Overly Simple Search Engine - Making search engines simple??
Pronunciation: "oh-see"




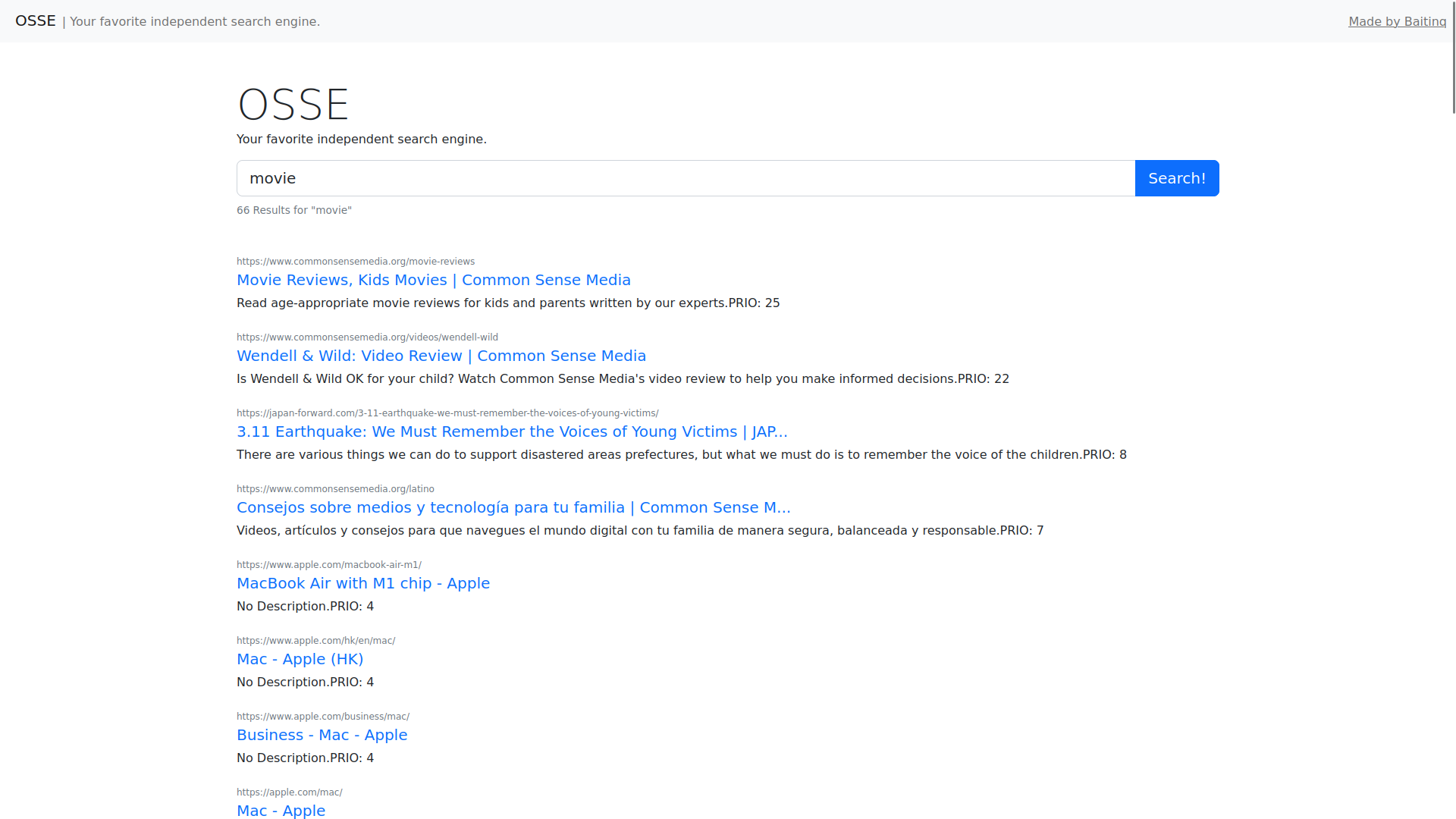
Just for fun! I really wanted to learn Rust and at the time I was really interested in how search engines worked, so there wasn't any better way of achieving both goals than with this very project!
This repository is a monorepo formed by the independent components that form the OSSE search engine.
-
With Nix:
$ nix develop
Install cargo and trunk with your preferred method (such as your favorite package manager).
$ cargo run --bin crawler
$ cargo run --bin indexer
$ trunk serve frontend/index.html --open
Once all the components are running, you can navigate to 127.0.0.1:8080 on your favorite web browser and start using OSSE!
- Completely Self-Hosted : OSSE does not use any external services, all you need is its three components (indexer, crawler & frontend) to have a "complete" search engine.
- Custom Indexing and Ranking Algorithms : OSSE uses its own open-source indexing and ranking algorithm, meaning that its code is reviewable and improvable by third parties, ensuring its technically and morally correct functionality.
- Hackable : OSSE is built with extensibility & modularity in mind, so it is entirely feasible to replace or customize its various components.
- Privacy Respecting : As a result of OSSE being completely independent, it does not send any metadata to any services.
The OSSE search engine is separated into three independent components:
This component provides both the actual search engine indexer's implementation and the REST API used to search and add indexed resources. It uses Actix Web for the REST API (running on port 4444). For the implementation of the actual indexer data structure, we currently use a very simple reverse index implemented with a hashmap, so all the indexed resources are currently lost each time the indexer is restarted.
This component is a simple recursive crawler that forwards the crawled raw HTML to the indexer. It uses reqwest for fetching a predefined list of root websites and parses them with scraper, sending the website contents to the indexer and extracting all its links, adding them to a queue of websites to be crawled. This process is "recursively" repeated indefinitely.
This component is a simple web interface to the indexer. It allows users to search and visualize results in a user friendly way. It is currently built using Yew, which allows us to write the frontend in rust and produce a "blazingly fast" Wasm based web-ui.
- Add frontend
- Change indexer to use a ngram index instead of a reverse index
- Improve frontend
- Improve responsiveness of searching when the indexer is recieving info from crawlers
- Rust cleanup
- Improve page ranking algorithm
"If you have any ideas or patches, please do not hesitate to contribute to OSSE!"
This software is licensed under the BSD-2-Clause © Baitinq.