This project provides ready-to-analyze datasets for Covid-19 and other related aspects in our daily life such as stock index, unemployment rate, job openings, business activities. We implement a full-stack solution that includes: (1) the front-end dashboard with Flask + jQuery, (2) ETL pipeline with Apache Spark + Python and Apache Airflow for scheduling ETL tasks and (3) MySQL as the back-end DBMS.
By integrating covid19 data sources and other related data sources, this project help users answer deeper analytics questions such as:
- Which stock indexes still going well during the pandemic?
- What occupation group has the highest/lowest unemployment rate during the pandemic?
- What occupation still has high job opens regardless of the pandemic?
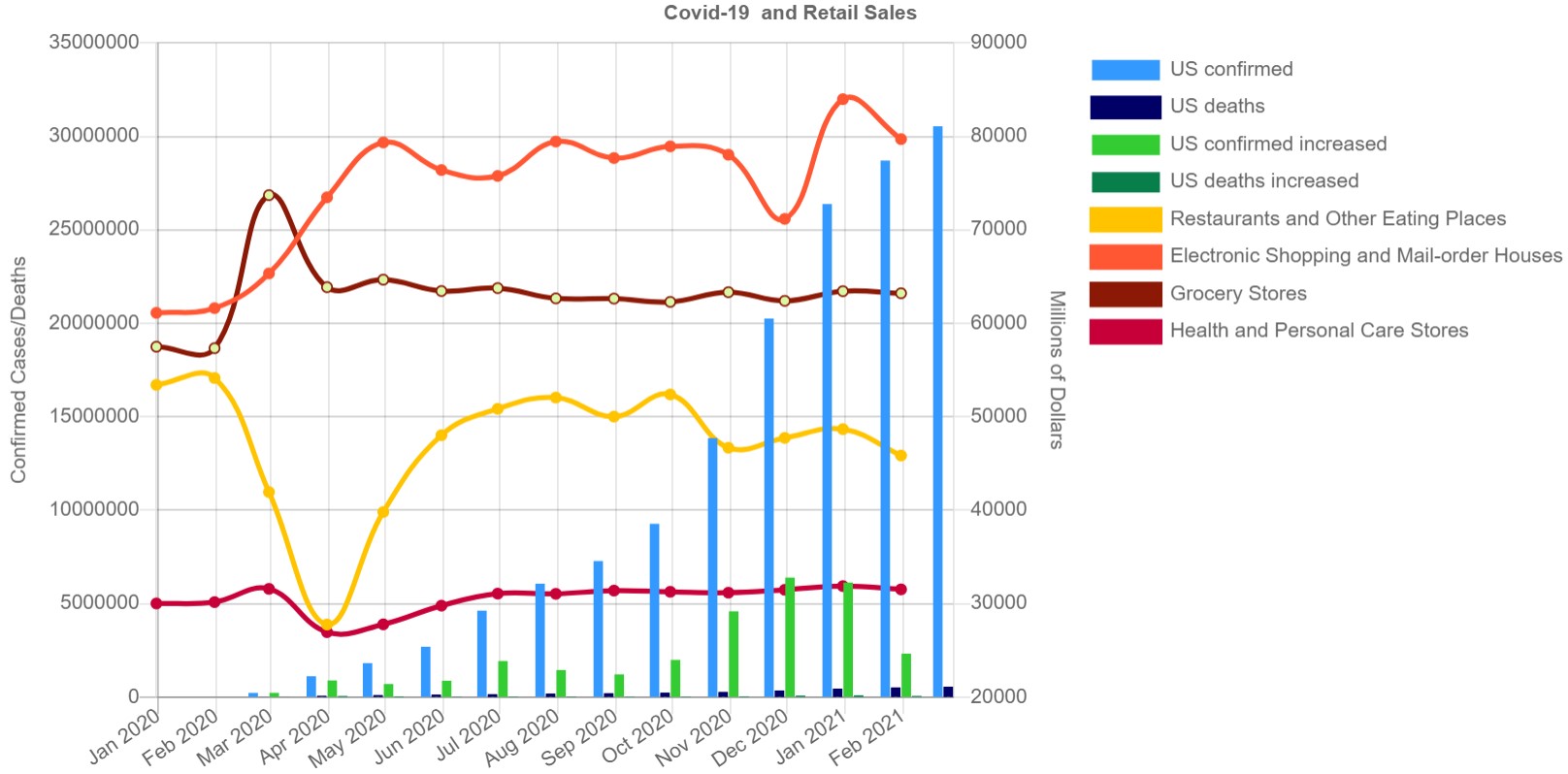
- Does the peak of the unemployment rate and the peak of the new cases of covid19 in the US happen at the same time?
- Percentage of travel time reduced during the pandemic?
The overall architecture is:
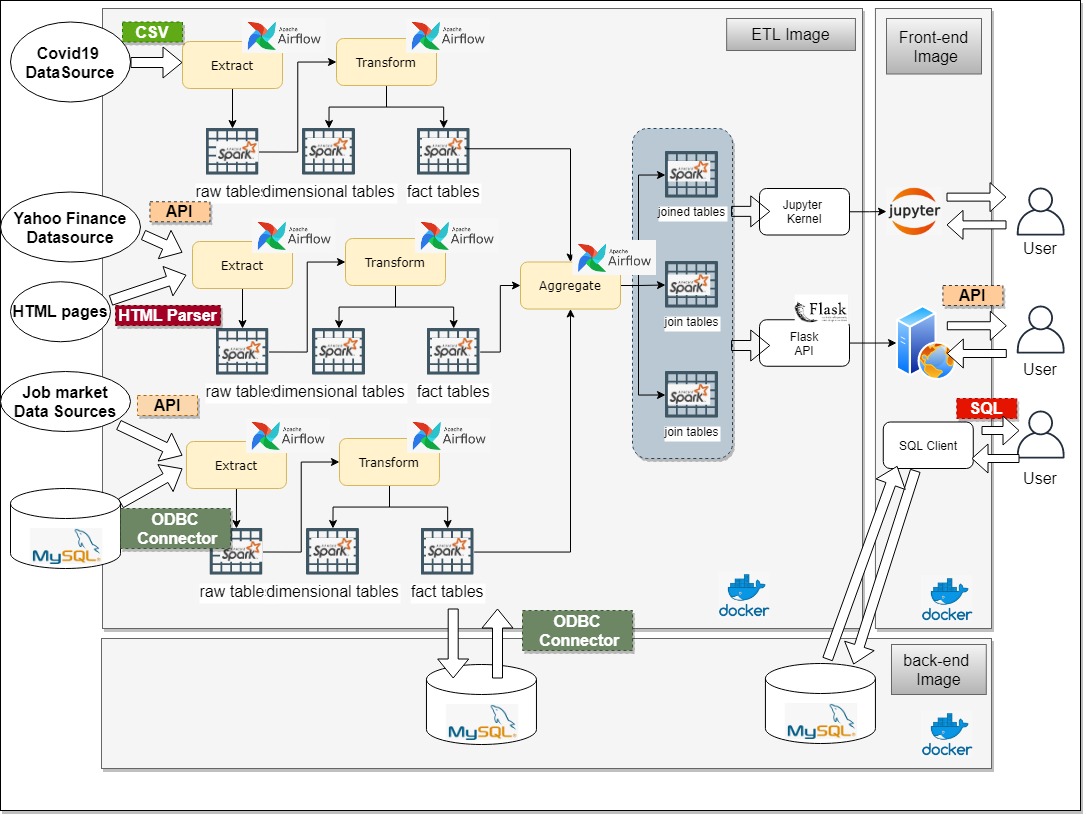
And the expected results from FLask App would look like:

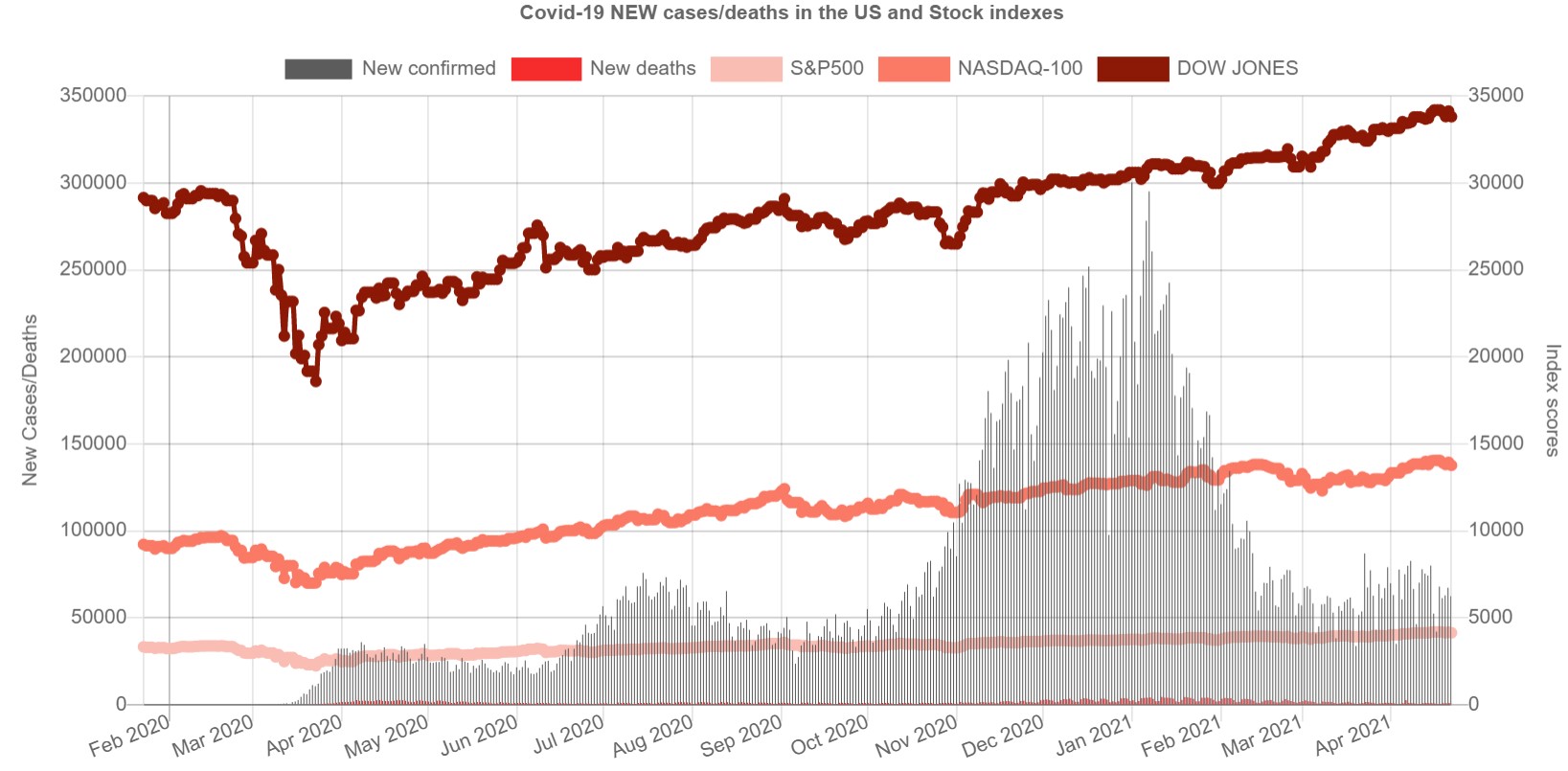
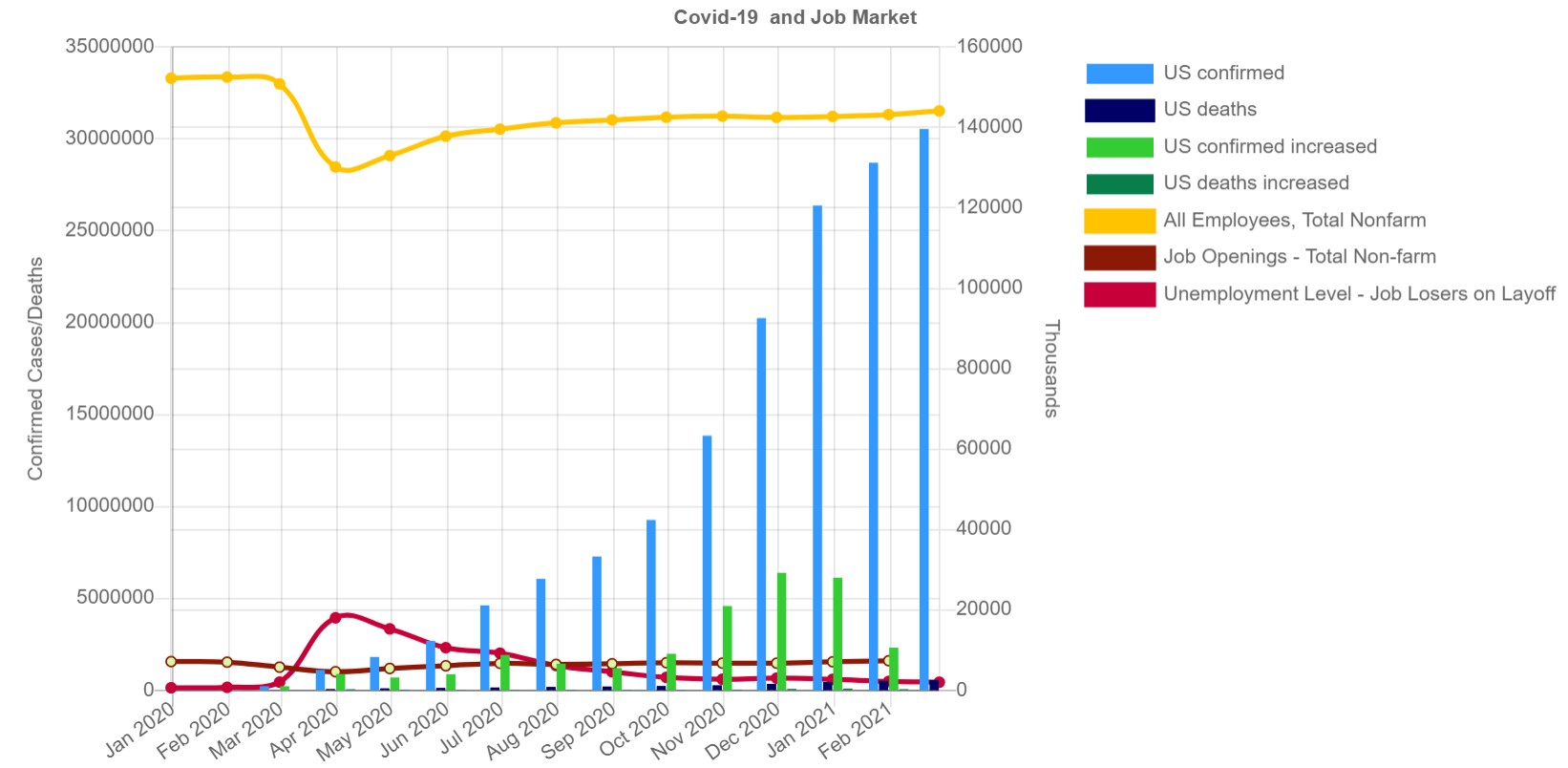

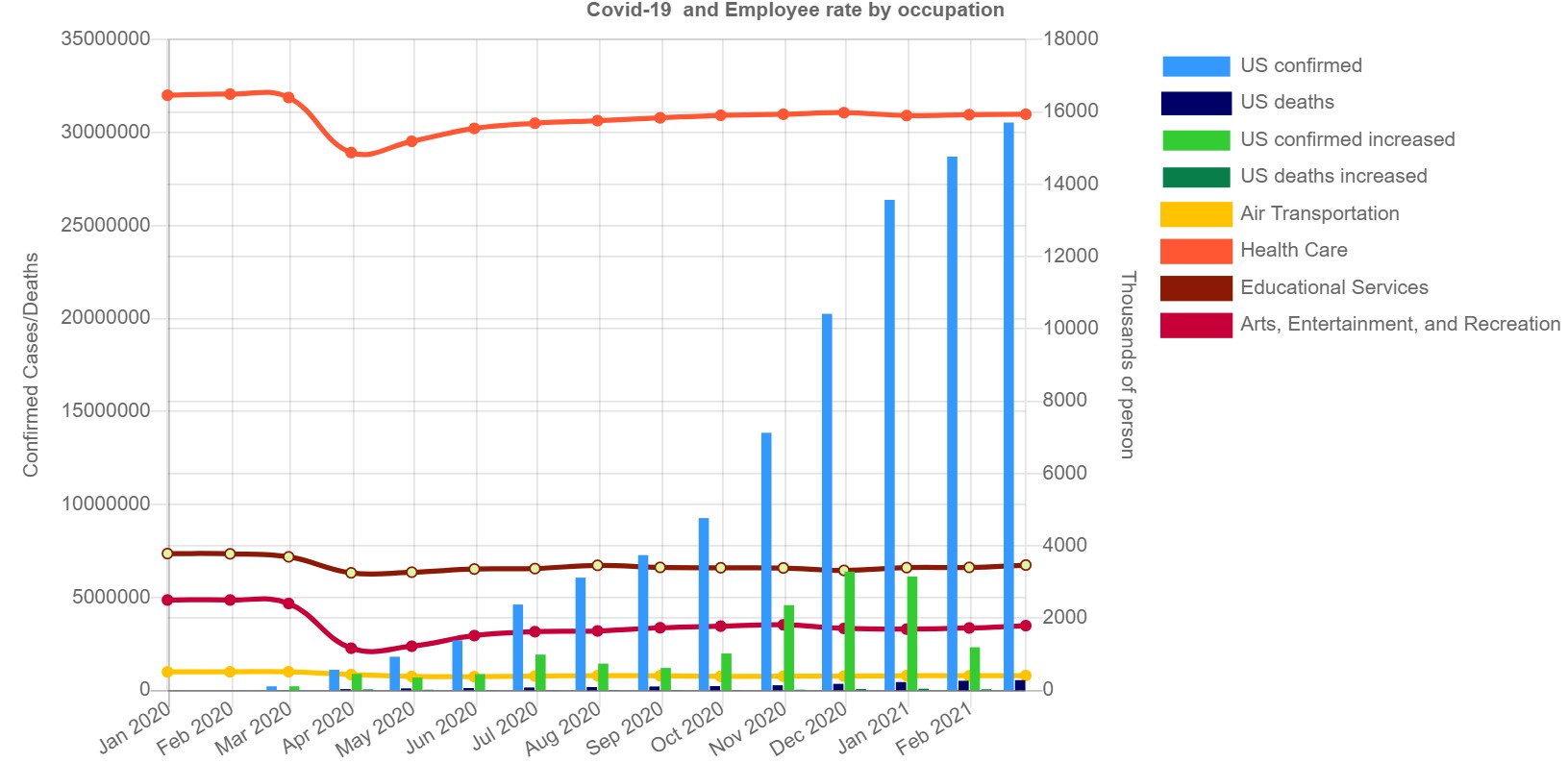
Updated: Added story telling Slide deck that walks you through the progress of building this project.
Clone the repository
$ git clone https://github.com/trdtnguyen/sb-capstone1
$ cd sb-capstone1
Step 1: Create and activate a virtual envirionment
$ virtualenv -p /usr/bin/python3.8 vevn
$ source venv/bin/activate
Note: To avoid Python version error due to differences of python version in Spark driver and Spark worker, following below notes:
- Ensure your python in Spark has the same version as the one in your veritual environment.
- Ensure
PYSPARK_PYTHONandPYSPARK_DRIVER_PYTHONpoint to the same python bin.
Step 2: Install Python packages
$ (venv) pip3 install -r requirements.txt
Step 3: Setup Database
This project use mysql as the back-end database. Change the config.cnf to match your mysql settings:
[DATABASE]
MYSQL_DATABASE=covid19cor
AIRFLOW_DATABASE=airflowdb
MYSQL_HOST=localhost
MYSQL_PORT=3306
MYSQL_ROOT_PASSWORD=rootpassword
MYSQL_USER=myusername
MYSQL_PASSWORD=mysqlpassword
Create database and tables:
$ mysqladmin -u root -p create covid19cor
$ mysql -u root -p covid19cor < sql/create_table.sql
Step 4: Run ETL manually Before running the ETL pipeline, ensure your Spark driver and workers are started and configurated properly.
We test the project using standalone Spark in a single machine.
- Single ETL load: run
etl_test.pywithout argument to get all data fromCOVID_OLDEST_DATE(Jan 2020) to the current date.
$ python tasks/etl_test.py
- Incremental ETL load: run
etl_test.pywith end date (yyyy-mm-dd) to simulation daily ETL task
$ python tasks/etl_test.py 2021-02-20
$ python tasks/etl_test.py 2021-02-21
$ python tasks/etl_test.py 2021-02-22
Step 5: Config and start front-end Flask App
Change Flask's configuration in config.cnf file to match yours settings:
[API]
API_HOST=<your_ip> # such as 192.168.0.2
API_PORT=8082
Start Flask web server
$ python flaskapp/app.py
Step 6: Access dashboard
After the flask app started, open your browser with url: http://<API_HOST>:<API_PORT> for example http://192.168.0.2:8082/.
$ docker-compose build && docker-compose up
In this current version, docker-compose up covers step 1 - step 3 of steps in running in a local machine.
We could do the same step 4 - step 6 inside docker container.
$ docker exec -it airflow bash
This section list common Data Engineering techniques and general programming techniques used in this project.
- Extract data source using various methods such as pandas' Datareader, parsing HTML page, API.
- Manipulate Spark's Dataframe and pandas Dataframe to load, cleaning, transforming data from raw tables to dimensional and fact tables.
- Add/remove columns into/from a Dataframe
- Transpose Dataframe's columns into rows
- Aggregate data from daily frequency into montly frequency
- Handling null values (filling null with previous non-null value) using Window functions.
- Exploit Apache Airflow to schedule ETL tasks
- Using MySQL as the back-end RDBMS for data wareshouse with star schema.
- The front-end apps (ETL tasks) use ODBC connector (for pyspark) and SqlAchemy for pandas.
- Data transform in ETL tasks combine both SQL and pyspark's APIs.
- Project support various front-end interfaces such as RESTful API using Flask, Tablue, and Jupyter notebook
- Drawing charts using Chart.js + jQuery
- Packing flask, airflow, spark, mysql into one docker container
- App image wait for database image ready
- Object-oriented programming in Python.
- Load configuration values through config.cnf file
- Exploit singleton desgin pattern to use a GlobalUtil class as a common shared utility between other classes in the project
- Logging
- Unit test using pytest.