计算机网络-自顶而下
1. 计算机网络与因特网
1.1. 基本概念
1.2. 接入网
1.3. 物理媒体
1.4. 网络核心
1.4.1. 分组交换
1.4.2. 电路交换
1.4.3. 分组交换对比电路交换
1.4.4. 网络的网络
1.4.5. 分组交换中的时延、丢包和吞吐量
1.5. 协议分层
1.6. 网络攻击
2. 应用层
2.1. 可供应用程序使用的运输服务
2.1.1. TCP服务
2.1.2. UDP服务
2.1.3. 因特网运输协议所不提供的服务
2.2. 应用层协议
2.3. Web与HTTP
2.3.1. 非持续连接和持续连接
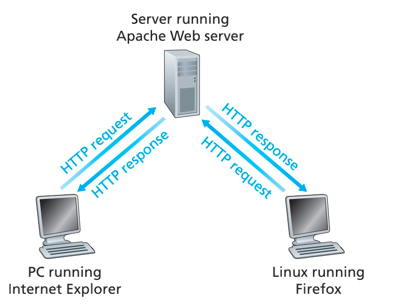
2.3.2. HTTP请求报文格式
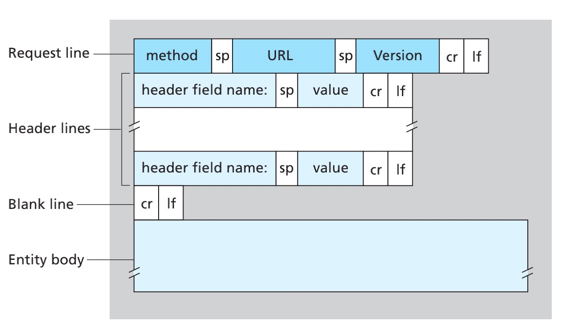
2.3.3. HTTP响应报文格式
2.3.4. 用户与服务器的交互:cookie
2.3.5. 代理服务器
2.4. 因特网的电子邮件
2.4.1. SMTP
2.4.2. 邮件DNS路由过程
2.4.3. 邮件组件拆分
2.4.4. POP3
2.4.5. IMAP
2.5. DNS:因特网的目录服务
2.5.1. DNS工作机理
2.5.2. DNS缓存
2.5.3. DNS记录和报文
2.5.4. DNS报文
2.5.5. DNS脆弱性
3. 运输层
3.1. 多路复用和多路分解
3.1.1. 无连接的多路复用与多路分解
3.1.2. 面向连接的多路复用与多路分解
3.2. 无连接运输 UDP
3.2.1. UDP报文段结构
3.3. 可靠数据传输协议原理
3.3.1. 构建一个可靠传输协议的过程
3.3.1.1. rdt1.0
3.3.1.2. rdt2.0
3.3.1.3. rdt2.1
3.3.1.4. rdt2.2
3.3.1.5. rdt3.0 经具有比特差错的丢包信道的可靠数据传输
3.3.2. 流水线可靠数据传输协议
3.3.2.1. 回退N步(Go-Back-N,GBN)
3.3.2.2. 选择重传(Select Repeat, SR)
3.3.3. 总结
3.4. 面向连接的TCP
3.4.1. TCP报文段结构
3.4.2. 往返时间RTT的估计与超时
3.4.3. TCP实践原则
3.4.4. TCP的可靠数据传输服务
3.4.5. TCP流量控制
3.4.6. TCP的连接管理
3.4.6.1. TCP三次握手
3.4.6.2. TCP四次挥手
3.4.6.3. TCP SYN洪泛攻击
3.4.6.4. TCP连接的三种情况
3.4.7. TCP拥塞控制
3.4.8. 其他
4. 网络层
4.1. 路由器组成
4.1.1. 交换技术
4.1.2. 输入输出端口处理
4.2. IPv4
4.2.1. IPv4数据报分片
4.2.2. IPv4编址
4.2.3. DHCP
4.2.4. 网络地址转换
4.3. IPv6
4.4. 通用转发与SDN
4.4.1. 通用传统转发
4.4.2. SDN
4.4.3. 流表OpenFlow
4.5. SDN 数据平面与控制平面交互
4.6. 控制平面路由选择算法
4.6.1. 链路状态路由选择LS(Link state)
4.6.2. 距离矢量路由选择DV(distance vector routing)
4.6.3. LS 和 DV 算法的比较
4.7. 因特网中自治系统内部的路由选择(路由选择协议)
4.7.1. RIP(Routing Information Protocol)
4.7.2. OSPF (Open Shortest Path First)
4.7.3. 层次路由
4.7.4. 互联网AS间路由:BGP
5. 其他概念
因特网定义:
- 从因特网的基本硬件和软件组件描述
- 为分布式应用提供服务的联网基础设置来描述
主机(端系统):与因特网连接的设备,包括客户PC和服务器
分组(package):当一台端系统要向另一台端系统发送数据时,发送端系统将数据分段,并为每段加上首部字节。形成的信息包用计算机网络的术语称为分组。
分组交换机(packet switch): 常见的类型有路由器(router)、链路层交换机(link-layer switch)
因特网服务提供商(Internet Service Provider, ISP):自身就是一个由多台分组交换机和多段通信链路组成的网络。
包括网线、住宅ISP、公司ISP、机场及公共场所提供WiFi接入的ISP
协议:定义了两个或多个通信实体之间交换的报文的格式和顺序,以及发送或接收一条报文或其他事件所采取的动作。
典型的陌生人之间的交互,可以用"您好?" 来发起一段对话,其实就是人之间交互的一个协议
带宽:连接期间链路为每条连接专用一个频段,该频段的宽度为带宽
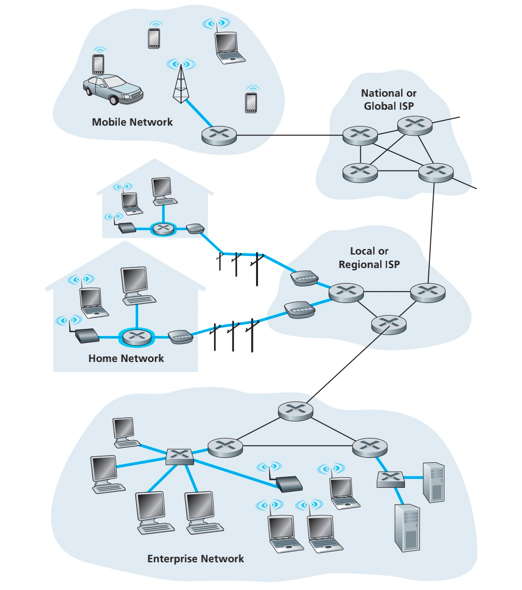
家庭接入:数字用户线(Digital Subscriber Line, DSL)和电缆
住户从提供本地电话接入的电话公司获得DSL因特网接入。当使用DSL时,用户的本地电话公司是它的ISP。
家庭电话线同时承载了数据和传统的电话信号,他们用不同的频率进行编码,使得单根DSL线路像是有3跟独立线路,因此电话呼叫和互联网连接能够同时共享DSL链路。
- 高速下行信道,位于50kHz到1MHz频段
- 中速下行信道,位于4kHz到50kHz频段
- 普通的双线电话信道,位于0到4kHz频段
光纤到户(FTTH):有源光纤网络(AON)和无源光纤网络(PON)
企业和家庭接入:以太网和WiFi
广域无线接入:3G和LTE
物理媒体分成两种类型:导引型媒体和非导引型媒体
- 导引型:电波沿着固体媒体前进,如光缆、双绞铜线、同轴电缆
- 非导引型:电波在空气或外层空间中传播,如无线局域网或数字卫星频道
通过网络链路和交换机移动数据的两个基本方法:电路交换(circuit switching)和分组交换(package switching)
分组交换的性能优于电路交换的性能:
- 分组交换提供了更好的带宽共享。电路交换不考虑需求,而是预先分配传输链路使用,使得已分配而并不需要的链路时间并未被利用。分组交换按需分配链路使用。
- 分组交换的实现比电路交换更简单、更有效,实现成本更低。
分组交换:从源端系统向目的地端系统发送一个报文,源将长报文划分为较小的数据块。在源和目的地之间,每个分组都通过通信链路和分组交换机传输。
使用统计多路复用
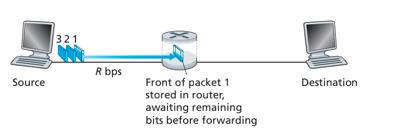
存储转发传输:在交换机能够开始向输出链路传输该分组的第一个比特之前,必须接收到整组。
资源共享,按需使用:存储-转发:分组每次移动一跳(hop)
每台分组交换机有多条链路与之相连,对于每条相连的链路,该分组交换机具有一个输出缓存(输出队列),用于存储路由器准备发往该链路的分组。
排队时延:链路正忙于传输其他分组,其后到达的分组必须等待。
分组丢失:到达的分组发现缓存已经被其他分组充满。
电路交换中,在端系统间通信会话期间,预留了端系统间沿路径通信所需要的资源(缓存、链路传输速率)
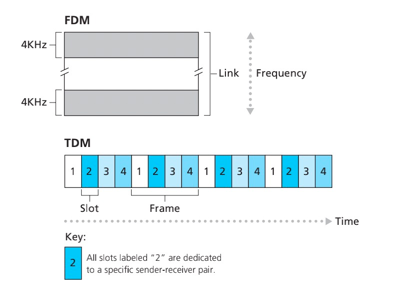
电路交换网络中的复用:
频分复用(Frequency-Division Multiplexing, FDM):链路的频率域被划分为多个频段。
时分复用(Time-Division Multiplexing, TDM):一条TDM链路,时间被划分为固定期间的帧,并且每个帧又被划分为固定数量的时隙。
波分复用(Wave-Division Multiplexing,WDM)
电路交换不适合计算机之间的通信
- 连接建立时间长
- 计算机之间的通信有突发性,如果使用线路交换,则浪费的片较多。并且即使这个呼叫没有数据传递,其所占据的片也不能够被别的呼叫使用
- 可靠性不高
- 同样的网络资源,分组交换允许更多用户使用网络!
- 分组交换是"突发数据的胜利者",过度使用会造成网络拥塞:分组延时和丢失
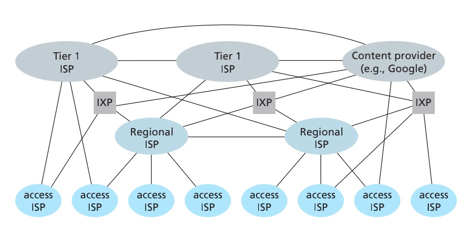
网络结构1:单一的全球传输ISP互联所有接入ISP。
网络结构2:多个全球传输ISP互联所有接入ISP。
网络结构3:多层的ISP结构,多个竞争的全球传输ISP、每个区域多个竞争的ISP(市级ISP、省级ISP、国家级ISP)并与上层区域连接。第一层ISP不向任何人付费,下层ISP向上层付费。
网络结构4:在结构3基础上增加存在点(Point of Presence,PoP)、多宿、对等和因特网交换点。有接入ISP、区域ISP、PoP、多宿、对等和IXP组成。
网络结构5:在结构4顶部增加内容提供商网络(content provider network)。内容服务商如Google,构建自己的网络与底层ISP对等(无结算),对于较高层ISP可以通过IXP与其连接,减少其向顶层ISP支付的费用。
相关概念:
- 存在点(Point of Presence,PoP):存在于登记结构的所有层次,但底层(接入ISP)等级除外。??
- 多宿(multi-home):任何一个ISP可以与两个或者多个提供商ISP连接。保证其中一个ISP故障,也可以通过其他ISP保障服务。
- 对等(peer):位于相同等级结构层次的邻近一对ISP对等,而不是通过上游的ISP传输,节省通信流量。对等表示两个对等ISP之间无需进行流量结算。
- 因特网交换点(Internet Exchange Point, IXP):IXP是一个汇总点,多个ISP能够在这里一起对等。
节点总时延 = 节点处理时延 + 排队时延 + 传输时延 + 传播时延
- 处理时延:检查分组首部和决定将该分组导向何处所需要的时间、检查比特级别的差错。
- 排队时延:分组在链路上等待传输。时间取决于先到达正在排队等待向链路传输的分组数量。
- 传输时延:将所有分组的比特推向链路所需要的时间。即推出分组所需要的时间,是分组长度和链路传输速率的函数,与两路由器的距离无关。
- 传播时延:从链路的起点到路由器B传播所需要的时间。
排队时延与丢包:一条链路钱的队列只有有限容量,随着流量强度接近1,到达的分组发现队列已满就会丢弃该分组,即该分组将丢失。
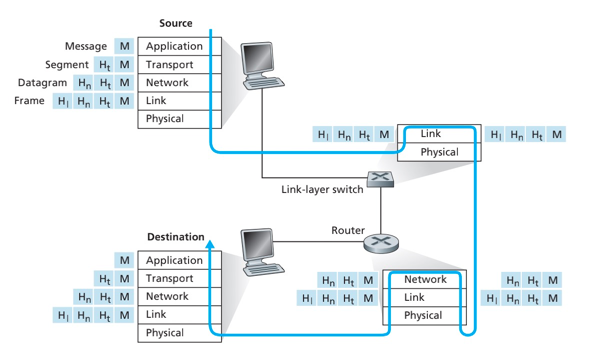
5层因特网协议栈:
- 应用层:HTTP、SMTP、FTP。位于应用层的信息分组称为报文(message)。
- 运输层:TCP、UDP。因特网的运输层在应用程序端之间传送应用层报文。运输层的分组称为报文段(segment)
- 网络层:IP。负责将数据报(datagram)的网络层分组从一台主机转移到另一台主机。
- 链路层:为了将分组从一个节点移动到下一饿节点,网络层必须依靠链路层的服务。链路层的服务取决于应用于该链路的特定链路层协议,如可靠传递的协议(不同于TCP协议)。链路层的分组称为帧(frame)
- 物理层:物理层的任务是将链路的帧中的一个个比特(bit)从一个节点移动到下一个节点。协议与链路相关,且进一步与传输媒体相关。
封装过程:
- 发送主机端,一个应用层报文(application-layer message)被传输给运输层。
- 运输层收取到报文并附上附加信息(运输层首部信息),该报文将被接收端的运输层使用。应用层报文和运输层首部信息构成运输层报文段(transport-layer segment),传输给网络层。
运输层报文段:附加的信息包括应用层报文、差错检测位信息(接收方判断报文是否改变)
- 网络层接收到报文段,增加了如源和目的端系统地址等网络层首部信息,生成网络层数据报(network-layer datagram),发送链路层。
- 链路层接收到数据报,增加链路层首部信息并生成链路层帧(link-layer frame)
在每一层一个分组都有两种类型的字段:首部字段和有效荷载字段(payload field)
- 病毒攻击:通过软件文件感染设备
- 分组嗅探器:如WiFi连接放置一台被动的接收器,接收器就能得到每个分组的副本。即网络传输的所有信息。
- IP哄骗
- 拒绝服务攻击(Denial-of-Service attack, DoS attack)
DoS攻击分为以下三类:
- 弱点攻击:利用主机上软件或系统的漏洞,进行攻击,造成服务器停止运行或主机崩溃。
- 带宽洪泛:向目标主机发送大量的分组,使目标的接入链路变得拥塞,合法的分组无法到达服务器。
- 连接洪泛:攻击者在目标主机中创建大量的半开或全开TCP连接。该主机因这些伪造的连接,而无法接受合法的连接。
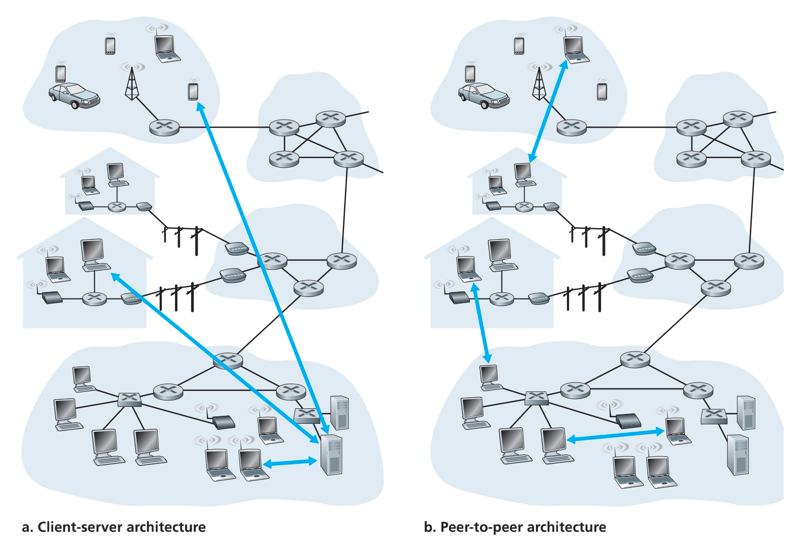
Web应用程序的两种应用程序体系结构:
- CS架构。用户主机 - Web服务器主机的服务器程序,如搜索服务、facebook、instagram
- 对等体系结构(P2P)。P2P文件共享系统。参与文件共享的社区中,每台主机中都有一个程序。如BitTorrent、迅雷
应用程序服务的对于运输协议要求可分为四大类:可靠数据传输、吞吐量、定时和安全性
可靠数据传输:一个协议确保由应用程序一端发送的数据正确、完全地交付给应用程序的另一端。
多媒体应用、交谈式音频/视频,能够承受一定量的数据丢失,为容忍丢失的应用。
吞吐量:指发送进程能够向接收进程交付比特的速率。即运输层能够以某种特定的速率提供确保的可用吞吐量。
带宽敏感的应用:具有吞吐量要求的应用程序。如一些多媒体应用,保证用户使用体验,必须保证一定的带宽速率
弹性应用:能够根据当时可用的带宽或多或少利用可供使用的吞吐量。如电子邮件、文件传输
定时(确定的时延):如发送方注入到套接字中的每个比特到达接收方的套接字不迟于100ms。相关需求的应用程序如因特网电话、多方游戏等
安全性:运输协议能够为应用程序提供一种或多种安全性服务。
TCP服务包括面向连接服务和可靠数据传输服务。另外TCP还具有拥塞控制机制
- 面向连接服务:应用层报文开始流动前,先建立连接。该连接是全双工的,即连接双方的进程可以在此连接上同时进行报文收发。
- 可靠的数据传输服务:通信进程能够依靠TCP,无差错、按适当顺序交付所有发送的字节。
- 拥塞控制机制:当发送方和接收方之间的网络出现拥塞时,TCP的拥塞控制机制会抑制发送进程。力求每个通过一条拥塞网络链路的连接平等地共享网络链路带宽。
加密传输机制:TCP提供安全套接字层(Secure Sockets Layer, SSL),用于加密的安全性服务。
UDP是一种不提供不必要服务的轻量级运输协议,仅提供最小服务。在通信前没有握手过程,仅提供了一种不可靠数据传输服务,不保证报文能到达接收进程。
UDP没有拥塞控制机制,所以UDP可以用它选定的任何速率向其下层(网络层)注入数据。
实际端到端的吞吐量可能小于该速率,这可能是由于中间链路的带宽受限或因为拥塞而造成的。
在TCP和UDP的描述中,没有对吞吐量和定时保证的讨论,这两个指标要求,目前的因特网运输协议并没有提供。
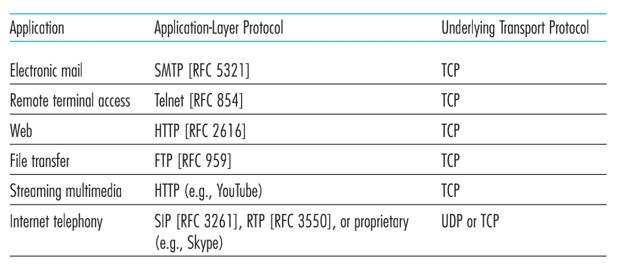
应用层协议定义了运行在不同端系统上的应用程序如何互相传递报文。
常规应用层的协议定义:
- 交换报文类型,如请求和响应报文。
- 各种报文类型的语法。
- 字段的语义
- 确定进程发送报文的时间跟方式,对报文进行响应的规则。
RFC文档定义的应用层协议如HTTP。邮箱的应用层协议SMTP。
web的应用层协议是超文本传输协议(HyperText Transfer Protocol, HTTP)
- 使用TCP作为它的支撑运输协议
- 无状态的协议(不保存客户的信息)
- 默认使用持续连接方式,支持配置非持续连接方式
- 非持续连接:每个请求/响应对是经一个单独的TCP连接。每个请求和响应使用同一个TCP连接。
- 持续连接:所有请求及其响应经相同的TCP连接发送。
往返时间(Round-Trip Time, RTT),指一个短分组从客户到服务器然后再返回客户所花费的时间。
包括分组传播时延、分组在中间路由器和交换机上的排队时延以及分组处理时延
非持续连接缺点:
- 必须为每一个请求对象建立和维护一个全新的连接。客户及服务器都需要分配TCP的缓冲区和变量,给Web服务器带来负担。
- 每个对象传输经受两倍RTT的交付时延,即一个RTT用于创建TCP,另一个RTT用于请求和接收一个对象。
持续连接:
Http1.1 持续连接,服务器在发送响应后保持该TCP连接打开。在相同的客户与服务器之间,后续的请求及响应能在相同的连接进行传送。
一个完整的Web页面可以用单独持续TCP连接进行传送,同一个客户的不同Web页面请求在请求同一个服务器,同样使用相同的TCP连接。
Http2,允许相同连接中多个请求和回答交错,并增加了在该连接中请求HTTP报文请求和回答机制。
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr
GET /somedir/page.html HTTP/1.1
请求行:由方法字段、URL字段和HTTP版本字段组成。方法字段包括GET、POST、HEAD、PUT、DELETE
Host: www.someschool.edu
首部行Host:指明了该对象所在的主机,是Web代理高速缓存所要求的。
Connection: close
首部行Connection:该浏览器告诉浏览器不要麻烦的使用持续连接,要求浏览器在发送完被请求对象后就关闭该条连接。
User-agent: Mozilla/5.0
首部行User-agent:指明向服务器发送请求的浏览器类型。
Accept-language: fr
首部行Accept-language:表示语言版本
- Request line:请求行
- Header lines:多个首部行
- Blank line
- Entity body:POST方法使用的请求参数体
HTTP方法:
- HEAD方法类似于GET方法。服务器接收到HEAD方法的请求时,将会用一个HTTP报文进行响应但不返回对象,HEAD方法常用于调试跟踪。
- PUT方法常与Web发行工具联合使用。允许用户上传对象到指定的Web服务器上的指定路径。也可以用于对象上传。
- DELETE方法允许用户或者应用程序删除Web服务器上的对象。
HTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
HTTP/1.1 200 OK
状态行:包括协议版本字段、状态码和响应的状态信息
Connection: close
首部行Connection: 告诉客户端,发送完报文后将关闭该TCP连接。
Date: Tue, 09 Aug 2011 15:44:04 GMT
首部行Date: 指服务器产生并发送该响应报文的时间和日期。时间为从系统中检索到该对象将该对象插入报文,并发送该响应报文的时间。
Server: Apache/2.2.3 (CentOS)
首部行Server: 服务器版本信息
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
首部行Last-Modified: 表示对象创建或最后的修改时间。该首部行与缓存的应用有关。
Content-Type: text/html
首部行Content-Type: 表示响应的对象类型。
状态码:
- 200 OK: 请求成功
- 301 Moved Permanently:请求的对象已经被永久转移了,新的URL定义在响应报文的首部行Location。客户端软件将自动获取新的URL地址。
- 400 Bad Request: 一个通用的差错代码,指示该请求不能被服务器理解。
- 404 Not Found:被请求的文档不再服务器上。
- 505 HTTP Version Not Supported: 服务器不支持报文使用的HTTP版本
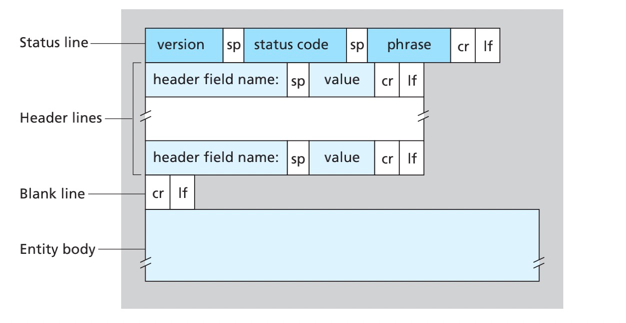
HTTP服务器是无状态的,该设计简化了服务器的设计。
cookie设计的4个组件:
- 在HTTP响应报文中的一个cookie首部行。
Set-cookie: 1678 - 在HTTP请求报文中一个cookie首部行。
Cookie: 1678 - 用户端系统中保留一个cookie文件,并由浏览器管理。
- 位于Web站点的一个后台数据库。
交互过程:
Web缓存器(Web cache) 也加代理服务器(proxy server),它是能够代表初始Web服务器来满足HTTP技术的网络实体。Web缓存器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的副本。
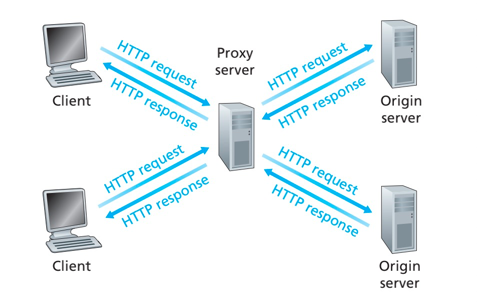 交互过程:
交互过程:
- 浏览器创建一个到Web缓存器的TCP连接,并发起HTTP请求。
- Web缓存器检查本地是否存储了该对象的副本。如果存在,Web缓存器就向客户浏览器用HTTP响应报文返回。
- 如果Web缓存器没有该对象,它就打开一个与该对象的初始服务器的TCP连接,并发起该对象的HTTP请求。服务器收到Web缓存器请求后,返回具有该对象的HTTP响应。
- 当Web服务器接收到该对象时,它在本地磁盘存储空间存储一份副本,冰箱客户端浏览器用HTTP报文响应。
Web缓存器的好处:
- 可以大大减少对客户端的响应时间,特别是客户与服务器之间的带宽远低于客户与Web缓存器间的瓶颈带宽的场景。因为客户与Web缓存器之间常常会有一个高速的连接。
- Web缓存器可以大大减少接入链路到互联网的通信量,从整体上大大减低因特网上的Web流量,从而改善所有应用性能。
例子:
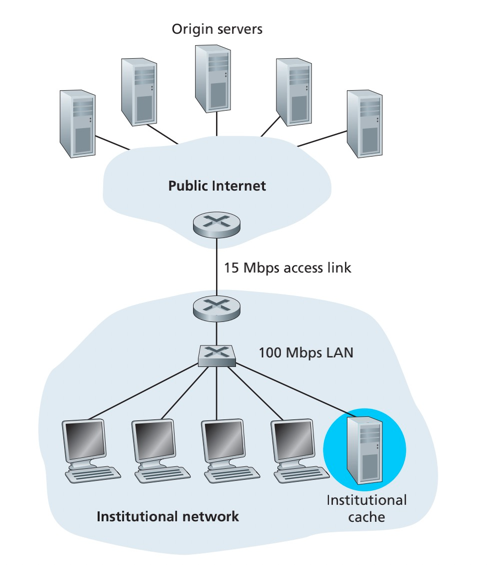
Institutional network为一个高速的100 Mbps的内部局域网,接入因特网的带宽为15 Mbps,假设机构内部15请求/秒,每个请求传输1M的数据
- 内部传输时延:
15*1M/100M= 0.15s - 因特网传输时延:
15*1M/15M= 1s - 总时延:因特网传输时延+ 内部传输时延+ 服务处理时延(假设为2s)
当机构的请求数增加大于15Mbps,链路的请求响应时延就会越来越长,因为链路无法完全接受就会出现累计的现象
一个解决方案是可以通过把接入因特网的带宽增大,但是费用过高。
另一个方案是增加一个Web缓存服务器,实践中的缓存命中率为0.2~0.7之间。假设缓存命中率为0.4,则整体的平均时延甚至比增加带宽的方案表现更为优秀
总结一下:缓存器减少了需要发送因特网的部分流量,同时节省了那部分流量的服务请求跟响应时间。
缓存实现机制:通过条件GET方法实现,条件GET方法为首先一个HTTP GET请求,并且请求报文包含一个If-Modified-Since的首部行。
实现机制:
- Web缓存器代理HTTP请求时,缓存了对象同时缓存了对象的最后修改日期。
- 若下次请求时,缓存仍然存在,则缓存器会发送条件GET命令到服务器执行最新检查。
- 若对象没有修改,则服务器返回
304 Not Modified状态码,告诉缓存服务器,可以使用该对象,响应报文为空,节省了带宽。
如下为两条件GET请求:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 7 Sep 2011 09:23:24
HTTP/1.1 304 Not Modified
Date: Sat, 15 Oct 2011 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)
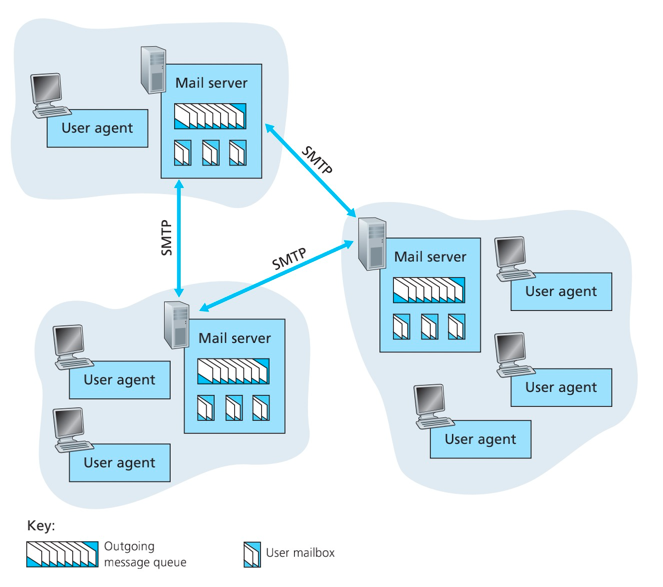
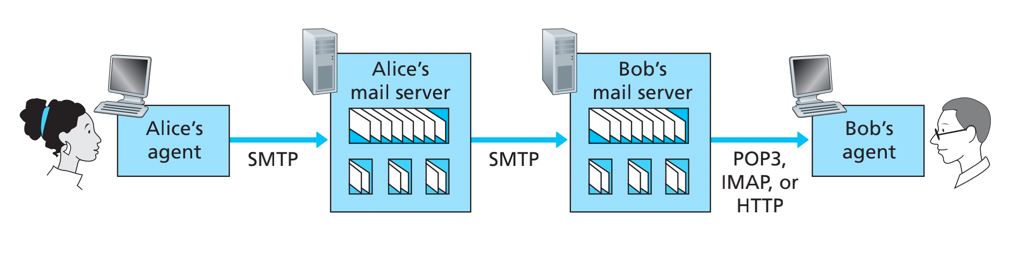
电子邮件系统的总体组成:
- 用户代理(user agent)
- 邮箱服务器(mail server)
- 简单邮件传输协议(Simple Mail Transfer Protocol, SMTP)
邮箱服务器:
- 邮箱(mailBox):接收方在邮件服务器上有一个邮箱(mailBox),邮箱管理和维护发送的报文。\
- 输出报文队列:保持着输出报文的队列。
- 邮箱服务器之间以SMTP进行通信
队列的作用:
- 进来的速度和出去的能力有差异,用队列平滑过度。
- 服务器发送设置了频率如5min、10min,减少服务器的耗能。
- 故障处理,如果发送方无法直接将邮件交付接收方,则在报文队列中存储,并等待再次发送,通常30min进行一次重试。
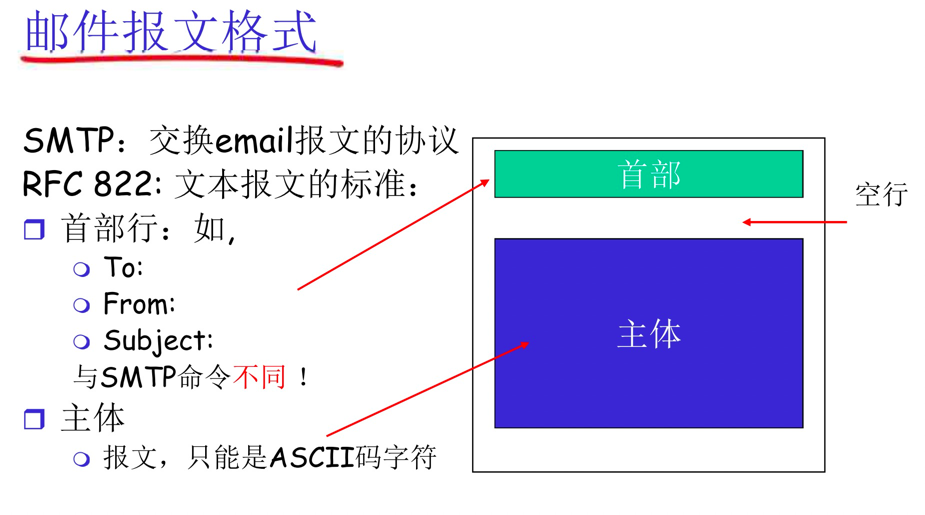
SMTP是用于从发送方的邮件服务器发送报文到接收方的邮件服务器。(RFC 5321定义)
报文必须为7位ASCII编码,英文看得懂
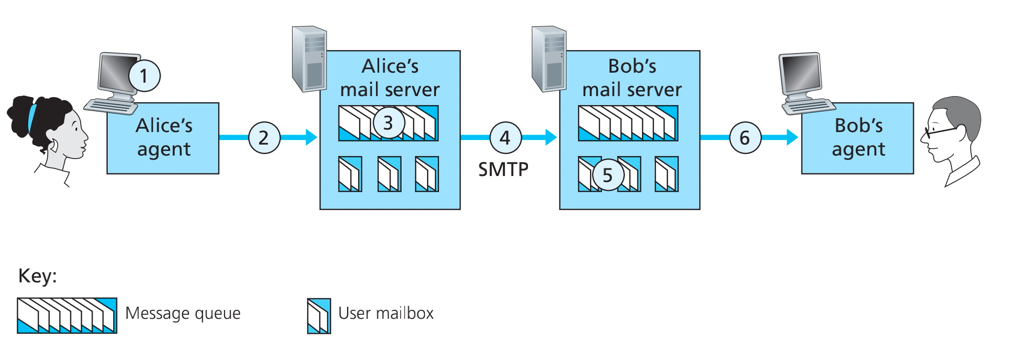
流程简述:
- 从发送方Alice的用户代理开始,调用邮件代理程序并提供Bob的邮件地址,进行发送。
- Alice用户代理把报文发送给她的邮件服务器,报文被放在队列中。
- 运行在Alice的邮件服务器的SMTP客户端发现了队列的报文,与Bod的邮件服务器上的SMTP服务器建立TCP连接。
- 两个邮箱服务器进行SMTP的握手,发送方通过TCP连接发送Alice报文。
- Bod的邮箱服务器接收到报文,分发到对应的邮箱中。
S: 220 hamburger.edu
C: HELO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <[email protected]>
S: 250 [email protected] ... Sender ok
C: RCPT TO: <[email protected]>
S: 250 [email protected] ... Recipient ok
C: DATA
S: 354 Enter mail, end with “.” on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection
SMTP与Http的比较:
- SMTP使用持久连接。
- SMTP及HTTP报文均为二者都是7位ASCII形式的命令、响应交互、状态码
不同:
- HTTP:拉(pull), SMTP:推(push)
- HTTP:每个对象封装在各自的响应报文中。一个request一个obj
- SMTP:多个对象包含在一个报文中。一个request包含多个obj,如邮件报文、附件、图片。

SMTP服务器基于DNS中的MX记录来路由电子邮件,MX记录注册了域名和相关的SMTP中继主机,属于该域的电子邮件都应向该主机发送。
若SMTP服务器 mail.abc.com 收到一封信要发到[email protected],则执行以下过程:
- sendmail 请求DNS给出主机sh.abc.com的CNAME 记录,如有,假若CNAME(别名记录)到shmail.abc.com,则再次请求shmail.abc.com的CNAME记录,直到没有为止。
- 假定被CNAME到shmail.abc.com,然后sendmail请求
@abc.com域的DNS给出shmail.abc.com的MX记录(邮件路由及记录)shmail MX 5 shmail.abc.com 10 shmail2.abc.com - Sendmail组合请求DNS给出shmail.abc.com的A记录(主机名或域名对应的IP地址记录),即IP地址,若返回值为1.2.3.4(假设值)。
- Sendmail与1.2.3.4连接,传送这封给[email protected] 的信到1.2.3.4
- MUA(Mail User Agent): 接收邮件所使用的邮件客户端,它提供了阅读,发送和接受电子邮件的用户接口。
- MSA(Mail Submission Agent):负责消息有MTA发送之前必须完成的所有准备工作和错误检测,MSA就像在MUA和MTA之间插入了一个头脑清醒的检测员对所有的主机名,从MUA得到的信息头等信息进行检测。
- MTA(Mail Transfer Agent): MTA是在邮件主机上的软件,它也是主要的邮件服务器。MTA负责发送邮件,中转邮件,当然也要接收邮件。
- MDA(Mail Delivery Agent): “邮件投递代理”主要的功能就是将MTA接收的信件依照信件的流向(送到哪里)将该信件放置到本机账户下的邮件文件中(收件箱),或者再经由MTA将信件送到下个MTA。
- MRA(Mail Receive Agent): 负责实现IMAP与POP3协议,与MUA进行交互;相当于让你的邮件账户支持离线邮件收取,而不是电脑打开才能收取邮件。
MAA(Mail Access Agent)邮件访问代理 用于将用户连接到系统邮件库,使用POP或IMAP协议收取邮件。Linux下常用的MAA有UW-IMAP,Cyrus-IMAP,COURIER-IMAP等邮件中继:就是当邮件向目的地址传输时,一旦源地址和目的地址都不是本地系统,那么本地系统就是邮件的中继(中转站)
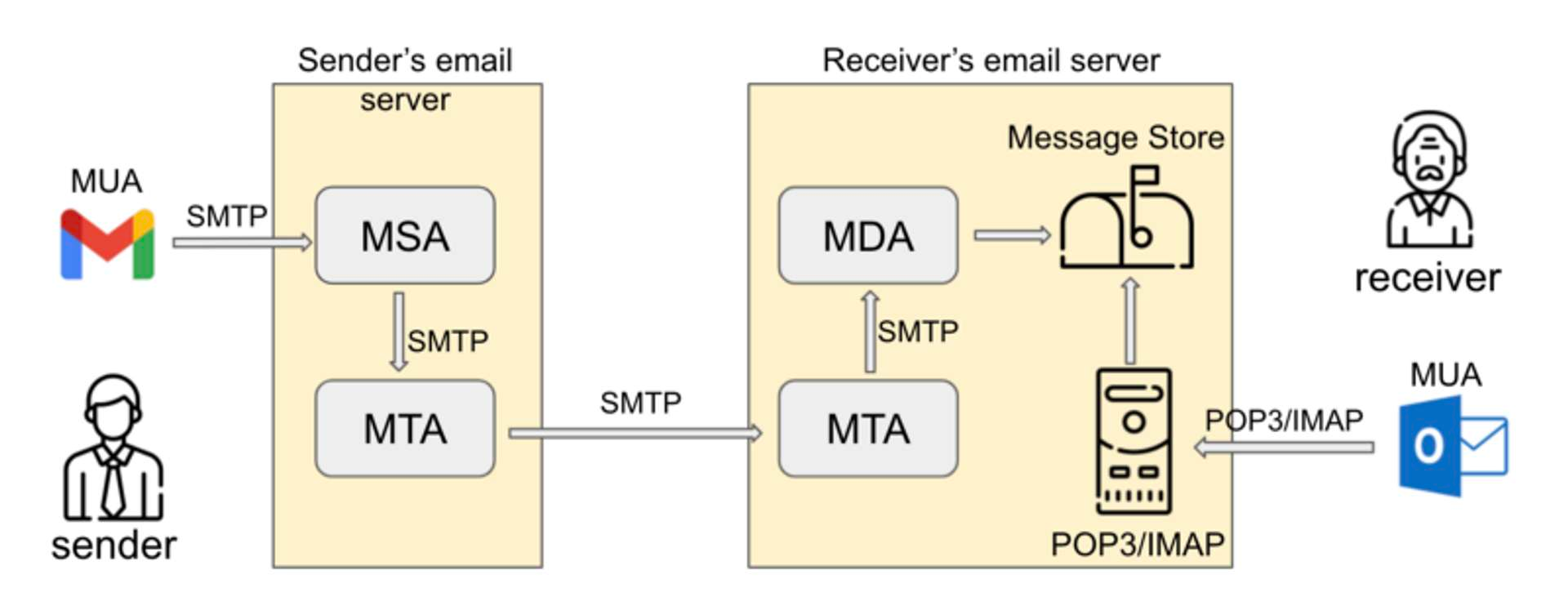
POP3(Post Office Protocol-Version 3, 第三版邮局协议) 由RFC 1939进行定义,当用户代理打开一个到邮件服务器端口110的TCP连接,POP3就开始工作了。
POP3按照三个阶段进行工作:
- Authorization 认证
- transaction 事务处理
- update 更新
认证
Authonrization
===============
user <user name> : 用户名
pass <password> : 密码
S: +OK POP3 server ready
C: user bob
S: +OK
C: pass hungry
S: +OK user successfully logged on
事务处理
Tansaction
====================
list: 报文号列表
retr: 根据报文号检索报文
dele: 删除
quit
C: list
S: 1 498
S: 2 912
S: ...
C: retr 1
S: <message 1 contents>
S: .
C: dele 1
C: retr 2
S: <message 1 contents>
S: .
C: dele 2
C: quit
S: +OK POP3 server signing off
更新:在处理quit命令后,POP3服务器进入更新阶段,从用户邮箱中删除事务处理阶段对应的邮件。
POP3在会话中是无状态的,且POP3没有给用户提供任何远程创建远程文件夹并为报文指派文件夹的方法。 因此在一台设备上设立文件,仅仅只在本地管理,并不会在多设备上同步。
IMAP(Internet Mail Access Protocol,因特网邮件访问协议),RFC 3501定义
- IMAP服务器将每个报文与一个文件夹联系起来
- 允许用户在远程文件夹中查询邮件
- 允许用户读取报文的部分内容,如获取一个报文的首部,或是MIME的报文的一部分。
- IMAP在会话过程中保留用户状态:目录名、报文ID与目录名之间映射
域名管理系统(Domain Name System, DNS) ,提供将主机名转换为其背后的IP地址的服务。
- 一个由分层的DNS服务器(DNS server)实现的分布式数据库。
- 一个是的主机能够查询分布式数据库的分布式协议。
DNS服务器通常是运行BIND软件(Berkeley Internet Name Domain)的UNIX机器
DNS协议运行在UDP协议之上,使用53 端口
DNS是通过客户-服务器模式提供的重要网络功能。DNS协议是应用层协议,其原因在于:
- 使用客户-服务器模式运行在通信的端系统之间。
- 在通信的端系统之间通过下层端到端的运输协议来传送DNS报文。
DNS的作用非常不同于HTTP与SMTP,因为其不直接和用户打交道。
DNS通过采用来位于网络边缘的客户和服务器,实现了关键的名到地址转换功能。
DNS的重要服务:
主机别名(host aliasing):有着复杂主机名的主机能拥有一个或多个别名。
如主机
relay1.west-coast.enterprise.com,可能还有别名enterprise.com和www.enterprise.com。此时relay1.west-coast.enterprise.com称为规范主机名
邮件服务器别名(mail server aliasing):与主机别名类似,作用于邮件服务器地址上。
事实上,MX记录允许一个公司的邮件服务器和Web服务器使用相同的主机名。
负载分配(load distribution):DNS也用于冗余的服务器之间进行负载分配。
如一个IP地址集合与同一个规范主机名相联系,在DNS进行解析时,循环IP地址进行响应,实现了Web服务器之间的负载分配。
DNS的为IP地址提供了目录服务,但也带来了额外的时延,使用主机地址请求时需要额外请求DNS拿到真实的IP地址。因此想要获得IP地址应尽量缓存在"附近的"DNS服务器中,这有助于减少DNS的网络流量和DNS的平均时延。
DNS的工作流程简述:
- 用户主机应用程序需要将主机名转换为IP地址,应用程序调用DNS客户端。
- 用户主机上的DNS接收到请求的主机名,向网络发送一个DNS的查询报文。
- 所有的DNS请求和响应报文使用UDP数据报经端口53发送,经过若干毫秒到若干秒的时延后,用户主机上的DNS收到回答报文
- 用户主机的DNS将映射结果传递到调用DNS的应用程序。
单一的DNS服务器架构会出现单点故障、通信容量、远距离集中式数据库、维护等问题,因此DNS的服务器使用是分布式的架构。
分布式、层次数据库
为了处理拓展性问题,DNS使用了大量的DNS服务器,它们以层次方法组织,并且分布在全世界范围内。没有一台DNS服务器拥有因特网上所有主机的映射。
DNS服务器大致可以分为3种类型
- 根DNS服务器(Root DNS server):有400多个根名字服务器遍及世界,由13个不同的组织管理。
- 顶级域DNS服务器(Top-Level Domain, TLD):对于每个顶级域如(如com、org、net、edu和gov) 和 所有国家的顶级域(如uk、fr、ca和jp),都有TLD服务器或服务器集群。
- 权威DNS服务器(authoritative DNS servers) :在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的DNS记录,这些记录将主机名映射成IP地址。实现的方式有两种,一是实现自己的DNS服务器,另一种是支付费用,让某个服务提供商的DNS服务器帮忙记录。
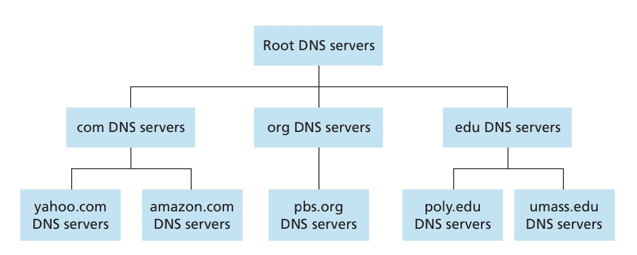
在更下层的中还有本地DNS服务器(local DNS server) ,对于居民区ISP,本地DNS服务通常与主机相隔不超过几个路由器。当主机发出DNS请求时,该请求被发往本地DNS服务器,该服务器起着代理作用,并转发请求到DNS服务层次结构中。
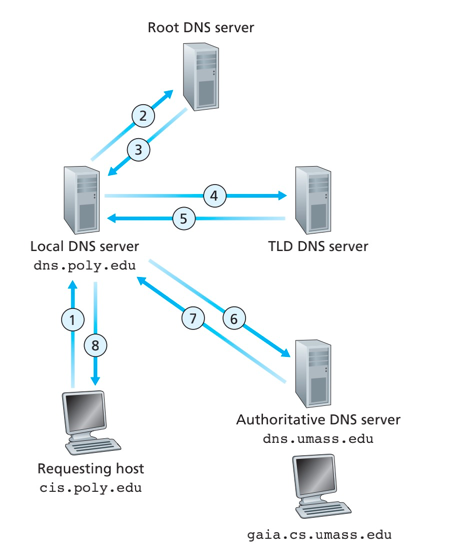
- 用户请求主机,发向本地DNS服务器。
- 本地DNS,请求根DNS获取地址
- 根DNS,根据前缀返回负责相关前缀的TLD的IP地址列表。
- 本地DNS依次请求TLD发送查询报文,TLD返回对应的权威DNS服务器IP地址。
- 最后本地DNS请求权威DNS服务器发送查询报文,获取最终真实的IP
上述过程中发送了8份DNS报文:4份查询报文4份回答报文。
为了改善时延性能并减少在因特网上到处传输的DNS报文数量,DNS广泛使用了缓存技术。
某个DNS服务器接收到一个回答时,它能够缓存包含在该回答中的任何信息。由于主机和主机名和IP地址间的映射并不是永久的,DNS服务器在一段时间(通常为2天)后将丢弃缓存信息
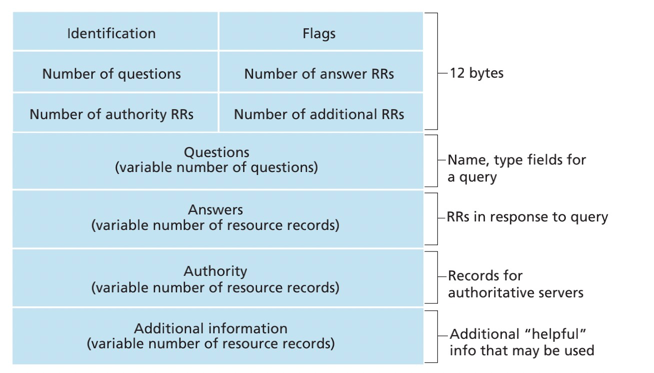
DNS服务器存储了资源记录(Resource Record, RR),RR提供了主机名到IP地址的映射。有下列关键信息:(Name, Value, Type, TTL)
TTL是记录的生存时间,Type类型可以分为4大类:
- Type=A,则Name是主机名,Value 为主机名对应的IP地址,提供了标准的主机名到IP地址的映射。
(relay1.bar.foo.com, 145.37.93.126, A) - Type=NS,则Name是个域(如foo.com),而Value是个知道如何获取该域中主机IP地址的权威DNS服务器的主机名。
(foo.com, dns.foo.com, NS) - Type=CNAME,则Value是别名为Name的主机对应的规范主机名。该记录提供一个主机名对应的规范主机名。
foo.com, relay1.bar.foo.com, CNAME - Type=MX,则Value是别名为Name的邮件服务器的规范主机名。MX记录允许邮件服务器具有简单的别名。一个公司的邮件服务器和其他服务器可以使用相同的别名
(foo.com, mail.bar.foo.com, MX)
为了获取邮件服务器的规范主机名,DNS客户应该请求一条MX记录。
为了获取其他服务器的规范主机名,DNS客户应该请求CNAME记录。
两者一个MX为邮件服务器服务,一个CNAME为其他服务器服务。
DDoS分布式拒绝服务带宽洪泛攻击,攻击根DNS服务器或TLD,对DNS的影响很小,主要是本地的DNS的缓存可以部分缓解。
中间人攻击,通过拦截请求并伪造回答。但是很难试下, 因为要求截获分组或扼制住服务器。
DNS自身显示了对抗攻击 令人惊讶的健壮性。
运输层协议为运行在不同主机上的应用程序之间提供逻辑通信(logic communication) 功能。
发送端,运输层将从发送应用程序接收到的报文转换为运输层分组,该分组称为运输层报文段(segment)
接收端,网络层从数据报提取运输层报文段,并将该报文段向上交给运输层。
网络层提供了主机之间的逻辑通信,而运输层为运行在不同主机上的进程之间提供了逻辑通信。
运输层协议只工作在端系统中。因此运输协议能够提供的服务常常受限于底层网络层协议的服务模型。
IP的服务模型是尽力而为交付服务(best-effort delivery service)。但是不确保报文段的交付、不保证报文段中数据的完整性。
多路分解:将运输层报文段中的数据交付到正确的套接字的工作。即接收端接收到数据,通过标识分发到各个应用层程序的套接字上。
多路复用:在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息从而生成报文段,然后将报文段传递到网络层,上述所有工作称为多路复用。即收集应用层程序发送到运输层的套接字数据,将数据封装成segment传输到网络层。
无连接的多路复用与多路分解,即UDP的连接。
UDP连接中,若未指定端口,运输层将自动为该套接字分配一个端口号。
一个UDP套接字是有一个二元组全面标识的,该二元组包含了一个目的IP地址和一个目的端口号。因此如果两个UDP报文段有不同的源IP地址或源端口号
,但具有相同的目的IP地址和目的端口号,那么两个报文段将通过相同的目的套接字被定向到相同的目的进程。
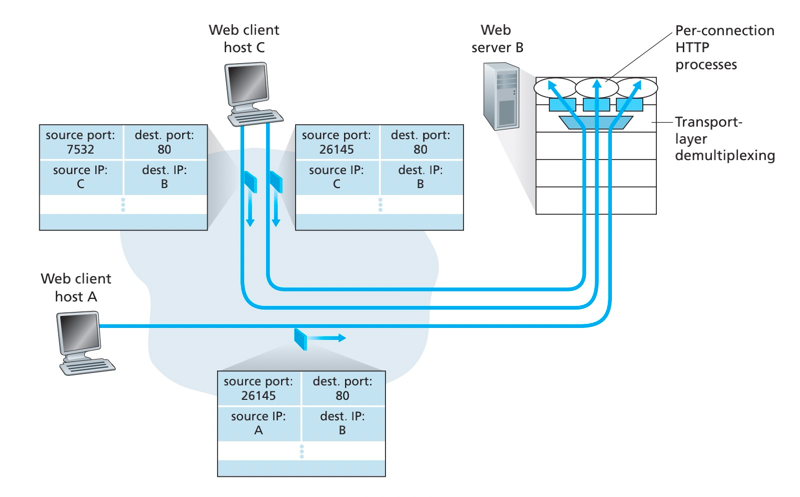
TCP套接字是由一个四元组(源IP地址、源端口号、目的IP地址、目的端口号)来标识的。
当一个TCP报文段从网络到达一台主机时,该主机使用全部4个值来将报文段定向(分解)到相应的套接字。
特别与UDP不同的是,两个具有不同源IP地址或源端口号的到达TCP报文段将被定向到两个不同的套接字,除非TCP报文段携带了初始创建连接的请求。
TCP套接字的四元组,用于标识连接,如果报文段的四元组都相同,则被分配到相同的套接字。
如下图,client C有两个不同的端口连接到server B,根据TCP套接字四元组,server B可以区分不同的连接
UDP除了复用/分解即少量的差错检测外,该协议几乎没有对IP协议增加别的东西。使用UDP发送报文段之前,发送方和接收方的运输层实体之间没有握手,这也是UDP无连接的体现。
DNS是一个通常使用UDP的应用层协议的例子。
使用UDP的应用是可能实现可靠传输的,这依靠于应用程序自身建立可靠性机制。
选用UDP的应用主要的原因:
- 关于发送什么数据以及何时发送的应用层控制更为惊喜。
采用UDP时,只要应用进程将数据传递给UDP,UDP就会将此数据打包进UDP报文段并立即将其传递给网络层。因为实时应用通常要求最小的发送速率,不希望过分地延迟报文段的传送,且能容忍一些数据的丢失。而TCP的拥塞控制机制,就不适合这些应用的需要。
- 无须连接建立。
UDP不会引入建立连接的延迟。若DNS运行在TCP之上,则会慢得多
- 无连接状态。
TCP需要在端系统中维护连接状态,连接状态包括接收和发送缓存、拥塞控制参数以及序号与确认号参数。某些专门用于某种特定应用的服务器运行在UDP上,通常能支持更多的活跃用户。
- 分组首部开销小。
每个TCP报文段都有20字节的首部开销,而UDP仅有8个字节的开销。
UDP常用于承载网络管理数据(SNMP),因为网络管理应用程序通常必须在该网络处于重压状态时运行,而这时候可靠、拥塞受控的数据传输难以实现。
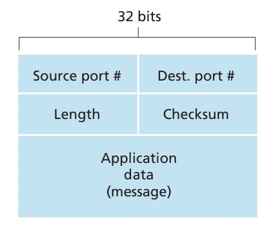
UDP首部只有4个字段,每个字段由2个字节组成。
- source port/Dest port: 端口号用于多路分解和复用
- Length: 长度由于说明数据长度
- checkSum: 检验和用于检查报文段是否出现了差错。
UDP校验和提供了差错检测功能。发送方的UDP对报文的所有16比特字的求和,遇到求和溢出则进行反码运算,求和时遇到的任何溢出都被回卷,结果放在检验和字段中,用于接收段的校验。
UDP提供了差错检测原因:不能保证源和目的之间的所有链路都提供了差错检测,且无法确保逐链路的可靠性,作为一个数据传输的保险措施。
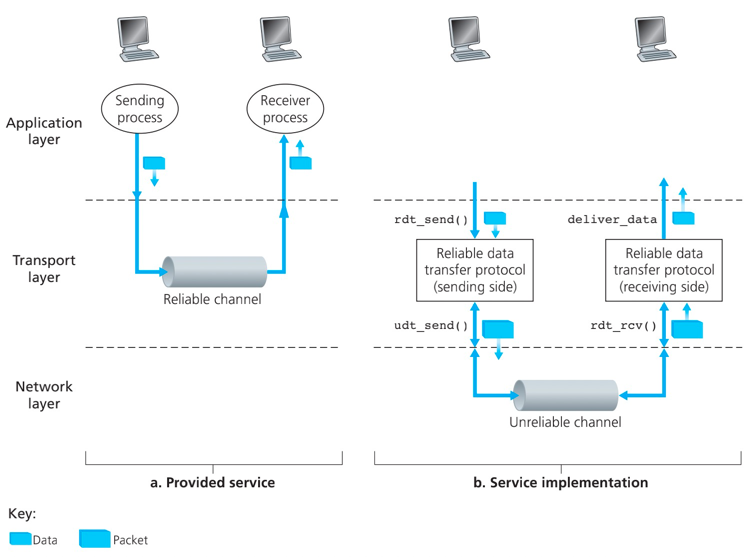
可靠数据传播协议的服务抽象(reliable data transfer protocol):数据可以通过一条可靠的信道传输。借助于可靠信道,传输数据比特就不会收到损坏或丢失,而且所有数据都是按照其发送顺序进行交付。
概念:
- 有限状态机(Finite-State Machine,FSM)
- rdt_send函数:上层可以调用数据传输协议的发送方。(rdt标识可靠传输协议,_send表示rdt的发送方正在被调用)
可靠数据传输协议的技术要点:检验和、答复机制(肯定和否定确认分组)、序号、定时器
rdt1.0:最简单的情况,底层信道完全可靠。
发送及接收端均不需要反馈信息,因为底层信道可靠。类似于依赖TCP的上游。
rdt2.0:底层信道模型是分组中比特可能受损的模型。
解决受损的三个实现:差错检测、接收方反馈、重传
- 差错检测,类似于UDP的checkSum
- 接收方反馈。接收方向发送方回送ACK与NAK分组。如0为NAK,1为ACK
- 重传。接收方收到有差错的分组时,发送方将重传该分组。
基于口述报文的重传机制的可靠数据传输协议被称为自重传请求协议(Automatic Repeat reQuest, ARQ)
停等协议(stop-and-wait): 发送方等待ACK或NCK的状态时,不能继续发送新数据,因为不知道ACK或NCK是答复哪个分组的响应。
问题:rtd2.0问题ACK或NCK答复分组受损?还可能是发送的分组数据受损?
解决方案:
- 引入新的发送方交互,如
repeat again等。缺点:过于复杂 - 增加NCK或ACK的校验机制。缺点:额外的数据传输
- 引入冗余分组。ACK或NCK接收不清,直接一次重传。缺点:接收方不知道重传分组是新分组还是重传
上述问题的通用解决方案:引入分组序号(sequence number),在数据分组中添加序号字段。
rtd2.1 实现: 引入序号字段。分组序号使用0和1,循环的表示分组,因为停等协议的存在,仅用两个编码就能表示新分组与旧分组重传。
rdt2.2简化发送方与接收方的交互,仅使用ACK。该协议是在有比特差错的情况下,实现一个无NAK的可靠数据传输协议。
实现:引入冗余ACK。如果发送方收到一个冗余ACK,表示接收方没有正确收到 被确认两次的分组 后面的分组。
问题:发送方不知道需要等待多长时间才能确认数据丢失,若ACK数据若传输过程丢包,那么传输将停滞。
解决方案:
- 引入倒计时定时器。发送方发送时就启动定时器,在指定时间内无答复,变开始一次重传。
- 配合定时器机制,引入接收端的冗余数据分组(duplicate data packet)
rtd3.0的传输过程:a-无丢包操作、b-分组丢失、c-丢失ACK、d-过早超时
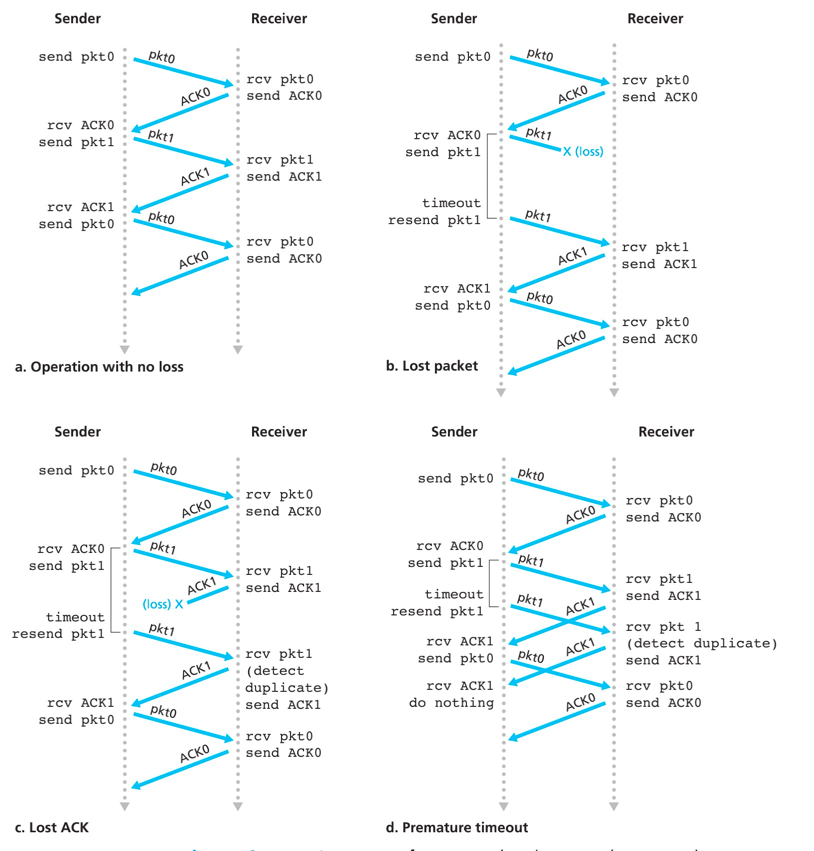
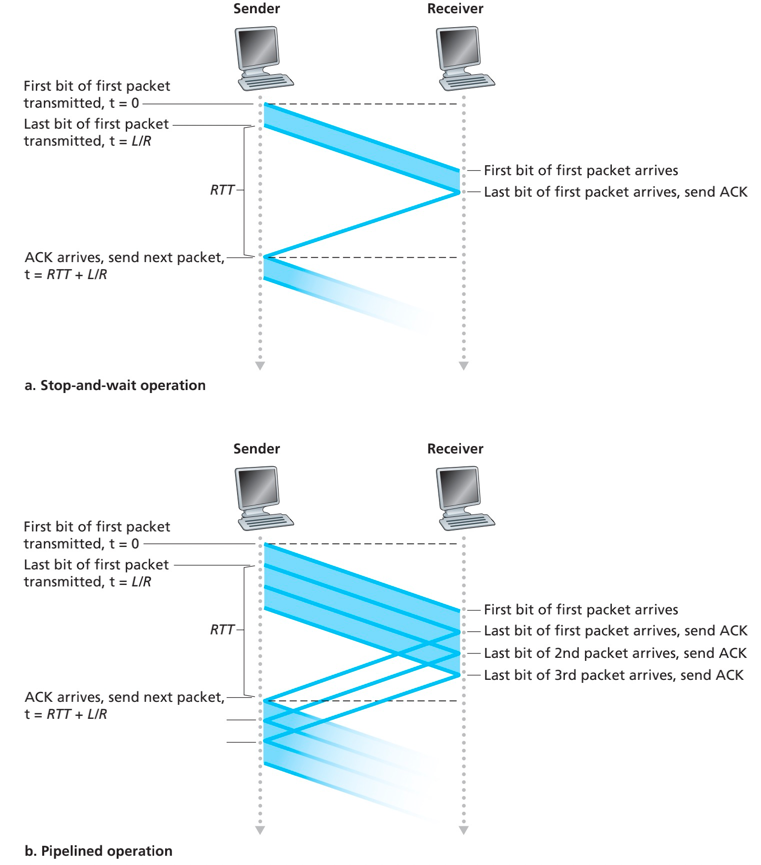
rtd3.0因为停等协议的存在,导致了严重的性能问题。对于整个传输的信道的利用率过低。
解决方案:允许发送方发送多个分组而无需等待确认,流水线技术。
影响:
- 必须增加序号范围。每个传输中的多个分组有唯一标识。
- 发送和接收方需要缓存多个分组。
- 对于分组丢失、损坏及延迟过大的分组处理。
解决流水线差错恢复的方法:回退N步、选择重传
回退N步协议:允许发送方发送多个分组而不需等待确认,但是受限于流水线中未确认的分组数不能超过某个最大允许数N。
N常被称为窗口长度,GBN协议也常被称为滑动窗口协议(sliding-window protocol)
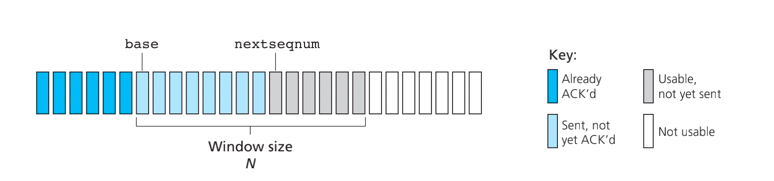
实现:
- 上层调用约束。发送前先检测发送窗口是否已满。
- 累积确认(cumulative acknowledgement)。表示接收方已正确接收到序号为n的以前包括n在内的所有分组已经正确接收。
- 超时事件。超时重传已发送但还未被确认的分组,继续进行累积确认。
为什么使用累积确认? 若使用选择确认则回退N步重传需要区分已确认的分组,处理会更加复杂。而使用累积确认,GBN的处理会更加简单。\
GBN协议中,接收方丢弃所有失序分组。
原因:如果保存失序的分组n+1,接收方也要等待其他分组n+1之前的分组到达才能交付到上层。先到达的失序的分组,在下次发送方重传的时候也会重新发送。
方法的优点:接收缓存处理简单,即接收方不需要缓存任何失序分组。
方法的缺点:随后对该分组的重传也许会出错,甚至需要更多的重传。
发送方维护变量:窗口上下边界、nextseqnum
接收方维护变量:expectedseqnum
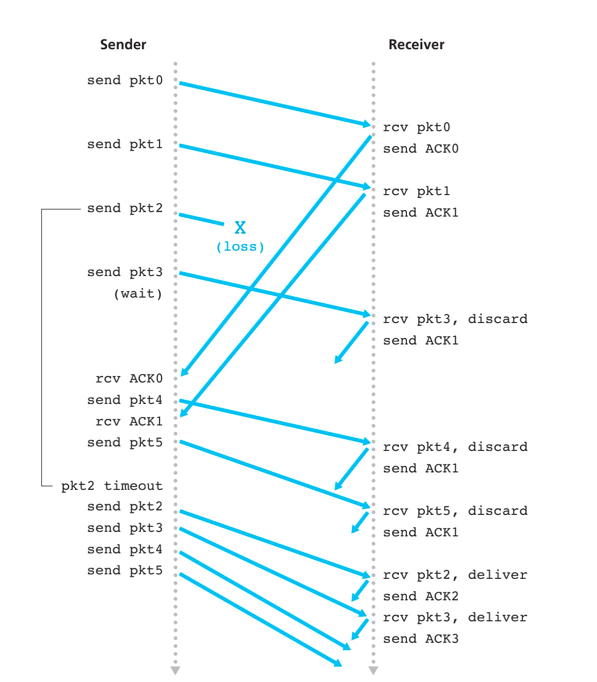
运行中的GBN,失序的分组丢弃并返回当前累积确认的最后一个分组序号的ACK
GBN协议潜在地允许发送发用多个分组"填充流水线",因此避免了停等协议中所提到的信道利用率问题。但是GBN本身也存在着性能问题,尤其是当窗口长度和带宽时延积都很大时。单个分组的差错就能引起GBN重传大量分组,许多分组根本没有必要重传。
选择重传(SR)协议通过让发送方仅重传那些怀疑在接收端出错(即丢失或受损)的分组而避免了不必要的重传。接收方需要对于正确接收的分组逐个确认。同时再次用窗口长度N来限制流水线中未完成、未被确认的分组数。
接收及发送流程,与GBN区别是接收方已接收到某些分组的ACK。
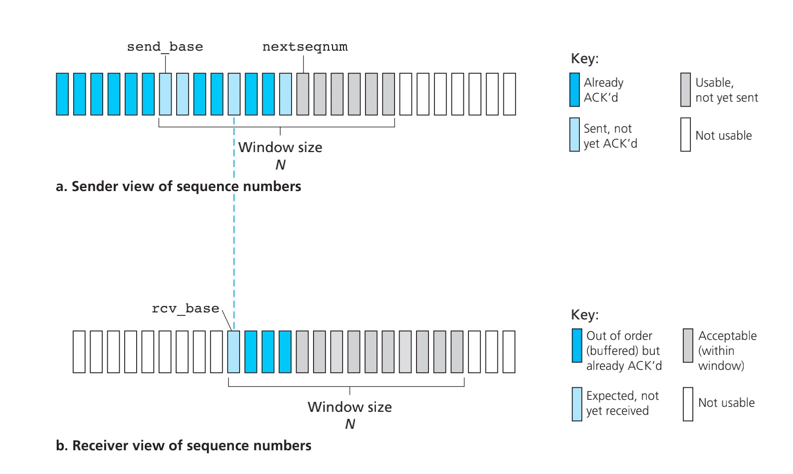
SR发送方事件与动作:
- 从上层收到数据。当从上层接收到数据后,SR发送方检查下一个可用于该分组的序号。若在发送窗口内则打包发送,若不再发送窗口,进行数据缓存或返回上层等待以后传输。
- 超时。定时器用来防止丢失分组进行重发。
- 收到ACK。如果收到ACK,若分组序号在窗口内,则SR发送方标记分组为已接收。若分组序号恰好为窗口左端点即
send_base,则移动窗口并发送窗口内未发送分组。
SR接收方事件与动作:
- 序号在窗口内的分组被正确接收,即分组序号在
rcv_base~rcv_base+N-1。收到的分组在接收方的窗口内,返回一个选择ACK给发送方。如果序号等于接收窗口基序号即rcv_base,则移动窗口向上层交付连续的分组。 - 序号在
rcv_base-N~rcv_base-1的分组被正确收到。在此情况下必须产生一个ACK,即使已确认过,做一个重复确认的操作。 - 其他情况,忽略接收到的分组。
SR接收方将确认一个正确接收的分组而不管其是否按序。失序的分组将被缓存直到所有丢失分组(及序号更小分组)皆被接收为止,这时才可以将一批分组按序交付给上层。
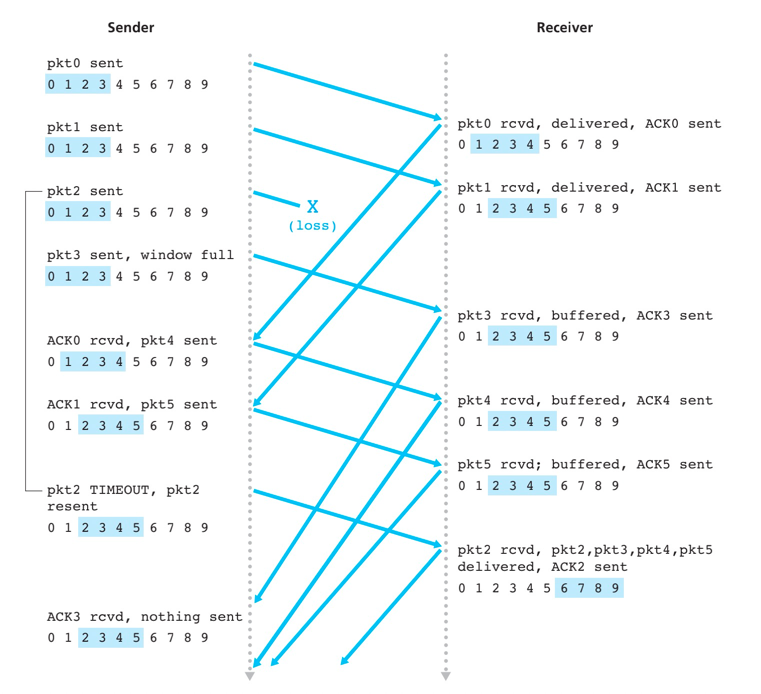
问题:接收方为啥要做rcv_base-N ~ rcv_base-1 的分组重复确认?
有可能接收方发送的ACK,发送方没接收到。
问题:为啥重复确认的范围为rcv_base-N ~ rcv_base-1?
考虑极端情况,接收方发送的ACK,发送方均未接收到。那么发送方不会向前移动窗口,而是超时重复发送send_base的分组。
问题:序号的长度与窗口的长度如何确定?
假设序号编号4位分布为0 1 2 3,而窗口长度为3。 当0分组的ACK发送方未接收到的时候,发送方及接收方的窗口如下:
|0 1 2| 3 0 1 2
0 1 2 |3 0 1| 2
当发送方对0分组进行重传时,接收方会进行误确认的情况。
因此对于SR协议而言,窗口长度必须小于或等于序号空间大小的一半。
构建可靠数据传输信息依赖于如下机制:
- 检测和
- 定时器
- 序号
- 确认
- 否定机制
- 窗口、流水线
与其他运输层协议类似,TCP的"连接"为一条逻辑连接,其共同状态仅保留在两个通信端系统的TCP程序中。
TCP协议只是在端系统中运行,而不在中间的网络元素(路由器和链路层交换机)中运行,所以中间的网络元素不会维持TCP连接状态。事实上,中间路由器对TCP连接完全视而不见,它们看到的是数据报,而不是连接。
TCP提供的是全双工服务(full-duplex service),建立连接的不同主机进程,可以互相发送消息。
TCP连接是点对点的(point-to-point),即单个发送方与单个接收方直接的连接。
TCP的应用层数据受限于最大报文段长度(Maximum Segment Size,MSS)
MSS通常根据最初确定的由本地发送主机发送的最大链路层长度(最大传输单元 Maximum Transmission Unit, MTU)设置
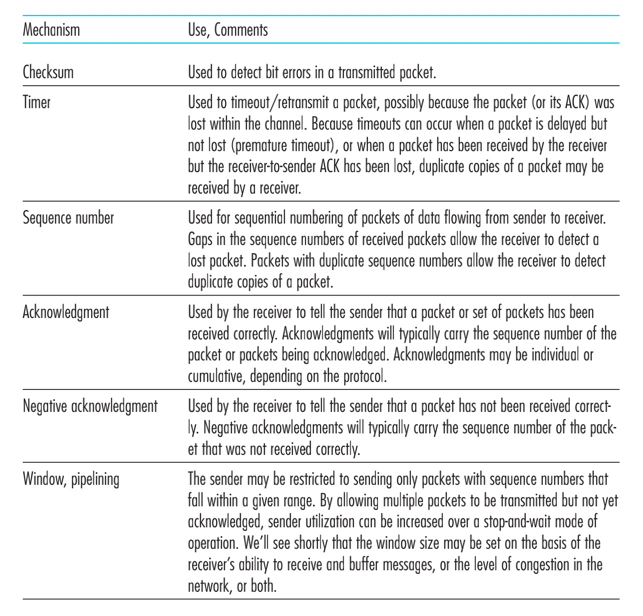
TCP报文段(TCP segment)由首部字段和一个数据字段组成。
首部字段一般是20字节,包括如下字段:
- 检验和字段(checksum field)
- 32比特的序号字段(sequence number field)和32比特的确认号字段(acknowledgment number field)
- 16比特接收窗口字段(receive window field),该字段用于流量控制。
- 4比特的首部长度字段(header length field)
- 可选与变长的选项字段(options field),该字段用于发送方与接收方协商最大报文段长度(MSS),或在高速网络环境下用作窗口调节因子。
- 6比特的标志字段(flag field)
- ACK比特用于指示确认字段中的值是有效的,即成功接收报文的确认。
- RST
- SYN
- FIN
序号与确认号
TCP把数据看成一个无结构的、有序的数据流。序号是建立在传输的字节流之上,因此一个报文段的序号(sequence number for a segment)是报文段首字节的字节流编号。
假定数据流由一个包含500000字节的文件组成,其MSS为1000字节。TCP将为该数据流构建500个报文段。第一个报文段序号0,第二个报文段序号1000,第三个报文段2000,以此类推。
确认号就是主机正在等待的数据的下个字节的序号: 发送方假设收到0~535及900~1000的两个报文段,在后续的发送方报文中确认号中包含536。
累积确认:因为TCP只确认流中至第一个丢失字节为主的字节。故后续的数据传输中确认号均会包含536,直到536序号的报文段被确认。
失序报文策略:发送方肯定为顺序发送,而接收方接收到数据的时候可能是失序的,接收方将保存失序的字节,并等待缺少的字节以填补空缺。
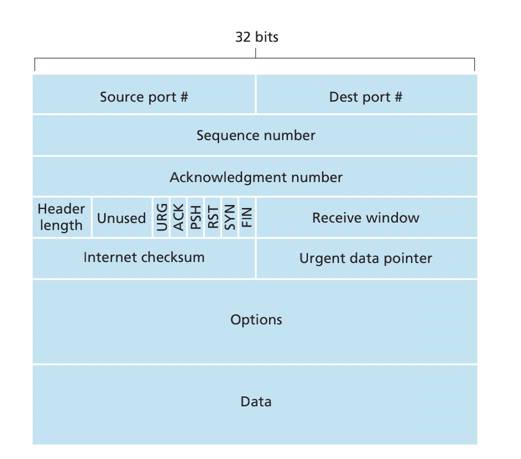
捎带(piggybacked)
- 报文1 Seq=42, ACK=79。Seq=42表示client报文段首字节序号,ACK=79表示server发送的第一个报文段序号。可以理解为TCP连接建立后,client等待字节79,而server等待字节42
- 报文2 Seq=79, ACK=43。Seq=79表示server的报文段序号,是server第一个字节的数据,ACK=43表示server确认收到字节42,等待43字节出现。
- 报文3 Seq=43, ACK=80。Seq=43表示client的报文段序号,ACK=80表示client确认接收79及以前的字节。
整体的交互过程是发送的数据的同时携带确认号,进行累积确认。
样本RTT(Sample RTT)的估计是通过从某个报文段被发出(即交给IP)到对该报文段的确认被收到之间的时间和。
TCP决不为已被重传的报文段计算Sample RTT,主要防止重传报文异常的Sample RTT的影响整体的往返时间的估计。
Sample RTT均值(EstimatedRTT)的计算
EstimatedRTT = (1 – a) * EstimatedRTT + a * SampleRTT
RFC 6298中对a的推荐值是0.85, 即
EstimatedRTT = 0.875 * EstimatedRTT + 0.125 * SampleRTT
Sample RTT与EstimatedRTT的偏移量估算 DevRTT:
DevRTT = (1 – b) * DevRTT + b * |SampleRTT – EstimatedRTT|
超时时间的设定应该比EstimatedRTT大,防止过早超时,具体设置如下:
TimeoutInterval = EstimatedRTT + 4*DevRTT
推荐的初始TimeoutInterval的值为1秒,当出现超时后,TimeoutInterval值将加倍,以避免确认的后继报文段过早的出现超时。而只要接收到报文段并使用公式更新EstimatedRTT,
- TCP使用肯定确认ACK与定时器来提供可靠数据传输。
- TCP无法明确的分辨一个报文段或其ACK是丢失了、受损了还是时延过长了,在发送方,TCP响应是相同的,使用重传机制处理有疑问报文。
- TCP使用流水线,是的发送方在任意时刻都可以有多个已发出但未被确认的报文段存在。
TCP在IP(不可靠的尽力而为服务)服务之上构建了一种可靠传输数据服务(reliable data transfer service)
- 定时器机制:每个报文段对应一个定时器会导致相当大的开销,因此推荐的定时器过程仅使用单一的重传定时器,即使有多个已发送但未被确认的报文段。
- 超时重发机制:对于定时器超时的报文,进行重发。
- 冗余ACK确认技术:再次确认某个报文段的ACK,而发送端先前已经收到过该报文段的确认。
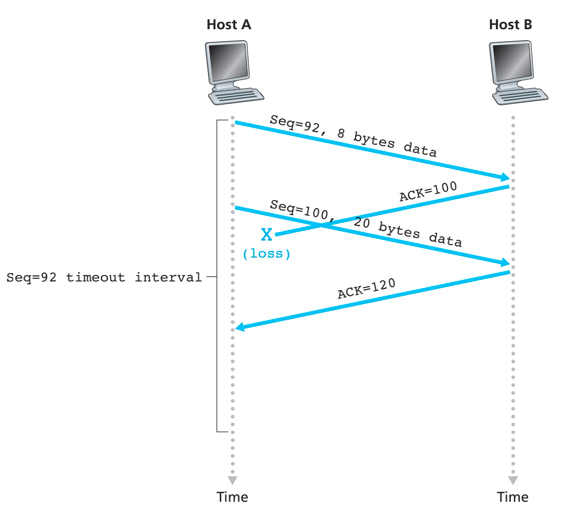
确认丢失导致重传
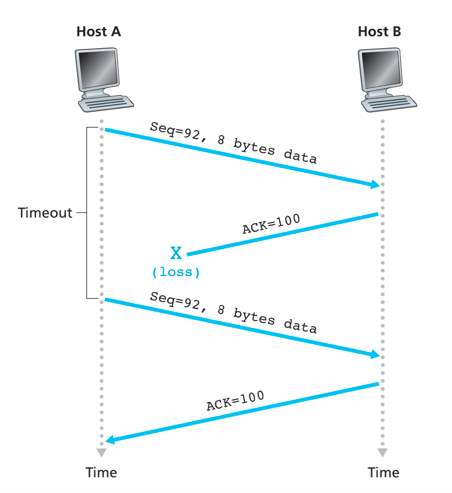
segment 100没有重传
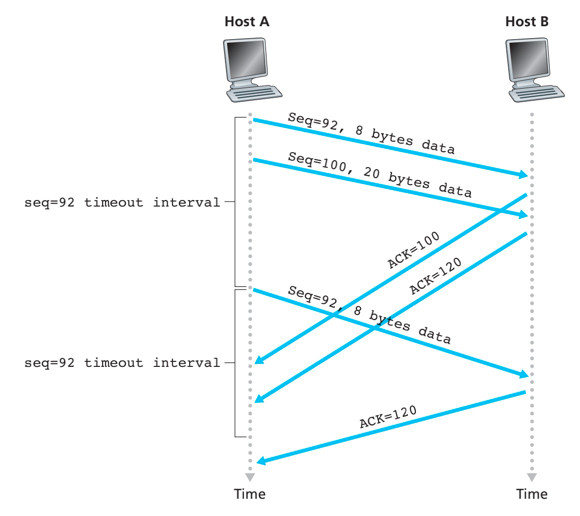
累积确认避免了第一个报文段的重传
TCP发送方处理的三个主要事件:
- 从上层应用程序接收数据,将数据封装到一个报文段中,并将报文段交给IP。报文段的序号为报文段中第一个数据字节的字节流编码
- 超时。TCP通过重传来响应超时事件,并重启定时器。
- 到达一个来自接收方的确认报文段(ACK)。当该事件发生时,TCP将ACK的值y与sendBase比较。如果
y>sendBase,则该ACK是确认一个或多个未被确认的报文。累积确认的实现。
超时间隔加倍:每次TCP重传时都会将下一次的超时间隔设为先前值的两倍。因此,超时间隔在每次重传后会呈指数型增长。
每当定时器的另两个事件(即收到上层应用的数据和收到ACK)中的任意一个启动时,TimeoutInternal由最近的EstimatedRTT值与DevRTT值推算得到。
超时间隔加倍提供了另一种形式受限的拥塞控制。
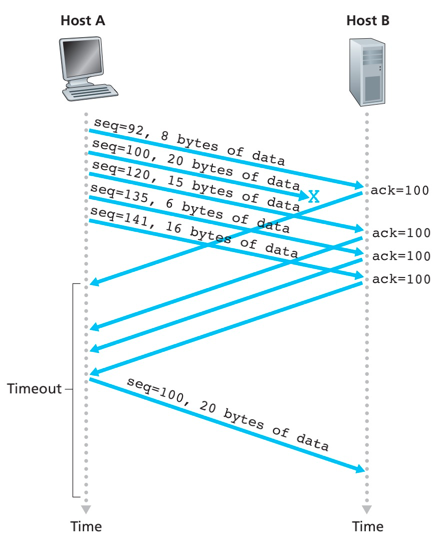
快速重传:超时触发的问题是超时周期可能相对较长,因而增加了端到端时延。在累积确认的机制下,收到3个冗余ACK进行快速重传。
因为TCP不使用否定确认,通过对已经接收到的最后一个按序字节数据进行重复确认(产生冗余ACK),进而提示发送端进行重传。TCP接收方对相同数据接收到3个冗余ACK,就执行快速重传。
为啥等待3个冗余ACK才开始重传? 网络传输是不可靠的,丢包、乱序和复制等情况,如果出现三次以上DupAck的就认为丢包的可能性很高,可以进入快速重传机制。
RFC 5681 产生ACK的建议:
- 延迟ACK:对另一个按序报文段的到达最多等待500ms。如果下一个按序报文段在这个事件间隔没有到达,则发送一个ACK。
- 累积ACK:期望序号的按序报文段到达,另一个按序报文段已到达等待ACK传输。立即发送单个累积ACK,确认两个按序报文。
- 冗余ACK:失序报文到达,检测出间隔,立即发送冗余ACK,指示下个期待字节的序号。
TCP差错恢复机制:GBN协议与SR协议的混合体
- TCP确认是累积式的即累积确认,维持变量SendBase和NextSeqNum。
- 选择确认:TCP接收方有选择地确认失序报文段,而不是累积地确认最后一个失序报文段。
- TCP超时重传是传输未确认的最小序号的数据。
流量控制服务(flow-control service):为消除发送方使接收方缓存溢出的可能性,而提供的一个速度匹配服务。
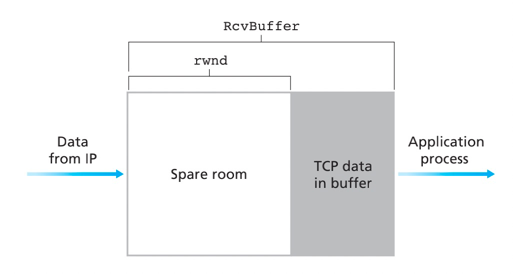
TCP通过若昂发送方维护一个称为接收窗口(receive window)的变量来提供流量控制。接收窗口用于给发送方一个提示,即该接收方还有多少可用的空间。TCP为全双工的通信,因此连接两端均维护了一个接收窗口。
- LastByteRead: 应用进程从缓存读出的数据流的最后一个字节的编号
- LastByteRcvd: 从网络中到达并且已经放入主机接收缓存中的数据流的最后一个字节的编号
- RcvBuffer: 接收缓存的大小
- rwnd:接收窗口大小
- LastByteSend: 应用进程发送的数据流的最后一个字节的编号
- LastByteAck: 最后收到的ACK
接收端防止缓存溢出约束:
LastByteRcvd - LastByteRead <= RcvRead
接收窗口rwnd窗口大小:
rwnd = RcvBuffer- [LastByteRcvd - LastByteRead]
由于该空间是随着事件变化的,所以rwnd是动态的。
发送端控制通过满足如下公式,就可以保证发送主机不会使接收主机的缓存溢出:
LastByteSend - LastByteAcked <= rwnd
窗口大小使用为0的通信:当接收主机的接收窗口为0是,发送主机继续发送只有一个字节数据的报文段。接收到接收到后将开始进行缓存情况,并确认报文包含一个非0的rwnd值。
TCP client状态转换序列
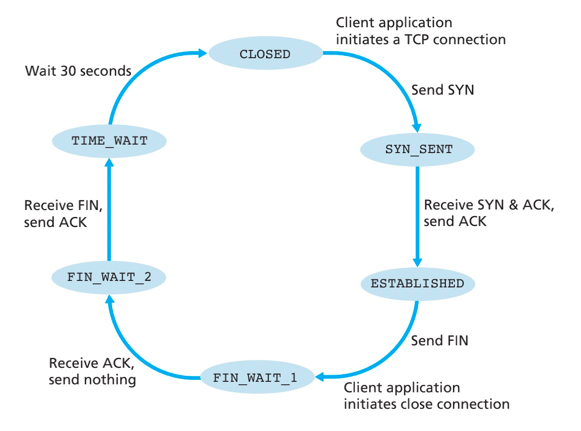
TCP server状态转换序列
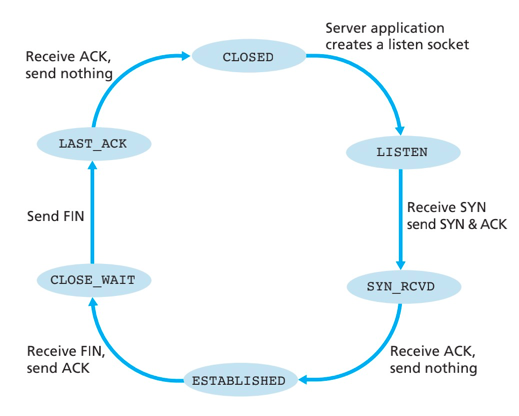
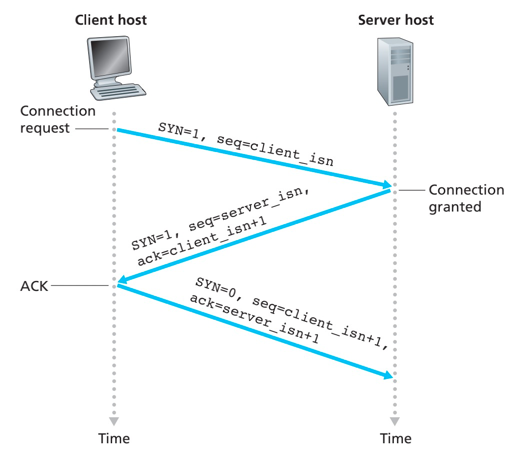
-
第一步:client发送server一个特殊的TCP报文段,即TCP SYN报文。
- 报文段不包含应用数据
- 报文段首部标志位SYN置为1
- client随机选择一个初始序号(
client_isn),放置在序号字段中
-
第二步:server接收TCP SYN报文,为该TCP分配TCP缓存和变量,返回TCP SYNACK报文段(SYNACK segment)
- 报文段不包含应用数据
- 报文段首部SYN比特置为1
- 报文段首部确认号ACK字段置为
client_isn+1 - server 随机选择一个初始序号(
server_isn),放置在序号字段中
-
第三步:收到SYNACK报文段后,client给该连接分配缓存和变量,发送对允许连接报文的确认报文
- 报文段允许包含应用数据
- 因为连接已经建立,首部标志位SYN置为0
- 确认号ACK设置为
server_isn+1, 序号设置为client_isn+1
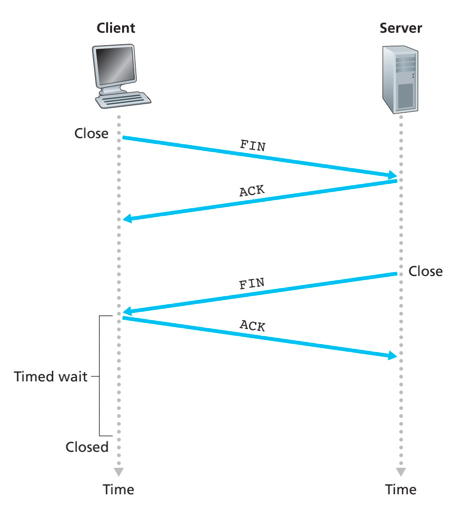
- client发送一个FIN报文段,将报文段首部的FIN设置为1
- server接收到返回FINACK报文段,报文段首部的FIN设置为1
- server发送自己的FIN报文段,将报文段首部的FIN设置为1
- client接收返回FINACK报文段,对FIN报文进行确认
SYN洪泛攻击:攻击者发送大量的TCP SYN报文,而不完成第三次握手,服务器不断为这些半开连接分配资源,导致服务器的连接资源消耗殆尽
防御措施SYN cookie:
- 接收到SYN报文段,服务器不分配资源,而是根据序号、IP、端口及私钥使用散列函数加密,作为初始序号存储在确认SYNACK的报文分组中返回。
- 客户发送确认SYNACK的ACK报文,服务器通过对报文ACK的序号-1,并重新运行散列函数加密,检查是否合法。
好处:如果客户没返回ACK报文,则初始SYN并没有对服务器造成危害,因为服务器没有分配任何资源。
当client对server发送连接的时候,可能产生如下三种情况:
- 从目标主机收到TCP SYNACK报文段
- 从目标主机收到RST报文段。意味着目标主机无应用程序运行在相应的端口上。
- 源主机没有收到任何返回。说明服务器的防火墙拦截了SYN报文。
拥塞控制(congestion control): TCP的发送方因为IP网络的拥塞而被遏制。
拥塞原因与代价
- 当分组的到达速率接近链路容量时,分组经历巨大的排队延迟。
当发送速率接近链路极限时,路由器的平均排队分组数就会无限增长,源与目的地之间的平均时延也会变成无穷大。
- 发送方在遇到大时延时所进行的不必要重传,会引起路由器利用其链路带宽来转发不必要的分组副本。
重传导致的链路带宽的占用
- 当分组沿一条路径被丢弃,每个上游路由器用于转发该分组到丢弃该分组的使用传输容量最终被浪费了。
分组在某个节点丢弃,进而浪费了该分组到达该节点前的几个传输容量
拥塞控制方法的两种方法:
- 端到端拥塞控制。网络成没有为运输层拥塞控制提供显示支持,端系统必须通过网络行为进行观察。
- 网络辅助的拥塞控制。路由器向发送方提供关于网络中的拥塞状态的显式反馈信息。
TCP使用端到端拥塞控制而不使用网络辅助的拥塞控制,因为IP层不向端系统提供显示的网络拥塞反馈。
TCP所采取的方法是让每个发送方根据所感知到的网络拥塞程度来限制其能向连接发送流量的速率。
TCP中运行在发送方的TCP拥塞机制跟踪一个额外变量拥塞窗口(congestion window, cwnd)
cwnd对一个TCP发送方向网络中发送流量与速率进行了限制,在一个发送方中未被确认的数据量不会超过rwnd与cwnd中的最小值:
LastByteSend - LastByteAcked <= min{cwnd, rwnd}
该限制条件允许发送方向向该连接发送cwnd个字节的数据,在该RTT结束时发送方接收对数据的确认报文。因此确认报文的传输慢,则cwnd增长慢,反之确认快,则cwnd窗口增长快。
TCP的指导性原则:
- 一个丢失的报文意味着拥塞,因此当丢失报文时应当降低TCP发送方速率。拥塞的现象:3个冗余ACK、超时
- 一个确认报文段指示该网络正在向接收方交付发送方的报文段,因此,当对先前未确认报文段的确认到达时,能增加发送方的速率。
- 带宽探测。TCP调节其传输速率的策略是增加其速率以响应到达的ACK,除非出现丢包事件,此时才减小传输速率。
TCP拥塞控制算法:慢启动、拥塞避免、快速恢复。
- 慢启动:cwnd以1个MSS开始并且每个传输的报文点首次被确认就增加1个MSS。因此慢启动发送速率起始慢,但是以指数增长。
- 拥塞避免:一旦进入拥塞避免模式,cwnd的值大约是上次遇到拥塞时的值的一半,每个RTT只将cwnd的值增加一个MSS,以线性增长。
- 快速恢复:在快速恢复中,若仍收到冗余ACK,cwnd值增加1个MSS。当对丢失报文段的1个ACK到达时,TCP在降低cwnd后进入拥塞避免状态
慢启动的FSM转换
- 转换拥塞避免:慢启动状态中,如果存在1个由超时指示的丢包事件,TCP发送方将
cwnd设置为1,ssthresh(慢启动阀值)设置为cwnd/2并重新开始慢启动。即当检测到拥塞时将ssthresh置为拥塞窗口值的一半。 当cwnd的值等于sshresh时,结束慢启动并且TCP转移到拥塞避免模式。 - 转换快速恢复:如果检测到3个冗余ACK,这时TCP执行一种快速重传并进入快速恢复状态。
拥塞避免的FSM转换:
- 转换慢启动:当出现超时时,cwnd值设置为1,sshresh更新为cwnd值一半,进入慢启动模式。
- 转换快速恢复:3个冗余ACK出现时,TCP将cwnd的值减半,将sshresh的值记录为cwnd的值的一半,进入快速恢复模式
快速恢复的FSM转换: 当出现超时事件,cwnd值设置为1,sshresh更新为cwnd值一半,进入慢启动模式。
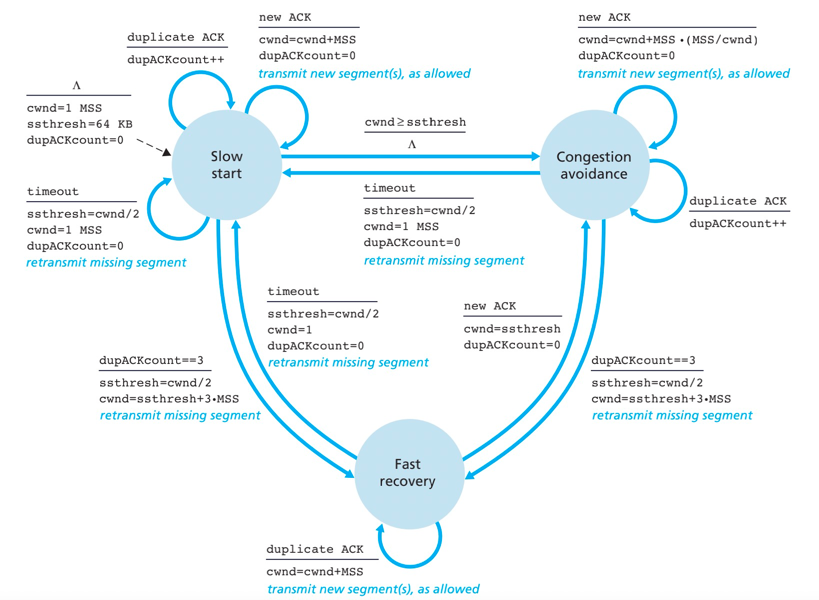
TCP分岔
背景:如果端系统远离数据中心,则RTT大,且由于慢启动潜在的导致低下的响应事件性能。
解决措施:部署邻近用户的前端服务器。在该前端服务器利用TCP分岔来分裂TCP连接。客户向临近前端连接一条TCP连接,并且前端以非常大的窗口与数据中心进行TCP连接。
网络层的协议:
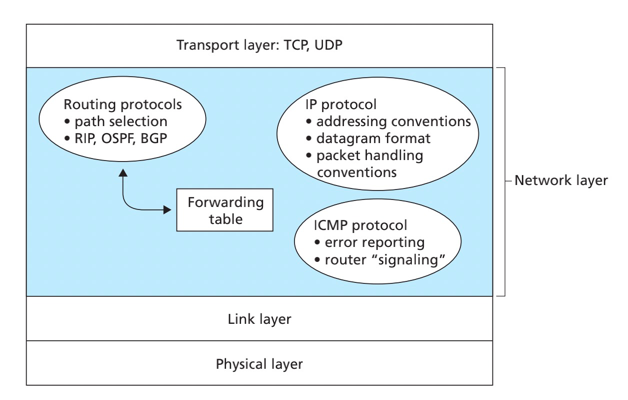
网络层数据平面:网络层中每台路由器的功能,该数据平面功能决定到达路由器输入链路之一的数据报(即网络层的分组)如何转发到该路由器的输出链路之一。一个局部的控制。
本地每个路由器功能,决定输入端口到达分组如何撞到输出端口
转发功能:传统方式(基于目标地址+转发表,数据控制平面紧耦合)、SDN方式(基于多个方式+流表)
网络层控制平面:网络范围的逻辑,该控制平面功能控制数据报沿着从源主机到目的主机的端到端路径中路由器之间的路由方式。一个全局的控制。
网络范围内的逻辑,决定数据如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径
控制平面方式:传统路由算法(在路由器中实现)、SDN(在远程服务器中实现)
转发:指将分组一个输入链路端口转移到适当的输出链路接口的路由器本地动作。
路由选择:确定分组从源到目的地所采取的端到端路径的网络范围处理过程。
SDN方式:逻辑集中的控制平面,使用统一的远程控制器下发流表。相比与传统的方式目标地址+转发表的分布式架构更容易控制。
因特网的网络层提供了单一的服务模型,称为尽力而为的服务(best-effort service)
路由器4个组件:
- 输入端口
- 交换机构
- 输出端口
- 路由选择处理器
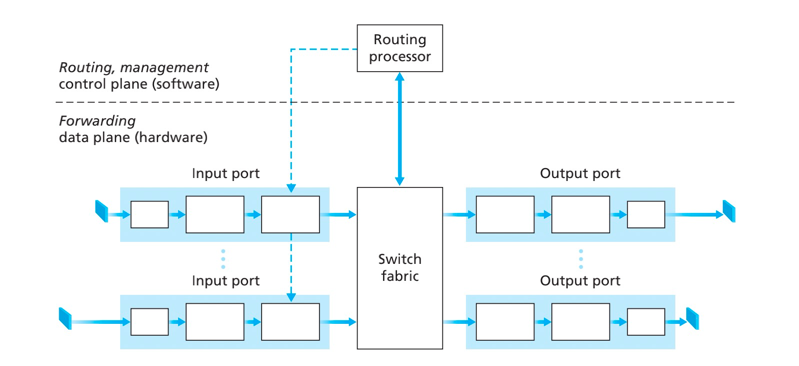
路由器使用分组目标路径的前缀与转发表进行最长前缀匹配,确定输出端口方向。
- 经内存交换:转发速率被内存的带宽限制、经过bus两次(输入内存、处理完成输出内存)、一次只能转发一个分组
- 经总线交换:交换速率受限于总线带宽
- 经互联网络交换:由2N条总线组成的互联网络,N个输入及N个输出、非阻塞的实现
输入端口为何存在队列?输出端口为何存在队列?
解决输入输出速率不一致的情况,引入队列协调。
交换速率与输入端口接收分组速率不一致的情况
解决交换速率与输出到链路层网卡包装速率不一致的情况
丢包:路由器队列增长,路由器的缓存空间最终将会耗尽,并且当无内存可用于存储到达的分组时出现丢包。
输入队列排队,主要是出现HOL(Head-Of-the-Line, HOL)阻塞,即在一个输入队列的排队分组必须等待通过交换结果发送,因为它被前一个分组所阻塞。
分组调度:
- FIFO:无法解决部分分组数据需要优先调度问题
- 优先权队列:队列分优先权,会出现低优先权饥饿问题
- 循环排队规则:循环遍历队列提供服务
- 加权公平排队(Weighted Fair Queuing, WFQ):每个队列有对应的权重,概率被服务的概率
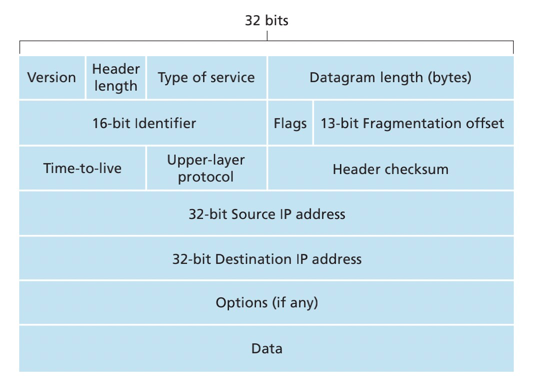
- 版本号(version): IP协议的版本
- 首部长度(header length)
- 服务类型(type of service): 表示payload的类型由于区分优先级,现在已经废除
- 数据报长度
- 标识、标志、片偏移:与IP分片有关
- 寿命(Time-To-Live, TTL): 每台路由器处理一个数据包,该字段值减1
- 上层协议:标识上层协议是UDP或TCP
- 首部校验和:帮助路由器校验检测收到IP数据包中的比特差错。
- 源和目的IP地址
- 选项:拓展字段
- 数据(有效载荷,payload data)
一个链路层帧能承载的最大数据量为最大传输单元(Maximum Transmission Unit, MTU)
当传输的数据报大于链路层帧的MTU,IP数据报就要进行分片,到目的地的传输层重新进行组装。
主机与物理链路之间的边界叫做接口。一个IP地址与一个接口相关联,而不是与包括该接口的主机或者路由器相关联。
子网(subnetwork):要判断一个子网,将每一个接口从主机或者路由器上分开,构成一个个网络孤岛。交互无需经过路由器。
子网掩码(network mask):如233.1.1.0/24的地址分配,其中/24的记法,有时称为子网掩码。
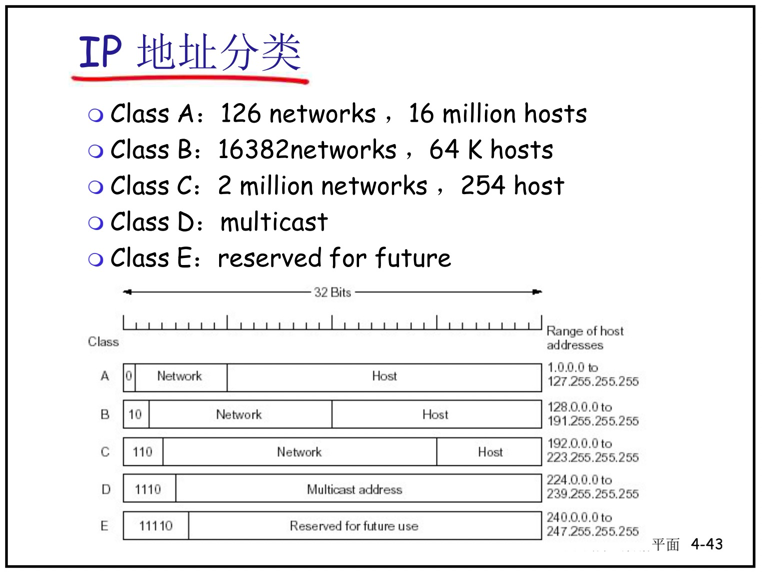

内网(专用)IP地址
- 专用地址:地址空间的一部份供专用地址使用
- 永远不会被当做公用地址来分配, 不会与公用地址重复 只在局部网络中有意义,区分不同的设备
- 路由器不对目标地址是专用地址的分组进行转发
- 专用地址范围
- Class A 10.0.0.0-10.255.255.255 MASK 255.0.0.0
- Class B 172.16.0.0-172.31.255.255 MASK 255.255.0.0
- Class C 192.168.0.0-192.168.255.255 MASK 255.255.255.0
无类别域间路由选择,不分配某类地址,而是以每个位置为号段分配,分组分发的时候以网络前缀分发。
- 子网部分可以在任意的位置
- 地址格式: a.b.c.d/x, 其中 x 是 地址中子网号的长度
路由聚合:使用单个网络前缀通告多个网络的能力,相当于一个路由代理了另一ISP的IP端进行通告。
一个组织的子网内,如何获得一块IP地址?
- 手工配置
- DHCP动态主机配置协议
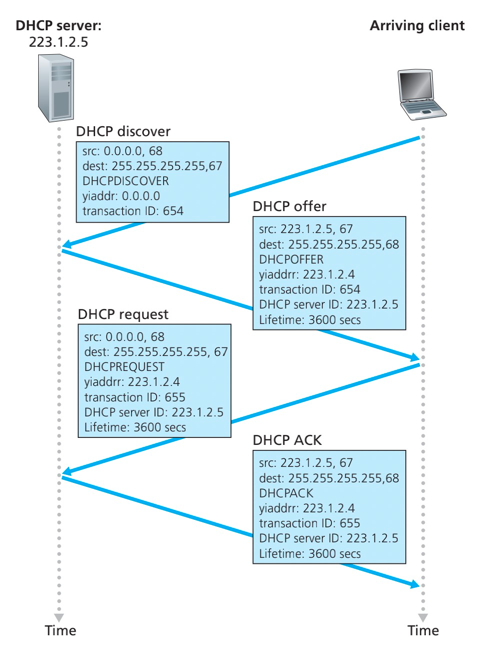
DHCP(Dynamic Host Configuration)动态主机配置协议:允许主机从服务器自动获取一个IP地址。
- 可以更新对主机在用IP地址的租用期-租期快到了
- 重新启动时,允许重新使用以前用过的IP地址
- 支持移动用户加入到该网络(短期在网)
DHCP工作概况:
- 主机广播“DHCP discover” 报文[可选]
- DHCP 服务器用 “DHCP offer”提供报文响应[可选]
- 主机请求IP地址:发送 “DHCP request” 报文
- DHCP服务器发送地址:“DHCP ack” 报文
DHCP客户-服务器交互
网络地址转换(Network Address Translation, NAT) 所有离开本地网络的数据报具有一个 相同的源地址NAT 如IP address:138.76.29.7, 但是具有不同的端口号
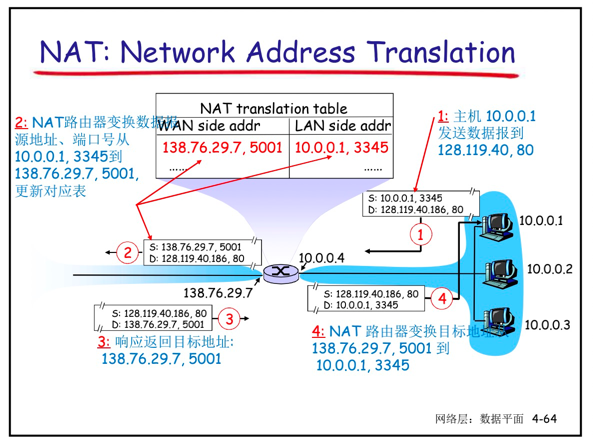
对NAT是有争议的:
- 路由器只应该对第3层做信息处理,而这里对端口号(4层)作了处理
- 违反了end-to-end 原则
- 端到端原则:复杂性放到网络边缘
- 无需借助中转和变换,就可以直接传送到目标主机
- NAT可能要被一些应用设计者考虑, eg, P2P applications
- 外网的机器无法主动连接到内网的机器上
- 端到端原则:复杂性放到网络边缘
- 地址短缺问题可以被IPv6 解决
- NAT穿越: 如果客户端需要连接在NAT后面的服务器,如何操作
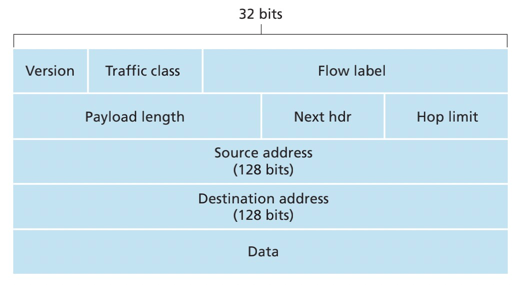 特点:
特点:
- 扩大的地址容量:将IP地址长度从32比特增加到128比特
- 简化高效的40字节首部
- 流标签(flow label):流标签没有被明确定义。主要由于区分流类型,目前确定的是可以用于区分流的优先级
- 升级ICMPv6,增加
Packet Too Big报文以及多播组管理功能
定义:
- 版本:IP版本号
- 流量类型(traffic class): 与IPv4中的TOS字段类似
- 流标签(flow label):标识一条数据包的流。
- 有效载荷长度(payload length)
- 下一个首部(next hdr): 标识下层交付的协议,如TCP、UDP
- 跳限制(hop limit):与IPv4中的TTL一样,经过一台路由器减1
- 源地址与目的地址
- 数据(data)
优化:
- 分片/重新组装:不允许中间路由器进行分片和重新组装,遇到数据与链路不匹配,直接返回发送方一个
Packet Too BigICMP差错报文。该功能加快了报文的传输。 - 首部校验和:因为运输层及数据链路层已经做了差错校验,简化多余的差错校验。
- 选项:选项字段不再是标准IP首部的一部分,使得IP首部固定为40个字节。使用下一个首部(next hdr)代替选项。
IPv4到IPv6的迁移:使用隧道技术,在IPv4路由器之间传输的IPv4数据报中携带IPv6数据报
网络设备控制平面的实现方式特点
互联网网络设备:传统方式都是通过分布式,每台 设备的方法来实现数据平面和控制平面功能
- 垂直集成:每台路由器或其他网络设备,包括:
- 1)硬件、在私有的操作系统;
- 2)互联网标准协议(IP, RIP, IS-IS, OSPF, BGP)的私有实现
- 从上到下都由一个厂商提供(代价大、被设备上“绑架”)
- 每个设备都实现了数据平面和控制平面的事情:控制平面的功能是分布式实现的
- 设备基本上只能(分布式升级困难)按照固定方式工作, 控制逻辑固化。不同的网络功能需要不同的 “middleboxes”:防火墙、负载均衡设备、NAT boxes, ..
(数据+控制平面)集成>(控制逻辑)分布->固化
代价大;升级困难;管理困难等
传统方式实现网络功能的问题
- 垂直集成>昂贵、不便于创新的生态
- 分布式、固化设备功能==网络设备种类繁多
- 无法改变路由等工作逻辑,无法实现流量工程等高级特性
- 配置错误影响全网运行;升级和维护会涉及到全网设备:管理困难
- 要增加新的网络功能,需要设计、实现以及部署新的特定设备,设备种类繁多
~2005: 开始重新思考网络控制平面的处理方式
- 集中:远程的控制器集中实现控制逻辑
- 远程:数据平面和控制平面的分离
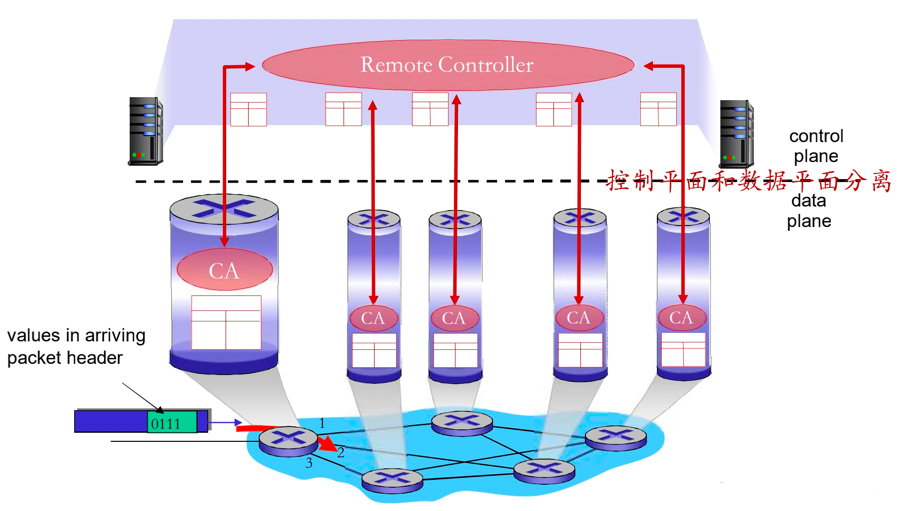
SDN:逻辑上集中的控制平面一个不同的(通常是远程)控制器和CA(Certification Authority)交互,控制器决定分组转发的逻辑(可编程),CA所在设备执行逻辑。
SDN的主要思路
- 网络设备数据平面和控制平面分离
- 数据平面-分组交换机
- 将路由器、交换机和目前大多数网络设备的功能进一步抽象成:按照流表(由控制平面设置的控制逻辑)进行PDU (帧、分组)的动作(包括转发、丢弃、拷贝、泛洪、阻塞)
- 统一化设备功能:SDN交换机(分组交换机),执行控制逻辑
- 控制平面-控制器+网络应用
- 分离、集中
- 计算和下发控制逻辑:流表
SDN控制平面和数据平面分离的优势:
- 水平集成控制平面的开放实现(而非私有实现),创造出好的产业生态,促进发展
分组交换机、控制器和各种控制逻辑网络应用app可由不同厂商生产,专业化,引入竞争形成良好生态
- 集中式实现控制逻辑,网络管理容易
1)集中式控制器了解网络状况,编程简单,传统方式困难避免路由器的误配置
2)基于流表的匹配+行动的工作方式允许“可编程的”分组交换机
- 实现流量工程等高级特性:在此框架下实现各种新型(未来)的网络设备
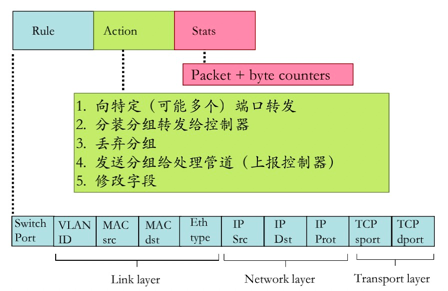
路由器中的流表定义了路由器的匹配+行动规则(流表由控制器计算并下发)
流: 由分组(帧)头部字段所定义
通用转发: 简单的分组处理规则
- 模式: 将分组头部字段和流表进行匹配
- 行动:对于匹配上的分组,可以是丢弃、转发、修改、将匹配的分组发送给控制器
- 优先权Priority: 几个模式匹配了,优先采用哪个,消除歧义
- 计数器Counters: #bytes 以及 #packets
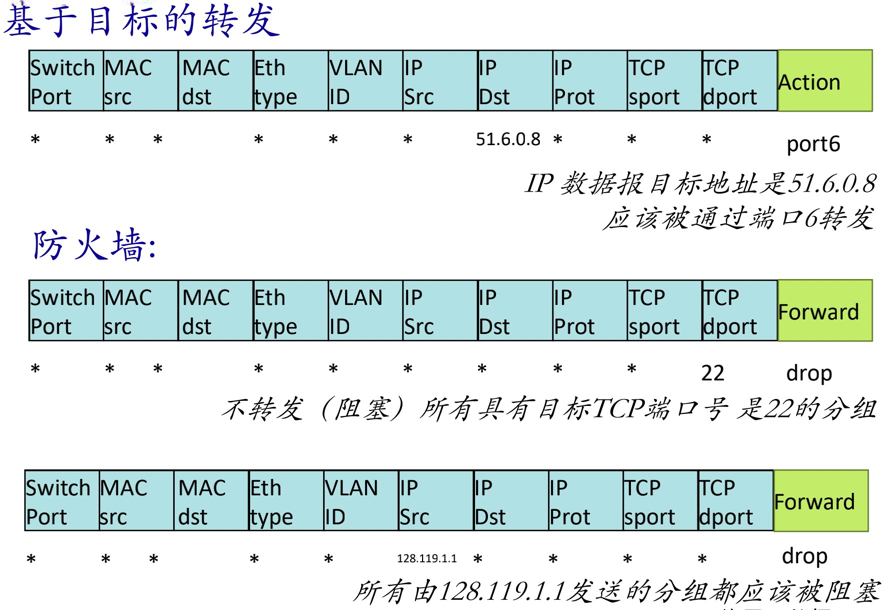
match+action: 统一化各种网络设备提供的功能
- 路由器:match: 最长前缀匹配。action: 通过一条链路转发。
- 防火墙:match: IP地址和TCP/UDP端口号。action: 允许或者禁止。
- 交换机:match: 目标MAC地址。action: 转发或者泛洪。
- NAT:match: IP地址和端口号。action: 重写地址和端口号。
目前几乎所有的网络设备都可以在这个 匹配+行动模式框架进行描述,具体化为各种网络设备包括未来的网络设备
路由:按照某种指标(传输延迟,所经过的站点数目等)找到一条从源节点到目标节点的较好路径
- 较好路径: 按照某种指标较小的路径
- 指标:站数, 延迟,费用,队列长度等, 或者是一些单纯指标的加权平均
- 采用什么样的指标,表示网络使用者希望网络在什么方面表现突出,什么指标网络使用者比较重视
以网络为单位进行路由(路由信息通告+路由计算)
- 网络为单位进行路由,路由信息传输、计算和匹配的代价低
- 前提条件:一个网络所有节点地址前缀相同,且物理上聚集
- 路由:计算网络到其他网络如何走的问题
网络到网络的路由 = 路由器-路由器之间路由
- 网络对应的路由器到其他网络对应的路由器的路由
- 在一个网络中:路由器-主机之间的通信,链路层解决
- 到了这个路由器就是到了这个网络
网络的图抽象
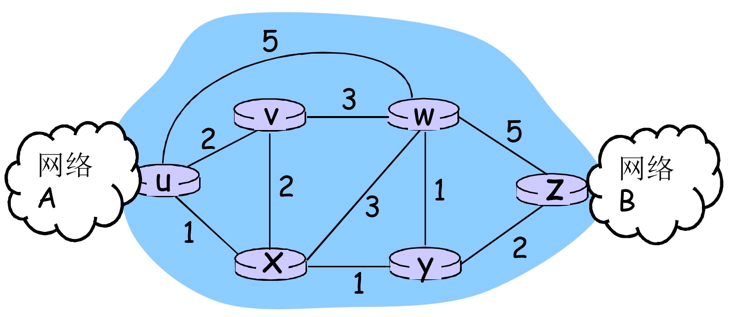
路由的输入:拓扑、边的代价、源节点
输出的输出:源节点的汇集树
汇集树(sink tree)
- 此节点到所有其它节点的最优路径形成的树
- 路由选择算法就是为所有路由器找到并使用汇集树
路由选择算法的原则
- 正确性(correctness): 算法必须是正确的和完整的,使分组一站一站接力,正确发向目标站;完整指的是目标所有的站地址,在路由表中都能找到相应的表项;没有处理不了的目标站地址;
- 简单性(simplicity): 算法在计算机上应简单:最优但复杂的算法,时间上延迟很大,不实用,不应为了获取路由信息增加很多的通信量;
- 健壮性(robustness): 算法应能适应通信量和网络拓扑的变化:通信量变化,网络拓扑的变化算法能很快适应;不向很拥挤的链路发数据,不向断了的链路发送数据;
- 稳定性(stability): 产生的路由不应该摇摆
- 公平性(fairness): 对每一个站点都公平
- 最优性(optimality): 某一个指标的最优,时间上,费用上,等指标,或综合指标;实际上,获取最优的结果代价较高,可以是次优的
算法分类:
- 全局路由信息:所有的路由器拥有完整的拓扑和边的代价的信息。对应的算法为
“link state”算法 - 分布式:路由器只知道与它有物理连接关系的邻居路由器,以及到相应邻居路由器的代价值。对应的算法为
“distance vector”算法 - 静态:路由随时间变化缓慢。对应的为非自适应算法(non-adaptive algorithm):不能适应网络拓扑和通信量的变化,路由表是事先计算好的
- 动态:路由变化快,周期性更新或者根据链路代价变化而变化。自适应路由选择(adaptive algorithm):能适应网络拓扑和通信量的变化
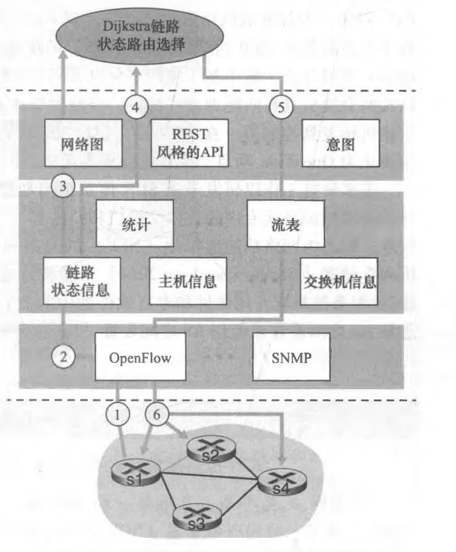
配置LS路由选择算法的路由工作过程:各点通过各种渠道获得整个网络拓扑, 网络中所有链路代价等信息(这部分和算法没关系,属于协议和实现),使用LS路由算法,计算本站点到其它站点的最优路径(汇集树),得到路由表。
LS路由的基本工作过程
- 发现相邻节点,获知对方网络地址
- 测量到相邻节点的代价(延迟,开销)
- 组装一个LS分组,描述它到相邻节点的代价情况
- 将分组通过扩散的方法发到所有其它路由器以上4步让每个路由器获得拓扑和边代价
- 通过Dijkstra算法找出最短路径(这才是路由算法)
- 每个节点独立算出来到其他节点(路由器=网络)的最短路径
- 迭代算法:第k步能够知道本节点到k个其他节点的最短路径
算法复杂度: n节点
- 每一次迭代: 需要检查所有不在永久集合N中节点
- n(n+1)/2 次比较: O(n2) 有很有效的实现: O(nlogn)
问题可能的网络震荡:Dijkstra算法会导致流量全走最优路径,进而导致最优路径变拥塞,进而产生链路震荡的情况
链路代价=链路承载的流量:
距离矢量路由选择的基本思想
- 各路由器维护一张路由表
- 各路由器与相邻路由器交换路由表
- 根据获得的路由信息,更新路由表
代价:跳数(hops),、延迟(delay)、队列长度
相邻节点间代价的获得:通过实测
定期测量它到相邻节点的代价、定期与相邻节点交换路由表(DV)
路由信息的更新
- 根据实测得到本节点A到相邻站点的代价(如:延迟)
- 根据各相邻站点'声称',它们到目标站点B的代价
- 计算出本站点A经过各相邻站点到目标站点B的代价
- 找到一个最小的代价,和相应的下一个节点Z,到达节点B经过此节点Z,并且代价为A-Z-B的代价
- 其它所有的目标节点一个计算法
Bellman-Ford 方程(动态规划)
dx(y) := 从x到y的最小路径代价
// c(x,v) x到邻居v的代价
// dv(y) 从邻居v到目标y的代价
dx(y) = min {c(x,v) + dv(y) }
DV的特点: 好消息传的快,坏消息传的慢
好消息传的快:好消息的传播以每一个交换周期前进一个路由器的速度进行,好消息:某个路由器接入或有更短的路径。
坏消息传的慢:坏消息的传播速度非常慢(无穷计算问题),如网络存在环路,且目标节点不可达INF,那么只能等待传输DDL扣减完成才知道节点不可达。 坏消息传的慢的一种解决算法:水平分裂(split horizon)算法,但是在存在环路的问题下仍然会失败。
消息复杂度(DV胜出)
- LS: 有 n 节点, E 条链路,发送报文O(nE)个。局部的路由信息;全局传播。
- DV: 只和邻居交换信息。全局的路由信息,局部传播
收敛时间(LS胜出)
- LS: O(n2) 算法。有可能震荡。
- DV: 收敛较慢。可能存在路由环路,count-to-infinity问题。
健壮性: 路由器故障会发生什么(LS胜出)
LS:
- 节点会通告不正确的链路代价
- 每个节点只计算自己的路由表
- 错误信息影响较小,局部,路由较健壮 DV:
- DV 节点可能通告对全网所有节点的不正确路径代价 —— 距离矢量
- 每一个节点的路由表可能被其它节点使用 —— 错误可以扩散到全网
RIP 基于Distance vector算法,距离矢量为每条链路cost=1,# of hops (max = 15 hops)跳数
- 通告:DV每隔30秒和邻居交换DV
- 每个通告包括:最多25个目标子网
通告报文通过UDP报文传送,周期性重复
- 使用LS算法 LS 分组在网络中(一个AS内部)分发
- 全局网络拓扑、代价在每一个节点中都保持
- 路由计算采用Dijkstra算法
- OSPF通告信息中携带:每一个邻居路由器一个表项
- 通告信息会传遍AS全部(通过泛洪),在IP数据报上直接传送OSPF报文 (而不是通过UDP和TCP)
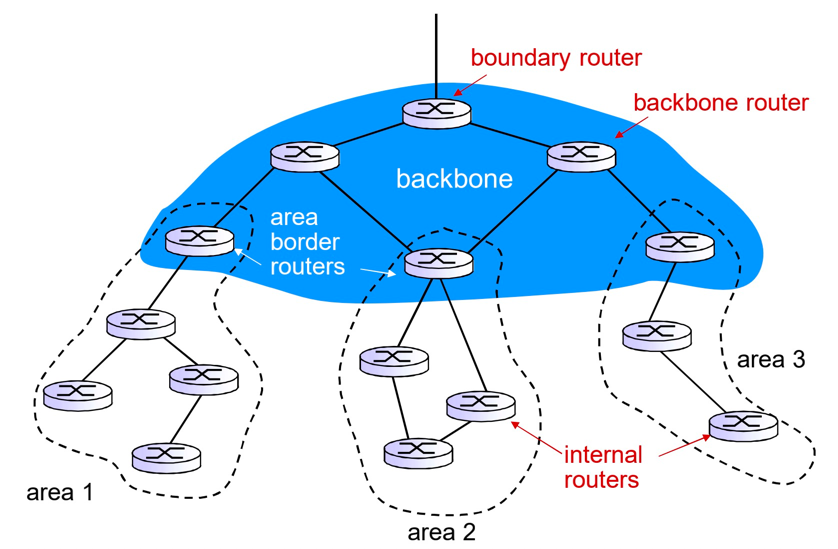
层次化的OSPF路由:2个级别的层次性: 本地, 骨干,链路状态通告仅仅在本地区域Area范围内进行
每一个节点拥有本地区域的拓扑信息;关于其他区域,知道去它的方向,通过区域边界路由器(最短路径)
- 区域边界路由器: “汇总(聚集)”到自己区域内网络的距离, 向其它区域边界路由器通告.
- 骨干路由器: 仅仅在骨干区域内,运行OSPF路由
- 边界路由器: 连接其它的AS’s.
BGP (Border Gateway Protocol): 自治区域间路由协议“事实上的”标准,“将互联网各个AS粘在一起的胶水”
BGP 提供给每个AS以以下方法:
- eBGP: 从相邻的ASes那里获得子网可达信息
- iBGP: 将获得的子网可达信息传遍到AS内部的所有路由器
- 根据子网可达信息和策略来决定到达子网的“好”路径