





基于 so-vits-svc4.0(V1)的一个分支,支持实时推理和图形化推理界面,且兼容其模型。
- 实时语音转换 (增强版本 v1.1.0)
- 与
QuickVC相结合 - 修复了原始版本中对
ContentVec的误用1 - 使用 CREPE 进行更准确的音高推测
- 图形化界面和统一命令行界面
- 相比之前双倍的训练速度
- 只需使用
pip安装即可使用,不需要安装fairseq - 自动下载预训练模型和 HuBERT 模型
- 使用 black、isort、autoflake 等完全格式化的代码
创建一个虚拟环境
Windows:
py -3.10 -m venv venv
venv\Scripts\activateLinux/MacOS:
python3.10 -m venv venv
source venv/bin/activateAnaconda:
conda create -n so-vits-svc-fork python=3.10 pip
conda activate so-vits-svc-fork如果 Python 安装在 Program Files,在安装时未创造虚拟环境可能会导致PermissionError
通过 pip 安装 (或者通过包管理器使用 pip 安装):
python -m pip install -U pip setuptools wheel
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -U so-vits-svc-fork- 如果没有可用 GPU 或使用 MacOS, 不需要执行
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118. MPS 可能已经安装了. - 如果在 Linux 下使用 AMD GPU, 请使用此命令
--index-url https://download.pytorch.org/whl/rocm5.4.2替换掉--index-url https://download.pytorch.org/whl/cu118. Windows 下不支持 AMD GPUs (#120).
请经常更新以获取最新功能和修复错误:
pip install -U so-vits-svc-fork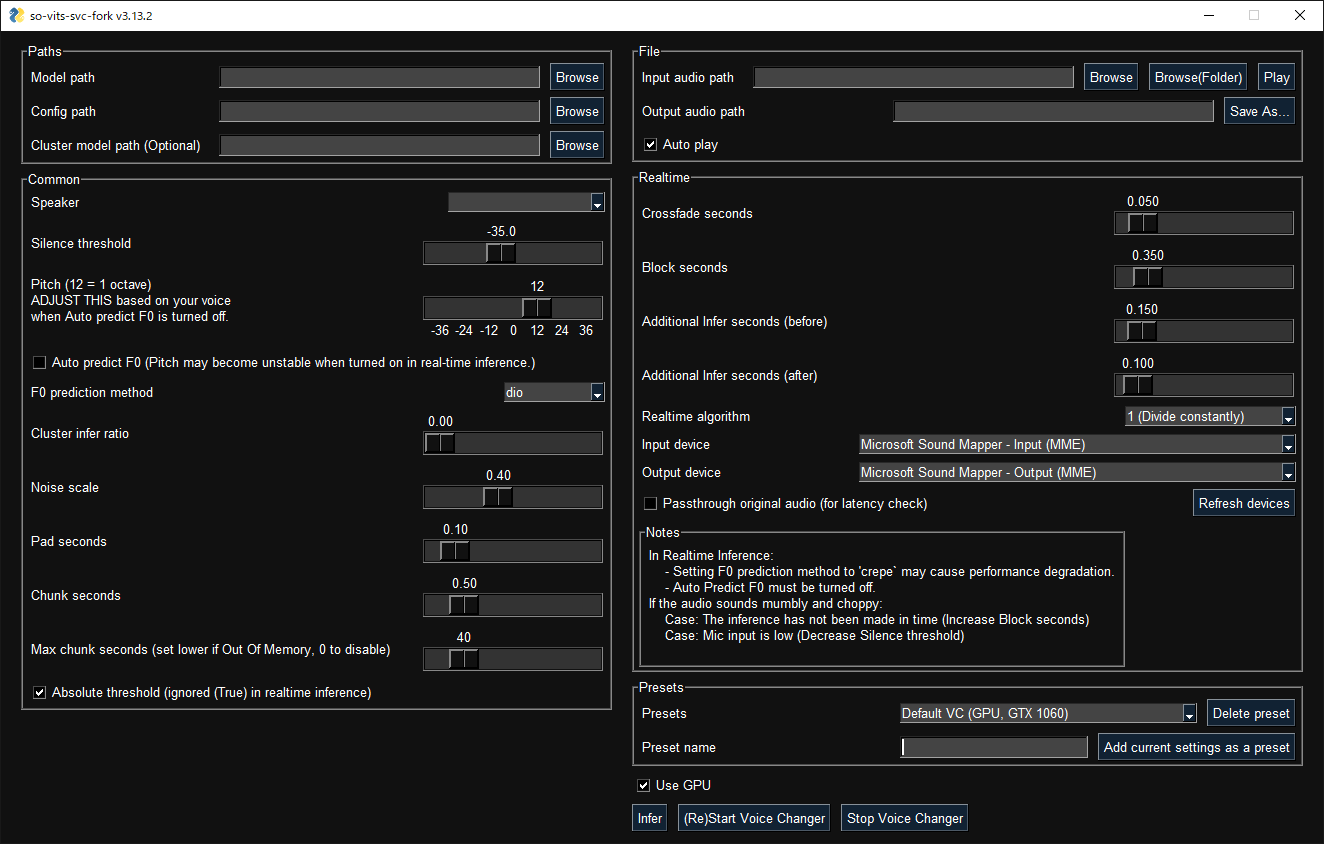
请使用以下命令运行图形化界面:
svcg- 实时转换 (输入源为麦克风)
svc vc- 从文件转换
svc infer source.wav预训练模型 可以在 HuggingFace 获得。
- 如果使用 WSL, 请注意 WSL 需要额外设置来处理音频,如果 GUI 找不到音频设备将不能正常工作。
- 在实时语音转换中, 如果输入源有杂音, HuBERT 模型依然会把杂音进行推理.可以考虑使用实时噪音减弱程序比如 RTX Voice 来解决.
- 如果数据集有 BGM,请用例如Ultimate Vocal Remover等软件去除 BGM.
推荐使用
3_HP-Vocal-UVR.pth或者UVR-MDX-NET Main. 2 - 如果数据集是包含单个歌手的长音频文件, 使用
svc pre-split将数据集拆分为多个文件 (使用librosa). - 如果数据集是包含多个歌手的长音频文件, 使用
svc pre-sd将数据集拆分为多个文件 (使用pyannote.audio) 。为了提高准确率,可能需要手动进行分类。如果歌手的声线多样,请把 --min-speakers 设置为大于实际说话者数量. 如果出现依赖未安装, 请通过pip install pyannote-audio来安装pyannote.audio。
如果你无法获取 10GB 显存以上的显卡,对于轻量用户,推荐使用 Google Colab 的免费方案;而重度用户,则建议使用 Paperspace 的 Pro/Growth Plan。当然,如果你有高端的显卡,就没必要使用云服务了。
将数据集处理成 dataset_raw/{speaker_id}/**/{wav_file}.{any_format} 的格式(可以使用子文件夹和非 ASCII 文件名)然后运行:
svc pre-resample
svc pre-config
svc pre-hubert
svc train -t- 数据集的每个文件应该小于 10s,不然显存会爆。
- 建议在执行
train命令之前提高config.json中的batch_size以匹配显存容量。 将batch_size设为auto-{init_batch_size}-{max_n_trials}(或者只需设为auto)就会自动提高batch_size,直到爆显存为止(不过自动调高 batch_size 有概率失效) - 如果想要 f0 的推理方式为
CREPE, 用svc pre-hubert -fm crepe替换svc pre-hubert. - 若想正确使用
ContentVec,用-t so-vits-svc-4.0v1替换svc pre-config。由于复用 generator weights,一些 weights 会被重置而导致训练时间稍微延长. - 若要使用
MS-iSTFT Decoder,用svc pre-config -t quickvc替换svc pre-config. - 在原始仓库中,会自动移除静音和进行音量平衡,且这个操作并不是必须要处理的。
- 倘若你已经大规模训练了一个免费公开版权的数据集,可以考虑将其作为底模发布。
- 对于更多细节(比如参数等),详见Wiki 或 Discussions.
更多命令, 运行 svc -h 或者 svc <subcommand> -h
> svc -h
用法: svc [OPTIONS] COMMAND [ARGS]...
so-vits-svc 允许任何文件夹结构用于训练数据
但是, 建议使用以下文件夹结构
训练: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}
推理: configs/44k/config.json, logs/44k/G_XXXX.pth
如果遵循文件夹结构,则无需指定模型路径,配置路径等,将自动加载最新模型
若要要训练模型, 运行 pre-resample, pre-config, pre-hubert, train.
若要要推理模型, 运行 infer.
可选:
-h, --help 显示信息并退出
命令:
clean 清理文件,仅在使用默认文件结构时有用
infer 推理
onnx 导出模型到onnx
pre-config 预处理第 2 部分: config
pre-hubert 预处理第 3 部分: 如果没有找到 HuBERT 模型,则会...
pre-resample 预处理第 1 部分: resample
pre-sd Speech diarization 使用 pyannote.audio
pre-split 将音频文件拆分为多个文件
train 训练模型 如果 D_0.pth 或 G_0.pth 没有找到,自动从集线器下载.
train-cluster 训练 k-means 聚类模型
vc 麦克风实时推理Thanks goes to these wonderful people (emoji key):
































This project follows the all-contributors specification. Contributions of any kind welcome!
Footnotes
-
If you register a referral code and then add a payment method, you may save about $5 on your first month's monthly billing. Note that both referral rewards are Paperspace credits and not cash. It was a tough decision but inserted because debugging and training the initial model requires a large amount of computing power and the developer is a student. ↩