| date | comments |
|---|---|
2023-12-25 |
true |
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

@kkjtmac 这个决定很大程度上取决于个人的价值观和生活目标。有些人可能更喜欢小县城的生活方式,包括较低的生活压力,亲近自然,以及紧密的社区联系。他们可能觉得这种生活更有意义,更能实现他们的人生价值。另一方面,有些人可能更倾向于大城市的生活,因为那里有更多的工作机会,更多元化的生活方式,以及更多的社交和文化活动。他们可能认为这样的生活更能满足他们的职业和个人发展需求。

细胞因子是一大类小型分泌蛋白,通过与靶细胞上的同源受体结合而局部或全身发挥作用,进而触发下游信号传导并协调免疫系统细胞类型之间的活动。基于细胞因子的疗法和细胞因子拮抗剂用于治疗多种疾病,包括癌症和自身免疫。作者使用86种细胞因子在小鼠身上的特异性反应。通过注射不同的细胞因子到小鼠体内,并在特定时间点收集皮肤引流淋巴结进行分析,绘制了细胞因子对各种免疫细胞的影响图谱,并搭建了富集分析平台。
2、Nucleic Acids Research | DeepBIO: 面向生物序列功能分析的“一站式”深度学习计算平台
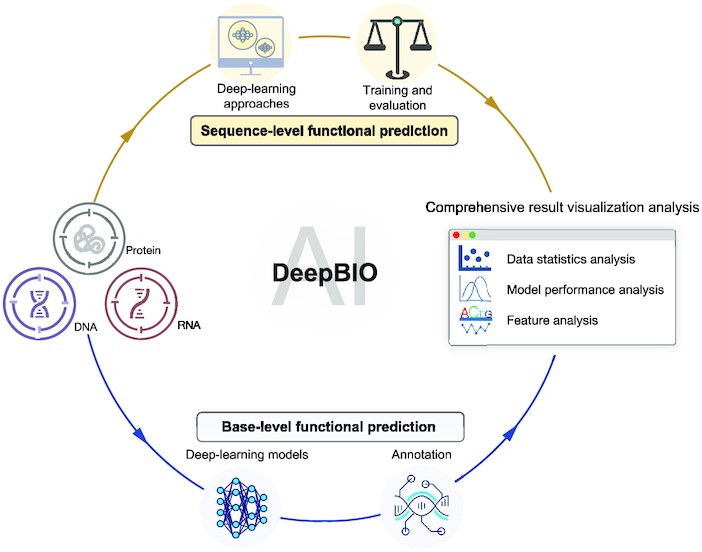
DeepBIO是首个生物序列功能分析的深度学习计算平台,该平台主要面向生物学家或者没有编程基础的研究者们提供“一站式”计算服务;给定任意的生物序列数据,平台总共支持42 种深度学习算法全自动建模训练、比较、优化等流程,以及提供全面的结果可视化分析,涵盖数据集分析,模型性能比较、可解释性、特征分析、序列功能区域发现等。
- 平台链接:https://inner.wei-group.net/DeepBIO
- 论文链接:https://academic.oup.com/nar/article/51/7/3017/7041952?login=false
3、Genome Research | 对32种癌症的预后至关重要的超4700个基因簇
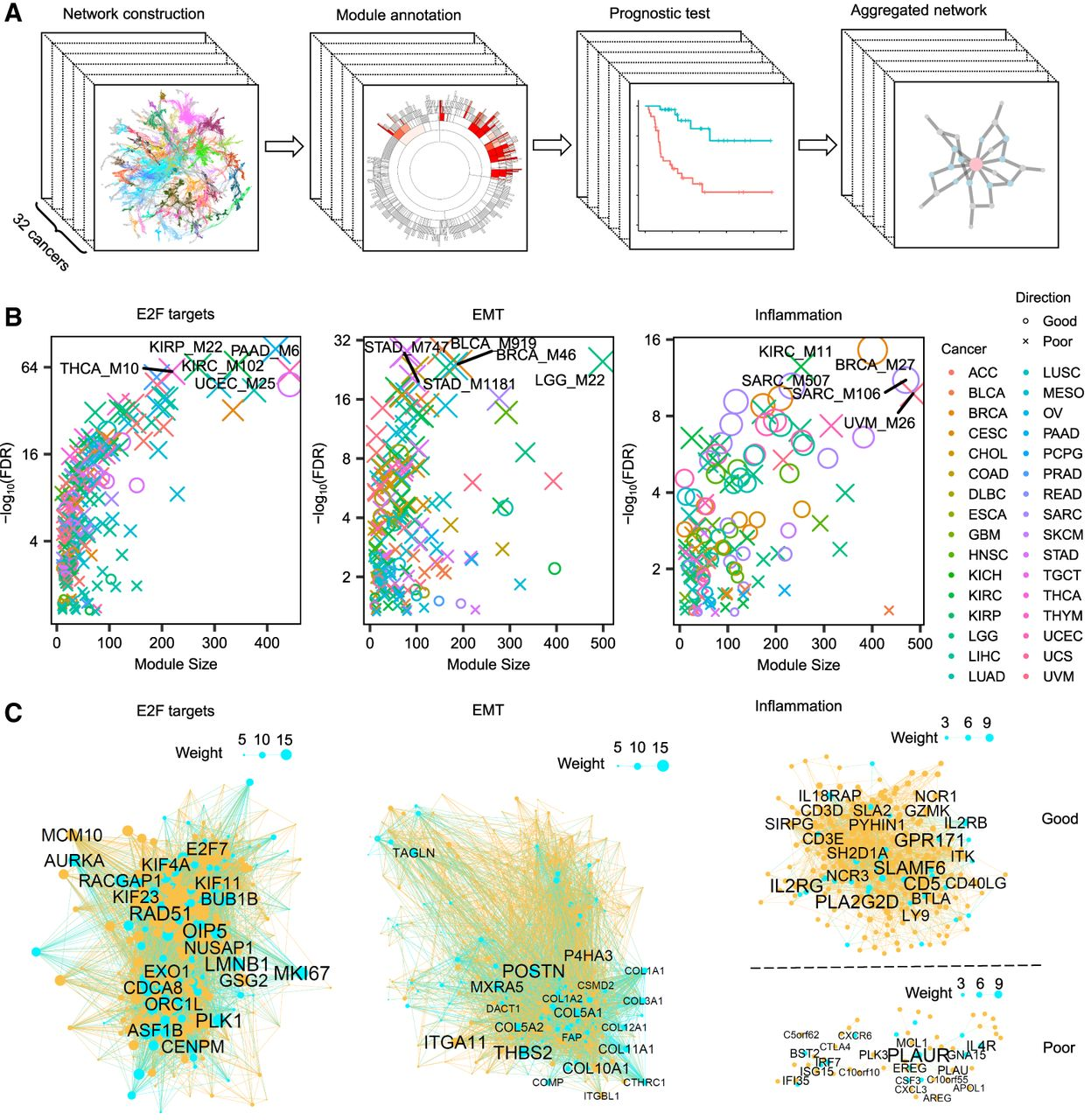
共表达基因模块(基因簇)反映了通路相关基因的整体特征,因此它们对癌症预后和功能解释具有强大的意义。本研究通过结合基因组、转录组学和表观基因组学数据,研究团队分析了癌症基因组图谱(TCGA)队列中的所有32种主要癌症类型,全面表征了癌症中的共表达网络,确定了在调控癌症进展中起重要作用的4749个关键预后模块。
- 论文链接:https://genome.cshlp.org/content/33/10/1806.full
- 代码链接:https://github.com/penguab/Pancancer_Networks;https://doi.org/10.5281/zenodo.8271601

BioEnricher是一个进行基因集富集分析和可视化的一站式R 包,本推文通过具体实例展示了如何通过BioEnricher进行富集分析及结果可视化。
5、使用 Micromamba + Apptainer 容器化 bioconda 应用
容器有时候比 conda 的更适合软件部署,而且容器和 conda 并不冲突,如果将 bioconda 的软件部署到容器里,能更方便进行软件部署,本文对此分享了一些经验。
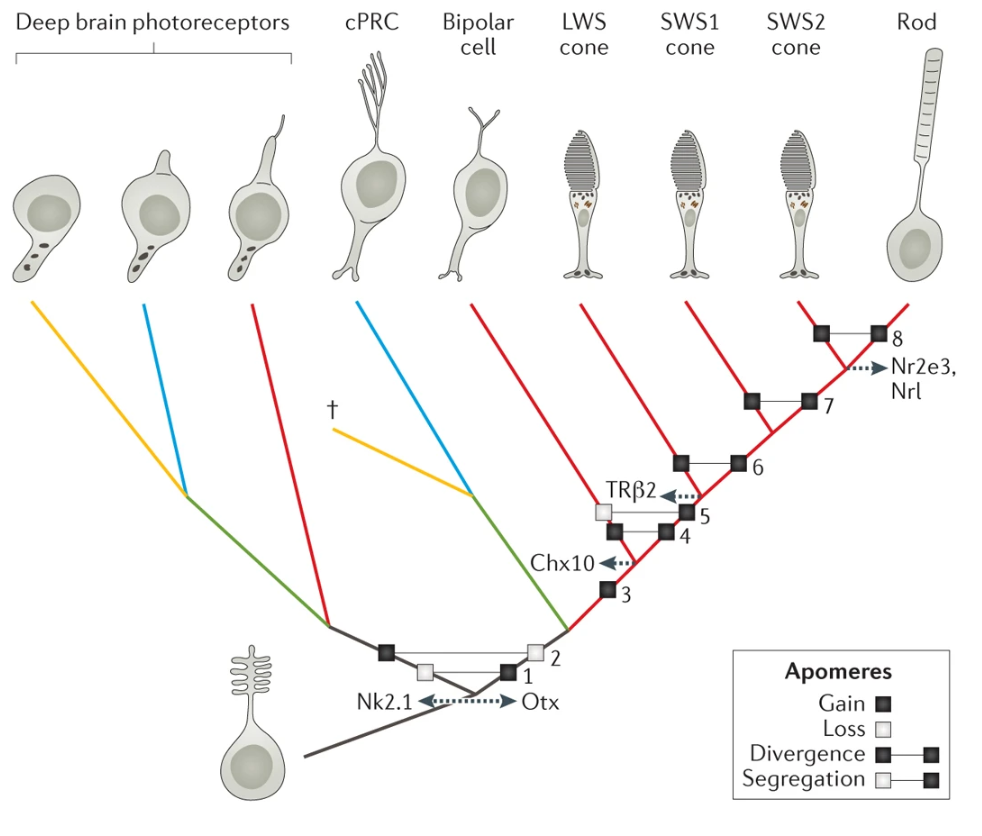
对于多细胞动物演化的研究来说,细胞类型的跨物种比较与基因序列比较同样重要。随着近年来单细胞组学技术的发展,这种比较在技术上变得可以实现。结合细胞谱系示踪、单细胞组学数据构建“一致性个体发育树”,以及基于细胞分化调控关键基因的同源性识别原则,为细胞类型演化领域的发展提供了一种可能的思路。
7、肿瘤多克隆起源

这篇文章探讨了单个肿瘤中存在多个独立起源的细胞克隆的可能性,这些克隆可能增加了肿瘤的遗传多样性和适应性。作者提出了一个进化假说,认为单个肿瘤中可能经常隐藏着多个独立起源的克隆,但只有一个克隆足够大而被检测到。这些克隆被称为肿瘤内肿瘤,尽管它们的尺寸很小,但它们可以将肿瘤内的多样性提高几个数量级。这种增加可能导致与癌症治疗耐药性相关的遗传多样性缺失。
8、PacBio WGS Variant Pipeline用于人类WGS数据分析的完整生信流程

PacBio WGS Variant Pipeline将使客户能够一次分析许多不同的变异类型,包括单碱基变异、插入和缺失、结构变异、串联重复、片段重复和拷贝数变异,此外还提供甲基化和单倍型定相数据。
9、irGSEA | 基于秩次的单细胞基因集富集分析整合框架
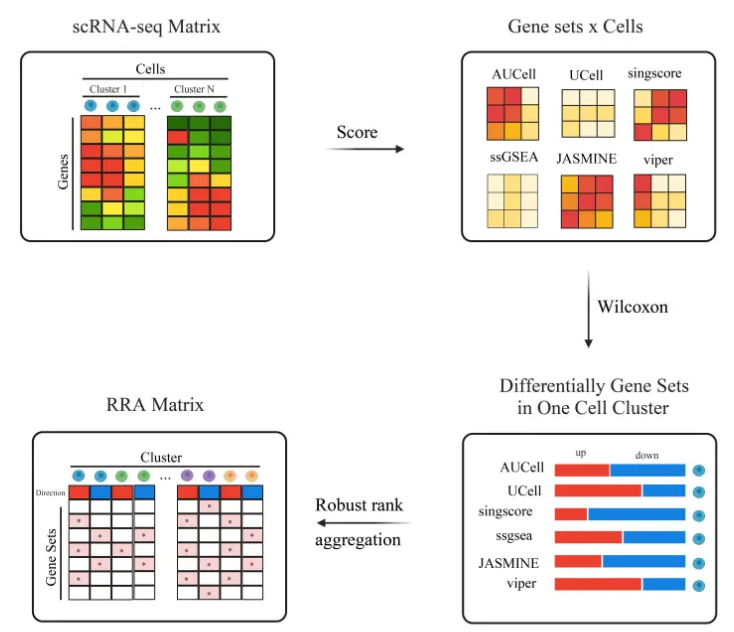
许多Functional Class Scoring (FCS)方法,如GSEA, GSVA,PLAGE, addModuleScore, SCSE, Vision, VAM, gficf, pagoda2和Sargent,都会受数据集组成的影响,数据集组成的轻微变化将改变细胞的基因集富集分数。相反,基于单个细胞表达等级的FCS,如AUCell、UCell、singscore、ssGSEA、JASMINE和Viper,只需要计算新添加的单细胞数据集的富集分数,而无需重新计算所有细胞的基因集富集分数。原因是这些方法生成的富集分数仅依赖于单个细胞水平上的相对基因表达,与数据集组成无关。因此,这些方法可以节省大量的时间。 本文详细地介绍了 irGSEA 这个全面的 FCS 方法整合工具包,为使用者带来福音。
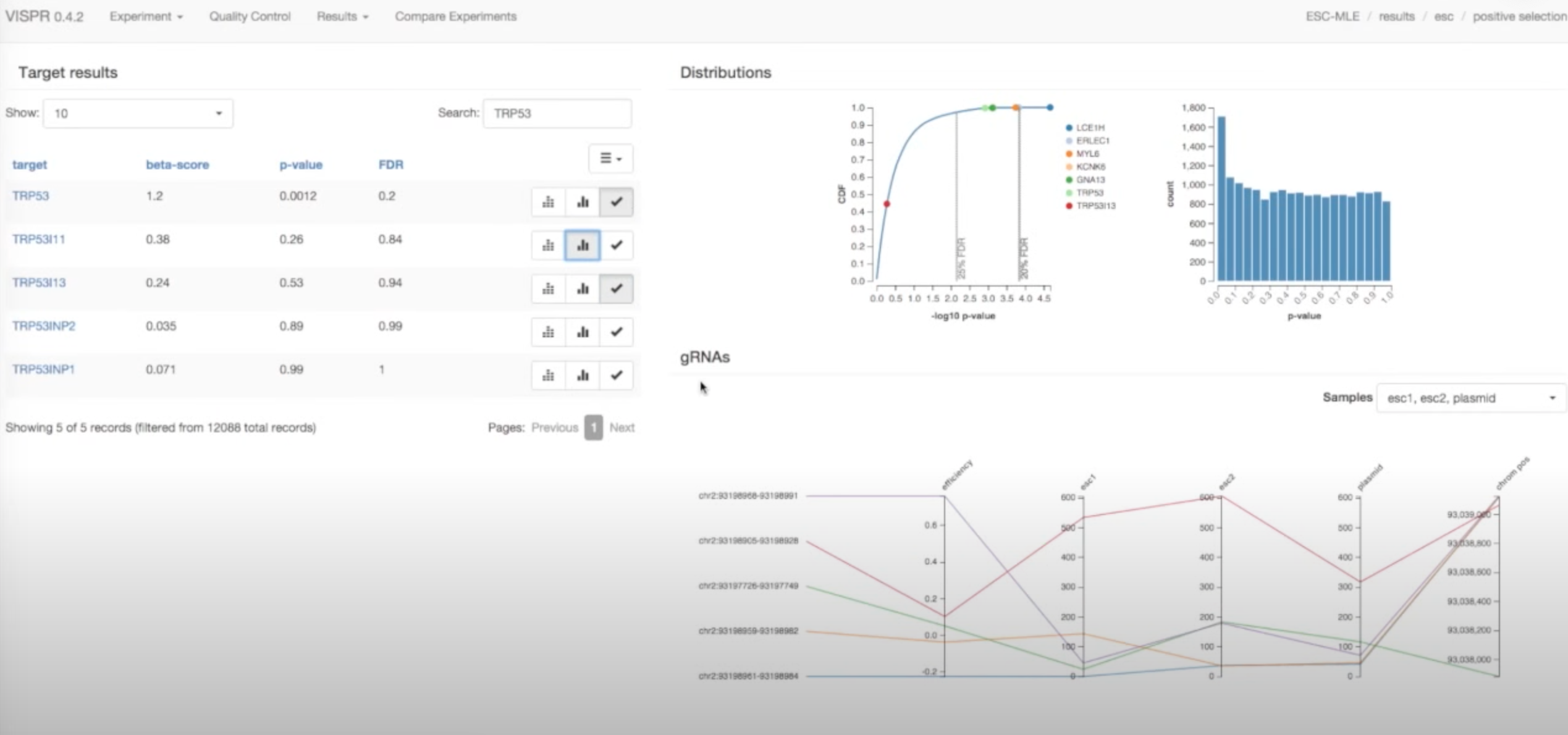
10、MAGeCK-VISPR | CRISPR/Cas9 筛选的质量控制、建模和可视化
- 第64期:“讨好型人格”:越是乞求,越是被推开
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)@kongjianyang(空间阳)
这个周刊每周日发布,同步更新在微信公众号「优雅R」(elegant-r)上。
微信搜索“优雅R”或者扫描二维码,即可订阅。

(完)