Spring Cloud
1. Open Feign 源码
2. Hystrix
2.1. @HystrixCommand
2.2. 断路器流程
2.2.1. 线程池与 信号量隔离
2.3. @HystrixCollapser
2.3.1. 合并请求的开销
2.3.2. 什么时候使用合并请求的功能?
2.3.2.1. 请求命令本身的延迟
2.3.2.2. 并发量
2.4. 相关资料
3. Eureka
3.1. 工作流程
3.2. 自我保护机制
3.2.1. 背景
3.2.2. 工作机制
3.3. CAP原则实现
3.3.1. Eureka AP原则
3.3.2. Zookeeper CP原则
3.4. 数据同步
3.5. 相关资料
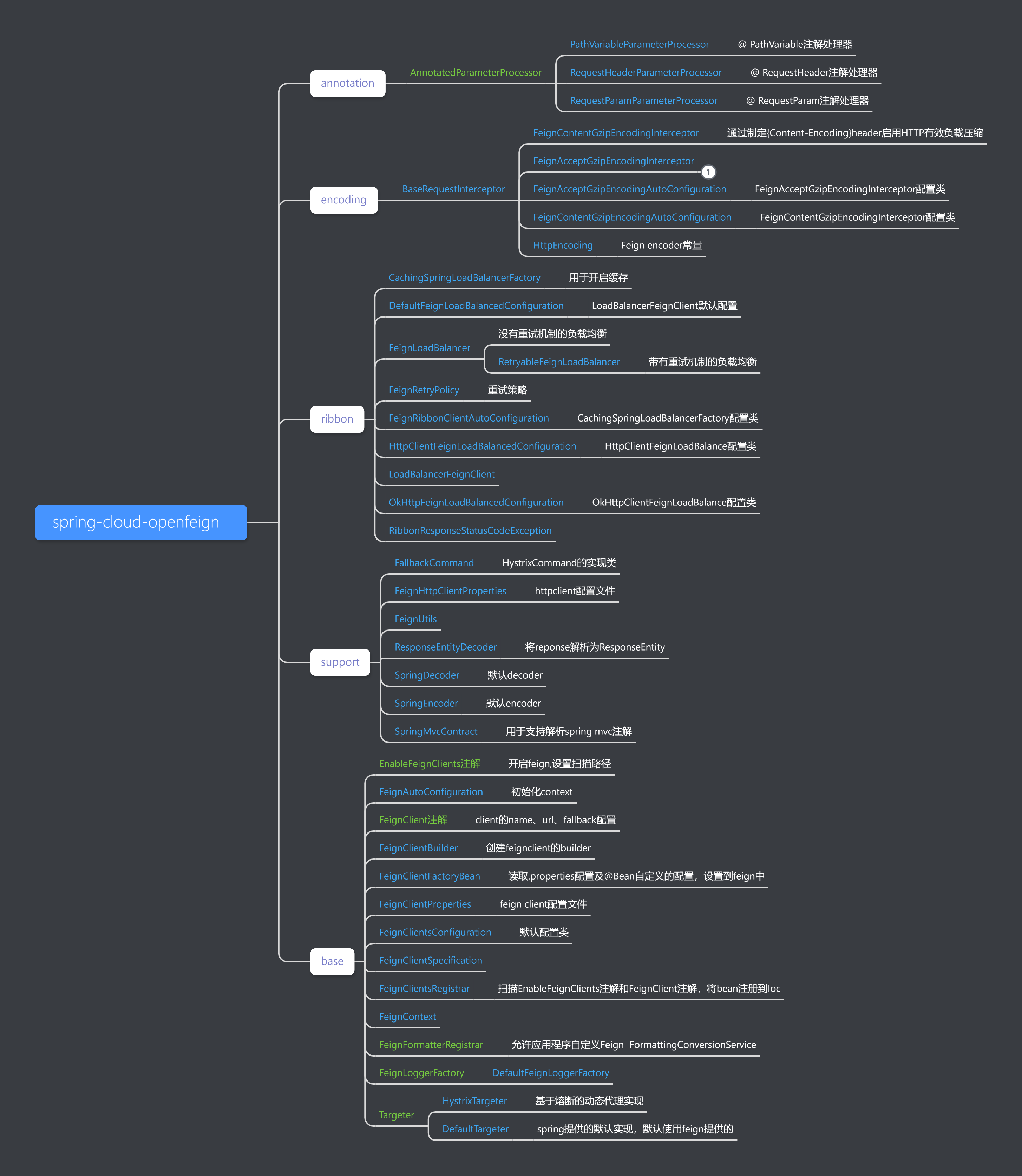
@EnableFeignClients开启FeignClients,主要通过@Import({FeignClientsRegistrar.class})注解注入到IOC容器FeignClientsRegistrar通过继承ImportBeanDefinitionRegistrar的registerBeanDefinitions方法扫描使用@Feign的相关接口及类- 将扫描到的接口获取其对应的相关属性,注入到
FeignClientFactoryBean的对象定义中,并设置为@primary,并注入到IOC容器的bean定义。 - IOC初始化时调用FeignClientFactoryBean的getObject方法,通过applicationContext 获取 FeignContext
- 通过FeignContext获取Builder,进而通过Builder配合FeignClientFactoryBean构建Client对象
LoadBalancerClient
相关资料: spring-cloud-openFeign源码深度
整体流程图
基于注解的实现流程:
- 使用HystrixCommandAspect切面实现,通过扫描注解属性进而新建不同的HystrixCommand对象。
- HystrixCommand对象会通过线程池进行请求调用,并在调用失败或成功均反馈结果实现。实现断路器的控制。
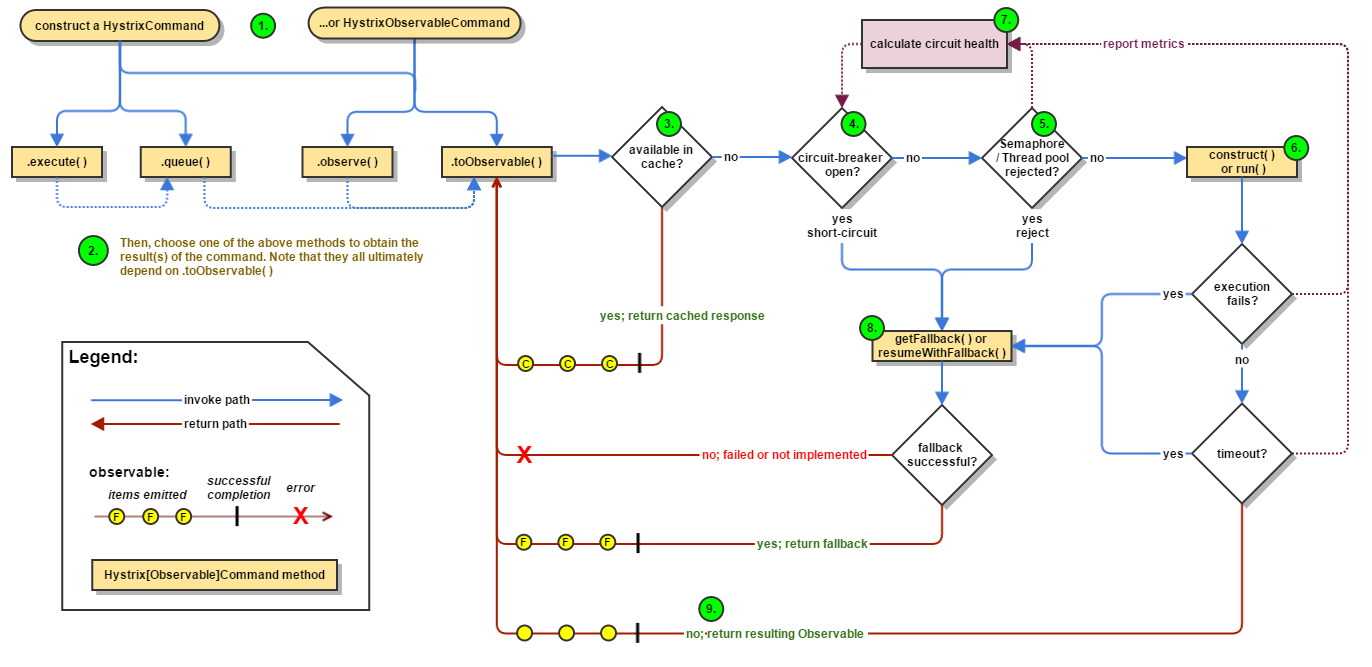
Hystrix有两个请求命令:HystrixCommand、HystrixObservableCommand。
HystrixCommand用在依赖服务返回单个操作结果的时候。又两种执行方式
- execute():同步执行。从依赖的服务返回一个单一的结果对象,或是在发生错误的时候抛出异常。
- queue();异步执行。直接返回一个Future对象,其中包含了服务执行结束时要返回的单一结果对象。
HystrixObservableCommand 用在依赖服务返回多个操作结果的时候。它也实现了两种执行方式
- observe():返回Obervable对象,他代表了操作的多个结果,他是一个HotObservable
- toObservable():同样返回Observable对象,也代表了操作多个结果,但它返回的是一个Cold Observable。
public HystrixInvokable create(MetaHolder metaHolder) {
HystrixInvokable executable;
if (metaHolder.isCollapserAnnotationPresent()) {
executable = new CommandCollapser(metaHolder);
} else if (metaHolder.isObservable()) {
executable = new GenericObservableCommand(HystrixCommandBuilderFactory.getInstance().create(metaHolder));
} else {
executable = new GenericCommand(HystrixCommandBuilderFactory.getInstance().create(metaHolder));
}
return executable;
}
public Observable<R> toObservable() {
final AbstractCommand<R> _cmd = this;
//doOnCompleted handler already did all of the SUCCESS work
//doOnError handler already did all of the FAILURE/TIMEOUT/REJECTION/BAD_REQUEST work
...
final Func0<Observable<R>> applyHystrixSemantics = new Func0<Observable<R>>() {
@Override
public Observable<R> call() {
if (commandState.get().equals(CommandState.UNSUBSCRIBED)) {
return Observable.never();
}
return applyHystrixSemantics(_cmd);
}
};
//mark the command as CANCELLED and store the latency (in addition to standard cleanup)
...
return Observable.defer(new Func0<Observable<R>>() {
@Override
public Observable<R> call() {
/* this is a stateful object so can only be used once */
if (!commandState.compareAndSet(CommandState.NOT_STARTED, CommandState.OBSERVABLE_CHAIN_CREATED)) {
IllegalStateException ex = new IllegalStateException("This instance can only be executed once. Please instantiate a new instance.");
//TODO make a new error type for this
throw new HystrixRuntimeException(FailureType.BAD_REQUEST_EXCEPTION, _cmd.getClass(), getLogMessagePrefix() + " command executed multiple times - this is not permitted.", ex, null);
}
commandStartTimestamp = System.currentTimeMillis();
/* try from cache first */
if (requestCacheEnabled) {
HystrixCommandResponseFromCache<R> fromCache = (HystrixCommandResponseFromCache<R>) requestCache.get(cacheKey);
if (fromCache != null) {
isResponseFromCache = true;
return handleRequestCacheHitAndEmitValues(fromCache, _cmd);
}
}
Observable<R> hystrixObservable =
Observable.defer(applyHystrixSemantics)
.map(wrapWithAllOnNextHooks);
...
// put in cache
return afterCache
.doOnTerminate(terminateCommandCleanup) // perform cleanup once (either on normal terminal state (this line), or unsubscribe (next line))
.doOnUnsubscribe(unsubscribeCommandCleanup) // perform cleanup once
.doOnCompleted(fireOnCompletedHook);
}
});
}
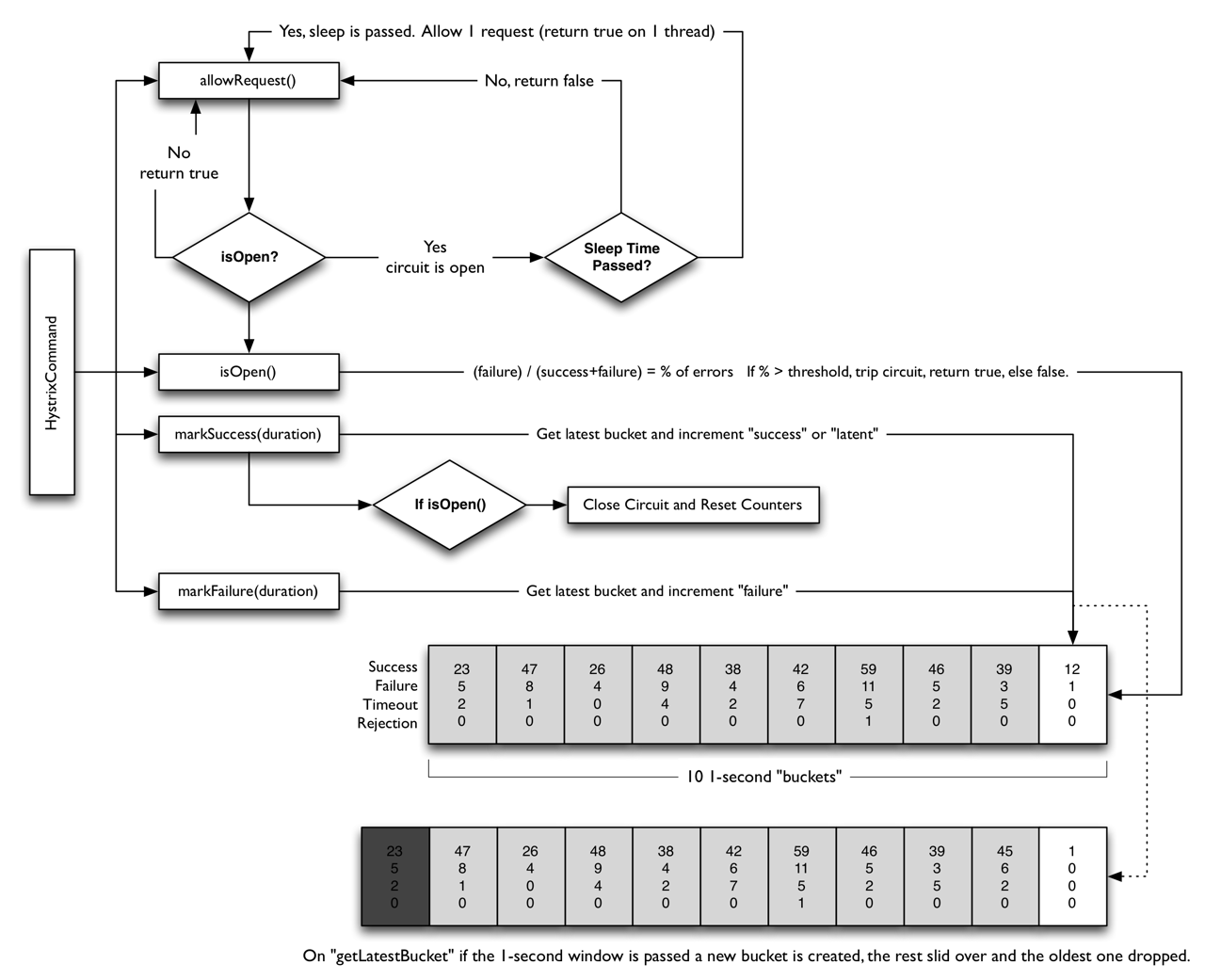
断路器整体逻辑实现
private Observable<R> applyHystrixSemantics(final AbstractCommand<R> _cmd) {
// mark that we're starting execution on the ExecutionHook
// if this hook throws an exception, then a fast-fail occurs with no fallback. No state is left inconsistent
executionHook.onStart(_cmd);
/* determine if we're allowed to execute */
if (circuitBreaker.allowRequest()) {
final TryableSemaphore executionSemaphore = getExecutionSemaphore();
final AtomicBoolean semaphoreHasBeenReleased = new AtomicBoolean(false);
final Action0 singleSemaphoreRelease = new Action0() {
@Override
public void call() {
if (semaphoreHasBeenReleased.compareAndSet(false, true)) {
executionSemaphore.release();
}
}
};
final Action1<Throwable> markExceptionThrown = new Action1<Throwable>() {
@Override
public void call(Throwable t) {
eventNotifier.markEvent(HystrixEventType.EXCEPTION_THROWN, commandKey);
}
};
if (executionSemaphore.tryAcquire()) {
try {
/* used to track userThreadExecutionTime */
executionResult = executionResult.setInvocationStartTime(System.currentTimeMillis());
return executeCommandAndObserve(_cmd)
.doOnError(markExceptionThrown)
.doOnTerminate(singleSemaphoreRelease)
.doOnUnsubscribe(singleSemaphoreRelease);
} catch (RuntimeException e) {
return Observable.error(e);
}
} else {
return handleSemaphoreRejectionViaFallback();
}
} else {
return handleShortCircuitViaFallback();
}
}使用线程池隔离的好处:—— 隔离、保护
- 应用程序完全不受客户端库失控的影响,可以将失败的请求隔离不影响整体应用。
- 客户端同样可以监控应用的情况,在应用恢复的时候再进行调用,而不是失败重复调用。
- 使用线程池隔离,可以实现超时中断及使用的线程调用的功能增强。
- 有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
信号量隔离:
- 优点:做接口限流
- 缺点:无法实现自定义超时时间
高并发下,将请求合并,提高整体的请求效率。
微服务架构中通常需要依赖多个远程的微服务,而远程调用中最常见的问题就是通信消耗与连接数占用。在高并发的情况之下,因通信次数的增加,总的通信时间消耗将会变得越来越长。同时,因为依赖服务的线程池资源有限,将出现排队等待与响应延迟的清况。
为了优化这两个问题,Hystrix 提供了HystrixCollapser来实现请求的合并,以减少通信消耗和线程数的占用。
HystrixCollapser实现了在 HystrixCommand之前放置一个合并处理器,将处于一个很短的时间窗(默认10毫秒)内对同一依赖服务的多个请求进行整合,并以批量方式发起请求的功能(前提是服务提供方提供相应的批量接口)。HystrixCollapser的封装多个请求合并发送的具体细节,开发者只需关注将业务上将单次请求合并成多次请求即可。
需要注意请求合并的额外开销:用于请求合并的延迟时间窗会使得依赖服务的请求延迟增高。比如,某个请求不通过请求合并器访问的平均耗时为5ms,请求合并的延迟时间窗为lOms (默认值), 那么当该请求设置了请求合并器之后,最坏情况下(在延迟时间 窗结束时才发起请求)该请求需要15ms才能完成。
合并请求存在额外开销,所以需要根据依赖服务调用的实际情况决定是否使用此功能,主要考虑下面两个方面:
对于单次请求而言,如果[单次请求平均时间/时间窗口]越小,对于单次请求的性能形象越小。如果依赖服务的请求命令本身是一个高延迟的命令,那么可以使用请求合并器,因为延迟时间窗的时间消耗显得微不足道了。
时间窗口内并发量越大,合并求情的性能提升越明显。如果一个时间窗内只有少数几个请求,那么就不适合使用请求合并器。相反,如果一个时间窗内具有很高的并发量,那么使用请求合并器可以有效减少网络连接数量并极大提升系统吞吐量,此时延迟时间窗所增加的消耗就可以忽略不计了。
工作流程:
- Eureka Server 启动成功,等待服务端注册。在启动过程中如果配置了集群,集群之间定时通过 Replicate 同步注册表,每个 Eureka Server 都存在独立完整的服务注册表信息
- Eureka Client 启动时根据配置的 Eureka Server 地址去注册中心注册服务
- Eureka Client 会每 30s 向 Eureka Server 发送一次心跳请求,证明客户端服务正常
- 当 Eureka Server 90s 内没有收到 Eureka Client 的心跳,注册中心则认为该节点失效,会注销该实例
- 单位时间内 Eureka Server 统计到有大量的 Eureka Client 没有上送心跳,则认为可能为网络异常,进入自我保护机制,不再剔除没有上送心跳的客户端
- 当 Eureka Client 心跳请求恢复正常之后,Eureka Server 自动退出自我保护模式
- Eureka Client 定时全量或者增量从注册中心获取服务注册表,并且将获取到的信息缓存到本地
- 服务调用时,Eureka Client 会先从本地缓存找寻调取的服务。如果获取不到,先从注册中心刷新注册表,再同步到本地缓存
- Eureka Client 获取到目标服务器信息,发起服务调用
- Eureka Client 程序关闭时向 Eureka Server 发送取消请求,Eureka Server 将实例从注册表中删除
对Eureka注册中心需要了解的是Eureka各个节点都是平等的,没有ZK中角色的概念, 即使N-1个节点挂掉也不会影响其他节点的正常运行。
默认情况下,如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。
自我保护机制的工作机制是:如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制,此时会出现以下几种情况:
- Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务。
- Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用。
- 当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中。 因此Eureka Server可以很好的应对因网络故障导致部分节点失联的情况,而不会像ZK那样如果有一半不可用的情况会导致整个集群不可用而变成瘫痪。
如果实现AP原则的,则集群允许在段时间里,各节点的数据出现不一致的情况,但是集群整体服务保持可用。
eureka 保证了可用性,实现最终一致性。
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性),其中说明了,eureka是不满足强一致性,但还是会保证最终一致性
如果实现CP原则的,则集群在各节点数据不一致的段时间里,整体服务是不可用的,需要等待可节点数据同步到一致,再恢复可用状态。
zookeeper在选举leader时,会停止服务,直到选举成功之后才会再次对外提供服务,这个时候就说明了服务不可用,但是在选举成功之后,因为一主多从的结构,zookeeper在这时还是一个高可用注册中心,只是在优先保证一致性的前提下,zookeeper才会顾及到可用性
Peer to Peer 平等复制 数据同步流程