This is an experimentation to learn about Swarm Robotics with help of MultiAgent Reinforcement learning. We have used KiloBot as a platform as these are very simple in the actions space and have very high degree of symmetry. The Main inspiration of this project is this paper[1]
git clone https://github.com/hex-plex/KiloBot-MultiAgent-RL
cd KiloBot-MultiAgent-RL
pip install --upgrade absl-python \
tensorflow \
gym \
opencv-python \
tensorflow_probability \
keras \
pygame
pip install -e gym-kiloBotThis should fetch and install the basics packages needed and should install the environment
These envs are running on a constant Dummy-actions!!
| Env with Graph Objective | Env with Localization Objective |
|---|---|
 |
 |
python env-test.py ## This will help you check the functionality of the environement and should give the sample code to understand the apis as well.
python model-train.py \
--headless=True \ ## for headless training default False
--objective="localization" \ ## defines the objective default is graph
--modules=10 \ ## This defines the no of modules to be initialized default 10
--time_steps=100000 \ ## This is the total no of steps the agent will take while learning
--histRange=10 \ ## This is the no of mu values for the histograms
--logdir="logs" \ ## This specifies the log location for TensorBoard
--checkpoints="checkpoints" ## This is for defining the location where the model is to be saved
--load_checkpoint="checkpoints/iter-500" ## This loads the specified iteration
python play-model.py \ ## This should load trained weights and show the performance
--load_checkpoint="checkpoints/graphs/10" \ ## loads this model
--modules=10 \ ## no of modules in the env
--objective="localization" \ ## Sets the objective function
--time_steps=10000 \ ## No of iterations to be run
--histRange=10 ## Same def as aboveAfter a exhaustive amount of training on varies combinations of no_of_modules and task in hand I have obtained results of the following algorithm for these parameters.
I have used [5, 10, 15, 20, 25, 50] number of modules to carryout the tests.
One may find the Tensorboard log files here:
log_kilobot [Drive Link] (403MB)
and the Model Weights for each parameters here:
checkpoint_kilobot [Drive Link] (63.3MB)
The below table is based on the number of modules used but for result tabulation I am considering
[5, 10, 20, 50]
number of modules. To infer many insights of the algorithm in hand.
Please click on the image to zoom in
| Model Trained on \ Model Run on | 10 | 20 | 50 |
|---|---|---|---|
| 10 |  |
 |
 |
| 20 | - | 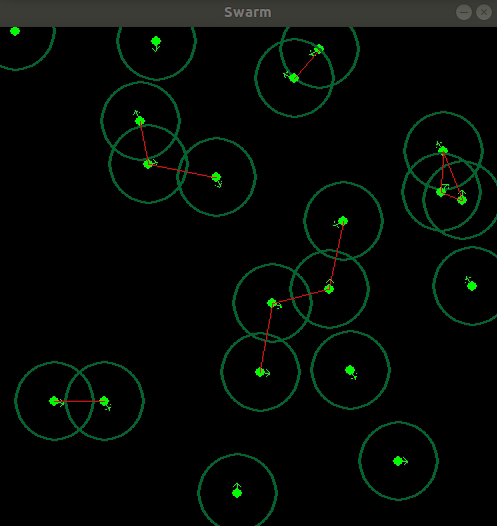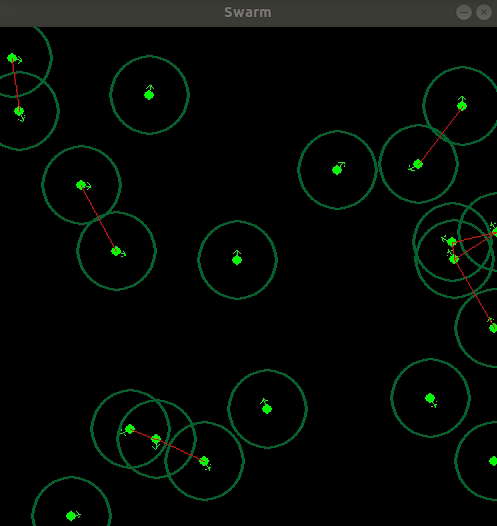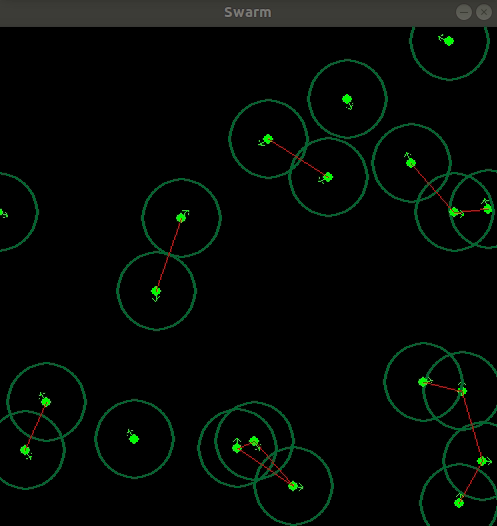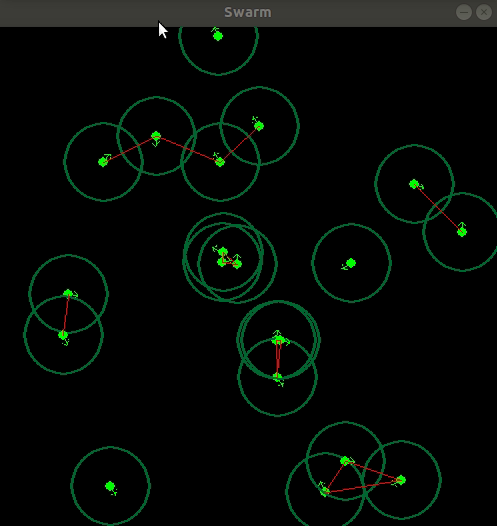 |
- |
| 50 | - | - |  |
The policies trained on 20 and 50 module system is completely random in sense it just goes forward.
We can see clearly the policy trained with 10 modules have yield a very good amount of coordination between each other that is the critic model taking in the input image of the system is able to specify the bots and guide them, Hence a very good amount of generalization is found when we use this model with system with different number of modules as can be seen with the 20 module system but the non stationarity of a higher order system makes it complex for the critic to reward or give baseline to the actor, As the
- The order of the reward changes drastically.
- The Reading from the histogram becomes Muddy.
- The correlation of a reward to action of a single agent reduces drastically.
Hence the Model trained with 10 modules is not able to generalize to the 50 module system, BUT It looks more promising than the policy trained for the 50 module system itself, hence a curiculum learning based approach seems promising to solve such a transfer learning problem.
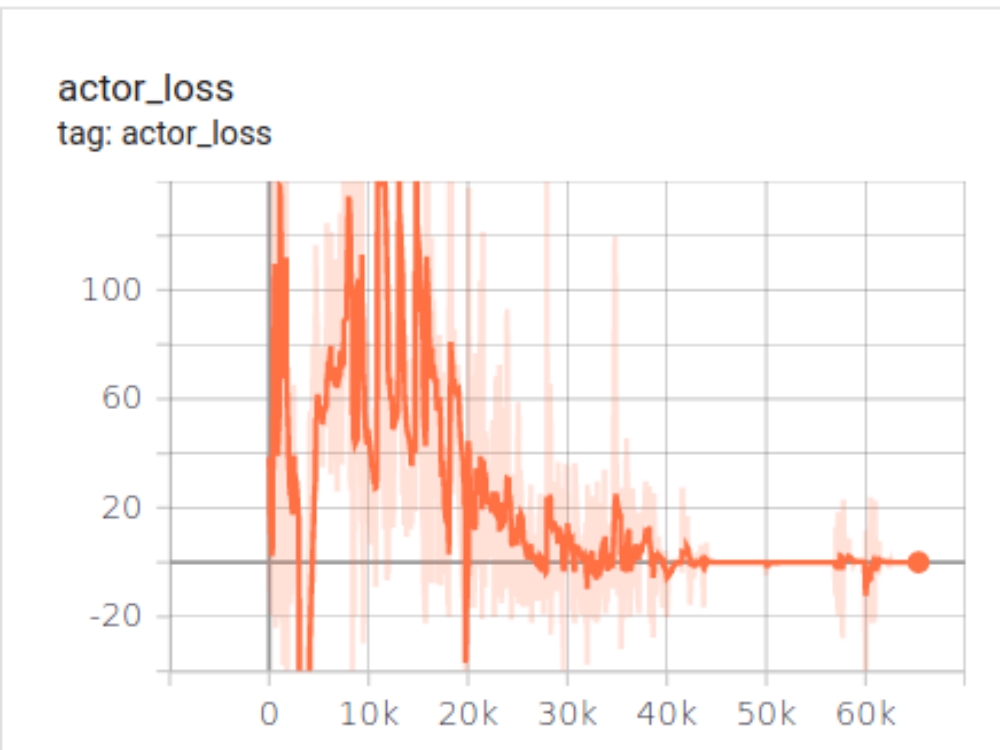
| Actor Loss | Critic Loss | Reward |
|---|---|---|
 |
 |
 |
The system can't comphensate for the negetive reward got by using fuel as the reward got for graphing is much smaller in order than it that it chooses to be stagnent.

Here the task was much easier but the training didnt yield any satisfactory result as.
- there were a lot of non stationarities and the fact the system was modelled based on a fashion which couldn't extend more than a small system of at best 10 modules [1].
- And the fact that the reward of localization couldnt exceed the negetive reward for moving the bot that is the bots choose to stand still to save fuel over exploring in most of the senarios.
Below are few runs with [10, 25]
Number of modules.
| Localization trained for small n(=10) | Localization trained for big n(=25) |
|---|---|
 |
 |
Here it is clearly visible that because of randomness and the fact more number of can cover a larger space of the system exploration is much easier than being greedy to stay at a point and save fuel.
To Center for Computing and Information Services, IIT (BHU) varanasi to provide the computational power, i.e., The Super Computer on which I was able to train for over 10 Million Timesteps for about 1.5 months.
For any other query feel free to reachout.
[1] Guided Deep Reinforcement Learning for Swarm Systems [arXiv:1709.06011v1] [cs.MA] 18 Sep 2017