footer: @hanneshapke, ML4All, 4/30/2019 slidenumbers: true
[.build-lists: false]
- Machine Learning Enthusiast
- Heading ML & Engineering at Caravel
- Excited about the ML Systems
- Co-author of "NLP in Action" (Manning) and "Building and Managing ML Workflows" (O'Reilly, Q4/2019)
Machine Learning allows almost unlimited access to information ^

^ :Photo by Mark Rasmuson on Unsplash
Machine Learning helps identifying species ^

^ :Photo by Massimiliano Latella on Unsplash
Machine Learning helps us to reduce congestions ^

^ :Photo by NASA on Unsplash
Machine Learning lets us use energy more efficiently ^

^ :Photo by Jason Blackeye on Unsplash


Why worry about deploying models? ^

^ :Photo by Tim Gouw on Unsplash
The Serving Infrastructure is what allows people to access your models. ^

^ :Photo by Ryoji Iwata on Unsplash
- Central model deployment?
- Do you need a GPU?
- Privacy concerns?
- Distribute the predictions to the clients?
- Central model deployment? -> Model Server
- Do you need a GPU? -> Model Server or Browser Deployment
- Privacy concerns? -> Edge or Browser Deployment
- Distribute the predictions to the clients? -> Edge or Browser Deployment
- Batch or online inferences
- Model A/B Testing
- Inferences on specific hardware
- Model is loaded in a server
- Server allows API requests and infers the model predicts
- Sufficient architecture for a simple deployment

- Docker: Dependency encapsulations
- Easy deployment across various operating systems
- Architecture for replicable deployments

- Kubernetes: Container orchestration system
- Allows you to scale your APIs
- Useful for scalable deployments or multiple model versions

- Using the popular Python API framework Flask
- Works with all Python ML Frameworks
- Quick and dirty deployment
- API code and models aren't separated
- APIs can be inconsistent
- Inefficient use of compute resources
import json
from flask import Flask
from keras.models import load_model
from utils import preprocess
_import json
from flask import Flask
from keras.models import load_model
from utils import preprocess
model = load_model('model.h5')
app = Flask(__name__)
_import json
from flask import Flask
from keras.models import load_model
from utils import preprocess
model = load_model('model.h5')
app = Flask(__name__)
@app.route('/classify', methods=['POST'])
def classify():
review = request.form["review"]
_import json
from flask import Flask
from keras.models import load_model
from utils import preprocess
model = load_model('model.h5')
app = Flask(__name__)
@app.route('/classify', methods=['POST'])
def classify():
review = request.form["review"]
preprocessed_review = preprocess(review)
prediction = model.predict_classes([preprocessed_review])[0]
return json.dumps({"score": int(prediction)})
^ : Photo by Goh Rhy Yan on Unsplash

^ :Photo by Martijn Baudoin on Unsplash
- Provides separation between API code and models
- Easy model deployment
- Batching!
- Consistent APIs (gRPC and REST)
- Supports multiple model versions
- Only works with Keras and TensorFlow
- Requires Docker installation or Ubuntu Linux
- Cryptic error messages
docker run \
-p 8501:8501 \
-e MODEL_NAME=my_model \
-t tensorflow/serving \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model2019-04-26 03:51:20.304826: I tensorflow_serving/model_servers/server.cc:82]
Building single TensorFlow model file config:
model_name: my_model model_base_path: /models/my_model
2019-04-26 03:51:20.307396: I tensorflow_serving/model_servers/server_core.cc:461]
Adding/updating models.
2019-04-26 03:51:20.307473: I tensorflow_serving/model_servers/server_core.cc:558]
(Re-)adding model: my_model
...
2019-04-26 03:51:34.507436: I tensorflow_serving/core/loader_harness.cc:86]
Successfully loaded servable version {name: my_model version: 1556250435}
[evhttp_server.cc : 237] RAW: Entering the event loop ...
2019-04-26 03:51:34.520287: I tensorflow_serving/model_servers/server.cc:333]
Exporting HTTP/REST API at:localhost:8501 ...def rest_request():
url = 'http://localhost:8501/v1/models/my_model:predict'
payload = json.dumps({"instances": [TEXTS[0]]})
r = requests.post(url, payload)
return r
rs_rest = rest_request()
rs_rest.json(){'predictions': [{'scores': [
0.293399,
0.101302,
0.162343,
0.179935,
0.0551261,
0.174151,
0.0378635,
0.102538,
0.358822],
'classes': ['0', '1', '2', '3', '4', '5', '6', '7', '8']}]}
^ :Photo by Thomas Jensen on Unsplash
- Managing and Building Machine Learning Workflows (Q4/2019)
- http://bit.ly/DeployDLModels
- TensorFlow Documentation
- Seldon: Scalable and framework agnostic
- GraphPipe: Deployment for mxnet, Caffe2 and PyTorch models (via ONNX)
- MLflow
- Simple TensorFlow Serving
- Google AI Platform
- Azure ML
- AWS SageMaker
- Central model deployment? -> Model Server
- Do you need a GPU? -> Model Server or Browser Deployment
- Privacy concerns? -> Edge or Browser Deployment
- Distribute the predictions to the clients? -> Edge or Browser Deployment
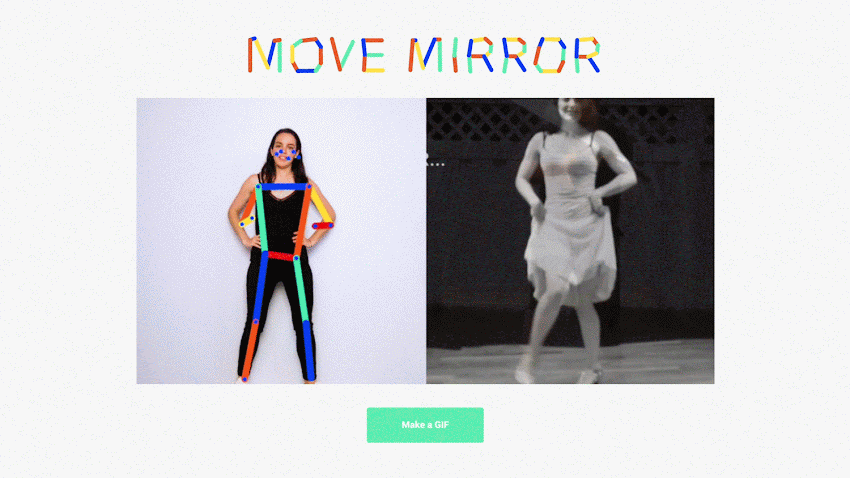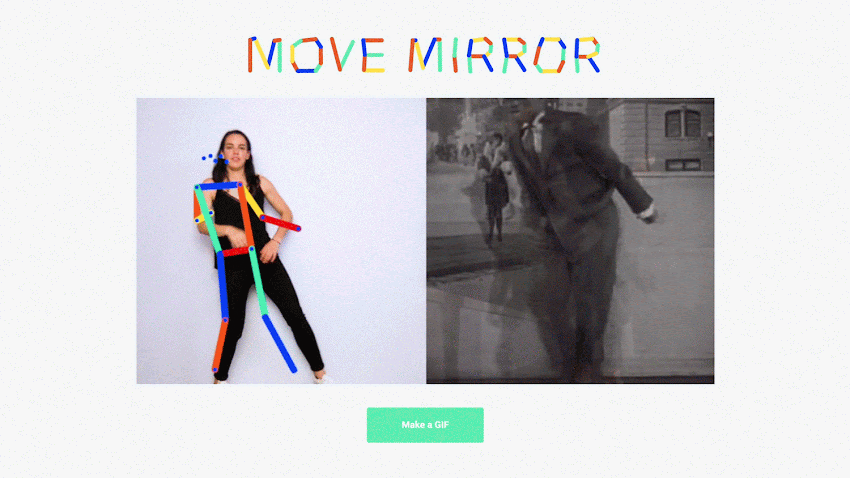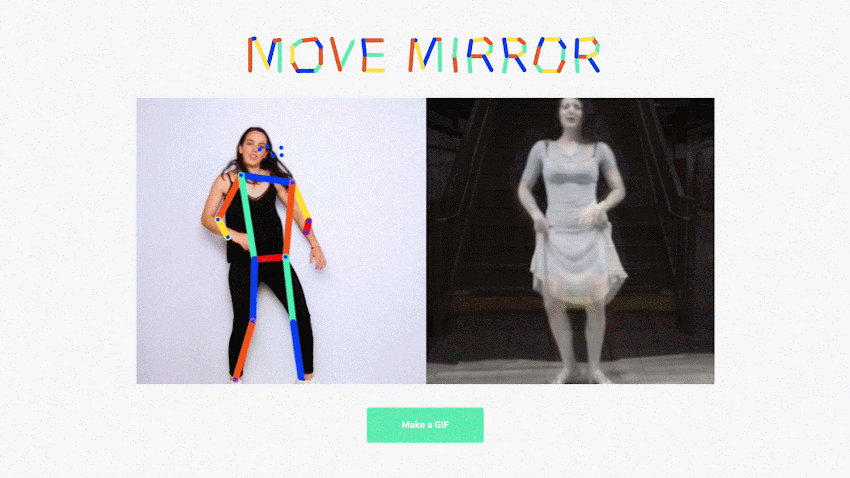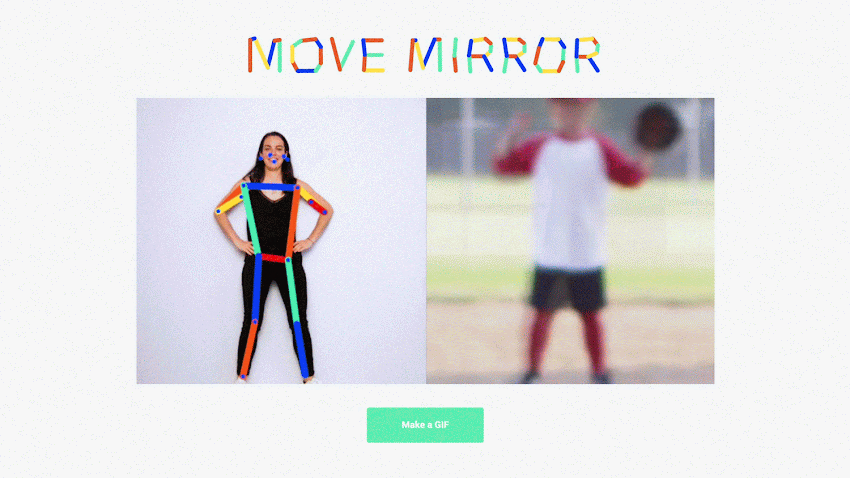
- Inference is happening in the brower
- Great for models using privacy related data
- No model server required
- Limited to TensorFlow and Keras
- Model needs to be converted
- Limited by the model size
- Model is been sent to the user (IP)
- Train your model (local/Cloud)
- Export the model as a
SavedModel - Install model converter with
pip install tensorflowjs - Convert the model with
tensorflowjs_converter - Integrate it into your js stack
- Central model deployment? -> Model Server
- Do you need a GPU? -> Model Server or Browser Deployment
- Privacy concerns? -> Edge or Browser Deployment
- Distribute the predictions to the clients? -> Edge or Browser Deployment

- Deployment to Edge Devices (e.g., watches, mobile phones)
- Great for models using privacy related data
- Allows inference under CPU, memory and battery constraints
- Limited to TensorFlow and Keras
- Model needs to be converted
- Limited number of TensorFlow Ops
- Train your model (local/Cloud)
- Export the model as a
SavedModelorhdffile - Convert the model with
tf.lite.TFLiteConverter - Quantizing your model post training
- Integrate in your Android or iOS app

| TF / Keras | Scikit | PyTorch | XGBoost | |
|---|---|---|---|---|
| Flask | x | x | x | x |
| TensorFlow Serving | x | x | (x) | |
| GraphPipe | x | x | ||
| Cloud Model Instance | x | x | x | |
| In the Browser | x | |||
| Mobile Devices | x | x | ||
| Other Edge Devices | x | x |
