SinGAN shows impressive capability in learning internal patch distribution despite its limited effective receptive field. We are interested in knowing how such a translation-invariant convolutional generator could capture the global structure with just a spatially i.i.d. input. In this work, taking SinGAN and StyleGAN2 as examples, we show that such capability, to a large extent, is brought by the implicit positional encoding when using zero padding in the generators. Such positional encoding is indispensable for generating images with high fidelity. The same phenomenon is observed in other generative architectures such as DCGAN and PGGAN. We further show that zero padding leads to an unbalanced spatial bias with a vague relation between locations. To offer a better spatial inductive bias, we investigate alternative positional encodings and analyze their effects. Based on a more flexible positional encoding explicitly, we propose a new multi-scale training strategy and demonstrate its effectiveness in the state-of-the-art unconditional generator StyleGAN2. Besides, the explicit spatial inductive bias substantially improve SinGAN for more versatile image manipulation.

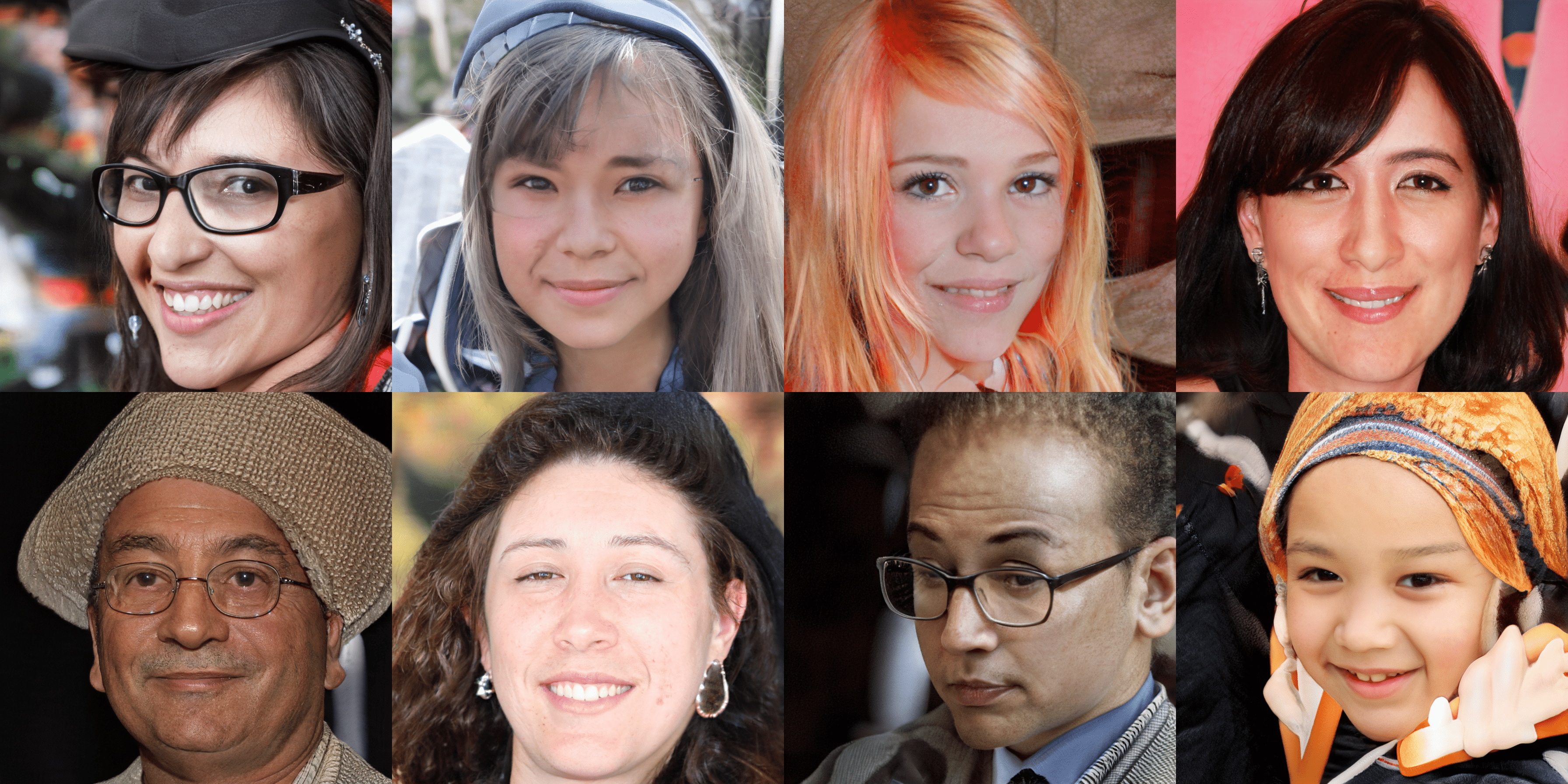
| Models | Reference in Paper | Scales | FID50k | P&R10k | Config | Download |
|---|---|---|---|---|---|---|
| stylegan2_c2_256_baseline | Tab.5 config-a | 256 | 5.56 | 75.92/51.24 | config | model |
| stylegan2_c2_512_baseline | Tab.5 config-b | 512 | 4.91 | 75.65/54.58 | config | model |
| ms-pie_stylegan2_c2_config-c | Tab.5 config-c | 256, 384, 512 | 3.35 | 73.84/55.77 | config | model |
| ms-pie_stylegan2_c2_config-d | Tab.5 config-d | 256, 384, 512 | 3.50 | 73.28/56.16 | config | model |
| ms-pie_stylegan2_c2_config-e | Tab.5 config-e | 256, 384, 512 | 3.15 | 74.13/56.88 | config | model |
| ms-pie_stylegan2_c2_config-f | Tab.5 config-f | 256, 384, 512 | 2.93 | 73.51/57.32 | config | model |
| ms-pie_stylegan2_c1_config-g | Tab.5 config-g | 256, 384, 512 | 3.40 | 73.05/56.45 | config | model |
| ms-pie_stylegan2_c2_config-h | Tab.5 config-h | 256, 384, 512 | 4.01 | 72.81/54.35 | config | model |
| ms-pie_stylegan2_c2_config-i | Tab.5 config-i | 256, 384, 512 | 3.76 | 73.26/54.71 | config | model |
| ms-pie_stylegan2_c2_config-j | Tab.5 config-j | 256, 384, 512 | 4.23 | 73.11/54.63 | config | model |
| ms-pie_stylegan2_c2_config-k | Tab.5 config-k | 256, 384, 512 | 4.17 | 73.05/51.07 | config | model |
| ms-pie_stylegan2_c2_config-f | higher-resolution | 256, 512, 896 | 4.10 | 72.21/50.29 | config | model |
| ms-pie_stylegan2_c1_config-f | higher-resolution | 256, 512, 1024 | 6.24 | 71.79/49.92 | config | model |
Note that we report the FID and P&R metric (FFHQ dataset) in the largest scale.

| Model | Data | Num Scales | Config | Download |
|---|---|---|---|---|
| SinGAN + no pad | balloons.png | 8 | config | ckpt | pkl |
| SinGAN + no pad + no bn in disc | balloons.png | 8 | config | ckpt | pkl |
| SinGAN + no pad + no bn in disc | fish.jpg | 10 | config | ckpt | pkl |
| SinGAN + CSG | fish.jpg | 10 | config | ckpt | pkl |
| SinGAN + CSG | bohemian.png | 10 | config | ckpt | pkl |
| SinGAN + SPE-dim4 | fish.jpg | 10 | config | ckpt | pkl |
| SinGAN + SPE-dim4 | bohemian.png | 10 | config | ckpt | pkl |
| SinGAN + SPE-dim8 | bohemian.png | 10 | config | ckpt | pkl |
{kind=link}
{kind=link}
{kind=link}
@article{xu2020positional,
title={Positional Encoding as Spatial Inductive Bias in GANs},
author={Xu, Rui and Wang, Xintao and Chen, Kai and Zhou, Bolei and Loy, Chen Change},
journal={arXiv preprint arXiv:2012.05217},
year={2020},
url={https://openaccess.thecvf.com/content/CVPR2021/html/Xu_Positional_Encoding_As_Spatial_Inductive_Bias_in_GANs_CVPR_2021_paper.html},
}