This repository contains an re-implementation of the paper Convolutional Neural Networks for Steady Flow Approximation. The premise is to learn a mapping from boundary conditions to steady state fluid flow. There are a few differences and improvements from this work and the original paper which are discussed bellow. This code and network architecture was later used to write this paper about optimizing wing airfoils to maximize the lift drag ratio.
This is the most difficult part of this project. Mechsys was used to generate the fluid simulations necessary for training however it can be difficult to set up and requires a fair number of packages. In light of this, I have made the data set available here (about 700 MB). Place this file in the data directory and this will be the train set. The test car set can be found here. Unzip this file in the data directory for the test car set.
To train enter the train directory and run
python flow_train.py
Some training information such as the loss is recorded and can be viewed with tensorboard. The checkpoint file is found in checkpoint and has a name corresponding to the parameters used.
Once the model is trained sufficiently you can evaluate it by running
python flow_test.py
This will run through the car dataset provided and do side by side comparisons. Here are a few cool images it will generated! The left image is true, the middle is generated, and right is difference. As you can see, the model is predicting flow extremely well. Comparing with the images seen in the original paper, we notice that our method predicts much smother flows on the boundaries.



While this isn't in this code base here are some cool videos form the paper optimizing a wing airfoil and heat sink.
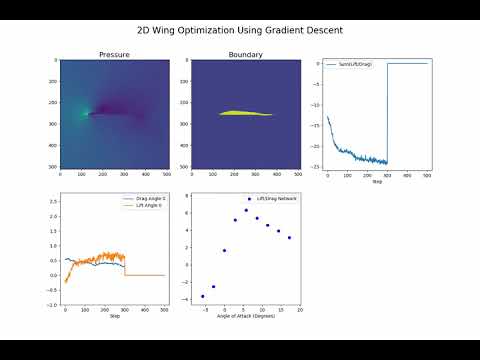

As mentioned above, this work deviates from that seen in the original paper. Instead of using Signed Distance Function as input we use a binary representation of the boundary conditions. This simplifies the input greatly. We also use a U-network approach with residual layers similar to that seen in Pixel-CNN++. This seems to make learning incredibly fast and decreases the requirement of a large dataset. Notably, our model is trained on only 3,000 flow images instead of the 100,000 listed in the paper and still produces comparable performance.
The time pre image in a batch size of 8 is 0.00287 seconds on a GTX 1080 GPU. This is 3x faster the reported time of 0.0085 seconds in the paper. While our network is more complex we are able to achieve higher speed by not relying on any fully connected layers and keep our network all convolutional.