Elasticsearch可以实现秒级的搜索,cluster是一种分布式的部署,极易扩展(scale )这样很容易使它处理PB级的数据库容量。最重要的是Elasticsearch是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果(relevance) 。
-
安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
-
JSON:输入/输出格式为 JSON,意味着不需要定义 Schema,快捷方便
-
RESTful:基本所有操作 ( 索引、查询、甚至是配置 ) 都可以通过 HTTP 接口进行
-
分布式:节点对外表现对等(每个节点都可以用来做入口) 加入节点自动负载均衡
-
多租户:可根据不同的用途分索引,可以同时操作多个索引
-
支持超大数据: 可以扩展到 PB 级的结构化和非结构化数据 海量数据的近实时处理
-
分布式的搜索引擎
分布式:Elasticsearch自动将海量数据分散到多台服务器上去存储和检索
-
全文检索
提供模糊搜索等自动度很高的查询方式,并进行相关性排名,高亮等功能
-
数据分析引擎(分组聚合)
社区网站,最近一周用户登录、最近一个月各功能使用情况
-
对海量数据进行近实时(秒级)的处理
海量数据的处理:因为是分布式架构,可以采用大量的服务器去存储和检索数据
-
搜索类场景
比如说人员检索、设备检索、App内的搜索、订单搜索。
-
日志分析类场景
经典的ELK组合(Elasticsearch/Logstash/Kibana),实现日志收集,日志存储,日志分析
-
数据预警平台及数据分析场景
例如社区团购提示,当优惠的价格低于某个值时,自动触发通知消息,通知用户购买。
分析竞争对手商品销量Top10,供运营分析等等。
-
**商业BI(Business Intelligence)**系统
比如社区周边,需要分析某一地区用户消费金额及商品类别,输出相应的报表数据,并预测该地区的热卖商品,通过区域和人群特征划分进行定向推荐。Elasticsearch执行数据分析和挖掘,Kibana做数据可视化。
Lucene
Java编写的信息搜索工具包(Jar包),Lucene只是一个框架,熟练运用Lucene非常复杂。
Solr
基于Lucene的HTTP接口查询服务器,是一个封装了很多Lucene细节搜索引擎系统
Elasticsearch
基于Lucene分布式海量数据近实时搜索引擎。采用的策略是将每一个字段都编入索引,使其可以被搜索。
1)Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能
2)Solr比Elasticsearch实现更加全面,而Elasticsearch本身更注重于核心功能, 高级功能多由第三方插件提供
3)Solr在传统的搜索应用中表现好于Elasticsearch,而Elasticsearch在实时搜索应用方面比Solr表现好
目前主流依然是Elasticsearch7.x 最新的是7.8
优化:默认集成JDK、升级Lucene8大幅提升TopK性能、引入熔断机制避免OOM发生
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
- 采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
- 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
- 支持个人词条的优化的词典存储,更小的内存占用。
- 针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索
- 排列组合,能极大的提高Lucene检索的命中率。
- 扩展词典:ext_dict
- 停用词典:stop_dict
- 同义词典:same_dict
settings:设置索引库,定义索引库的分片数副本数等
- 字段的数据类型
- 分词器类型
- 是否要进行存储或者创造索引
- 全量更新用Put
- 局部更新用Post
地理坐标点是指地球表面可以用经纬度描述的一个点。 地理坐标点可以用来计算两个坐标间的距离,还可以判断一个坐标是否在一个区域中。地理坐标点需要显式声明对应字段类型为 geo_point
使用dynamic mapping 来确定字段的数据类型并自动把新的字段添加到类型映射
-
查询所有(match_all query)
-
全文搜索(full-text query)
- 匹配搜索(match query)
- 短语搜索(match phrase query)
- 默认查询(query string)
- 多字段匹配搜索(multi match query)
-
词条级搜索(term-level query)
- 精确搜索term
- 集合搜索idx
- 范围搜索range
- 前缀搜索prefix
- 通配符搜索wildcard
- 正则搜索regexp
- 模糊搜索fuzzy
-
复合搜索
-
排序sort&分页size&高亮highLight&批量bluk
聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出某字段(或计算表达式的结果)的最大值、最小值,计算和、平均值等
- 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合 metric
- 对查询出的数据进行分桶group by,再在桶上进行指标桶聚合 bucketing
- Term Suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
如果Completion Suggester已经到了零匹配,可以猜测用户有输入错误,这时候可以尝试一下Phrase Suggester。如果还是未匹配则尝试Term Suggester。
精准程度上(Precision)看: Completion > Phrase > Term, 而召回率上(Recall)则反之。
从性能上看,Completion Suggester是最快的,如果能满足业务需求,只用Completion Suggester做前缀匹配是最理想的。 Phrase和Term由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制Suggester用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量map到内存。
-
副本数量0
首次 初始化数据时,将副本设置为0,写入完毕再改回,避免了副本建立索引的过程
-
自动生成id
可以避免写前判断是否存在的过程
-
合理使用分词器
binary类型不适用,title和text使用不同的分词器加快速度
-
禁用评分,延长索引刷新间隔
-
将多个索引操作放入到batch进行处理
-
使用Filter代替Query,减少打分缓解,使用bool组合query和filter查询
-
对数据进行分组,按照日,月,年不同维度分组,查询可集中在局部index中
-
外部数据导入
- 通过MQ的web控制台或cli命令行,发送指定的MQ消息
- MQ消息被微服务模块的消费者消费,触发ES数据重新导入功能
- 微服务模块从数据库里查询数据的总数及分页信息,并发送至MQ
- 微服务从MQ中根据分页信息从数据库获取到数据后,根据索引结构的定义,将数据组装成ES支持的JSON格式,并通过bulk命令将数据发送给Elasticsearch集群进行索引的重建工作。
-
基于Scroll+bulk+索引别名的方案
-
新建索引book_new,将mapping信息,settings信息等按新的要求全部定义好
-
使用scroll api将数据批量查询出来,指定scroll查询持续时间
-
采用bulk api将scoll查出来的一批数据,批量写入新索引
-
查询一批导入一批,注意每次都使用上次结束时的scoll_id
-
切换别名book_alias到新的索引book_new上面,此时Java客户端仍然使用别名访问,也不需要修
改任何代码,不需要停机。验证别名查询的是否为新索引的数据
-
-
Reindex API方案
- Elasticsearch v6.3.1已经支持Reindex API,它对scroll、bulk做了一层封装,能够 对文档重建索引而不需要任何插件或外部工具。
参与度 & 灵活性:自研 > scroll+bulk > reindex
稳定性 & 可靠性:自研 < scroll+bulk < reindex
比如超级管理员,要给某个省份用户发送公告或者广告,最容易想到的就是利用 from + size 来实现,但这是不现实的

chroot 是在 Unix 和 Linux 系统的一个操作,针对正在运作的软件行程和它的子进程,改变它外显的根目录。一个运行在这个环境下,经由 chroot 设置根目录的程序,它不能够对这个指定根目录之外的文件进行访问动作,不能读取,也不能更改它的内容。
虚拟化技术_VMware 、VirtualBox、KVM
虚拟化技术就是在操作系统上多加了一个虚拟化层(Hypervisor),可以将物理机的CPU、内存、硬盘、网络等资源进行虚拟化,再通过虚拟化出来的空间上安装操作系统,构建虚拟的应用程序执行环境。这就是我们通常说的虚拟机。
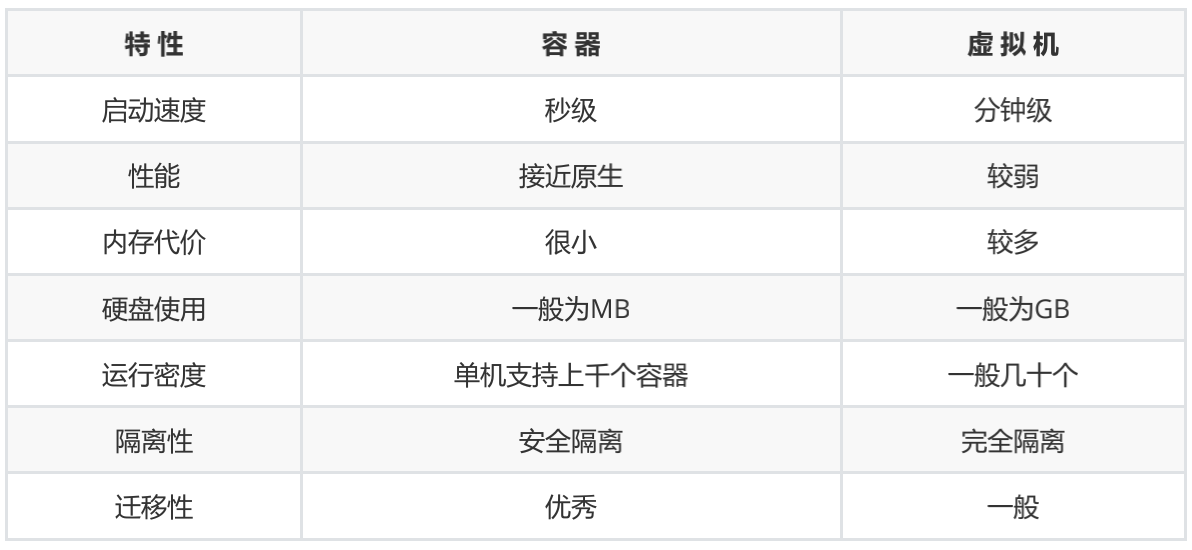
虚拟机的优点:
- 提升IT效率、降低运维成本
- 更快地部署工作负责
- 提高服务器可用性
虚拟机的缺点:
- 占用资源较多、性能较差
- 扩展、迁移能力较差
场景
- 开发人员在本地编写代码,并使用Docker容器与其他同事共享劳动成果。
- 使用Docker将应用程序推送到测试环境中,并执行自动和手动测试。
- 开发人员可以在开发环境中对其进行修复,然后将其重新部署到测试环境中以进行测试和验证。
- 测试完成后,将修补程序推送给生产环境就像将更新的镜像推送到生产环境一样简单。
需求
快速,一致地交付应用程序、镜像打包环境,避免了环境不一致的问题,简化开发的生命周期,适合于快速迭代敏捷开发的场景
Docker引擎-守护进程
Docker使用C / S架构 :用户通过Docker客户端与Docker守护进程(Docker引擎)通过Unix套接字或者RESTAPI进行通信,Docker引擎完成了构建,运行和分发Docker容器的繁重工作
Docker镜像-Dockerfile
Docker镜像类似于虚拟机镜像,是一个只读的模板,是创建Docker容器的基础
镜像是基于联合(Union)文件系统的一种层式的结构,由一系列指令一步一步构建出来。
比如:拷贝文件、执行命令
Docker仓库-Hub
Docker仓库可以分为**公开仓库 (Public)和私有仓库(Private)**两种形式。
最大的公开仓库是官方提供的Docker Hub,其中存放了数量庞大的镜像供用户下载。
镜像
[root@localhost ~]# docker pull mysql:5.7.30
5.7.30: Pulling from library/mysql ……
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql 5.7.30 9cfcce23593a 6 weeks ago 448MB
[root@localhost ~]# docker tag mysql:5.7.30 mysql5
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql5 latest 9cfcce23593a 6 weeks ago 448MB
mysql 5.7.30 9cfcce23593a 6 weeks ago 448MB
[root@localhost ~]# docker inspect mysql:5.7.30
[{显示docker 详细信息}]
[root@localhost ~]# docker search mysql
[root@localhost ~]# docker rmi mysql:5.7.30
[root@localhost ~]# docker push mysql[:TAG]容器
[root@localhost ~]# docker create -it nginx
[root@localhost ~]# docker start 9cfcce23593a
#查看运行的容器
[root@localhost ~]# docker ps
#查看所有容器
[root@localhost ~]# docker ps -a
#新建并启动容器
[root@localhost ~]# docker run -it --rm --network host tomcat:8.5.56-jdk8-openjdk-
创建一个卷,待后边使用
docker volume create test_volume
-
分别启动2个容器挂在上卷,
在2个终端窗口启动2个容器 docker run -it --rm -v test_volume:/test nginx:latest /bin/bash docker run -it --rm -v test_volume:/test nginx:latest /bin/bash cd /test; touch a.txt ls /test # 在两个容器中我们均可以看到我们创建的文件,shixian在多个容器之间实现数据共享
挂载在容器 /test 目录内创建。 Docker 不支持容器内安装点的相对路径。 多个容器可以在同一时间段内使用相同的卷。如果两个容器需要访问共享数据,例如,如果一个容器写入而另一个容器读取数据。 卷名 在驱动程序test必须唯一。这意味着不能将相同的卷名与两个不同的驱动程序一起使用。 如果我们指定了当前test_volume程序上已在使用的卷名,则Docker会假定我们要重用现有卷,并且不会返回错误。如果开始无 test_volume 则会创建这个卷当然除了使用卷,也可以使用将宿主机的文件映射到容器的卷,命令类似,只不过不用提前创建卷,而且数据会映射到宿主机上注意如果宿主机上的目录可以不存在,会在启动容器的时候创建

Core 核心层 Core 核心层是 Netty 最精华的内容,它提供了底层网络通信的通用抽象和实现,包括事件模型、通用API、支持零拷贝的 ByteBuf 等。
Protocol Support 协议支持层 协议支持层基本上覆盖了主流协议的编解码实现,如 HTTP、Protobuf、WebSocket、二进制等主流协议,此外 Netty 还支持自定义应用层协议。Netty 丰富的协议支持降低了用户的开发成本,基于 Netty 我们可以快速开发 HTTP、WebSocket 等服务。
Transport Service 传输服务层 传输服务层提供了网络传输能力的定义和实现方法。它支持 Socket、HTTP 隧道、虚拟机管道等传输方式。Netty 对 TCP、UDP 等数据传输做了抽象和封装,用户可以更聚焦在业务逻辑实现上,而不必关系底层数据传输的细节。

网络通信层 网络通信层的职责是执行网络 I/O 的操作。它支持多种网络协议和 I/O 模型的连接操作。当网络数据读取到内核缓冲区后,会触发各种网络事件,这些网络事件会分发给事件调度层进行处理。
网络通信层的核心组件包含BootStrap、ServerBootStrap、Channel三个组件。
Bootstrap 是“引导”的意思,负责 Netty 客户端程序的启动、初始化、服务器连接等过程,串联了 Netty 的其他核心组件。
ServerBootStrap 用于服务端启动绑定本地端口,会绑定Boss 和 Worker两个 EventLoopGroup。
Channel 的是“通道”,Netty Channel提供了基于NIO更高层次的抽象,如 register、bind、connect、read、write、flush 等。
事件调度层 事件调度层的职责是通过 Reactor 线程模型对各类事件进行聚合处理,通过 Selector 主循环线程集成多种事件( I/O 事件、信号事件、定时事件等),实际的业务处理逻辑是交由服务编排层中相关的 Handler 完成。
事件调度层的核心组件包括 EventLoopGroup、EventLoop。

EventLoop 负责处理 Channel 生命周期内的所有 I/O 事件,如 accept、connect、read、write 等 I/O 事件
①一个 EventLoopGroup 往往包含一个或者多个 EventLoop。
②EventLoop 同一时间会与一个Channel绑定,每个 EventLoop 负责处理一种类型 Channel。
③Channel 在生命周期内可以对和多个 EventLoop 进行多次绑定和解绑。
EventLoopGroup 是Netty 的核心处理引擎,本质是一个线程池,主要负责接收 I/O 请求,并分配线程执行处理请求。通过创建不同的 EventLoopGroup 参数配置,就可以支持 Reactor 的三种线程模型:
单线程模型:EventLoopGroup 只包含一个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
主从多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 是主 Reactor,Worker 是从 Reactor,它们分别使用不同的 EventLoopGroup,主 Reactor 负责新的网络连接 Channel 创建,然后把 Channel 注册到从 Reactor。
服务编排层 服务编排层的职责是负责组装各类服务,它是 Netty 的核心处理链,用以实现网络事件的动态编排和有序传播。
服务编排层的核心组件包括 ChannelPipeline、ChannelHandler、ChannelHandlerContext。
ChannelPipeline 是 Netty 的核心编排组件,负责组装各种 ChannelHandler,ChannelPipeline 内部通过双向链表将不同的 ChannelHandler 链接在一起。当 I/O 读写事件触发时,Pipeline 会依次调用 Handler 列表对 Channel 的数据进行拦截和处理。

客户端和服务端都有各自的 ChannelPipeline。客户端和服务端一次完整的请求:客户端出站(Encoder 请求数据)、服务端入站(Decoder接收数据并执行业务逻辑)、服务端出站(Encoder响应结果)。
ChannelHandler 完成数据的编解码以及处理工作。

ChannelHandlerContext 用于保存Handler 上下文,通过 HandlerContext 我们可以知道 Pipeline 和 Handler 的关联关系。HandlerContext 可以实现 Handler 之间的交互,HandlerContext 包含了 Handler 生命周期的所有事件,如 connect、bind、read、flush、write、close 等。同时,HandlerContext 实现了Handler通用的逻辑的模型抽象。

阻塞I/O:(BIO)

应用进程向内核发起 I/O 请求,发起调用的线程一直等待内核返回结果。一次完整的 I/O 请求称为BIO(Blocking IO,阻塞 I/O),所以 BIO 在实现异步操作时,只能使用多线程模型,一个请求对应一个线程。但是,线程的资源是有限且宝贵的,创建过多的线程会增加线程切换的开销。
同步非阻塞I/O(NIO):

应用进程向内核发起 I/O 请求后不再会同步等待结果,而是会立即返回,通过轮询的方式获取请求结果。NIO 相比 BIO 虽然大幅提升了性能,但是轮询过程中大量的系统调用导致上下文切换开销很大。所以,单独使用非阻塞 I/O 时效率并不高,而且随着并发量的提升,非阻塞 I/O 会存在严重的性能浪费。
多路复用I/O(select和poll):

多路复用实现了一个线程处理多个 I/O 句柄的操作。多路指的是多个数据通道,复用指的是使用一个或多个固定线程来处理每一个 Socket。select、poll、epoll 都是 I/O 多路复用的具体实现,线程一次 select 调用可以获取内核态中多个数据通道的数据状态。其中,select只负责等,recvfrom只负责拷贝,阻塞IO中可以对多个文件描述符进行阻塞监听,是一种非常高效的 I/O 模型。
信号驱动I/O(SIGIO):

信号驱动IO模型,应用进程告诉内核:当数据报准备好的时候,给我发送一个信号,对SIGIO信号进行捕捉,并且调用我的信号处理函数来获取数据报。
异步I/O(Posix.1的aio_系列函数):

当应用程序调用aio_read时,内核一方面去取数据报内容返回,另一方面将程序控制权还给应用进程,应用进程继续处理其他事情,是一种非阻塞的状态。当内核中有数据报就绪时,由内核将数据报拷贝到应用程序中,返回aio_read中定义好的函数处理程序。
Netty 的 I/O 模型是基于非阻塞 I/O 实现的,底层依赖的是 NIO 框架的多路复用器 Selector。采用 epoll 模式后,只需要一个线程负责 Selector 的轮询。当有数据处于就绪状态后,需要一个事件分发器(Event Dispather),它负责将读写事件分发给对应的读写事件处理器(Event Handler)。事件分发器有两种设计模式:Reactor 和 Proactor,Reactor 采用同步 I/O, Proactor 采用异步 I/O。

Reactor 实现相对简单,适合处理耗时短的场景,对于耗时长的 I/O 操作容易造成阻塞。Proactor 性能更高,但是实现逻辑非常复杂,适合图片或视频流分析服务器,目前主流的事件驱动模型还是依赖 select 或 epoll 来实现。
拆包TCP 传输协议是面向流的,没有数据包界限。 MTU(Maxitum Transmission Unit) 是链路层一次最大传输数据的大小。MTU 一般来说大小为 1500 byte。MSS(Maximum Segement Size) 是指 TCP 最大报文段长度,它是传输层一次发送最大数据的大小。

如上图所示,如果 MSS + TCP 首部 + IP 首部 > MTU,那么数据包将会被拆分为多个发送。这就是拆包现象。
Nagle 算法 Nagle 算法可以理解为批量发送,也是我们平时编程中经常用到的优化思路,它是在数据未得到确认之前先写入缓冲区,等待数据确认或者缓冲区积攒到一定大小再把数据包发送出去。Netty 中为了使数据传输延迟最小化,就默认禁用了 Nagle 算法。
拆包/粘包的解决方案
在客户端和服务端通信的过程中,服务端一次读到的数据大小是不确定的。需要确定边界:
消息长度固定 特定分隔符 消息长度 + 消息内容(Netty)
Netty 常用编码器类型:
MessageToByteEncoder //对象编码成字节流;
MessageToMessageEncoder //一种消息类型编码成另外一种消息类型。Netty 常用解码器类型:
ByteToMessageDecoder/ReplayingDecoder //将字节流解码为消息对象;
MessageToMessageDecoder //将一种消息类型解码为另外一种消息类型。编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
Netty自定义协议内容:
/*
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
*/如何判断 ByteBuf 是否存在完整的报文?最常用的做法就是通过读取消息长度 dataLength 进行判断。如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。

①writeAndFlush 属于出站操作,它是从 Pipeline 的 Tail 节点开始进行事件传播,一直向前传播到 Head 节点。不管在 write 还是 flush 过程,Head 节点都中扮演着重要的角色。
②write 方法并没有将数据写入 Socket 缓冲区,只是将数据写入到 ChannelOutboundBuffer 缓存中,ChannelOutboundBuffer 缓存内部是由单向链表实现的。
③flush 方法才最终将数据写入到 Socket 缓冲区。
在 Java 中对象都是在堆内分配的,通常我们说的JVM 内存也就指的堆内内存,堆内内存完全被JVM 虚拟机所管理,JVM 有自己的垃圾回收算法,对于使用者来说不必关心对象的内存如何回收。堆外内存与堆内内存相对应,对于整个机器内存而言,除堆内内存以外部分即为堆外内存。堆外内存不受 JVM 虚拟机管理,直接由操作系统管理。使用堆外内存有如下几个优点:
- 堆内内存由 JVM GC 自动回收内存,降低了 Java 用户的使用心智,堆外内存由于不受 JVM 管理,所以在一定程度上可以降低 GC 对应用运行时带来的影响。
- 堆外内存需要手动释放,这一点跟 C/C++ 很像,稍有不慎就会造成应用程序内存泄漏,当出现内存泄漏问题时排查起来会相对困难。
- 当进行网络 I/O 操作、文件读写时,堆内内存都需要转换为堆外内存,然后再与底层设备进行交互,所以直接使用堆外内存可以减少一次内存拷贝。
- 堆外内存可以方便实现进程之间、JVM 多实例之间的数据共享。
在堆内存放的 DirectByteBuffer 对象并不大,仅仅包含堆外内存的地址、大小等属性,同时还会创建对应的 Cleaner 对象,通过 ByteBuffer 分配的堆外内存不需要手动回收,它可以被 JVM 自动回收。当堆内的 DirectByteBuffer 对象被 GC 回收时,Cleaner 就会用于回收对应的堆外内存。

从 DirectByteBuffer 的构造函数中可以看出,真正分配堆外内存的逻辑还是通过 unsafe.allocateMemory(size),Unsafe 是一个非常不安全的类,它用于执行内存访问、分配、修改等敏感操作,可以越过 JVM 限制的枷锁。Unsafe 最初并不是为开发者设计的,使用它时虽然可以获取对底层资源的控制权,但也失去了安全性的保证,使用 Unsafe 一定要慎重(Java 中是不能直接使用 Unsafe 的,但是可以通过反射获取 Unsafe 实例)。Netty 中依赖了 Unsafe 工具类,是因为 Netty 需要与底层 Socket 进行交互,Unsafe 提升 Netty 的性能
因为DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理,如果长时间没有 GC执行,那么堆外内存即使不再使用,也会一直在占用内存不释放,很容易将机器的物理内存耗尽。-XX:MaxDirectMemorySize 指定堆外内存的上限大小,超出时触发GC,仍无法释放抛出OOM异常。
当初始化堆外内存时,内存中的对象引用情况如下图所示,first 是 Cleaner 类中的静态变量,Cleaner 对象在初始化时会加入 Cleaner 链表中。DirectByteBuffer 对象包含堆外内存的地址、大小以及 Cleaner 对象的引用,ReferenceQueue 用于保存需要回收的 Cleaner 对象。
JDK NIO 的 ByteBuffer
- mark:为某个读取过的关键位置做标记,方便回退到该位置;
- position:当前读取的位置;
- limit:buffer 中有效的数据长度大小;
- capacity:初始化时的空间容量。

第一,ByteBuffer 分配的长度是固定的,无法动态扩缩容,每次在存放数据的时候对容量大小做校验,扩容需要将已有的数据迁移。
第二,ByteBuffer 只能通过 position 获取当前可操作的位置,因为读写共用的 position 指针,所以需要频繁调用 flip、rewind 方法切换读写状态。
Netty中的ByteBuf
- 废弃字节,表示已经丢弃的无效字节数据。
- 可读字节,表示 ByteBuf 中可以被读取的字节内容,可以通过 writeIndex - readerIndex 计算得出。当读写位置重叠时时,表示 ByteBuf 已经不可读。
- 可写字节,向 ByteBuf 中写入数据都会存储到可写字节区域。当 writeIndex 超过 capacity,表示 ByteBuf 容量不足,需要扩容。
- 可扩容字节,表示 ByteBuf 最多还可以扩容多少字节,最多扩容到 maxCapacity 为止,超过 maxCapacity 再写入就会出错。

引用计数
当byteBuf当引用计数为 0,该 ByteBuf 可以被放入到对象池中,避免每次使用 ByteBuf 都重复创建。
JVM 并不知道 Netty 的引用计数是如何实现的,当 ByteBuf 对象不可达时,一样会被 GC 回收掉,但是如果此时 ByteBuf 的引用计数不为 0,那么该对象就不会释放或者被放入对象池,从而发生了内存泄漏。Netty 会对分配的 ByteBuf 进行抽样分析,检测 ByteBuf 是否已经不可达且引用计数大于 0,判定内存泄漏的位置并输出到日志中,通过关注日志中 LEAK 关键字可以找到内存泄漏的具体对象。
为了减少分配时产生的内部碎片和外部碎片,常见的内存分配算法动态内存分配、伙伴算法和Slab 算法
动态内存分配(DMA)
⾸次适应算法(first fit),空闲分区链以地址递增的顺序将空闲分区以双向链表的形式连接在一起,从空闲分区链中找到第一个满足分配条件的空闲分区,然后从空闲分区中划分出一块可用内存给请求进程,剩余的空闲分区仍然保留在空闲分区链中。

**循环首次适应算法(next fit)**不再是每次从链表的开始进行查找,而是从上次找到的空闲分区的以后开始查找。查找效率提升,会产生更多的碎片。
最佳适应算法(best fit),空闲分区链以空闲分区大小递增的顺序将空闲分区以双向链表的形式连接在一起,每次从空闲分区链的开头进行查找。
伙伴算法(外部碎片少,内部碎片多)
是一种非常经典的内存分配算法,它采用了分离适配的设计思想,将物理内存按照 2 的次幂进行划分,内存分配时也是按照 2 的次幂大小进行按需分配

- 首先需要找到存储 2^4 连续 Page 所对应的链表,即数组下标为 4;
- 查找 2^4 链表中是否有空闲的内存块,如果有则分配成功;
- 如果 2^4 链表不存在空闲的内存块,则继续沿数组向上查找,即定位到数组下标为 5 的链表,链表中每个节点存储 2^5 的连续 Page;
- 如果 2^5 链表中存在空闲的内存块,则取出该内存块并将它分割为 2 个 2^4 大小的内存块,其中一块分配给进程使用,剩余的一块链接到 2^4 链表中。
Slab 算法(解决伙伴算法内部碎片问题)
Slab 算法在伙伴算法的基础上,对小内存的场景专门做了优化,采用了内存池的方案,解决内部碎片问题。

在 Slab 算法中维护着大小不同的 Slab 集合,将这块内存划分为大小相同的 slot,不会对内存块再进行合并,同时使用位图 bitmap 记录每个 slot 的使用情况。
kmem_cache 中包含三个 Slab 链表:完全分配使用 slab_full、部分分配使用 slab_partial和完全空闲 slabs_empty,这三个链表负责内存的分配和释放。Slab 算法是基于对象进行内存管理的,它把相同类型的对象分为一类。当分配内存时,从 Slab 链表中划分相应的内存单元;单个 Slab 可以在不同的链表之间移动,例如当一个 Slab 被分配完,就会从 slab_partial 移动到 slabs_full,当一个 Slab 中有对象被释放后,就会从 slab_full 再次回到 slab_partial,所有对象都被释放完的话,就会从 slab_partial 移动到 slab_empty。当释放内存时,Slab 算法并不会丢弃已经分配的对象,而是将它保存在缓存中,当下次再为对象分配内存时,直接会使用最近释放的内存块。
- 内存是由一定数量的 arenas 负责管理,线程均匀分布在 arenas 当中;
- 每个 arena 都包含一个 bin 数组,每个 bin 管理不同档位的内存块;
- 每个 arena 被划分为若干个 chunks,每个 chunk 又包含若干个 runs,每个 run 由连续的 Page 组成,run 才是实际分配内存的操作对象;
- 每个 run 会被划分为一定数量的 regions,在小内存的分配场景,region 相当于用户内存;
- 每个 tcache 对应一个 arena,tcache 中包含多种类型的 bin。
内存管理Arena ,内存由一定数量的 arenas 负责管理。每个用户线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配。
分级管理Bin,每个 bin 管理的内存大小是按分类依次递增。jemalloc 中小内存的分配是基于 Slab 算法完成的,会产生不同类别的内存块。
Page集合chunk,chunk 以 Page 为单位管理内存。每个 chunk 可被用于多次小内存的申请,但是在大内存分配的场景下只能分配一次。
实际分配单位run,run 结构具体的大小由不同的 bin 决定,例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块进行分配。
run 细分region,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发。
tcache 是每个线程私有的缓存,tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,避免锁竞争,分配失败才会通过 run 执行内存分配。

Small 场景,如果请求分配内存的大小小于 arena 中的最小的 bin,那么优先从线程中对应的 tcache 中进行分配。首先确定查找对应的 tbin 中是否存在缓存的内存块,如果存在则分配成功,否则找到 tbin 对应的 arena,从 arena 中对应的 bin 中分配 region 保存在 tbin 的 avail 数组中,最终从 availl 数组中选取一个地址进行内存分配,当内存释放时也会将被回收的内存块进行缓存。
Large 场景的内存分配与 Smalll 类似,如果请求分配内存的大小大于 arena 中的最小的 bin,但是不大于 tcache 中能够缓存的最大块,依然会通过 tcache 进行分配,但是不同的是此时会分配 chunk 以及所对应的 run,从 chunk 中找到相应的内存空间进行分配。内存释放时也跟 samll 场景类似,会把释放的内存块缓存在 tacache 的 tbin 中。此外还有一种情况,当请求分配内存的大小大于tcache 中能够缓存的最大块,但是不大于 chunk 的大小,那么将不会采用 tcache 机制,直接在 chunk 中进行内存分配。
Huge 场景,如果请求分配内存的大小大于 chunk 的大小,那么直接通过 mmap 进行分配,调用 munmap 进行回收。
- 当用户进程发起 read() 调用后,上下文从用户态切换至内核态。DMA 引擎从文件中读取数据,并存储到内核态缓冲区,这里是第一次数据拷贝。
- 请求的数据从内核态缓冲区拷贝到用户态缓冲区,然后返回给用户进程。第二次数据拷贝的过程同时,会导致上下文从内核态再次切换到用户态。
- 用户进程调用 send() 方法期望将数据发送到网络中,用户态会再次切换到内核态,第三次数据拷贝请求的数据从用户态缓冲区被拷贝到 Socket 缓冲区。
- 最终 send() 系统调用结束返回给用户进程,发生了第四次上下文切换。第四次拷贝会异步执行,从 Socket 缓冲区拷贝到协议引擎中。

在 Linux 中系统调用 sendfile() 可以实现将数据从一个文件描述符传输到另一个文件描述符,从而实现了零拷贝技术。
在 Java 中也使用了零拷贝技术,它就是 NIO FileChannel 类中的 transferTo() 方法,它可以将数据从 FileChannel 直接传输到另外一个 Channel。

Netty 中的零拷贝技术除了操作系统级别的功能封装,更多的是面向用户态的数据操作优化,主要体现在以下 5 个方面:
- 堆外内存,避免 JVM 堆内存到堆外内存的数据拷贝。
- CompositeByteBuf 类,可以组合多个 Buffer 对象合并成一个逻辑上的对象,避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer。
- 通过 Unpooled.wrappedBuffer 可以将 byte 数组包装成 ByteBuf 对象,包装过程中不会产生内存拷贝。
- ByteBuf.slice ,slice 操作可以将一个 ByteBuf 对象切分成多个 ByteBuf 对象,切分过程中不会产生内存拷贝,底层共享一个 byte 数组的存储空间。
- Netty 使用 封装了transferTo() 方法 FileRegion,可以将文件缓冲区的数据直接传输到目标 Channel,避免内核缓冲区和用户态缓冲区之间的数据拷贝。
ThreadLocal 可以理解为线程本地变量。ThreadLocal 为变量在每个线程中都创建了一个副本,该副本只能被当前线程访问,多线程之间是隔离的,变量不能在多线程之间共享。这样每个线程修改变量副本时,不会对其他线程产生影响。
既然多线程访问 ThreadLocal 变量时都会有自己独立的实例副本,那么很容易想到的方案就是在 ThreadLocal 中维护一个 Map,记录线程与实例之间的映射关系。当新增线程和销毁线程时都需要更新 Map 中的映射关系,因为会存在多线程并发修改,所以需要保证 Map 是线程安全的。但是在高并发的场景并发修改 Map 需要加锁,势必会降低性能。

JDK 为了避免加锁,采用了相反的设计思路。以 Thread 入手,在 Thread 中维护一个 Map,记录 ThreadLocal 与实例之间的映射关系,这样在同一个线程内,Map 就不需要加锁了。

ThreadLocalMap 是一种使用线性探测法实现的哈希表,底层采用数组存储数据,通过魔数0x61c88647来使散列更加平衡。ThreadLocalMap 初始化一个长度为 16 的 Entry 数组。与 HashMap 不同的是,Entry 的 key 就是 ThreadLocal对象本身,value 就是用户具体需要存储的值。

Entry 继承自弱引用类 WeakReference,Entry 的 key 是弱引用,value 是强引用。在 JVM 垃圾回收时,只要发现了弱引用的对象,不管内存是否充足,都会被回收。那么为什么 Entry 的 key 要设计成弱引用呢?如果 key 都是强引用,当线 ThreadLocal 不再使用时,然而 ThreadLocalMap 中还是存在对 ThreadLocal 的强引用,那么 GC 是无法回收的,从而造成内存泄漏。

虽然 Entry 的 key 设计成了弱引用,但是当 ThreadLocal不再使用(业务逻辑走完,但是由于线程复用导致线程并没有结束)被 GC 回收后,ThreadLocalMap 中可能出现 Entry 的 key 为 NULL,那么 Entry 的 value 一直会强引用数据而得不到释放,只能等待线程销毁。那么应该如何避免 ThreadLocalMap 内存泄漏呢?ThreadLocal 已经帮助我们做了一定的保护措施,在执行 ThreadLocal.set()/get() 方法时,ThreadLocal 会清除 ThreadLocalMap 中 key 为 NULL 的 Entry 对象,让它还能够被 GC 回收。除此之外,当线程中某个 ThreadLocal 对象不再使用时,立即调用 remove() 方法删除 Entry 对象。如果是在异常的场景中,应在 finally 代码块中进行清理,保持良好的编码意识。在Netty中,可以方便的使用FashThreadLocal来防止内存泄漏

FastThreadLocal
FastThreadLocal 使用 Object 数组替代了 Entry 数组,Object[0] 存储的是一个Set<FastThreadLocal<?>> 集合,从数组下标 1 开始都是直接存储的 value 数据,不再采用 ThreadLocal 的键值对形式进行存储。主要是针对set方法,增加了两个额外的行为。
- 找到数组下标 index 位置,设置新的 value。
- 将 FastThreadLocal 对象保存到待清理的 Set 中。

- 高效查找。FastThreadLocal 在定位数据的时候可以直接根据数组下标 index 获取,时间复杂度 O(1)。而 JDK 原生的 ThreadLocal 在数据较多时哈希表很容易发生 Hash 冲突,线性探测法在解决 Hash 冲突时需要不停地向下寻找,效率较低。此外,FastThreadLocal 相比 ThreadLocal 数据扩容更加简单高效,FastThreadLocal 以 index 为基准向上取整到 2 的次幂作为扩容后容量,然后把原数据拷贝到新数组。而 ThreadLocal 由于采用的哈希表,所以在扩容后需要再做一轮 rehash。
- 安全性更高。JDK 原生的 ThreadLocal 使用不当可能造成内存泄漏,只能等待线程销毁。在使用线程池的场景下,ThreadLocal 只能通过主动检测的方式防止内存泄漏,从而造成了一定的开销。然而 FastThreadLocal 不仅提供了 remove() 主动清除对象的方法,而且在线程池场景中 Netty 还封装了 FastThreadLocalRunnable,任务执行完毕后一定会执行 FastThreadLocal.removeAll() 将 Set 集合中所有 FastThreadLocal 对象都清理掉
生成月统计报表、每日得分结算、邮件定时推送
定时任务三种形式:
1、按固定周期定时执行
2、延迟一定时间后执行
3、指定某个时刻执行
定时任务的三个关键方法:
Schedule 新增任务至任务集合;
Cancel 取消某个任务;
Run 执行到期的任务
JDK自带的三种定时器:Timer、DelayedQueue 和 ScheduledThreadPoolExecutor
Timer小根堆队列,deadline 任务位于堆顶端,弹出的始终是最优先被执行的任务。Run 操作时间复杂度 O(1),Schedule 和Cancel 操作的时间复杂度都是 O(logn)。
不论有多少任务被加入数组,始终由 异步线程TimerThread 负责处理。TimerThread 会定时轮询 TaskQueue 中的任务,如果堆顶的任务的 deadline 已到,那么执行任务;如果是周期性任务,执行完成后重新计算下一次任务的 deadline,并再次放入小根堆;如果是单次执行的任务,执行结束后会从 TaskQueue 中删除。
DelayedQueue 采用优先级队列 PriorityQueue延迟获取对象的阻塞队列。DelayQueue中的每个对象都必须实现Delayed 接口,并重写 compareTo 和 getDelay 方法。
DelayQueue 提供了 put() 和 take() 的阻塞方法,可以向队列中添加对象和取出对象。对象被添加到 DelayQueue 后,会根据 compareTo() 方法进行优先级排序。getDelay() 方法用于计算消息延迟的剩余时间,只有 getDelay <=0 时,该对象才能从 DelayQueue 中取出。
DelayQueue 在日常开发中最常用的场景就是实现重试机制。例如,接口调用失败或者请求超时后,可以将当前请求对象放入 DelayQueue,通过一个异步线程 take() 取出对象然后继续进行重试。如果还是请求失败,继续放回 DelayQueue。可以设置重试的最大次数以及采用指数退避算法设置对象的 deadline,如 2s、4s、8s、16s ……以此类推。DelayQueue的时间复杂度和Timer基本一致。
为了解决 Timer 的设计缺陷,JDK 提供了功能更加丰富的 ScheduledThreadPoolExecutor,多线程、相对时间、对异常 Timer 是单线程模式。如果某个 TimerTask 执行时间很久,会影响其他任务的调度。
Timer 的任务调度是基于系统绝对时间的,如果系统时间不正确,可能会出现问题。
TimerTask 如果执行出现异常,Timer 并不会捕获,会导致线程终止,其他任务永远不会执行。
时间轮原理分析

根据任务的到期时间进行取余和取模,然后根据取余结果将任务分布到不同的 slot 中,每个slot中根据round值决定是否操作,每次轮询到指定slot时,总时遍历最少round的对象进行执行,这样新增、执行两个操作的时间复杂度都近似O(1)。如果冲突较大可以增加数组长度,或者采用多级时间轮的方式处理。
public HashedWheelTimer(
ThreadFactory threadFactory, //线程池,但是只创建了一个线程
long tickDuration, //时针每次 tick 的时间,相当于时针间隔多久走到下一个 slot
TimeUnit unit, //表示 tickDuration 的时间单位,tickDuration * unit
int ticksPerWheel, //时间轮上一共有多少个 slot,默认 512 个。
boolean leakDetection,
long maxPendingTimeouts) {//最大允许等待任务数
// 省略其他代码
wheel = createWheel(ticksPerWheel); // 创建时间轮的环形数组结构
mask = wheel.length - 1; // 用于快速取模的掩码
long duration = unit.toNanos(tickDuration); // 转换成纳秒处理
workerThread = threadFactory.newThread(worker); // 创建工作线程
leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null; // 是否开启内存泄漏检测
this.maxPendingTimeouts = maxPendingTimeouts; // 最大允许等待任务数,HashedWheelTimer 中任务超出该阈值时会抛出异常
}
时间轮空推进问题
Netty 中的时间轮是通过固定的时间间隔 tickDuration 进行推动的,如果长时间没有到期任务,那么会存在时间轮空推进的现象,从而造成一定的性能损耗。此外,如果任务的到期时间跨度很大,例如 A 任务 1s 后执行,B 任务 6 小时之后执行,也会造成空推进的问题。
Kafka解决方案
为了解决空推进的问题,Kafka 借助 JDK 的 DelayQueue 来负责推进时间轮。DelayQueue 保存了时间轮中的每个 Bucket,并且根据 Bucket 的到期时间进行排序,最近的到期时间被放在 DelayQueue 的队头。Kafka 中会有一个线程来读取 DelayQueue 中的任务列表,如果时间没有到,那么 DelayQueue 会一直处于阻塞状态,从而解决空推进的问题。虽然DelayQueue 插入和删除的性能不是很好,但这其实就是一种权衡的策略,但是DelayQueue 只存放了 Bucket,Bucket 的数量并不多,相比空推进带来的影响是利大于弊的。
为了解决任务时间跨度很大的问题,Kafka 引入了层级时间轮,如下图所示。当任务的 deadline 超出当前所在层的时间轮表示范围时,就会尝试将任务添加到上一层时间轮中,跟钟表的时针、分针、秒针的转动规则是同一个道理。
select (windows)**poll **(linux)本质上和select没有区别,查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。
**epoll **支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
Epoll空轮询漏洞
在 JDK 中, Epoll 的实现是存在漏洞的,即使 Selector 轮询的事件列表为空,NIO 线程一样可以被唤醒,导致 CPU 100% 占用。实际上 Netty 并没有从根源上解决该问题,而是巧妙地规避了这个问题。
long time = System.nanoTime();
if (/*事件轮询的持续时间大于等于 timeoutMillis*/) {
selectCnt = 1;
} else if (/*不正常的次数 selectCnt 达到阈值 512*/) {
//重建Select并且SelectionKey重新注册到新Selector上
selector = selectRebuildSelector(selectCnt);
}NioEventLoop 线程的可靠性至关重要,一旦 NioEventLoop 发生阻塞或者陷入空轮询,就会导致整个系统不可用。
reduce(function, iterable[, initializer])
reduce(lambda x,y:x * y,ns) # 数组之乘积 (ns[0] * ns[1]) * ns[2]
reduce(lambda x,y:x + y,ns) # 数组之和
# 记忆化搜索
@functools.lru_cache(None)
res = helper(0,N,0)
helper.cache_clear()
tuple(ns) 可以hash做参数
# 大根堆
q = list(map(lambda x:-x,ns))
heapq.heapify(q)
key = -heapq.heappop(q)
# 过滤函数
filter(function, iterable)
filter(lambda x: 2 < x < 10 and x % 2 == 0, range(18))
filter(dfs, range(len(graph)))
# 除数
div, mod = divmod(sum(ns), 4)
random.randint(i,len(self.ns)-1)
#第一个降序,第二个升序
sorted(pss,key = lambda x:[x[0],-x[1]])
# 不可变str 常见函数
split(sep=None, maxsplit=-1) # 以sep来分割字符串
strip([chars]) # 去除首末两端的字符, 默认是 \r,\n," "
join(iterable) # 将iterable内的元素拼接成字符串,如','.join(['leet', 'code'])="leet,code"
replace(old, new[, count]) # 字符串替换, old to new
count(sub[, start[, end]]) # 统计子字符串sub的个数
startswith(prefix[, start[, end]]) # 以prefix开始的字符串
endswith(suffix[, start[, end]]) # 以suffix结束的字符串
cs in chrs: # chrs 中包含 cs
# deque 常见函数
queue = deque([iterable[, maxlen]])
queue.append(val) # 往右边添加一个元素
queue.appendleft(val) # 往左边添加一个元素
queue.clear() # 清空队列
queue.count(val) # 返回指定元素的出现次数
queue.insert(val[, start[, stop]]) # 在指定位置插入元素
queue.pop() # 获取最右边一个元素,并在队列中删除
queue.popleft() # 获取最左边一个元素,并在队列中删除
queue.reverse() # 队列反转
queue.remove(val) # 删除指定元素
queue.rotate(n=1) # 把右边元素放到左边
# list 常见函数
lst.sort(*, key=None, reverse=False)
lst.append(val) # 也可以 lst = lst + [val]
lst.clear() # 清空列表
lst.count(val) # val个数
lst.pop(val=lst[-1]) # (默认)从末端移除一个值
lst.remove(val) # 移除 val
lst.reverse() # 反转
lst.insert(i, val) # 在 i 处插入 val
# 字典dict 常见函数
d = defaultdict(lambda : value) # 取到不存在的值时不会报错,用{}时、需要设置get的default值
pop(key[, default]) # 通过键去删除键值对(若没有该键则返回default(没有设置default则报错))
setdefault(key[, default]) # 设置默认值
update([other]) # 批量添加
get(key[, default]) # 通过键获取值(若没有该键可设置默认值, 预防报错)
clear() # 清空字典
keys() # 将字典的键组成新的可迭代对象
values() # 将字典中的值组成新的可迭代对象
items() # 将字典的键值对凑成一个个元组, 组成新的可迭代对象
dict1 = dict2 #两个字典完全相等,滑窗时可用
# 集合set 常见函数
s = set(lambda : value)
add(elem) # 向集合中添加数据
update(*others) # 迭代着增加
clear() # 清空集合
discard(elem) # 删除集合中指定的值(不存在则不删除)
# 堆heapq 常见函数
heap = [] # 建堆
heapq.heappush(heap,item) # 往堆中插入新值
heapq.heappop(heap) # 弹出最小的值
heap[0] # 查看堆中最小的值, 不弹出
heapq.heapify(x) # 以线性时间将一个列表转为堆
heapq.heappoppush(heap, item) # 弹出最小的值.并且将新的值插入其中.
heapq.merge(*iterables, key=None, reverse=False) # 将多个堆进行合并
heapq.nlargest(n, iterable, key=None) # 从堆中找出最大的 n 个数,key的作用和sorted( )方法里面的key类似, 用列表元素的某个属性和函数作为关键字
heapq.nsmallest(n, iterable, key=None) # 从堆中找出最小的 n 个数, 与 nlargest 相反
# 二分查找函数
bisect.bisect_left(ps, T, L=0, R=len(ns)) #二分左边界
bisect.bisect_right(ps, T, L=0, R=len(ns)) #二分右边界
bisect.insort_left(a, x, lo=0, hi=len(a)) # 二分插入到左侧
bisect.insort_right(a, x, lo=0, hi=len(a)) # 二分插入到右侧
# bit操作
& 符号,x & y ,会将两个十进制数在二进制下进行与运算
| 符号,x | y ,会将两个十进制数在二进制下进行或运算
^ 符号,x ^ y ,会将两个十进制数在二进制下进行异或运算
<< 符号,x << y 左移操作,最右边用 0 填充
>> 符号,x >> y 右移操作,最左边用 0 填充
~ 符号,~x ,按位取反操作,将 x 在二进制下的每一位取反
# 整数集合set位运算
# 整数集合做标志时,可以做参数加速运算
vstd 访问 i :vstd | (1 << i)
vstd 离开 i :vstd & ~(1 << i)
vstd 不包含 i : not vstd & (1 << i)
并集 :A | B
交集 :A & B
全集 :(1 << n) - 1
补集 :((1 << n) - 1) ^ A
子集 :(A & B) == B
判断是否是 2 的幂 :A & (A - 1) == 0
最低位的 1 变为 0 :n &= (n - 1)
while n:
n &= n - 1
ret += 1
最低位的 1:A & (-A),最低位的 1 一般记为 lowbit(A)
# ^ :匹配字符串开头
# [\+\-]:代表一个+字符或-字符
# ? :前面一个字符可有可无
# \d :一个数字
# + :前面一个字符的一个或多个
# \D :一个非数字字符
# * :前面一个字符的0个或多个
matches = re.match('[ ]*([+-]?\d+)', s)「力扣」上的 0-1 背包问题:
-
组合问题模板
#0-1背包,不可重复 for n in ns: for i in range(T, n-1, -1): dp[i] = max(dp[i], dp[i - n] + ws[i]) #完全背包,可重复,无序,算重量 for n in ns: for i in range(n, T+1): dp[i] = max(dp[i], dp[i - n] + ws[i]) #完全背包,可重复,有序,算次数 for i in range(1, T+1): for n in ns: dp[i] += dp[i-n]
✅377 组合总和 Ⅳ ✅494 目标和 ✅518 零钱兑换 II
-
True、False问题
dp[i] |= dp[i-num]
✅139 单词拆分 ✅416 分割等和子集
#特殊的可以使用bit数组 -
最大最小问题:
dp[i] = min(dp[i], dp[i-num]+1) dp[i] = max(dp[i], dp[i-num]+1)
✅474 一和零 ✅322 零钱兑换
「力扣」第 879 题:盈利计划(困难); 「力扣」第 1449 题:数位成本和为目标值的最大数字(困难)。
# 回溯算法,复杂度较高2^n或者N!,因为回溯算法就是暴力穷举,可用lru剪枝
@functools.lru_cache(None)
def backtrack(路径, 选择列表):
if 满足结束条件:
结果.append(路径)
return
for 选择 in 选择列表: # 核心代码段
if vst[i]: # 辅助数组,减枝
continue
做出选择
递归执行backtrack
撤销选择「剪枝」第 46 题 全排列 第 47 题 全排列②
# 剪枝
def backtrack(temp_list, length):
if length == n:
res.append(temp_list)
for i in range(n):
if not visited[i]:
visited[i] = 1
backtrack(temp_list + [nums[i]], length + 1)
visited[i] = 0「索引遍历」第 78 题 子集 | 第 47 题 子集② | 第 131 题 分割字符串
第 **39 **题 组合 | 第 **40** 题 组合② | 第 **216** 题 组合③
# 索引遍历
def helper1(idx, n, temp_list):
if temp_list not in res:
res.append(temp_list)
for i in range(idx, n):
helper1(i + 1, n, temp_list + [nums[i]])「 资源消耗」第 22 题 夸号生成
# 资源消耗
def backtrack(S, L, R):
if not L and not R:
ans.append(''.join(S))
return
if L : backtrack(S + ['('], L-1, R)
if R > L : backtrack(S + [')'], L, R-1)「资源消耗」第 93 题 复原IP
资源消耗
def backtrack(i, tmp, flag):
if i == n and flag == 0:
res.append(tmp[:-1])
elif i<n and s[i] == '0':
backtrack(i + 1, tmp + s[i] + ".", flag - 1)
elif flag :
for j in range(i, min(n,i + 3)):
if 0 < int(s[i:j + 1]) <= 255:
backtrack(j + 1, tmp + s[i:j + 1] + ".", flag - 1)「资源消耗」第 17 题 电话号码
# 资源消耗
def dfs(path, remains):
if not remains:
res.append(path[:])
return
for i in range(len(remains)):
dfs(path + [remains[i]], remains[:i] + remains[i+1:])
# 套模板
def dfs(pth,idx):
if idx == len(ds):
res.append(pth)
return
for c in dic[ds[idx]]:
dfs(pth + c, idx + 1)「多重限制」第 37 题 解数独 | 第 51 题 N皇后
# 多重限制
def backtrack(pos):
if pos == n:
return True
i, j = empty[pos]
for num in row[i] & col[j] & block[bidx(i, j)]:
row[i].remove(num)
col[j].remove(num)
block[bidx(i, j)].remove(num)
board[i][j] = str(num)
if backtrack(pos + 1): return True
row[i].add(num)
col[j].add(num)
block[bidx(i, j)].add(num)「递归」第 10 题 正则匹配
# 递归
def isMatch(self, s: str, p: str) -> bool:
if not p:
return not s
f = bool(s and p[0] in {s[0],'.'})
if len(p) >= 2 and p[1] == "*":
return self.isMatch(s, p[2:]) or f and self.isMatch(s[1:], p)
else:
return f and self.isMatch(s[1:], p[1:])#虚拟节点用以连接某一特征的全部节点,类似于链表的preHead
dummy
parent = {}
size = collections.defaultdict(lambda:1)
cnt = 0
def find(x):
parent.setdefault(x,x)
while x != parent[x]:
x = parent[x]
#路径压缩 parent[x] = parent[parent[x]];
return x
def union(x,y):
nonlocal cnt
if connected(x,y): return
# 小的树挂到大的树上, 使树尽量平衡
xP = find(x)
yP = find(y)
if size[hP] < size[yP]:
parent[xP] = yP
else:
parent[yP] = xP
size[xP] += size[yP]
# 优化结束
parent[find(x)] = find(y)
# 不优化
cnt -= 1
return size[xP]
def connected(x, y):
return find(x) == find(y)
def add(self,x):
if x not in parent:
parent[x] = None
cnt += 1
# 检查是否有环
for a, b in edges:
if connected(a, b):
return True
union(a, b)
# 将每个集合组成以头为key的字典
res = collections.defaultdict(list)
for e in e2n:
res[uf.find(e)].append(e)# 【拓扑排序模板】
ins = [0] * n
ous = collections.defaultdict(list)
for cur, pre in ps:
ins[cur] += 1 #入度
ous[pre].append(cur) #出度
res = list(filter(lambda x:ins[x]==0, range(n)))
q = collections.deque(res)
while q:
pre = q.popleft()
for cur in ous[pre]: #释放出度队列
ins[cur] -= 1
if not ins[cur]:
q.append(cur) #入度为0解锁
res.append(cur)# s中一般存索引
for i in range(len(ns):
while stack and ns[stack[-1]] <= ns[i]: # 单调递减栈
stack.pop()
# 业务逻辑
stack.append(i)「单调递增」第 84 题 求最大矩形
# 第 **84** 题 求最大矩形
for i in range(len(hs)):
while s and hs[i] < hs[s[-1]]:
base = s.pop()
if s:
H = hs[base]
W = i - s[-1] - 1 # 当前弹出的做高,当前与次小做宽
res = max(res, H * W)
s.append(i)「单调递增,考虑剩余」第 316 题 去除重复字符
# 第 **316** 题 去除重复字符
for i,c in enumerate(ss):
if c not in s:
while s and c < s[-1] and s[-1] in ss[i:]:
s.pop()
s.append(c)「单调递减」第 42 题 接雨水
# 第 **42** 题 接雨水
for i in range(len(hgt)):
while stack and hgt[i] > hgt[stack[-1]]: #递减栈
base = stack.pop()
if stack:
LH = hgt[stack[-1]]
W = i - stack[-1] - 1
H = min(LH,hgt[i]) - hgt[base]
res += W * H
stack.append(i)「单调递减」第 739 题 每日温度
# 第 **739** 题 每日温度
for i in range(len(T)-1,-1,-1):
while s and T[s[-1]] <= T[i] : #递减栈
s.pop()
res[i] = s[-1] - i if s else 0
s.append(i)# 1355579 T=5 => 13(5)55579 返回2
# ps[i-1] < ps[i] <= ps[i+1]
bisect.bisect_left(ps, T, L=0, R=len(ns))
# 1355579 T=5 => 13555(5)79 返回5
# ps[i-1] <= ps[i] < ps[i+1]
bisect.bisect_right(ps, T, L=0, R=len(ns))
bisect.bisect(ps, T, L=0, R=len(ns)) 「中位返回」第 33 题 搜索旋转排序数组 | 第374题 猜数字大小 | 第69题 x平方根
# 中位返回
while L <= R:
M = (L + R) // 2
if nums[M] == T:
return M
elif nums[M] < T:
L = M + 1
else:
R = M - 1「区域压缩」第278题 第一个错误版本| 第162题 寻找峰值 | 第153题 寻找数组最小值
# 区域压缩
while L < R:
M = (L + R) // 2
if need in s[L:M]:
R = M
else:
L = M + 1- 70 爬楼梯问题
- 801 使序列递增的最小交换次数
- 746 使用最小花费爬楼梯
- 300 最长上升子序列
# 依赖前单个元素
dp[i] = dp[i-1] + ns[i]
# 依赖前部区域元素
for i in range(n)
for j in range(i)
dp[i] = min(dp[i], f(dp[j])-
887 鸡蛋掉落
# 鸡蛋掉落 while cur[K] < N: # 还剩 j 个蛋 测 ans 次 覆盖多少层 for j in range(1, K + 1): # 覆盖总层数 碎了 -1 次层数 + 1 + 没碎 -1 次层数 cur[j] = prev[j - 1] + 1 + prev[j] ans += 1 prev = copy.deepcopy(cur)
-
813 最大平均值分组
# 813 最大平均值分组 for k in range(K-1): #循环k次 for i in range(N): #每次均依赖上次的结果 for j in range(i+1, N): dp[i] = max(dp[i], avrg(i, j) + dp[j])
-
410 分割数组最大值
# 410 分割数组最大值 for k in range(1,K): for i in range(N): for j in range(i): # 0~i中分 k 段最大 即为 # 0~j中分k-1段最大 和 j到i的前缀和的最大 dp[i][k] = min(dp[i][k], max(dp[j][k-1], ps[i+1] - ps[j+1]))
# 经典双串LCS问题
dp = [[0] * (M+1) for _ in range(N+1)]
for i in range(N):
for j in range(M):
if t1[i] == t2[j] : dp[i+1][j+1] = dp[i][j] + 1
else : dp[i+1][j+1] = max(dp[i][j+1],dp[i+1][j])- 5 最长回文子串
- 647 最多回文子串
- 516 最长回文子序列
- 1312 最长回文插入次数
# dp[i][j] 代表从 i 到 j 的最长子串满足条件的数量
# i-- < j++ ==> i 在 0~j 范围内 --
dp = [[0] * (N) for _ in range(N)]
for j in range(N):
dp[j][j] = 1
for i in range(j-1,-1,-1):
if ss[i] == ss[j]:
dp[i][j] = dp[i+1][j-1] +2
else :
dp[i][j] = max(dp[i+1][j],dp[i][j-1])312 戳气球
664 奇怪的打印机
546 移除盒子
# 区间分治动态规划
def helper(self, ns: List[int]) :
N = len(ns)
dp = [[0] * N for _ in range(N+1)]
for l in range(N): # 长度从小到大
for i in range(N-l): # 以 i 为 开头
j = i + l # 以 j 为 终点
for k in range(i,j): # 以 k 为分割点,进行分治
// Todo 业务逻辑 「卡特兰数」
# 卡特兰数
g(n) = g(0)*g(n-1) + g(1)*g(n-2) ...g(n-1)*g(0)
dp=[1] + [0] * n
for i in range(1,n+1):
for j in range(1,i+1):
dp[i] += dp[j-1] * dp[i-j]"""给定待查串s和目标串t"""
nd, wd = {}, {}
nd = collections.Counter(s1)
L, R = 0, 0
cnt = 0 # 满足条件个数
while R < len(s): # 窗口右边界不断扩大,本质是搜索问题的可能解
c = s[R] # 即将加入到窗口中的字符
R += 1
更新窗口中的数据
while 满足窗口收缩条件: # 窗口的左边界收缩,本质是优化可行解
记录或返回结果
d = s[L] # 即将从窗口中删除的字符
L += 1
更新窗口中的数据
return 结果
# 固定窗口 ,比滑动窗口更快一些
i = j = cnt = 0
for j in range(len(A)):
if A[j] == 0:
cnt += 1
if cnt > K: #不满足时 平移
if A[i] == 0:
cnt -= 1
i += 1
return j - i + 1
for j in range(len(A)):
if A[j] == 0:
cnt += 1
while cnt > K:
if A[i] == 0:
cnt -= 1
i += 1
res = max(res, j - i + 1)
return res
「累加和存位置」
1371 最长偶数元音子数组
525 最长相等01子数组
325 最长和为k 子数组
# 前缀和初始化
psd = {0: -1}
for i in range(len(s)):
t ^= cd.get(s[i], 0) # 业务逻辑
if t not in psd:
psd[t] = i # 第一次存入数组
else:
ans = max(ans, i - psd[t]) #已存入则开始计算「累加和存数量」
560 和为K的子数组数量
统计优美子数组
# 累加和存数量
psd = {0:1}
for i in range(len(ns)):
s += ns[i]
if s - T in psd:
ans += psd[s - T] # 存数量
psd[s] = psd.get(s,0) + 1「模K状态前缀和」
523 连续和为 k 倍 的子数组(存索引)
974 和被k 整除 子数组数量(存数量)
# 模K状态前缀和
psd = {0:-1}
ans = s = 0
for i in range(len(ns)):
s += ns[i] # 业务逻辑
if T != 0: s %= abs(T) # 模k状态做key,索引做值
if s not in psd:
psd[s] = i
elif i - psd[s] > 1:
return True「矩阵前缀和」
- 363 不超过K的最大数值和
- 1074 和为目标值的子矩阵数量
# 矩阵前缀和
for i in range(m): #固定左边界
ps = [0] * n
for j in range(i, m): #固定右边界
psS = 0
dct = {0:1} #初始只有一种可能
for k in range(n): # 以高做前缀和
ps[k] += mtx[j][k] # 每行前缀和
psS += ps[k] # n行前缀和
cnt += dct.get(psS - T, 0) # 满足条件cnt
dct[psS] = dct.get(psS,0) + 1 # 保存当前状态
return cnt# 双指针
def removeElement(self, ns: List[int], val: int) -> int:
slow = 0
n = len(ns)
for fast in range(n):
if ns[fast] != val:
ns[slow] = ns[fast]
slow += 1
return slow「二叉树遍历模板」
# 递归
# 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。
# 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn)
# 递归1:二叉树遍历最易理解和实现版本
class Solution:
def preOrd(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preOrd(root.left) + self.preOrd(root.right)
# # 中序递归
# return self.inOrd(root.left) + [root.val] + self.inOrd(root.right)
# # 后序递归
# return self.postOrd(root.left) + self.postOrd(root.right) + [root.val]
# 递归2:通用模板,可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值
class Solution:
def preOrd(self, root: TreeNode) -> List[int]:
def dfs(cur):
if not cur:
return
# 前序递归
res.append(cur.val)
dfs(cur.left)
dfs(cur.right)
# # 中序递归
# dfs(cur.left)
# res.append(cur.val)
# dfs(cur.right)
# # 后序递归
# dfs(cur.left)
# dfs(cur.right)
# res.append(cur.val)
res = []
dfs(root)
return res
# 迭代
# 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。
# 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n)
# 迭代1:前序遍历最常用模板(后序同样可以用)
class Solution:
def preOrd(self, root: TreeNode) -> List[int]:
if not root:
return []
res = []
stack = [root]
# # 前序迭代模板:最常用的二叉树DFS迭代遍历模板
while stack:
cur = stack.pop()
res.append(cur.val)
if cur.right:
stack.append(cur.right)
if cur.left:
stack.append(cur.left)
return res
# # 后序迭代,相同模板:将前序迭代进栈顺序稍作修改,最后得到的结果反转
# while stack:
# cur = stack.pop()
# if cur.left:
# stack.append(cur.left)
# if cur.right:
# stack.append(cur.right)
# res.append(cur.val)
# return res[::-1]
# 迭代1:层序遍历最常用模板
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
if not root:
return []
q = deque([root])
res = []
while q :
l = []
for i in range(len(q)) :
t = q.popleft()
l.append(t.val)
if t.left : q.append(t.left)
if t.right : q.append(t.right)
res.append(l)
return res
# 迭代2:前、中、后序遍历通用模板(只需一个栈的空间)
class Solution:
def inOrd(self, root: TreeNode) -> List[int]:
res = []
stack = []
cur = root
# 中序,模板:先用指针找到每颗子树的最左下角,然后进行进出栈操作
while stack or cur:
while cur:
stack.append(cur)
cur = cur.left
cur = stack.pop()
res.append(cur.val)
cur = cur.right
return res
# # 前序,相同模板
# while stack or cur:
# while cur:
# res.append(cur.val)
# stack.append(cur)
# cur = cur.left
# cur = stack.pop()
# cur = cur.right
# return res
# # 后序,相同模板
# while stack or cur:
# while cur:
# res.append(cur.val)
# stack.append(cur)
# cur = cur.right
# cur = stack.pop()
# cur = cur.left
# return res[::-1]
# 迭代3:标记法迭代(需要双倍的空间来存储访问状态):
# 前、中、后、层序通用模板,只需改变进栈顺序或即可实现前后中序遍历,
# 而层序遍历则使用队列先进先出。0表示当前未访问,1表示已访问。
class Solution:
def preOrd(self, root: TreeNode) -> List[int]:
res = []
stack = [(0, root)]
while stack:
flag, cur = stack.pop()
if not cur: continue
if flag == 0:
# 前序,标记法
stack.append((0, cur.right))
stack.append((0, cur.left))
stack.append((1, cur))
# # 后序,标记法
# stack.append((1, cur))
# stack.append((0, cur.right))
# stack.append((0, cur.left))
# # 中序,标记法
# stack.append((0, cur.right))
# stack.append((1, cur))
# stack.append((0, cur.left))
else:
res.append(cur.val)
return res
# # 层序,标记法
# res = []
# queue = [(0, root)]
# while queue:
# flag, cur = queue.pop(0) # 注意是队列,先进先出
# if not cur: continue
# if flag == 0:
# 层序遍历这三个的顺序无所谓,因为是队列,只弹出队首元素
# queue.append((1, cur))
# queue.append((0, cur.left))
# queue.append((0, cur.right))
# else:
# res.append(cur.val)
# return res
# 莫里斯遍历
# 时间复杂度:O(n),n为节点数,看似超过O(n),有的节点可能要访问两次,实际分析还是O(n)
# 空间复杂度:O(1),如果在遍历过程中就输出节点值,则只需常数空间就能得到中序遍历结果,空间只需两个指针。
# 如果将结果储存最后输出,则空间复杂度还是O(n)。
# PS:莫里斯遍历实际上是在原有二叉树的结构基础上,构造了线索二叉树,
# 线索二叉树定义为:原本为空的右子节点指向了中序遍历顺序之后的那个节点,把所有原本为空的左子节点都指向了中序遍历之前的那个节点
# 此处只给出中序遍历,前序遍历只需修改输出顺序即可
# 而后序遍历,由于遍历是从根开始的,而线索二叉树是将为空的左右子节点连接到相应的顺序上,使其能够按照相应准则输出
# 但是后序遍历的根节点却已经没有额外的空间来标记自己下一个应该访问的节点,
# 所以这里需要建立一个临时节点dump,令其左孩子是root。并且还需要一个子过程,就是倒序输出某两个节点之间路径上的各个节点。
# 莫里斯遍历,借助线索二叉树中序遍历(附前序遍历)
class Solution:
def inOrd(self, root: TreeNode) -> List[int]:
res = []
# cur = pre = TreeNode(None)
cur = root
while cur:
if not cur.left:
res.append(cur.val)
# print(cur.val)
cur = cur.right
else:
pre = cur.left
while pre.right and pre.right != cur:
pre = pre.right
if not pre.right:
# print(cur.val) 这里是前序遍历的代码,前序与中序的唯一差别
pre.right = cur
cur = cur.left
else:
pre.right = None
res.append(cur.val)
# print(cur.val)
cur = cur.right
return res
# N叉树遍历
# 时间复杂度:时间复杂度:O(M),其中 M 是 N 叉树中的节点个数。每个节点只会入栈和出栈各一次。
# 空间复杂度:O(M)。在最坏的情况下,这棵 N 叉树只有 2 层,所有第 2 层的节点都是根节点的孩子。
# 将根节点推出栈后,需要将这些节点都放入栈,共有 M−1个节点,因此栈的大小为 O(M)。
# N叉树简洁递归
class Solution:
def preorder(self, root: 'Node') -> List[int]:
if not root: return []
res = [root.val]
for node in root.children:
res.extend(self.preorder(node))
return res
# N叉树通用递归模板
class Solution:
def preorder(self, root: 'Node') -> List[int]:
res = []
def helper(root):
if not root:
return
res.append(root.val)
for child in root.children:
helper(child)
helper(root)
return res
# N叉树迭代方法
class Solution:
def preorder(self, root: 'Node') -> List[int]:
if not root:
return []
s = [root]
# s.append(root)
res = []
while s:
node = s.pop()
res.append(node.val)
# for child in node.children[::-1]:
# s.append(child)
s.extend(node.children[::-1])
return res# 「**无向图的遍历**」
q = collections.deque([i])
while q:
cur = q.popleft()
for nxt in dt[cur]:
if not vst[nxt]:
vstd[nxt] = True
q.append(nxt)# 「**二叉树层序遍历**」
q = deque([root])
res = []
while q :
l = []
for i in range(len(q)) :
t = q.popleft()
l.append(t.val)
if t.left : q.append(t.left)
if t.right : q.append(t.right)
res.append(l)
return res#「Dijkstra最短路径」
dic = collections.defaultdict(list)
for u, v, w in edges:
dic[u].append([v, w])
dic[v].append([u, w])
q = [(0, n)]
dist = [-1] * (n + 1)
while q:
dis, cur = heapq.heappop(q)
if dist[cur] < 0:
dist[cur] = dis
for nxt, wi in dic[cur]:
heapq.heappush(q, [dis + wi, nxt])「Floyd 求图中路径」
# Floyd算法 求图中任意2点距离
ds = defaultdict(int)
st = set()
for i, (x, y) in enumerate(ess):
ds[(x, y)] = vs[i]
ds[(y, x)] = 1 / vs[i]
st.update({x,y})
arr = list(st)
for k in arr:
for i in arr:
for j in arr:
if ds[(i, k)] and ds[(k, j)]:
ds[(i, j)] = ds[(i, k)] * ds[(k, j)]100亿黑名单URL,每个64B,问这个黑名单要怎么存?判断一个URL是否在黑名单中
散列表:
如果把黑名单看成一个集合,将其存在 hashmap 中,貌似太大了,需要 640G,明显不科学。
布隆过滤器:
它实际上是一个很长的二进制矢量和一系列随机映射函数。
它可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。
在数组中的每一位都是二进制位。布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
2GB内存在20亿整数中找到出现次数最多的数
通常做法是使用哈希表对出现的每一个数做词频统计,哈希表的key是某个整数,value记录整数出现的次数。本题的数据量是20亿,有可能一个数出现20亿次,则为了避免溢出,哈希表的key是32位(4B),value也是 32位(4B),那么一条哈希表的记录就需要占用8B。
当哈希表记录数为2亿个时,需要16亿个字节数(8*2亿),需要至少1.6GB内存(16亿/2^30,1GB== 2 ^30个字节 == 10亿)。则20亿个记录,至少需要16GB的内存,不符合题目要求。
解决办法是将20亿个数的大文件利用哈希函数分成16个小文件,根据哈希函数可以把20亿条数据均匀分布到16个文件上,同一种数不可能被哈希函数分到不同的小文件上,假设哈希函数够好。然后对每一个小文件用哈希函数来统计其中每种数出现的次数,这样我们就得到16个文件中出现次数最多的数,接着从16个数中选出次数最大的那个key即可。
40亿个非负整数中找到没有出现的数
对于原问题,如果使用哈希表来保存出现过的数,那么最坏情况下是40亿个数都不相同,那么哈希表则需要保存40亿条数据,一个32位整数需要4B,那么40亿*4B = 160亿个字节,一般大概10亿个字节的数据需要1G的空间,那么大概需要16G的空间,这不符合要求。
我们换一种方式,申请一个bit数组,数组大小为4294967295,大概为40亿bit,40亿/8 = 5亿字节,那么需要0.5G空间, bit数组的每个位置有两种状态0和1,那么怎么使用这个bit数组呢?呵呵,数组的长度刚好满足我们整数的个数范围,那么数组的每个下标值对应4294967295中的一个数,逐个遍历40亿个无符号数,例如,遇到20,则bitArray[20] = 1;遇到666,则bitArray[666] = 1,遍历完所有的数,将数组相应位置变为1。
40亿个非负整数中找到一个没有出现的数,内存限制10MB
10亿个字节的数据大概需要1GB空间处理,那么10MB内存换算过来就是可以处理1千万字节的数据,也就是8千万bit,对于40亿非负整数如果申请bit数组的话,40亿bit / 0.8亿bit = 50,那么这样最少也得分50块来处理,下面就以64块来进行分析解答吧。
总结一下进阶的解法:
1.根据10MB的内存限制,确定统计区间的大小,就是第二次遍历时的bitArr大小。
2.利用区间计数的方式,找到那个计数不足的区间,这个区间上肯定有没出现的数。
3.对这个区间上的数做bit map映射,再遍历bit map,找到一个没出现的数即可。
自己的想法
如果只是找一个数,可以高位模运算,写到64个不同的文件,然后在最小的文件中通过bitArray一次处理掉。
40亿个无符号整数,1GB内存,找到所有出现两次的数
对于原问题,可以用bit map的方式来表示数出现的情况。具体地说,是申请一个长度为4294967295×2的bit类型的数组bitArr,用2个位置表示一个数出现的词频,1B占用8个bit,所以长度为4294967295×2的bit类型的数组占用1GB空间。怎么使用这个bitArr数组呢?遍历这40亿个无符号数,如果初次遇到num,就把bitArr[num2 + 1]和bitArr[num2]设置为01,如果第二次遇到num,就把bitArr[num2+1]和bitArr[num2]设置为10,如果第三次遇到num,就把bitArr[num2+1]和bitArr[num2]设置为11。以后再遇到num,发现此时bitArr[num2+1]和bitArr[num2]已经被设置为11,就不再做任何设置。遍历完成后,再依次遍历bitArr,如果发现bitArr[i2+1]和bitArr[i2]设置为10,那么i 就是出现了两次的数。
找到100亿个URL中重复的URL
原问题的解法使用解决大数据问题的一种常规方法:把大文件通过哈希函数分配到机器,或者通过哈希函数把大文件拆成小文件。一直进行这种划分,直到划分的结果满足资源限制的要求。首先,你要向面试官询问在资源上的限制有哪些,包括内存、计算时间等要求。在明确了限制要求之后,可以将每条URL通过哈希函数分配到若干机器或者拆分成若干小文件,这里的“若干”由具体的资源限制来计算出精确的数量。
例如,将100亿字节的大文件通过哈希函数分配到100台机器上,然后每一台机器分别统计分给自己的URL中是否有重复的URL,**同时哈希函数的性质决定了同一条URL不可能分给不同的机器;**或者在单机上将大文件通过哈希函数拆成1000个小文件,对每一个小文件再利用哈希表遍历,找出重复的URL;或者在分给机器或拆完文件之后,进行排序,排序过后再看是否有重复的URL出现。总之,牢记一点,很多大数据问题都离不开分流,要么是哈希函数把大文件的内容分配给不同的机器,要么是哈希函数把大文件拆成小文件,然后处理每一个小数量的集合。
海量搜索词汇,找到最热TOP100词汇的方法
最开始还是用哈希分流的思路来处理,把包含百亿数据量的词汇文件分流到不同的机器上,具体多少台机器由面试官规定或者由更多的限制来决定。对每一台机器来说,如果分到的数据量依然很大,比如,内存不够或其他问题,可以再用哈希函数把每台机器的分流文件拆成更小的文件处理。
处理每一个小文件的时候,哈希表统计每种词及其词频,哈希表记录建立完成后,再遍历哈希表,遍历哈希表的过程中使用大小为100的小根堆来选出每一个小文件的top 100(整体未排序的top 100)。每一个小文件都有自己词频的小根堆(整体未排序的top 100),将小根堆里的词按照词频排序,就得到了每个小文件的排序后top 100。然后把各个小文件排序后的top 100进行外排序或者继续利用小根堆,就可以选出每台机器上的top 100。不同机器之间的top100再进行外排序或者继续利用小根堆,最终求出整个百亿数据量中的top 100。对于top K 的问题,除哈希函数分流和用哈希表做词频统计之外,还经常用堆结构和外排序的手段进行处理。
10MB内存,找到100亿整数的中位数
①内存够:内存够还慌什么啊,直接把100亿个全部排序了,你用冒泡都可以...然后找到中间那个就可以了。但是你以为面试官会给你内存??
②内存不够:题目说是整数,我们认为是带符号的int,所以4字节,占32位。
假设100亿个数字保存在一个大文件中,依次读一部分文件到内存(不超过内存的限制),将每个数字用二进制表示,比较二进制的最高位(第32位,符号位,0是正,1是负),如果数字的最高位为0,则将这个数字写入 file_0文件中;如果最高位为 1,则将该数字写入file_1文件中。
从而将100亿个数字分成了两个文件,假设 file_0文件中有 60亿 个数字,file_1文件中有 40亿 个数字。那么中位数就在 file_0 文件中,并且是 file_0 文件中所有数字排序之后的第 10亿 个数字。(file_1中的数都是负数,file_0中的数都是正数,也即这里一共只有40亿个负数,那么排序之后的第50亿个数一定位于file_0中)
现在,我们只需要处理 file_0 文件了(不需要再考虑file_1文件)。对于 file_0 文件,同样采取上面的措施处理:将file_0文件依次读一部分到内存(不超内存限制),将每个数字用二进制表示,比较二进制的 次高位(第31位),如果数字的次高位为0,写入file_0_0文件中;如果次高位为1,写入file_0_1文件 中。
现假设 file_0_0文件中有30亿个数字,file_0_1中也有30亿个数字,则中位数就是:file_0_0文件中的数字从小到大排序之后的第10亿个数字。
抛弃file_0_1文件,继续对 file_0_0文件 根据 次次高位(第30位) 划分,假设此次划分的两个文件为:file_0_0_0中有5亿个数字,file_0_0_1中有25亿个数字,那么中位数就是 file_0_0_1文件中的所有数字排序之后的 第 5亿 个数。
按照上述思路,直到划分的文件可直接加载进内存时,就可以直接对数字进行快速排序,找出中位数了。
设计短域名系统,将长URL转化成短的URL.
(1)利用放号器,初始值为0,对于每一个短链接生成请求,都递增放号器的值,再将此值转换为62进制(a-zA-Z0-9),比如第一次请求时放号器的值为0,对应62进制为a,第二次请求时放号器的值为1,对应62进制为b,第10001次请求时放号器的值为10000,对应62进制为sBc。
(2)将短链接服务器域名与放号器的62进制值进行字符串连接,即为短链接的URL,比如:t.cn/sBc。
(3)重定向过程:生成短链接之后,需要存储短链接到长链接的映射关系,即sBc -> URL,浏览器访问短链接服务器时,根据URL Path取到原始的链接,然后进行302重定向。映射关系可使用K-V存储,比如Redis或Memcache。
假设有这么一个场景,有一条新闻,新闻的评论量可能很大,如何设计评论的读和写
前端页面直接给用户展示、通过消息队列异步方式入库
读可以进行读写分离、同时热点评论定时加载到缓存
显示网站的用户在线数的解决思路
维护在线用户表
使用Redis统计
显示网站并发用户数
- 每当用户访问服务时,把该用户的 ID 写入ZSORT队列,权重为当前时间
- 根据权重(即时间)计算一分钟内该机构的用户数Zrange
- 删掉一分钟以上过期的用户Zrem
假设目前有 1000w 个记录(这些查询串的重复度比较高,虽然总数是 1000w,但如果除去重复后,则不超过 300w 个)。请统计最热门的 10 个查询串,要求使用的内存不能超过 1G。(一个查询串的重复度越高,说明查询它的用户越多,也就越热门。)
HashMap 法
虽然字符串总数比较多,但去重后不超过 300w,因此,可以考虑把所有字符串及出现次数保存在一个 HashMap 中,所占用的空间为 300w*(255+4)≈777M(其中,4 表示整数占用的 4 个字节)。由此可见,1G 的内存空间完全够用。
思路如下:
首先,遍历字符串,若不在 map 中,直接存入 map,value 记为 1;若在 map 中,则把对应的 value 加 1,这一步时间复杂度 O(N) 。
接着遍历 map,构建一个 10 个元素的小顶堆,若遍历到的字符串的出现次数大于堆顶字符串的出现次数,则进行替换,并将堆调整为小顶堆。
遍历结束后,堆中 10 个字符串就是出现次数最多的字符串。这一步时间复杂度 O(Nlog10) 。
前缀树法
当这些字符串有大量相同前缀时,可以考虑使用前缀树来统计字符串出现的次数,树的结点保存字符串出现次数,0 表示没有出现。
思路如下:
在遍历字符串时,在前缀树中查找,如果找到,则把结点中保存的字符串次数加 1,否则为这个字符串构建新结点,构建完成后把叶子结点中字符串的出现次数置为 1。
最后依然使用小顶堆来对字符串的出现次数进行排序。
线性切割法,一个区间切N-1刀。越早越多
二倍均值法,【0 ~ 剩余金额 / 剩余人数 * 2】中随机,相对均匀


public class QuickSort {
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
/* 常规快排 */
public static void quickSort1(int[] arr, int L , int R) {
if (L > R) return;
int M = partition(arr, L, R);
quickSort1(arr, L, M - 1);
quickSort1(arr, M + 1, R);
}
public static int partition(int[] arr, int L, int R) {
if (L > R) return -1;
if (L == R) return L;
int lessEqual = L - 1;
int index = L;
while (index < R) {
if (arr[index] <= arr[R])
swap(arr, index, ++lessEqual);
index++;
}
swap(arr, ++lessEqual, R);
return lessEqual;
}
/* 荷兰国旗 */
public static void quickSort2(int[] arr, int L, int R) {
if (L > R) return;
int[] equalArea = netherlandsFlag(arr, L, R);
quickSort2(arr, L, equalArea[0] - 1);
quickSort2(arr, equalArea[1] + 1, R);
}
public static int[] netherlandsFlag(int[] arr, int L, int R) {
if (L > R) return new int[] { -1, -1 };
if (L == R) return new int[] { L, R };
int less = L - 1;
int more = R;
int index = L;
while (index < more) {
if (arr[index] == arr[R]) {
index++;
} else if (arr[index] < arr[R]) {
swap(arr, index++, ++less);
} else {
swap(arr, index, --more);
}
}
swap(arr, more, R);
return new int[] { less + 1, more };
}
// for test
public static void main(String[] args) {
int testTime = 1;
int maxSize = 10000000;
int maxValue = 100000;
boolean succeed = true;
long T1=0,T2=0;
for (int i = 0; i < testTime; i++) {
int[] arr1 = generateRandomArray(maxSize, maxValue);
int[] arr2 = copyArray(arr1);
int[] arr3 = copyArray(arr1);
// int[] arr1 = {9,8,7,6,5,4,3,2,1};
long t1 = System.currentTimeMillis();
quickSort1(arr1,0,arr1.length-1);
long t2 = System.currentTimeMillis();
quickSort2(arr2,0,arr2.length-1);
long t3 = System.currentTimeMillis();
T1 += (t2-t1);
T2 += (t3-t2);
if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {
succeed = false;
break;
}
}
System.out.println(T1+" "+T2);
// System.out.println(succeed ? "Nice!" : "Oops!");
}
private static int[] generateRandomArray(int maxSize, int maxValue) {
int[] arr = new int[(int) ((maxSize + 1) * Math.random())];
for (int i = 0; i < arr.length; i++) {
arr[i] = (int) ((maxValue + 1) * Math.random())
- (int) (maxValue * Math.random());
}
return arr;
}
private static int[] copyArray(int[] arr) {
if (arr == null) return null;
int[] res = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
res[i] = arr[i];
}
return res;
}
private static boolean isEqual(int[] arr1, int[] arr2) {
if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))
return false;
if (arr1 == null && arr2 == null)
return true;
if (arr1.length != arr2.length)
return false;
for (int i = 0; i < arr1.length; i++)
if (arr1[i] != arr2[i])
return false;
return true;
}
private static void printArray(int[] arr) {
if (arr == null)
return;
for (int i = 0; i < arr.length; i++)
System.out.print(arr[i] + " ");
System.out.println();
}
}public static void merge(int[] arr, int L, int M, int R) {
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R)
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
while (p1 <= M)
help[i++] = arr[p1++];
while (p2 <= R)
help[i++] = arr[p2++];
for (i = 0; i < help.length; i++)
arr[L + i] = help[i];
}
public static void mergeSort(int[] arr, int L, int R) {
if (L == R)
return;
int mid = L + ((R - L) >> 1);
process(arr, L, mid);
process(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void main(String[] args) {
int[] arr1 = {9,8,7,6,5,4,3,2,1};
mergeSort(arr, 0, arr.length - 1);
printArray(arr);
}// 堆排序额外空间复杂度O(1)
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2)
return;
for (int i = arr.length - 1; i >= 0; i--)
heapify(arr, i, arr.length);
int heapSize = arr.length;
swap(arr, 0, --heapSize);
// O(N*logN)
while (heapSize > 0) { // O(N)
heapify(arr, 0, heapSize); // O(logN)
swap(arr, 0, --heapSize); // O(1)
}
}
// arr[index]刚来的数,往上
public static void heapInsert(int[] arr, int index) {
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
// arr[index]位置的数,能否往下移动
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下标
while (left < heapSize) { // 下方还有孩子的时候
// 两个孩子中,谁的值大,把下标给largest
// 1)只有左孩子,left -> largest
// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest
// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largest
int largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;
// 父和较大的孩子之间,谁的值大,把下标给largest
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index)
break;
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
public static void main(String[] args) {
int[] arr1 = {9,8,7,6,5,4,3,2,1};
heapSort(arr1);
printArray(arr1);
}public class Singleton {
private volatile static Singleton singleton;
private Singleton() {}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}// 基于linkedHashMap
public class LRUCache {
private LinkedHashMap<Integer,Integer> cache;
private int capacity; //容量大小
public LRUCache(int capacity) {
cache = new LinkedHashMap<>(capacity);
this.capacity = capacity;
}
public int get(int key) {
//缓存中不存在此key,直接返回
if(!cache.containsKey(key)) {
return -1;
}
int res = cache.get(key);
cache.remove(key); //先从链表中删除
cache.put(key,res); //再把该节点放到链表末尾处
return res;
}
public void put(int key,int value) {
if(cache.containsKey(key)) {
cache.remove(key); //已经存在,在当前链表移除
}
if(capacity == cache.size()) {
//cache已满,删除链表头位置
Set<Integer> keySet = cache.keySet();
Iterator<Integer> iterator = keySet.iterator();
cache.remove(iterator.next());
}
cache.put(key,value); //插入到链表末尾
}
}//手写双向链表
class LRUCache {
class DNode {
DNode prev;
DNode next;
int val;
int key;
}
Map<Integer, DNode> map = new HashMap<>();
DNode head, tail;
int cap;
public LRUCache(int capacity) {
head = new DNode();
tail = new DNode();
head.next = tail;
tail.prev = head;
cap = capacity;
}
public int get(int key) {
if (map.containsKey(key)) {
DNode node = map.get(key);
removeNode(node);
addToHead(node);
return node.val;
} else {
return -1;
}
}
public void put(int key, int value) {
if (map.containsKey(key)) {
DNode node = map.get(key);
node.val = value;
removeNode(node);
addToHead(node);
} else {
DNode newNode = new DNode();
newNode.val = value;
newNode.key = key;
addToHead(newNode);
map.put(key, newNode);
if (map.size() > cap) {
map.remove(tail.prev.key);
removeNode(tail.prev);
}
}
}
public void removeNode(DNode node) {
DNode prevNode = node.prev;
DNode nextNode = node.next;
prevNode.next = nextNode;
nextNode.prev = prevNode;
}
public void addToHead(DNode node) {
DNode firstNode = head.next;
head.next = node;
node.prev = head;
node.next = firstNode;
firstNode.prev = node;
}
}package com.concurrent.pool;
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class MySelfThreadPool {
//默认线程池中的线程的数量
private static final int WORK_NUM = 5;
//默认处理任务的数量
private static final int TASK_NUM = 100;
private int workNum;//线程数量
private int taskNum;//任务数量
private final Set<WorkThread> workThreads;//保存线程的集合
private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务
public MySelfThreadPool() {
this(WORK_NUM, TASK_NUM);
}
public MySelfThreadPool(int workNum, int taskNum) {
if (workNum <= 0) workNum = WORK_NUM;
if (taskNum <= 0) taskNum = TASK_NUM;
taskQueue = new ArrayBlockingQueue<>(taskNum);
this.workNum = workNum;
this.taskNum = taskNum;
workThreads = new HashSet<>();
//启动一定数量的线程数,从队列中获取任务处理
for (int i=0;i<workNum;i++) {
WorkThread workThread = new WorkThread("thead_"+i);
workThread.start();
workThreads.add(workThread);
}
}
public void execute(Runnable task) {
try {
taskQueue.put(task);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void destroy() {
System.out.println("ready close thread pool...");
if (workThreads == null || workThreads.isEmpty()) return ;
for (WorkThread workThread : workThreads) {
workThread.stopWork();
workThread = null;//help gc
}
workThreads.clear();
}
private class WorkThread extends Thread{
public WorkThread(String name) {
super();
setName(name);
}
@Override
public void run() {
while (!interrupted()) {
try {
Runnable runnable = taskQueue.take();//获取任务
if (runnable !=null) {
System.out.println(getName()+" readyexecute:"+runnable.toString());
runnable.run();//执行任务
}
runnable = null;//help gc
} catch (Exception e) {
interrupt();
e.printStackTrace();
}
}
}
public void stopWork() {
interrupt();
}
}
}
package com.concurrent.pool;
public class TestMySelfThreadPool {
private static final int TASK_NUM = 50;//任务的个数
public static void main(String[] args) {
MySelfThreadPool myPool = new MySelfThreadPool(3,50);
for (int i=0;i<TASK_NUM;i++) {
myPool.execute(new MyTask("task_"+i));
}
}
static class MyTask implements Runnable{
private String name;
public MyTask(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("task :"+name+" end...");
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "name = "+name;
}
}
}public class Storage {
private static int MAX_VALUE = 100;
private List<Object> list = new ArrayList<>();
public void produce(int num) {
synchronized (list) {
while (list.size() + num > MAX_VALUE) {
System.out.println("暂时不能执行生产任务");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.add(new Object());
}
System.out.println("已生产产品数"+num+" 仓库容量"+list.size());
list.notifyAll();
}
}
public void consume(int num) {
synchronized (list) {
while (list.size() < num) {
System.out.println("暂时不能执行消费任务");
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for (int i = 0; i < num; i++) {
list.remove(0);
}
System.out.println("已消费产品数"+num+" 仓库容量" + list.size());
list.notifyAll();
}
}
}
public class Producer extends Thread {
private int num;
private Storage storage;
public Producer(Storage storage) {
this.storage = storage;
}
public void setNum(int num) {
this.num = num;
}
public void run() {
storage.produce(this.num);
}
}
public class Customer extends Thread {
private int num;
private Storage storage;
public Customer(Storage storage) {
this.storage = storage;
}
public void setNum(int num) {
this.num = num;
}
public void run() {
storage.consume(this.num);
}
}
public class Test {
public static void main(String[] args) {
Storage storage = new Storage();
Producer p1 = new Producer(storage);
Producer p2 = new Producer(storage);
Producer p3 = new Producer(storage);
Producer p4 = new Producer(storage);
Customer c1 = new Customer(storage);
Customer c2 = new Customer(storage);
Customer c3 = new Customer(storage);
p1.setNum(10);
p2.setNum(20);
p3.setNum(80);
c1.setNum(50);
c2.setNum(20);
c3.setNum(20);
c1.start();
c2.start();
c3.start();
p1.start();
p2.start();
p3.start();
}
}public class blockQueue {
private List<Integer> container = new ArrayList<>();
private volatile int size;
private volatile int capacity;
private Lock lock = new ReentrantLock();
private final Condition isNull = lock.newCondition();
private final Condition isFull = lock.newCondition();
blockQueue(int capacity) {
this.capacity = capacity;
}
public void add(int data) {
try {
lock.lock();
try {
while (size >= capacity) {
System.out.println("阻塞队列满了");
isFull.await();
}
} catch (Exception e) {
isFull.signal();
e.printStackTrace();
}
++size;
container.add(data);
isNull.signal();
} finally {
lock.unlock();
}
}
public int take() {
try {
lock.lock();
try {
while (size == 0) {
System.out.println("阻塞队列空了");
isNull.await();
}
} catch (Exception e) {
isNull.signal();
e.printStackTrace();
}
--size;
int res = container.get(0);
container.remove(0);
isFull.signal();
return res;
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) {
AxinBlockQueue queue = new AxinBlockQueue(5);
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100; i++) {
queue.add(i);
System.out.println("塞入" + i);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
for (; ; ) {
System.out.println("消费"+queue.take());
try {
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}package com.demo.test;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class syncPrinter implements Runnable{
// 打印次数
private static final int PRINT_COUNT = 10;
private final ReentrantLock reentrantLock;
private final Condition thisCondtion;
private final Condition nextCondtion;
private final char printChar;
public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {
this.reentrantLock = reentrantLock;
this.nextCondtion = nextCondition;
this.thisCondtion = thisCondtion;
this.printChar = printChar;
}
@Override
public void run() {
// 获取打印锁 进入临界区
reentrantLock.lock();
try {
// 连续打印PRINT_COUNT次
for (int i = 0; i < PRINT_COUNT; i++) {
//打印字符
System.out.print(printChar);
// 使用nextCondition唤醒下一个线程
// 因为只有一个线程在等待,所以signal或者signalAll都可以
nextCondtion.signal();
// 不是最后一次则通过thisCondtion等待被唤醒
// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁
if (i < PRINT_COUNT - 1) {
try {
// 本线程让出锁并等待唤醒
thisCondtion.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
} finally {
reentrantLock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
Condition conditionA = lock.newCondition();
Condition conditionB = lock.newCondition();
Condition conditionC = lock.newCondition();
Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));
Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));
Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));
printA.start();
Thread.sleep(100);
printB.start();
Thread.sleep(100);
printC.start();
}
}//手太阴肺经 BLOCKING Queue
public class FooBar {
private int n;
private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);
private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);
public FooBar(int n) {
this.n = n;
}
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
foo.put(i);
printFoo.run();
bar.put(i);
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n; i++) {
bar.take();
printBar.run();
foo.take();
}
}
}
//手阳明大肠经CyclicBarrier 控制先后
class FooBar6 {
private int n;
public FooBar6(int n) {
this.n = n;
}
CyclicBarrier cb = new CyclicBarrier(2);
volatile boolean fin = true;
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
while(!fin);
printFoo.run();
fin = false;
try {
cb.await();
} catch (BrokenBarrierException e) {}
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n; i++) {
try {
cb.await();
} catch (BrokenBarrierException e) {}
printBar.run();
fin = true;
}
}
}
//手少阴心经 自旋 + 让出CPU
class FooBar5 {
private int n;
public FooBar5(int n) {
this.n = n;
}
volatile boolean permitFoo = true;
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; ) {
if(permitFoo) {
printFoo.run();
i++;
permitFoo = false;
}else{
Thread.yield();
}
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n; ) {
if(!permitFoo) {
printBar.run();
i++;
permitFoo = true;
}else{
Thread.yield();
}
}
}
}
//手少阳三焦经 可重入锁 + Condition
class FooBar4 {
private int n;
public FooBar4(int n) {
this.n = n;
}
Lock lock = new ReentrantLock(true);
private final Condition foo = lock.newCondition();
volatile boolean flag = true;
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
lock.lock();
try {
while(!flag) {
foo.await();
}
printFoo.run();
flag = false;
foo.signal();
}finally {
lock.unlock();
}
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n;i++) {
lock.lock();
try {
while(flag) {
foo.await();
}
printBar.run();
flag = true;
foo.signal();
}finally {
lock.unlock();
}
}
}
}
//手厥阴心包经 synchronized + 标志位 + 唤醒
class FooBar3 {
private int n;
// 标志位,控制执行顺序,true执行printFoo,false执行printBar
private volatile boolean type = true;
private final Object foo= new Object(); // 锁标志
public FooBar3(int n) {
this.n = n;
}
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
synchronized (foo) {
while(!type){
foo.wait();
}
printFoo.run();
type = false;
foo.notifyAll();
}
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n; i++) {
synchronized (foo) {
while(type){
foo.wait();
}
printBar.run();
type = true;
foo.notifyAll();
}
}
}
}
//手太阳小肠经 信号量 适合控制顺序
class FooBar2 {
private int n;
private Semaphore foo = new Semaphore(1);
private Semaphore bar = new Semaphore(0);
public FooBar2(int n) {
this.n = n;
}
public void foo(Runnable printFoo) throws InterruptedException {
for (int i = 0; i < n; i++) {
foo.acquire();
printFoo.run();
bar.release();
}
}
public void bar(Runnable printBar) throws InterruptedException {
for (int i = 0; i < n; i++) {
bar.acquire();
printBar.run();
foo.release();
}
}
} 采用SpringBoot构建项目,主要通过分布式缓存、队列、限流保证系统高可用,Netty、缓存、反向代理保证高并发。
双人对战答题、公司对战抢答
- 个人总得分和总排名实时更新
- 个人排行榜按分数、时间、次数、正确率展示
- 日榜、过去N日榜滚动更新
第一条需求很简单,使用了Redis的Zset实现不过这里总得分采用了基于分数、时间、次数和正确率的混合加权。考虑到数据的持久化,以及关系数据库和缓存的一致性导致的设计的复杂性,使用了谷歌开源的JamsRanking
优点是可以直接使用现成的setScores和getRanking接口封装了Redis和Mysql和消息队列的完成事务和一致性的使用细节。缺点是并发比较低使用Jmeter进行压测,单机只有20左右的TPS**
后来看了下源码,主要是它针对每一次设置都进行了分布式事务处理,并且会返回事务提交或回滚的结果。了解了底层实现以后就去谷歌的开源社区去查阅了相关的解决方案,当时官方对这个问题并没有通过配置能直接解决问题的快捷方式,不过推荐了使用者自身如果对响应时间不高的场景下可以采用批量合并事务的方式进行优化。基于这个思路,我们把写操作进行了封装并放入了队列,然后在消费者端批量取得数据后进行事务的批量处理,压测环境下整体性能达到了500TPS。已经基本满足了线上更新的需求,但是当时压测的过程中,队列偶尔的吞吐量会大范围波动,经常会持续数十秒,然后业务一次性处理完再响应,导致局部响应时间大幅度增长
后来也是在官网上查询,了解到谷歌开源组件使用的队列服务底层是使用BigTable作为持久层,但是当BigTable分片过大时,会触发再分片的过程,再分片的过程中,是不会进行任务分发的,所以就会导致先前的问题。针对这个问题,谷歌官方的建议是提前配置队列的数量、负载策略和最大容量等信息,保证所有队列不同时触发再分片
进行两次优化后,压测环境已经基本可以满足预期了,在实际生产环境的部署中,发现对于事务更新失败时,JamsRanking会对失败的事务进行切分和重试,整个过程对于研发人员是透明的,不利于线上问题排查,所以我们当时特地写了一个watchdog的工具,监控事务回滚达到十次以上的事务,查明原因后通过后台管理系统进行相应补偿,保证最终一致性
最终结果:
-
高效快速:能在数百毫秒内找到玩家排名以及进行更新
-
强一致性以及持久化、排名准确
-
可以扩展到任意数量的玩家
-
吞吐量有限制,只能支持约每秒 500次更新。
针对这个缺点谷歌官方也是给出了使用分片树和近似排名的解决方案,当然复杂的方案有更高的运维成本,所以我们优化工作也就到此为止
首先记录每天的排行榜和一个滚动榜,加分时同时写入这两个榜单,每日零点后跑工具将前几天数据累加写入当日滚动榜,该方案缺点是时间复杂度高,7天榜还好,只需要读过去6天数据,如果是100天榜,该方案需要读过去99天榜,显然不可接受
要做到每日零点后榜单实时生效,而不需要等待离线作业的完成,一种方案是预写未来的榜单。可以写当天的滚动榜的同时,写往后N-1天的滚动榜一起写入该方案不仅能脱离离线作业做到实时更新,且可以省略每天的日榜。但缺点也不难看出,对于7天滚动榜,每次写操作需要更新7个榜单,但是对于百日榜,空间消耗无法接受,1000万榜单大约消耗1G内存
有不有办法做到既能实时更新,写榜数量也不随N的增加而增加呢?
仍然是记录每天的排行榜和一个滚动榜,加分操作也还是同时操作当日榜和全局榜,但每日零点的离线作业改为从全局榜中减去之前过期的数据,从而实现先滚动更新。 此方案每次只需读取一个日榜做减法,时间复杂度为O(1);但是无法做到实时更新。 这个方案的优点是在十二点前提前准备好差分榜,到了十二点直接加上当天数据就是滚动榜内容 ,这样就在常数次写操作的前提下,实现了滚动榜的实时更新
利用setnx防止重复答题 分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 利用Redis的单线程特性对共享资源进行串行化处理
// 获取锁推荐使用set的方式
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);// 推荐使用redis+lua脚本
String lua = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object result = jedis.eval(lua, Collections.singletonList(lockKey) 利用redis来实现乐观锁(抢答),好处是答错的人不影响状态,第一个秒杀答对的人才能得分。
1、利用redis的watch功能,监控这个 Corp:Activ:Qust: 的状态值 2、获取Corp:Activ:Qust: 的值,创建redis事务,给这个key的值-1 3、执行这个事务,如果key的值被修改过则回滚,key不变
使用布隆过滤器:
它实际上是一个很长的二进制矢量数组和 K 个哈希函数。当一个昵称加入布隆过滤器中的时候,会进行如下操作:
- 使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。 Na
用户新增昵称时需要首先计算K个哈希值,如果K个哈希值有一个不为0则通过,否则不通过,不通过时通过加随机字符串再次检验,检测通过后返回给前端,帮助用户自动填写。
布隆过滤器的好处是它可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。
BloomFilter 的优势是,全内存操作,性能很高。另外空间效率非常高,要达到 1% 的误判率,平均单条记录占用 1.2 字节即可。而且,平均单条记录每增加 0.6 字节,还可让误判率继续变为之前的 1/10,即平均单条记录占用 1.8 字节,误判率可以达到 1/1000;平均单条记录占用 2.4 字节,误判率可以到 1/10000,以此类推。这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,而非 key 的值,所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。对于 BloomFilter 判断不存在的 key ,则是 100% 不存在的,反证法,如果这个 key 存在,那它每次 Hash 后对应的 Hash 值位置肯定是 1,而不会是 0
压测环境中服务器通过Netty的主从Reactor多路复用NIO事件模型,单机可以轻松应对十万长连接,但是每个业务中,由于每个用户登录系统后需要按照指定顺序答题,例如一共要答十道,那么服务器针对这一个用户就会产生十个定时任务,所以对于系统来说,定时器的数量就是百万级别的。
通过压测结果发现:JDK自带的Timer,在大概三万并发时性能就急剧下降了。也是此时根据业务场景的需要,将定时任务改成了Netty自带的HashedWheelTimer时间轮方案,通过压测单机在50万级别下依然能够平滑的执行。
也是这个强烈的反差,使我在强烈的好奇心促使下,阅读源码了解到常规的JDK 的Timer 和 DelayedQueue 等工具类,可实现简单的定时任务,单底层用的是堆数据结构,存取复杂度都是 O(NlogN),无法支撑海量定时任务。Netty经典的时间轮方案,正是通过将任务存取及取消操作时间复杂度降为 O(1),而广泛应用在定时任务量大、性能要求高的场景中。

基于Netty的Websocket底层,服务器端维护一个高效批量管理定时任务的调度模型。时间轮一般会实现成一个环形数组结构,类似一个时钟,分为很多槽,一个槽代表一个时间间隔,每个槽使用双向链表存储定时任务。指针周期性地跳动,跳动到一个槽位,就执行该槽位的定时任务。
单层时间轮的容量和精度都是有限的,对于精度要求特别高、时间跨度特别大或是海量定时任务需要调度的场景,可以考虑使用多级时间轮以及持久化存储与时间轮结合的方案。时间轮的定时任务处理逻辑如下:
- 将缓存在 timeouts 队列中的定时任务转移到时间轮中对应的槽中
- 根据当前指针定位对应槽,处理该槽位的双向链表中的定时任务,从链表头部开始迭代:
- 属于当前时钟周期则取出运行
- 不属于则将其剩余的时钟周期数减一
- 检测时间轮的状态。如果时间轮处于运行状态,则循环执行上述步骤,不断执行定时任务。
使用Netty的重连检测狗ConnectionWatchdog
服务端定义refreshTime,当我们从channel中read到了服务端发来的心跳响应消息的话,就刷新refreshTime为当前时间
客户端在state是WRITER_IDLE的时候每隔一秒就发送一个心跳包到sever端,告诉server端我还活着。
当重连成功时,会触发channelActive方法,在这里我们开启了一个定时任务去判断refreshTime和当前时间的时间差,超过5秒说明断线了,要进行重连,最后计算重连次数,尝试连接2次以上连不上就会修改header信息强制重连去连另一个服务器。
秒杀用到的基础组件,主要有框架、KV 存储、关系型数据库、MQ。
框架主要有 Web 框架和 RPC 框架。
其中,Web 框架主要用于提供 HTTP 接口给浏览器访问,所以 Web 框架的选型在秒杀服务中非常重要。在这里,我推荐Gin,它的性能和易用性都不错,在 GitHub 上的 Star 达到了 44k。对比性能最好的 fasthttp,虽然 fasthttp 在请求延迟低于 10ms 时性能优势明显,但其底层使用的对象池容易让人踩坑,导致其易用性较差,所以没必要过于追求性能而忽略了稳定性
至于 RPC 框架,我推荐选用 gRPC,因为它的扩展性和性能都非常不错。在秒杀系统中,Redis 中的数据主要是给秒杀接口服务使用,以便将配置从管理后台同步到 Redis 缓存中。
KV 存储方面,秒杀系统中主要是用 Redis 缓存活动配置,用 etcd 存储集群信息。
关系型数据库中,MySQL 技术成熟且稳定可靠,秒杀系统用它存储活动配置数据很合适。主要 原因还是秒杀活动信息和库存数据都缓存在 Redis 中,活动过程中秒杀服务不操作数据库, 使用 MySQL 完全能够满足需求。
MQ 有很多种,其中 Kafka 在业界认可度最高,技术也非常成熟,性能很不错,非常适合用在秒杀系统中。Kafka 支持自动创建队列,秒杀服务各个节点可以用它自动创建属于自己的队列
背景
-
秒杀业务简单,每个秒杀活动的商品是事先定义好的,商品有明确的类型和数量,卖完即止
-
秒杀活动定时上架,消费者可以在活动开始后,通过秒杀入口进行抢购秒杀活动
-
秒杀活动由于商品物美价廉,开始售卖后,会被快速抢购一空。
现象
-
秒杀活动持续时间短,访问冲击量大,秒杀系统需要应对这种爆发性的访问模型
-
业务的请求量远远大于售卖量,大部分是陪跑的请求,秒杀系统需要提前规划好处理策略
-
前端访问量巨大,系统对后端数据的访问量也会短时间爆增,对数据存储资源进行良好设计
-
活动期间会给整个业务系统带来超大负荷,需要制定各种策略,避免系统过载而宕机
-
售卖活动商品价格低廉,存在套利空间,各种非法作弊手段层出,需要提前规划预防策略
秒杀系统设计
首先,要尽力将请求拦截在系统上游,层层设阻拦截,过滤掉无效或超量的请求。因为访问量远远大于商品数量,所有的请求打到后端服务的最后一步,其实并没有必要,反而会严重拖慢真正能成交的请求,降低用户体验。
秒杀系统专为秒杀活动服务,售卖商品确定,因此可以在设计秒杀商品页面时,将商品信息提前设计为静态信息,将静态的商品信息以及常规的 CSS、JS、宣传图片等静态资源,一起独立存放到 CDN 节点,加速访问,且降低系统访问压力,在访问前端也可以**制定种种限制策略,**比如活动没开始时,抢购按钮置灰,避免抢先访问,用户抢购一次后,也将按钮置灰,让用户排队等待,避免反复刷新。
其次,要充分利用缓存,提升系统的性能和可用性。
用户所有的请求进入秒杀系统前,通过负载均衡策略均匀分发到不同 Web 服务器,避免节点过载。在 Web 服务器中,首先检查用户的访问权限,识别并发刷订单的行为。如果发现售出数量已经达到秒杀数量,则直接返回结束,要将秒杀业务系统和其他业务系统进行功能分拆,尽量将秒杀系统及依赖服务独立分拆部署,避免影响其他核心业务系统。
秒杀系统需要构建访问记录缓存,记录访问 IP、用户的访问行为,发现异常访问,提前进行阻断及返回。同时还需要构建用户缓存,并针对历史数据分析,提前缓存僵尸强刷专业户,方便在秒杀期间对其进行策略限制。这些访问记录、用户数据,通过缓存进行存储,可以加速访问,另外,对用户数据还进行缓存预热,避免活动期间大量穿透。
mysql乐观锁+redis预减库存+redis缓存卖完标记
第一是基于数据库乐观锁的方式保证数据并发扣减的强一致性;
第二是基于数据库的事务实现批量扣减部分失败时的数据回滚。
在扣减指定数量前应先做一次前置数量校验的读请求(参考读写分离 + 全缓存方案)
纯数据库乐观锁+事务的方式性能比较差,但是如果不计成本和考虑场景的话也完全够用,因为任何没有机器配置的指标,都是耍流氓。如果我采用 Oracle 的数据库、100 多核的刀锋服务器、SSD 的硬盘,即使是纯数据库的扣减方案,也是可以达到单机上万的 TPS 的。
单线程Redis 的 lua 脚本实现批量扣减
当用户调用扣减接口时,将扣减的 对应数量 + 脚本标示传递至 Redis 即可,所有的扣减判断逻辑均在 Redis 中的 lua 脚本中执行,lua 脚本执行完成之后返还是否成功给客户端。

Redis 中的 lua 脚本执行时,首先会使用 get 命令查询 uuid 进行查重。当防重通过后,会批量获取对应的剩余库存状态并进行判断,如果一个扣减的数量大于剩余数量,则返回错误并提示数量不足。
Redis 的单线程模型,确保不会出现当所有扣减数量在判断均满足后,在实际扣减时却数量不够。同时,单线程保证判断数量的步骤和后续扣减步骤之间,没有其他任何线程出现并发的执行。
当 Redis 扣减成功后,扣减接口会异步的将此次扣减内容保存至数据库。异步保存数据库的目的是防止出现极端情况—— Redis 宕机后数据未持久化到磁盘,此时我们可以使用数据库恢复或者校准数据
最后,运营后台直连数据库,是运营和商家修改库存的入口。商家在运营后台进货物进行补充。同时,运营后台的实现需要将此数量同步的增加至 Redis,因为当前方案的所有实际扣减都在 Redis 中
纯缓存方案虽不会导致超卖,但因缓存不具备事务特性,极端情况下会存在缓存里的数据无法回滚,导致出现少卖的情况。且架构中的异步写库,也可能发生失败,导致多扣的数据丢失
可以借助顺序写的特性,将扣减任务同步插入任务表,发现异常时,将任务表作为undolog进行回滚
可以解决由于网络不通、调用缓存扣减超时、在扣减到一半时缓存突然宕机(故障 failover)了。针对上述请求,都有相应的异常抛出,根据异常进行数据库回滚即可,最终任务库里的数据都是准的
更进一步:由于任务库是无状态的,可以进行水平分库,提升整体性能
mysql唯一索引+分布式锁
IP限流 | 验证码 | 单用户 | 单设备 | IMEI | 源IP |均设置规则
redis集群+本地缓存+限流+key加随机值分布在多个实例中
1、缓存集群可以单节点进行主从复制和垂直扩容
2、利用应用内的前置缓存,但是需注意需要设置上限
3、延迟不敏感,定时刷新,实时感知用主动刷新
4、和缓存穿透一样,限制逃逸流量,单请求进行数据回源并刷新前置
5、无论如何设计,最后都要写一个兜底逻辑,千万级流量说来就来
使用缓存策略将请求挡在上层中的缓存中
使用CDN,能静态化的数据尽量做到静态化,
加入限流(比如对短时间之内来自某一个用户,某一个IP、某个设备的重复请求做丢弃处理)
资源隔离限流会将对应的资源按照指定的类型进行隔离,比如线程池和信号量。
-
计数器限流,例如5秒内技术1000请求,超数后限流,未超数重新计数
-
滑动窗口限流,解决计数器不够精确的问题,把一个窗口拆分多滚动窗口
-
令牌桶限流,类似景区售票,售票的速度是固定的,拿到令牌才能去处理请求
-
漏桶限流,生产者消费者模型,实现了恒定速度处理请求,能够绝对防止突发流量
流量控制效果从好到差依次是:漏桶限流 > 令牌桶限流 > 滑动窗口限流 > 计数器限流
其中,只有漏桶算法真正实现了恒定速度处理请求,能够绝对防止突发流量超过下游系统承载能力。 不过,漏桶限流也有个不足,就是需要分配内存资源缓存请求,这会增加内存的使用率。而令牌桶限流算法中的“桶”可以用一个整数表示,资源占用相对较小,这也让它成为最常用的限流算法。正是因为这些特点,漏桶限流和令牌桶限流经常在一些大流量系统中结合使用。

-
削峰:恶意用户拦截
对于单用户多次点击、单设备、IMEI、源IP均设置规则
-
采用比较成熟的漏桶算法、令牌桶算法,也可以使用guava开箱即用的限流算法
可以集群限流,但单机限流更加简洁和稳定
-
当前层直接过滤一定比例的请求,最大承载值前需要加上兜底逻辑
-
对于已经无货的产品,本地缓存直接返回
-
单独部署,减少对系统正常服务的影响,方便扩缩容
对于一段时间内的秒杀活动,需要保证写成功,我们可以使用 消息队列。
- 削去秒杀场景下的峰值写流量——流量削峰
- 通过异步处理简化秒杀请求中的业务流程——异步处理
- 解耦,实现秒杀系统模块之间松耦合——解耦
削去秒杀场景下的峰值写流量
- 将秒杀请求暂存于消息队列,业务服务器响应用户“秒杀结果正在处理中。。。”,释放系统资源去处理其它用户的请求。
- 削峰填谷,削平短暂的流量高峰,消息堆积会造成请求延迟处理,但秒杀用户对于短暂延迟有一定容忍度。秒杀商品有 1000 件,处理一次购买请求的时间是 500ms,那么总共就需要 500s 的时间。这时你部署 10 个队列处理程序,那么秒杀请求的处理时间就是 50s,也就是说用户需要等待 50s 才可以看到秒杀的结果,这是可以接受的。这时会并发 10 个请求到达数据库,并不会对数据库造成很大的压力。
通过异步处理简化秒杀请求中的业务流程
先处理主要的业务,异步处理次要的业务。
- 如主要流程是生成订单、扣减库存;
- 次要流程比如购买成功之后会给用户发优惠券,增加用户的积****分。
- 此时秒杀只要处理生成订单,扣减库存的耗时,发放优惠券、增加用户积分异步去处理了。
解耦
实现秒杀系统模块之间松耦合将秒杀数据同步给数据团队,有两种思路:
- 使用 HTTP 或者 RPC 同步调用,即提供一个接口,实时将数据推送给数据服务。系统的耦合度高,如果其中一个服务有问题,可能会导致另一个服务不可用。
- 使用消息队列将数据全部发送给消息队列,然后数据服务订阅这个消息队列,接收数据进行处理。
CacheAside旁路缓存读请求不命中查询数据库,查询完成写入缓存,写请求更新数据库后删除缓存数据。
// 延迟双删,用以保证最终一致性,防止小概率旧数据读请求在第一次删除后更新数据库
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}为防缓存失效这一信息丢失,可用消息队列确保。
- 更新数据库数据;
- 数据库会将操作信息写入binlog日志当中;
- 另起一段非业务代码,程序订阅提取出所需要的数据以及key;
- 尝试删除缓存操作,若删除失败,将这些信息发送至消息队列;
- 重新从消息队列中获得该数据,重试操作;
订阅binlog程序在mysql中有现成的中间件叫canal,重试机制,主要采用的是消息队列的方式。
终极方案:请求串行化
真正靠谱非秒杀的方案:将访问操作串行化
- 先删缓存,将更新数据库的写操作放进有序队列中
- 从缓存查不到的读操作也进入有序队列
需要解决的问题:
- 读请求积压,大量超时,导致数据库的压力:限流、熔断
- 如何避免大量请求积压:将队列水平拆分,提高并行度。
由一个或多个sentinel实例组成sentinel集群可以监视一个或多个主服务器和多个从服务器。哨兵模式适合读请求远多于写请求的业务场景,比如在秒杀系统中用来缓存活动信息。 如果写请求较多,当集群 Slave 节点数量多了后,Master 节点同步数据的压力会非常大。

当主服务器进入下线状态时,sentinel可以将该主服务器下的某一从服务器升级为主服务器继续提供服务,从而保证redis的高可用性。
秒杀服务单节点需要处理的请求 QPS 可能达到 10 万以上。一个请求从进入秒杀服务到处理失败或者成功,至少会产生两条日志。也就是说,高峰期间,一个秒杀节点每秒产生的日志可能达到 30 万条以上
一块性能比较好的固态硬盘,每秒写的IOPS 大概在 3 万左右。也就是说,一个秒杀节点的每秒日志条数是固态硬盘 IOPS 的 10 倍,磁盘都扛不住,更别说通过网络写入到监控系统中。
- 每秒日志量远高于磁盘 IOPS,直接写磁盘会影响服务性能和稳定性
- 大量日志导致服务频繁分配,频繁释放内存,影响服务性能。
- 服务异常退出丢失大量日志的问题
解决方案
- Tmpfs,即临时文件系统,它是一种基于内存的文件系统。我们可以将秒杀服务写日志的文件放在临时文件系统中。相比直接写磁盘,在临时文件系统中写日志的性能至少能提升 100 倍,每当日志文件达到 20MB 的时候,就将日志文件转移到磁盘上,并将临时文件系统中的日志文件清空。
- 可以参考内存池设计,将给logger分配缓冲区,每一次的新写可以复用Logger对象
- 参考kafka的缓冲池设计,当缓冲区达到大小和间隔时长临界值时,调用Flush函数,减少丢失的风险
10、池化技术

通常可以采用循环队列来保存空闲连接。使用的时候,可以从队列头部取出连接,用完后将空闲连接放到队列尾部。Netty中利用带缓冲区的 channel 来充当队列。
TCP保证消息可靠传输三板斧:超时、重传、确认。服务端和客户端通信MSG和ACK的共计6个报文
- 请求报文(request,后简称为为R),客户端主动发送给服务端。
- 应答报文(acknowledge,后简称为A),服务器被动应答客户端的报文。
- 通知报文(notify,后简称为N),服务器主动发送给客户端的报文
在线消息流程:
A 消息请求 MSG:R => S 消息应答 MSG:A => S 消息通知B MSG:N
S 确认通知 ACK:N <= S 确认应答 ACK:A <= B确认请求S ACK:R
超时与重传、确认和去重:
A发出了 MSG:R ,收到了MSG:A之后,在一个期待的时间内,如果没有收到ACK:N,A会尝试将 MSG:R 重发。可能A同时发出了很多消息,所以A需要在本地维护一个等待ack队列,并配合timer超时机制,来记录哪些消息没有收到ACK:N,定时重发。确认ACK保证必达,去重保证唯一
离线消息流程
原方案:根据离线好友的标识,交互拉取指定的消息

优化的方案:
- 如用户勾选全量则返回计数,在用户点击时拉取。
- 如用户未勾选全量则返回最近全部离线消息,客户端针对用户id进行计算。
- 全量离线信息可以通过客户端异步线程分页拉取,减少卡顿
- 将ACK和分页第二次拉取的报文重合,可以较少离线消息拉取交互的次数
在线的群友能第一时间收到消息; 离线的群友能在登陆后收到消息。

- 群消息发送者x向server发出群消息;
- server去db中查询群中有多少用户(x,A,B,C,D);
- server去cache中查询这些用户的在线状态;
- 对于群中在线的用户A与B,群消息server进行实时推送;
- 对于群中离线的用户C与D,群消息server进行离线存储。
对于同一份群消息的内容,多个离线用户存储了很多份。假设群中有200个用户离线,离线消息则冗余了200份,这极大的增加了数据库的存储压力
-
离线消息表只存储用户的群离线消息msg_id,降低数据库的冗余存储量
-
加入应用层的ACK,才能保证群消息一定到达,服务端幂等性校验及客户端去重,保证不重复
-
每条群消息都ACK,会给服务器造成巨大的冲击,通过批量ACK减少消息风暴扩散系数的影响
-
群离线消息过多:拉取过慢,可以通过分页懒拉取改善。
方案:
- Id通过借鉴微信号段+跳跃的方式保证趋势递增
- 单聊借鉴数据库设计,单点序列化同步到其他节点保证多机时序
- 群聊消息使用单点序列化保证各个发送者的消息相对时序

优化:
- 利用服务器单点序列化时序,可能出现服务端收到消息的时序,与发出序列不一致
- 在A往B发出的消息中,加上发送方A本地的一个绝对时序,来表示接收方B的展现时序。
- 群聊消息保证一个群聊落在一个service上然后通过本地递增解决全局递增的瓶颈问题
历史方案:
- 服务器在缓存集群里存储所有用户的在线状态 -> 保证状态可查
- 用户状态实时变更,任何用户登录/登出时,需要推送所有好友更新状态
- A登录时,先去数据库拉取自己的好友列表,再去缓存获取所有好友的在线状态
**“消息风暴扩散系数”**是指一个消息发出时,变成N个消息的扩散系数,这个系数与业务及数据相关,一定程度上它的大小决定了技术采用推送还是拉取。
优化方案:
- 好友状态推拉结合,首页置顶亲密、当前群聊,采用推送,否则可以采用轮询拉取的方式同步;
- 群友的状态,由于消息风暴扩散系数过大,可以采用按需拉取,延时拉取的方式同步;
- 系统消息/开屏广告等这种实时产生的消息,可以采用推送的方式获取消息;
Neo4j 图谱数据库
18年初,针对我们Dubbo框架的智慧楼宇项目的单体服务显得十分笨重,需要采用微服务的形式进行架构的重新设计,当时,我阅读了Eric Evans 写的《领域驱动设计:软件核心复杂性应对之道》和Martin fowler的《微服务架构:Microservice》两本重量级书籍,书中了解到转型微服务的重要原因之一就是利用分治的思想减少系统的复杂性,是一种针对复杂问题的宏观设计,来应对系统后来规模越来越大,维护越来越困难的问题。然而,拆分成微服务以后,并不意味着每个微服务都是各自独立地运行,而是彼此协作地组织在一起。这就好像一个团队,规模越大越需要一些方法来组织,这正是我们需要DDD模型为我们的架构设计提供理论并实践的方法。
当时每次版本更新迭代动辄十几个微服务同时修改,有时一个简单的数据库字段变更,也需要同时变更多个微服务,引起了团队的反思:微服务化看上去并没有减少我们的工作量。《企业架构设计》中对于微服务的定义是小而专,但在起初的设计时,我们只片面的理解了小却忽视了专,此时我们才意识到拆分的关键是要保证微服务内高内聚,微服务间低耦合。
物联网是互联网的外延。将用户端延伸和扩展到物与人的连接。物联网模式中,所有物品与网络连接,并进行通信和场景联动。互联网通过电脑、移动终端等设备将参与者联系起来,形成的一种全新的信息互换方式
- 设备感知层(Device):利用射频识别、二维码、传感器等技术进行数据采集
- 网络传输层(Connect):依托通信网络和协议,实现可信的信息交互和共享
- 应用控制层(Manage):分析和处理海量数据和信息,实现智能化的决策和控制

- 设备联网:通过不同的网络协议和通信标准,实现设备与控制端的连接
- 云端分析:提供监控、存储、分析等数据服务,以及保障客户的业务数据安全
- 云边协同:云端接受设备上报数据,下发设备管控指令
云端计算、终端计算和边缘计算是一个协同的系统,根据用户场景、资源约束程度、业务实时性等进行动态调 配,形成可靠、低成本的应用方案。从过去几年的发展积累来看,AI 已在物联网多个层面进行融合,比我们合作的海康威视、旷视宇视、商汤科技等纷纷发布了物联网AI相关平台和产品,和移动和小区进行了紧密的融合。

向下连接海量设备,支撑设备数据采集上云;
向上通过调用云端API将指令下发至设备端,实现远程控制。
上行数据链路
- 设备建立MQTT长连接,上报数据(发布Topic和Payload)到物联网平台
- 物联网平台通过配置规则,通过RocketMQ、AMQP等队列转发到业务平台
下行指令链路
- 业务服务器基于HTTPS协议调用的API接口,发布Topic指令到物联网平台。
- 物联网平台通过MQTT协议,使用发布(指定Topic和Payload)到设备端。
WIFI门锁:非保活 平常处于断电休眠状态,需要MCU 唤醒才能传输和发送数据
蓝牙门锁:MCU串口对接和SDK对接,近距离单点登录和远距离网关登录
Zigbee门锁:非保活 但是保持心跳,MCU对接,Zigbee协议控制。
NB-Iot门锁:可以通过公网连接,把门禁变成SAAS服务,MCU
| 名词 | 解释 |
|---|---|
| SaaS | Software-as-a-Service ,提供给客户的服务是运营商运行在云计算基础设施上的应用程序。用户可以在各种设备上通过客户端界面访问应用,例如计算机浏览器。用户不需要管理或控制任何云计算基础设施,包括网络、服务器、操作系统、存储等资源,一切由 SaaS 提供商管理和运维。 |
| PaaS | Platform-as-a-Service,表示平台即服务理念,客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置。 |
| IaaS | Infrastructure-as-a-Service ,表示基础设施即服务理念,提供的服务是对所有计算基础设施的利用,包括 CPU、内存、存储、网络等其它计算资源。用户能够部署和运行任意软件,包括操作系统和应用程序。 |
HTTP协议(CS用户上网)
HTTP协议是典型的CS通讯模式,由客户端主动发起连接,向服务器请求XML或JSON数据。该协议最早是为了适用web浏览器的上网浏览场景和设计的,目前在PC、手机、pad等终端上都应用广泛,但并不适用于物联网场景
- 由于必须由设备主动向服务器发送数据,难以主动向设备推送数据。
- 物联网场景中的设备多样,运算受限的设备,难以实现JSON数据格式的解析
RESTAPI(松耦合调用)
REST/HTTP主要为了简化互联网中的系统架构,快速实现客户端和服务器之间交互的松耦合,降低了客户端和服务器之间的交互延迟。因此适合在物联网的应用层面,通过REST开放物联网中资源,实现服务被其他应用所调用。
CoAP协议(无线传感)
简化了HTTP协议的RESTful API,它适用于在资源受限的通信的IP网络。
MQTT协议(低带宽)
MQTT协议采用发布/订阅模式,物联网终端都通过TCP连接到云端,云端通过主题的方式管理各个设备关注的通讯内容,负责将设备与设备之间消息的转发
适用范围:在低带宽、不可靠的集中星型网络架构(hub-and-spoke),不适用设备与设备之间通信,设备控制能力弱,另外实时性较差,一般都在秒级。协议要足够轻量,方便嵌入式设备去快速地解析和响应。具备足够的灵活性,使其足以为 IoT 设备和服务的多样化提供支持。应该设计为异步消息协议,这么做是因为大多数 IoT 设备的网络延迟很可能非常不稳定,若使用同步消息协议,IoT 设备需要等待服务器的响应,必须是双向通信,服务器和客户端应该可以互相发送消息。
AMQP协议(互操作性)
用于业务系统例如PLM,ERP,MES等进行数据交换。
适用范围:最早应用于金融系统之间的交易消息传递,在物联网应用中,主要适用于移动手持设备与后台数据中心的通信和分析。
XMPP协议(即时通信)
开源形式组织产生的网络即时通信协议。被IETF国际标准组织完成了标准化工作
适用范围:即时通信的应用程序,还能用在协同工具、游戏等。
XMPP在通讯的业务流程上是更适合物联网系统的,开发者不用花太多心思去解决设备通讯时的业务通讯流程,相对开发成本会更低。但是HTTP协议中的安全性以及计算资源消耗的硬伤并没有得到本质的解决。
JMS (Java消息服务)
Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。
Zigbee协议
低功耗,它保持IEEE 802.15.4(2003)标准
智慧社区IOT领域,不管是嵌入式芯片还是应用服务器都需要传递消息,常见上行的消息有:人脸识别开门、烟感雾感告警、共享充电桩充电,下行的广告下发、NB门禁开门指令、超级门板显示等,由于物联网设备时不时会故障和断网导致大量的流量洪峰,传统消息队列需要针对性优化。
-
上下行拆分
上行消息特征:并发量高、可靠性和时延性要求低
下行消息特征:并发量低、控制指令的成功率要求高
-
海量Topic下性能
Kafka海量Topic性能会急剧下降,Zookeeper协调也有瓶颈
多泳道消息队列可以实现IoT消息队列的故障隔离
-
实时消息优先处理
NB门禁实时产生的开门指令必须第一优先级处理,堆积的消息降级
设计成无序、不持久化的,并与传统的FIFO队列隔离
-
连接、计算、存储分离
Broker只做流转分发,实现无状态和水平扩展
计算交给Flink,存储交给nosqlDB,实现高吞吐写
-
消息策略-推拉结合
MQTT针对电池类物联网设备,AMQP针对安全性较高的门禁设备
消费端离线时存到queue,在线时将实时消息和从queue中拉取的消息一起推送

如果解决海量Topic
首先要做的就是分区、分组等水平拆分的方式,接下来考虑单实例如何处理更多Topic,传统消息队列在海量Topic下顺序写会退化成随机写,性能大幅下降
-
人工Sharding:部署多个Kafka集群,通过不同mq连接来隔离
-
合并Topic,客户端封装subTopic。比如一个服务的N个统计项,会消费到无关消息
基于这个思路,使用Kafka Streams或者Hbase列存储来聚合
针对单个Topic海量订阅的问题,可以在上层封装广播组件来协调批量发送

使用端 / 边 / 云三级架构,客户端加密传输,边缘节点转发、云侧转码并持久化
上线时间,从调研到正式上线用了 3个月时间,上线后一个月内就要经历双十二挑战。在这么紧的上线时间要求下,需要用到公司提供的所有优势,包括cdn网络,直播牌照等
-
直播数据是实时生成的,所有不能够进行预缓存
-
直播随时会发生,举办热点活动,相关服务器资源需要动态分配
-
直播的延迟对于用户体验影响很大,需要控制在秒级
-
直播sdk是内嵌在社区应用里的,整体要求不能超过5M
| 协议 | 上线时间 | 网络兼容 | 端对端延迟 | 应用大小 | 问题 |
|---|---|---|---|---|---|
| WebRTC | ✗ | Webrtc 基于 UDP,和社区应用的网络架构不兼容 | |||
| HTTP Upload | ✗ | 会导致网络高延迟 | |||
| Custom Protocol | ✗ | 工程师需要实现自己的客户端与服务端的库,无法按时上线 | |||
| Proprietary | ✗ | 协议就需要几兆的空间,超出额度 | |||
| RTMPS | ✔ | ✔ | ✔ | ✔ | TCP实时传输消息协议,更安全更可靠 |
RTMPS:基于TCP实时传输消息协议,更安全更可靠
MPEG-DASH:是一种基于HTTP协议自适应比特率流媒体技术,应对复杂的环境
-
直播端使用 RTMPS 协议发送直播数据到边缘节点(POP)
-
POP 使用RTMP发送数据到数据中心(DC)
-
DC 将数据编码成不同的清晰度并进行持久化存储
云端转码主要有两种分辨率400x400 和 720x720.
-
播放端通过 MPEG-DASH / RTMPS 协议接收直播数据
如果用户网络不好**MPEG-DASH**会自动转换成低分辨率
-
直播端使用 RTMPS 协议发送直播流数据到 POP 内的就近的代理服务器
-
代理服务器转发直播流数据到数据中心的网关服务器(443转80)
-
网关服务器使用直播 id 的一致性哈希算法发送直播数据到指定的编码服务器
-
编码服务器有几项职责:
-
4.1 验证直播数据的格式是否正确。
-
4.2 关联直播 id 以及编码服务器第一映射,保证客户端即使连接中断或者服务器扩容时,在重新连接的时候依然能够连接到相同的编码服务器
-
4.3 使用直播数据编码成不同解析度的输出数据
-
4.4 使用 DASH 协议输出数据并持久化存储
-
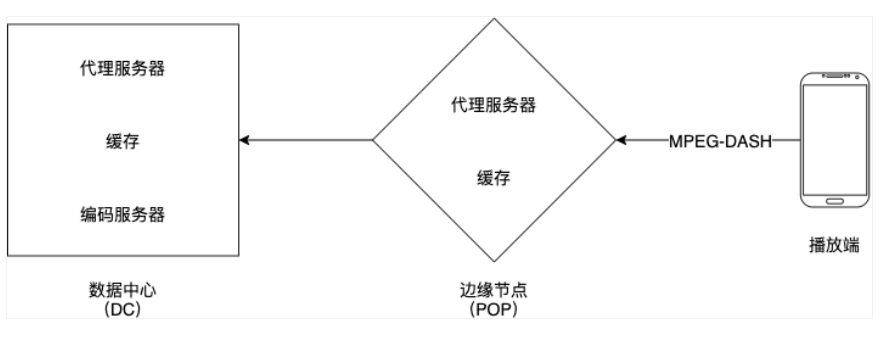
- 播放端使用 HTTP DASH 协议向 POP 拉取直播数据
- POP 里面的代理服务器会检查数据是否已经在 POP 的缓存内。如果是的话,缓存会返回数据给播放端,否则,代理服务器会向 DC 拉取直播数据
- DC 内的代理服务器会检查数据是否在 DC 的缓存内,如果是的话,缓存会返回数据给 POP,并更新 POP 的缓存,再返回给播放端。不是的话,代理服务器会使用一致性哈希算法向对应的编码服务器请求数据,并更新 DC 的缓存,返回到 POP,再返回到播放端。
收获
- 项目的成功不,代码只是内功,考虑适配不同的网络、利用可利用的资源
- 惊群效应在热点服务器以及许多组件中都可能发生
- 开发大型项目需要对吞吐量和时延、安全和性能做出妥协
- 保证架构的灵活度和可扩展性,为内存、服务器、带宽耗尽做好规划
网络可靠性:
- 根据网络连接速度来自动调整视频质量
- 使用短时间的数据缓存来解决直播端不稳定,瞬间断线的问题
- 根据网络质量自动降级为音频直播以及播放
惊群效应:
- 当多个播放端向同一个 POP 请求直播数据的时候,如果数据不在缓存中
- 这时候只有一个请求 A 会到 DC 中请求数据,其他请求会等待结果
- 但是如果请求 A 超时没有返回数据的话,所有请求会一起向 DC 访问数据
- 这时候就会加大 DC 的压力,触发惊群效应
- 解决这个问题的方法就是通过实际的情况来调整请求超时的时间。这个时间如果太长的话会带来直播的延迟,太短的话会经常触发惊群效应(每个时间窗口只允许触发一次,设置允许最大回源数量)

数据库优化: 数据库是最容易成为瓶颈的组件,考虑从 SQL 优化或者数据库本身去提高它的性能。如果瓶颈依然存在,则会考虑分库分表将数据打散,如果这样也没能解决问题,则可能会选择缓存组件进行优化
**集群最优:**存储节点的问题解决后,计算节点也有可能发生问题。一个集群系统如果获得了水平扩容的能力,就会给下层的优化提供非常大的时间空间,由最初的 3 个节点,扩容到最后的 200 多个节点,但由于人力问题,服务又没有什么新的需求,下层的优化就一直被搁置着。
**硬件升级:**水平扩容不总是有效的,原因在于单节点的计算量比较集中,或者 JVM 对内存的使用超出了宿主机的承载范围。在动手进行代码优化之前,我们会对节点的硬件配置进行升级。
代码优化:代码优化是提高性能最有效的方式,但需要收集一些数据,这个过程可能是服务治理,也有可能是代码流程优化。比如JavaAgent 技术,会无侵入的收集一些 profile 信息,供我们进行决策。
**并行优化:**并行优化是针对速度慢的接口进行并行调用。所以我们通常使用 ContDownLatch 对需要获取的数据进行并行处理,效果非常不错,比如在 200ms 内返回对 50 个耗时 100ms 的下层接口的调用。
JVM 优化: JVM 发生问题时,优化会获得巨大的性能提升。但在 JVM 不发生问题时,它的优化效果有限。但在代码优化、并行优化、JVM 优化的过程中,JVM 的知识却起到了关键性的作用
**操作系统优化:**操作系统优化是解决问题的杀手锏,比如像 HugePage、SWAP、“CPU 亲和性”这种比较底层的优化。但就计算节点来说,对操作系统进行优化并不是很常见。运维在背后会做一些诸如文件句柄的调整、网络参数的修改,这对于我们来说就已经够用了
系统级的重构,测试回归的工作量至少都是以月为单位,对于人力的消耗巨大。一种应对方案是,先不改造,到系统实在扛不住了再想办法。另一种应对方案是,先暂停需求,全力进行改造。但在实际工作场景中,上述应对策略往往很难实现。
场景:
1、读服务均是查询,它是无状态的。
2、不管是架构升级还是日常需求,读服务对外接口的出入参格式是没有变化的

-
日志收集,主要作用是收集被测系统的真实用户请求,基于一定规则处理后作为系统用例;
Spring 里的 Interceptor 、Servlet 里的 Filter 过滤器,对所有请求的入参和出参进行记录,并通过 MQ 发送出去。(注意错峰、过滤写、去重等)
-
数据回放是基于收集的用例,对被测系统进行数据回放,发起自动化测试回归;
**离线回放:**只调用新服务,将返回的数据和日志里的出参进行比较,日志比较大
**实时回放:**去实时调用线上系统和被测系统,并存储实时返回回放的结果信息,线上有负担
**并行回放:**新版本不即时上线,每次调用老版本接口时概率实时回放新版本接口,耗时间周期
-
差异对比,通过差异对比自动发现与预期不一致的用例,进而确定 Bug。
采用文本对比,可以直观地看到哪个字段数据有差异,从而更快定位到问题。正常情况下,只要存在差异的数据,均可认为是 Bug,是需要进行修复的。
方法论
Discovery
考虑企业战略,分析客户需求,制定产品目标
由外到内:竞争对手的方案,为什么做,以后怎么发展,如何去优化。
自上而下:基于公司的战略,考虑自身能力和所处环境。
自下而上:从资源、历史问题、优先级出发,形成一套可行性实施方法。
Define
基于收集的信息,综合跨业务线的抽象能力和服务,先做什么后做什么,怎么做
设计新的架构,重点设计解决痛点问题。
拆分业务领域,重点划分工作临界上下文。
Design
详细的业务设计,功能设计,交付计划,考核计划
产品愿景,产品形态,相关竞品方案对比,价值、优势、收益
梳理业务范围,要知道电商领域四大流(信息流、商流、资金流、物流)
MVP最小可用比,让客户和老大看到结果,最后通编写story把故事编圆
Delivery
交付阶段,根据反馈及时调整中台战略,减少损失和增大收益
合理制定每个阶段的绩效考核目标:
40%稳定+25%业务创新+20%服务接入+15%用户满意度

系统拆分
通过DDD领域模型,对服务进行拆分,将一个系统拆分为多个子系统,做成SpringCloud的微服务。微服务设计时要尽可能做到少扇出,多扇入,根据服务器的承载,进行客户端负载均衡,通过对核心服务的上游服务进行限流和降级改造。
一个服务的代码不要太多,1 万行左右,两三万撑死了吧。
大部分的系统,是要进行多轮拆分的,第一次拆分,可能就是将以前的多个模块该拆分开来了,比如说将电商系统拆分成订单系统、商品系统、采购系统、仓储系统、用户系统等等吧。
但是后面可能每个系统又变得越来越复杂了,比如说采购系统里面又分成了供应商管理系统、采购单管理系统,订单系统又拆分成了购物车系统、价格系统、订单管理系统。
CDN、Nginx静态缓存、JVM缓存
利用Java的模板thymeleaf可以将页面和数据动态渲染好,然后通过Nginx直接返回。动态数据可以从redis中获取。其中redis里的数据由一个缓存服务来进行消费指定的变更服务。
商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。
缓存
Redis cluster,10 台机器,5主5从,5 个节点对外提供读写服务,每个节点的读写高峰 QPS 可能可以达到每秒 5 万,5 台机器最多是 25 万读写请求每秒。
32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 Redis 进程的是 10g 内存,一般线上生产环境,Redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,Redis 从实例会自动变成主实例继续提供读写服务。
MQ
可以通过消息队列对微服务系统进行解耦,异步调用的更适合微服务的扩展
同时可以应对秒杀活动中[应对高并发写请求](# 6、应对高并发的写请求),比如kafka在毫秒延迟基础上可以实现10w级吞吐量
针对IOT流量洪峰做了一些特殊的优化,保证消息的及时性
同时可以使用消息队列保证分布式系统最终一致性
分库分表
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就 将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个 表,每个表的数据量保持少一点,提高 sql 跑的性能。在通讯录、订单和商城商品模块超过千万级别都应及时考虑分表分库
读写分离
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都 集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。 读流量太多的时候,还可以加更多的从库。比如统计监控类的微服务通过读写分离,只需访问从库就可以完成统计,例如ES
ElasticSearch
Elasticsearch,简称 es。es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,比如运营平台上的各地市的汇聚统计,还有一些全文搜索类的操作,比如通讯录和订单的查询。
基于 Hash 取模、一致性 Hash 实现分库分表
高并发读可以通过多级缓存应对
大促销热key读的问题通过redis集群+本地缓存+限流+key加随机值分布在多个实例中
高并发写的问题通过基于 Hash 取模、一致性 Hash 实现分库分表均匀落盘
业务分配不均导致的热key读写问题,可以根据业务场景进行range分片,将热点范围下的子key打散
具体实现:预先设定主键的生成规则,根据规则进行数据的分片路由,但这种方式会侵入商品各条线主数据的业务规则,更好的方式是基于分片元数据服务器(即每次访问分片前先询问分片元服务器在路由到实际分片)不过会带来复杂性,比如保证元数据服务器的一致性和可用性。
尽量避免分布式事务,单进程用数据库事务,跨进程用消息队列
主流实现分布式系统事务一致性的方案:
- 最终一致性:也就是基于 MQ 的可靠消息投递的机制,
- 基于重试加确认的的最大努力通知方案。
理论上也可以使用(2PC两阶段提交、3PC三阶段提交、TCC短事务、SAGA长事务方案),但是这些方案工业上落地代价很大,不适合互联网的业界场景。针对金融支付等需要强一致性的场景可以通过前两种方案实现。(展开说的话参考分布式事务)

本地数据库事务原理:undo log(原子性) + redo log(持久性) + 数据库锁(原子性&隔离性) + MVCC(隔离性)
分布式事务原理:全局事务协调器(原子性) + 全局锁(隔离性) + DB本地事务(原子性、持久性)
一、我们公司账单系统和第三方支付系统对账时,就采用“自研补偿/MQ方案 + 人工介入”方式
落地的话:方案最“轻”,性能损失最少。可掌控性好,简单易懂,易维护。 考虑到分布式事务问题是小概率事件,留有补救余地就行,性能的损失可是实打实的反应在线上每一个请求上
二、也了解到业界比如阿里成熟Seata AT模式,平均性能会降低35%以上
我觉得不是特殊的场景不推荐
三、RocketMQ事务消息
听起来挺好挺简单的方案,但它比较挑业务场景,同步性强的处理链路不适合。 【重要】要求下游MQ消费方一定能成功消费消息。否则转人工介入处理。 【重要】千万记得实现幂等性。
由于项目需要进行数据割接,保证用户多平台使用用户感知的一致,将广东项目的几百万用户及业务数据按照一定的逻辑灌到社区云平台上,由于依赖了第三方统一认证和省侧crm系统,按照之前系统内割接的方法,通过数据库将用户的唯一标识查出来然后使用多线程向省侧crm系统获取结果。
但是测试的过程中,发现每个线程请求的数据发生了错乱,导致每个请求处理的数据有重复,于是立即停止了脚本,当时怀疑是多线程对资源并发访问导致的,于是把ArrayList 改成了CopyOnWriteArrayList,但是折腾了一晚上,不管怎么修改,线程之间一直有重复数据,叫了一起加班的同事也没看出问题来,和同事估算了一下不使用多线程,大概30-40个小时能跑完,想了下也能接受,本来已经准备放弃了。
不过回到家,我还是用多线程仔细单步模拟了下,整个处理的过程,发现在起线程的时候,有些子线程并没有把分配给他的全部id的list处理完,导致最终状态没更新,新线程又去执行了一遍,然后我尝试通过修改在线程外深拷贝一个List再作为参数传入到子线程里,(后续clear的时候也是clear老的List)果然,整个测试过程中再也没出现过重复处理的情况。
事后,我也深究了下原因:
if(arrayBuffer.length == 99) {
val asList = arrayBuffer.toList
exec.execute ( openIdInsertMethod(asList) )
arrayBuffer.clear
}在一个线程中开启另外一个新线程,则新开线程称为该线程的子线程,子线程初始优先级与父线程相同。不过主线程先启动占用了cpu资源,因此主线程总是优于子线程。然而,即使设置了优先级,也无法保障线程的执行次序。只不过,优先级高的线程获取CPU资源的概率较大,优先级低的并非没机会执行。
所以主线程上的clear操作有可能先执行,那么子线程中未处理完的数据就变成一个空的数组,所以就出现了多个线程出现了重复数据的原因,所以我们要保证的是子线程每次执行完后再进行clear即可。而不是一开始定位的保证ArrayList的安全性。所以将赋值(buffer->list)操作放在外面去执行后,多线程数据就正常了。
[见秒杀项目方案设计](# 二、秒杀项目)
中小规模的计数服务(万级)
最常见的计数方案是采用缓存 + DB 的存储方案。当计数变更时,先变更计数 DB,计数加 1,然后再变更计数缓存,修改计数存储的 Memcached 或 Redis。这种方案比较通用且成熟,但在高并发访问场景,支持不够友好。在互联网社交系统中,有些业务的计数变更特别频繁,比如微博 feed 的阅读数,计数的变更次数和访问次数相当,每秒十万到百万级以上的更新量,如果用 DB 存储,会给 DB 带来巨大的压力,DB 就会成为整个计数服务的瓶颈所在。即便采用聚合延迟更新 DB 的方案,由于总量特别大,同时请求均衡分散在大量不同的业务端,巨大的写压力仍然是 DB 的不可承受之重。
大型互联网场景(百万级)
直接把计数全部存储在 Redis 中,通过 hash 分拆的方式,可以大幅提升计数服务在 Redis 集群的写性能,通过主从复制,在 master 后挂载多个从库,利用读写分离,可以大幅提升计数服务在 Redis 集群的读性能。而且 Redis 有持久化机制,不会丢数据
一方面 Redis 作为通用型存储来存储计数,内存存储效率低。以存储一个 key 为 long 型 id、value 为 4 字节的计数为例,Redis 至少需要 65 个字节左右,不同版本略有差异。但这个计数理论只需要占用 12 个字节即可。内存有效负荷只有 12/65=18.5%。如果再考虑一个 long 型 id 需要存 4 个不同类型的 4 字节计数,内存有效负荷只有 (8+16)/(65*4)= 9.2%。
另一方面,Redis 所有数据均存在内存,单存储历史千亿级记录,单份数据拷贝需要 10T 以上,要考虑核心业务上 1 主 3 从,需要 40T 以上的内存,再考虑多 IDC 部署,轻松占用上百 T 内存。就按单机 100G 内存来算,计数服务就要占用上千台大内存服务器。存储成本太高。
微博、微信、抖音(亿级)
定制数据结构,共享key 紧凑存储,提升计数有效负荷率
超过阈值后数据保存到SSD硬盘,内存里存索引
冷key从SSD硬盘中读取后,放入到LRU队列中
自定义主从复制的方式,海量冷数据异步多线程并发复制
确认使用的对象(ToC:高并发,ToB:高可用)
系统的服务场景(即时通信:低延迟,游戏:高性能,购物:秒杀-一致性)
用户量级(万级:双机、百万:集群、亿级:弹性分布式、容器化编排架构)
百万读:3主6从,每个节点的读写高峰 QPS 可能可以达到每秒 5 万,可以实现15万,30万读性能
亿级读,通过CDN、静态缓存、JVM缓存等多级缓存来提高读并发
百万写,通过消息队列削峰填谷,通过hash分拆,水平扩展分布式缓存
亿级写,redis可以定制数据结构、SSD+内存LRU、冷数据异步多线程复制
持久化,(Mysql)承受量约为 1K的QPS,读写分离提升读并发,分库分表提升写并发
核心功能包括什么:
写功能:发送微博
读功能:热点资讯
交互:点赞、关注
- 系统性能和延迟
- 边缘计算 | 动静分离 | 缓存 | 多线程 |
- 可扩展性和吞吐量
- 负载均衡 | 水平扩展 | 垂直扩展 | 异步 | 批处理 | 读写分离
- 可用性和一致性
- 主从复制 | 哨兵模式 | 集群 | 分布式事务
键值存储 : Redis ( 热点资讯 )
文档存储 : MongoDB ( 微博文档分类)
分词倒排:Elasticsearch(搜索)
列型存储:Hbase、BigTable(大数据)
图形存储:Neo4j (社交及推荐)
多媒体:FastDfs(图文视频微博)
实现哪些功能:
筛选出核心功能(Post a Tweet,Timeline,News Feed,Follow/Unfollow a user,Register/Login)
承担多大QPS:
QPS = 100,那么用我的笔记本作Web服务器就好了
QPS = 1K,一台好点的Web 服务器也能应付,需要考虑单点故障;
QPS = 1m,则需要建设一个1000台Web服务器的集群,考虑动态扩容、负载分担、故障转移
一台 SQL Database (Mysql)承受量约为 1K的QPS;
一台 NoSQL Database (Redis) 约承受量是 20k 的 QPS;
一台 NoSQL Database (Memcache) 约承受量是 200k 的 QPS;
微服务战略拆分

针对不同服务选择不同存储
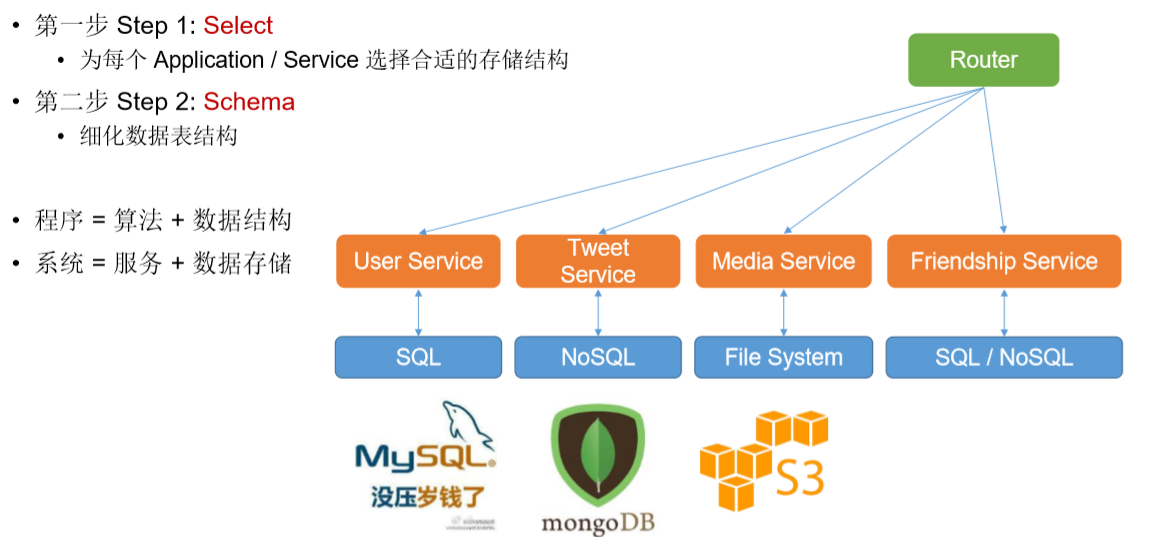
设计数据表的结构

基本差不多就形成了一个解决方案,但是并不是完美的,仍然需要小步快跑的不断的针对消息队列、缓存、分布式事务、分表分库、大数据、监控、可伸缩方面进行优化
微服务内高内聚,微服务间低耦合
微服务内高内聚即单一职责原则
每个微服务中的代码变化都是同一类原因。因这类原因而需要变更的代码都在这个微服务中,与其他微服务无关,那么就可以将代码修改的范围缩小到这个微服务内。把这个微服务修改好了,独立修改、独立发布,该需求就实现了。这样,微服务的优势才能发挥出来。
微服务间低耦合开放封闭原则
就是说在微服务实现自身业务的过程中,如果需要执行的某些过程不是自己的职责,就应当将这些过程交给其他微服务去实现,你只需要对它的接口进行调用。这样,微服务之间的调用就实现了解耦。
领域建模就是将一个系统划分成了多个子域,每个子域都是一个独立的业务场景,每个子域的边界就是“限界上下文”。该业务场景会涉及许多领域对象,但分析建模始终需要围绕着业务场景的上下文进行。
领域事件通知机制最有效的方式就是通过消息队列,实现领域事件在微服务间的通知。
“核心通讯录”微服务只负责发送变更消息到消息队列,不管谁会接收并处理这些消息;
“门禁管理”微服务只负责接收照片变更消息,不管谁发送的这个消息。
-
按照限界上下文进行微服务的拆分,将领域模型划分到多个问题子域
-
基于充血模型与贫血模型设计各个微服务的业务领域层(Service、Entity、Value)
-
通过领域事件通知机制和微服务调用的推拉结合,将各个子域进行解耦关联
- 核心:
-
通讯录 | 短信 | 推送通知 | 支付 | 文件服务
-
智慧通行
解决物业多品牌、多系统应用造成的信息孤岛,数据混乱的问题
- 人脸门禁 | 可视对讲 | 电梯梯控 | 停车系统 | 访客预约
-
安全社区
通过图像视频识别、传感数据采集,实现报警联动和风险预警
- 视频监控 | 周界报警 | 高空抛物 | 跨域追踪
-
全屋智能
围绕业主需求,逐步引入社区医疗、社区养老、社区团购、社区家政等服务
- 超级面板 | 无线门锁 | 烟感雾感
-
增值服务
实现跨品牌的产品体验,支持基于matrix引擎的智能生活场景裂变能力
- 智能充电 | 云广播 | 出入提醒 | 定向投放
通过合理的微服务设计,尽量让每次的需求变更都交给某个小团队独立完成,让需求变更落到某个微服务上进行变更。唯有这样,每次变更只需独立地修改这个微服务,独立打包、独立升级,新需求独立实现,才能发挥微服务的优势。
-
数据隔离:数据库中用户信息表的读写只有通讯录微服务。当其他微服务需要读写用户信息时,就不能直接读取用户信息表,而是通过 API 接口去调用通讯录微服务。
-
**接口复用:因此,当多个团队向你提需求时,必须要对这些接口进行规划,通过复用尽可能少的接口满足他们的需求;**当有新的接口提出时,要尽量通过现有接口解决问题。
-
**向前兼容:**当调用方需要接口变更时怎么办?变更现有接口应当尽可能向前兼容,即接口的名称与参数都不变,只是在内部增加新的功能。宁愿增加一个新的接口也最好不要去变更原有的接口。
-
本地调用:在访客申请微服务的本地,增加一个查询用户Service的 feign 接口。这样,访客申请Service就像本地调用一样调用查询用户Service,再通过 feign 接口实现远程调用。这种防腐层的设计,可以隔离当前微服务以外的其他微服务拆分变更导致的接口的失效的影响。
-
数据库去中心化:
- 微服务中通讯录服务与健康码服务分别对应的用户库与权限库,它们的共同特点是数据量小但频繁读取,可以选用小型的 MySQL 数据库并在前面架设 Redis 来提高查询性能;
- 微服务中访客通行与生活缴费分别对应的通行记录库、订单库,其特点是数据量大并且高并发写,选用一个数据库显然扛不住这样的压力,因此可以选用了 TiDB 这样的 NewSQL 数据库进行分布式存储,将数据压力分散到多个数据节点中,从而解决 I/O 瓶颈;
- 微服务中数据分析与通讯录查询这样的查询分析业务,则选用 NoSQL 数据库或大数据平台,通过读写分离将生产库上的数据同步过来进行分布式存储,然后宽表一系列的预处理,应对海量历史数据的决策分析与秒级查询。( NoSQL 为空的字段是不占用空间的,因此字段再多都不影响查询性能)
贫血模型、充血模型、策略模式、装饰者模式只是DDD实现的方式,而DDD的真谛是领域建模。
做事不能仅凭一腔热血,一定要符合自然规律。其实软件的设计开发过程也是这样。对业务理解不深刻全局架构设计往往是过度设计,这时候应该抓主要流程,开始领域建模。
- 接着,每次添加新功能的时候,一方面要满足当前的需求,另一方面业务相关的领域建模设计刚刚满足需求,从而使设计最简化、代码最少。
- 这样的设计过程叫小步快跑。采用小步快跑的设计方法,一开始不用思考那么多问题,从简单问题开始逐步深入。领域模型就像小树一样一点儿一点儿成长,最后完成所有的功能。
保持软件设计不退化的关键在于每次需求变更的设计,只有保证每次需求变更时做出正确的设计,才能保证软件以一种良性循环的方式不断维护下去。
有没有一种方法,让我们在第十次变更、第二十次变更、第三十次变更时,依然能够找到正确的设计呢?有,那就是领域驱动设计
那么在每次需求变更时,将变更还原到真实世界中,看看真实世界是什么样子的,根据真实世界进行变更。

领域和子域(Domain/Subdomain)
在上下文地图构建的领域中,对应模块,使用限界上下文划分领域,对应微服务
限界上下文(Bounded Context)
在一个领域/子域中,有概念上的领域边界,任何领域对象在该边界内部的有不依赖外部的确切含义。
领域对象
服务、实体与值对象是领域驱动设计的领域对象,可以通过贫血模型和充血模型转换为程序设计
实体和值对象
通过一个唯一标识字段来区分真实世界中的每一个个体的领域对象,称为实体。真实世界中那些一成不变的、本质性的事物的领域对象,称为值对象。 可变性是实体的特点,而不变性则是值对象的本质。
贫血模型与充血模型
POJO对象中只保存get/set方法,没有任何业务逻辑,这样的设计被称为贫血模型
充血模型是封装和继承思想的体现,门禁设备实体中,包含特征值下发、广告下发、通行记录回调等方法,不同厂商的实体针对多态进行聚合,并通过工厂或仓库对外提供服务。在充血模型中, Service 只干一件非常简单的事,就是直接去调用对象中的工厂方法生成不同产品,其他的什么都不干。
聚合
聚合体现的是一种整体与部分的关系。正是因为有这样的关系,在操作整体的时候,整体就封装了对部分的操作。如何正确理解是否存在聚合的关系:就是当整体不存在时,部分就变得没有了意义。部分是整体的一个部分,与整体有相同的生命周期。
工厂
**通过装配,创建领域对象,是领域对象生命周期的起点。**譬如,系统要通过 ID 装载一个访客申请:
-
表单工厂分别调用表单信息DAO、表单明细 DAO 和用户DAO 去进行查询;
-
将得到的表单明细对象、用户对象进行装配,分别 set 到表单信息对象的表单明细与用户属性中;
-
最后,表单工厂将装配好的表单对象返回给表单仓库。
仓库
如果服务器是一个非常强大的服务器,那么我们不需要任何数据库。系统创建的所有领域对象都放在仓库中,当需要这些对象时,通过 ID 到仓库中去获取。
-
当客户程序通过 ID 去获取某个领域对象时,仓库会通过这个 ID 先到缓存中进行查找:
-
查找到了,则直接返回,不需要查询数据库;
-
没有找到,则通知工厂,工厂调用 DAO 去数据库中查询,然后装配成领域对象返回给仓库。
-
仓库在收到这个领域对象以后,在返回给客户程序的同时,将该对象放到缓存中