 |
 |
|---|
- pip
- virtualenv (recommended)
- python 3
- numpy
- tensorflow
- OpenAI Gym with Atari environments
- Clone this repository
- Create new virtualenv environment
- For GPU enabled version of tensorflow, check installation instructions on the tensorflow site
- For Mac: Install requirements with
pip install -r requirements.txt - For other OSs edit requirements.txt with correct tensorflow version
- Train the model with
python AtariAgent.py - You can select the environment with
--env <ENV_NAME> - Enable rendering with
--render
- Evaluate agent using
python AtariAgent.py --evaluate - Load trained weights with
--load_weights <PATH_TO_WEIGHTS>
In the animation at the top of the page the Agent is playing breakout after ~10M frames, which corresponds to ~30 hours of training on Geforce GTX 770. In the Pong video, the agent has been trained for 4M frames.
dqn-agent is a TensorFlow implementation of a reinforcement learning agent using Deep Q Network (DQN) for OpenAI Gym environments. The agent learns to play Atari games in the OpenAI Gym Atari environment by repeatedly playing the games and learning to approximate which action (a press of a controller button) gives the most reward in the future. The future reward is approximated using a DQN.
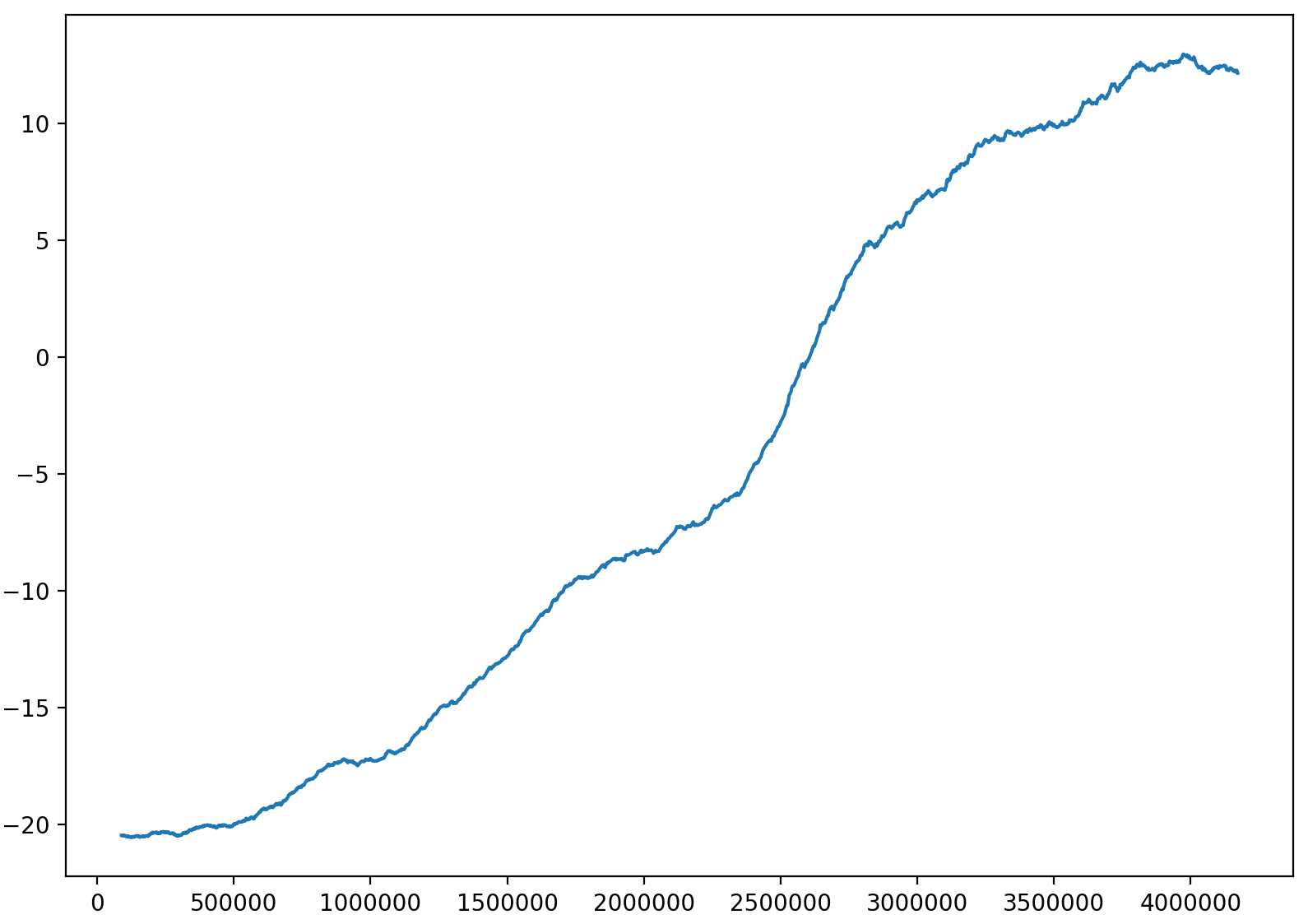 Smoothed PongDeterministic-v4 score over 4M frames. Note that the agent plays Pong with perfect score after this training after epsilon is set to 0.
Smoothed PongDeterministic-v4 score over 4M frames. Note that the agent plays Pong with perfect score after this training after epsilon is set to 0.
- In the DQN paper the input pixels are maximum of pixels in two consecutive frames to compensate for sprites only visible every other frame. In dqn-agent the input frames are used as is without applying max to them.
- In the Breakout-v0 environment dqn-agent achieves average reward of 75 over 100 episodes, whereas the DQN agent in the paper achieves avg reward of over 165. This could be due to differences in the game environment or due to some implementation difference.