https://wiki.thecrick.org/display/HPC/Analysis+%7C+Simulation+%7C+Processing
Delete bugged jobs yet to be processed
myq | sed 's/\|/ /'|awk '{print $1}' | sed ':a;N;$!ba;s/\n/ /g' > jobid.txt
cat jobid.txt
scancel PASTE excluding the int JOBID
http://github-pages.ucl.ac.uk/RCPSTrainingMaterials/HPCandHTCusingLegion/1_intro_to_hpc.html
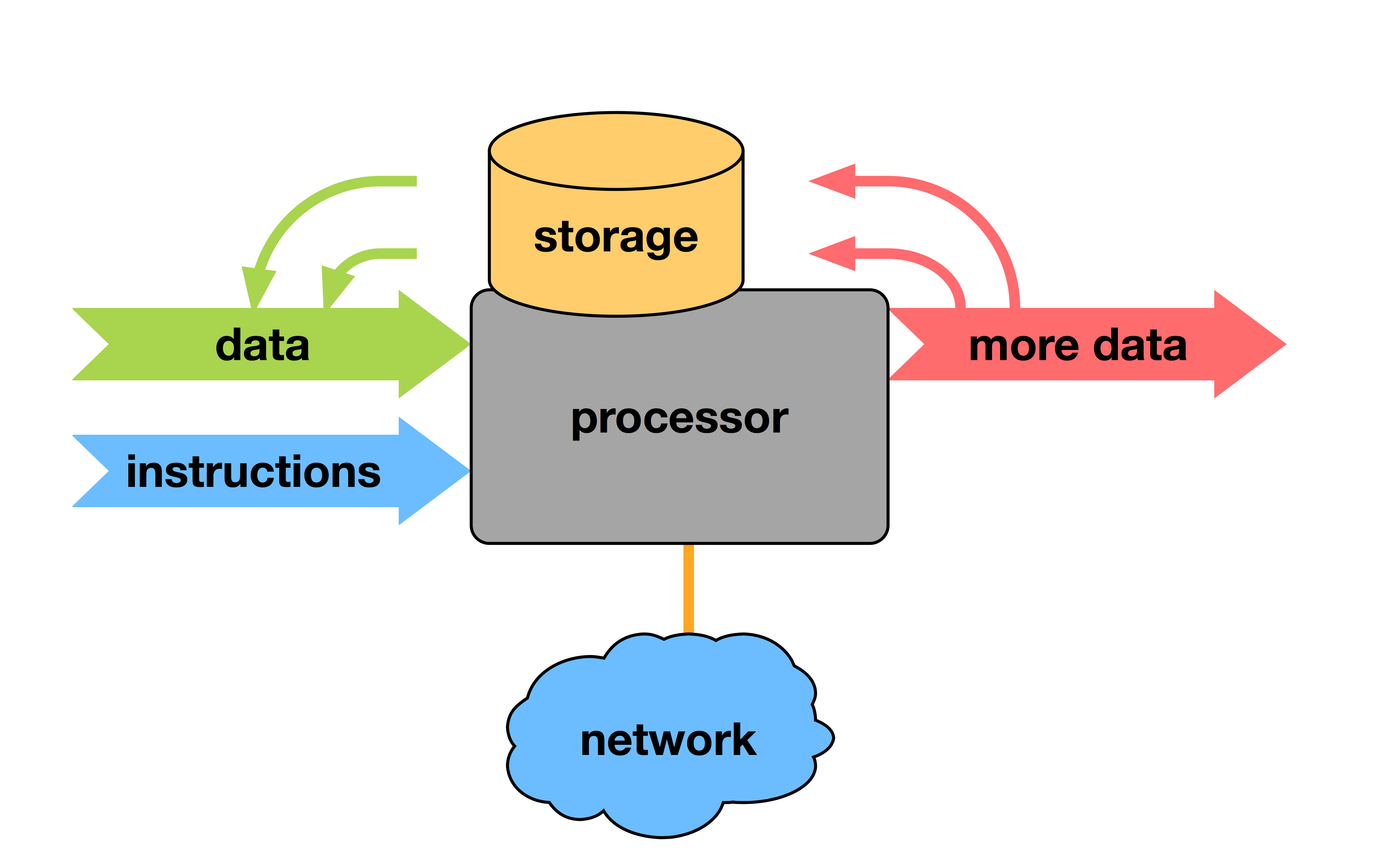
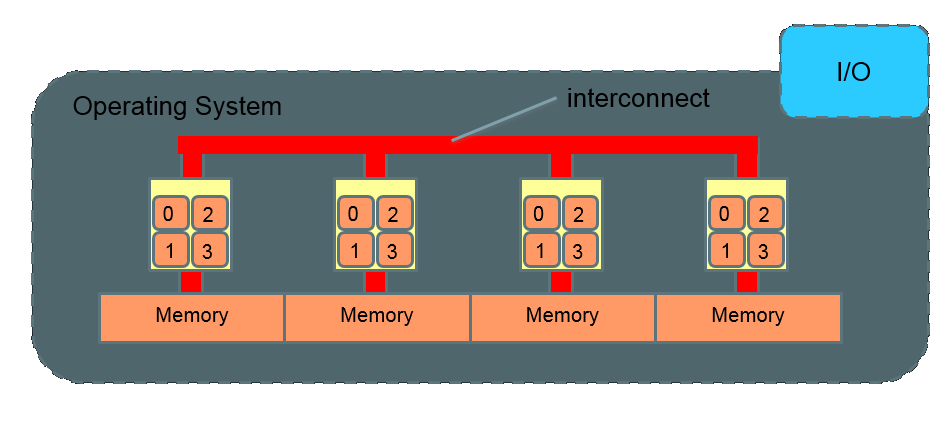
Overview of Cluster design:
Internet > login node (public) > compute node (private)
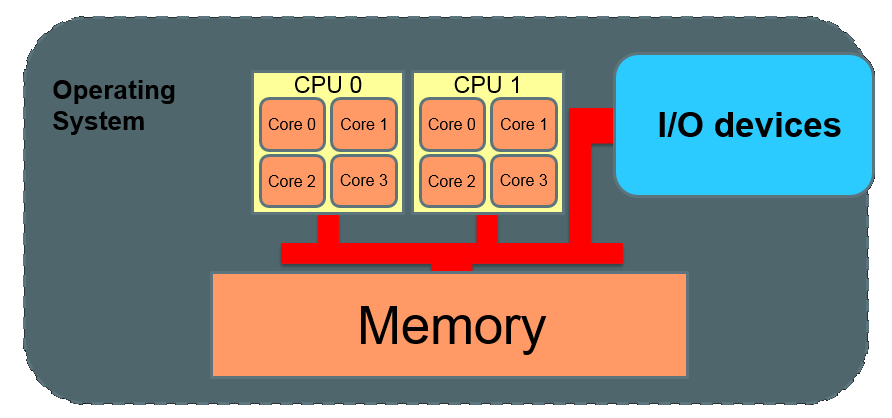
Symmetric Multi Processing (SMP) is used to paraellise computing jobs within a computer.
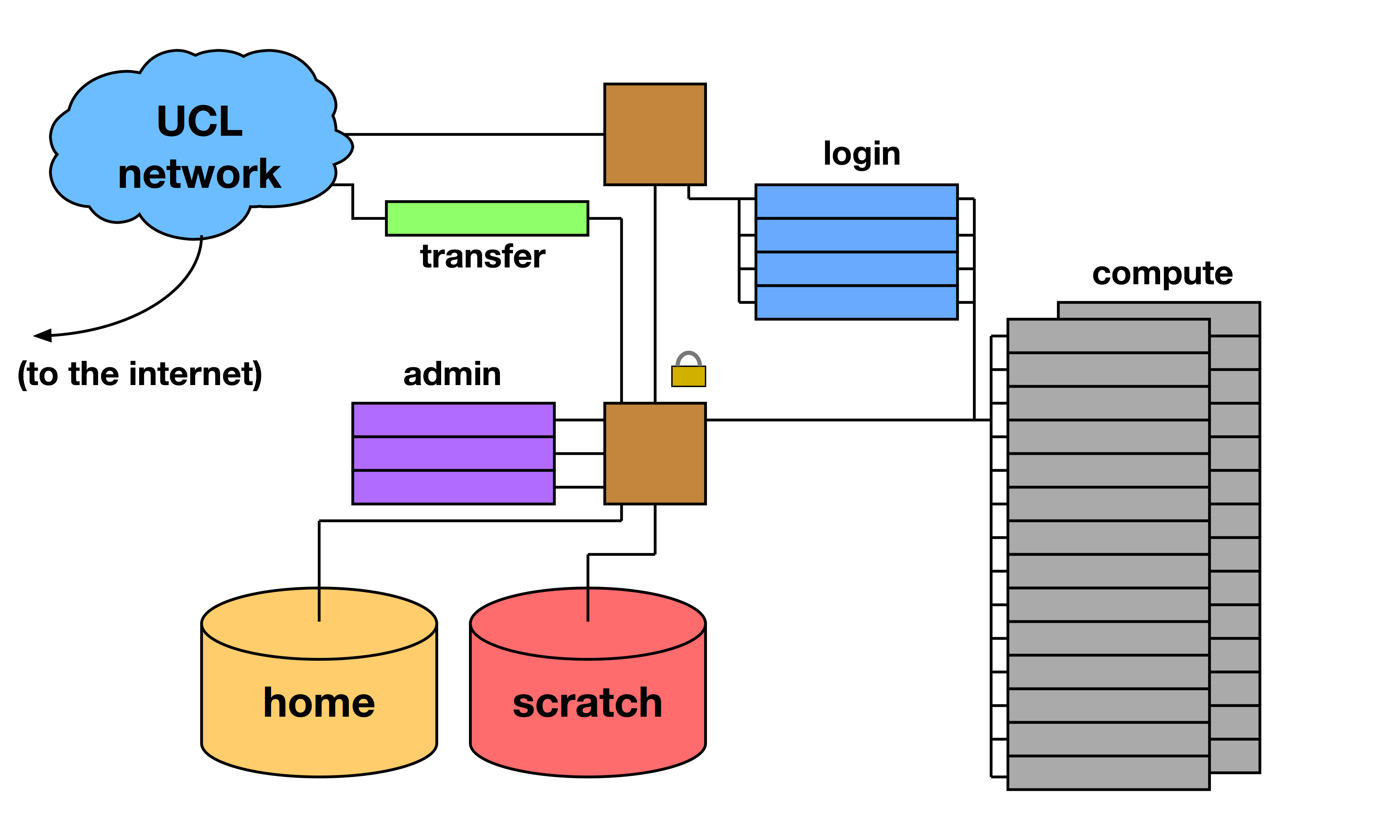
Compute cluster design:
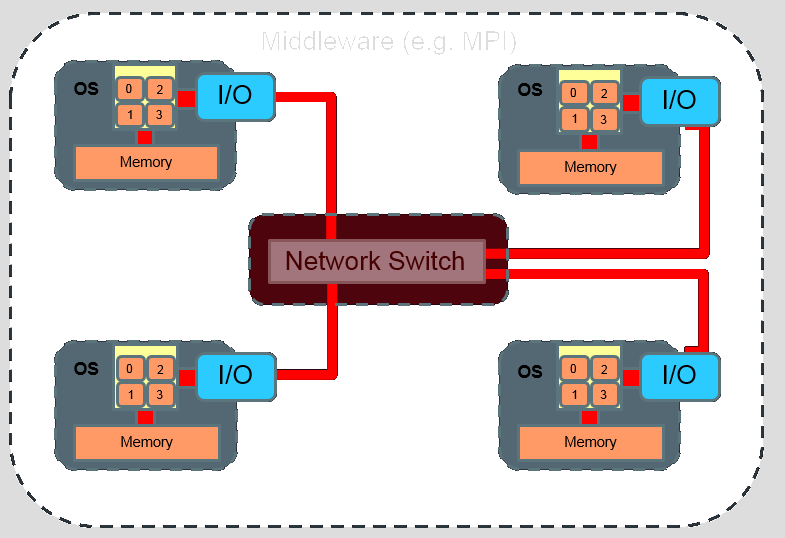
The Interconnect determines the speed and bandwidth (MB/s)
10 Bbs ethernet = 15 microseconds MPI latency > 800 MB/s bandwidth
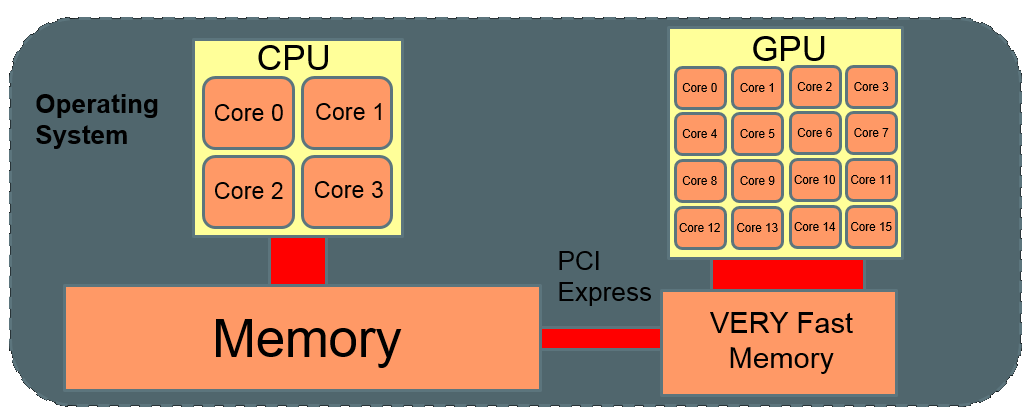
GPU accelerator:
- Set up default on iTerm2 to open CAMP
- To open non cluster window, right click on ITerm2 and open New Window —> Olivers Mac
- Once open, you will be on the Head Node. YOU MUST REQUEST AN INTERACTIVE SESSION TO GET ALLOCATED TO A COMPUTER (and come off the head node).
- int (alias set up in home directory ~ > nano .bash_profile —> code to request interactive session srun:
alias int2='srun -N 1 -c 1 --mem=8G --pty --partition=int -t 12:00:00 /bin/bash'- set partition as int. See all partitions with
sinfo
- set partition as int. See all partitions with
For more nodes & memory:
alias int2='srun -N 1 -c 4 --mem=16G --pty --partition=int -t 12:00:00 /bin/bash'
To run two tasks within 1 interactive node specify:
srun -n 2 -N 1 -c 1 --mem=8G --pty --partition=int -t 12:00:00 /bin/bash. When inside the job specify: srun -n 1 for first task & srun -n1 for second task.
-mem limit is ~120G on int partition.
-
Alternative is to submit a job to the cluster (use sbatch command)
-
To check your status on the cluster type myq (alias for squeue -u ziffo —> set up in .bashrc as .bash_profile doesn’t allow the command to work)
-
squeueshows all jobs submitted to cluster
https://slurm.schedmd.com/pdfs/summary.pdf
sbatch --help in command line
https://slurm.schedmd.com/overview.html
https://www.youtube.com/watch?v=NH_Fb7X6Db0&feature=relmfu
https://wiki.thecrick.org/display/HPC/Analysis+%7C+Simulation+%7C+Processing#Analysis|Simulation|Processing-batch
sbatch --cpus-per-task=8 --mem 0 -N 1 --partition=cpu --time=12:00:00 --wrap="Rscript ~/home/projects/vcp_fractionation/expression/deseq2/DGE_plotsRmd.R"
N is the number of nodes (usually leave at 1)
cpus-per-task is the number of cores (i.e. threads - so you could change the STAR command to runThreadN 8 with this example)
Can cancel jobs sent to the cluster with scancel then job id (identified from squeue -u ziffo)
Can remove the slurm files after download (that is just the log): rm slurm-*
--mem is the amount of memory you want. Limit is 250G for cpu partition node & 120G on int partition.
--mem=0 allocates the whole node so use this when you have a large job and not clear what limit to set. Then after job run sacct to check how much memory was actually used: shown under MaxRSS. Use this to correct for further jobs of same script.
sacct -j <jobid> --format="CPUTime,MaxRSS"
sacct -j <jobid> -l # shows long list of all variables of the job.
MaxRSS units are in Bytes with K. 1GB = 1,000,000,K
e.g. 240423400K = 240.4GB ~ rough limit on CPU node. In this case specify hmem instead e.g.:
sbatch --cpus-per-task=10 --mem=1500G -N 1 --partition=hmem -t 48:00:00 --wrap=
Also set ulimit to unlimited:
ulimit -s unlimited # to avoid C stack error
ulimit -s # check that ulimit is set to unlimited
394,734,200K = 394.7GB
1,221,176K
762,923,372K
R needs to create a copy of everything that’s in memory for each individual process (it doesn’t utilize shared memory).
Try:
- Using fewer cores - If you were trying to use 4 cores, it’s possible you have enough RAM to support 3 parallel threads, but not 4.
registerDoMC(2), for example, will set the number of parallel threads to 2 (if you are using thedoMCparallel backend). - Using less memory - without seeing the rest of your code, it’s hard to suggest ways to accomplish this. One thing that might help is figuring out which R objects are taking up all the memory (Determining memory usage of objects?) and then removing any objects from memory that you don’t need (
rm(my_big_object)) - Adding more RAM - if all else fails, throw hardware at it so you have more capacity.
- Sticking to single threading - multithreaded processing in R is a tradeoff of CPU and memory. It sounds like in this case you may not have enough memory to support the CPU power you have, so the best course of action might be to just stick to a single core.
batch- batch processing using CPU-only compute nodesint- interactive use via command line/X-windows using CPU-only compute nodesvis- interactive use via command line/X-windows GPU-accelerated nodes for visualisationgpu- batch processing using GPU-accelerated nodes. for gpu you’d have to add --gres=gpu:<1-4> or try with only --exclusivehmem- batch processing using large RAM machinessb- batch processing using GPU-accelerated nodes designed for Structural Biology applications
https://hpc.nih.gov/docs/job_dependencies.html
Job dependencies are used to defer the start of a job until the specified dependencies have been satisfied. They are specified with the --dependency option to sbatch or swarm in the format
sbatch --dependency=type:job_id[:job_id][,type:job_id[:job_id]] …
e.g delay job until another is complete:
sbatch --dependency=afterany:6854906 -N 1 -c 8 --mem 200G -t 12:00:00 --wrap="Rscript ~/home/projects/vcp_fractionation/expression/deseq2/GO_plotsRmd.R"
Dependency types:
after:jobid[:jobid…]
job can begin after the specified jobs have started
afterany:jobid[:jobid…]
job can begin after the specified jobs have terminated
afternotok:jobid[:jobid…]
job can begin after the specified jobs have failed
afterok:jobid[:jobid…]
job can begin after the specified jobs have run to completion with an exit code of zero (see the user guide for caveats).
singleton
jobs can begin execution after all previously launched jobs with the same name and user have ended. This is useful to collate results of a swarm or to send a notification
type alias into terminal to see already set alias’s:
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias int='srun -N 1 -c 1 --mem=8G --pty --partition=int -t 12:00:00 /bin/bash'
alias int2='srun -N 1 -c 4 --mem=16G --pty --partition=int -t 12:00:00 /bin/bash'
alias l.='ls -d .* --color=auto'
alias ll='ls -lh'
alias ls='ls --color=auto'
alias mc='. /usr/libexec/mc/mc-wrapper.sh'
alias myq='squeue -u ziffo'
alias oist='ssh -X [email protected]'
alias sango='ssh -X [email protected]'
alias vi='vim'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
open local mac terminal:
nano ~/.ssh/config
#add to start:
HOST *
UseKeychain yes
On the cluster the is hundreds of different software already pre installed. To see them type ml av (modules available)
To run a specific software use module load command: eg ml STAR
Remove a module that is already loaded:
ml -module_name
https://groups.oist.jp/it/accessing-file-servers-mac
On local Mac go to:
Finder > Click Go > Connect to Server > Type server address cifs://data.thecrick.org/lab-luscomben/ > Connect
Or via Terminal ssh
The ~/ directory only has 5GB of space and running software out of this will rapidly take this up.
To get around this need to create a soft-link from working/ to ~/ with:
mv ~/.nextflow/ /camp/lab/luscomben/home/ ln -s /camp/lab/luscomben/home/.nextflow ~/.nextflowmv ~/.singularity/ /camp/lab/luscomben/home/ ln -s /camp/lab/luscomben/home/.singularity ~/.singularity
mv ~/.conda/ /camp/lab/luscomben/home/ ln -s /camp/lab/luscomben/home/.conda ~/.conda
Check the symlink ls -lart
When you make a new folder or file you need to also ensure you have permissions. Sometimes this will happen automatically.
Command chmod -R 744 [file name] will ensure that you have full access (ie execute, read, write); others in group & public can read.
chmod +rwx [filename]
chmod -R 755 [directory name]
e.g. chmod -R 755 ACD_CB1D_counts/
Alias ll will list all your active sessions in the cluster and show permissions (rwxr—r—r—)
Bin
Genomes > Annotation; Sequences; Index
Projects
Scripts
Can use rsync after setting up in ~/.ssh/config:
host camp-ext
User ziffo
hostname login.camp.thecrick.org
Go to target folder:
cd /Users/ziffo/'Dropbox (The Francis Crick)'/Medical\ Files/Research/PhD/single_cell_astrocytes/scRNAseq_astrocytes_motorneurons_plots
Then run:
rsync -aP camp-ext:/camp/home/ziffo/home/projects/vcp_fractionation/expression/deseq2/DGE_plots.html .
rsync -aP camp-ext:/camp/home/ziffo/home/projects/vcp_fractionation/expression/deseq2/GO_plots.html .
rsync -aP camp-ext:/camp/home/ziffo/home/projects/single_cell_astrocytes/expression/seurat/figures/ .
rsync -aP camp-ext:/camp/home/ziffo/home/projects/single_cell_astrocytes/expression/seurat/scripts/scRNAseq_seurat_separate.html .
On local mac terminal
Use scp
specify path to file to transfer
specify CAMP destination directory as camp-ext:
scp rename.sh camp-ext:/camp/home/ziffo/home/projects/vcp_fractionation/reads
we can access the daily snapshots over the last week ourselves via /camp/lab/luscomben/.snapshots/
Go to the working target folder within camp then run rsync e.g.:
rsync -aP /camp/lab/luscomben/.snapshots/crick.camp.lab.luscomben.19-12-19/home/projects/vcp_fractionation/reads .
Can also do via Finder & enabling ‘show hidden files’ on your device.
Ensure you have saved all your work on your laptop before carrying out the following:
- Open terminal
- Enter the following: defaults write com.apple.Finder AppleShowAllFiles true [Press return]
- Enter the following in terminal: killall Finder [Press return]
Once you’ve done this, if you launch CAMP, you’ll see a folder called ‘.snapshots’ - this will have snapshots of CAMP for the past week, where you can restore your directory from.
/camp/lab/luscomben/.snapshots/crick.camp.lab.luscomben.19-12-19/home/projects/vcp_fractionation/reads
https://www.hamvocke.com/blog/a-quick-and-easy-guide-to-tmux/
Terminal multiplexer.
2 features:
- Terminal window management
- Terminal session management
Open multiple windows of terminal without the need to open multiple terminal emulator windows.
decatching: exit a session but keep it active until you kill the tmux server
attaching: pick up the detached session at anytime.
start session
tmux
list sessions
tmux ls
create a new session
tmux new-window (prefix + c)
creates a new tmux session named session_name
tmux new -s session_name
rename the current window
tmux rename-window (prefix + ,)
closing window
exit
attaches to an existing tmux session named session_name
tmux attach -t session_name
switch to an existing session named session_name
tmux switch -t session_name
lists existing tmux sessions
tmux list-sessions
detach the currently attached session
tmux detach (prefix + d)
tmux split-window (prefix + ")
splits the window into two vertical panes
tmux split-window -h (prefix + %)
splits the window into two horizontal panes
tmux swap-pane -[UDLR] (prefix + { or })
swaps pane with another in the specified direction
tmux select-pane -[UDLR]
selects the next pane in the specified direction
tmux select-pane -t :.+
selects the next pane in numerical order
lists out every bound key and the tmux command it runs
tmux list-keys
lists out every tmux command and its arguments
tmux list-commands
lists out every session, window, pane, its pid, etc.
tmux info
reloads the current tmux configuration (based on a default tmux config)
tmux source-file ~/.tmux.conf
tmux select-window -t :0-9 (prefix + 0-9)
move to the window based on index
To connect to that session you start tmux again but this time tell it which session to attach to:
tmux attach -t 0
Note that the -t 0 is the parameter that tells tmux which session to attach to. “0” is the first part of your tmux ls output.
rename session
tmux rename-session -t 0 database
The next time you attach to that session you simply use tmux attach -t database. If you’re using multiple sessions at once this can become an essential feature.
Left: currently opened window
Right: time & date
Begin an interactive job using srun --ntasks=1 --cpus-per-task=1 --partition=int --time=8:00:0 --mem=8G --pty /bin/bash .
Activate conda environment source activate rtest
run command for jupyter-lab:
unset XDG_RUNTIME_DIR;
jupyter-lab --ip=$(hostname -I | awk '{print $1}') --port=8080
Copy & paste the URL into web brower eg
http://10.28.2.10:8081/?token=9767b1d01a2f2de3ca22193b51ba43704d05595863745677