
Text summarization is the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks).
A module for E-mail Summarization which uses clustering of skip-thought sentence embeddings.
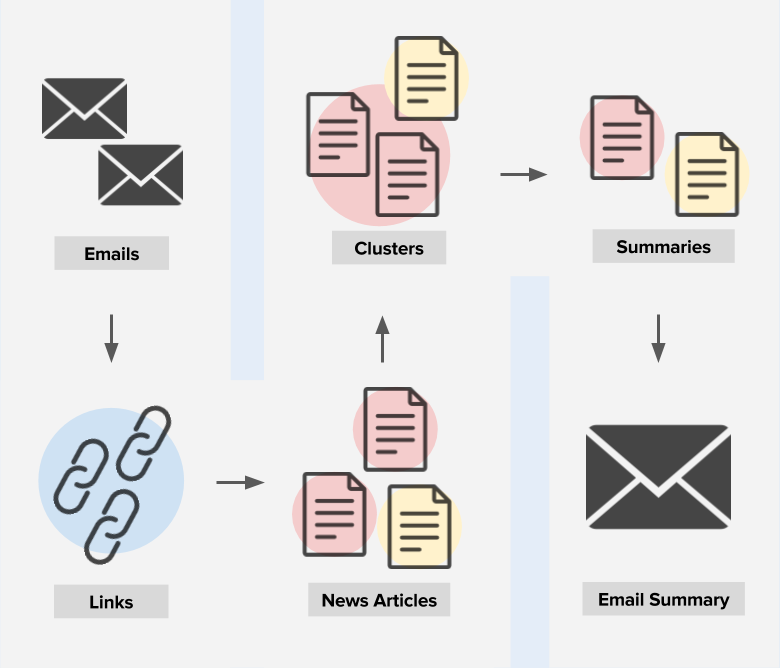
- The code is written in
Python 3. - The module uses code of the
Skip-Thoughtspaper which can be found in the repo.
-
Very first it's all about email parsing i mean removing
- Signatures (e-mail signature is a block of text that is appended to the end of an e-mail message you send)
- Salutation (e-mail salutation is a greeting, you write at the top of your email)
Given above two steps are really complicated and it requires you a good understanding for Regular Expression(Regex).
After these two initial steps we get the email body. Body is in different languages for using
- Google tranlate api convert them to one language"English".
- Perform Sent_tokenization
- Using Skip-thought-vector record the sentence embedding of each sentence.
- With kmeans clustring clustre the embedding
- After all that perform the Topic modelling on email data.
This is an migrated implementation of Skip-Thoughts for Python 3 from tensorflow/models.
Skip thoughts model is a powerful sentence encoder, which encodes sentences with Seq2Seq model. The meanings of sentences are kept in the encoded vectors through this method. However, the code mentioned above does not support Python3.
Due to the lack of compatibility with Python3, I made some modifications to the original implementations. And I write up a simple way to encode sentences with combined skip thought vectors.
The original design is described in:
Jamie Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel,
Antonio Torralba, Raquel Urtasun, Sanja Fidler.
Skip-Thought Vectors.
In NIPS, 2015.
Code editor: Vinay vikram (@vikramvinay)
Original code author: Chris Shallue (@cshallue)
To download the pre-trained models on the BookCorpus dataset.
bash get_skip_thoughts_pretrained_models.shTo encode sentences into combined skip-thought vectors (unidirectional + bidirectional):
Please go to encode-by-skip-thoughts.ipynb and put you data loader in.
Or follow the instructions in tensorflow/models:
# Encode sentences with unidirectional skip thought vectors
import numpy as np
from skip_thoughts import configuration
from skip_thoughts import encoder_manager
# TODO: Load your dataset here.
data = []
VOCAB_FILE = "skip_thoughts/pretrained/skip_thoughts_uni_2017_02_02/vocab.txt"
EMBEDDING_MATRIX_FILE = "skip_thoughts/pretrained/skip_thoughts_uni_2017_02_02/embeddings.npy"
CHECKPOINT_PATH = "skip_thoughts/pretrained/skip_thoughts_uni_2017_02_02/model.ckpt-501424"
encoder = encoder_manager.EncoderManager()
encoder.load_model(configuration.model_config(bidirectional_encoder=False),
vocabulary_file=VOCAB_FILE,
embedding_matrix_file=EMBEDDING_MATRIX_FILE,
checkpoint_path=CHECKPOINT_PATH)
encodings = encoder.encode(data)Vikram singh
- Twitter: https://twitter.com/vikramvinay1
- Linkdin: https://www.linkedin.com/in/vikram-singh-ai-venture/
- Facebook: https://www.facebook.com/AIVentureO/https://www.quora.com/profile/Vinay-Vikram-8
- Quora: https://www.quora.com/profile/Vinay-Vikram-8
-----Feel Free to contact us if you have any question-----