-
Notifications
You must be signed in to change notification settings - Fork 45
/
main.py
executable file
·209 lines (169 loc) · 9.04 KB
/
main.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
#!/usr/bin/env python
# coding: utf-8
"""Download historical candlestick data for all trading pairs on Binance.com.
All trading pair data is checked for integrity, sorted and saved as both a CSV
and a Parquet file. The CSV files act as a raw buffer on every update round.
The Parquet files are much more space efficient (~50GB vs ~10GB) and are
therefore the files used to upload to Kaggle after each run.
"""
__author__ = 'GOSUTO.AI'
import json
import os
import random
import subprocess
import time
from datetime import date, datetime, timedelta
import requests
import pandas as pd
import preprocessing as pp
API_BASE = 'https://api.binance.com/api/v3/'
LABELS = [
'open_time',
'open',
'high',
'low',
'close',
'volume',
'close_time',
'quote_asset_volume',
'number_of_trades',
'taker_buy_base_asset_volume',
'taker_buy_quote_asset_volume',
'ignore'
]
METADATA = {
'id': 'jorijnsmit/binance-full-history',
'title': 'Binance Full History',
'isPrivate': False,
'licenses': [{'name': 'other'}],
'keywords': [
'business',
'finance',
'investing',
'currencies and foreign exchange'
],
'collaborators': [],
'data': []
}
def write_metadata(n_count):
"""Write the metadata file dynamically so we can include a pair count."""
METADATA['subtitle'] = f'1 minute candlesticks for all {n_count} cryptocurrency pairs'
METADATA['description'] = f"""### Introduction\n\nThis is a collection of all 1 minute candlesticks of all cryptocurrency pairs on [Binance.com](https://binance.com). All {n_count} of them are included. Both retrieval and uploading the data is fully automated—see [this GitHub repo](https://github.com/gosuto-ai/candlestick_retriever).\n\n### Content\n\nFor every trading pair, the following fields from [Binance's official API endpoint for historical candlestick data](https://github.com/binance-exchange/binance-official-api-docs/blob/master/rest-api.md#klinecandlestick-data) are saved into a Parquet file:\n\n```\n # Column Dtype \n--- ------ ----- \n 0 open_time datetime64[ns]\n 1 open float32 \n 2 high float32 \n 3 low float32 \n 4 close float32 \n 5 volume float32 \n 6 quote_asset_volume float32 \n 7 number_of_trades uint16 \n 8 taker_buy_base_asset_volume float32 \n 9 taker_buy_quote_asset_volume float32 \ndtypes: datetime64[ns](1), float32(8), uint16(1)\n```\n\nThe dataframe is indexed by `open_time` and sorted from oldest to newest. The first row starts at the first timestamp available on the exchange, which is July 2017 for the longest running pairs.\n\nHere are two simple plots based on a single file; one of the opening price with an added indicator (MA50) and one of the volume and number of trades:\n\n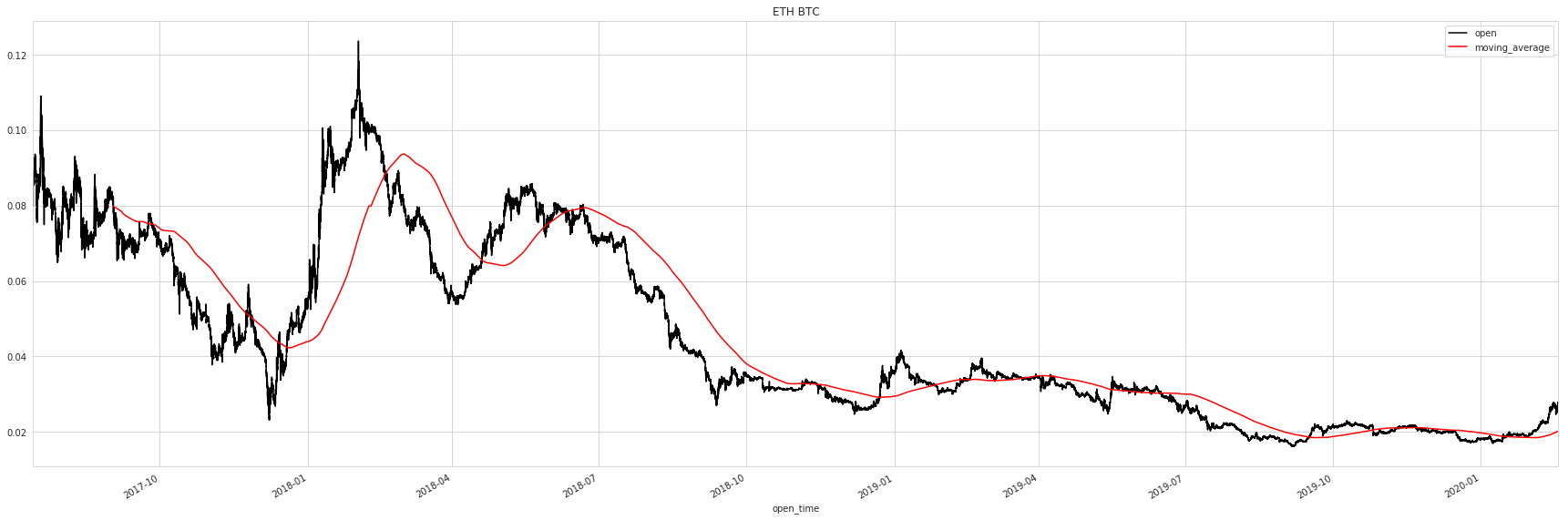\n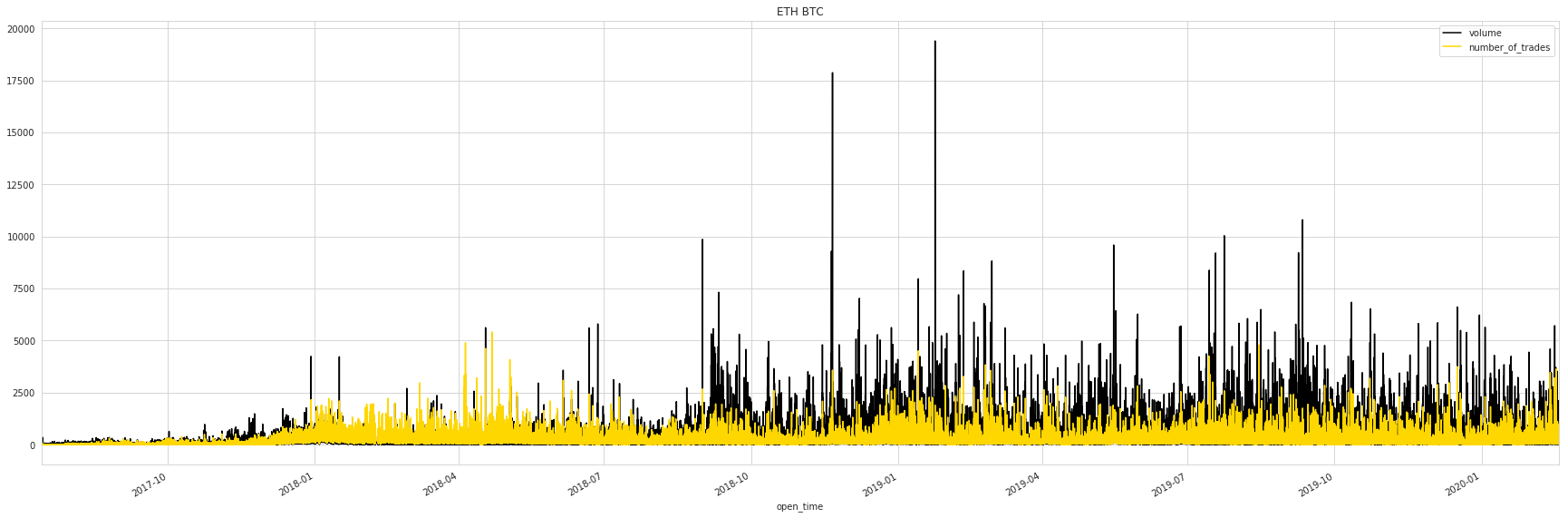\n\n### Inspiration\n\nOne obvious use-case for this data could be technical analysis by adding indicators such as moving averages, MACD, RSI, etc. Other approaches could include backtesting trading algorithms or computing arbitrage potential with other exchanges.\n\n### License\n\nThis data is being collected automatically from crypto exchange Binance."""
with open('compressed/dataset-metadata.json', 'w') as file:
json.dump(METADATA, file, indent=4)
def get_batch(symbol, interval='1m', start_time=0, limit=1000):
"""Use a GET request to retrieve a batch of candlesticks. Process the JSON into a pandas
dataframe and return it. If not successful, return an empty dataframe.
"""
params = {
'symbol': symbol,
'interval': interval,
'startTime': start_time,
'limit': limit
}
try:
# timeout should also be given as a parameter to the function
response = requests.get(f'{API_BASE}klines', params, timeout=30)
except requests.exceptions.ConnectionError:
print('Connection error, Cooling down for 5 mins...')
time.sleep(5 * 60)
return get_batch(symbol, interval, start_time, limit)
except requests.exceptions.Timeout:
print('Timeout, Cooling down for 5 min...')
time.sleep(5 * 60)
return get_batch(symbol, interval, start_time, limit)
except requests.exceptions.ConnectionResetError:
print('Connection reset by peer, Cooling down for 5 min...')
time.sleep(5 * 60)
return get_batch(symbol, interval, start_time, limit)
if response.status_code == 200:
return pd.DataFrame(response.json(), columns=LABELS)
print(f'Got erroneous response back: {response}')
return pd.DataFrame([])
def all_candles_to_csv(base, quote, interval='1m'):
"""Collect a list of candlestick batches with all candlesticks of a trading pair,
concat into a dataframe and write it to CSV.
"""
# see if there is any data saved on disk already
try:
batches = [pd.read_csv(f'data/{base}-{quote}.csv')]
last_timestamp = batches[-1]['open_time'].max()
except FileNotFoundError:
batches = [pd.DataFrame([], columns=LABELS)]
last_timestamp = 0
old_lines = len(batches[-1].index)
# gather all candlesticks available, starting from the last timestamp loaded from disk or 0
# stop if the timestamp that comes back from the api is the same as the last one
previous_timestamp = None
while previous_timestamp != last_timestamp:
# stop if we reached data from today
if date.fromtimestamp(last_timestamp / 1000) >= date.today():
break
previous_timestamp = last_timestamp
new_batch = get_batch(
symbol=base+quote,
interval=interval,
start_time=last_timestamp+1
)
# requesting candles from the future returns empty
# also stop in case response code was not 200
if new_batch.empty:
break
last_timestamp = new_batch['open_time'].max()
# sometimes no new trades took place yet on date.today();
# in this case the batch is nothing new
if previous_timestamp == last_timestamp:
break
batches.append(new_batch)
last_datetime = datetime.fromtimestamp(last_timestamp / 1000)
covering_spaces = 20 * ' '
print(datetime.now(), base, quote, interval, str(last_datetime)+covering_spaces, end='\r', flush=True)
# write clean version of csv to parquet
parquet_name = f'{base}-{quote}.parquet'
full_path = f'compressed/{parquet_name}'
df = pd.concat(batches, ignore_index=True)
df = pp.quick_clean(df)
pp.write_raw_to_parquet(df, full_path)
METADATA['data'].append({
'description': f'All trade history for the pair {base} and {quote} at 1 minute intervals. Counts {df.index.size} records.',
'name': parquet_name,
'totalBytes': os.stat(full_path).st_size,
'columns': []
})
# in the case that new data was gathered write it to disk
if len(batches) > 1:
df.to_csv(f'data/{base}-{quote}.csv', index=False)
return len(df.index) - old_lines
return 0
def main():
"""Main loop; loop over all currency pairs that exist on the exchange. Once done upload the
compressed (Parquet) dataset to Kaggle.
"""
# get all pairs currently available
all_symbols = pd.DataFrame(requests.get(f'{API_BASE}exchangeInfo').json()['symbols'])
all_pairs = [tuple(x) for x in all_symbols[['baseAsset', 'quoteAsset']].to_records(index=False)]
# randomising order helps during testing and doesn't make any difference in production
random.shuffle(all_pairs)
# make sure data folders exist
os.makedirs('data', exist_ok=True)
os.makedirs('compressed', exist_ok=True)
# do a full update on all pairs
n_count = len(all_pairs)
for n, pair in enumerate(all_pairs, 1):
base, quote = pair
new_lines = all_candles_to_csv(base=base, quote=quote)
if new_lines > 0:
print(f'{datetime.now()} {n}/{n_count} Wrote {new_lines} new lines to file for {base}-{quote}')
else:
print(f'{datetime.now()} {n}/{n_count} Already up to date with {base}-{quote}')
# clean the data folder and upload a new version of the dataset to kaggle
try:
os.remove('compressed/.DS_Store')
except FileNotFoundError:
pass
write_metadata(n_count)
yesterday = date.today() - timedelta(days=1)
subprocess.run(['kaggle', 'datasets', 'version', '-p', 'compressed/', '-m', f'full update of all {n_count} pairs up to {str(yesterday)}'])
os.remove('compressed/dataset-metadata.json')
if __name__ == '__main__':
main()