本项目旨在复现一个简单的列存储数据库管理系统Simplified C-Store,它将以面向列的数据库存储模式,实现数据库的最基础的功能。
①、Simplified SQL Compiler:一个简化版SQL语言的解释器;
②、Create操作:在数据库里建表;
③、Retrieve操作:通过主键检索表的记录;
④、External Sort:实现基于归并排序算法的外排序;
⑤、Compress操作:利用RLE算法对数据库列文件做压缩;
⑥、Count操作:计算数据库表的记录数,作为聚合函数的代表;
⑦、锁管理:为DBMS提供互斥锁和共享锁服务;
⑧、简单事务:提供简单的事务管理;
⑨、内存管理:为整个DBMS提供统一的内存管理服务;
⑩、多线程连接池:使DBMS能够处理并发的查询。
SSQL语言,即Simplified-SQL,是对结构化查询语言SQL的一种简化,它只保留了我们实现Simplified C-Store DBMS时所需要的查询语法和关键字,是一种严格的上下文无关文法语言。SSQL解释器作为C-Store DBMS中的核心组件之一,负责将用户输入的SSQL语言编译为数据库引擎可以理解的中间语言。限于正文的篇幅,SSQL语言的具体文法规则将在本文的附件A中做详细说明,因此不在此处赘述。
SSQL解释器的工作活动示意图如下图所示,在下文将根据此结构详细分析整个流程中的技术原理。

对给定的查询语句,词法分析器将分析句子里的每个字符,对单词进行识别并产生一个包含了单词信息和类型的数据结构词素,称之为Token。将识别出的所有Token全部放入Token流中,Token流将交由后续的语法分析器去继续进行处理。
SSQL的词法分析问题,实际上是一个识别和解析字符串的问题,可以用DFA(确定性有穷自动机)算法来实现。DFA是一个能实现状态转移的自动机,对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态(这个状态有可能是先前的状态)。DFA逐个扫描源代码字符,并根据给定的状态转移表到达下一状态。在读完该字符串后,如果自动机停在一个接受状态,那么它就接受该字符串,反之则拒绝该字符串。脚本编译过程中的词法分析阶段通常占据编译时间的25%左右,因此合理的DFA设计非常重要。
在词法分析过程中,采用忽略空白字符(\r, \t, \n, 空格)的最长匹配原则,当输入的多个前缀与一个或多个模式匹配时,采用以下规则解决冲突:
① 总是选择最长的前缀。比如,扫描到字符“<”时,会向字符流的前面再看一个字符,看是否能匹配为更长的“<=”或“<>”,若可以,则匹配为“<=”或“<>”,而不是“<”。
② 如果最长的可能前缀与多个模式匹配,总是优先匹配保留字表中的元素。比如,“CREATE”不会被作为标识符处理,而是被匹配为保留字。
句子 CREATE TABLE customer(custkey INT); 将被词法分析转化为以下的单词流
| 命中行 | 命中列 | Token类型 | 源码内容 | 附加值 |
|---|---|---|---|---|
| 0 | 0 | Keyword_create | CREATE | null |
| 0 | 7 | Keyword_table | TABLE | null |
| 0 | 13 | Identifier | customer | "customer"(string) |
| 0 | 21 | Token_LeftParentheses | ( | null |
| 0 | 22 | Identifier | custkey | "custkey" (string) |
| 0 | 30 | Keyword_int | INT | null |
| 0 | 31 | Token_RightParentheses | ) | null |
| 0 | 32 | Token_Semicolon | ; | null |
词法分析器利用DFA,将输入缓冲中的源代码行数据不断地解析成Token流,与此同时为编译器生成的错误消息与源代码的位置进行关联,例如,词法分析器会为每个Token赋予它在源代码中被命中时的位置戳(行号、列号)和具体的内容。表2-1展示了一个CREATE查询语句转化为Token流的例子。
在这个例子中,SSQL中的一个建表语句被解析成了8个Token,它们包含了自己在代码中的位置以及在DFA中命中的Token类型,常数类型的Token还会被附上一个与它在源码中字符串等价的对应类型的附加值。随后,词法分析器将把生成的Token流返回,由语法分析器去继续进行编译工作。
语法分析器从词法分析器获得Token流,为每一个SSQL语句对应的Token流去建立一棵语法分析树。从2.1.1小节中可以知道,SSQL语言是上下文无关的文法的语言,在消除左递归和二义性问题后,它可以使用LL(1)递归下降分析算法来构造语法分析树。并且很容易注意到,这个行为是可以并行化的。
需要注意的第一点是,对于左递归的情况,考虑直接左递归的产生式格式为:
A → Aα | β ……………………………(2.1)
可以通过将式(2.1)等价转换为式(2.2)、式(2.3)两个产生式来消除左递归:
A → βA’ ………………………………(2.2)
A’ → αA’ | ε …………………………(2.3)
第二点,二义性的消除。当一条产生式的左边看到下一个Token后发现有不止一条候选式,那么这个文法是有二义性的,也就是说,对于一个具有二义性的文法的产生式A → α | β,存在终结符号a使得α 和 β都能够推导出以a开头的串。通过消二义性规则[4],将不需要的语法分析树抛弃,只为每个句子留下一颗语法分析树。
继续考虑表达式文法Gexpr的LL1递归下降推导过程。在自顶向下语法分析过程中,FIRST集与FOLLOW集的引入使得我们可以根据向前看的下一个Token来选择应用哪个产生式。FIRST(α)被定义为可从α推导得到的串的第一个符号的集合,其中α是任意的文法符号串;FOLLOW(A)被定义为可能在某些句型中紧跟在A右边的终结符号的集合。利用FIRST集与FOLLOW集去计算出SELECT集, SELECT集就是需要构造的LL(1)预测分析表M。
其原理和构造方法为:
① 对于FIRST(α) 中的每个终结符号a,将A→α加入到M[A, a]中。
② 如果ε在FIRST(α)中,那么对FOLLOW(A)中的每个终结符号b,将A→α加入到M[A, b]中。如果ε在FIRST(α)中,且语句终止符号#在FOLLOW(A) 中,也将A→α加入到M[A, #]中。
③ 在完成上面的步骤之后,如果M[A, a]中没有产生式,那么将M[A, a]设置为error(用一个空条目表示)。
对于文法Gexpr递归下降的过程,就是不断地取匹配栈顶的符号,在Token流中向前看一个Token的类型后,查预测分析表M获得唯一的产生式来处理语法树当前节点,如果当前节点为非终结符,那么弹出匹配栈顶,展开当前节点,自左向右建子节点,自右向左将子节点压入匹配栈,这就是下降的过程;如果当前节点为终结符,则弹出匹配栈的栈顶元素,但无需展开节点。最后,还需确定下一个展开节点。如果当前节点有同辈分比自己小的节点,则选择离自己最近的那个节点为后继;如果没有同辈分比自己小的节点了,则选择父节点的同辈份比自己小的最大节点……递归终点是,当前节点指针回到语法树根节点,此时语法树生成完毕,匹配工作结束,将这颗语法树的根节点作为这一脚本行的语法树根节点参数字典中对应项目的键值。若未达到递归终点,则继续递归下降继续生长语法树。
总而言之,对表达式的文法在消除了左递归与二义性之后,结合上下文无关文法和LL(1)预测分析表,先从输入Token流中决定该脚本命令行的命令类型并决定语法树根节点的类型,采用上述的LL(1)递归下降的语法分析方法来对当前命令的每个属性等号右边的表达式生成语法分析树,并把它绑定到该命令的对应参数名的参数字典上。完整的SSQL语言关键字、FIRST集、FOLLOW集、LL(1)预测分析表将附录A中介绍。
语法分析的结果是生成了一颗语法分析树,它的根节点包含了它在脚本行中的命令类型和位置戳,它还包含了一个以参数名称作为键,参数值所对应的LL(1)表达式推导根节点作为值的字典对象,例如上表的SSQL语句行所对应的语法分析树如下图所示。语法分析树将被返回到编译器控制器,并交由语义分析器去继续进行剩余的编译工作。

经过语法分析,得到符合文法的语法分析树,接下来进行语法制导的翻译,目的是生成该语法树对应的DBMS中间代码单元Proxy,填充它的待定属性值。
在此过程中,语义分析器将首先根据每一棵语法树的根节点类型来确定要翻译成中间代码的指令码,并构造一个数据结构来包装这个指令和它的参数,记这个数据结构名称为动作包装。例如语义分析器遍历到语法分析树拥有CASE_CREATE_STMT类型的节点时,就可以断定这是一个建表语句,之后她将以此为前提,继续遍历语法树,来填充中间代码单元中与建表相关的属性的值。如opTable属性将在遍历到紧跟在语法节点类型为TAIL_TABLELEAVE的终结符之后的标识符的附加值决定,表2-2展示了图2-3所示的语法分析树所生产的中间代码单元。
对语法分析树中的表达式所对应的子树去递归遍历语法树,通过LL(1)文法的规则,将抽象语法树的表达式转换为逆波兰表达式。由于运行时环境的表达式求值是由一个栈机来维护的,逆波兰式在运行时环境虚拟机中的计算比使用AST更高效和方便。之后,语义分析器还会进行代码优化动作,如对表达式的逆波兰式做常数折叠和复制传播。
C-Store DBMS要求能够处理足够大的数据,这个数据量的尺寸可能无法被直接载入内存。因此,数据库引擎不得不将文件以分页二进制模式读入内存。页是C-Store DBMS进行文件IO的基本单元,它在本项目中被规定为4K,DBMS最大容许装入内存的页数是128页。
分页读入的实现机制是:
① 请求内存管理器DBAllocator分配指定页数的缓冲区;
② 二进制读文件,记录文件指针,写缓冲区,执行数据库动作;
③ 发生缺页中断,从文件指针继续读文件,重复步骤②;
④ 把缓冲区里的更改写到磁盘;
⑤ 请求内存管理器DBAllocator释放缓冲区资源。
锁机制将保证文件不发生访问冲突,保持数据库的一致性,它将在下文详述。
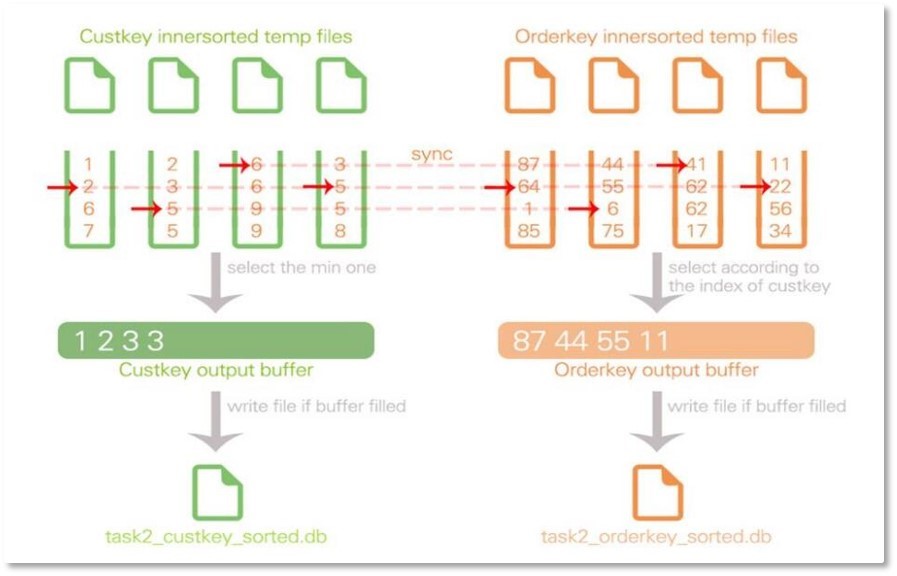
C-Store DBMS的外排序是使用多路归并排序和快速内排序组合来实现的。这个过程可以总结为如下的流程:
① 分页读入数据,将原列文件中的内容一页一页读到输入缓冲区中;
② 对缓冲区中的数据做内排序,即使用快速排序算法在内存中进行排序工作,形成有序趟(Run);
③ 将全部合计N个趟作为临时文件写到磁盘,重复步骤②直到把原来的列全部的值都进行过;
④ 维护N个文件指针,他们指向趟的头部,每次从这些指针指向的文件处读出最小的值,放入输出缓冲区。一旦输出缓冲区满就写到磁盘结果文件中,直到全部的趟都被遍历完,此时生成有序的列文件;
⑤ 请求内存管理器DBAllocator做收尾处理。
下图展示了外排序/归并排序作用于一张有orderkey、custkey两个属性的表,对custkey进行排序的过程。可以看到,对于P个属性,DBMS维护了P个输出缓冲区和N个内排序缓冲区。通过DBAllocator的动态内存分配,我们可以保证DBMS读入内存的数据量不会超过限制的最大页数所等价的内存容量。
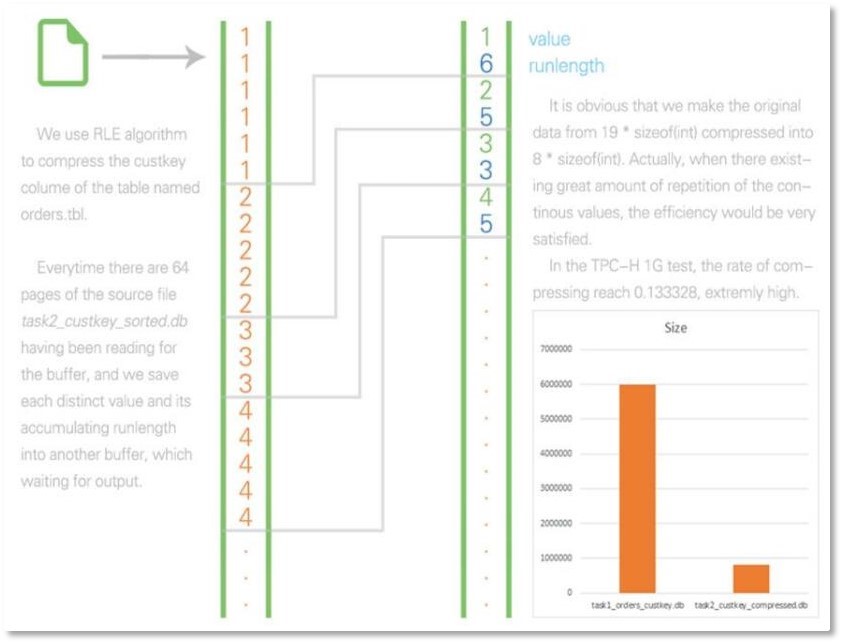
C-Store DBMS作为列存储数据库,其优势之一就是优秀的压缩性能。它的压缩机制我们采用了游程编码算法(Run Length Encode, RLE)。游程编码的原理是用一个<符号值, 串长>的元组去代替具有相同值的连续符号(连续符号构成了一段连续的游程),使符号长度少于原始数据的长度。只在各行或者各列数据的代码发生变化时,一次记录该代码及相同代码重复的个数,从而实现数据的高度压缩。
由于分页机制,C-Store DBMS的RLE算法与标准做法有所区别,下图展示了一个例子,下面详述它的流程:
① 请求内存管理器DBAllocator分配缓冲区,分页读压缩列文件到缓冲区;
② 维护一个指针P和一个计数器C,P从缓冲区头部开始遍历,每当P向前跳动一次,计数器C就加一,直到P跳动之后发现当前指向的值和它跳动前最后一次指向的值不同时,将P跳动前最后一次指向的值V和计数器值C组成一个<V, C>元组,放入输出缓冲区中。一旦输出缓冲区满,就写到磁盘文件上;
③ 如果指针P扫描完缓冲区,则要保存当前最后一次指向的值V和计数器C的值,重新读页并把指针P回归到缓冲区头部,重复步骤②,直到列文件中的所有元素都被处理过;
④ 请求内存管理器DBAllocator做收尾工作。
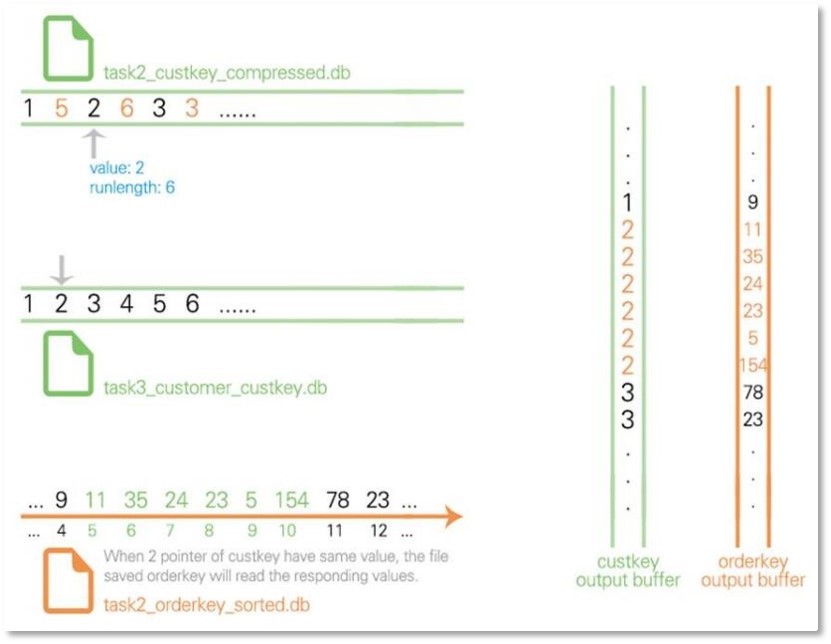
连接操作是DBMS的最重要操作之一。如果关系R与S具有相同的属性组B,且该属性组的值相等时,这个连接动作称为自然连接。
表格保持有序的另一个好处是进行连接时会带来性能的提升。两个有序表的自然连接的复杂度将是令人欢喜的O(M+N),其中M、N是两个表的长度的一个定值。它可以被总结为如下几个核心点:
① 请求内存管理器DBAllocator分配缓冲区,分页读有序列文件到缓冲区;
② 使用两个游标指针对用于自然连接的两个列进行扫描,遇到相同的值就把这两个表当前游标位置的元组写到输出缓冲区,一旦输出缓冲区满就写到磁盘;
③ 重复②直到两个游标到达表格末尾,写输出缓冲区;
④ 请求内存管理器DBAllocator做收尾工作。
以下图所展示的有序自然连接为例,它拼接了order表和customer表,以custkey为自然连接的属性。两个指针扫描这两个表的连接属性,一旦就把对应的所有其他属性一同放入输出缓冲区,这样保证了连接操作最多遍历两张表各一次。
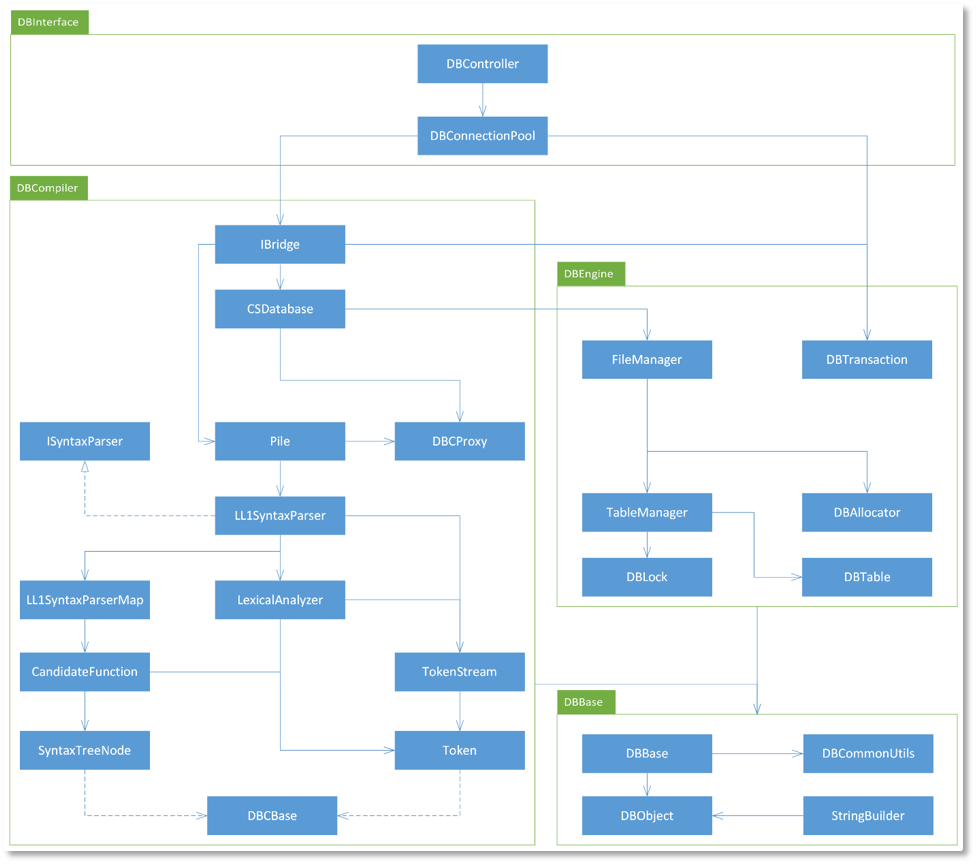
该包实现了用户交互接口以及对用户的输入进行事务封装、进程调度的类。它的类包图如图3-1。包里面的核心类有:
DBControlle:控制器类。负责接收用户的输入并提交给连接池,反馈DBMS的结果和信息输出给用户。
DBConnectionPoo:连接池类。将查询封装为事务并进入事务队列,处理线程从队列里取出事务,新建IBridge实例,将事务发送给它去处理。
该包实现与SSQL语言解释器以及事务处理相关的类。它的类包图如图3-2。包里面的核心类有:
IBridge:桥类。处理线程的执行单元,对事务进行处理;将查询发送给解释器,并将解释结果交给执行器。
CSDatabase:执行器类。接受中间代码单元,执行实际数据库操作。
Pile:语义分析器类。将语法分析树解析为中间代码单元。
SyntaxParser:语法分析器类。将词素流解析为语法分析树。
LexicalAnalyzer:词法分析器类。将查询字符串解析为词素流。
该包实现数据库核心引擎相关的类。图3-3是它的类包图。包里面的核心类有:
FileManager:文件管理器类。负责文件IO操作的类,大部分核心算法在此实现。
DBTransaction:简单事务类。将用户的查询输入封装为事务。
TableManager:表管理器类。维护数据库里的表;维护表格所绑定的锁;使DBMS的表格信息可以持久化。
DBAllocator:内存管理器类。管理动态分配的内存块和缓冲区;维护缓冲区安全地写出和释放。
DBLock:锁类。为事务和数据库操作提供共享锁和互斥锁服务。
DBTable:表类。维护数据库里的表实例;记录表的信息、状态和磁盘上的位置。
所有的类最终都继承自一个公共根类型DBObject,它为子类们提供了大量的可重写的公共辅助函数和接口,例如比较函数、类型名函数、字符串化函数等。这使得各包独立成为模块。