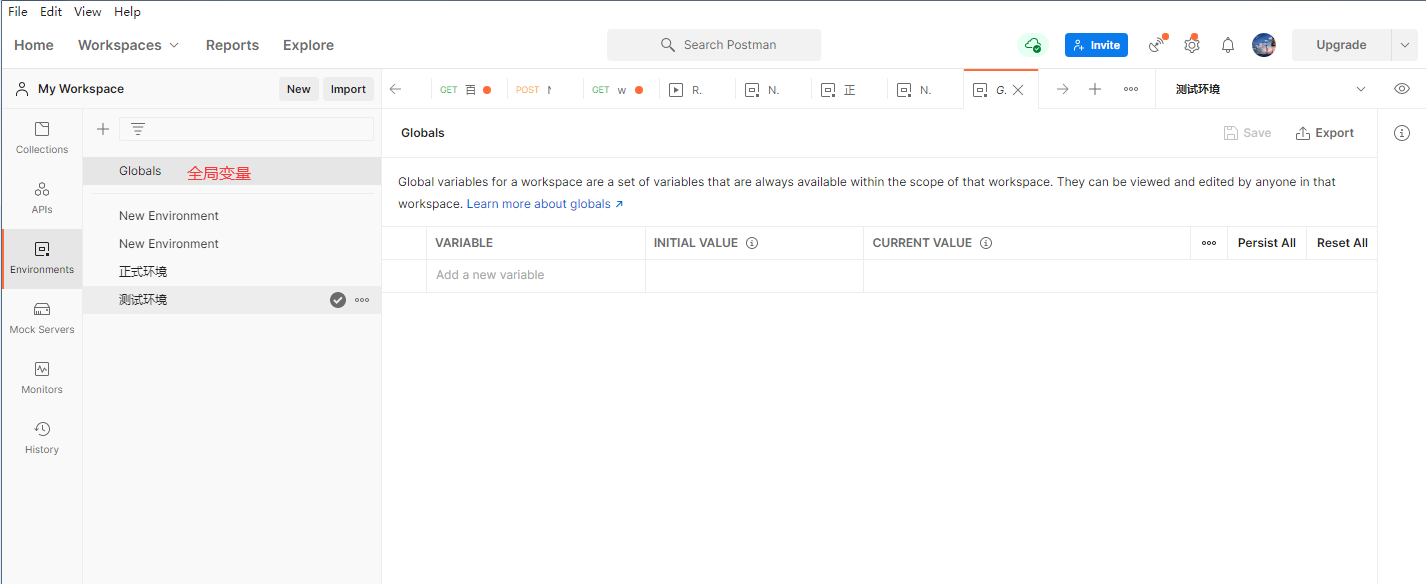
引用全局变量信息:
Cookie用途:一个请求需要用到用户的登录状态(sessionid或token),一般 登录状态会记录在cookie ,postman会自动记录登录状态写入cookies.所以执行非登录接口的请求前,需要先执行登录接口请求。
------------恢复内容结束------------
+------------恢复内容开始------------
## Postman安装 +++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求:
发送需要认证的get接口:
选择请求格式为post
传参:
使用参数时,变量名称要与文件里的变量名保持一致
引用环境信息:
也可以用javascript写变量:
引用全局变量信息:
Cookie用途:一个请求需要用到用户的登录状态(sessionid或token),一般 登录状态会记录在cookie ,postman会自动记录登录状态写入cookies.所以执行非登录接口的请求前,需要先执行登录接口请求。
Postman通过tests插入断言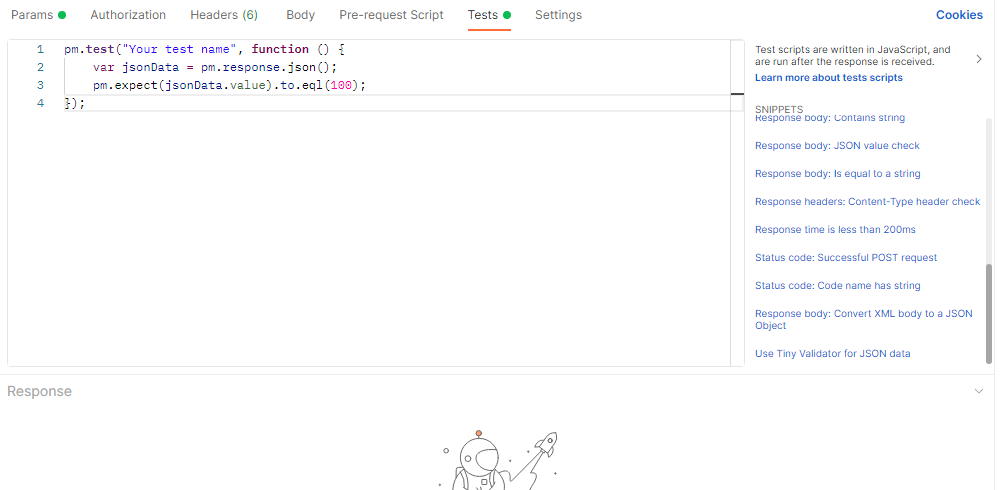
++把上一个接口的返回数据作为下一个参数的输入参数使用
+

++创建Excel数据表:learn.xlsx
+
 +
+++使用python的openpyxl模块来解析Excel
+1、读取Excel文件
openpyxl.load_workbook(‘文件路径’)
+
2、获取sheet页里面的数据
+
2
3
4
5
6
sheet = excel.active
# 获取指定的表单
for sheets in excel.sheetnames: #获取所有表单的名称
print(sheets)
sheet = excel[sheets] #获取指定表单3、获取单元格里面的内容
+
2
3
if type(value[0]) == int: #从第二行开始
print(values)运行代码:
+
 +
+把Excel表里面的数据以字典格式展示:
+1 | data = {} |
运行代码:
+ +
+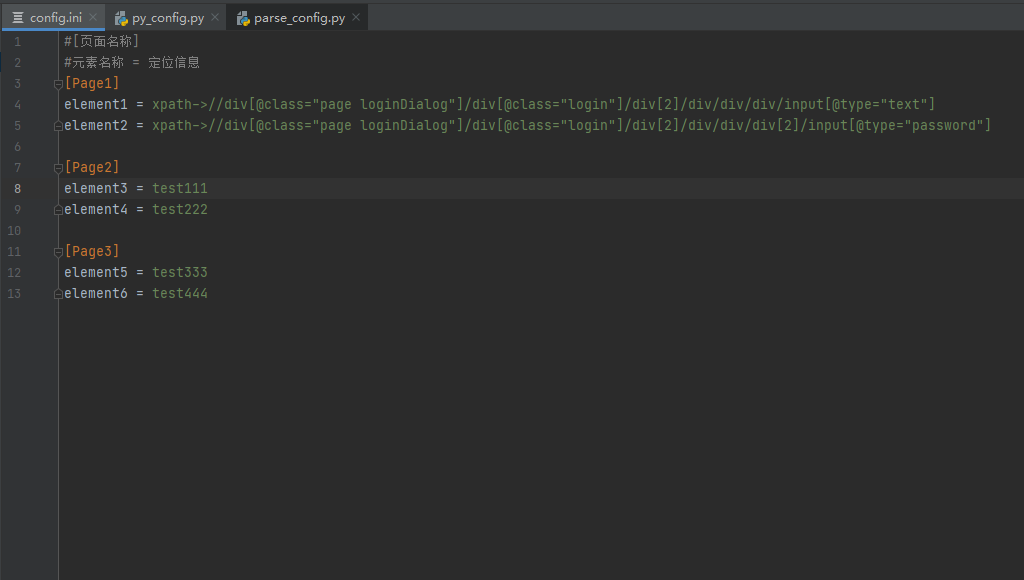
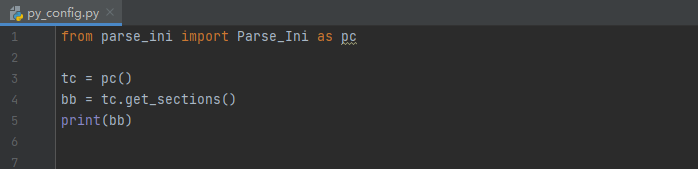
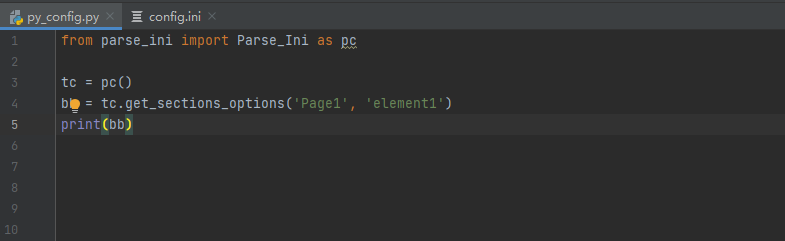
import configparser
+
+class Parse_Ini(object):
+
+ def __init__(self):
+ self.file = r"D:\dingdang_project\test\config.ini"
+ self.parse = configparser.ConfigParser()
+ self.parse.read(self.file, encoding="utf-8")
+
+ def get_sections(self):
+ """
+ :return: 由sections组成的列表
+ """
+ return self.parse.sections()
+
+ def get_options(self, sections):
+ """
+ :return: 返回指定 section 中可用选项的列表。
+ """
+ return self.parse.options(sections)
+
+ def get_sections_options(self, sections, options):
+ """
+ :param sections: 元素名称
+ :param options: 元素地址
+ :return: 指定sections下的options
+ """
+ try:
+ option = self.parse.get(sections, options)
+ if ("-->" in option):
+ option = tuple(option.split("-->"))
+ return option
+ except configparser.NoOptionError as e:
+ return 'error: No option "{}" in section: "{}"'.format(options, sections)
+
+
+if __name__ == "__init__":
+ pass
+

| 定位函数position | ++ |
|---|---|
| //*contains(text(),’文字’)/li[position()=3] | +找到第三个 li | +
| //*contains(text(),’文字’)/li[position()<=2] | +找到前两个 li | +
| 定位方式 | +描述 | +实例 | +
|---|---|---|
| contains | +匹配在元素文本中查找包含 ‘文字’ 的元素 | +//*contains(text(),’文字’) | +
| starts-with | +匹配所有id开头为 ‘s’ 的元素 | +//*[starts-with(@id,’s’)] | +
| ends-with | +匹配所有id结尾头为 ‘s’ 的元素 | +//*[ends-with(@id,”s”)] | +
| following-sibling | +匹配和 ‘ul’ 元素同级别的下一个元素 | +//div/following-sibling::ul | +
| preceding-sibling | +匹配当前节点之前的所有同级节点 | ++ |
| ancestor | +匹配当前节点的所有父级,祖父级还有更高级 | +//div/ancestor::li[@role=”menuitem”] | +
| parent | +匹配当前节点的父节点,相当于 .. | +//div/parent::button | +
| 文件后缀 | +函数方法 | ++ |
|---|---|---|
| .Properties | +load | +加载文件 | +
| + | setProperty | +设置 | +
| + | getProperty | +获取 | +
创建加载文件的方法
+1 | /** |
获取key后面的数据
+1 | /** |
获取定位类型或者定位表达式
+1 | /** |
| + | 定义方式 | +作用 | +调用方式 | +
|---|---|---|---|
| 函数 | +public static void 函数名(){} | +封装指定功能的代码块 | +函数名() | +
| 方法 | +public [static] void 方法名(){} | +类的行为,对象可以执行的一些功能 | +对象名.方法名 | +
++使用
+static修饰的内容成为静态的内容
1 | public static void function1(){ |
1 | function1() |
1 | public void class className1{ |
1 | className1.function1() |
1 | className1的对象,需要实例化 |
1 | public void class className1{ |
1 | public void class{ |
1 | public void className1{ |
运行git代码会提示Timed out错误
+1 | 使用git,会发生报错:Failed to connect to github.com port 443 after 21098 ms: Timed out |
设置代理
+1 | git config --global https.proxy |
取消代理
+1 | git config --global --unset https.proxy |
然后输入git 命令使用
+1 | # 拉取镜像 |
在github上下载安装包,解压后剪切到/home目录
1 | # 找到bin目录下的code-server* |
然后在浏览器输入http://ip:3000查看搭建情况
但是这样搭建有问题
+++使用上面方法部署的code-server,因为是http的,导致一些功能不好用,比如写md文档无法预览
+
下面就是配置使用https运行
+++使用openssl为IP签发证书
+
一般的linux系统已经内置openssl,可以输入openssl进行查看,没有的话就需要安装
+新建openssl.cnf,并编辑如下内容
1 | [req] |
san_domain_com 为最终生成的文件名,一般以服务器命名,可改。
+1 | openssl genrsa -out san_domain_com.key 2048 |
1 | openssl req -new -out san_domain_com.csr -key san_domain_com.key -config openssl.cnf |
执行后,系统提示输入组织等信息,按[]内容提示输入如即可。
+需要测试CSR文件是否生成成功1
> openssl req -text -noout -in san_domain_com.csr
有下面的信息,说明生成成功
1 | Certificate Request: |
1 | openssl x509 -req -days 3650 -in san_domain_com.csr -signkey san_domain_com.key -out san_domain_com.crt -extensions v3_req -extfile openssl.cnf |
在当前目录会生成三个文件1
2
3
4
5san_domain_com.crt
san_domain_com.csr
san_domain_com.key
将.crt证书发给用户,用户双击进行安装,然后重启浏览器
在code-server的bin目录下运行如下命令,设置端口号为8881,指定对应生成的crt和key密钥文件,即可正常访问https域名1
2
3
4# 给ssh创建密码
export PASSWORD="123456"
# 启动ssh
nohup ./code-server --port 8881 --host 0.0.0.0 --cert ../san_domain_com.crt --cert-key ../san_domain_com.key > vscode.log 2>&1 &
然后通过浏览器访问https://ip:3000
++拉取CentOS7镜像,下载安装Grafana和Influxdb
+
+ # 拉取阿里云的centos7镜像
+ git pull registry.cn-zhangjiakou.aliyuncs.com/ggls/centos:7.1
+ # 运行镜像生成容器
+ docker run -itd --name centos7-influx
+ -p 8083:8083 -p 8086:8086
+ -p 2003:2003 -p 3000:3000
+ -v /opt/centos7_influx:/opt
+ --privileged=true
+ registry.cn-zhangjiakou.aliyuncs.com/ggls/centos:7.1 /usr/sbin/init
+ # 进入容器
+ docker exec -it centos7-influx bash
+
+端口说明:
+新版本可以点击influxDB官网进行下载
+ + # 下载安装包 + wget https://dl.influxdata.com/influxdb/releases/influxdb-1.6.3.x86_64.rpm + # 安装运行 + yum localinstall influxdb-1.6.3.x86_64.rpm + +安装运行后,然后对influxDB进行配置,主要是配置Jmeter连接的数据库和端口号
+ + vim /etc/influxdb/influxdb.conf + +找到graphite并且修改它的库与端口1
2
3
4
5
6enabled = true
database = "jmeter"
retention-policy = ""
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
[http],将前面的#号去掉 +
+systemctl start influxdb.servicesystemctl status influxdb.service +
+新版本下载位置:Grafana官网下载:https://grafana.com/grafana/download
+1 | wget https://dl.grafana.com/oss/release/grafana-6.5.2-1.x86_64.rpm |
启动命令: systemctl start grafana-server.service
查看状态命令: systemctl status grafana-server.service
然后在浏览器访问登录http://ip:3000;
Thread GroupAdd -> Listener -> Backend ListenerBackend Listener implementation 默认选择GraphiteBackendListenerClient
+数据库里面有两个库,jmeter库就是jmeter运行生成表的数据库
+可以看到生成了三类前缀的表,分别是: jmeter.all 、 jmeter.[请求名称];最后还有 jmeter.test 开头的表,这个后面会单独拿出来说
+前缀的含义
+jmeter.all :代表了所有请求;当summaryOnly=true时,就只有samplerName=all的表了jmeter.[请求名称]:代表了HTTP请求,即samplerName=[请求名称]Thread/Virtual Users metrics - 线程/虚拟用户指标
跟线程组设置相关的
| 指标 | +全称 | +含义 | +
|---|---|---|
| jmeter.test.minAT | +Min active threads | +最小活跃线程数 | +
| jmeter.test.maxAT | +Max active threads | +最大活跃线程数 | +
| jmeter.test.meanAT | +Mean active threads | +平均活跃线程数 | +
| jmeter.test.startedT | +Started threads | +启动线程数 | +
| jmeter.test.endedT | +Finished threads | +结束线程数 | +
Response times metrics - 响应时间指标
+划重点:每个sampler(请求)都包含了所有响应时间指标,每个sampler(请求)的每个指标都会有单独的一个表存储结果数据
+| 指标 | +含义 | +
|---|---|
| sampler的成功响应数 | +|
| 服务器每秒命中次数(每秒点击数,即TPS) | +|
| sampler响应成功的最短响应时间 | +|
| sampler响应成功的最长响应时间 | +|
| sampler响应成功的平均响应时间 | +|
| sampler响应成功的所占百分比 | +|
| sampler的失败响应数 | +|
| sampler响应失败的最短响应时间 | +|
| sampler响应失败的最长响应时间 | +|
| sampler响应失败的平均响应时间 | +|
| sampler响应失败的所占百分比 | +|
| sampler响应数(ok.count+ko.count) | +|
| 已发送字节 | +|
| 已接收字节 | +|
| sampler响应的最短响应时间(ok.count和ko.count的最小值) | +|
| sampler响应的最长响应时间(ok.count和ko.count的最大值) | +|
| sampler响应的平均响应时间(ok.count和ko.count的平均值) | +|
| sampler响应的百分比(根据成功和失败的总数来计算) | +
步骤:
+配置数据源
+创建数据面板
+ +
+点击首页的Create your first data source,然后进行配置
 +
+点击选择influxDB
 +
+ +
+ +
+选择Add Query,然后进行配置
 +
+当我们只想看数据而不想看数据趋势图的话,可以改变它的类型;
+在同一个界面,点击左侧列表选中第二个icon,然后选择Singlestat即可
+ +
+基本的配置完成,Jmeter使用GraphiteBackendListenerClient来采集数据的,因为请求多起来的时候会有非常多的表,维护成本也会增加;后面将会介绍如何通过InfluxDBBackendListenerClient来采集数据
给Jmeter的Backend Listener配置为InfluxDBBackendListenerClient
+首先来看看每个配置项的含义
+inDB数据库
使用InfluxDBBackendListenerClient好处就是,再多的请求也只会生成两张表:
events :主要拿存事件的
jmeter :存测试结果数据的,Grafana也是从这个表获取数据再展示
配置数据面板
+首先,进入官方模板库: https://grafana.com/dashboards ,然后跟着图片导入模板并初始化即可
+ +
+ +
+ +
+ +
+然后jmeter再次执行一下测试计划
+ +
+模板自带了三个下拉筛选框
+data_source:数据源,在Grafana配置了多少个就显示多少个
+application:在Jmeter配置好的application,如果每次测试计划执行时的application都不一样,你就可以通过这个筛选出对应测试时机的结果数据了
+transaction:在Jmeter配置好的sampleList,譬如我只发了get、post请求,这里就只会给你选get、post;可以滑到页面下面看到针对某个请求的数据展示
+停止Grafana服务。1
systemctl stop grafana-server.service
1
systemctl disable grafana-server.service
查看要卸载的包的名称1
yum list installed
输入命令行卸载Grafana1
yum remove grafana.x86_64
在resources下面新建文件application.properties,名称不能变,只能是这个,运行时系统会自动获取这个端口数据
在里面输入代码数据
+1 | server.port=${port:8888} |
在maven下安装插件,需要在pox.xml文件输入下面的数据,然后更新文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<springboot.version>2.5.6</springboot.version>
<swagger.version>2.9.2</swagger.version>
</properties>
<dependencies>
<!-- springboot 2.5.6 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${springboot.version}</version>
</dependency>
</dependencies>
上面的${springboot.version}是在上面
1 | - java |
创建Application.java类,用来运行接口,类名只能是Application,不能自定义
1 |
|
@SpringBootApplication 作用是给当前类标明是运行的主类,相当于被SpringBoot托管了@Controller("com.course.server.intertype") 钩子标识符,扫描包下面的类,被Springboot托管创建MyGetMethod类
类名上有修饰符@RestController和@Api(value = "/")
@RestController 标识该类会被扫描到,然后被SpringBoot托管@Api(value = "/") 可加可不加@RequestMapping(value = "访问路径", method = 访问方法) 定义接口的访问路径及访问方法@ApiOperation(value = "接口信息", httpMethod = "接口的请求方法") 展示接口的基本信息和它的请求方法,可加可不加下面是代码信息,之后的所有GET接口都在该类里面写接口方法
+1 |
|
上面就是返回cookie的get接口开发,接下来就是 需要携带cookies信息才能访问的get请求
+这个接口还是在MyGetMethod类里面编写方法
1 | /** |
使用参数就要用到@RequestParam 参数类型 参数变量,可以有多个参数
这个接口还是在MyGetMethod类里面编写方法,有两种方法
第一种url:key=value&&key=value:
1 | /** |
方法二url: ip:port/get/with/param/10/20:
1 |
|
1 | create database 数据库名; |
1 | show databases; |
3、查看某个数据库的定义的信息:
+1 | show create database 数据库名; |
1 | drop database 数据库名称; |
5、切换数据库:
+1 | use 数据库名; |
6、查看正在使用的数据库:
+1 | select database(); |
7、查看数据库中的所有表:
+1 | show tables; |
8、查看表结构:
+1 | desc 表名; |
9、修改表删除列.
+1 | alter table 表名 drop 列名; |
10、修改表名
+1 | rename table 表名 to 新表名; |
11、修改表的字符集
+1 | alter table 表名 character set 字符集; |
12、数据类型与约束
+1 | create table 表名(字段名 类型 约束,.....) |
1 | drop table 表名 |
1 | insert into 表名 values(值1,值2...)给表中所有字段插入数据 |
1 | update 表名 set 字段1=值1,字段2=值2 where 条件 |
1 | delete from 表名 where 条件 |
1 | select * from 表名 where 条件 |
1 | select 字段1,字段2,字段3...from 表名 where 条件 |
1 | select 字段1 (as) 别名,字段2 别名 from 表名 where 条件 |
1 | select distinct 字段 from 表名 where 条件 |
1 | select * from 表名 where age>20 |
and 满足所有条件
+or 满足其中任意一个条件
+not 不满足条件
+3.5.1、排序
+1 | select * from 表名 where 条件 order by 列1 (asc)|desc,列2 asc|desc |
3.5.2、聚合函数
+1 | count: 总数 select count(*/字段)from 表名 where 条件 |
3.5.3、分组
+1 | select * from 表名 group by 字段,字段2 having 条件 |
3.5.4、分页
+1 | select * from 表名 limit 0,5 从第一行数据开始,显示5行 |
3.5.5、等值连接
+1 | 方式一 : |
3.5.6、左连接
+++左边的表全显示,右边表能匹配的上的数据连接显示,匹配不上(没有的)以null补充
+
1 | select * from 表1 left join 表2 on 表1.列=表2.列 left join 表3 on 表2.列=表3.列 where 条件 |
3.5.7、右连接
+++右边的表全显示,左边表能匹配上的数据连接显示,匹配不上(没有的)以null补充
+
1 | select * from 表1 right join 表2 on 表1.列=表2.列 right join 表3 on 表2.列=表3.列 where 条件 |
3.5.8、自关联
+1 | select * from 表 别名1 inner join 表 别名2 on 别名1.aid=别名2.pid |
++子查询结果输出的是一行一列
+
1 | select * from student where age>(select avg(age) from student) |
++子查询的结果输出的是一列多行
+
1 | in: |
++子查询的结果输出的是一行多列
+
1 | select * from student where(name,sex)=(select name,sex from student where sex='男' order by age desc limit 1) |
++子查询的输出结果是一个表
+
1 | select * from scores inner join (select cno from courses where cname in('数据库',‘系统测试’) as c on scores.cno=c.cno |
1 | insert into goods_cate(cate_name) select distinct cate from goods; |
首先,写一个User类,这将是添加时的字段数据
1 |
|
@RequestBody User u请求post接口时,在Body填写上传的数据
1 |
|
@RequestMapping(value = "/v1")的作用是把这个value和方法上的登录地址进行拼接,比如:/v1/login
@RestController标识该接口可以被托管
方法参数@RequestParam(value = "userName", required = true) String userName,代码中的required = true起到必填的作用
1 |
|
右键 HTTP Request
点击add --> Assertions --> Response Assertion
断言组件就添加成功
+Field to Test 下面就是断言的各种方法
++在
+Patterns to Test输入title之间包含的文字,及配置成功
++在
+Patterns to Test输入响应码,比如 200
然后运行但并发压测,验证断言添加是否正确,在View Results Tree中查看结果
右键 Thread Group
点击 Add --> Listener --> Aggregate Report
聚合报告就添加了
+++jmeter -n -t $jmx_file -l $jtl_file
+
如: jmeter -n -t HTTP代理服务器luzhi.jmx -l result.jtl
+jmx: Jmeter压测程序脚本文件
jtl: Jmeter压测请求响应数据的原始文件,查看结果树和聚合报告可以导入该文件查看
Http RequestAdd -> Post Processors -> JSON Extractor组件安装成功
+Names of created variables : 参数变量名称,提取出来的json使用这个变量Json Path expressions : JSON提取的正则 比如:$.access_token这个是提取response里面的tokenMatch NO.(0 for Random):这个是写提取出json的第几条, 比如使用正则能匹配多条,使用这个输入数字就可以匹配对应的${变量名}++帮助检查变量值,调试脚本
+
Thread GroupAdd -> Sampler -> Debug Sampler注意:把Debug放到所有请求的最底下,运行的后可以查看变量参数,方便调试
+Thread GroupAdd -> Config Element -> User Defined Variableshostname:localhostport:9090protocol:http然后再请求参数中使用对应的参数变量名
+${hostname}${port}${protocol}.csv文件Thread GroupAdd -> Config Element -> CSV Data Set ConfigFilename:文件位置File encoding:编码格式Variable Names(comma-delimited):数据参数 如:no,username,passwordlgnore first lline (only user if Variable Names is not empty):是否忽略第一行(表头)Delimiter(use "\t" for tab):分隔符Allow quoted data?:是否允许双引号括住数据Recycle on EOF?:到了文件结尾是否循环Stop thread on EOF?:到了文件结尾是否停止Sharinng mode:共享模式mysql.jar放在jmeter的lib目录下
+Thread GroupAdd -> Config Element -> JDBC Connection Configurationjdbc:mysql://8.142.144.75:3306/jmeter_class?alloMultiQueries = true&useSSL=falsecom.mysql.jbc.DriverusernamepasswordThread GroupAdd -> Sampler -> JDBC RequestVariable Name Bound to Pool: 配置参数区SQL Query:sql语句区
其他:变量配置区
JDBC Connection Configuration: db_connnection_pool #输入连接池名称Query Type:选择Prepared Updata StatementQuert:输入sql语句1 | INSERT INTO jmeter_class.user (`username`,`password`) VALUES(?,?) |
Paeameter values:testuser,aaaaaaPaeameter types:varchar,varcharQuery timeout(s):6运行结果ResponseBody:1
1 updates.
这就配置成功
上一节已经写了规则,这次直接来编写Get和Post请求
+模拟一个没有参数的get请求1
2
3
4
5
6
7
8
9
10{
"description": "模拟一个没有参数的get请求",
"request": {
"uri": "/getdemo",
"method": "get"
},
"response": {
"text": "这是一个没有参数的get请求"
}
}
模拟一个带参数的请求1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"description": "模拟一个带参数的请求",
"request": {
"uri": "getwithparam",
"method": "get",
"queries": {
"name": "胡汉三",
"age": "18"
}
},
"response": {
"text": "我胡汉三又回来了!!!!!"
}
}
模拟一个Post请求1
2
3
4
5
6
7
8
9
10{
"description": "模拟一个Post请求",
"request": {
"uri": "/postdemo",
"method": "post"
},
"response": {
"text": "这是我的第一个mosk的post请求"
}
}
这是一个带参数的post请求1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"description": "这是一个带参数的post请求",
"request": {
"uri": "/postwithparam",
"method": "post",
"forms": {
"name": "胡汉三",
"sex": "男人"
}
},
"response": {
"text": "我胡汉三带着参数来了!!!!"
}
}
上一节已经写了规则,这次直接来编写Get和Post请求
+1 | { |
1 | { |
1 | { |
以[]包裹着以{}包起来的接口脚本
description:接口简介
request:使用{}包含接口的请求信息
uri:接口的地址名称method:请求方法queries:get请求参数forms:post请求参数headers:请求头信息response:返回的数据,使用{}
text:返回的文字数据cookies:返回的cookie信息status:返回的响应码举个栗子demo
+1 | [ |
get请求demo1
2
3
4
5
6
7
8
9
10
11
12[
{
"description": "接口的get请求",
"request": {
"uri": "/#/test/xml",
"method": "get"
},
"response": {
"text": "get请求接口"
}
}
]
点击moke选择版本进行下载,我下载的的是moco-runner-0.11.0-standalone.jar
1 | java -jar jar包的存放路径 http -p 端口 -c json文件路径 |
上一节已经写了规则,这次直接来编写Get和Post请求
+redirectTo:目标地址1 | [ |
就是loadrunner上面的思考时间,就是模拟真实用户操作过程的等待时间
+定时器的父节点和子节点,如果想让一个请求强制停止一段时间,就把定时器放在这个请求的下面
+单位是以ms为单位,1s=1000ms
+指定子节点运行的次数,使用变量或数值进行控制
+把多个请求放入Simple Controller,可以多个请求进行同时操作
一个事务会包含并请求,然后查看一个事务的QPS等性能指标
+QPS:每秒处理完请求的次数,具体指1s内发出请求到服务器处理完成并返回结果的次数
+TPS:每秒处理完的事务次数,一般TPS是对整个系统来讲的,一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能对应多个请求,对于衡量单个接口服务的处理能力,一般使用QPS
+没有选中Generate Parent sample,运行后的结果是
 +
+ +
+ +
+ +
+限制整个运行过程中的生成的吞吐量不要超过某一个值,防止压死系统
+20 QPS,这里应该输入1200This Thread only:控制每个线程的吞吐量,这个模式的作用是:总的吞吐量=Target throughput * 线程的数量All active threads:设置的Target throughput将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理时间后再次运行。活跃线程指的是同一时刻同时运行的线程All active threads in current thread group:设置的`Target throughput将分配在当前线程祖的每一个活跃线程上,当测试计划只有一个线程组,这个模式作用和All active threads一样All active threads(shared):与All active threads选项基本一致,唯一区别是,每一个活跃线程都会在所有活跃线程上一次运行结束后等待合理时间再次运行All active threads in current thread group(shared):与All active threads in current thread group选项基本一致,唯一区别是,每个活跃线程都会在所有活跃线程的上一次运行结束等待合理的时间后再次运行生成随机等待时间
+Deviation(in milliseconds):高斯定时器参数,随机的Constant Delay Offset(in milliseconds):固定等待时长生成的时长是Deviation + Constant Delay Offset
():括起来的部分是要提取的.:匹配任何字符串+:一次或多次?:在找到第一个匹配项后停止用2$等,表示解析到的第几个值给title,$1$表示第一个
+0代表随机,1代表全部取值,通常使用0
+若参数没有取到值,那默认给一个值让他取
+log:写入信息到jmeterlog文件,使用方法:log.info(*Thisisloginfoctx:该变量引用了当前线程的上下文,使用方法可参考:org.apache.imeter.threads.JMeterContext。vars-(JMeterVariables):操作imeter变量,这个变量实际引用了JMeter线程中的局部变量容器(本质上是Map),它是测试用例与BeanShell交互的桥梁,props-(JMeterProperties-classjava.util.Properties):操作imeter属性,该变量引用了JMeter的配置信息,可以获取Jmeter的属性,它的使用方法与vars类似,但是只能put进去String类型的值,而不能是一个对象。prey-(SampleResult):获取前面的sample返回的信息,sampler-(Sampler):gives access to the current sampler安装插件,下载Custom Thread Groupsan插件
添加Arrivals Thread Group
QPS, 输入10就是10QPS +
+安装插件,下载Custom Thread Groupsan插件
添加Ultimate Thread Group
 +
+1 | docker pull prom/prometheus |
1 | docker run -itd --name=docker_prometheus --restart=always -p 3090:9090 -v /opt/prometheus:/ prom/prometheus |
验证
+通过浏览器访问http://ip:3090进行访问
首先,用浏览器访问:node_export 下载,然后上传到被监控的服务器并解压
进入解压文件夹,直接启动./node_exporter
1 | docker pull prom/node-exporter |
1 | docker run -itd --name=node-exporter \ |
验证
+在浏览器访问http://ip:9100/metrics进行访问
node_export的作用收集硬件数据
+使用vim修改yum文件容器内:/etc/prometheus/prometheus.yml
1 | scrape_configs: |
1 | docker restart docker_prometheus |
使用Grafana下载版本
+数据源:选择prometheus
URL输入http://prometheus机器ip:3090
点击Save & Test保存
使用官方仪表盘进行下载仪表盘
导入仪表盘
在import via grafana.com输入框输入模板ID12884
ID:12633也可以使用。
+点击 load,然后底部选择刚弄的数据源,点击import
+注意:
点击json下载12884的json文件
| 基本数据类型 | +包装类 | +大小(字节) | +
|---|---|---|
| byte | +Byte | +1—(-128~127) | +
| short | +Short | +2—(-32768~32767) | +
| int | +Integer | +4 | +
| long | +Long | +8 | +
| float | +Float | +4 | +
| double | +Double | +8 | +
| char | +Character | +2 | +
| boolean | +Boolean | +1 | +
| 方法 | +描述 | +
|---|---|
| compareTo() | +用于将对象与方法的参数进行比较(相同类型) | +
| decode() | +将方法的参数转为包装类对象 | +
| equals() | +判断对象是否与参数相等 | +
| Integer.parseInt(“字符串’) | +将字符串转为Int类型 | +
| Integer.toString(int数据) | +将Int类型转为字符串 | +
| 方法 | +描述 | +
|---|---|
| str.concat() | +将参数拼接到字符串上 | +
| trim() | +去除字符串两端的字符串,不能去除中间 | +
| replace(oldChar, newChar) | +将字符串的old参数替换为new参数 |
+
| length() | +返回此字符串的长度 | +
| isEmpty() | +判断字符串是否为空 | +
字符串在后面拼接
+1 | String str = "床前明月光"; |
1 | String str = " 床 前明 月光 "; |
1 | String str = "床前明月光"; |
返回int类型
+1 | String str = "床前明月光"; |
返回布尔类型
+1 | String str = "床前明月光"; |
使用abstract修饰一个类,把这个类变成抽象类,抽象类不能直接创建对象,需要其他类进行继承该抽象类
abstract进行修饰,不能有方法体子类必须实现父抽象类的方法
+1 | public abstract class Ahsse { |
使用interface定义接口,相当于class
+接口可以多继承
+继承是相对于类来说,通过关键字extends来实现
父类修改了内容,子类也会修改
+父类的属性和方法
+this表示当前对象的引用
+调用方法
+ +方法名和参数不变,只修改方法体
+静态的方法能被子类继承,能使用但不能被重写
+1 | public class testeass { |
重载是同一个类下对方法进行重载
+方法名相同,参数不相同 (参数个数不同/参数类型不同/参数排列顺序不同)
+1 | public class jichu { |
考研恋练有词必背词全部背锅一边
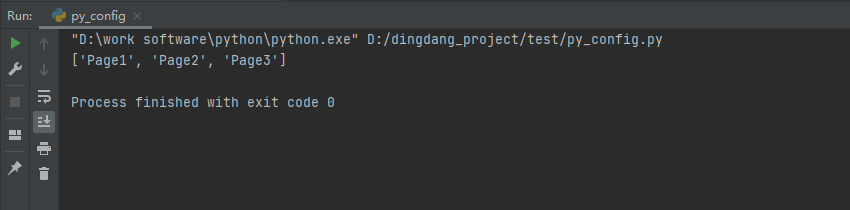
+自动化测试已部署
+Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
+1 | $ hexo new "My New Post" |
More info: Writing
+1 | $ hexo server |
More info: Server
+1 | $ hexo generate |
More info: Generating
+1 | $ hexo deploy |
More info: Deployment
+这个博客主要记录学习的技术,一方面是帮助别人学习,另一方面也是留给自己方便回顾和查找。
+${content}
+ ` + }, + empty: function (data) { + return ( + '${this.highlightKeyword(content, slice)}...
` + }) + + resultItem += '$ hexo new "My New Post" |
More info: Writing
+$ hexo server |
More info: Server
+$ hexo generate |
More info: Generating
+$ hexo deploy |
More info: Deployment
+]]>++redis-cli -p 6381
+
+++cluster info
+
+查看主机和从机之间的主从关系
+++cluster nodes
+
.assets\image-20220509101455220.png)
+Redis集群搭建之哈希槽算法解决一致性哈希算法数据倾斜问题
是一个数组,数组[0,2^14-1]形成hash slot空间
+解决均匀分配问题,在数据和节点之间加入一层(哈希槽slot)用于管理数据和节点之间的关系,现在相当于节点里放槽,槽里放数据
+
+方便数据移动
+哈希解决的映射问题,使用key的哈希值来计算所在的槽,便于数据分配
+一个集群只能有16384个槽,编号0-16383(0-2^14-1)
+这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。
+接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。
以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
+Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上
+首先有几个redis就把0-16383分成几个
+
+Redis集群搭建(上)docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381 |
运行成功,使用docker ps查看
进入容器redis-node-1并为6台机器构建集群关系
+进入一台redis进行配置docker exec -it redis-node-1 bash
#进入后执行
+redis-cli --cluster create 8.142.144.75:6381 8.142.144.75:6382 8.142.144.75:6383 8.142.144.75:6384 8.142.144.75:6385 8.142.144.75:6386 --cluster-replicas 1
+
+ --cluster create 构建集群
+ --cluster-replicas 1 集群关联一比一的关系
+
+--cluster-replicas 1 表示为每个master创建一个slave节点
+# 注意:上面的ip为真实IP
+有下面的绿色ok字样显示运行成功
+
+++如果运行不成功,一直显示
+Waiting for the cluster to join..一直………………………………….,则是端口没有全部开放,防火墙也要开放端口,以阿里云为例
就是需要在安全组上面配置6381~6386的6个端口,还需要配置16381~16386的6个端口,共12个端口都要开放,不然会一直提示等待
+++注意:
+jdk8需要和Dockerfile放到同一个文件夹
FROM centos:7 |
++仓库名和标签名全部为
+的镜像
碰到它还是进行删除的好
+使用docker image ls -f dangling=true查找虚悬镜像
使用docker image prune删除镜像
新建主服务器容器实例3307
+docker run -p 3307:3306 --name mysql-master -v /mydata/mysql-master/log/:/var/log/mysql -v /mydata/mysql-master/data:/var/lib/mysql -v /mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 |
进入/mydata/mysql-master/conf目录下新建my.cnf把下面内容粘贴到my.cnf
[mysqld] |
修改完配置后重启master容器
+master容器实例内创建数据同步用户
+建立一个用户 |
+新建从服务器实例3308
+docker run -p 3308:3306 --name mysql-slave -v /mydata/mysql-slave/log/:/var/log/mysql -v /mydata/mysql-slave/data:/var/lib/mysql -v /mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7 |
进入/mydata/mysql-slave/conf目录下新建my.cnf
+# 设置使用的二进制日志格式(mixed,statement,row) |
重启从机实例docker restart mysql-slave
在主数据库中查看主从同步状态show master status;
进入mysql-slave从机容器
+在从数据库中配置主从复制change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;
说明: |
在从数据库中查看主从同步状态show slave status \G;
在从数据库中开启主从同步start slave
查看从数据库状态发现已经同步
+
+主从复制测试
+主机创建数据库,创建表,插入数据,搜索表的数据
+从机直接搜索标的数据
+]]>++注意:进入集群环境后,不能使用单机版的
+redis-cli -p 6381
因为这样会在增加数据时有error报错出现
+使用set k1 v1错误是因为1号主机里面的编号是0到5460,超过了这个范围就会报错
++正确进入的方法
+redis-cli -p 6381 -c-c 的作用是优化路由
+
+++注:可以进入任意一台主机 + + +redis-cli —cluster check 8.142.144.75:6381
+
+++]]>主机宕机,从机自动切换成主机
+
启动docker
+++systemctl start docker
+
停止docker
+++systemctl stop docker
+
查看docker状态
+++systemctl status docker
+
重启 docker,没有任何提示说明启动成功
+++]]>systemctl restart docker
+
docker 开机启动
+++systemctl enable docker
+
查看 docker 概要信息
+++docker info
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker info |
查看 docker 总体帮助文档
+++docker —help
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker --help |
++docker images
+
OPTIONS说明:+
+- +
+
+- a 列出本地所有的镜像(含历史镜像)
+- +
+
+- q 只显示镜像ID
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images |
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images -a |
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker images -q |
++docker search 镜像名称
+
STARS 点赞数
OFFICIAL 官方认证
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker search hello-world |
++docker search —limit n 镜像名称
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker search --limit 5 redis |
++docker pull 镜像名称:标签版本号
+
没有tag就是最新版[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker pull redis:6.0.8
6.0.8: Pulling from library/redis
bb79b6b2107f: Pull complete
1ed3521a5dcb: Pull complete
5999b99cee8f: Pull complete
3f806f5245c9: Pull complete
f8a4497572b2: Pull complete
eafe3b6b8d06: Pull complete
Digest: sha256:21db12e5ab3cc343e9376d655e8eabbdbe5516801373e95a8a9e66010c5b8819
Status: Downloaded newer image for redis:6.0.8
docker.io/library/redis:6.0.8
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
++docker system df
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker system df |
++docker rmi 镜像ID
+
```shell
+Error response from daemon: conflict: unable to delete feb5d9fea6a5 (must be forced) - image is being used by stopped container 13111f725991
+说明之前运行过这个镜像,生成了容器,需要先删除容器,再删除镜像
+++docker rmi -f 镜像id
+
++xxxxxxxxxx # 没有任何提示说明启动成功[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# systemctl restart docker[root@iZ8vbfaek3x3ogtpxnpnwfZ /]#shell
+
++]]>docker rmi -f $(docker images -qa)
+
创建redis-node-7 |
docker exec -it redis-node-1 bash进入redis-node-1里面redis-cli --cluster add-node 8.142.144.75:6387 8.142.144.75:6381
+6387 新加入的节点
+6381 相当于6387的领路人
+redis-cli --cluster check 8.142.144.75:6381检查
+++redis-cli —cluster reshard IP地址:端口号
+
+
+在重新加载过程会碰到Do you want to proceed with the proposed reshard plan (yes/no)?一句话,选择yes就可以
+
+++redis-cli —cluster add-node ip:新slave端口 ip:新master端口 —cluster-slave —cluster-master-id 新主机节点ID
+
+
+++redis-cli —cluster check 8.142.144.75:6382
+
+++redis-cli —cluster del-node ip:从机端口 从机6388节点ID
+
+redis-cli --cluster check 8.142.144.75:6382进行集群检查
+6388删除成功
+本例将清出来的槽号都给6381
+使用redis-cli --cluster reshard ip:6381进行节点的重组
+上图中1输入的4096是6387主机所拥有的槽点数量,把他们全部拿出来分掉
+上图的2输入的ID是接收6387主机所放出的槽点数的主机id
+上图中3输入的ID是放出槽点数的6387主机的id
+上图中4输入的done指的是已经输入完所有的节点
+redis-cli --cluster check 8.142.144.75:6382进行集群检查
+++redis-cli —cluster del-node ip:端口 6387节点ID
+
+redis-cli --cluster check 8.142.144.75:6382进行集群检查
+使用docker pull mysql:5.7拉取mysql 5.7镜像
使用docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7运行镜像创建容器
++因为linux系统自己装了mysql,避免端口冲突,先运行ps -ef|grep mysql查询
+
使用docker ps查询容器编号
使用docker exec -it 容器编号 bash进入mysql容器
使用mysql -uroot -p,输入密码,登录mysql
show databases
mysql> show databases |
INSERT INTo t1 VALUES(3, "张三"); |
mysql> SHOW VARIABLES LIKE 'character%'; |
在宿主机的/ggls/mysql/conf目录下vim my.cnf文件,通过容器卷同步给容器实例
[client] |
SHOW VARIABLES LIKE 'character%';验证工作使用版启动容器方法
+docker run -d -p 3306:3306 --privileged=true |
使用docker pull redis:6.0.8拉取redis:6.0.8镜像
创建容器
+++容器卷要加入
+--privileged=true
在宿主机下新建目录mkdir -p /app/redis
首先把tomcat在镜像源中pull下来,使用docker images 查看镜像
使用docker run -d -p 8080:8080 tomcat:9.0新建容器运行tomcat
++运行后使用本地PC使用阿里云的ip和端口访问docker上面的
+tomcat
+使用docker ps查询到容器编号,docker exec -it 容器编号 bash 打开容器
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps |
使用ls-l查看文件列表
root@c52ab6b8b8df:/usr/local/tomcat# ls -l |
从列表可以看到有两个文件夹webapps和webapps.dist,数据全部在webapps.dist里面,需要将webapps删除,把webapps.dist重命名成webapps即可访问
使用rm -rf webapps删除webapps文件夹
使用mv webapps.dist webapps重命名
再次使用本地访问
+
+++]]>docker pull billygoo/tomcat8-jdk8
+docker run -d -p 8080:8080 —name tomcat8 billygoo/tomcat8-jdk8
+
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 |
++宿主vs容器之间映射添加容器卷
+
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 添加docker run -it --privileged=true -v /tmp/host_data:/tmp/docker_data --name=ui ubuntu |
`在容器内部创建一个dockerin.txt文件 |
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:ro 镜像名 |
++卷的继承和共享
+
docker run -it --privileged=true --volumes-from 父类 --name u2 ubuntu |
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker images |
docker run -it ubuntu:15.10 /bin/bash
/bin/bash 希望有交互式shell 就用/bin/bash
++docker ps [OPTIONS]
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a |
OPTIONS:
+List containers |
run进入容器,exit退出容器, 容器停止
+run进入容器,exit退出容器, 容器不停止[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker run -it ubuntu bash
root@562278524cda:/# [root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
562278524cda ubuntu "bash" 16 seconds ago Up 15 seconds loving_dewdney
(问题):使用docker run -d ubuntu命令启动后台模式的容器ubuntu,然后用docker ps 查询提示没有找到运行的容器
+++Docker容器后台运行就必须有一个前台进程,不然容器没事做,会自杀
+
解决方法:将运行的程序以前台进程的方式运行
常见方式:命令行模式
++docker logs 容器id
+
++docker top 容器id
+
++docker inspect 容器id
+
进入正在运行的容器并以命令行交互
+++docker exec -it 容器id bashShell
+
重新进入
+++docker attach 容器id
+
(区别)
attach直接进入容器启动命令的终端,不会启动新的进程,用exit退出,会导致容器的停止
exec是在容器中打开新的终端,并且可以启动新的进程,用exit退出,不会导致容器的停止
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps |
++docker cp 容器id:容器地址 主机地址
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker cp 26191ecfb227:/tmp/a.txt /opt/ab.txt |
export 导出容器的内容留作为一个tar归档文件[对应import命令]
+++docker export 容器id > 自定义文件名.tar
+
import从tar包中的内容创建一个新的文件系统再导入为镜像[export]
+++cat 文件名.tar | docker import - 自定义/镜像名:3.5(3.5是自定义)
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ opt]# docker ps |
[root@iZ8vbfaek3x3ogtpxnpnwfZ opt]# docker ps |
++docker start 容器id/容器名
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a |
++docker restart 容器id/容器名
+
++docker stop 容器id/容器名
+
++docker kill 容器id/容器名
+
++docker rm 容器id
+
注:xargs是linux系统的可变参数,把分隔符前面的结果传给xargs里面,然后执行分隔符后面的命令[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
562278524cda ubuntu "bash" 20 minutes ago Up 20 minutes loving_dewdney
cdee90a8c77d ubuntu "bash" 45 minutes ago Up 15 minutes ubuntu
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps -a -q | xargs docker rm -f
562278524cda
cdee90a8c77d
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@iZ8vbfaek3x3ogtpxnpnwfZ ~]#
运行git代码会提示Timed out错误
+使用git,会发生报错:Failed to connect to github.com port 443 after 21098 ms: Timed out |
设置代理
+git config --global https.proxy |
取消代理
+git config --global --unset https.proxy |
然后输入git 命令使用
+]]>今天使用PyCharm下载一个模块pip.exe install locust,有错误提示
https://visualstudio.microsoft.com/visual-cpp-build-tools/ |
++缺少对应的
+whl文件
碰到了这个错误ERROR: Failed building wheel for psutil,就需要下载psutil.whl
在下载网站点击进入网站
+下载psutil-5.9.0-cp38-cp38-win_amd64.whl文件
然后使用(pip install 文件的绝对路径)进行安装,然后使用pip.exe install locust正常安装
|
docker镜像是最小的,被精简过的Linux系统,是不带vim命令的
+++使用命令 ‘vim a.txt’ 进行新建编辑a.txt文件,就会提示找不到命令
+
更新镜像
+++apt-get update
+
下载vim功能
+++apt-get -y install vim
+
提交副本使成为一个新镜像
+++docker commit -m=”提交的描述信息” -a=”作者” 容器id 要创建的目标镜像名:[标签名]
+
[root@iZ8vbfaek3x3ogtpxnpnwfZ /]# docker ps |
| 文件后缀 | +函数方法 | ++ |
|---|---|---|
| .Properties | +load | +加载文件 | +
| + | setProperty | +设置 | +
| + | getProperty | +获取 | +
创建加载文件的方法
+/** |
获取key后面的数据
+/** |
获取定位类型或者定位表达式
+/** |
| + | 定义方式 | +作用 | +调用方式 | +
|---|---|---|---|
| 函数 | +public static void 函数名(){} | +封装指定功能的代码块 | +函数名() | +
| 方法 | +public [static] void 方法名(){} | +类的行为,对象可以执行的一些功能 | +对象名.方法名 | +
++使用
+static修饰的内容成为静态的内容
public static void function1(){ |
function1() |
public void class className1{ |
className1.function1() |
className1的对象,需要实例化 |
public void class className1{ |
public void class{ |
public void className1{ |
| 基本数据类型 | +包装类 | +大小(字节) | +
|---|---|---|
| byte | +Byte | +1—(-128~127) | +
| short | +Short | +2—(-32768~32767) | +
| int | +Integer | +4 | +
| long | +Long | +8 | +
| float | +Float | +4 | +
| double | +Double | +8 | +
| char | +Character | +2 | +
| boolean | +Boolean | +1 | +
| 方法 | +描述 | +
|---|---|
| compareTo() | +用于将对象与方法的参数进行比较(相同类型) | +
| decode() | +将方法的参数转为包装类对象 | +
| equals() | +判断对象是否与参数相等 | +
| Integer.parseInt(“字符串’) | +将字符串转为Int类型 | +
| Integer.toString(int数据) | +将Int类型转为字符串 | +
| 方法 | +描述 | +
|---|---|
| str.concat() | +将参数拼接到字符串上 | +
| trim() | +去除字符串两端的字符串,不能去除中间 | +
| replace(oldChar, newChar) | +将字符串的old参数替换为new参数 |
+
| length() | +返回此字符串的长度 | +
| isEmpty() | +判断字符串是否为空 | +
字符串在后面拼接
+String str = "床前明月光"; |
String str = " 床 前明 月光 "; |
String str = "床前明月光"; |
返回int类型
+String str = "床前明月光"; |
返回布尔类型
+String str = "床前明月光"; |
使用docker进行对docker镜像功能的新增后,需要发布到阿里云上对镜像进行同步,下次pull镜像就不要pull缩减版的镜像,直接pull更新后的镜像,方便后续使用
然后在基本信息上面就可以看到仓库指南
+++根据指南进行操作
++ + +
+
+使用abstract修饰一个类,把这个类变成抽象类,抽象类不能直接创建对象,需要其他类进行继承该抽象类
abstract进行修饰,不能有方法体子类必须实现父抽象类的方法
+public abstract class Ahsse { |
使用interface定义接口,相当于class
+接口可以多继承
+继承是相对于类来说,通过关键字extends来实现
父类修改了内容,子类也会修改
+父类的属性和方法
+this表示当前对象的引用
+调用方法
+ +方法名和参数不变,只修改方法体
+静态的方法能被子类继承,能使用但不能被重写
+public class testeass { |
重载是同一个类下对方法进行重载
+方法名相同,参数不相同 (参数个数不同/参数类型不同/参数排列顺序不同)
+public class jichu { |
++步骤
+
docker pull registry |
docker run -d -p 5000:5000 -v/ggls/myregistry/:/tmp/registry --privileged=true registry |
新启动ubuntu容器,新增ifconfig命令
apt-get update命令apt-get install net-tools命令容器外部执行docker commit -m="ifconfig cmd add" -a="ggls" ffcc5edf5071 ubuntu:1.6命令
curl验证私服库上有什么镜像
+curl -XGET http://8.142.144.75:5000/v2/_catalog |
docker tag 镜像:Tag Host:Port/Repository:Tag |
修改配置文件使之支持http
+++docker 默认不允许
+http方式推送镜像,通过此配置取消这个限制,若不生效,重启docker
vim /etc/docker/daemon.json打开配置文件json{ |
push推送到私服库
+docker push 符合私服库格式的镜像名称:tag |
pull到本地并运行docker pull 8.142.144.75:5000/ubuntu:1.6 |
添加录制器“HTTP(S) Test Script Recorder”
+添加线程组“Thread Group”
+添加录制控制器“Recording Controller”,
+录制脚本的配置(Test Plan Creation)
+Port=8088Target Controller = TestPlan > Tread Group > Recording Controller录制脚本的配置(Requests Filtering 请求过滤器)
+URl Patterns to Include上添加正则.*\.(baidu\.com).*;表示只抓取百度URL的内容,不抓取其他网站的URl Patterns to Exclude上添加正则.*\.(js|css|PNG|jpg|jpeg|ico|png|gif).*;去掉一些静态请求单击保存按钮,将Jmeter脚本存储
+http://localhost:8088,然后就可以进行访问录制了Recording Controller下面看到,然后停止录制录制结束后,要对录制的代码进行校验
+运行录制的代码,在查看结果树上查看运行的结果
+]]>右键 HTTP Request
点击add --> Assertions --> Response Assertion
断言组件就添加成功
+Field to Test 下面就是断言的各种方法
++在
+Patterns to Test输入title之间包含的文字,及配置成功
++在
+Patterns to Test输入响应码,比如 200
然后运行但并发压测,验证断言添加是否正确,在View Results Tree中查看结果
右键 Thread Group
点击 Add --> Listener --> Aggregate Report
聚合报告就添加了
+++jmeter -n -t $jmx_file -l $jtl_file
+
如: jmeter -n -t HTTP代理服务器luzhi.jmx -l result.jtl
+jmx: Jmeter压测程序脚本文件
jtl: Jmeter压测请求响应数据的原始文件,查看结果树和聚合报告可以导入该文件查看
Http RequestAdd -> Post Processors -> JSON Extractor组件安装成功
+Names of created variables : 参数变量名称,提取出来的json使用这个变量Json Path expressions : JSON提取的正则 比如:$.access_token这个是提取response里面的tokenMatch NO.(0 for Random):这个是写提取出json的第几条, 比如使用正则能匹配多条,使用这个输入数字就可以匹配对应的${变量名}++帮助检查变量值,调试脚本
+
Thread GroupAdd -> Sampler -> Debug Sampler注意:把Debug放到所有请求的最底下,运行的后可以查看变量参数,方便调试
+]]>Thread GroupAdd -> Config Element -> User Defined Variableshostname:localhostport:9090protocol:http然后再请求参数中使用对应的参数变量名
+${hostname}${port}${protocol}.csv文件Thread GroupAdd -> Config Element -> CSV Data Set ConfigFilename:文件位置File encoding:编码格式Variable Names(comma-delimited):数据参数 如:no,username,passwordlgnore first lline (only user if Variable Names is not empty):是否忽略第一行(表头)Delimiter(use "\t" for tab):分隔符Allow quoted data?:是否允许双引号括住数据Recycle on EOF?:到了文件结尾是否循环Stop thread on EOF?:到了文件结尾是否停止Sharinng mode:共享模式mysql.jar放在jmeter的lib目录下
+Thread GroupAdd -> Config Element -> JDBC Connection Configurationjdbc:mysql://8.142.144.75:3306/jmeter_class?alloMultiQueries = true&useSSL=falsecom.mysql.jbc.DriverusernamepasswordThread GroupAdd -> Sampler -> JDBC RequestVariable Name Bound to Pool: 配置参数区SQL Query:sql语句区
其他:变量配置区
JDBC Connection Configuration: db_connnection_pool #输入连接池名称Query Type:选择Prepared Updata StatementQuert:输入sql语句INSERT INTO jmeter_class.user (`username`,`password`) VALUES(?,?) |
Paeameter values:testuser,aaaaaaPaeameter types:varchar,varcharQuery timeout(s):6运行结果ResponseBody:1 updates.
这就配置成功
就是loadrunner上面的思考时间,就是模拟真实用户操作过程的等待时间
+定时器的父节点和子节点,如果想让一个请求强制停止一段时间,就把定时器放在这个请求的下面
+单位是以ms为单位,1s=1000ms
+]]>指定子节点运行的次数,使用变量或数值进行控制
+把多个请求放入Simple Controller,可以多个请求进行同时操作
一个事务会包含并请求,然后查看一个事务的QPS等性能指标
+QPS:每秒处理完请求的次数,具体指1s内发出请求到服务器处理完成并返回结果的次数
+TPS:每秒处理完的事务次数,一般TPS是对整个系统来讲的,一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能对应多个请求,对于衡量单个接口服务的处理能力,一般使用QPS
+没有选中Generate Parent sample,运行后的结果是
+
+
+
+限制整个运行过程中的生成的吞吐量不要超过某一个值,防止压死系统
+20 QPS,这里应该输入1200This Thread only:控制每个线程的吞吐量,这个模式的作用是:总的吞吐量=Target throughput * 线程的数量All active threads:设置的Target throughput将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理时间后再次运行。活跃线程指的是同一时刻同时运行的线程All active threads in current thread group:设置的`Target throughput将分配在当前线程祖的每一个活跃线程上,当测试计划只有一个线程组,这个模式作用和All active threads一样All active threads(shared):与All active threads选项基本一致,唯一区别是,每一个活跃线程都会在所有活跃线程上一次运行结束后等待合理时间再次运行All active threads in current thread group(shared):与All active threads in current thread group选项基本一致,唯一区别是,每个活跃线程都会在所有活跃线程的上一次运行结束等待合理的时间后再次运行生成随机等待时间
+Deviation(in milliseconds):高斯定时器参数,随机的Constant Delay Offset(in milliseconds):固定等待时长生成的时长是Deviation + Constant Delay Offset
():括起来的部分是要提取的.:匹配任何字符串+:一次或多次?:在找到第一个匹配项后停止用2$等,表示解析到的第几个值给title,$1$表示第一个
+0代表随机,1代表全部取值,通常使用0
+若参数没有取到值,那默认给一个值让他取
+]]>log:写入信息到jmeterlog文件,使用方法:log.info(*Thisisloginfoctx:该变量引用了当前线程的上下文,使用方法可参考:org.apache.imeter.threads.JMeterContext。vars-(JMeterVariables):操作imeter变量,这个变量实际引用了JMeter线程中的局部变量容器(本质上是Map),它是测试用例与BeanShell交互的桥梁,props-(JMeterProperties-classjava.util.Properties):操作imeter属性,该变量引用了JMeter的配置信息,可以获取Jmeter的属性,它的使用方法与vars类似,但是只能put进去String类型的值,而不能是一个对象。prey-(SampleResult):获取前面的sample返回的信息,sampler-(Sampler):gives access to the current sampler测试
+🐱
+❄️
+]]>模拟一个没有参数的get请求{
"description": "模拟一个没有参数的get请求",
"request": {
"uri": "/getdemo",
"method": "get"
},
"response": {
"text": "这是一个没有参数的get请求"
}
}
模拟一个带参数的请求{
"description": "模拟一个带参数的请求",
"request": {
"uri": "getwithparam",
"method": "get",
"queries": {
"name": "胡汉三",
"age": "18"
}
},
"response": {
"text": "我胡汉三又回来了!!!!!"
}
}
模拟一个Post请求{
"description": "模拟一个Post请求",
"request": {
"uri": "/postdemo",
"method": "post"
},
"response": {
"text": "这是我的第一个mosk的post请求"
}
}
这是一个带参数的post请求{
"description": "这是一个带参数的post请求",
"request": {
"uri": "/postwithparam",
"method": "post",
"forms": {
"name": "胡汉三",
"sex": "男人"
}
},
"response": {
"text": "我胡汉三带着参数来了!!!!"
}
}
{ |
{ |
{ |
以[]包裹着以{}包起来的接口脚本
description:接口简介
request:使用{}包含接口的请求信息
uri:接口的地址名称method:请求方法queries:get请求参数forms:post请求参数headers:请求头信息response:返回的数据,使用{}
text:返回的文字数据cookies:返回的cookie信息status:返回的响应码举个栗子demo
+[ |
get请求demo[
{
"description": "接口的get请求",
"request": {
"uri": "/#/test/xml",
"method": "get"
},
"response": {
"text": "get请求接口"
}
}
]
点击moke选择版本进行下载,我下载的的是moco-runner-0.11.0-standalone.jar
java -jar jar包的存放路径 http -p 端口 -c json文件路径 |
redirectTo:目标地址[ |
#字符串 |
回显的结果是:
+{ username: 'admin', |
forceStr: !!str 123 |
回显的结果是:
+forceStr: '123', |
#数组 |
回显的结果是:
+myFavourite: [ 'backaetball', 'football' ], |
#对象 |
回显的结果是:
+autotest: { username: 'root', password: 'root', age: 18, male: true }, |
#复合结构 |
回显的结果是:
+companies: |
#引用 |
回显的结果是:
+father: { lastName: '周' }, |
++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求:
发送需要认证的get接口:
------------恢复内容开始------------
## Postman安装 +++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求:
发送需要认证的get接口:
选择请求格式为post
传参:
使用参数时,变量名称要与文件里的变量名保持一致
引用环境信息:
也可以用javascript写变量:
引用全局变量信息:
Cookie用途:一个请求需要用到用户的登录状态(sessionid或token),一般 登录状态会记录在cookie ,postman会自动记录登录状态写入cookies.所以执行非登录接口的请求前,需要先执行登录接口请求。
------------恢复内容结束------------
+------------恢复内容开始------------
## Postman安装 +++Postman下载:https://www.postman.com/downloads/
+
下载后双击即可安装,安装后需要创建账号,登录后可以在不同平台同步数据。
点击最上面的测试集的添加目录图标,来新增一个根目录,这样等于新建了一个项目.可以将一个项目或一个模块的用例都存放在这个目录之下,并且在根目录下还可以创建子目录进行用例的细分.
创建了目录后可以进行用例的新建,具体是通过测试集右侧区域中的三个点来新增一个空的用例模板,当然也可以通过复制一个已有的用例来达到新建用例的目的.
++在postman中新建用例对应即将要执行的一次请求,默认为空,测试人员需要添加相应的请求信息,需要添加的信息包括:
+
请求的方法:get或post
请求的URL:协议+域名/IP+端口+资源路径
不带参数的请求:
发送需要认证的get接口:
选择请求格式为post
传参:
使用参数时,变量名称要与文件里的变量名保持一致
引用环境信息:
也可以用javascript写变量:
引用全局变量信息:
Cookie用途:一个请求需要用到用户的登录状态(sessionid或token),一般 登录状态会记录在cookie ,postman会自动记录登录状态写入cookies.所以执行非登录接口的请求前,需要先执行登录接口请求。
Postman通过tests插入断言
++把上一个接口的返回数据作为下一个参数的输入参数使用
+
create database 数据库名; |
show databases; |
3、查看某个数据库的定义的信息:
+show create database 数据库名; |
drop database 数据库名称; |
5、切换数据库:
+use 数据库名; |
6、查看正在使用的数据库:
+select database(); |
7、查看数据库中的所有表:
+show tables; |
8、查看表结构:
+desc 表名; |
9、修改表删除列.
+alter table 表名 drop 列名; |
10、修改表名
+rename table 表名 to 新表名; |
11、修改表的字符集
+alter table 表名 character set 字符集; |
12、数据类型与约束
+create table 表名(字段名 类型 约束,.....) |
drop table 表名 |
insert into 表名 values(值1,值2...)给表中所有字段插入数据 |
update 表名 set 字段1=值1,字段2=值2 where 条件 |
delete from 表名 where 条件 |
select * from 表名 where 条件 |
select 字段1,字段2,字段3...from 表名 where 条件 |
select 字段1 (as) 别名,字段2 别名 from 表名 where 条件 |
select distinct 字段 from 表名 where 条件 |
select * from 表名 where age>20 |
and 满足所有条件
+or 满足其中任意一个条件
+not 不满足条件
+3.5.1、排序
+select * from 表名 where 条件 order by 列1 (asc)|desc,列2 asc|desc |
3.5.2、聚合函数
+count: 总数 select count(*/字段)from 表名 where 条件 |
3.5.3、分组
+select * from 表名 group by 字段,字段2 having 条件 |
3.5.4、分页
+select * from 表名 limit 0,5 从第一行数据开始,显示5行 |
3.5.5、等值连接
+方式一 : |
3.5.6、左连接
+++左边的表全显示,右边表能匹配的上的数据连接显示,匹配不上(没有的)以null补充
+
select * from 表1 left join 表2 on 表1.列=表2.列 left join 表3 on 表2.列=表3.列 where 条件 |
3.5.7、右连接
+++右边的表全显示,左边表能匹配上的数据连接显示,匹配不上(没有的)以null补充
+
select * from 表1 right join 表2 on 表1.列=表2.列 right join 表3 on 表2.列=表3.列 where 条件 |
3.5.8、自关联
+select * from 表 别名1 inner join 表 别名2 on 别名1.aid=别名2.pid |
++子查询结果输出的是一行一列
+
select * from student where age>(select avg(age) from student) |
++子查询的结果输出的是一列多行
+
in: |
++子查询的结果输出的是一行多列
+
select * from student where(name,sex)=(select name,sex from student where sex='男' order by age desc limit 1) |
++子查询的输出结果是一个表
+
select * from scores inner join (select cno from courses where cname in('数据库',‘系统测试’) as c on scores.cno=c.cno |
insert into goods_cate(cate_name) select distinct cate from goods; |
接口响应时间
+吞吐量
+TPS: 事务处理能力,每秒处理事务数(打开页面、登录、选择商品、加入购物车、下单、付款)
+注意:“日活” 每日活跃用户数,是运营数据,与性能无关
+八二原则
+++计算QPS/TPS
+
相信80%会集中在20%时间内,24小时的流量集中在白天8小时内,同时在午高峰达到高峰
+根据相应耗时计算公式预估所需并发,一次请求100ms
+根据 QPS = Vue * Rt
1000000 80% / 8 3600 * 20% = 277 QPS
+需要27个并发
+]]>| 定位函数position | ++ |
|---|---|
| //*contains(text(),’文字’)/li[position()=3] | +找到第三个 li | +
| //*contains(text(),’文字’)/li[position()<=2] | +找到前两个 li | +
| 定位方式 | +描述 | +实例 | +
|---|---|---|
| contains | +匹配在元素文本中查找包含 ‘文字’ 的元素 | +//*contains(text(),’文字’) | +
| starts-with | +匹配所有id开头为 ‘s’ 的元素 | +//*[starts-with(@id,’s’)] | +
| ends-with | +匹配所有id结尾头为 ‘s’ 的元素 | +//*[ends-with(@id,”s”)] | +
| following-sibling | +匹配和 ‘ul’ 元素同级别的下一个元素 | +//div/following-sibling::ul | +
| preceding-sibling | +匹配当前节点之前的所有同级节点 | ++ |
| ancestor | +匹配当前节点的所有父级,祖父级还有更高级 | +//div/ancestor::li[@role=”menuitem”] | +
| parent | +匹配当前节点的父节点,相当于 .. | +//div/parent::button | +
# 拉取镜像 |
在github上下载安装包,解压后剪切到/home目录
# 找到bin目录下的code-server* |
然后在浏览器输入http://ip:3000查看搭建情况
但是这样搭建有问题
+++使用上面方法部署的code-server,因为是http的,导致一些功能不好用,比如写md文档无法预览
+
下面就是配置使用https运行
+++使用openssl为IP签发证书
+
一般的linux系统已经内置openssl,可以输入openssl进行查看,没有的话就需要安装
+新建openssl.cnf,并编辑如下内容
[req] |
san_domain_com 为最终生成的文件名,一般以服务器命名,可改。
+openssl genrsa -out san_domain_com.key 2048 |
openssl req -new -out san_domain_com.csr -key san_domain_com.key -config openssl.cnf |
执行后,系统提示输入组织等信息,按[]内容提示输入如即可。
+需要测试CSR文件是否生成成功> openssl req -text -noout -in san_domain_com.csr
有下面的信息,说明生成成功
Certificate Request: |
openssl x509 -req -days 3650 -in san_domain_com.csr -signkey san_domain_com.key -out san_domain_com.crt -extensions v3_req -extfile openssl.cnf |
在当前目录会生成三个文件san_domain_com.crt
san_domain_com.csr
san_domain_com.key
将.crt证书发给用户,用户双击进行安装,然后重启浏览器
在code-server的bin目录下运行如下命令,设置端口号为8881,指定对应生成的crt和key密钥文件,即可正常访问https域名# 给ssh创建密码
export PASSWORD="123456"
# 启动ssh
nohup ./code-server --port 8881 --host 0.0.0.0 --cert ../san_domain_com.crt --cert-key ../san_domain_com.key > vscode.log 2>&1 &
然后通过浏览器访问https://ip:3000
++拉取CentOS7镜像,下载安装Grafana和Influxdb
+
+ # 拉取阿里云的centos7镜像
+ git pull registry.cn-zhangjiakou.aliyuncs.com/ggls/centos:7.1
+ # 运行镜像生成容器
+ docker run -itd --name centos7-influx
+ -p 8083:8083 -p 8086:8086
+ -p 2003:2003 -p 3000:3000
+ -v /opt/centos7_influx:/opt
+ --privileged=true
+ registry.cn-zhangjiakou.aliyuncs.com/ggls/centos:7.1 /usr/sbin/init
+ # 进入容器
+ docker exec -it centos7-influx bash
+
+端口说明:
+新版本可以点击influxDB官网进行下载
+ + # 下载安装包 + wget https://dl.influxdata.com/influxdb/releases/influxdb-1.6.3.x86_64.rpm + # 安装运行 + yum localinstall influxdb-1.6.3.x86_64.rpm + +安装运行后,然后对influxDB进行配置,主要是配置Jmeter连接的数据库和端口号
+ + vim /etc/influxdb/influxdb.conf + +找到graphite并且修改它的库与端口enabled = true
database = "jmeter"
retention-policy = ""
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
[http],将前面的#号去掉
+systemctl start influxdb.servicesystemctl status influxdb.service
+新版本下载位置:Grafana官网下载:https://grafana.com/grafana/download
+wget https://dl.grafana.com/oss/release/grafana-6.5.2-1.x86_64.rpm |
启动命令: systemctl start grafana-server.service
查看状态命令: systemctl status grafana-server.service
然后在浏览器访问登录http://ip:3000;
Thread GroupAdd -> Listener -> Backend ListenerBackend Listener implementation 默认选择GraphiteBackendListenerClient
+数据库里面有两个库,jmeter库就是jmeter运行生成表的数据库
+可以看到生成了三类前缀的表,分别是: jmeter.all 、 jmeter.[请求名称];最后还有 jmeter.test 开头的表,这个后面会单独拿出来说
+前缀的含义
+jmeter.all :代表了所有请求;当summaryOnly=true时,就只有samplerName=all的表了jmeter.[请求名称]:代表了HTTP请求,即samplerName=[请求名称]Thread/Virtual Users metrics - 线程/虚拟用户指标
跟线程组设置相关的
| 指标 | +全称 | +含义 | +
|---|---|---|
| jmeter.test.minAT | +Min active threads | +最小活跃线程数 | +
| jmeter.test.maxAT | +Max active threads | +最大活跃线程数 | +
| jmeter.test.meanAT | +Mean active threads | +平均活跃线程数 | +
| jmeter.test.startedT | +Started threads | +启动线程数 | +
| jmeter.test.endedT | +Finished threads | +结束线程数 | +
Response times metrics - 响应时间指标
+划重点:每个sampler(请求)都包含了所有响应时间指标,每个sampler(请求)的每个指标都会有单独的一个表存储结果数据
+| 指标 | +含义 | +
|---|---|
| sampler的成功响应数 | +|
| 服务器每秒命中次数(每秒点击数,即TPS) | +|
| sampler响应成功的最短响应时间 | +|
| sampler响应成功的最长响应时间 | +|
| sampler响应成功的平均响应时间 | +|
| sampler响应成功的所占百分比 | +|
| sampler的失败响应数 | +|
| sampler响应失败的最短响应时间 | +|
| sampler响应失败的最长响应时间 | +|
| sampler响应失败的平均响应时间 | +|
| sampler响应失败的所占百分比 | +|
| sampler响应数(ok.count+ko.count) | +|
| 已发送字节 | +|
| 已接收字节 | +|
| sampler响应的最短响应时间(ok.count和ko.count的最小值) | +|
| sampler响应的最长响应时间(ok.count和ko.count的最大值) | +|
| sampler响应的平均响应时间(ok.count和ko.count的平均值) | +|
| sampler响应的百分比(根据成功和失败的总数来计算) | +
步骤:
+配置数据源
+创建数据面板
+
+点击首页的Create your first data source,然后进行配置
+点击选择influxDB
+
+
+选择Add Query,然后进行配置
+当我们只想看数据而不想看数据趋势图的话,可以改变它的类型;
+在同一个界面,点击左侧列表选中第二个icon,然后选择Singlestat即可
+
+基本的配置完成,Jmeter使用GraphiteBackendListenerClient来采集数据的,因为请求多起来的时候会有非常多的表,维护成本也会增加;后面将会介绍如何通过InfluxDBBackendListenerClient来采集数据
给Jmeter的Backend Listener配置为InfluxDBBackendListenerClient
+首先来看看每个配置项的含义
+inDB数据库
使用InfluxDBBackendListenerClient好处就是,再多的请求也只会生成两张表:
events :主要拿存事件的
jmeter :存测试结果数据的,Grafana也是从这个表获取数据再展示
配置数据面板
+首先,进入官方模板库: https://grafana.com/dashboards ,然后跟着图片导入模板并初始化即可
+
+
+
+
+然后jmeter再次执行一下测试计划
+
+模板自带了三个下拉筛选框
+data_source:数据源,在Grafana配置了多少个就显示多少个
+application:在Jmeter配置好的application,如果每次测试计划执行时的application都不一样,你就可以通过这个筛选出对应测试时机的结果数据了
+transaction:在Jmeter配置好的sampleList,譬如我只发了get、post请求,这里就只会给你选get、post;可以滑到页面下面看到针对某个请求的数据展示
+停止Grafana服务。systemctl stop grafana-server.service
systemctl disable grafana-server.service
查看要卸载的包的名称yum list installed
输入命令行卸载Grafanayum remove grafana.x86_64
docker pull prom/prometheus |
docker run -itd --name=docker_prometheus --restart=always -p 3090:9090 -v /opt/prometheus:/ prom/prometheus |
验证
+通过浏览器访问http://ip:3090进行访问
首先,用浏览器访问:node_export 下载,然后上传到被监控的服务器并解压
进入解压文件夹,直接启动./node_exporter
docker pull prom/node-exporter |
docker run -itd --name=node-exporter \ |
验证
+在浏览器访问http://ip:9100/metrics进行访问
node_export的作用收集硬件数据
+使用vim修改yum文件容器内:/etc/prometheus/prometheus.yml
scrape_configs: |
docker restart docker_prometheus |
使用Grafana下载版本
+数据源:选择prometheus
URL输入http://prometheus机器ip:3090
点击Save & Test保存
使用官方仪表盘进行下载仪表盘
导入仪表盘
在import via grafana.com输入框输入模板ID12884
ID:12633也可以使用。
+点击 load,然后底部选择刚弄的数据源,点击import
+注意:
点击json下载12884的json文件
在config目录下创建environment.yaml文件
+username: 周杰伦 |
首先创建yaml_config文件,为了方便自动化后面的引用,需要创建一个类,在__init__里面打开yaml文件,使用yaml.load(文件名称, Loader=yaml.FullLoader )方法获取数据
打印出字典格式的数据{'username': '周杰伦', 'password': 123456}
import yaml |
现在使用的是相对路径,后期如果换系统,或者更换文件位置,就需要自己获得文件路径,下面对代码进行优化
+创建get_project_path方法,获取项目根目录的绝对路径
首先定义一个变量,变量的值是项目的名称project_name = "trading_system_autotest"
获取当前文件的所在目录的绝对路径,需要使用python的os模块file_path=os.path.dirname(__file__)
在绝对路径中找到项目名称的下标位置file_path.find(project_name)
找到项目所在目录的绝对路径下标+项目名称的长度=项目根目录的绝对路径的下标file_path.find(project_name)+len(project_name)
然后对所在目录的绝对路径file_path进行切片获得项目根目录的绝对路径
file_path[: file_path.find(project_name)+len(project_name)]
def get_project_path(): |
创建sep(path, add_sep_before=False, add_sep_after=False)方法,获得文件和目录的拼接
变量
+path变量需要传输一个列表,列表里面是文件所在目录和文件名称,如[文件所在目录,文件名称]
首先使用os.sep.join对列表的字段进行拼接all_path = os.sep.join(path)
对add_sep_before进行判断,如果是True,就在前面添加拼接符:all_path = os.sep + all_path
对add_sep_after进行判断,如果是True,就在后面添加拼接符:all_path = all_path + os.sep
windows格式拼接符有可能错误,就要对拼接符转换格式all_path = all_path.replace('\\', '/'),就算没有这个代码,也可以运行出来,只是调试该代码看起来不好看
然后返回all_path
def sep(path, add_sep_before=False, add_sep_after=False): |
class GetConf: |
++创建Excel数据表:learn.xlsx
+
+++使用python的openpyxl模块来解析Excel
+1、读取Excel文件
openpyxl.load_workbook(‘文件路径’)
+
2、获取sheet页里面的数据
+
sheet = excel.active
# 获取指定的表单
for sheets in excel.sheetnames: #获取所有表单的名称
print(sheets)
sheet = excel[sheets] #获取指定表单3、获取单元格里面的内容
+
if type(value[0]) == int: #从第二行开始
print(values)运行代码:
+
+把Excel表里面的数据以字典格式展示:
+data = {} |
运行代码:
+
+
import configparser
+
+class Parse_Ini(object):
+
+ def __init__(self):
+ self.file = r"D:\dingdang_project\test\config.ini"
+ self.parse = configparser.ConfigParser()
+ self.parse.read(self.file, encoding="utf-8")
+
+ def get_sections(self):
+ """
+ :return: 由sections组成的列表
+ """
+ return self.parse.sections()
+
+ def get_options(self, sections):
+ """
+ :return: 返回指定 section 中可用选项的列表。
+ """
+ return self.parse.options(sections)
+
+ def get_sections_options(self, sections, options):
+ """
+ :param sections: 元素名称
+ :param options: 元素地址
+ :return: 指定sections下的options
+ """
+ try:
+ option = self.parse.get(sections, options)
+ if ("-->" in option):
+ option = tuple(option.split("-->"))
+ return option
+ except configparser.NoOptionError as e:
+ return 'error: No option "{}" in section: "{}"'.format(options, sections)
+
+
+if __name__ == "__init__":
+ pass
+
在linux创建helloworld.sh文件,在文件内输入:
!/bin/bash |
然后保存该文件
+运行.sh文件时,有两种方法可以运行
chmod +x ./helloworld.sh |
运行文件:./ 不能省略
+./helloworld.sh |
bash或sh 文件路径运行该文件bash helloworld.sh |
$HOME 获取当前用户的家目录
$PWD 获取当前目录的路径
$SHELL 获取shell的执行引擎
$USER 获取当前用户的名称
在linux系统中定义变量A=1,等号两边不能有空格,使用echo $A显示A的值
使用unset A命令,撤销变量
定义只读变量readonly b=3,使用echo $b显示b的值,不能unset
export命令进行设置全局变量,可以让其他shell命令进行使用
定义
+n表示数字,范围是0~9,$0表示脚本名称,$1~9表示1~9个参数,10以上的参数要用花括号包裹,如${10}
运行apple.sh文件时可以传递参数
举个栗子
+!/bin/bash |
运行后传递参数bash apple.sh 001 002 test "test sss" "hsgd_dee"
定义
+获取所有输入参数的个数,常用于循环
+举个栗子
+!/bin/bash |
定义
+$*代表命令行中所有参数,把参数作为一个整体
$@代表命令行中所有参数,把参数区分对待
定义
+最后一次命令的返回状态,如果返回变量的值为0,则表示最后一次命令执行正确,如果变量的值非0,则证明上一条变量返回不正确
+举个栗子
+[root@b09ed0cc2c9d opt]# $? |
首先创建test_shell.sh文件
touch test_shell.sh |
在test_shell.sh文件输入shell脚本
使用shell创建banzhang.txt文件
在文件中追加数据echo "aabbccdd" >> banzhang.txt
!/bin/bash |
basename [string/ pathname][文件后缀] |
basename命令会删掉所有的前缀,只留一个文件名
+选项:
+如果指定后缀,basename会将pathname或string中的文件后缀去掉
+截取该/opt/banzhang.txt路径的文件名称
[root@b09ed0cc2c9d opt]# basename /opt/banzhang.txt |
dirname 文件绝对路径 |
从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录部分)
+[root@b09ed0cc2c9d opt]# dirname /opt/banzhang.txt |
[function] funname[()] |
!/bin/bash |
++用于剪切数据
+
cut[选项参数] filename
+说明:默认分隔符是制表符
+| 选项参数 | +功能 | +
|---|---|
| -f | +列号,提取第几列 | +
| -d | +分隔符,按照指定分隔符分割列 | +
准备数据
+[root@b09ed0cc2c9d local]# touch cut.txt |
切割第一列数据
+[root@b09ed0cc2c9d local]# cut -d " " -f 1 cut.txt |
切割第二,三列
+[root@b09ed0cc2c9d local]# cut -d " " -f 2,3 cut.txt |
在cut.txt文件切割出guan
+[root@b09ed0cc2c9d local]# cat cut.txt |
选取系统PATH变量值,第二个“:”之后的所有路径
+[root@b09ed0cc2c9d local]# echo $PATH |
切割ifconfig后打印的IP地址
+[root@b09ed0cc2c9d local]# ifconfig |
++一种流编辑器,一次处理一行内容
+
sed [选项参数] command filename
选项参数说明
+| 选项参数 | +功能 | +
|---|---|
| -a | +直接在指定列模式上进行sed的动作编辑 | +
命令功能描述
+| 命令 | +功能描述 | +
|---|---|
| a | +新增,a的后面可以接字串,在下一行出现 | +
| d | +删除 | +
| s | +查找并替换 | +
数据准备
+[root@b09ed0cc2c9d opt]# touch sed.txt |
将mei nv 这个单词插入到 sed.txt 第二行下,打印
+[root@b09ed0cc2c9d opt]# sed "2a mei nv" sed.txt |
删除sed.txt文件所有包含 wo 的行
+[root@b09ed0cc2c9d opt]# sed "/wo/d" sed.txt |
将sed.txt文件中 wo 替换为 ni
+[root@b09ed0cc2c9d opt]# sed "s/wo/ni/g" sed.txt |
将sed.txt文件中的第二行删除并将wo替换成ni
+[root@b09ed0cc2c9d opt]# sed -e "2d" -e "s/wo/ni/g" sed.txt |
[ condition ] (注意,condition 前后要有空格)
+注意:条件非空即为 true,[ atguigu ]返回 true, [] 返回 false.
+= 字符串比较 |
举个栗子
+[23 -lt 80] |
-r 读 |
举个栗子
+[ -w 1.sh ] |
-f 文件存在且是一个常规文件 |
举个栗子
+[ -e 2.sh ] |
$$$$ 与 ,前对,才执行后
+|| 或
[ 条件判断式 ],中括号和条件判断式之间必须有空格
+if后要有空格
+if [ 条件判断式 ]:then |
输入一个数字,如果是1,则输出 banzhang zhen shuai,如果是2,则输出 cls zhen mei ,如果是其他,则什么都不输出
+!/bin/bash |
case $变量名 in |
输入一个数字,如果是 1,则输出 banzhang,如果是 2,则输出 cls,如果是其他,输出 renyao
+!/bin/bash |
for(( 初始值;循环控制添加;变量变化 )) |
输出从1加到100的值
+!/bin/bash |
for 变量 in 值1 值2 值3... |
打印所有输入参数
+!/bin/bash |
while[ 条件判断式 ] |
输出从1加到100的值
+!/bin/bash |
read(选项)(参数) |
提示7秒内,读取控制台输入的名称
+!/bin/bash |
expr 3 + 2 |
需要使用键盘左上角的`,把需要提前运算的包起来
+expr `expr 2 + 3` \* 4 |
或者
+s=$[(2+3)*4] |
++强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
+
awk [选项参数] ‘pattern1{action1}’ filename
+| 选项参数 | +功能 | +
|---|---|
| -F | +指定输入文件分隔符 | +
| -v | +赋值一个用户定义变量 | +
数据准备的是/etc/passwd
[root@b09ed0cc2c9d opt]# cat passwd |
搜素passwd文件以root关键字开头的所有航,并输出该行的第7列
+[root@b09ed0cc2c9d opt]# awk -F : '/^root/{print $7}' passwd |
搜素passwd文件以root关键字开头的所有航,并输出该行的第1列和第7列,输出时以逗号分隔
+[root@b09ed0cc2c9d opt]# awk -F : '/^root/{print $1","$7}' passwd |
只显示/etc/passwd的第一列和第7列,以逗号分隔,且在所有航前面添加列名 user,shell在最后一行添加 ddd, /bin/zuishuai
+[root@b09ed0cc2c9d opt]# awk -F : 'BEGIN{print "user,shell"} {print $1","$7} END{print "ddd,bin/zuishuai"}' passwd |
将passwd 文件中的用户id增加数值1并输出
+[root@b09ed0cc2c9d opt]# awk -F : -v i=1 '{print $3+i}' passwd |
| 变量 | +说明 | +
|---|---|
| filename | +文件名 | +
| nr | +已读的记录数 | +
| nf | +浏览记录的域的个数 | +
数据准备
+[root@b09ed0cc2c9d opt]# cat sed.txt |
统计passwd文件名,每行的行号,每列的列数
+[root@b09ed0cc2c9d opt]# awk -F : '{print FILENAME "," NR "," NF}' passwd |
打印空行所在的行号
+awk '/^$/ {print NR}' sed.txt |
++文件排序
+
sort(选项)(参数)
+| 选项 | +说明 | +
|---|---|
| -n | +按照数值大小排序 | +
| -r | +以相反的顺序排序 | +
| -t | +设置排序使用的分隔字符 | +
| -k | +指定需要排序的列 | +
参数是指定待排序文件列表
在resources下面新建文件application.properties,名称不能变,只能是这个,运行时系统会自动获取这个端口数据
在里面输入代码数据
+server.port=${port:8888} |
在maven下安装插件,需要在pox.xml文件输入下面的数据,然后更新文件
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<springboot.version>2.5.6</springboot.version>
<swagger.version>2.9.2</swagger.version>
</properties>
<dependencies>
<!-- springboot 2.5.6 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${springboot.version}</version>
</dependency>
</dependencies>
上面的${springboot.version}是在上面
- java |
创建Application.java类,用来运行接口,类名只能是Application,不能自定义
|
@SpringBootApplication 作用是给当前类标明是运行的主类,相当于被SpringBoot托管了@Controller("com.course.server.intertype") 钩子标识符,扫描包下面的类,被Springboot托管创建MyGetMethod类
类名上有修饰符@RestController和@Api(value = "/")
@RestController 标识该类会被扫描到,然后被SpringBoot托管@Api(value = "/") 可加可不加@RequestMapping(value = "访问路径", method = 访问方法) 定义接口的访问路径及访问方法@ApiOperation(value = "接口信息", httpMethod = "接口的请求方法") 展示接口的基本信息和它的请求方法,可加可不加下面是代码信息,之后的所有GET接口都在该类里面写接口方法
+
|
上面就是返回cookie的get接口开发,接下来就是 需要携带cookies信息才能访问的get请求
+]]>这个接口还是在MyGetMethod类里面编写方法
/** |
使用参数就要用到@RequestParam 参数类型 参数变量,可以有多个参数
这个接口还是在MyGetMethod类里面编写方法,有两种方法
第一种url:key=value&&key=value:
/** |
方法二url: ip:port/get/with/param/10/20:
|
首先,写一个User类,这将是添加时的字段数据
|
@RequestBody User u请求post接口时,在Body填写上传的数据
|
@RequestMapping(value = "/v1")的作用是把这个value和方法上的登录地址进行拼接,比如:/v1/login
@RestController标识该接口可以被托管
方法参数@RequestParam(value = "userName", required = true) String userName,代码中的required = true起到必填的作用
|
考研恋练有词必背词全部背锅一边
+自动化测试已部署
+安装插件,下载Custom Thread Groupsan插件
添加Arrivals Thread Group
QPS, 输入10就是10QPS
+安装插件,下载Custom Thread Groupsan插件
添加Ultimate Thread Group
+






 +
+  +
+  +
+