原文:https://research.swtch.com/tlog
作者:Russ Cox
- Go 语言代码贡献量 第一 的大神
发布于:2019-03-01 周五
- 译前名词解释
- 正文
- 密码学中的哈希、验证和承诺
- 默克尔树(Merkle Trees)
- 基于默克尔树结构的日志
- 存储日志
- 提供日志服务
- 验证日志
- 对日志进行瓦片化
- 存储瓦片
- 提供瓦片服务
- 验证瓦片
- 总结
- 延伸阅读
- 附录 A:后序存储设计
- 附录 B:中序存储设计
- 附录 C:瓦片存储设计
- log:即 日志,本文中的日志实质可理解为一份流水账目,账目的内容是一些数据(或叫 记录)。
- record:即 记录,也会译为 数据记录,即一份数据的意思。类似数据库中的 1 行数据的概念。
- hash:即 哈希,也有人译为 散列,都是一个意思,本文中均译为 哈希。
- level:本文中通常指树的层级编号,从 0 开始。
- tile:即 瓦片,数据还是那堆数据,只是按一定规则切分成小集合。
- Merkle Tree:译作 默克尔树。
- tree size:译作树的大小,在本文中特指树的叶子节点数
- top-level hash:译作 根哈希,即树的根节点(节点值是一个哈希值)。
假设我们想发布并维护一个仅追加数据的公共日志服务,并且客户端对我们的实现、操作不信任:为了对我们(译注:服务提供者)有利,我们可能随时增加、删除部分日志。我们该如何向客户端证明我们是没问题的(译注:即如何证明我们没改过日志)?
本文将介绍一个优雅的数据结构,我们可基于该结构发布一个包含 N 个数据记录的日志服务。该数据结构有 3 个特性:
- 对于长度为 N 的日志中的某个记录 R,我们可构建一个长度为 O(lg N) 的证据,以供客户端验证 R 确实存在于日志中。
- 对于客户端早期保存过的日志记录,我们可构建一个长度为 O(lg N) 的证据,以供客户端验证当前日志(译注:服务端的日志)确实包含早期的日志(译注:客户端保存的旧日志)。
- 检查者可高效地遍历日志中的记录。
(在本文,lg N 表示以 2 为底 N 的对数(译注:例如 = 8,则 lg 8 = 3),关键字
log 仅表示 一些数据记录(records) 而非对数)
证书透明度(Certificate Transparency) 项目正是采用这种日志方式发布 TLS 证书。Google Chrome 浏览器在信任 扩展验证证书(enhanced validation certificate) 前,会利用特性(1)来验证其是否曾被日志记录下来。特性(2)保证了一个已被信任的证书在以后不会突然在日志中消失。特性(3)允许检查者在事后扫描日志,检查证书记录是否消失或被偷换。有了这些特性,客户端无需盲目相信日志服务是否正确运行,相反,Chrome 以及任何其他检查者都应在访问日志时验证日志正确性(译注:即本服务本身设计就提供可验证机制)。
本文将介绍这种可验证日志(也称透明日志)的设计与实现。开始之前,我们需要先介绍一些密码学基础。
一个密码学的散列函数(译注:散列也可称为哈希)是一个确定的函数 H(译注:可理解为 hash 的首字母),可将任意大小的信息 M 映射到一个很小的固定大小的值 H(M)。H 有一个特性:实际应用中不可能生成一个 ≠
,且其哈希值 H(
) = H(
)。当然也有一些例外,在 1995 年,当时 SHA-1 是一个不可破解的哈希函数。然而到了 2017 年,SHA-1 被破解了,有研究者发现并演示了 一个实际可行的产生哈希碰撞的方法。今天,SHA-256 依然是一个不可破解的密码散列函数(译注:即在目前条件下不可能产生碰撞)。但未来有一天 SHA-256 也会最终被破解。
一个未被破解的哈希函数可将非常大的数据转化为很小的可信任数据。假设我想分享一个大文件给你,却担心文件在传输过程中存在丢失(无论是随机的丢失,还是 中间人攻击)。我可以当面把 SHA-256 写到一张纸上,并亲手交到你手上。这样,不管文件数据是从何种不可靠途径获取而来,你只需对下载到的数据进行 SHA-256 校验,得到哈希值,并与我给你的哈希值进行对比。若哈希值一致(且此时 SHA-256 还未被破解),则可认为下载到的数据与我给你的文件完全一致。尽管哈希值只有 256 bit(译注:相当于 32 字节),原始文件很大,SHA-256 哈希值依然可以证明下载到的文件的每个字节都与我想给你的文件一致。
我们还可以换个角度思考下,假设你不是不信任网络传输,而是不信任我(译注:可理解为我的账号被入侵了)。若我通过一个特殊服务(这个服务可证明特定数据没被篡改过)把 SHA-256 哈希值告诉你,一旦在日后再次告诉你不同的哈希值(译注:对应同一份记录数据),你会立即发现我篡改过数据。
哈希值可用于验证一个很大的数据,保证其未被篡改过。但每次求哈希值都需对整个原始数据进行哈希运算(译注:过多哈希运算会有性能问题)。为了可以选择性的只验证部分数据,我们不一定只用单一个哈希值,我们可以构建一个哈希值的平衡二叉树,也即著名的默克尔树(Merkle tree)。
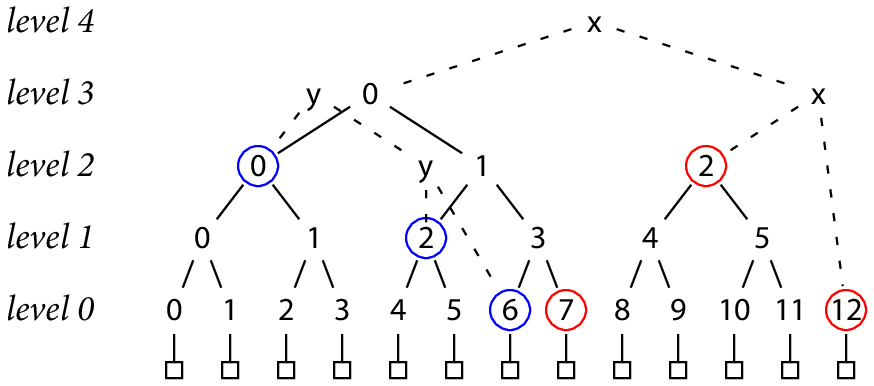
一棵默克尔树由 N 个记录组成,N 是 2 的某次方值(译注:例如 N = = 16)。首先,对每个数据记录分别算出其哈希值,即产生 N 个哈希值。然后对每两两哈希值再次算出其哈希值(译注:可大致理解为将这两个哈希值拼在一起作为数据再次求新哈希值),又产生 N/2 个哈希值。继续两两进行哈希,可得 N/4 个哈希值,如此类推,直到只剩 1 个哈希值。下图展示了一棵 N = 16 的默克尔树(译注:注意 level 从 0 起算)。
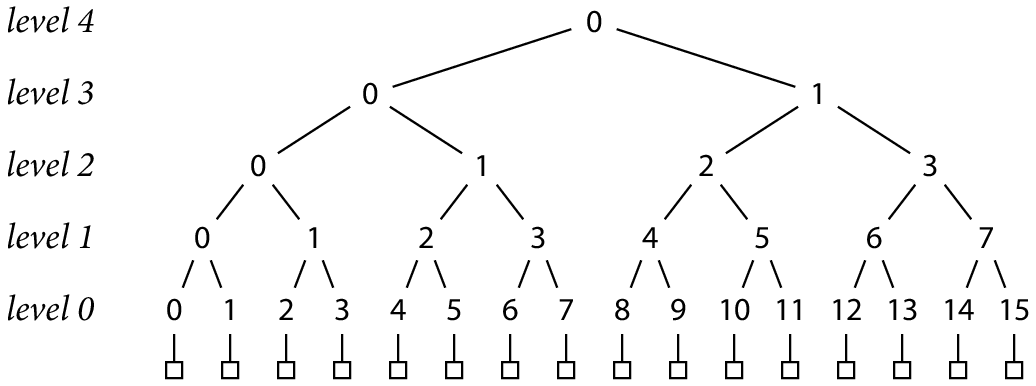
图中最底下的方格子代表 16 个数据记录,树中每个节点分别代表一个哈希值(此哈希值以其下方内容作为输入)。我们可通过树的坐标 L 级、编号 K(简写 h(L, K)) 来引用树中的任意哈希值。在 0 级,每个哈希值的输入都是一个记录数据。在更高层,每个哈希值均以其下层的两个哈希值作为输入。
译注:下图 L、K 均从 0 开始
h(0, K) = H(record K)
h(L+1, K) = H(h(L, 2 K), h(L, 2 K+1))
为了证明某个数据记录确实存在于由顶层哈希值所包含的数据中(也即允许客户端验证数据记录,或验证之前的承诺),只需重新计算从顶层哈希到数据记录哈希之间的节点即可。例如,我们想证明一个字符串 B 是属于根哈希为 T 的默克尔树中编号为 9 的数据记录,则我们还要其他需用于重建该哈希路径的哈希值。也即是说,客户端也可像我们这样做(译注:建议下面式子配合下面的黄路径图一起看):
T = h(4, 0)
= H(h(3, 0), h(3, 1))
= H(h(3, 0), H(h(2, 2), h(2, 3)))
= H(h(3, 0), H(H(h(1,4), h(1, 5)), h(2, 3)))
= H(h(3, 0), H(H(H(h(0, 8), h(0, 9)), h(1, 5)), h(2, 3)))
= H(h(3, 0), H(H(H(h(0, 8), H(record 9)), h(1, 5)), h(2, 3)))
= H(h(3, 0), H(H(H(h(0, 8), H(B)), h(1, 5)), h(2, 3)))
若给客户端提供这些值:[h(3, 0), h(0, 8), h(1, 5), h(2, 3)],再加上客户端可自行计算出的 H(B),则综合起来套入上述式子,即可计算出 T,从而判断 T 是否一致。若一致,则说明 B 真的就是根哈希为 T 的默克尔树中编号为 9 的数据记录。也即是说,只要提供以 H(B) 作为输入的关于 T 的可验证计算,即可证明 B 记录确实存在根哈希为 T 的默克尔树中。
画成图的话,所需的证据包括:兄弟哈希节点(蓝圈)、从底层记录一直到根节点的节点(黄色高亮)。
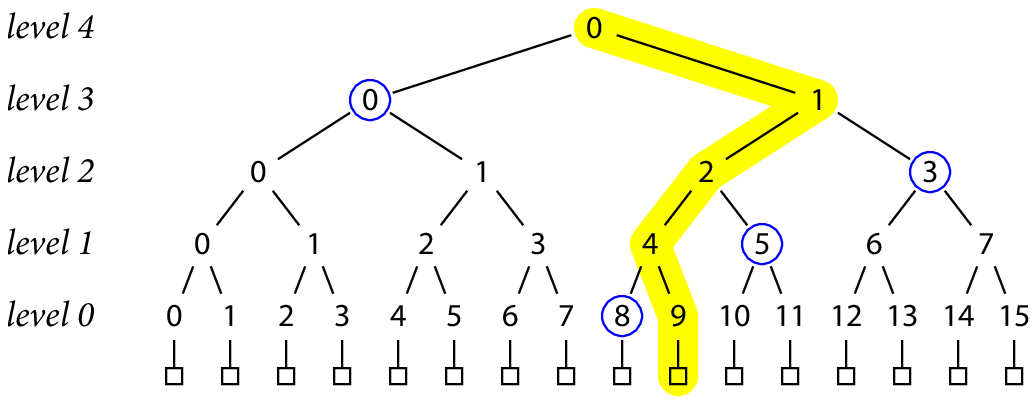
译注:上图蓝圈、黄色节点均将从日志服务端获取,后续会有说明
一般的,一个证据的所需组成部分:树中的一个记录数据,以及 lg N 个哈希值,也即根节点下的每层都需额外 1 个哈希值(译注:每次需 2 个哈希值,1 个是从日志服务端获取,1 个是由下层计算而得)。
将一堆数据记录的哈希值构建为默克尔树,可帮助我们高效地提供一个证据(证据的长度为 lg N 个哈希)证明某个数据记录确实存在于日志中。但还有两个问题需解决:
- 我们的日志是任意长度的,不一定刚好是 2 的次方
- 我们需提供高效的证据证明:某日志确实包含其他日志
为了将默克尔树一般化为非 2 次方的大小(译注:大小是指叶子数),我们可将 N 分解为多个递减的 2 的次方 组成的和。然后对这些分解数分别构建完整的默克尔树。子树个数不大于 lg N 个,最终将这些子树再合并为一棵大树,产生一个总的根哈希值。例如,13 = 8 + 4 + 1:
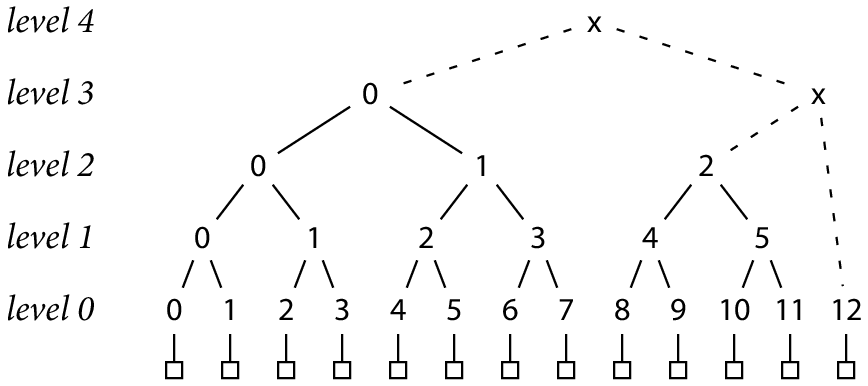
标记为 x 的新哈希将完整的子树从右到左开始连结起来(译注:注意顺序是 从右到左),形成最终大树的根哈希。注意,这些 x 对于合并不同的子树是必须的,因此这些 x 会由不同层级计算而得。例如,h(3, x) = H(h(2, 2), h(0, 12))。
完整默克尔树的证明同样适用于这些不完整的树。例如,证明数据记录 9 确实存在于树中的充分条件是:[h(3, 0), h(0, 8), h(1, 5), h(0, 12)]:
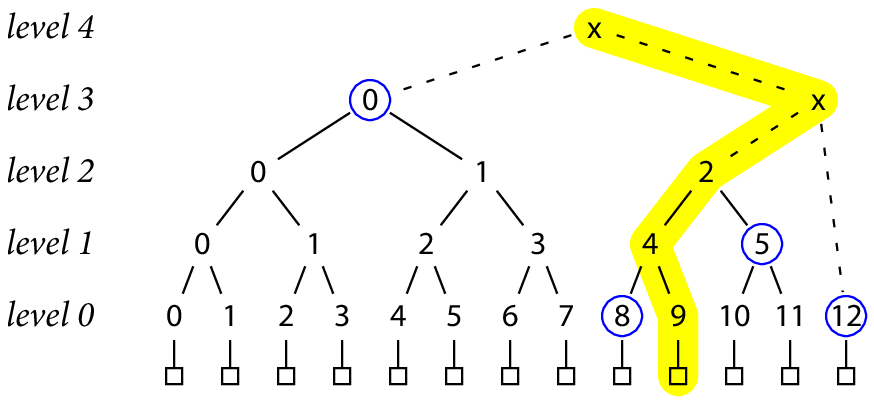
注意,h(0, 12) 对于证明来说是必须的,因为计算 h(3, x) 时 h(0, 12) 与 h(2, 2) 是其子节点。
我们还需一个高效的证据能够证明:以 T 为根哈希,数据记录数为 N 的日志,是以 T′ 为根哈希,大小为 N′ (> N) 的日志的前缀(译注:即日志 N′ 包含日志 N)。前面已提过,使用 H(B) 进行验证计算可证明 B 确实是以 T 为根哈希的默克尔树中的记录。若要证明以 T′ 作为根哈希的日志包含了以 T 作为根哈希的日志,我们可采用相同的方法:对于 T 和 T′ 进行验证计算。此时计算 T 所用的所有输入同时也是计算 T′ 中的输入。例如,假设有 N 分别为 7 和 13 的两棵树:
观察图中,名为 x 的几个节点使叶子数为 13 的树变得完整,称其根哈希为 。名为
y 的几个节点使叶子数为 7 的树变得完整,称其根哈希为 。若要证明
的叶子包含了
的叶子,我们需先计算完整子树中的值
(蓝圈):
然后我们为了计算出 ,需知道展开哈希来暴露同样的子树。这样会暴露兄弟子树(红圈):
若客户端已知两棵树的叶子数分别为 7 和 13,以及我们提供的这些哈希值 [h(2, 0), h(1, 2), h(0, 6), h(0, 7), h(2, 2), h(0, 12)],则客户端可自行进行分解计算。客户端通过这些已知条件计算出 和
后,即可验证与原来的哈希是否匹配。
译注:反证法,若
并不完全包含
,譬如
需注意的是,前面所述所需的证据只有这些完整子树的哈希值。也就是说,只需图中那些数字标记的节点,而无需 x 或 y 这样的连结不同大小子树的哈希值。那些数字标记的节点是永久的,意即只要这些节点哈希出现在子树中,那么也将出现在包含该子树的更大的树中。相对的,x、y 的哈希是临时的,仅针对一棵树进行计算,并不可再见。因此分解大小不同的两棵树后的公共哈希也必须是永久哈希。分解较大的树时,可以使用临时哈希作为兄弟节点,但我们也简单的用永久哈希替代之。上面的例子中,为了从 计算出
,我们使用了 h(2, 2) 和 h(0, 12) 而非
中的 h(3, x)。
避免使用临时哈希后,数据记录证据的最大大小从 lg N 哈希扩展到了 2 lg N 哈希。
↑ 译注:数据记录的证据是指:由底层至根节点所需计算根哈希的哈希数量。使用临时哈希时,只需每个层级 1 个哈希,再加上底层数据记录本身的哈希,所以此时证据大小为树的层级数,即 lg N。去掉临时哈希后,原本根节点的子节点一侧必须由数据记录计算而来,即
lg N- 1 个记录,而另一侧由于缺少临时哈希,所以需重新计算哈希,从而需再次从几乎最底层开始对由大树分解而来的 2 的次方的子树们的根哈希开始再次计算哈希,此时最大需约 lg N 个哈希值。最终根节点的左右两侧子节点哈希都已得到,才能计算根哈希。所以由 lg N 变为了 2 lg N。
避免使用临时哈希后,树证据的最大大小从 2 lg N 哈希扩展到了 3 lg N 哈希。
注意,那些顶层的哈希,包括 和
,本身都是临时哈希,需要 lg N 个永久哈希才能计算得到。但以下情况除外:大小刚好是 2 的次方的树
、
、
、
等等。
存储日志需要一些仅追加(append-only)的文件。第 1 个文件存储日志数据记录,然后,第 2 个文件存储第 1 个文件的每个数据记录的索引(即一系列 int64 的值,表示第 1 个文件中每个记录的起始偏移量)。此索引可用于根据数据记录的数字编号对数据记录进行高效的随机访问。尽管我们可以从所有数据记录重新计算树中的任何哈希,但若一棵树的叶子数为 N,则需要 N-1 个哈希计算操作。因此,需要以某种更易于访问的形式预先计算并存储这些哈希树。
正如我们前面小节提到的,这些树之间存在一些明显的共同部分。例如,最新的哈希树包含了更早的哈希树的全部永久哈希值,所以 只存储 最新的哈希树即可。一个直接的方法是维护 lg N 个只追加的文件,每个文件保存 1 棵树的 1 个层级的哈希值。由于哈希值都是固定大小,所以通过适当的偏移即可高效从文件读取这些哈希值。
若要增加一个新的日志记录,我们必须把数据记录追加到数据文件中,将数据的偏移值追加到索引文件中,并将数据的哈希值追加到 0 级的哈希文件中。然后,若我们在 0 级哈希文件中形成了一对哈希值,则将这对哈希的哈希追加到 1 级哈希文件中,若 1 级文件中也完成了一对哈希值,则继续将计算得到的哈希追加到 2 级哈希文件中,如此类推一直向上。每个日志记录的写操作会导致在 1 至 lg N 个哈希文件中分别追加 1 个哈希(译注:假设有 N 个叶子,则该树最多有 lg N 个层级,一个层级对应 1 个文件)。并且平均每个写操作只有 2 个新哈希值。(具有 N 个叶子的二叉树拥有 N-1 个非叶子节点)
译注:平均 2 个新哈希值的计算:假设最开始只有 1 个叶子节点,当增加到 N 个叶子节点时,非叶子节点增加了 N-1 个,所以 (
新增叶子节点数 N-1+新增非叶子节点数 N-1) /N-1 次写操作=2,得平均为 2 个新哈希值。
也可将 lg N 个仅追加数据的文件交叉整合到 1 个仅追加的文件中,这样日志中只需存储 3 个文件:数据记录文件、索引文件、哈希值文件,详细可见附录 A。还有一种方法是将日志存储在数据库的一对表中,一个表存储数据记录,另一个表存储哈希数据(数据库本身可提供数据记录的索引)。
无论是存储在文件还是数据库中,日志的存储形式都是仅追加。因此数据缓存永远不会过时,并使得并行读取、实现日志的只读副本都变得很简单。但是,日志的写入操作是集中式的,对所有数据记录都需要进行顺序编号(大部分情况下还需保证编号不重复)。使用两个表的数据库的话,可利用数据库本身的能力:副本(译注:副本可提高读取性能)、协调写操作(译注:提高写入性能)。若底层数据库支持全局复制及一致性那就更好了,如 Google Cloud Spanner 或 CockroachDB。
当然,仅存储日志还不够,我们还需让客户端可获取这些日志。
由于每个客户端都会对日志的正确性进行怀疑,所以日志服务必须让客户端很容易验证两个东西:
- 任何特定数据记录都确实存在于日志中
- 当前的日志总是曾访问过的旧日志的追加(译注:就小树属于大树)
为实现可用,日志服务必须使得:根据某些查找关键字可很容易找到想要的数据记录,并且允许检查者遍历整个日志,以检查是否存在异常的日志记录。
为此,日志服务必须响应以下 5 个查询:
Latest()返回:- 当前日志的大小(即叶子数)
- 树的根哈希
- 服务器的加密签名(为了不可抵赖)
-
译注:例如 https://sum.golang.org/latest ,可理解为服务器用私钥加密,客户端用公钥对此签名进行解密,从而证明此树的根哈希和叶子数确实是该服务器给出的。因为该公钥只能解密对应私钥加密的内容
-
RecordProof(R, N)返回:- 一个证据,证明记录 R 确实存在于大小为 N 的树中
TreeProof(N, N′)返回:- 一个证据,证明大小为 N 的树确实是大小为 N′ 的树的前缀
Lookup(K)返回:Data(R):- 返回记录 R 对应的数据
客户端使用前面 3 个查询来维护它最近使用过的本地日志缓存副本,并确保服务器从未删除日志中的任何内容。要做这一点,客户端应缓存最近查询过的日志大小 N 以及根哈希 T。然后,在信任记录编号 R 确实对应数据 B 之前,客户端应先验证 R 是否存在于日志中。若 R ≥ 本地缓存 N,则客户端应将缓存 N、T 更新为最新日志的编号与根哈希,前提是已验证当前最新日志确实包含了本地缓存日志。写成伪代码:
validate(bits B as record R):
if R ≥ cached.N:
N, T = server.Latest()
if server.TreeProof(cached.N, N) cannot be verified:
fail loudly
cached.N, cached.T = N, T
if server.RecordProof(R, cached.N) cannot be verified using B:
fail loudly
accept B as record R
翻译为中文:
验证(数据B 是 记录R):
如果 R ≥ 缓存.N:
N, T = 服务器.Latest()
如果 服务器.TreeProof(缓存.N, N) 验证不通过:
验证失败
缓存.N, 缓存.T = N, T
如果 服务器.RecordProof(R, 缓存.N) 验证没使用 B:
验证失败
信任 B 是 记录R
客户端的证据验证操作可确认日志服务的的行为正确,至少与本地客户端曾查询到的内容一致。若有一个坏人服务器能区分不同的客户端,并能针对不同客户端提供不同的日志。将导致部分受害的客户端接收到被篡改过的数据(且其他客户端、检查者并不知道这些数据)。若服务器欺骗了一个受害者,当受害者继续请求新的日志时(新日志必然包含旧日志,也就必然包含本地副本的日志),服务器必须持续给受害者发送欺骗的响应,也即永远提供一个欺骗的日志。这样一来,客户端会更容易发现被欺骗了。例如,当受害者曾访问过一个代理后,或与其他客户端进行对比后,或坏人服务器不小心在某个响应中没有发送欺骗内容后(译注:即一不小心发送了正确内容),客户端会立即发现其中的不一致之处。要求服务器对 Latest() 进行签名,使得服务器无法消除不一致之处,除非服务器声明已被完全破坏。
客户端侧的验证有点像 Git 客户端:本地维护远程仓库的副本,并在 git pull 接收更新前,先验证远程仓库确实包含了本地所有的提交(commit)。但透明日志(transparent log)客户端只需下载 lg N 个哈希值即可完成验证,而 Git 需下载所有的 cached.N 个哈希值(N 为新数据记录的数量)。更一般的,透明日志可选择性地读取和验证某些条目,而无需下载、存储整个日志。
如上所述,日志的存储需要简单的、总大小线性增加的、仅追加的存储方式。并且日志的服务和访问只需日志总大小的对数的网络流量。到这,已经可以停止继续探索了(在 RFC 6962 中定义的证书透明度(Certificate Transparency)也只描述到此)。但是,有一个更优的方法可以在稍微增加实现的复杂度后,使得:
- 哈希存储空间减半
- 网络传输对缓存更友好
该优化方法将哈希树拆分为多个瓦片,就像 Google Maps 将全球拆分为瓦片那样。
一个二叉树可被分割为固定的多个高为 H,宽为 的瓦片。例如,下面是一棵拥有 27 个数据记录的永久哈希树,被分割为多个高度为 2 的瓦片:
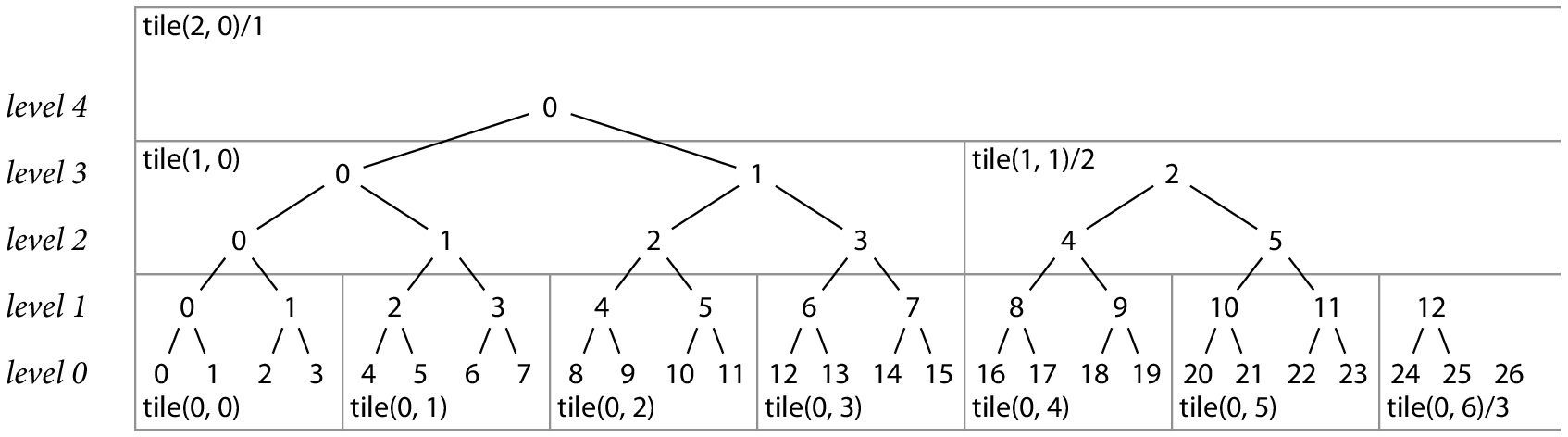
类似于我们前面提到的哈希坐标,我们可为每个瓦片分配一个二维坐标:tile(L, K),表示该瓦片处于 L 级(哈希将 H·L 对齐到 H·(L+1)),且处于从左起算第 K 个位置(译注:坐标都是从 0 开始)。对于任意给定的日志大小,每级的最右侧瓦片可能是不完整的:哈希的最底行可能只包含了 个哈希。此时,我们将最右的不完整瓦片表示为
tile(L, K)/W(当瓦片是完整时(即 ),
/W 将被省略)。
译注:
tile(L, K)/W只是一个表示方式,不是做除法。从上图右下角的title(0, 6)/3可知,里面的3是指该瓦片底层行中包含的哈希数量(即 24、25、26 这三个)
只有每个瓦片的最底行需要存储,因为更上层的行可通过根据其下层重新计算出来(译注:每层瓦片都会存储,且仅存储其最底下一行,而非仅存储叶子节点的瓦片)。在我们的例子中,高度为 2 的瓦片存储了 4 个哈希值,而非 6 个,减少了 33% 的存储。对于高度更高的瓦片,存储减少量逐渐趋于 50%。瓦片化后的代价是原本读取 1 个哈希,现需读半个瓦片,增加了 I/O 需求。对于一个实际的系统,一个瓦片高度为 4 似乎在存储成本与 I/O 开销之间取得较合理的平衡。它存储了 16 个哈希值,而非 30 个(存储量减少了 47%),并且(假设 SHA-256)1 个包含 16 个哈希值的瓦片只需 512 字节(刚好是一个磁盘扇区)(译注:512 = 256 * 16 / 8)。
前面已提过,每层存储一个哈希文件,共 lg N 个文件。使用瓦片存储后,我们只需存储瓦片高度值的倍数个哈希文件。若瓦片高度为 4,则我们只需为 0、4、8、12、16 级哈希层分别存储 1 个哈希文件。当我们需要另一个层的哈希值时,我们可通过读取瓦片重新计算其哈希值。
提供证据的服务 RecordProof(R, N) 和 TreeProof(N, N′) 对缓存不太友好。例如,RecordProof(R, N) 通常与 RecordProof(R+1, N)、 RecordProof(R, N+1) 有很多相同的哈希,但这 3 者是不同的请求,必须分别进行缓存。
一个对缓存更优化的方法是将 RecordProof、TreeProof 替换为一个综合的请求 Hash(L, K),提供一个永久的哈希值。客户端可很简单的计算出需要哪些哈希,只需更少的独立哈希,而非整个证据(2 N vs ),从而有助于提高缓存命中率。但不幸的是,切换到
Hash 请求是低效的:获取一个记录的证据之前只需 1 次请求,现在却需 2 lg N 次请求,树的证据更需达 3 lg N 次请求。而且,每个请求只传递了一个哈希(32 字节)(译注:32 字节 = 256bit,即一个 SHA-256 哈希值):请求的大小远大于有效信息的大小。
我们可以通过增加一个返回瓦片的接口 Tile(L, K),保留对缓存友好特性,同时减少请求次数、减少相关请求开销,以减少带宽开销。客户端可根据证据所需获取对应的瓦片,并缓存瓦片(尤其是树中较高的瓦片)以供日后的证据使用。
对于使用 SHA-256 的真实系统来说,高度为 8 的瓦片是 8kB(译注:8kB = 一个哈希值 256 bit * 高度为 8 的瓦片的底行节点数为 256 / 8bit 一字节)。在一个大型日志(例如 1 亿条记录)的证据只需 3 个完整的瓦片(或 24kB 的下载大小),以及一个包含根哈希的不完整瓦片(192 字节)。高度为 8 的瓦片可利用已存储的高度为 4(前面小节建议的大小)的瓦片提供服务。另一个合理的选择是同时提供高度为 6(每个 2kB)和 7(每个 4kB) 的瓦片服务。
如果在服务器之前存在缓存服务,则应为每个大小不同的瓦片指定不同名称,以避免请求较大瓦片时却返回一个旧的更小的瓦片(译注:可能相同坐标的瓦片在开始时是不完整的,后来日志逐渐变大,可能该坐标的瓦片变成完整的了)。虽然在给定的系统中,瓦片的高度是不变的,但明确说明瓦片的高度可能有助于系统从一个固定的瓦片高度转换到另一个固定的瓦片高度时不产生歧义。例如,在一个简单的 HTTP API 的 GET 请求中,我们可用 /tile/H/L/K 来命名一个完整的瓦片,用 /tile/H/L/K.W 来命名一个不完整的瓦片(表示该树有 W 个哈希)。
下载、缓存瓦片的一个潜在问题是:不能确定它们是否可信。攻击者可能会修改部分瓦片,从而导致验证失败。我们可通过在下载瓦片后对已签名的根哈希值进行验证,即可避免此类问题。具体来说,若我们有一个已签名的根哈希值 T,我们先下载最多不超过 (lg N)/H 个瓦片,并用瓦片中的哈希值组成完整子树计算出 T。在前面的图中 对应的是
tile(2, 0)/1、tile(1, 1)/2、tile(0, 6)/3(译注:可参考前的瓦片图和有 x、y 的图)。通过计算这些瓦片中的哈希值,如果我们得到正确的 T,这些哈希值就都是正确的。这些瓦片由瓦片树中的顶部瓦片、各层的最右侧瓦片组成,而且现在我们已知这些瓦片是正确的了。若需对其他的瓦片进行验证,我们应首先对该瓦片的父瓦片进行验证(因为顶层瓦片已通过验证),然后再利用该瓦片中的所有哈希计算出其父瓦片中对应的哈希值。还是以 为例,假设下载到的瓦片是
tile(0, 1),我们可这样计算:
h(2, 1) = H(H(h(0, 4), h(0, 5)), H(h(0, 6), h(0, 7)))
并检查该值是否与直接记录在已验证的 tile(1, 0) 中的 h(2, 1) 相匹配。若匹配,则此下载到的瓦片(译注:即此瓦片 tile(0, 1))通过验证。
总结一下,我们已了解该如何发布一个具有以下特性的透明(防篡改、不可变、仅追加)日志服务:
- 客户端可通过下载 O(lg N) 个字节来验证任意一个数据记录
- 客户端可通过下载 O(lg N) 个字节来验证一个新日志确实包含了旧日志
- 对于较大的日志,只需通过 3 个均为 8kB 的 RPC 请求即可验证
- 这些用于验证的 RPC 请求可被很好地代理和缓存,无论是出于网络效率考虑,还是出于隐私目的
- 检查者可轮询整个日志,以检查是否有条目异常情况
- 写入 N 个记录时,会产生一堆哈希树,其中第 n 棵树包含
2n-1个哈希节点,所有树加起来共个哈希值。但无需存储
-
译注:此处是指树的所有节点,含叶子节点,可理解为左下角的最小树为第 1 棵树,即仅对应第 1 个记录;第 2 棵树对应最左 2 个记录,此时这棵树共 3 个节点:底层 2 个,顶层 1 个
-
译注:
,a=1,d=2
-
译注:
-
- 这 2N 个哈希本身又可被压缩到 1.06N 个哈希,代价是需读取 8 个相邻的哈希来重建 2N 个哈希中的一个哈希
-
译注:1.06N ?
-
总而言之,这种结构使得无需信任日志的服务器本身。它不能删除一个被查看过的记录,因为会有检测。如果不能永远欺骗用户,它就不能欺骗用户,因为用户可与其他用户进行比较,从而轻松验证是否有问题。日志本身可很容易代理及缓存,所以即使主服务器消失了,其他副本也可以继续为缓存的日志提供服务。最后,检查者可检测日志中是否存在不该存在的条目,这样就可以在使用日志服务的时候异步验证日志的真实内容。
有一些关于本数据结构的原始资料,都非常易读,推荐大家认真去学习一下。
Ralph Merkle 在其博士论文 密保、验证和基于公钥的系统(Secrecy, authentication, and public-key systems,1979)中首次提出了默克尔树(Merkle trees)。默克尔树可用于,将具有单用途公共钥匙的签名方案,转换为一种具有多用途钥匙的方案。这个多用途钥匙是一棵树的根哈希,这棵树包含 个伪随机产生的单用途钥匙。每个签名都以一个特定的单用途钥匙开始,然后是其在树中的索引 K,然后是一个证据(由 L 个哈希组成)(这个证据可验证钥匙对应树中的 K 记录)。Adam Langley 的博客文章 基于签名的哈希(Hash based signatures,2013) 简要介绍了单用途签名方案,以及默克尔树如何起作用。
Scott Crosby 和 Dan Wallach 在他们的文章 防篡改日志的高效数据结构(Efficient Data Structures for Tamper-Evident Logging,2009) 提出了使用默克尔树来存储可验证的、仅追加的日志。此文的亮点是可提供高效的证据证明一棵树的日志是更大的树的日志的前缀。
Ben Laurie、Adam Langley、Emilia Kasper 在 证书透明度(Certificate Transparency (CT) system,2012) 的设计中采用这种可验证的透明日志,详细可见 RFC 6962(2013)。CT 对非二次幂的根哈希的计算与 Crosby、Wallach 的文章稍有不同。Ben Laurie 在 ACM Queue 发表的文章 证书透明度:公开、可验证、仅追加的日志(Certificate Transparency: Public, verifiable, append-only logs,2014) 给出了一个高层次的概述,及其动机和背景。
Adam Eijdenberg、Ben Laurie、Al Cutter 的文章 可验证的数据结构(Verifiable Data Structures,2015) 将日志透明度(Certificate Transparency)的日志转换为一个通用的组件(一个透明的日志),可用于各种系统。文章引入了一个类似的从任意键到任意值的透明映射。可能后续会写文章会介绍这个话题。
Google 的通用透明度(General Transparency)Trillian 项目,是一个可用于生产环境的,对透明日志、透明映射的存储实现。此 RPC 服务提供证据,而非哈希或瓦片。但服务的内部存储 使用了瓦片。
为了验证 Go 语言生态中的模块(modules)(即软件包),我们 计划使用透明日志 来存储特定模块版本的密码学哈希值。这样客户端可从密码理论上确定现在下载到的软件,以后也能下载到同样的数据。对于该系统的网络服务,我们计划直接提供瓦片服务,而非证据(proofs)。本文是属于 Go 语言的特定设计(the Go-specific design) 关于透明日志的延伸介绍。
前面介绍过的基于文件的存储方式:将永久哈希存储在 lg N 个仅追加的文件中,即树的每个层级对应一个文件。哈希值 h(L, K) 将被存储在第 L 个哈希文件的 K × 哈希值单位长度 偏移位置中。
Crosby 和 Wallach 指出,使用二叉树的后序编号,可很容易地将 lg N 个哈希层级合并为 1 个仅追加的哈希文件中。其中父哈希存储在最右子节点之后。例如,写入 N = 13 条记录后,永久哈希树的结构如下:
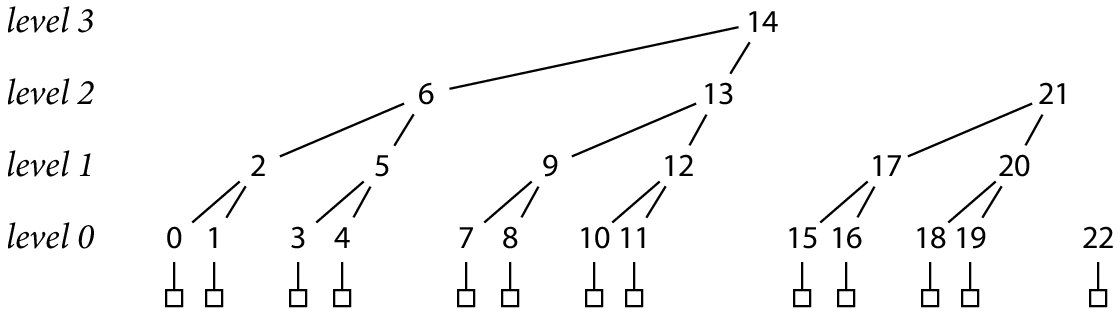
上图中,每个哈希均根据其在文件中的交错位置水平地进行编号。
后序编号方式使得文件仅可追加:每增加一个新的记录,需增加 1 至 lg N 个新的哈希值(平均为 2 个),这些新增哈希值可简单地追加到文件中,且优先写入低层级的哈希。
通过一个可计算的偏移量可从文件中读取指定的哈希值。0 级的哈希中间隔着一些更高层级的哈希,并且更高层级的哈希都紧跟在其最右子节点的哈希之后:
这种交错的存储方式还可改善读取时 I/O 性能。若读取一个证据(proof)通常意味着从每个层级读取 1 个哈希,这些哈希聚集在树中的某些叶子周围。若树的每个层级是分别存储在不同文件,每个哈希都在不同的文件中(译注:这里说的 每个哈希 应是指某个节点路径所组成的哈希列表中的哈希),也即一次 I/O 操作不能同时读取多个哈希。但当树以交错形式存储时,底层级的哈希都是相邻的,使得可以一次磁盘读取就能得到许多所需的哈希。
另一方式是使用中序遍历树的编号方式来安排 lg N 个哈希文件,这样每个父哈希都存储在其左右子树之间:
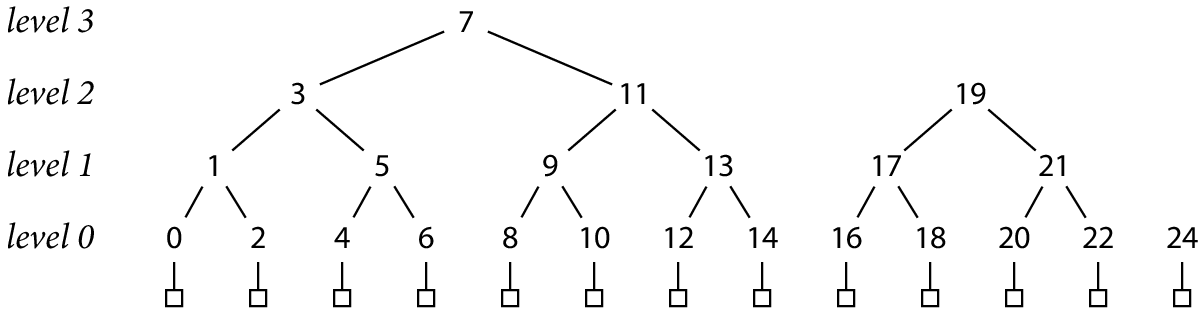
这种顺序的存储方式不能使用仅追加的方式写入到文件,但每个条目依然只需写入 1 次。例如,上图写入了 13 个记录,哈希被存储在 0-14、16-22、24 的索引中。注意,不含索引 15、23,因为这两个索引将被用于 h(4, 0)、h(3, 1)。实际上,当一个父哈希的左子树计算完毕后,就会预留一个父哈希的位置。而当其右子树也计算完毕后,就可填充刚预留的位置了。
尽管,此文件不再是仅追加的,但中序编号的方式也有其他有用的特性。首先,偏移量的计算更简单:
其次,存储的位置也改善了。现在每个父哈希都精确地位于其子树之间,而非右侧更远的地方。
将哈希树存储在 lg N 个独立的层级中,可使其很简单地转换为瓦片存储:只需少写入 (H–1)/H 个文件。最简单的瓦片实现可能是使用分散的文件,但还是解释一下,为什么值得去将交错存储的哈希文件转换为瓦片存储。这个转换并不是直接删除一些文件那么简单。直接忽略某些层级的哈希还不够:我们还希望文件中每个瓦片都是连续的。例如,对于高度为 2 的瓦片,在 1 级的第 1 个瓦片应存储 h(2, 0) 至 h(2, 3) 的哈希,但无论是后序还是中序交错,都将这 4 个哈希(译注:4 个哈希即 h(2, 0)、h(2, 1)、h(2, 2)、h(2, 3))放在相邻的位置。
相反,我们必须简单地定义瓦片都是连续存储的,然再选择一个线性的瓦片布局顺序。对于高度为 2 的瓦片,这些瓦片形成一个四叉树,更通用地说应该是形成一个 叉树。我们可使用附录 A 中提到的后序布局:
后序瓦片顺序将父瓦片放在紧跟其最右子瓦片的后面,但需在其最左子瓦片计算完成后才写入父瓦片。这就意味着父瓦片会被写入到哈希文件中离已填充内容越来越远的位置。例如,高度为 2 的瓦片,tile(2, 0) 的第 1 个哈希(即后序编号为 20)(译注:tile(2, 0) 表示从 0 起算层级值为 2,从左起算位置为 0 的瓦片)将被写入到 tile(1, 0)(后序编号 4)之后:
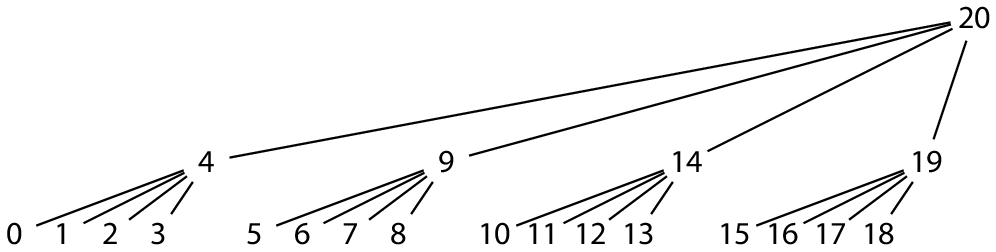
哈希文件在索引为 20 的数据位置之后不会写入任何瓦片,除非直到 20 之前的空隙已填充完(译注:此处描述的位置是:0 1 2 3 4 20 5 6 7 8 9 .... 17 18 19)。但然后又重复类似操作:在写完前面 20 个瓦片后会导致立即将接下来的第一个哈希写入到索引为 84 的瓦片中(译注:上图中 0-20 共 21 个瓦片整体将作为更大的四叉树的最左节点,因为是四叉树,所以还需 3 个类似上图的树才能拼凑出更大四叉树的 4 个节点,也即 21 * 4 = 84,实际大四叉树的根节点位置应在 84 之后即 85(从 1 起算的话),而因为本文一直以 0 起算索引值,所以文中说是 84)。一般化来说,文件中只有前面的 的哈希值是可保证相邻。大部分的系统都能高效支持文件中存在大孔,但也并非全部系统都支持:我们还是希望使用其他瓦片结构来避免大孔问题。
若将父瓦片放在紧跟其最左子节点之后,则可消除所有的孔(不完整的块除外),并且似乎刚好与附录 B 中的中序结构对应:
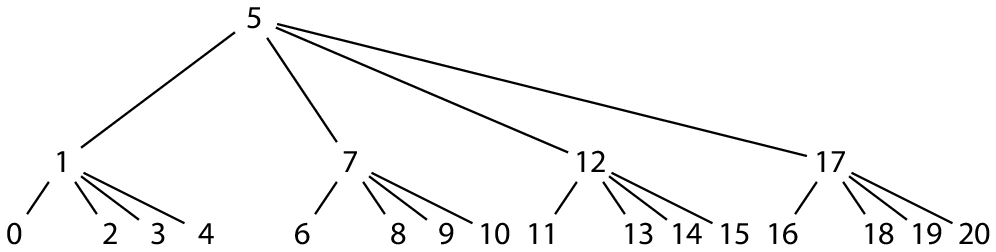
但是,虽然树的结构是规则的,但编号却不是。相反,偏移量的数学计算更像后续遍历。有一个更简单,但可能不太直观的方法是更改父瓦片在其子树中的具体位置:
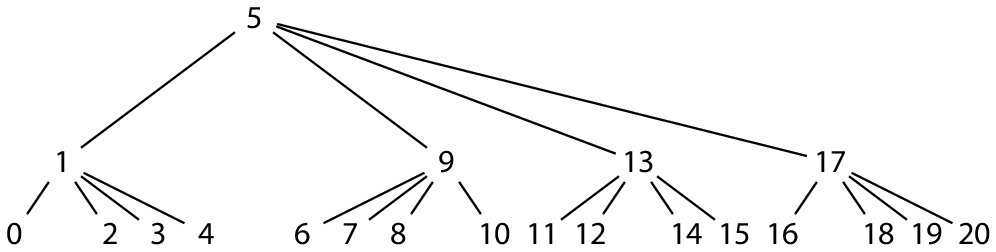
上图中, 表示
X 被写成 以 B 为基础的数字,|| 表示将 以 B 为基础的数字 串起来, 表示 以 B 为基础 的数字 1 重复了 L 次,
。
此编码方案形成了中序二叉树的遍历方式(H = 1,B = 2),保留了偏移量在数学上的规则性,代价是树的结构变得不规则。由于我们只关心数学计算,不关心树到底长什么样,所以此方案可能算是相对合理的平衡。关于此奇怪排序的细节,可见我的这篇文章 一个编码树的遍历(An Encoded Tree Traversal)。