{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Needleman-Wunsch Algorithm [wikipedia]
An algorithm from bioinformatics that computes global alignment, finding matching regions between two strings of characters. The assumption is that both sequences are related through the operations character replacement and character insertion/deletion (indels). See also: Levenshtein distance. Each operation usually has a cost associated with it depending on the application; replacement may be a less 'costly' operation than indels, for example. One way to interpret the algorithm is that it finds the least-costly way to transform one sequence into another under the given operations.
In this task, we are given a correct human transcript of a medieval manuscript and an OCRed version of that manuscript that likely contains many errors but has information on where each letter is placed on the page. By identifying similar strings of characters in these two sequences, we can match each word in the correct transcript with its occurrence in the noisy OCR, and thus find that word's location on the image of the manuscript.
Example: entirety of einsiedeln_001v. (In all examples, the first line is the human transcript, the second line is the noisy OCR of the manuscript, and the third shows the result of the alignment: O is a match, X is a mismatch (or, replacement), and a space is a gap (insertion / deletion) in one of the sequences.
opotentiam venientem et neb__ulam to_tam terra_m te_gentem Ite ob__viam ei et dicite _Nunt
opoten_nain iieenten et nebit lam to tam terrain te gen em__te ob llian e iet bicite slunt
OOOOOO XOXXXXXXOOOOXOOOOOOO XOOOOOO OOOOOOOOO XOOO OOOXOO OOOOO XOOXOOXXOOOXOOOOOO XOOO
ia no_bis si tu es ipse_ Qui regnaturus es in pop__ulo Israhel Quique terrigene et filii h
ia no bis si_ti es ipse. sli regnatuinises in popit lo_israhel. .in a t__rngene et sil_u h
OOOOO OOOOOO OXOOOOOOOO OXXOOOOOOOOOXXXXOOOOOOOOO XOO XOOOOOOXXXOXXXOO OXOOOOOOOOXOO XOO
o_minum si_m_ul in unum di_ves et pa_uper Ite Qui re__gis israhel intende qui deducis velu
onmunum siumiul in_unum di ies e_ ban ber lte v iure. gis israhel intende qiu deduc_s uelu
O OXOOOOOO O OOOOO OOOOOOO XOOOO OXO XXOOOXOOOXXOXOO OOOOOOOOOOOOOOOOOOOOOXXOOOOOO OOXOOO
d ovem ioseph qui sedes s__uper che__rubyn Nuntia Tol_lite portas principes vestras et ele
d ouem ioseph _ain edes sit per che ti byn lunt_av ol lite portas princapes iestras et ele
OOOXOOOOOOOOOO XOXXOOOOOO XOOOOOOO XXOOOOXOOO OXXOO OOOOOOOOOOOOOOOOOXOOOOXOOOOOOOOOOOOO
vamini porte eternales et int_roi_bit Qui Aspitieba_m in visu no_ctis et ecce in nu____bib
_amin_ por_e eteriales et intis i bit. a. s bitiebain imiu su nor tis eree te in_nu e. bib
OOOO OOOO OOOOOOXOOOOOOOOOOO XXO OOOXXXXOXXXOOOOOO XOOXXXXOOOOO XOOOOOXXOXXOOOO OO OOO
us celi filius hominis ve_nit Et da_tum est ei regnum et ho_nor et o_mnes p_opuli tribus e
is _e__ lili_s homin_s ie nit __ da tum elt ei iegnem et ho ror er ornnes ps puli ta b_r e
XOO O OXOOO OOOOOOO OOXO OOOO OOO OOOOOXOOOOOXOOOXOOOOOOO XOOOOXOO XOOOOO XOOOOOOXXO XOO
t lingue servient e_i Ecce dominator dominu_s cum virtute veniet_ Et datum Missus est ga_b
t lingue ser nent e. v. e doninatord iminuis cum_iurtute ieni t. kt da___ _issus est_ga b
OOOOOOOOOOOOXXOOOOO XOXXXOOOOXOOOOOOXXXOOOO OOOOO XXOOOOOOXOOOXO OXOOOO O OOOOOOOOO OO O
riel an_ge_lus ad mariam virginem desponsata io_sep_h _nuntians ei verbum et expa_vescit v
riel an ge lus ad _a__am iurgi_e_ndesponsata io sepli iuuntians e_ ierbum_et e_pa iescit i
OOOOOOO OO OOOOOOO O OOOXXOOO O XOOOOOOOOOOOOO OOO XO XOOOOOOOOO OXOOOOO OOOO OO XOOOOOOX
irg
irg
OOO
Einsiedeln_001v text layer image
{kind=link}
Einsiedeln_001v human transcript
Einsiedeln_001v OCRed transcript with Transkribus
Different operations can be assigned different costs in the alignment process. Consider the two strings abc and acb, and these two different ways to align them:
abc | abc_
acb | a_cb
OXX | O O
If both mismatches and gaps have the same cost, then the second alignment is better; it has two matches and two gaps, whereas the first has only one match and two mismatches. If mismatches are considered less costly than gaps, however, then the first alignment might be better.
So far the assumption has been that a gap incurs a fixed cost, regardless of context. In practice it can be desirable to assign two costs to gaps; the cost for opening a gap, and the cost for extending a gap. This can be used to encourage contiguous blocks of gaps in an alignment, which is desirable in some applications.
Einsiedeln_001r with a cost of -1 for gaps, -1 for mismatches, and 1 for matches
_Ecce___ di__________es__ ve_ni___ent Ro____rate caeli desuper Ecce no_men do_mini _ve_nit
naduentu din. at rcsvas. Ie dius int uo si oate c_eli drsupi. Eoce nonien donuini iue uit
XXXO OOO XO OXO XO XOOOXO XOOOOO OOOOOXOOOXXOOXOOOOO XOOOOO XOOOO XO XOO
de longin_q_uo_______ e________t _claritas eius replet orb_____________em _____terrarum e
_r longin qllo t i in elwangrlis a laritas ei_s irplct orbtii rra vo vae, nd uitatwann. g
O XOOOOOOO O XO OO XO XOOOOOOOOOO OOXXOOXOOOOO OXO OXXXOXXXOX
Einseideln_001r with a cost of -1 for gap extension, -4 for gap opening, -4 for mismatches, and 4 for matches:
__________________Ec_______ce dies venient Ro____rate caeli desuper Ecce no_men do_mini _v
.naduentu din. at rcsvas. Ie dius ___i_nt uo si oate c_eli drsupi. Eoce nonien donuini iu
O XOOOOXOO O OOOXO XOOOOO OOOOOXOOOXXOOXOOOOO XOOOOO XOOOO X
e_nit de longin_q_uo et _________________claritas eius _replet orbem t__errarum euo_uae___
e uit _r longin qllo _t i in elwangrlis a laritas ei_s ir_plct orb___tii rra___ _vo vae, n
O XOOO XOOOOOOO O XOO OO XOOOOOOOOOO OO O OOXOOOOO O XOOO O XO XOO
The algorithm will only interrupt a gap if it can get several matches out of it; smaller gaps are only beneficial when they permit several matches nearby.
Most sequence alignment algorithms do not care about the order of their inputs, and both are treated exactly the same. However, we have foreknowledge about the kinds of "mutations" present in the data, and this knowledge can be exploited by treating the transcription string differently to the OCRed string.
Most significantly, the transcript includes only text directly associated with neumes (referred to as musical text from here on out) whereas the OCR process attempts to process all text and all markings on the page that look like text. A perfect alignment would therefore have strictly more gaps in the transcript string than in the OCR string; more of the OCR string must be skipped, since errors will manifest as long strings of non-musical text in the OCR.
We can therefore set different penalties for gap extension and gap opening in each string such that long gaps are incentivised in the transcript string but discouraged in the OCR string.
Einsiedeln_001r with costs of:
- 4 for matches
- -4 for mismatches
- -4 for gap opening in the transcript
- -1 for gap extension in the transcript
- -4 for gap opening in OCRed text
- -4 for gap extension in OCRed text
___cce___ di__________es__ ve_ni___ent Ro____rate caeli desuper Ecce no_men do_mini _ve_ni
.naduentu din. at rcsvas. Ie dius int uo si oate c_eli drsupi. Eoce nonien donuini iue ui
XXO OOO XO OXO XO XOOOXO XOOOOO OOOOOXOOOXXOOXOOOOO XOOOOO XOOOO XO XO
t de longin_q_uo_______ e________t _claritas eius replet orbem terrarum __e_____uouae Ecce
t _r longin qllo t i in elwangrlis a laritas ei_s irplct orb_tii rra vo vae, nd uitatwann.
OO XOOOOOOO O XO OO XO XOOOOOOOOOO OOXXOOXOOOOO XXXXOOOXXXO O OXXOXXXXXX
I haven't yet run anything to quantify whether or not this gives better results on the full process. Since there are few parameters and these are very small documents, I can probably just run a brute-force test of the search space on all possible values for gap extension and gap opening once I have an evaluation metric in place.
(the topic of asymmetric costs is something I haven't been able to find much information on elsewhere; doesn't seem to be of great interest to most computational biologists?)
Wikipedia's Comparison of Major OCR Software. Most are not adaptive and support only printed text.
A 2015 test of then-current OCR methods on medieval manuscripts. Two proprietary OCR engines are used (Adobe Acrobat and ABBYY Finereader). On a printed source, FineReader has a per-character accuracy of 97.78%, and Acrobat has an accuracy of 87.57%. However, on the handwritten source examined (St. Gall 561), only Finereader bears any remote resemblance to the original text (no percentage given, but it'd be quite low; less than 50%).
Written in C++, python bindings with pytesseract. Overview of the OCR engine. Lots of options / parameters, but documentation is lacking, and it's not particularly transparent beyond the relatively high-level description in that paper.
Intended only for printed script, but can be trained on handwriting; paper achieving 90% per-character success rate on handwritten characters using Tesseract however, these characters are pre-segmented.
Early latin training set for Tesseract. Looks promising, and in principle uses a similar character set to the latin characters in plainchant manuscripts, but fails - can't segment handwriting with minims at all. A word like "dominus" is transcribed as "do11111111s." To use Tesseract with gothic script, would need totally pre-segmented characters.
Transkribus [Homepage]
A large application for recognizing handwriting in historical documents - totally centralized, training data shared between users. Also contains quite robust automatic layout detection / text line finding. Main project is GUI only, but there exists a python toolkit that allows interfacing with it and its main server, so in principle it would be possible to use its functionality in a separate program (if the project's maintainers allow).
Intended to be used by manually transcribing a large amount of text and then using that to train a model of your own manuscript. This requires manual assistance from their project managers. They suggest at least 15,000 words of ground truth before a model can be trained. They do have a few already-trained models of various types of handwriting, though, including gothic script. Here are some results of transcribing plainchant manuscripts using their gothic script model:
Einsiedeln | Klosterneuberg | Salzinnes | St. Maurf | St. Gall 390
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It's not perfect, but it might be close enough for a sequence alignment approach, at least for some manuscripts.
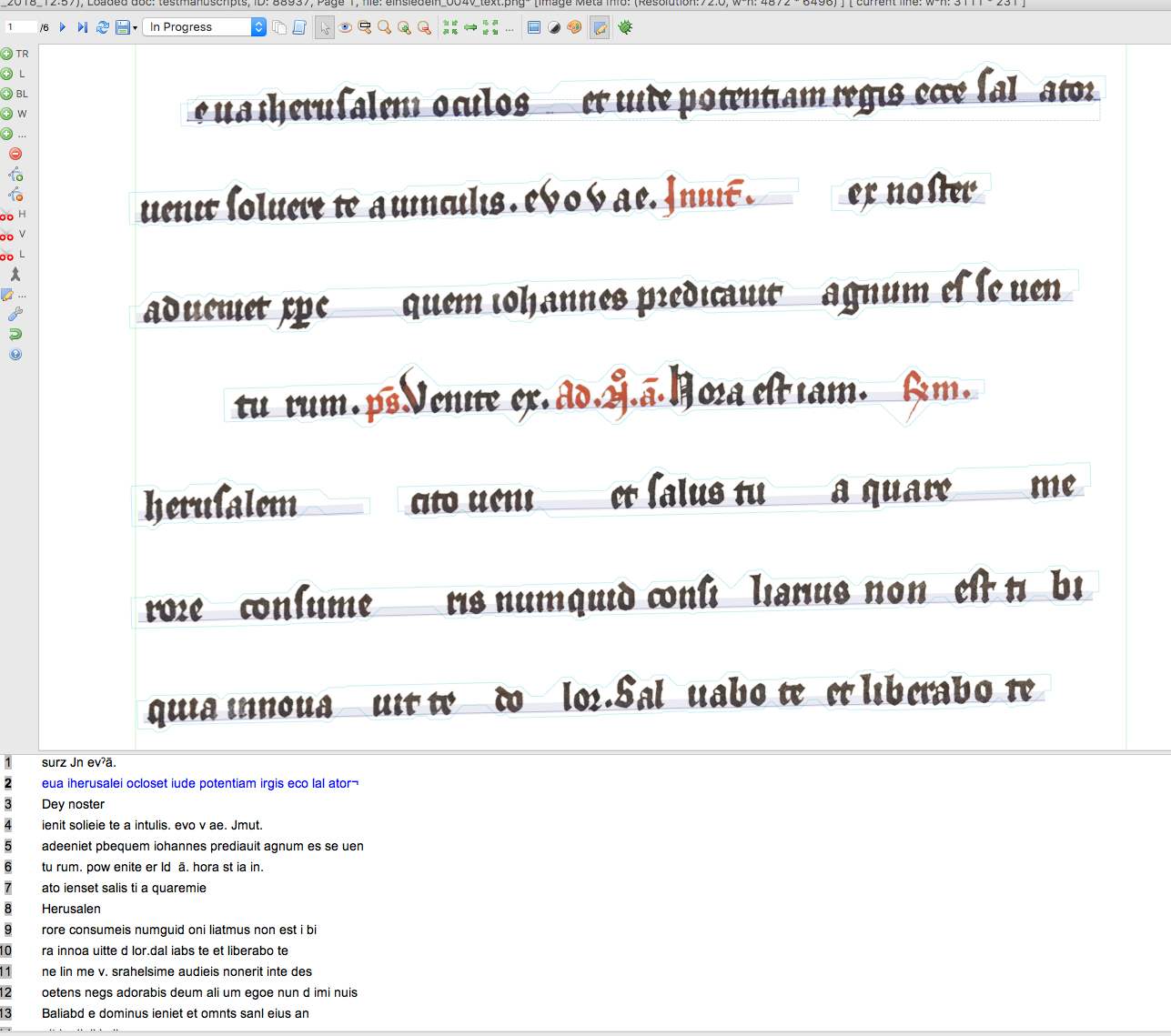
Problem: Transkribus's bounding boxes are not at all accurate. Here is its results on finding each chunk of text in Einsiedeln_001r. The small amount of vertical jitter was added by me so that overlapping boxes can be more easily distinguished. Some of the boxes are relatively sensible, but some are several times as big as they ought to be.
{kind=link}
Another Transkribus-based model of gothic handwriting that might be usable, though not yet public. Interesting note: language models are not that useful for these texts because spellings are so inconsistent even within individual manuscripts written by the same person.
OCRopus [Homepage]
Collection of OCR utilities, usable from command line, based on LSTM. Once contained specific support for handwriting / manuscripts, but that functionality has been removed. It can still be used for historical manuscripts, with some success: with lots of careful training, this project managed 9.7% error rates on handwriting similar to that of the Salzinnes manuscript. However, the same model did not work well on other manuscripts.
One benefit to OCRopus is that its character segmentation methods are more transparent and configurable; Tesseract works primarily off of connected components. Here is a case study using OCRopus on text that Tesseract struggles to segment correctly.
In Codice Ratio [Homepage]
OCR specifically for latin handwritten religious texts (The Vatican Secret Archives). Code fully available on website (in process of testing) but there is no documentation and many of the comments are in italian. Method based on training a CNN to distinguish images that represent a single character from those that represent a character fragment or more than one character. Ground truth for this purpose obtained through a custom crowdsourcing platform and 120 high school students.
Only works on images of manually extracted words. Does not include any layout analysis / text line detection.
Results on individual words are encouraging. Presents many of the same problems (different forms of same letter, ornamentation, inconsistent spacing) present in the plainchant manuscripts. The particular handwriting they use is similar to that of St. Gall 390, St. Maur.