Disk: 2T NVME
CPU: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz * 40
Memory: 256G
Network Card: 10-Gigabit
OS: CentOS Linux release 7.4
data size: 64bytes
key num: 1,000,000
| TEST | QPS |
|---|---|
| set | 124347 |
| get | 283849 |
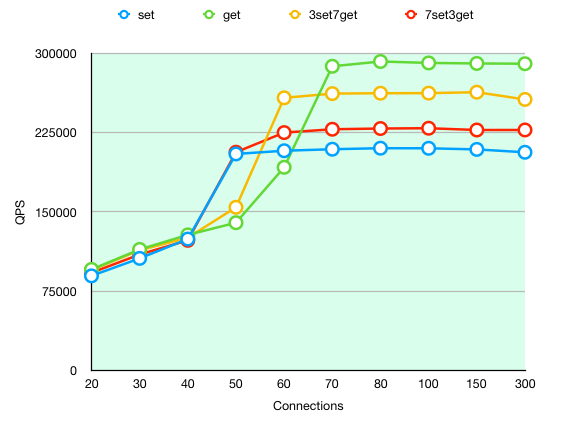
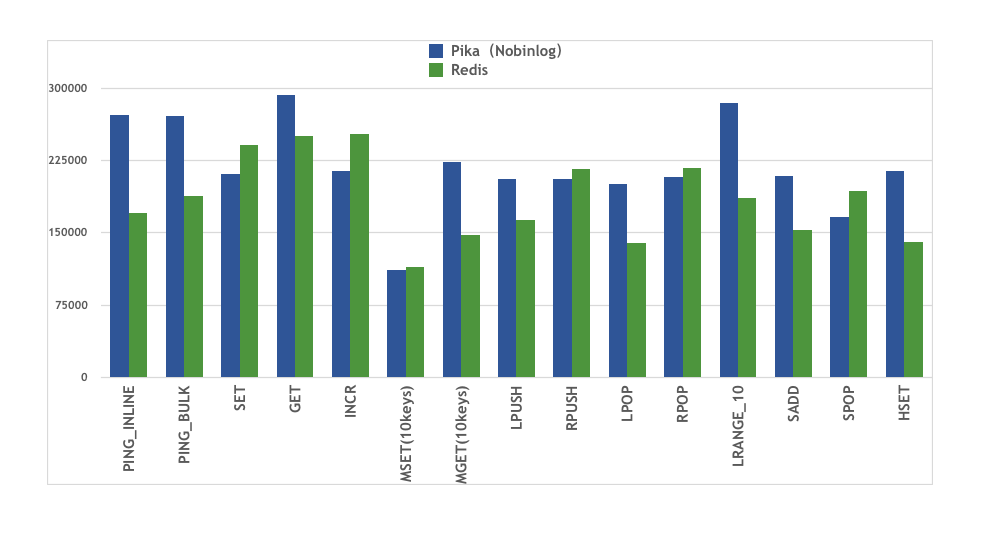
| WithBinlog&Slave QPS | NoBinlog&Slave QPS | |
|---|---|---|
| PING_INLINE | 262329 | 272479 |
| PING_BULK | 262467 | 270562 |
| SET | 124953 | 211327 |
| GET | 284900 | 292568 |
| INCR | 120004 | 213766 |
| MSET (10 keys) | 64863 | 111578 |
| MGET (10 keys) | 224416 | 223513 |
| MGET (100 keys) | 29935 | 29550 |
| MGET (200 keys) | 15128 | 14912 |
| LPUSH | 117799 | 205380 |
| RPUSH | 117481 | 205212 |
| LPOP | 112120 | 200320 |
| RPOP | 119932 | 207986 |
| LRANGE_10 (first 10 elements) | 277932 | 284414 |
| LRANGE_100 (first 100 elements) | 165118 | 164355 |
| LRANGE_300 (first 300 elements) | 54907 | 55096 |
| LRANGE_450 (first 450 elements) | 36656 | 36630 |
| LRANGE_600 (first 600 elements) | 27540 | 27510 |
| SADD | 126230 | 208768 |
| SPOP | 103135 | 166555 |
| HSET | 122443 | 214362 |
| HINCRBY | 114757 | 208942 |
| HINCRBYFLOAT | 114377 | 208550 |
| HGET | 284900 | 290951 |
| HMSET (10 fields) | 58937 | 111445 |
| HMGET (10 fields) | 203624 | 205592 |
| HGETALL | 166861 | 160797 |
| ZADD | 106780 | 189178 |
| ZREM | 112866 | 201938 |
| PFADD | 4708 | 4692 |
| PFCOUNT | 27412 | 27345 |
| PFMERGE | 478 | 494 |
With Redis AOF configuration appendfsync everysec, redis basically write data into memeory. However, pika uses rocksdb, which writes WAL on ssd druing every write batch. That comparation becomes multiple threads sequential write into ssd and one thread write into memory.
Put the fairness or unfairness aside. Here is the performance.
WithBInlog&Slave
4 machine * 2 pika instance (Master)
4 machine * 2 pika instance (Slave)
NoBinlog&Slave
4 machine * 2 pika instance (Master)
Slots Distribution:

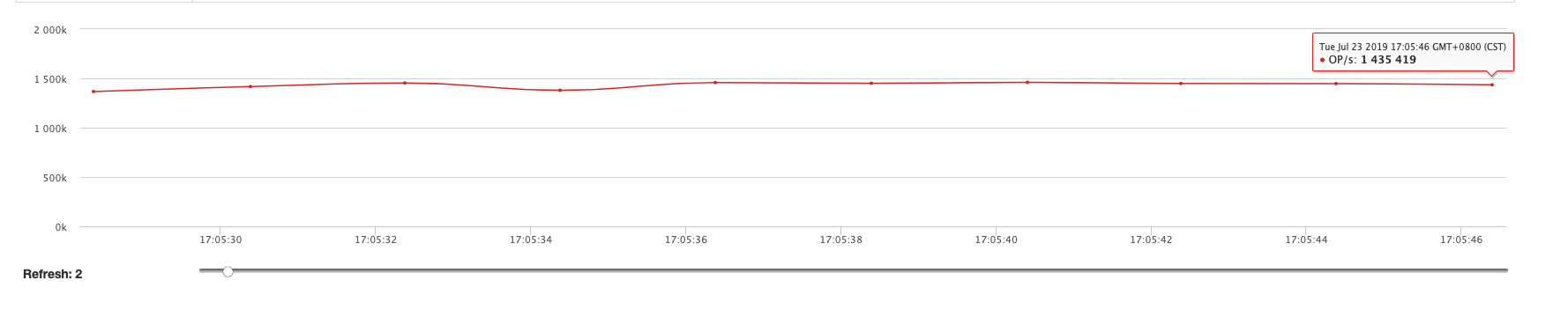
| Command | QPS |
|---|---|
| Set | 1,400,000+ |
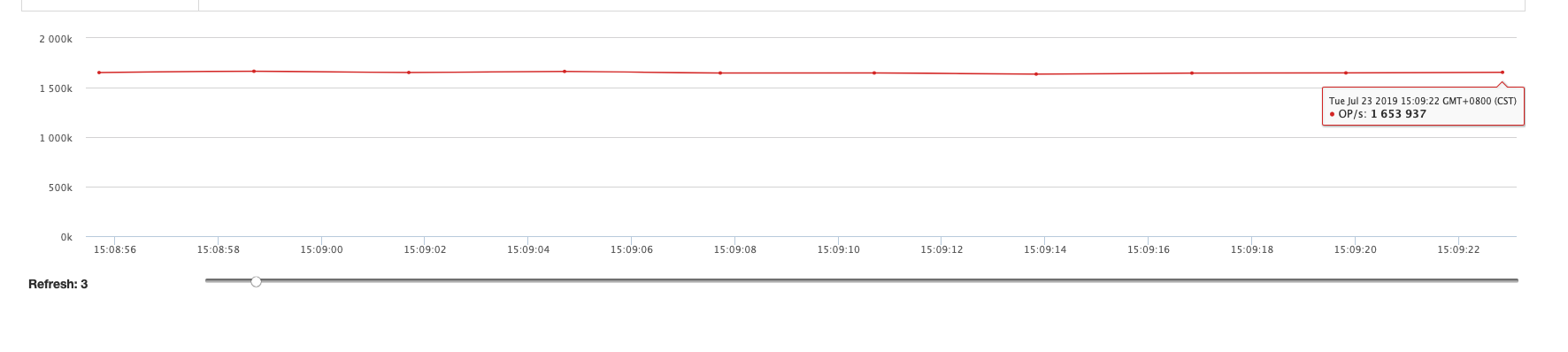
| Command | QPS |
|---|---|
| Set | 1,600,000+ |

| Command | QPS |
|---|---|
| Get | 2,300,000+ |
With or without binlog, for Get command, QPS is approximately the same.