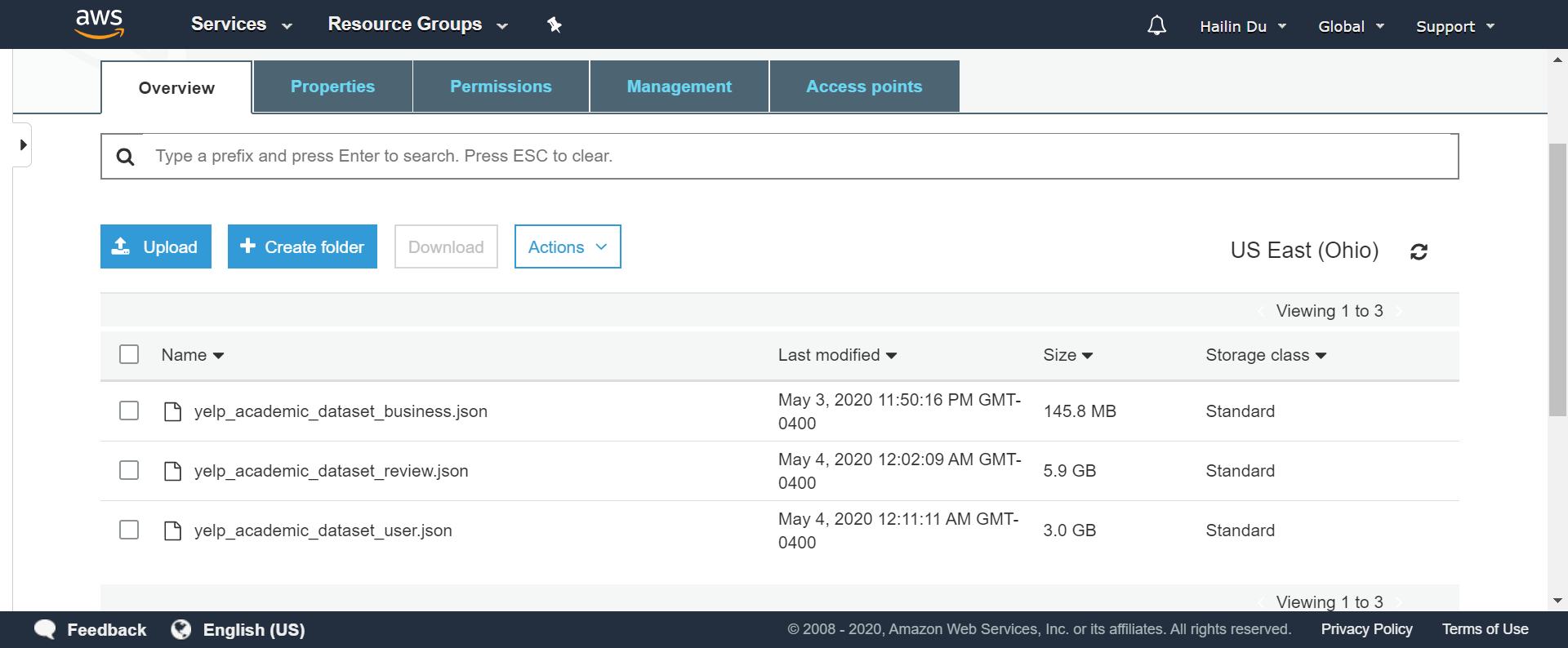
We will be using a Spark Cluster on AWS EMR for loading and running some analysis on Yelp’s Reviews and Businesses dataset (about 10gb) from Kaggle. We will run our analysis via Jupyer Notebook and the expected output arifact is a .ipynb file.
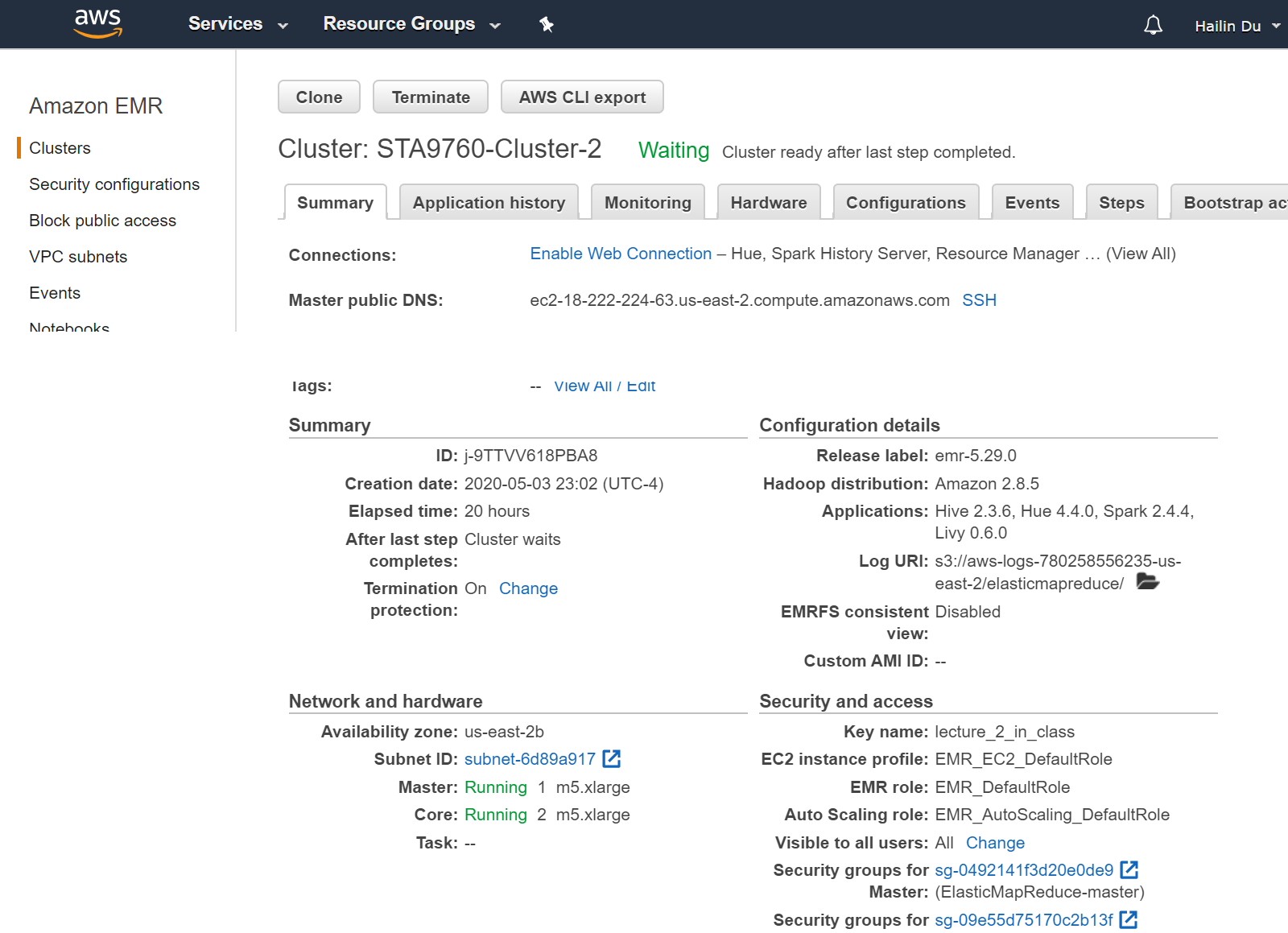
We first need to create a cluster on AWS EMR.
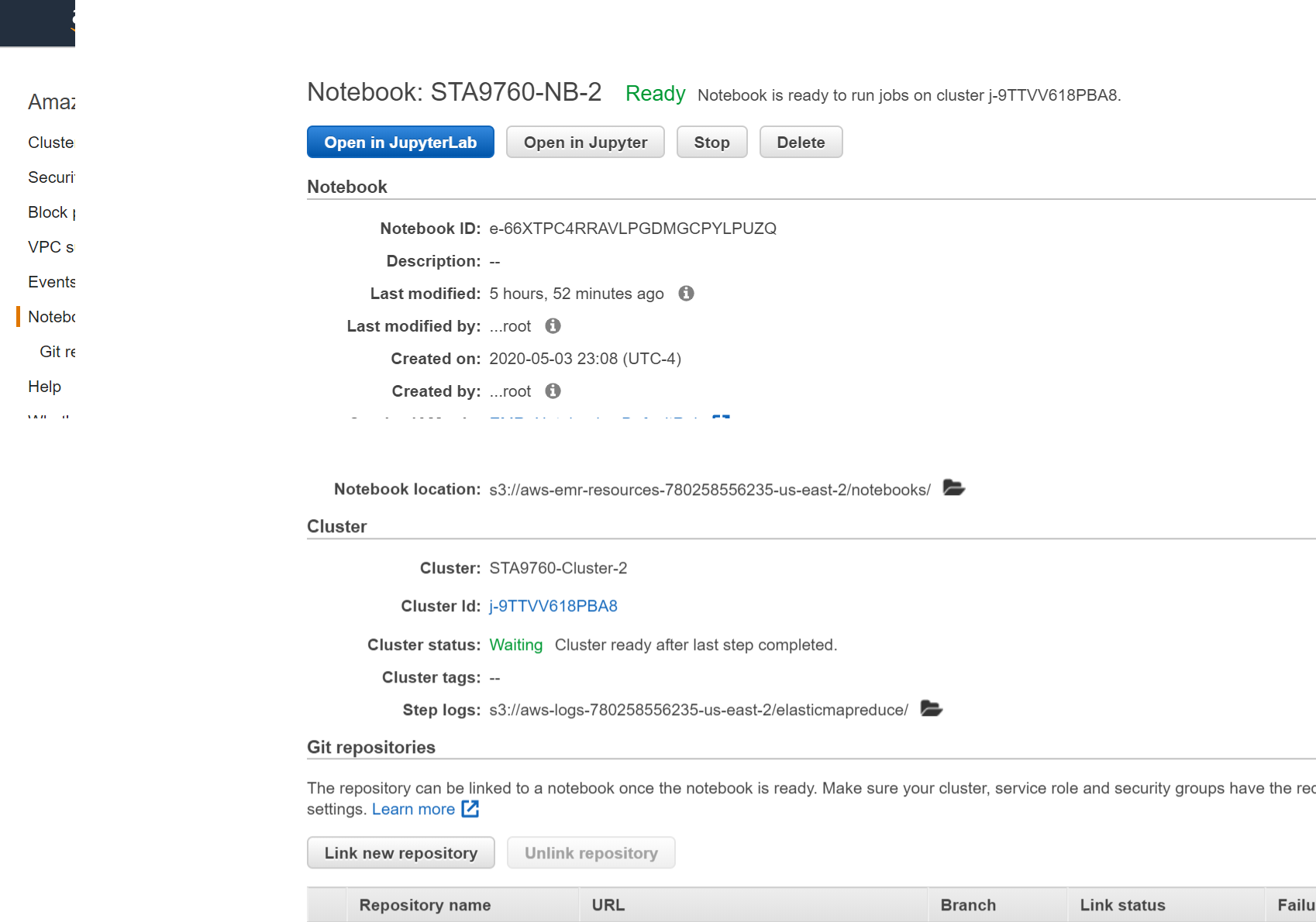
Then, we need to configure our Juypter Notebook.
Lastly, we will download the dataset and upload it to Amazon S3.