| date | comments |
|---|---|
2023-04-21 |
true |
这里记录每周值得分享的生信相关内容,周日发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

从获得首个人类基因组已经过去了二十年,在当时,人们曾畅想在获得基因组之后就可以了解到每一个基因甚至是碱基的具体功能。但是二十年过去了,虽然对于人类基因组的研究在治疗癌症、寻找药物靶点以及诊断疾病获得了一定程度的进展,但是我们仍旧缺乏基因对于衰老、复杂性状以及疾病甚至是一些单基因致病疾病的具体影响。对于目前的这种困境,其中一个重要的原因就是高质量表型数据的缺乏,因此无法通过统计学的方法寻求性状与基因之间的具体关联。针对这一问题,一些包含有遗传数据的超大型前瞻性队列应运而生,其中最具有代表性的就是英国生物银行(UK Biobank)。
@JnanZhang:"生物样本库作为生命科学基础研究与转化医学研究的宝贵资源,其重要性日益凸显,英国生物银行已成为了大数据时代下全世界队列研究的标杆。"
1、Genome Biology | 纳米孔测序可用于检测cfDNA的细胞起源和癌症特异性甲基化特征
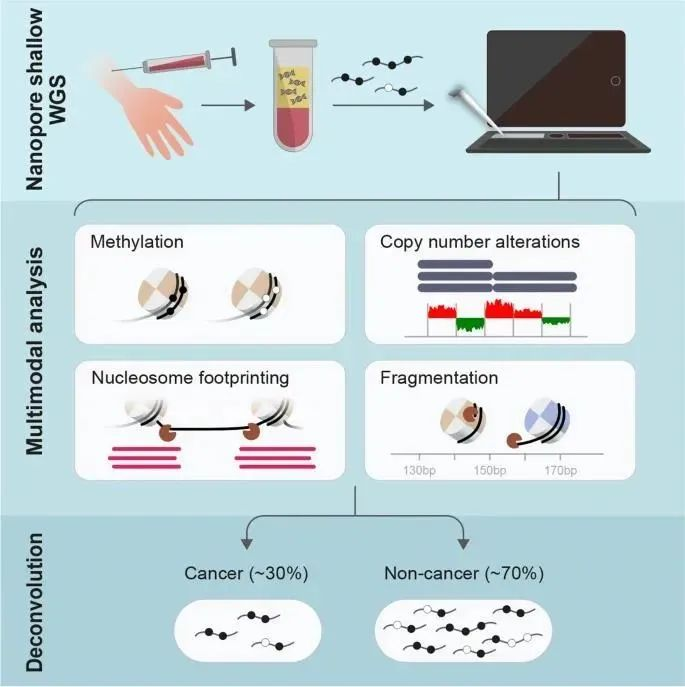
2、Cell Genomics|空间多组学技术解析肿瘤内空间异质性
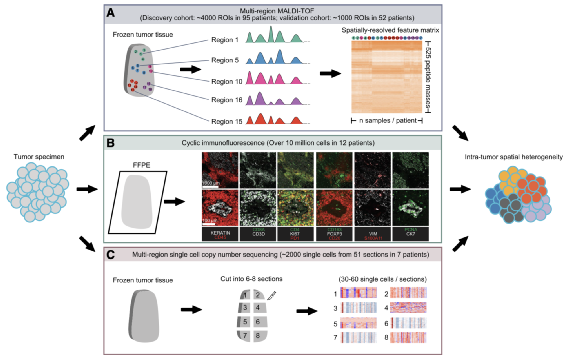
3、Nat. Commun|13.5小时即可获得WGS诊断结果!遗传病快速诊断管理系统GTRx与时间赛跑
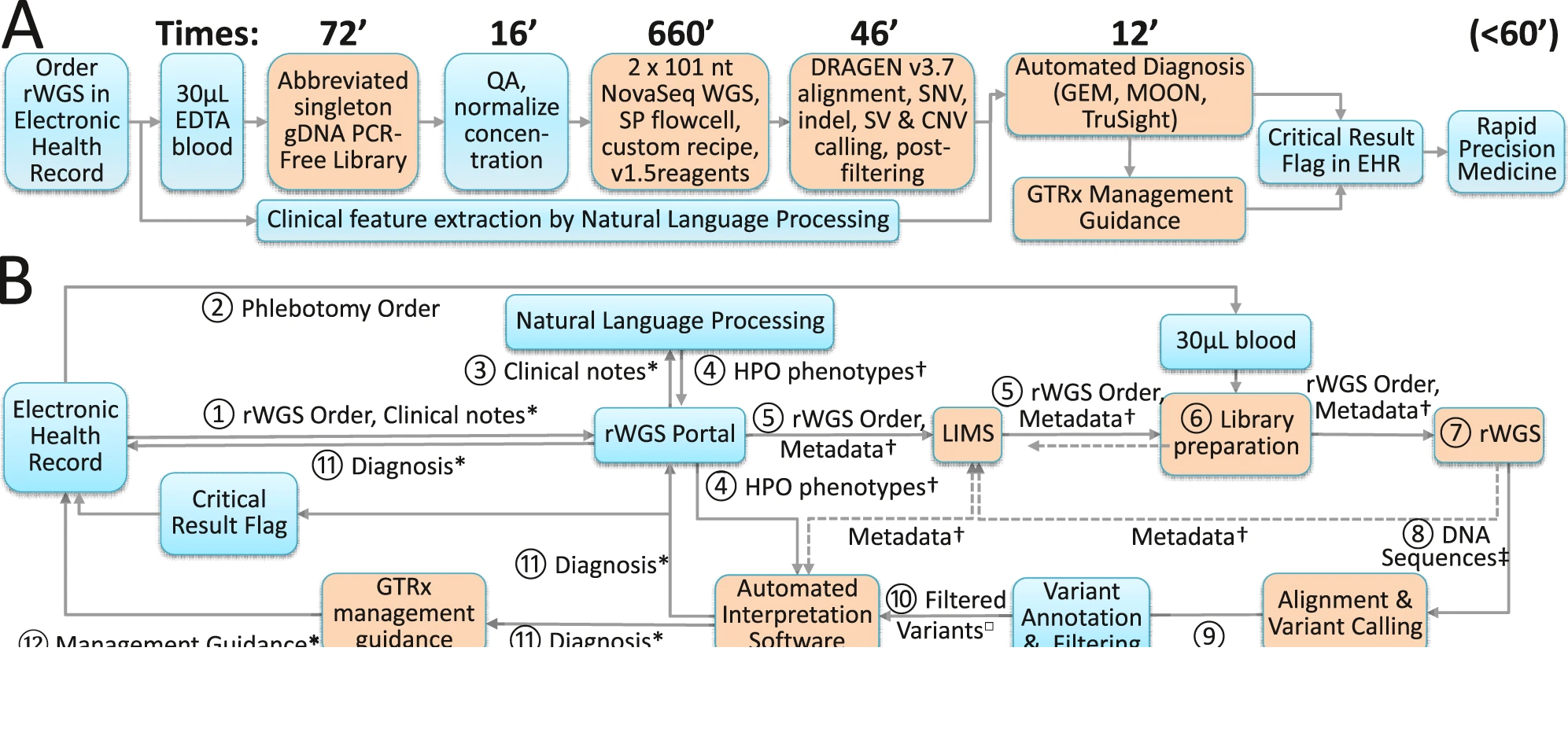
4、Nat. Commun|侯英勇/丁琛/贺福初团队合作发布中国人群鳞状细胞癌蛋白质组学图谱,揭示鳞状细胞癌和腺癌的分子差异
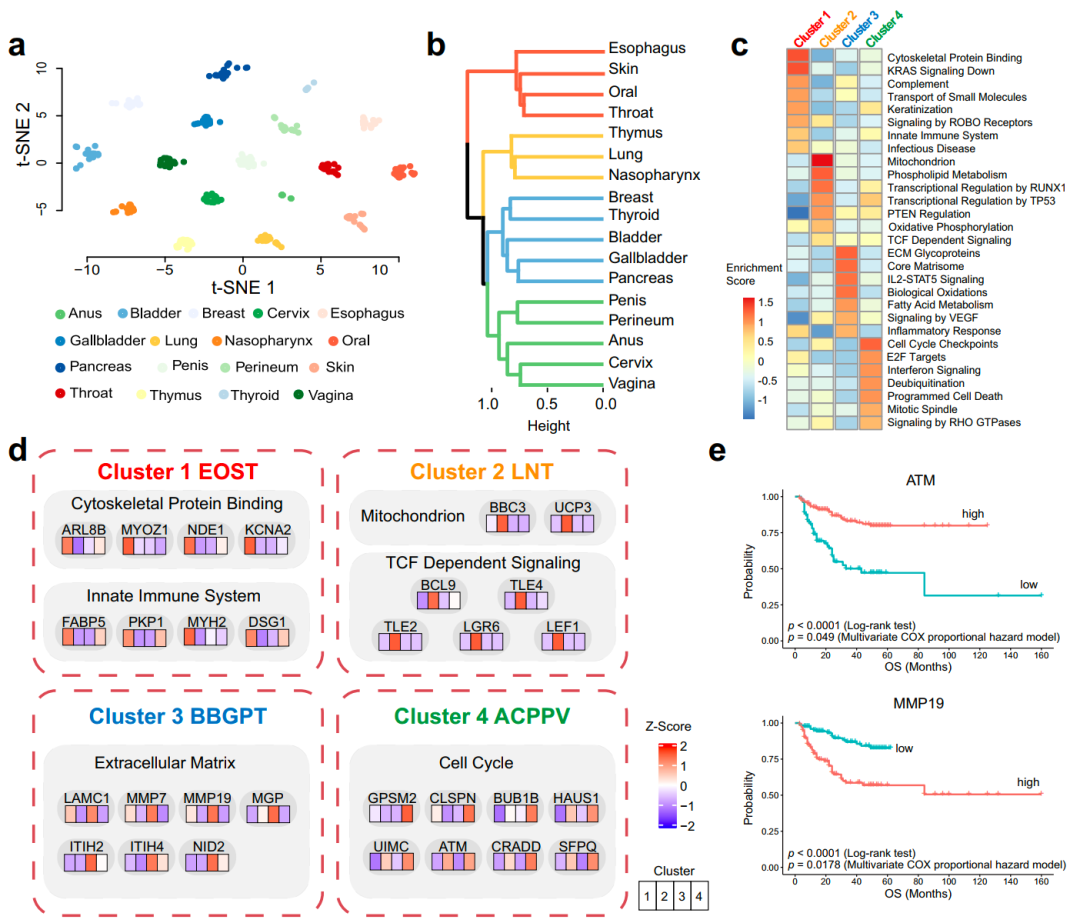
复旦大学附属中山医院侯英勇团队、复旦大学人类表型组研究院丁琛团队以及北京生命科学研究所贺福初团队合作,通过系统地蛋白质组学分析揭示了中国人群SCCs和ACs之间的差异,并初步阐明了肿瘤发生机制和治疗策略。通过对蛋白质组数据进行深入分析,构建了包含19个蛋白的诊断分类器,并验证了PRKCE、SLC27A1和CPXM2的诊断价值。该研究证实深度蛋白质组学研究能够带来功能上的新见解,将有助于推动未来的机制探索和精准治疗。
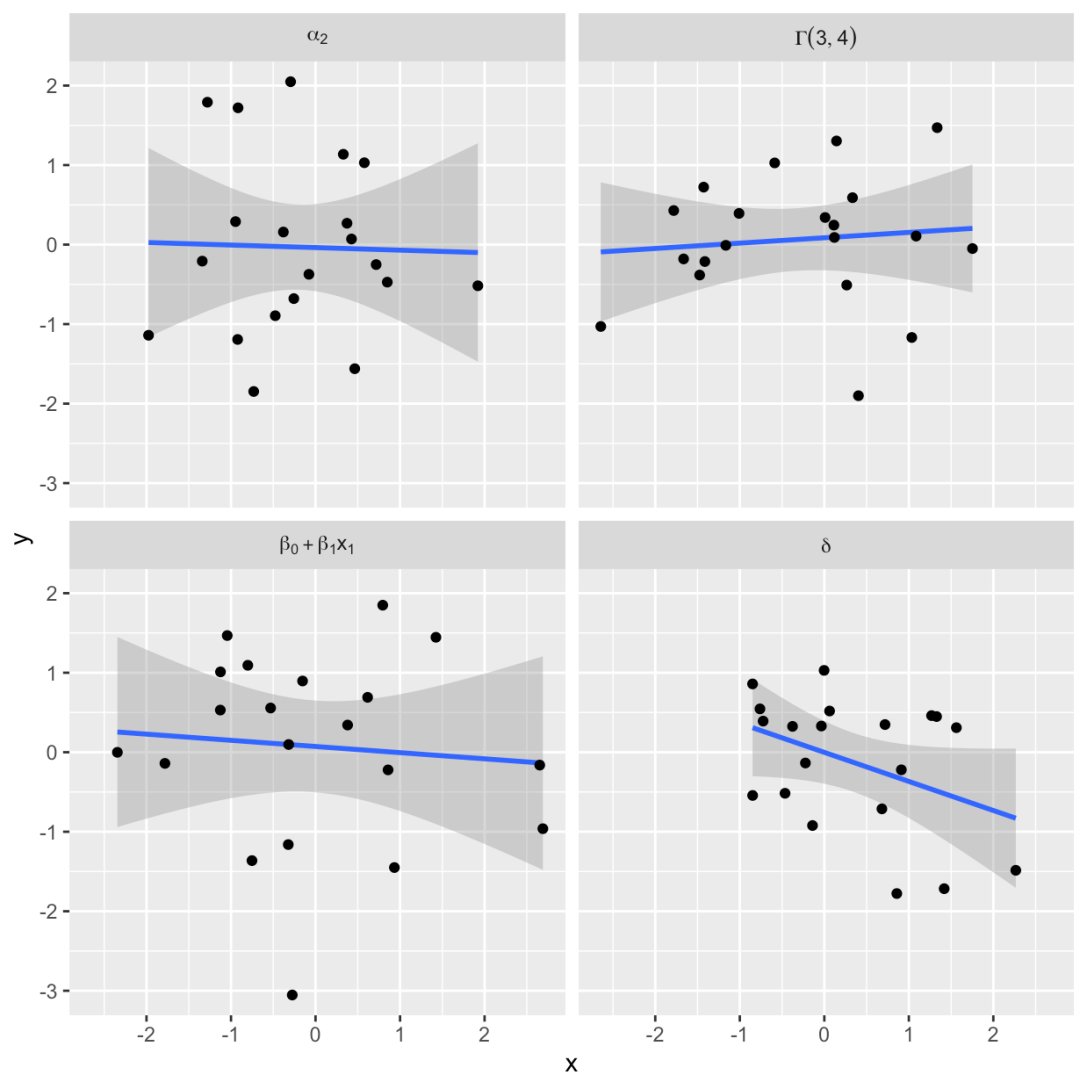
设置数学表达式是科研绘图的一个需求,本文介绍了使用 expression() 函数定义表达式标签,并通过 ggplot2 进行绘制展示。
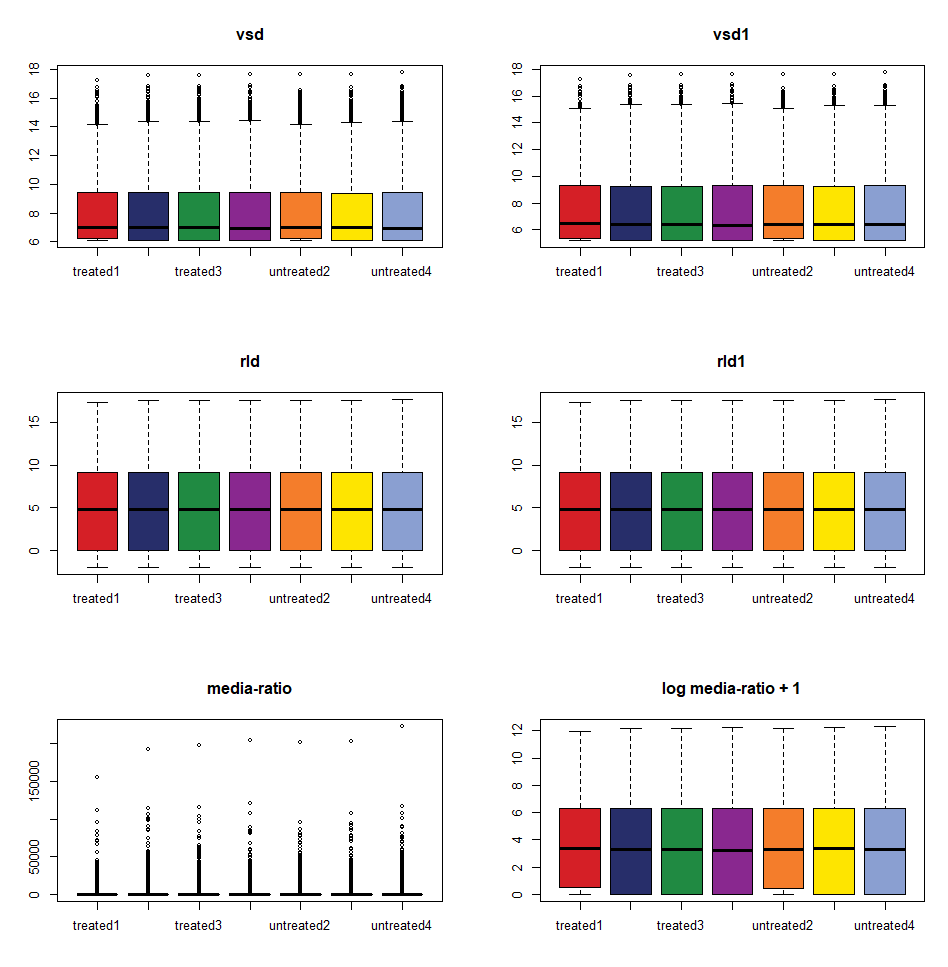
6、 DESeq2 的 vst、rlog 和 normalized value 傻傻分不清?
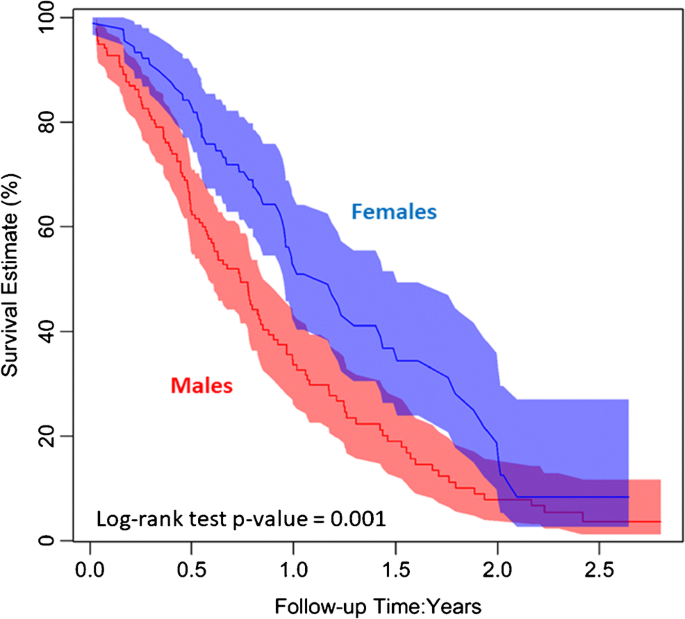
7、严谨的生存分析
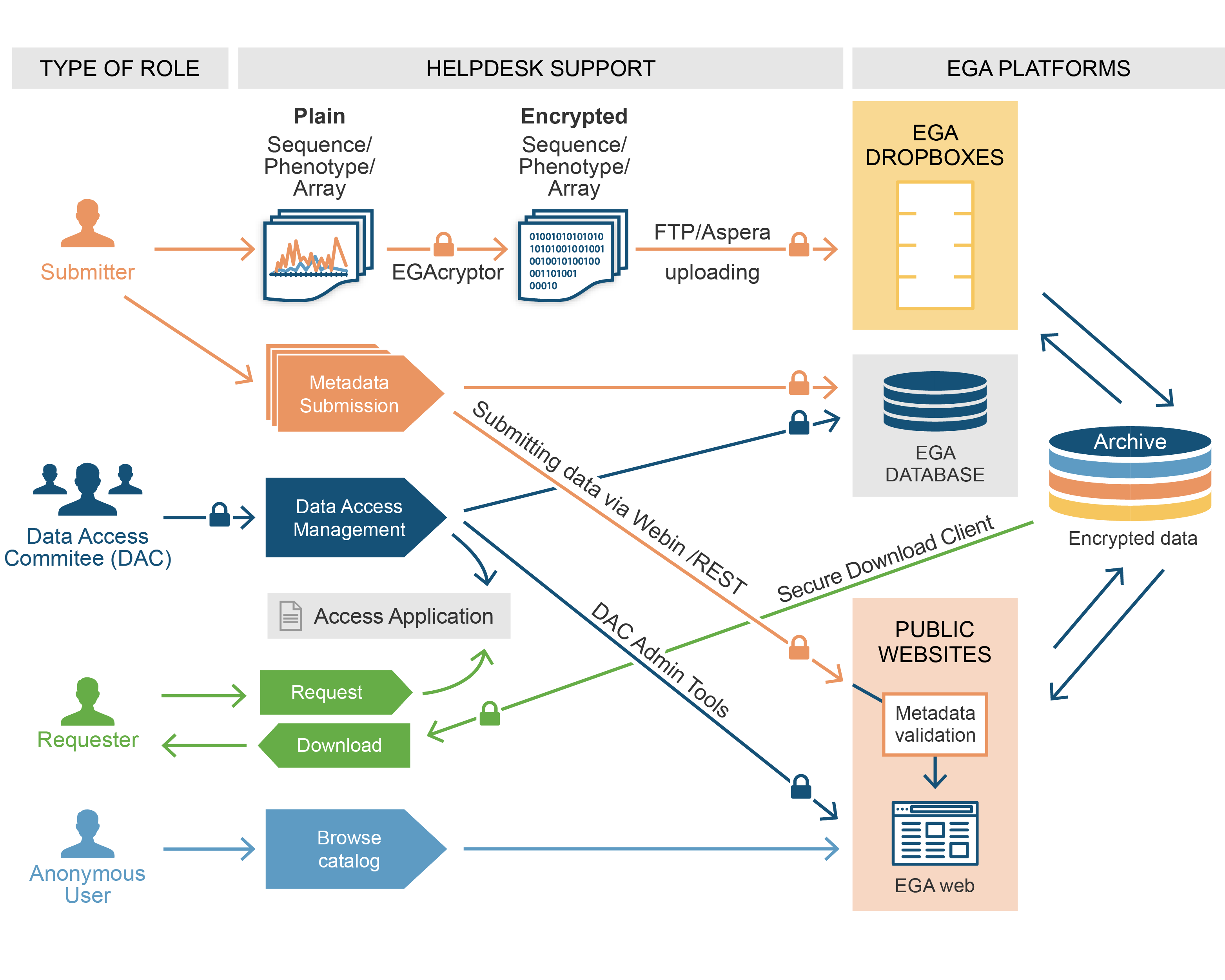
- 数据库地址:https://ega-archive.org/
9、Huxtable | 创建LaTeX和HTML表的友好现代接口
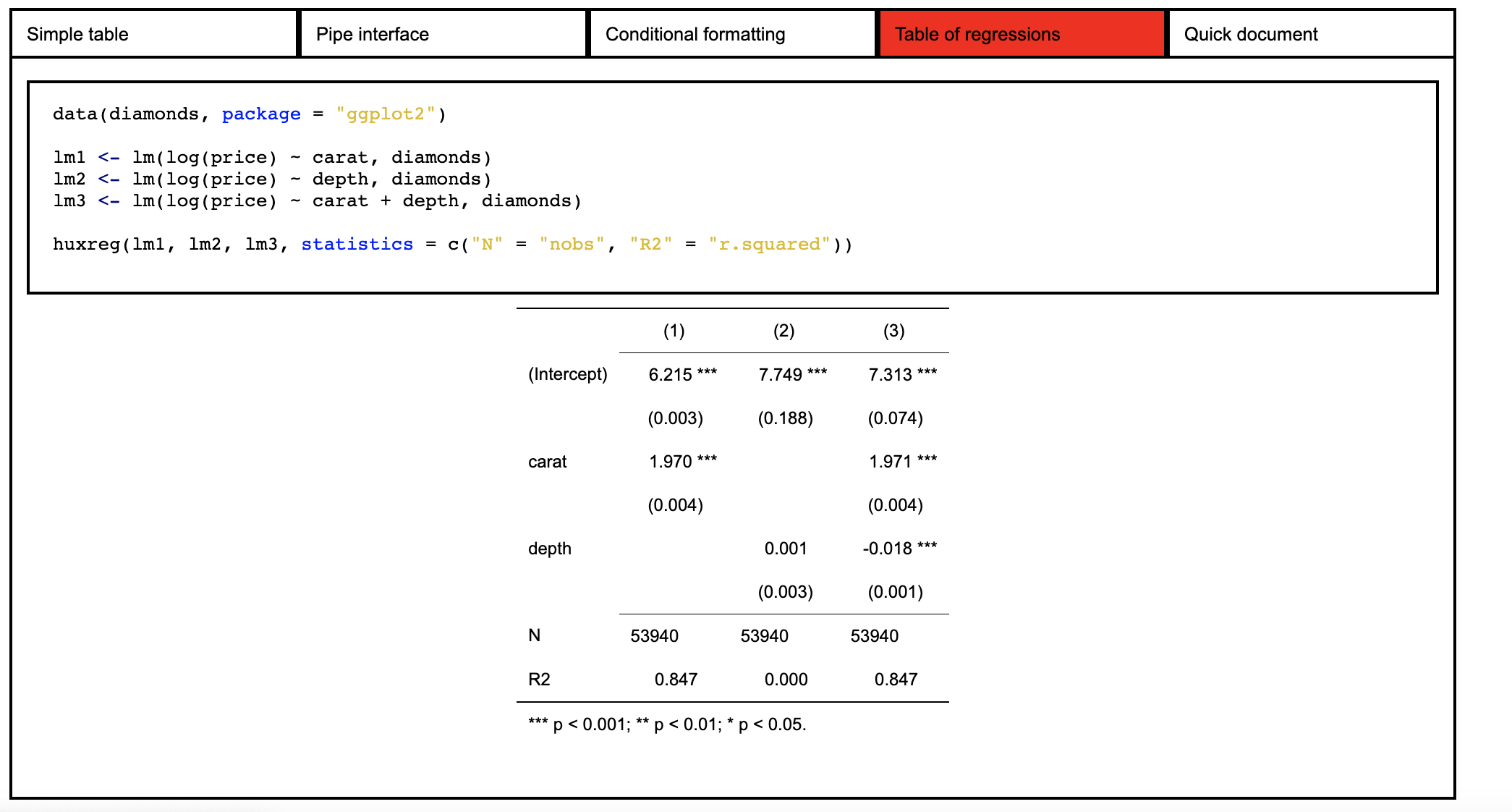
Huxtable 是一个强大的表格展示工具,具有多样的使用方式,完善的文档,丰富的样式和导出等特性,非常值得尝试。
10、 可视化代码库的7种工具
当需要撰写README文件时,可能会因为不知该说什么而感到纠结,这时就可以考虑用图表来更好的表现你的想法。毕竟,一图胜千言。本文就介绍了7种可视化代码库的工具。
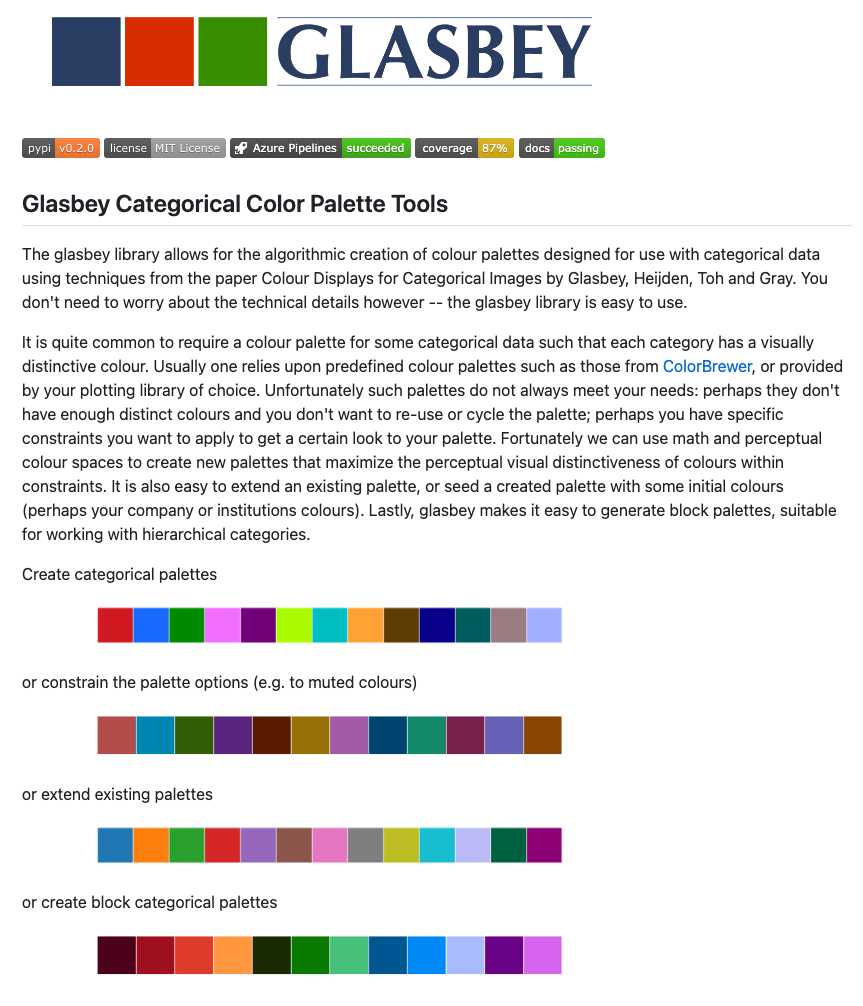
12、https://github.com/enblacar/SCpubr

13、通俗易懂的机器学习

对于了解机器学习,如果阅读网上关于机器学习的文章,你很可能会遇到两种情况:充斥各种定理的厚重学术三部曲,或是关于人工智能、数据科学魔法以及未来工作的天花乱坠的故事。这会对学习进程造成困难。本文作者希望通过本文对那些想了解机器学习的人做一个简单的介绍。不涉及高级原理,只用简单的语言来谈现实世界的问题和实际的解决方案。
14、得意黑字体

得意黑是一款在人文观感和几何特征中寻找平衡的中文黑体。整体字身窄而斜,细节融入了取法手绘美术字的特殊造型。字体支持简体中文常用字(覆盖 GB/T 2312-1980 编码字符集)、拉丁字母、西里尔字母、希腊字母、日文假名、阿拉伯数字和各类标点符号。
- 第32期:有害的同义突变
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)@kongjianyang(空间阳)
这个周刊每周日发布,同步更新在微信公众号「优雅R」(elegant-r)上。
微信搜索“优雅R”或者扫描二维码,即可订阅。

(完)