4. Approach 1: Kubeflow Pipelines & KALE

Kubeflow is the open-source machine learning toolkit for Kubernetes. The goal is to make scaling machine learning (ML) models and deploying them to production as simple as possible, by letting Kubernetes do what it’s great at:
- Easy, repeatable, portable deployments on a diverse infrastructure (for example, experimenting on a laptop, then moving to an on-premises cluster or to the cloud)
- Deploying and managing loosely-coupled microservices
- Scaling based on demand
The following diagram shows Kubeflow as a platform for arranging the components of a ML system on top of Kubernetes:

ML Tools: You can use whatever framework you are comfortable with.
Everything is built on top of Kubernetes so you can run the workflows across multiple environments.

Kubeflow Pipelines exists because Data Science and ML are inherently pipeline processes
Data science is inherently a pipeline workflow, from data preparation to training and deployment, every ML project is organized in these logical steps. Without enforcing a strict pipeline structure to Data Science projects, it is often too easy to create messy code, with complicated data and code dependencies and hard to reproduce results. Kubeflow Pipelines is an excellent tool to drive data scientists to adopt a disciplined (“pipelined”) mindset when developing ML code and scaling it up in the Cloud.

So, the Kubeflow Pipelines’ Python SDK is a great tool to automate the creation of these pipelines, especially when dealing with complex workflows and production environments.
Benefits of running a Notebook as a Pipeline
● The steps of the workflow are clearly defined
● Parallelization & isolation
- Hyperparameter tuning
● Data versioning
● Different infrastructure requirements
- Different hardware (GPU/CPU)
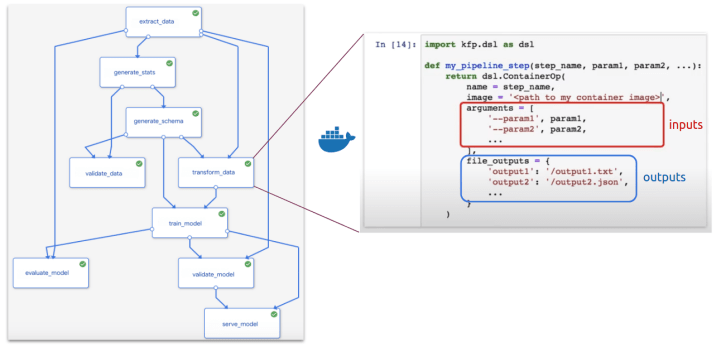
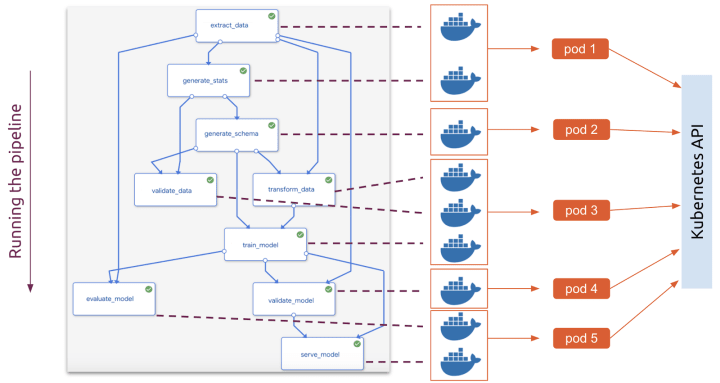

BUT!
ML researchers or Data Scientists that don’t have strong software engineering expertise, so KFP can be perceived as too complex and hard to use. Data Science is often a matter of prototyping new ideas, exploring new data and models, experimenting fast and iteratively. Usually, the experimentation phase often happens directly in Jupyter Notebooks, where a Data Scientist exploits the power of interactivity and visualizations of Jupyter. Then, refactoring a messy Notebook to an organized KFP pipeline can be a challenging and time-consuming task.
SO WHAT CAN WE DO?
Translating a Jupyter Notebook directly into a KFP
The main idea behind Kale is to exploit the JSON structure of Notebooks to annotate them, both at the Notebook level (Notebook metadata) and at the single Cell level (Cell metadata). These annotations allow to:
- Assign code cells to specific pipeline components
- Merge together multiple cells into a single pipeline component
- Define the (execution) dependencies between them
Kale takes as input the annotated Jupyter Notebook and generates a standalone Python script that defines the KFP pipeline

Kale JupyterLab extension: The extension provides a convenient Kubeflow specific left panel, where the user can set pipeline metadata and assign the Notebook’s cells to specific pipeline steps, as well as defining dependencies and merge multiple cells together. In this way, a Data Scientist can go from prototyping on a local laptop to a Kubeflow Pipelines workflow without ever interacting with the command line or additional SDKs.


Challenges
-
Kubeflow is complex - but we need Kubeflow Pipelines. What can we do?
KFP is available as a standalone deployment: Instructions to deploy Kubeflow Pipelines standalone to a cluster - Kudos to Jan for the idea
-
KALE is published on GitHub, so theoretically it can be installed on JupyterHub BUT: How can it be "connected" to the KFPs?
Run JupyterHub and KFP on the same cluster - Kudos to Jan for the idea
-
MAIN challenge: Arrikto suggests/distributes Kale in a bundle called MiniKF which includes:
- Kubernetes (using Minikube)
- Kubeflow
- Kale, a tool to convert general-purpose Jupyter Notebooks to Kubeflow Pipelines workflows (GitHub)
- Arrikto’s Rok, a data management software for data versioning and reproducibility <--- this is licensed
Can we install/use Kale without using Rok? <--- under investigation

Disclaimer: Original idea, including information and figures based on: From Notebook to Kubeflow Pipelines to KFServing: the Data Science Odyssey - Karl Weinmeister, Google & Stefano Fioravanzo, Arrikto & Automating Jupyter Notebook Deployments to Kubeflow Pipelines with Kale - Stefano Fioravanzo
