Extracting data from websites using AI to consistently get contact information.
Our system handles:
- gathering the data with crawls
- advanced filtering pages
- AI enhanced data extracting with OpenAI and Open-Source models
- contact management (coming soon)
Extracting contacts from a website used to be a very difficult challenge involving many steps that would change often. The challenges typically faced involve being able to get the data from a website without being blocked and setting up query selectors for the information you need using javascript. This would often break in two folds - the data extracting with a correct stealth technique or the css selector breaking as they update the website HTML code. Now we toss those two hard challenges away - one of them spider takes care of and the other the advancement in AI to process and extract information.
You can use the UI on the dashboard to extract contacts after you crawled a page. Go to the page you want to extract and click on the horizontal dropdown menu to display an option to extract the contact. The crawl will get the data first to see if anything new has changed. Afterwards if a contact was found usually within 10-60 seconds you will get a notification that the extraction is complete with the data.
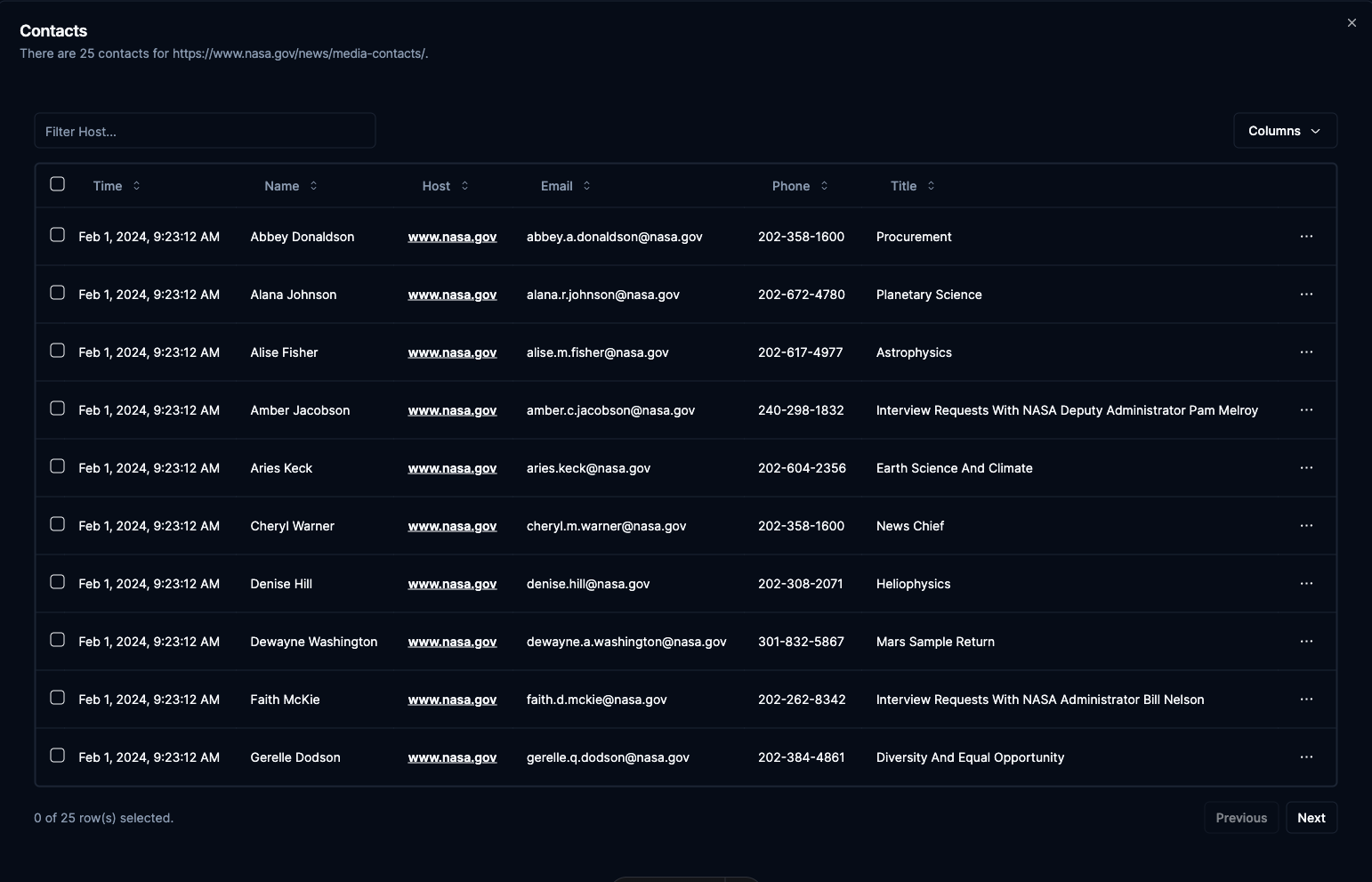
After extraction if the page has contact related data you can view it with a grid in the app.
The grid will display the name, email, phone, title, and host(website found) of the contact(s).
The endpoint /pipeline/extract-contacts provides the ability to extract all contacts from a website concurrently.
To extract contacts from a website you can follow the example below. All params are optional except url. Use the prompt param to adjust the way the AI handles the extracting. If you use the param store_data or if the website already exist in the dashboard the contact data will be saved with the page.
import requests, os, json
headers = {
'Authorization': os.environ["SPIDER_API_KEY"],
'Content-Type': 'application/json',
}
json_data = {"limit":1,"url":"http://www.example.com/contacts", "model": "gpt-4-1106-preview", "prompt": "A custom prompt to tailor the extracting."}
response = requests.post('https://api.spider.cloud/v1/pipeline/extract-contacts',
headers=headers,
json=json_data,
stream=True)
for line in response.iter_lines():
if line:
print(json.loads(line))Pipelines bring a whole new entry to workflows for data curation, if you combine the API endpoints to only use the extraction on pages you know may have contacts can save credits on the system. One way would be to perform gathering all the links first with the /links endpoint. After getting the links for the pages use /pipeline/filter-links with a custom prompt that can use AI to reduce the noise of the links to process before /pipline/extract-contacts.