diff --git a/README.md b/README.md
index dde36eeae..eed08502b 100644
--- a/README.md
+++ b/README.md
@@ -173,6 +173,7 @@ A summary can be found in the [Model Zoo](docs/en/model_zoo.md) page.
- [x] [PSC](configs/psc/README.md) (CVPR'2023)
- [x] [RTMDet](configs/rotated_rtmdet/README.md) (arXiv)
- [x] [H2RBox-v2](configs/h2rbox_v2/README.md) (NeurIPS'2023)
+- [x] [Point2RBox](configs/point2rbox/README.md) (CVPR'2024)
diff --git a/configs/h2rbox_v2/README.md b/configs/h2rbox_v2/README.md
index dfa93d3c3..47cef9fa3 100644
--- a/configs/h2rbox_v2/README.md
+++ b/configs/h2rbox_v2/README.md
@@ -44,9 +44,9 @@ HRSC
```
@inproceedings{yu2023h2rboxv2,
- title={H2RBox-v2: Incorporating Symmetry for Boosting Horizontal Box Supervised Oriented Object Detection},
- author={Yi Yu and Xue Yang and Qingyun Li and Yue Zhou and and Feipeng Da and Junchi Yan},
- year={2023},
- booktitle={Advances in Neural Information Processing Systems}
+title={H2RBox-v2: Incorporating Symmetry for Boosting Horizontal Box Supervised Oriented Object Detection},
+author={Yi Yu and Xue Yang and Qingyun Li and Yue Zhou and and Feipeng Da and Junchi Yan},
+year={2023},
+booktitle={Advances in Neural Information Processing Systems}
}
```
diff --git a/configs/point2rbox/README.md b/configs/point2rbox/README.md
new file mode 100644
index 000000000..d6a1338b3
--- /dev/null
+++ b/configs/point2rbox/README.md
@@ -0,0 +1,48 @@
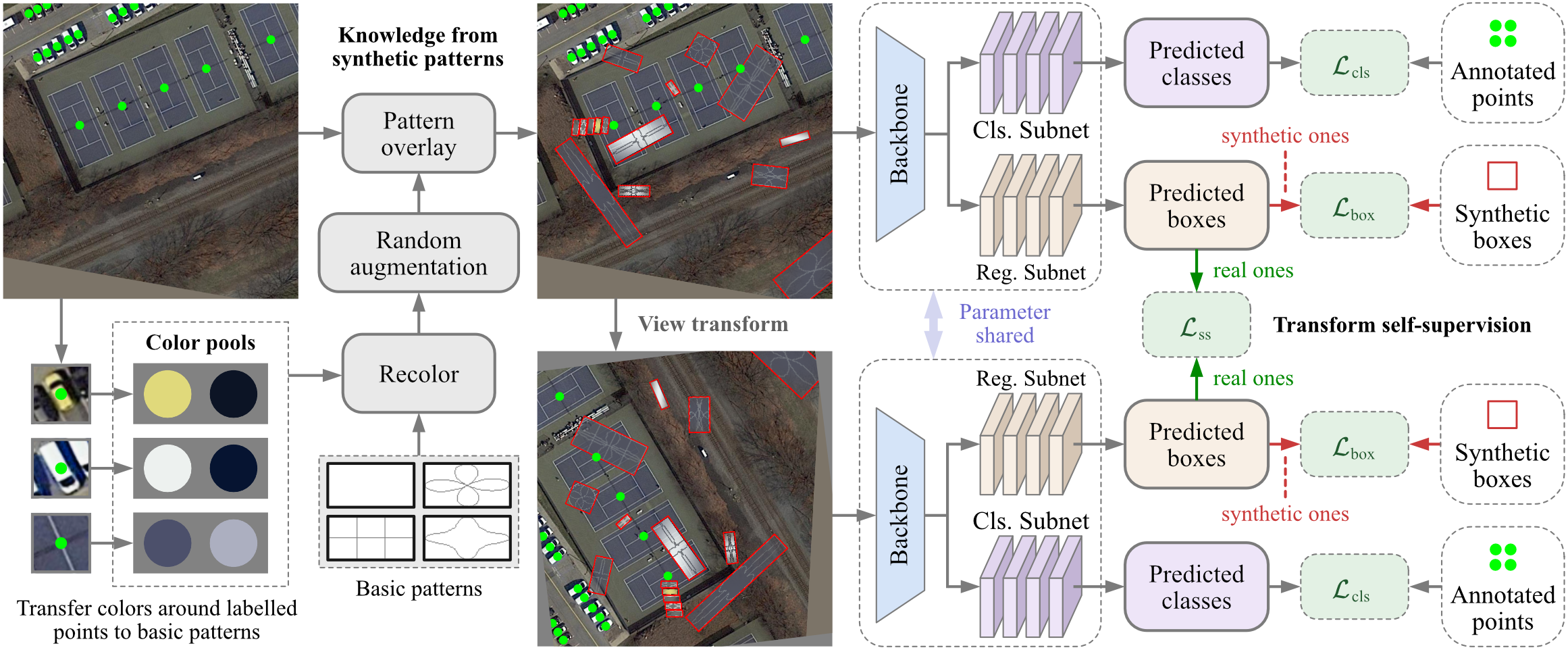
+# Point2RBox
+
+> [Point2RBox: Combine Knowledge from Synthetic Visual Patterns for End-to-end Oriented Object Detection with Single Point Supervision](https://arxiv.org/pdf/2311.14758)
+
+
+
+## Abstract
+
+
+
+