给定一个链接 startUrl 和一个接口 HtmlParser ,请你实现一个网络爬虫,以实现爬取同 startUrl 拥有相同 域名标签 的全部链接。该爬虫得到的全部链接可以 任何顺序 返回结果。
你的网络爬虫应当按照如下模式工作:
- 自链接
startUrl开始爬取 - 调用
HtmlParser.getUrls(url)来获得链接url页面中的全部链接 - 同一个链接最多只爬取一次
- 只输出 域名 与
startUrl相同 的链接集合

如上所示的一个链接,其域名为 example.org。简单起见,你可以假设所有的链接都采用 http协议 并没有指定 端口。例如,链接 http://leetcode.com/problems 和 http://leetcode.com/contest 是同一个域名下的,而链接http://example.org/test 和 http://example.com/abc 是不在同一域名下的。
HtmlParser 接口定义如下:
interface HtmlParser {
// 返回给定 url 对应的页面中的全部 url 。
public List<String> getUrls(String url);
}
下面是两个实例,用以解释该问题的设计功能,对于自定义测试,你可以使用三个变量 urls, edges 和 startUrl。注意在代码实现中,你只可以访问 startUrl ,而 urls 和 edges 不可以在你的代码中被直接访问。
示例 1:
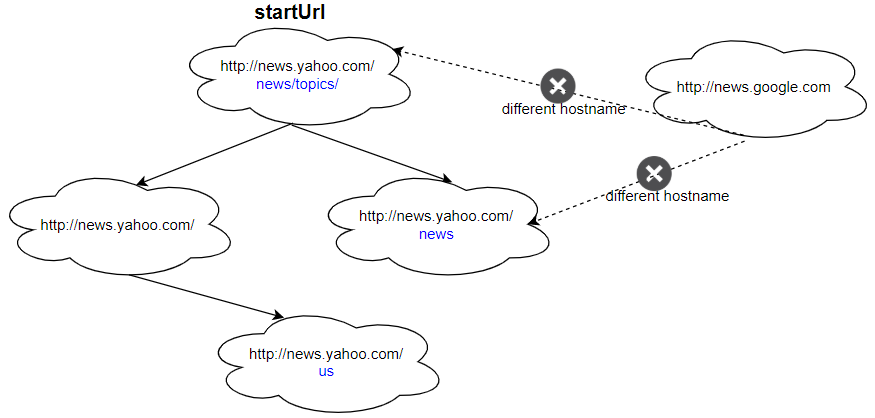
输入: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" 输出:[ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
示例 2:
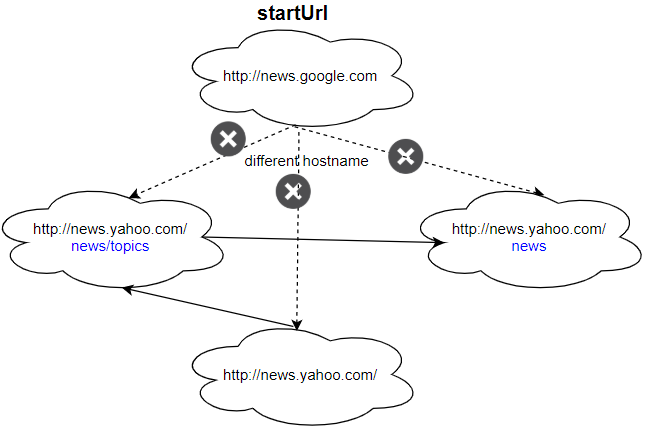
输入: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" 输入:["http://news.google.com"] 解释:startUrl 链接到所有其他不共享相同主机名的页面。
提示:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrl为urls中的一个。- 域名标签的长为1到63个字符(包括点),只能包含从‘a’到‘z’的ASCII字母、‘0’到‘9’的数字以及连字符即减号(‘-’)。
- 域名标签不会以连字符即减号(‘-’)开头或结尾。
- 关于域名有效性的约束可参考: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- 你可以假定url库中不包含重复项。