![]()
Parsing microplate data is an extremely common task in the life sciences. This package provides a simple, universal interface for parsing all different types of microplate data into a tidy format.
Note: this package is still early in development and may not work with all machines and data formats. If you are having trouble with a specific usecase, please reach out

One of the core problems of dealing with plate based data is that every manufacturer and machine has a different output format. Rather than build hundreds of separate parsers, we leverage the latest advancements in LLMs to build a single parser that can handle many different formats.
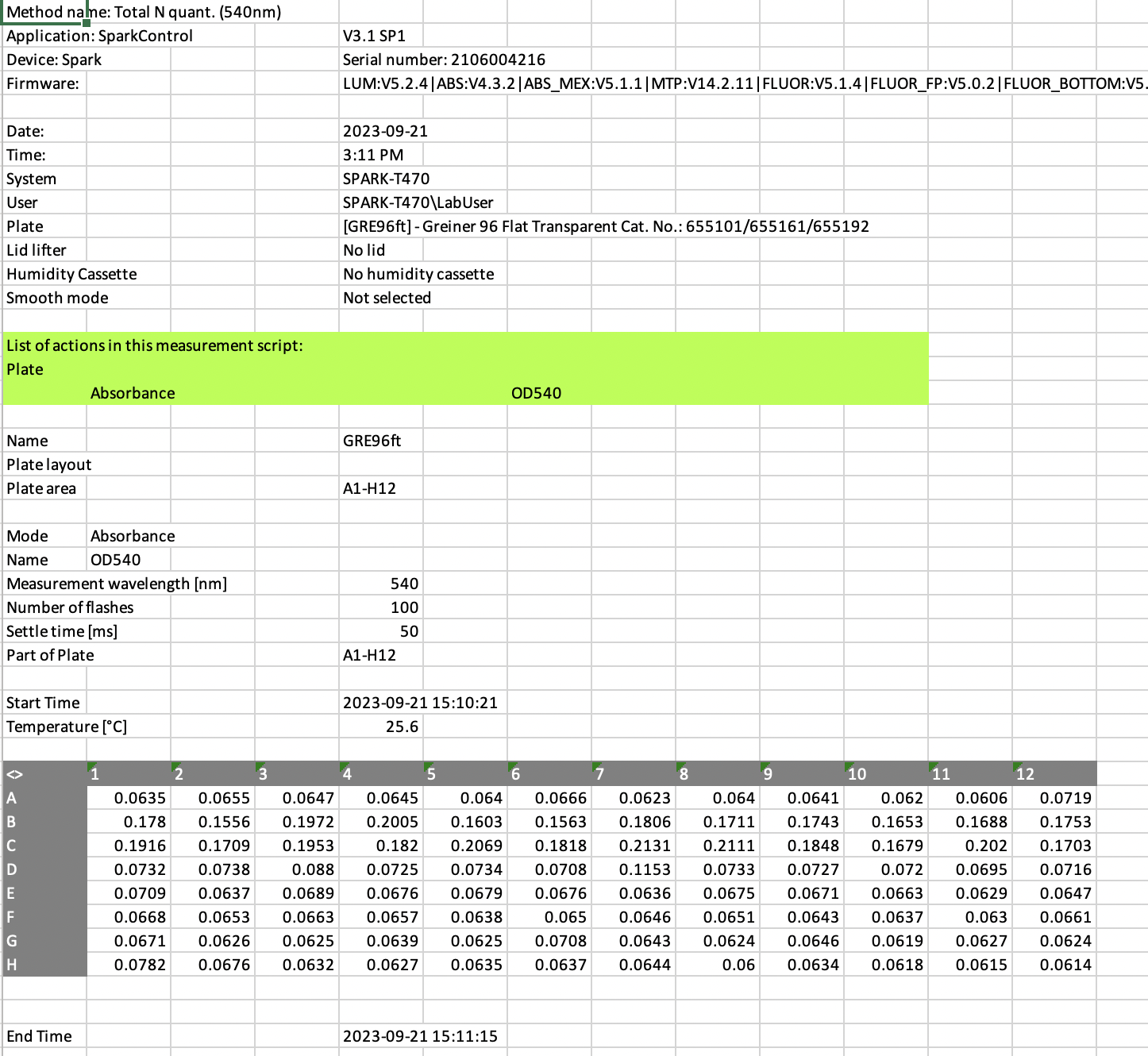

Platechain: From raw data output (left) to a parsed, structured format (right).
pip install platechainMake sure to set your OPENAI_API_KEY environment variable to your OpenAI API key.
You can also set up your LANGCHAIN_API_KEY for tracing (see docs for more info).
We have an example .env.template which listed the variables environment variables you can and should set.
import pandas as pd
from platechain import parse_plates
# Load your data
df = pd.read_csv('examples/byonoy_absolute_example.csv')
# Parse the plates
plate_dfs = parse_plates(df)
# Output: [[96 rows x 4 columns], [96 rows x 4 columns]]See the notebooks directory for more examples.
The core logic is implemented in chain.py.
This file contains a single function, parse_plates, which takes a dataframe and returns a list of dataframes, one for each plate.
It also exposes a LangChain chain using LCEL which can be modified to support your specific usecase.
- Currently only supports 24, 48, 96, and 384 well plates. 1536 well plates are coming soon!
- Only handles plate data that is visually laid out in a grid. If your plate data is already in a table (e.g. a timeseries), this package will not parse it correctly.
We welcome contributions! If you'd like to contribute, please check out our contribution guidelines.
This project is licensed under the terms of the Apache 2.0 license.
This is a Sphinx Bio project! If you're interested in a hosted solution for your lab, please reach out.
Thanks to Harrison and the Langchain team for their help as well!