DS21-02, [email protected]
Transforming the text with toxic style into the text with the same meaning but with neutral style
Explore the docs »
·
Check Project building report »
·
Check Project final report »
Text detoxification refers to the process of cleansing or purifying text content to make it more suitable for various purposes, such as enhancing readability, removing offensive or harmful language, or preparing data for natural language processing tasks. This can involve tasks like profanity filtering, content summarization, paraphrasing, or even removing irrelevant information. Text detoxification is crucial for creating a more inclusive and respectful online environment, as well as for improving the quality of text-based data used in machine learning models, sentiment analysis, and other language processing applications. It plays a vital role in ensuring that text content is both safe and effective in achieving its intended goals.
text-detoxification
├── README.md # The top-level README
│
├── data
│ ├── external # Data from third party sources
│ ├── interim # Intermediate data that has been transformed.
│ └── raw # The original, immutable data, *ATTACHED TO RELEASE
│
├── models # Trained and serialized models, final checkpoints
│
├── notebooks # Jupyter notebooks. Naming convention is a number (for ordering),
│ and a short delimited description, e.g.
│ "1.0-initial-data-exporation.ipynb"
│
├── references # Data dictionaries, manuals, and all other explanatory materials.
│
├── reports # Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures # Generated graphics and figures to be used in reporting
│
├── requirements.txt # The requirements file for reproducing the analysis environment, e.g.
│ generated with pip freeze › requirements. txt'
└── src # Source code for use in this assignment
│
├── data # Scripts to download or generate data
│ └── make_dataset.py
│
├── models # Scripts to train models and then use trained models to make predictions
│ ├── predict_model.py
│ └── train_model.py
│
└── visualization # Scripts to create exploratory and results oriented visualizations
└── visualize.py
The base architecture of PEGASUS is a standard Transformer encoder-decoder.In PEGASUS, the model generates important sentences that have been removed or masked from an input document as a unified output sequence. This process resembles the extraction of key content, similar to an extractive summary
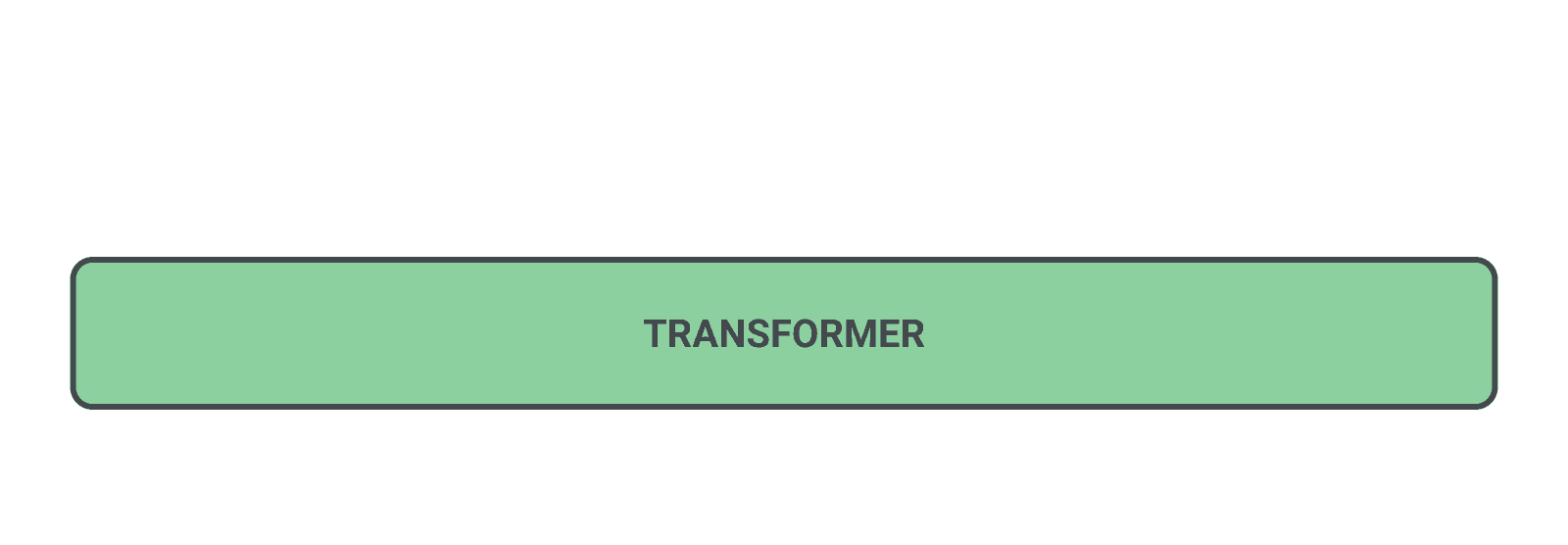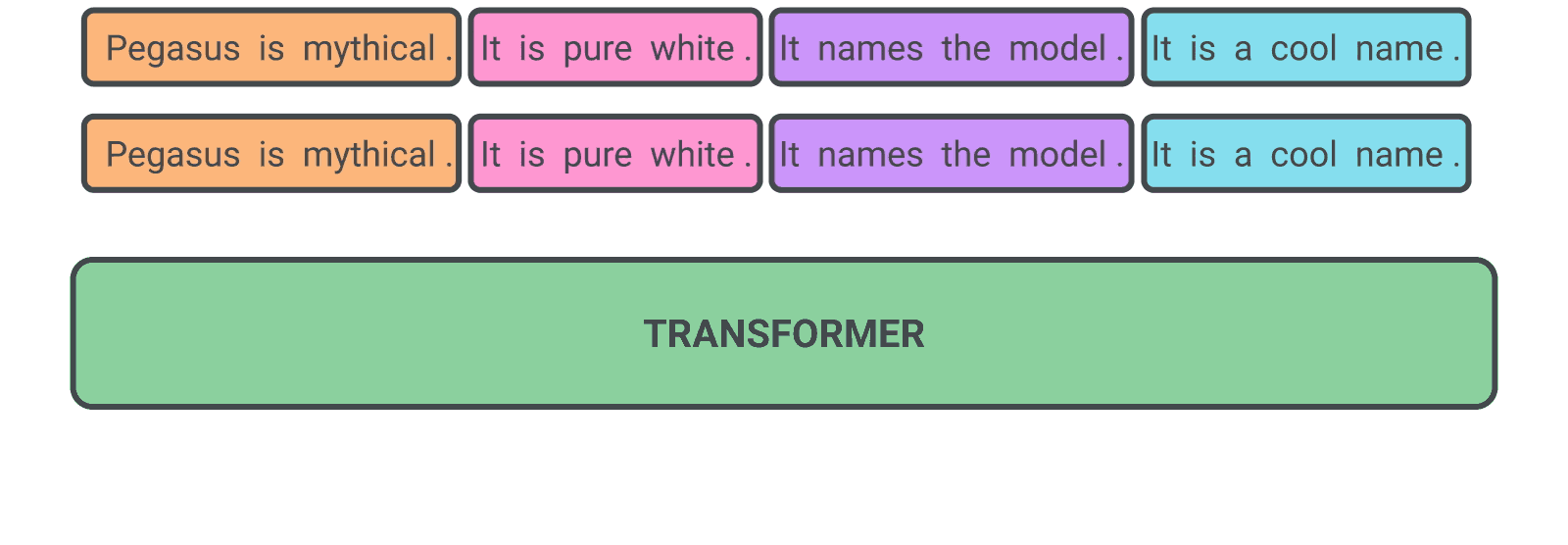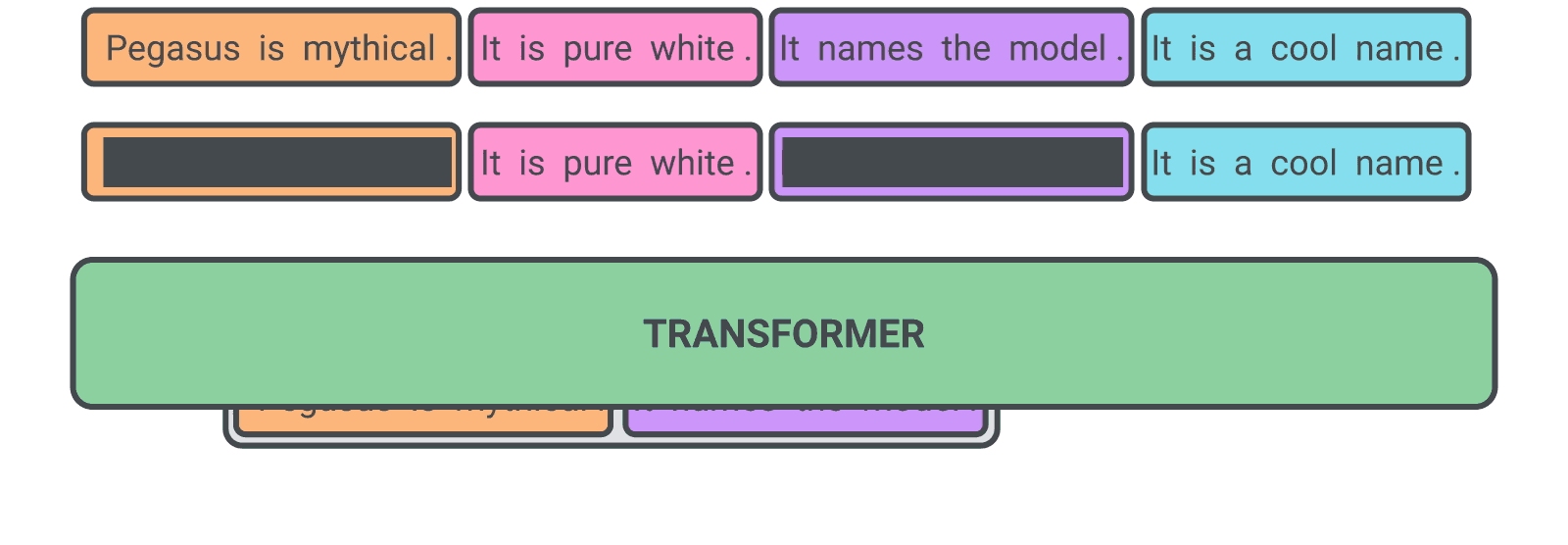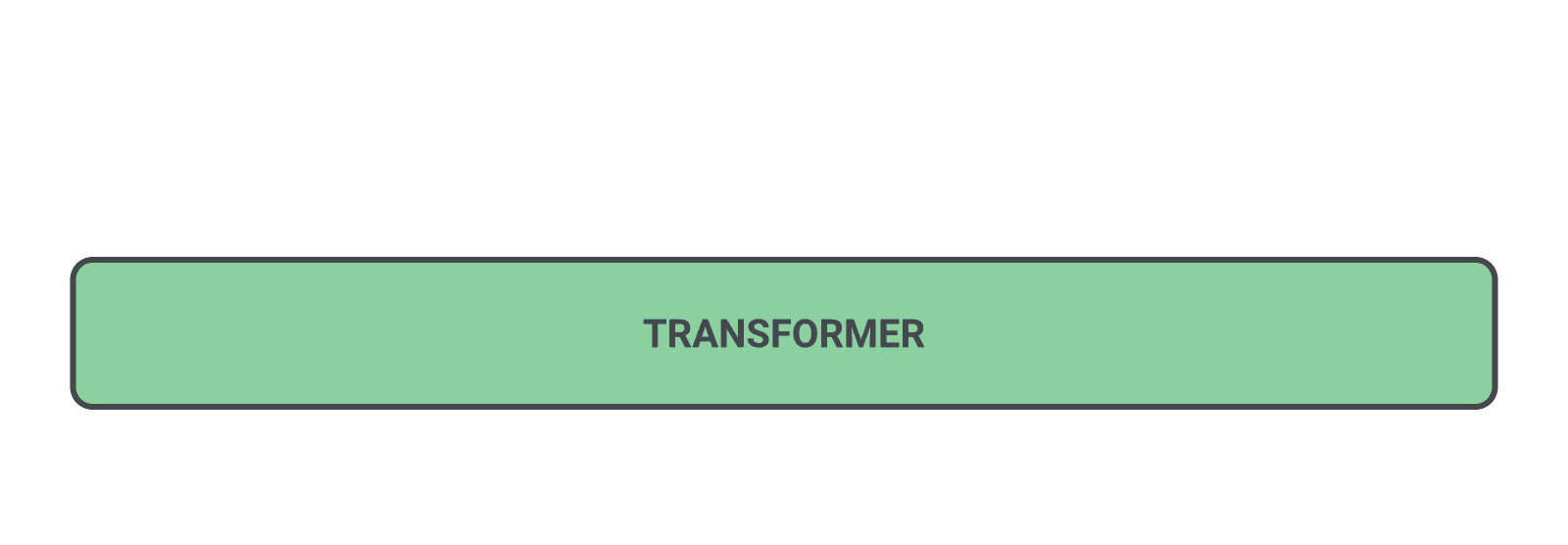
Models checkpoints are loaded to huggingface:
| Original | Pegasus fine-tuned for detoxification |
|---|---|
| You're in a titty bar. | you're in a bar. |
| I just want a glass of water. Oh, shit! | I just want a glass of water. |
| We have a big fuckin' problem. | we have a big problem. |
| Some freak just sent me this. | someone sent me this. |
| I knew this shit was gonna happen. | I knew it was going to happen. |
How to run inference:
python src/models/predict_model.py --input 'example of toxic sentence'
How to train models:
python src/models/train_model.py --batch_size=32 --lr=0.01 --wd=0.01 --stl=1 --model 'the-hir0/pegasus-detoxify'