[Extensibility] references the formal concept of the Decentralized Identifiers Data Model but there is nothing in the document with this formal name/concept #151
Comments
|
There is an ad-hoc reference to "data model" in the subtitle of the document and couple references in the front-mater of the document but nothing that is called out as the actual DID Data Model. |
|
This is a good point. Because valid DIDs always resolve to a DID Document, and NOT to any other type of resource, the DID spec specifies both the DID and the DID Document (which is what the data model is about). DID methods and DID resolution should be external specs. We should explain that sooner so it those distinctions are clear. There's a valid question about what content should be in a separate spec. For example, until recently, we had resolution-related text, which is now being moved to a dedicated DID Resolution specification. My perspective is that a DID that resolves to anything OTHER than a DID Document is not a valid DID, which makes the definition of the DID and DID Document intimately related. I suppose it is still an open question where we should state the requirements for ALL methods. These probably go to DID Resolution, but its worth discussing. |
|
Joe, the design from the start was that the main DID spec would include all
normative requirements (and also non-normative guidance) that applies to
ALL DID methods. In essence, it's the checklist/cookbook for a DID method
specification.
I could see some additional guidance about DID method development going
into the DID Resolution specification, but I strongly support all DID
method specification requirements going into the main DID spec.
…On Fri, Feb 1, 2019 at 10:56 AM Joe Andrieu ***@***.***> wrote:
This is a good point. Because valid DIDs *always* resolve to a DID
Document, and NOT to any other type of resource, the DID spec specifies
both the DID and the DID Document (which is what the data model is about).
DID methods and DID resolution should be external specs. We should explain
that sooner so it those distinctions are clear.
There's a valid question about what content should be in a separate spec.
For example, until recently, we had resolution-related text, which is now
being moved to a dedicated DID Resolution specification.
My perspective is that a DID that resolves to anything OTHER than a DID
Document is not a valid DID, which makes the definition of the DID and DID
Document intimately related.
I suppose it is still an open question where we should state the
requirements for ALL methods. These probably go to DID Resolution, but its
worth discussing.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADLkTQaDiNNnRLkz0bCpH51P19_THDJ4ks5vJI3jgaJpZM4Zupx7>
.
|
|
@rhiaro Why was this issue closed without the specific text being resolved in the draft DID spec? Please re-open it. |
I believe the above statement is not true/correct @jandrieu.
This comes back to @msporny 's comment/suggestion that we need to refactor the spec to have a section, for example, that only talks about a DID solely from the perspective of being a decentralized identifier, a separate section for the actions, etc. |
My bad: Why was #142 closed with no resolution? |
|
My two cents:
A DID should always resolve to a DID document. The fact that Indy does not
do this means it does not comply with the spec. (Work is underway right now
to change this and bring DID documents to Indy).
Even pairwise DIDs that may never be anchored to a ledger should resolve to
a DID document.
A DID should not resolve to anything other than a DID document.
A DID is not just a decentralized identifier, it is a decentralized
identifier tied to a document that outlines the ways to prove control of
the identifier.
…On Sat, Feb 2, 2019, 10:25 Amy Guy ***@***.***> wrote:
My bad: Why was #142 <#142>
closed with no resolution?
We should continue that conversation in #142
<#142>
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AJ5VP_LPu5jCxGMFdAU__JC4Pyjmy_-_ks5vJcnzgaJpZM4Zupx7>
.
|
Maybe this is the difference between a DID and a Verifiable (and/or Verified) DID? |
|
On Sat, Feb 2, 2019, 17:14 Michael Herman (Toronto) < ***@***.***> wrote:
A DID is not just a decentralized identifier, it is a decentralized
identifier tied to a document that outlines the ways to prove control of
the identifier.
Maybe this is the difference between a DID and a Verifiable DID?
If a DID isn't verifiable, isn't it just a GUID?
—
… You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AJ5VP9VZdNn29yU-bjG7-H1bYokjQs_hks5vJinXgaJpZM4Zupx7>
.
|
|
RE: If a DID isn't verifiable, isn't it just a GUID? That 'tis the question. For example, I can create a DID in my wallet and then use it for several different use cases without: (a) ever persisting to a Ledger, and (b) a requirement to create a DID Document. Here's some code: In fact, the entire getting_started-verbose.py script delivers a set of highly valuable business processes without using DID Documents at all ...just DIDs ...many of which are never persisted to the Ledger. |
|
I am familiar with that code, and would say that while it should certainly
be possible to use a DID without anchoring it to a ledger, creating one
without a corresponding DID document means it does not conform to the spec
(and therefore isn't really a DID).
That's why the indy codebase will be changing to add DID documents, even in
peer to peer scenarios.
…On Sun, Feb 3, 2019, 07:48 Michael Herman (Toronto) < ***@***.***> wrote:
That 'tis the question. For example, I can create a DID in my wallet and
then use it for several different use cases without: (a) ever persisting to
a Ledger and (b) a requirement to create a DID Document. Here's some code:
https://github.com/mwherman2000/indy-dev/blob/master/python/getting_started-verbose.py#L40-L55
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AJ5VP5sQ6rxhlJFgztEe9UL0U8SoirNxks5vJvaygaJpZM4Zupx7>
.
|
|
Note that the ledger or other target system where the DID is created/registered does not necessarily have to support DID documents natively, in order to conform to the spec. All that's required is to have a well-defined DID Resolution process that produces a DID document. Bitcoin- and Ethereum- based DID methods don't "store" a DID document anywhere, but a resolver can still produce one. In the case of Indy/Sovrin, it will be nice to have native support for DID documents in that particular target system, but even without it, e.g. the Universal Resolver can already resolve |
@brentzundel If you re-read the code, the script does in fact anchor the DIDs to the Ledger (e.g. 3 of the 4 DIDs generated in the first several tasks in the script are persisted to the Ledger with Verkeys) ...it doesn't require a DID Document to accomplish this. Here's a visualization of the message flow of the first several tasks...
|
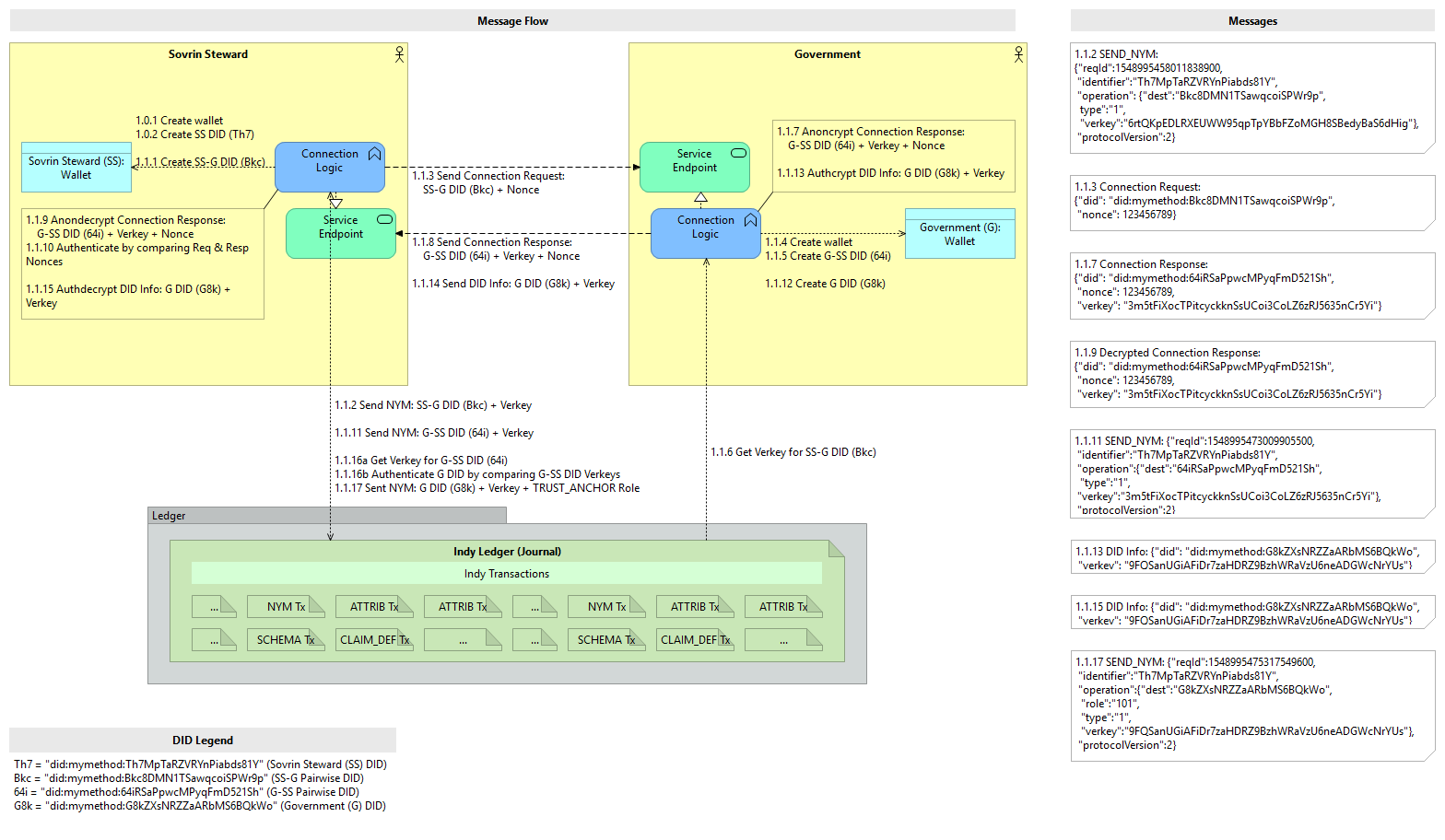
|
Strawman: A Verifiable DID is a DID that has associated with it a verifiable NYM Transaction (or equivalent). See Level 3 in the DID 6-Layer Model below (#151 (comment)). |
|
I A DID is not just a GUID or UUID. Those things exist and we do not need
to reinvent them. A DID is specifically a *cryptographically-verifiable
identifier*. So there is no need to add the adjective "Verifiable" in front
of it.
If you have invented an identifier that is cryptographically self-verifying
without reference to any external metadata, it feels like an academic
argument to call that a DID. But if that metadata is in fact virtual, i.e.,
encoded in the identifier itself, then IMHO there still IS a "virtual" DID
document (one that could be rendered with the proper algorithm), and thus
it could still be a DID.
Michael, is that what you have in mind?
I've been thinking about it a long time (that's the benefit of 2+ years
working on the evolution of the DID spec), and IMHO the most essential
quality of a DID is that it is *an addressable abstraction over
a cryptographic key pair.* In other words, with the DID, you can
always *get the cryptographic
key you need in your own context*. For example, if you're the DID
controller, you can get to either the public (verification) or private
(signing) key. If you're not the DID controller, you can only get to the
public key. But you can still verify it.
It doesn't have to come from a public ledger or private ledger or any
ledger. You just have to be able to retrieve it—that's why the DID is an
abstraction on the key (pair).
Thus the publicKey property of a DID document.
The second most essential quality of a DID is that it is *an addressable
abstraction over a service endpoint*, i.e., a network location where you
can interact with some kind of service associated with the DID (in Indy we
call them agents, others call them hubs—choose your name). But not all uses
of a DID need a service endpoint.
Thus the service property of a DID document.
The third most essential quality of a DID is that it *provides a standard
means of authentication* of the DID controller.
Thus the authentication property of a DID document.
Hope this helps,
=D
…On Sun, Feb 3, 2019 at 9:22 PM Michael Herman (Toronto) < ***@***.***> wrote:
Strawman: A Verifiable/Verified DID is a DID that has associated with it a
trusted, verifiable NYM
<https://github.com/hyperledger/indy-node/blob/master/docs/transactions.md#nym>
(or similar data structure).
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADLkTUkaO7skrOnfXlbNILZh3iVpdhlXks5vJ8OvgaJpZM4Zupx7>
.
|
|
@talltree Your discussion starts off in a good general direction, then for me it diverges :-) ...I'll comment in detail later today. In the meantime, my first reading of your comments (as well as the offline discussions about re-structuring the draft DID spec) inspired the following model... DID 6-Layer Model Draft document for discussion purposes (was DID 7-Layer Model) "I'll be back..." |
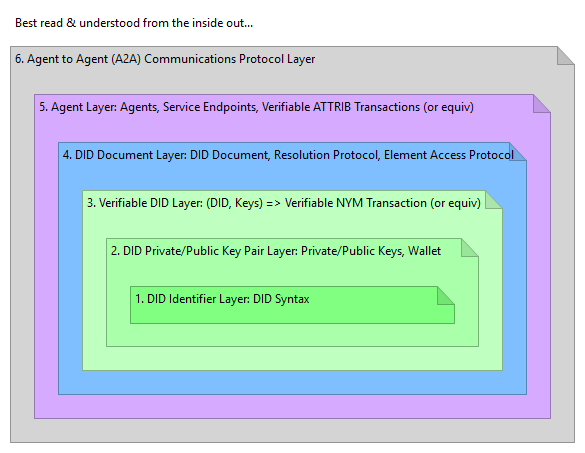
|
From @msporny (during the CCG call): https://w3c.github.io/vc-data-model/ is a good example of a) potential structure of the the overall DID spec as well as b) best practices for presenting a data model (the focus of this issue). |
|
@talltree Replying to your comments [above], ... We’re truly in the embryonic stages of giving birth to an exciting and powerful new technology/paradigm/platform. Nobody really understands what it is going to produce and the profound changes it is going to have – and here, I will use your analogy, like the birth of DNS. It's not a time to be exclusionary ...it's a time to be inclusionary. What I am asking for is for [Level 2 and Level 3](#151 (comment) (see above) to be recognized because they enable use cases we can’t imagine …for example, lightweight use cases in the IoT space, process control, other embedded systems, etc. where it isn’t easy or practical to support the heavy(ier) weight of the Levels 4-6 layers and protocols. ...additionally, from an Indy perspective, recognizing Level 2 and Level 3 don't require any new code to be written or existing code to be changed. Level 2 and Level 3 have already been implemented and are functioning well. If you watch @peacekeeper 's DID Resolution webcast starting 400 seconds into the video, Markus does a good job of explaining how a DID Document is reconstructed (aka resolved) from NYM and ATTRIB transactions on the Ledger: https://www.youtube.com/watch?v=gf2g4O3yqCc&feature=youtu.be&t=400 …watch for 3 minutes from 6:40 to timecode 9:30. Level 3 is saying: if you have a trusted/verifiable NYM Transaction (or equivalent), you have a Verifiable DID …with no DID Document overhead. …because a NYM Tx, by itself, is like the degenerate/simplest case of a DID Document. |
|
Michael, just to clarify, DID documents have always been able to be
"virtual", i.e., composed of metadata retrieved by a DID method from
wherever the DID method needs to get it. An actual DID document in a
specific serialization does not need to be stored anywhere. That's all up
to the DID method.
That's why all DIDs are verifiable, and why it strikes me as misleading to
talk about a "DID stack" (vs. an SSI stack, of which DIDs
registration/resolution is just the first layer). With DIDs, there's just:
1. The DID—a string conforming a particular syntax defined by the DID
spec (generic) and DID method spec (specific);
2. The DID method, which defines how a resolver will resolve the DID
into what *eventually* will be a conformant DID document (at the *end* of
the resolution process), and
3. The final result of the DID resolution process, which is a conformant
DID document (again, the richness of which depends on the capabilities of
the DID method).
Those three areas are what the DID spec needs to define the rules for (plus
security and privacy considerations, which are considerable).
=D
…On Wed, Feb 6, 2019 at 9:42 AM Michael Herman (Toronto) < ***@***.***> wrote:
@talltree <https://github.com/talltree> Replying to your comments [above
<#151 (comment)>],
...
We’re truly in the embryonic stages of giving birth to an exciting and
powerful new technology/paradigm/platform. Nobody really understands what
it is going to produce and the profound changes it is going to have – and
here, I will use your analogy, like the birth of DNS. It's not a time to be
*exclusionary* ...it's a time to be inclusionary.
What I am asking for is for Level 2 and Level 3 to be recognized because
they also have potential for use cases we can’t imagine …perhaps
lightweight use cases in the IoT space, process control, other embedded
systems, etc. where it isn’t easy or practical to support the heavy(ier)
weight of the Levels 4-6 layers and protocols.
...from an Indy perspective, recognizing Level 2 and Level 3 doesn’t
require any new code to be written or existing code to be changed. Levels 2
and Level 3 have already been implemented and are functioning well.
If you watch @peacekeeper <https://github.com/peacekeeper> 's DID
Resolution webcast starting 400 seconds into the video, Markus does a good
job of explaining how a DID Document is reconstructed (aka resolved) from
NYM and ATTRIB transactions on the Ledger:
https://www.youtube.com/watch?v=gf2g4O3yqCc&feature=youtu.be&t=400 …watch
for 3 minutes from 6:40 to timecode 9:30.
Level 3 is saying: if you have a NYM Transaction (or equivalent), you have
a Verifiable DID …with no DID Document. …because a NYM Tx, by itself, is
like the degenerate/simplest case of a DID Document.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADLkTfCmy00Gc1JsuYRZgMuQ5-oOixdLks5vKwYFgaJpZM4Zupx7>
.
|
|
[Humorous sidenote: @talltree I think you and I are dreaming the same dream at the same time (modulo time zones) :-)] I basically agree with you for the lower layers but want to postulate: Where should DID Documents be defined/spec'ed out? ...given that they are exclusively an output of the DID Resolution process? Digging deeper...
Reference: Here's a DNS primer that some people might find helpful (DNS is much more than a NOTE: This might come up on the first inaugural DID Resolution call "this afternoon". |
|
Here's an updated version of the DID 6-Layer Model to illustrate the points in the preceding comment...
|

|
Michael, sorry to be slow but I was in a DKMS workshop all day today.
When I looked at the two columns on the right of your diagram—in other
words, when I realized what you *meant* by your six-layer diagram on the
left—all I heard was beautiful music.
(And now I know what you meant by, "dreaming the same dream" ;-)
=Drummond
…On Thu, Feb 7, 2019 at 6:32 AM Michael Herman (Toronto) < ***@***.***> wrote:
Here's an updated version of the DID 6-Layer Model to illustrate the
points in the preceding comment...
[image: image]
<https://user-images.githubusercontent.com/6101736/52414647-20827580-2aa2-11e9-82a2-ad8fc2075ac4.png>
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#151 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADLkTb0XEFoHT3OlYYFhEj1l91qfkTkDks5vLCsCgaJpZM4Zupx7>
.
|
{kind=link}
|
There is now (0366ed0) a Core Data Model section in the spec. It's just a stub, and the precise contents will be ironed out and it will be filled out with an overview of the main concepts, so hopefully that resolves this issue. |
|
In the proposed changes 0366ed0, I don't see where the phrase "Decentralized Identifiers Data Model" was removed or changed. We should make sure Core Data Model is used consistently through the document (including the title: #130 (comment)). |
In https://w3c-ccg.github.io/did-spec/#extensibility, it references the formal concept of a
Decentralized Identifiers Data Modelfor the first time.However, there is no previous mention of a formal Data Model in the draft DID spec. There is no previous section or subsection with a heading of "Decentralized Identifiers Data Model" or simply "Data Model".
There is no picture/graphic of the DID Data Model.
I believe the lack of a clearly defined and visual Data Model is the root cause of many of the Issues that have been documented recently.
Here's an example of a possible solution ...
Hyperledger Indy/Sovrin Comprehensive Architecture Reference Model (INDY ARM) - latest version - bullets (12) thru (16) in both the diagram, Narration, and principles.
Also checkout https://hyperonomy.com/2019/01/04/the-path-from-a-id-did-to-a-real-life-something/
The text was updated successfully, but these errors were encountered: